

Commit
•
779abe8
1
Parent(s):
b706adf
Upload folder using huggingface_hub
Browse files- LICENSE +352 -0
- README.md +260 -0
- added_tokens.json +4 -0
- assets/infimm-logo.webp +0 -0
- assets/infimm-zephyr-mmmu-test.jpeg +0 -0
- assets/infimm-zephyr-mmmu-val.jpeg +0 -0
- config.json +66 -0
- configuration_infimm_zephyr.py +42 -0
- convert_infi_zephyr_tokenizer_to_hf.py +29 -0
- convert_infi_zephyr_weights_to_hf.py +6 -0
- eva_vit.py +948 -0
- flamingo.py +261 -0
- flamingo_lm.py +256 -0
- generation_config.json +7 -0
- helpers.py +410 -0
- modeling_infimm_zephyr.py +138 -0
- preprocessor_config.json +7 -0
- processing_infimm_zephyr.py +345 -0
- pytorch_model.bin +3 -0
- special_tokens_map.json +46 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +62 -0
- utils.py +48 -0
LICENSE
ADDED
|
@@ -0,0 +1,352 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Creative Commons Attribution-NonCommercial 4.0 International
|
| 2 |
+
|
| 3 |
+
Creative Commons Corporation ("Creative Commons") is not a law firm and
|
| 4 |
+
does not provide legal services or legal advice. Distribution of
|
| 5 |
+
Creative Commons public licenses does not create a lawyer-client or
|
| 6 |
+
other relationship. Creative Commons makes its licenses and related
|
| 7 |
+
information available on an "as-is" basis. Creative Commons gives no
|
| 8 |
+
warranties regarding its licenses, any material licensed under their
|
| 9 |
+
terms and conditions, or any related information. Creative Commons
|
| 10 |
+
disclaims all liability for damages resulting from their use to the
|
| 11 |
+
fullest extent possible.
|
| 12 |
+
|
| 13 |
+
Using Creative Commons Public Licenses
|
| 14 |
+
|
| 15 |
+
Creative Commons public licenses provide a standard set of terms and
|
| 16 |
+
conditions that creators and other rights holders may use to share
|
| 17 |
+
original works of authorship and other material subject to copyright and
|
| 18 |
+
certain other rights specified in the public license below. The
|
| 19 |
+
following considerations are for informational purposes only, are not
|
| 20 |
+
exhaustive, and do not form part of our licenses.
|
| 21 |
+
|
| 22 |
+
- Considerations for licensors: Our public licenses are intended for
|
| 23 |
+
use by those authorized to give the public permission to use
|
| 24 |
+
material in ways otherwise restricted by copyright and certain other
|
| 25 |
+
rights. Our licenses are irrevocable. Licensors should read and
|
| 26 |
+
understand the terms and conditions of the license they choose
|
| 27 |
+
before applying it. Licensors should also secure all rights
|
| 28 |
+
necessary before applying our licenses so that the public can reuse
|
| 29 |
+
the material as expected. Licensors should clearly mark any material
|
| 30 |
+
not subject to the license. This includes other CC-licensed
|
| 31 |
+
material, or material used under an exception or limitation to
|
| 32 |
+
copyright. More considerations for licensors :
|
| 33 |
+
wiki.creativecommons.org/Considerations\_for\_licensors
|
| 34 |
+
|
| 35 |
+
- Considerations for the public: By using one of our public licenses,
|
| 36 |
+
a licensor grants the public permission to use the licensed material
|
| 37 |
+
under specified terms and conditions. If the licensor's permission
|
| 38 |
+
is not necessary for any reason–for example, because of any
|
| 39 |
+
applicable exception or limitation to copyright–then that use is not
|
| 40 |
+
regulated by the license. Our licenses grant only permissions under
|
| 41 |
+
copyright and certain other rights that a licensor has authority to
|
| 42 |
+
grant. Use of the licensed material may still be restricted for
|
| 43 |
+
other reasons, including because others have copyright or other
|
| 44 |
+
rights in the material. A licensor may make special requests, such
|
| 45 |
+
as asking that all changes be marked or described. Although not
|
| 46 |
+
required by our licenses, you are encouraged to respect those
|
| 47 |
+
requests where reasonable. More considerations for the public :
|
| 48 |
+
wiki.creativecommons.org/Considerations\_for\_licensees
|
| 49 |
+
|
| 50 |
+
Creative Commons Attribution-NonCommercial 4.0 International Public
|
| 51 |
+
License
|
| 52 |
+
|
| 53 |
+
By exercising the Licensed Rights (defined below), You accept and agree
|
| 54 |
+
to be bound by the terms and conditions of this Creative Commons
|
| 55 |
+
Attribution-NonCommercial 4.0 International Public License ("Public
|
| 56 |
+
License"). To the extent this Public License may be interpreted as a
|
| 57 |
+
contract, You are granted the Licensed Rights in consideration of Your
|
| 58 |
+
acceptance of these terms and conditions, and the Licensor grants You
|
| 59 |
+
such rights in consideration of benefits the Licensor receives from
|
| 60 |
+
making the Licensed Material available under these terms and conditions.
|
| 61 |
+
|
| 62 |
+
- Section 1 – Definitions.
|
| 63 |
+
|
| 64 |
+
- a. Adapted Material means material subject to Copyright and
|
| 65 |
+
Similar Rights that is derived from or based upon the Licensed
|
| 66 |
+
Material and in which the Licensed Material is translated,
|
| 67 |
+
altered, arranged, transformed, or otherwise modified in a
|
| 68 |
+
manner requiring permission under the Copyright and Similar
|
| 69 |
+
Rights held by the Licensor. For purposes of this Public
|
| 70 |
+
License, where the Licensed Material is a musical work,
|
| 71 |
+
performance, or sound recording, Adapted Material is always
|
| 72 |
+
produced where the Licensed Material is synched in timed
|
| 73 |
+
relation with a moving image.
|
| 74 |
+
- b. Adapter's License means the license You apply to Your
|
| 75 |
+
Copyright and Similar Rights in Your contributions to Adapted
|
| 76 |
+
Material in accordance with the terms and conditions of this
|
| 77 |
+
Public License.
|
| 78 |
+
- c. Copyright and Similar Rights means copyright and/or similar
|
| 79 |
+
rights closely related to copyright including, without
|
| 80 |
+
limitation, performance, broadcast, sound recording, and Sui
|
| 81 |
+
Generis Database Rights, without regard to how the rights are
|
| 82 |
+
labeled or categorized. For purposes of this Public License, the
|
| 83 |
+
rights specified in Section 2(b)(1)-(2) are not Copyright and
|
| 84 |
+
Similar Rights.
|
| 85 |
+
- d. Effective Technological Measures means those measures that,
|
| 86 |
+
in the absence of proper authority, may not be circumvented
|
| 87 |
+
under laws fulfilling obligations under Article 11 of the WIPO
|
| 88 |
+
Copyright Treaty adopted on December 20, 1996, and/or similar
|
| 89 |
+
international agreements.
|
| 90 |
+
- e. Exceptions and Limitations means fair use, fair dealing,
|
| 91 |
+
and/or any other exception or limitation to Copyright and
|
| 92 |
+
Similar Rights that applies to Your use of the Licensed
|
| 93 |
+
Material.
|
| 94 |
+
- f. Licensed Material means the artistic or literary work,
|
| 95 |
+
database, or other material to which the Licensor applied this
|
| 96 |
+
Public License.
|
| 97 |
+
- g. Licensed Rights means the rights granted to You subject to
|
| 98 |
+
the terms and conditions of this Public License, which are
|
| 99 |
+
limited to all Copyright and Similar Rights that apply to Your
|
| 100 |
+
use of the Licensed Material and that the Licensor has authority
|
| 101 |
+
to license.
|
| 102 |
+
- h. Licensor means the individual(s) or entity(ies) granting
|
| 103 |
+
rights under this Public License.
|
| 104 |
+
- i. NonCommercial means not primarily intended for or directed
|
| 105 |
+
towards commercial advantage or monetary compensation. For
|
| 106 |
+
purposes of this Public License, the exchange of the Licensed
|
| 107 |
+
Material for other material subject to Copyright and Similar
|
| 108 |
+
Rights by digital file-sharing or similar means is NonCommercial
|
| 109 |
+
provided there is no payment of monetary compensation in
|
| 110 |
+
connection with the exchange.
|
| 111 |
+
- j. Share means to provide material to the public by any means or
|
| 112 |
+
process that requires permission under the Licensed Rights, such
|
| 113 |
+
as reproduction, public display, public performance,
|
| 114 |
+
distribution, dissemination, communication, or importation, and
|
| 115 |
+
to make material available to the public including in ways that
|
| 116 |
+
members of the public may access the material from a place and
|
| 117 |
+
at a time individually chosen by them.
|
| 118 |
+
- k. Sui Generis Database Rights means rights other than copyright
|
| 119 |
+
resulting from Directive 96/9/EC of the European Parliament and
|
| 120 |
+
of the Council of 11 March 1996 on the legal protection of
|
| 121 |
+
databases, as amended and/or succeeded, as well as other
|
| 122 |
+
essentially equivalent rights anywhere in the world.
|
| 123 |
+
- l. You means the individual or entity exercising the Licensed
|
| 124 |
+
Rights under this Public License. Your has a corresponding
|
| 125 |
+
meaning.
|
| 126 |
+
|
| 127 |
+
- Section 2 – Scope.
|
| 128 |
+
|
| 129 |
+
- a. License grant.
|
| 130 |
+
- 1. Subject to the terms and conditions of this Public
|
| 131 |
+
License, the Licensor hereby grants You a worldwide,
|
| 132 |
+
royalty-free, non-sublicensable, non-exclusive, irrevocable
|
| 133 |
+
license to exercise the Licensed Rights in the Licensed
|
| 134 |
+
Material to:
|
| 135 |
+
- A. reproduce and Share the Licensed Material, in whole
|
| 136 |
+
or in part, for NonCommercial purposes only; and
|
| 137 |
+
- B. produce, reproduce, and Share Adapted Material for
|
| 138 |
+
NonCommercial purposes only.
|
| 139 |
+
- 2. Exceptions and Limitations. For the avoidance of doubt,
|
| 140 |
+
where Exceptions and Limitations apply to Your use, this
|
| 141 |
+
Public License does not apply, and You do not need to comply
|
| 142 |
+
with its terms and conditions.
|
| 143 |
+
- 3. Term. The term of this Public License is specified in
|
| 144 |
+
Section 6(a).
|
| 145 |
+
- 4. Media and formats; technical modifications allowed. The
|
| 146 |
+
Licensor authorizes You to exercise the Licensed Rights in
|
| 147 |
+
all media and formats whether now known or hereafter
|
| 148 |
+
created, and to make technical modifications necessary to do
|
| 149 |
+
so. The Licensor waives and/or agrees not to assert any
|
| 150 |
+
right or authority to forbid You from making technical
|
| 151 |
+
modifications necessary to exercise the Licensed Rights,
|
| 152 |
+
including technical modifications necessary to circumvent
|
| 153 |
+
Effective Technological Measures. For purposes of this
|
| 154 |
+
Public License, simply making modifications authorized by
|
| 155 |
+
this Section 2(a)(4) never produces Adapted Material.
|
| 156 |
+
- 5. Downstream recipients.
|
| 157 |
+
- A. Offer from the Licensor – Licensed Material. Every
|
| 158 |
+
recipient of the Licensed Material automatically
|
| 159 |
+
receives an offer from the Licensor to exercise the
|
| 160 |
+
Licensed Rights under the terms and conditions of this
|
| 161 |
+
Public License.
|
| 162 |
+
- B. No downstream restrictions. You may not offer or
|
| 163 |
+
impose any additional or different terms or conditions
|
| 164 |
+
on, or apply any Effective Technological Measures to,
|
| 165 |
+
the Licensed Material if doing so restricts exercise of
|
| 166 |
+
the Licensed Rights by any recipient of the Licensed
|
| 167 |
+
Material.
|
| 168 |
+
- 6. No endorsement. Nothing in this Public License
|
| 169 |
+
constitutes or may be construed as permission to assert or
|
| 170 |
+
imply that You are, or that Your use of the Licensed
|
| 171 |
+
Material is, connected with, or sponsored, endorsed, or
|
| 172 |
+
granted official status by, the Licensor or others
|
| 173 |
+
designated to receive attribution as provided in Section
|
| 174 |
+
3(a)(1)(A)(i).
|
| 175 |
+
- b. Other rights.
|
| 176 |
+
- 1. Moral rights, such as the right of integrity, are not
|
| 177 |
+
licensed under this Public License, nor are publicity,
|
| 178 |
+
privacy, and/or other similar personality rights; however,
|
| 179 |
+
to the extent possible, the Licensor waives and/or agrees
|
| 180 |
+
not to assert any such rights held by the Licensor to the
|
| 181 |
+
limited extent necessary to allow You to exercise the
|
| 182 |
+
Licensed Rights, but not otherwise.
|
| 183 |
+
- 2. Patent and trademark rights are not licensed under this
|
| 184 |
+
Public License.
|
| 185 |
+
- 3. To the extent possible, the Licensor waives any right to
|
| 186 |
+
collect royalties from You for the exercise of the Licensed
|
| 187 |
+
Rights, whether directly or through a collecting society
|
| 188 |
+
under any voluntary or waivable statutory or compulsory
|
| 189 |
+
licensing scheme. In all other cases the Licensor expressly
|
| 190 |
+
reserves any right to collect such royalties, including when
|
| 191 |
+
the Licensed Material is used other than for NonCommercial
|
| 192 |
+
purposes.
|
| 193 |
+
|
| 194 |
+
- Section 3 – License Conditions.
|
| 195 |
+
|
| 196 |
+
Your exercise of the Licensed Rights is expressly made subject to
|
| 197 |
+
the following conditions.
|
| 198 |
+
|
| 199 |
+
- a. Attribution.
|
| 200 |
+
- 1. If You Share the Licensed Material (including in modified
|
| 201 |
+
form), You must:
|
| 202 |
+
- A. retain the following if it is supplied by the
|
| 203 |
+
Licensor with the Licensed Material:
|
| 204 |
+
- i. identification of the creator(s) of the Licensed
|
| 205 |
+
Material and any others designated to receive
|
| 206 |
+
attribution, in any reasonable manner requested by
|
| 207 |
+
the Licensor (including by pseudonym if designated);
|
| 208 |
+
- ii. a copyright notice;
|
| 209 |
+
- iii. a notice that refers to this Public License;
|
| 210 |
+
- iv. a notice that refers to the disclaimer of
|
| 211 |
+
warranties;
|
| 212 |
+
- v. a URI or hyperlink to the Licensed Material to
|
| 213 |
+
the extent reasonably practicable;
|
| 214 |
+
- B. indicate if You modified the Licensed Material and
|
| 215 |
+
retain an indication of any previous modifications; and
|
| 216 |
+
- C. indicate the Licensed Material is licensed under this
|
| 217 |
+
Public License, and include the text of, or the URI or
|
| 218 |
+
hyperlink to, this Public License.
|
| 219 |
+
- 2. You may satisfy the conditions in Section 3(a)(1) in any
|
| 220 |
+
reasonable manner based on the medium, means, and context in
|
| 221 |
+
which You Share the Licensed Material. For example, it may
|
| 222 |
+
be reasonable to satisfy the conditions by providing a URI
|
| 223 |
+
or hyperlink to a resource that includes the required
|
| 224 |
+
information.
|
| 225 |
+
- 3. If requested by the Licensor, You must remove any of the
|
| 226 |
+
information required by Section 3(a)(1)(A) to the extent
|
| 227 |
+
reasonably practicable.
|
| 228 |
+
- 4. If You Share Adapted Material You produce, the Adapter's
|
| 229 |
+
License You apply must not prevent recipients of the Adapted
|
| 230 |
+
Material from complying with this Public License.
|
| 231 |
+
|
| 232 |
+
- Section 4 – Sui Generis Database Rights.
|
| 233 |
+
|
| 234 |
+
Where the Licensed Rights include Sui Generis Database Rights that
|
| 235 |
+
apply to Your use of the Licensed Material:
|
| 236 |
+
|
| 237 |
+
- a. for the avoidance of doubt, Section 2(a)(1) grants You the
|
| 238 |
+
right to extract, reuse, reproduce, and Share all or a
|
| 239 |
+
substantial portion of the contents of the database for
|
| 240 |
+
NonCommercial purposes only;
|
| 241 |
+
- b. if You include all or a substantial portion of the database
|
| 242 |
+
contents in a database in which You have Sui Generis Database
|
| 243 |
+
Rights, then the database in which You have Sui Generis Database
|
| 244 |
+
Rights (but not its individual contents) is Adapted Material;
|
| 245 |
+
and
|
| 246 |
+
- c. You must comply with the conditions in Section 3(a) if You
|
| 247 |
+
Share all or a substantial portion of the contents of the
|
| 248 |
+
database.
|
| 249 |
+
|
| 250 |
+
For the avoidance of doubt, this Section 4 supplements and does not
|
| 251 |
+
replace Your obligations under this Public License where the
|
| 252 |
+
Licensed Rights include other Copyright and Similar Rights.
|
| 253 |
+
|
| 254 |
+
- Section 5 – Disclaimer of Warranties and Limitation of Liability.
|
| 255 |
+
|
| 256 |
+
- a. Unless otherwise separately undertaken by the Licensor, to
|
| 257 |
+
the extent possible, the Licensor offers the Licensed Material
|
| 258 |
+
as-is and as-available, and makes no representations or
|
| 259 |
+
warranties of any kind concerning the Licensed Material, whether
|
| 260 |
+
express, implied, statutory, or other. This includes, without
|
| 261 |
+
limitation, warranties of title, merchantability, fitness for a
|
| 262 |
+
particular purpose, non-infringement, absence of latent or other
|
| 263 |
+
defects, accuracy, or the presence or absence of errors, whether
|
| 264 |
+
or not known or discoverable. Where disclaimers of warranties
|
| 265 |
+
are not allowed in full or in part, this disclaimer may not
|
| 266 |
+
apply to You.
|
| 267 |
+
- b. To the extent possible, in no event will the Licensor be
|
| 268 |
+
liable to You on any legal theory (including, without
|
| 269 |
+
limitation, negligence) or otherwise for any direct, special,
|
| 270 |
+
indirect, incidental, consequential, punitive, exemplary, or
|
| 271 |
+
other losses, costs, expenses, or damages arising out of this
|
| 272 |
+
Public License or use of the Licensed Material, even if the
|
| 273 |
+
Licensor has been advised of the possibility of such losses,
|
| 274 |
+
costs, expenses, or damages. Where a limitation of liability is
|
| 275 |
+
not allowed in full or in part, this limitation may not apply to
|
| 276 |
+
You.
|
| 277 |
+
- c. The disclaimer of warranties and limitation of liability
|
| 278 |
+
provided above shall be interpreted in a manner that, to the
|
| 279 |
+
extent possible, most closely approximates an absolute
|
| 280 |
+
disclaimer and waiver of all liability.
|
| 281 |
+
|
| 282 |
+
- Section 6 – Term and Termination.
|
| 283 |
+
|
| 284 |
+
- a. This Public License applies for the term of the Copyright and
|
| 285 |
+
Similar Rights licensed here. However, if You fail to comply
|
| 286 |
+
with this Public License, then Your rights under this Public
|
| 287 |
+
License terminate automatically.
|
| 288 |
+
- b. Where Your right to use the Licensed Material has terminated
|
| 289 |
+
under Section 6(a), it reinstates:
|
| 290 |
+
|
| 291 |
+
- 1. automatically as of the date the violation is cured,
|
| 292 |
+
provided it is cured within 30 days of Your discovery of the
|
| 293 |
+
violation; or
|
| 294 |
+
- 2. upon express reinstatement by the Licensor.
|
| 295 |
+
|
| 296 |
+
For the avoidance of doubt, this Section 6(b) does not affect
|
| 297 |
+
any right the Licensor may have to seek remedies for Your
|
| 298 |
+
violations of this Public License.
|
| 299 |
+
|
| 300 |
+
- c. For the avoidance of doubt, the Licensor may also offer the
|
| 301 |
+
Licensed Material under separate terms or conditions or stop
|
| 302 |
+
distributing the Licensed Material at any time; however, doing
|
| 303 |
+
so will not terminate this Public License.
|
| 304 |
+
- d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
|
| 305 |
+
License.
|
| 306 |
+
|
| 307 |
+
- Section 7 – Other Terms and Conditions.
|
| 308 |
+
|
| 309 |
+
- a. The Licensor shall not be bound by any additional or
|
| 310 |
+
different terms or conditions communicated by You unless
|
| 311 |
+
expressly agreed.
|
| 312 |
+
- b. Any arrangements, understandings, or agreements regarding the
|
| 313 |
+
Licensed Material not stated herein are separate from and
|
| 314 |
+
independent of the terms and conditions of this Public License.
|
| 315 |
+
|
| 316 |
+
- Section 8 – Interpretation.
|
| 317 |
+
|
| 318 |
+
- a. For the avoidance of doubt, this Public License does not, and
|
| 319 |
+
shall not be interpreted to, reduce, limit, restrict, or impose
|
| 320 |
+
conditions on any use of the Licensed Material that could
|
| 321 |
+
lawfully be made without permission under this Public License.
|
| 322 |
+
- b. To the extent possible, if any provision of this Public
|
| 323 |
+
License is deemed unenforceable, it shall be automatically
|
| 324 |
+
reformed to the minimum extent necessary to make it enforceable.
|
| 325 |
+
If the provision cannot be reformed, it shall be severed from
|
| 326 |
+
this Public License without affecting the enforceability of the
|
| 327 |
+
remaining terms and conditions.
|
| 328 |
+
- c. No term or condition of this Public License will be waived
|
| 329 |
+
and no failure to comply consented to unless expressly agreed to
|
| 330 |
+
by the Licensor.
|
| 331 |
+
- d. Nothing in this Public License constitutes or may be
|
| 332 |
+
interpreted as a limitation upon, or waiver of, any privileges
|
| 333 |
+
and immunities that apply to the Licensor or You, including from
|
| 334 |
+
the legal processes of any jurisdiction or authority.
|
| 335 |
+
|
| 336 |
+
Creative Commons is not a party to its public licenses. Notwithstanding,
|
| 337 |
+
Creative Commons may elect to apply one of its public licenses to
|
| 338 |
+
material it publishes and in those instances will be considered the
|
| 339 |
+
"Licensor." The text of the Creative Commons public licenses is
|
| 340 |
+
dedicated to the public domain under the CC0 Public Domain Dedication.
|
| 341 |
+
Except for the limited purpose of indicating that material is shared
|
| 342 |
+
under a Creative Commons public license or as otherwise permitted by the
|
| 343 |
+
Creative Commons policies published at creativecommons.org/policies,
|
| 344 |
+
Creative Commons does not authorize the use of the trademark "Creative
|
| 345 |
+
Commons" or any other trademark or logo of Creative Commons without its
|
| 346 |
+
prior written consent including, without limitation, in connection with
|
| 347 |
+
any unauthorized modifications to any of its public licenses or any
|
| 348 |
+
other arrangements, understandings, or agreements concerning use of
|
| 349 |
+
licensed material. For the avoidance of doubt, this paragraph does not
|
| 350 |
+
form part of the public licenses.
|
| 351 |
+
|
| 352 |
+
Creative Commons may be contacted at creativecommons.org.
