

license: apache-2.0
datasets:
- CohereForAI/xP3x
- CohereForAI/aya_dataset
- CohereForAI/aya_collection
- DataProvenanceInitiative/Commercially-Verified-Licenses
- CohereForAI/aya_evaluation_suite
language:
- afr
- amh
- ara
- aze
- bel
- ben
- bul
- cat
- ceb
- ces
- cym
- dan
- deu
- ell
- eng
- epo
- est
- eus
- fin
- fil
- fra
- fry
- gla
- gle
- glg
- guj
- hat
- hau
- heb
- hin
- hun
- hye
- ibo
- ind
- isl
- ita
- jav
- jpn
- kan
- kat
- kaz
- khm
- kir
- kor
- kur
- lao
- lav
- lat
- lit
- ltz
- mal
- mar
- mkd
- mlg
- mlt
- mon
- mri
- msa
- mya
- nep
- nld
- nor
- nso
- nya
- ory
- pan
- pes
- pol
- por
- pus
- ron
- rus
- sin
- slk
- slv
- smo
- sna
- snd
- som
- sot
- spa
- sqi
- srp
- sun
- swa
- swe
- tam
- tel
- tgk
- tha
- tur
- twi
- ukr
- urd
- uzb
- vie
- xho
- yid
- yor
- zho
- zul
metrics:
- accuracy
- bleu
Model Card for Aya 101
Model Summary
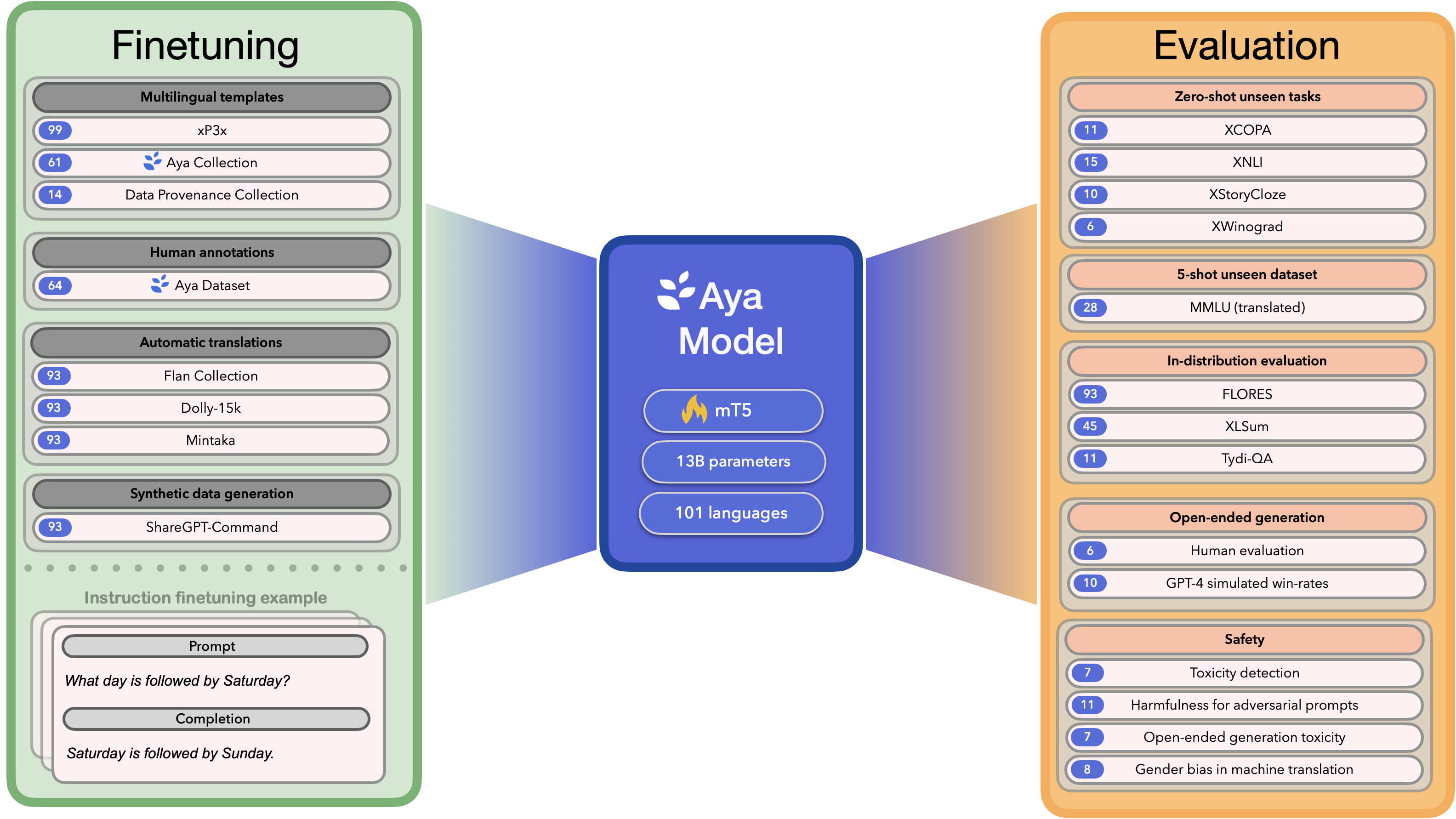
The Aya model is a massively multilingual generative language model that follows instructions in 101 languages. Aya outperforms mT0 and BLOOMZ a wide variety of automatic and human evaluations despite covering double the number of languages. The Aya model is trained using xP3x, Aya Dataset, Aya Collection, a subset of DataProvenance collection and ShareGPT-Command. We release the checkpoints under a Apache-2.0 license to further our mission of multilingual technologies empowering a multilingual world.
- Developed by: Cohere For AI
- Model type: a Transformer style autoregressive massively multilingual language model.
- Paper: Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model
- Point of Contact: Cohere For AI: cohere.for.ai
- Languages: Refer to the list of languages in the
languagesection of this model card. - License: Apache-2.0
- Model: Aya-101
- Model Size: 13 billion parameters
- Datasets: xP3x, Aya Dataset, Aya Collection, DataProvenance collection, ShareGPT-Command.
Use
# pip install -q transformers
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "CohereForAI/aya-101"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
