

Commit
·
a1fb934
1
Parent(s):
58d76d5
Add README (#2)
Browse files- Add README (7e833474a82e47770359739ca56b2935fac8767a)
- README.md +106 -0
- amber-arc-curve.pdf +0 -0
- amber-arc-curve.png +0 -0
- amber-hellaswag-curve.pdf +0 -0
- amber-hellaswag-curve.png +0 -0
- amber-mmlu-curve.pdf +0 -0
- amber-mmlu-curve.png +0 -0
- amber-truthfulqa-curve.pdf +0 -0
- amber-truthfulqa-curve.png +0 -0
- amber_logo.png +0 -0
- arc.png +0 -0
- hellaswag.png +0 -0
- loss_curve.png +0 -0
- mmlu.png +0 -0
- truthfulqa.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
pipeline_tag: text-generation
|
| 6 |
+
library_name: transformers
|
| 7 |
+
tags:
|
| 8 |
+
- nlp
|
| 9 |
+
- llm
|
| 10 |
+
---
|
| 11 |
+
# Amber
|
| 12 |
+
|
| 13 |
+
<center><img src="amber_logo.png" alt="amber logo" width="300"/></center>
|
| 14 |
+
|
| 15 |
+
We present Amber, the first model in the LLM360 family. Amber is an
|
| 16 |
+
7B English language model with the LLaMA architecture.
|
| 17 |
+
|
| 18 |
+
## About LLM360
|
| 19 |
+
LLM360 is an initiative for comprehensive and fully open-sourced LLMs,
|
| 20 |
+
where all training details, model checkpoints, intermediate results, and
|
| 21 |
+
additional analyses are made available to the community. Our goal is to advance
|
| 22 |
+
the field by inviting the community to deepen the understanding of LLMs
|
| 23 |
+
together. As the first step of the project LLM360, we release all intermediate
|
| 24 |
+
model checkpoints, our fully-prepared pre-training dataset, all source code and
|
| 25 |
+
configurations, and training details. We are
|
| 26 |
+
committed to continually pushing the boundaries of LLMs through this open-source
|
| 27 |
+
effort.
|
| 28 |
+
|
| 29 |
+
Get access now at [LLM360 site](https://www.llm360.ai/)
|
| 30 |
+
|
| 31 |
+
## Model Description
|
| 32 |
+
|
| 33 |
+
- **Model type:** Language model with the same architecture as LLaMA-7B
|
| 34 |
+
- **Language(s) (NLP):** English
|
| 35 |
+
- **License:** Apache 2.0
|
| 36 |
+
- **Resources for more information:**
|
| 37 |
+
- [Training Code](https://github.com/LLM360/amber-train)
|
| 38 |
+
- [Data Preparation](https://github.com/LLM360/amber-data-prep)
|
| 39 |
+
- [Metrics](https://github.com/LLM360/Analysis360)
|
| 40 |
+
- [Fully processed Amber pretraining data](https://huggingface.co/datasets/LLM360/AmberDatasets)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
# Loading Amber
|
| 44 |
+
|
| 45 |
+
To load a specific checkpoint, simply pass a revision with a value between `"ckpt_000"` and `"ckpt_358"`. If no revision is provided, it will load `"ckpt_359"`, which is the final checkpoint.
|
| 46 |
+
|
| 47 |
+
```python
|
| 48 |
+
from transformers import LlamaTokenizer, LlamaForCausalLM
|
| 49 |
+
|
| 50 |
+
tokenizer = LlamaTokenizer.from_pretrained("LLM360/Amber", revision="ckpt_356")
|
| 51 |
+
model = LlamaForCausalLM.from_pretrained("LLM360/Amber", revision="ckpt_356")
|
| 52 |
+
|
| 53 |
+
input_text = "translate English to German: How old are you?"
