
Upload 14 files
Browse files- .gitattributes +1 -0
- README.md +354 -0
- added_tokens.json +5 -0
- config.json +33 -0
- cross.png +0 -0
- generation_config.json +7 -0
- gitattributes +36 -0
- model.safetensors +3 -0
- multi.png +0 -0
- pytorch_model.bin +3 -0
- single.png +0 -0
- special_tokens_map.json +5 -0
- spiece.model +3 -0
- tokenizer.json +3 -0
- tokenizer_config.json +37 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,354 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- es
|
| 6 |
+
- fr
|
| 7 |
+
- it
|
| 8 |
+
widget:
|
| 9 |
+
- text: The best cough medicine is <extra_id_0> because <extra_id_1>
|
| 10 |
+
- text: El mejor medicamento para la tos es <extra_id_0> porque <extra_id_1>
|
| 11 |
+
- text: Le meilleur médicament contre la toux est <extra_id_0> car <extra_id_1
|
| 12 |
+
- text: La migliore medicina per la tosse è la <extra_id_0> perché la <extra_id_1
|
| 13 |
+
library_name: transformers
|
| 14 |
+
pipeline_tag: text2text-generation
|
| 15 |
+
tags:
|
| 16 |
+
- medical
|
| 17 |
+
- multilingual
|
| 18 |
+
- medic
|
| 19 |
+
datasets:
|
| 20 |
+
- HiTZ/Multilingual-Medical-Corpus
|
| 21 |
+
base_model: google/mt5-large
|
| 22 |
+
---
|
| 23 |
+
|
| 24 |
+
<p align="center">
|
| 25 |
+
<br>
|
| 26 |
+
<img src="http://www.ixa.eus/sites/default/files/anitdote.png" style="height: 250px;">
|
| 27 |
+
<h2 align="center">Medical mT5: An Open-Source Multilingual Text-to-Text LLM
|
| 28 |
+
for the Medical Domain</h2>
|
| 29 |
+
<br>
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
# Model Card for MedMT5-large
|
| 33 |
+
|
| 34 |
+
<p align="justify">
|
| 35 |
+
We present Medical mT5, the first open-source text-to-text multilingual model for the medical domain.
|
| 36 |
+
Medical mT5 is an encoder-decoder model developed by continuing the training of publicly available mT5 checkpoints on
|
| 37 |
+
medical domain data for English, Spanish, French, and Italian.
|
| 38 |
+
</p>
|
| 39 |
+
|
| 40 |
+
- 📖 Paper: [Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain](https://arxiv.org/abs/2404.07613)
|
| 41 |
+
- 🌐 Project Website: [https://univ-cotedazur.eu/antidote](https://univ-cotedazur.eu/antidote)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
<table border="1" cellspacing="0" cellpadding="5">
|
| 45 |
+
<caption>Pre-Training settings for MedMT5.</caption>
|
| 46 |
+
<thead>
|
| 47 |
+
<tr>
|
| 48 |
+
<th></th>
|
| 49 |
+
<th>Medical mT5-Large (<a href="https://huggingface.co/HiTZ/Medical-mT5-large">HiTZ/Medical-mT5-large</a>)</th>
|
| 50 |
+
<th>Medical mT5-XL (<a href="https://huggingface.co/HiTZ/Medical-mT5-xl">HiTZ/Medical-mT5-xl</a>)</th>
|
| 51 |
+
</tr>
|
| 52 |
+
</thead>
|
| 53 |
+
<tbody>
|
| 54 |
+
<tr>
|
| 55 |
+
<td>Param. no.</td>
|
| 56 |
+
<td>738M</td>
|
| 57 |
+
<td>3B</td>
