
Upload current files
Browse files- added_tokens.json +34 -0
- artifacts.ckpt +3 -0
- config.json +24 -0
- config.yaml +29 -0
- donut_simple.ipynb +113 -0
- donut_train.ipynb +110 -0
- dummy_data/CMA_000.jpg +0 -0
- dummy_data/COSCO_000.jpg +0 -0
- dummy_data/Evergreen_000.jpg +0 -0
- dummy_data/HAPAG_000.jpg +0 -0
- dummy_data/KMTC_000.jpg +0 -0
- dummy_data/MEGA_000.jpg +0 -0
- dummy_data/ONEY_000.jpg +0 -0
- dummy_data/OOCL_000.jpg +0 -0
- dummy_data/SITC_000.jpg +0 -0
- dummy_data/TSLines_000.jpg +0 -0
- dummy_data/WH_000.jpg +0 -0
- events.out.tfevents.1711546518.0dee2374164e.17241.0 +3 -0
- hparams.yaml +1 -0
- sentencepiece.bpe.model +3 -0
- special_tokens_map.json +18 -0
- tokenizer_config.json +23 -0
added_tokens.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</s_bkg_no>": 57529,
|
| 3 |
+
"</s_bkg_no_series>": 57547,
|
| 4 |
+
"</s_com>": 57543,
|
| 5 |
+
"</s_dp>": 57537,
|
| 6 |
+
"</s_fd>": 57539,
|
| 7 |
+
"</s_filetype>": 57525,
|
| 8 |
+
"</s_info>": 57549,
|
| 9 |
+
"</s_name>": 57545,
|
| 10 |
+
"</s_phone>": 57551,
|
| 11 |
+
"</s_ref>": 57531,
|
| 12 |
+
"</s_shipper>": 57527,
|
| 13 |
+
"</s_size_type>": 57541,
|
| 14 |
+
"</s_vessel_name>": 57533,
|
| 15 |
+
"</s_voyage_no>": 57535,
|
| 16 |
+
"<s_Booking>": 57553,
|
| 17 |
+
"<s_bkg_no>": 57530,
|
| 18 |
+
"<s_bkg_no_series>": 57548,
|
| 19 |
+
"<s_com>": 57544,
|
| 20 |
+
"<s_dp>": 57538,
|
| 21 |
+
"<s_fd>": 57540,
|
| 22 |
+
"<s_filetype>": 57526,
|
| 23 |
+
"<s_iitcdip>": 57523,
|
| 24 |
+
"<s_info>": 57550,
|
| 25 |
+
"<s_name>": 57546,
|
| 26 |
+
"<s_phone>": 57552,
|
| 27 |
+
"<s_ref>": 57532,
|
| 28 |
+
"<s_shipper>": 57528,
|
| 29 |
+
"<s_size_type>": 57542,
|
| 30 |
+
"<s_synthdog>": 57524,
|
| 31 |
+
"<s_vessel_name>": 57534,
|
| 32 |
+
"<s_voyage_no>": 57536,
|
| 33 |
+
"<sep/>": 57522
|
| 34 |
+
}
|
artifacts.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d459fc434e7aaef97d797e4d4289a92cb3b3f83130a783a4fa819febe522faaf
|
| 3 |
+
size 1609085328
|
config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "naver-clova-ix/donut-base",
|
| 3 |
+
"align_long_axis": false,
|
| 4 |
+
"architectures": [
|
| 5 |
+
"DonutModel"
|
| 6 |
+
],
|
| 7 |
+
"decoder_layer": 4,
|
| 8 |
+
"encoder_layer": [
|
| 9 |
+
2,
|
| 10 |
+
2,
|
| 11 |
+
14,
|
| 12 |
+
2
|
| 13 |
+
],
|
| 14 |
+
"input_size": [
|
| 15 |
+
1280,
|
| 16 |
+
960
|
| 17 |
+
],
|
| 18 |
+
"max_length": 768,
|
| 19 |
+
"max_position_embeddings": 768,
|
| 20 |
+
"model_type": "donut",
|
| 21 |
+
"torch_dtype": "float32",
|
| 22 |
+
"transformers_version": "4.25.1",
|
| 23 |
+
"window_size": 10
|
| 24 |
+
}
|
config.yaml
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
resume_from_checkpoint_path: None
|
| 2 |
+
result_path: './result'
|
| 3 |
+
pretrained_model_name_or_path: 'naver-clova-ix/donut-base'
|
| 4 |
+
dataset_name_or_paths:
|
| 5 |
+
- 'dataset/Booking'
|
| 6 |
+
sort_json_key: False
|
| 7 |
+
train_batch_sizes:
|
| 8 |
+
- 2
|
| 9 |
+
val_batch_sizes:
|
| 10 |
+
- 1
|
| 11 |
+
input_size:
|
| 12 |
+
- 1280
|
| 13 |
+
- 960
|
| 14 |
+
max_length: 768
|
| 15 |
+
align_long_axis: False
|
| 16 |
+
num_nodes: 1
|
| 17 |
+
seed: 2022
|
| 18 |
+
lr: 3e-05
|
| 19 |
+
warmup_steps: 550
|
| 20 |
+
num_training_samples_per_epoch: 1100
|
| 21 |
+
max_epochs: 10
|
| 22 |
+
max_steps: -1
|
| 23 |
+
num_workers: 8
|
| 24 |
+
val_check_interval: 1.0
|
| 25 |
+
check_val_every_n_epoch: 3
|
| 26 |
+
gradient_clip_val: 1.0
|
| 27 |
+
verbose: True
|
| 28 |
+
exp_name: 'train_Booking'
|
| 29 |
+
