
Commit
•
7fda566
1
Parent(s):
0deaa27
ExLLaMA V2 quant of Mistral-7B-OpenOrca-4.0bpw-h6-exl2
Browse files- README.md +170 -0
- added_tokens.json +7 -0
- config.json +25 -0
- generation_config.json +6 -0
- output.safetensors +3 -0
- pytorch_model.bin.index.json +298 -0
- special_tokens_map.json +6 -0
- tokenizer.model +3 -0
- tokenizer_config.json +60 -0
README.md
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
datasets:
|
| 3 |
+
- Open-Orca/OpenOrca
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
library_name: transformers
|
| 7 |
+
pipeline_tag: text-generation
|
| 8 |
+
license: apache-2.0
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
<p><h1>🐋 Mistral-7B-OpenOrca 🐋</h1></p>
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+

|
| 15 |
+
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# OpenOrca - Mistral - 7B - 8k
|
| 19 |
+
|
| 20 |
+
We have used our own [OpenOrca dataset](https://huggingface.co/datasets/Open-Orca/OpenOrca) to fine-tune on top of [Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1).
|
| 21 |
+
This dataset is our attempt to reproduce the dataset generated for Microsoft Research's [Orca Paper](https://arxiv.org/abs/2306.02707).
|
| 22 |
+
We use [OpenChat](https://huggingface.co/openchat) packing, trained with [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
|
| 23 |
+
|
| 24 |
+
This release is trained on a curated filtered subset of most of our GPT-4 augmented data.
|
| 25 |
+
It is the same subset of our data as was used in our [OpenOrcaxOpenChat-Preview2-13B model](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B).
|
| 26 |
+
|
| 27 |
+
**HF Leaderboard evals place this model as #2 for all models smaller than 30B at release time, outperforming all but one 13B model.**
|
| 28 |
+
|
| 29 |
+
This release provides a first: a fully open model with class-breaking performance, capable of running fully accelerated on even moderate consumer GPUs.
|
| 30 |
+
Our thanks to the Mistral team for leading the way here.
|
| 31 |
+
|
| 32 |
+
We affectionately codename this model: "*MistralOrca*"
|
| 33 |
+
|
| 34 |
+
If you'd like to try the model now, we have it running on fast GPUs unquantized: https://huggingface.co/spaces/Open-Orca/Mistral-7B-OpenOrca
|
| 35 |
+
|
| 36 |
+
Want to visualize our full (pre-filtering) dataset? Check out our [Nomic Atlas Map](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2).
|
| 37 |
+
|
| 38 |
+
[<img src="https://huggingface.co/Open-Orca/OpenOrca-Preview1-13B/resolve/main/OpenOrca%20Nomic%20Atlas.png" alt="Atlas Nomic Dataset Map" width="400" height="400" />](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
We are in-process with training more models, so keep a look out on our org for releases coming soon with exciting partners.
|
| 42 |
+
|
| 43 |
+
We will also give sneak-peak announcements on our Discord, which you can find here:
|
| 44 |
+
|
| 45 |
+
https://AlignmentLab.ai
|
| 46 |
+
|
| 47 |
+
or check the OpenAccess AI Collective Discord for more information about Axolotl trainer here:
|
| 48 |
+
|
| 49 |
+
https://discord.gg/5y8STgB3P3
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
# Quantized Models
|
| 53 |
+
|
| 54 |
+
Quantized versions of this model are generously made available by [TheBloke](https://huggingface.co/TheBloke).
|
| 55 |
+
|
| 56 |
+
- AWQ: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ
|
| 57 |
+
- GPTQ: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GPTQ
|
| 58 |
+
- GGUF: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
# Prompt Template
|
| 62 |
+
|
| 63 |
+
We used [OpenAI's Chat Markup Language (ChatML)](https://github.com/openai/openai-python/blob/main/chatml.md) format, with `<|im_start|>` and `<|im_end|>` tokens added to support this.
|
| 64 |
+
|
| 65 |
+
This means that, e.g., in [oobabooga](https://github.com/oobabooga/text-generation-webui/) the "`MPT-Chat`" instruction template should work, as it also uses ChatML.