|
| 58 |
+
</tr>
|
| 59 |
+
<tr>
|
| 60 |
+
<td>Sequence Length</td>
|
| 61 |
+
<td>1024</td>
|
| 62 |
+
<td>480</td>
|
| 63 |
+
</tr>
|
| 64 |
+
<tr>
|
| 65 |
+
<td>Token/step</td>
|
| 66 |
+
<td>65536</td>
|
| 67 |
+
<td>30720</td>
|
| 68 |
+
</tr>
|
| 69 |
+
<tr>
|
| 70 |
+
<td>Epochs</td>
|
| 71 |
+
<td>1</td>
|
| 72 |
+
<td>1</td>
|
| 73 |
+
</tr>
|
| 74 |
+
<tr>
|
| 75 |
+
<td>Total Tokens</td>
|
| 76 |
+
<td>4.5B</td>
|
| 77 |
+
<td>4.5B</td>
|
| 78 |
+
</tr>
|
| 79 |
+
<tr>
|
| 80 |
+
<td>Optimizer</td>
|
| 81 |
+
<td>Adafactor</td>
|
| 82 |
+
<td>Adafactor</td>
|
| 83 |
+
</tr>
|
| 84 |
+
<tr>
|
| 85 |
+
<td>LR</td>
|
| 86 |
+
<td>0.001</td>
|
| 87 |
+
<td>0.001</td>
|
| 88 |
+
</tr>
|
| 89 |
+
<tr>
|
| 90 |
+
<td>Scheduler</td>
|
| 91 |
+
<td>Constant</td>
|
| 92 |
+
<td>Constant</td>
|
| 93 |
+
</tr>
|
| 94 |
+
<tr>
|
| 95 |
+
<td>Hardware</td>
|
| 96 |
+
<td>4xA100</td>
|
| 97 |
+
<td>4xA100</td>
|
| 98 |
+
</tr>
|
| 99 |
+
<tr>
|
| 100 |
+
<td>Time (h)</td>
|
| 101 |
+
<td>10.5</td>
|
| 102 |
+
<td>20.5</td>
|
| 103 |
+
</tr>
|
| 104 |
+
<tr>
|
| 105 |
+
<td>CO<sub>2</sub>eq (kg)</td>
|
| 106 |
+
<td>2.9</td>
|
| 107 |
+
<td>5.6</td>
|
| 108 |
+
</tr>
|
| 109 |
+
</tbody>
|
| 110 |
+
</table>
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
# Model Description
|
| 114 |
+
|
| 115 |
+
- **Developed by**: Iker García-Ferrero, Rodrigo Agerri, Aitziber Atutxa Salazar, Elena Cabrio, Iker de la Iglesia, Alberto Lavelli, Bernardo Magnini, Benjamin Molinet, Johana Ramirez-Romero, German Rigau, Jose Maria Villa-Gonzalez, Serena Villata and Andrea Zaninello
|
| 116 |
+
- **Contact**: [Iker García-Ferrero](https://ikergarcia1996.github.io/Iker-Garcia-Ferrero/) and [Rodrigo Agerri](https://ragerri.github.io/)
|
| 117 |
+
- **Website**: [https://univ-cotedazur.eu/antidote](https://univ-cotedazur.eu/antidote)
|
| 118 |
+
- **Funding**: CHIST-ERA XAI 2019 call. Antidote (PCI2020-120717-2) funded by MCIN/AEI /10.13039/501100011033 and by European Union NextGenerationEU/PRTR
|
| 119 |
+
- **Model type**: text2text-generation
|
| 120 |
+
- **Language(s) (NLP)**: English, Spanish, French, Italian
|
| 121 |
+
- **License**: apache-2.0
|
| 122 |
+
- **Finetuned from model**: mT5
|
| 123 |
+
|
| 124 |
+
## How to Get Started with the Model
|
| 125 |
+
|
| 126 |
+
You can load the model using
|
| 127 |
+
|
| 128 |
+
```python
|
| 129 |
+
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
| 130 |
+
|
| 131 |
+
tokenizer = AutoTokenizer.from_pretrained("HiTZ/Medical-mT5-large")
|
| 132 |
+
model = AutoModelForSeq2SeqLM.from_pretrained("HiTZ/Medical-mT5-large")
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
The model has been trained using the T5 masked language modelling tasks. You need to finetune the model for your task.
