
Vui Seng Chua
commited on
Commit
•
43a66d3
1
Parent(s):
46f082d
Add content
Browse files- .gitattributes +3 -0
- README.md +45 -0
- gemma-2b-it_r0.6_g64.pth +3 -0
- llama-2-chat-7b_r0.8_g128.pth +3 -0
- mistral-7b_r0.6_g64.pth +3 -0
- scripts/inspect_ovir.py +69 -0
- scripts/nncf.quantization.algorithms.weight_compression.openvino_backend.py.patch +42 -0
- scripts/patch_usage.md +4 -0
- scripts/py-llm-chatbot.py +753 -0
- scripts/readblob.py +11 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
llama-2-chat-7b_r0.8_g128.pth filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
gemma-2b-it_r0.6_g64.pth filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
mistral-7b_r0.6_g64.pth filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## OpenVINO Weight-Quantized LLMs
|
| 2 |
+
|
| 3 |
+
This repo contains binary of weight quantized by [OpenVINO](https://github.com/openvinotoolkit/openvino_notebooks/blob/main/notebooks/254-llm-chatbot/254-llm-chatbot.ipynb).
|
| 4 |
+
| LLM | ratio | group_size |
|
| 5 |
+
|----------------- |------- |------------ |
|
| 6 |
+
| llama-2-chat-7b | 0.8 | 128 |
|
| 7 |
+
| mistral-7b | 0.6 | 64 |
|
| 8 |
+
| gemma-2b-it | 0.6 | 64 |
|
| 9 |
+
|
| 10 |
+
Notes:
|
| 11 |
+
* ratio=0.8 means 80% of FC (linear) layers are 4-bit weight quantized and the rest in 8-bit.
|
| 12 |
+
* group_size refers to number of elements being considered to be quantized. e.g. group size of 128 means each output channel of the weight is split into groups of 128 for quantization.
|
| 13 |
+
* q_weight is in uint8 even it is 4-bit.
|
| 14 |
+
* scripts are for internal use only.
|
| 15 |
+
|
| 16 |
+
### Example usage of the saved blob
|
| 17 |
+
```python
|
| 18 |
+
import torch
|
| 19 |
+
|
| 20 |
+
blob_path = "./mistral-7b_r0.6_g64.pth"
|
| 21 |
+
|
| 22 |
+
blob = torch.load(blob_path)
|
| 23 |
+
|
| 24 |
+
for layer, attr in blob.items():
|
| 25 |
+
print(f"{layer:30} | q_dtype: {attr['q_dtype']:5} | orig. shape: {str(attr['original_shape']):15} | quantized_shape: {str(attr['q_weight'].shape):15}")
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
```
|
| 29 |
+
# Sample outputs:
|
| 30 |
+
.
|
| 31 |
+
.
|
| 32 |
+
layers.14.mlp.gate_proj | q_dtype: u4 | orig. shape: (11008, 4096) | quantized_shape: (11008, 32, 128)
|
| 33 |
+
layers.14.mlp.down_proj | q_dtype: u4 | orig. shape: (4096, 11008) | quantized_shape: (4096, 86, 128)
|
| 34 |
+
layers.15.self_attn.k_proj | q_dtype: u8 | orig. shape: (4096, 4096) | quantized_shape: (4096, 4096)
|
| 35 |
+
layers.15.self_attn.v_proj | q_dtype: u8 | orig. shape: (4096, 4096) | quantized_shape: (4096, 4096)
|
| 36 |
+
layers.15.self_attn.q_proj | q_dtype: u4 | orig. shape: (4096, 4096) | quantized_shape: (4096, 32, 128)
|
| 37 |
+
layers.15.self_attn.o_proj | q_dtype: u4 | orig. shape: (4096, 4096) | quantized_shape: (4096, 32, 128)
|
| 38 |
+
layers.15.mlp.up_proj | q_dtype: u4 | orig. shape: (11008, 4096) | quantized_shape: (11008, 32, 128)
|
| 39 |
+
layers.15.mlp.gate_proj | q_dtype: u4 | orig. shape: (11008, 4096) | quantized_shape: (11008, 32, 128)
|
| 40 |
+
layers.15.mlp.down_proj | q_dtype: u4 | orig. shape: (4096, 11008) | quantized_shape: (4096, 86, 128)
|
| 41 |
+
layers.16.self_attn.k_proj | q_dtype: u8 | orig. shape: (4096, 4096) | quantized_shape: (4096, 4096)
|
| 42 |
+
layers.16.self_attn.v_proj | q_dtype: u8 | orig. shape: (4096, 4096) | quantized_shape: (4096, 4096)
|
| 43 |
+
.
|
| 44 |
+
.
|
| 45 |
+
```
|
gemma-2b-it_r0.6_g64.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a65823e61c5b872ed5f4c5855ea6ae75ea1ecfeb42b5948ace767fbe8f5c19ca
|
| 3 |
+
size 3184142484
|
llama-2-chat-7b_r0.8_g128.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bbf5734d51f87eb6c90e50249928e74fa8d5c9329d593972ad7c88946df6225d
|
| 3 |
+
size 7758244264
|
mistral-7b_r0.6_g64.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9a3e42bf3286bfcc189ae4fb4e55cb63b5b4ba4c8c0256d8a396e30dea105f3f
|
| 3 |
+
size 9183667088
|
scripts/inspect_ovir.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from openvino.runtime import Core
|
| 2 |
+
from tqdm import tqdm
|
| 3 |
+
import torch
|
| 4 |
+
from collections import OrderedDict
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
def get_ir_pair(model_dir):
|
| 9 |
+
p = Path(model_dir)
|
| 10 |
+
return p/"openvino_model.xml", p/"openvino_model.bin"
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
# fc_numel = {
|
| 14 |
+
# 'llama-2-chat-7b ': {'min': 16777216, 'max': 45088768},
|
| 15 |
+
# 'mistral-7b ': {'min': 4194304, 'max': 58720256},
|
| 16 |
+
# 'gemma-2b-it': {'min': 524288, 'max': 33554432},
|
| 17 |
+
# }
|
| 18 |
+
|
| 19 |
+
fc_numel = {
|
| 20 |
+
'llama-2-chat-7b': [16777216, 45088768],
|
| 21 |
+
'mistral-7b': [4194304, 16777216, 58720256],
|
| 22 |
+
'gemma-2b-it': [524288, 4194304, 33554432],
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
compressed_weight_folder="./new_321/gemma-2b-it/INT4_compressed_weights/"
|
| 26 |
+
compressed_weight_folder="./new_321/mistral-7b/INT4_compressed_weights/"
|
| 27 |
+
compressed_weight_folder="./new_321/llama-2-chat-7b/INT4_compressed_weights/"
|
| 28 |
+
|
| 29 |
+
model_key = compressed_weight_folder.split("/")[2]
|
| 30 |
+
|
| 31 |
