
Commit
•
9688990
1
Parent(s):
62f158c
Upload 9 files
Browse files- AI_user.py +28 -0
- Ai.py +98 -0
- Train loss lowered , val loss increased.png +0 -0
- Trained with all data val great , model handles well seen data but not unseen.png +0 -0
- Val Loss epochs = 100.png +0 -0
- datset.csv +121 -0
- model.h5 +3 -0
- tokenizer.pkl +3 -0
- val loss double neurons , 500 epochs.png +0 -0
AI_user.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#load model
|
| 2 |
+
from tensorflow.keras.models import load_model
|
| 3 |
+
from tensorflow.keras.preprocessing.sequence import pad_sequences
|
| 4 |
+
import pickle
|
| 5 |
+
|
| 6 |
+
model = load_model("model.h5")
|
| 7 |
+
|
| 8 |
+
#load tokenizer
|
| 9 |
+
with open("tokenizer.pkl","rb") as handle:
|
| 10 |
+
tokenizer = pickle.load(handle)
|
| 11 |
+
|
| 12 |
+
#make predictions
|
| 13 |
+
# Make predictions
|
| 14 |
+
while True:
|
| 15 |
+
text = input("write a review, press e to exit: ")
|
| 16 |
+
if text == 'e':
|
| 17 |
+
break
|
| 18 |
+
TokenText = tokenizer.texts_to_sequences([text])
|
| 19 |
+
PadText = pad_sequences(TokenText, maxlen=100)
|
| 20 |
+
Pred = model.predict(PadText)
|
| 21 |
+
Pred_float = Pred[0][0] # Extract the single float value
|
| 22 |
+
Pred_float *= 1.3
|
| 23 |
+
binary_pred = (Pred_float > 0.5).astype(int)
|
| 24 |
+
if binary_pred == 0:
|
| 25 |
+
print("bad review")
|
| 26 |
+
else:
|
| 27 |
+
print("good review")
|
| 28 |
+
print(Pred_float)
|
Ai.py
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import matplotlib.pyplot as plt
|
| 3 |
+
import numpy as np
|
| 4 |
+
import nltk
|
| 5 |
+
from nltk.tokenize import word_tokenize
|
| 6 |
+
import pickle
|
| 7 |
+
import tensorflow as tf
|
| 8 |
+
import tensorflow as tf
|
| 9 |
+
from tensorflow.keras.models import Sequential
|
| 10 |
+
from tensorflow.keras.layers import Dense
|
| 11 |
+
from tensorflow.keras.preprocessing.sequence import pad_sequences
|
| 12 |
+
from tensorflow.keras.preprocessing.text import Tokenizer
|
| 13 |
+
from sklearn.model_selection import train_test_split
|
| 14 |
+
nltk.download('punkt_tab')
|
| 15 |
+
# load dataset
|
| 16 |
+
DatasetLocation = r"datset.csv"
|
| 17 |
+
dataset = pd.read_csv(DatasetLocation)
|
| 18 |
+
print("data loaded")
|
| 19 |
+
|
| 20 |
+
#label data
|
| 21 |
+
x = dataset["text"]
|
| 22 |
+
y = dataset["output"]
|
| 23 |
+
|
| 24 |
+
#convert y
|
| 25 |
+
#convert -1 to 0
|
| 26 |
+
Newy = y + 1
|
| 27 |
+
Newy = Newy / 2
|
| 28 |
+
#remove NAN to 0
|
| 29 |