|
| 66 |
+
|
| 67 |
+
## Example Prompt Exchange
|
| 68 |
+
|
| 69 |
+
```
|
| 70 |
+
<|im_start|>system
|
| 71 |
+
You are MistralOrca, a large language model trained by Alignment Lab AI. Write out your reasoning step-by-step to be sure you get the right answers!
|
| 72 |
+
<|im_end|>
|
| 73 |
+
<|im_start|>user
|
| 74 |
+
How are you?<|im_end|>
|
| 75 |
+
<|im_start|>assistant
|
| 76 |
+
I am doing well!<|im_end|>
|
| 77 |
+
<|im_start|>user
|
| 78 |
+
Please tell me about how mistral winds have attracted super-orcas.<|im_end|>
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
# Inference
|
| 83 |
+
|
| 84 |
+
See [this notebook](https://colab.research.google.com/drive/1yZlLSifCGELAX5GN582kZypHCv0uJuNX?usp=sharing) for inference details.
|
| 85 |
+
|
| 86 |
+
Note that you need the development snapshot of Transformers currently, as support for Mistral hasn't been released into PyPI yet:
|
| 87 |
+
|
| 88 |
+
```
|
| 89 |
+
pip install git+https://github.com/huggingface/transformers
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
# Evaluation
|
| 94 |
+
|
| 95 |
+
## HuggingFace Leaderboard Performance
|
| 96 |
+
|
| 97 |
+
We have evaluated using the methodology and tools for the HuggingFace Leaderboard, and find that we have dramatically improved upon the base model.
|
| 98 |
+
We find **105%** of the base model's performance on HF Leaderboard evals, averaging **65.33**.
|
| 99 |
+
|
| 100 |
+
At release time, this beats all 7B models, and all but one 13B.
|
| 101 |
+
|
| 102 |
+
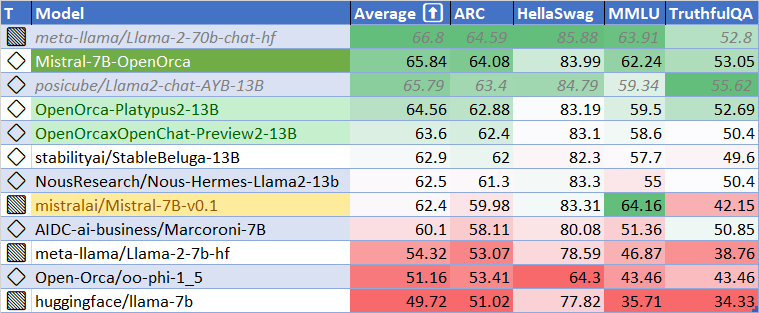
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
| Metric | Value |
|
| 106 |
+
|-----------------------|-------|
|
| 107 |
+
| MMLU (5-shot) | 61.73 |
|
| 108 |
+
| ARC (25-shot) | 63.57 |
|
| 109 |
+
| HellaSwag (10-shot) | 83.79 |
|
| 110 |
+
| TruthfulQA (0-shot) | 52.24 |
|
| 111 |
+
| Avg. | 65.33 |
|
| 112 |
+
|
| 113 |
+
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
## AGIEval Performance
|
| 117 |
+
|
| 118 |
+
We compare our results to the base Mistral-7B model (using LM Evaluation Harness).
|
| 119 |
+
|
| 120 |
+
We find **129%** of the base model's performance on AGI Eval, averaging **0.397**.
|
| 121 |
+
As well, we significantly improve upon the official `mistralai/Mistral-7B-Instruct-v0.1` finetuning, achieving **119%** of their performance.
|
| 122 |
+
|
| 123 |
+

|
| 124 |
+
|
| 125 |
+
## BigBench-Hard Performance
|
| 126 |
+
|
| 127 |
+
We find **119%** of the base model's performance on BigBench-Hard, averaging **0.416**.
|
| 128 |
+
|
| 129 |
+

|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
# Dataset
|
| 133 |
+
|
| 134 |
+
We used a curated, filtered selection of most of the GPT-4 augmented data from our OpenOrca dataset, which aims to reproduce the Orca Research Paper dataset.
