
Commit
•
33ccb6d
1
Parent(s):
7b76e5e
Upload 17 files
Browse files- README.md +59 -3
- adapter_config.json +29 -0
- adapter_model.safetensors +3 -0
- added_tokens.json +5 -0
- all_results.json +8 -0
- merges.txt +0 -0
- running_log.txt +163 -0
- special_tokens_map.json +20 -0
- tokenizer.json +0 -0
- tokenizer_config.json +44 -0
- train_results.json +8 -0
- trainer_config.yaml +30 -0
- trainer_log.jsonl +4 -0
- trainer_state.json +63 -0
- training_args.bin +3 -0
- training_loss.png +0 -0
- vocab.json +0 -0
README.md
CHANGED
|
@@ -1,3 +1,59 @@
|
|
| 1 |
-
---
|
| 2 |
-
license:
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: other
|
| 3 |
+
library_name: peft
|
| 4 |
+
tags:
|
| 5 |
+
- llama-factory
|
| 6 |
+
- lora
|
| 7 |
+
- generated_from_trainer
|
| 8 |
+
base_model: Qwen/Qwen1.5-0.5B-Chat
|
| 9 |
+
model-index:
|
| 10 |
+
- name: QwenTT2
|
| 11 |
+
results: []
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 15 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 16 |
+
|
| 17 |
+
# QwenTT2
|
| 18 |
+
|
| 19 |
+
This model is a fine-tuned version of [Qwen/Qwen1.5-0.5B-Chat](https://huggingface.co/Qwen/Qwen1.5-0.5B-Chat) on the identity dataset.
|
| 20 |
+
|
| 21 |
+
## Model description
|
| 22 |
+
|
| 23 |
+
More information needed
|
| 24 |
+
|
| 25 |
+
## Intended uses & limitations
|
| 26 |
+
|
| 27 |
+
More information needed
|
| 28 |
+
|
| 29 |
+
## Training and evaluation data
|
| 30 |
+
|
| 31 |
+
More information needed
|
| 32 |
+
|
| 33 |
+
## Training procedure
|
| 34 |
+
|
| 35 |
+
### Training hyperparameters
|
| 36 |
+
|
| 37 |
+
The following hyperparameters were used during training:
|
| 38 |
+
- learning_rate: 5e-05
|
| 39 |
+
- train_batch_size: 2
|
| 40 |
+
- eval_batch_size: 8
|
| 41 |
+
- seed: 42
|
| 42 |
+
- gradient_accumulation_steps: 8
|
| 43 |
+
- total_train_batch_size: 16
|
| 44 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 45 |
+
- lr_scheduler_type: cosine
|
| 46 |
+
- num_epochs: 3.0
|
| 47 |
+
- mixed_precision_training: Native AMP
|
| 48 |
+
|
| 49 |
+
### Training results
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
### Framework versions
|
| 54 |
+
|
| 55 |
+
- PEFT 0.11.1
|
| 56 |
+
- Transformers 4.41.0
|
| 57 |
+
- Pytorch 2.3.0+cu121
|
| 58 |
+
- Datasets 2.19.1
|
| 59 |
+
- Tokenizers 0.19.1
|
adapter_config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "Qwen/Qwen1.5-0.5B-Chat",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 16,
|
| 14 |
+
"lora_dropout": 0,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": null,
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 8,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": [
|
| 23 |
+
"q_proj",
|
| 24 |
+
"v_proj"
|
| 25 |
+
],
|
| 26 |
+
"task_type": "CAUSAL_LM",
|
| 27 |
+
"use_dora": false,
|
| 28 |
+
"use_rslora": false
|
| 29 |
+
}
|
adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c03a67e2294f637bb9fadff88b2213aee5464baf7446f0b9c91a02c17ad3296b
|
| 3 |
+
size 3158328
|
added_tokens.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|endoftext|>": 151643,
|
| 3 |
+
"<|im_end|>": 151645,
|
| 4 |
+
"<|im_start|>": 151644
|
| 5 |
+
}
|
all_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.608695652173913,
|
| 3 |
+
"total_flos": 27871774801920.0,
|
| 4 |
+
"train_loss": 3.344371541341146,
|
| 5 |
+
"train_runtime": 23.5673,
|
| 6 |
+
"train_samples_per_second": 11.584,
|
| 7 |
+
"train_steps_per_second": 0.636
|
| 8 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
