

Upload 14 files
Browse files- LICENSE +67 -0
- README_zh.md +93 -0
- config.json +33 -0
- configuration_index.py +185 -0
- generation_config.json +12 -0
- gitattributes +36 -0
- modeling_index.py +1091 -0
- special_tokens_map.json +23 -0
- tokenization_index.py +266 -0
- tokenizer.model +3 -0
- tokenizer_config.json +69 -0
- z-attach-pic-needle-bench-en.png +0 -0
- z-attach-pic-pk-all.png +0 -0
- z-attach-pic-qa-mark.png +0 -0
LICENSE
CHANGED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Bilibili Index 许可协议
|
| 2 |
+
版本 1.0,2024 年 6 月 11 日
|
| 3 |
+
版权所有 (c) 2024 Bilibili Index
|
| 4 |
+
第一部分:前言
|
| 5 |
+
大型生成模型正在被广泛采用和使用,但也存在对其潜在滥用的担忧,无论是由于其技术限制还是伦理考虑。本许可证旨在促进所附模型的开放和负责任的下游使用。
|
| 6 |
+
因此,现在您和 Bilibili Index 同意如下:
|
| 7 |
+
1. 定义
|
| 8 |
+
“许可证”是指本文件中定义的使用、复制和分发的条款和条件。
|
| 9 |
+
“数据”是指从与模型一起使用的数据集提取的信息和/或内容的集合,包括用于训练、预训练或以其他方式评估模型的数据。数据不受本许可证的许可。
|
| 10 |
+
“输出”是指操作模型的结果,以由此产生的信息内容体现。
|
| 11 |
+
“模型”是指任何伴随的机器学习基础组件(包括检查点),由学习的权重、参数(包括优化器状态)组成,对应于补充材料中体现的模型架构,这些权重、参数是在数据上使用补充材料进行训练或调整的,全部或部分。
|
| 12 |
+
“模型的衍生品”是指对模型的所有修改、基于模型的作品或任何其他通过将模型的权重、参数、激活或输出的模式转移到另一个模型而创建或初始化的模型,以便使另一个模型的性能类似于模型,包括但不限于涉及使用中间数据表示的蒸馏方法或基于模型生成合成数据用于训练另一个模型的方法。
|
| 13 |
+
“补充材料”是指用于定义、运行、加载、基准测试或评估模型的伴随源代码和脚本,如果有,还包括用于准备数据进行训练或评估的任何伴随文档、教程、示例等。
|
| 14 |
+
“分发”是指将模型或模型的衍生物传输、复制、发布或以其他方式共享给第三方,包括通过电子或其他远程方式提供模型作为托管服务 - 例如基于 API 或 Web 访问。
|
| 15 |
+
“Bilibili Index”(或“我们”)是指上海宽娱数码科技有限公司或其任何关联公司。
|
| 16 |
+
“您”(或“您的”)是指行使本许可证授予的权限并/或出于任何目的和在任何使用领域使用模型的个人或法律实体,包括在最终使用应用程序(例如聊天机器人、翻译器等)中使用模型。
|
| 17 |
+
“第三方”是指与 Bilibili Index 或您没有共同控制的个人或法律实体。
|
| 18 |
+
“商业用途”是指使用 Bilibili Index 模型,直接或间接为实体或个人进行运营、推广或产生收入,或用于任何其他盈利目的。
|
| 19 |
+
|
| 20 |
+
第二部分、许可及许可限制
|
| 21 |
+
根据本许可协议的条款和条件,许可方特此授予您一个非排他性、全球性、不可转让、不可再许可、可撤销、免版税的版权许可。您可以出于非商业用途使用此许可。许可方对您使用 Bilibili Index 模型的输出或基于 Bilibili Index 模型得到的模型衍生品不主张任何权利,但您必须满足如下许可限制条件:
|
| 22 |
+
1. 您不得出于任何军事或非法目的使用、复制、修改、合并、发布、分发、复制或创建Bilibili Index 模型的全部或部分衍生品。
|
| 23 |
+
2. 如果您计划将 Bilibili Index 模型及模型衍生品用作商业用途,应当按照本协议附则提供的联络方式,事先向许可方登记并获得许可方的书面授权。
|
| 24 |
+
3. 您对 Bilibili Index 模型的使用和修改(包括使用 Bilibili Index 模型的输出或者基于 Bilibili Index 模型得到的模型衍生品)不得违反任何国家的法律法规,尤其是中华人民共和国的法律法规,不得侵犯任何第三方的合法权益,包括但不限于肖像权、名誉权、隐私权等人格权,著作权、专利权、商业秘密等知识产权,或者其他财产权益。
|
| 25 |
+
4. 您必须向 Bilibili Index 模型或其模型衍生品的任何第三方使用者提供 Bilibili Index 模型的来源以及本协议的副本。
|
| 26 |
+
5. 您修改 Bilibili Index 模型得到模型衍生品,必须以显著的方式说明修改的内容,且上述修改不得违反本协议的许可限制条件,也不能允许、协助或以其他方式使得第三方违反本协议中的许可限制条件。
|
| 27 |
+
|
| 28 |
+
第三部分:知识产权
|
| 29 |
+
1. Bilibili Index 模型的所有权及其相关知识产权,由许可方单独所有。
|
| 30 |
+
2. 在任何情况下,未经许可方事先书面同意,您不得使用许可方任何商标、服务标记、商号、域名、网站名称或其他显著品牌特征(以下统称为"标识"),包括但不限于明示或暗示您自身为“许可方”。未经许可方事先书面同意,您不得将本条款前述标识以单独或结合的任何方式展示、使用或申请注册商标、进行域名注册等,也不得向他人明示或暗示有权展示、使用、或以其他方式处理这些标识的权利。由于您违反本协议使用许可方上述标识等给许可方或他人造成损失的,由您承担全部法律责任。
|
| 31 |
+
3. 在许可范围内,您可以对 Bilibili Index 模型进行修改以得到模型衍生品,对于模型衍生��中您付出创造性劳动的部分,您可以主张该部分的知识产权。
|
| 32 |
+
|
| 33 |
+
第四部分、免责声明及责任限制
|
| 34 |
+
1. 在任何情况下,许可方不对您根据本协议使用 Bilibili Index 模型而产生或与之相关的任何直接、间接、附带的后果、以及其他损失或损害承担责任。若由此导致许可方遭受损失,您应当向许可方承担全部赔偿责任。
|
| 35 |
+
2. 模型中的模型参数仅仅是一种示例,如果您需要满足其他要求,需自行训练,并遵守相应数据集的许可协议。您将对 Bilibili Index 模型的输出及模型衍生品所涉及的知识产权风险或与之相关的任何直接、间接、附带的后果、以及其他损失或损害负责。
|
| 36 |
+
3. 尽管许可方在 Bilibili Index 模型训练的所有阶段,都坚持努力维护数据的合规性和准确性,但受限于 Bilibili Index 模型的规模及其概率固有的随机性因素影响,其输出结果的准确性无法得到保证,模型存在被误导的可能。因此,许可方在此声明,许可方不承担您因使用 Bilibili Index 模型及其源代码而导致的数据安全问题、声誉风险,或任何涉及 Bilibili Index 模型被误导、误用、传播或不正当使用而产生的任何风险和责任。
|
| 37 |
+
4. 本协议所称损失或损害包括但不限于下列任何损失或损害(无论此类损失或损害是不可预见的、可预见的、已知的或其他的):(i)收入损失;(ii)实际或预期利润损失;(ii)货币使用损失;(iv)预期节约的损失;(v)业务损失;(vi)机会损失;(vii)商誉、声誉损失;(viii)软件的使用损失;或(x)任何间接、附带的特殊或间接损害损失。
|
| 38 |
+
5. 除非适用的法律另有要求或经过许可方书面同意,否则许可方将按“现状”授予Bilibili Index 模型的许可。针对本协议中的 Bilibili Index 模型,许可方不提供任何明示、暗示的保证,包括但不限于:关于所有权的任何保证或条件、关于适销性的保证或条件、适用于任何特定目的的保证或条件、过去、现在或未来关于 Bilibili Index 模型不侵权的任何类型的保证、以及因任何交易过程、贸易使用(如建议书、规范或样品)而产生的任何保证。您将对其通过使用、复制或再分发等方式利用 Bilibili Index 模型所产生的风险与后果,独自承担责任。
|
| 39 |
+
6. 您充分知悉并理解同意,Bilibili Index 模型中可能包含个人信息。您承诺将遵守所有适用的法律法规进行个人信息的处理,特别是遵守《中华人民共和国个人信息保护法》的相关规定。请注意,许可方给予您使用 Bilibili Index 模型的授权,并不意味着您已经获得处理相关个人信息的合法性基础。您作为独立的个人信息处理者,需要保证在处理 Bilibili Index 模型中可能包含的个人信息时,完全符合相关法律法规的要求,包括但不限于获得个人信息主体的授权同意等,并愿意独自承担由此可能产生的任何风险和后果。
|
| 40 |
+
7. 您充分理解并同意,许可方有权依合理判断对违反有关法律法规或本协议规定的行为进行处理,对您的违法违规行为采取适当的法律行动,并依据法律法规保存有关信息向有关部门报告等,您应独自承担由此而产生的一切法律责任。
|
| 41 |
+
|
| 42 |
+
第五部分、品牌曝光与显著标识
|
| 43 |
+
1. 您同意并理解,如您将您基于 Bilibili Index 模型二次开发的模型衍生品在国内外的开源社区提供开源许可的,您需要在该开源社区以显著方式标注该模型衍生品系基于 Bilibili Index 模型进行的二次开发,标注内容包括但不限于“Bilibili Index ”以及与 Bilibili Index 模型相关的品牌的其他元素。
|
| 44 |
+
2. 您同意并理解,如您将 Bilibili Index 模型二次开发的模型衍生品参加国内外任何组织和个人举行的排名活动,包括但不限于针对模型性能、准确度、算法、算力等任何维度的排名活动,您均需在模型说明中以显著方式标注该模型衍生品系基于 Bilibili Index 模型进行的二次开发,标注内容包括但不限于“Blibili Index Inside”以及与 Bilibili Index 模型相关的品牌的其他元素。
|
| 45 |
+
|
| 46 |
+
七、其他
|
| 47 |
+
1. 许可方在法律法规许可的范围内对协议条款享有最终解释权。
|
| 48 |
+
2. 本协议的订立、效力、解释、履行、修改和终止,使用 Bilibili Index 模型以及争议的解决均适用中华人民共和国大陆地区(仅为本协议之目的,不包括香港、澳门和台湾)法律,
|
| 49 |
+
并排除冲突法的适用。
|
| 50 |
+
3. 因使用 Bilibili Index 模型而发生的任何争议,各方应首先通过友好协商的方式加以解决。协商不成时,向许可方所在地人民法院提起诉讼。
|
| 51 |
+
|
| 52 |
+
附则
|
| 53 |
+
1. 若您期望基于本协议的许可条件与限制,将 Bilibili Index 模型或其衍生品用作商业用途,请您按照如下方式联系许可方,以进行登记并向许可方申��书面授权:联系邮箱:opensource@bilibili.com
|
| 54 |
+
|
| 55 |
+
附件 A 使用限制
|
| 56 |
+
您同意不使用模型或模型的衍生物:
|
| 57 |
+
以任何违反任何适用的国家或国际法律或法规或侵犯任何第三方合法权益的方式;
|
| 58 |
+
用于任何军事目的;
|
| 59 |
+
以任何方式用于剥削、伤害或企图剥削或伤害未成年人;
|
| 60 |
+
生成或传播可验证的虚假信息和/或内容,意图伤害他人;
|
| 61 |
+
生成或传播受适用监管要求限制的不适当内容;
|
| 62 |
+
在未经适当授权或不合理使用的情况下生成或传播个人可识别信息;
|
| 63 |
+
诽谤、贬低或以其他方式骚扰他人;
|
| 64 |
+
用于对个人的法律权利产生不利影响或创建或修改具有约束力的可执行义务的完全自动化决策;
|
| 65 |
+
用于基于在线或离线社会行为或已知或预测的个人或个性特征对个人或群体进行歧视或伤害的任何目的;
|
| 66 |
+
为了对特定群体的个人造成或可能造成身体或心理伤害,利用该群体的年龄、社会、身体或心理特征的任何漏洞,从而严重扭曲属于该群体的个人的行为;
|
| 67 |
+
用于任何旨在或具有基于法律保护的特征或类别对个人或群体进行歧视的目的
|
README_zh.md
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
<div align="center">
|
| 3 |
+
<h1>
|
| 4 |
+
Index-1.9B-32K
|
| 5 |
+
</h1>
|
| 6 |
+
</div>
|
| 7 |
+
|
| 8 |
+
<div style="text-align: center;">
|
| 9 |
+
[Switch to English](README.md) | [切换到中文](README_zh.md)
|
| 10 |
+
</div>
|
| 11 |
+
|
| 12 |
+
---
|
| 13 |
+
## 模型简介
|
| 14 |
+
Index-1.9B-32K 是一个仅有 1.9B 参数、却具备 32K 上下文长度的语言模型(这意味着,这个超小精灵可以一次性读完 3.5 万字的文档)。该模型专门针对 32K 以上的长文本进行了持续预训练(Continue Pre-Train)和监督微调(SFT),主要基于我们精心清洗的长文本预训练语料、自建的长文本指令集进行训练。目前,我们已在 Hugging Face 和 ModelScope 上同步开源。
|
| 15 |
+
|
| 16 |
+
Index-1.9B-32K **以极小的模型体积(体积约为GPT-4等模型的2%)实现了出色的长文本处理能力**。以下为与 GPT-4、GPT-3.5-turbo-16k 的对比评测结果:
|
| 17 |
+
<div style="text-align: center;">
|
| 18 |
+
<img src="z-attach-pic-pk-all.png" alt="" width="700">
|
| 19 |
+
<p><strong>Index-1.9B-32K与GPT-4等模型的长文本能力对比</strong></p>
|
| 20 |
+
</div>
|
| 21 |
+
|
| 22 |
+
Index-1.9B-32K在32K长度的大海捞针测试下,评测结果优异,如下图,评测结果只在(32K 长度,%10 深度)区域有一处黄斑(91.08分),其他范围表现优异,几乎全绿。
|
| 23 |
+
<div style="text-align: center;">
|
| 24 |
+
<img src="z-attach-pic-needle-bench-en.png" alt="" width="900">
|
| 25 |
+
<p><strong>大海捞针评测</strong></p>
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
## Index-1.9B-32K模型下载、使用、技术报告:
|
| 29 |
+
Index-1.9B-32K模型下载、使用方法、技术报告详见:
|
| 30 |
+
|
| 31 |
+
[**Index-1.9B-32K长上下文技术报告.md**](https://github.com/bilibili/Index-1.9B/blob/main/Index-1.9B-32K长上下文技术报告.md)
|
| 32 |
+
|
| 33 |
+
---
|
| 34 |
+
---
|
| 35 |
+
---
|
| 36 |
+
---
|
| 37 |
+
---
|
| 38 |
+
---
|
| 39 |
+
|
| 40 |
+
## 使用:长文本翻译&总结(Index-1.9B-32K)
|
| 41 |
+
- 下载仓库:
|
| 42 |
+
```shell
|
| 43 |
+
git clone https://github.com/bilibili/Index-1.9B
|
| 44 |
+
cd Index-1.9B
|
| 45 |
+
```
|
| 46 |
+
- 下载模型到本地.
