
Upload 98 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +28 -0
- .gitignore +24 -0
- LICENSE +201 -0
- README.md +262 -0
- __pycache__/distributed.cpython-310.pyc +0 -0
- __pycache__/models.cpython-310.pyc +0 -0
- __pycache__/models.cpython-38.pyc +0 -0
- __pycache__/utils.cpython-310.pyc +0 -0
- __pycache__/utils.cpython-38.pyc +0 -0
- __pycache__/vgg_model.cpython-310.pyc +0 -0
- __pycache__/vgg_model.cpython-38.pyc +0 -0
- assets/PFFB.png +0 -0
- assets/Pipeline.png +3 -0
- assets/network.png +3 -0
- data/__pycache__/data_loader.cpython-310.pyc +0 -0
- data/__pycache__/tps_transformation.cpython-310.pyc +0 -0
- data/data_loader.py +97 -0
- data/data_loader_sketch.py +120 -0
- data/prepare_data.py +84 -0
- data/prepare_data_sketch.py +84 -0
- data/thinplate/__init__.py +9 -0
- data/thinplate/__pycache__/__init__.cpython-310.pyc +0 -0
- data/thinplate/__pycache__/numpy.cpython-310.pyc +0 -0
- data/thinplate/__pycache__/pytorch.cpython-310.pyc +0 -0
- data/thinplate/numpy.py +115 -0
- data/thinplate/pytorch.py +126 -0
- data/thinplate/tests/__init__.py +0 -0
- data/thinplate/tests/test_tps_numpy.py +85 -0
- data/thinplate/tests/test_tps_pytorch.py +43 -0
- data/tps_transformation.py +44 -0
- discriminator.py +31 -0
- distributed.py +126 -0
- experiments/Color2Manga_gray/074000_gray.pt +3 -0
- experiments/Color2Manga_sketch/116000_sketch.pt +3 -0
- experiments/Discriminator/074000_d.pt +3 -0
- experiments/Discriminator/116000_d.pt +3 -0
- experiments/VGG19/vgg19-dcbb9e9d.pth +3 -0
- extractor/Open-Sans-Bold.ttf +0 -0
- extractor/__pycache__/manga_panel_extractor.cpython-310.pyc +0 -0
- extractor/__pycache__/manga_panel_extractor.cpython-38.pyc +0 -0
- extractor/manga_panel_extractor.py +174 -0
- inference.py +229 -0
- models.py +223 -0
- real_manga/class1/Color 1659315.jpg +3 -0
- real_manga/class1/Color 3223141571376159.jpg +3 -0
- real_manga/class1/Color 3486521.jpg +3 -0
- real_manga/class1/Color 5102676.jpg +3 -0
- real_manga/class1/Color 5570824.jpg +3 -0
- real_manga/class1/Color 5674950.jpg +3 -0
- real_manga/class1/Color 5828407151952509.jpg +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,31 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/network.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/Pipeline.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
real_manga/class1/Color[[:space:]]1659315.jpg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
real_manga/class1/Color[[:space:]]3223141571376159.jpg filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
real_manga/class1/Color[[:space:]]3486521.jpg filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
real_manga/class1/Color[[:space:]]5102676.jpg filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
real_manga/class1/Color[[:space:]]5570824.jpg filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
real_manga/class1/Color[[:space:]]5674950.jpg filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
real_manga/class1/Color[[:space:]]5828407151952509.jpg filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
real_manga/class1/Color[[:space:]]5851155317235124.jpg filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
real_manga/class1/Color[[:space:]]6429789966786911.jpg filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
real_manga/class1/Color[[:space:]]6813581942189493.jpg filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
real_manga/class1/Color[[:space:]]8096755.jpg filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
test_datasets/gray_test/001_in.png filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
test_datasets/gray_test/002_in_ref_b.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
test_datasets/gray_test/004_in.png filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
test_datasets/gray_test/005_in.png filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
test_datasets/gray_test/006_in.png filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
test_datasets/gray_test/006_ref.png filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
test_datasets/gray_test/out/001_in_color_a.png filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
test_datasets/gray_test/out/001_in_color_b.png filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
test_datasets/gray_test/out/002_in_color_a.png filter=lfs diff=lfs merge=lfs -text
|
| 58 |
+
test_datasets/gray_test/out/002_in_color_b.png filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
test_datasets/gray_test/out/003_in_color_a.png filter=lfs diff=lfs merge=lfs -text
|
| 60 |
+
test_datasets/gray_test/out/003_in_color_b.png filter=lfs diff=lfs merge=lfs -text
|
| 61 |
+
test_datasets/gray_test/out/004_in_color.png filter=lfs diff=lfs merge=lfs -text
|
| 62 |
+
test_datasets/gray_test/out/005_in_color.png filter=lfs diff=lfs merge=lfs -text
|
| 63 |
+
test_datasets/gray_test/out/006_in_color.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Example user template template
|
| 2 |
+
### Example user template
|
| 3 |
+
|
| 4 |
+
# IntelliJ project files
|
| 5 |
+
.idea
|
| 6 |
+
*.iml
|
| 7 |
+
out
|
| 8 |
+
gen
|
| 9 |
+
|
| 10 |
+
# Debug file
|
| 11 |
+
datacheck.py
|
| 12 |
+
test_gray2color.py
|
| 13 |
+
val.py
|
| 14 |
+
|
| 15 |
+
experiments/
|
| 16 |
+
misc/
|
| 17 |
+
results/
|
| 18 |
+
test_datasets/*
|
| 19 |
+
!/test_datasets/gray_test
|
| 20 |
+
!/test_datasets/gray_test/out
|
| 21 |
+
!/test_datasets/sketch_test
|
| 22 |
+
!/test_datasets/sketch_test/out
|
| 23 |
+
train_datasets/
|
| 24 |
+
training_logs/
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Reference-Image-Embed-Manga-Colorization
|
| 2 |
+
|
| 3 |
+
An amazing manga colorization project
|
| 4 |
+
|
| 5 |
+
You can colorize gray manga or character sketches using any reference image you want, this model will faithfully retain the color features and transfer them to your manga. This is useful when you wish the color of the character's hair or clothes to be consistent.
|
| 6 |
+
|
| 7 |
+
If the project is helpful, please leave a ⭐ this repo. best luck, my friend 😊 <br>
|
| 8 |
+
|
| 9 |
+
## Overview
|
| 10 |
+
<p align="left">
|
| 11 |
+
<img src="./assets/network.png">
|
| 12 |
+
</p>
|
| 13 |
+
|
| 14 |
+
It's basically a cGAN(Conditional Generative Adversarial Network) architecture.
|
| 15 |
+
|
| 16 |
+
### Generator
|
| 17 |
+
|
| 18 |
+
Generator is divided into two parts.
|
| 19 |
+
|
| 20 |
+
`Color Embedding Layer` consists of part of pretrained VGG19 net and an MLP(Multilayer Perceptron), which is used to extract `color embedding` from reference image(for training, its preprocessed Ground Truth Image).
|
| 21 |
+
|
| 22 |
+
Another part is a U-net-like network. The encoder layer extracts `content embedding` from gray input image(only contains L-channel information), and the decoder layer reconstructs the image with `color embedding` through PFFB(Progressive Feature Formalization Block) and outputs the ab_channel information.
|
| 23 |
+
|
| 24 |
+
<p align="left">
|
| 25 |
+
<img src="./assets/PFFB.png">
|
| 26 |
+
</p>
|
| 27 |
+
|
| 28 |
+
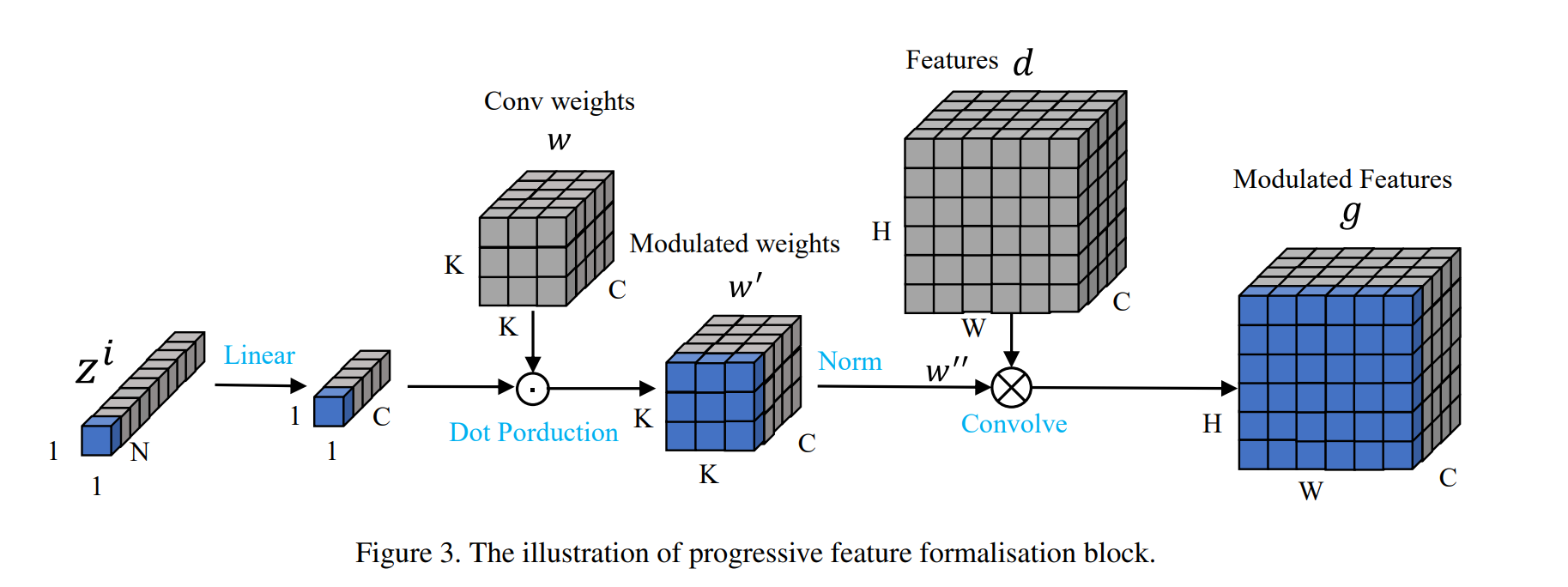
The figure shows how PFFB works.
|
| 29 |
+
|
| 30 |
+
It generates a filter by applying color embedding, and then convolving with content features. The figure is from this [paper](https://arxiv.org/abs/2106.08017) and check it for more details.
|
| 31 |
+
|
| 32 |
+
### Discriminator
|
| 33 |
+
|
| 34 |
+
Discriminator is a PatchGAN, referring to [pix2pix](https://arxiv.org/abs/1611.07004v3). The difference is that there are two conditions used for input. One is the gray image waiting for colorization, and one is the reference image providing color information.
|
| 35 |
+
|
| 36 |
+
### Loss
|
| 37 |
+
|
| 38 |
+
There are three losses in total, `L1 loss`, `perceptual loss` produced by pretrained vgg19, and `adversarial loss` produced by discriminator. The ratio is `1: 0.1: 0.01`.
|
| 39 |
+
|
| 40 |
+
### Pipeline
|
| 41 |
+
|
| 42 |
+
<p align="left">
|
| 43 |
+
<img src="./assets/Pipeline.png">
|
| 44 |
+
</p>
|
| 45 |
+
|
| 46 |
+
- a. Segment panels from input manga image, `Manga-Panel-Extractor` is from [here](https://github.com/pvnieo/Manga-Panel-Extractor).
|
| 47 |
+
- b. Select a reference image for each panel, and generator will colorize each panel.
|
| 48 |
+
- c. Concatenate all colorized panels into original format.
|
| 49 |
+
|
| 50 |
+
## Results
|
| 51 |
+
### Gray model
|
| 52 |
+
|
| 53 |
+
| Original | Reference | Colorization |
|
| 54 |
+
|:----------:|:-----------:|:----------:|
|
| 55 |
+
| <img src="test_datasets/gray_test/001_in.png" width="400"> | <img src="test_datasets/gray_test/001_ref_a.png" width="200"> | <img src="test_datasets/gray_test/out/001_in_color_a.png" width="400"> |
|
| 56 |
+
| <img src="test_datasets/gray_test/001_in.png" width="400"> | <img src="test_datasets/gray_test/001_ref_b.png" width="200"> | <img src="test_datasets/gray_test/out/001_in_color_b.png" width="400"> |
|
| 57 |
+
| <img src="test_datasets/gray_test/002_in.jpeg" width="400"> | <img src="test_datasets/gray_test/002_in_ref_a.jpg" width="200"> | <img src="test_datasets/gray_test/out/002_in_color_a.png" width="400"> |
|
| 58 |
+
| <img src="test_datasets/gray_test/002_in.jpeg" width="400"> | <img src="test_datasets/gray_test/002_in_ref_b.jpeg" width="200"> | <img src="test_datasets/gray_test/out/002_in_color_b.png" width="400"> |
|
| 59 |
+
| <img src="test_datasets/gray_test/003_in.jpeg" width="400"> | <img src="test_datasets/gray_test/003_in_ref_a.jpg" width="200"> | <img src="test_datasets/gray_test/out/003_in_color_a.png" width="400"> |
|
| 60 |
+
| <img src="test_datasets/gray_test/003_in.jpeg" width="400"> | <img src="test_datasets/gray_test/003_in_ref_b.jpg" width="200"> | <img src="test_datasets/gray_test/out/003_in_color_b.png" width="400"> |
|
| 61 |
+
| <img src="test_datasets/gray_test/004_in.png" width="400"> |<img src="test_datasets/gray_test/004_ref_1.jpg" width="100"><img src="test_datasets/gray_test/004_ref_2.jpg" width="100">| <img src="test_datasets/gray_test/out/004_in_color.png" width="400">|
|
| 62 |
+
| <img src="test_datasets/gray_test/005_in.png" width="400"> | <img src="test_datasets/gray_test/005_ref_1.jpeg" width="100"><img src="test_datasets/gray_test/005_ref_2.jpg" width="100"><img src="test_datasets/gray_test/005_ref_3.jpeg" width="100"> | <img src="test_datasets/gray_test/out/005_in_color.png" width="400"> |
|
| 63 |
+
| <img src="test_datasets/gray_test/006_in.png" width="400"> | <img src="test_datasets/gray_test/006_ref.png" width="200"> | <img src="test_datasets/gray_test/out/006_in_color.png" width="400"> |
|
| 64 |
+
|
| 65 |
+
### sketch model
|
| 66 |
+
|
| 67 |
+
| Original | Reference | Colorization |
|
| 68 |
+
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
| 69 |
+
| <img src="test_datasets/sketch_test/001_in.jpg" width="400"> | <img src="test_datasets/sketch_test/001_ref_a.jpg" width="200"> | <img src="test_datasets/sketch_test/out/001_in_color_a.png" width="400"> |
|
| 70 |
+
| <img src="test_datasets/sketch_test/001_in.jpg" width="400"> | <img src="test_datasets/sketch_test/001_ref_b.jpg" width="200"> | <img src="test_datasets/sketch_test/out/001_in_color_b.png" width="400"> |
