
Yue Yang
commited on
Commit
•
be555fc
1
Parent(s):
18a861e
update README
Browse files- README.md +46 -46
- skin-lesion-results.png +0 -0
- test.py +20 -0
- test_skin.jpg +0 -0
README.md
CHANGED
|
@@ -9,7 +9,7 @@ library_name: open_clip
|
|
| 9 |
pipeline_tag: zero-shot-image-classification
|
| 10 |
---
|
| 11 |
|
| 12 |
-
# Model Card for
|
| 13 |
|
| 14 |
# Table of Contents
|
| 15 |
|
|
@@ -22,7 +22,8 @@ pipeline_tag: zero-shot-image-classification
|
|
| 22 |
|
| 23 |
## Model Details
|
| 24 |
|
| 25 |
-
-
|
|
|
|
| 26 |
- **Paper:** https://arxiv.org/pdf/2405.14839
|
| 27 |
- **Website:** https://yueyang1996.github.io/knobo/
|
| 28 |
- **Repository:** https://github.com/YueYANG1996/KnoBo
|
|
@@ -32,84 +33,83 @@ pipeline_tag: zero-shot-image-classification
|
|
| 32 |
|
| 33 |
Use the code below to get started with the model.
|
| 34 |
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
## Uses
|
| 39 |
|
| 40 |
-
|
|
|
|
|
|
|
|
|
|
| 41 |
|
| 42 |
-
|
|
|
|
|
|
|
| 43 |
|
| 44 |
-
|
|
|
|
| 45 |
|
| 46 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 47 |
|
| 48 |
-
|
| 49 |
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
[More Information Needed]
|
| 53 |
|
| 54 |
-
### Out-of-Scope Use
|
| 55 |
|
| 56 |
-
|
| 57 |
|
| 58 |
-
[
|
| 59 |
|
| 60 |
-
|
| 61 |
|
|
|
|
| 62 |
|
| 63 |
-
|
| 64 |
|
| 65 |
-
|
| 66 |
|
| 67 |
-
|
| 68 |
|
| 69 |
-
|
| 70 |
|
| 71 |
-
### Preprocessing [optional]
|
| 72 |
|
| 73 |
-
|
| 74 |
|
|
|
|
|
|
|
| 75 |
|
| 76 |
-
### Training
|
| 77 |
|
| 78 |
-
|
| 79 |
|
| 80 |
## Evaluation
|
| 81 |
|
| 82 |
-
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 83 |
-
|
| 84 |
### Testing Data
|
| 85 |
|
| 86 |
-
|
| 87 |
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
|
| 91 |
-
### Metrics
|
| 92 |
-
|
| 93 |
-
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 94 |
-
|
| 95 |
-
[More Information Needed]
|
| 96 |
|
| 97 |
### Results
|
|
|
|
| 98 |
|
| 99 |
-
[
|
| 100 |
-
|
| 101 |
|
| 102 |
## Citation
|
| 103 |
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
**BibTeX:**
|
| 107 |
|
| 108 |
```
|
| 109 |
@article{yang2024textbook,
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
}
|
| 115 |
```
|
|
|
|
| 9 |
pipeline_tag: zero-shot-image-classification
|
| 10 |
---
|
| 11 |
|
| 12 |
+
# Model Card for WhyLesionCLIP 👍🏽
|
| 13 |
|
| 14 |
# Table of Contents
|
| 15 |
|
|
|
|
| 22 |
|
| 23 |
## Model Details
|
| 24 |
|
| 25 |
+
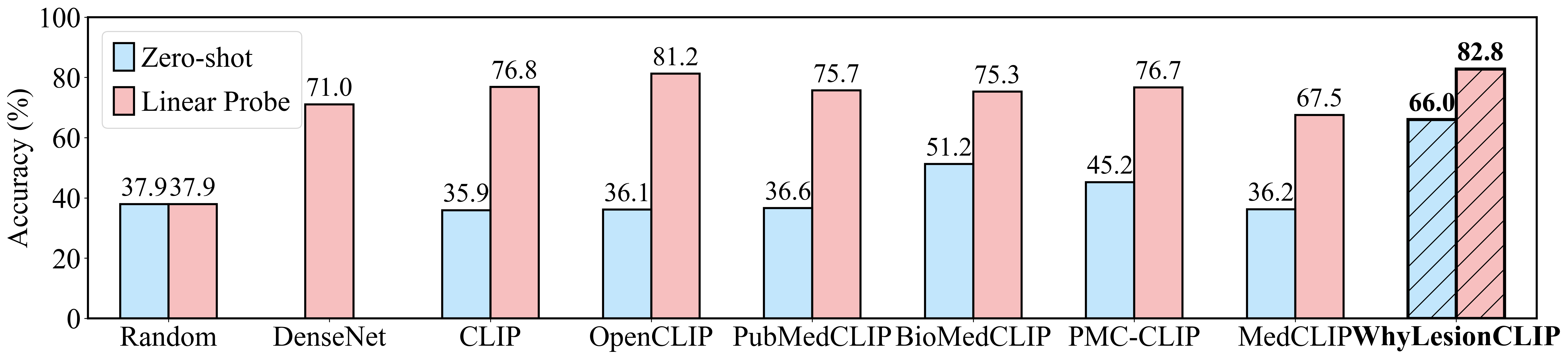
WhyLesionCLIP can align skin lesion images with text descriptions. It is fine-tuned from [OpenCLIP (ViT-L/14)](https://huggingface.co/laion/CLIP-ViT-L-14-laion2B-s32B-b82K) on [ISIC](https://gallery.isic-archive.com/#!/topWithHeader/onlyHeaderTop/gallery) with clinical reports generated by GPT-4V. WhyLesionCLIP significantly outperforms PubMedCLIP, BioMedCLIP, etc. in zero-shot and linear probing on various skin lesion datasets. (See results in [Evaluation](#evaluation)) While our CLIP models excel with careful data curation, training converges quickly, suggesting the current contrastive objective might not fully exploit the information from the data, potentially taking shortcuts, such as comparing images from different patients instead of focusing on diseases. Future research should explore more suitable objectives and larger-scale data collections to develop more robust medical foundation models.
