Spaces:
Configuration error

Configuration error
ZJ
commited on
Commit
·
0a1104e
1
Parent(s):
fb200e8
first version
Browse files- .gitignore +22 -0
- .idea/inspectionProfiles/profiles_settings.xml +6 -0
- .idea/misc.xml +4 -0
- .idea/modules.xml +8 -0
- .idea/nlp.iml +12 -0
- .idea/vcs.xml +6 -0
- .idea/workspace.xml +111 -0
- app.py +12 -5
- data/org_poetry.txt +0 -0
- data/poetry.txt +0 -0
- data/split_poetry.txt +0 -0
- example.jpg +0 -0
- inference.py +112 -0
- scripts/lstm_infer.sh +0 -0
- scripts/lstm_train.sh +0 -0
- src/__init__.py +0 -0
- src/apis/__init__.py +0 -0
- src/apis/train.py +68 -0
- src/datasets/__init__.py +0 -0
- src/datasets/dataloader.py +115 -0
- src/models/LSTM/__init__.py +0 -0
- src/models/LSTM/model.py +37 -0
- src/models/Transformer/__init__.py +0 -0
- src/models/Transformer/model.py +70 -0
- src/models/__init__.py +0 -0
- src/utils/__init__.py +0 -0
- src/utils/utils.py +15 -0
- train.py +70 -0
.gitignore
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# PyTorch
|
| 2 |
+
/.torch
|
| 3 |
+
|
| 4 |
+
# Data files
|
| 5 |
+
*.csv
|
| 6 |
+
*.json
|
| 7 |
+
*.tsv
|
| 8 |
+
|
| 9 |
+
# Model files
|
| 10 |
+
*.ckpt
|
| 11 |
+
*.pth
|
| 12 |
+
*.pkl
|
| 13 |
+
|
| 14 |
+
# Logs and checkpoints
|
| 15 |
+
logs/
|
| 16 |
+
checkpoints/
|
| 17 |
+
|
| 18 |
+
# Secondary files
|
| 19 |
+
*.pyc
|
| 20 |
+
__pycache__/
|
| 21 |
+
.DS_Store
|
| 22 |
+
|
.idea/inspectionProfiles/profiles_settings.xml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<component name="InspectionProjectProfileManager">
|
| 2 |
+
<settings>
|
| 3 |
+
<option name="USE_PROJECT_PROFILE" value="false" />
|
| 4 |
+
<version value="1.0" />
|
| 5 |
+
</settings>
|
| 6 |
+
</component>
|
.idea/misc.xml
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="ProjectRootManager" version="2" project-jdk-name="Python 3.9" project-jdk-type="Python SDK" />
|
| 4 |
+
</project>
|
.idea/modules.xml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="ProjectModuleManager">
|
| 4 |
+
<modules>
|
| 5 |
+
<module fileurl="file://$PROJECT_DIR$/.idea/nlp.iml" filepath="$PROJECT_DIR$/.idea/nlp.iml" />
|
| 6 |
+
</modules>
|
| 7 |
+
</component>
|
| 8 |
+
</project>
|
.idea/nlp.iml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<module type="PYTHON_MODULE" version="4">
|
| 3 |
+
<component name="NewModuleRootManager">
|
| 4 |
+
<content url="file://$MODULE_DIR$" />
|
| 5 |
+
<orderEntry type="inheritedJdk" />
|
| 6 |
+
<orderEntry type="sourceFolder" forTests="false" />
|
| 7 |
+
</component>
|
| 8 |
+
<component name="PyDocumentationSettings">
|
| 9 |
+
<option name="format" value="PLAIN" />
|
| 10 |
+
<option name="myDocStringFormat" value="Plain" />
|
| 11 |
+
</component>
|
| 12 |
+
</module>
|
.idea/vcs.xml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="VcsDirectoryMappings">
|
| 4 |
+
<mapping directory="$PROJECT_DIR$" vcs="Git" />
|
| 5 |
+
</component>
|
| 6 |
+
</project>
|
.idea/workspace.xml
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="ChangeListManager">
|
| 4 |
+
<list default="true" id="975e88fb-d387-4d2c-9625-dc69f610d124" name="Changes" comment="">
|
| 5 |
+
<change afterPath="$PROJECT_DIR$/.idea/inspectionProfiles/profiles_settings.xml" afterDir="false" />
|
| 6 |
+
<change afterPath="$PROJECT_DIR$/.idea/misc.xml" afterDir="false" />
