
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +8 -0
- .github/ISSUE_TEMPLATE/bug_report.yaml +88 -0
- .github/ISSUE_TEMPLATE/config.yaml +1 -0
- .github/ISSUE_TEMPLATE/feature_request.yaml +78 -0
- .gitignore +11 -0
- 1.jpg +0 -0
- FAQ.md +55 -0
- FAQ_zh.md +52 -0
- LICENSE +53 -0
- NOTICE +52 -0
- README.md +675 -7
- README_CN.md +666 -0
- TUTORIAL.md +221 -0
- TUTORIAL_zh.md +216 -0
- assets/apple.jpeg +3 -0
- assets/apple_r.jpeg +0 -0
- assets/demo.jpeg +0 -0
- assets/demo_highfive.jpg +0 -0
- assets/demo_spotting_caption.jpg +0 -0
- assets/demo_vl.gif +3 -0
- assets/logo.jpg +0 -0
- assets/mm_tutorial/Beijing.jpeg +3 -0
- assets/mm_tutorial/Beijing_Small.jpeg +0 -0
- assets/mm_tutorial/Chongqing.jpeg +3 -0
- assets/mm_tutorial/Chongqing_Small.jpeg +0 -0
- assets/mm_tutorial/Hospital.jpg +0 -0
- assets/mm_tutorial/Hospital_Small.jpg +0 -0
- assets/mm_tutorial/Menu.jpeg +0 -0
- assets/mm_tutorial/Rebecca_(1939_poster).jpeg +3 -0
- assets/mm_tutorial/Rebecca_(1939_poster)_Small.jpeg +0 -0
- assets/mm_tutorial/Shanghai.jpg +0 -0
- assets/mm_tutorial/Shanghai_Output.jpg +3 -0
- assets/mm_tutorial/Shanghai_Output_Small.jpeg +0 -0
- assets/mm_tutorial/Shanghai_Small.jpeg +0 -0
- assets/mm_tutorial/TUTORIAL.ipynb +0 -0
- assets/qwenvl.jpeg +0 -0
- assets/radar.png +0 -0
- assets/touchstone_datasets.jpg +3 -0
- assets/touchstone_eval.png +0 -0
- assets/touchstone_logo.png +3 -0
- eval_mm/EVALUATION.md +1 -0
- eval_mm/evaluate_caption.py +193 -0
- eval_mm/evaluate_grounding.py +213 -0
- eval_mm/evaluate_multiple_choice.py +184 -0
- eval_mm/evaluate_vizwiz_testdev.py +167 -0
- eval_mm/evaluate_vqa.py +357 -0
- eval_mm/vqa.py +206 -0
- eval_mm/vqa_eval.py +330 -0
- requirements.txt +10 -0
- requirements_web_demo.txt +1 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,11 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/apple.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/demo_vl.gif filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/mm_tutorial/Beijing.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
assets/mm_tutorial/Chongqing.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
assets/mm_tutorial/Rebecca_(1939_poster).jpeg filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
assets/mm_tutorial/Shanghai_Output.jpg filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
assets/touchstone_datasets.jpg filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
assets/touchstone_logo.png filter=lfs diff=lfs merge=lfs -text
|
.github/ISSUE_TEMPLATE/bug_report.yaml
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: 🐞 Bug
|
| 2 |
+
description: 提交错误报告 | File a bug/issue
|
| 3 |
+
title: "[BUG] <title>"
|
| 4 |
+
labels: []
|
| 5 |
+
body:
|
| 6 |
+
- type: checkboxes
|
| 7 |
+
attributes:
|
| 8 |
+
label: 是否已有关于该错误的issue或讨论? | Is there an existing issue / discussion for this?
|
| 9 |
+
description: |
|
| 10 |
+
请先搜索您遇到的错误是否在已有的issues或讨论中提到过。
|
| 11 |
+
Please search to see if an issue / discussion already exists for the bug you encountered.
|
| 12 |
+
[Issues](https://github.com/QwenLM/Qwen-7B/issues)
|
| 13 |
+
[Discussions](https://github.com/QwenLM/Qwen-7B/discussions)
|
| 14 |
+
options:
|
| 15 |
+
- label: 我已经搜索过已有的issues和讨论 | I have searched the existing issues / discussions
|
| 16 |
+
required: true
|
| 17 |
+
- type: checkboxes
|
| 18 |
+
attributes:
|
| 19 |
+
label: 该问题是否在FAQ中有解答? | Is there an existing answer for this in FAQ?
|
| 20 |
+
description: |
|
| 21 |
+
请先搜索您遇到的错误是否已在FAQ中有相关解答。
|
| 22 |
+
Please search to see if an answer already exists in FAQ for the bug you encountered.
|
| 23 |
+
[FAQ-en](https://github.com/QwenLM/Qwen-7B/blob/main/FAQ.md)
|
| 24 |
+
[FAQ-zh](https://github.com/QwenLM/Qwen-7B/blob/main/FAQ_zh.md)
|
| 25 |
+
options:
|
| 26 |
+
- label: 我已经搜索过FAQ | I have searched FAQ
|
| 27 |
+
required: true
|
| 28 |
+
- type: textarea
|
| 29 |
+
attributes:
|
| 30 |
+
label: 当前行为 | Current Behavior
|
| 31 |
+
description: |
|
| 32 |
+
准确描述遇到的行为。
|
| 33 |
+
A concise description of what you're experiencing.
|
| 34 |
+
validations:
|
| 35 |
+
required: false
|
| 36 |
+
- type: textarea
|
| 37 |
+
attributes:
|
| 38 |
+
label: 期望行为 | Expected Behavior
|
| 39 |
+
description: |
|
| 40 |
+
准确描述预期的行为。
|
| 41 |
+
A concise description of what you expected to happen.
|
| 42 |
+
validations:
|
| 43 |
+
required: false
|
| 44 |
+
- type: textarea
|
| 45 |
+
attributes:
|
| 46 |
+
label: 复现方法 | Steps To Reproduce
|
| 47 |
+
description: |
|
| 48 |
+
复现当前行为的详细步骤。
|
| 49 |
+
Steps to reproduce the behavior.
|
| 50 |
+
placeholder: |
|
| 51 |
+
1. In this environment...
|
| 52 |
+
2. With this config...
|
| 53 |
+
3. Run '...'
|
| 54 |
+
4. See error...
|
| 55 |
+
validations:
|
| 56 |
+
required: false
|
| 57 |
+
- type: textarea
|
| 58 |
+
attributes:
|
| 59 |
+
label: 运行环境 | Environment
|
| 60 |
+
description: |
|
| 61 |
+
examples:
|
| 62 |
+
- **OS**: Ubuntu 20.04
|
| 63 |
+
- **Python**: 3.8
|
| 64 |
+
- **Transformers**: 4.31.0
|
| 65 |
+
- **PyTorch**: 2.0.1
|
| 66 |
+
- **CUDA**: 11.4
|
| 67 |
+
value: |
|
| 68 |
+
- OS:
|
| 69 |
+
- Python:
|
| 70 |
+
- Transformers:
|
| 71 |
+
- PyTorch:
|
| 72 |
+
- CUDA (`python -c 'import torch; print(torch.version.cuda)'`):
|
| 73 |
+
render: Markdown
|
| 74 |
+
validations:
|
| 75 |
+
required: false
|
| 76 |
+
- type: textarea
|
| 77 |
+
attributes:
|
| 78 |
+
label: 备注 | Anything else?
|
| 79 |
+
description: |
|
| 80 |
+
您可以在这里补充其他关于该问题背景信息的描述、链接或引用等。
|
| 81 |
+
|
| 82 |
+
您可以通过点击高亮此区域然后拖动文件的方式上传图片或日志文件。
|
| 83 |
+
|
| 84 |
+
Links? References? Anything that will give us more context about the issue you are encountering!
|
| 85 |
+
|
| 86 |
+
Tip: You can attach images or log files by clicking this area to highlight it and then dragging files in.
|
| 87 |
+
validations:
|
| 88 |
+
required: false
|
.github/ISSUE_TEMPLATE/config.yaml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
blank_issues_enabled: true
|
.github/ISSUE_TEMPLATE/feature_request.yaml
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "💡 Feature Request"
|
| 2 |
+
description: 创建新功能请求 | Create a new ticket for a new feature request
|
| 3 |
+
title: "💡 [REQUEST] - <title>"
|
| 4 |
+
labels: [
|
| 5 |
+
"question"
|
| 6 |
+
]
|
| 7 |
+
body:
|
| 8 |
+
- type: input
|
| 9 |
+
id: start_date
|
| 10 |
+
attributes:
|
| 11 |
+
label: "起始日期 | Start Date"
|
| 12 |
+
description: |
|
| 13 |
+
起始开发日期
|
| 14 |
+
Start of development
|
| 15 |
+
placeholder: "month/day/year"
|
| 16 |
+
validations:
|
| 17 |
+
required: false
|
| 18 |
+
- type: textarea
|
| 19 |
+
id: implementation_pr
|
| 20 |
+
attributes:
|
| 21 |
+
label: "实现PR | Implementation PR"
|
| 22 |
+
description: |
|
| 23 |
+
实现该功能的Pull request
|
| 24 |
+
Pull request used
|
| 25 |
+
placeholder: "#Pull Request ID"
|
| 26 |
+
validations:
|
| 27 |
+
required: false
|
| 28 |
+
- type: textarea
|
| 29 |
+
id: reference_issues
|
| 30 |
+
attributes:
|
| 31 |
+
label: "相关Issues | Reference Issues"
|
| 32 |
+
description: |
|
| 33 |
+
与该功能相关的issues
|
| 34 |
+
Common issues
|
| 35 |
+
placeholder: "#Issues IDs"
|
| 36 |
+
validations:
|
| 37 |
+
required: false
|
| 38 |
+
- type: textarea
|
| 39 |
+
id: summary
|
| 40 |
+
attributes:
|
| 41 |
+
label: "摘要 | Summary"
|
| 42 |
+
description: |
|
| 43 |
+
简要描述新功能的特点
|
| 44 |
+
Provide a brief explanation of the feature
|
| 45 |
+
placeholder: |
|
| 46 |
+
Describe in a few lines your feature request
|
| 47 |
+
validations:
|
| 48 |
+
required: true
|
| 49 |
+
- type: textarea
|
| 50 |
+
id: basic_example
|
| 51 |
+
attributes:
|
| 52 |
+
label: "基本示例 | Basic Example"
|
| 53 |
+
description: Indicate here some basic examples of your feature.
|
| 54 |
+
placeholder: A few specific words about your feature request.
|
| 55 |
+
validations:
|
| 56 |
+
required: true
|
| 57 |
+
- type: textarea
|
| 58 |
+
id: drawbacks
|
| 59 |
+
attributes:
|
| 60 |
+
label: "缺陷 | Drawbacks"
|
| 61 |
+
description: |
|
| 62 |
+
该新功能有哪些缺陷/可能造成哪些影响?
|
| 63 |
+
What are the drawbacks/impacts of your feature request ?
|
| 64 |
+
placeholder: |
|
| 65 |
+
Identify the drawbacks and impacts while being neutral on your feature request
|
| 66 |
+
validations:
|
| 67 |
+
required: true
|
| 68 |
+
- type: textarea
|
| 69 |
+
id: unresolved_question
|
| 70 |
+
attributes:
|
| 71 |
+
label: "未解决问题 | Unresolved questions"
|
| 72 |
+
description: |
|
| 73 |
+
有哪些尚未解决的问题?
|
| 74 |
+
What questions still remain unresolved ?
|
| 75 |
+
placeholder: |
|
| 76 |
+
Identify any unresolved issues.
|
| 77 |
+
validations:
|
| 78 |
+
required: false
|
.gitignore
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
| 2 |
+
*.so
|
| 3 |
+
build
|
| 4 |
+
.coverage_*
|
| 5 |
+
*.egg-info
|
| 6 |
+
*~
|
| 7 |
+
.vscode/
|
| 8 |
+
.idea/
|
| 9 |
+
.DS_Store
|
| 10 |
+
|
| 11 |
+
/private/
|
1.jpg
ADDED

|
FAQ.md
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FAQ
|
| 2 |
+
|
| 3 |
+
## Installation & Environment
|
| 4 |
+
|
| 5 |
+
#### Which version of transformers should I use?
|
| 6 |
+
|
| 7 |
+
4.31.0 is preferred.
|
| 8 |
+
|
| 9 |
+
#### I downloaded the codes and checkpoints but I can't load the model locally. What should I do?
|
| 10 |
+
|
| 11 |
+
Please check if you have updated the code to the latest, and correctly downloaded all the sharded checkpoint files.
|
| 12 |
+
|
| 13 |
+
#### `qwen.tiktoken` is not found. What is it?
|
| 14 |
+
|
| 15 |
+
This is the merge file of the tokenizer. You have to download it. Note that if you just git clone the repo without [git-lfs](https://git-lfs.com), you cannot download this file.
|
| 16 |
+
|
| 17 |
+
#### transformers_stream_generator/tiktoken/accelerate not found
|
| 18 |
+
|
| 19 |
+
Run the command `pip install -r requirements.txt`. You can find the file at [https://github.com/QwenLM/Qwen-VL/blob/main/requirements.txt](https://github.com/QwenLM/Qwen-VL/blob/main/requirements.txt).
|
| 20 |
+
<br><br>
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
## Demo & Inference
|
| 25 |
+
|
| 26 |
+
#### Is there any demo?
|
| 27 |
+
|
| 28 |
+
Yes, see `web_demo_mm.py` for web demo. See README for more information.
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
#### Can Qwen-VL support streaming?
|
| 33 |
+
|
| 34 |
+
No. We do not support streaming yet.
|
| 35 |
+
|
| 36 |
+
#### It seems that the generation is not related to the instruction...
|
| 37 |
+
|
| 38 |
+
Please check if you are loading Qwen-VL-Chat instead of Qwen-VL. Qwen-VL is the base model without alignment, which behaves differently from the SFT/Chat model.
|
| 39 |
+
|
| 40 |
+
#### Is quantization supported?
|
| 41 |
+
|
| 42 |
+
No. We would support quantization asap.
|
| 43 |
+
|
| 44 |
+
#### Unsatisfactory performance in processing long sequences
|
| 45 |
+
|
| 46 |
+
Please ensure that NTK is applied. `use_dynamc_ntk` and `use_logn_attn` in `config.json` should be set to `true` (`true` by default).
|
| 47 |
+
<br><br>
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
## Tokenizer
|
| 51 |
+
|
| 52 |
+
#### bos_id/eos_id/pad_id not found
|
| 53 |
+
|
| 54 |
+
In our training, we only use `<|endoftext|>` as the separator and padding token. You can set bos_id, eos_id, and pad_id to tokenizer.eod_id. Learn more about our tokenizer from our documents about the tokenizer.
|
| 55 |
+
|
FAQ_zh.md
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FAQ
|
| 2 |
+
|
| 3 |
+
## 安装&环境
|
| 4 |
+
|
| 5 |
+
#### 我应该用哪个transformers版本?
|
| 6 |
+
|
| 7 |
+
建议使用4.31.0。
|
| 8 |
+
|
| 9 |
+
#### 我把模型和代码下到本地,按照教程无法使用,该怎么办?
|
| 10 |
+
|
| 11 |
+
答:别着急,先检查你的代码是不是更新到最新版本,然后确认你是否完整地将模型checkpoint下到本地。
|
| 12 |
+
|
| 13 |
+
#### `qwen.tiktoken`这个文件找不到,怎么办?
|
| 14 |
+
|
| 15 |
+
这个是我们的tokenizer的merge文件,你必须下载它才能使用我们的tokenizer。注意,如果你使用git clone却没有使用git-lfs,这个文件不会被下载。如果你不了解git-lfs,可点击[官网](https://git-lfs.com/)了解。
|
| 16 |
+
|
| 17 |
+
#### transformers_stream_generator/tiktoken/accelerate,这几个库提示找不到,怎么办?
|
| 18 |
+
|
| 19 |
+
运行如下命令:`pip install -r requirements.txt`。相关依赖库在[https://github.com/QwenLM/Qwen-VL/blob/main/requirements.txt](https://github.com/QwenLM/Qwen-VL/blob/main/requirements.txt) 可以找到。
|
| 20 |
+
<br><br>
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
## Demo & 推理
|
| 24 |
+
|
| 25 |
+
#### 是否提供Demo?
|
| 26 |
+
|
| 27 |
+
`web_demo_mm.py`提供了Web UI。请查看README相关内容了解更多。
|
| 28 |
+
|
| 29 |
+
#### Qwen-VL支持流式推理吗?
|
| 30 |
+
|
| 31 |
+
Qwen-VL当前不支持流式推理。
|
| 32 |
+
|
| 33 |
+
#### 模型的输出看起来与输入无关/没有遵循指令/看起来呆呆的
|
| 34 |
+
|
| 35 |
+
请检查是否加载的是Qwen-VL-Chat模型进行推理,Qwen-VL模型是未经align的预训练基模型,不期望具备响应用户指令的能力。我们在模型最新版本已经对`chat`接口内进行了检查,避免您误将预训练模型作为SFT/Chat模型使用。
|
| 36 |
+
|
| 37 |
+
#### 是否有量化版本模型
|
| 38 |
+
|
| 39 |
+
目前Qwen-VL不支持量化,后续我们将支持高效的量化推理实现。
|
| 40 |
+
|
| 41 |
+
#### 处理长序列时效果有问题
|
| 42 |
+
|
| 43 |
+
请确认是否开启ntk。若要启用这些技巧,请将`config.json`里的`use_dynamc_ntk`和`use_logn_attn`设置为`true`。最新代码默认为`true`。
|
| 44 |
+
<br><br>
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
## Tokenizer
|
| 48 |
+
|
| 49 |
+
#### bos_id/eos_id/pad_id,这些token id不存在,为什么?
|
| 50 |
+
|
| 51 |
+
在训练过程中,我们仅使用<|endoftext|>这一token作为sample/document之间的分隔符及padding位置占位符,你可以将bos_id, eos_id, pad_id均指向tokenizer.eod_id。请阅读我们关于tokenizer的文档,了解如何设置这些id。
|
| 52 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Tongyi Qianwen LICENSE AGREEMENT
|
| 2 |
+
|
| 3 |
+
Tongyi Qianwen Release Date: August 23, 2023
|
| 4 |
+
|
| 5 |
+
By clicking to agree or by using or distributing any portion or element of the Tongyi Qianwen Materials, you will be deemed to have recognized and accepted the content of this Agreement, which is effective immediately.
|
| 6 |
+
|
| 7 |
+
1. Definitions
|
| 8 |
+
a. This Tongyi Qianwen LICENSE AGREEMENT (this "Agreement") shall mean the terms and conditions for use, reproduction, distribution and modification of the Materials as defined by this Agreement.
|
| 9 |
+
b. "We"(or "Us") shall mean Alibaba Cloud.
|
| 10 |
+
c. "You" (or "Your") shall mean a natural person or legal entity exercising the rights granted by this Agreement and/or using the Materials for any purpose and in any field of use.
|
| 11 |
+
d. "Third Parties" shall mean individuals or legal entities that are not under common control with Us or You.
|
| 12 |
+
e. "Tongyi Qianwen" shall mean the large language models (including Qwen-VL model and Qwen-VL-Chat model), and software and algorithms, consisting of trained model weights, parameters (including optimizer states), machine-learning model code, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Us.
|
| 13 |
+
f. "Materials" shall mean, collectively, Alibaba Cloud's proprietary Tongyi Qianwen and Documentation (and any portion thereof) made available under this Agreement.
|
| 14 |
+
g. "Source" form shall mean the preferred form for making modifications, including but not limited to model source code, documentation source, and configuration files.
|
| 15 |
+
h. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation,
|
| 16 |
+
and conversions to other media types.
|
| 17 |
+
|
| 18 |
+
2. Grant of Rights
|
| 19 |
+
You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Alibaba Cloud's intellectual property or other rights owned by Us embodied in the Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Materials.
|
| 20 |
+
|
| 21 |
+
3. Redistribution
|
| 22 |
+
You may reproduce and distribute copies of the Materials or derivative works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
|
| 23 |
+
a. You shall give any other recipients of the Materials or derivative works a copy of this Agreement;
|
| 24 |
+
b. You shall cause any modified files to carry prominent notices stating that You changed the files;
|
| 25 |
+
c. You shall retain in all copies of the Materials that You distribute the following attribution notices within a "Notice" text file distributed as a part of such copies: "Tongyi Qianwen is licensed under the Tongyi Qianwen LICENSE AGREEMENT, Copyright (c) Alibaba Cloud. All Rights Reserved."; and
|
| 26 |
+
d. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such derivative works as a whole, provided Your use, reproduction, and distribution of the work otherwise complies with the terms and conditions of this Agreement.
|
| 27 |
+
|
| 28 |
+
4. Restrictions
|
| 29 |
+
If you are commercially using the Materials, and your product or service has more than 100 million monthly active users, You shall request a license from Us. You cannot exercise your rights under this Agreement without our express authorization.
|
| 30 |
+
|
| 31 |
+
5. Rules of use
|
| 32 |
+
a. The Materials may be subject to export controls or restrictions in China, the United States or other countries or regions. You shall comply with applicable laws and regulations in your use of the Materials.
|
| 33 |
+
b. You can not use the Materials or any output therefrom to improve any other large language model (excluding Tongyi Qianwen or derivative works thereof).
|
| 34 |
+
|
| 35 |
+
6. Intellectual Property
|
| 36 |
+
a. We retain ownership of all intellectual property rights in and to the Materials and derivatives made by or for Us. Conditioned upon compliance with the terms and conditions of this Agreement, with respect to any derivative works and modifications of the Materials that are made by you, you are and will be the owner of such derivative works and modifications.
|
| 37 |
+
b. No trademark license is granted to use the trade names, trademarks, service marks, or product names of Us, except as required to fulfill notice requirements under this Agreement or as required for reasonable and customary use in describing and redistributing the Materials.
|
| 38 |
+
c. If you commence a lawsuit or other proceedings (including a cross-claim or counterclaim in a lawsuit) against Us or any entity alleging that the Materials or any output therefrom, or any part of the foregoing, infringe any intellectual property or other right owned or licensable by you, then all licences granted to you under this Agreement shall terminate as of the date such lawsuit or other proceeding is commenced or brought.
|
| 39 |
+
|
| 40 |
+
7. Disclaimer of Warranty and Limitation of Liability
|
| 41 |
+
|
| 42 |
+
a. We are not obligated to support, update, provide training for, or develop any further version of the Tongyi Qianwen Materials or to grant any license thereto.
|
| 43 |
+
b. THE MATERIALS ARE PROVIDED "AS IS" WITHOUT ANY EXPRESS OR IMPLIED WARRANTY OF ANY KIND INCLUDING WARRANTIES OF MERCHANTABILITY, NONINFRINGEMENT, OR FITNESS FOR A PARTICULAR PURPOSE. WE MAKE NO WARRANTY AND ASSUME NO RESPONSIBILITY FOR THE SAFETY OR STABILITY OF THE MATERIALS AND ANY OUTPUT THEREFROM.
|
| 44 |
+
c. IN NO EVENT SHALL WE BE LIABLE TO YOU FOR ANY DAMAGES, INCLUDING, BUT NOT LIMITED TO ANY DIRECT, OR INDIRECT, SPECIAL OR CONSEQUENTIAL DAMAGES ARISING FROM YOUR USE OR INABILITY TO USE THE MATERIALS OR ANY OUTPUT OF IT, NO MATTER HOW IT’S CAUSED.
|
| 45 |
+
d. You will defend, indemnify and hold harmless Us from and against any claim by any third party arising out of or related to your use or distribution of the Materials.
|
| 46 |
+
|
| 47 |
+
8. Survival and Termination.
|
| 48 |
+
a. The term of this Agreement shall commence upon your acceptance of this Agreement or access to the Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein.
|
| 49 |
+
b. We may terminate this Agreement if you breach any of the terms or conditions of this Agreement. Upon termination of this Agreement, you must delete and cease use of the Materials. Sections 7 and 9 shall survive the termination of this Agreement.
|
| 50 |
+
|
| 51 |
+
9. Governing Law and Jurisdiction.
|
| 52 |
+
a. This Agreement and any dispute arising out of or relating to it will be governed by the laws of China, without regard to conflict of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement.
|
| 53 |
+
b. The People's Courts in Hangzhou City shall have exclusive jurisdiction over any dispute arising out of this Agreement.
|
NOTICE
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
------------- LICENSE FOR NVIDIA Megatron-LM code --------------
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
|
| 5 |
+
Redistribution and use in source and binary forms, with or without
|
| 6 |
+
modification, are permitted provided that the following conditions
|
| 7 |
+
are met:
|
| 8 |
+
* Redistributions of source code must retain the above copyright
|
| 9 |
+
notice, this list of conditions and the following disclaimer.
|
| 10 |
+
* Redistributions in binary form must reproduce the above copyright
|
| 11 |
+
notice, this list of conditions and the following disclaimer in the
|
| 12 |
+
documentation and/or other materials provided with the distribution.
|
| 13 |
+
* Neither the name of NVIDIA CORPORATION nor the names of its
|
| 14 |
+
contributors may be used to endorse or promote products derived
|
| 15 |
+
from this software without specific prior written permission.
|
| 16 |
+
|
| 17 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
|
| 18 |
+
EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 19 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 20 |
+
PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
|
| 21 |
+
CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
|
| 22 |
+
EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
|
| 23 |
+
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
|
| 24 |
+
PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
|
| 25 |
+
OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
| 26 |
+
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 27 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
------------- LICENSE FOR OpenAI tiktoken code --------------
|
| 31 |
+
|
| 32 |
+
MIT License
|
| 33 |
+
|
| 34 |
+
Copyright (c) 2022 OpenAI, Shantanu Jain
|
| 35 |
+
|
| 36 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 37 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 38 |
+
in the Software without restriction, including without limitation the rights
|
| 39 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 40 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 41 |
+
furnished to do so, subject to the following conditions:
|
| 42 |
+
|
| 43 |
+
The above copyright notice and this permission notice shall be included in all
|
| 44 |
+
copies or substantial portions of the Software.
|
| 45 |
+
|
| 46 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 47 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 48 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 49 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 50 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 51 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 52 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,12 +1,680 @@
|
|
| 1 |
---
|
| 2 |
-
title: Qwen
|
| 3 |
-
|
| 4 |
-
colorFrom: yellow
|
| 5 |
-
colorTo: yellow
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 3.40.1
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Qwen-VL
|
| 3 |
+
app_file: web_demo_mm.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 3.40.1
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
<br>
|
| 8 |
+
|
| 9 |
+
<p align="center">
|
| 10 |
+
<img src="assets/logo.jpg" width="400"/>
|
| 11 |
+
<p>
|
| 12 |
+
<br>
|
| 13 |
+
|
| 14 |
+
<p align="center">
|
| 15 |
+
Qwen-VL <a href="https://modelscope.cn/models/qwen/Qwen-VL/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-VL">🤗</a>  | Qwen-VL-Chat <a href="https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary">🤖 <a>| <a href="https://huggingface.co/Qwen/Qwen-VL-Chat">🤗</a>  |  <a href="https://modelscope.cn/studios/qwen/Qwen-VL-Chat-Demo/summary">Demo</a>  |  <a>Report</a>   |   <a href="https://discord.gg/z3GAxXZ9Ce">Discord</a>
|
| 16 |
+
|
| 17 |
+
</p>
|
| 18 |
+
<br>
|
| 19 |
+
|
| 20 |
+
<p align="center">
|
| 21 |
+
<a href="README_CN.md">中文</a>  |   English
|
| 22 |
+
</p>
|
| 23 |
+
<br><br>
|
| 24 |
+
|
| 25 |
+
**Qwen-VL** (Qwen Large Vision Language Model) is the multimodal version of the large model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-VL accepts image, text, and bounding box as inputs, outputs text and bounding box. The features of Qwen-VL include:
|
| 26 |
+
- **Strong performance**: It significantly surpasses existing open-source Large Vision Language Models (LVLM) under similar model scale on multiple English evaluation benchmarks (including Zero-shot Captioning, VQA, DocVQA, and Grounding).
|
| 27 |
+
- **Multi-lingual LVLM supporting text recognition**: Qwen-VL naturally supports English, Chinese, and multi-lingual conversation, and it promotes end-to-end recognition of Chinese and English bi-lingual text in images.
|
| 28 |
+
- **Multi-image interleaved conversations**: This feature allows for the input and comparison of multiple images, as well as the ability to specify questions related to the images and engage in multi-image storytelling.
|
| 29 |
+
- **First generalist model supporting grounding in Chinese**: Detecting bounding boxes through open-domain language expression in both Chinese and English.
|
| 30 |
+
- **Fine-grained recognition and understanding**: Compared to the 224\*224 resolution currently used by other open-source LVLM, the 448\*448 resolution promotes fine-grained text recognition, document QA, and bounding box annotation.
|
| 31 |
+
|
| 32 |
+
<br>
|
| 33 |
+
<p align="center">
|
| 34 |
+
<img src="assets/demo_vl.gif" width="400"/>
|
| 35 |
+
<p>
|
| 36 |
+
<br>
|
| 37 |
+
|
| 38 |
+
We release two models of the Qwen-VL series:
|
| 39 |
+
- Qwen-VL: The pre-trained LVLM model uses Qwen-7B as the initialization of the LLM, and [Openclip ViT-bigG](https://github.com/mlfoundations/open_clip) as the initialization of the visual encoder. And connects them with a randomly initialized cross-attention layer.
|
| 40 |
+
- Qwen-VL-Chat: A multimodal LLM-based AI assistant, which is trained with alignment techniques. Qwen-VL-Chat supports more flexible interaction, such as multiple image inputs, multi-round question answering, and creative capabilities.
