
Commit
•
c48909e
1
Parent(s):
82d1638
Upload 25 files
Browse files- .gitattributes +35 -35
- LICENSE.TXT +60 -0
- README.md +135 -0
- image_quality_one_step.png +0 -0
- model.safetensors +3 -0
- model_index.json +41 -0
- output_tile.jpg +0 -0
- prompt_alignment_one_step.png +0 -0
- scheduler/scheduler_config.json +17 -0
- text_encoder/config.json +24 -0
- text_encoder_2/config.json +24 -0
- text_encoder_2/model.onnx_data +3 -0
- tokenizer/merges.txt +0 -0
- tokenizer/special_tokens_map.json +30 -0
- tokenizer/tokenizer_config.json +30 -0
- tokenizer/vocab.json +0 -0
- tokenizer_2/merges.txt +0 -0
- tokenizer_2/special_tokens_map.json +24 -0
- tokenizer_2/tokenizer_config.json +38 -0
- tokenizer_2/vocab.json +0 -0
- unet/config.json +72 -0
- unet/model.onnx_data +3 -0
- vae/config.json +31 -0
- vae_decoder/config.json +31 -0
- vae_encoder/config.json +31 -0
.gitattributes
CHANGED
|
@@ -1,35 +1,35 @@
|
|
| 1 |
-
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
-
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
-
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
-
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
-
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
-
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
-
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
-
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
-
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
-
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
-
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
-
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
-
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
-
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
-
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
-
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
-
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
-
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
-
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
LICENSE.TXT
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
STABILITY AI NON-COMMERCIAL RESEARCH COMMUNITY LICENSE AGREEMENT
|
| 2 |
+
Dated: November 28, 2023
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
By using or distributing any portion or element of the Models, Software, Software Products or Derivative Works, you agree to be bound by this Agreement.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
"Agreement" means this Stable Non-Commercial Research Community License Agreement.
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
“AUP” means the Stability AI Acceptable Use Policy available at https://stability.ai/use-policy, as may be updated from time to time.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
"Derivative Work(s)” means (a) any derivative work of the Software Products as recognized by U.S. copyright laws and (b) any modifications to a Model, and any other model created which is based on or derived from the Model or the Model’s output. For clarity, Derivative Works do not include the output of any Model.
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
“Documentation” means any specifications, manuals, documentation, and other written information provided by Stability AI related to the Software.
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity's behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
“Model(s)" means, collectively, Stability AI’s proprietary models and algorithms, including machine-learning models, trained model weights and other elements of the foregoing, made available under this Agreement.
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
“Non-Commercial Uses” means exercising any of the rights granted herein for the purpose of research or non-commercial purposes. Non-Commercial Uses does not include any production use of the Software Products or any Derivative Works.
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
"Stability AI" or "we" means Stability AI Ltd. and its affiliates.
|
| 30 |
+
|
| 31 |
+
"Software" means Stability AI’s proprietary software made available under this Agreement.
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
“Software Products” means the Models, Software and Documentation, individually or in any combination.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
1. License Rights and Redistribution.
|
| 39 |
+
|
| 40 |
+
a. Subject to your compliance with this Agreement, the AUP (which is hereby incorporated herein by reference), and the Documentation, Stability AI grants you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty free and limited license under Stability AI’s intellectual property or other rights owned or controlled by Stability AI embodied in the Software Products to use, reproduce, distribute, and create Derivative Works of, the Software Products, in each case for Non-Commercial Uses only.
|
| 41 |
+
|
| 42 |
+
b. You may not use the Software Products or Derivative Works to enable third parties to use the Software Products or Derivative Works as part of your hosted service or via your APIs, whether you are adding substantial additional functionality thereto or not. Merely distributing the Software Products or Derivative Works for download online without offering any related service (ex. by distributing the Models on HuggingFace) is not a violation of this subsection. If you wish to use the Software Products or any Derivative Works for commercial or production use or you wish to make the Software Products or any Derivative Works available to third parties via your hosted service or your APIs, contact Stability AI at https://stability.ai/contact.