|
| 47 |
+
|
| 48 |
+
- 使用 pip 安装依赖:
|
| 49 |
+
|
| 50 |
+
```shell
|
| 51 |
+
pip install -r requirements.txt
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
- 运行长文本专用的交互工具:demo/cli_long_text_demo.py
|
| 55 |
+
- 模型默认会读取该文件:data/user_long_text.txt,将对文本内容进行中文总结。
|
| 56 |
+
- 可以新建一个窗口,实时修改文件内容,模型会读取最新的文件内容并总结。
|
| 57 |
+
|
| 58 |
+
```shell
|
| 59 |
+
cd demo/
|
| 60 |
+
CUDA_VISIBLE_DEVICES=0 python cli_long_text_demo.py --model_path '/path/to/model/' --input_file_path data/user_long_text.txt
|
| 61 |
+
```
|
| 62 |
+
- 运行&交互效果(翻译并总结哔哩哔哩公司于2024.8.22发布的英文财报 --- [英文财报原文在这里](https://github.com/bilibili/Index-1.9B/tree/main/demo/data/user_long_text.txt)):
|
| 63 |
+
<div style="text-align: center;">
|
| 64 |
+
<img src="z-attach-pic-qa-mark.png" alt="" width="1000">
|
| 65 |
+
<p><strong>翻译总结(哔哩哔哩公司于2024.8.22发布的英文财报)</strong></p>
|
| 66 |
+
</div>
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
## 局限性与免责申明
|
| 70 |
+
|
| 71 |
+
Index-1.9B-32K在某些情况下可能会产生不准确、有偏见或其他令人反感的内容。模型生成内容时无法理解、表达个人观点或价值判断,其输出内容不代表模型开发者的观点和立场。因此,请谨慎使用模型生成的内容,用户在使用时应自行负责对其进行评估和验证,请勿将生成的有害内容进行传播,且在部署任何相关应用之前,开发人员应根据具体应用对模型进行安全测试和调优。
|
| 72 |
+
|
| 73 |
+
我们强烈警告不要将这些模型用于制造或传播有害信息,或进行任何可能损害公众、国家、社会安全或违反法规的活动,也不要将其用于未经适当安全审查和备案的互联网服务。我们已尽所能确保模型训练数据的合规性,但由于模型和数据的复杂性,仍可能存在无法预见的问题。如果因使用这些模型而产生任何问题,无论是数据安全问题、公共舆论风险,还是因模型被误解、滥用、传播或不合规使用所引发的任何风险和问题,我们将不承担任何责任。
|
| 74 |
+
|
| 75 |
+
## 模型开源协议
|
| 76 |
+
|
| 77 |
+
使用本仓库的源码需要遵循 [[Apache-2.0]{.underline}](https://github.com/bilibili/Index-1.9B/blob/main/LICENSE) 开源协议,使用
|
| 78 |
+
Index-1.9B-32K的模型权重则需要遵循[[模型许可协议]{.underline}](https://github.com/bilibili/Index-1.9B/blob/main/INDEX_MODEL_LICENSE)。
|
| 79 |
+
|
| 80 |
+
Index-1.9B-32K模型权重对学术研究**完全开放**,并且支持**免费商用**。
|
| 81 |
+
|
| 82 |
+
## 引用
|
| 83 |
+
|
| 84 |
+
如果你觉得我们的工作对你有帮助,欢迎引用!
|
| 85 |
+
|
| 86 |
+
```shell
|
| 87 |
+
@article{Index-1.9B-32K,
|
| 88 |
+
title={Index-1.9B-32K Long Context Technical Report},
|
| 89 |
+
year={2024},
|
| 90 |
+
url={https://github.com/bilibili/Index-1.9B/blob/main/Index-1.9B-32K_Long_Context_Technical_Report.md},
|
| 91 |
+
author={Changye Yu, Tianjiao Li, Lusheng Zhang and IndexTeam}
|
| 92 |
+
}
|
| 93 |
+
```
|
config.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "Index_1_9B",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"IndexForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"auto_map": {
|
| 7 |
+
"AutoConfig": "configuration_index.IndexConfig",
|
| 8 |
+
"AutoModelForCausalLM": "modeling_index.IndexForCausalLM",
|
| 9 |
+
"AutoModelForSequenceClassification": "modeling_index.IndexForSequenceClassification"
|
| 10 |
+
},
|
| 11 |
+
"bos_token_id": 1,
|
| 12 |
+
"eos_token_id": 2,
|
| 13 |
+
"pad_token_id": 0,
|
| 14 |
+
"hidden_act": "silu",
|
| 15 |
+
"hidden_size": 2048,
|
| 16 |
+
"initializer_range": 0.01,
|
| 17 |
+
"intermediate_size": 5888,
|
| 18 |
+
"max_length": 32768,
|
| 19 |
+
"max_position_embeddings": 32768,
|
| 20 |
+
"model_type": "index",
|
| 21 |
+
"num_attention_heads": 16,
|
| 22 |
+
"num_key_value_heads": 16,
|
| 23 |
+
"num_hidden_layers": 36,
|
| 24 |
+
"rms_norm_eps": 1e-06,
|
| 25 |
+
"rope_scaling": null,
|
| 26 |
+
"tie_word_embeddings": false,
|
| 27 |
+
"norm_head":1,
|
| 28 |
+
"torch_dtype": "bfloat16",
|
| 29 |
+
"transformers_version": "4.39.2",
|
| 30 |
+
"use_cache": true,
|
| 31 |
+
"vocab_size": 65029,
|
| 32 |
+
"rope_ratio": 32
|
| 33 |
+
}
|
configuration_index.py
ADDED
|
@@ -0,0 +1,185 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2022 EleutherAI and the HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
+
# and OPT implementations in this library. It has been modified from its
|
| 6 |
+
# original forms to accommodate minor architectural differences compared
|
| 7 |
+
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
|
| 8 |
+
#
|
| 9 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 10 |
+
# you may not use this file except in compliance with the License.
|
| 11 |
+
# You may obtain a copy of the License at
|
| 12 |
+
#
|
| 13 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 14 |
+
#
|
| 15 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 16 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 17 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 18 |
+
# See the License for the specific language governing permissions and
|
| 19 |
+
# limitations under the License.
|
| 20 |
+
""" Index model configuration"""
|
| 21 |
+
|
| 22 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 23 |
+
from transformers.utils import logging
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
logger = logging.get_logger(__name__)
|
| 27 |
+
|
| 28 |
+
INDEX_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class IndexConfig(PretrainedConfig):
|
| 32 |
+
r"""
|
| 33 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 34 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
Args:
|
| 38 |
+
vocab_size (`int`, *optional*, defaults to 65029):
|
| 39 |
+
Vocabulary size of the Index model. Defines the number of different tokens that can be represented by the
|
| 40 |
+
`inputs_ids` passed when calling [`IndexModel`]
|
| 41 |
+
hidden_size (`int`, *optional*, defaults to 4096):
|
| 42 |
+
Dimension of the hidden representations.
|
| 43 |
+
intermediate_size (`int`, *optional*, defaults to 11008):
|
| 44 |
+
Dimension of the MLP representations.
|
| 45 |
+
num_hidden_layers (`int`, *optional*, defaults to 32):
|
| 46 |
+
Number of hidden layers in the Transformer decoder.
|
| 47 |
+
num_attention_heads (`int`, *optional*, defaults to 32):
|
| 48 |
+
Number of attention heads for each attention layer in the Transformer decoder.
|
| 49 |
+
num_key_value_heads (`int`, *optional*):
|
| 50 |
+
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
| 51 |
+
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
| 52 |
+
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
| 53 |
+
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
| 54 |
+
by meanpooling all the original heads within that group. For more details checkout [this
|
| 55 |
+
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
|
| 56 |
+
`num_attention_heads`.
|
| 57 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
| 58 |
+
The non-linear activation function (function or string) in the decoder.
|
| 59 |
+
max_position_embeddings (`int`, *optional*, defaults to 2048):
|
| 60 |
+
The maximum sequence length that this model might ever be used with. Index 1 supports up to 2048 tokens,
|
| 61 |
+
Index 2 up to 4096, CodeIndex up to 16384.
|
| 62 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 63 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 64 |
+
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
|
| 65 |
+
The epsilon used by the rms normalization layers.
|
| 66 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 67 |
+
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
| 68 |
+
relevant if `config.is_decoder=True`.
|
| 69 |
+
pad_token_id (`int`, *optional*):
|
| 70 |
+
Padding token id.
|
| 71 |
+
bos_token_id (`int`, *optional*, defaults to 1):
|
| 72 |
+
Beginning of stream token id.
|
| 73 |
+
eos_token_id (`int`, *optional*, defaults to 2):
|
| 74 |
+
End of stream token id.
