
Upload 187 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +8 -0
- Framework.png +0 -0
- README.md +86 -3
- main/.gitignore +129 -0
- main/LICENSE +21 -0
- main/assets/example_action_names_humanact12.txt +2 -0
- main/assets/example_action_names_uestc.txt +7 -0
- main/assets/example_stick_fig.gif +0 -0
- main/assets/example_text_prompts.txt +8 -0
- main/assets/in_between_edit.gif +3 -0
- main/assets/upper_body_edit.gif +0 -0
- main/body_models/README.md +3 -0
- main/data_loaders/a2m/dataset.py +255 -0
- main/data_loaders/a2m/humanact12poses.py +57 -0
- main/data_loaders/a2m/uestc.py +226 -0
- main/data_loaders/get_data.py +52 -0
- main/data_loaders/humanml/README.md +1 -0
- main/data_loaders/humanml/common/quaternion.py +423 -0
- main/data_loaders/humanml/common/skeleton.py +199 -0
- main/data_loaders/humanml/data/__init__.py +0 -0
- main/data_loaders/humanml/data/dataset.py +783 -0
- main/data_loaders/humanml/motion_loaders/__init__.py +0 -0
- main/data_loaders/humanml/motion_loaders/comp_v6_model_dataset.py +262 -0
- main/data_loaders/humanml/motion_loaders/dataset_motion_loader.py +27 -0
- main/data_loaders/humanml/motion_loaders/model_motion_loaders.py +91 -0
- main/data_loaders/humanml/networks/__init__.py +0 -0
- main/data_loaders/humanml/networks/evaluator_wrapper.py +187 -0
- main/data_loaders/humanml/networks/modules.py +438 -0
- main/data_loaders/humanml/networks/trainers.py +1089 -0
- main/data_loaders/humanml/scripts/motion_process.py +529 -0
- main/data_loaders/humanml/utils/get_opt.py +81 -0
- main/data_loaders/humanml/utils/metrics.py +146 -0
- main/data_loaders/humanml/utils/paramUtil.py +63 -0
- main/data_loaders/humanml/utils/plot_script.py +132 -0
- main/data_loaders/humanml/utils/utils.py +168 -0
- main/data_loaders/humanml/utils/word_vectorizer.py +80 -0
- main/data_loaders/humanml_utils.py +54 -0
- main/data_loaders/tensors.py +70 -0
- main/dataset/README.md +6 -0
- main/dataset/humanml_opt.txt +54 -0
- main/dataset/kit_mean.npy +3 -0
- main/dataset/kit_opt.txt +54 -0
- main/dataset/kit_std.npy +3 -0
- main/dataset/t2m_mean.npy +3 -0
- main/dataset/t2m_std.npy +3 -0
- main/diffusion/fp16_util.py +236 -0
- main/diffusion/gaussian_diffusion.py +1613 -0
- main/diffusion/logger.py +495 -0
- main/diffusion/losses.py +77 -0
- main/diffusion/nn.py +197 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,11 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
main/assets/in_between_edit.gif filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
main/mydiffusion_zeggs/0001-0933.mkv filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
main/mydiffusion_zeggs/0001-0933.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
main/mydiffusion_zeggs/015_Happy_4_x_1_0.wav filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
ubisoft-laforge-ZeroEGGS-main/ZEGGS/bvh2fbx/LaForgeFemale.fbx filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
ubisoft-laforge-ZeroEGGS-main/ZEGGS/bvh2fbx/Rendered/001_Neutral_0_x_0_9.bvh filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
ubisoft-laforge-ZeroEGGS-main/ZEGGS/bvh2fbx/Rendered/001_Neutral_0_x_0_9.fbx filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
ubisoft-laforge-ZeroEGGS-main/ZEGGS/bvh2fbx/Rendered/001_Neutral_0_x_0_9.wav filter=lfs diff=lfs merge=lfs -text
|
Framework.png
ADDED
|
README.md
CHANGED
|
@@ -1,3 +1,86 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DiffuseStyleGesture: Stylized Audio-Driven Co-Speech Gesture Generation with Diffusion Models
|
| 2 |
+
|
| 3 |
+
[](https://arxiv.org/abs/2305.04919)
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
<div align=center>
|
| 8 |
+
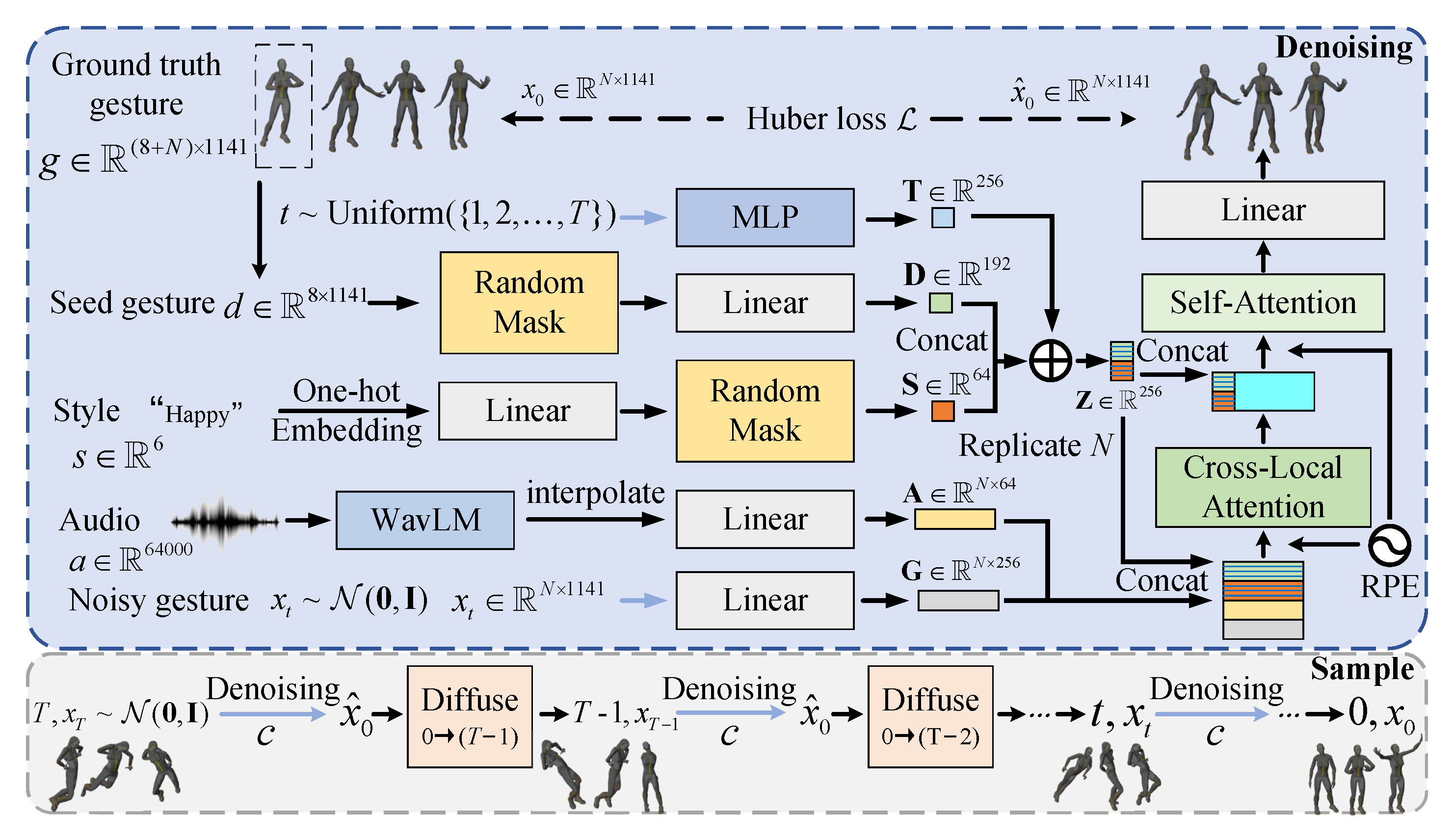
<img src="Framework.png" width="500px">
|
| 9 |
+
</div>
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
## News
|
| 13 |
+
|
| 14 |
+
📢 **9/May/23** - First release - arxiv, code and pre-trained models.
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
## 1. Getting started
|
| 18 |
+
|
| 19 |
+
This code was tested on `NVIDIA GeForce RTX 2080 Ti` and requires:
|
| 20 |
+
|
| 21 |
+
* conda3 or miniconda3
|
| 22 |
+
|
| 23 |
+
```
|
| 24 |
+
conda create -n DiffuseStyleGesture python=3.7
|
| 25 |
+
pip install -r requirements.txt
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
[//]: # (-i https://pypi.tuna.tsinghua.edu.cn/simple)
|
| 29 |
+
|
| 30 |
+
## 2. Quick Start
|
| 31 |
+
|
| 32 |
+
1. Download pre-trained model from [Tsinghua Cloud](https://cloud.tsinghua.edu.cn/f/8ade7c73e05c4549ac6b/) or [Google Cloud](https://drive.google.com/file/d/1RlusxWJFJMyauXdbfbI_XreJwVRnrBv_/view?usp=share_link)
|
| 33 |
+
and put it into `./main/mydiffusion_zeggs/`.
|
| 34 |
+
2. Download the [WavLM Large](https://github.com/microsoft/unilm/tree/master/wavlm) and put it into `./main/mydiffusion_zeggs/WavLM/`.
|
| 35 |
+
3. cd `./main/mydiffusion_zeggs/` and run
|
| 36 |
+
```python
|
| 37 |
+
python sample.py --config=./configs/DiffuseStyleGesture.yml --no_cuda 0 --gpu 0 --model_path './model000450000.pt' --audiowavlm_path "./015_Happy_4_x_1_0.wav" --max_len 320
|
| 38 |
+
```
|
| 39 |
+
You will get the `.bvh` file named `yyyymmdd_hhmmss_smoothing_SG_minibatch_320_[1, 0, 0, 0, 0, 0]_123456.bvh` in the `sample_dir` folder, which can then be visualized using [Blender](https://www.blender.org/).
|
| 40 |
+
|
| 41 |
+
## 3. Train your own model
|
| 42 |
+
|
| 43 |
+
### (1) Get ZEGGS dataset
|
| 44 |
+
|
| 45 |
+
Same as [ZEGGS](https://github.com/ubisoft/ubisoft-laforge-ZeroEGGS).
|
| 46 |
+
|
| 47 |
+
An example is as follows.
|
| 48 |
+
Download original ZEGGS datasets from [here](https://github.com/ubisoft/ubisoft-laforge-ZeroEGGS) and put it in `./ubisoft-laforge-ZeroEGGS-main/data/` folder.
|
| 49 |
+
Then `cd ./ubisoft-laforge-ZeroEGGS-main/ZEGGS` and run `python data_pipeline.py` to process the dataset.
|
| 50 |
+
You will get `./ubisoft-laforge-ZeroEGGS-main/data/processed_v1/trimmed/train/` and `./ubisoft-laforge-ZeroEGGS-main/data/processed_v1/trimmed/test/` folders.
|
| 51 |
+
|
| 52 |
+
If you find it difficult to obtain and process the data, you can download the data after it has been processed by ZEGGS from [Tsinghua Cloud](https://cloud.tsinghua.edu.cn/f/ba5f3b33d94b4cba875b/) or [Baidu Cloud](https://pan.baidu.com/s/1KakkGpRZWfaJzfN5gQvPAw?pwd=vfuc).
|
| 53 |
+
And put it in `./ubisoft-laforge-ZeroEGGS-main/data/processed_v1/trimmed/` folder.
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
### (2) Process ZEGGS dataset
|
| 57 |
+
|
| 58 |
+
```
|
| 59 |
+
cd ./main/mydiffusion_zeggs/
|
| 60 |
+
python zeggs_data_to_lmdb.py
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
### (3) Train
|
| 64 |
+
|
| 65 |
+
```
|
| 66 |
+
python end2end.py --config=./configs/DiffuseStyleGesture.yml --no_cuda 0 --gpu 0
|
| 67 |
+
```
|
| 68 |
+
The model will save in `./main/mydiffusion_zeggs/zeggs_mymodel3_wavlm/` folder.
|
| 69 |
+
|
| 70 |
+
## Reference
|
| 71 |
+
Our work mainly inspired by: [MDM](https://github.com/GuyTevet/motion-diffusion-model), [Text2Gesture](https://github.com/youngwoo-yoon/Co-Speech_Gesture_Generation), [Listen, denoise, action!](https://arxiv.org/abs/2211.09707)
|
| 72 |
+
|
| 73 |
+
## Citation
|
| 74 |
+
If you find this code useful in your research, please cite:
|
| 75 |
+
|
| 76 |
+
```
|
| 77 |
+
@inproceedings{yang2023DiffuseStyleGesture,
|
| 78 |
+
author = {Sicheng Yang and Zhiyong Wu and Minglei Li and Zhensong Zhang and Lei Hao and Weihong Bao and Ming Cheng and Long Xiao},
|
| 79 |
+
title = {DiffuseStyleGesture: Stylized Audio-Driven Co-Speech Gesture Generation with Diffusion Models},
|
| 80 |
+
booktitle = {Proceedings of the 32nd International Joint Conference on Artificial Intelligence, {IJCAI} 2023},
|
| 81 |
+
publisher = {ijcai.org},
|
| 82 |
+
year = {2023},
|
| 83 |
+
}
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
Please feel free to contact us ([yangsc21@mails.tsinghua.edu.cn](yangsc21@mails.tsinghua.edu.cn)) with any question or concerns.
|
main/.gitignore
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
pip-wheel-metadata/
|
| 24 |
+
share/python-wheels/
|
| 25 |
+
*.egg-info/
|
| 26 |
+
.installed.cfg
|
| 27 |
+
*.egg
|
| 28 |
+
MANIFEST
|
| 29 |
+
|
| 30 |
+
# PyInstaller
|
| 31 |
+
# Usually these files are written by a python script from a template
|
| 32 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 33 |
+
*.manifest
|
| 34 |
+
*.spec
|
| 35 |
+
|
| 36 |
+
# Installer logs
|
| 37 |
+
pip-log.txt
|
| 38 |
+
pip-delete-this-directory.txt
|
| 39 |
+
|
| 40 |
+
# Unit test / coverage reports
|
| 41 |
+
htmlcov/
|
| 42 |
+
.tox/
|
| 43 |
+
.nox/
|
| 44 |
+
.coverage
|
| 45 |
+
.coverage.*
|
| 46 |
+
.cache
|
| 47 |
+
nosetests.xml
|
| 48 |
+
coverage.xml
|
| 49 |
+
*.cover
|
| 50 |
+
*.py,cover
|
| 51 |
+
.hypothesis/
|
| 52 |
+
.pytest_cache/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
target/
|
| 76 |
+
|
| 77 |
+
# Jupyter Notebook
|
| 78 |
+
.ipynb_checkpoints
|
| 79 |
+
|
| 80 |
+
# IPython
|
| 81 |
+
profile_default/
|
| 82 |
+
ipython_config.py
|
| 83 |
+
|
| 84 |
+
# pyenv
|
| 85 |
+
.python-version
|
| 86 |
+
|
| 87 |
+
# pipenv
|
| 88 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 89 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 90 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 91 |
+
# install all needed dependencies.
|
| 92 |
+
#Pipfile.lock
|
| 93 |
+
|
| 94 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 95 |
+
__pypackages__/
|
| 96 |
+
|
| 97 |
+
# Celery stuff
|
| 98 |
+
celerybeat-schedule
|
| 99 |
+
celerybeat.pid
|
| 100 |
+
|
| 101 |
+
# SageMath parsed files
|
| 102 |
+
*.sage.py
|
| 103 |
+
|
| 104 |
+
# Environments
|
| 105 |
+
.env
|
| 106 |
+
.venv
|
| 107 |
+
env/
|
| 108 |
+
venv/
|
| 109 |
+
ENV/
|
| 110 |
+
env.bak/
|
| 111 |
+
venv.bak/
|
| 112 |
+
|
| 113 |
+
# Spyder project settings
|
| 114 |
+
.spyderproject
|
| 115 |
+
.spyproject
|
| 116 |
+
|
| 117 |
+
# Rope project settings
|
| 118 |
+
.ropeproject
|
| 119 |
+
|
| 120 |
+
# mkdocs documentation
|
| 121 |
+
/site
|
| 122 |
+
|
| 123 |
+
# mypy
|
| 124 |
+
.mypy_cache/
|
| 125 |
+
.dmypy.json
|
| 126 |
+
dmypy.json
|
| 127 |
+
|
| 128 |
+
# Pyre type checker
|
| 129 |
+
.pyre/
|
main/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Guy Tevet
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
main/assets/example_action_names_humanact12.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
drink
|
| 2 |
+
lift_dumbbell
|
main/assets/example_action_names_uestc.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
jumping-jack
|
| 2 |
+
left-lunging
|
| 3 |
+
left-stretching
|
| 4 |
+
raising-hand-and-jumping
|
| 5 |
+
rotation-clapping
|
| 6 |
+
front-raising
|
| 7 |
+
pulling-chest-expanders
|
main/assets/example_stick_fig.gif
ADDED

|
main/assets/example_text_prompts.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
person got down and is crawling across the floor.
|
| 2 |
+
a person walks forward with wide steps.
|
| 3 |
+
a person drops their hands then brings them together in front of their face clasped.
|
| 4 |
+
a person lifts their right arm and slaps something, then repeats the motion again.
|
| 5 |
+
a person walks forward and stops.
|
| 6 |
+
a person marches forward, turns around, and then marches back.
|
| 7 |
+
a person is stretching their arms.
|
| 8 |
+
person is making attention gesture
|
main/assets/in_between_edit.gif
ADDED

|
Git LFS Details
|
main/assets/upper_body_edit.gif
ADDED

|
main/body_models/README.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Body models
|
| 2 |
+
|
| 3 |
+
Put SMPL models here (full instractions in the main README)
|
main/data_loaders/a2m/dataset.py
ADDED
|
@@ -0,0 +1,255 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
# from utils.action_label_to_idx import action_label_to_idx
|
| 6 |
+
from data_loaders.tensors import collate
|
| 7 |
+
from utils.misc import to_torch
|
| 8 |
+
import utils.rotation_conversions as geometry
|
| 9 |
+
|
| 10 |
+
class Dataset(torch.utils.data.Dataset):
|
| 11 |
+
def __init__(self, num_frames=1, sampling="conseq", sampling_step=1, split="train",
|
| 12 |
+
pose_rep="rot6d", translation=True, glob=True, max_len=-1, min_len=-1, num_seq_max=-1, **kwargs):
|
| 13 |
+
self.num_frames = num_frames
|
| 14 |
+
self.sampling = sampling
|
| 15 |
+
self.sampling_step = sampling_step
|
| 16 |
+
self.split = split
|
| 17 |
+
self.pose_rep = pose_rep
|
| 18 |
+
self.translation = translation
|
| 19 |
+
self.glob = glob
|
| 20 |
+
self.max_len = max_len
|
| 21 |
+
self.min_len = min_len
|
| 22 |
+
self.num_seq_max = num_seq_max
|
| 23 |
+
|
| 24 |
+
self.align_pose_frontview = kwargs.get('align_pose_frontview', False)
|
| 25 |
+
self.use_action_cat_as_text_labels = kwargs.get('use_action_cat_as_text_labels', False)
|
| 26 |
+
self.only_60_classes = kwargs.get('only_60_classes', False)
|
| 27 |
+
self.leave_out_15_classes = kwargs.get('leave_out_15_classes', False)
|
| 28 |
+
self.use_only_15_classes = kwargs.get('use_only_15_classes', False)
|
| 29 |
+
|
| 30 |
+
if self.split not in ["train", "val", "test"]:
|
| 31 |
+
raise ValueError(f"{self.split} is not a valid split")
|
| 32 |
+
|
| 33 |
+
super().__init__()
|
| 34 |
+
|
| 35 |
+
# to remove shuffling
|
| 36 |
+
self._original_train = None
|
| 37 |
+
self._original_test = None
|
| 38 |
+
|
| 39 |
+
def action_to_label(self, action):
|
| 40 |
+
return self._action_to_label[action]
|
| 41 |
+
|
| 42 |
+
def label_to_action(self, label):
|
| 43 |
+
import numbers
|
| 44 |
+
if isinstance(label, numbers.Integral):
|
| 45 |
+
return self._label_to_action[label]
|
| 46 |
+
else: # if it is one hot vector
|
| 47 |
+
label = np.argmax(label)
|
| 48 |
+
return self._label_to_action[label]
|
| 49 |
+
|
| 50 |
+
def get_pose_data(self, data_index, frame_ix):
|
| 51 |
+
pose = self._load(data_index, frame_ix)
|
| 52 |
+
label = self.get_label(data_index)
|
| 53 |
+
return pose, label
|
| 54 |
+
|
| 55 |
+
def get_label(self, ind):
|
| 56 |
+
action = self.get_action(ind)
|
| 57 |
+
return self.action_to_label(action)
|
| 58 |
+
|
| 59 |
+
def get_action(self, ind):
|
| 60 |
+
return self._actions[ind]
|
| 61 |
+
|
| 62 |
+
def action_to_action_name(self, action):
|
| 63 |
+
return self._action_classes[action]
|
| 64 |
+
|
| 65 |
+
def action_name_to_action(self, action_name):
|
| 66 |
+
# self._action_classes is either a list or a dictionary. If it's a dictionary, we 1st convert it to a list
|
| 67 |
+
all_action_names = self._action_classes
|
| 68 |
+
if isinstance(all_action_names, dict):
|
| 69 |
+
all_action_names = list(all_action_names.values())
|
| 70 |
+
assert list(self._action_classes.keys()) == list(range(len(all_action_names))) # the keys should be ordered from 0 to num_actions
|
| 71 |
+
|
| 72 |
+
sorter = np.argsort(all_action_names)
|
| 73 |
+
actions = sorter[np.searchsorted(all_action_names, action_name, sorter=sorter)]
|
| 74 |
+
return actions
|
| 75 |
+
|
| 76 |
+
def __getitem__(self, index):
|
| 77 |
+
if self.split == 'train':
|
| 78 |
+
data_index = self._train[index]
|
| 79 |
+
else:
|
| 80 |
+
data_index = self._test[index]
|
| 81 |
+
|
| 82 |
+
# inp, target = self._get_item_data_index(data_index)
|
| 83 |
+
# return inp, target
|
| 84 |
+
return self._get_item_data_index(data_index)
|
| 85 |
+
|
| 86 |
+
def _load(self, ind, frame_ix):
|
| 87 |
+
pose_rep = self.pose_rep
|
| 88 |
+
if pose_rep == "xyz" or self.translation:
|
| 89 |
+
if getattr(self, "_load_joints3D", None) is not None:
|
| 90 |
+
# Locate the root joint of initial pose at origin
|
| 91 |
+
joints3D = self._load_joints3D(ind, frame_ix)
|
| 92 |
+
joints3D = joints3D - joints3D[0, 0, :]
|
| 93 |
+
ret = to_torch(joints3D)
|
| 94 |
+
if self.translation:
|
| 95 |
+
ret_tr = ret[:, 0, :]
|
| 96 |
+
else:
|
| 97 |
+
if pose_rep == "xyz":
|
| 98 |
+
raise ValueError("This representation is not possible.")
|
| 99 |
+
if getattr(self, "_load_translation") is None:
|
| 100 |
+
raise ValueError("Can't extract translations.")
|
| 101 |
+
ret_tr = self._load_translation(ind, frame_ix)
|
| 102 |
+
ret_tr = to_torch(ret_tr - ret_tr[0])
|
| 103 |
+
|
| 104 |
+
if pose_rep != "xyz":
|
| 105 |
+
if getattr(self, "_load_rotvec", None) is None:
|
| 106 |
+
raise ValueError("This representation is not possible.")
|
| 107 |
+
else:
|
| 108 |
+
pose = self._load_rotvec(ind, frame_ix)
|
| 109 |
+
if not self.glob:
|
| 110 |
+
pose = pose[:, 1:, :]
|
| 111 |
+
pose = to_torch(pose)
|
| 112 |
+
if self.align_pose_frontview:
|
| 113 |
+
first_frame_root_pose_matrix = geometry.axis_angle_to_matrix(pose[0][0])
|
| 114 |
+
all_root_poses_matrix = geometry.axis_angle_to_matrix(pose[:, 0, :])
|
| 115 |
+
aligned_root_poses_matrix = torch.matmul(torch.transpose(first_frame_root_pose_matrix, 0, 1),
|
| 116 |
+
all_root_poses_matrix)
|
| 117 |
+
pose[:, 0, :] = geometry.matrix_to_axis_angle(aligned_root_poses_matrix)
|
| 118 |
+
|
| 119 |
+
if self.translation:
|
| 120 |
+
ret_tr = torch.matmul(torch.transpose(first_frame_root_pose_matrix, 0, 1).float(),
|
| 121 |
+
torch.transpose(ret_tr, 0, 1))
|
| 122 |
+
ret_tr = torch.transpose(ret_tr, 0, 1)
|
| 123 |
+
|
| 124 |
+
if pose_rep == "rotvec":
|
| 125 |
+
ret = pose
|
| 126 |
+
elif pose_rep == "rotmat":
|
| 127 |
+
ret = geometry.axis_angle_to_matrix(pose).view(*pose.shape[:2], 9)
|
| 128 |
+
elif pose_rep == "rotquat":
|
| 129 |
+
ret = geometry.axis_angle_to_quaternion(pose)
|
| 130 |
+
elif pose_rep == "rot6d":
|
| 131 |
+
ret = geometry.matrix_to_rotation_6d(geometry.axis_angle_to_matrix(pose))
|
| 132 |
+
if pose_rep != "xyz" and self.translation:
|
| 133 |
+
padded_tr = torch.zeros((ret.shape[0], ret.shape[2]), dtype=ret.dtype)
|
| 134 |
+
padded_tr[:, :3] = ret_tr
|
| 135 |
+
ret = torch.cat((ret, padded_tr[:, None]), 1)
|
| 136 |
+
ret = ret.permute(1, 2, 0).contiguous()
|
| 137 |
+
return ret.float()
|
| 138 |
+
|
| 139 |
+
def _get_item_data_index(self, data_index):
|
| 140 |
+
nframes = self._num_frames_in_video[data_index]
|
| 141 |
+
|
| 142 |
+
if self.num_frames == -1 and (self.max_len == -1 or nframes <= self.max_len):
|
| 143 |
+
frame_ix = np.arange(nframes)
|
| 144 |
+
else:
|
| 145 |
+
if self.num_frames == -2:
|
| 146 |
+
if self.min_len <= 0:
|
| 147 |
+
raise ValueError("You should put a min_len > 0 for num_frames == -2 mode")
|
| 148 |
+
if self.max_len != -1:
|
| 149 |
+
max_frame = min(nframes, self.max_len)
|
| 150 |
+
else:
|
| 151 |
+
max_frame = nframes
|
| 152 |
+
|
| 153 |
+
num_frames = random.randint(self.min_len, max(max_frame, self.min_len))
|
| 154 |
+
else:
|
| 155 |
+
num_frames = self.num_frames if self.num_frames != -1 else self.max_len
|
| 156 |
+
|
| 157 |
+
if num_frames > nframes:
|
| 158 |
+
fair = False # True
|
| 159 |
+
if fair:
|
| 160 |
+
# distills redundancy everywhere
|
| 161 |
+
choices = np.random.choice(range(nframes),
|
| 162 |
+
num_frames,
|
| 163 |
+
replace=True)
|
| 164 |
+
frame_ix = sorted(choices)
|
| 165 |
+
else:
|
| 166 |
+
# adding the last frame until done
|
| 167 |
+
ntoadd = max(0, num_frames - nframes)
|
| 168 |
+
lastframe = nframes - 1
|
| 169 |
+
padding = lastframe * np.ones(ntoadd, dtype=int)
|
| 170 |
+
frame_ix = np.concatenate((np.arange(0, nframes),
|
| 171 |
+
padding))
|
| 172 |
+
|
| 173 |
+
elif self.sampling in ["conseq", "random_conseq"]:
|
| 174 |
+
step_max = (nframes - 1) // (num_frames - 1)
|
| 175 |
+
if self.sampling == "conseq":
|
| 176 |
+
if self.sampling_step == -1 or self.sampling_step * (num_frames - 1) >= nframes:
|
| 177 |
+
step = step_max
|
| 178 |
+
else:
|
| 179 |
+
step = self.sampling_step
|
| 180 |
+
elif self.sampling == "random_conseq":
|
| 181 |
+
step = random.randint(1, step_max)
|
| 182 |
+
|
| 183 |
+
lastone = step * (num_frames - 1)
|
| 184 |
+
shift_max = nframes - lastone - 1
|
| 185 |
+
shift = random.randint(0, max(0, shift_max - 1))
|
| 186 |
+
frame_ix = shift + np.arange(0, lastone + 1, step)
|
| 187 |
+
|
| 188 |
+
elif self.sampling == "random":
|
| 189 |
+
choices = np.random.choice(range(nframes),
|
| 190 |
+
num_frames,
|
| 191 |
+
replace=False)
|
| 192 |
+
frame_ix = sorted(choices)
|
| 193 |
+
|
| 194 |
+
else:
|
| 195 |
+
raise ValueError("Sampling not recognized.")
|
| 196 |
+
|
| 197 |
+
inp, action = self.get_pose_data(data_index, frame_ix)
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
output = {'inp': inp, 'action': action}
|
| 201 |
+
|
| 202 |
+
if hasattr(self, '_actions') and hasattr(self, '_action_classes'):
|
| 203 |
+
output['action_text'] = self.action_to_action_name(self.get_action(data_index))
|
| 204 |
+
|
| 205 |
+
return output
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
def get_mean_length_label(self, label):
|
| 209 |
+
if self.num_frames != -1:
|
| 210 |
+
return self.num_frames
|
| 211 |
+
|
| 212 |
+
if self.split == 'train':
|
| 213 |
+
index = self._train
|
| 214 |
+
else:
|
| 215 |
+
index = self._test
|
| 216 |
+
|
| 217 |
+
action = self.label_to_action(label)
|
| 218 |
+
choices = np.argwhere(self._actions[index] == action).squeeze(1)
|
| 219 |
+
lengths = self._num_frames_in_video[np.array(index)[choices]]
|
| 220 |
+
|
| 221 |
+
if self.max_len == -1:
|
| 222 |
+
return np.mean(lengths)
|
| 223 |
+
else:
|
| 224 |
+
# make the lengths less than max_len
|
| 225 |
+
lengths[lengths > self.max_len] = self.max_len
|
| 226 |
+
return np.mean(lengths)
|
| 227 |
+
|
| 228 |
+
def __len__(self):
|
| 229 |
+
num_seq_max = getattr(self, "num_seq_max", -1)
|
| 230 |
+
if num_seq_max == -1:
|
| 231 |
+
from math import inf
|
| 232 |
+
num_seq_max = inf
|
| 233 |
+
|
| 234 |
+
if self.split == 'train':
|
| 235 |
+
return min(len(self._train), num_seq_max)
|
| 236 |
+
else:
|
| 237 |
+
return min(len(self._test), num_seq_max)
|
| 238 |
+
|
| 239 |
+
def shuffle(self):
|
| 240 |
+
if self.split == 'train':
|
| 241 |
+
random.shuffle(self._train)
|
| 242 |
+
else:
|
| 243 |
+
random.shuffle(self._test)
|
| 244 |
+
|
| 245 |
+
def reset_shuffle(self):
|
| 246 |
+
if self.split == 'train':
|
| 247 |
+
if self._original_train is None:
|
| 248 |
+
self._original_train = self._train
|
| 249 |
+
else:
|
| 250 |
+
self._train = self._original_train
|
| 251 |
+
else:
|
| 252 |
+
if self._original_test is None:
|
| 253 |
+
self._original_test = self._test
|
| 254 |
+
else:
|
| 255 |
+
self._test = self._original_test
|
main/data_loaders/a2m/humanact12poses.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pickle as pkl
|
| 2 |
+
import numpy as np
|
| 3 |
+
import os
|
| 4 |
+
from .dataset import Dataset
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class HumanAct12Poses(Dataset):
|
| 8 |
+
dataname = "humanact12"
|
| 9 |
+
|
| 10 |
+
def __init__(self, datapath="dataset/HumanAct12Poses", split="train", **kargs):
|
| 11 |
+
self.datapath = datapath
|
| 12 |
+
|
| 13 |
+
super().__init__(**kargs)
|
| 14 |
+
|
| 15 |
+
pkldatafilepath = os.path.join(datapath, "humanact12poses.pkl")
|
| 16 |
+
data = pkl.load(open(pkldatafilepath, "rb"))
|
| 17 |
+
|
| 18 |
+
self._pose = [x for x in data["poses"]]
|
| 19 |
+
self._num_frames_in_video = [p.shape[0] for p in self._pose]
|
| 20 |
+
self._joints = [x for x in data["joints3D"]]
|
| 21 |
+
|
| 22 |
+
self._actions = [x for x in data["y"]]
|
| 23 |
+
|
| 24 |
+
total_num_actions = 12
|
| 25 |
+
self.num_actions = total_num_actions
|
| 26 |
+
|
| 27 |
+
self._train = list(range(len(self._pose)))
|
| 28 |
+
|
| 29 |
+
keep_actions = np.arange(0, total_num_actions)
|
| 30 |
+
|
| 31 |
+
self._action_to_label = {x: i for i, x in enumerate(keep_actions)}
|
| 32 |
+
self._label_to_action = {i: x for i, x in enumerate(keep_actions)}
|
| 33 |
+
|
| 34 |
+
self._action_classes = humanact12_coarse_action_enumerator
|
| 35 |
+
|
| 36 |
+
def _load_joints3D(self, ind, frame_ix):
|
| 37 |
+
return self._joints[ind][frame_ix]
|
| 38 |
+
|
| 39 |
+
def _load_rotvec(self, ind, frame_ix):
|
| 40 |
+
pose = self._pose[ind][frame_ix].reshape(-1, 24, 3)
|
| 41 |
+
return pose
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
humanact12_coarse_action_enumerator = {
|
| 45 |
+
0: "warm_up",
|
| 46 |
+
1: "walk",
|
| 47 |
+
2: "run",
|
| 48 |
+
3: "jump",
|
| 49 |
+
4: "drink",
|
| 50 |
+
5: "lift_dumbbell",
|
| 51 |
+
6: "sit",
|
| 52 |
+
7: "eat",
|
| 53 |
+
8: "turn steering wheel",
|
| 54 |
+
9: "phone",
|
| 55 |
+
10: "boxing",
|
| 56 |
+
11: "throw",
|
| 57 |
+
}
|
main/data_loaders/a2m/uestc.py
ADDED
|
@@ -0,0 +1,226 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from tqdm import tqdm
|
| 3 |
+
import numpy as np
|
| 4 |
+
import pickle as pkl
|
| 5 |
+
import utils.rotation_conversions as geometry
|
| 6 |
+
import torch
|
| 7 |
+
|
| 8 |
+
from .dataset import Dataset
|
| 9 |
+
# from torch.utils.data import Dataset
|
| 10 |
+
|
| 11 |
+
action2motion_joints = [8, 1, 2, 3, 4, 5, 6, 7, 0, 9, 10, 11, 12, 13, 14, 21, 24, 38]
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def get_z(cam_s, cam_pos, joints, img_size, flength):
|
| 15 |
+
"""
|
| 16 |
+
Solves for the depth offset of the model to approx. orth with persp camera.
|
| 17 |
+
"""
|
| 18 |
+
# Translate the model itself: Solve the best z that maps to orth_proj points
|
| 19 |
+
joints_orth_target = (cam_s * (joints[:, :2] + cam_pos) + 1) * 0.5 * img_size
|
| 20 |
+
height3d = np.linalg.norm(np.max(joints[:, :2], axis=0) - np.min(joints[:, :2], axis=0))
|
| 21 |
+
height2d = np.linalg.norm(np.max(joints_orth_target, axis=0) - np.min(joints_orth_target, axis=0))
|
| 22 |
+
tz = np.array(flength * (height3d / height2d))
|
| 23 |
+
return float(tz)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def get_trans_from_vibe(vibe, index, use_z=True):
|
| 27 |
+
alltrans = []
|
| 28 |
+
for t in range(vibe["joints3d"][index].shape[0]):
|
| 29 |
+
# Convert crop cam to orig cam
|
| 30 |
+
# No need! Because `convert_crop_cam_to_orig_img` from demoutils of vibe
|
| 31 |
+
# does this already for us :)
|
| 32 |
+
# Its format is: [sx, sy, tx, ty]
|
| 33 |
+
cam_orig = vibe["orig_cam"][index][t]
|
| 34 |
+
x = cam_orig[2]
|
| 35 |
+
y = cam_orig[3]
|
| 36 |
+
if use_z:
|
| 37 |
+
z = get_z(cam_s=cam_orig[0], # TODO: There are two scales instead of 1.
|
| 38 |
+
cam_pos=cam_orig[2:4],
|
| 39 |
+
joints=vibe['joints3d'][index][t],
|
| 40 |
+
img_size=540,
|
| 41 |
+
flength=500)
|
| 42 |
+
# z = 500 / (0.5 * 480 * cam_orig[0])
|
| 43 |
+
else:
|
| 44 |
+
z = 0
|
| 45 |
+
trans = [x, y, z]
|
| 46 |
+
alltrans.append(trans)
|
| 47 |
+
alltrans = np.array(alltrans)
|
| 48 |
+
return alltrans - alltrans[0]
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class UESTC(Dataset):
|
| 52 |
+
dataname = "uestc"
|
| 53 |
+
|
| 54 |
+
def __init__(self, datapath="dataset/uestc", method_name="vibe", view="all", **kargs):
|
| 55 |
+
|
| 56 |
+
self.datapath = datapath
|
| 57 |
+
self.method_name = method_name
|
| 58 |
+
self.view = view
|
| 59 |
+
super().__init__(**kargs)
|
| 60 |
+
|
| 61 |
+
# Load pre-computed #frames data
|
| 62 |
+
with open(os.path.join(datapath, 'info', 'num_frames_min.txt'), 'r') as f:
|
| 63 |
+
num_frames_video = np.asarray([int(s) for s in f.read().splitlines()])
|
| 64 |
+
|
| 65 |
+
# Out of 118 subjects -> 51 training, 67 in test
|
| 66 |
+
all_subjects = np.arange(1, 119)
|
| 67 |
+
self._tr_subjects = [
|
| 68 |
+
1, 2, 6, 12, 13, 16, 21, 24, 28, 29, 30, 31, 33, 35, 39, 41, 42, 45, 47, 50,
|
| 69 |
+
52, 54, 55, 57, 59, 61, 63, 64, 67, 69, 70, 71, 73, 77, 81, 84, 86, 87, 88,
|
| 70 |
+
90, 91, 93, 96, 99, 102, 103, 104, 107, 108, 112, 113]
|
| 71 |
+
self._test_subjects = [s for s in all_subjects if s not in self._tr_subjects]
|
| 72 |
+
|
| 73 |
+
# Load names of 25600 videos
|
| 74 |
+
with open(os.path.join(datapath, 'info', 'names.txt'), 'r') as f:
|
| 75 |
+
videos = f.read().splitlines()
|
| 76 |
+
|
| 77 |
+
self._videos = videos
|
| 78 |
+
|
| 79 |
+
if self.method_name == "vibe":
|
| 80 |
+
vibe_data_path = os.path.join(datapath, "vibe_cache_refined.pkl")
|
| 81 |
+
vibe_data = pkl.load(open(vibe_data_path, "rb"))
|
| 82 |
+
|
| 83 |
+
self._pose = vibe_data["pose"]
|
| 84 |
+
num_frames_method = [p.shape[0] for p in self._pose]
|
| 85 |
+
globpath = os.path.join(datapath, "globtrans_usez.pkl")
|
| 86 |
+
|
| 87 |
+
if os.path.exists(globpath):
|
| 88 |
+
self._globtrans = pkl.load(open(globpath, "rb"))
|
| 89 |
+
else:
|
| 90 |
+
self._globtrans = []
|
| 91 |
+
for index in tqdm(range(len(self._pose))):
|
| 92 |
+
self._globtrans.append(get_trans_from_vibe(vibe_data, index, use_z=True))
|
| 93 |
+
pkl.dump(self._globtrans, open("globtrans_usez.pkl", "wb"))
|
| 94 |
+
self._joints = vibe_data["joints3d"]
|
| 95 |
+
self._jointsIx = action2motion_joints
|
| 96 |
+
else:
|
| 97 |
+
raise ValueError("This method name is not recognized.")
|
| 98 |
+
|
| 99 |
+
num_frames_video = np.minimum(num_frames_video, num_frames_method)
|
| 100 |
+
num_frames_video = num_frames_video.astype(int)
|
| 101 |
+
self._num_frames_in_video = [x for x in num_frames_video]
|
| 102 |
+
|
| 103 |
+
N = len(videos)
|
| 104 |
+
self._actions = np.zeros(N, dtype=int)
|
| 105 |
+
for ind in range(N):
|
| 106 |
+
self._actions[ind] = self.parse_action(videos[ind])
|
| 107 |
+
|
| 108 |
+
self._actions = [x for x in self._actions]
|
| 109 |
+
|
| 110 |
+
total_num_actions = 40
|
| 111 |
+
self.num_actions = total_num_actions
|
| 112 |
+
keep_actions = np.arange(0, total_num_actions)
|
| 113 |
+
|
| 114 |
+
self._action_to_label = {x: i for i, x in enumerate(keep_actions)}
|
| 115 |
+
self._label_to_action = {i: x for i, x in enumerate(keep_actions)}
|
| 116 |
+
self.num_classes = len(keep_actions)
|
| 117 |
+
|
| 118 |
+
self._train = []
|
| 119 |
+
self._test = []
|
| 120 |
+
|
| 121 |
+
self.info_actions = []
|
| 122 |
+
|
| 123 |
+
def get_rotation(view):
|
| 124 |
+
theta = - view * np.pi/4
|
| 125 |
+
axis = torch.tensor([0, 1, 0], dtype=torch.float)
|
| 126 |
+
axisangle = theta*axis
|
| 127 |
+
matrix = geometry.axis_angle_to_matrix(axisangle)
|
| 128 |
+
return matrix
|
| 129 |
+
|
| 130 |
+
# 0 is identity if needed
|
| 131 |
+
rotations = {key: get_rotation(key) for key in [0, 1, 2, 3, 4, 5, 6, 7]}
|
| 132 |
+
|
| 133 |
+
for index, video in enumerate(tqdm(videos, desc='Preparing UESTC data..')):
|
| 134 |
+
act, view, subject, side = self._get_action_view_subject_side(video)
|
| 135 |
+
self.info_actions.append({"action": act,
|
| 136 |
+
"view": view,
|
| 137 |
+
"subject": subject,
|
| 138 |
+
"side": side})
|
| 139 |
+
if self.view == "frontview":
|
| 140 |
+
if side != 1:
|
| 141 |
+
continue
|
| 142 |
+
# rotate to front view
|
| 143 |
+
if side != 1:
|
| 144 |
+
# don't take the view 8 in side 2
|
| 145 |
+
if view == 8:
|
| 146 |
+
continue
|
| 147 |
+
rotation = rotations[view]
|
| 148 |
+
global_matrix = geometry.axis_angle_to_matrix(torch.from_numpy(self._pose[index][:, :3]))
|
| 149 |
+
# rotate the global pose
|
| 150 |
+
self._pose[index][:, :3] = geometry.matrix_to_axis_angle(rotation @ global_matrix).numpy()
|
| 151 |
+
# rotate the joints
|
| 152 |
+
self._joints[index] = self._joints[index] @ rotation.T.numpy()
|
| 153 |
+
self._globtrans[index] = (self._globtrans[index] @ rotation.T.numpy())
|
| 154 |
+
|
| 155 |
+
# add the global translation to the joints
|
| 156 |
+
self._joints[index] = self._joints[index] + self._globtrans[index][:, None]
|
| 157 |
+
|
| 158 |
+
if subject in self._tr_subjects:
|
| 159 |
+
self._train.append(index)
|
| 160 |
+
elif subject in self._test_subjects:
|
| 161 |
+
self._test.append(index)
|
| 162 |
+
else:
|
| 163 |
+
raise ValueError("This subject doesn't belong to any set.")
|
| 164 |
+
|
| 165 |
+
# if index > 200:
|
| 166 |
+
# break
|
| 167 |
+
|
| 168 |
+
# Select only sequences which have a minimum number of frames
|
| 169 |
+
if self.num_frames > 0:
|
| 170 |
+
threshold = self.num_frames*3/4
|
| 171 |
+
else:
|
| 172 |
+
threshold = 0
|
| 173 |
+
|
| 174 |
+
method_extracted_ix = np.where(num_frames_video >= threshold)[0].tolist()
|
| 175 |
+
self._train = list(set(self._train) & set(method_extracted_ix))
|
| 176 |
+
# keep the test set without modification
|
| 177 |
+
self._test = list(set(self._test))
|
| 178 |
+
|
| 179 |
+
action_classes_file = os.path.join(datapath, "info/action_classes.txt")
|
| 180 |
+
with open(action_classes_file, 'r') as f:
|
| 181 |
+
self._action_classes = np.array(f.read().splitlines())
|
| 182 |
+
|
| 183 |
+
# with open(processd_path, 'wb') as file:
|
| 184 |
+
# pkl.dump(xxx, file)
|
| 185 |
+
|
| 186 |
+
def _load_joints3D(self, ind, frame_ix):
|
| 187 |
+
if len(self._joints[ind]) == 0:
|
| 188 |
+
raise ValueError(
|
| 189 |
+
f"Cannot load index {ind} in _load_joints3D function.")
|
| 190 |
+
if self._jointsIx is not None:
|
| 191 |
+
joints3D = self._joints[ind][frame_ix][:, self._jointsIx]
|
| 192 |
+
else:
|
| 193 |
+
joints3D = self._joints[ind][frame_ix]
|
| 194 |
+
|
| 195 |
+
return joints3D
|
| 196 |
+
|
| 197 |
+
def _load_rotvec(self, ind, frame_ix):
|
| 198 |
+
# 72 dim smpl
|
| 199 |
+
pose = self._pose[ind][frame_ix, :].reshape(-1, 24, 3)
|
| 200 |
+
return pose
|
| 201 |
+
|
| 202 |
+
def _get_action_view_subject_side(self, videopath):
|
| 203 |
+
# TODO: Can be moved to tools.py
|
| 204 |
+
spl = videopath.split('_')
|
| 205 |
+
action = int(spl[0][1:])
|
| 206 |
+
view = int(spl[1][1:])
|
| 207 |
+
subject = int(spl[2][1:])
|
| 208 |
+
side = int(spl[3][1:])
|
| 209 |
+
return action, view, subject, side
|
| 210 |
+
|
| 211 |
+
def _get_videopath(self, action, view, subject, side):
|
| 212 |
+
# Unused function
|
| 213 |
+
return 'a{:d}_d{:d}_p{:03d}_c{:d}_color.avi'.format(
|
| 214 |
+
action, view, subject, side)
|
| 215 |
+
|
| 216 |
+
def parse_action(self, path, return_int=True):
|
| 217 |
+
# Override parent method
|
| 218 |
+
info, _, _, _ = self._get_action_view_subject_side(path)
|
| 219 |
+
if return_int:
|
| 220 |
+
return int(info)
|
| 221 |
+
else:
|
| 222 |
+
return info
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
if __name__ == "__main__":
|
| 226 |
+
dataset = UESTC()
|
main/data_loaders/get_data.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.utils.data import DataLoader
|
| 2 |
+
from data_loaders.tensors import collate as all_collate
|
| 3 |
+
from data_loaders.tensors import t2m_collate
|
| 4 |
+
|
| 5 |
+
def get_dataset_class(name):
|
| 6 |
+
if name == "amass":
|
| 7 |
+
from .amass import AMASS
|
| 8 |
+
return AMASS
|
| 9 |
+
elif name == "uestc":
|
| 10 |
+
from .a2m.uestc import UESTC
|
| 11 |
+
return UESTC
|
| 12 |
+
elif name == "humanact12":
|
| 13 |
+
from .a2m.humanact12poses import HumanAct12Poses
|
| 14 |
+
return HumanAct12Poses
|
| 15 |
+
elif name == "humanml":
|
| 16 |
+
from data_loaders.humanml.data.dataset import HumanML3D
|
| 17 |
+
return HumanML3D
|
| 18 |
+
elif name == "kit":
|
| 19 |
+
from data_loaders.humanml.data.dataset import KIT
|
| 20 |
+
return KIT
|
| 21 |
+
else:
|
| 22 |
+
raise ValueError(f'Unsupported dataset name [{name}]')
|
| 23 |
+
|
| 24 |
+
def get_collate_fn(name, hml_mode='train'):
|
| 25 |
+
if hml_mode == 'gt':
|
| 26 |
+
from data_loaders.humanml.data.dataset import collate_fn as t2m_eval_collate
|
| 27 |
+
return t2m_eval_collate
|
| 28 |
+
if name in ["humanml", "kit"]:
|
| 29 |
+
return t2m_collate
|
| 30 |
+
else:
|
| 31 |
+
return all_collate
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def get_dataset(name, num_frames, split='train', hml_mode='train'):
|
| 35 |
+
DATA = get_dataset_class(name)
|
| 36 |
+
if name in ["humanml", "kit"]:
|
| 37 |
+
dataset = DATA(split=split, num_frames=num_frames, mode=hml_mode)
|
| 38 |
+
else:
|
| 39 |
+
dataset = DATA(split=split, num_frames=num_frames)
|
| 40 |
+
return dataset
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def get_dataset_loader(name, batch_size, num_frames, split='train', hml_mode='train'):
|
| 44 |
+
dataset = get_dataset(name, num_frames, split, hml_mode)
|
| 45 |
+
collate = get_collate_fn(name, hml_mode)
|
| 46 |
+
|
| 47 |
+
loader = DataLoader(
|
| 48 |
+
dataset, batch_size=batch_size, shuffle=True,
|
| 49 |
+
num_workers=8, drop_last=True, collate_fn=collate
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
return loader
|
main/data_loaders/humanml/README.md
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
This code is based on https://github.com/EricGuo5513/text-to-motion.git
|
main/data_loaders/humanml/common/quaternion.py
ADDED
|
@@ -0,0 +1,423 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2018-present, Facebook, Inc.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import numpy as np
|
| 10 |
+
|
| 11 |
+
_EPS4 = np.finfo(float).eps * 4.0
|
| 12 |
+
|
| 13 |
+
_FLOAT_EPS = np.finfo(np.float).eps
|
| 14 |
+
|
| 15 |
+
# PyTorch-backed implementations
|
| 16 |
+
def qinv(q):
|
| 17 |
+
assert q.shape[-1] == 4, 'q must be a tensor of shape (*, 4)'
|
| 18 |
+
mask = torch.ones_like(q)
|
| 19 |
+
mask[..., 1:] = -mask[..., 1:]
|
| 20 |
+
return q * mask
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def qinv_np(q):
|
| 24 |
+
assert q.shape[-1] == 4, 'q must be a tensor of shape (*, 4)'
|
| 25 |
+
return qinv(torch.from_numpy(q).float()).numpy()
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def qnormalize(q):
|
| 29 |
+
assert q.shape[-1] == 4, 'q must be a tensor of shape (*, 4)'
|
| 30 |
+
return q / torch.norm(q, dim=-1, keepdim=True)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def qmul(q, r):
|
| 34 |
+
"""
|
| 35 |
+
Multiply quaternion(s) q with quaternion(s) r.
|
| 36 |
+
Expects two equally-sized tensors of shape (*, 4), where * denotes any number of dimensions.
|
| 37 |
+
Returns q*r as a tensor of shape (*, 4).
|
| 38 |
+
"""
|
| 39 |
+
assert q.shape[-1] == 4
|
| 40 |
+
assert r.shape[-1] == 4
|
| 41 |
+
|
| 42 |
+
original_shape = q.shape
|
| 43 |
+
|
| 44 |
+
# Compute outer product
|
| 45 |
+
terms = torch.bmm(r.view(-1, 4, 1), q.view(-1, 1, 4))
|
| 46 |
+
|
| 47 |
+
w = terms[:, 0, 0] - terms[:, 1, 1] - terms[:, 2, 2] - terms[:, 3, 3]
|
| 48 |
+
x = terms[:, 0, 1] + terms[:, 1, 0] - terms[:, 2, 3] + terms[:, 3, 2]
|
| 49 |
+
y = terms[:, 0, 2] + terms[:, 1, 3] + terms[:, 2, 0] - terms[:, 3, 1]
|
| 50 |
+
z = terms[:, 0, 3] - terms[:, 1, 2] + terms[:, 2, 1] + terms[:, 3, 0]
|
| 51 |
+
return torch.stack((w, x, y, z), dim=1).view(original_shape)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def qrot(q, v):
|
| 55 |
+
"""
|
| 56 |
+
Rotate vector(s) v about the rotation described by quaternion(s) q.
|
| 57 |
+
Expects a tensor of shape (*, 4) for q and a tensor of shape (*, 3) for v,
|
| 58 |
+
where * denotes any number of dimensions.
|
| 59 |
+
Returns a tensor of shape (*, 3).
|
| 60 |
+
"""
|
| 61 |
+
assert q.shape[-1] == 4
|
| 62 |
+
assert v.shape[-1] == 3
|
| 63 |
+
assert q.shape[:-1] == v.shape[:-1]
|
| 64 |
+
|
| 65 |
+
original_shape = list(v.shape)
|
| 66 |
+
# print(q.shape)
|
| 67 |
+
q = q.contiguous().view(-1, 4)
|
| 68 |
+
v = v.contiguous().view(-1, 3)
|
| 69 |
+
|
| 70 |
+
qvec = q[:, 1:]
|
| 71 |
+
uv = torch.cross(qvec, v, dim=1)
|
| 72 |
+
uuv = torch.cross(qvec, uv, dim=1)
|
| 73 |
+
return (v + 2 * (q[:, :1] * uv + uuv)).view(original_shape)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def qeuler(q, order, epsilon=0, deg=True):
|
| 77 |
+
"""
|
| 78 |
+
Convert quaternion(s) q to Euler angles.
|
| 79 |
+
Expects a tensor of shape (*, 4), where * denotes any number of dimensions.
|
| 80 |
+
Returns a tensor of shape (*, 3).
|
| 81 |
+
"""
|
| 82 |
+
assert q.shape[-1] == 4
|
| 83 |
+
|
| 84 |
+
original_shape = list(q.shape)
|
| 85 |
+
original_shape[-1] = 3
|
| 86 |
+
q = q.view(-1, 4)
|
| 87 |
+
|
| 88 |
+
q0 = q[:, 0]
|
| 89 |
+
q1 = q[:, 1]
|
| 90 |
+
q2 = q[:, 2]
|
| 91 |
+
q3 = q[:, 3]
|
| 92 |
+
|
| 93 |
+
if order == 'xyz':
|
| 94 |
+
x = torch.atan2(2 * (q0 * q1 - q2 * q3), 1 - 2 * (q1 * q1 + q2 * q2))
|
| 95 |
+
y = torch.asin(torch.clamp(2 * (q1 * q3 + q0 * q2), -1 + epsilon, 1 - epsilon))
|
| 96 |
+
z = torch.atan2(2 * (q0 * q3 - q1 * q2), 1 - 2 * (q2 * q2 + q3 * q3))
|
| 97 |
+
elif order == 'yzx':
|
| 98 |
+
x = torch.atan2(2 * (q0 * q1 - q2 * q3), 1 - 2 * (q1 * q1 + q3 * q3))
|
| 99 |
+
y = torch.atan2(2 * (q0 * q2 - q1 * q3), 1 - 2 * (q2 * q2 + q3 * q3))
|
| 100 |
+
z = torch.asin(torch.clamp(2 * (q1 * q2 + q0 * q3), -1 + epsilon, 1 - epsilon))
|
| 101 |
+
elif order == 'zxy':
|
| 102 |
+
x = torch.asin(torch.clamp(2 * (q0 * q1 + q2 * q3), -1 + epsilon, 1 - epsilon))
|
| 103 |
+
y = torch.atan2(2 * (q0 * q2 - q1 * q3), 1 - 2 * (q1 * q1 + q2 * q2))
|
| 104 |
+
z = torch.atan2(2 * (q0 * q3 - q1 * q2), 1 - 2 * (q1 * q1 + q3 * q3))
|
| 105 |
+
elif order == 'xzy':
|
| 106 |
+
x = torch.atan2(2 * (q0 * q1 + q2 * q3), 1 - 2 * (q1 * q1 + q3 * q3))
|
| 107 |
+
y = torch.atan2(2 * (q0 * q2 + q1 * q3), 1 - 2 * (q2 * q2 + q3 * q3))
|
| 108 |
+
z = torch.asin(torch.clamp(2 * (q0 * q3 - q1 * q2), -1 + epsilon, 1 - epsilon))
|
| 109 |
+
elif order == 'yxz':
|
| 110 |
+
x = torch.asin(torch.clamp(2 * (q0 * q1 - q2 * q3), -1 + epsilon, 1 - epsilon))
|
| 111 |
+
y = torch.atan2(2 * (q1 * q3 + q0 * q2), 1 - 2 * (q1 * q1 + q2 * q2))
|
| 112 |
+
z = torch.atan2(2 * (q1 * q2 + q0 * q3), 1 - 2 * (q1 * q1 + q3 * q3))
|
| 113 |
+
elif order == 'zyx':
|
| 114 |
+
x = torch.atan2(2 * (q0 * q1 + q2 * q3), 1 - 2 * (q1 * q1 + q2 * q2))
|
| 115 |
+
y = torch.asin(torch.clamp(2 * (q0 * q2 - q1 * q3), -1 + epsilon, 1 - epsilon))
|
| 116 |
+
z = torch.atan2(2 * (q0 * q3 + q1 * q2), 1 - 2 * (q2 * q2 + q3 * q3))
|
| 117 |
+
else:
|
| 118 |
+
raise
|
| 119 |
+
|
| 120 |
+
if deg:
|
| 121 |
+
return torch.stack((x, y, z), dim=1).view(original_shape) * 180 / np.pi
|
| 122 |
+
else:
|
| 123 |
+
return torch.stack((x, y, z), dim=1).view(original_shape)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
# Numpy-backed implementations
|
| 127 |
+
|
| 128 |
+
def qmul_np(q, r):
|
| 129 |
+
q = torch.from_numpy(q).contiguous().float()
|
| 130 |
+
r = torch.from_numpy(r).contiguous().float()
|
| 131 |
+
return qmul(q, r).numpy()
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
def qrot_np(q, v):
|
| 135 |
+
q = torch.from_numpy(q).contiguous().float()
|
| 136 |
+
v = torch.from_numpy(v).contiguous().float()
|
| 137 |
+
return qrot(q, v).numpy()
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def qeuler_np(q, order, epsilon=0, use_gpu=False):
|
| 141 |
+
if use_gpu:
|
| 142 |
+
q = torch.from_numpy(q).cuda().float()
|
| 143 |
+
return qeuler(q, order, epsilon).cpu().numpy()
|
| 144 |
+
else:
|
| 145 |
+
q = torch.from_numpy(q).contiguous().float()
|
| 146 |
+
return qeuler(q, order, epsilon).numpy()
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def qfix(q):
|
| 150 |
+
"""
|
| 151 |
+
Enforce quaternion continuity across the time dimension by selecting
|
| 152 |
+
the representation (q or -q) with minimal distance (or, equivalently, maximal dot product)
|
| 153 |
+
between two consecutive frames.
|
| 154 |
+
|
| 155 |
+
Expects a tensor of shape (L, J, 4), where L is the sequence length and J is the number of joints.
|
| 156 |
+
Returns a tensor of the same shape.
|
| 157 |
+
"""
|
| 158 |
+
assert len(q.shape) == 3
|
| 159 |
+
assert q.shape[-1] == 4
|
| 160 |
+
|
| 161 |
+
result = q.copy()
|
| 162 |
+
dot_products = np.sum(q[1:] * q[:-1], axis=2)
|
| 163 |
+
mask = dot_products < 0
|
| 164 |
+
mask = (np.cumsum(mask, axis=0) % 2).astype(bool)
|
| 165 |
+
result[1:][mask] *= -1
|
| 166 |
+
return result
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def euler2quat(e, order, deg=True):
|
| 170 |
+
"""
|
| 171 |
+
Convert Euler angles to quaternions.
|
| 172 |
+
"""
|
| 173 |
+
assert e.shape[-1] == 3
|
| 174 |
+
|
| 175 |
+
original_shape = list(e.shape)
|
| 176 |
+
original_shape[-1] = 4
|
| 177 |
+
|
| 178 |
+
e = e.view(-1, 3)
|
| 179 |
+
|
| 180 |
+
## if euler angles in degrees
|
| 181 |
+
if deg:
|
| 182 |
+
e = e * np.pi / 180.
