
1c7c9698ec203cd046019ed516088de12e4a9dc207c69205e2b125c1b3937d13
Browse files- extensions/a1111-microsoftexcel-locon/.gitignore +1 -0
- extensions/a1111-microsoftexcel-locon/LICENSE +201 -0
- extensions/a1111-microsoftexcel-locon/README.md +42 -0
- extensions/a1111-microsoftexcel-locon/__pycache__/locon.cpython-310.pyc +0 -0
- extensions/a1111-microsoftexcel-locon/__pycache__/locon_compvis.cpython-310.pyc +0 -0
- extensions/a1111-microsoftexcel-locon/locon.py +57 -0
- extensions/a1111-microsoftexcel-locon/locon_compvis.py +488 -0
- extensions/a1111-microsoftexcel-locon/scripts/__pycache__/main.cpython-310.pyc +0 -0
- extensions/a1111-microsoftexcel-locon/scripts/main.py +766 -0
- extensions/a1111-microsoftexcel-tagcomplete/.gitignore +2 -0
- extensions/a1111-microsoftexcel-tagcomplete/LICENSE +21 -0
- extensions/a1111-microsoftexcel-tagcomplete/README.md +209 -0
- extensions/a1111-microsoftexcel-tagcomplete/README_ZH.md +173 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/__globals.js +52 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/_baseParser.js +21 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/_caretPosition.js +145 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/_result.js +33 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/_textAreas.js +167 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/_utils.js +130 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_embeddings.js +61 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_hypernets.js +51 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_loras.js +51 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_lycos.js +51 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_umi.js +240 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_wildcards.js +123 -0
- extensions/a1111-microsoftexcel-tagcomplete/javascript/tagAutocomplete.js +935 -0
- extensions/a1111-microsoftexcel-tagcomplete/scripts/__pycache__/tag_autocomplete_helper.cpython-310.pyc +0 -0
- extensions/a1111-microsoftexcel-tagcomplete/scripts/tag_autocomplete_helper.py +358 -0
- extensions/a1111-microsoftexcel-tagcomplete/tags/danbooru.csv +0 -0
- extensions/a1111-microsoftexcel-tagcomplete/tags/e621.csv +0 -0
- extensions/a1111-microsoftexcel-tagcomplete/tags/extra-quality-tags.csv +6 -0
- extensions/a1111-microsoftexcel-tagcomplete/tags/temp/emb.txt +162 -0
- extensions/a1111-microsoftexcel-tagcomplete/tags/temp/hyp.txt +0 -0
- extensions/a1111-microsoftexcel-tagcomplete/tags/temp/lora.txt +0 -0
- extensions/a1111-microsoftexcel-tagcomplete/tags/temp/lyco.txt +0 -0
- extensions/a1111-microsoftexcel-tagcomplete/tags/temp/wc.txt +0 -0
- extensions/a1111-microsoftexcel-tagcomplete/tags/temp/wce.txt +0 -0
- extensions/a1111-microsoftexcel-tagcomplete/tags/temp/wcet.txt +0 -0
- extensions/a1111-sd-webui-lycoris/.gitignore +1 -0
- extensions/a1111-sd-webui-lycoris/LICENSE +201 -0
- extensions/a1111-sd-webui-lycoris/README.md +53 -0
- extensions/a1111-sd-webui-lycoris/__pycache__/extra_networks_lyco.cpython-310.pyc +0 -0
- extensions/a1111-sd-webui-lycoris/__pycache__/lycoris.cpython-310.pyc +0 -0
- extensions/a1111-sd-webui-lycoris/__pycache__/preload.cpython-310.pyc +0 -0
- extensions/a1111-sd-webui-lycoris/__pycache__/ui_extra_networks_lyco.cpython-310.pyc +0 -0
- extensions/a1111-sd-webui-lycoris/extra_networks_lyco.py +95 -0
- extensions/a1111-sd-webui-lycoris/lycoris.py +793 -0
- extensions/a1111-sd-webui-lycoris/preload.py +6 -0
- extensions/a1111-sd-webui-lycoris/scripts/__pycache__/lycoris_script.cpython-310.pyc +0 -0
- extensions/a1111-sd-webui-lycoris/scripts/lycoris_script.py +56 -0
extensions/a1111-microsoftexcel-locon/.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
extensions/a1111-microsoftexcel-locon/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [2023] [KohakuBlueLeaf]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
extensions/a1111-microsoftexcel-locon/README.md
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# a1111-sd-webui-locon
|
| 2 |
+
|
| 3 |
+
An extension for loading lycoris model in sd-webui. (include locon and loha)
|
| 4 |
+
|
| 5 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 6 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 7 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 8 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 9 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 10 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 11 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 12 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 13 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 14 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 15 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 16 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 17 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 18 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 19 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 20 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 21 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 22 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 23 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 24 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 25 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 26 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 27 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 28 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 29 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 30 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 31 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 32 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 33 |
+
# THIS EXTENSION IS NOT FOR ADDITIONAL NETWORK
|
| 34 |
+
|
| 35 |
+
### LyCORIS
|
| 36 |
+
https://github.com/KohakuBlueleaf/LyCORIS
|
| 37 |
+
|
| 38 |
+
### usage
|
| 39 |
+
Install and use locon model as lora model. <br>
|
| 40 |
+
Make sure your sd-webui has built-in lora
|
| 41 |
+
|
| 42 |
+

|
extensions/a1111-microsoftexcel-locon/__pycache__/locon.cpython-310.pyc
ADDED
|
Binary file (1.97 kB). View file
|
|
|
extensions/a1111-microsoftexcel-locon/__pycache__/locon_compvis.cpython-310.pyc
ADDED
|
Binary file (11.2 kB). View file
|
|
|
extensions/a1111-microsoftexcel-locon/locon.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
https://github.com/KohakuBlueleaf/LoCon
|
| 3 |
+
'''
|
| 4 |
+
|
| 5 |
+
import math
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class LoConModule(nn.Module):
|
| 13 |
+
"""
|
| 14 |
+
modifed from kohya-ss/sd-scripts/networks/lora:LoRAModule
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
def __init__(self, lora_name, org_module: nn.Module, multiplier=1.0, lora_dim=4, alpha=1):
|
| 18 |
+
""" if alpha == 0 or None, alpha is rank (no scaling). """
|
| 19 |
+
super().__init__()
|
| 20 |
+
self.lora_name = lora_name
|
| 21 |
+
self.lora_dim = lora_dim
|
| 22 |
+
|
| 23 |
+
if org_module.__class__.__name__ == 'Conv2d':
|
| 24 |
+
# For general LoCon
|
| 25 |
+
in_dim = org_module.in_channels
|
| 26 |
+
k_size = org_module.kernel_size
|
| 27 |
+
stride = org_module.stride
|
| 28 |
+
padding = org_module.padding
|
| 29 |
+
out_dim = org_module.out_channels
|
| 30 |
+
self.lora_down = nn.Conv2d(in_dim, lora_dim, k_size, stride, padding, bias=False)
|
| 31 |
+
self.lora_up = nn.Conv2d(lora_dim, out_dim, (1, 1), bias=False)
|
| 32 |
+
else:
|
| 33 |
+
in_dim = org_module.in_features
|
| 34 |
+
out_dim = org_module.out_features
|
| 35 |
+
self.lora_down = nn.Linear(in_dim, lora_dim, bias=False)
|
| 36 |
+
self.lora_up = nn.Linear(lora_dim, out_dim, bias=False)
|
| 37 |
+
|
| 38 |
+
if type(alpha) == torch.Tensor:
|
| 39 |
+
alpha = alpha.detach().float().numpy() # without casting, bf16 causes error
|
| 40 |
+
alpha = lora_dim if alpha is None or alpha == 0 else alpha
|
| 41 |
+
self.scale = alpha / self.lora_dim
|
| 42 |
+
self.register_buffer('alpha', torch.tensor(alpha)) # 定数として扱える
|
| 43 |
+
|
| 44 |
+
# same as microsoft's
|
| 45 |
+
torch.nn.init.kaiming_uniform_(self.lora_down.weight, a=math.sqrt(5))
|
| 46 |
+
torch.nn.init.zeros_(self.lora_up.weight)
|
| 47 |
+
|
| 48 |
+
self.multiplier = multiplier
|
| 49 |
+
self.org_module = org_module # remove in applying
|
| 50 |
+
|
| 51 |
+
def apply_to(self):
|
| 52 |
+
self.org_forward = self.org_module.forward
|
| 53 |
+
self.org_module.forward = self.forward
|
| 54 |
+
del self.org_module
|
| 55 |
+
|
| 56 |
+
def forward(self, x):
|
| 57 |
+
return self.org_forward(x) + self.lora_up(self.lora_down(x)) * self.multiplier * self.scale
|
extensions/a1111-microsoftexcel-locon/locon_compvis.py
ADDED
|
@@ -0,0 +1,488 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Hijack version of kohya-ss/additional_networks/scripts/lora_compvis.py
|
| 3 |
+
'''
|
| 4 |
+
# LoRA network module
|
| 5 |
+
# reference:
|
| 6 |
+
# https://github.com/microsoft/LoRA/blob/main/loralib/layers.py
|
| 7 |
+
# https://github.com/cloneofsimo/lora/blob/master/lora_diffusion/lora.py
|
| 8 |
+
|
| 9 |
+
import copy
|
| 10 |
+
import math
|
| 11 |
+
import re
|
| 12 |
+
from typing import NamedTuple
|
| 13 |
+
import torch
|
| 14 |
+
from locon import LoConModule
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class LoRAInfo(NamedTuple):
|
| 18 |
+
lora_name: str
|
| 19 |
+
module_name: str
|
| 20 |
+
module: torch.nn.Module
|
| 21 |
+
multiplier: float
|
| 22 |
+
dim: int
|
| 23 |
+
alpha: float
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def create_network_and_apply_compvis(du_state_dict, multiplier_tenc, multiplier_unet, text_encoder, unet, **kwargs):
|
| 27 |
+
# get device and dtype from unet
|
| 28 |
+
for module in unet.modules():
|
| 29 |
+
if module.__class__.__name__ == "Linear":
|
| 30 |
+
param: torch.nn.Parameter = module.weight
|
| 31 |
+
# device = param.device
|
| 32 |
+
dtype = param.dtype
|
| 33 |
+
break
|
| 34 |
+
|
| 35 |
+
# get dims (rank) and alpha from state dict
|
| 36 |
+
# currently it is assumed all LoRA have same alpha. alpha may be different in future.
|
| 37 |
+
network_alpha = None
|
| 38 |
+
conv_alpha = None
|
| 39 |
+
network_dim = None
|
| 40 |
+
conv_dim = None
|
| 41 |
+
for key, value in du_state_dict.items():
|
| 42 |
+
if network_alpha is None and 'alpha' in key:
|
| 43 |
+
network_alpha = value
|
| 44 |
+
if network_dim is None and 'lora_down' in key and len(value.size()) == 2:
|
| 45 |
+
network_dim = value.size()[0]
|
| 46 |
+
if network_alpha is not None and network_dim is not None:
|
| 47 |
+
break
|
| 48 |
+
if network_alpha is None:
|
| 49 |
+
network_alpha = network_dim
|
| 50 |
+
|
| 51 |
+
print(f"dimension: {network_dim},\n"
|
| 52 |
+
f"alpha: {network_alpha},\n"
|
| 53 |
+
f"multiplier_unet: {multiplier_unet},\n"
|
| 54 |
+
f"multiplier_tenc: {multiplier_tenc}"
|
| 55 |
+
)
|
| 56 |
+
if network_dim is None:
|
| 57 |
+
print(f"The selected model is not LoRA or not trained by `sd-scripts`?")
|
| 58 |
+
network_dim = 4
|
| 59 |
+
network_alpha = 1
|
| 60 |
+
|
| 61 |
+
# create, apply and load weights
|
| 62 |
+
network = LoConNetworkCompvis(
|
| 63 |
+
text_encoder, unet, du_state_dict,
|
| 64 |
+
multiplier_tenc = multiplier_tenc,
|
| 65 |
+
multiplier_unet = multiplier_unet,
|
| 66 |
+
)
|
| 67 |
+
state_dict = network.apply_lora_modules(du_state_dict) # some weights are applied to text encoder
|
| 68 |
+
network.to(dtype) # with this, if error comes from next line, the model will be used
|
| 69 |
+
info = network.load_state_dict(state_dict, strict=False)
|
| 70 |
+
|
| 71 |
+
# remove redundant warnings
|
| 72 |
+
if len(info.missing_keys) > 4:
|
| 73 |
+
missing_keys = []
|
| 74 |
+
alpha_count = 0
|
| 75 |
+
for key in info.missing_keys:
|
| 76 |
+
if 'alpha' not in key:
|
| 77 |
+
missing_keys.append(key)
|
| 78 |
+
else:
|
| 79 |
+
if alpha_count == 0:
|
| 80 |
+
missing_keys.append(key)
|
| 81 |
+
alpha_count += 1
|
| 82 |
+
if alpha_count > 1:
|
| 83 |
+
missing_keys.append(
|
| 84 |
+
f"... and {alpha_count-1} alphas. The model doesn't have alpha, use dim (rannk) as alpha. You can ignore this message.")
|
| 85 |
+
|
| 86 |
+
info = torch.nn.modules.module._IncompatibleKeys(missing_keys, info.unexpected_keys)
|
| 87 |
+
|
| 88 |
+
return network, info
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
class LoConNetworkCompvis(torch.nn.Module):
|
| 92 |
+
# UNET_TARGET_REPLACE_MODULE = ["Transformer2DModel", "Attention"]
|
| 93 |
+
# TEXT_ENCODER_TARGET_REPLACE_MODULE = ["CLIPAttention", "CLIPMLP"]
|
| 94 |
+
LOCON_TARGET = ["ResBlock", "Downsample", "Upsample"]
|
| 95 |
+
UNET_TARGET_REPLACE_MODULE = ["SpatialTransformer"] + LOCON_TARGET # , "Attention"]
|
| 96 |
+
TEXT_ENCODER_TARGET_REPLACE_MODULE = ["ResidualAttentionBlock", "CLIPAttention", "CLIPMLP"]
|
| 97 |
+
|
| 98 |
+
LORA_PREFIX_UNET = 'lora_unet'
|
| 99 |
+
LORA_PREFIX_TEXT_ENCODER = 'lora_te'
|
| 100 |
+
|
| 101 |
+
@classmethod
|
| 102 |
+
def convert_diffusers_name_to_compvis(cls, v2, du_name):
|
| 103 |
+
"""
|
| 104 |
+
convert diffusers's LoRA name to CompVis
|
| 105 |
+
"""
|
| 106 |
+
cv_name = None
|
| 107 |
+
if "lora_unet_" in du_name:
|
| 108 |
+
m = re.search(r"_down_blocks_(\d+)_attentions_(\d+)_(.+)", du_name)
|
| 109 |
+
if m:
|
| 110 |
+
du_block_index = int(m.group(1))
|
| 111 |
+
du_attn_index = int(m.group(2))
|
| 112 |
+
du_suffix = m.group(3)
|
| 113 |
+
|
| 114 |
+
cv_index = 1 + du_block_index * 3 + du_attn_index # 1,2, 4,5, 7,8
|
| 115 |
+
cv_name = f"lora_unet_input_blocks_{cv_index}_1_{du_suffix}"
|
| 116 |
+
return cv_name
|
| 117 |
+
|
| 118 |
+
m = re.search(r"_mid_block_attentions_(\d+)_(.+)", du_name)
|
| 119 |
+
if m:
|
| 120 |
+
du_suffix = m.group(2)
|
| 121 |
+
cv_name = f"lora_unet_middle_block_1_{du_suffix}"
|
| 122 |
+
return cv_name
|
| 123 |
+
|
| 124 |
+
m = re.search(r"_up_blocks_(\d+)_attentions_(\d+)_(.+)", du_name)
|
| 125 |
+
if m:
|
| 126 |
+
du_block_index = int(m.group(1))
|
| 127 |
+
du_attn_index = int(m.group(2))
|
| 128 |
+
du_suffix = m.group(3)
|
| 129 |
+
|
| 130 |
+
cv_index = du_block_index * 3 + du_attn_index # 3,4,5, 6,7,8, 9,10,11
|
| 131 |
+
cv_name = f"lora_unet_output_blocks_{cv_index}_1_{du_suffix}"
|
| 132 |
+
return cv_name
|
| 133 |
+
|
| 134 |
+
m = re.search(r"_down_blocks_(\d+)_resnets_(\d+)_(.+)", du_name)
|
| 135 |
+
if m:
|
| 136 |
+
du_block_index = int(m.group(1))
|
| 137 |
+
du_res_index = int(m.group(2))
|
| 138 |
+
du_suffix = m.group(3)
|
| 139 |
+
cv_suffix = {
|
| 140 |
+
'conv1': 'in_layers_2',
|
| 141 |
+
'conv2': 'out_layers_3',
|
| 142 |
+
'time_emb_proj': 'emb_layers_1',
|
| 143 |
+
'conv_shortcut': 'skip_connection'
|
| 144 |
+
}[du_suffix]
|
| 145 |
+
|
| 146 |
+
cv_index = 1 + du_block_index * 3 + du_res_index # 1,2, 4,5, 7,8
|
| 147 |
+
cv_name = f"lora_unet_input_blocks_{cv_index}_0_{cv_suffix}"
|
| 148 |
+
return cv_name
|
| 149 |
+
|
| 150 |
+
m = re.search(r"_down_blocks_(\d+)_downsamplers_0_conv", du_name)
|
| 151 |
+
if m:
|
| 152 |
+
block_index = int(m.group(1))
|
| 153 |
+
cv_index = 3 + block_index * 3
|
| 154 |
+
cv_name = f"lora_unet_input_blocks_{cv_index}_0_op"
|
| 155 |
+
return cv_name
|
| 156 |
+
|
| 157 |
+
m = re.search(r"_mid_block_resnets_(\d+)_(.+)", du_name)
|
| 158 |
+
if m:
|
| 159 |
+
index = int(m.group(1))
|
| 160 |
+
du_suffix = m.group(2)
|
| 161 |
+
cv_suffix = {
|
| 162 |
+
'conv1': 'in_layers_2',
|
| 163 |
+
'conv2': 'out_layers_3',
|
| 164 |
+
'time_emb_proj': 'emb_layers_1',
|
| 165 |
+
'conv_shortcut': 'skip_connection'
|
| 166 |
+
}[du_suffix]
|
| 167 |
+
cv_name = f"lora_unet_middle_block_{index*2}_{cv_suffix}"
|
| 168 |
+
return cv_name
|
| 169 |
+
|
| 170 |
+
m = re.search(r"_up_blocks_(\d+)_resnets_(\d+)_(.+)", du_name)
|
| 171 |
+
if m:
|
| 172 |
+
du_block_index = int(m.group(1))
|
| 173 |
+
du_res_index = int(m.group(2))
|
| 174 |
+
du_suffix = m.group(3)
|
| 175 |
+
cv_suffix = {
|
| 176 |
+
'conv1': 'in_layers_2',
|
| 177 |
+
'conv2': 'out_layers_3',
|
| 178 |
+
'time_emb_proj': 'emb_layers_1',
|
| 179 |
+
'conv_shortcut': 'skip_connection'
|
| 180 |
+
}[du_suffix]
|
| 181 |
+
|
| 182 |
+
cv_index = du_block_index * 3 + du_res_index # 1,2, 4,5, 7,8
|
| 183 |
+
cv_name = f"lora_unet_output_blocks_{cv_index}_0_{cv_suffix}"
|
| 184 |
+
return cv_name
|
| 185 |
+
|
| 186 |
+
m = re.search(r"_up_blocks_(\d+)_upsamplers_0_conv", du_name)
|
| 187 |
+
if m:
|
| 188 |
+
block_index = int(m.group(1))
|
| 189 |
+
cv_index = block_index * 3 + 2
|
| 190 |
+
cv_name = f"lora_unet_output_blocks_{cv_index}_{bool(block_index)+1}_conv"
|
| 191 |
+
return cv_name
|
| 192 |
+
|
| 193 |
+
elif "lora_te_" in du_name:
|
| 194 |
+
m = re.search(r"_model_encoder_layers_(\d+)_(.+)", du_name)
|
| 195 |
+
if m:
|
| 196 |
+
du_block_index = int(m.group(1))
|
| 197 |
+
du_suffix = m.group(2)
|
| 198 |
+
|
| 199 |
+
cv_index = du_block_index
|
| 200 |
+
if v2:
|
| 201 |
+
if 'mlp_fc1' in du_suffix:
|
| 202 |
+
cv_name = f"lora_te_wrapped_model_transformer_resblocks_{cv_index}_{du_suffix.replace('mlp_fc1', 'mlp_c_fc')}"
|
| 203 |
+
elif 'mlp_fc2' in du_suffix:
|
| 204 |
+
cv_name = f"lora_te_wrapped_model_transformer_resblocks_{cv_index}_{du_suffix.replace('mlp_fc2', 'mlp_c_proj')}"
|
| 205 |
+
elif 'self_attn':
|
| 206 |
+
# handled later
|
| 207 |
+
cv_name = f"lora_te_wrapped_model_transformer_resblocks_{cv_index}_{du_suffix.replace('self_attn', 'attn')}"
|
| 208 |
+
else:
|
| 209 |
+
cv_name = f"lora_te_wrapped_transformer_text_model_encoder_layers_{cv_index}_{du_suffix}"
|
| 210 |
+
|
| 211 |
+
assert cv_name is not None, f"conversion failed: {du_name}. the model may not be trained by `sd-scripts`."
|
| 212 |
+
return cv_name
|
| 213 |
+
|
| 214 |
+
@classmethod
|
| 215 |
+
def convert_state_dict_name_to_compvis(cls, v2, state_dict):
|
| 216 |
+
"""
|
| 217 |
+
convert keys in state dict to load it by load_state_dict
|
| 218 |
+
"""
|
| 219 |
+
new_sd = {}
|
| 220 |
+
for key, value in state_dict.items():
|
| 221 |
+
tokens = key.split('.')
|
| 222 |
+
compvis_name = LoConNetworkCompvis.convert_diffusers_name_to_compvis(v2, tokens[0])
|
| 223 |
+
new_key = compvis_name + '.' + '.'.join(tokens[1:])
|
| 224 |
+
new_sd[new_key] = value
|
| 225 |
+
|
| 226 |
+
return new_sd
|
| 227 |
+
|
| 228 |
+
def __init__(self, text_encoder, unet, du_state_dict, multiplier_tenc=1.0, multiplier_unet=1.0) -> None:
|
| 229 |
+
super().__init__()
|
| 230 |
+
self.multiplier_unet = multiplier_unet
|
| 231 |
+
self.multiplier_tenc = multiplier_tenc
|
| 232 |
+
|
| 233 |
+
# create module instances
|
| 234 |
+
for name, module in text_encoder.named_modules():
|
| 235 |
+
for child_name, child_module in module.named_modules():
|
| 236 |
+
if child_module.__class__.__name__ == 'MultiheadAttention':
|
| 237 |
+
self.v2 = True
|
| 238 |
+
break
|
| 239 |
+
else:
|
| 240 |
+
continue
|
| 241 |
+
break
|
| 242 |
+
else:
|
| 243 |
+
self.v2 = False
|
| 244 |
+
comp_state_dict = {}
|
| 245 |
+
|
| 246 |
+
def create_modules(prefix, root_module: torch.nn.Module, target_replace_modules, multiplier):
|
| 247 |
+
nonlocal comp_state_dict
|
| 248 |
+
loras = []
|
| 249 |
+
replaced_modules = []
|
| 250 |
+
for name, module in root_module.named_modules():
|
| 251 |
+
if module.__class__.__name__ in target_replace_modules:
|
| 252 |
+
for child_name, child_module in module.named_modules():
|
| 253 |
+
layer = child_module.__class__.__name__
|
| 254 |
+
lora_name = prefix + '.' + name + '.' + child_name
|
| 255 |
+
lora_name = lora_name.replace('.', '_')
|
| 256 |
+
if layer == "Linear" or layer == "Conv2d":
|
| 257 |
+
if '_resblocks_23_' in lora_name: # ignore last block in StabilityAi Text Encoder
|
| 258 |
+
break
|
| 259 |
+
if f'{lora_name}.lora_down.weight' not in comp_state_dict:
|
| 260 |
+
if module.__class__.__name__ in LoConNetworkCompvis.LOCON_TARGET:
|
| 261 |
+
continue
|
| 262 |
+
else:
|
| 263 |
+
print(f'Cannot find: "{lora_name}", skipped')
|
| 264 |
+
continue
|
| 265 |
+
rank = comp_state_dict[f'{lora_name}.lora_down.weight'].shape[0]
|
| 266 |
+
alpha = comp_state_dict.get(f'{lora_name}.alpha', torch.tensor(rank)).item()
|
| 267 |
+
lora = LoConModule(lora_name, child_module, multiplier, rank, alpha)
|
| 268 |
+
loras.append(lora)
|
| 269 |
+
|
| 270 |
+
replaced_modules.append(child_module)
|
| 271 |
+
elif child_module.__class__.__name__ == "MultiheadAttention":
|
| 272 |
+
# make four modules: not replacing forward method but merge weights
|
| 273 |
+
self.v2 = True
|
| 274 |
+
for suffix in ['q', 'k', 'v', 'out']:
|
| 275 |
+
module_name = prefix + '.' + name + '.' + child_name # ~.attn
|
| 276 |
+
module_name = module_name.replace('.', '_')
|
| 277 |
+
if '_resblocks_23_' in module_name: # ignore last block in StabilityAi Text Encoder
|
| 278 |
+
break
|
| 279 |
+
lora_name = module_name + '_' + suffix
|
| 280 |
+
lora_info = LoRAInfo(lora_name, module_name, child_module, multiplier, 0, 0)
|
| 281 |
+
loras.append(lora_info)
|
| 282 |
+
|
| 283 |
+
replaced_modules.append(child_module)
|
| 284 |
+
return loras, replaced_modules
|
| 285 |
+
|
| 286 |
+
for k,v in LoConNetworkCompvis.convert_state_dict_name_to_compvis(self.v2, du_state_dict).items():
|
| 287 |
+
comp_state_dict[k] = v
|
| 288 |
+
|
| 289 |
+
self.text_encoder_loras, te_rep_modules = create_modules(
|
| 290 |
+
LoConNetworkCompvis.LORA_PREFIX_TEXT_ENCODER,
|
| 291 |
+
text_encoder,
|
| 292 |
+
LoConNetworkCompvis.TEXT_ENCODER_TARGET_REPLACE_MODULE,
|
| 293 |
+
self.multiplier_tenc
|
| 294 |
+
)
|
| 295 |
+
print(f"create LoCon for Text Encoder: {len(self.text_encoder_loras)} modules.")
|
| 296 |
+
|
| 297 |
+
self.unet_loras, unet_rep_modules = create_modules(
|
| 298 |
+
LoConNetworkCompvis.LORA_PREFIX_UNET,
|
| 299 |
+
unet,
|
| 300 |
+
LoConNetworkCompvis.UNET_TARGET_REPLACE_MODULE,
|
| 301 |
+
self.multiplier_unet
|
| 302 |
+
)
|
| 303 |
+
print(f"create LoCon for U-Net: {len(self.unet_loras)} modules.")
|
| 304 |
+
|
| 305 |
+
# make backup of original forward/weights, if multiple modules are applied, do in 1st module only
|
| 306 |
+
backed_up = False # messaging purpose only
|
| 307 |
+
for rep_module in te_rep_modules + unet_rep_modules:
|
| 308 |
+
if rep_module.__class__.__name__ == "MultiheadAttention": # multiple MHA modules are in list, prevent to backed up forward
|
| 309 |
+
if not hasattr(rep_module, "_lora_org_weights"):
|
| 310 |
+
# avoid updating of original weights. state_dict is reference to original weights
|
| 311 |
+
rep_module._lora_org_weights = copy.deepcopy(rep_module.state_dict())
|
| 312 |
+
backed_up = True
|
| 313 |
+
elif not hasattr(rep_module, "_lora_org_forward"):
|
| 314 |
+
rep_module._lora_org_forward = rep_module.forward
|
| 315 |
+
backed_up = True
|
| 316 |
+
if backed_up:
|
| 317 |
+
print("original forward/weights is backed up.")
|
| 318 |
+
|
| 319 |
+
# assertion
|
| 320 |
+
names = set()
|
| 321 |
+
for lora in self.text_encoder_loras + self.unet_loras:
|
| 322 |
+
assert lora.lora_name not in names, f"duplicated lora name: {lora.lora_name}"
|
| 323 |
+
names.add(lora.lora_name)
|
| 324 |
+
|
| 325 |
+
def restore(self, text_encoder, unet):
|
| 326 |
+
# restore forward/weights from property for all modules
|
| 327 |
+
restored = False # messaging purpose only
|
| 328 |
+
modules = []
|
| 329 |
+
modules.extend(text_encoder.modules())
|
| 330 |
+
modules.extend(unet.modules())
|
| 331 |
+
for module in modules:
|
| 332 |
+
if hasattr(module, "_lora_org_forward"):
|
| 333 |
+
module.forward = module._lora_org_forward
|
| 334 |
+
del module._lora_org_forward
|
| 335 |
+
restored = True
|
| 336 |
+
if hasattr(module, "_lora_org_weights"): # module doesn't have forward and weights at same time currently, but supports it for future changing
|
| 337 |
+
module.load_state_dict(module._lora_org_weights)
|
| 338 |
+
del module._lora_org_weights
|
| 339 |
+
restored = True
|
| 340 |
+
|
| 341 |
+
if restored:
|
| 342 |
+
print("original forward/weights is restored.")
|
| 343 |
+
|
| 344 |
+
def apply_lora_modules(self, du_state_dict):
|
| 345 |
+
# conversion 1st step: convert names in state_dict
|
| 346 |
+
state_dict = LoConNetworkCompvis.convert_state_dict_name_to_compvis(self.v2, du_state_dict)
|
| 347 |
+
|
| 348 |
+
# check state_dict has text_encoder or unet
|
| 349 |
+
weights_has_text_encoder = weights_has_unet = False
|
| 350 |
+
for key in state_dict.keys():
|
| 351 |
+
if key.startswith(LoConNetworkCompvis.LORA_PREFIX_TEXT_ENCODER):
|
| 352 |
+
weights_has_text_encoder = True
|
| 353 |
+
elif key.startswith(LoConNetworkCompvis.LORA_PREFIX_UNET):
|
| 354 |
+
weights_has_unet = True
|
| 355 |
+
if weights_has_text_encoder and weights_has_unet:
|
| 356 |
+
break
|
| 357 |
+
|
| 358 |
+
apply_text_encoder = weights_has_text_encoder
|
| 359 |
+
apply_unet = weights_has_unet
|
| 360 |
+
|
| 361 |
+
if apply_text_encoder:
|
| 362 |
+
print("enable LoCon for text encoder")
|
| 363 |
+
else:
|
| 364 |
+
self.text_encoder_loras = []
|
| 365 |
+
|
| 366 |
+
if apply_unet:
|
| 367 |
+
print("enable LoCon for U-Net")
|
| 368 |
+
else:
|
| 369 |
+
self.unet_loras = []
|
| 370 |
+
|
| 371 |
+
# add modules to network: this makes state_dict can be got from LoRANetwork
|
| 372 |
+
mha_loras = {}
|
| 373 |
+
for lora in self.text_encoder_loras + self.unet_loras:
|
| 374 |
+
if type(lora) == LoConModule:
|
| 375 |
+
lora.apply_to() # ensure remove reference to original Linear: reference makes key of state_dict
|
| 376 |
+
self.add_module(lora.lora_name, lora)
|
| 377 |
+
else:
|
| 378 |
+
# SD2.x MultiheadAttention merge weights to MHA weights
|
| 379 |
+
lora_info: LoRAInfo = lora
|
| 380 |
+
if lora_info.module_name not in mha_loras:
|
| 381 |
+
mha_loras[lora_info.module_name] = {}
|
| 382 |
+
|
| 383 |
+
lora_dic = mha_loras[lora_info.module_name]
|
| 384 |
+
lora_dic[lora_info.lora_name] = lora_info
|
| 385 |
+
if len(lora_dic) == 4:
|
| 386 |
+
# calculate and apply
|
| 387 |
+
w_q_dw = state_dict.get(lora_info.module_name + '_q_proj.lora_down.weight')
|
| 388 |
+
if w_q_dw is not None: # corresponding LoRa module exists
|
| 389 |
+
w_q_up = state_dict[lora_info.module_name + '_q_proj.lora_up.weight']
|
| 390 |
+
w_q_ap = state_dict.get(lora_info.module_name + '_q_proj.alpha', None)
|
| 391 |
+
w_k_dw = state_dict[lora_info.module_name + '_k_proj.lora_down.weight']
|
| 392 |
+
w_k_up = state_dict[lora_info.module_name + '_k_proj.lora_up.weight']
|
| 393 |
+
w_k_ap = state_dict.get(lora_info.module_name + '_k_proj.alpha', None)
|
| 394 |
+
w_v_dw = state_dict[lora_info.module_name + '_v_proj.lora_down.weight']
|
| 395 |
+
w_v_up = state_dict[lora_info.module_name + '_v_proj.lora_up.weight']
|
| 396 |
+
w_v_ap = state_dict.get(lora_info.module_name + '_v_proj.alpha', None)
|
| 397 |
+
w_out_dw = state_dict[lora_info.module_name + '_out_proj.lora_down.weight']
|
| 398 |
+
w_out_up = state_dict[lora_info.module_name + '_out_proj.lora_up.weight']
|
| 399 |
+
w_out_ap = state_dict.get(lora_info.module_name + '_out_proj.alpha', None)
|
| 400 |
+
|
| 401 |
+
sd = lora_info.module.state_dict()
|
| 402 |
+
qkv_weight = sd['in_proj_weight']
|
| 403 |
+
out_weight = sd['out_proj.weight']
|
| 404 |
+
dev = qkv_weight.device
|
| 405 |
+
|
| 406 |
+
def merge_weights(weight, up_weight, down_weight, alpha=None):
|
| 407 |
+
# calculate in float
|
| 408 |
+
if alpha is None:
|
| 409 |
+
alpha = down_weight.shape[0]
|
| 410 |
+
alpha = float(alpha)
|
| 411 |
+
scale = alpha / down_weight.shape[0]
|
| 412 |
+
dtype = weight.dtype
|
| 413 |
+
weight = weight.float() + lora_info.multiplier * (up_weight.to(dev, dtype=torch.float) @ down_weight.to(dev, dtype=torch.float)) * scale
|
| 414 |
+
weight = weight.to(dtype)
|
| 415 |
+
return weight
|
| 416 |
+
|
| 417 |
+
q_weight, k_weight, v_weight = torch.chunk(qkv_weight, 3)
|
| 418 |
+
if q_weight.size()[1] == w_q_up.size()[0]:
|
| 419 |
+
q_weight = merge_weights(q_weight, w_q_up, w_q_dw, w_q_ap)
|
| 420 |
+
k_weight = merge_weights(k_weight, w_k_up, w_k_dw, w_k_ap)
|
| 421 |
+
v_weight = merge_weights(v_weight, w_v_up, w_v_dw, w_v_ap)
|
| 422 |
+
qkv_weight = torch.cat([q_weight, k_weight, v_weight])
|
| 423 |
+
|
| 424 |
+
out_weight = merge_weights(out_weight, w_out_up, w_out_dw, w_out_ap)
|
| 425 |
+
|
| 426 |
+
sd['in_proj_weight'] = qkv_weight.to(dev)
|
| 427 |
+
sd['out_proj.weight'] = out_weight.to(dev)
|
| 428 |
+
|
| 429 |
+
lora_info.module.load_state_dict(sd)
|
| 430 |
+
else:
|
| 431 |
+
# different dim, version mismatch
|
| 432 |
+
print(f"shape of weight is different: {lora_info.module_name}. SD version may be different")
|
| 433 |
+
|
| 434 |
+
for t in ["q", "k", "v", "out"]:
|
| 435 |
+
del state_dict[f"{lora_info.module_name}_{t}_proj.lora_down.weight"]
|
| 436 |
+
del state_dict[f"{lora_info.module_name}_{t}_proj.lora_up.weight"]
|
| 437 |
+
alpha_key = f"{lora_info.module_name}_{t}_proj.alpha"
|
| 438 |
+
if alpha_key in state_dict:
|
| 439 |
+
del state_dict[alpha_key]
|
| 440 |
+
else:
|
| 441 |
+
# corresponding weight not exists: version mismatch
|
| 442 |
+
pass
|
| 443 |
+
|
| 444 |
+
# conversion 2nd step: convert weight's shape (and handle wrapped)
|
| 445 |
+
state_dict = self.convert_state_dict_shape_to_compvis(state_dict)
|
| 446 |
+
|
| 447 |
+
return state_dict
|
| 448 |
+
|
| 449 |
+
def convert_state_dict_shape_to_compvis(self, state_dict):
|
| 450 |
+
# shape conversion
|
| 451 |
+
current_sd = self.state_dict() # to get target shape
|
| 452 |
+
wrapped = False
|
| 453 |
+
count = 0
|
| 454 |
+
for key in list(state_dict.keys()):
|
| 455 |
+
if key not in current_sd:
|
| 456 |
+
continue # might be error or another version
|
| 457 |
+
if "wrapped" in key:
|
| 458 |
+
wrapped = True
|
| 459 |
+
|
| 460 |
+
value: torch.Tensor = state_dict[key]
|
| 461 |
+
if value.size() != current_sd[key].size():
|
| 462 |
+
# print(key, value.size(), current_sd[key].size())
|
| 463 |
+
# print(f"convert weights shape: {key}, from: {value.size()}, {len(value.size())}")
|
| 464 |
+
count += 1
|
| 465 |
+
if '.alpha' in key:
|
| 466 |
+
assert value.size().numel() == 1
|
| 467 |
+
value = torch.tensor(value.item())
|
| 468 |
+
elif len(value.size()) == 4:
|
| 469 |
+
value = value.squeeze(3).squeeze(2)
|
| 470 |
+
else:
|
| 471 |
+
value = value.unsqueeze(2).unsqueeze(3)
|
| 472 |
+
state_dict[key] = value
|
| 473 |
+
if tuple(value.size()) != tuple(current_sd[key].size()):
|
| 474 |
+
print(
|
| 475 |
+
f"weight's shape is different: {key} expected {current_sd[key].size()} found {value.size()}. SD version may be different")
|
| 476 |
+
del state_dict[key]
|
| 477 |
+
print(f"shapes for {count} weights are converted.")