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
## Dependencies and Installation
|
| 75 |
+
|
| 76 |
+
1. Clone this GitHub repo.
|
| 77 |
+
```
|
| 78 |
+
git clone https://github.com/linSensiGit/Example_Based_Manga_Colorization---cGAN.git
|
| 79 |
+
|
| 80 |
+
cd Example_Based_Manga_Colorization---cGAN
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
2. Create Environment
|
| 84 |
+
- Python >= 3.6 (Recommend to use [Anaconda](https://www.anaconda.com/download/#linux))
|
| 85 |
+
|
| 86 |
+
- [PyTorch >= 1.5.0](https://pytorch.org/) (Default GPU mode)
|
| 87 |
+
|
| 88 |
+
```
|
| 89 |
+
# My environment for reference
|
| 90 |
+
- Python = 3.9.15
|
| 91 |
+
- PyTorch = 1.13.0
|
| 92 |
+
- Torchvision = 0.14.0
|
| 93 |
+
- Cuda = 11.7
|
| 94 |
+
- GPU = RTX 3060ti
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
3. Install Dependencies
|
| 98 |
+
|
| 99 |
+
```
|
| 100 |
+
pip3 install -r requirement.txt
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
## Get Started
|
| 104 |
+
|
| 105 |
+
Once you've set up the environment, several things need to be done before colorization.
|
| 106 |
+
|
| 107 |
+
### Prepare pretrained models
|
| 108 |
+
|
| 109 |
+
1. Download generator. I have trained two generators, for [gray manga](https://drive.google.com/file/d/11RQGvBKySEtRcBdYD8O5ZLb54jB7SAgN/view?usp=drive_link) colorization and [sketch](https://drive.google.com/file/d/1I4XwOYIGAoQwMOicknZl0s6AWcwpARmR/view?usp=drive_link) colorization. Choose what you need.
|
| 110 |
+
|
| 111 |
+
2. Download [VGG model](https://drive.google.com/file/d/1S7t3mD-tznEUrMmq5bRsLZk4fkN24QSV/view?usp=drive_link) , it's part of generator.
|
| 112 |
+
|
| 113 |
+
3. Download discriminator, for training [gray manga](https://drive.google.com/file/d/1DHHE9um_xOm0brTpbHb_R7K7J4mn37FS/view?usp=drive_link) colorization and [sketch](https://drive.google.com/file/d/1WgIPYY4b4GcpHW9EWFrFoTxL9SlilQbN/view?usp=drive_link) colorization. (optional)
|
| 114 |
+
|
| 115 |
+
4. Put the pretrained model in the correct directory:
|
| 116 |
+
|
| 117 |
+
```
|
| 118 |
+
Colorful-Manga-GAN
|
| 119 |
+
|- experiments
|
| 120 |
+
|- Color2Manga_gray
|
| 121 |
+
|- xxx000_gray.pt
|
| 122 |
+
|- Color2Manga_sketch
|
| 123 |
+
|- xxx000_sketch.pt
|
| 124 |
+
|- Discriminator
|
| 125 |
+
|- xxx000_d.pt
|
| 126 |
+
|- VGG19
|
| 127 |
+
|- vgg19-dcbb9e9d.pth
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
### Quick test
|
| 131 |
+
|
| 132 |
+
I have collected some test datasets which contain manga pages and corresponding reference images. You can check it in the path `./test_datasets`. When you use the file `inference.py` to test, you may need to edit the input file path or pretrained weights path in this file.
|
| 133 |
+
|
| 134 |
+
```
|
| 135 |
+
python inference.py
|
| 136 |
+
|
| 137 |
+
# If you don't want to segment your manga
|
| 138 |
+
python inference.py -ne
|
| 139 |
+
```
|
| 140 |
+
Initially, `Manga-Panel-Extractor` will segment the manga page into panels.
|
| 141 |
+
|
| 142 |
+
Then follow the instructions in the console and you will get the colorized image.
|
| 143 |
+
|
| 144 |
+
## Train your Own Model
|
| 145 |
+
### Prepare Datasets
|
| 146 |
+
|
| 147 |
+
There are three datasets I used to train the model.
|
| 148 |
+
|
| 149 |
+
For gray model, [Anime Face Dataset](https://www.kaggle.com/datasets/scribbless/another-anime-face-dataset) and Tagged [Anime Illustrations Dataset](https://www.kaggle.com/datasets/mylesoneill/tagged-anime-illustrations) are used. And I only use `danbooru-images` folder in the second Dataset.
|
| 150 |
+
|
| 151 |
+
For sketch model, [Anime Sketch Colorization Pair Dataset](https://www.kaggle.com/datasets/ktaebum/anime-sketch-colorization-pair) is used.
|
| 152 |
+
|
| 153 |
+
All the datasets are from [Kaggle](https://www.kaggle.com/).
|
| 154 |
+
|
| 155 |
+
Follow instructions are based on my dataset, but feel free to use your own dataset if you like.
|
| 156 |
+
|
| 157 |
+
### Preprocess training data
|
| 158 |
+
|
| 159 |
+
```
|
| 160 |
+
cd data
|
| 161 |
+
python prepare_data.py
|
| 162 |
+
```
|
| 163 |
+
|
| 164 |
+
If you are using ` Anime Sketch Colorization Pair` dataset :
|
| 165 |
+
|
| 166 |
+
```
|
| 167 |
+
python prepare_data_sketch.py
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
Several arguments needed to be assigned :
|
| 171 |
+
|
| 172 |
+
```
|
| 173 |
+
usage: prepare_data.py [-h] [--out OUT] [--size SIZE] [--n_worker N_WORKER]
|
| 174 |
+
[--resample RESAMPLE]
|
| 175 |
+
path
|
| 176 |
+
positional arguments:
|
| 177 |
+
path the path of datasets
|
| 178 |
+
optional arguments:
|
| 179 |
+
-h, --help show this help message and exit
|
| 180 |
+
--out OUT the path to save generated lmdb
|
| 181 |
+
--size SIZE compressed image size (128, 256, 512, 1024) alternative
|
| 182 |
+
--n_worker N_WORKER The number of threads, depends on your CPU
|
| 183 |
+
--resample RESAMPLE
|
| 184 |
+
```
|
| 185 |
+
|
| 186 |
+
For instance, you can run the command like this:
|
| 187 |
+
|
| 188 |
+
```
|
| 189 |
+
python prepare_data.py --out ../train_datasets/Sketch_train_lmdb --n_worker 20 --size 256 E:/Dataset/animefaces256cleaner
|
| 190 |
+
```
|
| 191 |
+
|
| 192 |
+
### Training
|
| 193 |
+
|
| 194 |
+
There are four scripts in total for training
|
| 195 |
+
|
| 196 |
+
`train.py` —— train only generator
|
| 197 |
+
|
| 198 |
+
`train_disc` —— train only discriminator
|
| 199 |
+
|
| 200 |
+
`train_all_gray.py`—— train both generator and discriminator, under the usual dataset
|
| 201 |
+
|
| 202 |
+
`train_all_sketch.py`—— train both generator and discriminator, under sketch pair dataset specific
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
All of these scripts share similar commands to drive:
|
| 207 |
+
|
| 208 |
+
```
|
| 209 |
+
usage: train_all_gray.py [-h] [--datasets DATASETS] [--iter ITER]
|
| 210 |
+
[--batch BATCH] [--size SIZE] [--ckpt CKPT]
|
| 211 |
+
[--ckpt_disc CKPT_DISC] [--lr LR] [--lr_disc LR_DISC]
|
| 212 |
+
[--experiment_name EXPERIMENT_NAME] [--wandb]
|
| 213 |
+
[--local_rank LOCAL_RANK]
|
| 214 |
+
optional arguments:
|
| 215 |
+
-h, --help show this help message and exit
|
| 216 |
+
--datasets DATASETS the path of training dataset
|
| 217 |
+
--iter ITER number of iteration in total
|
| 218 |
+
--batch BATCH batch size
|
| 219 |
+
--size SIZE size of image in dataset, usually 256
|
| 220 |
+
--ckpt CKPT path of pretrained generator
|
| 221 |
+
--ckpt_disc CKPT_DISC path of pretrained discriminator
|
| 222 |
+
--lr LR learning rate of generator
|
| 223 |
+
--lr_disc LR_DISC learning rate of discriminator
|
| 224 |
+
--experiment_name EXPERIMENT_NAME used to save training_logs and trained model
|
| 225 |
+
--wandb
|
| 226 |
+
--local_rank LOCAL_RANK
|
| 227 |
+
```
|
| 228 |
+
|
| 229 |
+
There may be a slight difference, you could check the code for more details.
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
For instance, you can run the command like this:
|
| 234 |
+
|
| 235 |
+
```
|
| 236 |
+
python train_all_gray.py --batch 8 --experiment_name Color2Manga_sketch --ckpt experiments/Color2Manga_sketch/078000.pt --datasets ./train_datasets/Sketch_train_lmdb --ckpt_disc experiments/Discriminator/078000_d.pt
|
| 237 |
+
```
|
| 238 |
+
|
| 239 |
+
## Work in Progress
|
| 240 |
+
- [ ] Add SR model instead of directly interpolate upscaling
|
| 241 |
+
- [ ] Optimize the generator network(adding L-channel information to output which is essential for colorize sketch)
|
| 242 |
+
- [ ] Better developed manga-panel-extractor(current segmentation is not precise enough)
|
| 243 |
+
- [ ] Develop a front UI and add color hint so that users could adjust the color of a specific area
|
| 244 |
+
|
| 245 |
+
## 😁Contact
|
| 246 |
+
|
| 247 |
+
If you have any questions, please feel free to contact me via `shizifeng0615@outlook.com`
|
| 248 |
+
|
| 249 |
+
## 🙌 Acknowledgement
|
| 250 |
+
Based on https://github.com/zhaohengyuan1/Color2Embed
|
| 251 |
+
|
| 252 |
+
Thx https://github.com/pvnieo/Manga-Panel-Extractor
|
| 253 |
+
|
| 254 |
+
## Reference
|
| 255 |
+
|
| 256 |
+
[1] Zhao, Hengyuan et al. “Color2Embed: Fast Exemplar-Based Image Colorization using Color Embeddings.” (2021).
|
| 257 |
+
|
| 258 |
+
[2] Isola, Phillip et al. “Image-to-Image Translation with Conditional Adversarial Networks.” *2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)* (2016): 5967-5976.
|
| 259 |
+
|
| 260 |
+
[3] Furusawa, Chie et al. “Comicolorization: semi-automatic manga colorization.” *SIGGRAPH Asia 2017 Technical Briefs* (2017): n. pag.
|
| 261 |
+
|
| 262 |
+
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. "Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification". ACM Transaction on Graphics (Proc. of SIGGRAPH), 35(4):110, 2016.
