
78b03c791cc4812032c1821476ee69eb0e69ffda99ce1a62a8b19dbc43cbc592
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +9 -0
- repositories/k-diffusion/k_diffusion/__pycache__/utils.cpython-310.pyc +0 -0
- repositories/k-diffusion/k_diffusion/augmentation.py +105 -0
- repositories/k-diffusion/k_diffusion/config.py +115 -0
- repositories/k-diffusion/k_diffusion/evaluation.py +134 -0
- repositories/k-diffusion/k_diffusion/external.py +177 -0
- repositories/k-diffusion/k_diffusion/gns.py +99 -0
- repositories/k-diffusion/k_diffusion/layers.py +256 -0
- repositories/k-diffusion/k_diffusion/models/__init__.py +1 -0
- repositories/k-diffusion/k_diffusion/models/__pycache__/__init__.cpython-310.pyc +0 -0
- repositories/k-diffusion/k_diffusion/models/__pycache__/image_v1.cpython-310.pyc +0 -0
- repositories/k-diffusion/k_diffusion/models/image_v1.py +156 -0
- repositories/k-diffusion/k_diffusion/sampling.py +651 -0
- repositories/k-diffusion/k_diffusion/utils.py +329 -0
- repositories/k-diffusion/make_grid.py +46 -0
- repositories/k-diffusion/pyproject.toml +3 -0
- repositories/k-diffusion/requirements.txt +16 -0
- repositories/k-diffusion/sample.py +73 -0
- repositories/k-diffusion/sample_clip_guided.py +131 -0
- repositories/k-diffusion/setup.cfg +30 -0
- repositories/k-diffusion/setup.py +5 -0
- repositories/k-diffusion/train.py +356 -0
- repositories/stable-diffusion-stability-ai/.gitignore +165 -0
- repositories/stable-diffusion-stability-ai/LICENSE +21 -0
- repositories/stable-diffusion-stability-ai/LICENSE-MODEL +84 -0
- repositories/stable-diffusion-stability-ai/README.md +302 -0
- repositories/stable-diffusion-stability-ai/assets/model-variants.jpg +0 -0
- repositories/stable-diffusion-stability-ai/assets/modelfigure.png +0 -0
- repositories/stable-diffusion-stability-ai/assets/rick.jpeg +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-inpainting/inpainting.gif +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-inpainting/merged-leopards.png +3 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/d2i.gif +3 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/depth2fantasy.jpeg +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/depth2img01.png +3 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/depth2img02.png +3 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/merged-0000.png +3 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/merged-0004.png +3 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/merged-0005.png +3 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/midas.jpeg +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/old_man.png +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/mountains-1.png +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/mountains-2.png +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/mountains-3.png +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/sketch-mountains-input.jpg +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/upscaling-in.png +3 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/upscaling-out.png +3 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/stable-unclip/houses_out.jpeg +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/stable-unclip/oldcar000.jpeg +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/stable-unclip/oldcar500.jpeg +0 -0
- repositories/stable-diffusion-stability-ai/assets/stable-samples/stable-unclip/oldcar800.jpeg +0 -0
.gitattributes
CHANGED
|
@@ -37,3 +37,12 @@ extensions/Stable-Diffusion-Webui-Civitai-Helper/img/all_in_one.png filter=lfs d
|
|
| 37 |
extensions/addtional/models/lora/README.md filter=lfs diff=lfs merge=lfs -text
|
| 38 |
repositories/BLIP/BLIP.gif filter=lfs diff=lfs merge=lfs -text
|
| 39 |
repositories/generative-models/assets/sdxl_report.pdf filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
extensions/addtional/models/lora/README.md filter=lfs diff=lfs merge=lfs -text
|
| 38 |
repositories/BLIP/BLIP.gif filter=lfs diff=lfs merge=lfs -text
|
| 39 |
repositories/generative-models/assets/sdxl_report.pdf filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
repositories/stable-diffusion-stability-ai/assets/stable-inpainting/merged-leopards.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/d2i.gif filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/depth2img01.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/depth2img02.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/merged-0000.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/merged-0004.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/merged-0005.png filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/upscaling-in.png filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/upscaling-out.png filter=lfs diff=lfs merge=lfs -text
|
repositories/k-diffusion/k_diffusion/__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (14.5 kB). View file
|
|
|
repositories/k-diffusion/k_diffusion/augmentation.py
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import reduce
|
| 2 |
+
import math
|
| 3 |
+
import operator
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
from skimage import transform
|
| 7 |
+
import torch
|
| 8 |
+
from torch import nn
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def translate2d(tx, ty):
|
| 12 |
+
mat = [[1, 0, tx],
|
| 13 |
+
[0, 1, ty],
|
| 14 |
+
[0, 0, 1]]
|
| 15 |
+
return torch.tensor(mat, dtype=torch.float32)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def scale2d(sx, sy):
|
| 19 |
+
mat = [[sx, 0, 0],
|
| 20 |
+
[ 0, sy, 0],
|
| 21 |
+
[ 0, 0, 1]]
|
| 22 |
+
return torch.tensor(mat, dtype=torch.float32)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def rotate2d(theta):
|
| 26 |
+
mat = [[torch.cos(theta), torch.sin(-theta), 0],
|
| 27 |
+
[torch.sin(theta), torch.cos(theta), 0],
|
| 28 |
+
[ 0, 0, 1]]
|
| 29 |
+
return torch.tensor(mat, dtype=torch.float32)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class KarrasAugmentationPipeline:
|
| 33 |
+
def __init__(self, a_prob=0.12, a_scale=2**0.2, a_aniso=2**0.2, a_trans=1/8):
|
| 34 |
+
self.a_prob = a_prob
|
| 35 |
+
self.a_scale = a_scale
|
| 36 |
+
self.a_aniso = a_aniso
|
| 37 |
+
self.a_trans = a_trans
|
| 38 |
+
|
| 39 |
+
def __call__(self, image):
|
| 40 |
+
h, w = image.size
|
| 41 |
+
mats = [translate2d(h / 2 - 0.5, w / 2 - 0.5)]
|
| 42 |
+
|
| 43 |
+
# x-flip
|
| 44 |
+
a0 = torch.randint(2, []).float()
|
| 45 |
+
mats.append(scale2d(1 - 2 * a0, 1))
|
| 46 |
+
# y-flip
|
| 47 |
+
do = (torch.rand([]) < self.a_prob).float()
|
| 48 |
+
a1 = torch.randint(2, []).float() * do
|
| 49 |
+
mats.append(scale2d(1, 1 - 2 * a1))
|
| 50 |
+
# scaling
|
| 51 |
+
do = (torch.rand([]) < self.a_prob).float()
|
| 52 |
+
a2 = torch.randn([]) * do
|
| 53 |
+
mats.append(scale2d(self.a_scale ** a2, self.a_scale ** a2))
|
| 54 |
+
# rotation
|
| 55 |
+
do = (torch.rand([]) < self.a_prob).float()
|
| 56 |
+
a3 = (torch.rand([]) * 2 * math.pi - math.pi) * do
|
| 57 |
+
mats.append(rotate2d(-a3))
|
| 58 |
+
# anisotropy
|
| 59 |
+
do = (torch.rand([]) < self.a_prob).float()
|
| 60 |
+
a4 = (torch.rand([]) * 2 * math.pi - math.pi) * do
|
| 61 |
+
a5 = torch.randn([]) * do
|
| 62 |
+
mats.append(rotate2d(a4))
|
| 63 |
+
mats.append(scale2d(self.a_aniso ** a5, self.a_aniso ** -a5))
|
| 64 |
+
mats.append(rotate2d(-a4))
|
| 65 |
+
# translation
|
| 66 |
+
do = (torch.rand([]) < self.a_prob).float()
|
| 67 |
+
a6 = torch.randn([]) * do
|
| 68 |
+
a7 = torch.randn([]) * do
|
| 69 |
+
mats.append(translate2d(self.a_trans * w * a6, self.a_trans * h * a7))
|
| 70 |
+
|
| 71 |
+
# form the transformation matrix and conditioning vector
|
| 72 |
+
mats.append(translate2d(-h / 2 + 0.5, -w / 2 + 0.5))
|
| 73 |
+
mat = reduce(operator.matmul, mats)
|
| 74 |
+
cond = torch.stack([a0, a1, a2, a3.cos() - 1, a3.sin(), a5 * a4.cos(), a5 * a4.sin(), a6, a7])
|
| 75 |
+
|
| 76 |
+
# apply the transformation
|
| 77 |
+
image_orig = np.array(image, dtype=np.float32) / 255
|
| 78 |
+
if image_orig.ndim == 2:
|
| 79 |
+
image_orig = image_orig[..., None]
|
| 80 |
+
tf = transform.AffineTransform(mat.numpy())
|
| 81 |
+
image = transform.warp(image_orig, tf.inverse, order=3, mode='reflect', cval=0.5, clip=False, preserve_range=True)
|
| 82 |
+
image_orig = torch.as_tensor(image_orig).movedim(2, 0) * 2 - 1
|
| 83 |
+
image = torch.as_tensor(image).movedim(2, 0) * 2 - 1
|
| 84 |
+
return image, image_orig, cond
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class KarrasAugmentWrapper(nn.Module):
|
| 88 |
+
def __init__(self, model):
|
| 89 |
+
super().__init__()
|
| 90 |
+
self.inner_model = model
|
| 91 |
+
|
| 92 |
+
def forward(self, input, sigma, aug_cond=None, mapping_cond=None, **kwargs):
|
| 93 |
+
if aug_cond is None:
|
| 94 |
+
aug_cond = input.new_zeros([input.shape[0], 9])
|
| 95 |
+
if mapping_cond is None:
|
| 96 |
+
mapping_cond = aug_cond
|
| 97 |
+
else:
|
| 98 |
+
mapping_cond = torch.cat([aug_cond, mapping_cond], dim=1)
|
| 99 |
+
return self.inner_model(input, sigma, mapping_cond=mapping_cond, **kwargs)
|
| 100 |
+
|
| 101 |
+
def set_skip_stages(self, skip_stages):
|
| 102 |
+
return self.inner_model.set_skip_stages(skip_stages)
|
| 103 |
+
|
| 104 |
+
def set_patch_size(self, patch_size):
|
| 105 |
+
return self.inner_model.set_patch_size(patch_size)
|
repositories/k-diffusion/k_diffusion/config.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
import json
|
| 3 |
+
import math
|
| 4 |
+
import warnings
|
| 5 |
+
|
| 6 |
+
from jsonmerge import merge
|
| 7 |
+
|
| 8 |
+
from . import augmentation, layers, models, utils
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def load_config(file):
|
| 12 |
+
defaults = {
|
| 13 |
+
'model': {
|
| 14 |
+
'sigma_data': 1.,
|
| 15 |
+
'patch_size': 1,
|
| 16 |
+
'dropout_rate': 0.,
|
| 17 |
+
'augment_wrapper': True,
|
| 18 |
+
'augment_prob': 0.,
|
| 19 |
+
'mapping_cond_dim': 0,
|
| 20 |
+
'unet_cond_dim': 0,
|
| 21 |
+
'cross_cond_dim': 0,
|
| 22 |
+
'cross_attn_depths': None,
|
| 23 |
+
'skip_stages': 0,
|
| 24 |
+
'has_variance': False,
|
| 25 |
+
'loss_config': 'karras',
|
| 26 |
+
},
|
| 27 |
+
'dataset': {
|
| 28 |
+
'type': 'imagefolder',
|
| 29 |
+
},
|
| 30 |
+
'optimizer': {
|
| 31 |
+
'type': 'adamw',
|
| 32 |
+
'lr': 1e-4,
|
| 33 |
+
'betas': [0.95, 0.999],
|
| 34 |
+
'eps': 1e-6,
|
| 35 |
+
'weight_decay': 1e-3,
|
| 36 |
+
},
|
| 37 |
+
'lr_sched': {
|
| 38 |
+
'type': 'constant',
|
| 39 |
+
},
|
| 40 |
+
'ema_sched': {
|
| 41 |
+
'type': 'inverse',
|
| 42 |
+
'power': 0.6667,
|
| 43 |
+
'max_value': 0.9999
|
| 44 |
+
},
|
| 45 |
+
}
|
| 46 |
+
config = json.load(file)
|
| 47 |
+
return merge(defaults, config)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def make_model(config):
|
| 51 |
+
config = config['model']
|
| 52 |
+
assert config['type'] == 'image_v1'
|
| 53 |
+
model = models.ImageDenoiserModelV1(
|
| 54 |
+
config['input_channels'],
|
| 55 |
+
config['mapping_out'],
|
| 56 |
+
config['depths'],
|
| 57 |
+
config['channels'],
|
| 58 |
+
config['self_attn_depths'],
|
| 59 |
+
config['cross_attn_depths'],
|
| 60 |
+
patch_size=config['patch_size'],
|
| 61 |
+
dropout_rate=config['dropout_rate'],
|
| 62 |
+
mapping_cond_dim=config['mapping_cond_dim'] + (9 if config['augment_wrapper'] else 0),
|
| 63 |
+
unet_cond_dim=config['unet_cond_dim'],
|
| 64 |
+
cross_cond_dim=config['cross_cond_dim'],
|
| 65 |
+
skip_stages=config['skip_stages'],
|
| 66 |
+
has_variance=config['has_variance'],
|
| 67 |
+
)
|
| 68 |
+
if config['augment_wrapper']:
|
| 69 |
+
model = augmentation.KarrasAugmentWrapper(model)
|
| 70 |
+
return model
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def make_denoiser_wrapper(config):
|
| 74 |
+
config = config['model']
|
| 75 |
+
sigma_data = config.get('sigma_data', 1.)
|
| 76 |
+
has_variance = config.get('has_variance', False)
|
| 77 |
+
loss_config = config.get('loss_config', 'karras')
|
| 78 |
+
if loss_config == 'karras':
|
| 79 |
+
if not has_variance:
|
| 80 |
+
return partial(layers.Denoiser, sigma_data=sigma_data)
|
| 81 |
+
return partial(layers.DenoiserWithVariance, sigma_data=sigma_data)
|
| 82 |
+
if loss_config == 'simple':
|
| 83 |
+
if has_variance:
|
| 84 |
+
raise ValueError('Simple loss config does not support a variance output')
|
| 85 |
+
return partial(layers.SimpleLossDenoiser, sigma_data=sigma_data)
|
| 86 |
+
raise ValueError('Unknown loss config type')
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def make_sample_density(config):
|
| 90 |
+
sd_config = config['sigma_sample_density']
|
| 91 |
+
sigma_data = config['sigma_data']
|
| 92 |
+
if sd_config['type'] == 'lognormal':
|
| 93 |
+
loc = sd_config['mean'] if 'mean' in sd_config else sd_config['loc']
|
| 94 |
+
scale = sd_config['std'] if 'std' in sd_config else sd_config['scale']
|
| 95 |
+
return partial(utils.rand_log_normal, loc=loc, scale=scale)
|
| 96 |
+
if sd_config['type'] == 'loglogistic':
|
| 97 |
+
loc = sd_config['loc'] if 'loc' in sd_config else math.log(sigma_data)
|
| 98 |
+
scale = sd_config['scale'] if 'scale' in sd_config else 0.5
|
| 99 |
+
min_value = sd_config['min_value'] if 'min_value' in sd_config else 0.
|
| 100 |
+
max_value = sd_config['max_value'] if 'max_value' in sd_config else float('inf')
|
| 101 |
+
return partial(utils.rand_log_logistic, loc=loc, scale=scale, min_value=min_value, max_value=max_value)
|
| 102 |
+
if sd_config['type'] == 'loguniform':
|
| 103 |
+
min_value = sd_config['min_value'] if 'min_value' in sd_config else config['sigma_min']
|
| 104 |
+
max_value = sd_config['max_value'] if 'max_value' in sd_config else config['sigma_max']
|
| 105 |
+
return partial(utils.rand_log_uniform, min_value=min_value, max_value=max_value)
|
| 106 |
+
if sd_config['type'] in {'v-diffusion', 'cosine'}:
|
| 107 |
+
min_value = sd_config['min_value'] if 'min_value' in sd_config else 1e-3
|
| 108 |
+
max_value = sd_config['max_value'] if 'max_value' in sd_config else 1e3
|
| 109 |
+
return partial(utils.rand_v_diffusion, sigma_data=sigma_data, min_value=min_value, max_value=max_value)
|
| 110 |
+
if sd_config['type'] == 'split-lognormal':
|
| 111 |
+
loc = sd_config['mean'] if 'mean' in sd_config else sd_config['loc']
|
| 112 |
+
scale_1 = sd_config['std_1'] if 'std_1' in sd_config else sd_config['scale_1']
|
| 113 |
+
scale_2 = sd_config['std_2'] if 'std_2' in sd_config else sd_config['scale_2']
|
| 114 |
+
return partial(utils.rand_split_log_normal, loc=loc, scale_1=scale_1, scale_2=scale_2)
|
| 115 |
+
raise ValueError('Unknown sample density type')
|
repositories/k-diffusion/k_diffusion/evaluation.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import os
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
from cleanfid.inception_torchscript import InceptionV3W
|
| 6 |
+
import clip
|
| 7 |
+
from resize_right import resize
|
| 8 |
+
import torch
|
| 9 |
+
from torch import nn
|
| 10 |
+
from torch.nn import functional as F
|
| 11 |
+
from torchvision import transforms
|
| 12 |
+
from tqdm.auto import trange
|
| 13 |
+
|
| 14 |
+
from . import utils
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class InceptionV3FeatureExtractor(nn.Module):
|
| 18 |
+
def __init__(self, device='cpu'):
|
| 19 |
+
super().__init__()
|
| 20 |
+
path = Path(os.environ.get('XDG_CACHE_HOME', Path.home() / '.cache')) / 'k-diffusion'
|
| 21 |
+
url = 'https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metrics/inception-2015-12-05.pt'
|
| 22 |
+
digest = 'f58cb9b6ec323ed63459aa4fb441fe750cfe39fafad6da5cb504a16f19e958f4'
|
| 23 |
+
utils.download_file(path / 'inception-2015-12-05.pt', url, digest)
|
| 24 |
+
self.model = InceptionV3W(str(path), resize_inside=False).to(device)
|
| 25 |
+
self.size = (299, 299)
|
| 26 |
+
|
| 27 |
+
def forward(self, x):
|
| 28 |
+
if x.shape[2:4] != self.size:
|
| 29 |
+
x = resize(x, out_shape=self.size, pad_mode='reflect')
|
| 30 |
+
if x.shape[1] == 1:
|
| 31 |
+
x = torch.cat([x] * 3, dim=1)
|
| 32 |
+
x = (x * 127.5 + 127.5).clamp(0, 255)
|
| 33 |
+
return self.model(x)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class CLIPFeatureExtractor(nn.Module):
|
| 37 |
+
def __init__(self, name='ViT-L/14@336px', device='cpu'):
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.model = clip.load(name, device=device)[0].eval().requires_grad_(False)
|
| 40 |
+
self.normalize = transforms.Normalize(mean=(0.48145466, 0.4578275, 0.40821073),
|
| 41 |
+
std=(0.26862954, 0.26130258, 0.27577711))
|
| 42 |
+
self.size = (self.model.visual.input_resolution, self.model.visual.input_resolution)
|
| 43 |
+
|
| 44 |
+
def forward(self, x):
|
| 45 |
+
if x.shape[2:4] != self.size:
|
| 46 |
+
x = resize(x.add(1).div(2), out_shape=self.size, pad_mode='reflect').clamp(0, 1)
|
| 47 |
+
x = self.normalize(x)
|
| 48 |
+
x = self.model.encode_image(x).float()
|
| 49 |
+
x = F.normalize(x) * x.shape[1] ** 0.5
|
| 50 |
+
return x
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def compute_features(accelerator, sample_fn, extractor_fn, n, batch_size):
|
| 54 |
+
n_per_proc = math.ceil(n / accelerator.num_processes)
|
| 55 |
+
feats_all = []
|
| 56 |
+
try:
|
| 57 |
+
for i in trange(0, n_per_proc, batch_size, disable=not accelerator.is_main_process):
|
| 58 |
+
cur_batch_size = min(n - i, batch_size)
|
| 59 |
+
samples = sample_fn(cur_batch_size)[:cur_batch_size]
|
| 60 |
+
feats_all.append(accelerator.gather(extractor_fn(samples)))
|
| 61 |
+
except StopIteration:
|
| 62 |
+
pass
|
| 63 |
+
return torch.cat(feats_all)[:n]
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def polynomial_kernel(x, y):
|
| 67 |
+
d = x.shape[-1]
|
| 68 |
+
dot = x @ y.transpose(-2, -1)
|
| 69 |
+
return (dot / d + 1) ** 3
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def squared_mmd(x, y, kernel=polynomial_kernel):
|
| 73 |
+
m = x.shape[-2]
|
| 74 |
+
n = y.shape[-2]
|
| 75 |
+
kxx = kernel(x, x)
|
| 76 |
+
kyy = kernel(y, y)
|
| 77 |
+
kxy = kernel(x, y)
|
| 78 |
+
kxx_sum = kxx.sum([-1, -2]) - kxx.diagonal(dim1=-1, dim2=-2).sum(-1)
|
| 79 |
+
kyy_sum = kyy.sum([-1, -2]) - kyy.diagonal(dim1=-1, dim2=-2).sum(-1)
|
| 80 |
+
kxy_sum = kxy.sum([-1, -2])
|
| 81 |
+
term_1 = kxx_sum / m / (m - 1)
|
| 82 |
+
term_2 = kyy_sum / n / (n - 1)
|
| 83 |
+
term_3 = kxy_sum * 2 / m / n
|
| 84 |
+
return term_1 + term_2 - term_3
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
@utils.tf32_mode(matmul=False)
|
| 88 |
+
def kid(x, y, max_size=5000):
|
| 89 |
+
x_size, y_size = x.shape[0], y.shape[0]
|
| 90 |
+
n_partitions = math.ceil(max(x_size / max_size, y_size / max_size))
|
| 91 |
+
total_mmd = x.new_zeros([])
|
| 92 |
+
for i in range(n_partitions):
|
| 93 |
+
cur_x = x[round(i * x_size / n_partitions):round((i + 1) * x_size / n_partitions)]
|
| 94 |
+
cur_y = y[round(i * y_size / n_partitions):round((i + 1) * y_size / n_partitions)]
|
| 95 |
+
total_mmd = total_mmd + squared_mmd(cur_x, cur_y)
|
| 96 |
+
return total_mmd / n_partitions
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class _MatrixSquareRootEig(torch.autograd.Function):
|
| 100 |
+
@staticmethod
|
| 101 |
+
def forward(ctx, a):
|
| 102 |
+
vals, vecs = torch.linalg.eigh(a)
|
| 103 |
+
ctx.save_for_backward(vals, vecs)
|
| 104 |
+
return vecs @ vals.abs().sqrt().diag_embed() @ vecs.transpose(-2, -1)
|
| 105 |
+
|
| 106 |
+
@staticmethod
|
| 107 |
+
def backward(ctx, grad_output):
|
| 108 |
+
vals, vecs = ctx.saved_tensors
|
| 109 |
+
d = vals.abs().sqrt().unsqueeze(-1).repeat_interleave(vals.shape[-1], -1)
|
| 110 |
+
vecs_t = vecs.transpose(-2, -1)
|
| 111 |
+
return vecs @ (vecs_t @ grad_output @ vecs / (d + d.transpose(-2, -1))) @ vecs_t
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def sqrtm_eig(a):
|
| 115 |
+
if a.ndim < 2:
|
| 116 |
+
raise RuntimeError('tensor of matrices must have at least 2 dimensions')
|
| 117 |
+
if a.shape[-2] != a.shape[-1]:
|
| 118 |
+
raise RuntimeError('tensor must be batches of square matrices')
|
| 119 |
+
return _MatrixSquareRootEig.apply(a)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
@utils.tf32_mode(matmul=False)
|
| 123 |
+
def fid(x, y, eps=1e-8):
|
| 124 |
+
x_mean = x.mean(dim=0)
|
| 125 |
+
y_mean = y.mean(dim=0)
|
| 126 |
+
mean_term = (x_mean - y_mean).pow(2).sum()
|
| 127 |
+
x_cov = torch.cov(x.T)
|
| 128 |
+
y_cov = torch.cov(y.T)
|
| 129 |
+
eps_eye = torch.eye(x_cov.shape[0], device=x_cov.device, dtype=x_cov.dtype) * eps
|
| 130 |
+
x_cov = x_cov + eps_eye
|
| 131 |
+
y_cov = y_cov + eps_eye
|
| 132 |
+
x_cov_sqrt = sqrtm_eig(x_cov)
|
| 133 |
+
cov_term = torch.trace(x_cov + y_cov - 2 * sqrtm_eig(x_cov_sqrt @ y_cov @ x_cov_sqrt))
|
| 134 |
+
return mean_term + cov_term
|
repositories/k-diffusion/k_diffusion/external.py
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
|
| 6 |
+
from . import sampling, utils
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class VDenoiser(nn.Module):
|
| 10 |
+
"""A v-diffusion-pytorch model wrapper for k-diffusion."""
|
| 11 |
+
|
| 12 |
+
def __init__(self, inner_model):
|
| 13 |
+
super().__init__()
|
| 14 |
+
self.inner_model = inner_model
|
| 15 |
+
self.sigma_data = 1.
|
| 16 |
+
|
| 17 |
+
def get_scalings(self, sigma):
|
| 18 |
+
c_skip = self.sigma_data ** 2 / (sigma ** 2 + self.sigma_data ** 2)
|
| 19 |
+
c_out = -sigma * self.sigma_data / (sigma ** 2 + self.sigma_data ** 2) ** 0.5
|
| 20 |
+
c_in = 1 / (sigma ** 2 + self.sigma_data ** 2) ** 0.5
|
| 21 |
+
return c_skip, c_out, c_in
|
| 22 |
+
|
| 23 |
+
def sigma_to_t(self, sigma):
|
| 24 |
+
return sigma.atan() / math.pi * 2
|
| 25 |
+
|
| 26 |
+
def t_to_sigma(self, t):
|
| 27 |
+
return (t * math.pi / 2).tan()
|
| 28 |
+
|
| 29 |
+
def loss(self, input, noise, sigma, **kwargs):
|
| 30 |
+
c_skip, c_out, c_in = [utils.append_dims(x, input.ndim) for x in self.get_scalings(sigma)]
|
| 31 |
+
noised_input = input + noise * utils.append_dims(sigma, input.ndim)
|
| 32 |
+
model_output = self.inner_model(noised_input * c_in, self.sigma_to_t(sigma), **kwargs)
|
| 33 |
+
target = (input - c_skip * noised_input) / c_out
|
| 34 |
+
return (model_output - target).pow(2).flatten(1).mean(1)
|
| 35 |
+
|
| 36 |
+
def forward(self, input, sigma, **kwargs):
|
| 37 |
+
c_skip, c_out, c_in = [utils.append_dims(x, input.ndim) for x in self.get_scalings(sigma)]
|
| 38 |
+
return self.inner_model(input * c_in, self.sigma_to_t(sigma), **kwargs) * c_out + input * c_skip
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class DiscreteSchedule(nn.Module):
|
| 42 |
+
"""A mapping between continuous noise levels (sigmas) and a list of discrete noise
|
| 43 |
+
levels."""
|
| 44 |
+
|
| 45 |
+
def __init__(self, sigmas, quantize):
|
| 46 |
+
super().__init__()
|
| 47 |
+
self.register_buffer('sigmas', sigmas)
|
| 48 |
+
self.register_buffer('log_sigmas', sigmas.log())
|
| 49 |
+
self.quantize = quantize
|
| 50 |
+
|
| 51 |
+
@property
|
| 52 |
+
def sigma_min(self):
|
| 53 |
+
return self.sigmas[0]
|
| 54 |
+
|
| 55 |
+
@property
|
| 56 |
+
def sigma_max(self):
|
| 57 |
+
return self.sigmas[-1]
|
| 58 |
+
|
| 59 |
+
def get_sigmas(self, n=None):
|
| 60 |
+
if n is None:
|
| 61 |
+
return sampling.append_zero(self.sigmas.flip(0))
|
| 62 |
+
t_max = len(self.sigmas) - 1
|
| 63 |
+
t = torch.linspace(t_max, 0, n, device=self.sigmas.device)
|
| 64 |
+
return sampling.append_zero(self.t_to_sigma(t))
|
| 65 |
+
|
| 66 |
+
def sigma_to_t(self, sigma, quantize=None):
|
| 67 |
+
quantize = self.quantize if quantize is None else quantize
|
| 68 |
+
log_sigma = sigma.log()
|
| 69 |
+
dists = log_sigma - self.log_sigmas[:, None]
|
| 70 |
+
if quantize:
|
| 71 |
+
return dists.abs().argmin(dim=0).view(sigma.shape)
|
| 72 |
+
low_idx = dists.ge(0).cumsum(dim=0).argmax(dim=0).clamp(max=self.log_sigmas.shape[0] - 2)
|
| 73 |
+
high_idx = low_idx + 1
|
| 74 |
+
low, high = self.log_sigmas[low_idx], self.log_sigmas[high_idx]
|
| 75 |
+
w = (low - log_sigma) / (low - high)
|
| 76 |
+
w = w.clamp(0, 1)
|
| 77 |
+
t = (1 - w) * low_idx + w * high_idx
|
| 78 |
+
return t.view(sigma.shape)
|
| 79 |
+
|
| 80 |
+
def t_to_sigma(self, t):
|
| 81 |
+
t = t.float()
|
| 82 |
+
low_idx, high_idx, w = t.floor().long(), t.ceil().long(), t.frac()
|
| 83 |
+
log_sigma = (1 - w) * self.log_sigmas[low_idx] + w * self.log_sigmas[high_idx]
|
| 84 |
+
return log_sigma.exp()
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class DiscreteEpsDDPMDenoiser(DiscreteSchedule):
|
| 88 |
+
"""A wrapper for discrete schedule DDPM models that output eps (the predicted
|
| 89 |
+
noise)."""
|
| 90 |
+
|
| 91 |
+
def __init__(self, model, alphas_cumprod, quantize):
|
| 92 |
+
super().__init__(((1 - alphas_cumprod) / alphas_cumprod) ** 0.5, quantize)
|
| 93 |
+
self.inner_model = model
|
| 94 |
+
self.sigma_data = 1.
|
| 95 |
+
|
| 96 |
+
def get_scalings(self, sigma):
|
| 97 |
+
c_out = -sigma
|
| 98 |
+