|
| 478 |
+
|
| 479 |
+
# convert wrapped
|
| 480 |
+
if not wrapped:
|
| 481 |
+
print("remove 'wrapped' from keys")
|
| 482 |
+
for key in list(state_dict.keys()):
|
| 483 |
+
if "_wrapped_" in key:
|
| 484 |
+
new_key = key.replace("_wrapped_", "_")
|
| 485 |
+
state_dict[new_key] = state_dict[key]
|
| 486 |
+
del state_dict[key]
|
| 487 |
+
|
| 488 |
+
return state_dict
|
extensions/a1111-microsoftexcel-locon/scripts/__pycache__/main.cpython-310.pyc
ADDED
|
Binary file (18 kB). View file
|
|
|
extensions/a1111-microsoftexcel-locon/scripts/main.py
ADDED
|
@@ -0,0 +1,766 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Modified version for full net lora
|
| 3 |
+
(Lora for ResBlock and up/down sample block)
|
| 4 |
+
'''
|
| 5 |
+
import os, sys
|
| 6 |
+
import re
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
from modules import shared, devices, sd_models
|
| 10 |
+
now_dir = os.path.dirname(os.path.abspath(__file__))
|
| 11 |
+
lora_path = os.path.join(now_dir, '..', '..', '..', 'extensions-builtin/Lora')
|
| 12 |
+
sys.path.insert(0, lora_path)
|
| 13 |
+
import lora
|
| 14 |
+
new_lora = 'lora_calc_updown' in dir(lora)
|
| 15 |
+
|
| 16 |
+
from locon_compvis import LoConModule, LoConNetworkCompvis, create_network_and_apply_compvis
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
try:
|
| 20 |
+
'''
|
| 21 |
+
Hijack Additional Network extension
|
| 22 |
+
'''
|
| 23 |
+
# skip addnet since don't support new version
|
| 24 |
+
raise
|
| 25 |
+
now_dir = os.path.dirname(os.path.abspath(__file__))
|
| 26 |
+
addnet_path = os.path.join(now_dir, '..', '..', 'sd-webui-additional-networks/scripts')
|
| 27 |
+
sys.path.append(addnet_path)
|
| 28 |
+
import lora_compvis
|
| 29 |
+
import scripts
|
| 30 |
+
scripts.lora_compvis = lora_compvis
|
| 31 |
+
scripts.lora_compvis.LoRAModule = LoConModule
|
| 32 |
+
scripts.lora_compvis.LoRANetworkCompvis = LoConNetworkCompvis
|
| 33 |
+
scripts.lora_compvis.create_network_and_apply_compvis = create_network_and_apply_compvis
|
| 34 |
+
print('LoCon Extension hijack addnet extension successfully')
|
| 35 |
+
except:
|
| 36 |
+
print('Additional Network extension not installed, Only hijack built-in lora')
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
'''
|
| 40 |
+
Hijack sd-webui LoRA
|
| 41 |
+
'''
|
| 42 |
+
re_digits = re.compile(r"\d+")
|
| 43 |
+
re_x_proj = re.compile(r"(.*)_([qkv]_proj)$")
|
| 44 |
+
|
| 45 |
+
re_unet_conv_in = re.compile(r"lora_unet_conv_in(.+)")
|
| 46 |
+
re_unet_conv_out = re.compile(r"lora_unet_conv_out(.+)")
|
| 47 |
+
re_unet_time_embed = re.compile(r"lora_unet_time_embedding_linear_(\d+)(.+)")
|
| 48 |
+
|
| 49 |
+
re_unet_down_blocks = re.compile(r"lora_unet_down_blocks_(\d+)_attentions_(\d+)_(.+)")
|
| 50 |
+
re_unet_mid_blocks = re.compile(r"lora_unet_mid_block_attentions_(\d+)_(.+)")
|
| 51 |
+
re_unet_up_blocks = re.compile(r"lora_unet_up_blocks_(\d+)_attentions_(\d+)_(.+)")
|
| 52 |
+
|
| 53 |
+
re_unet_down_blocks_res = re.compile(r"lora_unet_down_blocks_(\d+)_resnets_(\d+)_(.+)")
|
| 54 |
+
re_unet_mid_blocks_res = re.compile(r"lora_unet_mid_block_resnets_(\d+)_(.+)")
|
| 55 |
+
re_unet_up_blocks_res = re.compile(r"lora_unet_up_blocks_(\d+)_resnets_(\d+)_(.+)")
|
| 56 |
+
|
| 57 |
+
re_unet_downsample = re.compile(r"lora_unet_down_blocks_(\d+)_downsamplers_0_conv(.+)")
|
| 58 |
+
re_unet_upsample = re.compile(r"lora_unet_up_blocks_(\d+)_upsamplers_0_conv(.+)")
|
| 59 |
+
|
| 60 |
+
re_text_block = re.compile(r"lora_te_text_model_encoder_layers_(\d+)_(.+)")
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def convert_diffusers_name_to_compvis(key, is_sd2):
|
| 64 |
+
# I don't know why but some state dict has this kind of thing
|
| 65 |
+
key = key.replace('text_model_text_model', 'text_model')
|
| 66 |
+
def match(match_list, regex):
|
| 67 |
+
r = re.match(regex, key)
|
| 68 |
+
if not r:
|
| 69 |
+
return False
|
| 70 |
+
|
| 71 |
+
match_list.clear()
|
| 72 |
+
match_list.extend([int(x) if re.match(re_digits, x) else x for x in r.groups()])
|
| 73 |
+
return True
|
| 74 |
+
|
| 75 |
+
m = []
|
| 76 |
+
|
| 77 |
+
if match(m, re_unet_conv_in):
|
| 78 |
+
return f'diffusion_model_input_blocks_0_0{m[0]}'
|
| 79 |
+
|
| 80 |
+
if match(m, re_unet_conv_out):
|
| 81 |
+
return f'diffusion_model_out_2{m[0]}'
|
| 82 |
+
|
| 83 |
+
if match(m, re_unet_time_embed):
|
| 84 |
+
return f"diffusion_model_time_embed_{m[0]*2-2}{m[1]}"
|
| 85 |
+
|
| 86 |
+
if match(m, re_unet_down_blocks):
|
| 87 |
+
return f"diffusion_model_input_blocks_{1 + m[0] * 3 + m[1]}_1_{m[2]}"
|
| 88 |
+
|
| 89 |
+
if match(m, re_unet_mid_blocks):
|
| 90 |
+
return f"diffusion_model_middle_block_1_{m[1]}"
|
| 91 |
+
|
| 92 |
+
if match(m, re_unet_up_blocks):
|
| 93 |
+
return f"diffusion_model_output_blocks_{m[0] * 3 + m[1]}_1_{m[2]}"
|
| 94 |
+
|
| 95 |
+
if match(m, re_unet_down_blocks_res):
|
| 96 |
+
block = f"diffusion_model_input_blocks_{1 + m[0] * 3 + m[1]}_0_"
|
| 97 |
+
if m[2].startswith('conv1'):
|
| 98 |
+
return f"{block}in_layers_2{m[2][len('conv1'):]}"
|
| 99 |
+
elif m[2].startswith('conv2'):
|
| 100 |
+
return f"{block}out_layers_3{m[2][len('conv2'):]}"
|
| 101 |
+
elif m[2].startswith('time_emb_proj'):
|
| 102 |
+
return f"{block}emb_layers_1{m[2][len('time_emb_proj'):]}"
|
| 103 |
+
elif m[2].startswith('conv_shortcut'):
|
| 104 |
+
return f"{block}skip_connection{m[2][len('conv_shortcut'):]}"
|
| 105 |
+
|
| 106 |
+
if match(m, re_unet_mid_blocks_res):
|
| 107 |
+
block = f"diffusion_model_middle_block_{m[0]*2}_"
|
| 108 |
+
if m[1].startswith('conv1'):
|
| 109 |
+
return f"{block}in_layers_2{m[1][len('conv1'):]}"
|
| 110 |
+
elif m[1].startswith('conv2'):
|
| 111 |
+
return f"{block}out_layers_3{m[1][len('conv2'):]}"
|
| 112 |
+
elif m[1].startswith('time_emb_proj'):
|
| 113 |
+
return f"{block}emb_layers_1{m[1][len('time_emb_proj'):]}"
|
| 114 |
+
elif m[1].startswith('conv_shortcut'):
|
| 115 |
+
return f"{block}skip_connection{m[1][len('conv_shortcut'):]}"
|
| 116 |
+
|
| 117 |
+
if match(m, re_unet_up_blocks_res):
|
| 118 |
+
block = f"diffusion_model_output_blocks_{m[0] * 3 + m[1]}_0_"
|
| 119 |
+
if m[2].startswith('conv1'):
|
| 120 |
+
return f"{block}in_layers_2{m[2][len('conv1'):]}"
|
| 121 |
+
elif m[2].startswith('conv2'):
|
| 122 |
+
return f"{block}out_layers_3{m[2][len('conv2'):]}"
|
| 123 |
+
elif m[2].startswith('time_emb_proj'):
|
| 124 |
+
return f"{block}emb_layers_1{m[2][len('time_emb_proj'):]}"
|
| 125 |
+
elif m[2].startswith('conv_shortcut'):
|
| 126 |
+
return f"{block}skip_connection{m[2][len('conv_shortcut'):]}"
|
| 127 |
+
|
| 128 |
+
if match(m, re_unet_downsample):
|
| 129 |
+
return f"diffusion_model_input_blocks_{m[0]*3+3}_0_op{m[1]}"
|
| 130 |
+
|
| 131 |
+
if match(m, re_unet_upsample):
|
| 132 |
+
return f"diffusion_model_output_blocks_{m[0]*3 + 2}_{1+(m[0]!=0)}_conv{m[1]}"
|
| 133 |
+
|
| 134 |
+
if match(m, r"lora_te_text_model_encoder_layers_(\d+)_(.+)"):
|
| 135 |
+
if is_sd2:
|
| 136 |
+
if 'mlp_fc1' in m[1]:
|
| 137 |
+
return f"model_transformer_resblocks_{m[0]}_{m[1].replace('mlp_fc1', 'mlp_c_fc')}"
|
| 138 |
+
elif 'mlp_fc2' in m[1]:
|
| 139 |
+
return f"model_transformer_resblocks_{m[0]}_{m[1].replace('mlp_fc2', 'mlp_c_proj')}"
|
| 140 |
+
else:
|
| 141 |
+
return f"model_transformer_resblocks_{m[0]}_{m[1].replace('self_attn', 'attn')}"
|
| 142 |
+
|
| 143 |
+
return f"transformer_text_model_encoder_layers_{m[0]}_{m[1]}"
|
| 144 |
+
|
| 145 |
+
return key
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
class LoraOnDisk:
|
| 149 |
+
def __init__(self, name, filename):
|
| 150 |
+
self.name = name
|
| 151 |
+
self.filename = filename
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
class LoraModule:
|
| 155 |
+
def __init__(self, name):
|
| 156 |
+
self.name = name
|
| 157 |
+
self.multiplier = 1.0
|
| 158 |
+
self.modules = {}
|
| 159 |
+
self.mtime = None
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class FakeModule(torch.nn.Module):
|
| 163 |
+
def __init__(self, weight, func):
|
| 164 |
+
super().__init__()
|
| 165 |
+
self.weight = weight
|
| 166 |
+
self.func = func
|
| 167 |
+
|
| 168 |
+
def forward(self, x):
|
| 169 |
+
return self.func(x)
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
class FullModule:
|
| 173 |
+
def __init__(self):
|
| 174 |
+
self.weight = None
|
| 175 |
+
self.alpha = None
|
| 176 |
+
self.op = None
|
| 177 |
+
self.extra_args = {}
|
| 178 |
+
self.shape = None
|
| 179 |
+
self.up = None
|
| 180 |
+
|
| 181 |
+
def down(self, x):
|
| 182 |
+
return x
|
| 183 |
+
|
| 184 |
+
def inference(self, x):
|
| 185 |
+
return self.op(x, self.weight, **self.extra_args)
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
class LoraUpDownModule:
|
| 189 |
+
def __init__(self):
|
| 190 |
+
self.up_model = None
|
| 191 |
+
self.mid_model = None
|
| 192 |
+
self.down_model = None
|
| 193 |
+
self.alpha = None
|
| 194 |
+
self.dim = None
|
| 195 |
+
self.op = None
|
| 196 |
+
self.extra_args = {}
|
| 197 |
+
self.shape = None
|
| 198 |
+
self.bias = None
|
| 199 |
+
self.up = None
|
| 200 |
+
|
| 201 |
+
def down(self, x):
|
| 202 |
+
return x
|
| 203 |
+
|
| 204 |
+
def inference(self, x):
|
| 205 |
+
if hasattr(self, 'bias') and isinstance(self.bias, torch.Tensor):
|
| 206 |
+
out_dim = self.up_model.weight.size(0)
|
| 207 |
+
rank = self.down_model.weight.size(0)
|
| 208 |
+
rebuild_weight = (
|
| 209 |
+
self.up_model.weight.reshape(out_dim, -1) @ self.down_model.weight.reshape(rank, -1)
|
| 210 |
+
+ self.bias
|
| 211 |
+
).reshape(self.shape)
|
| 212 |
+
return self.op(
|
| 213 |
+
x, rebuild_weight,
|
| 214 |
+
bias=None,
|
| 215 |
+
**self.extra_args
|
| 216 |
+
)
|
| 217 |
+
else:
|
| 218 |
+
if self.mid_model is None:
|
| 219 |
+
return self.up_model(self.down_model(x))
|
| 220 |
+
else:
|
| 221 |
+
return self.up_model(self.mid_model(self.down_model(x)))
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def make_weight_cp(t, wa, wb):
|
| 225 |
+
temp = torch.einsum('i j k l, j r -> i r k l', t, wb)
|
| 226 |
+
return torch.einsum('i j k l, i r -> r j k l', temp, wa)
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
class LoraHadaModule:
|
| 230 |
+
def __init__(self):
|
| 231 |
+
self.t1 = None
|
| 232 |
+
self.w1a = None
|
| 233 |
+
self.w1b = None
|
| 234 |
+
self.t2 = None
|
| 235 |
+
self.w2a = None
|
| 236 |
+
self.w2b = None
|
| 237 |
+
self.alpha = None
|
| 238 |
+
self.dim = None
|
| 239 |
+
self.op = None
|
| 240 |
+
self.extra_args = {}
|
| 241 |
+
self.shape = None
|
| 242 |
+
self.bias = None
|
| 243 |
+
self.up = None
|
| 244 |
+
|
| 245 |
+
def down(self, x):
|
| 246 |
+
return x
|
| 247 |
+
|
| 248 |
+
def inference(self, x):
|
| 249 |
+
if hasattr(self, 'bias') and isinstance(self.bias, torch.Tensor):
|
| 250 |
+
bias = self.bias
|
| 251 |
+
else:
|
| 252 |
+
bias = 0
|
| 253 |
+
|
| 254 |
+
if self.t1 is None:
|
| 255 |
+
return self.op(
|
| 256 |
+
x,
|
| 257 |
+
((self.w1a @ self.w1b) * (self.w2a @ self.w2b) + bias).view(self.shape),
|
| 258 |
+
bias=None,
|
| 259 |
+
**self.extra_args
|
| 260 |
+
)
|
| 261 |
+
else:
|
| 262 |
+
return self.op(
|
| 263 |
+
x,
|
| 264 |
+
(make_weight_cp(self.t1, self.w1a, self.w1b)
|
| 265 |
+
* make_weight_cp(self.t2, self.w2a, self.w2b) + bias).view(self.shape),
|
| 266 |
+
bias=None,
|
| 267 |
+
**self.extra_args
|
| 268 |
+
)
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
class IA3Module:
|
| 272 |
+
def __init__(self):
|
| 273 |
+
self.w = None
|
| 274 |
+
self.alpha = None
|
| 275 |
+
self.on_input = None
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
def make_kron(orig_shape, w1, w2):
|
| 279 |
+
if len(w2.shape) == 4:
|
| 280 |
+
w1 = w1.unsqueeze(2).unsqueeze(2)
|
| 281 |
+
w2 = w2.contiguous()
|
| 282 |
+
return torch.kron(w1, w2).reshape(orig_shape)
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
class LoraKronModule:
|
| 286 |
+
def __init__(self):
|
| 287 |
+
self.w1 = None
|
| 288 |
+
self.w1a = None
|
| 289 |
+
self.w1b = None
|
| 290 |
+
self.w2 = None
|
| 291 |
+
self.t2 = None
|
| 292 |
+
self.w2a = None
|
| 293 |
+
self.w2b = None
|
| 294 |
+
self._alpha = None
|
| 295 |
+
self.dim = None
|
| 296 |
+
self.op = None
|
| 297 |
+
self.extra_args = {}
|
| 298 |
+
self.shape = None
|
| 299 |
+
self.bias = None
|
| 300 |
+
self.up = None
|
| 301 |
+
|
| 302 |
+
@property
|
| 303 |
+
def alpha(self):
|
| 304 |
+
if self.w1a is None and self.w2a is None:
|
| 305 |
+
return None
|
| 306 |
+
else:
|
| 307 |
+
return self._alpha
|
| 308 |
+
|
| 309 |
+
@alpha.setter
|
| 310 |
+
def alpha(self, x):
|
| 311 |
+
self._alpha = x
|
| 312 |
+
|
| 313 |
+
def down(self, x):
|
| 314 |
+
return x
|
| 315 |
+
|
| 316 |
+
def inference(self, x):
|
| 317 |
+
if hasattr(self, 'bias') and isinstance(self.bias, torch.Tensor):
|
| 318 |
+
bias = self.bias
|
| 319 |
+
else:
|
| 320 |
+
bias = 0
|
| 321 |
+
|
| 322 |
+
if self.t2 is None:
|
| 323 |
+
return self.op(
|
| 324 |
+
x,
|
| 325 |
+
(torch.kron(self.w1, self.w2a@self.w2b) + bias).view(self.shape),
|
| 326 |
+
**self.extra_args
|
| 327 |
+
)
|
| 328 |
+
else:
|
| 329 |
+
# will raise NotImplemented Error
|
| 330 |
+
return self.op(
|
| 331 |
+
x,
|
| 332 |
+
(torch.kron(self.w1, make_weight_cp(self.t2, self.w2a, self.w2b)) + bias).view(self.shape),
|
| 333 |
+
**self.extra_args
|
| 334 |
+
)
|
| 335 |
+
|
| 336 |
+
|
| 337 |
+
CON_KEY = {
|
| 338 |
+
"lora_up.weight",
|
| 339 |
+
"lora_down.weight",
|
| 340 |
+
"lora_mid.weight"
|
| 341 |
+
}
|
| 342 |
+
HADA_KEY = {
|
| 343 |
+
"hada_t1",
|
| 344 |
+
"hada_w1_a",
|
| 345 |
+
"hada_w1_b",
|
| 346 |
+
"hada_t2",
|
| 347 |
+
"hada_w2_a",
|
| 348 |
+
"hada_w2_b",
|
| 349 |
+
}
|
| 350 |
+
IA3_KEY = {
|
| 351 |
+
"weight",
|
| 352 |
+
"on_input"
|
| 353 |
+
}
|
| 354 |
+
KRON_KEY = {
|
| 355 |
+
"lokr_w1",
|
| 356 |
+
"lokr_w1_a",
|
| 357 |
+
"lokr_w1_b",
|
| 358 |
+
"lokr_t2",
|
| 359 |
+
"lokr_w2",
|
| 360 |
+
"lokr_w2_a",
|
| 361 |
+
"lokr_w2_b",
|
| 362 |
+
}
|
| 363 |
+
|
| 364 |
+
def load_lora(name, filename):
|
| 365 |
+
print('locon load lora method')
|
| 366 |
+
lora = LoraModule(name)
|
| 367 |
+
lora.mtime = os.path.getmtime(filename)
|
| 368 |
+
|
| 369 |
+
sd = sd_models.read_state_dict(filename)
|
| 370 |
+
is_sd2 = 'model_transformer_resblocks' in shared.sd_model.lora_layer_mapping
|
| 371 |
+
|
| 372 |
+
keys_failed_to_match = []
|
| 373 |
+
|
| 374 |
+
for key_diffusers, weight in sd.items():
|
| 375 |
+
fullkey = convert_diffusers_name_to_compvis(key_diffusers, is_sd2)
|
| 376 |
+
key, lora_key = fullkey.split(".", 1)
|
| 377 |
+
|
| 378 |
+
sd_module = shared.sd_model.lora_layer_mapping.get(key, None)
|
| 379 |
+
|
| 380 |
+
if sd_module is None:
|
| 381 |
+
m = re_x_proj.match(key)
|
| 382 |
+
if m:
|
| 383 |
+
sd_module = shared.sd_model.lora_layer_mapping.get(m.group(1), None)
|
| 384 |
+
|
| 385 |
+
if sd_module is None:
|
| 386 |
+
print(key)
|
| 387 |
+
keys_failed_to_match.append(key_diffusers)
|
| 388 |
+
continue
|
| 389 |
+
|
| 390 |
+
lora_module = lora.modules.get(key, None)
|
| 391 |
+
if lora_module is None:
|
| 392 |
+
lora_module = LoraUpDownModule()
|
| 393 |
+
lora.modules[key] = lora_module
|
| 394 |
+
|
| 395 |
+
if lora_key == "alpha":
|
| 396 |
+
lora_module.alpha = weight.item()
|
| 397 |
+
continue
|
| 398 |
+
|
| 399 |
+
if lora_key == "diff":
|
| 400 |
+
weight = weight.to(device=devices.device, dtype=devices.dtype)
|
| 401 |
+
weight.requires_grad_(False)
|
| 402 |
+
lora_module = FullModule()
|
| 403 |
+
lora.modules[key] = lora_module
|
| 404 |
+
lora_module.weight = weight
|
| 405 |
+
lora_module.alpha = weight.size(1)
|
| 406 |
+
lora_module.up = FakeModule(
|
| 407 |
+
weight,
|
| 408 |
+
lora_module.inference
|
| 409 |
+
)
|
| 410 |
+
lora_module.up.to(device=devices.cpu if new_lora else devices.device, dtype=devices.dtype)
|
| 411 |
+
if len(weight.shape)==2:
|
| 412 |
+
lora_module.op = torch.nn.functional.linear
|
| 413 |
+
lora_module.extra_args = {
|
| 414 |
+
'bias': None
|
| 415 |
+
}
|
| 416 |
+
else:
|
| 417 |
+
lora_module.op = torch.nn.functional.conv2d
|
| 418 |
+
lora_module.extra_args = {
|
| 419 |
+
'stride': sd_module.stride,
|
| 420 |
+
'padding': sd_module.padding,
|
| 421 |
+
'bias': None
|
| 422 |
+
}
|
| 423 |
+
continue
|
| 424 |
+
|
| 425 |
+
if 'bias_' in lora_key:
|
| 426 |
+
if lora_module.bias is None:
|
| 427 |
+
lora_module.bias = [None, None, None]
|
| 428 |
+
if 'bias_indices' == lora_key:
|
| 429 |
+
lora_module.bias[0] = weight
|
| 430 |
+
elif 'bias_values' == lora_key:
|
| 431 |
+
lora_module.bias[1] = weight
|
| 432 |
+
elif 'bias_size' == lora_key:
|
| 433 |
+
lora_module.bias[2] = weight
|
| 434 |
+
|
| 435 |
+
if all((i is not None) for i in lora_module.bias):
|
| 436 |
+
print('build bias')
|
| 437 |
+
lora_module.bias = torch.sparse_coo_tensor(
|
| 438 |
+
lora_module.bias[0],
|
| 439 |
+
lora_module.bias[1],
|
| 440 |
+
tuple(lora_module.bias[2]),
|
| 441 |
+
).to(device=devices.cpu if new_lora else devices.device, dtype=devices.dtype)
|
| 442 |
+
lora_module.bias.requires_grad_(False)
|
| 443 |
+
continue
|
| 444 |
+
|
| 445 |
+
if lora_key in CON_KEY:
|
| 446 |
+
if (type(sd_module) == torch.nn.Linear
|
| 447 |
+
or type(sd_module) == torch.nn.modules.linear.NonDynamicallyQuantizableLinear
|
| 448 |
+
or type(sd_module) == torch.nn.MultiheadAttention):
|
| 449 |
+
weight = weight.reshape(weight.shape[0], -1)
|
| 450 |
+
module = torch.nn.Linear(weight.shape[1], weight.shape[0], bias=False)
|
| 451 |
+
lora_module.op = torch.nn.functional.linear
|
| 452 |
+
elif type(sd_module) == torch.nn.Conv2d:
|
| 453 |
+
if lora_key == "lora_down.weight":
|
| 454 |
+
if len(weight.shape) == 2:
|
| 455 |
+
weight = weight.reshape(weight.shape[0], -1, 1, 1)
|
| 456 |
+
if weight.shape[2] != 1 or weight.shape[3] != 1:
|
| 457 |
+
module = torch.nn.Conv2d(weight.shape[1], weight.shape[0], sd_module.kernel_size, sd_module.stride, sd_module.padding, bias=False)
|
| 458 |
+
else:
|
| 459 |
+
module = torch.nn.Conv2d(weight.shape[1], weight.shape[0], (1, 1), bias=False)
|
| 460 |
+
elif lora_key == "lora_mid.weight":
|
| 461 |
+
module = torch.nn.Conv2d(weight.shape[1], weight.shape[0], sd_module.kernel_size, sd_module.stride, sd_module.padding, bias=False)
|
| 462 |
+
elif lora_key == "lora_up.weight":
|
| 463 |
+
module = torch.nn.Conv2d(weight.shape[1], weight.shape[0], (1, 1), bias=False)
|
| 464 |
+
lora_module.op = torch.nn.functional.conv2d
|
| 465 |
+
lora_module.extra_args = {
|
| 466 |
+
'stride': sd_module.stride,
|
| 467 |
+
'padding': sd_module.padding
|
| 468 |
+
}
|
| 469 |
+
else:
|
| 470 |
+
assert False, f'Lora layer {key_diffusers} matched a layer with unsupported type: {type(sd_module).__name__}'
|
| 471 |
+
|
| 472 |
+
if hasattr(sd_module, 'weight'):
|
| 473 |
+
lora_module.shape = sd_module.weight.shape
|
| 474 |
+
with torch.no_grad():
|
| 475 |
+
if weight.shape != module.weight.shape:
|
| 476 |
+
weight = weight.reshape(module.weight.shape)
|
| 477 |
+
module.weight.copy_(weight)
|
| 478 |
+
|
| 479 |
+
module.to(device=devices.cpu if new_lora else devices.device, dtype=devices.dtype)
|
| 480 |
+
module.requires_grad_(False)
|
| 481 |
+
|
| 482 |
+
if lora_key == "lora_up.weight":
|
| 483 |
+
lora_module.up_model = module
|
| 484 |
+
lora_module.up = FakeModule(
|
| 485 |
+
lora_module.up_model.weight,
|
| 486 |
+
lora_module.inference
|
| 487 |
+
)
|
| 488 |
+
elif lora_key == "lora_mid.weight":
|
| 489 |
+
lora_module.mid_model = module
|
| 490 |
+
elif lora_key == "lora_down.weight":
|
| 491 |
+
lora_module.down_model = module
|
| 492 |
+
lora_module.dim = weight.shape[0]
|
| 493 |
+
else:
|
| 494 |
+
print(lora_key)
|
| 495 |
+
elif lora_key in HADA_KEY:
|
| 496 |
+
if type(lora_module) != LoraHadaModule:
|
| 497 |
+
alpha = lora_module.alpha
|
| 498 |
+
bias = lora_module.bias
|
| 499 |
+
lora_module = LoraHadaModule()
|
| 500 |
+
lora_module.alpha = alpha
|
| 501 |
+
lora_module.bias = bias
|
| 502 |
+
lora.modules[key] = lora_module
|
| 503 |
+
if hasattr(sd_module, 'weight'):
|
| 504 |
+
lora_module.shape = sd_module.weight.shape
|
| 505 |
+
|
| 506 |
+
weight = weight.to(device=devices.cpu if new_lora else devices.device, dtype=devices.dtype)
|
| 507 |
+
weight.requires_grad_(False)
|
| 508 |
+
|
| 509 |
+
if lora_key == 'hada_w1_a':
|
| 510 |
+
lora_module.w1a = weight
|
| 511 |
+
if lora_module.up is None:
|
| 512 |
+
lora_module.up = FakeModule(
|
| 513 |
+
lora_module.w1a,
|
| 514 |
+
lora_module.inference
|
| 515 |
+
)
|
| 516 |
+
elif lora_key == 'hada_w1_b':
|
| 517 |
+
lora_module.w1b = weight
|
| 518 |
+
lora_module.dim = weight.shape[0]
|
| 519 |
+
elif lora_key == 'hada_w2_a':
|
| 520 |
+
lora_module.w2a = weight
|
| 521 |
+
elif lora_key == 'hada_w2_b':
|
| 522 |
+
lora_module.w2b = weight
|
| 523 |
+
elif lora_key == 'hada_t1':
|
| 524 |
+
lora_module.t1 = weight
|
| 525 |
+
lora_module.up = FakeModule(
|
| 526 |
+
lora_module.t1,
|
| 527 |
+
lora_module.inference
|
| 528 |
+
)
|
| 529 |
+
elif lora_key == 'hada_t2':
|
| 530 |
+
lora_module.t2 = weight
|
| 531 |
+
|
| 532 |
+
if (type(sd_module) == torch.nn.Linear
|
| 533 |
+
or type(sd_module) == torch.nn.modules.linear.NonDynamicallyQuantizableLinear
|
| 534 |
+
or type(sd_module) == torch.nn.MultiheadAttention):
|
| 535 |
+
lora_module.op = torch.nn.functional.linear
|
| 536 |
+
elif type(sd_module) == torch.nn.Conv2d:
|
| 537 |
+
lora_module.op = torch.nn.functional.conv2d
|
| 538 |
+
lora_module.extra_args = {
|
| 539 |
+
'stride': sd_module.stride,
|
| 540 |
+
'padding': sd_module.padding
|
| 541 |
+
}
|
| 542 |
+
else:
|
| 543 |
+
assert False, f'Lora layer {key_diffusers} matched a layer with unsupported type: {type(sd_module).__name__}'
|
| 544 |
+
elif lora_key in IA3_KEY:
|
| 545 |
+
if type(lora_module) != IA3Module:
|
| 546 |
+
lora_module = IA3Module()
|
| 547 |
+
lora.modules[key] = lora_module
|
| 548 |
+
|
| 549 |
+
if lora_key == "weight":
|
| 550 |
+
lora_module.w = weight.to(devices.device, dtype=devices.dtype)
|
| 551 |
+
elif lora_key == "on_input":
|
| 552 |
+
lora_module.on_input = weight
|
| 553 |
+
elif lora_key in KRON_KEY:
|
| 554 |
+
if not isinstance(lora_module, LoraKronModule):
|
| 555 |
+
alpha = lora_module.alpha
|
| 556 |
+
bias = lora_module.bias
|
| 557 |
+
lora_module = LoraKronModule()
|
| 558 |
+
lora_module.alpha = alpha
|
| 559 |
+
lora_module.bias = bias
|
| 560 |
+
lora.modules[key] = lora_module
|
| 561 |
+
if hasattr(sd_module, 'weight'):
|
| 562 |
+
lora_module.shape = sd_module.weight.shape
|
| 563 |
+
|
| 564 |
+
weight = weight.to(device=devices.cpu if new_lora else devices.device, dtype=devices.dtype)
|
| 565 |
+
weight.requires_grad_(False)
|
| 566 |
+
|
| 567 |
+
if lora_key == 'lokr_w1':
|
| 568 |
+
lora_module.w1 = weight
|
| 569 |
+
elif lora_key == 'lokr_w1_a':
|
| 570 |
+
lora_module.w1a = weight
|
| 571 |
+
if lora_module.up is None:
|
| 572 |
+
lora_module.up = FakeModule(
|
| 573 |
+
lora_module.w1a,
|
| 574 |
+
lora_module.inference
|
| 575 |
+
)
|
| 576 |
+
elif lora_key == 'lokr_w1_b':
|
| 577 |
+
lora_module.w1b = weight
|
| 578 |
+
elif lora_key == 'lokr_w2':
|
| 579 |
+
lora_module.w2 = weight
|
| 580 |
+
elif lora_key == 'lokr_w2_a':
|
| 581 |
+
lora_module.w2a = weight
|
| 582 |
+
lora_module.dim = weight.shape[0]
|
| 583 |
+
if lora_module.up is None:
|
| 584 |
+
lora_module.up = FakeModule(
|
| 585 |
+
lora_module.w2a,
|
| 586 |
+
lora_module.inference
|
| 587 |
+
)
|
| 588 |
+
elif lora_key == 'lokr_w2_b':
|
| 589 |
+
lora_module.w2b = weight
|
| 590 |
+
elif lora_key == 'lokr_t2':
|
| 591 |
+
lora_module.t2 = weight
|
| 592 |
+
|
| 593 |
+
if (any(isinstance(sd_module, torch_layer) for torch_layer in
|
| 594 |
+
[torch.nn.Linear, torch.nn.modules.linear.NonDynamicallyQuantizableLinear, torch.nn.MultiheadAttention])):
|
| 595 |
+
lora_module.op = torch.nn.functional.linear
|
| 596 |
+
elif isinstance(sd_module, torch.nn.Conv2d):
|
| 597 |
+
lora_module.op = torch.nn.functional.conv2d
|
| 598 |
+
lora_module.extra_args = {
|
| 599 |
+
'stride': sd_module.stride,
|
| 600 |
+
'padding': sd_module.padding
|
| 601 |
+
}
|
| 602 |
+
else:
|
| 603 |
+
assert False, f'Bad Lora layer name: {key_diffusers} - must end in lora_up.weight, lora_down.weight or alpha'
|
| 604 |
+
|
| 605 |
+
if len(keys_failed_to_match) > 0:
|
| 606 |
+
print(shared.sd_model.lora_layer_mapping)
|
| 607 |
+
print(f"Failed to match keys when loading Lora {filename}: {keys_failed_to_match}")
|
| 608 |
+
|
| 609 |
+
return lora
|
| 610 |
+
|
| 611 |
+
|
| 612 |
+
def lora_forward(module, input, res):
|
| 613 |
+
if len(lora.loaded_loras) == 0:
|
| 614 |
+
return res
|
| 615 |
+
|
| 616 |
+
lora_layer_name = getattr(module, 'lora_layer_name', None)
|
| 617 |
+
for lora_m in lora.loaded_loras:
|
| 618 |
+
module = lora_m.modules.get(lora_layer_name, None)
|
| 619 |
+
if module is not None and lora_m.multiplier:
|
| 620 |
+
if hasattr(module, 'up'):
|
| 621 |
+
scale = lora_m.multiplier * (module.alpha / module.up.weight.size(1) if module.alpha else 1.0)
|
| 622 |
+
else:
|
| 623 |
+
scale = lora_m.multiplier * (module.alpha / module.dim if module.alpha else 1.0)
|
| 624 |
+
|
| 625 |
+
if shared.opts.lora_apply_to_outputs and res.shape == input.shape:
|
| 626 |
+
x = res
|
| 627 |
+
else:
|
| 628 |
+
x = input
|
| 629 |
+
|
| 630 |
+
if hasattr(module, 'inference'):
|
| 631 |
+
res = res + module.inference(x) * scale
|
| 632 |
+
elif hasattr(module, 'up'):
|
| 633 |
+
res = res + module.up(module.down(x)) * scale
|
| 634 |
+
else:
|
| 635 |
+
raise NotImplementedError(
|
| 636 |
+
"Your settings, extensions or models are not compatible with each other."
|
| 637 |
+
)
|
| 638 |
+
return res
|
| 639 |
+
|
| 640 |
+
|
| 641 |
+
def _rebuild_conventional(up, down, shape):
|
| 642 |
+
return (up.reshape(up.size(0), -1) @ down.reshape(down.size(0), -1)).reshape(shape)
|
| 643 |
+
|
| 644 |
+
|
| 645 |
+
def _rebuild_cp_decomposition(up, down, mid):
|
| 646 |
+
up = up.reshape(up.size(0), -1)
|
| 647 |
+
down = down.reshape(down.size(0), -1)
|
| 648 |
+
return torch.einsum('n m k l, i n, m j -> i j k l', mid, up, down)
|
| 649 |
+
|
| 650 |
+
|
| 651 |
+
def rebuild_weight(module, orig_weight: torch.Tensor) -> torch.Tensor:
|
| 652 |
+
if module.__class__.__name__ == 'LoraUpDownModule':
|
| 653 |
+
up = module.up_model.weight.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 654 |
+
down = module.down_model.weight.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 655 |
+
|
| 656 |
+
output_shape = [up.size(0), down.size(1)]
|
| 657 |
+
if (mid:=module.mid_model) is not None:
|
| 658 |
+
# cp-decomposition
|
| 659 |
+
mid = mid.weight.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 660 |
+
updown = _rebuild_cp_decomposition(up, down, mid)
|
| 661 |
+
output_shape += mid.shape[2:]
|
| 662 |
+
else:
|
| 663 |
+
if len(down.shape) == 4:
|
| 664 |
+
output_shape += down.shape[2:]
|
| 665 |
+
updown = _rebuild_conventional(up, down, output_shape)
|
| 666 |
+
|
| 667 |
+
elif module.__class__.__name__ == 'LoraHadaModule':
|
| 668 |
+
w1a = module.w1a.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 669 |
+
w1b = module.w1b.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 670 |
+
w2a = module.w2a.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 671 |
+
w2b = module.w2b.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 672 |
+
|
| 673 |
+
output_shape = [w1a.size(0), w1b.size(1)]
|
| 674 |
+
|
| 675 |
+
if module.t1 is not None:
|
| 676 |
+
output_shape = [w1a.size(1), w1b.size(1)]
|
| 677 |
+
t1 = module.t1.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 678 |
+
updown1 = make_weight_cp(t1, w1a, w1b)
|
| 679 |
+
output_shape += t1.shape[2:]
|
| 680 |
+
else:
|
| 681 |
+
if len(w1b.shape) == 4:
|
| 682 |
+
output_shape += w1b.shape[2:]
|
| 683 |
+
updown1 = _rebuild_conventional(w1a, w1b, output_shape)
|
| 684 |
+
|
| 685 |
+
if module.t2 is not None:
|
| 686 |
+
t2 = module.t2.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 687 |
+
updown2 = make_weight_cp(t2, w2a, w2b)
|
| 688 |
+
else:
|
| 689 |
+
updown2 = _rebuild_conventional(w2a, w2b, output_shape)
|
| 690 |
+
|
| 691 |
+
updown = updown1 * updown2
|
| 692 |
+
|
| 693 |
+
elif module.__class__.__name__ == 'FullModule':
|
| 694 |
+
output_shape = module.weight.shape
|
| 695 |
+
updown = module.weight.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 696 |
+
|
| 697 |
+
elif module.__class__.__name__ == 'IA3Module':
|
| 698 |
+
output_shape = [module.w.size(0), orig_weight.size(1)]
|
| 699 |
+
if module.on_input:
|
| 700 |
+
output_shape.reverse()
|
| 701 |
+
else:
|
| 702 |
+
module.w = module.w.reshape(-1, 1)
|
| 703 |
+
updown = orig_weight * module.w
|
| 704 |
+
|
| 705 |
+
elif module.__class__.__name__ == 'LoraKronModule':
|
| 706 |
+
if module.w1 is not None:
|
| 707 |
+
w1 = module.w1.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 708 |
+
else:
|
| 709 |
+
w1a = module.w1a.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 710 |
+
w1b = module.w1b.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 711 |
+
w1 = w1a @ w1b
|
| 712 |
+
|
| 713 |
+
if module.w2 is not None:
|
| 714 |
+
w2 = module.w2.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 715 |
+
elif module.t2 is None:
|
| 716 |
+
w2a = module.w2a.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 717 |
+
w2b = module.w2b.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 718 |
+
w2 = w2a @ w2b
|
| 719 |
+
else:
|
| 720 |
+
t2 = module.t2.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 721 |
+
w2a = module.w2a.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 722 |
+
w2b = module.w2b.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 723 |
+
w2 = make_weight_cp(t2, w2a, w2b)
|
| 724 |
+
|
| 725 |
+
output_shape = [w1.size(0)*w2.size(0), w1.size(1)*w2.size(1)]
|
| 726 |
+
if len(orig_weight.shape) == 4:
|
| 727 |
+
output_shape = orig_weight.shape
|
| 728 |
+
|
| 729 |
+
updown = make_kron(
|
| 730 |
+
output_shape, w1, w2
|
| 731 |
+
)
|
| 732 |
+
|
| 733 |
+
else:
|
| 734 |
+
raise NotImplementedError(
|
| 735 |
+
f"Unknown module type: {module.__class__.__name__}\n"
|
| 736 |
+
"If the type is one of "
|
| 737 |
+
"'LoraUpDownModule', 'LoraHadaModule', 'FullModule', 'IA3Module', 'LoraKronModule'"
|
| 738 |
+
"You may have other lora extension that conflict with locon extension."
|
| 739 |
+
)
|
| 740 |
+
|
| 741 |
+
if hasattr(module, 'bias') and module.bias != None:
|
| 742 |
+
updown = updown.reshape(module.bias.shape)
|
| 743 |
+
updown += module.bias.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 744 |
+
updown = updown.reshape(output_shape)
|
| 745 |
+
|
| 746 |
+
if len(output_shape) == 4:
|
| 747 |
+
updown = updown.reshape(output_shape)
|
| 748 |
+
|
| 749 |
+
if orig_weight.size().numel() == updown.size().numel():
|
| 750 |
+
updown = updown.reshape(orig_weight.shape)
|
| 751 |
+
# print(torch.sum(updown))
|
| 752 |
+
return updown
|
| 753 |
+
|
| 754 |
+
|
| 755 |
+
def lora_calc_updown(lora, module, target):
|
| 756 |
+
with torch.no_grad():
|
| 757 |
+
updown = rebuild_weight(module, target)
|
| 758 |
+
updown = updown * lora.multiplier * (module.alpha / module.up.weight.shape[1] if module.alpha else 1.0)
|
| 759 |
+
return updown
|
| 760 |
+
|
| 761 |
+
|
| 762 |
+
lora.convert_diffusers_name_to_compvis = convert_diffusers_name_to_compvis
|
| 763 |
+
lora.load_lora = load_lora
|
| 764 |
+
lora.lora_forward = lora_forward
|
| 765 |
+
lora.lora_calc_updown = lora_calc_updown
|
| 766 |
+
print('LoCon Extension hijack built-in lora successfully')
|
extensions/a1111-microsoftexcel-tagcomplete/.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
tags/temp/
|
| 2 |
+
__pycache__/
|
extensions/a1111-microsoftexcel-tagcomplete/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Dominik Reh
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
extensions/a1111-microsoftexcel-tagcomplete/README.md
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+

|
| 2 |
+
|
| 3 |
+
# Booru tag autocompletion for A1111
|
| 4 |
+
|
| 5 |
+
[](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases)
|
| 6 |
+
|
| 7 |
+
## [中文文档](./README_ZH.md)
|
| 8 |
+
|
| 9 |
+
This custom script serves as a drop-in extension for the popular [AUTOMATIC1111 web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) for Stable Diffusion.
