
Multi-Turn Rollout
Note: This feature requires ms-swift>=3.6
In reinforcement learning training scenarios, model sampling may require multiple rounds of interaction with the environment (e.g., tool calls, external API access, etc.). This interactive training requires the model to perform continuous reasoning based on environmental feedback. This document details how to customize multi-round training workflows in GRPO training.
Based on how environmental feedback is inserted, multi-round interactions can be categorized into:
- New-round reasoning: Environmental feedback results serve as the query, and the model responds in a new dialogue turn.
- Current-round continuation: Environmental feedback results are inserted into the model's current response, and the model continues writing subsequent content based on this.
We can customize and set a multi-round sampling planner through the parameter multi_turn_scheduler to implement multi-round sampling logic:
--multi_turn_scheduler xxx
--max_turns xxx
MultiTurnScheduler
The multi-turn scheduler is the core component of multi-round training, and its workflow is shown in the following diagram:
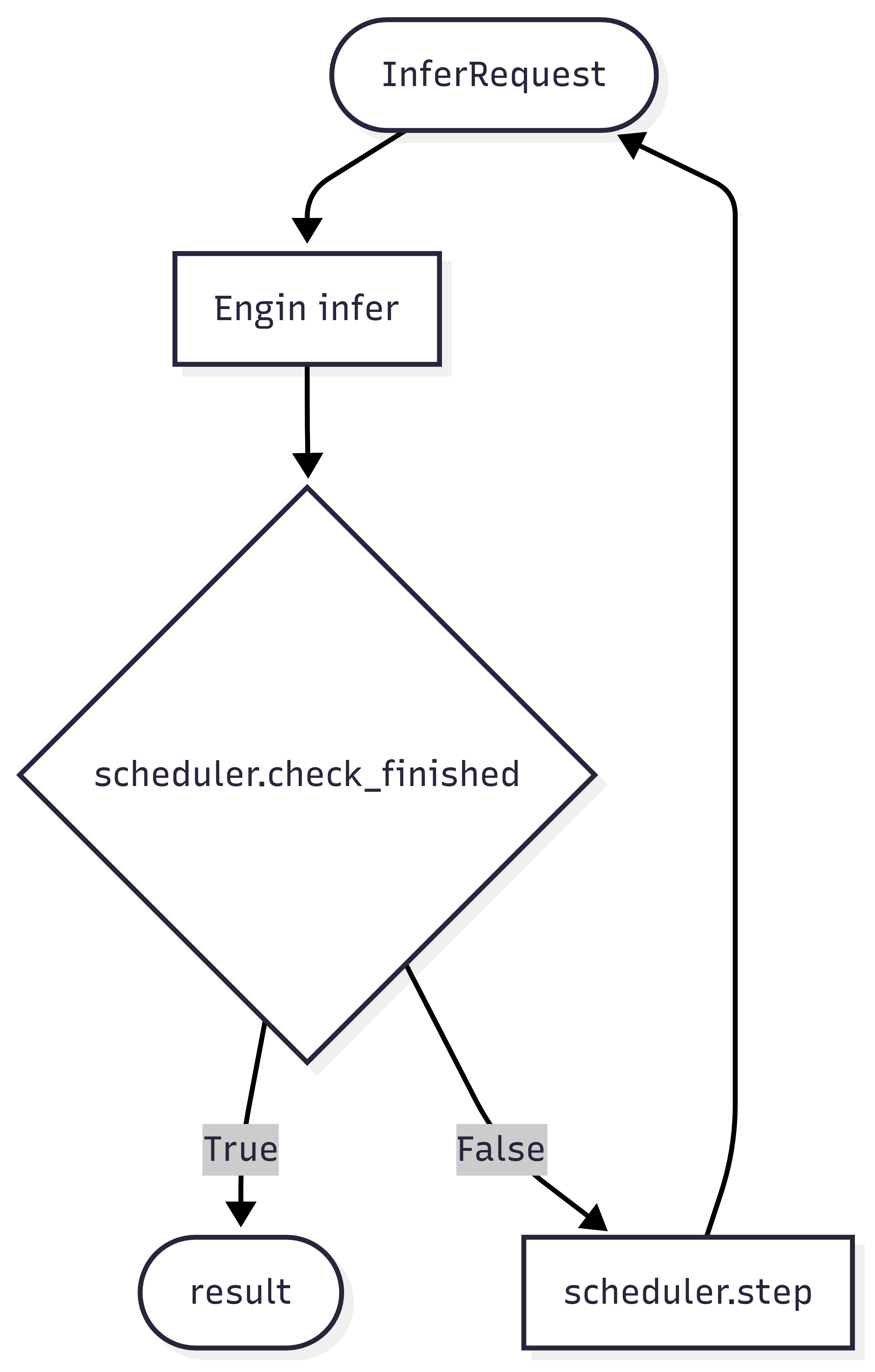
The multi-turn scheduler primarily performs two functions:
- Termination condition judgment: Determines whether the current round of reasoning should end via the
check_finishedmethod. - Reasoning request construction: Builds the request object for the next round of reasoning via the
stepmethod.
