
Yeb Havinga
commited on
Commit
·
54ba749
1
Parent(s):
1ca33c4
Autoupdate README.md
Browse files- README.md +149 -87
- evaluation_t5_dutch_english.png +0 -0
README.md
CHANGED
|
@@ -1,6 +1,7 @@
|
|
| 1 |
---
|
| 2 |
language:
|
| 3 |
- nl
|
|
|
|
| 4 |
datasets:
|
| 5 |
- yhavinga/mc4_nl_cleaned
|
| 6 |
- yhavinga/ccmatrix
|
|
@@ -11,25 +12,44 @@ tags:
|
|
| 11 |
|
| 12 |
pipeline_tag: translation
|
| 13 |
widget:
|
| 14 |
-
- text: "It is a painful and tragic spectacle that rises before me: I have drawn back the curtain from the rottenness of man. This word, in my mouth, is at least free from one suspicion: that it involves a moral accusation against humanity.
|
| 15 |
-
- text: "
|
| 16 |
|
| 17 |
license: apache-2.0
|
| 18 |
---
|
| 19 |
|
| 20 |
# t5-small-24L-ccmatrix-multi
|
| 21 |
|
| 22 |
-
A [
|
| 23 |
-
|
| 24 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 25 |
|
| 26 |
This **t5 eff** model has **249M** parameters.
|
| 27 |
-
It was pre-trained on the dataset
|
| 28 |
`mc4_nl_cleaned` config `large_en_nl` for **1** epoch(s) and a duration of **4d10h**,
|
| 29 |
-
with a sequence length of **512**, batch size **128** and **851852** total steps.
|
| 30 |
Pre-training evaluation loss and accuracy are **1,18** and **0,74**.
|
| 31 |
-
|
| 32 |
-
|
| 33 |
|
| 34 |
|
| 35 |
## Tokenizer
|
|
@@ -39,9 +59,9 @@ and has 32003 tokens.
|
|
| 39 |
It was trained on Dutch and English with scripts from the Huggingface Transformers [Flax examples](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling).
|
| 40 |
See [./raw/main/tokenizer.json](tokenizer.json) for details.
|
| 41 |
|
| 42 |
-
## Dataset
|
| 43 |
|
| 44 |
-
All models listed below are trained on
|
| 45 |
[cleaned Dutch mC4](https://huggingface.co/datasets/yhavinga/mc4_nl_cleaned),
|
| 46 |
which is the original mC4, except
|
| 47 |
|
|
@@ -52,96 +72,138 @@ which is the original mC4, except
|
|
| 52 |
* Documents with "javascript", "lorum ipsum", "terms of use", "privacy policy", "cookie policy", "uses cookies",
|
| 53 |
"use of cookies", "use cookies", "elementen ontbreken", "deze printversie" are removed.
|
| 54 |
|
| 55 |
-
The Dutch and English models are trained on a 50/50% mix of Dutch mC4 and English C4.
|
| 56 |
|
| 57 |
-
|
| 58 |
|
| 59 |
-
|
|
|
|
|
|
|
|
|
|
| 60 |
The other model types t5-v1.1 and t5-eff have `gated-relu` instead of `relu` as activation function,
|
| 61 |
and trained with a drop-out of `0.0` unless training would diverge (`t5-v1.1-large-dutch-cased`).
|
| 62 |
-
The T5-eff models are models
|
| 63 |
-
the several dimensions of these models.
