
Upload 98 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- LICENSE +21 -0
- MODEL_ZOO.md +20 -0
- README.md +0 -3
- augmentations/augmentations_cifar.py +190 -0
- augmentations/augmentations_stl.py +190 -0
- augmentations/augmentations_tiny.py +190 -0
- data_statistics.py +61 -0
- download_imagenet.sh +47 -0
- environment.yml +188 -0
- evaluate_imagenet.py +289 -0
- evaluate_transfer.py +168 -0
- figs/in-linear.png +0 -0
- figs/in-loss-bt.png +0 -0
- figs/in-loss-reg.png +3 -0
- figs/mix-bt.jpg +0 -0
- figs/mix-bt.svg +0 -0
- hubconf.py +19 -0
- linear.py +166 -0
- main.py +271 -0
- main_imagenet.py +463 -0
- model.py +40 -0
- preprocess_datasets/preprocess_tinyimagenet.sh +34 -0
- scripts-linear-resnet18/cifar10.sh +14 -0
- scripts-linear-resnet18/cifar100.sh +14 -0
- scripts-linear-resnet18/stl10.sh +14 -0
- scripts-linear-resnet18/tinyimagenet.sh +14 -0
- scripts-linear-resnet50/cifar10.sh +14 -0
- scripts-linear-resnet50/cifar100.sh +14 -0
- scripts-linear-resnet50/imagenet_sup.sh +11 -0
- scripts-linear-resnet50/stl10.sh +14 -0
- scripts-linear-resnet50/tinyimagenet.sh +14 -0
- scripts-pretrain-resnet18/cifar10.sh +21 -0
- scripts-pretrain-resnet18/cifar100.sh +20 -0
- scripts-pretrain-resnet18/stl10.sh +20 -0
- scripts-pretrain-resnet18/tinyimagenet.sh +20 -0
- scripts-pretrain-resnet50/cifar10.sh +20 -0
- scripts-pretrain-resnet50/cifar100.sh +20 -0
- scripts-pretrain-resnet50/imagenet.sh +15 -0
- scripts-pretrain-resnet50/stl10.sh +20 -0
- scripts-pretrain-resnet50/tinyimagenet.sh +20 -0
- scripts-transfer-resnet18/cifar10-to-x.sh +28 -0
- scripts-transfer-resnet18/cifar100-to-x.sh +28 -0
- scripts-transfer-resnet18/stl10-to-x-bt.sh +28 -0
- setup.sh +12 -0
- ssl-sota/README.md +87 -0
- ssl-sota/cfg.py +152 -0
- ssl-sota/datasets/__init__.py +22 -0
- ssl-sota/datasets/base.py +67 -0
- ssl-sota/datasets/cifar10.py +26 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
figs/in-loss-reg.png filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Wele Gedara Chaminda Bandara
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
MODEL_ZOO.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The following links provide pre-trained models:
|
| 2 |
+
# ResNet-18 Pre-trained Models
|
| 3 |
+
| Dataset | d | Lambda_BT | Lambda_Reg | Path to Pretrained Model | KNN Acc. | Linear Acc. |
|
| 4 |
+
| ---------- | --- | ---------- | ---------- | ------------------------ | -------- | ----------- |
|
| 5 |
+
| CIFAR-10 | 1024 | 0.0078125 | 4.0 | 4wdhbpcf_0.0078125_1024_256_cifar10_model.pth | 90.52 | 92.58 |
|
| 6 |
+
| CIFAR-100 | 1024 | 0.0078125 | 4.0 | 76kk7scz_0.0078125_1024_256_cifar100_model.pth | 61.25 | 69.31 |
|
| 7 |
+
| TinyImageNet | 1024 | 0.0009765 | 4.0 | 02azq6fs_0.0009765_1024_256_tiny_imagenet_model.pth | 38.11 | 51.67 |
|
| 8 |
+
| STL-10 | 1024 | 0.0078125 | 2.0 | i7det4xq_0.0078125_1024_256_stl10_model.pth | 88.94 | 91.02 |
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# ResNet-50 Pre-trained Models
|
| 13 |
+
| Dataset | d | Lambda_BT | Lambda_Reg | Path to Pretrained Model | KNN Acc. | Linear Acc. |
|
| 14 |
+
| ---------- | --- | ---------- | ---------- | ------------------------ | -------- | ----------- |
|
| 15 |
+
| CIFAR-10 | 1024 | 0.0078125 | 4.0 | v3gwgusq_0.0078125_1024_256_cifar10_model.pth | 91.39 | 93.89 |
|
| 16 |
+
| CIFAR-100 | 1024 | 0.0078125 | 4.0 | z6ngefw7_0.0078125_1024_256_cifar100_model_2000.pth | 64.32 | 72.51 |
|
| 17 |
+
| TinyImageNet | 1024 | 0.0009765 | 4.0 | kxlkigsv_0.0009765_1024_256_tiny_imagenet_model_2000.pth | 42.21 | 51.84 |
|
| 18 |
+
| STL-10 | 1024 | 0.0078125 | 2.0 | pbknx38b_0.0078125_1024_256_stl10_model.pth | 87.79 | 91.70 |
|
| 19 |
+
| ImageNet | 1024 | 0.0051 | 0.1 | 13awtq23_0.0051_8192_1024_imagenet_0.1_resnet50.pth | - | 72.1 |
|
| 20 |
+
|
README.md
CHANGED
|
@@ -1,6 +1,3 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: mit
|
| 3 |
-
---
|
| 4 |
# Mixed Barlow Twins
|
| 5 |
[**Guarding Barlow Twins Against Overfitting with Mixed Samples**](https://arxiv.org/abs/2312.02151)<br>
|
| 6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
# Mixed Barlow Twins
|
| 2 |
[**Guarding Barlow Twins Against Overfitting with Mixed Samples**](https://arxiv.org/abs/2312.02151)<br>
|
| 3 |
|
augmentations/augmentations_cifar.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2019 Google LLC
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
# ==============================================================================
|
| 15 |
+
"""Base augmentations operators."""
|
| 16 |
+
|
| 17 |
+
import numpy as np
|
| 18 |
+
from PIL import Image, ImageOps, ImageEnhance
|
| 19 |
+
|
| 20 |
+
# ImageNet code should change this value
|
| 21 |
+
IMAGE_SIZE = 32
|
| 22 |
+
import torch
|
| 23 |
+
from torchvision import transforms
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def int_parameter(level, maxval):
|
| 27 |
+
"""Helper function to scale `val` between 0 and maxval .
|
| 28 |
+
|
| 29 |
+
Args:
|
| 30 |
+
level: Level of the operation that will be between [0, `PARAMETER_MAX`].
|
| 31 |
+
maxval: Maximum value that the operation can have. This will be scaled to
|
| 32 |
+
level/PARAMETER_MAX.
|
| 33 |
+
|
| 34 |
+
Returns:
|
| 35 |
+
An int that results from scaling `maxval` according to `level`.
|
| 36 |
+
"""
|
| 37 |
+
return int(level * maxval / 10)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def float_parameter(level, maxval):
|
| 41 |
+
"""Helper function to scale `val` between 0 and maxval.
|
| 42 |
+
|
| 43 |
+
Args:
|
| 44 |
+
level: Level of the operation that will be between [0, `PARAMETER_MAX`].
|
| 45 |
+
maxval: Maximum value that the operation can have. This will be scaled to
|
| 46 |
+
level/PARAMETER_MAX.
|
| 47 |
+
|
| 48 |
+
Returns:
|
| 49 |
+
A float that results from scaling `maxval` according to `level`.
|
| 50 |
+
"""
|
| 51 |
+
return float(level) * maxval / 10.
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def sample_level(n):
|
| 55 |
+
return np.random.uniform(low=0.1, high=n)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def autocontrast(pil_img, _):
|
| 59 |
+
return ImageOps.autocontrast(pil_img)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def equalize(pil_img, _):
|
| 63 |
+
return ImageOps.equalize(pil_img)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def posterize(pil_img, level):
|
| 67 |
+
level = int_parameter(sample_level(level), 4)
|
| 68 |
+
return ImageOps.posterize(pil_img, 4 - level)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def rotate(pil_img, level):
|
| 72 |
+
degrees = int_parameter(sample_level(level), 30)
|
| 73 |
+
if np.random.uniform() > 0.5:
|
| 74 |
+
degrees = -degrees
|
| 75 |
+
return pil_img.rotate(degrees, resample=Image.BILINEAR)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def solarize(pil_img, level):
|
| 79 |
+
level = int_parameter(sample_level(level), 256)
|
| 80 |
+
return ImageOps.solarize(pil_img, 256 - level)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def shear_x(pil_img, level):
|
| 84 |
+
level = float_parameter(sample_level(level), 0.3)
|
| 85 |
+
if np.random.uniform() > 0.5:
|
| 86 |
+
level = -level
|
| 87 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 88 |
+
Image.AFFINE, (1, level, 0, 0, 1, 0),
|
| 89 |
+
resample=Image.BILINEAR)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def shear_y(pil_img, level):
|
| 93 |
+
level = float_parameter(sample_level(level), 0.3)
|
| 94 |
+
if np.random.uniform() > 0.5:
|
| 95 |
+
level = -level
|
| 96 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 97 |
+
Image.AFFINE, (1, 0, 0, level, 1, 0),
|
| 98 |
+
resample=Image.BILINEAR)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def translate_x(pil_img, level):
|
| 102 |
+
level = int_parameter(sample_level(level), IMAGE_SIZE / 3)
|
| 103 |
+
if np.random.random() > 0.5:
|
| 104 |
+
level = -level
|
| 105 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 106 |
+
Image.AFFINE, (1, 0, level, 0, 1, 0),
|
| 107 |
+
resample=Image.BILINEAR)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def translate_y(pil_img, level):
|
| 111 |
+
level = int_parameter(sample_level(level), IMAGE_SIZE / 3)
|
| 112 |
+
if np.random.random() > 0.5:
|
| 113 |
+
level = -level
|
| 114 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 115 |
+
Image.AFFINE, (1, 0, 0, 0, 1, level),
|
| 116 |
+
resample=Image.BILINEAR)
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
# operation that overlaps with ImageNet-C's test set
|
| 120 |
+
def color(pil_img, level):
|
| 121 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 122 |
+
return ImageEnhance.Color(pil_img).enhance(level)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
# operation that overlaps with ImageNet-C's test set
|
| 126 |
+
def contrast(pil_img, level):
|
| 127 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 128 |
+
return ImageEnhance.Contrast(pil_img).enhance(level)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
# operation that overlaps with ImageNet-C's test set
|
| 132 |
+
def brightness(pil_img, level):
|
| 133 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 134 |
+
return ImageEnhance.Brightness(pil_img).enhance(level)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# operation that overlaps with ImageNet-C's test set
|
| 138 |
+
def sharpness(pil_img, level):
|
| 139 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 140 |
+
return ImageEnhance.Sharpness(pil_img).enhance(level)
|
| 141 |
+
|
| 142 |
+
def random_resized_crop(pil_img, level):
|
| 143 |
+
return transforms.RandomResizedCrop(32)(pil_img)
|
| 144 |
+
|
| 145 |
+
def random_flip(pil_img, level):
|
| 146 |
+
return transforms.RandomHorizontalFlip(p=0.5)(pil_img)
|
| 147 |
+
|
| 148 |
+
def grayscale(pil_img, level):
|
| 149 |
+
return transforms.Grayscale(num_output_channels=3)(pil_img)
|
| 150 |
+
|
| 151 |
+
augmentations = [
|
| 152 |
+
autocontrast, equalize, posterize, rotate, solarize, shear_x, shear_y,
|
| 153 |
+
translate_x, translate_y, grayscale #random_resized_crop, random_flip
|
| 154 |
+
]
|
| 155 |
+
|
| 156 |
+
augmentations_all = [
|
| 157 |
+
autocontrast, equalize, posterize, rotate, solarize, shear_x, shear_y,
|
| 158 |
+
translate_x, translate_y, color, contrast, brightness, sharpness, grayscale #, random_resized_crop, random_flip
|
| 159 |
+
]
|
| 160 |
+
|
| 161 |
+
def aug_cifar(image, preprocess, mixture_width=3, mixture_depth=-1, aug_severity=3):
|
| 162 |
+
"""Perform AugMix augmentations and compute mixture.
|
| 163 |
+
|
| 164 |
+
Args:
|
| 165 |
+
image: PIL.Image input image
|
| 166 |
+
preprocess: Preprocessing function which should return a torch tensor.
|
| 167 |
+
|
| 168 |
+
Returns:
|
| 169 |
+
mixed: Augmented and mixed image.
|
| 170 |
+
"""
|
| 171 |
+
aug_list = augmentations_all
|
| 172 |
+
# if args.all_ops:
|
| 173 |
+
# aug_list = augmentations.augmentations_all
|
| 174 |
+
|
| 175 |
+
ws = np.float32(np.random.dirichlet([1] * mixture_width))
|
| 176 |
+
m = np.float32(np.random.beta(1, 1))
|
| 177 |
+
|
| 178 |
+
mix = torch.zeros_like(preprocess(image))
|
| 179 |
+
for i in range(mixture_width):
|
| 180 |
+
image_aug = image.copy()
|
| 181 |
+
depth = mixture_depth if mixture_depth > 0 else np.random.randint(
|
| 182 |
+
1, 4)
|
| 183 |
+
for _ in range(depth):
|
| 184 |
+
op = np.random.choice(aug_list)
|
| 185 |
+
image_aug = op(image_aug, aug_severity)
|
| 186 |
+
# Preprocessing commutes since all coefficients are convex
|
| 187 |
+
mix += ws[i] * preprocess(image_aug)
|
| 188 |
+
|
| 189 |
+
# mixed = (1 - m) * preprocess(image) + m * mix
|
| 190 |
+
return mix
|
augmentations/augmentations_stl.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2019 Google LLC
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
# ==============================================================================
|
| 15 |
+
"""Base augmentations operators."""
|
| 16 |
+
|
| 17 |
+
import numpy as np
|
| 18 |
+
from PIL import Image, ImageOps, ImageEnhance
|
| 19 |
+
|
| 20 |
+
# ImageNet code should change this value
|
| 21 |
+
IMAGE_SIZE = 64
|
| 22 |
+
import torch
|
| 23 |
+
from torchvision import transforms
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def int_parameter(level, maxval):
|
| 27 |
+
"""Helper function to scale `val` between 0 and maxval .
|
| 28 |
+
|
| 29 |
+
Args:
|
| 30 |
+
level: Level of the operation that will be between [0, `PARAMETER_MAX`].
|
| 31 |
+
maxval: Maximum value that the operation can have. This will be scaled to
|
| 32 |
+
level/PARAMETER_MAX.
|
| 33 |
+
|
| 34 |
+
Returns:
|
| 35 |
+
An int that results from scaling `maxval` according to `level`.
|
| 36 |
+
"""
|
| 37 |
+
return int(level * maxval / 10)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def float_parameter(level, maxval):
|
| 41 |
+
"""Helper function to scale `val` between 0 and maxval.
|
| 42 |
+
|
| 43 |
+
Args:
|
| 44 |
+
level: Level of the operation that will be between [0, `PARAMETER_MAX`].
|
| 45 |
+
maxval: Maximum value that the operation can have. This will be scaled to
|
| 46 |
+
level/PARAMETER_MAX.
|
| 47 |
+
|
| 48 |
+
Returns:
|
| 49 |
+
A float that results from scaling `maxval` according to `level`.
|
| 50 |
+
"""
|
| 51 |
+
return float(level) * maxval / 10.
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def sample_level(n):
|
| 55 |
+
return np.random.uniform(low=0.1, high=n)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def autocontrast(pil_img, _):
|
| 59 |
+
return ImageOps.autocontrast(pil_img)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def equalize(pil_img, _):
|
| 63 |
+
return ImageOps.equalize(pil_img)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def posterize(pil_img, level):
|
| 67 |
+
level = int_parameter(sample_level(level), 4)
|
| 68 |
+
return ImageOps.posterize(pil_img, 4 - level)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def rotate(pil_img, level):
|
| 72 |
+
degrees = int_parameter(sample_level(level), 30)
|
| 73 |
+
if np.random.uniform() > 0.5:
|
| 74 |
+
degrees = -degrees
|
| 75 |
+
return pil_img.rotate(degrees, resample=Image.BILINEAR)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def solarize(pil_img, level):
|
| 79 |
+
level = int_parameter(sample_level(level), 256)
|
| 80 |
+
return ImageOps.solarize(pil_img, 256 - level)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def shear_x(pil_img, level):
|
| 84 |
+
level = float_parameter(sample_level(level), 0.3)
|
| 85 |
+
if np.random.uniform() > 0.5:
|
| 86 |
+
level = -level
|
| 87 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 88 |
+
Image.AFFINE, (1, level, 0, 0, 1, 0),
|
| 89 |
+
resample=Image.BILINEAR)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def shear_y(pil_img, level):
|
| 93 |
+
level = float_parameter(sample_level(level), 0.3)
|
| 94 |
+
if np.random.uniform() > 0.5:
|
| 95 |
+
level = -level
|
| 96 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 97 |
+
Image.AFFINE, (1, 0, 0, level, 1, 0),
|
| 98 |
+
resample=Image.BILINEAR)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def translate_x(pil_img, level):
|
| 102 |
+
level = int_parameter(sample_level(level), IMAGE_SIZE / 3)
|
| 103 |
+
if np.random.random() > 0.5:
|
| 104 |
+
level = -level
|
| 105 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 106 |
+
Image.AFFINE, (1, 0, level, 0, 1, 0),
|
| 107 |
+
resample=Image.BILINEAR)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def translate_y(pil_img, level):
|
| 111 |
+
level = int_parameter(sample_level(level), IMAGE_SIZE / 3)
|
| 112 |
+
if np.random.random() > 0.5:
|
| 113 |
+
level = -level
|
| 114 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 115 |
+
Image.AFFINE, (1, 0, 0, 0, 1, level),
|
| 116 |
+
resample=Image.BILINEAR)
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
# operation that overlaps with ImageNet-C's test set
|
| 120 |
+
def color(pil_img, level):
|
| 121 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 122 |
+
return ImageEnhance.Color(pil_img).enhance(level)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
# operation that overlaps with ImageNet-C's test set
|
| 126 |
+
def contrast(pil_img, level):
|
| 127 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 128 |
+
return ImageEnhance.Contrast(pil_img).enhance(level)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
# operation that overlaps with ImageNet-C's test set
|
| 132 |
+
def brightness(pil_img, level):
|
| 133 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 134 |
+
return ImageEnhance.Brightness(pil_img).enhance(level)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# operation that overlaps with ImageNet-C's test set
|
| 138 |
+
def sharpness(pil_img, level):
|
| 139 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 140 |
+
return ImageEnhance.Sharpness(pil_img).enhance(level)
|
| 141 |
+
|
| 142 |
+
def random_resized_crop(pil_img, level):
|
| 143 |
+
return transforms.RandomResizedCrop(32)(pil_img)
|
| 144 |
+
|
| 145 |
+
def random_flip(pil_img, level):
|
| 146 |
+
return transforms.RandomHorizontalFlip(p=0.5)(pil_img)
|
| 147 |
+
|
| 148 |
+
def grayscale(pil_img, level):
|
| 149 |
+
return transforms.Grayscale(num_output_channels=3)(pil_img)
|
| 150 |
+
|
| 151 |
+
augmentations = [
|
| 152 |
+
autocontrast, equalize, posterize, rotate, solarize, shear_x, shear_y,
|
| 153 |
+
translate_x, translate_y, grayscale #random_resized_crop, random_flip
|
| 154 |
+
]
|
| 155 |
+
|
| 156 |
+
augmentations_all = [
|
| 157 |
+
autocontrast, equalize, posterize, rotate, solarize, shear_x, shear_y,
|
| 158 |
+
translate_x, translate_y, color, contrast, brightness, sharpness, grayscale #, random_resized_crop, random_flip
|
| 159 |
+
]
|
| 160 |
+
|
| 161 |
+
def aug_stl(image, preprocess, mixture_width=3, mixture_depth=-1, aug_severity=3):
|
| 162 |
+
"""Perform AugMix augmentations and compute mixture.
|
| 163 |
+
|
| 164 |
+
Args:
|
| 165 |
+
image: PIL.Image input image
|
| 166 |
+
preprocess: Preprocessing function which should return a torch tensor.
|
| 167 |
+
|
| 168 |
+
Returns:
|
| 169 |
+
mixed: Augmented and mixed image.
|
| 170 |
+
"""
|
| 171 |
+
aug_list = augmentations
|
| 172 |
+
# if args.all_ops:
|
| 173 |
+
# aug_list = augmentations.augmentations_all
|
| 174 |
+
|
| 175 |
+
ws = np.float32(np.random.dirichlet([1] * mixture_width))
|
| 176 |
+
m = np.float32(np.random.beta(1, 1))
|
| 177 |
+
|
| 178 |
+
mix = torch.zeros_like(preprocess(image))
|
| 179 |
+
for i in range(mixture_width):
|
| 180 |
+
image_aug = image.copy()
|
| 181 |
+
depth = mixture_depth if mixture_depth > 0 else np.random.randint(
|
| 182 |
+
1, 4)
|
| 183 |
+
for _ in range(depth):
|
| 184 |
+
op = np.random.choice(aug_list)
|
| 185 |
+
image_aug = op(image_aug, aug_severity)
|
| 186 |
+
# Preprocessing commutes since all coefficients are convex
|
| 187 |
+
mix += ws[i] * preprocess(image_aug)
|
| 188 |
+
|
| 189 |
+
mixed = (1 - m) * preprocess(image) + m * mix
|
| 190 |
+
return mixed
|
augmentations/augmentations_tiny.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2019 Google LLC
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
# ==============================================================================
|
| 15 |
+
"""Base augmentations operators."""
|
| 16 |
+
|
| 17 |
+
import numpy as np
|
| 18 |
+
from PIL import Image, ImageOps, ImageEnhance
|
| 19 |
+
|
| 20 |
+
# ImageNet code should change this value
|
| 21 |
+
IMAGE_SIZE = 64
|
| 22 |
+
import torch
|
| 23 |
+
from torchvision import transforms
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def int_parameter(level, maxval):
|
| 27 |
+
"""Helper function to scale `val` between 0 and maxval .
|
| 28 |
+
|
| 29 |
+
Args:
|
| 30 |
+
level: Level of the operation that will be between [0, `PARAMETER_MAX`].
|
| 31 |
+
maxval: Maximum value that the operation can have. This will be scaled to
|
| 32 |
+
level/PARAMETER_MAX.
|
| 33 |
+
|
| 34 |
+
Returns:
|
| 35 |
+
An int that results from scaling `maxval` according to `level`.
|
| 36 |
+
"""
|
| 37 |
+
return int(level * maxval / 10)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def float_parameter(level, maxval):
|
| 41 |
+
"""Helper function to scale `val` between 0 and maxval.
|
| 42 |
+
|
| 43 |
+
Args:
|
| 44 |
+
level: Level of the operation that will be between [0, `PARAMETER_MAX`].
|
| 45 |
+
maxval: Maximum value that the operation can have. This will be scaled to
|
| 46 |
+
level/PARAMETER_MAX.
|
| 47 |
+
|
| 48 |
+
Returns:
|
| 49 |
+
A float that results from scaling `maxval` according to `level`.
|
| 50 |
+
"""
|
| 51 |
+
return float(level) * maxval / 10.
