
Upload 7 files
Browse files- README.md +276 -0
- pytorch_model-00001-of-00005.bin +3 -0
- pytorch_model-00002-of-00005.bin +3 -0
- pytorch_model-00003-of-00005.bin +3 -0
- pytorch_model-00004-of-00005.bin +3 -0
- pytorch_model-00005-of-00005.bin +3 -0
- pytorch_model.bin.index.json +567 -0
README.md
ADDED
|
@@ -0,0 +1,276 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
- fr
|
| 5 |
+
- ro
|
| 6 |
+
- de
|
| 7 |
+
- multilingual
|
| 8 |
+
|
| 9 |
+
widget:
|
| 10 |
+
- text: "Translate to German: My name is Arthur"
|
| 11 |
+
example_title: "Translation"
|
| 12 |
+
- text: "Please answer to the following question. Who is going to be the next Ballon d'or?"
|
| 13 |
+
example_title: "Question Answering"
|
| 14 |
+
- text: "Q: Can Geoffrey Hinton have a conversation with George Washington? Give the rationale before answering."
|
| 15 |
+
example_title: "Logical reasoning"
|
| 16 |
+
- text: "Please answer the following question. What is the boiling point of Nitrogen?"
|
| 17 |
+
example_title: "Scientific knowledge"
|
| 18 |
+
- text: "Answer the following yes/no question. Can you write a whole Haiku in a single tweet?"
|
| 19 |
+
example_title: "Yes/no question"
|
| 20 |
+
- text: "Answer the following yes/no question by reasoning step-by-step. Can you write a whole Haiku in a single tweet?"
|
| 21 |
+
example_title: "Reasoning task"
|
| 22 |
+
- text: "Q: ( False or not False or False ) is? A: Let's think step by step"
|
| 23 |
+
example_title: "Boolean Expressions"
|
| 24 |
+
- text: "The square root of x is the cube root of y. What is y to the power of 2, if x = 4?"
|
| 25 |
+
example_title: "Math reasoning"
|
| 26 |
+
- text: "Premise: At my age you will probably have learnt one lesson. Hypothesis: It's not certain how many lessons you'll learn by your thirties. Does the premise entail the hypothesis?"
|
| 27 |
+
example_title: "Premise and hypothesis"
|
| 28 |
+
|
| 29 |
+
tags:
|
| 30 |
+
- text2text-generation
|
| 31 |
+
|
| 32 |
+
datasets:
|
| 33 |
+
- svakulenk0/qrecc
|
| 34 |
+
- taskmaster2
|
| 35 |
+
- djaym7/wiki_dialog
|
| 36 |
+
- deepmind/code_contests
|
| 37 |
+
- lambada
|
| 38 |
+
- gsm8k
|
| 39 |
+
- aqua_rat
|
| 40 |
+
- esnli
|
| 41 |
+
- quasc
|
| 42 |
+
- qed
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
license: apache-2.0
|
| 46 |
+
---
|
| 47 |
+
|
| 48 |
+
# Model Card for FLAN-T5 XXL
|
| 49 |
+
|
| 50 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/flan2_architecture.jpg"
|
| 51 |
+
alt="drawing" width="600"/>
|
| 52 |
+
|
| 53 |
+
# Table of Contents
|
| 54 |
+
|
| 55 |
+
0. [TL;DR](#TL;DR)
|
| 56 |
+
1. [Model Details](#model-details)
|
| 57 |
+
2. [Usage](#usage)
|
| 58 |
+
3. [Uses](#uses)
|
| 59 |
+
4. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
|
| 60 |
+
5. [Training Details](#training-details)
|
| 61 |
+
6. [Evaluation](#evaluation)
|
| 62 |
+
7. [Environmental Impact](#environmental-impact)
|
| 63 |
+
8. [Citation](#citation)
|
| 64 |
+
|
| 65 |
+
# TL;DR
|
| 66 |
+
|
| 67 |
+
If you already know T5, FLAN-T5 is just better at everything. For the same number of parameters, these models have been fine-tuned on more than 1000 additional tasks covering also more languages.
|
| 68 |
+
As mentioned in the first few lines of the abstract :
|
| 69 |
+
> Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints,1 which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
|
| 70 |
+
|
| 71 |
+
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the [T5 model card](https://huggingface.co/t5-large).
|
| 72 |
+
|
| 73 |
+
# Model Details
|
| 74 |
+
|
| 75 |
+
## Model Description
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
- **Model type:** Language model
|
| 79 |
+
- **Language(s) (NLP):** English, German, French
|
| 80 |
+
- **License:** Apache 2.0
|
| 81 |
+
- **Related Models:** [All FLAN-T5 Checkpoints](https://huggingface.co/models?search=flan-t5)
|
| 82 |
+
- **Original Checkpoints:** [All Original FLAN-T5 Checkpoints](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints)
|
| 83 |
+
- **Resources for more information:**
|
| 84 |
+
- [Research paper](https://arxiv.org/pdf/2210.11416.pdf)
|
| 85 |
+
- [GitHub Repo](https://github.com/google-research/t5x)
|
| 86 |
+
- [Hugging Face FLAN-T5 Docs (Similar to T5) ](https://huggingface.co/docs/transformers/model_doc/t5)
|
| 87 |
+
|
| 88 |
+
# Usage
|
| 89 |
+
|
| 90 |
+
Find below some example scripts on how to use the model in `transformers`:
|
| 91 |
+
|
| 92 |
+
## Using the Pytorch model
|
| 93 |
+
|
| 94 |
+
### Running the model on a CPU
|
| 95 |
+
|
| 96 |
+
<details>
|
| 97 |
+
<summary> Click to expand </summary>
|
| 98 |
+
|
| 99 |
+
```python
|
| 100 |
+
|
| 101 |
+
from transformers import T5Tokenizer, T5ForConditionalGeneration
|
| 102 |
+
|
| 103 |
+
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
|
| 104 |
+
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl")
|
| 105 |
+
|
| 106 |
+
input_text = "translate English to German: How old are you?"
|
| 107 |
+
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
|
| 108 |
+
|
| 109 |
+
outputs = model.generate(input_ids)
|
| 110 |
+
print(tokenizer.decode(outputs[0]))
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
</details>
|
| 114 |
+
|
| 115 |
+
### Running the model on a GPU
|
| 116 |
+
|
| 117 |
+
<details>
|
| 118 |
+
<summary> Click to expand </summary>
|
| 119 |
+
|
| 120 |
+
```python
|
| 121 |
+
# pip install accelerate
|
| 122 |
+
from transformers import T5Tokenizer, T5ForConditionalGeneration
|
| 123 |
+
|
| 124 |
+
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
|
| 125 |
+
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto")
|
| 126 |
+
|
| 127 |
+
input_text = "translate English to German: How old are you?"
|
| 128 |
+
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
|
| 129 |
+
|
| 130 |
+
outputs = model.generate(input_ids)
|
| 131 |
+
print(tokenizer.decode(outputs[0]))
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
</details>
|
| 135 |
+
|
| 136 |
+
### Running the model on a GPU using different precisions
|
| 137 |
+
|
| 138 |
+
#### FP16
|
| 139 |
+
|
| 140 |
+
<details>
|
| 141 |
+
<summary> Click to expand </summary>
|
| 142 |
+
|
| 143 |
+
```python
|
| 144 |
+
# pip install accelerate
|
| 145 |
+
import torch
|
| 146 |
+
from transformers import T5Tokenizer, T5ForConditionalGeneration
|
| 147 |
+
|
| 148 |
+
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
|
| 149 |
+
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto", torch_dtype=torch.float16)
|
| 150 |
+
|
| 151 |
+
input_text = "translate English to German: How old are you?"