|
| 54 |
+
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
|
| 55 |
+
|
| 56 |
+
outputs = model.generate(input_ids)
|
| 57 |
+
print(tokenizer.decode(outputs[0]))
|
| 58 |
+
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
# Amber Training Details
|
| 62 |
+
|
| 63 |
+
## DataMix
|
| 64 |
+
| Subset | Tokens (Billion) |
|
| 65 |
+
| ----------- | ----------- |
|
| 66 |
+
| Arxiv | 30.00 |
|
| 67 |
+
| Book | 28.86 |
|
| 68 |
+
| C4 | 197.67 |
|
| 69 |
+
| Refined-Web | 665.01 |
|
| 70 |
+
| StarCoder | 291.92 |
|
| 71 |
+
| StackExchange | 21.75 |
|
| 72 |
+
| Wikipedia | 23.90 |
|
| 73 |
+
| Total | 1259.13 |
|
| 74 |
+
|
| 75 |
+
## Hyperparameters
|
| 76 |
+
| Hyperparameter | Value |
|
| 77 |
+
| ----------- | ----------- |
|
| 78 |
+
| Total Parameters | 6.7B |
|
| 79 |
+
| Hidden Size | 4096 |
|
| 80 |
+
| Intermediate Size (MLPs) | 11008 |
|
| 81 |
+
| Number of Attention Heads | 32 |
|
| 82 |
+
| Number of Hidden Lyaers | 32 |
|
| 83 |
+
| RMSNorm ɛ | 1e^-6 |
|
| 84 |
+
| Max Seq Length | 2048 |
|
| 85 |
+
| Vocab Size | 32000 |
|
| 86 |
+
|
| 87 |
+
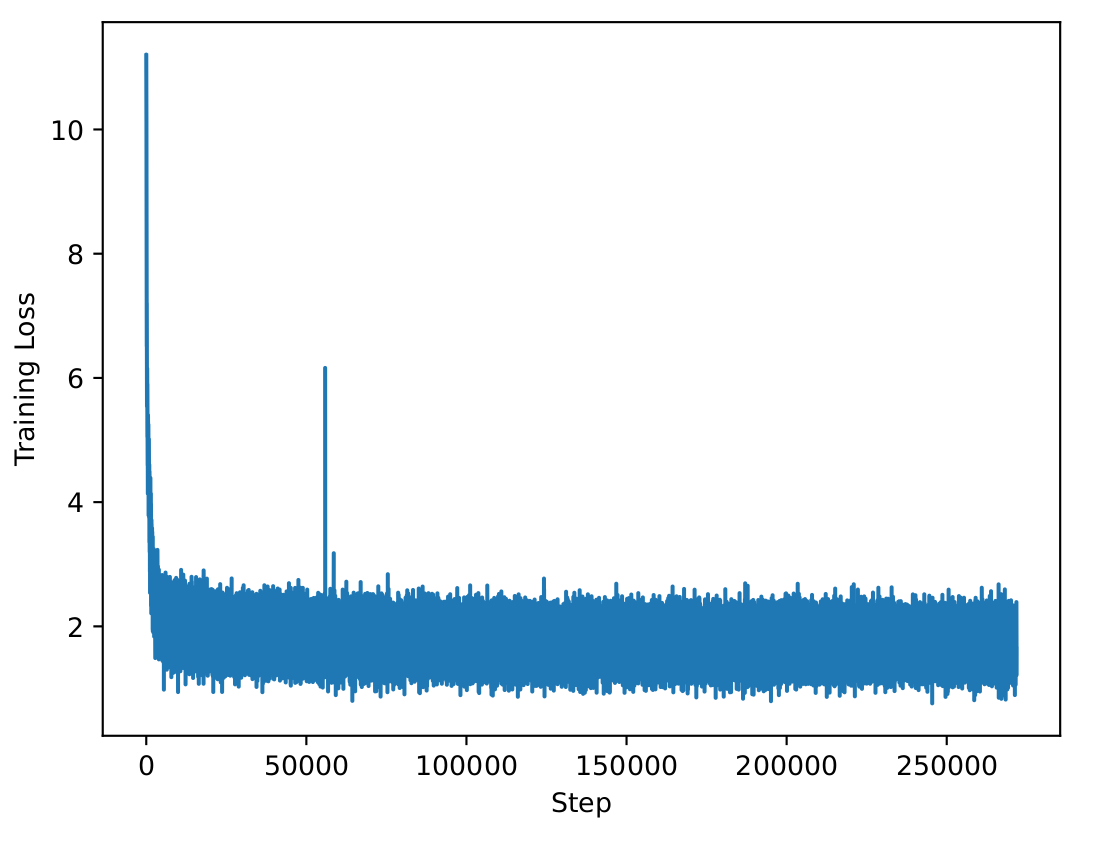
| Training Loss |
|
| 88 |
+
|------------------------------------------------------------|
|
| 89 |
+
| <img src="loss_curve.png" alt="loss curve" width="400"/> |
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
# Evaluation
|
| 93 |
+
|
| 94 |
+
Please refer to our [W&B project page](https://wandb.ai/llm360/CrystalCoder) for complete training logs and evaluation results.