The abstract base class MultiTurnScheduler is implemented as follows:
class MultiTurnScheduler(ABC):
def __init__(self, max_turns: Optional[int] = None, *args, **kwargs):
self.max_turns = max_turns
@abstractmethod
def step(self, infer_request: 'RolloutInferRequest', result: 'RolloutResponseChoice',
current_turn: int) -> Union['RolloutInferRequest', Tuple['RolloutInferRequest', Dict]]:
pass
def check_finished(self, infer_request: 'RolloutInferRequest', result: 'RolloutResponseChoice',
current_turn: int) -> bool:
if result.finish_reason == 'length':
return True
if self.max_turns and current_turn >= self.max_turns:
return True
return False
If you want the reward function to access information from multi-turn interactions, please return an extra dict object in the
stepmethod. In the reward function, you can then accessmulti_turn_infosfromkwargs.
class Scheduler():
def step(self, infer_request: 'RolloutInferRequest', result: 'RolloutResponseChoice',
current_turn: int) -> Union['RolloutInferRequest', Tuple['RolloutInferRequest', Dict]]:
...
return infer_request, extra_dict
class RewardFunction():
def __call__(self, completions, **kwargs):
infos = kwargs.get('multi_turn_infos', {})
...
The step and check_finished methods accept the following parameters:
- infer_request: The reasoning request from the previous round, including:
- The
messageskey contains the interaction history (note: it already includes the current model reasoning result). - Multimodal information, such as
images. data_dictcontains other columns from the dataset.
- The
- result: The reasoning result from the previous round.
- current_turn: The current reasoning round (starting from 1).
Example input parameters:
infer_request
"""
RolloutInferRequest(
messages=[
{'role': 'system', 'content': 'A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think><answer> answer here </answer>\n'}, {'role': 'user', 'content': 'What is the value of $\\sqrt{36 \\times \\sqrt{16}}$?'},
{'role': 'assistant', 'content': 'To find the value of , we will break down the problem step-by-step.\n\nFirst, we need to evaluate the inner square root:\n\\[\n\\sqrt{16}\n\\]\nWe know that:\n\\[\n4^2 = 16 \\implies \\sqrt{16} = 4\n\\]\n\nNext, we substitute this result back into the original expression:\n\\[\n\\sqrt{36 \\times \\sqrt{16}} = \\sqrt{36 \\times 4}\n\\]\n\nNow, we need to evaluate the product inside the square root:\n\\[\n36 \\times 4 = 144\n\\]\n\nSo, the expression simplifies to:\n\\[\n\\sqrt{144}\n\\]\n\nFinally, we determine the square root of 144:\n\\[\n\\sqrt{144} = 12\n\\]\n\nThus, the value of is:\n\\[\n\\boxed{12}\n\\]'}
],
images=[],
audios=[],
videos=[],
tools=None,
objects={},
data_dict={
'problem': 'What is the value of $\\sqrt{36 \\times \\sqrt{16}}$?',
'solution': "To solve the problem, we need to evaluate the expression .\n\nWe can break down the steps as follows:\n\n1. Evaluate the inner square root: .\n2. Multiply the result by 36.\n3. Take the square root of the product obtained in step 2.\n\nLet's compute this step by step using Python code for accuracy.\n```python\nimport math\n\n# Step 1: Evaluate the inner square root\ninner_sqrt = math.sqrt(16)\n\n# Step 2: Multiply the result by 36\nproduct = 36 * inner_sqrt\n\n# Step 3: Take the square root of the product\nfinal_result = math.sqrt(product)\nprint(final_result)\n```\n```output\n12.0\n```\nThe value of is /\\(\\boxed{12}\\)."