+
ir_xml, ir_bin = get_ir_pair(compressed_weight_folder)
|
| 32 |
+
|
| 33 |
+
ie = Core()
|
| 34 |
+
ir_model = ie.read_model(ir_xml)
|
| 35 |
+
|
| 36 |
+
model_params = OrderedDict()
|
| 37 |
+
|
| 38 |
+
# for op in tqdm(ir_model.get_ordered_ops()):
|
| 39 |
+
for op in ir_model.get_ordered_ops():
|
| 40 |
+
if 'constant' in str(op.get_type_info()).lower():
|
| 41 |
+
shape = tuple(op.get_output_shape(0))
|
| 42 |
+
numel = np.prod(shape)
|
| 43 |
+
# Note: This is to capture only Linear layers
|
| 44 |
+
# if len(shape) == 2 and shape[0] > 1 and shape[1] > 1 and shape[0] < 50000 and shape[0] != 2050:
|
| 45 |
+
|
| 46 |
+
# if (len(shape) >= 2) and (numel >= fc_numel[model_key]['min']) and (numel <= fc_numel[model_key]['max']):
|
| 47 |
+
|
| 48 |
+
if (len(shape) >= 2) and shape[-1] != 1 and numel in fc_numel[model_key]:
|
| 49 |
+
# if True:
|
| 50 |
+
print(f"{numel:15} | {str(shape):15} | {op.get_name()}")
|
| 51 |
+
layer = op.get_name()
|
| 52 |
+
|
| 53 |
+
model_params[layer] = {}
|
| 54 |
+
model_params[layer]['is_4bit'] = len(shape) == 3
|
| 55 |
+
model_params[layer]['ov_shape']= shape
|
| 56 |
+
if len(shape) == 3:
|
| 57 |
+
group_size = shape[-1]
|
| 58 |
+
|
| 59 |
+
array = op.data
|
| 60 |
+
lower_bits = array & 0x0F # Extract the lower 4 bits
|
| 61 |
+
upper_bits = array >> 4 # Extract the upper 4 bits
|
| 62 |
+
|
| 63 |
+
interleaved = []
|
| 64 |
+
for a, b in zip(upper_bits, lower_bits):
|
| 65 |
+
interleaved.append(a)
|
| 66 |
+
interleaved.append(b)
|
| 67 |
+
model_params[layer]['weight'] = np.array(interleaved).reshape(shape) #TODO must verify again
|
| 68 |
+
|
| 69 |
+
print('Done!')
|
scripts/nncf.quantization.algorithms.weight_compression.openvino_backend.py.patch
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
--- ori.openvino_backend.py 2024-03-21 12:35:49.552105914 -0700
|
| 2 |
+
+++ openvino_backend.py 2024-03-21 13:33:00.382049221 -0700
|
| 3 |
+
@@ -33,6 +33,8 @@
|
| 4 |
+
from nncf.quantization.algorithms.weight_compression.config import WeightCompressionParameters
|
| 5 |
+
from nncf.quantization.algorithms.weight_compression.weight_lowering import compress_weight
|
| 6 |
+
|
| 7 |
+
+from collections import OrderedDict
|
| 8 |
+
+import torch
|
| 9 |
+
|
| 10 |
+
class OVWeightCompressionAlgoBackend(WeightCompressionAlgoBackend):
|
| 11 |
+
def __init__(self, model: ov.Model):
|
| 12 |
+
@@ -123,6 +125,8 @@
|
| 13 |
+
def transform_model(
|
| 14 |
+
self, model: ov.Model, graph: NNCFGraph, weight_compression_parameters: Iterable[WeightCompressionParameters]
|
| 15 |
+
) -> ov.Model:
|
| 16 |
+
+ debug_wc = OrderedDict()
|
| 17 |
+
+
|
| 18 |
+
for wc_params in weight_compression_parameters:
|
| 19 |
+
compression_config = wc_params.compression_config
|
| 20 |
+
if compression_config.mode == CompressWeightsMode.NF4:
|
| 21 |
+
@@ -149,6 +153,13 @@
|
| 22 |
+
weight = Tensor(get_const_value(const_node))
|
| 23 |
+
original_shape = weight.shape
|
| 24 |
+
compressed_weight = compress_weight(weight, wc_params.reduction_axes, compression_config)
|
| 25 |
+
+ dkey = ".".join(const_node_name.split(".")[2:-1])
|
| 26 |
+
+ debug_wc[dkey] = {}
|
| 27 |
+
+ debug_wc[dkey]['original_shape'] = original_shape
|
| 28 |
+
+ debug_wc[dkey]['q_dtype'] = compression_dtype.type_name
|
| 29 |
+
+ debug_wc[dkey]['q_weight'] = compressed_weight.tensor.data
|
| 30 |
+
+ debug_wc[dkey]['q_scale'] = compressed_weight.scale.data
|
| 31 |
+
+ debug_wc[dkey]['q_zero_point'] = compressed_weight.zero_point.data
|
| 32 |
+
|
| 33 |
+
compressed_const = opset.constant(
|
| 34 |
+
compressed_weight.tensor.data, dtype=compression_dtype, name=const_node_name
|
| 35 |
+
@@ -182,6 +193,7 @@
|
| 36 |
+
# reset name_to_node_mapping
|
| 37 |
+
self.name_to_node_mapping = None
|
| 38 |
+
|
| 39 |
+
+ torch.save(debug_wc, 'llama-2-chat-7b_r0.8_g128.pth')
|
| 40 |
+
return model
|
| 41 |
+
|
| 42 |
+
@staticmethod
|
scripts/patch_usage.md
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
apply patch at
|
| 2 |
+
/data5/vchua/miniconda3/envs/sixer-240303-ovnb/lib/python3.10/site-packages/nncf/quantization/algorithms/weight_compression/
|
| 3 |
+
|
| 4 |
+
transform_model was the patch function
|
scripts/py-llm-chatbot.py
ADDED
|
@@ -0,0 +1,753 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
|
| 3 |
+
# based on
|
| 4 |
+
# https://github.com/openvinotoolkit/openvino_notebooks/blob/main/notebooks/254-llm-chatbot/254-llm-chatbot.ipynb
|
| 5 |
+
|
| 6 |
+
from config import SUPPORTED_LLM_MODELS
|
| 7 |
+
|
| 8 |
+
from transformers import AutoModelForCausalLM, AutoConfig
|
| 9 |
+
from optimum.intel.openvino import OVModelForCausalLM
|
| 10 |
+
import openvino as ov
|
| 11 |
+
from pathlib import Path
|
| 12 |
+
import shutil
|
| 13 |
+
import torch
|
| 14 |
+
import logging
|
| 15 |
+
import nncf
|
| 16 |
+
import gc
|
| 17 |
+
from converter import converters, register_configs
|
| 18 |
+
|
| 19 |
+
register_configs()
|
| 20 |
+
|
| 21 |
+
model_id = "llama-2-chat-7b"
|
| 22 |
+
# model_id = "gemma-2b-it"
|
| 23 |
+
# model_id = "red-pajama-3b-chat"
|
| 24 |
+
# model_id = "mistral-7b"
|
| 25 |
+
|
| 26 |
+
model_configuration = SUPPORTED_LLM_MODELS[model_id]
|
| 27 |
+
print(f"Selected model {model_id}")