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
## Evaluation
|
| 44 |
+
|
| 45 |
+
We evaluated the model's abilities from two perspectives:
|
| 46 |
+
1. **Standard Benchmarks**: We evaluate the model's basic task capabilities on four major categories of multimodal tasks:
|
| 47 |
+
- Zero-shot Captioning: Evaluate model's zero-shot image captioning ability on unseen datasets;
|
| 48 |
+
- General VQA: Evaluate the general question-answering ability of pictures, such as the judgment, color, number, category, etc;
|
| 49 |
+
- Text-based VQA: Evaluate the model's ability to recognize text in pictures, such as document QA, chart QA, etc;
|
| 50 |
+
- Referring Expression Comprehension: Evaluate the ability to localize a target object in an image described by a referring expression.
|
| 51 |
+
|
| 52 |
+
2. **TouchStone**: To evaluate the overall text-image dialogue capability and alignment level with humans, we have constructed a benchmark called TouchStone, which is based on scoring with GPT4 to evaluate the LVLM model.
|
| 53 |
+
- The TouchStone benchmark covers a total of 300+ images, 800+ questions, and 27 categories. Such as attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, math problem solving, etc;
|
| 54 |
+
- In order to break the current limitation of GPT4 in terms of direct image input, TouchStone provides fine-grained image annotations by human labeling. These detailed annotations, along with the questions and the model's output, are then presented to GPT4 for scoring.
|
| 55 |
+
- The benchmark includes both English and Chinese versions.
|
| 56 |
+
|
| 57 |
+
The results of the evaluation are as follows:
|
| 58 |
+
|
| 59 |
+
Qwen-VL outperforms current SOTA generalist models on multiple VL tasks and has a more comprehensive coverage in terms of capability range.
|
| 60 |
+
|
| 61 |
+
<p align="center">
|
| 62 |
+
<img src="assets/radar.png" width="600"/>
|
| 63 |
+
<p>
|
| 64 |
+
|
| 65 |
+
### Zero-shot Captioning & General VQA
|
| 66 |
+
<table>
|
| 67 |
+
<thead>
|
| 68 |
+
<tr>
|
| 69 |
+
<th rowspan="2">Model type</th>
|
| 70 |
+
<th rowspan="2">Model</th>
|
| 71 |
+
<th colspan="2">Zero-shot Captioning</th>
|
| 72 |
+
<th colspan="5">General VQA</th>
|
| 73 |
+
</tr>
|
| 74 |
+
<tr>
|
| 75 |
+
<th>NoCaps</th>
|
| 76 |
+
<th>Flickr30K</th>
|
| 77 |
+
<th>VQAv2<sup>dev</sup></th>
|
| 78 |
+
<th>OK-VQA</th>
|
| 79 |
+
<th>GQA</th>
|
| 80 |
+
<th>SciQA-Img<br>(0-shot)</th>
|
| 81 |
+
<th>VizWiz<br>(0-shot)</th>
|
| 82 |
+
</tr>
|
| 83 |
+
</thead>
|
| 84 |
+
<tbody align="center">
|
| 85 |
+
<tr>
|
| 86 |
+
<td rowspan="10">Generalist<br>Models</td>
|
| 87 |
+
<td>Flamingo-9B</td>
|
| 88 |
+
<td>-</td>
|
| 89 |
+
<td>61.5</td>
|
| 90 |
+
<td>51.8</td>
|
| 91 |
+
<td>44.7</td>
|
| 92 |
+
<td>-</td>
|
| 93 |
+
<td>-</td>
|
| 94 |
+
<td>28.8</td>
|
| 95 |
+
</tr>
|
| 96 |
+
<tr>
|
| 97 |
+
<td>Flamingo-80B</td>
|
| 98 |
+
<td>-</td>
|
| 99 |
+
<td>67.2</td>
|
| 100 |
+
<td>56.3</td>
|
| 101 |
+
<td>50.6</td>
|
| 102 |
+
<td>-</td>
|
| 103 |
+
<td>-</td>
|
| 104 |
+
<td>31.6</td>
|
| 105 |
+
</tr>
|
| 106 |
+
<tr>
|
| 107 |
+
<td>Unified-IO-XL</td>
|
| 108 |
+
<td>100.0</td>
|
| 109 |
+
<td>-</td>
|
| 110 |
+
<td>77.9</td>
|
| 111 |
+
<td>54.0</td>
|
| 112 |
+
<td>-</td>
|
| 113 |
+
<td>-</td>
|
| 114 |
+
<td>-</td>
|
| 115 |
+
</tr>
|
| 116 |
+
<tr>
|
| 117 |
+
<td>Kosmos-1</td>
|
| 118 |
+
<td>-</td>
|
| 119 |
+
<td>67.1</td>
|
| 120 |
+
<td>51.0</td>
|
| 121 |
+
<td>-</td>
|
| 122 |
+
<td>-</td>
|
| 123 |
+
<td>-</td>
|
| 124 |
+
<td>29.2</td>
|
| 125 |
+
</tr>
|
| 126 |
+
<tr>
|
| 127 |
+
<td>Kosmos-2</td>
|
| 128 |
+
<td>-</td>
|
| 129 |
+
<td>66.7</td>
|
| 130 |
+
<td>45.6</td>
|
| 131 |
+
<td>-</td>
|
| 132 |
+
<td>-</td>
|
| 133 |
+
<td>-</td>
|
| 134 |
+
<td>-</td>
|
| 135 |
+
</tr>
|
| 136 |
+
<tr>
|
| 137 |
+
<td>BLIP-2 (Vicuna-13B)</td>
|
| 138 |
+
<td>103.9</td>
|
| 139 |
+
<td>71.6</td>
|
| 140 |
+
<td>65.0</td>
|
| 141 |
+
<td>45.9</td>
|
| 142 |
+
<td>32.3</td>
|
| 143 |
+
<td>61.0</td>
|
| 144 |
+
<td>19.6</td>
|
| 145 |
+
</tr>
|
| 146 |
+
<tr>
|
| 147 |
+
<td>InstructBLIP (Vicuna-13B)</td>
|
| 148 |
+
<td><strong>121.9</strong></td>
|
| 149 |
+
<td>82.8</td>
|
| 150 |
+
<td>-</td>
|
| 151 |
+
<td>-</td>
|
| 152 |
+
<td>49.5</td>
|
| 153 |
+
<td>63.1</td>
|
| 154 |
+
<td>33.4</td>
|
| 155 |
+
</tr>
|
| 156 |
+
<tr>
|
| 157 |
+
<td>Shikra (Vicuna-13B)</td>
|
| 158 |
+
<td>-</td>
|
| 159 |
+
<td>73.9</td>
|
| 160 |
+
<td>77.36</td>
|
| 161 |
+
<td>47.16</td>
|
| 162 |
+
<td>-</td>
|
| 163 |
+
<td>-</td>
|
| 164 |
+
<td>-</td>
|
| 165 |
+
</tr>
|
| 166 |
+
<tr>
|
| 167 |
+
<td><strong>Qwen-VL (Qwen-7B)</strong></td>
|
| 168 |
+
<td>121.4</td>
|
| 169 |
+
<td><b>85.8</b></td>
|
| 170 |
+
<td><b>78.8</b></td>
|
| 171 |
+
<td><b>58.6</b></td>
|
| 172 |
+
<td><b>59.3</b></td>
|
| 173 |
+
<td>67.1</td>
|
| 174 |
+
<td>35.2</td>
|
| 175 |
+
</tr>
|
| 176 |
+
<!-- <tr>
|
| 177 |
+
<td>Qwen-VL (4-shot)</td>
|
| 178 |
+
<td>-</td>
|
| 179 |
+
<td>-</td>
|
| 180 |
+
<td>-</td>
|
| 181 |
+
<td>63.6</td>
|
| 182 |
+
<td>-</td>
|
| 183 |
+
<td>-</td>
|
| 184 |
+
<td>39.1</td>
|
| 185 |
+
</tr> -->
|
| 186 |
+
<tr>
|
| 187 |
+
<td>Qwen-VL-Chat</td>
|
| 188 |
+
<td>120.2</td>
|
| 189 |
+
<td>81.0</td>
|
| 190 |
+
<td>78.2</td>
|
| 191 |
+
<td>56.6</td>
|
| 192 |
+
<td>57.5</td>
|
| 193 |
+
<td><b>68.2</b></td>
|
| 194 |
+
<td><b>38.9</b></td>
|
| 195 |
+
</tr>
|
| 196 |
+
<!-- <tr>
|
| 197 |
+
<td>Qwen-VL-Chat (4-shot)</td>
|
| 198 |
+
<td>-</td>
|
| 199 |
+
<td>-</td>
|
| 200 |
+
<td>-</td>
|
| 201 |
+
<td>60.6</td>
|
| 202 |
+
<td>-</td>
|
| 203 |
+
<td>-</td>
|
| 204 |
+
<td>44.45</td>
|
| 205 |
+
</tr> -->
|
| 206 |
+
<tr>
|
| 207 |
+
<td>Previous SOTA<br>(Per Task Fine-tuning)</td>
|
| 208 |
+
<td>-</td>
|
| 209 |
+
<td>127.0<br>(PALI-17B)</td>
|
| 210 |
+
<td>84.5<br>(InstructBLIP<br>-FlanT5-XL)</td>
|
| 211 |
+
<td>86.1<br>(PALI-X<br>-55B)</td>
|
| 212 |
+
<td>66.1<br>(PALI-X<br>-55B)</td>
|
| 213 |
+
<td>72.1<br>(CFR)</td>
|
| 214 |
+
<td>92.53<br>(LLaVa+<br>GPT-4)</td>
|
| 215 |
+
<td>70.9<br>(PALI-X<br>-55B)</td>
|
| 216 |
+
</tr>
|
| 217 |
+
</tbody>
|
| 218 |
+
</table>
|
| 219 |
+
|
| 220 |
+
- For zero-shot image captioning, Qwen-VL achieves the **SOTA** on Flickr30K and competitive results on Nocaps with InstructBlip.
|
| 221 |
+
- For general VQA, Qwen-VL achieves the **SOTA** under the same generalist LVLM scale settings.
|
| 222 |
+
|
| 223 |
+
### Text-oriented VQA (focuse on text understanding capabilities in images)
|
| 224 |
+
|
| 225 |
+
<table>
|
| 226 |
+
<thead>
|
| 227 |
+
<tr>
|
| 228 |
+
<th>Model type</th>
|
| 229 |
+
<th>Model</th>
|
| 230 |
+
<th>TextVQA</th>
|
| 231 |
+
<th>DocVQA</th>
|
| 232 |
+
<th>ChartQA</th>
|
| 233 |
+
<th>AI2D</th>
|
| 234 |
+
<th>OCR-VQA</th>
|
| 235 |
+
</tr>
|
| 236 |
+
</thead>
|
| 237 |
+
<tbody align="center">
|
| 238 |
+
<tr>
|
| 239 |
+
<td rowspan="5">Generalist Models</td>
|
| 240 |
+
<td>BLIP-2 (Vicuna-13B)</td>
|
| 241 |
+
<td>42.4</td>
|
| 242 |
+
<td>-</td>
|
| 243 |
+
<td>-</td>
|
| 244 |
+
<td>-</td>
|
| 245 |
+
<td>-</td>
|
| 246 |
+
</tr>
|
| 247 |
+
<tr>
|
| 248 |
+
<td>InstructBLIP (Vicuna-13B)</td>
|
| 249 |
+
<td>50.7</td>
|
| 250 |
+
<td>-</td>
|
| 251 |
+
<td>-</td>
|
| 252 |
+
<td>-</td>
|
| 253 |
+
<td>-</td>
|
| 254 |
+
</tr>
|
| 255 |
+
<tr>
|
| 256 |
+
<td>mPLUG-DocOwl (LLaMA-7B)</td>
|
| 257 |
+
<td>52.6</td>
|
| 258 |
+
<td>62.2</td>
|
| 259 |
+
<td>57.4</td>
|
| 260 |
+
<td>-</td>
|
| 261 |
+
<td>-</td>
|
| 262 |
+
</tr>
|
| 263 |
+
<tr>
|
| 264 |
+
<td>Pic2Struct-Large (1.3B)</td>
|
| 265 |
+
<td>-</td>
|
| 266 |
+
<td><b>76.6</b></td>
|
| 267 |
+
<td>58.6</td>
|
| 268 |
+
<td>42.1</td>
|
| 269 |
+
<td>71.3</td>
|
| 270 |
+
</tr>
|
| 271 |
+
<tr>
|
| 272 |
+
<td>Qwen-VL (Qwen-7B)</td>
|
| 273 |
+
<td><b>63.8</b></td>
|
| 274 |
+
<td>65.1</td>
|
| 275 |
+
<td><b>65.7</b></td>
|
| 276 |
+
<td><b>62.3</b></td>
|
| 277 |
+
<td><b>75.7</b></td>
|
| 278 |
+
</tr>
|
| 279 |
+
<tr>
|
| 280 |
+
<td>Specialist SOTAs<br>(Specialist/Finetuned)</td>
|
| 281 |
+
<td>PALI-X-55B (Single-task FT)<br>(Without OCR Pipeline)</td>
|
| 282 |
+
<td>71.44</td>
|
| 283 |
+
<td>80.0</td>
|
| 284 |
+
<td>70.0</td>
|
| 285 |
+
<td>81.2</td>
|
| 286 |
+
<td>75.0</td>
|
| 287 |
+
</tr>
|
| 288 |
+
</tbody>
|
| 289 |
+
</table>
|
| 290 |
+
|
| 291 |
+
- In text-related recognition/QA evaluation, Qwen-VL achieves the SOTA under the generalist LVLM scale settings.
|
| 292 |
+
- Resolution is important for several above evaluations. While most open-source LVLM models with 224 resolution are incapable of these evaluations or can only solve these by cutting images, Qwen-VL scales the resolution to 448 so that it can be evaluated end-to-end. Qwen-VL even outperforms Pic2Struct-Large models of 1024 resolution on some tasks.
|
| 293 |
+
|
| 294 |
+
### Referring Expression Comprehension
|
| 295 |
+
<table>
|
| 296 |
+
<thead>
|
| 297 |
+
<tr>
|
| 298 |
+
<th rowspan="2">Model type</th>
|
| 299 |
+
<th rowspan="2">Model</th>
|
| 300 |
+
<th colspan="3">RefCOCO</th>
|
| 301 |
+
<th colspan="3">RefCOCO+</th>
|
| 302 |
+
<th colspan="2">RefCOCOg</th>
|
| 303 |
+
<th>GRIT</th>
|
| 304 |
+
</tr>
|
| 305 |
+
<tr>
|
| 306 |
+
<th>val</th>
|
| 307 |
+
<th>test-A</th>
|
| 308 |
+
<th>test-B</th>
|
| 309 |
+
<th>val</th>
|
| 310 |
+
<th>test-A</th>
|
| 311 |
+
<th>test-B</th>
|
| 312 |
+
<th>val-u</th>
|
| 313 |
+
<th>test-u</th>
|
| 314 |
+
<th>refexp</th>
|
| 315 |
+
</tr>
|
| 316 |
+
</thead>
|
| 317 |
+
<tbody align="center">
|
| 318 |
+
<tr>
|
| 319 |
+
<td rowspan="8">Generalist Models</td>
|
| 320 |
+
<td>GPV-2</td>
|
| 321 |
+
<td>-</td>
|
| 322 |
+
<td>-</td>
|
| 323 |
+
<td>-</td>
|
| 324 |
+
<td>-</td>
|
| 325 |
+
<td>-</td>
|
| 326 |
+
<td>-</td>
|
| 327 |
+
<td>-</td>
|
| 328 |
+
<td>-</td>
|
| 329 |
+
<td>51.50</td>
|
| 330 |
+
</tr>
|
| 331 |
+
<tr>
|
| 332 |
+
<td>OFA-L*</td>
|
| 333 |
+
<td>79.96</td>
|
| 334 |
+
<td>83.67</td>
|
| 335 |
+
<td>76.39</td>
|
| 336 |
+
<td>68.29</td>
|
| 337 |
+
<td>76.00</td>
|
| 338 |
+
<td>61.75</td>
|
| 339 |
+
<td>67.57</td>
|
| 340 |
+
<td>67.58</td>
|
| 341 |
+
<td>61.70</td>
|
| 342 |
+
</tr>
|
| 343 |
+
<tr>
|
| 344 |
+
<td>Unified-IO</td>
|
| 345 |
+
<td>-</td>
|
| 346 |
+
<td>-</td>
|
| 347 |
+
<td>-</td>
|
| 348 |
+
<td>-</td>
|
| 349 |
+
<td>-</td>
|
| 350 |
+
<td>-</td>
|
| 351 |
+
<td>-</td>
|
| 352 |
+
<td>-</td>
|
| 353 |
+
<td><b>78.61</b></td>
|
| 354 |
+
</tr>
|
| 355 |
+
<tr>
|
| 356 |
+
<td>VisionLLM-H</td>
|
| 357 |
+
<td></td>
|
| 358 |
+
<td>86.70</td>
|
| 359 |
+
<td>-</td>
|
| 360 |
+
<td>-</td>
|
| 361 |
+
<td>-</td>
|
| 362 |
+
<td>-</td>
|
| 363 |
+
<td>-</td>
|
| 364 |
+
<td>-</td>
|
| 365 |
+
<td>-</td>
|
| 366 |
+
</tr>
|
| 367 |
+
<tr>
|
| 368 |
+
<td>Shikra-7B</td>
|
| 369 |
+
<td>87.01</td>
|
| 370 |
+
<td>90.61</td>
|
| 371 |
+
<td>80.24 </td>
|
| 372 |
+
<td>81.60</td>
|
| 373 |
+
<td>87.36</td>
|
| 374 |
+
<td>72.12</td>
|
| 375 |
+
<td>82.27</td>
|
| 376 |
+
<td>82.19</td>
|
| 377 |
+
<td>69.34</td>
|
| 378 |
+
</tr>
|
| 379 |
+
<tr>
|
| 380 |
+
<td>Shikra-13B</td>
|
| 381 |
+
<td>87.83 </td>
|
| 382 |
+
<td>91.11</td>
|
| 383 |
+
<td>81.81</td>
|
| 384 |
+
<td>82.89</td>
|
| 385 |
+
<td>87.79</td>
|
| 386 |
+
<td>74.41</td>
|
| 387 |
+
<td>82.64</td>
|
| 388 |
+
<td>83.16</td>
|
| 389 |
+
<td>69.03</td>
|
| 390 |
+
</tr>
|
| 391 |
+
<tr>
|
| 392 |
+
<td>Qwen-VL-7B</td>
|
| 393 |
+
<td><b>89.36</b></td>
|
| 394 |
+
<td>92.26</td>
|
| 395 |
+
<td><b>85.34</b></td>
|
| 396 |
+
<td><b>83.12</b></td>
|
| 397 |
+
<td>88.25</td>
|
| 398 |
+
<td><b>77.21</b></td>
|
| 399 |
+
<td>85.58</td>
|
| 400 |
+
<td>85.48</td>
|
| 401 |
+
<td>78.22</td>
|
| 402 |
+
</tr>
|
| 403 |
+
<tr>
|
| 404 |
+
<td>Qwen-VL-7B-Chat</td>
|
| 405 |
+
<td>88.55</td>
|
| 406 |
+
<td><b>92.27</b></td>
|
| 407 |
+
<td>84.51</td>
|
| 408 |
+
<td>82.82</td>
|
| 409 |
+
<td><b>88.59</b></td>
|
| 410 |
+
<td>76.79</td>
|
| 411 |
+
<td><b>85.96</b></td>
|
| 412 |
+
<td><b>86.32</b></td>
|
| 413 |
+
<td>-</td>
|
| 414 |
+
<tr>
|
| 415 |
+
<td rowspan="3">Specialist SOTAs<br>(Specialist/Finetuned)</td>
|
| 416 |
+
<td>G-DINO-L</td>
|
| 417 |
+
<td>90.56 </td>
|
| 418 |
+
<td>93.19</td>
|
| 419 |
+
<td>88.24</td>
|
| 420 |
+
<td>82.75</td>
|
| 421 |
+
<td>88.95</td>
|
| 422 |
+
<td>75.92</td>
|
| 423 |
+
<td>86.13</td>
|
| 424 |
+
<td>87.02</td>
|
| 425 |
+
<td>-</td>
|
| 426 |
+
</tr>
|
| 427 |
+
<tr>
|
| 428 |
+
<td>UNINEXT-H</td>
|
| 429 |
+
<td>92.64 </td>
|
| 430 |
+
<td>94.33</td>
|
| 431 |
+
<td>91.46</td>
|
| 432 |
+
<td>85.24</td>
|
| 433 |
+
<td>89.63</td>
|
| 434 |
+
<td>79.79</td>
|
| 435 |
+
<td>88.73</td>
|
| 436 |
+
<td>89.37</td>
|
| 437 |
+
<td>-</td>
|
| 438 |
+
</tr>
|
| 439 |
+
<tr>
|
| 440 |
+
<td>ONE-PEACE</td>
|
| 441 |
+
<td>92.58 </td>
|
| 442 |
+
<td>94.18</td>
|
| 443 |
+
<td>89.26</td>
|
| 444 |
+
<td>88.77</td>
|
| 445 |
+
<td>92.21</td>
|
| 446 |
+
<td>83.23</td>
|
| 447 |
+
<td>89.22</td>
|
| 448 |
+
<td>89.27</td>
|
| 449 |
+
<td>-</td>
|
| 450 |
+
</tr>
|
| 451 |
+
</tbody>
|
| 452 |
+
</table>
|
| 453 |
+
|
| 454 |
+
- Qwen-VL achieves the **SOTA** in all above referring expression comprehension benchmarks.
|
| 455 |
+
- Qwen-VL has not been trained on any Chinese grounding data, but it can still generalize to the Chinese Grounding tasks in a zero-shot way by training Chinese Caption data and English Grounding data.
|
| 456 |
+
|
| 457 |
+
We provide all of the above evaluation scripts for reproducing our experimental results. Please read [eval_mm/EVALUATION.md](eval_mm/EVALUATION.md) for more information.
|
| 458 |
+
|
| 459 |
+
### Chat evaluation
|
| 460 |
+
|
| 461 |
+
TouchStone is a benchmark based on scoring with GPT4 to evaluate the abilities of the LVLM model on text-image dialogue and alignment levels with humans. It covers a total of 300+ images, 800+ questions, and 27 categories, such as attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, math problem solving, etc. Please read [touchstone/README.md](touchstone/README.md) for more information.
|
| 462 |
+
|
| 463 |
+
#### English evaluation
|
| 464 |
+
|
| 465 |
+
| Model | Score |
|
| 466 |
+
|---------------|-------|
|
| 467 |
+
| PandaGPT | 488.5 |
|
| 468 |
+
| MiniGPT4 | 531.7 |
|
| 469 |
+
| InstructBLIP | 552.4 |
|
| 470 |
+
| LLaMA-AdapterV2 | 590.1 |
|
| 471 |
+
| mPLUG-Owl | 605.4 |
|
| 472 |
+
| LLaVA | 602.7 |
|
| 473 |
+
| Qwen-VL-Chat | 645.2 |
|
| 474 |
+
|
| 475 |
+
#### Chinese evaluation
|
| 476 |
+
|
| 477 |
+
| Model | Score |
|
| 478 |
+
|---------------|-------|
|
| 479 |
+
| VisualGLM | 247.1 |
|
| 480 |
+
| Qwen-VL-Chat | 401.2 |
|
| 481 |
+
|
| 482 |
+
Qwen-VL-Chat has achieved the best results in both Chinese and English alignment evaluation.
|
| 483 |
+
|
| 484 |
+
## Requirements
|
| 485 |
+
|
| 486 |
+
* python 3.8 and above
|
| 487 |
+
* pytorch 1.12 and above, 2.0 and above are recommended
|
| 488 |
+
* CUDA 11.4 and above are recommended (this is for GPU users)
|
| 489 |
+
|
| 490 |
+
## Quickstart
|
| 491 |
+
|
| 492 |
+
Below, we provide simple examples to show how to use Qwen-VL and Qwen-VL-Chat with 🤖 ModelScope and 🤗 Transformers.
|
| 493 |
+
|
| 494 |
+
Before running the code, make sure you have setup the environment and installed the required packages. Make sure you meet the above requirements, and then install the dependent libraries.
|
| 495 |
+
|
| 496 |
+
```bash
|
| 497 |
+
pip install -r requirements.txt
|
| 498 |
+
```
|
| 499 |
+
|
| 500 |
+
Now you can start with ModelScope or Transformers. More usage aboue vision encoder, please refer to the [tutorial](TUTORIAL.md).