|
| 10 |
+
|
| 11 |
+
It displays autocompletion hints for recognized tags from "image booru" boards such as Danbooru, which are primarily used for browsing Anime-style illustrations.
|
| 12 |
+
Since some Stable Diffusion models were trained using this information, for example [Waifu Diffusion](https://github.com/harubaru/waifu-diffusion), using exact tags in prompts can often improve composition and help to achieve a wanted look.
|
| 13 |
+
|
| 14 |
+
You can install it using the inbuilt available extensions list, clone the files manually as described [below](#installation), or use a pre-packaged version from [Releases](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases).
|
| 15 |
+
|
| 16 |
+
## Common Problems & Known Issues:
|
| 17 |
+
- Depending on your browser settings, sometimes an old version of the script can get cached. Try `CTRL+F5` to force-reload the site without cache if e.g. a new feature doesn't appear for you after an update.
|
| 18 |
+
|
| 19 |
+
## Screenshots & Demo videos
|
| 20 |
+
<details>
|
| 21 |
+
<summary>Click to expand</summary>
|
| 22 |
+
Basic usage (with keyboard navigation):
|
| 23 |
+
|
| 24 |
+
https://user-images.githubusercontent.com/34448969/200128020-10d9a8b2-cea6-4e3f-bcd2-8c40c8c73233.mp4
|
| 25 |
+
|
| 26 |
+
Wildcard script support:
|
| 27 |
+
|
| 28 |
+
https://user-images.githubusercontent.com/34448969/200128031-22dd7c33-71d1-464f-ae36-5f6c8fd49df0.mp4
|
| 29 |
+
|
| 30 |
+
Dark and Light mode supported, including tag colors:
|
| 31 |
+
|
| 32 |
+
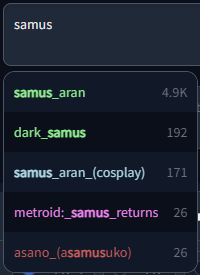
|
| 33 |
+
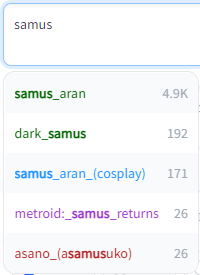
|
| 34 |
+
</details>
|
| 35 |
+
|
| 36 |
+
## Installation
|
| 37 |
+
### Using the built-in extension list
|
| 38 |
+
1. Open the Extensions tab
|
| 39 |
+
2. Open the Available sub-tab
|
| 40 |
+
3. Click "Load from:"
|
| 41 |
+
4. Find "Booru tag autocompletion" in the list
|
| 42 |
+
- The extension was one of the first available, so selecting "oldest first" will show it high up in the list.
|
| 43 |
+
5. Click "Install" on the right side
|
| 44 |
+
|
| 45 |
+

|
| 46 |
+

|
| 47 |
+
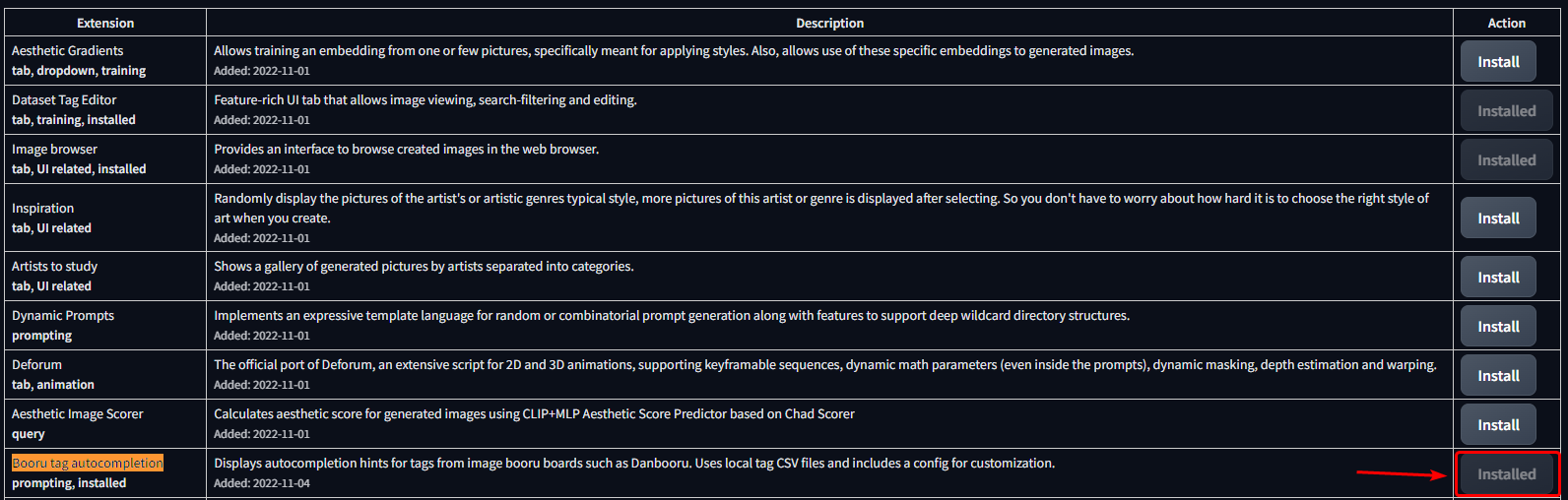
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
### Manual clone
|
| 51 |
+
```bash
|
| 52 |
+
git clone "https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git" extensions/tag-autocomplete
|
| 53 |
+
```
|
| 54 |
+
(The second argument specifies the name of the folder, you can choose whatever you like).
|
| 55 |
+
|
| 56 |
+
## Additional completion support
|
| 57 |
+
### Wildcards
|
| 58 |
+
Autocompletion also works with wildcard files used by https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards or other similar scripts/extensions.
|
| 59 |
+
Completion is triggered by typing `__` (double underscore). It will first show a list of your wildcard files, and upon choosing one, the replacement options inside that file.
|
| 60 |
+
This enables you to either insert categories to be replaced by the script, or directly choose one and use wildcards as a sort of categorized custom tag system.
|
| 61 |
+
|
| 62 |
+
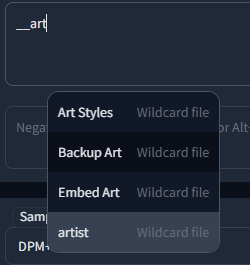
|
| 63 |
+
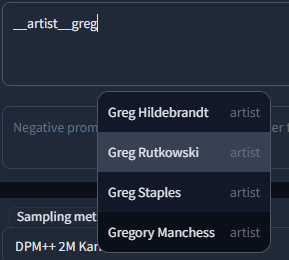
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
Wildcards are searched for in every extension folder, as well as the `scripts/wildcards` folder to support legacy versions. This means that you can combine wildcards from multiple extensions. Nested folders are also supported if you have grouped your wildcards in that way.
|
| 67 |
+
|
| 68 |
+
### Embeddings, Lora & Hypernets
|
| 69 |
+
Completion for these three types is triggered by typing `<`. By default it will show all three mixed together, but further filtering can be done in the following way:
|
| 70 |
+
- `<e:` will only show embeddings
|
| 71 |
+
- `<l:` or `<lora:` will only show Lora
|
| 72 |
+
- `<h:` or `<hypernet:` will only show Hypernetworks
|
| 73 |
+
|
| 74 |
+
#### Embedding type filtering
|
| 75 |
+
Embeddings trained for Stable Diffusion 1.x or 2.x models respectively are incompatible with the other type. To make it easier to find valid embeds, they are categorized by "v1 Embedding" and "v2 Embedding", including a slight color difference. You can also filter your search to include only v1 or v2 embeddings by typing `<v1/2` or `<e:v1/2` followed by the actual search term.
|
| 76 |
+
|
| 77 |
+
For example:
|
| 78 |
+
|
| 79 |
+
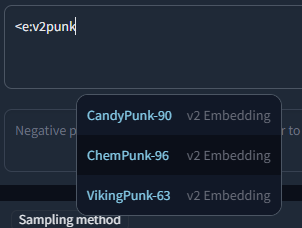
|
| 80 |
+
|
| 81 |
+
### Umi AI tags
|
| 82 |
+
https://github.com/Klokinator/Umi-AI is a feature-rich wildcard extension similar to Unprompted or Dynamic Wildcards.
|
| 83 |
+
In recent releases, it uses YAML-based wildcard tags to enable a complex chaining system,for example `<[preset][--female][sfw][species]>` will choose the preset category, exclude female related tags, further narrow it down with the following categories, and then choose one random fill-in matching all these criteria at runtime. Completion is triggered by `<[` and then each following new unclosed bracket, e.g. `<[xyz][`, until closed by `>`.
|
| 84 |
+
|
| 85 |
+
Tag Autocomplete can recommend these options in a smart way, meaning while you continue to add category tags, it will only show results still matching what comes before.
|
| 86 |
+
It also shows how many fill-in tags are available to choose from for that combo in place of the tag post count, enabling a quick overview and filtering of the large initial set.
|
| 87 |
+
|
| 88 |
+
Most of the credit goes to [@ctwrs](https://github.com/ctwrs) here, they contributed a lot as one of the Umi developers.
|
| 89 |
+
|
| 90 |
+
## Settings
|
| 91 |
+
|
| 92 |
+
The extension has a large amount of configuration & customizability built in:
|
| 93 |
+
|
| 94 |
+
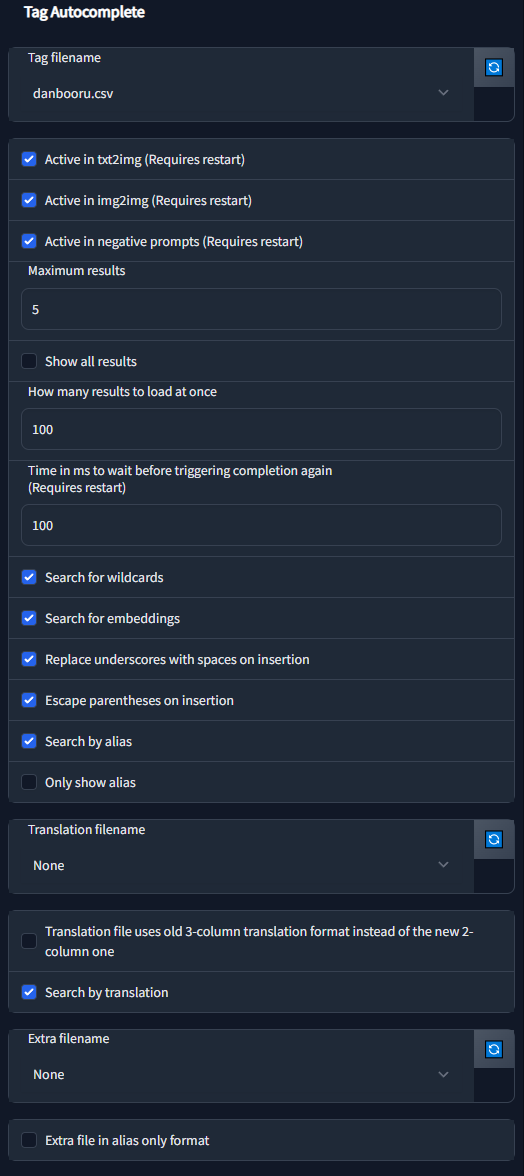
|
| 95 |
+
|
| 96 |
+
| Setting | Description |
|
| 97 |
+
|---------|-------------|
|
| 98 |
+
| tagFile | Specifies the tag file to use. You can provide a custom tag database of your liking, but since the script was developed with Danbooru tags in mind, it might not work properly with other configurations.|
|
| 99 |
+
| activeIn | Allows to selectively (de)activate the script for txt2img, img2img, and the negative prompts for both. |
|
| 100 |
+
| maxResults | How many results to show max. For the default tag set, the results are ordered by occurence count. For embeddings and wildcards it will show all results in a scrollable list. |
|
| 101 |
+
| resultStepLength | Allows to load results in smaller batches of the specified size for better performance in long lists or if showAllResults is true. |
|
| 102 |
+
| delayTime | Specifies how much to wait in milliseconds before triggering autocomplete. Helps prevent too frequent updates while typing. |
|
| 103 |
+
| showAllResults | If true, will ignore maxResults and show all results in a scrollable list. **Warning:** can lag your browser for long lists. |
|
| 104 |
+
| replaceUnderscores | If true, undescores are replaced with spaces on clicking a tag. Might work better for some models. |
|
| 105 |
+
| escapeParentheses | If true, escapes tags containing () so they don't contribute to the web UI's prompt weighting functionality. |
|
| 106 |
+
| appendComma | Specifies the starting value of the "Append commas" UI switch. If UI options are disabled, this will always be used. |
|
| 107 |
+
| useWildcards | Used to toggle the wildcard completion functionality. |
|
| 108 |
+
| useEmbeddings | Used to toggle the embedding completion functionality. |
|
| 109 |
+
| alias | Options for aliases. More info in the section below. |
|
| 110 |
+
| translation | Options for translations. More info in the section below. |
|
| 111 |
+
| extras | Options for additional tag files / aliases / translations. More info below. |
|
| 112 |
+
| keymap | Customizable hotkeys. |
|
| 113 |
+
| colors | Customizable tag colors. More info below. |
|
| 114 |
+
### Colors
|
| 115 |
+
Tag type colors can be specified by changing the JSON code in the tag autocomplete settings.
|
| 116 |
+
The format is standard JSON, with the object names corresponding to the tag filenames (without the .csv) they should be used for.
|
| 117 |
+
The first value in the square brackets is for dark, the second for light mode. Color names and hex codes should both work.
|
| 118 |
+
```json
|
| 119 |
+
{
|
| 120 |
+
"danbooru": {
|
| 121 |
+
"-1": ["red", "maroon"],
|
| 122 |
+
"0": ["lightblue", "dodgerblue"],
|
| 123 |
+
"1": ["indianred", "firebrick"],
|
| 124 |
+
"3": ["violet", "darkorchid"],
|
| 125 |
+
"4": ["lightgreen", "darkgreen"],
|
| 126 |
+
"5": ["orange", "darkorange"]
|
| 127 |
+
},
|
| 128 |
+
"e621": {
|
| 129 |
+
"-1": ["red", "maroon"],
|
| 130 |
+
"0": ["lightblue", "dodgerblue"],
|
| 131 |
+
"1": ["gold", "goldenrod"],
|
| 132 |
+
"3": ["violet", "darkorchid"],
|
| 133 |
+
"4": ["lightgreen", "darkgreen"],
|
| 134 |
+
"5": ["tomato", "darksalmon"],
|
| 135 |
+
"6": ["red", "maroon"],
|
| 136 |
+
"7": ["whitesmoke", "black"],
|
| 137 |
+
"8": ["seagreen", "darkseagreen"]
|
| 138 |
+
}
|
| 139 |
+
}
|
| 140 |
+
```
|
| 141 |
+
This can also be used to add new color sets for custom tag files.
|
| 142 |
+
The numbers are specifying the tag type, which is dependent on the tag source. For an example, see [CSV tag data](#csv-tag-data).
|
| 143 |
+
|
| 144 |
+
### Aliases, Translations & Extra tags
|
| 145 |
+
#### Aliases
|
| 146 |
+
Like on Booru sites, tags can have one or multiple aliases which redirect to the actual value on completion. These will be searchable / shown according to the settings in `config.json`:
|
| 147 |
+
- `searchByAlias` - Whether to also search for the alias or only the actual tag.
|
| 148 |
+
- `onlyShowAlias` - Shows only the alias instead of `alias -> actual`. Only for displaying, the inserted text at the end is still the actual tag.
|
| 149 |
+
|
| 150 |
+
#### Translations
|
| 151 |
+
An additional file can be added in the translation section, which will be used to translate both tags and aliases and also enables searching by translation.
|
| 152 |
+
This file needs to be a CSV in the format `<English tag/alias>,<Translation>`, but for backwards compatibility with older files that used a three column format, you can turn on `oldFormat` to use that instead.
|
| 153 |
+
|
| 154 |
+
Example with chinese translation:
|
| 155 |
+
|
| 156 |
+
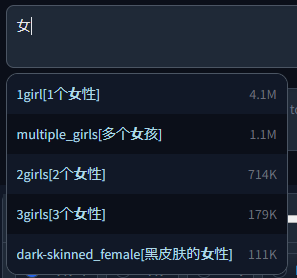
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
#### Extra file
|
| 160 |
+
An extra file can be used to add new / custom tags not included in the main set.
|
| 161 |
+
The format is identical to the normal tag format shown in [CSV tag data](#csv-tag-data) below, with one exception:
|
| 162 |
+
Since custom tags likely have no count, column three (or two if counting from zero) is instead used for the gray meta text displayed next to the tag.
|
| 163 |
+
If left empty, it will instead show "Custom tag".
|
| 164 |
+
|
| 165 |
+
An example with the included (very basic) extra-quality-tags.csv file:
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
Whether the custom tags should be added before or after the normal tags can be chosen in the settings.
|
| 170 |
+
|
| 171 |
+
## CSV tag data
|
| 172 |
+
The script expects a CSV file with tags saved in the following way:
|
| 173 |
+
```csv
|
| 174 |
+
<name>,<type>,<postCount>,"<aliases>"
|
| 175 |
+
```
|
| 176 |
+
Example:
|
| 177 |
+
```csv
|
| 178 |
+
1girl,0,4114588,"1girls,sole_female"
|
| 179 |
+
solo,0,3426446,"female_solo,solo_female"
|
| 180 |
+
highres,5,3008413,"high_res,high_resolution,hires"
|
| 181 |
+
long_hair,0,2898315,longhair
|
| 182 |
+
commentary_request,5,2610959,
|
| 183 |
+
```
|
| 184 |
+
Notably, it does not expect column names in the first row and both count and aliases are technically optional,
|
| 185 |
+
although count is always included in the default data. Multiple aliases need to be comma separated as well, but encased in string quotes to not break the CSV parsing.
|
| 186 |
+
|
| 187 |
+
The numbering system follows the [tag API docs](https://danbooru.donmai.us/wiki_pages/api%3Atags) of Danbooru:
|
| 188 |
+
| Value | Description |
|
| 189 |
+
|-------|-------------|
|
| 190 |
+
|0 | General |
|
| 191 |
+
|1 | Artist |
|
| 192 |
+
|3 | Copyright |
|
| 193 |
+
|4 | Character |
|
| 194 |
+
|5 | Meta |
|
| 195 |
+
|
| 196 |
+
or similarly for e621:
|
| 197 |
+
| Value | Description |
|
| 198 |
+
|-------|-------------|
|
| 199 |
+
|-1 | Invalid |
|
| 200 |
+
|0 | General |
|
| 201 |
+
|1 | Artist |
|
| 202 |
+
|3 | Copyright |
|
| 203 |
+
|4 | Character |
|
| 204 |
+
|5 | Species |
|
| 205 |
+
|6 | Invalid |
|
| 206 |
+
|7 | Meta |
|
| 207 |
+
|8 | Lore |
|
| 208 |
+
|
| 209 |
+
The tag type is used for coloring entries in the result list.
|
extensions/a1111-microsoftexcel-tagcomplete/README_ZH.md
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+

|
| 2 |
+
|
| 3 |
+
# Booru tag autocompletion for A1111
|
| 4 |
+
|
| 5 |
+
[](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases)
|
| 6 |
+
## [English Document](./README.md)
|
| 7 |
+
|
| 8 |
+
## 功能概述
|
| 9 |
+
|
| 10 |
+
本脚本为 [AUTOMATIC1111 web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui)的自定义脚本,能在输入Tag时提供booru风格(如Danbooru)的TAG自动补全。因为有一些模型是基于这种TAG风格训练的(例如[Waifu Diffusion](https://github.com/harubaru/waifu-diffusion)),因此使用这些Tag能获得较为精确的效果。
|
| 11 |
+
|
| 12 |
+
这个脚本的创建是为了减少因复制Tag在Web UI和 booru网站的反复切换。
|
| 13 |
+
你可以按照[以下方法](#installation)下载或拷贝文件,也可以使用[Releases](https://github.com/DominikDoom/a1111-sd-webui-tagcomplete/releases)中打包好的文件。
|
| 14 |
+
|
| 15 |
+
## 常见问题 & 已知缺陷:
|
| 16 |
+
- 当`replaceUnderscores`选项开启时, 脚本只会替换Tag的一部分如果Tag包含多个单词,比如将`atago (azur lane)`修改`atago`为`taihou`并使用自动补全时.会得到 `taihou (azur lane), lane)`的结果, 因为脚本没有把后面的部分认为成同一个Tag。
|
| 17 |
+
|
| 18 |
+
## 演示与截图
|
| 19 |
+
演示视频(使用了键盘导航):
|
| 20 |
+
|
| 21 |
+
https://user-images.githubusercontent.com/34448969/200128020-10d9a8b2-cea6-4e3f-bcd2-8c40c8c73233.mp4
|
| 22 |
+
|
| 23 |
+
Wildcard支持演示:
|
| 24 |
+
|
| 25 |
+
https://user-images.githubusercontent.com/34448969/200128031-22dd7c33-71d1-464f-ae36-5f6c8fd49df0.mp4
|
| 26 |
+
|
| 27 |
+
深浅色主题支持,包括Tag的颜色:
|
| 28 |
+
|
| 29 |
+

|
| 30 |
+

|
| 31 |
+
|
| 32 |
+
## 安装
|
| 33 |
+
### 作为一种扩展(推荐)
|
| 34 |
+
要么把它克隆到你的扩展文件夹里
|
| 35 |
+
```bash
|
| 36 |
+
git clone "https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git" extensions/tag-autocomplete
|
| 37 |
+
```
|
| 38 |
+
(第二个参数指定文件夹的名称,你可以选择任何你喜欢的东西)。
|
| 39 |
+
|
| 40 |
+
或者手动创建一个文件夹,将 `javascript`、`scripts`和`tags`文件夹放在其中。
|
| 41 |
+
|
| 42 |
+
### 在根目录下(过时的方法)
|
| 43 |
+
这种安装方法适用于添加扩展系统之前的旧版webui,在目前的版本上是行不通的。
|
| 44 |
+
|
| 45 |
+
---
|
| 46 |
+
在这两种配置中,标签文件夹包含`colors.json`和脚本用于自动完成的标签数据。
|
| 47 |
+
默认情况下,Tag数据包括`Danbooru.csv`和`e621.csv`。
|
| 48 |
+
|
| 49 |
+
在扫描过`/embeddings`和wildcards后,会将列表存放在`tags/temp`文件夹下。删除该文件夹不会有任何影响,下次启动时它会重新创建。
|
| 50 |
+
|
| 51 |
+
### 注意:
|
| 52 |
+
本脚本的允许需要**全部的三个文件夹**。
|
| 53 |
+
|
| 54 |
+
## [Wildcard](https://github.com/jtkelm2/stable-diffusion-webui-1/blob/master/scripts/wildcards.py) & Embedding 支持
|
| 55 |
+
自动补全同样适用于 [Wildcard](https://github.com/jtkelm2/stable-diffusion-webui-1/blob/master/scripts/wildcards.py)中所述的通配符文件(后面有演示视频)。这将使你能够插入Wildcard脚本需要的通配符,更进一步的,你还可以插入通配符文件内的某个具体Tag。
|
| 56 |
+
|
| 57 |
+
当输入`__`字符时,`/scripts/wildcards`文件夹下的通配符文件会列出到自动补全,当你选择某个具体通配符文件时,会列出其中的所有的具体Tag,但如果你仅需要选择某个通配符,请按下空格。
|
| 58 |
+
|
| 59 |
+
当输入`<`字符时,`embeddings`文件夹下的`.pt`和`.bin`文件会列出到自动完成。需要注意的是,一些颜文字也会包含`<`(比如`>_<`),所以它们也会出现在结果中。
|
| 60 |
+
|
| 61 |
+
现在这项功能默认是启用的,并会自动扫描`/embeddings`和`/scripts/wildcards`文件夹,不再需要使用`tags/wildcardNames.txt`文件了,早期版本的用户可以将它删除。
|
| 62 |
+
|
| 63 |
+
## 配置文件
|
| 64 |
+
该扩展有大量的配置和可定制性的内建:
|
| 65 |
+
|
| 66 |
+

|
| 67 |
+
|
| 68 |
+
| 设置 | 描述 |
|
| 69 |
+
|---------|-------------|
|
| 70 |
+
| tagFile | 指定要使用的标记文件。您可以提供您喜欢的自定义标签数据库,但由于该脚本是在考虑 Danbooru 标签的情况下开发的,因此它可能无法与其他配置一起正常工作。|
|
| 71 |
+
| activeIn | 允许有选择地(取消)激活 txt2img、img2img 和两者的否定提示的脚本。|
|
| 72 |
+
| maxResults | 最多显示多少个结果。对于默认标记集,结果按出现次数排序。对于嵌入和通配符,它将在可滚动列表中显示所有结果。 |
|
| 73 |
+
| showAllResults | 如果为真,将忽略 maxResults 并在可滚动列表中显示所有结果。 **警告:** 对于长列表,您的浏览器可能会滞后。 |
|
| 74 |
+
| resultStepLength | 允许以指定大小的小批次加载结果,以便在长列表中获得更好的性能,或者在showAllResults为真时。 |
|
| 75 |
+
| delayTime | 指定在触发自动完成之前要等待多少毫秒。有助于防止打字时过于频繁的更新。 |
|
| 76 |
+
| replaceUnderscores | 如果为 true,则在单击标签时将取消划线替换为空格。对于某些型号可能会更好。|
|
| 77 |
+
| escapeParentheses | 如果为 true,则转义包含 () 的标签,因此它们不会对 Web UI 的提示权重功能做出贡献。 |
|
| 78 |
+
| useWildcards | 用于切换通配符完成功能。 |
|
| 79 |
+
| useEmbeddings | 用于切换嵌入完成功能。 |
|
| 80 |
+
| alias | 标签别名的选项。更多信息在下面的部分。 |
|
| 81 |
+
| translation | 用于翻译标签的选项。更多信息在下面的部分。 |
|
| 82 |
+
| extras | 附加标签文件/翻译的选项。更多信息在下面的部分。|
|
| 83 |
+
|
| 84 |
+
### 标签颜色
|
| 85 |
+
标签类型的颜色可以通过改变标签自动完成设置中的JSON代码来指定。格式是标准的JSON,对象名称对应于它们应该使用的标签文件名(没有.csv)
|
| 86 |
+
|
| 87 |
+
方括号中的第一个值是指深色,第二个是指浅色模式。颜色名称和十六进制代码都应该有效。
|
| 88 |
+
```json
|
| 89 |
+
{
|
| 90 |
+
"danbooru": {
|
| 91 |
+
"-1": ["red", "maroon"],
|
| 92 |
+
"0": ["lightblue", "dodgerblue"],
|
| 93 |
+
"1": ["indianred", "firebrick"],
|
| 94 |
+
"3": ["violet", "darkorchid"],
|
| 95 |
+
"4": ["lightgreen", "darkgreen"],
|
| 96 |
+
"5": ["orange", "darkorange"]
|
| 97 |
+
},
|
| 98 |
+
"e621": {
|
| 99 |
+
"-1": ["red", "maroon"],
|
| 100 |
+
"0": ["lightblue", "dodgerblue"],
|
| 101 |
+
"1": ["gold", "goldenrod"],
|
| 102 |
+
"3": ["violet", "darkorchid"],
|
| 103 |
+
"4": ["lightgreen", "darkgreen"],
|
| 104 |
+
"5": ["tomato", "darksalmon"],
|
| 105 |
+
"6": ["red", "maroon"],
|
| 106 |
+
"7": ["whitesmoke", "black"],
|
| 107 |
+
"8": ["seagreen", "darkseagreen"]
|
| 108 |
+
}
|
| 109 |
+
}
|
| 110 |
+
```
|
| 111 |
+
这也可以用来为自定义标签文件添加新的颜色集。数字是指定标签的类型,这取决于标签来源。关于例子,见[CSV tag data](#csv-tag-data)。
|
| 112 |
+
|
| 113 |
+
### 别名,翻译&新增Tag
|
| 114 |
+
#### 别名
|
| 115 |
+
像Booru网站一样,标签可以有一个或多个别名,完成后重定向到实际值。这些将根据`config.json`中的设置进行搜索/显示。
|
| 116 |
+
- `searchByAlias` - 是否也要搜索别名,或只搜索实际的标签。
|
| 117 |
+
- `onlyShowAlias` - 只显示别名,不显示 `别名->实际`。仅用于显示,最后的文本仍然是实际的标签。
|
| 118 |
+
|
| 119 |
+
#### 翻译
|
| 120 |
+
可以在翻译部分添加一个额外的文件,它将被用来翻译标签和别名,同时也可以通过翻译进行搜索。
|
| 121 |
+
这个文件需要是CSV格式的`<英语标签/别名>,<翻译>`,但为了向后兼容使用三栏格式的旧的额外文件,你可以打开`oldFormat`来代替它。
|
| 122 |
+
|
| 123 |
+
完整和部分中文标签集的示例:
|
| 124 |
+
|
| 125 |
+

|
| 126 |
+

|
| 127 |
+
|
| 128 |
+
#### Extra文件
|
| 129 |
+
额外文件可以用来添加未包含在主集中的新的/自定义标签。
|
| 130 |
+
其格式与下面 [CSV tag data](#csv-tag-data) 中的正常标签格式相同,但有一个例外。
|
| 131 |
+
由于自定义标签没有帖子计数,第三列(如果从零开始计算,则为第二列)用于显示标签旁边的灰色元文本。
|
| 132 |
+
如果留空,它将显示 "Custom tag"。
|
| 133 |
+
|
| 134 |
+
以默认的(非常基本的)extra-quality-tags.csv为例:
|
| 135 |
+
|
| 136 |
+

|
| 137 |
+
|
| 138 |
+
你可以在设置中选择自定义标签是否应该加在常规标签之前或之后。
|
| 139 |
+
|
| 140 |
+
### CSV tag data
|
| 141 |
+
本脚本的Tag文件格式如下,你可以安装这个格式制作自己的Tag文件:
|
| 142 |
+
```csv
|
| 143 |
+
1girl,0,4114588,"1girls,sole_female"
|
| 144 |
+
solo,0,3426446,"female_solo,solo_female"
|
| 145 |
+
highres,5,3008413,"high_res,high_resolution,hires"
|
| 146 |
+
long_hair,0,2898315,longhair
|
| 147 |
+
commentary_request,5,2610959,
|
| 148 |
+
```
|
| 149 |
+
值得注意的是,不希望在第一行有列名,而且count和aliases在技术上都是可选的。
|
| 150 |
+
尽管count总是包含在默认数据中。多个别名也需要用逗号分隔,但要用字符串引号包裹,以免破坏CSV解析。
|
| 151 |
+
编号系统遵循 Danbooru 的 [tag API docs](https://danbooru.donmai.us/wiki_pages/api%3Atags):
|
| 152 |
+
| Value | Description |
|
| 153 |
+
|-------|-------------|
|
| 154 |
+
|0 | General |
|
| 155 |
+
|1 | Artist |
|
| 156 |
+
|3 | Copyright |
|
| 157 |
+
|4 | Character |
|
| 158 |
+
|5 | Meta |
|
| 159 |
+
|
| 160 |
+
类似的还有e621:
|
| 161 |
+
| Value | Description |
|
| 162 |
+
|-------|-------------|
|
| 163 |
+
|-1 | Invalid |
|
| 164 |
+
|0 | General |
|
| 165 |
+
|1 | Artist |
|
| 166 |
+
|3 | Copyright |
|
| 167 |
+
|4 | Character |
|
| 168 |
+
|5 | Species |
|
| 169 |
+
|6 | Invalid |
|
| 170 |
+
|7 | Meta |
|
| 171 |
+
|8 | Lore |
|
| 172 |
+
|
| 173 |
+
标记类型用于为结果列表中的条目着色.
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/__globals.js
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Core components
|
| 2 |
+
var CFG = null;
|
| 3 |
+
var tagBasePath = "";
|
| 4 |
+
|
| 5 |
+
// Tag completion data loaded from files
|
| 6 |
+
var allTags = [];
|
| 7 |
+
var translations = new Map();
|
| 8 |
+
var extras = [];
|
| 9 |
+
// Same for tag-likes
|
| 10 |
+
var wildcardFiles = [];
|
| 11 |
+
var wildcardExtFiles = [];
|
| 12 |
+
var yamlWildcards = [];
|
| 13 |
+
var embeddings = [];
|
| 14 |
+
var hypernetworks = [];
|
| 15 |
+
var loras = [];
|
| 16 |
+
var lycos = [];
|
| 17 |
+
|
| 18 |
+
// Selected model info for black/whitelisting
|
| 19 |
+
var currentModelHash = "";
|
| 20 |
+
var currentModelName = "";
|
| 21 |
+
|
| 22 |
+
// Current results
|
| 23 |
+
var results = [];
|
| 24 |
+
var resultCount = 0;
|
| 25 |
+
|
| 26 |
+
// Relevant for parsing
|
| 27 |
+
var previousTags = [];
|
| 28 |
+
var tagword = "";
|
| 29 |
+
var originalTagword = "";
|
| 30 |
+
let hideBlocked = false;
|
| 31 |
+
|
| 32 |
+
// Tag selection for keyboard navigation
|
| 33 |
+
var selectedTag = null;
|
| 34 |
+
var oldSelectedTag = null;
|
| 35 |
+
|
| 36 |
+
// UMI
|
| 37 |
+
var umiPreviousTags = [];
|
| 38 |
+
|
| 39 |
+
/// Extendability system:
|
| 40 |
+
/// Provides "queues" for other files of the script (or really any js)
|
| 41 |
+
/// to add functions to be called at certain points in the script.
|
| 42 |
+
/// Similar to a callback system, but primitive.
|
| 43 |
+
|
| 44 |
+
// Queues
|
| 45 |
+
const QUEUE_AFTER_INSERT = [];
|
| 46 |
+
const QUEUE_AFTER_SETUP = [];
|
| 47 |
+
const QUEUE_FILE_LOAD = [];
|
| 48 |
+
const QUEUE_AFTER_CONFIG_CHANGE = [];
|
| 49 |
+
const QUEUE_SANITIZE = [];
|
| 50 |
+
|
| 51 |
+
// List of parsers to try
|
| 52 |
+
const PARSERS = [];
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/_baseParser.js
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
class FunctionNotOverriddenError extends Error {
|
| 2 |
+
constructor(message = "", ...args) {
|
| 3 |
+
super(message, ...args);
|
| 4 |
+
this.message = message + " is an abstract base function and must be overwritten.";
|
| 5 |
+
}
|
| 6 |
+
}
|
| 7 |
+
|
| 8 |
+
class BaseTagParser {
|
| 9 |
+
triggerCondition = null;
|
| 10 |
+
|
| 11 |
+
constructor (triggerCondition) {
|
| 12 |
+
if (new.target === BaseTagParser) {
|
| 13 |
+
throw new TypeError("Cannot construct abstract BaseCompletionParser directly");
|
| 14 |
+
}
|
| 15 |
+
this.triggerCondition = triggerCondition;
|
| 16 |
+
}
|
| 17 |
+
|
| 18 |
+
parse() {
|
| 19 |
+
throw new FunctionNotOverriddenError("parse()");
|
| 20 |
+
}
|
| 21 |
+
}
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/_caretPosition.js
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// From https://github.com/component/textarea-caret-position
|
| 2 |
+
|
| 3 |
+
// We'll copy the properties below into the mirror div.
|
| 4 |
+
// Note that some browsers, such as Firefox, do not concatenate properties
|
| 5 |
+
// into their shorthand (e.g. padding-top, padding-bottom etc. -> padding),
|
| 6 |
+
// so we have to list every single property explicitly.
|
| 7 |
+
var properties = [
|
| 8 |
+
'direction', // RTL support
|
| 9 |
+
'boxSizing',
|
| 10 |
+
'width', // on Chrome and IE, exclude the scrollbar, so the mirror div wraps exactly as the textarea does
|
| 11 |
+
'height',
|
| 12 |
+
'overflowX',
|
| 13 |
+
'overflowY', // copy the scrollbar for IE
|
| 14 |
+
|
| 15 |
+
'borderTopWidth',
|
| 16 |
+
'borderRightWidth',
|
| 17 |
+
'borderBottomWidth',
|
| 18 |
+
'borderLeftWidth',
|
| 19 |
+
'borderStyle',
|
| 20 |
+
|
| 21 |
+
'paddingTop',
|
| 22 |
+
'paddingRight',
|
| 23 |
+
'paddingBottom',
|
| 24 |
+
'paddingLeft',
|
| 25 |
+
|
| 26 |
+
// https://developer.mozilla.org/en-US/docs/Web/CSS/font
|
| 27 |
+
'fontStyle',
|
| 28 |
+
'fontVariant',
|
| 29 |
+
'fontWeight',
|
| 30 |
+
'fontStretch',
|
| 31 |
+
'fontSize',
|
| 32 |
+
'fontSizeAdjust',
|
| 33 |
+
'lineHeight',
|
| 34 |
+
'fontFamily',
|
| 35 |
+
|
| 36 |
+
'textAlign',
|
| 37 |
+
'textTransform',
|
| 38 |
+
'textIndent',
|
| 39 |
+
'textDecoration', // might not make a difference, but better be safe
|
| 40 |
+
|
| 41 |
+
'letterSpacing',
|
| 42 |
+
'wordSpacing',
|
| 43 |
+
|
| 44 |
+
'tabSize',
|
| 45 |
+
'MozTabSize'
|
| 46 |
+
|
| 47 |
+
];
|
| 48 |
+
|
| 49 |
+
var isBrowser = (typeof window !== 'undefined');
|
| 50 |
+
var isFirefox = (isBrowser && window.mozInnerScreenX != null);
|
| 51 |
+
|
| 52 |
+
function getCaretCoordinates(element, position, options) {
|
| 53 |
+
if (!isBrowser) {
|
| 54 |
+
throw new Error('textarea-caret-position#getCaretCoordinates should only be called in a browser');
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
var debug = options && options.debug || false;
|
| 58 |
+
if (debug) {
|
| 59 |
+
var el = document.querySelector('#input-textarea-caret-position-mirror-div');
|
| 60 |
+
if (el) el.parentNode.removeChild(el);
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
// The mirror div will replicate the textarea's style
|
| 64 |
+
var div = document.createElement('div');
|
| 65 |
+
div.id = 'input-textarea-caret-position-mirror-div';
|
| 66 |
+
document.body.appendChild(div);
|
| 67 |
+
|
| 68 |
+
var style = div.style;
|
| 69 |
+
var computed = window.getComputedStyle ? window.getComputedStyle(element) : element.currentStyle; // currentStyle for IE < 9
|
| 70 |
+
var isInput = element.nodeName === 'INPUT';
|
| 71 |
+
|
| 72 |
+
// Default textarea styles
|
| 73 |
+
style.whiteSpace = 'pre-wrap';
|
| 74 |
+
if (!isInput)
|
| 75 |
+
style.wordWrap = 'break-word'; // only for textarea-s
|
| 76 |
+
|
| 77 |
+
// Position off-screen
|
| 78 |
+
style.position = 'absolute'; // required to return coordinates properly
|
| 79 |
+
if (!debug)
|
| 80 |
+
style.visibility = 'hidden'; // not 'display: none' because we want rendering
|
| 81 |
+
|
| 82 |
+
// Transfer the element's properties to the div
|
| 83 |
+
properties.forEach(function (prop) {
|
| 84 |
+
if (isInput && prop === 'lineHeight') {
|
| 85 |
+
// Special case for <input>s because text is rendered centered and line height may be != height
|
| 86 |
+
if (computed.boxSizing === "border-box") {
|
| 87 |
+
var height = parseInt(computed.height);
|
| 88 |
+
var outerHeight =
|
| 89 |
+
parseInt(computed.paddingTop) +
|
| 90 |
+
parseInt(computed.paddingBottom) +
|
| 91 |
+
parseInt(computed.borderTopWidth) +
|
| 92 |
+
parseInt(computed.borderBottomWidth);
|
| 93 |
+
var targetHeight = outerHeight + parseInt(computed.lineHeight);
|
| 94 |
+
if (height > targetHeight) {
|
| 95 |
+
style.lineHeight = height - outerHeight + "px";
|
| 96 |
+
} else if (height === targetHeight) {
|
| 97 |
+
style.lineHeight = computed.lineHeight;
|
| 98 |
+
} else {
|
| 99 |
+
style.lineHeight = 0;
|
| 100 |
+
}
|
| 101 |
+
} else {
|
| 102 |
+
style.lineHeight = computed.height;
|
| 103 |
+
}
|
| 104 |
+
} else {
|
| 105 |
+
style[prop] = computed[prop];
|
| 106 |
+
}
|
| 107 |
+
});
|
| 108 |
+
|
| 109 |
+
if (isFirefox) {
|
| 110 |
+
// Firefox lies about the overflow property for textareas: https://bugzilla.mozilla.org/show_bug.cgi?id=984275
|
| 111 |
+
if (element.scrollHeight > parseInt(computed.height))
|
| 112 |
+
style.overflowY = 'scroll';
|
| 113 |
+
} else {
|
| 114 |
+
style.overflow = 'hidden'; // for Chrome to not render a scrollbar; IE keeps overflowY = 'scroll'
|
| 115 |
+
}
|
| 116 |
+
|
| 117 |
+
div.textContent = element.value.substring(0, position);
|
| 118 |
+
// The second special handling for input type="text" vs textarea:
|
| 119 |
+
// spaces need to be replaced with non-breaking spaces - http://stackoverflow.com/a/13402035/1269037
|
| 120 |
+
if (isInput)
|
| 121 |
+
div.textContent = div.textContent.replace(/\s/g, '\u00a0');
|
| 122 |
+
|
| 123 |
+
var span = document.createElement('span');
|
| 124 |
+
// Wrapping must be replicated *exactly*, including when a long word gets
|
| 125 |
+
// onto the next line, with whitespace at the end of the line before (#7).