|
| 43 |
+
|
| 44 |
+
c. If you distribute or make the Software Products, or any Derivative Works thereof, available to a third party, the Software Products, Derivative Works, or any portion thereof, respectively, will remain subject to this Agreement and you must (i) provide a copy of this Agreement to such third party, and (ii) retain the following attribution notice within a "Notice" text file distributed as a part of such copies: "This Stability AI Model is licensed under the Stability AI Non-Commercial Research Community License, Copyright (c) Stability AI Ltd. All Rights Reserved.” If you create a Derivative Work of a Software Product, you may add your own attribution notices to the Notice file included with the Software Product, provided that you clearly indicate which attributions apply to the Software Product and you must state in the NOTICE file that you changed the Software Product and how it was modified.
|
| 45 |
+
|
| 46 |
+
2. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE SOFTWARE PRODUCTS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE SOFTWARE PRODUCTS, DERIVATIVE WORKS OR ANY OUTPUT OR RESULTS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE SOFTWARE PRODUCTS, DERIVATIVE WORKS AND ANY OUTPUT AND RESULTS.
|
| 47 |
+
|
| 48 |
+
3. Limitation of Liability. IN NO EVENT WILL STABILITY AI OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY DIRECT, INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF STABILITY AI OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
|
| 49 |
+
|
| 50 |
+
4. Intellectual Property.
|
| 51 |
+
|
| 52 |
+
a. No trademark licenses are granted under this Agreement, and in connection with the Software Products or Derivative Works, neither Stability AI nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Software Products or Derivative Works.
|
| 53 |
+
|
| 54 |
+
b. Subject to Stability AI’s ownership of the Software Products and Derivative Works made by or for Stability AI, with respect to any Derivative Works that are made by you, as between you and Stability AI, you are and will be the owner of such Derivative Works
|
| 55 |
+
|
| 56 |
+
c. If you institute litigation or other proceedings against Stability AI (including a cross-claim or counterclaim in a lawsuit) alleging that the Software Products, Derivative Works or associated outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Stability AI from and against any claim by any third party arising out of or related to your use or distribution of the Software Products or Derivative Works in violation of this Agreement.
|
| 57 |
+
|
| 58 |
+
5. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Software Products and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Stability AI may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of any Software Products or Derivative Works. Sections 2-4 shall survive the termination of this Agreement.
|
| 59 |
+
|
| 60 |
+
6. Governing Law. This Agreement will be governed by and construed in accordance with the laws of the United States and the State of California without regard to choice of law principles.
|
README.md
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pipeline_tag: text-to-image
|
| 3 |
+
inference: false
|
| 4 |
+
license: other
|
| 5 |
+
license_name: sai-nc-community
|
| 6 |
+
license_link: https://huggingface.co/stabilityai/sdxl-turbo/blob/main/LICENSE.TXT
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# SDXL-Turbo Model Card
|
| 10 |
+
|
| 11 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 12 |
+

|
| 13 |
+
SDXL-Turbo is a fast generative text-to-image model that can synthesize photorealistic images from a text prompt in a single network evaluation.
|
| 14 |
+
A real-time demo is available here: http://clipdrop.co/stable-diffusion-turbo
|
| 15 |
+
|
| 16 |
+
Please note: For commercial use, please refer to https://stability.ai/membership.
|
| 17 |
+
|
| 18 |
+
## Model Details
|
| 19 |
+
|
| 20 |
+
### Model Description
|
| 21 |
+
SDXL-Turbo is a distilled version of [SDXL 1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), trained for real-time synthesis.
|
| 22 |
+
SDXL-Turbo is based on a novel training method called Adversarial Diffusion Distillation (ADD) (see the [technical report](https://stability.ai/research/adversarial-diffusion-distillation)), which allows sampling large-scale foundational
|
| 23 |
+
image diffusion models in 1 to 4 steps at high image quality.
|
| 24 |
+
This approach uses score distillation to leverage large-scale off-the-shelf image diffusion models as a teacher signal and combines this with an
|
| 25 |
+
adversarial loss to ensure high image fidelity even in the low-step regime of one or two sampling steps.
