Spaces:
Sleeping

Sleeping
StyleDrop init
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- .gitignore +5 -0
- Dockerfile +57 -0
- README copy.md +13 -0
- app.py +264 -0
- assets/contexts/empty_context.npy +3 -0
- assets/fid_stats/fid_stats_cc3m_val.npz +3 -0
- assets/fid_stats/fid_stats_imagenet256_guided_diffusion.npz +3 -0
- assets/pipeline.png +0 -0
- configs/cc3m_xl_vqf16_jax_2048bs_featset_CLIP_G.py +92 -0
- configs/custom.py +83 -0
- configs/imagenet256_base_vq_jax.py +84 -0
- configs/vae_configs/vq-f16-jax.yaml +42 -0
- custom/custom_dataset.py +233 -0
- data/data.json +22 -0
- data/image_01_01.jpg +3 -0
- data/image_01_02.jpg +3 -0
- data/image_01_03.jpg +3 -0
- data/image_01_04.jpg +3 -0
- data/image_01_05.jpg +3 -0
- data/image_01_06.jpg +3 -0
- data/image_01_07.jpg +3 -0
- data/image_01_08.jpg +3 -0
- data/image_02_01.jpg +3 -0
- data/image_02_02.jpg +3 -0
- data/image_02_03.jpg +3 -0
- data/image_02_04.jpg +3 -0
- data/image_02_05.jpg +3 -0
- data/image_02_06.jpg +3 -0
- data/image_03_01.jpg +3 -0
- data/image_03_03.jpg +3 -0
- data/image_03_04.jpg +3 -0
- data/image_03_05.jpg +3 -0
- data/image_03_07.jpg +3 -0
- data/image_03_08.jpg +3 -0
- data/one_style.json +3 -0
- libs/__init__.py +1 -0
- libs/muse.py +107 -0
- libs/uvit_t2i_vq.py +282 -0
- libs/uvit_vq.py +264 -0
- open_clip/__init__.py +13 -0
- open_clip/bpe_simple_vocab_16e6.txt.gz +3 -0
- open_clip/coca_model.py +458 -0
- open_clip/constants.py +2 -0
- open_clip/factory.py +366 -0
- open_clip/generation_utils.py +0 -0
- open_clip/hf_configs.py +45 -0
- open_clip/hf_model.py +176 -0
- open_clip/loss.py +212 -0
- open_clip/model.py +445 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.jpg filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
| 2 |
+
*.ckpt
|
| 3 |
+
assets/ckpts
|
| 4 |
+
__pycache__/
|
| 5 |
+
*.sh
|
Dockerfile
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvidia/cuda:11.7.1-cudnn8-devel-ubuntu22.04
|
| 2 |
+
ENV DEBIAN_FRONTEND=noninteractive
|
| 3 |
+
RUN apt-get update && \
|
| 4 |
+
apt-get upgrade -y && \
|
| 5 |
+
apt-get install -y --no-install-recommends \
|
| 6 |
+
git \
|
| 7 |
+
git-lfs \
|
| 8 |
+
wget \
|
| 9 |
+
curl \
|
| 10 |
+
# ffmpeg \
|
| 11 |
+
ffmpeg \
|
| 12 |
+
x264 \
|
| 13 |
+
# python build dependencies \
|
| 14 |
+
build-essential \
|
| 15 |
+
libssl-dev \
|
| 16 |
+
zlib1g-dev \
|
| 17 |
+
libbz2-dev \
|
| 18 |
+
libreadline-dev \
|
| 19 |
+
libsqlite3-dev \
|
| 20 |
+
libncursesw5-dev \
|
| 21 |
+
xz-utils \
|
| 22 |
+
tk-dev \
|
| 23 |
+
libxml2-dev \
|
| 24 |
+
libxmlsec1-dev \
|
| 25 |
+
libffi-dev \
|
| 26 |
+
liblzma-dev && \
|
| 27 |
+
apt-get clean && \
|
| 28 |
+
rm -rf /var/lib/apt/lists/*
|
| 29 |
+
|
| 30 |
+
RUN useradd -m -u 1000 user
|
| 31 |
+
USER user
|
| 32 |
+
ENV HOME=/home/user \
|
| 33 |
+
PATH=/home/user/.local/bin:${PATH}
|
| 34 |
+
WORKDIR ${HOME}/app
|
| 35 |
+
|
| 36 |
+
RUN curl https://pyenv.run | bash
|
| 37 |
+
ENV PATH=${HOME}/.pyenv/shims:${HOME}/.pyenv/bin:${PATH}
|
| 38 |
+
ENV PYTHON_VERSION=3.8.16
|
| 39 |
+
RUN pyenv install ${PYTHON_VERSION} && \
|
| 40 |
+
pyenv global ${PYTHON_VERSION} && \
|
| 41 |
+
pyenv rehash && \
|
| 42 |
+
pip install --no-cache-dir -U pip setuptools wheel
|
| 43 |
+
|
| 44 |
+
RUN pip install --no-cache-dir -U torch==1.12.1 torchvision==0.13.1
|
| 45 |
+
COPY --chown=1000 requirements.txt /tmp/requirements.txt
|
| 46 |
+
RUN pip install --no-cache-dir -U -r /tmp/requirements.txt
|
| 47 |
+
|
| 48 |
+
COPY --chown=1000 . ${HOME}/app
|
| 49 |
+
# RUN cd Tune-A-Video && patch -p1 < ../patch
|
| 50 |
+
ENV PYTHONPATH=${HOME}/app \
|
| 51 |
+
PYTHONUNBUFFERED=1 \
|
| 52 |
+
GRADIO_ALLOW_FLAGGING=never \
|
| 53 |
+
GRADIO_NUM_PORTS=1 \
|
| 54 |
+
GRADIO_SERVER_NAME=0.0.0.0 \
|
| 55 |
+
GRADIO_THEME=huggingface \
|
| 56 |
+
SYSTEM=spaces
|
| 57 |
+
CMD ["python", "app.py"]
|
README copy.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: StyleDrop Pytorch
|
| 3 |
+
emoji: 📊
|
| 4 |
+
colorFrom: purple
|
| 5 |
+
colorTo: pink
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.35.2
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: mit
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
app.py
ADDED
|
@@ -0,0 +1,264 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import gradio as gr
|
| 3 |
+
import open_clip
|
| 4 |
+
import torch
|
| 5 |
+
import taming.models.vqgan
|
| 6 |
+
import ml_collections
|
| 7 |
+
import einops
|
| 8 |
+
import random
|
| 9 |
+
import pathlib
|
| 10 |
+
import subprocess
|
| 11 |
+
import shlex
|
| 12 |
+
import wget
|
| 13 |
+
# Model
|
| 14 |
+
from libs.muse import MUSE
|
| 15 |
+
import utils
|
| 16 |
+
import numpy as np
|
| 17 |
+
from PIL import Image
|
| 18 |
+
print("cuda available:",torch.cuda.is_available())
|
| 19 |
+
print("cuda device count:",torch.cuda.device_count())
|
| 20 |
+
print("cuda device name:",torch.cuda.get_device_name(0))
|
| 21 |
+
print(os.system("nvidia-smi"))
|
| 22 |
+
print(os.system("nvcc --version"))
|
| 23 |
+
|
| 24 |
+
empty_context = np.load("assets/contexts/empty_context.npy")
|
| 25 |
+
|
| 26 |
+
print("downloading cc3m-285000.ckpt")
|
| 27 |
+
os.makedirs("assets/ckpts/cc3m-285000.ckpt",exist_ok=True)
|
| 28 |
+
os.system("ls")
|
| 29 |
+
wget.download("https://huggingface.co/nzl-thu/MUSE/resolve/main/assets/ckpts/cc3m-285000.ckpt/lr_scheduler.pth","assets/ckpts/cc3m-285000.ckpt/lr_scheduler.pth")
|
| 30 |
+
wget.download("https://huggingface.co/nzl-thu/MUSE/resolve/main/assets/ckpts/cc3m-285000.ckpt/optimizer.pth","assets/ckpts/cc3m-285000.ckpt/optimizer.pth")
|
| 31 |
+
wget.download("https://huggingface.co/nzl-thu/MUSE/resolve/main/assets/ckpts/cc3m-285000.ckpt/nnet.pth","assets/ckpts/cc3m-285000.ckpt/nnet.pth")
|
| 32 |
+
wget.download("https://huggingface.co/nzl-thu/MUSE/resolve/main/assets/ckpts/cc3m-285000.ckpt/nnet_ema.pth","assets/ckpts/cc3m-285000.ckpt/nnet_ema.pth")
|
| 33 |
+
wget.download("https://huggingface.co/nzl-thu/MUSE/resolve/main/assets/ckpts/cc3m-285000.ckpt/step.pth","assets/ckpts/cc3m-285000.ckpt/step.pth")
|
| 34 |
+
wget.download("https://huggingface.co/zideliu/vqgan/resolve/main/vqgan_jax_strongaug.ckpt","assets/vqgan_jax_strongaug.ckpt")
|
| 35 |
+
|
| 36 |
+
def set_seed(seed: int):
|
| 37 |
+
random.seed(seed)
|
| 38 |
+
np.random.seed(seed)
|
| 39 |
+
torch.manual_seed(seed)
|
| 40 |
+
torch.cuda.manual_seed_all(seed)
|
| 41 |
+
|
| 42 |
+
def d(**kwargs):
|
| 43 |
+
"""Helper of creating a config dict."""
|
| 44 |
+
return ml_collections.ConfigDict(initial_dictionary=kwargs)
|
| 45 |
+
|
| 46 |
+
def get_config():
|
| 47 |
+
config = ml_collections.ConfigDict()
|
| 48 |
+
config.seed = 1234
|
| 49 |
+
config.z_shape = (8, 16, 16)
|
| 50 |
+
|
| 51 |
+
config.autoencoder = d(
|
| 52 |
+
config_file='vq-f16-jax.yaml',
|
| 53 |
+
)
|
| 54 |
+
config.resume_root="assets/ckpts/cc3m-285000.ckpt"
|
| 55 |
+
config.adapter_path=None
|
| 56 |
+
config.optimizer = d(
|
| 57 |
+
name='adamw',
|
| 58 |
+
lr=0.0002,
|
| 59 |
+
weight_decay=0.03,
|
| 60 |
+
betas=(0.99, 0.99),
|
| 61 |
+
)
|
| 62 |
+
config.lr_scheduler = d(
|
| 63 |
+
name='customized',
|
| 64 |
+
warmup_steps=5000
|
| 65 |
+
)
|
| 66 |
+
config.nnet = d(
|
| 67 |
+
name='uvit_t2i_vq',
|
| 68 |
+
img_size=16,
|
| 69 |
+
codebook_size=1024,
|
| 70 |
+
in_chans=4,
|
| 71 |
+
embed_dim=1152,
|
| 72 |
+
depth=28,
|
| 73 |
+
num_heads=16,
|
| 74 |
+
mlp_ratio=4,
|
| 75 |
+
qkv_bias=False,
|
| 76 |
+
clip_dim=1280,
|
| 77 |
+
num_clip_token=77,
|
| 78 |
+
use_checkpoint=True,
|
| 79 |
+
skip=True,
|
| 80 |
+
d_prj=32,
|
| 81 |
+
is_shared=False
|
| 82 |
+
)
|
| 83 |
+
config.muse = d(
|
| 84 |
+
ignore_ind=-1,
|
| 85 |
+
smoothing=0.1,
|
| 86 |
+
gen_temp=4.5
|
| 87 |
+
)
|
| 88 |
+
config.sample = d(
|
| 89 |
+
sample_steps=36,
|
| 90 |
+
n_samples=50,
|
| 91 |
+
mini_batch_size=8,
|
| 92 |
+
cfg=True,
|
| 93 |
+
linear_inc_scale=True,
|
| 94 |
+
scale=10.,
|
| 95 |
+
path='',
|
| 96 |
+
lambdaA=2.0, # Stage I: 2.0; Stage II: TODO
|
| 97 |
+
lambdaB=5.0, # Stage I: 5.0; Stage II: TODO
|
| 98 |
+
)
|
| 99 |
+
return config
|
| 100 |
+
|
| 101 |
+
def cfg_nnet(x, context, scale=None,lambdaA=None,lambdaB=None):
|
| 102 |
+
_cond = nnet_ema(x, context=context)
|
| 103 |
+
_cond_w_adapter = nnet_ema(x,context=context,use_adapter=True)
|
| 104 |
+
_empty_context = torch.tensor(empty_context, device=device)
|
| 105 |
+
_empty_context = einops.repeat(_empty_context, 'L D -> B L D', B=x.size(0))
|
| 106 |
+
_uncond = nnet_ema(x, context=_empty_context)
|
| 107 |
+
res = _cond + scale * (_cond - _uncond)
|
| 108 |
+
if lambdaA is not None:
|
| 109 |
+
res = _cond_w_adapter + lambdaA*(_cond_w_adapter - _cond) + lambdaB*(_cond - _uncond)
|
| 110 |
+
return res
|
| 111 |
+
|
| 112 |
+
def unprocess(x):
|
| 113 |
+
x.clamp_(0., 1.)
|
| 114 |
+
return x
|
| 115 |
+
|
| 116 |
+
config = get_config()
|
| 117 |
+
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
|
| 118 |
+
|
| 119 |
+
# Load open_clip and vq model
|
| 120 |
+
prompt_model,_,_ = open_clip.create_model_and_transforms('ViT-bigG-14', 'laion2b_s39b_b160k')
|
| 121 |
+
prompt_model = prompt_model.to(device)
|
| 122 |
+
prompt_model.eval()
|
| 123 |
+
tokenizer = open_clip.get_tokenizer('ViT-bigG-14')
|
| 124 |
+
|
| 125 |
+
vq_model = taming.models.vqgan.get_model('vq-f16-jax.yaml')
|
| 126 |
+
vq_model.eval()
|
| 127 |
+
vq_model.requires_grad_(False)
|
| 128 |
+
vq_model.to(device)
|
| 129 |
+
|
| 130 |
+
## config
|
| 131 |
+
|
| 132 |
+
muse = MUSE(codebook_size=vq_model.n_embed, device=device, **config.muse)
|
| 133 |
+
|
| 134 |
+
train_state = utils.initialize_train_state(config, device)
|
| 135 |
+
train_state.resume(ckpt_root=config.resume_root)
|
| 136 |
+
nnet_ema = train_state.nnet_ema
|
| 137 |
+
nnet_ema.eval()
|
| 138 |
+
nnet_ema.requires_grad_(False)
|
| 139 |
+
nnet_ema.to(device)
|
| 140 |
+
style_ref = {
|
| 141 |
+
"None":None,
|
| 142 |
+
"0102":"style_adapter/0102.pth",
|
| 143 |
+
"0103":"style_adapter/0103.pth",
|
| 144 |
+
"0106":"style_adapter/0106.pth",
|
| 145 |
+
"0108":"style_adapter/0108.pth",
|
| 146 |
+
"0301":"style_adapter/0301.pth",
|
| 147 |
+
"0305":"style_adapter/0305.pth",
|
| 148 |
+
}
|
| 149 |
+
style_postfix ={
|
| 150 |
+
"None":"",
|
| 151 |
+
"0102":" in watercolor painting style",
|
| 152 |
+
"0103":" in watercolor painting style",
|
| 153 |
+
"0106":" in line drawing style",
|
| 154 |
+
"0108":" in oil painting style",
|
| 155 |
+
"0301":" in 3d rendering style",
|
| 156 |
+
"0305":" in kid crayon drawing style",
|
| 157 |
+
}
|
| 158 |
+
|
| 159 |
+
def decode(_batch):
|
| 160 |
+
return vq_model.decode_code(_batch)
|
| 161 |
+
|
| 162 |
+
def process(prompt,num_samples,lambdaA,lambdaB,style,seed,sample_steps,image=None):
|
| 163 |
+
config.sample.lambdaA = lambdaA
|
| 164 |
+
config.sample.lambdaB = lambdaB
|
| 165 |
+
config.sample.sample_steps = sample_steps
|
| 166 |
+
print(style)
|
| 167 |
+
adapter_path = style_ref[style]
|
| 168 |
+
adapter_postfix = style_postfix[style]
|
| 169 |
+
print(f"load adapter path: {adapter_path}")
|
| 170 |
+
if adapter_path is not None:
|
| 171 |
+
nnet_ema.adapter.load_state_dict(torch.load(adapter_path))
|
| 172 |
+
else:
|
| 173 |
+
config.sample.lambdaA=None
|
| 174 |
+
config.sample.lambdaB=None
|
| 175 |
+
print("load adapter Done!")
|
| 176 |
+
# Encode prompt
|
| 177 |
+
prompt = prompt+adapter_postfix
|
| 178 |
+
text_tokens = tokenizer(prompt).to(device)
|
| 179 |
+
text_embedding = prompt_model.encode_text(text_tokens)
|
| 180 |
+
text_embedding = text_embedding.repeat(num_samples, 1, 1) # B 77 1280
|
| 181 |
+
print(text_embedding.shape)
|
| 182 |
+
|
| 183 |
+
print(f"lambdaA: {lambdaA}, lambdaB: {lambdaB}, sample_steps: {sample_steps}")
|
| 184 |
+
if seed==-1:
|
| 185 |
+
seed = random.randint(0,65535)
|
| 186 |
+
config.seed = seed
|
| 187 |
+
print(f"seed: {seed}")
|
| 188 |
+
set_seed(config.seed)
|
| 189 |
+
res = muse.generate(config,num_samples,cfg_nnet,decode,is_eval=True,context=text_embedding)
|
| 190 |
+
print(res.shape)
|
| 191 |
+
res = (res*255+0.5).clamp_(0,255).permute(0,2,3,1).to('cpu',torch.uint8).numpy()
|
| 192 |
+
im = [res[i] for i in range(num_samples)]
|
| 193 |
+
return im
|
| 194 |
+
|
| 195 |
+
block = gr.Blocks()
|
| 196 |
+
with block:
|
| 197 |
+
with gr.Row():
|
| 198 |
+
gr.Markdown("## StyleDrop based on Muse (Inference Only) ")
|
| 199 |
+
with gr.Row():
|
| 200 |
+
with gr.Column():
|
| 201 |
+
prompt = gr.Textbox(label="Prompt")
|
| 202 |
+
run_button = gr.Button(label="Run")
|
| 203 |
+
num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=1, step=1)
|
| 204 |
+
seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, value=1234)
|
| 205 |
+
style = gr.Radio(choices=["0102","0103","0106","0108","0305","None"],type="value",value="None",label="Style")
|
| 206 |
+
|
| 207 |
+
with gr.Accordion("Advanced options",open=False):
|
| 208 |
+
lambdaA = gr.Slider(label="lambdaA", minimum=0.0, maximum=5.0, value=2.0, step=0.01)
|
| 209 |
+
lambdaB = gr.Slider(label="lambdaB", minimum=0.0, maximum=10.0, value=5.0, step=0.01)
|
| 210 |
+
sample_steps = gr.Slider(label="Sample steps", minimum=1, maximum=50, value=36, step=1)
|
| 211 |
+
image=gr.Image(value=None)
|
| 212 |
+
with gr.Column():
|
| 213 |
+
result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(columns=2, height='auto')
|
| 214 |
+
|
| 215 |
+
with gr.Row():
|
| 216 |
+
examples = [
|
| 217 |
+
[
|
| 218 |
+
"A banana on the table",
|
| 219 |
+
1,2.0,5.0,"0103",1234,36,
|
| 220 |
+
"data/image_01_03.jpg",
|
| 221 |
+
],
|
| 222 |
+
[
|
| 223 |
+
|
| 224 |
+
"A cow",
|
| 225 |
+
1,2.0,5.0,"0102",1234,36,
|
| 226 |
+
"data/image_01_02.jpg",
|
| 227 |
+
],
|
| 228 |
+
[
|
| 229 |
+
|
| 230 |
+
"A portrait of tabby cat",
|
| 231 |
+
1,2.0,5.0,"0106",1234,36,
|
| 232 |
+
"data/image_01_06.jpg",
|
| 233 |
+
],
|
| 234 |
+
[
|
| 235 |
+
|
| 236 |
+
"A church in the field",
|
| 237 |
+
1,2.0,5.0,"0108",1234,36,
|
| 238 |
+
"data/image_01_08.jpg",
|
| 239 |
+
],
|
| 240 |
+
[
|
| 241 |
+
|
| 242 |
+
"A Christmas tree",
|
| 243 |
+
1,2.0,5.0,"0305",1234,36,
|
| 244 |
+
"data/image_03_05.jpg",
|
| 245 |
+
]
|
| 246 |
+
|
| 247 |
+
]
|
| 248 |
+
gr.Examples(examples=examples,
|
| 249 |
+
fn=process,
|
| 250 |
+
inputs=[
|
| 251 |
+
prompt,
|
| 252 |
+
num_samples,lambdaA,lambdaB,style,seed,sample_steps,image,
|
| 253 |
+
],
|
| 254 |
+
outputs=result_gallery,
|
| 255 |
+
cache_examples=os.getenv('SYSTEM') == 'spaces'
|
| 256 |
+
)
|
| 257 |
+
ips = [prompt,num_samples,lambdaA,lambdaB,style,seed,sample_steps,image]
|
| 258 |
+
run_button.click(
|
| 259 |
+
fn=process,
|
| 260 |
+
inputs=ips,
|
| 261 |
+
outputs=[result_gallery]
|
| 262 |
+
)
|
| 263 |
+
block.queue().launch(share=False)
|
| 264 |
+
|
assets/contexts/empty_context.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cf06c46310efa57d47e34e5221ffa757dc6c60e91c8758fcb1d19040ee61e9fc
|
| 3 |
+
size 394368
|
assets/fid_stats/fid_stats_cc3m_val.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:84605eaad681c8fdb13c5f96f9bcc7a7d8648e4e03023f2498aec7deb3ea3179
|
| 3 |
+
size 33571316
|
assets/fid_stats/fid_stats_imagenet256_guided_diffusion.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:374aa549982adbfd595eaecc8a014eea6566156f8b227fc2d9052c0482bb4a2f
|
| 3 |
+
size 33571316
|
assets/pipeline.png
ADDED
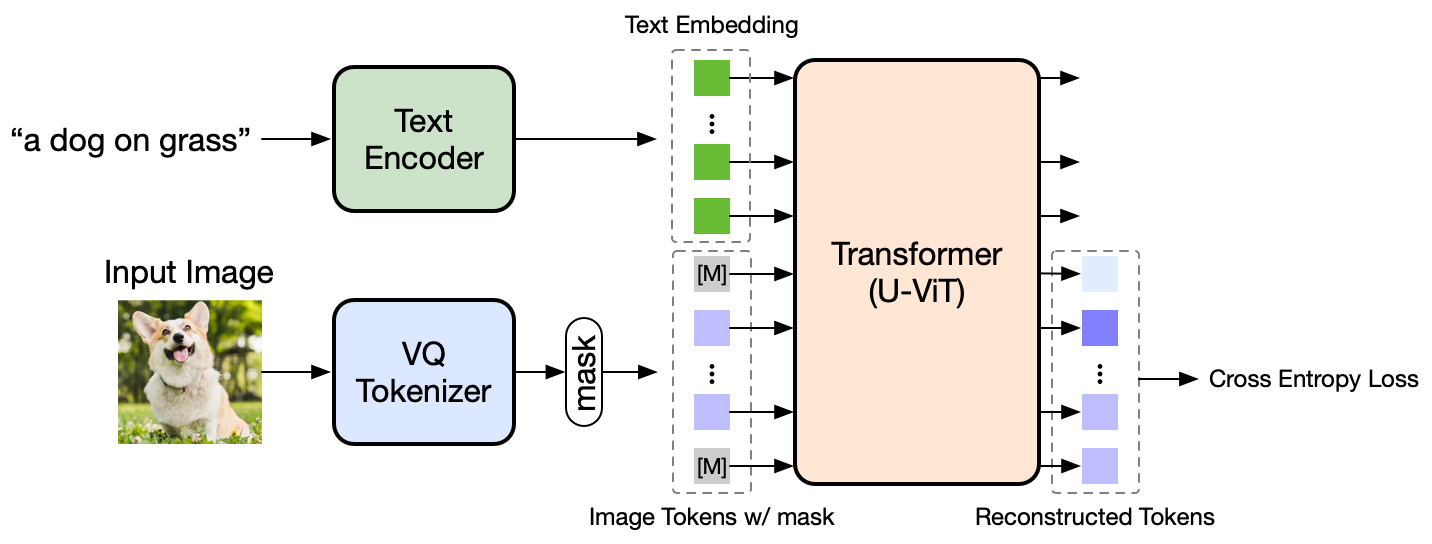
|
configs/cc3m_xl_vqf16_jax_2048bs_featset_CLIP_G.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ml_collections
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def d(**kwargs):
|
| 5 |
+
"""Helper of creating a config dict."""
|
| 6 |
+
return ml_collections.ConfigDict(initial_dictionary=kwargs)
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_config():
|
| 10 |
+
config = ml_collections.ConfigDict()
|
| 11 |
+
|
| 12 |
+
config.seed = 1234
|
| 13 |
+
config.z_shape = (8, 16, 16)
|
| 14 |
+
|
| 15 |
+
config.autoencoder = d(
|
| 16 |
+
config_file='vq-f16-jax.yaml',
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
config.train = d(
|
| 20 |
+
n_steps=999999999,
|
| 21 |
+
batch_size=2048,
|
| 22 |
+
log_interval=10,
|
| 23 |
+
eval_interval=5000,
|
| 24 |
+
save_interval=5000,
|
| 25 |
+
fid_interval=50000,
|
| 26 |
+
num_workers=8,
|
| 27 |
+
resampled=False,
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
config.eval = d(
|
| 31 |
+
n_samples=10000,
|
| 32 |
+
sample_steps=18,
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
config.optimizer = d(
|
| 36 |
+
name='adamw',
|
| 37 |
+
lr=0.0002,
|
| 38 |
+
weight_decay=0.03,
|
| 39 |
+
betas=(0.99, 0.99),
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
config.lr_scheduler = d(
|
| 43 |
+
name='customized',
|
| 44 |
+
warmup_steps=5000
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
+
config.nnet = d(
|
| 48 |
+
name='uvit_t2i_vq',
|
| 49 |
+
img_size=16,
|
| 50 |
+