|
| 64 |
-
|
| 65 |
|
| 66 |
-
| | t5-base-dutch | t5-v1.1-base-dutch-uncased | t5-v1.1-base-dutch-cased | t5-v1.1-large-dutch-cased | t5-v1_1-base-dutch-english-cased | t5-v1_1-base-dutch-english-cased-1024 | t5-small-24L-dutch-english | t5-xl-4L-dutch-english-cased | t5-base-36L-dutch-english-cased | t5-eff-xl-8l-dutch-english-cased | t5-eff-large-8l-dutch-english-cased |
|
| 67 |
|:------------------|:----------------|:-----------------------------|:---------------------------|:----------------------------|:-----------------------------------|:----------------------------------------|:-----------------------------|:-------------------------------|:----------------------------------|:-----------------------------------|:--------------------------------------|
|
| 68 |
-
| type
|
| 69 |
-
| d_model
|
| 70 |
-
| d_ff
|
| 71 |
-
| num_heads
|
| 72 |
-
| d_kv
|
| 73 |
-
| num_layers
|
| 74 |
-
| num parameters
|
| 75 |
-
| feed_forward_proj | relu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu |
|
| 76 |
-
| dropout
|
| 77 |
-
| dataset
|
| 78 |
-
| tr. seq len
|
| 79 |
-
| batch size
|
| 80 |
-
| total steps
|
| 81 |
-
| epochs
|
| 82 |
-
| duration
|
| 83 |
-
| optimizer
|
| 84 |
-
| lr
|
| 85 |
-
| warmup
|
| 86 |
-
| eval loss
|
| 87 |
-
| eval acc
|
| 88 |
-
|
| 89 |
-
## Evaluation
|
| 90 |
-
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
|
| 103 |
-
|
| 104 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 105 |
|
| 106 |
## Translation models
|
| 107 |
|
| 108 |
-
The small
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
|
| 118 |
-
|
| 119 |
-
|
|
| 120 |
-
|
|
| 121 |
-
|
|
| 122 |
-
|
|
| 123 |
-
| tatoeba_bp
|
| 124 |
-
|
|
| 125 |
-
|
|
| 126 |
-
|
|
| 127 |
-
|
|
| 128 |
-
|
|
| 129 |
-
|
|
| 130 |
-
|
|
| 131 |
-
|
|
| 132 |
-
|
|
| 133 |
-
|
|
| 134 |
-
|
|
|
|
|
|
|
|
|
|
|
| 135 |
|
| 136 |
## Acknowledgements
|
| 137 |
|
| 138 |
This project would not have been possible without compute generously provided by Google through the
|
| 139 |
-
[TPU Research Cloud](https://sites.research.google/trc/). The HuggingFace 🤗 ecosystem
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
have completed this project otherwise.
|
| 143 |
The following repositories where helpful in setting up the TPU-VM,
|
| 144 |
-
and getting an idea what sensible hyper-parameters are for training gpt2 from scratch
|
| 145 |
|
| 146 |
* [Gsarti's Pretrain and Fine-tune a T5 model with Flax on GCP](https://github.com/gsarti/t5-flax-gcp)
|
| 147 |
* [Flax/Jax Community week t5-base-dutch](https://huggingface.co/flax-community/t5-base-dutch)
|
|
|
|
| 1 |
---
|
| 2 |
language:
|
| 3 |
- nl
|
| 4 |
+
- en
|
| 5 |
datasets:
|
| 6 |
- yhavinga/mc4_nl_cleaned
|
| 7 |
- yhavinga/ccmatrix
|
|
|
|
| 12 |
|
| 13 |
pipeline_tag: translation
|
| 14 |
widget:
|
| 15 |
+
- text: "It is a painful and tragic spectacle that rises before me: I have drawn back the curtain from the rottenness of man. This word, in my mouth, is at least free from one suspicion: that it involves a moral accusation against humanity."
|
| 16 |
+
- text: "Young Wehling was hunched in his chair, his head in his hand. He was so rumpled, so still and colorless as to be virtually invisible. His camouflage was perfect, since the waiting room had a disorderly and demoralized air, too. Chairs and ashtrays had been moved away from the walls. The floor was paved with spattered dropcloths."
|
| 17 |
|
| 18 |
license: apache-2.0
|
| 19 |
---
|
| 20 |
|
| 21 |
# t5-small-24L-ccmatrix-multi
|
| 22 |
|
| 23 |
+
A [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english) model finetuned for Dutch to English and English to Dutch translation on the CCMatrix dataset.
|
| 24 |
+
Evaluation metrics of this model are listed in the **Translation models** section below.