|
| 26 |
+
|
| 27 |
- **Paper:** https://arxiv.org/pdf/2405.14839
|
| 28 |
- **Website:** https://yueyang1996.github.io/knobo/
|
| 29 |
- **Repository:** https://github.com/YueYANG1996/KnoBo
|
|
|
|
| 33 |
|
| 34 |
Use the code below to get started with the model.
|
| 35 |
|
| 36 |
+
```bash
|
| 37 |
+
pip install open_clip_torch
|
| 38 |
+
```
|
|
|
|
| 39 |
|
| 40 |
+
```python
|
| 41 |
+
import torch
|
| 42 |
+
from PIL import Image
|
| 43 |
+
import open_clip
|
| 44 |
|
| 45 |
+
model, _, preprocess = open_clip.create_model_and_transforms("hf-hub:yyupenn/whylesionclip")
|
| 46 |
+
model.eval()
|
| 47 |
+
tokenizer = open_clip.get_tokenizer("ViT-L-14")
|
| 48 |
|
| 49 |
+
image = preprocess(Image.open("test_skin.jpg")).unsqueeze(0)
|
| 50 |
+
text = tokenizer(["dark brown", "bleeding", "irregular shape"])
|
| 51 |
|
| 52 |
+
with torch.no_grad(), torch.cuda.amp.autocast():
|
| 53 |
+
image_features = model.encode_image(image)
|
| 54 |
+
text_features = model.encode_text(text)
|
| 55 |
+
image_features /= image_features.norm(dim=-1, keepdim=True)
|
| 56 |
+
text_features /= text_features.norm(dim=-1, keepdim=True)
|
| 57 |
|
| 58 |
+
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
|
| 59 |
|
| 60 |
+
print("Label probs:", text_probs)
|
| 61 |
+
```
|
|
|
|
| 62 |
|
|
|
|
| 63 |
|
| 64 |
+
## Uses
|
| 65 |
|
| 66 |
+
As per the original [OpenAI CLIP model card](https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/model-card.md), this model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot medical image (skin lesion) classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models.
|
| 67 |
|
| 68 |
+
### Direct Use
|
| 69 |
|
| 70 |
+
WhyLesionCLIP can be used for zero-shot skin lesion classification. You can use it to compute the similarity between an skin lesion image and a text description.
|
| 71 |
|
| 72 |
+
### Downstream Use
|
| 73 |
|
| 74 |
+
WhyLesionCLIP can be used as a feature extractor for downstream tasks. You can use it to extract features from skin lesion images and text descriptions for other downstream tasks.
|
| 75 |
|
| 76 |
+
### Out-of-Scope Use
|
| 77 |
|
| 78 |
+
WhyLesionCLIP should not be used for clinical diagnosis or treatment. It is not intended to be used for any clinical decision-making. Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
|
| 79 |
|
|
|
|
| 80 |
|
| 81 |
+
## Training Details
|
| 82 |
|
| 83 |
+
### Training Data
|
| 84 |
+
We employ the [ISIC](https://gallery.isic-archive.com/#!/topWithHeader/onlyHeaderTop/gallery) dataset and use GPT-4V to generate clinical reports for 56,590 images. We preprocess these reports by extracting medically relevant findings, each described in a short and concise term. In total, we assemble 438K image-text pairs for training WhyLesionCLIP.