c_in = 1 / (sigma ** 2 + self.sigma_data ** 2) ** 0.5
|
| 99 |
+
return c_out, c_in
|
| 100 |
+
|
| 101 |
+
def get_eps(self, *args, **kwargs):
|
| 102 |
+
return self.inner_model(*args, **kwargs)
|
| 103 |
+
|
| 104 |
+
def loss(self, input, noise, sigma, **kwargs):
|
| 105 |
+
c_out, c_in = [utils.append_dims(x, input.ndim) for x in self.get_scalings(sigma)]
|
| 106 |
+
noised_input = input + noise * utils.append_dims(sigma, input.ndim)
|
| 107 |
+
eps = self.get_eps(noised_input * c_in, self.sigma_to_t(sigma), **kwargs)
|
| 108 |
+
return (eps - noise).pow(2).flatten(1).mean(1)
|
| 109 |
+
|
| 110 |
+
def forward(self, input, sigma, **kwargs):
|
| 111 |
+
c_out, c_in = [utils.append_dims(x, input.ndim) for x in self.get_scalings(sigma)]
|
| 112 |
+
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
|
| 113 |
+
return input + eps * c_out
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
class OpenAIDenoiser(DiscreteEpsDDPMDenoiser):
|
| 117 |
+
"""A wrapper for OpenAI diffusion models."""
|
| 118 |
+
|
| 119 |
+
def __init__(self, model, diffusion, quantize=False, has_learned_sigmas=True, device='cpu'):
|
| 120 |
+
alphas_cumprod = torch.tensor(diffusion.alphas_cumprod, device=device, dtype=torch.float32)
|
| 121 |
+
super().__init__(model, alphas_cumprod, quantize=quantize)
|
| 122 |
+
self.has_learned_sigmas = has_learned_sigmas
|
| 123 |
+
|
| 124 |
+
def get_eps(self, *args, **kwargs):
|
| 125 |
+
model_output = self.inner_model(*args, **kwargs)
|
| 126 |
+
if self.has_learned_sigmas:
|
| 127 |
+
return model_output.chunk(2, dim=1)[0]
|
| 128 |
+
return model_output
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
class CompVisDenoiser(DiscreteEpsDDPMDenoiser):
|
| 132 |
+
"""A wrapper for CompVis diffusion models."""
|
| 133 |
+
|
| 134 |
+
def __init__(self, model, quantize=False, device='cpu'):
|
| 135 |
+
super().__init__(model, model.alphas_cumprod, quantize=quantize)
|
| 136 |
+
|
| 137 |
+
def get_eps(self, *args, **kwargs):
|
| 138 |
+
return self.inner_model.apply_model(*args, **kwargs)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
class DiscreteVDDPMDenoiser(DiscreteSchedule):
|
| 142 |
+
"""A wrapper for discrete schedule DDPM models that output v."""
|
| 143 |
+
|
| 144 |
+
def __init__(self, model, alphas_cumprod, quantize):
|
| 145 |
+
super().__init__(((1 - alphas_cumprod) / alphas_cumprod) ** 0.5, quantize)
|
| 146 |
+
self.inner_model = model
|
| 147 |
+
self.sigma_data = 1.
|
| 148 |
+
|
| 149 |
+
def get_scalings(self, sigma):
|
| 150 |
+
c_skip = self.sigma_data ** 2 / (sigma ** 2 + self.sigma_data ** 2)
|
| 151 |
+
c_out = -sigma * self.sigma_data / (sigma ** 2 + self.sigma_data ** 2) ** 0.5
|
| 152 |
+
c_in = 1 / (sigma ** 2 + self.sigma_data ** 2) ** 0.5
|
| 153 |
+
return c_skip, c_out, c_in
|
| 154 |
+
|
| 155 |
+
def get_v(self, *args, **kwargs):
|
| 156 |
+
return self.inner_model(*args, **kwargs)
|
| 157 |
+
|
| 158 |
+
def loss(self, input, noise, sigma, **kwargs):
|
| 159 |
+
c_skip, c_out, c_in = [utils.append_dims(x, input.ndim) for x in self.get_scalings(sigma)]
|
| 160 |
+
noised_input = input + noise * utils.append_dims(sigma, input.ndim)
|
| 161 |
+
model_output = self.get_v(noised_input * c_in, self.sigma_to_t(sigma), **kwargs)
|
| 162 |
+
target = (input - c_skip * noised_input) / c_out
|
| 163 |
+
return (model_output - target).pow(2).flatten(1).mean(1)
|
| 164 |
+
|
| 165 |
+
def forward(self, input, sigma, **kwargs):
|
| 166 |
+
c_skip, c_out, c_in = [utils.append_dims(x, input.ndim) for x in self.get_scalings(sigma)]
|
| 167 |
+
return self.get_v(input * c_in, self.sigma_to_t(sigma), **kwargs) * c_out + input * c_skip
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
class CompVisVDenoiser(DiscreteVDDPMDenoiser):
|
| 171 |
+
"""A wrapper for CompVis diffusion models that output v."""
|
| 172 |
+
|
| 173 |
+
def __init__(self, model, quantize=False, device='cpu'):
|
| 174 |
+
super().__init__(model, model.alphas_cumprod, quantize=quantize)
|
| 175 |
+
|
| 176 |
+
def get_v(self, x, t, cond, **kwargs):
|
| 177 |
+
return self.inner_model.apply_model(x, t, cond)
|
repositories/k-diffusion/k_diffusion/gns.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class DDPGradientStatsHook:
|
| 6 |
+
def __init__(self, ddp_module):
|
| 7 |
+
try:
|
| 8 |
+
ddp_module.register_comm_hook(self, self._hook_fn)
|
| 9 |
+
except AttributeError:
|
| 10 |
+
raise ValueError('DDPGradientStatsHook does not support non-DDP wrapped modules')
|
| 11 |
+
self._clear_state()
|
| 12 |
+
|
| 13 |
+
def _clear_state(self):
|
| 14 |
+
self.bucket_sq_norms_small_batch = []
|
| 15 |
+
self.bucket_sq_norms_large_batch = []
|
| 16 |
+
|
| 17 |
+
@staticmethod
|
| 18 |
+
def _hook_fn(self, bucket):
|
| 19 |
+
buf = bucket.buffer()
|
| 20 |
+
self.bucket_sq_norms_small_batch.append(buf.pow(2).sum())
|
| 21 |
+
fut = torch.distributed.all_reduce(buf, op=torch.distributed.ReduceOp.AVG, async_op=True).get_future()
|
| 22 |
+
def callback(fut):
|
| 23 |
+
buf = fut.value()[0]
|
| 24 |
+
self.bucket_sq_norms_large_batch.append(buf.pow(2).sum())
|
| 25 |
+
return buf
|
| 26 |
+
return fut.then(callback)
|
| 27 |
+
|
| 28 |
+
def get_stats(self):
|
| 29 |
+
sq_norm_small_batch = sum(self.bucket_sq_norms_small_batch)
|
| 30 |
+
sq_norm_large_batch = sum(self.bucket_sq_norms_large_batch)
|
| 31 |
+
self._clear_state()
|
| 32 |
+
stats = torch.stack([sq_norm_small_batch, sq_norm_large_batch])
|
| 33 |
+
torch.distributed.all_reduce(stats, op=torch.distributed.ReduceOp.AVG)
|
| 34 |
+
return stats[0].item(), stats[1].item()
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class GradientNoiseScale:
|
| 38 |
+
"""Calculates the gradient noise scale (1 / SNR), or critical batch size,
|
| 39 |
+
from _An Empirical Model of Large-Batch Training_,
|
| 40 |
+
https://arxiv.org/abs/1812.06162).
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
beta (float): The decay factor for the exponential moving averages used to
|
| 44 |
+
calculate the gradient noise scale.
|
| 45 |
+
Default: 0.9998
|
| 46 |
+
eps (float): Added for numerical stability.
|
| 47 |
+
Default: 1e-8
|
| 48 |
+
"""
|
| 49 |
+
|
| 50 |
+
def __init__(self, beta=0.9998, eps=1e-8):
|
| 51 |
+
self.beta = beta
|
| 52 |
+
self.eps = eps
|
| 53 |
+
self.ema_sq_norm = 0.
|
| 54 |
+
self.ema_var = 0.
|
| 55 |
+
self.beta_cumprod = 1.
|
| 56 |
+
self.gradient_noise_scale = float('nan')
|
| 57 |
+
|
| 58 |
+
def state_dict(self):
|
| 59 |
+
"""Returns the state of the object as a :class:`dict`."""
|
| 60 |
+
return dict(self.__dict__.items())
|
| 61 |
+
|
| 62 |
+
def load_state_dict(self, state_dict):
|
| 63 |
+
"""Loads the object's state.
|
| 64 |
+
Args:
|
| 65 |
+
state_dict (dict): object state. Should be an object returned
|
| 66 |
+
from a call to :meth:`state_dict`.
|
| 67 |
+
"""
|
| 68 |
+
self.__dict__.update(state_dict)
|
| 69 |
+
|
| 70 |
+
def update(self, sq_norm_small_batch, sq_norm_large_batch, n_small_batch, n_large_batch):
|
| 71 |
+
"""Updates the state with a new batch's gradient statistics, and returns the
|
| 72 |
+
current gradient noise scale.
|
| 73 |
+
|
| 74 |
+
Args:
|
| 75 |
+
sq_norm_small_batch (float): The mean of the squared 2-norms of microbatch or
|
| 76 |
+
per sample gradients.
|
| 77 |
+
sq_norm_large_batch (float): The squared 2-norm of the mean of the microbatch or
|
| 78 |
+
per sample gradients.
|
| 79 |
+
n_small_batch (int): The batch size of the individual microbatch or per sample
|
| 80 |
+
gradients (1 if per sample).
|
| 81 |
+
n_large_batch (int): The total batch size of the mean of the microbatch or
|
| 82 |
+
per sample gradients.
|
| 83 |
+
"""
|
| 84 |
+
est_sq_norm = (n_large_batch * sq_norm_large_batch - n_small_batch * sq_norm_small_batch) / (n_large_batch - n_small_batch)
|
| 85 |
+
est_var = (sq_norm_small_batch - sq_norm_large_batch) / (1 / n_small_batch - 1 / n_large_batch)
|
| 86 |
+
self.ema_sq_norm = self.beta * self.ema_sq_norm + (1 - self.beta) * est_sq_norm
|
| 87 |
+
self.ema_var = self.beta * self.ema_var + (1 - self.beta) * est_var
|
| 88 |
+
self.beta_cumprod *= self.beta
|
| 89 |
+
self.gradient_noise_scale = max(self.ema_var, self.eps) / max(self.ema_sq_norm, self.eps)
|
| 90 |
+
return self.gradient_noise_scale
|
| 91 |
+
|
| 92 |
+
def get_gns(self):
|
| 93 |
+
"""Returns the current gradient noise scale."""
|
| 94 |
+
return self.gradient_noise_scale
|
| 95 |
+
|
| 96 |
+
def get_stats(self):
|
| 97 |
+
"""Returns the current (debiased) estimates of the squared mean gradient
|
| 98 |
+
and gradient variance."""
|
| 99 |
+
return self.ema_sq_norm / (1 - self.beta_cumprod), self.ema_var / (1 - self.beta_cumprod)
|
repositories/k-diffusion/k_diffusion/layers.py
ADDED
|
@@ -0,0 +1,256 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
from einops import rearrange, repeat
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
from . import sampling, utils
|
| 9 |
+
|
| 10 |
+
# Karras et al. preconditioned denoiser
|
| 11 |
+
|
| 12 |
+
class Denoiser(nn.Module):
|
| 13 |
+
"""A Karras et al. preconditioner for denoising diffusion models."""
|
| 14 |
+
|
| 15 |
+
def __init__(self, inner_model, sigma_data=1.):
|
| 16 |
+
super().__init__()
|
| 17 |
+
self.inner_model = inner_model
|
| 18 |
+
self.sigma_data = sigma_data
|
| 19 |
+
|
| 20 |
+
def get_scalings(self, sigma):
|
| 21 |
+
c_skip = self.sigma_data ** 2 / (sigma ** 2 + self.sigma_data ** 2)
|
| 22 |
+
c_out = sigma * self.sigma_data / (sigma ** 2 + self.sigma_data ** 2) ** 0.5
|
| 23 |
+
c_in = 1 / (sigma ** 2 + self.sigma_data ** 2) ** 0.5
|
| 24 |
+
return c_skip, c_out, c_in
|
| 25 |
+
|
| 26 |
+
def loss(self, input, noise, sigma, **kwargs):
|
| 27 |
+
c_skip, c_out, c_in = [utils.append_dims(x, input.ndim) for x in self.get_scalings(sigma)]
|
| 28 |
+
noised_input = input + noise * utils.append_dims(sigma, input.ndim)
|
| 29 |
+
model_output = self.inner_model(noised_input * c_in, sigma, **kwargs)
|
| 30 |
+
target = (input - c_skip * noised_input) / c_out
|
| 31 |
+
return (model_output - target).pow(2).flatten(1).mean(1)
|
| 32 |
+
|
| 33 |
+
def forward(self, input, sigma, **kwargs):
|
| 34 |
+
c_skip, c_out, c_in = [utils.append_dims(x, input.ndim) for x in self.get_scalings(sigma)]
|
| 35 |
+
return self.inner_model(input * c_in, sigma, **kwargs) * c_out + input * c_skip
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class DenoiserWithVariance(Denoiser):
|
| 39 |
+
def loss(self, input, noise, sigma, **kwargs):
|
| 40 |
+
c_skip, c_out, c_in = [utils.append_dims(x, input.ndim) for x in self.get_scalings(sigma)]
|
| 41 |
+
noised_input = input + noise * utils.append_dims(sigma, input.ndim)
|
| 42 |
+
model_output, logvar = self.inner_model(noised_input * c_in, sigma, return_variance=True, **kwargs)
|
| 43 |
+
logvar = utils.append_dims(logvar, model_output.ndim)
|
| 44 |
+
target = (input - c_skip * noised_input) / c_out
|
| 45 |
+
losses = ((model_output - target) ** 2 / logvar.exp() + logvar) / 2
|
| 46 |
+
return losses.flatten(1).mean(1)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class SimpleLossDenoiser(Denoiser):
|
| 50 |
+
"""L_simple with the Karras et al. preconditioner."""
|
| 51 |
+
|
| 52 |
+
def loss(self, input, noise, sigma, **kwargs):
|
| 53 |
+
noised_input = input + noise * utils.append_dims(sigma, input.ndim)
|
| 54 |
+
denoised = self(noised_input, sigma, **kwargs)
|
| 55 |
+
eps = sampling.to_d(noised_input, sigma, denoised)
|
| 56 |
+
return (eps - noise).pow(2).flatten(1).mean(1)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# Residual blocks
|
| 60 |
+
|
| 61 |
+
class ResidualBlock(nn.Module):
|
| 62 |
+
def __init__(self, *main, skip=None):
|
| 63 |
+
super().__init__()
|
| 64 |
+
self.main = nn.Sequential(*main)
|
| 65 |
+
self.skip = skip if skip else nn.Identity()
|
| 66 |
+
|
| 67 |
+
def forward(self, input):
|
| 68 |
+
return self.main(input) + self.skip(input)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
# Noise level (and other) conditioning
|
| 72 |
+
|
| 73 |
+
class ConditionedModule(nn.Module):
|
| 74 |
+
pass
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class UnconditionedModule(ConditionedModule):
|
| 78 |
+
def __init__(self, module):
|
| 79 |
+
super().__init__()
|
| 80 |
+
self.module = module
|
| 81 |
+
|
| 82 |
+
def forward(self, input, cond=None):
|
| 83 |
+
return self.module(input)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
class ConditionedSequential(nn.Sequential, ConditionedModule):
|
| 87 |
+
def forward(self, input, cond):
|
| 88 |
+
for module in self:
|
| 89 |
+
if isinstance(module, ConditionedModule):
|
| 90 |
+
input = module(input, cond)
|
| 91 |
+
else:
|
| 92 |
+
input = module(input)
|
| 93 |
+
return input
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
class ConditionedResidualBlock(ConditionedModule):
|
| 97 |
+
def __init__(self, *main, skip=None):
|
| 98 |
+
super().__init__()
|
| 99 |
+
self.main = ConditionedSequential(*main)
|
| 100 |
+
self.skip = skip if skip else nn.Identity()
|
| 101 |
+
|
| 102 |
+
def forward(self, input, cond):
|
| 103 |
+
skip = self.skip(input, cond) if isinstance(self.skip, ConditionedModule) else self.skip(input)
|
| 104 |
+
return self.main(input, cond) + skip
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
class AdaGN(ConditionedModule):
|
| 108 |
+
def __init__(self, feats_in, c_out, num_groups, eps=1e-5, cond_key='cond'):
|
| 109 |
+
super().__init__()
|
| 110 |
+
self.num_groups = num_groups
|
| 111 |
+
self.eps = eps
|
| 112 |
+
self.cond_key = cond_key
|
| 113 |
+
self.mapper = nn.Linear(feats_in, c_out * 2)
|
| 114 |
+
|
| 115 |
+
def forward(self, input, cond):
|
| 116 |
+
weight, bias = self.mapper(cond[self.cond_key]).chunk(2, dim=-1)
|
| 117 |
+
input = F.group_norm(input, self.num_groups, eps=self.eps)
|
| 118 |
+
return torch.addcmul(utils.append_dims(bias, input.ndim), input, utils.append_dims(weight, input.ndim) + 1)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
# Attention
|
| 122 |
+
|
| 123 |
+
class SelfAttention2d(ConditionedModule):
|
| 124 |
+
def __init__(self, c_in, n_head, norm, dropout_rate=0.):
|
| 125 |
+
super().__init__()
|
| 126 |
+
assert c_in % n_head == 0
|
| 127 |
+
self.norm_in = norm(c_in)
|
| 128 |
+
self.n_head = n_head
|
| 129 |
+
self.qkv_proj = nn.Conv2d(c_in, c_in * 3, 1)
|
| 130 |
+
self.out_proj = nn.Conv2d(c_in, c_in, 1)
|
| 131 |
+
self.dropout = nn.Dropout(dropout_rate)
|
| 132 |
+
|
| 133 |
+
def forward(self, input, cond):
|
| 134 |
+
n, c, h, w = input.shape
|
| 135 |
+
qkv = self.qkv_proj(self.norm_in(input, cond))
|
| 136 |
+
qkv = qkv.view([n, self.n_head * 3, c // self.n_head, h * w]).transpose(2, 3)
|
| 137 |
+
q, k, v = qkv.chunk(3, dim=1)
|
| 138 |
+
scale = k.shape[3] ** -0.25
|
| 139 |
+
att = ((q * scale) @ (k.transpose(2, 3) * scale)).softmax(3)
|
| 140 |
+
att = self.dropout(att)
|
| 141 |
+
y = (att @ v).transpose(2, 3).contiguous().view([n, c, h, w])
|
| 142 |
+
return input + self.out_proj(y)
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
class CrossAttention2d(ConditionedModule):
|
| 146 |
+
def __init__(self, c_dec, c_enc, n_head, norm_dec, dropout_rate=0.,
|
| 147 |
+
cond_key='cross', cond_key_padding='cross_padding'):
|
| 148 |
+
super().__init__()
|
| 149 |
+
assert c_dec % n_head == 0
|
| 150 |
+
self.cond_key = cond_key
|
| 151 |
+
self.cond_key_padding = cond_key_padding
|
| 152 |
+
self.norm_enc = nn.LayerNorm(c_enc)
|
| 153 |
+
self.norm_dec = norm_dec(c_dec)
|
| 154 |
+
self.n_head = n_head
|
| 155 |
+
self.q_proj = nn.Conv2d(c_dec, c_dec, 1)
|
| 156 |
+
self.kv_proj = nn.Linear(c_enc, c_dec * 2)
|
| 157 |
+
self.out_proj = nn.Conv2d(c_dec, c_dec, 1)
|
| 158 |
+
self.dropout = nn.Dropout(dropout_rate)
|
| 159 |
+
|
| 160 |
+
def forward(self, input, cond):
|
| 161 |
+
n, c, h, w = input.shape
|
| 162 |
+
q = self.q_proj(self.norm_dec(input, cond))
|
| 163 |
+
q = q.view([n, self.n_head, c // self.n_head, h * w]).transpose(2, 3)
|
| 164 |
+
kv = self.kv_proj(self.norm_enc(cond[self.cond_key]))
|
| 165 |
+
kv = kv.view([n, -1, self.n_head * 2, c // self.n_head]).transpose(1, 2)
|
| 166 |
+
k, v = kv.chunk(2, dim=1)
|
| 167 |
+
scale = k.shape[3] ** -0.25
|
| 168 |
+
att = ((q * scale) @ (k.transpose(2, 3) * scale))
|
| 169 |
+
att = att - (cond[self.cond_key_padding][:, None, None, :]) * 10000
|
| 170 |
+
att = att.softmax(3)
|
| 171 |
+
att = self.dropout(att)
|
| 172 |
+
y = (att @ v).transpose(2, 3)
|
| 173 |
+
y = y.contiguous().view([n, c, h, w])
|
| 174 |
+
return input + self.out_proj(y)
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
# Downsampling/upsampling
|
| 178 |
+
|
| 179 |
+
_kernels = {
|
| 180 |
+
'linear':
|
| 181 |
+
[1 / 8, 3 / 8, 3 / 8, 1 / 8],
|
| 182 |
+
'cubic':
|
| 183 |
+
[-0.01171875, -0.03515625, 0.11328125, 0.43359375,
|
| 184 |
+
0.43359375, 0.11328125, -0.03515625, -0.01171875],
|
| 185 |
+
'lanczos3':
|
| 186 |
+
[0.003689131001010537, 0.015056144446134567, -0.03399861603975296,
|
| 187 |
+
-0.066637322306633, 0.13550527393817902, 0.44638532400131226,
|
| 188 |
+
0.44638532400131226, 0.13550527393817902, -0.066637322306633,
|
| 189 |
+
-0.03399861603975296, 0.015056144446134567, 0.003689131001010537]
|
| 190 |
+
}
|
| 191 |
+
_kernels['bilinear'] = _kernels['linear']
|
| 192 |
+
_kernels['bicubic'] = _kernels['cubic']
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
class Downsample2d(nn.Module):
|
| 196 |
+
def __init__(self, kernel='linear', pad_mode='reflect'):
|
| 197 |
+
super().__init__()
|
| 198 |
+
self.pad_mode = pad_mode
|
| 199 |
+
kernel_1d = torch.tensor([_kernels[kernel]])
|
| 200 |
+
self.pad = kernel_1d.shape[1] // 2 - 1
|
| 201 |
+
self.register_buffer('kernel', kernel_1d.T @ kernel_1d)
|
| 202 |
+
|
| 203 |
+
def forward(self, x):
|
| 204 |
+
x = F.pad(x, (self.pad,) * 4, self.pad_mode)
|
| 205 |
+
weight = x.new_zeros([x.shape[1], x.shape[1], self.kernel.shape[0], self.kernel.shape[1]])
|
| 206 |
+
indices = torch.arange(x.shape[1], device=x.device)
|
| 207 |
+
weight[indices, indices] = self.kernel.to(weight)
|
| 208 |
+
return F.conv2d(x, weight, stride=2)
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class Upsample2d(nn.Module):
|
| 212 |
+
def __init__(self, kernel='linear', pad_mode='reflect'):
|
| 213 |
+
super().__init__()
|
| 214 |
+
self.pad_mode = pad_mode
|
| 215 |
+
kernel_1d = torch.tensor([_kernels[kernel]]) * 2
|
| 216 |
+
self.pad = kernel_1d.shape[1] // 2 - 1
|
| 217 |
+
self.register_buffer('kernel', kernel_1d.T @ kernel_1d)
|
| 218 |
+
|
| 219 |
+
def forward(self, x):
|
| 220 |
+
x = F.pad(x, ((self.pad + 1) // 2,) * 4, self.pad_mode)
|
| 221 |
+
weight = x.new_zeros([x.shape[1], x.shape[1], self.kernel.shape[0], self.kernel.shape[1]])
|
| 222 |
+
indices = torch.arange(x.shape[1], device=x.device)
|
| 223 |
+
weight[indices, indices] = self.kernel.to(weight)
|
| 224 |
+
return F.conv_transpose2d(x, weight, stride=2, padding=self.pad * 2 + 1)
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
# Embeddings
|
| 228 |
+
|
| 229 |
+
class FourierFeatures(nn.Module):
|
| 230 |
+
def __init__(self, in_features, out_features, std=1.):
|
| 231 |
+
super().__init__()
|
| 232 |
+
assert out_features % 2 == 0
|
| 233 |
+
self.register_buffer('weight', torch.randn([out_features // 2, in_features]) * std)
|
| 234 |
+
|
| 235 |
+
def forward(self, input):
|
| 236 |
+
f = 2 * math.pi * input @ self.weight.T
|
| 237 |
+
return torch.cat([f.cos(), f.sin()], dim=-1)
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
# U-Nets
|
| 241 |
+
|
| 242 |
+
class UNet(ConditionedModule):
|
| 243 |
+
def __init__(self, d_blocks, u_blocks, skip_stages=0):
|
| 244 |
+
super().__init__()
|
| 245 |
+
self.d_blocks = nn.ModuleList(d_blocks)
|
| 246 |
+
self.u_blocks = nn.ModuleList(u_blocks)
|
| 247 |
+
self.skip_stages = skip_stages
|
| 248 |
+
|
| 249 |
+
def forward(self, input, cond):
|
| 250 |
+
skips = []
|
| 251 |
+
for block in self.d_blocks[self.skip_stages:]:
|
| 252 |
+
input = block(input, cond)
|
| 253 |
+
skips.append(input)
|
| 254 |
+
for i, (block, skip) in enumerate(zip(self.u_blocks, reversed(skips))):
|
| 255 |
+
input = block(input, cond, skip if i > 0 else None)
|
| 256 |
+
return input
|
repositories/k-diffusion/k_diffusion/models/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .image_v1 import ImageDenoiserModelV1
|
repositories/k-diffusion/k_diffusion/models/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (225 Bytes). View file
|
|
|
repositories/k-diffusion/k_diffusion/models/__pycache__/image_v1.cpython-310.pyc
ADDED
|
Binary file (7.16 kB). View file
|
|
|
repositories/k-diffusion/k_diffusion/models/image_v1.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
|
| 7 |
+
from .. import layers, utils
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def orthogonal_(module):
|
| 11 |
+
nn.init.orthogonal_(module.weight)
|
| 12 |
+
return module
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class ResConvBlock(layers.ConditionedResidualBlock):
|
| 16 |
+
def __init__(self, feats_in, c_in, c_mid, c_out, group_size=32, dropout_rate=0.):
|
| 17 |
+
skip = None if c_in == c_out else orthogonal_(nn.Conv2d(c_in, c_out, 1, bias=False))
|
| 18 |
+
super().__init__(
|
| 19 |
+
layers.AdaGN(feats_in, c_in, max(1, c_in // group_size)),
|
| 20 |
+
nn.GELU(),
|
| 21 |
+
nn.Conv2d(c_in, c_mid, 3, padding=1),
|
| 22 |
+
nn.Dropout2d(dropout_rate, inplace=True),
|
| 23 |
+
layers.AdaGN(feats_in, c_mid, max(1, c_mid // group_size)),
|
| 24 |
+
nn.GELU(),
|
| 25 |
+
nn.Conv2d(c_mid, c_out, 3, padding=1),
|
| 26 |
+
nn.Dropout2d(dropout_rate, inplace=True),
|
| 27 |
+
skip=skip)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class DBlock(layers.ConditionedSequential):
|
| 31 |
+
def __init__(self, n_layers, feats_in, c_in, c_mid, c_out, group_size=32, head_size=64, dropout_rate=0., downsample=False, self_attn=False, cross_attn=False, c_enc=0):
|
| 32 |
+
modules = [nn.Identity()]
|
| 33 |
+
for i in range(n_layers):
|
| 34 |
+
my_c_in = c_in if i == 0 else c_mid
|
| 35 |
+
my_c_out = c_mid if i < n_layers - 1 else c_out
|
| 36 |
+
modules.append(ResConvBlock(feats_in, my_c_in, c_mid, my_c_out, group_size, dropout_rate))
|
| 37 |
+
if self_attn:
|
| 38 |
+
norm = lambda c_in: layers.AdaGN(feats_in, c_in, max(1, my_c_out // group_size))
|
| 39 |
+
modules.append(layers.SelfAttention2d(my_c_out, max(1, my_c_out // head_size), norm, dropout_rate))
|
| 40 |
+
if cross_attn:
|
| 41 |
+
norm = lambda c_in: layers.AdaGN(feats_in, c_in, max(1, my_c_out // group_size))
|
| 42 |
+
modules.append(layers.CrossAttention2d(my_c_out, c_enc, max(1, my_c_out // head_size), norm, dropout_rate))
|
| 43 |
+
super().__init__(*modules)
|
| 44 |
+
self.set_downsample(downsample)
|
| 45 |
+
|
| 46 |
+
def set_downsample(self, downsample):
|
| 47 |
+
self[0] = layers.Downsample2d() if downsample else nn.Identity()
|
| 48 |
+
return self
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class UBlock(layers.ConditionedSequential):
|
| 52 |
+
def __init__(self, n_layers, feats_in, c_in, c_mid, c_out, group_size=32, head_size=64, dropout_rate=0., upsample=False, self_attn=False, cross_attn=False, c_enc=0):
|
| 53 |
+
modules = []
|
| 54 |
+
for i in range(n_layers):
|
| 55 |
+
my_c_in = c_in if i == 0 else c_mid
|
| 56 |
+
my_c_out = c_mid if i < n_layers - 1 else c_out
|
| 57 |
+
modules.append(ResConvBlock(feats_in, my_c_in, c_mid, my_c_out, group_size, dropout_rate))
|
| 58 |
+
if self_attn:
|
| 59 |
+
norm = lambda c_in: layers.AdaGN(feats_in, c_in, max(1, my_c_out // group_size))
|
| 60 |
+
modules.append(layers.SelfAttention2d(my_c_out, max(1, my_c_out // head_size), norm, dropout_rate))
|
| 61 |
+
if cross_attn:
|
| 62 |
+
norm = lambda c_in: layers.AdaGN(feats_in, c_in, max(1, my_c_out // group_size))
|
| 63 |
+
modules.append(layers.CrossAttention2d(my_c_out, c_enc, max(1, my_c_out // head_size), norm, dropout_rate))
|
| 64 |
+
modules.append(nn.Identity())
|
| 65 |
+
super().__init__(*modules)
|
| 66 |
+
self.set_upsample(upsample)
|
| 67 |
+
|
| 68 |
+
def forward(self, input, cond, skip=None):
|
| 69 |
+
if skip is not None:
|
| 70 |
+
input = torch.cat([input, skip], dim=1)
|
| 71 |
+
return super().forward(input, cond)
|
| 72 |
+
|
| 73 |
+
def set_upsample(self, upsample):
|
| 74 |
+
self[-1] = layers.Upsample2d() if upsample else nn.Identity()
|
| 75 |
+
return self
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
class MappingNet(nn.Sequential):
|
| 79 |
+
def __init__(self, feats_in, feats_out, n_layers=2):
|
| 80 |
+
layers = []
|
| 81 |
+
for i in range(n_layers):
|
| 82 |
+
layers.append(orthogonal_(nn.Linear(feats_in if i == 0 else feats_out, feats_out)))
|
| 83 |
+
layers.append(nn.GELU())
|
| 84 |
+
super().__init__(*layers)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class ImageDenoiserModelV1(nn.Module):
|
| 88 |