|
| 183 |
+
|
| 184 |
+
x = e[:, 0]
|
| 185 |
+
y = e[:, 1]
|
| 186 |
+
z = e[:, 2]
|
| 187 |
+
|
| 188 |
+
rx = torch.stack((torch.cos(x / 2), torch.sin(x / 2), torch.zeros_like(x), torch.zeros_like(x)), dim=1)
|
| 189 |
+
ry = torch.stack((torch.cos(y / 2), torch.zeros_like(y), torch.sin(y / 2), torch.zeros_like(y)), dim=1)
|
| 190 |
+
rz = torch.stack((torch.cos(z / 2), torch.zeros_like(z), torch.zeros_like(z), torch.sin(z / 2)), dim=1)
|
| 191 |
+
|
| 192 |
+
result = None
|
| 193 |
+
for coord in order:
|
| 194 |
+
if coord == 'x':
|
| 195 |
+
r = rx
|
| 196 |
+
elif coord == 'y':
|
| 197 |
+
r = ry
|
| 198 |
+
elif coord == 'z':
|
| 199 |
+
r = rz
|
| 200 |
+
else:
|
| 201 |
+
raise
|
| 202 |
+
if result is None:
|
| 203 |
+
result = r
|
| 204 |
+
else:
|
| 205 |
+
result = qmul(result, r)
|
| 206 |
+
|
| 207 |
+
# Reverse antipodal representation to have a non-negative "w"
|
| 208 |
+
if order in ['xyz', 'yzx', 'zxy']:
|
| 209 |
+
result *= -1
|
| 210 |
+
|
| 211 |
+
return result.view(original_shape)
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
def expmap_to_quaternion(e):
|
| 215 |
+
"""
|
| 216 |
+
Convert axis-angle rotations (aka exponential maps) to quaternions.
|
| 217 |
+
Stable formula from "Practical Parameterization of Rotations Using the Exponential Map".
|
| 218 |
+
Expects a tensor of shape (*, 3), where * denotes any number of dimensions.
|
| 219 |
+
Returns a tensor of shape (*, 4).
|
| 220 |
+
"""
|
| 221 |
+
assert e.shape[-1] == 3
|
| 222 |
+
|
| 223 |
+
original_shape = list(e.shape)
|
| 224 |
+
original_shape[-1] = 4
|
| 225 |
+
e = e.reshape(-1, 3)
|
| 226 |
+
|
| 227 |
+
theta = np.linalg.norm(e, axis=1).reshape(-1, 1)
|
| 228 |
+
w = np.cos(0.5 * theta).reshape(-1, 1)
|
| 229 |
+
xyz = 0.5 * np.sinc(0.5 * theta / np.pi) * e
|
| 230 |
+
return np.concatenate((w, xyz), axis=1).reshape(original_shape)
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
def euler_to_quaternion(e, order):
|
| 234 |
+
"""
|
| 235 |
+
Convert Euler angles to quaternions.
|
| 236 |
+
"""
|
| 237 |
+
assert e.shape[-1] == 3
|
| 238 |
+
|
| 239 |
+
original_shape = list(e.shape)
|
| 240 |
+
original_shape[-1] = 4
|
| 241 |
+
|
| 242 |
+
e = e.reshape(-1, 3)
|
| 243 |
+
|
| 244 |
+
x = e[:, 0]
|
| 245 |
+
y = e[:, 1]
|
| 246 |
+
z = e[:, 2]
|
| 247 |
+
|
| 248 |
+
rx = np.stack((np.cos(x / 2), np.sin(x / 2), np.zeros_like(x), np.zeros_like(x)), axis=1)
|
| 249 |
+
ry = np.stack((np.cos(y / 2), np.zeros_like(y), np.sin(y / 2), np.zeros_like(y)), axis=1)
|
| 250 |
+
rz = np.stack((np.cos(z / 2), np.zeros_like(z), np.zeros_like(z), np.sin(z / 2)), axis=1)
|
| 251 |
+
|
| 252 |
+
result = None
|
| 253 |
+
for coord in order:
|
| 254 |
+
if coord == 'x':
|
| 255 |
+
r = rx
|
| 256 |
+
elif coord == 'y':
|
| 257 |
+
r = ry
|
| 258 |
+
elif coord == 'z':
|
| 259 |
+
r = rz
|
| 260 |
+
else:
|
| 261 |
+
raise
|
| 262 |
+
if result is None:
|
| 263 |
+
result = r
|
| 264 |
+
else:
|
| 265 |
+
result = qmul_np(result, r)
|
| 266 |
+
|
| 267 |
+
# Reverse antipodal representation to have a non-negative "w"
|
| 268 |
+
if order in ['xyz', 'yzx', 'zxy']:
|
| 269 |
+
result *= -1
|
| 270 |
+
|
| 271 |
+
return result.reshape(original_shape)
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
def quaternion_to_matrix(quaternions):
|
| 275 |
+
"""
|
| 276 |
+
Convert rotations given as quaternions to rotation matrices.
|
| 277 |
+
Args:
|
| 278 |
+
quaternions: quaternions with real part first,
|
| 279 |
+
as tensor of shape (..., 4).
|
| 280 |
+
Returns:
|
| 281 |
+
Rotation matrices as tensor of shape (..., 3, 3).
|
| 282 |
+
"""
|
| 283 |
+
r, i, j, k = torch.unbind(quaternions, -1)
|
| 284 |
+
two_s = 2.0 / (quaternions * quaternions).sum(-1)
|
| 285 |
+
|
| 286 |
+
o = torch.stack(
|
| 287 |
+
(
|
| 288 |
+
1 - two_s * (j * j + k * k),
|
| 289 |
+
two_s * (i * j - k * r),
|
| 290 |
+
two_s * (i * k + j * r),
|
| 291 |
+
two_s * (i * j + k * r),
|
| 292 |
+
1 - two_s * (i * i + k * k),
|
| 293 |
+
two_s * (j * k - i * r),
|
| 294 |
+
two_s * (i * k - j * r),
|
| 295 |
+
two_s * (j * k + i * r),
|
| 296 |
+
1 - two_s * (i * i + j * j),
|
| 297 |
+
),
|
| 298 |
+
-1,
|
| 299 |
+
)
|
| 300 |
+
return o.reshape(quaternions.shape[:-1] + (3, 3))
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
def quaternion_to_matrix_np(quaternions):
|
| 304 |
+
q = torch.from_numpy(quaternions).contiguous().float()
|
| 305 |
+
return quaternion_to_matrix(q).numpy()
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
def quaternion_to_cont6d_np(quaternions):
|
| 309 |
+
rotation_mat = quaternion_to_matrix_np(quaternions)
|
| 310 |
+
cont_6d = np.concatenate([rotation_mat[..., 0], rotation_mat[..., 1]], axis=-1)
|
| 311 |
+
return cont_6d
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
def quaternion_to_cont6d(quaternions):
|
| 315 |
+
rotation_mat = quaternion_to_matrix(quaternions)
|
| 316 |
+
cont_6d = torch.cat([rotation_mat[..., 0], rotation_mat[..., 1]], dim=-1)
|
| 317 |
+
return cont_6d
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
def cont6d_to_matrix(cont6d):
|
| 321 |
+
assert cont6d.shape[-1] == 6, "The last dimension must be 6"
|
| 322 |
+
x_raw = cont6d[..., 0:3]
|
| 323 |
+
y_raw = cont6d[..., 3:6]
|
| 324 |
+
|
| 325 |
+
x = x_raw / torch.norm(x_raw, dim=-1, keepdim=True)
|
| 326 |
+
z = torch.cross(x, y_raw, dim=-1)
|
| 327 |
+
z = z / torch.norm(z, dim=-1, keepdim=True)
|
| 328 |
+
|
| 329 |
+
y = torch.cross(z, x, dim=-1)
|
| 330 |
+
|
| 331 |
+
x = x[..., None]
|
| 332 |
+
y = y[..., None]
|
| 333 |
+
z = z[..., None]
|
| 334 |
+
|
| 335 |
+
mat = torch.cat([x, y, z], dim=-1)
|
| 336 |
+
return mat
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
def cont6d_to_matrix_np(cont6d):
|
| 340 |
+
q = torch.from_numpy(cont6d).contiguous().float()
|
| 341 |
+
return cont6d_to_matrix(q).numpy()
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
def qpow(q0, t, dtype=torch.float):
|
| 345 |
+
''' q0 : tensor of quaternions
|
| 346 |
+
t: tensor of powers
|
| 347 |
+
'''
|
| 348 |
+
q0 = qnormalize(q0)
|
| 349 |
+
theta0 = torch.acos(q0[..., 0])
|
| 350 |
+
|
| 351 |
+
## if theta0 is close to zero, add epsilon to avoid NaNs
|
| 352 |
+
mask = (theta0 <= 10e-10) * (theta0 >= -10e-10)
|
| 353 |
+
theta0 = (1 - mask) * theta0 + mask * 10e-10
|
| 354 |
+
v0 = q0[..., 1:] / torch.sin(theta0).view(-1, 1)
|
| 355 |
+
|
| 356 |
+
if isinstance(t, torch.Tensor):
|
| 357 |
+
q = torch.zeros(t.shape + q0.shape)
|
| 358 |
+
theta = t.view(-1, 1) * theta0.view(1, -1)
|
| 359 |
+
else: ## if t is a number
|
| 360 |
+
q = torch.zeros(q0.shape)
|
| 361 |
+
theta = t * theta0
|
| 362 |
+
|
| 363 |
+
q[..., 0] = torch.cos(theta)
|
| 364 |
+
q[..., 1:] = v0 * torch.sin(theta).unsqueeze(-1)
|
| 365 |
+
|
| 366 |
+
return q.to(dtype)
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
def qslerp(q0, q1, t):
|
| 370 |
+
'''
|
| 371 |
+
q0: starting quaternion
|
| 372 |
+
q1: ending quaternion
|
| 373 |
+
t: array of points along the way
|
| 374 |
+
|
| 375 |
+
Returns:
|
| 376 |
+
Tensor of Slerps: t.shape + q0.shape
|
| 377 |
+
'''
|
| 378 |
+
|
| 379 |
+
q0 = qnormalize(q0)
|
| 380 |
+
q1 = qnormalize(q1)
|
| 381 |
+
q_ = qpow(qmul(q1, qinv(q0)), t)
|
| 382 |
+
|
| 383 |
+
return qmul(q_,
|
| 384 |
+
q0.contiguous().view(torch.Size([1] * len(t.shape)) + q0.shape).expand(t.shape + q0.shape).contiguous())
|
| 385 |
+
|
| 386 |
+
|
| 387 |
+
def qbetween(v0, v1):
|
| 388 |
+
'''
|
| 389 |
+
find the quaternion used to rotate v0 to v1
|
| 390 |
+
'''
|
| 391 |
+
assert v0.shape[-1] == 3, 'v0 must be of the shape (*, 3)'
|
| 392 |
+
assert v1.shape[-1] == 3, 'v1 must be of the shape (*, 3)'
|
| 393 |
+
|
| 394 |
+
v = torch.cross(v0, v1)
|
| 395 |
+
w = torch.sqrt((v0 ** 2).sum(dim=-1, keepdim=True) * (v1 ** 2).sum(dim=-1, keepdim=True)) + (v0 * v1).sum(dim=-1,
|
| 396 |
+
keepdim=True)
|
| 397 |
+
return qnormalize(torch.cat([w, v], dim=-1))
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
def qbetween_np(v0, v1):
|
| 401 |
+
'''
|
| 402 |
+
find the quaternion used to rotate v0 to v1
|
| 403 |
+
'''
|
| 404 |
+
assert v0.shape[-1] == 3, 'v0 must be of the shape (*, 3)'
|
| 405 |
+
assert v1.shape[-1] == 3, 'v1 must be of the shape (*, 3)'
|
| 406 |
+
|
| 407 |
+
v0 = torch.from_numpy(v0).float()
|
| 408 |
+
v1 = torch.from_numpy(v1).float()
|
| 409 |
+
return qbetween(v0, v1).numpy()
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
def lerp(p0, p1, t):
|
| 413 |
+
if not isinstance(t, torch.Tensor):
|
| 414 |
+
t = torch.Tensor([t])
|
| 415 |
+
|
| 416 |
+
new_shape = t.shape + p0.shape
|
| 417 |
+
new_view_t = t.shape + torch.Size([1] * len(p0.shape))
|
| 418 |
+
new_view_p = torch.Size([1] * len(t.shape)) + p0.shape
|
| 419 |
+
p0 = p0.view(new_view_p).expand(new_shape)
|
| 420 |
+
p1 = p1.view(new_view_p).expand(new_shape)
|
| 421 |
+
t = t.view(new_view_t).expand(new_shape)
|
| 422 |
+
|
| 423 |
+
return p0 + t * (p1 - p0)
|
main/data_loaders/humanml/common/skeleton.py
ADDED
|
@@ -0,0 +1,199 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from data_loaders.humanml.common.quaternion import *
|
| 2 |
+
import scipy.ndimage.filters as filters
|
| 3 |
+
|
| 4 |
+
class Skeleton(object):
|
| 5 |
+
def __init__(self, offset, kinematic_tree, device):
|
| 6 |
+
self.device = device
|
| 7 |
+
self._raw_offset_np = offset.numpy()
|
| 8 |
+
self._raw_offset = offset.clone().detach().to(device).float()
|
| 9 |
+
self._kinematic_tree = kinematic_tree
|
| 10 |
+
self._offset = None
|
| 11 |
+
self._parents = [0] * len(self._raw_offset)
|
| 12 |
+
self._parents[0] = -1
|
| 13 |
+
for chain in self._kinematic_tree:
|
| 14 |
+
for j in range(1, len(chain)):
|
| 15 |
+
self._parents[chain[j]] = chain[j-1]
|
| 16 |
+
|
| 17 |
+
def njoints(self):
|
| 18 |
+
return len(self._raw_offset)
|
| 19 |
+
|
| 20 |
+
def offset(self):
|
| 21 |
+
return self._offset
|
| 22 |
+
|
| 23 |
+
def set_offset(self, offsets):
|
| 24 |
+
self._offset = offsets.clone().detach().to(self.device).float()
|
| 25 |
+
|
| 26 |
+
def kinematic_tree(self):
|
| 27 |
+
return self._kinematic_tree
|
| 28 |
+
|
| 29 |
+
def parents(self):
|
| 30 |
+
return self._parents
|
| 31 |
+
|
| 32 |
+
# joints (batch_size, joints_num, 3)
|
| 33 |
+
def get_offsets_joints_batch(self, joints):
|
| 34 |
+
assert len(joints.shape) == 3
|
| 35 |
+
_offsets = self._raw_offset.expand(joints.shape[0], -1, -1).clone()
|
| 36 |
+
for i in range(1, self._raw_offset.shape[0]):
|
| 37 |
+
_offsets[:, i] = torch.norm(joints[:, i] - joints[:, self._parents[i]], p=2, dim=1)[:, None] * _offsets[:, i]
|
| 38 |
+
|
| 39 |
+
self._offset = _offsets.detach()
|
| 40 |
+
return _offsets
|
| 41 |
+
|
| 42 |
+
# joints (joints_num, 3)
|
| 43 |
+
def get_offsets_joints(self, joints):
|
| 44 |
+
assert len(joints.shape) == 2
|
| 45 |
+
_offsets = self._raw_offset.clone()
|
| 46 |
+
for i in range(1, self._raw_offset.shape[0]):
|
| 47 |
+
# print(joints.shape)
|
| 48 |
+
_offsets[i] = torch.norm(joints[i] - joints[self._parents[i]], p=2, dim=0) * _offsets[i]
|
| 49 |
+
|
| 50 |
+
self._offset = _offsets.detach()
|
| 51 |
+
return _offsets
|
| 52 |
+
|
| 53 |
+
# face_joint_idx should follow the order of right hip, left hip, right shoulder, left shoulder
|
| 54 |
+
# joints (batch_size, joints_num, 3)
|
| 55 |
+
def inverse_kinematics_np(self, joints, face_joint_idx, smooth_forward=False):
|
| 56 |
+
assert len(face_joint_idx) == 4
|
| 57 |
+
'''Get Forward Direction'''
|
| 58 |
+
l_hip, r_hip, sdr_r, sdr_l = face_joint_idx
|
| 59 |
+
across1 = joints[:, r_hip] - joints[:, l_hip]
|
| 60 |
+
across2 = joints[:, sdr_r] - joints[:, sdr_l]
|
| 61 |
+
across = across1 + across2
|
| 62 |
+
across = across / np.sqrt((across**2).sum(axis=-1))[:, np.newaxis]
|
| 63 |
+
# print(across1.shape, across2.shape)
|
| 64 |
+
|
| 65 |
+
# forward (batch_size, 3)
|
| 66 |
+
forward = np.cross(np.array([[0, 1, 0]]), across, axis=-1)
|
| 67 |
+
if smooth_forward:
|
| 68 |
+
forward = filters.gaussian_filter1d(forward, 20, axis=0, mode='nearest')
|
| 69 |
+
# forward (batch_size, 3)
|
| 70 |
+
forward = forward / np.sqrt((forward**2).sum(axis=-1))[..., np.newaxis]
|
| 71 |
+
|
| 72 |
+
'''Get Root Rotation'''
|
| 73 |
+
target = np.array([[0,0,1]]).repeat(len(forward), axis=0)
|
| 74 |
+
root_quat = qbetween_np(forward, target)
|
| 75 |
+
|
| 76 |
+
'''Inverse Kinematics'''
|
| 77 |
+
# quat_params (batch_size, joints_num, 4)
|
| 78 |
+
# print(joints.shape[:-1])
|
| 79 |
+
quat_params = np.zeros(joints.shape[:-1] + (4,))
|
| 80 |
+
# print(quat_params.shape)
|
| 81 |
+
root_quat[0] = np.array([[1.0, 0.0, 0.0, 0.0]])
|
| 82 |
+
quat_params[:, 0] = root_quat
|
| 83 |
+
# quat_params[0, 0] = np.array([[1.0, 0.0, 0.0, 0.0]])
|
| 84 |
+
for chain in self._kinematic_tree:
|
| 85 |
+
R = root_quat
|
| 86 |
+
for j in range(len(chain) - 1):
|
| 87 |
+
# (batch, 3)
|
| 88 |
+
u = self._raw_offset_np[chain[j+1]][np.newaxis,...].repeat(len(joints), axis=0)
|
| 89 |
+
# print(u.shape)
|
| 90 |
+
# (batch, 3)
|
| 91 |
+
v = joints[:, chain[j+1]] - joints[:, chain[j]]
|
| 92 |
+
v = v / np.sqrt((v**2).sum(axis=-1))[:, np.newaxis]
|
| 93 |
+
# print(u.shape, v.shape)
|
| 94 |
+
rot_u_v = qbetween_np(u, v)
|
| 95 |
+
|
| 96 |
+
R_loc = qmul_np(qinv_np(R), rot_u_v)
|
| 97 |
+
|
| 98 |
+
quat_params[:,chain[j + 1], :] = R_loc
|
| 99 |
+
R = qmul_np(R, R_loc)
|
| 100 |
+
|
| 101 |
+
return quat_params
|
| 102 |
+
|
| 103 |
+
# Be sure root joint is at the beginning of kinematic chains
|
| 104 |
+
def forward_kinematics(self, quat_params, root_pos, skel_joints=None, do_root_R=True):
|
| 105 |
+
# quat_params (batch_size, joints_num, 4)
|
| 106 |
+
# joints (batch_size, joints_num, 3)
|
| 107 |
+
# root_pos (batch_size, 3)
|
| 108 |
+
if skel_joints is not None:
|
| 109 |
+
offsets = self.get_offsets_joints_batch(skel_joints)
|
| 110 |
+
if len(self._offset.shape) == 2:
|
| 111 |
+
offsets = self._offset.expand(quat_params.shape[0], -1, -1)
|
| 112 |
+
joints = torch.zeros(quat_params.shape[:-1] + (3,)).to(self.device)
|
| 113 |
+
joints[:, 0] = root_pos
|
| 114 |
+
for chain in self._kinematic_tree:
|
| 115 |
+
if do_root_R:
|
| 116 |
+
R = quat_params[:, 0]
|
| 117 |
+
else:
|
| 118 |
+
R = torch.tensor([[1.0, 0.0, 0.0, 0.0]]).expand(len(quat_params), -1).detach().to(self.device)
|
| 119 |
+
for i in range(1, len(chain)):
|
| 120 |
+
R = qmul(R, quat_params[:, chain[i]])
|
| 121 |
+
offset_vec = offsets[:, chain[i]]
|
| 122 |
+
joints[:, chain[i]] = qrot(R, offset_vec) + joints[:, chain[i-1]]
|
| 123 |
+
return joints
|
| 124 |
+
|
| 125 |
+
# Be sure root joint is at the beginning of kinematic chains
|
| 126 |
+
def forward_kinematics_np(self, quat_params, root_pos, skel_joints=None, do_root_R=True):
|
| 127 |
+
# quat_params (batch_size, joints_num, 4)
|
| 128 |
+
# joints (batch_size, joints_num, 3)
|
| 129 |
+
# root_pos (batch_size, 3)
|
| 130 |
+
if skel_joints is not None:
|
| 131 |
+
skel_joints = torch.from_numpy(skel_joints)
|
| 132 |
+
offsets = self.get_offsets_joints_batch(skel_joints)
|
| 133 |
+
if len(self._offset.shape) == 2:
|
| 134 |
+
offsets = self._offset.expand(quat_params.shape[0], -1, -1)
|
| 135 |
+
offsets = offsets.numpy()
|
| 136 |
+
joints = np.zeros(quat_params.shape[:-1] + (3,))
|
| 137 |
+
joints[:, 0] = root_pos
|
| 138 |
+
for chain in self._kinematic_tree:
|
| 139 |
+
if do_root_R:
|
| 140 |
+
R = quat_params[:, 0]
|
| 141 |
+
else:
|
| 142 |
+
R = np.array([[1.0, 0.0, 0.0, 0.0]]).repeat(len(quat_params), axis=0)
|
| 143 |
+
for i in range(1, len(chain)):
|
| 144 |
+
R = qmul_np(R, quat_params[:, chain[i]])
|
| 145 |
+
offset_vec = offsets[:, chain[i]]
|
| 146 |
+
joints[:, chain[i]] = qrot_np(R, offset_vec) + joints[:, chain[i - 1]]
|
| 147 |
+
return joints
|
| 148 |
+
|
| 149 |
+
def forward_kinematics_cont6d_np(self, cont6d_params, root_pos, skel_joints=None, do_root_R=True):
|
| 150 |
+
# cont6d_params (batch_size, joints_num, 6)
|
| 151 |
+
# joints (batch_size, joints_num, 3)
|
| 152 |
+
# root_pos (batch_size, 3)
|
| 153 |
+
if skel_joints is not None:
|
| 154 |
+
skel_joints = torch.from_numpy(skel_joints)
|
| 155 |
+
offsets = self.get_offsets_joints_batch(skel_joints)
|
| 156 |
+
if len(self._offset.shape) == 2:
|
| 157 |
+
offsets = self._offset.expand(cont6d_params.shape[0], -1, -1)
|
| 158 |
+
offsets = offsets.numpy()
|
| 159 |
+
joints = np.zeros(cont6d_params.shape[:-1] + (3,))
|
| 160 |
+
joints[:, 0] = root_pos
|
| 161 |
+
for chain in self._kinematic_tree:
|
| 162 |
+
if do_root_R:
|
| 163 |
+
matR = cont6d_to_matrix_np(cont6d_params[:, 0])
|
| 164 |
+
else:
|
| 165 |
+
matR = np.eye(3)[np.newaxis, :].repeat(len(cont6d_params), axis=0)
|
| 166 |
+
for i in range(1, len(chain)):
|
| 167 |
+
matR = np.matmul(matR, cont6d_to_matrix_np(cont6d_params[:, chain[i]]))
|
| 168 |
+
offset_vec = offsets[:, chain[i]][..., np.newaxis]
|
| 169 |
+
# print(matR.shape, offset_vec.shape)
|
| 170 |
+
joints[:, chain[i]] = np.matmul(matR, offset_vec).squeeze(-1) + joints[:, chain[i-1]]
|
| 171 |
+
return joints
|
| 172 |
+
|
| 173 |
+
def forward_kinematics_cont6d(self, cont6d_params, root_pos, skel_joints=None, do_root_R=True):
|
| 174 |
+
# cont6d_params (batch_size, joints_num, 6)
|
| 175 |
+
# joints (batch_size, joints_num, 3)
|
| 176 |
+
# root_pos (batch_size, 3)
|
| 177 |
+
if skel_joints is not None:
|
| 178 |
+
# skel_joints = torch.from_numpy(skel_joints)
|
| 179 |
+
offsets = self.get_offsets_joints_batch(skel_joints)
|
| 180 |
+
if len(self._offset.shape) == 2:
|
| 181 |
+
offsets = self._offset.expand(cont6d_params.shape[0], -1, -1)
|
| 182 |
+
joints = torch.zeros(cont6d_params.shape[:-1] + (3,)).to(cont6d_params.device)
|
| 183 |
+
joints[..., 0, :] = root_pos
|
| 184 |
+
for chain in self._kinematic_tree:
|
| 185 |
+
if do_root_R:
|
| 186 |
+
matR = cont6d_to_matrix(cont6d_params[:, 0])
|
| 187 |
+
else:
|
| 188 |
+
matR = torch.eye(3).expand((len(cont6d_params), -1, -1)).detach().to(cont6d_params.device)
|
| 189 |
+
for i in range(1, len(chain)):
|
| 190 |
+
matR = torch.matmul(matR, cont6d_to_matrix(cont6d_params[:, chain[i]]))
|
| 191 |
+
offset_vec = offsets[:, chain[i]].unsqueeze(-1)
|
| 192 |
+
# print(matR.shape, offset_vec.shape)
|
| 193 |
+
joints[:, chain[i]] = torch.matmul(matR, offset_vec).squeeze(-1) + joints[:, chain[i-1]]
|
| 194 |
+
return joints
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
|
main/data_loaders/humanml/data/__init__.py
ADDED
|
File without changes
|
main/data_loaders/humanml/data/dataset.py
ADDED
|
@@ -0,0 +1,783 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.utils import data
|
| 3 |
+
import numpy as np
|
| 4 |
+
import os
|
| 5 |
+
from os.path import join as pjoin
|
| 6 |
+
import random
|
| 7 |
+
import codecs as cs
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
import spacy
|
| 10 |
+
|
| 11 |
+
from torch.utils.data._utils.collate import default_collate
|
| 12 |
+
from data_loaders.humanml.utils.word_vectorizer import WordVectorizer
|
| 13 |
+
from data_loaders.humanml.utils.get_opt import get_opt
|
| 14 |
+
|
| 15 |
+
# import spacy
|
| 16 |
+
|
| 17 |
+
def collate_fn(batch):
|
| 18 |
+
batch.sort(key=lambda x: x[3], reverse=True)
|
| 19 |
+
return default_collate(batch)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
'''For use of training text-2-motion generative model'''
|
| 23 |
+
class Text2MotionDataset(data.Dataset):
|
| 24 |
+
def __init__(self, opt, mean, std, split_file, w_vectorizer):
|
| 25 |
+
self.opt = opt
|
| 26 |
+
self.w_vectorizer = w_vectorizer
|
| 27 |
+
self.max_length = 20
|
| 28 |
+
self.pointer = 0
|
| 29 |
+
min_motion_len = 40 if self.opt.dataset_name =='t2m' else 24
|
| 30 |
+
|
| 31 |
+
joints_num = opt.joints_num
|
| 32 |
+
|
| 33 |
+
data_dict = {}
|
| 34 |
+
id_list = []
|
| 35 |
+
with cs.open(split_file, 'r') as f:
|
| 36 |
+
for line in f.readlines():
|
| 37 |
+
id_list.append(line.strip())
|
| 38 |
+
|
| 39 |
+
new_name_list = []
|
| 40 |
+
length_list = []
|
| 41 |
+
for name in tqdm(id_list):
|
| 42 |
+
try:
|
| 43 |
+
motion = np.load(pjoin(opt.motion_dir, name + '.npy'))
|
| 44 |
+
if (len(motion)) < min_motion_len or (len(motion) >= 200):
|
| 45 |
+
continue
|
| 46 |
+
text_data = []
|
| 47 |
+
flag = False
|
| 48 |
+
with cs.open(pjoin(opt.text_dir, name + '.txt')) as f:
|
| 49 |
+
for line in f.readlines():
|
| 50 |
+
text_dict = {}
|
| 51 |
+
line_split = line.strip().split('#')
|
| 52 |
+
caption = line_split[0]
|
| 53 |
+
tokens = line_split[1].split(' ')
|
| 54 |
+
f_tag = float(line_split[2])
|
| 55 |
+
to_tag = float(line_split[3])
|
| 56 |
+
f_tag = 0.0 if np.isnan(f_tag) else f_tag
|
| 57 |
+
to_tag = 0.0 if np.isnan(to_tag) else to_tag
|
| 58 |
+
|
| 59 |
+
text_dict['caption'] = caption
|
| 60 |
+
text_dict['tokens'] = tokens
|
| 61 |
+
if f_tag == 0.0 and to_tag == 0.0:
|
| 62 |
+
flag = True
|
| 63 |
+
text_data.append(text_dict)
|
| 64 |
+
else:
|
| 65 |
+
try:
|
| 66 |
+
n_motion = motion[int(f_tag*20) : int(to_tag*20)]
|
| 67 |
+
if (len(n_motion)) < min_motion_len or (len(n_motion) >= 200):
|
| 68 |
+
continue
|
| 69 |
+
new_name = random.choice('ABCDEFGHIJKLMNOPQRSTUVW') + '_' + name
|
| 70 |
+
while new_name in data_dict:
|
| 71 |
+
new_name = random.choice('ABCDEFGHIJKLMNOPQRSTUVW') + '_' + name
|
| 72 |
+
data_dict[new_name] = {'motion': n_motion,
|
| 73 |
+
'length': len(n_motion),
|
| 74 |
+
'text':[text_dict]}
|
| 75 |
+
new_name_list.append(new_name)
|
| 76 |
+
length_list.append(len(n_motion))
|
| 77 |
+
except:
|
| 78 |
+
print(line_split)
|
| 79 |
+
print(line_split[2], line_split[3], f_tag, to_tag, name)
|
| 80 |
+
# break
|
| 81 |
+
|
| 82 |
+
if flag:
|
| 83 |
+
data_dict[name] = {'motion': motion,
|
| 84 |
+
'length': len(motion),
|
| 85 |
+
'text':text_data}
|
| 86 |
+
new_name_list.append(name)
|
| 87 |
+
length_list.append(len(motion))
|
| 88 |
+
except:
|
| 89 |
+
# Some motion may not exist in KIT dataset
|
| 90 |
+
pass
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
name_list, length_list = zip(*sorted(zip(new_name_list, length_list), key=lambda x: x[1]))
|
| 94 |
+
|
| 95 |
+
if opt.is_train:
|
| 96 |
+
# root_rot_velocity (B, seq_len, 1)
|
| 97 |
+
std[0:1] = std[0:1] / opt.feat_bias
|
| 98 |
+
# root_linear_velocity (B, seq_len, 2)
|
| 99 |
+
std[1:3] = std[1:3] / opt.feat_bias
|
| 100 |
+
# root_y (B, seq_len, 1)
|
| 101 |
+
std[3:4] = std[3:4] / opt.feat_bias
|
| 102 |
+
# ric_data (B, seq_len, (joint_num - 1)*3)
|
| 103 |
+
std[4: 4 + (joints_num - 1) * 3] = std[4: 4 + (joints_num - 1) * 3] / 1.0
|
| 104 |
+
# rot_data (B, seq_len, (joint_num - 1)*6)
|
| 105 |
+
std[4 + (joints_num - 1) * 3: 4 + (joints_num - 1) * 9] = std[4 + (joints_num - 1) * 3: 4 + (
|
| 106 |
+
joints_num - 1) * 9] / 1.0
|
| 107 |
+
# local_velocity (B, seq_len, joint_num*3)
|
| 108 |
+
std[4 + (joints_num - 1) * 9: 4 + (joints_num - 1) * 9 + joints_num * 3] = std[
|
| 109 |
+
4 + (joints_num - 1) * 9: 4 + (
|
| 110 |
+
joints_num - 1) * 9 + joints_num * 3] / 1.0
|
| 111 |
+
# foot contact (B, seq_len, 4)
|
| 112 |
+
std[4 + (joints_num - 1) * 9 + joints_num * 3:] = std[
|
| 113 |
+
4 + (joints_num - 1) * 9 + joints_num * 3:] / opt.feat_bias
|
| 114 |
+
|
| 115 |
+
assert 4 + (joints_num - 1) * 9 + joints_num * 3 + 4 == mean.shape[-1]
|
| 116 |
+
np.save(pjoin(opt.meta_dir, 'mean.npy'), mean)
|
| 117 |
+
np.save(pjoin(opt.meta_dir, 'std.npy'), std)
|
| 118 |
+
|
| 119 |
+
self.mean = mean
|
| 120 |
+
self.std = std
|
| 121 |
+
self.length_arr = np.array(length_list)
|
| 122 |
+
self.data_dict = data_dict
|
| 123 |
+
self.name_list = name_list
|
| 124 |
+
self.reset_max_len(self.max_length)
|
| 125 |
+
|
| 126 |
+
def reset_max_len(self, length):
|
| 127 |
+
assert length <= self.opt.max_motion_length
|
| 128 |
+
self.pointer = np.searchsorted(self.length_arr, length)
|
| 129 |
+
print("Pointer Pointing at %d"%self.pointer)
|
| 130 |
+
self.max_length = length
|
| 131 |
+
|
| 132 |
+
def inv_transform(self, data):
|
| 133 |
+
return data * self.std + self.mean
|
| 134 |
+
|
| 135 |
+
def __len__(self):
|
| 136 |
+
return len(self.data_dict) - self.pointer
|
| 137 |
+
|
| 138 |
+
def __getitem__(self, item):
|
| 139 |
+
idx = self.pointer + item
|
| 140 |
+
data = self.data_dict[self.name_list[idx]]
|
| 141 |
+
motion, m_length, text_list = data['motion'], data['length'], data['text']
|
| 142 |
+
# Randomly select a caption
|
| 143 |
+
text_data = random.choice(text_list)
|
| 144 |
+
caption, tokens = text_data['caption'], text_data['tokens']
|
| 145 |
+
|
| 146 |
+
if len(tokens) < self.opt.max_text_len:
|
| 147 |
+
# pad with "unk"
|
| 148 |
+
tokens = ['sos/OTHER'] + tokens + ['eos/OTHER']
|
| 149 |
+
sent_len = len(tokens)
|
| 150 |
+
tokens = tokens + ['unk/OTHER'] * (self.opt.max_text_len + 2 - sent_len)
|
| 151 |
+
else:
|
| 152 |
+
# crop
|
| 153 |
+
tokens = tokens[:self.opt.max_text_len]
|
| 154 |
+
tokens = ['sos/OTHER'] + tokens + ['eos/OTHER']
|
| 155 |
+
sent_len = len(tokens)
|
| 156 |
+
pos_one_hots = []
|
| 157 |
+
word_embeddings = []
|
| 158 |
+
for token in tokens:
|
| 159 |
+
word_emb, pos_oh = self.w_vectorizer[token]
|
| 160 |
+
pos_one_hots.append(pos_oh[None, :])
|
| 161 |
+
word_embeddings.append(word_emb[None, :])
|
| 162 |
+
pos_one_hots = np.concatenate(pos_one_hots, axis=0)
|
| 163 |
+
word_embeddings = np.concatenate(word_embeddings, axis=0)
|
| 164 |
+
|
| 165 |
+
len_gap = (m_length - self.max_length) // self.opt.unit_length
|
| 166 |
+
|
| 167 |
+
if self.opt.is_train:
|
| 168 |
+
if m_length != self.max_length:
|
| 169 |
+
# print("Motion original length:%d_%d"%(m_length, len(motion)))
|
| 170 |
+
if self.opt.unit_length < 10:
|
| 171 |
+
coin2 = np.random.choice(['single', 'single', 'double'])
|
| 172 |
+
else:
|
| 173 |
+
coin2 = 'single'
|
| 174 |
+
if len_gap == 0 or (len_gap == 1 and coin2 == 'double'):
|
| 175 |
+
m_length = self.max_length
|
| 176 |
+
idx = random.randint(0, m_length - self.max_length)
|
| 177 |
+
motion = motion[idx:idx+self.max_length]
|
| 178 |
+
else:
|
| 179 |
+
if coin2 == 'single':
|
| 180 |
+
n_m_length = self.max_length + self.opt.unit_length * len_gap
|
| 181 |
+
else:
|
| 182 |
+
n_m_length = self.max_length + self.opt.unit_length * (len_gap - 1)
|
| 183 |
+
idx = random.randint(0, m_length - n_m_length)
|
| 184 |
+
motion = motion[idx:idx + self.max_length]
|
| 185 |
+
m_length = n_m_length
|
| 186 |
+
# print(len_gap, idx, coin2)
|
| 187 |
+
else:
|
| 188 |
+
if self.opt.unit_length < 10:
|
| 189 |
+
coin2 = np.random.choice(['single', 'single', 'double'])
|
| 190 |
+
else:
|
| 191 |
+
coin2 = 'single'
|
| 192 |
+
|
| 193 |
+
if coin2 == 'double':
|
| 194 |
+
m_length = (m_length // self.opt.unit_length - 1) * self.opt.unit_length
|
| 195 |
+
elif coin2 == 'single':
|
| 196 |
+
m_length = (m_length // self.opt.unit_length) * self.opt.unit_length
|
| 197 |
+
idx = random.randint(0, len(motion) - m_length)
|
| 198 |
+
motion = motion[idx:idx+m_length]
|
| 199 |
+
|
| 200 |
+
"Z Normalization"
|
| 201 |
+
motion = (motion - self.mean) / self.std
|
| 202 |
+
|
| 203 |
+
return word_embeddings, pos_one_hots, caption, sent_len, motion, m_length
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
'''For use of training text motion matching model, and evaluations'''
|
| 207 |
+
class Text2MotionDatasetV2(data.Dataset):
|
| 208 |
+
def __init__(self, opt, mean, std, split_file, w_vectorizer):
|
| 209 |
+
self.opt = opt
|
| 210 |
+
self.w_vectorizer = w_vectorizer
|
| 211 |
+
self.max_length = 20
|
| 212 |
+
self.pointer = 0
|
| 213 |
+
self.max_motion_length = opt.max_motion_length
|
| 214 |
+
min_motion_len = 40 if self.opt.dataset_name =='t2m' else 24
|
| 215 |
+
|
| 216 |
+
data_dict = {}
|
| 217 |
+
id_list = []
|
| 218 |
+
with cs.open(split_file, 'r') as f:
|
| 219 |
+
for line in f.readlines():
|
| 220 |
+
id_list.append(line.strip())
|
| 221 |
+
id_list = id_list[:100] # debug
|
| 222 |
+
|
| 223 |
+
new_name_list = []
|
| 224 |
+
length_list = []
|
| 225 |
+
for name in tqdm(id_list):
|
| 226 |
+
try:
|
| 227 |
+
motion = np.load(pjoin(opt.motion_dir, name + '.npy'))
|
| 228 |
+
if (len(motion)) < min_motion_len or (len(motion) >= 200):
|
| 229 |
+
continue
|
| 230 |
+
text_data = []
|
| 231 |
+
flag = False
|
| 232 |
+
with cs.open(pjoin(opt.text_dir, name + '.txt')) as f:
|
| 233 |
+
for line in f.readlines():
|
| 234 |
+
text_dict = {}
|
| 235 |
+
line_split = line.strip().split('#')
|
| 236 |
+
caption = line_split[0]
|
| 237 |
+
tokens = line_split[1].split(' ')
|
| 238 |
+
f_tag = float(line_split[2])
|
| 239 |
+
to_tag = float(line_split[3])
|
| 240 |
+
f_tag = 0.0 if np.isnan(f_tag) else f_tag
|
| 241 |
+
to_tag = 0.0 if np.isnan(to_tag) else to_tag
|
| 242 |
+
|
| 243 |
+
text_dict['caption'] = caption
|
| 244 |
+
text_dict['tokens'] = tokens
|
| 245 |
+
if f_tag == 0.0 and to_tag == 0.0:
|
| 246 |
+
flag = True
|
| 247 |
+
text_data.append(text_dict)
|
| 248 |
+
else:
|
| 249 |
+
try:
|
| 250 |
+
n_motion = motion[int(f_tag*20) : int(to_tag*20)]
|
| 251 |
+
if (len(n_motion)) < min_motion_len or (len(n_motion) >= 200):
|
| 252 |
+
continue
|
| 253 |
+
new_name = random.choice('ABCDEFGHIJKLMNOPQRSTUVW') + '_' + name
|
| 254 |
+
while new_name in data_dict:
|
| 255 |
+
new_name = random.choice('ABCDEFGHIJKLMNOPQRSTUVW') + '_' + name
|
| 256 |
+
data_dict[new_name] = {'motion': n_motion,
|
| 257 |
+
'length': len(n_motion),
|
| 258 |
+
'text':[text_dict]}
|
| 259 |
+
new_name_list.append(new_name)
|
| 260 |
+
length_list.append(len(n_motion))
|
| 261 |
+
except:
|
| 262 |
+
print(line_split)
|
| 263 |
+
print(line_split[2], line_split[3], f_tag, to_tag, name)
|
| 264 |
+
# break
|
| 265 |
+
|
| 266 |
+
if flag:
|
| 267 |
+
data_dict[name] = {'motion': motion,
|
| 268 |
+
'length': len(motion),
|
| 269 |
+
'text': text_data}
|
| 270 |
+
new_name_list.append(name)
|
| 271 |
+
length_list.append(len(motion))
|
| 272 |
+
except:
|
| 273 |
+
pass
|
| 274 |
+
|
| 275 |
+
name_list, length_list = zip(*sorted(zip(new_name_list, length_list), key=lambda x: x[1]))
|
| 276 |
+
|
| 277 |
+
self.mean = mean
|
| 278 |
+
self.std = std
|
| 279 |
+
self.length_arr = np.array(length_list)
|
| 280 |
+
self.data_dict = data_dict
|
| 281 |
+
self.name_list = name_list
|
| 282 |
+
self.reset_max_len(self.max_length)
|
| 283 |
+
|
| 284 |
+
def reset_max_len(self, length):
|
| 285 |
+
assert length <= self.max_motion_length
|
| 286 |
+
self.pointer = np.searchsorted(self.length_arr, length)
|
| 287 |
+
print("Pointer Pointing at %d"%self.pointer)
|
| 288 |
+
self.max_length = length
|
| 289 |
+
|
| 290 |
+
def inv_transform(self, data):
|
| 291 |
+
return data * self.std + self.mean
|
| 292 |
+
|
| 293 |
+
def __len__(self):
|
| 294 |
+
return len(self.data_dict) - self.pointer
|
| 295 |
+
|
| 296 |
+
def __getitem__(self, item):
|
| 297 |
+
idx = self.pointer + item
|
| 298 |
+
data = self.data_dict[self.name_list[idx]]
|
| 299 |
+
motion, m_length, text_list = data['motion'], data['length'], data['text']
|
| 300 |
+
# Randomly select a caption
|
| 301 |
+
text_data = random.choice(text_list)
|
| 302 |
+
caption, tokens = text_data['caption'], text_data['tokens']
|
| 303 |
+
|
| 304 |
+
if len(tokens) < self.opt.max_text_len:
|
| 305 |
+
# pad with "unk"
|
| 306 |
+
tokens = ['sos/OTHER'] + tokens + ['eos/OTHER']
|
| 307 |
+
sent_len = len(tokens)
|
| 308 |
+
tokens = tokens + ['unk/OTHER'] * (self.opt.max_text_len + 2 - sent_len)
|
| 309 |
+
else:
|
| 310 |
+
# crop
|
| 311 |
+
tokens = tokens[:self.opt.max_text_len]
|
| 312 |
+
tokens = ['sos/OTHER'] + tokens + ['eos/OTHER']
|
| 313 |
+
sent_len = len(tokens)
|
| 314 |
+
pos_one_hots = []
|
| 315 |
+
word_embeddings = []
|
| 316 |
+
for token in tokens:
|
| 317 |
+
word_emb, pos_oh = self.w_vectorizer[token]
|
| 318 |
+
pos_one_hots.append(pos_oh[None, :])
|
| 319 |
+
word_embeddings.append(word_emb[None, :])
|
| 320 |
+
pos_one_hots = np.concatenate(pos_one_hots, axis=0)
|
| 321 |
+
word_embeddings = np.concatenate(word_embeddings, axis=0)
|
| 322 |
+
|
| 323 |
+
# Crop the motions in to times of 4, and introduce small variations
|
| 324 |
+
if self.opt.unit_length < 10:
|
| 325 |
+
coin2 = np.random.choice(['single', 'single', 'double'])
|
| 326 |
+
else:
|
| 327 |
+
coin2 = 'single'
|
| 328 |
+
|
| 329 |
+
if coin2 == 'double':
|
| 330 |
+
m_length = (m_length // self.opt.unit_length - 1) * self.opt.unit_length
|
| 331 |
+
elif coin2 == 'single':
|
| 332 |
+
m_length = (m_length // self.opt.unit_length) * self.opt.unit_length
|
| 333 |
+
idx = random.randint(0, len(motion) - m_length)
|
| 334 |
+
motion = motion[idx:idx+m_length]
|
| 335 |
+
|
| 336 |
+
"Z Normalization"
|
| 337 |
+
motion = (motion - self.mean) / self.std
|
| 338 |
+
|
| 339 |
+
if m_length < self.max_motion_length:
|
| 340 |
+
motion = np.concatenate([motion,
|
| 341 |
+
np.zeros((self.max_motion_length - m_length, motion.shape[1]))
|
| 342 |
+
], axis=0)
|
| 343 |
+
# print(word_embeddings.shape, motion.shape)
|
| 344 |
+
# print(tokens)
|
| 345 |
+
return word_embeddings, pos_one_hots, caption, sent_len, motion, m_length, '_'.join(tokens)
|
| 346 |
+
|
| 347 |
+
|
| 348 |
+
'''For use of training baseline'''
|
| 349 |
+
class Text2MotionDatasetBaseline(data.Dataset):
|
| 350 |
+
def __init__(self, opt, mean, std, split_file, w_vectorizer):
|
| 351 |
+
self.opt = opt
|
| 352 |
+
self.w_vectorizer = w_vectorizer
|
| 353 |
+
self.max_length = 20
|
| 354 |
+
self.pointer = 0
|
| 355 |
+
self.max_motion_length = opt.max_motion_length
|
| 356 |
+
min_motion_len = 40 if self.opt.dataset_name =='t2m' else 24
|
| 357 |
+
|
| 358 |
+
data_dict = {}
|
| 359 |
+
id_list = []
|
| 360 |
+
with cs.open(split_file, 'r') as f:
|
| 361 |
+
for line in f.readlines():
|
| 362 |
+
id_list.append(line.strip())
|
| 363 |
+
# id_list = id_list[:200]
|
| 364 |
+
|
| 365 |
+
new_name_list = []
|
| 366 |
+
length_list = []
|
| 367 |
+
for name in tqdm(id_list):
|
| 368 |
+
try:
|
| 369 |
+
motion = np.load(pjoin(opt.motion_dir, name + '.npy'))
|
| 370 |
+
if (len(motion)) < min_motion_len or (len(motion) >= 200):
|
| 371 |
+
continue
|
| 372 |
+
text_data = []
|
| 373 |
+
flag = False
|
| 374 |
+
with cs.open(pjoin(opt.text_dir, name + '.txt')) as f:
|
| 375 |
+
for line in f.readlines():
|
| 376 |
+
text_dict = {}
|
| 377 |
+
line_split = line.strip().split('#')
|
| 378 |
+
caption = line_split[0]
|
| 379 |
+
tokens = line_split[1].split(' ')
|
| 380 |
+
f_tag = float(line_split[2])
|
| 381 |
+
to_tag = float(line_split[3])
|
| 382 |
+
f_tag = 0.0 if np.isnan(f_tag) else f_tag
|
| 383 |
+
to_tag = 0.0 if np.isnan(to_tag) else to_tag
|
| 384 |
+
|
| 385 |
+
text_dict['caption'] = caption
|
| 386 |
+
text_dict['tokens'] = tokens
|
| 387 |
+
if f_tag == 0.0 and to_tag == 0.0:
|
| 388 |
+
flag = True
|
| 389 |
+
text_data.append(text_dict)
|
| 390 |
+
else:
|
| 391 |
+
try:
|
| 392 |
+
n_motion = motion[int(f_tag*20) : int(to_tag*20)]
|
| 393 |
+
if (len(n_motion)) < min_motion_len or (len(n_motion) >= 200):
|
| 394 |
+
continue
|
| 395 |
+
new_name = random.choice('ABCDEFGHIJKLMNOPQRSTUVW') + '_' + name
|
| 396 |
+
while new_name in data_dict:
|
| 397 |
+
new_name = random.choice('ABCDEFGHIJKLMNOPQRSTUVW') + '_' + name
|
| 398 |
+
data_dict[new_name] = {'motion': n_motion,
|
| 399 |
+
'length': len(n_motion),
|
| 400 |
+
'text':[text_dict]}
|
| 401 |
+
new_name_list.append(new_name)
|
| 402 |
+
length_list.append(len(n_motion))
|
| 403 |
+
except:
|
| 404 |
+
print(line_split)
|
| 405 |
+
print(line_split[2], line_split[3], f_tag, to_tag, name)
|
| 406 |
+
# break
|
| 407 |
+
|
| 408 |
+
if flag:
|
| 409 |
+
data_dict[name] = {'motion': motion,
|
| 410 |
+
'length': len(motion),
|
| 411 |
+
'text': text_data}
|
| 412 |
+
new_name_list.append(name)
|
| 413 |
+
length_list.append(len(motion))
|
| 414 |
+
except:
|
| 415 |
+
pass
|
| 416 |
+
|
| 417 |
+
name_list, length_list = zip(*sorted(zip(new_name_list, length_list), key=lambda x: x[1]))
|
| 418 |
+
|
| 419 |
+
self.mean = mean
|
| 420 |
+
self.std = std
|
| 421 |
+
self.length_arr = np.array(length_list)
|
| 422 |
+
self.data_dict = data_dict
|
| 423 |
+
self.name_list = name_list
|
| 424 |
+
self.reset_max_len(self.max_length)
|
| 425 |
+
|
| 426 |
+
def reset_max_len(self, length):
|
| 427 |
+
assert length <= self.max_motion_length
|
| 428 |
+
self.pointer = np.searchsorted(self.length_arr, length)
|
| 429 |
+
print("Pointer Pointing at %d"%self.pointer)
|
| 430 |
+
self.max_length = length
|
| 431 |
+
|
| 432 |
+
def inv_transform(self, data):
|
| 433 |
+
return data * self.std + self.mean
|
| 434 |
+
|
| 435 |
+
def __len__(self):
|
| 436 |
+
return len(self.data_dict) - self.pointer
|
| 437 |
+
|
| 438 |
+
def __getitem__(self, item):
|
| 439 |
+
idx = self.pointer + item
|
| 440 |
+
data = self.data_dict[self.name_list[idx]]
|
| 441 |
+
motion, m_length, text_list = data['motion'], data['length'], data['text']
|
| 442 |
+
# Randomly select a caption
|
| 443 |
+
text_data = random.choice(text_list)
|
| 444 |
+
caption, tokens = text_data['caption'], text_data['tokens']
|
| 445 |
+
|
| 446 |
+
if len(tokens) < self.opt.max_text_len:
|
| 447 |
+
# pad with "unk"
|
| 448 |
+
tokens = ['sos/OTHER'] + tokens + ['eos/OTHER']
|
| 449 |
+
sent_len = len(tokens)
|
| 450 |
+
tokens = tokens + ['unk/OTHER'] * (self.opt.max_text_len + 2 - sent_len)
|
| 451 |
+
else:
|
| 452 |
+
# crop
|
| 453 |
+
tokens = tokens[:self.opt.max_text_len]
|
| 454 |
+
tokens = ['sos/OTHER'] + tokens + ['eos/OTHER']
|
| 455 |
+
sent_len = len(tokens)
|
| 456 |
+
pos_one_hots = []
|
| 457 |
+
word_embeddings = []
|
| 458 |
+
for token in tokens:
|
| 459 |
+
word_emb, pos_oh = self.w_vectorizer[token]
|
| 460 |
+
pos_one_hots.append(pos_oh[None, :])
|
| 461 |
+
word_embeddings.append(word_emb[None, :])
|
| 462 |
+
pos_one_hots = np.concatenate(pos_one_hots, axis=0)
|
| 463 |
+
word_embeddings = np.concatenate(word_embeddings, axis=0)
|
| 464 |
+
|
| 465 |
+
len_gap = (m_length - self.max_length) // self.opt.unit_length
|
| 466 |
+
|
| 467 |
+
if m_length != self.max_length:
|
| 468 |
+
# print("Motion original length:%d_%d"%(m_length, len(motion)))
|
| 469 |
+
if self.opt.unit_length < 10:
|
| 470 |
+
coin2 = np.random.choice(['single', 'single', 'double'])
|
| 471 |
+
else:
|
| 472 |
+
coin2 = 'single'
|
| 473 |
+
if len_gap == 0 or (len_gap == 1 and coin2 == 'double'):
|
| 474 |
+
m_length = self.max_length
|
| 475 |
+
s_idx = random.randint(0, m_length - self.max_length)
|
| 476 |
+
else:
|
| 477 |
+
if coin2 == 'single':
|
| 478 |
+
n_m_length = self.max_length + self.opt.unit_length * len_gap
|
| 479 |
+
else:
|
| 480 |
+
n_m_length = self.max_length + self.opt.unit_length * (len_gap - 1)
|
| 481 |
+
s_idx = random.randint(0, m_length - n_m_length)
|
| 482 |
+
m_length = n_m_length
|
| 483 |
+
else:
|
| 484 |
+
s_idx = 0
|
| 485 |
+
|
| 486 |
+
src_motion = motion[s_idx: s_idx + m_length]
|
| 487 |
+
tgt_motion = motion[s_idx: s_idx + self.max_length]
|
| 488 |
+
|
| 489 |
+
"Z Normalization"
|
| 490 |
+
src_motion = (src_motion - self.mean) / self.std
|
| 491 |
+
tgt_motion = (tgt_motion - self.mean) / self.std
|
| 492 |
+
|
| 493 |
+
if m_length < self.max_motion_length:
|
| 494 |
+
src_motion = np.concatenate([src_motion,
|
| 495 |
+
np.zeros((self.max_motion_length - m_length, motion.shape[1]))
|
| 496 |
+
], axis=0)
|
| 497 |
+
# print(m_length, src_motion.shape, tgt_motion.shape)
|
| 498 |
+
# print(word_embeddings.shape, motion.shape)
|
| 499 |
+
# print(tokens)
|
| 500 |
+
return word_embeddings, caption, sent_len, src_motion, tgt_motion, m_length
|
| 501 |
+
|
| 502 |
+
|
| 503 |
+
class MotionDatasetV2(data.Dataset):
|
| 504 |
+
def __init__(self, opt, mean, std, split_file):
|
| 505 |
+
self.opt = opt
|
| 506 |
+
joints_num = opt.joints_num
|
| 507 |
+
|
| 508 |
+
self.data = []
|
| 509 |
+
self.lengths = []
|
| 510 |
+
id_list = []
|
| 511 |
+
with cs.open(split_file, 'r') as f:
|
| 512 |
+
for line in f.readlines():
|
| 513 |
+
id_list.append(line.strip())
|
| 514 |
+
|
| 515 |
+
for name in tqdm(id_list):
|
| 516 |
+
try:
|
| 517 |
+
motion = np.load(pjoin(opt.motion_dir, name + '.npy'))
|
| 518 |
+
if motion.shape[0] < opt.window_size:
|
| 519 |
+
continue
|
| 520 |
+
self.lengths.append(motion.shape[0] - opt.window_size)
|
| 521 |
+
self.data.append(motion)
|
| 522 |
+
except:
|
| 523 |
+
# Some motion may not exist in KIT dataset
|
| 524 |
+
pass
|
| 525 |
+
|
| 526 |
+
self.cumsum = np.cumsum([0] + self.lengths)
|
| 527 |
+
|
| 528 |
+
if opt.is_train:
|
| 529 |
+
# root_rot_velocity (B, seq_len, 1)
|
| 530 |
+
std[0:1] = std[0:1] / opt.feat_bias
|
| 531 |
+
# root_linear_velocity (B, seq_len, 2)
|
| 532 |
+
std[1:3] = std[1:3] / opt.feat_bias
|
| 533 |
+
# root_y (B, seq_len, 1)
|
| 534 |
+
std[3:4] = std[3:4] / opt.feat_bias
|
| 535 |
+
# ric_data (B, seq_len, (joint_num - 1)*3)
|
| 536 |
+
std[4: 4 + (joints_num - 1) * 3] = std[4: 4 + (joints_num - 1) * 3] / 1.0
|
| 537 |
+
# rot_data (B, seq_len, (joint_num - 1)*6)
|
| 538 |
+
std[4 + (joints_num - 1) * 3: 4 + (joints_num - 1) * 9] = std[4 + (joints_num - 1) * 3: 4 + (
|
| 539 |
+
joints_num - 1) * 9] / 1.0
|
| 540 |
+
# local_velocity (B, seq_len, joint_num*3)
|
| 541 |
+
std[4 + (joints_num - 1) * 9: 4 + (joints_num - 1) * 9 + joints_num * 3] = std[
|
| 542 |
+
4 + (joints_num - 1) * 9: 4 + (
|
| 543 |
+
joints_num - 1) * 9 + joints_num * 3] / 1.0
|
| 544 |
+
# foot contact (B, seq_len, 4)
|
| 545 |
+
std[4 + (joints_num - 1) * 9 + joints_num * 3:] = std[
|
| 546 |
+
4 + (joints_num - 1) * 9 + joints_num * 3:] / opt.feat_bias
|
| 547 |
+
|
| 548 |
+
assert 4 + (joints_num - 1) * 9 + joints_num * 3 + 4 == mean.shape[-1]
|
| 549 |
+
np.save(pjoin(opt.meta_dir, 'mean.npy'), mean)
|
| 550 |
+
np.save(pjoin(opt.meta_dir, 'std.npy'), std)
|
| 551 |
+
|
| 552 |
+
self.mean = mean
|
| 553 |
+
self.std = std
|
| 554 |
+
print("Total number of motions {}, snippets {}".format(len(self.data), self.cumsum[-1]))
|
| 555 |
+
|
| 556 |
+
def inv_transform(self, data):
|
| 557 |
+
return data * self.std + self.mean
|
| 558 |
+
|
| 559 |
+
def __len__(self):
|
| 560 |
+
return self.cumsum[-1]
|
| 561 |
+
|
| 562 |
+
def __getitem__(self, item):
|
| 563 |
+
if item != 0:
|
| 564 |
+
motion_id = np.searchsorted(self.cumsum, item) - 1
|
| 565 |
+
idx = item - self.cumsum[motion_id] - 1
|
| 566 |
+
else:
|
| 567 |
+
motion_id = 0
|
| 568 |
+
idx = 0
|
| 569 |
+
motion = self.data[motion_id][idx:idx+self.opt.window_size]
|
| 570 |
+
"Z Normalization"
|
| 571 |
+
motion = (motion - self.mean) / self.std
|
| 572 |
+
|
| 573 |
+
return motion
|
| 574 |
+
|
| 575 |
+
|
| 576 |
+
class RawTextDataset(data.Dataset):
|
| 577 |
+
def __init__(self, opt, mean, std, text_file, w_vectorizer):
|
| 578 |
+
self.mean = mean
|
| 579 |
+
self.std = std
|
| 580 |
+
self.opt = opt
|
| 581 |
+
self.data_dict = []
|
| 582 |
+
self.nlp = spacy.load('en_core_web_sm')
|
| 583 |
+
|
| 584 |
+
with cs.open(text_file) as f:
|
| 585 |
+
for line in f.readlines():
|
| 586 |
+
word_list, pos_list = self.process_text(line.strip())
|
| 587 |
+
tokens = ['%s/%s'%(word_list[i], pos_list[i]) for i in range(len(word_list))]
|
| 588 |
+
self.data_dict.append({'caption':line.strip(), "tokens":tokens})
|
| 589 |
+
|
| 590 |
+
self.w_vectorizer = w_vectorizer
|
| 591 |
+
print("Total number of descriptions {}".format(len(self.data_dict)))
|
| 592 |
+
|
| 593 |
+
|
| 594 |
+
def process_text(self, sentence):
|
| 595 |
+
sentence = sentence.replace('-', '')
|
| 596 |
+
doc = self.nlp(sentence)
|
| 597 |
+
word_list = []
|
| 598 |
+
pos_list = []
|
| 599 |
+
for token in doc:
|
| 600 |
+
word = token.text
|
| 601 |
+
if not word.isalpha():
|
| 602 |
+
continue
|
| 603 |
+
if (token.pos_ == 'NOUN' or token.pos_ == 'VERB') and (word != 'left'):
|
| 604 |
+
word_list.append(token.lemma_)
|
| 605 |
+
else:
|
| 606 |
+
word_list.append(word)
|
| 607 |
+
pos_list.append(token.pos_)
|
| 608 |
+
return word_list, pos_list
|
| 609 |
+
|
| 610 |
+
def inv_transform(self, data):
|
| 611 |
+
return data * self.std + self.mean
|
| 612 |
+
|
| 613 |
+
def __len__(self):
|
| 614 |
+
return len(self.data_dict)
|
| 615 |
+
|
| 616 |
+
def __getitem__(self, item):
|
| 617 |
+
data = self.data_dict[item]
|
| 618 |
+
caption, tokens = data['caption'], data['tokens']
|
| 619 |
+
|
| 620 |
+
if len(tokens) < self.opt.max_text_len:
|
| 621 |
+
# pad with "unk"
|
| 622 |
+
tokens = ['sos/OTHER'] + tokens + ['eos/OTHER']
|
| 623 |
+
sent_len = len(tokens)
|
| 624 |
+
tokens = tokens + ['unk/OTHER'] * (self.opt.max_text_len + 2 - sent_len)
|
| 625 |
+
else:
|
| 626 |
+
# crop
|
| 627 |
+
tokens = tokens[:self.opt.max_text_len]
|
| 628 |
+
tokens = ['sos/OTHER'] + tokens + ['eos/OTHER']
|
| 629 |
+
sent_len = len(tokens)
|
| 630 |
+
pos_one_hots = []
|
| 631 |
+
word_embeddings = []
|
| 632 |
+
for token in tokens:
|
| 633 |
+
word_emb, pos_oh = self.w_vectorizer[token]
|
| 634 |
+
pos_one_hots.append(pos_oh[None, :])
|
| 635 |
+
word_embeddings.append(word_emb[None, :])
|
| 636 |
+
pos_one_hots = np.concatenate(pos_one_hots, axis=0)
|
| 637 |
+
word_embeddings = np.concatenate(word_embeddings, axis=0)
|
| 638 |
+
|
| 639 |
+
return word_embeddings, pos_one_hots, caption, sent_len
|
| 640 |
+
|
| 641 |
+
class TextOnlyDataset(data.Dataset):
|
| 642 |
+
def __init__(self, opt, mean, std, split_file):
|
| 643 |
+
self.mean = mean
|
| 644 |
+
self.std = std
|
| 645 |
+
self.opt = opt
|
| 646 |
+
self.data_dict = []
|
| 647 |
+
self.max_length = 20
|
| 648 |
+
self.pointer = 0
|
| 649 |
+
self.fixed_length = 120
|
| 650 |
+
|
| 651 |
+
|
| 652 |
+
data_dict = {}
|
| 653 |
+
id_list = []
|
| 654 |
+
with cs.open(split_file, 'r') as f:
|
| 655 |
+
for line in f.readlines():
|
| 656 |
+
id_list.append(line.strip())
|
| 657 |
+
# id_list = id_list[:200]
|
| 658 |
+
|
| 659 |
+
new_name_list = []
|
| 660 |
+
length_list = []
|
| 661 |
+
for name in tqdm(id_list):
|
| 662 |
+
try:
|
| 663 |
+
text_data = []
|
| 664 |
+
flag = False
|
| 665 |
+
with cs.open(pjoin(opt.text_dir, name + '.txt')) as f:
|
| 666 |
+
for line in f.readlines():
|
| 667 |
+
text_dict = {}
|
| 668 |
+
line_split = line.strip().split('#')
|
| 669 |
+
caption = line_split[0]
|
| 670 |
+
tokens = line_split[1].split(' ')
|
| 671 |
+
f_tag = float(line_split[2])
|
| 672 |
+
to_tag = float(line_split[3])
|
| 673 |
+
f_tag = 0.0 if np.isnan(f_tag) else f_tag
|
| 674 |
+
to_tag = 0.0 if np.isnan(to_tag) else to_tag
|
| 675 |
+
|
| 676 |
+
text_dict['caption'] = caption
|
| 677 |
+
text_dict['tokens'] = tokens
|
| 678 |
+
if f_tag == 0.0 and to_tag == 0.0:
|
| 679 |
+
flag = True
|
| 680 |
+
text_data.append(text_dict)
|
| 681 |
+
else:
|
| 682 |
+
try:
|
| 683 |
+
new_name = random.choice('ABCDEFGHIJKLMNOPQRSTUVW') + '_' + name
|
| 684 |
+
while new_name in data_dict:
|
| 685 |
+
new_name = random.choice('ABCDEFGHIJKLMNOPQRSTUVW') + '_' + name
|
| 686 |
+
data_dict[new_name] = {'text':[text_dict]}
|
| 687 |
+
new_name_list.append(new_name)
|
| 688 |
+
except:
|
| 689 |
+
print(line_split)
|
| 690 |
+
print(line_split[2], line_split[3], f_tag, to_tag, name)
|
| 691 |
+
# break
|
| 692 |
+
|
| 693 |
+
if flag:
|
| 694 |
+
data_dict[name] = {'text': text_data}
|
| 695 |
+
new_name_list.append(name)
|
| 696 |
+
except:
|
| 697 |
+
pass
|
| 698 |
+
|
| 699 |
+
self.length_arr = np.array(length_list)
|
| 700 |
+
self.data_dict = data_dict
|
| 701 |
+
self.name_list = new_name_list
|
| 702 |
+
|
| 703 |
+
def inv_transform(self, data):
|
| 704 |
+
return data * self.std + self.mean
|
| 705 |
+
|
| 706 |
+
def __len__(self):
|
| 707 |
+
return len(self.data_dict)
|
| 708 |
+
|
| 709 |
+
def __getitem__(self, item):
|
| 710 |
+
idx = self.pointer + item
|
| 711 |
+
data = self.data_dict[self.name_list[idx]]
|
| 712 |
+
text_list = data['text']
|
| 713 |
+
|
| 714 |
+
# Randomly select a caption
|
| 715 |
+
text_data = random.choice(text_list)
|
| 716 |
+
caption, tokens = text_data['caption'], text_data['tokens']
|
| 717 |
+
return None, None, caption, None, np.array([0]), self.fixed_length, None
|
| 718 |
+
# fixed_length can be set from outside before sampling
|
| 719 |
+
|
| 720 |
+
# A wrapper class for t2m original dataset for MDM purposes
|
| 721 |
+
class HumanML3D(data.Dataset):
|
| 722 |
+
def __init__(self, mode, datapath='./dataset/humanml_opt.txt', split="train", **kwargs):
|
| 723 |
+
self.mode = mode
|
| 724 |
+
|
| 725 |
+
self.dataset_name = 't2m'
|
| 726 |
+
self.dataname = 't2m'
|
| 727 |
+
|
| 728 |
+
# Configurations of T2M dataset and KIT dataset is almost the same
|
| 729 |
+
abs_base_path = f'../motion-diffusion-model'