|
| 126 |
+
// The *only* reliable way to do that is to copy the *entire* rest of the
|
| 127 |
+
// textarea's content into the <span> created at the caret position.
|
| 128 |
+
// For inputs, just '.' would be enough, but no need to bother.
|
| 129 |
+
span.textContent = element.value.substring(position) || '.'; // || because a completely empty faux span doesn't render at all
|
| 130 |
+
div.appendChild(span);
|
| 131 |
+
|
| 132 |
+
var coordinates = {
|
| 133 |
+
top: span.offsetTop + parseInt(computed['borderTopWidth']),
|
| 134 |
+
left: span.offsetLeft + parseInt(computed['borderLeftWidth']),
|
| 135 |
+
height: parseInt(computed['lineHeight'])
|
| 136 |
+
};
|
| 137 |
+
|
| 138 |
+
if (debug) {
|
| 139 |
+
span.style.backgroundColor = '#aaa';
|
| 140 |
+
} else {
|
| 141 |
+
document.body.removeChild(div);
|
| 142 |
+
}
|
| 143 |
+
|
| 144 |
+
return coordinates;
|
| 145 |
+
}
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/_result.js
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Result data type for cleaner use of optional completion result properties
|
| 2 |
+
|
| 3 |
+
// Type enum
|
| 4 |
+
const ResultType = Object.freeze({
|
| 5 |
+
"tag": 1,
|
| 6 |
+
"extra": 2,
|
| 7 |
+
"embedding": 3,
|
| 8 |
+
"wildcardTag": 4,
|
| 9 |
+
"wildcardFile": 5,
|
| 10 |
+
"yamlWildcard": 6,
|
| 11 |
+
"hypernetwork": 7,
|
| 12 |
+
"lora": 8,
|
| 13 |
+
"lyco": 9
|
| 14 |
+
});
|
| 15 |
+
|
| 16 |
+
// Class to hold result data and annotations to make it clearer to use
|
| 17 |
+
class AutocompleteResult {
|
| 18 |
+
// Main properties
|
| 19 |
+
text = "";
|
| 20 |
+
type = ResultType.tag;
|
| 21 |
+
|
| 22 |
+
// Additional info, only used in some cases
|
| 23 |
+
category = null;
|
| 24 |
+
count = null;
|
| 25 |
+
aliases = null;
|
| 26 |
+
meta = null;
|
| 27 |
+
|
| 28 |
+
// Constructor
|
| 29 |
+
constructor(text, type) {
|
| 30 |
+
this.text = text;
|
| 31 |
+
this.type = type;
|
| 32 |
+
}
|
| 33 |
+
}
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/_textAreas.js
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Utility functions to select text areas the script should work on,
|
| 2 |
+
// including third party options.
|
| 3 |
+
// Supported third party options so far:
|
| 4 |
+
// - Dataset Tag Editor
|
| 5 |
+
|
| 6 |
+
// Core text area selectors
|
| 7 |
+
const core = [
|
| 8 |
+
"#txt2img_prompt > label > textarea",
|
| 9 |
+
"#img2img_prompt > label > textarea",
|
| 10 |
+
"#txt2img_neg_prompt > label > textarea",
|
| 11 |
+
"#img2img_neg_prompt > label > textarea"
|
| 12 |
+
];
|
| 13 |
+
|
| 14 |
+
// Third party text area selectors
|
| 15 |
+
const thirdParty = {
|
| 16 |
+
"dataset-tag-editor": {
|
| 17 |
+
"base": "#tab_dataset_tag_editor_interface",
|
| 18 |
+
"hasIds": false,
|
| 19 |
+
"selectors": [
|
| 20 |
+
"Caption of Selected Image",
|
| 21 |
+
"Interrogate Result",
|
| 22 |
+
"Edit Caption",
|
| 23 |
+
"Edit Tags"
|
| 24 |
+
]
|
| 25 |
+
},
|
| 26 |
+
"image browser": {
|
| 27 |
+
"base": "#tab_image_browser",
|
| 28 |
+
"hasIds": false,
|
| 29 |
+
"selectors": [
|
| 30 |
+
"Filename keyword search",
|
| 31 |
+
"EXIF keyword search"
|
| 32 |
+
]
|
| 33 |
+
},
|
| 34 |
+
"tab_tagger": {
|
| 35 |
+
"base": "#tab_tagger",
|
| 36 |
+
"hasIds": false,
|
| 37 |
+
"selectors": [
|
| 38 |
+
"Additional tags (split by comma)",
|
| 39 |
+
"Exclude tags (split by comma)"
|
| 40 |
+
]
|
| 41 |
+
},
|
| 42 |
+
"tiled-diffusion-t2i": {
|
| 43 |
+
"base": "#txt2img_script_container",
|
| 44 |
+
"hasIds": true,
|
| 45 |
+
"onDemand": true,
|
| 46 |
+
"selectors": [
|
| 47 |
+
"[id^=MD-t2i][id$=prompt] textarea",
|
| 48 |
+
"[id^=MD-t2i][id$=prompt] input[type='text']"
|
| 49 |
+
]
|
| 50 |
+
},
|
| 51 |
+
"tiled-diffusion-i2i": {
|
| 52 |
+
"base": "#img2img_script_container",
|
| 53 |
+
"hasIds": true,
|
| 54 |
+
"onDemand": true,
|
| 55 |
+
"selectors": [
|
| 56 |
+
"[id^=MD-i2i][id$=prompt] textarea",
|
| 57 |
+
"[id^=MD-i2i][id$=prompt] input[type='text']"
|
| 58 |
+
]
|
| 59 |
+
}
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
function getTextAreas() {
|
| 63 |
+
// First get all core text areas
|
| 64 |
+
let textAreas = [...gradioApp().querySelectorAll(core.join(", "))];
|
| 65 |
+
|
| 66 |
+
for (const [key, entry] of Object.entries(thirdParty)) {
|
| 67 |
+
if (entry.hasIds) { // If the entry has proper ids, we can just select them
|
| 68 |
+
textAreas = textAreas.concat([...gradioApp().querySelectorAll(entry.selectors.join(", "))]);
|
| 69 |
+
} else { // Otherwise, we have to find the text areas by their adjacent labels
|
| 70 |
+
let base = gradioApp().querySelector(entry.base);
|
| 71 |
+
|
| 72 |
+
// Safety check
|
| 73 |
+
if (!base) continue;
|
| 74 |
+
|
| 75 |
+
let allTextAreas = [...base.querySelectorAll("textarea, input[type='text']")];
|
| 76 |
+
|
| 77 |
+
// Filter the text areas where the adjacent label matches one of the selectors
|
| 78 |
+
let matchingTextAreas = allTextAreas.filter(ta => [...ta.parentElement.childNodes].some(x => entry.selectors.includes(x.innerText)));
|
| 79 |
+
textAreas = textAreas.concat(matchingTextAreas);
|
| 80 |
+
}
|
| 81 |
+
};
|
| 82 |
+
|
| 83 |
+
return textAreas;
|
| 84 |
+
}
|
| 85 |
+
|
| 86 |
+
function addOnDemandObservers(setupFunction) {
|
| 87 |
+
for (const [key, entry] of Object.entries(thirdParty)) {
|
| 88 |
+
if (!entry.onDemand) continue;
|
| 89 |
+
|
| 90 |
+
let base = gradioApp().querySelector(entry.base);
|
| 91 |
+
if (!base) continue;
|
| 92 |
+
|
| 93 |
+
let accordions = [...base?.querySelectorAll(".gradio-accordion")];
|
| 94 |
+
if (!accordions) continue;
|
| 95 |
+
|
| 96 |
+
accordions.forEach(acc => {
|
| 97 |
+
let accObserver = new MutationObserver((mutationList, observer) => {
|
| 98 |
+
for (const mutation of mutationList) {
|
| 99 |
+
if (mutation.type === "childList") {
|
| 100 |
+
let newChildren = mutation.addedNodes;
|
| 101 |
+
if (!newChildren) {
|
| 102 |
+
accObserver.disconnect();
|
| 103 |
+
continue;
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
newChildren.forEach(child => {
|
| 107 |
+
if (child.classList.contains("gradio-accordion") || child.querySelector(".gradio-accordion")) {
|
| 108 |
+
let newAccordions = [...child.querySelectorAll(".gradio-accordion")];
|
| 109 |
+
newAccordions.forEach(nAcc => accObserver.observe(nAcc, { childList: true }));
|
| 110 |
+
}
|
| 111 |
+
});
|
| 112 |
+
|
| 113 |
+
if (entry.hasIds) { // If the entry has proper ids, we can just select them
|
| 114 |
+
[...gradioApp().querySelectorAll(entry.selectors.join(", "))].forEach(x => setupFunction(x));
|
| 115 |
+
} else { // Otherwise, we have to find the text areas by their adjacent labels
|
| 116 |
+
let base = gradioApp().querySelector(entry.base);
|
| 117 |
+
|
| 118 |
+
// Safety check
|
| 119 |
+
if (!base) continue;
|
| 120 |
+
|
| 121 |
+
let allTextAreas = [...base.querySelectorAll("textarea, input[type='text']")];
|
| 122 |
+
|
| 123 |
+
// Filter the text areas where the adjacent label matches one of the selectors
|
| 124 |
+
let matchingTextAreas = allTextAreas.filter(ta => [...ta.parentElement.childNodes].some(x => entry.selectors.includes(x.innerText)));
|
| 125 |
+
matchingTextAreas.forEach(x => setupFunction(x));
|
| 126 |
+
}
|
| 127 |
+
}
|
| 128 |
+
}
|
| 129 |
+
});
|
| 130 |
+
accObserver.observe(acc, { childList: true });
|
| 131 |
+
});
|
| 132 |
+
};
|
| 133 |
+
}
|
| 134 |
+
|
| 135 |
+
const thirdPartyIdSet = new Set();
|
| 136 |
+
// Get the identifier for the text area to differentiate between positive and negative
|
| 137 |
+
function getTextAreaIdentifier(textArea) {
|
| 138 |
+
let txt2img_p = gradioApp().querySelector('#txt2img_prompt > label > textarea');
|
| 139 |
+
let txt2img_n = gradioApp().querySelector('#txt2img_neg_prompt > label > textarea');
|
| 140 |
+
let img2img_p = gradioApp().querySelector('#img2img_prompt > label > textarea');
|
| 141 |
+
let img2img_n = gradioApp().querySelector('#img2img_neg_prompt > label > textarea');
|
| 142 |
+
|
| 143 |
+
let modifier = "";
|
| 144 |
+
switch (textArea) {
|
| 145 |
+
case txt2img_p:
|
| 146 |
+
modifier = ".txt2img.p";
|
| 147 |
+
break;
|
| 148 |
+
case txt2img_n:
|
| 149 |
+
modifier = ".txt2img.n";
|
| 150 |
+
break;
|
| 151 |
+
case img2img_p:
|
| 152 |
+
modifier = ".img2img.p";
|
| 153 |
+
break;
|
| 154 |
+
case img2img_n:
|
| 155 |
+
modifier = ".img2img.n";
|
| 156 |
+
break;
|
| 157 |
+
default:
|
| 158 |
+
// If the text area is not a core text area, it must be a third party text area
|
| 159 |
+
// Add it to the set of third party text areas and get its index as a unique identifier
|
| 160 |
+
if (!thirdPartyIdSet.has(textArea))
|
| 161 |
+
thirdPartyIdSet.add(textArea);
|
| 162 |
+
|
| 163 |
+
modifier = `.thirdParty.ta${[...thirdPartyIdSet].indexOf(textArea)}`;
|
| 164 |
+
break;
|
| 165 |
+
}
|
| 166 |
+
return modifier;
|
| 167 |
+
}
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/_utils.js
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Utility functions for tag autocomplete
|
| 2 |
+
|
| 3 |
+
// Parse the CSV file into a 2D array. Doesn't use regex, so it is very lightweight.
|
| 4 |
+
function parseCSV(str) {
|
| 5 |
+
var arr = [];
|
| 6 |
+
var quote = false; // 'true' means we're inside a quoted field
|
| 7 |
+
|
| 8 |
+
// Iterate over each character, keep track of current row and column (of the returned array)
|
| 9 |
+
for (var row = 0, col = 0, c = 0; c < str.length; c++) {
|
| 10 |
+
var cc = str[c], nc = str[c + 1]; // Current character, next character
|
| 11 |
+
arr[row] = arr[row] || []; // Create a new row if necessary
|
| 12 |
+
arr[row][col] = arr[row][col] || ''; // Create a new column (start with empty string) if necessary
|
| 13 |
+
|
| 14 |
+
// If the current character is a quotation mark, and we're inside a
|
| 15 |
+
// quoted field, and the next character is also a quotation mark,
|
| 16 |
+
// add a quotation mark to the current column and skip the next character
|
| 17 |
+
if (cc == '"' && quote && nc == '"') { arr[row][col] += cc; ++c; continue; }
|
| 18 |
+
|
| 19 |
+
// If it's just one quotation mark, begin/end quoted field
|
| 20 |
+
if (cc == '"') { quote = !quote; continue; }
|
| 21 |
+
|
| 22 |
+
// If it's a comma and we're not in a quoted field, move on to the next column
|
| 23 |
+
if (cc == ',' && !quote) { ++col; continue; }
|
| 24 |
+
|
| 25 |
+
// If it's a newline (CRLF) and we're not in a quoted field, skip the next character
|
| 26 |
+
// and move on to the next row and move to column 0 of that new row
|
| 27 |
+
if (cc == '\r' && nc == '\n' && !quote) { ++row; col = 0; ++c; continue; }
|
| 28 |
+
|
| 29 |
+
// If it's a newline (LF or CR) and we're not in a quoted field,
|
| 30 |
+
// move on to the next row and move to column 0 of that new row
|
| 31 |
+
if (cc == '\n' && !quote) { ++row; col = 0; continue; }
|
| 32 |
+
if (cc == '\r' && !quote) { ++row; col = 0; continue; }
|
| 33 |
+
|
| 34 |
+
// Otherwise, append the current character to the current column
|
| 35 |
+
arr[row][col] += cc;
|
| 36 |
+
}
|
| 37 |
+
return arr;
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
// Load file
|
| 41 |
+
async function readFile(filePath, json = false, cache = false) {
|
| 42 |
+
if (!cache)
|
| 43 |
+
filePath += `?${new Date().getTime()}`;
|
| 44 |
+
|
| 45 |
+
let response = await fetch(`file=${filePath}`);
|
| 46 |
+
|
| 47 |
+
if (response.status != 200) {
|
| 48 |
+
console.error(`Error loading file "${filePath}": ` + response.status, response.statusText);
|
| 49 |
+
return null;
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
if (json)
|
| 53 |
+
return await response.json();
|
| 54 |
+
else
|
| 55 |
+
return await response.text();
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
// Load CSV
|
| 59 |
+
async function loadCSV(path) {
|
| 60 |
+
let text = await readFile(path);
|
| 61 |
+
return parseCSV(text);
|
| 62 |
+
}
|
| 63 |
+
|
| 64 |
+
// Debounce function to prevent spamming the autocomplete function
|
| 65 |
+
var dbTimeOut;
|
| 66 |
+
const debounce = (func, wait = 300) => {
|
| 67 |
+
return function (...args) {
|
| 68 |
+
if (dbTimeOut) {
|
| 69 |
+
clearTimeout(dbTimeOut);
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
dbTimeOut = setTimeout(() => {
|
| 73 |
+
func.apply(this, args);
|
| 74 |
+
}, wait);
|
| 75 |
+
}
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
// Difference function to fix duplicates not being seen as changes in normal filter
|
| 79 |
+
function difference(a, b) {
|
| 80 |
+
if (a.length == 0) {
|
| 81 |
+
return b;
|
| 82 |
+
}
|
| 83 |
+
if (b.length == 0) {
|
| 84 |
+
return a;
|
| 85 |
+
}
|
| 86 |
+
|
| 87 |
+
return [...b.reduce((acc, v) => acc.set(v, (acc.get(v) || 0) - 1),
|
| 88 |
+
a.reduce((acc, v) => acc.set(v, (acc.get(v) || 0) + 1), new Map())
|
| 89 |
+
)].reduce((acc, [v, count]) => acc.concat(Array(Math.abs(count)).fill(v)), []);
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
function escapeRegExp(string) {
|
| 93 |
+
return string.replace(/[.*+?^${}()|[\]\\]/g, '\\$&'); // $& means the whole matched string
|
| 94 |
+
}
|
| 95 |
+
function escapeHTML(unsafeText) {
|
| 96 |
+
let div = document.createElement('div');
|
| 97 |
+
div.textContent = unsafeText;
|
| 98 |
+
return div.innerHTML;
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
// Queue calling function to process global queues
|
| 102 |
+
async function processQueue(queue, context, ...args) {
|
| 103 |
+
for (let i = 0; i < queue.length; i++) {
|
| 104 |
+
await queue[i].call(context, ...args);
|
| 105 |
+
}
|
| 106 |
+
}
|
| 107 |
+
// The same but with return values
|
| 108 |
+
async function processQueueReturn(queue, context, ...args)
|
| 109 |
+
{
|
| 110 |
+
let qeueueReturns = [];
|
| 111 |
+
for (let i = 0; i < queue.length; i++) {
|
| 112 |
+
let returnValue = await queue[i].call(context, ...args);
|
| 113 |
+
if (returnValue)
|
| 114 |
+
qeueueReturns.push(returnValue);
|
| 115 |
+
}
|
| 116 |
+
return qeueueReturns;
|
| 117 |
+
}
|
| 118 |
+
// Specific to tag completion parsers
|
| 119 |
+
async function processParsers(textArea, prompt) {
|
| 120 |
+
// Get all parsers that have a successful trigger condition
|
| 121 |
+
let matchingParsers = PARSERS.filter(parser => parser.triggerCondition());
|
| 122 |
+
// Guard condition
|
| 123 |
+
if (matchingParsers.length === 0) {
|
| 124 |
+
return null;
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
let parseFunctions = matchingParsers.map(parser => parser.parse);
|
| 128 |
+
// Process them and return the results
|
| 129 |
+
return await processQueueReturn(parseFunctions, null, textArea, prompt);
|
| 130 |
+
}
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_embeddings.js
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
const EMB_REGEX = /<(?!l:|h:)[^,> ]*>?/g;
|
| 2 |
+
const EMB_TRIGGER = () => CFG.useEmbeddings && tagword.match(EMB_REGEX);
|
| 3 |
+
|
| 4 |
+
class EmbeddingParser extends BaseTagParser {
|
| 5 |
+
parse() {
|
| 6 |
+
// Show embeddings
|
| 7 |
+
let tempResults = [];
|
| 8 |
+
if (tagword !== "<" && tagword !== "<e:") {
|
| 9 |
+
let searchTerm = tagword.replace("<e:", "").replace("<", "");
|
| 10 |
+
let versionString;
|
| 11 |
+
if (searchTerm.startsWith("v1") || searchTerm.startsWith("v2")) {
|
| 12 |
+
versionString = searchTerm.slice(0, 2);
|
| 13 |
+
searchTerm = searchTerm.slice(2);
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
let filterCondition = x => x[0].toLowerCase().includes(searchTerm) || x[0].toLowerCase().replaceAll(" ", "_").includes(searchTerm);
|
| 17 |
+
|
| 18 |
+
if (versionString)
|
| 19 |
+
tempResults = embeddings.filter(x => filterCondition(x) && x[1] && x[1] === versionString); // Filter by tagword
|
| 20 |
+
else
|
| 21 |
+
tempResults = embeddings.filter(x => filterCondition(x)); // Filter by tagword
|
| 22 |
+
} else {
|
| 23 |
+
tempResults = embeddings;
|
| 24 |
+
}
|
| 25 |
+
|
| 26 |
+
// Add final results
|
| 27 |
+
let finalResults = [];
|
| 28 |
+
tempResults.forEach(t => {
|
| 29 |
+
let result = new AutocompleteResult(t[0].trim(), ResultType.embedding)
|
| 30 |
+
result.meta = t[1] + " Embedding";
|
| 31 |
+
finalResults.push(result);
|
| 32 |
+
});
|
| 33 |
+
|
| 34 |
+
return finalResults;
|
| 35 |
+
}
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
async function load() {
|
| 39 |
+
if (embeddings.length === 0) {
|
| 40 |
+
try {
|
| 41 |
+
embeddings = (await readFile(`${tagBasePath}/temp/emb.txt`)).split("\n")
|
| 42 |
+
.filter(x => x.trim().length > 0) // Remove empty lines
|
| 43 |
+
.map(x => x.trim().split(",")); // Split into name, version type pairs
|
| 44 |
+
} catch (e) {
|
| 45 |
+
console.error("Error loading embeddings.txt: " + e);
|
| 46 |
+
}
|
| 47 |
+
}
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
function sanitize(tagType, text) {
|
| 51 |
+
if (tagType === ResultType.embedding) {
|
| 52 |
+
return text.replace(/^.*?: /g, "");
|
| 53 |
+
}
|
| 54 |
+
return null;
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
PARSERS.push(new EmbeddingParser(EMB_TRIGGER));
|
| 58 |
+
|
| 59 |
+
// Add our utility functions to their respective queues
|
| 60 |
+
QUEUE_FILE_LOAD.push(load);
|
| 61 |
+
QUEUE_SANITIZE.push(sanitize);
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_hypernets.js
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
const HYP_REGEX = /<(?!e:|l:)[^,> ]*>?/g;
|
| 2 |
+
const HYP_TRIGGER = () => CFG.useHypernetworks && tagword.match(HYP_REGEX);
|
| 3 |
+
|
| 4 |
+
class HypernetParser extends BaseTagParser {
|
| 5 |
+
parse() {
|
| 6 |
+
// Show hypernetworks
|
| 7 |
+
let tempResults = [];
|
| 8 |
+
if (tagword !== "<" && tagword !== "<h:" && tagword !== "<hypernet:") {
|
| 9 |
+
let searchTerm = tagword.replace("<hypernet:", "").replace("<h:", "").replace("<", "");
|
| 10 |
+
let filterCondition = x => x.toLowerCase().includes(searchTerm) || x.toLowerCase().replaceAll(" ", "_").includes(searchTerm);
|
| 11 |
+
tempResults = hypernetworks.filter(x => filterCondition(x)); // Filter by tagword
|
| 12 |
+
} else {
|
| 13 |
+
tempResults = hypernetworks;
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
// Add final results
|
| 17 |
+
let finalResults = [];
|
| 18 |
+
tempResults.forEach(t => {
|
| 19 |
+
let result = new AutocompleteResult(t.trim(), ResultType.hypernetwork)
|
| 20 |
+
result.meta = "Hypernetwork";
|
| 21 |
+
finalResults.push(result);
|
| 22 |
+
});
|
| 23 |
+
|
| 24 |
+
return finalResults;
|
| 25 |
+
}
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
async function load() {
|
| 29 |
+
if (hypernetworks.length === 0) {
|
| 30 |
+
try {
|
| 31 |
+
hypernetworks = (await readFile(`${tagBasePath}/temp/hyp.txt`)).split("\n")
|
| 32 |
+
.filter(x => x.trim().length > 0) //Remove empty lines
|
| 33 |
+
.map(x => x.trim()); // Remove carriage returns and padding if it exists
|
| 34 |
+
} catch (e) {
|
| 35 |
+
console.error("Error loading hypernetworks.txt: " + e);
|
| 36 |
+
}
|
| 37 |
+
}
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
function sanitize(tagType, text) {
|
| 41 |
+
if (tagType === ResultType.hypernetwork) {
|
| 42 |
+
return `<hypernet:${text}:${CFG.extraNetworksDefaultMultiplier}>`;
|
| 43 |
+
}
|
| 44 |
+
return null;
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
PARSERS.push(new HypernetParser(HYP_TRIGGER));
|
| 48 |
+
|
| 49 |
+
// Add our utility functions to their respective queues
|
| 50 |
+
QUEUE_FILE_LOAD.push(load);
|
| 51 |
+
QUEUE_SANITIZE.push(sanitize);
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_loras.js
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
const LORA_REGEX = /<(?!e:|h:)[^,> ]*>?/g;
|
| 2 |
+
const LORA_TRIGGER = () => CFG.useLoras && tagword.match(LORA_REGEX);
|
| 3 |
+
|
| 4 |
+
class LoraParser extends BaseTagParser {
|
| 5 |
+
parse() {
|
| 6 |
+
// Show lora
|
| 7 |
+
let tempResults = [];
|
| 8 |
+
if (tagword !== "<" && tagword !== "<l:" && tagword !== "<lora:") {
|
| 9 |
+
let searchTerm = tagword.replace("<lora:", "").replace("<l:", "").replace("<", "");
|
| 10 |
+
let filterCondition = x => x.toLowerCase().includes(searchTerm) || x.toLowerCase().replaceAll(" ", "_").includes(searchTerm);
|
| 11 |
+
tempResults = loras.filter(x => filterCondition(x)); // Filter by tagword
|
| 12 |
+
} else {
|
| 13 |
+
tempResults = loras;
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
// Add final results
|
| 17 |
+
let finalResults = [];
|
| 18 |
+
tempResults.forEach(t => {
|
| 19 |
+
let result = new AutocompleteResult(t.trim(), ResultType.lora)
|
| 20 |
+
result.meta = "Lora";
|
| 21 |
+
finalResults.push(result);
|
| 22 |
+
});
|
| 23 |
+
|
| 24 |
+
return finalResults;
|
| 25 |
+
}
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
async function load() {
|
| 29 |
+
if (loras.length === 0) {
|
| 30 |
+
try {
|
| 31 |
+
loras = (await readFile(`${tagBasePath}/temp/lora.txt`)).split("\n")
|
| 32 |
+
.filter(x => x.trim().length > 0) // Remove empty lines
|
| 33 |
+
.map(x => x.trim()); // Remove carriage returns and padding if it exists
|
| 34 |
+
} catch (e) {
|
| 35 |
+
console.error("Error loading lora.txt: " + e);
|
| 36 |
+
}
|
| 37 |
+
}
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
function sanitize(tagType, text) {
|
| 41 |
+
if (tagType === ResultType.lora) {
|
| 42 |
+
return `<lora:${text}:${CFG.extraNetworksDefaultMultiplier}>`;
|
| 43 |
+
}
|
| 44 |
+
return null;
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
PARSERS.push(new LoraParser(LORA_TRIGGER));
|
| 48 |
+
|
| 49 |
+
// Add our utility functions to their respective queues
|
| 50 |
+
QUEUE_FILE_LOAD.push(load);
|
| 51 |
+
QUEUE_SANITIZE.push(sanitize);
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_lycos.js
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
const LYCO_REGEX = /<(?!e:|h:)[^,> ]*>?/g;
|
| 2 |
+
const LYCO_TRIGGER = () => CFG.useLycos && tagword.match(LYCO_REGEX);
|
| 3 |
+
|
| 4 |
+
class LycoParser extends BaseTagParser {
|
| 5 |
+
parse() {
|
| 6 |
+
// Show lyco
|
| 7 |
+
let tempResults = [];
|
| 8 |
+
if (tagword !== "<" && tagword !== "<l:" && tagword !== "<lyco:") {
|
| 9 |
+
let searchTerm = tagword.replace("<lyco:", "").replace("<l:", "").replace("<", "");
|
| 10 |
+
let filterCondition = x => x.toLowerCase().includes(searchTerm) || x.toLowerCase().replaceAll(" ", "_").includes(searchTerm);
|
| 11 |
+
tempResults = lycos.filter(x => filterCondition(x)); // Filter by tagword
|
| 12 |
+
} else {
|
| 13 |
+
tempResults = lycos;
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
// Add final results
|
| 17 |
+
let finalResults = [];
|
| 18 |
+
tempResults.forEach(t => {
|
| 19 |
+
let result = new AutocompleteResult(t.trim(), ResultType.lyco)
|
| 20 |
+
result.meta = "Lyco";
|
| 21 |
+
finalResults.push(result);
|
| 22 |
+
});
|
| 23 |
+
|
| 24 |
+
return finalResults;
|
| 25 |
+
}
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
async function load() {
|
| 29 |
+
if (lycos.length === 0) {
|
| 30 |
+
try {
|
| 31 |
+
lycos = (await readFile(`${tagBasePath}/temp/lyco.txt`)).split("\n")
|
| 32 |
+
.filter(x => x.trim().length > 0) // Remove empty lines
|
| 33 |
+
.map(x => x.trim()); // Remove carriage returns and padding if it exists
|
| 34 |
+
} catch (e) {
|
| 35 |
+
console.error("Error loading lyco.txt: " + e);
|
| 36 |
+
}
|
| 37 |
+
}
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
function sanitize(tagType, text) {
|
| 41 |
+
if (tagType === ResultType.lyco) {
|
| 42 |
+
return `<lyco:${text}:${CFG.extraNetworksDefaultMultiplier}>`;
|
| 43 |
+
}
|
| 44 |
+
return null;
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
PARSERS.push(new LycoParser(LYCO_TRIGGER));
|
| 48 |
+
|
| 49 |
+
// Add our utility functions to their respective queues
|
| 50 |
+
QUEUE_FILE_LOAD.push(load);
|
| 51 |
+
QUEUE_SANITIZE.push(sanitize);
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_umi.js
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
const UMI_PROMPT_REGEX = /<[^\s]*?\[[^,<>]*[\]|]?>?/gi;
|
| 2 |
+
const UMI_TAG_REGEX = /(?:\[|\||--)([^<>\[\]\-|]+)/gi;
|
| 3 |
+
|
| 4 |
+
const UMI_TRIGGER = () => CFG.useWildcards && [...tagword.matchAll(UMI_PROMPT_REGEX)].length > 0;
|
| 5 |
+
|
| 6 |
+
class UmiParser extends BaseTagParser {
|
| 7 |
+
parse(textArea, prompt) {
|
| 8 |
+
// We are in a UMI yaml tag definition, parse further
|
| 9 |
+
let umiSubPrompts = [...prompt.matchAll(UMI_PROMPT_REGEX)];
|
| 10 |
+
|
| 11 |
+
let umiTags = [];
|
| 12 |
+
let umiTagsWithOperators = []
|
| 13 |
+
|
| 14 |
+
const insertAt = (str,char,pos) => str.slice(0,pos) + char + str.slice(pos);
|
| 15 |
+
|
| 16 |
+
umiSubPrompts.forEach(umiSubPrompt => {
|
| 17 |
+
umiTags = umiTags.concat([...umiSubPrompt[0].matchAll(UMI_TAG_REGEX)].map(x => x[1].toLowerCase()));
|
| 18 |
+
|
| 19 |
+
const start = umiSubPrompt.index;
|
| 20 |
+
const end = umiSubPrompt.index + umiSubPrompt[0].length;
|
| 21 |
+
if (textArea.selectionStart >= start && textArea.selectionStart <= end) {
|
| 22 |
+
umiTagsWithOperators = insertAt(umiSubPrompt[0], '###', textArea.selectionStart - start);
|
| 23 |
+
}
|
| 24 |
+
});
|
| 25 |
+
|
| 26 |
+
// Safety check since UMI parsing sometimes seems to trigger outside of an UMI subprompt and thus fails
|
| 27 |
+
if (umiTagsWithOperators.length === 0) {
|
| 28 |
+
return null;
|
| 29 |
+
}
|
| 30 |
+
|
| 31 |
+
const promptSplitToTags = umiTagsWithOperators.replace(']###[', '][').split("][");
|
| 32 |
+
|
| 33 |
+
const clean = (str) => str
|
| 34 |
+
.replaceAll('>', '')
|
| 35 |
+
.replaceAll('<', '')
|
| 36 |
+
.replaceAll('[', '')
|
| 37 |
+
.replaceAll(']', '')
|
| 38 |
+
.trim();
|
| 39 |
+
|
| 40 |
+
const matches = promptSplitToTags.reduce((acc, curr) => {
|
| 41 |
+
let isOptional = curr.includes("|");
|
| 42 |
+
let isNegative = curr.startsWith("--");
|
| 43 |
+
let out;
|
| 44 |
+
if (isOptional) {
|
| 45 |
+
out = {
|
| 46 |
+
hasCursor: curr.includes("###"),
|
| 47 |
+
tags: clean(curr).split('|').map(x => ({
|
| 48 |
+
hasCursor: x.includes("###"),
|
| 49 |
+
isNegative: x.startsWith("--"),
|
| 50 |
+
tag: clean(x).replaceAll("###", '').replaceAll("--", '')
|
| 51 |
+
}))
|
| 52 |
+
};
|
| 53 |
+
acc.optional.push(out);
|
| 54 |
+
acc.all.push(...out.tags.map(x => x.tag));
|
| 55 |
+
} else if (isNegative) {
|
| 56 |
+
out = {
|
| 57 |
+
hasCursor: curr.includes("###"),
|
| 58 |
+
tags: clean(curr).replaceAll("###", '').split('|'),
|
| 59 |
+
};
|
| 60 |
+
out.tags = out.tags.map(x => x.startsWith("--") ? x.substring(2) : x);
|
| 61 |
+
acc.negative.push(out);
|
| 62 |
+
acc.all.push(...out.tags);
|
| 63 |
+
} else {
|
| 64 |
+
out = {
|
| 65 |
+
hasCursor: curr.includes("###"),
|
| 66 |
+
tags: clean(curr).replaceAll("###", '').split('|'),
|
| 67 |
+
};
|
| 68 |
+
acc.positive.push(out);
|
| 69 |
+
acc.all.push(...out.tags);
|
| 70 |
+
}
|
| 71 |
+
return acc;
|
| 72 |
+
}, { positive: [], negative: [], optional: [], all: [] });
|
| 73 |
+
|
| 74 |
+
//console.log({ matches })
|
| 75 |
+
|
| 76 |
+
const filteredWildcards = (tagword) => {
|
| 77 |
+
const wildcards = yamlWildcards.filter(x => {