|
| 152 |
+
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
|
| 153 |
+
|
| 154 |
+
outputs = model.generate(input_ids)
|
| 155 |
+
print(tokenizer.decode(outputs[0]))
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
</details>
|
| 159 |
+
|
| 160 |
+
#### INT8
|
| 161 |
+
|
| 162 |
+
<details>
|
| 163 |
+
<summary> Click to expand </summary>
|
| 164 |
+
|
| 165 |
+
```python
|
| 166 |
+
# pip install bitsandbytes accelerate
|
| 167 |
+
from transformers import T5Tokenizer, T5ForConditionalGeneration
|
| 168 |
+
|
| 169 |
+
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
|
| 170 |
+
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto", load_in_8bit=True)
|
| 171 |
+
|
| 172 |
+
input_text = "translate English to German: How old are you?"
|
| 173 |
+
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
|
| 174 |
+
|
| 175 |
+
outputs = model.generate(input_ids)
|
| 176 |
+
print(tokenizer.decode(outputs[0]))
|
| 177 |
+
```
|
| 178 |
+
|
| 179 |
+
</details>
|
| 180 |
+
|
| 181 |
+
# Uses
|
| 182 |
+
|
| 183 |
+
## Direct Use and Downstream Use
|
| 184 |
+
|
| 185 |
+
The authors write in [the original paper's model card](https://arxiv.org/pdf/2210.11416.pdf) that:
|
| 186 |
+
|
| 187 |
+
> The primary use is research on language models, including: research on zero-shot NLP tasks and in-context few-shot learning NLP tasks, such as reasoning, and question answering; advancing fairness and safety research, and understanding limitations of current large language models
|
| 188 |
+
|
| 189 |
+
See the [research paper](https://arxiv.org/pdf/2210.11416.pdf) for further details.
|
| 190 |
+
|
| 191 |
+
## Out-of-Scope Use
|
| 192 |
+
|
| 193 |
+
More information needed.
|
| 194 |
+
|
| 195 |
+
# Bias, Risks, and Limitations
|
| 196 |
+
|
| 197 |
+
The information below in this section are copied from the model's [official model card](https://arxiv.org/pdf/2210.11416.pdf):
|
| 198 |
+
|
| 199 |
+
> Language models, including Flan-T5, can potentially be used for language generation in a harmful way, according to Rae et al. (2021). Flan-T5 should not be used directly in any application, without a prior assessment of safety and fairness concerns specific to the application.
|
| 200 |
+
|
| 201 |
+
## Ethical considerations and risks
|
| 202 |
+
|
| 203 |
+
> Flan-T5 is fine-tuned on a large corpus of text data that was not filtered for explicit content or assessed for existing biases. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
|
| 204 |
+
|
| 205 |
+
## Known Limitations
|
| 206 |
+
|
| 207 |
+
> Flan-T5 has not been tested in real world applications.
|
| 208 |
+
|
| 209 |
+
## Sensitive Use:
|
| 210 |
+
|
| 211 |
+
> Flan-T5 should not be applied for any unacceptable use cases, e.g., generation of abusive speech.
|
| 212 |
+
|
| 213 |
+
# Training Details
|
| 214 |
+
|
| 215 |
+
## Training Data
|
| 216 |
+
|
| 217 |
+
The model was trained on a mixture of tasks, that includes the tasks described in the table below (from the original paper, figure 2):
|
| 218 |
+
|
| 219 |
+
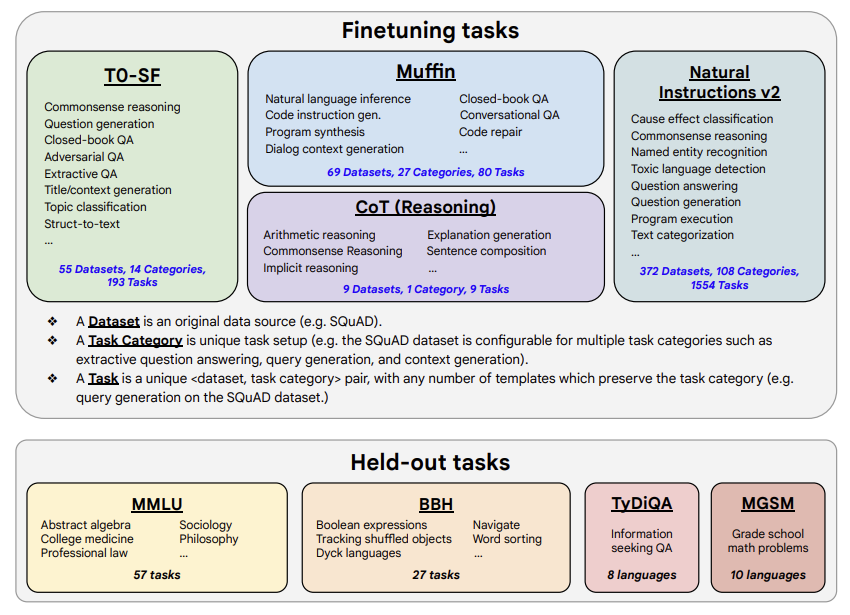
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
## Training Procedure
|
| 223 |
+
|
| 224 |
+
According to the model card from the [original paper](https://arxiv.org/pdf/2210.11416.pdf):
|
| 225 |
+
|
| 226 |
+
> These models are based on pretrained T5 (Raffel et al., 2020) and fine-tuned with instructions for better zero-shot and few-shot performance. There is one fine-tuned Flan model per T5 model size.
|
| 227 |
+
|
| 228 |
+
The model has been trained on TPU v3 or TPU v4 pods, using [`t5x`](https://github.com/google-research/t5x) codebase together with [`jax`](https://github.com/google/jax).
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
# Evaluation
|
| 232 |
+
|
| 233 |
+
## Testing Data, Factors & Metrics
|
| 234 |
+
|
| 235 |
+
The authors evaluated the model on various tasks covering several languages (1836 in total). See the table below for some quantitative evaluation:
|
| 236 |
+
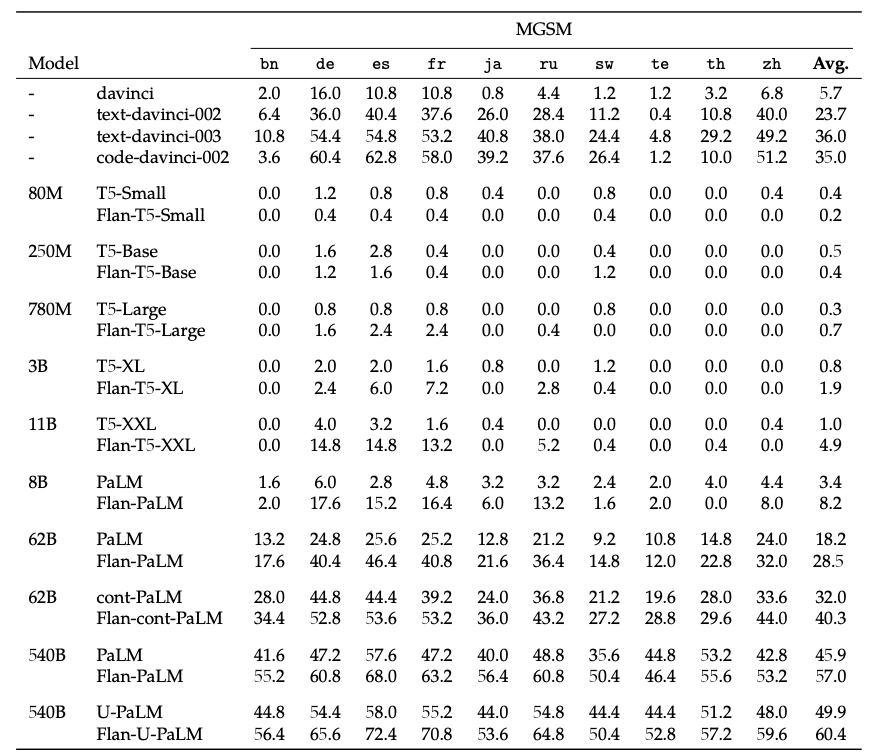
|
| 237 |
+
For full details, please check the [research paper](https://arxiv.org/pdf/2210.11416.pdf).
