


Welcome to Keras Dreambooth event! 🤗
This document summarises all the relevant information required for the event 📋.
Introduction
Dreambooth is a fine-tuning technique to teach new visual concepts to text-conditioned Diffusion models with just 3-5 images. With Dreambooth, you could generate funny and realistic images of your dog, yourself and any concept with few images using Stable Diffusion. DreamBooth was proposed in DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation by Ruiz et al. In this guide, we will walk you through what we will do in this event.
We will be training Dreambooth models using KerasCV and building demos on them.
Important Dates
- Kick-Off Event: March 6th, 2023
- Sprint start: March 7th, 2023
- Sprint end: April 1st, 2023
- Results: April 7th, 2023
Getting Started 🚀
To get started, join us in hf.co/join/discord and take the role #open-source, and meet us in #keras-working-group channel.
We will be hosting our demos in this organization on Hugging Face Hub: keras-dreambooth, send a request to join here if you’d like to make a submission 🙂
We will:
- Fine-tune Stable Diffusion on any concept we want using Dreambooth,
- Push the model to Hugging Face Hub,
- Fill the model card,
- Build a demo on top of the model.
Warning: The trained models need to be in one of the 4 categories mentioned in the Submission section. Please take a look at that before training your model.
Let’s get started 🚀
Model Training
You can find the notebook here and adjust it according to your own dataset 👇
You can fine-tune on any concept that you want. Couple of inspirations for you:
- Lowpoly World: This model generates lowpoly worlds 🤯🌍
- Future Diffusion: This model generates images in futuristic sci-fi concepts 🤖
- Fantasy sword: This model generates swords for fantasy themed games 🧙♂️
If you need more pointers on Dreambooth implementation with Keras, you can check out this repository.
Important: To learn how to launch a cloud GPU instance and train with Lambda, please refer to Compute with Lambda.
Dreambooth Diffusers Integration with KerasCV
As of now, inference and deployment options of KerasCV are limited, which is when the diffusers library comes to the rescue. With only few lines of code, we can convert a KerasCV model into a diffusers one and use diffusers’ pipelines to perform inference. You can get more information here. Also check out this Space for converting your KerasCV model to diffusersone.
diffusersrepositories on the Hub get a free Inference API and small widgets in the model page where users can play with the model.
from diffusers import StableDiffusionPipeline
# checkpoint of the converted Stable Diffusion from KerasCV
model_ckpt = "sayakpaul/text-unet-dogs-kerascv_sd_diffusers_pipeline"
pipeline = StableDiffusionPipeline.from_pretrained(model_ckpt)
pipeline.to("cuda")
unique_id = "sks"
class_label = "dog"
prompt = f"A photo of {unique_id} {class_label} in a bucket"
image = pipeline(prompt, num_inference_steps=50).images[0]
Model Hosting
At the end of this notebook you will see a section dedicated for hosting, and a separate one for inference. We will be using the huggingface_hub library’s Keras-specific model pushing and loading functions: push_to_hub_keras and from_pretrained_keras . We will first push the model using push_to_hub_keras. After model is pushed, you will see the model is hosted with a model card like below 👇

To version the models better, enable discoverability and reproducibility, we will fill the model card. Click Edit model card. We will first fill the Metadata section of the model card. If your model is trained with a dataset from the Hugging Face Hub, you can fill the datasets section with the dataset. We will provide fill pipeline_tag with text-to-image and pick a license for our model.

Then, we will fill the markdown part. Hyperparameters and plot is automatically generated so we can write a short explanation for description, intended use and dataset.
You can find the example repository below 👇
keras-dreambooth/dreambooth_diffusion_model
Model Demo
We will use Gradio to build our demos for the models we have trained. With Interface class it’s straightforward 👇
from huggingface_hub import from_pretrained_keras
from keras_cv import models
import gradio as gr
sd_dreambooth_model = models.StableDiffusion(
img_width=512, img_height=512
)
db_diffusion_model = from_pretrained_keras("merve/dreambooth_diffusion_model")
sd_dreambooth_model._diffusion_model = db_diffusion_model
# generate images
def infer(prompt):
generated_images = sd_dreambooth_model.text_to_image(
prompt
)
return generated_images
output = gr.Gallery(label="Outputs").style(grid=(2,2))
# pass function, input type for prompt, the output for multiple images
gr.Interface(infer, inputs=["text"], outputs=[output]).launch()
You can check out app.pyfile of the application below and repurpose it for your model!
Dreambooth Submission - a Hugging Face Space by keras-dreambooth
This app generates images of a corgi 🐶

Hosting the Demo on Spaces
After our application is written, we can create a Hugging Face Space to host our app. You can go to huggingface.co, click on your profile on top right and select “New Space”.