running_log.txt
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
05/21/2024 22:33:38 - INFO - transformers.tokenization_utils_base - loading file vocab.json from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen1.5-0.5B-Chat/snapshots/4d14e384a4b037942bb3f3016665157c8bcb70ea/vocab.json
|
| 2 |
+
|
| 3 |
+
05/21/2024 22:33:38 - INFO - transformers.tokenization_utils_base - loading file merges.txt from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen1.5-0.5B-Chat/snapshots/4d14e384a4b037942bb3f3016665157c8bcb70ea/merges.txt
|
| 4 |
+
|
| 5 |
+
05/21/2024 22:33:38 - INFO - transformers.tokenization_utils_base - loading file tokenizer.json from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen1.5-0.5B-Chat/snapshots/4d14e384a4b037942bb3f3016665157c8bcb70ea/tokenizer.json
|
| 6 |
+
|
| 7 |
+
05/21/2024 22:33:38 - INFO - transformers.tokenization_utils_base - loading file added_tokens.json from cache at None
|
| 8 |
+
|
| 9 |
+
05/21/2024 22:33:38 - INFO - transformers.tokenization_utils_base - loading file special_tokens_map.json from cache at None
|
| 10 |
+
|
| 11 |
+
05/21/2024 22:33:38 - INFO - transformers.tokenization_utils_base - loading file tokenizer_config.json from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen1.5-0.5B-Chat/snapshots/4d14e384a4b037942bb3f3016665157c8bcb70ea/tokenizer_config.json
|
| 12 |
+
|
| 13 |
+
05/21/2024 22:33:38 - WARNING - transformers.tokenization_utils_base - Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
|
| 14 |
+
|
| 15 |
+
05/21/2024 22:33:38 - INFO - llamafactory.data.template - Replace eos token: <|im_end|>
|
| 16 |
+
|
| 17 |
+
05/21/2024 22:33:38 - INFO - llamafactory.data.loader - Loading dataset identity.json...
|
| 18 |
+
|
| 19 |
+
05/21/2024 22:33:52 - INFO - transformers.configuration_utils - loading configuration file config.json from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen1.5-0.5B-Chat/snapshots/4d14e384a4b037942bb3f3016665157c8bcb70ea/config.json
|
| 20 |
+
|
| 21 |
+
05/21/2024 22:33:52 - INFO - transformers.configuration_utils - Model config Qwen2Config {
|
| 22 |
+
"_name_or_path": "Qwen/Qwen1.5-0.5B-Chat",
|
| 23 |
+
"architectures": [
|
| 24 |
+
"Qwen2ForCausalLM"
|
| 25 |
+
],
|
| 26 |
+
"attention_dropout": 0.0,
|
| 27 |
+
"bos_token_id": 151643,
|
| 28 |
+
"eos_token_id": 151645,
|
| 29 |
+
"hidden_act": "silu",
|
| 30 |
+
"hidden_size": 1024,
|
| 31 |
+
"initializer_range": 0.02,
|
| 32 |
+
"intermediate_size": 2816,
|
| 33 |
+
"max_position_embeddings": 32768,
|
| 34 |
+
"max_window_layers": 21,
|
| 35 |
+
"model_type": "qwen2",
|
| 36 |
+
"num_attention_heads": 16,
|
| 37 |
+
"num_hidden_layers": 24,
|
| 38 |
+
"num_key_value_heads": 16,
|
| 39 |
+
"rms_norm_eps": 1e-06,
|
| 40 |
+
"rope_theta": 1000000.0,
|
| 41 |
+
"sliding_window": 32768,
|
| 42 |
+
"tie_word_embeddings": true,
|
| 43 |
+
"torch_dtype": "bfloat16",
|
| 44 |
+
"transformers_version": "4.41.0",
|
| 45 |
+
"use_cache": true,
|
| 46 |
+
"use_sliding_window": false,
|
| 47 |
+
"vocab_size": 151936
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
05/21/2024 22:34:00 - INFO - transformers.modeling_utils - loading weights file model.safetensors from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen1.5-0.5B-Chat/snapshots/4d14e384a4b037942bb3f3016665157c8bcb70ea/model.safetensors
|
| 52 |
+
|
| 53 |
+
05/21/2024 22:34:00 - INFO - transformers.modeling_utils - Instantiating Qwen2ForCausalLM model under default dtype torch.float16.