|
| 78 |
+
let tags = x[1];
|
| 79 |
+
const matchesNeg =
|
| 80 |
+
matches.negative.length === 0
|
| 81 |
+
|| matches.negative.every(x =>
|
| 82 |
+
x.hasCursor
|
| 83 |
+
|| x.tags.every(t => !tags[t])
|
| 84 |
+
);
|
| 85 |
+
if (!matchesNeg) return false;
|
| 86 |
+
const matchesPos =
|
| 87 |
+
matches.positive.length === 0
|
| 88 |
+
|| matches.positive.every(x =>
|
| 89 |
+
x.hasCursor
|
| 90 |
+
|| x.tags.every(t => tags[t])
|
| 91 |
+
);
|
| 92 |
+
if (!matchesPos) return false;
|
| 93 |
+
const matchesOpt =
|
| 94 |
+
matches.optional.length === 0
|
| 95 |
+
|| matches.optional.some(x =>
|
| 96 |
+
x.tags.some(t =>
|
| 97 |
+
t.hasCursor
|
| 98 |
+
|| t.isNegative
|
| 99 |
+
? !tags[t.tag]
|
| 100 |
+
: tags[t.tag]
|
| 101 |
+
));
|
| 102 |
+
if (!matchesOpt) return false;
|
| 103 |
+
return true;
|
| 104 |
+
}).reduce((acc, val) => {
|
| 105 |
+
Object.keys(val[1]).forEach(tag => acc[tag] = acc[tag] + 1 || 1);
|
| 106 |
+
return acc;
|
| 107 |
+
}, {});
|
| 108 |
+
|
| 109 |
+
return Object.entries(wildcards)
|
| 110 |
+
.sort((a, b) => b[1] - a[1])
|
| 111 |
+
.filter(x =>
|
| 112 |
+
x[0] === tagword
|
| 113 |
+
|| !matches.all.includes(x[0])
|
| 114 |
+
);
|
| 115 |
+
}
|
| 116 |
+
|
| 117 |
+
if (umiTags.length > 0) {
|
| 118 |
+
// Get difference for subprompt
|
| 119 |
+
let tagCountChange = umiTags.length - umiPreviousTags.length;
|
| 120 |
+
let diff = difference(umiTags, umiPreviousTags);
|
| 121 |
+
umiPreviousTags = umiTags;
|
| 122 |
+
|
| 123 |
+
// Show all condition
|
| 124 |
+
let showAll = tagword.endsWith("[") || tagword.endsWith("[--") || tagword.endsWith("|");
|
| 125 |
+
|
| 126 |
+
// Exit early if the user closed the bracket manually
|
| 127 |
+
if ((!diff || diff.length === 0 || (diff.length === 1 && tagCountChange < 0)) && !showAll) {
|
| 128 |
+
if (!hideBlocked) hideResults(textArea);
|
| 129 |
+
return;
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
let umiTagword = diff[0] || '';
|
| 133 |
+
let tempResults = [];
|
| 134 |
+
if (umiTagword && umiTagword.length > 0) {
|
| 135 |
+
umiTagword = umiTagword.toLowerCase().replace(/[\n\r]/g, "");
|
| 136 |
+
originalTagword = tagword;
|
| 137 |
+
tagword = umiTagword;
|
| 138 |
+
let filteredWildcardsSorted = filteredWildcards(umiTagword);
|
| 139 |
+
let searchRegex = new RegExp(`(^|[^a-zA-Z])${escapeRegExp(umiTagword)}`, 'i')
|
| 140 |
+
let baseFilter = x => x[0].toLowerCase().search(searchRegex) > -1;
|
| 141 |
+
let spaceIncludeFilter = x => x[0].toLowerCase().replaceAll(" ", "_").search(searchRegex) > -1;
|
| 142 |
+
tempResults = filteredWildcardsSorted.filter(x => baseFilter(x) || spaceIncludeFilter(x)) // Filter by tagword
|
| 143 |
+
|
| 144 |
+
// Add final results
|
| 145 |
+
let finalResults = [];
|
| 146 |
+
tempResults.forEach(t => {
|
| 147 |
+
let result = new AutocompleteResult(t[0].trim(), ResultType.yamlWildcard)
|
| 148 |
+
result.count = t[1];
|
| 149 |
+
finalResults.push(result);
|
| 150 |
+
});
|
| 151 |
+
|
| 152 |
+
return finalResults;
|
| 153 |
+
} else if (showAll) {
|
| 154 |
+
let filteredWildcardsSorted = filteredWildcards("");
|
| 155 |
+
|
| 156 |
+
// Add final results
|
| 157 |
+
let finalResults = [];
|
| 158 |
+
filteredWildcardsSorted.forEach(t => {
|
| 159 |
+
let result = new AutocompleteResult(t[0].trim(), ResultType.yamlWildcard)
|
| 160 |
+
result.count = t[1];
|
| 161 |
+
finalResults.push(result);
|
| 162 |
+
});
|
| 163 |
+
|
| 164 |
+
originalTagword = tagword;
|
| 165 |
+
tagword = "";
|
| 166 |
+
return finalResults;
|
| 167 |
+
}
|
| 168 |
+
} else {
|
| 169 |
+
let filteredWildcardsSorted = filteredWildcards("");
|
| 170 |
+
|
| 171 |
+
// Add final results
|
| 172 |
+
let finalResults = [];
|
| 173 |
+
filteredWildcardsSorted.forEach(t => {
|
| 174 |
+
let result = new AutocompleteResult(t[0].trim(), ResultType.yamlWildcard)
|
| 175 |
+
result.count = t[1];
|
| 176 |
+
finalResults.push(result);
|
| 177 |
+
});
|
| 178 |
+
|
| 179 |
+
originalTagword = tagword;
|
| 180 |
+
tagword = "";
|
| 181 |
+
return finalResults;
|
| 182 |
+
}
|
| 183 |
+
}
|
| 184 |
+
}
|
| 185 |
+
|
| 186 |
+
function updateUmiTags( tagType, sanitizedText, newPrompt, textArea) {
|
| 187 |
+
// If it was a yaml wildcard, also update the umiPreviousTags
|
| 188 |
+
if (tagType === ResultType.yamlWildcard && originalTagword.length > 0) {
|
| 189 |
+
let umiSubPrompts = [...newPrompt.matchAll(UMI_PROMPT_REGEX)];
|
| 190 |
+
|
| 191 |
+
let umiTags = [];
|
| 192 |
+
umiSubPrompts.forEach(umiSubPrompt => {
|
| 193 |
+
umiTags = umiTags.concat([...umiSubPrompt[0].matchAll(UMI_TAG_REGEX)].map(x => x[1].toLowerCase()));
|
| 194 |
+
});
|
| 195 |
+
|
| 196 |
+
umiPreviousTags = umiTags;
|
| 197 |
+
|
| 198 |
+
hideResults(textArea);
|
| 199 |
+
|
| 200 |
+
return true;
|
| 201 |
+
}
|
| 202 |
+
return false;
|
| 203 |
+
}
|
| 204 |
+
|
| 205 |
+
async function load() {
|
| 206 |
+
if (yamlWildcards.length === 0) {
|
| 207 |
+
try {
|
| 208 |
+
let yamlTags = (await readFile(`${tagBasePath}/temp/wcet.txt`)).split("\n");
|
| 209 |
+
// Split into tag, count pairs
|
| 210 |
+
yamlWildcards = yamlTags.map(x => x
|
| 211 |
+
.trim()
|
| 212 |
+
.split(","))
|
| 213 |
+
.map(([i, ...rest]) => [
|
| 214 |
+
i,
|
| 215 |
+
rest.reduce((a, b) => {
|
| 216 |
+
a[b.toLowerCase()] = true;
|
| 217 |
+
return a;
|
| 218 |
+
}, {}),
|
| 219 |
+
]);
|
| 220 |
+
} catch (e) {
|
| 221 |
+
console.error("Error loading yaml wildcards: " + e);
|
| 222 |
+
}
|
| 223 |
+
}
|
| 224 |
+
}
|
| 225 |
+
|
| 226 |
+
function sanitize(tagType, text) {
|
| 227 |
+
// Replace underscores only if the yaml tag is not using them
|
| 228 |
+
if (tagType === ResultType.yamlWildcard && !yamlWildcards.includes(text)) {
|
| 229 |
+
return text.replaceAll("_", " ");
|
| 230 |
+
}
|
| 231 |
+
return null;
|
| 232 |
+
}
|
| 233 |
+
|
| 234 |
+
// Add UMI parser
|
| 235 |
+
PARSERS.push(new UmiParser(UMI_TRIGGER));
|
| 236 |
+
|
| 237 |
+
// Add our utility functions to their respective queues
|
| 238 |
+
QUEUE_FILE_LOAD.push(load);
|
| 239 |
+
QUEUE_SANITIZE.push(sanitize);
|
| 240 |
+
QUEUE_AFTER_INSERT.push(updateUmiTags);
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/ext_wildcards.js
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Regex
|
| 2 |
+
const WC_REGEX = /\b__([^,]+)__([^, ]*)\b/g;
|
| 3 |
+
|
| 4 |
+
// Trigger conditions
|
| 5 |
+
const WC_TRIGGER = () => CFG.useWildcards && [...tagword.matchAll(WC_REGEX)].length > 0;
|
| 6 |
+
const WC_FILE_TRIGGER = () => CFG.useWildcards && (tagword.startsWith("__") && !tagword.endsWith("__") || tagword === "__");
|
| 7 |
+
|
| 8 |
+
class WildcardParser extends BaseTagParser {
|
| 9 |
+
async parse() {
|
| 10 |
+
// Show wildcards from a file with that name
|
| 11 |
+
let wcMatch = [...tagword.matchAll(WC_REGEX)]
|
| 12 |
+
let wcFile = wcMatch[0][1];
|
| 13 |
+
let wcWord = wcMatch[0][2];
|
| 14 |
+
|
| 15 |
+
// Look in normal wildcard files
|
| 16 |
+
let wcFound = wildcardFiles.find(x => x[1].toLowerCase() === wcFile);
|
| 17 |
+
// Use found wildcard file or look in external wildcard files
|
| 18 |
+
let wcPair = wcFound || wildcardExtFiles.find(x => x[1].toLowerCase() === wcFile);
|
| 19 |
+
|
| 20 |
+
let wildcards = (await readFile(`${wcPair[0]}/${wcPair[1]}.txt`)).split("\n")
|
| 21 |
+
.filter(x => x.trim().length > 0 && !x.startsWith('#')); // Remove empty lines and comments
|
| 22 |
+
|
| 23 |
+
let finalResults = [];
|
| 24 |
+
let tempResults = wildcards.filter(x => (wcWord !== null && wcWord.length > 0) ? x.toLowerCase().includes(wcWord) : x) // Filter by tagword
|
| 25 |
+
tempResults.forEach(t => {
|
| 26 |
+
let result = new AutocompleteResult(t.trim(), ResultType.wildcardTag);
|
| 27 |
+
result.meta = wcFile;
|
| 28 |
+
finalResults.push(result);
|
| 29 |
+
});
|
| 30 |
+
|
| 31 |
+
return finalResults;
|
| 32 |
+
}
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
class WildcardFileParser extends BaseTagParser {
|
| 36 |
+
parse() {
|
| 37 |
+
// Show available wildcard files
|
| 38 |
+
let tempResults = [];
|
| 39 |
+
if (tagword !== "__") {
|
| 40 |
+
let lmb = (x) => x[1].toLowerCase().includes(tagword.replace("__", ""))
|
| 41 |
+
tempResults = wildcardFiles.filter(lmb).concat(wildcardExtFiles.filter(lmb)) // Filter by tagword
|
| 42 |
+
} else {
|
| 43 |
+
tempResults = wildcardFiles.concat(wildcardExtFiles);
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
let finalResults = [];
|
| 47 |
+
// Get final results
|
| 48 |
+
tempResults.forEach(wcFile => {
|
| 49 |
+
let result = new AutocompleteResult(wcFile[1].trim(), ResultType.wildcardFile);
|
| 50 |
+
result.meta = "Wildcard file";
|
| 51 |
+
finalResults.push(result);
|
| 52 |
+
});
|
| 53 |
+
|
| 54 |
+
return finalResults;
|
| 55 |
+
}
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
async function load() {
|
| 59 |
+
if (wildcardFiles.length === 0 && wildcardExtFiles.length === 0) {
|
| 60 |
+
try {
|
| 61 |
+
let wcFileArr = (await readFile(`${tagBasePath}/temp/wc.txt`)).split("\n");
|
| 62 |
+
let wcBasePath = wcFileArr[0].trim(); // First line should be the base path
|
| 63 |
+
wildcardFiles = wcFileArr.slice(1)
|
| 64 |
+
.filter(x => x.trim().length > 0) // Remove empty lines
|
| 65 |
+
.map(x => [wcBasePath, x.trim().replace(".txt", "")]); // Remove file extension & newlines
|
| 66 |
+
|
| 67 |
+
// To support multiple sources, we need to separate them using the provided "-----" strings
|
| 68 |
+
let wcExtFileArr = (await readFile(`${tagBasePath}/temp/wce.txt`)).split("\n");
|
| 69 |
+
let splitIndices = [];
|
| 70 |
+
for (let index = 0; index < wcExtFileArr.length; index++) {
|
| 71 |
+
if (wcExtFileArr[index].trim() === "-----") {
|
| 72 |
+
splitIndices.push(index);
|
| 73 |
+
}
|
| 74 |
+
}
|
| 75 |
+
// For each group, add them to the wildcardFiles array with the base path as the first element
|
| 76 |
+
for (let i = 0; i < splitIndices.length; i++) {
|
| 77 |
+
let start = splitIndices[i - 1] || 0;
|
| 78 |
+
if (i > 0) start++; // Skip the "-----" line
|
| 79 |
+
let end = splitIndices[i];
|
| 80 |
+
|
| 81 |
+
let wcExtFile = wcExtFileArr.slice(start, end);
|
| 82 |
+
let base = wcExtFile[0].trim() + "/";
|
| 83 |
+
wcExtFile = wcExtFile.slice(1)
|
| 84 |
+
.filter(x => x.trim().length > 0) // Remove empty lines
|
| 85 |
+
.map(x => x.trim().replace(base, "").replace(".txt", "")); // Remove file extension & newlines;
|
| 86 |
+
|
| 87 |
+
wcExtFile = wcExtFile.map(x => [base, x]);
|
| 88 |
+
wildcardExtFiles.push(...wcExtFile);
|
| 89 |
+
}
|
| 90 |
+
} catch (e) {
|
| 91 |
+
console.error("Error loading wildcards: " + e);
|
| 92 |
+
}
|
| 93 |
+
}
|
| 94 |
+
}
|
| 95 |
+
|
| 96 |
+
function sanitize(tagType, text) {
|
| 97 |
+
if (tagType === ResultType.wildcardFile) {
|
| 98 |
+
return `__${text}__`;
|
| 99 |
+
} else if (tagType === ResultType.wildcardTag) {
|
| 100 |
+
return text.replace(/^.*?: /g, "");
|
| 101 |
+
}
|
| 102 |
+
return null;
|
| 103 |
+
}
|
| 104 |
+
|
| 105 |
+
function keepOpenIfWildcard(tagType, sanitizedText, newPrompt, textArea) {
|
| 106 |
+
// If it's a wildcard, we want to keep the results open so the user can select another wildcard
|
| 107 |
+
if (tagType === ResultType.wildcardFile) {
|
| 108 |
+
hideBlocked = true;
|
| 109 |
+
autocomplete(textArea, newPrompt, sanitizedText);
|
| 110 |
+
setTimeout(() => { hideBlocked = false; }, 100);
|
| 111 |
+
return true;
|
| 112 |
+
}
|
| 113 |
+
return false;
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
// Register the parsers
|
| 117 |
+
PARSERS.push(new WildcardParser(WC_TRIGGER));
|
| 118 |
+
PARSERS.push(new WildcardFileParser(WC_FILE_TRIGGER));
|
| 119 |
+
|
| 120 |
+
// Add our utility functions to their respective queues
|
| 121 |
+
QUEUE_FILE_LOAD.push(load);
|
| 122 |
+
QUEUE_SANITIZE.push(sanitize);
|
| 123 |
+
QUEUE_AFTER_INSERT.push(keepOpenIfWildcard);
|
extensions/a1111-microsoftexcel-tagcomplete/javascript/tagAutocomplete.js
ADDED
|
@@ -0,0 +1,935 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
const styleColors = {
|
| 2 |
+
"--results-bg": ["#0b0f19", "#ffffff"],
|
| 3 |
+
"--results-border-color": ["#4b5563", "#e5e7eb"],
|
| 4 |
+
"--results-border-width": ["1px", "1.5px"],
|
| 5 |
+
"--results-bg-odd": ["#111827", "#f9fafb"],
|
| 6 |
+
"--results-hover": ["#1f2937", "#f5f6f8"],
|
| 7 |
+
"--results-selected": ["#374151", "#e5e7eb"],
|
| 8 |
+
"--meta-text-color": ["#6b6f7b", "#a2a9b4"],
|
| 9 |
+
"--embedding-v1-color": ["lightsteelblue", "#2b5797"],
|
| 10 |
+
"--embedding-v2-color": ["skyblue", "#2d89ef"],
|
| 11 |
+
}
|
| 12 |
+
const browserVars = {
|
| 13 |
+
"--results-overflow-y": {
|
| 14 |
+
"firefox": "scroll",
|
| 15 |
+
"other": "auto"
|
| 16 |
+
}
|
| 17 |
+
}
|
| 18 |
+
// Style for new elements. Gets appended to the Gradio root.
|
| 19 |
+
const autocompleteCSS = `
|
| 20 |
+
#quicksettings [id^=setting_tac] {
|
| 21 |
+
background-color: transparent;
|
| 22 |
+
min-width: fit-content;
|
| 23 |
+
}
|
| 24 |
+
.autocompleteResults {
|
| 25 |
+
position: absolute;
|
| 26 |
+
z-index: 999;
|
| 27 |
+
max-width: calc(100% - 1.5rem);
|
| 28 |
+
margin: 5px 0 0 0;
|
| 29 |
+
background-color: var(--results-bg) !important;
|
| 30 |
+
border: var(--results-border-width) solid var(--results-border-color) !important;
|
| 31 |
+
border-radius: 12px !important;
|
| 32 |
+
overflow-y: var(--results-overflow-y);
|
| 33 |
+
overflow-x: hidden;
|
| 34 |
+
word-break: break-word;
|
| 35 |
+
}
|
| 36 |
+
.autocompleteResultsList > li:nth-child(odd) {
|
| 37 |
+
background-color: var(--results-bg-odd);
|
| 38 |
+
}
|
| 39 |
+
.autocompleteResultsList > li {
|
| 40 |
+
list-style-type: none;
|
| 41 |
+
padding: 10px;
|
| 42 |
+
cursor: pointer;
|
| 43 |
+
}
|
| 44 |
+
.autocompleteResultsList > li:hover {
|
| 45 |
+
background-color: var(--results-hover);
|
| 46 |
+
}
|
| 47 |
+
.autocompleteResultsList > li.selected {
|
| 48 |
+
background-color: var(--results-selected);
|
| 49 |
+
}
|
| 50 |
+
.resultsFlexContainer {
|
| 51 |
+
display: flex;
|
| 52 |
+
}
|
| 53 |
+
.acListItem {
|
| 54 |
+
white-space: break-spaces;
|
| 55 |
+
}
|
| 56 |
+
.acMetaText {
|
| 57 |
+
position: relative;
|
| 58 |
+
flex-grow: 1;
|
| 59 |
+
text-align: end;
|
| 60 |
+
padding: 0 0 0 15px;
|
| 61 |
+
white-space: nowrap;
|
| 62 |
+
color: var(--meta-text-color);
|
| 63 |
+
}
|
| 64 |
+
.acWikiLink {
|
| 65 |
+
padding: 0.5rem;
|
| 66 |
+
margin: -0.5rem 0 -0.5rem -0.5rem;
|
| 67 |
+
}
|
| 68 |
+
.acWikiLink:hover {
|
| 69 |
+
text-decoration: underline;
|
| 70 |
+
}
|
| 71 |
+
.acListItem.acEmbeddingV1 {
|
| 72 |
+
color: var(--embedding-v1-color);
|
| 73 |
+
}
|
| 74 |
+
.acListItem.acEmbeddingV2 {
|
| 75 |
+
color: var(--embedding-v2-color);
|
| 76 |
+
}
|
| 77 |
+
`;
|
| 78 |
+
|
| 79 |
+
async function loadTags(c) {
|
| 80 |
+
// Load main tags and aliases
|
| 81 |
+
if (allTags.length === 0 && c.tagFile && c.tagFile !== "None") {
|
| 82 |
+
try {
|
| 83 |
+
allTags = await loadCSV(`${tagBasePath}/${c.tagFile}`);
|
| 84 |
+
} catch (e) {
|
| 85 |
+
console.error("Error loading tags file: " + e);
|
| 86 |
+
return;
|
| 87 |
+
}
|
| 88 |
+
}
|
| 89 |
+
await loadExtraTags(c);
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
async function loadExtraTags(c) {
|
| 93 |
+
if (c.extra.extraFile && c.extra.extraFile !== "None") {
|
| 94 |
+
try {
|
| 95 |
+
extras = await loadCSV(`${tagBasePath}/${c.extra.extraFile}`);
|
| 96 |
+
// Add translations to the main translation map for extra tags that have them
|
| 97 |
+
extras.forEach(e => {
|
| 98 |
+
if (e[4]) translations.set(e[0], e[4]);
|
| 99 |
+
});
|
| 100 |
+
} catch (e) {
|
| 101 |
+
console.error("Error loading extra file: " + e);
|
| 102 |
+
return;
|
| 103 |
+
}
|
| 104 |
+
}
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
async function loadTranslations(c) {
|
| 108 |
+
if (c.translation.translationFile && c.translation.translationFile !== "None") {
|
| 109 |
+
try {
|
| 110 |
+
let tArray = await loadCSV(`${tagBasePath}/${c.translation.translationFile}`);
|
| 111 |
+
tArray.forEach(t => {
|
| 112 |
+
if (c.translation.oldFormat)
|
| 113 |
+
translations.set(t[0], t[2]);
|
| 114 |
+
else
|
| 115 |
+
translations.set(t[0], t[1]);
|
| 116 |
+
});
|
| 117 |
+
} catch (e) {
|
| 118 |
+
console.error("Error loading translations file: " + e);
|
| 119 |
+
return;
|
| 120 |
+
}
|
| 121 |
+
}
|
| 122 |
+
}
|
| 123 |
+
|
| 124 |
+
async function syncOptions() {
|
| 125 |
+
let newCFG = {
|
| 126 |
+
// Main tag file
|
| 127 |
+
tagFile: opts["tac_tagFile"],
|
| 128 |
+
// Active in settings
|
| 129 |
+
activeIn: {
|
| 130 |
+
global: opts["tac_active"],
|
| 131 |
+
txt2img: opts["tac_activeIn.txt2img"],
|
| 132 |
+
img2img: opts["tac_activeIn.img2img"],
|
| 133 |
+
negativePrompts: opts["tac_activeIn.negativePrompts"],
|
| 134 |
+
thirdParty: opts["tac_activeIn.thirdParty"],
|
| 135 |
+
modelList: opts["tac_activeIn.modelList"],
|
| 136 |
+
modelListMode: opts["tac_activeIn.modelListMode"]
|
| 137 |
+
},
|
| 138 |
+
// Results related settings
|
| 139 |
+
slidingPopup: opts["tac_slidingPopup"],
|
| 140 |
+
maxResults: opts["tac_maxResults"],
|
| 141 |
+
showAllResults: opts["tac_showAllResults"],
|
| 142 |
+
resultStepLength: opts["tac_resultStepLength"],
|
| 143 |
+
delayTime: opts["tac_delayTime"],
|
| 144 |
+
useWildcards: opts["tac_useWildcards"],
|
| 145 |
+
useEmbeddings: opts["tac_useEmbeddings"],
|
| 146 |
+
useHypernetworks: opts["tac_useHypernetworks"],
|
| 147 |
+
useLoras: opts["tac_useLoras"],
|
| 148 |
+
useLycos: opts["tac_useLycos"],
|
| 149 |
+
showWikiLinks: opts["tac_showWikiLinks"],
|
| 150 |
+
// Insertion related settings
|
| 151 |
+
replaceUnderscores: opts["tac_replaceUnderscores"],
|
| 152 |
+
escapeParentheses: opts["tac_escapeParentheses"],
|
| 153 |
+
appendComma: opts["tac_appendComma"],
|
| 154 |
+
// Alias settings
|
| 155 |
+
alias: {
|
| 156 |
+
searchByAlias: opts["tac_alias.searchByAlias"],
|
| 157 |
+
onlyShowAlias: opts["tac_alias.onlyShowAlias"]
|
| 158 |
+
},
|
| 159 |
+
// Translation settings
|
| 160 |
+
translation: {
|
| 161 |
+
translationFile: opts["tac_translation.translationFile"],
|
| 162 |
+
oldFormat: opts["tac_translation.oldFormat"],
|
| 163 |
+
searchByTranslation: opts["tac_translation.searchByTranslation"],
|
| 164 |
+
},
|
| 165 |
+
// Extra file settings
|
| 166 |
+
extra: {
|
| 167 |
+
extraFile: opts["tac_extra.extraFile"],
|
| 168 |
+
addMode: opts["tac_extra.addMode"]
|
| 169 |
+
},
|
| 170 |
+
// Settings not from tac but still used by the script
|
| 171 |
+
extraNetworksDefaultMultiplier: opts["extra_networks_default_multiplier"],
|
| 172 |
+
extraNetworksSeparator: opts["extra_networks_add_text_separator"],
|
| 173 |
+
// Custom mapping settings
|
| 174 |
+
keymap: JSON.parse(opts["tac_keymap"]),
|
| 175 |
+
colorMap: JSON.parse(opts["tac_colormap"])
|
| 176 |
+
}
|
| 177 |
+
if (newCFG.alias.onlyShowAlias) {
|
| 178 |
+
newCFG.alias.searchByAlias = true; // if only show translation, enable search by translation is necessary
|
| 179 |
+
}
|
| 180 |
+
|
| 181 |
+
// Reload translations if the translation file changed
|
| 182 |
+
if (!CFG || newCFG.translation.translationFile !== CFG.translation.translationFile) {
|
| 183 |
+
translations.clear();
|
| 184 |
+
await loadTranslations(newCFG);
|
| 185 |
+
await loadExtraTags(newCFG);
|
| 186 |
+
}
|
| 187 |
+
// Reload tags if the tag file changed (after translations so extra tag translations get re-added)
|
| 188 |
+
if (!CFG || newCFG.tagFile !== CFG.tagFile || newCFG.extra.extraFile !== CFG.extra.extraFile) {
|
| 189 |
+
allTags = [];
|
| 190 |
+
await loadTags(newCFG);
|
| 191 |
+
}
|
| 192 |
+
|
| 193 |
+
// Update CSS if maxResults changed
|
| 194 |
+
if (CFG && newCFG.maxResults !== CFG.maxResults) {
|
| 195 |
+
gradioApp().querySelectorAll(".autocompleteResults").forEach(r => {
|
| 196 |
+
r.style.maxHeight = `${newCFG.maxResults * 50}px`;
|
| 197 |
+
});
|
| 198 |
+
}
|
| 199 |
+
|
| 200 |
+
// Apply changes
|
| 201 |
+
CFG = newCFG;
|
| 202 |
+
|
| 203 |
+
// Callback
|
| 204 |
+
await processQueue(QUEUE_AFTER_CONFIG_CHANGE, null);
|
| 205 |
+
}
|
| 206 |
+
|
| 207 |
+
// Create the result list div and necessary styling
|
| 208 |
+
function createResultsDiv(textArea) {
|
| 209 |
+
let resultsDiv = document.createElement("div");
|
| 210 |
+
let resultsList = document.createElement("ul");
|
| 211 |
+
|
| 212 |
+
let textAreaId = getTextAreaIdentifier(textArea);
|
| 213 |
+
let typeClass = textAreaId.replaceAll(".", " ");
|
| 214 |
+
|
| 215 |
+
resultsDiv.style.maxHeight = `${CFG.maxResults * 50}px`;
|
| 216 |
+
resultsDiv.setAttribute("class", `autocompleteResults ${typeClass} notranslate`);
|
| 217 |
+
resultsDiv.setAttribute("translate", "no");
|
| 218 |
+
resultsList.setAttribute("class", "autocompleteResultsList");
|
| 219 |
+
resultsDiv.appendChild(resultsList);
|
| 220 |
+
|
| 221 |
+
return resultsDiv;
|
| 222 |
+
}
|
| 223 |
+
|
| 224 |
+
// Show or hide the results div
|
| 225 |
+
function isVisible(textArea) {
|
| 226 |
+
let textAreaId = getTextAreaIdentifier(textArea);
|
| 227 |
+
let resultsDiv = gradioApp().querySelector('.autocompleteResults' + textAreaId);
|
| 228 |
+
return resultsDiv.style.display === "block";
|
| 229 |
+
}
|
| 230 |
+
function showResults(textArea) {
|
| 231 |
+
let textAreaId = getTextAreaIdentifier(textArea);
|
| 232 |
+
let resultsDiv = gradioApp().querySelector('.autocompleteResults' + textAreaId);
|
| 233 |
+
resultsDiv.style.display = "block";
|
| 234 |
+
|
| 235 |
+
if (CFG.slidingPopup) {
|
| 236 |
+
let caretPosition = getCaretCoordinates(textArea, textArea.selectionEnd).left;
|
| 237 |
+
let offset = Math.min(textArea.offsetLeft - textArea.scrollLeft + caretPosition, textArea.offsetWidth - resultsDiv.offsetWidth);
|
| 238 |
+
|
| 239 |
+
resultsDiv.style.left = `${offset}px`;
|
| 240 |
+
} else {
|
| 241 |
+
if (resultsDiv.style.left)
|
| 242 |
+
resultsDiv.style.removeProperty("left");
|
| 243 |
+
}
|
| 244 |
+
}
|
| 245 |
+
function hideResults(textArea) {
|
| 246 |
+
let textAreaId = getTextAreaIdentifier(textArea);
|
| 247 |
+
let resultsDiv = gradioApp().querySelector('.autocompleteResults' + textAreaId);
|
| 248 |
+
|
| 249 |
+
if (!resultsDiv) return;
|
| 250 |
+
|
| 251 |
+
resultsDiv.style.display = "none";
|
| 252 |
+
selectedTag = null;
|
| 253 |
+
}
|
| 254 |
+
|
| 255 |
+
// Function to check activation criteria
|
| 256 |
+
function isEnabled() {
|
| 257 |
+
if (CFG.activeIn.global) {
|
| 258 |
+
// Skip check if the current model was not correctly detected, since it could wrongly disable the script otherwise
|
| 259 |
+
if (!currentModelName || !currentModelHash) return true;
|
| 260 |
+
|
| 261 |
+
let modelList = CFG.activeIn.modelList
|
| 262 |
+
.split(",")
|
| 263 |
+
.map(x => x.trim())
|
| 264 |
+
.filter(x => x.length > 0);
|
| 265 |
+
|
| 266 |
+
let shortHash = currentModelHash.substring(0, 10);
|
| 267 |
+
let modelNameWithoutHash = currentModelName.replace(/\[.*\]$/g, "").trim();
|
| 268 |
+
if (CFG.activeIn.modelListMode.toLowerCase() === "blacklist") {
|
| 269 |
+
// If the current model is in the blacklist, disable
|
| 270 |
+
return modelList.filter(x => x === currentModelName || x === modelNameWithoutHash || x === currentModelHash || x === shortHash).length === 0;
|
| 271 |
+
} else {
|
| 272 |
+
// If the current model is in the whitelist, enable.
|
| 273 |
+
// An empty whitelist is ignored.
|
| 274 |
+
return modelList.length === 0 || modelList.filter(x => x === currentModelName || x === modelNameWithoutHash || x === currentModelHash || x === shortHash).length > 0;
|
| 275 |
+
}
|
| 276 |
+
} else {
|
| 277 |
+
return false;
|
| 278 |
+
}
|
| 279 |
+
}
|
| 280 |
+
|
| 281 |
+
const WEIGHT_REGEX = /[([]([^()[\]:|]+)(?::(?:\d+(?:\.\d+)?|\.\d+))?[)\]]/g;
|
| 282 |
+
const POINTY_REGEX = /<[^\s,<](?:[^\t\n\r,<>]*>|[^\t\n\r,> ]*)/g;
|
| 283 |
+
const COMPLETED_WILDCARD_REGEX = /__[^\s,_][^\t\n\r,_]*[^\s,_]__[^\s,_]*/g;
|
| 284 |
+
const NORMAL_TAG_REGEX = /[^\s,|<>)\]]+|</g;
|
| 285 |
+
const TAG_REGEX = new RegExp(`${POINTY_REGEX.source}|${COMPLETED_WILDCARD_REGEX.source}|${NORMAL_TAG_REGEX.source}`, "g");
|
| 286 |
+
|
| 287 |
+
// On click, insert the tag into the prompt textbox with respect to the cursor position
|
| 288 |
+
async function insertTextAtCursor(textArea, result, tagword) {
|
| 289 |
+
let text = result.text;
|
| 290 |
+
let tagType = result.type;
|
| 291 |
+
|
| 292 |
+
let cursorPos = textArea.selectionStart;
|
| 293 |
+
var sanitizedText = text
|
| 294 |
+
|
| 295 |
+
// Run sanitize queue and use first result as sanitized text
|
| 296 |
+
sanitizeResults = await processQueueReturn(QUEUE_SANITIZE, null, tagType, text);
|
| 297 |
+
|
| 298 |
+
if (sanitizeResults && sanitizeResults.length > 0) {
|
| 299 |
+
sanitizedText = sanitizeResults[0];
|
| 300 |
+
} else {
|
| 301 |
+
sanitizedText = CFG.replaceUnderscores ? text.replaceAll("_", " ") : text;
|
| 302 |
+
|
| 303 |
+
if (CFG.escapeParentheses && tagType === ResultType.tag) {
|
| 304 |
+
sanitizedText = sanitizedText
|
| 305 |
+
.replaceAll("(", "\\(")
|
| 306 |
+
.replaceAll(")", "\\)")
|
| 307 |
+
.replaceAll("[", "\\[")
|
| 308 |
+
.replaceAll("]", "\\]");
|
| 309 |
+
}
|
| 310 |
+
}
|
| 311 |
+
|
| 312 |
+
var prompt = textArea.value;
|
| 313 |
+
|
| 314 |
+
// Edit prompt text
|
| 315 |
+
let editStart = Math.max(cursorPos - tagword.length, 0);
|
| 316 |
+
let editEnd = Math.min(cursorPos + tagword.length, prompt.length);
|
| 317 |
+
let surrounding = prompt.substring(editStart, editEnd);
|
| 318 |
+
let match = surrounding.match(new RegExp(escapeRegExp(`${tagword}`), "i"));
|
| 319 |
+
let afterInsertCursorPos = editStart + match.index + sanitizedText.length;
|
| 320 |
+
|
| 321 |
+
var optionalSeparator = "";
|
| 322 |
+
let extraNetworkTypes = [ResultType.hypernetwork, ResultType.lora];
|
| 323 |
+
let noCommaTypes = [ResultType.wildcardFile, ResultType.yamlWildcard].concat(extraNetworkTypes);
|
| 324 |
+
if (CFG.appendComma && !noCommaTypes.includes(tagType)) {
|
| 325 |
+
optionalSeparator = surrounding.match(new RegExp(`${escapeRegExp(tagword)}[,:]`, "i")) !== null ? "" : ", ";
|
| 326 |
+
} else if (extraNetworkTypes.includes(tagType)) {
|
| 327 |
+
// Use the dedicated separator for extra networks if it's defined, otherwise fall back to space
|
| 328 |
+
optionalSeparator = CFG.extraNetworksSeparator || " ";
|
| 329 |
+
}
|
| 330 |
+
|
| 331 |
+
// Replace partial tag word with new text, add comma if needed
|
| 332 |
+
let insert = surrounding.replace(match, sanitizedText + optionalSeparator);
|
| 333 |
+
|
| 334 |
+
// Add back start
|
| 335 |
+
var newPrompt = prompt.substring(0, editStart) + insert + prompt.substring(editEnd);
|
| 336 |
+
textArea.value = newPrompt;
|
| 337 |
+
textArea.selectionStart = afterInsertCursorPos + optionalSeparator.length;
|
| 338 |
+
textArea.selectionEnd = textArea.selectionStart
|
| 339 |
+
|
| 340 |
+
// Since we've modified a Gradio Textbox component manually, we need to simulate an `input` DOM event to ensure it's propagated back to python.