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def sample_level(n):
|
| 55 |
+
return np.random.uniform(low=0.1, high=n)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def autocontrast(pil_img, _):
|
| 59 |
+
return ImageOps.autocontrast(pil_img)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def equalize(pil_img, _):
|
| 63 |
+
return ImageOps.equalize(pil_img)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def posterize(pil_img, level):
|
| 67 |
+
level = int_parameter(sample_level(level), 4)
|
| 68 |
+
return ImageOps.posterize(pil_img, 4 - level)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def rotate(pil_img, level):
|
| 72 |
+
degrees = int_parameter(sample_level(level), 30)
|
| 73 |
+
if np.random.uniform() > 0.5:
|
| 74 |
+
degrees = -degrees
|
| 75 |
+
return pil_img.rotate(degrees, resample=Image.BILINEAR)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def solarize(pil_img, level):
|
| 79 |
+
level = int_parameter(sample_level(level), 256)
|
| 80 |
+
return ImageOps.solarize(pil_img, 256 - level)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def shear_x(pil_img, level):
|
| 84 |
+
level = float_parameter(sample_level(level), 0.3)
|
| 85 |
+
if np.random.uniform() > 0.5:
|
| 86 |
+
level = -level
|
| 87 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 88 |
+
Image.AFFINE, (1, level, 0, 0, 1, 0),
|
| 89 |
+
resample=Image.BILINEAR)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def shear_y(pil_img, level):
|
| 93 |
+
level = float_parameter(sample_level(level), 0.3)
|
| 94 |
+
if np.random.uniform() > 0.5:
|
| 95 |
+
level = -level
|
| 96 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 97 |
+
Image.AFFINE, (1, 0, 0, level, 1, 0),
|
| 98 |
+
resample=Image.BILINEAR)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def translate_x(pil_img, level):
|
| 102 |
+
level = int_parameter(sample_level(level), IMAGE_SIZE / 3)
|
| 103 |
+
if np.random.random() > 0.5:
|
| 104 |
+
level = -level
|
| 105 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 106 |
+
Image.AFFINE, (1, 0, level, 0, 1, 0),
|
| 107 |
+
resample=Image.BILINEAR)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def translate_y(pil_img, level):
|
| 111 |
+
level = int_parameter(sample_level(level), IMAGE_SIZE / 3)
|
| 112 |
+
if np.random.random() > 0.5:
|
| 113 |
+
level = -level
|
| 114 |
+
return pil_img.transform((IMAGE_SIZE, IMAGE_SIZE),
|
| 115 |
+
Image.AFFINE, (1, 0, 0, 0, 1, level),
|
| 116 |
+
resample=Image.BILINEAR)
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
# operation that overlaps with ImageNet-C's test set
|
| 120 |
+
def color(pil_img, level):
|
| 121 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 122 |
+
return ImageEnhance.Color(pil_img).enhance(level)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
# operation that overlaps with ImageNet-C's test set
|
| 126 |
+
def contrast(pil_img, level):
|
| 127 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 128 |
+
return ImageEnhance.Contrast(pil_img).enhance(level)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
# operation that overlaps with ImageNet-C's test set
|
| 132 |
+
def brightness(pil_img, level):
|
| 133 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 134 |
+
return ImageEnhance.Brightness(pil_img).enhance(level)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# operation that overlaps with ImageNet-C's test set
|
| 138 |
+
def sharpness(pil_img, level):
|
| 139 |
+
level = float_parameter(sample_level(level), 1.8) + 0.1
|
| 140 |
+
return ImageEnhance.Sharpness(pil_img).enhance(level)
|
| 141 |
+
|
| 142 |
+
def random_resized_crop(pil_img, level):
|
| 143 |
+
return transforms.RandomResizedCrop(32)(pil_img)
|
| 144 |
+
|
| 145 |
+
def random_flip(pil_img, level):
|
| 146 |
+
return transforms.RandomHorizontalFlip(p=0.5)(pil_img)
|
| 147 |
+
|
| 148 |
+
def grayscale(pil_img, level):
|
| 149 |
+
return transforms.Grayscale(num_output_channels=3)(pil_img)
|
| 150 |
+
|
| 151 |
+
augmentations = [
|
| 152 |
+
autocontrast, equalize, posterize, rotate, solarize, shear_x, shear_y,
|
| 153 |
+
translate_x, translate_y, grayscale #random_resized_crop, random_flip
|
| 154 |
+
]
|
| 155 |
+
|
| 156 |
+
augmentations_all = [
|
| 157 |
+
autocontrast, equalize, posterize, rotate, solarize, shear_x, shear_y,
|
| 158 |
+
translate_x, translate_y, color, contrast, brightness, sharpness, grayscale #, random_resized_crop, random_flip
|
| 159 |
+
]
|
| 160 |
+
|
| 161 |
+
def aug_tiny(image, preprocess, mixture_width=3, mixture_depth=-1, aug_severity=3):
|
| 162 |
+
"""Perform AugMix augmentations and compute mixture.
|
| 163 |
+
|
| 164 |
+
Args:
|
| 165 |
+
image: PIL.Image input image
|
| 166 |
+
preprocess: Preprocessing function which should return a torch tensor.
|
| 167 |
+
|
| 168 |
+
Returns:
|
| 169 |
+
mixed: Augmented and mixed image.
|
| 170 |
+
"""
|
| 171 |
+
aug_list = augmentations
|
| 172 |
+
# if args.all_ops:
|
| 173 |
+
# aug_list = augmentations.augmentations_all
|
| 174 |
+
|
| 175 |
+
ws = np.float32(np.random.dirichlet([1] * mixture_width))
|
| 176 |
+
m = np.float32(np.random.beta(1, 1))
|
| 177 |
+
|
| 178 |
+
mix = torch.zeros_like(preprocess(image))
|
| 179 |
+
for i in range(mixture_width):
|
| 180 |
+
image_aug = image.copy()
|
| 181 |
+
depth = mixture_depth if mixture_depth > 0 else np.random.randint(
|
| 182 |
+
1, 4)
|
| 183 |
+
for _ in range(depth):
|
| 184 |
+
op = np.random.choice(aug_list)
|
| 185 |
+
image_aug = op(image_aug, aug_severity)
|
| 186 |
+
# Preprocessing commutes since all coefficients are convex
|
| 187 |
+
mix += ws[i] * preprocess(image_aug)
|
| 188 |
+
|
| 189 |
+
mixed = (1 - m) * preprocess(image) + m * mix
|
| 190 |
+
return mixed
|
data_statistics.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def get_data_mean_and_stdev(dataset):
|
| 2 |
+
if dataset == 'CIFAR10' or dataset == 'CIFAR100':
|
| 3 |
+
mean = [0.5, 0.5, 0.5]
|
| 4 |
+
std = [0.5, 0.5, 0.5]
|
| 5 |
+
elif dataset == 'STL-10':
|
| 6 |
+
mean = [0.491, 0.482, 0.447]
|
| 7 |
+
std = [0.247, 0.244, 0.262]
|
| 8 |
+
elif dataset == 'ImageNet':
|
| 9 |
+
mean = [0.485, 0.456, 0.406]
|
| 10 |
+
std = [0.229, 0.224, 0.225]
|
| 11 |
+
elif dataset == 'aircraft':
|
| 12 |
+
mean = [0.486, 0.507, 0.525]
|
| 13 |
+
std = [0.266, 0.260, 0.276]
|
| 14 |
+
elif dataset == 'cu_birds':
|
| 15 |
+
mean = [0.483, 0.491, 0.424]
|
| 16 |
+
std = [0.228, 0.224, 0.259]
|
| 17 |
+
elif dataset == 'dtd':
|
| 18 |
+
mean = [0.533, 0.474, 0.426]
|
| 19 |
+
std = [0.261, 0.250, 0.259]
|
| 20 |
+
elif dataset == 'fashionmnist':
|
| 21 |
+
mean = [0.348, 0.348, 0.348]
|
| 22 |
+
std = [0.347, 0.347, 0.347]
|
| 23 |
+
elif dataset == 'mnist':
|
| 24 |
+
mean = [0.170, 0.170, 0.170]
|
| 25 |
+
std = [0.320, 0.320, 0.320]
|
| 26 |
+
elif dataset == 'traffic_sign':
|
| 27 |
+
mean = [0.335, 0.291, 0.295]
|
| 28 |
+
std = [0.267, 0.249, 0.251]
|
| 29 |
+
elif dataset == 'vgg_flower':
|
| 30 |
+
mean = [0.518, 0.410, 0.329]
|
| 31 |
+
std = [0.296, 0.249, 0.285]
|
| 32 |
+
else:
|
| 33 |
+
raise Exception('Dataset %s not supported.'%dataset)
|
| 34 |
+
return mean, std
|
| 35 |
+
|
| 36 |
+
def get_data_nclass(dataset):
|
| 37 |
+
if dataset == 'cifar10':
|
| 38 |
+
nclass = 10
|
| 39 |
+
elif dataset == 'cifar100cifar10':
|
| 40 |
+
nclass = 100
|
| 41 |
+
elif dataset == 'stl-10':
|
| 42 |
+
nclass = 10
|
| 43 |
+
elif dataset == 'ImageNet':
|
| 44 |
+
nclass = 1000
|
| 45 |
+
elif dataset == 'aircraft':
|
| 46 |
+
nclass = 102
|
| 47 |
+
elif dataset == 'cu_birds':
|
| 48 |
+
nclass = 200
|
| 49 |
+
elif dataset == 'dtd':
|
| 50 |
+
nclass = 47
|
| 51 |
+
elif dataset == 'fashionmnist':
|
| 52 |
+
nclass = 10
|
| 53 |
+
elif dataset == 'mnist':
|
| 54 |
+
nclass = 10
|
| 55 |
+
elif dataset == 'traffic_sign':
|
| 56 |
+
nclass = 43
|
| 57 |
+
elif dataset == 'vgg_flower':
|
| 58 |
+
nclass = 102
|
| 59 |
+
else:
|
| 60 |
+
raise Exception('Dataset %s not supported.'%dataset)
|
| 61 |
+
return nclass
|
download_imagenet.sh
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# https://gist.github.com/BIGBALLON/8a71d225eff18d88e469e6ea9b39cef4
|
| 3 |
+
cd /mnt/store/wbandar1/datasets
|
| 4 |
+
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_train.tar --no-check-certificate
|
| 5 |
+
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar --no-check-certificate
|
| 6 |
+
|
| 7 |
+
#
|
| 8 |
+
# script to extract ImageNet dataset
|
| 9 |
+
# ILSVRC2012_img_train.tar (about 138 GB)
|
| 10 |
+
# ILSVRC2012_img_val.tar (about 6.3 GB)
|
| 11 |
+
# make sure ILSVRC2012_img_train.tar & ILSVRC2012_img_val.tar in your current directory
|
| 12 |
+
#
|
| 13 |
+
# https://github.com/facebook/fb.resnet.torch/blob/master/INSTALL.md
|
| 14 |
+
#
|
| 15 |
+
# train/
|
| 16 |
+
# ├── n01440764
|
| 17 |
+
# │ ├── n01440764_10026.JPEG
|
| 18 |
+
# │ ├── n01440764_10027.JPEG
|
| 19 |
+
# │ ├── ......
|
| 20 |
+
# ├── ......
|
| 21 |
+
# val/
|
| 22 |
+
# ├── n01440764
|
| 23 |
+
# │ ├── ILSVRC2012_val_00000293.JPEG
|
| 24 |
+
# │ ├── ILSVRC2012_val_00002138.JPEG
|
| 25 |
+
# │ ├── ......
|
| 26 |
+
# ├── ......
|
| 27 |
+
#
|
| 28 |
+
#
|
| 29 |
+
# Extract the training data:
|
| 30 |
+
#
|
| 31 |
+
mkdir train && mv ILSVRC2012_img_train.tar train/ && cd train
|
| 32 |
+
tar -xvf ILSVRC2012_img_train.tar && rm -f ILSVRC2012_img_train.tar
|
| 33 |
+
find . -name "*.tar" | while read NAME ; do mkdir -p "${NAME%.tar}"; tar -xvf "${NAME}" -C "${NAME%.tar}"; rm -f "${NAME}"; done
|
| 34 |
+
cd ..
|
| 35 |
+
#
|
| 36 |
+
# Extract the validation data and move images to subfolders:
|
| 37 |
+
#
|
| 38 |
+
mkdir val && mv ILSVRC2012_img_val.tar val/ && cd val && tar -xvf ILSVRC2012_img_val.tar
|
| 39 |
+
wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bash
|
| 40 |
+
#
|
| 41 |
+
# Check total files after extract
|
| 42 |
+
#
|
| 43 |
+
# $ find train/ -name "*.JPEG" | wc -l
|
| 44 |
+
# 1281167
|
| 45 |
+
# $ find val/ -name "*.JPEG" | wc -l
|
| 46 |
+
# 50000
|
| 47 |
+
#
|
environment.yml
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: ssl-aug
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- anaconda
|
| 5 |
+
- conda-forge
|
| 6 |
+
- defaults
|
| 7 |
+
dependencies:
|
| 8 |
+
- _libgcc_mutex=0.1=main
|
| 9 |
+
- _openmp_mutex=5.1=1_gnu
|
| 10 |
+
- blas=1.0=mkl
|
| 11 |
+
- bottleneck=1.3.4=py38hce1f21e_0
|
| 12 |
+
- brotlipy=0.7.0=py38h27cfd23_1003
|
| 13 |
+
- bzip2=1.0.8=h7b6447c_0
|
| 14 |
+
- ca-certificates=2022.6.15=ha878542_0
|
| 15 |
+
- cairo=1.16.0=hcf35c78_1003
|
| 16 |
+
- certifi=2022.6.15=py38h578d9bd_0
|
| 17 |
+
- cffi=1.15.0=py38h7f8727e_0
|
| 18 |
+
- charset-normalizer=2.0.4=pyhd3eb1b0_0
|
| 19 |
+
- cryptography=37.0.1=py38h9ce1e76_0
|
| 20 |
+
- cudatoolkit=11.3.1=h2bc3f7f_2
|
| 21 |
+
- dataclasses=0.8=pyh6d0b6a4_7
|
| 22 |
+
- dbus=1.13.18=hb2f20db_0
|
| 23 |
+
- expat=2.4.8=h27087fc_0
|
| 24 |
+
- ffmpeg=4.3.2=hca11adc_0
|
| 25 |
+
- fontconfig=2.14.0=h8e229c2_0
|
| 26 |
+
- freetype=2.11.0=h70c0345_0
|
| 27 |
+
- fvcore=0.1.5.post20220512=pyhd8ed1ab_0
|
| 28 |
+
- gettext=0.19.8.1=hd7bead4_3
|
| 29 |
+
- gh=2.12.1=ha8f183a_0
|
| 30 |
+
- giflib=5.2.1=h7b6447c_0
|
| 31 |
+
- glib=2.66.3=h58526e2_0
|
| 32 |
+
- gmp=6.2.1=h295c915_3
|
| 33 |
+
- gnutls=3.6.15=he1e5248_0
|
| 34 |
+
- graphite2=1.3.14=h295c915_1
|
| 35 |
+
- gst-plugins-base=1.14.5=h0935bb2_2
|
| 36 |
+
- gstreamer=1.14.5=h36ae1b5_2
|
| 37 |
+
- harfbuzz=2.4.0=h9f30f68_3
|
| 38 |
+
- hdf5=1.10.6=hb1b8bf9_0
|
| 39 |
+
- icu=64.2=he1b5a44_1
|
| 40 |
+
- idna=3.3=pyhd3eb1b0_0
|
| 41 |
+
- intel-openmp=2021.4.0=h06a4308_3561
|
| 42 |
+
- iopath=0.1.9=pyhd8ed1ab_0
|
| 43 |
+
- jasper=1.900.1=hd497a04_4
|
| 44 |
+
- jpeg=9e=h7f8727e_0
|
| 45 |
+
- lame=3.100=h7b6447c_0
|
| 46 |
+
- lcms2=2.12=h3be6417_0
|
| 47 |
+
- libblas=3.9.0=12_linux64_mkl
|
| 48 |
+
- libcblas=3.9.0=12_linux64_mkl
|
| 49 |
+
- libclang=9.0.1=default_hb4e5071_5
|
| 50 |
+
- libedit=3.1.20210910=h7f8727e_0
|
| 51 |
+
- libffi=3.2.1=hf484d3e_1007
|
| 52 |
+
- libgcc-ng=11.2.0=h1234567_1
|
| 53 |
+
- libgfortran-ng=7.5.0=ha8ba4b0_17
|
| 54 |
+
- libgfortran4=7.5.0=ha8ba4b0_17
|
| 55 |
+
- libglib=2.66.3=hbe7bbb4_0
|
| 56 |
+
- libgomp=11.2.0=h1234567_1
|
| 57 |
+
- libiconv=1.16=h7f8727e_2
|
| 58 |
+
- libidn2=2.3.2=h7f8727e_0
|
| 59 |
+
- liblapack=3.9.0=12_linux64_mkl
|
| 60 |
+
- liblapacke=3.9.0=12_linux64_mkl
|
| 61 |
+
- libllvm9=9.0.1=h4a3c616_1
|
| 62 |
+
- libopencv=4.5.1=py38h703c3c0_0
|
| 63 |
+
- libpng=1.6.37=hbc83047_0
|
| 64 |
+
- libprotobuf=3.15.8=h780b84a_1
|
| 65 |
+
- libstdcxx-ng=11.2.0=h1234567_1
|
| 66 |
+
- libtasn1=4.16.0=h27cfd23_0
|
| 67 |
+
- libtiff=4.2.0=h2818925_1
|
| 68 |
+
- libunistring=0.9.10=h27cfd23_0
|
| 69 |
+
- libuuid=2.32.1=h7f98852_1000
|
| 70 |
+
- libuv=1.40.0=h7b6447c_0
|
| 71 |
+
- libwebp=1.2.2=h55f646e_0
|
| 72 |
+
- libwebp-base=1.2.2=h7f8727e_0
|
| 73 |
+
- libxcb=1.15=h7f8727e_0
|
| 74 |
+
- libxkbcommon=0.10.0=he1b5a44_0
|
| 75 |
+
- libxml2=2.9.9=hea5a465_1
|
| 76 |
+
- lz4-c=1.9.3=h295c915_1
|
| 77 |
+
- mkl=2021.4.0=h06a4308_640
|
| 78 |
+
- mkl-service=2.4.0=py38h7f8727e_0
|
| 79 |
+
- mkl_fft=1.3.1=py38hd3c417c_0
|
| 80 |
+
- mkl_random=1.2.2=py38h51133e4_0
|
| 81 |
+
- ncurses=6.3=h7f8727e_2
|
| 82 |
+
- nettle=3.7.3=hbbd107a_1
|
| 83 |
+
- nspr=4.33=h295c915_0
|
| 84 |
+
- nss=3.46.1=hab99668_0
|
| 85 |
+
- numexpr=2.8.1=py38h6abb31d_0
|
| 86 |
+
- numpy=1.22.3=py38he7a7128_0
|
| 87 |
+
- numpy-base=1.22.3=py38hf524024_0
|
| 88 |
+
- opencv=4.5.1=py38h578d9bd_0
|
| 89 |
+
- openh264=2.1.1=h4ff587b_0
|
| 90 |
+
- openssl=1.1.1o=h166bdaf_0
|
| 91 |
+
- packaging=21.3=pyhd3eb1b0_0
|
| 92 |
+
- pandas=1.4.2=py38h295c915_0
|
| 93 |
+
- pcre=8.45=h295c915_0
|
| 94 |
+
- pillow=9.0.1=py38h22f2fdc_0
|
| 95 |
+
- pip=21.2.4=py38h06a4308_0
|
| 96 |
+
- pixman=0.38.0=h7b6447c_0
|
| 97 |
+
- portalocker=2.3.0=py38h06a4308_0
|
| 98 |
+
- protobuf=3.15.8=py38h709712a_0
|
| 99 |
+
- py-opencv=4.5.1=py38h81c977d_0
|
| 100 |
+
- pycparser=2.21=pyhd3eb1b0_0
|
| 101 |
+
- pyopenssl=22.0.0=pyhd3eb1b0_0
|
| 102 |
+
- pyparsing=3.0.9=pyhd8ed1ab_0
|
| 103 |
+
- pysocks=1.7.1=py38h06a4308_0
|
| 104 |
+
- python=3.8.0=h0371630_2
|
| 105 |
+
- python-dateutil=2.8.2=pyhd3eb1b0_0
|
| 106 |
+
- python_abi=3.8=2_cp38
|
| 107 |
+
- pytorch=1.11.0=py3.8_cuda11.3_cudnn8.2.0_0
|
| 108 |
+
- pytorch-mutex=1.0=cuda
|
| 109 |
+
- pytz=2021.3=pyhd3eb1b0_0
|
| 110 |
+
- pyyaml=6.0=py38h7f8727e_1
|
| 111 |
+
- qt=5.12.5=hd8c4c69_1
|
| 112 |
+
- readline=7.0=h7b6447c_5
|
| 113 |
+
- requests=2.27.1=pyhd3eb1b0_0
|
| 114 |
+
- setuptools=61.2.0=py38h06a4308_0
|
| 115 |
+
- six=1.16.0=pyhd3eb1b0_1
|
| 116 |
+
- sqlite=3.33.0=h62c20be_0
|
| 117 |
+
- tabulate=0.8.9=py38h06a4308_0
|
| 118 |
+
- tensorboardx=2.5.1=pyhd8ed1ab_0
|
| 119 |
+