|
README.md
ADDED
|
@@ -0,0 +1,260 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language: en
|
| 3 |
+
tags:
|
| 4 |
+
- multimodal
|
| 5 |
+
- text
|
| 6 |
+
- image
|
| 7 |
+
- image-to-text
|
| 8 |
+
license: mit
|
| 9 |
+
datasets:
|
| 10 |
+
- HuggingFaceM4/OBELICS
|
| 11 |
+
- laion/laion2B-en
|
| 12 |
+
- coyo-700m
|
| 13 |
+
- mmc4
|
| 14 |
+
pipeline_tag: text-generation
|
| 15 |
+
inference: true
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
<h1 align="center">
|
| 19 |
+
<br>
|
| 20 |
+
<img src="assets/infimm-logo.webp" alt="Markdownify" width="200"></a>
|
| 21 |
+
</h1>
|
| 22 |
+
|
| 23 |
+
# InfiMM
|
| 24 |
+
|
| 25 |
+
InfiMM, inspired by the Flamingo architecture, sets itself apart with unique training data and diverse large language models (LLMs). This approach allows InfiMM to maintain the core strengths of Flamingo while offering enhanced capabilities. As the premier open-sourced variant in this domain, InfiMM excels in accessibility and adaptability, driven by community collaboration. It's more than an emulation of Flamingo; it's an innovation in visual language processing.
|
| 26 |
+
|
| 27 |
+
Our model is another attempt to produce the result reported in the paper "Flamingo: A Large-scale Visual Language Model for Multimodal Understanding" by DeepMind.
|
| 28 |
+
Compared with previous open-sourced attempts ([OpenFlamingo](https://github.com/mlfoundations/open_flamingo) and [IDEFIC](https://huggingface.co/blog/idefics)), InfiMM offers a more flexible models, allowing for a wide range of applications.
|
| 29 |
+
In particular, InfiMM integrates the latest LLM models into VLM domain the reveals the impact of LLMs with different scales and architectures.
|
| 30 |
+
|
| 31 |
+
Please note that InfiMM is currently in beta stage and we are continuously working on improving it.
|
| 32 |
+
|
| 33 |
+
## Model Details
|
| 34 |
+
|
| 35 |
+
- **Developed by**: Institute of Automation, Chinese Academy of Sciences and ByteDance
|
| 36 |
+
- **Model Type**: Visual Language Model (VLM)
|
| 37 |
+
- **Language**: English
|
| 38 |
+
- **LLMs**: [Zephyr](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta), [LLaMA2-13B](https://ai.meta.com/llama/), [Vicuna-13B](https://huggingface.co/lmsys/vicuna-13b-v1.5)
|
| 39 |
+
- **Vision Model**: [EVA CLIP](https://huggingface.co/QuanSun/EVA-CLIP)
|
| 40 |
+
- **Language(s) (NLP):** en
|
| 41 |
+
- **License:** see [License section](#license)
|
| 42 |
+
<!---
|
| 43 |
+
- **Parent Models:** [QuanSun/EVA-CLIP](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA02_CLIP_L_336_psz14_s6B.pt) and [HuggingFaceH4/zephyr-7b--beta ta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)
|
| 44 |
+
-->
|
| 45 |
+
|
| 46 |
+
## Model Family
|
| 47 |
+
|
| 48 |
+
Our model consists of several different model. Please see the details below.
|
| 49 |
+
| Model | LLM | Vision Encoder | IFT |
|
| 50 |
+
| ---------------------- | -------------- | -------------- | --- |
|
| 51 |
+
| InfiMM-Zephyr | Zehpyr-7B-beta | ViT-L-336 | No |
|
| 52 |
+
| InfiMM-Llama-13B | Llama2-13B | ViT-G-224 | No |
|
| 53 |
+
| InfiMM-Vicuna-13B | Vicuna-13B | ViT-E-224 | No |
|
| 54 |
+
| InfiMM-Zephyr-Chat | Zehpyr-7B-beta | ViT-L-336 | Yes |
|
| 55 |
+
| InfiMM-Llama-13B-Chat | Llama2-13B | ViT-G-224 | Yes |
|
| 56 |
+
| InfiMM-Vicuna-13B-Chat | Vicuna-13B | ViT-E-224 | Yes |
|
| 57 |
+
|
| 58 |
+
<!-- InfiMM-Zephyr-Chat is an light-weighted, open-source re-production of Flamingo-style Multimodal large language models with chat capability that takes sequences of interleaved images and texts as inputs and generates text outputs, with only 9B parameters.
|
| 59 |
+
-->
|
| 60 |
+
|
| 61 |
+
## Demo
|
| 62 |
+
|
| 63 |
+
Will be released soon.
|
| 64 |
+
|
| 65 |
+
Our model adopts the Flamingo architecture, leveraging EVA CLIP as the visual encoder and employing LLaMA2, Vicuna, and Zephyr as language models. The visual and language modalities are connected through a Cross Attention module.
|
| 66 |
+
|
| 67 |
+
## Quickstart
|
| 68 |
+
|
| 69 |
+
Use the code below to get started with the base model:
|
| 70 |
+
```python
|
| 71 |
+
import torch
|
| 72 |
+
from transformers import AutoModelForCausalLM, AutoProcessor
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
processor = AutoProcessor.from_pretrained("InfiMM/infimm-zephyr", trust_remote_code=True)
|
| 76 |
+
|
| 77 |
+
prompts = [
|
| 78 |
+
{
|
| 79 |
+
"role": "user",
|
| 80 |
+
"content": [
|
| 81 |
+
{"image": "assets/infimm-logo.webp"},
|
| 82 |
+
"Please explain this image to me.",
|
| 83 |
+
],
|
| 84 |
+
}
|
| 85 |
+
]
|
| 86 |
+
inputs = processor(prompts)
|
| 87 |
+
|
| 88 |
+
# use bf16
|
| 89 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 90 |
+
"InfiMM/infimm-zephyr",
|
| 91 |
+
local_files_only=True,
|
| 92 |
+
torch_dtype=torch.bfloat16,
|
| 93 |
+
trust_remote_code=True,
|
| 94 |
+
).eval()
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
inputs = inputs.to(model.device)
|
| 98 |
+
inputs["batch_images"] = inputs["batch_images"].to(torch.bfloat16)
|
| 99 |
+
generated_ids = model.generate(
|
| 100 |
+
**inputs,
|
| 101 |
+
min_generation_length=0,
|
| 102 |
+
max_generation_length=256,
|
| 103 |
+
)
|
| 104 |
+
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
|
| 105 |
+
print(generated_text)
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
## Training Details
|
| 109 |
+
|
| 110 |
+
We employed three stages to train our model: pretraining (PT), multi-task training (MTT), and instruction finetuning (IFT). Refer to the table below for detailed configurations in each stage. Due to significant noise in the pretraining data, we aimed to enhance the model's accuracy by incorporating higher-quality data. In the multi-task training (MTT) phase, we utilized substantial training data from diverse datasets. However, as the answer in these data mainly consisted of single words or phrases, the model's conversational ability was limited. Therefore, in the third stage, we introduced a considerable amount of image-text dialogue data (llava665k) for fine-tuning the model's instructions.
|
| 111 |
+
|
| 112 |
+
### Pretraining (PT)
|
| 113 |
+
|
| 114 |
+
We follow similar training procedures used in [IDEFICS](https://huggingface.co/HuggingFaceM4/idefics-9b-instruct/blob/main/README.md).
|
| 115 |
+
|
| 116 |
+
The model is trained on a mixture of image-text pairs and unstructured multimodal web documents. All data are from public sources. Many image URL links are expired, we are capable of only downloading partial samples. We filter low quality data, here are resulting data we used:
|
| 117 |
+
|
| 118 |
+
| Data Source | Type of Data | Number of Tokens in Source | Number of Images in Source | Number of Samples | Epochs |
|
| 119 |
+
| ---------------------------------------------------------------- | ------------------------------------- | -------------------------- | -------------------------- | ----------------- | ------ |
|
| 120 |
+
| [OBELICS](https://huggingface.co/datasets/HuggingFaceM4/OBELICS) | Unstructured Multimodal Web Documents | - | - | 101M | 1 |
|
| 121 |
+
| [MMC4](https://github.com/allenai/mmc4) | Unstructured Multimodal Web Documents | - | - | 53M | 1 |
|
| 122 |
+
| [LAION](https://huggingface.co/datasets/laion/laion2B-en) | Image-Text Pairs | - | 115M | 115M | 1 |
|
| 123 |
+
| [COYO](https://github.com/kakaobrain/coyo-dataset) | Image-Text Pairs | - | 238M | 238M | 1 |
|
| 124 |
+
| [LAION-COCO](https://laion.ai/blog/laion-coco/) | Image-Text Pairs | - | 140M | 140M | 1 |
|
| 125 |
+
| [PMD\*](https://huggingface.co/datasets/facebook/pmd) | Image-Text Pairs | - | 20M | 1 |
|
| 126 |
+
|
| 127 |
+
\*PMD is only used in models with 13B LLMs, not the 7B Zephyr model.
|
| 128 |
+
|
| 129 |
+
During pretraining of interleaved image text sample, we apply masked cross-attention, however, we didn't strictly follow Flamingo, which alternate attention of image to its previous text or later text by change of 0.5.
|
| 130 |
+
|
| 131 |
+
We use the following hyper parameters:
|
| 132 |
+
| Categories | Parameters | Value |
|
| 133 |
+
| ------------------------ | -------------------------- | -------------------- |
|
| 134 |
+
| Perceiver Resampler | Number of Layers | 6 |
|
| 135 |
+
| | Number of Latents | 64 |
|
| 136 |
+
| | Number of Heads | 16 |
|
| 137 |
+
| | Resampler Head Dimension | 96 |
|
| 138 |
+
| Training | Sequence Length | 384 (13B) / 792 (7B) |
|
| 139 |
+
| | Effective Batch Size | 40\*128 |
|
| 140 |
+
| | Max Images per Sample | 6 |
|
| 141 |
+
| | Weight Decay | 0.1 |
|
| 142 |
+
| | Optimizer | Adam(0.9, 0.999) |
|
| 143 |
+
| | Gradient Accumulation Step | 2 |
|
| 144 |
+
| Learning Rate | Initial Max | 1e-4 |
|
| 145 |
+
| | Decay Schedule | Constant |
|
| 146 |
+
| | Warmup Step rate | 0.005 |
|
| 147 |
+
| Large-scale Optimization | Gradient Checkpointing | False |
|
| 148 |
+
| | Precision | bf16 |
|
| 149 |
+
| | ZeRO Optimization | Stage 2 |
|
| 150 |
+
|
| 151 |
+
### Multi-Task Training (MTT)
|
| 152 |
+
|
| 153 |
+
Here we use mix_cap_vqa to represent the mixed training set from COCO caption, TextCap, VizWiz Caption, VQAv2, OKVQA, VizWiz VQA, TextVQA, OCRVQA, STVQA, DocVQA, GQA and ScienceQA-image. For caption, we add prefix such as "Please describe the image." before the question. And for QA, we add "Answer the question using a single word or phrase.". Specifically, for VizWiz VQA, we use "When the provided information is insufficient, respond with 'Unanswerable'. Answer the question using a single word or phrase.". While for ScienceQA-image, we use "Answer with the option's letter from the given choices directly."
|
| 154 |
+
|
| 155 |
+
### Instruction Fine-Tuning (IFT)
|
| 156 |
+
|
| 157 |
+
For instruction fine-tuning stage, we use the recently released [LLaVA-MIX-665k](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/tree/main).
|
| 158 |
+
|
| 159 |
+
We use the following hyper parameters:
|
| 160 |
+
| Categories | Parameters | Value |
|
| 161 |
+
| ------------------------ | -------------------------- | -------------------- |
|
| 162 |
+
| Perceiver Resampler | Number of Layers | 6 |
|
| 163 |
+
| | Number of Latents | 64 |
|
| 164 |
+
| | Number of Heads | 16 |
|
| 165 |
+
| | Resampler Head Dimension | 96 |
|
| 166 |
+
| Training | Sequence Length | 384 (13B) / 792 (7B) |
|
| 167 |
+
| | Effective Batch Size | 64 |
|
| 168 |
+
| | Max Images per Sample | 6 |
|
| 169 |
+
| | Weight Decay | 0.1 |
|
| 170 |
+
| | Optimizer | Adam(0.9, 0.999) |
|
| 171 |
+
| | Gradient Accumulation Step | 2 |
|
| 172 |
+
| Learning Rate | Initial Max | 1e-5 |
|
| 173 |
+
| | Decay Schedule | Constant |
|
| 174 |
+
| | Warmup Step rate | 0.005 |
|
| 175 |
+
| Large-scale Optimization | Gradient Checkpointing | False |
|
| 176 |
+
| | Precision | bf16 |
|
| 177 |
+
| | ZeRO Optimization | Stage 2 |
|
| 178 |
+
|
| 179 |
+
During IFT, similar to pretrain, we keep ViT and LLM frozen for both chat-based LLM (Vicuna and Zephyr). For Llama model, we keep LLM trainable during the IFT stage. We also apply chat-template to process the training samples.
|
| 180 |
+
|
| 181 |
+
## Evaluation
|
| 182 |
+
|
| 183 |
+
### PreTraining Evaluation
|
| 184 |
+
|
| 185 |
+
We evaluate the pretrained models on the following downstream tasks: Image Captioning and VQA. We also compare with our results with [IDEFICS](https://huggingface.co/blog/idefics).
|
| 186 |
+
|
| 187 |
+
| Model | Shots | COCO CIDEr | Flickr30K CIDEr | VQA v2 Acc | TextVQA Acc | OK-VQA Acc |
|
| 188 |
+
| ----------------- | ----- | ---------- | --------------- | ---------- | ----------- | ---------- |
|
| 189 |
+
| IDEFICS-9B | 0 | 46 | 27.3 | 50.9 | 25.9 | 38.4 |
|
| 190 |
+
| | 4 | 93 | 59.7 | 55.4 | 27.6 | 45.5 |
|
| 191 |
+
| IDEFICS-80B | 0 | 91.8 | 53.7 | 60 | 30.9 | 45.2 |
|
| 192 |
+
| | 4 | 110.3 | 73.7 | 64.6 | 34.4 | 52.4 |
|
| 193 |
+
| InfiMM-Zephyr-7B | 0 | 78.8 | 60.7 | 33.7 | 15.2 | 17.1 |
|
| 194 |
+
| | 4 | 108.6 | 71.9 | 59.1 | 34.3 | 50.5 |
|
| 195 |
+
| InfiMM-Llama2-13B | 0 | 85.4 | 54.6 | 51.6 | 24.2 | 26.4 |
|
| 196 |
+
| | 4 | 125.2 | 87.1 | 66.1 | 38.2 | 55.5 |
|
| 197 |
+
| InfiMM-Vicuna13B | 0 | 69.6 | 49.6 | 60.4 | 32.8 | 49.2 |
|
| 198 |
+
| | 4 | 118.1 | 81.4 | 64.2 | 38.4 | 53.7 |
|
| 199 |
+
|
| 200 |
+
### IFT Evaluation
|
| 201 |
+
|
| 202 |
+
In our analysis, we concentrate on two primary benchmarks for evaluating MLLMs: 1) Multi-choice Question Answering (QA) and 2) Open-ended Evaluation. We've observed that the evaluation metrics for tasks like Visual Question Answering (VQA) and Text-VQA are overly sensitive to exact answer matches. This approach can be misleading, particularly when models provide synonymous but technically accurate responses. Therefore, these metrics have been omitted from our comparison for a more precise assessment. The evaluation results are shown in the table below.
|
| 203 |
+
|
| 204 |
+
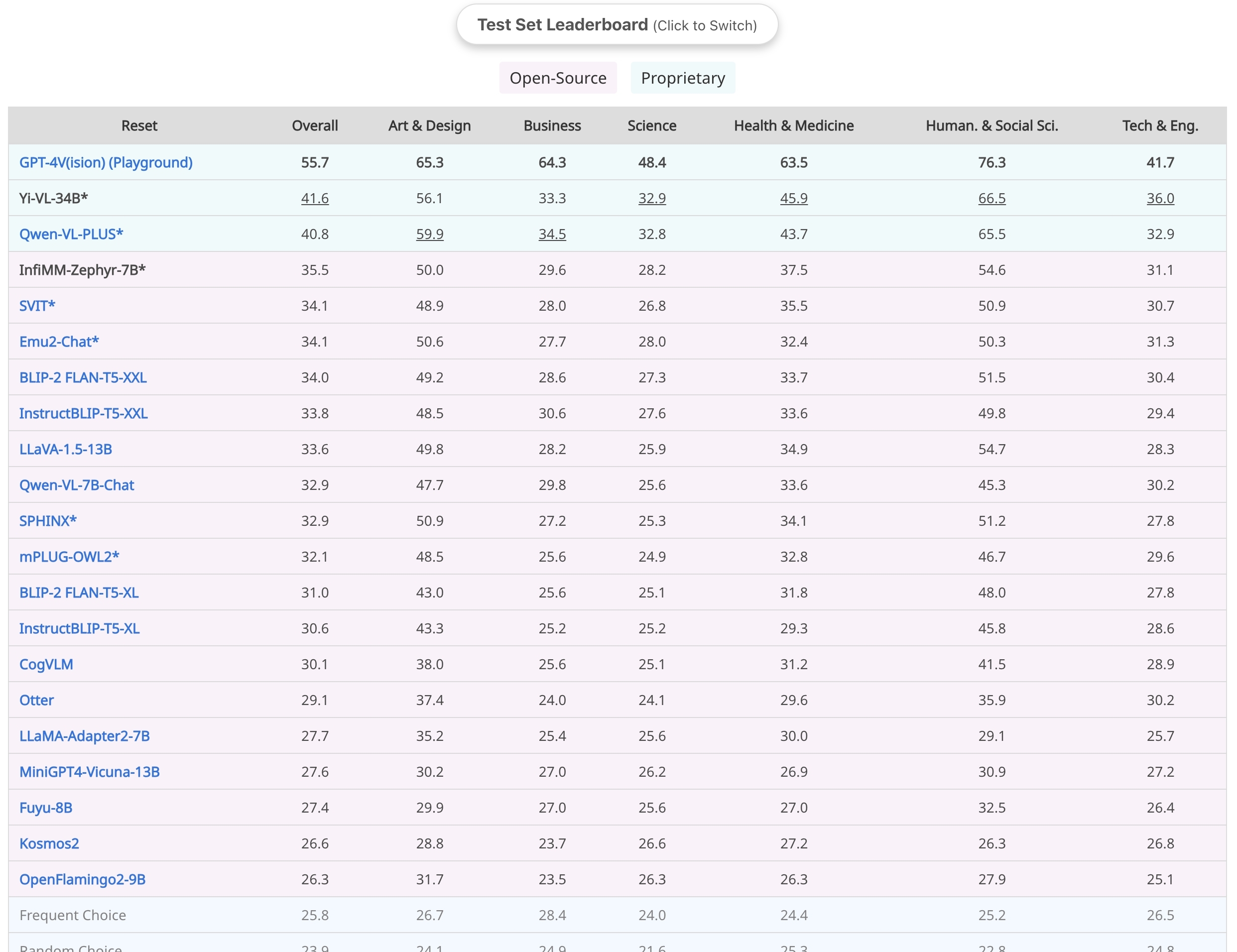
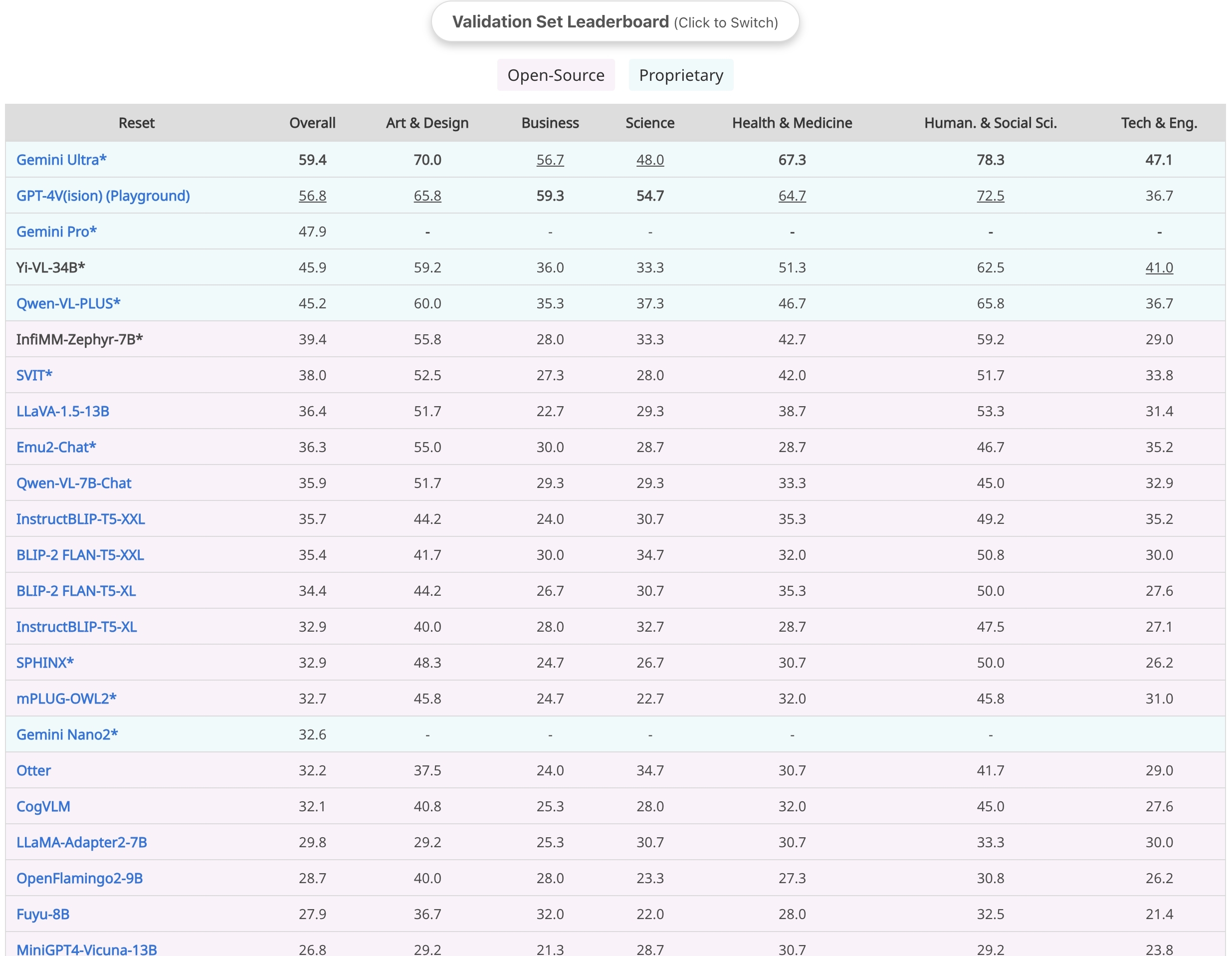
| Model | ScienceQA-Img | MME | MM-VET | InfiMM-Eval | MMbench | MMMU-Val | MMMU-Test |
|
| 205 |
+
| ------------------- | ------------- | --------------------- | ------ | ------------ | ------- | -------- | --------- |
|
| 206 |
+
| Otter-9B | - | 1292/306 | 24.6 | 32.2 | - | 22.69 | - |
|
| 207 |
+
| IDEFICS-9B-Instruct | 60.6 | -/- | - | - | - | 24.53 | - |
|
| 208 |
+
| InfiMM-Zephyr-7B | 71.1 | P: 1406<br>C:327 | 32.8 | 36.0 | 59.7 | 39.4 | 35.5 |
|
| 209 |
+
| InfiMM-Llama-13b | 73.0 | P: 1444.5<br>C: 337.6 | 39.2 | 0.4559/0.414 | 66.4 | 39.1 | 35.2 |
|
| 210 |
+
| InfiMM-Vicuna-13B | 74.0 | P: 1461.2<br>C: 323.5 | 36.0 | 40.0 | 66.7 | 37.6 | 34.6 |
|
| 211 |
+
|
| 212 |
+
<!--
|
| 213 |
+
| Model | TextVQA (no ocr) | OK-VQA | VQAv2 | ScienceQA-Img | GQA | MME | MM-VET | MMMU | InfiMM-Eval | MMbench |
|
| 214 |
+
| ----------------- | ---------------- | ------ | ----- | ------------- | ---- | --------------------- | ------ | ---- | ------------ | ------- |
|
| 215 |
+
| InfiMM-Zephyr-7B | 36.7 | 55.4 | / | 71.1 | | P: 1406<br>C:327 | 32.8 | 39.4 | 36.0 | 59.7 |
|
| 216 |
+
| InfiMM-Llama-13b | 44.6 | 62.3 | 78.5 | 73.0 | 61.2 | P: 1444.5<br>C: 337.6 | 39.2 | 39.1 | 0.4559/0.414 | 66.4 |
|
| 217 |
+
| InfiMM-Vicuna-13B | 41.7 | 58.5 | 73.0 | 74.0 | 58.5 | P: 1461.2<br>C: 323.5 | 36.0 | 37.6 | 40.0 | 66.7 |
|
| 218 |
+
|
| 219 |
+
We select checkpoint after 1 epoch instruction fine-tuning.