|
__pycache__/distributed.cpython-310.pyc
ADDED
|
Binary file (2.98 kB). View file
|
|
|
__pycache__/models.cpython-310.pyc
ADDED
|
Binary file (6.13 kB). View file
|
|
|
__pycache__/models.cpython-38.pyc
ADDED
|
Binary file (6.22 kB). View file
|
|
|
__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (2.72 kB). View file
|
|
|
__pycache__/utils.cpython-38.pyc
ADDED
|
Binary file (2.72 kB). View file
|
|
|
__pycache__/vgg_model.cpython-310.pyc
ADDED
|
Binary file (3.97 kB). View file
|
|
|
__pycache__/vgg_model.cpython-38.pyc
ADDED
|
Binary file (3.96 kB). View file
|
|
|
assets/PFFB.png
ADDED
|
assets/Pipeline.png
ADDED

|
Git LFS Details
|
assets/network.png
ADDED

|
Git LFS Details
|
data/__pycache__/data_loader.cpython-310.pyc
ADDED
|
Binary file (3.04 kB). View file
|
|
|
data/__pycache__/tps_transformation.cpython-310.pyc
ADDED
|
Binary file (1.1 kB). View file
|
|
|
data/data_loader.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from io import BytesIO
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import lmdb
|
| 5 |
+
from PIL import Image
|
| 6 |
+
from skimage import color
|
| 7 |
+
import torch
|
| 8 |
+
from torch.utils.data import Dataset
|
| 9 |
+
from data.tps_transformation import tps_transform
|
| 10 |
+
|
| 11 |
+
def RGB2Lab(inputs):
|
| 12 |
+
return color.rgb2lab(inputs)
|
| 13 |
+
|
| 14 |
+
def Normalize(inputs):
|
| 15 |
+
# output l [-50,50] ab[-128,128]
|
| 16 |
+
l = inputs[:, :, 0:1]
|
| 17 |
+
ab = inputs[:, :, 1:3]
|
| 18 |
+
l = l - 50
|
| 19 |
+
# ab = ab
|
| 20 |
+
lab = np.concatenate((l, ab), 2)
|
| 21 |
+
|
| 22 |
+
return lab.astype('float32')
|
| 23 |
+
|
| 24 |
+
def selfnormalize(inputs):
|
| 25 |
+
d = torch.max(inputs) - torch.min(inputs)
|
| 26 |
+
out = (inputs) / d
|
| 27 |
+
return out
|
| 28 |
+
|
| 29 |
+
def to_gray(inputs):
|
| 30 |
+
img_gray = np.clip((np.concatenate((inputs[:,:,:1], inputs[:,:,:1], inputs[:,:,:1]), 2)+50)/100*255, 0, 255).astype('uint8')
|
| 31 |
+
|
| 32 |
+
return img_gray
|
| 33 |
+
|
| 34 |
+
def numpy2tensor(inputs):
|
| 35 |
+
out = torch.from_numpy(inputs.transpose(2,0,1))
|
| 36 |
+
return out
|
| 37 |
+
|
| 38 |
+
class MultiResolutionDataset(Dataset):
|
| 39 |
+
def __init__(self, path, transform, resolution=256):
|
| 40 |
+
self.env = lmdb.open(
|
| 41 |
+
path,
|
| 42 |
+
max_readers=32,
|
| 43 |
+
readonly=True,
|
| 44 |
+
lock=False,
|
| 45 |
+
readahead=False,
|
| 46 |
+
meminit=False,
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
if not self.env:
|
| 50 |
+
raise IOError('Cannot open lmdb dataset', path)
|
| 51 |
+
|
| 52 |
+
with self.env.begin(write=False) as txn:
|
| 53 |
+
self.length = int(txn.get('length'.encode('utf-8')).decode('utf-8'))
|
| 54 |
+
|
| 55 |
+
self.resolution = resolution
|
| 56 |
+
self.transform = transform
|
| 57 |
+
|
| 58 |
+
def __len__(self):
|
| 59 |
+
return self.length
|
| 60 |
+
|
| 61 |
+
def __getitem__(self, index):
|
| 62 |
+
with self.env.begin(write=False) as txn:
|
| 63 |
+
key = f'{self.resolution}-{str(index).zfill(5)}'.encode('utf-8')
|
| 64 |
+
img_bytes = txn.get(key)
|
| 65 |
+
|
| 66 |
+
buffer = BytesIO(img_bytes)
|
| 67 |
+
img = Image.open(buffer)
|
| 68 |
+
img_src = np.array(img) # [0,255] uint8
|
| 69 |
+
|
| 70 |
+
# ima_a = img_src
|
| 71 |
+
# ima_a = ima_a.astype('uint8')
|
| 72 |
+
# ima_a = Image.fromarray(ima_a)
|
| 73 |
+
# ima_a.show()
|
| 74 |
+
|
| 75 |
+
## add gaussian noise
|
| 76 |
+
noise = np.random.uniform(-5, 5, np.shape(img_src))
|
| 77 |
+
img_ref = np.clip(np.array(img_src) + noise, 0, 255)
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
img_ref = tps_transform(img_ref) # [0,255] uint8
|
| 81 |
+
img_ref = np.clip(img_ref, 0, 255)
|
| 82 |
+
img_ref = img_ref.astype('uint8')
|
| 83 |
+
img_ref = Image.fromarray(img_ref)
|
| 84 |
+
img_ref = np.array(self.transform(img_ref)) # [0,255] uint8
|
| 85 |
+
|
| 86 |
+
img_lab = Normalize(RGB2Lab(img_src)) # l [-50,50] ab [-128, 128]
|
| 87 |
+
|
| 88 |
+
img = img_src.astype('float32') # [0,255] float32 RGB
|
| 89 |
+
img_ref = img_ref.astype('float32') # [0,255] float32 RGB
|
| 90 |
+
|
| 91 |
+
img = numpy2tensor(img)
|
| 92 |
+
img_ref = numpy2tensor(img_ref) # [B, 3, 256, 256]
|
| 93 |
+
img_lab = numpy2tensor(img_lab)
|
| 94 |
+
|
| 95 |
+
return img, img_ref, img_lab
|
| 96 |
+
|
| 97 |
+
|
data/data_loader_sketch.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from io import BytesIO
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import lmdb
|
| 5 |
+
from PIL import Image
|
| 6 |
+
from skimage import color
|
| 7 |
+
import torch
|
| 8 |
+
from torch.utils.data import Dataset
|
| 9 |
+
from data.tps_transformation import tps_transform
|
| 10 |
+
|
| 11 |
+
def RGB2Lab(inputs):
|
| 12 |
+
return color.rgb2lab(inputs)
|
| 13 |
+
|
| 14 |
+
def Normalize(inputs):
|
| 15 |
+
# output l [-50,50] ab[-128,128]
|
| 16 |
+
l = inputs[:, :, 0:1]
|
| 17 |
+
ab = inputs[:, :, 1:3]
|
| 18 |
+
l = l - 50
|
| 19 |
+
# ab = ab
|
| 20 |
+
lab = np.concatenate((l, ab), 2)
|
| 21 |
+
|
| 22 |
+
return lab.astype('float32')
|
| 23 |
+
|
| 24 |
+
def selfnormalize(inputs):
|
| 25 |
+
d = torch.max(inputs) - torch.min(inputs)
|
| 26 |
+
out = (inputs) / d
|
| 27 |
+
return out
|
| 28 |
+
|
| 29 |
+
def to_gray(inputs):
|
| 30 |
+
img_gray = np.clip((np.concatenate((inputs[:,:,:1], inputs[:,:,:1], inputs[:,:,:1]), 2)+50)/100*255, 0, 255).astype('uint8')
|
| 31 |
+
|
| 32 |
+
return img_gray
|
| 33 |
+
|
| 34 |
+
def numpy2tensor(inputs):
|
| 35 |
+
out = torch.from_numpy(inputs.transpose(2,0,1))
|
| 36 |
+
return out
|
| 37 |
+
|
| 38 |
+
class MultiResolutionDataset(Dataset):
|
| 39 |
+
def __init__(self, path, transform, resolution=256):
|
| 40 |
+
self.env = lmdb.open(
|
| 41 |
+
path,
|
| 42 |
+
max_readers=32,
|
| 43 |
+
readonly=True,
|
| 44 |
+
lock=False,
|
| 45 |
+
readahead=False,
|
| 46 |
+
meminit=False,
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
if not self.env:
|
| 50 |
+
raise IOError('Cannot open lmdb dataset', path)
|
| 51 |
+
|
| 52 |
+
with self.env.begin(write=False) as txn:
|
| 53 |
+
self.length = int(txn.get('length'.encode('utf-8')).decode('utf-8'))
|
| 54 |
+
|
| 55 |
+
self.resolution = resolution
|
| 56 |
+
self.transform = transform
|
| 57 |
+
|
| 58 |
+
def __len__(self):
|
| 59 |
+
return self.length
|
| 60 |
+
|
| 61 |
+
def __getitem__(self, index):
|
| 62 |
+
with self.env.begin(write=False) as txn:
|
| 63 |
+
key = f'{self.resolution}-{str(index).zfill(5)}'.encode('utf-8')
|
| 64 |
+
img_bytes = txn.get(key)
|
| 65 |
+
|
| 66 |
+
buffer = BytesIO(img_bytes)
|
| 67 |
+
img = Image.open(buffer)
|
| 68 |
+
img_src = np.array(img) # [0,255] uint8
|
| 69 |
+
|
| 70 |
+
# ima_a = img_src
|
| 71 |
+
# ima_a = ima_a.astype('uint8')
|
| 72 |
+
# ima_a = Image.fromarray(ima_a)
|
| 73 |
+
# ima_a.show()
|
| 74 |
+
|
| 75 |
+
# get the left color image
|
| 76 |
+
img_ref = img_src[:, :256]
|
| 77 |
+
## add gaussian noise
|
| 78 |
+
noise = np.random.uniform(-5, 5, np.shape(img_ref))
|
| 79 |
+
img_ref = np.clip(np.array(img_ref) + noise, 0, 255)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
img_ref = tps_transform(img_ref) # [0,255] uint8
|
| 83 |
+
img_ref = np.clip(img_ref, 0, 255)
|
| 84 |
+
img_ref = img_ref.astype('uint8')
|
| 85 |
+
img_ref = Image.fromarray(img_ref)
|
| 86 |
+
img_ref = np.array(self.transform(img_ref)) # [0,255] uint8
|
| 87 |
+
|
| 88 |
+
img_lab = img_src[:, :256]
|
| 89 |
+
img_lab = Normalize(RGB2Lab(img_lab)) # l [-50,50] ab [-128, 128]
|
| 90 |
+
|
| 91 |
+
img_lab_sketch = img_src[:, 256:]
|
| 92 |
+
img_lab_sketch = Normalize(RGB2Lab(img_lab_sketch)) # l [-50,50] ab [-128, 128]
|
| 93 |
+
|
| 94 |
+
img = img_src[:, :256].astype('float32') # [0,255] float32 RGB
|
| 95 |
+
img_ref = img_ref.astype('float32') # [0,255] float32 RGB
|
| 96 |
+
|
| 97 |
+
# ima_a = img
|
| 98 |
+
# ima_a = ima_a.astype('uint8')
|
| 99 |
+
# ima_a = Image.fromarray(ima_a)
|
| 100 |
+
# ima_a.show()
|
| 101 |
+
#
|
| 102 |
+
# ima_a = img_ref
|
| 103 |
+
# ima_a = ima_a.astype('uint8')
|
| 104 |
+
# ima_a = Image.fromarray(ima_a)
|
| 105 |
+
# ima_a.show()
|
| 106 |
+
#
|
| 107 |
+
# ima_a = img_lab
|
| 108 |
+
# ima_a = ima_a.astype('uint8')
|
| 109 |
+
# ima_a = Image.fromarray(ima_a)
|
| 110 |
+
# ima_a.show()
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
img = numpy2tensor(img)
|
| 114 |
+
img_ref = numpy2tensor(img_ref) # [B, 3, 256, 256]
|
| 115 |
+
img_lab = numpy2tensor(img_lab)
|
| 116 |
+
img_lab_sketch = numpy2tensor(img_lab_sketch)
|
| 117 |
+
|
| 118 |
+
return img, img_ref, img_lab, img_lab_sketch
|
| 119 |
+
|
| 120 |
+
|
data/prepare_data.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from io import BytesIO
|
| 3 |
+
import multiprocessing
|
| 4 |
+
from functools import partial
|
| 5 |
+
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import lmdb
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
from torchvision import datasets
|
| 10 |
+
from torchvision.transforms import functional as trans_fn
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def resize_and_convert(img, size, resample, quality=100):
|
| 14 |
+
img = trans_fn.resize(img, size, resample)
|
| 15 |
+
img = trans_fn.center_crop(img, size)
|
| 16 |
+
buffer = BytesIO()
|
| 17 |
+
img.save(buffer, format='jpeg', quality=quality)
|
| 18 |
+
val = buffer.getvalue()
|
| 19 |
+
|
| 20 |
+
return val
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def resize_multiple(img, sizes=(128, 256, 512, 1024), resample=Image.LANCZOS, quality=100):
|
| 24 |
+
imgs = []
|
| 25 |
+
|
| 26 |
+
for size in sizes:
|
| 27 |
+
imgs.append(resize_and_convert(img, size, resample, quality))
|
| 28 |
+
|
| 29 |
+
return imgs
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def resize_worker(img_file, sizes, resample):
|
| 33 |
+
i, file = img_file
|
| 34 |
+
img = Image.open(file)
|
| 35 |
+
img = img.convert('RGB')
|
| 36 |
+
out = resize_multiple(img, sizes=sizes, resample=resample)
|
| 37 |
+
|
| 38 |
+
return i, out
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def prepare(env, dataset, n_worker, sizes=(128, 256, 512, 1024), resample=Image.LANCZOS):
|
| 42 |
+
resize_fn = partial(resize_worker, sizes=sizes, resample=resample)
|
| 43 |
+
|
| 44 |
+
files = sorted(dataset.imgs, key=lambda x: x[0])
|
| 45 |
+
# print(files)
|
| 46 |
+
# eixt()
|
| 47 |
+
files = [(i, file) for i, (file, label) in enumerate(files)]
|
| 48 |
+
total = 0
|
| 49 |
+
|
| 50 |
+
with multiprocessing.Pool(n_worker) as pool:
|
| 51 |
+
for i, imgs in tqdm(pool.imap_unordered(resize_fn, files)):
|
| 52 |
+
for size, img in zip(sizes, imgs):
|
| 53 |
+
key = f'{size}-{str(i).zfill(5)}'.encode('utf-8')
|
| 54 |
+
|
| 55 |
+
with env.begin(write=True) as txn:
|
| 56 |
+
txn.put(key, img)
|
| 57 |
+
|
| 58 |
+
total += 1
|
| 59 |
+
|
| 60 |
+
with env.begin(write=True) as txn:
|
| 61 |
+
txn.put('length'.encode('utf-8'), str(total).encode('utf-8'))
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
if __name__ == '__main__':
|
| 65 |
+
parser = argparse.ArgumentParser()
|
| 66 |
+
parser.add_argument('--out', type=str)
|
| 67 |
+
parser.add_argument('--size', type=str, default='128,256,512,1024')
|
| 68 |
+