|
| 7 |
+
<change afterPath="$PROJECT_DIR$/.idea/modules.xml" afterDir="false" />
|
| 8 |
+
<change afterPath="$PROJECT_DIR$/.idea/nlp.iml" afterDir="false" />
|
| 9 |
+
<change afterPath="$PROJECT_DIR$/.idea/vcs.xml" afterDir="false" />
|
| 10 |
+
<change beforePath="$PROJECT_DIR$/.idea/workspace.xml" beforeDir="false" afterPath="$PROJECT_DIR$/.idea/workspace.xml" afterDir="false" />
|
| 11 |
+
<change beforePath="$PROJECT_DIR$/src/apis/train.py" beforeDir="false" afterPath="$PROJECT_DIR$/src/apis/train.py" afterDir="false" />
|
| 12 |
+
<change beforePath="$PROJECT_DIR$/src/datasets/dataloader.py" beforeDir="false" afterPath="$PROJECT_DIR$/src/datasets/dataloader.py" afterDir="false" />
|
| 13 |
+
<change beforePath="$PROJECT_DIR$/src/models/LSTM/model.py" beforeDir="false" afterPath="$PROJECT_DIR$/src/models/LSTM/model.py" afterDir="false" />
|
| 14 |
+
</list>
|
| 15 |
+
<option name="SHOW_DIALOG" value="false" />
|
| 16 |
+
<option name="HIGHLIGHT_CONFLICTS" value="true" />
|
| 17 |
+
<option name="HIGHLIGHT_NON_ACTIVE_CHANGELIST" value="false" />
|
| 18 |
+
<option name="LAST_RESOLUTION" value="IGNORE" />
|
| 19 |
+
</component>
|
| 20 |
+
<component name="Git.Settings">
|
| 21 |
+
<option name="RECENT_GIT_ROOT_PATH" value="$PROJECT_DIR$" />
|
| 22 |
+
</component>
|
| 23 |
+
<component name="MarkdownSettingsMigration">
|
| 24 |
+
<option name="stateVersion" value="1" />
|
| 25 |
+
</component>
|
| 26 |
+
<component name="ProjectId" id="2Q8D9XoYiTKL5jiaHLTd3rsHf4Y" />
|
| 27 |
+
<component name="ProjectViewState">
|
| 28 |
+
<option name="hideEmptyMiddlePackages" value="true" />
|
| 29 |
+
<option name="showLibraryContents" value="true" />
|
| 30 |
+
</component>
|
| 31 |
+
<component name="PropertiesComponent">{
|
| 32 |
+
"keyToString": {
|
| 33 |
+
"RunOnceActivity.OpenProjectViewOnStart": "true",
|
| 34 |
+
"RunOnceActivity.ShowReadmeOnStart": "true",
|
| 35 |
+
"last_opened_file_path": "D:/YOU/dasanxia/NLP/new0522/nlp",
|
| 36 |
+
"settings.editor.selected.configurable": "com.jetbrains.python.configuration.PyActiveSdkModuleConfigurable"
|
| 37 |
+
}
|
| 38 |
+
}</component>
|
| 39 |
+
<component name="RunManager" selected="Python.run_gradio">
|
| 40 |
+
<configuration name="inference" type="PythonConfigurationType" factoryName="Python" temporary="true" nameIsGenerated="true">
|
| 41 |
+
<module name="nlp" />
|
| 42 |
+
<option name="INTERPRETER_OPTIONS" value="" />
|
| 43 |
+
<option name="PARENT_ENVS" value="true" />
|
| 44 |
+
<envs>
|
| 45 |
+
<env name="PYTHONUNBUFFERED" value="1" />
|
| 46 |
+
</envs>
|
| 47 |
+
<option name="SDK_HOME" value="" />
|
| 48 |
+
<option name="WORKING_DIRECTORY" value="$PROJECT_DIR$" />
|
| 49 |
+
<option name="IS_MODULE_SDK" value="true" />
|
| 50 |
+
<option name="ADD_CONTENT_ROOTS" value="true" />
|
| 51 |
+
<option name="ADD_SOURCE_ROOTS" value="true" />
|
| 52 |
+
<option name="SCRIPT_NAME" value="$PROJECT_DIR$/inference.py" />
|
| 53 |
+
<option name="PARAMETERS" value="" />
|
| 54 |
+
<option name="SHOW_COMMAND_LINE" value="false" />
|
| 55 |
+
<option name="EMULATE_TERMINAL" value="false" />
|
| 56 |
+
<option name="MODULE_MODE" value="false" />
|
| 57 |
+
<option name="REDIRECT_INPUT" value="false" />
|
| 58 |
+
<option name="INPUT_FILE" value="" />
|
| 59 |