|
| 85 |
|
| 86 |
+
### Training Details
|
| 87 |
|
| 88 |
+
We utilize the training script from [OpenCLIP](https://github.com/mlfoundations/open_clip) and select [ViT-L/14](https://huggingface.co/laion/CLIP-ViT-L-14-laion2B-s32B-b82K) as the backbone. Training is performed on 4 RTX A6000 GPUs for 10 epochs with a batch size of 128 and a learning rate of 1e−5. We choose checkpoints based on the lowest contrastive loss on validation sets.
|
| 89 |
|
| 90 |
## Evaluation
|
| 91 |
|
|
|
|
|
|
|
| 92 |
### Testing Data
|
| 93 |
|
| 94 |
+
We evaluate on 5 skin lesion classification datasets: [HAM10000](https://www.kaggle.com/datasets/kmader/skin-cancer-mnist-ham10000), [BCN20000](https://challenge.isic-archive.com/landing/2019/), [PAD-UFES-20](https://www.kaggle.com/datasets/mahdavi1202/skin-cancer), [Melanoma](https://www.kaggle.com/datasets/hasnainjaved/melanoma-skin-cancer-dataset-of-10000-images), and [UWaterloo](https://uwaterloo.ca/vision-image-processing-lab/research-demos/skin-cancer-detection). We report the zero-shot and linear probing accuracy on the above 5 datasets.
|
| 95 |
|
| 96 |
+
### Baselines
|
| 97 |
+
We compare various CLIP models, including [OpenAI-CLIP](https://huggingface.co/openai/clip-vit-large-patch14), [OpenCLIP](https://huggingface.co/laion/CLIP-ViT-L-14-laion2B-s32B-b82K), [PubMedCLIP](https://huggingface.co/flaviagiammarino/pubmed-clip-vit-base-patch32), [BioMedCLIP](https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224), [PMC-CLIP](https://huggingface.co/ryanyip7777/pmc_vit_l_14) and [MedCLIP](https://github.com/RyanWangZf/MedCLIP). We evaluate these models in both zero-shot and linear probe scenarios. In zero-shot, GPT-4 generates prompts for each class, and we use the ensemble of cosine similarities between the image and prompts as the score for each class. In linear probing, we use the CLIP models as image encoders to extract features for logistic regression. Additionally, we include [DenseNet-121](https://arxiv.org/pdf/1608.06993) (fine-tuned on the pretraining datasets with cross-entropy loss) as a baseline for linear probing.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 98 |
|
| 99 |
### Results
|
| 100 |
+
The figure below shows the averaged Zero-shot and Linear Probe performance of different models on five skin lesion datasets.
|
| 101 |
|
| 102 |
+

|
|
|
|
| 103 |
|
| 104 |
## Citation
|
| 105 |
|
| 106 |
+
Please cite our paper if you use this model in your work:
|
|
|
|
|
|
|
| 107 |
|
| 108 |
```
|
| 109 |
@article{yang2024textbook,
|
| 110 |
+
title={A Textbook Remedy for Domain Shifts: Knowledge Priors for Medical Image Analysis},
|
| 111 |
+
author={Yue Yang and Mona Gandhi and Yufei Wang and Yifan Wu and Michael S. Yao and Chris Callison-Burch and James C. Gee and Mark Yatskar},
|
| 112 |
+
journal={arXiv preprint arXiv:2405.14839},
|
| 113 |
+
year={2024}
|
| 114 |
}
|
| 115 |
```
|
skin-lesion-results.png
ADDED
|
test.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import open_clip
|
| 4 |
+
|
| 5 |
+
model, _, preprocess = open_clip.create_model_and_transforms("hf-hub:yyupenn/whylesionclip")
|
| 6 |
+
model.eval()
|
| 7 |
+
tokenizer = open_clip.get_tokenizer("ViT-L-14")
|
| 8 |
+
|
| 9 |
+
image = preprocess(Image.open("test_skin.jpg")).unsqueeze(0)
|
| 10 |
+
text = tokenizer(["dark brown", "bleeding", "irregular shape"])
|
| 11 |
+
|
| 12 |
+
with torch.no_grad(), torch.cuda.amp.autocast():
|
| 13 |
+
image_features = model.encode_image(image)
|
| 14 |
+
text_features = model.encode_text(text)
|
| 15 |
+
image_features /= image_features.norm(dim=-1, keepdim=True)
|
| 16 |
+
text_features /= text_features.norm(dim=-1, keepdim=True)
|
| 17 |
+
|
| 18 |
+
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
|
| 19 |
+
|
| 20 |
+
print("Label probs:", text_probs)
|
test_skin.jpg
ADDED
|