|
| 341 |
+
// Uses a built-in method from the webui's ui.js which also already accounts for event target
|
| 342 |
+
updateInput(textArea);
|
| 343 |
+
|
| 344 |
+
// Update previous tags with the edited prompt to prevent re-searching the same term
|
| 345 |
+
let weightedTags = [...newPrompt.matchAll(WEIGHT_REGEX)]
|
| 346 |
+
.map(match => match[1]);
|
| 347 |
+
let tags = newPrompt.match(TAG_REGEX)
|
| 348 |
+
if (weightedTags !== null) {
|
| 349 |
+
tags = tags.filter(tag => !weightedTags.some(weighted => tag.includes(weighted)))
|
| 350 |
+
.concat(weightedTags);
|
| 351 |
+
}
|
| 352 |
+
previousTags = tags;
|
| 353 |
+
|
| 354 |
+
// Callback
|
| 355 |
+
let returns = await processQueueReturn(QUEUE_AFTER_INSERT, null, tagType, sanitizedText, newPrompt, textArea);
|
| 356 |
+
// Return if any queue function returned true (has handled hide/show already)
|
| 357 |
+
if (returns.some(x => x === true))
|
| 358 |
+
return;
|
| 359 |
+
|
| 360 |
+
// Hide results after inserting, if it hasn't been hidden already by a queue function
|
| 361 |
+
if (!hideBlocked && isVisible(textArea)) {
|
| 362 |
+
hideResults(textArea);
|
| 363 |
+
}
|
| 364 |
+
}
|
| 365 |
+
|
| 366 |
+
function addResultsToList(textArea, results, tagword, resetList) {
|
| 367 |
+
let textAreaId = getTextAreaIdentifier(textArea);
|
| 368 |
+
let resultDiv = gradioApp().querySelector('.autocompleteResults' + textAreaId);
|
| 369 |
+
let resultsList = resultDiv.querySelector('ul');
|
| 370 |
+
|
| 371 |
+
// Reset list, selection and scrollTop since the list changed
|
| 372 |
+
if (resetList) {
|
| 373 |
+
resultsList.innerHTML = "";
|
| 374 |
+
selectedTag = null;
|
| 375 |
+
resultDiv.scrollTop = 0;
|
| 376 |
+
resultCount = 0;
|
| 377 |
+
}
|
| 378 |
+
|
| 379 |
+
// Find right colors from config
|
| 380 |
+
let tagFileName = CFG.tagFile.split(".")[0];
|
| 381 |
+
let tagColors = CFG.colorMap;
|
| 382 |
+
let mode = (document.querySelector(".dark") || gradioApp().querySelector(".dark")) ? 0 : 1;
|
| 383 |
+
let nextLength = Math.min(results.length, resultCount + CFG.resultStepLength);
|
| 384 |
+
|
| 385 |
+
for (let i = resultCount; i < nextLength; i++) {
|
| 386 |
+
let result = results[i];
|
| 387 |
+
|
| 388 |
+
// Skip if the result is null or undefined
|
| 389 |
+
if (!result)
|
| 390 |
+
continue;
|
| 391 |
+
|
| 392 |
+
let li = document.createElement("li");
|
| 393 |
+
|
| 394 |
+
let flexDiv = document.createElement("div");
|
| 395 |
+
flexDiv.classList.add("resultsFlexContainer");
|
| 396 |
+
li.appendChild(flexDiv);
|
| 397 |
+
|
| 398 |
+
let itemText = document.createElement("div");
|
| 399 |
+
itemText.classList.add("acListItem");
|
| 400 |
+
|
| 401 |
+
let displayText = "";
|
| 402 |
+
// If the tag matches the tagword, we don't need to display the alias
|
| 403 |
+
if (result.aliases && !result.text.includes(tagword)) { // Alias
|
| 404 |
+
let splitAliases = result.aliases.split(",");
|
| 405 |
+
let bestAlias = splitAliases.find(a => a.toLowerCase().includes(tagword));
|
| 406 |
+
|
| 407 |
+
// search in translations if no alias matches
|
| 408 |
+
if (!bestAlias) {
|
| 409 |
+
let tagOrAlias = pair => pair[0] === result.text || splitAliases.includes(pair[0]);
|
| 410 |
+
var tArray = [...translations];
|
| 411 |
+
if (tArray) {
|
| 412 |
+
var translationKey = [...translations].find(pair => tagOrAlias(pair) && pair[1].includes(tagword));
|
| 413 |
+
if (translationKey)
|
| 414 |
+
bestAlias = translationKey[0];
|
| 415 |
+
}
|
| 416 |
+
}
|
| 417 |
+
|
| 418 |
+
displayText = escapeHTML(bestAlias);
|
| 419 |
+
|
| 420 |
+
// Append translation for alias if it exists and is not what the user typed
|
| 421 |
+
if (translations.has(bestAlias) && translations.get(bestAlias) !== bestAlias && bestAlias !== result.text)
|
| 422 |
+
displayText += `[${translations.get(bestAlias)}]`;
|
| 423 |
+
|
| 424 |
+
if (!CFG.alias.onlyShowAlias && result.text !== bestAlias)
|
| 425 |
+
displayText += " ➝ " + result.text;
|
| 426 |
+
} else { // No alias
|
| 427 |
+
displayText = escapeHTML(result.text);
|
| 428 |
+
}
|
| 429 |
+
|
| 430 |
+
// Append translation for result if it exists
|
| 431 |
+
if (translations.has(result.text))
|
| 432 |
+
displayText += `[${translations.get(result.text)}]`;
|
| 433 |
+
|
| 434 |
+
// Print search term bolded in result
|
| 435 |
+
itemText.innerHTML = displayText.replace(tagword, `<b>${tagword}</b>`);
|
| 436 |
+
|
| 437 |
+
// Add wiki link if the setting is enabled and a supported tag set loaded
|
| 438 |
+
if (CFG.showWikiLinks
|
| 439 |
+
&& (result.type === ResultType.tag)
|
| 440 |
+
&& (tagFileName.toLowerCase().startsWith("danbooru") || tagFileName.toLowerCase().startsWith("e621"))) {
|
| 441 |
+
let wikiLink = document.createElement("a");
|
| 442 |
+
wikiLink.classList.add("acWikiLink");
|
| 443 |
+
wikiLink.innerText = "?";
|
| 444 |
+
|
| 445 |
+
let linkPart = displayText;
|
| 446 |
+
// Only use alias result if it is one
|
| 447 |
+
if (displayText.includes("➝"))
|
| 448 |
+
linkPart = displayText.split(" ➝ ")[1];
|
| 449 |
+
|
| 450 |
+
// Set link based on selected file
|
| 451 |
+
let tagFileNameLower = tagFileName.toLowerCase();
|
| 452 |
+
if (tagFileNameLower.startsWith("danbooru")) {
|
| 453 |
+
wikiLink.href = `https://danbooru.donmai.us/wiki_pages/${linkPart}`;
|
| 454 |
+
} else if (tagFileNameLower.startsWith("e621")) {
|
| 455 |
+
wikiLink.href = `https://e621.net/wiki_pages/${linkPart}`;
|
| 456 |
+
}
|
| 457 |
+
|
| 458 |
+
wikiLink.target = "_blank";
|
| 459 |
+
flexDiv.appendChild(wikiLink);
|
| 460 |
+
}
|
| 461 |
+
|
| 462 |
+
flexDiv.appendChild(itemText);
|
| 463 |
+
|
| 464 |
+
// Add post count & color if it's a tag
|
| 465 |
+
// Wildcards & Embeds have no tag category
|
| 466 |
+
if (result.category) {
|
| 467 |
+
// Set the color of the tag
|
| 468 |
+
let cat = result.category;
|
| 469 |
+
let colorGroup = tagColors[tagFileName];
|
| 470 |
+
// Default to danbooru scheme if no matching one is found
|
| 471 |
+
if (!colorGroup)
|
| 472 |
+
colorGroup = tagColors["danbooru"];
|
| 473 |
+
|
| 474 |
+
// Set tag type to invalid if not found
|
| 475 |
+
if (!colorGroup[cat])
|
| 476 |
+
cat = "-1";
|
| 477 |
+
|
| 478 |
+
flexDiv.style = `color: ${colorGroup[cat][mode]};`;
|
| 479 |
+
}
|
| 480 |
+
|
| 481 |
+
// Post count
|
| 482 |
+
if (result.count && !isNaN(result.count)) {
|
| 483 |
+
let postCount = result.count;
|
| 484 |
+
let formatter;
|
| 485 |
+
|
| 486 |
+
// Danbooru formats numbers with a padded fraction for 1M or 1k, but not for 10/100k
|
| 487 |
+
if (postCount >= 1000000 || (postCount >= 1000 && postCount < 10000))
|
| 488 |
+
formatter = Intl.NumberFormat("en", { notation: "compact", minimumFractionDigits: 1, maximumFractionDigits: 1 });
|
| 489 |
+
else
|
| 490 |
+
formatter = Intl.NumberFormat("en", {notation: "compact"});
|
| 491 |
+
|
| 492 |
+
let formattedCount = formatter.format(postCount);
|
| 493 |
+
|
| 494 |
+
let countDiv = document.createElement("div");
|
| 495 |
+
countDiv.textContent = formattedCount;
|
| 496 |
+
countDiv.classList.add("acMetaText");
|
| 497 |
+
flexDiv.appendChild(countDiv);
|
| 498 |
+
} else if (result.meta) { // Check if there is meta info to display
|
| 499 |
+
let metaDiv = document.createElement("div");
|
| 500 |
+
metaDiv.textContent = result.meta;
|
| 501 |
+
metaDiv.classList.add("acMetaText");
|
| 502 |
+
|
| 503 |
+
// Add version info classes if it is an embedding
|
| 504 |
+
if (result.type === ResultType.embedding) {
|
| 505 |
+
if (result.meta.startsWith("v1"))
|
| 506 |
+
itemText.classList.add("acEmbeddingV1");
|
| 507 |
+
else if (result.meta.startsWith("v2"))
|
| 508 |
+
itemText.classList.add("acEmbeddingV2");
|
| 509 |
+
}
|
| 510 |
+
|
| 511 |
+
flexDiv.appendChild(metaDiv);
|
| 512 |
+
}
|
| 513 |
+
|
| 514 |
+
// Add listener
|
| 515 |
+
li.addEventListener("click", function () { insertTextAtCursor(textArea, result, tagword); });
|
| 516 |
+
// Add element to list
|
| 517 |
+
resultsList.appendChild(li);
|
| 518 |
+
}
|
| 519 |
+
resultCount = nextLength;
|
| 520 |
+
|
| 521 |
+
if (resetList)
|
| 522 |
+
resultDiv.scrollTop = 0;
|
| 523 |
+
}
|
| 524 |
+
|
| 525 |
+
function updateSelectionStyle(textArea, newIndex, oldIndex) {
|
| 526 |
+
let textAreaId = getTextAreaIdentifier(textArea);
|
| 527 |
+
let resultDiv = gradioApp().querySelector('.autocompleteResults' + textAreaId);
|
| 528 |
+
let resultsList = resultDiv.querySelector('ul');
|
| 529 |
+
let items = resultsList.getElementsByTagName('li');
|
| 530 |
+
|
| 531 |
+
if (oldIndex != null) {
|
| 532 |
+
items[oldIndex].classList.remove('selected');
|
| 533 |
+
}
|
| 534 |
+
|
| 535 |
+
// make it safer
|
| 536 |
+
if (newIndex !== null) {
|
| 537 |
+
items[newIndex].classList.add('selected');
|
| 538 |
+
}
|
| 539 |
+
|
| 540 |
+
// Set scrolltop to selected item if we are showing more than max results
|
| 541 |
+
if (items.length > CFG.maxResults) {
|
| 542 |
+
let selected = items[newIndex];
|
| 543 |
+
resultDiv.scrollTop = selected.offsetTop - resultDiv.offsetTop;
|
| 544 |
+
}
|
| 545 |
+
}
|
| 546 |
+
|
| 547 |
+
async function autocomplete(textArea, prompt, fixedTag = null) {
|
| 548 |
+
// Return if the function is deactivated in the UI
|
| 549 |
+
if (!isEnabled()) return;
|
| 550 |
+
|
| 551 |
+
// Guard for empty prompt
|
| 552 |
+
if (prompt.length === 0) {
|
| 553 |
+
hideResults(textArea);
|
| 554 |
+
previousTags = [];
|
| 555 |
+
tagword = "";
|
| 556 |
+
return;
|
| 557 |
+
}
|
| 558 |
+
|
| 559 |
+
if (fixedTag === null) {
|
| 560 |
+
// Match tags with RegEx to get the last edited one
|
| 561 |
+
// We also match for the weighting format (e.g. "tag:1.0") here, and combine the two to get the full tag word set
|
| 562 |
+
let weightedTags = [...prompt.matchAll(WEIGHT_REGEX)]
|
| 563 |
+
.map(match => match[1]);
|
| 564 |
+
let tags = prompt.match(TAG_REGEX)
|
| 565 |
+
if (weightedTags !== null && tags !== null) {
|
| 566 |
+
tags = tags.filter(tag => !weightedTags.some(weighted => tag.includes(weighted) && !tag.startsWith("<[")))
|
| 567 |
+
.concat(weightedTags);
|
| 568 |
+
}
|
| 569 |
+
|
| 570 |
+
// Guard for no tags
|
| 571 |
+
if (!tags || tags.length === 0) {
|
| 572 |
+
previousTags = [];
|
| 573 |
+
tagword = "";
|
| 574 |
+
hideResults(textArea);
|
| 575 |
+
return;
|
| 576 |
+
}
|
| 577 |
+
|
| 578 |
+
let tagCountChange = tags.length - previousTags.length;
|
| 579 |
+
let diff = difference(tags, previousTags);
|
| 580 |
+
previousTags = tags;
|
| 581 |
+
|
| 582 |
+
// Guard for no difference / only whitespace remaining / last edited tag was fully removed
|
| 583 |
+
if (diff === null || diff.length === 0 || (diff.length === 1 && tagCountChange < 0)) {
|
| 584 |
+
if (!hideBlocked) hideResults(textArea);
|
| 585 |
+
return;
|
| 586 |
+
}
|
| 587 |
+
|
| 588 |
+
tagword = diff[0]
|
| 589 |
+
|
| 590 |
+
// Guard for empty tagword
|
| 591 |
+
if (tagword === null || tagword.length === 0) {
|
| 592 |
+
hideResults(textArea);
|
| 593 |
+
return;
|
| 594 |
+
}
|
| 595 |
+
} else {
|
| 596 |
+
tagword = fixedTag;
|
| 597 |
+
}
|
| 598 |
+
|
| 599 |
+
results = [];
|
| 600 |
+
tagword = tagword.toLowerCase().replace(/[\n\r]/g, "");
|
| 601 |
+
|
| 602 |
+
// Process all parsers
|
| 603 |
+
let resultCandidates = await processParsers(textArea, prompt);
|
| 604 |
+
// If one ore more result candidates match, use their results
|
| 605 |
+
if (resultCandidates && resultCandidates.length > 0) {
|
| 606 |
+
// Flatten our candidate(s)
|
| 607 |
+
results = resultCandidates.flat();
|
| 608 |
+
// If there was more than one candidate, sort the results by text to mix them
|
| 609 |
+
// instead of having them added in the order of the parsers
|
| 610 |
+
let shouldSort = resultCandidates.length > 1;
|
| 611 |
+
if (shouldSort) {
|
| 612 |
+
results = results.sort((a, b) => a.text.localeCompare(b.text));
|
| 613 |
+
|
| 614 |
+
// Since some tags are kaomoji, we have to add the normal results in some cases
|
| 615 |
+
if (tagword.startsWith("<") || tagword.startsWith("*<")) {
|
| 616 |
+
// Create escaped search regex with support for * as a start placeholder
|
| 617 |
+
let searchRegex;
|
| 618 |
+
if (tagword.startsWith("*")) {
|
| 619 |
+
tagword = tagword.slice(1);
|
| 620 |
+
searchRegex = new RegExp(`${escapeRegExp(tagword)}`, 'i');
|
| 621 |
+
} else {
|
| 622 |
+
searchRegex = new RegExp(`(^|[^a-zA-Z])${escapeRegExp(tagword)}`, 'i');
|
| 623 |
+
}
|
| 624 |
+
let genericResults = allTags.filter(x => x[0].toLowerCase().search(searchRegex) > -1).slice(0, CFG.maxResults);
|
| 625 |
+
|
| 626 |
+
genericResults.forEach(g => {
|
| 627 |
+
let result = new AutocompleteResult(g[0].trim(), ResultType.tag)
|
| 628 |
+
result.category = g[1];
|
| 629 |
+
result.count = g[2];
|
| 630 |
+
result.aliases = g[3];
|
| 631 |
+
results.push(result);
|
| 632 |
+
});
|
| 633 |
+
}
|
| 634 |
+
}
|
| 635 |
+
} else { // Else search the normal tag list
|
| 636 |
+
// Create escaped search regex with support for * as a start placeholder
|
| 637 |
+
let searchRegex;
|
| 638 |
+
if (tagword.startsWith("*")) {
|
| 639 |
+
tagword = tagword.slice(1);
|
| 640 |
+
searchRegex = new RegExp(`${escapeRegExp(tagword)}`, 'i');
|
| 641 |
+
} else {
|
| 642 |
+
searchRegex = new RegExp(`(^|[^a-zA-Z])${escapeRegExp(tagword)}`, 'i');
|
| 643 |
+
}
|
| 644 |
+
|
| 645 |
+
// Both normal tags and aliases/translations are included depending on the config
|
| 646 |
+
let baseFilter = (x) => x[0].toLowerCase().search(searchRegex) > -1;
|
| 647 |
+
let aliasFilter = (x) => x[3] && x[3].toLowerCase().search(searchRegex) > -1;
|
| 648 |
+
let translationFilter = (x) => (translations.has(x[0]) && translations.get(x[0]).toLowerCase().search(searchRegex) > -1)
|
| 649 |
+
|| x[3] && x[3].split(",").some(y => translations.has(y) && translations.get(y).toLowerCase().search(searchRegex) > -1);
|
| 650 |
+
|
| 651 |
+
let fil;
|
| 652 |
+
if (CFG.alias.searchByAlias && CFG.translation.searchByTranslation)
|
| 653 |
+
fil = (x) => baseFilter(x) || aliasFilter(x) || translationFilter(x);
|
| 654 |
+
else if (CFG.alias.searchByAlias && !CFG.translation.searchByTranslation)
|
| 655 |
+
fil = (x) => baseFilter(x) || aliasFilter(x);
|
| 656 |
+
else if (CFG.translation.searchByTranslation && !CFG.alias.searchByAlias)
|
| 657 |
+
fil = (x) => baseFilter(x) || translationFilter(x);
|
| 658 |
+
else
|
| 659 |
+
fil = (x) => baseFilter(x);
|
| 660 |
+
|
| 661 |
+
// Add final results
|
| 662 |
+
allTags.filter(fil).forEach(t => {
|
| 663 |
+
let result = new AutocompleteResult(t[0].trim(), ResultType.tag)
|
| 664 |
+
result.category = t[1];
|
| 665 |
+
result.count = t[2];
|
| 666 |
+
result.aliases = t[3];
|
| 667 |
+
results.push(result);
|
| 668 |
+
});
|
| 669 |
+
|
| 670 |
+
// Add extras
|
| 671 |
+
if (CFG.extra.extraFile) {
|
| 672 |
+
let extraResults = [];
|
| 673 |
+
|
| 674 |
+
extras.filter(fil).forEach(e => {
|
| 675 |
+
let result = new AutocompleteResult(e[0].trim(), ResultType.extra)
|
| 676 |
+
result.category = e[1] || 0; // If no category is given, use 0 as the default
|
| 677 |
+
result.meta = e[2] || "Custom tag";
|
| 678 |
+
result.aliases = e[3] || "";
|
| 679 |
+
extraResults.push(result);
|
| 680 |
+
});
|
| 681 |
+
|
| 682 |
+
if (CFG.extra.addMode === "Insert before") {
|
| 683 |
+
results = extraResults.concat(results);
|
| 684 |
+
} else {
|
| 685 |
+
results = results.concat(extraResults);
|
| 686 |
+
}
|
| 687 |
+
}
|
| 688 |
+
|
| 689 |
+
// Slice if the user has set a max result count
|
| 690 |
+
if (!CFG.showAllResults) {
|
| 691 |
+
results = results.slice(0, CFG.maxResults);
|
| 692 |
+
}
|
| 693 |
+
}
|
| 694 |
+
|
| 695 |
+
// Guard for empty results
|
| 696 |
+
if (!results || results.length === 0) {
|
| 697 |
+
//console.log('No results found for "' + tagword + '"');
|
| 698 |
+
hideResults(textArea);
|
| 699 |
+
return;
|
| 700 |
+
}
|
| 701 |
+
|
| 702 |
+
addResultsToList(textArea, results, tagword, true);
|
| 703 |
+
showResults(textArea);
|
| 704 |
+
}
|
| 705 |
+
|
| 706 |
+
function navigateInList(textArea, event) {
|
| 707 |
+
// Return if the function is deactivated in the UI or the current model is excluded due to white/blacklist settings
|
| 708 |
+
if (!isEnabled()) return;
|
| 709 |
+
|
| 710 |
+
let keys = CFG.keymap;
|
| 711 |
+
|
| 712 |
+
// Close window if Home or End is pressed while not a keybinding, since it would break completion on leaving the original tag
|
| 713 |
+
if ((event.key === "Home" || event.key === "End") && !Object.values(keys).includes(event.key)) {
|
| 714 |
+
hideResults(textArea);
|
| 715 |
+
return;
|
| 716 |
+
}
|
| 717 |
+
|
| 718 |
+
// All set keys that are not None or empty are valid
|
| 719 |
+
// Default keys are: ArrowUp, ArrowDown, PageUp, PageDown, Home, End, Enter, Tab, Escape
|
| 720 |
+
validKeys = Object.values(keys).filter(x => x !== "None" && x !== "");
|
| 721 |
+
|
| 722 |
+
if (!validKeys.includes(event.key)) return;
|
| 723 |
+
if (!isVisible(textArea)) return
|
| 724 |
+
// Return if ctrl key is pressed to not interfere with weight editing shortcut
|
| 725 |
+
if (event.ctrlKey || event.altKey) return;
|
| 726 |
+
|
| 727 |
+
oldSelectedTag = selectedTag;
|
| 728 |
+
|
| 729 |
+
switch (event.key) {
|
| 730 |
+
case keys["MoveUp"]:
|
| 731 |
+
if (selectedTag === null) {
|
| 732 |
+
selectedTag = resultCount - 1;
|
| 733 |
+
} else {
|
| 734 |
+
selectedTag = (selectedTag - 1 + resultCount) % resultCount;
|
| 735 |
+
}
|
| 736 |
+
break;
|
| 737 |
+
case keys["MoveDown"]:
|
| 738 |
+
if (selectedTag === null) {
|
| 739 |
+
selectedTag = 0;
|
| 740 |
+
} else {
|
| 741 |
+
selectedTag = (selectedTag + 1) % resultCount;
|
| 742 |
+
}
|
| 743 |
+
break;
|
| 744 |
+
case keys["JumpUp"]:
|
| 745 |
+
if (selectedTag === null || selectedTag === 0) {
|
| 746 |
+
selectedTag = resultCount - 1;
|
| 747 |
+
} else {
|
| 748 |
+
selectedTag = (Math.max(selectedTag - 5, 0) + resultCount) % resultCount;
|
| 749 |
+
}
|
| 750 |
+
break;
|
| 751 |
+
case keys["JumpDown"]:
|
| 752 |
+
if (selectedTag === null || selectedTag === resultCount - 1) {
|
| 753 |
+
selectedTag = 0;
|
| 754 |
+
} else {
|
| 755 |
+
selectedTag = Math.min(selectedTag + 5, resultCount - 1) % resultCount;
|
| 756 |
+
}
|
| 757 |
+
break;
|
| 758 |
+
case keys["JumpToStart"]:
|
| 759 |
+
selectedTag = 0;
|
| 760 |
+
break;
|
| 761 |
+
case keys["JumpToEnd"]:
|
| 762 |
+
selectedTag = resultCount - 1;
|
| 763 |
+
break;
|
| 764 |
+
case keys["ChooseSelected"]:
|
| 765 |
+
if (selectedTag !== null) {
|
| 766 |
+
insertTextAtCursor(textArea, results[selectedTag], tagword);
|
| 767 |
+
} else {
|
| 768 |
+
hideResults(textArea);
|
| 769 |
+
return;
|
| 770 |
+
}
|
| 771 |
+
break;
|
| 772 |
+
case keys["ChooseFirstOrSelected"]:
|
| 773 |
+
if (selectedTag === null) {
|
| 774 |
+
selectedTag = 0;
|
| 775 |
+
}
|
| 776 |
+
insertTextAtCursor(textArea, results[selectedTag], tagword);
|
| 777 |
+
break;
|
| 778 |
+
case keys["Close"]:
|
| 779 |
+
hideResults(textArea);
|
| 780 |
+
break;
|
| 781 |
+
}
|
| 782 |
+
if (selectedTag === resultCount - 1
|
| 783 |
+
&& (event.key === keys["MoveUp"] || event.key === keys["MoveDown"] || event.key === keys["JumpToStart"] || event.key === keys["JumpToEnd"])) {
|
| 784 |
+
addResultsToList(textArea, results, tagword, false);
|
| 785 |
+
}
|
| 786 |
+
// Update highlighting
|
| 787 |
+
if (selectedTag !== null)
|
| 788 |
+
updateSelectionStyle(textArea, selectedTag, oldSelectedTag);
|
| 789 |
+
|
| 790 |
+
// Prevent default behavior
|
| 791 |
+
event.preventDefault();
|
| 792 |
+
event.stopPropagation();
|
| 793 |
+
}
|
| 794 |
+
|
| 795 |
+
function addAutocompleteToArea(area) {
|
| 796 |
+
// Return if autocomplete is disabled for the current area type in config
|
| 797 |
+
let textAreaId = getTextAreaIdentifier(area);
|
| 798 |
+
if ((!CFG.activeIn.img2img && textAreaId.includes("img2img"))
|
| 799 |
+
|| (!CFG.activeIn.txt2img && textAreaId.includes("txt2img"))
|
| 800 |
+
|| (!CFG.activeIn.negativePrompts && textAreaId.includes("n"))
|
| 801 |
+
|| (!CFG.activeIn.thirdParty && textAreaId.includes("thirdParty"))) {
|
| 802 |
+
return;
|
| 803 |
+
}
|
| 804 |
+
|
| 805 |
+
// Only add listeners once
|
| 806 |
+
if (!area.classList.contains('autocomplete')) {
|
| 807 |
+
// Add our new element
|
| 808 |
+
var resultsDiv = createResultsDiv(area);
|
| 809 |
+
area.parentNode.insertBefore(resultsDiv, area.nextSibling);
|
| 810 |
+
// Hide by default so it doesn't show up on page load
|
| 811 |
+
hideResults(area);
|
| 812 |
+
|
| 813 |
+
// Add autocomplete event listener
|
| 814 |
+
area.addEventListener('input', debounce(() => autocomplete(area, area.value), CFG.delayTime));
|
| 815 |
+
// Add focusout event listener
|
| 816 |
+
area.addEventListener('focusout', debounce(() => hideResults(area), 400));
|
| 817 |
+
// Add up and down arrow event listener
|
| 818 |
+
area.addEventListener('keydown', (e) => navigateInList(area, e));
|
| 819 |
+
// CompositionEnd fires after the user has finished IME composing
|
| 820 |
+
// We need to block hide here to prevent the enter key from insta-closing the results
|
| 821 |
+
area.addEventListener('compositionend', () => {
|
| 822 |
+
hideBlocked = true;
|
| 823 |
+
setTimeout(() => { hideBlocked = false; }, 100);
|
| 824 |
+
});
|
| 825 |
+
|
| 826 |
+
// Add class so we know we've already added the listeners
|
| 827 |
+
area.classList.add('autocomplete');
|
| 828 |
+
}
|
| 829 |
+
}
|
| 830 |
+
|
| 831 |
+
// One-time setup, triggered from onUiUpdate
|
| 832 |
+
async function setup() {
|
| 833 |
+
// Load external files needed by completion extensions
|
| 834 |
+
await processQueue(QUEUE_FILE_LOAD, null);
|
| 835 |
+
|
| 836 |
+
// Find all textareas
|
| 837 |
+
let textAreas = getTextAreas();
|
| 838 |
+
|
| 839 |
+
// Add mutation observer to accordions inside a base that has onDemand set to true
|
| 840 |
+
addOnDemandObservers(addAutocompleteToArea);
|
| 841 |
+
|
| 842 |
+
// Add event listener to apply settings button so we can mirror the changes to our internal config
|
| 843 |
+
let applySettingsButton = gradioApp().querySelector("#tab_settings #settings_submit") || gradioApp().querySelector("#tab_settings > div > .gr-button-primary");
|
| 844 |
+
applySettingsButton?.addEventListener("click", () => {
|
| 845 |
+
// Wait 500ms to make sure the settings have been applied to the webui opts object
|
| 846 |
+
setTimeout(async () => {
|
| 847 |
+
await syncOptions();
|
| 848 |
+
}, 500);
|
| 849 |
+
});
|
| 850 |
+
// Add change listener to our quicksettings to change our internal config without the apply button for them
|
| 851 |
+
let quicksettings = gradioApp().querySelector('#quicksettings');
|
| 852 |
+
let commonQueryPart = "[id^=setting_tac] > label >";
|
| 853 |
+
quicksettings?.querySelectorAll(`${commonQueryPart} input, ${commonQueryPart} textarea, ${commonQueryPart} select`).forEach(e => {
|
| 854 |
+
e.addEventListener("change", () => {
|
| 855 |
+
setTimeout(async () => {
|
| 856 |
+
await syncOptions();
|
| 857 |
+
}, 500);
|
| 858 |
+
});
|
| 859 |
+
});
|
| 860 |
+
|
| 861 |
+
// Add mutation observer for the model hash text to also allow hash-based blacklist again
|
| 862 |
+
let modelHashText = gradioApp().querySelector("#sd_checkpoint_hash");
|
| 863 |
+
if (modelHashText) {
|
| 864 |
+
currentModelHash = modelHashText.title
|
| 865 |
+
let modelHashObserver = new MutationObserver((mutationList, observer) => {
|
| 866 |
+
for (const mutation of mutationList) {
|
| 867 |
+
if (mutation.type === "attributes" && mutation.attributeName === "title") {
|
| 868 |
+
currentModelHash = mutation.target.title;
|
| 869 |
+
let sdm = gradioApp().querySelector("#setting_sd_model_checkpoint");
|
| 870 |
+
let modelDropdown = sdm.querySelector("input") || sdm.querySelector("#select");
|
| 871 |
+
if (modelDropdown) {
|
| 872 |
+
currentModelName = modelDropdown.value;
|
| 873 |
+
} else {
|
| 874 |
+
// Fallback for intermediate versions
|
| 875 |
+
modelDropdown = sdm.querySelector("span.single-select");
|
| 876 |
+
currentModelName = modelDropdown.textContent;
|
| 877 |
+
}
|
| 878 |
+
}
|
| 879 |
+
}
|
| 880 |
+
});
|
| 881 |
+
modelHashObserver.observe(modelHashText, { attributes: true });
|
| 882 |
+
}
|
| 883 |
+
|
| 884 |
+
// Not found, we're on a page without prompt textareas
|
| 885 |
+
if (textAreas.every(v => v === null || v === undefined)) return;
|
| 886 |
+
// Already added or unnecessary to add
|
| 887 |
+
if (gradioApp().querySelector('.autocompleteResults.p')) {
|
| 888 |
+
if (gradioApp().querySelector('.autocompleteResults.n') || !CFG.activeIn.negativePrompts) {
|
| 889 |
+
return;
|
| 890 |
+
}
|
| 891 |
+
} else if (!CFG.activeIn.txt2img && !CFG.activeIn.img2img) {
|
| 892 |
+
return;
|
| 893 |
+
}
|
| 894 |
+
|
| 895 |
+
textAreas.forEach(area => addAutocompleteToArea(area));
|
| 896 |
+
|
| 897 |
+
// Add style to dom
|
| 898 |
+
let acStyle = document.createElement('style');
|
| 899 |
+
let mode = (document.querySelector(".dark") || gradioApp().querySelector(".dark")) ? 0 : 1;
|
| 900 |
+
// Check if we are on webkit
|
| 901 |
+
let browser = navigator.userAgent.toLowerCase().indexOf('firefox') > -1 ? "firefox" : "other";
|
| 902 |
+
|
| 903 |
+
let css = autocompleteCSS;
|
| 904 |
+
// Replace vars with actual values (can't use actual css vars because of the way we inject the css)
|
| 905 |
+
Object.keys(styleColors).forEach((key) => {
|
| 906 |
+
css = css.replace(`var(${key})`, styleColors[key][mode]);
|
| 907 |
+
})
|
| 908 |
+
Object.keys(browserVars).forEach((key) => {
|
| 909 |
+
css = css.replace(`var(${key})`, browserVars[key][browser]);
|
| 910 |
+
})
|
| 911 |
+
|
| 912 |
+
if (acStyle.styleSheet) {
|
| 913 |
+
acStyle.styleSheet.cssText = css;
|
| 914 |
+
} else {
|
| 915 |
+
acStyle.appendChild(document.createTextNode(css));
|
| 916 |
+
}
|
| 917 |
+
gradioApp().appendChild(acStyle);
|
| 918 |
+
|
| 919 |
+
// Callback
|
| 920 |
+
await processQueue(QUEUE_AFTER_SETUP, null);
|
| 921 |
+
}
|
| 922 |
+
let loading = false;
|
| 923 |
+
onUiUpdate(async () => {
|
| 924 |
+
if (loading) return;
|
| 925 |
+
if (Object.keys(opts).length === 0) return;
|
| 926 |
+
if (CFG) return;
|
| 927 |
+
loading = true;
|
| 928 |
+
// Get our tag base path from the temp file
|
| 929 |
+
tagBasePath = await readFile(`tmp/tagAutocompletePath.txt`);
|
| 930 |
+
// Load config from webui opts
|
| 931 |
+
await syncOptions();
|
| 932 |
+
// Rest of setup
|
| 933 |
+
setup();
|
| 934 |
+
loading = false;
|
| 935 |
+
});
|
extensions/a1111-microsoftexcel-tagcomplete/scripts/__pycache__/tag_autocomplete_helper.cpython-310.pyc
ADDED
|
Binary file (14 kB). View file
|
|
|
extensions/a1111-microsoftexcel-tagcomplete/scripts/tag_autocomplete_helper.py
ADDED
|
@@ -0,0 +1,358 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This helper script scans folders for wildcards and embeddings and writes them
|
| 2 |
+
# to a temporary file to expose it to the javascript side
|
| 3 |
+
|
| 4 |
+
import glob
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
|
| 7 |
+
import gradio as gr
|
| 8 |
+
import yaml
|
| 9 |
+
from modules import script_callbacks, scripts, sd_hijack, shared
|
| 10 |
+
|
| 11 |
+
try:
|
| 12 |
+
from modules.paths import extensions_dir, script_path
|
| 13 |
+
|
| 14 |
+
# Webui root path
|
| 15 |
+
FILE_DIR = Path(script_path)
|
| 16 |
+
|
| 17 |
+
# The extension base path
|
| 18 |
+
EXT_PATH = Path(extensions_dir)
|
| 19 |
+
except ImportError:
|
| 20 |
+
# Webui root path
|
| 21 |
+
FILE_DIR = Path().absolute()
|
| 22 |
+
# The extension base path
|
| 23 |
+
EXT_PATH = FILE_DIR.joinpath('extensions')
|
| 24 |
+
|
| 25 |
+
# Tags base path
|
| 26 |
+
TAGS_PATH = Path(scripts.basedir()).joinpath('tags')
|
| 27 |
+
|
| 28 |
+
# The path to the folder containing the wildcards and embeddings
|
| 29 |
+
WILDCARD_PATH = FILE_DIR.joinpath('scripts/wildcards')
|
| 30 |
+
EMB_PATH = Path(shared.cmd_opts.embeddings_dir)
|
| 31 |
+
HYP_PATH = Path(shared.cmd_opts.hypernetwork_dir)
|
| 32 |
+
|
| 33 |
+
try:
|
| 34 |
+
LORA_PATH = Path(shared.cmd_opts.lora_dir)
|
| 35 |
+
except AttributeError:
|
| 36 |
+
LORA_PATH = None
|
| 37 |
+
|
| 38 |
+
try:
|
| 39 |
+
LYCO_PATH = Path(shared.cmd_opts.lyco_dir)
|
| 40 |
+
except AttributeError:
|
| 41 |
+
LYCO_PATH = None
|
| 42 |
+
|
| 43 |
+
def find_ext_wildcard_paths():
|
| 44 |
+
"""Returns the path to the extension wildcards folder"""
|
| 45 |
+
found = list(EXT_PATH.glob('*/wildcards/'))
|
| 46 |
+
return found
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
# The path to the extension wildcards folder
|
| 50 |
+
WILDCARD_EXT_PATHS = find_ext_wildcard_paths()
|
| 51 |
+
|
| 52 |
+
# The path to the temporary files
|
| 53 |
+
STATIC_TEMP_PATH = FILE_DIR.joinpath('tmp') # In the webui root, on windows it exists by default, on linux it doesn't
|
| 54 |
+
TEMP_PATH = TAGS_PATH.joinpath('temp') # Extension specific temp files
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def get_wildcards():
|
| 58 |
+
"""Returns a list of all wildcards. Works on nested folders."""
|
| 59 |
+
wildcard_files = list(WILDCARD_PATH.rglob("*.txt"))
|
| 60 |
+
resolved = [w.relative_to(WILDCARD_PATH).as_posix(
|
| 61 |
+
) for w in wildcard_files if w.name != "put wildcards here.txt"]
|
| 62 |
+
return resolved
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def get_ext_wildcards():
|
| 66 |
+
"""Returns a list of all extension wildcards. Works on nested folders."""
|
| 67 |
+
wildcard_files = []
|
| 68 |
+
|
| 69 |
+
for path in WILDCARD_EXT_PATHS:
|
| 70 |
+
wildcard_files.append(path.relative_to(FILE_DIR).as_posix())
|
| 71 |
+
wildcard_files.extend(p.relative_to(path).as_posix() for p in path.rglob("*.txt") if p.name != "put wildcards here.txt")
|
| 72 |
+
wildcard_files.append("-----")
|
| 73 |
+
|
| 74 |
+
return wildcard_files
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def get_ext_wildcard_tags():
|
| 78 |
+
"""Returns a list of all tags found in extension YAML files found under a Tags: key."""
|
| 79 |
+
wildcard_tags = {} # { tag: count }
|
| 80 |
+
yaml_files = []
|
| 81 |
+
for path in WILDCARD_EXT_PATHS:
|
| 82 |
+
yaml_files.extend(p for p in path.rglob("*.yml"))
|
| 83 |
+
yaml_files.extend(p for p in path.rglob("*.yaml"))
|
| 84 |
+
count = 0
|
| 85 |
+
for path in yaml_files:
|
| 86 |
+
try:
|
| 87 |
+
with open(path, encoding="utf8") as file:
|
| 88 |
+
data = yaml.safe_load(file)
|
| 89 |
+
for item in data:
|
| 90 |
+
if data[item] and 'Tags' in data[item]:
|
| 91 |
+
wildcard_tags[count] = ','.join(data[item]['Tags'])
|
| 92 |
+
count += 1
|
| 93 |
+
else:
|
| 94 |
+
print('Issue with tags found in ' + path.name + ' at item ' + item)
|
| 95 |
+
except yaml.YAMLError as exc:
|
| 96 |
+
print(exc)
|
| 97 |
+
# Sort by count
|
| 98 |
+
sorted_tags = sorted(wildcard_tags.items(), key=lambda item: item[1], reverse=True)
|
| 99 |
+
output = []
|
| 100 |
+
for tag, count in sorted_tags:
|
| 101 |
+
output.append(f"{tag},{count}")
|
| 102 |
+
return output
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def get_embeddings(sd_model):
|
| 106 |
+
"""Write a list of all embeddings with their version"""
|
| 107 |
+
|
| 108 |
+
# Version constants
|
| 109 |
+
V1_SHAPE = 768
|
| 110 |
+
V2_SHAPE = 1024
|
| 111 |
+
emb_v1 = []
|
| 112 |
+
emb_v2 = []
|
| 113 |
+
results = []
|
| 114 |
+
|
| 115 |
+
try:
|
| 116 |
+
# Get embedding dict from sd_hijack to separate v1/v2 embeddings
|
| 117 |
+
emb_type_a = sd_hijack.model_hijack.embedding_db.word_embeddings
|
| 118 |
+
emb_type_b = sd_hijack.model_hijack.embedding_db.skipped_embeddings
|
| 119 |
+
# Get the shape of the first item in the dict
|
| 120 |
+
emb_a_shape = -1
|
| 121 |
+
emb_b_shape = -1
|
| 122 |
+
if (len(emb_type_a) > 0):
|
| 123 |
+
emb_a_shape = next(iter(emb_type_a.items()))[1].shape
|
| 124 |
+
if (len(emb_type_b) > 0):
|
| 125 |
+
emb_b_shape = next(iter(emb_type_b.items()))[1].shape
|
| 126 |
+
|
| 127 |
+
# Add embeddings to the correct list
|
| 128 |
+
if (emb_a_shape == V1_SHAPE):
|
| 129 |
+
emb_v1 = list(emb_type_a.keys())
|
| 130 |
+
elif (emb_a_shape == V2_SHAPE):
|
| 131 |
+
emb_v2 = list(emb_type_a.keys())
|
| 132 |
+
|
| 133 |
+
if (emb_b_shape == V1_SHAPE):
|
| 134 |
+
emb_v1 = list(emb_type_b.keys())
|
| 135 |
+
elif (emb_b_shape == V2_SHAPE):
|
| 136 |
+
emb_v2 = list(emb_type_b.keys())
|
| 137 |
+
|
| 138 |
+
# Get shape of current model
|
| 139 |
+
#vec = sd_model.cond_stage_model.encode_embedding_init_text(",", 1)
|
| 140 |
+
#model_shape = vec.shape[1]
|
| 141 |
+
# Show relevant entries at the top
|
| 142 |
+
#if (model_shape == V1_SHAPE):
|
| 143 |
+
# results = [e + ",v1" for e in emb_v1] + [e + ",v2" for e in emb_v2]
|
| 144 |
+
#elif (model_shape == V2_SHAPE):
|
| 145 |
+
# results = [e + ",v2" for e in emb_v2] + [e + ",v1" for e in emb_v1]
|
| 146 |
+
#else:
|
| 147 |
+
# raise AttributeError # Fallback to old method
|
| 148 |
+
results = sorted([e + ",v1" for e in emb_v1] + [e + ",v2" for e in emb_v2], key=lambda x: x.lower())
|
| 149 |
+
except AttributeError:
|
| 150 |
+
print("tag_autocomplete_helper: Old webui version or unrecognized model shape, using fallback for embedding completion.")
