
license: mit
metrics:
- accuracy
pipeline_tag: image-segmentation
tags:
- medical
[OTO–HNS2024] A Deep Learning Framework for Analysis of the Eustachian Tube and the Internal Carotid Artery
Ameen Amanian, Aseem Jain, Yuliang Xiao, Chanha Kim, Andy S. Ding, Manish Sahu, Russell Taylor, Mathias Unberath, Bryan K. Ward, Deepa Galaiya, Masaru Ishii, Francis X. Creighton
News | Abstract | Installation | Train | Inference | Evaluation
News
2024.04.30 - The data preprocessing , training, inference, and evaluation code are released.
2024.04.05 - Our paper is accepted to American Academy of Otolaryngology–Head and Neck Surgery 2024 (OTO-HNS2024).
Abstract
Objective: Obtaining automated, objective 3-dimensional (3D) models of the Eustachian tube (ET) and the internal carotid artery (ICA) from computed tomography (CT) scans could provide useful navigational and diagnostic information for ET pathologies and interventions. We aim to develop a deep learning (DL) pipeline to automatically segment the ET and ICA and use these segmentations to compute distances between these structures.
Methods: From a database of 30 CT scans, 60 ET and ICA pairs were manually segmented and used to train an nnU-Net model, a DL segmentation framework. These segmentations were also used to develop a quantitative tool to capture the magnitude and location of the minimum distance point (MDP) between ET and ICA. Performance metrics for the nnU-Net automated segmentations were calculated via the average Hausdorff distance (AHD) and dice similarity coefficient (DSC).
Results: The AHD for the ETand ICA were 0.922 and 0.246 mm, respectively. Similarly, the DSC values for the ET and ICA were 0.578 and 0.884. The mean MDP from ET to ICA in the cartilaginous region was 2.6 mm (0.7-5.3 mm) and was located on average 1.9 mm caudal from the bony cartilaginous junction.
Conclusion: This study describes the first end-to-end DL pipeline for automated ET and ICA segmentation and analyzes distances between these structures. In addition to helping to ensure the safe selection of patients for ET dilation, this method can facilitate large-scale studies exploring the relationship between ET pathologies and the 3D shape of the ET.
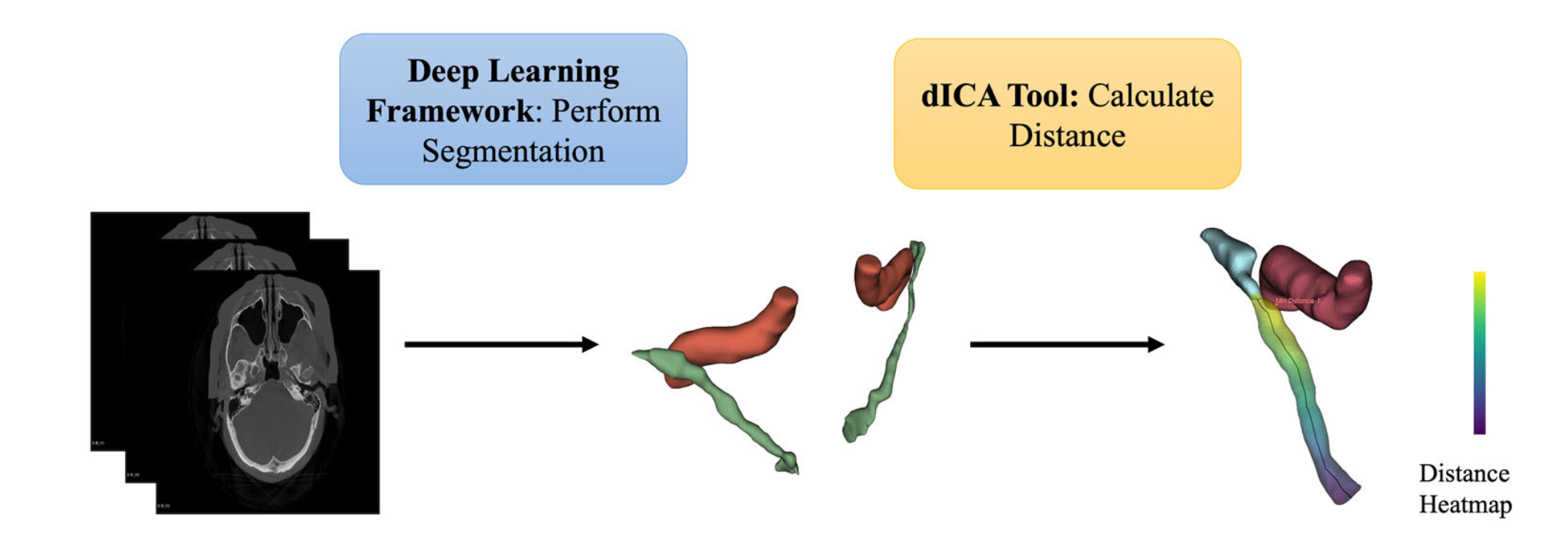 Figure 1: Overview of Workflow
Figure 1: Overview of Workflow
Installation
Step 1: Fork This GitHub Repository
git clone https://huggingface.co/ChrisXiao/AutoSeg4ETICA && cd AutoSeg4ETICA
Step 2: Set Up Two Environments Using requirements.txt Files (virtual environment is recommended)
pip install -r requirements.txt
source /path/to/VIRTUAL_ENVIRONMENT/bin/activate