|
| 238 |
+
|
| 239 |
+
## Results
|
| 240 |
+
|
| 241 |
+
For full results for FLAN-T5-XXL, see the [research paper](https://arxiv.org/pdf/2210.11416.pdf), Table 3.
|
| 242 |
+
|
| 243 |
+
# Environmental Impact
|
| 244 |
+
|
| 245 |
+
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 246 |
+
|
| 247 |
+
- **Hardware Type:** Google Cloud TPU Pods - TPU v3 or TPU v4 | Number of chips ≥ 4.
|
| 248 |
+
- **Hours used:** More information needed
|
| 249 |
+
- **Cloud Provider:** GCP
|
| 250 |
+
- **Compute Region:** More information needed
|
| 251 |
+
- **Carbon Emitted:** More information needed
|
| 252 |
+
|
| 253 |
+
# Citation
|
| 254 |
+
|
| 255 |
+
**BibTeX:**
|
| 256 |
+
|
| 257 |
+
```bibtex
|
| 258 |
+
@misc{https://doi.org/10.48550/arxiv.2210.11416,
|
| 259 |
+
doi = {10.48550/ARXIV.2210.11416},
|
| 260 |
+
|
| 261 |
+
url = {https://arxiv.org/abs/2210.11416},
|
| 262 |
+
|
| 263 |
+
author = {Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Eric and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Narang, Sharan and Mishra, Gaurav and Yu, Adams and Zhao, Vincent and Huang, Yanping and Dai, Andrew and Yu, Hongkun and Petrov, Slav and Chi, Ed H. and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V. and Wei, Jason},
|
| 264 |
+
|
| 265 |
+
keywords = {Machine Learning (cs.LG), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
|
| 266 |
+
|
| 267 |
+
title = {Scaling Instruction-Finetuned Language Models},
|
| 268 |
+
|
| 269 |
+
publisher = {arXiv},
|
| 270 |
+
|
| 271 |
+
year = {2022},
|
| 272 |
+
|
| 273 |
+
copyright = {Creative Commons Attribution 4.0 International}
|
| 274 |
+
}
|
| 275 |
+
```
|
| 276 |
+
|
pytorch_model-00001-of-00005.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0e59f5b92cddafc7352b236b6cb5d1eac010712cae9ed23be81caf701255e719
|
| 3 |
+
size 9452284099
|
pytorch_model-00002-of-00005.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:685334dbb04020ebe63f1d10c6d1401d8fc11dc650fd83582311dc8a3d7c9f1f
|
| 3 |
+
size 9597030149
|
pytorch_model-00003-of-00005.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:25fbb7a31f026dece0c7db7fb997f4b658c45ef36e748d653dccac4b1625759d
|
| 3 |
+
size 9955673595
|
pytorch_model-00004-of-00005.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fe2d4605b8d1dd52feb8963df9d2b377d6a4dcbdcc8a41cdd49022214cfcaeb5
|
| 3 |
+
size 9999740781
|
pytorch_model-00005-of-00005.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ae0643b508fcd5cbe22447d588c12ddb81e04f451acc92e63ed0ecdfa4fc7080
|
| 3 |
+
size 6063168980
|
pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,567 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 45594099712
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"decoder.block.0.layer.0.SelfAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 7 |
+
"decoder.block.0.layer.0.SelfAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 8 |
+
"decoder.block.0.layer.0.SelfAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 9 |
+
"decoder.block.0.layer.0.SelfAttention.relative_attention_bias.weight": "pytorch_model-00003-of-00005.bin",
|
| 10 |
+
"decoder.block.0.layer.0.SelfAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 11 |
+
"decoder.block.0.layer.0.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 12 |
+
"decoder.block.0.layer.1.EncDecAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 13 |
+
"decoder.block.0.layer.1.EncDecAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 14 |
+
"decoder.block.0.layer.1.EncDecAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 15 |
+
"decoder.block.0.layer.1.EncDecAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 16 |
+
"decoder.block.0.layer.1.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 17 |
+
"decoder.block.0.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00003-of-00005.bin",
|
| 18 |
+
"decoder.block.0.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00003-of-00005.bin",
|
| 19 |
+
"decoder.block.0.layer.2.DenseReluDense.wo.weight": "pytorch_model-00003-of-00005.bin",
|
| 20 |
+
"decoder.block.0.layer.2.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 21 |
+
"decoder.block.1.layer.0.SelfAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 22 |
+
"decoder.block.1.layer.0.SelfAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 23 |
+
"decoder.block.1.layer.0.SelfAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 24 |
+
"decoder.block.1.layer.0.SelfAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 25 |
+
"decoder.block.1.layer.0.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 26 |
+
"decoder.block.1.layer.1.EncDecAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 27 |
+
"decoder.block.1.layer.1.EncDecAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 28 |
+
"decoder.block.1.layer.1.EncDecAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 29 |
+
"decoder.block.1.layer.1.EncDecAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 30 |
+
"decoder.block.1.layer.1.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 31 |
+
"decoder.block.1.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00003-of-00005.bin",
|
| 32 |
+
"decoder.block.1.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00003-of-00005.bin",
|
| 33 |
+
"decoder.block.1.layer.2.DenseReluDense.wo.weight": "pytorch_model-00003-of-00005.bin",
|
| 34 |
+
"decoder.block.1.layer.2.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 35 |
+
"decoder.block.10.layer.0.SelfAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 36 |
+
"decoder.block.10.layer.0.SelfAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 37 |
+
"decoder.block.10.layer.0.SelfAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 38 |
+
"decoder.block.10.layer.0.SelfAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 39 |
+
"decoder.block.10.layer.0.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 40 |
+
"decoder.block.10.layer.1.EncDecAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 41 |
+
"decoder.block.10.layer.1.EncDecAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 42 |
+
"decoder.block.10.layer.1.EncDecAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 43 |
+
"decoder.block.10.layer.1.EncDecAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 44 |
+
"decoder.block.10.layer.1.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 45 |
+
"decoder.block.10.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00004-of-00005.bin",
|
| 46 |
+
"decoder.block.10.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00004-of-00005.bin",
|
| 47 |
+
"decoder.block.10.layer.2.DenseReluDense.wo.weight": "pytorch_model-00004-of-00005.bin",
|
| 48 |
+
"decoder.block.10.layer.2.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 49 |
+
"decoder.block.11.layer.0.SelfAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 50 |
+
"decoder.block.11.layer.0.SelfAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 51 |
+
"decoder.block.11.layer.0.SelfAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 52 |
+
"decoder.block.11.layer.0.SelfAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 53 |
+
"decoder.block.11.layer.0.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 54 |
+
"decoder.block.11.layer.1.EncDecAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 55 |
+
"decoder.block.11.layer.1.EncDecAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 56 |
+
"decoder.block.11.layer.1.EncDecAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 57 |
+
"decoder.block.11.layer.1.EncDecAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 58 |
+
"decoder.block.11.layer.1.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 59 |
+
"decoder.block.11.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00004-of-00005.bin",
|
| 60 |
+
"decoder.block.11.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00004-of-00005.bin",
|
| 61 |
+
"decoder.block.11.layer.2.DenseReluDense.wo.weight": "pytorch_model-00004-of-00005.bin",
|
| 62 |
+
"decoder.block.11.layer.2.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 63 |
+
"decoder.block.12.layer.0.SelfAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 64 |
+
"decoder.block.12.layer.0.SelfAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 65 |
+
"decoder.block.12.layer.0.SelfAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 66 |
+
"decoder.block.12.layer.0.SelfAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 67 |
+
"decoder.block.12.layer.0.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 68 |
+
"decoder.block.12.layer.1.EncDecAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 69 |
+
"decoder.block.12.layer.1.EncDecAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 70 |
+
"decoder.block.12.layer.1.EncDecAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 71 |
+
"decoder.block.12.layer.1.EncDecAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 72 |
+