exp_version: '20240327_133350'
|
donut_simple.ipynb
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"source": [
|
| 6 |
+
"1. Download the donut folder from Github https://github.com/clovaai/donut\n",
|
| 7 |
+
"2. Copy a config file in folder and change the name to hold your configuration.\n",
|
| 8 |
+
"3. Place your dataset (train, validation, test) along with JSONL files on the dataset folder.\n",
|
| 9 |
+
"4. Refer to donut_training.ipynb to train your model. Use A-100/V-100 GPU to avoid troublesome settings / slow training time.\n",
|
| 10 |
+
"5. Run the trained model using this ipynb file."
|
| 11 |
+
],
|
| 12 |
+
"metadata": {
|
| 13 |
+
"id": "L5U1ACZZBxfh"
|
| 14 |
+
}
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"cell_type": "code",
|
| 18 |
+
"source": [
|
| 19 |
+
"# Enable Google Drive and Go to the donut folder\n",
|
| 20 |
+
"from google.colab import drive\n",
|
| 21 |
+
"drive.mount('/content/drive')\n",
|
| 22 |
+
"%cd /content/drive/MyDrive/donut"
|
| 23 |
+
],
|
| 24 |
+
"metadata": {
|
| 25 |
+
"id": "-BZ2HFB9OtWP"
|
| 26 |
+
},
|
| 27 |
+
"execution_count": null,
|
| 28 |
+
"outputs": []
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"cell_type": "code",
|
| 32 |
+
"execution_count": null,
|
| 33 |
+
"metadata": {
|
| 34 |
+
"id": "SJpD4AAj7qeZ"
|
| 35 |
+
},
|
| 36 |
+
"outputs": [],
|
| 37 |
+
"source": [
|
| 38 |
+
"#Install all necessary modules. Don't change the version number!\n",
|
| 39 |
+
"!pip install transformers==4.25.1\n",
|
| 40 |
+
"!pip install timm==0.5.4\n",
|
| 41 |
+
"!pip install donut-python"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "code",
|
| 46 |
+
"source": [
|
| 47 |
+
"# import necessary modules\n",
|
| 48 |
+
"from donut import DonutModel\n",
|
| 49 |
+
"from PIL import Image\n",
|
| 50 |
+
"import torch"
|
| 51 |
+
],
|
| 52 |
+
"metadata": {
|
| 53 |
+
"id": "gSatjcDn5S89"
|
| 54 |
+
},
|
| 55 |
+
"execution_count": null,
|
| 56 |
+
"outputs": []
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"cell_type": "code",
|
| 60 |
+
"source": [
|
| 61 |
+
"# Test the model with testing data. Just to initiate model.\n",
|
| 62 |
+
"!python test.py --task_name Booking --dataset_name_or_path dataset/Booking --pretrained_model_name_or_path ./result/train_Booking/donut-booking-extract"
|
| 63 |
+
],
|
| 64 |
+
"metadata": {
|
| 65 |
+
"id": "dyOv9Omo8dJU"
|
| 66 |
+
},
|
| 67 |
+
"execution_count": null,
|
| 68 |
+
"outputs": []
|
| 69 |
+
},
|
| 70 |
+
{
|
| 71 |
+
"cell_type": "code",
|
| 72 |
+
"source": [
|
| 73 |
+
"\n",
|
| 74 |
+
"model = DonutModel.from_pretrained(\"./result/train_Booking/donut-booking-extract\")\n",
|
| 75 |
+
"if torch.cuda.is_available():\n",
|
| 76 |
+
" model.half()\n",
|
| 77 |
+
" device = torch.device(\"cuda\")\n",
|
| 78 |
+
" model.to(device)\n",
|
| 79 |
+
"else:\n",
|
| 80 |
+
" model.encoder.to(torch.bfloat16)\n",
|
| 81 |
+
"\n",
|
| 82 |
+
"model.eval()\n",
|
| 83 |
+
"\n",
|
| 84 |
+
"image = Image.open(\"/content/drive/MyDrive/donut/test/4.jpg\").convert(\"RGB\")\n",
|
| 85 |
+
"\n",
|
| 86 |
+
"with torch.no_grad():\n",
|
| 87 |
+
" output = model.inference(image=image, prompt=\"<s_Booking>\")\n",
|
| 88 |
+
"output"
|
| 89 |
+
],
|
| 90 |
+
"metadata": {
|
| 91 |
+
"id": "dFfm72T93Z8G"
|
| 92 |
+
},
|
| 93 |
+
"execution_count": null,
|
| 94 |
+
"outputs": []
|
| 95 |
+
}
|
| 96 |
+
],
|
| 97 |
+
"metadata": {
|
| 98 |
+
"accelerator": "GPU",
|
| 99 |
+
"colab": {
|
| 100 |
+
"gpuType": "V100",
|
| 101 |
+
"provenance": []
|