|
| 28 |
+
|
| 29 |
+
prepare_int4_model = True
|
| 30 |
+
prepare_int8_model = False
|
| 31 |
+
prepare_fp16_model = False
|
| 32 |
+
|
| 33 |
+
from optimum.intel import OVWeightQuantizationConfig
|
| 34 |
+
|
| 35 |
+
nncf.set_log_level(logging.ERROR)
|
| 36 |
+
|
| 37 |
+
DIRNAME="new_321"
|
| 38 |
+
DIRNAME="temp"
|
| 39 |
+
|
| 40 |
+
pt_model_id = model_configuration["model_id"]
|
| 41 |
+
pt_model_name = model_id.split("-")[0]
|
| 42 |
+
model_type = AutoConfig.from_pretrained(pt_model_id, trust_remote_code=True).model_type
|
| 43 |
+
fp16_model_dir = Path(DIRNAME) / Path(model_id) / "FP16"
|
| 44 |
+
int8_model_dir = Path(DIRNAME) / Path(model_id) / "INT8_compressed_weights"
|
| 45 |
+
int4_model_dir = Path(DIRNAME) / Path(model_id) / "INT4_compressed_weights"
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def convert_to_fp16():
|
| 49 |
+
if (fp16_model_dir / "openvino_model.xml").exists():
|
| 50 |
+
return
|
| 51 |
+
if not model_configuration["remote"]:
|
| 52 |
+
remote_code = model_configuration.get("remote_code", False)
|
| 53 |
+
model_kwargs = {}
|
| 54 |
+
if remote_code:
|
| 55 |
+
model_kwargs = {
|
| 56 |
+
"trust_remote_code": True,
|
| 57 |
+
"config": AutoConfig.from_pretrained(pt_model_id, trust_remote_code=True)
|
| 58 |
+
}
|
| 59 |
+
ov_model = OVModelForCausalLM.from_pretrained(
|
| 60 |
+
pt_model_id, export=True, compile=False, load_in_8bit=False, **model_kwargs
|
| 61 |
+
)
|
| 62 |
+
ov_model.half()
|
| 63 |
+
ov_model.save_pretrained(fp16_model_dir)
|
| 64 |
+
del ov_model
|
| 65 |
+
else:
|
| 66 |
+
model_kwargs = {}
|
| 67 |
+
if "revision" in model_configuration:
|
| 68 |
+
model_kwargs["revision"] = model_configuration["revision"]
|
| 69 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 70 |
+
model_configuration["model_id"],
|
| 71 |
+
torch_dtype=torch.float32,
|
| 72 |
+
trust_remote_code=True,
|
| 73 |
+
**model_kwargs
|
| 74 |
+
)
|
| 75 |
+
converters[pt_model_name](model, fp16_model_dir)
|
| 76 |
+
del model
|
| 77 |
+
gc.collect()
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def convert_to_int8():
|
| 81 |
+
if (int8_model_dir / "openvino_model.xml").exists():
|
| 82 |
+
return
|
| 83 |
+
int8_model_dir.mkdir(parents=True, exist_ok=True)
|
| 84 |
+
if not model_configuration["remote"]:
|
| 85 |
+
remote_code = model_configuration.get("remote_code", False)
|
| 86 |
+
model_kwargs = {}
|
| 87 |
+
if remote_code:
|
| 88 |
+
model_kwargs = {
|
| 89 |
+
"trust_remote_code": True,
|
| 90 |
+
"config": AutoConfig.from_pretrained(pt_model_id, trust_remote_code=True)
|
| 91 |
+
}
|
| 92 |
+
ov_model = OVModelForCausalLM.from_pretrained(
|
| 93 |
+
pt_model_id, export=True, compile=False, load_in_8bit=True, **model_kwargs
|
| 94 |
+
)
|
| 95 |
+
ov_model.save_pretrained(int8_model_dir)
|
| 96 |
+
del ov_model
|
| 97 |
+
else:
|
| 98 |
+
convert_to_fp16()
|
| 99 |
+
ov_model = ov.Core().read_model(fp16_model_dir / "openvino_model.xml")
|
| 100 |
+
shutil.copy(fp16_model_dir / "config.json", int8_model_dir / "config.json")
|
| 101 |
+
configuration_file = fp16_model_dir / f"configuration_{model_type}.py"
|
| 102 |
+
if configuration_file.exists():
|
| 103 |
+
shutil.copy(
|
| 104 |
+
configuration_file, int8_model_dir / f"configuration_{model_type}.py"
|
| 105 |
+
)
|
| 106 |
+
compressed_model = nncf.compress_weights(ov_model)
|
| 107 |
+
ov.save_model(compressed_model, int8_model_dir / "openvino_model.xml")
|
| 108 |
+
del ov_model
|
| 109 |
+
del compressed_model
|
| 110 |
+
gc.collect()
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def convert_to_int4():
|
| 114 |
+
compression_configs = {
|
| 115 |
+
"zephyr-7b-beta": {
|
| 116 |
+
"sym": True,
|
| 117 |
+
"group_size": 64,
|
| 118 |
+
"ratio": 0.6,
|
| 119 |
+
},
|
| 120 |
+
"mistral-7b": {
|
| 121 |
+
"sym": True,
|
| 122 |
+
"group_size": 64,
|
| 123 |
+
"ratio": 0.6,
|
| 124 |
+
},
|
| 125 |
+
"minicpm-2b-dpo": {
|
| 126 |
+
"sym": True,
|
| 127 |
+
"group_size": 64,
|
| 128 |
+
"ratio": 0.6,
|
| 129 |
+
},
|
| 130 |
+
"gemma-2b-it": {
|
| 131 |
+
"sym": True,
|
| 132 |
+
"group_size": 64,
|
| 133 |
+
# "ratio": 1.0,
|
| 134 |
+
"ratio": 0.6,
|
| 135 |
+
},
|
| 136 |
+
"notus-7b-v1": {
|
| 137 |
+
"sym": True,
|
| 138 |
+
"group_size": 64,
|
| 139 |
+
"ratio": 0.6,
|
| 140 |
+
},
|
| 141 |
+
"neural-chat-7b-v3-1": {
|
| 142 |
+
"sym": True,
|
| 143 |
+
"group_size": 64,
|
| 144 |
+
"ratio": 0.6,
|
| 145 |
+
},
|
| 146 |
+
"llama-2-chat-7b": {
|
| 147 |
+
"sym": True,
|
| 148 |
+
# "group_size": 64,
|
| 149 |
+
"group_size": 128,
|
| 150 |
+
"ratio": 0.8,
|
| 151 |
+
# "ratio": 1.0,
|
| 152 |
+
},
|
| 153 |
+
"gemma-7b-it": {
|
| 154 |
+
"sym": True,
|
| 155 |
+
"group_size": 128,
|
| 156 |
+
"ratio": 1.0,
|
| 157 |
+
},
|
| 158 |
+
"chatglm2-6b": {
|
| 159 |
+
"sym": True,
|
| 160 |
+
"group_size": 128,
|
| 161 |
+
"ratio": 0.72,
|
| 162 |
+
},
|
| 163 |
+
"qwen-7b-chat": {
|
| 164 |
+
"sym": True,
|
| 165 |
+
"group_size": 128,
|
| 166 |
+
"ratio": 0.6
|
| 167 |
+
},
|
| 168 |
+
'red-pajama-3b-chat': {
|
| 169 |
+
"sym": False,
|
| 170 |
+
"group_size": 128,
|
| 171 |
+
"ratio": 0.5,
|
| 172 |
+
},
|
| 173 |
+
"default": {
|
| 174 |
+
"sym": False,
|
| 175 |
+
"group_size": 128,
|
| 176 |
+