parser.add_argument('--n_worker', type=int, default=8)
|
| 69 |
+
parser.add_argument('--resample', type=str, default='lanczos')
|
| 70 |
+
parser.add_argument('path', type=str)
|
| 71 |
+
|
| 72 |
+
args = parser.parse_args()
|
| 73 |
+
|
| 74 |
+
resample_map = {'lanczos': Image.LANCZOS, 'bilinear': Image.BILINEAR}
|
| 75 |
+
resample = resample_map[args.resample]
|
| 76 |
+
|
| 77 |
+
sizes = [int(s.strip()) for s in args.size.split(',')]
|
| 78 |
+
|
| 79 |
+
print(f'Make dataset of image sizes:', ', '.join(str(s) for s in sizes))
|
| 80 |
+
|
| 81 |
+
imgset = datasets.ImageFolder(args.path)
|
| 82 |
+
|
| 83 |
+
with lmdb.open(args.out, map_size=6 * 1024 * 1024 * 1024, readahead=False) as env:
|
| 84 |
+
prepare(env, imgset, args.n_worker, sizes=sizes, resample=resample)
|
data/prepare_data_sketch.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from io import BytesIO
|
| 3 |
+
import multiprocessing
|
| 4 |
+
from functools import partial
|
| 5 |
+
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import lmdb
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
from torchvision import datasets
|
| 10 |
+
from torchvision.transforms import functional as trans_fn
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def resize_and_convert(img, size, resample, quality=100):
|
| 14 |
+
img = trans_fn.resize(img, size=[256, 512], interpolation=resample)
|
| 15 |
+
img = trans_fn.center_crop(img, output_size=[256, 512])
|
| 16 |
+
buffer = BytesIO()
|
| 17 |
+
img.save(buffer, format='jpeg', quality=quality)
|
| 18 |
+
val = buffer.getvalue()
|
| 19 |
+
|
| 20 |
+
return val
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def resize_multiple(img, sizes=(128, 256, 512, 1024), resample=Image.LANCZOS, quality=100):
|
| 24 |
+
imgs = []
|
| 25 |
+
|
| 26 |
+
for size in sizes:
|
| 27 |
+
imgs.append(resize_and_convert(img, size, resample, quality))
|
| 28 |
+
|
| 29 |
+
return imgs
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def resize_worker(img_file, sizes, resample):
|
| 33 |
+
i, file = img_file
|
| 34 |
+
img = Image.open(file)
|
| 35 |
+
img = img.convert('RGB')
|
| 36 |
+
out = resize_multiple(img, sizes=sizes, resample=resample)
|
| 37 |
+
|
| 38 |
+
return i, out
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def prepare(env, dataset, n_worker, sizes=(128, 256, 512, 1024), resample=Image.LANCZOS):
|
| 42 |
+
resize_fn = partial(resize_worker, sizes=sizes, resample=resample)
|
| 43 |
+
|
| 44 |
+
files = sorted(dataset.imgs, key=lambda x: x[0])
|
| 45 |
+
# print(files)
|
| 46 |
+
# eixt()
|
| 47 |
+
files = [(i, file) for i, (file, label) in enumerate(files)]
|
| 48 |
+
total = 0
|
| 49 |
+
|
| 50 |
+
with multiprocessing.Pool(n_worker) as pool:
|
| 51 |
+
for i, imgs in tqdm(pool.imap_unordered(resize_fn, files)):
|
| 52 |
+
for size, img in zip(sizes, imgs):
|
| 53 |
+
key = f'{size}-{str(i).zfill(5)}'.encode('utf-8')
|
| 54 |
+
|
| 55 |
+
with env.begin(write=True) as txn:
|
| 56 |
+
txn.put(key, img)
|
| 57 |
+
|
| 58 |
+
total += 1
|
| 59 |
+
|
| 60 |
+
with env.begin(write=True) as txn:
|
| 61 |
+
txn.put('length'.encode('utf-8'), str(total).encode('utf-8'))
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
if __name__ == '__main__':
|
| 65 |
+
parser = argparse.ArgumentParser()
|
| 66 |
+
parser.add_argument('--out', type=str)
|
| 67 |
+
parser.add_argument('--size', type=str, default='128,256,512,1024')
|
| 68 |
+
parser.add_argument('--n_worker', type=int, default=8)
|
| 69 |
+
parser.add_argument('--resample', type=str, default='lanczos')
|
| 70 |
+
parser.add_argument('path', type=str)
|
| 71 |
+
|
| 72 |
+
args = parser.parse_args()
|
| 73 |
+
|
| 74 |
+
resample_map = {'lanczos': Image.LANCZOS, 'bilinear': Image.BILINEAR}
|
| 75 |
+
resample = resample_map[args.resample]
|
| 76 |
+
|
| 77 |
+
sizes = [int(s.strip()) for s in args.size.split(',')]
|
| 78 |
+
|
| 79 |
+
print(f'Make dataset of image sizes:', ', '.join(str(s) for s in sizes))
|
| 80 |
+
|
| 81 |
+
imgset = datasets.ImageFolder(args.path)
|
| 82 |
+
|
| 83 |
+
with lmdb.open(args.out, map_size=6 * 1024 * 1024 * 1024, readahead=False) as env:
|
| 84 |
+
prepare(env, imgset, args.n_worker, sizes=sizes, resample=resample)
|
data/thinplate/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from data.thinplate.numpy import *
|
| 2 |
+
|
| 3 |
+
try:
|
| 4 |
+
import torch
|
| 5 |
+
import data.thinplate.pytorch as torch
|
| 6 |
+
except ImportError:
|
| 7 |
+
pass
|
| 8 |
+
|
| 9 |
+
__version__ = '1.0.0'
|
data/thinplate/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (432 Bytes). View file
|
|
|
data/thinplate/__pycache__/numpy.cpython-310.pyc
ADDED
|
Binary file (3.59 kB). View file
|
|
|
data/thinplate/__pycache__/pytorch.cpython-310.pyc
ADDED
|
Binary file (4 kB). View file
|
|
|
data/thinplate/numpy.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2018 Christoph Heindl.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under MIT License
|
| 4 |
+
# ============================================================
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
class TPS:
|
| 9 |
+
@staticmethod
|
| 10 |
+
def fit(c, lambd=0., reduced=False):
|
| 11 |
+
n = c.shape[0]
|
| 12 |
+
|
| 13 |
+
U = TPS.u(TPS.d(c, c))
|
| 14 |
+
K = U + np.eye(n, dtype=np.float32)*lambd
|
| 15 |
+
|
| 16 |
+
P = np.ones((n, 3), dtype=np.float32)
|
| 17 |
+
P[:, 1:] = c[:, :2]
|
| 18 |
+
|
| 19 |
+
v = np.zeros(n+3, dtype=np.float32)
|
| 20 |
+
v[:n] = c[:, -1]
|
| 21 |
+
|
| 22 |
+
A = np.zeros((n+3, n+3), dtype=np.float32)
|
| 23 |
+
A[:n, :n] = K
|
| 24 |
+
A[:n, -3:] = P
|
| 25 |
+
A[-3:, :n] = P.T
|
| 26 |
+
|
| 27 |
+
theta = np.linalg.solve(A, v) # p has structure w,a
|
| 28 |
+
return theta[1:] if reduced else theta
|
| 29 |
+
|
| 30 |
+
@staticmethod
|
| 31 |
+
def d(a, b):
|
| 32 |
+
return np.sqrt(np.square(a[:, None, :2] - b[None, :, :2]).sum(-1))
|
| 33 |
+
|
| 34 |
+
@staticmethod
|
| 35 |
+
def u(r):
|
| 36 |
+
return r**2 * np.log(r + 1e-6)
|
| 37 |
+
|
| 38 |
+
@staticmethod
|
| 39 |
+
def z(x, c, theta):
|
| 40 |
+
x = np.atleast_2d(x)
|
| 41 |
+
U = TPS.u(TPS.d(x, c))
|
| 42 |
+
w, a = theta[:-3], theta[-3:]
|
| 43 |
+
reduced = theta.shape[0] == c.shape[0] + 2
|
| 44 |
+
if reduced:
|
| 45 |
+
w = np.concatenate((-np.sum(w, keepdims=True), w))
|
| 46 |
+
b = np.dot(U, w)
|
| 47 |
+
return a[0] + a[1]*x[:, 0] + a[2]*x[:, 1] + b
|
| 48 |
+
|
| 49 |
+
def uniform_grid(shape):
|
| 50 |
+
'''Uniform grid coordinates.
|
| 51 |
+
|
| 52 |
+
Params
|
| 53 |
+
------
|
| 54 |
+
shape : tuple
|
| 55 |
+
HxW defining the number of height and width dimension of the grid
|
| 56 |
+
|
| 57 |
+
Returns
|
| 58 |
+
-------
|
| 59 |
+
points: HxWx2 tensor
|
| 60 |
+
Grid coordinates over [0,1] normalized image range.
|
| 61 |
+
'''
|
| 62 |
+
|
| 63 |
+
H,W = shape[:2]
|
| 64 |
+
c = np.empty((H, W, 2))
|
| 65 |
+
c[..., 0] = np.linspace(0, 1, W, dtype=np.float32)
|
| 66 |
+
c[..., 1] = np.expand_dims(np.linspace(0, 1, H, dtype=np.float32), -1)
|
| 67 |
+
|
| 68 |
+
return c
|
| 69 |
+
|
| 70 |
+
def tps_theta_from_points(c_src, c_dst, reduced=False):
|
| 71 |
+
delta = c_src - c_dst
|
| 72 |
+
|
| 73 |
+
cx = np.column_stack((c_dst, delta[:, 0]))
|
| 74 |
+
cy = np.column_stack((c_dst, delta[:, 1]))
|
| 75 |
+
|
| 76 |
+
theta_dx = TPS.fit(cx, reduced=reduced)
|
| 77 |
+
theta_dy = TPS.fit(cy, reduced=reduced)
|
| 78 |
+
|
| 79 |
+
return np.stack((theta_dx, theta_dy), -1)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def tps_grid(theta, c_dst, dshape):
|
| 83 |
+
ugrid = uniform_grid(dshape)
|
| 84 |
+
|
| 85 |
+
reduced = c_dst.shape[0] + 2 == theta.shape[0]
|
| 86 |
+
|
| 87 |
+
dx = TPS.z(ugrid.reshape((-1, 2)), c_dst, theta[:, 0]).reshape(dshape[:2])
|
| 88 |
+
dy = TPS.z(ugrid.reshape((-1, 2)), c_dst, theta[:, 1]).reshape(dshape[:2])
|
| 89 |
+
dgrid = np.stack((dx, dy), -1)
|
| 90 |
+
|
| 91 |
+
grid = dgrid + ugrid
|
| 92 |
+
|
| 93 |
+
return grid # H'xW'x2 grid[i,j] in range [0..1]
|
| 94 |
+
|
| 95 |
+
def tps_grid_to_remap(grid, sshape):
|
| 96 |
+
'''Convert a dense grid to OpenCV's remap compatible maps.
|
| 97 |
+
|
| 98 |
+
Params
|
| 99 |
+
------
|
| 100 |
+
grid : HxWx2 array
|
| 101 |
+
Normalized flow field coordinates as computed by compute_densegrid.
|
| 102 |
+
sshape : tuple
|
| 103 |
+
Height and width of source image in pixels.
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
Returns
|
| 107 |
+
-------
|
| 108 |
+
mapx : HxW array
|
| 109 |
+
mapy : HxW array
|
| 110 |
+
'''
|
| 111 |
+
|
| 112 |
+
mx = (grid[:, :, 0] * sshape[1]).astype(np.float32)
|
| 113 |
+
my = (grid[:, :, 1] * sshape[0]).astype(np.float32)
|
| 114 |
+
|
| 115 |
+
return mx, my
|
data/thinplate/pytorch.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2018 Christoph Heindl.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under MIT License
|
| 4 |
+
# ============================================================
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
|
| 8 |
+
def tps(theta, ctrl, grid):
|
| 9 |
+
'''Evaluate the thin-plate-spline (TPS) surface at xy locations arranged in a grid.
|
| 10 |
+
The TPS surface is a minimum bend interpolation surface defined by a set of control points.
|
| 11 |
+
The function value for a x,y location is given by
|
| 12 |
+
|
| 13 |
+
TPS(x,y) := theta[-3] + theta[-2]*x + theta[-1]*y + \sum_t=0,T theta[t] U(x,y,ctrl[t])
|
| 14 |
+
|
| 15 |
+
This method computes the TPS value for multiple batches over multiple grid locations for 2
|
| 16 |
+
surfaces in one go.
|
| 17 |
+
|
| 18 |
+
Params
|
| 19 |
+
------
|
| 20 |
+
theta: Nx(T+3)x2 tensor, or Nx(T+2)x2 tensor
|
| 21 |
+
Batch size N, T+3 or T+2 (reduced form) model parameters for T control points in dx and dy.
|
| 22 |
+
ctrl: NxTx2 tensor or Tx2 tensor
|
| 23 |
+
T control points in normalized image coordinates [0..1]
|
| 24 |
+
grid: NxHxWx3 tensor
|
| 25 |
+
Grid locations to evaluate with homogeneous 1 in first coordinate.
|
| 26 |
+
|
| 27 |
+
Returns
|
| 28 |
+
-------
|
| 29 |
+
z: NxHxWx2 tensor
|
| 30 |
+
Function values at each grid location in dx and dy.
|
| 31 |
+
'''
|
| 32 |
+
|
| 33 |
+
N, H, W, _ = grid.size()
|
| 34 |
+
|
| 35 |
+
if ctrl.dim() == 2:
|
| 36 |
+
ctrl = ctrl.expand(N, *ctrl.size())
|
| 37 |
+
|
| 38 |
+
T = ctrl.shape[1]
|
| 39 |
+
|
| 40 |
+
diff = grid[...,1:].unsqueeze(-2) - ctrl.unsqueeze(1).unsqueeze(1)
|
| 41 |
+
D = torch.sqrt((diff**2).sum(-1))
|
| 42 |
+
U = (D**2) * torch.log(D + 1e-6)
|
| 43 |
+
|
| 44 |
+
w, a = theta[:, :-3, :], theta[:, -3:, :]
|
| 45 |
+
|
| 46 |
+
reduced = T + 2 == theta.shape[1]
|
| 47 |
+
if reduced:
|
| 48 |
+
w = torch.cat((-w.sum(dim=1, keepdim=True), w), dim=1)
|
| 49 |
+
|
| 50 |
+
# U is NxHxWxT
|
| 51 |
+
b = torch.bmm(U.view(N, -1, T), w).view(N,H,W,2)
|
| 52 |
+
# b is NxHxWx2
|
| 53 |
+
z = torch.bmm(grid.view(N,-1,3), a).view(N,H,W,2) + b
|
| 54 |
+
|
| 55 |
+
return z
|
| 56 |
+
|
| 57 |
+
def tps_grid(theta, ctrl, size):
|
| 58 |
+
'''Compute a thin-plate-spline grid from parameters for sampling.
|
| 59 |
+
|
| 60 |
+
Params
|
| 61 |
+
------
|
| 62 |
+
theta: Nx(T+3)x2 tensor
|
| 63 |
+
Batch size N, T+3 model parameters for T control points in dx and dy.