|
| 26 |
+
|
| 27 |
+
- **Developed by:** Stability AI
|
| 28 |
+
- **Funded by:** Stability AI
|
| 29 |
+
- **Model type:** Generative text-to-image model
|
| 30 |
+
- **Finetuned from model:** [SDXL 1.0 Base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
|
| 31 |
+
|
| 32 |
+
### Model Sources
|
| 33 |
+
|
| 34 |
+
For research purposes, we recommend our `generative-models` Github repository (https://github.com/Stability-AI/generative-models),
|
| 35 |
+
which implements the most popular diffusion frameworks (both training and inference).
|
| 36 |
+
|
| 37 |
+
- **Repository:** https://github.com/Stability-AI/generative-models
|
| 38 |
+
- **Paper:** https://stability.ai/research/adversarial-diffusion-distillation
|
| 39 |
+
- **Demo:** http://clipdrop.co/stable-diffusion-turbo
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
## Evaluation
|
| 43 |
+

|
| 44 |
+

|
| 45 |
+
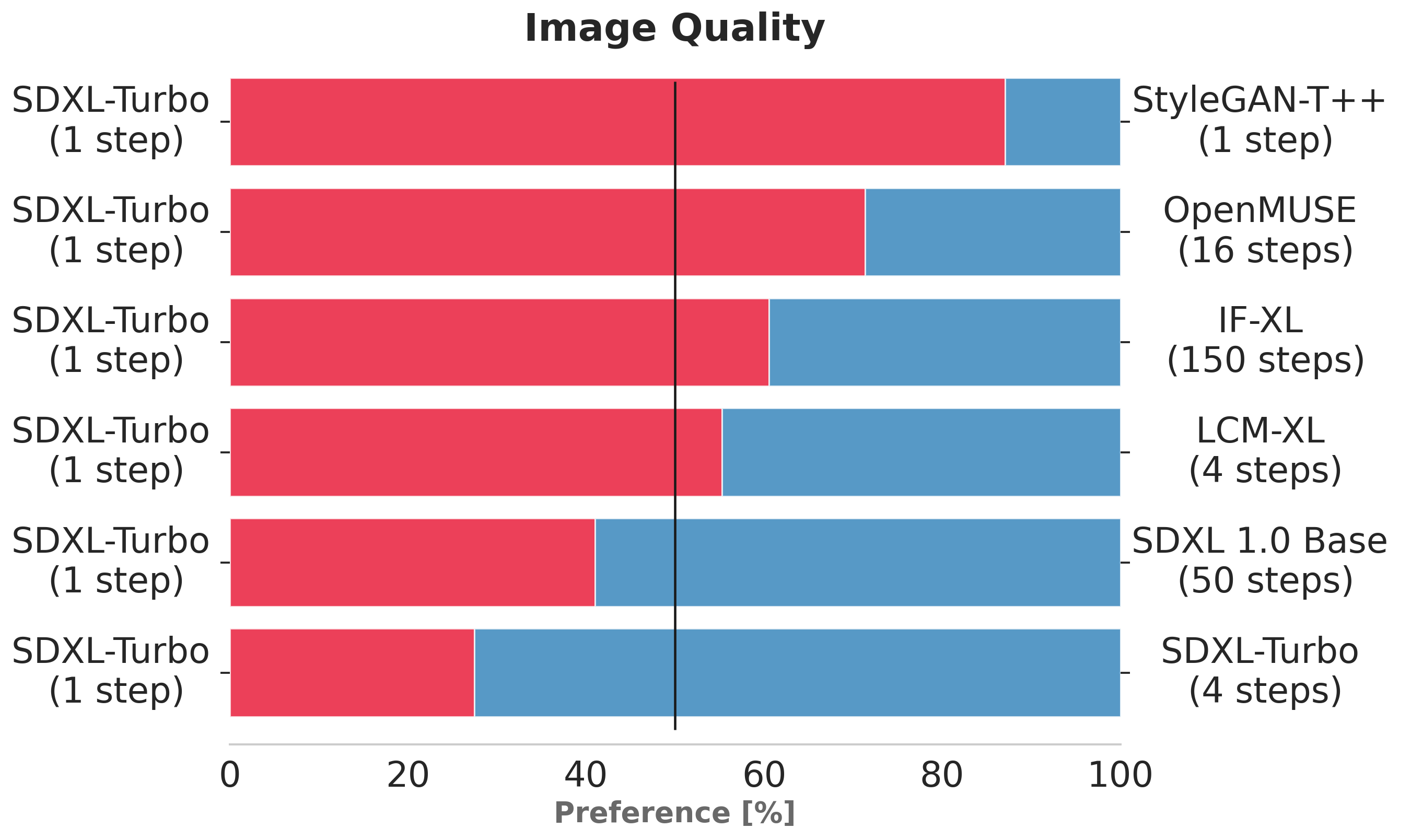
The charts above evaluate user preference for SDXL-Turbo over other single- and multi-step models.