}
)
"""
result
"""
RolloutResponseChoice(
index=0,
message=ChatMessage(
role='assistant',
content='To find the value of , we will break down the problem step-by-step.\n\nFirst, we need to evaluate the inner square root:\n\\[\n\\sqrt{16}\n\\]\nWe know that:\n\\[\n4^2 = 16 \\implies \\sqrt{16} = 4\n\\]\n\nNext, we substitute this result back into the original expression:\n\\[\n\\sqrt{36 \\times \\sqrt{16}} = \\sqrt{36 \\times 4}\n\\]\n\nNow, we need to evaluate the product inside the square root:\n\\[\n36 \\times 4 = 144\n\\]\n\nSo, the expression simplifies to:\n\\[\n\\sqrt{144}\n\\]\n\nFinally, we determine the square root of 144:\n\\[\n\\sqrt{144} = 12\n\\]\n\nThus, the value of is:\n\\[\n\\boxed{12}\n\\]', tool_calls=None),
finish_reason='stop',
logprobs=None,
messages=None)
"""
# result.messages will be copied at the end of multi-turn inference.
The default check_finished logic stops reasoning under two conditions:
- The model's response is truncated, i.e., it exceeds
max_completion_length. - The number of reasoning rounds exceeds the maximum allowed limit.
It is recommended to use AsyncEngine for efficient batch data asynchronous multi-round sampling (only supported in external server mode). AsyncEngine can reduce computational bubbles during multi-round reasoning (as shown in the diagram).
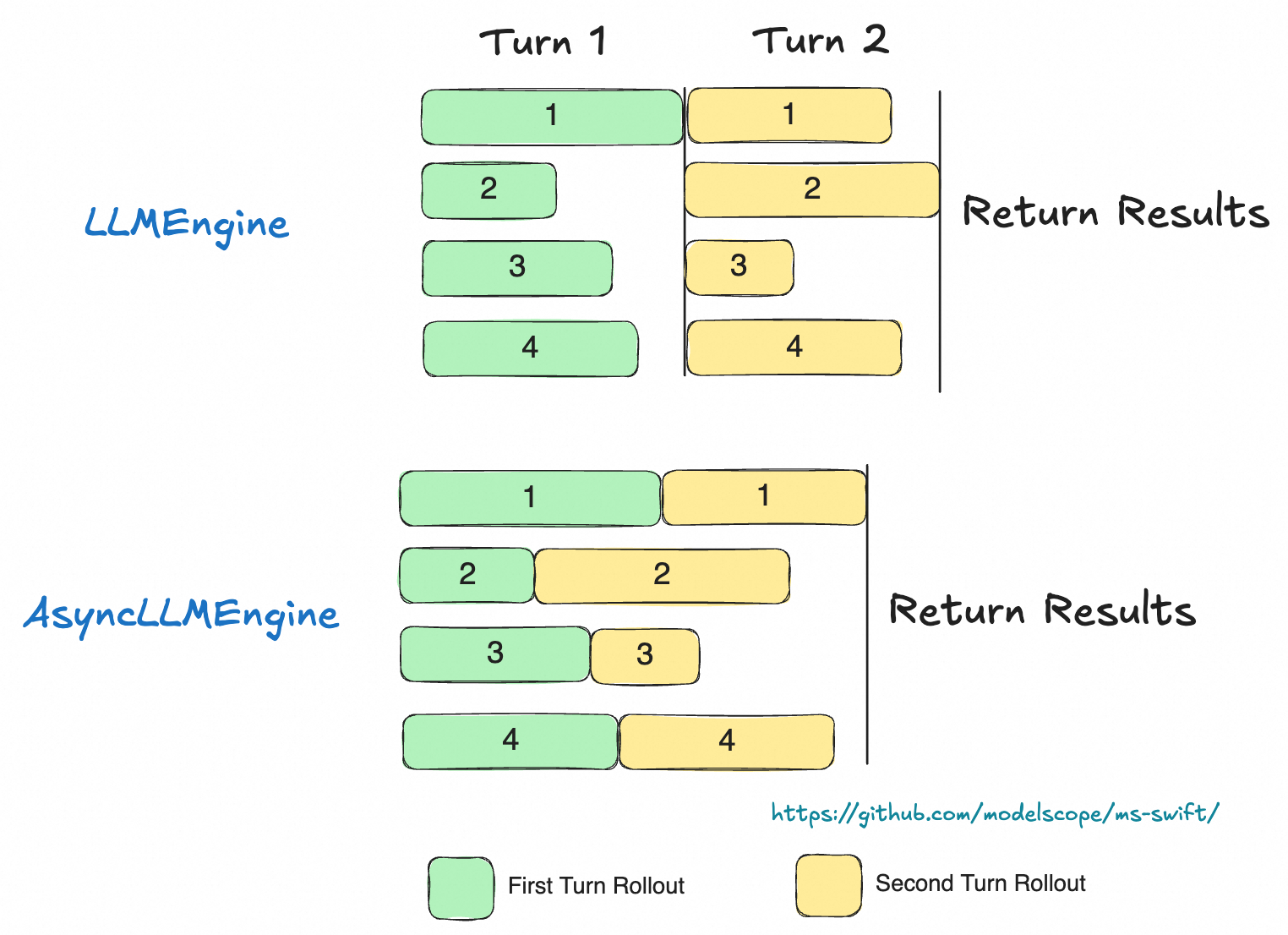
Use the use_async_engine parameter in the rollout command to specify the engine type:
swift rollout \
--model xxx \
--use_async_engine true \
--multi_turn_scheduler xxx \
--max_turns xxx
Through the external_plugins parameter, we can register local multi-round planners into ms-swift. For specific implementation, refer to the code.
Multi-round training script references:
Best Practices
The plugin code example provides two examples of multi-round planners, implementing two types of multi-round reasoning for prompting the model to rethink and provide answers in mathematical problems:
- New-round reasoning: Inserts a new round of dialogue to prompt the model that its answer is incorrect and needs rethinking (math_tip_trick_multi_turn).
- Continuation: Backtracks to the model's thinking phase and adds a prompt indicating incorrect reasoning (math_tip_trick).
Notes
Reward Function
Note that in the reward function, the completions parameter represents the model's response in the final round. If the reward function needs to calculate rewards based on the model's multi-round responses, it must retrieve the messages key to obtain the complete multi-round dialogue history.
class Reward(ORM):
def __call__(completions, **kwargs):
print(kwargs.keys())
# dict_keys(['problem', 'solution', 'messages', 'is_truncated'])
messages = kwargs.get('messages')
...
Loss Masking
When tool calls or environment interaction results are returned and need to be included as part of the model's response, it is recommended to mask these inserted contents to ensure the model does not compute loss on externally generated content during training.
This requires setting the loss_scale parameter to implement custom masking logic. For details, refer to the Custom loss_scale Documentation.
Default loss_scale values:
Multi-round training (i.e., when multi_turn_scheduler is set): loss_scale defaults to default, meaning training is performed on each round's response in messages.
If the dataset itself contains assistant responses, they will also be included in the calculation. To exclude these, a custom loss_scale is required.
Single-round training: loss_scale defaults to last_round, computing loss only for the final round's response (rollout result).
Note that loss_scale can be used to:
- Label tokens to be trained (0 means no training).
- Scale the training weight of tokens.
However, GRPO currently does not support weight settings in loss_scale.