|
| 730 |
+
# abs_base_path = f'.'
|
| 731 |
+
|
| 732 |
+
dataset_opt_path = pjoin(abs_base_path, datapath)
|
| 733 |
+
device = None # torch.device('cuda:4') # This param is not in use in this context
|
| 734 |
+
opt = get_opt(dataset_opt_path, device)
|
| 735 |
+
opt.meta_dir = pjoin(abs_base_path, opt.meta_dir)
|
| 736 |
+
opt.motion_dir = pjoin(abs_base_path, opt.motion_dir)
|
| 737 |
+
opt.text_dir = pjoin(abs_base_path, opt.text_dir)
|
| 738 |
+
opt.model_dir = pjoin(abs_base_path, opt.model_dir)
|
| 739 |
+
opt.checkpoints_dir = pjoin(abs_base_path, opt.checkpoints_dir)
|
| 740 |
+
opt.data_root = pjoin(abs_base_path, opt.data_root)
|
| 741 |
+
opt.save_root = pjoin(abs_base_path, opt.save_root)
|
| 742 |
+
opt.meta_dir = './dataset'
|
| 743 |
+
self.opt = opt
|
| 744 |
+
print('Loading dataset %s ...' % opt.dataset_name)
|
| 745 |
+
|
| 746 |
+
if mode == 'gt':
|
| 747 |
+
# used by T2M models (including evaluators)
|
| 748 |
+
self.mean = np.load(pjoin(opt.meta_dir, f'{opt.dataset_name}_mean.npy'))
|
| 749 |
+
self.std = np.load(pjoin(opt.meta_dir, f'{opt.dataset_name}_std.npy'))
|
| 750 |
+
elif mode in ['train', 'eval', 'text_only']:
|
| 751 |
+
# used by our models
|
| 752 |
+
self.mean = np.load(pjoin(opt.data_root, 'Mean.npy'))
|
| 753 |
+
self.std = np.load(pjoin(opt.data_root, 'Std.npy'))
|
| 754 |
+
|
| 755 |
+
if mode == 'eval':
|
| 756 |
+
# used by T2M models (including evaluators)
|
| 757 |
+
# this is to translate their norms to ours
|
| 758 |
+
self.mean_for_eval = np.load(pjoin(opt.meta_dir, f'{opt.dataset_name}_mean.npy'))
|
| 759 |
+
self.std_for_eval = np.load(pjoin(opt.meta_dir, f'{opt.dataset_name}_std.npy'))
|
| 760 |
+
|
| 761 |
+
self.split_file = pjoin(opt.data_root, f'{split}.txt')
|
| 762 |
+
if mode == 'text_only':
|
| 763 |
+
self.t2m_dataset = TextOnlyDataset(self.opt, self.mean, self.std, self.split_file)
|
| 764 |
+
else:
|
| 765 |
+
self.w_vectorizer = WordVectorizer(pjoin(abs_base_path, 'glove'), 'our_vab')
|
| 766 |
+
self.t2m_dataset = Text2MotionDatasetV2(self.opt, self.mean, self.std, self.split_file, self.w_vectorizer)
|
| 767 |
+
self.num_actions = 1 # dummy placeholder
|
| 768 |
+
|
| 769 |
+
assert len(self.t2m_dataset) > 1, 'You loaded an empty dataset, ' \
|
| 770 |
+
'it is probably because your data dir has only texts and no motions.\n' \
|
| 771 |
+
'To train and evaluate MDM you should get the FULL data as described ' \
|
| 772 |
+
'in the README file.'
|
| 773 |
+
|
| 774 |
+
def __getitem__(self, item):
|
| 775 |
+
return self.t2m_dataset.__getitem__(item)
|
| 776 |
+
|
| 777 |
+
def __len__(self):
|
| 778 |
+
return self.t2m_dataset.__len__()
|
| 779 |
+
|
| 780 |
+
# A wrapper class for t2m original dataset for MDM purposes
|
| 781 |
+
class KIT(HumanML3D):
|
| 782 |
+
def __init__(self, mode, datapath='./dataset/kit_opt.txt', split="train", **kwargs):
|
| 783 |
+
super(KIT, self).__init__(mode, datapath, split, **kwargs)
|
main/data_loaders/humanml/motion_loaders/__init__.py
ADDED
|
File without changes
|
main/data_loaders/humanml/motion_loaders/comp_v6_model_dataset.py
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from data_loaders.humanml.networks.modules import *
|
| 3 |
+
from data_loaders.humanml.networks.trainers import CompTrainerV6
|
| 4 |
+
from torch.utils.data import Dataset, DataLoader
|
| 5 |
+
from os.path import join as pjoin
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
from utils import dist_util
|
| 8 |
+
|
| 9 |
+
def build_models(opt):
|
| 10 |
+
if opt.text_enc_mod == 'bigru':
|
| 11 |
+
text_encoder = TextEncoderBiGRU(word_size=opt.dim_word,
|
| 12 |
+
pos_size=opt.dim_pos_ohot,
|
| 13 |
+
hidden_size=opt.dim_text_hidden,
|
| 14 |
+
device=opt.device)
|
| 15 |
+
text_size = opt.dim_text_hidden * 2
|
| 16 |
+
else:
|
| 17 |
+
raise Exception("Text Encoder Mode not Recognized!!!")
|
| 18 |
+
|
| 19 |
+
seq_prior = TextDecoder(text_size=text_size,
|
| 20 |
+
input_size=opt.dim_att_vec + opt.dim_movement_latent,
|
| 21 |
+
output_size=opt.dim_z,
|
| 22 |
+
hidden_size=opt.dim_pri_hidden,
|
| 23 |
+
n_layers=opt.n_layers_pri)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
seq_decoder = TextVAEDecoder(text_size=text_size,
|
| 27 |
+
input_size=opt.dim_att_vec + opt.dim_z + opt.dim_movement_latent,
|
| 28 |
+
output_size=opt.dim_movement_latent,
|
| 29 |
+
hidden_size=opt.dim_dec_hidden,
|
| 30 |
+
n_layers=opt.n_layers_dec)
|
| 31 |
+
|
| 32 |
+
att_layer = AttLayer(query_dim=opt.dim_pos_hidden,
|
| 33 |
+
key_dim=text_size,
|
| 34 |
+
value_dim=opt.dim_att_vec)
|
| 35 |
+
|
| 36 |
+
movement_enc = MovementConvEncoder(opt.dim_pose - 4, opt.dim_movement_enc_hidden, opt.dim_movement_latent)
|
| 37 |
+
movement_dec = MovementConvDecoder(opt.dim_movement_latent, opt.dim_movement_dec_hidden, opt.dim_pose)
|
| 38 |
+
|
| 39 |
+
len_estimator = MotionLenEstimatorBiGRU(opt.dim_word, opt.dim_pos_ohot, 512, opt.num_classes)
|
| 40 |
+
|
| 41 |
+
# latent_dis = LatentDis(input_size=opt.dim_z * 2)
|
| 42 |
+
checkpoints = torch.load(pjoin(opt.checkpoints_dir, opt.dataset_name, 'length_est_bigru', 'model', 'latest.tar'), map_location=opt.device)
|
| 43 |
+
len_estimator.load_state_dict(checkpoints['estimator'])
|
| 44 |
+
len_estimator.to(opt.device)
|
| 45 |
+
len_estimator.eval()
|
| 46 |
+
|
| 47 |
+
# return text_encoder, text_decoder, att_layer, vae_pri, vae_dec, vae_pos, motion_dis, movement_dis, latent_dis
|
| 48 |
+
return text_encoder, seq_prior, seq_decoder, att_layer, movement_enc, movement_dec, len_estimator
|
| 49 |
+
|
| 50 |
+
class CompV6GeneratedDataset(Dataset):
|
| 51 |
+
|
| 52 |
+
def __init__(self, opt, dataset, w_vectorizer, mm_num_samples, mm_num_repeats):
|
| 53 |
+
assert mm_num_samples < len(dataset)
|
| 54 |
+
print(opt.model_dir)
|
| 55 |
+
|
| 56 |
+
dataloader = DataLoader(dataset, batch_size=1, num_workers=1, shuffle=True)
|
| 57 |
+
text_enc, seq_pri, seq_dec, att_layer, mov_enc, mov_dec, len_estimator = build_models(opt)
|
| 58 |
+
trainer = CompTrainerV6(opt, text_enc, seq_pri, seq_dec, att_layer, mov_dec, mov_enc=mov_enc)
|
| 59 |
+
epoch, it, sub_ep, schedule_len = trainer.load(pjoin(opt.model_dir, opt.which_epoch + '.tar'))
|
| 60 |
+
generated_motion = []
|
| 61 |
+
mm_generated_motions = []
|
| 62 |
+
mm_idxs = np.random.choice(len(dataset), mm_num_samples, replace=False)
|
| 63 |
+
mm_idxs = np.sort(mm_idxs)
|
| 64 |
+
min_mov_length = 10 if opt.dataset_name == 't2m' else 6
|
| 65 |
+
# print(mm_idxs)
|
| 66 |
+
|
| 67 |
+
print('Loading model: Epoch %03d Schedule_len %03d' % (epoch, schedule_len))
|
| 68 |
+
trainer.eval_mode()
|
| 69 |
+
trainer.to(opt.device)
|
| 70 |
+
with torch.no_grad():
|
| 71 |
+
for i, data in tqdm(enumerate(dataloader)):
|
| 72 |
+
word_emb, pos_ohot, caption, cap_lens, motions, m_lens, tokens = data
|
| 73 |
+
tokens = tokens[0].split('_')
|
| 74 |
+
word_emb = word_emb.detach().to(opt.device).float()
|
| 75 |
+
pos_ohot = pos_ohot.detach().to(opt.device).float()
|
| 76 |
+
|
| 77 |
+
pred_dis = len_estimator(word_emb, pos_ohot, cap_lens)
|
| 78 |
+
pred_dis = nn.Softmax(-1)(pred_dis).squeeze()
|
| 79 |
+
|
| 80 |
+
mm_num_now = len(mm_generated_motions)
|
| 81 |
+
is_mm = True if ((mm_num_now < mm_num_samples) and (i == mm_idxs[mm_num_now])) else False
|
| 82 |
+
|
| 83 |
+
repeat_times = mm_num_repeats if is_mm else 1
|
| 84 |
+
mm_motions = []
|
| 85 |
+
for t in range(repeat_times):
|
| 86 |
+
mov_length = torch.multinomial(pred_dis, 1, replacement=True)
|
| 87 |
+
if mov_length < min_mov_length:
|
| 88 |
+
mov_length = torch.multinomial(pred_dis, 1, replacement=True)
|
| 89 |
+
if mov_length < min_mov_length:
|
| 90 |
+
mov_length = torch.multinomial(pred_dis, 1, replacement=True)
|
| 91 |
+
|
| 92 |
+
m_lens = mov_length * opt.unit_length
|
| 93 |
+
pred_motions, _, _ = trainer.generate(word_emb, pos_ohot, cap_lens, m_lens,
|
| 94 |
+
m_lens[0]//opt.unit_length, opt.dim_pose)
|
| 95 |
+
if t == 0:
|
| 96 |
+
# print(m_lens)
|
| 97 |
+
# print(text_data)
|
| 98 |
+
sub_dict = {'motion': pred_motions[0].cpu().numpy(),
|
| 99 |
+
'length': m_lens[0].item(),
|
| 100 |
+
'cap_len': cap_lens[0].item(),
|
| 101 |
+
'caption': caption[0],
|
| 102 |
+
'tokens': tokens}
|
| 103 |
+
generated_motion.append(sub_dict)
|
| 104 |
+
|
| 105 |
+
if is_mm:
|
| 106 |
+
mm_motions.append({
|
| 107 |
+
'motion': pred_motions[0].cpu().numpy(),
|
| 108 |
+
'length': m_lens[0].item()
|
| 109 |
+
})
|
| 110 |
+
if is_mm:
|
| 111 |
+
mm_generated_motions.append({'caption': caption[0],
|
| 112 |
+
'tokens': tokens,
|
| 113 |
+
'cap_len': cap_lens[0].item(),
|
| 114 |
+
'mm_motions': mm_motions})
|
| 115 |
+
|
| 116 |
+
self.generated_motion = generated_motion
|
| 117 |
+
self.mm_generated_motion = mm_generated_motions
|
| 118 |
+
self.opt = opt
|
| 119 |
+
self.w_vectorizer = w_vectorizer
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def __len__(self):
|
| 123 |
+
return len(self.generated_motion)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def __getitem__(self, item):
|
| 127 |
+
data = self.generated_motion[item]
|
| 128 |
+
motion, m_length, caption, tokens = data['motion'], data['length'], data['caption'], data['tokens']
|
| 129 |
+
sent_len = data['cap_len']
|
| 130 |
+
|
| 131 |
+
pos_one_hots = []
|
| 132 |
+
word_embeddings = []
|
| 133 |
+
for token in tokens:
|
| 134 |
+
word_emb, pos_oh = self.w_vectorizer[token]
|
| 135 |
+
pos_one_hots.append(pos_oh[None, :])
|
| 136 |
+
word_embeddings.append(word_emb[None, :])
|
| 137 |
+
pos_one_hots = np.concatenate(pos_one_hots, axis=0)
|
| 138 |
+
word_embeddings = np.concatenate(word_embeddings, axis=0)
|
| 139 |
+
|
| 140 |
+
if m_length < self.opt.max_motion_length:
|
| 141 |
+
motion = np.concatenate([motion,
|
| 142 |
+
np.zeros((self.opt.max_motion_length - m_length, motion.shape[1]))
|
| 143 |
+
], axis=0)
|
| 144 |
+
return word_embeddings, pos_one_hots, caption, sent_len, motion, m_length, '_'.join(tokens)
|
| 145 |
+
|
| 146 |
+
class CompMDMGeneratedDataset(Dataset):
|
| 147 |
+
|
| 148 |
+
def __init__(self, model, diffusion, dataloader, mm_num_samples, mm_num_repeats, max_motion_length, num_samples_limit, scale=1.):
|
| 149 |
+
self.dataloader = dataloader
|
| 150 |
+
self.dataset = dataloader.dataset
|
| 151 |
+
assert mm_num_samples < len(dataloader.dataset)
|
| 152 |
+
use_ddim = False # FIXME - hardcoded
|
| 153 |
+
clip_denoised = False # FIXME - hardcoded
|
| 154 |
+
self.max_motion_length = max_motion_length
|
| 155 |
+
sample_fn = (
|
| 156 |
+
diffusion.p_sample_loop if not use_ddim else diffusion.ddim_sample_loop
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
real_num_batches = len(dataloader)
|
| 160 |
+
if num_samples_limit is not None:
|
| 161 |
+
real_num_batches = num_samples_limit // dataloader.batch_size + 1
|
| 162 |
+
print('real_num_batches', real_num_batches)
|
| 163 |
+
|
| 164 |
+
generated_motion = []
|
| 165 |
+
mm_generated_motions = []
|
| 166 |
+
if mm_num_samples > 0:
|
| 167 |
+
mm_idxs = np.random.choice(real_num_batches, mm_num_samples // dataloader.batch_size +1, replace=False)
|
| 168 |
+
mm_idxs = np.sort(mm_idxs)
|
| 169 |
+
else:
|
| 170 |
+
mm_idxs = []
|
| 171 |
+
print('mm_idxs', mm_idxs)
|
| 172 |
+
|
| 173 |
+
model.eval()
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
with torch.no_grad():
|
| 177 |
+
for i, (motion, model_kwargs) in tqdm(enumerate(dataloader)):
|
| 178 |
+
|
| 179 |
+
if num_samples_limit is not None and len(generated_motion) >= num_samples_limit:
|
| 180 |
+
break
|
| 181 |
+
|
| 182 |
+
tokens = [t.split('_') for t in model_kwargs['y']['tokens']]
|
| 183 |
+
|
| 184 |
+
# add CFG scale to batch
|
| 185 |
+
if scale != 1.:
|
| 186 |
+
model_kwargs['y']['scale'] = torch.ones(motion.shape[0],
|
| 187 |
+
device=dist_util.dev()) * scale
|
| 188 |
+
|
| 189 |
+
mm_num_now = len(mm_generated_motions) // dataloader.batch_size
|
| 190 |
+
is_mm = i in mm_idxs
|
| 191 |
+
repeat_times = mm_num_repeats if is_mm else 1
|
| 192 |
+
mm_motions = []
|
| 193 |
+
for t in range(repeat_times):
|
| 194 |
+
|
| 195 |
+
sample = sample_fn(
|
| 196 |
+
model,
|
| 197 |
+
motion.shape,
|
| 198 |
+
clip_denoised=clip_denoised,
|
| 199 |
+
model_kwargs=model_kwargs,
|
| 200 |
+
skip_timesteps=0, # 0 is the default value - i.e. don't skip any step
|
| 201 |
+
init_image=None,
|
| 202 |
+
progress=False,
|
| 203 |
+
dump_steps=None,
|
| 204 |
+
noise=None,
|
| 205 |
+
const_noise=False,
|
| 206 |
+
# when experimenting guidance_scale we want to nutrileze the effect of noise on generation
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
if t == 0:
|
| 210 |
+
sub_dicts = [{'motion': sample[bs_i].squeeze().permute(1,0).cpu().numpy(),
|
| 211 |
+
'length': model_kwargs['y']['lengths'][bs_i].cpu().numpy(),
|
| 212 |
+
'caption': model_kwargs['y']['text'][bs_i],
|
| 213 |
+
'tokens': tokens[bs_i],
|
| 214 |
+
'cap_len': len(tokens[bs_i]),
|
| 215 |
+
} for bs_i in range(dataloader.batch_size)]
|
| 216 |
+
generated_motion += sub_dicts
|
| 217 |
+
|
| 218 |
+
if is_mm:
|
| 219 |
+
mm_motions += [{'motion': sample[bs_i].squeeze().permute(1, 0).cpu().numpy(),
|
| 220 |
+
'length': model_kwargs['y']['lengths'][bs_i].cpu().numpy(),
|
| 221 |
+
} for bs_i in range(dataloader.batch_size)]
|
| 222 |
+
|
| 223 |
+
if is_mm:
|
| 224 |
+
mm_generated_motions += [{
|
| 225 |
+
'caption': model_kwargs['y']['text'][bs_i],
|
| 226 |
+
'tokens': tokens[bs_i],
|
| 227 |
+
'cap_len': len(tokens[bs_i]),
|
| 228 |
+
'mm_motions': mm_motions[bs_i::dataloader.batch_size], # collect all 10 repeats from the (32*10) generated motions
|
| 229 |
+
} for bs_i in range(dataloader.batch_size)]
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
self.generated_motion = generated_motion
|
| 233 |
+
self.mm_generated_motion = mm_generated_motions
|
| 234 |
+
self.w_vectorizer = dataloader.dataset.w_vectorizer
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
def __len__(self):
|
| 238 |
+
return len(self.generated_motion)
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
def __getitem__(self, item):
|
| 242 |
+
data = self.generated_motion[item]
|
| 243 |
+
motion, m_length, caption, tokens = data['motion'], data['length'], data['caption'], data['tokens']
|
| 244 |
+
sent_len = data['cap_len']
|
| 245 |
+
|
| 246 |
+
if self.dataset.mode == 'eval':
|
| 247 |
+
normed_motion = motion
|
| 248 |
+
denormed_motion = self.dataset.t2m_dataset.inv_transform(normed_motion)
|
| 249 |
+
renormed_motion = (denormed_motion - self.dataset.mean_for_eval) / self.dataset.std_for_eval # according to T2M norms
|
| 250 |
+
motion = renormed_motion
|
| 251 |
+
# This step is needed because T2M evaluators expect their norm convention
|
| 252 |
+
|
| 253 |
+
pos_one_hots = []
|
| 254 |
+
word_embeddings = []
|
| 255 |
+
for token in tokens:
|
| 256 |
+
word_emb, pos_oh = self.w_vectorizer[token]
|
| 257 |
+
pos_one_hots.append(pos_oh[None, :])
|
| 258 |
+
word_embeddings.append(word_emb[None, :])
|
| 259 |
+
pos_one_hots = np.concatenate(pos_one_hots, axis=0)
|
| 260 |
+
word_embeddings = np.concatenate(word_embeddings, axis=0)
|
| 261 |
+
|
| 262 |
+
return word_embeddings, pos_one_hots, caption, sent_len, motion, m_length, '_'.join(tokens)
|
main/data_loaders/humanml/motion_loaders/dataset_motion_loader.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from t2m.data.dataset import Text2MotionDatasetV2, collate_fn
|
| 2 |
+
from t2m.utils.word_vectorizer import WordVectorizer
|
| 3 |
+
import numpy as np
|
| 4 |
+
from os.path import join as pjoin
|
| 5 |
+
from torch.utils.data import DataLoader
|
| 6 |
+
from t2m.utils.get_opt import get_opt
|
| 7 |
+
|
| 8 |
+
def get_dataset_motion_loader(opt_path, batch_size, device):
|
| 9 |
+
opt = get_opt(opt_path, device)
|
| 10 |
+
|
| 11 |
+
# Configurations of T2M dataset and KIT dataset is almost the same
|
| 12 |
+
if opt.dataset_name == 't2m' or opt.dataset_name == 'kit':
|
| 13 |
+
print('Loading dataset %s ...' % opt.dataset_name)
|
| 14 |
+
|
| 15 |
+
mean = np.load(pjoin(opt.meta_dir, 'mean.npy'))
|
| 16 |
+
std = np.load(pjoin(opt.meta_dir, 'std.npy'))
|
| 17 |
+
|
| 18 |
+
w_vectorizer = WordVectorizer('./glove', 'our_vab')
|
| 19 |
+
split_file = pjoin(opt.data_root, 'test.txt')
|
| 20 |
+
dataset = Text2MotionDatasetV2(opt, mean, std, split_file, w_vectorizer)
|
| 21 |
+
dataloader = DataLoader(dataset, batch_size=batch_size, num_workers=4, drop_last=True,
|
| 22 |
+
collate_fn=collate_fn, shuffle=True)
|
| 23 |
+
else:
|
| 24 |
+
raise KeyError('Dataset not Recognized !!')
|
| 25 |
+
|
| 26 |
+
print('Ground Truth Dataset Loading Completed!!!')
|
| 27 |
+
return dataloader, dataset
|
main/data_loaders/humanml/motion_loaders/model_motion_loaders.py
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.utils.data import DataLoader, Dataset
|
| 2 |
+
from data_loaders.humanml.utils.get_opt import get_opt
|
| 3 |
+
from data_loaders.humanml.motion_loaders.comp_v6_model_dataset import CompMDMGeneratedDataset
|
| 4 |
+
from data_loaders.humanml.utils.word_vectorizer import WordVectorizer
|
| 5 |
+
import numpy as np
|
| 6 |
+
from torch.utils.data._utils.collate import default_collate
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def collate_fn(batch):
|
| 10 |
+
batch.sort(key=lambda x: x[3], reverse=True)
|
| 11 |
+
return default_collate(batch)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class MMGeneratedDataset(Dataset):
|
| 15 |
+
def __init__(self, opt, motion_dataset, w_vectorizer):
|
| 16 |
+
self.opt = opt
|
| 17 |
+
self.dataset = motion_dataset.mm_generated_motion
|
| 18 |
+
self.w_vectorizer = w_vectorizer
|
| 19 |
+
|
| 20 |
+
def __len__(self):
|
| 21 |
+
return len(self.dataset)
|
| 22 |
+
|
| 23 |
+
def __getitem__(self, item):
|
| 24 |
+
data = self.dataset[item]
|
| 25 |
+
mm_motions = data['mm_motions']
|
| 26 |
+
m_lens = []
|
| 27 |
+
motions = []
|
| 28 |
+
for mm_motion in mm_motions:
|
| 29 |
+
m_lens.append(mm_motion['length'])
|
| 30 |
+
motion = mm_motion['motion']
|
| 31 |
+
# We don't need the following logic because our sample func generates the full tensor anyway:
|
| 32 |
+
# if len(motion) < self.opt.max_motion_length:
|
| 33 |
+
# motion = np.concatenate([motion,
|
| 34 |
+
# np.zeros((self.opt.max_motion_length - len(motion), motion.shape[1]))
|
| 35 |
+
# ], axis=0)
|
| 36 |
+
motion = motion[None, :]
|
| 37 |
+
motions.append(motion)
|
| 38 |
+
m_lens = np.array(m_lens, dtype=np.int)
|
| 39 |
+
motions = np.concatenate(motions, axis=0)
|
| 40 |
+
sort_indx = np.argsort(m_lens)[::-1].copy()
|
| 41 |
+
# print(m_lens)
|
| 42 |
+
# print(sort_indx)
|
| 43 |
+
# print(m_lens[sort_indx])
|
| 44 |
+
m_lens = m_lens[sort_indx]
|
| 45 |
+
motions = motions[sort_indx]
|
| 46 |
+
return motions, m_lens
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def get_motion_loader(opt_path, batch_size, ground_truth_dataset, mm_num_samples, mm_num_repeats, device):
|
| 51 |
+
opt = get_opt(opt_path, device)
|
| 52 |
+
|
| 53 |
+
# Currently the configurations of two datasets are almost the same
|
| 54 |
+
if opt.dataset_name == 't2m' or opt.dataset_name == 'kit':
|
| 55 |
+
w_vectorizer = WordVectorizer('./glove', 'our_vab')
|
| 56 |
+
else:
|
| 57 |
+
raise KeyError('Dataset not recognized!!')
|
| 58 |
+
print('Generating %s ...' % opt.name)
|
| 59 |
+
|
| 60 |
+
if 'v6' in opt.name:
|
| 61 |
+
dataset = CompV6GeneratedDataset(opt, ground_truth_dataset, w_vectorizer, mm_num_samples, mm_num_repeats)
|
| 62 |
+
else:
|
| 63 |
+
raise KeyError('Dataset not recognized!!')
|
| 64 |
+
|
| 65 |
+
mm_dataset = MMGeneratedDataset(opt, dataset, w_vectorizer)
|
| 66 |
+
|
| 67 |
+
motion_loader = DataLoader(dataset, batch_size=batch_size, collate_fn=collate_fn, drop_last=True, num_workers=4)
|
| 68 |
+
mm_motion_loader = DataLoader(mm_dataset, batch_size=1, num_workers=1)
|
| 69 |
+
|
| 70 |
+
print('Generated Dataset Loading Completed!!!')
|
| 71 |
+
|
| 72 |
+
return motion_loader, mm_motion_loader
|
| 73 |
+
|
| 74 |
+
# our loader
|
| 75 |
+
def get_mdm_loader(model, diffusion, batch_size, ground_truth_loader, mm_num_samples, mm_num_repeats, max_motion_length, num_samples_limit, scale):
|
| 76 |
+
opt = {
|
| 77 |
+
'name': 'test', # FIXME
|
| 78 |
+
}
|
| 79 |
+
print('Generating %s ...' % opt['name'])
|
| 80 |
+
# dataset = CompMDMGeneratedDataset(opt, ground_truth_dataset, ground_truth_dataset.w_vectorizer, mm_num_samples, mm_num_repeats)
|
| 81 |
+
dataset = CompMDMGeneratedDataset(model, diffusion, ground_truth_loader, mm_num_samples, mm_num_repeats, max_motion_length, num_samples_limit, scale)
|
| 82 |
+
|
| 83 |
+
mm_dataset = MMGeneratedDataset(opt, dataset, ground_truth_loader.dataset.w_vectorizer)
|
| 84 |
+
|
| 85 |
+
# NOTE: bs must not be changed! this will cause a bug in R precision calc!
|
| 86 |
+
motion_loader = DataLoader(dataset, batch_size=batch_size, collate_fn=collate_fn, drop_last=True, num_workers=4)
|
| 87 |
+
mm_motion_loader = DataLoader(mm_dataset, batch_size=1, num_workers=1)
|
| 88 |
+
|
| 89 |
+
print('Generated Dataset Loading Completed!!!')
|
| 90 |
+
|
| 91 |
+
return motion_loader, mm_motion_loader
|
main/data_loaders/humanml/networks/__init__.py
ADDED
|
File without changes
|
main/data_loaders/humanml/networks/evaluator_wrapper.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from data_loaders.humanml.networks.modules import *
|
| 2 |
+
from data_loaders.humanml.utils.word_vectorizer import POS_enumerator
|
| 3 |
+
from os.path import join as pjoin
|
| 4 |
+
|
| 5 |
+
def build_models(opt):
|
| 6 |
+
movement_enc = MovementConvEncoder(opt.dim_pose-4, opt.dim_movement_enc_hidden, opt.dim_movement_latent)
|
| 7 |
+
text_enc = TextEncoderBiGRUCo(word_size=opt.dim_word,
|
| 8 |
+
pos_size=opt.dim_pos_ohot,
|
| 9 |
+
hidden_size=opt.dim_text_hidden,
|
| 10 |
+
output_size=opt.dim_coemb_hidden,
|
| 11 |
+
device=opt.device)
|
| 12 |
+
|
| 13 |
+
motion_enc = MotionEncoderBiGRUCo(input_size=opt.dim_movement_latent,
|
| 14 |
+
hidden_size=opt.dim_motion_hidden,
|
| 15 |
+
output_size=opt.dim_coemb_hidden,
|
| 16 |
+
device=opt.device)
|
| 17 |
+
|
| 18 |
+
checkpoint = torch.load(pjoin(opt.checkpoints_dir, opt.dataset_name, 'text_mot_match', 'model', 'finest.tar'),
|
| 19 |
+
map_location=opt.device)
|
| 20 |
+
movement_enc.load_state_dict(checkpoint['movement_encoder'])
|
| 21 |
+
text_enc.load_state_dict(checkpoint['text_encoder'])
|
| 22 |
+
motion_enc.load_state_dict(checkpoint['motion_encoder'])
|
| 23 |
+
print('Loading Evaluation Model Wrapper (Epoch %d) Completed!!' % (checkpoint['epoch']))
|
| 24 |
+
return text_enc, motion_enc, movement_enc
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class EvaluatorModelWrapper(object):
|
| 28 |
+
|
| 29 |
+
def __init__(self, opt):
|
| 30 |
+
|
| 31 |
+
if opt.dataset_name == 't2m':
|
| 32 |
+
opt.dim_pose = 263
|
| 33 |
+
elif opt.dataset_name == 'kit':
|
| 34 |
+
opt.dim_pose = 251
|
| 35 |
+
else:
|
| 36 |
+
raise KeyError('Dataset not Recognized!!!')
|
| 37 |
+
|
| 38 |
+
opt.dim_word = 300
|
| 39 |
+
opt.max_motion_length = 196
|
| 40 |
+
opt.dim_pos_ohot = len(POS_enumerator)
|
| 41 |
+
opt.dim_motion_hidden = 1024
|
| 42 |
+
opt.max_text_len = 20
|
| 43 |
+
opt.dim_text_hidden = 512
|
| 44 |
+
opt.dim_coemb_hidden = 512
|
| 45 |
+
|
| 46 |
+
self.text_encoder, self.motion_encoder, self.movement_encoder = build_models(opt)
|
| 47 |
+
self.opt = opt
|
| 48 |
+
self.device = opt.device
|
| 49 |
+
|
| 50 |
+
self.text_encoder.to(opt.device)
|
| 51 |
+
self.motion_encoder.to(opt.device)
|
| 52 |
+
self.movement_encoder.to(opt.device)
|
| 53 |
+
|
| 54 |
+
self.text_encoder.eval()
|
| 55 |
+
self.motion_encoder.eval()
|
| 56 |
+
self.movement_encoder.eval()
|
| 57 |
+
|
| 58 |
+
# Please note that the results does not following the order of inputs
|
| 59 |
+
def get_co_embeddings(self, word_embs, pos_ohot, cap_lens, motions, m_lens):
|
| 60 |
+
with torch.no_grad():
|
| 61 |
+
word_embs = word_embs.detach().to(self.device).float()
|
| 62 |
+
pos_ohot = pos_ohot.detach().to(self.device).float()
|
| 63 |
+
motions = motions.detach().to(self.device).float()
|
| 64 |
+
|
| 65 |
+
align_idx = np.argsort(m_lens.data.tolist())[::-1].copy()
|
| 66 |
+
motions = motions[align_idx]
|
| 67 |
+
m_lens = m_lens[align_idx]
|
| 68 |
+
|
| 69 |
+
'''Movement Encoding'''
|
| 70 |
+
movements = self.movement_encoder(motions[..., :-4]).detach()
|
| 71 |
+
m_lens = m_lens // self.opt.unit_length
|
| 72 |
+
motion_embedding = self.motion_encoder(movements, m_lens)
|
| 73 |
+
|
| 74 |
+
'''Text Encoding'''
|
| 75 |
+
text_embedding = self.text_encoder(word_embs, pos_ohot, cap_lens)
|
| 76 |
+
text_embedding = text_embedding[align_idx]
|
| 77 |
+
return text_embedding, motion_embedding
|
| 78 |
+
|
| 79 |
+
# Please note that the results does not following the order of inputs
|
| 80 |
+
def get_motion_embeddings(self, motions, m_lens):
|
| 81 |
+
with torch.no_grad():
|
| 82 |
+
motions = motions.detach().to(self.device).float()
|
| 83 |
+
|
| 84 |
+
align_idx = np.argsort(m_lens.data.tolist())[::-1].copy()
|
| 85 |
+
motions = motions[align_idx]
|
| 86 |
+
m_lens = m_lens[align_idx]
|
| 87 |
+
|
| 88 |
+
'''Movement Encoding'''
|
| 89 |
+
movements = self.movement_encoder(motions[..., :-4]).detach()
|
| 90 |
+
m_lens = m_lens // self.opt.unit_length
|
| 91 |
+
motion_embedding = self.motion_encoder(movements, m_lens)
|
| 92 |
+
return motion_embedding
|
| 93 |
+
|
| 94 |
+
# our version
|
| 95 |
+
def build_evaluators(opt):
|
| 96 |
+
movement_enc = MovementConvEncoder(opt['dim_pose']-4, opt['dim_movement_enc_hidden'], opt['dim_movement_latent'])
|
| 97 |
+
text_enc = TextEncoderBiGRUCo(word_size=opt['dim_word'],
|
| 98 |
+
pos_size=opt['dim_pos_ohot'],
|
| 99 |
+
hidden_size=opt['dim_text_hidden'],
|
| 100 |
+
output_size=opt['dim_coemb_hidden'],
|
| 101 |
+
device=opt['device'])
|
| 102 |
+
|
| 103 |
+
motion_enc = MotionEncoderBiGRUCo(input_size=opt['dim_movement_latent'],
|
| 104 |
+
hidden_size=opt['dim_motion_hidden'],
|
| 105 |
+
output_size=opt['dim_coemb_hidden'],
|
| 106 |
+
device=opt['device'])
|
| 107 |
+
|
| 108 |
+
ckpt_dir = opt['dataset_name']
|
| 109 |
+
if opt['dataset_name'] == 'humanml':
|
| 110 |
+
ckpt_dir = 't2m'
|
| 111 |
+
|
| 112 |
+
checkpoint = torch.load(pjoin(opt['checkpoints_dir'], ckpt_dir, 'text_mot_match', 'model', 'finest.tar'),
|
| 113 |
+
map_location=opt['device'])
|
| 114 |
+
movement_enc.load_state_dict(checkpoint['movement_encoder'])
|
| 115 |
+
text_enc.load_state_dict(checkpoint['text_encoder'])
|
| 116 |
+
motion_enc.load_state_dict(checkpoint['motion_encoder'])
|
| 117 |
+
print('Loading Evaluation Model Wrapper (Epoch %d) Completed!!' % (checkpoint['epoch']))
|
| 118 |
+
return text_enc, motion_enc, movement_enc
|
| 119 |
+
|
| 120 |
+
# our wrapper
|
| 121 |
+
class EvaluatorMDMWrapper(object):
|
| 122 |
+
|
| 123 |
+
def __init__(self, dataset_name, device):
|
| 124 |
+
opt = {
|
| 125 |
+
'dataset_name': dataset_name,
|
| 126 |
+
'device': device,
|
| 127 |
+
'dim_word': 300,
|
| 128 |
+
'max_motion_length': 196,
|
| 129 |
+
'dim_pos_ohot': len(POS_enumerator),
|
| 130 |
+
'dim_motion_hidden': 1024,
|
| 131 |
+
'max_text_len': 20,
|
| 132 |
+
'dim_text_hidden': 512,
|
| 133 |
+
'dim_coemb_hidden': 512,
|
| 134 |
+
'dim_pose': 263 if dataset_name == 'humanml' else 251,
|
| 135 |
+
'dim_movement_enc_hidden': 512,
|
| 136 |
+
'dim_movement_latent': 512,
|
| 137 |
+
'checkpoints_dir': '.',
|
| 138 |
+
'unit_length': 4,
|
| 139 |
+
}
|
| 140 |
+
|
| 141 |
+
self.text_encoder, self.motion_encoder, self.movement_encoder = build_evaluators(opt)
|
| 142 |
+
self.opt = opt
|
| 143 |
+
self.device = opt['device']
|
| 144 |
+
|
| 145 |
+
self.text_encoder.to(opt['device'])
|
| 146 |
+
self.motion_encoder.to(opt['device'])
|
| 147 |
+
self.movement_encoder.to(opt['device'])
|
| 148 |
+
|
| 149 |
+
self.text_encoder.eval()
|
| 150 |
+
self.motion_encoder.eval()
|
| 151 |
+
self.movement_encoder.eval()
|
| 152 |
+
|
| 153 |
+
# Please note that the results does not following the order of inputs
|
| 154 |
+
def get_co_embeddings(self, word_embs, pos_ohot, cap_lens, motions, m_lens):
|
| 155 |
+
with torch.no_grad():
|
| 156 |
+
word_embs = word_embs.detach().to(self.device).float()
|
| 157 |
+
pos_ohot = pos_ohot.detach().to(self.device).float()
|
| 158 |
+
motions = motions.detach().to(self.device).float()
|
| 159 |
+
|
| 160 |
+
align_idx = np.argsort(m_lens.data.tolist())[::-1].copy()
|
| 161 |
+
motions = motions[align_idx]
|
| 162 |
+
m_lens = m_lens[align_idx]
|
| 163 |
+
|
| 164 |
+
'''Movement Encoding'''
|
| 165 |
+
movements = self.movement_encoder(motions[..., :-4]).detach()
|
| 166 |
+
m_lens = m_lens // self.opt['unit_length']
|
| 167 |
+
motion_embedding = self.motion_encoder(movements, m_lens)
|
| 168 |
+
|
| 169 |
+
'''Text Encoding'''
|
| 170 |
+
text_embedding = self.text_encoder(word_embs, pos_ohot, cap_lens)
|
| 171 |
+
text_embedding = text_embedding[align_idx]
|
| 172 |
+
return text_embedding, motion_embedding
|
| 173 |
+
|
| 174 |
+
# Please note that the results does not following the order of inputs
|
| 175 |
+
def get_motion_embeddings(self, motions, m_lens):
|
| 176 |
+
with torch.no_grad():
|
| 177 |
+
motions = motions.detach().to(self.device).float()
|
| 178 |
+
|
| 179 |
+
align_idx = np.argsort(m_lens.data.tolist())[::-1].copy()
|
| 180 |
+
motions = motions[align_idx]
|
| 181 |
+
m_lens = m_lens[align_idx]
|
| 182 |
+
|
| 183 |
+
'''Movement Encoding'''
|
| 184 |
+
movements = self.movement_encoder(motions[..., :-4]).detach()
|
| 185 |
+
m_lens = m_lens // self.opt['unit_length']
|
| 186 |
+
motion_embedding = self.motion_encoder(movements, m_lens)
|
| 187 |
+
return motion_embedding
|
main/data_loaders/humanml/networks/modules.py
ADDED
|
@@ -0,0 +1,438 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import numpy as np
|
| 4 |
+
import time
|
| 5 |
+
import math
|
| 6 |
+
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
|
| 7 |
+
# from networks.layers import *
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class ContrastiveLoss(torch.nn.Module):
|
| 12 |
+
"""
|
| 13 |
+
Contrastive loss function.