aya_model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
# Turkish to English translation
tur_inputs = tokenizer.encode("Translate to English: Aya cok dilli bir dil modelidir.", return_tensors="pt")
tur_outputs = aya_model.generate(tur_inputs, max_new_tokens=128)
print(tokenizer.decode(tur_outputs[0]))
# Aya is a multi-lingual language model
# Q: Why are there so many languages in India?
hin_inputs = tokenizer.encode("भारत में इतनी सारी भाषाएँ क्यों हैं?", return_tensors="pt")
hin_outputs = aya_model.generate(hin_inputs, max_new_tokens=128)
print(tokenizer.decode(hin_outputs[0]))
# Expected output: भारत में कई भाषाएँ हैं और विभिन्न भाषाओं के बोली जाने वाले लोग हैं। यह विभिन्नता भाषाई विविधता और सांस्कृतिक विविधता का परिणाम है। Translates to "India has many languages and people speaking different languages. This diversity is the result of linguistic diversity and cultural diversity."
Model Details
Finetuning
- Architecture: Same as mt5-xxl
- Number of Samples seen during Finetuning: 25M
- Batch size: 256
- Hardware: TPUv4-128
- Software: T5X, Jax
Data Sources
The Aya model is trained on the following datasets:
- xP3x
- Aya Dataset
- Aya Collection
- DataProvenance collection
- ShareGPT-Command
All datasets are subset to the 101 languages supported by mT5. See the paper for details about filtering and pruning.
Evaluation
We refer to Section 5 from our paper for multilingual eval across 99 languages – including discriminative and generative tasks, human evaluation, and simulated win rates that cover both held-out tasks and in-distribution performance.
Bias, Risks, and Limitations
For a detailed overview of our effort at safety mitigation and benchmarking toxicity and bias across multiple languages, we refer to Sections 6 and 7 of our paper: Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model.
We hope that the release of the Aya model will make community-based redteaming efforts possible, by exposing an open-source massively-multilingual model for community research.