| 102 |
+
},
|
| 103 |
+
"kernelspec": {
|
| 104 |
+
"display_name": "Python 3",
|
| 105 |
+
"name": "python3"
|
| 106 |
+
},
|
| 107 |
+
"language_info": {
|
| 108 |
+
"name": "python"
|
| 109 |
+
}
|
| 110 |
+
},
|
| 111 |
+
"nbformat": 4,
|
| 112 |
+
"nbformat_minor": 0
|
| 113 |
+
}
|
donut_train.ipynb
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {
|
| 7 |
+
"id": "-BZ2HFB9OtWP"
|
| 8 |
+
},
|
| 9 |
+
"outputs": [],
|
| 10 |
+
"source": [
|
| 11 |
+
"from google.colab import drive\n",
|
| 12 |
+
"drive.mount('/content/drive')\n",
|
| 13 |
+
"%cd /content/drive/MyDrive/donut"
|
| 14 |
+
]
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"cell_type": "code",
|
| 18 |
+
"execution_count": null,
|
| 19 |
+
"metadata": {
|
| 20 |
+
"colab": {
|
| 21 |
+
"background_save": true
|
| 22 |
+
},
|
| 23 |
+
"id": "SJpD4AAj7qeZ"
|
| 24 |
+
},
|
| 25 |
+
"outputs": [],
|
| 26 |
+
"source": [
|
| 27 |
+
"!pip install transformers==4.25.1\n",
|
| 28 |
+
"!pip install timm==0.5.4\n",
|
| 29 |
+
"!pip install donut-python"
|
| 30 |
+
]
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"cell_type": "code",
|
| 34 |
+
"source": [
|
| 35 |
+
"from donut import DonutModel\n",
|
| 36 |
+
"from PIL import Image\n",
|
| 37 |
+
"import torch"
|
| 38 |
+
],
|
| 39 |
+
"metadata": {
|
| 40 |
+
"id": "PxFaO3rfDHQJ"
|
| 41 |
+
},
|
| 42 |
+
"execution_count": null,
|
| 43 |
+
"outputs": []
|
| 44 |
+
},
|
| 45 |
+
{
|
| 46 |
+
"cell_type": "code",
|
| 47 |
+
"execution_count": null,
|
| 48 |
+
"metadata": {
|
| 49 |
+
"id": "Ro21MdJPSTZs"
|
| 50 |
+
},
|
| 51 |
+
"outputs": [],
|
| 52 |
+
"source": [
|
| 53 |
+
"# Copy one default config yaml file and amend to fit your use case.\n",
|
| 54 |
+
"!python train.py --config ./config/train_Booking.yaml"
|
| 55 |
+
]
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"cell_type": "code",
|
| 59 |
+
"execution_count": null,
|
| 60 |
+
"metadata": {
|
| 61 |
+
"id": "J1ITHX4jV2Go"
|
| 62 |
+
},
|
| 63 |
+
"outputs": [],
|
| 64 |
+
"source": [
|
| 65 |
+
"# After train, you can evaluate and use the model.\n",
|
| 66 |
+
"\n",
|
| 67 |
+
"model = DonutModel.from_pretrained(\"/content/drive/MyDrive/donut/result/train_Booking/20240327_032854\")\n",
|
| 68 |
+
"if torch.cuda.is_available():\n",
|
| 69 |
+
" model.half()\n",
|
| 70 |
+
" device = torch.device(\"cuda\")\n",
|
| 71 |
+
" model.to(device)\n",
|
| 72 |
+
"else:\n",
|
| 73 |
+
" model.encoder.to(torch.bfloat16)\n",
|
| 74 |
+
"\n",
|
| 75 |
+
"model.eval()"
|
| 76 |
+
]
|
| 77 |
+
},
|
| 78 |
+
{
|
| 79 |
+
"cell_type": "code",
|
| 80 |
+
"execution_count": null,
|
| 81 |
+
"metadata": {
|
| 82 |
+
"id": "2UhjFTmrWIrX"
|
| 83 |
+
},
|
| 84 |
+
"outputs": [],
|
| 85 |
+
"source": [
|
| 86 |
+
"image = Image.open(\"/content/COSCO_000.jpg\").convert(\"RGB\")\n",
|
| 87 |
+
"with torch.no_grad():\n",
|
| 88 |
+
" # My dataset name is Booking , tag i.e. <s_Booking>\n",
|
| 89 |
+
" output = model.inference(image=image, prompt=\"<s_Booking>\")\n",
|
| 90 |
+
"output"
|
| 91 |
+
]
|
| 92 |
+
}
|
| 93 |
+
],
|
| 94 |
+
"metadata": {
|
| 95 |
+
"accelerator": "GPU",
|
| 96 |
+
"colab": {
|
| 97 |
+
"gpuType": "V100",
|
| 98 |
+
"provenance": []
|
| 99 |
+
},
|
| 100 |
+
"kernelspec": {
|
| 101 |
+
"display_name": "Python 3",
|
| 102 |
+
"name": "python3"
|
| 103 |
+
},
|
| 104 |
+
"language_info": {
|
| 105 |
+
"name": "python"
|
| 106 |
+
}
|
| 107 |
+
},
|
| 108 |
+
"nbformat": 4,
|
| 109 |
+
"nbformat_minor": 0
|
| 110 |
+
}
|
dummy_data/CMA_000.jpg
ADDED