"ratio": 0.8,
|
| 177 |
+
},
|
| 178 |
+
}
|
| 179 |
+
|
| 180 |
+
model_compression_params = compression_configs.get(
|
| 181 |
+
model_id, compression_configs["default"]
|
| 182 |
+
)
|
| 183 |
+
if (int4_model_dir / "openvino_model.xml").exists():
|
| 184 |
+
return
|
| 185 |
+
int4_model_dir.mkdir(parents=True, exist_ok=True)
|
| 186 |
+
if not model_configuration["remote"]:
|
| 187 |
+
remote_code = model_configuration.get("remote_code", False)
|
| 188 |
+
model_kwargs = {}
|
| 189 |
+
if remote_code:
|
| 190 |
+
model_kwargs = {
|
| 191 |
+
"trust_remote_code" : True,
|
| 192 |
+
"config": AutoConfig.from_pretrained(pt_model_id, trust_remote_code=True)
|
| 193 |
+
}
|
| 194 |
+
ov_model = OVModelForCausalLM.from_pretrained(
|
| 195 |
+
pt_model_id, export=True, compile=False,
|
| 196 |
+
quantization_config=OVWeightQuantizationConfig(bits=4, **model_compression_params),
|
| 197 |
+
**model_kwargs
|
| 198 |
+
)
|
| 199 |
+
ov_model.save_pretrained(int4_model_dir)
|
| 200 |
+
del ov_model
|
| 201 |
+
else:
|
| 202 |
+
convert_to_fp16()
|
| 203 |
+
ov_model = ov.Core().read_model(fp16_model_dir / "openvino_model.xml")
|
| 204 |
+
shutil.copy(fp16_model_dir / "config.json", int4_model_dir / "config.json")
|
| 205 |
+
configuration_file = fp16_model_dir / f"configuration_{model_type}.py"
|
| 206 |
+
if configuration_file.exists():
|
| 207 |
+
shutil.copy(
|
| 208 |
+
configuration_file, int4_model_dir / f"configuration_{model_type}.py"
|
| 209 |
+
)
|
| 210 |
+
mode = nncf.CompressWeightsMode.INT4_SYM if model_compression_params["sym"] else \
|
| 211 |
+
nncf.CompressWeightsMode.INT4_ASYM
|
| 212 |
+
del model_compression_params["sym"]
|
| 213 |
+
compressed_model = nncf.compress_weights(ov_model, mode=mode, **model_compression_params)
|
| 214 |
+
ov.save_model(compressed_model, int4_model_dir / "openvino_model.xml")
|
| 215 |
+
del ov_model
|
| 216 |
+
del compressed_model
|
| 217 |
+
gc.collect()
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
if prepare_fp16_model:
|
| 221 |
+
convert_to_fp16()
|
| 222 |
+
if prepare_int8_model:
|
| 223 |
+
convert_to_int8()
|
| 224 |
+
if prepare_int4_model:
|
| 225 |
+
convert_to_int4()
|
| 226 |
+
|
| 227 |
+
# TODO
|
| 228 |
+
exit()
|
| 229 |
+
|
| 230 |
+
fp16_weights = fp16_model_dir / "openvino_model.bin"
|
| 231 |
+
int8_weights = int8_model_dir / "openvino_model.bin"
|
| 232 |
+
int4_weights = int4_model_dir / "openvino_model.bin"
|
| 233 |
+
|
| 234 |
+
if fp16_weights.exists():
|
| 235 |
+
print(f"Size of FP16 model is {fp16_weights.stat().st_size / 1024 / 1024:.2f} MB")
|
| 236 |
+
for precision, compressed_weights in zip([8, 4], [int8_weights, int4_weights]):
|
| 237 |
+
if compressed_weights.exists():
|
| 238 |
+
print(
|
| 239 |
+
f"Size of model with INT{precision} compressed weights is {compressed_weights.stat().st_size / 1024 / 1024:.2f} MB"
|
| 240 |
+
)
|
| 241 |
+
if compressed_weights.exists() and fp16_weights.exists():
|
| 242 |
+
print(
|
| 243 |
+
f"Compression rate for INT{precision} model: {fp16_weights.stat().st_size / compressed_weights.stat().st_size:.3f}"
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
# ## Select device for inference and model variant
|
| 248 |
+
# [back to top ⬆️](#Table-of-contents:)
|
| 249 |
+
#
|
| 250 |
+
# >**Note**: There may be no speedup for INT4/INT8 compressed models on dGPU.
|
| 251 |
+
|
| 252 |
+
# In[8]:
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
core = ov.Core()
|
| 256 |
+
device = widgets.Dropdown(
|
| 257 |
+
options=core.available_devices + ["AUTO"],
|
| 258 |
+
value="CPU",
|
| 259 |
+
description="Device:",
|
| 260 |
+
disabled=False,
|
| 261 |
+
)
|
| 262 |
+
|
| 263 |
+
device
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
# The cell below create `OVMPTModel`, `OVQWENModel` and `OVCHATGLM2Model` wrapper based on `OVModelForCausalLM` model.
|
| 267 |
+
|
| 268 |
+
# In[9]:
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
from ov_llm_model import model_classes
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
# The cell below demonstrates how to instantiate model based on selected variant of model weights and inference device
|
| 275 |
+
|
| 276 |
+
# In[10]:
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
available_models = []
|
| 280 |
+
if int4_model_dir.exists():
|
| 281 |
+
available_models.append("INT4")
|
| 282 |
+
if int8_model_dir.exists():
|
| 283 |
+
available_models.append("INT8")
|
| 284 |
+
if fp16_model_dir.exists():
|
| 285 |
+
available_models.append("FP16")
|
| 286 |
+
|
| 287 |
+
model_to_run = widgets.Dropdown(
|
| 288 |
+
options=available_models,
|
| 289 |
+
value=available_models[0],
|
| 290 |
+
description="Model to run:",
|
| 291 |
+
disabled=False,
|
| 292 |
+
)
|
| 293 |
+
|
| 294 |
+
model_to_run
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
# In[11]:
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
from transformers import AutoTokenizer
|
| 301 |
+
|
| 302 |
+
if model_to_run.value == "INT4":
|
| 303 |
+
model_dir = int4_model_dir
|
| 304 |
+
elif model_to_run.value == "INT8":
|
| 305 |
+
model_dir = int8_model_dir
|
| 306 |
+
else:
|
| 307 |
+
model_dir = fp16_model_dir
|
| 308 |
+
print(f"Loading model from {model_dir}")