|
| 136 |
+
|
| 137 |
+
<p align="center">
|
| 138 |
+
<br>
|
| 139 |
+
<img src="https://miro.medium.com/v2/0*yeXSc6Qs-SGKDzZP.png" style="height: 250px;">
|
| 140 |
+
<br>
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
## Training Data
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
<table border="1" cellspacing="0" cellpadding="5">
|
| 150 |
+
<caption>Data sources and word counts by language.</caption>
|
| 151 |
+
<thead>
|
| 152 |
+
<tr>
|
| 153 |
+
<th>Language</th>
|
| 154 |
+
<th>Source</th>
|
| 155 |
+
<th>Words</th>
|
| 156 |
+
</tr>
|
| 157 |
+
</thead>
|
| 158 |
+
<tbody>
|
| 159 |
+
<tr>
|
| 160 |
+
<td rowspan="3">English</td>
|
| 161 |
+
<td>ClinicalTrials</td>
|
| 162 |
+
<td>127.4M</td>
|
| 163 |
+
</tr>
|
| 164 |
+
<tr>
|
| 165 |
+
<td>EMEA</td>
|
| 166 |
+
<td>12M</td>
|
| 167 |
+
</tr>
|
| 168 |
+
<tr>
|
| 169 |
+
<td>PubMed</td>
|
| 170 |
+
<td>968.4M</td>
|
| 171 |
+
</tr>
|
| 172 |
+
<tr>
|
| 173 |
+
<td rowspan="6">Spanish</td>
|
| 174 |
+
<td>EMEA</td>
|
| 175 |
+
<td>13.6M</td>
|
| 176 |
+
</tr>
|
| 177 |
+
<tr>
|
| 178 |
+
<td>PubMed</td>
|
| 179 |
+
<td>8.4M</td>
|
| 180 |
+
</tr>
|
| 181 |
+
<tr>
|
| 182 |
+
<td>Medical Crawler</td>
|
| 183 |
+
<td>918M</td>
|
| 184 |
+
</tr>
|
| 185 |
+
<tr>
|
| 186 |
+
<td>SPACC</td>
|
| 187 |
+
<td>350K</td>
|
| 188 |
+
</tr>
|
| 189 |
+
<tr>
|
| 190 |
+
<td>UFAL</td>
|
| 191 |
+
<td>10.5M</td>
|
| 192 |
+
</tr>
|
| 193 |
+
<tr>
|
| 194 |
+
<td>WikiMed</td>
|
| 195 |
+
<td>5.2M</td>
|
| 196 |
+
</tr>
|
| 197 |
+
<tr>
|
| 198 |
+
<td rowspan="5">French</td>
|
| 199 |
+
<td>PubMed</td>
|
| 200 |
+
<td>1.4M</td>
|
| 201 |
+
</tr>
|
| 202 |
+
<tr>
|
| 203 |
+
<td>Science Direct</td>
|
| 204 |
+
<td>15.2M</td>
|
| 205 |
+
</tr>
|
| 206 |
+
<tr>
|
| 207 |
+
<td>Wikipedia - Médecine</td>
|
| 208 |
+