|
dummy_data/COSCO_000.jpg
ADDED

|
dummy_data/Evergreen_000.jpg
ADDED

|
dummy_data/HAPAG_000.jpg
ADDED

|
dummy_data/KMTC_000.jpg
ADDED

|
dummy_data/MEGA_000.jpg
ADDED
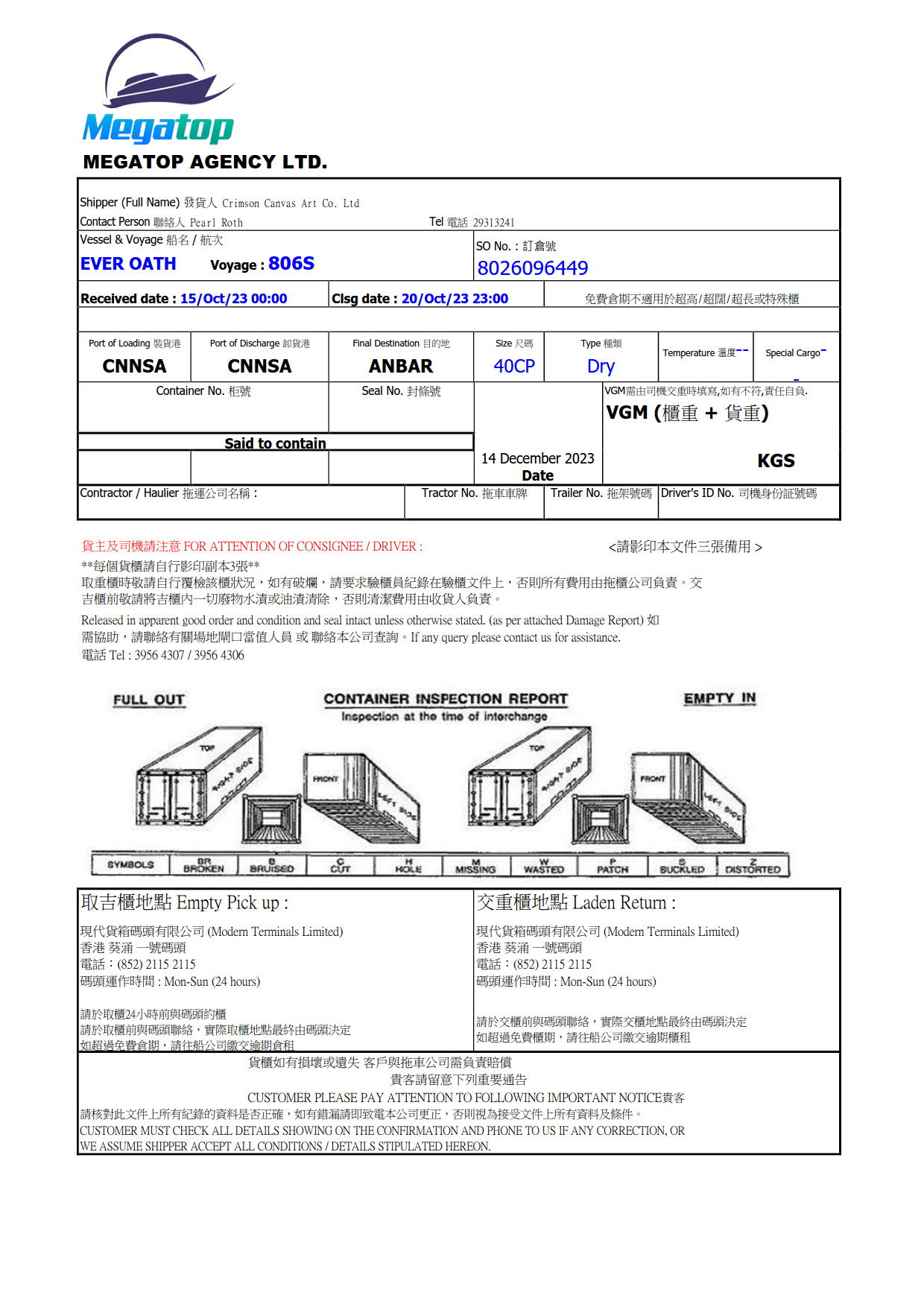
|
dummy_data/ONEY_000.jpg
ADDED