|
| 309 |
+
|
| 310 |
+
ov_config = {"PERFORMANCE_HINT": "LATENCY", "NUM_STREAMS": "1", "CACHE_DIR": ""}
|
| 311 |
+
|
| 312 |
+
# On a GPU device a model is executed in FP16 precision. For red-pajama-3b-chat model there known accuracy
|
| 313 |
+
# issues caused by this, which we avoid by setting precision hint to "f32".
|
| 314 |
+
if model_id == "red-pajama-3b-chat" and "GPU" in core.available_devices and device.value in ["GPU", "AUTO"]:
|
| 315 |
+
ov_config["INFERENCE_PRECISION_HINT"] = "f32"
|
| 316 |
+
|
| 317 |
+
model_name = model_configuration["model_id"]
|
| 318 |
+
class_key = model_id.split("-")[0]
|
| 319 |
+
tok = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 320 |
+
|
| 321 |
+
model_class = (
|
| 322 |
+
OVModelForCausalLM
|
| 323 |
+
if not model_configuration["remote"]
|
| 324 |
+
else model_classes[class_key]
|
| 325 |
+
)
|
| 326 |
+
ov_model = model_class.from_pretrained(
|
| 327 |
+
model_dir,
|
| 328 |
+
device=device.value,
|
| 329 |
+
ov_config=ov_config,
|
| 330 |
+
config=AutoConfig.from_pretrained(model_dir, trust_remote_code=True),
|
| 331 |
+
trust_remote_code=True,
|
| 332 |
+
)
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
# In[12]:
|
| 336 |
+
|
| 337 |
+
|
| 338 |
+
tokenizer_kwargs = model_configuration.get("tokenizer_kwargs", {})
|
| 339 |
+
test_string = "2 + 2 ="
|
| 340 |
+
input_tokens = tok(test_string, return_tensors="pt", **tokenizer_kwargs)
|
| 341 |
+
answer = ov_model.generate(**input_tokens, max_new_tokens=2)
|
| 342 |
+
print(tok.batch_decode(answer, skip_special_tokens=True)[0])
|
| 343 |
+
|
| 344 |
+
|
| 345 |
+
# ## Run Chatbot
|
| 346 |
+
# [back to top ⬆️](#Table-of-contents:)
|
| 347 |
+
#
|
| 348 |
+
# Now, when model created, we can setup Chatbot interface using [Gradio](https://www.gradio.app/).
|
| 349 |
+
# The diagram below illustrates how the chatbot pipeline works
|
| 350 |
+
#
|
| 351 |
+
# 
|
| 352 |
+
#
|
| 353 |
+
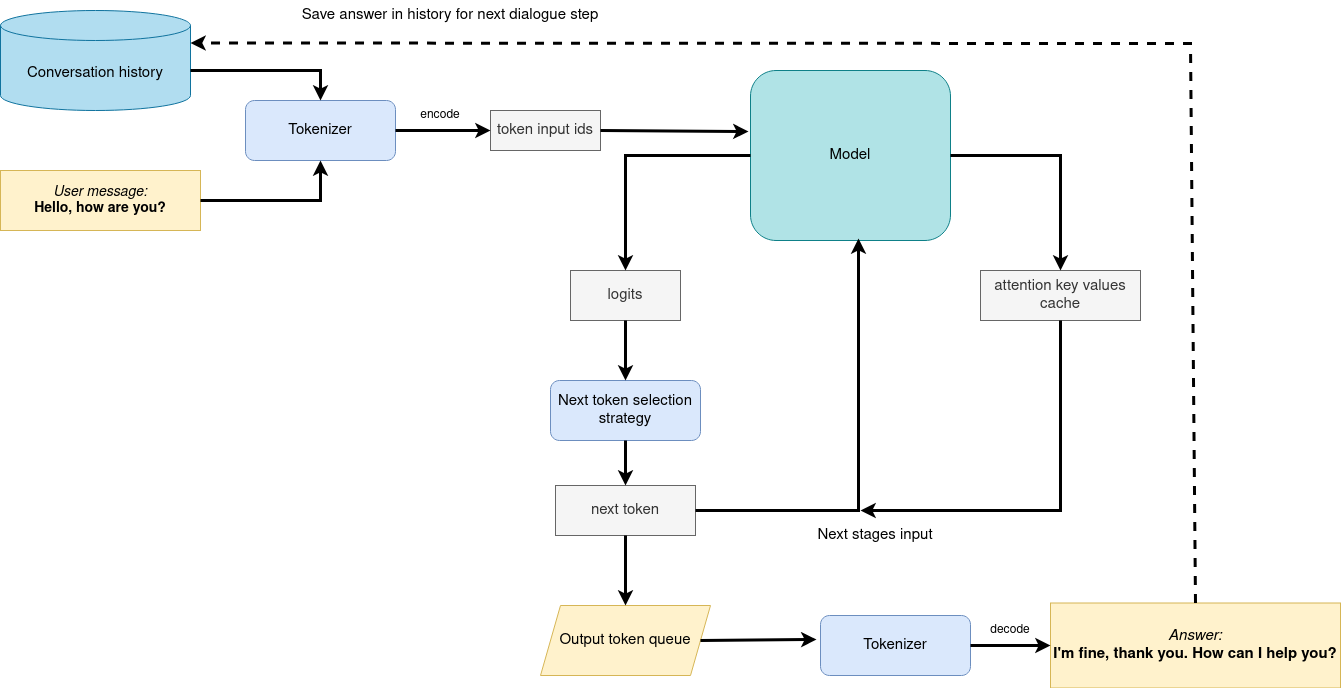
# As can be seen, the pipeline very similar to instruction-following with only changes that previous conversation history additionally passed as input with next user question for getting wider input context. On the first iteration, the user provided instructions joined to conversation history (if exists) converted to token ids using a tokenizer, then prepared input provided to the model. The model generates probabilities for all tokens in logits format The way the next token will be selected over predicted probabilities is driven by the selected decoding methodology. You can find more information about the most popular decoding methods in this [blog](https://huggingface.co/blog/how-to-generate). The result generation updates conversation history for next conversation step. it makes stronger connection of next question with previously provided and allows user to make clarifications regarding previously provided answers.
|
| 354 |
+
|
| 355 |
+
# There are several parameters that can control text generation quality:
|
| 356 |
+
# * `Temperature` is a parameter used to control the level of creativity in AI-generated text. By adjusting the `temperature`, you can influence the AI model's probability distribution, making the text more focused or diverse.
|
| 357 |
+
# Consider the following example: The AI model has to complete the sentence "The cat is ____." with the following token probabilities:
|
| 358 |
+
#
|
| 359 |
+
# playing: 0.5
|
| 360 |
+
# sleeping: 0.25
|
| 361 |
+
# eating: 0.15
|
| 362 |
+
# driving: 0.05
|
| 363 |
+
# flying: 0.05
|
| 364 |
+
#
|
| 365 |
+
# - **Low temperature** (e.g., 0.2): The AI model becomes more focused and deterministic, choosing tokens with the highest probability, such as "playing."
|
| 366 |
+
# - **Medium temperature** (e.g., 1.0): The AI model maintains a balance between creativity and focus, selecting tokens based on their probabilities without significant bias, such as "playing," "sleeping," or "eating."