+
#convert 1 to 0.5
|
| 30 |
+
|
| 31 |
+
y = Newy
|
| 32 |
+
for i in range(len(y)):
|
| 33 |
+
if np.isnan(y[i]):
|
| 34 |
+
y[i] = 0
|
| 35 |
+
print(y)
|
| 36 |
+
#tokenize data
|
| 37 |
+
tokenizer = Tokenizer()
|
| 38 |
+
|
| 39 |
+
#fit tokenizer
|
| 40 |
+
tokenizer.fit_on_texts(x)
|
| 41 |
+
|
| 42 |
+
TokenX = tokenizer.texts_to_sequences(x)
|
| 43 |
+
|
| 44 |
+
#save tokenizer
|
| 45 |
+
with open("tokenizer.pkl","wb") as handle:
|
| 46 |
+
pickle.dump(tokenizer,handle,protocol=pickle.HIGHEST_PROTOCOL)
|
| 47 |
+
|
| 48 |
+
print(TokenX)
|
| 49 |
+
|
| 50 |
+
#pad data
|
| 51 |
+
|
| 52 |
+
max_length = 100 # Choose a suitable maximum length
|
| 53 |
+
X_Padded = pad_sequences(TokenX,maxlen= max_length)
|
| 54 |
+
|
| 55 |
+
print("data padded correctly")
|
| 56 |
+
|
| 57 |
+
#set train and validation
|
| 58 |
+
X_train, X_val, y_train, y_val = train_test_split(X_Padded, y, test_size=0.2, random_state=42)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
# Define the model
|
| 62 |
+
model = Sequential([
|
| 63 |
+
Dense(256, activation='relu'),
|
| 64 |
+
Dense(128, activation='relu'),
|
| 65 |
+
Dense(1, activation='sigmoid') # For binary classification
|
| 66 |
+
])
|
| 67 |
+
from tensorflow.keras.optimizers import Adam
|
| 68 |
+
|
| 69 |
+
model.compile(optimizer=Adam(learning_rate=0.0001), loss='binary_crossentropy', metrics=['accuracy'])
|
| 70 |
+
print("model defined correctly")
|
| 71 |
+
print(np.isnan(y).sum()) # Should be 0
|
| 72 |
+
# train model
|
| 73 |
+
epochs = 3
|
| 74 |
+
i = 0
|
| 75 |
+
TrainLoss= []
|
| 76 |
+
ValLoss= []
|
| 77 |
+
Num = []
|
| 78 |
+
while i < epochs:
|
| 79 |
+
history = model.fit(X_Padded, y, epochs=100, verbose=2)
|
| 80 |
+
Train_loss = history.history['loss'][-1] # Get the last value of training loss
|
| 81 |
+
Train_accuracy = history.history['accuracy'][-1] # Get the last value of training accuracy
|
| 82 |
+
Val_loss, Val_accuracy = model.evaluate(X_val, y_val)
|
| 83 |
+
ValLoss.append(Val_loss)
|
| 84 |
+
TrainLoss.append(Train_loss)
|
| 85 |
+
Num.append(i)
|
| 86 |
+
i += 1
|
| 87 |
+
#save the model
|
| 88 |
+
model.save("model.h5")
|
| 89 |
+
#graph loss
|
| 90 |
+
plt.figure(figsize=(10, 6))
|
| 91 |
+
plt.plot(Num, ValLoss, label='Validation Loss', color='orange')
|
| 92 |
+
plt.plot(Num, TrainLoss, label='Training Loss', color='blue')
|
| 93 |
+
plt.title('Training and Validation Loss')
|
| 94 |
+
plt.xlabel('Epochs')
|
| 95 |
+
plt.ylabel('Loss')
|
| 96 |
+
plt.legend()