Preprocessing
Step 1: Register Data to Template
cd <path to repo>/preprocessing
Register data to template (can be used for multiple segmentations propagation)
python registration.py -bp <full path of base dir> -ip <relative path to nifti images dir> -sp <relative path to segmentations dir>
If you want to make sure correspondence of the name and value of segmentations, you can add the following commands after above command
-sl LabelValue1 LabelName1 LabelValue2 LabelName2 LabelValue3 LabelName3 ...
For example, if I have two labels for maxillary sinus named L-MS and R-MS
python registration.py -bp /Users/mikamixiao/Desktop -ip images -sp labels -sl 1 L-MS 2 R-MS
Final output of registered images and segmentations will be saved in
imagesRS/ && labelsRS/
Step 2: Create Datasplit for Training/Testing. Validation will be chosen automatically by nnUNet (filename format should be taskname_xxx.nii.gz)
python split_data.py -bp <full path of base dir> -ip <relative path to nifti images dir (imagesRS)> -sp <relative path to nifti segmentations dir (labelsRS)> -sl <a list of label name and corresponding label value> -ti <task id for nnUNet preprocessing> -tn <name of task>
For example
python split_data.py -bp /Users/mikamixiao/Desktop -ip imagesRS -sp labelsRS -sl 1 L-MS 2 R-MS -ti 001 -tn Sinus
Step 3: Setup Bashrc
Edit your ~/.bashrc file with gedit ~/.bashrc or nano ~/.bashrc. At the end of the file, add the following lines:
export nnUNet_raw_data_base="<ABSOLUTE PATH TO BASE_DIR>/nnUnet/nnUNet_raw_data_base"
export nnUNet_preprocessed="<ABSOLUTE PATH TO BASE_DIR>/nnUNet_preprocessed"
export RESULTS_FOLDER="<ABSOLUTE PATH TO BASE_DIR>/nnUnet/nnUNet_trained_models"
After updating this you will need to source your ~/.bashrc file.
source ~/.bashrc
This will deactivate your current conda environment.
Step 4: Verify and Preprocess Data
Activate nnUNet environment
source /path/to/VIRTUAL_ENVIRONMENT/bin/activate
Run nnUNet preprocessing script.
nnUNet_plan_and_preprocess -t <task_id> --verify_dataset_integrity
Potential Error: You may need to edit the dataset.json file so that the labels are sequential. If you have at least 10 labels, then labels 10, 11, 12,... will be arranged before labels 2, 3, 4, .... Doing this in a text editor is completely fine!
Train
To train the model:
nnUNet_train 3d_fullres nnUNetTrainerV2 Task<task_num>_TemporalBone Y --npz
Y refers to the number of folds for cross-validation. If Y is set to all then all of the data will be used for training. If you want to try 5-folds cross validation, you should define Y as 0, 1, 2, 3, 4 for five times.