|
| 367 |
+
# - **High temperature** (e.g., 2.0): The AI model becomes more adventurous, increasing the chances of selecting less likely tokens, such as "driving" and "flying."
|
| 368 |
+
# * `Top-p`, also known as nucleus sampling, is a parameter used to control the range of tokens considered by the AI model based on their cumulative probability. By adjusting the `top-p` value, you can influence the AI model's token selection, making it more focused or diverse.
|
| 369 |
+
# Using the same example with the cat, consider the following top_p settings:
|
| 370 |
+
# - **Low top_p** (e.g., 0.5): The AI model considers only tokens with the highest cumulative probability, such as "playing."
|
| 371 |
+
# - **Medium top_p** (e.g., 0.8): The AI model considers tokens with a higher cumulative probability, such as "playing," "sleeping," and "eating."
|
| 372 |
+
# - **High top_p** (e.g., 1.0): The AI model considers all tokens, including those with lower probabilities, such as "driving" and "flying."
|
| 373 |
+
# * `Top-k` is an another popular sampling strategy. In comparison with Top-P, which chooses from the smallest possible set of words whose cumulative probability exceeds the probability P, in Top-K sampling K most likely next words are filtered and the probability mass is redistributed among only those K next words. In our example with cat, if k=3, then only "playing", "sleeping" and "eating" will be taken into account as possible next word.
|
| 374 |
+
# * `Repetition Penalty` This parameter can help penalize tokens based on how frequently they occur in the text, including the input prompt. A token that has already appeared five times is penalized more heavily than a token that has appeared only one time. A value of 1 means that there is no penalty and values larger than 1 discourage repeated tokens.
|
| 375 |
+
|
| 376 |
+
# In[13]:
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
from threading import Event, Thread
|
| 380 |
+
from uuid import uuid4
|
| 381 |
+
from typing import List, Tuple
|
| 382 |
+
import gradio as gr
|
| 383 |
+
from transformers import (
|
| 384 |
+
AutoTokenizer,
|
| 385 |
+
StoppingCriteria,
|
| 386 |
+
StoppingCriteriaList,
|
| 387 |
+
TextIteratorStreamer,
|
| 388 |
+
)
|
| 389 |
+
|
| 390 |
+
|
| 391 |
+
model_name = model_configuration["model_id"]
|
| 392 |
+
start_message = model_configuration["start_message"]
|
| 393 |
+
history_template = model_configuration.get("history_template")
|
| 394 |
+
current_message_template = model_configuration.get("current_message_template")
|
| 395 |
+
stop_tokens = model_configuration.get("stop_tokens")
|
| 396 |
+
roles = model_configuration.get("roles")
|
| 397 |
+
tokenizer_kwargs = model_configuration.get("tokenizer_kwargs", {})
|
| 398 |
+
|
| 399 |
+
chinese_examples = [
|
| 400 |
+
["你好!"],
|
| 401 |
+
["你是谁?"],
|
| 402 |
+
["请介绍一下上海"],
|
| 403 |
+
["请介绍一下英特尔公司"],
|
| 404 |
+
["晚上睡不着怎么办?"],
|
| 405 |
+
["给我讲一个年轻人奋斗创业最终取得成功的故事。"],
|
| 406 |
+
["给这个故事起一个标题。"],
|
| 407 |
+
]
|
| 408 |
+
|
| 409 |
+
english_examples = [
|
| 410 |
+
["Hello there! How are you doing?"],
|
| 411 |
+
["What is OpenVINO?"],
|
| 412 |
+
["Who are you?"],
|
| 413 |
+
["Can you explain to me briefly what is Python programming language?"],
|
| 414 |
+
["Explain the plot of Cinderella in a sentence."],
|
| 415 |
+
["What are some common mistakes to avoid when writing code?"],
|
| 416 |
+
[
|
| 417 |
+
"Write a 100-word blog post on “Benefits of Artificial Intelligence and OpenVINO“"
|
| 418 |
+
],
|
| 419 |
+
]
|
| 420 |
+
|
| 421 |
+
japanese_examples = [
|
| 422 |
+
["こんにちは!調子はどうですか?"],
|
| 423 |
+
["OpenVINOとは何ですか?"],
|
| 424 |
+
["あなたは誰ですか?"],
|
| 425 |
+
["Pythonプログラミング言語とは何か簡単に説明してもらえますか?"],
|
| 426 |
+
["シンデレラのあらすじを一文で説明してください。"],
|
| 427 |
+
["コードを書くときに避けるべきよくある間違いは何ですか?"],
|
| 428 |
+
["人工知能と「OpenVINOの利点」について100語程度のブログ記事を書いてください。"],
|
| 429 |
+
]
|
| 430 |
+
|
| 431 |
+
examples = (
|
| 432 |
+
chinese_examples
|
| 433 |
+
if ("qwen" in model_id or "chatglm" in model_id or "baichuan" in model_id)
|
| 434 |
+
else japanese_examples
|
| 435 |
+
if ("youri" in model_id)
|
| 436 |
+
else english_examples
|
| 437 |
+
)
|
| 438 |
+
|
| 439 |
+
max_new_tokens = 256
|
| 440 |
+
|
| 441 |
+
|
| 442 |
+
class StopOnTokens(StoppingCriteria):
|
| 443 |
+
def __init__(self, token_ids):
|
| 444 |
+
self.token_ids = token_ids
|
| 445 |
+
|
| 446 |
+
def __call__(
|
| 447 |
+
self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs
|
| 448 |
+
) -> bool:
|
| 449 |
+
for stop_id in self.token_ids:
|
| 450 |
+
if input_ids[0][-1] == stop_id:
|
| 451 |
+
return True
|
| 452 |
+
return False
|
| 453 |
+
|
| 454 |
+
|
| 455 |
+
if stop_tokens is not None:
|
| 456 |
+
if isinstance(stop_tokens[0], str):
|
| 457 |
+
stop_tokens = tok.convert_tokens_to_ids(stop_tokens)
|
| 458 |
+
|
| 459 |
+
stop_tokens = [StopOnTokens(stop_tokens)]
|
| 460 |
+
|
| 461 |
+
|
| 462 |
+
def default_partial_text_processor(partial_text: str, new_text: str):
|
| 463 |
+
"""
|
| 464 |
+
helper for updating partially generated answer, used by default
|
| 465 |
+
|
| 466 |
+
Params:
|
| 467 |
+
partial_text: text buffer for storing previosly generated text
|
| 468 |
+
new_text: text update for the current step
|
| 469 |
+
Returns:
|
| 470 |
+
updated text string
|
| 471 |
+
|
| 472 |
+
"""
|
| 473 |
+
partial_text += new_text
|
| 474 |
+