- termcolor=1.1.0=py38h06a4308_1
|
| 120 |
+
- tk=8.6.12=h1ccaba5_0
|
| 121 |
+
- torchvision=0.12.0=py38_cu113
|
| 122 |
+
- tqdm=4.64.0=py38h06a4308_0
|
| 123 |
+
- typing_extensions=4.1.1=pyh06a4308_0
|
| 124 |
+
- wheel=0.37.1=pyhd3eb1b0_0
|
| 125 |
+
- x264=1!161.3030=h7f98852_1
|
| 126 |
+
- xorg-kbproto=1.0.7=h7f98852_1002
|
| 127 |
+
- xorg-libice=1.0.10=h7f98852_0
|
| 128 |
+
- xorg-libsm=1.2.3=hd9c2040_1000
|
| 129 |
+
- xorg-libx11=1.7.2=h7f98852_0
|
| 130 |
+
- xorg-libxext=1.3.4=h7f98852_1
|
| 131 |
+
- xorg-libxrender=0.9.10=h7f98852_1003
|
| 132 |
+
- xorg-renderproto=0.11.1=h7f98852_1002
|
| 133 |
+
- xorg-xextproto=7.3.0=h7f98852_1002
|
| 134 |
+
- xorg-xproto=7.0.31=h27cfd23_1007
|
| 135 |
+
- xz=5.2.5=h7f8727e_1
|
| 136 |
+
- yacs=0.1.6=pyhd3eb1b0_1
|
| 137 |
+
- yaml=0.2.5=h7b6447c_0
|
| 138 |
+
- zip=3.0=h7f98852_1
|
| 139 |
+
- zlib=1.2.12=h7f8727e_2
|
| 140 |
+
- zstd=1.5.2=ha4553b6_0
|
| 141 |
+
- pip:
|
| 142 |
+
- absl-py==1.1.0
|
| 143 |
+
- appdirs==1.4.4
|
| 144 |
+
- cachetools==5.2.0
|
| 145 |
+
- click==8.1.7
|
| 146 |
+
- contourpy==1.0.6
|
| 147 |
+
- cycler==0.11.0
|
| 148 |
+
- decord==0.6.0
|
| 149 |
+
- deepspeed==0.5.8
|
| 150 |
+
- docker-pycreds==0.4.0
|
| 151 |
+
- einops==0.4.1
|
| 152 |
+
- filelock==3.7.1
|
| 153 |
+
- fonttools==4.38.0
|
| 154 |
+
- future==0.18.2
|
| 155 |
+
- gitdb==4.0.10
|
| 156 |
+
- gitpython==3.1.33
|
| 157 |
+
- google-auth==2.7.0
|
| 158 |
+
- google-auth-oauthlib==0.4.6
|
| 159 |
+
- grpcio==1.46.3
|
| 160 |
+
- hjson==3.0.2
|
| 161 |
+
- imageio==2.22.2
|
| 162 |
+
- importlib-metadata==4.11.4
|
| 163 |
+
- kiwisolver==1.4.4
|
| 164 |
+
- markdown==3.3.7
|
| 165 |
+
- matplotlib==3.6.1
|
| 166 |
+
- ninja==1.10.2.3
|
| 167 |
+
- oauthlib==3.2.0
|
| 168 |
+
- pathtools==0.1.2
|
| 169 |
+
- psutil==5.9.1
|
| 170 |
+
- pyasn1==0.4.8
|
| 171 |
+
- pyasn1-modules==0.2.8
|
| 172 |
+
- requests-oauthlib==1.3.1
|
| 173 |
+
- rsa==4.8
|
| 174 |
+
- scipy==1.9.0
|
| 175 |
+
- sentry-sdk==1.30.0
|
| 176 |
+
- setproctitle==1.3.2
|
| 177 |
+
- smmap==5.0.0
|
| 178 |
+
- tensorboard==2.9.1
|
| 179 |
+
- tensorboard-data-server==0.6.1
|
| 180 |
+
- tensorboard-plugin-wit==1.8.1
|
| 181 |
+
- thop==0.1.1-2209072238
|
| 182 |
+
- timm==0.4.12
|
| 183 |
+
- triton==1.1.1
|
| 184 |
+
- urllib3==1.26.16
|
| 185 |
+
- wandb==0.15.9
|
| 186 |
+
- werkzeug==2.1.2
|
| 187 |
+
- zipp==3.8.0
|
| 188 |
+
prefix: /home/wbandar1/anaconda3/envs/ssl-aug
|
evaluate_imagenet.py
ADDED
|
@@ -0,0 +1,289 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
import argparse
|
| 9 |
+
import json
|
| 10 |
+
import os
|
| 11 |
+
import random
|
| 12 |
+
import signal
|
| 13 |
+
import sys
|
| 14 |
+
import time
|
| 15 |
+
import urllib
|
| 16 |
+
|
| 17 |
+
from torch import nn, optim
|
| 18 |
+
from torchvision import models, datasets, transforms
|
| 19 |
+
import torch
|
| 20 |
+
import torchvision
|
| 21 |
+
import wandb
|
| 22 |
+
|
| 23 |
+
parser = argparse.ArgumentParser(description='Evaluate resnet50 features on ImageNet')
|
| 24 |
+
parser.add_argument('data', type=Path, metavar='DIR',
|
| 25 |
+
help='path to dataset')
|
| 26 |
+
parser.add_argument('pretrained', type=Path, metavar='FILE',
|
| 27 |
+
help='path to pretrained model')
|
| 28 |
+
parser.add_argument('--weights', default='freeze', type=str,
|
| 29 |
+
choices=('finetune', 'freeze'),
|
| 30 |
+
help='finetune or freeze resnet weights')
|
| 31 |
+
parser.add_argument('--train-percent', default=100, type=int,
|
| 32 |
+
choices=(100, 10, 1),
|
| 33 |
+
help='size of traing set in percent')
|
| 34 |
+
parser.add_argument('--workers', default=8, type=int, metavar='N',
|
| 35 |
+
help='number of data loader workers')
|
| 36 |
+
parser.add_argument('--epochs', default=100, type=int, metavar='N',
|
| 37 |
+
help='number of total epochs to run')
|
| 38 |
+
parser.add_argument('--batch-size', default=256, type=int, metavar='N',
|
| 39 |
+
help='mini-batch size')
|
| 40 |
+
parser.add_argument('--lr-backbone', default=0.0, type=float, metavar='LR',
|
| 41 |
+
help='backbone base learning rate')
|
| 42 |
+
parser.add_argument('--lr-classifier', default=0.3, type=float, metavar='LR',
|
| 43 |
+
help='classifier base learning rate')
|
| 44 |
+
parser.add_argument('--weight-decay', default=1e-6, type=float, metavar='W',
|
| 45 |
+
help='weight decay')
|
| 46 |
+
parser.add_argument('--print-freq', default=100, type=int, metavar='N',
|
| 47 |
+
help='print frequency')
|
| 48 |
+
parser.add_argument('--checkpoint-dir', default='/mnt/store/wbandar1/projects/ssl-aug-artifacts/', type=Path,
|
| 49 |
+
metavar='DIR', help='path to checkpoint directory')
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def main():
|
| 53 |
+
args = parser.parse_args()
|
| 54 |
+
if args.train_percent in {1, 10}:
|
| 55 |
+
args.train_files = urllib.request.urlopen(f'https://raw.githubusercontent.com/google-research/simclr/master/imagenet_subsets/{args.train_percent}percent.txt').readlines()
|
| 56 |
+
args.ngpus_per_node = torch.cuda.device_count()
|
| 57 |
+
if 'SLURM_JOB_ID' in os.environ:
|
| 58 |
+
signal.signal(signal.SIGUSR1, handle_sigusr1)
|
| 59 |
+
signal.signal(signal.SIGTERM, handle_sigterm)
|
| 60 |
+
# single-node distributed training
|
| 61 |
+
args.rank = 0
|
| 62 |
+
args.dist_url = f'tcp://localhost:{random.randrange(49152, 65535)}'
|
| 63 |
+
args.world_size = args.ngpus_per_node
|
| 64 |
+
torch.multiprocessing.spawn(main_worker, (args,), args.ngpus_per_node)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def main_worker(gpu, args):
|
| 68 |
+
args.rank += gpu
|
| 69 |
+
torch.distributed.init_process_group(
|
| 70 |
+
backend='nccl', init_method=args.dist_url,
|
| 71 |
+
world_size=args.world_size, rank=args.rank)
|
| 72 |
+
|
| 73 |
+
# initializing wandb
|
| 74 |
+
if args.rank == 0:
|
| 75 |
+
run = wandb.init(project="bt-in1k-eval", config=args, dir='/mnt/store/wbandar1/projects/ssl-aug-artifacts/wandb_logs/')
|
| 76 |
+
run_id = wandb.run.id
|
| 77 |
+
args.checkpoint_dir=Path(os.path.join(args.checkpoint_dir, run_id))
|
| 78 |
+
|
| 79 |
+
if args.rank == 0:
|
| 80 |
+
args.checkpoint_dir.mkdir(parents=True, exist_ok=True)
|
| 81 |
+
stats_file = open(args.checkpoint_dir / 'stats.txt', 'a', buffering=1)
|
| 82 |
+
print(' '.join(sys.argv))
|
| 83 |
+
print(' '.join(sys.argv), file=stats_file)
|
| 84 |
+
|
| 85 |
+
torch.cuda.set_device(gpu)
|
| 86 |
+
torch.backends.cudnn.benchmark = True
|
| 87 |
+
|
| 88 |
+
model = models.resnet50().cuda(gpu)
|
| 89 |
+
state_dict = torch.load(args.pretrained, map_location='cpu')
|
| 90 |
+
missing_keys, unexpected_keys = model.load_state_dict(state_dict, strict=False)
|
| 91 |
+
assert missing_keys == ['fc.weight', 'fc.bias'] and unexpected_keys == []
|
| 92 |
+
model.fc.weight.data.normal_(mean=0.0, std=0.01)
|
| 93 |
+
model.fc.bias.data.zero_()
|
| 94 |
+
if args.weights == 'freeze':
|
| 95 |
+
model.requires_grad_(False)
|
| 96 |
+
model.fc.requires_grad_(True)
|
| 97 |
+
classifier_parameters, model_parameters = [], []
|
| 98 |
+
for name, param in model.named_parameters():
|
| 99 |
+
if name in {'fc.weight', 'fc.bias'}:
|
| 100 |
+
classifier_parameters.append(param)
|
| 101 |
+
else:
|
| 102 |
+
model_parameters.append(param)
|
| 103 |
+
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
|
| 104 |
+
|
| 105 |
+
criterion = nn.CrossEntropyLoss().cuda(gpu)
|
| 106 |
+
|
| 107 |
+
param_groups = [dict(params=classifier_parameters, lr=args.lr_classifier)]
|
| 108 |
+
if args.weights == 'finetune':
|
| 109 |
+
param_groups.append(dict(params=model_parameters, lr=args.lr_backbone))
|
| 110 |
+
optimizer = optim.SGD(param_groups, 0, momentum=0.9, weight_decay=args.weight_decay)
|
| 111 |
+
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, args.epochs)
|
| 112 |
+
|
| 113 |
+
# automatically resume from checkpoint if it exists
|
| 114 |
+
if (args.checkpoint_dir / 'checkpoint.pth').is_file():
|
| 115 |
+
ckpt = torch.load(args.checkpoint_dir / 'checkpoint.pth',
|
| 116 |
+
map_location='cpu')
|
| 117 |
+
start_epoch = ckpt['epoch']
|
| 118 |
+
best_acc = ckpt['best_acc']
|
| 119 |
+
model.load_state_dict(ckpt['model'])
|
| 120 |
+
optimizer.load_state_dict(ckpt['optimizer'])
|
| 121 |
+
scheduler.load_state_dict(ckpt['scheduler'])
|
| 122 |
+
else:
|
| 123 |
+
start_epoch = 0
|
| 124 |
+
best_acc = argparse.Namespace(top1=0, top5=0)
|
| 125 |
+
|
| 126 |
+
# Data loading code
|
| 127 |
+
traindir = args.data / 'train'
|
| 128 |
+
valdir = args.data / 'val'
|
| 129 |
+
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
|
| 130 |
+
std=[0.229, 0.224, 0.225])
|
| 131 |
+
|
| 132 |
+
train_dataset = datasets.ImageFolder(traindir, transforms.Compose([
|
| 133 |
+
transforms.RandomResizedCrop(224),
|
| 134 |
+
transforms.RandomHorizontalFlip(),
|
| 135 |
+
transforms.ToTensor(),
|
| 136 |
+
normalize,
|
| 137 |
+
]))
|
| 138 |
+
val_dataset = datasets.ImageFolder(valdir, transforms.Compose([
|
| 139 |
+
transforms.Resize(256),
|
| 140 |
+
transforms.CenterCrop(224),
|
| 141 |
+
transforms.ToTensor(),
|
| 142 |
+
normalize,
|
| 143 |
+
]))
|
| 144 |
+
|
| 145 |
+
if args.train_percent in {1, 10}:
|
| 146 |
+
train_dataset.samples = []
|
| 147 |
+
for fname in args.train_files:
|
| 148 |
+
fname = fname.decode().strip()
|
| 149 |
+
cls = fname.split('_')[0]
|
| 150 |
+
train_dataset.samples.append(
|
| 151 |
+
(traindir / cls / fname, train_dataset.class_to_idx[cls]))
|
| 152 |
+
|
| 153 |
+
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
|
| 154 |
+
kwargs = dict(batch_size=args.batch_size // args.world_size, num_workers=args.workers, pin_memory=True)
|
| 155 |
+
train_loader = torch.utils.data.DataLoader(train_dataset, sampler=train_sampler, **kwargs)
|
| 156 |
+
val_loader = torch.utils.data.DataLoader(val_dataset, **kwargs)
|
| 157 |
+
|
| 158 |
+
start_time = time.time()
|
| 159 |
+
for epoch in range(start_epoch, args.epochs):
|
| 160 |
+
# train
|
| 161 |
+
if args.weights == 'finetune':
|
| 162 |
+
model.train()
|
| 163 |
+
elif args.weights == 'freeze':
|
| 164 |
+
model.eval()
|
| 165 |
+
else:
|
| 166 |
+
assert False
|
| 167 |
+
train_sampler.set_epoch(epoch)
|
| 168 |
+
for step, (images, target) in enumerate(train_loader, start=epoch * len(train_loader)):
|
| 169 |
+
output = model(images.cuda(gpu, non_blocking=True))
|
| 170 |
+
loss = criterion(output, target.cuda(gpu, non_blocking=True))
|
| 171 |
+
optimizer.zero_grad()
|
| 172 |
+
loss.backward()
|
| 173 |
+
optimizer.step()
|
| 174 |
+
if step % args.print_freq == 0:
|
| 175 |
+
torch.distributed.reduce(loss.div_(args.world_size), 0)
|
| 176 |
+
if args.rank == 0:
|
| 177 |
+
pg = optimizer.param_groups
|
| 178 |
+
lr_classifier = pg[0]['lr']
|
| 179 |
+
lr_backbone = pg[1]['lr'] if len(pg) == 2 else 0
|
| 180 |
+
stats = dict(epoch=epoch, step=step, lr_backbone=lr_backbone,
|
| 181 |
+
lr_classifier=lr_classifier, loss=loss.item(),
|
| 182 |
+
time=int(time.time() - start_time))
|
| 183 |
+
print(json.dumps(stats))
|
| 184 |
+
print(json.dumps(stats), file=stats_file)
|
| 185 |
+
run.log(
|
| 186 |
+
{
|
| 187 |
+
"epoch": epoch,
|
| 188 |
+
"step": step,
|
| 189 |
+
"lr_backbone": lr_backbone,
|
| 190 |
+
"lr_classifier": lr_classifier,
|
| 191 |
+
"loss": loss.item(),
|
| 192 |
+
"time": int(time.time() - start_time),
|
| 193 |
+
}
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
# evaluate
|
| 197 |
+
model.eval()
|
| 198 |
+
if args.rank == 0:
|
| 199 |
+
top1 = AverageMeter('Acc@1')
|
| 200 |
+
top5 = AverageMeter('Acc@5')
|
| 201 |
+
with torch.no_grad():
|
| 202 |
+
for images, target in val_loader:
|
| 203 |
+
output = model(images.cuda(gpu, non_blocking=True))
|
| 204 |
+
acc1, acc5 = accuracy(output, target.cuda(gpu, non_blocking=True), topk=(1, 5))
|
| 205 |
+
top1.update(acc1[0].item(), images.size(0))
|
| 206 |
+
top5.update(acc5[0].item(), images.size(0))
|
| 207 |
+
best_acc.top1 = max(best_acc.top1, top1.avg)
|
| 208 |
+
best_acc.top5 = max(best_acc.top5, top5.avg)
|
| 209 |
+
stats = dict(epoch=epoch, acc1=top1.avg, acc5=top5.avg, best_acc1=best_acc.top1, best_acc5=best_acc.top5)
|
| 210 |
+
print(json.dumps(stats))
|
| 211 |
+
print(json.dumps(stats), file=stats_file)
|
| 212 |
+
run.log(
|
| 213 |
+
{
|
| 214 |
+
"epoch": epoch,
|
| 215 |
+
"eval_acc1": top1.avg,
|
| 216 |
+
"eval_acc5": top5.avg,
|
| 217 |
+
"eval_best_acc1": best_acc.top1,
|
| 218 |
+
"eval_best_acc5": best_acc.top5,
|
| 219 |
+
}
|
| 220 |
+
)
|
| 221 |
+
|
| 222 |
+
# sanity check
|
| 223 |
+
if args.weights == 'freeze':
|
| 224 |
+
reference_state_dict = torch.load(args.pretrained, map_location='cpu')
|
| 225 |
+
model_state_dict = model.module.state_dict()
|
| 226 |
+
for k in reference_state_dict:
|
| 227 |
+
assert torch.equal(model_state_dict[k].cpu(), reference_state_dict[k]), k
|
| 228 |
+
|
| 229 |
+
scheduler.step()
|
| 230 |
+
if args.rank == 0:
|
| 231 |
+
state = dict(
|
| 232 |
+
epoch=epoch + 1, best_acc=best_acc, model=model.state_dict(),
|
| 233 |
+
optimizer=optimizer.state_dict(), scheduler=scheduler.state_dict())
|
| 234 |
+
torch.save(state, args.checkpoint_dir / 'checkpoint.pth')
|
| 235 |
+
wandb.finish()
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
def handle_sigusr1(signum, frame):
|
| 239 |
+
os.system(f'scontrol requeue {os.getenv("SLURM_JOB_ID")}')
|
| 240 |
+
exit()
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
def handle_sigterm(signum, frame):
|
| 244 |
+
pass
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
class AverageMeter(object):
|
| 248 |
+
"""Computes and stores the average and current value"""
|
| 249 |
+
def __init__(self, name, fmt=':f'):
|
| 250 |
+
self.name = name
|
| 251 |
+
self.fmt = fmt
|
| 252 |
+
self.reset()
|
| 253 |
+
|
| 254 |
+
def reset(self):
|
| 255 |
+
self.val = 0
|
| 256 |
+
self.avg = 0
|
| 257 |
+
self.sum = 0
|
| 258 |
+
self.count = 0
|
| 259 |
+
|
| 260 |
+
def update(self, val, n=1):
|
| 261 |
+
self.val = val
|
| 262 |
+
self.sum += val * n
|
| 263 |
+
self.count += n
|
| 264 |
+
self.avg = self.sum / self.count
|
| 265 |
+
|
| 266 |
+
def __str__(self):
|
| 267 |
+
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
|
| 268 |
+
return fmtstr.format(**self.__dict__)
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
def accuracy(output, target, topk=(1,)):
|
| 272 |
+
"""Computes the accuracy over the k top predictions for the specified values of k"""
|
| 273 |
+
with torch.no_grad():
|
| 274 |
+
maxk = max(topk)
|
| 275 |
+
batch_size = target.size(0)
|
| 276 |
+
|
| 277 |
+
_, pred = output.topk(maxk, 1, True, True)
|
| 278 |
+
pred = pred.t()
|
| 279 |
+
correct = pred.eq(target.view(1, -1).expand_as(pred))
|
| 280 |
+
|
| 281 |
+
res = []
|
| 282 |
+
for k in topk:
|
| 283 |
+
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