|
| 14 |
+
Based on: http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
|
| 15 |
+
"""
|
| 16 |
+
def __init__(self, margin=3.0):
|
| 17 |
+
super(ContrastiveLoss, self).__init__()
|
| 18 |
+
self.margin = margin
|
| 19 |
+
|
| 20 |
+
def forward(self, output1, output2, label):
|
| 21 |
+
euclidean_distance = F.pairwise_distance(output1, output2, keepdim=True)
|
| 22 |
+
loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +
|
| 23 |
+
(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
|
| 24 |
+
return loss_contrastive
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def init_weight(m):
|
| 28 |
+
if isinstance(m, nn.Conv1d) or isinstance(m, nn.Linear) or isinstance(m, nn.ConvTranspose1d):
|
| 29 |
+
nn.init.xavier_normal_(m.weight)
|
| 30 |
+
# m.bias.data.fill_(0.01)
|
| 31 |
+
if m.bias is not None:
|
| 32 |
+
nn.init.constant_(m.bias, 0)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def reparameterize(mu, logvar):
|
| 36 |
+
s_var = logvar.mul(0.5).exp_()
|
| 37 |
+
eps = s_var.data.new(s_var.size()).normal_()
|
| 38 |
+
return eps.mul(s_var).add_(mu)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
# batch_size, dimension and position
|
| 42 |
+
# output: (batch_size, dim)
|
| 43 |
+
def positional_encoding(batch_size, dim, pos):
|
| 44 |
+
assert batch_size == pos.shape[0]
|
| 45 |
+
positions_enc = np.array([
|
| 46 |
+
[pos[j] / np.power(10000, (i-i%2)/dim) for i in range(dim)]
|
| 47 |
+
for j in range(batch_size)
|
| 48 |
+
], dtype=np.float32)
|
| 49 |
+
positions_enc[:, 0::2] = np.sin(positions_enc[:, 0::2])
|
| 50 |
+
positions_enc[:, 1::2] = np.cos(positions_enc[:, 1::2])
|
| 51 |
+
return torch.from_numpy(positions_enc).float()
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def get_padding_mask(batch_size, seq_len, cap_lens):
|
| 55 |
+
cap_lens = cap_lens.data.tolist()
|
| 56 |
+
mask_2d = torch.ones((batch_size, seq_len, seq_len), dtype=torch.float32)
|
| 57 |
+
for i, cap_len in enumerate(cap_lens):
|
| 58 |
+
mask_2d[i, :, :cap_len] = 0
|
| 59 |
+
return mask_2d.bool(), 1 - mask_2d[:, :, 0].clone()
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class PositionalEncoding(nn.Module):
|
| 63 |
+
|
| 64 |
+
def __init__(self, d_model, max_len=300):
|
| 65 |
+
super(PositionalEncoding, self).__init__()
|
| 66 |
+
|
| 67 |
+
pe = torch.zeros(max_len, d_model)
|
| 68 |
+
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
|
| 69 |
+
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
|
| 70 |
+
pe[:, 0::2] = torch.sin(position * div_term)
|
| 71 |
+
pe[:, 1::2] = torch.cos(position * div_term)
|
| 72 |
+
# pe = pe.unsqueeze(0).transpose(0, 1)
|
| 73 |
+
self.register_buffer('pe', pe)
|
| 74 |
+
|
| 75 |
+
def forward(self, pos):
|
| 76 |
+
return self.pe[pos]
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class MovementConvEncoder(nn.Module):
|
| 80 |
+
def __init__(self, input_size, hidden_size, output_size):
|
| 81 |
+
super(MovementConvEncoder, self).__init__()
|
| 82 |
+
self.main = nn.Sequential(
|
| 83 |
+
nn.Conv1d(input_size, hidden_size, 4, 2, 1),
|
| 84 |
+
nn.Dropout(0.2, inplace=True),
|
| 85 |
+
nn.LeakyReLU(0.2, inplace=True),
|
| 86 |
+
nn.Conv1d(hidden_size, output_size, 4, 2, 1),
|
| 87 |
+
nn.Dropout(0.2, inplace=True),
|
| 88 |
+
nn.LeakyReLU(0.2, inplace=True),
|
| 89 |
+
)
|
| 90 |
+
self.out_net = nn.Linear(output_size, output_size)
|
| 91 |
+
self.main.apply(init_weight)
|
| 92 |
+
self.out_net.apply(init_weight)
|
| 93 |
+
|
| 94 |
+
def forward(self, inputs):
|
| 95 |
+
inputs = inputs.permute(0, 2, 1)
|
| 96 |
+
outputs = self.main(inputs).permute(0, 2, 1)
|
| 97 |
+
# print(outputs.shape)
|
| 98 |
+
return self.out_net(outputs)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class MovementConvDecoder(nn.Module):
|
| 102 |
+
def __init__(self, input_size, hidden_size, output_size):
|
| 103 |
+
super(MovementConvDecoder, self).__init__()
|
| 104 |
+
self.main = nn.Sequential(
|
| 105 |
+
nn.ConvTranspose1d(input_size, hidden_size, 4, 2, 1),
|
| 106 |
+
# nn.Dropout(0.2, inplace=True),
|
| 107 |
+
nn.LeakyReLU(0.2, inplace=True),
|
| 108 |
+
nn.ConvTranspose1d(hidden_size, output_size, 4, 2, 1),
|
| 109 |
+
# nn.Dropout(0.2, inplace=True),
|
| 110 |
+
nn.LeakyReLU(0.2, inplace=True),
|
| 111 |
+
)
|
| 112 |
+
self.out_net = nn.Linear(output_size, output_size)
|
| 113 |
+
|
| 114 |
+
self.main.apply(init_weight)
|
| 115 |
+
self.out_net.apply(init_weight)
|
| 116 |
+
|
| 117 |
+
def forward(self, inputs):
|
| 118 |
+
inputs = inputs.permute(0, 2, 1)
|
| 119 |
+
outputs = self.main(inputs).permute(0, 2, 1)
|
| 120 |
+
return self.out_net(outputs)
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
class TextVAEDecoder(nn.Module):
|
| 124 |
+
def __init__(self, text_size, input_size, output_size, hidden_size, n_layers):
|
| 125 |
+
super(TextVAEDecoder, self).__init__()
|
| 126 |
+
self.input_size = input_size
|
| 127 |
+
self.output_size = output_size
|
| 128 |
+
self.hidden_size = hidden_size
|
| 129 |
+
self.n_layers = n_layers
|
| 130 |
+
self.emb = nn.Sequential(
|
| 131 |
+
nn.Linear(input_size, hidden_size),
|
| 132 |
+
nn.LayerNorm(hidden_size),
|
| 133 |
+
nn.LeakyReLU(0.2, inplace=True))
|
| 134 |
+
|
| 135 |
+
self.z2init = nn.Linear(text_size, hidden_size * n_layers)
|
| 136 |
+
self.gru = nn.ModuleList([nn.GRUCell(hidden_size, hidden_size) for i in range(self.n_layers)])
|
| 137 |
+
self.positional_encoder = PositionalEncoding(hidden_size)
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
self.output = nn.Sequential(
|
| 141 |
+
nn.Linear(hidden_size, hidden_size),
|
| 142 |
+
nn.LayerNorm(hidden_size),
|
| 143 |
+
nn.LeakyReLU(0.2, inplace=True),
|
| 144 |
+
nn.Linear(hidden_size, output_size)
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
#
|
| 148 |
+
# self.output = nn.Sequential(
|
| 149 |
+
# nn.Linear(hidden_size, hidden_size),
|
| 150 |
+
# nn.LayerNorm(hidden_size),
|
| 151 |
+
# nn.LeakyReLU(0.2, inplace=True),
|
| 152 |
+
# nn.Linear(hidden_size, output_size-4)
|
| 153 |
+
# )
|
| 154 |
+
|
| 155 |
+
# self.contact_net = nn.Sequential(
|
| 156 |
+
# nn.Linear(output_size-4, 64),
|
| 157 |
+
# nn.LayerNorm(64),
|
| 158 |
+
# nn.LeakyReLU(0.2, inplace=True),
|
| 159 |
+
# nn.Linear(64, 4)
|
| 160 |
+
# )
|
| 161 |
+
|
| 162 |
+
self.output.apply(init_weight)
|
| 163 |
+
self.emb.apply(init_weight)
|
| 164 |
+
self.z2init.apply(init_weight)
|
| 165 |
+
# self.contact_net.apply(init_weight)
|
| 166 |
+
|
| 167 |
+
def get_init_hidden(self, latent):
|
| 168 |
+
hidden = self.z2init(latent)
|
| 169 |
+
hidden = torch.split(hidden, self.hidden_size, dim=-1)
|
| 170 |
+
return list(hidden)
|
| 171 |
+
|
| 172 |
+
def forward(self, inputs, last_pred, hidden, p):
|
| 173 |
+
h_in = self.emb(inputs)
|
| 174 |
+
pos_enc = self.positional_encoder(p).to(inputs.device).detach()
|
| 175 |
+
h_in = h_in + pos_enc
|
| 176 |
+
for i in range(self.n_layers):
|
| 177 |
+
# print(h_in.shape)
|
| 178 |
+
hidden[i] = self.gru[i](h_in, hidden[i])
|
| 179 |
+
h_in = hidden[i]
|
| 180 |
+
pose_pred = self.output(h_in)
|
| 181 |
+
# pose_pred = self.output(h_in) + last_pred.detach()
|
| 182 |
+
# contact = self.contact_net(pose_pred)
|
| 183 |
+
# return torch.cat([pose_pred, contact], dim=-1), hidden
|
| 184 |
+
return pose_pred, hidden
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
class TextDecoder(nn.Module):
|
| 188 |
+
def __init__(self, text_size, input_size, output_size, hidden_size, n_layers):
|
| 189 |
+
super(TextDecoder, self).__init__()
|
| 190 |
+
self.input_size = input_size
|
| 191 |
+
self.output_size = output_size
|
| 192 |
+
self.hidden_size = hidden_size
|
| 193 |
+
self.n_layers = n_layers
|
| 194 |
+
self.emb = nn.Sequential(
|
| 195 |
+
nn.Linear(input_size, hidden_size),
|
| 196 |
+
nn.LayerNorm(hidden_size),
|
| 197 |
+
nn.LeakyReLU(0.2, inplace=True))
|
| 198 |
+
|
| 199 |
+
self.gru = nn.ModuleList([nn.GRUCell(hidden_size, hidden_size) for i in range(self.n_layers)])
|
| 200 |
+
self.z2init = nn.Linear(text_size, hidden_size * n_layers)
|
| 201 |
+
self.positional_encoder = PositionalEncoding(hidden_size)
|
| 202 |
+
|
| 203 |
+
self.mu_net = nn.Linear(hidden_size, output_size)
|
| 204 |
+
self.logvar_net = nn.Linear(hidden_size, output_size)
|
| 205 |
+
|
| 206 |
+
self.emb.apply(init_weight)
|
| 207 |
+
self.z2init.apply(init_weight)
|
| 208 |
+
self.mu_net.apply(init_weight)
|
| 209 |
+
self.logvar_net.apply(init_weight)
|
| 210 |
+
|
| 211 |
+
def get_init_hidden(self, latent):
|
| 212 |
+
|
| 213 |
+
hidden = self.z2init(latent)
|
| 214 |
+
hidden = torch.split(hidden, self.hidden_size, dim=-1)
|
| 215 |
+
|
| 216 |
+
return list(hidden)
|
| 217 |
+
|
| 218 |
+
def forward(self, inputs, hidden, p):
|
| 219 |
+
# print(inputs.shape)
|
| 220 |
+
x_in = self.emb(inputs)
|
| 221 |
+
pos_enc = self.positional_encoder(p).to(inputs.device).detach()
|
| 222 |
+
x_in = x_in + pos_enc
|
| 223 |
+
|
| 224 |
+
for i in range(self.n_layers):
|
| 225 |
+
hidden[i] = self.gru[i](x_in, hidden[i])
|
| 226 |
+
h_in = hidden[i]
|
| 227 |
+
mu = self.mu_net(h_in)
|
| 228 |
+
logvar = self.logvar_net(h_in)
|
| 229 |
+
z = reparameterize(mu, logvar)
|
| 230 |
+
return z, mu, logvar, hidden
|
| 231 |
+
|
| 232 |
+
class AttLayer(nn.Module):
|
| 233 |
+
def __init__(self, query_dim, key_dim, value_dim):
|
| 234 |
+
super(AttLayer, self).__init__()
|
| 235 |
+
self.W_q = nn.Linear(query_dim, value_dim)
|
| 236 |
+
self.W_k = nn.Linear(key_dim, value_dim, bias=False)
|
| 237 |
+
self.W_v = nn.Linear(key_dim, value_dim)
|
| 238 |
+
|
| 239 |
+
self.softmax = nn.Softmax(dim=1)
|
| 240 |
+
self.dim = value_dim
|
| 241 |
+
|
| 242 |
+
self.W_q.apply(init_weight)
|
| 243 |
+
self.W_k.apply(init_weight)
|
| 244 |
+
self.W_v.apply(init_weight)
|
| 245 |
+
|
| 246 |
+
def forward(self, query, key_mat):
|
| 247 |
+
'''
|
| 248 |
+
query (batch, query_dim)
|
| 249 |
+
key (batch, seq_len, key_dim)
|
| 250 |
+
'''
|
| 251 |
+
# print(query.shape)
|
| 252 |
+
query_vec = self.W_q(query).unsqueeze(-1) # (batch, value_dim, 1)
|
| 253 |
+
val_set = self.W_v(key_mat) # (batch, seq_len, value_dim)
|
| 254 |
+
key_set = self.W_k(key_mat) # (batch, seq_len, value_dim)
|
| 255 |
+
|
| 256 |
+
weights = torch.matmul(key_set, query_vec) / np.sqrt(self.dim)
|
| 257 |
+
|
| 258 |
+
co_weights = self.softmax(weights) # (batch, seq_len, 1)
|
| 259 |
+
values = val_set * co_weights # (batch, seq_len, value_dim)
|
| 260 |
+
pred = values.sum(dim=1) # (batch, value_dim)
|
| 261 |
+
return pred, co_weights
|
| 262 |
+
|
| 263 |
+
def short_cut(self, querys, keys):
|
| 264 |
+
return self.W_q(querys), self.W_k(keys)
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
class TextEncoderBiGRU(nn.Module):
|
| 268 |
+
def __init__(self, word_size, pos_size, hidden_size, device):
|
| 269 |
+
super(TextEncoderBiGRU, self).__init__()
|
| 270 |
+
self.device = device
|
| 271 |
+
|
| 272 |
+
self.pos_emb = nn.Linear(pos_size, word_size)
|
| 273 |
+
self.input_emb = nn.Linear(word_size, hidden_size)
|
| 274 |
+
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True, bidirectional=True)
|
| 275 |
+
# self.linear2 = nn.Linear(hidden_size, output_size)
|
| 276 |
+
|
| 277 |
+
self.input_emb.apply(init_weight)
|
| 278 |
+
self.pos_emb.apply(init_weight)
|
| 279 |
+
# self.linear2.apply(init_weight)
|
| 280 |
+
# self.batch_size = batch_size
|
| 281 |
+
self.hidden_size = hidden_size
|
| 282 |
+
self.hidden = nn.Parameter(torch.randn((2, 1, self.hidden_size), requires_grad=True))
|
| 283 |
+
|
| 284 |
+
# input(batch_size, seq_len, dim)
|
| 285 |
+
def forward(self, word_embs, pos_onehot, cap_lens):
|
| 286 |
+
num_samples = word_embs.shape[0]
|
| 287 |
+
|
| 288 |
+
pos_embs = self.pos_emb(pos_onehot)
|
| 289 |
+
inputs = word_embs + pos_embs
|
| 290 |
+
input_embs = self.input_emb(inputs)
|
| 291 |
+
hidden = self.hidden.repeat(1, num_samples, 1)
|
| 292 |
+
|
| 293 |
+
cap_lens = cap_lens.data.tolist()
|
| 294 |
+
emb = pack_padded_sequence(input_embs, cap_lens, batch_first=True)
|
| 295 |
+
|
| 296 |
+
gru_seq, gru_last = self.gru(emb, hidden)
|
| 297 |
+
|
| 298 |
+
gru_last = torch.cat([gru_last[0], gru_last[1]], dim=-1)
|
| 299 |
+
gru_seq = pad_packed_sequence(gru_seq, batch_first=True)[0]
|
| 300 |
+
forward_seq = gru_seq[..., :self.hidden_size]
|
| 301 |
+
backward_seq = gru_seq[..., self.hidden_size:].clone()
|
| 302 |
+
|
| 303 |
+
# Concate the forward and backward word embeddings
|
| 304 |
+
for i, length in enumerate(cap_lens):
|
| 305 |
+
backward_seq[i:i+1, :length] = torch.flip(backward_seq[i:i+1, :length].clone(), dims=[1])
|
| 306 |
+
gru_seq = torch.cat([forward_seq, backward_seq], dim=-1)
|
| 307 |
+
|
| 308 |
+
return gru_seq, gru_last
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
class TextEncoderBiGRUCo(nn.Module):
|
| 312 |
+
def __init__(self, word_size, pos_size, hidden_size, output_size, device):
|
| 313 |
+
super(TextEncoderBiGRUCo, self).__init__()
|
| 314 |
+
self.device = device
|
| 315 |
+
|
| 316 |
+
self.pos_emb = nn.Linear(pos_size, word_size)
|
| 317 |
+
self.input_emb = nn.Linear(word_size, hidden_size)
|
| 318 |
+
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True, bidirectional=True)
|
| 319 |
+
self.output_net = nn.Sequential(
|
| 320 |
+
nn.Linear(hidden_size * 2, hidden_size),
|
| 321 |
+
nn.LayerNorm(hidden_size),
|
| 322 |
+
nn.LeakyReLU(0.2, inplace=True),
|
| 323 |
+
nn.Linear(hidden_size, output_size)
|
| 324 |
+
)
|
| 325 |
+
|
| 326 |
+
self.input_emb.apply(init_weight)
|
| 327 |
+
self.pos_emb.apply(init_weight)
|
| 328 |
+
self.output_net.apply(init_weight)
|
| 329 |
+
# self.linear2.apply(init_weight)
|
| 330 |
+
# self.batch_size = batch_size
|
| 331 |
+
self.hidden_size = hidden_size
|
| 332 |
+
self.hidden = nn.Parameter(torch.randn((2, 1, self.hidden_size), requires_grad=True))
|
| 333 |
+
|
| 334 |
+
# input(batch_size, seq_len, dim)
|
| 335 |
+
def forward(self, word_embs, pos_onehot, cap_lens):
|
| 336 |
+
num_samples = word_embs.shape[0]
|
| 337 |
+
|
| 338 |
+
pos_embs = self.pos_emb(pos_onehot)
|
| 339 |
+
inputs = word_embs + pos_embs
|
| 340 |
+
input_embs = self.input_emb(inputs)
|
| 341 |
+
hidden = self.hidden.repeat(1, num_samples, 1)
|
| 342 |
+
|
| 343 |
+
cap_lens = cap_lens.data.tolist()
|
| 344 |
+
emb = pack_padded_sequence(input_embs, cap_lens, batch_first=True)
|
| 345 |
+
|
| 346 |
+
gru_seq, gru_last = self.gru(emb, hidden)
|
| 347 |
+
|
| 348 |
+
gru_last = torch.cat([gru_last[0], gru_last[1]], dim=-1)
|
| 349 |
+
|
| 350 |
+
return self.output_net(gru_last)
|
| 351 |
+
|
| 352 |
+
|
| 353 |
+
class MotionEncoderBiGRUCo(nn.Module):
|
| 354 |
+
def __init__(self, input_size, hidden_size, output_size, device):
|
| 355 |
+
super(MotionEncoderBiGRUCo, self).__init__()
|
| 356 |
+
self.device = device
|
| 357 |
+
|
| 358 |
+
self.input_emb = nn.Linear(input_size, hidden_size)
|
| 359 |
+
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True, bidirectional=True)
|
| 360 |
+
self.output_net = nn.Sequential(
|
| 361 |
+
nn.Linear(hidden_size*2, hidden_size),
|
| 362 |
+
nn.LayerNorm(hidden_size),
|
| 363 |
+
nn.LeakyReLU(0.2, inplace=True),
|
| 364 |
+
nn.Linear(hidden_size, output_size)
|
| 365 |
+
)
|
| 366 |
+
|
| 367 |
+
self.input_emb.apply(init_weight)
|
| 368 |
+
self.output_net.apply(init_weight)
|
| 369 |
+
self.hidden_size = hidden_size
|
| 370 |
+
self.hidden = nn.Parameter(torch.randn((2, 1, self.hidden_size), requires_grad=True))
|
| 371 |
+
|
| 372 |
+
# input(batch_size, seq_len, dim)
|
| 373 |
+
def forward(self, inputs, m_lens):
|
| 374 |
+
num_samples = inputs.shape[0]
|
| 375 |
+
|
| 376 |
+
input_embs = self.input_emb(inputs)
|
| 377 |
+
hidden = self.hidden.repeat(1, num_samples, 1)
|
| 378 |
+
|
| 379 |
+
cap_lens = m_lens.data.tolist()
|
| 380 |
+
emb = pack_padded_sequence(input_embs, cap_lens, batch_first=True)
|
| 381 |
+
|
| 382 |
+
gru_seq, gru_last = self.gru(emb, hidden)
|
| 383 |
+
|
| 384 |
+
gru_last = torch.cat([gru_last[0], gru_last[1]], dim=-1)
|
| 385 |
+
|
| 386 |
+
return self.output_net(gru_last)
|
| 387 |
+
|
| 388 |
+
|
| 389 |
+
class MotionLenEstimatorBiGRU(nn.Module):
|
| 390 |
+
def __init__(self, word_size, pos_size, hidden_size, output_size):
|
| 391 |
+
super(MotionLenEstimatorBiGRU, self).__init__()
|
| 392 |
+
|
| 393 |
+
self.pos_emb = nn.Linear(pos_size, word_size)
|
| 394 |
+
self.input_emb = nn.Linear(word_size, hidden_size)
|
| 395 |
+
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True, bidirectional=True)
|
| 396 |
+
nd = 512
|
| 397 |
+
self.output = nn.Sequential(
|
| 398 |
+
nn.Linear(hidden_size*2, nd),
|
| 399 |
+
nn.LayerNorm(nd),
|
| 400 |
+
nn.LeakyReLU(0.2, inplace=True),
|
| 401 |
+
|
| 402 |
+
nn.Linear(nd, nd // 2),
|
| 403 |
+
nn.LayerNorm(nd // 2),
|
| 404 |
+
nn.LeakyReLU(0.2, inplace=True),
|
| 405 |
+
|
| 406 |
+
nn.Linear(nd // 2, nd // 4),
|
| 407 |
+
nn.LayerNorm(nd // 4),
|
| 408 |
+
nn.LeakyReLU(0.2, inplace=True),
|
| 409 |
+
|
| 410 |
+
nn.Linear(nd // 4, output_size)
|
| 411 |
+
)
|
| 412 |
+
# self.linear2 = nn.Linear(hidden_size, output_size)
|
| 413 |
+
|
| 414 |
+
self.input_emb.apply(init_weight)
|
| 415 |
+
self.pos_emb.apply(init_weight)
|
| 416 |
+
self.output.apply(init_weight)
|
| 417 |
+
# self.linear2.apply(init_weight)
|
| 418 |
+
# self.batch_size = batch_size
|
| 419 |
+
self.hidden_size = hidden_size
|
| 420 |
+
self.hidden = nn.Parameter(torch.randn((2, 1, self.hidden_size), requires_grad=True))
|
| 421 |
+
|
| 422 |
+
# input(batch_size, seq_len, dim)
|
| 423 |
+
def forward(self, word_embs, pos_onehot, cap_lens):
|
| 424 |
+
num_samples = word_embs.shape[0]
|
| 425 |
+
|
| 426 |
+
pos_embs = self.pos_emb(pos_onehot)
|
| 427 |
+
inputs = word_embs + pos_embs
|
| 428 |
+
input_embs = self.input_emb(inputs)
|
| 429 |
+
hidden = self.hidden.repeat(1, num_samples, 1)
|
| 430 |
+
|
| 431 |
+
cap_lens = cap_lens.data.tolist()
|
| 432 |
+
emb = pack_padded_sequence(input_embs, cap_lens, batch_first=True)
|
| 433 |
+
|
| 434 |
+
gru_seq, gru_last = self.gru(emb, hidden)
|
| 435 |
+
|
| 436 |
+
gru_last = torch.cat([gru_last[0], gru_last[1]], dim=-1)
|
| 437 |
+
|
| 438 |
+
return self.output(gru_last)
|
main/data_loaders/humanml/networks/trainers.py
ADDED
|
@@ -0,0 +1,1089 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
import random
|
| 4 |
+
from data_loaders.humanml.networks.modules import *
|
| 5 |
+
from torch.utils.data import DataLoader
|
| 6 |
+
import torch.optim as optim
|
| 7 |
+
from torch.nn.utils import clip_grad_norm_
|
| 8 |
+
# import tensorflow as tf
|
| 9 |
+
from collections import OrderedDict
|
| 10 |
+
from data_loaders.humanml.utils.utils import *
|
| 11 |
+
from os.path import join as pjoin
|
| 12 |
+
from data_loaders.humanml.data.dataset import collate_fn
|
| 13 |
+
import codecs as cs
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class Logger(object):
|
| 17 |
+
def __init__(self, log_dir):
|
| 18 |
+
self.writer = tf.summary.create_file_writer(log_dir)
|
| 19 |
+
|
| 20 |
+
def scalar_summary(self, tag, value, step):
|
| 21 |
+
with self.writer.as_default():
|
| 22 |
+
tf.summary.scalar(tag, value, step=step)
|
| 23 |
+
self.writer.flush()
|
| 24 |
+
|
| 25 |
+
class DecompTrainerV3(object):
|
| 26 |
+
def __init__(self, args, movement_enc, movement_dec):
|
| 27 |
+
self.opt = args
|
| 28 |
+
self.movement_enc = movement_enc
|
| 29 |
+
self.movement_dec = movement_dec
|
| 30 |
+
self.device = args.device
|
| 31 |
+
|
| 32 |
+
if args.is_train:
|
| 33 |
+
self.logger = Logger(args.log_dir)
|
| 34 |
+
self.sml1_criterion = torch.nn.SmoothL1Loss()
|
| 35 |
+
self.l1_criterion = torch.nn.L1Loss()
|
| 36 |
+
self.mse_criterion = torch.nn.MSELoss()
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
@staticmethod
|
| 40 |
+
def zero_grad(opt_list):
|
| 41 |
+
for opt in opt_list:
|
| 42 |
+
opt.zero_grad()
|
| 43 |
+
|
| 44 |
+
@staticmethod
|
| 45 |
+
def clip_norm(network_list):
|
| 46 |
+
for network in network_list:
|
| 47 |
+
clip_grad_norm_(network.parameters(), 0.5)
|
| 48 |
+
|
| 49 |
+
@staticmethod
|
| 50 |
+
def step(opt_list):
|
| 51 |
+
for opt in opt_list:
|
| 52 |
+
opt.step()
|
| 53 |
+
|
| 54 |
+
def forward(self, batch_data):
|
| 55 |
+
motions = batch_data
|
| 56 |
+
self.motions = motions.detach().to(self.device).float()
|
| 57 |
+
self.latents = self.movement_enc(self.motions[..., :-4])
|
| 58 |
+
self.recon_motions = self.movement_dec(self.latents)
|
| 59 |
+
|
| 60 |
+
def backward(self):
|
| 61 |
+
self.loss_rec = self.l1_criterion(self.recon_motions, self.motions)
|
| 62 |
+
# self.sml1_criterion(self.recon_motions[:, 1:] - self.recon_motions[:, :-1],
|
| 63 |
+
# self.motions[:, 1:] - self.recon_motions[:, :-1])
|
| 64 |
+
self.loss_sparsity = torch.mean(torch.abs(self.latents))
|
| 65 |
+
self.loss_smooth = self.l1_criterion(self.latents[:, 1:], self.latents[:, :-1])
|
| 66 |
+
self.loss = self.loss_rec + self.loss_sparsity * self.opt.lambda_sparsity +\
|
| 67 |
+
self.loss_smooth*self.opt.lambda_smooth
|
| 68 |
+
|
| 69 |
+
def update(self):
|
| 70 |
+
# time0 = time.time()
|
| 71 |
+
self.zero_grad([self.opt_movement_enc, self.opt_movement_dec])
|
| 72 |
+
# time1 = time.time()
|
| 73 |
+
# print('\t Zero_grad Time: %.5f s' % (time1 - time0))
|
| 74 |
+
self.backward()
|
| 75 |
+
# time2 = time.time()
|
| 76 |
+
# print('\t Backward Time: %.5f s' % (time2 - time1))
|
| 77 |
+
self.loss.backward()
|
| 78 |
+
# time3 = time.time()
|
| 79 |
+
# print('\t Loss backward Time: %.5f s' % (time3 - time2))
|
| 80 |
+
# self.clip_norm([self.movement_enc, self.movement_dec])
|
| 81 |
+
# time4 = time.time()
|
| 82 |
+
# print('\t Clip_norm Time: %.5f s' % (time4 - time3))
|
| 83 |
+
self.step([self.opt_movement_enc, self.opt_movement_dec])
|
| 84 |
+
# time5 = time.time()
|
| 85 |
+
# print('\t Step Time: %.5f s' % (time5 - time4))
|
| 86 |
+
|
| 87 |
+
loss_logs = OrderedDict({})
|
| 88 |
+
loss_logs['loss'] = self.loss_rec.item()
|
| 89 |
+
loss_logs['loss_rec'] = self.loss_rec.item()
|
| 90 |
+
loss_logs['loss_sparsity'] = self.loss_sparsity.item()
|
| 91 |
+
loss_logs['loss_smooth'] = self.loss_smooth.item()
|
| 92 |
+
return loss_logs
|
| 93 |
+
|
| 94 |
+
def save(self, file_name, ep, total_it):
|
| 95 |
+
state = {
|
| 96 |
+
'movement_enc': self.movement_enc.state_dict(),
|
| 97 |
+
'movement_dec': self.movement_dec.state_dict(),
|
| 98 |
+
|
| 99 |
+
'opt_movement_enc': self.opt_movement_enc.state_dict(),
|
| 100 |
+
'opt_movement_dec': self.opt_movement_dec.state_dict(),
|
| 101 |
+
|
| 102 |
+
'ep': ep,
|
| 103 |
+
'total_it': total_it,
|
| 104 |
+
}
|
| 105 |
+
torch.save(state, file_name)
|
| 106 |
+
return
|
| 107 |
+
|
| 108 |
+
def resume(self, model_dir):
|
| 109 |
+
checkpoint = torch.load(model_dir, map_location=self.device)
|
| 110 |
+
|
| 111 |
+
self.movement_dec.load_state_dict(checkpoint['movement_dec'])
|
| 112 |
+
self.movement_enc.load_state_dict(checkpoint['movement_enc'])
|
| 113 |
+
|
| 114 |
+
self.opt_movement_enc.load_state_dict(checkpoint['opt_movement_enc'])
|
| 115 |
+
self.opt_movement_dec.load_state_dict(checkpoint['opt_movement_dec'])
|
| 116 |
+
|
| 117 |
+
return checkpoint['ep'], checkpoint['total_it']
|
| 118 |
+
|
| 119 |
+
def train(self, train_dataloader, val_dataloader, plot_eval):
|
| 120 |
+
self.movement_enc.to(self.device)
|
| 121 |
+
self.movement_dec.to(self.device)
|
| 122 |
+
|
| 123 |
+
self.opt_movement_enc = optim.Adam(self.movement_enc.parameters(), lr=self.opt.lr)
|
| 124 |
+
self.opt_movement_dec = optim.Adam(self.movement_dec.parameters(), lr=self.opt.lr)
|
| 125 |
+
|
| 126 |
+
epoch = 0
|
| 127 |
+
it = 0
|
| 128 |
+
|
| 129 |
+
if self.opt.is_continue:
|
| 130 |
+
model_dir = pjoin(self.opt.model_dir, 'latest.tar')
|
| 131 |
+
epoch, it = self.resume(model_dir)
|
| 132 |
+
|
| 133 |
+
start_time = time.time()
|
| 134 |
+
total_iters = self.opt.max_epoch * len(train_dataloader)
|
| 135 |
+
print('Iters Per Epoch, Training: %04d, Validation: %03d' % (len(train_dataloader), len(val_dataloader)))
|
| 136 |
+
val_loss = 0
|
| 137 |
+
logs = OrderedDict()
|
| 138 |
+
while epoch < self.opt.max_epoch:
|
| 139 |
+
# time0 = time.time()
|
| 140 |
+
for i, batch_data in enumerate(train_dataloader):
|
| 141 |
+
self.movement_dec.train()
|
| 142 |
+
self.movement_enc.train()
|
| 143 |
+
|
| 144 |
+
# time1 = time.time()
|
| 145 |
+
# print('DataLoader Time: %.5f s'%(time1-time0) )
|
| 146 |
+
self.forward(batch_data)
|
| 147 |
+
# time2 = time.time()
|
| 148 |
+
# print('Forward Time: %.5f s'%(time2-time1))
|
| 149 |
+
log_dict = self.update()
|
| 150 |
+
# time3 = time.time()
|
| 151 |
+
# print('Update Time: %.5f s' % (time3 - time2))
|
| 152 |
+
# time0 = time3
|
| 153 |
+
for k, v in log_dict.items():
|
| 154 |
+
if k not in logs:
|
| 155 |
+
logs[k] = v
|
| 156 |
+
else:
|
| 157 |
+
logs[k] += v
|
| 158 |
+
|
| 159 |
+
it += 1
|
| 160 |
+
if it % self.opt.log_every == 0:
|
| 161 |
+
mean_loss = OrderedDict({'val_loss': val_loss})
|
| 162 |
+
self.logger.scalar_summary('val_loss', val_loss, it)
|
| 163 |
+
|
| 164 |
+
for tag, value in logs.items():
|
| 165 |
+
self.logger.scalar_summary(tag, value / self.opt.log_every, it)
|
| 166 |
+
mean_loss[tag] = value / self.opt.log_every
|
| 167 |
+
logs = OrderedDict()
|
| 168 |
+
print_current_loss_decomp(start_time, it, total_iters, mean_loss, epoch, i)
|
| 169 |
+
|
| 170 |
+
if it % self.opt.save_latest == 0:
|
| 171 |
+
self.save(pjoin(self.opt.model_dir, 'latest.tar'), epoch, it)
|
| 172 |
+
|
| 173 |
+
self.save(pjoin(self.opt.model_dir, 'latest.tar'), epoch, it)
|
| 174 |
+
|
| 175 |
+
epoch += 1
|
| 176 |
+
if epoch % self.opt.save_every_e == 0:
|
| 177 |
+
self.save(pjoin(self.opt.model_dir, 'E%04d.tar' % (epoch)), epoch, total_it=it)
|
| 178 |
+
|
| 179 |
+
print('Validation time:')
|
| 180 |
+
|
| 181 |
+
val_loss = 0
|
| 182 |
+
val_rec_loss = 0
|
| 183 |
+
val_sparcity_loss = 0
|
| 184 |
+
val_smooth_loss = 0
|
| 185 |
+
with torch.no_grad():
|
| 186 |
+
for i, batch_data in enumerate(val_dataloader):
|
| 187 |
+
self.forward(batch_data)
|
| 188 |
+
self.backward()
|
| 189 |
+
val_rec_loss += self.loss_rec.item()
|
| 190 |
+
val_smooth_loss += self.loss.item()
|
| 191 |
+
val_sparcity_loss += self.loss_sparsity.item()
|
| 192 |
+
val_smooth_loss += self.loss_smooth.item()
|
| 193 |
+
val_loss += self.loss.item()
|
| 194 |
+
|
| 195 |
+
val_loss = val_loss / (len(val_dataloader) + 1)
|
| 196 |
+
val_rec_loss = val_rec_loss / (len(val_dataloader) + 1)
|
| 197 |
+
val_sparcity_loss = val_sparcity_loss / (len(val_dataloader) + 1)
|
| 198 |
+
val_smooth_loss = val_smooth_loss / (len(val_dataloader) + 1)
|
| 199 |
+
print('Validation Loss: %.5f Reconstruction Loss: %.5f '
|
| 200 |
+
'Sparsity Loss: %.5f Smooth Loss: %.5f' % (val_loss, val_rec_loss, val_sparcity_loss, \
|
| 201 |
+
val_smooth_loss))
|
| 202 |
+
|
| 203 |
+
if epoch % self.opt.eval_every_e == 0:
|
| 204 |
+
data = torch.cat([self.recon_motions[:4], self.motions[:4]], dim=0).detach().cpu().numpy()
|
| 205 |
+
save_dir = pjoin(self.opt.eval_dir, 'E%04d' % (epoch))
|
| 206 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 207 |
+
plot_eval(data, save_dir)
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
# VAE Sequence Decoder/Prior/Posterior latent by latent
|
| 211 |
+
class CompTrainerV6(object):
|
| 212 |
+
|
| 213 |
+
def __init__(self, args, text_enc, seq_pri, seq_dec, att_layer, mov_dec, mov_enc=None, seq_post=None):
|
| 214 |
+
self.opt = args
|
| 215 |
+
self.text_enc = text_enc
|
| 216 |
+
self.seq_pri = seq_pri
|
| 217 |
+
self.att_layer = att_layer
|
| 218 |
+
self.device = args.device
|
| 219 |
+
self.seq_dec = seq_dec
|
| 220 |
+
self.mov_dec = mov_dec
|
| 221 |
+
self.mov_enc = mov_enc
|
| 222 |
+
|
| 223 |
+
if args.is_train:
|
| 224 |
+
self.seq_post = seq_post
|
| 225 |
+
# self.motion_dis
|
| 226 |
+
self.logger = Logger(args.log_dir)
|
| 227 |
+
self.l1_criterion = torch.nn.SmoothL1Loss()
|
| 228 |
+
self.gan_criterion = torch.nn.BCEWithLogitsLoss()
|
| 229 |
+
self.mse_criterion = torch.nn.MSELoss()
|
| 230 |
+
|
| 231 |
+
@staticmethod
|
| 232 |
+
def reparametrize(mu, logvar):
|
| 233 |
+
s_var = logvar.mul(0.5).exp_()
|
| 234 |
+
eps = s_var.data.new(s_var.size()).normal_()
|
| 235 |
+
return eps.mul(s_var).add_(mu)
|
| 236 |
+
|
| 237 |
+
@staticmethod
|
| 238 |
+
def ones_like(tensor, val=1.):
|
| 239 |
+
return torch.FloatTensor(tensor.size()).fill_(val).to(tensor.device).requires_grad_(False)
|
| 240 |
+
|
| 241 |
+
@staticmethod
|
| 242 |
+
def zeros_like(tensor, val=0.):
|
| 243 |
+
return torch.FloatTensor(tensor.size()).fill_(val).to(tensor.device).requires_grad_(False)
|
| 244 |
+
|
| 245 |
+
@staticmethod
|
| 246 |
+
def zero_grad(opt_list):
|
| 247 |
+
for opt in opt_list:
|
| 248 |
+
opt.zero_grad()
|
| 249 |
+
|
| 250 |
+
@staticmethod
|
| 251 |
+
def clip_norm(network_list):
|
| 252 |
+
for network in network_list:
|
| 253 |
+
clip_grad_norm_(network.parameters(), 0.5)
|
| 254 |
+
|
| 255 |
+
@staticmethod
|
| 256 |
+
def step(opt_list):
|
| 257 |
+
for opt in opt_list:
|
| 258 |
+
opt.step()
|
| 259 |
+
|
| 260 |
+
@staticmethod
|
| 261 |
+
def kl_criterion(mu1, logvar1, mu2, logvar2):
|
| 262 |
+
# KL( N(mu1, sigma2_1) || N(mu_2, sigma2_2))
|
| 263 |
+
# loss = log(sigma2/sigma1) + (sigma1^2 + (mu1 - mu2)^2)/(2*sigma2^2) - 1/2
|
| 264 |
+
sigma1 = logvar1.mul(0.5).exp()
|
| 265 |
+
sigma2 = logvar2.mul(0.5).exp()
|
| 266 |
+
kld = torch.log(sigma2 / sigma1) + (torch.exp(logvar1) + (mu1 - mu2) ** 2) / (
|
| 267 |
+
2 * torch.exp(logvar2)) - 1 / 2
|
| 268 |
+
return kld.sum() / mu1.shape[0]
|
| 269 |
+
|
| 270 |
+
@staticmethod
|
| 271 |
+
def kl_criterion_unit(mu, logvar):
|
| 272 |
+
# KL( N(mu1, sigma2_1) || N(mu_2, sigma2_2))
|
| 273 |
+
# loss = log(sigma2/sigma1) + (sigma1^2 + (mu1 - mu2)^2)/(2*sigma2^2) - 1/2
|
| 274 |
+
kld = ((torch.exp(logvar) + mu ** 2) - logvar - 1) / 2
|
| 275 |
+
return kld.sum() / mu.shape[0]
|
| 276 |
+
|
| 277 |
+
def forward(self, batch_data, tf_ratio, mov_len, eval_mode=False):
|
| 278 |
+
word_emb, pos_ohot, caption, cap_lens, motions, m_lens = batch_data
|
| 279 |
+
word_emb = word_emb.detach().to(self.device).float()
|
| 280 |
+
pos_ohot = pos_ohot.detach().to(self.device).float()
|
| 281 |
+
motions = motions.detach().to(self.device).float()
|
| 282 |
+
self.cap_lens = cap_lens
|
| 283 |
+
self.caption = caption
|
| 284 |
+
|
| 285 |
+
# print(motions.shape)
|
| 286 |
+
# (batch_size, motion_len, pose_dim)
|
| 287 |
+
self.motions = motions
|
| 288 |
+
|
| 289 |
+
'''Movement Encoding'''
|
| 290 |
+
self.movements = self.mov_enc(self.motions[..., :-4]).detach()
|
| 291 |
+
# Initially input a mean vector
|
| 292 |
+
mov_in = self.mov_enc(
|
| 293 |
+
torch.zeros((self.motions.shape[0], self.opt.unit_length, self.motions.shape[-1] - 4), device=self.device)
|
| 294 |
+
).squeeze(1).detach()
|
| 295 |
+
assert self.movements.shape[1] == mov_len
|
| 296 |
+
|
| 297 |
+
teacher_force = True if random.random() < tf_ratio else False
|
| 298 |
+
|
| 299 |
+
'''Text Encoding'''
|
| 300 |
+
# time0 = time.time()
|
| 301 |
+
# text_input = torch.cat([word_emb, pos_ohot], dim=-1)
|
| 302 |
+
word_hids, hidden = self.text_enc(word_emb, pos_ohot, cap_lens)
|
| 303 |
+
# print(word_hids.shape, hidden.shape)
|
| 304 |
+
|
| 305 |
+
if self.opt.text_enc_mod == 'bigru':
|
| 306 |
+
hidden_pos = self.seq_post.get_init_hidden(hidden)
|
| 307 |
+
hidden_pri = self.seq_pri.get_init_hidden(hidden)
|
| 308 |
+
hidden_dec = self.seq_dec.get_init_hidden(hidden)
|
| 309 |
+
elif self.opt.text_enc_mod == 'transformer':
|
| 310 |
+
hidden_pos = self.seq_post.get_init_hidden(hidden.detach())
|
| 311 |
+
hidden_pri = self.seq_pri.get_init_hidden(hidden.detach())
|
| 312 |
+
hidden_dec = self.seq_dec.get_init_hidden(hidden)
|
| 313 |
+
|
| 314 |
+
mus_pri = []
|
| 315 |
+
logvars_pri = []
|
| 316 |
+
mus_post = []
|
| 317 |
+
logvars_post = []
|
| 318 |
+
fake_mov_batch = []
|
| 319 |
+
|
| 320 |
+
query_input = []
|
| 321 |
+
|
| 322 |
+
# time1 = time.time()
|
| 323 |
+
# print("\t Text Encoder Cost:%5f" % (time1 - time0))
|
| 324 |
+
# print(self.movements.shape)
|
| 325 |
+
|
| 326 |
+
for i in range(mov_len):
|
| 327 |
+
# print("\t Sequence Measure")
|
| 328 |
+
# print(mov_in.shape)
|
| 329 |
+
mov_tgt = self.movements[:, i]
|
| 330 |
+
'''Local Attention Vector'''
|
| 331 |
+
att_vec, _ = self.att_layer(hidden_dec[-1], word_hids)
|
| 332 |
+
query_input.append(hidden_dec[-1])
|
| 333 |
+
|
| 334 |
+
tta = m_lens // self.opt.unit_length - i
|
| 335 |
+
|
| 336 |
+
if self.opt.text_enc_mod == 'bigru':
|
| 337 |
+
pos_in = torch.cat([mov_in, mov_tgt, att_vec], dim=-1)
|
| 338 |
+
pri_in = torch.cat([mov_in, att_vec], dim=-1)
|
| 339 |
+
|
| 340 |
+
elif self.opt.text_enc_mod == 'transformer':
|
| 341 |
+
pos_in = torch.cat([mov_in, mov_tgt, att_vec.detach()], dim=-1)
|
| 342 |
+
pri_in = torch.cat([mov_in, att_vec.detach()], dim=-1)
|
| 343 |
+
|
| 344 |
+
'''Posterior'''
|
| 345 |
+
z_pos, mu_pos, logvar_pos, hidden_pos = self.seq_post(pos_in, hidden_pos, tta)
|
| 346 |
+
|
| 347 |
+
'''Prior'''
|
| 348 |
+
z_pri, mu_pri, logvar_pri, hidden_pri = self.seq_pri(pri_in, hidden_pri, tta)
|
| 349 |
+
|
| 350 |
+
'''Decoder'''
|
| 351 |
+
if eval_mode:
|
| 352 |
+
dec_in = torch.cat([mov_in, att_vec, z_pri], dim=-1)
|
| 353 |
+
else:
|
| 354 |
+
dec_in = torch.cat([mov_in, att_vec, z_pos], dim=-1)
|
| 355 |
+
fake_mov, hidden_dec = self.seq_dec(dec_in, mov_in, hidden_dec, tta)
|
| 356 |
+
|
| 357 |
+
# print(fake_mov.shape)
|
| 358 |
+
|
| 359 |
+
mus_post.append(mu_pos)
|
| 360 |
+
logvars_post.append(logvar_pos)
|
| 361 |
+
mus_pri.append(mu_pri)
|
| 362 |
+
logvars_pri.append(logvar_pri)
|
| 363 |
+
fake_mov_batch.append(fake_mov.unsqueeze(1))
|
| 364 |
+
|
| 365 |
+
if teacher_force:
|
| 366 |
+
mov_in = self.movements[:, i].detach()
|
| 367 |
+
else:
|
| 368 |
+
mov_in = fake_mov.detach()
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
self.fake_movements = torch.cat(fake_mov_batch, dim=1)
|
| 372 |
+
|
| 373 |
+
# print(self.fake_movements.shape)
|
| 374 |
+
|
| 375 |
+
self.fake_motions = self.mov_dec(self.fake_movements)
|
| 376 |
+
|
| 377 |
+
self.mus_post = torch.cat(mus_post, dim=0)
|
| 378 |
+
self.mus_pri = torch.cat(mus_pri, dim=0)
|
| 379 |
+
self.logvars_post = torch.cat(logvars_post, dim=0)
|
| 380 |
+
self.logvars_pri = torch.cat(logvars_pri, dim=0)
|
| 381 |
+
|
| 382 |
+
def generate(self, word_emb, pos_ohot, cap_lens, m_lens, mov_len, dim_pose):
|
| 383 |
+
word_emb = word_emb.detach().to(self.device).float()
|
| 384 |
+
pos_ohot = pos_ohot.detach().to(self.device).float()
|
| 385 |
+
self.cap_lens = cap_lens
|
| 386 |
+
|
| 387 |
+
# print(motions.shape)
|
| 388 |
+
# (batch_size, motion_len, pose_dim)
|
| 389 |
+
|
| 390 |
+
'''Movement Encoding'''
|
| 391 |
+
# Initially input a mean vector
|
| 392 |
+
mov_in = self.mov_enc(
|
| 393 |
+
torch.zeros((word_emb.shape[0], self.opt.unit_length, dim_pose - 4), device=self.device)
|
| 394 |
+
).squeeze(1).detach()
|
| 395 |
+
|
| 396 |
+
'''Text Encoding'''
|
| 397 |
+
# time0 = time.time()
|
| 398 |
+
# text_input = torch.cat([word_emb, pos_ohot], dim=-1)
|
| 399 |
+
word_hids, hidden = self.text_enc(word_emb, pos_ohot, cap_lens)
|
| 400 |
+
# print(word_hids.shape, hidden.shape)
|
| 401 |
+
|
| 402 |
+
hidden_pri = self.seq_pri.get_init_hidden(hidden)
|
| 403 |
+
hidden_dec = self.seq_dec.get_init_hidden(hidden)
|
| 404 |
+
|
| 405 |
+
mus_pri = []
|
| 406 |
+
logvars_pri = []
|
| 407 |
+
fake_mov_batch = []
|
| 408 |
+
att_wgt = []
|
| 409 |
+
|
| 410 |
+
# time1 = time.time()
|
| 411 |
+
# print("\t Text Encoder Cost:%5f" % (time1 - time0))
|
| 412 |
+
# print(self.movements.shape)
|
| 413 |
+
|
| 414 |
+
for i in range(mov_len):
|
| 415 |
+
# print("\t Sequence Measure")
|
| 416 |
+
# print(mov_in.shape)
|
| 417 |
+
'''Local Attention Vector'''
|
| 418 |
+
att_vec, co_weights = self.att_layer(hidden_dec[-1], word_hids)
|
| 419 |
+
|
| 420 |
+
tta = m_lens // self.opt.unit_length - i
|
| 421 |
+
# tta = m_lens - i
|
| 422 |
+
|
| 423 |
+
'''Prior'''
|
| 424 |
+
pri_in = torch.cat([mov_in, att_vec], dim=-1)
|
| 425 |
+
z_pri, mu_pri, logvar_pri, hidden_pri = self.seq_pri(pri_in, hidden_pri, tta)
|
| 426 |
+
|
| 427 |
+
'''Decoder'''
|
| 428 |
+
dec_in = torch.cat([mov_in, att_vec, z_pri], dim=-1)
|
| 429 |
+
|
| 430 |
+
fake_mov, hidden_dec = self.seq_dec(dec_in, mov_in, hidden_dec, tta)
|
| 431 |
+
|
| 432 |
+
# print(fake_mov.shape)
|
| 433 |
+
mus_pri.append(mu_pri)
|
| 434 |
+
logvars_pri.append(logvar_pri)
|
| 435 |
+
fake_mov_batch.append(fake_mov.unsqueeze(1))
|
| 436 |
+
att_wgt.append(co_weights)
|
| 437 |
+
|
| 438 |
+
mov_in = fake_mov.detach()
|
| 439 |
+
|
| 440 |
+
fake_movements = torch.cat(fake_mov_batch, dim=1)
|
| 441 |
+
att_wgts = torch.cat(att_wgt, dim=-1)
|
| 442 |
+
|
| 443 |
+
# print(self.fake_movements.shape)
|
| 444 |
+
|
| 445 |
+
fake_motions = self.mov_dec(fake_movements)
|
| 446 |
+
|
| 447 |
+
mus_pri = torch.cat(mus_pri, dim=0)
|
| 448 |
+
logvars_pri = torch.cat(logvars_pri, dim=0)
|
| 449 |
+
|
| 450 |
+
return fake_motions, mus_pri, att_wgts
|
| 451 |
+
|
| 452 |
+
def backward_G(self):
|
| 453 |
+
self.loss_mot_rec = self.l1_criterion(self.fake_motions, self.motions)
|
| 454 |
+
self.loss_mov_rec = self.l1_criterion(self.fake_movements, self.movements)
|
| 455 |
+
|
| 456 |
+
self.loss_kld = self.kl_criterion(self.mus_post, self.logvars_post, self.mus_pri, self.logvars_pri)
|
| 457 |
+
|
| 458 |
+
self.loss_gen = self.loss_mot_rec * self.opt.lambda_rec_mov + self.loss_mov_rec * self.opt.lambda_rec_mot + \
|
| 459 |
+
self.loss_kld * self.opt.lambda_kld
|
| 460 |
+
loss_logs = OrderedDict({})
|
| 461 |
+
loss_logs['loss_gen'] = self.loss_gen.item()
|
| 462 |
+
loss_logs['loss_mot_rec'] = self.loss_mot_rec.item()
|
| 463 |
+
loss_logs['loss_mov_rec'] = self.loss_mov_rec.item()
|
| 464 |
+
loss_logs['loss_kld'] = self.loss_kld.item()
|
| 465 |
+
|
| 466 |
+
return loss_logs
|
| 467 |
+
# self.loss_gen = self.loss_rec_mov
|
| 468 |
+
|
| 469 |
+
# self.loss_gen = self.loss_rec_mov * self.opt.lambda_rec_mov + self.loss_rec_mot + \
|
| 470 |
+
# self.loss_kld * self.opt.lambda_kld + \
|
| 471 |
+
# self.loss_mtgan_G * self.opt.lambda_gan_mt + self.loss_mvgan_G * self.opt.lambda_gan_mv
|
| 472 |
+
|
| 473 |
+
|
| 474 |
+
def update(self):
|
| 475 |
+
|
| 476 |
+
self.zero_grad([self.opt_text_enc, self.opt_seq_dec, self.opt_seq_post,
|
| 477 |
+
self.opt_seq_pri, self.opt_att_layer, self.opt_mov_dec])
|
| 478 |
+
# time2_0 = time.time()
|
| 479 |
+
# print("\t\t Zero Grad:%5f" % (time2_0 - time1))
|
| 480 |
+
loss_logs = self.backward_G()
|
| 481 |
+
|
| 482 |
+
# time2_1 = time.time()
|
| 483 |
+
# print("\t\t Backward_G :%5f" % (time2_1 - time2_0))
|
| 484 |
+
self.loss_gen.backward()
|
| 485 |
+
|
| 486 |
+
# time2_2 = time.time()
|
| 487 |
+
# print("\t\t Backward :%5f" % (time2_2 - time2_1))
|
| 488 |
+
self.clip_norm([self.text_enc, self.seq_dec, self.seq_post, self.seq_pri,
|
| 489 |
+
self.att_layer, self.mov_dec])
|
| 490 |
+
|
| 491 |
+
# time2_3 = time.time()
|
| 492 |
+
# print("\t\t Clip Norm :%5f" % (time2_3 - time2_2))
|
| 493 |
+
self.step([self.opt_text_enc, self.opt_seq_dec, self.opt_seq_post,
|
| 494 |
+
self.opt_seq_pri, self.opt_att_layer, self.opt_mov_dec])
|
| 495 |
+
|
| 496 |
+
# time2_4 = time.time()
|
| 497 |
+
# print("\t\t Step :%5f" % (time2_4 - time2_3))
|
| 498 |
+
|
| 499 |
+
# time2 = time.time()
|
| 500 |
+
# print("\t Update Generator Cost:%5f" % (time2 - time1))
|
| 501 |
+
|
| 502 |
+
# self.zero_grad([self.opt_att_layer])
|
| 503 |
+
# self.backward_Att()
|
| 504 |
+
# self.loss_lgan_G_.backward()
|
| 505 |
+
# self.clip_norm([self.att_layer])
|
| 506 |
+
# self.step([self.opt_att_layer])
|
| 507 |
+
# # time3 = time.time()
|
| 508 |
+
# # print("\t Update Att Cost:%5f" % (time3 - time2))
|
| 509 |
+
|
| 510 |
+
# self.loss_gen += self.loss_lgan_G_
|
| 511 |
+
|
| 512 |
+
return loss_logs
|
| 513 |
+
|
| 514 |
+
def to(self, device):
|
| 515 |
+
if self.opt.is_train:
|
| 516 |
+
self.gan_criterion.to(device)
|
| 517 |
+
self.mse_criterion.to(device)
|
| 518 |
+
self.l1_criterion.to(device)
|
| 519 |
+
self.seq_post.to(device)
|
| 520 |
+
self.mov_enc.to(device)
|
| 521 |
+
self.text_enc.to(device)
|
| 522 |
+
self.mov_dec.to(device)
|
| 523 |
+
self.seq_pri.to(device)
|
| 524 |
+
self.att_layer.to(device)
|
| 525 |
+
self.seq_dec.to(device)
|
| 526 |
+
|
| 527 |
+
def train_mode(self):
|
| 528 |
+
if self.opt.is_train:
|
| 529 |
+
self.seq_post.train()
|
| 530 |
+
self.mov_enc.eval()
|
| 531 |
+
# self.motion_dis.train()
|
| 532 |
+
# self.movement_dis.train()
|
| 533 |
+
self.mov_dec.train()
|
| 534 |
+
self.text_enc.train()
|
| 535 |
+
self.seq_pri.train()
|
| 536 |
+
self.att_layer.train()
|
| 537 |
+
self.seq_dec.train()
|
| 538 |
+
|
| 539 |
+
|
| 540 |
+
def eval_mode(self):
|
| 541 |
+
if self.opt.is_train:
|
| 542 |
+
self.seq_post.eval()
|
| 543 |
+
self.mov_enc.eval()
|
| 544 |
+
# self.motion_dis.train()
|
| 545 |
+
# self.movement_dis.train()
|
| 546 |
+
self.mov_dec.eval()
|
| 547 |
+
self.text_enc.eval()
|
| 548 |
+
self.seq_pri.eval()
|
| 549 |
+
self.att_layer.eval()
|
| 550 |
+
self.seq_dec.eval()
|
| 551 |
+
|
| 552 |
+
|
| 553 |
+
def save(self, file_name, ep, total_it, sub_ep, sl_len):
|
| 554 |
+
state = {
|
| 555 |
+
# 'latent_dis': self.latent_dis.state_dict(),
|
| 556 |
+
# 'motion_dis': self.motion_dis.state_dict(),
|
| 557 |
+
'text_enc': self.text_enc.state_dict(),
|
| 558 |
+
'seq_post': self.seq_post.state_dict(),
|
| 559 |
+
'att_layer': self.att_layer.state_dict(),
|
| 560 |
+
'seq_dec': self.seq_dec.state_dict(),
|
| 561 |
+
'seq_pri': self.seq_pri.state_dict(),
|
| 562 |
+
'mov_enc': self.mov_enc.state_dict(),
|
| 563 |
+
'mov_dec': self.mov_dec.state_dict(),
|
| 564 |
+
|
| 565 |
+
# 'opt_motion_dis': self.opt_motion_dis.state_dict(),
|
| 566 |
+
'opt_mov_dec': self.opt_mov_dec.state_dict(),
|
| 567 |
+
'opt_text_enc': self.opt_text_enc.state_dict(),
|
| 568 |
+
'opt_seq_pri': self.opt_seq_pri.state_dict(),
|
| 569 |
+
'opt_att_layer': self.opt_att_layer.state_dict(),
|
| 570 |
+
'opt_seq_post': self.opt_seq_post.state_dict(),
|
| 571 |
+
'opt_seq_dec': self.opt_seq_dec.state_dict(),
|
| 572 |
+
# 'opt_movement_dis': self.opt_movement_dis.state_dict(),
|
| 573 |
+
|
| 574 |
+
'ep': ep,
|
| 575 |
+
'total_it': total_it,
|
| 576 |
+
'sub_ep': sub_ep,
|
| 577 |
+
'sl_len': sl_len
|
| 578 |
+
}
|
| 579 |
+
torch.save(state, file_name)
|
| 580 |
+
return
|
| 581 |
+
|
| 582 |
+
def load(self, model_dir):
|
| 583 |
+
checkpoint = torch.load(model_dir, map_location=self.device)
|
| 584 |
+
if self.opt.is_train:
|
| 585 |
+
self.seq_post.load_state_dict(checkpoint['seq_post'])
|
| 586 |
+
# self.opt_latent_dis.load_state_dict(checkpoint['opt_latent_dis'])
|
| 587 |
+
|
| 588 |
+
self.opt_text_enc.load_state_dict(checkpoint['opt_text_enc'])
|
| 589 |
+
self.opt_seq_post.load_state_dict(checkpoint['opt_seq_post'])
|
| 590 |
+
self.opt_att_layer.load_state_dict(checkpoint['opt_att_layer'])
|
| 591 |
+
self.opt_seq_pri.load_state_dict(checkpoint['opt_seq_pri'])
|
| 592 |
+
self.opt_seq_dec.load_state_dict(checkpoint['opt_seq_dec'])
|
| 593 |
+
self.opt_mov_dec.load_state_dict(checkpoint['opt_mov_dec'])
|
| 594 |
+
|
| 595 |
+
self.text_enc.load_state_dict(checkpoint['text_enc'])
|
| 596 |
+
self.mov_dec.load_state_dict(checkpoint['mov_dec'])
|
| 597 |
+
self.seq_pri.load_state_dict(checkpoint['seq_pri'])
|
| 598 |
+
self.att_layer.load_state_dict(checkpoint['att_layer'])
|
| 599 |
+
self.seq_dec.load_state_dict(checkpoint['seq_dec'])
|
| 600 |
+
self.mov_enc.load_state_dict(checkpoint['mov_enc'])
|
| 601 |
+
|
| 602 |
+
return checkpoint['ep'], checkpoint['total_it'], checkpoint['sub_ep'], checkpoint['sl_len']
|
| 603 |
+
|
| 604 |
+
def train(self, train_dataset, val_dataset, plot_eval):
|
| 605 |
+
self.to(self.device)
|
| 606 |
+
|
| 607 |
+
self.opt_text_enc = optim.Adam(self.text_enc.parameters(), lr=self.opt.lr)
|
| 608 |
+
self.opt_seq_post = optim.Adam(self.seq_post.parameters(), lr=self.opt.lr)
|
| 609 |
+
self.opt_seq_pri = optim.Adam(self.seq_pri.parameters(), lr=self.opt.lr)
|
| 610 |
+
self.opt_att_layer = optim.Adam(self.att_layer.parameters(), lr=self.opt.lr)
|
| 611 |
+
self.opt_seq_dec = optim.Adam(self.seq_dec.parameters(), lr=self.opt.lr)
|
| 612 |
+
|
| 613 |
+
self.opt_mov_dec = optim.Adam(self.mov_dec.parameters(), lr=self.opt.lr*0.1)
|
| 614 |
+
|
| 615 |
+
epoch = 0
|
| 616 |
+
it = 0
|
| 617 |
+
if self.opt.dataset_name == 't2m':
|
| 618 |
+
schedule_len = 10
|
| 619 |
+
elif self.opt.dataset_name == 'kit':
|
| 620 |
+
schedule_len = 6
|
| 621 |
+
sub_ep = 0
|
| 622 |
+
|
| 623 |
+
if self.opt.is_continue:
|
| 624 |
+
model_dir = pjoin(self.opt.model_dir, 'latest.tar')
|
| 625 |
+
epoch, it, sub_ep, schedule_len = self.load(model_dir)
|
| 626 |
+
|
| 627 |
+
invalid = True
|
| 628 |
+
start_time = time.time()
|
| 629 |
+
val_loss = 0
|
| 630 |
+
is_continue_and_first = self.opt.is_continue
|
| 631 |
+
while invalid:
|
| 632 |
+
train_dataset.reset_max_len(schedule_len * self.opt.unit_length)
|
| 633 |
+
val_dataset.reset_max_len(schedule_len * self.opt.unit_length)
|
| 634 |
+
|
| 635 |
+
train_loader = DataLoader(train_dataset, batch_size=self.opt.batch_size, drop_last=True, num_workers=4,
|
| 636 |
+
shuffle=True, collate_fn=collate_fn, pin_memory=True)
|
| 637 |
+
val_loader = DataLoader(val_dataset, batch_size=self.opt.batch_size, drop_last=True, num_workers=4,
|
| 638 |
+
shuffle=True, collate_fn=collate_fn, pin_memory=True)
|
| 639 |
+
print("Max_Length:%03d Training Split:%05d Validation Split:%04d" % (schedule_len, len(train_loader), len(val_loader)))
|
| 640 |
+
|
| 641 |
+
min_val_loss = np.inf
|
| 642 |
+
stop_cnt = 0
|
| 643 |
+
logs = OrderedDict()
|
| 644 |
+
for sub_epoch in range(sub_ep, self.opt.max_sub_epoch):
|
| 645 |
+
self.train_mode()
|
| 646 |
+
|
| 647 |
+
if is_continue_and_first:
|
| 648 |
+
sub_ep = 0
|
| 649 |
+
is_continue_and_first = False
|
| 650 |
+
|
| 651 |
+
tf_ratio = self.opt.tf_ratio
|
| 652 |
+
|
| 653 |
+
time1 = time.time()
|
| 654 |
+
for i, batch_data in enumerate(train_loader):
|
| 655 |
+
time2 = time.time()
|
| 656 |
+
self.forward(batch_data, tf_ratio, schedule_len)
|
| 657 |
+
time3 = time.time()
|
| 658 |
+
log_dict = self.update()
|
| 659 |
+
for k, v in log_dict.items():
|
| 660 |
+
if k not in logs:
|
| 661 |
+
logs[k] = v
|
| 662 |
+
else:
|
| 663 |
+
logs[k] += v
|
| 664 |
+
time4 = time.time()
|
| 665 |
+
|
| 666 |
+
|
| 667 |
+
it += 1
|
| 668 |
+
if it % self.opt.log_every == 0:
|
| 669 |
+
mean_loss = OrderedDict({'val_loss': val_loss})
|
| 670 |
+
self.logger.scalar_summary('val_loss', val_loss, it)
|
| 671 |
+
self.logger.scalar_summary('scheduled_length', schedule_len, it)
|
| 672 |
+
|
| 673 |
+
for tag, value in logs.items():
|
| 674 |
+
self.logger.scalar_summary(tag, value/self.opt.log_every, it)
|
| 675 |
+
mean_loss[tag] = value / self.opt.log_every
|
| 676 |
+
logs = OrderedDict()
|
| 677 |
+
print_current_loss(start_time, it, mean_loss, epoch, sub_epoch=sub_epoch, inner_iter=i,
|
| 678 |
+
tf_ratio=tf_ratio, sl_steps=schedule_len)
|
| 679 |
+
|
| 680 |
+
if it % self.opt.save_latest == 0:
|
| 681 |
+
self.save(pjoin(self.opt.model_dir, 'latest.tar'), epoch, it, sub_epoch, schedule_len)
|
| 682 |
+
|
| 683 |
+
time5 = time.time()
|
| 684 |
+
# print("Data Loader Time: %5f s" % ((time2 - time1)))
|
| 685 |
+
# print("Forward Time: %5f s" % ((time3 - time2)))
|
| 686 |
+
# print("Update Time: %5f s" % ((time4 - time3)))
|
| 687 |
+
# print('Per Iteration: %5f s' % ((time5 - time1)))
|
| 688 |
+
time1 = time5
|
| 689 |
+
|
| 690 |
+
self.save(pjoin(self.opt.model_dir, 'latest.tar'), epoch, it, sub_epoch, schedule_len)
|
| 691 |
+
|
| 692 |
+
epoch += 1
|
| 693 |
+
if epoch % self.opt.save_every_e == 0:
|
| 694 |
+
self.save(pjoin(self.opt.model_dir, 'E%03d_SE%02d_SL%02d.tar'%(epoch, sub_epoch, schedule_len)),
|
| 695 |
+
epoch, total_it=it, sub_ep=sub_epoch, sl_len=schedule_len)
|
| 696 |
+
|
| 697 |
+
print('Validation time:')
|
| 698 |
+
|
| 699 |
+
loss_mot_rec = 0
|
| 700 |
+
loss_mov_rec = 0
|
| 701 |
+
loss_kld = 0
|
| 702 |
+
val_loss = 0
|
| 703 |
+
with torch.no_grad():
|
| 704 |
+
for i, batch_data in enumerate(val_loader):
|
| 705 |
+
self.forward(batch_data, 0, schedule_len)
|
| 706 |
+
self.backward_G()
|
| 707 |
+
loss_mot_rec += self.loss_mot_rec.item()
|
| 708 |
+
loss_mov_rec += self.loss_mov_rec.item()
|
| 709 |
+
loss_kld += self.loss_kld.item()
|
| 710 |
+
val_loss += self.loss_gen.item()
|
| 711 |
+
|
| 712 |
+
loss_mot_rec /= len(val_loader) + 1
|
| 713 |
+
loss_mov_rec /= len(val_loader) + 1
|
| 714 |
+