|
| 75 |
+
pretraining_tp (`int`, *optional*, defaults to 1):
|
| 76 |
+
Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
|
| 77 |
+
document](https://huggingface.co/docs/transformers/main/perf_train_gpu_many#tensor-parallelism) to understand more about it. This value is
|
| 78 |
+
necessary to ensure exact reproducibility of the pretraining results. Please refer to [this
|
| 79 |
+
issue](https://github.com/pytorch/pytorch/issues/76232).
|
| 80 |
+
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
| 81 |
+
Whether to tie weight embeddings
|
| 82 |
+
rope_theta (`float`, *optional*, defaults to 10000.0):
|
| 83 |
+
The base period of the RoPE embeddings.
|
| 84 |
+
rope_scaling (`Dict`, *optional*):
|
| 85 |
+
Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
|
| 86 |
+
strategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is
|
| 87 |
+
`{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
|
| 88 |
+
`max_position_embeddings` to the expected new maximum. See the following thread for more information on how
|
| 89 |
+
these scaling strategies behave
|
| 90 |
+
attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
|
| 91 |
+
Whether to use a bias in the query, key, value and output projection layers during self-attention.
|
| 92 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 93 |
+
The dropout ratio for the attention probabilities.
|
| 94 |
+
|
| 95 |
+
```python
|
| 96 |
+
>>> from transformers import IndexModel, IndexConfig
|
| 97 |
+
|
| 98 |
+
>>> configuration = IndexConfig()
|
| 99 |
+
>>> model = IndexModel(configuration)
|
| 100 |
+
>>> configuration = model.config
|
| 101 |
+
```"""
|
| 102 |
+
|
| 103 |
+
model_type = "index"
|
| 104 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 105 |
+
|
| 106 |
+
def __init__(
|
| 107 |
+
self,
|
| 108 |
+
vocab_size=65029,
|
| 109 |
+
hidden_size=4096,
|
| 110 |
+
intermediate_size=11008,
|
| 111 |
+
num_hidden_layers=32,
|
| 112 |
+
num_attention_heads=32,
|
| 113 |
+
num_key_value_heads=None,
|
| 114 |
+
hidden_act="silu",
|
| 115 |
+
max_position_embeddings=2048,
|
| 116 |
+
initializer_range=0.02,
|
| 117 |
+
rms_norm_eps=1e-6,
|
| 118 |
+
use_cache=True,
|
| 119 |
+
pad_token_id=None,
|
| 120 |
+
bos_token_id=1,
|
| 121 |
+
eos_token_id=2,
|
| 122 |
+
pretraining_tp=1,
|
| 123 |
+
tie_word_embeddings=False,
|
| 124 |
+
norm_head=False,
|
| 125 |
+
rope_theta=10000.0,
|
| 126 |
+
rope_scaling=None,
|
| 127 |
+
attention_bias=False,
|
| 128 |
+
attention_dropout=0.0,
|
| 129 |
+
rope_ratio=1.0,
|
| 130 |
+
**kwargs,
|
| 131 |
+
):
|
| 132 |
+
self.vocab_size = vocab_size
|
| 133 |
+
self.max_position_embeddings = max_position_embeddings
|
| 134 |
+
self.hidden_size = hidden_size
|
| 135 |
+
self.intermediate_size = intermediate_size
|
| 136 |
+
self.num_hidden_layers = num_hidden_layers
|
| 137 |
+
self.num_attention_heads = num_attention_heads
|
| 138 |
+
|
| 139 |
+
# for backward compatibility
|
| 140 |
+
if num_key_value_heads is None:
|
| 141 |
+
num_key_value_heads = num_attention_heads
|
| 142 |
+
|
| 143 |
+
self.num_key_value_heads = num_key_value_heads
|
| 144 |
+
self.hidden_act = hidden_act
|
| 145 |
+
self.initializer_range = initializer_range
|
| 146 |
+
self.rms_norm_eps = rms_norm_eps
|
| 147 |
+
self.pretraining_tp = pretraining_tp
|
| 148 |
+
self.use_cache = use_cache
|
| 149 |
+
self.rope_theta = rope_theta
|
| 150 |
+
self.rope_scaling = rope_scaling
|
| 151 |
+
self._rope_scaling_validation()
|
| 152 |
+
self.attention_bias = attention_bias
|
| 153 |
+
self.attention_dropout = attention_dropout
|
| 154 |
+
|
| 155 |
+
self.norm_head = norm_head
|
| 156 |
+
self.rope_ratio = rope_ratio
|
| 157 |
+
|
| 158 |
+
super().__init__(
|
| 159 |
+
pad_token_id=pad_token_id,
|
| 160 |
+
bos_token_id=bos_token_id,
|
| 161 |
+
eos_token_id=eos_token_id,
|
| 162 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 163 |
+
**kwargs,
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
def _rope_scaling_validation(self):
|
| 167 |
+
"""
|
| 168 |
+
Validate the `rope_scaling` configuration.
|
| 169 |
+
"""
|
| 170 |
+
if self.rope_scaling is None:
|
| 171 |
+
return
|
| 172 |
+
|
| 173 |
+
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
|
| 174 |
+
raise ValueError(
|
| 175 |
+
"`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
|
| 176 |
+
f"got {self.rope_scaling}"
|
| 177 |
+
)
|
| 178 |
+
rope_scaling_type = self.rope_scaling.get("type", None)
|
| 179 |
+
rope_scaling_factor = self.rope_scaling.get("factor", None)
|
| 180 |
+
if rope_scaling_type is None or rope_scaling_type not in ["linear", "dynamic"]:
|
| 181 |
+
raise ValueError(
|
| 182 |
+
f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
|
| 183 |
+
)
|
| 184 |
+
if rope_scaling_factor is None or not isinstance(rope_scaling_factor, float) or rope_scaling_factor <= 1.0:
|
| 185 |
+
raise ValueError(f"`rope_scaling`'s factor field must be a float > 1, got {rope_scaling_factor}")
|
generation_config.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"transformers_version": "4.39.2",
|
| 7 |
+
"top_k": 5,
|
| 8 |
+
"top_p": 0.8,
|
| 9 |
+
"temperature": 0.3,
|
| 10 |
+
"repetition_penalty":1.1,
|
| 11 |
+
"do_sample": true
|
| 12 |
+
}
|
gitattributes
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
pytorch_model.bin filter=lfs diff=lfs merge=lfs -text
|
modeling_index.py
ADDED
|
@@ -0,0 +1,1091 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2022 EleutherAI and the HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
+
# and OPT implementations in this library. It has been modified from its
|
| 6 |
+
# original forms to accommodate minor architectural differences compared
|
| 7 |
+
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
|
| 8 |
+
#
|
| 9 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 10 |
+
# you may not use this file except in compliance with the License.
|
| 11 |
+
# You may obtain a copy of the License at
|
| 12 |
+
#
|
| 13 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 14 |
+
#
|
| 15 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 16 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 17 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 18 |
+
# See the License for the specific language governing permissions and
|
| 19 |
+
# limitations under the License.
|
| 20 |
+
""" PyTorch Index model."""
|
| 21 |
+
import math
|
| 22 |
+
import numpy as np
|
| 23 |
+
from typing import List, Optional, Tuple, Union
|
| 24 |
+
|
| 25 |
+
import torch
|
| 26 |
+
import torch.nn.functional as F
|
| 27 |
+
import torch.utils.checkpoint
|
| 28 |
+
from torch import nn
|
| 29 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
| 30 |
+
|
| 31 |
+
from transformers.activations import ACT2FN
|
| 32 |
+
from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast, SequenceClassifierOutputWithPast
|
| 33 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 34 |
+
from transformers.utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
|
| 35 |
+
from .configuration_index import IndexConfig
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
logger = logging.get_logger(__name__)
|
| 39 |
+
|
| 40 |
+
_CONFIG_FOR_DOC = "IndexConfig"
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
|
| 44 |
+
def _make_causal_mask(
|
| 45 |
+
input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
|
| 46 |
+
):
|
| 47 |
+
"""
|
| 48 |
+
Make causal mask used for bi-directional self-attention.
|
| 49 |
+
"""
|
| 50 |
+
bsz, tgt_len = input_ids_shape
|
| 51 |
+
mask = torch.full((tgt_len, tgt_len), torch.finfo(dtype).min, device=device)
|
| 52 |
+
mask_cond = torch.arange(mask.size(-1), device=device)
|
| 53 |
+
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
|
| 54 |
+
mask = mask.to(dtype)
|
| 55 |
+
|
| 56 |
+
if past_key_values_length > 0:
|
| 57 |
+
mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
|
| 58 |
+
return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
# Copied from transformers.models.bart.modeling_bart._expand_mask
|
| 62 |
+
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
| 63 |
+
"""
|
| 64 |
+
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
| 65 |
+
"""
|
| 66 |
+
bsz, src_len = mask.size()
|
| 67 |
+
tgt_len = tgt_len if tgt_len is not None else src_len
|
| 68 |
+
|
| 69 |
+
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
|
| 70 |
+
|
| 71 |
+
inverted_mask = 1.0 - expanded_mask
|
| 72 |
+
|
| 73 |
+
return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class IndexRMSNorm(nn.Module):
|
| 77 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 78 |
+
"""
|
| 79 |
+
IndexRMSNorm is equivalent to T5LayerNorm
|
| 80 |
+
"""
|
| 81 |
+
super().__init__()
|
| 82 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 83 |
+
self.variance_epsilon = eps
|
| 84 |
+
|
| 85 |
+
def forward(self, hidden_states):
|
| 86 |
+
input_dtype = hidden_states.dtype
|
| 87 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 88 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 89 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
| 90 |
+
return self.weight * hidden_states.to(input_dtype)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
class IndexRotaryEmbedding(torch.nn.Module):
|
| 94 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, rope_ratio=1.0, device=None):
|
| 95 |
+
super().__init__()
|
| 96 |
+
|
| 97 |
+
self.dim = dim
|
| 98 |
+
self.max_position_embeddings = max_position_embeddings
|
| 99 |
+
self.base = base
|
| 100 |
+
self.rope_ratio = rope_ratio
|
| 101 |
+
self.base_scaled = self.base * self.rope_ratio
|
| 102 |
+
self.device = device
|
| 103 |
+
|
| 104 |
+
self._init_rope_cache_buffer()
|
| 105 |
+
|
| 106 |
+
def _init_rope_cache_buffer(self):
|
| 107 |
+
inv_freq = 1.0 / (self.base_scaled ** (torch.arange(0, self.dim, 2).float().to(self.device) / self.dim))