|
| 64 |
+
ctrl: NxTx2 tensor, or Tx2 tensor
|
| 65 |
+
T control points in normalized image coordinates [0..1]
|
| 66 |
+
size: tuple
|
| 67 |
+
Output grid size as NxCxHxW. C unused. This defines the output image
|
| 68 |
+
size when sampling.
|
| 69 |
+
|
| 70 |
+
Returns
|
| 71 |
+
-------
|
| 72 |
+
grid : NxHxWx2 tensor
|
| 73 |
+
Grid suitable for sampling in pytorch containing source image
|
| 74 |
+
locations for each output pixel.
|
| 75 |
+
'''
|
| 76 |
+
N, _, H, W = size
|
| 77 |
+
|
| 78 |
+
grid = theta.new(N, H, W, 3)
|
| 79 |
+
grid[:, :, :, 0] = 1.
|
| 80 |
+
grid[:, :, :, 1] = torch.linspace(0, 1, W)
|
| 81 |
+
grid[:, :, :, 2] = torch.linspace(0, 1, H).unsqueeze(-1)
|
| 82 |
+
|
| 83 |
+
z = tps(theta, ctrl, grid)
|
| 84 |
+
return (grid[...,1:] + z)*2-1 # [-1,1] range required by F.sample_grid
|
| 85 |
+
|
| 86 |
+
def tps_sparse(theta, ctrl, xy):
|
| 87 |
+
if xy.dim() == 2:
|
| 88 |
+
xy = xy.expand(theta.shape[0], *xy.size())
|
| 89 |
+
|
| 90 |
+
N, M = xy.shape[:2]
|
| 91 |
+
grid = xy.new(N, M, 3)
|
| 92 |
+
grid[..., 0] = 1.
|
| 93 |
+
grid[..., 1:] = xy
|
| 94 |
+
|
| 95 |
+
z = tps(theta, ctrl, grid.view(N,M,1,3))
|
| 96 |
+
return xy + z.view(N, M, 2)
|
| 97 |
+
|
| 98 |
+
def uniform_grid(shape):
|
| 99 |
+
'''Uniformly places control points aranged in grid accross normalized image coordinates.
|
| 100 |
+
|
| 101 |
+
Params
|
| 102 |
+
------
|
| 103 |
+
shape : tuple
|
| 104 |
+
HxW defining the number of control points in height and width dimension
|
| 105 |
+
|
| 106 |
+
Returns
|
| 107 |
+
-------
|
| 108 |
+
points: HxWx2 tensor
|
| 109 |
+
Control points over [0,1] normalized image range.
|
| 110 |
+
'''
|
| 111 |
+
H,W = shape[:2]
|
| 112 |
+
c = torch.zeros(H, W, 2)
|
| 113 |
+
c[..., 0] = torch.linspace(0, 1, W)
|
| 114 |
+
c[..., 1] = torch.linspace(0, 1, H).unsqueeze(-1)
|
| 115 |
+
return c
|
| 116 |
+
|
| 117 |
+
if __name__ == '__main__':
|
| 118 |
+
c = torch.tensor([
|
| 119 |
+
[0., 0],
|
| 120 |
+
[1., 0],
|
| 121 |
+
[1., 1],
|
| 122 |
+
[0, 1],
|
| 123 |
+
]).unsqueeze(0)
|
| 124 |
+
theta = torch.zeros(1, 4+3, 2)
|
| 125 |
+
size= (1,1,6,3)
|
| 126 |
+
print(tps_grid(theta, c, size).shape)
|
data/thinplate/tests/__init__.py
ADDED
|
File without changes
|
data/thinplate/tests/test_tps_numpy.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import numpy as np
|
| 3 |
+
from numpy.testing import assert_allclose
|
| 4 |
+
import thinplate as tps
|
| 5 |
+
|
| 6 |
+
def test_numpy_fit():
|
| 7 |
+
c = np.array([
|
| 8 |
+
[0., 0, 0.0],
|
| 9 |
+
[1., 0, 0.0],
|
| 10 |
+
[1., 1, 0.0],
|
| 11 |
+
[0, 1, 0.0],
|
| 12 |
+
])
|
| 13 |
+
|
| 14 |
+
theta = tps.TPS.fit(c)
|
| 15 |
+
assert_allclose(theta, 0)
|
| 16 |
+
assert_allclose(tps.TPS.z(c, c, theta), c[:, 2])
|
| 17 |
+
|
| 18 |
+
c = np.array([
|
| 19 |
+
[0., 0, 1.0],
|
| 20 |
+
[1., 0, 1.0],
|
| 21 |
+
[1., 1, 1.0],
|
| 22 |
+
[0, 1, 1.0],
|
| 23 |
+
])
|
| 24 |
+
|
| 25 |
+
theta = tps.TPS.fit(c)
|
| 26 |
+
assert_allclose(theta[:-3], 0)
|
| 27 |
+
assert_allclose(theta[-3:], [1, 0, 0])
|
| 28 |
+
assert_allclose(tps.TPS.z(c, c, theta), c[:, 2], atol=1e-3)
|
| 29 |
+
|
| 30 |
+
# reduced form
|
| 31 |
+
theta = tps.TPS.fit(c, reduced=True)
|
| 32 |
+
assert len(theta) == c.shape[0] + 2
|
| 33 |
+
assert_allclose(theta[:-3], 0)
|
| 34 |
+
assert_allclose(theta[-3:], [1, 0, 0])
|
| 35 |
+
assert_allclose(tps.TPS.z(c, c, theta), c[:, 2], atol=1e-3)
|
| 36 |
+
|
| 37 |
+
c = np.array([
|
| 38 |
+
[0., 0, -.5],
|
| 39 |
+
[1., 0, 0.5],
|
| 40 |
+
[1., 1, 0.2],
|
| 41 |
+
[0, 1, 0.8],
|
| 42 |
+
])
|
| 43 |
+
|
| 44 |
+
theta = tps.TPS.fit(c)
|
| 45 |
+
assert_allclose(tps.TPS.z(c, c, theta), c[:, 2], atol=1e-3)
|
| 46 |
+
|
| 47 |
+
def test_numpy_densegrid():
|
| 48 |
+
|
| 49 |
+
# enlarges a small rectangle to full view
|
| 50 |
+
|
| 51 |
+
import cv2
|
| 52 |
+
|
| 53 |
+
img = np.zeros((40, 40), dtype=np.uint8)
|
| 54 |
+
img[10:21, 10:21] = 255
|
| 55 |
+
|
| 56 |
+
c_dst = np.array([
|
| 57 |
+
[0., 0],
|
| 58 |
+
[1., 0],
|
| 59 |
+
[1, 1],
|
| 60 |
+
[0, 1],
|
| 61 |
+
])
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
c_src = np.array([
|
| 65 |
+
[10., 10],
|
| 66 |
+
[20., 10],
|
| 67 |
+
[20, 20],
|
| 68 |
+
[10, 20],
|
| 69 |
+
]) / 40.
|
| 70 |
+
|
| 71 |
+
theta = tps.tps_theta_from_points(c_src, c_dst)
|
| 72 |
+
theta_r = tps.tps_theta_from_points(c_src, c_dst, reduced=True)
|
| 73 |
+
|
| 74 |
+
grid = tps.tps_grid(theta, c_dst, (20,20))
|
| 75 |
+
grid_r = tps.tps_grid(theta_r, c_dst, (20,20))
|
| 76 |
+
|
| 77 |
+
mapx, mapy = tps.tps_grid_to_remap(grid, img.shape)
|
| 78 |
+
warped = cv2.remap(img, mapx, mapy, cv2.INTER_CUBIC)
|
| 79 |
+
|
| 80 |
+
assert img.min() == 0.
|
| 81 |
+
assert img.max() == 255.
|
| 82 |
+
assert warped.shape == (20,20)
|
| 83 |
+
assert warped.min() == 255.
|
| 84 |
+
assert warped.max() == 255.
|
| 85 |
+
assert np.linalg.norm(grid.reshape(-1,2) - grid_r.reshape(-1,2)) < 1e-3
|
data/thinplate/tests/test_tps_pytorch.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.optim as optim
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import thinplate as tps
|
| 7 |
+
|
| 8 |
+
from numpy.testing import assert_allclose
|
| 9 |
+
|
| 10 |
+
def test_pytorch_grid():
|
| 11 |
+
|
| 12 |
+
c_dst = np.array([
|
| 13 |
+
[0., 0],
|
| 14 |
+
[1., 0],
|
| 15 |
+
[1, 1],
|
| 16 |
+
[0, 1],
|
| 17 |
+
], dtype=np.float32)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
c_src = np.array([
|
| 21 |
+
[10., 10],
|
| 22 |
+
[20., 10],
|
| 23 |
+
[20, 20],
|
| 24 |
+
[10, 20],
|
| 25 |
+
], dtype=np.float32) / 40.
|
| 26 |
+
|
| 27 |
+
theta = tps.tps_theta_from_points(c_src, c_dst)
|
| 28 |
+
theta_r = tps.tps_theta_from_points(c_src, c_dst, reduced=True)
|
| 29 |
+
|
| 30 |
+
np_grid = tps.tps_grid(theta, c_dst, (20,20))
|
| 31 |
+
np_grid_r = tps.tps_grid(theta_r, c_dst, (20,20))
|
| 32 |
+
|
| 33 |
+
pth_theta = torch.tensor(theta).unsqueeze(0)
|
| 34 |
+
pth_grid = tps.torch.tps_grid(pth_theta, torch.tensor(c_dst), (1, 1, 20, 20)).squeeze().numpy()
|
| 35 |
+
pth_grid = (pth_grid + 1) / 2 # convert [-1,1] range to [0,1]
|
| 36 |
+
|
| 37 |
+
pth_theta_r = torch.tensor(theta_r).unsqueeze(0)
|
| 38 |
+
pth_grid_r = tps.torch.tps_grid(pth_theta_r, torch.tensor(c_dst), (1, 1, 20, 20)).squeeze().numpy()
|
| 39 |
+
pth_grid_r = (pth_grid_r + 1) / 2 # convert [-1,1] range to [0,1]
|
| 40 |
+
|
| 41 |
+
assert_allclose(np_grid, pth_grid)
|
| 42 |
+
assert_allclose(np_grid_r, pth_grid_r)
|
| 43 |
+
assert_allclose(np_grid_r, np_grid)
|
data/tps_transformation.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import data.thinplate as tps
|
| 3 |
+
import cv2
|
| 4 |
+
import random
|
| 5 |
+
import math
|
| 6 |
+
|
| 7 |
+
# Reference : https://github.com/cheind/py-thin-plate-spline
|
| 8 |
+
|
| 9 |
+
def tps_transform(img, dshape=None):
|
| 10 |
+
|
| 11 |
+
while True:
|
| 12 |
+
point1 = round(random.uniform(0.3, 0.7), 2)
|
| 13 |
+
point2 = round(random.uniform(0.3, 0.7), 2)
|
| 14 |
+
range_1 = round(random.uniform(-0.25, 0.25), 2)
|
| 15 |
+
range_2 = round(random.uniform(-0.25, 0.25), 2)
|
| 16 |
+
if math.isclose(point1 + range_1, point2 + range_2):
|
| 17 |
+
continue
|
| 18 |
+
else:
|
| 19 |
+
break
|
| 20 |
+
|
| 21 |
+
c_src = np.array([
|
| 22 |
+
[0.0, 0.0],
|
| 23 |
+
[1., 0],
|
| 24 |
+
[1, 1],
|
| 25 |
+
[0, 1],
|
| 26 |
+
[point1, point1],
|
| 27 |
+
[point2, point2],
|
| 28 |
+
])
|
| 29 |
+
|
| 30 |
+
c_dst = np.array([
|
| 31 |
+
[0., 0],
|
| 32 |
+
[1., 0],
|
| 33 |
+
[1, 1],
|
| 34 |
+
[0, 1],
|
| 35 |
+
[point1 + range_1, point1 + range_1],
|
| 36 |
+
[point2 + range_2, point2 + range_2],
|
| 37 |
+
])
|
| 38 |
+
|
| 39 |
+
dshape = dshape or img.shape
|
| 40 |
+
theta = tps.tps_theta_from_points(c_src, c_dst, reduced=True)
|
| 41 |
+
grid = tps.tps_grid(theta, c_dst, dshape)
|
| 42 |
+
mapx, mapy = tps.tps_grid_to_remap(grid, img.shape)
|
| 43 |
+
return cv2.remap(img, mapx, mapy, cv2.INTER_CUBIC)
|
| 44 |
+
|
discriminator.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class Discriminator(nn.Module):
|
| 7 |
+
def __init__(self, in_channels=3):
|
| 8 |
+
super(Discriminator, self).__init__()
|
| 9 |
+
|
| 10 |
+
def discriminator_block(in_filters, out_filters, normalization=True):
|
| 11 |
+
"""Returns downsampling layers of each discriminator block"""
|
| 12 |
+
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
|
| 13 |
+
if normalization:
|
| 14 |
+
layers.append(nn.InstanceNorm2d(out_filters))
|
| 15 |
+
layers.append(nn.LeakyReLU(0.2, inplace=True))
|
| 16 |
+
return layers
|
| 17 |
+
|
| 18 |
+
self.model = nn.Sequential(
|
| 19 |
+
*discriminator_block(in_channels * 3, 64, normalization=False),
|
| 20 |
+
*discriminator_block(64, 128),
|
| 21 |
+
*discriminator_block(128, 256),
|
| 22 |
+
*discriminator_block(256, 512),
|
| 23 |
+
nn.ZeroPad2d((1, 0, 1, 0)),
|
| 24 |
+
nn.Conv2d(512, 1, 4, padding=1, bias=False)
|
| 25 |
+
)
|
| 26 |
+
|
| 27 |
+
def forward(self, img_out, img_l, img_ref ):
|
| 28 |
+
# Concatenate image and condition image by channels to produce input
|
| 29 |
+
img_input = torch.cat((img_out, img_l, img_ref), 1)
|
| 30 |
+
return self.model(img_input)
|
| 31 |
+
|
distributed.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import pickle
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import distributed as dist
|
| 6 |
+
from torch.utils.data.sampler import Sampler
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_rank():
|
| 10 |
+
if not dist.is_available():
|
| 11 |
+
return 0
|
| 12 |
+
|
| 13 |
+
if not dist.is_initialized():
|
| 14 |
+
return 0
|
| 15 |
+
|
| 16 |
+
return dist.get_rank()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def synchronize():
|
| 20 |
+
if not dist.is_available():
|
| 21 |
+
return
|
| 22 |
+
|
| 23 |
+
if not dist.is_initialized():
|
| 24 |
+
return
|
| 25 |
+
|
| 26 |
+
world_size = dist.get_world_size()
|
| 27 |
+
|
| 28 |
+
if world_size == 1:
|
| 29 |
+
return
|
| 30 |
+
|
| 31 |
+
dist.barrier()
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def get_world_size():
|
| 35 |
+
if not dist.is_available():
|
| 36 |
+
return 1
|
| 37 |
+
|
| 38 |
+
if not dist.is_initialized():
|
| 39 |
+
return 1
|
| 40 |
+
|
| 41 |
+
return dist.get_world_size()
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def reduce_sum(tensor):
|
| 45 |
+
if not dist.is_available():
|
| 46 |
+
return tensor
|
| 47 |
+
|
| 48 |
+
if not dist.is_initialized():
|
| 49 |
+
return tensor
|
| 50 |
+
|
| 51 |
+
tensor = tensor.clone()
|
| 52 |
+
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
|
| 53 |
+
|
| 54 |
+
return tensor
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def gather_grad(params):
|
| 58 |
+
world_size = get_world_size()
|
| 59 |
+
|
| 60 |
+
if world_size == 1:
|
| 61 |
+
return
|
| 62 |
+
|
| 63 |
+
for param in params:
|
| 64 |
+
if param.grad is not None:
|
| 65 |
+