|
| 284 |
+
res.append(correct_k.mul_(100.0 / batch_size))
|
| 285 |
+
return res
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
if __name__ == '__main__':
|
| 289 |
+
main()
|
evaluate_transfer.py
ADDED
|
@@ -0,0 +1,168 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.optim as optim
|
| 7 |
+
from thop import profile, clever_format
|
| 8 |
+
from torch.utils.data import DataLoader
|
| 9 |
+
from transfer_datasets import TRANSFER_DATASET
|
| 10 |
+
import torchvision.transforms as transforms
|
| 11 |
+
from data_statistics import get_data_mean_and_stdev, get_data_nclass
|
| 12 |
+
from tqdm import tqdm
|
| 13 |
+
|
| 14 |
+
import utils
|
| 15 |
+
|
| 16 |
+
import wandb
|
| 17 |
+
|
| 18 |
+
import torchvision
|
| 19 |
+
|
| 20 |
+
def load_transform(dataset, size=32):
|
| 21 |
+
mean, std = get_data_mean_and_stdev(dataset)
|
| 22 |
+
transform = transforms.Compose([
|
| 23 |
+
transforms.Resize((size, size)),
|
| 24 |
+
transforms.ToTensor(),
|
| 25 |
+
transforms.Normalize(mean=mean, std=std)])
|
| 26 |
+
return transform
|
| 27 |
+
|
| 28 |
+
class Net(nn.Module):
|
| 29 |
+
def __init__(self, num_class, pretrained_path, dataset, arch):
|
| 30 |
+
super(Net, self).__init__()
|
| 31 |
+
|
| 32 |
+
if arch=='resnet18':
|
| 33 |
+
embedding_size = 512
|
| 34 |
+
elif arch=='resnet50':
|
| 35 |
+
embedding_size = 2048
|
| 36 |
+
else:
|
| 37 |
+
raise NotImplementedError
|
| 38 |
+
|
| 39 |
+
# encoder
|
| 40 |
+
from model import Model
|
| 41 |
+
self.f = Model(dataset=dataset, arch=arch).f
|
| 42 |
+
# classifier
|
| 43 |
+
self.fc = nn.Linear(embedding_size, num_class, bias=True)
|
| 44 |
+
self.load_state_dict(torch.load(pretrained_path, map_location='cpu'), strict=False)
|
| 45 |
+
|
| 46 |
+
def forward(self, x):
|
| 47 |
+
x = self.f(x)
|
| 48 |
+
feature = torch.flatten(x, start_dim=1)
|
| 49 |
+
out = self.fc(feature)
|
| 50 |
+
return out
|
| 51 |
+
|
| 52 |
+
# train or test for one epoch
|
| 53 |
+
def train_val(net, data_loader, train_optimizer):
|
| 54 |
+
is_train = train_optimizer is not None
|
| 55 |
+
net.train() if is_train else net.eval()
|
| 56 |
+
|
| 57 |
+
total_loss, total_correct_1, total_correct_5, total_num, data_bar = 0.0, 0.0, 0.0, 0, tqdm(data_loader)
|
| 58 |
+
with (torch.enable_grad() if is_train else torch.no_grad()):
|
| 59 |
+
for data, target in data_bar:
|
| 60 |
+
data, target = data.cuda(non_blocking=True), target.cuda(non_blocking=True)
|
| 61 |
+
out = net(data)
|
| 62 |
+
loss = loss_criterion(out, target)
|
| 63 |
+
|
| 64 |
+
if is_train:
|
| 65 |
+
train_optimizer.zero_grad()
|
| 66 |
+
loss.backward()
|
| 67 |
+
train_optimizer.step()
|
| 68 |
+
|
| 69 |
+
total_num += data.size(0)
|
| 70 |
+
total_loss += loss.item() * data.size(0)
|
| 71 |
+
prediction = torch.argsort(out, dim=-1, descending=True)
|
| 72 |
+
total_correct_1 += torch.sum((prediction[:, 0:1] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
|
| 73 |
+
total_correct_5 += torch.sum((prediction[:, 0:5] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
|
| 74 |
+
|
| 75 |
+
data_bar.set_description('{} Epoch: [{}/{}] Loss: {:.4f} ACC@1: {:.2f}% ACC@5: {:.2f}% model: {}'
|
| 76 |
+
.format('Train' if is_train else 'Test', epoch, epochs, total_loss / total_num,
|
| 77 |
+
total_correct_1 / total_num * 100, total_correct_5 / total_num * 100,
|
| 78 |
+
model_path.split('/')[-1]))
|
| 79 |
+
|
| 80 |
+
return total_loss / total_num, total_correct_1 / total_num * 100, total_correct_5 / total_num * 100
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
if __name__ == '__main__':
|
| 84 |
+
parser = argparse.ArgumentParser(description='Linear Evaluation')
|
| 85 |
+
parser.add_argument('--dataset', default='cifar10', type=str, help='Pre-trained dataset.', choices=['cifar10', 'cifar100', 'stl10', 'tiny_imagenet'])
|
| 86 |
+
parser.add_argument('--transfer_dataset', default='cifar10', type=str, help='Transfer dataset (i.e., testing dataset)', choices=['cifar10', 'cifar100', 'stl-10', 'aircraft', 'cu_birds', 'dtd', 'fashionmnist', 'mnist', 'traffic_sign', 'vgg_flower'])
|
| 87 |
+
parser.add_argument('--arch', default='resnet50', type=str, help='Backbone architecture for experiments', choices=['resnet50', 'resnet18'])
|
| 88 |
+
parser.add_argument('--model_path', type=str, default='results/Barlow_Twins/0.005_64_128_model.pth',
|
| 89 |
+
help='The base string of the pretrained model path')
|
| 90 |
+
parser.add_argument('--batch_size', type=int, default=128, help='Number of images in each mini-batch')
|
| 91 |
+
parser.add_argument('--epochs', type=int, default=100, help='Number of sweeps over the dataset to train')
|
| 92 |
+
parser.add_argument('--screen', type=str, help='screen session id')
|
| 93 |
+
# wandb related args
|
| 94 |
+
parser.add_argument('--wandb_group', type=str, help='group for wandb')
|
| 95 |
+
|
| 96 |
+
args = parser.parse_args()
|
| 97 |
+
|
| 98 |
+
wandb.init(project=f"Barlow-Twins-MixUp-TransferLearn-[{args.dataset}-to-X]-{args.arch}", config=args, dir='/data/wbandar1/projects/ssl-aug-artifacts/wandb_logs/', group=args.wandb_group, name=f'{args.transfer_dataset}')
|
| 99 |
+
run_id = wandb.run.id
|
| 100 |
+
|
| 101 |
+
model_path, batch_size, epochs = args.model_path, args.batch_size, args.epochs
|
| 102 |
+
dataset = args.dataset
|
| 103 |
+
transfer_dataset = args.transfer_dataset
|
| 104 |
+
|
| 105 |
+
if dataset in ['cifar10', 'cifar100']:
|
| 106 |
+
print("reshaping data into 32x32")
|
| 107 |
+
resize = 32
|
| 108 |
+
else:
|
| 109 |
+
print("reshaping data into 64x64")
|
| 110 |
+
resize = 64
|
| 111 |
+
|
| 112 |
+
train_data = TRANSFER_DATASET[args.transfer_dataset](train=True, image_transforms=load_transform(args.transfer_dataset, resize))
|
| 113 |
+
test_data = TRANSFER_DATASET[args.transfer_dataset](train=False, image_transforms=load_transform(args.transfer_dataset, resize))
|
| 114 |
+
|
| 115 |
+
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=16, pin_memory=True)
|
| 116 |
+
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=16, pin_memory=True)
|
| 117 |
+
|
| 118 |
+
model = Net(num_class=get_data_nclass(args.transfer_dataset), pretrained_path=model_path, dataset=dataset, arch=args.arch).cuda()
|
| 119 |
+
for param in model.f.parameters():
|
| 120 |
+
param.requires_grad = False
|
| 121 |
+
|
| 122 |
+
# optimizer with lr sheduler
|
| 123 |
+
# lr_start, lr_end = 1e-2, 1e-6
|
| 124 |
+
# gamma = (lr_end / lr_start) ** (1 / epochs)
|
| 125 |
+
# optimizer = optim.Adam(model.fc.parameters(), lr=lr_start, weight_decay=5e-6)
|
| 126 |
+
# scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
|
| 127 |
+
|
| 128 |
+
# adpoted from
|
| 129 |
+
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
|
| 130 |
+
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, [60, 80], gamma=0.1)
|
| 131 |
+
|
| 132 |
+
# optimizer with no sheuduler
|
| 133 |
+
# optimizer = optim.Adam(model.fc.parameters(), lr=1e-3, weight_decay=1e-6)
|
| 134 |
+
|
| 135 |
+
loss_criterion = nn.CrossEntropyLoss()
|
| 136 |
+
results = {'train_loss': [], 'train_acc@1': [], 'train_acc@5': [],
|
| 137 |
+
'test_loss': [], 'test_acc@1': [], 'test_acc@5': []}
|
| 138 |
+
|
| 139 |
+
save_name = model_path.split('.pth')[0] + '_linear.csv'
|
| 140 |
+
|
| 141 |
+
best_acc = 0.0
|
| 142 |
+
for epoch in range(1, epochs + 1):
|
| 143 |
+
train_loss, train_acc_1, train_acc_5 = train_val(model, train_loader, optimizer)
|
| 144 |
+
results['train_loss'].append(train_loss)
|
| 145 |
+
results['train_acc@1'].append(train_acc_1)
|
| 146 |
+
results['train_acc@5'].append(train_acc_5)
|
| 147 |
+
test_loss, test_acc_1, test_acc_5 = train_val(model, test_loader, None)
|
| 148 |
+
results['test_loss'].append(test_loss)
|
| 149 |
+
results['test_acc@1'].append(test_acc_1)
|
| 150 |
+
results['test_acc@5'].append(test_acc_5)
|
| 151 |
+
# save statistics
|
| 152 |
+
# data_frame = pd.DataFrame(data=results, index=range(1, epoch + 1))
|
| 153 |
+
# data_frame.to_csv(save_name, index_label='epoch')
|
| 154 |
+
if test_acc_1 > best_acc:
|
| 155 |
+
best_acc = test_acc_1
|
| 156 |
+
wandb.log(
|
| 157 |
+
{
|
| 158 |
+
"train_loss": train_loss,
|
| 159 |
+
"train_acc@1": train_acc_1,
|
| 160 |
+
"train_acc@5": train_acc_5,
|
| 161 |
+
"test_loss": test_loss,
|
| 162 |
+
"test_acc@1": test_acc_1,
|
| 163 |
+
"test_acc@5": test_acc_5,
|
| 164 |
+
"best_acc": best_acc
|
| 165 |
+
}
|
| 166 |
+
)
|
| 167 |
+
scheduler.step()
|
| 168 |
+
wandb.finish()
|
figs/in-linear.png
ADDED
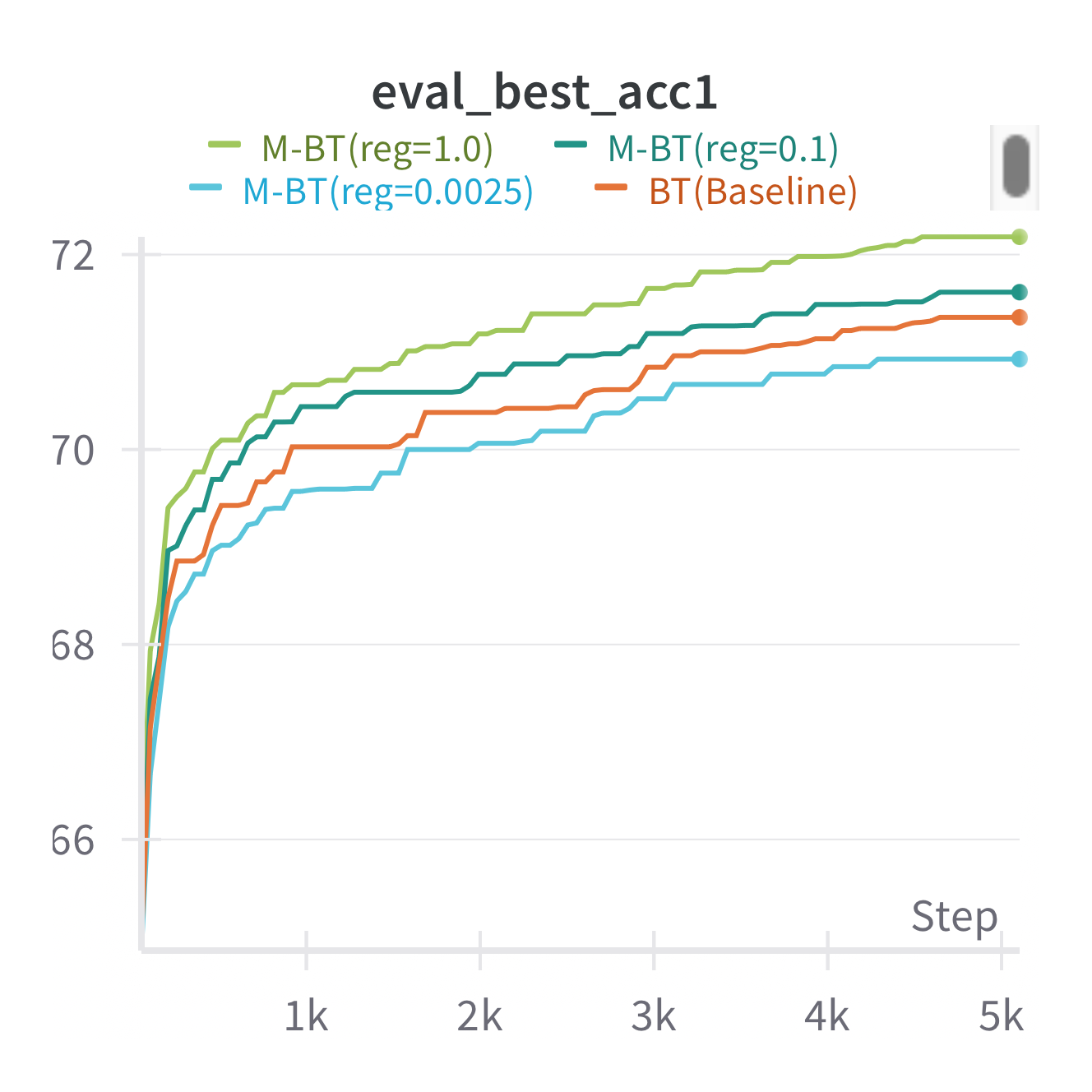
|
figs/in-loss-bt.png
ADDED
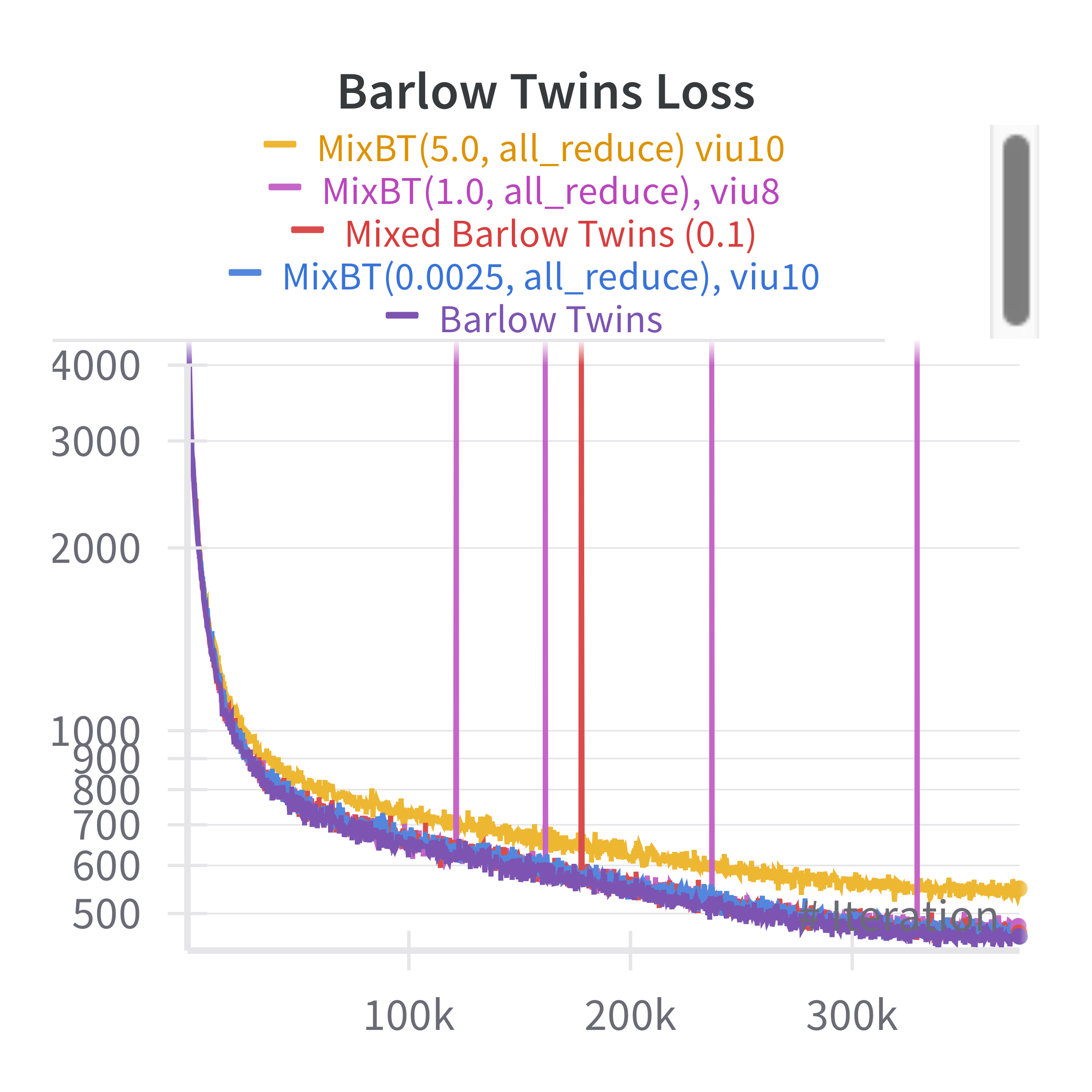
|
figs/in-loss-reg.png
ADDED

|
Git LFS Details
|
figs/mix-bt.jpg
ADDED
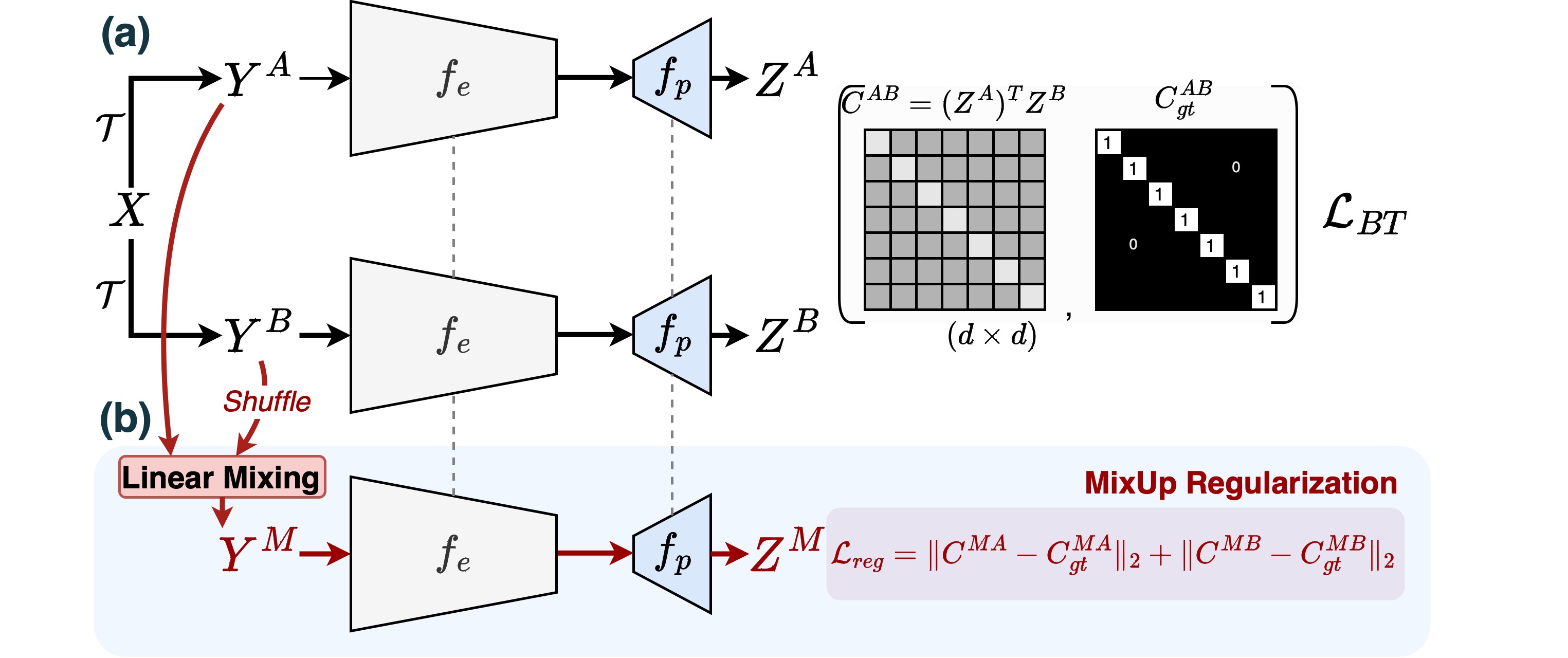
|
figs/mix-bt.svg
ADDED

|
hubconf.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from torchvision.models.resnet import resnet50 as _resnet50
|
| 9 |
+
|
| 10 |
+
dependencies = ['torch', 'torchvision']
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def resnet50(pretrained=True, **kwargs):
|
| 14 |
+
model = _resnet50(pretrained=False, **kwargs)
|
| 15 |
+
if pretrained:
|
| 16 |
+
url = 'https://dl.fbaipublicfiles.com/barlowtwins/ep1000_bs2048_lrw0.2_lrb0.0048_lambd0.0051/resnet50.pth'
|
| 17 |
+
state_dict = torch.hub.load_state_dict_from_url(url, map_location='cpu')
|
| 18 |
+
model.load_state_dict(state_dict, strict=False)
|
| 19 |
+
return model
|
linear.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.optim as optim
|
| 7 |
+
from thop import profile, clever_format
|
| 8 |
+
from torch.utils.data import DataLoader
|
| 9 |
+
from torchvision.datasets import CIFAR10, CIFAR100
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
|
| 12 |
+
import utils
|
| 13 |
+
|
| 14 |
+
import wandb
|
| 15 |
+
|
| 16 |
+
import torchvision
|
| 17 |
+
|
| 18 |
+
class Net(nn.Module):
|
| 19 |
+
def __init__(self, num_class, pretrained_path, dataset, arch):
|
| 20 |
+
super(Net, self).__init__()
|
| 21 |
+
|
| 22 |
+
if arch=='resnet18':
|
| 23 |
+
embedding_size = 512
|
| 24 |
+
elif arch=='resnet50':
|
| 25 |
+
embedding_size = 2048
|
| 26 |
+
else:
|
| 27 |
+
raise NotImplementedError
|
| 28 |
+
|
| 29 |
+
# encoder
|
| 30 |
+
from model import Model
|
| 31 |
+
self.f = Model(dataset=dataset, arch=arch).f
|
| 32 |
+
# classifier
|
| 33 |
+
self.fc = nn.Linear(embedding_size, num_class, bias=True)
|
| 34 |
+
self.load_state_dict(torch.load(pretrained_path, map_location='cpu'), strict=False)
|
| 35 |
+
|
| 36 |
+
def forward(self, x):
|
| 37 |
+
x = self.f(x)
|
| 38 |
+
feature = torch.flatten(x, start_dim=1)
|
| 39 |
+
out = self.fc(feature)
|
| 40 |
+
return out
|
| 41 |
+
|
| 42 |
+
# train or test for one epoch
|
| 43 |
+
def train_val(net, data_loader, train_optimizer):
|
| 44 |
+
is_train = train_optimizer is not None
|
| 45 |
+
net.train() if is_train else net.eval()
|
| 46 |
+
|
| 47 |
+
total_loss, total_correct_1, total_correct_5, total_num, data_bar = 0.0, 0.0, 0.0, 0, tqdm(data_loader)
|
| 48 |
+
with (torch.enable_grad() if is_train else torch.no_grad()):
|
| 49 |
+
for data, target in data_bar:
|
| 50 |
+
data, target = data.cuda(non_blocking=True), target.cuda(non_blocking=True)
|
| 51 |
+
out = net(data)
|
| 52 |
+
loss = loss_criterion(out, target)
|
| 53 |
+
|
| 54 |
+
if is_train:
|
| 55 |
+
train_optimizer.zero_grad()
|
| 56 |
+
loss.backward()
|
| 57 |
+
train_optimizer.step()
|
| 58 |
+
|
| 59 |
+
total_num += data.size(0)
|
| 60 |
+
total_loss += loss.item() * data.size(0)
|
| 61 |
+
prediction = torch.argsort(out, dim=-1, descending=True)
|
| 62 |
+
total_correct_1 += torch.sum((prediction[:, 0:1] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
|
| 63 |
+
total_correct_5 += torch.sum((prediction[:, 0:5] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
|
| 64 |
+
|
| 65 |
+
data_bar.set_description('{} Epoch: [{}/{}] Loss: {:.4f} ACC@1: {:.2f}% ACC@5: {:.2f}% model: {}'
|
| 66 |
+
.format('Train' if is_train else 'Test', epoch, epochs, total_loss / total_num,
|
| 67 |
+
total_correct_1 / total_num * 100, total_correct_5 / total_num * 100,
|
| 68 |
+
model_path.split('/')[-1]))
|
| 69 |
+
|
| 70 |
+
return total_loss / total_num, total_correct_1 / total_num * 100, total_correct_5 / total_num * 100
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
if __name__ == '__main__':
|
| 74 |
+
parser = argparse.ArgumentParser(description='Linear Evaluation')
|
| 75 |
+
parser.add_argument('--dataset', default='cifar10', type=str, help='Dataset: cifar10 or tiny_imagenet or stl10')
|
| 76 |
+
parser.add_argument('--arch', default='resnet50', type=str, help='Backbone architecture for experiments', choices=['resnet50', 'resnet18'])
|
| 77 |
+
parser.add_argument('--model_path', type=str, default='results/Barlow_Twins/0.005_64_128_model.pth',
|
| 78 |
+
help='The base string of the pretrained model path')
|
| 79 |
+
parser.add_argument('--batch_size', type=int, default=512, help='Number of images in each mini-batch')
|
| 80 |
+
parser.add_argument('--epochs', type=int, default=200, help='Number of sweeps over the dataset to train')
|
| 81 |
+
|
| 82 |
+
args = parser.parse_args()
|
| 83 |
+
|
| 84 |
+
wandb.init(project=f"Barlow-Twins-MixUp-Linear-{args.dataset}-{args.arch}", config=args, dir='/data/wbandar1/projects/ssl-aug-artifacts/wandb_logs/')
|
| 85 |
+
run_id = wandb.run.id
|
| 86 |
+
|
| 87 |
+
model_path, batch_size, epochs = args.model_path, args.batch_size, args.epochs
|
| 88 |
+
dataset = args.dataset
|
| 89 |
+
if dataset == 'cifar10':
|
| 90 |
+
train_data = CIFAR10(root='data', train=True,\
|
| 91 |
+
transform=utils.CifarPairTransform(train_transform = True, pair_transform=False), download=True)
|
| 92 |
+
test_data = CIFAR10(root='data', train=False,\
|
| 93 |
+
transform=utils.CifarPairTransform(train_transform = False, pair_transform=False), download=True)
|
| 94 |
+
if dataset == 'cifar100':
|
| 95 |
+
train_data = CIFAR100(root='data', train=True,\
|
| 96 |
+
transform=utils.CifarPairTransform(train_transform = True, pair_transform=False), download=True)
|
| 97 |
+
test_data = CIFAR100(root='data', train=False,\
|
| 98 |
+
transform=utils.CifarPairTransform(train_transform = False, pair_transform=False), download=True)
|
| 99 |
+
elif dataset == 'stl10':
|
| 100 |
+
train_data = torchvision.datasets.STL10(root='data', split="train", \
|
| 101 |
+
transform=utils.StlPairTransform(train_transform = True, pair_transform=False), download=True)
|
| 102 |
+
test_data = torchvision.datasets.STL10(root='data', split="test", \
|
| 103 |
+
transform=utils.StlPairTransform(train_transform = False, pair_transform=False), download=True)
|
| 104 |
+
elif dataset == 'tiny_imagenet':
|
| 105 |
+
train_data = torchvision.datasets.ImageFolder('/data/wbandar1/datasets/tiny-imagenet-200/train', \