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# Training
|
| 138 |
+
|
| 139 |
+
We trained with 8x A6000 GPUs for 62 hours, completing 4 epochs of full fine tuning on our dataset in one training run.
|
| 140 |
+
Commodity cost was ~$400.
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
# Citation
|
| 144 |
+
|
| 145 |
+
```bibtex
|
| 146 |
+
@software{lian2023mistralorca1
|
| 147 |
+
title = {MistralOrca: Mistral-7B Model Instruct-tuned on Filtered OpenOrcaV1 GPT-4 Dataset},
|
| 148 |
+
author = {Wing Lian and Bleys Goodson and Guan Wang and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
|
| 149 |
+
year = {2023},
|
| 150 |
+
publisher = {HuggingFace},
|
| 151 |
+
journal = {HuggingFace repository},
|
| 152 |
+
howpublished = {\url{https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca},
|
| 153 |
+
}
|
| 154 |
+
@misc{mukherjee2023orca,
|
| 155 |
+
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
|
| 156 |
+
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
|
| 157 |
+
year={2023},
|
| 158 |
+
eprint={2306.02707},
|
| 159 |
+
archivePrefix={arXiv},
|
| 160 |
+
primaryClass={cs.CL}
|
| 161 |
+
}
|
| 162 |
+
@misc{longpre2023flan,
|
| 163 |
+
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
|
| 164 |
+
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
|
| 165 |
+
year={2023},
|
| 166 |
+
eprint={2301.13688},
|
| 167 |
+
archivePrefix={arXiv},
|
| 168 |
+
primaryClass={cs.AI}
|
| 169 |
+
}
|
| 170 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</s>": 2,
|
| 3 |
+
"<s>": 1,
|
| 4 |
+
"<unk>": 0,
|
| 5 |
+
"<|im_end|>": 32000,
|
| 6 |
+
"<|im_start|>": 32001
|
| 7 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "mistralai/Mistral-7B-v0.1",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MistralForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"bos_token_id": 1,
|
| 7 |
+
"eos_token_id": 32000,
|
| 8 |
+
"hidden_act": "silu",
|
| 9 |
+
"hidden_size": 4096,
|
| 10 |
+
"initializer_range": 0.02,
|
| 11 |
+
"intermediate_size": 14336,
|
| 12 |
+
"max_position_embeddings": 32768,
|
| 13 |
+
"model_type": "mistral",
|
| 14 |
+
"num_attention_heads": 32,
|
| 15 |
+
"num_hidden_layers": 32,
|
| 16 |
+
"num_key_value_heads": 8,
|
| 17 |
+
"rms_norm_eps": 1e-05,
|
| 18 |
+
"rope_theta": 10000.0,
|
| 19 |
+
"sliding_window": 4096,
|
| 20 |
+
"tie_word_embeddings": false,
|
| 21 |
+
"torch_dtype": "bfloat16",
|
| 22 |
+
"transformers_version": "4.34.0.dev0",
|
| 23 |
+
"use_cache": true,
|
| 24 |
+
"vocab_size": 32002
|
| 25 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 32000,
|
| 5 |
+
"transformers_version": "4.34.0.dev0"
|
| 6 |
+
}
|
output.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7f1d75a4706065abc57b9e80d263058ee030d210b5c4afec07177650ee424f28
|
| 3 |
+
size 3863322760
|
pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 14483496960
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "pytorch_model-00002-of-00002.bin",
|
| 7 |
+
"model.embed_tokens.weight": "pytorch_model-00001-of-00002.bin",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 16 |
+
"model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 17 |
+
"model.layers.1.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 18 |
+
"model.layers.1.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 19 |
+
"model.layers.1.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 20 |
+
"model.layers.1.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 21 |
+
"model.layers.1.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 22 |
+
"model.layers.1.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 23 |
+
"model.layers.1.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 24 |
+
"model.layers.1.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 25 |
+
"model.layers.1.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 26 |
+
"model.layers.10.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 27 |
+
"model.layers.10.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 28 |
+
"model.layers.10.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 29 |
+
"model.layers.10.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 30 |
+
"model.layers.10.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 31 |
+
"model.layers.10.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 32 |
+
"model.layers.10.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 33 |
+
"model.layers.10.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 34 |
+
"model.layers.10.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 35 |
+
"model.layers.11.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 36 |
+
"model.layers.11.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 37 |
+
"model.layers.11.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 38 |
+
"model.layers.11.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 39 |
+
"model.layers.11.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 40 |
+
"model.layers.11.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 41 |
+
"model.layers.11.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 42 |
+
"model.layers.11.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 43 |
+
"model.layers.11.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 44 |
+
"model.layers.12.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 45 |
+
"model.layers.12.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 46 |
+
"model.layers.12.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 47 |
+
"model.layers.12.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 48 |
+
"model.layers.12.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 49 |
+
"model.layers.12.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 50 |
+
"model.layers.12.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 51 |
+
"model.layers.12.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 52 |
+
"model.layers.12.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 53 |
+
"model.layers.13.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 54 |
+
"model.layers.13.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 55 |
+
"model.layers.13.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 56 |
+
"model.layers.13.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 57 |
+
"model.layers.13.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 58 |
+
"model.layers.13.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 59 |
+
"model.layers.13.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 60 |
+
"model.layers.13.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 61 |
+
"model.layers.13.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 62 |
+
"model.layers.14.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 63 |
