

license: apache-2.0
datasets:
- liuhaotian/LLaVA-Pretrain
- liuhaotian/LLaVA-Instruct-150K
language:
- zh
- en
metrics:
- accuracy
base_model:
- Qwen/Qwen1.5-7B-Chat
- google/siglip-so400m-patch14-384
pipeline_tag: image-text-to-text
library_name: transformers
tags:
- Wings
- Multimodal-LLM
- Text-only-Forgetting
- NeurIPS2024
Wings: A Versatile Multimodal LLM without Text-only Forgetting
📝 Paper • 🤗 Hugging Face
🚀 Ask questions or discuss ideas on GitHub
🪽 Here is the demo of Inference. We apologize for any inconvenience. Currently, Wings can only be loaded through the raw method, but we are working on improving this.
git clone https://github.com/AIDC-AI/Wings.git
cd Wings
pip install -r requirements.txt
# Place the path of the downloaded safetensors into the run/infer.sh.
bash run/infer.sh
We have released Wingsbase-Qwen1_5-8B, a version aligned with LLaVA-v1.5 pretrain and finetune training data.
Table of Contents
Why Wings?
💡 TL;DR
Wings is a brand-new universal Multimodal Large Language Model (MLLM). Its flexible multimodal structure enhances the MLLM as if giving it wings that enhance the performance of multimodal capabilities while minimizing text-only forgetting.
Any architecture of MLLM can adapt the Wings component.
Multimodal large language models (MLLMs), initiated with a trained LLM, first align images with text and then fine-tune on multimodal mixed inputs. However, the MLLM catastrophically forgets the text-only instructions, which do not include images and can be addressed within the initial LLM.
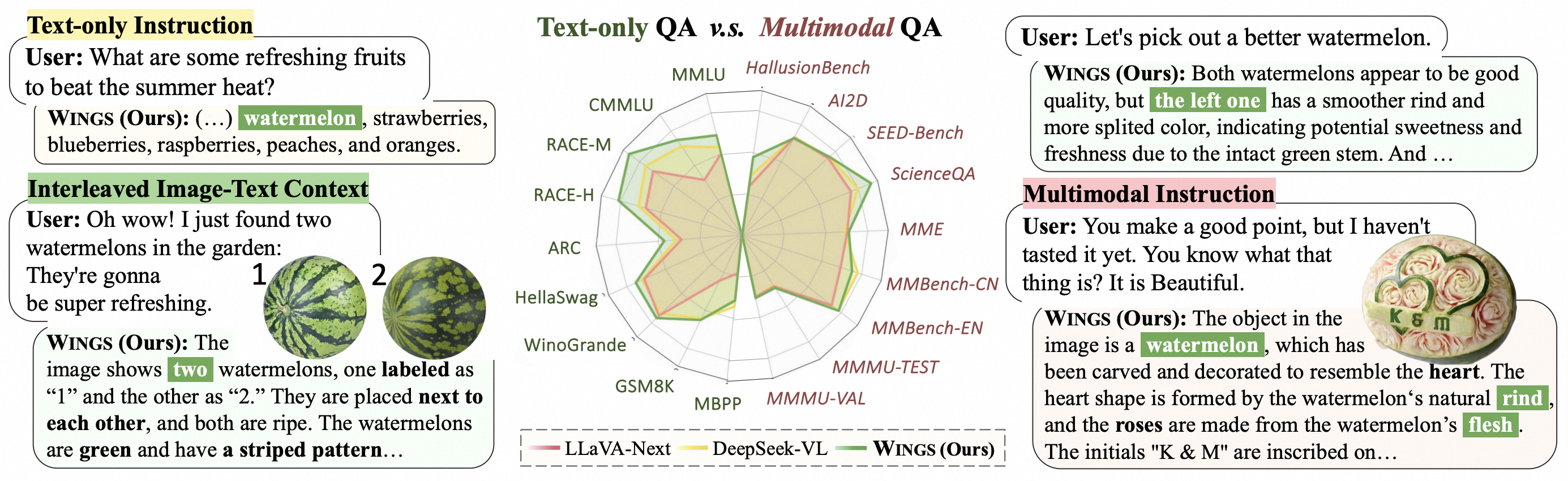
In this work, we present Wings, a novel MLLM that excels in both text-only dialogues and multimodal comprehension. Analyzing MLLM attention in multimodal instructions reveals that text-only forgetting is related to the attention shifts from pre-image to post-image text. From that, we construct extra modules that act as the boosted learner to compensate for the attention shift. The complementary visual and textual learners, like "wings" on either side, are connected in parallel within each layer's attention block. Initially, image and text inputs are aligned with visual learners operating alongside the main attention, balancing focus on visual elements. Textual learners are later collaboratively integrated with attention-based routing to blend the outputs of the visual and textual learners. We design the Low-Rank Residual Attention (LoRRA) to guarantee high efficiency for learners.
Our experimental results demonstrate that Wings outperforms equally-scaled MLLMs in both text-only and visual question-answering tasks. On a newly constructed Interleaved Image-Text (IIT) benchmark, Wings exhibits superior performance from text-only-rich to multimodal-rich question-answering tasks.
How to use
Quick start (please route to GitHub)
Environment Setups:
conda create --name your_env_name python=3.10 conda activate your_env_name pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cu121 pip install -r requirements.txtTraining:
bash run/pretrain_base.sh # Set path for pretrained MLLM bash run/finetune_base.sh
Citation
If you find Wings useful, please cite the paper:
@article{zhang_wings, author = {Yi{-}Kai Zhang and Shiyin Lu and Yang Li and Yanqing Ma and Qing{-}Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and De{-}Chuan Zhan and Han{-}Jia Ye}, title = {Wings: Learning Multimodal LLMs without Text-only Forgetting}, journal = {CoRR}, volume = {abs/2406.03496}, year = {2024} }
License
This project is licensed under the Apache License, Version 2.0 (SPDX-License-Identifier: Apache-2.0).
Disclaimer
We used compliance-checking algorithms during the training process, to ensure the compliance of the trained model to the best of our ability. Due to the complexity of the data and the diversity of language model usage scenarios, we cannot guarantee that the model is completely free of copyright issues or improper content. If you believe anything infringes on your rights or generates improper content, please contact us, and we will promptly address the matter.