|
| 46 |
+
SDXL-Turbo evaluated at a single step is preferred by human voters in terms of image quality and prompt following over LCM-XL evaluated at four (or fewer) steps.
|
| 47 |
+
In addition, we see that using four steps for SDXL-Turbo further improves performance.
|
| 48 |
+
For details on the user study, we refer to the [research paper](https://stability.ai/research/adversarial-diffusion-distillation).
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
## Uses
|
| 52 |
+
|
| 53 |
+
### Direct Use
|
| 54 |
+
|
| 55 |
+
The model is intended for both non-commercial and commercial usage. You can use this model for non-commercial or research purposes under this [license](https://huggingface.co/stabilityai/sdxl-turbo/blob/main/LICENSE.TXT). Possible research areas and tasks include
|
| 56 |
+
|
| 57 |
+
- Research on generative models.
|
| 58 |
+
- Research on real-time applications of generative models.
|
| 59 |
+
- Research on the impact of real-time generative models.
|
| 60 |
+
- Safe deployment of models which have the potential to generate harmful content.
|
| 61 |
+
- Probing and understanding the limitations and biases of generative models.
|
| 62 |
+
- Generation of artworks and use in design and other artistic processes.
|
| 63 |
+
- Applications in educational or creative tools.
|
| 64 |
+
|
| 65 |
+
For commercial use, please refer to https://stability.ai/membership.
|
| 66 |
+
|
| 67 |
+
Excluded uses are described below.
|
| 68 |
+
|
| 69 |
+
### Diffusers
|
| 70 |
+
|
| 71 |
+
```
|
| 72 |
+
pip install diffusers transformers accelerate --upgrade
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
- **Text-to-image**:
|
| 76 |
+
|
| 77 |
+
SDXL-Turbo does not make use of `guidance_scale` or `negative_prompt`, we disable it with `guidance_scale=0.0`.
|
| 78 |
+
Preferably, the model generates images of size 512x512 but higher image sizes work as well.
|
| 79 |
+
A **single step** is enough to generate high quality images.
|
| 80 |
+
|
| 81 |
+
```py
|
| 82 |
+
from diffusers import AutoPipelineForText2Image
|
| 83 |
+
import torch
|
| 84 |
+
|
| 85 |
+
pipe = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
|
| 86 |
+
pipe.to("cuda")
|
| 87 |
+
|
| 88 |
+
prompt = "A cinematic shot of a baby racoon wearing an intricate italian priest robe."
|
| 89 |
+
|
| 90 |
+
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
- **Image-to-image**:
|
| 94 |
+
|
| 95 |
+
When using SDXL-Turbo for image-to-image generation, make sure that `num_inference_steps` * `strength` is larger or equal
|
| 96 |
+
to 1. The image-to-image pipeline will run for `int(num_inference_steps * strength)` steps, *e.g.* 0.5 * 2.0 = 1 step in our example
|
| 97 |
+
below.
|
| 98 |
+
|
| 99 |
+
```py
|
| 100 |
+
from diffusers import AutoPipelineForImage2Image
|
| 101 |
+
from diffusers.utils import load_image
|
| 102 |
+
import torch
|
| 103 |
+
|
| 104 |
+
pipe = AutoPipelineForImage2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
|
| 105 |
+
pipe.to("cuda")
|
| 106 |
+
|
| 107 |
+
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png").resize((512, 512))
|
| 108 |
+
|
| 109 |
+
prompt = "cat wizard, gandalf, lord of the rings, detailed, fantasy, cute, adorable, Pixar, Disney, 8k"
|
| 110 |
+
|
| 111 |
+
image = pipe(prompt, image=init_image, num_inference_steps=2, strength=0.5, guidance_scale=0.0).images[0]
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
### Out-of-Scope Use
|
| 115 |
+
|
| 116 |
+
The model was not trained to be factual or true representations of people or events,
|
| 117 |
+
and therefore using the model to generate such content is out-of-scope for the abilities of this model.