+
def __init__(self, c_in, feats_in, depths, channels, self_attn_depths, cross_attn_depths=None, mapping_cond_dim=0, unet_cond_dim=0, cross_cond_dim=0, dropout_rate=0., patch_size=1, skip_stages=0, has_variance=False):
|
| 89 |
+
super().__init__()
|
| 90 |
+
self.c_in = c_in
|
| 91 |
+
self.channels = channels
|
| 92 |
+
self.unet_cond_dim = unet_cond_dim
|
| 93 |
+
self.patch_size = patch_size
|
| 94 |
+
self.has_variance = has_variance
|
| 95 |
+
self.timestep_embed = layers.FourierFeatures(1, feats_in)
|
| 96 |
+
if mapping_cond_dim > 0:
|
| 97 |
+
self.mapping_cond = nn.Linear(mapping_cond_dim, feats_in, bias=False)
|
| 98 |
+
self.mapping = MappingNet(feats_in, feats_in)
|
| 99 |
+
self.proj_in = nn.Conv2d((c_in + unet_cond_dim) * self.patch_size ** 2, channels[max(0, skip_stages - 1)], 1)
|
| 100 |
+
self.proj_out = nn.Conv2d(channels[max(0, skip_stages - 1)], c_in * self.patch_size ** 2 + (1 if self.has_variance else 0), 1)
|
| 101 |
+
nn.init.zeros_(self.proj_out.weight)
|
| 102 |
+
nn.init.zeros_(self.proj_out.bias)
|
| 103 |
+
if cross_cond_dim == 0:
|
| 104 |
+
cross_attn_depths = [False] * len(self_attn_depths)
|
| 105 |
+
d_blocks, u_blocks = [], []
|
| 106 |
+
for i in range(len(depths)):
|
| 107 |
+
my_c_in = channels[max(0, i - 1)]
|
| 108 |
+
d_blocks.append(DBlock(depths[i], feats_in, my_c_in, channels[i], channels[i], downsample=i > skip_stages, self_attn=self_attn_depths[i], cross_attn=cross_attn_depths[i], c_enc=cross_cond_dim, dropout_rate=dropout_rate))
|
| 109 |
+
for i in range(len(depths)):
|
| 110 |
+
my_c_in = channels[i] * 2 if i < len(depths) - 1 else channels[i]
|
| 111 |
+
my_c_out = channels[max(0, i - 1)]
|
| 112 |
+
u_blocks.append(UBlock(depths[i], feats_in, my_c_in, channels[i], my_c_out, upsample=i > skip_stages, self_attn=self_attn_depths[i], cross_attn=cross_attn_depths[i], c_enc=cross_cond_dim, dropout_rate=dropout_rate))
|
| 113 |
+
self.u_net = layers.UNet(d_blocks, reversed(u_blocks), skip_stages=skip_stages)
|
| 114 |
+
|
| 115 |
+
def forward(self, input, sigma, mapping_cond=None, unet_cond=None, cross_cond=None, cross_cond_padding=None, return_variance=False):
|
| 116 |
+
c_noise = sigma.log() / 4
|
| 117 |
+
timestep_embed = self.timestep_embed(utils.append_dims(c_noise, 2))
|
| 118 |
+
mapping_cond_embed = torch.zeros_like(timestep_embed) if mapping_cond is None else self.mapping_cond(mapping_cond)
|
| 119 |
+
mapping_out = self.mapping(timestep_embed + mapping_cond_embed)
|
| 120 |
+
cond = {'cond': mapping_out}
|
| 121 |
+
if unet_cond is not None:
|
| 122 |
+
input = torch.cat([input, unet_cond], dim=1)
|
| 123 |
+
if cross_cond is not None:
|
| 124 |
+
cond['cross'] = cross_cond
|
| 125 |
+
cond['cross_padding'] = cross_cond_padding
|
| 126 |
+
if self.patch_size > 1:
|
| 127 |
+
input = F.pixel_unshuffle(input, self.patch_size)
|
| 128 |
+
input = self.proj_in(input)
|
| 129 |
+
input = self.u_net(input, cond)
|
| 130 |
+
input = self.proj_out(input)
|
| 131 |
+
if self.has_variance:
|
| 132 |
+
input, logvar = input[:, :-1], input[:, -1].flatten(1).mean(1)
|
| 133 |
+
if self.patch_size > 1:
|
| 134 |
+
input = F.pixel_shuffle(input, self.patch_size)
|
| 135 |
+
if self.has_variance and return_variance:
|
| 136 |
+
return input, logvar
|
| 137 |
+
return input
|
| 138 |
+
|
| 139 |
+
def set_skip_stages(self, skip_stages):
|
| 140 |
+
self.proj_in = nn.Conv2d(self.proj_in.in_channels, self.channels[max(0, skip_stages - 1)], 1)
|
| 141 |
+
self.proj_out = nn.Conv2d(self.channels[max(0, skip_stages - 1)], self.proj_out.out_channels, 1)
|
| 142 |
+
nn.init.zeros_(self.proj_out.weight)
|
| 143 |
+
nn.init.zeros_(self.proj_out.bias)
|
| 144 |
+
self.u_net.skip_stages = skip_stages
|
| 145 |
+
for i, block in enumerate(self.u_net.d_blocks):
|
| 146 |
+
block.set_downsample(i > skip_stages)
|
| 147 |
+
for i, block in enumerate(reversed(self.u_net.u_blocks)):
|
| 148 |
+
block.set_upsample(i > skip_stages)
|
| 149 |
+
return self
|
| 150 |
+
|
| 151 |
+
def set_patch_size(self, patch_size):
|
| 152 |
+
self.patch_size = patch_size
|
| 153 |
+
self.proj_in = nn.Conv2d((self.c_in + self.unet_cond_dim) * self.patch_size ** 2, self.channels[max(0, self.u_net.skip_stages - 1)], 1)
|
| 154 |
+
self.proj_out = nn.Conv2d(self.channels[max(0, self.u_net.skip_stages - 1)], self.c_in * self.patch_size ** 2 + (1 if self.has_variance else 0), 1)
|
| 155 |
+
nn.init.zeros_(self.proj_out.weight)
|
| 156 |
+
nn.init.zeros_(self.proj_out.bias)
|
repositories/k-diffusion/k_diffusion/sampling.py
ADDED
|
@@ -0,0 +1,651 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
from scipy import integrate
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torchdiffeq import odeint
|
| 7 |
+
import torchsde
|
| 8 |
+
from tqdm.auto import trange, tqdm
|
| 9 |
+
|
| 10 |
+
from . import utils
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def append_zero(x):
|
| 14 |
+
return torch.cat([x, x.new_zeros([1])])
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def get_sigmas_karras(n, sigma_min, sigma_max, rho=7., device='cpu'):
|
| 18 |
+
"""Constructs the noise schedule of Karras et al. (2022)."""
|
| 19 |
+
ramp = torch.linspace(0, 1, n)
|
| 20 |
+
min_inv_rho = sigma_min ** (1 / rho)
|
| 21 |
+
max_inv_rho = sigma_max ** (1 / rho)
|
| 22 |
+
sigmas = (max_inv_rho + ramp * (min_inv_rho - max_inv_rho)) ** rho
|
| 23 |
+
return append_zero(sigmas).to(device)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def get_sigmas_exponential(n, sigma_min, sigma_max, device='cpu'):
|
| 27 |
+
"""Constructs an exponential noise schedule."""
|
| 28 |
+
sigmas = torch.linspace(math.log(sigma_max), math.log(sigma_min), n, device=device).exp()
|
| 29 |
+
return append_zero(sigmas)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def get_sigmas_polyexponential(n, sigma_min, sigma_max, rho=1., device='cpu'):
|
| 33 |
+
"""Constructs an polynomial in log sigma noise schedule."""
|
| 34 |
+
ramp = torch.linspace(1, 0, n, device=device) ** rho
|
| 35 |
+
sigmas = torch.exp(ramp * (math.log(sigma_max) - math.log(sigma_min)) + math.log(sigma_min))
|
| 36 |
+
return append_zero(sigmas)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def get_sigmas_vp(n, beta_d=19.9, beta_min=0.1, eps_s=1e-3, device='cpu'):
|
| 40 |
+
"""Constructs a continuous VP noise schedule."""
|
| 41 |
+
t = torch.linspace(1, eps_s, n, device=device)
|
| 42 |
+
sigmas = torch.sqrt(torch.exp(beta_d * t ** 2 / 2 + beta_min * t) - 1)
|
| 43 |
+
return append_zero(sigmas)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def to_d(x, sigma, denoised):
|
| 47 |
+
"""Converts a denoiser output to a Karras ODE derivative."""
|
| 48 |
+
return (x - denoised) / utils.append_dims(sigma, x.ndim)
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def get_ancestral_step(sigma_from, sigma_to, eta=1.):
|
| 52 |
+
"""Calculates the noise level (sigma_down) to step down to and the amount
|
| 53 |
+
of noise to add (sigma_up) when doing an ancestral sampling step."""
|
| 54 |
+
if not eta:
|
| 55 |
+
return sigma_to, 0.
|
| 56 |
+
sigma_up = min(sigma_to, eta * (sigma_to ** 2 * (sigma_from ** 2 - sigma_to ** 2) / sigma_from ** 2) ** 0.5)
|
| 57 |
+
sigma_down = (sigma_to ** 2 - sigma_up ** 2) ** 0.5
|
| 58 |
+
return sigma_down, sigma_up
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def default_noise_sampler(x):
|
| 62 |
+
return lambda sigma, sigma_next: torch.randn_like(x)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class BatchedBrownianTree:
|
| 66 |
+
"""A wrapper around torchsde.BrownianTree that enables batches of entropy."""
|
| 67 |
+
|
| 68 |
+
def __init__(self, x, t0, t1, seed=None, **kwargs):
|
| 69 |
+
t0, t1, self.sign = self.sort(t0, t1)
|
| 70 |
+
w0 = kwargs.get('w0', torch.zeros_like(x))
|
| 71 |
+
if seed is None:
|
| 72 |
+
seed = torch.randint(0, 2 ** 63 - 1, []).item()
|
| 73 |
+
self.batched = True
|
| 74 |
+
try:
|
| 75 |
+
assert len(seed) == x.shape[0]
|
| 76 |
+
w0 = w0[0]
|
| 77 |
+
except TypeError:
|
| 78 |
+
seed = [seed]
|
| 79 |
+
self.batched = False
|
| 80 |
+
self.trees = [torchsde.BrownianTree(t0, w0, t1, entropy=s, **kwargs) for s in seed]
|
| 81 |
+
|
| 82 |
+
@staticmethod
|
| 83 |
+
def sort(a, b):
|
| 84 |
+
return (a, b, 1) if a < b else (b, a, -1)
|
| 85 |
+
|
| 86 |
+
def __call__(self, t0, t1):
|
| 87 |
+
t0, t1, sign = self.sort(t0, t1)
|
| 88 |
+
w = torch.stack([tree(t0, t1) for tree in self.trees]) * (self.sign * sign)
|
| 89 |
+
return w if self.batched else w[0]
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class BrownianTreeNoiseSampler:
|
| 93 |
+
"""A noise sampler backed by a torchsde.BrownianTree.
|
| 94 |
+
|
| 95 |
+
Args:
|
| 96 |
+
x (Tensor): The tensor whose shape, device and dtype to use to generate
|
| 97 |
+
random samples.
|
| 98 |
+
sigma_min (float): The low end of the valid interval.
|
| 99 |
+
sigma_max (float): The high end of the valid interval.
|
| 100 |
+
seed (int or List[int]): The random seed. If a list of seeds is
|
| 101 |
+
supplied instead of a single integer, then the noise sampler will
|
| 102 |
+
use one BrownianTree per batch item, each with its own seed.
|
| 103 |
+
transform (callable): A function that maps sigma to the sampler's
|
| 104 |
+
internal timestep.
|
| 105 |
+
"""
|
| 106 |
+
|
| 107 |
+
def __init__(self, x, sigma_min, sigma_max, seed=None, transform=lambda x: x):
|
| 108 |
+
self.transform = transform
|
| 109 |
+
t0, t1 = self.transform(torch.as_tensor(sigma_min)), self.transform(torch.as_tensor(sigma_max))
|
| 110 |
+
self.tree = BatchedBrownianTree(x, t0, t1, seed)
|
| 111 |
+
|
| 112 |
+
def __call__(self, sigma, sigma_next):
|
| 113 |
+
t0, t1 = self.transform(torch.as_tensor(sigma)), self.transform(torch.as_tensor(sigma_next))
|
| 114 |
+
return self.tree(t0, t1) / (t1 - t0).abs().sqrt()
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
@torch.no_grad()
|
| 118 |
+
def sample_euler(model, x, sigmas, extra_args=None, callback=None, disable=None, s_churn=0., s_tmin=0., s_tmax=float('inf'), s_noise=1.):
|
| 119 |
+
"""Implements Algorithm 2 (Euler steps) from Karras et al. (2022)."""
|
| 120 |
+
extra_args = {} if extra_args is None else extra_args
|
| 121 |
+
s_in = x.new_ones([x.shape[0]])
|
| 122 |
+
for i in trange(len(sigmas) - 1, disable=disable):
|
| 123 |
+
gamma = min(s_churn / (len(sigmas) - 1), 2 ** 0.5 - 1) if s_tmin <= sigmas[i] <= s_tmax else 0.
|
| 124 |
+
eps = torch.randn_like(x) * s_noise
|
| 125 |
+
sigma_hat = sigmas[i] * (gamma + 1)
|
| 126 |
+
if gamma > 0:
|
| 127 |
+
x = x + eps * (sigma_hat ** 2 - sigmas[i] ** 2) ** 0.5
|
| 128 |
+
denoised = model(x, sigma_hat * s_in, **extra_args)
|
| 129 |
+
d = to_d(x, sigma_hat, denoised)
|
| 130 |
+
if callback is not None:
|
| 131 |
+
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigma_hat, 'denoised': denoised})
|
| 132 |
+
dt = sigmas[i + 1] - sigma_hat
|
| 133 |
+
# Euler method
|
| 134 |
+
x = x + d * dt
|
| 135 |
+
return x
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
@torch.no_grad()
|
| 139 |
+
def sample_euler_ancestral(model, x, sigmas, extra_args=None, callback=None, disable=None, eta=1., s_noise=1., noise_sampler=None):
|
| 140 |
+
"""Ancestral sampling with Euler method steps."""
|
| 141 |
+
extra_args = {} if extra_args is None else extra_args
|
| 142 |
+
noise_sampler = default_noise_sampler(x) if noise_sampler is None else noise_sampler
|
| 143 |
+
s_in = x.new_ones([x.shape[0]])
|
| 144 |
+
for i in trange(len(sigmas) - 1, disable=disable):
|
| 145 |
+
denoised = model(x, sigmas[i] * s_in, **extra_args)
|
| 146 |
+
sigma_down, sigma_up = get_ancestral_step(sigmas[i], sigmas[i + 1], eta=eta)
|
| 147 |
+
if callback is not None:
|
| 148 |
+
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigmas[i], 'denoised': denoised})
|
| 149 |
+
d = to_d(x, sigmas[i], denoised)
|
| 150 |
+
# Euler method
|
| 151 |
+
dt = sigma_down - sigmas[i]
|
| 152 |
+
x = x + d * dt
|
| 153 |
+
if sigmas[i + 1] > 0:
|
| 154 |
+
x = x + noise_sampler(sigmas[i], sigmas[i + 1]) * s_noise * sigma_up
|
| 155 |
+
return x
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
@torch.no_grad()
|
| 159 |
+
def sample_heun(model, x, sigmas, extra_args=None, callback=None, disable=None, s_churn=0., s_tmin=0., s_tmax=float('inf'), s_noise=1.):
|
| 160 |
+
"""Implements Algorithm 2 (Heun steps) from Karras et al. (2022)."""
|
| 161 |
+
extra_args = {} if extra_args is None else extra_args
|
| 162 |
+
s_in = x.new_ones([x.shape[0]])
|
| 163 |
+
for i in trange(len(sigmas) - 1, disable=disable):
|
| 164 |
+
gamma = min(s_churn / (len(sigmas) - 1), 2 ** 0.5 - 1) if s_tmin <= sigmas[i] <= s_tmax else 0.
|
| 165 |
+
eps = torch.randn_like(x) * s_noise
|
| 166 |
+
sigma_hat = sigmas[i] * (gamma + 1)
|
| 167 |
+
if gamma > 0:
|
| 168 |
+
x = x + eps * (sigma_hat ** 2 - sigmas[i] ** 2) ** 0.5
|
| 169 |
+
denoised = model(x, sigma_hat * s_in, **extra_args)
|
| 170 |
+
d = to_d(x, sigma_hat, denoised)
|
| 171 |
+
if callback is not None:
|
| 172 |
+
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigma_hat, 'denoised': denoised})
|
| 173 |
+
dt = sigmas[i + 1] - sigma_hat
|
| 174 |
+
if sigmas[i + 1] == 0:
|
| 175 |
+
# Euler method
|
| 176 |
+
x = x + d * dt
|
| 177 |
+
else:
|
| 178 |
+
# Heun's method
|
| 179 |
+
x_2 = x + d * dt
|
| 180 |
+
denoised_2 = model(x_2, sigmas[i + 1] * s_in, **extra_args)
|
| 181 |
+
d_2 = to_d(x_2, sigmas[i + 1], denoised_2)
|
| 182 |
+
d_prime = (d + d_2) / 2
|
| 183 |
+
x = x + d_prime * dt
|
| 184 |
+
return x
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
@torch.no_grad()
|
| 188 |
+
def sample_dpm_2(model, x, sigmas, extra_args=None, callback=None, disable=None, s_churn=0., s_tmin=0., s_tmax=float('inf'), s_noise=1.):
|
| 189 |
+
"""A sampler inspired by DPM-Solver-2 and Algorithm 2 from Karras et al. (2022)."""
|
| 190 |
+
extra_args = {} if extra_args is None else extra_args
|
| 191 |
+
s_in = x.new_ones([x.shape[0]])
|
| 192 |
+
for i in trange(len(sigmas) - 1, disable=disable):
|
| 193 |
+
gamma = min(s_churn / (len(sigmas) - 1), 2 ** 0.5 - 1) if s_tmin <= sigmas[i] <= s_tmax else 0.
|
| 194 |
+
eps = torch.randn_like(x) * s_noise
|
| 195 |
+
sigma_hat = sigmas[i] * (gamma + 1)
|
| 196 |
+
if gamma > 0:
|
| 197 |
+
x = x + eps * (sigma_hat ** 2 - sigmas[i] ** 2) ** 0.5
|
| 198 |
+
denoised = model(x, sigma_hat * s_in, **extra_args)
|
| 199 |
+
d = to_d(x, sigma_hat, denoised)
|
| 200 |
+
if callback is not None:
|
| 201 |
+
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigma_hat, 'denoised': denoised})
|
| 202 |
+
if sigmas[i + 1] == 0:
|
| 203 |
+
# Euler method
|
| 204 |
+
dt = sigmas[i + 1] - sigma_hat
|
| 205 |
+
x = x + d * dt
|
| 206 |
+
else:
|
| 207 |
+
# DPM-Solver-2
|
| 208 |
+
sigma_mid = sigma_hat.log().lerp(sigmas[i + 1].log(), 0.5).exp()
|
| 209 |
+
dt_1 = sigma_mid - sigma_hat
|
| 210 |
+
dt_2 = sigmas[i + 1] - sigma_hat
|
| 211 |
+
x_2 = x + d * dt_1
|
| 212 |
+
denoised_2 = model(x_2, sigma_mid * s_in, **extra_args)
|
| 213 |
+
d_2 = to_d(x_2, sigma_mid, denoised_2)
|
| 214 |
+
x = x + d_2 * dt_2
|
| 215 |
+
return x
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
@torch.no_grad()
|
| 219 |
+
def sample_dpm_2_ancestral(model, x, sigmas, extra_args=None, callback=None, disable=None, eta=1., s_noise=1., noise_sampler=None):
|
| 220 |
+
"""Ancestral sampling with DPM-Solver second-order steps."""
|
| 221 |
+
extra_args = {} if extra_args is None else extra_args
|
| 222 |
+
noise_sampler = default_noise_sampler(x) if noise_sampler is None else noise_sampler
|
| 223 |
+
s_in = x.new_ones([x.shape[0]])
|
| 224 |
+
for i in trange(len(sigmas) - 1, disable=disable):
|
| 225 |
+
denoised = model(x, sigmas[i] * s_in, **extra_args)
|
| 226 |
+
sigma_down, sigma_up = get_ancestral_step(sigmas[i], sigmas[i + 1], eta=eta)
|
| 227 |
+
if callback is not None:
|
| 228 |
+
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigmas[i], 'denoised': denoised})
|
| 229 |
+
d = to_d(x, sigmas[i], denoised)
|
| 230 |
+
if sigma_down == 0:
|
| 231 |
+
# Euler method
|
| 232 |
+
dt = sigma_down - sigmas[i]
|
| 233 |
+
x = x + d * dt
|
| 234 |
+
else:
|
| 235 |
+
# DPM-Solver-2
|
| 236 |
+
sigma_mid = sigmas[i].log().lerp(sigma_down.log(), 0.5).exp()
|
| 237 |
+
dt_1 = sigma_mid - sigmas[i]
|
| 238 |
+
dt_2 = sigma_down - sigmas[i]
|
| 239 |
+
x_2 = x + d * dt_1
|
| 240 |
+
denoised_2 = model(x_2, sigma_mid * s_in, **extra_args)
|
| 241 |
+
d_2 = to_d(x_2, sigma_mid, denoised_2)
|
| 242 |
+
x = x + d_2 * dt_2
|
| 243 |
+
x = x + noise_sampler(sigmas[i], sigmas[i + 1]) * s_noise * sigma_up
|
| 244 |
+
return x
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
def linear_multistep_coeff(order, t, i, j):
|
| 248 |
+
if order - 1 > i:
|
| 249 |
+
raise ValueError(f'Order {order} too high for step {i}')
|
| 250 |
+
def fn(tau):
|
| 251 |
+
prod = 1.
|
| 252 |
+
for k in range(order):
|
| 253 |
+
if j == k:
|
| 254 |
+
continue
|
| 255 |
+
prod *= (tau - t[i - k]) / (t[i - j] - t[i - k])
|
| 256 |
+
return prod
|
| 257 |
+
return integrate.quad(fn, t[i], t[i + 1], epsrel=1e-4)[0]
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
@torch.no_grad()
|
| 261 |
+
def sample_lms(model, x, sigmas, extra_args=None, callback=None, disable=None, order=4):
|
| 262 |
+
extra_args = {} if extra_args is None else extra_args
|
| 263 |
+
s_in = x.new_ones([x.shape[0]])
|
| 264 |
+
sigmas_cpu = sigmas.detach().cpu().numpy()
|
| 265 |
+
ds = []
|
| 266 |
+
for i in trange(len(sigmas) - 1, disable=disable):
|
| 267 |
+
denoised = model(x, sigmas[i] * s_in, **extra_args)
|
| 268 |
+
d = to_d(x, sigmas[i], denoised)
|
| 269 |
+
ds.append(d)
|
| 270 |
+
if len(ds) > order:
|
| 271 |
+
ds.pop(0)
|
| 272 |
+
if callback is not None:
|
| 273 |
+
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigmas[i], 'denoised': denoised})
|
| 274 |
+
cur_order = min(i + 1, order)
|
| 275 |
+
coeffs = [linear_multistep_coeff(cur_order, sigmas_cpu, i, j) for j in range(cur_order)]
|
| 276 |
+
x = x + sum(coeff * d for coeff, d in zip(coeffs, reversed(ds)))
|
| 277 |
+
return x
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
@torch.no_grad()
|
| 281 |
+
def log_likelihood(model, x, sigma_min, sigma_max, extra_args=None, atol=1e-4, rtol=1e-4):
|
| 282 |
+
extra_args = {} if extra_args is None else extra_args
|
| 283 |
+
s_in = x.new_ones([x.shape[0]])
|
| 284 |
+
v = torch.randint_like(x, 2) * 2 - 1
|
| 285 |
+
fevals = 0
|
| 286 |
+
def ode_fn(sigma, x):
|
| 287 |
+
nonlocal fevals
|
| 288 |
+
with torch.enable_grad():
|
| 289 |
+
x = x[0].detach().requires_grad_()
|
| 290 |
+
denoised = model(x, sigma * s_in, **extra_args)
|
| 291 |
+
d = to_d(x, sigma, denoised)
|
| 292 |
+
fevals += 1
|
| 293 |
+
grad = torch.autograd.grad((d * v).sum(), x)[0]
|
| 294 |
+
d_ll = (v * grad).flatten(1).sum(1)
|
| 295 |
+
return d.detach(), d_ll
|
| 296 |
+
x_min = x, x.new_zeros([x.shape[0]])
|
| 297 |
+
t = x.new_tensor([sigma_min, sigma_max])
|
| 298 |
+
sol = odeint(ode_fn, x_min, t, atol=atol, rtol=rtol, method='dopri5')
|
| 299 |
+
latent, delta_ll = sol[0][-1], sol[1][-1]
|
| 300 |
+
ll_prior = torch.distributions.Normal(0, sigma_max).log_prob(latent).flatten(1).sum(1)
|
| 301 |
+
return ll_prior + delta_ll, {'fevals': fevals}
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
class PIDStepSizeController:
|
| 305 |
+
"""A PID controller for ODE adaptive step size control."""
|
| 306 |
+
def __init__(self, h, pcoeff, icoeff, dcoeff, order=1, accept_safety=0.81, eps=1e-8):
|
| 307 |
+
self.h = h
|
| 308 |
+
self.b1 = (pcoeff + icoeff + dcoeff) / order
|
| 309 |
+
self.b2 = -(pcoeff + 2 * dcoeff) / order
|
| 310 |
+
self.b3 = dcoeff / order
|
| 311 |
+
self.accept_safety = accept_safety
|
| 312 |
+
self.eps = eps
|
| 313 |
+
self.errs = []
|
| 314 |
+
|
| 315 |
+
def limiter(self, x):
|
| 316 |
+
return 1 + math.atan(x - 1)
|
| 317 |
+
|
| 318 |
+
def propose_step(self, error):
|
| 319 |
+
inv_error = 1 / (float(error) + self.eps)
|
| 320 |
+
if not self.errs:
|
| 321 |
+
self.errs = [inv_error, inv_error, inv_error]
|
| 322 |
+
self.errs[0] = inv_error
|
| 323 |
+
factor = self.errs[0] ** self.b1 * self.errs[1] ** self.b2 * self.errs[2] ** self.b3
|
| 324 |
+
factor = self.limiter(factor)
|
| 325 |
+
accept = factor >= self.accept_safety
|
| 326 |
+
if accept:
|
| 327 |
+
self.errs[2] = self.errs[1]
|
| 328 |
+
self.errs[1] = self.errs[0]
|
| 329 |
+
self.h *= factor
|
| 330 |
+
return accept
|
| 331 |
+
|
| 332 |
+
|
| 333 |
+
class DPMSolver(nn.Module):
|
| 334 |
+
"""DPM-Solver. See https://arxiv.org/abs/2206.00927."""
|
| 335 |
+
|
| 336 |
+
def __init__(self, model, extra_args=None, eps_callback=None, info_callback=None):
|
| 337 |
+
super().__init__()
|
| 338 |
+
self.model = model
|
| 339 |
+
self.extra_args = {} if extra_args is None else extra_args
|
| 340 |
+
self.eps_callback = eps_callback
|
| 341 |
+
self.info_callback = info_callback
|
| 342 |
+
|
| 343 |
+
def t(self, sigma):
|
| 344 |
+
return -sigma.log()
|
| 345 |
+
|
| 346 |
+
def sigma(self, t):
|
| 347 |
+
return t.neg().exp()
|
| 348 |
+
|
| 349 |
+
def eps(self, eps_cache, key, x, t, *args, **kwargs):
|
| 350 |
+
if key in eps_cache:
|
| 351 |
+
return eps_cache[key], eps_cache
|
| 352 |
+
sigma = self.sigma(t) * x.new_ones([x.shape[0]])
|
| 353 |
+
eps = (x - self.model(x, sigma, *args, **self.extra_args, **kwargs)) / self.sigma(t)
|
| 354 |
+
if self.eps_callback is not None:
|
| 355 |
+
self.eps_callback()
|
| 356 |
+
return eps, {key: eps, **eps_cache}
|
| 357 |
+
|
| 358 |
+
def dpm_solver_1_step(self, x, t, t_next, eps_cache=None):
|
| 359 |
+
eps_cache = {} if eps_cache is None else eps_cache
|
| 360 |
+
h = t_next - t
|
| 361 |
+
eps, eps_cache = self.eps(eps_cache, 'eps', x, t)
|
| 362 |
+
x_1 = x - self.sigma(t_next) * h.expm1() * eps
|
| 363 |
+
return x_1, eps_cache
|
| 364 |
+
|
| 365 |
+
def dpm_solver_2_step(self, x, t, t_next, r1=1 / 2, eps_cache=None):
|
| 366 |
+
eps_cache = {} if eps_cache is None else eps_cache
|
| 367 |
+
h = t_next - t
|
| 368 |
+
eps, eps_cache = self.eps(eps_cache, 'eps', x, t)
|
| 369 |
+
s1 = t + r1 * h
|
| 370 |
+
u1 = x - self.sigma(s1) * (r1 * h).expm1() * eps
|
| 371 |
+
eps_r1, eps_cache = self.eps(eps_cache, 'eps_r1', u1, s1)
|
| 372 |
+
x_2 = x - self.sigma(t_next) * h.expm1() * eps - self.sigma(t_next) / (2 * r1) * h.expm1() * (eps_r1 - eps)
|
| 373 |
+
return x_2, eps_cache
|
| 374 |
+
|
| 375 |
+
def dpm_solver_3_step(self, x, t, t_next, r1=1 / 3, r2=2 / 3, eps_cache=None):
|
| 376 |
+
eps_cache = {} if eps_cache is None else eps_cache
|
| 377 |
+
h = t_next - t
|
| 378 |
+
eps, eps_cache = self.eps(eps_cache, 'eps', x, t)
|
| 379 |
+
s1 = t + r1 * h
|
| 380 |
+
s2 = t + r2 * h
|
| 381 |
+
u1 = x - self.sigma(s1) * (r1 * h).expm1() * eps
|
| 382 |
+
eps_r1, eps_cache = self.eps(eps_cache, 'eps_r1', u1, s1)
|
| 383 |
+
u2 = x - self.sigma(s2) * (r2 * h).expm1() * eps - self.sigma(s2) * (r2 / r1) * ((r2 * h).expm1() / (r2 * h) - 1) * (eps_r1 - eps)
|
| 384 |
+
eps_r2, eps_cache = self.eps(eps_cache, 'eps_r2', u2, s2)
|
| 385 |
+
x_3 = x - self.sigma(t_next) * h.expm1() * eps - self.sigma(t_next) / r2 * (h.expm1() / h - 1) * (eps_r2 - eps)
|
| 386 |
+
return x_3, eps_cache
|
| 387 |
+
|
| 388 |
+
def dpm_solver_fast(self, x, t_start, t_end, nfe, eta=0., s_noise=1., noise_sampler=None):
|
| 389 |
+
noise_sampler = default_noise_sampler(x) if noise_sampler is None else noise_sampler
|
| 390 |
+
if not t_end > t_start and eta:
|
| 391 |
+
raise ValueError('eta must be 0 for reverse sampling')
|
| 392 |
+
|
| 393 |
+
m = math.floor(nfe / 3) + 1
|
| 394 |
+
ts = torch.linspace(t_start, t_end, m + 1, device=x.device)
|
| 395 |
+
|
| 396 |
+
if nfe % 3 == 0:
|
| 397 |
+
orders = [3] * (m - 2) + [2, 1]
|
| 398 |
+
else:
|
| 399 |
+
orders = [3] * (m - 1) + [nfe % 3]
|
| 400 |
+
|
| 401 |
+
for i in range(len(orders)):
|
| 402 |
+
eps_cache = {}
|
| 403 |
+
t, t_next = ts[i], ts[i + 1]
|
| 404 |
+
if eta:
|
| 405 |
+
sd, su = get_ancestral_step(self.sigma(t), self.sigma(t_next), eta)
|
| 406 |
+
t_next_ = torch.minimum(t_end, self.t(sd))
|
| 407 |
+
su = (self.sigma(t_next) ** 2 - self.sigma(t_next_) ** 2) ** 0.5
|
| 408 |
+
else:
|
| 409 |
+
t_next_, su = t_next, 0.
|
| 410 |
+
|
| 411 |
+
eps, eps_cache = self.eps(eps_cache, 'eps', x, t)
|
| 412 |
+
denoised = x - self.sigma(t) * eps
|
| 413 |
+
if self.info_callback is not None:
|
| 414 |
+
self.info_callback({'x': x, 'i': i, 't': ts[i], 't_up': t, 'denoised': denoised})
|
| 415 |
+
|
| 416 |
+
if orders[i] == 1:
|
| 417 |
+
x, eps_cache = self.dpm_solver_1_step(x, t, t_next_, eps_cache=eps_cache)
|
| 418 |
+
elif orders[i] == 2:
|
| 419 |
+
x, eps_cache = self.dpm_solver_2_step(x, t, t_next_, eps_cache=eps_cache)
|
| 420 |
+
else:
|
| 421 |
+
x, eps_cache = self.dpm_solver_3_step(x, t, t_next_, eps_cache=eps_cache)
|
| 422 |