Citation
BibTeX:
@article{üstün2024aya,
title={Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model},
author={Ahmet Üstün and Viraat Aryabumi and Zheng-Xin Yong and Wei-Yin Ko and Daniel D'souza and Gbemileke Onilude and Neel Bhandari and Shivalika Singh and Hui-Lee Ooi and Amr Kayid and Freddie Vargus and Phil Blunsom and Shayne Longpre and Niklas Muennighoff and Marzieh Fadaee and Julia Kreutzer and Sara Hooker},
journal={arXiv preprint arXiv:2402.07827},
year={2024}
}
Languages Covered
Click to see Languages Covered
Below is the list of languages used in finetuning the Aya Model. We group languages into higher-, mid-, and lower-resourcedness based on a language classification by Joshi et. al, 2020. For further details, we refer to our paper
| ISO Code | Language Name | Script | Family | Subgrouping | Resourcedness |
|---|---|---|---|---|---|
| afr | Afrikaans | Latin | Indo-European | Germanic | Mid |
| amh | Amharic | Ge'ez | Afro-Asiatic | Semitic | Low |
| ara | Arabic | Arabic | Afro-Asiatic | Semitic | High |
| aze | Azerbaijani | Arabic/Latin | Turkic | Common Turkic | Low |
| bel | Belarusian | Cyrillic | Indo-European | Balto-Slavic | Mid |
| ben | Bengali | Bengali | Indo-European | Indo-Aryan | Mid |
| bul | Bulgarian | Cyrillic | Indo-European | Balto-Slavic | Mid |
| cat | Catalan | Latin | Indo-European | Italic | High |
| ceb | Cebuano | Latin | Austronesian | Malayo-Polynesian | Mid |
| ces | Czech | Latin | Indo-European | Balto-Slavic | High |
| cym | Welsh | Latin | Indo-European | Celtic | Low |
| dan | Danish | Latin | Indo-European | Germanic | Mid |
| deu | German | Latin | Indo-European | Germanic | High |
| ell | Greek | Greek | Indo-European | Graeco-Phrygian | Mid |
| eng | English | Latin | Indo-European | Germanic | High |
| epo | Esperanto | Latin | Constructed | Esperantic | Low |
| est | Estonian | Latin | Uralic | Finnic | Mid |
| eus | Basque | Latin | Basque | - | High |
| fin | Finnish | Latin | Uralic | Finnic | High |
| fil | Tagalog | Latin | Austronesian | Malayo-Polynesian | Mid |
| fra | French | Latin | Indo-European | Italic | High |
| fry | Western Frisian | Latin | Indo-European | Germanic | Low |
| gla | Scottish Gaelic | Latin | Indo-European | Celtic | Low |
| gle | Irish | Latin | Indo-European | Celtic | Low |
| glg | Galician | Latin | Indo-European | Italic | Mid |
| guj | Gujarati | Gujarati | Indo-European | Indo-Aryan | Low |
| hat | Haitian Creole | Latin | Indo-European | Italic | Low |
| hau | Hausa | Latin | Afro-Asiatic | Chadic | Low |
| heb | Hebrew | Hebrew | Afro-Asiatic | Semitic | Mid |
| hin | Hindi | Devanagari | Indo-European | Indo-Aryan | High |
| hun | Hungarian | Latin | Uralic | - | High |
| hye | Armenian | Armenian | Indo-European | Armenic | Low |
| ibo | Igbo | Latin | Atlantic-Congo | Benue-Congo | Low |
| ind | Indonesian | Latin | Austronesian | Malayo-Polynesian | Mid |
| isl | Icelandic | Latin | Indo-European | Germanic | Low |
| ita | Italian | Latin | Indo-European | Italic | High |
| jav | Javanese | Latin | Austronesian | Malayo-Polynesian | Low |
| jpn | Japanese | Japanese | Japonic | Japanesic | High |
| kan | Kannada | Kannada | Dravidian | South Dravidian | Low |
| kat | Georgian | Georgian | Kartvelian | Georgian-Zan | Mid |
| kaz | Kazakh | Cyrillic | Turkic | Common Turkic | Mid |
| khm | Khmer | Khmer | Austroasiatic | Khmeric | Low |
| kir | Kyrgyz | Cyrillic | Turkic | Common Turkic | Low |
| kor | Korean | Hangul | Koreanic | Korean | High |
| kur | Kurdish | Latin | Indo-European | Iranian | Low |