|
| 95 |
+
|
| 96 |
+
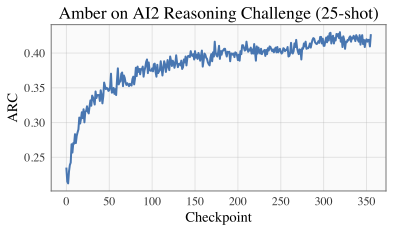
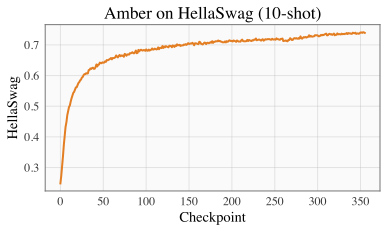
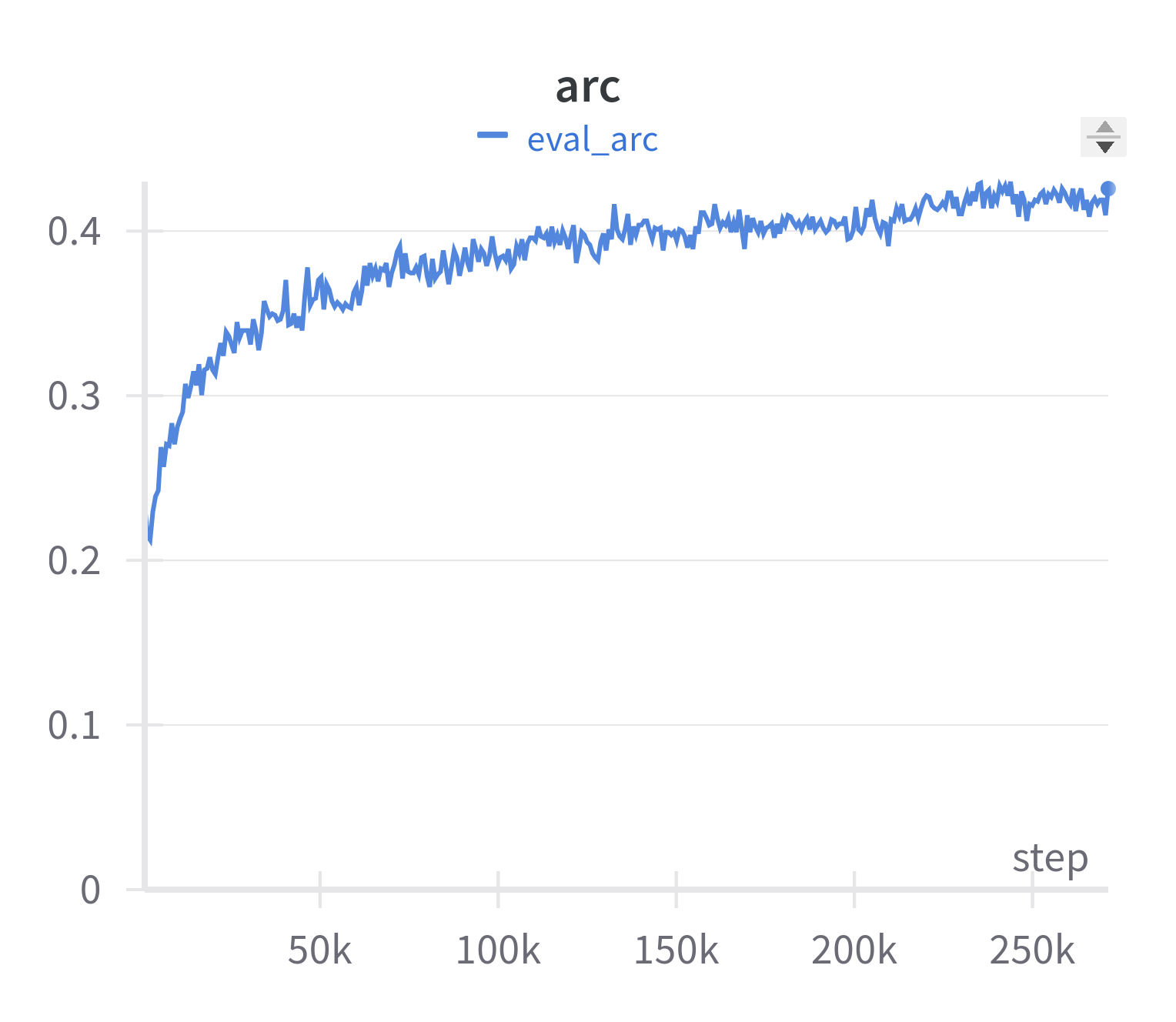
| ARC | HellaSwag |
|
| 97 |
+
|--------------------------------------------------------|--------------------------------------------------------------------|
|
