
metadata
datasets:
- AdamCodd/Civitai-2m-prompts
metrics:
- accuracy
- f1
- precision
- recall
- roc_auc
inference: true
model-index:
- name: distilroberta-nsfw-prompt-stable-diffusion
results:
- task:
type: text-classification
name: Text Classification
metrics:
- type: loss
value: 0.3103
- type: accuracy
value: 0.8642
name: Accuracy
- type: f1
value: 0.8612
name: F1
- type: precision
value: 0.8805
name: Precision
- type: recall
value: 0.8427
name: Recall
- type: ROC_AUC
value: 0.9408
name: AUC
language:
- en
DistilRoBERTa-nsfw-prompt-stable-diffusion
This model utilizes the Distilroberta base architecture, which has been fine-tuned for a classification task on AdamCodd/Civitai-2m-prompts dataset, on the positive prompts. It achieves the following results on the evaluation set:
- Loss: 0.3103
- Accuracy: 0.8642
- F1: 0.8612
- AUC: 0.9408
- Precision: 0.8805
- Recall: 0.8427
Model description
This model was made to detect NSFW Stable-diffusion prompts by training it on 2M SFW and NSFW prompts (1043475 samples of each, perfectly balanced). One words prompts have been excluded to remove useless noise for the prediction.
Usage
from transformers import pipeline
prompt_detector = pipeline("text-classification", model="AdamCodd/distilroberta-nsfw-prompt-stable-diffusion")
predicted_class = prompt_detector("masterpiece, 1girl, yellow sundress, looking at viewer")
print(predicted_class)
#[{'label': 'SFW', 'score': 0.9983291029930115}]
Training and evaluation data
More information needed
Training procedure
Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: AdamW with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 150
- num_epochs: 1
- weight_decay: 0.01
Training results
Metrics: Accuracy, F1, Precision, Recall, AUC
'eval_loss': 0.3103,
'eval_accuracy': 0.8642,
'eval_f1': 0.8612,
'eval_precision': 0.8805,
'eval_recall': 0.8427,
'eval_roc_auc': 0.9408,
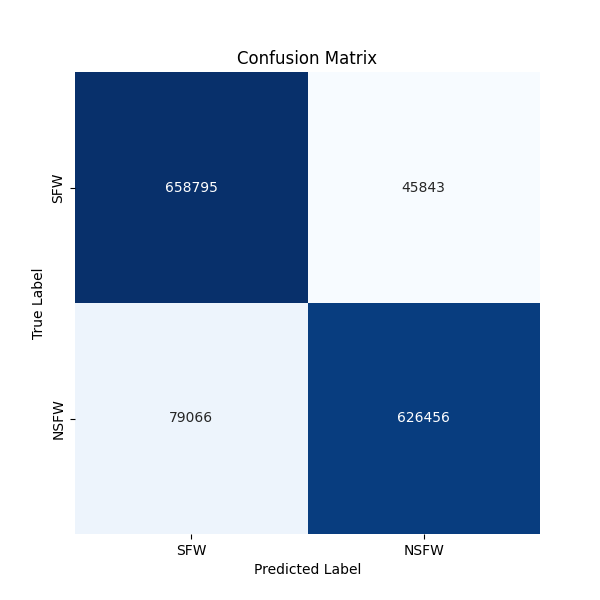{kind=link}
[[184931 23859]
[32820 175780]]
Framework versions
- Transformers 4.36.2
- Datasets 2.16.1
- Tokenizers 0.15.0
- Evaluate 0.4.1
If you want to support me, you can here.