|
| 501 |
+
|
| 502 |
+
#### 🤗 Transformers
|
| 503 |
+
|
| 504 |
+
To use Qwen-VL-Chat for the inference, all you need to do is to input a few lines of codes as demonstrated below. However, **please make sure that you are using the latest code.**
|
| 505 |
+
|
| 506 |
+
```python
|
| 507 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 508 |
+
from transformers.generation import GenerationConfig
|
| 509 |
+
import torch
|
| 510 |
+
torch.manual_seed(1234)
|
| 511 |
+
|
| 512 |
+
# Note: The default behavior now has injection attack prevention off.
|
| 513 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
|
| 514 |
+
|
| 515 |
+
# use bf16
|
| 516 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 517 |
+
# use fp16
|
| 518 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 519 |
+
# use cpu only
|
| 520 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cpu", trust_remote_code=True).eval()
|
| 521 |
+
# use cuda device
|
| 522 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cuda", trust_remote_code=True).eval()
|
| 523 |
+
|
| 524 |
+
# Specify hyperparameters for generation
|
| 525 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
|
| 526 |
+
|
| 527 |
+
# 1st dialogue turn
|
| 528 |
+
query = tokenizer.from_list_format([
|
| 529 |
+
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
|
| 530 |
+
{'text': '这是什么?'},
|
| 531 |
+
])
|
| 532 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 533 |
+
print(response)
|
| 534 |
+
# 图中是一名女子在沙滩上和狗玩耍,旁边是一只拉布拉多犬,它们处于沙滩上。
|
| 535 |
+
|
| 536 |
+
# 2st dialogue turn
|
| 537 |
+
response, history = model.chat(tokenizer, '框出图中击掌的位置', history=history)
|
| 538 |
+
print(response)
|
| 539 |
+
# <ref>击掌</ref><box>(536,509),(588,602)</box>
|
| 540 |
+
image = tokenizer.draw_bbox_on_latest_picture(response, history)
|
| 541 |
+
if image:
|
| 542 |
+
image.save('1.jpg')
|
| 543 |
+
else:
|
| 544 |
+
print("no box")
|
| 545 |
+
```
|
| 546 |
+
|
| 547 |
+
<p align="center">
|
| 548 |
+
<img src="assets/demo_highfive.jpg" width="500"/>
|
| 549 |
+
<p>
|
| 550 |
+
|
| 551 |
+
<details>
|
| 552 |
+
<summary>Running Qwen-VL</summary>
|
| 553 |
+
|
| 554 |
+
Running Qwen-VL pretrained base model is also simple.
|
| 555 |
+
|
| 556 |
+
```python
|
| 557 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 558 |
+
from transformers.generation import GenerationConfig
|
| 559 |
+
import torch
|
| 560 |
+
torch.manual_seed(1234)
|
| 561 |
+
|
| 562 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
|
| 563 |
+
|
| 564 |
+
# use bf16
|
| 565 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 566 |
+
# use fp16
|
| 567 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 568 |
+
# use cpu only
|
| 569 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cpu", trust_remote_code=True).eval()
|
| 570 |
+
# use cuda device
|
| 571 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cuda", trust_remote_code=True).eval()
|
| 572 |
+
|
| 573 |
+
# Specify hyperparameters for generation
|
| 574 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
|
| 575 |
+
|
| 576 |
+
query = tokenizer.from_list_format([
|
| 577 |
+
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
|
| 578 |
+
{'text': 'Generate the caption in English with grounding:'},
|
| 579 |
+
])
|
| 580 |
+
inputs = tokenizer(query, return_tensors='pt')
|
| 581 |
+
inputs = inputs.to(model.device)
|
| 582 |
+
pred = model.generate(**inputs)
|
| 583 |
+
response = tokenizer.decode(pred.cpu()[0], skip_special_tokens=False)
|
| 584 |
+
print(response)
|
| 585 |
+
# <img>https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg</img>Generate the caption in English with grounding:<ref> Woman</ref><box>(451,379),(731,806)</box> and<ref> her dog</ref><box>(219,424),(576,896)</box> playing on the beach<|endoftext|>
|
| 586 |
+
image = tokenizer.draw_bbox_on_latest_picture(response)
|
| 587 |
+
if image:
|
| 588 |
+
image.save('2.jpg')
|
| 589 |
+
else:
|
| 590 |
+
print("no box")
|
| 591 |
+
```
|
| 592 |
+
|
| 593 |
+
<p align="center">
|
| 594 |
+
<img src="assets/demo_spotting_caption.jpg" width="500"/>
|
| 595 |
+
<p>
|
| 596 |
+
|
| 597 |
+
</details>
|
| 598 |
+
|
| 599 |
+
|
| 600 |
+
#### 🤖 ModelScope
|
| 601 |
+
|
| 602 |
+
ModelScope is an opensource platform for Model-as-a-Service (MaaS), which provides flexible and cost-effective model service to AI developers. Similarly, you can run the models with ModelScope as shown below:
|
| 603 |
+
|
| 604 |
+
```python
|
| 605 |
+
from modelscope import (
|
| 606 |
+
snapshot_download, AutoModelForCausalLM, AutoTokenizer, GenerationConfig
|
| 607 |
+
)
|
| 608 |
+
import torch
|
| 609 |
+
model_id = 'qwen/Qwen-VL-Chat'
|
| 610 |
+
revision = 'v1.0.0'
|
| 611 |
+
|
| 612 |
+
model_dir = snapshot_download(model_id, revision=revision)
|
| 613 |
+
torch.manual_seed(1234)
|
| 614 |
+
|
| 615 |
+
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
|
| 616 |
+
if not hasattr(tokenizer, 'model_dir'):
|
| 617 |
+
tokenizer.model_dir = model_dir
|
| 618 |
+
# use bf16
|
| 619 |
+
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 620 |
+
# use fp16
|
| 621 |
+
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 622 |
+
# use cpu
|
| 623 |
+
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="cpu", trust_remote_code=True).eval()
|
| 624 |
+
# use auto
|
| 625 |
+
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
|
| 626 |
+
|
| 627 |
+
# Specify hyperparameters for generation
|
| 628 |
+
model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True)
|
| 629 |
+
|
| 630 |
+
# 1st dialogue turn
|
| 631 |
+
# Either a local path or an url between <img></img> tags.
|
| 632 |
+
image_path = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
|
| 633 |
+
response, history = model.chat(tokenizer, query=f'<img>{image_path}</img>这是什么', history=None)
|
| 634 |
+
print(response)
|
| 635 |
+
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,与人互动。
|
| 636 |
+
|
| 637 |
+
# 2st dialogue turn
|
| 638 |
+
response, history = model.chat(tokenizer, '输出击掌的检测框', history=history)
|
| 639 |
+
print(response)
|
| 640 |
+
# <ref>"击掌"</ref><box>(211,412),(577,891)</box>
|
| 641 |
+
image = tokenizer.draw_bbox_on_latest_picture(response, history)
|
| 642 |
+
if image:
|
| 643 |
+
image.save('output_chat.jpg')
|
| 644 |
+
else:
|
| 645 |
+
print("no box")
|
| 646 |
+
```
|
| 647 |
+
|
| 648 |
+
<p align="center">
|
| 649 |
+
<img src="assets/demo_highfive.jpg" width="500"/>
|
| 650 |
+
<p>
|
| 651 |
+
|
| 652 |
+
## Demo
|
| 653 |
+
|
| 654 |
+
### Web UI
|
| 655 |
+
|
| 656 |
+
We provide code for users to build a web UI demo. Before you start, make sure you install the following packages:
|
| 657 |
+
|
| 658 |
+
```
|
| 659 |
+
pip install -r requirements_web_demo.txt
|
| 660 |
+
```
|
| 661 |
+
|
| 662 |
+
Then run the command below and click on the generated link:
|
| 663 |
+
|
| 664 |
+
```
|
| 665 |
+
python web_demo_mm.py
|
| 666 |
+
```
|
| 667 |
+
|
| 668 |
+
## FAQ
|
| 669 |
+
|
| 670 |
+
If you meet problems, please refer to [FAQ](FAQ.md) and the issues first to search a solution before you launch a new issue.
|
| 671 |
+
|
| 672 |
+
|
| 673 |
+
## License Agreement
|
| 674 |
+
|
| 675 |
+
Researchers and developers are free to use the codes and model weights of both Qwen-VL and Qwen-VL-Chat. We also allow their commercial use. Check our license at [LICENSE](LICENSE) for more details.
|
| 676 |
+
|
| 677 |
+
## Contact Us
|
| 678 |
+
|
| 679 |
+
If you are interested to leave a message to either our research team or product team, feel free to send an email to qianwen_opensource@alibabacloud.com.
|
| 680 |
|
|
|
README_CN.md
ADDED
|
@@ -0,0 +1,666 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<br>
|
| 2 |
+
|
| 3 |
+
<p align="center">
|
| 4 |
+
<img src="assets/logo.jpg" width="400"/>
|
| 5 |
+
<p>
|
| 6 |
+
<br>
|
| 7 |
+
|
| 8 |
+
<p align="center">
|
| 9 |
+
Qwen-VL <a href="https://modelscope.cn/models/qwen/Qwen-VL/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-VL">🤗</a>  | Qwen-VL-Chat <a href="https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary">🤖 <a>| <a href="https://huggingface.co/Qwen/Qwen-VL-Chat">🤗</a>  |  <a href="https://modelscope.cn/studios/qwen/Qwen-VL-Chat-Demo/summary">Demo</a>  |  <a>Report</a>   |   <a href="https://discord.gg/z3GAxXZ9Ce">Discord</a>
|
| 10 |
+
</p>
|
| 11 |
+
<br>
|
| 12 |
+
|
| 13 |
+
<p align="center">
|
| 14 |
+
中文</a>  |  <a href="README.md">English</a>
|
| 15 |
+
</p>
|
| 16 |
+
<br><br>
|
| 17 |
+
|
| 18 |
+
**Qwen-VL** 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型的特点包括:
|
| 19 |
+
- **强大的性能**:在四大类多模态任务的标准英文测评中(Zero-shot Captioning/VQA/DocVQA/Grounding)上,均取得同等通用模型大小下最好效果;
|
| 20 |
+
- **多语言对话模型**:天然支持英文、中文等多语言对话,端到端支持图片里中英双语的长文本识别;
|
| 21 |
+
- **多图交错对话**:支持多图输入和比较,指定图片问答,多图文学创作等;
|
| 22 |
+
- **首个支持中文开放域定位的通用模型**:通过中文开放域语言表达进行检测框标注;
|
| 23 |
+
- **细粒度识别和理解**:相比于目前其它开源LVLM使用的224分辨率,Qwen-VL是首个开源的448分辨率的LVLM模型。更高分辨率可以提升细粒度的文字识别、文档问答和检测框标注。
|
| 24 |
+
|
| 25 |
+
<br>
|
| 26 |
+
<p align="center">
|
| 27 |
+
<img src="assets/demo_vl.gif" width="400"/>
|
| 28 |
+
<p>
|
| 29 |
+
<br>
|
| 30 |
+
|
| 31 |
+
目前,我们提供了 Qwen-VL 系列的两个模型:
|
| 32 |
+
- Qwen-VL: Qwen-VL 以 Qwen-7B 的预训练模型作为语言模型的初始化,并以 [Openclip ViT-bigG](https://github.com/mlfoundations/open_clip) 作为视觉编码器的初始化,中间加入单层随机初始化的 cross-attention,经过约1.5B的图文数据训练得到。最终图像输入分辨率为448。
|
| 33 |
+
- Qwen-VL-Chat: 在 Qwen-VL 的基础上,我们使用对齐机制打造了基于大语言模型的视觉AI助手Qwen-VL-Chat,它支持更灵活的交互方式,包括多图、多轮问答、创作等能力。
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
## 评测
|
| 37 |
+
|
| 38 |
+
我们从两个角度评测了两个模型的能力:
|
| 39 |
+
1. 在**英文标准 Benchmark** 上评测模型的基础任务能力。目前评测了四大类多模态任务:
|
| 40 |
+
- Zero-shot Captioning: 评测模型在未见过数据集上的零样本图片描述能力;
|
| 41 |
+
- General VQA: 评测模型的通用问答能力,例如判断题、颜色、个数、类目等问答能力;
|
| 42 |
+
- Text-based VQA:评测模型对于图片中文字相关的识别/问答能力,例如文档问答、图表问答、文字问答等;
|
| 43 |
+
- Referring Expression Compression:评测模型给定物体描述画检测框的能力;
|
| 44 |
+
|
| 45 |
+
2. **试金石 (TouchStone)**:为了评测模型整体的图文对话能力和人类对齐水平。我们为此构建了一个基于 GPT4 打分来评测 LVLM 模型的 Benchmark:TouchStone。在 TouchStone-v0.1 中:
|
| 46 |
+
- 评测基准总计涵盖 300+张图片、800+道题目、27个类别。包括基础属性问答、人物地标问答、影视作品问答、视觉推理、反事实推理、诗歌创作、故事写作,商品比较、图片解题等**尽可能广泛的类别**。
|
| 47 |
+
- 为了弥补目前 GPT4 无法直接读取图片的缺陷,我们给所有的带评测图片提供了**人工标注的充分详细描述**,并且将图片的详细描述、问题和模型的输出结果一起交给 GPT4 打分。
|
| 48 |
+
- 评测同时包含英文版本和中文版本。
|
| 49 |
+
|
| 50 |
+
评测结果如下:
|
| 51 |
+
|
| 52 |
+
Qwen-VL在多个VL任务上相比目前SOTA的Generalist Models都有明显优势,并且在能力范围也覆盖更加全面。
|
| 53 |
+
|
| 54 |
+
<p align="center">
|
| 55 |
+
<img src="assets/radar.png" width="600"/>
|
| 56 |
+
<p>
|
| 57 |
+
|
| 58 |
+
### 零样本图像描述生成(Zero-shot Image Caption) 及 通用视觉问答(General VQA)
|
| 59 |
+
<table>
|
| 60 |
+
<thead>
|
| 61 |
+
<tr>
|
| 62 |
+
<th rowspan="2">Model type</th>
|
| 63 |
+
<th rowspan="2">Model</th>
|
| 64 |
+
<th colspan="2">Zero-shot Captioning</th>
|
| 65 |
+
<th colspan="5">General VQA</th>
|
| 66 |
+
</tr>
|
| 67 |
+
<tr>
|
| 68 |
+
<th>NoCaps</th>
|
| 69 |
+
<th>Flickr30K</th>
|
| 70 |
+
<th>VQAv2<sup>dev</sup></th>
|
| 71 |
+
<th>OK-VQA</th>
|
| 72 |
+
<th>GQA</th>
|
| 73 |
+
<th>SciQA-Img<br>(0-shot)</th>
|
| 74 |
+
<th>VizWiz<br>(0-shot)</th>
|
| 75 |
+
</tr>
|
| 76 |
+
</thead>
|
| 77 |
+
<tbody align="center">
|
| 78 |
+
<tr>
|
| 79 |
+
<td rowspan="10">Generalist<br>Models</td>
|
| 80 |
+
<td>Flamingo-9B</td>
|
| 81 |
+
<td>-</td>
|
| 82 |
+
<td>61.5</td>
|
| 83 |
+
<td>51.8</td>
|
| 84 |
+
<td>44.7</td>
|
| 85 |
+
<td>-</td>
|
| 86 |
+
<td>-</td>
|
| 87 |
+
<td>28.8</td>
|
| 88 |
+
</tr>
|
| 89 |
+
<tr>
|
| 90 |
+
<td>Flamingo-80B</td>
|
| 91 |
+
<td>-</td>
|
| 92 |
+
<td>67.2</td>
|
| 93 |
+
<td>56.3</td>
|
| 94 |
+
<td>50.6</td>
|
| 95 |
+
<td>-</td>
|
| 96 |
+
<td>-</td>
|
| 97 |
+
<td>31.6</td>
|
| 98 |
+
</tr>
|
| 99 |
+
<tr>
|
| 100 |
+
<td>Unified-IO-XL</td>
|
| 101 |
+
<td>100.0</td>
|
| 102 |
+
<td>-</td>
|
| 103 |
+
<td>77.9</td>
|
| 104 |
+
<td>54.0</td>
|
| 105 |
+
<td>-</td>
|
| 106 |
+
<td>-</td>
|
| 107 |
+
<td>-</td>
|
| 108 |
+
</tr>
|
| 109 |
+
<tr>
|
| 110 |
+
<td>Kosmos-1</td>
|
| 111 |
+
<td>-</td>
|
| 112 |
+
<td>67.1</td>
|
| 113 |
+
<td>51.0</td>
|
| 114 |
+
<td>-</td>
|
| 115 |
+
<td>-</td>
|
| 116 |
+
<td>-</td>
|
| 117 |
+
<td>29.2</td>
|
| 118 |
+
</tr>
|
| 119 |
+
<tr>
|
| 120 |
+
<td>Kosmos-2</td>
|
| 121 |
+
<td>-</td>
|
| 122 |
+
<td>66.7</td>
|
| 123 |
+
<td>45.6</td>
|
| 124 |
+
<td>-</td>
|
| 125 |
+
<td>-</td>
|
| 126 |
+
<td>-</td>
|
| 127 |
+
<td>-</td>
|
| 128 |
+
</tr>
|
| 129 |
+
<tr>
|
| 130 |
+
<td>BLIP-2 (Vicuna-13B)</td>
|
| 131 |
+
<td>103.9</td>
|
| 132 |
+
<td>71.6</td>
|
| 133 |
+
<td>65.0</td>
|
| 134 |
+
<td>45.9</td>
|
| 135 |
+
<td>32.3</td>
|
| 136 |
+
<td>61.0</td>
|
| 137 |
+
<td>19.6</td>
|
| 138 |
+
</tr>
|
| 139 |
+
<tr>
|
| 140 |
+
<td>InstructBLIP (Vicuna-13B)</td>
|
| 141 |
+
<td><strong>121.9</strong></td>
|
| 142 |
+
<td>82.8</td>
|
| 143 |
+
<td>-</td>
|
| 144 |
+
<td>-</td>
|
| 145 |
+
<td>49.5</td>
|
| 146 |
+
<td>63.1</td>
|
| 147 |
+
<td>33.4</td>
|
| 148 |
+
</tr>
|
| 149 |
+
<tr>
|
| 150 |
+
<td>Shikra (Vicuna-13B)</td>
|
| 151 |
+
<td>-</td>
|
| 152 |
+
<td>73.9</td>
|
| 153 |
+
<td>77.36</td>
|
| 154 |
+
<td>47.16</td>
|
| 155 |
+
<td>-</td>
|
| 156 |
+
<td>-</td>
|
| 157 |
+
<td>-</td>
|
| 158 |
+
</tr>
|
| 159 |
+
<tr>
|
| 160 |
+
<td><strong>Qwen-VL (Qwen-7B)</strong></td>
|
| 161 |
+
<td>121.4</td>
|
| 162 |
+
<td><b>85.8</b></td>
|
| 163 |
+
<td><b>78.8</b></td>
|
| 164 |
+
<td><b>58.6</b></td>
|
| 165 |
+
<td><b>59.3</b></td>
|
| 166 |
+
<td>67.1</td>
|
| 167 |
+
<td>35.2</td>
|
| 168 |
+
</tr>
|
| 169 |
+
<!-- <tr>
|
| 170 |
+
<td>Qwen-VL (4-shot)</td>
|
| 171 |
+
<td>-</td>
|
| 172 |
+
<td>-</td>
|
| 173 |
+
<td>-</td>
|
| 174 |
+
<td>63.6</td>
|
| 175 |
+
<td>-</td>
|
| 176 |
+
<td>-</td>
|
| 177 |
+
<td>39.1</td>
|
| 178 |
+
</tr> -->
|
| 179 |
+
<tr>
|
| 180 |
+
<td>Qwen-VL-Chat</td>
|
| 181 |
+
<td>120.2</td>
|
| 182 |
+
<td>81.0</td>
|
| 183 |
+
<td>78.2</td>
|
| 184 |
+
<td>56.6</td>
|
| 185 |
+
<td>57.5</td>
|
| 186 |
+
<td><b>68.2</b></td>
|
| 187 |
+
<td><b>38.9</b></td>
|
| 188 |
+
</tr>
|
| 189 |
+
<!-- <tr>
|
| 190 |
+
<td>Qwen-VL-Chat (4-shot)</td>
|
| 191 |
+
<td>-</td>
|
| 192 |
+
<td>-</td>
|
| 193 |
+
<td>-</td>
|
| 194 |
+
<td>60.6</td>
|
| 195 |
+
<td>-</td>
|
| 196 |
+
<td>-</td>
|
| 197 |
+
<td>44.45</td>
|
| 198 |
+
</tr> -->
|
| 199 |
+
<tr>
|
| 200 |
+
<td>Previous SOTA<br>(Per Task Fine-tuning)</td>
|
| 201 |
+
<td>-</td>
|
| 202 |
+
<td>127.0<br>(PALI-17B)</td>
|
| 203 |
+
<td>84.5<br>(InstructBLIP<br>-FlanT5-XL)</td>
|
| 204 |
+
<td>86.1<br>(PALI-X<br>-55B)</td>
|
| 205 |
+
<td>66.1<br>(PALI-X<br>-55B)</td>
|
| 206 |
+
<td>72.1<br>(CFR)</td>
|
| 207 |
+
<td>92.53<br>(LLaVa+<br>GPT-4)</td>
|
| 208 |
+
<td>70.9<br>(PALI-X<br>-55B)</td>
|
| 209 |
+
</tr>
|
| 210 |
+
</tbody>
|
| 211 |
+
</table>
|
| 212 |
+
|
| 213 |
+
- 在 Zero-shot Captioning 中,Qwen-VL 在 Flickr30K 数据集上取得了 **SOTA** 的结果,并在 Nocaps 数据集上取得了和 InstructBlip 可竞争的结果。
|
| 214 |
+
- 在 General VQA 中,Qwen-VL 取得了 LVLM 模型同等量级和设定下 **SOTA** 的结果。
|
| 215 |
+
|
| 216 |
+
### 文本导向的视觉问答(Text-oriented VQA)
|
| 217 |
+
|
| 218 |
+
<table>
|
| 219 |
+
<thead>
|
| 220 |
+
<tr>
|
| 221 |
+
<th>Model type</th>
|
| 222 |
+
<th>Model</th>
|
| 223 |
+
<th>TextVQA</th>
|
| 224 |
+
<th>DocVQA</th>
|
| 225 |
+
<th>ChartQA</th>
|
| 226 |
+
<th>AI2D</th>
|
| 227 |
+
<th>OCR-VQA</th>
|
| 228 |
+
</tr>
|
| 229 |
+
</thead>
|
| 230 |
+
<tbody align="center">
|
| 231 |
+
<tr>
|
| 232 |
+
<td rowspan="5">Generalist Models</td>
|
| 233 |
+
<td>BLIP-2 (Vicuna-13B)</td>
|
| 234 |
+
<td>42.4</td>
|
| 235 |
+
<td>-</td>
|
| 236 |
+
<td>-</td>
|
| 237 |
+
<td>-</td>
|
| 238 |
+
<td>-</td>
|
| 239 |
+
</tr>
|
| 240 |
+
<tr>
|
| 241 |
+
<td>InstructBLIP (Vicuna-13B)</td>
|
| 242 |
+
<td>50.7</td>
|
| 243 |
+
<td>-</td>
|
| 244 |
+
<td>-</td>
|
| 245 |
+
<td>-</td>
|
| 246 |
+
<td>-</td>
|
| 247 |
+
</tr>
|
| 248 |
+
<tr>
|
| 249 |
+
<td>mPLUG-DocOwl (LLaMA-7B)</td>
|
| 250 |
+
<td>52.6</td>
|
| 251 |
+
<td>62.2</td>
|
| 252 |
+
<td>57.4</td>
|
| 253 |
+
<td>-</td>
|
| 254 |
+
<td>-</td>
|
| 255 |
+
</tr>
|
| 256 |
+
<tr>
|
| 257 |
+
<td>Pic2Struct-Large (1.3B)</td>
|
| 258 |
+
<td>-</td>
|
| 259 |
+
<td><b>76.6</b></td>
|
| 260 |
+
<td>58.6</td>
|
| 261 |
+
<td>42.1</td>
|
| 262 |
+
<td>71.3</td>
|
| 263 |
+
</tr>
|
| 264 |
+
<tr>
|
| 265 |
+
<td>Qwen-VL (Qwen-7B)</td>
|
| 266 |
+
<td><b>63.8</b></td>
|
| 267 |
+
<td>65.1</td>
|
| 268 |
+
<td><b>65.7</b></td>
|
| 269 |
+
<td><b>62.3</b></td>
|
| 270 |
+
<td><b>75.7</b></td>
|
| 271 |
+
</tr>
|
| 272 |
+
<tr>
|
| 273 |
+
<td>Specialist SOTAs<br>(Specialist/Finetuned)</td>
|
| 274 |
+
<td>PALI-X-55B (Single-task FT)<br>(Without OCR Pipeline)</td>
|
| 275 |
+
<td>71.44</td>
|
| 276 |
+
<td>80.0</td>
|
| 277 |
+
<td>70.0</td>
|
| 278 |
+
<td>81.2</td>
|
| 279 |
+
<td>75.0</td>
|
| 280 |
+
</tr>
|
| 281 |
+
</tbody>
|
| 282 |
+
</table>
|
| 283 |
+
|
| 284 |
+
- 在文字相关的识别/问答评测上,取得了当前规模下通用 LVLM 达到的最好结果。
|
| 285 |
+
- 分辨率对上述某几个评测非常重要,大部分 224 分辨率的开源 LVLM 模型无法完成以上评测,或只能通过切图的方式解决。Qwen-VL 将分辨率提升到 448,可以直接以端到端的方式进行以上评测。Qwen-VL 在很多任务上甚至超过了 1024 分辨率的 Pic2Struct-Large 模型。
|
| 286 |
+
|
| 287 |
+
### 细粒度视觉定位(Referring Expression Comprehension)
|
| 288 |
+
<table>
|
| 289 |
+
<thead>
|
| 290 |
+
<tr>
|
| 291 |
+
<th rowspan="2">Model type</th>
|
| 292 |
+
<th rowspan="2">Model</th>
|
| 293 |
+
<th colspan="3">RefCOCO</th>
|
| 294 |
+
<th colspan="3">RefCOCO+</th>
|
| 295 |
+
<th colspan="2">RefCOCOg</th>
|
| 296 |
+
<th>GRIT</th>
|
| 297 |
+
</tr>
|
| 298 |
+
<tr>
|
| 299 |
+
<th>val</th>
|
| 300 |
+
<th>test-A</th>
|
| 301 |
+
<th>test-B</th>
|
| 302 |
+
<th>val</th>
|
| 303 |
+
<th>test-A</th>
|
| 304 |
+
<th>test-B</th>
|
| 305 |
+
<th>val-u</th>
|
| 306 |
+
<th>test-u</th>
|
| 307 |
+
<th>refexp</th>
|
| 308 |
+
</tr>
|
| 309 |
+
</thead>
|
| 310 |
+
<tbody align="center">
|
| 311 |
+
<tr>
|
| 312 |
+
<td rowspan="8">Generalist Models</td>
|
| 313 |
+
<td>GPV-2</td>
|
| 314 |
+
<td>-</td>
|
| 315 |
+
<td>-</td>
|
| 316 |
+
<td>-</td>
|
| 317 |
+
<td>-</td>
|
| 318 |
+
<td>-</td>
|
| 319 |
+
<td>-</td>
|
| 320 |
+
<td>-</td>
|
| 321 |
+
<td>-</td>
|
| 322 |
+
<td>51.50</td>
|
| 323 |
+
</tr>
|
| 324 |
+
<tr>
|
| 325 |
+
<td>OFA-L*</td>
|
| 326 |
+
<td>79.96</td>
|
| 327 |
+
<td>83.67</td>
|
| 328 |
+
<td>76.39</td>
|
| 329 |
+
<td>68.29</td>
|
| 330 |
+
<td>76.00</td>
|
| 331 |
+
<td>61.75</td>
|
| 332 |
+
<td>67.57</td>
|
| 333 |
+
<td>67.58</td>
|
| 334 |
+
<td>61.70</td>
|
| 335 |
+
</tr>
|
| 336 |
+
<tr>
|
| 337 |
+
<td>Unified-IO</td>
|
| 338 |
+
<td>-</td>
|
| 339 |
+
<td>-</td>
|
| 340 |
+
<td>-</td>
|
| 341 |
+
<td>-</td>
|
| 342 |
+
<td>-</td>
|
| 343 |
+
<td>-</td>
|
| 344 |
+
<td>-</td>
|
| 345 |
+
<td>-</td>
|
| 346 |
+
<td><b>78.61</b></td>
|
| 347 |
+
</tr>
|
| 348 |
+
<tr>
|
| 349 |
+
<td>VisionLLM-H</td>
|
| 350 |
+
<td></td>
|
| 351 |
+
<td>86.70</td>
|
| 352 |
+
<td>-</td>
|
| 353 |
+
<td>-</td>
|
| 354 |
+
<td>-</td>
|
| 355 |
+
<td>-</td>
|
| 356 |
+
<td>-</td>
|
| 357 |
+
<td>-</td>
|
| 358 |
+
<td>-</td>
|
| 359 |
+
</tr>
|
| 360 |
+
<tr>
|
| 361 |
+
<td>Shikra-7B</td>
|
| 362 |
+
<td>87.01</td>
|
| 363 |
+
<td>90.61</td>
|
| 364 |
+
<td>80.24 </td>
|
| 365 |
+
<td>81.60</td>
|
| 366 |
+
<td>87.36</td>
|
| 367 |
+
<td>72.12</td>
|
| 368 |
+
<td>82.27</td>
|
| 369 |
+
<td>82.19</td>
|
| 370 |
+
<td>69.34</td>
|
| 371 |
+
</tr>
|
| 372 |
+
<tr>
|
| 373 |
+
<td>Shikra-13B</td>
|
| 374 |
+
<td>87.83 </td>
|
| 375 |
+
<td>91.11</td>
|
| 376 |
+
<td>81.81</td>
|
| 377 |
+
<td>82.89</td>
|
| 378 |
+
<td>87.79</td>
|
| 379 |
+
<td>74.41</td>
|
| 380 |
+
<td>82.64</td>
|
| 381 |
+
<td>83.16</td>
|
| 382 |
+
<td>69.03</td>
|
| 383 |
+
</tr>
|
| 384 |
+
<tr>
|
| 385 |
+
<td>Qwen-VL-7B</td>
|
| 386 |
+
<td><b>89.36</b></td>
|
| 387 |
+
<td>92.26</td>
|
| 388 |
+
<td><b>85.34</b></td>
|
| 389 |
+
<td><b>83.12</b></td>
|
| 390 |
+
<td>88.25</td>
|
| 391 |
+
<td><b>77.21</b></td>
|
| 392 |
+
<td>85.58</td>
|
| 393 |
+
<td>85.48</td>
|
| 394 |
+
<td>78.22</td>
|
| 395 |
+
</tr>
|
| 396 |
+
<tr>
|
| 397 |
+
<td>Qwen-VL-7B-Chat</td>
|
| 398 |
+
<td>88.55</td>
|
| 399 |
+
<td><b>92.27</b></td>
|
| 400 |
+
<td>84.51</td>
|
| 401 |
+
<td>82.82</td>
|
| 402 |
+
<td><b>88.59</b></td>
|
| 403 |
+
<td>76.79</td>
|
| 404 |
+
<td><b>85.96</b></td>
|
| 405 |