|
| 220 |
+
|
| 221 |
+
| Model | <nobr>ScienceQA <br>acc.</nobr> | <nobr>MME <br>P/C</nobr> | <nobr>MM-Vet</nobr> | <nobr>InfiMM-Eval</nobr> | <nobr>MMMU (val)</nobr> |
|
| 222 |
+
| :------------------ | ------------------------------: | -----------------------: | ------------------: | -----------------------: | ----------------------: |
|
| 223 |
+
| Otter-9B | - | 1292/306 | 24.6 | 22.69 | 32.2 |
|
| 224 |
+
| IDEFICS-9B-Instruct | 60.6 | -/- | - | 24.53 | - |
|
| 225 |
+
| InfiMM-Zephyr-Chat | 71.14 | 1406/327 | 33.3 | 35.97 | 39.4 |
|
| 226 |
+
-->
|
| 227 |
+
|
| 228 |
+
<details>
|
| 229 |
+
<summary>Leaderboard Details</summary>
|
| 230 |
+
|
| 231 |
+
<img src="assets/infimm-zephyr-mmmu-val.jpeg" style="zoom:40%;" />
|
| 232 |
+
<br>MMMU-Val split results<br>
|
| 233 |
+
<img src="assets/infimm-zephyr-mmmu-test.jpeg" style="zoom:40%;" />
|
| 234 |
+
<br>MMMU-Test split results<br>
|
| 235 |
+
|
| 236 |
+
</details>
|
| 237 |
+
|
| 238 |
+
## Citation
|
| 239 |
+
|
| 240 |
+
@misc{infimm-v1,
|
| 241 |
+
title={InfiMM: },
|
| 242 |
+
author={InfiMM Team},
|
| 243 |
+
year={2024}
|
| 244 |
+
}
|
| 245 |
+
|
| 246 |
+
## License
|
| 247 |
+
|
| 248 |
+
<a href="https://creativecommons.org/licenses/by-nc/4.0/deed.en">
|
| 249 |
+
<img src="https://upload.wikimedia.org/wikipedia/commons/thumb/d/d3/Cc_by-nc_icon.svg/600px-Cc_by-nc_icon.svg.png" width="160">
|
| 250 |
+
</a>
|
| 251 |
+
|
| 252 |
+
This project is licensed under the **CC BY-NC 4.0**.
|
| 253 |
+
|
| 254 |
+
The copyright of the images belongs to the original authors.
|
| 255 |
+
|
| 256 |
+
See [LICENSE](LICENSE) for more information.
|
| 257 |
+
|
| 258 |
+
## Contact Us
|
| 259 |
+
|
| 260 |
+
Please feel free to contact us via email [infimmbytedance@gmail.com](infimmbytedance@gmail.com) if you have any questions.
|
added_tokens.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<image>": 32001,
|
| 3 |
+
"<|endofchunk|>": 32000
|
| 4 |
+
}
|
assets/infimm-logo.webp
ADDED
|
|
assets/infimm-zephyr-mmmu-test.jpeg
ADDED
|
assets/infimm-zephyr-mmmu-val.jpeg
ADDED
|
config.json
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "./",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"InfiMMZephyrModel"
|
| 5 |
+
],
|
| 6 |
+
"auto_map": {
|
| 7 |
+
"AutoConfig": "configuration_infimm_zephyr.InfiMMConfig",
|
| 8 |
+
"AutoModelForCausalLM": "modeling_infimm_zephyr.InfiMMZephyrModel"
|
| 9 |
+
},
|
| 10 |
+
"model_type": "infimm-zephyr",
|
| 11 |
+
"seq_length": 1024,
|
| 12 |
+
"tokenizer_type": "LlamaTokenizer",
|
| 13 |
+
"torch_dtype": "bfloat16",
|
| 14 |
+
"transformers_version": "4.35.2",
|
| 15 |
+
"use_cache": true,
|
| 16 |
+
"use_flash_attn": false,
|
| 17 |
+
"cross_attn_every_n_layers": 2,
|
| 18 |
+
"use_grad_checkpoint": false,
|
| 19 |
+
"freeze_llm": true,
|
| 20 |
+
"image_token_id": 32001,
|
| 21 |
+
"eoc_token_id": 32000,
|
| 22 |
+
"visual": {
|
| 23 |
+
"image_size": 336,
|
| 24 |
+
"layers": 24,
|
| 25 |
+
"width": 1024,
|
| 26 |
+
"head_width": 64,
|
| 27 |
+
"patch_size": 14,
|
| 28 |
+
"mlp_ratio": 2.6667,
|
| 29 |
+
"eva_model_name": "eva-clip-l-14-336",
|
| 30 |
+
"drop_path_rate": 0.0,
|
| 31 |
+
"xattn": false,
|
| 32 |
+
"fusedLN": true,
|
| 33 |
+
"rope": true,
|
| 34 |
+
"pt_hw_seq_len": 16,
|
| 35 |
+
"intp_freq": true,
|
| 36 |
+
"naiveswiglu": true,
|
| 37 |
+
"subln": true,
|
| 38 |
+
"embed_dim": 768
|
| 39 |
+
},
|
| 40 |
+
"language": {
|
| 41 |
+
"_name_or_path": "HuggingFaceH4/zephyr-7b-beta",
|
| 42 |
+
"architectures": [
|
| 43 |
+
"MistralForCausalLM"
|
| 44 |
+
],
|
| 45 |
+
"bos_token_id": 1,
|
| 46 |
+
"eos_token_id": 2,
|
| 47 |
+
"hidden_act": "silu",
|
| 48 |
+
"hidden_size": 4096,
|
| 49 |
+
"initializer_range": 0.02,
|
| 50 |
+
"intermediate_size": 14336,
|
| 51 |
+
"max_position_embeddings": 32768,
|
| 52 |
+
"model_type": "mistral",
|
| 53 |
+
"num_attention_heads": 32,
|
| 54 |
+
"num_hidden_layers": 32,
|
| 55 |
+
"num_key_value_heads": 8,
|
| 56 |
+
"pad_token_id": 2,
|
| 57 |
+
"rms_norm_eps": 1e-05,
|
| 58 |
+
"rope_theta": 10000.0,
|
| 59 |
+
"sliding_window": 4096,
|
| 60 |
+
"tie_word_embeddings": false,
|
| 61 |
+
"torch_dtype": "bfloat16",
|
| 62 |
+
"transformers_version": "4.35.0",
|
| 63 |
+
"use_cache": true,
|
| 64 |
+
"vocab_size": 32002
|
| 65 |
+
}
|
| 66 |
+
}
|
configuration_infimm_zephyr.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This source code is licensed under the license found in the
|
| 2 |
+
# LICENSE file in the root directory of this source tree.
|
| 3 |
+
|
| 4 |
+
from transformers import PretrainedConfig
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class InfiMMConfig(PretrainedConfig):
|
| 8 |
+
model_type = "infimm"
|
| 9 |
+
|
| 10 |
+
def __init__(
|
| 11 |
+
self,
|
| 12 |
+
model_type="infimm-zephyr",
|
| 13 |
+
seq_length=1024,
|
| 14 |
+
tokenizer_type="ZephyrTokenizer",
|
| 15 |
+
torch_dtype="bfloat16",
|
| 16 |
+
transformers_version="4.35.2",
|
| 17 |
+
use_cache=True,
|
| 18 |
+
use_flash_attn=False,
|
| 19 |
+
cross_attn_every_n_layers=2,
|
| 20 |
+
use_grad_checkpoint=False,
|
| 21 |
+
freeze_llm=True,
|
| 22 |
+
visual=None,
|
| 23 |
+
language=None,
|
| 24 |
+
image_token_id=None,
|
| 25 |
+
eoc_token_id=None,
|
| 26 |
+
**kwargs,
|
| 27 |
+
):
|
| 28 |
+
self.model_type = model_type
|
| 29 |
+
self.seq_length = seq_length
|
| 30 |
+
self.tokenizer_type = tokenizer_type
|
| 31 |
+
self.torch_dtype = torch_dtype
|
| 32 |
+
self.transformers_version = transformers_version
|
| 33 |
+
self.use_cache = use_cache
|
| 34 |
+
self.use_flash_attn = use_flash_attn
|
| 35 |
+
self.cross_attn_every_n_layers = cross_attn_every_n_layers
|
| 36 |
+
self.use_grad_checkpoint = use_grad_checkpoint
|
| 37 |
+
self.freeze_llm = freeze_llm
|
| 38 |
+
self.visual = visual
|
| 39 |
+
self.language = language
|
| 40 |
+
self.image_token_id = image_token_id
|
| 41 |
+
self.eoc_token_id = eoc_token_id
|
| 42 |
+
super().__init__(**kwargs)
|
convert_infi_zephyr_tokenizer_to_hf.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
|
| 3 |
+
from open_flamingo.eval.models.mistral_model import EvalModel
|
| 4 |
+
from open_flamingo.train.distributed import init_distributed_device, world_info_from_env
|
| 5 |
+
|
| 6 |
+
parser = argparse.ArgumentParser()
|
| 7 |
+
|
| 8 |
+
parser.add_argument(
|
| 9 |
+
"--model",
|
| 10 |
+
type=str,
|
| 11 |
+
help="Model name. Currently only `OpenFlamingo` is supported.",
|
| 12 |
+
default="open_flamingo",
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def main():
|
| 17 |
+
model_args = {
|
| 18 |
+
"config_yaml": "configs/mlm_multi_source_v1_zephyr_ift_zero2.yaml",
|
| 19 |
+
"checkpoint_path": "cruise_logs/zephyr_freeze_ift/mp_rank_00_model_states.pt",
|
| 20 |
+
"precision": "bf16",
|
| 21 |
+
}
|
| 22 |
+
eval_model = EvalModel(model_args)
|
| 23 |
+
|
| 24 |
+
tokenizer = eval_model.tokenizer
|
| 25 |
+
# tokenizer.save_pretrained('hf_weights')
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
if __name__ == "__main__":
|
| 29 |
+
main()
|
convert_infi_zephyr_weights_to_hf.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
state_dict = torch.load(
|
| 4 |
+
"cruise_logs/zephyr_freeze_ift/mp_rank_00_model_states.pt", map_location="cpu"
|
| 5 |
+
)
|
| 6 |
+
state_dict = {k.replace("module.", ""): v for k, v in state_dict["module"].items()}
|
eva_vit.py
ADDED
|
@@ -0,0 +1,948 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# Adapted from https://github.com/baaivision/EVA/blob/master/EVA-CLIP/rei/eva_clip/eva_vit_model.py
|
| 3 |
+
# --------------------------------------------------------
|
| 4 |
+
import logging
|
| 5 |
+
import math
|
| 6 |
+
import os
|
| 7 |
+
from dataclasses import dataclass
|
| 8 |
+
from functools import partial
|
| 9 |
+
from math import pi
|
| 10 |
+
from typing import Optional, Tuple, Union
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
from einops import rearrange, repeat
|
| 15 |
+
from timm.models.layers import drop_path, to_2tuple, trunc_normal_
|
| 16 |
+
|
| 17 |
+
if os.getenv("ENV_TYPE") == "deepspeed":
|
| 18 |
+
try:
|
| 19 |
+
from deepspeed.runtime.activation_checkpointing.checkpointing import checkpoint
|
| 20 |
+
except:
|
| 21 |
+
from torch.utils.checkpoint import checkpoint
|
| 22 |
+
else:
|
| 23 |
+
from torch.utils.checkpoint import checkpoint
|
| 24 |
+
|
| 25 |
+
try:
|
| 26 |
+
import xformers.ops as xops
|
| 27 |
+
except ImportError:
|
| 28 |
+
xops = None
|
| 29 |
+
print("Please 'pip install xformers'")
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class PatchDropout(nn.Module):
|
| 33 |
+
"""
|
| 34 |
+
https://arxiv.org/abs/2212.00794
|
| 35 |
+
"""
|
| 36 |
+
|
| 37 |
+
def __init__(self, prob, exclude_first_token=True):
|
| 38 |
+
super().__init__()
|
| 39 |
+
assert 0 <= prob < 1.0
|
| 40 |
+
self.prob = prob
|
| 41 |
+
self.exclude_first_token = exclude_first_token # exclude CLS token
|
| 42 |
+
|
| 43 |
+
def forward(self, x):
|
| 44 |
+
if not self.training or self.prob == 0.0:
|
| 45 |
+
return x
|
| 46 |
+
|
| 47 |
+
if self.exclude_first_token:
|
| 48 |
+
cls_tokens, x = x[:, :1], x[:, 1:]
|
| 49 |
+
else:
|
| 50 |
+
cls_tokens = torch.jit.annotate(torch.Tensor, x[:, :1])
|
| 51 |
+
|
| 52 |
+
batch = x.size()[0]
|
| 53 |
+
num_tokens = x.size()[1]
|
| 54 |
+
|
| 55 |
+
batch_indices = torch.arange(batch)
|
| 56 |
+
batch_indices = batch_indices[..., None]
|
| 57 |
+
|
| 58 |
+
keep_prob = 1 - self.prob
|
| 59 |
+
num_patches_keep = max(1, int(num_tokens * keep_prob))
|
| 60 |
+
|
| 61 |
+
rand = torch.randn(batch, num_tokens)
|
| 62 |
+
patch_indices_keep = rand.topk(num_patches_keep, dim=-1).indices
|
| 63 |
+
|
| 64 |
+
x = x[batch_indices, patch_indices_keep]
|
| 65 |
+
|
| 66 |
+
if self.exclude_first_token:
|
| 67 |
+
x = torch.cat((cls_tokens, x), dim=1)
|
| 68 |
+
|
| 69 |
+
if self.training and os.getenv("RoPE") == "1":
|
| 70 |
+
return x, patch_indices_keep
|
| 71 |
+
|
| 72 |
+
return x
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class DropPath(nn.Module):
|
| 76 |
+
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
|
| 77 |
+
|
| 78 |
+
def __init__(self, drop_prob=None):
|
| 79 |
+
super(DropPath, self).__init__()
|
| 80 |
+
self.drop_prob = drop_prob
|
| 81 |
+
|
| 82 |
+
def forward(self, x):
|
| 83 |
+
return drop_path(x, self.drop_prob, self.training)
|
| 84 |
+
|
| 85 |
+
def extra_repr(self) -> str:
|
| 86 |
+
return "p={}".format(self.drop_prob)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class Mlp(nn.Module):
|
| 90 |
+
def __init__(
|
| 91 |
+
self,
|
| 92 |
+
in_features,
|
| 93 |
+
hidden_features=None,
|
| 94 |
+
out_features=None,
|
| 95 |
+
act_layer=nn.GELU,
|
| 96 |
+
norm_layer=nn.LayerNorm,
|
| 97 |
+
drop=0.0,
|
| 98 |
+
subln=False,
|
| 99 |
+
):
|
| 100 |
+
super().__init__()
|
| 101 |
+
out_features = out_features or in_features
|
| 102 |
+
hidden_features = hidden_features or in_features
|
| 103 |
+
|
| 104 |
+
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 105 |
+
self.act = act_layer()
|
| 106 |
+
|
| 107 |
+
self.ffn_ln = norm_layer(hidden_features) if subln else nn.Identity()
|
| 108 |
+
|
| 109 |
+
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 110 |
+
self.drop = nn.Dropout(drop)
|
| 111 |
+
|
| 112 |
+
def forward(self, x):
|
| 113 |
+
x = self.fc1(x)
|
| 114 |
+
x = self.act(x)
|
| 115 |
+
# x = self.drop(x)
|
| 116 |
+
# commit this for the orignal BERT implement
|
| 117 |
+
x = self.ffn_ln(x)
|
| 118 |
+
|
| 119 |
+
x = self.fc2(x)
|
| 120 |
+
x = self.drop(x)
|
| 121 |
+
return x
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
class SwiGLU(nn.Module):
|
| 125 |
+
def __init__(
|
| 126 |
+
self,
|
| 127 |
+
in_features,
|
| 128 |
+
hidden_features=None,
|
| 129 |
+
out_features=None,
|
| 130 |
+
act_layer=nn.SiLU,
|
| 131 |
+
drop=0.0,
|
| 132 |
+
norm_layer=nn.LayerNorm,
|
| 133 |
+
subln=False,
|
| 134 |
+
):
|
| 135 |
+
super().__init__()
|
| 136 |
+
out_features = out_features or in_features
|
| 137 |
+
hidden_features = hidden_features or in_features
|
| 138 |
+
|
| 139 |
+
self.w1 = nn.Linear(in_features, hidden_features)
|
| 140 |
+
self.w2 = nn.Linear(in_features, hidden_features)
|
| 141 |
+
|
| 142 |
+
self.act = act_layer()
|
| 143 |
+
self.ffn_ln = norm_layer(hidden_features) if subln else nn.Identity()
|
| 144 |
+
|
| 145 |
+
self.w3 = nn.Linear(hidden_features, out_features)
|
| 146 |
+
|
| 147 |
+
self.drop = nn.Dropout(drop)
|
| 148 |
+
|
| 149 |
+
def forward(self, x):
|
| 150 |
+
x1 = self.w1(x)
|
| 151 |
+
x2 = self.w2(x)
|
| 152 |
+
hidden = self.act(x1) * x2
|
| 153 |
+
x = self.ffn_ln(hidden)
|
| 154 |
+
x = self.w3(x)
|
| 155 |
+
x = self.drop(x)
|
| 156 |
+
return x
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
class Attention(nn.Module):
|
| 160 |
+
def __init__(
|
| 161 |
+
self,
|
| 162 |
+
dim,
|
| 163 |
+
num_heads=8,
|
| 164 |
+
qkv_bias=False,
|
| 165 |
+
qk_scale=None,
|
| 166 |
+
attn_drop=0.0,
|
| 167 |
+
proj_drop=0.0,
|
| 168 |
+
window_size=None,
|
| 169 |
+
attn_head_dim=None,
|
| 170 |
+
xattn=False,
|
| 171 |
+
rope=None,
|
| 172 |
+
subln=False,
|
| 173 |
+
norm_layer=nn.LayerNorm,
|
| 174 |
+
):
|
| 175 |
+
super().__init__()
|
| 176 |
+
self.num_heads = num_heads
|
| 177 |
+
head_dim = dim // num_heads
|
| 178 |
+
if attn_head_dim is not None:
|
| 179 |
+
head_dim = attn_head_dim
|
| 180 |
+
all_head_dim = head_dim * self.num_heads
|
| 181 |
+
self.scale = qk_scale or head_dim**-0.5
|
| 182 |
+
|
| 183 |
+
self.subln = subln
|
| 184 |
+
if self.subln:
|
| 185 |
+
self.q_proj = nn.Linear(dim, all_head_dim, bias=False)
|
| 186 |
+
self.k_proj = nn.Linear(dim, all_head_dim, bias=False)
|
| 187 |
+
self.v_proj = nn.Linear(dim, all_head_dim, bias=False)
|
| 188 |
+
|
| 189 |
+
else:
|
| 190 |
+
self.qkv = nn.Linear(dim, all_head_dim * 3, bias=False)
|
| 191 |
+
|
| 192 |
+
if qkv_bias:
|
| 193 |
+
self.q_bias = nn.Parameter(torch.zeros(all_head_dim))
|
| 194 |
+
self.v_bias = nn.Parameter(torch.zeros(all_head_dim))
|
| 195 |
+
else:
|
| 196 |
+
self.q_bias = None
|
| 197 |
+
self.v_bias = None
|
| 198 |
+
|
| 199 |
+
if window_size:
|
| 200 |
+
self.window_size = window_size
|
| 201 |
+
self.num_relative_distance = (2 * window_size[0] - 1) * (
|
| 202 |
+
2 * window_size[1] - 1
|
| 203 |
+
) + 3
|
| 204 |
+
self.relative_position_bias_table = nn.Parameter(
|
| 205 |
+
torch.zeros(self.num_relative_distance, num_heads)
|
| 206 |
+
) # 2*Wh-1 * 2*Ww-1, nH
|
| 207 |
+
# cls to token & token 2 cls & cls to cls
|
| 208 |
+
|
| 209 |
+
# get pair-wise relative position index for each token inside the window
|
| 210 |
+
coords_h = torch.arange(window_size[0])
|
| 211 |
+
coords_w = torch.arange(window_size[1])
|
| 212 |
+
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
|
| 213 |
+
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
|
| 214 |
+
relative_coords = (
|
| 215 |
+
coords_flatten[:, :, None] - coords_flatten[:, None, :]
|
| 216 |
+
) # 2, Wh*Ww, Wh*Ww
|
| 217 |
+
relative_coords = relative_coords.permute(
|
| 218 |
+
1, 2, 0
|
| 219 |
+
).contiguous() # Wh*Ww, Wh*Ww, 2
|
| 220 |
+
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
|
| 221 |
+
relative_coords[:, :, 1] += window_size[1] - 1
|
| 222 |
+
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
|
| 223 |
+
relative_position_index = torch.zeros(
|
| 224 |
+
size=(window_size[0] * window_size[1] + 1,) * 2,
|
| 225 |
+
dtype=relative_coords.dtype,
|
| 226 |
+
)
|
| 227 |
+
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
|
| 228 |
+
relative_position_index[0, 0:] = self.num_relative_distance - 3
|
| 229 |
+
relative_position_index[0:, 0] = self.num_relative_distance - 2
|
| 230 |
+
relative_position_index[0, 0] = self.num_relative_distance - 1
|
| 231 |
+
|
| 232 |
+
self.register_buffer("relative_position_index", relative_position_index)
|
| 233 |
+
else:
|
| 234 |
+
self.window_size = None
|
| 235 |
+
self.relative_position_bias_table = None
|
| 236 |
+
self.relative_position_index = None
|
| 237 |
+
|
| 238 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 239 |
+
self.inner_attn_ln = norm_layer(all_head_dim) if subln else nn.Identity()
|
| 240 |
+
# self.proj = nn.Linear(all_head_dim, all_head_dim)
|
| 241 |
+
self.proj = nn.Linear(all_head_dim, dim)
|
| 242 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 243 |
+
self.xattn = xattn
|
| 244 |
+
self.xattn_drop = attn_drop
|
| 245 |
+
|
| 246 |
+
self.rope = rope
|
| 247 |
+
|
| 248 |
+
def forward(self, x, rel_pos_bias=None, attn_mask=None):
|
| 249 |
+
B, N, C = x.shape
|
| 250 |
+
if self.subln:
|
| 251 |
+
q = F.linear(input=x, weight=self.q_proj.weight, bias=self.q_bias)
|
| 252 |
+
k = F.linear(input=x, weight=self.k_proj.weight, bias=None)
|
| 253 |
+
v = F.linear(input=x, weight=self.v_proj.weight, bias=self.v_bias)
