
datasets:
- AdamCodd/Civitai-8m-prompts
metrics:
- accuracy
- f1
- precision
- recall
- roc_auc
inference: true
base_model: distilroberta-base
model-index:
- name: distilroberta-nsfw-prompt-stable-diffusion
results:
- task:
type: text-classification
name: Text Classification
metrics:
- type: loss
value: 0.2139
- type: accuracy
value: 0.9114
name: Accuracy
- type: f1
value: 0.9093
name: F1
- type: precision
value: 0.9318
name: Precision
- type: recall
value: 0.8879
name: Recall
- type: ROC_AUC
value: 0.9716
name: AUC
widget:
- text: masterpiece, 1girl, looking at viewer, sitting, tea, table, garden
example_title: Prompt
language:
- en
license: cc-by-nc-4.0
DistilRoBERTa-nsfw-prompt-stable-diffusion
=== V2 ===
This model has been retrained on the improved AdamCodd/Civitai-8m-prompts dataset, on ~5 million positive prompts, evenly split between SFW and NSFW categories (2,820,319 samples of each, ensuring a balanced dataset).
It's a massive improvement over the V1 model. It achieves the following results on the evaluation set:
- Loss: 0.2139 (↓ 31.07% over V1)
- Accuracy: 0.9114 (↑ 5.46% over V1)
- F1: 0.9093 (↑ 5.58% over V1)
- AUC: 0.9716 (↑ 3.27% over V1)
- Precision: 0.9318 (↑ 5.81% over V1)
- Recall: 0.8879 (↑ 5.36% over V1)
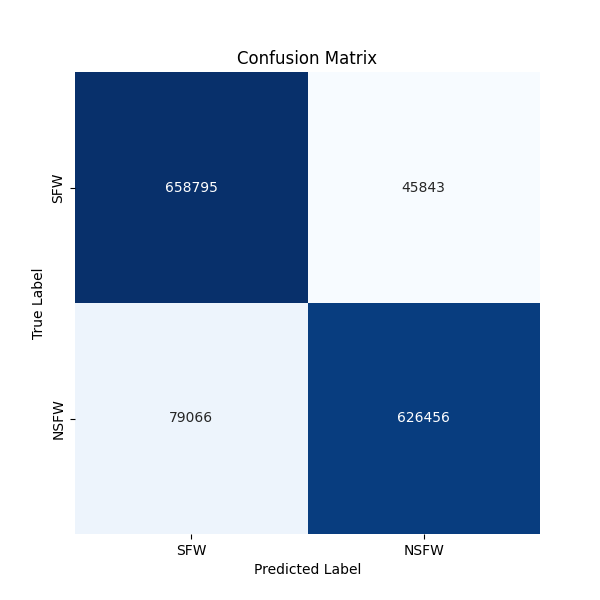{kind=link}
[[658795 45843]
[ 79066 626456]]
The V2 model is less prone to false positives compared to V1, which avoid to classify as NSFW a little bit of cleavage for example (the cutoff for the NSFW classification is nsfwLevel == 2 on the dataset).
NB: The new license for the V2 model is cc-by-nc-4.0. For commercial use rights, please contact me. Meanwhile, the V1 model remains available under the MIT license (under v1 branch).
The V1 and V2 models are both compatible with Transformers.js.
=== V1 ===
This model utilizes the Distilroberta base architecture, which has been fine-tuned for a classification task on AdamCodd/Civitai-2m-prompts dataset, on the positive prompts.
It achieves the following results on the evaluation set:
- Loss: 0.3103
- Accuracy: 0.8642
- F1: 0.8612
- AUC: 0.9408
- Precision: 0.8805
- Recall: 0.8427
Model description
This model is designed to identify NSFW prompts in Stable-diffusion, trained on a dataset comprising of ~2 million prompts, evenly split between SFW and NSFW categories (1,043,475 samples of each, ensuring a balanced dataset). Single-word prompts have been excluded to enhance the accuracy and relevance of the predictions.
Additionally, it is important to note that the model assesses the likelihood of a prompt being NSFW based on statistical occurrences, rather than evaluating the specific words. This approach allows for the identification of NSFW content in prompts that may appear SFW. The accuracy of the model tends to increase with the length of the prompt. Therefore, prompts that are extremely brief, such as those comprising only two or three words, might be subject to less accurate evaluations.
Although this model demonstrates satisfactory accuracy, it is recommended to use with this image NSFW detector to improve overall detection capabilities and minimize the occurrence of false positives.
Usage
from transformers import pipeline
prompt_detector = pipeline("text-classification", model="AdamCodd/distilroberta-nsfw-prompt-stable-diffusion")
predicted_class = prompt_detector("masterpiece, 1girl, looking at viewer, sitting, tea, table, garden")
print(predicted_class)
#[{'label': 'SFW', 'score': 0.868}]
Training and evaluation data
More information needed
Training procedure
Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: AdamW with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 150
- Mixed precision
- num_epochs: 1
- weight_decay: 0.01
Training results
Metrics: Accuracy, F1, Precision, Recall, AUC
'eval_loss': 0.3103,
'eval_accuracy': 0.8642,
'eval_f1': 0.8612,
'eval_precision': 0.8805,
'eval_recall': 0.8427,
'eval_roc_auc': 0.9408,
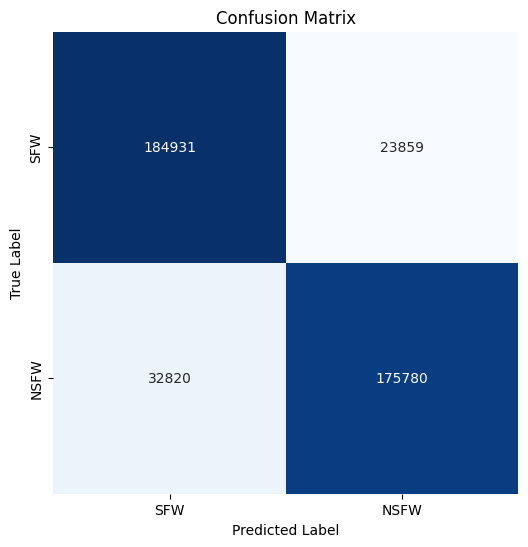{kind=link}
[[184931 23859]
[32820 175780]]
Framework versions
- Transformers 4.36.2
- Datasets 2.16.1
- Tokenizers 0.15.0
- Evaluate 0.4.1
If you want to support me, you can here.
Citation and Acknowledgments
This model was utilized in the following arXiv paper:
@misc{li2024art,
title={ART: Automatic Red-teaming for Text-to-Image Models to Protect Benign Users},
author={Guanlin Li and Kangjie Chen and Shudong Zhang and Jie Zhang and Tianwei Zhang},
year={2024},
eprint={2405.19360},
archivePrefix={arXiv},
primaryClass={cs.CR}
}