codebook_size=1024,
|
| 51 |
+
in_chans=4,
|
| 52 |
+
embed_dim=1152,
|
| 53 |
+
depth=28,
|
| 54 |
+
num_heads=16,
|
| 55 |
+
mlp_ratio=4,
|
| 56 |
+
qkv_bias=False,
|
| 57 |
+
clip_dim=1280,
|
| 58 |
+
num_clip_token=77,
|
| 59 |
+
use_checkpoint=True,
|
| 60 |
+
skip=True,
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
config.muse = d(
|
| 64 |
+
ignore_ind=-1,
|
| 65 |
+
smoothing=0.1,
|
| 66 |
+
gen_temp=4.5
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
config.dataset = d(
|
| 70 |
+
name='cc3m_web',
|
| 71 |
+
cfg=True,
|
| 72 |
+
p_uncond=0.15,
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
config.wds = d(
|
| 76 |
+
train_data='assets/datasets/cc3m/vq_f16_jax_clipG_cc3m_train_emb/{00000..03044}.tar',
|
| 77 |
+
val_data='assets/datasets/cc3m/vq_f16_jax_clipG_cc3m_val_emb/{00000..00012}.tar',
|
| 78 |
+
ctx_path='assets/contexts',
|
| 79 |
+
dist_eval=True,
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
config.sample = d(
|
| 83 |
+
sample_steps=18,
|
| 84 |
+
n_samples=30000,
|
| 85 |
+
mini_batch_size=2,
|
| 86 |
+
cfg=True,
|
| 87 |
+
linear_inc_scale=True,
|
| 88 |
+
scale=10.,
|
| 89 |
+
path='',
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
return config
|
configs/custom.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ml_collections
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def d(**kwargs):
|
| 5 |
+
"""Helper of creating a config dict."""
|
| 6 |
+
return ml_collections.ConfigDict(initial_dictionary=kwargs)
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_config():
|
| 10 |
+
config = ml_collections.ConfigDict()
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
config.seed = 1234
|
| 14 |
+
config.z_shape = (8, 16, 16)
|
| 15 |
+
|
| 16 |
+
config.autoencoder = d(
|
| 17 |
+
config_file='vq-f16-jax.yaml',
|
| 18 |
+
)
|
| 19 |
+
config.data_path="data/one_style.json"
|
| 20 |
+
config.resume_root="assets/ckpts/cc3m-285000.ckpt"
|
| 21 |
+
config.adapter_path=None
|
| 22 |
+
config.sample_interval=True
|
| 23 |
+
config.train = d(
|
| 24 |
+
n_steps=1000,
|
| 25 |
+
batch_size=8,
|
| 26 |
+
log_interval=20,
|
| 27 |
+
eval_interval=100,
|
| 28 |
+
save_interval=100,
|
| 29 |
+
fid_interval=20000,
|
| 30 |
+
num_workers=8,
|
| 31 |
+
resampled=False,
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
config.optimizer = d(
|
| 35 |
+
name='adamw',
|
| 36 |
+
lr=0.0003,
|
| 37 |
+
weight_decay=0.03,
|
| 38 |
+
betas=(0.99, 0.99),
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
config.lr_scheduler = d(
|
| 42 |
+
name='customized',
|
| 43 |
+
warmup_steps=-1, # 5000
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
config.nnet = d(
|
| 47 |
+
name='uvit_t2i_vq',
|
| 48 |
+
img_size=16,
|
| 49 |
+
codebook_size=1024,
|
| 50 |
+
in_chans=4,
|
| 51 |
+
embed_dim=1152,
|
| 52 |
+
depth=28,
|
| 53 |
+
num_heads=16,
|
| 54 |
+
mlp_ratio=4,
|
| 55 |
+
qkv_bias=False,
|
| 56 |
+
clip_dim=1280,
|
| 57 |
+
num_clip_token=77,
|
| 58 |
+
use_checkpoint=False,
|
| 59 |
+
skip=True,
|
| 60 |
+
d_prj=32,# Stage I: 32; Stage II: TODO
|
| 61 |
+
is_shared=False, # Stage I: False; Stage II: False
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
config.muse = d(
|
| 65 |
+
ignore_ind=-1,
|
| 66 |
+
smoothing=0.1,
|
| 67 |
+
gen_temp=4.5
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
config.sample = d(
|
| 72 |
+
sample_steps=36,
|
| 73 |
+
n_samples=50,
|
| 74 |
+
mini_batch_size=8,
|
| 75 |
+
cfg=True,
|
| 76 |
+
linear_inc_scale=True,
|
| 77 |
+
scale=10.,
|
| 78 |
+
path='',
|
| 79 |
+
lambdaA=2.0, # Stage I: 2.0; Stage II: TODO
|
| 80 |
+
lambdaB=5.0, # Stage I: 5.0; Stage II: TODO
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
return config
|
configs/imagenet256_base_vq_jax.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ml_collections
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def d(**kwargs):
|
| 5 |
+
"""Helper of creating a config dict."""
|
| 6 |
+
return ml_collections.ConfigDict(initial_dictionary=kwargs)
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_config():
|
| 10 |
+
config = ml_collections.ConfigDict()
|
| 11 |
+
|
| 12 |
+
config.seed = 1234
|
| 13 |
+
config.z_shape = (8, 16, 16)
|
| 14 |
+
|
| 15 |
+
config.autoencoder = d(
|
| 16 |
+
config_file='vq-f16-jax.yaml',
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
config.train = d(
|
| 20 |
+
n_steps=99999999,
|
| 21 |
+
batch_size=2048,
|
| 22 |
+
log_interval=10,
|
| 23 |
+
eval_interval=5000,
|
| 24 |
+
save_interval=5000,
|
| 25 |
+
fid_interval=50000,
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
config.eval = d(
|
| 29 |
+
n_samples=10000,
|
| 30 |
+
sample_steps=12,
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
config.optimizer = d(
|
| 34 |
+
name='adamw',
|
| 35 |
+
lr=0.0004,
|
| 36 |
+
weight_decay=0.03,
|
| 37 |
+
betas=(0.99, 0.99),
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
config.lr_scheduler = d(
|
| 41 |
+
name='customized',
|
| 42 |
+
warmup_steps=5000
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
config.nnet = d(
|
| 46 |
+
name='uvit_vq',
|
| 47 |
+
img_size=16,
|
| 48 |
+
codebook_size=1024,
|
| 49 |
+
in_chans=256,
|
| 50 |
+
patch_size=1,
|
| 51 |
+
embed_dim=768,
|
| 52 |
+
depth=12,
|
| 53 |
+
num_heads=12,
|
| 54 |
+
mlp_ratio=4,
|
| 55 |
+
qkv_bias=False,
|
| 56 |
+
num_classes=1001,
|
| 57 |
+
use_checkpoint=False,
|
| 58 |
+
skip=True,
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
config.muse = d(
|
| 62 |
+
ignore_ind=-1,
|
| 63 |
+
smoothing=0.1,
|
| 64 |
+
gen_temp=4.5
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
config.dataset = d(
|
| 68 |
+
name='imagenet256_features',
|
| 69 |
+
path='assets/datasets/imagenet256_vq_features/vq-f16-jax',
|
| 70 |
+
cfg=True,
|
| 71 |
+
p_uncond=0.15,
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
config.sample = d(
|
| 75 |
+
sample_steps=12,
|
| 76 |
+
n_samples=50000,
|
| 77 |
+
mini_batch_size=50,
|
| 78 |
+
cfg=True,
|
| 79 |
+
linear_inc_scale=True,
|
| 80 |
+
scale=3.,
|
| 81 |
+
path=''
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
return config
|
configs/vae_configs/vq-f16-jax.yaml
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 4.5e-6
|
| 3 |
+
target: taming.models.vqgan.VQModel
|
| 4 |
+
params:
|
| 5 |
+
embed_dim: 256
|
| 6 |
+
n_embed: 1024
|
| 7 |
+
ddconfig:
|
| 8 |
+
double_z: False
|
| 9 |
+
z_channels: 256
|
| 10 |
+
resolution: 256
|
| 11 |
+
in_channels: 3
|
| 12 |
+
out_ch: 3
|
| 13 |
+
ch: 128
|
| 14 |
+
ch_mult: [ 1,1,2,2,4] # num_down = len(ch_mult)-1
|
| 15 |
+
num_res_blocks: 2
|
| 16 |
+
attn_resolutions: [16]
|
| 17 |
+
dropout: 0.0
|
| 18 |
+
|
| 19 |
+
lossconfig:
|
| 20 |
+
target: taming.modules.losses.vqperceptual.VQLPIPSWithDiscriminator
|
| 21 |
+
params:
|
| 22 |
+
disc_conditional: False
|
| 23 |
+
disc_in_channels: 3
|
| 24 |
+
disc_start: 250001
|
| 25 |
+
disc_weight: 0.8
|
| 26 |
+
codebook_weight: 1.0
|
| 27 |
+
|
| 28 |
+
data:
|
| 29 |
+
target: main.DataModuleFromConfig
|
| 30 |
+
params:
|
| 31 |
+
batch_size: 8
|
| 32 |
+
num_workers: 24
|
| 33 |
+
train:
|
| 34 |
+
target: taming.data.imagenet.ImageNetTrain
|
| 35 |
+
params:
|
| 36 |
+
config:
|
| 37 |
+
size: 256
|
| 38 |
+
validation:
|
| 39 |
+
target: taming.data.imagenet.ImageNetValidation
|
| 40 |
+
params:
|
| 41 |
+
config:
|
| 42 |
+
size: 256
|
custom/custom_dataset.py
ADDED
|
@@ -0,0 +1,233 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from torch.utils.data import Dataset
|
| 3 |
+
|
| 4 |
+
import os
|
| 5 |
+
import numpy as np
|
| 6 |
+
import taming.models.vqgan
|
| 7 |
+
import open_clip
|
| 8 |
+
import random
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import torch
|
| 11 |
+
import math
|
| 12 |
+
import json
|
| 13 |
+
import torchvision.transforms as transforms
|
| 14 |
+
torch.manual_seed(0)
|
| 15 |
+
np.random.seed(0)
|
| 16 |
+
|
| 17 |
+
class test_custom_dataset(Dataset):
|
| 18 |
+
|
| 19 |
+
def __init__(self, style: str = None):
|
| 20 |
+
self.empty_context = np.load("assets/contexts/empty_context.npy")
|
| 21 |
+
self.object=[
|
| 22 |
+
"A chihuahua ",
|
| 23 |
+
"A tabby cat ",
|
| 24 |
+
"A portrait of chihuahua ",
|
| 25 |
+
"An apple on the table ",
|
| 26 |
+
"A banana on the table ",
|
| 27 |
+
"A church on the street ",
|
| 28 |
+
"A church in the mountain ",
|
| 29 |
+
"A church in the field ",
|
| 30 |
+
"A church on the beach ",
|
| 31 |
+
"A chihuahua walking on the street ",
|
| 32 |
+
"A tabby cat walking on the street",
|
| 33 |
+
"A portrait of tabby cat ",
|
| 34 |
+
"An apple on the dish ",
|
| 35 |
+
"A banana on the dish ",
|
| 36 |
+
"A human walking on the street ",
|
| 37 |
+
"A temple on the street ",
|
| 38 |
+
"A temple in the mountain ",
|
| 39 |
+
"A temple in the field ",
|
| 40 |
+
"A temple on the beach ",
|
| 41 |
+
"A chihuahua walking in the forest ",
|
| 42 |
+
"A tabby cat walking in the forest ",
|
| 43 |
+
"A portrait of human face ",
|
| 44 |
+
"An apple on the ground ",
|
| 45 |
+
"A banana on the ground ",
|
| 46 |
+
"A human walking in the forest ",
|
| 47 |
+
"A cabin on the street ",
|
| 48 |
+
"A cabin in the mountain ",
|
| 49 |
+
"A cabin in the field ",
|
| 50 |
+
"A cabin on the beach ",
|
| 51 |
+
]
|
| 52 |
+
self.style = [
|
| 53 |
+
"in 3d rendering style",
|
| 54 |
+
]
|
| 55 |
+
if style is not None:
|
| 56 |
+
self.style = [style]
|
| 57 |
+
|
| 58 |
+
def __getitem__(self, index):
|
| 59 |
+
prompt = self.object[index]+self.style[0]
|
| 60 |
+
|
| 61 |
+
return prompt, prompt
|
| 62 |
+
|
| 63 |
+
def __len__(self):
|
| 64 |
+
return len(self.object)
|
| 65 |
+
|
| 66 |
+
def unpreprocess(self, v): # to B C H W and [0, 1]
|
| 67 |
+
v.clamp_(0., 1.)
|
| 68 |
+
return v
|
| 69 |
+
|
| 70 |
+
@property
|
| 71 |
+
def fid_stat(self):
|
| 72 |
+
return f'assets/fid_stats/fid_stats_cc3m_val.npz'
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class train_custom_dataset(Dataset):
|
| 76 |
+
|
| 77 |
+
def __init__(self, train_file: str=None, ):
|
| 78 |
+
|
| 79 |
+
self.train_img = json.load(open(train_file, 'r'))
|
| 80 |
+
self.path_preffix = "/".join(train_file.split("/")[:-1])
|
| 81 |
+
self.prompt = []
|
| 82 |
+
self.image = []
|
| 83 |
+
self.style = []
|
| 84 |
+
for im in self.train_img.keys():
|
| 85 |
+
im_path = os.path.join(self.path_preffix, im)
|
| 86 |
+
self.object = self.train_img[im][0]
|
| 87 |
+
self.style = self.train_img[im][1]
|
| 88 |
+
im_prompt = self.object +" "+self.style
|
| 89 |
+
self.image.append(im_path)
|
| 90 |
+
self.prompt.append(im_prompt)
|
| 91 |
+
self.empty_context = np.load("assets/contexts/empty_context.npy")
|
| 92 |
+
|
| 93 |
+
self.transform = transforms.Compose([
|
| 94 |
+
transforms.Resize((256, 256)),
|
| 95 |
+
transforms.RandomHorizontalFlip(),
|
| 96 |
+
# transforms.RandomVerticalFlip(),
|
| 97 |
+
transforms.ToTensor(),
|
| 98 |
+
])
|
| 99 |
+
print("-----------------"*3)
|
| 100 |
+
print("train dataset length: ", len(self.prompt))
|
| 101 |
+
print("train dataset length: ", len(self.image))
|
| 102 |
+
print(self.prompt[0])
|
| 103 |
+
print(self.image[0])
|
| 104 |
+
print("-----------------"*3)
|
| 105 |
+
def __getitem__(self, index):
|
| 106 |
+
prompt = self.prompt[0]
|
| 107 |
+
image = Image.open(self.image[0]).convert("RGB")
|
| 108 |
+
image = self.transform(image)
|
| 109 |
+
|
| 110 |
+
return image,prompt
|
| 111 |
+
# return dict(img=image_embedding, text=text_embedding)
|
| 112 |
+
|
| 113 |
+
def __len__(self):
|
| 114 |
+
return 24
|
| 115 |
+
|
| 116 |
+
def unpreprocess(self, v): # to B C H W and [0, 1]
|
| 117 |
+
v.clamp_(0., 1.)
|
| 118 |
+
return v
|
| 119 |
+
|
| 120 |
+
@property
|
| 121 |
+
def fid_stat(self):
|
| 122 |
+
return f'assets/fid_stats/fid_stats_cc3m_val.npz'
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
class Discriptor(Dataset):
|
| 129 |
+
def __init__(self,style: str=None):
|
| 130 |
+
self.object =[
|
| 131 |
+
# "A parrot ",
|
| 132 |
+
# "A bird ",
|
| 133 |
+
# "A chihuahua in the snow",
|
| 134 |
+
# "A towel ",
|
| 135 |
+
# "A number '1' ",
|
| 136 |
+
# "A number '2' ",
|
| 137 |
+
# "A number '3' ",
|
| 138 |
+
# "A number '6' ",
|
| 139 |
+
# "A letter 'L' ",
|
| 140 |
+
# "A letter 'Z' ",
|
| 141 |
+
# "A letter 'D' ",
|
| 142 |
+
# "A rabbit ",
|
| 143 |
+
# "A train ",
|
| 144 |
+
# "A table ",
|
| 145 |
+
# "A dish ",
|
| 146 |
+
# "A large boat ",
|
| 147 |
+
# "A puppy ",
|
| 148 |
+
# "A cup ",
|
| 149 |
+
# "A watermelon ",
|
| 150 |
+
# "An apple ",
|
| 151 |
+
# "A banana ",
|
| 152 |
+
# "A chair ",
|
| 153 |
+
# "A Welsh Corgi ",
|
| 154 |
+
# "A cat ",
|
| 155 |
+
# "A house ",
|
| 156 |
+
# "A flower ",
|
| 157 |
+
# "A sunflower ",
|
| 158 |
+
# "A car ",
|
| 159 |
+
# "A jeep car ",
|
| 160 |
+
# "A truck ",
|
| 161 |
+
# "A Posche car ",
|
| 162 |
+
# "A vase ",
|
| 163 |
+
# "A chihuahua ",
|
| 164 |
+
# "A tabby cat ",
|
| 165 |
+
"A portrait of chihuahua ",
|
| 166 |
+
"An apple on the table ",
|
| 167 |
+
"A banana on the table ",
|
| 168 |
+
"A human ",
|
| 169 |
+
"A church on the street ",
|
| 170 |
+
"A church in the mountain ",
|
| 171 |
+
"A church in the field ",
|
| 172 |
+
"A church on the beach ",
|
| 173 |
+
"A chihuahua walking on the street ",
|
| 174 |
+
"A tabby cat walking on the street",
|
| 175 |
+
"A portrait of tabby cat ",
|
| 176 |
+
"An apple on the dish ",
|
| 177 |
+
"A banana on the dish ",
|
| 178 |
+
"A human walking on the street ",
|
| 179 |
+
"A temple on the street ",
|
| 180 |
+
"A temple in the mountain ",
|
| 181 |
+
"A temple in the field ",
|
| 182 |
+
"A temple on the beach ",
|
| 183 |
+
"A chihuahua walking in the forest ",
|
| 184 |
+
"A tabby cat walking in the forest ",
|
| 185 |
+
"A portrait of human face ",
|
| 186 |
+
"An apple on the ground ",
|
| 187 |
+
"A banana on the ground ",
|
| 188 |
+
"A human walking in the forest ",
|
| 189 |
+
"A cabin on the street ",
|
| 190 |
+
"A cabin in the mountain ",
|
| 191 |
+
"A cabin in the field ",
|
| 192 |
+
"A cabin on the beach ",
|
| 193 |
+
"A letter 'A' ",
|
| 194 |
+
"A letter 'B' ",
|
| 195 |
+
"A letter 'C' ",
|
| 196 |
+
"A letter 'D' ",
|
| 197 |
+
"A letter 'E' ",
|
| 198 |
+
"A letter 'F' ",
|
| 199 |
+
"A letter 'G' ",
|
| 200 |
+
"A butterfly ",
|
| 201 |
+
" A baby penguin ",
|
| 202 |
+
"A bench ",
|
| 203 |
+
"A boat ",
|
| 204 |
+
"A cow ",
|
| 205 |
+
"A hat ",
|
| 206 |
+
"A piano ",
|
| 207 |
+
"A robot ",
|
| 208 |
+
"A christmas tree ",
|
| 209 |
+
"A dog ",
|
| 210 |
+
"A moose ",
|
| 211 |
+
]
|
| 212 |
+
|
| 213 |
+
self.style =[
|
| 214 |
+
"in 3d rendering style",
|
| 215 |
+
]
|
| 216 |
+
if style is not None:
|
| 217 |
+
self.style = [style]
|
| 218 |
+
|
| 219 |
+
def __getitem__(self, index):
|
| 220 |
+
prompt = self.object[index]+self.style[0]
|
| 221 |
+
return prompt
|
| 222 |
+
|
| 223 |
+
def __len__(self):
|
| 224 |
+
return len(self.object)
|
| 225 |
+
|
| 226 |
+
def unpreprocess(self, v): # to B C H W and [0, 1]
|
| 227 |
+
v.clamp_(0., 1.)
|
| 228 |
+
return v
|
| 229 |
+
|
| 230 |
+
@property
|
| 231 |
+
def fid_stat(self):
|
| 232 |
+
return f'assets/fid_stats/fid_stats_cc3m_val.npz'
|
| 233 |
+
|
data/data.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"image_01_01.jpg":["A bay","in watercolor painting style"],
|
| 3 |
+
"image_01_02.jpg":["A house", "in watercolor painting style"],
|
| 4 |
+
"image_01_03.jpg":["A cat", "in watercolor painting style"],
|
| 5 |
+
"image_01_04.jpg":["Flowers", "in watercolor painting style"],
|
| 6 |
+
"image_01_05.jpg":["A village", "in oil painting style"],
|
| 7 |
+
"image_01_06.jpg":["A village", "in line drawing style"],
|
| 8 |
+
"image_01_07.jpg":["A portrait of a person", "in oil painting style"],
|
| 9 |
+
"image_01_08.jpg":["A portrait of a person wearing a hat", "in oil painting style"],
|
| 10 |
+
"image_02_01.jpg":["A person drwoning into th phone", "in cartoon line drawing style"],
|
| 11 |
+
"image_02_02.jpg":["A woman walking a dog", "in flat cartoon illustration style"],
|
| 12 |
+
"image_02_03.jpg":["A woman working on a laptop", "in flat cartoon illustration style"],
|
| 13 |
+
"image_02_04.jpg":["A Christmas tree", "in sticker style"],
|
| 14 |
+
"image_02_05.jpg":["A wave", "in abstract rainbow colored flowing smoke wave design"],
|
| 15 |
+
"image_02_06.jpg":["A mushroom", "in glowing style"],
|
| 16 |
+
"image_03_01.jpg":["Slice of watermelon and clouds in the background", "in 3d rendering style"],
|
| 17 |
+
"image_03_03.jpg":["A thumbs up", "in glowing 3d rendering style"],
|
| 18 |
+
"image_03_04.jpg":["A woman", "in 3d rendering style"],
|
| 19 |
+
"image_03_05.jpg":["A bear", "in kid crayon drawing style"],
|
| 20 |
+
"image_03_07.jpg":["A flower", "in melting golden 3d rendering style"],
|
| 21 |
+
"image_03_08.jpg":["A Viking face with beard", "in wooden sculpture"]
|
| 22 |
+
}
|
data/image_01_01.jpg
ADDED