|
| 151 |
+
# Get a list of all embeddings in the folder
|
| 152 |
+
all_embeds = [str(e.relative_to(EMB_PATH)) for e in EMB_PATH.rglob("*") if e.suffix in {".bin", ".pt", ".png",'.webp', '.jxl', '.avif'}]
|
| 153 |
+
# Remove files with a size of 0
|
| 154 |
+
all_embeds = [e for e in all_embeds if EMB_PATH.joinpath(e).stat().st_size > 0]
|
| 155 |
+
# Remove file extensions
|
| 156 |
+
all_embeds = [e[:e.rfind('.')] for e in all_embeds]
|
| 157 |
+
results = [e + "," for e in all_embeds]
|
| 158 |
+
|
| 159 |
+
write_to_temp_file('emb.txt', results)
|
| 160 |
+
|
| 161 |
+
def get_hypernetworks():
|
| 162 |
+
"""Write a list of all hypernetworks"""
|
| 163 |
+
|
| 164 |
+
# Get a list of all hypernetworks in the folder
|
| 165 |
+
hyp_paths = [Path(h) for h in glob.glob(HYP_PATH.joinpath("**/*").as_posix(), recursive=True)]
|
| 166 |
+
all_hypernetworks = [str(h.name) for h in hyp_paths if h.suffix in {".pt"}]
|
| 167 |
+
# Remove file extensions
|
| 168 |
+
return sorted([h[:h.rfind('.')] for h in all_hypernetworks], key=lambda x: x.lower())
|
| 169 |
+
|
| 170 |
+
def get_lora():
|
| 171 |
+
"""Write a list of all lora"""
|
| 172 |
+
|
| 173 |
+
# Get a list of all lora in the folder
|
| 174 |
+
lora_paths = [Path(l) for l in glob.glob(LORA_PATH.joinpath("**/*").as_posix(), recursive=True)]
|
| 175 |
+
all_lora = [str(l.name) for l in lora_paths if l.suffix in {".safetensors", ".ckpt", ".pt"}]
|
| 176 |
+
# Remove file extensions
|
| 177 |
+
return sorted([l[:l.rfind('.')] for l in all_lora], key=lambda x: x.lower())
|
| 178 |
+
|
| 179 |
+
def get_lyco():
|
| 180 |
+
"""Write a list of all LyCORIS/LOHA from https://github.com/KohakuBlueleaf/a1111-sd-webui-lycoris"""
|
| 181 |
+
|
| 182 |
+
# Get a list of all LyCORIS in the folder
|
| 183 |
+
lyco_paths = [Path(ly) for ly in glob.glob(LYCO_PATH.joinpath("**/*").as_posix(), recursive=True)]
|
| 184 |
+
all_lyco = [str(ly.name) for ly in lyco_paths if ly.suffix in {".safetensors", ".ckpt", ".pt"}]
|
| 185 |
+
# Remove file extensions
|
| 186 |
+
return sorted([ly[:ly.rfind('.')] for ly in all_lyco], key=lambda x: x.lower())
|
| 187 |
+
|
| 188 |
+
def write_tag_base_path():
|
| 189 |
+
"""Writes the tag base path to a fixed location temporary file"""
|
| 190 |
+
with open(STATIC_TEMP_PATH.joinpath('tagAutocompletePath.txt'), 'w', encoding="utf-8") as f:
|
| 191 |
+
f.write(TAGS_PATH.relative_to(FILE_DIR).as_posix())
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def write_to_temp_file(name, data):
|
| 195 |
+
"""Writes the given data to a temporary file"""
|
| 196 |
+
with open(TEMP_PATH.joinpath(name), 'w', encoding="utf-8") as f:
|
| 197 |
+
f.write(('\n'.join(data)))
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
csv_files = []
|
| 201 |
+
csv_files_withnone = []
|
| 202 |
+
def update_tag_files():
|
| 203 |
+
"""Returns a list of all potential tag files"""
|
| 204 |
+
global csv_files, csv_files_withnone
|
| 205 |
+
files = [str(t.relative_to(TAGS_PATH)) for t in TAGS_PATH.glob("*.csv")]
|
| 206 |
+
csv_files = files
|
| 207 |
+
csv_files_withnone = ["None"] + files
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
# Write the tag base path to a fixed location temporary file
|
| 212 |
+
# to enable the javascript side to find our files regardless of extension folder name
|
| 213 |
+
if not STATIC_TEMP_PATH.exists():
|
| 214 |
+
STATIC_TEMP_PATH.mkdir(exist_ok=True)
|
| 215 |
+
|
| 216 |
+
write_tag_base_path()
|
| 217 |
+
update_tag_files()
|
| 218 |
+
|
| 219 |
+
# Check if the temp path exists and create it if not
|
| 220 |
+
if not TEMP_PATH.exists():
|
| 221 |
+
TEMP_PATH.mkdir(parents=True, exist_ok=True)
|
| 222 |
+
|
| 223 |
+
# Set up files to ensure the script doesn't fail to load them
|
| 224 |
+
# even if no wildcards or embeddings are found
|
| 225 |
+
write_to_temp_file('wc.txt', [])
|
| 226 |
+
write_to_temp_file('wce.txt', [])
|
| 227 |
+
write_to_temp_file('wcet.txt', [])
|
| 228 |
+
write_to_temp_file('hyp.txt', [])
|
| 229 |
+
write_to_temp_file('lora.txt', [])
|
| 230 |
+
write_to_temp_file('lyco.txt', [])
|
| 231 |
+
# Only reload embeddings if the file doesn't exist, since they are already re-written on model load
|
| 232 |
+
if not TEMP_PATH.joinpath("emb.txt").exists():
|
| 233 |
+
write_to_temp_file('emb.txt', [])
|
| 234 |
+
|
| 235 |
+
# Write wildcards to wc.txt if found
|
| 236 |
+
if WILDCARD_PATH.exists():
|
| 237 |
+
wildcards = [WILDCARD_PATH.relative_to(FILE_DIR).as_posix()] + get_wildcards()
|
| 238 |
+
if wildcards:
|
| 239 |
+
write_to_temp_file('wc.txt', wildcards)
|
| 240 |
+
|
| 241 |
+
# Write extension wildcards to wce.txt if found
|
| 242 |
+
if WILDCARD_EXT_PATHS is not None:
|
| 243 |
+
wildcards_ext = get_ext_wildcards()
|
| 244 |
+
if wildcards_ext:
|
| 245 |
+
write_to_temp_file('wce.txt', wildcards_ext)
|
| 246 |
+
# Write yaml extension wildcards to wcet.txt if found
|
| 247 |
+
wildcards_yaml_ext = get_ext_wildcard_tags()
|
| 248 |
+
if wildcards_yaml_ext:
|
| 249 |
+
write_to_temp_file('wcet.txt', wildcards_yaml_ext)
|
| 250 |
+
|
| 251 |
+
# Write embeddings to emb.txt if found
|
| 252 |
+
if EMB_PATH.exists():
|
| 253 |
+
# Get embeddings after the model loaded callback
|
| 254 |
+
script_callbacks.on_model_loaded(get_embeddings)
|
| 255 |
+
|
| 256 |
+
if HYP_PATH.exists():
|
| 257 |
+
hypernets = get_hypernetworks()
|
| 258 |
+
if hypernets:
|
| 259 |
+
write_to_temp_file('hyp.txt', hypernets)
|
| 260 |
+
|
| 261 |
+
if LORA_PATH is not None and LORA_PATH.exists():
|
| 262 |
+
lora = get_lora()
|
| 263 |
+
if lora:
|
| 264 |
+
write_to_temp_file('lora.txt', lora)
|
| 265 |
+
|
| 266 |
+
if LYCO_PATH is not None and LYCO_PATH.exists():
|
| 267 |
+
lyco = get_lyco()
|
| 268 |
+
if lyco:
|
| 269 |
+
write_to_temp_file('lyco.txt', lyco)
|
| 270 |
+
|
| 271 |
+
# Register autocomplete options
|
| 272 |
+
def on_ui_settings():
|
| 273 |
+
TAC_SECTION = ("tac", "Tag Autocomplete")
|
| 274 |
+
# Main tag file
|
| 275 |
+
shared.opts.add_option("tac_tagFile", shared.OptionInfo("danbooru.csv", "Tag filename", gr.Dropdown, lambda: {"choices": csv_files_withnone}, refresh=update_tag_files, section=TAC_SECTION))
|
| 276 |
+
# Active in settings
|
| 277 |
+
shared.opts.add_option("tac_active", shared.OptionInfo(True, "Enable Tag Autocompletion", section=TAC_SECTION))
|
| 278 |
+
shared.opts.add_option("tac_activeIn.txt2img", shared.OptionInfo(True, "Active in txt2img (Requires restart)", section=TAC_SECTION))
|
| 279 |
+
shared.opts.add_option("tac_activeIn.img2img", shared.OptionInfo(True, "Active in img2img (Requires restart)", section=TAC_SECTION))
|
| 280 |
+
shared.opts.add_option("tac_activeIn.negativePrompts", shared.OptionInfo(True, "Active in negative prompts (Requires restart)", section=TAC_SECTION))
|
| 281 |
+
shared.opts.add_option("tac_activeIn.thirdParty", shared.OptionInfo(True, "Active in third party textboxes [Dataset Tag Editor] [Image Browser] [Tagger] [Multidiffusion Upscaler] (Requires restart)", section=TAC_SECTION))
|
| 282 |
+
shared.opts.add_option("tac_activeIn.modelList", shared.OptionInfo("", "List of model names (with file extension) or their hashes to use as black/whitelist, separated by commas.", section=TAC_SECTION))
|
| 283 |
+
shared.opts.add_option("tac_activeIn.modelListMode", shared.OptionInfo("Blacklist", "Mode to use for model list", gr.Dropdown, lambda: {"choices": ["Blacklist","Whitelist"]}, section=TAC_SECTION))
|
| 284 |
+
# Results related settings
|
| 285 |
+
shared.opts.add_option("tac_slidingPopup", shared.OptionInfo(True, "Move completion popup together with text cursor", section=TAC_SECTION))
|
| 286 |
+
shared.opts.add_option("tac_maxResults", shared.OptionInfo(5, "Maximum results", section=TAC_SECTION))
|
| 287 |
+
shared.opts.add_option("tac_showAllResults", shared.OptionInfo(False, "Show all results", section=TAC_SECTION))
|
| 288 |
+
shared.opts.add_option("tac_resultStepLength", shared.OptionInfo(100, "How many results to load at once", section=TAC_SECTION))
|
| 289 |
+
shared.opts.add_option("tac_delayTime", shared.OptionInfo(100, "Time in ms to wait before triggering completion again (Requires restart)", section=TAC_SECTION))
|
| 290 |
+
shared.opts.add_option("tac_useWildcards", shared.OptionInfo(True, "Search for wildcards", section=TAC_SECTION))
|
| 291 |
+
shared.opts.add_option("tac_useEmbeddings", shared.OptionInfo(True, "Search for embeddings", section=TAC_SECTION))
|
| 292 |
+
shared.opts.add_option("tac_useHypernetworks", shared.OptionInfo(True, "Search for hypernetworks", section=TAC_SECTION))
|
| 293 |
+
shared.opts.add_option("tac_useLoras", shared.OptionInfo(True, "Search for Loras", section=TAC_SECTION))
|
| 294 |
+
shared.opts.add_option("tac_useLycos", shared.OptionInfo(True, "Search for LyCORIS/LoHa", section=TAC_SECTION))
|
| 295 |
+
shared.opts.add_option("tac_showWikiLinks", shared.OptionInfo(False, "Show '?' next to tags, linking to its Danbooru or e621 wiki page (Warning: This is an external site and very likely contains NSFW examples!)", section=TAC_SECTION))
|
| 296 |
+
# Insertion related settings
|
| 297 |
+
shared.opts.add_option("tac_replaceUnderscores", shared.OptionInfo(True, "Replace underscores with spaces on insertion", section=TAC_SECTION))
|
| 298 |
+
shared.opts.add_option("tac_escapeParentheses", shared.OptionInfo(True, "Escape parentheses on insertion", section=TAC_SECTION))
|
| 299 |
+
shared.opts.add_option("tac_appendComma", shared.OptionInfo(True, "Append comma on tag autocompletion", section=TAC_SECTION))
|
| 300 |
+
# Alias settings
|
| 301 |
+
shared.opts.add_option("tac_alias.searchByAlias", shared.OptionInfo(True, "Search by alias", section=TAC_SECTION))
|
| 302 |
+
shared.opts.add_option("tac_alias.onlyShowAlias", shared.OptionInfo(False, "Only show alias", section=TAC_SECTION))
|
| 303 |
+
# Translation settings
|
| 304 |
+
shared.opts.add_option("tac_translation.translationFile", shared.OptionInfo("None", "Translation filename", gr.Dropdown, lambda: {"choices": csv_files_withnone}, refresh=update_tag_files, section=TAC_SECTION))
|
| 305 |
+
shared.opts.add_option("tac_translation.oldFormat", shared.OptionInfo(False, "Translation file uses old 3-column translation format instead of the new 2-column one", section=TAC_SECTION))
|
| 306 |
+
shared.opts.add_option("tac_translation.searchByTranslation", shared.OptionInfo(True, "Search by translation", section=TAC_SECTION))
|
| 307 |
+
# Extra file settings
|
| 308 |
+
shared.opts.add_option("tac_extra.extraFile", shared.OptionInfo("extra-quality-tags.csv", "Extra filename (for small sets of custom tags)", gr.Dropdown, lambda: {"choices": csv_files_withnone}, refresh=update_tag_files, section=TAC_SECTION))
|
| 309 |
+
shared.opts.add_option("tac_extra.addMode", shared.OptionInfo("Insert before", "Mode to add the extra tags to the main tag list", gr.Dropdown, lambda: {"choices": ["Insert before","Insert after"]}, section=TAC_SECTION))
|
| 310 |
+
# Custom mappings
|
| 311 |
+
keymapDefault = """\
|
| 312 |
+
{
|
| 313 |
+
"MoveUp": "ArrowUp",
|
| 314 |
+
"MoveDown": "ArrowDown",
|
| 315 |
+
"JumpUp": "PageUp",
|
| 316 |
+
"JumpDown": "PageDown",
|
| 317 |
+
"JumpToStart": "Home",
|
| 318 |
+
"JumpToEnd": "End",
|
| 319 |
+
"ChooseSelected": "Enter",
|
| 320 |
+
"ChooseFirstOrSelected": "Tab",
|
| 321 |
+
"Close": "Escape"
|
| 322 |
+
}\
|
| 323 |
+
"""
|
| 324 |
+
colorDefault = """\
|
| 325 |
+
{
|
| 326 |
+
"danbooru": {
|
| 327 |
+
"-1": ["red", "maroon"],
|
| 328 |
+
"0": ["lightblue", "dodgerblue"],
|
| 329 |
+
"1": ["indianred", "firebrick"],
|
| 330 |
+
"3": ["violet", "darkorchid"],
|
| 331 |
+
"4": ["lightgreen", "darkgreen"],
|
| 332 |
+
"5": ["orange", "darkorange"]
|
| 333 |
+
},
|
| 334 |
+
"e621": {
|
| 335 |
+
"-1": ["red", "maroon"],
|
| 336 |
+
"0": ["lightblue", "dodgerblue"],
|
| 337 |
+
"1": ["gold", "goldenrod"],
|
| 338 |
+
"3": ["violet", "darkorchid"],
|
| 339 |
+
"4": ["lightgreen", "darkgreen"],
|
| 340 |
+
"5": ["tomato", "darksalmon"],
|
| 341 |
+
"6": ["red", "maroon"],
|
| 342 |
+
"7": ["whitesmoke", "black"],
|
| 343 |
+
"8": ["seagreen", "darkseagreen"]
|
| 344 |
+
}
|
| 345 |
+
}\
|
| 346 |
+
"""
|
| 347 |
+
keymapLabel = "Configure Hotkeys. For possible values, see https://www.w3.org/TR/uievents-key, or leave empty / set to 'None' to disable. Must be valid JSON."
|
| 348 |
+
colorLabel = "Configure colors. See https://github.com/DominikDoom/a1111-sd-webui-tagcomplete#colors for info. Must be valid JSON."
|
| 349 |
+
|
| 350 |
+
try:
|
| 351 |
+
shared.opts.add_option("tac_keymap", shared.OptionInfo(keymapDefault, keymapLabel, gr.Code, lambda: {"language": "json", "interactive": True}, section=TAC_SECTION))
|
| 352 |
+
shared.opts.add_option("tac_colormap", shared.OptionInfo(colorDefault, colorLabel, gr.Code, lambda: {"language": "json", "interactive": True}, section=TAC_SECTION))
|
| 353 |
+
except AttributeError:
|
| 354 |
+
shared.opts.add_option("tac_keymap", shared.OptionInfo(keymapDefault, keymapLabel, gr.Textbox, section=TAC_SECTION))
|
| 355 |
+
shared.opts.add_option("tac_colormap", shared.OptionInfo(colorDefault, colorLabel, gr.Textbox, section=TAC_SECTION))
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
script_callbacks.on_ui_settings(on_ui_settings)
|
extensions/a1111-microsoftexcel-tagcomplete/tags/danbooru.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
extensions/a1111-microsoftexcel-tagcomplete/tags/e621.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
extensions/a1111-microsoftexcel-tagcomplete/tags/extra-quality-tags.csv
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
masterpiece,5,Quality tag,,
|
| 2 |
+
best_quality,5,Quality tag,,
|
| 3 |
+
high_quality,5,Quality tag,,
|
| 4 |
+
normal_quality,5,Quality tag,,
|
| 5 |
+
low_quality,5,Quality tag,,
|
| 6 |
+
worst_quality,5,Quality tag,,
|
extensions/a1111-microsoftexcel-tagcomplete/tags/temp/emb.txt
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
21charturnerv2,v2
|
| 2 |
+
aid210,v1
|
| 3 |
+
albino_style,v1
|
| 4 |
+
ao_style,v1
|
| 5 |
+
ao_style-7500,v1
|
| 6 |
+
Asian-Less-Neg,v1
|
| 7 |
+
bad-artist,v1
|
| 8 |
+
bad-artist-anime,v1
|
| 9 |
+
bad-hands-3,v1
|
| 10 |
+
bad-hands-5,v1
|
| 11 |
+
bad-image-v2-39000,v1
|
| 12 |
+
bad-picture-chill-75v,v1
|
| 13 |
+
bad_pictures,v1
|
| 14 |
+
bad_prompt,v1
|
| 15 |
+
bad_prompt_version2,v1
|
| 16 |
+
bad_quality,v1
|
| 17 |
+
badhandv4,v1
|
| 18 |
+
barbosa_style,v1
|
| 19 |
+
bjbb,v1
|
| 20 |
+
bjbb-1450,v1
|
| 21 |
+
brush_style,v1
|
| 22 |
+
brush_style-7500,v1
|
| 23 |
+
charturnerv2,v1
|
| 24 |
+
chibi_style,v1
|
| 25 |
+
chunli_alpha,v1
|
| 26 |
+
corneo_anal,v1
|
| 27 |
+
corneo_ball_gag,v1
|
| 28 |
+
corneo_bound_missionary,v1
|
| 29 |
+
corneo_covering_breasts_arms_crossed,v1
|
| 30 |
+
corneo_covering_breasts_one_arm,v1
|
| 31 |
+
corneo_covering_breasts_two_hands,v1
|
| 32 |
+
corneo_cowgirl,v1
|
| 33 |
+
corneo_paizuri,v1
|
| 34 |
+
corneo_pov_oral,v1
|
| 35 |
+
corneo_side_deepthroat,v1
|
| 36 |
+
corneo_side_doggy,v1
|
| 37 |
+
corneo_spitroast,v1
|
| 38 |
+
corneo_tentacle_sex,v1
|
| 39 |
+
corneo_x_pasties,v1
|
| 40 |
+
cute_style,v1
|
| 41 |
+
CyberRealistic_Negative-neg,v1
|
| 42 |
+
cyberware_style,v1
|
| 43 |
+
dark_ouroboros,v1
|
| 44 |
+
darkmode,v1
|
| 45 |
+
deep penetration missionary,v1
|
| 46 |
+
deepthroat4b-250,v1
|
| 47 |
+
deepthroat4b-3000,v1
|
| 48 |
+
deepthroat4b-3250,v1
|
| 49 |
+
deepthroat4b-3500,v1
|
| 50 |
+
deepthroat4b-4750,v1
|
| 51 |
+
deepthroat4b-500,v1
|
| 52 |
+
deepthroat4b-5000,v1
|
| 53 |
+
deepthroat4b-5250,v1
|
| 54 |
+
deepthroat4b-6000,v1
|
| 55 |
+
deepthroat4b-750,v1
|
| 56 |
+
discomixV2_v2,v1
|
| 57 |
+
dpin_style,v1
|
| 58 |
+
easynegative,v1
|
| 59 |
+
EasyNegativeV2,v1
|
| 60 |
+
elden_ring,v1
|
| 61 |
+
EMB_lolstyle,v1
|
| 62 |
+
emb_makima,v1
|
| 63 |
+
EMB_makima_girl,v1
|
| 64 |
+
EMB_makima_girl-50,v1
|
| 65 |
+
EMB_makima_woman,v1
|
| 66 |
+
EMB_makimatest,v1
|
| 67 |
+
EMB_muratastyle,v1
|
| 68 |
+
EMB_sksdenji,v1
|
| 69 |
+
EMB_skseyes,v1
|
| 70 |
+
EMB_skseyestest,v1
|
| 71 |
+
EMB_sksiru,v1
|
| 72 |
+
EMB_sksmakima2-2075,v1
|
| 73 |
+
EMB_sksmakimatest,v1
|
| 74 |
+
EMB_sksmuratastyle,v1
|
| 75 |
+
EMB_skspixel,v1
|
| 76 |
+
EMB_skspixelart,v1
|
| 77 |
+
EMB_skspower,v1
|
| 78 |
+
EMB_sksringed,v1
|
| 79 |
+
EMB_skstest,v1
|
| 80 |
+
EMB_skstest2,v1
|
| 81 |
+
EMB_skstest3,v1
|
| 82 |
+
EMB_skstest4,v1
|
| 83 |
+
EMB_skstestdenji,v1
|
| 84 |
+
EMBMurata,v1
|
| 85 |
+
flame_surge_style,v1
|
| 86 |
+
flame_surge_style-7500,v1
|
| 87 |
+
flower_style,v1
|
| 88 |
+
flower_style-7500,v1
|
| 89 |
+
guweiz_style,v1
|
| 90 |
+
Gwen,v1
|
| 91 |
+
hades-65800,v1
|
| 92 |
+
hurybone_style,v1
|
| 93 |
+
HyperStylizeV6,v1
|
| 94 |
+
iskou_style,v1
|
| 95 |
+
john_kafka,v1
|
| 96 |
+
land_style,v1
|
| 97 |
+
lands_between,v1
|
| 98 |
+
landscape_style,v1
|
| 99 |
+
lightning_style,v1
|
| 100 |
+
lightning_style-7500,v1
|
| 101 |
+
magic_armor,v1
|
| 102 |
+
magic_armor-7500,v1
|
| 103 |
+
makima woman,v1
|
| 104 |
+
makima girl,v1
|
| 105 |
+
makima,v1
|
| 106 |
+
makima2-300,v1
|
| 107 |
+
makima3,v1
|
| 108 |
+
mikeou_art,v1
|
| 109 |
+
mikeou_art-7500,v1
|
| 110 |
+
mm_malenia,v1
|
| 111 |
+
nartfixer,v2
|
| 112 |
+
negative_hand-neg,v1
|
| 113 |
+
NegLowRes-2400,v2
|
| 114 |
+
nfixer,v2
|
| 115 |
+
ng_deepnegative_v1_75t,v1
|
| 116 |
+
NG_DeepNegative_V1_75T,v1
|
| 117 |
+
nixeu_basic,v1
|
| 118 |
+
nixeu_basic2,v1
|
| 119 |
+
nixeu_extra,v1
|
| 120 |
+
nixeu_soft,v1
|
| 121 |
+
nixeu_style,v1
|
| 122 |
+
nixeu_white,v1
|
| 123 |
+
nrealfixer,v2
|
| 124 |
+
oraaaa,v1
|
| 125 |
+
pastel_style,v1
|
| 126 |
+
pureerosface_v1,v1
|
| 127 |
+
ratat,v1
|
| 128 |
+
ratatatat74,v1
|
| 129 |
+
ratatatat74-15000,v1
|
| 130 |
+
Reze,v1
|
| 131 |
+
ringed,v1
|
| 132 |
+
rmadanegative402_sd15-neg,v1
|
| 133 |
+
sam_yang,v1
|
| 134 |
+
SamDoesArt1,v1
|
| 135 |
+
saska_style,v1
|
| 136 |
+
sciamano,v1
|
| 137 |
+
shatter_style,v1
|
| 138 |
+
shy_lily,v1
|
| 139 |
+
sksbbmurata,v1
|
| 140 |
+
sksksmuratastyle,v1
|
| 141 |
+
sksmurata,v1
|
| 142 |
+
space_style,v1
|
| 143 |
+
space_style-7500,v1
|
| 144 |
+
splash_style,v1
|
| 145 |
+
splash_style2,v1
|
| 146 |
+
star_style,v1
|
| 147 |
+
stripe_style,v1
|
| 148 |
+
Style-Hamunaptra,v1
|
| 149 |
+
torino_art,v1
|
| 150 |
+
torino_art-6400,v1
|
| 151 |
+
ulzzang-6500,v1
|
| 152 |
+
ulzzang-6500-v1.1,v1
|
| 153 |
+
verybadimagenegative_v1.3,v1
|
| 154 |
+
vile_prompt3,v1
|
| 155 |
+
wano_style_30100,v1
|
| 156 |
+
white_ouroboros,v1
|
| 157 |
+
winter_style,v1
|
| 158 |
+
winter_style-4500,v1
|
| 159 |
+
winter_style-7500,v1
|
| 160 |
+
wlop_style,v1
|
| 161 |
+
wryyyyy,v1
|
| 162 |
+
yor_forger,v1
|
extensions/a1111-microsoftexcel-tagcomplete/tags/temp/hyp.txt
ADDED
|
File without changes
|
extensions/a1111-microsoftexcel-tagcomplete/tags/temp/lora.txt
ADDED
|
File without changes
|
extensions/a1111-microsoftexcel-tagcomplete/tags/temp/lyco.txt
ADDED
|
File without changes
|
extensions/a1111-microsoftexcel-tagcomplete/tags/temp/wc.txt
ADDED
|
File without changes
|
extensions/a1111-microsoftexcel-tagcomplete/tags/temp/wce.txt
ADDED
|
File without changes
|
extensions/a1111-microsoftexcel-tagcomplete/tags/temp/wcet.txt
ADDED
|
File without changes
|
extensions/a1111-sd-webui-lycoris/.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
extensions/a1111-sd-webui-lycoris/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [2023] [KohakuBlueLeaf]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
extensions/a1111-sd-webui-lycoris/README.md
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# a1111-sd-webui-lycoris
|
| 2 |
+
|
| 3 |
+
An extension for loading lycoris model in sd-webui.
|
| 4 |
+
I made this stand alone extension (Use sd-webui's extra networks api) to avoid some conflict with other loras extensions.
|
| 5 |
+
|
| 6 |
+
## How to install
|
| 7 |
+
There are some options you can choose to install this extension
|
| 8 |
+
* Open the extension tab and go to "available" tab, search "lycoris" to find this extension and then install it.
|
| 9 |
+
* Open the extension tab and go to "from url" tab, copy-paste the url of this repo (https://github.com/KohakuBlueleaf/a1111-sd-webui-lycoris) and click install.
|
| 10 |
+
* Manually clone this repo to the extension folder or download the zip.
|
| 11 |
+
|
| 12 |
+
## The version of stable-diffusion-webui
|
| 13 |
+
Lot of people struggling on some bugs or unexpected behavior after install the extension. We do some research and test on it and can only get this conclusion:<br>
|
| 14 |
+
**Make sure your stable diffusion webui is after commit: a9fed7c3** <br>
|
| 15 |
+
(a9fed7c3 itself should work, but if you meet problem on that commit, you should consider to update your sd-webui)
|
| 16 |
+
|
| 17 |
+
### LyCORIS
|
| 18 |
+
https://github.com/KohakuBlueleaf/LyCORIS
|
| 19 |
+
|
| 20 |
+
### usage
|
| 21 |
+
Install it and restart the webui
|
| 22 |
+
**Don't use "Apply and restart UI", please restart the webui process**
|
| 23 |
+
|
| 24 |
+
And you will find "LyCORIS" tab in the extra networks page
|
| 25 |
+
Use `<lyco:MODEL:WEIGHT>` to utilize the lycoris model
|
| 26 |
+

|
| 27 |
+
|
| 28 |
+
The launch parameter `--lyco-dir` can be used to define LyCORIS models location path
|
| 29 |
+
|
| 30 |
+
## Arguments
|
| 31 |
+
sd-webui use this format to use extra networks: `<TYPE:MODEL_NAME:arg1:arg2:arg3...:argn>`<br>
|
| 32 |
+
With more and more different algorithm be implemented into lycoris, the arguments become more.<br>
|
| 33 |
+
So I design this arg system to use it more easily(Maybe):<br>
|
| 34 |
+
<br>
|
| 35 |
+
`<lyco:MODEL:arg1:arg2:k1=v1:k2=v2>`<br>
|
| 36 |
+
<br>
|
| 37 |
+
For example, we have te/unet/dyn these 3 arguments, if you want te=1, unet=0.5, dyn=13, you can use it like these:<br>
|
| 38 |
+
`<lyco:Model:1:0.5:13>`<br>
|
| 39 |
+
`<lyco:Model:1:0.5:dyn=13>`<br>
|
| 40 |
+
`<lyco:Model:1:unet=0.5:dyn=13>`<br>
|
| 41 |
+
And if you specify ALL the key name, you can ignore the order:<br>
|
| 42 |
+
(or, actually, we only count the args, no k-v pair, so dyn=13:unet=1:0.5 also work, but 0.5 is for te (the first argument))<br>
|
| 43 |
+
`<lyco:Model:dyn=13:te=1:unet=0.5>`<br>
|
| 44 |
+
<br>
|
| 45 |
+
And since te=1 is default value, you can also do it like this:<br>
|
| 46 |
+
`<lyco:Model:unet=0.5:dyn=13>`<br>
|
| 47 |
+
|
| 48 |
+
And here is the list for arguments:
|
| 49 |
+
| Argument | What it does| default type and value|
|
| 50 |
+
| ----------- | ----------- | ----------- |
|
| 51 |
+
| te | the weight for text encoder | `float: 1.0`|
|
| 52 |
+
| unet | the weight for UNet, when it is None, it use same value as te | `float: None`|
|
| 53 |
+
| dyn | How many row you want to utilize when using dylora, if you set to 0, it will disable the dylora| `int: None` |
|
extensions/a1111-sd-webui-lycoris/__pycache__/extra_networks_lyco.cpython-310.pyc
ADDED
|
Binary file (2.85 kB). View file
|
|
|
extensions/a1111-sd-webui-lycoris/__pycache__/lycoris.cpython-310.pyc
ADDED
|
Binary file (19.8 kB). View file
|
|
|
extensions/a1111-sd-webui-lycoris/__pycache__/preload.cpython-310.pyc
ADDED
|
Binary file (486 Bytes). View file
|
|
|
extensions/a1111-sd-webui-lycoris/__pycache__/ui_extra_networks_lyco.cpython-310.pyc
ADDED
|
Binary file (1.74 kB). View file
|
|
|
extensions/a1111-sd-webui-lycoris/extra_networks_lyco.py
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from modules import extra_networks, shared
|
| 2 |
+
import lycoris
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
default_args = [
|
| 6 |
+
('te', 1.0, float),
|
| 7 |
+
('unet', None, float),
|
| 8 |
+
('dyn', None, int)
|
| 9 |
+
]
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def parse_args(params:list):
|
| 13 |
+
arg_list = []
|
| 14 |
+
kwarg_list = {}
|
| 15 |
+
|
| 16 |
+
for i in params:
|
| 17 |
+
if '=' in str(i):
|
| 18 |
+
k, v = i.split('=', 1)
|
| 19 |
+
kwarg_list[k] = v
|
| 20 |
+
else:
|
| 21 |
+
arg_list.append(i)
|
| 22 |
+
|
| 23 |
+
args = []
|
| 24 |
+
for name, default, type in default_args:
|
| 25 |
+
if name in kwarg_list:
|
| 26 |
+
x = kwarg_list[name]
|
| 27 |
+
elif arg_list:
|
| 28 |
+
x = arg_list.pop(0)
|
| 29 |
+
else:
|
| 30 |
+
x = default
|
| 31 |
+
|
| 32 |
+
if x == 'default':
|
| 33 |
+
x = default
|
| 34 |
+
elif x is not None:
|
| 35 |
+
x = type(x)
|
| 36 |
+
|
| 37 |
+
args.append(x)
|
| 38 |
+
|
| 39 |
+
return args
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class ExtraNetworkLyCORIS(extra_networks.ExtraNetwork):
|
| 43 |
+
def __init__(self):
|
| 44 |
+
super().__init__('lyco')
|
| 45 |
+
self.cache = ()
|
| 46 |
+
|
| 47 |
+
def activate(self, p, params_list):
|
| 48 |
+
additional = shared.opts.sd_lyco
|
| 49 |
+
|
| 50 |
+
if additional != "" and additional in lycoris.available_lycos and len([x for x in params_list if x.items[0] == additional]) == 0:
|
| 51 |
+
p.all_prompts = [
|
| 52 |
+
x +
|
| 53 |
+
f"<lyco:{additional}:{shared.opts.extra_networks_default_multiplier}>"
|
| 54 |
+
for x in p.all_prompts
|
| 55 |
+
]
|
| 56 |
+
params_list.append(
|
| 57 |
+
extra_networks.ExtraNetworkParams(
|
| 58 |
+
items=[additional, shared.opts.extra_networks_default_multiplier])
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
names = []
|
| 62 |
+
te_multipliers = []
|
| 63 |
+
unet_multipliers = []
|
| 64 |
+
dyn_dims = []
|
| 65 |
+
for params in params_list:
|
| 66 |
+
assert len(params.items) > 0
|
| 67 |
+
|
| 68 |
+
names.append(params.items[0])
|
| 69 |
+
te, unet, dyn_dim = parse_args(params.items[1:])
|
| 70 |
+
if unet is None:
|
| 71 |
+
unet = te
|
| 72 |
+
te_multipliers.append(te)
|
| 73 |
+
unet_multipliers.append(unet)
|
| 74 |
+
dyn_dims.append(dyn_dim)
|
| 75 |
+
|
| 76 |
+
all_lycos = tuple(
|
| 77 |
+
(name, te, unet, dyn)
|
| 78 |
+
for name, te, unet, dyn in zip(names, te_multipliers, unet_multipliers, dyn_dims)
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
if all_lycos != self.cache:
|
| 82 |
+
for name, te, unet, dyn in all_lycos:
|
| 83 |
+
print(
|
| 84 |
+
"========================================\n"
|
| 85 |
+
f"Apply LyCORIS model: {name}\n"
|
| 86 |
+
f"Text encoder weight: {te}\n"
|
| 87 |
+
f"Unet weight: {unet}\n"
|
| 88 |
+
f"DyLoRA Dim: {dyn}"
|
| 89 |
+
)
|
| 90 |
+
print("========================================")
|
| 91 |
+
self.cache = all_lycos
|
| 92 |
+
lycoris.load_lycos(names, te_multipliers, unet_multipliers, dyn_dims)
|
| 93 |
+
|
| 94 |
+
def deactivate(self, p):
|
| 95 |
+
pass
|
extensions/a1111-sd-webui-lycoris/lycoris.py
ADDED
|
@@ -0,0 +1,793 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import *
|
| 2 |
+
import os, sys
|
| 3 |
+
import re
|
| 4 |
+
import glob
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
|
| 10 |
+
from modules import shared, devices, sd_models, errors
|
| 11 |
+
|
| 12 |
+
metadata_tags_order = {"ss_sd_model_name": 1, "ss_resolution": 2, "ss_clip_skip": 3, "ss_num_train_images": 10, "ss_tag_frequency": 20}
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
re_digits = re.compile(r"\d+")
|
| 16 |
+
re_x_proj = re.compile(r"(.*)_([qkv]_proj)$")
|
| 17 |
+
|
| 18 |
+
re_unet_conv_in = re.compile(r"lora_unet_conv_in(.+)")
|
| 19 |
+
re_unet_conv_out = re.compile(r"lora_unet_conv_out(.+)")
|
| 20 |
+
re_unet_time_embed = re.compile(r"lora_unet_time_embedding_linear_(\d+)(.+)")
|
| 21 |
+
|
| 22 |
+
re_unet_down_blocks = re.compile(r"lora_unet_down_blocks_(\d+)_attentions_(\d+)_(.+)")
|
| 23 |
+
re_unet_mid_blocks = re.compile(r"lora_unet_mid_block_attentions_(\d+)_(.+)")
|
| 24 |
+
re_unet_up_blocks = re.compile(r"lora_unet_up_blocks_(\d+)_attentions_(\d+)_(.+)")
|
| 25 |
+
|
| 26 |
+
re_unet_down_blocks_res = re.compile(r"lora_unet_down_blocks_(\d+)_resnets_(\d+)_(.+)")
|
| 27 |
+
re_unet_mid_blocks_res = re.compile(r"lora_unet_mid_block_resnets_(\d+)_(.+)")
|
| 28 |
+
re_unet_up_blocks_res = re.compile(r"lora_unet_up_blocks_(\d+)_resnets_(\d+)_(.+)")
|
| 29 |
+
|
| 30 |
+
re_unet_downsample = re.compile(r"lora_unet_down_blocks_(\d+)_downsamplers_0_conv(.+)")
|
| 31 |
+
re_unet_upsample = re.compile(r"lora_unet_up_blocks_(\d+)_upsamplers_0_conv(.+)")
|
| 32 |
+
|
| 33 |
+
re_text_block = re.compile(r"lora_te_text_model_encoder_layers_(\d+)_(.+)")
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def convert_diffusers_name_to_compvis(key, is_sd2):
|
| 37 |
+
# I don't know why but some state dict has this kind of thing
|
| 38 |
+
key = key.replace('text_model_text_model', 'text_model')
|
| 39 |
+
def match(match_list, regex):
|
| 40 |
+
r = re.match(regex, key)
|
| 41 |
+
if not r:
|
| 42 |
+
return False
|
| 43 |
+
|
| 44 |
+
match_list.clear()
|
| 45 |
+
match_list.extend([int(x) if re.match(re_digits, x) else x for x in r.groups()])
|
| 46 |
+
return True
|
| 47 |
+
|
| 48 |
+
m = []
|
| 49 |
+
|
| 50 |
+
if match(m, re_unet_conv_in):
|
| 51 |
+
return f'diffusion_model_input_blocks_0_0{m[0]}'
|
| 52 |
+
|
| 53 |
+
if match(m, re_unet_conv_out):
|
| 54 |
+
return f'diffusion_model_out_2{m[0]}'
|
| 55 |
+
|
| 56 |
+
if match(m, re_unet_time_embed):
|
| 57 |
+
return f"diffusion_model_time_embed_{m[0]*2-2}{m[1]}"
|
| 58 |
+
|
| 59 |
+
if match(m, re_unet_down_blocks):
|
| 60 |
+
return f"diffusion_model_input_blocks_{1 + m[0] * 3 + m[1]}_1_{m[2]}"
|
| 61 |
+
|
| 62 |
+
if match(m, re_unet_mid_blocks):
|
| 63 |
+
return f"diffusion_model_middle_block_1_{m[1]}"
|
| 64 |
+
|
| 65 |
+
if match(m, re_unet_up_blocks):
|
| 66 |
+
return f"diffusion_model_output_blocks_{m[0] * 3 + m[1]}_1_{m[2]}"
|
| 67 |
+
|
| 68 |
+
if match(m, re_unet_down_blocks_res):
|
| 69 |
+
block = f"diffusion_model_input_blocks_{1 + m[0] * 3 + m[1]}_0_"
|
| 70 |
+
if m[2].startswith('conv1'):
|
| 71 |
+
return f"{block}in_layers_2{m[2][len('conv1'):]}"
|
| 72 |
+
elif m[2].startswith('conv2'):
|
| 73 |
+
return f"{block}out_layers_3{m[2][len('conv2'):]}"
|
| 74 |
+
elif m[2].startswith('time_emb_proj'):
|
| 75 |
+
return f"{block}emb_layers_1{m[2][len('time_emb_proj'):]}"
|
| 76 |
+
elif m[2].startswith('conv_shortcut'):
|
| 77 |
+
return f"{block}skip_connection{m[2][len('conv_shortcut'):]}"
|
| 78 |
+
|
| 79 |
+
if match(m, re_unet_mid_blocks_res):
|
| 80 |
+
block = f"diffusion_model_middle_block_{m[0]*2}_"
|
| 81 |
+
if m[1].startswith('conv1'):
|
| 82 |
+
return f"{block}in_layers_2{m[1][len('conv1'):]}"
|
| 83 |
+
elif m[1].startswith('conv2'):
|
| 84 |
+
return f"{block}out_layers_3{m[1][len('conv2'):]}"
|
| 85 |
+
elif m[1].startswith('time_emb_proj'):
|
| 86 |
+
return f"{block}emb_layers_1{m[1][len('time_emb_proj'):]}"
|
| 87 |
+
elif m[1].startswith('conv_shortcut'):
|
| 88 |
+
return f"{block}skip_connection{m[1][len('conv_shortcut'):]}"
|
| 89 |
+
|
| 90 |
+
if match(m, re_unet_up_blocks_res):
|
| 91 |
+
block = f"diffusion_model_output_blocks_{m[0] * 3 + m[1]}_0_"
|
| 92 |
+
if m[2].startswith('conv1'):
|
| 93 |
+
return f"{block}in_layers_2{m[2][len('conv1'):]}"
|
| 94 |
+
elif m[2].startswith('conv2'):
|
| 95 |
+
return f"{block}out_layers_3{m[2][len('conv2'):]}"
|
| 96 |
+
elif m[2].startswith('time_emb_proj'):
|
| 97 |
+
return f"{block}emb_layers_1{m[2][len('time_emb_proj'):]}"
|
| 98 |
+
elif m[2].startswith('conv_shortcut'):
|
| 99 |
+
return f"{block}skip_connection{m[2][len('conv_shortcut'):]}"
|
| 100 |
+
|
| 101 |
+
if match(m, re_unet_downsample):
|
| 102 |
+
return f"diffusion_model_input_blocks_{m[0]*3+3}_0_op{m[1]}"
|
| 103 |
+
|
| 104 |
+
if match(m, re_unet_upsample):
|
| 105 |
+
return f"diffusion_model_output_blocks_{m[0]*3 + 2}_{1+(m[0]!=0)}_conv{m[1]}"
|
| 106 |
+
|
| 107 |
+
if match(m, r"lora_te_text_model_encoder_layers_(\d+)_(.+)"):
|
| 108 |
+
if is_sd2:
|
| 109 |
+
if 'mlp_fc1' in m[1]:
|
| 110 |
+
return f"model_transformer_resblocks_{m[0]}_{m[1].replace('mlp_fc1', 'mlp_c_fc')}"
|
| 111 |
+
elif 'mlp_fc2' in m[1]:
|
| 112 |
+
return f"model_transformer_resblocks_{m[0]}_{m[1].replace('mlp_fc2', 'mlp_c_proj')}"