loss_kld /= len(val_loader) + 1
|
| 715 |
+
val_loss /= len(val_loader) + 1
|
| 716 |
+
print('Validation Loss: %.5f Movement Recon Loss: %.5f Motion Recon Loss: %.5f KLD Loss: %.5f:' %
|
| 717 |
+
(val_loss, loss_mov_rec, loss_mot_rec, loss_kld))
|
| 718 |
+
|
| 719 |
+
if epoch % self.opt.eval_every_e == 0:
|
| 720 |
+
reco_data = self.fake_motions[:4]
|
| 721 |
+
with torch.no_grad():
|
| 722 |
+
self.forward(batch_data, 0, schedule_len, eval_mode=True)
|
| 723 |
+
fake_data = self.fake_motions[:4]
|
| 724 |
+
gt_data = self.motions[:4]
|
| 725 |
+
data = torch.cat([fake_data, reco_data, gt_data], dim=0).cpu().numpy()
|
| 726 |
+
captions = self.caption[:4] * 3
|
| 727 |
+
save_dir = pjoin(self.opt.eval_dir, 'E%03d_SE%02d_SL%02d'%(epoch, sub_epoch, schedule_len))
|
| 728 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 729 |
+
plot_eval(data, save_dir, captions)
|
| 730 |
+
|
| 731 |
+
# if cl_ratio == 1:
|
| 732 |
+
if val_loss < min_val_loss:
|
| 733 |
+
min_val_loss = val_loss
|
| 734 |
+
stop_cnt = 0
|
| 735 |
+
elif stop_cnt < self.opt.early_stop_count:
|
| 736 |
+
stop_cnt += 1
|
| 737 |
+
elif stop_cnt >= self.opt.early_stop_count:
|
| 738 |
+
break
|
| 739 |
+
if val_loss - min_val_loss >= 0.1:
|
| 740 |
+
break
|
| 741 |
+
|
| 742 |
+
schedule_len += 1
|
| 743 |
+
|
| 744 |
+
if schedule_len > 49:
|
| 745 |
+
invalid = False
|
| 746 |
+
|
| 747 |
+
|
| 748 |
+
class LengthEstTrainer(object):
|
| 749 |
+
|
| 750 |
+
def __init__(self, args, estimator):
|
| 751 |
+
self.opt = args
|
| 752 |
+
self.estimator = estimator
|
| 753 |
+
self.device = args.device
|
| 754 |
+
|
| 755 |
+
if args.is_train:
|
| 756 |
+
# self.motion_dis
|
| 757 |
+
self.logger = Logger(args.log_dir)
|
| 758 |
+
self.mul_cls_criterion = torch.nn.CrossEntropyLoss()
|
| 759 |
+
|
| 760 |
+
def resume(self, model_dir):
|
| 761 |
+
checkpoints = torch.load(model_dir, map_location=self.device)
|
| 762 |
+
self.estimator.load_state_dict(checkpoints['estimator'])
|
| 763 |
+
self.opt_estimator.load_state_dict(checkpoints['opt_estimator'])
|
| 764 |
+
return checkpoints['epoch'], checkpoints['iter']
|
| 765 |
+
|
| 766 |
+
def save(self, model_dir, epoch, niter):
|
| 767 |
+
state = {
|
| 768 |
+
'estimator': self.estimator.state_dict(),
|
| 769 |
+
'opt_estimator': self.opt_estimator.state_dict(),
|
| 770 |
+
'epoch': epoch,
|
| 771 |
+
'niter': niter,
|
| 772 |
+
}
|
| 773 |
+
torch.save(state, model_dir)
|
| 774 |
+
|
| 775 |
+
@staticmethod
|
| 776 |
+
def zero_grad(opt_list):
|
| 777 |
+
for opt in opt_list:
|
| 778 |
+
opt.zero_grad()
|
| 779 |
+
|
| 780 |
+
@staticmethod
|
| 781 |
+
def clip_norm(network_list):
|
| 782 |
+
for network in network_list:
|
| 783 |
+
clip_grad_norm_(network.parameters(), 0.5)
|
| 784 |
+
|
| 785 |
+
@staticmethod
|
| 786 |
+
def step(opt_list):
|
| 787 |
+
for opt in opt_list:
|
| 788 |
+
opt.step()
|
| 789 |
+
|
| 790 |
+
def train(self, train_dataloader, val_dataloader):
|
| 791 |
+
self.estimator.to(self.device)
|
| 792 |
+
|
| 793 |
+
self.opt_estimator = optim.Adam(self.estimator.parameters(), lr=self.opt.lr)
|
| 794 |
+
|
| 795 |
+
epoch = 0
|
| 796 |
+
it = 0
|
| 797 |
+
|
| 798 |
+
if self.opt.is_continue:
|
| 799 |
+
model_dir = pjoin(self.opt.model_dir, 'latest.tar')
|
| 800 |
+
epoch, it = self.resume(model_dir)
|
| 801 |
+
|
| 802 |
+
start_time = time.time()
|
| 803 |
+
total_iters = self.opt.max_epoch * len(train_dataloader)
|
| 804 |
+
print('Iters Per Epoch, Training: %04d, Validation: %03d' % (len(train_dataloader), len(val_dataloader)))
|
| 805 |
+
val_loss = 0
|
| 806 |
+
min_val_loss = np.inf
|
| 807 |
+
logs = OrderedDict({'loss': 0})
|
| 808 |
+
while epoch < self.opt.max_epoch:
|
| 809 |
+
# time0 = time.time()
|
| 810 |
+
for i, batch_data in enumerate(train_dataloader):
|
| 811 |
+
self.estimator.train()
|
| 812 |
+
|
| 813 |
+
word_emb, pos_ohot, _, cap_lens, _, m_lens = batch_data
|
| 814 |
+
word_emb = word_emb.detach().to(self.device).float()
|
| 815 |
+
pos_ohot = pos_ohot.detach().to(self.device).float()
|
| 816 |
+
|
| 817 |
+
pred_dis = self.estimator(word_emb, pos_ohot, cap_lens)
|
| 818 |
+
|
| 819 |
+
self.zero_grad([self.opt_estimator])
|
| 820 |
+
|
| 821 |
+
gt_labels = m_lens // self.opt.unit_length
|
| 822 |
+
gt_labels = gt_labels.long().to(self.device)
|
| 823 |
+
# print(gt_labels)
|
| 824 |
+
# print(pred_dis)
|
| 825 |
+
loss = self.mul_cls_criterion(pred_dis, gt_labels)
|
| 826 |
+
|
| 827 |
+
loss.backward()
|
| 828 |
+
|
| 829 |
+
self.clip_norm([self.estimator])
|
| 830 |
+
self.step([self.opt_estimator])
|
| 831 |
+
|
| 832 |
+
logs['loss'] += loss.item()
|
| 833 |
+
|
| 834 |
+
it += 1
|
| 835 |
+
if it % self.opt.log_every == 0:
|
| 836 |
+
mean_loss = OrderedDict({'val_loss': val_loss})
|
| 837 |
+
self.logger.scalar_summary('val_loss', val_loss, it)
|
| 838 |
+
|
| 839 |
+
for tag, value in logs.items():
|
| 840 |
+
self.logger.scalar_summary(tag, value / self.opt.log_every, it)
|
| 841 |
+
mean_loss[tag] = value / self.opt.log_every
|
| 842 |
+
logs = OrderedDict({'loss': 0})
|
| 843 |
+
print_current_loss_decomp(start_time, it, total_iters, mean_loss, epoch, i)
|
| 844 |
+
|
| 845 |
+
if it % self.opt.save_latest == 0:
|
| 846 |
+
self.save(pjoin(self.opt.model_dir, 'latest.tar'), epoch, it)
|
| 847 |
+
|
| 848 |
+
self.save(pjoin(self.opt.model_dir, 'latest.tar'), epoch, it)
|
| 849 |
+
|
| 850 |
+
epoch += 1
|
| 851 |
+
if epoch % self.opt.save_every_e == 0:
|
| 852 |
+
self.save(pjoin(self.opt.model_dir, 'E%04d.tar' % (epoch)), epoch, it)
|
| 853 |
+
|
| 854 |
+
print('Validation time:')
|
| 855 |
+
|
| 856 |
+
val_loss = 0
|
| 857 |
+
with torch.no_grad():
|
| 858 |
+
for i, batch_data in enumerate(val_dataloader):
|
| 859 |
+
word_emb, pos_ohot, _, cap_lens, _, m_lens = batch_data
|
| 860 |
+
word_emb = word_emb.detach().to(self.device).float()
|
| 861 |
+
pos_ohot = pos_ohot.detach().to(self.device).float()
|
| 862 |
+
|
| 863 |
+
pred_dis = self.estimator(word_emb, pos_ohot, cap_lens)
|
| 864 |
+
|
| 865 |
+
gt_labels = m_lens // self.opt.unit_length
|
| 866 |
+
gt_labels = gt_labels.long().to(self.device)
|
| 867 |
+
loss = self.mul_cls_criterion(pred_dis, gt_labels)
|
| 868 |
+
|
| 869 |
+
val_loss += loss.item()
|
| 870 |
+
|
| 871 |
+
val_loss = val_loss / (len(val_dataloader) + 1)
|
| 872 |
+
print('Validation Loss: %.5f' % (val_loss))
|
| 873 |
+
|
| 874 |
+
if val_loss < min_val_loss:
|
| 875 |
+
self.save(pjoin(self.opt.model_dir, 'finest.tar'), epoch, it)
|
| 876 |
+
min_val_loss = val_loss
|
| 877 |
+
|
| 878 |
+
|
| 879 |
+
class TextMotionMatchTrainer(object):
|
| 880 |
+
|
| 881 |
+
def __init__(self, args, text_encoder, motion_encoder, movement_encoder):
|
| 882 |
+
self.opt = args
|
| 883 |
+
self.text_encoder = text_encoder
|
| 884 |
+
self.motion_encoder = motion_encoder
|
| 885 |
+
self.movement_encoder = movement_encoder
|
| 886 |
+
self.device = args.device
|
| 887 |
+
|
| 888 |
+
if args.is_train:
|
| 889 |
+
# self.motion_dis
|
| 890 |
+
self.logger = Logger(args.log_dir)
|
| 891 |
+
self.contrastive_loss = ContrastiveLoss(self.opt.negative_margin)
|
| 892 |
+
|
| 893 |
+
def resume(self, model_dir):
|
| 894 |
+
checkpoints = torch.load(model_dir, map_location=self.device)
|
| 895 |
+
self.text_encoder.load_state_dict(checkpoints['text_encoder'])
|
| 896 |
+
self.motion_encoder.load_state_dict(checkpoints['motion_encoder'])
|
| 897 |
+
self.movement_encoder.load_state_dict(checkpoints['movement_encoder'])
|
| 898 |
+
|
| 899 |
+
self.opt_text_encoder.load_state_dict(checkpoints['opt_text_encoder'])
|
| 900 |
+
self.opt_motion_encoder.load_state_dict(checkpoints['opt_motion_encoder'])
|
| 901 |
+
return checkpoints['epoch'], checkpoints['iter']
|
| 902 |
+
|
| 903 |
+
def save(self, model_dir, epoch, niter):
|
| 904 |
+
state = {
|
| 905 |
+
'text_encoder': self.text_encoder.state_dict(),
|
| 906 |
+
'motion_encoder': self.motion_encoder.state_dict(),
|
| 907 |
+
'movement_encoder': self.movement_encoder.state_dict(),
|
| 908 |
+
|
| 909 |
+
'opt_text_encoder': self.opt_text_encoder.state_dict(),
|
| 910 |
+
'opt_motion_encoder': self.opt_motion_encoder.state_dict(),
|
| 911 |
+
'epoch': epoch,
|
| 912 |
+
'iter': niter,
|
| 913 |
+
}
|
| 914 |
+
torch.save(state, model_dir)
|
| 915 |
+
|
| 916 |
+
@staticmethod
|
| 917 |
+
def zero_grad(opt_list):
|
| 918 |
+
for opt in opt_list:
|
| 919 |
+
opt.zero_grad()
|
| 920 |
+
|
| 921 |
+
@staticmethod
|
| 922 |
+
def clip_norm(network_list):
|
| 923 |
+
for network in network_list:
|
| 924 |
+
clip_grad_norm_(network.parameters(), 0.5)
|
| 925 |
+
|
| 926 |
+
@staticmethod
|
| 927 |
+
def step(opt_list):
|
| 928 |
+
for opt in opt_list:
|
| 929 |
+
opt.step()
|
| 930 |
+
|
| 931 |
+
def to(self, device):
|
| 932 |
+
self.text_encoder.to(device)
|
| 933 |
+
self.motion_encoder.to(device)
|
| 934 |
+
self.movement_encoder.to(device)
|
| 935 |
+
|
| 936 |
+
def train_mode(self):
|
| 937 |
+
self.text_encoder.train()
|
| 938 |
+
self.motion_encoder.train()
|
| 939 |
+
self.movement_encoder.eval()
|
| 940 |
+
|
| 941 |
+
def forward(self, batch_data):
|
| 942 |
+
word_emb, pos_ohot, caption, cap_lens, motions, m_lens, _ = batch_data
|
| 943 |
+
word_emb = word_emb.detach().to(self.device).float()
|
| 944 |
+
pos_ohot = pos_ohot.detach().to(self.device).float()
|
| 945 |
+
motions = motions.detach().to(self.device).float()
|
| 946 |
+
|
| 947 |
+
# Sort the length of motions in descending order, (length of text has been sorted)
|
| 948 |
+
self.align_idx = np.argsort(m_lens.data.tolist())[::-1].copy()
|
| 949 |
+
# print(self.align_idx)
|
| 950 |
+
# print(m_lens[self.align_idx])
|
| 951 |
+
motions = motions[self.align_idx]
|
| 952 |
+
m_lens = m_lens[self.align_idx]
|
| 953 |
+
|
| 954 |
+
'''Movement Encoding'''
|
| 955 |
+
movements = self.movement_encoder(motions[..., :-4]).detach()
|
| 956 |
+
m_lens = m_lens // self.opt.unit_length
|
| 957 |
+
self.motion_embedding = self.motion_encoder(movements, m_lens)
|
| 958 |
+
|
| 959 |
+
'''Text Encoding'''
|
| 960 |
+
# time0 = time.time()
|
| 961 |
+
# text_input = torch.cat([word_emb, pos_ohot], dim=-1)
|
| 962 |
+
self.text_embedding = self.text_encoder(word_emb, pos_ohot, cap_lens)
|
| 963 |
+
self.text_embedding = self.text_embedding.clone()[self.align_idx]
|
| 964 |
+
|
| 965 |
+
|
| 966 |
+
def backward(self):
|
| 967 |
+
|
| 968 |
+
batch_size = self.text_embedding.shape[0]
|
| 969 |
+
'''Positive pairs'''
|
| 970 |
+
pos_labels = torch.zeros(batch_size).to(self.text_embedding.device)
|
| 971 |
+
self.loss_pos = self.contrastive_loss(self.text_embedding, self.motion_embedding, pos_labels)
|
| 972 |
+
|
| 973 |
+
'''Negative Pairs, shifting index'''
|
| 974 |
+
neg_labels = torch.ones(batch_size).to(self.text_embedding.device)
|
| 975 |
+
shift = np.random.randint(0, batch_size-1)
|
| 976 |
+
new_idx = np.arange(shift, batch_size + shift) % batch_size
|
| 977 |
+
self.mis_motion_embedding = self.motion_embedding.clone()[new_idx]
|
| 978 |
+
self.loss_neg = self.contrastive_loss(self.text_embedding, self.mis_motion_embedding, neg_labels)
|
| 979 |
+
self.loss = self.loss_pos + self.loss_neg
|
| 980 |
+
|
| 981 |
+
loss_logs = OrderedDict({})
|
| 982 |
+
loss_logs['loss'] = self.loss.item()
|
| 983 |
+
loss_logs['loss_pos'] = self.loss_pos.item()
|
| 984 |
+
loss_logs['loss_neg'] = self.loss_neg.item()
|
| 985 |
+
return loss_logs
|
| 986 |
+
|
| 987 |
+
|
| 988 |
+
def update(self):
|
| 989 |
+
|
| 990 |
+
self.zero_grad([self.opt_motion_encoder, self.opt_text_encoder])
|
| 991 |
+
loss_logs = self.backward()
|
| 992 |
+
self.loss.backward()
|
| 993 |
+
self.clip_norm([self.text_encoder, self.motion_encoder])
|
| 994 |
+
self.step([self.opt_text_encoder, self.opt_motion_encoder])
|
| 995 |
+
|
| 996 |
+
return loss_logs
|
| 997 |
+
|
| 998 |
+
|
| 999 |
+
def train(self, train_dataloader, val_dataloader):
|
| 1000 |
+
self.to(self.device)
|
| 1001 |
+
|
| 1002 |
+
self.opt_motion_encoder = optim.Adam(self.motion_encoder.parameters(), lr=self.opt.lr)
|
| 1003 |
+
self.opt_text_encoder = optim.Adam(self.text_encoder.parameters(), lr=self.opt.lr)
|
| 1004 |
+
|
| 1005 |
+
epoch = 0
|
| 1006 |
+
it = 0
|
| 1007 |
+
|
| 1008 |
+
if self.opt.is_continue:
|
| 1009 |
+
model_dir = pjoin(self.opt.model_dir, 'latest.tar')
|
| 1010 |
+
epoch, it = self.resume(model_dir)
|
| 1011 |
+
|
| 1012 |
+
start_time = time.time()
|
| 1013 |
+
total_iters = self.opt.max_epoch * len(train_dataloader)
|
| 1014 |
+
print('Iters Per Epoch, Training: %04d, Validation: %03d' % (len(train_dataloader), len(val_dataloader)))
|
| 1015 |
+
val_loss = 0
|
| 1016 |
+
logs = OrderedDict()
|
| 1017 |
+
|
| 1018 |
+
min_val_loss = np.inf
|
| 1019 |
+
while epoch < self.opt.max_epoch:
|
| 1020 |
+
# time0 = time.time()
|
| 1021 |
+
for i, batch_data in enumerate(train_dataloader):
|
| 1022 |
+
self.train_mode()
|
| 1023 |
+
|
| 1024 |
+
self.forward(batch_data)
|
| 1025 |
+
# time3 = time.time()
|
| 1026 |
+
log_dict = self.update()
|
| 1027 |
+
for k, v in log_dict.items():
|
| 1028 |
+
if k not in logs:
|
| 1029 |
+
logs[k] = v
|
| 1030 |
+
else:
|
| 1031 |
+
logs[k] += v
|
| 1032 |
+
|
| 1033 |
+
|
| 1034 |
+
it += 1
|
| 1035 |
+
if it % self.opt.log_every == 0:
|
| 1036 |
+
mean_loss = OrderedDict({'val_loss': val_loss})
|
| 1037 |
+
self.logger.scalar_summary('val_loss', val_loss, it)
|
| 1038 |
+
|
| 1039 |
+
for tag, value in logs.items():
|
| 1040 |
+
self.logger.scalar_summary(tag, value / self.opt.log_every, it)
|
| 1041 |
+
mean_loss[tag] = value / self.opt.log_every
|
| 1042 |
+
logs = OrderedDict()
|
| 1043 |
+
print_current_loss_decomp(start_time, it, total_iters, mean_loss, epoch, i)
|
| 1044 |
+
|
| 1045 |
+
if it % self.opt.save_latest == 0:
|
| 1046 |
+
self.save(pjoin(self.opt.model_dir, 'latest.tar'), epoch, it)
|
| 1047 |
+
|
| 1048 |
+
self.save(pjoin(self.opt.model_dir, 'latest.tar'), epoch, it)
|
| 1049 |
+
|
| 1050 |
+
epoch += 1
|
| 1051 |
+
if epoch % self.opt.save_every_e == 0:
|
| 1052 |
+
self.save(pjoin(self.opt.model_dir, 'E%04d.tar' % (epoch)), epoch, it)
|
| 1053 |
+
|
| 1054 |
+
print('Validation time:')
|
| 1055 |
+
|
| 1056 |
+
loss_pos_pair = 0
|
| 1057 |
+
loss_neg_pair = 0
|
| 1058 |
+
val_loss = 0
|
| 1059 |
+
with torch.no_grad():
|
| 1060 |
+
for i, batch_data in enumerate(val_dataloader):
|
| 1061 |
+
self.forward(batch_data)
|
| 1062 |
+
self.backward()
|
| 1063 |
+
loss_pos_pair += self.loss_pos.item()
|
| 1064 |
+
loss_neg_pair += self.loss_neg.item()
|
| 1065 |
+
val_loss += self.loss.item()
|
| 1066 |
+
|
| 1067 |
+
loss_pos_pair /= len(val_dataloader) + 1
|
| 1068 |
+
loss_neg_pair /= len(val_dataloader) + 1
|
| 1069 |
+
val_loss /= len(val_dataloader) + 1
|
| 1070 |
+
print('Validation Loss: %.5f Positive Loss: %.5f Negative Loss: %.5f' %
|
| 1071 |
+
(val_loss, loss_pos_pair, loss_neg_pair))
|
| 1072 |
+
|
| 1073 |
+
if val_loss < min_val_loss:
|
| 1074 |
+
self.save(pjoin(self.opt.model_dir, 'finest.tar'), epoch, it)
|
| 1075 |
+
min_val_loss = val_loss
|
| 1076 |
+
|
| 1077 |
+
if epoch % self.opt.eval_every_e == 0:
|
| 1078 |
+
pos_dist = F.pairwise_distance(self.text_embedding, self.motion_embedding)
|
| 1079 |
+
neg_dist = F.pairwise_distance(self.text_embedding, self.mis_motion_embedding)
|
| 1080 |
+
|
| 1081 |
+
pos_str = ' '.join(['%.3f' % (pos_dist[i]) for i in range(pos_dist.shape[0])])
|
| 1082 |
+
neg_str = ' '.join(['%.3f' % (neg_dist[i]) for i in range(neg_dist.shape[0])])
|
| 1083 |
+
|
| 1084 |
+
save_path = pjoin(self.opt.eval_dir, 'E%03d.txt' % (epoch))
|
| 1085 |
+
with cs.open(save_path, 'w') as f:
|
| 1086 |
+
f.write('Positive Pairs Distance\n')
|
| 1087 |
+
f.write(pos_str + '\n')
|
| 1088 |
+
f.write('Negative Pairs Distance\n')
|
| 1089 |
+
f.write(neg_str + '\n')
|
main/data_loaders/humanml/scripts/motion_process.py
ADDED
|
@@ -0,0 +1,529 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from os.path import join as pjoin
|
| 2 |
+
|
| 3 |
+
from data_loaders.humanml.common.skeleton import Skeleton
|
| 4 |
+
import numpy as np
|
| 5 |
+
import os
|
| 6 |
+
from data_loaders.humanml.common.quaternion import *
|
| 7 |
+
from data_loaders.humanml.utils.paramUtil import *
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
|
| 12 |
+
# positions (batch, joint_num, 3)
|
| 13 |
+
def uniform_skeleton(positions, target_offset):
|
| 14 |
+
src_skel = Skeleton(n_raw_offsets, kinematic_chain, 'cpu')
|
| 15 |
+
src_offset = src_skel.get_offsets_joints(torch.from_numpy(positions[0]))
|
| 16 |
+
src_offset = src_offset.numpy()
|
| 17 |
+
tgt_offset = target_offset.numpy()
|
| 18 |
+
# print(src_offset)
|
| 19 |
+
# print(tgt_offset)
|
| 20 |
+
'''Calculate Scale Ratio as the ratio of legs'''
|
| 21 |
+
src_leg_len = np.abs(src_offset[l_idx1]).max() + np.abs(src_offset[l_idx2]).max()
|
| 22 |
+
tgt_leg_len = np.abs(tgt_offset[l_idx1]).max() + np.abs(tgt_offset[l_idx2]).max()
|
| 23 |
+
|
| 24 |
+
scale_rt = tgt_leg_len / src_leg_len
|
| 25 |
+
# print(scale_rt)
|
| 26 |
+
src_root_pos = positions[:, 0]
|
| 27 |
+
tgt_root_pos = src_root_pos * scale_rt
|
| 28 |
+
|
| 29 |
+
'''Inverse Kinematics'''
|
| 30 |
+
quat_params = src_skel.inverse_kinematics_np(positions, face_joint_indx)
|
| 31 |
+
# print(quat_params.shape)
|
| 32 |
+
|
| 33 |
+
'''Forward Kinematics'''
|
| 34 |
+
src_skel.set_offset(target_offset)
|
| 35 |
+
new_joints = src_skel.forward_kinematics_np(quat_params, tgt_root_pos)
|
| 36 |
+
return new_joints
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def extract_features(positions, feet_thre, n_raw_offsets, kinematic_chain, face_joint_indx, fid_r, fid_l):
|
| 40 |
+
global_positions = positions.copy()
|
| 41 |
+
""" Get Foot Contacts """
|
| 42 |
+
|
| 43 |
+
def foot_detect(positions, thres):
|
| 44 |
+
velfactor, heightfactor = np.array([thres, thres]), np.array([3.0, 2.0])
|
| 45 |
+
|
| 46 |
+
feet_l_x = (positions[1:, fid_l, 0] - positions[:-1, fid_l, 0]) ** 2
|
| 47 |
+
feet_l_y = (positions[1:, fid_l, 1] - positions[:-1, fid_l, 1]) ** 2
|
| 48 |
+
feet_l_z = (positions[1:, fid_l, 2] - positions[:-1, fid_l, 2]) ** 2
|
| 49 |
+
# feet_l_h = positions[:-1,fid_l,1]
|
| 50 |
+
# feet_l = (((feet_l_x + feet_l_y + feet_l_z) < velfactor) & (feet_l_h < heightfactor)).astype(np.float)
|
| 51 |
+
feet_l = ((feet_l_x + feet_l_y + feet_l_z) < velfactor).astype(np.float)
|
| 52 |
+
|
| 53 |
+
feet_r_x = (positions[1:, fid_r, 0] - positions[:-1, fid_r, 0]) ** 2
|
| 54 |
+
feet_r_y = (positions[1:, fid_r, 1] - positions[:-1, fid_r, 1]) ** 2
|
| 55 |
+
feet_r_z = (positions[1:, fid_r, 2] - positions[:-1, fid_r, 2]) ** 2
|
| 56 |
+
# feet_r_h = positions[:-1,fid_r,1]
|
| 57 |
+
# feet_r = (((feet_r_x + feet_r_y + feet_r_z) < velfactor) & (feet_r_h < heightfactor)).astype(np.float)
|
| 58 |
+
feet_r = (((feet_r_x + feet_r_y + feet_r_z) < velfactor)).astype(np.float)
|
| 59 |
+
return feet_l, feet_r
|
| 60 |
+
|
| 61 |
+
#
|
| 62 |
+
feet_l, feet_r = foot_detect(positions, feet_thre)
|
| 63 |
+
# feet_l, feet_r = foot_detect(positions, 0.002)
|
| 64 |
+
|
| 65 |
+
'''Quaternion and Cartesian representation'''
|
| 66 |
+
r_rot = None
|
| 67 |
+
|
| 68 |
+
def get_rifke(positions):
|
| 69 |
+
'''Local pose'''
|
| 70 |
+
positions[..., 0] -= positions[:, 0:1, 0]
|
| 71 |
+
positions[..., 2] -= positions[:, 0:1, 2]
|
| 72 |
+
'''All pose face Z+'''
|
| 73 |
+
positions = qrot_np(np.repeat(r_rot[:, None], positions.shape[1], axis=1), positions)
|
| 74 |
+
return positions
|
| 75 |
+
|
| 76 |
+
def get_quaternion(positions):
|
| 77 |
+
skel = Skeleton(n_raw_offsets, kinematic_chain, "cpu")
|
| 78 |
+
# (seq_len, joints_num, 4)
|
| 79 |
+
quat_params = skel.inverse_kinematics_np(positions, face_joint_indx, smooth_forward=False)
|
| 80 |
+
|
| 81 |
+
'''Fix Quaternion Discontinuity'''
|
| 82 |
+
quat_params = qfix(quat_params)
|
| 83 |
+
# (seq_len, 4)
|
| 84 |
+
r_rot = quat_params[:, 0].copy()
|
| 85 |
+
# print(r_rot[0])
|
| 86 |
+
'''Root Linear Velocity'''
|
| 87 |
+
# (seq_len - 1, 3)
|
| 88 |
+
velocity = (positions[1:, 0] - positions[:-1, 0]).copy()
|
| 89 |
+
# print(r_rot.shape, velocity.shape)
|
| 90 |
+
velocity = qrot_np(r_rot[1:], velocity)
|
| 91 |
+
'''Root Angular Velocity'''
|
| 92 |
+
# (seq_len - 1, 4)
|
| 93 |
+
r_velocity = qmul_np(r_rot[1:], qinv_np(r_rot[:-1]))
|
| 94 |
+
quat_params[1:, 0] = r_velocity
|
| 95 |
+
# (seq_len, joints_num, 4)
|
| 96 |
+
return quat_params, r_velocity, velocity, r_rot
|
| 97 |
+
|
| 98 |
+
def get_cont6d_params(positions):
|
| 99 |
+
skel = Skeleton(n_raw_offsets, kinematic_chain, "cpu")
|
| 100 |
+
# (seq_len, joints_num, 4)
|
| 101 |
+
quat_params = skel.inverse_kinematics_np(positions, face_joint_indx, smooth_forward=True)
|
| 102 |
+
|
| 103 |
+
'''Quaternion to continuous 6D'''
|
| 104 |
+
cont_6d_params = quaternion_to_cont6d_np(quat_params)
|
| 105 |
+
# (seq_len, 4)
|
| 106 |
+
r_rot = quat_params[:, 0].copy()
|
| 107 |
+
# print(r_rot[0])
|
| 108 |
+
'''Root Linear Velocity'''
|
| 109 |
+
# (seq_len - 1, 3)
|
| 110 |
+
velocity = (positions[1:, 0] - positions[:-1, 0]).copy()
|
| 111 |
+
# print(r_rot.shape, velocity.shape)
|
| 112 |
+
velocity = qrot_np(r_rot[1:], velocity)
|
| 113 |
+
'''Root Angular Velocity'''
|
| 114 |
+
# (seq_len - 1, 4)
|
| 115 |
+
r_velocity = qmul_np(r_rot[1:], qinv_np(r_rot[:-1]))
|
| 116 |
+
# (seq_len, joints_num, 4)
|
| 117 |
+
return cont_6d_params, r_velocity, velocity, r_rot
|
| 118 |
+
|
| 119 |
+
cont_6d_params, r_velocity, velocity, r_rot = get_cont6d_params(positions)
|
| 120 |
+
positions = get_rifke(positions)
|
| 121 |
+
|
| 122 |
+
# trejec = np.cumsum(np.concatenate([np.array([[0, 0, 0]]), velocity], axis=0), axis=0)
|
| 123 |
+
# r_rotations, r_pos = recover_ric_glo_np(r_velocity, velocity[:, [0, 2]])
|
| 124 |
+
|
| 125 |
+
# plt.plot(positions_b[:, 0, 0], positions_b[:, 0, 2], marker='*')
|
| 126 |
+
# plt.plot(ground_positions[:, 0, 0], ground_positions[:, 0, 2], marker='o', color='r')
|
| 127 |
+
# plt.plot(trejec[:, 0], trejec[:, 2], marker='^', color='g')
|
| 128 |
+
# plt.plot(r_pos[:, 0], r_pos[:, 2], marker='s', color='y')
|
| 129 |
+
# plt.xlabel('x')
|
| 130 |
+
# plt.ylabel('z')
|
| 131 |
+
# plt.axis('equal')
|
| 132 |
+
# plt.show()
|
| 133 |
+
|
| 134 |
+
'''Root height'''
|
| 135 |
+
root_y = positions[:, 0, 1:2]
|
| 136 |
+
|
| 137 |
+
'''Root rotation and linear velocity'''
|
| 138 |
+
# (seq_len-1, 1) rotation velocity along y-axis
|
| 139 |
+
# (seq_len-1, 2) linear velovity on xz plane
|
| 140 |
+
r_velocity = np.arcsin(r_velocity[:, 2:3])
|
| 141 |
+
l_velocity = velocity[:, [0, 2]]
|
| 142 |
+
# print(r_velocity.shape, l_velocity.shape, root_y.shape)
|
| 143 |
+
root_data = np.concatenate([r_velocity, l_velocity, root_y[:-1]], axis=-1)
|
| 144 |
+
|
| 145 |
+
'''Get Joint Rotation Representation'''
|
| 146 |
+
# (seq_len, (joints_num-1) *6) quaternion for skeleton joints
|
| 147 |
+
rot_data = cont_6d_params[:, 1:].reshape(len(cont_6d_params), -1)
|
| 148 |
+
|
| 149 |
+
'''Get Joint Rotation Invariant Position Represention'''
|
| 150 |
+
# (seq_len, (joints_num-1)*3) local joint position
|
| 151 |
+
ric_data = positions[:, 1:].reshape(len(positions), -1)
|
| 152 |
+
|
| 153 |
+
'''Get Joint Velocity Representation'''
|
| 154 |
+
# (seq_len-1, joints_num*3)
|
| 155 |
+
local_vel = qrot_np(np.repeat(r_rot[:-1, None], global_positions.shape[1], axis=1),
|
| 156 |
+
global_positions[1:] - global_positions[:-1])
|
| 157 |
+
local_vel = local_vel.reshape(len(local_vel), -1)
|
| 158 |
+
|
| 159 |
+
data = root_data
|
| 160 |
+
data = np.concatenate([data, ric_data[:-1]], axis=-1)
|
| 161 |
+
data = np.concatenate([data, rot_data[:-1]], axis=-1)
|
| 162 |
+
# print(dataset.shape, local_vel.shape)
|
| 163 |
+
data = np.concatenate([data, local_vel], axis=-1)
|
| 164 |
+
data = np.concatenate([data, feet_l, feet_r], axis=-1)
|
| 165 |
+
|
| 166 |
+
return data
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def process_file(positions, feet_thre):
|
| 170 |
+
# (seq_len, joints_num, 3)
|
| 171 |
+
# '''Down Sample'''
|
| 172 |
+
# positions = positions[::ds_num]
|
| 173 |
+
|
| 174 |
+
'''Uniform Skeleton'''
|
| 175 |
+
positions = uniform_skeleton(positions, tgt_offsets)
|
| 176 |
+
|
| 177 |
+
'''Put on Floor'''
|
| 178 |
+
floor_height = positions.min(axis=0).min(axis=0)[1]
|
| 179 |
+
positions[:, :, 1] -= floor_height
|
| 180 |
+
# print(floor_height)
|
| 181 |
+
|
| 182 |
+
# plot_3d_motion("./positions_1.mp4", kinematic_chain, positions, 'title', fps=20)
|
| 183 |
+
|
| 184 |
+
'''XZ at origin'''
|
| 185 |
+
root_pos_init = positions[0]
|
| 186 |
+
root_pose_init_xz = root_pos_init[0] * np.array([1, 0, 1])
|
| 187 |
+
positions = positions - root_pose_init_xz
|
| 188 |
+
|
| 189 |
+
# '''Move the first pose to origin '''
|
| 190 |
+
# root_pos_init = positions[0]
|
| 191 |
+
# positions = positions - root_pos_init[0]
|
| 192 |
+
|
| 193 |
+
'''All initially face Z+'''
|
| 194 |
+
r_hip, l_hip, sdr_r, sdr_l = face_joint_indx
|
| 195 |
+
across1 = root_pos_init[r_hip] - root_pos_init[l_hip]
|
| 196 |
+
across2 = root_pos_init[sdr_r] - root_pos_init[sdr_l]
|
| 197 |
+
across = across1 + across2
|
| 198 |
+
across = across / np.sqrt((across ** 2).sum(axis=-1))[..., np.newaxis]
|
| 199 |
+
|
| 200 |
+
# forward (3,), rotate around y-axis
|
| 201 |
+
forward_init = np.cross(np.array([[0, 1, 0]]), across, axis=-1)
|
| 202 |
+
# forward (3,)
|
| 203 |
+
forward_init = forward_init / np.sqrt((forward_init ** 2).sum(axis=-1))[..., np.newaxis]
|
| 204 |
+
|
| 205 |
+
# print(forward_init)
|
| 206 |
+
|
| 207 |
+
target = np.array([[0, 0, 1]])
|
| 208 |
+
root_quat_init = qbetween_np(forward_init, target)
|
| 209 |
+
root_quat_init = np.ones(positions.shape[:-1] + (4,)) * root_quat_init
|
| 210 |
+
|
| 211 |
+
positions_b = positions.copy()
|
| 212 |
+
|
| 213 |
+
positions = qrot_np(root_quat_init, positions)
|
| 214 |
+
|
| 215 |
+
# plot_3d_motion("./positions_2.mp4", kinematic_chain, positions, 'title', fps=20)
|
| 216 |
+
|
| 217 |
+
'''New ground truth positions'''
|
| 218 |
+
global_positions = positions.copy()
|
| 219 |
+
|
| 220 |
+
# plt.plot(positions_b[:, 0, 0], positions_b[:, 0, 2], marker='*')
|
| 221 |
+
# plt.plot(positions[:, 0, 0], positions[:, 0, 2], marker='o', color='r')
|
| 222 |
+
# plt.xlabel('x')
|
| 223 |
+
# plt.ylabel('z')
|
| 224 |
+
# plt.axis('equal')
|
| 225 |
+
# plt.show()
|
| 226 |
+
|
| 227 |
+
""" Get Foot Contacts """
|
| 228 |
+
|
| 229 |
+
def foot_detect(positions, thres):
|
| 230 |
+
velfactor, heightfactor = np.array([thres, thres]), np.array([3.0, 2.0])
|
| 231 |
+
|
| 232 |
+
feet_l_x = (positions[1:, fid_l, 0] - positions[:-1, fid_l, 0]) ** 2
|
| 233 |
+
feet_l_y = (positions[1:, fid_l, 1] - positions[:-1, fid_l, 1]) ** 2
|
| 234 |
+
feet_l_z = (positions[1:, fid_l, 2] - positions[:-1, fid_l, 2]) ** 2
|
| 235 |
+
# feet_l_h = positions[:-1,fid_l,1]
|
| 236 |
+
# feet_l = (((feet_l_x + feet_l_y + feet_l_z) < velfactor) & (feet_l_h < heightfactor)).astype(np.float)
|
| 237 |
+
feet_l = ((feet_l_x + feet_l_y + feet_l_z) < velfactor).astype(np.float)
|
| 238 |
+
|
| 239 |
+
feet_r_x = (positions[1:, fid_r, 0] - positions[:-1, fid_r, 0]) ** 2
|
| 240 |
+
feet_r_y = (positions[1:, fid_r, 1] - positions[:-1, fid_r, 1]) ** 2
|
| 241 |
+
feet_r_z = (positions[1:, fid_r, 2] - positions[:-1, fid_r, 2]) ** 2
|
| 242 |
+
# feet_r_h = positions[:-1,fid_r,1]
|
| 243 |
+
# feet_r = (((feet_r_x + feet_r_y + feet_r_z) < velfactor) & (feet_r_h < heightfactor)).astype(np.float)
|
| 244 |
+
feet_r = (((feet_r_x + feet_r_y + feet_r_z) < velfactor)).astype(np.float)
|
| 245 |
+
return feet_l, feet_r
|
| 246 |
+
#
|
| 247 |
+
feet_l, feet_r = foot_detect(positions, feet_thre)
|
| 248 |
+
# feet_l, feet_r = foot_detect(positions, 0.002)
|
| 249 |
+
|
| 250 |
+
'''Quaternion and Cartesian representation'''
|
| 251 |
+
r_rot = None
|
| 252 |
+
|
| 253 |
+
def get_rifke(positions):
|
| 254 |
+
'''Local pose'''
|
| 255 |
+
positions[..., 0] -= positions[:, 0:1, 0]
|
| 256 |
+
positions[..., 2] -= positions[:, 0:1, 2]
|
| 257 |
+
'''All pose face Z+'''
|
| 258 |
+
positions = qrot_np(np.repeat(r_rot[:, None], positions.shape[1], axis=1), positions)
|
| 259 |
+
return positions
|
| 260 |
+
|
| 261 |
+
def get_quaternion(positions):
|
| 262 |
+
skel = Skeleton(n_raw_offsets, kinematic_chain, "cpu")
|
| 263 |
+
# (seq_len, joints_num, 4)
|
| 264 |
+
quat_params = skel.inverse_kinematics_np(positions, face_joint_indx, smooth_forward=False)
|
| 265 |
+
|
| 266 |
+
'''Fix Quaternion Discontinuity'''
|
| 267 |
+
quat_params = qfix(quat_params)
|
| 268 |
+
# (seq_len, 4)
|
| 269 |
+
r_rot = quat_params[:, 0].copy()
|
| 270 |
+
# print(r_rot[0])
|
| 271 |
+
'''Root Linear Velocity'''
|
| 272 |
+
# (seq_len - 1, 3)
|
| 273 |
+
velocity = (positions[1:, 0] - positions[:-1, 0]).copy()
|
| 274 |
+
# print(r_rot.shape, velocity.shape)
|
| 275 |
+
velocity = qrot_np(r_rot[1:], velocity)
|
| 276 |
+
'''Root Angular Velocity'''
|
| 277 |
+
# (seq_len - 1, 4)
|
| 278 |
+
r_velocity = qmul_np(r_rot[1:], qinv_np(r_rot[:-1]))
|
| 279 |
+
quat_params[1:, 0] = r_velocity
|
| 280 |
+
# (seq_len, joints_num, 4)
|
| 281 |
+
return quat_params, r_velocity, velocity, r_rot
|
| 282 |
+
|
| 283 |
+
def get_cont6d_params(positions):
|
| 284 |
+
skel = Skeleton(n_raw_offsets, kinematic_chain, "cpu")
|
| 285 |
+
# (seq_len, joints_num, 4)
|
| 286 |
+
quat_params = skel.inverse_kinematics_np(positions, face_joint_indx, smooth_forward=True)
|
| 287 |
+
|
| 288 |
+
'''Quaternion to continuous 6D'''
|
| 289 |
+
cont_6d_params = quaternion_to_cont6d_np(quat_params)
|
| 290 |
+
# (seq_len, 4)
|
| 291 |
+
r_rot = quat_params[:, 0].copy()
|
| 292 |
+
# print(r_rot[0])
|
| 293 |
+
'''Root Linear Velocity'''
|
| 294 |
+
# (seq_len - 1, 3)
|
| 295 |
+
velocity = (positions[1:, 0] - positions[:-1, 0]).copy()
|
| 296 |
+
# print(r_rot.shape, velocity.shape)
|
| 297 |
+
velocity = qrot_np(r_rot[1:], velocity)
|
| 298 |
+
'''Root Angular Velocity'''
|
| 299 |
+
# (seq_len - 1, 4)
|
| 300 |
+
r_velocity = qmul_np(r_rot[1:], qinv_np(r_rot[:-1]))
|
| 301 |
+
# (seq_len, joints_num, 4)
|
| 302 |
+
return cont_6d_params, r_velocity, velocity, r_rot
|
| 303 |
+
|
| 304 |
+
cont_6d_params, r_velocity, velocity, r_rot = get_cont6d_params(positions)
|
| 305 |
+
positions = get_rifke(positions)
|
| 306 |
+
|
| 307 |
+
# trejec = np.cumsum(np.concatenate([np.array([[0, 0, 0]]), velocity], axis=0), axis=0)
|
| 308 |
+
# r_rotations, r_pos = recover_ric_glo_np(r_velocity, velocity[:, [0, 2]])
|
| 309 |
+
|
| 310 |
+
# plt.plot(positions_b[:, 0, 0], positions_b[:, 0, 2], marker='*')
|
| 311 |
+
# plt.plot(ground_positions[:, 0, 0], ground_positions[:, 0, 2], marker='o', color='r')
|
| 312 |
+
# plt.plot(trejec[:, 0], trejec[:, 2], marker='^', color='g')
|
| 313 |
+
# plt.plot(r_pos[:, 0], r_pos[:, 2], marker='s', color='y')
|
| 314 |
+
# plt.xlabel('x')
|
| 315 |
+
# plt.ylabel('z')
|
| 316 |
+
# plt.axis('equal')
|
| 317 |
+
# plt.show()
|
| 318 |
+
|
| 319 |
+
'''Root height'''
|
| 320 |
+
root_y = positions[:, 0, 1:2]
|
| 321 |
+
|
| 322 |
+
'''Root rotation and linear velocity'''
|
| 323 |
+
# (seq_len-1, 1) rotation velocity along y-axis
|
| 324 |
+
# (seq_len-1, 2) linear velovity on xz plane
|
| 325 |
+
r_velocity = np.arcsin(r_velocity[:, 2:3])
|
| 326 |
+
l_velocity = velocity[:, [0, 2]]
|
| 327 |
+
# print(r_velocity.shape, l_velocity.shape, root_y.shape)
|
| 328 |
+
root_data = np.concatenate([r_velocity, l_velocity, root_y[:-1]], axis=-1)
|
| 329 |
+
|
| 330 |
+
'''Get Joint Rotation Representation'''
|
| 331 |
+
# (seq_len, (joints_num-1) *6) quaternion for skeleton joints
|
| 332 |
+
rot_data = cont_6d_params[:, 1:].reshape(len(cont_6d_params), -1)
|
| 333 |
+
|
| 334 |
+
'''Get Joint Rotation Invariant Position Represention'''
|
| 335 |
+
# (seq_len, (joints_num-1)*3) local joint position
|
| 336 |
+
ric_data = positions[:, 1:].reshape(len(positions), -1)
|
| 337 |
+
|
| 338 |
+
'''Get Joint Velocity Representation'''
|
| 339 |
+
# (seq_len-1, joints_num*3)
|
| 340 |
+
local_vel = qrot_np(np.repeat(r_rot[:-1, None], global_positions.shape[1], axis=1),
|
| 341 |
+
global_positions[1:] - global_positions[:-1])
|
| 342 |
+
local_vel = local_vel.reshape(len(local_vel), -1)
|
| 343 |
+
|
| 344 |
+
data = root_data
|
| 345 |
+
data = np.concatenate([data, ric_data[:-1]], axis=-1)
|
| 346 |
+
data = np.concatenate([data, rot_data[:-1]], axis=-1)
|
| 347 |
+
# print(dataset.shape, local_vel.shape)
|
| 348 |
+
data = np.concatenate([data, local_vel], axis=-1)
|
| 349 |
+
data = np.concatenate([data, feet_l, feet_r], axis=-1)
|
| 350 |
+
|
| 351 |
+
return data, global_positions, positions, l_velocity
|
| 352 |
+
|
| 353 |
+
|
| 354 |
+
# Recover global angle and positions for rotation dataset
|
| 355 |
+
# root_rot_velocity (B, seq_len, 1)
|
| 356 |
+
# root_linear_velocity (B, seq_len, 2)
|
| 357 |
+
# root_y (B, seq_len, 1)
|
| 358 |
+
# ric_data (B, seq_len, (joint_num - 1)*3)
|
| 359 |
+
# rot_data (B, seq_len, (joint_num - 1)*6)
|
| 360 |
+
# local_velocity (B, seq_len, joint_num*3)
|
| 361 |
+
# foot contact (B, seq_len, 4)
|
| 362 |
+
def recover_root_rot_pos(data):
|
| 363 |
+
rot_vel = data[..., 0]
|
| 364 |
+
r_rot_ang = torch.zeros_like(rot_vel).to(data.device)
|
| 365 |
+
'''Get Y-axis rotation from rotation velocity'''
|
| 366 |
+
r_rot_ang[..., 1:] = rot_vel[..., :-1]
|
| 367 |
+
r_rot_ang = torch.cumsum(r_rot_ang, dim=-1)
|
| 368 |
+
|
| 369 |
+
r_rot_quat = torch.zeros(data.shape[:-1] + (4,)).to(data.device)
|
| 370 |
+
r_rot_quat[..., 0] = torch.cos(r_rot_ang)
|
| 371 |
+
r_rot_quat[..., 2] = torch.sin(r_rot_ang)
|
| 372 |
+
|
| 373 |
+
r_pos = torch.zeros(data.shape[:-1] + (3,)).to(data.device)
|
| 374 |
+
r_pos[..., 1:, [0, 2]] = data[..., :-1, 1:3]
|
| 375 |
+
'''Add Y-axis rotation to root position'''
|
| 376 |
+
r_pos = qrot(qinv(r_rot_quat), r_pos)
|
| 377 |
+
|
| 378 |
+
r_pos = torch.cumsum(r_pos, dim=-2)
|
| 379 |
+
|
| 380 |
+
r_pos[..., 1] = data[..., 3]
|
| 381 |
+
return r_rot_quat, r_pos
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
def recover_from_rot(data, joints_num, skeleton):
|
| 385 |
+
r_rot_quat, r_pos = recover_root_rot_pos(data)
|
| 386 |
+
|
| 387 |
+
r_rot_cont6d = quaternion_to_cont6d(r_rot_quat)
|
| 388 |
+
|
| 389 |
+
start_indx = 1 + 2 + 1 + (joints_num - 1) * 3
|
| 390 |
+
end_indx = start_indx + (joints_num - 1) * 6
|
| 391 |
+
cont6d_params = data[..., start_indx:end_indx]
|
| 392 |
+
# print(r_rot_cont6d.shape, cont6d_params.shape, r_pos.shape)
|
| 393 |
+
cont6d_params = torch.cat([r_rot_cont6d, cont6d_params], dim=-1)
|
| 394 |
+
cont6d_params = cont6d_params.view(-1, joints_num, 6)
|
| 395 |
+
|
| 396 |
+
positions = skeleton.forward_kinematics_cont6d(cont6d_params, r_pos)
|
| 397 |
+
|
| 398 |
+
return positions
|
| 399 |
+
|
| 400 |
+
def recover_rot(data):
|
| 401 |
+
# dataset [bs, seqlen, 263/251] HumanML/KIT
|
| 402 |
+
joints_num = 22 if data.shape[-1] == 263 else 21
|
| 403 |
+
r_rot_quat, r_pos = recover_root_rot_pos(data)
|
| 404 |
+
r_pos_pad = torch.cat([r_pos, torch.zeros_like(r_pos)], dim=-1).unsqueeze(-2)
|
| 405 |
+
r_rot_cont6d = quaternion_to_cont6d(r_rot_quat)
|
| 406 |
+
start_indx = 1 + 2 + 1 + (joints_num - 1) * 3
|
| 407 |
+
end_indx = start_indx + (joints_num - 1) * 6
|
| 408 |
+
cont6d_params = data[..., start_indx:end_indx]
|
| 409 |
+
cont6d_params = torch.cat([r_rot_cont6d, cont6d_params], dim=-1)
|
| 410 |
+
cont6d_params = cont6d_params.view(-1, joints_num, 6)
|
| 411 |
+
cont6d_params = torch.cat([cont6d_params, r_pos_pad], dim=-2)
|
| 412 |
+
return cont6d_params
|
| 413 |
+
|
| 414 |
+
|
| 415 |
+
def recover_from_ric(data, joints_num):
|
| 416 |
+
r_rot_quat, r_pos = recover_root_rot_pos(data)
|
| 417 |
+
positions = data[..., 4:(joints_num - 1) * 3 + 4]
|
| 418 |
+
positions = positions.view(positions.shape[:-1] + (-1, 3))
|
| 419 |
+
|
| 420 |
+
'''Add Y-axis rotation to local joints'''
|
| 421 |
+
positions = qrot(qinv(r_rot_quat[..., None, :]).expand(positions.shape[:-1] + (4,)), positions)
|
| 422 |
+
|
| 423 |
+
'''Add root XZ to joints'''
|
| 424 |
+
positions[..., 0] += r_pos[..., 0:1]
|
| 425 |
+
positions[..., 2] += r_pos[..., 2:3]
|
| 426 |
+
|
| 427 |
+
'''Concate root and joints'''
|
| 428 |
+
positions = torch.cat([r_pos.unsqueeze(-2), positions], dim=-2)
|
| 429 |
+
|
| 430 |
+
return positions
|
| 431 |
+
'''
|
| 432 |
+
For Text2Motion Dataset
|
| 433 |
+
'''
|
| 434 |
+
'''
|
| 435 |
+
if __name__ == "__main__":
|
| 436 |
+
example_id = "000021"
|
| 437 |
+
# Lower legs
|
| 438 |
+
l_idx1, l_idx2 = 5, 8
|
| 439 |
+
# Right/Left foot
|
| 440 |
+
fid_r, fid_l = [8, 11], [7, 10]
|
| 441 |
+
# Face direction, r_hip, l_hip, sdr_r, sdr_l
|
| 442 |
+
face_joint_indx = [2, 1, 17, 16]
|
| 443 |
+
# l_hip, r_hip
|
| 444 |
+
r_hip, l_hip = 2, 1
|
| 445 |
+
joints_num = 22
|
| 446 |
+
# ds_num = 8
|
| 447 |
+
data_dir = '../dataset/pose_data_raw/joints/'
|
| 448 |
+
save_dir1 = '../dataset/pose_data_raw/new_joints/'
|
| 449 |
+
save_dir2 = '../dataset/pose_data_raw/new_joint_vecs/'
|
| 450 |
+
|
| 451 |
+
n_raw_offsets = torch.from_numpy(t2m_raw_offsets)
|
| 452 |
+
kinematic_chain = t2m_kinematic_chain
|
| 453 |
+
|
| 454 |
+
# Get offsets of target skeleton
|
| 455 |
+
example_data = np.load(os.path.join(data_dir, example_id + '.npy'))
|
| 456 |
+
example_data = example_data.reshape(len(example_data), -1, 3)
|
| 457 |
+
example_data = torch.from_numpy(example_data)
|
| 458 |
+
tgt_skel = Skeleton(n_raw_offsets, kinematic_chain, 'cpu')
|
| 459 |
+
# (joints_num, 3)
|
| 460 |
+
tgt_offsets = tgt_skel.get_offsets_joints(example_data[0])
|
| 461 |
+
# print(tgt_offsets)
|
| 462 |
+
|
| 463 |
+
source_list = os.listdir(data_dir)
|
| 464 |
+
frame_num = 0
|
| 465 |
+
for source_file in tqdm(source_list):
|
| 466 |
+
source_data = np.load(os.path.join(data_dir, source_file))[:, :joints_num]
|
| 467 |
+
try:
|
| 468 |
+
dataset, ground_positions, positions, l_velocity = process_file(source_data, 0.002)
|
| 469 |
+
rec_ric_data = recover_from_ric(torch.from_numpy(dataset).unsqueeze(0).float(), joints_num)
|
| 470 |
+
np.save(pjoin(save_dir1, source_file), rec_ric_data.squeeze().numpy())
|
| 471 |
+
np.save(pjoin(save_dir2, source_file), dataset)
|
| 472 |
+
frame_num += dataset.shape[0]
|
| 473 |
+
except Exception as e:
|
| 474 |
+
print(source_file)
|
| 475 |
+
print(e)
|
| 476 |
+
|
| 477 |
+
print('Total clips: %d, Frames: %d, Duration: %fm' %
|
| 478 |
+
(len(source_list), frame_num, frame_num / 20 / 60))
|
| 479 |
+
'''
|
| 480 |
+
|
| 481 |
+
if __name__ == "__main__":
|
| 482 |
+
example_id = "03950_gt"
|
| 483 |
+
# Lower legs
|
| 484 |
+
l_idx1, l_idx2 = 17, 18
|
| 485 |
+
# Right/Left foot
|
| 486 |
+
fid_r, fid_l = [14, 15], [19, 20]
|
| 487 |
+
# Face direction, r_hip, l_hip, sdr_r, sdr_l
|
| 488 |
+
face_joint_indx = [11, 16, 5, 8]
|
| 489 |
+
# l_hip, r_hip
|
| 490 |
+
r_hip, l_hip = 11, 16
|
| 491 |
+
joints_num = 21
|
| 492 |
+
# ds_num = 8
|
| 493 |
+
data_dir = '../dataset/kit_mocap_dataset/joints/'
|
| 494 |
+
save_dir1 = '../dataset/kit_mocap_dataset/new_joints/'
|
| 495 |
+
save_dir2 = '../dataset/kit_mocap_dataset/new_joint_vecs/'
|
| 496 |
+
|
| 497 |
+
n_raw_offsets = torch.from_numpy(kit_raw_offsets)
|
| 498 |
+
kinematic_chain = kit_kinematic_chain
|
| 499 |
+
|
| 500 |
+
'''Get offsets of target skeleton'''
|
| 501 |
+
example_data = np.load(os.path.join(data_dir, example_id + '.npy'))
|
| 502 |
+
example_data = example_data.reshape(len(example_data), -1, 3)
|
| 503 |
+
example_data = torch.from_numpy(example_data)
|
| 504 |
+
tgt_skel = Skeleton(n_raw_offsets, kinematic_chain, 'cpu')
|
| 505 |
+
# (joints_num, 3)
|
| 506 |
+
tgt_offsets = tgt_skel.get_offsets_joints(example_data[0])
|
| 507 |
+
# print(tgt_offsets)
|
| 508 |
+
|
| 509 |
+
source_list = os.listdir(data_dir)
|
| 510 |
+
frame_num = 0
|
| 511 |
+
'''Read source dataset'''
|
| 512 |
+
for source_file in tqdm(source_list):
|
| 513 |
+
source_data = np.load(os.path.join(data_dir, source_file))[:, :joints_num]
|
| 514 |
+
try:
|
| 515 |
+
name = ''.join(source_file[:-7].split('_')) + '.npy'
|
| 516 |
+
data, ground_positions, positions, l_velocity = process_file(source_data, 0.05)
|
| 517 |
+
rec_ric_data = recover_from_ric(torch.from_numpy(data).unsqueeze(0).float(), joints_num)
|
| 518 |
+
if np.isnan(rec_ric_data.numpy()).any():
|
| 519 |
+
print(source_file)
|
| 520 |
+
continue
|
| 521 |
+
np.save(pjoin(save_dir1, name), rec_ric_data.squeeze().numpy())
|
| 522 |
+
np.save(pjoin(save_dir2, name), data)
|
| 523 |
+
frame_num += data.shape[0]
|
| 524 |
+
except Exception as e:
|
| 525 |
+
print(source_file)
|
| 526 |
+
print(e)
|
| 527 |
+
|
| 528 |
+
print('Total clips: %d, Frames: %d, Duration: %fm' %
|
| 529 |
+
(len(source_list), frame_num, frame_num / 12.5 / 60))
|
main/data_loaders/humanml/utils/get_opt.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from argparse import Namespace
|
| 3 |
+
import re
|
| 4 |
+
from os.path import join as pjoin
|
| 5 |
+
from data_loaders.humanml.utils.word_vectorizer import POS_enumerator
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def is_float(numStr):
|
| 9 |
+
flag = False
|
| 10 |
+
numStr = str(numStr).strip().lstrip('-').lstrip('+') # 去除正数(+)、负数(-)符号
|
| 11 |
+
try:
|
| 12 |
+
reg = re.compile(r'^[-+]?[0-9]+\.[0-9]+$')
|
| 13 |
+
res = reg.match(str(numStr))
|
| 14 |
+
if res:
|
| 15 |
+
flag = True
|
| 16 |
+
except Exception as ex:
|
| 17 |
+
print("is_float() - error: " + str(ex))
|
| 18 |
+
return flag
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def is_number(numStr):
|
| 22 |
+
flag = False
|
| 23 |
+
numStr = str(numStr).strip().lstrip('-').lstrip('+') # 去除正数(+)、负数(-)符号
|
| 24 |
+
if str(numStr).isdigit():
|
| 25 |
+
flag = True
|
| 26 |
+
return flag
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def get_opt(opt_path, device):
|
| 30 |
+
opt = Namespace()
|
| 31 |
+
opt_dict = vars(opt)
|
| 32 |
+
|
| 33 |
+
skip = ('-------------- End ----------------',
|
| 34 |
+
'------------ Options -------------',
|
| 35 |
+
'\n')
|
| 36 |
+
print('Reading', opt_path)
|
| 37 |
+
with open(opt_path) as f:
|
| 38 |
+
for line in f:
|
| 39 |
+
if line.strip() not in skip:
|
| 40 |
+
# print(line.strip())
|
| 41 |
+
key, value = line.strip().split(': ')
|
| 42 |
+
if value in ('True', 'False'):
|
| 43 |
+
opt_dict[key] = bool(value)
|
| 44 |
+
elif is_float(value):
|
| 45 |
+
opt_dict[key] = float(value)
|
| 46 |
+
elif is_number(value):
|
| 47 |
+
opt_dict[key] = int(value)
|
| 48 |
+
else:
|
| 49 |
+
opt_dict[key] = str(value)
|
| 50 |
+
|
| 51 |
+
# print(opt)
|
| 52 |
+
opt_dict['which_epoch'] = 'latest'
|
| 53 |
+
opt.save_root = pjoin(opt.checkpoints_dir, opt.dataset_name, opt.name)
|
| 54 |
+
opt.model_dir = pjoin(opt.save_root, 'model')
|
| 55 |
+
opt.meta_dir = pjoin(opt.save_root, 'meta')
|
| 56 |
+
|
| 57 |
+
if opt.dataset_name == 't2m':
|
| 58 |
+
opt.data_root = './dataset/HumanML3D'
|
| 59 |
+
opt.motion_dir = pjoin(opt.data_root, 'new_joint_vecs')
|
| 60 |
+
opt.text_dir = pjoin(opt.data_root, 'texts')
|
| 61 |
+
opt.joints_num = 22
|
| 62 |
+
opt.dim_pose = 263
|
| 63 |
+
opt.max_motion_length = 196
|
| 64 |
+
elif opt.dataset_name == 'kit':
|
| 65 |
+
opt.data_root = './dataset/KIT-ML'
|
| 66 |
+
opt.motion_dir = pjoin(opt.data_root, 'new_joint_vecs')
|
| 67 |
+
opt.text_dir = pjoin(opt.data_root, 'texts')
|
| 68 |
+
opt.joints_num = 21
|
| 69 |
+
opt.dim_pose = 251
|
| 70 |
+
opt.max_motion_length = 196
|
| 71 |
+
else:
|
| 72 |
+
raise KeyError('Dataset not recognized')
|
| 73 |
+
|
| 74 |
+
opt.dim_word = 300
|
| 75 |
+
opt.num_classes = 200 // opt.unit_length
|
| 76 |
+
opt.dim_pos_ohot = len(POS_enumerator)
|
| 77 |
+
opt.is_train = False
|
| 78 |
+
opt.is_continue = False
|
| 79 |
+
opt.device = device
|
| 80 |
+
|
| 81 |
+
return opt
|
main/data_loaders/humanml/utils/metrics.py
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from scipy import linalg
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
# (X - X_train)*(X - X_train) = -2X*X_train + X*X + X_train*X_train
|
| 6 |
+
def euclidean_distance_matrix(matrix1, matrix2):
|
| 7 |
+
"""
|
| 8 |
+
Params:
|
| 9 |
+
-- matrix1: N1 x D
|
| 10 |
+
-- matrix2: N2 x D
|
| 11 |
+
Returns:
|
| 12 |
+
-- dist: N1 x N2
|
| 13 |
+
dist[i, j] == distance(matrix1[i], matrix2[j])
|
| 14 |
+
"""
|
| 15 |
+
assert matrix1.shape[1] == matrix2.shape[1]
|
| 16 |
+
d1 = -2 * np.dot(matrix1, matrix2.T) # shape (num_test, num_train)
|
| 17 |
+
d2 = np.sum(np.square(matrix1), axis=1, keepdims=True) # shape (num_test, 1)
|
| 18 |
+
d3 = np.sum(np.square(matrix2), axis=1) # shape (num_train, )
|
| 19 |
+
dists = np.sqrt(d1 + d2 + d3) # broadcasting
|
| 20 |
+
return dists
|
| 21 |
+
|
| 22 |
+
def calculate_top_k(mat, top_k):
|
| 23 |
+
size = mat.shape[0]
|
| 24 |
+
gt_mat = np.expand_dims(np.arange(size), 1).repeat(size, 1)
|
| 25 |
+
bool_mat = (mat == gt_mat)
|
| 26 |
+
correct_vec = False
|
| 27 |
+
top_k_list = []
|
| 28 |
+
for i in range(top_k):
|
| 29 |
+
# print(correct_vec, bool_mat[:, i])
|
| 30 |
+
correct_vec = (correct_vec | bool_mat[:, i])
|
| 31 |
+
# print(correct_vec)
|
| 32 |
+
top_k_list.append(correct_vec[:, None])
|
| 33 |
+
top_k_mat = np.concatenate(top_k_list, axis=1)
|
| 34 |
+
return top_k_mat
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def calculate_R_precision(embedding1, embedding2, top_k, sum_all=False):
|
| 38 |
+
dist_mat = euclidean_distance_matrix(embedding1, embedding2)
|
| 39 |
+
argmax = np.argsort(dist_mat, axis=1)
|
| 40 |
+
top_k_mat = calculate_top_k(argmax, top_k)
|
| 41 |
+
if sum_all:
|
| 42 |
+
return top_k_mat.sum(axis=0)
|
| 43 |
+
else:
|
| 44 |
+
return top_k_mat
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def calculate_matching_score(embedding1, embedding2, sum_all=False):
|
| 48 |
+
assert len(embedding1.shape) == 2
|
| 49 |
+
assert embedding1.shape[0] == embedding2.shape[0]
|
| 50 |
+
assert embedding1.shape[1] == embedding2.shape[1]
|
| 51 |
+
|
| 52 |
+
dist = linalg.norm(embedding1 - embedding2, axis=1)
|
| 53 |
+
if sum_all:
|
| 54 |
+
return dist.sum(axis=0)
|
| 55 |
+
else:
|
| 56 |
+
return dist
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def calculate_activation_statistics(activations):
|
| 61 |
+
"""
|
| 62 |
+
Params:
|
| 63 |
+
-- activation: num_samples x dim_feat
|
| 64 |
+
Returns:
|
| 65 |
+
-- mu: dim_feat
|
| 66 |
+
-- sigma: dim_feat x dim_feat
|
| 67 |
+
"""
|
| 68 |
+
mu = np.mean(activations, axis=0)
|
| 69 |
+
cov = np.cov(activations, rowvar=False)
|
| 70 |
+
return mu, cov
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def calculate_diversity(activation, diversity_times):
|
| 74 |
+
assert len(activation.shape) == 2
|
| 75 |
+
assert activation.shape[0] > diversity_times
|
| 76 |
+
num_samples = activation.shape[0]
|
| 77 |
+
|
| 78 |
+
first_indices = np.random.choice(num_samples, diversity_times, replace=False)
|
| 79 |
+
second_indices = np.random.choice(num_samples, diversity_times, replace=False)
|
| 80 |
+
dist = linalg.norm(activation[first_indices] - activation[second_indices], axis=1)
|
| 81 |
+
return dist.mean()
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def calculate_multimodality(activation, multimodality_times):
|
| 85 |
+
assert len(activation.shape) == 3
|
| 86 |
+
assert activation.shape[1] > multimodality_times
|
| 87 |
+
num_per_sent = activation.shape[1]
|
| 88 |
+
|
| 89 |
+
first_dices = np.random.choice(num_per_sent, multimodality_times, replace=False)
|
| 90 |
+
second_dices = np.random.choice(num_per_sent, multimodality_times, replace=False)
|
| 91 |
+
dist = linalg.norm(activation[:, first_dices] - activation[:, second_dices], axis=2)
|
| 92 |
+
return dist.mean()
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def calculate_frechet_distance(mu1, sigma1, mu2, sigma2, eps=1e-6):
|
| 96 |
+
"""Numpy implementation of the Frechet Distance.
|
| 97 |
+
The Frechet distance between two multivariate Gaussians X_1 ~ N(mu_1, C_1)
|
| 98 |
+
and X_2 ~ N(mu_2, C_2) is
|
| 99 |
+
d^2 = ||mu_1 - mu_2||^2 + Tr(C_1 + C_2 - 2*sqrt(C_1*C_2)).
|
| 100 |
+
Stable version by Dougal J. Sutherland.
|
| 101 |
+
Params:
|
| 102 |
+
-- mu1 : Numpy array containing the activations of a layer of the
|
| 103 |
+
inception net (like returned by the function 'get_predictions')
|
| 104 |
+
for generated samples.
|
| 105 |
+
-- mu2 : The sample mean over activations, precalculated on an
|
| 106 |
+
representative dataset set.
|
| 107 |
+
-- sigma1: The covariance matrix over activations for generated samples.
|
| 108 |
+
-- sigma2: The covariance matrix over activations, precalculated on an
|
| 109 |
+
representative dataset set.
|
| 110 |
+
Returns:
|
| 111 |
+
-- : The Frechet Distance.