|
| 108 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 109 |
+
|
| 110 |
+
# Build here to make `torch.jit.trace` work.
|
| 111 |
+
self._set_cos_sin_cache(
|
| 112 |
+
seq_len=self.max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
|
| 113 |
+
)
|
| 114 |
+
#print("rope cache value:")
|
| 115 |
+
#self._show_rope_cache_info()
|
| 116 |
+
|
| 117 |
+
def _show_rope_cache_info( self ):
|
| 118 |
+
np.set_printoptions(precision=6, threshold=10, edgeitems=5, linewidth=200, suppress=True)
|
| 119 |
+
print("rope emb cos_cached:", self.cos_cached.cpu().to(dtype=torch.float32).numpy())
|
| 120 |
+
print("rope emb sin_cached:", self.sin_cached.cpu().to(dtype=torch.float32).numpy())
|
| 121 |
+
print("rope emb cos_cached shape:", self.cos_cached.cpu().to(dtype=torch.float32).numpy().shape)
|
| 122 |
+
print("rope emb sin_cached shape:", self.sin_cached.cpu().to(dtype=torch.float32).numpy().shape)
|
| 123 |
+
print(f"self.dim:{self.dim}, self.base:{self.base}")
|
| 124 |
+
print(f"self.rope_ratio:{self.rope_ratio}, "
|
| 125 |
+
f"self.max_position_embeddings:{self.max_position_embeddings}, "
|
| 126 |
+
f"self.base_scaled:{self.base_scaled} , "
|
| 127 |
+
f"max_seq_len_cached:{self.max_seq_len_cached}"
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 131 |
+
self.max_seq_len_cached = seq_len
|
| 132 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 133 |
+
|
| 134 |
+
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
| 135 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 136 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 137 |
+
self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False)
|
| 138 |
+
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
|
| 139 |
+
|
| 140 |
+
def forward(self, x, seq_len=None):
|
| 141 |
+
# x: [bs, num_attention_heads, seq_len, head_size]
|
| 142 |
+
if seq_len > self.max_seq_len_cached:
|
| 143 |
+
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
|
| 144 |
+
|
| 145 |
+
return (
|
| 146 |
+
self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
|
| 147 |
+
self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
class IndexLinearScalingRotaryEmbedding(IndexRotaryEmbedding):
|
| 152 |
+
"""IndexRotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
|
| 153 |
+
|
| 154 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 155 |
+
self.scaling_factor = scaling_factor
|
| 156 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 157 |
+
|
| 158 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 159 |
+
self.max_seq_len_cached = seq_len
|
| 160 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 161 |
+
t = t / self.scaling_factor
|
| 162 |
+
|
| 163 |
+
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
| 164 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 165 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 166 |
+
self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False)
|
| 167 |
+
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
class IndexDynamicNTKScalingRotaryEmbedding(IndexRotaryEmbedding):
|
| 171 |
+
"""IndexRotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla"""
|
| 172 |
+
|
| 173 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 174 |
+
self.scaling_factor = scaling_factor
|
| 175 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 176 |
+
|
| 177 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 178 |
+
self.max_seq_len_cached = seq_len
|
| 179 |
+
|
| 180 |
+
if seq_len > self.max_position_embeddings:
|
| 181 |
+
base = self.base * (
|
| 182 |
+
(self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)
|
| 183 |
+
) ** (self.dim / (self.dim - 2))
|
| 184 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
|
| 185 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 186 |
+
|
| 187 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 188 |
+
|
| 189 |
+
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
| 190 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 191 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 192 |
+
self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False)
|
| 193 |
+
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def rotate_half(x):
|
| 197 |
+
"""Rotates half the hidden dims of the input."""
|
| 198 |
+
x1 = x[..., : x.shape[-1] // 2]
|
| 199 |
+
x2 = x[..., x.shape[-1] // 2 :]
|
| 200 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
|
| 204 |
+
# The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
|
| 205 |
+
cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
|
| 206 |
+
sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
|
| 207 |
+
cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
|
| 208 |
+
sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
|
| 209 |
+
q_embed = (q * cos) + (rotate_half(q) * sin)
|
| 210 |
+
k_embed = (k * cos) + (rotate_half(k) * sin)
|
| 211 |
+
return q_embed, k_embed
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
class IndexMLP(nn.Module):
|
| 215 |
+
def __init__(self, config):
|
| 216 |
+
super().__init__()
|
| 217 |
+
self.config = config
|
| 218 |
+
self.hidden_size = config.hidden_size
|
| 219 |
+
self.intermediate_size = config.intermediate_size
|
| 220 |
+
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 221 |
+
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 222 |
+
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
| 223 |
+
self.act_fn = ACT2FN[config.hidden_act]
|
| 224 |
+
|
| 225 |
+
def forward(self, x):
|
| 226 |
+
if self.config.pretraining_tp > 1:
|
| 227 |
+
slice = self.intermediate_size // self.config.pretraining_tp
|
| 228 |
+
gate_proj_slices = self.gate_proj.weight.split(slice, dim=0)
|
| 229 |
+
up_proj_slices = self.up_proj.weight.split(slice, dim=0)
|
| 230 |
+
down_proj_slices = self.down_proj.weight.split(slice, dim=1)
|
| 231 |
+
|
| 232 |
+
gate_proj = torch.cat(
|
| 233 |
+
[F.linear(x, gate_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1
|
| 234 |
+
)
|
| 235 |
+
up_proj = torch.cat([F.linear(x, up_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1)
|
| 236 |
+
|
| 237 |
+
intermediate_states = (self.act_fn(gate_proj) * up_proj).split(slice, dim=2)
|
| 238 |
+
down_proj = [
|
| 239 |
+
F.linear(intermediate_states[i], down_proj_slices[i]) for i in range(self.config.pretraining_tp)
|
| 240 |
+
]
|
| 241 |
+
down_proj = sum(down_proj)
|
| 242 |
+
else:
|
| 243 |
+
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
|
| 244 |
+
|
| 245 |
+
return down_proj
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 249 |
+
"""
|
| 250 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 251 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 252 |
+
"""
|
| 253 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 254 |
+
if n_rep == 1:
|
| 255 |
+
return hidden_states
|
| 256 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
| 257 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
class IndexAttention(nn.Module):
|
| 261 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 262 |
+
|
| 263 |
+
def __init__(self, config: IndexConfig):
|
| 264 |
+
super().__init__()
|
| 265 |
+
self.config = config
|
| 266 |
+
self.hidden_size = config.hidden_size
|
| 267 |
+
self.num_heads = config.num_attention_heads
|
| 268 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 269 |
+
self.num_key_value_heads = config.num_key_value_heads
|
| 270 |
+
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
|
| 271 |
+
self.max_position_embeddings = config.max_position_embeddings
|
| 272 |
+
self.rope_theta = config.rope_theta
|
| 273 |
+
self.rope_ratio = config.rope_ratio
|
| 274 |
+
|
| 275 |
+
if (self.head_dim * self.num_heads) != self.hidden_size:
|
| 276 |
+
raise ValueError(
|
| 277 |
+
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
|
| 278 |
+
f" and `num_heads`: {self.num_heads})."
|
| 279 |
+
)
|
| 280 |
+
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
|
| 281 |
+
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
|
| 282 |
+
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
|
| 283 |
+
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
|
| 284 |
+
self._init_rope()
|
| 285 |
+
|
| 286 |
+
def _init_rope(self):
|
| 287 |
+
if self.config.rope_scaling is None:
|
| 288 |
+
self.rotary_emb = IndexRotaryEmbedding(
|
| 289 |
+
self.head_dim,
|
| 290 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 291 |
+
base=self.rope_theta,
|
| 292 |
+
rope_ratio=self.rope_ratio
|
| 293 |
+
)
|
| 294 |
+
else:
|
| 295 |
+
scaling_type = self.config.rope_scaling["type"]
|
| 296 |
+
scaling_factor = self.config.rope_scaling["factor"]
|
| 297 |
+
if scaling_type == "linear":
|
| 298 |
+
self.rotary_emb = IndexLinearScalingRotaryEmbedding(
|
| 299 |
+
self.head_dim,
|
| 300 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 301 |
+
scaling_factor=scaling_factor,
|
| 302 |
+
base=self.rope_theta,
|
| 303 |
+
)
|
| 304 |
+
elif scaling_type == "dynamic":
|
| 305 |
+
self.rotary_emb = IndexDynamicNTKScalingRotaryEmbedding(
|
| 306 |
+
self.head_dim,
|
| 307 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 308 |
+
scaling_factor=scaling_factor,
|
| 309 |
+
base=self.rope_theta,
|
| 310 |
+
)
|
| 311 |
+
else:
|
| 312 |
+
raise ValueError(f"Unknown RoPE scaling type {scaling_type}")
|
| 313 |
+
|
| 314 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 315 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 316 |
+
|
| 317 |
+
def forward(
|
| 318 |
+
self,
|
| 319 |
+
hidden_states: torch.Tensor,
|
| 320 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 321 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 322 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 323 |
+
output_attentions: bool = False,
|
| 324 |
+
use_cache: bool = False,
|
| 325 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 326 |
+
bsz, q_len, _ = hidden_states.size()
|
| 327 |
+
|
| 328 |
+
if self.config.pretraining_tp > 1:
|
| 329 |
+
key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.config.pretraining_tp
|
| 330 |
+
query_slices = self.q_proj.weight.split(
|
| 331 |
+
(self.num_heads * self.head_dim) // self.config.pretraining_tp, dim=0
|
| 332 |
+
)
|
| 333 |
+
key_slices = self.k_proj.weight.split(key_value_slicing, dim=0)
|
| 334 |
+
value_slices = self.v_proj.weight.split(key_value_slicing, dim=0)
|
| 335 |
+
|
| 336 |
+
query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 337 |
+
query_states = torch.cat(query_states, dim=-1)
|
| 338 |
+
|
| 339 |
+
key_states = [F.linear(hidden_states, key_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 340 |
+
key_states = torch.cat(key_states, dim=-1)
|
| 341 |
+
|
| 342 |
+
value_states = [F.linear(hidden_states, value_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 343 |
+
value_states = torch.cat(value_states, dim=-1)
|
| 344 |
+
|
| 345 |
+
else:
|
| 346 |
+
query_states = self.q_proj(hidden_states)
|
| 347 |
+
key_states = self.k_proj(hidden_states)
|
| 348 |
+
value_states = self.v_proj(hidden_states)
|
| 349 |
+
|
| 350 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 351 |
+
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 352 |
+
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 353 |
+
|
| 354 |
+
kv_seq_len = key_states.shape[-2]
|
| 355 |
+
if past_key_value is not None:
|
| 356 |
+
kv_seq_len += past_key_value[0].shape[-2]
|
| 357 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 358 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 359 |
+
|
| 360 |
+
if past_key_value is not None:
|
| 361 |
+
# reuse k, v, self_attention
|
| 362 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 363 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 364 |
+
|
| 365 |
+
past_key_value = (key_states, value_states) if use_cache else None
|
| 366 |
+
|
| 367 |
+
# repeat k/v heads if n_kv_heads < n_heads
|
| 368 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 369 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 370 |
+
|
| 371 |
+
# attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
| 372 |
+
# (3-1) After GPU Memory Optimization for Handling Long Context.
|
| 373 |
+
block_size = 8192
|
| 374 |
+
if q_len < block_size:
|
| 375 |
+
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
| 376 |
+
else:
|
| 377 |
+
attn_weights = torch.zeros((bsz, self.num_heads, q_len, q_len), dtype=query_states.dtype, device=query_states.device)
|
| 378 |
+
for i in range(0, q_len, block_size):
|
| 379 |
+
for j in range(0, q_len, block_size):
|
| 380 |
+
q_block = query_states[:, :, i:i+block_size, :]
|
| 381 |
+
k_block = key_states[:, :, j:j+block_size, :].transpose(-1, -2)
|
| 382 |
+
attn_weights[:, :, i:i+block_size, j:j+block_size] = torch.matmul(q_block, k_block) / math.sqrt(self.head_dim)
|
| 383 |
+
|
| 384 |
+
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
| 385 |
+
raise ValueError(
|
| 386 |
+
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
|
| 387 |
+
f" {attn_weights.size()}"
|
| 388 |
+
)
|
| 389 |
+
|
| 390 |
+
if attention_mask is not None:
|
| 391 |
+
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
| 392 |
+
raise ValueError(
|
| 393 |
+
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
|
| 394 |
+
)
|
| 395 |
+
# attn_weights = attn_weights + attention_mask
|
| 396 |
+
# (3-2) After GPU Memory Optimization for Handling Long Context.
|
| 397 |
+
attn_weights.add_(attention_mask)
|
| 398 |
+
|
| 399 |
+
# upcast attention to fp32
|
| 400 |
+
# attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
| 401 |
+
# (3-3) After GPU Memory Optimization for Handling Long Context.
|
| 402 |
+
for i in range(self.num_heads):
|
| 403 |
+
head_weights = attn_weights[:, i, :, :].to(torch.float32)
|
| 404 |
+
head_weights = nn.functional.softmax(head_weights, dim=-1)
|
| 405 |
+
attn_weights[:, i, :, :] = head_weights.to(query_states.dtype)
|
| 406 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 407 |
+
|
| 408 |
+
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
| 409 |
+
raise ValueError(
|
| 410 |
+
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
|
| 411 |
+
f" {attn_output.size()}"
|
| 412 |
+
)
|
| 413 |
+
|
| 414 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 415 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 416 |
+
|
| 417 |
+
if self.config.pretraining_tp > 1:
|
| 418 |
+
attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2)
|
| 419 |
+
o_proj_slices = self.o_proj.weight.split(self.hidden_size // self.config.pretraining_tp, dim=1)
|
| 420 |
+
attn_output = sum([F.linear(attn_output[i], o_proj_slices[i]) for i in range(self.config.pretraining_tp)])
|
| 421 |
+
else:
|
| 422 |
+
attn_output = self.o_proj(attn_output)
|
| 423 |
+
|
| 424 |
+
if not output_attentions:
|
| 425 |
+
attn_weights = None
|
| 426 |
+
|
| 427 |
+
return attn_output, attn_weights, past_key_value
|
| 428 |
+
|
| 429 |
+
|
| 430 |
+
class IndexDecoderLayer(nn.Module):
|
| 431 |
+
def __init__(self, config: IndexConfig):
|
| 432 |
+
super().__init__()
|
| 433 |
+
self.hidden_size = config.hidden_size
|
| 434 |
+
self.self_attn = IndexAttention(config=config)
|
| 435 |
+
self.mlp = IndexMLP(config)
|
| 436 |
+
self.input_layernorm = IndexRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 437 |
+
self.post_attention_layernorm = IndexRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 438 |
+
|
| 439 |
+
def forward(
|
| 440 |
+
self,
|
| 441 |
+
hidden_states: torch.Tensor,
|
| 442 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 443 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 444 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 445 |
+
output_attentions: Optional[bool] = False,
|
| 446 |
+
use_cache: Optional[bool] = False,
|
| 447 |
+
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
| 448 |
+
"""
|
| 449 |
+
Args:
|
| 450 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 451 |
+
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
|
| 452 |
+
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
| 453 |
+
output_attentions (`bool`, *optional*):
|
| 454 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 455 |
+
returned tensors for more detail.