+
|
| 423 |
+
x = x + su * s_noise * noise_sampler(self.sigma(t), self.sigma(t_next))
|
| 424 |
+
|
| 425 |
+
return x
|
| 426 |
+
|
| 427 |
+
def dpm_solver_adaptive(self, x, t_start, t_end, order=3, rtol=0.05, atol=0.0078, h_init=0.05, pcoeff=0., icoeff=1., dcoeff=0., accept_safety=0.81, eta=0., s_noise=1., noise_sampler=None):
|
| 428 |
+
noise_sampler = default_noise_sampler(x) if noise_sampler is None else noise_sampler
|
| 429 |
+
if order not in {2, 3}:
|
| 430 |
+
raise ValueError('order should be 2 or 3')
|
| 431 |
+
forward = t_end > t_start
|
| 432 |
+
if not forward and eta:
|
| 433 |
+
raise ValueError('eta must be 0 for reverse sampling')
|
| 434 |
+
h_init = abs(h_init) * (1 if forward else -1)
|
| 435 |
+
atol = torch.tensor(atol)
|
| 436 |
+
rtol = torch.tensor(rtol)
|
| 437 |
+
s = t_start
|
| 438 |
+
x_prev = x
|
| 439 |
+
accept = True
|
| 440 |
+
pid = PIDStepSizeController(h_init, pcoeff, icoeff, dcoeff, 1.5 if eta else order, accept_safety)
|
| 441 |
+
info = {'steps': 0, 'nfe': 0, 'n_accept': 0, 'n_reject': 0}
|
| 442 |
+
|
| 443 |
+
while s < t_end - 1e-5 if forward else s > t_end + 1e-5:
|
| 444 |
+
eps_cache = {}
|
| 445 |
+
t = torch.minimum(t_end, s + pid.h) if forward else torch.maximum(t_end, s + pid.h)
|
| 446 |
+
if eta:
|
| 447 |
+
sd, su = get_ancestral_step(self.sigma(s), self.sigma(t), eta)
|
| 448 |
+
t_ = torch.minimum(t_end, self.t(sd))
|
| 449 |
+
su = (self.sigma(t) ** 2 - self.sigma(t_) ** 2) ** 0.5
|
| 450 |
+
else:
|
| 451 |
+
t_, su = t, 0.
|
| 452 |
+
|
| 453 |
+
eps, eps_cache = self.eps(eps_cache, 'eps', x, s)
|
| 454 |
+
denoised = x - self.sigma(s) * eps
|
| 455 |
+
|
| 456 |
+
if order == 2:
|
| 457 |
+
x_low, eps_cache = self.dpm_solver_1_step(x, s, t_, eps_cache=eps_cache)
|
| 458 |
+
x_high, eps_cache = self.dpm_solver_2_step(x, s, t_, eps_cache=eps_cache)
|
| 459 |
+
else:
|
| 460 |
+
x_low, eps_cache = self.dpm_solver_2_step(x, s, t_, r1=1 / 3, eps_cache=eps_cache)
|
| 461 |
+
x_high, eps_cache = self.dpm_solver_3_step(x, s, t_, eps_cache=eps_cache)
|
| 462 |
+
delta = torch.maximum(atol, rtol * torch.maximum(x_low.abs(), x_prev.abs()))
|
| 463 |
+
error = torch.linalg.norm((x_low - x_high) / delta) / x.numel() ** 0.5
|
| 464 |
+
accept = pid.propose_step(error)
|
| 465 |
+
if accept:
|
| 466 |
+
x_prev = x_low
|
| 467 |
+
x = x_high + su * s_noise * noise_sampler(self.sigma(s), self.sigma(t))
|
| 468 |
+
s = t
|
| 469 |
+
info['n_accept'] += 1
|
| 470 |
+
else:
|
| 471 |
+
info['n_reject'] += 1
|
| 472 |
+
info['nfe'] += order
|
| 473 |
+
info['steps'] += 1
|
| 474 |
+
|
| 475 |
+
if self.info_callback is not None:
|
| 476 |
+
self.info_callback({'x': x, 'i': info['steps'] - 1, 't': s, 't_up': s, 'denoised': denoised, 'error': error, 'h': pid.h, **info})
|
| 477 |
+
|
| 478 |
+
return x, info
|
| 479 |
+
|
| 480 |
+
|
| 481 |
+
@torch.no_grad()
|
| 482 |
+
def sample_dpm_fast(model, x, sigma_min, sigma_max, n, extra_args=None, callback=None, disable=None, eta=0., s_noise=1., noise_sampler=None):
|
| 483 |
+
"""DPM-Solver-Fast (fixed step size). See https://arxiv.org/abs/2206.00927."""
|
| 484 |
+
if sigma_min <= 0 or sigma_max <= 0:
|
| 485 |
+
raise ValueError('sigma_min and sigma_max must not be 0')
|
| 486 |
+
with tqdm(total=n, disable=disable) as pbar:
|
| 487 |
+
dpm_solver = DPMSolver(model, extra_args, eps_callback=pbar.update)
|
| 488 |
+
if callback is not None:
|
| 489 |
+
dpm_solver.info_callback = lambda info: callback({'sigma': dpm_solver.sigma(info['t']), 'sigma_hat': dpm_solver.sigma(info['t_up']), **info})
|
| 490 |
+
return dpm_solver.dpm_solver_fast(x, dpm_solver.t(torch.tensor(sigma_max)), dpm_solver.t(torch.tensor(sigma_min)), n, eta, s_noise, noise_sampler)
|
| 491 |
+
|
| 492 |
+
|
| 493 |
+
@torch.no_grad()
|
| 494 |
+
def sample_dpm_adaptive(model, x, sigma_min, sigma_max, extra_args=None, callback=None, disable=None, order=3, rtol=0.05, atol=0.0078, h_init=0.05, pcoeff=0., icoeff=1., dcoeff=0., accept_safety=0.81, eta=0., s_noise=1., noise_sampler=None, return_info=False):
|
| 495 |
+
"""DPM-Solver-12 and 23 (adaptive step size). See https://arxiv.org/abs/2206.00927."""
|
| 496 |
+
if sigma_min <= 0 or sigma_max <= 0:
|
| 497 |
+
raise ValueError('sigma_min and sigma_max must not be 0')
|
| 498 |
+
with tqdm(disable=disable) as pbar:
|
| 499 |
+
dpm_solver = DPMSolver(model, extra_args, eps_callback=pbar.update)
|
| 500 |
+
if callback is not None:
|
| 501 |
+
dpm_solver.info_callback = lambda info: callback({'sigma': dpm_solver.sigma(info['t']), 'sigma_hat': dpm_solver.sigma(info['t_up']), **info})
|
| 502 |
+
x, info = dpm_solver.dpm_solver_adaptive(x, dpm_solver.t(torch.tensor(sigma_max)), dpm_solver.t(torch.tensor(sigma_min)), order, rtol, atol, h_init, pcoeff, icoeff, dcoeff, accept_safety, eta, s_noise, noise_sampler)
|
| 503 |
+
if return_info:
|
| 504 |
+
return x, info
|
| 505 |
+
return x
|
| 506 |
+
|
| 507 |
+
|
| 508 |
+
@torch.no_grad()
|
| 509 |
+
def sample_dpmpp_2s_ancestral(model, x, sigmas, extra_args=None, callback=None, disable=None, eta=1., s_noise=1., noise_sampler=None):
|
| 510 |
+
"""Ancestral sampling with DPM-Solver++(2S) second-order steps."""
|
| 511 |
+
extra_args = {} if extra_args is None else extra_args
|
| 512 |
+
noise_sampler = default_noise_sampler(x) if noise_sampler is None else noise_sampler
|
| 513 |
+
s_in = x.new_ones([x.shape[0]])
|
| 514 |
+
sigma_fn = lambda t: t.neg().exp()
|
| 515 |
+
t_fn = lambda sigma: sigma.log().neg()
|
| 516 |
+
|
| 517 |
+
for i in trange(len(sigmas) - 1, disable=disable):
|
| 518 |
+
denoised = model(x, sigmas[i] * s_in, **extra_args)
|
| 519 |
+
sigma_down, sigma_up = get_ancestral_step(sigmas[i], sigmas[i + 1], eta=eta)
|
| 520 |
+
if callback is not None:
|
| 521 |
+
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigmas[i], 'denoised': denoised})
|
| 522 |
+
if sigma_down == 0:
|
| 523 |
+
# Euler method
|
| 524 |
+
d = to_d(x, sigmas[i], denoised)
|
| 525 |
+
dt = sigma_down - sigmas[i]
|
| 526 |
+
x = x + d * dt
|
| 527 |
+
else:
|
| 528 |
+
# DPM-Solver++(2S)
|
| 529 |
+
t, t_next = t_fn(sigmas[i]), t_fn(sigma_down)
|
| 530 |
+
r = 1 / 2
|
| 531 |
+
h = t_next - t
|
| 532 |
+
s = t + r * h
|
| 533 |
+
x_2 = (sigma_fn(s) / sigma_fn(t)) * x - (-h * r).expm1() * denoised
|
| 534 |
+
denoised_2 = model(x_2, sigma_fn(s) * s_in, **extra_args)
|
| 535 |
+
x = (sigma_fn(t_next) / sigma_fn(t)) * x - (-h).expm1() * denoised_2
|
| 536 |
+
# Noise addition
|
| 537 |
+
if sigmas[i + 1] > 0:
|
| 538 |
+
x = x + noise_sampler(sigmas[i], sigmas[i + 1]) * s_noise * sigma_up
|
| 539 |
+
return x
|
| 540 |
+
|
| 541 |
+
|
| 542 |
+
@torch.no_grad()
|
| 543 |
+
def sample_dpmpp_sde(model, x, sigmas, extra_args=None, callback=None, disable=None, eta=1., s_noise=1., noise_sampler=None, r=1 / 2):
|
| 544 |
+
"""DPM-Solver++ (stochastic)."""
|
| 545 |
+
sigma_min, sigma_max = sigmas[sigmas > 0].min(), sigmas.max()
|
| 546 |
+
noise_sampler = BrownianTreeNoiseSampler(x, sigma_min, sigma_max) if noise_sampler is None else noise_sampler
|
| 547 |
+
extra_args = {} if extra_args is None else extra_args
|
| 548 |
+
s_in = x.new_ones([x.shape[0]])
|
| 549 |
+
sigma_fn = lambda t: t.neg().exp()
|
| 550 |
+
t_fn = lambda sigma: sigma.log().neg()
|
| 551 |
+
|
| 552 |
+
for i in trange(len(sigmas) - 1, disable=disable):
|
| 553 |
+
denoised = model(x, sigmas[i] * s_in, **extra_args)
|
| 554 |
+
if callback is not None:
|
| 555 |
+
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigmas[i], 'denoised': denoised})
|
| 556 |
+
if sigmas[i + 1] == 0:
|
| 557 |
+
# Euler method
|
| 558 |
+
d = to_d(x, sigmas[i], denoised)
|
| 559 |
+
dt = sigmas[i + 1] - sigmas[i]
|
| 560 |
+
x = x + d * dt
|
| 561 |
+
else:
|
| 562 |
+
# DPM-Solver++
|
| 563 |
+
t, t_next = t_fn(sigmas[i]), t_fn(sigmas[i + 1])
|
| 564 |
+
h = t_next - t
|
| 565 |
+
s = t + h * r
|
| 566 |
+
fac = 1 / (2 * r)
|
| 567 |
+
|
| 568 |
+
# Step 1
|
| 569 |
+
sd, su = get_ancestral_step(sigma_fn(t), sigma_fn(s), eta)
|
| 570 |
+
s_ = t_fn(sd)
|
| 571 |
+
x_2 = (sigma_fn(s_) / sigma_fn(t)) * x - (t - s_).expm1() * denoised
|
| 572 |
+
x_2 = x_2 + noise_sampler(sigma_fn(t), sigma_fn(s)) * s_noise * su
|
| 573 |
+
denoised_2 = model(x_2, sigma_fn(s) * s_in, **extra_args)
|
| 574 |
+
|
| 575 |
+
# Step 2
|
| 576 |
+
sd, su = get_ancestral_step(sigma_fn(t), sigma_fn(t_next), eta)
|
| 577 |
+
t_next_ = t_fn(sd)
|
| 578 |
+
denoised_d = (1 - fac) * denoised + fac * denoised_2
|
| 579 |
+
x = (sigma_fn(t_next_) / sigma_fn(t)) * x - (t - t_next_).expm1() * denoised_d
|
| 580 |
+
x = x + noise_sampler(sigma_fn(t), sigma_fn(t_next)) * s_noise * su
|
| 581 |
+
return x
|
| 582 |
+
|
| 583 |
+
|
| 584 |
+
@torch.no_grad()
|
| 585 |
+
def sample_dpmpp_2m(model, x, sigmas, extra_args=None, callback=None, disable=None):
|
| 586 |
+
"""DPM-Solver++(2M)."""
|
| 587 |
+
extra_args = {} if extra_args is None else extra_args
|
| 588 |
+
s_in = x.new_ones([x.shape[0]])
|
| 589 |
+
sigma_fn = lambda t: t.neg().exp()
|
| 590 |
+
t_fn = lambda sigma: sigma.log().neg()
|
| 591 |
+
old_denoised = None
|
| 592 |
+
|
| 593 |
+
for i in trange(len(sigmas) - 1, disable=disable):
|
| 594 |
+
denoised = model(x, sigmas[i] * s_in, **extra_args)
|
| 595 |
+
if callback is not None:
|
| 596 |
+
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigmas[i], 'denoised': denoised})
|
| 597 |
+
t, t_next = t_fn(sigmas[i]), t_fn(sigmas[i + 1])
|
| 598 |
+
h = t_next - t
|
| 599 |
+
if old_denoised is None or sigmas[i + 1] == 0:
|
| 600 |
+
x = (sigma_fn(t_next) / sigma_fn(t)) * x - (-h).expm1() * denoised
|
| 601 |
+
else:
|
| 602 |
+
h_last = t - t_fn(sigmas[i - 1])
|
| 603 |
+
r = h_last / h
|
| 604 |
+
denoised_d = (1 + 1 / (2 * r)) * denoised - (1 / (2 * r)) * old_denoised
|
| 605 |
+
x = (sigma_fn(t_next) / sigma_fn(t)) * x - (-h).expm1() * denoised_d
|
| 606 |
+
old_denoised = denoised
|
| 607 |
+
return x
|
| 608 |
+
|
| 609 |
+
|
| 610 |
+
@torch.no_grad()
|
| 611 |
+
def sample_dpmpp_2m_sde(model, x, sigmas, extra_args=None, callback=None, disable=None, eta=1., s_noise=1., noise_sampler=None, solver_type='midpoint'):
|
| 612 |
+
"""DPM-Solver++(2M) SDE."""
|
| 613 |
+
|
| 614 |
+
if solver_type not in {'heun', 'midpoint'}:
|
| 615 |
+
raise ValueError('solver_type must be \'heun\' or \'midpoint\'')
|
| 616 |
+
|
| 617 |
+
sigma_min, sigma_max = sigmas[sigmas > 0].min(), sigmas.max()
|
| 618 |
+
noise_sampler = BrownianTreeNoiseSampler(x, sigma_min, sigma_max) if noise_sampler is None else noise_sampler
|
| 619 |
+
extra_args = {} if extra_args is None else extra_args
|
| 620 |
+
s_in = x.new_ones([x.shape[0]])
|
| 621 |
+
|
| 622 |
+
old_denoised = None
|
| 623 |
+
h_last = None
|
| 624 |
+
|
| 625 |
+
for i in trange(len(sigmas) - 1, disable=disable):
|
| 626 |
+
denoised = model(x, sigmas[i] * s_in, **extra_args)
|
| 627 |
+
if callback is not None:
|
| 628 |
+
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigmas[i], 'denoised': denoised})
|
| 629 |
+
if sigmas[i + 1] == 0:
|
| 630 |
+
# Denoising step
|
| 631 |
+
x = denoised
|
| 632 |
+
else:
|
| 633 |
+
# DPM-Solver++(2M) SDE
|
| 634 |
+
t, s = -sigmas[i].log(), -sigmas[i + 1].log()
|
| 635 |
+
h = s - t
|
| 636 |
+
eta_h = eta * h
|
| 637 |
+
|
| 638 |
+
x = sigmas[i + 1] / sigmas[i] * (-eta_h).exp() * x + (-h - eta_h).expm1().neg() * denoised
|
| 639 |
+
|
| 640 |
+
if old_denoised is not None:
|
| 641 |
+
r = h_last / h
|
| 642 |
+
if solver_type == 'heun':
|
| 643 |
+
x = x + ((-h - eta_h).expm1().neg() / (-h - eta_h) + 1) * (1 / r) * (denoised - old_denoised)
|
| 644 |
+
elif solver_type == 'midpoint':
|
| 645 |
+
x = x + 0.5 * (-h - eta_h).expm1().neg() * (1 / r) * (denoised - old_denoised)
|
| 646 |
+
|
| 647 |
+
x = x + noise_sampler(sigmas[i], sigmas[i + 1]) * sigmas[i + 1] * (-2 * eta_h).expm1().neg().sqrt() * s_noise
|
| 648 |
+
|
| 649 |
+
old_denoised = denoised
|
| 650 |
+
h_last = h
|
| 651 |
+
return x
|
repositories/k-diffusion/k_diffusion/utils.py
ADDED
|
@@ -0,0 +1,329 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from contextlib import contextmanager
|
| 2 |
+
import hashlib
|
| 3 |
+
import math
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
import shutil
|
| 6 |
+
import urllib
|
| 7 |
+
import warnings
|
| 8 |
+
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import torch
|
| 11 |
+
from torch import nn, optim
|
| 12 |
+
from torch.utils import data
|
| 13 |
+
from torchvision.transforms import functional as TF
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def from_pil_image(x):
|
| 17 |
+
"""Converts from a PIL image to a tensor."""
|
| 18 |
+
x = TF.to_tensor(x)
|
| 19 |
+
if x.ndim == 2:
|
| 20 |
+
x = x[..., None]
|
| 21 |
+
return x * 2 - 1
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def to_pil_image(x):
|
| 25 |
+
"""Converts from a tensor to a PIL image."""
|
| 26 |
+
if x.ndim == 4:
|
| 27 |
+
assert x.shape[0] == 1
|
| 28 |
+
x = x[0]
|
| 29 |
+
if x.shape[0] == 1:
|
| 30 |
+
x = x[0]
|
| 31 |
+
return TF.to_pil_image((x.clamp(-1, 1) + 1) / 2)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def hf_datasets_augs_helper(examples, transform, image_key, mode='RGB'):
|
| 35 |
+
"""Apply passed in transforms for HuggingFace Datasets."""
|
| 36 |
+
images = [transform(image.convert(mode)) for image in examples[image_key]]
|
| 37 |
+
return {image_key: images}
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def append_dims(x, target_dims):
|
| 41 |
+
"""Appends dimensions to the end of a tensor until it has target_dims dimensions."""
|
| 42 |
+
dims_to_append = target_dims - x.ndim
|
| 43 |
+
if dims_to_append < 0:
|
| 44 |
+
raise ValueError(f'input has {x.ndim} dims but target_dims is {target_dims}, which is less')
|
| 45 |
+
return x[(...,) + (None,) * dims_to_append]
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def n_params(module):
|
| 49 |
+
"""Returns the number of trainable parameters in a module."""
|
| 50 |
+
return sum(p.numel() for p in module.parameters())
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def download_file(path, url, digest=None):
|
| 54 |
+
"""Downloads a file if it does not exist, optionally checking its SHA-256 hash."""
|
| 55 |
+
path = Path(path)
|
| 56 |
+
path.parent.mkdir(parents=True, exist_ok=True)
|
| 57 |
+
if not path.exists():
|
| 58 |
+
with urllib.request.urlopen(url) as response, open(path, 'wb') as f:
|
| 59 |
+
shutil.copyfileobj(response, f)
|
| 60 |
+
if digest is not None:
|
| 61 |
+
file_digest = hashlib.sha256(open(path, 'rb').read()).hexdigest()
|
| 62 |
+
if digest != file_digest:
|
| 63 |
+
raise OSError(f'hash of {path} (url: {url}) failed to validate')
|
| 64 |
+
return path
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
@contextmanager
|
| 68 |
+
def train_mode(model, mode=True):
|
| 69 |
+
"""A context manager that places a model into training mode and restores
|
| 70 |
+
the previous mode on exit."""
|
| 71 |
+
modes = [module.training for module in model.modules()]
|
| 72 |
+
try:
|
| 73 |
+
yield model.train(mode)
|
| 74 |
+
finally:
|
| 75 |
+
for i, module in enumerate(model.modules()):
|
| 76 |
+
module.training = modes[i]
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def eval_mode(model):
|
| 80 |
+
"""A context manager that places a model into evaluation mode and restores
|
| 81 |
+
the previous mode on exit."""
|
| 82 |
+
return train_mode(model, False)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
@torch.no_grad()
|
| 86 |
+
def ema_update(model, averaged_model, decay):
|
| 87 |
+
"""Incorporates updated model parameters into an exponential moving averaged
|
| 88 |
+
version of a model. It should be called after each optimizer step."""
|
| 89 |
+
model_params = dict(model.named_parameters())
|
| 90 |
+
averaged_params = dict(averaged_model.named_parameters())
|
| 91 |
+
assert model_params.keys() == averaged_params.keys()
|
| 92 |
+
|
| 93 |
+
for name, param in model_params.items():
|
| 94 |
+
averaged_params[name].mul_(decay).add_(param, alpha=1 - decay)
|
| 95 |
+
|
| 96 |
+
model_buffers = dict(model.named_buffers())
|
| 97 |
+
averaged_buffers = dict(averaged_model.named_buffers())
|
| 98 |
+
assert model_buffers.keys() == averaged_buffers.keys()
|
| 99 |
+
|
| 100 |
+
for name, buf in model_buffers.items():
|
| 101 |
+
averaged_buffers[name].copy_(buf)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class EMAWarmup:
|
| 105 |
+
"""Implements an EMA warmup using an inverse decay schedule.
|
| 106 |
+
If inv_gamma=1 and power=1, implements a simple average. inv_gamma=1, power=2/3 are
|
| 107 |
+
good values for models you plan to train for a million or more steps (reaches decay
|
| 108 |
+
factor 0.999 at 31.6K steps, 0.9999 at 1M steps), inv_gamma=1, power=3/4 for models
|
| 109 |
+
you plan to train for less (reaches decay factor 0.999 at 10K steps, 0.9999 at
|
| 110 |
+
215.4k steps).
|
| 111 |
+
Args:
|
| 112 |
+
inv_gamma (float): Inverse multiplicative factor of EMA warmup. Default: 1.
|
| 113 |
+
power (float): Exponential factor of EMA warmup. Default: 1.
|
| 114 |
+
min_value (float): The minimum EMA decay rate. Default: 0.
|
| 115 |
+
max_value (float): The maximum EMA decay rate. Default: 1.
|
| 116 |
+
start_at (int): The epoch to start averaging at. Default: 0.
|
| 117 |
+
last_epoch (int): The index of last epoch. Default: 0.
|
| 118 |
+
"""
|
| 119 |
+
|
| 120 |
+
def __init__(self, inv_gamma=1., power=1., min_value=0., max_value=1., start_at=0,
|
| 121 |
+
last_epoch=0):
|
| 122 |
+
self.inv_gamma = inv_gamma
|
| 123 |
+
self.power = power
|
| 124 |
+
self.min_value = min_value
|
| 125 |
+
self.max_value = max_value
|
| 126 |
+
self.start_at = start_at
|
| 127 |
+
self.last_epoch = last_epoch
|
| 128 |
+
|
| 129 |
+
def state_dict(self):
|
| 130 |
+
"""Returns the state of the class as a :class:`dict`."""
|
| 131 |
+
return dict(self.__dict__.items())
|
| 132 |
+
|
| 133 |
+
def load_state_dict(self, state_dict):
|
| 134 |
+
"""Loads the class's state.
|
| 135 |
+
Args:
|
| 136 |
+
state_dict (dict): scaler state. Should be an object returned
|
| 137 |
+
from a call to :meth:`state_dict`.
|
| 138 |
+
"""
|
| 139 |
+
self.__dict__.update(state_dict)
|
| 140 |
+
|
| 141 |
+
def get_value(self):
|
| 142 |
+
"""Gets the current EMA decay rate."""
|
| 143 |
+
epoch = max(0, self.last_epoch - self.start_at)
|
| 144 |
+
value = 1 - (1 + epoch / self.inv_gamma) ** -self.power
|
| 145 |
+
return 0. if epoch < 0 else min(self.max_value, max(self.min_value, value))
|
| 146 |
+
|
| 147 |
+
def step(self):
|
| 148 |
+
"""Updates the step count."""
|
| 149 |
+
self.last_epoch += 1
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
class InverseLR(optim.lr_scheduler._LRScheduler):
|
| 153 |
+
"""Implements an inverse decay learning rate schedule with an optional exponential
|
| 154 |
+
warmup. When last_epoch=-1, sets initial lr as lr.
|
| 155 |
+
inv_gamma is the number of steps/epochs required for the learning rate to decay to
|
| 156 |
+
(1 / 2)**power of its original value.
|
| 157 |
+
Args:
|
| 158 |
+
optimizer (Optimizer): Wrapped optimizer.
|
| 159 |
+
inv_gamma (float): Inverse multiplicative factor of learning rate decay. Default: 1.
|
| 160 |
+
power (float): Exponential factor of learning rate decay. Default: 1.
|
| 161 |
+
warmup (float): Exponential warmup factor (0 <= warmup < 1, 0 to disable)
|
| 162 |
+
Default: 0.
|
| 163 |
+
min_lr (float): The minimum learning rate. Default: 0.
|
| 164 |
+
last_epoch (int): The index of last epoch. Default: -1.
|
| 165 |
+
verbose (bool): If ``True``, prints a message to stdout for
|
| 166 |
+
each update. Default: ``False``.
|
| 167 |
+
"""
|
| 168 |
+
|
| 169 |
+
def __init__(self, optimizer, inv_gamma=1., power=1., warmup=0., min_lr=0.,
|
| 170 |
+
last_epoch=-1, verbose=False):
|
| 171 |
+
self.inv_gamma = inv_gamma
|
| 172 |
+
self.power = power
|
| 173 |
+
if not 0. <= warmup < 1:
|
| 174 |
+
raise ValueError('Invalid value for warmup')
|
| 175 |
+
self.warmup = warmup
|
| 176 |
+
self.min_lr = min_lr
|
| 177 |
+
super().__init__(optimizer, last_epoch, verbose)
|
| 178 |
+
|
| 179 |
+
def get_lr(self):
|
| 180 |
+
if not self._get_lr_called_within_step:
|
| 181 |
+
warnings.warn("To get the last learning rate computed by the scheduler, "
|
| 182 |
+
"please use `get_last_lr()`.")
|
| 183 |
+
|
| 184 |
+
return self._get_closed_form_lr()
|
| 185 |
+
|
| 186 |
+
def _get_closed_form_lr(self):
|
| 187 |
+
warmup = 1 - self.warmup ** (self.last_epoch + 1)
|
| 188 |
+
lr_mult = (1 + self.last_epoch / self.inv_gamma) ** -self.power
|
| 189 |
+
return [warmup * max(self.min_lr, base_lr * lr_mult)
|
| 190 |
+
for base_lr in self.base_lrs]
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
class ExponentialLR(optim.lr_scheduler._LRScheduler):
|
| 194 |
+
"""Implements an exponential learning rate schedule with an optional exponential
|
| 195 |
+
warmup. When last_epoch=-1, sets initial lr as lr. Decays the learning rate
|
| 196 |
+
continuously by decay (default 0.5) every num_steps steps.
|
| 197 |
+
Args:
|
| 198 |
+
optimizer (Optimizer): Wrapped optimizer.
|
| 199 |
+
num_steps (float): The number of steps to decay the learning rate by decay in.
|
| 200 |
+
decay (float): The factor by which to decay the learning rate every num_steps
|
| 201 |
+
steps. Default: 0.5.
|
| 202 |
+
warmup (float): Exponential warmup factor (0 <= warmup < 1, 0 to disable)
|
| 203 |
+
Default: 0.
|
| 204 |
+
min_lr (float): The minimum learning rate. Default: 0.
|
| 205 |
+
last_epoch (int): The index of last epoch. Default: -1.
|
| 206 |
+
verbose (bool): If ``True``, prints a message to stdout for
|
| 207 |
+
each update. Default: ``False``.
|
| 208 |
+
"""
|
| 209 |
+
|
| 210 |
+
def __init__(self, optimizer, num_steps, decay=0.5, warmup=0., min_lr=0.,
|
| 211 |
+
last_epoch=-1, verbose=False):
|
| 212 |
+
self.num_steps = num_steps
|
| 213 |
+
self.decay = decay
|
| 214 |
+
if not 0. <= warmup < 1:
|
| 215 |
+
raise ValueError('Invalid value for warmup')
|
| 216 |
+
self.warmup = warmup
|
| 217 |
+
self.min_lr = min_lr
|
| 218 |
+
super().__init__(optimizer, last_epoch, verbose)
|
| 219 |
+
|
| 220 |
+
def get_lr(self):
|
| 221 |
+
if not self._get_lr_called_within_step:
|
| 222 |
+
warnings.warn("To get the last learning rate computed by the scheduler, "
|
| 223 |
+
"please use `get_last_lr()`.")
|
| 224 |
+
|
| 225 |
+
return self._get_closed_form_lr()
|
| 226 |
+
|
| 227 |
+
def _get_closed_form_lr(self):
|
| 228 |
+
warmup = 1 - self.warmup ** (self.last_epoch + 1)
|
| 229 |
+
lr_mult = (self.decay ** (1 / self.num_steps)) ** self.last_epoch
|
| 230 |
+
return [warmup * max(self.min_lr, base_lr * lr_mult)
|
| 231 |
+
for base_lr in self.base_lrs]
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
def rand_log_normal(shape, loc=0., scale=1., device='cpu', dtype=torch.float32):
|
| 235 |
+
"""Draws samples from an lognormal distribution."""
|
| 236 |
+
return (torch.randn(shape, device=device, dtype=dtype) * scale + loc).exp()
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
def rand_log_logistic(shape, loc=0., scale=1., min_value=0., max_value=float('inf'), device='cpu', dtype=torch.float32):
|
| 240 |
+
"""Draws samples from an optionally truncated log-logistic distribution."""
|
| 241 |
+
min_value = torch.as_tensor(min_value, device=device, dtype=torch.float64)
|
| 242 |
+
max_value = torch.as_tensor(max_value, device=device, dtype=torch.float64)
|
| 243 |
+
min_cdf = min_value.log().sub(loc).div(scale).sigmoid()
|
| 244 |
+
max_cdf = max_value.log().sub(loc).div(scale).sigmoid()
|
| 245 |
+
u = torch.rand(shape, device=device, dtype=torch.float64) * (max_cdf - min_cdf) + min_cdf
|
| 246 |
+
return u.logit().mul(scale).add(loc).exp().to(dtype)
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
def rand_log_uniform(shape, min_value, max_value, device='cpu', dtype=torch.float32):
|
| 250 |
+
"""Draws samples from an log-uniform distribution."""
|
| 251 |
+
min_value = math.log(min_value)
|
| 252 |
+
max_value = math.log(max_value)
|
| 253 |
+
return (torch.rand(shape, device=device, dtype=dtype) * (max_value - min_value) + min_value).exp()
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
def rand_v_diffusion(shape, sigma_data=1., min_value=0., max_value=float('inf'), device='cpu', dtype=torch.float32):
|
| 257 |
+
"""Draws samples from a truncated v-diffusion training timestep distribution."""
|
| 258 |
+
min_cdf = math.atan(min_value / sigma_data) * 2 / math.pi
|
| 259 |
+
max_cdf = math.atan(max_value / sigma_data) * 2 / math.pi
|
| 260 |
+
u = torch.rand(shape, device=device, dtype=dtype) * (max_cdf - min_cdf) + min_cdf
|
| 261 |
+
return torch.tan(u * math.pi / 2) * sigma_data
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
def rand_split_log_normal(shape, loc, scale_1, scale_2, device='cpu', dtype=torch.float32):