+
<td><b>86.32</b></td>
|
| 406 |
+
<td>-</td>
|
| 407 |
+
</tr>
|
| 408 |
+
<tr>
|
| 409 |
+
<td rowspan="3">Specialist SOTAs<br>(Specialist/Finetuned)</td>
|
| 410 |
+
<td>G-DINO-L</td>
|
| 411 |
+
<td>90.56 </td>
|
| 412 |
+
<td>93.19</td>
|
| 413 |
+
<td>88.24</td>
|
| 414 |
+
<td>82.75</td>
|
| 415 |
+
<td>88.95</td>
|
| 416 |
+
<td>75.92</td>
|
| 417 |
+
<td>86.13</td>
|
| 418 |
+
<td>87.02</td>
|
| 419 |
+
<td>-</td>
|
| 420 |
+
</tr>
|
| 421 |
+
<tr>
|
| 422 |
+
<td>UNINEXT-H</td>
|
| 423 |
+
<td>92.64 </td>
|
| 424 |
+
<td>94.33</td>
|
| 425 |
+
<td>91.46</td>
|
| 426 |
+
<td>85.24</td>
|
| 427 |
+
<td>89.63</td>
|
| 428 |
+
<td>79.79</td>
|
| 429 |
+
<td>88.73</td>
|
| 430 |
+
<td>89.37</td>
|
| 431 |
+
<td>-</td>
|
| 432 |
+
</tr>
|
| 433 |
+
<tr>
|
| 434 |
+
<td>ONE-PEACE</td>
|
| 435 |
+
<td>92.58 </td>
|
| 436 |
+
<td>94.18</td>
|
| 437 |
+
<td>89.26</td>
|
| 438 |
+
<td>88.77</td>
|
| 439 |
+
<td>92.21</td>
|
| 440 |
+
<td>83.23</td>
|
| 441 |
+
<td>89.22</td>
|
| 442 |
+
<td>89.27</td>
|
| 443 |
+
<td>-</td>
|
| 444 |
+
</tr>
|
| 445 |
+
</tbody>
|
| 446 |
+
</table>
|
| 447 |
+
|
| 448 |
+
- 在定位任务上,Qwen-VL 全面超过 Shikra-13B,取得了目前 Generalist LVLM 模型上在 Refcoco 上的 **SOTA**。
|
| 449 |
+
- Qwen-VL 并没有在任何中文定位数据上训练过,但通过中文 Caption 数据和 英文 Grounding 数据的训练,可以 Zero-shot 泛化出中文 Grounding 能力。
|
| 450 |
+
|
| 451 |
+
我们提供了以上**所有**评测脚本以供复现我们的实验结果。请阅读 [eval_mm/EVALUATION.md](eval_mm/EVALUATION.md) 了解更多信息。
|
| 452 |
+
|
| 453 |
+
### Chat 能力测评
|
| 454 |
+
|
| 455 |
+
TouchStone 是一个基于 GPT4 打分来评测 LVLM 模型的图文对话能力和人类对齐水平的基准。它涵盖了 300+张图片、800+道题目、27个类别,包括基础属性、人物地标、视觉推理、诗歌创作、故事写作、商品比较、图片解题等**尽可能广泛的类别**。关于 TouchStone 的详细介绍,请参考[touchstone/README_CN.md](touchstone/README_CN.md)了解更多信息。
|
| 456 |
+
|
| 457 |
+
#### 英文版本测评
|
| 458 |
+
|
| 459 |
+
| Model | Score |
|
| 460 |
+
|---------------|-------|
|
| 461 |
+
| PandaGPT | 488.5 |
|
| 462 |
+
| MiniGPT4 | 531.7 |
|
| 463 |
+
| InstructBLIP | 552.4 |
|
| 464 |
+
| LLaMA-AdapterV2 | 590.1 |
|
| 465 |
+
| mPLUG-Owl | 605.4 |
|
| 466 |
+
| LLaVA | 602.7 |
|
| 467 |
+
| Qwen-VL-Chat | 645.2 |
|
| 468 |
+
|
| 469 |
+
#### 中文版本测评
|
| 470 |
+
|
| 471 |
+
| Model | Score |
|
| 472 |
+
|---------------|-------|
|
| 473 |
+
| VisualGLM | 247.1 |
|
| 474 |
+
| Qwen-VL-Chat | 401.2 |
|
| 475 |
+
|
| 476 |
+
Qwen-VL-Chat 模型在中英文的对齐评测中均取得当前 LVLM 模型下的最好结果。
|
| 477 |
+
|
| 478 |
+
## 部署要求
|
| 479 |
+
|
| 480 |
+
* python 3.8及以上版本
|
| 481 |
+
* pytorch 1.12及以上版本,推荐2.0及以上版本
|
| 482 |
+
* 建议使用CUDA 11.4及以上(GPU用户需考虑此选项)
|
| 483 |
+
|
| 484 |
+
## 快速使用
|
| 485 |
+
|
| 486 |
+
我们提供简单的示例来说明如何利用 🤖 ModelScope 和 🤗 Transformers 快速使用 Qwen-VL 和 Qwen-VL-Chat。
|
| 487 |
+
|
| 488 |
+
在开始前,请确保你已经配置好环境并安装好相关的代码包。最重要的是,确保你满足上述要求,然后安装相关的依赖库。
|
| 489 |
+
|
| 490 |
+
```bash
|
| 491 |
+
pip install -r requirements.txt
|
| 492 |
+
```
|
| 493 |
+
|
| 494 |
+
接下来你可以开始使用Transformers或者ModelScope来使用我们的模型。关于视觉模块的更多用法,请参考[教程](TUTORIAL_zh.md)。
|
| 495 |
+
|
| 496 |
+
#### 🤗 Transformers
|
| 497 |
+
|
| 498 |
+
如希望使用 Qwen-VL-chat 进行推理,所需要写的只是如下所示的数行代码。**请确保你使用的是最新代码。**
|
| 499 |
+
|
| 500 |
+
```python
|
| 501 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 502 |
+
from transformers.generation import GenerationConfig
|
| 503 |
+
import torch
|
| 504 |
+
torch.manual_seed(1234)
|
| 505 |
+
|
| 506 |
+
# 请注意:分词器默认行为已更改为默认关闭特殊token攻击防护。
|
| 507 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
|
| 508 |
+
|
| 509 |
+
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
|
| 510 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 511 |
+
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
|
| 512 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 513 |
+
# 使用CPU进行推理,需要约32GB内存
|
| 514 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cpu", trust_remote_code=True).eval()
|
| 515 |
+
# 默认gpu进行推理,需要约24GB显存
|
| 516 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cuda", trust_remote_code=True).eval()
|
| 517 |
+
|
| 518 |
+
# 可指定不同的生成长度、top_p等相关超参
|
| 519 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
|
| 520 |
+
|
| 521 |
+
# 第一轮对话 1st dialogue turn
|
| 522 |
+
query = tokenizer.from_list_format([
|
| 523 |
+
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
|
| 524 |
+
{'text': '这是什么?'},
|
| 525 |
+
])
|
| 526 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 527 |
+
print(response)
|
| 528 |
+
# 图中是一名女子在沙滩上和狗玩耍,旁边是一只拉布拉多犬,它们处于沙滩上。
|
| 529 |
+
|
| 530 |
+
# 第二轮对话 2st dialogue turn
|
| 531 |
+
response, history = model.chat(tokenizer, '框出图中击掌的位置', history=history)
|
| 532 |
+
print(response)
|
| 533 |
+
# <ref>击掌</ref><box>(536,509),(588,602)</box>
|
| 534 |
+
image = tokenizer.draw_bbox_on_latest_picture(response, history)
|
| 535 |
+
if image:
|
| 536 |
+
image.save('1.jpg')
|
| 537 |
+
else:
|
| 538 |
+
print("no box")
|
| 539 |
+
```
|
| 540 |
+
|
| 541 |
+
<p align="center">
|
| 542 |
+
<img src="assets/demo_highfive.jpg" width="500"/>
|
| 543 |
+
<p>
|
| 544 |
+
|
| 545 |
+
运行Qwen-VL同样非常简单。
|
| 546 |
+
|
| 547 |
+
<summary>运行Qwen-VL</summary>
|
| 548 |
+
|
| 549 |
+
```python
|
| 550 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 551 |
+
from transformers.generation import GenerationConfig
|
| 552 |
+
import torch
|
| 553 |
+
torch.manual_seed(1234)
|
| 554 |
+
|
| 555 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
|
| 556 |
+
|
| 557 |
+
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
|
| 558 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 559 |
+
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
|
| 560 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 561 |
+
# 使用CPU进行推理,需要约32GB内存
|
| 562 |
+
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cpu", trust_remote_code=True).eval()
|
| 563 |
+
# 默认gpu进行推理,需要约24GB显存
|
| 564 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cuda", trust_remote_code=True).eval()
|
| 565 |
+
|
| 566 |
+
# 可指定不同的生成长度、top_p等相关超参
|
| 567 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
|
| 568 |
+
|
| 569 |
+
query = tokenizer.from_list_format([
|
| 570 |
+
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
|
| 571 |
+
{'text': 'Generate the caption in English with grounding:'},
|
| 572 |
+
])
|
| 573 |
+
inputs = tokenizer(query, return_tensors='pt')
|
| 574 |
+
inputs = inputs.to(model.device)
|
| 575 |
+
pred = model.generate(**inputs)
|
| 576 |
+
response = tokenizer.decode(pred.cpu()[0], skip_special_tokens=False)
|
| 577 |
+
print(response)
|
| 578 |
+
# <img>https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg</img>Generate the caption in English with grounding:<ref> Woman</ref><box>(451,379),(731,806)</box> and<ref> her dog</ref><box>(219,424),(576,896)</box> playing on the beach<|endoftext|>
|
| 579 |
+
image = tokenizer.draw_bbox_on_latest_picture(response)
|
| 580 |
+
if image:
|
| 581 |
+
image.save('2.jpg')
|
| 582 |
+
else:
|
| 583 |
+
print("no box")
|
| 584 |
+
```
|
| 585 |
+
|
| 586 |
+
<p align="center">
|
| 587 |
+
<img src="assets/demo_spotting_caption.jpg" width="500"/>
|
| 588 |
+
<p>
|
| 589 |
+
|
| 590 |
+
|
| 591 |
+
#### 🤖 ModelScope
|
| 592 |
+
|
| 593 |
+
魔搭(ModelScope)是开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品。使用ModelScope同样非常简单,代码如下所示:
|
| 594 |
+
|
| 595 |
+
```python
|
| 596 |
+
from modelscope import (
|
| 597 |
+
snapshot_download, AutoModelForCausalLM, AutoTokenizer, GenerationConfig
|
| 598 |
+
)
|
| 599 |
+
import torch
|
| 600 |
+
model_id = 'qwen/Qwen-VL-Chat'
|
| 601 |
+
revision = 'v1.0.0'
|
| 602 |
+
|
| 603 |
+
model_dir = snapshot_download(model_id, revision=revision)
|
| 604 |
+
torch.manual_seed(1234)
|
| 605 |
+
|
| 606 |
+
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
|
| 607 |
+
if not hasattr(tokenizer, 'model_dir'):
|
| 608 |
+
tokenizer.model_dir = model_dir
|
| 609 |
+
# use bf16
|
| 610 |
+
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 611 |
+
# use fp16
|
| 612 |
+
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 613 |
+
# use cpu
|
| 614 |
+
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="cpu", trust_remote_code=True).eval()
|
| 615 |
+
# use auto
|
| 616 |
+
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
|
| 617 |
+
|
| 618 |
+
# Specify hyperparameters for generation
|
| 619 |
+
model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True)
|
| 620 |
+
|
| 621 |
+
# 1st dialogue turn
|
| 622 |
+
# Either a local path or an url between <img></img> tags.
|
| 623 |
+
image_path = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
|
| 624 |
+
response, history = model.chat(tokenizer, query=f'<img>{image_path}</img>这是什么', history=None)
|
| 625 |
+
print(response)
|
| 626 |
+
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,与人互动。
|
| 627 |
+
|
| 628 |
+
# 2st dialogue turn
|
| 629 |
+
response, history = model.chat(tokenizer, '输出击掌的检测框', history=history)
|
| 630 |
+
print(response)
|
| 631 |
+
# <ref>"击掌"</ref><box>(211,412),(577,891)</box>
|
| 632 |
+
image = tokenizer.draw_bbox_on_latest_picture(response, history)
|
| 633 |
+
if image:
|
| 634 |
+
image.save('output_chat.jpg')
|
| 635 |
+
else:
|
| 636 |
+
print("no box")
|
| 637 |
+
```
|
| 638 |
+
|
| 639 |
+
## Demo
|
| 640 |
+
|
| 641 |
+
### Web UI
|
| 642 |
+
|
| 643 |
+
我们提供了Web UI的demo供用户使用。在开始前,确保已经安装如下代码库:
|
| 644 |
+
|
| 645 |
+
```
|
| 646 |
+
pip install -r requirements_web_demo.txt
|
| 647 |
+
```
|
| 648 |
+
|
| 649 |
+
随后运行如下命令,并点击生成链接:
|
| 650 |
+
|
| 651 |
+
```
|
| 652 |
+
python web_demo_mm.py
|
| 653 |
+
```
|
| 654 |
+
|
| 655 |
+
## FAQ
|
| 656 |
+
|
| 657 |
+
如遇到问题,敬请查阅 [FAQ](FAQ_zh.md)以及issue区,如仍无法解决再提交issue。
|
| 658 |
+
|
| 659 |
+
|
| 660 |
+
## 使用协议
|
| 661 |
+
|
| 662 |
+
研究人员与开发者可使用Qwen-VL和Qwen-VL-Chat或进行二次开发。我们同样允许商业使用,具体细节请查看[LICENSE](LICENSE)。如需商用,请填写[问卷](https://dashscope.console.aliyun.com/openModelApply/qianwen)申请。
|
| 663 |
+
|
| 664 |
+
## 联系我们
|
| 665 |
+
|
| 666 |
+
如果你想给我们的研发团队和产品团队留言,请通过邮件(qianwen_opensource@alibabacloud.com)联系我们。
|
TUTORIAL.md
ADDED
|
@@ -0,0 +1,221 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Qwen-VL-Chat Tutorial
|
| 2 |
+
Qwen-VL-Chat is a generalist multimodal large-scale language model, and it can perform a wide range of vision-language tasks. In this tutorial, we will give some concise examples to demonstrate the capabilities of Qwen-VL-Chat in **Visual Question Answering, Text Understanding, Mathematical Reasoning with Diagrams, Multi-Figure Reasoning, and Grounding**. Please note that the examples shown are far from the limit of Qwen-VL-Chat's capabilities, **you can further explore Qwen-VL-Chat's capabilities by changing the input images and prompts!**
|
| 3 |
+
|
| 4 |
+
## Initializing Qwen-VL-Chat
|
| 5 |
+
## Initializing the Qwen-VL-Chat model
|
| 6 |
+
Before you can use Qwen-VL-Chat, you first need to initialize Qwen-VL-Chat's tokenizer and Qwen-VL-Chat's model:
|
| 7 |
+
|
| 8 |
+
```python
|
| 9 |
+
import torch
|
| 10 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 11 |
+
from transformers.generation import GenerationConfig
|
| 12 |
+
|
| 13 |
+
# If you expect the results to be reproducible, set a random seed.
|
| 14 |
+
# torch.manual_seed(1234)
|
| 15 |
+
|
| 16 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat-Chat", trust_remote_code=True)
|
| 17 |
+
|
| 18 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat-Chat", device_map="cuda", trust_remote_code=True).eval()
|
| 19 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL-Chat-Chat", trust_remote_code=True)
|
| 20 |
+
```
|
| 21 |
+
After executing the above code, ```tokenizer``` will correspond to the classifier used by Qwen-VL-Chat, while ```model``` will correspond to the model of Qwen-VL-Chat. The ```tokenizer``` is used for preprocessing the interleaved multimodal inputs, while the ```model``` is the Qwen-VL-Chat model itself.
|
| 22 |
+
|
| 23 |
+
## Using Qwen-VL-Chat
|
| 24 |
+
### **Multi-round visual question answering**
|
| 25 |
+
#### **The first question**
|
| 26 |
+
Let's get started with a simple example. As shown below, the file ```assets/mm_tutorial/Rebecca_(1939_poster).jpeg`` is a poster for the 1940 film Rebecca.
|
| 27 |
+
|
| 28 |
+
_Small.jpeg)
|
| 29 |
+
|
| 30 |
+
Let's ask what is the name of the film on the Qwen-VL-Chat poster. First of all, we use ```tokenizer.from_list_format``` which can preprocess and tokenize the input:
|
| 31 |
+
```python
|
| 32 |
+
query = tokenizer.from_list_format([
|
| 33 |
+
{'image': 'assets/mm_tutorial/Rebecca_(1939_poster).jpeg'},
|
| 34 |
+
{'text': 'What is the name of the movie in the poster?'},
|
| 35 |
+
])
|
| 36 |
+
```
|
| 37 |
+
Next, we can use ```model.chat``` to ask questions to the Qwen-VL-Chat model and get its response. Note that for the first question, the dialogue history is empty, so we use ```history=None```.
|
| 38 |
+
```python
|
| 39 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 40 |
+
print(response)
|
| 41 |
+
```
|
| 42 |
+
You are expected to get an output similar to the following:
|
| 43 |
+
|
| 44 |
+
> The name of the movie in the poster is "Rebecca."
|
| 45 |
+
|
| 46 |
+
This shows that the model correctly answered the given question! According to the poster, the title of the film is
|
| 47 |
+
indeed **Rebecca**.
|
| 48 |
+
|
| 49 |
+
#### **Multi-round question answering**
|
| 50 |
+
We can also continue to ask the model other questions, such as who is the director of the film. The dialogue history is not empty for subsequent questions, therefore we use ```history=history``` to pass the history of previous conversations to ``model.chat``:
|
| 51 |
+
|
| 52 |
+
```python
|
| 53 |
+
query = tokenizer.from_list_format([
|
| 54 |
+
{'text': 'Who directed this movie?'},
|
| 55 |
+
])
|
| 56 |
+
response, history = model.chat(tokenizer, query=query, history=history)
|
| 57 |
+
print(response)
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
You are expected to get an output similar to the following:
|
| 61 |
+
|
| 62 |
+
> The movie "Rebecca" was directed by Alfred Hitchcock.
|
| 63 |
+
|
| 64 |
+
Again, the model answered the given question correctly! According to the poster, the director of the film is Alfred Hitchcock。
|
| 65 |
+
|
| 66 |
+
### **Text Understanding**
|
| 67 |
+
Qwen-VL-Chat also has the ability to understand images containing dense text. As shown below, the file ```assets/mm_tutorial/Hospital.jpeg``` is a hospital signage containing dense text.
|
| 68 |
+
|
| 69 |
+

|
| 70 |
+
|
| 71 |
+
We can ask questions about the location of different departments in the Hospital. Since the dialogue history is empty, so we use ```history=None```.
|
| 72 |
+
```python
|
| 73 |
+
query = tokenizer.from_list_format([
|
| 74 |
+
{'image': 'assets/mm_tutorial/Hospital.jpg'},
|
| 75 |
+
{'text': 'Based on the photo, which floor is the Department of Otorhinolaryngology on?'},
|
| 76 |
+
])
|
| 77 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 78 |
+
print(response)
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
You are expected to get an output similar to the following:
|
| 82 |
+
|
| 83 |
+
> The Department of Otorhinolaryngology is located on the 4th floor.
|
| 84 |
+
|
| 85 |
+
You can also ask further questions. In this case you need to use ```history=history``` to pass a history of previous conversations to ```model.chat```.
|
| 86 |
+
|
| 87 |
+
```python
|
| 88 |
+
query = tokenizer.from_list_format([
|
| 89 |
+
{'text': 'Based on the photo, which floor is the Department of Surgery on?'},
|
| 90 |
+
])
|
| 91 |
+
response, history = model.chat(tokenizer, query=query, history=history)
|
| 92 |
+
print(response)
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
You are expected to get an output similar to the following:
|
| 96 |
+
|
| 97 |
+
> The Department of Surgery is located on the 3rd floor.
|
| 98 |
+
|
| 99 |
+
### **Mathematical Reasoning with Diagram**
|
| 100 |
+
Using the model's diagram comprehension and mathematical reasoning capabilities, Qwen-VL-Chat can also perform some more complex tasks! As shown below, the file ```assets/mm_tutorial/Menu.jpeg``` is the menu of a restaurant. Now we want to know how much it would cost to purchase two Salmon Burgers and three Meat Lover's Pizzas.
|
| 101 |
+
|
| 102 |
+

|
| 103 |
+
|
| 104 |
+
```python
|
| 105 |
+
query = tokenizer.from_list_format([
|
| 106 |
+
{'image': 'assets/mm_tutorial/Menu.jpeg'},
|
| 107 |
+
{'text': 'How much would I pay if I want to order two Salmon Burger and three Meat Lover\'s Pizza? Think carefully step by step.'},
|
| 108 |
+
])
|
| 109 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 110 |
+
print(response)
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
```Think carefully step by step.``` is a common prompt that guides the model through complex tasks step by step. So if you have a complex task to complete, try using it to improve the accuracy of the model. You are expected to get an output similar to the following:
|
| 114 |
+
|
| 115 |
+
> To order two Salmon Burgers and three Meat Lover's Pizzas, you would need to pay the following:
|
| 116 |
+
>
|
| 117 |
+
> 1. For two Salmon Burgers: x2 Salmon Burgers at $10 each = $20
|
| 118 |
+
> 2. For three Meat Lover's Pizzas: x3 Meat Lover's Pizzas at $12 each = $36
|
| 119 |
+
>
|
| 120 |
+
> Therefore, the total cost would be $56.
|
| 121 |
+
|
| 122 |
+
### **Multi-Figure Reasoning and Chinese Input**
|
| 123 |
+
In the previous examples, we have demonstrated Qwen-VL-Chat's question-answering capability for a single image and English questions. However, Qwen-VL-Chat is actually a multilingual model that supports Chinese input and multiple images! In the following example, we let Qwen-VL-Chat compare the photos of two cities (Chongqing and Beijing) for us (```assets/mm_tutorial/Chongqing.jpeg``` and ```assets/mm_tutorial/Beijing.jpeg```) in Chinese:
|
| 124 |
+
|
| 125 |
+

|
| 126 |
+
|
| 127 |
+

|
| 128 |
+
|
| 129 |
+
```python
|
| 130 |
+
query = tokenizer.from_list_format([
|
| 131 |
+
{'image': 'assets/mm_tutorial/Chongqing.jpeg'},
|
| 132 |
+
{'image': 'assets/mm_tutorial/Beijing.jpeg'},
|
| 133 |
+
{'text': '上面两张图片分别是哪两个城市?请对它们进行对比。'},
|
| 134 |
+
])
|
| 135 |
+
torch.manual_seed(5678)
|
| 136 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 137 |
+
print(response)
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
You are expected to get an output similar to the following:
|
| 141 |
+
|
| 142 |
+
> 第一张图片是重庆的城市天际线,它反映了现代都市的繁华与喧嚣。第二张图片是北京的天际线,它象征着中国首都的现代化和国际化。两座城市都是中国的重要城市,拥有独特的文化和发展历史。
|
| 143 |
+
|
| 144 |
+
**Please note that comparing cities is a fairly subjective question, so the responses generated by the model may be subject to a high degree of randomness. If you do not set the random seed using ```torch.manual_seed(5678)```, the output will be different each time. Even if you set the random seed, the results obtained may still differ from this tutorial due to differences in hardware and software environments.**
|
| 145 |
+
|
| 146 |
+
### **Grounding Capability**
|
| 147 |
+
In the last section of the tutorial, we demonstrate the ability of the Qwen-VL-Chat model to produce a bounding box. Qwen-VL-Chat can frame a specified area of an image with a rectangular box according to your language description. This may be a bit abstract, so let's look at the following example. As shown below, the file ```assets/mm_tutorial/Shanghai.jpg``` is a photo of Shanghai, and we'll start by asking the model to describe the image with a regular prompt.
|
| 148 |
+
|
| 149 |
+

|
| 150 |
+
|
| 151 |
+
```python
|
| 152 |
+
torch.manual_seed(1234)
|
| 153 |
+
query = tokenizer.from_list_format([
|
| 154 |
+
{'image': 'assets/mm_tutorial/Shanghai.jpg'},
|
| 155 |
+
{'text': '图里有啥'},
|
| 156 |
+
])
|
| 157 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 158 |
+
print(response)
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
You are expected to get an output similar to the following:
|
| 162 |
+
|
| 163 |
+
> 图中是中国上海的天际线,包括了上海塔、金茂大厦、上海环球金融中心、海洋大厦等著名建筑。
|
| 164 |
+
|
| 165 |
+
Next, let's talk to the model by using the prompt ```请给我框出图中上海环球金融中心和东方明珠``` and see what happens. Note that at this point you need to pass the history of previous conversations to ```model.chat``` using ```history=history```.
