

metadata
license: apache-2.0
tags:
- vision
inference: false
pipeline_tag: zero-shot-object-detection
Grounding DINO model (tiny variant)
The Grounding DINO model was proposed in Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
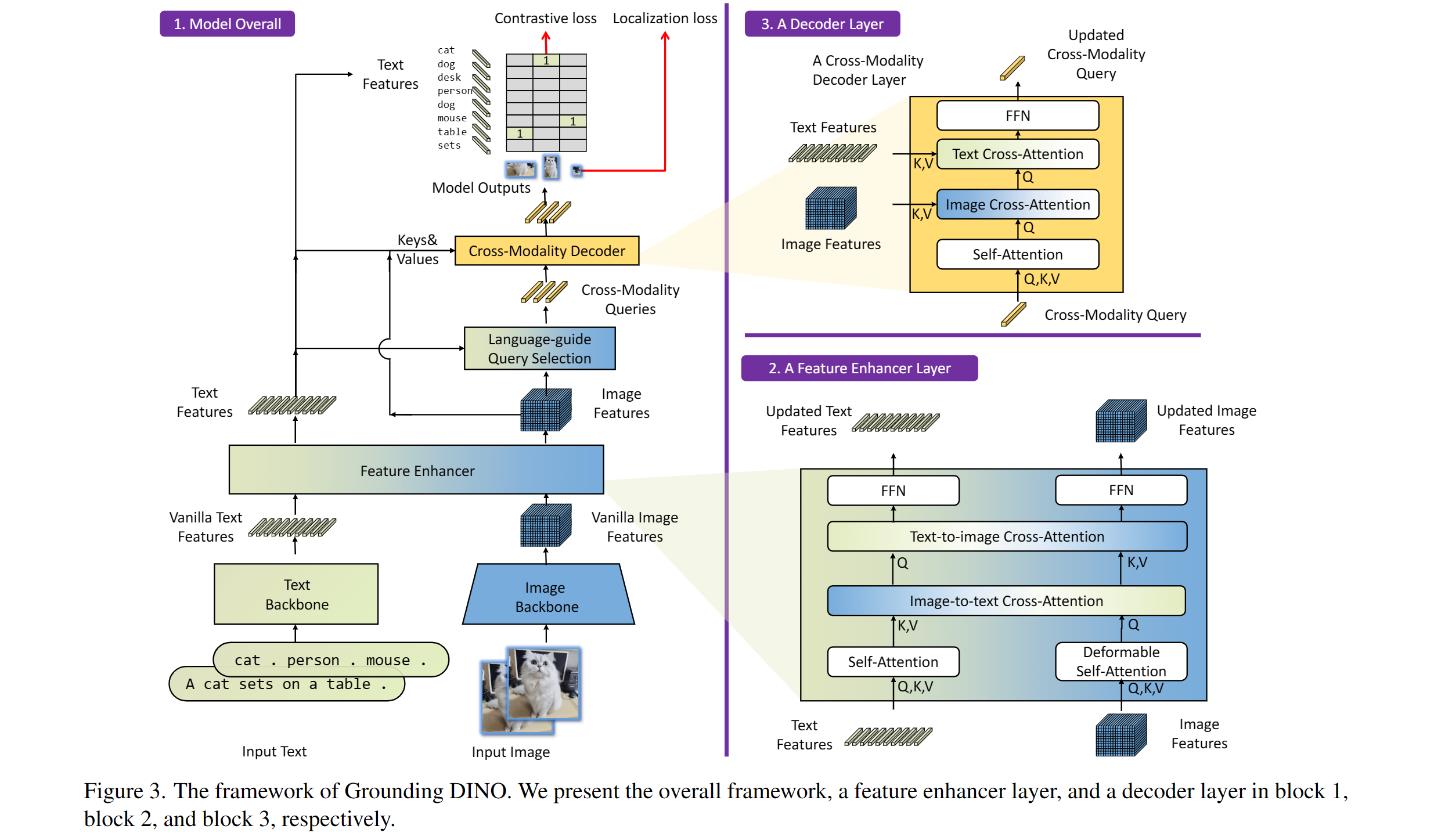
Grounding DINO overview. Taken from the original paper.
Intended uses & limitations
You can use the raw model for zero-shot object detection (the task of detecting things in an image out-of-the-box without labeled data).
How to use
Here's how to use the model for zero-shot object detection:
import requests
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
model_id = "IDEA-Research/grounding-dino-tiny"
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
# Check for cats and remote controls
# VERY important: text queries need to be lowercased + end with a dot
text = "a cat. a remote control."
inputs = processor(images=image, text=text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
results = processor.post_process_grounded_object_detection(
outputs,
inputs.input_ids,
box_threshold=0.4,
text_threshold=0.3,
target_sizes=[image.size[::-1]]
)
BibTeX entry and citation info
@misc{liu2023grounding,
title={Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection},
author={Shilong Liu and Zhaoyang Zeng and Tianhe Ren and Feng Li and Hao Zhang and Jie Yang and Chunyuan Li and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang},
year={2023},
eprint={2303.05499},
archivePrefix={arXiv},
primaryClass={cs.CV}
}