| 98 |
+
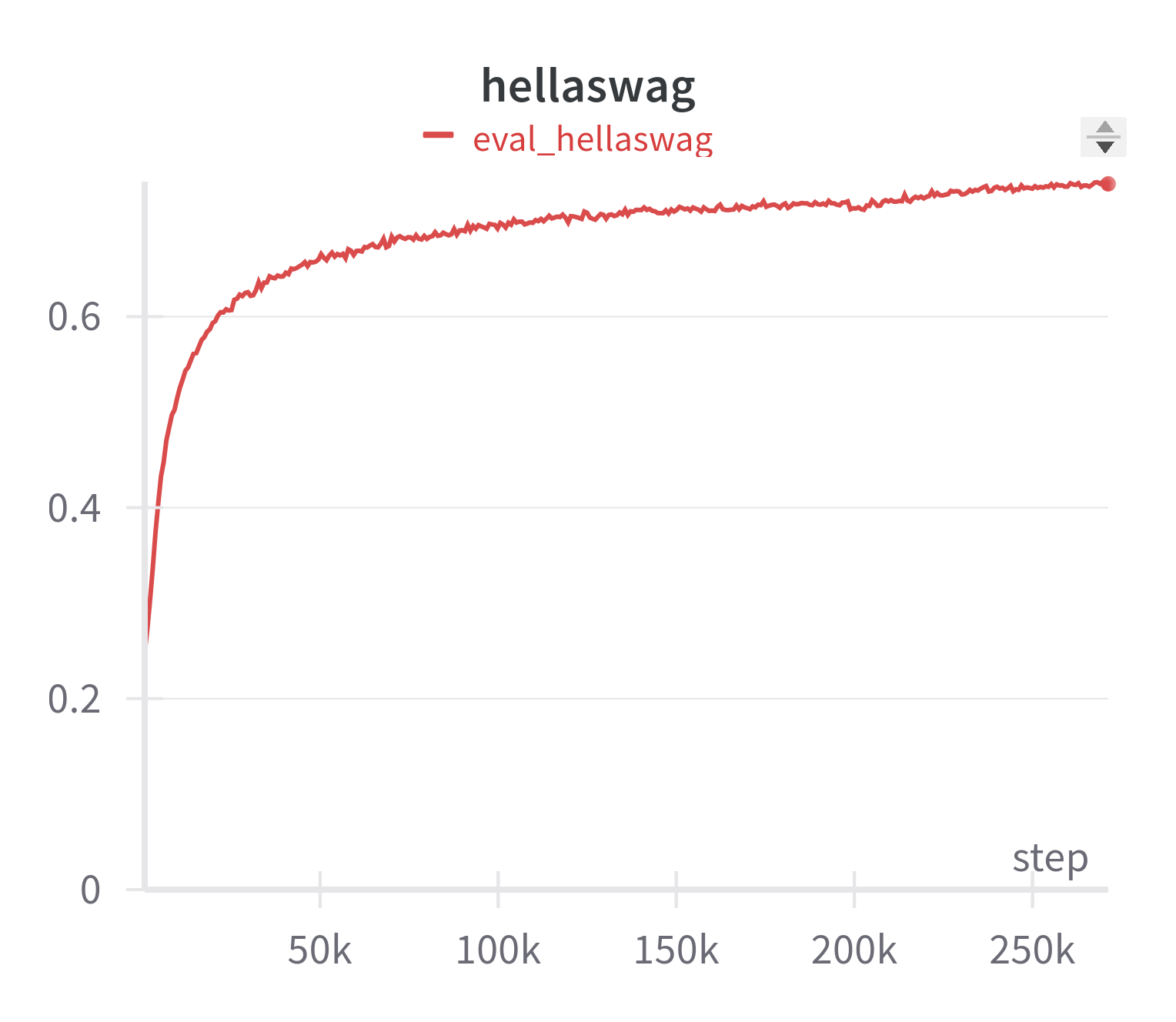
| <img src="amber-arc-curve.png" alt="arc" width="400"/> | <img src="amber-hellaswag-curve.png" alt="hellaswag" width="400"/> |
|
| 99 |
+
|
| 100 |
+
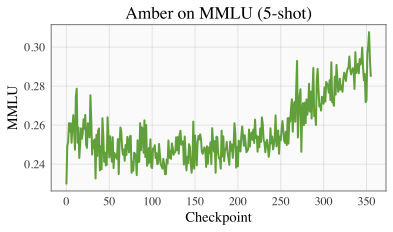
|MMLU | TruthfulQA |
|
| 101 |
+