|
| 25 |
+
|
| 26 |
+
You can use this model directly with a pipeline for text translation:
|
| 27 |
+
|
| 28 |
+
```python
|
| 29 |
+
model_name = "yhavinga/t5-small-24L-ccmatrix-multi"
|
| 30 |
+
from transformers import AutoTokenizer
|
| 31 |
+
from transformers import AutoModelForSeq2SeqLM
|
| 32 |
+
from transformers import pipeline
|
| 33 |
+
import torch
|
| 34 |
+
device_num = 0 if torch.cuda.is_available() else -1
|
| 35 |
+
device = "cpu" if device_num < 0 else f"cuda:{device_num}"
|
| 36 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 37 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(device)
|
| 38 |
+
params = {"max_length": 128, "num_beams": 4, "early_stopping": True}
|
| 39 |
+
en_to_nl = pipeline("translation_en_to_nl", tokenizer=tokenizer, model=model, device=device_num)
|
| 40 |
+
print(en_to_nl("""Young Wehling was hunched in his chair, his head in his hand. He was so rumpled, so still and colorless as to be virtually invisible.""",
|
| 41 |
+
**params)[0]['translation_text'])
|
| 42 |
+
nl_to_en = pipeline("translation_nl_to_en", tokenizer=tokenizer, model=model, device=device_num)
|
| 43 |
+
print(nl_to_en("""De jonge Wehling zat gebogen in zijn stoel, zijn hoofd in zijn hand. Hij was zo stoffig, zo stil en kleurloos dat hij vrijwel onzichtbaar was.""",
|
| 44 |
+
**params)[0]['translation_text'])
|
| 45 |
+
```
|
| 46 |
|
| 47 |
This **t5 eff** model has **249M** parameters.
|
| 48 |
+
It was pre-trained with masked language modeling (denoise token span corruption) objective on the dataset
|
| 49 |
`mc4_nl_cleaned` config `large_en_nl` for **1** epoch(s) and a duration of **4d10h**,
|
| 50 |
+
with a sequence length of **512**, batch size **128** and **851852** total steps (**56B** tokens).
|
| 51 |
Pre-training evaluation loss and accuracy are **1,18** and **0,74**.
|
| 52 |
+
Refer to the evaluation section below for a comparison of the pre-trained models on summarization and translation.
|
|
|
|
| 53 |
|
| 54 |
|
| 55 |
## Tokenizer
|
|
|
|
| 59 |
It was trained on Dutch and English with scripts from the Huggingface Transformers [Flax examples](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling).
|
| 60 |
See [./raw/main/tokenizer.json](tokenizer.json) for details.
|
| 61 |
|
| 62 |
+
## Dataset(s)
|
| 63 |
|
| 64 |
+
All models listed below are pre-trained on
|
| 65 |
[cleaned Dutch mC4](https://huggingface.co/datasets/yhavinga/mc4_nl_cleaned),
|
| 66 |
which is the original mC4, except
|
| 67 |
|
|
|
|
| 72 |
* Documents with "javascript", "lorum ipsum", "terms of use", "privacy policy", "cookie policy", "uses cookies",
|
| 73 |
"use of cookies", "use cookies", "elementen ontbreken", "deze printversie" are removed.
|
| 74 |
|
| 75 |
+
The Dutch and English models are pre-trained on a 50/50% mix of Dutch mC4 and English C4.
|
| 76 |
|
| 77 |
+
The translation models are fine-tuned on [CCMatrix](https://huggingface.co/datasets/yhavinga/ccmatrix).
|
| 78 |
|
| 79 |
+
## Dutch T5 Models
|
| 80 |
+
|
| 81 |
+
Three types of [Dutch T5 models have been trained (blog)](https://huggingface.co/spaces/yhavinga/pre-training-dutch-t5-models).
|
| 82 |
+
`t5-base-dutch` is the only model with an original T5 config.
|
| 83 |
The other model types t5-v1.1 and t5-eff have `gated-relu` instead of `relu` as activation function,
|
| 84 |
and trained with a drop-out of `0.0` unless training would diverge (`t5-v1.1-large-dutch-cased`).
|
| 85 |
+
The T5-eff models are models that differ in their number of layers. The table will list
|
| 86 |
+
the several dimensions of these models. Not all t5-eff models are efficient, the best example being the inefficient
|
| 87 |
+
`t5-xl-4L-dutch-english-cased`.