--npz makes the models save the softmax outputs (uncompressed, large files) during the final validation. It should only be used if you are training multiple configurations, which requires nnUNet_find_best_configuration to find the best model. We omit this by default.
Inference
To run inference on trained checkpoints and obtain evaluation results:
nnUNet_find_best_configuration will print a string to the terminal with the inference commands you need to use.
The easiest way to run inference is to simply use these commands.
If you wish to manually specify the configuration(s) used for inference, use the following commands:
For each of the desired configurations, run:
nnUNet_predict -i INPUT_FOLDER -o OUTPUT_FOLDER -t TASK_NAME_OR_ID -m CONFIGURATION --save_npz
Only specify --save_npz if you intend to use ensembling. --save_npz will make the command save the softmax
probabilities alongside of the predicted segmentation masks requiring a lot of disk space.
Please select a separate OUTPUT_FOLDER for each configuration!
If you wish to run ensembling, you can ensemble the predictions from several configurations with the following command:
nnUNet_ensemble -f FOLDER1 FOLDER2 ... -o OUTPUT_FOLDER -pp POSTPROCESSING_FILE
You can specify an arbitrary number of folders, but remember that each folder needs to contain npz files that were
generated by nnUNet_predict. For ensembling you can also specify a file that tells the command how to postprocess.
These files are created when running nnUNet_find_best_configuration and are located in the respective trained model directory (RESULTS_FOLDER/nnUNet/CONFIGURATION/TaskXXX_MYTASK/TRAINER_CLASS_NAME__PLANS_FILE_IDENTIFIER/postprocessing.json or RESULTS_FOLDER/nnUNet/ensembles/TaskXXX_MYTASK/ensemble_X__Y__Z--X__Y__Z/postprocessing.json). You can also choose to not provide a file (simply omit -pp) and nnU-Net will not run postprocessing.
Note that per default, inference will be done with all available folds. We very strongly recommend you use all 5 folds. Thus, all 5 folds must have been trained prior to running inference. The list of available folds nnU-Net found will be printed at the start of the inference.
Evaluation
To compute the dice score, average hausdorff distance and weighted hausdorff distance:
cd <path to repo>/metrics
Run the metrics.py to output a CSV file that contain the dice score and hausdorff distance for each segmentation:
python metrics.py -bp <full path of base dir> -gp <relative path of ground truth dir> -pp <relative path of predicted segmentations dir> -sp <save dir> -vt <Validation type: 'dsc', 'ahd', 'whd'>
Users can choose any combinations of evaluation types among these three choices.
dsc: Dice Score
ahd: Average Hausdorff Distance
whd: Weighted Hausdorff Distance
If choosing whd and you do not have a probability map, you can use get_probability_map.pyto obtain one. Here is the way to use:
python get_probability_map.py -bp <full path of base dir> -pp <relative path of predicted segmentations dir> -rr <ratio to split skeleton> -ps <probability sequences>
Currently, we split the skeleton alongside the x axis and from ear end to nasal. Please make sure the probability sequences are matched to the splitted regions. The output probability map which is a text file will be stored in output/under the base directory. Once obtaining the probability map, you can import your customized probability map by adding following command when using metrics.py:
-pm <relative path of probability map>
To draw the heat map to see the failing part of prediction:
python distanceVertex2Mesh.py -bp <full path of base dir> -gp <relative path of ground truth dir> -pp <relative path of predicted segmentations dir>
Once you get the closest distance (save in output/ under base directory) from prediction to ground truth, you can easily draw the heat map and use the color bar to show the change of differences (ParaView is recommended)
Citing Paper
If you find this paper helpful, please consider citing:
@article{amanian2024deep,
title={A Deep Learning Framework for Analysis of the Eustachian Tube and the Internal Carotid Artery},
author={Amanian, Ameen and Jain, Aseem and Xiao, Yuliang and Kim, Chanha and Ding, Andy S and Sahu, Manish and Taylor, Russell and Unberath, Mathias and Ward, Bryan K and Galaiya, Deepa and others},
journal={Otolaryngology--Head and Neck Surgery},
publisher={Wiley Online Library}
}