|
| 112 |
+
"""
|
| 113 |
+
|
| 114 |
+
mu1 = np.atleast_1d(mu1)
|
| 115 |
+
mu2 = np.atleast_1d(mu2)
|
| 116 |
+
|
| 117 |
+
sigma1 = np.atleast_2d(sigma1)
|
| 118 |
+
sigma2 = np.atleast_2d(sigma2)
|
| 119 |
+
|
| 120 |
+
assert mu1.shape == mu2.shape, \
|
| 121 |
+
'Training and test mean vectors have different lengths'
|
| 122 |
+
assert sigma1.shape == sigma2.shape, \
|
| 123 |
+
'Training and test covariances have different dimensions'
|
| 124 |
+
|
| 125 |
+
diff = mu1 - mu2
|
| 126 |
+
|
| 127 |
+
# Product might be almost singular
|
| 128 |
+
covmean, _ = linalg.sqrtm(sigma1.dot(sigma2), disp=False)
|
| 129 |
+
if not np.isfinite(covmean).all():
|
| 130 |
+
msg = ('fid calculation produces singular product; '
|
| 131 |
+
'adding %s to diagonal of cov estimates') % eps
|
| 132 |
+
print(msg)
|
| 133 |
+
offset = np.eye(sigma1.shape[0]) * eps
|
| 134 |
+
covmean = linalg.sqrtm((sigma1 + offset).dot(sigma2 + offset))
|
| 135 |
+
|
| 136 |
+
# Numerical error might give slight imaginary component
|
| 137 |
+
if np.iscomplexobj(covmean):
|
| 138 |
+
if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
|
| 139 |
+
m = np.max(np.abs(covmean.imag))
|
| 140 |
+
raise ValueError('Imaginary component {}'.format(m))
|
| 141 |
+
covmean = covmean.real
|
| 142 |
+
|
| 143 |
+
tr_covmean = np.trace(covmean)
|
| 144 |
+
|
| 145 |
+
return (diff.dot(diff) + np.trace(sigma1) +
|
| 146 |
+
np.trace(sigma2) - 2 * tr_covmean)
|
main/data_loaders/humanml/utils/paramUtil.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
# Define a kinematic tree for the skeletal struture
|
| 4 |
+
kit_kinematic_chain = [[0, 11, 12, 13, 14, 15], [0, 16, 17, 18, 19, 20], [0, 1, 2, 3, 4], [3, 5, 6, 7], [3, 8, 9, 10]]
|
| 5 |
+
|
| 6 |
+
kit_raw_offsets = np.array(
|
| 7 |
+
[
|
| 8 |
+
[0, 0, 0],
|
| 9 |
+
[0, 1, 0],
|
| 10 |
+
[0, 1, 0],
|
| 11 |
+
[0, 1, 0],
|
| 12 |
+
[0, 1, 0],
|
| 13 |
+
[1, 0, 0],
|
| 14 |
+
[0, -1, 0],
|
| 15 |
+
[0, -1, 0],
|
| 16 |
+
[-1, 0, 0],
|
| 17 |
+
[0, -1, 0],
|
| 18 |
+
[0, -1, 0],
|
| 19 |
+
[1, 0, 0],
|
| 20 |
+
[0, -1, 0],
|
| 21 |
+
[0, -1, 0],
|
| 22 |
+
[0, 0, 1],
|
| 23 |
+
[0, 0, 1],
|
| 24 |
+
[-1, 0, 0],
|
| 25 |
+
[0, -1, 0],
|
| 26 |
+
[0, -1, 0],
|
| 27 |
+
[0, 0, 1],
|
| 28 |
+
[0, 0, 1]
|
| 29 |
+
]
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
t2m_raw_offsets = np.array([[0,0,0],
|
| 33 |
+
[1,0,0],
|
| 34 |
+
[-1,0,0],
|
| 35 |
+
[0,1,0],
|
| 36 |
+
[0,-1,0],
|
| 37 |
+
[0,-1,0],
|
| 38 |
+
[0,1,0],
|
| 39 |
+
[0,-1,0],
|
| 40 |
+
[0,-1,0],
|
| 41 |
+
[0,1,0],
|
| 42 |
+
[0,0,1],
|
| 43 |
+
[0,0,1],
|
| 44 |
+
[0,1,0],
|
| 45 |
+
[1,0,0],
|
| 46 |
+
[-1,0,0],
|
| 47 |
+
[0,0,1],
|
| 48 |
+
[0,-1,0],
|
| 49 |
+
[0,-1,0],
|
| 50 |
+
[0,-1,0],
|
| 51 |
+
[0,-1,0],
|
| 52 |
+
[0,-1,0],
|
| 53 |
+
[0,-1,0]])
|
| 54 |
+
|
| 55 |
+
t2m_kinematic_chain = [[0, 2, 5, 8, 11], [0, 1, 4, 7, 10], [0, 3, 6, 9, 12, 15], [9, 14, 17, 19, 21], [9, 13, 16, 18, 20]]
|
| 56 |
+
t2m_left_hand_chain = [[20, 22, 23, 24], [20, 34, 35, 36], [20, 25, 26, 27], [20, 31, 32, 33], [20, 28, 29, 30]]
|
| 57 |
+
t2m_right_hand_chain = [[21, 43, 44, 45], [21, 46, 47, 48], [21, 40, 41, 42], [21, 37, 38, 39], [21, 49, 50, 51]]
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
kit_tgt_skel_id = '03950'
|
| 61 |
+
|
| 62 |
+
t2m_tgt_skel_id = '000021'
|
| 63 |
+
|
main/data_loaders/humanml/utils/plot_script.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import numpy as np
|
| 3 |
+
import matplotlib
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
from mpl_toolkits.mplot3d import Axes3D
|
| 6 |
+
from matplotlib.animation import FuncAnimation, FFMpegFileWriter
|
| 7 |
+
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
|
| 8 |
+
import mpl_toolkits.mplot3d.axes3d as p3
|
| 9 |
+
# import cv2
|
| 10 |
+
from textwrap import wrap
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def list_cut_average(ll, intervals):
|
| 14 |
+
if intervals == 1:
|
| 15 |
+
return ll
|
| 16 |
+
|
| 17 |
+
bins = math.ceil(len(ll) * 1.0 / intervals)
|
| 18 |
+
ll_new = []
|
| 19 |
+
for i in range(bins):
|
| 20 |
+
l_low = intervals * i
|
| 21 |
+
l_high = l_low + intervals
|
| 22 |
+
l_high = l_high if l_high < len(ll) else len(ll)
|
| 23 |
+
ll_new.append(np.mean(ll[l_low:l_high]))
|
| 24 |
+
return ll_new
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def plot_3d_motion(save_path, kinematic_tree, joints, title, dataset, figsize=(3, 3), fps=120, radius=3,
|
| 28 |
+
vis_mode='default', gt_frames=[]):
|
| 29 |
+
matplotlib.use('Agg')
|
| 30 |
+
|
| 31 |
+
title = '\n'.join(wrap(title, 20))
|
| 32 |
+
|
| 33 |
+
def init():
|
| 34 |
+
ax.set_xlim3d([-radius / 2, radius / 2])
|
| 35 |
+
ax.set_ylim3d([0, radius])
|
| 36 |
+
ax.set_zlim3d([-radius / 3., radius * 2 / 3.])
|
| 37 |
+
# print(title)
|
| 38 |
+
fig.suptitle(title, fontsize=10)
|
| 39 |
+
ax.grid(b=False)
|
| 40 |
+
|
| 41 |
+
def plot_xzPlane(minx, maxx, miny, minz, maxz):
|
| 42 |
+
## Plot a plane XZ
|
| 43 |
+
verts = [
|
| 44 |
+
[minx, miny, minz],
|
| 45 |
+
[minx, miny, maxz],
|
| 46 |
+
[maxx, miny, maxz],
|
| 47 |
+
[maxx, miny, minz]
|
| 48 |
+
]
|
| 49 |
+
xz_plane = Poly3DCollection([verts])
|
| 50 |
+
xz_plane.set_facecolor((0.5, 0.5, 0.5, 0.5))
|
| 51 |
+
ax.add_collection3d(xz_plane)
|
| 52 |
+
|
| 53 |
+
# return ax
|
| 54 |
+
|
| 55 |
+
# (seq_len, joints_num, 3)
|
| 56 |
+
data = joints.copy().reshape(len(joints), -1, 3)
|
| 57 |
+
|
| 58 |
+
# preparation related to specific datasets
|
| 59 |
+
if dataset == 'kit':
|
| 60 |
+
data *= 0.003 # scale for visualization
|
| 61 |
+
elif dataset == 'humanml':
|
| 62 |
+
data *= 1.3 # scale for visualization
|
| 63 |
+
elif dataset in ['humanact12', 'uestc']:
|
| 64 |
+
data *= -1.5 # reverse axes, scale for visualization
|
| 65 |
+
|
| 66 |
+
fig = plt.figure(figsize=figsize)
|
| 67 |
+
plt.tight_layout()
|
| 68 |
+
ax = p3.Axes3D(fig)
|
| 69 |
+
init()
|
| 70 |
+
MINS = data.min(axis=0).min(axis=0)
|
| 71 |
+
MAXS = data.max(axis=0).max(axis=0)
|
| 72 |
+
colors_blue = ["#4D84AA", "#5B9965", "#61CEB9", "#34C1E2", "#80B79A"] # GT color
|
| 73 |
+
colors_orange = ["#DD5A37", "#D69E00", "#B75A39", "#FF6D00", "#DDB50E"] # Generation color
|
| 74 |
+
colors = colors_orange
|
| 75 |
+
if vis_mode == 'upper_body': # lower body taken fixed to input motion
|
| 76 |
+
colors[0] = colors_blue[0]
|
| 77 |
+
colors[1] = colors_blue[1]
|
| 78 |
+
elif vis_mode == 'gt':
|
| 79 |
+
colors = colors_blue
|
| 80 |
+
|
| 81 |
+
frame_number = data.shape[0]
|
| 82 |
+
# print(dataset.shape)
|
| 83 |
+
|
| 84 |
+
height_offset = MINS[1]
|
| 85 |
+
data[:, :, 1] -= height_offset
|
| 86 |
+
trajec = data[:, 0, [0, 2]]
|
| 87 |
+
|
| 88 |
+
data[..., 0] -= data[:, 0:1, 0]
|
| 89 |
+
data[..., 2] -= data[:, 0:1, 2]
|
| 90 |
+
|
| 91 |
+
# print(trajec.shape)
|
| 92 |
+
|
| 93 |
+
def update(index):
|
| 94 |
+
# print(index)
|
| 95 |
+
ax.lines = []
|
| 96 |
+
ax.collections = []
|
| 97 |
+
ax.view_init(elev=120, azim=-90)
|
| 98 |
+
ax.dist = 7.5
|
| 99 |
+
# ax =
|
| 100 |
+
plot_xzPlane(MINS[0] - trajec[index, 0], MAXS[0] - trajec[index, 0], 0, MINS[2] - trajec[index, 1],
|
| 101 |
+
MAXS[2] - trajec[index, 1])
|
| 102 |
+
# ax.scatter(dataset[index, :22, 0], dataset[index, :22, 1], dataset[index, :22, 2], color='black', s=3)
|
| 103 |
+
|
| 104 |
+
# if index > 1:
|
| 105 |
+
# ax.plot3D(trajec[:index, 0] - trajec[index, 0], np.zeros_like(trajec[:index, 0]),
|
| 106 |
+
# trajec[:index, 1] - trajec[index, 1], linewidth=1.0,
|
| 107 |
+
# color='blue')
|
| 108 |
+
# # ax = plot_xzPlane(ax, MINS[0], MAXS[0], 0, MINS[2], MAXS[2])
|
| 109 |
+
|
| 110 |
+
used_colors = colors_blue if index in gt_frames else colors
|
| 111 |
+
for i, (chain, color) in enumerate(zip(kinematic_tree, used_colors)):
|
| 112 |
+
if i < 5:
|
| 113 |
+
linewidth = 4.0
|
| 114 |
+
else:
|
| 115 |
+
linewidth = 2.0
|
| 116 |
+
ax.plot3D(data[index, chain, 0], data[index, chain, 1], data[index, chain, 2], linewidth=linewidth,
|
| 117 |
+
color=color)
|
| 118 |
+
# print(trajec[:index, 0].shape)
|
| 119 |
+
|
| 120 |
+
plt.axis('off')
|
| 121 |
+
ax.set_xticklabels([])
|
| 122 |
+
ax.set_yticklabels([])
|
| 123 |
+
ax.set_zticklabels([])
|
| 124 |
+
|
| 125 |
+
ani = FuncAnimation(fig, update, frames=frame_number, interval=1000 / fps, repeat=False)
|
| 126 |
+
|
| 127 |
+
# writer = FFMpegFileWriter(fps=fps)
|
| 128 |
+
ani.save(save_path, fps=fps)
|
| 129 |
+
# ani = FuncAnimation(fig, update, frames=frame_number, interval=1000 / fps, repeat=False, init_func=init)
|
| 130 |
+
# ani.save(save_path, writer='pillow', fps=1000 / fps)
|
| 131 |
+
|
| 132 |
+
plt.close()
|
main/data_loaders/humanml/utils/utils.py
ADDED
|
@@ -0,0 +1,168 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import numpy as np
|
| 3 |
+
# import cv2
|
| 4 |
+
from PIL import Image
|
| 5 |
+
from data_loaders.humanml.utils import paramUtil
|
| 6 |
+
import math
|
| 7 |
+
import time
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
from scipy.ndimage import gaussian_filter
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def mkdir(path):
|
| 13 |
+
if not os.path.exists(path):
|
| 14 |
+
os.makedirs(path)
|
| 15 |
+
|
| 16 |
+
COLORS = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0],
|
| 17 |
+
[0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255],
|
| 18 |
+
[170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]]
|
| 19 |
+
|
| 20 |
+
MISSING_VALUE = -1
|
| 21 |
+
|
| 22 |
+
def save_image(image_numpy, image_path):
|
| 23 |
+
img_pil = Image.fromarray(image_numpy)
|
| 24 |
+
img_pil.save(image_path)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def save_logfile(log_loss, save_path):
|
| 28 |
+
with open(save_path, 'wt') as f:
|
| 29 |
+
for k, v in log_loss.items():
|
| 30 |
+
w_line = k
|
| 31 |
+
for digit in v:
|
| 32 |
+
w_line += ' %.3f' % digit
|
| 33 |
+
f.write(w_line + '\n')
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def print_current_loss(start_time, niter_state, losses, epoch=None, sub_epoch=None,
|
| 37 |
+
inner_iter=None, tf_ratio=None, sl_steps=None):
|
| 38 |
+
|
| 39 |
+
def as_minutes(s):
|
| 40 |
+
m = math.floor(s / 60)
|
| 41 |
+
s -= m * 60
|
| 42 |
+
return '%dm %ds' % (m, s)
|
| 43 |
+
|
| 44 |
+
def time_since(since, percent):
|
| 45 |
+
now = time.time()
|
| 46 |
+
s = now - since
|
| 47 |
+
es = s / percent
|
| 48 |
+
rs = es - s
|
| 49 |
+
return '%s (- %s)' % (as_minutes(s), as_minutes(rs))
|
| 50 |
+
|
| 51 |
+
if epoch is not None:
|
| 52 |
+
print('epoch: %3d niter: %6d sub_epoch: %2d inner_iter: %4d' % (epoch, niter_state, sub_epoch, inner_iter), end=" ")
|
| 53 |
+
|
| 54 |
+
# message = '%s niter: %d completed: %3d%%)' % (time_since(start_time, niter_state / total_niters),
|
| 55 |
+
# niter_state, niter_state / total_niters * 100)
|
| 56 |
+
now = time.time()
|
| 57 |
+
message = '%s'%(as_minutes(now - start_time))
|
| 58 |
+
|
| 59 |
+
for k, v in losses.items():
|
| 60 |
+
message += ' %s: %.4f ' % (k, v)
|
| 61 |
+
message += ' sl_length:%2d tf_ratio:%.2f'%(sl_steps, tf_ratio)
|
| 62 |
+
print(message)
|
| 63 |
+
|
| 64 |
+
def print_current_loss_decomp(start_time, niter_state, total_niters, losses, epoch=None, inner_iter=None):
|
| 65 |
+
|
| 66 |
+
def as_minutes(s):
|
| 67 |
+
m = math.floor(s / 60)
|
| 68 |
+
s -= m * 60
|
| 69 |
+
return '%dm %ds' % (m, s)
|
| 70 |
+
|
| 71 |
+
def time_since(since, percent):
|
| 72 |
+
now = time.time()
|
| 73 |
+
s = now - since
|
| 74 |
+
es = s / percent
|
| 75 |
+
rs = es - s
|
| 76 |
+
return '%s (- %s)' % (as_minutes(s), as_minutes(rs))
|
| 77 |
+
|
| 78 |
+
print('epoch: %03d inner_iter: %5d' % (epoch, inner_iter), end=" ")
|
| 79 |
+
# now = time.time()
|
| 80 |
+
message = '%s niter: %07d completed: %3d%%)'%(time_since(start_time, niter_state / total_niters), niter_state, niter_state / total_niters * 100)
|
| 81 |
+
for k, v in losses.items():
|
| 82 |
+
message += ' %s: %.4f ' % (k, v)
|
| 83 |
+
print(message)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def compose_gif_img_list(img_list, fp_out, duration):
|
| 87 |
+
img, *imgs = [Image.fromarray(np.array(image)) for image in img_list]
|
| 88 |
+
img.save(fp=fp_out, format='GIF', append_images=imgs, optimize=False,
|
| 89 |
+
save_all=True, loop=0, duration=duration)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def save_images(visuals, image_path):
|
| 93 |
+
if not os.path.exists(image_path):
|
| 94 |
+
os.makedirs(image_path)
|
| 95 |
+
|
| 96 |
+
for i, (label, img_numpy) in enumerate(visuals.items()):
|
| 97 |
+
img_name = '%d_%s.jpg' % (i, label)
|
| 98 |
+
save_path = os.path.join(image_path, img_name)
|
| 99 |
+
save_image(img_numpy, save_path)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def save_images_test(visuals, image_path, from_name, to_name):
|
| 103 |
+
if not os.path.exists(image_path):
|
| 104 |
+
os.makedirs(image_path)
|
| 105 |
+
|
| 106 |
+
for i, (label, img_numpy) in enumerate(visuals.items()):
|
| 107 |
+
img_name = "%s_%s_%s" % (from_name, to_name, label)
|
| 108 |
+
save_path = os.path.join(image_path, img_name)
|
| 109 |
+
save_image(img_numpy, save_path)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def compose_and_save_img(img_list, save_dir, img_name, col=4, row=1, img_size=(256, 200)):
|
| 113 |
+
# print(col, row)
|
| 114 |
+
compose_img = compose_image(img_list, col, row, img_size)
|
| 115 |
+
if not os.path.exists(save_dir):
|
| 116 |
+
os.makedirs(save_dir)
|
| 117 |
+
img_path = os.path.join(save_dir, img_name)
|
| 118 |
+
# print(img_path)
|
| 119 |
+
compose_img.save(img_path)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def compose_image(img_list, col, row, img_size):
|
| 123 |
+
to_image = Image.new('RGB', (col * img_size[0], row * img_size[1]))
|
| 124 |
+
for y in range(0, row):
|
| 125 |
+
for x in range(0, col):
|
| 126 |
+
from_img = Image.fromarray(img_list[y * col + x])
|
| 127 |
+
# print((x * img_size[0], y*img_size[1],
|
| 128 |
+
# (x + 1) * img_size[0], (y + 1) * img_size[1]))
|
| 129 |
+
paste_area = (x * img_size[0], y*img_size[1],
|
| 130 |
+
(x + 1) * img_size[0], (y + 1) * img_size[1])
|
| 131 |
+
to_image.paste(from_img, paste_area)
|
| 132 |
+
# to_image[y*img_size[1]:(y + 1) * img_size[1], x * img_size[0] :(x + 1) * img_size[0]] = from_img
|
| 133 |
+
return to_image
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def plot_loss_curve(losses, save_path, intervals=500):
|
| 137 |
+
plt.figure(figsize=(10, 5))
|
| 138 |
+
plt.title("Loss During Training")
|
| 139 |
+
for key in losses.keys():
|
| 140 |
+
plt.plot(list_cut_average(losses[key], intervals), label=key)
|
| 141 |
+
plt.xlabel("Iterations/" + str(intervals))
|
| 142 |
+
plt.ylabel("Loss")
|
| 143 |
+
plt.legend()
|
| 144 |
+
plt.savefig(save_path)
|
| 145 |
+
plt.show()
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def list_cut_average(ll, intervals):
|
| 149 |
+
if intervals == 1:
|
| 150 |
+
return ll
|
| 151 |
+
|
| 152 |
+
bins = math.ceil(len(ll) * 1.0 / intervals)
|
| 153 |
+
ll_new = []
|
| 154 |
+
for i in range(bins):
|
| 155 |
+
l_low = intervals * i
|
| 156 |
+
l_high = l_low + intervals
|
| 157 |
+
l_high = l_high if l_high < len(ll) else len(ll)
|
| 158 |
+
ll_new.append(np.mean(ll[l_low:l_high]))
|
| 159 |
+
return ll_new
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def motion_temporal_filter(motion, sigma=1):
|
| 163 |
+
motion = motion.reshape(motion.shape[0], -1)
|
| 164 |
+
# print(motion.shape)
|
| 165 |
+
for i in range(motion.shape[1]):
|
| 166 |
+
motion[:, i] = gaussian_filter(motion[:, i], sigma=sigma, mode="nearest")
|
| 167 |
+
return motion.reshape(motion.shape[0], -1, 3)
|
| 168 |
+
|
main/data_loaders/humanml/utils/word_vectorizer.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import pickle
|
| 3 |
+
from os.path import join as pjoin
|
| 4 |
+
|
| 5 |
+
POS_enumerator = {
|
| 6 |
+
'VERB': 0,
|
| 7 |
+
'NOUN': 1,
|
| 8 |
+
'DET': 2,
|
| 9 |
+
'ADP': 3,
|
| 10 |
+
'NUM': 4,
|
| 11 |
+
'AUX': 5,
|
| 12 |
+
'PRON': 6,
|
| 13 |
+
'ADJ': 7,
|
| 14 |
+
'ADV': 8,
|
| 15 |
+
'Loc_VIP': 9,
|
| 16 |
+
'Body_VIP': 10,
|
| 17 |
+
'Obj_VIP': 11,
|
| 18 |
+
'Act_VIP': 12,
|
| 19 |
+
'Desc_VIP': 13,
|
| 20 |
+
'OTHER': 14,
|
| 21 |
+
}
|
| 22 |
+
|
| 23 |
+
Loc_list = ('left', 'right', 'clockwise', 'counterclockwise', 'anticlockwise', 'forward', 'back', 'backward',
|
| 24 |
+
'up', 'down', 'straight', 'curve')
|
| 25 |
+
|
| 26 |
+
Body_list = ('arm', 'chin', 'foot', 'feet', 'face', 'hand', 'mouth', 'leg', 'waist', 'eye', 'knee', 'shoulder', 'thigh')
|
| 27 |
+
|
| 28 |
+
Obj_List = ('stair', 'dumbbell', 'chair', 'window', 'floor', 'car', 'ball', 'handrail', 'baseball', 'basketball')
|
| 29 |
+
|
| 30 |
+
Act_list = ('walk', 'run', 'swing', 'pick', 'bring', 'kick', 'put', 'squat', 'throw', 'hop', 'dance', 'jump', 'turn',
|
| 31 |
+
'stumble', 'dance', 'stop', 'sit', 'lift', 'lower', 'raise', 'wash', 'stand', 'kneel', 'stroll',
|
| 32 |
+
'rub', 'bend', 'balance', 'flap', 'jog', 'shuffle', 'lean', 'rotate', 'spin', 'spread', 'climb')
|
| 33 |
+
|
| 34 |
+
Desc_list = ('slowly', 'carefully', 'fast', 'careful', 'slow', 'quickly', 'happy', 'angry', 'sad', 'happily',
|
| 35 |
+
'angrily', 'sadly')
|
| 36 |
+
|
| 37 |
+
VIP_dict = {
|
| 38 |
+
'Loc_VIP': Loc_list,
|
| 39 |
+
'Body_VIP': Body_list,
|
| 40 |
+
'Obj_VIP': Obj_List,
|
| 41 |
+
'Act_VIP': Act_list,
|
| 42 |
+
'Desc_VIP': Desc_list,
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class WordVectorizer(object):
|
| 47 |
+
def __init__(self, meta_root, prefix):
|
| 48 |
+
vectors = np.load(pjoin(meta_root, '%s_data.npy'%prefix))
|
| 49 |
+
words = pickle.load(open(pjoin(meta_root, '%s_words.pkl'%prefix), 'rb'))
|
| 50 |
+
word2idx = pickle.load(open(pjoin(meta_root, '%s_idx.pkl'%prefix), 'rb'))
|
| 51 |
+
self.word2vec = {w: vectors[word2idx[w]] for w in words}
|
| 52 |
+
|
| 53 |
+
def _get_pos_ohot(self, pos):
|
| 54 |
+
pos_vec = np.zeros(len(POS_enumerator))
|
| 55 |
+
if pos in POS_enumerator:
|
| 56 |
+
pos_vec[POS_enumerator[pos]] = 1
|
| 57 |
+
else:
|
| 58 |
+
pos_vec[POS_enumerator['OTHER']] = 1
|
| 59 |
+
return pos_vec
|
| 60 |
+
|
| 61 |
+
def __len__(self):
|
| 62 |
+
return len(self.word2vec)
|
| 63 |
+
|
| 64 |
+
def __getitem__(self, item):
|
| 65 |
+
word, pos = item.split('/')
|
| 66 |
+
if word in self.word2vec:
|
| 67 |
+
word_vec = self.word2vec[word]
|
| 68 |
+
vip_pos = None
|
| 69 |
+
for key, values in VIP_dict.items():
|
| 70 |
+
if word in values:
|
| 71 |
+
vip_pos = key
|
| 72 |
+
break
|
| 73 |
+
if vip_pos is not None:
|
| 74 |
+
pos_vec = self._get_pos_ohot(vip_pos)
|
| 75 |
+
else:
|
| 76 |
+
pos_vec = self._get_pos_ohot(pos)
|
| 77 |
+
else:
|
| 78 |
+
word_vec = self.word2vec['unk']
|
| 79 |
+
pos_vec = self._get_pos_ohot('OTHER')
|
| 80 |
+
return word_vec, pos_vec
|
main/data_loaders/humanml_utils.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
HML_JOINT_NAMES = [
|
| 4 |
+
'pelvis',
|
| 5 |
+
'left_hip',
|
| 6 |
+
'right_hip',
|
| 7 |
+
'spine1',
|
| 8 |
+
'left_knee',
|
| 9 |
+
'right_knee',
|
| 10 |
+
'spine2',
|
| 11 |
+
'left_ankle',
|
| 12 |
+
'right_ankle',
|
| 13 |
+
'spine3',
|
| 14 |
+
'left_foot',
|
| 15 |
+
'right_foot',
|
| 16 |
+
'neck',
|
| 17 |
+
'left_collar',
|
| 18 |
+
'right_collar',
|
| 19 |
+
'head',
|
| 20 |
+
'left_shoulder',
|
| 21 |
+
'right_shoulder',
|
| 22 |
+
'left_elbow',
|
| 23 |
+
'right_elbow',
|
| 24 |
+
'left_wrist',
|
| 25 |
+
'right_wrist',
|
| 26 |
+
]
|
| 27 |
+
|
| 28 |
+
NUM_HML_JOINTS = len(HML_JOINT_NAMES) # 22 SMPLH body joints
|
| 29 |
+
|
| 30 |
+
HML_LOWER_BODY_JOINTS = [HML_JOINT_NAMES.index(name) for name in ['pelvis', 'left_hip', 'right_hip', 'left_knee', 'right_knee', 'left_ankle', 'right_ankle', 'left_foot', 'right_foot',]]
|
| 31 |
+
SMPL_UPPER_BODY_JOINTS = [i for i in range(len(HML_JOINT_NAMES)) if i not in HML_LOWER_BODY_JOINTS]
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
# Recover global angle and positions for rotation data
|
| 35 |
+
# root_rot_velocity (B, seq_len, 1)
|
| 36 |
+
# root_linear_velocity (B, seq_len, 2)
|
| 37 |
+
# root_y (B, seq_len, 1)
|
| 38 |
+
# ric_data (B, seq_len, (joint_num - 1)*3)
|
| 39 |
+
# rot_data (B, seq_len, (joint_num - 1)*6)
|
| 40 |
+
# local_velocity (B, seq_len, joint_num*3)
|
| 41 |
+
# foot contact (B, seq_len, 4)
|
| 42 |
+
HML_ROOT_BINARY = np.array([True] + [False] * (NUM_HML_JOINTS-1))
|
| 43 |
+
HML_ROOT_MASK = np.concatenate(([True]*(1+2+1),
|
| 44 |
+
HML_ROOT_BINARY[1:].repeat(3),
|
| 45 |
+
HML_ROOT_BINARY[1:].repeat(6),
|
| 46 |
+
HML_ROOT_BINARY.repeat(3),
|
| 47 |
+
[False] * 4))
|
| 48 |
+
HML_LOWER_BODY_JOINTS_BINARY = np.array([i in HML_LOWER_BODY_JOINTS for i in range(NUM_HML_JOINTS)])
|
| 49 |
+
HML_LOWER_BODY_MASK = np.concatenate(([True]*(1+2+1),
|
| 50 |
+
HML_LOWER_BODY_JOINTS_BINARY[1:].repeat(3),
|
| 51 |
+
HML_LOWER_BODY_JOINTS_BINARY[1:].repeat(6),
|
| 52 |
+
HML_LOWER_BODY_JOINTS_BINARY.repeat(3),
|
| 53 |
+
[True]*4))
|
| 54 |
+
HML_UPPER_BODY_MASK = ~HML_LOWER_BODY_MASK
|
main/data_loaders/tensors.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pdb
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
def lengths_to_mask(lengths, max_len):
|
| 6 |
+
# max_len = max(lengths)
|
| 7 |
+
mask = torch.arange(max_len, device=lengths.device).expand(len(lengths), max_len) < lengths.unsqueeze(1)
|
| 8 |
+
return mask
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def collate_tensors(batch):
|
| 12 |
+
dims = batch[0].dim()
|
| 13 |
+
max_size = [max([b.size(i) for b in batch]) for i in range(dims)]
|
| 14 |
+
size = (len(batch),) + tuple(max_size)
|
| 15 |
+
canvas = batch[0].new_zeros(size=size)
|
| 16 |
+
for i, b in enumerate(batch):
|
| 17 |
+
sub_tensor = canvas[i]
|
| 18 |
+
for d in range(dims):
|
| 19 |
+
sub_tensor = sub_tensor.narrow(d, 0, b.size(d))
|
| 20 |
+
sub_tensor.add_(b)
|
| 21 |
+
return canvas
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def collate(batch):
|
| 25 |
+
notnone_batches = [b for b in batch if b is not None]
|
| 26 |
+
databatch = [b['inp'] for b in notnone_batches]
|
| 27 |
+
if 'lengths' in notnone_batches[0]:
|
| 28 |
+
lenbatch = [b['lengths'] for b in notnone_batches]
|
| 29 |
+
else:
|
| 30 |
+
lenbatch = [len(b['inp'][0][0]) for b in notnone_batches]
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
databatchTensor = collate_tensors(databatch)
|
| 34 |
+
lenbatchTensor = torch.as_tensor(lenbatch)
|
| 35 |
+
maskbatchTensor = lengths_to_mask(lenbatchTensor, databatchTensor.shape[-1]).unsqueeze(1).unsqueeze(1) # unqueeze for broadcasting
|
| 36 |
+
|
| 37 |
+
motion = databatchTensor
|
| 38 |
+
cond = {'y': {'mask': maskbatchTensor, 'lengths': lenbatchTensor}}
|
| 39 |
+
|
| 40 |
+
if 'text' in notnone_batches[0]:
|
| 41 |
+
textbatch = [b['text'] for b in notnone_batches]
|
| 42 |
+
cond['y'].update({'text': textbatch})
|
| 43 |
+
|
| 44 |
+
if 'tokens' in notnone_batches[0]:
|
| 45 |
+
textbatch = [b['tokens'] for b in notnone_batches]
|
| 46 |
+
cond['y'].update({'tokens': textbatch})
|
| 47 |
+
|
| 48 |
+
if 'action' in notnone_batches[0]:
|
| 49 |
+
actionbatch = [b['action'] for b in notnone_batches]
|
| 50 |
+
cond['y'].update({'action': torch.as_tensor(actionbatch).unsqueeze(1)})
|
| 51 |
+
|
| 52 |
+
# collate action textual names
|
| 53 |
+
if 'action_text' in notnone_batches[0]:
|
| 54 |
+
action_text = [b['action_text']for b in notnone_batches]
|
| 55 |
+
cond['y'].update({'action_text': action_text})
|
| 56 |
+
|
| 57 |
+
return motion, cond
|
| 58 |
+
|
| 59 |
+
# an adapter to our collate func
|
| 60 |
+
def t2m_collate(batch):
|
| 61 |
+
# batch.sort(key=lambda x: x[3], reverse=True)
|
| 62 |
+
adapted_batch = [{
|
| 63 |
+
'inp': torch.tensor(b[4].T).float().unsqueeze(1), # [seqlen, J] -> [J, 1, seqlen]
|
| 64 |
+
'text': b[2], #b[0]['caption']
|
| 65 |
+
'tokens': b[6],
|
| 66 |
+
'lengths': b[5],
|
| 67 |
+
} for b in batch]
|
| 68 |
+
return collate(adapted_batch)
|
| 69 |
+
|
| 70 |
+
|
main/dataset/README.md
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Data
|
| 2 |
+
|
| 3 |
+
* Data dirs should be placed here.
|
| 4 |
+
|
| 5 |
+
* The `opt` files are configurations for how to read the data according to [text-to-motion](https://github.com/EricGuo5513/text-to-motion).
|
| 6 |
+
* The `*_mean.npy` and `*_std.npy` files, are stats used for evaluation only, according to [text-to-motion](https://github.com/EricGuo5513/text-to-motion).
|
main/dataset/humanml_opt.txt
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
------------ Options -------------
|
| 2 |
+
batch_size: 32
|
| 3 |
+
checkpoints_dir: ./checkpoints
|
| 4 |
+
dataset_name: t2m
|
| 5 |
+
decomp_name: Decomp_SP001_SM001_H512
|
| 6 |
+
dim_att_vec: 512
|
| 7 |
+
dim_dec_hidden: 1024
|
| 8 |
+
dim_movement2_dec_hidden: 512
|
| 9 |
+
dim_movement_dec_hidden: 512
|
| 10 |
+
dim_movement_enc_hidden: 512
|
| 11 |
+
dim_movement_latent: 512
|
| 12 |
+
dim_msd_hidden: 512
|
| 13 |
+
dim_pos_hidden: 1024
|
| 14 |
+
dim_pri_hidden: 1024
|
| 15 |
+
dim_seq_de_hidden: 512
|
| 16 |
+
dim_seq_en_hidden: 512
|
| 17 |
+
dim_text_hidden: 512
|
| 18 |
+
dim_z: 128
|
| 19 |
+
early_stop_count: 3
|
| 20 |
+
estimator_mod: bigru
|
| 21 |
+
eval_every_e: 5
|
| 22 |
+
feat_bias: 5
|
| 23 |
+
fixed_steps: 5
|
| 24 |
+
gpu_id: 3
|
| 25 |
+
input_z: False
|
| 26 |
+
is_continue: True
|
| 27 |
+
is_train: True
|
| 28 |
+
lambda_fake: 10
|
| 29 |
+
lambda_gan_l: 0.1
|
| 30 |
+
lambda_gan_mt: 0.1
|
| 31 |
+
lambda_gan_mv: 0.1
|
| 32 |
+
lambda_kld: 0.01
|
| 33 |
+
lambda_rec: 1
|
| 34 |
+
lambda_rec_init: 1
|
| 35 |
+
lambda_rec_mot: 1
|
| 36 |
+
lambda_rec_mov: 1
|
| 37 |
+
log_every: 50
|
| 38 |
+
lr: 0.0002
|
| 39 |
+
max_sub_epoch: 50
|
| 40 |
+
max_text_len: 20
|
| 41 |
+
n_layers_dec: 1
|
| 42 |
+
n_layers_msd: 2
|
| 43 |
+
n_layers_pos: 1
|
| 44 |
+
n_layers_pri: 1
|
| 45 |
+
n_layers_seq_de: 2
|
| 46 |
+
n_layers_seq_en: 1
|
| 47 |
+
name: Comp_v6_KLD01
|
| 48 |
+
num_experts: 4
|
| 49 |
+
save_every_e: 10
|
| 50 |
+
save_latest: 500
|
| 51 |
+
text_enc_mod: bigru
|
| 52 |
+
tf_ratio: 0.4
|
| 53 |
+
unit_length: 4
|
| 54 |
+
-------------- End ----------------
|
main/dataset/kit_mean.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e23fac51db2215ab5666324226be48f27efd6a6e7b22ebd17c28e0f056a7c22
|
| 3 |
+
size 2136
|
main/dataset/kit_opt.txt
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
------------ Options -------------
|
| 2 |
+
batch_size: 32
|
| 3 |
+
checkpoints_dir: ./checkpoints
|
| 4 |
+
dataset_name: kit
|
| 5 |
+
decomp_name: Decomp_SP001_SM001_H512
|
| 6 |
+
dim_att_vec: 512
|
| 7 |
+
dim_dec_hidden: 1024
|
| 8 |
+
dim_movement2_dec_hidden: 512
|
| 9 |
+
dim_movement_dec_hidden: 512
|
| 10 |
+
dim_movement_enc_hidden: 512
|
| 11 |
+
dim_movement_latent: 512
|
| 12 |
+
dim_msd_hidden: 512
|
| 13 |
+
dim_pos_hidden: 1024
|
| 14 |
+
dim_pri_hidden: 1024
|
| 15 |
+
dim_seq_de_hidden: 512
|
| 16 |
+
dim_seq_en_hidden: 512
|
| 17 |
+
dim_text_hidden: 512
|
| 18 |
+
dim_z: 128
|
| 19 |
+
early_stop_count: 3
|
| 20 |
+
estimator_mod: bigru
|
| 21 |
+
eval_every_e: 5
|
| 22 |
+
feat_bias: 5
|
| 23 |
+
fixed_steps: 5
|
| 24 |
+
gpu_id: 2
|
| 25 |
+
input_z: False
|
| 26 |
+
is_continue: True
|
| 27 |
+
is_train: True
|
| 28 |
+
lambda_fake: 10
|
| 29 |
+
lambda_gan_l: 0.1
|
| 30 |
+
lambda_gan_mt: 0.1
|
| 31 |
+
lambda_gan_mv: 0.1
|
| 32 |
+
lambda_kld: 0.005
|
| 33 |
+
lambda_rec: 1
|
| 34 |
+
lambda_rec_init: 1
|
| 35 |
+
lambda_rec_mot: 1
|
| 36 |
+
lambda_rec_mov: 1
|
| 37 |
+
log_every: 50
|
| 38 |
+
lr: 0.0002
|
| 39 |
+
max_sub_epoch: 50
|
| 40 |
+
max_text_len: 20
|
| 41 |
+
n_layers_dec: 1
|
| 42 |
+
n_layers_msd: 2
|
| 43 |
+
n_layers_pos: 1
|
| 44 |
+
n_layers_pri: 1
|
| 45 |
+
n_layers_seq_de: 2
|
| 46 |
+
n_layers_seq_en: 1
|
| 47 |
+
name: Comp_v6_KLD005
|
| 48 |
+
num_experts: 4
|
| 49 |
+
save_every_e: 10
|
| 50 |
+
save_latest: 500
|
| 51 |
+
text_enc_mod: bigru
|
| 52 |
+
tf_ratio: 0.4
|
| 53 |
+
unit_length: 4
|
| 54 |
+
-------------- End ----------------
|
main/dataset/kit_std.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:296a60656cea07e65ee64512d73d47c0412df0698b35194116330661be32fa90
|
| 3 |
+
size 2136
|
main/dataset/t2m_mean.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0bdb5ba69a3a9e34d71990db15bc535ebc024c8d95ddb5574196f96058faa7d3
|
| 3 |
+
size 2232
|
main/dataset/t2m_std.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6a5f7d60301c9465972fc225f8ad0ee8f957e7720431189123eb6d15873a9557
|
| 3 |
+
size 2232
|
main/diffusion/fp16_util.py
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Helpers to train with 16-bit precision.
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch as th
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
from torch._utils import _flatten_dense_tensors, _unflatten_dense_tensors
|
| 9 |
+
|
| 10 |
+
from diffusion import logger
|
| 11 |
+
|
| 12 |
+
INITIAL_LOG_LOSS_SCALE = 20.0
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def convert_module_to_f16(l):
|
| 16 |
+
"""
|
| 17 |
+
Convert primitive modules to float16.
|
| 18 |
+
"""
|
| 19 |
+
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Conv3d)):
|
| 20 |
+
l.weight.data = l.weight.data.half()
|
| 21 |
+
if l.bias is not None:
|
| 22 |
+
l.bias.data = l.bias.data.half()
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def convert_module_to_f32(l):
|
| 26 |
+
"""
|
| 27 |
+
Convert primitive modules to float32, undoing convert_module_to_f16().
|
| 28 |
+
"""
|
| 29 |
+
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Conv3d)):
|
| 30 |
+
l.weight.data = l.weight.data.float()
|
| 31 |
+
if l.bias is not None:
|
| 32 |
+
l.bias.data = l.bias.data.float()
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def make_master_params(param_groups_and_shapes):
|
| 36 |
+
"""
|
| 37 |
+
Copy model parameters into a (differently-shaped) list of full-precision
|
| 38 |
+
parameters.
|
| 39 |
+
"""
|
| 40 |
+
master_params = []
|
| 41 |
+
for param_group, shape in param_groups_and_shapes:
|
| 42 |
+
master_param = nn.Parameter(
|
| 43 |
+
_flatten_dense_tensors(
|
| 44 |
+
[param.detach().float() for (_, param) in param_group]
|
| 45 |
+
).view(shape)
|
| 46 |
+
)
|
| 47 |
+
master_param.requires_grad = True
|
| 48 |
+
master_params.append(master_param)
|
| 49 |
+
return master_params
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def model_grads_to_master_grads(param_groups_and_shapes, master_params):
|
| 53 |
+
"""
|
| 54 |
+
Copy the gradients from the model parameters into the master parameters
|
| 55 |
+
from make_master_params().
|
| 56 |
+
"""
|
| 57 |
+
for master_param, (param_group, shape) in zip(
|
| 58 |
+
master_params, param_groups_and_shapes
|
| 59 |
+
):
|
| 60 |
+
master_param.grad = _flatten_dense_tensors(
|
| 61 |
+
[param_grad_or_zeros(param) for (_, param) in param_group]
|
| 62 |
+
).view(shape)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def master_params_to_model_params(param_groups_and_shapes, master_params):
|
| 66 |
+
"""
|
| 67 |
+
Copy the master parameter data back into the model parameters.
|
| 68 |
+
"""
|
| 69 |
+
# Without copying to a list, if a generator is passed, this will
|
| 70 |
+
# silently not copy any parameters.
|
| 71 |
+
for master_param, (param_group, _) in zip(master_params, param_groups_and_shapes):
|
| 72 |
+
for (_, param), unflat_master_param in zip(
|
| 73 |
+
param_group, unflatten_master_params(param_group, master_param.view(-1))
|
| 74 |
+
):
|
| 75 |
+
param.detach().copy_(unflat_master_param)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def unflatten_master_params(param_group, master_param):
|
| 79 |
+
return _unflatten_dense_tensors(master_param, [param for (_, param) in param_group])
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def get_param_groups_and_shapes(named_model_params):
|
| 83 |
+
named_model_params = list(named_model_params)
|
| 84 |
+
scalar_vector_named_params = (
|
| 85 |
+
[(n, p) for (n, p) in named_model_params if p.ndim <= 1],
|
| 86 |
+
(-1),
|
| 87 |
+
)
|
| 88 |
+
matrix_named_params = (
|
| 89 |
+
[(n, p) for (n, p) in named_model_params if p.ndim > 1],
|
| 90 |
+
(1, -1),
|
| 91 |
+
)
|
| 92 |
+
return [scalar_vector_named_params, matrix_named_params]
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def master_params_to_state_dict(
|
| 96 |
+
model, param_groups_and_shapes, master_params, use_fp16
|
| 97 |
+
):
|
| 98 |
+
if use_fp16:
|
| 99 |
+
state_dict = model.state_dict()
|
| 100 |
+
for master_param, (param_group, _) in zip(
|
| 101 |
+
master_params, param_groups_and_shapes
|
| 102 |
+
):
|
| 103 |
+
for (name, _), unflat_master_param in zip(
|
| 104 |
+
param_group, unflatten_master_params(param_group, master_param.view(-1))
|
| 105 |
+
):
|
| 106 |
+
assert name in state_dict
|
| 107 |
+
state_dict[name] = unflat_master_param
|
| 108 |
+
else:
|
| 109 |
+
state_dict = model.state_dict()
|
| 110 |
+
for i, (name, _value) in enumerate(model.named_parameters()):
|
| 111 |
+
assert name in state_dict
|
| 112 |
+
state_dict[name] = master_params[i]
|
| 113 |
+
return state_dict
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def state_dict_to_master_params(model, state_dict, use_fp16):
|
| 117 |
+
if use_fp16:
|
| 118 |
+
named_model_params = [
|
| 119 |
+
(name, state_dict[name]) for name, _ in model.named_parameters()
|
| 120 |
+
]
|
| 121 |
+
param_groups_and_shapes = get_param_groups_and_shapes(named_model_params)
|
| 122 |
+
master_params = make_master_params(param_groups_and_shapes)
|
| 123 |
+
else:
|
| 124 |
+
master_params = [state_dict[name] for name, _ in model.named_parameters()]
|
| 125 |
+
return master_params
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def zero_master_grads(master_params):
|
| 129 |
+
for param in master_params:
|
| 130 |
+
param.grad = None
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def zero_grad(model_params):
|
| 134 |
+
for param in model_params:
|
| 135 |
+
# Taken from https://pytorch.org/docs/stable/_modules/torch/optim/optimizer.html#Optimizer.add_param_group
|
| 136 |
+
if param.grad is not None:
|
| 137 |
+
param.grad.detach_()
|
| 138 |
+
param.grad.zero_()
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def param_grad_or_zeros(param):
|
| 142 |
+
if param.grad is not None:
|
| 143 |
+
return param.grad.data.detach()
|
| 144 |
+
else:
|
| 145 |
+
return th.zeros_like(param)
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
class MixedPrecisionTrainer:
|
| 149 |
+
def __init__(
|
| 150 |
+
self,
|
| 151 |
+
*,
|
| 152 |
+
model,
|
| 153 |
+
use_fp16=False,
|
| 154 |
+
fp16_scale_growth=1e-3,
|
| 155 |
+
initial_lg_loss_scale=INITIAL_LOG_LOSS_SCALE,
|
| 156 |
+
):
|
| 157 |
+
self.model = model
|
| 158 |
+
self.use_fp16 = use_fp16
|
| 159 |
+
self.fp16_scale_growth = fp16_scale_growth
|
| 160 |
+
|
| 161 |
+
self.model_params = list(self.model.parameters())
|
| 162 |
+
self.master_params = self.model_params
|
| 163 |
+
self.param_groups_and_shapes = None
|
| 164 |
+
self.lg_loss_scale = initial_lg_loss_scale
|
| 165 |
+
|
| 166 |
+
if self.use_fp16:
|
| 167 |
+
self.param_groups_and_shapes = get_param_groups_and_shapes(
|
| 168 |
+
self.model.named_parameters()
|
| 169 |
+
)
|
| 170 |
+
self.master_params = make_master_params(self.param_groups_and_shapes)
|
| 171 |
+
self.model.convert_to_fp16()
|
| 172 |
+
|
| 173 |
+
def zero_grad(self):
|
| 174 |
+
zero_grad(self.model_params)
|
| 175 |
+
|
| 176 |
+
def backward(self, loss: th.Tensor):
|
| 177 |
+
if self.use_fp16:
|
| 178 |
+
loss_scale = 2 ** self.lg_loss_scale
|
| 179 |
+
(loss * loss_scale).backward()
|
| 180 |
+
else:
|
| 181 |
+
loss.backward()
|
| 182 |
+
|
| 183 |
+
def optimize(self, opt: th.optim.Optimizer):
|
| 184 |
+
if self.use_fp16:
|
| 185 |
+
return self._optimize_fp16(opt)
|
| 186 |
+
else:
|
| 187 |
+
return self._optimize_normal(opt)
|
| 188 |
+
|
| 189 |
+
def _optimize_fp16(self, opt: th.optim.Optimizer):
|
| 190 |
+
logger.logkv_mean("lg_loss_scale", self.lg_loss_scale)
|
| 191 |
+
model_grads_to_master_grads(self.param_groups_and_shapes, self.master_params)
|
| 192 |
+
grad_norm, param_norm = self._compute_norms(grad_scale=2 ** self.lg_loss_scale)
|
| 193 |
+
if check_overflow(grad_norm):
|
| 194 |
+
self.lg_loss_scale -= 1
|
| 195 |
+
logger.log(f"Found NaN, decreased lg_loss_scale to {self.lg_loss_scale}")
|
| 196 |
+
zero_master_grads(self.master_params)
|
| 197 |
+
return False
|
| 198 |
+
|
| 199 |
+
logger.logkv_mean("grad_norm", grad_norm)
|
| 200 |
+
logger.logkv_mean("param_norm", param_norm)
|
| 201 |
+
|
| 202 |
+
self.master_params[0].grad.mul_(1.0 / (2 ** self.lg_loss_scale))
|
| 203 |
+
opt.step()
|
| 204 |
+
zero_master_grads(self.master_params)
|
| 205 |
+
master_params_to_model_params(self.param_groups_and_shapes, self.master_params)
|
| 206 |
+
self.lg_loss_scale += self.fp16_scale_growth
|
| 207 |
+
return True
|
| 208 |
+
|
| 209 |
+
def _optimize_normal(self, opt: th.optim.Optimizer):
|
| 210 |
+
grad_norm, param_norm = self._compute_norms()
|
| 211 |
+
logger.logkv_mean("grad_norm", grad_norm)
|
| 212 |
+
logger.logkv_mean("param_norm", param_norm)
|
| 213 |
+
opt.step()
|
| 214 |
+
return True
|
| 215 |
+
|
| 216 |
+
def _compute_norms(self, grad_scale=1.0):
|
| 217 |
+
grad_norm = 0.0
|
| 218 |
+
param_norm = 0.0
|
| 219 |
+
for p in self.master_params:
|
| 220 |
+
with th.no_grad():
|
| 221 |
+
param_norm += th.norm(p, p=2, dtype=th.float32).item() ** 2
|
| 222 |
+
if p.grad is not None:
|
| 223 |
+
grad_norm += th.norm(p.grad, p=2, dtype=th.float32).item() ** 2
|
| 224 |
+
return np.sqrt(grad_norm) / grad_scale, np.sqrt(param_norm)
|
| 225 |
+
|
| 226 |
+
def master_params_to_state_dict(self, master_params):
|
| 227 |
+
return master_params_to_state_dict(
|
| 228 |
+
self.model, self.param_groups_and_shapes, master_params, self.use_fp16
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
def state_dict_to_master_params(self, state_dict):
|
| 232 |
+
return state_dict_to_master_params(self.model, state_dict, self.use_fp16)
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
def check_overflow(value):
|
| 236 |
+
return (value == float("inf")) or (value == -float("inf")) or (value != value)
|
main/diffusion/gaussian_diffusion.py
ADDED
|
@@ -0,0 +1,1613 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This code is based on https://github.com/openai/guided-diffusion
|
| 2 |
+
"""
|
| 3 |
+
This code started out as a PyTorch port of Ho et al's diffusion models:
|
| 4 |
+
https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py
|
| 5 |
+
|
| 6 |
+
Docstrings have been added, as well as DDIM sampling and a new collection of beta schedules.
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
import enum
|
| 10 |
+
import math
|
| 11 |
+
import pdb
|
| 12 |
+
|
| 13 |
+
import numpy as np
|
| 14 |
+
import torch
|
| 15 |
+
import torch as th
|
| 16 |
+
from copy import deepcopy
|
| 17 |
+
from diffusion.nn import mean_flat, sum_flat
|
| 18 |
+
from diffusion.losses import normal_kl, discretized_gaussian_log_likelihood
|
| 19 |
+
from data_loaders.humanml.scripts import motion_process
|
| 20 |
+
|
| 21 |
+
def get_named_beta_schedule(schedule_name, num_diffusion_timesteps, scale_betas=1.):
|
| 22 |
+
"""
|
| 23 |
+
Get a pre-defined beta schedule for the given name.
|
| 24 |
+
|
| 25 |
+
The beta schedule library consists of beta schedules which remain similar
|
| 26 |
+
in the limit of num_diffusion_timesteps.
|
| 27 |
+
Beta schedules may be added, but should not be removed or changed once
|
| 28 |
+
they are committed to maintain backwards compatibility.
|
| 29 |
+
"""
|
| 30 |
+
if schedule_name == "linear":
|
| 31 |
+
# Linear schedule from Ho et al, extended to work for any number of
|
| 32 |
+
# diffusion steps.
|
| 33 |
+
scale = scale_betas * 1000 / num_diffusion_timesteps
|
| 34 |
+
beta_start = scale * 0.0001
|
| 35 |
+
beta_end = scale * 0.02
|
| 36 |
+
return np.linspace(
|
| 37 |
+
beta_start, beta_end, num_diffusion_timesteps, dtype=np.float64
|
| 38 |
+
)
|
| 39 |
+
elif schedule_name == "cosine":
|
| 40 |
+
return betas_for_alpha_bar(
|
| 41 |
+
num_diffusion_timesteps,
|
| 42 |
+
lambda t: math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2,
|
| 43 |
+
)
|
| 44 |
+
else:
|
| 45 |
+
raise NotImplementedError(f"unknown beta schedule: {schedule_name}")
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
|
| 49 |
+
"""
|
| 50 |
+
Create a beta schedule that discretizes the given alpha_t_bar function,
|
| 51 |
+
which defines the cumulative product of (1-beta) over time from t = [0,1].
|
| 52 |
+
|
| 53 |
+
:param num_diffusion_timesteps: the number of betas to produce.
|
| 54 |
+
:param alpha_bar: a lambda that takes an argument t from 0 to 1 and
|
| 55 |
+
produces the cumulative product of (1-beta) up to that
|
| 56 |
+
part of the diffusion process.
|
| 57 |
+
:param max_beta: the maximum beta to use; use values lower than 1 to
|
| 58 |
+
prevent singularities.
|
| 59 |
+
"""
|
| 60 |
+
betas = []
|
| 61 |
+
for i in range(num_diffusion_timesteps):
|
| 62 |
+
t1 = i / num_diffusion_timesteps
|
| 63 |
+
t2 = (i + 1) / num_diffusion_timesteps
|
| 64 |
+
betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
|
| 65 |
+
return np.array(betas)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
class ModelMeanType(enum.Enum):
|
| 69 |
+
"""
|
| 70 |
+
Which type of output the model predicts.
|
| 71 |
+
"""
|
| 72 |
+
|
| 73 |
+
PREVIOUS_X = enum.auto() # the model predicts x_{t-1}
|
| 74 |
+
START_X = enum.auto() # the model predicts x_0
|
| 75 |
+
EPSILON = enum.auto() # the model predicts epsilon
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
class ModelVarType(enum.Enum):
|
| 79 |
+
"""
|
| 80 |
+
What is used as the model's output variance.
|
| 81 |
+
|
| 82 |
+
The LEARNED_RANGE option has been added to allow the model to predict
|
| 83 |
+
values between FIXED_SMALL and FIXED_LARGE, making its job easier.
|
| 84 |
+
"""
|
| 85 |
+
|
| 86 |
+
LEARNED = enum.auto()
|
| 87 |
+
FIXED_SMALL = enum.auto()
|
| 88 |
+
FIXED_LARGE = enum.auto()
|
| 89 |
+
LEARNED_RANGE = enum.auto()
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class LossType(enum.Enum):
|
| 93 |
+
MSE = enum.auto() # use raw MSE loss (and KL when learning variances)
|
| 94 |
+
RESCALED_MSE = (
|
| 95 |
+
enum.auto()
|
| 96 |
+
) # use raw MSE loss (with RESCALED_KL when learning variances)
|
| 97 |
+
KL = enum.auto() # use the variational lower-bound
|
| 98 |
+
RESCALED_KL = enum.auto() # like KL, but rescale to estimate the full VLB
|
| 99 |
+
|
| 100 |
+
def is_vb(self):
|
| 101 |
+
return self == LossType.KL or self == LossType.RESCALED_KL
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class GaussianDiffusion:
|
| 105 |
+
"""
|
| 106 |
+
Utilities for training and sampling diffusion models.
|
| 107 |
+
|
| 108 |
+
Ported directly from here, and then adapted over time to further experimentation.
|
| 109 |
+
https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py#L42
|
| 110 |
+
|
| 111 |
+
:param betas: a 1-D numpy array of betas for each diffusion timestep,
|
| 112 |
+
starting at T and going to 1.
|
| 113 |
+
:param model_mean_type: a ModelMeanType determining what the model outputs.
|
| 114 |
+
:param model_var_type: a ModelVarType determining how variance is output.
|
| 115 |
+
:param loss_type: a LossType determining the loss function to use.
|
| 116 |
+
:param rescale_timesteps: if True, pass floating point timesteps into the
|
| 117 |
+
model so that they are always scaled like in the
|
| 118 |
+
original paper (0 to 1000).
|
| 119 |
+
"""
|
| 120 |
+
|
| 121 |
+
def __init__(
|
| 122 |
+
self,
|
| 123 |
+
*,
|
| 124 |
+
betas,
|
| 125 |
+
model_mean_type,
|
| 126 |
+
model_var_type,
|
| 127 |
+
loss_type,
|
| 128 |
+
rescale_timesteps=False,
|
| 129 |
+
lambda_rcxyz=0.,
|
| 130 |
+
lambda_vel=0.,
|
| 131 |
+
lambda_pose=1.,
|
| 132 |
+
lambda_orient=1.,
|
| 133 |
+
lambda_loc=1.,
|
| 134 |
+
data_rep='rot6d',
|
| 135 |
+
lambda_root_vel=0.,
|
| 136 |
+
lambda_vel_rcxyz=0.,
|
| 137 |
+
lambda_fc=0.,
|
| 138 |
+
):
|
| 139 |
+
self.model_mean_type = model_mean_type
|
| 140 |
+
self.model_var_type = model_var_type
|
| 141 |
+
self.loss_type = loss_type
|
| 142 |
+
self.rescale_timesteps = rescale_timesteps
|
| 143 |
+
self.data_rep = data_rep
|
| 144 |
+
|
| 145 |
+
if data_rep != 'rot_vel' and lambda_pose != 1.:
|
| 146 |
+
raise ValueError('lambda_pose is relevant only when training on velocities!')
|
| 147 |
+
self.lambda_pose = lambda_pose
|
| 148 |
+
self.lambda_orient = lambda_orient
|
| 149 |
+
self.lambda_loc = lambda_loc
|
| 150 |
+
|
| 151 |
+
self.lambda_rcxyz = lambda_rcxyz
|
| 152 |
+
self.lambda_vel = lambda_vel
|
| 153 |
+
self.lambda_root_vel = lambda_root_vel
|
| 154 |
+
self.lambda_vel_rcxyz = lambda_vel_rcxyz
|
| 155 |
+
self.lambda_fc = lambda_fc
|
| 156 |
+
|
| 157 |
+
if self.lambda_rcxyz > 0. or self.lambda_vel > 0. or self.lambda_root_vel > 0. or \
|
| 158 |
+
self.lambda_vel_rcxyz > 0. or self.lambda_fc > 0.:
|
| 159 |
+
assert self.loss_type == LossType.MSE, 'Geometric losses are supported by MSE loss type only!'
|
| 160 |
+
|
| 161 |
+
# Use float64 for accuracy.
|
| 162 |
+
betas = np.array(betas, dtype=np.float64)
|
| 163 |
+
self.betas = betas
|
| 164 |
+
assert len(betas.shape) == 1, "betas must be 1-D"
|
| 165 |
+
assert (betas > 0).all() and (betas <= 1).all()
|
| 166 |
+
|
| 167 |
+
self.num_timesteps = int(betas.shape[0])
|
| 168 |
+
|
| 169 |
+
alphas = 1.0 - betas
|
| 170 |
+
self.alphas_cumprod = np.cumprod(alphas, axis=0)
|
| 171 |
+
self.alphas_cumprod_prev = np.append(1.0, self.alphas_cumprod[:-1])
|
| 172 |
+
self.alphas_cumprod_next = np.append(self.alphas_cumprod[1:], 0.0)
|
| 173 |
+
assert self.alphas_cumprod_prev.shape == (self.num_timesteps,)
|
| 174 |
+
|
| 175 |
+
# calculations for diffusion q(x_t | x_{t-1}) and others
|
| 176 |
+
self.sqrt_alphas_cumprod = np.sqrt(self.alphas_cumprod)
|
| 177 |
+
self.sqrt_one_minus_alphas_cumprod = np.sqrt(1.0 - self.alphas_cumprod)
|
| 178 |
+
self.log_one_minus_alphas_cumprod = np.log(1.0 - self.alphas_cumprod)
|
| 179 |
+
self.sqrt_recip_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod)
|
| 180 |
+
self.sqrt_recipm1_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod - 1)
|
| 181 |
+
|
| 182 |
+
# calculations for posterior q(x_{t-1} | x_t, x_0)
|
| 183 |
+
self.posterior_variance = (
|
| 184 |
+
betas * (1.0 - self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod)
|
| 185 |
+
)
|
| 186 |
+
# log calculation clipped because the posterior variance is 0 at the
|
| 187 |
+
# beginning of the diffusion chain.
|
| 188 |
+
self.posterior_log_variance_clipped = np.log(
|
| 189 |
+
np.append(self.posterior_variance[1], self.posterior_variance[1:])
|
| 190 |
+
)
|
| 191 |
+
self.posterior_mean_coef1 = (
|
| 192 |
+
betas * np.sqrt(self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod)
|
| 193 |
+
)
|
| 194 |
+
self.posterior_mean_coef2 = (
|
| 195 |
+
(1.0 - self.alphas_cumprod_prev)
|
| 196 |
+
* np.sqrt(alphas)
|
| 197 |
+
/ (1.0 - self.alphas_cumprod)
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
self.l2_loss = lambda a, b: (a - b) ** 2 # th.nn.MSELoss(reduction='none') # must be None for handling mask later on.