|
| 254 |
+
|
| 255 |
+
q = q.reshape(B, N, self.num_heads, -1).permute(
|
| 256 |
+
0, 2, 1, 3
|
| 257 |
+
) # B, num_heads, N, C
|
| 258 |
+
k = k.reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
|
| 259 |
+
v = v.reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
|
| 260 |
+
else:
|
| 261 |
+
qkv_bias = None
|
| 262 |
+
if self.q_bias is not None:
|
| 263 |
+
qkv_bias = torch.cat(
|
| 264 |
+
(
|
| 265 |
+
self.q_bias,
|
| 266 |
+
torch.zeros_like(self.v_bias, requires_grad=False),
|
| 267 |
+
self.v_bias,
|
| 268 |
+
)
|
| 269 |
+
)
|
| 270 |
+
|
| 271 |
+
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
|
| 272 |
+
qkv = qkv.reshape(B, N, 3, self.num_heads, -1).permute(
|
| 273 |
+
2, 0, 3, 1, 4
|
| 274 |
+
) # 3, B, num_heads, N, C
|
| 275 |
+
q, k, v = qkv[0], qkv[1], qkv[2]
|
| 276 |
+
|
| 277 |
+
if self.rope:
|
| 278 |
+
# slightly fast impl
|
| 279 |
+
q_t = q[:, :, 1:, :]
|
| 280 |
+
ro_q_t = self.rope(q_t)
|
| 281 |
+
q = torch.cat((q[:, :, :1, :], ro_q_t), -2).type_as(v)
|
| 282 |
+
|
| 283 |
+
k_t = k[:, :, 1:, :]
|
| 284 |
+
ro_k_t = self.rope(k_t)
|
| 285 |
+
k = torch.cat((k[:, :, :1, :], ro_k_t), -2).type_as(v)
|
| 286 |
+
|
| 287 |
+
if self.xattn:
|
| 288 |
+
q = q.permute(0, 2, 1, 3) # B, num_heads, N, C -> B, N, num_heads, C
|
| 289 |
+
k = k.permute(0, 2, 1, 3)
|
| 290 |
+
v = v.permute(0, 2, 1, 3)
|
| 291 |
+
|
| 292 |
+
x = xops.memory_efficient_attention(
|
| 293 |
+
q,
|
| 294 |
+
k,
|
| 295 |
+
v,
|
| 296 |
+
p=self.xattn_drop,
|
| 297 |
+
scale=self.scale,
|
| 298 |
+
)
|
| 299 |
+
x = x.reshape(B, N, -1)
|
| 300 |
+
x = self.inner_attn_ln(x)
|
| 301 |
+
x = self.proj(x)
|
| 302 |
+
x = self.proj_drop(x)
|
| 303 |
+
else:
|
| 304 |
+
q = q * self.scale
|
| 305 |
+
attn = q @ k.transpose(-2, -1)
|
| 306 |
+
|
| 307 |
+
if self.relative_position_bias_table is not None:
|
| 308 |
+
relative_position_bias = self.relative_position_bias_table[
|
| 309 |
+
self.relative_position_index.view(-1)
|
| 310 |
+
].view(
|
| 311 |
+
self.window_size[0] * self.window_size[1] + 1,
|
| 312 |
+
self.window_size[0] * self.window_size[1] + 1,
|
| 313 |
+
-1,
|
| 314 |
+
) # Wh*Ww,Wh*Ww,nH
|
| 315 |
+
relative_position_bias = relative_position_bias.permute(
|
| 316 |
+
2, 0, 1
|
| 317 |
+
).contiguous() # nH, Wh*Ww, Wh*Ww
|
| 318 |
+
attn = attn + relative_position_bias.unsqueeze(0).type_as(attn)
|
| 319 |
+
|
| 320 |
+
if rel_pos_bias is not None:
|
| 321 |
+
attn = attn + rel_pos_bias.type_as(attn)
|
| 322 |
+
|
| 323 |
+
if attn_mask is not None:
|
| 324 |
+
attn_mask = attn_mask.bool()
|
| 325 |
+
attn = attn.masked_fill(~attn_mask[:, None, None, :], float("-inf"))
|
| 326 |
+
|
| 327 |
+
attn = attn.softmax(dim=-1)
|
| 328 |
+
attn = self.attn_drop(attn)
|
| 329 |
+
|
| 330 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
|
| 331 |
+
x = self.inner_attn_ln(x)
|
| 332 |
+
x = self.proj(x)
|
| 333 |
+
x = self.proj_drop(x)
|
| 334 |
+
return x
|
| 335 |
+
|
| 336 |
+
|
| 337 |
+
class Block(nn.Module):
|
| 338 |
+
def __init__(
|
| 339 |
+
self,
|
| 340 |
+
dim,
|
| 341 |
+
num_heads,
|
| 342 |
+
mlp_ratio=4.0,
|
| 343 |
+
qkv_bias=False,
|
| 344 |
+
qk_scale=None,
|
| 345 |
+
drop=0.0,
|
| 346 |
+
attn_drop=0.0,
|
| 347 |
+
drop_path=0.0,
|
| 348 |
+
init_values=None,
|
| 349 |
+
act_layer=nn.GELU,
|
| 350 |
+
norm_layer=nn.LayerNorm,
|
| 351 |
+
window_size=None,
|
| 352 |
+
attn_head_dim=None,
|
| 353 |
+
xattn=False,
|
| 354 |
+
rope=None,
|
| 355 |
+
postnorm=False,
|
| 356 |
+
subln=False,
|
| 357 |
+
naiveswiglu=False,
|
| 358 |
+
):
|
| 359 |
+
super().__init__()
|
| 360 |
+
self.norm1 = norm_layer(dim)
|
| 361 |
+
self.attn = Attention(
|
| 362 |
+
dim,
|
| 363 |
+
num_heads=num_heads,
|
| 364 |
+
qkv_bias=qkv_bias,
|
| 365 |
+
qk_scale=qk_scale,
|
| 366 |
+
attn_drop=attn_drop,
|
| 367 |
+
proj_drop=drop,
|
| 368 |
+
window_size=window_size,
|
| 369 |
+
attn_head_dim=attn_head_dim,
|
| 370 |
+
xattn=xattn,
|
| 371 |
+
rope=rope,
|
| 372 |
+
subln=subln,
|
| 373 |
+
norm_layer=norm_layer,
|
| 374 |
+
)
|
| 375 |
+
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
|
| 376 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 377 |
+
self.norm2 = norm_layer(dim)
|
| 378 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 379 |
+
|
| 380 |
+
if naiveswiglu:
|
| 381 |
+
self.mlp = SwiGLU(
|
| 382 |
+
in_features=dim,
|
| 383 |
+
hidden_features=mlp_hidden_dim,
|
| 384 |
+
subln=subln,
|
| 385 |
+
norm_layer=norm_layer,
|
| 386 |
+
)
|
| 387 |
+
else:
|
| 388 |
+
self.mlp = Mlp(
|
| 389 |
+
in_features=dim,
|
| 390 |
+
hidden_features=mlp_hidden_dim,
|
| 391 |
+
act_layer=act_layer,
|
| 392 |
+
subln=subln,
|
| 393 |
+
drop=drop,
|
| 394 |
+
)
|
| 395 |
+
|
| 396 |
+
if init_values is not None and init_values > 0:
|
| 397 |
+
self.gamma_1 = nn.Parameter(
|
| 398 |
+
init_values * torch.ones((dim)), requires_grad=True
|
| 399 |
+
)
|
| 400 |
+
self.gamma_2 = nn.Parameter(
|
| 401 |
+
init_values * torch.ones((dim)), requires_grad=True
|
| 402 |
+
)
|
| 403 |
+
else:
|
| 404 |
+
self.gamma_1, self.gamma_2 = None, None
|
| 405 |
+
|
| 406 |
+
self.postnorm = postnorm
|
| 407 |
+
|
| 408 |
+
def forward(self, x, rel_pos_bias=None, attn_mask=None):
|
| 409 |
+
if self.gamma_1 is None:
|
| 410 |
+
if self.postnorm:
|
| 411 |
+
x = x + self.drop_path(
|
| 412 |
+
self.norm1(
|
| 413 |
+
self.attn(x, rel_pos_bias=rel_pos_bias, attn_mask=attn_mask)
|
| 414 |
+
)
|
| 415 |
+
)
|
| 416 |
+
x = x + self.drop_path(self.norm2(self.mlp(x)))
|
| 417 |
+
else:
|
| 418 |
+
x = x + self.drop_path(
|
| 419 |
+
self.attn(
|
| 420 |
+
self.norm1(x), rel_pos_bias=rel_pos_bias, attn_mask=attn_mask
|
| 421 |
+
)
|
| 422 |
+
)
|
| 423 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 424 |
+
else:
|
| 425 |
+
if self.postnorm:
|
| 426 |
+
x = x + self.drop_path(
|
| 427 |
+
self.gamma_1
|
| 428 |
+
* self.norm1(
|
| 429 |
+
self.attn(x, rel_pos_bias=rel_pos_bias, attn_mask=attn_mask)
|
| 430 |
+
)
|
| 431 |
+
)
|
| 432 |
+
x = x + self.drop_path(self.gamma_2 * self.norm2(self.mlp(x)))
|
| 433 |
+
else:
|
| 434 |
+
x = x + self.drop_path(
|
| 435 |
+
self.gamma_1
|
| 436 |
+
* self.attn(
|
| 437 |
+
self.norm1(x), rel_pos_bias=rel_pos_bias, attn_mask=attn_mask
|
| 438 |
+
)
|
| 439 |
+
)
|
| 440 |
+
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
|
| 441 |
+
return x
|
| 442 |
+
|
| 443 |
+
|
| 444 |
+
class PatchEmbed(nn.Module):
|
| 445 |
+
"""Image to Patch Embedding"""
|
| 446 |
+
|
| 447 |
+
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
|
| 448 |
+
super().__init__()
|
| 449 |
+
img_size = to_2tuple(img_size)
|
| 450 |
+
patch_size = to_2tuple(patch_size)
|
| 451 |
+
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
|
| 452 |
+
self.patch_shape = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
|
| 453 |
+
self.img_size = img_size
|
| 454 |
+
self.patch_size = patch_size
|
| 455 |
+
self.num_patches = num_patches
|
| 456 |
+
|
| 457 |
+
self.proj = nn.Conv2d(
|
| 458 |
+
in_chans, embed_dim, kernel_size=patch_size, stride=patch_size
|
| 459 |
+
)
|
| 460 |
+
|
| 461 |
+
def forward(self, x, **kwargs):
|
| 462 |
+
B, C, H, W = x.shape
|
| 463 |
+
# FIXME look at relaxing size constraints
|
| 464 |
+
assert H == self.img_size[0] and W == self.img_size[1], (
|
| 465 |
+
f"Input image size ({H}*{W}) doesn't match model"
|
| 466 |
+
f" ({self.img_size[0]}*{self.img_size[1]})."
|
| 467 |
+
)
|
| 468 |
+
x = self.proj(x).flatten(2).transpose(1, 2)
|
| 469 |
+
return x
|
| 470 |
+
|
| 471 |
+
|
| 472 |
+
class RelativePositionBias(nn.Module):
|
| 473 |
+
def __init__(self, window_size, num_heads):
|
| 474 |
+
super().__init__()
|
| 475 |
+
self.window_size = window_size
|
| 476 |
+
self.num_relative_distance = (2 * window_size[0] - 1) * (
|
| 477 |
+
2 * window_size[1] - 1
|
| 478 |
+
) + 3
|
| 479 |
+
self.relative_position_bias_table = nn.Parameter(
|
| 480 |
+
torch.zeros(self.num_relative_distance, num_heads)
|
| 481 |
+
) # 2*Wh-1 * 2*Ww-1, nH
|
| 482 |
+
# cls to token & token 2 cls & cls to cls
|
| 483 |
+
|
| 484 |
+
# get pair-wise relative position index for each token inside the window
|
| 485 |
+
coords_h = torch.arange(window_size[0])
|
| 486 |
+
coords_w = torch.arange(window_size[1])
|
| 487 |
+
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
|
| 488 |
+
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
|
| 489 |
+
relative_coords = (
|
| 490 |
+
coords_flatten[:, :, None] - coords_flatten[:, None, :]
|
| 491 |
+
) # 2, Wh*Ww, Wh*Ww
|
| 492 |
+
relative_coords = relative_coords.permute(
|
| 493 |
+
1, 2, 0
|
| 494 |
+
).contiguous() # Wh*Ww, Wh*Ww, 2
|
| 495 |
+
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
|
| 496 |
+
relative_coords[:, :, 1] += window_size[1] - 1
|
| 497 |
+
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
|
| 498 |
+
relative_position_index = torch.zeros(
|
| 499 |
+
size=(window_size[0] * window_size[1] + 1,) * 2, dtype=relative_coords.dtype
|
| 500 |
+
)
|
| 501 |
+
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
|
| 502 |
+
relative_position_index[0, 0:] = self.num_relative_distance - 3
|
| 503 |
+
relative_position_index[0:, 0] = self.num_relative_distance - 2
|
| 504 |
+
relative_position_index[0, 0] = self.num_relative_distance - 1
|
| 505 |
+
|
| 506 |
+
self.register_buffer("relative_position_index", relative_position_index)
|
| 507 |
+
|
| 508 |
+
def forward(self):
|
| 509 |
+
relative_position_bias = self.relative_position_bias_table[
|
| 510 |
+
self.relative_position_index.view(-1)
|
| 511 |
+
].view(
|
| 512 |
+
self.window_size[0] * self.window_size[1] + 1,
|
| 513 |
+
self.window_size[0] * self.window_size[1] + 1,
|
| 514 |
+
-1,
|
| 515 |
+
) # Wh*Ww,Wh*Ww,nH
|
| 516 |
+
return relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
|
| 517 |
+
|
| 518 |
+
|
| 519 |
+
class EVAVisionTransformer(nn.Module):
|
| 520 |
+
"""Vision Transformer with support for patch or hybrid CNN input stage"""
|
| 521 |
+
|
| 522 |
+
def __init__(
|
| 523 |
+
self,
|
| 524 |
+
img_size=224,
|
| 525 |
+
patch_size=16,
|
| 526 |
+
in_chans=3,
|
| 527 |
+
num_classes=1000,
|
| 528 |
+
embed_dim=768,
|
| 529 |
+
depth=12,
|
| 530 |
+
num_heads=12,
|
| 531 |
+
mlp_ratio=4.0,
|
| 532 |
+
qkv_bias=False,
|
| 533 |
+
qk_scale=None,
|
| 534 |
+
drop_rate=0.0,
|
| 535 |
+
attn_drop_rate=0.0,
|
| 536 |
+
drop_path_rate=0.0,
|
| 537 |
+
norm_layer=nn.LayerNorm,
|
| 538 |
+
init_values=None,
|
| 539 |
+
patch_dropout=0.0,
|
| 540 |
+
use_abs_pos_emb=True,
|
| 541 |
+
use_rel_pos_bias=False,
|
| 542 |
+
use_shared_rel_pos_bias=False,
|
| 543 |
+
rope=False,
|
| 544 |
+
use_mean_pooling=True,
|
| 545 |
+
init_scale=0.001,
|
| 546 |
+
grad_checkpointing=False,
|
| 547 |
+
xattn=False,
|
| 548 |
+
postnorm=False,
|
| 549 |
+
pt_hw_seq_len=16,
|
| 550 |
+
intp_freq=False,
|
| 551 |
+
naiveswiglu=False,
|
| 552 |
+
subln=False,
|
| 553 |
+
):
|
| 554 |
+
super().__init__()
|
| 555 |
+
self.image_size = img_size
|
| 556 |
+
self.num_classes = num_classes
|
| 557 |
+
self.num_features = (
|
| 558 |
+
self.embed_dim
|
| 559 |
+
) = embed_dim # num_features for consistency with other models
|
| 560 |
+
|
| 561 |
+
self.patch_embed = PatchEmbed(
|
| 562 |
+
img_size=img_size,
|
| 563 |
+
patch_size=patch_size,
|
| 564 |
+
in_chans=in_chans,
|
| 565 |
+
embed_dim=embed_dim,
|
| 566 |
+
)
|
| 567 |
+
num_patches = self.patch_embed.num_patches
|
| 568 |
+
|
| 569 |
+
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
|
| 570 |
+
# self.mask_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
|
| 571 |
+
if use_abs_pos_emb:
|
| 572 |
+
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
|
| 573 |
+
else:
|
| 574 |
+
self.pos_embed = None
|
| 575 |
+
self.pos_drop = nn.Dropout(p=drop_rate)
|
| 576 |
+
|
| 577 |
+
if use_shared_rel_pos_bias:
|
| 578 |
+
self.rel_pos_bias = RelativePositionBias(
|
| 579 |
+
window_size=self.patch_embed.patch_shape, num_heads=num_heads
|
| 580 |
+
)
|
| 581 |
+
else:
|
| 582 |
+
self.rel_pos_bias = None
|
| 583 |
+
|
| 584 |
+
if rope:
|
| 585 |
+
half_head_dim = embed_dim // num_heads // 2
|
| 586 |
+
hw_seq_len = img_size // patch_size
|
| 587 |
+
self.rope = VisionRotaryEmbeddingFast(
|
| 588 |
+
dim=half_head_dim,
|
| 589 |
+
pt_seq_len=pt_hw_seq_len,
|
| 590 |
+
ft_seq_len=hw_seq_len if intp_freq else None,
|
| 591 |
+
# patch_dropout=patch_dropout
|
| 592 |
+
)
|
| 593 |
+
else:
|
| 594 |
+
self.rope = None
|
| 595 |
+
|
| 596 |
+
self.naiveswiglu = naiveswiglu
|
| 597 |
+
|
| 598 |
+
dpr = [
|
| 599 |
+
x.item() for x in torch.linspace(0, drop_path_rate, depth)
|
| 600 |
+
] # stochastic depth decay rule
|
| 601 |
+
self.use_rel_pos_bias = use_rel_pos_bias
|
| 602 |
+
self.blocks = nn.ModuleList(
|
| 603 |
+
[
|
| 604 |
+
Block(
|
| 605 |
+
dim=embed_dim,
|
| 606 |
+
num_heads=num_heads,
|
| 607 |
+
mlp_ratio=mlp_ratio,
|
| 608 |
+
qkv_bias=qkv_bias,
|
| 609 |
+
qk_scale=qk_scale,
|
| 610 |
+
drop=drop_rate,
|
| 611 |
+
attn_drop=attn_drop_rate,
|
| 612 |
+
drop_path=dpr[i],
|
| 613 |
+
norm_layer=norm_layer,
|
| 614 |
+
init_values=init_values,
|
| 615 |
+
window_size=(
|
| 616 |
+
self.patch_embed.patch_shape if use_rel_pos_bias else None
|
| 617 |
+
),
|
| 618 |
+
xattn=xattn,
|
| 619 |
+
rope=self.rope,
|
| 620 |
+
postnorm=postnorm,
|
| 621 |
+
subln=subln,
|
| 622 |
+
naiveswiglu=naiveswiglu,
|
| 623 |
+
)
|
| 624 |
+
for i in range(depth)
|
| 625 |
+
]
|
| 626 |
+
)
|
| 627 |
+
self.norm = nn.Identity() if use_mean_pooling else norm_layer(embed_dim)
|
| 628 |
+
self.fc_norm = norm_layer(embed_dim) if use_mean_pooling else None
|
| 629 |
+
self.head = (
|
| 630 |
+
nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 631 |
+
)
|
| 632 |
+
|
| 633 |
+
if self.pos_embed is not None:
|
| 634 |
+
trunc_normal_(self.pos_embed, std=0.02)
|
| 635 |
+
|
| 636 |
+
trunc_normal_(self.cls_token, std=0.02)
|
| 637 |
+
# trunc_normal_(self.mask_token, std=.02)
|
| 638 |
+
|
| 639 |
+
self.apply(self._init_weights)
|
| 640 |
+
self.fix_init_weight()
|
| 641 |
+
|
| 642 |
+
if isinstance(self.head, nn.Linear):
|
| 643 |
+
trunc_normal_(self.head.weight, std=0.02)
|
| 644 |
+
self.head.weight.data.mul_(init_scale)
|
| 645 |
+
self.head.bias.data.mul_(init_scale)
|
| 646 |
+
|
| 647 |
+
# setting a patch_dropout of 0. would mean it is disabled and this function would be the identity fn
|
| 648 |
+
self.patch_dropout = (
|
| 649 |
+
PatchDropout(patch_dropout) if patch_dropout > 0.0 else nn.Identity()
|
| 650 |
+
)
|
| 651 |
+
|
| 652 |
+
self.grad_checkpointing = grad_checkpointing
|
| 653 |
+
|
| 654 |
+
def fix_init_weight(self):
|
| 655 |
+
def rescale(param, layer_id):
|
| 656 |
+
param.div_(math.sqrt(2.0 * layer_id))
|
| 657 |
+
|
| 658 |
+
for layer_id, layer in enumerate(self.blocks):
|
| 659 |
+
rescale(layer.attn.proj.weight.data, layer_id + 1)
|
| 660 |
+
if self.naiveswiglu:
|
| 661 |
+
rescale(layer.mlp.w3.weight.data, layer_id + 1)
|
| 662 |
+
else:
|
| 663 |
+
rescale(layer.mlp.fc2.weight.data, layer_id + 1)
|
| 664 |
+
|
| 665 |
+
def get_cast_dtype(self) -> torch.dtype:
|
| 666 |
+
return self.blocks[0].mlp.fc2.weight.dtype
|
| 667 |
+
|
| 668 |
+
def _init_weights(self, m):
|
| 669 |
+
if isinstance(m, nn.Linear):
|
| 670 |
+
trunc_normal_(m.weight, std=0.02)
|
| 671 |
+
if m.bias is not None:
|
| 672 |
+
nn.init.constant_(m.bias, 0)
|
| 673 |
+
elif isinstance(m, nn.LayerNorm):
|
| 674 |
+
nn.init.constant_(m.bias, 0)
|
| 675 |
+
nn.init.constant_(m.weight, 1.0)
|
| 676 |
+
|
| 677 |
+
def get_num_layers(self):
|
| 678 |
+
return len(self.blocks)
|
| 679 |
+
|
| 680 |
+
def lock(self, unlocked_groups=0, freeze_bn_stats=False):
|
| 681 |
+
assert (
|
| 682 |
+
unlocked_groups == 0
|
| 683 |
+
), "partial locking not currently supported for this model"
|
| 684 |
+
for param in self.parameters():
|
| 685 |
+
param.requires_grad = False
|
| 686 |
+
|
| 687 |
+
@torch.jit.ignore
|
| 688 |
+
def set_grad_checkpointing(self, enable=True):
|
| 689 |
+
self.grad_checkpointing = enable
|
| 690 |
+
|
| 691 |
+
@torch.jit.ignore
|
| 692 |
+
def no_weight_decay(self):
|
| 693 |
+
return {"pos_embed", "cls_token"}
|
| 694 |
+
|
| 695 |
+
def get_classifier(self):
|
| 696 |
+
return self.head
|
| 697 |
+
|
| 698 |
+
def reset_classifier(self, num_classes, global_pool=""):
|
| 699 |
+
self.num_classes = num_classes
|
| 700 |
+
self.head = (
|
| 701 |
+
nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 702 |
+
)
|
| 703 |
+
|
| 704 |
+
def forward_features(self, x, return_all_features=False, return_all_layers=False):
|
| 705 |
+
x = self.patch_embed(x)
|
| 706 |
+
batch_size, seq_len, _ = x.size()
|
| 707 |
+
|
| 708 |
+
cls_tokens = self.cls_token.expand(
|
| 709 |
+
batch_size, -1, -1
|
| 710 |
+
) # stole cls_tokens impl from Phil Wang, thanks
|