|
Git LFS Details
|
data/image_01_02.jpg
ADDED

|
Git LFS Details
|
data/image_01_03.jpg
ADDED

|
Git LFS Details
|
data/image_01_04.jpg
ADDED

|
Git LFS Details
|
data/image_01_05.jpg
ADDED

|
Git LFS Details
|
data/image_01_06.jpg
ADDED

|
Git LFS Details
|
data/image_01_07.jpg
ADDED

|
Git LFS Details
|
data/image_01_08.jpg
ADDED

|
Git LFS Details
|
data/image_02_01.jpg
ADDED

|
Git LFS Details
|
data/image_02_02.jpg
ADDED

|
Git LFS Details
|
data/image_02_03.jpg
ADDED

|
Git LFS Details
|
data/image_02_04.jpg
ADDED

|
Git LFS Details
|
data/image_02_05.jpg
ADDED

|
Git LFS Details
|
data/image_02_06.jpg
ADDED

|
Git LFS Details
|
data/image_03_01.jpg
ADDED

|
Git LFS Details
|
data/image_03_03.jpg
ADDED

|
Git LFS Details
|
data/image_03_04.jpg
ADDED

|
Git LFS Details
|
data/image_03_05.jpg
ADDED

|
Git LFS Details
|
data/image_03_07.jpg
ADDED

|
Git LFS Details
|
data/image_03_08.jpg
ADDED

|
Git LFS Details
|
data/one_style.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"image_01_02.jpg":["A house", "in watercolor painting style"]
|
| 3 |
+
}
|
libs/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# codes from third party
|
libs/muse.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import math
|
| 4 |
+
from einops import rearrange
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def add_gumbel_noise(t, temperature, device):
|
| 9 |
+
return (t + torch.Tensor(temperature * np.random.gumbel(size=t.shape)).to(device))
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class MUSE(object):
|
| 13 |
+
def __init__(self, codebook_size, device, ignore_ind=-1, smoothing=0., gen_temp=4.5):
|
| 14 |
+
self.mask_ind = codebook_size # for input masking
|
| 15 |
+
self.ignore_ind = ignore_ind # for ce loss, excluding visible
|
| 16 |
+
self.device = device
|
| 17 |
+
self.smoothing = smoothing
|
| 18 |
+
self.gen_temp = gen_temp
|
| 19 |
+
|
| 20 |
+
@staticmethod
|
| 21 |
+
def cosine_schedule(t):
|
| 22 |
+
return torch.cos(t * math.pi * 0.5)
|
| 23 |
+
|
| 24 |
+
def sample(self, x0):
|
| 25 |
+
N, L, device = *x0.shape, self.device
|
| 26 |
+
timesteps = torch.zeros((N,), device=device).float().uniform_(0, 1)
|
| 27 |
+
rand_mask_probs = self.cosine_schedule(timesteps) # cosine schedule
|
| 28 |
+
num_token_masked = (L * rand_mask_probs).round().clamp(min=1)
|
| 29 |
+
batch_randperm = torch.rand(N, L, device=device).argsort(dim=-1)
|
| 30 |
+
mask = batch_randperm < rearrange(num_token_masked, 'b -> b 1')
|
| 31 |
+
masked_ids = torch.where(mask, self.mask_ind, x0)
|
| 32 |
+
labels = torch.where(mask, x0, self.ignore_ind)
|
| 33 |
+
return labels, masked_ids
|
| 34 |
+
|
| 35 |
+
def loss(self, pred, label):
|
| 36 |
+
return F.cross_entropy(pred.transpose(1, 2), label.long(),
|
| 37 |
+
ignore_index=self.ignore_ind, label_smoothing=self.smoothing)
|
| 38 |
+
|
| 39 |
+
@torch.no_grad()
|
| 40 |
+
def generate(self, config, _n_samples, nnet, decode_fn, is_eval=False, **kwargs):
|
| 41 |
+
fmap_size, _sample_steps, device = config.z_shape[-1], config.sample.sample_steps, self.device
|
| 42 |
+
|
| 43 |
+
seq_len = fmap_size ** 2
|
| 44 |
+
ids = torch.full((_n_samples, seq_len), self.mask_ind, dtype=torch.long, device=device)
|
| 45 |
+
cfg_scale = 0.
|
| 46 |
+
for step in range(_sample_steps):
|
| 47 |
+
ratio = 1. * (step + 1) / _sample_steps
|
| 48 |
+
annealed_temp = self.gen_temp * (1 - ratio)
|
| 49 |
+
is_mask = (ids == self.mask_ind)
|
| 50 |
+
logits = nnet(ids, **kwargs, scale=cfg_scale)
|
| 51 |
+
# sampling & scoring
|
| 52 |
+
sampled_ids = add_gumbel_noise(logits, annealed_temp, device).argmax(dim=-1)
|
| 53 |
+
sampled_logits = torch.squeeze(
|
| 54 |
+
torch.gather(logits, dim=-1, index=torch.unsqueeze(sampled_ids, -1)), -1)
|
| 55 |
+
sampled_ids = torch.where(is_mask, sampled_ids, ids)
|
| 56 |
+
sampled_logits = torch.where(is_mask, sampled_logits, +np.inf).float()
|
| 57 |
+
# masking
|
| 58 |
+
mask_ratio = np.cos(ratio * math.pi * 0.5)
|
| 59 |
+
mask_len = torch.Tensor([np.floor(seq_len * mask_ratio)]).to(device)
|
| 60 |
+
mask_len = torch.maximum(torch.Tensor([1]).to(device),
|
| 61 |
+
torch.minimum(torch.sum(is_mask, dim=-1, keepdims=True) - 1,
|
| 62 |
+
mask_len))[0].squeeze()
|
| 63 |
+
confidence = add_gumbel_noise(sampled_logits, annealed_temp, device)
|
| 64 |
+
sorted_confidence, _ = torch.sort(confidence, axis=-1)
|
| 65 |
+
cut_off = sorted_confidence[:, mask_len.long() - 1:mask_len.long()]
|
| 66 |
+
masking = (confidence <= cut_off)
|
| 67 |
+
ids = torch.where(masking, self.mask_ind, sampled_ids)
|
| 68 |
+
cfg_scale = ratio * config.sample.scale
|
| 69 |
+
|
| 70 |
+
_z1 = rearrange(sampled_ids, 'b (i j) -> b i j', i=fmap_size, j=fmap_size)
|
| 71 |
+
|
| 72 |
+
# with adapter
|
| 73 |
+
ids = torch.full((_n_samples, seq_len), self.mask_ind, dtype=torch.long, device=device)
|
| 74 |
+
cfg_scale = 0.
|
| 75 |
+
lambdaA=0.
|
| 76 |
+
lambdaB=0.
|
| 77 |
+
for step in range(_sample_steps):
|
| 78 |
+
ratio = 1. * (step + 1) / _sample_steps
|
| 79 |
+
annealed_temp = self.gen_temp * (1 - ratio)
|
| 80 |
+
is_mask = (ids == self.mask_ind)
|
| 81 |
+
# 尝试使用 *ratio
|
| 82 |
+
logits = nnet(ids, **kwargs, scale=cfg_scale,lambdaA=lambdaA,lambdaB=lambdaB)
|
| 83 |
+
# sampling & scoring
|
| 84 |
+
sampled_ids = add_gumbel_noise(logits, annealed_temp, device).argmax(dim=-1)
|
| 85 |
+
sampled_logits = torch.squeeze(
|
| 86 |
+
torch.gather(logits, dim=-1, index=torch.unsqueeze(sampled_ids, -1)), -1)
|
| 87 |
+
sampled_ids = torch.where(is_mask, sampled_ids, ids)
|
| 88 |
+
sampled_logits = torch.where(is_mask, sampled_logits, +np.inf).float()
|
| 89 |
+
# masking
|
| 90 |
+
mask_ratio = np.cos(ratio * math.pi * 0.5)
|
| 91 |
+
mask_len = torch.Tensor([np.floor(seq_len * mask_ratio)]).to(device)
|
| 92 |
+
mask_len = torch.maximum(torch.Tensor([1]).to(device),
|
| 93 |
+
torch.minimum(torch.sum(is_mask, dim=-1, keepdims=True) - 1,
|
| 94 |
+
mask_len))[0].squeeze()
|
| 95 |
+
confidence = add_gumbel_noise(sampled_logits, annealed_temp, device)
|
| 96 |
+
sorted_confidence, _ = torch.sort(confidence, axis=-1)
|
| 97 |
+
cut_off = sorted_confidence[:, mask_len.long() - 1:mask_len.long()]
|
| 98 |
+
masking = (confidence <= cut_off)
|
| 99 |
+
ids = torch.where(masking, self.mask_ind, sampled_ids)
|
| 100 |
+
cfg_scale = ratio * config.sample.scale
|
| 101 |
+
lambdaA = config.sample.lambdaA
|
| 102 |
+
lambdaB = config.sample.lambdaB
|
| 103 |
+
|
| 104 |
+
_z2 = rearrange(sampled_ids, 'b (i j) -> b i j', i=fmap_size, j=fmap_size)
|
| 105 |
+
_z = _z2 if is_eval else torch.cat([_z1,_z2],dim=0)
|
| 106 |
+
out = decode_fn(_z)
|
| 107 |
+
return out
|
libs/uvit_t2i_vq.py
ADDED
|
@@ -0,0 +1,282 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import math
|
| 4 |
+
|
| 5 |
+
from loguru import logger
|
| 6 |
+
|
| 7 |
+
import timm
|
| 8 |
+
from timm.models.layers import trunc_normal_
|
| 9 |
+
from timm.models.vision_transformer import PatchEmbed, Mlp
|
| 10 |
+
|
| 11 |
+
assert timm.__version__ == "0.3.2" # version check
|
| 12 |
+
import einops
|
| 13 |
+
import torch.utils.checkpoint
|
| 14 |
+
import torch.nn.functional as F
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
import xformers
|
| 18 |
+
import xformers.ops
|
| 19 |
+
|
| 20 |
+
XFORMERS_IS_AVAILBLE = True
|
| 21 |
+
print("xformers available, will use xformers attention")
|
| 22 |
+
except:
|
| 23 |
+
XFORMERS_IS_AVAILBLE = False
|
| 24 |
+
print("xformers not available, will use pytorch attention instead")
|
| 25 |
+
|
| 26 |
+
class BertEmbeddings(nn.Module):
|
| 27 |
+
"""Construct the embeddings from word, position and token_type embeddings."""
|
| 28 |
+
|
| 29 |
+
def __init__(self, vocab_size, hidden_size, max_position_embeddings, dropout=0.1):
|
| 30 |
+
super().__init__()
|
| 31 |
+
self.word_embeddings = nn.Embedding(vocab_size, hidden_size)
|
| 32 |
+
self.position_embeddings = nn.Embedding(max_position_embeddings, hidden_size)
|
| 33 |
+
|
| 34 |
+
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
|
| 35 |
+
# any TensorFlow checkpoint file
|
| 36 |
+
self.LayerNorm = nn.LayerNorm(hidden_size, eps=1e-6)
|
| 37 |
+
self.dropout = nn.Dropout(dropout)
|
| 38 |
+
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
|
| 39 |
+
self.register_buffer("position_ids", torch.arange(max_position_embeddings).expand((1, -1)))
|
| 40 |
+
|
| 41 |
+
torch.nn.init.normal_(self.word_embeddings.weight, std=.02)
|
| 42 |
+
torch.nn.init.normal_(self.position_embeddings.weight, std=.02)
|
| 43 |
+
|
| 44 |
+
def forward(
|
| 45 |
+
self, input_ids
|
| 46 |
+
):
|
| 47 |
+
input_shape = input_ids.size()
|
| 48 |
+
|
| 49 |
+
seq_length = input_shape[1]
|
| 50 |
+
|
| 51 |
+
position_ids = self.position_ids[:, :seq_length]
|
| 52 |
+
|
| 53 |
+
inputs_embeds = self.word_embeddings(input_ids)
|
| 54 |
+
|
| 55 |
+
position_embeddings = self.position_embeddings(position_ids)
|
| 56 |
+
embeddings = inputs_embeds + position_embeddings
|
| 57 |
+
|
| 58 |
+
embeddings = self.LayerNorm(embeddings)
|
| 59 |
+
embeddings = self.dropout(embeddings)
|
| 60 |
+
return embeddings
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class MlmLayer(nn.Module):
|
| 64 |
+
|
| 65 |
+
def __init__(self, feat_emb_dim, word_emb_dim, vocab_size):
|
| 66 |
+
super().__init__()
|
| 67 |
+
self.fc = nn.Linear(feat_emb_dim, word_emb_dim)
|
| 68 |
+
self.gelu = nn.GELU()
|
| 69 |
+
self.ln = nn.LayerNorm(word_emb_dim)
|
| 70 |
+
self.bias = nn.Parameter(torch.zeros(1, 1, vocab_size))
|
| 71 |
+
|
| 72 |
+
def forward(self, x, word_embeddings):
|
| 73 |
+
mlm_hidden = self.fc(x)
|
| 74 |
+
mlm_hidden = self.gelu(mlm_hidden)
|
| 75 |
+
mlm_hidden = self.ln(mlm_hidden)
|
| 76 |
+
word_embeddings = word_embeddings.transpose(0, 1)
|
| 77 |
+
logits = torch.matmul(mlm_hidden, word_embeddings)
|
| 78 |
+
logits = logits + self.bias
|
| 79 |
+
return logits
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class Attention(nn.Module):
|
| 83 |
+
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
|
| 84 |
+
super().__init__()
|
| 85 |
+
self.num_heads = num_heads
|
| 86 |
+
head_dim = dim // num_heads
|
| 87 |
+
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
|
| 88 |
+
self.scale = qk_scale or head_dim ** -0.5
|
| 89 |
+
|
| 90 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 91 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 92 |
+
self.proj = nn.Linear(dim, dim)
|
| 93 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 94 |
+
|
| 95 |
+
def forward(self, x):
|
| 96 |
+
B, N, C = x.shape
|
| 97 |
+
if XFORMERS_IS_AVAILBLE:
|
| 98 |
+
qkv = self.qkv(x)
|
| 99 |
+
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B L H D', K=3, H=self.num_heads)
|
| 100 |
+
q, k, v = qkv[0], qkv[1], qkv[2] # B L H D
|
| 101 |
+
x = xformers.ops.memory_efficient_attention(q, k, v)
|
| 102 |
+
x = einops.rearrange(x, 'B L H D -> B L (H D)', H=self.num_heads)
|
| 103 |
+
else:
|
| 104 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 105 |
+
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
|
| 106 |
+
|
| 107 |
+
attn = (q @ k.transpose(-2, -1)) * self.scale
|
| 108 |
+
attn = attn.softmax(dim=-1)
|
| 109 |
+
attn = self.attn_drop(attn)
|
| 110 |
+
|
| 111 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
|
| 112 |
+
|
| 113 |
+
x = self.proj(x)
|
| 114 |
+
x = self.proj_drop(x)
|
| 115 |
+
return x
|
| 116 |
+
|
| 117 |
+
class Adapter(nn.Module):
|
| 118 |
+
def __init__(self, d_emb:int, d_prj:int,n_layer: int, is_shared: bool):
|
| 119 |
+
super().__init__()
|
| 120 |
+
self.D = d_emb
|
| 121 |
+
self.H = d_prj
|
| 122 |
+
self.L = n_layer
|
| 123 |
+
self.is_shared = is_shared
|
| 124 |
+
if self.is_shared:
|
| 125 |
+
self.DD = nn.Embedding(self.L,self.H)
|
| 126 |
+
self.DU = nn.Embedding(self.L,self.D)
|
| 127 |
+
self.WD = nn.Embedding(1,self.D*self.H)
|
| 128 |
+
self.WU = nn.Embedding(1,self.H*self.D)
|
| 129 |
+
else:
|
| 130 |
+
self.WD = nn.Embedding(self.L,self.D*self.H)
|
| 131 |
+
self.WU = nn.Embedding(self.L,self.H*self.D)
|
| 132 |
+
self.activate = nn.GELU()
|
| 133 |
+
|
| 134 |
+
self._init_weights()
|
| 135 |
+
def _init_weights(self):
|
| 136 |
+
for p in self.WU.parameters():
|
| 137 |
+
p.detach().zero_()
|
| 138 |
+
nn.init.trunc_normal_(self.WD.weight,mean=0,std=0.02)
|
| 139 |
+
|
| 140 |
+
if self.is_shared:
|
| 141 |
+
nn.init.trunc_normal_(self.DD.weight,mean=0,std=0.02)
|
| 142 |
+
for p in self.DU.parameters():
|
| 143 |
+
p.detach().zero_()
|
| 144 |
+
|
| 145 |
+
def forward(self, emb, layer):
|
| 146 |
+
idx = torch.arange(self.L).to(emb.device)
|
| 147 |
+
layer = torch.tensor(layer).to(emb.device)
|
| 148 |
+
if self.is_shared:
|
| 149 |
+
idx0 = torch.zeros_like(idx).to(emb.device)
|
| 150 |
+
dd = self.DD(idx).reshape(self.L, 1,self.H)
|
| 151 |
+
du = self.DU(idx).reshape(self.L, 1,self.D)
|
| 152 |
+
wd = self.WD(idx0).reshape(self.L, self.D,self.H) + dd
|
| 153 |
+
wu = self.WU(idx0).reshape(self.L, self.H,self.D) + du
|
| 154 |
+
else:
|
| 155 |
+
wd = self.WD(idx).reshape(self.L, self.D,self.H)
|
| 156 |
+
wu = self.WU(idx).reshape(self.L, self.H,self.D)
|
| 157 |
+
|
| 158 |
+
prj = torch.einsum('...d,dh->...h',emb,wd[layer])
|
| 159 |
+
prj = self.activate(prj)
|
| 160 |
+
prj = torch.einsum('...h,hd->...d',prj,wu[layer])
|
| 161 |
+
return emb + prj
|
| 162 |
+
class Block(nn.Module):
|
| 163 |
+
|
| 164 |
+
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None,
|
| 165 |
+
act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip=False, use_checkpoint=False):
|
| 166 |
+
super().__init__()
|
| 167 |
+
self.norm1 = norm_layer(dim)
|
| 168 |
+
self.attn = Attention(
|
| 169 |
+
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale)
|
| 170 |
+
self.norm2 = norm_layer(dim)
|
| 171 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 172 |
+
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
|
| 173 |
+
self.skip_linear = nn.Linear(2 * dim, dim) if skip else None
|
| 174 |
+
self.use_checkpoint = use_checkpoint
|
| 175 |
+
|
| 176 |
+
def forward(self, x, skip=None, adapter=None, layer=None):
|
| 177 |
+
if self.use_checkpoint:
|
| 178 |
+
return torch.utils.checkpoint.checkpoint(self._forward, x, skip, adapter, layer)
|
| 179 |
+
else:
|
| 180 |
+
return self._forward(x, skip, adapter, layer)
|
| 181 |
+
|
| 182 |
+
def _forward(self, x, skip=None,adapter=None, layer=None):
|
| 183 |
+
if self.skip_linear is not None:
|
| 184 |
+
x = self.skip_linear(torch.cat([x, skip], dim=-1))
|
| 185 |
+
|
| 186 |
+
attn = self.attn(self.norm1(x))
|
| 187 |
+
if adapter is not None:
|
| 188 |
+
attn = adapter(attn, layer)
|
| 189 |
+
|
| 190 |
+
x = x + attn
|
| 191 |
+
x = x + self.mlp(self.norm2(x))
|
| 192 |
+
return x
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
class UViT(nn.Module):
|
| 196 |
+
def __init__(self, img_size=16, in_chans=8, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.,
|
| 197 |
+
qkv_bias=False, qk_scale=None, norm_layer=nn.LayerNorm, use_checkpoint=False,
|
| 198 |
+
clip_dim=768, num_clip_token=77, skip=True, codebook_size=1024,d_prj=4,is_shared=True):
|
| 199 |
+
super().__init__()
|
| 200 |
+
logger.debug(f'codebook size in nnet: {codebook_size}')
|
| 201 |
+
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
|
| 202 |
+
self.in_chans = in_chans
|
| 203 |
+
self.skip = skip
|
| 204 |
+
|
| 205 |
+
self.codebook_size = codebook_size
|
| 206 |
+
vocab_size = codebook_size + 1
|
| 207 |
+
self.time_embed = None
|
| 208 |
+
self.extras = num_clip_token
|
| 209 |
+
self.num_vis_tokens = int((img_size) ** 2)
|
| 210 |
+
self.token_emb = BertEmbeddings(vocab_size=vocab_size,
|
| 211 |
+
hidden_size=embed_dim,
|
| 212 |
+
max_position_embeddings=self.num_vis_tokens,
|
| 213 |
+
dropout=0.1)
|
| 214 |
+
print(f'num vis tokens: {self.num_vis_tokens}')
|
| 215 |
+
|
| 216 |
+
self.context_embed = nn.Linear(clip_dim, embed_dim)
|
| 217 |
+
|
| 218 |
+
self.in_blocks = nn.ModuleList([
|
| 219 |
+
Block(
|
| 220 |
+
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 221 |
+
norm_layer=norm_layer, use_checkpoint=use_checkpoint)
|
| 222 |
+
for _ in range(depth // 2)])
|
| 223 |
+
|
| 224 |
+
self.mid_block = Block(
|
| 225 |
+
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 226 |
+
norm_layer=norm_layer, use_checkpoint=use_checkpoint)
|
| 227 |
+
|
| 228 |
+
self.out_blocks = nn.ModuleList([
|
| 229 |
+
Block(
|
| 230 |
+
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 231 |
+
norm_layer=norm_layer, skip=skip, use_checkpoint=use_checkpoint)
|
| 232 |
+
for _ in range(depth // 2)])
|
| 233 |
+
|
| 234 |
+
self.norm = norm_layer(embed_dim)
|
| 235 |
+
self.mlm_layer = MlmLayer(feat_emb_dim=embed_dim, word_emb_dim=embed_dim, vocab_size=vocab_size)
|
| 236 |
+
self.adapter = Adapter(d_emb=embed_dim, d_prj=d_prj, n_layer=depth, is_shared=is_shared)
|
| 237 |
+
self.apply(self._init_weights)
|
| 238 |
+
|
| 239 |
+
def _init_weights(self, m):
|
| 240 |
+
if isinstance(m, nn.Linear):
|
| 241 |
+
trunc_normal_(m.weight, std=.02)
|
| 242 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 243 |
+
nn.init.constant_(m.bias, 0)
|
| 244 |
+
elif isinstance(m, nn.LayerNorm):
|
| 245 |
+
nn.init.constant_(m.bias, 0)
|
| 246 |
+
nn.init.constant_(m.weight, 1.0)
|
| 247 |
+
|
| 248 |
+
@torch.jit.ignore # type: ignore
|
| 249 |
+
def no_weight_decay(self):