|
| 456 |
+
use_cache (`bool`, *optional*):
|
| 457 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
| 458 |
+
(see `past_key_values`).
|
| 459 |
+
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
| 460 |
+
"""
|
| 461 |
+
|
| 462 |
+
residual = hidden_states
|
| 463 |
+
|
| 464 |
+
hidden_states = self.input_layernorm(hidden_states)
|
| 465 |
+
|
| 466 |
+
# Self Attention
|
| 467 |
+
hidden_states, self_attn_weights, present_key_value = self.self_attn(
|
| 468 |
+
hidden_states=hidden_states,
|
| 469 |
+
attention_mask=attention_mask,
|
| 470 |
+
position_ids=position_ids,
|
| 471 |
+
past_key_value=past_key_value,
|
| 472 |
+
output_attentions=output_attentions,
|
| 473 |
+
use_cache=use_cache,
|
| 474 |
+
)
|
| 475 |
+
hidden_states = residual + hidden_states
|
| 476 |
+
|
| 477 |
+
# Fully Connected
|
| 478 |
+
residual = hidden_states
|
| 479 |
+
hidden_states = self.post_attention_layernorm(hidden_states)
|
| 480 |
+
hidden_states = self.mlp(hidden_states)
|
| 481 |
+
hidden_states = residual + hidden_states
|
| 482 |
+
|
| 483 |
+
outputs = (hidden_states,)
|
| 484 |
+
|
| 485 |
+
if output_attentions:
|
| 486 |
+
outputs += (self_attn_weights,)
|
| 487 |
+
|
| 488 |
+
if use_cache:
|
| 489 |
+
outputs += (present_key_value,)
|
| 490 |
+
|
| 491 |
+
return outputs
|
| 492 |
+
|
| 493 |
+
|
| 494 |
+
INDEX_START_DOCSTRING = r"""
|
| 495 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 496 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 497 |
+
etc.)
|
| 498 |
+
|
| 499 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 500 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 501 |
+
and behavior.
|
| 502 |
+
|
| 503 |
+
Parameters:
|
| 504 |
+
config ([`IndexConfig`]):
|
| 505 |
+
Model configuration class with all the parameters of the model. Initializing with a config file does not
|
| 506 |
+
load the weights associated with the model, only the configuration. Check out the
|
| 507 |
+
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 508 |
+
"""
|
| 509 |
+
|
| 510 |
+
|
| 511 |
+
@add_start_docstrings(
|
| 512 |
+
"The bare Index Model outputting raw hidden-states without any specific head on top.",
|
| 513 |
+
INDEX_START_DOCSTRING,
|
| 514 |
+
)
|
| 515 |
+
class IndexPreTrainedModel(PreTrainedModel):
|
| 516 |
+
config_class = IndexConfig
|
| 517 |
+
base_model_prefix = "model"
|
| 518 |
+
supports_gradient_checkpointing = True
|
| 519 |
+
_no_split_modules = ["IndexDecoderLayer"]
|
| 520 |
+
_skip_keys_device_placement = "past_key_values"
|
| 521 |
+
|
| 522 |
+
def _init_weights(self, module):
|
| 523 |
+
std = self.config.initializer_range
|
| 524 |
+
if isinstance(module, nn.Linear):
|
| 525 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 526 |
+
if module.bias is not None:
|
| 527 |
+
module.bias.data.zero_()
|
| 528 |
+
elif isinstance(module, nn.Embedding):
|
| 529 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 530 |
+
if module.padding_idx is not None:
|
| 531 |
+
module.weight.data[module.padding_idx].zero_()
|
| 532 |
+
|
| 533 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 534 |
+
if isinstance(module, IndexModel):
|
| 535 |
+
module.gradient_checkpointing = value
|
| 536 |
+
|
| 537 |
+
|
| 538 |
+
INDEX_INPUTS_DOCSTRING = r"""
|
| 539 |
+
Args:
|
| 540 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
| 541 |
+
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
| 542 |
+
it.
|
| 543 |
+
|
| 544 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 545 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 546 |
+
|
| 547 |
+
[What are input IDs?](../glossary#input-ids)
|
| 548 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 549 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 550 |
+
|
| 551 |
+
- 1 for tokens that are **not masked**,
|
| 552 |
+
- 0 for tokens that are **masked**.
|
| 553 |
+
|
| 554 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 555 |
+
|
| 556 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 557 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 558 |
+
|
| 559 |
+
If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
|
| 560 |
+
`past_key_values`).
|
| 561 |
+
|
| 562 |
+
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
|
| 563 |
+
and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
|
| 564 |
+
information on the default strategy.
|
| 565 |
+
|
| 566 |
+
- 1 indicates the head is **not masked**,
|
| 567 |
+
- 0 indicates the head is **masked**.
|
| 568 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 569 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 570 |
+
config.n_positions - 1]`.
|
| 571 |
+
|
| 572 |
+
[What are position IDs?](../glossary#position-ids)
|
| 573 |
+
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
|
| 574 |
+
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
|
| 575 |
+
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
|
| 576 |
+
`(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
|
| 577 |
+
|
| 578 |
+
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
|
| 579 |
+
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
|
| 580 |
+
|
| 581 |
+
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
|
| 582 |
+
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
|
| 583 |
+
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
|
| 584 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
|
| 585 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
|
| 586 |
+
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
|
| 587 |
+
model's internal embedding lookup matrix.
|
| 588 |
+
use_cache (`bool`, *optional*):
|
| 589 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
|
| 590 |
+
`past_key_values`).
|
| 591 |
+
output_attentions (`bool`, *optional*):
|
| 592 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 593 |
+
tensors for more detail.
|
| 594 |
+
output_hidden_states (`bool`, *optional*):
|
| 595 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 596 |
+
more detail.
|
| 597 |
+
return_dict (`bool`, *optional*):
|
| 598 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 599 |
+
"""
|
| 600 |
+
|
| 601 |
+
|
| 602 |
+
@add_start_docstrings(
|
| 603 |
+
"The bare Index Model outputting raw hidden-states without any specific head on top.",
|
| 604 |
+
INDEX_START_DOCSTRING,
|
| 605 |
+
)
|
| 606 |
+
class IndexModel(IndexPreTrainedModel):
|
| 607 |
+
"""
|
| 608 |
+
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`IndexDecoderLayer`]
|
| 609 |
+
|
| 610 |
+
Args:
|
| 611 |
+
config: IndexConfig
|
| 612 |
+
"""
|
| 613 |
+
|
| 614 |
+
def __init__(self, config: IndexConfig):
|
| 615 |
+
super().__init__(config)
|
| 616 |
+
self.padding_idx = config.pad_token_id
|
| 617 |
+
self.vocab_size = config.vocab_size
|
| 618 |
+
|
| 619 |
+
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
| 620 |
+
self.layers = nn.ModuleList([IndexDecoderLayer(config) for _ in range(config.num_hidden_layers)])
|
| 621 |
+
self.norm = IndexRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 622 |
+
|
| 623 |
+
self.gradient_checkpointing = False
|
| 624 |
+
# Initialize weights and apply final processing
|
| 625 |
+
self.post_init()
|
| 626 |
+
|
| 627 |
+
def get_input_embeddings(self):
|
| 628 |
+
return self.embed_tokens
|
| 629 |
+
|
| 630 |
+
def set_input_embeddings(self, value):
|
| 631 |
+
self.embed_tokens = value
|
| 632 |
+
|
| 633 |
+
# Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_mask
|
| 634 |
+
def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
|
| 635 |
+
# create causal mask
|
| 636 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 637 |
+
combined_attention_mask = None
|
| 638 |
+
if input_shape[-1] > 1:
|
| 639 |
+
combined_attention_mask = _make_causal_mask(
|
| 640 |
+
input_shape,
|
| 641 |
+
inputs_embeds.dtype,
|
| 642 |
+
device=inputs_embeds.device,
|
| 643 |
+
past_key_values_length=past_key_values_length,
|
| 644 |
+
)
|
| 645 |
+
|
| 646 |
+
if attention_mask is not None:
|
| 647 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 648 |
+
expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(
|
| 649 |
+
inputs_embeds.device
|
| 650 |
+
)
|
| 651 |
+
combined_attention_mask = (
|
| 652 |
+
expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
|
| 653 |
+
)
|
| 654 |
+
|
| 655 |
+
return combined_attention_mask
|
| 656 |
+
|
| 657 |
+
@add_start_docstrings_to_model_forward(INDEX_INPUTS_DOCSTRING)
|
| 658 |
+
def forward(
|
| 659 |
+
self,
|
| 660 |
+
input_ids: torch.LongTensor = None,
|
| 661 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 662 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 663 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 664 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 665 |
+
use_cache: Optional[bool] = None,
|
| 666 |
+
output_attentions: Optional[bool] = None,
|
| 667 |
+
output_hidden_states: Optional[bool] = None,
|
| 668 |
+
return_dict: Optional[bool] = None,
|
| 669 |
+
) -> Union[Tuple, BaseModelOutputWithPast]:
|
| 670 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 671 |
+
output_hidden_states = (
|
| 672 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 673 |
+
)
|
| 674 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 675 |
+
|
| 676 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 677 |
+
|
| 678 |
+
# retrieve input_ids and inputs_embeds
|
| 679 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 680 |
+
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
|
| 681 |
+
elif input_ids is not None:
|
| 682 |
+
batch_size, seq_length = input_ids.shape
|
| 683 |
+
elif inputs_embeds is not None:
|
| 684 |
+
batch_size, seq_length, _ = inputs_embeds.shape
|
| 685 |
+
else:
|
| 686 |
+
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
|
| 687 |
+
|
| 688 |
+
seq_length_with_past = seq_length
|
| 689 |
+
past_key_values_length = 0
|
| 690 |
+
|
| 691 |
+
if past_key_values is not None:
|
| 692 |
+
past_key_values_length = past_key_values[0][0].shape[2]
|
| 693 |
+
seq_length_with_past = seq_length_with_past + past_key_values_length
|
| 694 |
+
|
| 695 |
+
if position_ids is None:
|
| 696 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 697 |
+
position_ids = torch.arange(
|
| 698 |
+
past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
|
| 699 |
+
)
|
| 700 |
+
position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
|
| 701 |
+
else:
|
| 702 |
+
position_ids = position_ids.view(-1, seq_length).long()
|
| 703 |
+
|
| 704 |
+
if inputs_embeds is None:
|
| 705 |
+
inputs_embeds = self.embed_tokens(input_ids)
|
| 706 |
+
# embed positions
|