|
| 166 |
+
|
| 167 |
+
```python
|
| 168 |
+
query = tokenizer.from_list_format([
|
| 169 |
+
{'text': '请给我框出图中上海环球金融中心和东方明珠'},
|
| 170 |
+
])
|
| 171 |
+
response, history = model.chat(tokenizer, query=query, history=history)
|
| 172 |
+
print(response)
|
| 173 |
+
```
|
| 174 |
+
You are expected to get an output similar to the following:
|
| 175 |
+
```xml
|
| 176 |
+
<ref>上海环球金融中心</ref><box>(667,437),(760,874)</box>和<ref>东方明珠</ref><box>(506,75),(582,946)</box>
|
| 177 |
+
```
|
| 178 |
+
The Qwen-VL-Chat model doesn't have a hand, but it doesn't reject your request either. Instead, it outputs something "strange" - In fact, the output of the model gives the location of the 上海环球金融中心(Shanghai World Financial Centre) and the 东方明珠(Oriental Pearl Tower) in markup language. You can visualise it using the following code:
|
| 179 |
+
```python
|
| 180 |
+
image = tokenizer.draw_bbox_on_latest_picture(response, history)
|
| 181 |
+
image.save('Shanghai_Output.jpg')
|
| 182 |
+
```
|
| 183 |
+
The saved ```Shanghai_Output.jpg``` will look similar to the screenshot below:
|
| 184 |
+
|
| 185 |
+

|
| 186 |
+
|
| 187 |
+
After that, you can still chat with Qwen-VL-Chat as before:
|
| 188 |
+
```python
|
| 189 |
+
query = tokenizer.from_list_format([
|
| 190 |
+
{'text': '帮我写个这座城市的旅游计划'},
|
| 191 |
+
])
|
| 192 |
+
response, history = model.chat(tokenizer, query=query, history=history)
|
| 193 |
+
print(response)
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
You are expected to get an output similar to the following:
|
| 197 |
+
|
| 198 |
+
> 好的,以下是一个简单的上海旅游计划:
|
| 199 |
+
>
|
| 200 |
+
> 第一天:
|
| 201 |
+
> 上午:抵达上海,前往酒店办理入住手续。
|
| 202 |
+
> 中午:享用午餐后,前往外滩,欣赏黄浦江畔的美景,游览上海地标性建筑如浦发银行大楼、汇丰银行大楼等。
|
| 203 |
+
> 下午:游览南京路步行街,购买特色礼品或品尝当地美食。
|
| 204 |
+
> 晚上:在南京路附近的餐厅享用晚餐,然后去看上海的夜景。
|
| 205 |
+
>
|
| 206 |
+
> 第二天:
|
| 207 |
+
> 上午:前往上海科技馆,了解科技发展历史,观看各种科技展览。
|
| 208 |
+
> 中午:在科技馆附近的餐厅享用午餐。
|
| 209 |
+
> 下午:游览世纪公园,欣赏美景并放松身心。
|
| 210 |
+
> 晚上:在南京路或附近的陆家嘴地区享用晚餐,然后去看上海的夜景。
|
| 211 |
+
>
|
| 212 |
+
> 第三天:
|
| 213 |
+
> 上午:游览上海迪士尼乐园或上海海昌海洋公园,与各种迪士尼角色互动,或者在海洋公园观看海洋生物表演。
|
| 214 |
+
> 中午:在迪士尼乐园或海洋公园附近的餐厅享用午餐。
|
| 215 |
+
> 下午:自由活动,可以去购物、品尝当地美食或者去博物馆等。
|
| 216 |
+
> 晚上:在酒店附近享用晚餐,然后离开上海。
|
| 217 |
+
>
|
| 218 |
+
> 当然,以上只是一个简单的计划,上海有许多其他景点和活动,例如参观上海博物馆、游览田子坊、观看上海话剧等。具体计划可以根据个人兴趣和时间进行调整。
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
**Please note that travel planning is a fairly subjective question, so the responses generated by the model may be subject to a high degree of randomness. If you do not set the random seed using ```torch.manual_seed(1234)```, the output will be different each time. Even if you set the random seed, the results obtained may still differ from this tutorial due to differences in hardware and software environments.**
|
TUTORIAL_zh.md
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Qwen-VL-Chat使用教程
|
| 2 |
+
Qwen-VL-Chat是通用多模态大规模语言模型,因此它可以完成多种视觉语言任务。在本教程之中,我们会给出一些简明的例子,用以展示Qwen-VL-Chat在**视觉问答,文字理解,图表数学推理,多图理解和Grounding**(根据指令标注图片中指定区域的包围框)等多方面的能力。请注意,展示的例子远非Qwen-VL-Chat能力的极限,**您可以通过更换不同的输入图像和提示词(Prompt),来进一步挖掘Qwen-VL-Chat的能力!**
|
| 3 |
+
|
| 4 |
+
## 初始化Qwen-VL-Chat
|
| 5 |
+
## 初始化Qwen-VL-Chat模型
|
| 6 |
+
在使用Qwen-VL-Chat之前,您首先需要初始化Qwen-VL-Chat的分词器(Tokenizer)和Qwen-VL-Chat的模型:
|
| 7 |
+
```python
|
| 8 |
+
import torch
|
| 9 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 10 |
+
from transformers.generation import GenerationConfig
|
| 11 |
+
|
| 12 |
+
# 如果您希望结果可复现,可以设置随机数种子。
|
| 13 |
+
# torch.manual_seed(1234)
|
| 14 |
+
|
| 15 |
+
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat-Chat", trust_remote_code=True)
|
| 16 |
+
|
| 17 |
+
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat-Chat", device_map="cuda", trust_remote_code=True).eval()
|
| 18 |
+
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL-Chat-Chat", trust_remote_code=True)
|
| 19 |
+
```
|
| 20 |
+
在执行完上述代码后,```tokenizer```将对应Qwen-VL-Chat使用的分词器,而```model```将对应Qwen-VL-Chat的模型。```tokenizer```用于对图文混排输入进行分词和预处理,而```model```则是Qwen-VL-Chat模型本身。
|
| 21 |
+
|
| 22 |
+
## 使用Qwen-VL-Chat
|
| 23 |
+
### **多轮视觉问答**
|
| 24 |
+
#### **第一个问题**
|
| 25 |
+
首先我们来看一个最简单的例子,如下图所示,文件```assets/mm_tutorial/Rebecca_(1939_poster).jpeg```是1940年电影Rebecca的于1939发布的海报。
|
| 26 |
+
|
| 27 |
+
_Small.jpeg)
|
| 28 |
+
|
| 29 |
+
我们来问一问Qwen-VL-Chat海报上电影的名称是什么。首先,我们使用tokenizer.from_list_format可以对图文混排输入进行分词与处理:
|
| 30 |
+
```python
|
| 31 |
+
query = tokenizer.from_list_format([
|
| 32 |
+
{'image': 'assets/mm_tutorial/Rebecca_(1939_poster).jpeg'},
|
| 33 |
+
{'text': 'What is the name of the movie in the poster?'},
|
| 34 |
+
])
|
| 35 |
+
```
|
| 36 |
+
接下来,我们可以使用```model.chat```向Qwen-VL-Chat模型提问并获得回复。注意在第一次提问时,对话历史为空,因此我们使用```history=None```。
|
| 37 |
+
```python
|
| 38 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 39 |
+
print(response)
|
| 40 |
+
```
|
| 41 |
+
您应该会得到类似下列的输出结果:
|
| 42 |
+
|
| 43 |
+
> The name of the movie in the poster is "Rebecca."
|
| 44 |
+
|
| 45 |
+
这说明模型正确的回答了问题!根据海报,该电影的名称的确是**Rebecca**。
|
| 46 |
+
|
| 47 |
+
#### **多轮问答**
|
| 48 |
+
我们还可以继续向模型发问,例如询问电影的导演是谁。在后续提问时,对话历史并不为空,我们使用```history=history```向```model.chat```传递之前的对话历史:
|
| 49 |
+
```python
|
| 50 |
+
query = tokenizer.from_list_format([
|
| 51 |
+
{'text': 'Who directed this movie?'},
|
| 52 |
+
])
|
| 53 |
+
response, history = model.chat(tokenizer, query=query, history=history)
|
| 54 |
+
print(response)
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
您应该会得到类似下列的输出结果:
|
| 58 |
+
|
| 59 |
+
> The movie "Rebecca" was directed by Alfred Hitchcock.
|
| 60 |
+
|
| 61 |
+
模型再次正确回答了问题!根据海报,该电影的导演是Alfred Hitchcock。
|
| 62 |
+
|
| 63 |
+
### **文字理解**
|
| 64 |
+
Qwen-VL-Chat具有一定的针对包含密集文字图片的理解能力。如下图所示,文件```assets/mm_tutorial/Hospital.jpeg```是一个包含密集文字的医院指示牌。
|
| 65 |
+
|
| 66 |
+

|
| 67 |
+
|
| 68 |
+
我们可以像之前一样向模型询问医院中各个科室的位置,对话历史为空,因此我们使用```history=None```。
|
| 69 |
+
```python
|
| 70 |
+
query = tokenizer.from_list_format([
|
| 71 |
+
{'image': 'assets/mm_tutorial/Hospital.jpg'},
|
| 72 |
+
{'text': 'Based on the photo, which floor is the Department of Otorhinolaryngology on?'},
|
| 73 |
+
])
|
| 74 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 75 |
+
print(response)
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
您应该会得到类似下列的输出结果:
|
| 79 |
+
|
| 80 |
+
> The Department of Otorhinolaryngology is located on the 4th floor.
|
| 81 |
+
|
| 82 |
+
您同样可以进一步提出后续问题,此时需要使用```history=history```向```model.chat```传递之前的对话历史。
|
| 83 |
+
|
| 84 |
+
```python
|
| 85 |
+
query = tokenizer.from_list_format([
|
| 86 |
+
{'text': 'Based on the photo, which floor is the Department of Surgery on?'},
|
| 87 |
+
])
|
| 88 |
+
response, history = model.chat(tokenizer, query=query, history=history)
|
| 89 |
+
print(response)
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
您应该会得到类似下列的输出结果:
|
| 93 |
+
|
| 94 |
+
> The Department of Surgery is located on the 3rd floor.
|
| 95 |
+
|
| 96 |
+
### **图表数学推理**
|
| 97 |
+
利用模型的图表理解和数学推理能力,Qwen-VL-Chat还可以完成更复杂的一些任务!如下图所示,文件```assets/mm_tutorial/Menu.jpeg```展示了一家餐厅的菜单。现在我们想知道,如果购买两个Salmon Burger和三个Meat Lover's Pizza需要花多少钱呢?
|
| 98 |
+
|
| 99 |
+

|
| 100 |
+
|
| 101 |
+
```python
|
| 102 |
+
query = tokenizer.from_list_format([
|
| 103 |
+
{'image': 'assets/mm_tutorial/Menu.jpeg'},
|
| 104 |
+
{'text': 'How much would I pay if I want to order two Salmon Burger and three Meat Lover\'s Pizza? Think carefully step by step.'},
|
| 105 |
+
])
|
| 106 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 107 |
+
print(response)
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
```Think carefully step by step.```是一个引导模型分步处理复杂任务的常见提示词,如果您需要完成的任务较为复杂,可以试着使用它来提高准确率。您应该会得到类似下列的输出结果:
|
| 111 |
+
|
| 112 |
+
> To order two Salmon Burgers and three Meat Lover's Pizzas, you would need to pay the following:
|
| 113 |
+
>
|
| 114 |
+
> 1. For two Salmon Burgers: x2 Salmon Burgers at $10 each = $20
|
| 115 |
+
> 2. For three Meat Lover's Pizzas: x3 Meat Lover's Pizzas at $12 each = $36
|
| 116 |
+
>
|
| 117 |
+
> Therefore, the total cost would be $56.
|
| 118 |
+
|
| 119 |
+
### **多图理解与中文输入**
|
| 120 |
+
在之前的例子中,我们主要展示了Qwen-VL-Chat针对单张图像和英文问题的问答能力。但实际上,Qwen-VL-Chat是支持中文输入的多语言模型,而且也支持多张图片的输入!下面的例子中,我们用中文让Qwen-VL-Chat来为我们比较重庆和北京这两个城市的照片(```assets/mm_tutorial/Chongqing.jpeg```和```assets/mm_tutorial/Beijing.jpeg```):
|
| 121 |
+
|
| 122 |
+

|
| 123 |
+
|
| 124 |
+

|
| 125 |
+
|
| 126 |
+
```python
|
| 127 |
+
query = tokenizer.from_list_format([
|
| 128 |
+
{'image': 'assets/mm_tutorial/Chongqing.jpeg'},
|
| 129 |
+
{'image': 'assets/mm_tutorial/Beijing.jpeg'},
|
| 130 |
+
{'text': '上面两张图片分别是哪两个城市?请对它们进行对比。'},
|
| 131 |
+
])
|
| 132 |
+
torch.manual_seed(5678)
|
| 133 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 134 |
+
print(response)
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
您应该会得到类似下列的输出结果:
|
| 138 |
+
|
| 139 |
+
> 第一张图片是重庆的城市天际线,它反映了现代都市的繁华与喧嚣。第二张图片是北京的天际线,它象征着中国首都的现代化和国际化。两座城市都是中国的重要城市,拥有独特的文化和发展历史。
|
| 140 |
+
|
| 141 |
+
**请注意,城市间的比较是一个具有相当主观性的问题,因此模型产生的回复可能具有相当高的随机性。若不使用```torch.manual_seed(5678)```设置随机数种子,每次的输出结果会不一样。即使您设置了随机数种子,由于软硬件环境的差异,得到的结果也可能与本文档中的有所不同。**
|
| 142 |
+
|
| 143 |
+
### **Grounding能力**
|
| 144 |
+
在最后,我们展示Qwen-VL-Chat模型产生包围框的能力。Qwen-VL-Chat可以根据您的语言描述,在图像中用矩形框框出指定区域。这样说可能有些抽象,让我们来看下面的例子。如下图所示,文件```assets/mm_tutorial/Shanghai.jpg```是上海的一张照片,我们先用常规的提示词,问一下模型图里有什么。
|
| 145 |
+
|
| 146 |
+

|
| 147 |
+
|
| 148 |
+
```python
|
| 149 |
+
torch.manual_seed(1234)
|
| 150 |
+
query = tokenizer.from_list_format([
|
| 151 |
+
{'image': 'assets/mm_tutorial/Shanghai.jpg'},
|
| 152 |
+
{'text': '图里有啥'},
|
| 153 |
+
])
|
| 154 |
+
response, history = model.chat(tokenizer, query=query, history=None)
|
| 155 |
+
print(response)
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
您应该会得到类似下列的输出结果:
|
| 159 |
+
|
| 160 |
+
> 图中是中国上海的天际线,包括了上海塔、金茂大厦、上海环球金融中心、海洋大厦等著名建筑。
|
| 161 |
+
|
| 162 |
+
接下来,我们通过使用```请给我框出图中上海环球金融中心和东方明珠```这个提示词来和模型对话,看看会发生什么。注意此时需要使用```history=history```向```model.chat```传递之前的对话历史。
|
| 163 |
+
```python
|
| 164 |
+
query = tokenizer.from_list_format([
|
| 165 |
+
{'text': '请给我框出图中上海环球金融中心和东方明珠'},
|
| 166 |
+
])
|
| 167 |
+
response, history = model.chat(tokenizer, query=query, history=history)
|
| 168 |
+
print(response)
|
| 169 |
+
```
|
| 170 |
+
您应该会得到类似下列的输出结果:
|
| 171 |
+
```xml
|
| 172 |
+
<ref>上海环球金融中心</ref><box>(667,437),(760,874)</box>和<ref>东方明珠</ref><box>(506,75),(582,946)</box>
|
| 173 |
+
```
|
| 174 |
+
Qwen-VL-Chat模型没有手,但也没有拒绝您的请求,而是输出了一些“奇怪”的东西——并不是,实际上,模型的输出以标记语言的形式给出了上海环球金融中心和东方明珠在图中的具体位置。您可以使用下列代码将其可视化:
|
| 175 |
+
```python
|
| 176 |
+
image = tokenizer.draw_bbox_on_latest_picture(response, history)
|
| 177 |
+
image.save('Shanghai_Output.jpg')
|
| 178 |
+
```
|
| 179 |
+
保存下来的```Shanghai_Output.jpg```结果将类似于下面的截图:
|
| 180 |
+
|
| 181 |
+

|
| 182 |
+
|
| 183 |
+
在此之后,您还可以继续照常和Qwen-VL-Chat对话:
|
| 184 |
+
```python
|
| 185 |
+
query = tokenizer.from_list_format([
|
| 186 |
+
{'text': '帮我写个这座城市的旅游计划'},
|
| 187 |
+
])
|
| 188 |
+
response, history = model.chat(tokenizer, query=query, history=history)
|
| 189 |
+
print(response)
|
| 190 |
+
```
|
| 191 |
+
|
| 192 |
+
您应该会得到类似下列的输出结果:
|
| 193 |
+
|
| 194 |
+
> 好的,以下是一个简单的上海旅游计划:
|
| 195 |
+
>
|
| 196 |
+
> 第一天:
|
| 197 |
+
> 上午:抵达上海,前往酒店办理入住手续。
|
| 198 |
+
> 中午:享用午餐后,前往外滩,欣赏黄浦江畔的美景,游览上海地标性建筑如浦发银行大楼、汇丰银行大楼等。
|
| 199 |
+
> 下午:游览南京路步行街,购买特色礼品或品尝当地美食。
|
| 200 |
+
> 晚上:在南京路附近的餐厅享用晚餐,然后去看上海的夜景。
|
| 201 |
+
>
|
| 202 |
+
> 第二天:
|
| 203 |
+
> 上午:前往上海科技馆,了解科技发展历史,观看各种科技展览。
|
| 204 |
+
> 中午:在科技馆附近的餐厅享用午餐。
|
| 205 |
+
> 下午:游览世纪公园,欣赏美景并放松身心。
|
| 206 |
+
> 晚上:在南京路或附近的陆家嘴地区享用晚餐,然后去看上海的夜景。
|
| 207 |
+
>
|
| 208 |
+
> 第三天:
|
| 209 |
+
> 上午:游览上海迪士尼乐园或上海海昌海洋公园,与各种迪士尼角色互动,或者在海洋公园观看海洋生物表演。
|
| 210 |
+
> 中午:在迪士尼乐园或海洋公园附近的餐厅享用午餐。
|
| 211 |
+
> 下午:自由活动,可以去购物、品尝当地美食或者去博物馆等。
|
| 212 |
+
> 晚上:在酒店附近享用晚餐,然后离开上海。
|
| 213 |
+
>
|
| 214 |
+
> 当然,以上只是一个简单的计划,上海有许多其他景点和活动,例如参观上海博物馆、游览田子坊、观看上海话剧等。具体计划可以根据个人兴趣和时间进行调整。
|
| 215 |
+
|
| 216 |
+
**请注意,旅游计划是一个具有相当主观性的问题,因此模型产生的回复可能具有相当高的随机性。若不使用```torch.manual_seed(1234)```设置随机数种子,每次的输出结果会不一样。即使您设置了随机数种子,由于软硬件环境的差异,得到的结果也可能与本文档中的有所不同。**
|
assets/apple.jpeg
ADDED

|
Git LFS Details
|
assets/apple_r.jpeg
ADDED

|
assets/demo.jpeg
ADDED

|
assets/demo_highfive.jpg
ADDED

|
assets/demo_spotting_caption.jpg
ADDED

|
assets/demo_vl.gif
ADDED

|
Git LFS Details
|
assets/logo.jpg
ADDED
|
|
assets/mm_tutorial/Beijing.jpeg
ADDED

|
Git LFS Details
|
assets/mm_tutorial/Beijing_Small.jpeg
ADDED

|
assets/mm_tutorial/Chongqing.jpeg
ADDED

|
Git LFS Details
|
assets/mm_tutorial/Chongqing_Small.jpeg
ADDED

|
assets/mm_tutorial/Hospital.jpg
ADDED

|
assets/mm_tutorial/Hospital_Small.jpg
ADDED

|
assets/mm_tutorial/Menu.jpeg
ADDED

|
assets/mm_tutorial/Rebecca_(1939_poster).jpeg
ADDED
.jpeg)
|
Git LFS Details
|
assets/mm_tutorial/Rebecca_(1939_poster)_Small.jpeg
ADDED
_Small.jpeg)
|
assets/mm_tutorial/Shanghai.jpg
ADDED

|
assets/mm_tutorial/Shanghai_Output.jpg
ADDED

|
Git LFS Details
|
assets/mm_tutorial/Shanghai_Output_Small.jpeg
ADDED

|
assets/mm_tutorial/Shanghai_Small.jpeg
ADDED

|
assets/mm_tutorial/TUTORIAL.ipynb
ADDED
|
File without changes
|
assets/qwenvl.jpeg
ADDED
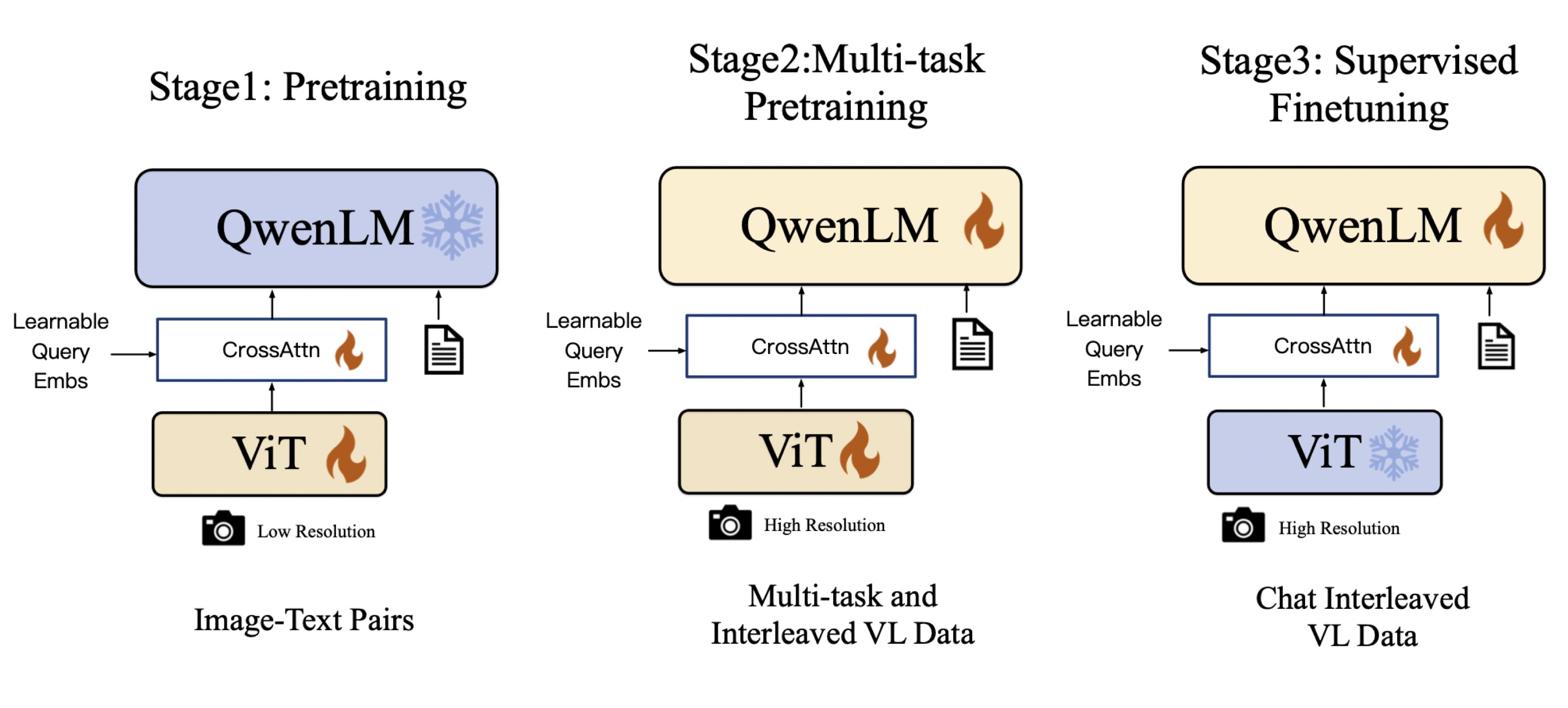
|
assets/radar.png
ADDED

|
assets/touchstone_datasets.jpg
ADDED

|
Git LFS Details
|
assets/touchstone_eval.png
ADDED

|
assets/touchstone_logo.png
ADDED
|
|
Git LFS Details
|
eval_mm/EVALUATION.md
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# We will release the evaluation documentation soon.