We can name our Space, pick a license and select Space SDK as “Gradio”.

After creating the Space, you can use either the instructions below to clone the repository locally, adding your files and push, OR, graphical interface to create the files and write the code in the browser.

To upload your application file, pick “Add File” and drag and drop your file.
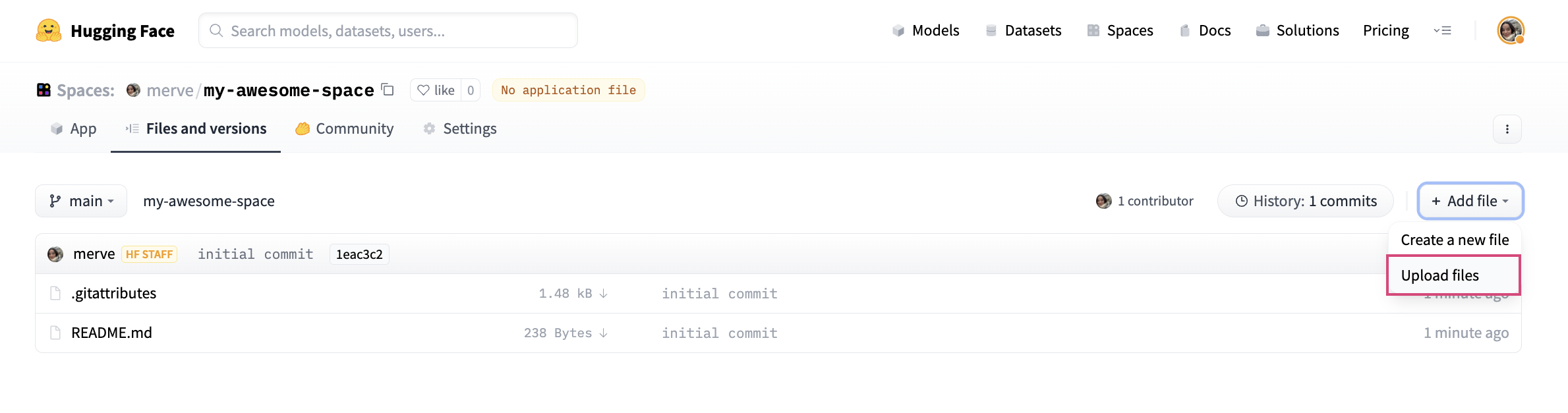
Lastly, we have to create a file called requirements.txt and add requirements of Dreambooth project like below:
keras-cv
tensorflow
huggingface-hub
And your app should be up and running!
We will host our models and Spaces under this organization. You can carry your models and Spaces on the settings tab under Rename or transfer this model and select keras-dreambooth from the dropdown.
If you don't see keras-dreambooth in the dropdown, it's likely that you aren't a member of the organization. Use this link to request to join the organization.
Submission
You can make submission in three themes:
- Nature and Animals (
nature) - Sci-fi/Fantasy Universes (
sci-fi) - Consentful (
consentful): Partner up with an artist to fine-tune on their style, with their consent! Make sure to include a reference to the artist’s express consent (e.g. a tweet) in your model card. - Wild Card (
wild-card): If your submission belongs to any category that is not above, feel free to tag it with wild-card so we can evaluate it out of that category.
Add the category with their IDs to the model cards for submission and add keras-dreambooth to model card metadata in tags section. Here's an example model card. All the submissions will be populated in this leaderboard and ranked according to likes on a given Space to determine the winners.
Sprint Prizes
We will pick three winners among the applications submitted, according to the number of likes given to a Space in a given category.
🛍️ First place will win a 100$ voucher on hf.co/shop or one year subscription to Hugging Face Pro
🛍️ Second place will win a 50$ voucher on hf.co/shop or the book “Natural Language Processing with Transformers”
🛍️ Third place will win a 30$ voucher on hf.co/shop or three months subscription to Hugging Face Pro