"decoder.block.12.layer.1.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 73 |
+
"decoder.block.12.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00004-of-00005.bin",
|
| 74 |
+
"decoder.block.12.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00004-of-00005.bin",
|
| 75 |
+
"decoder.block.12.layer.2.DenseReluDense.wo.weight": "pytorch_model-00004-of-00005.bin",
|
| 76 |
+
"decoder.block.12.layer.2.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 77 |
+
"decoder.block.13.layer.0.SelfAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 78 |
+
"decoder.block.13.layer.0.SelfAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 79 |
+
"decoder.block.13.layer.0.SelfAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 80 |
+
"decoder.block.13.layer.0.SelfAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 81 |
+
"decoder.block.13.layer.0.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 82 |
+
"decoder.block.13.layer.1.EncDecAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 83 |
+
"decoder.block.13.layer.1.EncDecAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 84 |
+
"decoder.block.13.layer.1.EncDecAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 85 |
+
"decoder.block.13.layer.1.EncDecAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 86 |
+
"decoder.block.13.layer.1.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 87 |
+
"decoder.block.13.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00004-of-00005.bin",
|
| 88 |
+
"decoder.block.13.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00004-of-00005.bin",
|
| 89 |
+
"decoder.block.13.layer.2.DenseReluDense.wo.weight": "pytorch_model-00004-of-00005.bin",
|
| 90 |
+
"decoder.block.13.layer.2.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 91 |
+
"decoder.block.14.layer.0.SelfAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 92 |
+
"decoder.block.14.layer.0.SelfAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 93 |
+
"decoder.block.14.layer.0.SelfAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 94 |
+
"decoder.block.14.layer.0.SelfAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 95 |
+
"decoder.block.14.layer.0.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 96 |
+
"decoder.block.14.layer.1.EncDecAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 97 |
+
"decoder.block.14.layer.1.EncDecAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 98 |
+
"decoder.block.14.layer.1.EncDecAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 99 |
+
"decoder.block.14.layer.1.EncDecAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 100 |
+
"decoder.block.14.layer.1.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 101 |
+
"decoder.block.14.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00004-of-00005.bin",
|
| 102 |
+
"decoder.block.14.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00004-of-00005.bin",
|
| 103 |
+
"decoder.block.14.layer.2.DenseReluDense.wo.weight": "pytorch_model-00004-of-00005.bin",
|
| 104 |
+
"decoder.block.14.layer.2.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 105 |
+
"decoder.block.15.layer.0.SelfAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 106 |
+
"decoder.block.15.layer.0.SelfAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 107 |
+
"decoder.block.15.layer.0.SelfAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 108 |
+
"decoder.block.15.layer.0.SelfAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 109 |
+
"decoder.block.15.layer.0.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 110 |
+
"decoder.block.15.layer.1.EncDecAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 111 |
+
"decoder.block.15.layer.1.EncDecAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 112 |
+
"decoder.block.15.layer.1.EncDecAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 113 |
+
"decoder.block.15.layer.1.EncDecAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 114 |
+
"decoder.block.15.layer.1.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 115 |
+
"decoder.block.15.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00004-of-00005.bin",
|
| 116 |
+
"decoder.block.15.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00004-of-00005.bin",
|
| 117 |
+
"decoder.block.15.layer.2.DenseReluDense.wo.weight": "pytorch_model-00004-of-00005.bin",
|
| 118 |
+
"decoder.block.15.layer.2.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 119 |
+
"decoder.block.16.layer.0.SelfAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 120 |
+
"decoder.block.16.layer.0.SelfAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 121 |
+
"decoder.block.16.layer.0.SelfAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 122 |
+
"decoder.block.16.layer.0.SelfAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 123 |
+
"decoder.block.16.layer.0.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 124 |
+
"decoder.block.16.layer.1.EncDecAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 125 |
+
"decoder.block.16.layer.1.EncDecAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 126 |
+
"decoder.block.16.layer.1.EncDecAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 127 |
+
"decoder.block.16.layer.1.EncDecAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 128 |
+
"decoder.block.16.layer.1.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 129 |
+
"decoder.block.16.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00004-of-00005.bin",
|
| 130 |
+
"decoder.block.16.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00004-of-00005.bin",
|
| 131 |
+
"decoder.block.16.layer.2.DenseReluDense.wo.weight": "pytorch_model-00004-of-00005.bin",
|
| 132 |
+
"decoder.block.16.layer.2.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 133 |
+
"decoder.block.17.layer.0.SelfAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 134 |
+
"decoder.block.17.layer.0.SelfAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 135 |
+
"decoder.block.17.layer.0.SelfAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 136 |
+
"decoder.block.17.layer.0.SelfAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 137 |
+
"decoder.block.17.layer.0.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 138 |
+
"decoder.block.17.layer.1.EncDecAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 139 |
+
"decoder.block.17.layer.1.EncDecAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 140 |
+
"decoder.block.17.layer.1.EncDecAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 141 |
+
"decoder.block.17.layer.1.EncDecAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 142 |
+
"decoder.block.17.layer.1.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 143 |
+
"decoder.block.17.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00004-of-00005.bin",
|
| 144 |
+
"decoder.block.17.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00004-of-00005.bin",
|
| 145 |
+
"decoder.block.17.layer.2.DenseReluDense.wo.weight": "pytorch_model-00004-of-00005.bin",
|
| 146 |
+
"decoder.block.17.layer.2.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 147 |
+
"decoder.block.18.layer.0.SelfAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 148 |
+
"decoder.block.18.layer.0.SelfAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 149 |
+
"decoder.block.18.layer.0.SelfAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 150 |
+
"decoder.block.18.layer.0.SelfAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 151 |
+
"decoder.block.18.layer.0.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 152 |
+
"decoder.block.18.layer.1.EncDecAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 153 |
+
"decoder.block.18.layer.1.EncDecAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 154 |
+
"decoder.block.18.layer.1.EncDecAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 155 |
+
"decoder.block.18.layer.1.EncDecAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 156 |
+
"decoder.block.18.layer.1.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 157 |
+
"decoder.block.18.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00004-of-00005.bin",
|
| 158 |
+
"decoder.block.18.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00005-of-00005.bin",
|
| 159 |
+
"decoder.block.18.layer.2.DenseReluDense.wo.weight": "pytorch_model-00005-of-00005.bin",
|
| 160 |
+
"decoder.block.18.layer.2.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 161 |
+
"decoder.block.19.layer.0.SelfAttention.k.weight": "pytorch_model-00005-of-00005.bin",
|
| 162 |
+
"decoder.block.19.layer.0.SelfAttention.o.weight": "pytorch_model-00005-of-00005.bin",
|
| 163 |
+
"decoder.block.19.layer.0.SelfAttention.q.weight": "pytorch_model-00005-of-00005.bin",
|
| 164 |
+
"decoder.block.19.layer.0.SelfAttention.v.weight": "pytorch_model-00005-of-00005.bin",
|
| 165 |
+
"decoder.block.19.layer.0.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 166 |
+