|
| 118 |
+
The model should not be used in any way that violates Stability AI's [Acceptable Use Policy](https://stability.ai/use-policy).
|
| 119 |
+
|
| 120 |
+
## Limitations and Bias
|
| 121 |
+
|
| 122 |
+
### Limitations
|
| 123 |
+
- The generated images are of a fixed resolution (512x512 pix), and the model does not achieve perfect photorealism.
|
| 124 |
+
- The model cannot render legible text.
|
| 125 |
+
- Faces and people in general may not be generated properly.
|
| 126 |
+
- The autoencoding part of the model is lossy.
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
### Recommendations
|
| 130 |
+
|
| 131 |
+
The model is intended for both non-commercial and commercial usage.
|
| 132 |
+
|
| 133 |
+
## How to Get Started with the Model
|
| 134 |
+
|
| 135 |
+
Check out https://github.com/Stability-AI/generative-models
|
image_quality_one_step.png
ADDED
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e869ac7d6942cb327d68d5ed83a40447aadf20e0c3358d98b2cc9e270db0da26
|
| 3 |
+
size 6938081905
|
model_index.json
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "StableDiffusionXLPipeline",
|
| 3 |
+
"_diffusers_version": "0.24.0.dev0",
|
| 4 |
+
"feature_extractor": [
|
| 5 |
+
null,
|
| 6 |
+
null
|
| 7 |
+
],
|
| 8 |
+
"force_zeros_for_empty_prompt": true,
|
| 9 |
+
"image_encoder": [
|
| 10 |
+
null,
|
| 11 |
+
null
|
| 12 |
+
],
|
| 13 |
+
"scheduler": [
|
| 14 |
+
"diffusers",
|
| 15 |
+
"EulerAncestralDiscreteScheduler"
|
| 16 |
+
],
|
| 17 |
+
"text_encoder": [
|
| 18 |
+
"transformers",
|
| 19 |
+
"CLIPTextModel"
|
| 20 |
+
],
|
| 21 |
+
"text_encoder_2": [
|
| 22 |
+
"transformers",
|
| 23 |
+
"CLIPTextModelWithProjection"
|
| 24 |
+
],
|
| 25 |
+
"tokenizer": [
|
| 26 |
+
"transformers",
|
| 27 |
+
"CLIPTokenizer"
|
| 28 |
+
],
|
| 29 |
+
"tokenizer_2": [
|
| 30 |
+
"transformers",
|
| 31 |
+
"CLIPTokenizer"
|
| 32 |
+
],
|
| 33 |
+
"unet": [
|
| 34 |
+
"diffusers",
|
| 35 |
+
"UNet2DConditionModel"
|
| 36 |
+
],
|
| 37 |
+
"vae": [
|
| 38 |
+
"diffusers",
|
| 39 |
+
"AutoencoderKL"
|
| 40 |
+
]
|
| 41 |
+
}
|
output_tile.jpg
ADDED

|
prompt_alignment_one_step.png
ADDED

|
scheduler/scheduler_config.json
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "EulerAncestralDiscreteScheduler",
|
| 3 |
+
"_diffusers_version": "0.24.0.dev0",
|
| 4 |
+
"beta_end": 0.012,
|
| 5 |
+
"beta_schedule": "scaled_linear",
|
| 6 |
+
"beta_start": 0.00085,
|
| 7 |
+
"clip_sample": false,
|
| 8 |
+
"interpolation_type": "linear",
|
| 9 |
+
"num_train_timesteps": 1000,
|
| 10 |
+
"prediction_type": "epsilon",
|
| 11 |
+
"sample_max_value": 1.0,
|
| 12 |
+
"set_alpha_to_one": false,
|
| 13 |
+
"skip_prk_steps": true,
|
| 14 |
+
"steps_offset": 1,
|
| 15 |
+
"timestep_spacing": "trailing",
|
| 16 |
+
"trained_betas": null
|
| 17 |
+
}
|
text_encoder/config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"CLIPTextModel"
|
| 4 |
+
],
|
| 5 |
+
"attention_dropout": 0.0,
|
| 6 |
+
"bos_token_id": 0,
|
| 7 |
+
"dropout": 0.0,
|
| 8 |
+
"eos_token_id": 2,
|
| 9 |
+
"hidden_act": "quick_gelu",
|
| 10 |
+
"hidden_size": 768,
|
| 11 |
+
"initializer_factor": 1.0,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 3072,