|
eval_mm/evaluate_caption.py
ADDED
|
@@ -0,0 +1,193 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import itertools
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
import random
|
| 6 |
+
import time
|
| 7 |
+
from functools import partial
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from pycocoevalcap.eval import COCOEvalCap
|
| 11 |
+
from pycocotools.coco import COCO
|
| 12 |
+
from tqdm import tqdm
|
| 13 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 14 |
+
|
| 15 |
+
ds_collections = {
|
| 16 |
+
'flickr': {
|
| 17 |
+
'train': 'data/flickr30k/flickr30k_karpathy_test.json',
|
| 18 |
+
'test': 'data/flickr30k/flickr30k_karpathy_test.json',
|
| 19 |
+
},
|
| 20 |
+
'nocaps': {
|
| 21 |
+
'train': '',
|
| 22 |
+
'test': 'data/nocaps/nocaps_val.json',
|
| 23 |
+
},
|
| 24 |
+
}
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class CaptionDataset(torch.utils.data.Dataset):
|
| 28 |
+
|
| 29 |
+
def __init__(self, train, test, prompt, few_shot=0):
|
| 30 |
+
self.images = json.load(open(test))['images']
|
| 31 |
+
self.prompt = prompt
|
| 32 |
+
|
| 33 |
+
self.few_shot = few_shot
|
| 34 |
+
if few_shot > 0:
|
| 35 |
+
self.train = json.load(open(train))['annotations']
|
| 36 |
+
|
| 37 |
+
def __len__(self):
|
| 38 |
+
return len(self.images)
|
| 39 |
+
|
| 40 |
+
def __getitem__(self, idx):
|
| 41 |
+
image_id, image_path = self.images[idx]['id'], self.images[idx][
|
| 42 |
+
'image']
|
| 43 |
+
|
| 44 |
+
few_shot_prompt = ''
|
| 45 |
+
if self.few_shot > 0:
|
| 46 |
+
few_shot_samples = random.sample(self.train, self.few_shot)
|
| 47 |
+
for sample in few_shot_samples:
|
| 48 |
+
few_shot_prompt += self.prompt.format(
|
| 49 |
+
sample['image']) + f" {sample['caption']}"
|
| 50 |
+
|
| 51 |
+
return {
|
| 52 |
+
'image_id': image_id,
|
| 53 |
+
'input_text': few_shot_prompt + self.prompt.format(image_path)
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def collate_fn(inputs, tokenizer):
|
| 58 |
+
|
| 59 |
+
image_ids = [_['image_id'] for _ in inputs]
|
| 60 |
+
input_texts = [_['input_text'] for _ in inputs]
|
| 61 |
+
input_tokens = tokenizer(input_texts,
|
| 62 |
+
return_tensors='pt',
|
| 63 |
+
padding='longest')
|
| 64 |
+
|
| 65 |
+
return image_ids, input_tokens.input_ids, input_tokens.attention_mask
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
class InferenceSampler(torch.utils.data.sampler.Sampler):
|
| 69 |
+
|
| 70 |
+
def __init__(self, size):
|
| 71 |
+
self._size = int(size)
|
| 72 |
+
assert size > 0
|
| 73 |
+
self._rank = torch.distributed.get_rank()
|
| 74 |
+
self._world_size = torch.distributed.get_world_size()
|
| 75 |
+
self._local_indices = self._get_local_indices(size, self._world_size,
|
| 76 |
+
self._rank)
|
| 77 |
+
|
| 78 |
+
@staticmethod
|
| 79 |
+
def _get_local_indices(total_size, world_size, rank):
|
| 80 |
+
shard_size = total_size // world_size
|
| 81 |
+
left = total_size % world_size
|
| 82 |
+
shard_sizes = [shard_size + int(r < left) for r in range(world_size)]
|
| 83 |
+
|
| 84 |
+
begin = sum(shard_sizes[:rank])
|
| 85 |
+
end = min(sum(shard_sizes[:rank + 1]), total_size)
|
| 86 |
+
return range(begin, end)
|
| 87 |
+
|
| 88 |
+
def __iter__(self):
|
| 89 |
+
yield from self._local_indices
|
| 90 |
+
|
| 91 |
+
def __len__(self):
|
| 92 |
+
return len(self._local_indices)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
if __name__ == '__main__':
|
| 96 |
+
|
| 97 |
+
parser = argparse.ArgumentParser()
|
| 98 |
+
parser.add_argument('--checkpoint', type=str, default='')
|
| 99 |
+
parser.add_argument('--dataset', type=str, default='')
|
| 100 |
+
parser.add_argument('--batch-size', type=int, default=1)
|
| 101 |
+
parser.add_argument('--num-workers', type=int, default=1)
|
| 102 |
+
parser.add_argument('--few-shot', type=int, default=0)
|
| 103 |
+
parser.add_argument('--seed', type=int, default=0)
|
| 104 |
+
args = parser.parse_args()
|
| 105 |
+
|
| 106 |
+
torch.distributed.init_process_group(
|
| 107 |
+
backend='nccl',
|
| 108 |
+
world_size=int(os.getenv('WORLD_SIZE', '1')),
|
| 109 |
+
rank=int(os.getenv('RANK', '0')),
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
torch.cuda.set_device(torch.distributed.get_rank())
|
| 113 |
+
|
| 114 |
+
prompt = '<img>{}</img>Describe the image in English:'
|
| 115 |
+
|
| 116 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 117 |
+
args.checkpoint, device_map='cuda', trust_remote_code=True).eval()
|
| 118 |
+
|
| 119 |
+
tokenizer = AutoTokenizer.from_pretrained(args.checkpoint,
|
| 120 |
+
trust_remote_code=True)
|
| 121 |
+
|
| 122 |
+
random.seed(args.seed)
|
| 123 |
+
dataset = CaptionDataset(
|
| 124 |
+
train=ds_collections[args.dataset]['train'],
|
| 125 |
+
test=ds_collections[args.dataset]['test'],
|
| 126 |
+
tokenizer=tokenizer,
|
| 127 |
+
prompt=prompt,
|
| 128 |
+
few_shot=args.few_shot,
|
| 129 |
+
)
|
| 130 |
+
coco_karpathy_test_loader = torch.utils.data.DataLoader(
|
| 131 |
+
dataset=dataset,
|
| 132 |
+
sampler=InferenceSampler(len(dataset)),
|
| 133 |
+
batch_size=args.batch_size,
|
| 134 |
+
num_workers=args.num_workers,
|
| 135 |
+
pin_memory=True,
|
| 136 |
+
drop_last=False,
|
| 137 |
+
collate_fn=partial(collate_fn, tokenizer=tokenizer),
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
image_ids = []
|
| 141 |
+
captions = []
|
| 142 |
+
for _, (ids, input_ids,
|
| 143 |
+
attention_mask) in tqdm(enumerate(coco_karpathy_test_loader)):
|
| 144 |
+
pred = model.generate(
|
| 145 |
+
input_ids=input_ids.cuda(),
|
| 146 |
+
attention_mask=attention_mask.cuda(),
|
| 147 |
+
do_sample=False,
|
| 148 |
+
num_beams=1,
|
| 149 |
+
max_new_tokens=30,
|
| 150 |
+
min_new_tokens=8,
|
| 151 |
+
length_penalty=0,
|
| 152 |
+
num_return_sequences=1,
|
| 153 |
+
use_cache=True,
|
| 154 |
+
pad_token_id=tokenizer.eod_id,
|
| 155 |
+
eos_token_id=tokenizer.eod_id,
|
| 156 |
+
)
|
| 157 |
+
image_ids.extend(ids)
|
| 158 |
+
captions.extend([
|
| 159 |
+
tokenizer.decode(_[input_ids.size(1):].cpu(),
|
| 160 |
+
skip_special_tokens=True).strip() for _ in pred
|
| 161 |
+
])
|
| 162 |
+
|
| 163 |
+
torch.distributed.barrier()
|
| 164 |
+
|
| 165 |
+
world_size = torch.distributed.get_world_size()
|
| 166 |
+
merged_ids = [None for _ in range(world_size)]
|
| 167 |
+
merged_captions = [None for _ in range(world_size)]
|
| 168 |
+
torch.distributed.all_gather_object(merged_ids, image_ids)
|
| 169 |
+
torch.distributed.all_gather_object(merged_captions, captions)
|
| 170 |
+
|
| 171 |
+
merged_ids = [_ for _ in itertools.chain.from_iterable(merged_ids)]
|
| 172 |
+
merged_captions = [
|
| 173 |
+
_ for _ in itertools.chain.from_iterable(merged_captions)
|
| 174 |
+
]
|
| 175 |
+
|
| 176 |
+
if torch.distributed.get_rank() == 0:
|
| 177 |
+
results = []
|
| 178 |
+
for image_id, caption in zip(merged_ids, merged_captions):
|
| 179 |
+
results.append({
|
| 180 |
+
'image_id': int(image_id),
|
| 181 |
+
'caption': caption,
|
| 182 |
+
})
|
| 183 |
+
time_prefix = time.strftime('%y%m%d%H%M%S', time.localtime())
|
| 184 |
+
results_file = f'{args.dataset}_{time_prefix}.json'
|
| 185 |
+
json.dump(results, open(results_file, 'w'))
|
| 186 |
+
|
| 187 |
+
coco = COCO(ds_collections[args.dataset]['test'])
|
| 188 |
+
coco_result = coco.loadRes(results_file)
|
| 189 |
+
coco_eval = COCOEvalCap(coco, coco_result)
|
| 190 |
+
coco_eval.evaluate()
|
| 191 |
+
|
| 192 |
+
print(coco_eval.eval.items())
|
| 193 |
+
torch.distributed.barrier()
|
eval_mm/evaluate_grounding.py
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import itertools
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
import re
|
| 6 |
+
from functools import partial
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
from torchvision.ops.boxes import box_area
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 12 |
+
|
| 13 |
+
ds_collections = {
|
| 14 |
+
'refcoco_val': 'data/refcoco/refcoco_val.jsonl',
|
| 15 |
+
'refcoco_testA': 'data/refcoco/refcoco_testA.jsonl',
|
| 16 |
+
'refcoco_testB': 'data/refcoco/refcoco_testB.jsonl',
|
| 17 |
+
'refcoco+_val': 'data/refcoco+/refcoco+_val.jsonl',
|
| 18 |
+
'refcoco+_testA': 'data/refcoco+/refcoco+_testA.jsonl',
|
| 19 |
+
'refcoco+_testB': 'data/refcoco+/refcoco+_testB.jsonl',
|
| 20 |
+
'refcocog_val': 'data/refcocog/refcocog_val.jsonl',
|
| 21 |
+
'refcocog_test': 'data/refcocog/refcocog_test.jsonl',
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def box_iou(boxes1, boxes2):
|
| 26 |
+
area1 = box_area(boxes1)
|
| 27 |
+
area2 = box_area(boxes2)
|
| 28 |
+
|
| 29 |
+
lt = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
|
| 30 |
+
rb = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
|
| 31 |
+
|
| 32 |
+
wh = (rb - lt).clamp(min=0) # [N,M,2]
|
| 33 |
+
inter = wh[:, :, 0] * wh[:, :, 1] # [N,M]
|
| 34 |
+
|
| 35 |
+
union = area1[:, None] + area2 - inter
|
| 36 |
+
|
| 37 |
+
iou = inter / union
|
| 38 |
+
return iou, union
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def collate_fn(batches, tokenizer):
|
| 42 |
+
|
| 43 |
+
texts = [_['text'] for _ in batches]
|
| 44 |
+
bboxes = [_['bbox'] for _ in batches]
|
| 45 |
+
hws = [_['hw'] for _ in batches]
|
| 46 |
+
|
| 47 |
+
input_ids = tokenizer(texts, return_tensors='pt', padding='longest')
|
| 48 |
+
|
| 49 |
+
return input_ids.input_ids, input_ids.attention_mask, bboxes, hws
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class RefCOCODataset(torch.utils.data.Dataset):
|
| 53 |
+
|
| 54 |
+
def __init__(self, test, tokenizer, prompt):
|
| 55 |
+
self.datas = open(test).readlines()
|
| 56 |
+
self.tokenizer = tokenizer
|
| 57 |
+
self.prompt = prompt
|
| 58 |
+
|
| 59 |
+
def __len__(self):
|
| 60 |
+
return len(self.datas)
|
| 61 |
+
|
| 62 |
+
def __getitem__(self, idx):
|
| 63 |
+
data = json.loads(self.datas[idx].strip())
|
| 64 |
+
image = data['image']
|
| 65 |
+
text = data['sent']
|
| 66 |
+
bbox = data['bbox']
|
| 67 |
+
|
| 68 |
+
w, h = data['width'], data['height']
|
| 69 |
+
|
| 70 |
+
return {
|
| 71 |
+
'text': self.prompt.format(image, text),
|
| 72 |
+
'bbox': bbox,
|
| 73 |
+
'hw': (h, w),
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class InferenceSampler(torch.utils.data.sampler.Sampler):
|
| 78 |
+
|
| 79 |
+
def __init__(self, size):
|
| 80 |
+
self._size = int(size)
|
| 81 |
+
assert size > 0
|
| 82 |
+
self._rank = torch.distributed.get_rank()
|
| 83 |
+
self._world_size = torch.distributed.get_world_size()
|
| 84 |
+
self._local_indices = self._get_local_indices(size, self._world_size,
|
| 85 |
+
self._rank)
|
| 86 |
+
|
| 87 |
+
@staticmethod
|
| 88 |
+
def _get_local_indices(total_size, world_size, rank):
|
| 89 |
+
shard_size = total_size // world_size
|
| 90 |
+
left = total_size % world_size
|
| 91 |
+
shard_sizes = [shard_size + int(r < left) for r in range(world_size)]
|
| 92 |
+
|
| 93 |
+
begin = sum(shard_sizes[:rank])
|
| 94 |
+
end = min(sum(shard_sizes[:rank + 1]), total_size)
|
| 95 |
+
return range(begin, end)
|
| 96 |
+
|
| 97 |
+
def __iter__(self):
|
| 98 |
+
yield from self._local_indices
|
| 99 |
+
|
| 100 |
+
def __len__(self):
|
| 101 |
+
return len(self._local_indices)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
if __name__ == '__main__':
|
| 105 |
+
|
| 106 |
+
parser = argparse.ArgumentParser()
|
| 107 |
+
parser.add_argument('--checkpoint', type=str, default='')
|
| 108 |
+
parser.add_argument('--dataset', type=str, default='')
|
| 109 |
+
parser.add_argument('--batch-size', type=int, default=1)
|
| 110 |
+
parser.add_argument('--num-workers', type=int, default=1)
|
| 111 |
+
args = parser.parse_args()
|
| 112 |
+
|
| 113 |
+
torch.distributed.init_process_group(
|
| 114 |
+
backend='nccl',
|
| 115 |
+
world_size=int(os.getenv('WORLD_SIZE', '1')),
|
| 116 |
+
rank=int(os.getenv('RANK', '0')),
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
torch.cuda.set_device(torch.distributed.get_rank())
|
| 120 |
+
|
| 121 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 122 |
+
args.checkpoint, device_map='cuda', trust_remote_code=True).eval()
|
| 123 |
+
|
| 124 |
+
tokenizer = AutoTokenizer.from_pretrained(args.checkpoint,
|
| 125 |
+
trust_remote_code=True)
|
| 126 |
+
tokenizer.padding_side = 'left'
|
| 127 |
+
tokenizer.pad_token_id = tokenizer.eod_id
|
| 128 |
+
|
| 129 |
+
prompt = '<img>{}</img><ref>{}</ref><box>'
|
| 130 |
+
|
| 131 |
+
dataset = RefCOCODataset(test=ds_collections[args.dataset],
|
| 132 |
+
tokenizer=tokenizer,
|
| 133 |
+
prompt=prompt)
|
| 134 |
+
|
| 135 |
+
dataloader = torch.utils.data.DataLoader(
|
| 136 |
+
dataset=dataset,
|
| 137 |
+
sampler=InferenceSampler(len(dataset)),
|
| 138 |
+
batch_size=args.batch_size,
|
| 139 |
+
num_workers=args.num_workers,
|
| 140 |
+
pin_memory=True,
|
| 141 |
+
drop_last=True,
|
| 142 |
+
collate_fn=partial(collate_fn, tokenizer=tokenizer),
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
outputs = []
|
| 146 |
+
for _, (input_ids, attention_mask, bboxes,
|
| 147 |
+
hws) in tqdm(enumerate(dataloader)):
|
| 148 |
+
pred = model.generate(
|
| 149 |
+
input_ids=input_ids.cuda(),
|
| 150 |
+
attention_mask=attention_mask.cuda(),
|
| 151 |
+
do_sample=False,
|
| 152 |
+
num_beams=1,
|
| 153 |
+
max_new_tokens=28,
|
| 154 |
+
min_new_tokens=10,
|
| 155 |
+
length_penalty=1,
|
| 156 |
+
num_return_sequences=1,
|
| 157 |
+
use_cache=True,
|
| 158 |
+
pad_token_id=tokenizer.eod_id,
|
| 159 |
+
eos_token_id=tokenizer.eod_id,
|
| 160 |
+
)
|
| 161 |
+
answers = [
|
| 162 |
+
tokenizer.decode(_[input_ids.size(1):].cpu(),
|
| 163 |
+
skip_special_tokens=True) for _ in pred
|
| 164 |
+
]
|
| 165 |
+
|
| 166 |
+
for bbox, hw, answer in zip(bboxes, hws, answers):
|
| 167 |
+
outputs.append({
|
| 168 |
+
'answer': answer,
|
| 169 |
+
'gt_bbox': bbox,
|
| 170 |
+
'hw': hw,
|
| 171 |
+
})
|
| 172 |
+
|
| 173 |
+
torch.distributed.barrier()
|
| 174 |
+
|
| 175 |
+
world_size = torch.distributed.get_world_size()
|
| 176 |
+
merged_outputs = [None for _ in range(world_size)]
|
| 177 |
+
torch.distributed.all_gather_object(merged_outputs, outputs)
|
| 178 |
+
|
| 179 |
+
merged_outputs = [_ for _ in itertools.chain.from_iterable(merged_outputs)]
|
| 180 |
+
PATTERN = re.compile(r'\((.*?)\),\((.*?)\)')
|
| 181 |
+
|
| 182 |
+
if torch.distributed.get_rank() == 0:
|
| 183 |
+
correct = total_cnt = 0
|
| 184 |
+
for i, output in enumerate(merged_outputs):
|
| 185 |
+
predict_bbox = re.findall(PATTERN, output['answer'])
|
| 186 |
+
try:
|
| 187 |
+
if ',' not in predict_bbox[0][0] or ',' not in predict_bbox[0][
|
| 188 |
+
1]:
|
| 189 |
+
predict_bbox = (0., 0., 0., 0.)
|
| 190 |
+
else:
|
| 191 |
+
x1, y1 = [
|
| 192 |
+
float(tmp) for tmp in predict_bbox[0][0].split(',')
|
| 193 |
+
]
|
| 194 |
+
x2, y2 = [
|
| 195 |
+
float(tmp) for tmp in predict_bbox[0][1].split(',')
|
| 196 |
+
]
|
| 197 |
+
predict_bbox = (x1, y1, x2, y2)
|
| 198 |
+
except:
|
| 199 |
+
predict_bbox = (0., 0., 0., 0.)
|
| 200 |
+
target_bbox = torch.tensor(output['gt_bbox'],
|
| 201 |
+
dtype=torch.float32).view(-1, 4)
|
| 202 |
+
predict_bbox = torch.tensor(predict_bbox,
|
| 203 |
+
dtype=torch.float32).view(-1, 4) / 999
|
| 204 |
+
predict_bbox[:, 0::2] *= output['hw'][1]
|
| 205 |
+
predict_bbox[:, 1::2] *= output['hw'][0]
|
| 206 |
+
iou, _ = box_iou(predict_bbox, target_bbox)
|
| 207 |
+
iou = iou.item()
|
| 208 |
+
total_cnt += 1
|
| 209 |
+
if iou >= 0.5:
|
| 210 |
+
correct += 1
|
| 211 |
+
|
| 212 |
+
print(f'Precision @ 1: {correct / total_cnt} \n')
|
| 213 |
+
torch.distributed.barrier()
|
eval_mm/evaluate_multiple_choice.py
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import itertools
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
from functools import partial
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 10 |
+
|
| 11 |
+
multiple_choices = ['A', 'B', 'C', 'D', 'E']
|
| 12 |
+
|
| 13 |
+
ds_collections = {
|
| 14 |
+
'scienceqa_test_img': {
|
| 15 |
+
'test': 'data/scienceqa/scienceqa_test_img.jsonl',
|
| 16 |
+
}
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def collate_fn(batches, pad_token_id):
|
| 21 |
+
|
| 22 |
+
input_tokens = [_['input_tokens'] for _ in batches]
|
| 23 |
+
target_lengths = [_['target_lengths'] for _ in batches]
|
| 24 |
+
answers = [_['answer'] for _ in batches]
|
| 25 |
+
|
| 26 |
+
chunk_sizes = [len(_) for _ in input_tokens]
|
| 27 |
+
|
| 28 |
+
input_tokens = [_ for _ in itertools.chain.from_iterable(input_tokens)]
|
| 29 |
+
|
| 30 |
+
max_lengths = max([len(_) for _ in input_tokens])
|
| 31 |
+
input_tokens = [[pad_token_id] * (max_lengths - len(_)) + _
|
| 32 |
+
for _ in input_tokens]
|
| 33 |
+
input_tokens = torch.LongTensor(input_tokens)
|
| 34 |
+
|
| 35 |
+
attention_mask = 1 - input_tokens.eq(pad_token_id).float()
|
| 36 |
+
|
| 37 |
+
return input_tokens, attention_mask, target_lengths, answers, chunk_sizes
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class MultipleChoiceDataste(torch.utils.data.Dataset):
|
| 41 |
+
|
| 42 |
+
def __init__(self, test, prompt, tokenizer):
|
| 43 |
+
self.datas = open(test).readlines()
|
| 44 |
+
self.prompt = prompt
|
| 45 |
+
self.tokenizer = tokenizer
|
| 46 |
+
|
| 47 |
+
def __len__(self):
|
| 48 |
+
return len(self.datas)
|
| 49 |
+
|
| 50 |
+
def __getitem__(self, idx):
|
| 51 |
+
|
| 52 |
+
data = json.loads(self.datas[idx].strip())
|
| 53 |
+
image = data['image']
|
| 54 |
+
hint = data['hint'] if data['hint'] else 'N/A'
|
| 55 |
+
question = data['question']
|
| 56 |
+
|
| 57 |
+
choices = data['choices']
|
| 58 |
+
choice_list = []
|
| 59 |
+
for i, c in enumerate(choices):
|
| 60 |
+
choice_list.append('{}. {}'.format(multiple_choices[i], c))
|
| 61 |
+
choice_txt = '\n'.join(choice_list)
|
| 62 |
+
|
| 63 |
+
prompt = self.prompt.format(image, hint, question, choice_txt)
|
| 64 |
+
|
| 65 |
+
prompt_tokens = self.tokenizer(prompt).input_ids
|
| 66 |
+
target_tokens = [
|
| 67 |
+
self.tokenizer(' ' + _).input_ids
|
| 68 |
+
for _ in multiple_choices[:len(choices)]
|
| 69 |
+
]
|
| 70 |
+
|
| 71 |
+
return {
|
| 72 |
+
'input_tokens': [prompt_tokens + _ for _ in target_tokens],
|
| 73 |
+
'target_lengths': [len(_) for _ in target_tokens],
|
| 74 |
+
'answer': data['answer'],
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
class InferenceSampler(torch.utils.data.sampler.Sampler):
|
| 79 |
+
|
| 80 |
+
def __init__(self, size):
|
| 81 |
+
self._size = int(size)
|
| 82 |
+
assert size > 0
|
| 83 |
+
self._rank = torch.distributed.get_rank()
|
| 84 |
+
self._world_size = torch.distributed.get_world_size()
|
| 85 |
+
self._local_indices = self._get_local_indices(size, self._world_size,
|
| 86 |
+
self._rank)
|
| 87 |
+
|
| 88 |
+
@staticmethod
|
| 89 |
+
def _get_local_indices(total_size, world_size, rank):
|
| 90 |
+
shard_size = total_size // world_size
|
| 91 |
+
left = total_size % world_size
|
| 92 |
+
shard_sizes = [shard_size + int(r < left) for r in range(world_size)]
|
| 93 |
+
|
| 94 |
+
begin = sum(shard_sizes[:rank])
|
| 95 |
+
end = min(sum(shard_sizes[:rank + 1]), total_size)
|
| 96 |
+
return range(begin, end)
|
| 97 |
+
|
| 98 |
+
def __iter__(self):
|
| 99 |
+
yield from self._local_indices
|
| 100 |
+
|
| 101 |
+
def __len__(self):
|
| 102 |
+
return len(self._local_indices)
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
if __name__ == '__main__':
|
| 106 |
+
|
| 107 |
+
parser = argparse.ArgumentParser()
|
| 108 |
+
parser.add_argument('--checkpoint', type=str, default='')
|
| 109 |
+
parser.add_argument('--dataset', type=str, default='')
|
| 110 |
+
parser.add_argument('--batch-size', type=int, default=1)
|
| 111 |
+
parser.add_argument('--num-workers', type=int, default=1)
|
| 112 |
+
args = parser.parse_args()
|
| 113 |
+
|
| 114 |
+
torch.distributed.init_process_group(
|
| 115 |
+
backend='nccl',
|
| 116 |
+
world_size=int(os.getenv('WORLD_SIZE', '1')),
|
| 117 |
+
rank=int(os.getenv('RANK', '0')),
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
torch.cuda.set_device(torch.distributed.get_rank())
|
| 121 |
+
|
| 122 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 123 |
+
args.checkpoint, device_map='cuda', trust_remote_code=True).eval()
|
| 124 |
+
|
| 125 |
+
tokenizer = AutoTokenizer.from_pretrained(args.checkpoint,
|
| 126 |
+
trust_remote_code=True)
|
| 127 |
+
|
| 128 |
+
prompt = '<img>{}</img>Context: {}\nQuestion: {}\nOptions: {}\nAnswer:'
|
| 129 |
+
|
| 130 |
+
dataset = MultipleChoiceDataste(test=ds_collections[args.dataset]['test'],
|
| 131 |
+
prompt=prompt,
|
| 132 |
+
tokenizer=tokenizer)
|
| 133 |
+
dataloader = torch.utils.data.DataLoader(
|
| 134 |
+
dataset=dataset,
|
| 135 |
+
sampler=InferenceSampler(len(dataset)),
|
| 136 |
+
batch_size=args.batch_size,
|
| 137 |
+
num_workers=args.num_workers,
|
| 138 |
+
pin_memory=True,
|
| 139 |
+
drop_last=False,
|
| 140 |
+
collate_fn=partial(collate_fn, pad_token_id=tokenizer.eod_id),
|
| 141 |
+
)
|
| 142 |
+
|
| 143 |
+
results = []
|
| 144 |
+
with torch.no_grad():
|
| 145 |
+
for _, (input_tokens, attention_mask, target_lengths, answer,
|
| 146 |
+
chunk_sizes) in tqdm(enumerate(dataloader)):
|
| 147 |
+
|
| 148 |
+
outputs = model(
|
| 149 |
+
input_ids=input_tokens[:, :-1].cuda(),
|
| 150 |
+
attention_mask=attention_mask[:, :-1].cuda(),
|
| 151 |
+
return_dict=True,
|
| 152 |
+
)
|
| 153 |
+
losses = torch.nn.functional.cross_entropy(outputs.logits.permute(
|
| 154 |
+
0, 2, 1),
|
| 155 |
+
input_tokens[:,
|
| 156 |
+
1:].cuda(),
|
| 157 |
+
reduction='none')
|
| 158 |
+
|
| 159 |
+
losses = losses.split(chunk_sizes, dim=0)
|
| 160 |
+
|
| 161 |
+
for loss, target_length, answer in zip(losses, target_lengths,
|
| 162 |
+
answer):
|
| 163 |
+
|
| 164 |
+
target_loss = loss.mean(-1)
|
| 165 |
+
for _ in range(len(target_length)):
|
| 166 |
+
target_loss[_] = loss[_, -target_length[_]:].mean()
|
| 167 |
+
pred = target_loss.argmin().item()
|
| 168 |
+
if pred == answer:
|
| 169 |
+
results.append(1)
|
| 170 |
+
else:
|
| 171 |
+
results.append(0)
|
| 172 |
+
|
| 173 |
+
torch.distributed.barrier()
|
| 174 |
+
|
| 175 |
+
world_size = torch.distributed.get_world_size()
|
| 176 |
+
merged_results = [None for _ in range(world_size)]
|
| 177 |
+
torch.distributed.all_gather_object(merged_results, results)
|
| 178 |
+
|
| 179 |
+
merged_results = [_ for _ in itertools.chain.from_iterable(merged_results)]
|
| 180 |
+
|
| 181 |
+
if torch.distributed.get_rank() == 0:
|
| 182 |
+
print(f'Acc@1: {sum(merged_results) / len(merged_results)}')
|
| 183 |
+
|
| 184 |
+
torch.distributed.barrier()
|
eval_mm/evaluate_vizwiz_testdev.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import itertools
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
import random
|
| 6 |
+
import time
|
| 7 |