|
dummy_data/OOCL_000.jpg
ADDED

|
dummy_data/SITC_000.jpg
ADDED

|
dummy_data/TSLines_000.jpg
ADDED

|
dummy_data/WH_000.jpg
ADDED

|
events.out.tfevents.1711546518.0dee2374164e.17241.0
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5eb74293bd8a2b529e2de2c7a612d471fa7bab334a546eca42bbbb8d84c2fb21
|
| 3 |
+
size 21222
|
hparams.yaml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{}
|
sentencepiece.bpe.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cb9e3dce4c326195d08fc3dd0f7e2eee1da8595c847bf4c1a9c78b7a82d47e2d
|
| 3 |
+
size 1296245
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<s_Booking>"
|
| 4 |
+
],
|
| 5 |
+
"bos_token": "<s>",
|
| 6 |
+
"cls_token": "<s>",
|
| 7 |
+
"eos_token": "</s>",
|
| 8 |
+
"mask_token": {
|
| 9 |
+
"content": "<mask>",
|
| 10 |
+
"lstrip": true,
|
| 11 |
+
"normalized": true,
|
| 12 |
+
"rstrip": false,
|
| 13 |
+
"single_word": false
|
| 14 |
+
},
|
| 15 |
+
"pad_token": "<pad>",
|
| 16 |
+
"sep_token": "</s>",
|
| 17 |
+
"unk_token": "<unk>"
|
| 18 |
+
}
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<s>",
|
| 3 |
+
"cls_token": "<s>",
|
| 4 |
+
"eos_token": "</s>",
|
| 5 |
+
"from_slow": true,
|
| 6 |
+
"mask_token": {
|
| 7 |
+
"__type": "AddedToken",
|
| 8 |
+
"content": "<mask>",
|
| 9 |
+
"lstrip": true,
|
| 10 |
+
"normalized": true,
|
| 11 |
+
"rstrip": false,
|
| 12 |
+
"single_word": false
|
| 13 |
+
},
|
| 14 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 15 |
+
"name_or_path": "naver-clova-ix/donut-base",
|
| 16 |
+
"pad_token": "<pad>",
|
| 17 |
+
"processor_class": "DonutProcessor",
|
| 18 |
+
"sep_token": "</s>",
|
| 19 |
+
"sp_model_kwargs": {},
|
| 20 |
+
"special_tokens_map_file": null,
|
| 21 |
+
"tokenizer_class": "XLMRobertaTokenizer",
|
| 22 |
+
"unk_token": "<unk>"
|
| 23 |
+
}
|