|
| 54 |
+
|
| 55 |
+
05/21/2024 22:34:00 - INFO - transformers.generation.configuration_utils - Generate config GenerationConfig {
|
| 56 |
+
"bos_token_id": 151643,
|
| 57 |
+
"eos_token_id": 151645
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
05/21/2024 22:34:03 - INFO - transformers.modeling_utils - All model checkpoint weights were used when initializing Qwen2ForCausalLM.
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
05/21/2024 22:34:03 - INFO - transformers.modeling_utils - All the weights of Qwen2ForCausalLM were initialized from the model checkpoint at Qwen/Qwen1.5-0.5B-Chat.
|
| 65 |
+
If your task is similar to the task the model of the checkpoint was trained on, you can already use Qwen2ForCausalLM for predictions without further training.
|
| 66 |
+
|
| 67 |
+
05/21/2024 22:34:04 - INFO - transformers.generation.configuration_utils - loading configuration file generation_config.json from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen1.5-0.5B-Chat/snapshots/4d14e384a4b037942bb3f3016665157c8bcb70ea/generation_config.json
|
| 68 |
+
|
| 69 |
+
05/21/2024 22:34:04 - INFO - transformers.generation.configuration_utils - Generate config GenerationConfig {
|
| 70 |
+
"bos_token_id": 151643,
|
| 71 |
+
"do_sample": true,
|
| 72 |
+
"eos_token_id": [
|
| 73 |
+
151645,
|
| 74 |
+
151643
|
| 75 |
+
],
|
| 76 |
+
"pad_token_id": 151643,
|
| 77 |
+
"repetition_penalty": 1.1,
|
| 78 |
+
"top_p": 0.8
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
05/21/2024 22:34:04 - INFO - llamafactory.model.utils.checkpointing - Gradient checkpointing enabled.
|
| 83 |
+
|
| 84 |
+
05/21/2024 22:34:04 - INFO - llamafactory.model.utils.attention - Using torch SDPA for faster training and inference.
|
| 85 |
+
|
| 86 |
+
05/21/2024 22:34:04 - INFO - llamafactory.model.adapter - Upcasting trainable params to float32.
|
| 87 |
+
|
| 88 |
+
05/21/2024 22:34:04 - INFO - llamafactory.model.adapter - Fine-tuning method: LoRA
|
| 89 |
+
|
| 90 |
+
05/21/2024 22:34:05 - INFO - llamafactory.model.loader - trainable params: 786432 || all params: 464774144 || trainable%: 0.1692
|
| 91 |
+
|
| 92 |
+
05/21/2024 22:34:05 - INFO - transformers.trainer - Using auto half precision backend
|
| 93 |
+
|
| 94 |
+
05/21/2024 22:34:05 - INFO - transformers.trainer - ***** Running training *****
|
| 95 |
+
|
| 96 |
+
05/21/2024 22:34:05 - INFO - transformers.trainer - Num examples = 91
|
| 97 |
+
|
| 98 |
+
05/21/2024 22:34:05 - INFO - transformers.trainer - Num Epochs = 3
|
| 99 |
+
|
| 100 |
+
05/21/2024 22:34:05 - INFO - transformers.trainer - Instantaneous batch size per device = 2
|
| 101 |
+
|
| 102 |
+
05/21/2024 22:34:05 - INFO - transformers.trainer - Total train batch size (w. parallel, distributed & accumulation) = 16
|
| 103 |
+
|
| 104 |
+
05/21/2024 22:34:05 - INFO - transformers.trainer - Gradient Accumulation steps = 8