|
| 106 |
+
utils.TinyImageNetPairTransform(train_transform=True, pair_transform=False))
|
| 107 |
+
test_data = torchvision.datasets.ImageFolder('/data/wbandar1/datasets/tiny-imagenet-200/val', \
|
| 108 |
+
utils.TinyImageNetPairTransform(train_transform = False, pair_transform=False))
|
| 109 |
+
|
| 110 |
+
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=16, pin_memory=True)
|
| 111 |
+
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=16, pin_memory=True)
|
| 112 |
+
|
| 113 |
+
model = Net(num_class=len(train_data.classes), pretrained_path=model_path, dataset=dataset, arch=args.arch).cuda()
|
| 114 |
+
for param in model.f.parameters():
|
| 115 |
+
param.requires_grad = False
|
| 116 |
+
|
| 117 |
+
if dataset == 'cifar10' or dataset == 'cifar100':
|
| 118 |
+
flops, params = profile(model, inputs=(torch.randn(1, 3, 32, 32).cuda(),))
|
| 119 |
+
elif dataset == 'tiny_imagenet' or dataset == 'stl10':
|
| 120 |
+
flops, params = profile(model, inputs=(torch.randn(1, 3, 64, 64).cuda(),))
|
| 121 |
+
flops, params = clever_format([flops, params])
|
| 122 |
+
print('# Model Params: {} FLOPs: {}'.format(params, flops))
|
| 123 |
+
|
| 124 |
+
# optimizer with lr sheduler
|
| 125 |
+
lr_start, lr_end = 1e-2, 1e-6
|
| 126 |
+
gamma = (lr_end / lr_start) ** (1 / epochs)
|
| 127 |
+
optimizer = optim.Adam(model.fc.parameters(), lr=lr_start, weight_decay=5e-6)
|
| 128 |
+
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
|
| 129 |
+
|
| 130 |
+
# optimizer with no sheuduler
|
| 131 |
+
# optimizer = optim.Adam(model.fc.parameters(), lr=1e-3, weight_decay=1e-6)
|
| 132 |
+
|
| 133 |
+
loss_criterion = nn.CrossEntropyLoss()
|
| 134 |
+
results = {'train_loss': [], 'train_acc@1': [], 'train_acc@5': [],
|
| 135 |
+
'test_loss': [], 'test_acc@1': [], 'test_acc@5': []}
|
| 136 |
+
|
| 137 |
+
save_name = model_path.split('.pth')[0] + '_linear.csv'
|
| 138 |
+
|
| 139 |
+
best_acc = 0.0
|
| 140 |
+
for epoch in range(1, epochs + 1):
|
| 141 |
+
train_loss, train_acc_1, train_acc_5 = train_val(model, train_loader, optimizer)
|
| 142 |
+
scheduler.step()
|
| 143 |
+
results['train_loss'].append(train_loss)
|
| 144 |
+
results['train_acc@1'].append(train_acc_1)
|
| 145 |
+
results['train_acc@5'].append(train_acc_5)
|
| 146 |
+
test_loss, test_acc_1, test_acc_5 = train_val(model, test_loader, None)
|
| 147 |
+
results['test_loss'].append(test_loss)
|
| 148 |
+
results['test_acc@1'].append(test_acc_1)
|
| 149 |
+
results['test_acc@5'].append(test_acc_5)
|
| 150 |
+
# save statistics
|
| 151 |
+
# data_frame = pd.DataFrame(data=results, index=range(1, epoch + 1))
|
| 152 |
+
# data_frame.to_csv(save_name, index_label='epoch')
|
| 153 |
+
#if test_acc_1 > best_acc:
|
| 154 |
+
# best_acc = test_acc_1
|
| 155 |
+
# torch.save(model.state_dict(), 'results/linear_model.pth')
|
| 156 |
+
wandb.log(
|
| 157 |
+
{
|
| 158 |
+
"train_loss": train_loss,
|
| 159 |
+
"train_acc@1": train_acc_1,
|
| 160 |
+
"train_acc@5": train_acc_5,
|
| 161 |
+
"test_loss": test_loss,
|
| 162 |
+
"test_acc@1": test_acc_1,
|
| 163 |
+
"test_acc@5": test_acc_5
|
| 164 |
+
}
|
| 165 |
+
)
|
| 166 |
+
wandb.finish()
|
main.py
ADDED
|
@@ -0,0 +1,271 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import torch
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch.optim as optim
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
from thop import profile, clever_format
|
| 10 |
+
from torch.utils.data import DataLoader
|
| 11 |
+
from torch.optim.lr_scheduler import MultiStepLR, CosineAnnealingWarmRestarts
|
| 12 |
+
from tqdm import tqdm
|
| 13 |
+
|
| 14 |
+
import utils
|
| 15 |
+
from model import Model
|
| 16 |
+
import math
|
| 17 |
+
|
| 18 |
+
import torchvision
|
| 19 |
+
|
| 20 |
+
import wandb
|
| 21 |
+
|
| 22 |
+
if torch.cuda.is_available():
|
| 23 |
+
torch.backends.cudnn.benchmark = True
|
| 24 |
+
|
| 25 |
+
def off_diagonal(x):
|
| 26 |
+
n, m = x.shape
|
| 27 |
+
assert n == m
|
| 28 |
+
return x.flatten()[:-1].view(n - 1, n + 1)[:, 1:].flatten()
|
| 29 |
+
|
| 30 |
+
def adjust_learning_rate(args, optimizer, loader, step):
|
| 31 |
+
max_steps = args.epochs * len(loader)
|
| 32 |
+
warmup_steps = 10 * len(loader)
|
| 33 |
+
base_lr = args.batch_size / 256
|
| 34 |
+
if step < warmup_steps:
|
| 35 |
+
lr = base_lr * step / warmup_steps
|
| 36 |
+
else:
|
| 37 |
+
step -= warmup_steps
|
| 38 |
+
max_steps -= warmup_steps
|
| 39 |
+
q = 0.5 * (1 + math.cos(math.pi * step / max_steps))
|
| 40 |
+
end_lr = base_lr * 0.001
|
| 41 |
+
lr = base_lr * q + end_lr * (1 - q)
|
| 42 |
+
optimizer.param_groups[0]['lr'] = lr * args.lr
|
| 43 |
+
|
| 44 |
+
def train(args, epoch, net, data_loader, train_optimizer):
|
| 45 |
+
net.train()
|
| 46 |
+
total_loss, total_loss_bt, total_loss_mix, total_num, train_bar = 0.0, 0.0, 0.0, 0, tqdm(data_loader)
|
| 47 |
+
for step, data_tuple in enumerate(train_bar, start=epoch * len(train_bar)):
|
| 48 |
+
if args.lr_shed == "cosine":
|
| 49 |
+
adjust_learning_rate(args, train_optimizer, data_loader, step)
|
| 50 |
+
(pos_1, pos_2), _ = data_tuple
|
| 51 |
+
pos_1, pos_2 = pos_1.cuda(non_blocking=True), pos_2.cuda(non_blocking=True)
|
| 52 |
+
_, out_1 = net(pos_1)
|
| 53 |
+
_, out_2 = net(pos_2)
|
| 54 |
+
|
| 55 |
+
out_1_norm = (out_1 - out_1.mean(dim=0)) / out_1.std(dim=0)
|
| 56 |
+
out_2_norm = (out_2 - out_2.mean(dim=0)) / out_2.std(dim=0)
|
| 57 |
+
c = torch.matmul(out_1_norm.T, out_2_norm) / batch_size
|
| 58 |
+
on_diag = torch.diagonal(c).add_(-1).pow_(2).sum()
|
| 59 |
+
off_diag = off_diagonal(c).pow_(2).sum()
|
| 60 |
+
loss_bt = on_diag + lmbda * off_diag
|
| 61 |
+
|
| 62 |
+
## MixUp (Our Contribution) ##
|
| 63 |
+
if args.is_mixup.lower() == 'true':
|
| 64 |
+
index = torch.randperm(batch_size).cuda(non_blocking=True)
|
| 65 |
+
alpha = np.random.beta(1.0, 1.0)
|
| 66 |
+
pos_m = alpha * pos_1 + (1 - alpha) * pos_2[index, :]
|
| 67 |
+
|
| 68 |
+
_, out_m = net(pos_m)
|
| 69 |
+
out_m_norm = (out_m - out_m.mean(dim=0)) / out_m.std(dim=0)
|
| 70 |
+
|
| 71 |
+
cc_m_1 = torch.matmul(out_m_norm.T, out_1_norm) / batch_size
|
| 72 |
+
cc_m_1_gt = alpha*torch.matmul(out_1_norm.T, out_1_norm) / batch_size + \
|
| 73 |
+
(1-alpha)*torch.matmul(out_2_norm[index,:].T, out_1_norm) / batch_size
|
| 74 |
+
|
| 75 |
+
cc_m_2 = torch.matmul(out_m_norm.T, out_2_norm) / batch_size
|
| 76 |
+
cc_m_2_gt = alpha*torch.matmul(out_1_norm.T, out_2_norm) / batch_size + \
|
| 77 |
+
(1-alpha)*torch.matmul(out_2_norm[index,:].T, out_2_norm) / batch_size
|
| 78 |
+
|
| 79 |
+
loss_mix = args.mixup_loss_scale*lmbda*((cc_m_1-cc_m_1_gt).pow_(2).sum() + (cc_m_2-cc_m_2_gt).pow_(2).sum())
|
| 80 |
+
else:
|
| 81 |
+
loss_mix = torch.zeros(1).cuda()
|
| 82 |
+
## MixUp (Our Contribution) ##
|
| 83 |
+
|
| 84 |
+
loss = loss_bt + loss_mix
|
| 85 |
+
train_optimizer.zero_grad()
|
| 86 |
+
loss.backward()
|
| 87 |
+
train_optimizer.step()
|
| 88 |
+
|
| 89 |
+
total_num += batch_size
|
| 90 |
+
total_loss += loss.item() * batch_size
|
| 91 |
+
total_loss_bt += loss_bt.item() * batch_size
|
| 92 |
+
total_loss_mix += loss_mix.item() * batch_size
|
| 93 |
+
|
| 94 |
+
train_bar.set_description('Train Epoch: [{}/{}] lr: {:.3f}x10-3 Loss: {:.4f} lmbda:{:.4f} bsz:{} f_dim:{} dataset: {}'.format(\
|
| 95 |
+
epoch, epochs, train_optimizer.param_groups[0]['lr'] * 1000, total_loss / total_num, lmbda, batch_size, feature_dim, dataset))
|
| 96 |
+
return total_loss_bt / total_num, total_loss_mix / total_num, total_loss / total_num
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def test(net, memory_data_loader, test_data_loader):
|
| 100 |
+
net.eval()
|
| 101 |
+
total_top1, total_top5, total_num, feature_bank, target_bank = 0.0, 0.0, 0, [], []
|
| 102 |
+
with torch.no_grad():
|
| 103 |
+
# generate feature bank and target bank
|
| 104 |
+
for data_tuple in tqdm(memory_data_loader, desc='Feature extracting'):
|
| 105 |
+
(data, _), target = data_tuple
|
| 106 |
+
target_bank.append(target)
|
| 107 |
+
feature, out = net(data.cuda(non_blocking=True))
|
| 108 |
+
feature_bank.append(feature)
|
| 109 |
+
# [D, N]
|
| 110 |
+
feature_bank = torch.cat(feature_bank, dim=0).t().contiguous()
|
| 111 |
+
# [N]
|
| 112 |
+
feature_labels = torch.cat(target_bank, dim=0).contiguous().to(feature_bank.device)
|
| 113 |
+
# loop test data to predict the label by weighted knn search
|
| 114 |
+
test_bar = tqdm(test_data_loader)
|
| 115 |
+
for data_tuple in test_bar:
|
| 116 |
+
(data, _), target = data_tuple
|
| 117 |
+
data, target = data.cuda(non_blocking=True), target.cuda(non_blocking=True)
|
| 118 |
+
feature, out = net(data)
|
| 119 |
+
|
| 120 |
+
total_num += data.size(0)
|
| 121 |
+
# compute cos similarity between each feature vector and feature bank ---> [B, N]
|
| 122 |
+
sim_matrix = torch.mm(feature, feature_bank)
|
| 123 |
+
# [B, K]
|
| 124 |
+
sim_weight, sim_indices = sim_matrix.topk(k=k, dim=-1)
|
| 125 |
+
# [B, K]
|
| 126 |
+
sim_labels = torch.gather(feature_labels.expand(data.size(0), -1), dim=-1, index=sim_indices)
|
| 127 |
+
sim_weight = (sim_weight / temperature).exp()
|
| 128 |
+
|
| 129 |
+
# counts for each class
|
| 130 |
+
one_hot_label = torch.zeros(data.size(0) * k, c, device=sim_labels.device)
|
| 131 |
+
# [B*K, C]
|
| 132 |
+
one_hot_label = one_hot_label.scatter(dim=-1, index=sim_labels.view(-1, 1), value=1.0)
|
| 133 |
+
# weighted score ---> [B, C]
|
| 134 |
+
pred_scores = torch.sum(one_hot_label.view(data.size(0), -1, c) * sim_weight.unsqueeze(dim=-1), dim=1)
|
| 135 |
+
|
| 136 |
+
pred_labels = pred_scores.argsort(dim=-1, descending=True)
|
| 137 |
+
total_top1 += torch.sum((pred_labels[:, :1] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
|
| 138 |
+
total_top5 += torch.sum((pred_labels[:, :5] == target.unsqueeze(dim=-1)).any(dim=-1).float()).item()
|
| 139 |
+
test_bar.set_description('Test Epoch: [{}/{}] Acc@1:{:.2f}% Acc@5:{:.2f}%'
|
| 140 |
+
.format(epoch, epochs, total_top1 / total_num * 100, total_top5 / total_num * 100))
|
| 141 |
+
return total_top1 / total_num * 100, total_top5 / total_num * 100
|
| 142 |
+
|
| 143 |
+
if __name__ == '__main__':
|
| 144 |
+
parser = argparse.ArgumentParser(description='Training Barlow Twins')
|
| 145 |
+
parser.add_argument('--dataset', default='cifar10', type=str, help='Dataset: cifar10, cifar100, tiny_imagenet, stl10', choices=['cifar10', 'cifar100', 'tiny_imagenet', 'stl10'])
|
| 146 |
+
parser.add_argument('--arch', default='resnet50', type=str, help='Backbone architecture', choices=['resnet50', 'resnet18'])
|
| 147 |
+
parser.add_argument('--feature_dim', default=128, type=int, help='Feature dim for embedding vector')
|
| 148 |
+
parser.add_argument('--temperature', default=0.5, type=float, help='Temperature used in softmax (kNN evaluation)')
|
| 149 |
+
parser.add_argument('--k', default=200, type=int, help='Top k most similar images used to predict the label')
|
| 150 |
+
parser.add_argument('--batch_size', default=512, type=int, help='Number of images in each mini-batch')
|
| 151 |
+
parser.add_argument('--epochs', default=1000, type=int, help='Number of sweeps over the dataset to train')
|
| 152 |
+
parser.add_argument('--lr', default=1e-3, type=float, help='Base learning rate')
|
| 153 |
+
parser.add_argument('--lr_shed', default="step", choices=["step", "cosine"], type=str, help='Learning rate scheduler: step / cosine')
|
| 154 |
+
|
| 155 |
+
# for barlow twins
|
| 156 |
+
parser.add_argument('--lmbda', default=0.005, type=float, help='Lambda that controls the on- and off-diagonal terms')
|
| 157 |
+
parser.add_argument('--corr_neg_one', dest='corr_neg_one', action='store_true')
|
| 158 |
+
parser.add_argument('--corr_zero', dest='corr_neg_one', action='store_false')
|
| 159 |
+
parser.set_defaults(corr_neg_one=False)
|
| 160 |
+
|
| 161 |
+
# for mixup
|
| 162 |
+
parser.add_argument('--is_mixup', dest='is_mixup', type=str, default='false', choices=['true', 'false'])
|
| 163 |
+
parser.add_argument('--mixup_loss_scale', dest='mixup_loss_scale', type=float, default=5.0)
|
| 164 |
+
|
| 165 |
+
# GPU id (just for record)
|
| 166 |
+
parser.add_argument('--gpu', dest='gpu', type=int, default=0)
|
| 167 |
+
|
| 168 |
+
args = parser.parse_args()
|
| 169 |
+
is_mixup = args.is_mixup.lower() == 'true'
|
| 170 |
+
|
| 171 |
+
wandb.init(project=f"Barlow-Twins-MixUp-{args.dataset}-{args.arch}", config=args, dir='results/wandb_logs/')
|
| 172 |
+
run_id = wandb.run.id
|
| 173 |
+
dataset = args.dataset
|
| 174 |
+
feature_dim, temperature, k = args.feature_dim, args.temperature, args.k
|
| 175 |
+
batch_size, epochs = args.batch_size, args.epochs
|
| 176 |
+
lmbda = args.lmbda
|
| 177 |
+
corr_neg_one = args.corr_neg_one
|
| 178 |
+
|
| 179 |
+
if dataset == 'cifar10':
|
| 180 |
+
train_data = torchvision.datasets.CIFAR10(root='/data/wbandar1/datasets', train=True, \
|
| 181 |
+
transform=utils.CifarPairTransform(train_transform = True), download=True)
|
| 182 |
+
memory_data = torchvision.datasets.CIFAR10(root='/data/wbandar1/datasets', train=True, \
|
| 183 |
+
transform=utils.CifarPairTransform(train_transform = False), download=True)
|
| 184 |
+
test_data = torchvision.datasets.CIFAR10(root='/data/wbandar1/datasets', train=False, \
|
| 185 |
+
transform=utils.CifarPairTransform(train_transform = False), download=True)
|
| 186 |
+
elif dataset == 'cifar100':
|
| 187 |
+
train_data = torchvision.datasets.CIFAR100(root='/data/wbandar1/datasets', train=True, \
|
| 188 |
+
transform=utils.CifarPairTransform(train_transform = True), download=True)
|
| 189 |
+
memory_data = torchvision.datasets.CIFAR100(root='/data/wbandar1/datasets', train=True, \
|
| 190 |
+
transform=utils.CifarPairTransform(train_transform = False), download=True)
|
| 191 |
+
test_data = torchvision.datasets.CIFAR100(root='/data/wbandar1/datasets', train=False, \
|
| 192 |
+
transform=utils.CifarPairTransform(train_transform = False), download=True)
|
| 193 |
+
elif dataset == 'stl10':
|
| 194 |
+
train_data = torchvision.datasets.STL10(root='/data/wbandar1/datasets', split="train+unlabeled", \
|
| 195 |
+
transform=utils.StlPairTransform(train_transform = True), download=True)
|
| 196 |
+
memory_data = torchvision.datasets.STL10(root='/data/wbandar1/datasets', split="train", \
|
| 197 |
+
transform=utils.StlPairTransform(train_transform = False), download=True)
|
| 198 |
+
test_data = torchvision.datasets.STL10(root='/data/wbandar1/datasets', split="test", \
|
| 199 |
+
transform=utils.StlPairTransform(train_transform = False), download=True)
|
| 200 |
+
elif dataset == 'tiny_imagenet':
|
| 201 |
+
# download if not exits
|
| 202 |
+
if not os.path.isdir('/data/wbandar1/datasets/tiny-imagenet-200'):
|
| 203 |
+
raise ValueError("First preprocess the tinyimagenet dataset...")