|
| 113 |
+
else:
|
| 114 |
+
return f"model_transformer_resblocks_{m[0]}_{m[1].replace('self_attn', 'attn')}"
|
| 115 |
+
|
| 116 |
+
return f"transformer_text_model_encoder_layers_{m[0]}_{m[1]}"
|
| 117 |
+
|
| 118 |
+
return key
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def assign_lyco_names_to_compvis_modules(sd_model):
|
| 122 |
+
lyco_layer_mapping = {}
|
| 123 |
+
|
| 124 |
+
for name, module in shared.sd_model.cond_stage_model.wrapped.named_modules():
|
| 125 |
+
lyco_name = name.replace(".", "_")
|
| 126 |
+
lyco_layer_mapping[lyco_name] = module
|
| 127 |
+
module.lyco_layer_name = lyco_name
|
| 128 |
+
|
| 129 |
+
for name, module in shared.sd_model.model.named_modules():
|
| 130 |
+
lyco_name = name.replace(".", "_")
|
| 131 |
+
lyco_layer_mapping[lyco_name] = module
|
| 132 |
+
module.lyco_layer_name = lyco_name
|
| 133 |
+
|
| 134 |
+
sd_model.lyco_layer_mapping = lyco_layer_mapping
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
class LycoOnDisk:
|
| 138 |
+
def __init__(self, name, filename):
|
| 139 |
+
self.name = name
|
| 140 |
+
self.filename = filename
|
| 141 |
+
self.metadata = {}
|
| 142 |
+
|
| 143 |
+
_, ext = os.path.splitext(filename)
|
| 144 |
+
if ext.lower() == ".safetensors":
|
| 145 |
+
try:
|
| 146 |
+
self.metadata = sd_models.read_metadata_from_safetensors(filename)
|
| 147 |
+
except Exception as e:
|
| 148 |
+
errors.display(e, f"reading lora {filename}")
|
| 149 |
+
|
| 150 |
+
if self.metadata:
|
| 151 |
+
m = {}
|
| 152 |
+
for k, v in sorted(self.metadata.items(), key=lambda x: metadata_tags_order.get(x[0], 999)):
|
| 153 |
+
m[k] = v
|
| 154 |
+
|
| 155 |
+
self.metadata = m
|
| 156 |
+
|
| 157 |
+
self.ssmd_cover_images = self.metadata.pop('ssmd_cover_images', None) # those are cover images and they are too big to display in UI as text
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
class LycoModule:
|
| 161 |
+
def __init__(self, name):
|
| 162 |
+
self.name = name
|
| 163 |
+
self.te_multiplier = 1.0
|
| 164 |
+
self.unet_multiplier = 1.0
|
| 165 |
+
self.dyn_dim = None
|
| 166 |
+
self.modules = {}
|
| 167 |
+
self.mtime = None
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
class FullModule:
|
| 171 |
+
def __init__(self):
|
| 172 |
+
self.weight = None
|
| 173 |
+
self.alpha = None
|
| 174 |
+
self.scale = None
|
| 175 |
+
self.dim = None
|
| 176 |
+
self.shape = None
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
class LycoUpDownModule:
|
| 180 |
+
def __init__(self):
|
| 181 |
+
self.up_model = None
|
| 182 |
+
self.mid_model = None
|
| 183 |
+
self.down_model = None
|
| 184 |
+
self.alpha = None
|
| 185 |
+
self.scale = None
|
| 186 |
+
self.dim = None
|
| 187 |
+
self.shape = None
|
| 188 |
+
self.bias = None
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
def make_weight_cp(t, wa, wb):
|
| 192 |
+
temp = torch.einsum('i j k l, j r -> i r k l', t, wb)
|
| 193 |
+
return torch.einsum('i j k l, i r -> r j k l', temp, wa)
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
class LycoHadaModule:
|
| 197 |
+
def __init__(self):
|
| 198 |
+
self.t1 = None
|
| 199 |
+
self.w1a = None
|
| 200 |
+
self.w1b = None
|
| 201 |
+
self.t2 = None
|
| 202 |
+
self.w2a = None
|
| 203 |
+
self.w2b = None
|
| 204 |
+
self.alpha = None
|
| 205 |
+
self.scale = None
|
| 206 |
+
self.dim = None
|
| 207 |
+
self.shape = None
|
| 208 |
+
self.bias = None
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class IA3Module:
|
| 212 |
+
def __init__(self):
|
| 213 |
+
self.w = None
|
| 214 |
+
self.alpha = None
|
| 215 |
+
self.scale = None
|
| 216 |
+
self.dim = None
|
| 217 |
+
self.on_input = None
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
def make_kron(orig_shape, w1, w2):
|
| 221 |
+
if len(w2.shape) == 4:
|
| 222 |
+
w1 = w1.unsqueeze(2).unsqueeze(2)
|
| 223 |
+
w2 = w2.contiguous()
|
| 224 |
+
return torch.kron(w1, w2).reshape(orig_shape)
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
class LycoKronModule:
|
| 228 |
+
def __init__(self):
|
| 229 |
+
self.w1 = None
|
| 230 |
+
self.w1a = None
|
| 231 |
+
self.w1b = None
|
| 232 |
+
self.w2 = None
|
| 233 |
+
self.t2 = None
|
| 234 |
+
self.w2a = None
|
| 235 |
+
self.w2b = None
|
| 236 |
+
self._alpha = None
|
| 237 |
+
self.scale = None
|
| 238 |
+
self.dim = None
|
| 239 |
+
self.shape = None
|
| 240 |
+
self.bias = None
|
| 241 |
+
|
| 242 |
+
@property
|
| 243 |
+
def alpha(self):
|
| 244 |
+
if self.w1a is None and self.w2a is None:
|
| 245 |
+
return None
|
| 246 |
+
else:
|
| 247 |
+
return self._alpha
|
| 248 |
+
|
| 249 |
+
@alpha.setter
|
| 250 |
+
def alpha(self, x):
|
| 251 |
+
self._alpha = x
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
CON_KEY = {
|
| 255 |
+
"lora_up.weight", "dyn_up",
|
| 256 |
+
"lora_down.weight", "dyn_down",
|
| 257 |
+
"lora_mid.weight"
|
| 258 |
+
}
|
| 259 |
+
HADA_KEY = {
|
| 260 |
+
"hada_t1",
|
| 261 |
+
"hada_w1_a",
|
| 262 |
+
"hada_w1_b",
|
| 263 |
+
"hada_t2",
|
| 264 |
+
"hada_w2_a",
|
| 265 |
+
"hada_w2_b",
|
| 266 |
+
}
|
| 267 |
+
IA3_KEY = {
|
| 268 |
+
"weight",
|
| 269 |
+
"on_input"
|
| 270 |
+
}
|
| 271 |
+
KRON_KEY = {
|
| 272 |
+
"lokr_w1",
|
| 273 |
+
"lokr_w1_a",
|
| 274 |
+
"lokr_w1_b",
|
| 275 |
+
"lokr_t2",
|
| 276 |
+
"lokr_w2",
|
| 277 |
+
"lokr_w2_a",
|
| 278 |
+
"lokr_w2_b",
|
| 279 |
+
}
|
| 280 |
+
|
| 281 |
+
def load_lyco(name, filename):
|
| 282 |
+
lyco = LycoModule(name)
|
| 283 |
+
lyco.mtime = os.path.getmtime(filename)
|
| 284 |
+
|
| 285 |
+
sd = sd_models.read_state_dict(filename)
|
| 286 |
+
is_sd2 = 'model_transformer_resblocks' in shared.sd_model.lyco_layer_mapping
|
| 287 |
+
|
| 288 |
+
keys_failed_to_match = []
|
| 289 |
+
|
| 290 |
+
for key_diffusers, weight in sd.items():
|
| 291 |
+
fullkey = convert_diffusers_name_to_compvis(key_diffusers, is_sd2)
|
| 292 |
+
key, lyco_key = fullkey.split(".", 1)
|
| 293 |
+
|
| 294 |
+
sd_module = shared.sd_model.lyco_layer_mapping.get(key, None)
|
| 295 |
+
|
| 296 |
+
if sd_module is None:
|
| 297 |
+
m = re_x_proj.match(key)
|
| 298 |
+
if m:
|
| 299 |
+
sd_module = shared.sd_model.lyco_layer_mapping.get(m.group(1), None)
|
| 300 |
+
|
| 301 |
+
if sd_module is None:
|
| 302 |
+
print(key)
|
| 303 |
+
keys_failed_to_match.append(key_diffusers)
|
| 304 |
+
continue
|
| 305 |
+
|
| 306 |
+
lyco_module = lyco.modules.get(key, None)
|
| 307 |
+
if lyco_module is None:
|
| 308 |
+
lyco_module = LycoUpDownModule()
|
| 309 |
+
lyco.modules[key] = lyco_module
|
| 310 |
+
|
| 311 |
+
if lyco_key == "alpha":
|
| 312 |
+
lyco_module.alpha = weight.item()
|
| 313 |
+
continue
|
| 314 |
+
|
| 315 |
+
if lyco_key == "scale":
|
| 316 |
+
lyco_module.scale = weight.item()
|
| 317 |
+
continue
|
| 318 |
+
|
| 319 |
+
if lyco_key == "diff":
|
| 320 |
+
weight = weight.to(device=devices.cpu, dtype=devices.dtype)
|
| 321 |
+
weight.requires_grad_(False)
|
| 322 |
+
lyco_module = FullModule()
|
| 323 |
+
lyco.modules[key] = lyco_module
|
| 324 |
+
lyco_module.weight = weight
|
| 325 |
+
continue
|
| 326 |
+
|
| 327 |
+
if 'bias_' in lyco_key:
|
| 328 |
+
if lyco_module.bias is None:
|
| 329 |
+
lyco_module.bias = [None, None, None]
|
| 330 |
+
if 'bias_indices' == lyco_key:
|
| 331 |
+
lyco_module.bias[0] = weight
|
| 332 |
+
elif 'bias_values' == lyco_key:
|
| 333 |
+
lyco_module.bias[1] = weight
|
| 334 |
+
elif 'bias_size' == lyco_key:
|
| 335 |
+
lyco_module.bias[2] = weight
|
| 336 |
+
|
| 337 |
+
if all((i is not None) for i in lyco_module.bias):
|
| 338 |
+
print('build bias')
|
| 339 |
+
lyco_module.bias = torch.sparse_coo_tensor(
|
| 340 |
+
lyco_module.bias[0],
|
| 341 |
+
lyco_module.bias[1],
|
| 342 |
+
tuple(lyco_module.bias[2]),
|
| 343 |
+
).to(device=devices.cpu, dtype=devices.dtype)
|
| 344 |
+
lyco_module.bias.requires_grad_(False)
|
| 345 |
+
continue
|
| 346 |
+
|
| 347 |
+
if lyco_key in CON_KEY:
|
| 348 |
+
if (type(sd_module) == torch.nn.Linear
|
| 349 |
+
or type(sd_module) == torch.nn.modules.linear.NonDynamicallyQuantizableLinear
|
| 350 |
+
or type(sd_module) == torch.nn.MultiheadAttention):
|
| 351 |
+
weight = weight.reshape(weight.shape[0], -1)
|
| 352 |
+
module = torch.nn.Linear(weight.shape[1], weight.shape[0], bias=False)
|
| 353 |
+
elif type(sd_module) == torch.nn.Conv2d:
|
| 354 |
+
if lyco_key == "lora_down.weight" or lyco_key == "dyn_up":
|
| 355 |
+
if len(weight.shape) == 2:
|
| 356 |
+
weight = weight.reshape(weight.shape[0], -1, 1, 1)
|
| 357 |
+
if weight.shape[2] != 1 or weight.shape[3] != 1:
|
| 358 |
+
module = torch.nn.Conv2d(weight.shape[1], weight.shape[0], sd_module.kernel_size, sd_module.stride, sd_module.padding, bias=False)
|
| 359 |
+
else:
|
| 360 |
+
module = torch.nn.Conv2d(weight.shape[1], weight.shape[0], (1, 1), bias=False)
|
| 361 |
+
elif lyco_key == "lora_mid.weight":
|
| 362 |
+
module = torch.nn.Conv2d(weight.shape[1], weight.shape[0], sd_module.kernel_size, sd_module.stride, sd_module.padding, bias=False)
|
| 363 |
+
elif lyco_key == "lora_up.weight" or lyco_key == "dyn_down":
|
| 364 |
+
module = torch.nn.Conv2d(weight.shape[1], weight.shape[0], (1, 1), bias=False)
|
| 365 |
+
else:
|
| 366 |
+
assert False, f'Lyco layer {key_diffusers} matched a layer with unsupported type: {type(sd_module).__name__}'
|
| 367 |
+
|
| 368 |
+
if hasattr(sd_module, 'weight'):
|
| 369 |
+
lyco_module.shape = sd_module.weight.shape
|
| 370 |
+
with torch.no_grad():
|
| 371 |
+
if weight.shape != module.weight.shape:
|
| 372 |
+
weight = weight.reshape(module.weight.shape)
|
| 373 |
+
module.weight.copy_(weight)
|
| 374 |
+
|
| 375 |
+
module.to(device=devices.cpu, dtype=devices.dtype)
|
| 376 |
+
module.requires_grad_(False)
|
| 377 |
+
|
| 378 |
+
if lyco_key == "lora_up.weight" or lyco_key == "dyn_up":
|
| 379 |
+
lyco_module.up_model = module
|
| 380 |
+
elif lyco_key == "lora_mid.weight":
|
| 381 |
+
lyco_module.mid_model = module
|
| 382 |
+
elif lyco_key == "lora_down.weight" or lyco_key == "dyn_down":
|
| 383 |
+
lyco_module.down_model = module
|
| 384 |
+
lyco_module.dim = weight.shape[0]
|
| 385 |
+
else:
|
| 386 |
+
print(lyco_key)
|
| 387 |
+
elif lyco_key in HADA_KEY:
|
| 388 |
+
if type(lyco_module) != LycoHadaModule:
|
| 389 |
+
alpha = lyco_module.alpha
|
| 390 |
+
bias = lyco_module.bias
|
| 391 |
+
lyco_module = LycoHadaModule()
|
| 392 |
+
lyco_module.alpha = alpha
|
| 393 |
+
lyco_module.bias = bias
|
| 394 |
+
lyco.modules[key] = lyco_module
|
| 395 |
+
if hasattr(sd_module, 'weight'):
|
| 396 |
+
lyco_module.shape = sd_module.weight.shape
|
| 397 |
+
|
| 398 |
+
weight = weight.to(device=devices.cpu, dtype=devices.dtype)
|
| 399 |
+
weight.requires_grad_(False)
|
| 400 |
+
|
| 401 |
+
if lyco_key == 'hada_w1_a':
|
| 402 |
+
lyco_module.w1a = weight
|
| 403 |
+
elif lyco_key == 'hada_w1_b':
|
| 404 |
+
lyco_module.w1b = weight
|
| 405 |
+
lyco_module.dim = weight.shape[0]
|
| 406 |
+
elif lyco_key == 'hada_w2_a':
|
| 407 |
+
lyco_module.w2a = weight
|
| 408 |
+
elif lyco_key == 'hada_w2_b':
|
| 409 |
+
lyco_module.w2b = weight
|
| 410 |
+
lyco_module.dim = weight.shape[0]
|
| 411 |
+
elif lyco_key == 'hada_t1':
|
| 412 |
+
lyco_module.t1 = weight
|
| 413 |
+
elif lyco_key == 'hada_t2':
|
| 414 |
+
lyco_module.t2 = weight
|
| 415 |
+
|
| 416 |
+
elif lyco_key in IA3_KEY:
|
| 417 |
+
if type(lyco_module) != IA3Module:
|
| 418 |
+
lyco_module = IA3Module()
|
| 419 |
+
lyco.modules[key] = lyco_module
|
| 420 |
+
|
| 421 |
+
if lyco_key == "weight":
|
| 422 |
+
lyco_module.w = weight.to(devices.device, dtype=devices.dtype)
|
| 423 |
+
elif lyco_key == "on_input":
|
| 424 |
+
lyco_module.on_input = weight
|
| 425 |
+
elif lyco_key in KRON_KEY:
|
| 426 |
+
if not isinstance(lyco_module, LycoKronModule):
|
| 427 |
+
alpha = lyco_module.alpha
|
| 428 |
+
bias = lyco_module.bias
|
| 429 |
+
lyco_module = LycoKronModule()
|
| 430 |
+
lyco_module.alpha = alpha
|
| 431 |
+
lyco_module.bias = bias
|
| 432 |
+
lyco.modules[key] = lyco_module
|
| 433 |
+
if hasattr(sd_module, 'weight'):
|
| 434 |
+
lyco_module.shape = sd_module.weight.shape
|
| 435 |
+
|
| 436 |
+
weight = weight.to(device=devices.cpu, dtype=devices.dtype)
|
| 437 |
+
weight.requires_grad_(False)
|
| 438 |
+
|
| 439 |
+
if lyco_key == 'lokr_w1':
|
| 440 |
+
lyco_module.w1 = weight
|
| 441 |
+
elif lyco_key == 'lokr_w1_a':
|
| 442 |
+
lyco_module.w1a = weight
|
| 443 |
+
elif lyco_key == 'lokr_w1_b':
|
| 444 |
+
lyco_module.w1b = weight
|
| 445 |
+
lyco_module.dim = weight.shape[0]
|
| 446 |
+
elif lyco_key == 'lokr_w2':
|
| 447 |
+
lyco_module.w2 = weight
|
| 448 |
+
elif lyco_key == 'lokr_w2_a':
|
| 449 |
+
lyco_module.w2a = weight
|
| 450 |
+
elif lyco_key == 'lokr_w2_b':
|
| 451 |
+
lyco_module.w2b = weight
|
| 452 |
+
lyco_module.dim = weight.shape[0]
|
| 453 |
+
elif lyco_key == 'lokr_t2':
|
| 454 |
+
lyco_module.t2 = weight
|
| 455 |
+
else:
|
| 456 |
+
assert False, f'Bad Lyco layer name: {key_diffusers} - must end in lyco_up.weight, lyco_down.weight or alpha'
|
| 457 |
+
|
| 458 |
+
if len(keys_failed_to_match) > 0:
|
| 459 |
+
print(shared.sd_model.lyco_layer_mapping)
|
| 460 |
+
print(f"Failed to match keys when loading Lyco {filename}: {keys_failed_to_match}")
|
| 461 |
+
|
| 462 |
+
return lyco
|
| 463 |
+
|
| 464 |
+
|
| 465 |
+
def load_lycos(names, te_multipliers=None, unet_multipliers=None, dyn_dims=None):
|
| 466 |
+
already_loaded = {}
|
| 467 |
+
|
| 468 |
+
for lyco in loaded_lycos:
|
| 469 |
+
if lyco.name in names:
|
| 470 |
+
already_loaded[lyco.name] = lyco
|
| 471 |
+
|
| 472 |
+
loaded_lycos.clear()
|
| 473 |
+
|
| 474 |
+
lycos_on_disk = [available_lycos.get(name, None) for name in names]
|
| 475 |
+
if any([x is None for x in lycos_on_disk]):
|
| 476 |
+
list_available_lycos()
|
| 477 |
+
|
| 478 |
+
lycos_on_disk = [available_lycos.get(name, None) for name in names]
|
| 479 |
+
|
| 480 |
+
for i, name in enumerate(names):
|
| 481 |
+
lyco = already_loaded.get(name, None)
|
| 482 |
+
|
| 483 |
+
lyco_on_disk = lycos_on_disk[i]
|
| 484 |
+
if lyco_on_disk is not None:
|
| 485 |
+
if lyco is None or os.path.getmtime(lyco_on_disk.filename) > lyco.mtime:
|
| 486 |
+
lyco = load_lyco(name, lyco_on_disk.filename)
|
| 487 |
+
|
| 488 |
+
if lyco is None:
|
| 489 |
+
print(f"Couldn't find Lora with name {name}")
|
| 490 |
+
continue
|
| 491 |
+
|
| 492 |
+
lyco.te_multiplier = te_multipliers[i] if te_multipliers else 1.0
|
| 493 |
+
lyco.unet_multiplier = unet_multipliers[i] if unet_multipliers else lyco.te_multiplier
|
| 494 |
+
lyco.dyn_dim = dyn_dims[i] if dyn_dims else None
|
| 495 |
+
loaded_lycos.append(lyco)
|
| 496 |
+
|
| 497 |
+
|
| 498 |
+
def _rebuild_conventional(up, down, shape, dyn_dim=None):
|
| 499 |
+
up = up.reshape(up.size(0), -1)
|
| 500 |
+
down = down.reshape(down.size(0), -1)
|
| 501 |
+
if dyn_dim is not None:
|
| 502 |
+
up = up[:, :dyn_dim]
|
| 503 |
+
down = down[:dyn_dim, :]
|
| 504 |
+
return (up @ down).reshape(shape)
|
| 505 |
+
|
| 506 |
+
|
| 507 |
+
def _rebuild_cp_decomposition(up, down, mid):
|
| 508 |
+
up = up.reshape(up.size(0), -1)
|
| 509 |
+
down = down.reshape(down.size(0), -1)
|
| 510 |
+
return torch.einsum('n m k l, i n, m j -> i j k l', mid, up, down)
|
| 511 |
+
|
| 512 |
+
|
| 513 |
+
def rebuild_weight(module, orig_weight: torch.Tensor, dyn_dim: int=None) -> torch.Tensor:
|
| 514 |
+
output_shape: Sized
|
| 515 |
+
if module.__class__.__name__ == 'LycoUpDownModule':
|
| 516 |
+
up = module.up_model.weight.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 517 |
+
down = module.down_model.weight.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 518 |
+
|
| 519 |
+
output_shape = [up.size(0), down.size(1)]
|
| 520 |
+
if (mid:=module.mid_model) is not None:
|
| 521 |
+
# cp-decomposition
|
| 522 |
+
mid = mid.weight.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 523 |
+
updown = _rebuild_cp_decomposition(up, down, mid)
|
| 524 |
+
output_shape += mid.shape[2:]
|
| 525 |
+
else:
|
| 526 |
+
if len(down.shape) == 4:
|
| 527 |
+
output_shape += down.shape[2:]
|
| 528 |
+
updown = _rebuild_conventional(up, down, output_shape, dyn_dim)
|
| 529 |
+
|
| 530 |
+
elif module.__class__.__name__ == 'LycoHadaModule':
|
| 531 |
+
w1a = module.w1a.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 532 |
+
w1b = module.w1b.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 533 |
+
w2a = module.w2a.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 534 |
+
w2b = module.w2b.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 535 |
+
|
| 536 |
+
output_shape = [w1a.size(0), w1b.size(1)]
|
| 537 |
+
|
| 538 |
+
if module.t1 is not None:
|
| 539 |
+
output_shape = [w1a.size(1), w1b.size(1)]
|
| 540 |
+
t1 = module.t1.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 541 |
+
updown1 = make_weight_cp(t1, w1a, w1b)
|
| 542 |
+
output_shape += t1.shape[2:]
|
| 543 |
+
else:
|
| 544 |
+
if len(w1b.shape) == 4:
|
| 545 |
+
output_shape += w1b.shape[2:]
|
| 546 |
+
updown1 = _rebuild_conventional(w1a, w1b, output_shape)
|
| 547 |
+
|
| 548 |
+
if module.t2 is not None:
|
| 549 |
+
t2 = module.t2.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 550 |
+
updown2 = make_weight_cp(t2, w2a, w2b)
|
| 551 |
+
else:
|
| 552 |
+
updown2 = _rebuild_conventional(w2a, w2b, output_shape)
|
| 553 |
+
|
| 554 |
+
updown = updown1 * updown2
|
| 555 |
+
|
| 556 |
+
elif module.__class__.__name__ == 'FullModule':
|
| 557 |
+
output_shape = module.weight.shape
|
| 558 |
+
updown = module.weight.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 559 |
+
|
| 560 |
+
elif module.__class__.__name__ == 'IA3Module':
|
| 561 |
+
output_shape = [module.w.size(0), orig_weight.size(1)]
|
| 562 |
+
if module.on_input:
|
| 563 |
+
output_shape.reverse()
|
| 564 |
+
else:
|
| 565 |
+
module.w = module.w.reshape(-1, 1)
|
| 566 |
+
updown = orig_weight * module.w
|
| 567 |
+
|
| 568 |
+
elif module.__class__.__name__ == 'LycoKronModule':
|
| 569 |
+
if module.w1 is not None:
|
| 570 |
+
w1 = module.w1.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 571 |
+
else:
|
| 572 |
+
w1a = module.w1a.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 573 |
+
w1b = module.w1b.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 574 |
+
w1 = w1a @ w1b
|
| 575 |
+
|
| 576 |
+
if module.w2 is not None:
|
| 577 |
+
w2 = module.w2.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 578 |
+
elif module.t2 is None:
|
| 579 |
+
w2a = module.w2a.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 580 |
+
w2b = module.w2b.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 581 |
+
w2 = w2a @ w2b
|
| 582 |
+
else:
|
| 583 |
+
t2 = module.t2.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 584 |
+
w2a = module.w2a.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 585 |
+
w2b = module.w2b.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 586 |
+
w2 = make_weight_cp(t2, w2a, w2b)
|
| 587 |
+
|
| 588 |
+
output_shape = [w1.size(0)*w2.size(0), w1.size(1)*w2.size(1)]
|
| 589 |
+
if len(orig_weight.shape) == 4:
|
| 590 |
+
output_shape = orig_weight.shape
|
| 591 |
+
|
| 592 |
+
updown = make_kron(
|
| 593 |
+
output_shape, w1, w2
|
| 594 |
+
)
|
| 595 |
+
|
| 596 |
+
else:
|
| 597 |
+
raise NotImplementedError(
|
| 598 |
+
f"Unknown module type: {module.__class__.__name__}\n"
|
| 599 |
+
"If the type is one of "
|
| 600 |
+
"'LycoUpDownModule', 'LycoHadaModule', 'FullModule', 'IA3Module', 'LycoKronModule'"
|
| 601 |
+
"You may have other lyco extension that conflict with locon extension."
|
| 602 |
+
)
|
| 603 |
+
|
| 604 |
+
if hasattr(module, 'bias') and module.bias != None:
|
| 605 |
+
updown = updown.reshape(module.bias.shape)
|
| 606 |
+
updown += module.bias.to(orig_weight.device, dtype=orig_weight.dtype)
|
| 607 |
+
updown = updown.reshape(output_shape)
|
| 608 |
+
|
| 609 |
+
if len(output_shape) == 4:
|
| 610 |
+
updown = updown.reshape(output_shape)
|
| 611 |
+
|
| 612 |
+
if orig_weight.size().numel() == updown.size().numel():
|
| 613 |
+
updown = updown.reshape(orig_weight.shape)
|
| 614 |
+
# print(torch.sum(updown))
|
| 615 |
+
return updown
|
| 616 |
+
|
| 617 |
+
|
| 618 |
+
def lyco_calc_updown(lyco, module, target):
|
| 619 |
+
with torch.no_grad():
|
| 620 |
+
updown = rebuild_weight(module, target, lyco.dyn_dim)
|
| 621 |
+
if lyco.dyn_dim and module.dim:
|
| 622 |
+
dim = min(lyco.dyn_dim, module.dim)
|
| 623 |
+
elif lyco.dyn_dim:
|
| 624 |
+
dim = lyco.dyn_dim
|
| 625 |
+
elif module.dim:
|
| 626 |
+
dim = module.dim
|
| 627 |
+
else:
|
| 628 |
+
dim = None
|
| 629 |
+
scale = (
|
| 630 |
+
module.scale if module.scale is not None
|
| 631 |
+
else module.alpha / dim if dim is not None and module.alpha is not None
|
| 632 |
+
else 1.0
|
| 633 |
+
)
|
| 634 |
+
# print(scale, module.alpha, module.dim, lyco.dyn_dim)
|
| 635 |
+
updown = updown * scale
|
| 636 |
+
return updown
|
| 637 |
+
|
| 638 |
+
|
| 639 |
+
def lyco_apply_weights(self: Union[torch.nn.Conv2d, torch.nn.Linear, torch.nn.MultiheadAttention]):
|
| 640 |
+
"""
|
| 641 |
+
Applies the currently selected set of Lycos to the weights of torch layer self.
|
| 642 |
+
If weights already have this particular set of lycos applied, does nothing.
|
| 643 |
+
If not, restores orginal weights from backup and alters weights according to lycos.
|
| 644 |
+
"""
|
| 645 |
+
|
| 646 |
+
lyco_layer_name = getattr(self, 'lyco_layer_name', None)
|
| 647 |
+
if lyco_layer_name is None:
|
| 648 |
+
return
|
| 649 |
+
|
| 650 |
+
current_names = getattr(self, "lyco_current_names", ())
|
| 651 |
+
lora_prev_names = getattr(self, "lora_prev_names", ())
|
| 652 |
+
lora_names = getattr(self, "lora_current_names", ())
|
| 653 |
+
wanted_names = tuple((x.name, x.te_multiplier, x.unet_multiplier, x.dyn_dim) for x in loaded_lycos)
|
| 654 |
+
|
| 655 |
+
weights_backup = getattr(self, "lyco_weights_backup", None)
|
| 656 |
+
lora_weights_backup = getattr(self, "lora_weights_backup", None)
|
| 657 |
+
if weights_backup is None and len(loaded_lycos):
|
| 658 |
+
# print('lyco save weight')
|
| 659 |
+
if isinstance(self, torch.nn.MultiheadAttention):
|
| 660 |
+
weights_backup = (
|
| 661 |
+
self.in_proj_weight.to(devices.cpu, copy=True),
|
| 662 |
+
self.out_proj.weight.to(devices.cpu, copy=True)
|
| 663 |
+
)
|
| 664 |
+
else:
|
| 665 |
+
weights_backup = self.weight.to(devices.cpu, copy=True)
|
| 666 |
+
self.lyco_weights_backup = weights_backup
|
| 667 |
+
elif lora_prev_names != lora_names:
|
| 668 |
+
# print('lyco remove weight')
|
| 669 |
+
self.lyco_weights_backup = None
|
| 670 |
+
lora_weights_backup = None
|
| 671 |
+
elif len(loaded_lycos) == 0:
|
| 672 |
+
self.lyco_weights_backup = None
|
| 673 |
+
|
| 674 |
+
if current_names != wanted_names or lora_prev_names != lora_names:
|
| 675 |
+
if weights_backup is not None and lora_names == lora_prev_names:
|
| 676 |
+
# print('lyco restore weight')
|
| 677 |
+
if isinstance(self, torch.nn.MultiheadAttention):
|
| 678 |
+
self.in_proj_weight.copy_(weights_backup[0])
|
| 679 |
+
self.out_proj.weight.copy_(weights_backup[1])
|
| 680 |
+
else:
|
| 681 |
+
self.weight.copy_(weights_backup)
|
| 682 |
+
elif lora_weights_backup is not None and lora_names == ():
|
| 683 |
+
# print('lora restore weight')
|
| 684 |
+
if isinstance(self, torch.nn.MultiheadAttention):
|
| 685 |
+
self.in_proj_weight.copy_(lora_weights_backup[0])
|
| 686 |
+
self.out_proj.weight.copy_(lora_weights_backup[1])
|
| 687 |
+
else:
|
| 688 |
+
self.weight.copy_(lora_weights_backup)
|
| 689 |
+
|
| 690 |
+
for lyco in loaded_lycos:
|
| 691 |
+
module = lyco.modules.get(lyco_layer_name, None)
|
| 692 |
+
multiplier = (
|
| 693 |
+
lyco.te_multiplier if 'transformer' in lyco_layer_name[:20]
|
| 694 |
+
else lyco.unet_multiplier
|
| 695 |
+
)
|
| 696 |
+
if module is not None and hasattr(self, 'weight'):
|
| 697 |
+
# print(lyco_layer_name, multiplier)
|
| 698 |
+
updown = lyco_calc_updown(lyco, module, self.weight)
|
| 699 |
+
if len(self.weight.shape) == 4 and self.weight.shape[1] == 9:
|
| 700 |
+
# inpainting model. zero pad updown to make channel[1] 4 to 9
|
| 701 |
+
updown = F.pad(updown, (0, 0, 0, 0, 0, 5))
|
| 702 |
+
self.weight += updown * multiplier
|
| 703 |
+
continue
|
| 704 |
+
|
| 705 |
+
module_q = lyco.modules.get(lyco_layer_name + "_q_proj", None)
|
| 706 |
+
module_k = lyco.modules.get(lyco_layer_name + "_k_proj", None)
|
| 707 |
+
module_v = lyco.modules.get(lyco_layer_name + "_v_proj", None)
|
| 708 |
+
module_out = lyco.modules.get(lyco_layer_name + "_out_proj", None)
|
| 709 |
+
|
| 710 |
+
if isinstance(self, torch.nn.MultiheadAttention) and module_q and module_k and module_v and module_out:
|
| 711 |
+
updown_q = lyco_calc_updown(lyco, module_q, self.in_proj_weight)
|
| 712 |
+
updown_k = lyco_calc_updown(lyco, module_k, self.in_proj_weight)
|
| 713 |
+
updown_v = lyco_calc_updown(lyco, module_v, self.in_proj_weight)
|
| 714 |
+
updown_qkv = torch.vstack([updown_q, updown_k, updown_v])
|
| 715 |
+
|
| 716 |
+
self.in_proj_weight += updown_qkv
|
| 717 |
+
self.out_proj.weight += lyco_calc_updown(lyco, module_out, self.out_proj.weight)
|
| 718 |
+
continue
|
| 719 |
+
|
| 720 |
+
if module is None:
|
| 721 |
+
continue
|
| 722 |
+
|
| 723 |
+
print(3, f'failed to calculate lyco weights for layer {lyco_layer_name}')
|
| 724 |
+
# print(lyco_his, lyco.name not in lyco_his)
|
| 725 |
+
|
| 726 |
+
setattr(self, "lora_prev_names", lora_names)
|
| 727 |
+
setattr(self, "lyco_current_names", wanted_names)
|
| 728 |
+
|
| 729 |
+
|
| 730 |
+
def lyco_reset_cached_weight(self: Union[torch.nn.Conv2d, torch.nn.Linear]):
|
| 731 |
+
setattr(self, "lyco_current_names", ())
|
| 732 |
+
setattr(self, "lyco_weights_backup", None)
|
| 733 |
+
|
| 734 |
+
|
| 735 |
+
def lyco_Linear_forward(self, input):
|
| 736 |
+
lyco_apply_weights(self)
|
| 737 |
+
|
| 738 |
+
return torch.nn.Linear_forward_before_lyco(self, input)
|
| 739 |
+
|
| 740 |
+
|
| 741 |
+
def lyco_Linear_load_state_dict(self, *args, **kwargs):
|
| 742 |
+
lyco_reset_cached_weight(self)
|
| 743 |
+
|
| 744 |
+
return torch.nn.Linear_load_state_dict_before_lyco(self, *args, **kwargs)
|
| 745 |
+
|
| 746 |
+
|
| 747 |
+
def lyco_Conv2d_forward(self, input):
|
| 748 |
+
lyco_apply_weights(self)
|
| 749 |
+
|
| 750 |
+
return torch.nn.Conv2d_forward_before_lyco(self, input)
|
| 751 |
+
|
| 752 |
+
|
| 753 |
+
def lyco_Conv2d_load_state_dict(self, *args, **kwargs):
|
| 754 |
+
lyco_reset_cached_weight(self)
|
| 755 |
+
|
| 756 |
+
return torch.nn.Conv2d_load_state_dict_before_lyco(self, *args, **kwargs)
|
| 757 |
+
|
| 758 |
+
|
| 759 |
+
def lyco_MultiheadAttention_forward(self, *args, **kwargs):
|
| 760 |
+
lyco_apply_weights(self)
|
| 761 |
+
|
| 762 |
+
return torch.nn.MultiheadAttention_forward_before_lyco(self, *args, **kwargs)
|
| 763 |
+
|
| 764 |
+
|
| 765 |
+
def lyco_MultiheadAttention_load_state_dict(self, *args, **kwargs):
|
| 766 |
+
lyco_reset_cached_weight(self)
|
| 767 |
+
|
| 768 |
+
return torch.nn.MultiheadAttention_load_state_dict_before_lyco(self, *args, **kwargs)
|
| 769 |
+
|
| 770 |
+
|
| 771 |
+
def list_available_lycos():
|
| 772 |
+
available_lycos.clear()
|
| 773 |
+
|
| 774 |
+
os.makedirs(shared.cmd_opts.lyco_dir, exist_ok=True)
|
| 775 |
+
|
| 776 |
+
candidates = \
|
| 777 |
+
glob.glob(os.path.join(shared.cmd_opts.lyco_dir, '**/*.pt'), recursive=True) + \
|
| 778 |
+
glob.glob(os.path.join(shared.cmd_opts.lyco_dir, '**/*.safetensors'), recursive=True) + \
|
| 779 |
+
glob.glob(os.path.join(shared.cmd_opts.lyco_dir, '**/*.ckpt'), recursive=True)
|
| 780 |
+
|
| 781 |
+
for filename in sorted(candidates, key=str.lower):
|
| 782 |
+
if os.path.isdir(filename):
|
| 783 |
+
continue
|
| 784 |
+
|
| 785 |
+
name = os.path.splitext(os.path.basename(filename))[0]
|
| 786 |
+
|
| 787 |
+
available_lycos[name] = LycoOnDisk(name, filename)
|
| 788 |
+
|
| 789 |
+
|
| 790 |
+
available_lycos: Dict[str, LycoOnDisk] = {}
|
| 791 |
+
loaded_lycos: List[LycoModule] = []
|
| 792 |
+
|
| 793 |
+
list_available_lycos()
|
extensions/a1111-sd-webui-lycoris/preload.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from modules import paths
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def preload(parser):
|
| 6 |
+
parser.add_argument("--lyco-dir", type=str, help="Path to directory with LyCORIS networks.", default=os.path.join(paths.models_path, 'LyCORIS'))
|
extensions/a1111-sd-webui-lycoris/scripts/__pycache__/lycoris_script.cpython-310.pyc
ADDED
|
Binary file (2.3 kB). View file
|
|
|
extensions/a1111-sd-webui-lycoris/scripts/lycoris_script.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import gradio as gr
|
| 3 |
+
|
| 4 |
+
import lycoris
|
| 5 |
+
import extra_networks_lyco
|
| 6 |
+
import ui_extra_networks_lyco
|
| 7 |
+
from modules import script_callbacks, ui_extra_networks, extra_networks, shared
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def unload():
|
| 11 |
+
torch.nn.Linear.forward = torch.nn.Linear_forward_before_lyco
|
| 12 |
+
torch.nn.Linear._load_from_state_dict = torch.nn.Linear_load_state_dict_before_lyco
|
| 13 |
+
torch.nn.Conv2d.forward = torch.nn.Conv2d_forward_before_lyco
|
| 14 |
+
torch.nn.Conv2d._load_from_state_dict = torch.nn.Conv2d_load_state_dict_before_lyco
|
| 15 |
+
torch.nn.MultiheadAttention.forward = torch.nn.MultiheadAttention_forward_before_lyco
|
| 16 |
+
torch.nn.MultiheadAttention._load_from_state_dict = torch.nn.MultiheadAttention_load_state_dict_before_lyco
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def before_ui():
|
| 20 |
+
ui_extra_networks.register_page(ui_extra_networks_lyco.ExtraNetworksPageLyCORIS())
|
| 21 |
+
extra_networks.register_extra_network(extra_networks_lyco.ExtraNetworkLyCORIS())
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
if not hasattr(torch.nn, 'Linear_forward_before_lyco'):
|
| 25 |
+
torch.nn.Linear_forward_before_lyco = torch.nn.Linear.forward
|
| 26 |
+
|
| 27 |
+
if not hasattr(torch.nn, 'Linear_load_state_dict_before_lyco'):
|
| 28 |
+
torch.nn.Linear_load_state_dict_before_lyco = torch.nn.Linear._load_from_state_dict
|
| 29 |
+
|
| 30 |
+
if not hasattr(torch.nn, 'Conv2d_forward_before_lyco'):
|
| 31 |
+
torch.nn.Conv2d_forward_before_lyco = torch.nn.Conv2d.forward
|
| 32 |
+
|
| 33 |
+
if not hasattr(torch.nn, 'Conv2d_load_state_dict_before_lyco'):
|
| 34 |
+
torch.nn.Conv2d_load_state_dict_before_lyco = torch.nn.Conv2d._load_from_state_dict
|
| 35 |
+
|
| 36 |
+
if not hasattr(torch.nn, 'MultiheadAttention_forward_before_lyco'):
|
| 37 |
+
torch.nn.MultiheadAttention_forward_before_lyco = torch.nn.MultiheadAttention.forward
|
| 38 |
+
|
| 39 |
+
if not hasattr(torch.nn, 'MultiheadAttention_load_state_dict_before_lyco'):
|
| 40 |
+
torch.nn.MultiheadAttention_load_state_dict_before_lyco = torch.nn.MultiheadAttention._load_from_state_dict
|
| 41 |
+
|
| 42 |
+
torch.nn.Linear.forward = lycoris.lyco_Linear_forward
|
| 43 |
+
torch.nn.Linear._load_from_state_dict = lycoris.lyco_Linear_load_state_dict
|
| 44 |
+
torch.nn.Conv2d.forward = lycoris.lyco_Conv2d_forward
|
| 45 |
+
torch.nn.Conv2d._load_from_state_dict = lycoris.lyco_Conv2d_load_state_dict
|
| 46 |
+
torch.nn.MultiheadAttention.forward = lycoris.lyco_MultiheadAttention_forward
|
| 47 |
+
torch.nn.MultiheadAttention._load_from_state_dict = lycoris.lyco_MultiheadAttention_load_state_dict
|
| 48 |
+
|
| 49 |
+
script_callbacks.on_model_loaded(lycoris.assign_lyco_names_to_compvis_modules)
|
| 50 |
+
script_callbacks.on_script_unloaded(unload)
|
| 51 |
+
script_callbacks.on_before_ui(before_ui)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
shared.options_templates.update(shared.options_section(('extra_networks', "Extra Networks"), {
|
| 55 |
+
"sd_lyco": shared.OptionInfo("None", "Add LyCORIS to prompt", gr.Dropdown, lambda: {"choices": ["None"] + [x for x in lycoris.available_lycos]}, refresh=lycoris.list_available_lycos),
|
| 56 |
+
}))
|