|
| 105 |
+
|
| 106 |
+
05/21/2024 22:34:05 - INFO - transformers.trainer - Total optimization steps = 15
|
| 107 |
+
|
| 108 |
+
05/21/2024 22:34:05 - INFO - transformers.trainer - Number of trainable parameters = 786,432
|
| 109 |
+
|
| 110 |
+
05/21/2024 22:34:13 - INFO - llamafactory.extras.callbacks - {'loss': 3.4077, 'learning_rate': 3.7500e-05, 'epoch': 0.87}
|
| 111 |
+
|
| 112 |
+
05/21/2024 22:34:22 - INFO - llamafactory.extras.callbacks - {'loss': 3.3417, 'learning_rate': 1.2500e-05, 'epoch': 1.74}
|
| 113 |
+
|
| 114 |
+
05/21/2024 22:34:29 - INFO - llamafactory.extras.callbacks - {'loss': 3.2838, 'learning_rate': 0.0000e+00, 'epoch': 2.61}
|
| 115 |
+
|
| 116 |
+
05/21/2024 22:34:29 - INFO - transformers.trainer -
|
| 117 |
+
|
| 118 |
+
Training completed. Do not forget to share your model on huggingface.co/models =)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
05/21/2024 22:34:29 - INFO - transformers.trainer - Saving model checkpoint to saves/Qwen1.5-0.5B-Chat/lora/QwenTT2
|
| 123 |
+
|
| 124 |
+
05/21/2024 22:34:29 - INFO - transformers.configuration_utils - loading configuration file config.json from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen1.5-0.5B-Chat/snapshots/4d14e384a4b037942bb3f3016665157c8bcb70ea/config.json
|
| 125 |
+
|
| 126 |
+
05/21/2024 22:34:29 - INFO - transformers.configuration_utils - Model config Qwen2Config {
|
| 127 |
+
"architectures": [
|
| 128 |
+
"Qwen2ForCausalLM"
|
| 129 |
+
],
|
| 130 |
+
"attention_dropout": 0.0,
|
| 131 |
+
"bos_token_id": 151643,
|
| 132 |
+
"eos_token_id": 151645,
|
| 133 |
+
"hidden_act": "silu",
|
| 134 |
+
"hidden_size": 1024,
|
| 135 |
+
"initializer_range": 0.02,
|
| 136 |
+
"intermediate_size": 2816,
|
| 137 |
+
"max_position_embeddings": 32768,
|
| 138 |
+
"max_window_layers": 21,
|
| 139 |
+
"model_type": "qwen2",
|
| 140 |
+
"num_attention_heads": 16,
|
| 141 |
+
"num_hidden_layers": 24,
|
| 142 |
+
"num_key_value_heads": 16,
|
| 143 |
+
"rms_norm_eps": 1e-06,
|
| 144 |
+
"rope_theta": 1000000.0,
|
| 145 |
+
"sliding_window": 32768,
|
| 146 |
+
"tie_word_embeddings": true,
|
| 147 |
+
"torch_dtype": "bfloat16",
|
| 148 |
+
"transformers_version": "4.41.0",
|
| 149 |
+
"use_cache": true,
|
| 150 |
+
"use_sliding_window": false,
|
| 151 |
+
"vocab_size": 151936
|
| 152 |
+
}
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
05/21/2024 22:34:29 - INFO - transformers.tokenization_utils_base - tokenizer config file saved in saves/Qwen1.5-0.5B-Chat/lora/QwenTT2/tokenizer_config.json
|
| 156 |
+
|
| 157 |
+
05/21/2024 22:34:29 - INFO - transformers.tokenization_utils_base - Special tokens file saved in saves/Qwen1.5-0.5B-Chat/lora/QwenTT2/special_tokens_map.json
|
| 158 |
+
|
| 159 |
+
05/21/2024 22:34:30 - WARNING - llamafactory.extras.ploting - No metric eval_loss to plot.