| 711 |
+
x = torch.cat((cls_tokens, x), dim=1)
|
| 712 |
+
if self.pos_embed is not None:
|
| 713 |
+
x = x + self.pos_embed
|
| 714 |
+
x = self.pos_drop(x)
|
| 715 |
+
|
| 716 |
+
# a patch_dropout of 0. would mean it is disabled and this function would do nothing but return what was passed in
|
| 717 |
+
if os.getenv("RoPE") == "1":
|
| 718 |
+
if self.training and not isinstance(self.patch_dropout, nn.Identity):
|
| 719 |
+
x, patch_indices_keep = self.patch_dropout(x)
|
| 720 |
+
self.rope.forward = partial(
|
| 721 |
+
self.rope.forward, patch_indices_keep=patch_indices_keep
|
| 722 |
+
)
|
| 723 |
+
else:
|
| 724 |
+
self.rope.forward = partial(self.rope.forward, patch_indices_keep=None)
|
| 725 |
+
x = self.patch_dropout(x)
|
| 726 |
+
else:
|
| 727 |
+
x = self.patch_dropout(x)
|
| 728 |
+
|
| 729 |
+
rel_pos_bias = self.rel_pos_bias() if self.rel_pos_bias is not None else None
|
| 730 |
+
|
| 731 |
+
all_x = []
|
| 732 |
+
for blk in self.blocks:
|
| 733 |
+
if self.grad_checkpointing:
|
| 734 |
+
x = checkpoint(blk, x, (rel_pos_bias,))
|
| 735 |
+
else:
|
| 736 |
+
x = blk(x, rel_pos_bias=rel_pos_bias)
|
| 737 |
+
|
| 738 |
+
if return_all_layers:
|
| 739 |
+
all_x.append(x)
|
| 740 |
+
|
| 741 |
+
if not return_all_features:
|
| 742 |
+
x = self.norm(x)
|
| 743 |
+
if self.fc_norm is not None:
|
| 744 |
+
return self.fc_norm(x.mean(1))
|
| 745 |
+
else:
|
| 746 |
+
return x[:, 0]
|
| 747 |
+
return x if not return_all_layers else all_x
|
| 748 |
+
|
| 749 |
+
def forward(self, x, return_all_features=False, return_all_layers=False):
|
| 750 |
+
if return_all_features:
|
| 751 |
+
return self.forward_features(x, return_all_features, return_all_layers)
|
| 752 |
+
x = self.forward_features(x)
|
| 753 |
+
x = self.head(x)
|
| 754 |
+
return x
|
| 755 |
+
|
| 756 |
+
|
| 757 |
+
@dataclass
|
| 758 |
+
class CLIPVisionCfg:
|
| 759 |
+
layers: Union[Tuple[int, int, int, int], int] = 12
|
| 760 |
+
width: int = 768
|
| 761 |
+
head_width: int = 64
|
| 762 |
+
mlp_ratio: float = 4.0
|
| 763 |
+
patch_size: int = 16
|
| 764 |
+
image_size: Union[Tuple[int, int], int] = 224
|
| 765 |
+
ls_init_value: Optional[float] = None # layer scale initial value
|
| 766 |
+
patch_dropout: float = 0.0 # what fraction of patches to dropout during training (0 would mean disabled and no patches dropped) - 0.5 to 0.75 recommended in the paper for optimal results
|
| 767 |
+
global_average_pool: bool = False # whether to global average pool the last embedding layer, instead of using CLS token (https://arxiv.org/abs/2205.01580)
|
| 768 |
+
drop_path_rate: Optional[float] = None # drop path rate
|
| 769 |
+
timm_model_name: str = (
|
| 770 |
+
None # a valid model name overrides layers, width, patch_size
|
| 771 |
+
)
|
| 772 |
+
timm_model_pretrained: bool = (
|
| 773 |
+
False # use (imagenet) pretrained weights for named model
|
| 774 |
+
)
|
| 775 |
+
timm_pool: str = ( # feature pooling for timm model ('abs_attn', 'rot_attn', 'avg', '')
|
| 776 |
+
"avg"
|
| 777 |
+
)
|
| 778 |
+
timm_proj: str = ( # linear projection for timm model output ('linear', 'mlp', '')
|
| 779 |
+
"linear"
|
| 780 |
+
)
|
| 781 |
+
timm_proj_bias: bool = False # enable bias final projection
|
| 782 |
+
eva_model_name: str = (
|
| 783 |
+
None # a valid eva model name overrides layers, width, patch_size
|
| 784 |
+
)
|
| 785 |
+
qkv_bias: bool = True
|
| 786 |
+
fusedLN: bool = False
|
| 787 |
+
embed_dim: int = 1024
|
| 788 |
+
xattn: bool = False
|
| 789 |
+
postnorm: bool = False
|
| 790 |
+
rope: bool = False
|
| 791 |
+
pt_hw_seq_len: int = 16 # 224/14
|
| 792 |
+
intp_freq: bool = False
|
| 793 |
+
naiveswiglu: bool = False
|
| 794 |
+
subln: bool = False
|
| 795 |
+
|
| 796 |
+
|
| 797 |
+
def broadcat(tensors, dim=-1):
|
| 798 |
+
num_tensors = len(tensors)
|
| 799 |
+
shape_lens = set(list(map(lambda t: len(t.shape), tensors)))
|
| 800 |
+
assert len(shape_lens) == 1, "tensors must all have the same number of dimensions"
|
| 801 |
+
shape_len = list(shape_lens)[0]
|
| 802 |
+
dim = (dim + shape_len) if dim < 0 else dim
|
| 803 |
+
dims = list(zip(*map(lambda t: list(t.shape), tensors)))
|
| 804 |
+
expandable_dims = [(i, val) for i, val in enumerate(dims) if i != dim]
|
| 805 |
+
assert all(
|
| 806 |
+
[*map(lambda t: len(set(t[1])) <= 2, expandable_dims)]
|
| 807 |
+
), "invalid dimensions for broadcastable concatentation"
|
| 808 |
+
max_dims = list(map(lambda t: (t[0], max(t[1])), expandable_dims))
|
| 809 |
+
expanded_dims = list(map(lambda t: (t[0], (t[1],) * num_tensors), max_dims))
|
| 810 |
+
expanded_dims.insert(dim, (dim, dims[dim]))
|
| 811 |
+
expandable_shapes = list(zip(*map(lambda t: t[1], expanded_dims)))
|
| 812 |
+
tensors = list(map(lambda t: t[0].expand(*t[1]), zip(tensors, expandable_shapes)))
|
| 813 |
+
return torch.cat(tensors, dim=dim)
|
| 814 |
+
|
| 815 |
+
|
| 816 |
+
def rotate_half(x):
|
| 817 |
+
x = rearrange(x, "... (d r) -> ... d r", r=2)
|
| 818 |
+
x1, x2 = x.unbind(dim=-1)
|
| 819 |
+
x = torch.stack((-x2, x1), dim=-1)
|
| 820 |
+
return rearrange(x, "... d r -> ... (d r)")
|
| 821 |
+
|
| 822 |
+
|
| 823 |
+
class VisionRotaryEmbedding(nn.Module):
|
| 824 |
+
def __init__(
|
| 825 |
+
self,
|
| 826 |
+
dim,
|
| 827 |
+
pt_seq_len,
|
| 828 |
+
ft_seq_len=None,
|
| 829 |
+
custom_freqs=None,
|
| 830 |
+
freqs_for="lang",
|
| 831 |
+
theta=10000,
|
| 832 |
+
max_freq=10,
|
| 833 |
+
num_freqs=1,
|
| 834 |
+
):
|
| 835 |
+
super().__init__()
|
| 836 |
+
if custom_freqs:
|
| 837 |
+
freqs = custom_freqs
|
| 838 |
+
elif freqs_for == "lang":
|
| 839 |
+
freqs = 1.0 / (
|
| 840 |
+
theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim)
|
| 841 |
+
)
|
| 842 |
+
elif freqs_for == "pixel":
|
| 843 |
+
freqs = torch.linspace(1.0, max_freq / 2, dim // 2) * pi
|
| 844 |
+
elif freqs_for == "constant":
|
| 845 |
+
freqs = torch.ones(num_freqs).float()
|
| 846 |
+
else:
|
| 847 |
+
raise ValueError(f"unknown modality {freqs_for}")
|
| 848 |
+
|
| 849 |
+
if ft_seq_len is None:
|
| 850 |
+
ft_seq_len = pt_seq_len
|
| 851 |
+
t = torch.arange(ft_seq_len) / ft_seq_len * pt_seq_len
|
| 852 |
+
|
| 853 |
+
freqs_h = torch.einsum("..., f -> ... f", t, freqs)
|
| 854 |
+
freqs_h = repeat(freqs_h, "... n -> ... (n r)", r=2)
|
| 855 |
+
|
| 856 |
+
freqs_w = torch.einsum("..., f -> ... f", t, freqs)
|
| 857 |
+
freqs_w = repeat(freqs_w, "... n -> ... (n r)", r=2)
|
| 858 |
+
|
| 859 |
+
freqs = broadcat((freqs_h[:, None, :], freqs_w[None, :, :]), dim=-1)
|
| 860 |
+
|
| 861 |
+
self.register_buffer("freqs_cos", freqs.cos())
|
| 862 |
+
self.register_buffer("freqs_sin", freqs.sin())
|
| 863 |
+
|
| 864 |
+
logging.info(f"Shape of rope freq: {self.freqs_cos.shape}")
|
| 865 |
+
|
| 866 |
+
def forward(self, t, start_index=0):
|
| 867 |
+
rot_dim = self.freqs_cos.shape[-1]
|
| 868 |
+
end_index = start_index + rot_dim
|
| 869 |
+
assert rot_dim <= t.shape[-1], (
|
| 870 |
+
f"feature dimension {t.shape[-1]} is not of sufficient size to rotate in"
|
| 871 |
+
f" all the positions {rot_dim}"
|
| 872 |
+
)
|
| 873 |
+
t_left, t, t_right = (
|
| 874 |
+
t[..., :start_index],
|
| 875 |
+
t[..., start_index:end_index],
|
| 876 |
+
t[..., end_index:],
|
| 877 |
+
)
|
| 878 |
+
t = (t * self.freqs_cos) + (rotate_half(t) * self.freqs_sin)
|
| 879 |
+
|
| 880 |
+
return torch.cat((t_left, t, t_right), dim=-1)
|
| 881 |
+
|
| 882 |
+
|
| 883 |
+
class VisionRotaryEmbeddingFast(nn.Module):
|
| 884 |
+
def __init__(
|
| 885 |
+
self,
|
| 886 |
+
dim,
|
| 887 |
+
pt_seq_len,
|
| 888 |
+
ft_seq_len=None,
|
| 889 |
+
custom_freqs=None,
|
| 890 |
+
freqs_for="lang",
|
| 891 |
+
theta=10000,
|
| 892 |
+
max_freq=10,
|
| 893 |
+
num_freqs=1,
|
| 894 |
+
patch_dropout=0.0,
|
| 895 |
+
):
|
| 896 |
+
super().__init__()
|
| 897 |
+
if custom_freqs:
|
| 898 |
+
freqs = custom_freqs
|
| 899 |
+
elif freqs_for == "lang":
|
| 900 |
+
freqs = 1.0 / (
|
| 901 |
+
theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim)
|
| 902 |
+
)
|
| 903 |
+
elif freqs_for == "pixel":
|
| 904 |
+
freqs = torch.linspace(1.0, max_freq / 2, dim // 2) * pi
|
| 905 |
+
elif freqs_for == "constant":
|
| 906 |
+
freqs = torch.ones(num_freqs).float()
|
| 907 |
+
else:
|
| 908 |
+
raise ValueError(f"unknown modality {freqs_for}")
|
| 909 |
+
|
| 910 |
+
if ft_seq_len is None:
|
| 911 |
+
ft_seq_len = pt_seq_len
|
| 912 |
+
t = torch.arange(ft_seq_len) / ft_seq_len * pt_seq_len
|
| 913 |
+
|
| 914 |
+
freqs = torch.einsum("..., f -> ... f", t, freqs)
|
| 915 |
+
freqs = repeat(freqs, "... n -> ... (n r)", r=2)
|
| 916 |
+
freqs = broadcat((freqs[:, None, :], freqs[None, :, :]), dim=-1)
|
| 917 |
+
|
| 918 |
+
freqs_cos = freqs.cos().view(-1, freqs.shape[-1])
|
| 919 |
+
freqs_sin = freqs.sin().view(-1, freqs.shape[-1])
|
| 920 |
+
|
| 921 |
+
self.patch_dropout = patch_dropout
|
| 922 |
+
|
| 923 |
+
self.register_buffer("freqs_cos", freqs_cos)
|
| 924 |
+
self.register_buffer("freqs_sin", freqs_sin)
|
| 925 |
+
|
| 926 |
+
logging.info(f"Shape of rope freq: {self.freqs_cos.shape}")
|
| 927 |
+
|
| 928 |
+
def forward(self, t, patch_indices_keep=None):
|
| 929 |
+
if patch_indices_keep is not None:
|
| 930 |
+
batch = t.size()[0]
|
| 931 |
+
batch_indices = torch.arange(batch)
|
| 932 |
+
batch_indices = batch_indices[..., None]
|
| 933 |
+
|
| 934 |
+
freqs_cos = repeat(
|
| 935 |
+
self.freqs_cos, "i j -> n i m j", n=t.shape[0], m=t.shape[1]
|
| 936 |
+
)
|
| 937 |
+
freqs_sin = repeat(
|
| 938 |
+
self.freqs_sin, "i j -> n i m j", n=t.shape[0], m=t.shape[1]
|
| 939 |
+
)
|
| 940 |
+
|
| 941 |
+
freqs_cos = freqs_cos[batch_indices, patch_indices_keep]
|
| 942 |
+
freqs_cos = rearrange(freqs_cos, "n i m j -> n m i j")
|
| 943 |
+
freqs_sin = freqs_sin[batch_indices, patch_indices_keep]
|
| 944 |
+
freqs_sin = rearrange(freqs_sin, "n i m j -> n m i j")
|
| 945 |
+
|
| 946 |
+
return t * freqs_cos + rotate_half(t) * freqs_sin
|
| 947 |
+
|
| 948 |
+
return t * self.freqs_cos + rotate_half(t) * self.freqs_sin
|
flamingo.py
ADDED
|
@@ -0,0 +1,261 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import inspect
|
| 2 |
+
import torch
|
| 3 |
+
from einops import rearrange
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
|
| 6 |
+
|
| 7 |
+
from .helpers import PerceiverResampler
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def unwrap_fsdp(m):
|
| 11 |
+
if isinstance(m, FSDP):
|
| 12 |
+
return unwrap_fsdp(m.module)
|
| 13 |
+
return m
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def accepts_parameter(func, parameter_name):
|
| 17 |
+
signature = inspect.signature(func)
|
| 18 |
+
return parameter_name in signature.parameters
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class Flamingo(nn.Module):
|
| 22 |
+
def __init__(
|
| 23 |
+
self,
|
| 24 |
+
vision_encoder: nn.Module,
|
| 25 |
+
lang_encoder: nn.Module,
|
| 26 |
+
eoc_token_id: int,
|
| 27 |
+
media_token_id: int,
|
| 28 |
+
vis_dim: int,
|
| 29 |
+
cross_attn_every_n_layers: int = 1,
|
| 30 |
+
gradient_checkpointing: bool = False,
|
| 31 |
+
enable_init_network_params: bool = False,
|
| 32 |
+
initializer_range: float = 0.02,
|
| 33 |
+
):
|
| 34 |
+
"""
|
| 35 |
+
Args:
|
| 36 |
+
vision_encoder (nn.Module): HF CLIPModel
|
| 37 |
+
lang_encoder (nn.Module): HF causal language model
|
| 38 |
+
eoc_token_id (int): Token id for <|endofchunk|>
|
| 39 |
+
media_token_id (int): Token id for <image>
|
| 40 |
+
vis_dim (int): Dimension of the visual features.
|
| 41 |
+
Visual features are projected to match this shape along the last dimension.
|
| 42 |
+
cross_attn_every_n_layers (int, optional): How often to apply cross attention after transformer layer. Defaults to 1.
|
| 43 |
+
"""
|
| 44 |
+
super().__init__()
|
| 45 |
+
self.eoc_token_id = eoc_token_id
|
| 46 |
+
self.media_token_id = media_token_id
|
| 47 |
+
self.vis_dim = vis_dim
|
| 48 |
+
if hasattr(lang_encoder.config, "d_model"):
|
| 49 |
+
self.lang_dim = lang_encoder.config.d_model # mpt uses d_model
|
| 50 |
+
else:
|
| 51 |
+
self.lang_dim = lang_encoder.config.hidden_size
|
| 52 |
+
|
| 53 |
+
self.vision_encoder = (
|
| 54 |
+
vision_encoder.visual
|
| 55 |
+
if hasattr(vision_encoder, "visual")
|
| 56 |
+
else vision_encoder
|
| 57 |
+
)
|
| 58 |
+
self.perceiver = PerceiverResampler(
|
| 59 |
+
dim=self.vis_dim,
|
| 60 |
+
enable_init_network_params=enable_init_network_params,
|
| 61 |
+
initializer_range=initializer_range,
|
| 62 |
+
gradient_checkpointing=gradient_checkpointing,
|
| 63 |
+
)
|
| 64 |
+
self.lang_encoder = lang_encoder
|
| 65 |
+
self.lang_encoder.init_flamingo(
|
| 66 |
+
media_token_id=media_token_id,
|
| 67 |
+
lang_hidden_size=self.lang_dim,
|
| 68 |
+
vis_hidden_size=self.vis_dim,
|
| 69 |
+
cross_attn_every_n_layers=cross_attn_every_n_layers,
|
| 70 |
+
gradient_checkpointing=gradient_checkpointing,
|
| 71 |
+
enable_init_network_params=enable_init_network_params,
|
| 72 |
+
initializer_range=initializer_range,
|
| 73 |
+
)
|
| 74 |
+
self._use_gradient_checkpointing = gradient_checkpointing
|
| 75 |
+
self.perceiver._use_gradient_checkpointing = gradient_checkpointing
|
| 76 |
+
|
| 77 |
+
def forward(
|
| 78 |
+
self,
|
| 79 |
+
vision_x: torch.Tensor,
|
| 80 |
+
lang_x: torch.Tensor,
|
| 81 |
+
attention_mask: torch.Tensor = None,
|
| 82 |
+
labels: torch.Tensor = None,
|
| 83 |
+
clear_conditioned_layers: bool = True,
|
| 84 |
+
past_key_values=None,
|
| 85 |
+
use_cache: bool = False,
|
| 86 |
+
):
|
| 87 |
+
"""
|
| 88 |
+
Forward pass of Flamingo.
|
| 89 |
+
|
| 90 |
+
Args:
|
| 91 |
+
vision_x (torch.Tensor): Vision input
|
| 92 |
+
shape (B, T_img, F, C, H, W) with F=1
|
| 93 |
+
lang_x (torch.Tensor): Language input ids
|
| 94 |
+
shape (B, T_txt)
|
| 95 |
+
attention_mask (torch.Tensor, optional): Attention mask. Defaults to None.
|
| 96 |
+
labels (torch.Tensor, optional): Labels. Defaults to None.
|
| 97 |
+
clear_conditioned_layers: if True, clear the conditioned layers
|
| 98 |
+
once the foward pass is completed. Set this to false if the
|
| 99 |
+
same set of images will be reused in another subsequent
|
| 100 |
+
forward pass.
|
| 101 |
+
past_key_values: pre-computed values to pass to language model.
|
| 102 |
+
See past_key_values documentation in Hugging Face
|
| 103 |
+
CausalLM models.
|
| 104 |
+
use_cache: whether to use cached key values. See use_cache
|
| 105 |
+
documentation in Hugging Face CausalLM models.
|
| 106 |
+
"""
|
| 107 |
+
assert (
|
| 108 |
+
self.lang_encoder.initialized_flamingo
|
| 109 |
+
), "Flamingo layers are not initialized. Please call `init_flamingo` first."
|
| 110 |
+
|
| 111 |
+
assert (
|
| 112 |
+
self.lang_encoder._use_cached_vision_x or vision_x is not None
|
| 113 |
+
), "Must provide either vision_x or have precached media using cache_media()."
|
| 114 |
+
|
| 115 |
+
if self.lang_encoder._use_cached_vision_x:
|
| 116 |
+
# Case: use cached; vision_x should be cached and other
|
| 117 |
+
# vision-related inputs should not be provided.
|
| 118 |
+
assert vision_x is None, (
|
| 119 |
+
"Expect vision_x to be None when media has been cached using"
|
| 120 |
+
" cache_media(). Try uncache_media() first."
|
| 121 |
+
)
|
| 122 |
+
assert self.lang_encoder.is_conditioned()
|
| 123 |
+
|
| 124 |
+
else:
|
| 125 |
+
# Case: do not use caching (i.e. this is a standard forward pass);
|
| 126 |
+
self._encode_vision_x(vision_x=vision_x)
|
| 127 |
+
self._condition_media_locations(input_ids=lang_x)
|
| 128 |
+
|
| 129 |
+
output = self.lang_encoder(
|
| 130 |
+
input_ids=lang_x,
|
| 131 |
+
attention_mask=attention_mask,
|
| 132 |
+
labels=labels,
|
| 133 |
+
past_key_values=past_key_values,
|
| 134 |
+
use_cache=use_cache,
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
if clear_conditioned_layers:
|
| 138 |
+
self.lang_encoder.clear_conditioned_layers()
|
| 139 |
+
|
| 140 |
+
return output
|
| 141 |
+
|
| 142 |
+
def generate(
|
| 143 |
+
self,
|
| 144 |
+
vision_x: torch.Tensor,
|
| 145 |
+
lang_x: torch.Tensor,
|
| 146 |
+
attention_mask: torch.Tensor = None,
|
| 147 |
+
**kwargs,
|
| 148 |
+
):
|
| 149 |
+
"""
|
| 150 |
+
Generate text conditioned on vision and language inputs.
|
| 151 |
+
|
| 152 |
+
Args:
|
| 153 |
+
vision_x (torch.Tensor): Vision input
|
| 154 |
+
shape (B, T_img, F, C, H, W)
|
| 155 |
+
images in the same chunk are collated along T_img, and frames are collated along F
|
| 156 |
+
currently only F=1 is supported (single-frame videos)
|
| 157 |
+
lang_x (torch.Tensor): Language input
|
| 158 |
+
shape (B, T_txt)
|
| 159 |
+
**kwargs: see generate documentation in Hugging Face CausalLM models. Some notable kwargs:
|
| 160 |
+
max_length (int, optional): Maximum length of the output. Defaults to None.
|
| 161 |
+
attention_mask (torch.Tensor, optional): Attention mask. Defaults to None.