"decoder.block.19.layer.1.EncDecAttention.k.weight": "pytorch_model-00005-of-00005.bin",
|
| 167 |
+
"decoder.block.19.layer.1.EncDecAttention.o.weight": "pytorch_model-00005-of-00005.bin",
|
| 168 |
+
"decoder.block.19.layer.1.EncDecAttention.q.weight": "pytorch_model-00005-of-00005.bin",
|
| 169 |
+
"decoder.block.19.layer.1.EncDecAttention.v.weight": "pytorch_model-00005-of-00005.bin",
|
| 170 |
+
"decoder.block.19.layer.1.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 171 |
+
"decoder.block.19.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00005-of-00005.bin",
|
| 172 |
+
"decoder.block.19.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00005-of-00005.bin",
|
| 173 |
+
"decoder.block.19.layer.2.DenseReluDense.wo.weight": "pytorch_model-00005-of-00005.bin",
|
| 174 |
+
"decoder.block.19.layer.2.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 175 |
+
"decoder.block.2.layer.0.SelfAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 176 |
+
"decoder.block.2.layer.0.SelfAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 177 |
+
"decoder.block.2.layer.0.SelfAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 178 |
+
"decoder.block.2.layer.0.SelfAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 179 |
+
"decoder.block.2.layer.0.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 180 |
+
"decoder.block.2.layer.1.EncDecAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 181 |
+
"decoder.block.2.layer.1.EncDecAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 182 |
+
"decoder.block.2.layer.1.EncDecAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 183 |
+
"decoder.block.2.layer.1.EncDecAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 184 |
+
"decoder.block.2.layer.1.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 185 |
+
"decoder.block.2.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00003-of-00005.bin",
|
| 186 |
+
"decoder.block.2.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00003-of-00005.bin",
|
| 187 |
+
"decoder.block.2.layer.2.DenseReluDense.wo.weight": "pytorch_model-00003-of-00005.bin",
|
| 188 |
+
"decoder.block.2.layer.2.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 189 |
+
"decoder.block.20.layer.0.SelfAttention.k.weight": "pytorch_model-00005-of-00005.bin",
|
| 190 |
+
"decoder.block.20.layer.0.SelfAttention.o.weight": "pytorch_model-00005-of-00005.bin",
|
| 191 |
+
"decoder.block.20.layer.0.SelfAttention.q.weight": "pytorch_model-00005-of-00005.bin",
|
| 192 |
+
"decoder.block.20.layer.0.SelfAttention.v.weight": "pytorch_model-00005-of-00005.bin",
|
| 193 |
+
"decoder.block.20.layer.0.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 194 |
+
"decoder.block.20.layer.1.EncDecAttention.k.weight": "pytorch_model-00005-of-00005.bin",
|
| 195 |
+
"decoder.block.20.layer.1.EncDecAttention.o.weight": "pytorch_model-00005-of-00005.bin",
|
| 196 |
+
"decoder.block.20.layer.1.EncDecAttention.q.weight": "pytorch_model-00005-of-00005.bin",
|
| 197 |
+
"decoder.block.20.layer.1.EncDecAttention.v.weight": "pytorch_model-00005-of-00005.bin",
|
| 198 |
+
"decoder.block.20.layer.1.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 199 |
+
"decoder.block.20.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00005-of-00005.bin",
|
| 200 |
+
"decoder.block.20.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00005-of-00005.bin",
|
| 201 |
+
"decoder.block.20.layer.2.DenseReluDense.wo.weight": "pytorch_model-00005-of-00005.bin",
|
| 202 |
+
"decoder.block.20.layer.2.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 203 |
+
"decoder.block.21.layer.0.SelfAttention.k.weight": "pytorch_model-00005-of-00005.bin",
|
| 204 |
+
"decoder.block.21.layer.0.SelfAttention.o.weight": "pytorch_model-00005-of-00005.bin",
|
| 205 |
+
"decoder.block.21.layer.0.SelfAttention.q.weight": "pytorch_model-00005-of-00005.bin",
|
| 206 |
+
"decoder.block.21.layer.0.SelfAttention.v.weight": "pytorch_model-00005-of-00005.bin",
|
| 207 |
+
"decoder.block.21.layer.0.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 208 |
+
"decoder.block.21.layer.1.EncDecAttention.k.weight": "pytorch_model-00005-of-00005.bin",
|
| 209 |
+
"decoder.block.21.layer.1.EncDecAttention.o.weight": "pytorch_model-00005-of-00005.bin",
|
| 210 |
+
"decoder.block.21.layer.1.EncDecAttention.q.weight": "pytorch_model-00005-of-00005.bin",
|
| 211 |
+
"decoder.block.21.layer.1.EncDecAttention.v.weight": "pytorch_model-00005-of-00005.bin",
|
| 212 |
+
"decoder.block.21.layer.1.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 213 |
+
"decoder.block.21.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00005-of-00005.bin",
|
| 214 |
+
"decoder.block.21.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00005-of-00005.bin",
|
| 215 |
+
"decoder.block.21.layer.2.DenseReluDense.wo.weight": "pytorch_model-00005-of-00005.bin",
|
| 216 |
+
"decoder.block.21.layer.2.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 217 |
+
"decoder.block.22.layer.0.SelfAttention.k.weight": "pytorch_model-00005-of-00005.bin",
|
| 218 |
+
"decoder.block.22.layer.0.SelfAttention.o.weight": "pytorch_model-00005-of-00005.bin",
|
| 219 |
+
"decoder.block.22.layer.0.SelfAttention.q.weight": "pytorch_model-00005-of-00005.bin",
|
| 220 |
+
"decoder.block.22.layer.0.SelfAttention.v.weight": "pytorch_model-00005-of-00005.bin",
|
| 221 |
+
"decoder.block.22.layer.0.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 222 |
+
"decoder.block.22.layer.1.EncDecAttention.k.weight": "pytorch_model-00005-of-00005.bin",
|
| 223 |
+
"decoder.block.22.layer.1.EncDecAttention.o.weight": "pytorch_model-00005-of-00005.bin",
|
| 224 |
+
"decoder.block.22.layer.1.EncDecAttention.q.weight": "pytorch_model-00005-of-00005.bin",
|
| 225 |
+
"decoder.block.22.layer.1.EncDecAttention.v.weight": "pytorch_model-00005-of-00005.bin",
|
| 226 |
+
"decoder.block.22.layer.1.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 227 |
+
"decoder.block.22.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00005-of-00005.bin",
|
| 228 |
+
"decoder.block.22.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00005-of-00005.bin",
|
| 229 |
+
"decoder.block.22.layer.2.DenseReluDense.wo.weight": "pytorch_model-00005-of-00005.bin",
|
| 230 |
+
"decoder.block.22.layer.2.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 231 |
+
"decoder.block.23.layer.0.SelfAttention.k.weight": "pytorch_model-00005-of-00005.bin",
|
| 232 |
+
"decoder.block.23.layer.0.SelfAttention.o.weight": "pytorch_model-00005-of-00005.bin",
|
| 233 |
+
"decoder.block.23.layer.0.SelfAttention.q.weight": "pytorch_model-00005-of-00005.bin",
|
| 234 |
+
"decoder.block.23.layer.0.SelfAttention.v.weight": "pytorch_model-00005-of-00005.bin",
|
| 235 |
+
"decoder.block.23.layer.0.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 236 |
+
"decoder.block.23.layer.1.EncDecAttention.k.weight": "pytorch_model-00005-of-00005.bin",
|
| 237 |
+
"decoder.block.23.layer.1.EncDecAttention.o.weight": "pytorch_model-00005-of-00005.bin",
|
| 238 |
+
"decoder.block.23.layer.1.EncDecAttention.q.weight": "pytorch_model-00005-of-00005.bin",
|
| 239 |
+
"decoder.block.23.layer.1.EncDecAttention.v.weight": "pytorch_model-00005-of-00005.bin",
|
| 240 |
+
"decoder.block.23.layer.1.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 241 |
+
"decoder.block.23.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00005-of-00005.bin",
|
| 242 |
+
"decoder.block.23.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00005-of-00005.bin",
|
| 243 |
+
"decoder.block.23.layer.2.DenseReluDense.wo.weight": "pytorch_model-00005-of-00005.bin",
|
| 244 |
+
"decoder.block.23.layer.2.layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 245 |
+
"decoder.block.3.layer.0.SelfAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 246 |
+
"decoder.block.3.layer.0.SelfAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 247 |
+
"decoder.block.3.layer.0.SelfAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 248 |
+
"decoder.block.3.layer.0.SelfAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 249 |
+
"decoder.block.3.layer.0.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 250 |
+
"decoder.block.3.layer.1.EncDecAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 251 |
+
"decoder.block.3.layer.1.EncDecAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 252 |
+
"decoder.block.3.layer.1.EncDecAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 253 |
+
"decoder.block.3.layer.1.EncDecAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 254 |
+
"decoder.block.3.layer.1.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 255 |
+
"decoder.block.3.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00003-of-00005.bin",
|
| 256 |
+
"decoder.block.3.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00003-of-00005.bin",
|
| 257 |
+
"decoder.block.3.layer.2.DenseReluDense.wo.weight": "pytorch_model-00003-of-00005.bin",