return partial_text
|
| 475 |
+
|
| 476 |
+
|
| 477 |
+
text_processor = model_configuration.get(
|
| 478 |
+
"partial_text_processor", default_partial_text_processor
|
| 479 |
+
)
|
| 480 |
+
|
| 481 |
+
|
| 482 |
+
def convert_history_to_token(history: List[Tuple[str, str]], roles=None):
|
| 483 |
+
"""
|
| 484 |
+
function for conversion history stored as list pairs of user and assistant messages to tokens according to model expected conversation template
|
| 485 |
+
Params:
|
| 486 |
+
history: dialogue history
|
| 487 |
+
Returns:
|
| 488 |
+
history in token format
|
| 489 |
+
"""
|
| 490 |
+
if roles is None:
|
| 491 |
+
text = start_message + "".join(
|
| 492 |
+
[
|
| 493 |
+
"".join(
|
| 494 |
+
[
|
| 495 |
+
history_template.format(
|
| 496 |
+
num=round, user=item[0], assistant=item[1]
|
| 497 |
+
)
|
| 498 |
+
]
|
| 499 |
+
)
|
| 500 |
+
for round, item in enumerate(history[:-1])
|
| 501 |
+
]
|
| 502 |
+
)
|
| 503 |
+
text += "".join(
|
| 504 |
+
[
|
| 505 |
+
"".join(
|
| 506 |
+
[
|
| 507 |
+
current_message_template.format(
|
| 508 |
+
num=len(history) + 1,
|
| 509 |
+
user=history[-1][0],
|
| 510 |
+
assistant=history[-1][1],
|
| 511 |
+
)
|
| 512 |
+
]
|
| 513 |
+
)
|
| 514 |
+
]
|
| 515 |
+
)
|
| 516 |
+
input_token = tok(text, return_tensors="pt", **tokenizer_kwargs).input_ids
|
| 517 |
+
elif pt_model_name == "chatglm3":
|
| 518 |
+
input_ids = []
|
| 519 |
+
input_ids.extend(tok.build_single_message(roles[0], "", start_message))
|
| 520 |
+
for old_query, response in history[:-1]:
|
| 521 |
+
input_ids.extend(tok.build_single_message(roles[1], "", old_query))
|
| 522 |
+
input_ids.extend(tok.build_single_message(roles[2], "", response))
|
| 523 |
+
input_ids.extend(tok.build_single_message(
|
| 524 |
+
roles[1], "", history[-1][0]))
|
| 525 |
+
input_ids.extend([tok.get_command(f"<|{roles[2]}|>")])
|
| 526 |
+
input_token = tok.batch_encode_plus(
|
| 527 |
+
[input_ids], return_tensors="pt", is_split_into_words=True
|
| 528 |
+
).input_ids
|
| 529 |
+
else:
|
| 530 |
+
system_tokens = tok.encode(start_message)
|
| 531 |
+
history_tokens = []
|
| 532 |
+
for (old_query, response) in history[:-1]:
|
| 533 |
+
round_tokens = []
|
| 534 |
+
round_tokens.append(roles[0])
|
| 535 |
+
round_tokens.extend(tok.encode(old_query))
|
| 536 |
+
round_tokens.append(roles[1])
|
| 537 |
+
round_tokens.extend(tok.encode(response))
|
| 538 |
+
history_tokens = round_tokens + history_tokens
|
| 539 |
+
input_tokens = system_tokens + history_tokens
|
| 540 |
+
input_tokens.append(roles[0])
|
| 541 |
+
input_tokens.extend(tok.encode(history[-1][0]))
|
| 542 |
+
input_tokens.append(roles[1])
|
| 543 |
+
input_token = torch.LongTensor([input_tokens])
|
| 544 |
+
return input_token
|
| 545 |
+
|
| 546 |
+
|
| 547 |
+
def user(message, history):
|
| 548 |
+
"""
|
| 549 |
+
callback function for updating user messages in interface on submit button click
|
| 550 |
+
|
| 551 |
+
Params:
|
| 552 |
+
message: current message
|
| 553 |
+
history: conversation history
|
| 554 |
+
Returns:
|
| 555 |
+
None
|
| 556 |
+
"""
|
| 557 |
+
# Append the user's message to the conversation history
|
| 558 |
+
return "", history + [[message, ""]]
|
| 559 |
+
|
| 560 |
+
|
| 561 |
+
def bot(history, temperature, top_p, top_k, repetition_penalty, conversation_id):
|
| 562 |
+
"""
|
| 563 |
+
callback function for running chatbot on submit button click
|
| 564 |
+
|
| 565 |
+
Params:
|
| 566 |
+
history: conversation history
|
| 567 |
+
temperature: parameter for control the level of creativity in AI-generated text.
|
| 568 |
+
By adjusting the `temperature`, you can influence the AI model's probability distribution, making the text more focused or diverse.
|
| 569 |
+
top_p: parameter for control the range of tokens considered by the AI model based on their cumulative probability.
|
| 570 |
+
top_k: parameter for control the range of tokens considered by the AI model based on their cumulative probability, selecting number of tokens with highest probability.
|
| 571 |
+
repetition_penalty: parameter for penalizing tokens based on how frequently they occur in the text.
|
| 572 |
+
conversation_id: unique conversation identifier.
|
| 573 |
+
|
| 574 |
+
"""
|
| 575 |
+
|
| 576 |
+
# Construct the input message string for the model by concatenating the current system message and conversation history
|
| 577 |
+
# Tokenize the messages string
|
| 578 |
+
input_ids = convert_history_to_token(history, roles)
|
| 579 |
+
if input_ids.shape[1] > 2000:
|
| 580 |
+
history = [history[-1]]
|
| 581 |
+
input_ids = convert_history_to_token(history, roles)
|
| 582 |
+
streamer = TextIteratorStreamer(
|
| 583 |
+
tok, timeout=30.0, skip_prompt=True, skip_special_tokens=True
|
| 584 |
+
)
|
| 585 |
+
generate_kwargs = dict(
|
| 586 |
+
input_ids=input_ids,
|
| 587 |
+
max_new_tokens=max_new_tokens,
|
| 588 |
+
temperature=temperature,
|
| 589 |
+
do_sample=temperature > 0.0,
|
| 590 |
+
top_p=top_p,
|
| 591 |
+
top_k=top_k,
|
| 592 |
+
repetition_penalty=repetition_penalty,
|
| 593 |
+
streamer=streamer,
|
| 594 |
+
)
|
| 595 |
+
if stop_tokens is not None:
|
| 596 |
+
generate_kwargs["stopping_criteria"] = StoppingCriteriaList(
|
| 597 |
+
stop_tokens)
|
| 598 |
+
|
| 599 |
+
stream_complete = Event()
|
| 600 |
+
|
| 601 |
+
def generate_and_signal_complete():
|
| 602 |
+
"""
|
| 603 |