|
| 97 |
+
plt.grid()
|
| 98 |
+
plt.show()
|
Train loss lowered , val loss increased.png
ADDED
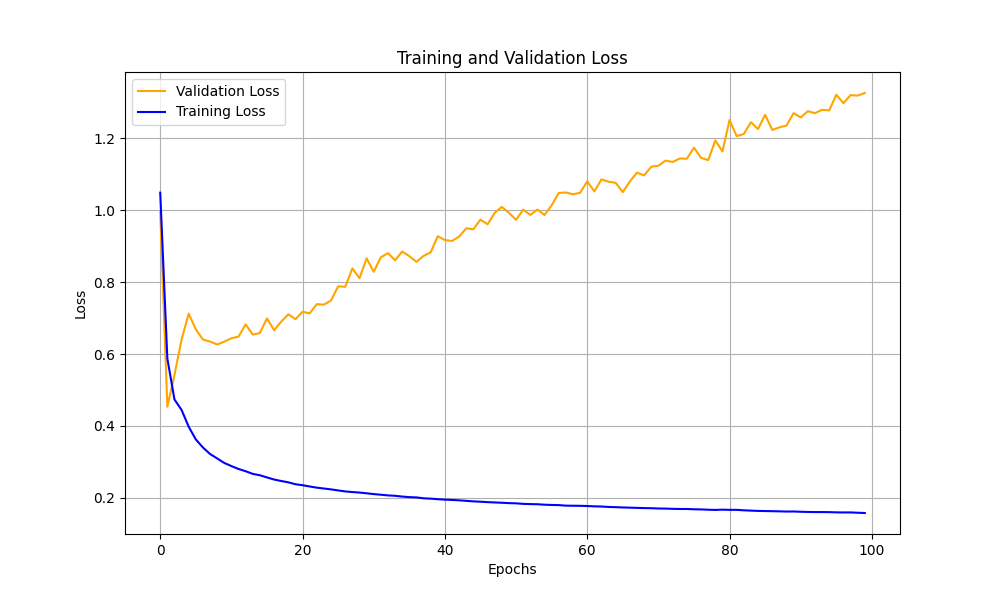
|
Trained with all data val great , model handles well seen data but not unseen.png
ADDED

|
Val Loss epochs = 100.png
ADDED

|
datset.csv
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
text,output
|
| 2 |
+
|
| 3 |
+
"This movie was a shit",-1
|
| 4 |
+
|
| 5 |
+
"The plot was terrible and boring",-1
|
| 6 |
+
|
| 7 |
+
"I regret watching this movie",-1
|
| 8 |
+
|
| 9 |
+
"I hate this movie",-1
|
| 10 |
+
|
| 11 |
+
"This was the worst film I've ever seen.",-1
|
| 12 |
+
|
| 13 |
+
"I felt like I wasted my time on this movie.",-1
|
| 14 |
+
|
| 15 |
+
"The storyline was nonsensical and confusing.",-1
|
| 16 |
+
|
| 17 |
+
"The special effects were awful.",-1
|
| 18 |
+
|
| 19 |
+
"I couldn't connect with any of the characters.",-1
|
| 20 |
+
|
| 21 |
+
"The pacing was so slow that I almost fell asleep.",-1
|
| 22 |
+
|
| 23 |
+
"A complete disappointment from start to finish.",-1
|
| 24 |
+
|
| 25 |
+
"The dialogue was cringeworthy and unrealistic.",-1
|
| 26 |
+
|
| 27 |
+
"I can't believe I spent money on this film.",-1
|
| 28 |
+
|
| 29 |
+
"The ending was predictable and unsatisfying.",-1
|
| 30 |
+
|
| 31 |
+
"It felt like a chore to sit through this movie.",-1
|
| 32 |
+
|
| 33 |
+
"I loved this movie",1
|
| 34 |
+
|
| 35 |
+
"Absolutely brilliant! A must-see for everyone.",1
|
| 36 |
+
|
| 37 |
+
"The acting was superb, truly a masterpiece!",1
|
| 38 |
+
|
| 39 |
+
"A delightful experience from start to finish!",1
|
| 40 |
+
|
| 41 |
+
"An emotional rollercoaster that I loved!",1
|
| 42 |
+
|
| 43 |
+
"A visually stunning film that captivated me!",1
|
| 44 |
+
|
| 45 |
+
"This movie made me feel so happy!",1
|
| 46 |
+
|
| 47 |
+
"A heartwarming story that touched my soul.",1
|
| 48 |
+
|
| 49 |
+
"The soundtrack was amazing and perfectly matched!",1
|
| 50 |
+
|
| 51 |
+
"A great blend of humor and drama!",1
|
| 52 |
+
|
| 53 |
+
"I can't wait to watch it again!",1
|
| 54 |
+
|
| 55 |
+
"This film inspired me in so many ways!",1
|
| 56 |
+
|
| 57 |
+
"The cinematography was breathtaking!",1
|
| 58 |
+
|
| 59 |
+
"Every character had depth and complexity.",1
|
| 60 |
+
|
| 61 |
+
"It kept me on the edge of my seat the entire time!",
|
| 62 |
+
|
| 63 |
+
"The film lacked originality and creativity",-1
|
| 64 |
+
|
| 65 |
+
"The plot twists were predictable and uninspired",-1
|
| 66 |
+
|