|
| 250 |
+
return {'pos_embed'}
|
| 251 |
+
|
| 252 |
+
def forward(self, masked_ids, context,use_adapter=False):
|
| 253 |
+
assert len(masked_ids.shape) == 2
|
| 254 |
+
x = self.token_emb(masked_ids)
|
| 255 |
+
context_token = self.context_embed(context.type_as(x))
|
| 256 |
+
x = torch.cat((context_token, x), dim=1)
|
| 257 |
+
|
| 258 |
+
layer=0
|
| 259 |
+
|
| 260 |
+
if self.skip:
|
| 261 |
+
skips = []
|
| 262 |
+
for blk in self.in_blocks:
|
| 263 |
+
# 将adapter放在attention之后
|
| 264 |
+
x = blk(x,adapter=self.adapter if use_adapter else None,layer=layer)
|
| 265 |
+
if self.skip:
|
| 266 |
+
skips.append(x)# type: ignore
|
| 267 |
+
layer+=1
|
| 268 |
+
|
| 269 |
+
x = self.mid_block(x)
|
| 270 |
+
|
| 271 |
+
for blk in self.out_blocks:
|
| 272 |
+
if self.skip:
|
| 273 |
+
x = blk(x, skips.pop(),adapter = self.adapter if use_adapter else None,layer=layer)# type: ignore
|
| 274 |
+
else:
|
| 275 |
+
x = blk(x,adapter = self.adapter if use_adapter else None,layer=layer)
|
| 276 |
+
|
| 277 |
+
x = self.norm(x)
|
| 278 |
+
|
| 279 |
+
word_embeddings = self.token_emb.word_embeddings.weight.data.detach()
|
| 280 |
+
x = self.mlm_layer(x, word_embeddings)
|
| 281 |
+
x = x[:, self.extras:, :self.codebook_size]
|
| 282 |
+
return x
|
libs/uvit_vq.py
ADDED
|
@@ -0,0 +1,264 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import math
|
| 6 |
+
|
| 7 |
+
from loguru import logger
|
| 8 |
+
|
| 9 |
+
import timm
|
| 10 |
+
from timm.models.layers import trunc_normal_
|
| 11 |
+
from timm.models.vision_transformer import PatchEmbed, Mlp
|
| 12 |
+
|
| 13 |
+
assert timm.__version__ == "0.3.2" # version check
|
| 14 |
+
import einops
|
| 15 |
+
import torch.utils.checkpoint
|
| 16 |
+
import torch.nn.functional as F
|
| 17 |
+
|
| 18 |
+
try:
|
| 19 |
+
import xformers
|
| 20 |
+
import xformers.ops
|
| 21 |
+
|
| 22 |
+
XFORMERS_IS_AVAILBLE = True
|
| 23 |
+
except:
|
| 24 |
+
XFORMERS_IS_AVAILBLE = False
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class BertEmbeddings(nn.Module):
|
| 28 |
+
"""Construct the embeddings from word, position and token_type embeddings."""
|
| 29 |
+
|
| 30 |
+
def __init__(self, vocab_size, hidden_size, max_position_embeddings, dropout=0.1):
|
| 31 |
+
super().__init__()
|
| 32 |
+
self.word_embeddings = nn.Embedding(vocab_size, hidden_size)
|
| 33 |
+
self.position_embeddings = nn.Embedding(max_position_embeddings, hidden_size)
|
| 34 |
+
|
| 35 |
+
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
|
| 36 |
+
# any TensorFlow checkpoint file
|
| 37 |
+
self.LayerNorm = nn.LayerNorm(hidden_size, eps=1e-6)
|
| 38 |
+
self.dropout = nn.Dropout(dropout)
|
| 39 |
+
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
|
| 40 |
+
self.register_buffer("position_ids", torch.arange(max_position_embeddings).expand((1, -1)))
|
| 41 |
+
|
| 42 |
+
torch.nn.init.normal_(self.word_embeddings.weight, std=.02)
|
| 43 |
+
torch.nn.init.normal_(self.position_embeddings.weight, std=.02)
|
| 44 |
+
|
| 45 |
+
def forward(
|
| 46 |
+
self, input_ids
|
| 47 |
+
):
|
| 48 |
+
input_shape = input_ids.size()
|
| 49 |
+
|
| 50 |
+
seq_length = input_shape[1]
|
| 51 |
+
|
| 52 |
+
position_ids = self.position_ids[:, :seq_length]
|
| 53 |
+
|
| 54 |
+
inputs_embeds = self.word_embeddings(input_ids)
|
| 55 |
+
|
| 56 |
+
position_embeddings = self.position_embeddings(position_ids)
|
| 57 |
+
embeddings = inputs_embeds + position_embeddings
|
| 58 |
+
|
| 59 |
+
embeddings = self.LayerNorm(embeddings)
|
| 60 |
+
embeddings = self.dropout(embeddings)
|
| 61 |
+
return embeddings
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class MlmLayer(nn.Module):
|
| 65 |
+
|
| 66 |
+
def __init__(self, feat_emb_dim, word_emb_dim, vocab_size):
|
| 67 |
+
super().__init__()
|
| 68 |
+
self.fc = nn.Linear(feat_emb_dim, word_emb_dim)
|
| 69 |
+
self.gelu = nn.GELU()
|
| 70 |
+
self.ln = nn.LayerNorm(word_emb_dim)
|
| 71 |
+
self.bias = nn.Parameter(torch.zeros(1, 1, vocab_size))
|
| 72 |
+
|
| 73 |
+
def forward(self, x, word_embeddings):
|
| 74 |
+
mlm_hidden = self.fc(x)
|
| 75 |
+
mlm_hidden = self.gelu(mlm_hidden)
|
| 76 |
+
mlm_hidden = self.ln(mlm_hidden)
|
| 77 |
+
word_embeddings = word_embeddings.transpose(0, 1)
|
| 78 |
+
logits = torch.matmul(mlm_hidden, word_embeddings)
|
| 79 |
+
logits = logits + self.bias
|
| 80 |
+
return logits
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def patchify(imgs, patch_size):
|
| 84 |
+
x = einops.rearrange(imgs, 'B C (h p1) (w p2) -> B (h w) (p1 p2 C)', p1=patch_size, p2=patch_size)
|
| 85 |
+
return x
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def unpatchify(x, channels=3, flatten=False):
|
| 89 |
+
patch_size = int((x.shape[2] // channels) ** 0.5)
|
| 90 |
+
h = w = int(x.shape[1] ** .5)
|
| 91 |
+
assert h * w == x.shape[1] and patch_size ** 2 * channels == x.shape[2]
|
| 92 |
+
if flatten:
|
| 93 |
+
x = einops.rearrange(x, 'B (h w) (p1 p2 C) -> B (h p1 w p2) C', h=h, p1=patch_size, p2=patch_size)
|
| 94 |
+
else:
|
| 95 |
+
x = einops.rearrange(x, 'B (h w) (p1 p2 C) -> B C (h p1) (w p2)', h=h, p1=patch_size, p2=patch_size)
|
| 96 |
+
return x
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class Attention(nn.Module):
|
| 100 |
+
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
|
| 101 |
+
super().__init__()
|
| 102 |
+
self.num_heads = num_heads
|
| 103 |
+
head_dim = dim // num_heads
|
| 104 |
+
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
|
| 105 |
+
self.scale = qk_scale or head_dim ** -0.5
|
| 106 |
+
|
| 107 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 108 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 109 |
+
self.proj = nn.Linear(dim, dim)
|
| 110 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 111 |
+
|
| 112 |
+
def forward(self, x):
|
| 113 |
+
B, N, C = x.shape
|
| 114 |
+
if XFORMERS_IS_AVAILBLE:
|
| 115 |
+
qkv = self.qkv(x)
|
| 116 |
+
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B L H D', K=3, H=self.num_heads)
|
| 117 |
+
q, k, v = qkv[0], qkv[1], qkv[2] # B L H D
|
| 118 |
+
x = xformers.ops.memory_efficient_attention(q, k, v)
|
| 119 |
+
x = einops.rearrange(x, 'B L H D -> B L (H D)', H=self.num_heads)
|
| 120 |
+
else:
|
| 121 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 122 |
+
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
|
| 123 |
+
|
| 124 |
+
attn = (q @ k.transpose(-2, -1)) * self.scale
|
| 125 |
+
attn = attn.softmax(dim=-1)
|
| 126 |
+
attn = self.attn_drop(attn)
|
| 127 |
+
|
| 128 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
|
| 129 |
+
|
| 130 |
+
x = self.proj(x)
|
| 131 |
+
x = self.proj_drop(x)
|
| 132 |
+
return x
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class Block(nn.Module):
|
| 136 |
+
|
| 137 |
+
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None,
|
| 138 |
+
act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip=False, use_checkpoint=False):
|
| 139 |
+
super().__init__()
|
| 140 |
+
self.norm1 = norm_layer(dim)
|
| 141 |
+
self.attn = Attention(
|
| 142 |
+
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale)
|
| 143 |
+
self.norm2 = norm_layer(dim)
|
| 144 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 145 |
+
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
|
| 146 |
+
self.skip_linear = nn.Linear(2 * dim, dim) if skip else None
|
| 147 |
+
self.use_checkpoint = use_checkpoint
|
| 148 |
+
|
| 149 |
+
def forward(self, x, skip=None):
|
| 150 |
+
if self.use_checkpoint:
|
| 151 |
+
return torch.utils.checkpoint.checkpoint(self._forward, x, skip)
|
| 152 |
+
else:
|
| 153 |
+
return self._forward(x, skip)
|
| 154 |
+
|
| 155 |
+
def _forward(self, x, skip=None):
|
| 156 |
+
if self.skip_linear is not None:
|
| 157 |
+
x = self.skip_linear(torch.cat([x, skip], dim=-1))
|
| 158 |
+
x = x + self.attn(self.norm1(x))
|
| 159 |
+
x = x + self.mlp(self.norm2(x))
|
| 160 |
+
return x
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
class UViT(nn.Module):
|
| 164 |
+
def __init__(self, img_size=16, patch_size=1, in_chans=8, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.,
|
| 165 |
+
qkv_bias=False, qk_scale=None, norm_layer=nn.LayerNorm, num_classes=-1,
|
| 166 |
+
use_checkpoint=False, skip=True, codebook_size=1024):
|
| 167 |
+
super().__init__()
|
| 168 |
+
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
|
| 169 |
+
self.num_classes = num_classes
|
| 170 |
+
self.in_chans = in_chans
|
| 171 |
+
self.skip = skip
|
| 172 |
+
|
| 173 |
+
logger.debug(f'codebook size in nnet: {codebook_size}')
|
| 174 |
+
self.codebook_size = codebook_size
|
| 175 |
+
if num_classes > 0:
|
| 176 |
+
self.extras = 1
|
| 177 |
+
vocab_size = codebook_size + num_classes + 1
|
| 178 |
+
else:
|
| 179 |
+
self.extras = 0
|
| 180 |
+
vocab_size = codebook_size + 1
|
| 181 |
+
|
| 182 |
+
self.token_emb = BertEmbeddings(vocab_size=vocab_size,
|
| 183 |
+
hidden_size=embed_dim,
|
| 184 |
+
max_position_embeddings=int(img_size ** 2) + self.extras,
|
| 185 |
+
dropout=0.1)
|
| 186 |
+
logger.debug(f'token emb weight shape: {self.token_emb.word_embeddings.weight.shape}')
|
| 187 |
+
|
| 188 |
+
if patch_size != 1: # downsamp
|
| 189 |
+
self.patch_embed = PatchEmbed(
|
| 190 |
+
img_size=img_size, patch_size=patch_size, in_chans=embed_dim, embed_dim=embed_dim, input_shape='bhwc')
|
| 191 |
+
logger.debug(f'patch emb weight shape: {self.patch_embed.proj.weight.shape}')
|
| 192 |
+
self.decoder_pred = nn.Linear(embed_dim, patch_size ** 2 * embed_dim, bias=True)
|
| 193 |
+
else:
|
| 194 |
+
self.patch_embed = None
|
| 195 |
+
self.decoder_pred = None
|
| 196 |
+
|
| 197 |
+
self.in_blocks = nn.ModuleList([
|
| 198 |
+
Block(
|
| 199 |
+
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 200 |
+
norm_layer=norm_layer, use_checkpoint=use_checkpoint)
|
| 201 |
+
for _ in range(depth // 2)])
|
| 202 |
+
|
| 203 |
+
self.mid_block = Block(
|
| 204 |
+
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 205 |
+
norm_layer=norm_layer, use_checkpoint=use_checkpoint)
|
| 206 |
+
|
| 207 |
+
self.out_blocks = nn.ModuleList([
|
| 208 |
+
Block(
|
| 209 |
+
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 210 |
+
norm_layer=norm_layer, skip=skip, use_checkpoint=use_checkpoint)
|
| 211 |
+
for _ in range(depth // 2)])
|
| 212 |
+
|
| 213 |
+
self.norm = norm_layer(embed_dim)
|
| 214 |
+
self.mlm_layer = MlmLayer(feat_emb_dim=embed_dim, word_emb_dim=embed_dim, vocab_size=vocab_size)
|
| 215 |
+
|
| 216 |
+
self.apply(self._init_weights)
|
| 217 |
+
|
| 218 |
+
def _init_weights(self, m):
|
| 219 |
+
if isinstance(m, nn.Linear):
|
| 220 |
+
trunc_normal_(m.weight, std=.02)
|
| 221 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 222 |
+
nn.init.constant_(m.bias, 0)
|
| 223 |
+
elif isinstance(m, nn.LayerNorm):
|
| 224 |
+
nn.init.constant_(m.bias, 0)
|
| 225 |
+
nn.init.constant_(m.weight, 1.0)
|
| 226 |
+
|
| 227 |
+
@torch.jit.ignore
|
| 228 |
+
def no_weight_decay(self):
|
| 229 |
+
return {'pos_embed'}
|
| 230 |
+
|
| 231 |
+
def forward(self, x, context=None):
|
| 232 |
+
assert len(x.shape) == 2
|
| 233 |
+
if context is not None:
|
| 234 |
+
context = context + self.codebook_size + 1 # shift, mask token is self.codebook_size
|
| 235 |
+
x = torch.cat((context, x), dim=1)
|
| 236 |
+
x = self.token_emb(x.long())
|
| 237 |
+
if self.patch_embed is not None:
|
| 238 |
+
featmap_downsampled = self.patch_embed(
|
| 239 |
+
x[:, self.extras:].reshape(-1, *self.patch_embed.img_size, self.embed_dim)).reshape(x.shape[0], -1, self.embed_dim)
|
| 240 |
+
x = torch.cat((x[:, :self.extras], featmap_downsampled), dim=1)
|
| 241 |
+
|
| 242 |
+
if self.skip:
|
| 243 |
+
skips = []
|
| 244 |
+
for blk in self.in_blocks:
|
| 245 |
+
x = blk(x)
|
| 246 |
+
if self.skip:
|
| 247 |
+
skips.append(x)
|
| 248 |
+
|
| 249 |
+
x = self.mid_block(x)
|
| 250 |
+
|
| 251 |
+
for blk in self.out_blocks:
|
| 252 |
+
if self.skip:
|
| 253 |
+
x = blk(x, skips.pop())
|
| 254 |
+
else:
|
| 255 |
+
x = blk(x)
|
| 256 |
+
|
| 257 |
+
x = self.norm(x)
|
| 258 |
+
if self.decoder_pred is not None:
|
| 259 |
+
featmap_upsampled = unpatchify(self.decoder_pred(x[:, self.extras:]), self.embed_dim, flatten=True)
|
| 260 |
+
x = torch.cat((x[:, :self.extras], featmap_upsampled), dim=1)
|
| 261 |
+
word_embeddings = self.token_emb.word_embeddings.weight.data.detach()
|
| 262 |
+
x = self.mlm_layer(x, word_embeddings)
|
| 263 |
+
x = x[:, self.extras:, :self.codebook_size]
|
| 264 |
+
return x
|
open_clip/__init__.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .coca_model import CoCa
|
| 2 |
+
from .constants import OPENAI_DATASET_MEAN, OPENAI_DATASET_STD
|
| 3 |
+
from .factory import create_model, create_model_and_transforms, create_model_from_pretrained, get_tokenizer, create_loss
|
| 4 |
+
from .factory import list_models, add_model_config, get_model_config, load_checkpoint
|
| 5 |
+
from .loss import ClipLoss, DistillClipLoss, CoCaLoss
|
| 6 |
+
from .model import CLIP, CustomTextCLIP, CLIPTextCfg, CLIPVisionCfg, \
|
| 7 |
+
convert_weights_to_lp, convert_weights_to_fp16, trace_model, get_cast_dtype
|
| 8 |
+
from .openai import load_openai_model, list_openai_models
|
| 9 |
+
from .pretrained import list_pretrained, list_pretrained_models_by_tag, list_pretrained_tags_by_model, \
|
| 10 |
+
get_pretrained_url, download_pretrained_from_url, is_pretrained_cfg, get_pretrained_cfg, download_pretrained
|
| 11 |
+
from .push_to_hf_hub import push_pretrained_to_hf_hub, push_to_hf_hub
|
| 12 |
+
from .tokenizer import SimpleTokenizer, tokenize, decode
|
| 13 |
+
from .transform import image_transform, AugmentationCfg
|
open_clip/bpe_simple_vocab_16e6.txt.gz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:924691ac288e54409236115652ad4aa250f48203de50a9e4722a6ecd48d6804a
|
| 3 |
+
size 1356917
|
open_clip/coca_model.py
ADDED
|
@@ -0,0 +1,458 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
import numpy as np
|
| 7 |
+
from dataclasses import dataclass
|
| 8 |
+
|
| 9 |
+
from .transformer import (
|
| 10 |
+
LayerNormFp32,
|
| 11 |
+
LayerNorm,
|
| 12 |
+
QuickGELU,
|
| 13 |
+
MultimodalTransformer,
|
| 14 |
+
)
|
| 15 |
+
from .model import CLIPTextCfg, CLIPVisionCfg, _build_vision_tower, _build_text_tower
|
| 16 |
+
|
| 17 |
+
try:
|
| 18 |
+
from transformers import (
|
| 19 |
+
BeamSearchScorer,
|
| 20 |
+
LogitsProcessorList,
|
| 21 |
+
TopPLogitsWarper,
|
| 22 |
+
TopKLogitsWarper,
|
| 23 |
+
RepetitionPenaltyLogitsProcessor,
|
| 24 |
+
MinLengthLogitsProcessor,
|
| 25 |
+
MaxLengthCriteria,
|
| 26 |
+
StoppingCriteriaList
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
GENERATION_TYPES = {
|
| 30 |
+
"top_k": TopKLogitsWarper,
|
| 31 |
+
"top_p": TopPLogitsWarper,
|
| 32 |
+
"beam_search": "beam_search"
|
| 33 |
+
}
|
| 34 |
+
_has_transformers = True
|
| 35 |
+
except ImportError as e:
|
| 36 |
+
GENERATION_TYPES = {
|
| 37 |
+
"top_k": None,
|
| 38 |
+
"top_p": None,
|
| 39 |
+
"beam_search": "beam_search"
|
| 40 |
+
}
|
| 41 |
+
_has_transformers = False
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
@dataclass
|
| 45 |
+
class MultimodalCfg(CLIPTextCfg):
|
| 46 |
+
mlp_ratio: int = 4
|
| 47 |
+
dim_head: int = 64
|
| 48 |
+
heads: int = 8
|
| 49 |
+
n_queries: int = 256
|
| 50 |
+
attn_pooler_heads: int = 8
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def _build_text_decoder_tower(
|
| 54 |
+
embed_dim,
|
| 55 |
+
multimodal_cfg,
|
| 56 |
+
quick_gelu: bool = False,
|
| 57 |
+
cast_dtype: Optional[torch.dtype] = None,
|
| 58 |
+
):
|
| 59 |
+
multimodal_cfg = MultimodalCfg(**multimodal_cfg) if isinstance(multimodal_cfg, dict) else multimodal_cfg
|
| 60 |
+
act_layer = QuickGELU if quick_gelu else nn.GELU
|
| 61 |
+
norm_layer = (
|
| 62 |
+
LayerNormFp32 if cast_dtype in (torch.float16, torch.bfloat16) else LayerNorm
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
decoder = MultimodalTransformer(
|
| 66 |
+
context_length=multimodal_cfg.context_length,
|
| 67 |
+
width=multimodal_cfg.width,
|
| 68 |
+
heads=multimodal_cfg.heads,
|
| 69 |
+
layers=multimodal_cfg.layers,
|
| 70 |
+
ls_init_value=multimodal_cfg.ls_init_value,
|
| 71 |
+
output_dim=embed_dim,
|
| 72 |
+
act_layer=act_layer,
|
| 73 |
+
norm_layer=norm_layer,
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
return decoder
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class CoCa(nn.Module):
|
| 80 |
+
def __init__(
|
| 81 |
+
self,
|
| 82 |
+
embed_dim,
|
| 83 |
+
multimodal_cfg: MultimodalCfg,
|
| 84 |
+
text_cfg: CLIPTextCfg,
|
| 85 |
+
vision_cfg: CLIPVisionCfg,
|
| 86 |
+
quick_gelu: bool = False,
|
| 87 |
+
cast_dtype: Optional[torch.dtype] = None,
|
| 88 |
+
pad_id: int = 0,
|
| 89 |
+
):
|
| 90 |
+
super().__init__()
|
| 91 |
+
multimodal_cfg = MultimodalCfg(**multimodal_cfg) if isinstance(multimodal_cfg, dict) else multimodal_cfg
|
| 92 |
+
text_cfg = CLIPTextCfg(**text_cfg) if isinstance(text_cfg, dict) else text_cfg
|
| 93 |
+
vision_cfg = CLIPVisionCfg(**vision_cfg) if isinstance(vision_cfg, dict) else vision_cfg
|
| 94 |
+
|
| 95 |
+
self.text = _build_text_tower(
|
| 96 |
+
embed_dim=embed_dim,
|
| 97 |
+
text_cfg=text_cfg,
|
| 98 |
+
quick_gelu=quick_gelu,
|
| 99 |
+
cast_dtype=cast_dtype,
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
vocab_size = (
|
| 103 |
+
text_cfg.vocab_size # for hf models
|
| 104 |
+