| 707 |
+
if attention_mask is None:
|
| 708 |
+
attention_mask = torch.ones(
|
| 709 |
+
(batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device
|
| 710 |
+
)
|
| 711 |
+
attention_mask = self._prepare_decoder_attention_mask(
|
| 712 |
+
attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
|
| 713 |
+
)
|
| 714 |
+
|
| 715 |
+
hidden_states = inputs_embeds
|
| 716 |
+
|
| 717 |
+
if self.gradient_checkpointing and self.training:
|
| 718 |
+
if use_cache:
|
| 719 |
+
logger.warning_once(
|
| 720 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 721 |
+
)
|
| 722 |
+
use_cache = False
|
| 723 |
+
|
| 724 |
+
# decoder layers
|
| 725 |
+
all_hidden_states = () if output_hidden_states else None
|
| 726 |
+
all_self_attns = () if output_attentions else None
|
| 727 |
+
next_decoder_cache = () if use_cache else None
|
| 728 |
+
|
| 729 |
+
for idx, decoder_layer in enumerate(self.layers):
|
| 730 |
+
if output_hidden_states:
|
| 731 |
+
all_hidden_states += (hidden_states,)
|
| 732 |
+
|
| 733 |
+
past_key_value = past_key_values[idx] if past_key_values is not None else None
|
| 734 |
+
|
| 735 |
+
if self.gradient_checkpointing and self.training:
|
| 736 |
+
|
| 737 |
+
def create_custom_forward(module):
|
| 738 |
+
def custom_forward(*inputs):
|
| 739 |
+
# None for past_key_value
|
| 740 |
+
return module(*inputs, past_key_value, output_attentions)
|
| 741 |
+
|
| 742 |
+
return custom_forward
|
| 743 |
+
|
| 744 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 745 |
+
create_custom_forward(decoder_layer),
|
| 746 |
+
hidden_states,
|
| 747 |
+
attention_mask,
|
| 748 |
+
position_ids,
|
| 749 |
+
)
|
| 750 |
+
else:
|
| 751 |
+
layer_outputs = decoder_layer(
|
| 752 |
+
hidden_states,
|
| 753 |
+
attention_mask=attention_mask,
|
| 754 |
+
position_ids=position_ids,
|
| 755 |
+
past_key_value=past_key_value,
|
| 756 |
+
output_attentions=output_attentions,
|
| 757 |
+
use_cache=use_cache,
|
| 758 |
+
)
|
| 759 |
+
|
| 760 |
+
hidden_states = layer_outputs[0]
|
| 761 |
+
|
| 762 |
+
if use_cache:
|
| 763 |
+
next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
|
| 764 |
+
|
| 765 |
+
if output_attentions:
|
| 766 |
+
all_self_attns += (layer_outputs[1],)
|
| 767 |
+
|
| 768 |
+
hidden_states = self.norm(hidden_states)
|
| 769 |
+
|
| 770 |
+
# add hidden states from the last decoder layer
|
| 771 |
+
if output_hidden_states:
|
| 772 |
+
all_hidden_states += (hidden_states,)
|
| 773 |
+
|
| 774 |
+
next_cache = next_decoder_cache if use_cache else None
|
| 775 |
+
if not return_dict:
|
| 776 |
+
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
|
| 777 |
+
return BaseModelOutputWithPast(
|
| 778 |
+
last_hidden_state=hidden_states,
|
| 779 |
+
past_key_values=next_cache,
|
| 780 |
+
hidden_states=all_hidden_states,
|
| 781 |
+
attentions=all_self_attns,
|
| 782 |
+
)
|
| 783 |
+
|
| 784 |
+
|
| 785 |
+
class NormHead(nn.Module):
|
| 786 |
+
def __init__(self, hidden_size, vocab_size, bias=False):
|
| 787 |
+
super().__init__()
|
| 788 |
+
self.weight = nn.Parameter(torch.empty((vocab_size, hidden_size)))
|
| 789 |
+
nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
|
| 790 |
+
self.first_flag = True
|
| 791 |
+
|
| 792 |
+
def forward(self, hidden_states):
|
| 793 |
+
if self.training:
|
| 794 |
+
norm_weight = nn.functional.normalize(self.weight)
|
| 795 |
+
self.first_flag = True
|
| 796 |
+
elif self.first_flag:
|
| 797 |
+
self.first_flag = False
|
| 798 |
+
self.weight = nn.Parameter(nn.functional.normalize(self.weight))
|
| 799 |
+
norm_weight = self.weight
|
| 800 |
+
else:
|
| 801 |
+
norm_weight = self.weight
|
| 802 |
+
return nn.functional.linear(hidden_states, norm_weight)
|
| 803 |
+
|
| 804 |
+
|
| 805 |
+
class IndexForCausalLM(IndexPreTrainedModel):
|
| 806 |
+
_tied_weights_keys = ["lm_head.weight"]
|
| 807 |
+
|
| 808 |
+
def __init__(self, config):
|
| 809 |
+
super().__init__(config)
|
| 810 |
+
self.model = IndexModel(config)
|
| 811 |
+
self.vocab_size = config.vocab_size
|
| 812 |
+
if config.norm_head:
|
| 813 |
+
self.lm_head = NormHead(config.hidden_size, config.vocab_size, bias=False)
|
| 814 |
+
else:
|
| 815 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 816 |
+
|
| 817 |
+
# Initialize weights and apply final processing
|
| 818 |
+
self.post_init()
|
| 819 |
+
|
| 820 |
+
def get_input_embeddings(self):
|
| 821 |
+
return self.model.embed_tokens
|
| 822 |
+
|
| 823 |
+
def set_input_embeddings(self, value):
|
| 824 |
+
self.model.embed_tokens = value
|
| 825 |
+
|
| 826 |
+
def get_output_embeddings(self):
|
| 827 |
+
return self.lm_head
|
| 828 |
+
|
| 829 |
+
def set_output_embeddings(self, new_embeddings):
|
| 830 |
+
self.lm_head = new_embeddings
|
| 831 |
+
|
| 832 |
+
def set_decoder(self, decoder):
|
| 833 |
+
self.model = decoder
|
| 834 |
+
|
| 835 |
+
def get_decoder(self):
|
| 836 |
+
return self.model
|
| 837 |
+
|
| 838 |
+
@add_start_docstrings_to_model_forward(INDEX_INPUTS_DOCSTRING)
|
| 839 |
+
@replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
|
| 840 |
+
def forward(
|
| 841 |
+
self,
|
| 842 |
+
input_ids: torch.LongTensor = None,
|
| 843 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 844 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 845 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 846 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 847 |
+
labels: Optional[torch.LongTensor] = None,
|
| 848 |
+
use_cache: Optional[bool] = None,
|
| 849 |
+
output_attentions: Optional[bool] = None,
|
| 850 |
+
output_hidden_states: Optional[bool] = None,
|
| 851 |
+
return_dict: Optional[bool] = None,
|
| 852 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 853 |
+
r"""
|
| 854 |
+
Args:
|
| 855 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 856 |
+
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
| 857 |
+
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
| 858 |
+
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
| 859 |
+
|
| 860 |
+
Returns:
|
| 861 |
+
|
| 862 |
+
Example:
|
| 863 |
+
|
| 864 |
+
```python
|
| 865 |
+
>>> from transformers import AutoTokenizer, IndexForCausalLM
|
| 866 |
+
|
| 867 |
+
>>> model = IndexForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
|
| 868 |
+
>>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
|
| 869 |
+
|
| 870 |
+
>>> prompt = "Hey, are you conscious? Can you talk to me?"
|
| 871 |
+
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
| 872 |
+
|
| 873 |
+
>>> # Generate
|
| 874 |
+
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
| 875 |
+
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 876 |
+
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
|
| 877 |
+
```"""
|
| 878 |
+
|
| 879 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 880 |
+
output_hidden_states = (
|
| 881 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 882 |
+
)
|
| 883 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 884 |
+
|
| 885 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 886 |
+
outputs = self.model(
|
| 887 |
+
input_ids=input_ids,
|
| 888 |
+
attention_mask=attention_mask,
|
| 889 |
+
position_ids=position_ids,
|
| 890 |
+
past_key_values=past_key_values,
|
| 891 |
+
inputs_embeds=inputs_embeds,
|
| 892 |
+
use_cache=use_cache,
|
| 893 |
+
output_attentions=output_attentions,
|
| 894 |
+
output_hidden_states=output_hidden_states,
|
| 895 |
+
return_dict=return_dict,
|
| 896 |
+
)
|
| 897 |
+
|
| 898 |
+
hidden_states = outputs[0]
|
| 899 |
+
if self.config.pretraining_tp > 1:
|
| 900 |
+
lm_head_slices = self.lm_head.weight.split(self.vocab_size // self.config.pretraining_tp, dim=0)
|
| 901 |
+
logits = [F.linear(hidden_states, lm_head_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 902 |
+
logits = torch.cat(logits, dim=-1)
|
| 903 |
+
else:
|
| 904 |
+
logits = self.lm_head(hidden_states)
|
| 905 |
+
logits = logits.float()
|
| 906 |
+
|
| 907 |
+
loss = None
|
| 908 |
+
if labels is not None:
|
| 909 |
+
# Shift so that tokens < n predict n
|
| 910 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 911 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 912 |
+
# Flatten the tokens
|
| 913 |
+
loss_fct = CrossEntropyLoss()
|
| 914 |
+
shift_logits = shift_logits.view(-1, self.config.vocab_size)
|
| 915 |
+
shift_labels = shift_labels.view(-1)
|
| 916 |
+
# Enable model parallelism
|
| 917 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 918 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 919 |
+
|
| 920 |
+
if not return_dict:
|
| 921 |
+
output = (logits,) + outputs[1:]
|
| 922 |
+
return (loss,) + output if loss is not None else output
|
| 923 |
+
|
| 924 |
+
return CausalLMOutputWithPast(
|
| 925 |
+
loss=loss,
|
| 926 |
+
logits=logits,
|
| 927 |
+
past_key_values=outputs.past_key_values,
|
| 928 |
+
hidden_states=outputs.hidden_states,
|
| 929 |
+
attentions=outputs.attentions,
|
| 930 |
+
)
|
| 931 |
+
|
| 932 |
+
def prepare_inputs_for_generation(
|
| 933 |
+
self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
|
| 934 |
+
):
|
| 935 |
+
if past_key_values:
|
| 936 |
+
input_ids = input_ids[:, -1:]
|
| 937 |
+
|
| 938 |
+
position_ids = kwargs.get("position_ids", None)
|
| 939 |
+
if attention_mask is not None and position_ids is None:
|
| 940 |
+
# create position_ids on the fly for batch generation
|
| 941 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 942 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 943 |
+
if past_key_values:
|
| 944 |
+
position_ids = position_ids[:, -1].unsqueeze(-1)
|
| 945 |
+
|
| 946 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 947 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 948 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 949 |
+
else:
|
| 950 |
+
model_inputs = {"input_ids": input_ids}
|
| 951 |
+
|
| 952 |
+
model_inputs.update(
|
| 953 |
+
{
|
| 954 |
+
"position_ids": position_ids,
|
| 955 |
+
"past_key_values": past_key_values,
|
| 956 |
+
"use_cache": kwargs.get("use_cache"),
|
| 957 |
+
"attention_mask": attention_mask,
|
| 958 |
+
}
|
| 959 |
+
)
|
| 960 |
+
return model_inputs
|
| 961 |
+
|
| 962 |
+
@staticmethod
|
| 963 |
+
def _reorder_cache(past_key_values, beam_idx):
|
| 964 |
+
reordered_past = ()
|
| 965 |
+
for layer_past in past_key_values:
|
| 966 |
+
reordered_past += (
|
| 967 |
+
tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
|
| 968 |
+
)
|
| 969 |
+
return reordered_past
|
| 970 |
+
|
| 971 |
+
|
| 972 |
+
@add_start_docstrings(
|
| 973 |
+
"""
|
| 974 |
+
The Index Model transformer with a sequence classification head on top (linear layer).