|
| 201 |
+
self.smooth_l1_loss = th.nn.SmoothL1Loss(reduction='none')
|
| 202 |
+
|
| 203 |
+
def masked_l2(self, a, b, mask):
|
| 204 |
+
# assuming a.shape == b.shape == bs, J, Jdim, seqlen
|
| 205 |
+
# assuming mask.shape == bs, 1, 1, seqlen
|
| 206 |
+
# loss = self.l2_loss(a, b) # 20221217
|
| 207 |
+
loss = self.smooth_l1_loss(a, b)
|
| 208 |
+
loss = sum_flat(loss * mask.float()) # gives \sigma_euclidean over unmasked elements
|
| 209 |
+
n_entries = a.shape[1] * a.shape[2]
|
| 210 |
+
non_zero_elements = sum_flat(mask) * n_entries
|
| 211 |
+
# print('mask', mask.shape)
|
| 212 |
+
# print('non_zero_elements', non_zero_elements)
|
| 213 |
+
# print('loss', loss)
|
| 214 |
+
mse_loss_val = loss / non_zero_elements
|
| 215 |
+
# print('mse_loss_val', mse_loss_val)
|
| 216 |
+
return mse_loss_val
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
def q_mean_variance(self, x_start, t):
|
| 220 |
+
"""
|
| 221 |
+
Get the distribution q(x_t | x_0).
|
| 222 |
+
|
| 223 |
+
:param x_start: the [N x C x ...] tensor of noiseless inputs.
|
| 224 |
+
:param t: the number of diffusion steps (minus 1). Here, 0 means one step.
|
| 225 |
+
:return: A tuple (mean, variance, log_variance), all of x_start's shape.
|
| 226 |
+
"""
|
| 227 |
+
mean = (
|
| 228 |
+
_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start
|
| 229 |
+
)
|
| 230 |
+
variance = _extract_into_tensor(1.0 - self.alphas_cumprod, t, x_start.shape)
|
| 231 |
+
log_variance = _extract_into_tensor(
|
| 232 |
+
self.log_one_minus_alphas_cumprod, t, x_start.shape
|
| 233 |
+
)
|
| 234 |
+
return mean, variance, log_variance
|
| 235 |
+
|
| 236 |
+
def q_sample(self, x_start, t, noise=None):
|
| 237 |
+
"""
|
| 238 |
+
Diffuse the dataset for a given number of diffusion steps.
|
| 239 |
+
|
| 240 |
+
In other words, sample from q(x_t | x_0).
|
| 241 |
+
|
| 242 |
+
:param x_start: the initial dataset batch.
|
| 243 |
+
:param t: the number of diffusion steps (minus 1). Here, 0 means one step.
|
| 244 |
+
:param noise: if specified, the split-out normal noise.
|
| 245 |
+
:return: A noisy version of x_start.
|
| 246 |
+
"""
|
| 247 |
+
if noise is None:
|
| 248 |
+
noise = th.randn_like(x_start)
|
| 249 |
+
assert noise.shape == x_start.shape
|
| 250 |
+
return (
|
| 251 |
+
_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start
|
| 252 |
+
+ _extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape)
|
| 253 |
+
* noise
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
def q_posterior_mean_variance(self, x_start, x_t, t):
|
| 257 |
+
"""
|
| 258 |
+
Compute the mean and variance of the diffusion posterior:
|
| 259 |
+
|
| 260 |
+
q(x_{t-1} | x_t, x_0)
|
| 261 |
+
|
| 262 |
+
"""
|
| 263 |
+
assert x_start.shape == x_t.shape
|
| 264 |
+
posterior_mean = (
|
| 265 |
+
_extract_into_tensor(self.posterior_mean_coef1, t, x_t.shape) * x_start
|
| 266 |
+
+ _extract_into_tensor(self.posterior_mean_coef2, t, x_t.shape) * x_t
|
| 267 |
+
)
|
| 268 |
+
posterior_variance = _extract_into_tensor(self.posterior_variance, t, x_t.shape)
|
| 269 |
+
posterior_log_variance_clipped = _extract_into_tensor(
|
| 270 |
+
self.posterior_log_variance_clipped, t, x_t.shape
|
| 271 |
+
)
|
| 272 |
+
assert (
|
| 273 |
+
posterior_mean.shape[0]
|
| 274 |
+
== posterior_variance.shape[0]
|
| 275 |
+
== posterior_log_variance_clipped.shape[0]
|
| 276 |
+
== x_start.shape[0]
|
| 277 |
+
)
|
| 278 |
+
return posterior_mean, posterior_variance, posterior_log_variance_clipped
|
| 279 |
+
|
| 280 |
+
def p_mean_variance(
|
| 281 |
+
self, model, x, t, clip_denoised=True, denoised_fn=None, model_kwargs=None
|
| 282 |
+
):
|
| 283 |
+
"""
|
| 284 |
+
Apply the model to get p(x_{t-1} | x_t), as well as a prediction of
|
| 285 |
+
the initial x, x_0.
|
| 286 |
+
|
| 287 |
+
:param model: the model, which takes a signal and a batch of timesteps
|
| 288 |
+
as input.
|
| 289 |
+
:param x: the [N x C x ...] tensor at time t.
|
| 290 |
+
:param t: a 1-D Tensor of timesteps.
|
| 291 |
+
:param clip_denoised: if True, clip the denoised signal into [-1, 1].
|
| 292 |
+
:param denoised_fn: if not None, a function which applies to the
|
| 293 |
+
x_start prediction before it is used to sample. Applies before
|
| 294 |
+
clip_denoised.
|
| 295 |
+
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
| 296 |
+
pass to the model. This can be used for conditioning.
|
| 297 |
+
:return: a dict with the following keys:
|
| 298 |
+
- 'mean': the model mean output.
|
| 299 |
+
- 'variance': the model variance output.
|
| 300 |
+
- 'log_variance': the log of 'variance'.
|
| 301 |
+
- 'pred_xstart': the prediction for x_0.
|
| 302 |
+
"""
|
| 303 |
+
if model_kwargs is None:
|
| 304 |
+
model_kwargs = {}
|
| 305 |
+
|
| 306 |
+
B, C = x.shape[:2]
|
| 307 |
+
assert t.shape == (B,)
|
| 308 |
+
model_output = model(x, self._scale_timesteps(t), **model_kwargs)
|
| 309 |
+
|
| 310 |
+
if 'inpainting_mask' in model_kwargs['y'].keys() and 'inpainted_motion' in model_kwargs['y'].keys():
|
| 311 |
+
inpainting_mask, inpainted_motion = model_kwargs['y']['inpainting_mask'], model_kwargs['y']['inpainted_motion']
|
| 312 |
+
assert self.model_mean_type == ModelMeanType.START_X, 'This feature supports only X_start pred for mow!'
|
| 313 |
+
assert model_output.shape == inpainting_mask.shape == inpainted_motion.shape
|
| 314 |
+
model_output = (model_output * ~inpainting_mask) + (inpainted_motion * inpainting_mask)
|
| 315 |
+
# print('model_output', model_output.shape, model_output)
|
| 316 |
+
# print('inpainting_mask', inpainting_mask.shape, inpainting_mask[0,0,0,:])
|
| 317 |
+
# print('inpainted_motion', inpainted_motion.shape, inpainted_motion)
|
| 318 |
+
|
| 319 |
+
if self.model_var_type in [ModelVarType.LEARNED, ModelVarType.LEARNED_RANGE]:
|
| 320 |
+
assert model_output.shape == (B, C * 2, *x.shape[2:])
|
| 321 |
+
model_output, model_var_values = th.split(model_output, C, dim=1)
|
| 322 |
+
if self.model_var_type == ModelVarType.LEARNED:
|
| 323 |
+
model_log_variance = model_var_values
|
| 324 |
+
model_variance = th.exp(model_log_variance)
|
| 325 |
+
else:
|
| 326 |
+
min_log = _extract_into_tensor(
|
| 327 |
+
self.posterior_log_variance_clipped, t, x.shape
|
| 328 |
+
)
|
| 329 |
+
max_log = _extract_into_tensor(np.log(self.betas), t, x.shape)
|
| 330 |
+
# The model_var_values is [-1, 1] for [min_var, max_var].
|
| 331 |
+
frac = (model_var_values + 1) / 2
|
| 332 |
+
model_log_variance = frac * max_log + (1 - frac) * min_log
|
| 333 |
+
model_variance = th.exp(model_log_variance)
|
| 334 |
+
else:
|
| 335 |
+
model_variance, model_log_variance = {
|
| 336 |
+
# for fixedlarge, we set the initial (log-)variance like so
|
| 337 |
+
# to get a better decoder log likelihood.
|
| 338 |
+
ModelVarType.FIXED_LARGE: (
|
| 339 |
+
np.append(self.posterior_variance[1], self.betas[1:]),
|
| 340 |
+
np.log(np.append(self.posterior_variance[1], self.betas[1:])),
|
| 341 |
+
),
|
| 342 |
+
ModelVarType.FIXED_SMALL: (
|
| 343 |
+
self.posterior_variance,
|
| 344 |
+
self.posterior_log_variance_clipped,
|
| 345 |
+
),
|
| 346 |
+
}[self.model_var_type]
|
| 347 |
+
# print('model_variance', model_variance)
|
| 348 |
+
# print('model_log_variance',model_log_variance)
|
| 349 |
+
# print('self.posterior_variance', self.posterior_variance)
|
| 350 |
+
# print('self.posterior_log_variance_clipped', self.posterior_log_variance_clipped)
|
| 351 |
+
# print('self.model_var_type', self.model_var_type)
|
| 352 |
+
|
| 353 |
+
|
| 354 |
+
model_variance = _extract_into_tensor(model_variance, t, x.shape)
|
| 355 |
+
model_log_variance = _extract_into_tensor(model_log_variance, t, x.shape)
|
| 356 |
+
|
| 357 |
+
def process_xstart(x):
|
| 358 |
+
if denoised_fn is not None:
|
| 359 |
+
x = denoised_fn(x)
|
| 360 |
+
if clip_denoised:
|
| 361 |
+
# print('clip_denoised', clip_denoised)
|
| 362 |
+
return x.clamp(-1, 1)
|
| 363 |
+
return x
|
| 364 |
+
|
| 365 |
+
if self.model_mean_type == ModelMeanType.PREVIOUS_X:
|
| 366 |
+
pred_xstart = process_xstart(
|
| 367 |
+
self._predict_xstart_from_xprev(x_t=x, t=t, xprev=model_output)
|
| 368 |
+
)
|
| 369 |
+
model_mean = model_output
|
| 370 |
+
elif self.model_mean_type in [ModelMeanType.START_X, ModelMeanType.EPSILON]: # THIS IS US!
|
| 371 |
+
if self.model_mean_type == ModelMeanType.START_X:
|
| 372 |
+
pred_xstart = process_xstart(model_output)
|
| 373 |
+
else:
|
| 374 |
+
pred_xstart = process_xstart(
|
| 375 |
+
self._predict_xstart_from_eps(x_t=x, t=t, eps=model_output)
|
| 376 |
+
)
|
| 377 |
+
model_mean, _, _ = self.q_posterior_mean_variance(
|
| 378 |
+
x_start=pred_xstart, x_t=x, t=t
|
| 379 |
+
)
|
| 380 |
+
else:
|
| 381 |
+
raise NotImplementedError(self.model_mean_type)
|
| 382 |
+
|
| 383 |
+
assert (
|
| 384 |
+
model_mean.shape == model_log_variance.shape == pred_xstart.shape == x.shape
|
| 385 |
+
)
|
| 386 |
+
return {
|
| 387 |
+
"mean": model_mean,
|
| 388 |
+
"variance": model_variance,
|
| 389 |
+
"log_variance": model_log_variance,
|
| 390 |
+
"pred_xstart": pred_xstart,
|
| 391 |
+
}
|
| 392 |
+
|
| 393 |
+
def _predict_xstart_from_eps(self, x_t, t, eps):
|
| 394 |
+
assert x_t.shape == eps.shape
|
| 395 |
+
return (
|
| 396 |
+
_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t
|
| 397 |
+
- _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * eps
|
| 398 |
+
)
|
| 399 |
+
|
| 400 |
+
def _predict_xstart_from_xprev(self, x_t, t, xprev):
|
| 401 |
+
assert x_t.shape == xprev.shape
|
| 402 |
+
return ( # (xprev - coef2*x_t) / coef1
|
| 403 |
+
_extract_into_tensor(1.0 / self.posterior_mean_coef1, t, x_t.shape) * xprev
|
| 404 |
+
- _extract_into_tensor(
|
| 405 |
+
self.posterior_mean_coef2 / self.posterior_mean_coef1, t, x_t.shape
|
| 406 |
+
)
|
| 407 |
+
* x_t
|
| 408 |
+
)
|
| 409 |
+
|
| 410 |
+
def _predict_eps_from_xstart(self, x_t, t, pred_xstart):
|
| 411 |
+
return (
|
| 412 |
+
_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t
|
| 413 |
+
- pred_xstart
|
| 414 |
+
) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
|
| 415 |
+
|
| 416 |
+
def _scale_timesteps(self, t):
|
| 417 |
+
if self.rescale_timesteps:
|
| 418 |
+
return t.float() * (1000.0 / self.num_timesteps)
|
| 419 |
+
return t
|
| 420 |
+
|
| 421 |
+
def condition_mean(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
|
| 422 |
+
"""
|
| 423 |
+
Compute the mean for the previous step, given a function cond_fn that
|
| 424 |
+
computes the gradient of a conditional log probability with respect to
|
| 425 |
+
x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
|
| 426 |
+
condition on y.
|
| 427 |
+
|
| 428 |
+
This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
|
| 429 |
+
"""
|
| 430 |
+
gradient = cond_fn(x, self._scale_timesteps(t), **model_kwargs)
|
| 431 |
+
new_mean = (
|
| 432 |
+
p_mean_var["mean"].float() + p_mean_var["variance"] * gradient.float()
|
| 433 |
+
)
|
| 434 |
+
return new_mean
|
| 435 |
+
|
| 436 |
+
def condition_mean_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
|
| 437 |
+
"""
|
| 438 |
+
Compute the mean for the previous step, given a function cond_fn that
|
| 439 |
+
computes the gradient of a conditional log probability with respect to
|
| 440 |
+
x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
|
| 441 |
+
condition on y.
|
| 442 |
+
|
| 443 |
+
This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
|
| 444 |
+
"""
|
| 445 |
+
gradient = cond_fn(x, t, p_mean_var, **model_kwargs)
|
| 446 |
+
new_mean = (
|
| 447 |
+
p_mean_var["mean"].float() + p_mean_var["variance"] * gradient.float()
|
| 448 |
+
)
|
| 449 |
+
return new_mean
|
| 450 |
+
|
| 451 |
+
def condition_score(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
|
| 452 |
+
"""
|
| 453 |
+
Compute what the p_mean_variance output would have been, should the
|
| 454 |
+
model's score function be conditioned by cond_fn.
|
| 455 |
+
|
| 456 |
+
See condition_mean() for details on cond_fn.
|
| 457 |
+
|
| 458 |
+
Unlike condition_mean(), this instead uses the conditioning strategy
|
| 459 |
+
from Song et al (2020).
|
| 460 |
+
"""
|
| 461 |
+
alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
|
| 462 |
+
|
| 463 |
+
eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
|
| 464 |
+
eps = eps - (1 - alpha_bar).sqrt() * cond_fn(
|
| 465 |
+
x, self._scale_timesteps(t), **model_kwargs
|
| 466 |
+
)
|
| 467 |
+
|
| 468 |
+
out = p_mean_var.copy()
|
| 469 |
+
out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
|
| 470 |
+
out["mean"], _, _ = self.q_posterior_mean_variance(
|
| 471 |
+
x_start=out["pred_xstart"], x_t=x, t=t
|
| 472 |
+
)
|
| 473 |
+
return out
|
| 474 |
+
|
| 475 |
+
def condition_score_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
|
| 476 |
+
"""
|
| 477 |
+
Compute what the p_mean_variance output would have been, should the
|
| 478 |
+
model's score function be conditioned by cond_fn.
|
| 479 |
+
|
| 480 |
+
See condition_mean() for details on cond_fn.
|
| 481 |
+
|
| 482 |
+
Unlike condition_mean(), this instead uses the conditioning strategy
|
| 483 |
+
from Song et al (2020).
|
| 484 |
+
"""
|
| 485 |
+
alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
|
| 486 |
+
|
| 487 |
+
eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
|
| 488 |
+
eps = eps - (1 - alpha_bar).sqrt() * cond_fn(
|
| 489 |
+
x, t, p_mean_var, **model_kwargs
|
| 490 |
+
)
|
| 491 |
+
|
| 492 |
+
out = p_mean_var.copy()
|
| 493 |
+
out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
|
| 494 |
+
out["mean"], _, _ = self.q_posterior_mean_variance(
|
| 495 |
+
x_start=out["pred_xstart"], x_t=x, t=t
|
| 496 |
+
)
|
| 497 |
+
return out
|
| 498 |
+
|
| 499 |
+
def p_sample(
|
| 500 |
+
self,
|
| 501 |
+
model,
|
| 502 |
+
x,
|
| 503 |
+
t,
|
| 504 |
+
clip_denoised=True,
|
| 505 |
+
denoised_fn=None,
|
| 506 |
+
cond_fn=None,
|
| 507 |
+
model_kwargs=None,
|
| 508 |
+
const_noise=False,
|
| 509 |
+
):
|
| 510 |
+
"""
|
| 511 |
+
Sample x_{t-1} from the model at the given timestep.
|
| 512 |
+
|
| 513 |
+
:param model: the model to sample from.
|
| 514 |
+
:param x: the current tensor at x_{t-1}.
|
| 515 |
+
:param t: the value of t, starting at 0 for the first diffusion step.
|
| 516 |
+
:param clip_denoised: if True, clip the x_start prediction to [-1, 1].
|
| 517 |
+
:param denoised_fn: if not None, a function which applies to the
|
| 518 |
+
x_start prediction before it is used to sample.
|
| 519 |
+
:param cond_fn: if not None, this is a gradient function that acts
|
| 520 |
+
similarly to the model.
|
| 521 |
+
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
| 522 |
+
pass to the model. This can be used for conditioning.
|
| 523 |
+
:return: a dict containing the following keys:
|
| 524 |
+
- 'sample': a random sample from the model.
|
| 525 |
+
- 'pred_xstart': a prediction of x_0.
|
| 526 |
+
"""
|
| 527 |
+
out = self.p_mean_variance(
|
| 528 |
+
model,
|
| 529 |
+
x,
|
| 530 |
+
t,
|
| 531 |
+
clip_denoised=clip_denoised,
|
| 532 |
+
denoised_fn=denoised_fn,
|
| 533 |
+
model_kwargs=model_kwargs,
|
| 534 |
+
) # 'mean' (1, 135, 1, 240), 'variance', 'log_variance', 'pred_xstart'
|
| 535 |
+
noise = th.randn_like(x)
|
| 536 |
+
# print('const_noise', const_noise)
|
| 537 |
+
if const_noise:
|
| 538 |
+
noise = noise[[0]].repeat(x.shape[0], 1, 1, 1)
|
| 539 |
+
|
| 540 |
+
nonzero_mask = (
|
| 541 |
+
(t != 0).float().view(-1, *([1] * (len(x.shape) - 1)))
|
| 542 |
+
) # no noise when t == 0
|
| 543 |
+
if cond_fn is not None:
|
| 544 |
+
out["mean"] = self.condition_mean(
|
| 545 |
+
cond_fn, out, x, t, model_kwargs=model_kwargs
|
| 546 |
+
)
|
| 547 |
+
# print('mean', out["mean"].shape, out["mean"])
|
| 548 |
+
# print('log_variance', out["log_variance"].shape, out["log_variance"])
|
| 549 |
+
# print('nonzero_mask', nonzero_mask.shape, nonzero_mask)
|
| 550 |
+
sample = out["mean"] + nonzero_mask * th.exp(0.5 * out["log_variance"]) * noise
|
| 551 |
+
return {"sample": sample, "pred_xstart": out["pred_xstart"]}
|
| 552 |
+
|
| 553 |
+
def p_sample_with_grad(
|
| 554 |
+
self,
|
| 555 |
+
model,
|
| 556 |
+
x,
|
| 557 |
+
t,
|
| 558 |
+
clip_denoised=True,
|
| 559 |
+
denoised_fn=None,
|
| 560 |
+
cond_fn=None,
|
| 561 |
+
model_kwargs=None,
|
| 562 |
+
):
|
| 563 |
+
"""
|
| 564 |
+
Sample x_{t-1} from the model at the given timestep.
|
| 565 |
+
|
| 566 |
+
:param model: the model to sample from.
|
| 567 |
+
:param x: the current tensor at x_{t-1}.
|
| 568 |
+
:param t: the value of t, starting at 0 for the first diffusion step.
|
| 569 |
+
:param clip_denoised: if True, clip the x_start prediction to [-1, 1].
|
| 570 |
+
:param denoised_fn: if not None, a function which applies to the
|
| 571 |
+
x_start prediction before it is used to sample.
|
| 572 |
+
:param cond_fn: if not None, this is a gradient function that acts
|
| 573 |
+
similarly to the model.
|
| 574 |
+
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
| 575 |
+
pass to the model. This can be used for conditioning.
|
| 576 |
+
:return: a dict containing the following keys:
|
| 577 |
+
- 'sample': a random sample from the model.
|
| 578 |
+
- 'pred_xstart': a prediction of x_0.
|
| 579 |
+
"""
|
| 580 |
+
with th.enable_grad():
|
| 581 |
+
x = x.detach().requires_grad_()
|
| 582 |
+
out = self.p_mean_variance(
|
| 583 |
+
model,
|
| 584 |
+
x,
|
| 585 |
+
t,
|
| 586 |
+
clip_denoised=clip_denoised,
|
| 587 |
+
denoised_fn=denoised_fn,
|
| 588 |
+
model_kwargs=model_kwargs,
|
| 589 |
+
)
|
| 590 |
+
noise = th.randn_like(x)
|
| 591 |
+
nonzero_mask = (
|
| 592 |
+
(t != 0).float().view(-1, *([1] * (len(x.shape) - 1)))
|
| 593 |
+
) # no noise when t == 0
|
| 594 |
+
if cond_fn is not None:
|
| 595 |
+
out["mean"] = self.condition_mean_with_grad(
|
| 596 |
+
cond_fn, out, x, t, model_kwargs=model_kwargs
|
| 597 |
+
)
|
| 598 |
+
sample = out["mean"] + nonzero_mask * th.exp(0.5 * out["log_variance"]) * noise
|
| 599 |
+
return {"sample": sample, "pred_xstart": out["pred_xstart"].detach()}
|
| 600 |
+
|
| 601 |
+
def p_sample_loop(
|
| 602 |
+
self,
|
| 603 |
+
model,
|
| 604 |
+
shape,
|
| 605 |
+
noise=None,
|
| 606 |
+
clip_denoised=True,
|
| 607 |
+
denoised_fn=None,
|
| 608 |
+
cond_fn=None,
|
| 609 |
+
model_kwargs=None,
|
| 610 |
+
device=None,
|
| 611 |
+
progress=False,
|
| 612 |
+
skip_timesteps=0,
|
| 613 |
+
init_image=None,
|
| 614 |
+
randomize_class=False,
|
| 615 |
+
cond_fn_with_grad=False,
|
| 616 |
+
dump_steps=None,
|
| 617 |
+
const_noise=False,
|
| 618 |
+
):
|
| 619 |
+
"""
|
| 620 |
+
Generate samples from the model.
|
| 621 |
+
|
| 622 |
+
:param model: the model module.
|
| 623 |
+
:param shape: the shape of the samples, (N, C, H, W).
|
| 624 |
+
:param noise: if specified, the noise from the encoder to sample.
|
| 625 |
+
Should be of the same shape as `shape`.
|
| 626 |
+
:param clip_denoised: if True, clip x_start predictions to [-1, 1].
|
| 627 |
+
:param denoised_fn: if not None, a function which applies to the
|
| 628 |
+
x_start prediction before it is used to sample.
|
| 629 |
+
:param cond_fn: if not None, this is a gradient function that acts
|
| 630 |
+
similarly to the model.
|
| 631 |
+
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
| 632 |
+
pass to the model. This can be used for conditioning.
|
| 633 |
+
:param device: if specified, the device to create the samples on.
|
| 634 |
+
If not specified, use a model parameter's device.
|
| 635 |
+
:param progress: if True, show a tqdm progress bar.
|
| 636 |
+
:param const_noise: If True, will noise all samples with the same noise throughout sampling
|
| 637 |
+
:return: a non-differentiable batch of samples.
|
| 638 |
+
"""
|
| 639 |
+
final = None
|
| 640 |
+
if dump_steps is not None:
|
| 641 |
+
dump = []
|
| 642 |
+
|
| 643 |
+
for i, sample in enumerate(self.p_sample_loop_progressive(
|
| 644 |
+
model,
|
| 645 |
+
shape,
|
| 646 |
+
noise=noise,
|
| 647 |
+
clip_denoised=clip_denoised,
|
| 648 |
+
denoised_fn=denoised_fn,
|
| 649 |
+
cond_fn=cond_fn,
|
| 650 |
+
model_kwargs=model_kwargs,
|
| 651 |
+
device=device,
|
| 652 |
+
progress=progress,
|
| 653 |
+
skip_timesteps=skip_timesteps,
|
| 654 |
+
init_image=init_image,
|
| 655 |
+
randomize_class=randomize_class,
|
| 656 |
+
cond_fn_with_grad=cond_fn_with_grad,
|
| 657 |
+
const_noise=const_noise,
|
| 658 |
+
)):
|
| 659 |
+
if dump_steps is not None and i in dump_steps:
|
| 660 |
+
dump.append(deepcopy(sample["sample"]))
|
| 661 |
+
final = sample
|
| 662 |
+
if dump_steps is not None:
|
| 663 |
+
return dump
|
| 664 |
+
return final["sample"]
|
| 665 |
+
|
| 666 |
+
def p_sample_loop_progressive(
|
| 667 |
+
self,
|
| 668 |
+
model,
|
| 669 |
+
shape,
|
| 670 |
+
noise=None,
|
| 671 |
+
clip_denoised=True,
|
| 672 |
+
denoised_fn=None,
|
| 673 |
+
cond_fn=None,
|
| 674 |
+
model_kwargs=None,
|
| 675 |
+
device=None,
|
| 676 |
+
progress=False,
|
| 677 |
+
skip_timesteps=0,
|
| 678 |
+
init_image=None,
|
| 679 |
+
randomize_class=False,
|
| 680 |
+
cond_fn_with_grad=False,
|
| 681 |
+
const_noise=False,
|
| 682 |
+
):
|
| 683 |
+
"""
|
| 684 |
+
Generate samples from the model and yield intermediate samples from
|
| 685 |
+
each timestep of diffusion.
|
| 686 |
+
|
| 687 |
+
Arguments are the same as p_sample_loop().
|
| 688 |
+
Returns a generator over dicts, where each dict is the return value of
|
| 689 |
+
p_sample().
|
| 690 |
+
"""
|
| 691 |
+
if device is None:
|
| 692 |
+
device = next(model.parameters()).device
|
| 693 |
+
assert isinstance(shape, (tuple, list))
|
| 694 |
+
if noise is not None:
|
| 695 |
+
img = noise
|
| 696 |
+
else:
|
| 697 |
+
img = th.randn(*shape, device=device)
|
| 698 |
+
|
| 699 |
+
if skip_timesteps and init_image is None:
|
| 700 |
+
init_image = th.zeros_like(img)
|
| 701 |
+
|
| 702 |
+
indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
|
| 703 |
+
|
| 704 |
+
if init_image is not None:
|
| 705 |
+
my_t = th.ones([shape[0]], device=device, dtype=th.long) * indices[0]
|
| 706 |
+
img = self.q_sample(init_image, my_t, img)
|
| 707 |
+
|
| 708 |
+
if progress:
|
| 709 |
+
# Lazy import so that we don't depend on tqdm.
|
| 710 |
+
from tqdm.auto import tqdm
|
| 711 |
+
|
| 712 |
+
indices = tqdm(indices)
|
| 713 |
+
|
| 714 |
+
for i in indices:
|
| 715 |
+
t = th.tensor([i] * shape[0], device=device)
|
| 716 |
+
if randomize_class and 'y' in model_kwargs:
|
| 717 |
+
model_kwargs['y'] = th.randint(low=0, high=model.num_classes,
|
| 718 |
+
size=model_kwargs['y'].shape,
|
| 719 |
+
device=model_kwargs['y'].device)
|
| 720 |
+
with th.no_grad():
|
| 721 |
+
sample_fn = self.p_sample_with_grad if cond_fn_with_grad else self.p_sample
|
| 722 |
+
out = sample_fn(
|
| 723 |
+
model,
|
| 724 |
+
img,
|
| 725 |
+
t,
|
| 726 |
+
clip_denoised=clip_denoised,
|
| 727 |
+
denoised_fn=denoised_fn,
|
| 728 |
+
cond_fn=cond_fn,
|
| 729 |
+
model_kwargs=model_kwargs,
|
| 730 |
+
const_noise=const_noise,
|
| 731 |
+
)
|
| 732 |
+
yield out
|
| 733 |
+
img = out["sample"]
|
| 734 |
+
|
| 735 |
+
def ddim_sample(
|
| 736 |
+
self,
|
| 737 |
+
model,
|
| 738 |
+
x,
|
| 739 |
+
t,
|
| 740 |
+
clip_denoised=True,
|
| 741 |
+
denoised_fn=None,
|
| 742 |
+
cond_fn=None,
|
| 743 |
+
model_kwargs=None,
|
| 744 |
+
eta=0.0,
|
| 745 |
+
):
|
| 746 |
+
"""
|
| 747 |
+
Sample x_{t-1} from the model using DDIM.
|
| 748 |
+
|
| 749 |
+
Same usage as p_sample().
|
| 750 |
+
"""
|
| 751 |
+
out_orig = self.p_mean_variance(
|
| 752 |
+
model,
|
| 753 |
+
x,
|
| 754 |
+
t,
|
| 755 |
+
clip_denoised=clip_denoised,
|
| 756 |
+
denoised_fn=denoised_fn,
|
| 757 |
+
model_kwargs=model_kwargs,
|
| 758 |
+
)
|
| 759 |
+
if cond_fn is not None:
|
| 760 |
+
out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
|
| 761 |
+
else:
|
| 762 |
+
out = out_orig
|
| 763 |
+
|
| 764 |
+
# Usually our model outputs epsilon, but we re-derive it
|
| 765 |
+
# in case we used x_start or x_prev prediction.
|
| 766 |
+
eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
|
| 767 |
+
|
| 768 |
+
alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
|
| 769 |
+
alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
|
| 770 |
+
sigma = (
|
| 771 |
+
eta
|
| 772 |
+
* th.sqrt((1 - alpha_bar_prev) / (1 - alpha_bar))
|
| 773 |
+
* th.sqrt(1 - alpha_bar / alpha_bar_prev)
|
| 774 |
+
)
|
| 775 |
+
# Equation 12.
|
| 776 |
+
noise = th.randn_like(x)
|
| 777 |
+
mean_pred = (
|
| 778 |
+
out["pred_xstart"] * th.sqrt(alpha_bar_prev)
|
| 779 |
+
+ th.sqrt(1 - alpha_bar_prev - sigma ** 2) * eps
|
| 780 |
+
)
|
| 781 |
+
nonzero_mask = (
|
| 782 |
+
(t != 0).float().view(-1, *([1] * (len(x.shape) - 1)))
|
| 783 |
+
) # no noise when t == 0
|
| 784 |
+
sample = mean_pred + nonzero_mask * sigma * noise
|
| 785 |
+
return {"sample": sample, "pred_xstart": out_orig["pred_xstart"]}
|
| 786 |
+
|
| 787 |
+
def ddim_sample_with_grad(
|
| 788 |
+
self,
|
| 789 |
+
model,
|
| 790 |
+
x,
|
| 791 |
+
t,
|
| 792 |
+
clip_denoised=True,
|
| 793 |
+
denoised_fn=None,
|
| 794 |
+
cond_fn=None,
|
| 795 |
+
model_kwargs=None,
|
| 796 |
+
eta=0.0,
|
| 797 |
+
):
|
| 798 |
+
"""
|
| 799 |
+
Sample x_{t-1} from the model using DDIM.
|
| 800 |
+
|
| 801 |
+
Same usage as p_sample().
|
| 802 |
+
"""
|
| 803 |
+
with th.enable_grad():
|
| 804 |
+
x = x.detach().requires_grad_()
|
| 805 |
+
out_orig = self.p_mean_variance(
|
| 806 |
+
model,
|
| 807 |
+
x,
|
| 808 |
+
t,
|
| 809 |
+
clip_denoised=clip_denoised,
|
| 810 |
+
denoised_fn=denoised_fn,
|
| 811 |
+
model_kwargs=model_kwargs,
|
| 812 |
+
)
|
| 813 |
+
if cond_fn is not None:
|
| 814 |
+
out = self.condition_score_with_grad(cond_fn, out_orig, x, t,
|
| 815 |
+
model_kwargs=model_kwargs)
|
| 816 |
+
else:
|
| 817 |
+
out = out_orig
|
| 818 |
+
|
| 819 |
+
out["pred_xstart"] = out["pred_xstart"].detach()
|
| 820 |
+
|
| 821 |
+
# Usually our model outputs epsilon, but we re-derive it
|
| 822 |
+
# in case we used x_start or x_prev prediction.
|
| 823 |
+
eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
|
| 824 |
+
|
| 825 |
+
alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
|
| 826 |
+
alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
|
| 827 |
+
sigma = (
|
| 828 |
+
eta
|
| 829 |
+
* th.sqrt((1 - alpha_bar_prev) / (1 - alpha_bar))
|
| 830 |
+
* th.sqrt(1 - alpha_bar / alpha_bar_prev)
|
| 831 |
+
)
|
| 832 |
+
# Equation 12.
|
| 833 |
+
noise = th.randn_like(x)
|
| 834 |
+
mean_pred = (
|
| 835 |
+
out["pred_xstart"] * th.sqrt(alpha_bar_prev)
|
| 836 |
+
+ th.sqrt(1 - alpha_bar_prev - sigma ** 2) * eps
|
| 837 |
+
)
|
| 838 |
+
nonzero_mask = (
|
| 839 |
+
(t != 0).float().view(-1, *([1] * (len(x.shape) - 1)))
|
| 840 |
+
) # no noise when t == 0
|
| 841 |
+
sample = mean_pred + nonzero_mask * sigma * noise
|
| 842 |
+
return {"sample": sample, "pred_xstart": out_orig["pred_xstart"].detach()}
|
| 843 |
+
|
| 844 |
+
def ddim_reverse_sample(
|
| 845 |
+
self,
|
| 846 |
+
model,
|
| 847 |
+
x,
|
| 848 |
+
t,
|
| 849 |
+
clip_denoised=True,
|
| 850 |
+
denoised_fn=None,
|
| 851 |
+
model_kwargs=None,
|
| 852 |
+
eta=0.0,
|
| 853 |
+
):
|
| 854 |
+
"""
|
| 855 |
+
Sample x_{t+1} from the model using DDIM reverse ODE.
|
| 856 |
+
"""
|
| 857 |
+
assert eta == 0.0, "Reverse ODE only for deterministic path"
|
| 858 |
+
out = self.p_mean_variance(
|
| 859 |
+
model,
|
| 860 |
+
x,
|
| 861 |
+
t,
|
| 862 |
+
clip_denoised=clip_denoised,
|
| 863 |
+
denoised_fn=denoised_fn,
|
| 864 |
+
model_kwargs=model_kwargs,
|
| 865 |
+
)
|
| 866 |
+
# Usually our model outputs epsilon, but we re-derive it
|
| 867 |
+
# in case we used x_start or x_prev prediction.
|
| 868 |
+
eps = (
|
| 869 |
+
_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x.shape) * x
|
| 870 |
+
- out["pred_xstart"]
|
| 871 |
+
) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x.shape)
|
| 872 |
+
alpha_bar_next = _extract_into_tensor(self.alphas_cumprod_next, t, x.shape)
|
| 873 |
+
|
| 874 |
+
# Equation 12. reversed
|
| 875 |
+
mean_pred = (
|
| 876 |
+
out["pred_xstart"] * th.sqrt(alpha_bar_next)
|
| 877 |
+
+ th.sqrt(1 - alpha_bar_next) * eps
|
| 878 |
+
)
|
| 879 |
+
|
| 880 |
+
return {"sample": mean_pred, "pred_xstart": out["pred_xstart"]}
|
| 881 |
+
|
| 882 |
+
def ddim_sample_loop(
|
| 883 |
+
self,
|
| 884 |
+
model,
|
| 885 |
+
shape,
|
| 886 |
+
noise=None,
|
| 887 |
+
clip_denoised=True,
|
| 888 |
+
denoised_fn=None,
|
| 889 |
+
cond_fn=None,
|
| 890 |
+
model_kwargs=None,
|
| 891 |
+
device=None,
|
| 892 |
+
progress=False,
|
| 893 |
+
eta=0.0,
|
| 894 |
+
skip_timesteps=0,
|
| 895 |
+
init_image=None,
|
| 896 |
+
randomize_class=False,
|
| 897 |
+
cond_fn_with_grad=False,
|
| 898 |
+
dump_steps=None,
|
| 899 |
+
const_noise=False,
|
| 900 |
+
):
|
| 901 |
+
"""
|
| 902 |
+
Generate samples from the model using DDIM.
|
| 903 |
+
|
| 904 |
+
Same usage as p_sample_loop().
|
| 905 |
+
"""
|
| 906 |
+
if dump_steps is not None:
|
| 907 |
+
raise NotImplementedError()
|
| 908 |
+
if const_noise == True:
|
| 909 |
+
raise NotImplementedError()
|
| 910 |
+
|
| 911 |
+
final = None
|
| 912 |
+
for sample in self.ddim_sample_loop_progressive(
|
| 913 |
+
model,
|
| 914 |
+
shape,
|
| 915 |
+
noise=noise,
|
| 916 |
+
clip_denoised=clip_denoised,
|
| 917 |
+
denoised_fn=denoised_fn,
|
| 918 |
+
cond_fn=cond_fn,
|
| 919 |
+
model_kwargs=model_kwargs,
|
| 920 |
+
device=device,
|
| 921 |
+
progress=progress,
|
| 922 |
+
eta=eta,
|
| 923 |
+
skip_timesteps=skip_timesteps,
|
| 924 |
+
init_image=init_image,
|
| 925 |
+
randomize_class=randomize_class,
|
| 926 |
+
cond_fn_with_grad=cond_fn_with_grad,
|
| 927 |
+
):
|
| 928 |
+
final = sample
|
| 929 |
+
return final["sample"]
|
| 930 |
+
|
| 931 |
+
def ddim_sample_loop_progressive(
|
| 932 |
+
self,
|
| 933 |
+
model,
|
| 934 |
+
shape,
|
| 935 |
+
noise=None,
|
| 936 |
+
clip_denoised=True,
|
| 937 |
+
denoised_fn=None,
|
| 938 |
+
cond_fn=None,
|
| 939 |
+
model_kwargs=None,
|
| 940 |
+
device=None,
|
| 941 |
+
progress=False,
|
| 942 |
+
eta=0.0,
|
| 943 |
+
skip_timesteps=0,
|
| 944 |
+
init_image=None,
|
| 945 |
+
randomize_class=False,
|
| 946 |
+
cond_fn_with_grad=False,
|
| 947 |
+
):
|
| 948 |
+
"""
|
| 949 |
+
Use DDIM to sample from the model and yield intermediate samples from
|
| 950 |
+
each timestep of DDIM.
|
| 951 |
+
|
| 952 |
+
Same usage as p_sample_loop_progressive().
|
| 953 |
+
"""
|
| 954 |
+
if device is None:
|
| 955 |
+
device = next(model.parameters()).device
|
| 956 |
+
assert isinstance(shape, (tuple, list))
|
| 957 |
+
if noise is not None:
|
| 958 |
+
img = noise
|
| 959 |
+
else:
|
| 960 |
+
img = th.randn(*shape, device=device)
|
| 961 |
+
|
| 962 |
+
if skip_timesteps and init_image is None:
|
| 963 |
+
init_image = th.zeros_like(img)
|
| 964 |
+
|
| 965 |
+
indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
|
| 966 |
+
|
| 967 |
+
if init_image is not None:
|
| 968 |
+
my_t = th.ones([shape[0]], device=device, dtype=th.long) * indices[0]
|
| 969 |
+
img = self.q_sample(init_image, my_t, img)
|
| 970 |
+
|
| 971 |
+
if progress:
|
| 972 |
+
# Lazy import so that we don't depend on tqdm.
|
| 973 |
+
from tqdm.auto import tqdm
|
| 974 |
+
|
| 975 |
+
indices = tqdm(indices)
|
| 976 |
+
|
| 977 |
+
for i in indices:
|
| 978 |
+
t = th.tensor([i] * shape[0], device=device)
|
| 979 |
+
if randomize_class and 'y' in model_kwargs:
|
| 980 |
+
model_kwargs['y'] = th.randint(low=0, high=model.num_classes,
|
| 981 |
+
size=model_kwargs['y'].shape,
|
| 982 |
+
device=model_kwargs['y'].device)
|
| 983 |
+
with th.no_grad():
|
| 984 |
+
sample_fn = self.ddim_sample_with_grad if cond_fn_with_grad else self.ddim_sample
|
| 985 |
+
out = sample_fn(
|
| 986 |
+
model,
|
| 987 |
+
img,
|
| 988 |
+
t,
|
| 989 |
+
clip_denoised=clip_denoised,
|
| 990 |
+
denoised_fn=denoised_fn,
|
| 991 |
+
cond_fn=cond_fn,
|
| 992 |
+
model_kwargs=model_kwargs,
|
| 993 |
+
eta=eta,
|
| 994 |
+
)
|
| 995 |
+
yield out
|
| 996 |
+
img = out["sample"]
|
| 997 |
+
|
| 998 |
+
def plms_sample(
|
| 999 |
+
self,
|
| 1000 |
+
model,
|
| 1001 |
+
x,
|
| 1002 |
+
t,
|
| 1003 |
+
clip_denoised=True,
|
| 1004 |
+
denoised_fn=None,
|
| 1005 |
+
cond_fn=None,
|
| 1006 |
+
model_kwargs=None,
|
| 1007 |
+
cond_fn_with_grad=False,
|
| 1008 |
+
order=2,
|
| 1009 |
+
old_out=None,
|
| 1010 |
+
):
|
| 1011 |
+
"""
|
| 1012 |
+
Sample x_{t-1} from the model using Pseudo Linear Multistep.
|
| 1013 |
+
|
| 1014 |
+
Same usage as p_sample().
|
| 1015 |
+
"""
|
| 1016 |
+
if not int(order) or not 1 <= order <= 4:
|
| 1017 |
+
raise ValueError('order is invalid (should be int from 1-4).')
|
| 1018 |
+
|
| 1019 |
+
def get_model_output(x, t):
|
| 1020 |
+
with th.set_grad_enabled(cond_fn_with_grad and cond_fn is not None):
|
| 1021 |
+
x = x.detach().requires_grad_() if cond_fn_with_grad else x
|
| 1022 |
+
out_orig = self.p_mean_variance(
|
| 1023 |
+
model,
|
| 1024 |
+
x,
|
| 1025 |
+
t,
|
| 1026 |
+
clip_denoised=clip_denoised,
|
| 1027 |
+
denoised_fn=denoised_fn,
|
| 1028 |
+
model_kwargs=model_kwargs,
|
| 1029 |
+
)
|
| 1030 |
+
if cond_fn is not None:
|
| 1031 |
+
if cond_fn_with_grad:
|
| 1032 |
+
out = self.condition_score_with_grad(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
|
| 1033 |
+
x = x.detach()
|
| 1034 |
+
else:
|
| 1035 |
+
out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
|
| 1036 |
+
else:
|
| 1037 |
+
out = out_orig
|
| 1038 |
+
|
| 1039 |
+
# Usually our model outputs epsilon, but we re-derive it
|
| 1040 |
+
# in case we used x_start or x_prev prediction.
|
| 1041 |
+
eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
|
| 1042 |
+
return eps, out, out_orig
|
| 1043 |
+
|
| 1044 |
+
alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
|
| 1045 |
+
alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
|
| 1046 |
+
eps, out, out_orig = get_model_output(x, t)
|
| 1047 |
+
|
| 1048 |
+
if order > 1 and old_out is None:
|
| 1049 |
+
# Pseudo Improved Euler
|
| 1050 |
+
old_eps = [eps]
|
| 1051 |
+
mean_pred = out["pred_xstart"] * th.sqrt(alpha_bar_prev) + th.sqrt(1 - alpha_bar_prev) * eps
|
| 1052 |
+
eps_2, _, _ = get_model_output(mean_pred, t - 1)
|
| 1053 |
+
eps_prime = (eps + eps_2) / 2
|
| 1054 |
+
pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
|
| 1055 |
+
mean_pred = pred_prime * th.sqrt(alpha_bar_prev) + th.sqrt(1 - alpha_bar_prev) * eps_prime
|
| 1056 |
+
else:
|
| 1057 |
+
# Pseudo Linear Multistep (Adams-Bashforth)
|
| 1058 |
+
old_eps = old_out["old_eps"]
|
| 1059 |
+
old_eps.append(eps)
|
| 1060 |
+
cur_order = min(order, len(old_eps))
|
| 1061 |
+
if cur_order == 1:
|
| 1062 |
+
eps_prime = old_eps[-1]
|
| 1063 |
+
elif cur_order == 2:
|
| 1064 |
+
eps_prime = (3 * old_eps[-1] - old_eps[-2]) / 2
|
| 1065 |
+
elif cur_order == 3:
|
| 1066 |
+
eps_prime = (23 * old_eps[-1] - 16 * old_eps[-2] + 5 * old_eps[-3]) / 12
|
| 1067 |
+
elif cur_order == 4:
|
| 1068 |
+
eps_prime = (55 * old_eps[-1] - 59 * old_eps[-2] + 37 * old_eps[-3] - 9 * old_eps[-4]) / 24
|
| 1069 |
+
else:
|
| 1070 |
+
raise RuntimeError('cur_order is invalid.')
|
| 1071 |
+
pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
|
| 1072 |
+
mean_pred = pred_prime * th.sqrt(alpha_bar_prev) + th.sqrt(1 - alpha_bar_prev) * eps_prime
|
| 1073 |
+
|
| 1074 |
+
if len(old_eps) >= order:
|
| 1075 |
+
old_eps.pop(0)
|
| 1076 |
+
|
| 1077 |
+
nonzero_mask = (t != 0).float().view(-1, *([1] * (len(x.shape) - 1)))
|
| 1078 |
+
sample = mean_pred * nonzero_mask + out["pred_xstart"] * (1 - nonzero_mask)
|
| 1079 |
+
|
| 1080 |
+
return {"sample": sample, "pred_xstart": out_orig["pred_xstart"], "old_eps": old_eps}
|
| 1081 |
+
|
| 1082 |
+
def plms_sample_loop(
|
| 1083 |
+
self,
|
| 1084 |
+
model,
|
| 1085 |
+
shape,
|
| 1086 |
+
noise=None,
|
| 1087 |
+
clip_denoised=True,
|
| 1088 |
+
denoised_fn=None,
|
| 1089 |
+
cond_fn=None,
|
| 1090 |
+
model_kwargs=None,
|
| 1091 |
+
device=None,
|
| 1092 |
+
progress=False,
|
| 1093 |
+
skip_timesteps=0,
|
| 1094 |
+
init_image=None,
|
| 1095 |
+
randomize_class=False,
|
| 1096 |
+
cond_fn_with_grad=False,
|
| 1097 |
+
order=2,
|
| 1098 |
+
):
|
| 1099 |
+
"""
|
| 1100 |
+
Generate samples from the model using Pseudo Linear Multistep.
|
| 1101 |
+
|
| 1102 |
+
Same usage as p_sample_loop().
|
| 1103 |
+
"""
|
| 1104 |
+
final = None
|
| 1105 |
+
for sample in self.plms_sample_loop_progressive(
|
| 1106 |
+
model,
|
| 1107 |
+
shape,
|
| 1108 |
+
noise=noise,
|
| 1109 |
+
clip_denoised=clip_denoised,
|
| 1110 |
+
denoised_fn=denoised_fn,
|
| 1111 |
+
cond_fn=cond_fn,
|
| 1112 |
+
model_kwargs=model_kwargs,
|
| 1113 |
+
device=device,
|
| 1114 |
+
progress=progress,
|
| 1115 |
+
skip_timesteps=skip_timesteps,
|
| 1116 |
+
init_image=init_image,
|
| 1117 |
+
randomize_class=randomize_class,
|
| 1118 |
+
cond_fn_with_grad=cond_fn_with_grad,
|
| 1119 |
+
order=order,
|
| 1120 |
+
):
|
| 1121 |
+
final = sample
|
| 1122 |
+
return final["sample"]
|
| 1123 |
+
|
| 1124 |
+
def plms_sample_loop_progressive(
|
| 1125 |
+
self,
|
| 1126 |
+
model,
|
| 1127 |
+
shape,
|
| 1128 |
+
noise=None,
|
| 1129 |
+
clip_denoised=True,
|
| 1130 |
+
denoised_fn=None,
|
| 1131 |
+
cond_fn=None,
|
| 1132 |
+
model_kwargs=None,
|
| 1133 |
+
device=None,
|
| 1134 |
+
progress=False,
|
| 1135 |
+
skip_timesteps=0,
|
| 1136 |
+
init_image=None,
|
| 1137 |
+
randomize_class=False,
|
| 1138 |
+
cond_fn_with_grad=False,
|
| 1139 |
+
order=2,
|
| 1140 |
+
):
|
| 1141 |
+
"""
|
| 1142 |
+
Use PLMS to sample from the model and yield intermediate samples from each
|
| 1143 |
+
timestep of PLMS.
|
| 1144 |
+
|
| 1145 |
+
Same usage as p_sample_loop_progressive().
|
| 1146 |
+
"""
|
| 1147 |
+
if device is None:
|
| 1148 |
+
device = next(model.parameters()).device
|
| 1149 |
+
assert isinstance(shape, (tuple, list))
|
| 1150 |
+
if noise is not None:
|
| 1151 |
+
img = noise
|
| 1152 |
+
else:
|
| 1153 |
+
img = th.randn(*shape, device=device)
|
| 1154 |
+
|
| 1155 |
+
if skip_timesteps and init_image is None:
|
| 1156 |
+
init_image = th.zeros_like(img)
|
| 1157 |
+
|
| 1158 |
+
indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
|
| 1159 |
+
|
| 1160 |
+
if init_image is not None:
|
| 1161 |
+
my_t = th.ones([shape[0]], device=device, dtype=th.long) * indices[0]
|
| 1162 |
+
img = self.q_sample(init_image, my_t, img)
|
| 1163 |
+
|
| 1164 |
+
if progress:
|
| 1165 |
+
# Lazy import so that we don't depend on tqdm.
|
| 1166 |
+
from tqdm.auto import tqdm
|
| 1167 |
+
|
| 1168 |
+
indices = tqdm(indices)
|
| 1169 |
+
|
| 1170 |
+
old_out = None
|
| 1171 |
+
|
| 1172 |
+
for i in indices:
|
| 1173 |
+
t = th.tensor([i] * shape[0], device=device)
|
| 1174 |
+
if randomize_class and 'y' in model_kwargs:
|
| 1175 |
+
model_kwargs['y'] = th.randint(low=0, high=model.num_classes,
|
| 1176 |
+
size=model_kwargs['y'].shape,
|
| 1177 |
+
device=model_kwargs['y'].device)
|
| 1178 |
+
with th.no_grad():
|
| 1179 |
+
out = self.plms_sample(
|
| 1180 |
+
model,
|
| 1181 |
+
img,
|
| 1182 |
+
t,
|
| 1183 |
+
clip_denoised=clip_denoised,
|
| 1184 |
+
denoised_fn=denoised_fn,
|
| 1185 |
+
cond_fn=cond_fn,
|
| 1186 |
+
model_kwargs=model_kwargs,
|
| 1187 |
+
cond_fn_with_grad=cond_fn_with_grad,
|
| 1188 |
+
order=order,
|
| 1189 |
+
old_out=old_out,
|
| 1190 |
+
)
|
| 1191 |
+
yield out
|
| 1192 |
+
old_out = out
|
| 1193 |
+
img = out["sample"]
|
| 1194 |
+
|
| 1195 |
+
def _vb_terms_bpd(
|
| 1196 |
+
self, model, x_start, x_t, t, clip_denoised=True, model_kwargs=None
|
| 1197 |
+
):
|
| 1198 |
+
"""
|
| 1199 |
+
Get a term for the variational lower-bound.
|
| 1200 |
+
|
| 1201 |
+
The resulting units are bits (rather than nats, as one might expect).
|
| 1202 |
+
This allows for comparison to other papers.
|
| 1203 |
+
|
| 1204 |
+
:return: a dict with the following keys:
|
| 1205 |
+
- 'output': a shape [N] tensor of NLLs or KLs.
|
| 1206 |
+
- 'pred_xstart': the x_0 predictions.
|
| 1207 |
+
"""
|
| 1208 |
+
true_mean, _, true_log_variance_clipped = self.q_posterior_mean_variance(
|
| 1209 |
+
x_start=x_start, x_t=x_t, t=t
|
| 1210 |
+
)
|
| 1211 |
+
out = self.p_mean_variance(
|
| 1212 |
+
model, x_t, t, clip_denoised=clip_denoised, model_kwargs=model_kwargs
|
| 1213 |
+
)
|
| 1214 |
+
kl = normal_kl(
|
| 1215 |
+
true_mean, true_log_variance_clipped, out["mean"], out["log_variance"]
|
| 1216 |
+
)
|
| 1217 |
+
kl = mean_flat(kl) / np.log(2.0)
|
| 1218 |
+
|
| 1219 |
+
decoder_nll = -discretized_gaussian_log_likelihood(
|
| 1220 |
+
x_start, means=out["mean"], log_scales=0.5 * out["log_variance"]
|
| 1221 |
+
)
|
| 1222 |
+
assert decoder_nll.shape == x_start.shape
|
| 1223 |
+
decoder_nll = mean_flat(decoder_nll) / np.log(2.0)
|
| 1224 |
+
|
| 1225 |
+
# At the first timestep return the decoder NLL,
|
| 1226 |
+
# otherwise return KL(q(x_{t-1}|x_t,x_0) || p(x_{t-1}|x_t))
|
| 1227 |
+
output = th.where((t == 0), decoder_nll, kl)
|
| 1228 |
+
return {"output": output, "pred_xstart": out["pred_xstart"]}
|
| 1229 |
+
|
| 1230 |
+
def training_losses(self, model, x_start, t, model_kwargs=None, noise=None, dataset=None):
|
| 1231 |
+
"""
|
| 1232 |
+
Compute training losses for a single timestep.
|
| 1233 |
+
|
| 1234 |
+
:param model: the model to evaluate loss on.
|
| 1235 |
+
:param x_start: the [N x C x ...] tensor of inputs.
|
| 1236 |
+
:param t: a batch of timestep indices.
|
| 1237 |
+
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
| 1238 |
+
pass to the model. This can be used for conditioning.
|
| 1239 |
+
:param noise: if specified, the specific Gaussian noise to try to remove.
|
| 1240 |
+
:return: a dict with the key "loss" containing a tensor of shape [N].
|
| 1241 |
+
Some mean or variance settings may also have other keys.
|
| 1242 |
+
"""
|
| 1243 |
+
|
| 1244 |
+
# enc = model.model._modules['module']
|
| 1245 |
+
enc = model.model
|
| 1246 |
+
mask = model_kwargs['y']['mask']
|
| 1247 |
+
# get_xyz = lambda sample: enc.rot2xyz(sample, mask=None, pose_rep=enc.pose_rep, translation=enc.translation,
|
| 1248 |
+
# glob=enc.glob,
|
| 1249 |
+
# # jointstype='vertices', # 3.4 iter/sec # USED ALSO IN MotionCLIP
|
| 1250 |
+
# jointstype='smpl', # 3.4 iter/sec
|
| 1251 |
+
# vertstrans=False)
|
| 1252 |
+
|
| 1253 |
+
if model_kwargs is None:
|
| 1254 |
+
model_kwargs = {}
|
| 1255 |
+
if noise is None:
|
| 1256 |
+
noise = th.randn_like(x_start)
|
| 1257 |
+
x_t = self.q_sample(x_start, t, noise=noise) # torch.Size([64, 251, 1, 196]), add noisy
|
| 1258 |
+
|
| 1259 |
+
terms = {}
|
| 1260 |
+
|
| 1261 |
+
if self.loss_type == LossType.KL or self.loss_type == LossType.RESCALED_KL: # LossType.MSE
|
| 1262 |
+
terms["loss"] = self._vb_terms_bpd(
|
| 1263 |
+
model=model,
|
| 1264 |
+
x_start=x_start,
|
| 1265 |
+
x_t=x_t,
|
| 1266 |
+
t=t,
|
| 1267 |
+
clip_denoised=False,
|
| 1268 |
+
model_kwargs=model_kwargs,
|
| 1269 |
+
)["output"]
|
| 1270 |
+
if self.loss_type == LossType.RESCALED_KL:
|
| 1271 |
+
terms["loss"] *= self.num_timesteps
|
| 1272 |
+
elif self.loss_type == LossType.MSE or self.loss_type == LossType.RESCALED_MSE:
|
| 1273 |
+
model_output = model(x_t, self._scale_timesteps(t), **model_kwargs)
|
| 1274 |
+
|
| 1275 |
+
if self.model_var_type in [ # ModelVarType.FIXED_SMALL: 2
|
| 1276 |
+
ModelVarType.LEARNED,
|
| 1277 |
+
ModelVarType.LEARNED_RANGE,
|
| 1278 |
+
]:
|
| 1279 |
+
B, C = x_t.shape[:2]
|
| 1280 |
+
assert model_output.shape == (B, C * 2, *x_t.shape[2:])
|
| 1281 |
+
model_output, model_var_values = th.split(model_output, C, dim=1)
|
| 1282 |
+
# Learn the variance using the variational bound, but don't let
|
| 1283 |
+
# it affect our mean prediction.
|
| 1284 |
+
frozen_out = th.cat([model_output.detach(), model_var_values], dim=1)
|
| 1285 |
+
terms["vb"] = self._vb_terms_bpd(
|
| 1286 |
+
model=lambda *args, r=frozen_out: r,
|
| 1287 |
+
x_start=x_start,
|
| 1288 |
+
x_t=x_t,
|
| 1289 |
+
t=t,
|
| 1290 |
+
clip_denoised=False,
|
| 1291 |
+
)["output"]
|
| 1292 |
+
if self.loss_type == LossType.RESCALED_MSE:
|
| 1293 |
+
# Divide by 1000 for equivalence with initial implementation.
|
| 1294 |
+
# Without a factor of 1/1000, the VB term hurts the MSE term.
|
| 1295 |
+
terms["vb"] *= self.num_timesteps / 1000.0
|
| 1296 |
+
|
| 1297 |
+
target = {
|
| 1298 |
+
ModelMeanType.PREVIOUS_X: self.q_posterior_mean_variance(
|
| 1299 |
+
x_start=x_start, x_t=x_t, t=t
|
| 1300 |
+
)[0],
|
| 1301 |
+
ModelMeanType.START_X: x_start,
|
| 1302 |
+
ModelMeanType.EPSILON: noise,
|
| 1303 |
+
}[self.model_mean_type] # ModelMeanType.START_X: 2
|
| 1304 |
+
assert model_output.shape == target.shape == x_start.shape # [bs, njoints, nfeats, nframes]
|
| 1305 |
+
|
| 1306 |
+
# pdb.set_trace() # target (2, 135, 1, 240)
|
| 1307 |
+
|
| 1308 |
+
terms["rot_mse"] = self.masked_l2(target, model_output, mask) # mean_flat(rot_mse) # [64, 251, 1, 196], -, [64, 1, 1, 196]
|
| 1309 |
+
|
| 1310 |
+
target_xyz, model_output_xyz = None, None
|
| 1311 |
+
|
| 1312 |
+
if self.lambda_rcxyz > 0.: # 0.0
|
| 1313 |
+
target_xyz = get_xyz(target) # [bs, nvertices(vertices)/njoints(smpl), 3, nframes]
|
| 1314 |
+
model_output_xyz = get_xyz(model_output) # [bs, nvertices, 3, nframes]
|
| 1315 |
+
terms["rcxyz_mse"] = self.masked_l2(target_xyz, model_output_xyz, mask) # mean_flat((target_xyz - model_output_xyz) ** 2)
|
| 1316 |
+
|
| 1317 |
+
if self.lambda_vel_rcxyz > 0.: # 0.0
|
| 1318 |
+
if self.data_rep == 'rot6d' and dataset.dataname in ['humanact12', 'uestc']:
|
| 1319 |
+
target_xyz = get_xyz(target) if target_xyz is None else target_xyz
|
| 1320 |
+
model_output_xyz = get_xyz(model_output) if model_output_xyz is None else model_output_xyz
|
| 1321 |
+
target_xyz_vel = (target_xyz[:, :, :, 1:] - target_xyz[:, :, :, :-1])
|
| 1322 |
+
model_output_xyz_vel = (model_output_xyz[:, :, :, 1:] - model_output_xyz[:, :, :, :-1])
|
| 1323 |
+
terms["vel_xyz_mse"] = self.masked_l2(target_xyz_vel, model_output_xyz_vel, mask[:, :, :, 1:])
|
| 1324 |
+
|
| 1325 |
+
if self.lambda_fc > 0.: # 0.0
|
| 1326 |
+
torch.autograd.set_detect_anomaly(True)
|
| 1327 |
+
if self.data_rep == 'rot6d' and dataset.dataname in ['humanact12', 'uestc']:
|
| 1328 |
+
target_xyz = get_xyz(target) if target_xyz is None else target_xyz
|
| 1329 |
+
model_output_xyz = get_xyz(model_output) if model_output_xyz is None else model_output_xyz
|
| 1330 |
+
# 'L_Ankle', # 7, 'R_Ankle', # 8 , 'L_Foot', # 10, 'R_Foot', # 11
|
| 1331 |
+
l_ankle_idx, r_ankle_idx, l_foot_idx, r_foot_idx = 7, 8, 10, 11
|
| 1332 |
+
relevant_joints = [l_ankle_idx, l_foot_idx, r_ankle_idx, r_foot_idx]
|
| 1333 |
+
gt_joint_xyz = target_xyz[:, relevant_joints, :, :] # [BatchSize, 4, 3, Frames]
|
| 1334 |
+
gt_joint_vel = torch.linalg.norm(gt_joint_xyz[:, :, :, 1:] - gt_joint_xyz[:, :, :, :-1], axis=2) # [BatchSize, 4, Frames]
|
| 1335 |
+
fc_mask = torch.unsqueeze((gt_joint_vel <= 0.01), dim=2).repeat(1, 1, 3, 1)
|
| 1336 |
+
pred_joint_xyz = model_output_xyz[:, relevant_joints, :, :] # [BatchSize, 4, 3, Frames]
|
| 1337 |
+
pred_vel = pred_joint_xyz[:, :, :, 1:] - pred_joint_xyz[:, :, :, :-1]
|
| 1338 |
+
pred_vel[~fc_mask] = 0
|
| 1339 |
+
terms["fc"] = self.masked_l2(pred_vel,
|
| 1340 |
+
torch.zeros(pred_vel.shape, device=pred_vel.device),
|
| 1341 |
+
mask[:, :, :, 1:])
|
| 1342 |
+
if self.lambda_vel > 0.: # 0.0
|
| 1343 |
+
target_vel = (target[..., 1:] - target[..., :-1])
|
| 1344 |
+
model_output_vel = (model_output[..., 1:] - model_output[..., :-1])
|
| 1345 |
+
terms["vel_mse"] = self.masked_l2(target_vel[:, :-1, :, :], # Remove last joint, is the root location!