|-----------------------------------------------------|-----------------------------------------------------------|
|
| 102 |
+
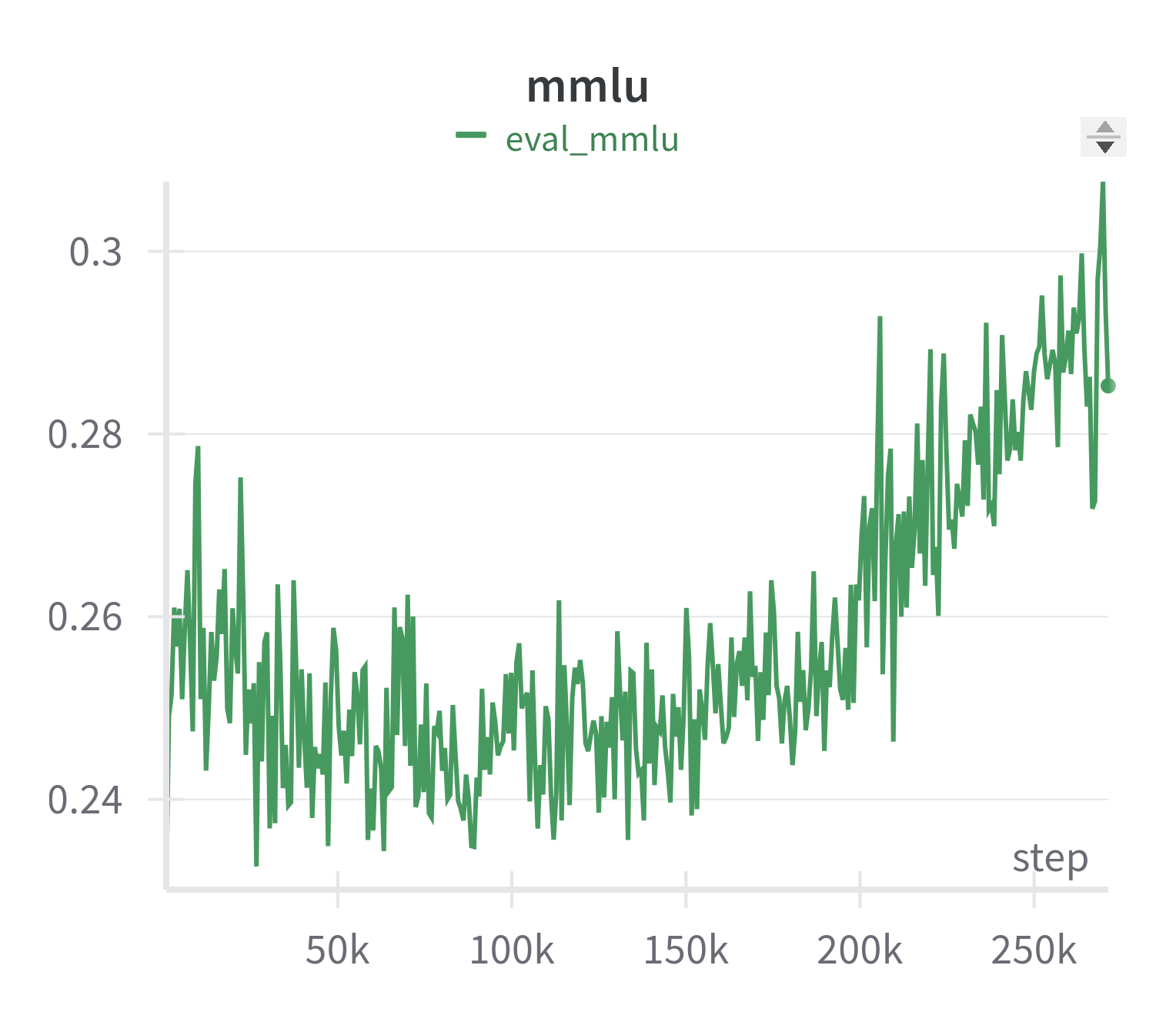
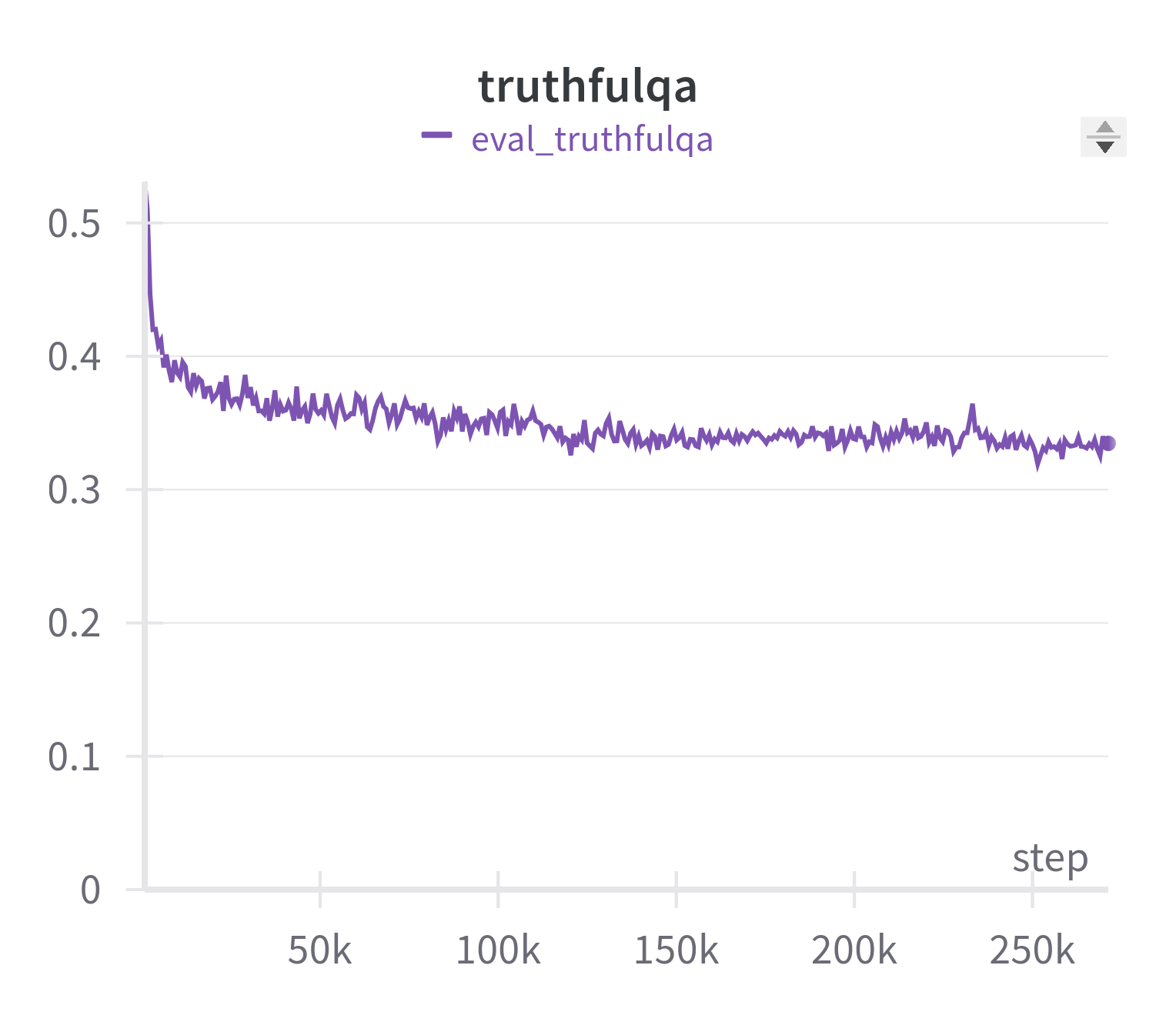
|<img src="amber-mmlu-curve.png" alt="mmlu" width="400"/> | <img src="amber-truthfulqa-curve.png" alt="truthfulqa" width="400"/> |
|
| 103 |
+
|
| 104 |
+
# Citation
|
| 105 |
+
|
| 106 |
+
Coming soon...
|
amber-arc-curve.pdf
ADDED
|
Binary file (18.5 kB). View file
|
|
|
amber-arc-curve.png
ADDED
|
amber-hellaswag-curve.pdf
ADDED
|
Binary file (20.3 kB). View file
|
|
|
amber-hellaswag-curve.png
ADDED
|
amber-mmlu-curve.pdf
ADDED
|
Binary file (19.1 kB). View file
|
|
|
amber-mmlu-curve.png
ADDED
|
amber-truthfulqa-curve.pdf
ADDED
|
Binary file (19.2 kB). View file
|
|
|
amber-truthfulqa-curve.png
ADDED

|
amber_logo.png
ADDED
|
|
arc.png
ADDED
|
hellaswag.png
ADDED
|
loss_curve.png
ADDED
|
mmlu.png
ADDED
|
truthfulqa.png
ADDED
|