|
| 14 |
+
"layer_norm_eps": 1e-05,
|
| 15 |
+
"max_position_embeddings": 77,
|
| 16 |
+
"model_type": "clip_text_model",
|
| 17 |
+
"num_attention_heads": 12,
|
| 18 |
+
"num_hidden_layers": 12,
|
| 19 |
+
"pad_token_id": 1,
|
| 20 |
+
"projection_dim": 768,
|
| 21 |
+
"torch_dtype": "float16",
|
| 22 |
+
"transformers_version": "4.36.0.dev0",
|
| 23 |
+
"vocab_size": 49408
|
| 24 |
+
}
|
text_encoder_2/config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"CLIPTextModelWithProjection"
|
| 4 |
+
],
|
| 5 |
+
"attention_dropout": 0.0,
|
| 6 |
+
"bos_token_id": 0,
|
| 7 |
+
"dropout": 0.0,
|
| 8 |
+
"eos_token_id": 2,
|
| 9 |
+
"hidden_act": "gelu",
|
| 10 |
+
"hidden_size": 1280,
|
| 11 |
+
"initializer_factor": 1.0,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 5120,
|
| 14 |
+
"layer_norm_eps": 1e-05,
|
| 15 |
+
"max_position_embeddings": 77,
|
| 16 |
+
"model_type": "clip_text_model",
|
| 17 |
+
"num_attention_heads": 20,
|
| 18 |
+
"num_hidden_layers": 32,
|
| 19 |
+
"pad_token_id": 1,
|
| 20 |
+
"projection_dim": 1280,
|
| 21 |
+
"torch_dtype": "float16",
|
| 22 |
+
"transformers_version": "4.36.0.dev0",
|
| 23 |
+
"vocab_size": 49408
|
| 24 |
+
}
|
text_encoder_2/model.onnx_data
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0c29d6ace4f348ccbcd302ab0d858994e64240a5b54d7c5ef431a88f2f287e2c
|
| 3 |
+
size 2778639360
|
tokenizer/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer/special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|startoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": true,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": true,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<|endoftext|>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<|endoftext|>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": true,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
tokenizer/tokenizer_config.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"49406": {
|
| 5 |
+
"content": "<|startoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": true,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"49407": {
|
| 13 |
+
"content": "<|endoftext|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": true,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
}
|
| 20 |
+
},
|
| 21 |
+
"bos_token": "<|startoftext|>",
|
| 22 |
+
"clean_up_tokenization_spaces": true,
|
| 23 |
+
"do_lower_case": true,
|
| 24 |
+
"eos_token": "<|endoftext|>",
|
| 25 |
+
"errors": "replace",
|
| 26 |
+
"model_max_length": 77,
|
| 27 |
+
"pad_token": "<|endoftext|>",
|
| 28 |
+
"tokenizer_class": "CLIPTokenizer",
|
| 29 |
+
"unk_token": "<|endoftext|>"
|
| 30 |
+
}
|
tokenizer/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_2/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_2/special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|startoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": true,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": true,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "!",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<|endoftext|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": true,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