|
| 265 |
+
"""Draws samples from a split lognormal distribution."""
|
| 266 |
+
n = torch.randn(shape, device=device, dtype=dtype).abs()
|
| 267 |
+
u = torch.rand(shape, device=device, dtype=dtype)
|
| 268 |
+
n_left = n * -scale_1 + loc
|
| 269 |
+
n_right = n * scale_2 + loc
|
| 270 |
+
ratio = scale_1 / (scale_1 + scale_2)
|
| 271 |
+
return torch.where(u < ratio, n_left, n_right).exp()
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
class FolderOfImages(data.Dataset):
|
| 275 |
+
"""Recursively finds all images in a directory. It does not support
|
| 276 |
+
classes/targets."""
|
| 277 |
+
|
| 278 |
+
IMG_EXTENSIONS = {'.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif', '.tiff', '.webp'}
|
| 279 |
+
|
| 280 |
+
def __init__(self, root, transform=None):
|
| 281 |
+
super().__init__()
|
| 282 |
+
self.root = Path(root)
|
| 283 |
+
self.transform = nn.Identity() if transform is None else transform
|
| 284 |
+
self.paths = sorted(path for path in self.root.rglob('*') if path.suffix.lower() in self.IMG_EXTENSIONS)
|
| 285 |
+
|
| 286 |
+
def __repr__(self):
|
| 287 |
+
return f'FolderOfImages(root="{self.root}", len: {len(self)})'
|
| 288 |
+
|
| 289 |
+
def __len__(self):
|
| 290 |
+
return len(self.paths)
|
| 291 |
+
|
| 292 |
+
def __getitem__(self, key):
|
| 293 |
+
path = self.paths[key]
|
| 294 |
+
with open(path, 'rb') as f:
|
| 295 |
+
image = Image.open(f).convert('RGB')
|
| 296 |
+
image = self.transform(image)
|
| 297 |
+
return image,
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
class CSVLogger:
|
| 301 |
+
def __init__(self, filename, columns):
|
| 302 |
+
self.filename = Path(filename)
|
| 303 |
+
self.columns = columns
|
| 304 |
+
if self.filename.exists():
|
| 305 |
+
self.file = open(self.filename, 'a')
|
| 306 |
+
else:
|
| 307 |
+
self.file = open(self.filename, 'w')
|
| 308 |
+
self.write(*self.columns)
|
| 309 |
+
|
| 310 |
+
def write(self, *args):
|
| 311 |
+
print(*args, sep=',', file=self.file, flush=True)
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
@contextmanager
|
| 315 |
+
def tf32_mode(cudnn=None, matmul=None):
|
| 316 |
+
"""A context manager that sets whether TF32 is allowed on cuDNN or matmul."""
|
| 317 |
+
cudnn_old = torch.backends.cudnn.allow_tf32
|
| 318 |
+
matmul_old = torch.backends.cuda.matmul.allow_tf32
|
| 319 |
+
try:
|
| 320 |
+
if cudnn is not None:
|
| 321 |
+
torch.backends.cudnn.allow_tf32 = cudnn
|
| 322 |
+
if matmul is not None:
|
| 323 |
+
torch.backends.cuda.matmul.allow_tf32 = matmul
|
| 324 |
+
yield
|
| 325 |
+
finally:
|
| 326 |
+
if cudnn is not None:
|
| 327 |
+
torch.backends.cudnn.allow_tf32 = cudnn_old
|
| 328 |
+
if matmul is not None:
|
| 329 |
+
torch.backends.cuda.matmul.allow_tf32 = matmul_old
|
repositories/k-diffusion/make_grid.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
|
| 3 |
+
"""Assembles images into a grid."""
|
| 4 |
+
|
| 5 |
+
import argparse
|
| 6 |
+
import math
|
| 7 |
+
import sys
|
| 8 |
+
|
| 9 |
+
from PIL import Image
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def main():
|
| 13 |
+
p = argparse.ArgumentParser(description=__doc__)
|
| 14 |
+
p.add_argument('images', type=str, nargs='+', metavar='image',
|
| 15 |
+
help='the input images')
|
| 16 |
+
p.add_argument('--output', '-o', type=str, default='out.png',
|
| 17 |
+
help='the output image')
|
| 18 |
+
p.add_argument('--nrow', type=int,
|
| 19 |
+
help='the number of images per row')
|
| 20 |
+
args = p.parse_args()
|
| 21 |
+
|
| 22 |
+
images = [Image.open(image) for image in args.images]
|
| 23 |
+
mode = images[0].mode
|
| 24 |
+
size = images[0].size
|
| 25 |
+
for image, name in zip(images, args.images):
|
| 26 |
+
if image.mode != mode:
|
| 27 |
+
print(f'Error: Image {name} had mode {image.mode}, expected {mode}', file=sys.stderr)
|
| 28 |
+
sys.exit(1)
|
| 29 |
+
if image.size != size:
|
| 30 |
+
print(f'Error: Image {name} had size {image.size}, expected {size}', file=sys.stderr)
|
| 31 |
+
sys.exit(1)
|
| 32 |
+
|
| 33 |
+
n = len(images)
|
| 34 |
+
x = args.nrow if args.nrow else math.ceil(n**0.5)
|
| 35 |
+
y = math.ceil(n / x)
|
| 36 |
+
|
| 37 |
+
output = Image.new(mode, (size[0] * x, size[1] * y))
|
| 38 |
+
for i, image in enumerate(images):
|
| 39 |
+
cur_x, cur_y = i % x, i // x
|
| 40 |
+
output.paste(image, (size[0] * cur_x, size[1] * cur_y))
|
| 41 |
+
|
| 42 |
+
output.save(args.output)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
if __name__ == '__main__':
|
| 46 |
+
main()
|
repositories/k-diffusion/pyproject.toml
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[build-system]
|
| 2 |
+
requires = ["setuptools"]
|
| 3 |
+
build-backend = "setuptools.build_meta"
|
repositories/k-diffusion/requirements.txt
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate
|
| 2 |
+
clean-fid
|
| 3 |
+
clip-anytorch
|
| 4 |
+
einops
|
| 5 |
+
jsonmerge
|
| 6 |
+
kornia
|
| 7 |
+
Pillow
|
| 8 |
+
resize-right
|
| 9 |
+
scikit-image
|
| 10 |
+
scipy
|
| 11 |
+
torch
|
| 12 |
+
torchdiffeq
|
| 13 |
+
torchsde
|
| 14 |
+
torchvision
|
| 15 |
+
tqdm
|
| 16 |
+
wandb
|
repositories/k-diffusion/sample.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
|
| 3 |
+
"""Samples from k-diffusion models."""
|
| 4 |
+
|
| 5 |
+
import argparse
|
| 6 |
+
import math
|
| 7 |
+
|
| 8 |
+
import accelerate
|
| 9 |
+
import torch
|
| 10 |
+
from tqdm import trange, tqdm
|
| 11 |
+
|
| 12 |
+
import k_diffusion as K
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def main():
|
| 16 |
+
p = argparse.ArgumentParser(description=__doc__,
|
| 17 |
+
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 18 |
+
p.add_argument('--batch-size', type=int, default=64,
|
| 19 |
+
help='the batch size')
|
| 20 |
+
p.add_argument('--checkpoint', type=str, required=True,
|
| 21 |
+
help='the checkpoint to use')
|
| 22 |
+
p.add_argument('--config', type=str, required=True,
|
| 23 |
+
help='the model config')
|
| 24 |
+
p.add_argument('-n', type=int, default=64,
|
| 25 |
+
help='the number of images to sample')
|
| 26 |
+
p.add_argument('--prefix', type=str, default='out',
|
| 27 |
+
help='the output prefix')
|
| 28 |
+
p.add_argument('--steps', type=int, default=50,
|
| 29 |
+
help='the number of denoising steps')
|
| 30 |
+
args = p.parse_args()
|
| 31 |
+
|
| 32 |
+
config = K.config.load_config(open(args.config))
|
| 33 |
+
model_config = config['model']
|
| 34 |
+
# TODO: allow non-square input sizes
|
| 35 |
+
assert len(model_config['input_size']) == 2 and model_config['input_size'][0] == model_config['input_size'][1]
|
| 36 |
+
size = model_config['input_size']
|
| 37 |
+
|
| 38 |
+
accelerator = accelerate.Accelerator()
|
| 39 |
+
device = accelerator.device
|
| 40 |
+
print('Using device:', device, flush=True)
|
| 41 |
+
|
| 42 |
+
inner_model = K.config.make_model(config).eval().requires_grad_(False).to(device)
|
| 43 |
+
inner_model.load_state_dict(torch.load(args.checkpoint, map_location='cpu')['model_ema'])
|
| 44 |
+
accelerator.print('Parameters:', K.utils.n_params(inner_model))
|
| 45 |
+
model = K.Denoiser(inner_model, sigma_data=model_config['sigma_data'])
|
| 46 |
+
|
| 47 |
+
sigma_min = model_config['sigma_min']
|
| 48 |
+
sigma_max = model_config['sigma_max']
|
| 49 |
+
|
| 50 |
+
@torch.no_grad()
|
| 51 |
+
@K.utils.eval_mode(model)
|
| 52 |
+
def run():
|
| 53 |
+
if accelerator.is_local_main_process:
|
| 54 |
+
tqdm.write('Sampling...')
|
| 55 |
+
sigmas = K.sampling.get_sigmas_karras(args.steps, sigma_min, sigma_max, rho=7., device=device)
|
| 56 |
+
def sample_fn(n):
|
| 57 |
+
x = torch.randn([n, model_config['input_channels'], size[0], size[1]], device=device) * sigma_max
|
| 58 |
+
x_0 = K.sampling.sample_lms(model, x, sigmas, disable=not accelerator.is_local_main_process)
|
| 59 |
+
return x_0
|
| 60 |
+
x_0 = K.evaluation.compute_features(accelerator, sample_fn, lambda x: x, args.n, args.batch_size)
|
| 61 |
+
if accelerator.is_main_process:
|
| 62 |
+
for i, out in enumerate(x_0):
|
| 63 |
+
filename = f'{args.prefix}_{i:05}.png'
|
| 64 |
+
K.utils.to_pil_image(out).save(filename)
|
| 65 |
+
|
| 66 |
+
try:
|
| 67 |
+
run()
|
| 68 |
+
except KeyboardInterrupt:
|
| 69 |
+
pass
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
if __name__ == '__main__':
|
| 73 |
+
main()
|
repositories/k-diffusion/sample_clip_guided.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
|
| 3 |
+
"""CLIP guided sampling from k-diffusion models."""
|
| 4 |
+
|
| 5 |
+
import argparse
|
| 6 |
+
import math
|
| 7 |
+
|
| 8 |
+
import accelerate
|
| 9 |
+
import clip
|
| 10 |
+
from kornia import augmentation as KA
|
| 11 |
+
from resize_right import resize
|
| 12 |
+
import torch
|
| 13 |
+
from torch.nn import functional as F
|
| 14 |
+
from torchvision import transforms
|
| 15 |
+
from tqdm import trange, tqdm
|
| 16 |
+
|
| 17 |
+
import k_diffusion as K
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def spherical_dist_loss(x, y):
|
| 21 |
+
x = F.normalize(x, dim=-1)
|
| 22 |
+
y = F.normalize(y, dim=-1)
|
| 23 |
+
return (x - y).norm(dim=-1).div(2).arcsin().pow(2).mul(2)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def make_cond_model_fn(model, cond_fn):
|
| 27 |
+
def model_fn(x, sigma, **kwargs):
|
| 28 |
+
with torch.enable_grad():
|
| 29 |
+
x = x.detach().requires_grad_()
|
| 30 |
+
denoised = model(x, sigma, **kwargs)
|
| 31 |
+
cond_grad = cond_fn(x, sigma, denoised=denoised, **kwargs).detach()
|
| 32 |
+
cond_denoised = denoised.detach() + cond_grad * K.utils.append_dims(sigma**2, x.ndim)
|
| 33 |
+
return cond_denoised
|
| 34 |
+
return model_fn
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def make_static_thresh_model_fn(model, value=1.):
|
| 38 |
+
def model_fn(x, sigma, **kwargs):
|
| 39 |
+
return model(x, sigma, **kwargs).clamp(-value, value)
|
| 40 |
+
return model_fn
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def main():
|
| 44 |
+
p = argparse.ArgumentParser(description=__doc__,
|
| 45 |
+
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 46 |
+
p.add_argument('prompt', type=str,
|
| 47 |
+
default='the prompt to use')
|
| 48 |
+
p.add_argument('--batch-size', type=int, default=16,
|
| 49 |
+
help='the batch size')
|
| 50 |
+
p.add_argument('--checkpoint', type=str, required=True,
|
| 51 |
+
help='the checkpoint to use')
|
| 52 |
+
p.add_argument('--clip-guidance-scale', '-cgs', type=float, default=500.,
|
| 53 |
+
help='the CLIP guidance scale')
|
| 54 |
+
p.add_argument('--clip-model', type=str, default='ViT-B/16', choices=clip.available_models(),
|
| 55 |
+
help='the CLIP model to use')
|
| 56 |
+
p.add_argument('--config', type=str, required=True,
|
| 57 |
+
help='the model config')
|
| 58 |
+
p.add_argument('-n', type=int, default=64,
|
| 59 |
+
help='the number of images to sample')
|
| 60 |
+
p.add_argument('--prefix', type=str, default='out',
|
| 61 |
+
help='the output prefix')
|
| 62 |
+
p.add_argument('--steps', type=int, default=100,
|
| 63 |
+
help='the number of denoising steps')
|
| 64 |
+
args = p.parse_args()
|
| 65 |
+
|
| 66 |
+
config = K.config.load_config(open(args.config))
|
| 67 |
+
model_config = config['model']
|
| 68 |
+
# TODO: allow non-square input sizes
|
| 69 |
+
assert len(model_config['input_size']) == 2 and model_config['input_size'][0] == model_config['input_size'][1]
|
| 70 |
+
size = model_config['input_size']
|
| 71 |
+
|
| 72 |
+
accelerator = accelerate.Accelerator()
|
| 73 |
+
device = accelerator.device
|
| 74 |
+
print('Using device:', device, flush=True)
|
| 75 |
+
|
| 76 |
+
inner_model = K.config.make_model(config).eval().requires_grad_(False).to(device)
|
| 77 |
+
inner_model.load_state_dict(torch.load(args.checkpoint, map_location='cpu')['model_ema'])
|
| 78 |
+
accelerator.print('Parameters:', K.utils.n_params(inner_model))
|
| 79 |
+
model = K.Denoiser(inner_model, sigma_data=model_config['sigma_data'])
|
| 80 |
+
|
| 81 |
+
sigma_min = model_config['sigma_min']
|
| 82 |
+
sigma_max = model_config['sigma_max']
|
| 83 |
+
|
| 84 |
+
clip_model = clip.load(args.clip_model, device=device)[0].eval().requires_grad_(False)
|
| 85 |
+
clip_normalize = transforms.Normalize(mean=(0.48145466, 0.4578275, 0.40821073),
|
| 86 |
+
std=(0.26862954, 0.26130258, 0.27577711))
|
| 87 |
+
clip_size = (clip_model.visual.input_resolution, clip_model.visual.input_resolution)
|
| 88 |
+
aug = KA.RandomAffine(0, (1/14, 1/14), p=1, padding_mode='border')
|
| 89 |
+
|
| 90 |
+
def get_image_embed(x):
|
| 91 |
+
if x.shape[2:4] != clip_size:
|
| 92 |
+
x = resize(x, out_shape=clip_size, pad_mode='reflect')
|
| 93 |
+
x = clip_normalize(x)
|
| 94 |
+
x = clip_model.encode_image(x).float()
|
| 95 |
+
return F.normalize(x)
|
| 96 |
+
|
| 97 |
+
target_embed = F.normalize(clip_model.encode_text(clip.tokenize(args.prompt, truncate=True).to(device)).float())
|
| 98 |
+
|
| 99 |
+
def cond_fn(x, t, denoised):
|
| 100 |
+
image_embed = get_image_embed(aug(denoised.add(1).div(2)))
|
| 101 |
+
loss = spherical_dist_loss(image_embed, target_embed).sum() * args.clip_guidance_scale
|
| 102 |
+
grad = -torch.autograd.grad(loss, x)[0]
|
| 103 |
+
return grad
|
| 104 |
+
|
| 105 |
+
model_fn = make_cond_model_fn(model, cond_fn)
|
| 106 |
+
model_fn = make_static_thresh_model_fn(model_fn)
|
| 107 |
+
|
| 108 |
+
@torch.no_grad()
|
| 109 |
+
@K.utils.eval_mode(model)
|
| 110 |
+
def run():
|
| 111 |
+
if accelerator.is_local_main_process:
|
| 112 |
+
tqdm.write('Sampling...')
|
| 113 |
+
sigmas = K.sampling.get_sigmas_karras(args.steps, sigma_min, sigma_max, rho=7., device=device)
|
| 114 |
+
def sample_fn(n):
|
| 115 |
+
x = torch.randn([n, model_config['input_channels'], size[0], size[1]], device=device) * sigmas[0]
|
| 116 |
+
x_0 = K.sampling.sample_dpmpp_2s_ancestral(model_fn, x, sigmas, eta=1., disable=not accelerator.is_local_main_process)
|
| 117 |
+
return x_0
|
| 118 |
+
x_0 = K.evaluation.compute_features(accelerator, sample_fn, lambda x: x, args.n, args.batch_size)
|
| 119 |
+
if accelerator.is_main_process:
|
| 120 |
+
for i, out in enumerate(x_0):
|
| 121 |
+
filename = f'{args.prefix}_{i:05}.png'
|
| 122 |
+
K.utils.to_pil_image(out).save(filename)
|
| 123 |
+
|
| 124 |
+
try:
|
| 125 |
+
run()
|
| 126 |
+
except KeyboardInterrupt:
|
| 127 |
+
pass
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
if __name__ == '__main__':
|
| 131 |
+
main()
|
repositories/k-diffusion/setup.cfg
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[metadata]
|
| 2 |
+
name = k-diffusion
|
| 3 |
+
version = 0.0.15
|
| 4 |
+
author = Katherine Crowson
|
| 5 |
+
author_email = crowsonkb@gmail.com
|
| 6 |
+
url = https://github.com/crowsonkb/k-diffusion
|
| 7 |
+
description = Karras et al. (2022) diffusion models for PyTorch
|
| 8 |
+
long_description = file: README.md
|
| 9 |
+
long_description_content_type = text/markdown
|
| 10 |
+
license = MIT
|
| 11 |
+
|
| 12 |
+
[options]
|
| 13 |
+
packages = find:
|
| 14 |
+
install_requires =
|
| 15 |
+
accelerate
|
| 16 |
+
clean-fid
|
| 17 |
+
clip-anytorch
|
| 18 |
+
einops
|
| 19 |
+
jsonmerge
|
| 20 |
+
kornia
|
| 21 |
+
Pillow
|
| 22 |
+
resize-right
|
| 23 |
+
scikit-image
|
| 24 |
+
scipy
|
| 25 |
+
torch
|
| 26 |
+
torchdiffeq
|
| 27 |
+
torchsde
|
| 28 |
+
torchvision
|
| 29 |
+
tqdm
|
| 30 |
+
wandb
|
repositories/k-diffusion/setup.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from setuptools import setup
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
if __name__ == '__main__':
|
| 5 |
+
setup()
|
repositories/k-diffusion/train.py
ADDED
|
@@ -0,0 +1,356 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
|
| 3 |
+
"""Trains Karras et al. (2022) diffusion models."""
|
| 4 |
+
|
| 5 |
+
import argparse
|
| 6 |
+
from copy import deepcopy
|
| 7 |
+
from functools import partial
|
| 8 |
+
import math
|
| 9 |
+
import json
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
|
| 12 |
+
import accelerate
|
| 13 |
+
import torch
|
| 14 |
+
from torch import nn, optim
|
| 15 |
+
from torch import multiprocessing as mp
|
| 16 |
+
from torch.utils import data
|
| 17 |
+
from torchvision import datasets, transforms, utils
|
| 18 |
+
from tqdm.auto import trange, tqdm
|
| 19 |
+
|
| 20 |
+
import k_diffusion as K
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def main():
|
| 24 |
+
p = argparse.ArgumentParser(description=__doc__,
|
| 25 |
+
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 26 |
+
p.add_argument('--batch-size', type=int, default=64,
|
| 27 |
+
help='the batch size')
|
| 28 |
+
p.add_argument('--config', type=str, required=True,
|
| 29 |
+
help='the configuration file')
|
| 30 |
+
p.add_argument('--demo-every', type=int, default=500,
|
| 31 |
+
help='save a demo grid every this many steps')
|
| 32 |
+
p.add_argument('--evaluate-every', type=int, default=10000,
|
| 33 |
+
help='save a demo grid every this many steps')
|
| 34 |
+
p.add_argument('--evaluate-n', type=int, default=2000,
|
| 35 |
+
help='the number of samples to draw to evaluate')
|
| 36 |
+
p.add_argument('--gns', action='store_true',
|
| 37 |
+
help='measure the gradient noise scale (DDP only)')
|
| 38 |
+
p.add_argument('--grad-accum-steps', type=int, default=1,
|
| 39 |
+
help='the number of gradient accumulation steps')
|
| 40 |
+
p.add_argument('--grow', type=str,
|
| 41 |
+
help='the checkpoint to grow from')
|
| 42 |
+
p.add_argument('--grow-config', type=str,
|
| 43 |
+
help='the configuration file of the model to grow from')
|
| 44 |
+
p.add_argument('--lr', type=float,
|
| 45 |
+
help='the learning rate')
|
| 46 |
+
p.add_argument('--name', type=str, default='model',
|
| 47 |
+
help='the name of the run')
|
| 48 |
+
p.add_argument('--num-workers', type=int, default=8,
|
| 49 |
+
help='the number of data loader workers')
|
| 50 |
+
p.add_argument('--resume', type=str,
|
| 51 |
+
help='the checkpoint to resume from')
|
| 52 |
+
p.add_argument('--sample-n', type=int, default=64,
|
| 53 |
+
help='the number of images to sample for demo grids')
|
| 54 |
+
p.add_argument('--save-every', type=int, default=10000,
|
| 55 |
+
help='save every this many steps')
|
| 56 |
+
p.add_argument('--seed', type=int,
|
| 57 |
+
help='the random seed')
|
| 58 |
+
p.add_argument('--start-method', type=str, default='spawn',
|
| 59 |
+
choices=['fork', 'forkserver', 'spawn'],
|
| 60 |
+
help='the multiprocessing start method')
|
| 61 |
+
p.add_argument('--wandb-entity', type=str,
|
| 62 |
+
help='the wandb entity name')
|
| 63 |
+
p.add_argument('--wandb-group', type=str,
|
| 64 |
+
help='the wandb group name')
|
| 65 |
+
p.add_argument('--wandb-project', type=str,
|
| 66 |
+
help='the wandb project name (specify this to enable wandb)')
|
| 67 |
+
p.add_argument('--wandb-save-model', action='store_true',
|
| 68 |
+
help='save model to wandb')
|
| 69 |
+
args = p.parse_args()
|
| 70 |
+
|
| 71 |
+
mp.set_start_method(args.start_method)
|
| 72 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 73 |
+
|
| 74 |
+
config = K.config.load_config(open(args.config))
|
| 75 |
+
model_config = config['model']
|
| 76 |
+
dataset_config = config['dataset']
|
| 77 |
+
opt_config = config['optimizer']
|
| 78 |
+
sched_config = config['lr_sched']
|
| 79 |
+
ema_sched_config = config['ema_sched']
|
| 80 |
+
|
| 81 |
+
# TODO: allow non-square input sizes
|
| 82 |
+
assert len(model_config['input_size']) == 2 and model_config['input_size'][0] == model_config['input_size'][1]
|
| 83 |
+
size = model_config['input_size']
|
| 84 |
+
|
| 85 |
+
ddp_kwargs = accelerate.DistributedDataParallelKwargs(find_unused_parameters=model_config['skip_stages'] > 0)
|
| 86 |
+
accelerator = accelerate.Accelerator(kwargs_handlers=[ddp_kwargs], gradient_accumulation_steps=args.grad_accum_steps)
|
| 87 |
+
device = accelerator.device
|
| 88 |
+
print(f'Process {accelerator.process_index} using device: {device}', flush=True)
|
| 89 |
+
|
| 90 |
+
if args.seed is not None:
|
| 91 |
+
seeds = torch.randint(-2 ** 63, 2 ** 63 - 1, [accelerator.num_processes], generator=torch.Generator().manual_seed(args.seed))
|
| 92 |
+
torch.manual_seed(seeds[accelerator.process_index])
|
| 93 |
+
|
| 94 |
+
inner_model = K.config.make_model(config)
|
| 95 |
+
inner_model_ema = deepcopy(inner_model)
|
| 96 |
+
if accelerator.is_main_process:
|
| 97 |
+
print('Parameters:', K.utils.n_params(inner_model))
|
| 98 |
+
|
| 99 |
+
# If logging to wandb, initialize the run
|
| 100 |
+
use_wandb = accelerator.is_main_process and args.wandb_project
|
| 101 |
+
if use_wandb:
|
| 102 |
+
import wandb
|
| 103 |
+
log_config = vars(args)
|
| 104 |
+
log_config['config'] = config
|
| 105 |
+
log_config['parameters'] = K.utils.n_params(inner_model)
|
| 106 |
+
wandb.init(project=args.wandb_project, entity=args.wandb_entity, group=args.wandb_group, config=log_config, save_code=True)
|
| 107 |
+
|
| 108 |
+
if opt_config['type'] == 'adamw':
|
| 109 |
+
opt = optim.AdamW(inner_model.parameters(),
|
| 110 |
+
lr=opt_config['lr'] if args.lr is None else args.lr,
|
| 111 |
+
betas=tuple(opt_config['betas']),
|
| 112 |
+
eps=opt_config['eps'],
|
| 113 |
+
weight_decay=opt_config['weight_decay'])
|
| 114 |
+
elif opt_config['type'] == 'sgd':
|
| 115 |
+
opt = optim.SGD(inner_model.parameters(),
|
| 116 |
+
lr=opt_config['lr'] if args.lr is None else args.lr,
|
| 117 |
+
momentum=opt_config.get('momentum', 0.),
|
| 118 |
+
nesterov=opt_config.get('nesterov', False),
|
| 119 |
+
weight_decay=opt_config.get('weight_decay', 0.))
|
| 120 |
+
else:
|
| 121 |
+
raise ValueError('Invalid optimizer type')
|
| 122 |
+
|
| 123 |
+
if sched_config['type'] == 'inverse':
|
| 124 |
+
sched = K.utils.InverseLR(opt,
|
| 125 |
+
inv_gamma=sched_config['inv_gamma'],
|
| 126 |
+
power=sched_config['power'],
|
| 127 |
+
warmup=sched_config['warmup'])
|
| 128 |
+
elif sched_config['type'] == 'exponential':
|
| 129 |
+
sched = K.utils.ExponentialLR(opt,
|
| 130 |
+
num_steps=sched_config['num_steps'],
|
| 131 |
+
decay=sched_config['decay'],
|
| 132 |
+
warmup=sched_config['warmup'])
|
| 133 |
+
elif sched_config['type'] == 'constant':
|
| 134 |
+
sched = optim.lr_scheduler.LambdaLR(opt, lambda _: 1.0)
|
| 135 |
+
else:
|
| 136 |
+
raise ValueError('Invalid schedule type')
|
| 137 |
+
|
| 138 |
+
assert ema_sched_config['type'] == 'inverse'
|
| 139 |
+
ema_sched = K.utils.EMAWarmup(power=ema_sched_config['power'],
|
| 140 |
+
max_value=ema_sched_config['max_value'])
|
| 141 |
+
|
| 142 |
+
tf = transforms.Compose([
|
| 143 |
+
transforms.Resize(size[0], interpolation=transforms.InterpolationMode.LANCZOS),
|
| 144 |
+
transforms.CenterCrop(size[0]),
|
| 145 |
+
K.augmentation.KarrasAugmentationPipeline(model_config['augment_prob']),
|
| 146 |
+
])
|
| 147 |
+
|
| 148 |
+
if dataset_config['type'] == 'imagefolder':
|
| 149 |
+
train_set = K.utils.FolderOfImages(dataset_config['location'], transform=tf)
|
| 150 |
+
elif dataset_config['type'] == 'cifar10':
|
| 151 |
+
train_set = datasets.CIFAR10(dataset_config['location'], train=True, download=True, transform=tf)
|
| 152 |
+
elif dataset_config['type'] == 'mnist':
|
| 153 |
+
train_set = datasets.MNIST(dataset_config['location'], train=True, download=True, transform=tf)
|
| 154 |
+
elif dataset_config['type'] == 'huggingface':
|
| 155 |
+
from datasets import load_dataset
|
| 156 |
+
train_set = load_dataset(dataset_config['location'])
|
| 157 |
+
train_set.set_transform(partial(K.utils.hf_datasets_augs_helper, transform=tf, image_key=dataset_config['image_key']))
|
| 158 |
+
train_set = train_set['train']
|
| 159 |
+
else:
|
| 160 |
+
raise ValueError('Invalid dataset type')
|
| 161 |
+
|
| 162 |
+
if accelerator.is_main_process:
|
| 163 |
+
try:
|
| 164 |
+
print('Number of items in dataset:', len(train_set))
|
| 165 |
+
except TypeError:
|
| 166 |
+
pass
|
| 167 |
+
|
| 168 |
+
image_key = dataset_config.get('image_key', 0)
|
| 169 |
+
|
| 170 |
+
train_dl = data.DataLoader(train_set, args.batch_size, shuffle=True, drop_last=True,
|
| 171 |
+
num_workers=args.num_workers, persistent_workers=True)
|
| 172 |
+
|
| 173 |
+
if args.grow:
|
| 174 |
+
if not args.grow_config:
|
| 175 |
+
raise ValueError('--grow requires --grow-config')
|
| 176 |
+
ckpt = torch.load(args.grow, map_location='cpu')
|
| 177 |
+
old_config = K.config.load_config(open(args.grow_config))
|
| 178 |
+
old_inner_model = K.config.make_model(old_config)
|
| 179 |
+
old_inner_model.load_state_dict(ckpt['model_ema'])
|
| 180 |
+
if old_config['model']['skip_stages'] != model_config['skip_stages']:
|
| 181 |
+
old_inner_model.set_skip_stages(model_config['skip_stages'])
|
| 182 |
+
if old_config['model']['patch_size'] != model_config['patch_size']:
|
| 183 |
+
old_inner_model.set_patch_size(model_config['patch_size'])
|
| 184 |
+
inner_model.load_state_dict(old_inner_model.state_dict())
|
| 185 |
+
del ckpt, old_inner_model
|
| 186 |