|
| 258 |
+
"decoder.block.3.layer.2.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 259 |
+
"decoder.block.4.layer.0.SelfAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 260 |
+
"decoder.block.4.layer.0.SelfAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 261 |
+
"decoder.block.4.layer.0.SelfAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 262 |
+
"decoder.block.4.layer.0.SelfAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 263 |
+
"decoder.block.4.layer.0.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 264 |
+
"decoder.block.4.layer.1.EncDecAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 265 |
+
"decoder.block.4.layer.1.EncDecAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 266 |
+
"decoder.block.4.layer.1.EncDecAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 267 |
+
"decoder.block.4.layer.1.EncDecAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 268 |
+
"decoder.block.4.layer.1.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 269 |
+
"decoder.block.4.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00003-of-00005.bin",
|
| 270 |
+
"decoder.block.4.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00003-of-00005.bin",
|
| 271 |
+
"decoder.block.4.layer.2.DenseReluDense.wo.weight": "pytorch_model-00003-of-00005.bin",
|
| 272 |
+
"decoder.block.4.layer.2.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 273 |
+
"decoder.block.5.layer.0.SelfAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 274 |
+
"decoder.block.5.layer.0.SelfAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 275 |
+
"decoder.block.5.layer.0.SelfAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 276 |
+
"decoder.block.5.layer.0.SelfAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 277 |
+
"decoder.block.5.layer.0.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 278 |
+
"decoder.block.5.layer.1.EncDecAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 279 |
+
"decoder.block.5.layer.1.EncDecAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 280 |
+
"decoder.block.5.layer.1.EncDecAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 281 |
+
"decoder.block.5.layer.1.EncDecAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 282 |
+
"decoder.block.5.layer.1.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 283 |
+
"decoder.block.5.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00003-of-00005.bin",
|
| 284 |
+
"decoder.block.5.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00003-of-00005.bin",
|
| 285 |
+
"decoder.block.5.layer.2.DenseReluDense.wo.weight": "pytorch_model-00003-of-00005.bin",
|
| 286 |
+
"decoder.block.5.layer.2.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 287 |
+
"decoder.block.6.layer.0.SelfAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 288 |
+
"decoder.block.6.layer.0.SelfAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 289 |
+
"decoder.block.6.layer.0.SelfAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 290 |
+
"decoder.block.6.layer.0.SelfAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 291 |
+
"decoder.block.6.layer.0.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 292 |
+
"decoder.block.6.layer.1.EncDecAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 293 |
+
"decoder.block.6.layer.1.EncDecAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 294 |
+
"decoder.block.6.layer.1.EncDecAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 295 |
+
"decoder.block.6.layer.1.EncDecAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 296 |
+
"decoder.block.6.layer.1.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 297 |
+
"decoder.block.6.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00003-of-00005.bin",
|
| 298 |
+
"decoder.block.6.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00003-of-00005.bin",
|
| 299 |
+
"decoder.block.6.layer.2.DenseReluDense.wo.weight": "pytorch_model-00003-of-00005.bin",
|
| 300 |
+
"decoder.block.6.layer.2.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 301 |
+
"decoder.block.7.layer.0.SelfAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 302 |
+
"decoder.block.7.layer.0.SelfAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 303 |
+
"decoder.block.7.layer.0.SelfAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 304 |
+
"decoder.block.7.layer.0.SelfAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 305 |
+
"decoder.block.7.layer.0.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 306 |
+
"decoder.block.7.layer.1.EncDecAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 307 |
+
"decoder.block.7.layer.1.EncDecAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 308 |
+
"decoder.block.7.layer.1.EncDecAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 309 |
+
"decoder.block.7.layer.1.EncDecAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 310 |
+
"decoder.block.7.layer.1.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 311 |
+
"decoder.block.7.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00003-of-00005.bin",
|
| 312 |
+
"decoder.block.7.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00003-of-00005.bin",
|
| 313 |
+
"decoder.block.7.layer.2.DenseReluDense.wo.weight": "pytorch_model-00003-of-00005.bin",
|
| 314 |
+
"decoder.block.7.layer.2.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 315 |
+
"decoder.block.8.layer.0.SelfAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 316 |
+
"decoder.block.8.layer.0.SelfAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 317 |
+
"decoder.block.8.layer.0.SelfAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 318 |
+
"decoder.block.8.layer.0.SelfAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 319 |
+
"decoder.block.8.layer.0.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 320 |
+
"decoder.block.8.layer.1.EncDecAttention.k.weight": "pytorch_model-00003-of-00005.bin",
|
| 321 |
+
"decoder.block.8.layer.1.EncDecAttention.o.weight": "pytorch_model-00003-of-00005.bin",
|
| 322 |
+
"decoder.block.8.layer.1.EncDecAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 323 |
+
"decoder.block.8.layer.1.EncDecAttention.v.weight": "pytorch_model-00003-of-00005.bin",
|
| 324 |
+
"decoder.block.8.layer.1.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 325 |
+
"decoder.block.8.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00003-of-00005.bin",
|
| 326 |
+
"decoder.block.8.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00003-of-00005.bin",
|
| 327 |
+
"decoder.block.8.layer.2.DenseReluDense.wo.weight": "pytorch_model-00003-of-00005.bin",
|
| 328 |
+
"decoder.block.8.layer.2.layer_norm.weight": "pytorch_model-00003-of-00005.bin",
|
| 329 |
+
"decoder.block.9.layer.0.SelfAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 330 |
+
"decoder.block.9.layer.0.SelfAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 331 |
+
"decoder.block.9.layer.0.SelfAttention.q.weight": "pytorch_model-00003-of-00005.bin",
|
| 332 |
+
"decoder.block.9.layer.0.SelfAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 333 |
+
"decoder.block.9.layer.0.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 334 |
+
"decoder.block.9.layer.1.EncDecAttention.k.weight": "pytorch_model-00004-of-00005.bin",
|
| 335 |
+
"decoder.block.9.layer.1.EncDecAttention.o.weight": "pytorch_model-00004-of-00005.bin",
|
| 336 |
+
"decoder.block.9.layer.1.EncDecAttention.q.weight": "pytorch_model-00004-of-00005.bin",
|
| 337 |
+
"decoder.block.9.layer.1.EncDecAttention.v.weight": "pytorch_model-00004-of-00005.bin",
|
| 338 |
+
"decoder.block.9.layer.1.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 339 |
+
"decoder.block.9.layer.2.DenseReluDense.wi_0.weight": "pytorch_model-00004-of-00005.bin",
|
| 340 |
+
"decoder.block.9.layer.2.DenseReluDense.wi_1.weight": "pytorch_model-00004-of-00005.bin",
|
| 341 |
+
"decoder.block.9.layer.2.DenseReluDense.wo.weight": "pytorch_model-00004-of-00005.bin",
|
| 342 |
+
"decoder.block.9.layer.2.layer_norm.weight": "pytorch_model-00004-of-00005.bin",
|
| 343 |
+
"decoder.embed_tokens.weight": "pytorch_model-00003-of-00005.bin",
|
| 344 |
+
"decoder.final_layer_norm.weight": "pytorch_model-00005-of-00005.bin",
|
| 345 |
+
"encoder.block.0.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 346 |
+
"encoder.block.0.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 347 |
+
"encoder.block.0.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 348 |
+
"encoder.block.0.layer.0.SelfAttention.relative_attention_bias.weight": "pytorch_model-00001-of-00005.bin",
|
| 349 |
+
"encoder.block.0.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 350 |
+
"encoder.block.0.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 351 |
+
"encoder.block.0.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 352 |
+
"encoder.block.0.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00001-of-00005.bin",
|
| 353 |
+