|
| 975 |
+
|
| 976 |
+
[`IndexForSequenceClassification`] uses the last token in order to do the classification, as other causal models
|
| 977 |
+
(e.g. GPT-2) do.
|
| 978 |
+
|
| 979 |
+
Since it does classification on the last token, it requires to know the position of the last token. If a
|
| 980 |
+
`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
|
| 981 |
+
no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
|
| 982 |
+
padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
|
| 983 |
+
each row of the batch).
|
| 984 |
+
""",
|
| 985 |
+
INDEX_START_DOCSTRING,
|
| 986 |
+
)
|
| 987 |
+
class IndexForSequenceClassification(IndexPreTrainedModel):
|
| 988 |
+
def __init__(self, config):
|
| 989 |
+
super().__init__(config)
|
| 990 |
+
self.num_labels = config.num_labels
|
| 991 |
+
self.model = IndexModel(config)
|
| 992 |
+
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
| 993 |
+
|
| 994 |
+
# Initialize weights and apply final processing
|
| 995 |
+
self.post_init()
|
| 996 |
+
|
| 997 |
+
def get_input_embeddings(self):
|
| 998 |
+
return self.model.embed_tokens
|
| 999 |
+
|
| 1000 |
+
def set_input_embeddings(self, value):
|
| 1001 |
+
self.model.embed_tokens = value
|
| 1002 |
+
|
| 1003 |
+
@add_start_docstrings_to_model_forward(INDEX_INPUTS_DOCSTRING)
|
| 1004 |
+
def forward(
|
| 1005 |
+
self,
|
| 1006 |
+
input_ids: torch.LongTensor = None,
|
| 1007 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1008 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1009 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1010 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1011 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1012 |
+
use_cache: Optional[bool] = None,
|
| 1013 |
+
output_attentions: Optional[bool] = None,
|
| 1014 |
+
output_hidden_states: Optional[bool] = None,
|
| 1015 |
+
return_dict: Optional[bool] = None,
|
| 1016 |
+
) -> Union[Tuple, SequenceClassifierOutputWithPast]:
|
| 1017 |
+
r"""
|
| 1018 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1019 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 1020 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 1021 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 1022 |
+
"""
|
| 1023 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1024 |
+
|
| 1025 |
+
transformer_outputs = self.model(
|
| 1026 |
+
input_ids,
|
| 1027 |
+
attention_mask=attention_mask,
|
| 1028 |
+
position_ids=position_ids,
|
| 1029 |
+
past_key_values=past_key_values,
|
| 1030 |
+
inputs_embeds=inputs_embeds,
|
| 1031 |
+
use_cache=use_cache,
|
| 1032 |
+
output_attentions=output_attentions,
|
| 1033 |
+
output_hidden_states=output_hidden_states,
|
| 1034 |
+
return_dict=return_dict,
|
| 1035 |
+
)
|
| 1036 |
+
hidden_states = transformer_outputs[0]
|
| 1037 |
+
logits = self.score(hidden_states)
|
| 1038 |
+
|
| 1039 |
+
if input_ids is not None:
|
| 1040 |
+
batch_size = input_ids.shape[0]
|
| 1041 |
+
else:
|
| 1042 |
+
batch_size = inputs_embeds.shape[0]
|
| 1043 |
+
|
| 1044 |
+
if self.config.pad_token_id is None and batch_size != 1:
|
| 1045 |
+
raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
|
| 1046 |
+
if self.config.pad_token_id is None:
|
| 1047 |
+
sequence_lengths = -1
|
| 1048 |
+
else:
|
| 1049 |
+
if input_ids is not None:
|
| 1050 |
+
sequence_lengths = (torch.eq(input_ids, self.config.pad_token_id).long().argmax(-1) - 1).to(
|
| 1051 |
+
logits.device
|
| 1052 |
+
)
|
| 1053 |
+
else:
|
| 1054 |
+
sequence_lengths = -1
|
| 1055 |
+
|
| 1056 |
+
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
|
| 1057 |
+
|
| 1058 |
+
loss = None
|
| 1059 |
+
if labels is not None:
|
| 1060 |
+
labels = labels.to(logits.device)
|
| 1061 |
+
if self.config.problem_type is None:
|
| 1062 |
+
if self.num_labels == 1:
|
| 1063 |
+
self.config.problem_type = "regression"
|
| 1064 |
+
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
|
| 1065 |
+
self.config.problem_type = "single_label_classification"
|
| 1066 |
+
else:
|
| 1067 |
+
self.config.problem_type = "multi_label_classification"
|
| 1068 |
+
|
| 1069 |
+
if self.config.problem_type == "regression":
|
| 1070 |
+
loss_fct = MSELoss()
|
| 1071 |
+
if self.num_labels == 1:
|
| 1072 |
+
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
|
| 1073 |
+
else:
|
| 1074 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1075 |
+
elif self.config.problem_type == "single_label_classification":
|
| 1076 |
+
loss_fct = CrossEntropyLoss()
|
| 1077 |
+
loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
|
| 1078 |
+
elif self.config.problem_type == "multi_label_classification":
|
| 1079 |
+
loss_fct = BCEWithLogitsLoss()
|
| 1080 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1081 |
+
if not return_dict:
|
| 1082 |
+
output = (pooled_logits,) + transformer_outputs[1:]
|
| 1083 |
+
return ((loss,) + output) if loss is not None else output
|
| 1084 |
+
|
| 1085 |
+
return SequenceClassifierOutputWithPast(
|
| 1086 |
+
loss=loss,
|
| 1087 |
+
logits=pooled_logits,
|
| 1088 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1089 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1090 |
+
attentions=transformer_outputs.attentions,
|
| 1091 |
+
)
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"unk_token": {
|
| 17 |
+
"content": "<unk>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
}
|
| 23 |
+
}
|
tokenization_index.py
ADDED
|
@@ -0,0 +1,266 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2022 EleutherAI and the HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
+
# and OPT implementations in this library. It has been modified from its
|
| 6 |
+
# original forms to accommodate minor architectural differences compared
|
| 7 |
+
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
|
| 8 |
+
#
|
| 9 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 10 |
+
# you may not use this file except in compliance with the License.
|
| 11 |
+
# You may obtain a copy of the License at
|
| 12 |
+
#
|
| 13 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 14 |
+
#
|
| 15 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 16 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 17 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 18 |
+
# See the License for the specific language governing permissions and
|
| 19 |
+
# limitations under the License.
|
| 20 |
+
|
| 21 |
+
"""Tokenization classes for Index, Modify from llama tokenzier."""
|
| 22 |
+
import os
|
| 23 |
+
from shutil import copyfile
|
| 24 |
+
from typing import Any, Dict, List, Optional, Tuple
|
| 25 |
+
|
| 26 |
+
import sentencepiece as spm
|
| 27 |
+
|
| 28 |
+
from transformers.tokenization_utils import AddedToken, PreTrainedTokenizer
|
| 29 |
+
from transformers.utils import logging
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
logger = logging.get_logger(__name__)
|
| 33 |
+
|
| 34 |
+
VOCAB_FILES_NAMES = {"vocab_file": "tokenizer.model"}
|
| 35 |
+
|
| 36 |
+
PRETRAINED_VOCAB_FILES_MAP = {}
|
| 37 |
+
|
| 38 |
+
SPIECE_UNDERLINE = "▁"
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class IndexTokenizer(PreTrainedTokenizer):
|
| 42 |
+
"""
|
| 43 |
+
Construct a Index tokenizer. Based on Byte-Pair-Encoding.
|
| 44 |
+
|
| 45 |
+
Args:
|
| 46 |
+
vocab_file (`str`):
|
| 47 |
+
Path to the vocabulary file.
|
| 48 |
+
"""
|
| 49 |
+
|
| 50 |
+
vocab_files_names = VOCAB_FILES_NAMES
|
| 51 |
+
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
| 52 |
+
model_input_names = ["input_ids", "attention_mask"]
|
| 53 |
+
|
| 54 |
+
def __init__(
|
| 55 |
+
self,
|
| 56 |
+
vocab_file,
|
| 57 |
+
unk_token="<unk>",
|
| 58 |
+
bos_token="<s>",
|
| 59 |
+
eos_token="</s>",
|
| 60 |
+
pad_token=None,
|
| 61 |
+
sp_model_kwargs: Optional[Dict[str, Any]] = None,
|
| 62 |
+
add_bos_token=False,
|
| 63 |
+
add_eos_token=False,
|
| 64 |
+
decode_with_prefix_space=False,
|
| 65 |
+
clean_up_tokenization_spaces=False,
|
| 66 |
+
legacy=False,
|
| 67 |
+
**kwargs,
|
| 68 |
+
):
|
| 69 |
+
self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
|
| 70 |
+
bos_token = AddedToken(bos_token, lstrip=False, rstrip=False) if isinstance(bos_token, str) else bos_token
|
| 71 |
+
eos_token = AddedToken(eos_token, lstrip=False, rstrip=False) if isinstance(eos_token, str) else eos_token
|
| 72 |
+
unk_token = AddedToken(unk_token, lstrip=False, rstrip=False) if isinstance(unk_token, str) else unk_token
|
| 73 |
+
pad_token = AddedToken(pad_token, lstrip=False, rstrip=False) if isinstance(pad_token, str) else pad_token
|
| 74 |
+
self.legacy = legacy
|
| 75 |
+
|
| 76 |
+
self.vocab_file = vocab_file
|
| 77 |
+
self.add_bos_token = add_bos_token
|
| 78 |
+
self.add_eos_token = add_eos_token
|
| 79 |
+
self.decode_with_prefix_space = decode_with_prefix_space
|
| 80 |
+
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
|
| 81 |
+
self.sp_model.Load(vocab_file)
|
| 82 |
+
self._no_prefix_space_tokens = None
|
| 83 |
+
|
| 84 |
+
super().__init__(
|
| 85 |
+
bos_token=bos_token,
|
| 86 |
+
eos_token=eos_token,
|
| 87 |
+
unk_token=unk_token,
|
| 88 |
+
pad_token=pad_token,
|
| 89 |
+
add_bos_token=add_bos_token,
|
| 90 |
+
add_eos_token=add_eos_token,
|
| 91 |
+
sp_model_kwargs=self.sp_model_kwargs,
|
| 92 |
+
decode_with_prefix_space=decode_with_prefix_space,
|
| 93 |
+
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
|
| 94 |
+
legacy=legacy,
|
| 95 |
+
**kwargs,
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
@property
|
| 99 |
+
def no_prefix_space_tokens(self):
|
| 100 |
+
if self._no_prefix_space_tokens is None:
|
| 101 |
+
vocab = self.convert_ids_to_tokens(list(range(self.vocab_size)))
|
| 102 |
+
self._no_prefix_space_tokens = {i for i, tok in enumerate(vocab) if not tok.startswith("▁")}
|
| 103 |
+
return self._no_prefix_space_tokens
|
| 104 |
+
|
| 105 |
+
@property
|
| 106 |
+
def vocab_size(self):
|
| 107 |
+
"""Returns vocab size"""
|
| 108 |
+
return self.sp_model.get_piece_size()
|
| 109 |
+
|
| 110 |
+
@property
|
| 111 |
+
def bos_token_id(self) -> Optional[int]:
|
| 112 |
+
return self.sp_model.bos_id()
|
| 113 |
+
|
| 114 |
+
@property
|
| 115 |
+
def eos_token_id(self) -> Optional[int]:
|
| 116 |
+
return self.sp_model.eos_id()
|
| 117 |
+
|
| 118 |
+
def get_vocab(self):
|
| 119 |
+
"""Returns vocab as a dict"""
|
| 120 |
+
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
|
| 121 |
+
vocab.update(self.added_tokens_encoder)
|
| 122 |
+
return vocab
|
| 123 |
+
|
| 124 |
+
def _tokenize(self, text):
|
| 125 |
+
"""Returns a tokenized string."""