|
| 162 |
+
num_beams (int, optional): Number of beams. Defaults to 1.
|
| 163 |
+
max_new_tokens (int, optional): Maximum new tokens. Defaults to None.
|
| 164 |
+
temperature (float, optional): Temperature. Defaults to 1.0.
|
| 165 |
+
top_k (int, optional): Top k. Defaults to 50.
|
| 166 |
+
top_p (float, optional): Top p. Defaults to 1.0.
|
| 167 |
+
no_repeat_ngram_size (int, optional): No repeat ngram size. Defaults to 0.
|
| 168 |
+
length_penalty (float, optional): Length penalty. Defaults to 1.0.
|
| 169 |
+
num_return_sequences (int, optional): Number of return sequences. Defaults to 1.
|
| 170 |
+
do_sample (bool, optional): Do sample. Defaults to False.
|
| 171 |
+
early_stopping (bool, optional): Early stopping. Defaults to False.
|
| 172 |
+
Returns:
|
| 173 |
+
torch.Tensor: lang_x with generated tokens appended to it
|
| 174 |
+
"""
|
| 175 |
+
num_beams = kwargs.pop("num_beams", 1)
|
| 176 |
+
if num_beams > 1:
|
| 177 |
+
vision_x = vision_x.repeat_interleave(num_beams, dim=0)
|
| 178 |
+
|
| 179 |
+
self.lang_encoder._use_cached_vision_x = True
|
| 180 |
+
self._encode_vision_x(vision_x=vision_x)
|
| 181 |
+
|
| 182 |
+
# eos_token_id = kwargs.pop("eos_token_id", self.eoc_token_id)
|
| 183 |
+
output = self.lang_encoder.generate(
|
| 184 |
+
input_ids=lang_x,
|
| 185 |
+
attention_mask=attention_mask,
|
| 186 |
+
# eos_token_id=eos_token_id,
|
| 187 |
+
num_beams=num_beams,
|
| 188 |
+
**kwargs,
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
self.lang_encoder.clear_conditioned_layers()
|
| 192 |
+
self.lang_encoder._use_cached_vision_x = False
|
| 193 |
+
return output
|
| 194 |
+
|
| 195 |
+
def _encode_vision_x(self, vision_x: torch.Tensor):
|
| 196 |
+
"""
|
| 197 |
+
Compute media tokens from vision input by passing it through vision encoder and conditioning language model.
|
| 198 |
+
Args:
|
| 199 |
+
vision_x (torch.Tensor): Vision input
|
| 200 |
+
shape (B, T_img, F, C, H, W)
|
| 201 |
+
Images in the same chunk are collated along T_img, and frames are collated along F
|
| 202 |
+
Currently only F=1 is supported (single-frame videos)
|
| 203 |
+
|
| 204 |
+
rearrange code based on https://github.com/dhansmair/flamingo-mini
|
| 205 |
+
"""
|
| 206 |
+
|
| 207 |
+
assert vision_x.ndim == 6, "vision_x should be of shape (b, T_img, F, C, H, W)"
|
| 208 |
+
b, T, F = vision_x.shape[:3]
|
| 209 |
+
assert F == 1, "Only single frame supported"
|
| 210 |
+
|
| 211 |
+
vision_x = rearrange(vision_x, "b T F c h w -> (b T F) c h w")
|
| 212 |
+
|
| 213 |
+
with torch.no_grad():
|
| 214 |
+
module_to_inspect = unwrap_fsdp(self.vision_encoder)
|
| 215 |
+
if accepts_parameter(module_to_inspect.forward, "return_all_features"):
|
| 216 |
+
vision_x = self.vision_encoder(vision_x, return_all_features=True)
|
| 217 |
+
else:
|
| 218 |
+
vision_x = self.vision_encoder(vision_x)[1]
|
| 219 |
+
|
| 220 |
+
vision_x = rearrange(vision_x, "(b T F) v d -> b T F v d", b=b, T=T, F=F)
|
| 221 |
+
vision_x = self.perceiver(vision_x)
|
| 222 |
+
|
| 223 |
+
for layer in self.lang_encoder._get_decoder_layers():
|
| 224 |
+
layer.condition_vis_x(vision_x)
|
| 225 |
+
|
| 226 |
+
def _condition_media_locations(self, input_ids: torch.Tensor):
|
| 227 |
+
"""
|
| 228 |
+
Compute the media token locations from lang_x and condition the language model on these.
|
| 229 |
+
Args:
|
| 230 |
+
input_ids (torch.Tensor): Language input
|
| 231 |
+
shape (B, T_txt)
|
| 232 |
+
"""
|
| 233 |
+
media_locations = input_ids == self.media_token_id
|
| 234 |
+
|
| 235 |
+
for layer in self.lang_encoder._get_decoder_layers():
|
| 236 |
+
layer.condition_media_locations(media_locations)
|
| 237 |
+
|
| 238 |
+
def cache_media(self, input_ids: torch.Tensor, vision_x: torch.Tensor):
|
| 239 |
+
"""
|
| 240 |
+
Pre-cache a prompt/sequence of images / text for log-likelihood evaluations.
|
| 241 |
+
All subsequent calls to forward() will generate attending to the LAST
|
| 242 |
+
image in vision_x.
|
| 243 |
+
This is not meant to be used to cache things for generate().
|
| 244 |
+
Args:
|
| 245 |
+
input_ids (torch.Tensor): Language input
|
| 246 |
+
shape (B, T_txt)
|
| 247 |
+
vision_x (torch.Tensor): Vision input
|
| 248 |
+
shape (B, T_img, F, C, H, W)
|
| 249 |
+
Images in the same chunk are collated along T_img, and frames are collated along F
|
| 250 |
+
Currently only F=1 is supported (single-frame videos)
|
| 251 |
+
"""
|
| 252 |
+
self._encode_vision_x(vision_x=vision_x)
|
| 253 |
+
self._condition_media_locations(input_ids=input_ids)
|
| 254 |
+
self.lang_encoder._use_cached_vision_x = True
|
| 255 |
+
|
| 256 |
+
def uncache_media(self):
|
| 257 |
+
"""
|
| 258 |
+
Clear all conditioning.
|
| 259 |
+
"""
|
| 260 |
+
self.lang_encoder.clear_conditioned_layers()
|
| 261 |
+
self.lang_encoder._use_cached_vision_x = False
|
flamingo_lm.py
ADDED
|
@@ -0,0 +1,256 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import functools
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.utils.checkpoint import checkpoint
|
| 4 |
+
|
| 5 |
+
from transformers.models.mistral.modeling_mistral import MistralDecoderLayer
|
| 6 |
+
from transformers.utils import logging
|
| 7 |
+
|
| 8 |
+
from .helpers import GatedCrossAttentionBlock
|
| 9 |
+
from .utils import getattr_recursive, setattr_recursive
|
| 10 |
+
|
| 11 |
+
logger = logging.get_logger(__name__)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class FlamingoLayer(nn.Module):
|
| 15 |
+
"""
|
| 16 |
+
FlamingoLayer is a wrapper around the GatedCrossAttentionBlock and DecoderLayer.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
def __init__(
|
| 20 |
+
self, gated_cross_attn_layer, decoder_layer, gradient_checkpointing=False
|
| 21 |
+
):
|
| 22 |
+
super().__init__()
|
| 23 |
+
self.gated_cross_attn_layer = gated_cross_attn_layer
|
| 24 |
+
self.decoder_layer = decoder_layer
|
| 25 |
+
self.vis_x = None
|
| 26 |
+
self.media_locations = None
|
| 27 |
+
if self.gated_cross_attn_layer is not None:
|
| 28 |
+
self.gated_cross_attn_layer._use_gradient_checkpointing = (
|
| 29 |
+
gradient_checkpointing
|
| 30 |
+
)
|
| 31 |
+
self.decoder_layer._use_gradient_checkpointing = gradient_checkpointing
|
| 32 |
+
self._use_gradient_checkpointing = gradient_checkpointing
|
| 33 |
+
if self._use_gradient_checkpointing:
|
| 34 |
+
self.gradient_checkpointing_enable()
|
| 35 |
+
|
| 36 |
+
def is_conditioned(self) -> bool:
|
| 37 |
+
"""Check whether the layer is conditioned."""
|
| 38 |
+
return self.vis_x is not None and self.media_locations is not None
|
| 39 |
+
|
| 40 |
+
# Used this great idea from this implementation of Flamingo (https://github.com/dhansmair/flamingo-mini/)
|
| 41 |
+
def condition_vis_x(self, vis_x):
|
| 42 |
+
self.vis_x = vis_x
|
| 43 |
+
|
| 44 |
+
def condition_media_locations(self, media_locations):
|
| 45 |
+
self.media_locations = media_locations
|
| 46 |
+
|
| 47 |
+
def condition_use_cached_media(self, use_cached_media):
|
| 48 |
+
self.use_cached_media = use_cached_media
|
| 49 |
+
|
| 50 |
+
def forward(
|
| 51 |
+
self,
|
| 52 |
+
lang_x,
|
| 53 |
+
attention_mask=None,
|
| 54 |
+
**decoder_layer_kwargs,
|
| 55 |
+
):
|
| 56 |
+
# Cross attention
|
| 57 |
+
if self.gated_cross_attn_layer is not None:
|
| 58 |
+
if self.vis_x is None:
|
| 59 |
+
raise ValueError("vis_x must be conditioned before forward pass")
|
| 60 |
+
|
| 61 |
+
if self.media_locations is None:
|
| 62 |
+
raise ValueError(
|
| 63 |
+
"media_locations must be conditioned before forward pass"
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
lang_x = self.gated_cross_attn_layer(
|
| 67 |
+
lang_x,
|
| 68 |
+
self.vis_x,
|
| 69 |
+
media_locations=self.media_locations,
|
| 70 |
+
use_cached_media=self.use_cached_media,
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
# Normal decoder layer
|
| 74 |
+
if (
|
| 75 |
+
self._use_gradient_checkpointing
|
| 76 |
+
and self.training
|
| 77 |
+
and isinstance(self.decoder_layer, MistralDecoderLayer)
|
| 78 |
+
):
|
| 79 |
+
if (
|
| 80 |
+
"use_cache" in decoder_layer_kwargs
|
| 81 |
+
and decoder_layer_kwargs["use_cache"] is True
|
| 82 |
+
):
|
| 83 |
+
logger.warning_once(
|
| 84 |
+
"`use_cache=True` is incompatible with gradient checkpointing."
|
| 85 |
+
" Setting `use_cache=False`..."
|
| 86 |
+
)
|
| 87 |
+
decoder_layer_kwargs["use_cache"] = False
|
| 88 |
+
# lang_x = self._gradient_checkpointing_func(
|
| 89 |
+
# self.decoder_layer.__call__,
|
| 90 |
+
# lang_x, attention_mask=attention_mask, **decoder_layer_kwargs
|
| 91 |
+
# )
|
| 92 |
+
|
| 93 |
+
# Only work for Mistral
|
| 94 |
+
lang_x = self._gradient_checkpointing_func(
|
| 95 |
+
self.decoder_layer.__call__,
|
| 96 |
+
lang_x,
|
| 97 |
+
attention_mask,
|
| 98 |
+
decoder_layer_kwargs["position_ids"],
|
| 99 |
+
decoder_layer_kwargs["past_key_value"],
|
| 100 |
+
decoder_layer_kwargs["output_attentions"],
|
| 101 |
+
decoder_layer_kwargs["use_cache"],
|
| 102 |
+
)
|
| 103 |
+
else:
|
| 104 |
+
lang_x = self.decoder_layer(
|
| 105 |
+
lang_x, attention_mask=attention_mask, **decoder_layer_kwargs
|
| 106 |
+
)
|
| 107 |
+
return lang_x
|
| 108 |
+
|
| 109 |
+
def gradient_checkpointing_enable(self, gradient_checkpointing_kwargs=None):
|
| 110 |
+
"""
|
| 111 |
+
Activates gradient checkpointing for the current model.
|
| 112 |
+
|
| 113 |
+
Note that in other frameworks this feature can be referred to as "activation checkpointing" or "checkpoint
|
| 114 |
+
activations".
|
| 115 |
+
|
| 116 |
+
We pass the `__call__` method of the modules instead of `forward` because `__call__` attaches all the hooks of
|
| 117 |
+
the module. https://discuss.pytorch.org/t/any-different-between-model-input-and-model-forward-input/3690/2
|
| 118 |
+
|
| 119 |
+
Args:
|
| 120 |
+
gradient_checkpointing_kwargs (dict, *optional*):
|
| 121 |
+
Additional keyword arguments passed along to the `torch.utils.checkpoint.checkpoint` function.
|
| 122 |
+
"""
|
| 123 |
+
if gradient_checkpointing_kwargs is None:
|
| 124 |
+
gradient_checkpointing_kwargs = {}
|
| 125 |
+
|
| 126 |
+
gradient_checkpointing_func = functools.partial(
|
| 127 |
+
checkpoint, **gradient_checkpointing_kwargs
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
self._gradient_checkpointing_func = gradient_checkpointing_func
|
| 131 |
+
|
| 132 |
+
if getattr(self, "_hf_peft_config_loaded", False):
|
| 133 |
+
# When using PEFT + gradient checkpointing + Trainer we need to make sure the input has requires_grad=True
|
| 134 |
+
# we do it also on PEFT: https://github.com/huggingface/peft/blob/85013987aa82aa1af3da1236b6902556ce3e483e/src/peft/peft_model.py#L334
|
| 135 |
+
# When training with PEFT, only LoRA layers will have requires grad set to True, but the output of frozen layers need to propagate
|
| 136 |
+
# the gradients to make sure the gradient flows.
|
| 137 |
+
self.enable_input_require_grads()
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
class FlamingoLMMixin(nn.Module):
|
| 141 |
+
"""
|
| 142 |
+
Mixin to add cross-attention layers to a language model.
|
| 143 |
+
"""
|
| 144 |
+
|
| 145 |
+
def set_decoder_layers_attr_name(self, decoder_layers_attr_name):
|
| 146 |
+
self.decoder_layers_attr_name = decoder_layers_attr_name
|
| 147 |
+
|
| 148 |
+
def _get_decoder_layers(self):
|
| 149 |
+
return getattr_recursive(self, self.decoder_layers_attr_name)
|
| 150 |
+
|
| 151 |
+
def _set_decoder_layers(self, value):
|
| 152 |
+
setattr_recursive(self, self.decoder_layers_attr_name, value)
|
| 153 |
+
|
| 154 |
+
def init_flamingo(
|
| 155 |
+
self,
|
| 156 |
+
media_token_id,
|
| 157 |
+
lang_hidden_size,
|
| 158 |
+
vis_hidden_size,
|
| 159 |
+
cross_attn_every_n_layers,
|
| 160 |
+
*,
|
| 161 |
+
enable_init_network_params=False,
|
| 162 |
+
initializer_range=0.02,
|
| 163 |
+
gradient_checkpointing=False,
|
| 164 |
+
):
|
| 165 |
+
"""
|
| 166 |
+
Initialize Flamingo by adding a new gated cross attn to the decoder. Store the media token id for computing the media locations.
|
| 167 |
+
"""
|
| 168 |
+
self.old_decoder_blocks = self._get_decoder_layers()
|
| 169 |
+
self.gated_cross_attn_layers = nn.ModuleList(
|
| 170 |
+
[
|
| 171 |
+
(
|
| 172 |
+
GatedCrossAttentionBlock(
|
| 173 |
+
dim=lang_hidden_size,
|
| 174 |
+
dim_visual=vis_hidden_size,
|
| 175 |
+
ff_mult=4,
|
| 176 |
+
enable_init_network_params=enable_init_network_params,
|
| 177 |
+
initializer_range=initializer_range,
|
| 178 |
+
gradient_checkpointing=gradient_checkpointing,
|
| 179 |
+
)
|
| 180 |
+
if (layer_idx + 1) % cross_attn_every_n_layers == 0
|
| 181 |
+
else None
|
| 182 |
+
)
|
| 183 |
+
for layer_idx, _ in enumerate(self._get_decoder_layers())
|
| 184 |
+
]
|
| 185 |
+
)
|
| 186 |
+
self.init_flamingo_layers(gradient_checkpointing)
|
| 187 |
+
self.media_token_id = media_token_id
|
| 188 |
+
self.initialized_flamingo = True
|
| 189 |
+
self._use_cached_vision_x = False
|
| 190 |
+
self.gradient_checkpointing = gradient_checkpointing
|
| 191 |
+
|
| 192 |
+
def init_flamingo_layers(self, gradient_checkpointing):
|
| 193 |
+
"""
|
| 194 |
+
Re initializes the FlamingoLayers.
|
| 195 |
+
Propagates any changes made to self.gated_corss_attn_layers or self.old_decoder_blocks
|
| 196 |
+
"""
|
| 197 |
+
self._set_decoder_layers(
|
| 198 |
+
nn.ModuleList(
|
| 199 |
+
[
|
| 200 |
+
FlamingoLayer(
|
| 201 |
+
gated_cross_attn_layer, decoder_layer, gradient_checkpointing
|
| 202 |
+
)
|
| 203 |
+
for gated_cross_attn_layer, decoder_layer in zip(
|
| 204 |
+
self.gated_cross_attn_layers, self.old_decoder_blocks
|
| 205 |
+
)
|
| 206 |
+
]
|
| 207 |
+
)
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
def forward(self, input_ids, attention_mask, **kwargs):
|
| 211 |
+
"""Condition the Flamingo layers on the media locations before forward()"""
|
| 212 |
+
if not self.initialized_flamingo:
|
| 213 |
+
raise ValueError(
|
| 214 |
+
"Flamingo layers are not initialized. Please call `init_flamingo`"
|
| 215 |
+
" first."
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
media_locations = input_ids == self.media_token_id
|
| 219 |
+
|
| 220 |
+
# if there are media already cached and we're generating and there are no media tokens in the input,
|
| 221 |
+
# we'll assume that ALL input tokens should attend to the last previous media that is cached.
|
| 222 |
+
# this is especially important for HF generate() compatibility, since generate() calls forward()
|
| 223 |
+
# repeatedly one token at a time (with no media tokens).
|
| 224 |
+
# without this check, the model would not attend to any images when generating (after the first token)
|
| 225 |
+
use_cached_media_locations = (
|
| 226 |
+
self._use_cached_vision_x
|
| 227 |
+
and self.is_conditioned()
|
| 228 |
+
and not media_locations.any()
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
for layer in self._get_decoder_layers():
|
| 232 |
+
if not use_cached_media_locations:
|
| 233 |
+
layer.condition_media_locations(media_locations)
|
| 234 |
+
layer.condition_use_cached_media(use_cached_media_locations)
|
| 235 |
+
|
| 236 |
+
# package arguments for the other parent's forward. since we don't know the order of the arguments,
|
| 237 |
+
# make them all kwargs
|
| 238 |
+
kwargs["input_ids"] = input_ids
|
| 239 |
+
kwargs["attention_mask"] = attention_mask
|
| 240 |
+
|
| 241 |
+
# Mistral also need to set 'use_cache' to False when enable gradient checkpointing
|
| 242 |
+
if self.gradient_checkpointing and isinstance(
|
| 243 |
+
self.old_decoder_blocks[0], MistralDecoderLayer
|
| 244 |
+
):
|
| 245 |
+
kwargs["use_cache"] = False
|
| 246 |
+
return super().forward(**kwargs) # Call the other parent's forward method
|
| 247 |
+
|
| 248 |
+
def is_conditioned(self) -> bool:
|
| 249 |
+
"""Check whether all decoder layers are already conditioned."""