<td>5M</td>
|
| 209 |
+
</tr>
|
| 210 |
+
<tr>
|
| 211 |
+
<td>EDP</td>
|
| 212 |
+
<td>48K</td>
|
| 213 |
+
</tr>
|
| 214 |
+
<tr>
|
| 215 |
+
<td>Google Patents</td>
|
| 216 |
+
<td>654M</td>
|
| 217 |
+
</tr>
|
| 218 |
+
<tr>
|
| 219 |
+
<td rowspan="13">Italian</td>
|
| 220 |
+
<td>Medical Commoncrawl - IT</td>
|
| 221 |
+
<td>67M</td>
|
| 222 |
+
</tr>
|
| 223 |
+
<tr>
|
| 224 |
+
<td>Drug instructions</td>
|
| 225 |
+
<td>30.5M</td>
|
| 226 |
+
</tr>
|
| 227 |
+
<tr>
|
| 228 |
+
<td>Wikipedia - Medicina</td>
|
| 229 |
+
<td>13.3M</td>
|
| 230 |
+
</tr>
|
| 231 |
+
<tr>
|
| 232 |
+
<td>E3C Corpus - IT</td>
|
| 233 |
+
<td>11.6M</td>
|
| 234 |
+
</tr>
|
| 235 |
+
<tr>
|
| 236 |
+
<td>Medicine descriptions</td>
|
| 237 |
+
<td>6.3M</td>
|
| 238 |
+
</tr>
|
| 239 |
+
<tr>
|
| 240 |
+
<td>Medical theses</td>
|
| 241 |
+
<td>5.8M</td>
|
| 242 |
+
</tr>
|
| 243 |
+
<tr>
|
| 244 |
+
<td>Medical websites</td>
|
| 245 |
+
<td>4M</td>
|
| 246 |
+
</tr>
|
| 247 |
+
<tr>
|
| 248 |
+
<td>PubMed</td>
|
| 249 |
+
<td>2.3M</td>
|
| 250 |
+
</tr>
|
| 251 |
+
<tr>
|
| 252 |
+
<td>Supplement description</td>
|
| 253 |
+
<td>1.3M</td>
|
| 254 |
+
</tr>
|
| 255 |
+
<tr>
|
| 256 |
+
<td>Medical notes</td>
|
| 257 |
+
<td>975K</td>
|
| 258 |
+
</tr>
|
| 259 |
+
<tr>
|
| 260 |
+
<td>Pathologies</td>
|
| 261 |
+
<td>157K</td>
|
| 262 |
+
</tr>
|
| 263 |
+
<tr>
|
| 264 |
+
<td>Medical test simulations</td>
|
| 265 |
+
<td>26K</td>
|
| 266 |
+
</tr>
|
| 267 |
+
<tr>
|
| 268 |
+
<td>Clinical cases</td>
|
| 269 |
+
<td>20K</td>
|
| 270 |
+
</tr>
|
| 271 |
+
</tbody>
|
| 272 |
+
</table>
|
| 273 |
+
|
| 274 |
+
## Evaluation
|
| 275 |
+
|
| 276 |
+
### Medical mT5 for Sequence Labelling
|
| 277 |
+
|
| 278 |
+
We have released two Medical mT5 models finetuned for multilingual sequence labelling.