+
from functools import partial
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def collate_fn(batches, tokenizer):
|
| 15 |
+
|
| 16 |
+
images = [_['image'] for _ in batches]
|
| 17 |
+
questions = [_['question'] for _ in batches]
|
| 18 |
+
|
| 19 |
+
input_ids = tokenizer(questions, return_tensors='pt', padding='longest')
|
| 20 |
+
|
| 21 |
+
return images, input_ids.input_ids, input_ids.attention_mask
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class VQADataset(torch.utils.data.Dataset):
|
| 25 |
+
|
| 26 |
+
def __init__(self, train, test, prompt, few_shot):
|
| 27 |
+
self.test = json.load(open(test))
|
| 28 |
+
self.prompt = prompt
|
| 29 |
+
|
| 30 |
+
self.few_shot = few_shot
|
| 31 |
+
if few_shot > 0:
|
| 32 |
+
self.train = open(train).readlines()
|
| 33 |
+
|
| 34 |
+
def __len__(self):
|
| 35 |
+
return len(self.test)
|
| 36 |
+
|
| 37 |
+
def __getitem__(self, idx):
|
| 38 |
+
data = self.test[idx]
|
| 39 |
+
image, question = data['image'], data['question']
|
| 40 |
+
|
| 41 |
+
few_shot_prompt = ''
|
| 42 |
+
if self.few_shot > 0:
|
| 43 |
+
few_shot_samples = random.sample(self.train, self.few_shot)
|
| 44 |
+
for sample in few_shot_samples:
|
| 45 |
+
sample = json.loads(sample.strip())
|
| 46 |
+
few_shot_prompt += self.prompt.format(
|
| 47 |
+
sample['image'],
|
| 48 |
+
sample['question']) + f" {sample['answer']}"
|
| 49 |
+
|
| 50 |
+
return {
|
| 51 |
+
'image': data['image'],
|
| 52 |
+
'question': few_shot_prompt + self.prompt.format(image, question),
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class InferenceSampler(torch.utils.data.sampler.Sampler):
|
| 57 |
+
|
| 58 |
+
def __init__(self, size):
|
| 59 |
+
self._size = int(size)
|
| 60 |
+
assert size > 0
|
| 61 |
+
self._rank = torch.distributed.get_rank()
|
| 62 |
+
self._world_size = torch.distributed.get_world_size()
|
| 63 |
+
self._local_indices = self._get_local_indices(size, self._world_size,
|
| 64 |
+
self._rank)
|
| 65 |
+
|
| 66 |
+
@staticmethod
|
| 67 |
+
def _get_local_indices(total_size, world_size, rank):
|
| 68 |
+
shard_size = total_size // world_size
|
| 69 |
+
left = total_size % world_size
|
| 70 |
+
shard_sizes = [shard_size + int(r < left) for r in range(world_size)]
|
| 71 |
+
|
| 72 |
+
begin = sum(shard_sizes[:rank])
|
| 73 |
+
end = min(sum(shard_sizes[:rank + 1]), total_size)
|
| 74 |
+
return range(begin, end)
|
| 75 |
+
|
| 76 |
+
def __iter__(self):
|
| 77 |
+
yield from self._local_indices
|
| 78 |
+
|
| 79 |
+
def __len__(self):
|
| 80 |
+
return len(self._local_indices)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
if __name__ == '__main__':
|
| 84 |
+
|
| 85 |
+
parser = argparse.ArgumentParser()
|
| 86 |
+
parser.add_argument('--checkpoint', type=str, default='')
|
| 87 |
+
parser.add_argument('--batch-size', type=int, default=1)
|
| 88 |
+
parser.add_argument('--num-workers', type=int, default=1)
|
| 89 |
+
parser.add_argument('--few-shot', type=int, default=0)
|
| 90 |
+
parser.add_argument('--seed', type=int, default=0)
|
| 91 |
+
args = parser.parse_args()
|
| 92 |
+
|
| 93 |
+
torch.distributed.init_process_group(
|
| 94 |
+
backend='nccl',
|
| 95 |
+
world_size=int(os.getenv('WORLD_SIZE', '1')),
|
| 96 |
+
rank=int(os.getenv('RANK', '0')),
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
torch.cuda.set_device(torch.distributed.get_rank())
|
| 100 |
+
|
| 101 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 102 |
+
args.checkpoint, device_map='cuda', trust_remote_code=True).eval()
|
| 103 |
+
|
| 104 |
+
tokenizer = AutoTokenizer.from_pretrained(args.checkpoint,
|
| 105 |
+
trust_remote_code=True)
|
| 106 |
+
tokenizer.padding_side = 'left'
|
| 107 |
+
tokenizer.pad_token_id = tokenizer.eod_id
|
| 108 |
+
|
| 109 |
+
prompt = '<img>data/vizwiz/test/{}</img>{} Answer:'
|
| 110 |
+
|
| 111 |
+
random.seed(args.seed)
|
| 112 |
+
dataset = VQADataset(
|
| 113 |
+
train='data/vizwiz/vizwiz_train.jsonl',
|
| 114 |
+
test='data/vizwiz/test.json',
|
| 115 |
+
prompt=prompt,
|
| 116 |
+
few_shot=args.few_shot,
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
dataloader = torch.utils.data.DataLoader(
|
| 120 |
+
dataset=dataset,
|
| 121 |
+
sampler=InferenceSampler(len(dataset)),
|
| 122 |
+
batch_size=args.batch_size,
|
| 123 |
+
num_workers=args.num_workers,
|
| 124 |
+
pin_memory=True,
|
| 125 |
+
drop_last=False,
|
| 126 |
+
collate_fn=partial(collate_fn, tokenizer=tokenizer),
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
outputs = []
|
| 130 |
+
for _, (images, input_ids, attention_mask) in tqdm(enumerate(dataloader)):
|
| 131 |
+
pred = model.generate(
|
| 132 |
+
input_ids=input_ids.cuda(),
|
| 133 |
+
attention_mask=attention_mask.cuda(),
|
| 134 |
+
do_sample=False,
|
| 135 |
+
num_beams=1,
|
| 136 |
+
max_new_tokens=10,
|
| 137 |
+
min_new_tokens=1,
|
| 138 |
+
length_penalty=1,
|
| 139 |
+
num_return_sequences=1,
|
| 140 |
+
output_hidden_states=True,
|
| 141 |
+
use_cache=True,
|
| 142 |
+
pad_token_id=tokenizer.eod_id,
|
| 143 |
+
eos_token_id=tokenizer.eod_id,
|
| 144 |
+
)
|
| 145 |
+
answers = [
|
| 146 |
+
tokenizer.decode(_[input_ids.size(1):].cpu(),
|
| 147 |
+
skip_special_tokens=True).strip() for _ in pred
|
| 148 |
+
]
|
| 149 |
+
|
| 150 |
+
for image, answer in zip(images, answers):
|
| 151 |
+
outputs.append({'image': image, 'answer': answer})
|
| 152 |
+
|
| 153 |
+
torch.distributed.barrier()
|
| 154 |
+
|
| 155 |
+
world_size = torch.distributed.get_world_size()
|
| 156 |
+
merged_outputs = [None for _ in range(world_size)]
|
| 157 |
+
torch.distributed.all_gather_object(merged_outputs, outputs)
|
| 158 |
+
|
| 159 |
+
merged_outputs = [_ for _ in itertools.chain.from_iterable(merged_outputs)]
|
| 160 |
+
|
| 161 |
+
if torch.distributed.get_rank() == 0:
|
| 162 |
+
time_prefix = time.strftime('%y%m%d%H%M%S', time.localtime())
|
| 163 |
+
results_file = f'vizwiz_testdev_{time_prefix}_fs{args.few_shot}_s{args.seed}.json'
|
| 164 |
+
json.dump(merged_outputs, open(results_file, 'w'),
|
| 165 |
+
ensure_ascii=False) # save to results
|
| 166 |
+
|
| 167 |
+
torch.distributed.barrier()
|
eval_mm/evaluate_vqa.py
ADDED
|
@@ -0,0 +1,357 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import itertools
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
import random
|
| 6 |
+
import time
|
| 7 |
+
from functools import partial
|
| 8 |
+
from typing import Optional
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
from tqdm import tqdm
|
| 12 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 13 |
+
from vqa import VQA
|
| 14 |
+
from vqa_eval import VQAEval
|
| 15 |
+
|
| 16 |
+
ds_collections = {
|
| 17 |
+
'vqav2_val': {
|
| 18 |
+
'train': 'data/vqav2/vqav2_train.jsonl',
|
| 19 |
+
'test': 'data/vqav2/vqav2_val.jsonl',
|
| 20 |
+
'question': 'data/vqav2/v2_OpenEnded_mscoco_val2014_questions.json',
|
| 21 |
+
'annotation': 'data/vqav2/v2_mscoco_val2014_annotations.json',
|
| 22 |
+
'metric': 'vqa_score',
|
| 23 |
+
'max_new_tokens': 10,
|
| 24 |
+
},
|
| 25 |
+
'okvqa_val': {
|
| 26 |
+
'train': 'data/okvqa/okvqa_train.jsonl',
|
| 27 |
+
'test': 'data/okvqa/okvqa_val.jsonl',
|
| 28 |
+
'question': 'data/okvqa/OpenEnded_mscoco_val2014_questions.json',
|
| 29 |
+
'annotation': 'data/okvqa/mscoco_val2014_annotations.json',
|
| 30 |
+
'metric': 'vqa_score',
|
| 31 |
+
'max_new_tokens': 10,
|
| 32 |
+
},
|
| 33 |
+
'textvqa_val': {
|
| 34 |
+
'train': 'data/textvqa/textvqa_train.jsonl',
|
| 35 |
+
'test': 'data/textvqa/textvqa_val.jsonl',
|
| 36 |
+
'question': 'data/textvqa/textvqa_val_questions.json',
|
| 37 |
+
'annotation': 'data/textvqa/textvqa_val_annotations.json',
|
| 38 |
+
'metric': 'vqa_score',
|
| 39 |
+
'max_new_tokens': 10,
|
| 40 |
+
},
|
| 41 |
+
'vizwiz_val': {
|
| 42 |
+
'train': 'data/vizwiz/vizwiz_train.jsonl',
|
| 43 |
+
'test': 'data/vizwiz/vizwiz_val.jsonl',
|
| 44 |
+
'question': 'data/vizwiz/vizwiz_val_questions.json',
|
| 45 |
+
'annotation': 'data/vizwiz/vizwiz_val_annotations.json',
|
| 46 |
+
'metric': 'vqa_score',
|
| 47 |
+
'max_new_tokens': 10,
|
| 48 |
+
},
|
| 49 |
+
'docvqa': {
|
| 50 |
+
'train': 'data/DocVQA/train.jsonl',
|
| 51 |
+
'test': 'data/DocVQA/val.jsonl',
|
| 52 |
+
# 'question': '',
|
| 53 |
+
'annotation': './data/DocVQA/val/val_v1.0.json',
|
| 54 |
+
'metric': 'anls',
|
| 55 |
+
'max_new_tokens': 100,
|
| 56 |
+
},
|
| 57 |
+
'infographicsvqa': {
|
| 58 |
+
'train': 'data/InfographicsVQA/train.jsonl',
|
| 59 |
+
'test': 'data/InfographicsVQA/val.jsonl',
|
| 60 |
+
# 'question': '',
|
| 61 |
+
'annotation': './data/InfographicsVQA/infographicVQA_val_v1.0.json',
|
| 62 |
+
'metric': 'anls',
|
| 63 |
+
'max_new_tokens': 100,
|
| 64 |
+
},
|
| 65 |
+
'chartqa': {
|
| 66 |
+
'train': 'data/ChartQA/train.jsonl',
|
| 67 |
+
'test': 'data/ChartQA/val_human.jsonl',
|
| 68 |
+
# 'question': '',
|
| 69 |
+
# 'annotation': '',
|
| 70 |
+
'metric': 'relaxed_accuracy',
|
| 71 |
+
'max_new_tokens': 100,
|
| 72 |
+
},
|
| 73 |
+
'gqa': {
|
| 74 |
+
'train': 'data/GQA/train.jsonl',
|
| 75 |
+
'test': 'data/GQA/testdev_balanced.jsonl',
|
| 76 |
+
# 'question': '',
|
| 77 |
+
# 'annotation': '',
|
| 78 |
+
'metric': 'accuracy',
|
| 79 |
+
'max_new_tokens': 10,
|
| 80 |
+
},
|
| 81 |
+
'ocrvqa': {
|
| 82 |
+
'train': 'data/OCR-VQA/train.jsonl',
|
| 83 |
+
'test': 'data/OCR-VQA/val.jsonl',
|
| 84 |
+
# 'question': '',
|
| 85 |
+
# 'annotation': '',
|
| 86 |
+
'metric': 'accuracy',
|
| 87 |
+
'max_new_tokens': 10,
|
| 88 |
+
},
|
| 89 |
+
'ai2diagram': {
|
| 90 |
+
'train': 'data/AI2Diagram/train.jsonl',
|
| 91 |
+
'test': 'data/AI2Diagram/test.jsonl',
|
| 92 |
+
# 'question': '',
|
| 93 |
+
# 'annotation': '',
|
| 94 |
+
'metric': 'accuracy',
|
| 95 |
+
'max_new_tokens': 10,
|
| 96 |
+
}
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
# https://github.com/google-research/pix2struct/blob/main/pix2struct/metrics.py#L81
|
| 100 |
+
def relaxed_correctness(target: str,
|
| 101 |
+
prediction: str,
|
| 102 |
+
max_relative_change: float = 0.05) -> bool:
|
| 103 |
+
"""Calculates relaxed correctness.
|
| 104 |
+
|
| 105 |
+
The correctness tolerates certain error ratio defined by max_relative_change.
|
| 106 |
+
See https://arxiv.org/pdf/2203.10244.pdf, end of section 5.1:
|
| 107 |
+
“Following Methani et al. (2020), we use a relaxed accuracy measure for the
|
| 108 |
+
numeric answers to allow a minor inaccuracy that may result from the automatic
|
| 109 |
+
data extraction process. We consider an answer to be correct if it is within
|
| 110 |
+
5% of the gold answer. For non-numeric answers, we still need an exact match
|
| 111 |
+
to consider an answer to be correct.”
|
| 112 |
+
|
| 113 |
+
Args:
|
| 114 |
+
target: Target string.
|
| 115 |
+
prediction: Predicted string.
|
| 116 |
+
max_relative_change: Maximum relative change.
|
| 117 |
+
|
| 118 |
+
Returns:
|
| 119 |
+
Whether the prediction was correct given the specified tolerance.
|
| 120 |
+
"""
|
| 121 |
+
|
| 122 |
+
def _to_float(text: str) -> Optional[float]:
|
| 123 |
+
try:
|
| 124 |
+
if text.endswith("%"):
|
| 125 |
+
# Convert percentages to floats.
|
| 126 |
+
return float(text.rstrip("%")) / 100.0
|
| 127 |
+
else:
|
| 128 |
+
return float(text)
|
| 129 |
+
except ValueError:
|
| 130 |
+
return None
|
| 131 |
+
|
| 132 |
+
prediction_float = _to_float(prediction)
|
| 133 |
+
target_float = _to_float(target)
|
| 134 |
+
if prediction_float is not None and target_float:
|
| 135 |
+
relative_change = abs(
|
| 136 |
+
prediction_float - target_float) / abs(target_float)
|
| 137 |
+
return relative_change <= max_relative_change
|
| 138 |
+
else:
|
| 139 |
+
return prediction.lower() == target.lower()
|
| 140 |
+
|
| 141 |
+
def evaluate_relaxed_accuracy(entries):
|
| 142 |
+
scores = []
|
| 143 |
+
for elem in entries:
|
| 144 |
+
score = max([relaxed_correctness(elem['answer'].strip(), ann) for ann in elem['annotation']])
|
| 145 |
+
scores.append(score)
|
| 146 |
+
return sum(scores) / len(scores)
|
| 147 |
+
|
| 148 |
+
def evaluate_exact_match_accuracy(entries):
|
| 149 |
+
scores = []
|
| 150 |
+
for elem in entries:
|
| 151 |
+
score = max([(1.0 if (elem['answer'].strip().lower() == ann.strip().lower()) else 0.0) for ann in elem['annotation']])
|
| 152 |
+
scores.append(score)
|
| 153 |
+
return sum(scores) / len(scores)
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def collate_fn(batches, tokenizer):
|
| 157 |
+
|
| 158 |
+
questions = [_['question'] for _ in batches]
|
| 159 |
+
question_ids = [_['question_id'] for _ in batches]
|
| 160 |
+
annotations = [_['annotation'] for _ in batches]
|
| 161 |
+
|
| 162 |
+
input_ids = tokenizer(questions, return_tensors='pt', padding='longest')
|
| 163 |
+
|
| 164 |
+
return question_ids, input_ids.input_ids, input_ids.attention_mask, annotations
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
class VQADataset(torch.utils.data.Dataset):
|
| 168 |
+
|
| 169 |
+
def __init__(self, train, test, prompt, few_shot):
|
| 170 |
+
self.test = open(test).readlines()
|
| 171 |
+
self.prompt = prompt
|
| 172 |
+
|
| 173 |
+
self.few_shot = few_shot
|
| 174 |
+
if few_shot > 0:
|
| 175 |
+
self.train = open(train).readlines()
|
| 176 |
+
|
| 177 |
+
def __len__(self):
|
| 178 |
+
return len(self.test)
|
| 179 |
+
|
| 180 |
+
def __getitem__(self, idx):
|
| 181 |
+
data = json.loads(self.test[idx].strip())
|
| 182 |
+
image, question, question_id, annotation = data['image'], data['question'], data[
|
| 183 |
+
'question_id'], data['answer']
|
| 184 |
+
|
| 185 |
+
few_shot_prompt = ''
|
| 186 |
+
if self.few_shot > 0:
|
| 187 |
+
few_shot_samples = random.sample(self.train, self.few_shot)
|
| 188 |
+
for sample in few_shot_samples:
|
| 189 |
+
sample = json.loads(sample.strip())
|
| 190 |
+
few_shot_prompt += self.prompt.format(
|
| 191 |
+
sample['image'],
|
| 192 |
+
sample['question']) + f" {sample['answer']}"
|
| 193 |
+
|
| 194 |
+
return {
|
| 195 |
+
'question': few_shot_prompt + self.prompt.format(image, question),
|
| 196 |
+
'question_id': question_id,
|
| 197 |
+
'annotation': annotation
|
| 198 |
+
}
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
class InferenceSampler(torch.utils.data.sampler.Sampler):
|
| 202 |
+
|
| 203 |
+
def __init__(self, size):
|
| 204 |
+
self._size = int(size)
|
| 205 |
+
assert size > 0
|
| 206 |
+
self._rank = torch.distributed.get_rank()
|
| 207 |
+
self._world_size = torch.distributed.get_world_size()
|
| 208 |
+
self._local_indices = self._get_local_indices(size, self._world_size,
|
| 209 |
+
self._rank)
|
| 210 |
+
|
| 211 |
+
@staticmethod
|
| 212 |
+
def _get_local_indices(total_size, world_size, rank):
|
| 213 |
+
shard_size = total_size // world_size
|
| 214 |
+
left = total_size % world_size
|
| 215 |
+
shard_sizes = [shard_size + int(r < left) for r in range(world_size)]
|
| 216 |
+
|
| 217 |
+
begin = sum(shard_sizes[:rank])
|
| 218 |
+
end = min(sum(shard_sizes[:rank + 1]), total_size)
|
| 219 |
+
return range(begin, end)
|
| 220 |
+
|
| 221 |
+
def __iter__(self):
|
| 222 |
+
yield from self._local_indices
|
| 223 |
+
|
| 224 |
+
def __len__(self):
|
| 225 |
+
return len(self._local_indices)
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
if __name__ == '__main__':
|
| 229 |
+
|
| 230 |
+
parser = argparse.ArgumentParser()
|
| 231 |
+
parser.add_argument('--checkpoint', type=str, default='')
|
| 232 |
+
parser.add_argument('--dataset', type=str, default='')
|
| 233 |
+
parser.add_argument('--batch-size', type=int, default=1)
|
| 234 |
+
parser.add_argument('--num-workers', type=int, default=1)
|
| 235 |
+
parser.add_argument('--few-shot', type=int, default=0)
|
| 236 |
+
parser.add_argument('--seed', type=int, default=0)
|
| 237 |
+
args = parser.parse_args()
|
| 238 |
+
|
| 239 |
+
torch.distributed.init_process_group(
|
| 240 |
+
backend='nccl',
|
| 241 |
+
world_size=int(os.getenv('WORLD_SIZE', '1')),
|
| 242 |
+
rank=int(os.getenv('RANK', '0')),
|
| 243 |
+
)
|
| 244 |
+
|
| 245 |
+
torch.cuda.set_device(torch.distributed.get_rank())
|
| 246 |
+
|
| 247 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 248 |
+
args.checkpoint, device_map='cuda', trust_remote_code=True).eval()
|
| 249 |
+
|
| 250 |
+
tokenizer = AutoTokenizer.from_pretrained(args.checkpoint,
|
| 251 |
+
trust_remote_code=True)
|
| 252 |
+
tokenizer.padding_side = 'left'
|
| 253 |
+
tokenizer.pad_token_id = tokenizer.eod_id
|
| 254 |
+
|
| 255 |
+
prompt = '<img>{}</img>{} Answer:'
|
| 256 |
+
|
| 257 |
+
random.seed(args.seed)
|
| 258 |
+
dataset = VQADataset(
|
| 259 |
+
train=ds_collections[args.dataset]['train'],
|
| 260 |
+
test=ds_collections[args.dataset]['test'],
|
| 261 |
+
prompt=prompt,
|
| 262 |
+
few_shot=args.few_shot,
|
| 263 |
+
)
|
| 264 |
+
|
| 265 |
+
dataloader = torch.utils.data.DataLoader(
|
| 266 |
+
dataset=dataset,
|
| 267 |
+
sampler=InferenceSampler(len(dataset)),
|
| 268 |
+
batch_size=args.batch_size,
|
| 269 |
+
num_workers=args.num_workers,
|
| 270 |
+
pin_memory=True,
|
| 271 |
+
drop_last=False,
|
| 272 |
+
collate_fn=partial(collate_fn, tokenizer=tokenizer),
|
| 273 |
+
)
|
| 274 |
+
|
| 275 |
+
outputs = []
|
| 276 |
+
for _, (question_ids, input_ids,
|
| 277 |
+
attention_mask, annotations) in tqdm(enumerate(dataloader)):
|
| 278 |
+
pred = model.generate(
|
| 279 |
+
input_ids=input_ids.cuda(),
|
| 280 |
+
attention_mask=attention_mask.cuda(),
|
| 281 |
+
do_sample=False,
|
| 282 |
+
num_beams=1,
|
| 283 |
+
max_new_tokens=ds_collections[args.dataset]['max_new_tokens'],
|
| 284 |
+
min_new_tokens=1,
|
| 285 |
+
length_penalty=1,
|
| 286 |
+
num_return_sequences=1,
|
| 287 |
+
output_hidden_states=True,
|
| 288 |
+
use_cache=True,
|
| 289 |
+
pad_token_id=tokenizer.eod_id,
|
| 290 |
+
eos_token_id=tokenizer.eod_id,
|
| 291 |
+
)
|
| 292 |
+
answers = [
|
| 293 |
+
tokenizer.decode(_[input_ids.size(1):].cpu(),
|
| 294 |
+
skip_special_tokens=True).strip() for _ in pred
|
| 295 |
+
]
|
| 296 |
+
|
| 297 |
+
for question_id, answer, annotation in zip(question_ids, answers, annotations):
|
| 298 |
+
try:
|
| 299 |
+
outputs.append({'question_id': int(question_id), 'answer': answer, 'annotation': annotation})
|
| 300 |
+
except:
|
| 301 |
+
outputs.append({'question_id': question_id, 'answer': answer, 'annotation': annotation})
|
| 302 |
+
|
| 303 |
+
torch.distributed.barrier()
|
| 304 |
+
|
| 305 |
+
world_size = torch.distributed.get_world_size()
|
| 306 |
+
merged_outputs = [None for _ in range(world_size)]
|
| 307 |
+
torch.distributed.all_gather_object(merged_outputs, outputs)
|
| 308 |
+
|
| 309 |
+
merged_outputs = [_ for _ in itertools.chain.from_iterable(merged_outputs)]
|
| 310 |
+
|
| 311 |
+
if torch.distributed.get_rank() == 0:
|
| 312 |
+
time_prefix = time.strftime('%y%m%d%H%M%S', time.localtime())
|
| 313 |
+
results_file = f'{args.dataset}_{time_prefix}_fs{args.few_shot}_s{args.seed}.json'
|
| 314 |
+
json.dump(merged_outputs, open(results_file, 'w'),
|
| 315 |
+
ensure_ascii=False) # save to results
|
| 316 |
+
|
| 317 |
+
if ds_collections[args.dataset]['metric'] == 'vqa_score':
|
| 318 |
+
vqa = VQA(ds_collections[args.dataset]['annotation'],
|
| 319 |
+
ds_collections[args.dataset]['question'])
|
| 320 |
+
results = vqa.loadRes(
|
| 321 |
+
resFile=results_file,
|
| 322 |
+
quesFile=ds_collections[args.dataset]['question'])
|
| 323 |
+
vqa_scorer = VQAEval(vqa, results, n=2)
|
| 324 |
+
vqa_scorer.evaluate()
|
| 325 |
+
|
| 326 |
+
print(vqa_scorer.accuracy)
|
| 327 |
+
|
| 328 |
+
elif ds_collections[args.dataset]['metric'] == 'anls':
|
| 329 |
+
merged_outputs = [{'answer': _['answer'], 'questionId': _['question_id']} for _ in merged_outputs]
|
| 330 |
+
results_file = f'{args.dataset}_official_{time_prefix}.json'
|
| 331 |
+
json.dump(merged_outputs, open(results_file, 'w'), ensure_ascii=False)
|
| 332 |
+
print('python infographicsvqa_eval.py -g ' + ds_collections[args.dataset]['annotation'] + ' -s ' + results_file)
|
| 333 |
+
os.system('python infographicsvqa_eval.py -g ' + ds_collections[args.dataset]['annotation'] + ' -s ' + results_file)
|
| 334 |
+
elif ds_collections[args.dataset]['metric'] == 'relaxed_accuracy':
|
| 335 |
+
print({'relaxed_accuracy': evaluate_relaxed_accuracy(merged_outputs)})
|
| 336 |
+
elif ds_collections[args.dataset]['metric'] == 'accuracy':
|
| 337 |
+
if 'gqa' in args.dataset:
|
| 338 |
+
for entry in merged_outputs:
|
| 339 |
+
response = entry['answer']
|
| 340 |
+
response = response.strip().split('.')[0].split(',')[0].split('!')[0].lower()
|
| 341 |
+
if 'is ' in response:
|
| 342 |
+
response = response.split('is ')[1]
|
| 343 |
+
if 'are ' in response:
|
| 344 |
+
response = response.split('are ')[1]
|
| 345 |
+
if 'a ' in response:
|
| 346 |
+
response = response.split('a ')[1]
|
| 347 |
+
if 'an ' in response:
|
| 348 |
+
response = response.split('an ')[1]
|
| 349 |
+
if 'the ' in response:
|
| 350 |
+
response = response.split('the ')[1]
|
| 351 |
+
if ' of' in response:
|
| 352 |
+
response = response.split(' of')[0]
|
| 353 |
+
response = response.strip()
|
| 354 |
+
entry['answer'] = response
|
| 355 |
+
print({'accuracy': evaluate_exact_match_accuracy(merged_outputs)})
|
| 356 |
+
|
| 357 |
+
torch.distributed.barrier()
|
eval_mm/vqa.py
ADDED
|
@@ -0,0 +1,206 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Copyright (c) 2022, salesforce.com, inc.
|
| 2 |
+
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
__author__ = 'aagrawal'
|
| 9 |
+
__version__ = '0.9'
|
| 10 |
+
|
| 11 |
+
# Interface for accessing the VQA dataset.
|
| 12 |
+
|
| 13 |
+
# This code is based on the code written by Tsung-Yi Lin for MSCOCO Python API available at the following link:
|
| 14 |
+
# (https://github.com/pdollar/coco/blob/master/PythonAPI/pycocotools/coco.py).
|
| 15 |
+
|
| 16 |
+
# The following functions are defined:
|
| 17 |
+
# VQA - VQA class that loads VQA annotation file and prepares data structures.
|
| 18 |
+
# getQuesIds - Get question ids that satisfy given filter conditions.
|
| 19 |
+
# getImgIds - Get image ids that satisfy given filter conditions.
|
| 20 |
+
# loadQA - Load questions and answers with the specified question ids.
|
| 21 |
+
# showQA - Display the specified questions and answers.
|
| 22 |
+
# loadRes - Load result file and create result object.
|
| 23 |
+
|
| 24 |
+
# Help on each function can be accessed by: "help(COCO.function)"
|
| 25 |
+
|
| 26 |
+
import copy
|
| 27 |
+
import datetime
|
| 28 |
+
import json
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class VQA:
|
| 32 |
+
|
| 33 |
+
def __init__(self, annotation_file=None, question_file=None):
|
| 34 |
+
"""Constructor of VQA helper class for reading and visualizing
|
| 35 |
+
questions and answers.