|
| 250 |
+
return all(l.is_conditioned() for l in self._get_decoder_layers())
|
| 251 |
+
|
| 252 |
+
def clear_conditioned_layers(self):
|
| 253 |
+
for layer in self._get_decoder_layers():
|
| 254 |
+
layer.condition_vis_x(None)
|
| 255 |
+
layer.condition_media_locations(None)
|
| 256 |
+
layer.condition_use_cached_media(None)
|
generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"do_sample": true,
|
| 3 |
+
"max_new_tokens": 512,
|
| 4 |
+
"top_k": 0,
|
| 5 |
+
"top_p": 0.5,
|
| 6 |
+
"transformers_version": "4.31.0"
|
| 7 |
+
}
|
helpers.py
ADDED
|
@@ -0,0 +1,410 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Based on: https://github.com/lucidrains/flamingo-pytorch
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
from einops import rearrange, repeat
|
| 7 |
+
from torch import einsum, nn
|
| 8 |
+
|
| 9 |
+
from einops_exts import rearrange_many
|
| 10 |
+
|
| 11 |
+
try:
|
| 12 |
+
from deepspeed.runtime.activation_checkpointing.checkpointing import checkpoint
|
| 13 |
+
except:
|
| 14 |
+
from torch.utils.checkpoint import checkpoint
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def exists(val):
|
| 18 |
+
return val is not None
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def FeedForward(
|
| 22 |
+
dim,
|
| 23 |
+
mult=4,
|
| 24 |
+
enable_init_network_params=False,
|
| 25 |
+
initializer_range=0.02,
|
| 26 |
+
):
|
| 27 |
+
inner_dim = int(dim * mult)
|
| 28 |
+
net = nn.Sequential(
|
| 29 |
+
nn.LayerNorm(dim),
|
| 30 |
+
nn.Linear(dim, inner_dim, bias=False),
|
| 31 |
+
nn.GELU(),
|
| 32 |
+
nn.Linear(inner_dim, dim, bias=False),
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
if enable_init_network_params:
|
| 36 |
+
# then start the initialization
|
| 37 |
+
net[0].weight.data.normal_(mean=0.0, std=initializer_range)
|
| 38 |
+
net[0].bias.data.zero_()
|
| 39 |
+
net[1].weight.data.normal_(mean=0.0, std=initializer_range)
|
| 40 |
+
net[3].weight.data.normal_(mean=0.0, std=initializer_range)
|
| 41 |
+
return net
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class PerceiverAttention(nn.Module):
|
| 45 |
+
def __init__(
|
| 46 |
+
self,
|
| 47 |
+
*,
|
| 48 |
+
dim,
|
| 49 |
+
dim_head=64,
|
| 50 |
+
heads=8,
|
| 51 |
+
enable_init_network_params=False,
|
| 52 |
+
initializer_range=0.02,
|
| 53 |
+
):
|
| 54 |
+
super().__init__()
|
| 55 |
+
|
| 56 |
+
self.scale = dim_head**-0.5
|
| 57 |
+
self.heads = heads
|
| 58 |
+
self.initializer_range = initializer_range
|
| 59 |
+
|
| 60 |
+
inner_dim = dim_head * heads
|
| 61 |
+
|
| 62 |
+
self.norm_media = nn.LayerNorm(dim)
|
| 63 |
+
self.norm_latents = nn.LayerNorm(dim)
|
| 64 |
+
|
| 65 |
+
self.to_q = nn.Linear(dim, inner_dim, bias=False)
|
| 66 |
+
self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
|
| 67 |
+
self.to_out = nn.Linear(inner_dim, dim, bias=False)
|
| 68 |
+
|
| 69 |
+
if enable_init_network_params:
|
| 70 |
+
self.apply(self._init_weights)
|
| 71 |
+
|
| 72 |
+
def _init_weights(self, module):
|
| 73 |
+
if isinstance(module, nn.Linear):
|
| 74 |
+
# Slightly different from the TF version which uses truncated_normal for initialization
|
| 75 |
+
# cf https://github.com/pytorch/pytorch/pull/5617
|
| 76 |
+
module.weight.data.normal_(mean=0.0, std=self.initializer_range)
|
| 77 |
+
if module.bias is not None:
|
| 78 |
+
module.bias.data.zero_()
|
| 79 |
+
|
| 80 |
+
elif isinstance(module, nn.LayerNorm):
|
| 81 |
+
module.bias.data.zero_()
|
| 82 |
+
module.weight.data.fill_(1.0)
|
| 83 |
+
|
| 84 |
+
def forward(self, x, latents):
|
| 85 |
+
"""
|
| 86 |
+
Args:
|
| 87 |
+
x (torch.Tensor): image features
|
| 88 |
+
shape (b, T, n1, D)
|
| 89 |
+
latent (torch.Tensor): latent features
|
| 90 |
+
shape (b, T, n2, D)
|
| 91 |
+
"""
|
| 92 |
+
x = self.norm_media(x)
|
| 93 |
+
latents = self.norm_latents(latents.contiguous())
|
| 94 |
+
|
| 95 |
+
h = self.heads
|
| 96 |
+
|
| 97 |
+
q = self.to_q(latents)
|
| 98 |
+
kv_input = torch.cat((x, latents), dim=-2)
|
| 99 |
+
k, v = self.to_kv(kv_input).chunk(2, dim=-1)
|
| 100 |
+
|
| 101 |
+
q, k, v = rearrange_many((q, k, v), "b t n (h d) -> b h t n d", h=h)
|
| 102 |
+
q = q * self.scale
|
| 103 |
+
# attention
|
| 104 |
+
sim = einsum("... i d, ... j d -> ... i j", q, k)
|
| 105 |
+
sim = sim - sim.amax(dim=-1, keepdim=True).detach()
|
| 106 |
+
attn = sim.softmax(dim=-1)
|
| 107 |
+
|
| 108 |
+
out = einsum("... i j, ... j d -> ... i d", attn, v)
|
| 109 |
+
out = rearrange(out, "b h t n d -> b t n (h d)", h=h)
|
| 110 |
+
return self.to_out(out)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
class PerceiverResampler(nn.Module):
|
| 114 |
+
def __init__(
|
| 115 |
+
self,
|
| 116 |
+
*,
|
| 117 |
+
dim,
|
| 118 |
+
depth=6,
|
| 119 |
+
dim_head=64,
|
| 120 |
+
heads=8,
|
| 121 |
+
num_latents=64,
|
| 122 |
+
max_num_media=None,
|
| 123 |
+
max_num_frames=None,
|
| 124 |
+
ff_mult=4,
|
| 125 |
+
enable_init_network_params=False,
|
| 126 |
+
initializer_range=0.02,
|
| 127 |
+
gradient_checkpointing=False,
|
| 128 |
+
):
|
| 129 |
+
super().__init__()
|
| 130 |
+
|
| 131 |
+
self.gradient_checkpointing = gradient_checkpointing
|
| 132 |
+
self.initializer_range = initializer_range
|
| 133 |
+
|
| 134 |
+
self.latents = nn.Parameter(torch.randn(num_latents, dim))
|
| 135 |
+
self.frame_embs = (
|
| 136 |
+
nn.Parameter(torch.randn(max_num_frames, dim))
|
| 137 |
+
if exists(max_num_frames)
|
| 138 |
+
else None
|
| 139 |
+
)
|
| 140 |
+
self.media_time_embs = (
|
| 141 |
+
nn.Parameter(torch.randn(max_num_media, 1, dim))
|
| 142 |
+
if exists(max_num_media)
|
| 143 |
+
else None
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
self.layers = nn.ModuleList([])
|
| 147 |
+
|
| 148 |
+
for _ in range(depth):
|
| 149 |
+
self.layers.append(
|
| 150 |
+
nn.ModuleList(
|
| 151 |
+
[
|
| 152 |
+
PerceiverAttention(
|
| 153 |
+
dim=dim,
|
| 154 |
+
dim_head=dim_head,
|
| 155 |
+
heads=heads,
|
| 156 |
+
enable_init_network_params=enable_init_network_params,
|
| 157 |
+
initializer_range=initializer_range,
|
| 158 |
+
),
|
| 159 |
+
FeedForward(
|
| 160 |
+
dim=dim,
|
| 161 |
+
mult=ff_mult,
|
| 162 |
+
enable_init_network_params=enable_init_network_params,
|
| 163 |
+
initializer_range=initializer_range,
|
| 164 |
+
),
|
| 165 |
+
]
|
| 166 |
+
)
|
| 167 |
+
)
|
| 168 |
+
# Should this norm layer also change?
|
| 169 |
+
self.norm = nn.LayerNorm(dim)
|
| 170 |
+
if enable_init_network_params:
|
| 171 |
+
self.apply(self._init_weights)
|
| 172 |
+
|
| 173 |
+
def _init_weights(self, module):
|
| 174 |
+
if isinstance(module, nn.Linear):
|
| 175 |
+
# Slightly different from the TF version which uses truncated_normal for initialization
|
| 176 |
+
# cf https://github.com/pytorch/pytorch/pull/5617
|
| 177 |
+
module.weight.data.normal_(mean=0.0, std=self.initializer_range)
|
| 178 |
+
if module.bias is not None:
|
| 179 |
+
module.bias.data.zero_()
|
| 180 |
+
|
| 181 |
+
elif isinstance(module, nn.LayerNorm):
|
| 182 |
+
module.bias.data.zero_()
|
| 183 |
+
module.weight.data.fill_(1.0)
|
| 184 |
+
|
| 185 |
+
elif isinstance(module, nn.Parameter):
|
| 186 |
+
module.data.normal_(mean=0.0, std=self.initializer_range)
|
| 187 |
+
|
| 188 |
+
def forward(self, x):
|
| 189 |
+
"""
|
| 190 |
+
Args:
|
| 191 |
+
x (torch.Tensor): image features
|
| 192 |
+
shape (b, T, F, v, D)
|
| 193 |
+
Returns:
|
| 194 |
+
shape (b, T, n, D) where n is self.num_latents
|
| 195 |
+
"""
|
| 196 |
+
|
| 197 |
+
b, T, F, v = x.shape[:4]
|
| 198 |
+
|
| 199 |
+
# frame and media time embeddings
|
| 200 |
+
if exists(self.frame_embs):
|
| 201 |
+
frame_embs = repeat(self.frame_embs[:F], "F d -> b T F v d", b=b, T=T, v=v)
|
| 202 |
+
x = x + frame_embs
|
| 203 |
+
x = rearrange(
|
| 204 |
+
x, "b T F v d -> b T (F v) d"
|
| 205 |
+
) # flatten the frame and spatial dimensions
|
| 206 |
+
if exists(self.media_time_embs):
|
| 207 |
+
x = x + self.media_time_embs[:T]
|
| 208 |
+
|
| 209 |
+
# blocks
|
| 210 |
+
latents = repeat(self.latents, "n d -> b T n d", b=b, T=T)
|
| 211 |
+
for attn, ff in self.layers:
|
| 212 |
+
if self.gradient_checkpointing and latents.requires_grad:
|
| 213 |
+
latents = checkpoint(attn, x, (latents)) + latents
|
| 214 |
+
latents = checkpoint(ff, latents) + latents
|
| 215 |
+
else:
|
| 216 |
+
latents = attn(x, latents) + latents
|
| 217 |
+
latents = ff(latents) + latents
|
| 218 |
+
|
| 219 |
+
return self.norm(latents)
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
# gated cross attention
|
| 223 |
+
class MaskedCrossAttention(nn.Module):
|
| 224 |
+
def __init__(
|
| 225 |
+
self,
|
| 226 |
+
*,
|
| 227 |
+
dim,
|
| 228 |
+
dim_visual,
|
| 229 |
+
dim_head=64,
|
| 230 |
+
heads=8,
|
| 231 |
+
only_attend_immediate_media=True,
|
| 232 |
+
enable_init_network_params=False,
|
| 233 |
+
initializer_range=0.02,
|
| 234 |
+
):
|
| 235 |
+
super().__init__()
|
| 236 |
+
self.scale = dim_head**-0.5
|
| 237 |
+
self.heads = heads
|
| 238 |
+
self.initializer_range = initializer_range
|
| 239 |
+
inner_dim = dim_head * heads
|
| 240 |
+
|
| 241 |
+
self.norm = nn.LayerNorm(dim)
|
| 242 |
+
|
| 243 |
+
self.to_q = nn.Linear(dim, inner_dim, bias=False)
|
| 244 |
+
self.to_kv = nn.Linear(dim_visual, inner_dim * 2, bias=False)
|
| 245 |
+
self.to_out = nn.Linear(inner_dim, dim, bias=False)
|
| 246 |
+
|
| 247 |
+
# whether for text to only attend to immediate preceding image, or all previous images
|
| 248 |
+
self.only_attend_immediate_media = only_attend_immediate_media
|
| 249 |
+
|
| 250 |
+
if enable_init_network_params:
|
| 251 |
+
self.apply(self._init_weights)
|
| 252 |
+
|
| 253 |
+
def _init_weights(self, module):
|
| 254 |
+
if isinstance(module, nn.Linear):
|
| 255 |
+
# Slightly different from the TF version which uses truncated_normal for initialization
|
| 256 |
+
# cf https://github.com/pytorch/pytorch/pull/5617
|
| 257 |
+
module.weight.data.normal_(mean=0.0, std=self.initializer_range)
|
| 258 |
+
if module.bias is not None:
|
| 259 |
+
module.bias.data.zero_()
|
| 260 |
+
|
| 261 |
+
elif isinstance(module, nn.LayerNorm):
|
| 262 |
+
module.bias.data.zero_()
|
| 263 |
+
module.weight.data.fill_(1.0)
|
| 264 |
+
|
| 265 |
+
def forward(self, x, media, media_locations=None, use_cached_media=False):
|
| 266 |
+
"""
|
| 267 |
+
Args:
|
| 268 |
+
x (torch.Tensor): text features
|
| 269 |
+
shape (B, T_txt, D_txt)
|
| 270 |
+
media (torch.Tensor): image features
|
| 271 |
+
shape (B, T_img, n, D_img) where n is the dim of the latents
|
| 272 |
+
media_locations: boolean mask identifying the media tokens in x
|
| 273 |
+
shape (B, T_txt)
|
| 274 |
+
use_cached_media: bool
|
| 275 |
+
If true, treat all of x as if they occur after the last media
|
| 276 |
+
registered in media_locations. T_txt does not need to exactly
|
| 277 |
+
equal media_locations.shape[1] in this case
|
| 278 |
+
"""
|
| 279 |
+
|
| 280 |
+
if not use_cached_media:
|
| 281 |
+
assert media_locations.shape[1] == x.shape[1], (
|
| 282 |
+
f"media_location.shape is {media_locations.shape} but x.shape is"
|
| 283 |
+
f" {x.shape}"
|
| 284 |
+
)
|
| 285 |
+
|
| 286 |
+
T_txt = x.shape[1]
|
| 287 |
+
_, T_img, n = media.shape[:3]
|
| 288 |
+
h = self.heads
|
| 289 |
+
|
| 290 |
+
x = self.norm(x.contiguous())
|
| 291 |
+
q = self.to_q(x)
|
| 292 |
+
media = rearrange(media, "b t n d -> b (t n) d")
|
| 293 |
+
|
| 294 |
+
k, v = self.to_kv(media).chunk(2, dim=-1)
|
| 295 |
+
|
| 296 |
+
if exists(media_locations):
|
| 297 |
+
media_time = torch.arange(T_img, device=x.device) + 1
|
| 298 |
+
|
| 299 |
+
if use_cached_media:
|
| 300 |
+
# text time is set to the last cached media location
|
| 301 |
+
text_time = repeat(
|
| 302 |
+
torch.count_nonzero(media_locations, dim=1),
|
| 303 |
+
"b -> b i",
|
| 304 |
+
i=T_txt,
|
| 305 |
+
)
|
| 306 |
+
else:
|
| 307 |
+
# at each boolean of True, increment the time counter (relative to media time)
|
| 308 |
+
text_time = media_locations.cumsum(dim=-1)
|
| 309 |
+
|
| 310 |
+
# text time must equal media time if only attending to most immediate image
|
| 311 |
+
# otherwise, as long as text time is greater than media time (if attending to all previous images / media)
|
| 312 |
+
mask_op = torch.eq if self.only_attend_immediate_media else torch.ge
|
| 313 |
+
text_to_media_mask = mask_op(
|
| 314 |
+
rearrange(text_time, "b i -> b 1 i 1"),
|
| 315 |
+
repeat(media_time, "j -> 1 1 1 (j n)", n=n),
|
| 316 |
+
)
|
| 317 |
+
|
| 318 |
+
if self.only_attend_immediate_media:
|
| 319 |
+
# any text without a preceding media needs to have attention zeroed out
|
| 320 |
+
text_without_media_mask = text_time == 0
|
| 321 |
+
text_without_media_mask = rearrange(
|
| 322 |
+
text_without_media_mask, "b i -> b 1 i 1"
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
q, k, v = rearrange_many((q, k, v), "b n (h d) -> b h n d", h=h)
|
| 326 |
+
q = q * self.scale
|
| 327 |
+
sim = einsum("... i d, ... j d -> ... i j", q, k)
|
| 328 |
+
|
| 329 |
+
if exists(media_locations):
|
| 330 |
+
sim = sim.masked_fill(~text_to_media_mask, -torch.finfo(sim.dtype).max)
|
| 331 |
+
|
| 332 |
+
sim = sim - sim.amax(dim=-1, keepdim=True).detach()
|
| 333 |
+
attn = sim.softmax(dim=-1)
|
| 334 |
+
|
| 335 |
+
if exists(media_locations) and self.only_attend_immediate_media:
|
| 336 |
+
# any text without a preceding media needs to have attention zeroed out
|
| 337 |
+
attn = attn.masked_fill(text_without_media_mask, 0.0)
|
| 338 |
+
|
| 339 |
+
out = einsum("... i j, ... j d -> ... i d", attn, v)
|
| 340 |
+
out = rearrange(out, "b h n d -> b n (h d)")
|
| 341 |
+
return self.to_out(out)
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
class GatedCrossAttentionBlock(nn.Module):
|
| 345 |
+
def __init__(
|
| 346 |
+
self,
|
| 347 |
+
*,
|
| 348 |
+
dim,
|
| 349 |
+
dim_visual,
|
| 350 |
+
dim_head=64,
|
| 351 |
+
heads=8,
|
| 352 |
+
ff_mult=4,
|
| 353 |
+
only_attend_immediate_media=True,
|
| 354 |
+
enable_init_network_params=False,
|
| 355 |
+
initializer_range=0.02,
|
| 356 |
+
gradient_checkpointing=False,
|
| 357 |
+
):
|
| 358 |
+
super().__init__()
|
| 359 |
+
self.attn = MaskedCrossAttention(
|
| 360 |
+
dim=dim,
|
| 361 |
+
dim_visual=dim_visual,
|
| 362 |
+
dim_head=dim_head,
|
| 363 |
+
heads=heads,
|
| 364 |
+
only_attend_immediate_media=only_attend_immediate_media,
|
| 365 |
+
enable_init_network_params=enable_init_network_params,
|
| 366 |
+
initializer_range=initializer_range,
|
| 367 |
+
)
|
| 368 |
+
self.attn_gate = nn.Parameter(torch.tensor([0.0]))
|
| 369 |
+
self.ff = FeedForward(dim, mult=ff_mult)
|
| 370 |
+
self.ff_gate = nn.Parameter(torch.tensor([0.0]))
|
| 371 |
+
self.gradient_checkpointing = gradient_checkpointing
|
| 372 |
+
|
| 373 |
+
def forward(
|
| 374 |
+
self,
|
| 375 |
+
x,
|
| 376 |
+
media,
|
| 377 |
+
media_locations=None,
|
| 378 |
+
use_cached_media=False,
|
| 379 |
+
):
|
| 380 |
+
if exists(media_locations):
|
| 381 |
+
flag = torch.sum(media_locations, dim=-1)
|
| 382 |
+
flag = torch.where(flag > 0.0, 1.0, 0.0)
|
| 383 |
+
flag = flag.unsqueeze(1).unsqueeze(1).to(torch.bfloat16)
|
| 384 |
+
else:
|
| 385 |
+
flag = 1.0
|
| 386 |
+
|
| 387 |
+
if self.gradient_checkpointing and media.requires_grad:
|
| 388 |
+
x = (
|
| 389 |
+
flag
|
| 390 |
+
* checkpoint(self.attn, x, media, media_locations, use_cached_media)
|
| 391 |
+
* self.attn_gate.tanh()
|
| 392 |
+
+ x
|
| 393 |
+
)
|
| 394 |
+
x = flag * checkpoint(self.ff, x) * self.ff_gate.tanh() + x
|
| 395 |
+
|
| 396 |
+
else:
|
| 397 |
+
x = (
|
| 398 |
+
flag
|
| 399 |
+
* self.attn(
|
| 400 |
+
x,
|
| 401 |
+
media,
|
| 402 |
+
media_locations=media_locations,
|
| 403 |
+
use_cached_media=use_cached_media,
|
| 404 |
+
)
|
| 405 |
+
* self.attn_gate.tanh()
|
| 406 |
+
+ x
|
| 407 |
+
)
|
| 408 |
+
x = flag * self.ff(x) * self.ff_gate.tanh() + x
|
| 409 |
+
|
| 410 |
+
return x
|
modeling_infimm_zephyr.py
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import importlib
|
| 2 |
+
import math
|
| 3 |
+
from functools import partial
|
| 4 |
+
from typing import TYPE_CHECKING, Any, Callable, Generator, List, Optional, Tuple, Union
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
import torch.utils.checkpoint
|
| 8 |
+
from torch.cuda.amp import autocast
|
| 9 |
+
|
| 10 |
+
from transformers import GenerationConfig, PreTrainedTokenizer, StoppingCriteriaList
|
| 11 |
+
from transformers.generation.logits_process import LogitsProcessorList
|
| 12 |
+
|
| 13 |
+
if TYPE_CHECKING:
|
| 14 |
+
from transformers.generation.streamers import BaseStreamer
|
| 15 |
+
|
| 16 |
+
from transformers.generation.utils import GenerateOutput
|
| 17 |
+
from transformers.modeling_outputs import (
|
| 18 |
+
BaseModelOutputWithPast,
|
| 19 |
+
CausalLMOutputWithPast,
|
| 20 |
+
)
|
| 21 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 22 |
+
from transformers.models.mistral.configuration_mistral import MistralConfig
|
| 23 |
+
from transformers.models.mistral.modeling_mistral import MistralForCausalLM
|
| 24 |
+
from transformers.utils import logging
|
| 25 |
+
|
| 26 |
+
try:
|
| 27 |
+
from einops import rearrange
|
| 28 |
+
except ImportError:
|
| 29 |
+
rearrange = None
|
| 30 |
+
from torch import nn
|
| 31 |
+
|
| 32 |
+
from .configuration_infimm_zephyr import InfiMMConfig
|
| 33 |
+
from .eva_vit import CLIPVisionCfg, EVAVisionTransformer
|
| 34 |
+
from .flamingo import Flamingo
|
| 35 |
+
from .flamingo_lm import FlamingoLMMixin
|
| 36 |
+
from .helpers import PerceiverResampler
|
| 37 |
+
from .utils import _infer_decoder_layers_attr_name, extend_instance
|
| 38 |
+
|
| 39 |
+
SUPPORT_CUDA = torch.cuda.is_available()
|
| 40 |
+
SUPPORT_BF16 = SUPPORT_CUDA and torch.cuda.is_bf16_supported()
|
| 41 |
+
SUPPORT_FP16 = SUPPORT_CUDA and torch.cuda.get_device_capability(0)[0] >= 7
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class InfiMMPreTrainedModel(PreTrainedModel):
|
| 45 |
+
config_class = InfiMMConfig
|
| 46 |
+
base_model_prefix = "transformer"
|
| 47 |
+
is_parallelizable = False
|
| 48 |
+
supports_gradient_checkpointing = True
|
| 49 |
+
|
| 50 |
+
def __init__(self, *inputs, **kwargs):
|
| 51 |
+
super().__init__(*inputs, **kwargs)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
class InfiMMZephyrModel(InfiMMPreTrainedModel):
|
| 55 |
+
def __init__(self, config):
|
| 56 |
+
super().__init__(config)
|
| 57 |
+
|
| 58 |
+
self.vision_config = config.visual
|
| 59 |
+
vision_encoder = self.build_vision_encoder()
|
| 60 |
+
self.language_config = config.language
|
| 61 |
+
language_encoder = self.build_language_encoder()
|
| 62 |
+
|
| 63 |
+
self.model = self.build_flamingo(vision_encoder, language_encoder)
|
| 64 |
+
|
| 65 |
+
def build_vision_encoder(self):
|
| 66 |
+
vision_cfg = CLIPVisionCfg(**self.vision_config)
|
| 67 |
+
|
| 68 |
+
vision_encoder = EVAVisionTransformer(
|
| 69 |
+
img_size=vision_cfg.image_size,
|
| 70 |
+
patch_size=vision_cfg.patch_size,
|
| 71 |
+
num_classes=vision_cfg.embed_dim,
|
| 72 |
+
use_mean_pooling=vision_cfg.global_average_pool, # False
|
| 73 |
+
init_values=vision_cfg.ls_init_value,
|
| 74 |
+
patch_dropout=vision_cfg.patch_dropout,
|
| 75 |
+
embed_dim=vision_cfg.width,
|
| 76 |
+
depth=vision_cfg.layers,
|
| 77 |
+
num_heads=vision_cfg.width // vision_cfg.head_width,
|
| 78 |
+
mlp_ratio=vision_cfg.mlp_ratio,
|
| 79 |
+
qkv_bias=vision_cfg.qkv_bias,
|
| 80 |
+
drop_path_rate=vision_cfg.drop_path_rate,
|
| 81 |
+
norm_layer=partial(nn.LayerNorm, eps=1e-6),
|
| 82 |
+
xattn=vision_cfg.xattn,
|
| 83 |
+
rope=vision_cfg.rope,
|
| 84 |
+
postnorm=vision_cfg.postnorm,
|
| 85 |
+
pt_hw_seq_len=vision_cfg.pt_hw_seq_len, # 224/14
|
| 86 |
+
intp_freq=vision_cfg.intp_freq,
|
| 87 |
+
naiveswiglu=vision_cfg.naiveswiglu,
|
| 88 |
+
subln=vision_cfg.subln,
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
return vision_encoder
|
| 92 |
+
|
| 93 |
+
def build_language_encoder(self):
|
| 94 |
+
mistral_config = MistralConfig(**self.language_config)
|
| 95 |
+
lang_encoder = MistralForCausalLM(mistral_config)
|
| 96 |
+
return lang_encoder
|
| 97 |
+
|
| 98 |
+
def build_flamingo(self, vision_encoder, lang_encoder):
|
| 99 |
+
extend_instance(lang_encoder, FlamingoLMMixin)
|
| 100 |
+
|
| 101 |
+
decoder_layers_attr_name = _infer_decoder_layers_attr_name(lang_encoder)
|
| 102 |
+
lang_encoder.set_decoder_layers_attr_name(decoder_layers_attr_name)