+
|
| 187 |
+
inner_model, inner_model_ema, opt, train_dl = accelerator.prepare(inner_model, inner_model_ema, opt, train_dl)
|
| 188 |
+
if use_wandb:
|
| 189 |
+
wandb.watch(inner_model)
|
| 190 |
+
if args.gns:
|
| 191 |
+
gns_stats_hook = K.gns.DDPGradientStatsHook(inner_model)
|
| 192 |
+
gns_stats = K.gns.GradientNoiseScale()
|
| 193 |
+
else:
|
| 194 |
+
gns_stats = None
|
| 195 |
+
sigma_min = model_config['sigma_min']
|
| 196 |
+
sigma_max = model_config['sigma_max']
|
| 197 |
+
sample_density = K.config.make_sample_density(model_config)
|
| 198 |
+
|
| 199 |
+
model = K.config.make_denoiser_wrapper(config)(inner_model)
|
| 200 |
+
model_ema = K.config.make_denoiser_wrapper(config)(inner_model_ema)
|
| 201 |
+
|
| 202 |
+
state_path = Path(f'{args.name}_state.json')
|
| 203 |
+
|
| 204 |
+
if state_path.exists() or args.resume:
|
| 205 |
+
if args.resume:
|
| 206 |
+
ckpt_path = args.resume
|
| 207 |
+
if not args.resume:
|
| 208 |
+
state = json.load(open(state_path))
|
| 209 |
+
ckpt_path = state['latest_checkpoint']
|
| 210 |
+
if accelerator.is_main_process:
|
| 211 |
+
print(f'Resuming from {ckpt_path}...')
|
| 212 |
+
ckpt = torch.load(ckpt_path, map_location='cpu')
|
| 213 |
+
accelerator.unwrap_model(model.inner_model).load_state_dict(ckpt['model'])
|
| 214 |
+
accelerator.unwrap_model(model_ema.inner_model).load_state_dict(ckpt['model_ema'])
|
| 215 |
+
opt.load_state_dict(ckpt['opt'])
|
| 216 |
+
sched.load_state_dict(ckpt['sched'])
|
| 217 |
+
ema_sched.load_state_dict(ckpt['ema_sched'])
|
| 218 |
+
epoch = ckpt['epoch'] + 1
|
| 219 |
+
step = ckpt['step'] + 1
|
| 220 |
+
if args.gns and ckpt.get('gns_stats', None) is not None:
|
| 221 |
+
gns_stats.load_state_dict(ckpt['gns_stats'])
|
| 222 |
+
|
| 223 |
+
del ckpt
|
| 224 |
+
else:
|
| 225 |
+
epoch = 0
|
| 226 |
+
step = 0
|
| 227 |
+
|
| 228 |
+
evaluate_enabled = args.evaluate_every > 0 and args.evaluate_n > 0
|
| 229 |
+
if evaluate_enabled:
|
| 230 |
+
extractor = K.evaluation.InceptionV3FeatureExtractor(device=device)
|
| 231 |
+
train_iter = iter(train_dl)
|
| 232 |
+
if accelerator.is_main_process:
|
| 233 |
+
print('Computing features for reals...')
|
| 234 |
+
reals_features = K.evaluation.compute_features(accelerator, lambda x: next(train_iter)[image_key][1], extractor, args.evaluate_n, args.batch_size)
|
| 235 |
+
if accelerator.is_main_process:
|
| 236 |
+
metrics_log = K.utils.CSVLogger(f'{args.name}_metrics.csv', ['step', 'fid', 'kid'])
|
| 237 |
+
del train_iter
|
| 238 |
+
|
| 239 |
+
@torch.no_grad()
|
| 240 |
+
@K.utils.eval_mode(model_ema)
|
| 241 |
+
def demo():
|
| 242 |
+
if accelerator.is_main_process:
|
| 243 |
+
tqdm.write('Sampling...')
|
| 244 |
+
filename = f'{args.name}_demo_{step:08}.png'
|
| 245 |
+
n_per_proc = math.ceil(args.sample_n / accelerator.num_processes)
|
| 246 |
+
x = torch.randn([n_per_proc, model_config['input_channels'], size[0], size[1]], device=device) * sigma_max
|
| 247 |
+
sigmas = K.sampling.get_sigmas_karras(50, sigma_min, sigma_max, rho=7., device=device)
|
| 248 |
+
x_0 = K.sampling.sample_dpmpp_2m(model_ema, x, sigmas, disable=not accelerator.is_main_process)
|
| 249 |
+
x_0 = accelerator.gather(x_0)[:args.sample_n]
|
| 250 |
+
if accelerator.is_main_process:
|
| 251 |
+
grid = utils.make_grid(x_0, nrow=math.ceil(args.sample_n ** 0.5), padding=0)
|
| 252 |
+
K.utils.to_pil_image(grid).save(filename)
|
| 253 |
+
if use_wandb:
|
| 254 |
+
wandb.log({'demo_grid': wandb.Image(filename)}, step=step)
|
| 255 |
+
|
| 256 |
+
@torch.no_grad()
|
| 257 |
+
@K.utils.eval_mode(model_ema)
|
| 258 |
+
def evaluate():
|
| 259 |
+
if not evaluate_enabled:
|
| 260 |
+
return
|
| 261 |
+
if accelerator.is_main_process:
|
| 262 |
+
tqdm.write('Evaluating...')
|
| 263 |
+
sigmas = K.sampling.get_sigmas_karras(50, sigma_min, sigma_max, rho=7., device=device)
|
| 264 |
+
def sample_fn(n):
|
| 265 |
+
x = torch.randn([n, model_config['input_channels'], size[0], size[1]], device=device) * sigma_max
|
| 266 |
+
x_0 = K.sampling.sample_dpmpp_2m(model_ema, x, sigmas, disable=True)
|
| 267 |
+
return x_0
|
| 268 |
+
fakes_features = K.evaluation.compute_features(accelerator, sample_fn, extractor, args.evaluate_n, args.batch_size)
|
| 269 |
+
if accelerator.is_main_process:
|
| 270 |
+
fid = K.evaluation.fid(fakes_features, reals_features)
|
| 271 |
+
kid = K.evaluation.kid(fakes_features, reals_features)
|
| 272 |
+
print(f'FID: {fid.item():g}, KID: {kid.item():g}')
|
| 273 |
+
if accelerator.is_main_process:
|
| 274 |
+
metrics_log.write(step, fid.item(), kid.item())
|
| 275 |
+
if use_wandb:
|
| 276 |
+
wandb.log({'FID': fid.item(), 'KID': kid.item()}, step=step)
|
| 277 |
+
|
| 278 |
+
def save():
|
| 279 |
+
accelerator.wait_for_everyone()
|
| 280 |
+
filename = f'{args.name}_{step:08}.pth'
|
| 281 |
+
if accelerator.is_main_process:
|
| 282 |
+
tqdm.write(f'Saving to {filename}...')
|
| 283 |
+
obj = {
|
| 284 |
+
'model': accelerator.unwrap_model(model.inner_model).state_dict(),
|
| 285 |
+
'model_ema': accelerator.unwrap_model(model_ema.inner_model).state_dict(),
|
| 286 |
+
'opt': opt.state_dict(),
|
| 287 |
+
'sched': sched.state_dict(),
|
| 288 |
+
'ema_sched': ema_sched.state_dict(),
|
| 289 |
+
'epoch': epoch,
|
| 290 |
+
'step': step,
|
| 291 |
+
'gns_stats': gns_stats.state_dict() if gns_stats is not None else None,
|
| 292 |
+
}
|
| 293 |
+
accelerator.save(obj, filename)
|
| 294 |
+
if accelerator.is_main_process:
|
| 295 |
+
state_obj = {'latest_checkpoint': filename}
|
| 296 |
+
json.dump(state_obj, open(state_path, 'w'))
|
| 297 |
+
if args.wandb_save_model and use_wandb:
|
| 298 |
+
wandb.save(filename)
|
| 299 |
+
|
| 300 |
+
try:
|
| 301 |
+
while True:
|
| 302 |
+
for batch in tqdm(train_dl, disable=not accelerator.is_main_process):
|
| 303 |
+
with accelerator.accumulate(model):
|
| 304 |
+
reals, _, aug_cond = batch[image_key]
|
| 305 |
+
noise = torch.randn_like(reals)
|
| 306 |
+
sigma = sample_density([reals.shape[0]], device=device)
|
| 307 |
+
losses = model.loss(reals, noise, sigma, aug_cond=aug_cond)
|
| 308 |
+
losses_all = accelerator.gather(losses)
|
| 309 |
+
loss = losses_all.mean()
|
| 310 |
+
accelerator.backward(losses.mean())
|
| 311 |
+
if args.gns:
|
| 312 |
+
sq_norm_small_batch, sq_norm_large_batch = gns_stats_hook.get_stats()
|
| 313 |
+
gns_stats.update(sq_norm_small_batch, sq_norm_large_batch, reals.shape[0], reals.shape[0] * accelerator.num_processes)
|
| 314 |
+
opt.step()
|
| 315 |
+
sched.step()
|
| 316 |
+
opt.zero_grad()
|
| 317 |
+
if accelerator.sync_gradients:
|
| 318 |
+
ema_decay = ema_sched.get_value()
|
| 319 |
+
K.utils.ema_update(model, model_ema, ema_decay)
|
| 320 |
+
ema_sched.step()
|
| 321 |
+
|
| 322 |
+
if accelerator.is_main_process:
|
| 323 |
+
if step % 25 == 0:
|
| 324 |
+
if args.gns:
|
| 325 |
+
tqdm.write(f'Epoch: {epoch}, step: {step}, loss: {loss.item():g}, gns: {gns_stats.get_gns():g}')
|
| 326 |
+
else:
|
| 327 |
+
tqdm.write(f'Epoch: {epoch}, step: {step}, loss: {loss.item():g}')
|
| 328 |
+
|
| 329 |
+
if use_wandb:
|
| 330 |
+
log_dict = {
|
| 331 |
+
'epoch': epoch,
|
| 332 |
+
'loss': loss.item(),
|
| 333 |
+
'lr': sched.get_last_lr()[0],
|
| 334 |
+
'ema_decay': ema_decay,
|
| 335 |
+
}
|
| 336 |
+
if args.gns:
|
| 337 |
+
log_dict['gradient_noise_scale'] = gns_stats.get_gns()
|
| 338 |
+
wandb.log(log_dict, step=step)
|
| 339 |
+
|
| 340 |
+
if step % args.demo_every == 0:
|
| 341 |
+
demo()
|
| 342 |
+
|
| 343 |
+
if evaluate_enabled and step > 0 and step % args.evaluate_every == 0:
|
| 344 |
+
evaluate()
|
| 345 |
+
|
| 346 |
+
if step > 0 and step % args.save_every == 0:
|
| 347 |
+
save()
|
| 348 |
+
|
| 349 |
+
step += 1
|
| 350 |
+
epoch += 1
|
| 351 |
+
except KeyboardInterrupt:
|
| 352 |
+
pass
|
| 353 |
+
|
| 354 |
+
|
| 355 |
+
if __name__ == '__main__':
|
| 356 |
+
main()
|
repositories/stable-diffusion-stability-ai/.gitignore
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Generated by project
|
| 2 |
+
outputs/
|
| 3 |
+
|
| 4 |
+
# Byte-compiled / optimized / DLL files
|
| 5 |
+
__pycache__/
|
| 6 |
+
*.py[cod]
|
| 7 |
+
*$py.class
|
| 8 |
+
|
| 9 |
+
# C extensions
|
| 10 |
+
*.so
|
| 11 |
+
|
| 12 |
+
# General MacOS
|
| 13 |
+
.DS_Store
|
| 14 |
+
.AppleDouble
|
| 15 |
+
.LSOverride
|
| 16 |
+
|
| 17 |
+
# Distribution / packaging
|
| 18 |
+
.Python
|
| 19 |
+
build/
|
| 20 |
+
develop-eggs/
|
| 21 |
+
dist/
|
| 22 |
+
downloads/
|
| 23 |
+
eggs/
|
| 24 |
+
.eggs/
|
| 25 |
+
lib/
|
| 26 |
+
lib64/
|
| 27 |
+
parts/
|
| 28 |
+
sdist/
|
| 29 |
+
var/
|
| 30 |
+
wheels/
|
| 31 |
+
share/python-wheels/
|
| 32 |
+
*.egg-info/
|
| 33 |
+
.installed.cfg
|
| 34 |
+
*.egg
|
| 35 |
+
MANIFEST
|
| 36 |
+
|
| 37 |
+
# PyInstaller
|
| 38 |
+
# Usually these files are written by a python script from a template
|
| 39 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 40 |
+
*.manifest
|
| 41 |
+
*.spec
|
| 42 |
+
|
| 43 |
+
# Installer logs
|
| 44 |
+
pip-log.txt
|
| 45 |
+
pip-delete-this-directory.txt
|
| 46 |
+
|
| 47 |
+
# Unit test / coverage reports
|
| 48 |
+
htmlcov/
|
| 49 |
+
.tox/
|
| 50 |
+
.nox/
|
| 51 |
+
.coverage
|
| 52 |
+
.coverage.*
|
| 53 |
+
.cache
|
| 54 |
+
nosetests.xml
|
| 55 |
+
coverage.xml
|
| 56 |
+
*.cover
|
| 57 |
+
*.py,cover
|
| 58 |
+
.hypothesis/
|
| 59 |
+
.pytest_cache/
|
| 60 |
+
cover/
|
| 61 |
+
|
| 62 |
+
# Translations
|
| 63 |
+
*.mo
|
| 64 |
+
*.pot
|
| 65 |
+
|
| 66 |
+
# Django stuff:
|
| 67 |
+
*.log
|
| 68 |
+
local_settings.py
|
| 69 |
+
db.sqlite3
|
| 70 |
+
db.sqlite3-journal
|
| 71 |
+
|
| 72 |
+
# Flask stuff:
|
| 73 |
+
instance/
|
| 74 |
+
.webassets-cache
|
| 75 |
+
|
| 76 |
+
# Scrapy stuff:
|
| 77 |
+
.scrapy
|
| 78 |
+
|
| 79 |
+
# Sphinx documentation
|
| 80 |
+
docs/_build/
|
| 81 |
+
|
| 82 |
+
# PyBuilder
|
| 83 |
+
.pybuilder/
|
| 84 |
+
target/
|
| 85 |
+
|
| 86 |
+
# Jupyter Notebook
|
| 87 |
+
.ipynb_checkpoints
|
| 88 |
+
|
| 89 |
+
# IPython
|
| 90 |
+
profile_default/
|
| 91 |
+
ipython_config.py
|
| 92 |
+
|
| 93 |
+
# pyenv
|
| 94 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 95 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 96 |
+
# .python-version
|
| 97 |
+
|
| 98 |
+
# pipenv
|
| 99 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 100 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 101 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 102 |
+
# install all needed dependencies.
|
| 103 |
+
#Pipfile.lock
|
| 104 |
+
|
| 105 |
+
# poetry
|
| 106 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 107 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 108 |
+
# commonly ignored for libraries.
|
| 109 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 110 |
+
#poetry.lock
|
| 111 |
+
|
| 112 |
+
# pdm
|
| 113 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 114 |
+
#pdm.lock
|
| 115 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 116 |
+
# in version control.
|
| 117 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 118 |
+
.pdm.toml
|
| 119 |
+
|
| 120 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 121 |
+
__pypackages__/
|
| 122 |
+
|
| 123 |
+
# Celery stuff
|
| 124 |
+
celerybeat-schedule
|
| 125 |
+
celerybeat.pid
|
| 126 |
+
|
| 127 |
+
# SageMath parsed files
|
| 128 |
+
*.sage.py
|
| 129 |
+
|
| 130 |
+
# Environments
|
| 131 |
+
.env
|
| 132 |
+
.venv
|
| 133 |
+
env/
|
| 134 |
+
venv/
|
| 135 |
+
ENV/
|
| 136 |
+
env.bak/
|
| 137 |
+
venv.bak/
|
| 138 |
+
|
| 139 |
+
# Spyder project settings
|
| 140 |
+
.spyderproject
|
| 141 |
+
.spyproject
|
| 142 |
+
|
| 143 |
+
# Rope project settings
|
| 144 |
+
.ropeproject
|
| 145 |
+
|
| 146 |
+
# mkdocs documentation
|
| 147 |
+
/site
|
| 148 |
+
|
| 149 |
+
# mypy
|
| 150 |
+
.mypy_cache/
|
| 151 |
+
.dmypy.json
|
| 152 |
+
dmypy.json
|
| 153 |
+
|
| 154 |
+
# Pyre type checker
|
| 155 |
+
.pyre/
|
| 156 |
+
|
| 157 |
+
# pytype static type analyzer
|
| 158 |
+
.pytype/
|
| 159 |
+
|
| 160 |
+
# Cython debug symbols
|
| 161 |
+
cython_debug/
|
| 162 |
+
|
| 163 |
+
# IDEs
|
| 164 |
+
.idea/
|
| 165 |
+
.vscode/
|
repositories/stable-diffusion-stability-ai/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Stability AI
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
repositories/stable-diffusion-stability-ai/LICENSE-MODEL
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2022 Stability AI and contributors
|
| 2 |
+
|
| 3 |
+
CreativeML Open RAIL++-M License
|
| 4 |
+
dated November 24, 2022
|
| 5 |
+
|
| 6 |
+
Section I: PREAMBLE
|
| 7 |
+
|
| 8 |
+
Multimodal generative models are being widely adopted and used, and have the potential to transform the way artists, among other individuals, conceive and benefit from AI or ML technologies as a tool for content creation.
|
| 9 |
+
|
| 10 |
+
Notwithstanding the current and potential benefits that these artifacts can bring to society at large, there are also concerns about potential misuses of them, either due to their technical limitations or ethical considerations.
|
| 11 |
+
|
| 12 |
+
In short, this license strives for both the open and responsible downstream use of the accompanying model. When it comes to the open character, we took inspiration from open source permissive licenses regarding the grant of IP rights. Referring to the downstream responsible use, we added use-based restrictions not permitting the use of the Model in very specific scenarios, in order for the licensor to be able to enforce the license in case potential misuses of the Model may occur. At the same time, we strive to promote open and responsible research on generative models for art and content generation.
|
| 13 |
+
|
| 14 |
+
Even though downstream derivative versions of the model could be released under different licensing terms, the latter will always have to include - at minimum - the same use-based restrictions as the ones in the original license (this license). We believe in the intersection between open and responsible AI development; thus, this License aims to strike a balance between both in order to enable responsible open-science in the field of AI.
|
| 15 |
+
|
| 16 |
+
This License governs the use of the model (and its derivatives) and is informed by the model card associated with the model.
|
| 17 |
+
|
| 18 |
+
NOW THEREFORE, You and Licensor agree as follows:
|
| 19 |
+
|
| 20 |
+
1. Definitions
|
| 21 |
+
|
| 22 |
+
- "License" means the terms and conditions for use, reproduction, and Distribution as defined in this document.
|
| 23 |
+
- "Data" means a collection of information and/or content extracted from the dataset used with the Model, including to train, pretrain, or otherwise evaluate the Model. The Data is not licensed under this License.
|
| 24 |
+
- "Output" means the results of operating a Model as embodied in informational content resulting therefrom.
|
| 25 |
+
- "Model" means any accompanying machine-learning based assemblies (including checkpoints), consisting of learnt weights, parameters (including optimizer states), corresponding to the model architecture as embodied in the Complementary Material, that have been trained or tuned, in whole or in part on the Data, using the Complementary Material.
|
| 26 |
+
- "Derivatives of the Model" means all modifications to the Model, works based on the Model, or any other model which is created or initialized by transfer of patterns of the weights, parameters, activations or output of the Model, to the other model, in order to cause the other model to perform similarly to the Model, including - but not limited to - distillation methods entailing the use of intermediate data representations or methods based on the generation of synthetic data by the Model for training the other model.
|
| 27 |
+
- "Complementary Material" means the accompanying source code and scripts used to define, run, load, benchmark or evaluate the Model, and used to prepare data for training or evaluation, if any. This includes any accompanying documentation, tutorials, examples, etc, if any.
|
| 28 |
+
- "Distribution" means any transmission, reproduction, publication or other sharing of the Model or Derivatives of the Model to a third party, including providing the Model as a hosted service made available by electronic or other remote means - e.g. API-based or web access.
|
| 29 |
+
- "Licensor" means the copyright owner or entity authorized by the copyright owner that is granting the License, including the persons or entities that may have rights in the Model and/or distributing the Model.
|
| 30 |
+
- "You" (or "Your") means an individual or Legal Entity exercising permissions granted by this License and/or making use of the Model for whichever purpose and in any field of use, including usage of the Model in an end-use application - e.g. chatbot, translator, image generator.
|
| 31 |
+
- "Third Parties" means individuals or legal entities that are not under common control with Licensor or You.
|
| 32 |
+
- "Contribution" means any work of authorship, including the original version of the Model and any modifications or additions to that Model or Derivatives of the Model thereof, that is intentionally submitted to Licensor for inclusion in the Model by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Model, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
|
| 33 |
+
- "Contributor" means Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Model.
|
| 34 |
+
|
| 35 |
+
Section II: INTELLECTUAL PROPERTY RIGHTS
|
| 36 |
+
|
| 37 |
+
Both copyright and patent grants apply to the Model, Derivatives of the Model and Complementary Material. The Model and Derivatives of the Model are subject to additional terms as described in Section III.
|
| 38 |
+
|
| 39 |
+
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare, publicly display, publicly perform, sublicense, and distribute the Complementary Material, the Model, and Derivatives of the Model.
|
| 40 |
+
3. Grant of Patent License. Subject to the terms and conditions of this License and where and as applicable, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this paragraph) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Model and the Complementary Material, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Model to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Model and/or Complementary Material or a Contribution incorporated within the Model and/or Complementary Material constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for the Model and/or Work shall terminate as of the date such litigation is asserted or filed.
|
| 41 |
+
|
| 42 |
+
Section III: CONDITIONS OF USAGE, DISTRIBUTION AND REDISTRIBUTION
|
| 43 |
+
|
| 44 |
+
4. Distribution and Redistribution. You may host for Third Party remote access purposes (e.g. software-as-a-service), reproduce and distribute copies of the Model or Derivatives of the Model thereof in any medium, with or without modifications, provided that You meet the following conditions:
|
| 45 |
+
Use-based restrictions as referenced in paragraph 5 MUST be included as an enforceable provision by You in any type of legal agreement (e.g. a license) governing the use and/or distribution of the Model or Derivatives of the Model, and You shall give notice to subsequent users You Distribute to, that the Model or Derivatives of the Model are subject to paragraph 5. This provision does not apply to the use of Complementary Material.
|
| 46 |
+
You must give any Third Party recipients of the Model or Derivatives of the Model a copy of this License;
|
| 47 |
+
You must cause any modified files to carry prominent notices stating that You changed the files;
|
| 48 |
+
You must retain all copyright, patent, trademark, and attribution notices excluding those notices that do not pertain to any part of the Model, Derivatives of the Model.
|
| 49 |
+
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions - respecting paragraph 4.a. - for use, reproduction, or Distribution of Your modifications, or for any such Derivatives of the Model as a whole, provided Your use, reproduction, and Distribution of the Model otherwise complies with the conditions stated in this License.
|
| 50 |
+
5. Use-based restrictions. The restrictions set forth in Attachment A are considered Use-based restrictions. Therefore You cannot use the Model and the Derivatives of the Model for the specified restricted uses. You may use the Model subject to this License, including only for lawful purposes and in accordance with the License. Use may include creating any content with, finetuning, updating, running, training, evaluating and/or reparametrizing the Model. You shall require all of Your users who use the Model or a Derivative of the Model to comply with the terms of this paragraph (paragraph 5).
|
| 51 |
+
6. The Output You Generate. Except as set forth herein, Licensor claims no rights in the Output You generate using the Model. You are accountable for the Output you generate and its subsequent uses. No use of the output can contravene any provision as stated in the License.
|
| 52 |
+
|
| 53 |
+
Section IV: OTHER PROVISIONS
|
| 54 |
+
|
| 55 |
+
7. Updates and Runtime Restrictions. To the maximum extent permitted by law, Licensor reserves the right to restrict (remotely or otherwise) usage of the Model in violation of this License.
|
| 56 |
+
8. Trademarks and related. Nothing in this License permits You to make use of Licensors’ trademarks, trade names, logos or to otherwise suggest endorsement or misrepresent the relationship between the parties; and any rights not expressly granted herein are reserved by the Licensors.
|
| 57 |
+
9. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Model and the Complementary Material (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Model, Derivatives of the Model, and the Complementary Material and assume any risks associated with Your exercise of permissions under this License.
|
| 58 |
+
10. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Model and the Complementary Material (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
|
| 59 |
+
11. Accepting Warranty or Additional Liability. While redistributing the Model, Derivatives of the Model and the Complementary Material thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
|
| 60 |
+
12. If any provision of this License is held to be invalid, illegal or unenforceable, the remaining provisions shall be unaffected thereby and remain valid as if such provision had not been set forth herein.
|
| 61 |
+
|
| 62 |
+
END OF TERMS AND CONDITIONS
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
Attachment A
|
| 68 |
+
|
| 69 |
+
Use Restrictions
|
| 70 |
+
|
| 71 |
+
You agree not to use the Model or Derivatives of the Model:
|
| 72 |
+
|
| 73 |
+
- In any way that violates any applicable national, federal, state, local or international law or regulation;
|
| 74 |
+
- For the purpose of exploiting, harming or attempting to exploit or harm minors in any way;
|
| 75 |
+
- To generate or disseminate verifiably false information and/or content with the purpose of harming others;
|
| 76 |
+
- To generate or disseminate personal identifiable information that can be used to harm an individual;
|
| 77 |
+
- To defame, disparage or otherwise harass others;
|
| 78 |
+
- For fully automated decision making that adversely impacts an individual’s legal rights or otherwise creates or modifies a binding, enforceable obligation;
|
| 79 |
+
- For any use intended to or which has the effect of discriminating against or harming individuals or groups based on online or offline social behavior or known or predicted personal or personality characteristics;
|
| 80 |
+
- To exploit any of the vulnerabilities of a specific group of persons based on their age, social, physical or mental characteristics, in order to materially distort the behavior of a person pertaining to that group in a manner that causes or is likely to cause that person or another person physical or psychological harm;
|
| 81 |
+
- For any use intended to or which has the effect of discriminating against individuals or groups based on legally protected characteristics or categories;
|
| 82 |
+
- To provide medical advice and medical results interpretation;
|
| 83 |
+
- To generate or disseminate information for the purpose to be used for administration of justice, law enforcement, immigration or asylum processes, such as predicting an individual will commit fraud/crime commitment (e.g. by text profiling, drawing causal relationships between assertions made in documents, indiscriminate and arbitrarily-targeted use).
|
| 84 |
+
|
repositories/stable-diffusion-stability-ai/README.md
ADDED
|
@@ -0,0 +1,302 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Stable Diffusion Version 2
|
| 2 |
+