+
"model.layers.14.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 64 |
+
"model.layers.14.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 65 |
+
"model.layers.14.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 66 |
+
"model.layers.14.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 67 |
+
"model.layers.14.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 68 |
+
"model.layers.14.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 69 |
+
"model.layers.14.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 70 |
+
"model.layers.14.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 71 |
+
"model.layers.15.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 72 |
+
"model.layers.15.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 73 |
+
"model.layers.15.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 74 |
+
"model.layers.15.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 75 |
+
"model.layers.15.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 76 |
+
"model.layers.15.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 77 |
+
"model.layers.15.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 78 |
+
"model.layers.15.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 79 |
+
"model.layers.15.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 80 |
+
"model.layers.16.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 81 |
+
"model.layers.16.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 82 |
+
"model.layers.16.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 83 |
+
"model.layers.16.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 84 |
+
"model.layers.16.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 85 |
+
"model.layers.16.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 86 |
+
"model.layers.16.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 87 |
+
"model.layers.16.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 88 |
+
"model.layers.16.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 89 |
+
"model.layers.17.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 90 |
+
"model.layers.17.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 91 |
+
"model.layers.17.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 92 |
+
"model.layers.17.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 93 |
+
"model.layers.17.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 94 |
+
"model.layers.17.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 95 |
+
"model.layers.17.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 96 |
+
"model.layers.17.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 97 |
+
"model.layers.17.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 98 |
+
"model.layers.18.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 99 |
+
"model.layers.18.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 100 |
+
"model.layers.18.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 101 |
+
"model.layers.18.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 102 |
+
"model.layers.18.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 103 |
+
"model.layers.18.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 104 |
+
"model.layers.18.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 105 |
+
"model.layers.18.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 106 |
+
"model.layers.18.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 107 |
+
"model.layers.19.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 108 |
+
"model.layers.19.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 109 |
+
"model.layers.19.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 110 |
+
"model.layers.19.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 111 |
+
"model.layers.19.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 112 |
+
"model.layers.19.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 113 |
+
"model.layers.19.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 114 |
+
"model.layers.19.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 115 |
+
"model.layers.19.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 116 |
+
"model.layers.2.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 117 |
+
"model.layers.2.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 118 |
+
"model.layers.2.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 119 |
+
"model.layers.2.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 120 |
+
"model.layers.2.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 121 |
+
"model.layers.2.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 122 |
+
"model.layers.2.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 123 |
+
"model.layers.2.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 124 |
+
"model.layers.2.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 125 |
+
"model.layers.20.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 126 |
+
"model.layers.20.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 127 |
+
"model.layers.20.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 128 |
+
"model.layers.20.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 129 |
+
"model.layers.20.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 130 |
+
"model.layers.20.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 131 |
+
"model.layers.20.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 132 |
+
"model.layers.20.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 133 |
+
"model.layers.20.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 134 |
+
"model.layers.21.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 135 |
+
"model.layers.21.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 136 |
+
"model.layers.21.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 137 |
+
"model.layers.21.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 138 |
+
"model.layers.21.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 139 |
+
"model.layers.21.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 140 |
+
"model.layers.21.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 141 |
+
"model.layers.21.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 142 |
+
"model.layers.21.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 143 |
+
"model.layers.22.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 144 |
+
"model.layers.22.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 145 |
+
"model.layers.22.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 146 |
+
"model.layers.22.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 147 |
+
"model.layers.22.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 148 |