|
| 36 |
+
|
| 37 |
+
:param annotation_file (str): location of VQA annotation file
|
| 38 |
+
:return:
|
| 39 |
+
"""
|
| 40 |
+
# load dataset
|
| 41 |
+
self.dataset = {}
|
| 42 |
+
self.questions = {}
|
| 43 |
+
self.qa = {}
|
| 44 |
+
self.qqa = {}
|
| 45 |
+
self.imgToQA = {}
|
| 46 |
+
if not annotation_file == None and not question_file == None:
|
| 47 |
+
print('loading VQA annotations and questions into memory...')
|
| 48 |
+
time_t = datetime.datetime.utcnow()
|
| 49 |
+
dataset = json.load(open(annotation_file, 'r'))
|
| 50 |
+
questions = json.load(open(question_file, 'r'))
|
| 51 |
+
self.dataset = dataset
|
| 52 |
+
self.questions = questions
|
| 53 |
+
self.createIndex()
|
| 54 |
+
|
| 55 |
+
def createIndex(self):
|
| 56 |
+
# create index
|
| 57 |
+
print('creating index...')
|
| 58 |
+
imgToQA = {ann['image_id']: [] for ann in self.dataset['annotations']}
|
| 59 |
+
qa = {ann['question_id']: [] for ann in self.dataset['annotations']}
|
| 60 |
+
qqa = {ann['question_id']: [] for ann in self.dataset['annotations']}
|
| 61 |
+
for ann in self.dataset['annotations']:
|
| 62 |
+
imgToQA[ann['image_id']] += [ann]
|
| 63 |
+
qa[ann['question_id']] = ann
|
| 64 |
+
for ques in self.questions['questions']:
|
| 65 |
+
qqa[ques['question_id']] = ques
|
| 66 |
+
print('index created!')
|
| 67 |
+
|
| 68 |
+
# create class members
|
| 69 |
+
self.qa = qa
|
| 70 |
+
self.qqa = qqa
|
| 71 |
+
self.imgToQA = imgToQA
|
| 72 |
+
|
| 73 |
+
def info(self):
|
| 74 |
+
"""Print information about the VQA annotation file.
|
| 75 |
+
|
| 76 |
+
:return:
|
| 77 |
+
"""
|
| 78 |
+
for key, value in self.datset['info'].items():
|
| 79 |
+
print('%s: %s' % (key, value))
|
| 80 |
+
|
| 81 |
+
def getQuesIds(self, imgIds=[], quesTypes=[], ansTypes=[]):
|
| 82 |
+
"""Get question ids that satisfy given filter conditions. default skips
|
| 83 |
+
that filter.
|
| 84 |
+
|
| 85 |
+
:param imgIds (int array) : get question ids for given imgs
|
| 86 |
+
quesTypes (str array) : get question ids for given question types
|
| 87 |
+
ansTypes (str array) : get question ids for given answer types
|
| 88 |
+
:return: ids (int array) : integer array of question ids
|
| 89 |
+
"""
|
| 90 |
+
imgIds = imgIds if type(imgIds) == list else [imgIds]
|
| 91 |
+
quesTypes = quesTypes if type(quesTypes) == list else [quesTypes]
|
| 92 |
+
ansTypes = ansTypes if type(ansTypes) == list else [ansTypes]
|
| 93 |
+
|
| 94 |
+
if len(imgIds) == len(quesTypes) == len(ansTypes) == 0:
|
| 95 |
+
anns = self.dataset['annotations']
|
| 96 |
+
else:
|
| 97 |
+
if not len(imgIds) == 0:
|
| 98 |
+
anns = sum(
|
| 99 |
+
[
|
| 100 |
+
self.imgToQA[imgId]
|
| 101 |
+
for imgId in imgIds if imgId in self.imgToQA
|
| 102 |
+
],
|
| 103 |
+
[],
|
| 104 |
+
)
|
| 105 |
+
else:
|
| 106 |
+
anns = self.dataset['annotations']
|
| 107 |
+
anns = (anns if len(quesTypes) == 0 else
|
| 108 |
+
[ann for ann in anns if ann['question_type'] in quesTypes])
|
| 109 |
+
anns = (anns if len(ansTypes) == 0 else
|
| 110 |
+
[ann for ann in anns if ann['answer_type'] in ansTypes])
|
| 111 |
+
ids = [ann['question_id'] for ann in anns]
|
| 112 |
+
return ids
|
| 113 |
+
|
| 114 |
+
def getImgIds(self, quesIds=[], quesTypes=[], ansTypes=[]):
|
| 115 |
+
"""Get image ids that satisfy given filter conditions. default skips
|
| 116 |
+
that filter.
|
| 117 |
+
|
| 118 |
+
:param quesIds (int array) : get image ids for given question ids
|
| 119 |
+
quesTypes (str array) : get image ids for given question types
|
| 120 |
+
ansTypes (str array) : get image ids for given answer types
|
| 121 |
+
:return: ids (int array) : integer array of image ids
|
| 122 |
+
"""
|
| 123 |
+
quesIds = quesIds if type(quesIds) == list else [quesIds]
|
| 124 |
+
quesTypes = quesTypes if type(quesTypes) == list else [quesTypes]
|
| 125 |
+
ansTypes = ansTypes if type(ansTypes) == list else [ansTypes]
|
| 126 |
+
|
| 127 |
+
if len(quesIds) == len(quesTypes) == len(ansTypes) == 0:
|
| 128 |
+
anns = self.dataset['annotations']
|
| 129 |
+
else:
|
| 130 |
+
if not len(quesIds) == 0:
|
| 131 |
+
anns = sum([
|
| 132 |
+
self.qa[quesId] for quesId in quesIds if quesId in self.qa
|
| 133 |
+
], [])
|
| 134 |
+
else:
|
| 135 |
+
anns = self.dataset['annotations']
|
| 136 |
+
anns = (anns if len(quesTypes) == 0 else
|
| 137 |
+
[ann for ann in anns if ann['question_type'] in quesTypes])
|
| 138 |
+
anns = (anns if len(ansTypes) == 0 else
|
| 139 |
+
[ann for ann in anns if ann['answer_type'] in ansTypes])
|
| 140 |
+
ids = [ann['image_id'] for ann in anns]
|
| 141 |
+
return ids
|
| 142 |
+
|
| 143 |
+
def loadQA(self, ids=[]):
|
| 144 |
+
"""Load questions and answers with the specified question ids.
|
| 145 |
+
|
| 146 |
+
:param ids (int array) : integer ids specifying question ids
|
| 147 |
+
:return: qa (object array) : loaded qa objects
|
| 148 |
+
"""
|
| 149 |
+
if type(ids) == list:
|
| 150 |
+
return [self.qa[id] for id in ids]
|
| 151 |
+
elif type(ids) == int:
|
| 152 |
+
return [self.qa[ids]]
|
| 153 |
+
|
| 154 |
+
def showQA(self, anns):
|
| 155 |
+
"""Display the specified annotations.
|
| 156 |
+
|
| 157 |
+
:param anns (array of object): annotations to display
|
| 158 |
+
:return: None
|
| 159 |
+
"""
|
| 160 |
+
if len(anns) == 0:
|
| 161 |
+
return 0
|
| 162 |
+
for ann in anns:
|
| 163 |
+
quesId = ann['question_id']
|
| 164 |
+
print('Question: %s' % (self.qqa[quesId]['question']))
|
| 165 |
+
for ans in ann['answers']:
|
| 166 |
+
print('Answer %d: %s' % (ans['answer_id'], ans['answer']))
|
| 167 |
+
|
| 168 |
+
def loadRes(self, resFile, quesFile):
|
| 169 |
+
"""Load result file and return a result object.
|
| 170 |
+
|
| 171 |
+
:param resFile (str) : file name of result file
|
| 172 |
+
:return: res (obj) : result api object
|
| 173 |
+
"""
|
| 174 |
+
res = VQA()
|
| 175 |
+
res.questions = json.load(open(quesFile))
|
| 176 |
+
res.dataset['info'] = copy.deepcopy(self.questions['info'])
|
| 177 |
+
res.dataset['task_type'] = copy.deepcopy(self.questions['task_type'])
|
| 178 |
+
res.dataset['data_type'] = copy.deepcopy(self.questions['data_type'])
|
| 179 |
+
res.dataset['data_subtype'] = copy.deepcopy(
|
| 180 |
+
self.questions['data_subtype'])
|
| 181 |
+
res.dataset['license'] = copy.deepcopy(self.questions['license'])
|
| 182 |
+
|
| 183 |
+
print('Loading and preparing results... ')
|
| 184 |
+
time_t = datetime.datetime.utcnow()
|
| 185 |
+
anns = json.load(open(resFile))
|
| 186 |
+
assert type(anns) == list, 'results is not an array of objects'
|
| 187 |
+
annsQuesIds = [ann['question_id'] for ann in anns]
|
| 188 |
+
assert set(annsQuesIds) == set(
|
| 189 |
+
self.getQuesIds()
|
| 190 |
+
), 'Results do not correspond to current VQA set. Either the results do not have predictions for all question ids in annotation file or there is atleast one question id that does not belong to the question ids in the annotation file.'
|
| 191 |
+
for ann in anns:
|
| 192 |
+
quesId = ann['question_id']
|
| 193 |
+
if res.dataset['task_type'] == 'Multiple Choice':
|
| 194 |
+
assert (
|
| 195 |
+
ann['answer'] in self.qqa[quesId]['multiple_choices']
|
| 196 |
+
), 'predicted answer is not one of the multiple choices'
|
| 197 |
+
qaAnn = self.qa[quesId]
|
| 198 |
+
ann['image_id'] = qaAnn['image_id']
|
| 199 |
+
ann['question_type'] = qaAnn['question_type']
|
| 200 |
+
ann['answer_type'] = qaAnn['answer_type']
|
| 201 |
+
print('DONE (t=%0.2fs)' %
|
| 202 |
+
((datetime.datetime.utcnow() - time_t).total_seconds()))
|
| 203 |
+
|
| 204 |
+
res.dataset['annotations'] = anns
|
| 205 |
+
res.createIndex()
|
| 206 |
+
return res
|
eval_mm/vqa_eval.py
ADDED
|
@@ -0,0 +1,330 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Copyright (c) 2022, salesforce.com, inc.
|
| 2 |
+
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
# coding=utf-8
|
| 9 |
+
|
| 10 |
+
__author__ = 'aagrawal'
|
| 11 |
+
|
| 12 |
+
import re
|
| 13 |
+
# This code is based on the code written by Tsung-Yi Lin for MSCOCO Python API available at the following link:
|
| 14 |
+
# (https://github.com/tylin/coco-caption/blob/master/pycocoevalcap/eval.py).
|
| 15 |
+
import sys
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class VQAEval:
|
| 19 |
+
|
| 20 |
+
def __init__(self, vqa=None, vqaRes=None, n=2):
|
| 21 |
+
self.n = n
|
| 22 |
+
self.accuracy = {}
|
| 23 |
+
self.evalQA = {}
|
| 24 |
+
self.evalQuesType = {}
|
| 25 |
+
self.evalAnsType = {}
|
| 26 |
+
self.vqa = vqa
|
| 27 |
+
self.vqaRes = vqaRes
|
| 28 |
+
if vqa is not None:
|
| 29 |
+
self.params = {'question_id': vqa.getQuesIds()}
|
| 30 |
+
self.contractions = {
|
| 31 |
+
'aint': "ain't",
|
| 32 |
+
'arent': "aren't",
|
| 33 |
+
'cant': "can't",
|
| 34 |
+
'couldve': "could've",
|
| 35 |
+
'couldnt': "couldn't",
|
| 36 |
+
"couldn'tve": "couldn't've",
|
| 37 |
+
"couldnt've": "couldn't've",
|
| 38 |
+
'didnt': "didn't",
|
| 39 |
+
'doesnt': "doesn't",
|
| 40 |
+
'dont': "don't",
|
| 41 |
+
'hadnt': "hadn't",
|
| 42 |
+
"hadnt've": "hadn't've",
|
| 43 |
+
"hadn'tve": "hadn't've",
|
| 44 |
+
'hasnt': "hasn't",
|
| 45 |
+
'havent': "haven't",
|
| 46 |
+
'hed': "he'd",
|
| 47 |
+
"hed've": "he'd've",
|
| 48 |
+
"he'dve": "he'd've",
|
| 49 |
+
'hes': "he's",
|
| 50 |
+
'howd': "how'd",
|
| 51 |
+
'howll': "how'll",
|
| 52 |
+
'hows': "how's",
|
| 53 |
+
"Id've": "I'd've",
|
| 54 |
+
"I'dve": "I'd've",
|
| 55 |
+
'Im': "I'm",
|
| 56 |
+
'Ive': "I've",
|
| 57 |
+
'isnt': "isn't",
|
| 58 |
+
'itd': "it'd",
|
| 59 |
+
"itd've": "it'd've",
|
| 60 |
+
"it'dve": "it'd've",
|
| 61 |
+
'itll': "it'll",
|
| 62 |
+
"let's": "let's",
|
| 63 |
+
'maam': "ma'am",
|
| 64 |
+
'mightnt': "mightn't",
|
| 65 |
+
"mightnt've": "mightn't've",
|
| 66 |
+
"mightn'tve": "mightn't've",
|
| 67 |
+
'mightve': "might've",
|
| 68 |
+
'mustnt': "mustn't",
|
| 69 |
+
'mustve': "must've",
|
| 70 |
+
'neednt': "needn't",
|
| 71 |
+
'notve': "not've",
|
| 72 |
+
'oclock': "o'clock",
|
| 73 |
+
'oughtnt': "oughtn't",
|
| 74 |
+
"ow's'at": "'ow's'at",
|
| 75 |
+
"'ows'at": "'ow's'at",
|
| 76 |
+
"'ow'sat": "'ow's'at",
|
| 77 |
+
'shant': "shan't",
|
| 78 |
+
"shed've": "she'd've",
|
| 79 |
+
"she'dve": "she'd've",
|
| 80 |
+
"she's": "she's",
|
| 81 |
+
'shouldve': "should've",
|
| 82 |
+
'shouldnt': "shouldn't",
|
| 83 |
+
"shouldnt've": "shouldn't've",
|
| 84 |
+
"shouldn'tve": "shouldn't've",
|
| 85 |
+
"somebody'd": 'somebodyd',
|
| 86 |
+
"somebodyd've": "somebody'd've",
|
| 87 |
+
"somebody'dve": "somebody'd've",
|
| 88 |
+
'somebodyll': "somebody'll",
|
| 89 |
+
'somebodys': "somebody's",
|
| 90 |
+
'someoned': "someone'd",
|
| 91 |
+
"someoned've": "someone'd've",
|
| 92 |
+
"someone'dve": "someone'd've",
|
| 93 |
+
'someonell': "someone'll",
|
| 94 |
+
'someones': "someone's",
|
| 95 |
+
'somethingd': "something'd",
|
| 96 |
+
"somethingd've": "something'd've",
|
| 97 |
+
"something'dve": "something'd've",
|
| 98 |
+
'somethingll': "something'll",
|
| 99 |
+
'thats': "that's",
|
| 100 |
+
'thered': "there'd",
|
| 101 |
+
"thered've": "there'd've",
|
| 102 |
+
"there'dve": "there'd've",
|
| 103 |
+
'therere': "there're",
|
| 104 |
+
'theres': "there's",
|
| 105 |
+
'theyd': "they'd",
|
| 106 |
+
"theyd've": "they'd've",
|
| 107 |
+
"they'dve": "they'd've",
|
| 108 |
+
'theyll': "they'll",
|
| 109 |
+
'theyre': "they're",
|
| 110 |
+
'theyve': "they've",
|
| 111 |
+
'twas': "'twas",
|
| 112 |
+
'wasnt': "wasn't",
|
| 113 |
+
"wed've": "we'd've",
|
| 114 |
+
"we'dve": "we'd've",
|
| 115 |
+
'weve': "we've",
|
| 116 |
+
'werent': "weren't",
|
| 117 |
+
'whatll': "what'll",
|
| 118 |
+
'whatre': "what're",
|
| 119 |
+
'whats': "what's",
|
| 120 |
+
'whatve': "what've",
|
| 121 |
+
'whens': "when's",
|
| 122 |
+
'whered': "where'd",
|
| 123 |
+
'wheres': "where's",
|
| 124 |
+
'whereve': "where've",
|
| 125 |
+
'whod': "who'd",
|
| 126 |
+
"whod've": "who'd've",
|
| 127 |
+
"who'dve": "who'd've",
|
| 128 |
+
'wholl': "who'll",
|
| 129 |
+
'whos': "who's",
|
| 130 |
+
'whove': "who've",
|
| 131 |
+
'whyll': "why'll",
|
| 132 |
+
'whyre': "why're",
|
| 133 |
+
'whys': "why's",
|
| 134 |
+
'wont': "won't",
|
| 135 |
+
'wouldve': "would've",
|
| 136 |
+
'wouldnt': "wouldn't",
|
| 137 |
+
"wouldnt've": "wouldn't've",
|
| 138 |
+
"wouldn'tve": "wouldn't've",
|
| 139 |
+
'yall': "y'all",
|
| 140 |
+
"yall'll": "y'all'll",
|
| 141 |
+
"y'allll": "y'all'll",
|
| 142 |
+
"yall'd've": "y'all'd've",
|
| 143 |
+
"y'alld've": "y'all'd've",
|
| 144 |
+
"y'all'dve": "y'all'd've",
|
| 145 |
+
'youd': "you'd",
|
| 146 |
+
"youd've": "you'd've",
|
| 147 |
+
"you'dve": "you'd've",
|
| 148 |
+
'youll': "you'll",
|
| 149 |
+
'youre': "you're",
|
| 150 |
+
'youve': "you've",
|
| 151 |
+
}
|
| 152 |
+
self.manualMap = {
|
| 153 |
+
'none': '0',
|
| 154 |
+
'zero': '0',
|
| 155 |
+
'one': '1',
|
| 156 |
+
'two': '2',
|
| 157 |
+
'three': '3',
|
| 158 |
+
'four': '4',
|
| 159 |
+
'five': '5',
|
| 160 |
+
'six': '6',
|
| 161 |
+
'seven': '7',
|
| 162 |
+
'eight': '8',
|
| 163 |
+
'nine': '9',
|
| 164 |
+
'ten': '10',
|
| 165 |
+
}
|
| 166 |
+
self.articles = ['a', 'an', 'the']
|
| 167 |
+
|
| 168 |
+
self.periodStrip = re.compile('(?!<=\d)(\.)(?!\d)')
|
| 169 |
+
self.commaStrip = re.compile('(\d)(,)(\d)')
|
| 170 |
+
self.punct = [
|
| 171 |
+
';',
|
| 172 |
+
r'/',
|
| 173 |
+
'[',
|
| 174 |
+
']',
|
| 175 |
+
'"',
|
| 176 |
+
'{',
|
| 177 |
+
'}',
|
| 178 |
+
'(',
|
| 179 |
+
')',
|
| 180 |
+
'=',
|
| 181 |
+
'+',
|
| 182 |
+
'\\',
|
| 183 |
+
'_',
|
| 184 |
+
'-',
|
| 185 |
+
'>',
|
| 186 |
+
'<',
|
| 187 |
+
'@',
|
| 188 |
+
'`',
|
| 189 |
+
',',
|
| 190 |
+
'?',
|
| 191 |
+
'!',
|
| 192 |
+
]
|
| 193 |
+
|
| 194 |
+
def evaluate(self, quesIds=None):
|
| 195 |
+
if quesIds == None:
|
| 196 |
+
quesIds = [quesId for quesId in self.params['question_id']]
|
| 197 |
+
gts = {}
|
| 198 |
+
res = {}
|
| 199 |
+
for quesId in quesIds:
|
| 200 |
+
gts[quesId] = self.vqa.qa[quesId]
|
| 201 |
+
res[quesId] = self.vqaRes.qa[quesId]
|
| 202 |
+
|
| 203 |
+
# =================================================
|
| 204 |
+
# Compute accuracy
|
| 205 |
+
# =================================================
|
| 206 |
+
accQA = []
|
| 207 |
+
accQuesType = {}
|
| 208 |
+
accAnsType = {}
|
| 209 |
+
print('computing accuracy')
|
| 210 |
+
step = 0
|
| 211 |
+
for quesId in quesIds:
|
| 212 |
+
resAns = res[quesId]['answer']
|
| 213 |
+
resAns = resAns.replace('\n', ' ')
|
| 214 |
+
resAns = resAns.replace('\t', ' ')
|
| 215 |
+
resAns = resAns.strip()
|
| 216 |
+
resAns = self.processPunctuation(resAns)
|
| 217 |
+
resAns = self.processDigitArticle(resAns)
|
| 218 |
+
gtAcc = []
|
| 219 |
+
gtAnswers = [ans['answer'] for ans in gts[quesId]['answers']]
|
| 220 |
+
if len(set(gtAnswers)) > 1:
|
| 221 |
+
for ansDic in gts[quesId]['answers']:
|
| 222 |
+
ansDic['answer'] = self.processPunctuation(
|
| 223 |
+
ansDic['answer'])
|
| 224 |
+
for gtAnsDatum in gts[quesId]['answers']:
|
| 225 |
+
otherGTAns = [
|
| 226 |
+
item for item in gts[quesId]['answers']
|
| 227 |
+
if item != gtAnsDatum
|
| 228 |
+
]
|
| 229 |
+
matchingAns = [
|
| 230 |
+
item for item in otherGTAns if item['answer'] == resAns
|
| 231 |
+
]
|
| 232 |
+
acc = min(1, float(len(matchingAns)) / 3)
|
| 233 |
+
gtAcc.append(acc)
|
| 234 |
+
quesType = gts[quesId]['question_type']
|
| 235 |
+
ansType = gts[quesId]['answer_type']
|
| 236 |
+
avgGTAcc = float(sum(gtAcc)) / len(gtAcc)
|
| 237 |
+
accQA.append(avgGTAcc)
|
| 238 |
+
if quesType not in accQuesType:
|
| 239 |
+
accQuesType[quesType] = []
|
| 240 |
+
accQuesType[quesType].append(avgGTAcc)
|
| 241 |
+
if ansType not in accAnsType:
|
| 242 |
+
accAnsType[ansType] = []
|
| 243 |
+
accAnsType[ansType].append(avgGTAcc)
|
| 244 |
+
self.setEvalQA(quesId, avgGTAcc)
|
| 245 |
+
self.setEvalQuesType(quesId, quesType, avgGTAcc)
|
| 246 |
+
self.setEvalAnsType(quesId, ansType, avgGTAcc)
|
| 247 |
+
if step % 100 == 0:
|
| 248 |
+
self.updateProgress(step / float(len(quesIds)))
|
| 249 |
+
step = step + 1
|
| 250 |
+
|
| 251 |
+
self.setAccuracy(accQA, accQuesType, accAnsType)
|
| 252 |
+
print('Done computing accuracy')
|
| 253 |
+
|
| 254 |
+
def processPunctuation(self, inText):
|
| 255 |
+
outText = inText
|
| 256 |
+
for p in self.punct:
|
| 257 |
+
if (p + ' ' in inText or ' ' + p
|
| 258 |
+
in inText) or (re.search(self.commaStrip, inText) != None):
|
| 259 |
+
outText = outText.replace(p, '')
|
| 260 |
+
else:
|
| 261 |
+
outText = outText.replace(p, ' ')
|
| 262 |
+
outText = self.periodStrip.sub('', outText, re.UNICODE)
|
| 263 |
+
return outText
|
| 264 |
+
|
| 265 |
+
def processDigitArticle(self, inText):
|
| 266 |
+
outText = []
|
| 267 |
+
tempText = inText.lower().split()
|
| 268 |
+
for word in tempText:
|
| 269 |
+
word = self.manualMap.setdefault(word, word)
|
| 270 |
+
if word not in self.articles:
|
| 271 |
+
outText.append(word)
|
| 272 |
+
else:
|
| 273 |
+
pass
|
| 274 |
+
for wordId, word in enumerate(outText):
|
| 275 |
+
if word in self.contractions:
|
| 276 |
+
outText[wordId] = self.contractions[word]
|
| 277 |
+
outText = ' '.join(outText)
|
| 278 |
+
return outText
|
| 279 |
+
|
| 280 |
+
def setAccuracy(self, accQA, accQuesType, accAnsType):
|
| 281 |
+
self.accuracy['overall'] = round(100 * float(sum(accQA)) / len(accQA),
|
| 282 |
+
self.n)
|
| 283 |
+
self.accuracy['perQuestionType'] = {
|
| 284 |
+
quesType: round(
|
| 285 |
+
100 * float(sum(accQuesType[quesType])) /
|
| 286 |
+
len(accQuesType[quesType]),
|
| 287 |
+
self.n,
|
| 288 |
+
)
|
| 289 |
+
for quesType in accQuesType
|
| 290 |
+
}
|
| 291 |
+
self.accuracy['perAnswerType'] = {
|
| 292 |
+
ansType: round(
|
| 293 |
+
100 * float(sum(accAnsType[ansType])) /
|
| 294 |
+
len(accAnsType[ansType]), self.n)
|
| 295 |
+
for ansType in accAnsType
|
| 296 |
+
}
|
| 297 |
+
|
| 298 |
+
def setEvalQA(self, quesId, acc):
|
| 299 |
+
self.evalQA[quesId] = round(100 * acc, self.n)
|
| 300 |
+
|
| 301 |
+
def setEvalQuesType(self, quesId, quesType, acc):
|
| 302 |
+
if quesType not in self.evalQuesType:
|
| 303 |
+
self.evalQuesType[quesType] = {}
|
| 304 |
+
self.evalQuesType[quesType][quesId] = round(100 * acc, self.n)
|
| 305 |
+
|
| 306 |
+
def setEvalAnsType(self, quesId, ansType, acc):
|
| 307 |
+
if ansType not in self.evalAnsType:
|
| 308 |
+
self.evalAnsType[ansType] = {}
|
| 309 |
+
self.evalAnsType[ansType][quesId] = round(100 * acc, self.n)
|
| 310 |
+
|
| 311 |
+
def updateProgress(self, progress):
|
| 312 |
+
barLength = 20
|
| 313 |
+
status = ''
|
| 314 |
+
if isinstance(progress, int):
|
| 315 |
+
progress = float(progress)
|
| 316 |
+
if not isinstance(progress, float):
|
| 317 |
+
progress = 0
|
| 318 |
+
status = 'error: progress var must be float\r\n'
|
| 319 |
+
if progress < 0:
|
| 320 |
+
progress = 0
|
| 321 |
+
status = 'Halt...\r\n'
|
| 322 |
+
if progress >= 1:
|
| 323 |
+
progress = 1
|
| 324 |
+
status = 'Done...\r\n'
|
| 325 |
+
block = int(round(barLength * progress))
|
| 326 |
+
text = '\rFinshed Percent: [{0}] {1}% {2}'.format(
|
| 327 |
+
'#' * block + '-' * (barLength - block), int(progress * 100),
|
| 328 |
+
status)
|
| 329 |
+
sys.stdout.write(text)
|
| 330 |
+
sys.stdout.flush()
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
transformers==4.31.0
|
| 2 |
+
accelerate
|
| 3 |
+
tiktoken
|
| 4 |
+
einops
|
| 5 |
+
transformers_stream_generator==0.0.4
|
| 6 |
+
scipy
|
| 7 |
+
torchvision
|
| 8 |
+
pillow
|
| 9 |
+
tensorboard
|
| 10 |
+
matplotlib
|
requirements_web_demo.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
gradio
|