|
| 88 |
|
| 89 |
+
| | [t5-base-dutch](https://huggingface.co/yhavinga/t5-base-dutch) | [t5-v1.1-base-dutch-uncased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-uncased) | [t5-v1.1-base-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-cased) | [t5-v1.1-large-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-large-dutch-cased) | [t5-v1_1-base-dutch-english-cased](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased) | [t5-v1_1-base-dutch-english-cased-1024](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased-1024) | [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english) | [t5-xl-4L-dutch-english-cased](https://huggingface.co/yhavinga/t5-xl-4L-dutch-english-cased) | [t5-base-36L-dutch-english-cased](https://huggingface.co/yhavinga/t5-base-36L-dutch-english-cased) | [t5-eff-xl-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-xl-8l-dutch-english-cased) | [t5-eff-large-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-large-8l-dutch-english-cased) |
|
| 90 |
|:------------------|:----------------|:-----------------------------|:---------------------------|:----------------------------|:-----------------------------------|:----------------------------------------|:-----------------------------|:-------------------------------|:----------------------------------|:-----------------------------------|:--------------------------------------|
|
| 91 |
+
| *type* | t5 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5 eff | t5 eff | t5 eff | t5 eff | t5 eff |
|
| 92 |
+
| *d_model* | 768 | 768 | 768 | 1024 | 768 | 768 | 512 | 2048 | 768 | 1024 | 1024 |
|
| 93 |
+
| *d_ff* | 3072 | 2048 | 2048 | 2816 | 2048 | 2048 | 1920 | 5120 | 2560 | 16384 | 4096 |
|
| 94 |
+
| *num_heads* | 12 | 12 | 12 | 16 | 12 | 12 | 8 | 32 | 12 | 32 | 16 |
|
| 95 |
+
| *d_kv* | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 128 | 64 |
|
| 96 |
+
| *num_layers* | 12 | 12 | 12 | 24 | 12 | 12 | 24 | 4 | 36 | 8 | 8 |
|
| 97 |
+
| *num parameters* | 223M | 248M | 248M | 783M | 248M | 248M | 250M | 585M | 729M | 1241M | 335M |
|
| 98 |
+
| *feed_forward_proj* | relu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu |
|
| 99 |
+
| *dropout* | 0.1 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 |
|
| 100 |
+
| *dataset* | mc4_nl_cleaned | mc4_nl_cleaned full | mc4_nl_cleaned full | mc4_nl_cleaned | mc4_nl_cleaned small_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl |
|
| 101 |
+
| *tr. seq len* | 512 | 1024 | 1024 | 512 | 512 | 1024 | 512 | 512 | 512 | 512 | 512 |
|
| 102 |
+
| *batch size* | 128 | 64 | 64 | 64 | 128 | 64 | 128 | 512 | 512 | 64 | 128 |
|
| 103 |
+
| *total steps* | 527500 | 1014525 | 1210154 | 1120k/2427498 | 2839630 | 1520k/3397024 | 851852 | 212963 | 212963 | 538k/1703705 | 851850 |
|
| 104 |
+
| *epochs* | 1 | 2 | 2 | 2 | 10 | 4 | 1 | 1 | 1 | 1 | 1 |
|
| 105 |
+
| *duration* | 2d9h | 5d5h | 6d6h | 8d13h | 11d18h | 9d1h | 4d10h | 6d1h | 17d15h | 4d 19h | 3d 23h |
|
| 106 |
+
| *optimizer* | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor |
|
| 107 |
+
| *lr* | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.009 | 0.005 | 0.005 |
|
| 108 |
+
| *warmup* | 10000.0 | 10000.0 | 10000.0 | 10000.0 | 10000.0 | 5000.0 | 20000.0 | 2500.0 | 1000.0 | 1500.0 | 1500.0 |
|
| 109 |
+
| *eval loss* | 1,38 | 1,20 | 0,96 | 1,07 | 1,11 | 1,13 | 1,18 | 1,27 | 1,05 | 1,3019 | 1,15 |
|
| 110 |
+
| *eval acc* | 0,70 | 0,73 | 0,78 | 0,76 | 0,75 | 0,74 | 0,74 | 0,72 | 0,76 | 0,71 | 0,74 |
|
| 111 |
+
|
| 112 |
+
## Evaluation
|
| 113 |
+
|
| 114 |
+
Most models from the list above have been fine-tuned for summarization and translation.
|
| 115 |
+
The figure below shows the evaluation scores, where the x-axis shows the translation Bleu score (higher is better)
|
| 116 |
+
and y-axis the summarization Rouge1 translation score (higher is better).