|
| 204 |
+
|
| 205 |
+
train_data = torchvision.datasets.ImageFolder('/data/wbandar1/datasets/tiny-imagenet-200/train', \
|
| 206 |
+
utils.TinyImageNetPairTransform(train_transform = True))
|
| 207 |
+
memory_data = torchvision.datasets.ImageFolder('/data/wbandar1/datasets/tiny-imagenet-200/train', \
|
| 208 |
+
utils.TinyImageNetPairTransform(train_transform = False))
|
| 209 |
+
test_data = torchvision.datasets.ImageFolder('/data/wbandar1/datasets/tiny-imagenet-200/val', \
|
| 210 |
+
utils.TinyImageNetPairTransform(train_transform = False))
|
| 211 |
+
|
| 212 |
+
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=16, pin_memory=True,
|
| 213 |
+
drop_last=True)
|
| 214 |
+
memory_loader = DataLoader(memory_data, batch_size=batch_size, shuffle=False, num_workers=16, pin_memory=True)
|
| 215 |
+
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=16, pin_memory=True)
|
| 216 |
+
|
| 217 |
+
# model setup and optimizer config
|
| 218 |
+
model = Model(feature_dim, dataset, args.arch).cuda()
|
| 219 |
+
if dataset == 'cifar10' or dataset == 'cifar100':
|
| 220 |
+
flops, params = profile(model, inputs=(torch.randn(1, 3, 32, 32).cuda(),))
|
| 221 |
+
elif dataset == 'tiny_imagenet' or dataset == 'stl10':
|
| 222 |
+
flops, params = profile(model, inputs=(torch.randn(1, 3, 64, 64).cuda(),))
|
| 223 |
+
flops, params = clever_format([flops, params])
|
| 224 |
+
print('# Model Params: {} FLOPs: {}'.format(params, flops))
|
| 225 |
+
|
| 226 |
+
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-6)
|
| 227 |
+
if args.lr_shed == "step":
|
| 228 |
+
m = [args.epochs - a for a in [50, 25]]
|
| 229 |
+
scheduler = MultiStepLR(optimizer, milestones=m, gamma=0.2)
|
| 230 |
+
c = len(memory_data.classes)
|
| 231 |
+
|
| 232 |
+
results = {'train_loss': [], 'test_acc@1': [], 'test_acc@5': []}
|
| 233 |
+
save_name_pre = '{}_{}_{}_{}_{}'.format(run_id, lmbda, feature_dim, batch_size, dataset)
|
| 234 |
+
run_id_dir = os.path.join('results/', run_id)
|
| 235 |
+
if not os.path.exists(run_id_dir):
|
| 236 |
+
print('Creating directory {}'.format(run_id_dir))
|
| 237 |
+
os.mkdir(run_id_dir)
|
| 238 |
+
|
| 239 |
+
best_acc = 0.0
|
| 240 |
+
for epoch in range(1, epochs + 1):
|
| 241 |
+
loss_bt, loss_mix, train_loss = train(args, epoch, model, train_loader, optimizer)
|
| 242 |
+
if args.lr_shed == "step":
|
| 243 |
+
scheduler.step()
|
| 244 |
+
wandb.log(
|
| 245 |
+
{
|
| 246 |
+
"epoch": epoch,
|
| 247 |
+
"lr": optimizer.param_groups[0]['lr'],
|
| 248 |
+
"loss_bt": loss_bt,
|
| 249 |
+
"loss_mix": loss_mix,
|
| 250 |
+
"train_loss": train_loss}
|
| 251 |
+
)
|
| 252 |
+
if epoch % 5 == 0:
|
| 253 |
+
test_acc_1, test_acc_5 = test(model, memory_loader, test_loader)
|
| 254 |
+
|
| 255 |
+
results['train_loss'].append(train_loss)
|
| 256 |
+
results['test_acc@1'].append(test_acc_1)
|
| 257 |
+
results['test_acc@5'].append(test_acc_5)
|
| 258 |
+
data_frame = pd.DataFrame(data=results, index=range(5, epoch + 1, 5))
|
| 259 |
+
data_frame.to_csv('results/{}_statistics.csv'.format(save_name_pre), index_label='epoch')
|
| 260 |
+
wandb.log(
|
| 261 |
+
{
|
| 262 |
+
"test_acc@1": test_acc_1,
|
| 263 |
+
"test_acc@5": test_acc_5
|
| 264 |
+
}
|
| 265 |
+
)
|
| 266 |
+
if test_acc_1 > best_acc:
|
| 267 |
+
best_acc = test_acc_1
|
| 268 |
+
torch.save(model.state_dict(), 'results/{}/{}_model.pth'.format(run_id, save_name_pre))
|
| 269 |
+
if epoch % 50 == 0:
|
| 270 |
+
torch.save(model.state_dict(), 'results/{}/{}_model_{}.pth'.format(run_id, save_name_pre, epoch))
|
| 271 |
+
wandb.finish()
|
main_imagenet.py
ADDED
|
@@ -0,0 +1,463 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
import argparse
|
| 9 |
+
import json
|
| 10 |
+
import math
|
| 11 |
+
import os
|
| 12 |
+
import random
|
| 13 |
+
import signal
|
| 14 |
+
import subprocess
|
| 15 |
+
import sys
|
| 16 |
+
import time
|
| 17 |
+
import numpy as np
|
| 18 |
+
import wandb
|
| 19 |
+
|
| 20 |
+
from PIL import Image, ImageOps, ImageFilter
|
| 21 |
+
from torch import nn, optim
|
| 22 |
+
import torch
|
| 23 |
+
import torchvision
|
| 24 |
+
import torchvision.transforms as transforms
|
| 25 |
+
|
| 26 |
+
parser = argparse.ArgumentParser(description='Barlow Twins Training')
|
| 27 |
+
parser.add_argument('data', type=Path, metavar='DIR',
|
| 28 |
+
help='path to dataset')
|
| 29 |
+
parser.add_argument('--workers', default=8, type=int, metavar='N',
|
| 30 |
+
help='number of data loader workers')
|
| 31 |
+
parser.add_argument('--epochs', default=300, type=int, metavar='N',
|
| 32 |
+
help='number of total epochs to run')
|
| 33 |
+
parser.add_argument('--batch-size', default=512, type=int, metavar='N',
|
| 34 |
+
help='mini-batch size')
|
| 35 |
+
parser.add_argument('--learning-rate-weights', default=0.2, type=float, metavar='LR',
|
| 36 |
+
help='base learning rate for weights')
|
| 37 |
+
parser.add_argument('--learning-rate-biases', default=0.0048, type=float, metavar='LR',
|
| 38 |
+
help='base learning rate for biases and batch norm parameters')
|
| 39 |
+
parser.add_argument('--weight-decay', default=1e-6, type=float, metavar='W',
|
| 40 |
+
help='weight decay')
|
| 41 |
+
parser.add_argument('--lambd', default=0.0051, type=float, metavar='L',
|
| 42 |
+
help='weight on off-diagonal terms')
|
| 43 |
+
parser.add_argument('--projector', default='8192-8192-8192', type=str,
|
| 44 |
+
metavar='MLP', help='projector MLP')
|
| 45 |
+
parser.add_argument('--print-freq', default=1, type=int, metavar='N',
|
| 46 |
+
help='print frequency')
|
| 47 |
+
parser.add_argument('--checkpoint-dir', default='/mnt/store/wbandar1/projects/ssl-aug-artifacts/', type=Path,
|
| 48 |
+
metavar='DIR', help='path to checkpoint directory')
|
| 49 |
+
parser.add_argument('--is_mixup', default='false', type=str,
|
| 50 |
+
metavar='L', help='mixup regularization', choices=['true', 'false'])
|
| 51 |
+
parser.add_argument('--lambda_mixup', default=0.1, type=float, metavar='L',
|
| 52 |
+
help='Hyperparamter for the regularization loss')
|
| 53 |
+
|
| 54 |
+
def main():
|
| 55 |
+
args = parser.parse_args()
|
| 56 |
+
args.is_mixup = args.is_mixup.lower() == 'true'
|
| 57 |
+
args.ngpus_per_node = torch.cuda.device_count()
|
| 58 |
+
|
| 59 |
+
run = wandb.init(project="Barlow-Twins-MixUp-ImageNet", config=args, dir='/mnt/store/wbandar1/projects/ssl-aug-artifacts/wandb_logs/')
|
| 60 |
+
run_id = wandb.run.id
|
| 61 |
+
args.checkpoint_dir=Path(os.path.join(args.checkpoint_dir, run_id))
|
| 62 |
+
|
| 63 |
+
if 'SLURM_JOB_ID' in os.environ:
|
| 64 |
+
# single-node and multi-node distributed training on SLURM cluster
|
| 65 |
+
# requeue job on SLURM preemption
|
| 66 |
+
signal.signal(signal.SIGUSR1, handle_sigusr1)
|
| 67 |
+
signal.signal(signal.SIGTERM, handle_sigterm)
|
| 68 |
+
# find a common host name on all nodes
|
| 69 |
+
# assume scontrol returns hosts in the same order on all nodes
|
| 70 |
+
cmd = 'scontrol show hostnames ' + os.getenv('SLURM_JOB_NODELIST')
|
| 71 |
+
stdout = subprocess.check_output(cmd.split())
|
| 72 |
+
host_name = stdout.decode().splitlines()[0]
|
| 73 |
+
args.rank = int(os.getenv('SLURM_NODEID')) * args.ngpus_per_node
|
| 74 |
+
args.world_size = int(os.getenv('SLURM_NNODES')) * args.ngpus_per_node
|
| 75 |
+
args.dist_url = f'tcp://{host_name}:58472'
|
| 76 |
+
else:
|
| 77 |
+
# single-node distributed training
|
| 78 |
+
args.rank = 0
|
| 79 |
+
args.dist_url = 'tcp://localhost:58472'
|
| 80 |
+
args.world_size = args.ngpus_per_node
|
| 81 |
+
torch.multiprocessing.spawn(main_worker, (args,run,), args.ngpus_per_node)
|
| 82 |
+
wandb.finish()
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def main_worker(gpu, args, run):
|
| 86 |
+
args.rank += gpu
|
| 87 |
+
torch.distributed.init_process_group(
|
| 88 |
+
backend='nccl', init_method=args.dist_url,
|
| 89 |
+
world_size=args.world_size, rank=args.rank)
|
| 90 |
+
|
| 91 |
+
if args.rank == 0:
|
| 92 |
+
args.checkpoint_dir.mkdir(parents=True, exist_ok=True)
|
| 93 |
+
stats_file = open(args.checkpoint_dir / 'stats.txt', 'a', buffering=1)
|
| 94 |
+
print(' '.join(sys.argv))
|
| 95 |
+
print(' '.join(sys.argv), file=stats_file)
|
| 96 |
+
|
| 97 |
+
torch.cuda.set_device(gpu)
|
| 98 |
+
torch.backends.cudnn.benchmark = True
|
| 99 |
+
|
| 100 |
+
model = BarlowTwins(args).cuda(gpu)
|
| 101 |
+
model = nn.SyncBatchNorm.convert_sync_batchnorm(model)
|
| 102 |
+
param_weights = []
|
| 103 |
+
param_biases = []
|
| 104 |
+
for param in model.parameters():
|
| 105 |
+
if param.ndim == 1:
|
| 106 |
+
param_biases.append(param)
|
| 107 |
+
else:
|
| 108 |
+
param_weights.append(param)
|
| 109 |
+
parameters = [{'params': param_weights}, {'params': param_biases}]
|
| 110 |
+
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
|
| 111 |
+
optimizer = LARS(parameters, lr=0, weight_decay=args.weight_decay,
|
| 112 |
+
weight_decay_filter=True,
|
| 113 |
+
lars_adaptation_filter=True)
|
| 114 |
+
|
| 115 |
+
# automatically resume from checkpoint if it exists
|
| 116 |
+
if (args.checkpoint_dir / 'checkpoint.pth').is_file():
|
| 117 |
+
ckpt = torch.load(args.checkpoint_dir / 'checkpoint.pth',
|
| 118 |
+
map_location='cpu')
|
| 119 |
+
start_epoch = ckpt['epoch']
|
| 120 |
+
model.load_state_dict(ckpt['model'])
|
| 121 |
+
optimizer.load_state_dict(ckpt['optimizer'])
|
| 122 |
+
else:
|
| 123 |
+
start_epoch = 0
|
| 124 |
+
|
| 125 |
+
dataset = torchvision.datasets.ImageFolder(args.data / 'train', Transform())
|
| 126 |
+
sampler = torch.utils.data.distributed.DistributedSampler(dataset)
|
| 127 |
+
assert args.batch_size % args.world_size == 0
|
| 128 |
+
per_device_batch_size = args.batch_size // args.world_size
|
| 129 |
+
loader = torch.utils.data.DataLoader(
|
| 130 |
+
dataset, batch_size=per_device_batch_size, num_workers=args.workers,
|
| 131 |
+
pin_memory=True, sampler=sampler)
|
| 132 |
+
|
| 133 |
+
start_time = time.time()
|
| 134 |
+
scaler = torch.cuda.amp.GradScaler(growth_interval=100, enabled=True)
|
| 135 |
+
for epoch in range(start_epoch, args.epochs):
|
| 136 |
+
sampler.set_epoch(epoch)
|
| 137 |
+
for step, ((y1, y2), _) in enumerate(loader, start=epoch * len(loader)):
|
| 138 |
+
y1 = y1.cuda(gpu, non_blocking=True)
|
| 139 |
+
y2 = y2.cuda(gpu, non_blocking=True)
|
| 140 |
+
adjust_learning_rate(args, optimizer, loader, step)
|
| 141 |
+
mixup_loss_scale = adjust_mixup_scale(loader, step, args.lambda_mixup)
|
| 142 |
+
optimizer.zero_grad()
|
| 143 |
+
with torch.cuda.amp.autocast(enabled=True):
|
| 144 |
+
loss_bt, loss_reg = model(y1, y2, args.is_mixup)
|
| 145 |
+
loss_regs = mixup_loss_scale * loss_reg
|
| 146 |
+
loss = loss_bt + loss_regs
|
| 147 |
+
scaler.scale(loss).backward()
|
| 148 |
+
scaler.step(optimizer)
|
| 149 |
+
scaler.update()
|
| 150 |
+
if step % args.print_freq == 0:
|
| 151 |
+
if args.rank == 0:
|
| 152 |
+
stats = dict(epoch=epoch, step=step,
|
| 153 |
+
lr_weights=optimizer.param_groups[0]['lr'],
|
| 154 |
+
lr_biases=optimizer.param_groups[1]['lr'],
|
| 155 |
+
loss=loss.item(),
|
| 156 |
+
time=int(time.time() - start_time))
|
| 157 |
+
print(json.dumps(stats))
|
| 158 |
+
print(json.dumps(stats), file=stats_file)
|
| 159 |
+
if args.is_mixup:
|
| 160 |
+
run.log(
|
| 161 |
+
{
|
| 162 |
+
"epoch": epoch,
|
| 163 |
+
"step": step,
|
| 164 |
+
"lr_weights": optimizer.param_groups[0]['lr'],
|
| 165 |
+
"lr_biases": optimizer.param_groups[1]['lr'],
|
| 166 |
+
"loss": loss.item(),
|
| 167 |
+
"loss_bt": loss_bt.item(),
|
| 168 |
+
"loss_reg(unscaled)": loss_reg.item(),
|
| 169 |
+
"reg_scale": mixup_loss_scale,
|
| 170 |
+
"loss_reg(scaled)": loss_regs.item(),
|
| 171 |
+
"time": int(time.time() - start_time)}
|
| 172 |
+
)
|
| 173 |
+
else:
|
| 174 |
+
run.log(
|
| 175 |
+
{
|
| 176 |
+
"epoch": epoch,
|
| 177 |
+
"step": step,
|
| 178 |
+
"lr_weights": optimizer.param_groups[0]['lr'],
|
| 179 |
+
"lr_biases": optimizer.param_groups[1]['lr'],
|
| 180 |
+
"loss": loss.item(),
|
| 181 |
+
"loss_bt": loss.item(),
|
| 182 |
+
"loss_reg(unscaled)": 0.,
|
| 183 |
+
"reg_scale": 0.,
|
| 184 |
+
"loss_reg(scaled)": 0.,
|
| 185 |
+
"time": int(time.time() - start_time)}
|
| 186 |
+
)
|
| 187 |
+
if args.rank == 0:
|
| 188 |
+
# save checkpoint
|
| 189 |
+
state = dict(epoch=epoch + 1, model=model.state_dict(),
|
| 190 |
+
optimizer=optimizer.state_dict())
|
| 191 |
+
torch.save(state, args.checkpoint_dir / 'checkpoint.pth')
|
| 192 |
+
if args.rank == 0:
|
| 193 |
+
# save final model
|
| 194 |
+
print("Saving final model ...")
|
| 195 |
+
torch.save(model.module.backbone.state_dict(),
|
| 196 |
+
args.checkpoint_dir / 'resnet50.pth')
|
| 197 |
+
print("Finished saving final model ...")
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
def adjust_learning_rate(args, optimizer, loader, step):
|
| 201 |
+
max_steps = args.epochs * len(loader)
|
| 202 |
+
warmup_steps = 10 * len(loader)
|
| 203 |
+
base_lr = args.batch_size / 256
|
| 204 |
+
if step < warmup_steps:
|
| 205 |
+
lr = base_lr * step / warmup_steps
|
| 206 |
+
else:
|
| 207 |
+
step -= warmup_steps
|
| 208 |
+
max_steps -= warmup_steps
|
| 209 |
+
q = 0.5 * (1 + math.cos(math.pi * step / max_steps))
|
| 210 |
+
end_lr = base_lr * 0.001
|
| 211 |
+
lr = base_lr * q + end_lr * (1 - q)
|
| 212 |
+
optimizer.param_groups[0]['lr'] = lr * args.learning_rate_weights
|
| 213 |
+
optimizer.param_groups[1]['lr'] = lr * args.learning_rate_biases
|
| 214 |
+
|
| 215 |
+
def adjust_mixup_scale(loader, step, lambda_mixup):
|
| 216 |
+
warmup_steps = 10 * len(loader)
|
| 217 |
+
if step < warmup_steps:
|
| 218 |
+
return lambda_mixup * step / warmup_steps
|
| 219 |
+
else:
|
| 220 |
+
return lambda_mixup
|
| 221 |
+
|
| 222 |
+
def handle_sigusr1(signum, frame):
|
| 223 |
+
os.system(f'scontrol requeue {os.getenv("SLURM_JOB_ID")}')
|
| 224 |
+
exit()
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
def handle_sigterm(signum, frame):
|
| 228 |
+
pass
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
def off_diagonal(x):
|
| 232 |
+
# return a flattened view of the off-diagonal elements of a square matrix
|
| 233 |
+
n, m = x.shape
|
| 234 |
+
assert n == m
|
| 235 |
+
return x.flatten()[:-1].view(n - 1, n + 1)[:, 1:].flatten()
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
class BarlowTwins(nn.Module):
|
| 239 |
+
def __init__(self, args):
|
| 240 |
+
super().__init__()
|
| 241 |
+
self.args = args
|
| 242 |
+
self.backbone = torchvision.models.resnet50(zero_init_residual=True)
|
| 243 |
+
self.backbone.fc = nn.Identity()
|
| 244 |
+
|
| 245 |
+
# projector
|
| 246 |
+
sizes = [2048] + list(map(int, args.projector.split('-')))
|
| 247 |
+
layers = []
|
| 248 |
+
for i in range(len(sizes) - 2):
|
| 249 |
+
layers.append(nn.Linear(sizes[i], sizes[i + 1], bias=False))
|
| 250 |
+
layers.append(nn.BatchNorm1d(sizes[i + 1]))
|
| 251 |
+
layers.append(nn.ReLU(inplace=True))
|
| 252 |
+
layers.append(nn.Linear(sizes[-2], sizes[-1], bias=False))
|
| 253 |
+
self.projector = nn.Sequential(*layers)
|
| 254 |
+
|
| 255 |
+
# normalization layer for the representations z1 and z2
|
| 256 |
+
# self.bn = nn.BatchNorm1d(sizes[-1], affine=False)
|
| 257 |
+
|
| 258 |
+
# def forward(self, y1, y2):
|
| 259 |
+
# z1 = self.projector(self.backbone(y1))
|
| 260 |
+
# z2 = self.projector(self.backbone(y2))
|
| 261 |
+
|
| 262 |
+
# # empirical cross-correlation matrix
|
| 263 |
+
# c = self.bn(z1).T @ self.bn(z2)
|
| 264 |
+
|
| 265 |
+
# # sum the cross-correlation matrix between all gpus
|
| 266 |
+
# c.div_(self.args.batch_size)
|
| 267 |
+
# torch.distributed.all_reduce(c)
|
| 268 |
+
|
| 269 |
+
# on_diag = torch.diagonal(c).add_(-1).pow_(2).sum()
|
| 270 |
+
# off_diag = off_diagonal(c).pow_(2).sum()
|
| 271 |
+
# loss = on_diag + self.args.lambd * off_diag
|
| 272 |
+
# return loss
|
| 273 |
+
|
| 274 |
+
def forward(self, y1, y2, is_mixup):
|
| 275 |
+
batch_size = y1.shape[0]
|
| 276 |
+
|
| 277 |
+
### original barlow twins ###
|
| 278 |
+
z1 = self.projector(self.backbone(y1))
|
| 279 |
+
z2 = self.projector(self.backbone(y2))
|
| 280 |
+
|
| 281 |
+
# normilization
|
| 282 |
+
z1 = (z1 - z1.mean(dim=0)) / z1.std(dim=0)
|
| 283 |
+
z2 = (z2 - z2.mean(dim=0)) / z2.std(dim=0)
|
| 284 |
+
|
| 285 |
+
# empirical cross-correlation matrix
|
| 286 |
+
c = z1.T @ z2
|
| 287 |
+
|
| 288 |
+
# sum the cross-correlation matrix between all gpus
|
| 289 |
+
c.div_(self.args.batch_size)
|
| 290 |
+
torch.distributed.all_reduce(c)
|
| 291 |
+
|
| 292 |
+
on_diag = torch.diagonal(c).add_(-1).pow_(2).sum()
|
| 293 |
+
off_diag = off_diagonal(c).pow_(2).sum()
|
| 294 |
+
loss = on_diag + self.args.lambd * off_diag
|
| 295 |
+
|
| 296 |
+
if is_mixup:
|
| 297 |
+
##############################################
|
| 298 |
+
### mixup regularization: Implementation 1 ###
|
| 299 |
+
##############################################
|
| 300 |
+
|
| 301 |
+
# index = torch.randperm(batch_size).cuda(non_blocking=True)
|
| 302 |
+
# alpha = np.random.beta(1.0, 1.0)
|
| 303 |
+
# ym = alpha * y1 + (1. - alpha) * y2[index, :]
|
| 304 |
+
# zm = self.projector(self.backbone(ym))
|
| 305 |
+
|
| 306 |
+
# # normilization
|
| 307 |
+
# zm = (zm - zm.mean(dim=0)) / zm.std(dim=0)
|
| 308 |
+
|
| 309 |
+
# # cc
|
| 310 |
+
# cc_m_1 = zm.T @ z1
|
| 311 |
+
# cc_m_1.div_(batch_size)
|
| 312 |
+
# cc_m_1_gt = alpha*(z1.T @ z1) + (1.-alpha)*(z2[index,:].T @ z1)
|
| 313 |
+
# cc_m_1_gt.div_(batch_size)
|
| 314 |
+
|
| 315 |
+
# cc_m_2 = zm.T @ z2
|
| 316 |
+
# cc_m_2.div_(batch_size)
|
| 317 |
+
# cc_m_2_gt = alpha*(z2.T @ z2) + (1.-alpha)*(z2[index,:].T @ z2)
|
| 318 |
+
# cc_m_2_gt.div_(batch_size)
|
| 319 |
+
|
| 320 |
+
# # mixup reg. loss
|
| 321 |
+
# lossm = 0.5*self.args.lambd*((cc_m_1-cc_m_1_gt).pow_(2).sum() + (cc_m_2-cc_m_2_gt).pow_(2).sum())
|
| 322 |
+
|
| 323 |
+
##############################################
|
| 324 |
+
### mixup regularization: Implementation 2 ###
|
| 325 |
+
##############################################
|
| 326 |
+
index = torch.randperm(batch_size).cuda(non_blocking=True)
|
| 327 |
+
alpha = np.random.beta(1.0, 1.0)
|
| 328 |
+
ym = alpha * y1 + (1. - alpha) * y2[index, :]
|
| 329 |
+
zm = self.projector(self.backbone(ym))
|
| 330 |
+
|
| 331 |
+
# normilization
|
| 332 |
+
zm = (zm - zm.mean(dim=0)) / zm.std(dim=0)
|
| 333 |
+
|
| 334 |
+
# cc
|
| 335 |
+
cc_m_1 = zm.T @ z1
|
| 336 |
+
cc_m_1.div_(self.args.batch_size)
|
| 337 |
+
cc_m_1_gt = alpha*(z1.T @ z1) + (1.-alpha)*(z2[index,:].T @ z1)
|
| 338 |
+
cc_m_1_gt.div_(self.args.batch_size)
|
| 339 |
+
|
| 340 |
+
cc_m_2 = zm.T @ z2
|
| 341 |
+
cc_m_2.div_(self.args.batch_size)
|
| 342 |
+
cc_m_2_gt = alpha*(z2.T @ z2) + (1.-alpha)*(z2[index,:].T @ z2)
|
| 343 |
+
cc_m_2_gt.div_(self.args.batch_size)
|
| 344 |
+
|
| 345 |
+
# gathering all cc
|
| 346 |
+
torch.distributed.all_reduce(cc_m_1)
|
| 347 |
+
torch.distributed.all_reduce(cc_m_1_gt)
|
| 348 |
+
torch.distributed.all_reduce(cc_m_2)
|
| 349 |
+
torch.distributed.all_reduce(cc_m_2_gt)
|
| 350 |
+
|
| 351 |
+
# mixup reg. loss
|
| 352 |
+
lossm = 0.5*self.args.lambd*((cc_m_1-cc_m_1_gt).pow_(2).sum() + (cc_m_2-cc_m_2_gt).pow_(2).sum())
|
| 353 |
+
else:
|
| 354 |
+
lossm = torch.zeros(1)
|
| 355 |
+
return loss, lossm
|
| 356 |
+
|
| 357 |
+
class LARS(optim.Optimizer):
|
| 358 |
+
def __init__(self, params, lr, weight_decay=0, momentum=0.9, eta=0.001,
|
| 359 |
+
weight_decay_filter=False, lars_adaptation_filter=False):
|
| 360 |
+
defaults = dict(lr=lr, weight_decay=weight_decay, momentum=momentum,
|
| 361 |
+
eta=eta, weight_decay_filter=weight_decay_filter,
|
| 362 |
+
lars_adaptation_filter=lars_adaptation_filter)
|
| 363 |
+
super().__init__(params, defaults)
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
def exclude_bias_and_norm(self, p):
|
| 367 |
+
return p.ndim == 1
|
| 368 |
+
|
| 369 |
+
@torch.no_grad()
|
| 370 |
+
def step(self):
|
| 371 |
+
for g in self.param_groups:
|
| 372 |
+
for p in g['params']:
|
| 373 |
+
dp = p.grad
|
| 374 |
+
|
| 375 |
+
if dp is None:
|
| 376 |
+
continue
|
| 377 |
+
|
| 378 |
+
if not g['weight_decay_filter'] or not self.exclude_bias_and_norm(p):
|
| 379 |
+
dp = dp.add(p, alpha=g['weight_decay'])
|
| 380 |
+
|
| 381 |
+
if not g['lars_adaptation_filter'] or not self.exclude_bias_and_norm(p):
|
| 382 |
+
param_norm = torch.norm(p)
|
| 383 |
+
update_norm = torch.norm(dp)
|
| 384 |
+
one = torch.ones_like(param_norm)
|
| 385 |
+
q = torch.where(param_norm > 0.,
|
| 386 |
+
torch.where(update_norm > 0,
|
| 387 |
+
(g['eta'] * param_norm / update_norm), one), one)
|
| 388 |
+
dp = dp.mul(q)
|
| 389 |
+
|
| 390 |
+
param_state = self.state[p]
|
| 391 |
+
if 'mu' not in param_state:
|
| 392 |
+
param_state['mu'] = torch.zeros_like(p)
|
| 393 |
+
mu = param_state['mu']
|
| 394 |
+
mu.mul_(g['momentum']).add_(dp)
|
| 395 |
+
|
| 396 |
+
p.add_(mu, alpha=-g['lr'])
|
| 397 |
+
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
class GaussianBlur(object):
|
| 401 |
+
def __init__(self, p):
|
| 402 |
+
self.p = p
|
| 403 |
+
|
| 404 |
+
def __call__(self, img):
|
| 405 |
+
if random.random() < self.p:
|
| 406 |
+
sigma = random.random() * 1.9 + 0.1
|
| 407 |
+
return img.filter(ImageFilter.GaussianBlur(sigma))
|
| 408 |
+
else:
|
| 409 |
+
return img
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
class Solarization(object):
|
| 413 |
+
def __init__(self, p):
|
| 414 |
+
self.p = p
|
| 415 |
+
|
| 416 |
+
def __call__(self, img):
|
| 417 |
+
if random.random() < self.p:
|
| 418 |
+
return ImageOps.solarize(img)
|
| 419 |
+
else:
|
| 420 |
+
return img
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
class Transform:
|
| 424 |
+
def __init__(self):
|
| 425 |
+
self.transform = transforms.Compose([
|
| 426 |
+
transforms.RandomResizedCrop(224, interpolation=Image.BICUBIC),
|
| 427 |
+
transforms.RandomHorizontalFlip(p=0.5),
|
| 428 |
+
transforms.RandomApply(
|
| 429 |
+
[transforms.ColorJitter(brightness=0.4, contrast=0.4,
|
| 430 |
+
saturation=0.2, hue=0.1)],
|
| 431 |
+
p=0.8
|
| 432 |
+
),
|
| 433 |
+
transforms.RandomGrayscale(p=0.2),
|
| 434 |
+
GaussianBlur(p=1.0),
|
| 435 |
+
Solarization(p=0.0),
|
| 436 |
+
transforms.ToTensor(),
|
| 437 |
+
transforms.Normalize(mean=[0.485, 0.456, 0.406],
|
| 438 |
+
std=[0.229, 0.224, 0.225])
|
| 439 |
+
])
|
| 440 |
+
self.transform_prime = transforms.Compose([
|
| 441 |
+
transforms.RandomResizedCrop(224, interpolation=Image.BICUBIC),
|
| 442 |
+
transforms.RandomHorizontalFlip(p=0.5),
|
| 443 |
+
transforms.RandomApply(
|
| 444 |
+
[transforms.ColorJitter(brightness=0.4, contrast=0.4,
|
| 445 |
+
saturation=0.2, hue=0.1)],
|
| 446 |
+
p=0.8
|
| 447 |
+
),
|
| 448 |
+
transforms.RandomGrayscale(p=0.2),
|
| 449 |
+
GaussianBlur(p=0.1),
|
| 450 |
+
Solarization(p=0.2),
|
| 451 |
+
transforms.ToTensor(),
|
| 452 |
+
transforms.Normalize(mean=[0.485, 0.456, 0.406],
|
| 453 |
+
std=[0.229, 0.224, 0.225])
|
| 454 |
+
])
|
| 455 |
+
|
| 456 |
+
def __call__(self, x):
|
| 457 |
+
y1 = self.transform(x)
|
| 458 |
+
y2 = self.transform_prime(x)
|
| 459 |
+
return y1, y2
|
| 460 |
+
|
| 461 |
+
|
| 462 |
+
if __name__ == '__main__':
|
| 463 |
+
main()
|
model.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
from torchvision.models.resnet import resnet50, resnet18
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class Model(nn.Module):
|
| 8 |
+
def __init__(self, feature_dim=128, dataset='cifar10', arch='resnet50'):
|
| 9 |
+
super(Model, self).__init__()
|
| 10 |
+
|
| 11 |
+
self.f = []
|
| 12 |
+
if arch == 'resnet18':
|
| 13 |
+
temp_model = resnet18().named_children()
|
| 14 |
+
embedding_size = 512
|
| 15 |
+
elif arch == 'resnet50':
|
| 16 |
+
temp_model = resnet50().named_children()
|
| 17 |
+
embedding_size = 2048
|
| 18 |
+
else:
|
| 19 |
+
raise NotImplementedError
|
| 20 |
+
|
| 21 |
+
for name, module in temp_model:
|
| 22 |
+
if name == 'conv1':
|
| 23 |
+
module = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
|
| 24 |
+
if dataset == 'cifar10' or dataset == 'cifar100':
|
| 25 |
+
if not isinstance(module, nn.Linear) and not isinstance(module, nn.MaxPool2d):
|
| 26 |
+
self.f.append(module)
|
| 27 |
+
elif dataset == 'tiny_imagenet' or dataset == 'stl10':
|
| 28 |
+
if not isinstance(module, nn.Linear):
|
| 29 |
+
self.f.append(module)
|
| 30 |
+
# encoder
|
| 31 |
+
self.f = nn.Sequential(*self.f)
|
| 32 |
+
# projection head
|
| 33 |
+
self.g = nn.Sequential(nn.Linear(embedding_size, 512, bias=False), nn.BatchNorm1d(512),
|
| 34 |
+
nn.ReLU(inplace=True), nn.Linear(512, feature_dim, bias=True))
|
| 35 |
+
|
| 36 |
+
def forward(self, x):
|
| 37 |
+
x = self.f(x)
|
| 38 |
+
feature = torch.flatten(x, start_dim=1)
|
| 39 |
+
out = self.g(feature)
|
| 40 |
+
return F.normalize(feature, dim=-1), F.normalize(out, dim=-1)
|
preprocess_datasets/preprocess_tinyimagenet.sh
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# download and unzip dataset
|
| 4 |
+
cd /data/wbandar1/datasets
|
| 5 |
+
wget http://cs231n.stanford.edu/tiny-imagenet-200.zip
|
| 6 |
+
unzip tiny-imagenet-200.zip
|
| 7 |
+
|
| 8 |
+
current="$(pwd)/tiny-imagenet-200"
|
| 9 |
+
|
| 10 |
+
# training data
|
| 11 |
+
cd $current/train
|
| 12 |
+
for DIR in $(ls); do
|
| 13 |
+
cd $DIR
|
| 14 |
+
rm *.txt
|
| 15 |
+
mv images/* .