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
|
| 66 |
+
param.grad.data.div_(world_size)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def all_gather(data):
|
| 70 |
+
world_size = get_world_size()
|
| 71 |
+
|
| 72 |
+
if world_size == 1:
|
| 73 |
+
return [data]
|
| 74 |
+
|
| 75 |
+
buffer = pickle.dumps(data)
|
| 76 |
+
storage = torch.ByteStorage.from_buffer(buffer)
|
| 77 |
+
tensor = torch.ByteTensor(storage).to('cuda')
|
| 78 |
+
|
| 79 |
+
local_size = torch.IntTensor([tensor.numel()]).to('cuda')
|
| 80 |
+
size_list = [torch.IntTensor([0]).to('cuda') for _ in range(world_size)]
|
| 81 |
+
dist.all_gather(size_list, local_size)
|
| 82 |
+
size_list = [int(size.item()) for size in size_list]
|
| 83 |
+
max_size = max(size_list)
|
| 84 |
+
|
| 85 |
+
tensor_list = []
|
| 86 |
+
for _ in size_list:
|
| 87 |
+
tensor_list.append(torch.ByteTensor(size=(max_size,)).to('cuda'))
|
| 88 |
+
|
| 89 |
+
if local_size != max_size:
|
| 90 |
+
padding = torch.ByteTensor(size=(max_size - local_size,)).to('cuda')
|
| 91 |
+
tensor = torch.cat((tensor, padding), 0)
|
| 92 |
+
|
| 93 |
+
dist.all_gather(tensor_list, tensor)
|
| 94 |
+
|
| 95 |
+
data_list = []
|
| 96 |
+
|
| 97 |
+
for size, tensor in zip(size_list, tensor_list):
|
| 98 |
+
buffer = tensor.cpu().numpy().tobytes()[:size]
|
| 99 |
+
data_list.append(pickle.loads(buffer))
|
| 100 |
+
|
| 101 |
+
return data_list
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def reduce_loss_dict(loss_dict):
|
| 105 |
+
world_size = get_world_size()
|
| 106 |
+
|
| 107 |
+
if world_size < 2:
|
| 108 |
+
return loss_dict
|
| 109 |
+
|
| 110 |
+
with torch.no_grad():
|
| 111 |
+
keys = []
|
| 112 |
+
losses = []
|
| 113 |
+
|
| 114 |
+
for k in sorted(loss_dict.keys()):
|
| 115 |
+
keys.append(k)
|
| 116 |
+
losses.append(loss_dict[k])
|
| 117 |
+
|
| 118 |
+
losses = torch.stack(losses, 0)
|
| 119 |
+
dist.reduce(losses, dst=0)
|
| 120 |
+
|
| 121 |
+
if dist.get_rank() == 0:
|
| 122 |
+
losses /= world_size
|
| 123 |
+
|
| 124 |
+
reduced_losses = {k: v for k, v in zip(keys, losses)}
|
| 125 |
+
|
| 126 |
+
return reduced_losses
|
experiments/Color2Manga_gray/074000_gray.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e2f4785d00d4463ecb5f02d79f79f9da747a57179b5b016408e65da0e4f62572
|
| 3 |
+
size 1091510163
|
experiments/Color2Manga_sketch/116000_sketch.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:52505452ec908ffd1ae4499a205a55263a8cd7d7bdf4623b59edccf8e8636d33
|
| 3 |
+
size 1091510163
|
experiments/Discriminator/074000_d.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e622a55cb8bae33377e85963eaa496d7e9bd9e1f4449b853d41235729cc7d40f
|
| 3 |
+
size 33261919
|
experiments/Discriminator/116000_d.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:169ae73ef7c788ec3921c918d0a9ebdecc4115492b177dfd98660b7816d6ce5a
|
| 3 |
+
size 33261983
|
experiments/VGG19/vgg19-dcbb9e9d.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dcbb9e9dad569fff7a846263a77324fc34978fea2bfb039c012d710e1776ae44
|
| 3 |
+
size 574673361
|
extractor/Open-Sans-Bold.ttf
ADDED
|
Binary file (225 kB). View file
|
|
|
extractor/__pycache__/manga_panel_extractor.cpython-310.pyc
ADDED
|
Binary file (5.89 kB). View file
|
|
|
extractor/__pycache__/manga_panel_extractor.cpython-38.pyc
ADDED
|
Binary file (5.89 kB). View file
|
|
|
extractor/manga_panel_extractor.py
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# stdlib
|
| 2 |
+
import argparse
|
| 3 |
+
from argparse import RawTextHelpFormatter
|
| 4 |
+
import os
|
| 5 |
+
from os.path import splitext, basename, exists, join
|
| 6 |
+
from os import makedirs
|
| 7 |
+
# 3p
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
import numpy as np
|
| 10 |
+
from skimage import measure
|
| 11 |
+
from PIL import Image
|
| 12 |
+
from PIL import ImageFont
|
| 13 |
+
from PIL import ImageDraw
|
| 14 |
+
import cv2
|
| 15 |
+
# project
|
| 16 |
+
from utils import get_files, load_image
|
| 17 |
+
from skimage import io
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class PanelExtractor:
|
| 21 |
+
def __init__(self, min_pct_panel=2, max_pct_panel=90, paper_th=0.35):
|
| 22 |
+
assert min_pct_panel < max_pct_panel, "Minimum percentage must be smaller than maximum percentage"
|
| 23 |
+
self.min_panel = min_pct_panel / 100
|
| 24 |
+
self.max_panel = max_pct_panel / 100
|
| 25 |
+
self.paper_th = paper_th
|
| 26 |
+
|
| 27 |
+
def _generate_panel_blocks(self, img):
|
| 28 |
+
img = img if len(img.shape) == 2 else img[:, :, 0]
|
| 29 |
+
blur = cv2.GaussianBlur(img, (5, 5), 0)
|
| 30 |
+
thresh = cv2.threshold(blur, 230, 255, cv2.THRESH_BINARY)[1]
|
| 31 |
+
cv2.rectangle(thresh, (0, 0), tuple(img.shape[::-1]), (0, 0, 0), 10)
|
| 32 |
+
num_labels, labels, stats, centroids = cv2.connectedComponentsWithStats(thresh, 4, cv2.CV_32S)
|
| 33 |
+
ind = np.argsort(stats[:, 4], )[::-1][1]
|
| 34 |
+
panel_block_mask = ((labels == ind) * 255).astype("uint8")
|
| 35 |
+
# Image.fromarray(panel_block_mask).show()
|
| 36 |
+
return panel_block_mask
|
| 37 |
+
|
| 38 |
+
def generate_panels(self, img):
|
| 39 |
+
block_mask = self._generate_panel_blocks(img)
|
| 40 |
+
cv2.rectangle(block_mask, (0, 0), tuple(block_mask.shape[::-1]), (255, 255, 255), 10)
|
| 41 |
+
# Image.fromarray(block_mask).show()
|
| 42 |
+
|
| 43 |
+
# detect contours
|
| 44 |
+
contours, hierarchy = cv2.findContours(block_mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
|
| 45 |
+
panels = []
|
| 46 |
+
masks = []
|
| 47 |
+
panel_masks = []
|
| 48 |
+
# print(len(contours))
|
| 49 |
+
|
| 50 |
+
for i in range(len(contours)):
|
| 51 |
+
area = cv2.contourArea(contours[i])
|
| 52 |
+
img_area = img.shape[0] * img.shape[1]
|
| 53 |
+
|
| 54 |
+
# if the contour is very small or very big, it's likely wrongly detected
|
| 55 |
+
if area < (self.min_panel * img_area) or area > (self.max_panel * img_area):
|
| 56 |
+
continue
|
| 57 |
+
|
| 58 |
+
x, y, w, h = cv2.boundingRect(contours[i])
|
| 59 |
+
masks.append(cv2.boundingRect(contours[i]))
|
| 60 |
+
# create panel mask
|
| 61 |
+
panel_mask = np.ones_like(block_mask, "int32")
|
| 62 |
+
cv2.fillPoly(panel_mask, [contours[i].astype("int32")], color=(0, 0, 0))
|
| 63 |
+
# Image.fromarray(panel_mask).show()
|
| 64 |
+
panel_mask = panel_mask[y:y + h, x:x + w].copy()
|
| 65 |
+
# Image.fromarray(panel_mask).show()
|
| 66 |
+
|
| 67 |
+
# apply panel mask
|
| 68 |
+
panel = img[y:y + h, x:x + w].copy()
|
| 69 |
+
# Image.fromarray(panel).show()
|
| 70 |
+
panel[panel_mask == 1] = 255
|
| 71 |
+
# Image.fromarray(panel).show()
|
| 72 |
+
|
| 73 |
+
panels.append(panel)
|
| 74 |
+
panel_masks.append(panel_mask)
|
| 75 |
+
|
| 76 |
+
return panels, masks, panel_masks
|
| 77 |
+
|
| 78 |
+
def extract(self, folder):
|
| 79 |
+
print("Loading images ... ", end="")
|
| 80 |
+
# image_list, _, _ = get_files(folder)
|
| 81 |
+
image_list = []
|
| 82 |
+
image_list.append(folder)
|
| 83 |
+
imgs = [load_image(x) for x in image_list]
|
| 84 |
+
print("Done!")
|
| 85 |
+
|
| 86 |
+
folder = os.path.dirname(folder)
|
| 87 |
+
# create panels dir
|
| 88 |
+
if not exists(join(folder, "panels")):
|
| 89 |
+
makedirs(join(folder, "panels"))
|
| 90 |
+
folder = join(folder, "panels")
|
| 91 |
+
|
| 92 |
+
# remove images with paper texture, not well segmented
|
| 93 |
+
paperless_imgs = []
|
| 94 |
+
for img in tqdm(imgs, desc="Removing images with paper texture"):
|
| 95 |
+
hist, bins = np.histogram(img.copy().ravel(), 256, [0, 256])
|
| 96 |
+
if np.sum(hist[50:200]) / np.sum(hist) < self.paper_th:
|
| 97 |
+
paperless_imgs.append(img)
|
| 98 |
+
|
| 99 |
+
if not paperless_imgs:
|
| 100 |
+
return imgs, [], []
|
| 101 |
+
for i, img in tqdm(enumerate(paperless_imgs), desc="extracting panels"):
|
| 102 |
+
panels, masks, panel_masks = self.generate_panels(img)
|
| 103 |
+
name, ext = splitext(basename(image_list[i]))
|
| 104 |
+
for j, panel in enumerate(panels):
|
| 105 |
+
cv2.imwrite(join(folder, f'{name}_{j}.{ext}'), panel)
|
| 106 |
+
|
| 107 |
+
# show the order of colorized panels
|
| 108 |
+
img = Image.fromarray(img)
|
| 109 |
+
draw = ImageDraw.Draw(img)
|
| 110 |
+
font = ImageFont.truetype('extractor/Open-Sans-Bold.ttf', 160)
|
| 111 |
+
|
| 112 |
+
def flatten(l):
|
| 113 |
+
for el in l:
|
| 114 |
+
if isinstance(el, list):
|
| 115 |
+
yield from flatten(el)
|
| 116 |
+
else:
|
| 117 |
+
yield el
|
| 118 |
+
|
| 119 |
+
for i, bbox in enumerate(flatten(masks), start=1):
|
| 120 |
+
w, h = draw.textsize(str(i), font=font)
|
| 121 |
+
y = (bbox[1] + bbox[3] / 2 - h / 2)
|
| 122 |
+
x = (bbox[0] + bbox[2] / 2 - w / 2)
|
| 123 |
+
draw.text((x, y), str(i), (255, 215, 0), font=font)
|
| 124 |
+
img.show()
|
| 125 |
+
return panels, masks, panel_masks
|
| 126 |
+
|
| 127 |
+
def concatPanels(self, img_file, fake_imgs, masks, panel_masks):
|
| 128 |
+
img = io.imread(img_file)
|
| 129 |
+
# out_imgs.append(f"D:\MyProject\Python\DL_learning\Manga-Panel-Extractor-master\out\in0_ref0.png")
|
| 130 |
+
# out_imgs.append(f"D:\MyProject\Python\DL_learning\Manga-Panel-Extractor-master\out\in1_ref1.png")
|
| 131 |
+
# out_imgs.append(f"D:\MyProject\Python\DL_learning\Manga-Panel-Extractor-master\out\in2_ref2.png")
|
| 132 |
+
for i in range(len(fake_imgs)):
|
| 133 |
+
x, y, w, h = masks[i]
|
| 134 |
+
# fake_img = io.imread(fake_imgs[i])
|
| 135 |
+
# fake_img = np.array(fake_img)
|
| 136 |
+
fake_img = fake_imgs[i]
|
| 137 |
+
panel_mask = panel_masks[i]
|
| 138 |
+
img[y:y + h, x:x + w][panel_mask == 0] = fake_img[panel_mask == 0]
|
| 139 |
+
# Image.fromarray(img).show()
|
| 140 |
+
out_folder = os.path.dirname(img_file)
|
| 141 |
+
out_name = os.path.basename(img_file)
|
| 142 |
+
out_name = os.path.splitext(out_name)[0]
|
| 143 |
+
out_img_path = os.path.join(out_folder,'color',f'{out_name}_color.png')
|
| 144 |
+
|
| 145 |
+
# show image
|
| 146 |
+
Image.fromarray(img).show()
|
| 147 |
+
# save image
|
| 148 |
+
folder_path = os.path.join(out_folder, 'color')
|
| 149 |
+
if not os.path.exists(folder_path):
|
| 150 |
+
os.mkdir(folder_path)
|
| 151 |
+
io.imsave(out_img_path, img)
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def main(args):
|
| 155 |
+
panel_extractor = PanelExtractor(min_pct_panel=args.min_panel, max_pct_panel=args.max_panel)
|
| 156 |
+
panels, masks, panel_masks = panel_extractor.extract(args.folder)
|
| 157 |
+
panel_extractor.concatPanels(args.folder, [], masks, panel_masks)
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
if __name__ == "__main__":
|
| 161 |
+
parser = argparse.ArgumentParser(
|
| 162 |
+
description="Implementation of a Manga Panel Extractor and dialogue bubble text eraser.",
|
| 163 |
+
formatter_class=RawTextHelpFormatter
|
| 164 |
+
)
|
| 165 |
+
parser.add_argument("-minp", "--min_panel", type=int, choices=range(1, 99), default=5, metavar="[1-99]",
|
| 166 |
+
help="Percentage of minimum panel area in relation to total page area.")