|
| 117 |
+
Point size is proportional to the model size. Models with faster inference speed are green, slower inference speed is
|
| 118 |
+
plotted as bleu.
|
| 119 |
+
|
| 120 |
+

|
| 121 |
+
|
| 122 |
+
Evaluation was run on fine-tuned models trained with the following settings:
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
| | Summarization | Translation |
|
| 126 |
+
|---------------:|------------------|-------------------|
|
| 127 |
+
| Dataset | CNN Dailymail NL | CCMatrix en -> nl |
|
| 128 |
+
| #train samples | 50K | 50K |
|
| 129 |
+
| Optimizer | Adam | Adam |
|
| 130 |
+
| learning rate | 0.001 | 0.0005 |
|
| 131 |
+
| source length | 1024 | 128 |
|
| 132 |
+
| target length | 142 | 128 |
|
| 133 |
+
|label smoothing | 0.05 | 0.1 |
|
| 134 |
+
| #eval samples | 1000 | 1000 |
|
| 135 |
+
|
| 136 |
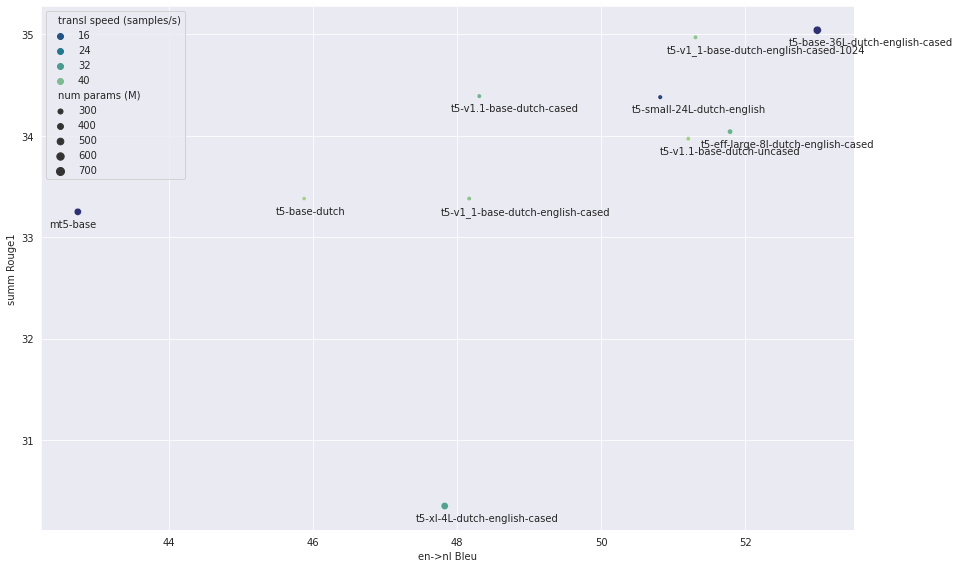
+
Note that the amount of training data is limited to a fraction of the total dataset sizes, therefore the scores
|
| 137 |
+
below can only be used to compare the 'transfer-learning' strength. The fine-tuned checkpoints for this evaluation
|
| 138 |
+
are not saved, since they were trained for comparison of pre-trained models only.
|
| 139 |
+
|
| 140 |
+
The numbers for summarization are the Rouge scores on 1000 documents from the test split.