|
| 3 |
+

|
| 4 |
+

|
| 5 |
+
|
| 6 |
+
This repository contains [Stable Diffusion](https://github.com/CompVis/stable-diffusion) models trained from scratch and will be continuously updated with
|
| 7 |
+
new checkpoints. The following list provides an overview of all currently available models. More coming soon.
|
| 8 |
+
|
| 9 |
+
## News
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
**March 24, 2023**
|
| 13 |
+
|
| 14 |
+
*Stable UnCLIP 2.1*
|
| 15 |
+
|
| 16 |
+
- New stable diffusion finetune (_Stable unCLIP 2.1_, [Hugging Face](https://huggingface.co/stabilityai/)) at 768x768 resolution, based on SD2.1-768. This model allows for image variations and mixing operations as described in [*Hierarchical Text-Conditional Image Generation with CLIP Latents*](https://arxiv.org/abs/2204.06125), and, thanks to its modularity, can be combined with other models such as [KARLO](https://github.com/kakaobrain/karlo). Comes in two variants: [*Stable unCLIP-L*](https://huggingface.co/stabilityai/stable-diffusion-2-1-unclip/blob/main/sd21-unclip-l.ckpt) and [*Stable unCLIP-H*](https://huggingface.co/stabilityai/stable-diffusion-2-1-unclip/blob/main/sd21-unclip-h.ckpt), which are conditioned on CLIP ViT-L and ViT-H image embeddings, respectively. Instructions are available [here](doc/UNCLIP.MD).
|
| 17 |
+
|
| 18 |
+
- A public demo of SD-unCLIP is already available at [clipdrop.co/stable-diffusion-reimagine](https://clipdrop.co/stable-diffusion-reimagine)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
**December 7, 2022**
|
| 22 |
+
|
| 23 |
+
*Version 2.1*
|
| 24 |
+
|
| 25 |
+
- New stable diffusion model (_Stable Diffusion 2.1-v_, [Hugging Face](https://huggingface.co/stabilityai/stable-diffusion-2-1)) at 768x768 resolution and (_Stable Diffusion 2.1-base_, [HuggingFace](https://huggingface.co/stabilityai/stable-diffusion-2-1-base)) at 512x512 resolution, both based on the same number of parameters and architecture as 2.0 and fine-tuned on 2.0, on a less restrictive NSFW filtering of the [LAION-5B](https://laion.ai/blog/laion-5b/) dataset.
|
| 26 |
+
Per default, the attention operation of the model is evaluated at full precision when `xformers` is not installed. To enable fp16 (which can cause numerical instabilities with the vanilla attention module on the v2.1 model) , run your script with `ATTN_PRECISION=fp16 python <thescript.py>`
|
| 27 |
+
|
| 28 |
+
**November 24, 2022**
|
| 29 |
+
|
| 30 |
+
*Version 2.0*
|
| 31 |
+
|
| 32 |
+
- New stable diffusion model (_Stable Diffusion 2.0-v_) at 768x768 resolution. Same number of parameters in the U-Net as 1.5, but uses [OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip) as the text encoder and is trained from scratch. _SD 2.0-v_ is a so-called [v-prediction](https://arxiv.org/abs/2202.00512) model.
|
| 33 |
+
- The above model is finetuned from _SD 2.0-base_, which was trained as a standard noise-prediction model on 512x512 images and is also made available.
|
| 34 |
+
- Added a [x4 upscaling latent text-guided diffusion model](#image-upscaling-with-stable-diffusion).
|
| 35 |
+
- New [depth-guided stable diffusion model](#depth-conditional-stable-diffusion), finetuned from _SD 2.0-base_. The model is conditioned on monocular depth estimates inferred via [MiDaS](https://github.com/isl-org/MiDaS) and can be used for structure-preserving img2img and shape-conditional synthesis.
|
| 36 |
+
|
| 37 |
+