tokenizer_2/tokenizer_config.json
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"0": {
|
| 5 |
+
"content": "!",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"49406": {
|
| 13 |
+
"content": "<|startoftext|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": true,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"49407": {
|
| 21 |
+
"content": "<|endoftext|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": true,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
"bos_token": "<|startoftext|>",
|
| 30 |
+
"clean_up_tokenization_spaces": true,
|
| 31 |
+
"do_lower_case": true,
|
| 32 |
+
"eos_token": "<|endoftext|>",
|
| 33 |
+
"errors": "replace",
|
| 34 |
+
"model_max_length": 77,
|
| 35 |
+
"pad_token": "!",
|
| 36 |
+
"tokenizer_class": "CLIPTokenizer",
|
| 37 |
+
"unk_token": "<|endoftext|>"
|
| 38 |
+
}
|
tokenizer_2/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
unet/config.json
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "UNet2DConditionModel",
|
| 3 |
+
"_diffusers_version": "0.24.0.dev0",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"addition_embed_type": "text_time",
|
| 6 |
+
"addition_embed_type_num_heads": 64,
|
| 7 |
+
"addition_time_embed_dim": 256,
|
| 8 |
+
"attention_head_dim": [
|
| 9 |
+
5,
|
| 10 |
+
10,
|
| 11 |
+
20
|
| 12 |
+
],
|
| 13 |
+
"attention_type": "default",
|
| 14 |
+
"block_out_channels": [
|
| 15 |
+
320,
|
| 16 |
+
640,
|
| 17 |
+
1280
|
| 18 |
+
],
|
| 19 |
+
"center_input_sample": false,
|
| 20 |
+
"class_embed_type": null,
|
| 21 |
+
"class_embeddings_concat": false,
|
| 22 |
+
"conv_in_kernel": 3,
|
| 23 |
+
"conv_out_kernel": 3,
|
| 24 |
+
"cross_attention_dim": 2048,
|
| 25 |
+
"cross_attention_norm": null,
|
| 26 |
+
"down_block_types": [
|
| 27 |
+
"DownBlock2D",
|
| 28 |
+
"CrossAttnDownBlock2D",
|
| 29 |
+
"CrossAttnDownBlock2D"
|
| 30 |
+
],
|
| 31 |
+
"downsample_padding": 1,
|
| 32 |
+
"dropout": 0.0,
|
| 33 |
+
"dual_cross_attention": false,
|
| 34 |
+
"encoder_hid_dim": null,
|
| 35 |
+
"encoder_hid_dim_type": null,
|
| 36 |
+
"flip_sin_to_cos": true,
|
| 37 |
+
"freq_shift": 0,
|
| 38 |
+
"in_channels": 4,
|
| 39 |
+
"layers_per_block": 2,
|
| 40 |
+
"mid_block_only_cross_attention": null,
|
| 41 |
+
"mid_block_scale_factor": 1,
|
| 42 |
+
"mid_block_type": "UNetMidBlock2DCrossAttn",
|
| 43 |
+
"norm_eps": 1e-05,
|
| 44 |
+
"norm_num_groups": 32,
|
| 45 |
+
"num_attention_heads": null,
|
| 46 |
+
"num_class_embeds": null,
|
| 47 |
+
"only_cross_attention": false,
|
| 48 |
+
"out_channels": 4,
|
| 49 |
+
"projection_class_embeddings_input_dim": 2816,
|
| 50 |
+
"resnet_out_scale_factor": 1.0,
|
| 51 |
+
"resnet_skip_time_act": false,
|
| 52 |
+
"resnet_time_scale_shift": "default",
|
| 53 |
+
"reverse_transformer_layers_per_block": null,
|
| 54 |
+
"sample_size": 64,
|
| 55 |
+
"time_cond_proj_dim": null,
|
| 56 |
+
"time_embedding_act_fn": null,
|
| 57 |
+
"time_embedding_dim": null,
|
| 58 |
+
"time_embedding_type": "positional",
|
| 59 |
+
"timestep_post_act": null,
|
| 60 |
+
"transformer_layers_per_block": [
|
| 61 |