if hasattr(text_cfg, "hf_model_name") and text_cfg.hf_model_name is not None
|
| 105 |
+
else text_cfg.vocab_size
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
self.visual = _build_vision_tower(
|
| 109 |
+
embed_dim=embed_dim,
|
| 110 |
+
vision_cfg=vision_cfg,
|
| 111 |
+
quick_gelu=quick_gelu,
|
| 112 |
+
cast_dtype=cast_dtype,
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
self.text_decoder = _build_text_decoder_tower(
|
| 116 |
+
vocab_size,
|
| 117 |
+
multimodal_cfg=multimodal_cfg,
|
| 118 |
+
quick_gelu=quick_gelu,
|
| 119 |
+
cast_dtype=cast_dtype,
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
|
| 123 |
+
self.pad_id = pad_id
|
| 124 |
+
|
| 125 |
+
@torch.jit.ignore
|
| 126 |
+
def set_grad_checkpointing(self, enable=True):
|
| 127 |
+
self.visual.set_grad_checkpointing(enable)
|
| 128 |
+
self.text.set_grad_checkpointing(enable)
|
| 129 |
+
self.text_decoder.set_grad_checkpointing(enable)
|
| 130 |
+
|
| 131 |
+
def _encode_image(self, images, normalize=True):
|
| 132 |
+
image_latent, tokens_embs = self.visual(images)
|
| 133 |
+
image_latent = F.normalize(image_latent, dim=-1) if normalize else image_latent
|
| 134 |
+
return image_latent, tokens_embs
|
| 135 |
+
|
| 136 |
+
def _encode_text(self, text, normalize=True, embed_cls=True):
|
| 137 |
+
text = text[:, :-1] if embed_cls else text # make space for CLS token
|
| 138 |
+
text_latent, token_emb = self.text(text)
|
| 139 |
+
text_latent = F.normalize(text_latent, dim=-1) if normalize else text_latent
|
| 140 |
+
return text_latent, token_emb
|
| 141 |
+
|
| 142 |
+
def encode_image(self, images, normalize=True):
|
| 143 |
+
image_latent, _ = self._encode_image(images, normalize=normalize)
|
| 144 |
+
return image_latent
|
| 145 |
+
|
| 146 |
+
def encode_text(self, text, normalize=True, embed_cls=True):
|
| 147 |
+
text_latent, _ = self._encode_text(text, normalize=normalize, embed_cls=embed_cls)
|
| 148 |
+
return text_latent
|
| 149 |
+
|
| 150 |
+
def forward(self, image, text, embed_cls=True, image_latent=None, image_embs=None):
|
| 151 |
+
text_latent, token_embs = self._encode_text(text, embed_cls=embed_cls)
|
| 152 |
+
if image_latent is None or image_embs is None:
|
| 153 |
+
image_latent, image_embs = self._encode_image(image)
|
| 154 |
+
|
| 155 |
+
# TODO: add assertion to avoid bugs?
|
| 156 |
+
labels = text[:, -token_embs.shape[1]:]
|
| 157 |
+
|
| 158 |
+
logits = self.text_decoder(image_embs, token_embs)
|
| 159 |
+
return {
|
| 160 |
+
"image_features": image_latent,
|
| 161 |
+
"text_features": text_latent,
|
| 162 |
+
"logits": logits,
|
| 163 |
+
"labels": labels,
|
| 164 |
+
"logit_scale": self.logit_scale.exp()
|
| 165 |
+
}
|
| 166 |
+
|
| 167 |
+
def generate(
|
| 168 |
+
self,
|
| 169 |
+
image,
|
| 170 |
+
text=None,
|
| 171 |
+
seq_len=30,
|
| 172 |
+
max_seq_len=77,
|
| 173 |
+
temperature=1.,
|
| 174 |
+
generation_type="beam_search",
|
| 175 |
+
top_p=0.1, # keep tokens in the 1 - top_p quantile
|
| 176 |
+
top_k=1, # keeps the top_k most probable tokens
|
| 177 |
+
pad_token_id=None,
|
| 178 |
+
eos_token_id=None,
|
| 179 |
+
sot_token_id=None,
|
| 180 |
+
num_beams=6,
|
| 181 |
+
num_beam_groups=3,
|
| 182 |
+
min_seq_len=5,
|
| 183 |
+
stopping_criteria=None,
|
| 184 |
+
repetition_penalty=1.0,
|
| 185 |
+
fixed_output_length=False # if True output.shape == (batch_size, seq_len)
|
| 186 |
+
):
|
| 187 |
+
# taking many ideas and components from HuggingFace GenerationMixin
|
| 188 |
+
# https://huggingface.co/docs/transformers/main/en/main_classes/text_generation
|
| 189 |
+
assert _has_transformers, "Please install transformers for generate functionality. `pip install transformers`."
|
| 190 |
+
assert seq_len > min_seq_len, "seq_len must be larger than min_seq_len"
|
| 191 |
+
|
| 192 |
+
with torch.no_grad():
|
| 193 |
+
sot_token_id = 49406 if sot_token_id is None else sot_token_id
|
| 194 |
+
eos_token_id = 49407 if eos_token_id is None else eos_token_id
|
| 195 |
+
pad_token_id = self.pad_id if pad_token_id is None else pad_token_id
|
| 196 |
+
logit_processor = LogitsProcessorList(
|
| 197 |
+
[
|
| 198 |
+
MinLengthLogitsProcessor(min_seq_len, eos_token_id),
|
| 199 |
+
RepetitionPenaltyLogitsProcessor(repetition_penalty),
|
| 200 |
+
]
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
if stopping_criteria is None:
|
| 204 |
+
stopping_criteria = [MaxLengthCriteria(max_length=seq_len)]
|
| 205 |
+
|
| 206 |
+
stopping_criteria = StoppingCriteriaList(
|
| 207 |
+
stopping_criteria
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
device = image.device
|
| 211 |
+
|
| 212 |
+
if generation_type == "beam_search":
|
| 213 |
+
output = self._generate_beamsearch(
|
| 214 |
+
image_inputs = image,
|
| 215 |
+
pad_token_id=pad_token_id,
|
| 216 |
+
eos_token_id=eos_token_id,
|
| 217 |
+
sot_token_id=sot_token_id,
|
| 218 |
+
num_beams=num_beams,
|
| 219 |
+
num_beam_groups=num_beam_groups,
|
| 220 |
+
min_seq_len=min_seq_len,
|
| 221 |
+
stopping_criteria=stopping_criteria,
|
| 222 |
+
logit_processor=logit_processor,
|
| 223 |
+
)
|
| 224 |
+
if fixed_output_length and output.shape[1] < seq_len:
|
| 225 |
+
return torch.cat(
|
| 226 |
+
(output, torch.ones(output.shape[0], seq_len-output.shape[1], device=device, dtype=output.dtype) * self.pad_id),
|
| 227 |
+
dim=1
|
| 228 |
+
)
|
| 229 |
+
return output
|
| 230 |
+
|
| 231 |
+
elif generation_type == "top_p":
|
| 232 |
+
logit_warper = GENERATION_TYPES[generation_type](top_p)
|
| 233 |
+
elif generation_type == "top_k":
|
| 234 |
+
logit_warper = GENERATION_TYPES[generation_type](top_k)
|
| 235 |
+
else:
|
| 236 |
+
raise ValueError(
|
| 237 |
+
f"generation_type has to be one of "
|
| 238 |
+
f"{'| ' + ' | '.join(list(GENERATION_TYPES.keys())) + ' |'}."
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
image_latent, image_embs = self._encode_image(image)
|
| 242 |
+
|
| 243 |
+
if text is None:
|
| 244 |
+
text = torch.ones((image.shape[0], 1), device=device, dtype=torch.long) * sot_token_id
|
| 245 |
+
|
| 246 |
+
was_training = self.training
|
| 247 |
+
num_dims = len(text.shape)
|
| 248 |
+
|
| 249 |
+
if num_dims == 1:
|
| 250 |
+
text = text[None, :]
|
| 251 |
+
|
| 252 |
+
cur_len = text.shape[1]
|
| 253 |
+
self.eval()
|
| 254 |
+
out = text
|
| 255 |
+
|
| 256 |
+
while True:
|
| 257 |
+
x = out[:, -max_seq_len:]
|
| 258 |
+
cur_len = x.shape[1]
|
| 259 |
+
logits = self(image, x, image_latent=image_latent, image_embs=image_embs, embed_cls=False)["logits"][:, -1]
|
| 260 |
+
mask = (out[:, -1] == eos_token_id) | (out[:, -1] == pad_token_id)
|
| 261 |
+
sample = torch.ones((out.shape[0], 1), device=device, dtype=torch.long) * pad_token_id
|
| 262 |
+
|
| 263 |
+
if mask.all():
|
| 264 |
+
if not fixed_output_length:
|
| 265 |
+
break
|
| 266 |
+
else:
|
| 267 |
+
logits = logits[~mask, :]
|
| 268 |
+
filtered_logits = logit_processor(x[~mask, :], logits)
|
| 269 |
+
filtered_logits = logit_warper(x[~mask, :], filtered_logits)
|
| 270 |
+
probs = F.softmax(filtered_logits / temperature, dim=-1)
|
| 271 |
+
|
| 272 |
+
if (cur_len + 1 == seq_len):
|
| 273 |
+
sample[~mask, :] = torch.ones((sum(~mask), 1), device=device, dtype=torch.long) * eos_token_id
|
| 274 |
+
else:
|
| 275 |
+
sample[~mask, :] = torch.multinomial(probs, 1)
|
| 276 |
+
|
| 277 |
+
out = torch.cat((out, sample), dim=-1)
|
| 278 |
+
|
| 279 |
+
cur_len += 1
|
| 280 |
+
|
| 281 |
+
if stopping_criteria(out, None):
|
| 282 |
+
break
|
| 283 |
+
|
| 284 |
+
if num_dims == 1:
|
| 285 |
+
out = out.squeeze(0)
|
| 286 |
+
|
| 287 |
+
self.train(was_training)
|
| 288 |
+
return out
|
| 289 |
+
|
| 290 |
+
def _generate_beamsearch(
|
| 291 |
+
self,
|
| 292 |
+
image_inputs,
|
| 293 |
+
pad_token_id=None,
|
| 294 |
+
eos_token_id=None,
|
| 295 |
+
sot_token_id=None,
|
| 296 |
+
num_beams=6,
|
| 297 |
+
num_beam_groups=3,
|
| 298 |
+
min_seq_len=5,
|
| 299 |
+
stopping_criteria=None,
|
| 300 |
+
logit_processor=None,
|
| 301 |
+
logit_warper=None,
|
| 302 |
+
):
|
| 303 |
+
device = image_inputs.device
|
| 304 |
+
batch_size = image_inputs.shape[0]
|
| 305 |
+
image_inputs = torch.repeat_interleave(image_inputs, num_beams, dim=0)
|
| 306 |
+
image_latent, image_embs = self._encode_image(image_inputs)
|
| 307 |
+
|
| 308 |
+
input_ids = torch.ones((batch_size * num_beams, 1), device=device, dtype=torch.long)
|
| 309 |
+
input_ids = input_ids * sot_token_id
|
| 310 |
+
beam_scorer = BeamSearchScorer(
|
| 311 |
+
batch_size=batch_size,
|
| 312 |
+
num_beams=num_beams,
|
| 313 |
+
device=device,
|
| 314 |
+
num_beam_groups=num_beam_groups,
|
| 315 |
+
)
|
| 316 |
+
# instantiate logits processors
|
| 317 |
+
logits_processor = (
|
| 318 |
+
LogitsProcessorList([MinLengthLogitsProcessor(min_seq_len, eos_token_id=eos_token_id)])
|
| 319 |
+
if logit_processor is None
|
| 320 |
+
else logit_processor
|
| 321 |
+
)
|
| 322 |
+
|
| 323 |
+
batch_size = len(beam_scorer._beam_hyps)
|
| 324 |
+
num_beams = beam_scorer.num_beams
|
| 325 |
+
num_beam_groups = beam_scorer.num_beam_groups
|
| 326 |
+
num_sub_beams = num_beams // num_beam_groups
|
| 327 |
+
batch_beam_size, cur_len = input_ids.shape
|
| 328 |
+
beam_indices = None
|
| 329 |
+
|
| 330 |
+
if num_beams * batch_size != batch_beam_size:
|
| 331 |
+
raise ValueError(
|
| 332 |
+
f"Batch dimension of `input_ids` should be {num_beams * batch_size}, but is {batch_beam_size}."
|
| 333 |
+
)
|
| 334 |
+
|
| 335 |
+
beam_scores = torch.full((batch_size, num_beams), -1e9, dtype=torch.float, device=device)
|
| 336 |
+
# initialise score of first beam of each group with 0 and the rest with 1e-9. This ensures that the beams in
|
| 337 |
+
# the same group don't produce same tokens everytime.
|
| 338 |
+
beam_scores[:, ::num_sub_beams] = 0
|
| 339 |
+
beam_scores = beam_scores.view((batch_size * num_beams,))
|
| 340 |
+
|
| 341 |
+
while True:
|
| 342 |
+
|
| 343 |
+
# predicted tokens in cur_len step
|
| 344 |
+
current_tokens = torch.zeros(batch_size * num_beams, dtype=input_ids.dtype, device=device)
|
| 345 |
+
|
| 346 |
+
# indices which will form the beams in the next time step
|
| 347 |
+
reordering_indices = torch.zeros(batch_size * num_beams, dtype=torch.long, device=device)
|
| 348 |
+
|
| 349 |
+
# do one decoder step on all beams of all sentences in batch
|
| 350 |
+
model_inputs = prepare_inputs_for_generation(input_ids=input_ids, image_inputs=image_inputs)
|
| 351 |
+
outputs = self(
|
| 352 |
+
model_inputs['images'],
|
| 353 |
+
model_inputs['text'],
|
| 354 |
+
embed_cls=False,
|
| 355 |
+
image_latent=image_latent,
|
| 356 |
+
image_embs=image_embs
|
| 357 |
+
)
|
| 358 |
+
|
| 359 |
+
for beam_group_idx in range(num_beam_groups):
|
| 360 |
+
group_start_idx = beam_group_idx * num_sub_beams
|
| 361 |
+
group_end_idx = min(group_start_idx + num_sub_beams, num_beams)
|
| 362 |
+
group_size = group_end_idx - group_start_idx
|
| 363 |
+
|
| 364 |
+
# indices of beams of current group among all sentences in batch
|
| 365 |
+
batch_group_indices = []
|
| 366 |
+
|
| 367 |
+
for batch_idx in range(batch_size):
|
| 368 |
+
batch_group_indices.extend(
|
| 369 |
+
[batch_idx * num_beams + idx for idx in range(group_start_idx, group_end_idx)]
|
| 370 |
+
)
|
| 371 |
+
group_input_ids = input_ids[batch_group_indices]
|
| 372 |
+
|
| 373 |
+
# select outputs of beams of currentg group only
|
| 374 |
+
next_token_logits = outputs['logits'][batch_group_indices, -1, :]
|
| 375 |
+
vocab_size = next_token_logits.shape[-1]
|
| 376 |
+
|
| 377 |
+
next_token_scores_processed = logits_processor(
|
| 378 |
+
group_input_ids, next_token_logits, current_tokens=current_tokens, beam_group_idx=beam_group_idx
|
| 379 |
+
)
|
| 380 |
+
next_token_scores = next_token_scores_processed + beam_scores[batch_group_indices].unsqueeze(-1)
|
| 381 |
+
next_token_scores = next_token_scores.expand_as(next_token_scores_processed)
|
| 382 |
+
|
| 383 |
+
# reshape for beam search
|
| 384 |
+
next_token_scores = next_token_scores.view(batch_size, group_size * vocab_size)
|
| 385 |
+
|
| 386 |
+
next_token_scores, next_tokens = torch.topk(
|
| 387 |
+
next_token_scores, 2 * group_size, dim=1, largest=True, sorted=True
|
| 388 |
+
)
|
| 389 |
+
|
| 390 |
+
next_indices = torch.div(next_tokens, vocab_size, rounding_mode="floor")
|
| 391 |
+
next_tokens = next_tokens % vocab_size
|
| 392 |
+
|
| 393 |
+
# stateless
|
| 394 |
+
process_beam_indices = sum(beam_indices, ()) if beam_indices is not None else None
|
| 395 |
+
beam_outputs = beam_scorer.process(
|
| 396 |
+
group_input_ids,
|
| 397 |
+
next_token_scores,
|
| 398 |
+
next_tokens,
|
| 399 |
+
next_indices,
|
| 400 |
+
pad_token_id=pad_token_id,
|
| 401 |
+
eos_token_id=eos_token_id,
|
| 402 |
+
beam_indices=process_beam_indices,
|
| 403 |
+
)
|
| 404 |
+
beam_scores[batch_group_indices] = beam_outputs["next_beam_scores"]
|
| 405 |
+
beam_next_tokens = beam_outputs["next_beam_tokens"]
|
| 406 |
+
beam_idx = beam_outputs["next_beam_indices"]
|
| 407 |
+
|
| 408 |
+
input_ids[batch_group_indices] = group_input_ids[beam_idx]
|
| 409 |
+
group_input_ids = torch.cat([group_input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)
|
| 410 |
+
current_tokens[batch_group_indices] = group_input_ids[:, -1]
|
| 411 |
+
|
| 412 |
+
# (beam_idx // group_size) -> batch_idx
|
| 413 |
+
# (beam_idx % group_size) -> offset of idx inside the group
|
| 414 |
+
reordering_indices[batch_group_indices] = (
|
| 415 |
+
num_beams * torch.div(beam_idx, group_size, rounding_mode="floor") + group_start_idx + (beam_idx % group_size)
|
| 416 |
+
)
|
| 417 |
+
|
| 418 |
+
input_ids = torch.cat([input_ids, current_tokens.unsqueeze(-1)], dim=-1)
|
| 419 |
+
|
| 420 |
+
# increase cur_len
|
| 421 |
+
cur_len = cur_len + 1
|
| 422 |
+
if beam_scorer.is_done or stopping_criteria(input_ids, None):
|
| 423 |
+
break
|
| 424 |
+
|
| 425 |
+
final_beam_indices = sum(beam_indices, ()) if beam_indices is not None else None
|
| 426 |
+
sequence_outputs = beam_scorer.finalize(
|
| 427 |
+
input_ids,
|
| 428 |
+
beam_scores,
|
| 429 |
+
next_tokens,
|
| 430 |
+
next_indices,
|
| 431 |
+
pad_token_id=pad_token_id,
|
| 432 |
+
eos_token_id=eos_token_id,
|
| 433 |
+
max_length=stopping_criteria.max_length,
|
| 434 |
+
beam_indices=final_beam_indices,
|
| 435 |
+
)
|
| 436 |
+
return sequence_outputs['sequences']
|
| 437 |
+
|
| 438 |
+
|
| 439 |
+
def prepare_inputs_for_generation(input_ids, image_inputs, past=None, **kwargs):
|
| 440 |
+
if past:
|
| 441 |
+
input_ids = input_ids[:, -1].unsqueeze(-1)
|
| 442 |
+
|
| 443 |
+
attention_mask = kwargs.get("attention_mask", None)
|
| 444 |
+
position_ids = kwargs.get("position_ids", None)
|
| 445 |
+
|
| 446 |
+
if attention_mask is not None and position_ids is None:
|
| 447 |
+
# create position_ids on the fly for batch generation
|
| 448 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 449 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 450 |
+
else:
|
| 451 |
+
position_ids = None
|
| 452 |
+
return {
|
| 453 |
+
"text": input_ids,
|
| 454 |
+
"images": image_inputs,
|
| 455 |
+
"past_key_values": past,
|
| 456 |
+
"position_ids": position_ids,
|
| 457 |
+
"attention_mask": attention_mask,
|
| 458 |
+
}
|
open_clip/constants.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
OPENAI_DATASET_MEAN = (0.48145466, 0.4578275, 0.40821073)
|
| 2 |
+
OPENAI_DATASET_STD = (0.26862954, 0.26130258, 0.27577711)
|
open_clip/factory.py
ADDED
|
@@ -0,0 +1,366 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import pathlib
|
| 5 |
+
import re
|
| 6 |
+
from copy import deepcopy
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
from typing import Any, Dict, Optional, Tuple, Union
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
|
| 12 |
+
from .constants import OPENAI_DATASET_MEAN, OPENAI_DATASET_STD
|
| 13 |
+
from .model import CLIP, CustomTextCLIP, convert_weights_to_lp, convert_to_custom_text_state_dict,\
|
| 14 |
+
resize_pos_embed, get_cast_dtype
|
| 15 |
+
from .coca_model import CoCa
|
| 16 |
+
from .loss import ClipLoss, DistillClipLoss, CoCaLoss
|
| 17 |
+
from .openai import load_openai_model
|
| 18 |
+
from .pretrained import is_pretrained_cfg, get_pretrained_cfg, download_pretrained, list_pretrained_tags_by_model, download_pretrained_from_hf
|
| 19 |
+
from .transform import image_transform, AugmentationCfg
|
| 20 |
+
from .tokenizer import HFTokenizer, tokenize
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
HF_HUB_PREFIX = 'hf-hub:'
|
| 24 |
+
_MODEL_CONFIG_PATHS = [Path(__file__).parent / f"model_configs/"]
|
| 25 |
+
_MODEL_CONFIGS = {} # directory (model_name: config) of model architecture configs
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def _natural_key(string_):
|
| 29 |
+
return [int(s) if s.isdigit() else s for s in re.split(r'(\d+)', string_.lower())]
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def _rescan_model_configs():
|
| 33 |
+
global _MODEL_CONFIGS
|
| 34 |
+
|
| 35 |
+
config_ext = ('.json',)
|
| 36 |
+
config_files = []
|
| 37 |
+
for config_path in _MODEL_CONFIG_PATHS:
|
| 38 |
+
if config_path.is_file() and config_path.suffix in config_ext:
|
| 39 |
+
config_files.append(config_path)
|
| 40 |
+
elif config_path.is_dir():
|
| 41 |
+
for ext in config_ext:
|
| 42 |
+
config_files.extend(config_path.glob(f'*{ext}'))
|
| 43 |
+
|
| 44 |
+
for cf in config_files:
|
| 45 |
+
with open(cf, 'r') as f:
|
| 46 |
+
model_cfg = json.load(f)
|
| 47 |
+
if all(a in model_cfg for a in ('embed_dim', 'vision_cfg', 'text_cfg')):
|
| 48 |
+
_MODEL_CONFIGS[cf.stem] = model_cfg
|
| 49 |
+
|
| 50 |
+
_MODEL_CONFIGS = {k: v for k, v in sorted(_MODEL_CONFIGS.items(), key=lambda x: _natural_key(x[0]))}
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
_rescan_model_configs() # initial populate of model config registry
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def list_models():
|
| 57 |
+
""" enumerate available model architectures based on config files """
|
| 58 |
+
return list(_MODEL_CONFIGS.keys())
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def add_model_config(path):
|
| 62 |
+
""" add model config path or file and update registry """
|
| 63 |
+
if not isinstance(path, Path):
|
| 64 |
+
path = Path(path)
|
| 65 |
+
_MODEL_CONFIG_PATHS.append(path)
|
| 66 |
+
_rescan_model_configs()
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def get_model_config(model_name):
|
| 70 |
+
if model_name in _MODEL_CONFIGS:
|
| 71 |
+
return deepcopy(_MODEL_CONFIGS[model_name])
|
| 72 |
+
else:
|
| 73 |
+
return None
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def get_tokenizer(model_name):
|
| 77 |
+
if model_name.startswith(HF_HUB_PREFIX):
|
| 78 |
+
tokenizer = HFTokenizer(model_name[len(HF_HUB_PREFIX):])
|
| 79 |
+
else:
|
| 80 |
+
config = get_model_config(model_name)
|
| 81 |
+
tokenizer = HFTokenizer(
|
| 82 |
+
config['text_cfg']['hf_tokenizer_name']) if 'hf_tokenizer_name' in config['text_cfg'] else tokenize
|
| 83 |
+
return tokenizer
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def load_state_dict(checkpoint_path: str, map_location='cpu'):
|
| 87 |
+
checkpoint = torch.load(checkpoint_path, map_location=map_location)
|
| 88 |
+
if isinstance(checkpoint, dict) and 'state_dict' in checkpoint:
|
| 89 |
+
state_dict = checkpoint['state_dict']
|
| 90 |
+
else:
|
| 91 |
+
state_dict = checkpoint
|
| 92 |
+
if next(iter(state_dict.items()))[0].startswith('module'):
|
| 93 |
+
state_dict = {k[7:]: v for k, v in state_dict.items()}
|
| 94 |
+
return state_dict
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def load_checkpoint(model, checkpoint_path, strict=True):
|
| 98 |
+
state_dict = load_state_dict(checkpoint_path)
|
| 99 |
+
# detect old format and make compatible with new format
|
| 100 |
+
if 'positional_embedding' in state_dict and not hasattr(model, 'positional_embedding'):
|
| 101 |
+
state_dict = convert_to_custom_text_state_dict(state_dict)
|
| 102 |
+
resize_pos_embed(state_dict, model)
|
| 103 |
+
incompatible_keys = model.load_state_dict(state_dict, strict=strict)
|
| 104 |
+
return incompatible_keys
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def create_model(
|
| 108 |
+
model_name: str,
|
| 109 |
+
pretrained: Optional[str] = None,
|
| 110 |
+
precision: str = 'fp32',
|
| 111 |
+
device: Union[str, torch.device] = 'cpu',
|
| 112 |
+
jit: bool = False,
|
| 113 |
+
force_quick_gelu: bool = False,
|
| 114 |
+
force_custom_text: bool = False,
|
| 115 |
+
force_patch_dropout: Optional[float] = None,
|
| 116 |
+
force_image_size: Optional[Union[int, Tuple[int, int]]] = None,
|
| 117 |
+
pretrained_image: bool = False,
|
| 118 |
+
pretrained_hf: bool = True,
|
| 119 |
+
cache_dir: Optional[str] = None,
|
| 120 |
+
output_dict: Optional[bool] = None,
|
| 121 |
+
require_pretrained: bool = False,
|
| 122 |
+
):
|
| 123 |
+
has_hf_hub_prefix = model_name.startswith(HF_HUB_PREFIX)
|
| 124 |
+
if has_hf_hub_prefix:
|
| 125 |
+
model_id = model_name[len(HF_HUB_PREFIX):]
|
| 126 |
+
checkpoint_path = download_pretrained_from_hf(model_id, cache_dir=cache_dir)
|
| 127 |
+
config_path = download_pretrained_from_hf(model_id, filename='open_clip_config.json', cache_dir=cache_dir)
|
| 128 |
+
|
| 129 |
+
with open(config_path, 'r', encoding='utf-8') as f:
|
| 130 |
+
config = json.load(f)
|
| 131 |
+
pretrained_cfg = config['preprocess_cfg']
|
| 132 |
+
model_cfg = config['model_cfg']
|
| 133 |
+
else:
|
| 134 |
+
model_name = model_name.replace('/', '-') # for callers using old naming with / in ViT names
|
| 135 |
+
checkpoint_path = None
|
| 136 |
+
pretrained_cfg = {}
|
| 137 |
+
model_cfg = None
|
| 138 |
+
|
| 139 |
+
if isinstance(device, str):
|
| 140 |
+
device = torch.device(device)
|
| 141 |
+
|
| 142 |
+
if pretrained and pretrained.lower() == 'openai':
|
| 143 |
+
logging.info(f'Loading pretrained {model_name} from OpenAI.')
|
| 144 |
+
model = load_openai_model(
|
| 145 |
+
model_name,
|
| 146 |
+
precision=precision,
|
| 147 |
+
device=device,
|
| 148 |
+
jit=jit,
|
| 149 |
+
cache_dir=cache_dir,
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
# to always output dict even if it is clip
|
| 153 |
+
if output_dict and hasattr(model, "output_dict"):
|
| 154 |
+
model.output_dict = True
|
| 155 |
+
else:
|
| 156 |
+
model_cfg = model_cfg or get_model_config(model_name)
|
| 157 |
+
if model_cfg is not None:
|
| 158 |
+
logging.info(f'Loaded {model_name} model config.')
|
| 159 |
+
else:
|
| 160 |
+
logging.error(f'Model config for {model_name} not found; available models {list_models()}.')
|
| 161 |
+
raise RuntimeError(f'Model config for {model_name} not found.')
|
| 162 |
+
|
| 163 |
+
if force_quick_gelu:
|
| 164 |
+
# override for use of QuickGELU on non-OpenAI transformer models
|
| 165 |
+
model_cfg["quick_gelu"] = True
|
| 166 |
+
|
| 167 |
+
if force_patch_dropout is not None:
|
| 168 |
+
# override the default patch dropout value
|
| 169 |
+
model_cfg["vision_cfg"]["patch_dropout"] = force_patch_dropout
|
| 170 |
+
|
| 171 |
+
if force_image_size is not None:
|
| 172 |
+
# override model config's image size
|
| 173 |
+
model_cfg["vision_cfg"]["image_size"] = force_image_size
|
| 174 |
+
|
| 175 |
+
if pretrained_image:
|
| 176 |
+
if 'timm_model_name' in model_cfg.get('vision_cfg', {}):
|
| 177 |
+
# pretrained weight loading for timm models set via vision_cfg
|
| 178 |
+
model_cfg['vision_cfg']['timm_model_pretrained'] = True
|
| 179 |
+
else:
|
| 180 |
+
assert False, 'pretrained image towers currently only supported for timm models'
|
| 181 |
+
|
| 182 |
+
cast_dtype = get_cast_dtype(precision)
|
| 183 |
+
is_hf_model = 'hf_model_name' in model_cfg.get('text_cfg', {})
|
| 184 |
+
custom_text = model_cfg.pop('custom_text', False) or force_custom_text or is_hf_model
|
| 185 |
+
|
| 186 |
+
if custom_text:
|
| 187 |
+
if is_hf_model:
|
| 188 |
+
model_cfg['text_cfg']['hf_model_pretrained'] = pretrained_hf
|
| 189 |
+
if "coca" in model_name:
|
| 190 |
+
model = CoCa(**model_cfg, cast_dtype=cast_dtype)
|
| 191 |
+
else:
|
| 192 |
+
model = CustomTextCLIP(**model_cfg, cast_dtype=cast_dtype)
|
| 193 |
+
else:
|
| 194 |
+
model = CLIP(**model_cfg, cast_dtype=cast_dtype)
|
| 195 |
+
|
| 196 |
+
pretrained_loaded = False
|
| 197 |
+
if pretrained:
|
| 198 |
+
checkpoint_path = ''
|
| 199 |
+
pretrained_cfg = get_pretrained_cfg(model_name, pretrained)
|
| 200 |
+
if pretrained_cfg:
|
| 201 |
+
checkpoint_path = download_pretrained(pretrained_cfg, cache_dir=cache_dir)
|
| 202 |
+
elif os.path.exists(pretrained):
|
| 203 |
+
checkpoint_path = pretrained
|
| 204 |
+
|
| 205 |
+
if checkpoint_path:
|
| 206 |
+
logging.info(f'Loading pretrained {model_name} weights ({pretrained}).')
|
| 207 |
+
load_checkpoint(model, checkpoint_path)
|
| 208 |
+
else:
|
| 209 |
+
error_str = (
|
| 210 |
+
f'Pretrained weights ({pretrained}) not found for model {model_name}.'
|
| 211 |
+
f'Available pretrained tags ({list_pretrained_tags_by_model(model_name)}.')
|
| 212 |
+
logging.warning(error_str)
|
| 213 |
+
raise RuntimeError(error_str)
|
| 214 |
+
pretrained_loaded = True
|
| 215 |
+
elif has_hf_hub_prefix:
|
| 216 |
+
logging.info(f'Loading pretrained {model_name} weights ({pretrained}).')
|
| 217 |
+
load_checkpoint(model, checkpoint_path)
|
| 218 |
+
pretrained_loaded = True
|
| 219 |
+
|
| 220 |
+
if require_pretrained and not pretrained_loaded:
|
| 221 |
+
# callers of create_model_from_pretrained always expect pretrained weights
|
| 222 |
+
raise RuntimeError(
|
| 223 |
+
f'Pretrained weights were required for (model: {model_name}, pretrained: {pretrained}) but not loaded.')
|
| 224 |
+
|
| 225 |
+
model.to(device=device)
|
| 226 |
+
if precision in ("fp16", "bf16"):
|
| 227 |
+
convert_weights_to_lp(model, dtype=torch.bfloat16 if precision == 'bf16' else torch.float16)
|
| 228 |
+
|
| 229 |
+
# set image / mean metadata from pretrained_cfg if available, or use default
|
| 230 |
+
model.visual.image_mean = pretrained_cfg.get('mean', None) or OPENAI_DATASET_MEAN
|
| 231 |
+
model.visual.image_std = pretrained_cfg.get('std', None) or OPENAI_DATASET_STD
|
| 232 |
+
|
| 233 |
+
# to always output dict even if it is clip
|
| 234 |
+
if output_dict and hasattr(model, "output_dict"):
|
| 235 |
+
model.output_dict = True
|
| 236 |
+
|
| 237 |
+
if jit:
|
| 238 |
+
model = torch.jit.script(model)
|
| 239 |
+
|
| 240 |
+
return model
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
def create_loss(args):
|
| 244 |
+
if args.distill:
|
| 245 |
+
return DistillClipLoss(
|
| 246 |
+
local_loss=args.local_loss,
|
| 247 |
+
gather_with_grad=args.gather_with_grad,
|
| 248 |
+
cache_labels=True,
|
| 249 |
+
rank=args.rank,
|
| 250 |
+
world_size=args.world_size,
|
| 251 |
+
use_horovod=args.horovod,
|
| 252 |
+
)
|
| 253 |
+
elif "coca" in args.model.lower():
|
| 254 |
+
return CoCaLoss(
|
| 255 |
+
caption_loss_weight=args.coca_caption_loss_weight,
|
| 256 |
+
clip_loss_weight=args.coca_contrastive_loss_weight,
|
| 257 |
+
local_loss=args.local_loss,
|
| 258 |
+
gather_with_grad=args.gather_with_grad,
|
| 259 |
+
cache_labels=True,
|
| 260 |
+
rank=args.rank,
|
| 261 |
+
world_size=args.world_size,
|
| 262 |
+
use_horovod=args.horovod,
|
| 263 |
+
)
|
| 264 |
+
return ClipLoss(
|
| 265 |
+
local_loss=args.local_loss,
|
| 266 |
+
gather_with_grad=args.gather_with_grad,
|
| 267 |
+
cache_labels=True,
|
| 268 |
+
rank=args.rank,
|
| 269 |
+
world_size=args.world_size,
|
| 270 |
+
use_horovod=args.horovod,
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
def create_model_and_transforms(
|
| 275 |
+
model_name: str,
|
| 276 |
+
pretrained: Optional[str] = None,
|
| 277 |
+
precision: str = 'fp32',
|
| 278 |
+
device: Union[str, torch.device] = 'cpu',
|
| 279 |
+
jit: bool = False,
|
| 280 |
+
force_quick_gelu: bool = False,
|
| 281 |
+
force_custom_text: bool = False,
|
| 282 |
+
force_patch_dropout: Optional[float] = None,
|
| 283 |
+
force_image_size: Optional[Union[int, Tuple[int, int]]] = None,
|
| 284 |
+
pretrained_image: bool = False,
|
| 285 |
+
pretrained_hf: bool = True,
|
| 286 |
+
image_mean: Optional[Tuple[float, ...]] = None,
|
| 287 |
+
image_std: Optional[Tuple[float, ...]] = None,
|
| 288 |
+
aug_cfg: Optional[Union[Dict[str, Any], AugmentationCfg]] = None,
|
| 289 |
+
cache_dir: Optional[str] = None,
|
| 290 |
+
output_dict: Optional[bool] = None,
|
| 291 |
+
):
|
| 292 |
+
model = create_model(
|
| 293 |
+
model_name,
|
| 294 |
+
pretrained,
|
| 295 |
+
precision=precision,
|
| 296 |
+
device=device,
|
| 297 |
+
jit=jit,
|
| 298 |
+
force_quick_gelu=force_quick_gelu,
|
| 299 |
+
force_custom_text=force_custom_text,
|
| 300 |
+
force_patch_dropout=force_patch_dropout,
|
| 301 |
+
force_image_size=force_image_size,
|
| 302 |
+
pretrained_image=pretrained_image,
|
| 303 |
+
pretrained_hf=pretrained_hf,
|
| 304 |
+
cache_dir=cache_dir,
|
| 305 |
+
output_dict=output_dict,
|
| 306 |
+
)
|
| 307 |
+
|
| 308 |
+
image_mean = image_mean or getattr(model.visual, 'image_mean', None)
|
| 309 |
+
image_std = image_std or getattr(model.visual, 'image_std', None)
|
| 310 |
+
preprocess_train = image_transform(
|
| 311 |
+
model.visual.image_size,
|
| 312 |
+
is_train=True,
|
| 313 |
+
mean=image_mean,
|
| 314 |
+
std=image_std,
|
| 315 |
+
aug_cfg=aug_cfg,
|
| 316 |
+
)
|
| 317 |
+
preprocess_val = image_transform(
|
| 318 |
+
model.visual.image_size,
|
| 319 |
+
is_train=False,
|
| 320 |
+
mean=image_mean,
|
| 321 |
+
std=image_std,
|
| 322 |
+
)
|
| 323 |
+
|
| 324 |
+
return model, preprocess_train, preprocess_val
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
def create_model_from_pretrained(
|
| 328 |
+
model_name: str,
|
| 329 |
+
pretrained: Optional[str] = None,
|
| 330 |
+
precision: str = 'fp32',
|
| 331 |
+
device: Union[str, torch.device] = 'cpu',
|
| 332 |
+
jit: bool = False,
|
| 333 |
+
force_quick_gelu: bool = False,
|
| 334 |
+
force_custom_text: bool = False,
|
| 335 |
+
force_image_size: Optional[Union[int, Tuple[int, int]]] = None,
|
| 336 |
+
return_transform: bool = True,
|
| 337 |
+
image_mean: Optional[Tuple[float, ...]] = None,
|
| 338 |
+
image_std: Optional[Tuple[float, ...]] = None,
|
| 339 |
+
cache_dir: Optional[str] = None,
|
| 340 |
+
):
|
| 341 |
+
model = create_model(
|
| 342 |
+
model_name,
|
| 343 |
+
pretrained,
|
| 344 |
+
precision=precision,
|
| 345 |
+
device=device,
|
| 346 |
+
jit=jit,
|
| 347 |
+
force_quick_gelu=force_quick_gelu,
|
| 348 |
+
force_custom_text=force_custom_text,
|
| 349 |
+
force_image_size=force_image_size,
|
| 350 |
+
cache_dir=cache_dir,
|
| 351 |
+
require_pretrained=True,
|
| 352 |
+
)
|
| 353 |
+
|
| 354 |
+
if not return_transform:
|
| 355 |
+
return model
|
| 356 |
+
|
| 357 |
+
image_mean = image_mean or getattr(model.visual, 'image_mean', None)
|
| 358 |
+
image_std = image_std or getattr(model.visual, 'image_std', None)
|
| 359 |
+
preprocess = image_transform(
|
| 360 |
+
model.visual.image_size,
|
| 361 |
+
is_train=False,
|
| 362 |
+
mean=image_mean,
|
| 363 |
+
std=image_std,
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
return model, preprocess
|
open_clip/generation_utils.py
ADDED
|
File without changes
|
open_clip/hf_configs.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# HF architecture dict:
|
| 2 |
+
arch_dict = {
|
| 3 |
+
# https://huggingface.co/docs/transformers/model_doc/roberta#roberta
|
| 4 |
+
"roberta": {
|
| 5 |
+
"config_names": {
|
| 6 |
+
"context_length": "max_position_embeddings",
|
| 7 |
+
"vocab_size": "vocab_size",
|
| 8 |
+
"width": "hidden_size",
|
| 9 |
+
"heads": "num_attention_heads",
|
| 10 |
+
"layers": "num_hidden_layers",
|
| 11 |
+
"layer_attr": "layer",
|
| 12 |
+
"token_embeddings_attr": "embeddings"
|
| 13 |
+
},
|
| 14 |
+
"pooler": "mean_pooler",
|
| 15 |
+
},
|
| 16 |
+
# https://huggingface.co/docs/transformers/model_doc/xlm-roberta#transformers.XLMRobertaConfig
|
| 17 |
+
"xlm-roberta": {
|
| 18 |
+
"config_names": {
|
| 19 |
+
"context_length": "max_position_embeddings",
|
| 20 |
+
"vocab_size": "vocab_size",
|
| 21 |
+
"width": "hidden_size",
|
| 22 |
+
"heads": "num_attention_heads",
|
| 23 |
+
"layers": "num_hidden_layers",
|
| 24 |
+
"layer_attr": "layer",
|
| 25 |
+
"token_embeddings_attr": "embeddings"
|
| 26 |
+
},
|
| 27 |
+
"pooler": "mean_pooler",
|
| 28 |
+
},
|
| 29 |
+
# https://huggingface.co/docs/transformers/model_doc/mt5#mt5
|
| 30 |
+
"mt5": {
|
| 31 |
+
"config_names": {
|
| 32 |
+
# unlimited seqlen
|
| 33 |
+
# https://github.com/google-research/text-to-text-transfer-transformer/issues/273
|
| 34 |
+
# https://github.com/huggingface/transformers/blob/v4.24.0/src/transformers/models/t5/modeling_t5.py#L374
|
| 35 |
+
"context_length": "",
|
| 36 |
+
"vocab_size": "vocab_size",
|
| 37 |
+
"width": "d_model",
|
| 38 |
+
"heads": "num_heads",
|
| 39 |
+
"layers": "num_layers",
|
| 40 |
+
"layer_attr": "block",
|
| 41 |
+
"token_embeddings_attr": "embed_tokens"
|
| 42 |
+
},
|
| 43 |
+
"pooler": "mean_pooler",
|
| 44 |
+
},
|
| 45 |
+
}
|
open_clip/hf_model.py
ADDED
|
@@ -0,0 +1,176 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" huggingface model adapter
|
| 2 |
+
|
| 3 |
+
Wraps HuggingFace transformers (https://github.com/huggingface/transformers) models for use as a text tower in CLIP model.
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
import re
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn as nn
|
| 10 |
+
from torch import TensorType
|
| 11 |
+
|
| 12 |
+
try:
|
| 13 |
+
import transformers
|
| 14 |
+
from transformers import AutoModel, AutoTokenizer, AutoConfig, PretrainedConfig
|
| 15 |
+
from transformers.modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, \
|
| 16 |
+
BaseModelOutputWithPoolingAndCrossAttentions
|
| 17 |
+
except ImportError as e:
|
| 18 |
+
transformers = None
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class BaseModelOutput:
|
| 22 |
+
pass
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class PretrainedConfig:
|
| 26 |
+
pass
|
| 27 |
+
|
| 28 |
+
from .hf_configs import arch_dict
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
# utils
|
| 32 |
+
def _camel2snake(s):
|
| 33 |
+
return re.sub(r'(?<!^)(?=[A-Z])', '_', s).lower()
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# TODO: ?last - for gpt-like models
|
| 37 |
+
_POOLERS = {}
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def register_pooler(cls):
|
| 41 |
+
"""Decorator registering pooler class"""
|
| 42 |
+
_POOLERS[_camel2snake(cls.__name__)] = cls
|
| 43 |
+
return cls
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
@register_pooler
|
| 47 |
+
class MeanPooler(nn.Module):
|
| 48 |
+
"""Mean pooling"""
|
| 49 |
+
|
| 50 |
+