|
| 1346 |
+
model_output_vel[:, :-1, :, :],
|
| 1347 |
+
mask[:, :, :, 1:]) # mean_flat((target_vel - model_output_vel) ** 2)
|
| 1348 |
+
|
| 1349 |
+
terms["loss"] = terms["rot_mse"] + terms.get('vb', 0.) +\
|
| 1350 |
+
(self.lambda_vel * terms.get('vel_mse', 0.)) +\
|
| 1351 |
+
(self.lambda_rcxyz * terms.get('rcxyz_mse', 0.)) + \
|
| 1352 |
+
(self.lambda_fc * terms.get('fc', 0.))
|
| 1353 |
+
|
| 1354 |
+
else:
|
| 1355 |
+
raise NotImplementedError(self.loss_type)
|
| 1356 |
+
|
| 1357 |
+
return terms
|
| 1358 |
+
|
| 1359 |
+
def fc_loss_rot_repr(self, gt_xyz, pred_xyz, mask):
|
| 1360 |
+
def to_np_cpu(x):
|
| 1361 |
+
return x.detach().cpu().numpy()
|
| 1362 |
+
"""
|
| 1363 |
+
pose_xyz: SMPL batch tensor of shape: [BatchSize, 24, 3, Frames]
|
| 1364 |
+
"""
|
| 1365 |
+
# 'L_Ankle', # 7, 'R_Ankle', # 8 , 'L_Foot', # 10, 'R_Foot', # 11
|
| 1366 |
+
|
| 1367 |
+
l_ankle_idx, r_ankle_idx = 7, 8
|
| 1368 |
+
l_foot_idx, r_foot_idx = 10, 11
|
| 1369 |
+
""" Contact calculated by 'Kfir Method' Commented code)"""
|
| 1370 |
+
# contact_signal = torch.zeros((pose_xyz.shape[0], pose_xyz.shape[3], 2), device=pose_xyz.device) # [BatchSize, Frames, 2]
|
| 1371 |
+
# left_xyz = 0.5 * (pose_xyz[:, l_ankle_idx, :, :] + pose_xyz[:, l_foot_idx, :, :]) # [BatchSize, 3, Frames]
|
| 1372 |
+
# right_xyz = 0.5 * (pose_xyz[:, r_ankle_idx, :, :] + pose_xyz[:, r_foot_idx, :, :])
|
| 1373 |
+
# left_z, right_z = left_xyz[:, 2, :], right_xyz[:, 2, :] # [BatchSize, Frames]
|
| 1374 |
+
# left_velocity = torch.linalg.norm(left_xyz[:, :, 2:] - left_xyz[:, :, :-2], axis=1) # [BatchSize, Frames]
|
| 1375 |
+
# right_velocity = torch.linalg.norm(left_xyz[:, :, 2:] - left_xyz[:, :, :-2], axis=1)
|
| 1376 |
+
#
|
| 1377 |
+
# left_z_mask = left_z <= torch.mean(torch.sort(left_z)[0][:, :left_z.shape[1] // 5], axis=-1)
|
| 1378 |
+
# left_z_mask = torch.stack([left_z_mask, left_z_mask], dim=-1) # [BatchSize, Frames, 2]
|
| 1379 |
+
# left_z_mask[:, :, 1] = False # Blank right side
|
| 1380 |
+
# contact_signal[left_z_mask] = 0.4
|
| 1381 |
+
#
|
| 1382 |
+
# right_z_mask = right_z <= torch.mean(torch.sort(right_z)[0][:, :right_z.shape[1] // 5], axis=-1)
|
| 1383 |
+
# right_z_mask = torch.stack([right_z_mask, right_z_mask], dim=-1) # [BatchSize, Frames, 2]
|
| 1384 |
+
# right_z_mask[:, :, 0] = False # Blank left side
|
| 1385 |
+
# contact_signal[right_z_mask] = 0.4
|
| 1386 |
+
# contact_signal[left_z <= (torch.mean(torch.sort(left_z)[:left_z.shape[0] // 5]) + 20), 0] = 1
|
| 1387 |
+
# contact_signal[right_z <= (torch.mean(torch.sort(right_z)[:right_z.shape[0] // 5]) + 20), 1] = 1
|
| 1388 |
+
|
| 1389 |
+
# plt.plot(to_np_cpu(left_z[0]), label='left_z')
|
| 1390 |
+
# plt.plot(to_np_cpu(left_velocity[0]), label='left_velocity')
|
| 1391 |
+
# plt.plot(to_np_cpu(contact_signal[0, :, 0]), label='left_fc')
|
| 1392 |
+
# plt.grid()
|
| 1393 |
+
# plt.legend()
|
| 1394 |
+
# plt.show()
|
| 1395 |
+
# plt.plot(to_np_cpu(right_z[0]), label='right_z')
|
| 1396 |
+
# plt.plot(to_np_cpu(right_velocity[0]), label='right_velocity')
|
| 1397 |
+
# plt.plot(to_np_cpu(contact_signal[0, :, 1]), label='right_fc')
|
| 1398 |
+
# plt.grid()
|
| 1399 |
+
# plt.legend()
|
| 1400 |
+
# plt.show()
|
| 1401 |
+
|
| 1402 |
+
gt_joint_xyz = gt_xyz[:, [l_ankle_idx, l_foot_idx, r_ankle_idx, r_foot_idx], :, :] # [BatchSize, 4, 3, Frames]
|
| 1403 |
+
gt_joint_vel = torch.linalg.norm(gt_joint_xyz[:, :, :, 1:] - gt_joint_xyz[:, :, :, :-1], axis=2) # [BatchSize, 4, Frames]
|
| 1404 |
+
fc_mask = (gt_joint_vel <= 0.01)
|
| 1405 |
+
pred_joint_xyz = pred_xyz[:, [l_ankle_idx, l_foot_idx, r_ankle_idx, r_foot_idx], :, :] # [BatchSize, 4, 3, Frames]
|
| 1406 |
+
pred_joint_vel = torch.linalg.norm(pred_joint_xyz[:, :, :, 1:] - pred_joint_xyz[:, :, :, :-1], axis=2) # [BatchSize, 4, Frames]
|
| 1407 |
+
pred_joint_vel[~fc_mask] = 0 # Blank non-contact velocities frames. [BS,4,FRAMES]
|
| 1408 |
+
pred_joint_vel = torch.unsqueeze(pred_joint_vel, dim=2)
|
| 1409 |
+
|
| 1410 |
+
"""DEBUG CODE"""
|
| 1411 |
+
# print(f'mask: {mask.shape}')
|
| 1412 |
+
# print(f'pred_joint_vel: {pred_joint_vel.shape}')
|
| 1413 |
+
# plt.title(f'Joint: {joint_idx}')
|
| 1414 |
+
# plt.plot(to_np_cpu(gt_joint_vel[0]), label='velocity')
|
| 1415 |
+
# plt.plot(to_np_cpu(fc_mask[0]), label='fc')
|
| 1416 |
+
# plt.grid()
|
| 1417 |
+
# plt.legend()
|
| 1418 |
+
# plt.show()
|
| 1419 |
+
return self.masked_l2(pred_joint_vel, torch.zeros(pred_joint_vel.shape, device=pred_joint_vel.device),
|
| 1420 |
+
mask[:, :, :, 1:])
|
| 1421 |
+
# TODO - NOT USED YET, JUST COMMITING TO NOT DELETE THIS AND KEEP INITIAL IMPLEMENTATION, NOT DONE!
|
| 1422 |
+
def foot_contact_loss_humanml3d(self, target, model_output):
|
| 1423 |
+
# root_rot_velocity (B, seq_len, 1)
|
| 1424 |
+
# root_linear_velocity (B, seq_len, 2)
|
| 1425 |
+
# root_y (B, seq_len, 1)
|
| 1426 |
+
# ric_data (B, seq_len, (joint_num - 1)*3) , XYZ
|
| 1427 |
+
# rot_data (B, seq_len, (joint_num - 1)*6) , 6D
|
| 1428 |
+
# local_velocity (B, seq_len, joint_num*3) , XYZ
|
| 1429 |
+
# foot contact (B, seq_len, 4) ,
|
| 1430 |
+
|
| 1431 |
+
target_fc = target[:, -4:, :, :]
|
| 1432 |
+
root_rot_velocity = target[:, :1, :, :]
|
| 1433 |
+
root_linear_velocity = target[:, 1:3, :, :]
|
| 1434 |
+
root_y = target[:, 3:4, :, :]
|
| 1435 |
+
ric_data = target[:, 4:67, :, :] # 4+(3*21)=67
|
| 1436 |
+
rot_data = target[:, 67:193, :, :] # 67+(6*21)=193
|
| 1437 |
+
local_velocity = target[:, 193:259, :, :] # 193+(3*22)=259
|
| 1438 |
+
contact = target[:, 259:, :, :] # 193+(3*22)=259
|
| 1439 |
+
contact_mask_gt = contact > 0.5 # contact mask order for indexes are fid_l [7, 10], fid_r [8, 11]
|
| 1440 |
+
vel_lf_7 = local_velocity[:, 7 * 3:8 * 3, :, :]
|
| 1441 |
+
vel_rf_8 = local_velocity[:, 8 * 3:9 * 3, :, :]
|
| 1442 |
+
vel_lf_10 = local_velocity[:, 10 * 3:11 * 3, :, :]
|
| 1443 |
+
vel_rf_11 = local_velocity[:, 11 * 3:12 * 3, :, :]
|
| 1444 |
+
|
| 1445 |
+
calc_vel_lf_7 = ric_data[:, 6 * 3:7 * 3, :, 1:] - ric_data[:, 6 * 3:7 * 3, :, :-1]
|
| 1446 |
+
calc_vel_rf_8 = ric_data[:, 7 * 3:8 * 3, :, 1:] - ric_data[:, 7 * 3:8 * 3, :, :-1]
|
| 1447 |
+
calc_vel_lf_10 = ric_data[:, 9 * 3:10 * 3, :, 1:] - ric_data[:, 9 * 3:10 * 3, :, :-1]
|
| 1448 |
+
calc_vel_rf_11 = ric_data[:, 10 * 3:11 * 3, :, 1:] - ric_data[:, 10 * 3:11 * 3, :, :-1]
|
| 1449 |
+
|
| 1450 |
+
# vel_foots = torch.stack([vel_lf_7, vel_lf_10, vel_rf_8, vel_rf_11], dim=1)
|
| 1451 |
+
for chosen_vel_foot_calc, chosen_vel_foot, joint_idx, contact_mask_idx in zip(
|
| 1452 |
+
[calc_vel_lf_7, calc_vel_rf_8, calc_vel_lf_10, calc_vel_rf_11],
|
| 1453 |
+
[vel_lf_7, vel_lf_10, vel_rf_8, vel_rf_11],
|
| 1454 |
+
[7, 10, 8, 11],
|
| 1455 |
+
[0, 1, 2, 3]):
|
| 1456 |
+
tmp_mask_gt = contact_mask_gt[:, contact_mask_idx, :, :].cpu().detach().numpy().reshape(-1).astype(int)
|
| 1457 |
+
chosen_vel_norm = np.linalg.norm(chosen_vel_foot.cpu().detach().numpy().reshape((3, -1)), axis=0)
|
| 1458 |
+
chosen_vel_calc_norm = np.linalg.norm(chosen_vel_foot_calc.cpu().detach().numpy().reshape((3, -1)),
|
| 1459 |
+
axis=0)
|
| 1460 |
+
|
| 1461 |
+
print(tmp_mask_gt.shape)
|
| 1462 |
+
print(chosen_vel_foot.shape)
|
| 1463 |
+
print(chosen_vel_calc_norm.shape)
|
| 1464 |
+
import matplotlib.pyplot as plt
|
| 1465 |
+
plt.plot(tmp_mask_gt, label='FC mask')
|
| 1466 |
+
plt.plot(chosen_vel_norm, label='Vel. XYZ norm (from vector)')
|
| 1467 |
+
plt.plot(chosen_vel_calc_norm, label='Vel. XYZ norm (calculated diff XYZ)')
|
| 1468 |
+
|
| 1469 |
+
plt.title(f'FC idx {contact_mask_idx}, Joint Index {joint_idx}')
|
| 1470 |
+
plt.legend()
|
| 1471 |
+
plt.show()
|
| 1472 |
+
# print(vel_foots.shape)
|
| 1473 |
+
return 0
|
| 1474 |
+
# TODO - NOT USED YET, JUST COMMITING TO NOT DELETE THIS AND KEEP INITIAL IMPLEMENTATION, NOT DONE!
|
| 1475 |
+
def velocity_consistency_loss_humanml3d(self, target, model_output):
|
| 1476 |
+
# root_rot_velocity (B, seq_len, 1)
|
| 1477 |
+
# root_linear_velocity (B, seq_len, 2)
|
| 1478 |
+
# root_y (B, seq_len, 1)
|
| 1479 |
+
# ric_data (B, seq_len, (joint_num - 1)*3) , XYZ
|
| 1480 |
+
# rot_data (B, seq_len, (joint_num - 1)*6) , 6D
|
| 1481 |
+
# local_velocity (B, seq_len, joint_num*3) , XYZ
|
| 1482 |
+
# foot contact (B, seq_len, 4) ,
|
| 1483 |
+
|
| 1484 |
+
target_fc = target[:, -4:, :, :]
|
| 1485 |
+
root_rot_velocity = target[:, :1, :, :]
|
| 1486 |
+
root_linear_velocity = target[:, 1:3, :, :]
|
| 1487 |
+
root_y = target[:, 3:4, :, :]
|
| 1488 |
+
ric_data = target[:, 4:67, :, :] # 4+(3*21)=67
|
| 1489 |
+
rot_data = target[:, 67:193, :, :] # 67+(6*21)=193
|
| 1490 |
+
local_velocity = target[:, 193:259, :, :] # 193+(3*22)=259
|
| 1491 |
+
contact = target[:, 259:, :, :] # 193+(3*22)=259
|
| 1492 |
+
|
| 1493 |
+
calc_vel_from_xyz = ric_data[:, :, :, 1:] - ric_data[:, :, :, :-1]
|
| 1494 |
+
velocity_from_vector = local_velocity[:, 3:, :, 1:] # Slicing out root
|
| 1495 |
+
r_rot_quat, r_pos = motion_process.recover_root_rot_pos(target.permute(0, 2, 3, 1).type(th.FloatTensor))
|
| 1496 |
+
print(f'r_rot_quat: {r_rot_quat.shape}')
|
| 1497 |
+
print(f'calc_vel_from_xyz: {calc_vel_from_xyz.shape}')
|
| 1498 |
+
calc_vel_from_xyz = calc_vel_from_xyz.permute(0, 2, 3, 1)
|
| 1499 |
+
calc_vel_from_xyz = calc_vel_from_xyz.reshape((1, 1, -1, 21, 3)).type(th.FloatTensor)
|
| 1500 |
+
r_rot_quat_adapted = r_rot_quat[..., :-1, None, :].repeat((1,1,1,21,1)).to(calc_vel_from_xyz.device)
|
| 1501 |
+
print(f'calc_vel_from_xyz: {calc_vel_from_xyz.shape} , {calc_vel_from_xyz.device}')
|
| 1502 |
+
print(f'r_rot_quat_adapted: {r_rot_quat_adapted.shape}, {r_rot_quat_adapted.device}')
|
| 1503 |
+
|
| 1504 |
+
calc_vel_from_xyz = motion_process.qrot(r_rot_quat_adapted, calc_vel_from_xyz)
|
| 1505 |
+
calc_vel_from_xyz = calc_vel_from_xyz.reshape((1, 1, -1, 21 * 3))
|
| 1506 |
+
calc_vel_from_xyz = calc_vel_from_xyz.permute(0, 3, 1, 2)
|
| 1507 |
+
print(f'calc_vel_from_xyz: {calc_vel_from_xyz.shape} , {calc_vel_from_xyz.device}')
|
| 1508 |
+
|
| 1509 |
+
import matplotlib.pyplot as plt
|
| 1510 |
+
for i in range(21):
|
| 1511 |
+
plt.plot(np.linalg.norm(calc_vel_from_xyz[:,i*3:(i+1)*3,:,:].cpu().detach().numpy().reshape((3, -1)), axis=0), label='Calc Vel')
|
| 1512 |
+
plt.plot(np.linalg.norm(velocity_from_vector[:,i*3:(i+1)*3,:,:].cpu().detach().numpy().reshape((3, -1)), axis=0), label='Vector Vel')
|
| 1513 |
+
plt.title(f'Joint idx: {i}')
|
| 1514 |
+
plt.legend()
|
| 1515 |
+
plt.show()
|
| 1516 |
+
print(calc_vel_from_xyz.shape)
|
| 1517 |
+
print(velocity_from_vector.shape)
|
| 1518 |
+
diff = calc_vel_from_xyz-velocity_from_vector
|
| 1519 |
+
print(np.linalg.norm(diff.cpu().detach().numpy().reshape((63, -1)), axis=0))
|
| 1520 |
+
|
| 1521 |
+
return 0
|
| 1522 |
+
|
| 1523 |
+
|
| 1524 |
+
def _prior_bpd(self, x_start):
|
| 1525 |
+
"""
|
| 1526 |
+
Get the prior KL term for the variational lower-bound, measured in
|
| 1527 |
+
bits-per-dim.
|
| 1528 |
+
|
| 1529 |
+
This term can't be optimized, as it only depends on the encoder.
|
| 1530 |
+
|
| 1531 |
+
:param x_start: the [N x C x ...] tensor of inputs.
|
| 1532 |
+
:return: a batch of [N] KL values (in bits), one per batch element.
|
| 1533 |
+
"""
|
| 1534 |
+
batch_size = x_start.shape[0]
|
| 1535 |
+
t = th.tensor([self.num_timesteps - 1] * batch_size, device=x_start.device)
|
| 1536 |
+
qt_mean, _, qt_log_variance = self.q_mean_variance(x_start, t)
|
| 1537 |
+
kl_prior = normal_kl(
|
| 1538 |
+
mean1=qt_mean, logvar1=qt_log_variance, mean2=0.0, logvar2=0.0
|
| 1539 |
+
)
|
| 1540 |
+
return mean_flat(kl_prior) / np.log(2.0)
|
| 1541 |
+
|
| 1542 |
+
def calc_bpd_loop(self, model, x_start, clip_denoised=True, model_kwargs=None):
|
| 1543 |
+
"""
|
| 1544 |
+
Compute the entire variational lower-bound, measured in bits-per-dim,
|
| 1545 |
+
as well as other related quantities.
|
| 1546 |
+
|
| 1547 |
+
:param model: the model to evaluate loss on.
|
| 1548 |
+
:param x_start: the [N x C x ...] tensor of inputs.
|
| 1549 |
+
:param clip_denoised: if True, clip denoised samples.
|
| 1550 |
+
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
| 1551 |
+
pass to the model. This can be used for conditioning.
|
| 1552 |
+
|
| 1553 |
+
:return: a dict containing the following keys:
|
| 1554 |
+
- total_bpd: the total variational lower-bound, per batch element.
|
| 1555 |
+
- prior_bpd: the prior term in the lower-bound.
|
| 1556 |
+
- vb: an [N x T] tensor of terms in the lower-bound.
|
| 1557 |
+
- xstart_mse: an [N x T] tensor of x_0 MSEs for each timestep.
|
| 1558 |
+
- mse: an [N x T] tensor of epsilon MSEs for each timestep.
|
| 1559 |
+
"""
|
| 1560 |
+
device = x_start.device
|
| 1561 |
+
batch_size = x_start.shape[0]
|
| 1562 |
+
|
| 1563 |
+
vb = []
|
| 1564 |
+
xstart_mse = []
|
| 1565 |
+
mse = []
|
| 1566 |
+
for t in list(range(self.num_timesteps))[::-1]:
|
| 1567 |
+
t_batch = th.tensor([t] * batch_size, device=device)
|
| 1568 |
+
noise = th.randn_like(x_start)
|
| 1569 |
+
x_t = self.q_sample(x_start=x_start, t=t_batch, noise=noise)
|
| 1570 |
+
# Calculate VLB term at the current timestep
|
| 1571 |
+
with th.no_grad():
|
| 1572 |
+
out = self._vb_terms_bpd(
|
| 1573 |
+
model,
|
| 1574 |
+
x_start=x_start,
|
| 1575 |
+
x_t=x_t,
|
| 1576 |
+
t=t_batch,
|
| 1577 |
+
clip_denoised=clip_denoised,
|
| 1578 |
+
model_kwargs=model_kwargs,
|
| 1579 |
+
)
|
| 1580 |
+
vb.append(out["output"])
|
| 1581 |
+
xstart_mse.append(mean_flat((out["pred_xstart"] - x_start) ** 2))
|
| 1582 |
+
eps = self._predict_eps_from_xstart(x_t, t_batch, out["pred_xstart"])
|
| 1583 |
+
mse.append(mean_flat((eps - noise) ** 2))
|
| 1584 |
+
|
| 1585 |
+
vb = th.stack(vb, dim=1)
|
| 1586 |
+
xstart_mse = th.stack(xstart_mse, dim=1)
|
| 1587 |
+
mse = th.stack(mse, dim=1)
|
| 1588 |
+
|
| 1589 |
+
prior_bpd = self._prior_bpd(x_start)
|
| 1590 |
+
total_bpd = vb.sum(dim=1) + prior_bpd
|
| 1591 |
+
return {
|
| 1592 |
+
"total_bpd": total_bpd,
|
| 1593 |
+
"prior_bpd": prior_bpd,
|
| 1594 |
+
"vb": vb,
|
| 1595 |
+
"xstart_mse": xstart_mse,
|
| 1596 |
+
"mse": mse,
|
| 1597 |
+
}
|
| 1598 |
+
|
| 1599 |
+
|
| 1600 |
+
def _extract_into_tensor(arr, timesteps, broadcast_shape):
|
| 1601 |
+
"""
|
| 1602 |
+
Extract values from a 1-D numpy array for a batch of indices.
|
| 1603 |
+
|
| 1604 |
+
:param arr: the 1-D numpy array.
|
| 1605 |
+
:param timesteps: a tensor of indices into the array to extract.
|
| 1606 |
+
:param broadcast_shape: a larger shape of K dimensions with the batch
|
| 1607 |
+
dimension equal to the length of timesteps.
|
| 1608 |
+
:return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
|
| 1609 |
+
"""
|
| 1610 |
+
res = th.from_numpy(arr).to(device=timesteps.device)[timesteps].float()
|
| 1611 |
+
while len(res.shape) < len(broadcast_shape):
|
| 1612 |
+
res = res[..., None]
|
| 1613 |
+
return res.expand(broadcast_shape)
|
main/diffusion/logger.py
ADDED
|
@@ -0,0 +1,495 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Logger copied from OpenAI baselines to avoid extra RL-based dependencies:
|
| 3 |
+
https://github.com/openai/baselines/blob/ea25b9e8b234e6ee1bca43083f8f3cf974143998/baselines/logger.py
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import sys
|
| 8 |
+
import shutil
|
| 9 |
+
import os.path as osp
|
| 10 |
+
import json
|
| 11 |
+
import time
|
| 12 |
+
import datetime
|
| 13 |
+
import tempfile
|
| 14 |
+
import warnings
|
| 15 |
+
from collections import defaultdict
|
| 16 |
+
from contextlib import contextmanager
|
| 17 |
+
|
| 18 |
+
DEBUG = 10
|
| 19 |
+
INFO = 20
|
| 20 |
+
WARN = 30
|
| 21 |
+
ERROR = 40
|
| 22 |
+
|
| 23 |
+
DISABLED = 50
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class KVWriter(object):
|
| 27 |
+
def writekvs(self, kvs):
|
| 28 |
+
raise NotImplementedError
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class SeqWriter(object):
|
| 32 |
+
def writeseq(self, seq):
|
| 33 |
+
raise NotImplementedError
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class HumanOutputFormat(KVWriter, SeqWriter):
|
| 37 |
+
def __init__(self, filename_or_file):
|
| 38 |
+
if isinstance(filename_or_file, str):
|
| 39 |
+
self.file = open(filename_or_file, "wt")
|
| 40 |
+
self.own_file = True
|
| 41 |
+
else:
|
| 42 |
+
assert hasattr(filename_or_file, "read"), (
|
| 43 |
+
"expected file or str, got %s" % filename_or_file
|
| 44 |
+
)
|
| 45 |
+
self.file = filename_or_file
|
| 46 |
+
self.own_file = False
|
| 47 |
+
|
| 48 |
+
def writekvs(self, kvs):
|
| 49 |
+
# Create strings for printing
|
| 50 |
+
key2str = {}
|
| 51 |
+
for (key, val) in sorted(kvs.items()):
|
| 52 |
+
if hasattr(val, "__float__"):
|
| 53 |
+
valstr = "%-8.3g" % val
|
| 54 |
+
else:
|
| 55 |
+
valstr = str(val)
|
| 56 |
+
key2str[self._truncate(key)] = self._truncate(valstr)
|
| 57 |
+
|
| 58 |
+
# Find max widths
|
| 59 |
+
if len(key2str) == 0:
|
| 60 |
+
print("WARNING: tried to write empty key-value dict")
|
| 61 |
+
return
|
| 62 |
+
else:
|
| 63 |
+
keywidth = max(map(len, key2str.keys()))
|
| 64 |
+
valwidth = max(map(len, key2str.values()))
|
| 65 |
+
|
| 66 |
+
# Write out the data
|
| 67 |
+
dashes = "-" * (keywidth + valwidth + 7)
|
| 68 |
+
lines = [dashes]
|
| 69 |
+
for (key, val) in sorted(key2str.items(), key=lambda kv: kv[0].lower()):
|
| 70 |
+
lines.append(
|
| 71 |
+
"| %s%s | %s%s |"
|
| 72 |
+
% (key, " " * (keywidth - len(key)), val, " " * (valwidth - len(val)))
|
| 73 |
+
)
|
| 74 |
+
lines.append(dashes)
|
| 75 |
+
self.file.write("\n".join(lines) + "\n")
|
| 76 |
+
|
| 77 |
+
# Flush the output to the file
|
| 78 |
+
self.file.flush()
|
| 79 |
+
|
| 80 |
+
def _truncate(self, s):
|
| 81 |
+
maxlen = 30
|
| 82 |
+
return s[: maxlen - 3] + "..." if len(s) > maxlen else s
|
| 83 |
+
|
| 84 |
+
def writeseq(self, seq):
|
| 85 |
+
seq = list(seq)
|
| 86 |
+
for (i, elem) in enumerate(seq):
|
| 87 |
+
self.file.write(elem)
|
| 88 |
+
if i < len(seq) - 1: # add space unless this is the last one
|
| 89 |
+
self.file.write(" ")
|
| 90 |
+
self.file.write("\n")
|
| 91 |
+
self.file.flush()
|
| 92 |
+
|
| 93 |
+
def close(self):
|
| 94 |
+
if self.own_file:
|
| 95 |
+
self.file.close()
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
class JSONOutputFormat(KVWriter):
|
| 99 |
+
def __init__(self, filename):
|
| 100 |
+
self.file = open(filename, "wt")
|
| 101 |
+
|
| 102 |
+
def writekvs(self, kvs):
|
| 103 |
+
for k, v in sorted(kvs.items()):
|
| 104 |
+
if hasattr(v, "dtype"):
|
| 105 |
+
kvs[k] = float(v)
|
| 106 |
+
self.file.write(json.dumps(kvs) + "\n")
|
| 107 |
+
self.file.flush()
|
| 108 |
+
|
| 109 |
+
def close(self):
|
| 110 |
+
self.file.close()
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
class CSVOutputFormat(KVWriter):
|
| 114 |
+
def __init__(self, filename):
|
| 115 |
+
self.file = open(filename, "w+t")
|
| 116 |
+
self.keys = []
|
| 117 |
+
self.sep = ","
|
| 118 |
+
|
| 119 |
+
def writekvs(self, kvs):
|
| 120 |
+
# Add our current row to the history
|
| 121 |
+
extra_keys = list(kvs.keys() - self.keys)
|
| 122 |
+
extra_keys.sort()
|
| 123 |
+
if extra_keys:
|
| 124 |
+
self.keys.extend(extra_keys)
|
| 125 |
+
self.file.seek(0)
|
| 126 |
+
lines = self.file.readlines()
|
| 127 |
+
self.file.seek(0)
|
| 128 |
+
for (i, k) in enumerate(self.keys):
|
| 129 |
+
if i > 0:
|
| 130 |
+
self.file.write(",")
|
| 131 |
+
self.file.write(k)
|
| 132 |
+
self.file.write("\n")
|
| 133 |
+
for line in lines[1:]:
|
| 134 |
+
self.file.write(line[:-1])
|
| 135 |
+
self.file.write(self.sep * len(extra_keys))
|
| 136 |
+
self.file.write("\n")
|
| 137 |
+
for (i, k) in enumerate(self.keys):
|
| 138 |
+
if i > 0:
|
| 139 |
+
self.file.write(",")
|
| 140 |
+
v = kvs.get(k)
|
| 141 |
+
if v is not None:
|
| 142 |
+
self.file.write(str(v))
|
| 143 |
+
self.file.write("\n")
|
| 144 |
+
self.file.flush()
|
| 145 |
+
|
| 146 |
+
def close(self):
|
| 147 |
+
self.file.close()
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
class TensorBoardOutputFormat(KVWriter):
|
| 151 |
+
"""
|
| 152 |
+
Dumps key/value pairs into TensorBoard's numeric format.
|
| 153 |
+
"""
|
| 154 |
+
|
| 155 |
+
def __init__(self, dir):
|
| 156 |
+
os.makedirs(dir, exist_ok=True)
|
| 157 |
+
self.dir = dir
|
| 158 |
+
self.step = 1
|
| 159 |
+
prefix = "events"
|
| 160 |
+
path = osp.join(osp.abspath(dir), prefix)
|
| 161 |
+
import tensorflow as tf
|
| 162 |
+
from tensorflow.python import pywrap_tensorflow
|
| 163 |
+
from tensorflow.core.util import event_pb2
|
| 164 |
+
from tensorflow.python.util import compat
|
| 165 |
+
|
| 166 |
+
self.tf = tf
|
| 167 |
+
self.event_pb2 = event_pb2
|
| 168 |
+
self.pywrap_tensorflow = pywrap_tensorflow
|
| 169 |
+
self.writer = pywrap_tensorflow.EventsWriter(compat.as_bytes(path))
|
| 170 |
+
|
| 171 |
+
def writekvs(self, kvs):
|
| 172 |
+
def summary_val(k, v):
|
| 173 |
+
kwargs = {"tag": k, "simple_value": float(v)}
|
| 174 |
+
return self.tf.Summary.Value(**kwargs)
|
| 175 |
+
|
| 176 |
+
summary = self.tf.Summary(value=[summary_val(k, v) for k, v in kvs.items()])
|
| 177 |
+
event = self.event_pb2.Event(wall_time=time.time(), summary=summary)
|
| 178 |
+
event.step = (
|
| 179 |
+
self.step
|
| 180 |
+
) # is there any reason why you'd want to specify the step?
|
| 181 |
+
self.writer.WriteEvent(event)
|
| 182 |
+
self.writer.Flush()
|
| 183 |
+
self.step += 1
|
| 184 |
+
|
| 185 |
+
def close(self):
|
| 186 |
+
if self.writer:
|
| 187 |
+
self.writer.Close()
|
| 188 |
+
self.writer = None
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
def make_output_format(format, ev_dir, log_suffix=""):
|
| 192 |
+
os.makedirs(ev_dir, exist_ok=True)
|
| 193 |
+
if format == "stdout":
|
| 194 |
+
return HumanOutputFormat(sys.stdout)
|
| 195 |
+
elif format == "log":
|
| 196 |
+
return HumanOutputFormat(osp.join(ev_dir, "log%s.txt" % log_suffix))
|
| 197 |
+
elif format == "json":
|
| 198 |
+
return JSONOutputFormat(osp.join(ev_dir, "progress%s.json" % log_suffix))
|
| 199 |
+
elif format == "csv":
|
| 200 |
+
return CSVOutputFormat(osp.join(ev_dir, "progress%s.csv" % log_suffix))
|
| 201 |
+
elif format == "tensorboard":
|
| 202 |
+
return TensorBoardOutputFormat(osp.join(ev_dir, "tb%s" % log_suffix))
|
| 203 |
+
else:
|
| 204 |
+
raise ValueError("Unknown format specified: %s" % (format,))
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
# ================================================================
|
| 208 |
+
# API
|
| 209 |
+
# ================================================================
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def logkv(key, val):
|
| 213 |
+
"""
|
| 214 |
+
Log a value of some diagnostic
|
| 215 |
+
Call this once for each diagnostic quantity, each iteration
|
| 216 |
+
If called many times, last value will be used.
|
| 217 |
+
"""
|
| 218 |
+
get_current().logkv(key, val)
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
def logkv_mean(key, val):
|
| 222 |
+
"""
|
| 223 |
+
The same as logkv(), but if called many times, values averaged.
|
| 224 |
+
"""
|
| 225 |
+
get_current().logkv_mean(key, val)
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
def logkvs(d):
|
| 229 |
+
"""
|
| 230 |
+
Log a dictionary of key-value pairs
|
| 231 |
+
"""
|
| 232 |
+
for (k, v) in d.items():
|
| 233 |
+
logkv(k, v)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def dumpkvs():
|
| 237 |
+
"""
|
| 238 |
+
Write all of the diagnostics from the current iteration
|
| 239 |
+
"""
|
| 240 |
+
return get_current().dumpkvs()
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
def getkvs():
|
| 244 |
+
return get_current().name2val
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
def log(*args, level=INFO):
|
| 248 |
+
"""
|
| 249 |
+
Write the sequence of args, with no separators, to the console and output files (if you've configured an output file).
|
| 250 |
+
"""
|
| 251 |
+
get_current().log(*args, level=level)
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
def debug(*args):
|
| 255 |
+
log(*args, level=DEBUG)
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
def info(*args):
|
| 259 |
+
log(*args, level=INFO)
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
def warn(*args):
|
| 263 |
+
log(*args, level=WARN)
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
def error(*args):
|
| 267 |
+
log(*args, level=ERROR)
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
def set_level(level):
|
| 271 |
+
"""
|
| 272 |
+
Set logging threshold on current logger.
|
| 273 |
+
"""
|
| 274 |
+
get_current().set_level(level)
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
def set_comm(comm):
|
| 278 |
+
get_current().set_comm(comm)
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
def get_dir():
|
| 282 |
+
"""
|
| 283 |
+
Get directory that log files are being written to.
|
| 284 |
+
will be None if there is no output directory (i.e., if you didn't call start)
|
| 285 |
+
"""
|
| 286 |
+
return get_current().get_dir()
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
record_tabular = logkv
|
| 290 |
+
dump_tabular = dumpkvs
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
@contextmanager
|
| 294 |
+
def profile_kv(scopename):
|
| 295 |
+
logkey = "wait_" + scopename
|
| 296 |
+
tstart = time.time()
|
| 297 |
+
try:
|
| 298 |
+
yield
|
| 299 |
+
finally:
|
| 300 |
+
get_current().name2val[logkey] += time.time() - tstart
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
def profile(n):
|
| 304 |
+
"""
|
| 305 |
+
Usage:
|
| 306 |
+
@profile("my_func")
|
| 307 |
+
def my_func(): code
|
| 308 |
+
"""
|
| 309 |
+
|
| 310 |
+
def decorator_with_name(func):
|
| 311 |
+
def func_wrapper(*args, **kwargs):
|
| 312 |
+
with profile_kv(n):
|
| 313 |
+
return func(*args, **kwargs)
|
| 314 |
+
|
| 315 |
+
return func_wrapper
|
| 316 |
+
|
| 317 |
+
return decorator_with_name
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
# ================================================================
|
| 321 |
+
# Backend
|
| 322 |
+
# ================================================================
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
def get_current():
|
| 326 |
+
if Logger.CURRENT is None:
|
| 327 |
+
_configure_default_logger()
|
| 328 |
+
|
| 329 |
+
return Logger.CURRENT
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
class Logger(object):
|
| 333 |
+
DEFAULT = None # A logger with no output files. (See right below class definition)
|
| 334 |
+
# So that you can still log to the terminal without setting up any output files
|
| 335 |
+
CURRENT = None # Current logger being used by the free functions above
|
| 336 |
+
|
| 337 |
+
def __init__(self, dir, output_formats, comm=None):
|
| 338 |
+
self.name2val = defaultdict(float) # values this iteration
|
| 339 |
+
self.name2cnt = defaultdict(int)
|
| 340 |
+
self.level = INFO
|
| 341 |
+
self.dir = dir
|
| 342 |
+
self.output_formats = output_formats
|
| 343 |
+
self.comm = comm
|
| 344 |
+
|
| 345 |
+
# Logging API, forwarded
|
| 346 |
+
# ----------------------------------------
|
| 347 |
+
def logkv(self, key, val):
|
| 348 |
+
self.name2val[key] = val
|
| 349 |
+
|
| 350 |
+
def logkv_mean(self, key, val):
|
| 351 |
+
oldval, cnt = self.name2val[key], self.name2cnt[key]
|
| 352 |
+
self.name2val[key] = oldval * cnt / (cnt + 1) + val / (cnt + 1)
|
| 353 |
+
self.name2cnt[key] = cnt + 1
|
| 354 |
+
|
| 355 |
+
def dumpkvs(self):
|
| 356 |
+
if self.comm is None:
|
| 357 |
+
d = self.name2val
|
| 358 |
+
else:
|
| 359 |
+
d = mpi_weighted_mean(
|
| 360 |
+
self.comm,
|
| 361 |
+
{
|
| 362 |
+
name: (val, self.name2cnt.get(name, 1))
|
| 363 |
+
for (name, val) in self.name2val.items()
|
| 364 |
+
},
|
| 365 |
+
)
|
| 366 |
+
if self.comm.rank != 0:
|
| 367 |
+
d["dummy"] = 1 # so we don't get a warning about empty dict
|
| 368 |
+
out = d.copy() # Return the dict for unit testing purposes
|
| 369 |
+
for fmt in self.output_formats:
|
| 370 |
+
if isinstance(fmt, KVWriter):
|
| 371 |
+
fmt.writekvs(d)
|
| 372 |
+
self.name2val.clear()
|
| 373 |
+
self.name2cnt.clear()
|
| 374 |
+
return out
|
| 375 |
+
|
| 376 |
+
def log(self, *args, level=INFO):
|
| 377 |
+
if self.level <= level:
|
| 378 |
+
self._do_log(args)
|
| 379 |
+
|
| 380 |
+
# Configuration
|
| 381 |
+
# ----------------------------------------
|
| 382 |
+
def set_level(self, level):
|
| 383 |
+
self.level = level
|
| 384 |
+
|
| 385 |
+
def set_comm(self, comm):
|
| 386 |
+
self.comm = comm
|
| 387 |
+
|
| 388 |
+
def get_dir(self):
|
| 389 |
+
return self.dir
|
| 390 |
+
|
| 391 |
+
def close(self):
|
| 392 |
+
for fmt in self.output_formats:
|
| 393 |
+
fmt.close()
|
| 394 |
+
|
| 395 |
+
# Misc
|
| 396 |
+
# ----------------------------------------
|
| 397 |
+
def _do_log(self, args):
|
| 398 |
+
for fmt in self.output_formats:
|
| 399 |
+
if isinstance(fmt, SeqWriter):
|
| 400 |
+
fmt.writeseq(map(str, args))
|
| 401 |
+
|
| 402 |
+
|
| 403 |
+
def get_rank_without_mpi_import():
|
| 404 |
+
# check environment variables here instead of importing mpi4py
|
| 405 |
+
# to avoid calling MPI_Init() when this module is imported
|
| 406 |
+
for varname in ["PMI_RANK", "OMPI_COMM_WORLD_RANK"]:
|
| 407 |
+
if varname in os.environ:
|
| 408 |
+
return int(os.environ[varname])
|
| 409 |
+
return 0
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
def mpi_weighted_mean(comm, local_name2valcount):
|
| 413 |
+
"""
|
| 414 |
+
Copied from: https://github.com/openai/baselines/blob/ea25b9e8b234e6ee1bca43083f8f3cf974143998/baselines/common/mpi_util.py#L110
|
| 415 |
+
Perform a weighted average over dicts that are each on a different node
|
| 416 |
+
Input: local_name2valcount: dict mapping key -> (value, count)
|
| 417 |
+
Returns: key -> mean
|
| 418 |
+
"""
|
| 419 |
+
all_name2valcount = comm.gather(local_name2valcount)
|
| 420 |
+
if comm.rank == 0:
|
| 421 |
+
name2sum = defaultdict(float)
|
| 422 |
+
name2count = defaultdict(float)
|
| 423 |
+
for n2vc in all_name2valcount:
|
| 424 |
+
for (name, (val, count)) in n2vc.items():
|
| 425 |
+
try:
|
| 426 |
+
val = float(val)
|
| 427 |
+
except ValueError:
|
| 428 |
+
if comm.rank == 0:
|
| 429 |
+
warnings.warn(
|
| 430 |
+
"WARNING: tried to compute mean on non-float {}={}".format(
|
| 431 |
+
name, val
|
| 432 |
+
)
|
| 433 |
+
)
|
| 434 |
+
else:
|
| 435 |
+
name2sum[name] += val * count
|
| 436 |
+
name2count[name] += count
|
| 437 |
+
return {name: name2sum[name] / name2count[name] for name in name2sum}
|
| 438 |
+
else:
|
| 439 |
+
return {}
|
| 440 |
+
|
| 441 |
+
|
| 442 |
+
def configure(dir=None, format_strs=None, comm=None, log_suffix=""):
|
| 443 |
+
"""
|
| 444 |
+
If comm is provided, average all numerical stats across that comm
|
| 445 |
+
"""
|
| 446 |
+
if dir is None:
|
| 447 |
+
dir = os.getenv("OPENAI_LOGDIR")
|
| 448 |
+
if dir is None:
|
| 449 |
+
dir = osp.join(
|
| 450 |
+
tempfile.gettempdir(),
|
| 451 |
+
datetime.datetime.now().strftime("openai-%Y-%m-%d-%H-%M-%S-%f"),
|
| 452 |
+
)
|
| 453 |
+
assert isinstance(dir, str)
|
| 454 |
+
dir = os.path.expanduser(dir)
|
| 455 |
+
os.makedirs(os.path.expanduser(dir), exist_ok=True)
|
| 456 |
+
|
| 457 |
+
rank = get_rank_without_mpi_import()
|
| 458 |
+
if rank > 0:
|
| 459 |
+
log_suffix = log_suffix + "-rank%03i" % rank
|
| 460 |
+
|
| 461 |
+
if format_strs is None:
|
| 462 |
+
if rank == 0:
|
| 463 |
+
format_strs = os.getenv("OPENAI_LOG_FORMAT", "stdout,log,csv").split(",")
|
| 464 |
+
else:
|
| 465 |
+
format_strs = os.getenv("OPENAI_LOG_FORMAT_MPI", "log").split(",")
|
| 466 |
+
format_strs = filter(None, format_strs)
|
| 467 |
+
output_formats = [make_output_format(f, dir, log_suffix) for f in format_strs]
|
| 468 |
+
|
| 469 |
+
Logger.CURRENT = Logger(dir=dir, output_formats=output_formats, comm=comm)
|
| 470 |
+
if output_formats:
|
| 471 |
+
log("Logging to %s" % dir)
|
| 472 |
+
|
| 473 |
+
|
| 474 |
+
def _configure_default_logger():
|
| 475 |
+
configure()
|
| 476 |
+
Logger.DEFAULT = Logger.CURRENT
|
| 477 |
+
|
| 478 |
+
|
| 479 |
+
def reset():
|
| 480 |
+
if Logger.CURRENT is not Logger.DEFAULT:
|
| 481 |
+
Logger.CURRENT.close()
|
| 482 |
+
Logger.CURRENT = Logger.DEFAULT
|
| 483 |
+
log("Reset logger")
|
| 484 |
+
|
| 485 |
+
|
| 486 |
+
@contextmanager
|
| 487 |
+
def scoped_configure(dir=None, format_strs=None, comm=None):
|
| 488 |
+
prevlogger = Logger.CURRENT
|
| 489 |
+
configure(dir=dir, format_strs=format_strs, comm=comm)
|
| 490 |
+
try:
|
| 491 |
+
yield
|
| 492 |
+
finally:
|
| 493 |
+
Logger.CURRENT.close()
|
| 494 |
+
Logger.CURRENT = prevlogger
|
| 495 |
+
|
main/diffusion/losses.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This code is based on https://github.com/openai/guided-diffusion
|
| 2 |
+
"""
|
| 3 |
+
Helpers for various likelihood-based losses. These are ported from the original
|
| 4 |
+
Ho et al. diffusion models codebase:
|
| 5 |
+
https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/utils.py
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch as th
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def normal_kl(mean1, logvar1, mean2, logvar2):
|
| 13 |
+
"""
|
| 14 |
+
Compute the KL divergence between two gaussians.
|
| 15 |
+
|
| 16 |
+
Shapes are automatically broadcasted, so batches can be compared to
|
| 17 |
+
scalars, among other use cases.
|
| 18 |
+
"""
|
| 19 |
+
tensor = None
|
| 20 |
+
for obj in (mean1, logvar1, mean2, logvar2):
|
| 21 |
+
if isinstance(obj, th.Tensor):
|
| 22 |
+
tensor = obj
|
| 23 |
+
break
|
| 24 |
+
assert tensor is not None, "at least one argument must be a Tensor"
|
| 25 |
+
|
| 26 |
+
# Force variances to be Tensors. Broadcasting helps convert scalars to
|
| 27 |
+
# Tensors, but it does not work for th.exp().
|
| 28 |
+
logvar1, logvar2 = [
|
| 29 |
+
x if isinstance(x, th.Tensor) else th.tensor(x).to(tensor)
|
| 30 |
+
for x in (logvar1, logvar2)
|
| 31 |
+
]
|
| 32 |
+
|
| 33 |
+
return 0.5 * (
|
| 34 |
+
-1.0
|
| 35 |
+
+ logvar2
|
| 36 |
+
- logvar1
|
| 37 |
+
+ th.exp(logvar1 - logvar2)
|
| 38 |
+
+ ((mean1 - mean2) ** 2) * th.exp(-logvar2)
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def approx_standard_normal_cdf(x):
|
| 43 |
+
"""
|
| 44 |
+
A fast approximation of the cumulative distribution function of the
|
| 45 |
+
standard normal.
|
| 46 |
+
"""
|
| 47 |
+
return 0.5 * (1.0 + th.tanh(np.sqrt(2.0 / np.pi) * (x + 0.044715 * th.pow(x, 3))))
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def discretized_gaussian_log_likelihood(x, *, means, log_scales):
|
| 51 |
+
"""
|
| 52 |
+
Compute the log-likelihood of a Gaussian distribution discretizing to a
|
| 53 |
+
given image.
|
| 54 |
+
|
| 55 |
+
:param x: the target images. It is assumed that this was uint8 values,
|
| 56 |
+
rescaled to the range [-1, 1].
|
| 57 |
+
:param means: the Gaussian mean Tensor.
|
| 58 |
+
:param log_scales: the Gaussian log stddev Tensor.
|
| 59 |
+
:return: a tensor like x of log probabilities (in nats).
|
| 60 |
+
"""
|
| 61 |
+
assert x.shape == means.shape == log_scales.shape
|
| 62 |
+
centered_x = x - means
|
| 63 |
+
inv_stdv = th.exp(-log_scales)
|
| 64 |
+
plus_in = inv_stdv * (centered_x + 1.0 / 255.0)
|
| 65 |
+
cdf_plus = approx_standard_normal_cdf(plus_in)
|
| 66 |
+
min_in = inv_stdv * (centered_x - 1.0 / 255.0)
|
| 67 |
+
cdf_min = approx_standard_normal_cdf(min_in)
|
| 68 |
+
log_cdf_plus = th.log(cdf_plus.clamp(min=1e-12))
|
| 69 |
+
log_one_minus_cdf_min = th.log((1.0 - cdf_min).clamp(min=1e-12))
|
| 70 |
+
cdf_delta = cdf_plus - cdf_min
|
| 71 |
+
log_probs = th.where(
|
| 72 |
+
x < -0.999,
|
| 73 |
+
log_cdf_plus,
|
| 74 |
+
th.where(x > 0.999, log_one_minus_cdf_min, th.log(cdf_delta.clamp(min=1e-12))),
|
| 75 |
+
)
|
| 76 |
+
assert log_probs.shape == x.shape
|
| 77 |
+
return log_probs
|
main/diffusion/nn.py
ADDED
|
@@ -0,0 +1,197 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This code is based on https://github.com/openai/guided-diffusion
|
| 2 |
+
"""
|
| 3 |
+
Various utilities for neural networks.
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
import math
|
| 7 |
+
|
| 8 |
+
import torch as th
|
| 9 |
+
import torch.nn as nn
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# PyTorch 1.7 has SiLU, but we support PyTorch 1.5.
|
| 13 |
+
class SiLU(nn.Module):
|
| 14 |
+
def forward(self, x):
|
| 15 |
+
return x * th.sigmoid(x)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class GroupNorm32(nn.GroupNorm):
|
| 19 |
+
def forward(self, x):
|
| 20 |
+
return super().forward(x.float()).type(x.dtype)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def conv_nd(dims, *args, **kwargs):
|
| 24 |
+
"""
|
| 25 |
+
Create a 1D, 2D, or 3D convolution module.
|
| 26 |
+
"""
|
| 27 |
+
if dims == 1:
|
| 28 |
+
return nn.Conv1d(*args, **kwargs)
|
| 29 |
+
elif dims == 2:
|
| 30 |
+
return nn.Conv2d(*args, **kwargs)
|
| 31 |
+
elif dims == 3:
|
| 32 |
+
return nn.Conv3d(*args, **kwargs)
|
| 33 |
+
raise ValueError(f"unsupported dimensions: {dims}")
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def linear(*args, **kwargs):
|
| 37 |
+
"""
|
| 38 |
+
Create a linear module.
|
| 39 |
+
"""
|
| 40 |
+
return nn.Linear(*args, **kwargs)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def avg_pool_nd(dims, *args, **kwargs):
|
| 44 |
+
"""
|
| 45 |
+
Create a 1D, 2D, or 3D average pooling module.
|
| 46 |
+
"""
|
| 47 |
+
if dims == 1:
|
| 48 |
+
return nn.AvgPool1d(*args, **kwargs)
|
| 49 |
+
elif dims == 2:
|
| 50 |
+
return nn.AvgPool2d(*args, **kwargs)
|
| 51 |
+
elif dims == 3:
|
| 52 |
+
return nn.AvgPool3d(*args, **kwargs)
|
| 53 |
+
raise ValueError(f"unsupported dimensions: {dims}")
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def update_ema(target_params, source_params, rate=0.99):
|
| 57 |
+
"""
|
| 58 |
+
Update target parameters to be closer to those of source parameters using
|
| 59 |
+
an exponential moving average.
|
| 60 |
+
|
| 61 |
+
:param target_params: the target parameter sequence.
|
| 62 |
+
:param source_params: the source parameter sequence.
|
| 63 |
+
:param rate: the EMA rate (closer to 1 means slower).
|
| 64 |
+
"""
|
| 65 |
+
for targ, src in zip(target_params, source_params):
|
| 66 |
+
targ.detach().mul_(rate).add_(src, alpha=1 - rate)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def zero_module(module):
|
| 70 |
+
"""
|
| 71 |
+
Zero out the parameters of a module and return it.
|
| 72 |
+
"""
|
| 73 |
+
for p in module.parameters():
|
| 74 |
+
p.detach().zero_()
|
| 75 |
+
return module
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def scale_module(module, scale):
|
| 79 |
+
"""
|
| 80 |
+
Scale the parameters of a module and return it.
|
| 81 |
+
"""
|
| 82 |
+
for p in module.parameters():
|
| 83 |
+
p.detach().mul_(scale)
|
| 84 |
+
return module
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def mean_flat(tensor):
|
| 88 |
+
"""
|
| 89 |
+
Take the mean over all non-batch dimensions.
|
| 90 |
+
"""
|
| 91 |
+
return tensor.mean(dim=list(range(1, len(tensor.shape))))
|
| 92 |
+
|
| 93 |
+
def sum_flat(tensor):
|
| 94 |
+
"""
|
| 95 |
+
Take the sum over all non-batch dimensions.
|
| 96 |
+
"""
|
| 97 |
+
return tensor.sum(dim=list(range(1, len(tensor.shape))))
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def normalization(channels):
|
| 101 |
+
"""
|
| 102 |
+
Make a standard normalization layer.
|
| 103 |
+
|
| 104 |
+
:param channels: number of input channels.
|
| 105 |
+
:return: an nn.Module for normalization.
|
| 106 |
+
"""
|
| 107 |
+
return GroupNorm32(32, channels)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def timestep_embedding(timesteps, dim, max_period=10000):
|
| 111 |
+
"""
|
| 112 |
+
Create sinusoidal timestep embeddings.
|
| 113 |
+
|
| 114 |
+
:param timesteps: a 1-D Tensor of N indices, one per batch element.
|
| 115 |
+
These may be fractional.
|
| 116 |
+
:param dim: the dimension of the output.
|
| 117 |
+
:param max_period: controls the minimum frequency of the embeddings.
|
| 118 |
+
:return: an [N x dim] Tensor of positional embeddings.
|
| 119 |
+
"""
|
| 120 |
+
half = dim // 2
|
| 121 |
+
freqs = th.exp(
|
| 122 |
+
-math.log(max_period) * th.arange(start=0, end=half, dtype=th.float32) / half
|
| 123 |
+
).to(device=timesteps.device)
|
| 124 |
+
args = timesteps[:, None].float() * freqs[None]
|
| 125 |
+
embedding = th.cat([th.cos(args), th.sin(args)], dim=-1)
|
| 126 |
+
if dim % 2:
|
| 127 |
+
embedding = th.cat([embedding, th.zeros_like(embedding[:, :1])], dim=-1)
|
| 128 |
+
return embedding
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def checkpoint(func, inputs, params, flag):
|
| 132 |
+
"""
|
| 133 |
+
Evaluate a function without caching intermediate activations, allowing for
|
| 134 |
+
reduced memory at the expense of extra compute in the backward pass.
|
| 135 |
+
:param func: the function to evaluate.
|
| 136 |
+
:param inputs: the argument sequence to pass to `func`.
|
| 137 |
+
:param params: a sequence of parameters `func` depends on but does not
|
| 138 |
+
explicitly take as arguments.
|
| 139 |
+
:param flag: if False, disable gradient checkpointing.
|
| 140 |
+
"""
|
| 141 |
+
if flag:
|
| 142 |
+
args = tuple(inputs) + tuple(params)
|
| 143 |
+
return CheckpointFunction.apply(func, len(inputs), *args)
|
| 144 |
+
else:
|
| 145 |
+
return func(*inputs)
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
class CheckpointFunction(th.autograd.Function):
|
| 149 |
+
@staticmethod
|
| 150 |
+
@th.cuda.amp.custom_fwd
|
| 151 |
+
def forward(ctx, run_function, length, *args):
|
| 152 |
+
ctx.run_function = run_function
|
| 153 |
+
ctx.input_length = length
|
| 154 |
+
ctx.save_for_backward(*args)
|
| 155 |
+
with th.no_grad():
|
| 156 |
+
output_tensors = ctx.run_function(*args[:length])
|
| 157 |
+
return output_tensors
|
| 158 |
+
|
| 159 |
+
@staticmethod
|
| 160 |
+
@th.cuda.amp.custom_bwd
|
| 161 |
+
def backward(ctx, *output_grads):
|
| 162 |
+
args = list(ctx.saved_tensors)
|
| 163 |
+
|
| 164 |
+
# Filter for inputs that require grad. If none, exit early.
|
| 165 |
+
input_indices = [i for (i, x) in enumerate(args) if x.requires_grad]
|
| 166 |
+
if not input_indices:
|
| 167 |
+
return (None, None) + tuple(None for _ in args)
|
| 168 |
+
|
| 169 |
+
with th.enable_grad():
|
| 170 |
+
for i in input_indices:
|
| 171 |
+
if i < ctx.input_length:
|
| 172 |
+
# Not sure why the OAI code does this little
|
| 173 |
+
# dance. It might not be necessary.
|
| 174 |
+
args[i] = args[i].detach().requires_grad_()
|
| 175 |
+
args[i] = args[i].view_as(args[i])
|
| 176 |
+
output_tensors = ctx.run_function(*args[:ctx.input_length])
|
| 177 |
+
|
| 178 |
+
if isinstance(output_tensors, th.Tensor):
|
| 179 |
+
output_tensors = [output_tensors]
|
| 180 |
+
|
| 181 |
+
# Filter for outputs that require grad. If none, exit early.
|
| 182 |
+
out_and_grads = [(o, g) for (o, g) in zip(output_tensors, output_grads) if o.requires_grad]
|
| 183 |
+
if not out_and_grads:
|
| 184 |
+
return (None, None) + tuple(None for _ in args)
|
| 185 |
+
|
| 186 |
+
# Compute gradients on the filtered tensors.
|
| 187 |
+
computed_grads = th.autograd.grad(
|
| 188 |
+
[o for (o, g) in out_and_grads],
|
| 189 |
+
[args[i] for i in input_indices],
|
| 190 |
+
[g for (o, g) in out_and_grads]
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
# Reassemble the complete gradient tuple.
|
| 194 |
+
input_grads = [None for _ in args]
|
| 195 |
+
for (i, g) in zip(input_indices, computed_grads):
|
| 196 |
+
input_grads[i] = g
|
| 197 |
+
return (None, None) + tuple(input_grads)
|