|
| 103 |
+
# lang_encoder.resize_token_embeddings(self.config.)
|
| 104 |
+
|
| 105 |
+
model = Flamingo(
|
| 106 |
+
vision_encoder,
|
| 107 |
+
lang_encoder,
|
| 108 |
+
self.config.eoc_token_id,
|
| 109 |
+
self.config.image_token_id,
|
| 110 |
+
vis_dim=self.vision_config["width"],
|
| 111 |
+
cross_attn_every_n_layers=self.config.cross_attn_every_n_layers,
|
| 112 |
+
gradient_checkpointing=self.config.use_grad_checkpoint,
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
return model
|
| 116 |
+
|
| 117 |
+
def generate(
|
| 118 |
+
self,
|
| 119 |
+
input_ids,
|
| 120 |
+
attention_mask,
|
| 121 |
+
batch_images,
|
| 122 |
+
min_generation_length: int,
|
| 123 |
+
max_generation_length: int,
|
| 124 |
+
**kwargs,
|
| 125 |
+
):
|
| 126 |
+
with torch.inference_mode():
|
| 127 |
+
outputs = self.model.generate(
|
| 128 |
+
batch_images,
|
| 129 |
+
input_ids,
|
| 130 |
+
attention_mask,
|
| 131 |
+
min_new_tokens=min_generation_length,
|
| 132 |
+
max_new_tokens=max_generation_length,
|
| 133 |
+
**kwargs,
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
# Extract only the new gnerated tokens
|
| 137 |
+
outputs = outputs[:, len(input_ids[0]) :]
|
| 138 |
+
return outputs
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "./",
|
| 3 |
+
"auto_map": {
|
| 4 |
+
"AutoProcessor": "processing_infimm_zephyr.InfiMMZephyrProcessor"
|
| 5 |
+
},
|
| 6 |
+
"image_size": 336
|
| 7 |
+
}
|
processing_infimm_zephyr.py
ADDED
|
@@ -0,0 +1,345 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2022 The HuggingFace Inc. team.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
"""
|
| 16 |
+
Processor class for InfiMMZephyr.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
import random
|
| 20 |
+
from typing import List, Optional, Tuple, Union
|
| 21 |
+
import torch
|
| 22 |
+
import torchvision.transforms.functional as F
|
| 23 |
+
from PIL import Image
|
| 24 |
+
from torchvision.transforms import (
|
| 25 |
+
CenterCrop,
|
| 26 |
+
Compose,
|
| 27 |
+
InterpolationMode,
|
| 28 |
+
Normalize,
|
| 29 |
+
Resize,
|
| 30 |
+
ToTensor,
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
from transformers import AutoTokenizer
|
| 34 |
+
from transformers.image_processing_utils import ImageProcessingMixin
|
| 35 |
+
from transformers.processing_utils import ProcessorMixin
|
| 36 |
+
from transformers.tokenization_utils_base import BatchEncoding
|
| 37 |
+
|
| 38 |
+
IMAGE_TOKEN = "<image>"
|
| 39 |
+
END_OF_CHUNK_TOKEN = "<|endofchunk|>"
|
| 40 |
+
|
| 41 |
+
OPENAI_DATASET_MEAN = (0.48145466, 0.4578275, 0.40821073)
|
| 42 |
+
OPENAI_DATASET_STD = (0.26862954, 0.26130258, 0.27577711)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def _convert_to_rgb(image):
|
| 46 |
+
return image.convert("RGB")
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class ResizeKeepRatio:
|
| 50 |
+
"""Resize and Keep Ratio
|
| 51 |
+
|
| 52 |
+
Copy & paste from `timm`
|
| 53 |
+
"""
|
| 54 |
+
|
| 55 |
+
def __init__(
|
| 56 |
+
self,
|
| 57 |
+
size,
|
| 58 |
+
longest=0.0,
|
| 59 |
+
interpolation=InterpolationMode.BICUBIC,
|
| 60 |
+
random_scale_prob=0.0,
|
| 61 |
+
random_scale_range=(0.85, 1.05),
|
| 62 |
+
random_aspect_prob=0.0,
|
| 63 |
+
random_aspect_range=(0.9, 1.11),
|
| 64 |
+
):
|
| 65 |
+
if isinstance(size, (list, tuple)):
|
| 66 |
+
self.size = tuple(size)
|
| 67 |
+
else:
|
| 68 |
+
self.size = (size, size)
|
| 69 |
+
self.interpolation = interpolation
|
| 70 |
+
self.longest = float(longest) # [0, 1] where 0 == shortest edge, 1 == longest
|
| 71 |
+
self.random_scale_prob = random_scale_prob
|
| 72 |
+
self.random_scale_range = random_scale_range
|
| 73 |
+
self.random_aspect_prob = random_aspect_prob
|
| 74 |
+
self.random_aspect_range = random_aspect_range
|
| 75 |
+
|
| 76 |
+
@staticmethod
|
| 77 |
+
def get_params(
|
| 78 |
+
img,
|
| 79 |
+
target_size,
|
| 80 |
+
longest,
|
| 81 |
+
random_scale_prob=0.0,
|
| 82 |
+
random_scale_range=(0.85, 1.05),
|
| 83 |
+
random_aspect_prob=0.0,
|
| 84 |
+
random_aspect_range=(0.9, 1.11),
|
| 85 |
+
):
|
| 86 |
+
"""Get parameters"""
|
| 87 |
+
source_size = img.size[::-1] # h, w
|
| 88 |
+
h, w = source_size
|
| 89 |
+
target_h, target_w = target_size
|
| 90 |
+
ratio_h = h / target_h
|
| 91 |
+
ratio_w = w / target_w
|
| 92 |
+
ratio = max(ratio_h, ratio_w) * longest + min(ratio_h, ratio_w) * (
|
| 93 |
+
1.0 - longest
|
| 94 |
+
)
|
| 95 |
+
if random_scale_prob > 0 and random.random() < random_scale_prob:
|
| 96 |
+
ratio_factor = random.uniform(random_scale_range[0], random_scale_range[1])
|
| 97 |
+
ratio_factor = (ratio_factor, ratio_factor)
|
| 98 |
+
else:
|
| 99 |
+
ratio_factor = (1.0, 1.0)
|
| 100 |
+
if random_aspect_prob > 0 and random.random() < random_aspect_prob:
|
| 101 |
+
aspect_factor = random.uniform(
|
| 102 |
+
random_aspect_range[0], random_aspect_range[1]
|
| 103 |
+
)
|
| 104 |
+
ratio_factor = (
|
| 105 |
+
ratio_factor[0] / aspect_factor,
|
| 106 |
+
ratio_factor[1] * aspect_factor,
|
| 107 |
+
)
|
| 108 |
+
size = [round(x * f / ratio) for x, f in zip(source_size, ratio_factor)]
|
| 109 |
+
return size
|
| 110 |
+
|
| 111 |
+
def __call__(self, img):
|
| 112 |
+
"""
|
| 113 |
+
Args:
|
| 114 |
+
img (PIL Image): Image to be cropped and resized.
|
| 115 |
+
|
| 116 |
+
Returns:
|
| 117 |
+
PIL Image: Resized, padded to at least target size, possibly cropped to exactly target size
|
| 118 |
+
"""
|
| 119 |
+
size = self.get_params(
|
| 120 |
+
img,
|
| 121 |
+
self.size,
|
| 122 |
+
self.longest,
|
| 123 |
+
self.random_scale_prob,
|
| 124 |
+
self.random_scale_range,
|
| 125 |
+
self.random_aspect_prob,
|
| 126 |
+
self.random_aspect_range,
|
| 127 |
+
)
|
| 128 |
+
img = F.resize(img, size, self.interpolation)
|
| 129 |
+
return img
|
| 130 |
+
|
| 131 |
+
def __repr__(self):
|
| 132 |
+
format_string = self.__class__.__name__ + "(size={0}".format(self.size)
|
| 133 |
+
format_string += f", interpolation={self.interpolation})"
|
| 134 |
+
format_string += f", longest={self.longest:.3f})"
|
| 135 |
+
return format_string
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def image_transform(
|
| 139 |
+
image_size: Union[int, Tuple[int, int]],
|
| 140 |
+
mean: Optional[Tuple[float, ...]] = None,
|
| 141 |
+
std: Optional[Tuple[float, ...]] = None,
|
| 142 |
+
resize_mode: Optional[str] = None,
|
| 143 |
+
interpolation: Optional[str] = None,
|
| 144 |
+
):
|
| 145 |
+
mean = mean or OPENAI_DATASET_MEAN
|
| 146 |
+
if not isinstance(mean, (list, tuple)):
|
| 147 |
+
mean = (mean,) * 3
|
| 148 |
+
|
| 149 |
+
std = std or OPENAI_DATASET_STD
|
| 150 |
+
if not isinstance(std, (list, tuple)):
|
| 151 |
+
std = (std,) * 3
|
| 152 |
+
|
| 153 |
+
interpolation = interpolation or "bicubic"
|
| 154 |
+
assert interpolation in ["bicubic", "bilinear", "random"]
|
| 155 |
+
# NOTE random is ignored for interpolation_mode, so defaults to BICUBIC for inference if set
|
| 156 |
+
interpolation_mode = (
|
| 157 |
+
InterpolationMode.BILINEAR
|
| 158 |
+
if interpolation == "bilinear"
|
| 159 |
+
else InterpolationMode.BICUBIC
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
resize_mode = resize_mode or "shortest"
|
| 163 |
+
assert resize_mode in ("shortest", "longest", "squash")
|
| 164 |
+
|
| 165 |
+
normalize = Normalize(mean=mean, std=std)
|
| 166 |
+
|
| 167 |
+
assert resize_mode == "shortest"
|
| 168 |
+
if not isinstance(image_size, (tuple, list)):
|
| 169 |
+
image_size = (image_size, image_size)
|
| 170 |
+
if image_size[0] == image_size[1]:
|
| 171 |
+
# simple case, use torchvision built-in Resize w/ shortest edge mode (scalar size arg)
|
| 172 |
+
transforms = [Resize(image_size[0], interpolation=interpolation_mode)]
|
| 173 |
+
else:
|
| 174 |
+
# resize shortest edge to matching target dim for non-square target
|
| 175 |
+
transforms = [ResizeKeepRatio(image_size)]
|
| 176 |
+
transforms += [CenterCrop(image_size)]
|
| 177 |
+
|
| 178 |
+
transforms.extend(
|
| 179 |
+
[
|
| 180 |
+
_convert_to_rgb,
|
| 181 |
+
ToTensor(),
|
| 182 |
+
normalize,
|
| 183 |
+
]
|
| 184 |
+
)
|
| 185 |
+
return Compose(transforms)
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
class EVAClipImageProcessor(ImageProcessingMixin):
|
| 189 |
+
def __init__(self, **kwargs) -> None:
|
| 190 |
+
super().__init__(**kwargs)
|
| 191 |
+
self.processor = image_transform(image_size=336)
|
| 192 |
+
|
| 193 |
+
def _prepare_images(self, batch: List[List[Image.Image]]) -> torch.Tensor:
|
| 194 |
+
"""
|
| 195 |
+
Convert images to tensors, reshape them, and stack them.
|
| 196 |
+
Args:
|
| 197 |
+
batch: A list of lists of images.
|
| 198 |
+
Returns:
|
| 199 |
+
preprocessed images (tensors) or None
|
| 200 |
+
shape (B, T_img, F, C, H, W)
|
| 201 |
+
None if no images in batch
|
| 202 |
+
"""
|
| 203 |
+
images_per_example = max(len(x) for x in batch)
|
| 204 |
+
batch_images = None
|
| 205 |
+
for iexample, example in enumerate(batch):
|
| 206 |
+
for iimage, image in enumerate(example):
|
| 207 |
+
preprocessed = self.processor(image)
|
| 208 |
+
if batch_images is None:
|
| 209 |
+
batch_images = torch.zeros(
|
| 210 |
+
(len(batch), images_per_example, 1) + preprocessed.shape,
|
| 211 |
+
dtype=preprocessed.dtype,
|
| 212 |
+
)
|
| 213 |
+
batch_images[iexample, iimage, 0] = preprocessed
|
| 214 |
+
return batch_images
|
| 215 |
+
|
| 216 |
+
def preprocess(self, imgpaths=None):
|
| 217 |
+
if imgpaths is None or len(imgpaths) == 0:
|
| 218 |
+
images = [(Image.new("RGB", (336, 336), color="black"))]
|
| 219 |
+
else:
|
| 220 |
+
images = [Image.open(fp) for fp in imgpaths]
|
| 221 |
+
return self._prepare_images([images])
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
class InfiMMZephyrProcessor(ProcessorMixin):
|
| 225 |
+
r"""
|
| 226 |
+
Constructs a InfiMMZephyr processor which wraps a tokenizer and an image processor into a single processor.
|
| 227 |
+
|
| 228 |
+
Args:
|
| 229 |
+
image_processor (`EVAClipImageProcessor`):
|
| 230 |
+
An instance of [`EVAClipImageProcessor`]. The image processor is a required input.
|
| 231 |
+
tokenizer (`LlamaTokenizer`):
|
| 232 |
+
An instance of [`LlamaTokenizer`]. The tokenizer is a required input.
|
| 233 |
+
image_size (`int`, *optional*, defaults to 336): Image size (assuming a square image)
|
| 234 |
+
"""
|
| 235 |
+
|
| 236 |
+
attributes = ["tokenizer"]
|
| 237 |
+
tokenizer_class = "LlamaTokenizer"
|
| 238 |
+
|
| 239 |
+
def __init__(self, tokenizer=None, **kwargs):
|
| 240 |
+
self.image_processor = EVAClipImageProcessor()
|
| 241 |
+
if tokenizer is None:
|
| 242 |
+
tokenizer = AutoTokenizer.from_pretrained("infimm-zephyr", verbose=False)
|
| 243 |
+
|
| 244 |
+
super().__init__(tokenizer, tokenizer)
|
| 245 |
+
|
| 246 |
+
def _prepare_text(
|
| 247 |
+
self,
|
| 248 |
+
batch: List[List[str]],
|
| 249 |
+
padding="longest",
|
| 250 |
+
truncation=True,
|
| 251 |
+
max_length=2048,
|
| 252 |
+
):
|
| 253 |
+
"""
|
| 254 |
+
Tokenize the text and stack them.
|
| 255 |
+
Args:
|
| 256 |
+
batch: A list of lists of strings.
|
| 257 |
+
Returns:
|
| 258 |
+
input_ids (tensor)
|
| 259 |
+
shape (B, T_txt)
|
| 260 |
+
attention_mask (tensor)
|
| 261 |
+
shape (B, T_txt)
|
| 262 |
+
"""
|
| 263 |
+
encodings = self.tokenizer(
|
| 264 |
+
batch,
|
| 265 |
+
padding=padding,
|
| 266 |
+
truncation=truncation,
|
| 267 |
+
return_tensors="pt",
|
| 268 |
+
max_length=max_length,
|
| 269 |
+
)
|
| 270 |
+
input_ids, attention_mask = encodings["input_ids"], encodings["attention_mask"]
|
| 271 |
+
return input_ids, attention_mask
|
| 272 |
+
|
| 273 |
+
def __call__(
|
| 274 |
+
self,
|
| 275 |
+
prompts,
|
| 276 |
+
) -> BatchEncoding:
|
| 277 |
+
"""This method takes batched or non-batched prompts made of text and images and converts them into prompts that
|
| 278 |
+
the model was trained on and prepares the image pixel values for the model to process.
|
| 279 |
+
"""
|
| 280 |
+
image_paths = self._extract_image_paths(prompts)
|
| 281 |
+
images = self.image_processor.preprocess(image_paths)
|
| 282 |
+
prompts = self._replace_with_media_tokens(prompts)
|
| 283 |
+
final_prompt = self.apply_chat_template(prompts)
|
| 284 |
+
input_ids, attention_mask = self._prepare_text([final_prompt])
|
| 285 |
+
return BatchEncoding(
|
| 286 |
+
data={
|
| 287 |
+
"input_ids": input_ids,
|
| 288 |
+
"attention_mask": attention_mask,
|
| 289 |
+
"batch_images": images,
|
| 290 |
+
}
|
| 291 |
+
)
|
| 292 |
+
|
| 293 |
+
def _extract_image_paths(self, prompts):
|
| 294 |
+
image_paths = []
|
| 295 |
+
for round in prompts:
|
| 296 |
+
if round["role"] != "user":
|
| 297 |
+
continue
|
| 298 |
+
for piece in round["content"]:
|
| 299 |
+
if isinstance(piece, dict):
|
| 300 |
+
image_paths.append(piece["image"])
|
| 301 |
+
return image_paths
|
| 302 |
+
|
| 303 |
+
def _replace_with_media_tokens(self, prompts):
|
| 304 |
+
new_prompts = []
|
| 305 |
+
for round in prompts:
|
| 306 |
+
if round["role"] != "user":
|
| 307 |
+
new_prompts.append(round)
|
| 308 |
+
new_content = []
|
| 309 |
+
for piece in round["content"]:
|
| 310 |
+
if isinstance(piece, dict):
|
| 311 |
+
new_content.append(f"{END_OF_CHUNK_TOKEN}{IMAGE_TOKEN}")
|
| 312 |
+
else:
|
| 313 |
+
new_content.append(piece)
|
| 314 |
+
new_prompts.append({"role": "user", "content": "".join(new_content)})
|
| 315 |
+
return new_prompts
|
| 316 |
+
|
| 317 |
+
def apply_chat_template(self, messages, task="generation"):
|
| 318 |
+
if messages[0]["role"] != "system":
|
| 319 |
+
messages.insert(0, {"role": "system", "content": ""})
|
| 320 |
+
prompt = self.tokenizer.apply_chat_template(
|
| 321 |
+
messages,
|
| 322 |
+
tokenize=False,
|
| 323 |
+
add_generation_prompt=True if task == "generation" else False,
|
| 324 |
+
)
|
| 325 |
+
return prompt
|
| 326 |
+
|
| 327 |
+
def batch_decode(self, *args, **kwargs):
|
| 328 |
+
"""
|
| 329 |
+
This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
|
| 330 |
+
refer to the docstring of this method for more information.
|
| 331 |
+
"""
|
| 332 |
+
return self.tokenizer.batch_decode(*args, **kwargs)
|
| 333 |
+
|
| 334 |
+
def decode(self, *args, **kwargs):
|
| 335 |
+
"""
|
| 336 |
+
This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
|
| 337 |
+
the docstring of this method for more information.
|
| 338 |
+
"""
|
| 339 |
+
return self.tokenizer.decode(*args, **kwargs)
|
| 340 |
+
|
| 341 |
+
@property
|
| 342 |
+
def model_input_names(self):
|
| 343 |
+
tokenizer_input_names = self.tokenizer.model_input_names
|
| 344 |
+
image_processor_input_names = self.image_processor.model_input_names
|
| 345 |
+
return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4561b0cf112593ac6fd3f4dd6705cac172fbbc9876ff798e58dc303cc941c8b7
|
| 3 |
+
size 19682192822
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
{
|
| 4 |
+
"content": "<|endofchunk|>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"content": "<image>",
|
| 12 |
+
"lstrip": false,
|
| 13 |
+
"normalized": false,
|
| 14 |
+
"rstrip": false,
|
| 15 |
+
"single_word": false
|
| 16 |
+
}
|
| 17 |
+
],
|
| 18 |
+
"bos_token": {
|
| 19 |
+
"content": "<s>",
|
| 20 |
+
"lstrip": false,
|
| 21 |
+
"normalized": false,
|
| 22 |
+
"rstrip": false,
|
| 23 |
+
"single_word": false
|
| 24 |
+
},
|
| 25 |
+
"eos_token": {
|
| 26 |
+
"content": "</s>",
|
| 27 |
+
"lstrip": false,
|
| 28 |
+
"normalized": false,
|
| 29 |
+
"rstrip": false,
|
| 30 |
+
"single_word": false
|
| 31 |
+
},
|
| 32 |
+
"pad_token": {
|
| 33 |
+
"content": "</s>",
|
| 34 |
+
"lstrip": false,
|
| 35 |
+
"normalized": false,
|
| 36 |
+
"rstrip": false,
|
| 37 |
+
"single_word": false
|
| 38 |
+
},
|
| 39 |
+
"unk_token": {
|
| 40 |
+
"content": "<unk>",
|
| 41 |
+
"lstrip": false,
|
| 42 |
+
"normalized": false,
|
| 43 |
+
"rstrip": false,
|
| 44 |
+
"single_word": false
|
| 45 |
+
}
|
| 46 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dadfd56d766715c61d2ef780a525ab43b8e6da4de6865bda3d95fdef5e134055
|
| 3 |
+
size 493443
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<unk>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<s>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "</s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"32000": {
|
| 28 |
+
"content": "<|endofchunk|>",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"32001": {
|
| 36 |
+
"content": "<image>",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
}
|
| 43 |
+
},
|
| 44 |
+
"additional_special_tokens": [
|
| 45 |
+
"<|endofchunk|>",
|
| 46 |
+
"<image>"
|
| 47 |
+
],
|
| 48 |
+
"bos_token": "<s>",
|
| 49 |
+
"chat_template": "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}",
|
| 50 |
+
"clean_up_tokenization_spaces": false,
|
| 51 |
+
"eos_token": "</s>",
|
| 52 |
+
"legacy": true,
|
| 53 |
+
"model_max_length": 2048,
|
| 54 |
+
"pad_token": "</s>",
|
| 55 |
+
"sp_model_kwargs": {},
|
| 56 |
+
"spaces_between_special_tokens": false,
|
| 57 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 58 |
+
"truncation_side": "left",
|
| 59 |
+
"unk_token": "<unk>",
|
| 60 |
+
"use_default_system_prompt": true,
|
| 61 |
+
"verbose": false
|
| 62 |
+
}
|
utils.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def extend_instance(obj, mixin):
|
| 2 |
+
"""Apply mixins to a class instance after creation"""
|
| 3 |
+
base_cls = obj.__class__
|
| 4 |
+
base_cls_name = obj.__class__.__name__
|
| 5 |
+
obj.__class__ = type(
|
| 6 |
+
base_cls_name, (mixin, base_cls), {}
|
| 7 |
+
) # mixin needs to go first for our forward() logic to work
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def getattr_recursive(obj, att):
|
| 11 |
+
"""
|
| 12 |
+
Return nested attribute of obj
|
| 13 |
+
Example: getattr_recursive(obj, 'a.b.c') is equivalent to obj.a.b.c
|
| 14 |
+
"""
|
| 15 |
+
if att == "":
|
| 16 |
+
return obj
|
| 17 |
+
i = att.find(".")
|
| 18 |
+
if i < 0:
|
| 19 |
+
return getattr(obj, att)
|
| 20 |
+
else:
|
| 21 |
+
return getattr_recursive(getattr(obj, att[:i]), att[i + 1 :])
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def setattr_recursive(obj, att, val):
|
| 25 |
+
"""
|
| 26 |
+
Set nested attribute of obj
|
| 27 |
+
Example: setattr_recursive(obj, 'a.b.c', val) is equivalent to obj.a.b.c = val
|
| 28 |
+
"""
|
| 29 |
+
if "." in att:
|
| 30 |
+
obj = getattr_recursive(obj, ".".join(att.split(".")[:-1]))
|
| 31 |
+
setattr(obj, att.split(".")[-1], val)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def _infer_decoder_layers_attr_name(model):
|
| 35 |
+
for k in __KNOWN_DECODER_LAYERS_ATTR_NAMES:
|
| 36 |
+
if k.lower() in model.__class__.__name__.lower():
|
| 37 |
+
return __KNOWN_DECODER_LAYERS_ATTR_NAMES[k]
|
| 38 |
+
|
| 39 |
+
raise ValueError(
|
| 40 |
+
"We require the attribute name for the nn.ModuleList in the decoder storing"
|
| 41 |
+
" the transformer block layers. Please supply this string manually."
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
__KNOWN_DECODER_LAYERS_ATTR_NAMES = {
|
| 46 |
+
"llama": "model.layers",
|
| 47 |
+
"mistral": "model.layers",
|
| 48 |
+
}
|