def forward(self, x: BaseModelOutput, attention_mask: TensorType):
|
| 51 |
+
masked_output = x.last_hidden_state * attention_mask.unsqueeze(-1)
|
| 52 |
+
return masked_output.sum(dim=1) / attention_mask.sum(-1, keepdim=True)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
@register_pooler
|
| 56 |
+
class MaxPooler(nn.Module):
|
| 57 |
+
"""Max pooling"""
|
| 58 |
+
|
| 59 |
+
def forward(self, x: BaseModelOutput, attention_mask: TensorType):
|
| 60 |
+
masked_output = x.last_hidden_state.masked_fill(attention_mask.unsqueeze(-1), -torch.inf)
|
| 61 |
+
return masked_output.max(1).values
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
@register_pooler
|
| 65 |
+
class ClsPooler(nn.Module):
|
| 66 |
+
"""CLS token pooling"""
|
| 67 |
+
|
| 68 |
+
def __init__(self, use_pooler_output=True):
|
| 69 |
+
super().__init__()
|
| 70 |
+
self.cls_token_position = 0
|
| 71 |
+
self.use_pooler_output = use_pooler_output
|
| 72 |
+
|
| 73 |
+
def forward(self, x: BaseModelOutput, attention_mask: TensorType):
|
| 74 |
+
if (self.use_pooler_output and
|
| 75 |
+
isinstance(x, (BaseModelOutputWithPooling, BaseModelOutputWithPoolingAndCrossAttentions)) and
|
| 76 |
+
(x.pooler_output is not None)
|
| 77 |
+
):
|
| 78 |
+
return x.pooler_output
|
| 79 |
+
|
| 80 |
+
return x.last_hidden_state[:, self.cls_token_position, :]
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
class HFTextEncoder(nn.Module):
|
| 84 |
+
"""HuggingFace model adapter"""
|
| 85 |
+
output_tokens: torch.jit.Final[bool]
|
| 86 |
+
|
| 87 |
+
def __init__(
|
| 88 |
+
self,
|
| 89 |
+
model_name_or_path: str,
|
| 90 |
+
output_dim: int,
|
| 91 |
+
config: PretrainedConfig = None,
|
| 92 |
+
pooler_type: str = None,
|
| 93 |
+
proj: str = None,
|
| 94 |
+
pretrained: bool = True,
|
| 95 |
+
output_tokens: bool = False,
|
| 96 |
+
):
|
| 97 |
+
super().__init__()
|
| 98 |
+
self.output_tokens = output_tokens
|
| 99 |
+
self.output_dim = output_dim
|
| 100 |
+
|
| 101 |
+
# TODO: find better way to get this information
|
| 102 |
+
uses_transformer_pooler = (pooler_type == "cls_pooler")
|
| 103 |
+
|
| 104 |
+
if transformers is None:
|
| 105 |
+
raise RuntimeError("Please `pip install transformers` to use pre-trained HuggingFace models")
|
| 106 |
+
if config is None:
|
| 107 |
+
self.config = AutoConfig.from_pretrained(model_name_or_path)
|
| 108 |
+
create_func, model_args = (AutoModel.from_pretrained, model_name_or_path) if pretrained else (
|
| 109 |
+
AutoModel.from_config, self.config)
|
| 110 |
+
# TODO: do all model configs have this attribute? PretrainedConfig does so yes??
|
| 111 |
+
if hasattr(self.config, "is_encoder_decoder") and self.config.is_encoder_decoder:
|
| 112 |
+
self.transformer = create_func(model_args)
|
| 113 |
+
self.transformer = self.transformer.encoder
|
| 114 |
+
else:
|
| 115 |
+
self.transformer = create_func(model_args, add_pooling_layer=uses_transformer_pooler)
|
| 116 |
+
else:
|
| 117 |
+
self.config = config
|
| 118 |
+
self.transformer = AutoModel.from_config(config)
|
| 119 |
+
if pooler_type is None: # get default arch pooler
|
| 120 |
+
pooler_type = (arch_dict[self.config.model_type]["pooler"])
|
| 121 |
+
|
| 122 |
+
self.pooler = _POOLERS[pooler_type]()
|
| 123 |
+
|
| 124 |
+
d_model = getattr(self.config, arch_dict[self.config.model_type]["config_names"]["width"])
|
| 125 |
+
if (d_model == output_dim) and (proj is None): # do we always need a proj?
|
| 126 |
+
self.proj = nn.Identity()
|
| 127 |
+
elif proj == 'linear':
|
| 128 |
+
self.proj = nn.Linear(d_model, output_dim, bias=False)
|
| 129 |
+
elif proj == 'mlp':
|
| 130 |
+
hidden_size = (d_model + output_dim) // 2
|
| 131 |
+
self.proj = nn.Sequential(
|
| 132 |
+
nn.Linear(d_model, hidden_size, bias=False),
|
| 133 |
+
nn.GELU(),
|
| 134 |
+
nn.Linear(hidden_size, output_dim, bias=False),
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
def forward(self, x: TensorType):
|
| 138 |
+
attn_mask = (x != self.config.pad_token_id).long()
|
| 139 |
+
out = self.transformer(input_ids=x, attention_mask=attn_mask)
|
| 140 |
+
pooled_out = self.pooler(out, attn_mask)
|
| 141 |
+
projected = self.proj(pooled_out)
|
| 142 |
+
|
| 143 |
+
seq_len = out.last_hidden_state.shape[1]
|
| 144 |
+
tokens = (
|
| 145 |
+
out.last_hidden_state[:, torch.arange(seq_len) != self.pooler.cls_token_position, :]
|
| 146 |
+
if type(self.pooler) == ClsPooler
|
| 147 |
+
else out.last_hidden_state
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
if self.output_tokens:
|
| 151 |
+
return projected, tokens
|
| 152 |
+
return projected
|
| 153 |
+
|
| 154 |
+
def lock(self, unlocked_layers: int = 0, freeze_layer_norm: bool = True):
|
| 155 |
+
if not unlocked_layers: # full freezing
|
| 156 |
+
for n, p in self.transformer.named_parameters():
|
| 157 |
+
p.requires_grad = (not freeze_layer_norm) if "LayerNorm" in n.split(".") else False
|
| 158 |
+
return
|
| 159 |
+
|
| 160 |
+
encoder = self.transformer.encoder if hasattr(self.transformer, 'encoder') else self.transformer
|
| 161 |
+
layer_list = getattr(encoder, arch_dict[self.config.model_type]["config_names"]["layer_attr"])
|
| 162 |
+
print(f"Unlocking {unlocked_layers}/{len(layer_list) + 1} layers of hf model")
|
| 163 |
+
embeddings = getattr(
|
| 164 |
+
self.transformer, arch_dict[self.config.model_type]["config_names"]["token_embeddings_attr"])
|
| 165 |
+
modules = [embeddings, *layer_list][:-unlocked_layers]
|
| 166 |
+
# freeze layers
|
| 167 |
+
for module in modules:
|
| 168 |
+
for n, p in module.named_parameters():
|
| 169 |
+
p.requires_grad = (not freeze_layer_norm) if "LayerNorm" in n.split(".") else False
|
| 170 |
+
|
| 171 |
+
@torch.jit.ignore
|
| 172 |
+
def set_grad_checkpointing(self, enable=True):
|
| 173 |
+
self.transformer.gradient_checkpointing_enable()
|
| 174 |
+
|
| 175 |
+
def init_parameters(self):
|
| 176 |
+
pass
|
open_clip/loss.py
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.nn import functional as F
|
| 4 |
+
|
| 5 |
+
try:
|
| 6 |
+
import torch.distributed.nn
|
| 7 |
+
from torch import distributed as dist
|
| 8 |
+
|
| 9 |
+
has_distributed = True
|
| 10 |
+
except ImportError:
|
| 11 |
+
has_distributed = False
|
| 12 |
+
|
| 13 |
+
try:
|
| 14 |
+
import horovod.torch as hvd
|
| 15 |
+
except ImportError:
|
| 16 |
+
hvd = None
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def gather_features(
|
| 20 |
+
image_features,
|
| 21 |
+
text_features,
|
| 22 |
+
local_loss=False,
|
| 23 |
+
gather_with_grad=False,
|
| 24 |
+
rank=0,
|
| 25 |
+
world_size=1,
|
| 26 |
+
use_horovod=False
|
| 27 |
+
):
|
| 28 |
+
assert has_distributed, 'torch.distributed did not import correctly, please use a PyTorch version with support.'
|
| 29 |
+
if use_horovod:
|
| 30 |
+
assert hvd is not None, 'Please install horovod'
|
| 31 |
+
if gather_with_grad:
|
| 32 |
+
all_image_features = hvd.allgather(image_features)
|
| 33 |
+
all_text_features = hvd.allgather(text_features)
|
| 34 |
+
else:
|
| 35 |
+
with torch.no_grad():
|
| 36 |
+
all_image_features = hvd.allgather(image_features)
|
| 37 |
+
all_text_features = hvd.allgather(text_features)
|
| 38 |
+
if not local_loss:
|
| 39 |
+
# ensure grads for local rank when all_* features don't have a gradient
|
| 40 |
+
gathered_image_features = list(all_image_features.chunk(world_size, dim=0))
|
| 41 |
+
gathered_text_features = list(all_text_features.chunk(world_size, dim=0))
|
| 42 |
+
gathered_image_features[rank] = image_features
|
| 43 |
+
gathered_text_features[rank] = text_features
|
| 44 |
+
all_image_features = torch.cat(gathered_image_features, dim=0)
|
| 45 |
+
all_text_features = torch.cat(gathered_text_features, dim=0)
|
| 46 |
+
else:
|
| 47 |
+
# We gather tensors from all gpus
|
| 48 |
+
if gather_with_grad:
|
| 49 |
+
all_image_features = torch.cat(torch.distributed.nn.all_gather(image_features), dim=0)
|
| 50 |
+
all_text_features = torch.cat(torch.distributed.nn.all_gather(text_features), dim=0)
|
| 51 |
+
else:
|
| 52 |
+
gathered_image_features = [torch.zeros_like(image_features) for _ in range(world_size)]
|
| 53 |
+
gathered_text_features = [torch.zeros_like(text_features) for _ in range(world_size)]
|
| 54 |
+
dist.all_gather(gathered_image_features, image_features)
|
| 55 |
+
dist.all_gather(gathered_text_features, text_features)
|
| 56 |
+
if not local_loss:
|
| 57 |
+
# ensure grads for local rank when all_* features don't have a gradient
|
| 58 |
+
gathered_image_features[rank] = image_features
|
| 59 |
+
gathered_text_features[rank] = text_features
|
| 60 |
+
all_image_features = torch.cat(gathered_image_features, dim=0)
|
| 61 |
+
all_text_features = torch.cat(gathered_text_features, dim=0)
|
| 62 |
+
|
| 63 |
+
return all_image_features, all_text_features
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
class ClipLoss(nn.Module):
|
| 67 |
+
|
| 68 |
+
def __init__(
|
| 69 |
+
self,
|
| 70 |
+
local_loss=False,
|
| 71 |
+
gather_with_grad=False,
|
| 72 |
+
cache_labels=False,
|
| 73 |
+
rank=0,
|
| 74 |
+
world_size=1,
|
| 75 |
+
use_horovod=False,
|
| 76 |
+
):
|
| 77 |
+
super().__init__()
|
| 78 |
+
self.local_loss = local_loss
|
| 79 |
+
self.gather_with_grad = gather_with_grad
|
| 80 |
+
self.cache_labels = cache_labels
|
| 81 |
+
self.rank = rank
|
| 82 |
+
self.world_size = world_size
|
| 83 |
+
self.use_horovod = use_horovod
|
| 84 |
+
|
| 85 |
+
# cache state
|
| 86 |
+
self.prev_num_logits = 0
|
| 87 |
+
self.labels = {}
|
| 88 |
+
|
| 89 |
+
def get_ground_truth(self, device, num_logits) -> torch.Tensor:
|
| 90 |
+
# calculated ground-truth and cache if enabled
|
| 91 |
+
if self.prev_num_logits != num_logits or device not in self.labels:
|
| 92 |
+
labels = torch.arange(num_logits, device=device, dtype=torch.long)
|
| 93 |
+
if self.world_size > 1 and self.local_loss:
|
| 94 |
+
labels = labels + num_logits * self.rank
|
| 95 |
+
if self.cache_labels:
|
| 96 |
+
self.labels[device] = labels
|
| 97 |
+
self.prev_num_logits = num_logits
|
| 98 |
+
else:
|
| 99 |
+
labels = self.labels[device]
|
| 100 |
+
return labels
|
| 101 |
+
|
| 102 |
+
def get_logits(self, image_features, text_features, logit_scale):
|
| 103 |
+
if self.world_size > 1:
|
| 104 |
+
all_image_features, all_text_features = gather_features(
|
| 105 |
+
image_features, text_features,
|
| 106 |
+
self.local_loss, self.gather_with_grad, self.rank, self.world_size, self.use_horovod)
|
| 107 |
+
|
| 108 |
+
if self.local_loss:
|
| 109 |
+
logits_per_image = logit_scale * image_features @ all_text_features.T
|
| 110 |
+
logits_per_text = logit_scale * text_features @ all_image_features.T
|
| 111 |
+
else:
|
| 112 |
+
logits_per_image = logit_scale * all_image_features @ all_text_features.T
|
| 113 |
+
logits_per_text = logits_per_image.T
|
| 114 |
+
else:
|
| 115 |
+
logits_per_image = logit_scale * image_features @ text_features.T
|
| 116 |
+
logits_per_text = logit_scale * text_features @ image_features.T
|
| 117 |
+
|
| 118 |
+
return logits_per_image, logits_per_text
|
| 119 |
+
|
| 120 |
+
def forward(self, image_features, text_features, logit_scale, output_dict=False):
|
| 121 |
+
device = image_features.device
|
| 122 |
+
logits_per_image, logits_per_text = self.get_logits(image_features, text_features, logit_scale)
|
| 123 |
+
|
| 124 |
+
labels = self.get_ground_truth(device, logits_per_image.shape[0])
|
| 125 |
+
|
| 126 |
+
total_loss = (
|
| 127 |
+
F.cross_entropy(logits_per_image, labels) +
|
| 128 |
+
F.cross_entropy(logits_per_text, labels)
|
| 129 |
+
) / 2
|
| 130 |
+
|
| 131 |
+
return {"contrastive_loss": total_loss} if output_dict else total_loss
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
class CoCaLoss(ClipLoss):
|
| 135 |
+
def __init__(
|
| 136 |
+
self,
|
| 137 |
+
caption_loss_weight,
|
| 138 |
+
clip_loss_weight,
|
| 139 |
+
pad_id=0, # pad_token for open_clip custom tokenizer
|
| 140 |
+
local_loss=False,
|
| 141 |
+
gather_with_grad=False,
|
| 142 |
+
cache_labels=False,
|
| 143 |
+
rank=0,
|
| 144 |
+
world_size=1,
|
| 145 |
+
use_horovod=False,
|
| 146 |
+
):
|
| 147 |
+
super().__init__(
|
| 148 |
+
local_loss=local_loss,
|
| 149 |
+
gather_with_grad=gather_with_grad,
|
| 150 |
+
cache_labels=cache_labels,
|
| 151 |
+
rank=rank,
|
| 152 |
+
world_size=world_size,
|
| 153 |
+
use_horovod=use_horovod
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
self.clip_loss_weight = clip_loss_weight
|
| 157 |
+
self.caption_loss_weight = caption_loss_weight
|
| 158 |
+
self.caption_loss = nn.CrossEntropyLoss(ignore_index=pad_id)
|
| 159 |
+
|
| 160 |
+
def forward(self, image_features, text_features, logits, labels, logit_scale, output_dict=False):
|
| 161 |
+
clip_loss = super().forward(image_features, text_features, logit_scale)
|
| 162 |
+
clip_loss = self.clip_loss_weight * clip_loss
|
| 163 |
+
|
| 164 |
+
caption_loss = self.caption_loss(
|
| 165 |
+
logits.permute(0, 2, 1),
|
| 166 |
+
labels,
|
| 167 |
+
)
|
| 168 |
+
caption_loss = caption_loss * self.caption_loss_weight
|
| 169 |
+
|
| 170 |
+
if output_dict:
|
| 171 |
+
return {"contrastive_loss": clip_loss, "caption_loss": caption_loss}
|
| 172 |
+
|
| 173 |
+
return clip_loss, caption_loss
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
class DistillClipLoss(ClipLoss):
|
| 177 |
+
|
| 178 |
+
def dist_loss(self, teacher_logits, student_logits):
|
| 179 |
+
return -(teacher_logits.softmax(dim=1) * student_logits.log_softmax(dim=1)).sum(dim=1).mean(dim=0)
|
| 180 |
+
|
| 181 |
+
def forward(
|
| 182 |
+
self,
|
| 183 |
+
image_features,
|
| 184 |
+
text_features,
|
| 185 |
+
logit_scale,
|
| 186 |
+
dist_image_features,
|
| 187 |
+
dist_text_features,
|
| 188 |
+
dist_logit_scale,
|
| 189 |
+
output_dict=False,
|
| 190 |
+
):
|
| 191 |
+
logits_per_image, logits_per_text = \
|
| 192 |
+
self.get_logits(image_features, text_features, logit_scale)
|
| 193 |
+
|
| 194 |
+
dist_logits_per_image, dist_logits_per_text = \
|
| 195 |
+
self.get_logits(dist_image_features, dist_text_features, dist_logit_scale)
|
| 196 |
+
|
| 197 |
+
labels = self.get_ground_truth(image_features.device, logits_per_image.shape[0])
|
| 198 |
+
|
| 199 |
+
contrastive_loss = (
|
| 200 |
+
F.cross_entropy(logits_per_image, labels) +
|
| 201 |
+
F.cross_entropy(logits_per_text, labels)
|
| 202 |
+
) / 2
|
| 203 |
+
|
| 204 |
+
distill_loss = (
|
| 205 |
+
self.dist_loss(dist_logits_per_image, logits_per_image) +
|
| 206 |
+
self.dist_loss(dist_logits_per_text, logits_per_text)
|
| 207 |
+
) / 2
|
| 208 |
+
|
| 209 |
+
if output_dict:
|
| 210 |
+
return {"contrastive_loss": contrastive_loss, "distill_loss": distill_loss}
|
| 211 |
+
|
| 212 |
+
return contrastive_loss, distill_loss
|
open_clip/model.py
ADDED
|
@@ -0,0 +1,445 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" CLIP Model
|
| 2 |
+
|
| 3 |
+
Adapted from https://github.com/openai/CLIP. Originally MIT License, Copyright (c) 2021 OpenAI.
|
| 4 |
+
"""
|
| 5 |
+
from dataclasses import dataclass
|
| 6 |
+
import logging
|
| 7 |
+
import math
|
| 8 |
+
from typing import Optional, Tuple, Union
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
from torch import nn
|
| 14 |
+
from torch.utils.checkpoint import checkpoint
|
| 15 |
+
|
| 16 |
+
from .hf_model import HFTextEncoder
|
| 17 |
+
from .modified_resnet import ModifiedResNet
|
| 18 |
+
from .timm_model import TimmModel
|
| 19 |
+
from .transformer import LayerNormFp32, LayerNorm, QuickGELU, Attention, VisionTransformer, TextTransformer
|
| 20 |
+
from .utils import to_2tuple
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
@dataclass
|
| 24 |
+
class CLIPVisionCfg:
|
| 25 |
+
layers: Union[Tuple[int, int, int, int], int] = 12
|
| 26 |
+
width: int = 768
|
| 27 |
+
head_width: int = 64
|
| 28 |
+
mlp_ratio: float = 4.0
|
| 29 |
+
patch_size: int = 16
|
| 30 |
+
image_size: Union[Tuple[int, int], int] = 224
|
| 31 |
+
ls_init_value: Optional[float] = None # layer scale initial value
|
| 32 |
+
patch_dropout: float = 0. # what fraction of patches to dropout during training (0 would mean disabled and no patches dropped) - 0.5 to 0.75 recommended in the paper for optimal results
|
| 33 |
+
input_patchnorm: bool = False # whether to use dual patchnorm - would only apply the input layernorm on each patch, as post-layernorm already exist in original clip vit design
|
| 34 |
+
global_average_pool: bool = False # whether to global average pool the last embedding layer, instead of using CLS token (https://arxiv.org/abs/2205.01580)
|
| 35 |
+
attentional_pool: bool = False # whether to use attentional pooler in the last embedding layer
|
| 36 |
+
n_queries: int = 256 # n_queries for attentional pooler
|
| 37 |
+
attn_pooler_heads: int = 8 # n heads for attentional_pooling
|
| 38 |
+
timm_model_name: str = None # a valid model name overrides layers, width, patch_size
|
| 39 |
+
timm_model_pretrained: bool = False # use (imagenet) pretrained weights for named model
|
| 40 |
+
timm_pool: str = 'avg' # feature pooling for timm model ('abs_attn', 'rot_attn', 'avg', '')
|
| 41 |
+
timm_proj: str = 'linear' # linear projection for timm model output ('linear', 'mlp', '')
|
| 42 |
+
timm_proj_bias: bool = False # enable bias final projection
|
| 43 |
+
timm_drop: float = 0. # head dropout
|
| 44 |
+
timm_drop_path: Optional[float] = None # backbone stochastic depth
|
| 45 |
+
output_tokens: bool = False