"encoder.block.0.layer.1.DenseReluDense.wo.weight": "pytorch_model-00001-of-00005.bin",
|
| 354 |
+
"encoder.block.0.layer.1.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 355 |
+
"encoder.block.1.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 356 |
+
"encoder.block.1.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 357 |
+
"encoder.block.1.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 358 |
+
"encoder.block.1.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 359 |
+
"encoder.block.1.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 360 |
+
"encoder.block.1.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 361 |
+
"encoder.block.1.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00001-of-00005.bin",
|
| 362 |
+
"encoder.block.1.layer.1.DenseReluDense.wo.weight": "pytorch_model-00001-of-00005.bin",
|
| 363 |
+
"encoder.block.1.layer.1.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 364 |
+
"encoder.block.10.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 365 |
+
"encoder.block.10.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 366 |
+
"encoder.block.10.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 367 |
+
"encoder.block.10.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 368 |
+
"encoder.block.10.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 369 |
+
"encoder.block.10.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 370 |
+
"encoder.block.10.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00001-of-00005.bin",
|
| 371 |
+
"encoder.block.10.layer.1.DenseReluDense.wo.weight": "pytorch_model-00001-of-00005.bin",
|
| 372 |
+
"encoder.block.10.layer.1.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 373 |
+
"encoder.block.11.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 374 |
+
"encoder.block.11.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 375 |
+
"encoder.block.11.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 376 |
+
"encoder.block.11.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 377 |
+
"encoder.block.11.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 378 |
+
"encoder.block.11.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 379 |
+
"encoder.block.11.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 380 |
+
"encoder.block.11.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 381 |
+
"encoder.block.11.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 382 |
+
"encoder.block.12.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 383 |
+
"encoder.block.12.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 384 |
+
"encoder.block.12.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 385 |
+
"encoder.block.12.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 386 |
+
"encoder.block.12.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 387 |
+
"encoder.block.12.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 388 |
+
"encoder.block.12.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 389 |
+
"encoder.block.12.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 390 |
+
"encoder.block.12.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 391 |
+
"encoder.block.13.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 392 |
+
"encoder.block.13.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 393 |
+
"encoder.block.13.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 394 |
+
"encoder.block.13.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 395 |
+
"encoder.block.13.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 396 |
+
"encoder.block.13.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 397 |
+
"encoder.block.13.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 398 |
+
"encoder.block.13.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 399 |
+
"encoder.block.13.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 400 |
+
"encoder.block.14.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 401 |
+
"encoder.block.14.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 402 |
+
"encoder.block.14.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 403 |
+
"encoder.block.14.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 404 |
+
"encoder.block.14.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 405 |
+
"encoder.block.14.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 406 |
+
"encoder.block.14.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 407 |
+
"encoder.block.14.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 408 |
+
"encoder.block.14.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 409 |
+
"encoder.block.15.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 410 |
+
"encoder.block.15.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 411 |
+
"encoder.block.15.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 412 |
+
"encoder.block.15.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 413 |
+
"encoder.block.15.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 414 |
+
"encoder.block.15.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 415 |
+
"encoder.block.15.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 416 |
+
"encoder.block.15.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 417 |
+
"encoder.block.15.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 418 |
+
"encoder.block.16.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 419 |
+
"encoder.block.16.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 420 |
+
"encoder.block.16.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 421 |
+
"encoder.block.16.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 422 |
+
"encoder.block.16.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 423 |
+
"encoder.block.16.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 424 |
+
"encoder.block.16.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 425 |
+
"encoder.block.16.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 426 |
+
"encoder.block.16.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 427 |
+
"encoder.block.17.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 428 |
+
"encoder.block.17.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 429 |
+
"encoder.block.17.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 430 |
+
"encoder.block.17.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 431 |
+
"encoder.block.17.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 432 |
+
"encoder.block.17.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 433 |
+
"encoder.block.17.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 434 |
+
"encoder.block.17.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 435 |
+
"encoder.block.17.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 436 |
+
"encoder.block.18.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 437 |
+
"encoder.block.18.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 438 |
+
"encoder.block.18.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 439 |
+
"encoder.block.18.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 440 |
+
"encoder.block.18.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 441 |
+
"encoder.block.18.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 442 |
+
"encoder.block.18.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 443 |
+
"encoder.block.18.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 444 |
+
"encoder.block.18.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 445 |
+
"encoder.block.19.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 446 |
+
"encoder.block.19.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 447 |
+
"encoder.block.19.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 448 |
+
"encoder.block.19.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 449 |
+
"encoder.block.19.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 450 |
+
"encoder.block.19.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 451 |
+
"encoder.block.19.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 452 |
+
"encoder.block.19.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 453 |
+
"encoder.block.19.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 454 |
+
"encoder.block.2.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 455 |
+
"encoder.block.2.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 456 |
+
"encoder.block.2.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 457 |
+
"encoder.block.2.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 458 |
+
"encoder.block.2.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 459 |
+
"encoder.block.2.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 460 |
+
"encoder.block.2.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00001-of-00005.bin",
|
| 461 |
+
"encoder.block.2.layer.1.DenseReluDense.wo.weight": "pytorch_model-00001-of-00005.bin",
|
| 462 |
+