+
"model.layers.22.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 149 |
+
"model.layers.22.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 150 |
+
"model.layers.22.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 151 |
+
"model.layers.22.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 152 |
+
"model.layers.23.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 153 |
+
"model.layers.23.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 154 |
+
"model.layers.23.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 155 |
+
"model.layers.23.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 156 |
+
"model.layers.23.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 157 |
+
"model.layers.23.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 158 |
+
"model.layers.23.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 159 |
+
"model.layers.23.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 160 |
+
"model.layers.23.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 161 |
+
"model.layers.24.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 162 |
+
"model.layers.24.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 163 |
+
"model.layers.24.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 164 |
+
"model.layers.24.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 165 |
+
"model.layers.24.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 166 |
+
"model.layers.24.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 167 |
+
"model.layers.24.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 168 |
+
"model.layers.24.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 169 |
+
"model.layers.24.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 170 |
+
"model.layers.25.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 171 |
+
"model.layers.25.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 172 |
+
"model.layers.25.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 173 |
+
"model.layers.25.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 174 |
+
"model.layers.25.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 175 |
+
"model.layers.25.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 176 |
+
"model.layers.25.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 177 |
+
"model.layers.25.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 178 |
+
"model.layers.25.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 179 |
+
"model.layers.26.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 180 |
+
"model.layers.26.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 181 |
+
"model.layers.26.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 182 |
+
"model.layers.26.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 183 |
+
"model.layers.26.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 184 |
+
"model.layers.26.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 185 |
+
"model.layers.26.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 186 |
+
"model.layers.26.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 187 |
+
"model.layers.26.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 188 |
+
"model.layers.27.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 189 |
+
"model.layers.27.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 190 |
+
"model.layers.27.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 191 |
+
"model.layers.27.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 192 |
+
"model.layers.27.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 193 |
+
"model.layers.27.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 194 |
+
"model.layers.27.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 195 |
+
"model.layers.27.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 196 |
+
"model.layers.27.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 197 |
+
"model.layers.28.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 198 |
+
"model.layers.28.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 199 |
+
"model.layers.28.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 200 |
+
"model.layers.28.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 201 |
+
"model.layers.28.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 202 |
+
"model.layers.28.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 203 |
+
"model.layers.28.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 204 |
+
"model.layers.28.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 205 |
+
"model.layers.28.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 206 |
+
"model.layers.29.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 207 |
+
"model.layers.29.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 208 |
+
"model.layers.29.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 209 |
+
"model.layers.29.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 210 |
+
"model.layers.29.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 211 |
+
"model.layers.29.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 212 |
+
"model.layers.29.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 213 |
+
"model.layers.29.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 214 |
+
"model.layers.29.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 215 |
+
"model.layers.3.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 216 |
+
"model.layers.3.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 217 |
+
"model.layers.3.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 218 |
+
"model.layers.3.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 219 |
+
"model.layers.3.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 220 |
+
"model.layers.3.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 221 |
+
"model.layers.3.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 222 |
+
"model.layers.3.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 223 |
+
"model.layers.3.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 224 |
+
"model.layers.30.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 225 |
+
"model.layers.30.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 226 |
+
"model.layers.30.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 227 |
+
"model.layers.30.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 228 |
+
"model.layers.30.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 229 |
+
"model.layers.30.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 230 |
+
"model.layers.30.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 231 |
+
"model.layers.30.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 232 |
+
"model.layers.30.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 233 |