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
@dataclass
|
| 49 |
+
class CLIPTextCfg:
|
| 50 |
+
context_length: int = 77
|
| 51 |
+
vocab_size: int = 49408
|
| 52 |
+
width: int = 512
|
| 53 |
+
heads: int = 8
|
| 54 |
+
layers: int = 12
|
| 55 |
+
ls_init_value: Optional[float] = None # layer scale initial value
|
| 56 |
+
hf_model_name: str = None
|
| 57 |
+
hf_tokenizer_name: str = None
|
| 58 |
+
hf_model_pretrained: bool = True
|
| 59 |
+
proj: str = 'mlp'
|
| 60 |
+
pooler_type: str = 'mean_pooler'
|
| 61 |
+
embed_cls: bool = False
|
| 62 |
+
pad_id: int = 0
|
| 63 |
+
output_tokens: bool = False
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def get_cast_dtype(precision: str):
|
| 67 |
+
cast_dtype = None
|
| 68 |
+
if precision == 'bf16':
|
| 69 |
+
cast_dtype = torch.bfloat16
|
| 70 |
+
elif precision == 'fp16':
|
| 71 |
+
cast_dtype = torch.float16
|
| 72 |
+
return cast_dtype
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def _build_vision_tower(
|
| 76 |
+
embed_dim: int,
|
| 77 |
+
vision_cfg: CLIPVisionCfg,
|
| 78 |
+
quick_gelu: bool = False,
|
| 79 |
+
cast_dtype: Optional[torch.dtype] = None
|
| 80 |
+
):
|
| 81 |
+
if isinstance(vision_cfg, dict):
|
| 82 |
+
vision_cfg = CLIPVisionCfg(**vision_cfg)
|
| 83 |
+
|
| 84 |
+
# OpenAI models are pretrained w/ QuickGELU but native nn.GELU is both faster and more
|
| 85 |
+
# memory efficient in recent PyTorch releases (>= 1.10).
|
| 86 |
+
# NOTE: timm models always use native GELU regardless of quick_gelu flag.
|
| 87 |
+
act_layer = QuickGELU if quick_gelu else nn.GELU
|
| 88 |
+
|
| 89 |
+
if vision_cfg.timm_model_name:
|
| 90 |
+
visual = TimmModel(
|
| 91 |
+
vision_cfg.timm_model_name,
|
| 92 |
+
pretrained=vision_cfg.timm_model_pretrained,
|
| 93 |
+
pool=vision_cfg.timm_pool,
|
| 94 |
+
proj=vision_cfg.timm_proj,
|
| 95 |
+
proj_bias=vision_cfg.timm_proj_bias,
|
| 96 |
+
drop=vision_cfg.timm_drop,
|
| 97 |
+
drop_path=vision_cfg.timm_drop_path,
|
| 98 |
+
embed_dim=embed_dim,
|
| 99 |
+
image_size=vision_cfg.image_size,
|
| 100 |
+
)
|
| 101 |
+
act_layer = nn.GELU # so that text transformer doesn't use QuickGELU w/ timm models
|
| 102 |
+
elif isinstance(vision_cfg.layers, (tuple, list)):
|
| 103 |
+
vision_heads = vision_cfg.width * 32 // vision_cfg.head_width
|
| 104 |
+
visual = ModifiedResNet(
|
| 105 |
+
layers=vision_cfg.layers,
|
| 106 |
+
output_dim=embed_dim,
|
| 107 |
+
heads=vision_heads,
|
| 108 |
+
image_size=vision_cfg.image_size,
|
| 109 |
+
width=vision_cfg.width,
|
| 110 |
+
)
|
| 111 |
+
else:
|
| 112 |
+
vision_heads = vision_cfg.width // vision_cfg.head_width
|
| 113 |
+
norm_layer = LayerNormFp32 if cast_dtype in (torch.float16, torch.bfloat16) else LayerNorm
|
| 114 |
+
visual = VisionTransformer(
|
| 115 |
+
image_size=vision_cfg.image_size,
|
| 116 |
+
patch_size=vision_cfg.patch_size,
|
| 117 |
+
width=vision_cfg.width,
|
| 118 |
+
layers=vision_cfg.layers,
|
| 119 |
+
heads=vision_heads,
|
| 120 |
+
mlp_ratio=vision_cfg.mlp_ratio,
|
| 121 |
+
ls_init_value=vision_cfg.ls_init_value,
|
| 122 |
+
patch_dropout=vision_cfg.patch_dropout,
|
| 123 |
+
input_patchnorm=vision_cfg.input_patchnorm,
|
| 124 |
+
global_average_pool=vision_cfg.global_average_pool,
|
| 125 |
+
attentional_pool=vision_cfg.attentional_pool,
|
| 126 |
+
n_queries=vision_cfg.n_queries,
|
| 127 |
+
attn_pooler_heads=vision_cfg.attn_pooler_heads,
|
| 128 |
+
output_tokens=vision_cfg.output_tokens,
|
| 129 |
+
output_dim=embed_dim,
|
| 130 |
+
act_layer=act_layer,
|
| 131 |
+
norm_layer=norm_layer,
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
return visual
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def _build_text_tower(
|
| 138 |
+
embed_dim: int,
|
| 139 |
+
text_cfg: CLIPTextCfg,
|
| 140 |
+
quick_gelu: bool = False,
|
| 141 |
+
cast_dtype: Optional[torch.dtype] = None,
|
| 142 |
+
):
|
| 143 |
+
if isinstance(text_cfg, dict):
|
| 144 |
+
text_cfg = CLIPTextCfg(**text_cfg)
|
| 145 |
+
|
| 146 |
+
if text_cfg.hf_model_name:
|
| 147 |
+
text = HFTextEncoder(
|
| 148 |
+
text_cfg.hf_model_name,
|
| 149 |
+
output_dim=embed_dim,
|
| 150 |
+
proj=text_cfg.proj,
|
| 151 |
+
pooler_type=text_cfg.pooler_type,
|
| 152 |
+
pretrained=text_cfg.hf_model_pretrained,
|
| 153 |
+
output_tokens=text_cfg.output_tokens,
|
| 154 |
+
)
|
| 155 |
+
else:
|
| 156 |
+
act_layer = QuickGELU if quick_gelu else nn.GELU
|
| 157 |
+
norm_layer = LayerNormFp32 if cast_dtype in (torch.float16, torch.bfloat16) else LayerNorm
|
| 158 |
+
|
| 159 |
+
text = TextTransformer(
|
| 160 |
+
context_length=text_cfg.context_length,
|
| 161 |
+
vocab_size=text_cfg.vocab_size,
|
| 162 |
+
width=text_cfg.width,
|
| 163 |
+
heads=text_cfg.heads,
|
| 164 |
+
layers=text_cfg.layers,
|
| 165 |
+
ls_init_value=text_cfg.ls_init_value,
|
| 166 |
+
output_dim=embed_dim,
|
| 167 |
+
embed_cls=text_cfg.embed_cls,
|
| 168 |
+
output_tokens=text_cfg.output_tokens,
|
| 169 |
+
pad_id=text_cfg.pad_id,
|
| 170 |
+
act_layer=act_layer,
|
| 171 |
+
norm_layer=norm_layer,
|
| 172 |
+
)
|
| 173 |
+
return text
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
class CLIP(nn.Module):
|
| 177 |
+
output_dict: torch.jit.Final[bool]
|
| 178 |
+
|
| 179 |
+
def __init__(
|
| 180 |
+
self,
|
| 181 |
+
embed_dim: int,
|
| 182 |
+
vision_cfg: CLIPVisionCfg,
|
| 183 |
+
text_cfg: CLIPTextCfg,
|
| 184 |
+
quick_gelu: bool = False,
|
| 185 |
+
cast_dtype: Optional[torch.dtype] = None,
|
| 186 |
+
output_dict: bool = False,
|
| 187 |
+
):
|
| 188 |
+
super().__init__()
|
| 189 |
+
self.output_dict = output_dict
|
| 190 |
+
self.visual = _build_vision_tower(embed_dim, vision_cfg, quick_gelu, cast_dtype)
|
| 191 |
+
|
| 192 |
+
text = _build_text_tower(embed_dim, text_cfg, quick_gelu, cast_dtype)
|
| 193 |
+
self.transformer = text.transformer
|
| 194 |
+
self.vocab_size = text.vocab_size
|
| 195 |
+
self.token_embedding = text.token_embedding
|
| 196 |
+
self.positional_embedding = text.positional_embedding
|
| 197 |
+
self.ln_final = text.ln_final
|
| 198 |
+
self.text_projection = text.text_projection
|
| 199 |
+
self.register_buffer('attn_mask', text.attn_mask, persistent=False)
|
| 200 |
+
|
| 201 |
+
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
|
| 202 |
+
|
| 203 |
+
def lock_image_tower(self, unlocked_groups=0, freeze_bn_stats=False):
|
| 204 |
+
# lock image tower as per LiT - https://arxiv.org/abs/2111.07991
|
| 205 |
+
self.visual.lock(unlocked_groups=unlocked_groups, freeze_bn_stats=freeze_bn_stats)
|
| 206 |
+
|
| 207 |
+
@torch.jit.ignore
|
| 208 |
+
def set_grad_checkpointing(self, enable=True):
|
| 209 |
+
self.visual.set_grad_checkpointing(enable)
|
| 210 |
+
self.transformer.grad_checkpointing = enable
|
| 211 |
+
|
| 212 |
+
def encode_image(self, image, normalize: bool = False):
|
| 213 |
+
features = self.visual(image)
|
| 214 |
+
return F.normalize(features, dim=-1) if normalize else features
|
| 215 |
+
|
| 216 |
+
def encode_text(self, text, normalize: bool = False):
|
| 217 |
+
cast_dtype = self.transformer.get_cast_dtype()
|
| 218 |
+
|
| 219 |
+
x = self.token_embedding(text).to(cast_dtype) # [batch_size, n_ctx, d_model]
|
| 220 |
+
|
| 221 |
+
x = x + self.positional_embedding.to(cast_dtype)
|
| 222 |
+
x = x.permute(1, 0, 2) # NLD -> LND
|
| 223 |
+
x = self.transformer(x, attn_mask=self.attn_mask)
|
| 224 |
+
x = x.permute(1, 0, 2) # LND -> NLD
|
| 225 |
+
x = self.ln_final(x) # [batch_size, n_ctx, transformer.width]
|
| 226 |
+
# take features from the eot embedding (eot_token is the highest number in each sequence)
|
| 227 |
+
# x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
|
| 228 |
+
return F.normalize(x, dim=-1) if normalize else x
|
| 229 |
+
|
| 230 |
+
def forward(self, image, text):
|
| 231 |
+
image_features = self.encode_image(image, normalize=True)
|
| 232 |
+
text_features = self.encode_text(text, normalize=True)
|
| 233 |
+
if self.output_dict:
|
| 234 |
+
return {
|
| 235 |
+
"image_features": image_features,
|
| 236 |
+
"text_features": text_features,
|
| 237 |
+
"logit_scale": self.logit_scale.exp()
|
| 238 |
+
}
|
| 239 |
+
return image_features, text_features, self.logit_scale.exp()
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
class CustomTextCLIP(nn.Module):
|
| 243 |
+
output_dict: torch.jit.Final[bool]
|
| 244 |
+
|
| 245 |
+
def __init__(
|
| 246 |
+
self,
|
| 247 |
+
embed_dim: int,
|
| 248 |
+
vision_cfg: CLIPVisionCfg,
|
| 249 |
+
text_cfg: CLIPTextCfg,
|
| 250 |
+
quick_gelu: bool = False,
|
| 251 |
+
cast_dtype: Optional[torch.dtype] = None,
|
| 252 |
+
output_dict: bool = False,
|
| 253 |
+
):
|
| 254 |
+
super().__init__()
|
| 255 |
+
self.output_dict = output_dict
|
| 256 |
+
self.visual = _build_vision_tower(embed_dim, vision_cfg, quick_gelu, cast_dtype)
|
| 257 |
+
self.text = _build_text_tower(embed_dim, text_cfg, quick_gelu, cast_dtype)
|
| 258 |
+
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
|
| 259 |
+
|
| 260 |
+
def lock_image_tower(self, unlocked_groups=0, freeze_bn_stats=False):
|
| 261 |
+
# lock image tower as per LiT - https://arxiv.org/abs/2111.07991
|
| 262 |
+
self.visual.lock(unlocked_groups=unlocked_groups, freeze_bn_stats=freeze_bn_stats)
|
| 263 |
+
|
| 264 |
+
def lock_text_tower(self, unlocked_layers: int = 0, freeze_layer_norm: bool = True):
|
| 265 |
+
self.text.lock(unlocked_layers, freeze_layer_norm)
|
| 266 |
+
|
| 267 |
+
@torch.jit.ignore
|
| 268 |
+
def set_grad_checkpointing(self, enable=True):
|
| 269 |
+
self.visual.set_grad_checkpointing(enable)
|
| 270 |
+
self.text.set_grad_checkpointing(enable)
|
| 271 |
+
|
| 272 |
+
def encode_image(self, image, normalize: bool = False):
|
| 273 |
+
features = self.visual(image)
|
| 274 |
+
return F.normalize(features, dim=-1) if normalize else features
|
| 275 |
+
|
| 276 |
+
def encode_text(self, text, normalize: bool = False):
|
| 277 |
+
features = self.text(text)
|
| 278 |
+
return F.normalize(features, dim=-1) if normalize else features
|
| 279 |
+
|
| 280 |
+
def forward(self, image, text):
|
| 281 |
+
image_features = self.encode_image(image, normalize=True)
|
| 282 |
+
text_features = self.encode_text(text, normalize=True)
|
| 283 |
+
if self.output_dict:
|
| 284 |
+
return {
|
| 285 |
+
"image_features": image_features,
|
| 286 |
+
"text_features": text_features,
|
| 287 |
+
"logit_scale": self.logit_scale.exp()
|
| 288 |
+
}
|
| 289 |
+
return image_features, text_features, self.logit_scale.exp()
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
def convert_weights_to_lp(model: nn.Module, dtype=torch.float16):
|
| 293 |
+
"""Convert applicable model parameters to low-precision (bf16 or fp16)"""
|
| 294 |
+
|
| 295 |
+
def _convert_weights(l):
|
| 296 |
+
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Linear)):
|
| 297 |
+
l.weight.data = l.weight.data.to(dtype)
|
| 298 |
+
if l.bias is not None:
|
| 299 |
+
l.bias.data = l.bias.data.to(dtype)
|
| 300 |
+
|
| 301 |
+
if isinstance(l, (nn.MultiheadAttention, Attention)):
|
| 302 |
+
for attr in [*[f"{s}_proj_weight" for s in ["in", "q", "k", "v"]], "in_proj_bias", "bias_k", "bias_v"]:
|
| 303 |
+
tensor = getattr(l, attr)
|
| 304 |
+
if tensor is not None:
|
| 305 |
+
tensor.data = tensor.data.to(dtype)
|
| 306 |
+
|
| 307 |
+
for name in ["text_projection", "proj"]:
|
| 308 |
+
if hasattr(l, name):
|
| 309 |
+
attr = getattr(l, name)
|
| 310 |
+
if attr is not None:
|
| 311 |
+
attr.data = attr.data.to(dtype)
|
| 312 |
+
|
| 313 |
+
model.apply(_convert_weights)
|
| 314 |
+
|
| 315 |
+
|
| 316 |
+
convert_weights_to_fp16 = convert_weights_to_lp # backwards compat
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
# used to maintain checkpoint compatibility
|
| 320 |
+
def convert_to_custom_text_state_dict(state_dict: dict):
|
| 321 |
+
if 'text_projection' in state_dict:
|
| 322 |
+
# old format state_dict, move text tower -> .text
|
| 323 |
+
new_state_dict = {}
|
| 324 |
+
for k, v in state_dict.items():
|
| 325 |
+
if any(k.startswith(p) for p in (
|
| 326 |
+
'text_projection',
|
| 327 |
+
'positional_embedding',
|
| 328 |
+
'token_embedding',
|
| 329 |
+
'transformer',
|
| 330 |
+
'ln_final',
|
| 331 |
+
)):
|
| 332 |
+
k = 'text.' + k
|
| 333 |
+
new_state_dict[k] = v
|
| 334 |
+
return new_state_dict
|
| 335 |
+
return state_dict
|
| 336 |
+
|
| 337 |
+
|
| 338 |
+
def build_model_from_openai_state_dict(
|
| 339 |
+
state_dict: dict,
|
| 340 |
+
quick_gelu=True,
|
| 341 |
+
cast_dtype=torch.float16,
|
| 342 |
+
):
|
| 343 |
+
vit = "visual.proj" in state_dict
|
| 344 |
+
|
| 345 |
+
if vit:
|
| 346 |
+
vision_width = state_dict["visual.conv1.weight"].shape[0]
|
| 347 |
+
vision_layers = len(
|
| 348 |
+
[k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
|
| 349 |
+
vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
|
| 350 |
+
grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
|
| 351 |
+
image_size = vision_patch_size * grid_size
|
| 352 |
+
else:
|
| 353 |
+
counts: list = [
|
| 354 |
+
len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in [1, 2, 3, 4]]
|
| 355 |
+
vision_layers = tuple(counts)
|
| 356 |
+
vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]
|
| 357 |
+
output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)
|
| 358 |
+
vision_patch_size = None
|
| 359 |
+
assert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]
|
| 360 |
+
image_size = output_width * 32
|
| 361 |
+
|
| 362 |
+
embed_dim = state_dict["text_projection"].shape[1]
|
| 363 |
+
context_length = state_dict["positional_embedding"].shape[0]
|
| 364 |
+
vocab_size = state_dict["token_embedding.weight"].shape[0]
|
| 365 |
+
transformer_width = state_dict["ln_final.weight"].shape[0]
|
| 366 |
+
transformer_heads = transformer_width // 64
|
| 367 |
+
transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith(f"transformer.resblocks")))
|
| 368 |
+
|
| 369 |
+
vision_cfg = CLIPVisionCfg(
|
| 370 |
+
layers=vision_layers,
|
| 371 |
+
width=vision_width,
|
| 372 |
+
patch_size=vision_patch_size,
|
| 373 |
+
image_size=image_size,
|
| 374 |
+
)
|
| 375 |
+
text_cfg = CLIPTextCfg(
|
| 376 |
+
context_length=context_length,
|
| 377 |
+
vocab_size=vocab_size,
|
| 378 |
+
width=transformer_width,
|
| 379 |
+
heads=transformer_heads,
|
| 380 |
+
layers=transformer_layers,
|
| 381 |
+
)
|
| 382 |
+
model = CLIP(
|
| 383 |
+
embed_dim,
|
| 384 |
+
vision_cfg=vision_cfg,
|
| 385 |
+
text_cfg=text_cfg,
|
| 386 |
+
quick_gelu=quick_gelu, # OpenAI models were trained with QuickGELU
|
| 387 |
+
cast_dtype=cast_dtype,
|
| 388 |
+
)
|
| 389 |
+
|
| 390 |
+
for key in ["input_resolution", "context_length", "vocab_size"]:
|
| 391 |
+
state_dict.pop(key, None)
|
| 392 |
+
|
| 393 |
+
convert_weights_to_fp16(model) # OpenAI state dicts are partially converted to float16
|
| 394 |
+
model.load_state_dict(state_dict)
|
| 395 |
+
return model.eval()
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
def trace_model(model, batch_size=256, device=torch.device('cpu')):
|
| 399 |
+
model.eval()
|
| 400 |
+
image_size = model.visual.image_size
|
| 401 |
+
example_images = torch.ones((batch_size, 3, image_size, image_size), device=device)
|
| 402 |
+
example_text = torch.zeros((batch_size, model.context_length), dtype=torch.int, device=device)
|
| 403 |
+
model = torch.jit.trace_module(
|
| 404 |
+
model,
|
| 405 |
+
inputs=dict(
|
| 406 |
+
forward=(example_images, example_text),
|
| 407 |
+
encode_text=(example_text,),
|
| 408 |
+
encode_image=(example_images,)
|
| 409 |
+
))
|
| 410 |
+
model.visual.image_size = image_size
|
| 411 |
+
return model
|
| 412 |
+
|
| 413 |
+
|
| 414 |
+
def resize_pos_embed(state_dict, model, interpolation: str = 'bicubic', antialias: bool = True):
|
| 415 |
+
# Rescale the grid of position embeddings when loading from state_dict
|
| 416 |
+
old_pos_embed = state_dict.get('visual.positional_embedding', None)
|
| 417 |
+
if old_pos_embed is None or not hasattr(model.visual, 'grid_size'):
|
| 418 |
+
return
|
| 419 |
+
grid_size = to_2tuple(model.visual.grid_size)
|
| 420 |
+
extra_tokens = 1 # FIXME detect different token configs (ie no class token, or more)
|
| 421 |
+
new_seq_len = grid_size[0] * grid_size[1] + extra_tokens
|
| 422 |
+
if new_seq_len == old_pos_embed.shape[0]:
|
| 423 |
+
return
|
| 424 |
+
|
| 425 |
+
if extra_tokens:
|
| 426 |
+
pos_emb_tok, pos_emb_img = old_pos_embed[:extra_tokens], old_pos_embed[extra_tokens:]
|
| 427 |
+
else:
|
| 428 |
+
pos_emb_tok, pos_emb_img = None, old_pos_embed
|
| 429 |
+
old_grid_size = to_2tuple(int(math.sqrt(len(pos_emb_img))))
|
| 430 |
+
|
| 431 |
+
logging.info('Resizing position embedding grid-size from %s to %s', old_grid_size, grid_size)
|
| 432 |
+
pos_emb_img = pos_emb_img.reshape(1, old_grid_size[0], old_grid_size[1], -1).permute(0, 3, 1, 2)
|
| 433 |
+
pos_emb_img = F.interpolate(
|
| 434 |
+
pos_emb_img,
|
| 435 |
+
size=grid_size,
|
| 436 |
+
mode=interpolation,
|
| 437 |
+
antialias=antialias,
|
| 438 |
+
align_corners=False,
|
| 439 |
+
)
|
| 440 |
+
pos_emb_img = pos_emb_img.permute(0, 2, 3, 1).reshape(1, grid_size[0] * grid_size[1], -1)[0]
|
| 441 |
+
if pos_emb_tok is not None:
|
| 442 |
+
new_pos_embed = torch.cat([pos_emb_tok, pos_emb_img], dim=0)
|
| 443 |
+
else:
|
| 444 |
+
new_pos_embed = pos_emb_img
|
| 445 |
+
state_dict['visual.positional_embedding'] = new_pos_embed
|