"encoder.block.2.layer.1.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 463 |
+
"encoder.block.20.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 464 |
+
"encoder.block.20.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 465 |
+
"encoder.block.20.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 466 |
+
"encoder.block.20.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 467 |
+
"encoder.block.20.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 468 |
+
"encoder.block.20.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 469 |
+
"encoder.block.20.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 470 |
+
"encoder.block.20.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 471 |
+
"encoder.block.20.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 472 |
+
"encoder.block.21.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 473 |
+
"encoder.block.21.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 474 |
+
"encoder.block.21.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 475 |
+
"encoder.block.21.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 476 |
+
"encoder.block.21.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 477 |
+
"encoder.block.21.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 478 |
+
"encoder.block.21.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 479 |
+
"encoder.block.21.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 480 |
+
"encoder.block.21.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 481 |
+
"encoder.block.22.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 482 |
+
"encoder.block.22.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 483 |
+
"encoder.block.22.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 484 |
+
"encoder.block.22.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 485 |
+
"encoder.block.22.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 486 |
+
"encoder.block.22.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 487 |
+
"encoder.block.22.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 488 |
+
"encoder.block.22.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 489 |
+
"encoder.block.22.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 490 |
+
"encoder.block.23.layer.0.SelfAttention.k.weight": "pytorch_model-00002-of-00005.bin",
|
| 491 |
+
"encoder.block.23.layer.0.SelfAttention.o.weight": "pytorch_model-00002-of-00005.bin",
|
| 492 |
+
"encoder.block.23.layer.0.SelfAttention.q.weight": "pytorch_model-00002-of-00005.bin",
|
| 493 |
+
"encoder.block.23.layer.0.SelfAttention.v.weight": "pytorch_model-00002-of-00005.bin",
|
| 494 |
+
"encoder.block.23.layer.0.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 495 |
+
"encoder.block.23.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00002-of-00005.bin",
|
| 496 |
+
"encoder.block.23.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00002-of-00005.bin",
|
| 497 |
+
"encoder.block.23.layer.1.DenseReluDense.wo.weight": "pytorch_model-00002-of-00005.bin",
|
| 498 |
+
"encoder.block.23.layer.1.layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 499 |
+
"encoder.block.3.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 500 |
+
"encoder.block.3.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 501 |
+
"encoder.block.3.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 502 |
+
"encoder.block.3.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 503 |
+
"encoder.block.3.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 504 |
+
"encoder.block.3.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 505 |
+
"encoder.block.3.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00001-of-00005.bin",
|
| 506 |
+
"encoder.block.3.layer.1.DenseReluDense.wo.weight": "pytorch_model-00001-of-00005.bin",
|
| 507 |
+
"encoder.block.3.layer.1.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 508 |
+
"encoder.block.4.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 509 |
+
"encoder.block.4.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 510 |
+
"encoder.block.4.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 511 |
+
"encoder.block.4.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 512 |
+
"encoder.block.4.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 513 |
+
"encoder.block.4.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 514 |
+
"encoder.block.4.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00001-of-00005.bin",
|
| 515 |
+
"encoder.block.4.layer.1.DenseReluDense.wo.weight": "pytorch_model-00001-of-00005.bin",
|
| 516 |
+
"encoder.block.4.layer.1.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 517 |
+
"encoder.block.5.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 518 |
+
"encoder.block.5.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 519 |
+
"encoder.block.5.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 520 |
+
"encoder.block.5.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 521 |
+
"encoder.block.5.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 522 |
+
"encoder.block.5.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 523 |
+
"encoder.block.5.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00001-of-00005.bin",
|
| 524 |
+
"encoder.block.5.layer.1.DenseReluDense.wo.weight": "pytorch_model-00001-of-00005.bin",
|
| 525 |
+
"encoder.block.5.layer.1.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 526 |
+
"encoder.block.6.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 527 |
+
"encoder.block.6.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 528 |
+
"encoder.block.6.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 529 |
+
"encoder.block.6.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 530 |
+
"encoder.block.6.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 531 |
+
"encoder.block.6.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 532 |
+
"encoder.block.6.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00001-of-00005.bin",
|
| 533 |
+
"encoder.block.6.layer.1.DenseReluDense.wo.weight": "pytorch_model-00001-of-00005.bin",
|
| 534 |
+
"encoder.block.6.layer.1.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 535 |
+
"encoder.block.7.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 536 |
+
"encoder.block.7.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 537 |
+
"encoder.block.7.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 538 |
+
"encoder.block.7.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 539 |
+
"encoder.block.7.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 540 |
+
"encoder.block.7.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 541 |
+
"encoder.block.7.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00001-of-00005.bin",
|
| 542 |
+
"encoder.block.7.layer.1.DenseReluDense.wo.weight": "pytorch_model-00001-of-00005.bin",
|
| 543 |
+
"encoder.block.7.layer.1.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 544 |
+
"encoder.block.8.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 545 |
+
"encoder.block.8.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 546 |
+
"encoder.block.8.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 547 |
+
"encoder.block.8.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 548 |
+
"encoder.block.8.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 549 |
+
"encoder.block.8.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 550 |
+
"encoder.block.8.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00001-of-00005.bin",
|
| 551 |
+
"encoder.block.8.layer.1.DenseReluDense.wo.weight": "pytorch_model-00001-of-00005.bin",
|
| 552 |
+
"encoder.block.8.layer.1.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 553 |
+
"encoder.block.9.layer.0.SelfAttention.k.weight": "pytorch_model-00001-of-00005.bin",
|
| 554 |
+
"encoder.block.9.layer.0.SelfAttention.o.weight": "pytorch_model-00001-of-00005.bin",
|
| 555 |
+
"encoder.block.9.layer.0.SelfAttention.q.weight": "pytorch_model-00001-of-00005.bin",
|
| 556 |
+
"encoder.block.9.layer.0.SelfAttention.v.weight": "pytorch_model-00001-of-00005.bin",
|
| 557 |
+
"encoder.block.9.layer.0.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 558 |
+
"encoder.block.9.layer.1.DenseReluDense.wi_0.weight": "pytorch_model-00001-of-00005.bin",
|
| 559 |
+
"encoder.block.9.layer.1.DenseReluDense.wi_1.weight": "pytorch_model-00001-of-00005.bin",
|
| 560 |
+
"encoder.block.9.layer.1.DenseReluDense.wo.weight": "pytorch_model-00001-of-00005.bin",
|
| 561 |
+
"encoder.block.9.layer.1.layer_norm.weight": "pytorch_model-00001-of-00005.bin",
|
| 562 |
+
"encoder.embed_tokens.weight": "pytorch_model-00001-of-00005.bin",
|
| 563 |
+
"encoder.final_layer_norm.weight": "pytorch_model-00002-of-00005.bin",
|
| 564 |
+
"lm_head.weight": "pytorch_model-00005-of-00005.bin",
|
| 565 |
+
"shared.weight": "pytorch_model-00001-of-00005.bin"
|
| 566 |
+
}
|
| 567 |
+
}
|