| lao | Lao | Lao | Tai-Kadai | Kam-Tai | Low |
| lav | Latvian | Latin | Indo-European | Balto-Slavic | Mid |
| lat | Latin | Latin | Indo-European | Italic | Mid |
| lit | Lithuanian | Latin | Indo-European | Balto-Slavic | Mid |
| ltz | Luxembourgish | Latin | Indo-European | Germanic | Low |
| mal | Malayalam | Malayalam | Dravidian | South Dravidian | Low |
| mar | Marathi | Devanagari | Indo-European | Indo-Aryan | Low |
| mkd | Macedonian | Cyrillic | Indo-European | Balto-Slavic | Low |
| mlg | Malagasy | Latin | Austronesian | Malayo-Polynesian | Low |
| mlt | Maltese | Latin | Afro-Asiatic | Semitic | Low |
| mon | Mongolian | Cyrillic | Mongolic-Khitan | Mongolic | Low |
| mri | Maori | Latin | Austronesian | Malayo-Polynesian | Low |
| msa | Malay | Latin | Austronesian | Malayo-Polynesian | Mid |
| mya | Burmese | Myanmar | Sino-Tibetan | Burmo-Qiangic | Low |
| nep | Nepali | Devanagari | Indo-European | Indo-Aryan | Low |
| nld | Dutch | Latin | Indo-European | Germanic | High |
| nor | Norwegian | Latin | Indo-European | Germanic | Low |
| nso | Northern Sotho | Latin | Atlantic-Congo | Benue-Congo | Low |
| nya | Chichewa | Latin | Atlantic-Congo | Benue-Congo | Low |
| ory | Oriya | Oriya | Indo-European | Indo-Aryan | Low |
| pan | Punjabi | Gurmukhi | Indo-European | Indo-Aryan | Low |
| pes | Persian | Arabic | Indo-European | Iranian | High |
| pol | Polish | Latin | Indo-European | Balto-Slavic | High |
| por | Portuguese | Latin | Indo-European | Italic | High |
| pus | Pashto | Arabic | Indo-European | Iranian | Low |
| ron | Romanian | Latin | Indo-European | Italic | Mid |
| rus | Russian | Cyrillic | Indo-European | Balto-Slavic | High |
| sin | Sinhala | Sinhala | Indo-European | Indo-Aryan | Low |
| slk | Slovak | Latin | Indo-European | Balto-Slavic | Mid |
| slv | Slovenian | Latin | Indo-European | Balto-Slavic | Mid |
| smo | Samoan | Latin | Austronesian | Malayo-Polynesian | Low |
| sna | Shona | Latin | Indo-European | Indo-Aryan | Low |
| snd | Sindhi | Arabic | Indo-European | Indo-Aryan | Low |
| som | Somali | Latin | Afro-Asiatic | Cushitic | Low |
| sot | Southern Sotho | Latin | Atlantic-Congo | Benue-Congo | Low |
| spa | Spanish | Latin | Indo-European | Italic | High |
| sqi | Albanian | Latin | Indo-European | Albanian | Low |
| srp | Serbian | Cyrillic | Indo-European | Balto-Slavic | High |
| sun | Sundanese | Latin | Austronesian | Malayo-Polynesian | Low |
| swa | Swahili | Latin | Atlantic-Congo | Benue-Congo | Low |
| swe | Swedish | Latin | Indo-European | Germanic | High |
| tam | Tamil | Tamil | Dravidian | South Dravidian | Mid |
| tel | Telugu | Telugu | Dravidian | South Dravidian | Low |
| tgk | Tajik | Cyrillic | Indo-European | Iranian | Low |
| tha | Thai | Thai | Tai-Kadai | Kam-Tai | Mid |
| tur | Turkish | Latin | Turkic | Common Turkic | High |
| twi | Twi | Latin | Atlantic-Congo | Niger-Congo | Low |
| ukr | Ukrainian | Cyrillic | Indo-European | Balto-Slavic | Mid |
| urd | Urdu | Arabic | Indo-European | Indo-Aryan | Mid |
| uzb | Uzbek | Latin | Turkic | Common Turkic | Mid |
| vie | Vietnamese | Latin | Austroasiatic | Vietic | High |
| xho | Xhosa | Latin | Atlantic-Congo | Benue-Congo | Low |
| yid | Yiddish | Hebrew | Indo-European | Germanic | Low |
| yor | Yoruba | Latin | Atlantic-Congo | Benue-Congo | Low |
| zho | Chinese | Han | Sino-Tibetan | Sinitic | High |
| zul | Zulu | Latin | Atlantic-Congo | Benue-Congo | Low |
Model Card Contact
For errors in this model card, contact Ahmet or Viraat, {ahmet, viraat} at cohere dot com.