|
| 279 |
+
<table border="1" cellspacing="0" cellpadding="5">
|
| 280 |
+
<thead>
|
| 281 |
+
<tr>
|
| 282 |
+
<th></th>
|
| 283 |
+
<th><a href="https://huggingface.co/HiTZ/Medical-mT5-large">HiTZ/Medical-mT5-large</a></th>
|
| 284 |
+
<th><a href="https://huggingface.co/HiTZ/Medical-mT5-xl">HiTZ/Medical-mT5-xl</a></th>
|
| 285 |
+
<th><a href="https://huggingface.co/HiTZ/Medical-mT5-large-multitask">HiTZ/Medical-mT5-large-multitask</a></th>
|
| 286 |
+
<th><a href="https://huggingface.co/HiTZ/Medical-mT5-xl-multitask">HiTZ/Medical-mT5-xl-multitask</a></th>
|
| 287 |
+
</tr>
|
| 288 |
+
</thead>
|
| 289 |
+
<tbody>
|
| 290 |
+
<tr>
|
| 291 |
+
<td>Param. no.</td>
|
| 292 |
+
<td>738M</td>
|
| 293 |
+
<td>3B</td>
|
| 294 |
+
<td>738M</td>
|
| 295 |
+
<td>3B</td>
|
| 296 |
+
</tr>
|
| 297 |
+
<tr>
|
| 298 |
+
<td>Task</td>
|
| 299 |
+
<td>Language Modeling</td>
|
| 300 |
+
<td>Language Modeling</td>
|
| 301 |
+
<td>Multitask Sequence Labeling</td>
|
| 302 |
+
<td>Multitask Sequence Labeling</td>
|
| 303 |
+
</tr>
|
| 304 |
+
<tr>
|
| 305 |
+
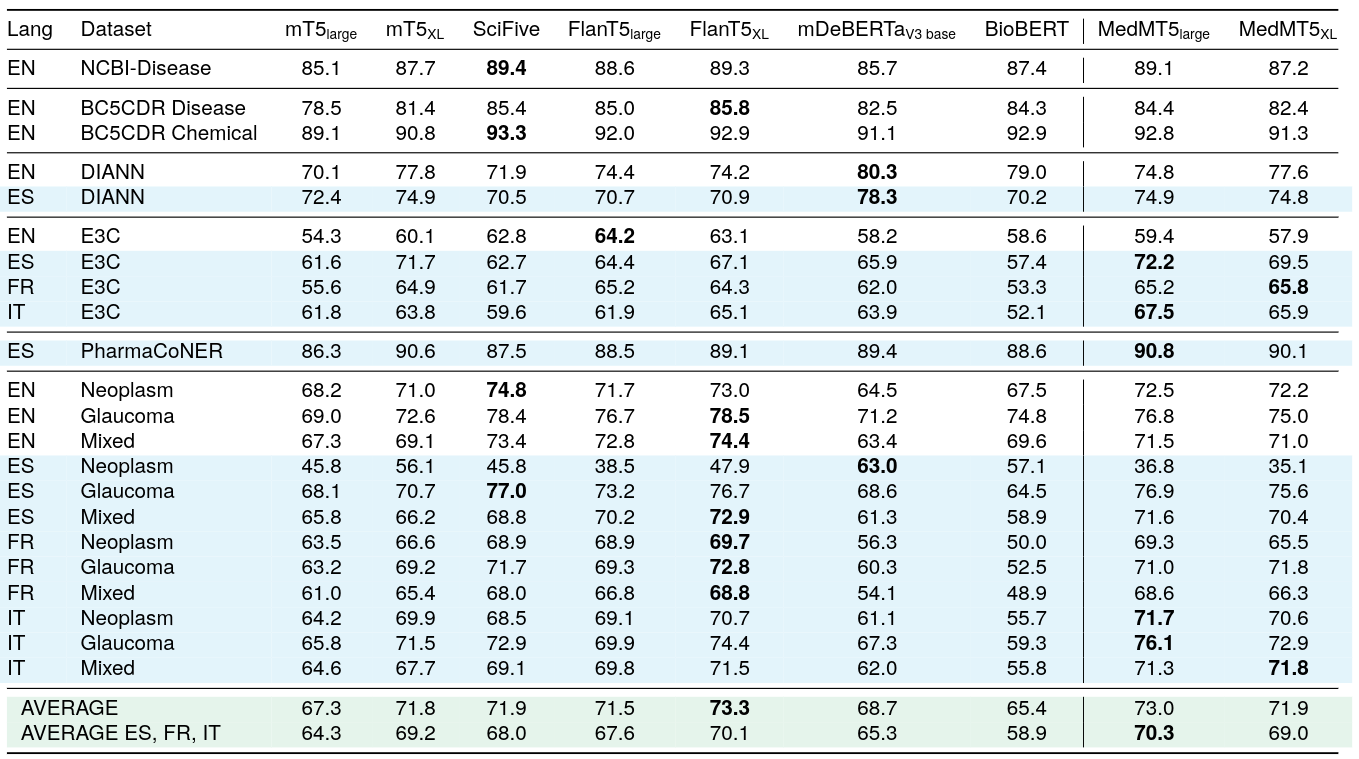
</tbody>
|
| 306 |
+
</table>
|
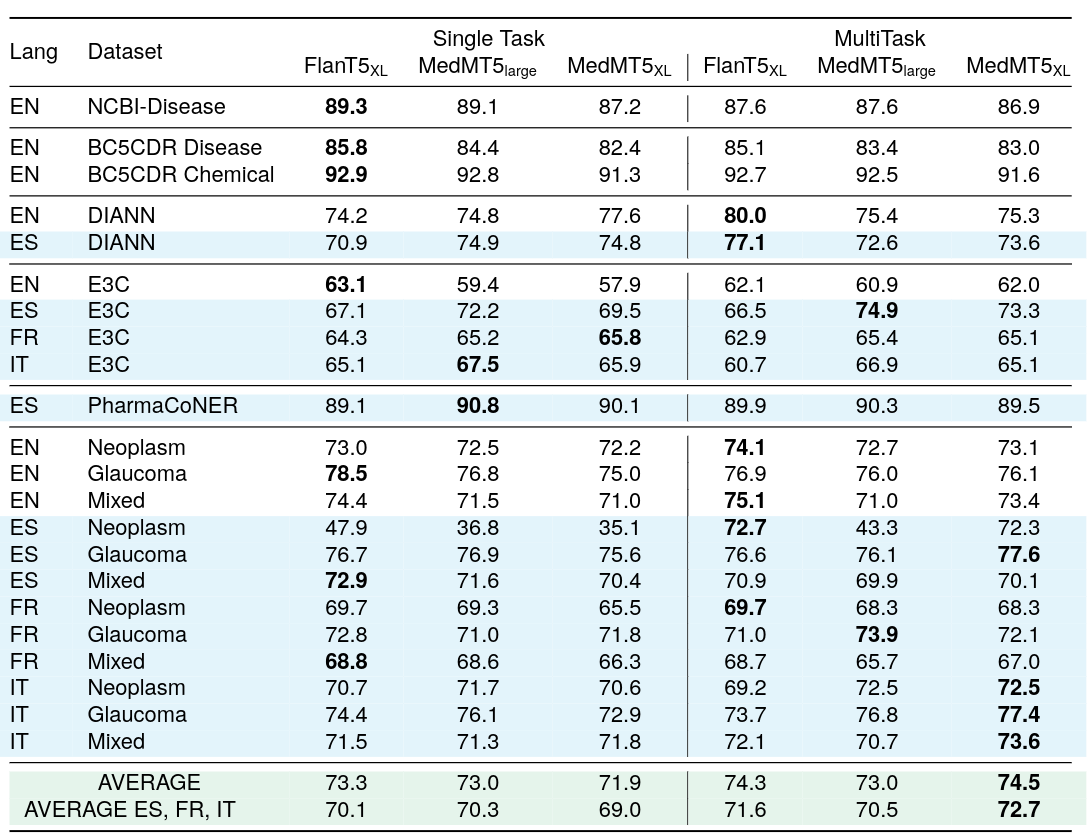