|
| 160 |
+
|
| 161 |
+
05/21/2024 22:34:30 - INFO - transformers.modelcard - Dropping the following result as it does not have all the necessary fields:
|
| 162 |
+
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}}
|
| 163 |
+
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>"
|
| 5 |
+
],
|
| 6 |
+
"eos_token": {
|
| 7 |
+
"content": "<|im_end|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false
|
| 12 |
+
},
|
| 13 |
+
"pad_token": {
|
| 14 |
+
"content": "<|endoftext|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false
|
| 19 |
+
}
|
| 20 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"151643": {
|
| 5 |
+
"content": "<|endoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"151644": {
|
| 13 |
+
"content": "<|im_start|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"151645": {
|
| 21 |
+
"content": "<|im_end|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
"additional_special_tokens": [
|
| 30 |
+
"<|im_start|>",
|
| 31 |
+
"<|im_end|>"
|
| 32 |
+
],
|
| 33 |
+
"bos_token": null,
|
| 34 |
+
"chat_template": "{% set system_message = 'You are a helpful assistant.' %}{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ '<|im_start|>system\n' + system_message + '<|im_end|>\n' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|im_start|>user\n' + content + '<|im_end|>\n<|im_start|>assistant\n' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>' + '\n' }}{% endif %}{% endfor %}",
|
| 35 |
+
"clean_up_tokenization_spaces": false,
|
| 36 |
+
"eos_token": "<|im_end|>",
|
| 37 |
+
"errors": "replace",
|
| 38 |
+
"model_max_length": 32768,
|
| 39 |
+
"pad_token": "<|endoftext|>",
|
| 40 |
+
"padding_side": "right",
|
| 41 |
+
"split_special_tokens": false,
|
| 42 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 43 |
+
"unk_token": null
|
| 44 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.608695652173913,
|
| 3 |
+
"total_flos": 27871774801920.0,
|
| 4 |
+
"train_loss": 3.344371541341146,
|
| 5 |
+
"train_runtime": 23.5673,
|
| 6 |
+
"train_samples_per_second": 11.584,
|
| 7 |
+
"train_steps_per_second": 0.636
|
| 8 |
+
}
|
trainer_config.yaml
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cutoff_len: 1024
|
| 2 |
+
dataset: identity
|
| 3 |
+
dataset_dir: data
|
| 4 |
+
do_train: true
|
| 5 |
+
finetuning_type: lora
|
| 6 |
+
flash_attn: auto
|
| 7 |
+
fp16: true
|
| 8 |
+
gradient_accumulation_steps: 8
|
| 9 |
+
learning_rate: 5.0e-05
|
| 10 |
+
logging_steps: 5
|
| 11 |
+
lora_alpha: 16
|
| 12 |
+
lora_dropout: 0
|
| 13 |
+
lora_rank: 8
|
| 14 |
+
lora_target: q_proj,v_proj
|
| 15 |
+
lr_scheduler_type: cosine
|
| 16 |
+
max_grad_norm: 1.0
|
| 17 |
+
max_samples: 100000
|
| 18 |
+
model_name_or_path: Qwen/Qwen1.5-0.5B-Chat
|
| 19 |
+
num_train_epochs: 3.0
|
| 20 |
+
optim: adamw_torch
|
| 21 |
+
output_dir: saves/Qwen1.5-0.5B-Chat/lora/QwenTT2
|
| 22 |
+
packing: false
|
| 23 |
+
per_device_train_batch_size: 2
|
| 24 |
+
plot_loss: true
|
| 25 |
+
preprocessing_num_workers: 16
|
| 26 |
+