|
| 167 |
+
parser.add_argument("-maxp", "--max_panel", type=int, choices=range(1, 99), default=90, metavar="[1-99]",
|
| 168 |
+
help="Percentage of minimum panel area in relation to total page area.")
|
| 169 |
+
parser.add_argument("-f", '--folder', default='./images/002.png', type=str,
|
| 170 |
+
help="""folder path to input manga pages.
|
| 171 |
+
Panels will be saved to a directory named `panels` in this folder.""")
|
| 172 |
+
|
| 173 |
+
args = parser.parse_args()
|
| 174 |
+
main(args)
|
inference.py
ADDED
|
@@ -0,0 +1,229 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import numpy as np
|
| 3 |
+
from skimage import color, io
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
from PIL import Image
|
| 9 |
+
from models import ColorEncoder, ColorUNet
|
| 10 |
+
from extractor.manga_panel_extractor import PanelExtractor
|
| 11 |
+
import argparse
|
| 12 |
+
|
| 13 |
+
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
|
| 14 |
+
|
| 15 |
+
def mkdirs(path):
|
| 16 |
+
if not os.path.exists(path):
|
| 17 |
+
os.makedirs(path)
|
| 18 |
+
|
| 19 |
+
def Lab2RGB_out(img_lab):
|
| 20 |
+
img_lab = img_lab.detach().cpu()
|
| 21 |
+
img_l = img_lab[:,:1,:,:]
|
| 22 |
+
img_ab = img_lab[:,1:,:,:]
|
| 23 |
+
# print(torch.max(img_l), torch.min(img_l))
|
| 24 |
+
# print(torch.max(img_ab), torch.min(img_ab))
|
| 25 |
+
img_l = img_l + 50
|
| 26 |
+
pred_lab = torch.cat((img_l, img_ab), 1)[0,...].numpy()
|
| 27 |
+
# grid_lab = utils.make_grid(pred_lab, nrow=1).numpy().astype("float64")
|
| 28 |
+
# print(grid_lab.shape)
|
| 29 |
+
out = (np.clip(color.lab2rgb(pred_lab.transpose(1, 2, 0)), 0, 1)* 255).astype("uint8")
|
| 30 |
+
return out
|
| 31 |
+
|
| 32 |
+
def RGB2Lab(inputs):
|
| 33 |
+
return color.rgb2lab(inputs)
|
| 34 |
+
|
| 35 |
+
def Normalize(inputs):
|
| 36 |
+
l = inputs[:, :, 0:1]
|
| 37 |
+
ab = inputs[:, :, 1:3]
|
| 38 |
+
l = l - 50
|
| 39 |
+
lab = np.concatenate((l, ab), 2)
|
| 40 |
+
|
| 41 |
+
return lab.astype('float32')
|
| 42 |
+
|
| 43 |
+
def numpy2tensor(inputs):
|
| 44 |
+
out = torch.from_numpy(inputs.transpose(2,0,1))
|
| 45 |
+
return out
|
| 46 |
+
|
| 47 |
+
def tensor2numpy(inputs):
|
| 48 |
+
out = inputs[0,...].detach().cpu().numpy().transpose(1,2,0)
|
| 49 |
+
return out
|
| 50 |
+
|
| 51 |
+
def preprocessing(inputs):
|
| 52 |
+
# input: rgb, [0, 255], uint8
|
| 53 |
+
img_lab = Normalize(RGB2Lab(inputs))
|
| 54 |
+
img = np.array(inputs, 'float32') # [0, 255]
|
| 55 |
+
img = numpy2tensor(img)
|
| 56 |
+
img_lab = numpy2tensor(img_lab)
|
| 57 |
+
return img.unsqueeze(0), img_lab.unsqueeze(0)
|
| 58 |
+
|
| 59 |
+
if __name__ == "__main__":
|
| 60 |
+
device = "cuda"
|
| 61 |
+
|
| 62 |
+
# model_name = 'Color2Manga_sketch'
|
| 63 |
+
ckpt_path = 'experiments/Color2Manga_gray/074000_gray.pt'
|
| 64 |
+
test_dir_path = 'test_datasets/gray_test'
|
| 65 |
+
no_extractor = False
|
| 66 |
+
# imgs_num = len(os.listdir(test_dir_path)) // 2
|
| 67 |
+
imgsize = 256
|
| 68 |
+
|
| 69 |
+
parser = argparse.ArgumentParser()
|
| 70 |
+
|
| 71 |
+
parser.add_argument("--path", type=str, default=None, help="path of input image")
|
| 72 |
+
parser.add_argument("--size", type=int, default=None)
|
| 73 |
+
parser.add_argument("--ckpt", type=str, default=None, help="path of model weight")
|
| 74 |
+
parser.add_argument("-ne", "--no_extractor", action='store_true',
|
| 75 |
+
help="Do not segment the manga panels.")
|
| 76 |
+
|
| 77 |
+
args = parser.parse_args()
|
| 78 |
+
|
| 79 |
+
if args.path:
|
| 80 |
+
ckpt_path = args.path
|
| 81 |
+
if args.size:
|
| 82 |
+
imgsize = args.size
|
| 83 |
+
if args.ckpt:
|
| 84 |
+
test_dir_path = args.ckpt
|
| 85 |
+
if args.no_extractor:
|
| 86 |
+
no_extractor = args.no_extractor
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
ckpt = torch.load(ckpt_path, map_location=lambda storage, loc: storage)
|
| 90 |
+
|
| 91 |
+
colorEncoder = ColorEncoder().to(device)
|
| 92 |
+
colorEncoder.load_state_dict(ckpt["colorEncoder"])
|
| 93 |
+
colorEncoder.eval()
|
| 94 |
+
|
| 95 |
+
colorUNet = ColorUNet().to(device)
|
| 96 |
+
colorUNet.load_state_dict(ckpt["colorUNet"])
|
| 97 |
+
colorUNet.eval()
|
| 98 |
+
|
| 99 |
+
imgs = []
|
| 100 |
+
imgs_lab = []
|
| 101 |
+
|
| 102 |
+
# for i in range(imgs_num):
|
| 103 |
+
# idx = i
|
| 104 |
+
# print('Image', idx, 'Input Image', 'in%d.JPEG'%idx, 'Ref Image', 'ref%d.JPEG'%idx)
|
| 105 |
+
|
| 106 |
+
while 1:
|
| 107 |
+
print(f'make sure both manga image and reference images are under this path{test_dir_path}')
|
| 108 |
+
img_path = input("please input the name of image needed to be colorized(with file extension): ")
|
| 109 |
+
img_path = os.path.join(test_dir_path, img_path)
|
| 110 |
+
img_name = os.path.basename(img_path)
|
| 111 |
+
img_name = os.path.splitext(img_name)[0]
|
| 112 |
+
|
| 113 |
+
if no_extractor:
|
| 114 |
+
ref_img_path = os.path.join(test_dir_path, input(f"{1}/{1} reference image:"))
|
| 115 |
+
|
| 116 |
+
img1 = Image.open(img_path).convert("RGB")
|
| 117 |
+
width, height = img1.size
|
| 118 |
+
img2 = Image.open(ref_img_path).convert("RGB")
|
| 119 |
+
|
| 120 |
+
img1, img1_lab = preprocessing(img1)
|
| 121 |
+
img2, img2_lab = preprocessing(img2)
|
| 122 |
+
|
| 123 |
+
img1 = img1.to(device)
|
| 124 |
+
img1_lab = img1_lab.to(device)
|
| 125 |
+
img2 = img2.to(device)
|
| 126 |
+
img2_lab = img2_lab.to(device)
|
| 127 |
+
|
| 128 |
+
# print('-------',torch.max(img1_lab[:,:1,:,:]), torch.min(img1_lab[:,1:,:,:]))
|
| 129 |
+
|
| 130 |
+
with torch.no_grad():
|
| 131 |
+
img2_resize = F.interpolate(img2 / 255., size=(imgsize, imgsize), mode='bilinear',
|
| 132 |
+
recompute_scale_factor=False, align_corners=False)
|
| 133 |
+
img1_L_resize = F.interpolate(img1_lab[:, :1, :, :] / 50., size=(imgsize, imgsize), mode='bilinear',
|
| 134 |
+
recompute_scale_factor=False, align_corners=False)
|
| 135 |
+
|
| 136 |
+
color_vector = colorEncoder(img2_resize)
|
| 137 |
+
|
| 138 |
+
fake_ab = colorUNet((img1_L_resize, color_vector))
|
| 139 |
+
fake_ab = F.interpolate(fake_ab * 110, size=(height, width), mode='bilinear',
|
| 140 |
+
recompute_scale_factor=False, align_corners=False)
|
| 141 |
+
|
| 142 |
+
fake_img = torch.cat((img1_lab[:, :1, :, :], fake_ab), 1)
|
| 143 |
+
fake_img = Lab2RGB_out(fake_img)
|
| 144 |
+
# io.imsave(out_img_path, fake_img)
|
| 145 |
+
|
| 146 |
+
out_folder = os.path.dirname(img_path)
|
| 147 |
+
out_name = os.path.basename(img_path)
|
| 148 |
+
out_name = os.path.splitext(out_name)[0]
|
| 149 |
+
out_img_path = os.path.join(out_folder, 'color', f'{out_name}_color.png')
|
| 150 |
+
|
| 151 |
+
# show image
|
| 152 |
+
Image.fromarray(fake_img).show()
|
| 153 |
+
# save image
|
| 154 |
+
folder_path = os.path.join(out_folder, 'color')
|
| 155 |
+
if not os.path.exists(folder_path):
|
| 156 |
+
os.mkdir(folder_path)
|
| 157 |
+
io.imsave(out_img_path, fake_img)
|
| 158 |
+
|
| 159 |
+
continue
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
# extract panels from manga
|
| 164 |
+
panel_extractor = PanelExtractor(min_pct_panel=5, max_pct_panel=90)
|
| 165 |
+
panels, masks, panel_masks = panel_extractor.extract(img_path)
|
| 166 |
+
panel_num = len(panels)
|
| 167 |
+
|
| 168 |
+
ref_img_paths = []
|
| 169 |
+
# ref_img_path = os.path.join(test_dir_path, '%03d_ref.png' % idx)
|
| 170 |
+
print("Please enter the name of the reference image in order according to the number prompts on the picture")
|
| 171 |
+
for i in range(panel_num):
|
| 172 |
+
ref_img_path = os.path.join(test_dir_path, input(f"{i+1}/{panel_num} reference image:"))
|
| 173 |
+
ref_img_paths.append(ref_img_path)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
fake_imgs = []
|
| 179 |
+
for i in range(panel_num):
|
| 180 |
+
img1 = Image.fromarray(panels[i]).convert("RGB")
|
| 181 |
+
width, height = img1.size
|
| 182 |
+
img2 = Image.open(ref_img_paths[i]).convert("RGB")
|
| 183 |
+
|
| 184 |
+
# img1 = Image.open(img_path).convert("RGB")
|
| 185 |
+
# width, height = img1.size
|
| 186 |
+
# img2 = Image.open(ref_img_path).convert("RGB")
|
| 187 |
+
|
| 188 |
+
img1, img1_lab = preprocessing(img1)
|
| 189 |
+
img2, img2_lab = preprocessing(img2)
|
| 190 |
+
|
| 191 |
+
img1 = img1.to(device)
|
| 192 |
+
img1_lab = img1_lab.to(device)
|
| 193 |
+
img2 = img2.to(device)
|
| 194 |
+
img2_lab = img2_lab.to(device)
|
| 195 |
+
|
| 196 |
+
# print('-------',torch.max(img1_lab[:,:1,:,:]), torch.min(img1_lab[:,1:,:,:]))
|
| 197 |
+
|
| 198 |
+
with torch.no_grad():
|
| 199 |
+
img2_resize = F.interpolate(img2 / 255., size=(imgsize, imgsize), mode='bilinear', recompute_scale_factor=False, align_corners=False)
|
| 200 |
+
img1_L_resize = F.interpolate(img1_lab[:,:1,:,:] / 50., size=(imgsize, imgsize), mode='bilinear', recompute_scale_factor=False, align_corners=False)
|
| 201 |
+
|
| 202 |
+
color_vector = colorEncoder(img2_resize)
|
| 203 |
+
|
| 204 |
+
fake_ab = colorUNet((img1_L_resize, color_vector))
|
| 205 |
+
fake_ab = F.interpolate(fake_ab*110, size=(height, width), mode='bilinear', recompute_scale_factor=False, align_corners=False)
|
| 206 |
+
|
| 207 |
+
fake_img = torch.cat((img1_lab[:,:1,:,:], fake_ab), 1)
|
| 208 |
+
fake_img = Lab2RGB_out(fake_img)
|
| 209 |
+
# io.imsave(f'test_datasets/gray_test/panels/{i}.png', fake_img)
|
| 210 |
+
fake_imgs.append(fake_img)
|
| 211 |
+
|
| 212 |
+
if panel_num == 1:
|
| 213 |
+
out_folder = os.path.dirname(img_path)
|
| 214 |
+
out_name = os.path.basename(img_path)
|
| 215 |
+
out_name = os.path.splitext(out_name)[0]