+
"model.layers.31.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 234 |
+
"model.layers.31.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 235 |
+
"model.layers.31.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 236 |
+
"model.layers.31.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 237 |
+
"model.layers.31.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 238 |
+
"model.layers.31.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 239 |
+
"model.layers.31.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 240 |
+
"model.layers.31.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 241 |
+
"model.layers.31.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 242 |
+
"model.layers.4.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 243 |
+
"model.layers.4.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 244 |
+
"model.layers.4.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 245 |
+
"model.layers.4.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 246 |
+
"model.layers.4.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 247 |
+
"model.layers.4.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 248 |
+
"model.layers.4.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 249 |
+
"model.layers.4.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 250 |
+
"model.layers.4.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 251 |
+
"model.layers.5.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 252 |
+
"model.layers.5.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 253 |
+
"model.layers.5.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 254 |
+
"model.layers.5.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 255 |
+
"model.layers.5.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 256 |
+
"model.layers.5.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 257 |
+
"model.layers.5.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 258 |
+
"model.layers.5.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 259 |
+
"model.layers.5.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 260 |
+
"model.layers.6.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 261 |
+
"model.layers.6.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 262 |
+
"model.layers.6.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 263 |
+
"model.layers.6.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 264 |
+
"model.layers.6.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 265 |
+
"model.layers.6.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 266 |
+
"model.layers.6.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 267 |
+
"model.layers.6.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 268 |
+
"model.layers.6.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 269 |
+
"model.layers.7.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 270 |
+
"model.layers.7.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 271 |
+
"model.layers.7.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 272 |
+
"model.layers.7.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 273 |
+
"model.layers.7.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 274 |
+
"model.layers.7.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 275 |
+
"model.layers.7.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 276 |
+
"model.layers.7.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 277 |
+
"model.layers.7.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 278 |
+
"model.layers.8.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 279 |
+
"model.layers.8.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 280 |
+
"model.layers.8.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 281 |
+
"model.layers.8.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 282 |
+
"model.layers.8.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 283 |
+
"model.layers.8.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 284 |
+
"model.layers.8.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 285 |
+
"model.layers.8.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 286 |
+
"model.layers.8.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 287 |
+
"model.layers.9.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 288 |
+
"model.layers.9.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 289 |
+
"model.layers.9.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 290 |
+
"model.layers.9.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 291 |
+
"model.layers.9.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 292 |
+
"model.layers.9.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 293 |
+
"model.layers.9.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 294 |
+
"model.layers.9.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 295 |
+
"model.layers.9.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 296 |
+
"model.norm.weight": "pytorch_model-00002-of-00002.bin"
|
| 297 |
+
}
|
| 298 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<s>",
|
| 3 |
+
"eos_token": "<|im_end|>",
|
| 4 |
+
"pad_token": "</s>",
|
| 5 |
+
"unk_token": "<unk>"
|
| 6 |
+
}
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dadfd56d766715c61d2ef780a525ab43b8e6da4de6865bda3d95fdef5e134055
|
| 3 |
+
size 493443
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"0": {
|
| 6 |
+
"content": "<unk>",
|
| 7 |
+
"lstrip": true,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": true,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"1": {
|
| 14 |
+
"content": "<s>",
|
| 15 |
+
"lstrip": true,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": true,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"2": {
|
| 22 |
+
"content": "</s>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"32000": {
|
| 30 |
+
"content": "<|im_end|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"32001": {
|
| 38 |
+
"content": "<|im_start|>",
|
| 39 |
+
"lstrip": true,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": true,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
}
|
| 45 |
+
},
|
| 46 |
+
"additional_special_tokens": [],
|
| 47 |
+
"bos_token": "<s>",
|
| 48 |
+
"clean_up_tokenization_spaces": false,
|
| 49 |
+
"eos_token": "<|im_end|>",
|
| 50 |
+
"legacy": true,
|
| 51 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 52 |
+
"pad_token": null,
|
| 53 |
+
"sp_model_kwargs": {},
|
| 54 |
+
"spaces_between_special_tokens": false,
|
| 55 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 56 |
+
"trust_remote_code": false,
|
| 57 |
+
"unk_token": "<unk>",
|
| 58 |
+
"use_default_system_prompt": true,
|
| 59 |
+
"use_fast": true
|
| 60 |
+
}
|