+
genration function for single thread
|
| 604 |
+
"""
|
| 605 |
+
global start_time
|
| 606 |
+
ov_model.generate(**generate_kwargs)
|
| 607 |
+
stream_complete.set()
|
| 608 |
+
|
| 609 |
+
t1 = Thread(target=generate_and_signal_complete)
|
| 610 |
+
t1.start()
|
| 611 |
+
|
| 612 |
+
# Initialize an empty string to store the generated text
|
| 613 |
+
partial_text = ""
|
| 614 |
+
for new_text in streamer:
|
| 615 |
+
partial_text = text_processor(partial_text, new_text)
|
| 616 |
+
history[-1][1] = partial_text
|
| 617 |
+
yield history
|
| 618 |
+
|
| 619 |
+
|
| 620 |
+
def get_uuid():
|
| 621 |
+
"""
|
| 622 |
+
universal unique identifier for thread
|
| 623 |
+
"""
|
| 624 |
+
return str(uuid4())
|
| 625 |
+
|
| 626 |
+
|
| 627 |
+
with gr.Blocks(
|
| 628 |
+
theme=gr.themes.Soft(),
|
| 629 |
+
css=".disclaimer {font-variant-caps: all-small-caps;}",
|
| 630 |
+
) as demo:
|
| 631 |
+
conversation_id = gr.State(get_uuid)
|
| 632 |
+
gr.Markdown(
|
| 633 |
+
f"""<h1><center>OpenVINO {model_id} Chatbot</center></h1>""")
|
| 634 |
+
chatbot = gr.Chatbot(height=500)
|
| 635 |
+
with gr.Row():
|
| 636 |
+
with gr.Column():
|
| 637 |
+
msg = gr.Textbox(
|
| 638 |
+
label="Chat Message Box",
|
| 639 |
+
placeholder="Chat Message Box",
|
| 640 |
+
show_label=False,
|
| 641 |
+
container=False,
|
| 642 |
+
)
|
| 643 |
+
with gr.Column():
|
| 644 |
+
with gr.Row():
|
| 645 |
+
submit = gr.Button("Submit")
|
| 646 |
+
stop = gr.Button("Stop")
|
| 647 |
+
clear = gr.Button("Clear")
|
| 648 |
+
with gr.Row():
|
| 649 |
+
with gr.Accordion("Advanced Options:", open=False):
|
| 650 |
+
with gr.Row():
|
| 651 |
+
with gr.Column():
|
| 652 |
+
with gr.Row():
|
| 653 |
+
temperature = gr.Slider(
|
| 654 |
+
label="Temperature",
|
| 655 |
+
value=0.1,
|
| 656 |
+
minimum=0.0,
|
| 657 |
+
maximum=1.0,
|
| 658 |
+
step=0.1,
|
| 659 |
+
interactive=True,
|
| 660 |
+
info="Higher values produce more diverse outputs",
|
| 661 |
+
)
|
| 662 |
+
with gr.Column():
|
| 663 |
+
with gr.Row():
|
| 664 |
+
top_p = gr.Slider(
|
| 665 |
+
label="Top-p (nucleus sampling)",
|
| 666 |
+
value=1.0,
|
| 667 |
+
minimum=0.0,
|
| 668 |
+
maximum=1,
|
| 669 |
+
step=0.01,
|
| 670 |
+
interactive=True,
|
| 671 |
+
info=(
|
| 672 |
+
"Sample from the smallest possible set of tokens whose cumulative probability "
|
| 673 |
+
"exceeds top_p. Set to 1 to disable and sample from all tokens."
|
| 674 |
+
),
|
| 675 |
+
)
|
| 676 |
+
with gr.Column():
|
| 677 |
+
with gr.Row():
|
| 678 |
+
top_k = gr.Slider(
|
| 679 |
+
label="Top-k",
|
| 680 |
+
value=50,
|
| 681 |
+
minimum=0.0,
|
| 682 |
+
maximum=200,
|
| 683 |
+
step=1,
|
| 684 |
+
interactive=True,
|
| 685 |
+
info="Sample from a shortlist of top-k tokens — 0 to disable and sample from all tokens.",
|
| 686 |
+
)
|
| 687 |
+
with gr.Column():
|
| 688 |
+
with gr.Row():
|
| 689 |
+
repetition_penalty = gr.Slider(
|
| 690 |
+
label="Repetition Penalty",
|
| 691 |
+
value=1.1,
|
| 692 |
+
minimum=1.0,
|
| 693 |
+
maximum=2.0,
|
| 694 |
+
step=0.1,
|
| 695 |
+
interactive=True,
|
| 696 |
+
info="Penalize repetition — 1.0 to disable.",
|
| 697 |
+
)
|
| 698 |
+
gr.Examples(
|
| 699 |
+
examples, inputs=msg, label="Click on any example and press the 'Submit' button"
|
| 700 |
+
)
|
| 701 |
+
|
| 702 |
+
submit_event = msg.submit(
|
| 703 |
+
fn=user,
|
| 704 |
+
inputs=[msg, chatbot],
|
| 705 |
+
outputs=[msg, chatbot],
|
| 706 |
+
queue=False,
|
| 707 |
+
).then(
|
| 708 |
+
fn=bot,
|
| 709 |
+
inputs=[
|
| 710 |
+
chatbot,
|
| 711 |
+
temperature,
|
| 712 |
+
top_p,
|
| 713 |
+
top_k,
|
| 714 |
+
repetition_penalty,
|
| 715 |
+
conversation_id,
|
| 716 |
+
],
|
| 717 |
+
outputs=chatbot,
|
| 718 |
+
queue=True,
|
| 719 |
+
)
|
| 720 |
+
submit_click_event = submit.click(
|
| 721 |
+
fn=user,
|
| 722 |
+
inputs=[msg, chatbot],
|
| 723 |
+
outputs=[msg, chatbot],
|
| 724 |
+
queue=False,
|
| 725 |
+
).then(
|
| 726 |
+
fn=bot,
|
| 727 |
+
inputs=[
|
| 728 |
+
chatbot,
|
| 729 |
+
temperature,
|
| 730 |
+
top_p,
|
| 731 |
+
top_k,
|
| 732 |
+
repetition_penalty,
|
| 733 |
+
conversation_id,
|
| 734 |
+
],
|
| 735 |
+
outputs=chatbot,
|
| 736 |
+
queue=True,
|
| 737 |
+
)
|
| 738 |
+
stop.click(
|
| 739 |
+
fn=None,
|
| 740 |
+
inputs=None,
|
| 741 |
+
outputs=None,
|
| 742 |
+
cancels=[submit_event, submit_click_event],
|
| 743 |
+
queue=False,
|
| 744 |
+
)
|
| 745 |
+
clear.click(lambda: None, None, chatbot, queue=False)
|
| 746 |
+
|
| 747 |
+
# if you are launching remotely, specify server_name and server_port
|
| 748 |
+
# demo.launch(server_name='your server name', server_port='server port in int')
|
| 749 |
+
# if you have any issue to launch on your platform, you can pass share=True to launch method:
|
| 750 |
+
# demo.launch(share=True)
|
| 751 |
+
# it creates a publicly shareable link for the interface. Read more in the docs: https://gradio.app/docs/
|
| 752 |
+
demo.launch()
|
| 753 |
+
|
scripts/readblob.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
blob_path = "./llama-2-chat-7b_r0.8_g128.pth"
|
| 4 |
+
|
| 5 |
+
blob = torch.load(blob_path)
|
| 6 |
+
|
| 7 |
+
for layer, attr in blob.items():
|
| 8 |
+
print(f"{layer:30} | q_dtype: {attr['q_dtype']:5} | orig. shape: {str(attr['original_shape']):15} | quantized_shape: {str(attr['q_weight'].shape):15}")
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
print("done.")
|