|
| 216 |
+
out_img_path = os.path.join(out_folder,'color',f'{out_name}_color.png')
|
| 217 |
+
|
| 218 |
+
# show image
|
| 219 |
+
Image.fromarray(fake_imgs[0]).show()
|
| 220 |
+
# save image
|
| 221 |
+
folder_path = os.path.join(out_folder, 'color')
|
| 222 |
+
if not os.path.exists(folder_path):
|
| 223 |
+
os.mkdir(folder_path)
|
| 224 |
+
io.imsave(out_img_path, fake_imgs[0])
|
| 225 |
+
else:
|
| 226 |
+
panel_extractor.concatPanels(img_path, fake_imgs, masks, panel_masks)
|
| 227 |
+
|
| 228 |
+
print(f'colored image has been put to: {test_dir_path}color')
|
| 229 |
+
|
models.py
ADDED
|
@@ -0,0 +1,223 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
from vgg_model import vgg19
|
| 8 |
+
|
| 9 |
+
class DoubleConv(nn.Module):
|
| 10 |
+
"""(convolution => [BN] => ReLU) * 2"""
|
| 11 |
+
|
| 12 |
+
def __init__(self, in_channels, out_channels, mid_channels=None):
|
| 13 |
+
super().__init__()
|
| 14 |
+
if not mid_channels:
|
| 15 |
+
mid_channels = out_channels
|
| 16 |
+
self.double_conv = nn.Sequential(
|
| 17 |
+
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1),
|
| 18 |
+
nn.BatchNorm2d(mid_channels),
|
| 19 |
+
nn.LeakyReLU(0.1, True),
|
| 20 |
+
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1),
|
| 21 |
+
nn.BatchNorm2d(out_channels),
|
| 22 |
+
nn.LeakyReLU(0.1, True)
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
def forward(self, x):
|
| 26 |
+
x = self.double_conv(x)
|
| 27 |
+
return x
|
| 28 |
+
|
| 29 |
+
class ResBlock(nn.Module):
|
| 30 |
+
"""(convolution => [BN] => ReLU) * 2"""
|
| 31 |
+
|
| 32 |
+
def __init__(self, in_channels, out_channels):
|
| 33 |
+
super().__init__()
|
| 34 |
+
self.bottle_conv = nn.Conv2d(in_channels, out_channels, 1, 1, 0)
|
| 35 |
+
self.double_conv = nn.Sequential(
|
| 36 |
+
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
|
| 37 |
+
nn.BatchNorm2d(out_channels),
|
| 38 |
+
nn.LeakyReLU(0.2, True),
|
| 39 |
+
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
def forward(self, x):
|
| 43 |
+
x = self.bottle_conv(x)
|
| 44 |
+
x = self.double_conv(x) + x
|
| 45 |
+
return x / math.sqrt(2)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class Down(nn.Module):
|
| 49 |
+
"""Downscaling with stride conv then double conv"""
|
| 50 |
+
|
| 51 |
+
def __init__(self, in_channels, out_channels):
|
| 52 |
+
super().__init__()
|
| 53 |
+
self.main = nn.Sequential(
|
| 54 |
+
nn.Conv2d(in_channels, in_channels, 4, 2, 1),
|
| 55 |
+
nn.LeakyReLU(0.1, True),
|
| 56 |
+
# DoubleConv(in_channels, out_channels)
|
| 57 |
+
ResBlock(in_channels, out_channels)
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def forward(self, x):
|
| 62 |
+
|
| 63 |
+
x = self.main(x)
|
| 64 |
+
|
| 65 |
+
return x
|
| 66 |
+
|
| 67 |
+
class SDFT(nn.Module):
|
| 68 |
+
|
| 69 |
+
def __init__(self, color_dim, channels, kernel_size = 3):
|
| 70 |
+
super().__init__()
|
| 71 |
+
|
| 72 |
+
# generate global conv weights
|
| 73 |
+
fan_in = channels * kernel_size ** 2
|
| 74 |
+
self.kernel_size = kernel_size
|
| 75 |
+
self.padding = kernel_size // 2
|
| 76 |
+
|
| 77 |
+
self.scale = 1 / math.sqrt(fan_in)
|
| 78 |
+
self.modulation = nn.Conv2d(color_dim, channels, 1)
|
| 79 |
+
self.weight = nn.Parameter(
|
| 80 |
+
torch.randn(1, channels, channels, kernel_size, kernel_size)
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
def forward(self, fea, color_style):
|
| 84 |
+
# for global adjustation
|
| 85 |
+
B, C, H, W = fea.size()
|
| 86 |
+
# print(fea.shape, color_style.shape)
|
| 87 |
+
style = self.modulation(color_style).view(B, 1, C, 1, 1)
|
| 88 |
+
weight = self.scale * self.weight * style
|
| 89 |
+
# demodulation
|
| 90 |
+
demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8)
|
| 91 |
+
weight = weight * demod.view(B, C, 1, 1, 1)
|
| 92 |
+
|
| 93 |
+
weight = weight.view(
|
| 94 |
+
B * C, C, self.kernel_size, self.kernel_size
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
fea = fea.view(1, B * C, H, W)
|
| 98 |
+
fea = F.conv2d(fea, weight, padding=self.padding, groups=B)
|
| 99 |
+
fea = fea.view(B, C, H, W)
|
| 100 |
+
|
| 101 |
+
return fea
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class UpBlock(nn.Module):
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def __init__(self, color_dim, in_channels, out_channels, kernel_size = 3, bilinear=True):
|
| 108 |
+
super().__init__()
|
| 109 |
+
|
| 110 |
+
# if bilinear, use the normal convolutions to reduce the number of channels
|
| 111 |
+
if bilinear:
|
| 112 |
+
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
|
| 113 |
+
|
| 114 |
+
else:
|
| 115 |
+
self.up = nn.ConvTranspose2d(in_channels , in_channels // 2, kernel_size=2, stride=2)
|
| 116 |
+
|
| 117 |
+
self.conv_cat = nn.Sequential(
|
| 118 |
+
nn.Conv2d(in_channels // 2 + in_channels // 8, out_channels, 1, 1, 0),
|
| 119 |
+
nn.LeakyReLU(0.2, True),
|
| 120 |
+
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
|
| 121 |
+
nn.LeakyReLU(0.2, True)
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
self.conv_s = nn.Conv2d(in_channels//2, out_channels, 1, 1, 0)
|
| 125 |
+
|
| 126 |
+
# generate global conv weights
|
| 127 |
+
self.SDFT = SDFT(color_dim, out_channels, kernel_size)
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def forward(self, x1, x2, color_style):
|
| 131 |
+
# print(x1.shape, x2.shape, color_style.shape)
|
| 132 |
+
x1 = self.up(x1)
|
| 133 |
+
x1_s = self.conv_s(x1)
|
| 134 |
+
|
| 135 |
+
x = torch.cat([x1, x2[:, ::4, :, :]], dim=1)
|
| 136 |
+
x = self.conv_cat(x)
|
| 137 |
+
x = self.SDFT(x, color_style)
|
| 138 |
+
|
| 139 |
+
x = x + x1_s #ResBlock
|
| 140 |
+
|
| 141 |
+
return x
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
class ColorEncoder(nn.Module):
|
| 145 |
+
def __init__(self, color_dim=512):
|
| 146 |
+
super(ColorEncoder, self).__init__()
|
| 147 |
+
|
| 148 |
+
# self.vgg = vgg19(pretrained_path=None)
|
| 149 |
+
self.vgg = vgg19()
|
| 150 |
+
|
| 151 |
+
self.feature2vector = nn.Sequential(
|
| 152 |
+
nn.Conv2d(color_dim, color_dim, 4, 2, 2), # 8x8
|
| 153 |
+
nn.LeakyReLU(0.2, True),
|
| 154 |
+
nn.Conv2d(color_dim, color_dim, 3, 1, 1),
|
| 155 |
+
nn.LeakyReLU(0.2, True),
|
| 156 |
+
nn.Conv2d(color_dim, color_dim, 4, 2, 2), # 4x4
|
| 157 |
+
nn.LeakyReLU(0.2, True),
|
| 158 |
+
nn.Conv2d(color_dim, color_dim, 3, 1, 1),
|
| 159 |
+
nn.LeakyReLU(0.2, True),
|
| 160 |
+
nn.AdaptiveAvgPool2d((1, 1)), # 1x1
|
| 161 |
+
nn.Conv2d(color_dim, color_dim//2, 1), # linear-1
|
| 162 |
+
nn.LeakyReLU(0.2, True),
|
| 163 |
+
nn.Conv2d(color_dim//2, color_dim//2, 1), # linear-2
|
| 164 |
+
nn.LeakyReLU(0.2, True),
|
| 165 |
+
nn.Conv2d(color_dim//2, color_dim, 1), # linear-3
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
self.color_dim = color_dim
|
| 169 |
+
|
| 170 |
+
def forward(self, x):
|
| 171 |
+
# x #[0, 1] RGB
|
| 172 |
+
vgg_fea = self.vgg(x, layer_name='relu5_2') # [B, 512, 16, 16]
|
| 173 |
+
|
| 174 |
+
x_color = self.feature2vector(vgg_fea[-1]) # [B, 512, 1, 1]
|
| 175 |
+
|
| 176 |
+
return x_color
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
class ColorUNet(nn.Module):
|
| 180 |
+
### this model output is ab
|
| 181 |
+
def __init__(self, n_channels=1, n_classes=3, bilinear=True):
|
| 182 |
+
super(ColorUNet, self).__init__()
|
| 183 |
+
self.n_channels = n_channels
|
| 184 |
+
self.n_classes = n_classes
|
| 185 |
+
self.bilinear = bilinear
|
| 186 |
+
|
| 187 |
+
self.inc = DoubleConv(n_channels, 64)
|
| 188 |
+
self.down1 = Down(64, 128)
|
| 189 |
+
self.down2 = Down(128, 256)
|
| 190 |
+
self.down3 = Down(256, 512)
|
| 191 |
+
factor = 2 if bilinear else 1
|
| 192 |
+
self.down4 = Down(512, 1024 // factor)
|
| 193 |
+
|
| 194 |
+
self.up1 = UpBlock(512, 1024, 512 // factor, 3, bilinear)
|
| 195 |
+
self.up2 = UpBlock(512, 512, 256 // factor, 3, bilinear)
|
| 196 |
+
self.up3 = UpBlock(512, 256, 128 // factor, 5, bilinear)
|
| 197 |
+
self.up4 = UpBlock(512, 128, 64, 5, bilinear)
|
| 198 |
+
self.outc = nn.Sequential(
|
| 199 |
+
nn.Conv2d(64, 64, 3, 1, 1),
|
| 200 |
+
nn.LeakyReLU(0.2, True),
|
| 201 |
+
nn.Conv2d(64, 2, 3, 1, 1),
|
| 202 |
+
nn.Tanh() # [-1,1]
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
def forward(self, x):
|
| 206 |
+
# print(torch.max(x[0]), torch.min(x[0])) #[-1, 1] gray image L
|
| 207 |
+
# print(torch.max(x[1]), torch.min(x[1])) # color vector
|
| 208 |
+
|
| 209 |
+
x_color = x[1] # [B, 512, 1, 1]
|
| 210 |
+
|
| 211 |
+
x1 = self.inc(x[0]) # [B, 64, 256, 256]
|
| 212 |
+
x2 = self.down1(x1) # [B, 128, 128, 128]
|
| 213 |
+
x3 = self.down2(x2) # [B, 256, 64, 64]
|
| 214 |
+
x4 = self.down3(x3) # [B, 512, 32, 32]
|
| 215 |
+
x5 = self.down4(x4) # [B, 512, 16, 16]
|
| 216 |
+
|
| 217 |
+
x6 = self.up1(x5, x4, x_color) # [B, 256, 32, 32]
|
| 218 |
+
x7 = self.up2(x6, x3, x_color) # [B, 128, 64, 64]
|
| 219 |
+
x8 = self.up3(x7, x2, x_color) # [B, 64, 128, 128]
|
| 220 |
+
x9 = self.up4(x8, x1, x_color) # [B, 64, 256, 256]
|
| 221 |
+
x_ab = self.outc(x9)
|
| 222 |
+
|
| 223 |
+
return x_ab
|
real_manga/class1/Color 1659315.jpg
ADDED

|
Git LFS Details
|
real_manga/class1/Color 3223141571376159.jpg
ADDED

|
Git LFS Details
|
real_manga/class1/Color 3486521.jpg
ADDED

|
Git LFS Details
|
real_manga/class1/Color 5102676.jpg
ADDED

|
Git LFS Details
|
real_manga/class1/Color 5570824.jpg
ADDED

|
Git LFS Details
|
real_manga/class1/Color 5674950.jpg
ADDED

|
Git LFS Details
|
real_manga/class1/Color 5828407151952509.jpg
ADDED

|
Git LFS Details
|