| 307 |
+
|
| 308 |
+
|
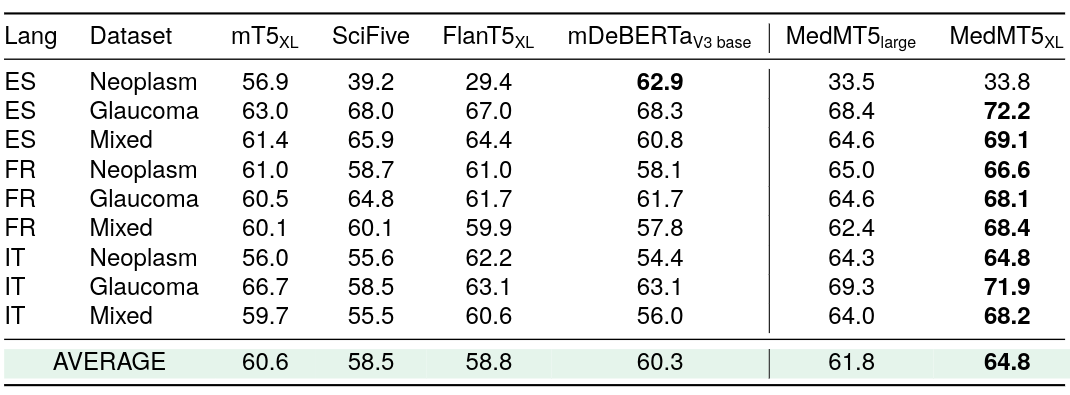
| 309 |
+
|
| 310 |
+
|
| 311 |
+
### Single-task supervised F1 scores for Sequence Labelling
|
| 312 |
+
<p align="center">
|
| 313 |
+
<br>
|
| 314 |
+
<img src="https://huggingface.co/HiTZ/Medical-mT5-large/resolve/main/single.png" style="height: 600px;">
|
| 315 |
+
<br>
|
| 316 |
+
|
| 317 |
+
### Multi-task supervised F1 scores for Sequence Labelling
|
| 318 |
+
<p align="center">
|
| 319 |
+
<br>
|
| 320 |
+
<img src="https://huggingface.co/HiTZ/Medical-mT5-large/resolve/main/multi.png" style="height: 600px;">
|
| 321 |
+
<br>
|
| 322 |
+
|
| 323 |
+
### Zero-shot F1 scores for Argument Mining. Models have been trained in English and evaluated in Spanish, French and Italian.
|
| 324 |
+
<p align="center">
|
| 325 |
+
<br>
|
| 326 |
+
<img src="https://huggingface.co/HiTZ/Medical-mT5-large/resolve/main/cross.png" style="height: 320px;">
|
| 327 |
+
<br>
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
## Ethical Statement
|
| 331 |
+
<p align="justify">
|
| 332 |
+
Our research in developing Medical mT5, a multilingual text-to-text model for the medical domain, has ethical implications that we acknowledge.
|
| 333 |
+
Firstly, the broader impact of this work lies in its potential to improve medical communication and understanding across languages, which
|
| 334 |
+
can enhance healthcare access and quality for diverse linguistic communities. However, it also raises ethical considerations related to privacy and data security.
|
| 335 |
+
To create our multilingual corpus, we have taken measures to anonymize and protect sensitive patient information, adhering to
|
| 336 |
+
data protection regulations in each language's jurisdiction or deriving our data from sources that explicitly address this issue in line with
|
| 337 |
+
privacy and safety regulations and guidelines. Furthermore, we are committed to transparency and fairness in our model's development and evaluation.
|
| 338 |
+
We have worked to ensure that our benchmarks are representative and unbiased, and we will continue to monitor and address any potential biases in the future.
|
| 339 |
+
Finally, we emphasize our commitment to open source by making our data, code, and models publicly available, with the aim of promoting collaboration within
|
| 340 |
+
the research community.