|
| 38 |
+
- A [text-guided inpainting model](#image-inpainting-with-stable-diffusion), finetuned from SD _2.0-base_.
|
| 39 |
+
|
| 40 |
+
We follow the [original repository](https://github.com/CompVis/stable-diffusion) and provide basic inference scripts to sample from the models.
|
| 41 |
+
|
| 42 |
+
________________
|
| 43 |
+
*The original Stable Diffusion model was created in a collaboration with [CompVis](https://arxiv.org/abs/2202.00512) and [RunwayML](https://runwayml.com/) and builds upon the work:*
|
| 44 |
+
|
| 45 |
+
[**High-Resolution Image Synthesis with Latent Diffusion Models**](https://ommer-lab.com/research/latent-diffusion-models/)<br/>
|
| 46 |
+
[Robin Rombach](https://github.com/rromb)\*,
|
| 47 |
+
[Andreas Blattmann](https://github.com/ablattmann)\*,
|
| 48 |
+
[Dominik Lorenz](https://github.com/qp-qp)\,
|
| 49 |
+
[Patrick Esser](https://github.com/pesser),
|
| 50 |
+
[Björn Ommer](https://hci.iwr.uni-heidelberg.de/Staff/bommer)<br/>
|
| 51 |
+
_[CVPR '22 Oral](https://openaccess.thecvf.com/content/CVPR2022/html/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.html) |
|
| 52 |
+
[GitHub](https://github.com/CompVis/latent-diffusion) | [arXiv](https://arxiv.org/abs/2112.10752) | [Project page](https://ommer-lab.com/research/latent-diffusion-models/)_
|
| 53 |
+
|
| 54 |
+
and [many others](#shout-outs).
|
| 55 |
+
|
| 56 |
+
Stable Diffusion is a latent text-to-image diffusion model.
|
| 57 |
+
________________________________
|
| 58 |
+
|
| 59 |
+
## Requirements
|
| 60 |
+
|
| 61 |
+
You can update an existing [latent diffusion](https://github.com/CompVis/latent-diffusion) environment by running
|
| 62 |
+
|
| 63 |
+
```
|
| 64 |
+
conda install pytorch==1.12.1 torchvision==0.13.1 -c pytorch
|
| 65 |
+
pip install transformers==4.19.2 diffusers invisible-watermark
|
| 66 |
+
pip install -e .
|
| 67 |
+
```
|
| 68 |
+
#### xformers efficient attention
|
| 69 |
+
For more efficiency and speed on GPUs,
|
| 70 |
+
we highly recommended installing the [xformers](https://github.com/facebookresearch/xformers)
|
| 71 |
+
library.
|
| 72 |
+
|
| 73 |
+
Tested on A100 with CUDA 11.4.
|
| 74 |
+
Installation needs a somewhat recent version of nvcc and gcc/g++, obtain those, e.g., via
|
| 75 |
+
```commandline
|
| 76 |
+
export CUDA_HOME=/usr/local/cuda-11.4
|
| 77 |
+
conda install -c nvidia/label/cuda-11.4.0 cuda-nvcc
|
| 78 |
+
conda install -c conda-forge gcc
|
| 79 |
+
conda install -c conda-forge gxx_linux-64==9.5.0
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
Then, run the following (compiling takes up to 30 min).
|
| 83 |
+
|
| 84 |
+
```commandline
|
| 85 |
+
cd ..
|
| 86 |
+
git clone https://github.com/facebookresearch/xformers.git
|
| 87 |
+
cd xformers
|
| 88 |
+
git submodule update --init --recursive
|
| 89 |
+
pip install -r requirements.txt
|
| 90 |
+
pip install -e .
|
| 91 |
+
cd ../stablediffusion
|
| 92 |
+
```
|
| 93 |
+
Upon successful installation, the code will automatically default to [memory efficient attention](https://github.com/facebookresearch/xformers)
|
| 94 |
+
for the self- and cross-attention layers in the U-Net and autoencoder.
|
| 95 |
+
|
| 96 |
+
## General Disclaimer
|
| 97 |
+
Stable Diffusion models are general text-to-image diffusion models and therefore mirror biases and (mis-)conceptions that are present
|
| 98 |
+
in their training data. Although efforts were made to reduce the inclusion of explicit pornographic material, **we do not recommend using the provided weights for services or products without additional safety mechanisms and considerations.
|
| 99 |
+
The weights are research artifacts and should be treated as such.**
|
| 100 |
+
Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding [model card](https://huggingface.co/stabilityai/stable-diffusion-2).
|
| 101 |
+
The weights are available via [the StabilityAI organization at Hugging Face](https://huggingface.co/StabilityAI) under the [CreativeML Open RAIL++-M License](LICENSE-MODEL).
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
## Stable Diffusion v2
|
| 106 |
+
|
| 107 |
+
Stable Diffusion v2 refers to a specific configuration of the model
|
| 108 |
+
architecture that uses a downsampling-factor 8 autoencoder with an 865M UNet
|
| 109 |
+
and OpenCLIP ViT-H/14 text encoder for the diffusion model. The _SD 2-v_ model produces 768x768 px outputs.
|
| 110 |
+
|
| 111 |
+
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
|
| 112 |
+
5.0, 6.0, 7.0, 8.0) and 50 DDIM sampling steps show the relative improvements of the checkpoints:
|
| 113 |
+
|
| 114 |
+

|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
### Text-to-Image
|
| 119 |
+

|
| 120 |
+

|
| 121 |
+
|
| 122 |
+
Stable Diffusion 2 is a latent diffusion model conditioned on the penultimate text embeddings of a CLIP ViT-H/14 text encoder.
|
| 123 |
+
We provide a [reference script for sampling](#reference-sampling-script).
|
| 124 |
+
#### Reference Sampling Script
|
| 125 |
+
|
| 126 |
+
This script incorporates an [invisible watermarking](https://github.com/ShieldMnt/invisible-watermark) of the outputs, to help viewers [identify the images as machine-generated](scripts/tests/test_watermark.py).
|
| 127 |
+
We provide the configs for the _SD2-v_ (768px) and _SD2-base_ (512px) model.
|
| 128 |
+
|
| 129 |
+
First, download the weights for [_SD2.1-v_](https://huggingface.co/stabilityai/stable-diffusion-2-1) and [_SD2.1-base_](https://huggingface.co/stabilityai/stable-diffusion-2-1-base).
|
| 130 |
+
|
| 131 |
+
To sample from the _SD2.1-v_ model, run the following:
|
| 132 |
+
|
| 133 |
+
```
|
| 134 |
+
python scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt <path/to/768model.ckpt/> --config configs/stable-diffusion/v2-inference-v.yaml --H 768 --W 768
|
| 135 |
+
```
|
| 136 |
+
or try out the Web Demo: [](https://huggingface.co/spaces/stabilityai/stable-diffusion).
|
| 137 |
+
|
| 138 |
+
To sample from the base model, use
|
| 139 |
+
```
|
| 140 |
+
python scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt <path/to/model.ckpt/> --config <path/to/config.yaml/>
|
| 141 |
+
```
|
| 142 |
+
|
| 143 |
+
By default, this uses the [DDIM sampler](https://arxiv.org/abs/2010.02502), and renders images of size 768x768 (which it was trained on) in 50 steps.
|
| 144 |
+
Empirically, the v-models can be sampled with higher guidance scales.
|
| 145 |
+
|
| 146 |
+
Note: The inference config for all model versions is designed to be used with EMA-only checkpoints.
|
| 147 |
+
For this reason `use_ema=False` is set in the configuration, otherwise the code will try to switch from
|
| 148 |
+
non-EMA to EMA weights.
|
| 149 |
+
|
| 150 |
+
#### Enable Intel® Extension for PyTorch* optimizations in Text-to-Image script
|
| 151 |
+
|
| 152 |
+
If you're planning on running Text-to-Image on Intel® CPU, try to sample an image with TorchScript and Intel® Extension for PyTorch* optimizations. Intel® Extension for PyTorch* extends PyTorch by enabling up-to-date features optimizations for an extra performance boost on Intel® hardware. It can optimize memory layout of the operators to Channel Last memory format, which is generally beneficial for Intel CPUs, take advantage of the most advanced instruction set available on a machine, optimize operators and many more.
|
| 153 |
+
|
| 154 |
+
**Prerequisites**
|
| 155 |
+
|
| 156 |
+
Before running the script, make sure you have all needed libraries installed. (the optimization was checked on `Ubuntu 20.04`). Install [jemalloc](https://github.com/jemalloc/jemalloc), [numactl](https://linux.die.net/man/8/numactl), Intel® OpenMP and Intel® Extension for PyTorch*.
|
| 157 |
+
|
| 158 |
+
```bash
|
| 159 |
+
apt-get install numactl libjemalloc-dev
|
| 160 |
+
pip install intel-openmp
|
| 161 |
+
pip install intel_extension_for_pytorch -f https://software.intel.com/ipex-whl-stable
|
| 162 |
+
```
|
| 163 |
+
|
| 164 |
+
To sample from the _SD2.1-v_ model with TorchScript+IPEX optimizations, run the following. Remember to specify desired number of instances you want to run the program on ([more](https://github.com/intel/intel-extension-for-pytorch/blob/master/intel_extension_for_pytorch/cpu/launch.py#L48)).
|
| 165 |
+
|
| 166 |
+
```
|
| 167 |
+
MALLOC_CONF=oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms:9000000000,muzzy_decay_ms:9000000000 python -m intel_extension_for_pytorch.cpu.launch --ninstance <number of an instance> --enable_jemalloc scripts/txt2img.py --prompt \"a corgi is playing guitar, oil on canvas\" --ckpt <path/to/768model.ckpt/> --config configs/stable-diffusion/intel/v2-inference-v-fp32.yaml --H 768 --W 768 --precision full --device cpu --torchscript --ipex
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
To sample from the base model with IPEX optimizations, use
|
| 171 |
+
|
| 172 |
+
```
|
| 173 |
+
MALLOC_CONF=oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms:9000000000,muzzy_decay_ms:9000000000 python -m intel_extension_for_pytorch.cpu.launch --ninstance <number of an instance> --enable_jemalloc scripts/txt2img.py --prompt \"a corgi is playing guitar, oil on canvas\" --ckpt <path/to/model.ckpt/> --config configs/stable-diffusion/intel/v2-inference-fp32.yaml --n_samples 1 --n_iter 4 --precision full --device cpu --torchscript --ipex
|
| 174 |
+
```
|
| 175 |
+
|
| 176 |
+
If you're using a CPU that supports `bfloat16`, consider sample from the model with bfloat16 enabled for a performance boost, like so
|
| 177 |
+
|
| 178 |
+
```bash
|
| 179 |
+
# SD2.1-v
|
| 180 |
+
MALLOC_CONF=oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms:9000000000,muzzy_decay_ms:9000000000 python -m intel_extension_for_pytorch.cpu.launch --ninstance <number of an instance> --enable_jemalloc scripts/txt2img.py --prompt \"a corgi is playing guitar, oil on canvas\" --ckpt <path/to/768model.ckpt/> --config configs/stable-diffusion/intel/v2-inference-v-bf16.yaml --H 768 --W 768 --precision full --device cpu --torchscript --ipex --bf16
|
| 181 |
+
# SD2.1-base
|
| 182 |
+
MALLOC_CONF=oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms:9000000000,muzzy_decay_ms:9000000000 python -m intel_extension_for_pytorch.cpu.launch --ninstance <number of an instance> --enable_jemalloc scripts/txt2img.py --prompt \"a corgi is playing guitar, oil on canvas\" --ckpt <path/to/model.ckpt/> --config configs/stable-diffusion/intel/v2-inference-bf16.yaml --precision full --device cpu --torchscript --ipex --bf16
|
| 183 |
+
```
|
| 184 |
+
|
| 185 |
+
### Image Modification with Stable Diffusion
|
| 186 |
+
|
| 187 |
+

|
| 188 |
+
#### Depth-Conditional Stable Diffusion
|
| 189 |
+
|
| 190 |
+
To augment the well-established [img2img](https://github.com/CompVis/stable-diffusion#image-modification-with-stable-diffusion) functionality of Stable Diffusion, we provide a _shape-preserving_ stable diffusion model.
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
Note that the original method for image modification introduces significant semantic changes w.r.t. the initial image.
|
| 194 |
+
If that is not desired, download our [depth-conditional stable diffusion](https://huggingface.co/stabilityai/stable-diffusion-2-depth) model and the `dpt_hybrid` MiDaS [model weights](https://github.com/intel-isl/DPT/releases/download/1_0/dpt_hybrid-midas-501f0c75.pt), place the latter in a folder `midas_models` and sample via
|
| 195 |
+
```
|
| 196 |
+
python scripts/gradio/depth2img.py configs/stable-diffusion/v2-midas-inference.yaml <path-to-ckpt>
|
| 197 |
+
```
|
| 198 |
+
|
| 199 |
+
or
|
| 200 |
+
|
| 201 |
+
```
|
| 202 |
+
streamlit run scripts/streamlit/depth2img.py configs/stable-diffusion/v2-midas-inference.yaml <path-to-ckpt>
|
| 203 |
+
```
|
| 204 |
+
|
| 205 |
+
This method can be used on the samples of the base model itself.
|
| 206 |
+
For example, take [this sample](assets/stable-samples/depth2img/old_man.png) generated by an anonymous discord user.
|
| 207 |
+
Using the [gradio](https://gradio.app) or [streamlit](https://streamlit.io/) script `depth2img.py`, the MiDaS model first infers a monocular depth estimate given this input,
|
| 208 |
+
and the diffusion model is then conditioned on the (relative) depth output.
|
| 209 |
+
|
| 210 |
+
<p align="center">
|
| 211 |
+
<b> depth2image </b><br/>
|
| 212 |
+
<img src=assets/stable-samples/depth2img/d2i.gif>
|
| 213 |
+
</p>
|
| 214 |
+
|
| 215 |
+
This model is particularly useful for a photorealistic style; see the [examples](assets/stable-samples/depth2img).
|
| 216 |
+
For a maximum strength of 1.0, the model removes all pixel-based information and only relies on the text prompt and the inferred monocular depth estimate.
|
| 217 |
+
|
| 218 |
+

|
| 219 |
+
|
| 220 |
+
#### Classic Img2Img
|
| 221 |
+
|
| 222 |
+
For running the "classic" img2img, use
|
| 223 |
+
```
|
| 224 |
+
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8 --ckpt <path/to/model.ckpt>
|
| 225 |
+
```
|
| 226 |
+
and adapt the checkpoint and config paths accordingly.
|
| 227 |
+
|
| 228 |
+
### Image Upscaling with Stable Diffusion
|
| 229 |
+

|
| 230 |
+
After [downloading the weights](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler), run
|
| 231 |
+
```
|
| 232 |
+
python scripts/gradio/superresolution.py configs/stable-diffusion/x4-upscaling.yaml <path-to-checkpoint>
|
| 233 |
+
```
|
| 234 |
+
|
| 235 |
+
or
|
| 236 |
+
|
| 237 |
+
```
|
| 238 |
+
streamlit run scripts/streamlit/superresolution.py -- configs/stable-diffusion/x4-upscaling.yaml <path-to-checkpoint>
|
| 239 |
+
```
|
| 240 |
+
|
| 241 |
+
for a Gradio or Streamlit demo of the text-guided x4 superresolution model.
|
| 242 |
+
This model can be used both on real inputs and on synthesized examples. For the latter, we recommend setting a higher
|
| 243 |
+
`noise_level`, e.g. `noise_level=100`.
|
| 244 |
+
|
| 245 |
+
### Image Inpainting with Stable Diffusion
|
| 246 |
+
|
| 247 |
+

|
| 248 |
+
|
| 249 |
+
[Download the SD 2.0-inpainting checkpoint](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) and run
|
| 250 |
+
|
| 251 |
+
```
|
| 252 |
+
python scripts/gradio/inpainting.py configs/stable-diffusion/v2-inpainting-inference.yaml <path-to-checkpoint>
|
| 253 |
+
```
|
| 254 |
+
|
| 255 |
+
or
|
| 256 |
+
|
| 257 |
+
```
|
| 258 |
+
streamlit run scripts/streamlit/inpainting.py -- configs/stable-diffusion/v2-inpainting-inference.yaml <path-to-checkpoint>
|
| 259 |
+
```
|
| 260 |
+
|
| 261 |
+
for a Gradio or Streamlit demo of the inpainting model.
|
| 262 |
+
This scripts adds invisible watermarking to the demo in the [RunwayML](https://github.com/runwayml/stable-diffusion/blob/main/scripts/inpaint_st.py) repository, but both should work interchangeably with the checkpoints/configs.
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
## Shout-Outs
|
| 267 |
+
- Thanks to [Hugging Face](https://huggingface.co/) and in particular [Apolinário](https://github.com/apolinario) for support with our model releases!
|
| 268 |
+
- Stable Diffusion would not be possible without [LAION](https://laion.ai/) and their efforts to create open, large-scale datasets.
|
| 269 |
+
- The [DeepFloyd team](https://twitter.com/deepfloydai) at Stability AI, for creating the subset of [LAION-5B](https://laion.ai/blog/laion-5b/) dataset used to train the model.
|
| 270 |
+
- Stable Diffusion 2.0 uses [OpenCLIP](https://laion.ai/blog/large-openclip/), trained by [Romain Beaumont](https://github.com/rom1504).
|
| 271 |
+
- Our codebase for the diffusion models builds heavily on [OpenAI's ADM codebase](https://github.com/openai/guided-diffusion)
|
| 272 |
+
and [https://github.com/lucidrains/denoising-diffusion-pytorch](https://github.com/lucidrains/denoising-diffusion-pytorch).
|
| 273 |
+
Thanks for open-sourcing!
|
| 274 |
+
- [CompVis](https://github.com/CompVis/stable-diffusion) initial stable diffusion release
|
| 275 |
+
- [Patrick](https://github.com/pesser)'s [implementation](https://github.com/runwayml/stable-diffusion/blob/main/scripts/inpaint_st.py) of the streamlit demo for inpainting.
|
| 276 |
+
- `img2img` is an application of [SDEdit](https://arxiv.org/abs/2108.01073) by [Chenlin Meng](https://cs.stanford.edu/~chenlin/) from the [Stanford AI Lab](https://cs.stanford.edu/~ermon/website/).
|
| 277 |
+
- [Kat's implementation]((https://github.com/CompVis/latent-diffusion/pull/51)) of the [PLMS](https://arxiv.org/abs/2202.09778) sampler, and [more](https://github.com/crowsonkb/k-diffusion).
|
| 278 |
+
- [DPMSolver](https://arxiv.org/abs/2206.00927) [integration](https://github.com/CompVis/stable-diffusion/pull/440) by [Cheng Lu](https://github.com/LuChengTHU).
|
| 279 |
+
- Facebook's [xformers](https://github.com/facebookresearch/xformers) for efficient attention computation.
|
| 280 |
+
- [MiDaS](https://github.com/isl-org/MiDaS) for monocular depth estimation.
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
## License
|
| 284 |
+
|
| 285 |
+
The code in this repository is released under the MIT License.
|
| 286 |
+
|
| 287 |
+
The weights are available via [the StabilityAI organization at Hugging Face](https://huggingface.co/StabilityAI), and released under the [CreativeML Open RAIL++-M License](LICENSE-MODEL) License.
|
| 288 |
+
|
| 289 |
+
## BibTeX
|
| 290 |
+
|
| 291 |
+
```
|
| 292 |
+
@misc{rombach2021highresolution,
|
| 293 |
+
title={High-Resolution Image Synthesis with Latent Diffusion Models},
|
| 294 |
+
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
|
| 295 |
+
year={2021},
|
| 296 |
+
eprint={2112.10752},
|
| 297 |
+
archivePrefix={arXiv},
|
| 298 |
+
primaryClass={cs.CV}
|
| 299 |
+
}
|
| 300 |
+
```
|
| 301 |
+
|
| 302 |
+
|
repositories/stable-diffusion-stability-ai/assets/model-variants.jpg
ADDED
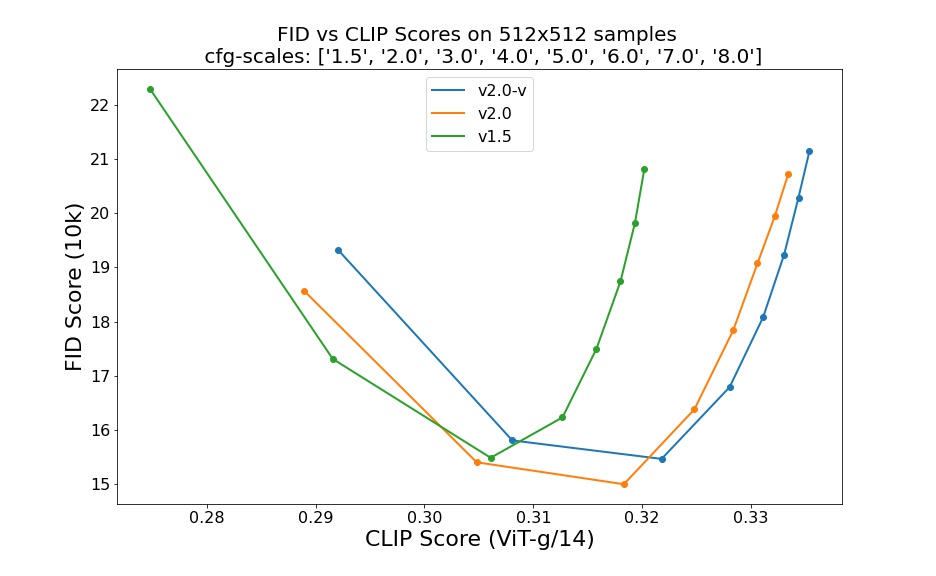
|
repositories/stable-diffusion-stability-ai/assets/modelfigure.png
ADDED
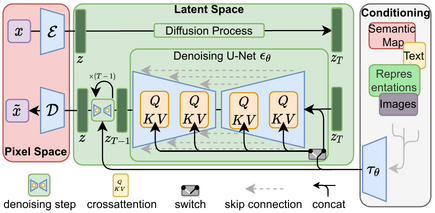
|
repositories/stable-diffusion-stability-ai/assets/rick.jpeg
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-inpainting/inpainting.gif
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-inpainting/merged-leopards.png
ADDED

|
Git LFS Details
|
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/d2i.gif
ADDED

|
Git LFS Details
|
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/depth2fantasy.jpeg
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/depth2img01.png
ADDED

|
Git LFS Details
|
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/depth2img02.png
ADDED

|
Git LFS Details
|
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/merged-0000.png
ADDED

|
Git LFS Details
|
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/merged-0004.png
ADDED

|
Git LFS Details
|
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/merged-0005.png
ADDED

|
Git LFS Details
|
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/midas.jpeg
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-samples/depth2img/old_man.png
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/mountains-1.png
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/mountains-2.png
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/mountains-3.png
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/sketch-mountains-input.jpg
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/upscaling-in.png
ADDED

|
Git LFS Details
|
repositories/stable-diffusion-stability-ai/assets/stable-samples/img2img/upscaling-out.png
ADDED

|
Git LFS Details
|
repositories/stable-diffusion-stability-ai/assets/stable-samples/stable-unclip/houses_out.jpeg
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-samples/stable-unclip/oldcar000.jpeg
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-samples/stable-unclip/oldcar500.jpeg
ADDED

|
repositories/stable-diffusion-stability-ai/assets/stable-samples/stable-unclip/oldcar800.jpeg
ADDED

|