report_to: none
|
| 27 |
+
save_steps: 100
|
| 28 |
+
stage: sft
|
| 29 |
+
template: qwen
|
| 30 |
+
warmup_steps: 0
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"current_steps": 5, "total_steps": 15, "loss": 3.4077, "learning_rate": 3.7500000000000003e-05, "epoch": 0.8695652173913043, "percentage": 33.33, "elapsed_time": "0:00:08", "remaining_time": "0:00:16"}
|
| 2 |
+
{"current_steps": 10, "total_steps": 15, "loss": 3.3417, "learning_rate": 1.2500000000000006e-05, "epoch": 1.7391304347826086, "percentage": 66.67, "elapsed_time": "0:00:16", "remaining_time": "0:00:08"}
|
| 3 |
+
{"current_steps": 15, "total_steps": 15, "loss": 3.2838, "learning_rate": 0.0, "epoch": 2.608695652173913, "percentage": 100.0, "elapsed_time": "0:00:23", "remaining_time": "0:00:00"}
|
| 4 |
+
{"current_steps": 15, "total_steps": 15, "epoch": 2.608695652173913, "percentage": 100.0, "elapsed_time": "0:00:23", "remaining_time": "0:00:00"}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
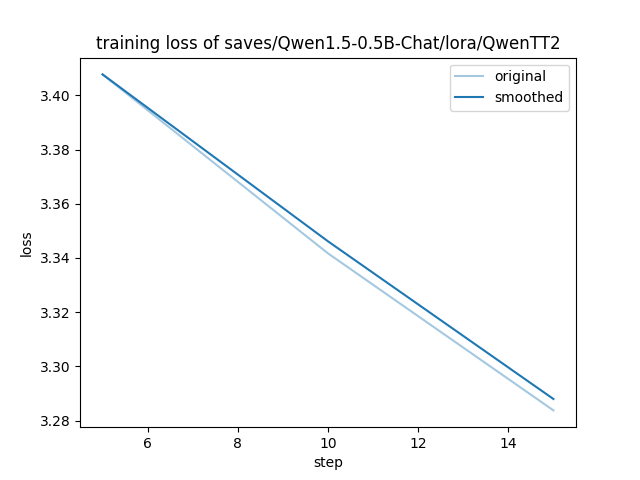
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 2.608695652173913,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 15,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.8695652173913043,
|
| 13 |
+
"grad_norm": 1.5976989269256592,
|
| 14 |
+
"learning_rate": 3.7500000000000003e-05,
|
| 15 |
+
"loss": 3.4077,
|
| 16 |
+
"step": 5
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 1.7391304347826086,
|
| 20 |
+
"grad_norm": 1.022597074508667,
|
| 21 |
+
"learning_rate": 1.2500000000000006e-05,
|
| 22 |
+
"loss": 3.3417,
|
| 23 |
+
"step": 10
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 2.608695652173913,
|
| 27 |
+
"grad_norm": 1.2863354682922363,
|
| 28 |
+
"learning_rate": 0.0,
|
| 29 |
+
"loss": 3.2838,
|
| 30 |
+
"step": 15
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"epoch": 2.608695652173913,
|
| 34 |
+
"step": 15,
|
| 35 |
+
"total_flos": 27871774801920.0,
|
| 36 |
+
"train_loss": 3.344371541341146,
|
| 37 |
+
"train_runtime": 23.5673,
|
| 38 |
+
"train_samples_per_second": 11.584,
|
| 39 |
+
"train_steps_per_second": 0.636
|
| 40 |
+
}
|
| 41 |
+
],
|
| 42 |
+
"logging_steps": 5,
|
| 43 |
+
"max_steps": 15,
|
| 44 |
+
"num_input_tokens_seen": 0,
|
| 45 |
+
"num_train_epochs": 3,
|
| 46 |
+
"save_steps": 100,
|
| 47 |
+
"stateful_callbacks": {
|
| 48 |
+
"TrainerControl": {
|
| 49 |
+
"args": {
|
| 50 |
+
"should_epoch_stop": false,
|
| 51 |
+
"should_evaluate": false,
|
| 52 |
+
"should_log": false,
|
| 53 |
+
"should_save": false,
|
| 54 |
+
"should_training_stop": false
|
| 55 |
+
},
|
| 56 |
+
"attributes": {}
|
| 57 |
+
}
|
| 58 |
+
},
|
| 59 |
+
"total_flos": 27871774801920.0,
|
| 60 |
+
"train_batch_size": 2,
|
| 61 |
+
"trial_name": null,
|
| 62 |
+
"trial_params": null
|
| 63 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0bd61820596769228d703f2800851b9b7278c17a5510e137944800c600bbd918
|
| 3 |
+
size 5240
|
training_loss.png
ADDED
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|