|
| 341 |
+
</p>
|
| 342 |
+
|
| 343 |
+
## Citation
|
| 344 |
+
|
| 345 |
+
```bibtext
|
| 346 |
+
@misc{garcíaferrero2024medical,
|
| 347 |
+
title={Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain},
|
| 348 |
+
author={Iker García-Ferrero and Rodrigo Agerri and Aitziber Atutxa Salazar and Elena Cabrio and Iker de la Iglesia and Alberto Lavelli and Bernardo Magnini and Benjamin Molinet and Johana Ramirez-Romero and German Rigau and Jose Maria Villa-Gonzalez and Serena Villata and Andrea Zaninello},
|
| 349 |
+
year={2024},
|
| 350 |
+
eprint={2404.07613},
|
| 351 |
+
archivePrefix={arXiv},
|
| 352 |
+
primaryClass={cs.CL}
|
| 353 |
+
}
|
| 354 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</s>": 1,
|
| 3 |
+
"<pad>": 0,
|
| 4 |
+
"<unk>": 2
|
| 5 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "medT5-large",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MT5ForConditionalGeneration"
|
| 5 |
+
],
|
| 6 |
+
"classifier_dropout": 0.0,
|
| 7 |
+
"d_ff": 2816,
|
| 8 |
+
"d_kv": 64,
|
| 9 |
+
"d_model": 1024,
|
| 10 |
+
"decoder_start_token_id": 0,
|
| 11 |
+
"dense_act_fn": "gelu_new",
|
| 12 |
+
"dropout_rate": 0.1,
|
| 13 |
+
"eos_token_id": 1,
|
| 14 |
+
"feed_forward_proj": "gated-gelu",
|
| 15 |
+
"initializer_factor": 1.0,
|
| 16 |
+
"is_encoder_decoder": true,
|
| 17 |
+
"is_gated_act": true,
|
| 18 |
+
"layer_norm_epsilon": 1e-06,
|
| 19 |
+
"model_type": "mt5",
|
| 20 |
+
"num_decoder_layers": 24,
|
| 21 |
+
"num_heads": 16,
|
| 22 |
+
"num_layers": 24,
|
| 23 |
+
"output_past": true,
|
| 24 |
+
"pad_token_id": 0,
|
| 25 |
+
"relative_attention_max_distance": 128,
|
| 26 |
+
"relative_attention_num_buckets": 32,
|
| 27 |
+
"tie_word_embeddings": false,
|
| 28 |
+
"tokenizer_class": "T5Tokenizer",
|
| 29 |
+
"torch_dtype": "float32",
|
| 30 |
+
"transformers_version": "4.34.0",
|
| 31 |
+
"use_cache": true,
|
| 32 |
+
"vocab_size": 250112
|
| 33 |
+
}
|
cross.png
ADDED
|
generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"decoder_start_token_id": 0,
|
| 4 |
+
"eos_token_id": 1,
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"transformers_version": "4.34.0"
|
| 7 |
+
}
|
gitattributes
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7f0c40c0334550dd3c2502f360bbe8a95712083a1b346d00245f4591c216c61a
|
| 3 |
+
size 4918393832
|
multi.png
ADDED
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2dce96f7d93fea8a747d3abfd724b2c6f56433dcf491d4c757c4e51f5e6c386b
|
| 3 |
+
size 4918511518
|
single.png
ADDED
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"eos_token": "</s>",
|
| 3 |
+
"pad_token": "<pad>",
|
| 4 |
+
"unk_token": "<unk>"
|
| 5 |
+
}
|
spiece.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ef78f86560d809067d12bac6c09f19a462cb3af3f54d2b8acbba26e1433125d6
|
| 3 |
+
size 4309802
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d842e6af904403ce6bf8ee58faffd9abad1682513c28c27454d81dc67eaf296c
|
| 3 |
+
size 16315149
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<pad>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "</s>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "<unk>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
}
|
| 27 |
+
},
|
| 28 |
+
"additional_special_tokens": [],
|
| 29 |
+
"clean_up_tokenization_spaces": true,
|
| 30 |
+
"eos_token": "</s>",
|
| 31 |
+
"extra_ids": 0,
|
| 32 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 33 |
+
"pad_token": "<pad>",
|
| 34 |
+
"sp_model_kwargs": {},
|
| 35 |
+
"tokenizer_class": "T5Tokenizer",
|
| 36 |
+
"unk_token": "<unk>"
|
| 37 |
+
}
|