| 67 |
+
"The character development was shallow and rushed",-1
|
| 68 |
+
|
| 69 |
+
"The direction was lackluster and uninspired",-1
|
| 70 |
+
|
| 71 |
+
"It felt like a cash grab with no real substance",-1
|
| 72 |
+
|
| 73 |
+
"The pacing was uneven and poorly executed",-1
|
| 74 |
+
|
| 75 |
+
"It tried too hard to be funny but failed miserably",-1
|
| 76 |
+
|
| 77 |
+
"The themes were clichéd and overused",-1
|
| 78 |
+
|
| 79 |
+
"A missed opportunity for something great",-1
|
| 80 |
+
|
| 81 |
+
"It felt disjointed and poorly constructed overall",-1
|
| 82 |
+
|
| 83 |
+
"This movie was just okay nothing special",0
|
| 84 |
+
|
| 85 |
+
"I had a decent time watching it but wouldn't recommend it",0
|
| 86 |
+
|
| 87 |
+
"It was fun but not something I would watch again",0
|
| 88 |
+
|
| 89 |
+
"Some parts were entertaining while others dragged on",0
|
| 90 |
+
|
| 91 |
+
"I liked it but it didn't blow me away",0
|
| 92 |
+
|
| 93 |
+
"Not bad for a weekend watch but forgettable",0
|
| 94 |
+
|
| 95 |
+
"It had its moments but overall it was average",0
|
| 96 |
+
|
| 97 |
+
"I enjoyed some scenes but the movie felt long",0
|
| 98 |
+
|
| 99 |
+
"It was fine for what it was nothing more nothing less",0
|
| 100 |
+
|
| 101 |
+
"I laughed a bit but didn't feel invested in the story",0
|
| 102 |
+
|
| 103 |
+
"As a horror film it failed to scare me at all",-1
|
| 104 |
+
|
| 105 |
+
"An action-packed adventure that kept me on my toes",1
|
| 106 |
+
|
| 107 |
+
"This romantic comedy made me cringe more than laugh",-1
|
| 108 |
+
|
| 109 |
+
"A thrilling mystery that kept me guessing until the end",1
|
| 110 |
+
|
| 111 |
+
"The sci-fi elements were fascinating and well done",1
|
| 112 |
+
|
| 113 |
+
"This drama felt overly melodramatic and forced",-1
|
| 114 |
+
|
| 115 |
+
"An inspiring sports film that motivated me to chase my dreams",1
|
| 116 |
+
|
| 117 |
+
"The fantasy world was rich and beautifully crafted",1
|
| 118 |
+
|
| 119 |
+
"This documentary opened my eyes to important issues in society",1
|
| 120 |
+
|
| 121 |
+
"A forgettable family film that didn’t resonate with anyone in my house",-1
|
model.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7133f699e53939da1c9f7918efa4045f2ea379773ee68418437c2f0219311b7a
|
| 3 |
+
size 737848
|
tokenizer.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fb33b05c184d69db72218673c8af1b25bda6710420dfbb2a2c6077475505f789
|
| 3 |
+
size 6787
|
val loss double neurons , 500 epochs.png
ADDED

|