|
| 141 |
+
|
| 142 |
+
| | [t5-base-dutch](https://huggingface.co/yhavinga/t5-base-dutch) | [t5-v1.1-base-dutch-uncased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-uncased) | [t5-v1.1-base-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-cased) | [t5-v1_1-base-dutch-english-cased](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased) | [t5-v1_1-base-dutch-english-cased-1024](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased-1024) | [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english) | [t5-xl-4L-dutch-english-cased](https://huggingface.co/yhavinga/t5-xl-4L-dutch-english-cased) | [t5-base-36L-dutch-english-cased](https://huggingface.co/yhavinga/t5-base-36L-dutch-english-cased) | [t5-eff-large-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-large-8l-dutch-english-cased) | mt5-base |
|
| 143 |
+
|:------------------------|----------------:|-----------------------------:|---------------------------:|-----------------------------------:|----------------------------------------:|-----------------------------:|-------------------------------:|----------------------------------:|--------------------------------------:|-----------:|
|
| 144 |
+
| *rouge1* | 33.38 | 33.97 | 34.39 | 33.38 | 34.97 | 34.38 | 30.35 | **35.04** | 34.04 | 33.25 |
|
| 145 |
+
| *rouge2* | 13.32 | 13.85 | 13.98 | 13.47 | 14.01 | 13.89 | 11.57 | **14.23** | 13.76 | 12.74 |
|
| 146 |
+
| *rougeL* | 24.22 | 24.72 | 25.1 | 24.34 | 24.99 | **25.25** | 22.69 | 25.05 | 24.75 | 23.5 |
|
| 147 |
+
| *rougeLsum* | 30.23 | 30.9 | 31.44 | 30.51 | 32.01 | 31.38 | 27.5 | **32.12** | 31.12 | 30.15 |
|
| 148 |
+
| *samples_per_second* | 3.18 | 3.02 | 2.99 | 3.22 | 2.97 | 1.57 | 2.8 | 0.61 | **3.27** | 1.22 |
|
| 149 |
+
|
| 150 |
+
The models below have been evaluated for English to Dutch translation.
|
| 151 |
+
Note that the first four models are pre-trained on Dutch only. That they still perform adequate is probably because
|
| 152 |
+
the translation direction is English to Dutch.
|
| 153 |
+
The numbers reported are the Bleu scores on 1000 documents from the test split.
|
| 154 |
+
|
| 155 |
+
| | [t5-base-dutch](https://huggingface.co/yhavinga/t5-base-dutch) | [t5-v1.1-base-dutch-uncased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-uncased) | [t5-v1.1-base-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-cased) | [t5-v1.1-large-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-large-dutch-cased) | [t5-v1_1-base-dutch-english-cased](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased) | [t5-v1_1-base-dutch-english-cased-1024](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased-1024) | [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english) | [t5-xl-4L-dutch-english-cased](https://huggingface.co/yhavinga/t5-xl-4L-dutch-english-cased) | [t5-base-36L-dutch-english-cased](https://huggingface.co/yhavinga/t5-base-36L-dutch-english-cased) | [t5-eff-large-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-large-8l-dutch-english-cased) | mt5-base |
|
| 156 |
+
|:-------------------------------|----------------:|-----------------------------:|---------------------------:|----------------------------:|-----------------------------------:|----------------------------------------:|-----------------------------:|-------------------------------:|----------------------------------:|--------------------------------------:|-----------:|
|
| 157 |
+
| *precision_ng1* | 74.17 | 78.09 | 77.08 | 72.12 | 77.19 | 78.76 | 78.59 | 77.3 | **79.75** | 78.88 | 73.47 |
|
| 158 |
+
| *precision_ng2* | 52.42 | 57.52 | 55.31 | 48.7 | 55.39 | 58.01 | 57.83 | 55.27 | **59.89** | 58.27 | 50.12 |
|
| 159 |
+
| *precision_ng3* | 39.55 | 45.2 | 42.54 | 35.54 | 42.25 | 45.13 | 45.02 | 42.06 | **47.4** | 45.95 | 36.59 |
|
| 160 |
+
| *precision_ng4* | 30.23 | 36.04 | 33.26 | 26.27 | 32.74 | 35.72 | 35.41 | 32.61 | **38.1** | 36.91 | 27.26 |
|
| 161 |
+
| *bp* | 0.99 | 0.98 | 0.97 | 0.98 | 0.98 | 0.98 | 0.98 | 0.97 | 0.98 | 0.98 | 0.98 |
|
| 162 |
+
| *score* | 45.88 | 51.21 | 48.31 | 41.59 | 48.17 | 51.31 | 50.82 | 47.83 | **53** | 51.79 | 42.74 |
|
| 163 |
+
| *samples_per_second* | **45.19** | 45.05 | 38.67 | 10.12 | 42.19 | 42.61 | 12.85 | 33.74 | 9.07 | 37.86 | 9.03 |
|
| 164 |
+
|
| 165 |
|
| 166 |
## Translation models
|
| 167 |
|
| 168 |
+
The models `t5-small-24L-dutch-english` and `t5-base-36L-dutch-english` have been fine-tuned for both language
|
| 169 |
+
directions on the first 25M samples from CCMatrix, giving a total of 50M training samples.