|
| 126 |
+
return self.sp_model.encode(text, out_type=str)
|
| 127 |
+
|
| 128 |
+
def _convert_token_to_id(self, token):
|
| 129 |
+
"""Converts a token (str) in an id using the vocab."""
|
| 130 |
+
return self.sp_model.piece_to_id(token)
|
| 131 |
+
|
| 132 |
+
def _convert_id_to_token(self, index):
|
| 133 |
+
"""Converts an index (integer) in a token (str) using the vocab."""
|
| 134 |
+
token = self.sp_model.IdToPiece(index)
|
| 135 |
+
return token
|
| 136 |
+
|
| 137 |
+
def convert_tokens_to_string(self, tokens):
|
| 138 |
+
"""Converts a sequence of tokens (string) in a single string."""
|
| 139 |
+
# since we manually add the prefix space, we have to remove it when decoding
|
| 140 |
+
if tokens[0].startswith(SPIECE_UNDERLINE):
|
| 141 |
+
tokens[0] = tokens[0][1:]
|
| 142 |
+
|
| 143 |
+
current_sub_tokens = []
|
| 144 |
+
out_string = ""
|
| 145 |
+
prev_is_special = False
|
| 146 |
+
for i, token in enumerate(tokens):
|
| 147 |
+
# make sure that special tokens are not decoded using sentencepiece model
|
| 148 |
+
if token in self.all_special_tokens:
|
| 149 |
+
if not prev_is_special and i != 0 and self.legacy:
|
| 150 |
+
out_string += " "
|
| 151 |
+
out_string += self.sp_model.decode(current_sub_tokens) + token
|
| 152 |
+
prev_is_special = True
|
| 153 |
+
current_sub_tokens = []
|
| 154 |
+
else:
|
| 155 |
+
current_sub_tokens.append(token)
|
| 156 |
+
prev_is_special = False
|
| 157 |
+
out_string += self.sp_model.decode(current_sub_tokens)
|
| 158 |
+
return out_string
|
| 159 |
+
|
| 160 |
+
def save_vocabulary(self, save_directory, filename_prefix: Optional[str] = None) -> Tuple[str]:
|
| 161 |
+
"""
|
| 162 |
+
Save the vocabulary and special tokens file to a directory.
|
| 163 |
+
|
| 164 |
+
Args:
|
| 165 |
+
save_directory (`str`):
|
| 166 |
+
The directory in which to save the vocabulary.
|
| 167 |
+
|
| 168 |
+
Returns:
|
| 169 |
+
`Tuple(str)`: Paths to the files saved.
|
| 170 |
+
"""
|
| 171 |
+
if not os.path.isdir(save_directory):
|
| 172 |
+
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
|
| 173 |
+
return
|
| 174 |
+
out_vocab_file = os.path.join(
|
| 175 |
+
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file) and os.path.isfile(self.vocab_file):
|
| 179 |
+
copyfile(self.vocab_file, out_vocab_file)
|
| 180 |
+
elif not os.path.isfile(self.vocab_file):
|
| 181 |
+
with open(out_vocab_file, "wb") as fi:
|
| 182 |
+
content_spiece_model = self.sp_model.serialized_model_proto()
|
| 183 |
+
fi.write(content_spiece_model)
|
| 184 |
+
|
| 185 |
+
return (out_vocab_file,)
|
| 186 |
+
|
| 187 |
+
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
|
| 188 |
+
bos_token_id = [self.bos_token_id] if self.add_bos_token else []
|
| 189 |
+
eos_token_id = [self.eos_token_id] if self.add_eos_token else []
|
| 190 |
+
|
| 191 |
+
output = bos_token_id + token_ids_0 + eos_token_id
|
| 192 |
+
|
| 193 |
+
if token_ids_1 is not None:
|
| 194 |
+
output = output + bos_token_id + token_ids_1 + eos_token_id
|
| 195 |
+
|
| 196 |
+
return output
|
| 197 |
+
|
| 198 |
+
def get_special_tokens_mask(
|
| 199 |
+
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
|
| 200 |
+
) -> List[int]:
|
| 201 |
+
"""
|
| 202 |
+
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
|
| 203 |
+
special tokens using the tokenizer `prepare_for_model` method.
|
| 204 |
+
|
| 205 |
+
Args:
|
| 206 |
+
token_ids_0 (`List[int]`):
|
| 207 |
+
List of IDs.
|
| 208 |
+
token_ids_1 (`List[int]`, *optional*):
|
| 209 |
+
Optional second list of IDs for sequence pairs.
|
| 210 |
+
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
|
| 211 |
+
Whether or not the token list is already formatted with special tokens for the model.
|
| 212 |
+
|
| 213 |
+
Returns:
|
| 214 |
+
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
|
| 215 |
+
"""
|
| 216 |
+
if already_has_special_tokens:
|
| 217 |
+
return super().get_special_tokens_mask(
|
| 218 |
+
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
|
| 219 |
+
)
|
| 220 |
+
|
| 221 |
+
bos_token_id = [1] if self.add_bos_token else []
|
| 222 |
+
eos_token_id = [1] if self.add_eos_token else []
|
| 223 |
+
|
| 224 |
+
if token_ids_1 is None:
|
| 225 |
+
return bos_token_id + ([0] * len(token_ids_0)) + eos_token_id
|
| 226 |
+
return (
|
| 227 |
+
bos_token_id
|
| 228 |
+
+ ([0] * len(token_ids_0))
|
| 229 |
+
+ eos_token_id
|
| 230 |
+
+ bos_token_id
|
| 231 |
+
+ ([0] * len(token_ids_1))
|
| 232 |
+
+ eos_token_id
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
def create_token_type_ids_from_sequences(
|
| 236 |
+
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
|
| 237 |
+
) -> List[int]:
|
| 238 |
+
"""
|
| 239 |
+
Creates a mask from the two sequences passed to be used in a sequence-pair classification task. An ALBERT
|
| 240 |
+
sequence pair mask has the following format:
|
| 241 |
+
|
| 242 |
+
```
|
| 243 |
+
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
|
| 244 |
+
| first sequence | second sequence |
|
| 245 |
+
```
|
| 246 |
+
|
| 247 |
+
if token_ids_1 is None, only returns the first portion of the mask (0s).
|
| 248 |
+
|
| 249 |
+
Args:
|
| 250 |
+
token_ids_0 (`List[int]`):
|
| 251 |
+
List of ids.
|
| 252 |
+
token_ids_1 (`List[int]`, *optional*):
|
| 253 |
+
Optional second list of IDs for sequence pairs.
|
| 254 |
+
|
| 255 |
+
Returns:
|
| 256 |
+
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
|
| 257 |
+
"""
|
| 258 |
+
bos_token_id = [self.bos_token_id] if self.add_bos_token else []
|
| 259 |
+
eos_token_id = [self.eos_token_id] if self.add_eos_token else []
|
| 260 |
+
|
| 261 |
+
output = [0] * len(bos_token_id + token_ids_0 + eos_token_id)
|
| 262 |
+
|
| 263 |
+
if token_ids_1 is not None:
|
| 264 |
+
output += [1] * len(bos_token_id + token_ids_1 + eos_token_id)
|
| 265 |
+
|
| 266 |
+
return output
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3a11626b3c80cbfdd5f4b5585fce8938d178f3a0df739c3dd1c708ce944878af
|
| 3 |
+
size 1010047
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"bos_token": {
|
| 5 |
+
"__type": "AddedToken",
|
| 6 |
+
"content": "<s>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false
|
| 11 |
+
},
|
| 12 |
+
"eos_token": {
|
| 13 |
+
"__type": "AddedToken",
|
| 14 |
+
"content": "</s>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false
|
| 19 |
+
},
|
| 20 |
+
"unk_token": {
|
| 21 |
+
"__type": "AddedToken",
|
| 22 |
+
"content": "<unk>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false
|
| 27 |
+
},
|
| 28 |
+
"pad_token": {
|
| 29 |
+
"__type": "AddedToken",
|
| 30 |
+
"content": "<unk>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": true
|
| 35 |
+
},
|
| 36 |
+
"added_tokens_decoder": {
|
| 37 |
+
"3": {
|
| 38 |
+
"content": "reserved_0",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"4": {
|
| 46 |
+
"content": "reserved_1",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
}
|
| 53 |
+
},
|
| 54 |
+
"clean_up_tokenization_spaces": false,
|
| 55 |
+
"spaces_between_special_tokens": false,
|
| 56 |
+
"add_prefix_space": false,
|
| 57 |
+
"legacy": false,
|
| 58 |
+
"model_max_length": 1e+30,
|
| 59 |
+
"sp_model_kwargs": {},
|
| 60 |
+
"tokenizer_class": "IndexTokenizer",
|
| 61 |
+
"auto_map": {
|
| 62 |
+
"AutoTokenizer": [
|
| 63 |
+
"tokenization_index.IndexTokenizer",
|
| 64 |
+
null
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
"use_default_system_prompt": false,
|
| 68 |
+
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ unk_token + system_message }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ 'reserved_0' + content.strip() + 'reserved_1' }}{% elif message['role'] == 'assistant' %}{{ content.strip() }}{% endif %}{% endfor %}"
|
| 69 |
+
}
|
z-attach-pic-needle-bench-en.png
ADDED

|
z-attach-pic-pk-all.png
ADDED

|
z-attach-pic-qa-mark.png
ADDED
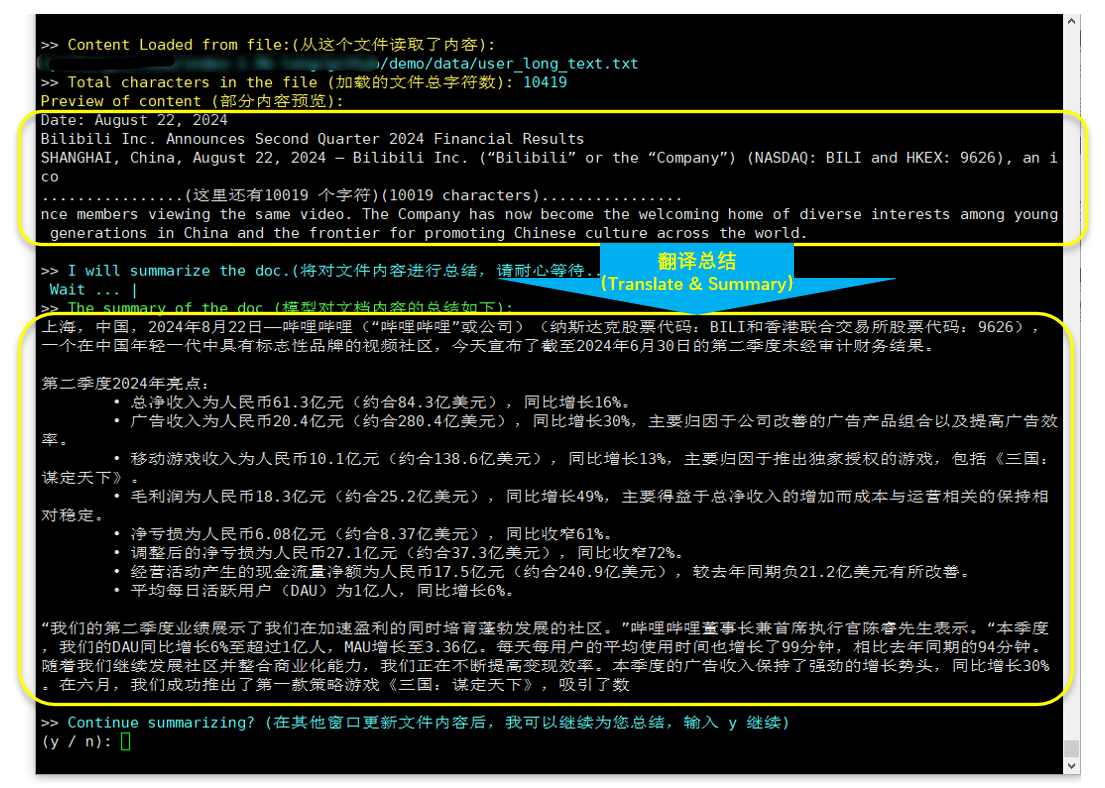
|