|
| 16 |
+
rm -r images
|
| 17 |
+
cd ..
|
| 18 |
+
done
|
| 19 |
+
|
| 20 |
+
# validation data
|
| 21 |
+
cd $current/val
|
| 22 |
+
annotate_file="val_annotations.txt"
|
| 23 |
+
length=$(cat $annotate_file | wc -l)
|
| 24 |
+
for i in $(seq 1 $length); do
|
| 25 |
+
# fetch i th line
|
| 26 |
+
line=$(sed -n ${i}p $annotate_file)
|
| 27 |
+
# get file name and directory name
|
| 28 |
+
file=$(echo $line | cut -f1 -d" " )
|
| 29 |
+
directory=$(echo $line | cut -f2 -d" ")
|
| 30 |
+
mkdir -p $directory
|
| 31 |
+
mv images/$file $directory
|
| 32 |
+
done
|
| 33 |
+
rm -r images
|
| 34 |
+
echo "done"
|
scripts-linear-resnet18/cifar10.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=cifar10
|
| 4 |
+
arch=resnet18
|
| 5 |
+
batch_size=512
|
| 6 |
+
model_path=checkpoints/4wdhbpcf_0.0078125_1024_256_cifar10_model.pth
|
| 7 |
+
|
| 8 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 9 |
+
session_name="python_session_$timestamp"
|
| 10 |
+
echo ${session_name}
|
| 11 |
+
screen -dmS "$session_name"
|
| 12 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 13 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python linear.py --dataset ${dataset} --model_path ${model_path} --arch ${arch}^M"
|
| 14 |
+
screen -S "$session_name" -X detachs
|
scripts-linear-resnet18/cifar100.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=cifar100
|
| 4 |
+
arch=resnet18
|
| 5 |
+
batch_size=512
|
| 6 |
+
model_path=checkpoints/76kk7scz_0.0078125_1024_256_cifar100_model.pth
|
| 7 |
+
|
| 8 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 9 |
+
session_name="python_session_$timestamp"
|
| 10 |
+
echo ${session_name}
|
| 11 |
+
screen -dmS "$session_name"
|
| 12 |
+
screen -S "$session_name" -X stuff "conda activate ssl-sug^M"
|
| 13 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python linear.py --dataset ${dataset} --model_path ${model_path} --arch ${arch}^M"
|
| 14 |
+
screen -S "$session_name" -X detachs
|
scripts-linear-resnet18/stl10.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=stl10
|
| 4 |
+
arch=resnet18
|
| 5 |
+
batch_size=512
|
| 6 |
+
model_path=checkpoints/i7det4xq_0.0078125_1024_256_stl10_model.pth
|
| 7 |
+
|
| 8 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 9 |
+
session_name="python_session_$timestamp"
|
| 10 |
+
echo ${session_name}
|
| 11 |
+
screen -dmS "$session_name"
|
| 12 |
+
screen -S "$session_name" -X stuff "conda activate ssl-sug^M"
|
| 13 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python linear.py --dataset ${dataset} --model_path ${model_path} --arch ${arch}^M"
|
| 14 |
+
screen -S "$session_name" -X detachs
|
scripts-linear-resnet18/tinyimagenet.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=tiny_imagenet
|
| 4 |
+
arch=resnet18
|
| 5 |
+
batch_size=512
|
| 6 |
+
model_path=checkpoints/02azq6fs_0.0009765_1024_256_tiny_imagenet_model.pth
|
| 7 |
+
|
| 8 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 9 |
+
session_name="python_session_$timestamp"
|
| 10 |
+
echo ${session_name}
|
| 11 |
+
screen -dmS "$session_name"
|
| 12 |
+
screen -S "$session_name" -X stuff "conda activate ssl-sug^M"
|
| 13 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python linear.py --dataset ${dataset} --model_path ${model_path} --arch ${arch}^M"
|
| 14 |
+
screen -S "$session_name" -X detachs
|
scripts-linear-resnet50/cifar10.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=cifar10
|
| 4 |
+
arch=resnet50
|
| 5 |
+
batch_size=512
|
| 6 |
+
model_path=checkpoints/v3gwgusq_0.0078125_1024_256_cifar10_model.pth
|
| 7 |
+
|
| 8 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 9 |
+
session_name="python_session_$timestamp"
|
| 10 |
+
echo ${session_name}
|
| 11 |
+
screen -dmS "$session_name"
|
| 12 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 13 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python linear.py --dataset ${dataset} --model_path ${model_path} --arch ${arch}^M"
|
| 14 |
+
screen -S "$session_name" -X detachs
|
scripts-linear-resnet50/cifar100.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=cifar100
|
| 4 |
+
arch=resnet50
|
| 5 |
+
batch_size=512
|
| 6 |
+
model_path=checkpoints/z6ngefw7_0.0078125_1024_256_cifar100_model.pth
|
| 7 |
+
|
| 8 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 9 |
+
session_name="python_session_$timestamp"
|
| 10 |
+
echo ${session_name}
|
| 11 |
+
screen -dmS "$session_name"
|
| 12 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 13 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python linear.py --dataset ${dataset} --model_path ${model_path} --arch ${arch}^M"
|
| 14 |
+
screen -S "$session_name" -X detachs
|
scripts-linear-resnet50/imagenet_sup.sh
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
path_to_imagenet_data=datasets/imagenet1k/
|
| 3 |
+
path_to_model=checkpoints/13awtq23_0.0051_8192_1024_imagenet_0.1_resnet50.pth
|
| 4 |
+
|
| 5 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 6 |
+
session_name="python_session_$timestamp"
|
| 7 |
+
echo ${session_name}
|
| 8 |
+
screen -dmS "$session_name"
|
| 9 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 10 |
+
screen -S "$session_name" -X stuff "NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python evaluate_imagenet.py ${path_to_imagenet_data} ${path_to_model} --lr-classifier 0.3^M"
|
| 11 |
+
screen -S "$session_name" -X detachs
|
scripts-linear-resnet50/stl10.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=stl10
|
| 4 |
+
arch=resnet50
|
| 5 |
+
batch_size=512
|
| 6 |
+
model_path=checkpoints/pbknx38b_0.0078125_1024_256_stl10_model.pth
|
| 7 |
+
|
| 8 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 9 |
+
session_name="python_session_$timestamp"
|
| 10 |
+
echo ${session_name}
|
| 11 |
+
screen -dmS "$session_name"
|
| 12 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 13 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python linear.py --dataset ${dataset} --model_path ${model_path} --arch ${arch}^M"
|
| 14 |
+
screen -S "$session_name" -X detachs
|
scripts-linear-resnet50/tinyimagenet.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=tiny_imagenet
|
| 4 |
+
arch=resnet50
|
| 5 |
+
batch_size=512
|
| 6 |
+
model_path=checkpoints/kxlkigsv_0.0009765_1024_256_tiny_imagenet_model.pth
|
| 7 |
+
|
| 8 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 9 |
+
session_name="python_session_$timestamp"
|
| 10 |
+
echo ${session_name}
|
| 11 |
+
screen -dmS "$session_name"
|
| 12 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 13 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python linear.py --dataset ${dataset} --model_path ${model_path} --arch ${arch}^M"
|
| 14 |
+
screen -S "$session_name" -X detachs
|
scripts-pretrain-resnet18/cifar10.sh
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# default: https://wandb.ai/cha-yas/Barlow-Twins-MixUp-cifar10-resnet18/runs/4wdhbpcf/overview?workspace=user-wgcban
|
| 3 |
+
gpu=0
|
| 4 |
+
dataset=cifar10
|
| 5 |
+
arch=resnet18
|
| 6 |
+
feature_dim=1024
|
| 7 |
+
is_mixup=true # true, false
|
| 8 |
+
batch_size=256
|
| 9 |
+
epochs=2000
|
| 10 |
+
lr=0.01
|
| 11 |
+
lr_shed=cosine # step, cosine
|
| 12 |
+
mixup_loss_scale=4.0 # scale w.r.t. lambda: 0.0078125 * 5 = 0.0390625
|
| 13 |
+
lmbda=0.0078125
|
| 14 |
+
|
| 15 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 16 |
+
session_name="python_session_$timestamp"
|
| 17 |
+
echo ${session_name}
|
| 18 |
+
screen -dmS "$session_name"
|
| 19 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 20 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python main.py --lmbda ${lmbda} --corr_zero --batch_size ${batch_size} --feature_dim ${feature_dim} --dataset ${dataset} --is_mixup ${is_mixup} --mixup_loss_scale ${mixup_loss_scale} --epochs ${epochs} --arch ${arch} --gpu ${gpu} --lr_shed ${lr_shed} --lr ${lr}^M"
|
| 21 |
+
screen -S "$session_name" -X detach
|
scripts-pretrain-resnet18/cifar100.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=cifar100
|
| 4 |
+
arch=resnet18
|
| 5 |
+
feature_dim=2048
|
| 6 |
+
is_mixup=true # true, false
|
| 7 |
+
batch_size=256
|
| 8 |
+
epochs=2000
|
| 9 |
+
lr=0.01
|
| 10 |
+
lr_shed=cosine #"step", "cosine" # step, cosine
|
| 11 |
+
mixup_loss_scale=4.0 # scale w.r.t. lambda: 0.0078125 * 5 = 0.0390625
|
| 12 |
+
lmbda=0.0078125
|
| 13 |
+
|
| 14 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 15 |
+
session_name="python_session_$timestamp"
|
| 16 |
+
echo ${session_name}
|
| 17 |
+
screen -dmS "$session_name"
|
| 18 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 19 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python main.py --lmbda ${lmbda} --corr_zero --batch_size ${batch_size} --feature_dim ${feature_dim} --dataset ${dataset} --is_mixup ${is_mixup} --mixup_loss_scale ${mixup_loss_scale} --epochs ${epochs} --arch ${arch} --gpu ${gpu} --lr_shed ${lr_shed} --lr ${lr}^M"
|
| 20 |
+
screen -S "$session_name" -X detach
|
scripts-pretrain-resnet18/stl10.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=stl10
|
| 4 |
+
arch=resnet18
|
| 5 |
+
feature_dim=1024
|
| 6 |
+
is_mixup=true # true, false
|
| 7 |
+
batch_size=256
|
| 8 |
+
epochs=2000
|
| 9 |
+
lr=0.01
|
| 10 |
+
lr_shed=cosine #"step", "cosine" # step, cosine
|
| 11 |
+
mixup_loss_scale=2.0 # scale w.r.t. lambda: 0.0078125 * 5 = 0.0390625pochs=2000
|
| 12 |
+
lmbda=0.0078125
|
| 13 |
+
|
| 14 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 15 |
+
session_name="python_session_$timestamp"
|
| 16 |
+
echo ${session_name}
|
| 17 |
+
screen -dmS "$session_name"
|
| 18 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 19 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python main.py --lmbda ${lmbda} --corr_zero --batch_size ${batch_size} --feature_dim ${feature_dim} --dataset ${dataset} --is_mixup ${is_mixup} --mixup_loss_scale ${mixup_loss_scale} --epochs ${epochs} --arch ${arch} --gpu ${gpu} --lr_shed ${lr_shed} --lr ${lr}^M"
|
| 20 |
+
screen -S "$session_name" -X detach
|
scripts-pretrain-resnet18/tinyimagenet.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=tiny_imagenet
|
| 4 |
+
arch=resnet18
|
| 5 |
+
feature_dim=1024
|
| 6 |
+
is_mixup=true # true, false
|
| 7 |
+
batch_size=256
|
| 8 |
+
epochs=2000
|
| 9 |
+
lr=0.01
|
| 10 |
+
lr_shed=cosine #"step", "cosine" # step, cosine
|
| 11 |
+
mixup_loss_scale=4.0 # scale w.r.t. lambda
|
| 12 |
+
lmbda=$(echo "scale=7; 1 / ${feature_dim}" | bc)
|
| 13 |
+
|
| 14 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 15 |
+
session_name="python_session_$timestamp"
|
| 16 |
+
echo ${session_name}
|
| 17 |
+
screen -dmS "$session_name"
|
| 18 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 19 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python main.py --lmbda ${lmbda} --corr_zero --batch_size ${batch_size} --feature_dim ${feature_dim} --dataset ${dataset} --is_mixup ${is_mixup} --mixup_loss_scale ${mixup_loss_scale} --epochs ${epochs} --arch ${arch} --gpu ${gpu} --lr_shed ${lr_shed} --lr ${lr}^M"
|
| 20 |
+
screen -S "$session_name" -X detach
|
scripts-pretrain-resnet50/cifar10.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=cifar10
|
| 4 |
+
arch=resnet50
|
| 5 |
+
feature_dim=1024
|
| 6 |
+
is_mixup=true # true, false
|
| 7 |
+
batch_size=256
|
| 8 |
+
epochs=1000
|
| 9 |
+
lr=0.01
|
| 10 |
+
lr_shed=cosine # step, cosine
|
| 11 |
+
mixup_loss_scale=4.0 # scale w.r.t. lambda: 0.0078125 * 5 = 0.0390625
|
| 12 |
+
lmbda=0.0078125
|
| 13 |
+
|
| 14 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 15 |
+
session_name="python_session_$timestamp"
|
| 16 |
+
echo ${session_name}
|
| 17 |
+
screen -dmS "$session_name"
|
| 18 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 19 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python main.py --lmbda ${lmbda} --corr_zero --batch_size ${batch_size} --feature_dim ${feature_dim} --dataset ${dataset} --is_mixup ${is_mixup} --mixup_loss_scale ${mixup_loss_scale} --epochs ${epochs} --arch ${arch} --gpu ${gpu} --lr_shed ${lr_shed} --lr ${lr}^M"
|
| 20 |
+
screen -S "$session_name" -X detach
|
scripts-pretrain-resnet50/cifar100.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=cifar100
|
| 4 |
+
arch=resnet50
|
| 5 |
+
feature_dim=1024
|
| 6 |
+
is_mixup=true # true, false
|
| 7 |
+
batch_size=256
|
| 8 |
+
epochs=1000
|
| 9 |
+
lr=0.01
|
| 10 |
+
lr_shed=cosine # step, cosine
|
| 11 |
+
mixup_loss_scale=4.0 # scale w.r.t. lambda: 0.0078125 * 5 = 0.0390625
|
| 12 |
+
lmbda=0.0078125
|
| 13 |
+
|
| 14 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 15 |
+
session_name="python_session_$timestamp"
|
| 16 |
+
echo ${session_name}
|
| 17 |
+
screen -dmS "$session_name"
|
| 18 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 19 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python main.py --lmbda ${lmbda} --corr_zero --batch_size ${batch_size} --feature_dim ${feature_dim} --dataset ${dataset} --is_mixup ${is_mixup} --mixup_loss_scale ${mixup_loss_scale} --epochs ${epochs} --arch ${arch} --gpu ${gpu} --lr_shed ${lr_shed} --lr ${lr}^M"
|
| 20 |
+
screen -S "$session_name" -X detach
|
scripts-pretrain-resnet50/imagenet.sh
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
is_mixup=true
|
| 3 |
+
batch_size=1024 #128/gpu works
|
| 4 |
+
lr_w=0.2 #0.2
|
| 5 |
+
lr_b=0.0048 #0.0048
|
| 6 |
+
lambda_mixup=1.0
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 10 |
+
session_name="python_session_$timestamp"
|
| 11 |
+
echo ${session_name}
|
| 12 |
+
screen -dmS "$session_name"
|
| 13 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 14 |
+
screen -S "$session_name" -X stuff "NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python main_imagenet.py /data/wbandar1/datasets/imagenet1k/ --is_mixup ${is_mixup} --batch-size ${batch_size} --learning-rate-weights ${lr_w} --learning-rate-biases ${lr_b} --lambda_mixup ${lambda_mixup}^M"
|
| 15 |
+
screen -S "$session_name" -X detachs
|
scripts-pretrain-resnet50/stl10.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=stl10
|
| 4 |
+
arch=resnet50
|
| 5 |
+
feature_dim=4096
|
| 6 |
+
is_mixup=true # true, false
|
| 7 |
+
batch_size=256
|
| 8 |
+
epochs=2000
|
| 9 |
+
lr=0.01
|
| 10 |
+
lr_shed=cosine # step, cosine
|
| 11 |
+
mixup_loss_scale=2.0 # scale w.r.t. lambda: 0.0078125 * 5 = 0.0390625
|
| 12 |
+
lmbda=0.0078125
|
| 13 |
+
|
| 14 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 15 |
+
session_name="python_session_$timestamp"
|
| 16 |
+
echo ${session_name}
|
| 17 |
+
screen -dmS "$session_name"
|
| 18 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 19 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python main.py --lmbda ${lmbda} --corr_zero --batch_size ${batch_size} --feature_dim ${feature_dim} --dataset ${dataset} --is_mixup ${is_mixup} --mixup_loss_scale ${mixup_loss_scale} --epochs ${epochs} --arch ${arch} --gpu ${gpu} --lr_shed ${lr_shed} --lr ${lr}^M"
|
| 20 |
+
screen -S "$session_name" -X detach
|
scripts-pretrain-resnet50/tinyimagenet.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=tiny_imagenet
|
| 4 |
+
arch=resnet50
|
| 5 |
+
feature_dim=4096
|
| 6 |
+
is_mixup=false # true, false
|
| 7 |
+
batch_size=256
|
| 8 |
+
epochs=2000
|
| 9 |
+
lr=0.01
|
| 10 |
+
lr_shed=cosine # step, cosine
|
| 11 |
+
mixup_loss_scale=4.0 # scale w.r.t. lambda
|
| 12 |
+
lmbda=$(echo "scale=7; 1 / ${feature_dim}" | bc)
|
| 13 |
+
|
| 14 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 15 |
+
session_name="python_session_$timestamp"
|
| 16 |
+
echo ${session_name}
|
| 17 |
+
screen -dmS "$session_name"
|
| 18 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 19 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python main.py --lmbda ${lmbda} --corr_zero --batch_size ${batch_size} --feature_dim ${feature_dim} --dataset ${dataset} --is_mixup ${is_mixup} --mixup_loss_scale ${mixup_loss_scale} --epochs ${epochs} --arch ${arch} --gpu ${gpu} --lr_shed ${lr_shed} --lr ${lr}^M"
|
| 20 |
+
screen -S "$session_name" -X detach
|
scripts-transfer-resnet18/cifar10-to-x.sh
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=cifar10
|
| 4 |
+
arch=resnet18
|
| 5 |
+
batch_size=128
|
| 6 |
+
wandb_group='best-mbt'
|
| 7 |
+
model_path=checkpoints/4wdhbpcf_0.0078125_1024_256_cifar10_model.pth
|
| 8 |
+
|
| 9 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 10 |
+
session_name="python_session_$timestamp"
|
| 11 |
+
echo ${session_name}
|
| 12 |
+
screen -dmS "$session_name"
|
| 13 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 14 |
+
transfer_dataset='dtd'
|
| 15 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 16 |
+
transfer_dataset='mnist'
|
| 17 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 18 |
+
transfer_dataset='fashionmnist'
|
| 19 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 20 |
+
transfer_dataset='cu_birds'
|
| 21 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 22 |
+
transfer_dataset='vgg_flower'
|
| 23 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 24 |
+
transfer_dataset='traffic_sign'
|
| 25 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 26 |
+
transfer_dataset='aircraft'
|
| 27 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 28 |
+
screen -S "$session_name" -X detach
|
scripts-transfer-resnet18/cifar100-to-x.sh
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=cifar100
|
| 4 |
+
arch=resnet18
|
| 5 |
+
batch_size=128
|
| 6 |
+
wandb_group='mbt'
|
| 7 |
+
model_path=checkpoints/76kk7scz_0.0078125_1024_256_cifar100_model.pth
|
| 8 |
+
|
| 9 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 10 |
+
session_name="python_session_$timestamp"
|
| 11 |
+
echo ${session_name}
|
| 12 |
+
screen -dmS "$session_name"
|
| 13 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 14 |
+
transfer_dataset='dtd'
|
| 15 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 16 |
+
transfer_dataset='mnist'
|
| 17 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 18 |
+
transfer_dataset='fashionmnist'
|
| 19 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 20 |
+
transfer_dataset='cu_birds'
|
| 21 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 22 |
+
transfer_dataset='vgg_flower'
|
| 23 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 24 |
+
transfer_dataset='traffic_sign'
|
| 25 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 26 |
+
transfer_dataset='aircraft'
|
| 27 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 28 |
+
screen -S "$session_name" -X detach
|
scripts-transfer-resnet18/stl10-to-x-bt.sh
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
gpu=0
|
| 3 |
+
dataset=stl10
|
| 4 |
+
arch=resnet18
|
| 5 |
+
batch_size=128
|
| 6 |
+
wandb_group='mbt'
|
| 7 |
+
model_path=checkpoints/i7det4xq_0.0078125_1024_256_stl10_model.pth
|
| 8 |
+
|
| 9 |
+
timestamp=$(date +"%Y%m%d%H%M%S")
|
| 10 |
+
session_name="python_session_$timestamp"
|
| 11 |
+
echo ${session_name}
|
| 12 |
+
screen -dmS "$session_name"
|
| 13 |
+
screen -S "$session_name" -X stuff "conda activate ssl-aug^M"
|
| 14 |
+
transfer_dataset='dtd'
|
| 15 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 16 |
+
transfer_dataset='mnist'
|
| 17 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 18 |
+
transfer_dataset='fashionmnist'
|
| 19 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 20 |
+
transfer_dataset='cu_birds'
|
| 21 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 22 |
+
transfer_dataset='vgg_flower'
|
| 23 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 24 |
+
transfer_dataset='traffic_sign'
|
| 25 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 26 |
+
transfer_dataset='aircraft'
|
| 27 |
+
screen -S "$session_name" -X stuff "CUDA_VISIBLE_DEVICES=${gpu} python evaluate_transfer.py --dataset ${dataset} --transfer_dataset ${transfer_dataset} --model_path ${model_path} --arch ${arch} --screen ${session_name} --wandb_group ${wandb_group}^M"
|
| 28 |
+
screen -S "$session_name" -X detach
|
setup.sh
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
mkdir ssl-aug
|
| 4 |
+
mkdir Barlow-Twins-HSIC
|
| 5 |
+
mkdir /data/wbandar1/projects/ssl-aug-artifacts/results
|
| 6 |
+
git clone https://github.com/wgcban/ssl-aug.git Barlow-Twins-HSIC
|
| 7 |
+
|
| 8 |
+
cd Barlow-Twins-HSIC
|
| 9 |
+
conda env create -f environment.yml
|
| 10 |
+
conda activate ssl-aug
|
| 11 |
+
|
| 12 |
+
|
ssl-sota/README.md
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Self-Supervised Representation Learning
|
| 2 |
+
|
| 3 |
+
Official repository of the paper **Whitening for Self-Supervised Representation Learning**
|
| 4 |
+
|
| 5 |
+
ICML 2021 | [arXiv:2007.06346](https://arxiv.org/abs/2007.06346)
|
| 6 |
+
|
| 7 |
+
It includes 3 types of losses:
|
| 8 |
+
- W-MSE [arXiv](https://arxiv.org/abs/2007.06346)
|
| 9 |
+
- Contrastive [SimCLR arXiv](https://arxiv.org/abs/2002.05709)
|
| 10 |
+
- BYOL [arXiv](https://arxiv.org/abs/2006.07733)
|
| 11 |
+
|
| 12 |
+
And 5 datasets:
|
| 13 |
+
- CIFAR-10 and CIFAR-100
|
| 14 |
+
- STL-10
|
| 15 |
+
- Tiny ImageNet
|
| 16 |
+
- ImageNet-100
|
| 17 |
+
Checkpoints are stored in `data` each 100 epochs during training.