|
| 170 |
+
Evaluation is performed on out-of-sample CCMatrix and also on Tatoeba and Opus Books.
|
| 171 |
+
The `_bp` columns list the *brevity penalty*. The `avg_bleu` score is the bleu score
|
| 172 |
+
averaged over all three evaluation datasets. The best scores displayed in bold for both translation directions.
|
| 173 |
+
|
| 174 |
+
| | [t5-base-36L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-base-36L-ccmatrix-multi) | [t5-base-36L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-base-36L-ccmatrix-multi) | [t5-small-24L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-small-24L-ccmatrix-multi) | [t5-small-24L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-small-24L-ccmatrix-multi) |
|
| 175 |
+
|:-----------------------|:-----------------------------|:-----------------------------|:------------------------------|:------------------------------|
|
| 176 |
+
| *source_lang* | en | nl | en | nl |
|
| 177 |
+
| *target_lang* | nl | en | nl | en |
|
| 178 |
+
| *source_prefix* | translate English to Dutch: | translate Dutch to English: | translate English to Dutch: | translate Dutch to English: |
|
| 179 |
+
| *ccmatrix_bleu* | **56.8** | 62.8 | 57.4 | **63.1** |
|
| 180 |
+
| *tatoeba_bleu* | **46.6** | **52.8** | 46.4 | 51.7 |
|
| 181 |
+
| *opus_books_bleu* | **13.5** | **24.9** | 12.9 | 23.4 |
|
| 182 |
+
| *ccmatrix_bp* | 0.95 | 0.96 | 0.95 | 0.96 |
|
| 183 |
+
| *tatoeba_bp* | 0.97 | 0.94 | 0.98 | 0.94 |
|
| 184 |
+
| *opus_books_bp* | 0.8 | 0.94 | 0.77 | 0.89 |
|
| 185 |
+
| *avg_bleu* | **38.96** | **46.86** | 38.92 | 46.06 |
|
| 186 |
+
| *max_source_length* | 128 | 128 | 128 | 128 |
|
| 187 |
+
| *max_target_length* | 128 | 128 | 128 | 128 |
|
| 188 |
+
| *adam_beta1* | 0.9 | 0.9 | 0.9 | 0.9 |
|
| 189 |
+
| *adam_beta2* | 0.997 | 0.997 | 0.997 | 0.997 |
|
| 190 |
+
| *weight_decay* | 0.05 | 0.05 | 0.002 | 0.002 |
|
| 191 |
+
| *lr* | 5e-05 | 5e-05 | 0.0005 | 0.0005 |
|
| 192 |
+
| *label_smoothing_factor* | 0.15 | 0.15 | 0.1 | 0.1 |
|
| 193 |
+
| *train_batch_size* | 128 | 128 | 128 | 128 |
|
| 194 |
+
| *warmup_steps* | 2000 | 2000 | 2000 | 2000 |
|
| 195 |
+
| *total steps* | 390625 | 390625 | 390625 | 390625 |
|
| 196 |
+
| *duration* | 4d 5h | 4d 5h | 3d 2h | 3d 2h |
|
| 197 |
+
| *num parameters* | 729M | 729M | 250M | 250M |
|
| 198 |
|
| 199 |
## Acknowledgements
|
| 200 |
|
| 201 |
This project would not have been possible without compute generously provided by Google through the
|
| 202 |
+
[TPU Research Cloud](https://sites.research.google/trc/). The HuggingFace 🤗 ecosystem was instrumental in all parts
|
| 203 |
+
of the training. Weights & Biases made it possible to keep track of many training sessions
|
| 204 |
+
and orchestrate hyper-parameter sweeps with insightful visualizations.
|
|
|
|
| 205 |
The following repositories where helpful in setting up the TPU-VM,
|
| 206 |
+
and getting an idea what sensible hyper-parameters are for training gpt2 from scratch:
|
| 207 |
|
| 208 |
* [Gsarti's Pretrain and Fine-tune a T5 model with Flax on GCP](https://github.com/gsarti/t5-flax-gcp)
|
| 209 |
* [Flax/Jax Community week t5-base-dutch](https://huggingface.co/flax-community/t5-base-dutch)
|
evaluation_t5_dutch_english.png
ADDED
|