+
1,
|
| 62 |
+
2,
|
| 63 |
+
10
|
| 64 |
+
],
|
| 65 |
+
"up_block_types": [
|
| 66 |
+
"CrossAttnUpBlock2D",
|
| 67 |
+
"CrossAttnUpBlock2D",
|
| 68 |
+
"UpBlock2D"
|
| 69 |
+
],
|
| 70 |
+
"upcast_attention": null,
|
| 71 |
+
"use_linear_projection": true
|
| 72 |
+
}
|
unet/model.onnx_data
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:479e70b02ced4312debca3a12506ac928f80b2ce95ad48755c9c789bd8e80ac2
|
| 3 |
+
size 10269854720
|
vae/config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AutoencoderKL",
|
| 3 |
+
"_diffusers_version": "0.24.0.dev0",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"block_out_channels": [
|
| 6 |
+
128,
|
| 7 |
+
256,
|
| 8 |
+
512,
|
| 9 |
+
512
|
| 10 |
+
],
|
| 11 |
+
"down_block_types": [
|
| 12 |
+
"DownEncoderBlock2D",
|
| 13 |
+
"DownEncoderBlock2D",
|
| 14 |
+
"DownEncoderBlock2D",
|
| 15 |
+
"DownEncoderBlock2D"
|
| 16 |
+
],
|
| 17 |
+
"force_upcast": true,
|
| 18 |
+
"in_channels": 3,
|
| 19 |
+
"latent_channels": 4,
|
| 20 |
+
"layers_per_block": 2,
|
| 21 |
+
"norm_num_groups": 32,
|
| 22 |
+
"out_channels": 3,
|
| 23 |
+
"sample_size": 1024,
|
| 24 |
+
"scaling_factor": 0.13025,
|
| 25 |
+
"up_block_types": [
|
| 26 |
+
"UpDecoderBlock2D",
|
| 27 |
+
"UpDecoderBlock2D",
|
| 28 |
+
"UpDecoderBlock2D",
|
| 29 |
+
"UpDecoderBlock2D"
|
| 30 |
+
]
|
| 31 |
+
}
|
vae_decoder/config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AutoencoderKL",
|
| 3 |
+
"_diffusers_version": "0.24.0.dev0",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"block_out_channels": [
|
| 6 |
+
128,
|
| 7 |
+
256,
|
| 8 |
+
512,
|
| 9 |
+
512
|
| 10 |
+
],
|
| 11 |
+
"down_block_types": [
|
| 12 |
+
"DownEncoderBlock2D",
|
| 13 |
+
"DownEncoderBlock2D",
|
| 14 |
+
"DownEncoderBlock2D",
|
| 15 |
+
"DownEncoderBlock2D"
|
| 16 |
+
],
|
| 17 |
+
"force_upcast": true,
|
| 18 |
+
"in_channels": 3,
|
| 19 |
+
"latent_channels": 4,
|
| 20 |
+
"layers_per_block": 2,
|
| 21 |
+
"norm_num_groups": 32,
|
| 22 |
+
"out_channels": 3,
|
| 23 |
+
"sample_size": 1024,
|
| 24 |
+
"scaling_factor": 0.13025,
|
| 25 |
+
"up_block_types": [
|
| 26 |
+
"UpDecoderBlock2D",
|
| 27 |
+
"UpDecoderBlock2D",
|
| 28 |
+
"UpDecoderBlock2D",
|
| 29 |
+
"UpDecoderBlock2D"
|
| 30 |
+
]
|
| 31 |
+
}
|
vae_encoder/config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AutoencoderKL",
|
| 3 |
+
"_diffusers_version": "0.24.0.dev0",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"block_out_channels": [
|
| 6 |
+
128,
|
| 7 |
+
256,
|
| 8 |
+
512,
|
| 9 |
+
512
|
| 10 |
+
],
|
| 11 |
+
"down_block_types": [
|
| 12 |
+
"DownEncoderBlock2D",
|
| 13 |
+
"DownEncoderBlock2D",
|
| 14 |
+
"DownEncoderBlock2D",
|
| 15 |
+
"DownEncoderBlock2D"
|
| 16 |
+
],
|
| 17 |
+
"force_upcast": true,
|
| 18 |
+
"in_channels": 3,
|
| 19 |
+
"latent_channels": 4,
|
| 20 |
+
"layers_per_block": 2,
|
| 21 |
+
"norm_num_groups": 32,
|
| 22 |
+
"out_channels": 3,
|
| 23 |
+
"sample_size": 1024,
|
| 24 |
+
"scaling_factor": 0.13025,
|
| 25 |
+
"up_block_types": [
|
| 26 |
+
"UpDecoderBlock2D",
|
| 27 |
+
"UpDecoderBlock2D",
|
| 28 |
+
"UpDecoderBlock2D",
|
| 29 |
+
"UpDecoderBlock2D"
|
| 30 |
+
]
|
| 31 |
+
}
|