|
| 18 |
+
|
| 19 |
+
The implementation is optimized for a single GPU, although multiple are also supported. It includes fast evaluation: we pre-compute embeddings for the entire dataset and then train a classifier on top. The evaluation of the ResNet-18 encoder takes about one minute.
|
| 20 |
+
|
| 21 |
+
## Installation
|
| 22 |
+
|
| 23 |
+
The implementation is based on PyTorch. Logging works on [wandb.ai](https://wandb.ai/). See `docker/Dockerfile`.
|
| 24 |
+
|
| 25 |
+
#### ImageNet-100
|
| 26 |
+
To get this dataset, take the original ImageNet and filter out [this subset of classes](https://github.com/HobbitLong/CMC/blob/master/imagenet100.txt). We do not use augmentations during testing, and loading big images with resizing on the fly is slow, so we can preprocess classifier train and test images. We recommend [mogrify](https://imagemagick.org/script/mogrify.php) for it. First, you need to resize to 256 (just like `torchvision.transforms.Resize(256)`) and then crop to 224 (like `torchvision.transforms.CenterCrop(224)`). Finally, put the original images to `train`, and resized to `clf` and `test`.
|
| 27 |
+
|
| 28 |
+
## Usage
|
| 29 |
+
|
| 30 |
+
Detailed settings are good by default, to see all options:
|
| 31 |
+
```
|
| 32 |
+
python -m train --help
|
| 33 |
+
python -m test --help
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
To reproduce the results from [table 1](https://arxiv.org/abs/2007.06346):
|
| 37 |
+
#### W-MSE 4
|
| 38 |
+
```
|
| 39 |
+
python -m train --dataset cifar10 --epoch 1000 --lr 3e-3 --num_samples 4 --bs 256 --emb 64 --w_size 128
|
| 40 |
+
python -m train --dataset cifar100 --epoch 1000 --lr 3e-3 --num_samples 4 --bs 256 --emb 64 --w_size 128
|
| 41 |
+
python -m train --dataset stl10 --epoch 2000 --lr 2e-3 --num_samples 4 --bs 256 --emb 128 --w_size 256
|
| 42 |
+
python -m train --dataset tiny_in --epoch 1000 --lr 2e-3 --num_samples 4 --bs 256 --emb 128 --w_size 256
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
#### W-MSE 2
|
| 46 |
+
```
|
| 47 |
+
python -m train --dataset cifar10 --epoch 1000 --lr 3e-3 --emb 64 --w_size 128
|
| 48 |
+
python -m train --dataset cifar100 --epoch 1000 --lr 3e-3 --emb 64 --w_size 128
|
| 49 |
+
python -m train --dataset stl10 --epoch 2000 --lr 2e-3 --emb 128 --w_size 256 --w_iter 4
|
| 50 |
+
python -m train --dataset tiny_in --epoch 1000 --lr 2e-3 --emb 128 --w_size 256 --w_iter 4
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
#### Contrastive
|
| 54 |
+
```
|
| 55 |
+
python -m train --dataset cifar10 --epoch 1000 --lr 3e-3 --emb 64 --method contrastive --arch resnet50
|
| 56 |
+
python -m train --dataset cifar100 --epoch 1000 --lr 3e-3 --emb 64 --method contrastive --arch resnet50
|
| 57 |
+
python -m train --dataset stl10 --epoch 2000 --lr 2e-3 --emb 128 --method contrastive --arch resnet50
|
| 58 |
+
python -m train --dataset tiny_in --epoch 1000 --lr 2e-3 --emb 128 --method contrastive --arch resnet50
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
#### BYOL
|
| 62 |
+
```
|
| 63 |
+
python -m train --dataset cifar10 --epoch 1000 --lr 3e-3 --emb 64 --method byol
|
| 64 |
+
python -m train --dataset cifar100 --epoch 1000 --lr 3e-3 --emb 64 --method byol
|
| 65 |
+
python -m train --dataset stl10 --epoch 2000 --lr 2e-3 --emb 128 --method byol
|
| 66 |
+
python -m train --dataset tiny_in --epoch 1000 --lr 2e-3 --emb 128 --method byol
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
#### ImageNet-100
|
| 70 |
+
```
|
| 71 |
+
python -m train --dataset imagenet --epoch 240 --lr 2e-3 --emb 128 --w_size 256 --crop_s0 0.08 --cj0 0.8 --cj1 0.8 --cj2 0.8 --cj3 0.2 --gs_p 0.2
|
| 72 |
+
python -m train --dataset imagenet --epoch 240 --lr 2e-3 --num_samples 4 --bs 256 --emb 128 --w_size 256 --crop_s0 0.08 --cj0 0.8 --cj1 0.8 --cj2 0.8 --cj3 0.2 --gs_p 0.2
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
Use `--no_norm` to disable normalization (for Euclidean distance).
|
| 76 |
+
|
| 77 |
+
## Citation
|
| 78 |
+
```
|
| 79 |
+
@inproceedings{ermolov2021whitening,
|
| 80 |
+
title={Whitening for self-supervised representation learning},
|
| 81 |
+
author={Ermolov, Aleksandr and Siarohin, Aliaksandr and Sangineto, Enver and Sebe, Nicu},
|
| 82 |
+
booktitle={International Conference on Machine Learning},
|
| 83 |
+
pages={3015--3024},
|
| 84 |
+
year={2021},
|
| 85 |
+
organization={PMLR}
|
| 86 |
+
}
|
| 87 |
+
```
|
ssl-sota/cfg.py
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
import argparse
|
| 3 |
+
from torchvision import models
|
| 4 |
+
import multiprocessing
|
| 5 |
+
from datasets import DS_LIST
|
| 6 |
+
from methods import METHOD_LIST
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_cfg():
|
| 10 |
+
""" generates configuration from user input in console """
|
| 11 |
+
parser = argparse.ArgumentParser(description="")
|
| 12 |
+
parser.add_argument(
|
| 13 |
+
"--method", type=str, choices=METHOD_LIST, default="w_mse", help="loss type",
|
| 14 |
+
)
|
| 15 |
+
parser.add_argument(
|
| 16 |
+
"--wandb",
|
| 17 |
+
type=str,
|
| 18 |
+
default="ssl-sota",
|
| 19 |
+
help="name of the project for logging at https://wandb.ai",
|
| 20 |
+
)
|
| 21 |
+
parser.add_argument(
|
| 22 |
+
"--byol_tau", type=float, default=0.99, help="starting tau for byol loss"
|
| 23 |
+
)
|
| 24 |
+
parser.add_argument(
|
| 25 |
+
"--num_samples",
|
| 26 |
+
type=int,
|
| 27 |
+
default=2,
|
| 28 |
+
help="number of samples (d) generated from each image",
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
addf = partial(parser.add_argument, type=float)
|
| 32 |
+
addf("--cj0", default=0.4, help="color jitter brightness")
|
| 33 |
+
addf("--cj1", default=0.4, help="color jitter contrast")
|
| 34 |
+
addf("--cj2", default=0.4, help="color jitter saturation")
|
| 35 |
+
addf("--cj3", default=0.1, help="color jitter hue")
|
| 36 |
+
addf("--cj_p", default=0.8, help="color jitter probability")
|
| 37 |
+
addf("--gs_p", default=0.1, help="grayscale probability")
|
| 38 |
+
addf("--crop_s0", default=0.2, help="crop size from")
|
| 39 |
+
addf("--crop_s1", default=1.0, help="crop size to")
|
| 40 |
+
addf("--crop_r0", default=0.75, help="crop ratio from")
|
| 41 |
+
addf("--crop_r1", default=(4 / 3), help="crop ratio to")
|
| 42 |
+
addf("--hf_p", default=0.5, help="horizontal flip probability")
|
| 43 |
+
|
| 44 |
+
parser.add_argument(
|
| 45 |
+
"--no_lr_warmup",
|
| 46 |
+
dest="lr_warmup",
|
| 47 |
+
action="store_false",
|
| 48 |
+
help="do not use learning rate warmup",
|
| 49 |
+
)
|
| 50 |
+
parser.add_argument(
|
| 51 |
+
"--no_add_bn", dest="add_bn", action="store_false", help="do not use BN in head"
|
| 52 |
+
)
|
| 53 |
+
parser.add_argument("--knn", type=int, default=5, help="k in k-nn classifier")
|
| 54 |
+
parser.add_argument("--fname", type=str, help="load model from file")
|
| 55 |
+
parser.add_argument(
|
| 56 |
+
"--lr_step",
|
| 57 |
+
type=str,
|
| 58 |
+
choices=["cos", "step", "none"],
|
| 59 |
+
default="step",
|
| 60 |
+
help="learning rate schedule type",
|
| 61 |
+
)
|
| 62 |
+
parser.add_argument("--lr", type=float, default=1e-3, help="learning rate")
|
| 63 |
+
parser.add_argument(
|
| 64 |
+
"--eta_min", type=float, default=0, help="min learning rate (for --lr_step cos)"
|
| 65 |
+
)
|
| 66 |
+
parser.add_argument(
|
| 67 |
+
"--adam_l2", type=float, default=1e-6, help="weight decay (L2 penalty)"
|
| 68 |
+
)
|
| 69 |
+
parser.add_argument("--T0", type=int, help="period (for --lr_step cos)")
|
| 70 |
+
parser.add_argument(
|
| 71 |
+
"--Tmult", type=int, default=1, help="period factor (for --lr_step cos)"
|
| 72 |
+
)
|
| 73 |
+
parser.add_argument(
|
| 74 |
+
"--w_eps", type=float, default=1e-4, help="eps for stability for whitening"
|
| 75 |
+
)
|
| 76 |
+
parser.add_argument(
|
| 77 |
+
"--head_layers", type=int, default=2, help="number of FC layers in head"
|
| 78 |
+
)
|
| 79 |
+
parser.add_argument(
|
| 80 |
+
"--head_size", type=int, default=1024, help="size of FC layers in head"
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
parser.add_argument(
|
| 84 |
+
"--w_size", type=int, default=128, help="size of sub-batch for W-MSE loss"
|
| 85 |
+
)
|
| 86 |
+
parser.add_argument(
|
| 87 |
+
"--w_iter",
|
| 88 |
+
type=int,
|
| 89 |
+
default=1,
|
| 90 |
+
help="iterations for whitening matrix estimation",
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
parser.add_argument(
|
| 94 |
+
"--no_norm", dest="norm", action="store_false", help="don't normalize latents",
|
| 95 |
+
)
|
| 96 |
+
parser.add_argument(
|
| 97 |
+
"--tau", type=float, default=0.5, help="contrastive loss temperature"
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
parser.add_argument("--epoch", type=int, default=200, help="total epoch number")
|
| 101 |
+
parser.add_argument(
|
| 102 |
+
"--eval_every_drop",
|
| 103 |
+
type=int,
|
| 104 |
+
default=5,
|
| 105 |
+
help="how often to evaluate after learning rate drop",
|
| 106 |
+
)
|
| 107 |
+
parser.add_argument(
|
| 108 |
+
"--eval_every", type=int, default=20, help="how often to evaluate"
|
| 109 |
+
)
|
| 110 |
+
parser.add_argument("--emb", type=int, default=64, help="embedding size")
|
| 111 |
+
parser.add_argument(
|
| 112 |
+
"--bs", type=int, default=384, help="number of original images in batch N",
|
| 113 |
+
)
|
| 114 |
+
parser.add_argument(
|
| 115 |
+
"--drop",
|
| 116 |
+
type=int,
|
| 117 |
+
nargs="*",
|
| 118 |
+
default=[50, 25],
|
| 119 |
+
help="milestones for learning rate decay (0 = last epoch)",
|
| 120 |
+
)
|
| 121 |
+
parser.add_argument(
|
| 122 |
+
"--drop_gamma",
|
| 123 |
+
type=float,
|
| 124 |
+
default=0.2,
|
| 125 |
+
help="multiplicative factor of learning rate decay",
|
| 126 |
+
)
|
| 127 |
+
parser.add_argument(
|
| 128 |
+
"--arch",
|
| 129 |
+
type=str,
|
| 130 |
+
choices=[x for x in dir(models) if "resn" in x],
|
| 131 |
+
default="resnet18",
|
| 132 |
+
help="encoder architecture",
|
| 133 |
+
)
|
| 134 |
+
parser.add_argument("--dataset", type=str, choices=DS_LIST, default="cifar10")
|
| 135 |
+
parser.add_argument(
|
| 136 |
+
"--num_workers",
|
| 137 |
+
type=int,
|
| 138 |
+
default=0,
|
| 139 |
+
help="dataset workers number",
|
| 140 |
+
)
|
| 141 |
+
parser.add_argument(
|
| 142 |
+
"--clf",
|
| 143 |
+
type=str,
|
| 144 |
+
default="sgd",
|
| 145 |
+
choices=["sgd", "knn", "lbfgs"],
|
| 146 |
+
help="classifier for test.py",
|
| 147 |
+
)
|
| 148 |
+
parser.add_argument(
|
| 149 |
+
"--eval_head", action="store_true", help="eval head output instead of model",
|
| 150 |
+
)
|
| 151 |
+
parser.add_argument("--imagenet_path", type=str, default="~/IN100/")
|
| 152 |
+
return parser.parse_args()
|
ssl-sota/datasets/__init__.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .cifar10 import CIFAR10
|
| 2 |
+
from .cifar100 import CIFAR100
|
| 3 |
+
from .stl10 import STL10
|
| 4 |
+
from .tiny_in import TinyImageNet
|
| 5 |
+
from .imagenet import ImageNet
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
DS_LIST = ["cifar10", "cifar100", "stl10", "tinyimagenet", "imagenet"]
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_ds(name):
|
| 12 |
+
assert name in DS_LIST
|
| 13 |
+
if name == "cifar10":
|
| 14 |
+
return CIFAR10
|
| 15 |
+
elif name == "cifar100":
|
| 16 |
+
return CIFAR100
|
| 17 |
+
elif name == "stl10":
|
| 18 |
+
return STL10
|
| 19 |
+
elif name == "tinyimagenet":
|
| 20 |
+
return TinyImageNet
|
| 21 |
+
elif name == "imagenet":
|
| 22 |
+
return ImageNet
|
ssl-sota/datasets/base.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABCMeta, abstractmethod
|
| 2 |
+
from functools import lru_cache
|
| 3 |
+
from torch.utils.data import DataLoader
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class BaseDataset(metaclass=ABCMeta):
|
| 7 |
+
"""
|
| 8 |
+
base class for datasets, it includes 3 types:
|
| 9 |
+
- for self-supervised training,
|
| 10 |
+
- for classifier training for evaluation,
|
| 11 |
+
- for testing
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
def __init__(
|
| 15 |
+
self, bs_train, aug_cfg, num_workers, bs_clf=1000, bs_test=1000,
|
| 16 |
+
):
|
| 17 |
+
self.aug_cfg = aug_cfg
|
| 18 |
+
self.bs_train, self.bs_clf, self.bs_test = bs_train, bs_clf, bs_test
|
| 19 |
+
self.num_workers = num_workers
|
| 20 |
+
|
| 21 |
+
@abstractmethod
|
| 22 |
+
def ds_train(self):
|
| 23 |
+
raise NotImplementedError
|
| 24 |
+
|
| 25 |
+
@abstractmethod
|
| 26 |
+
def ds_clf(self):
|
| 27 |
+
raise NotImplementedError
|
| 28 |
+
|
| 29 |
+
@abstractmethod
|
| 30 |
+
def ds_test(self):
|
| 31 |
+
raise NotImplementedError
|
| 32 |
+
|
| 33 |
+
@property
|
| 34 |
+
@lru_cache()
|
| 35 |
+
def train(self):
|
| 36 |
+
return DataLoader(
|
| 37 |
+
dataset=self.ds_train(),
|
| 38 |
+
batch_size=self.bs_train,
|
| 39 |
+
shuffle=True,
|
| 40 |
+
num_workers=self.num_workers,
|
| 41 |
+
pin_memory=True,
|
| 42 |
+
drop_last=True,
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
@property
|
| 46 |
+
@lru_cache()
|
| 47 |
+
def clf(self):
|
| 48 |
+
return DataLoader(
|
| 49 |
+
dataset=self.ds_clf(),
|
| 50 |
+
batch_size=self.bs_clf,
|
| 51 |
+
shuffle=True,
|
| 52 |
+
num_workers=self.num_workers,
|
| 53 |
+
pin_memory=True,
|
| 54 |
+
drop_last=True,
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
@property
|
| 58 |
+
@lru_cache()
|
| 59 |
+
def test(self):
|
| 60 |
+
return DataLoader(
|
| 61 |
+
dataset=self.ds_test(),
|
| 62 |
+
batch_size=self.bs_test,
|
| 63 |
+
shuffle=False,
|
| 64 |
+
num_workers=self.num_workers,
|
| 65 |
+
pin_memory=True,
|
| 66 |
+
drop_last=False,
|
| 67 |
+
)
|
ssl-sota/datasets/cifar10.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torchvision.datasets import CIFAR10 as C10
|
| 2 |
+
import torchvision.transforms as T
|
| 3 |
+
from .transforms import MultiSample, aug_transform
|
| 4 |
+
from .base import BaseDataset
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def base_transform():
|
| 8 |
+
return T.Compose(
|
| 9 |
+
[T.ToTensor(), T.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))]
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class CIFAR10(BaseDataset):
|
| 14 |
+
def ds_train(self):
|
| 15 |
+
t = MultiSample(
|
| 16 |
+
aug_transform(32, base_transform, self.aug_cfg), n=self.aug_cfg.num_samples
|
| 17 |
+
)
|
| 18 |
+
return C10(root="/mnt/store/wbandar1/datasets/", train=True, download=True, transform=t)
|
| 19 |
+
|
| 20 |
+
def ds_clf(self):
|
| 21 |
+
t = base_transform()
|
| 22 |
+
return C10(root="/mnt/store/wbandar1/datasets/", train=True, download=True, transform=t)
|
| 23 |
+
|
| 24 |
+
def ds_test(self):
|
| 25 |
+
t = base_transform()
|
| 26 |
+
return C10(root="/mnt/store/wbandar1/datasets/", train=False, download=True, transform=t)
|