+
<method v="2" />
|
| 60 |
+
</configuration>
|
| 61 |
+
<configuration name="run_gradio" type="PythonConfigurationType" factoryName="Python" temporary="true" nameIsGenerated="true">
|
| 62 |
+
<module name="nlp" />
|
| 63 |
+
<option name="INTERPRETER_OPTIONS" value="" />
|
| 64 |
+
<option name="PARENT_ENVS" value="true" />
|
| 65 |
+
<envs>
|
| 66 |
+
<env name="PYTHONUNBUFFERED" value="1" />
|
| 67 |
+
</envs>
|
| 68 |
+
<option name="SDK_HOME" value="" />
|
| 69 |
+
<option name="WORKING_DIRECTORY" value="$PROJECT_DIR$" />
|
| 70 |
+
<option name="IS_MODULE_SDK" value="true" />
|
| 71 |
+
<option name="ADD_CONTENT_ROOTS" value="true" />
|
| 72 |
+
<option name="ADD_SOURCE_ROOTS" value="true" />
|
| 73 |
+
<option name="SCRIPT_NAME" value="$PROJECT_DIR$/run_gradio.py" />
|
| 74 |
+
<option name="PARAMETERS" value="" />
|
| 75 |
+
<option name="SHOW_COMMAND_LINE" value="false" />
|
| 76 |
+
<option name="EMULATE_TERMINAL" value="false" />
|
| 77 |
+
<option name="MODULE_MODE" value="false" />
|
| 78 |
+
<option name="REDIRECT_INPUT" value="false" />
|
| 79 |
+
<option name="INPUT_FILE" value="" />
|
| 80 |
+
<method v="2" />
|
| 81 |
+
</configuration>
|
| 82 |
+
<recent_temporary>
|
| 83 |
+
<list>
|
| 84 |
+
<item itemvalue="Python.run_gradio" />
|
| 85 |
+
<item itemvalue="Python.inference" />
|
| 86 |
+
</list>
|
| 87 |
+
</recent_temporary>
|
| 88 |
+
</component>
|
| 89 |
+
<component name="SpellCheckerSettings" RuntimeDictionaries="0" Folders="0" CustomDictionaries="0" DefaultDictionary="application-level" UseSingleDictionary="true" transferred="true" />
|
| 90 |
+
<component name="TaskManager">
|
| 91 |
+
<task active="true" id="Default" summary="Default task">
|
| 92 |
+
<changelist id="975e88fb-d387-4d2c-9625-dc69f610d124" name="Changes" comment="" />
|
| 93 |
+
<created>1684726163448</created>
|
| 94 |
+
<option name="number" value="Default" />
|
| 95 |
+
<option name="presentableId" value="Default" />
|
| 96 |
+
<updated>1684726163448</updated>
|
| 97 |
+
</task>
|
| 98 |
+
<servers />
|
| 99 |
+
</component>
|
| 100 |
+
<component name="Vcs.Log.Tabs.Properties">
|
| 101 |
+
<option name="TAB_STATES">
|
| 102 |
+
<map>
|
| 103 |
+
<entry key="MAIN">
|
| 104 |
+
<value>
|
| 105 |
+
<State />
|
| 106 |
+
</value>
|
| 107 |
+
</entry>
|
| 108 |
+
</map>
|
| 109 |
+
</option>
|
| 110 |
+
</component>
|
| 111 |
+
</project>
|
app.py
CHANGED
|
@@ -1,7 +1,14 @@
|
|
| 1 |
-
|
|
|
|
| 2 |
|
| 3 |
-
|
| 4 |
-
|
| 5 |
|
| 6 |
-
|
| 7 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# !/user/bin/env python3
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
|
| 4 |
+
import gradio
|
| 5 |
+
from inference import infer
|
| 6 |
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
INTERFACE = gradio.Interface(fn=infer, inputs=["text","text"], outputs=["text"], title="Poem Generation",
|
| 11 |
+
description="model: lstm/GRU/Seq2Seq/Transformer/GPT-2",
|
| 12 |
+
thumbnail="https://github.com/gradio-app/gpt-2/raw/master/screenshots/interface.png?raw=true")
|
| 13 |
+
|
| 14 |
+
INTERFACE.launch(inbrowser=True)
|
data/org_poetry.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/poetry.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/split_poetry.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
example.jpg
ADDED
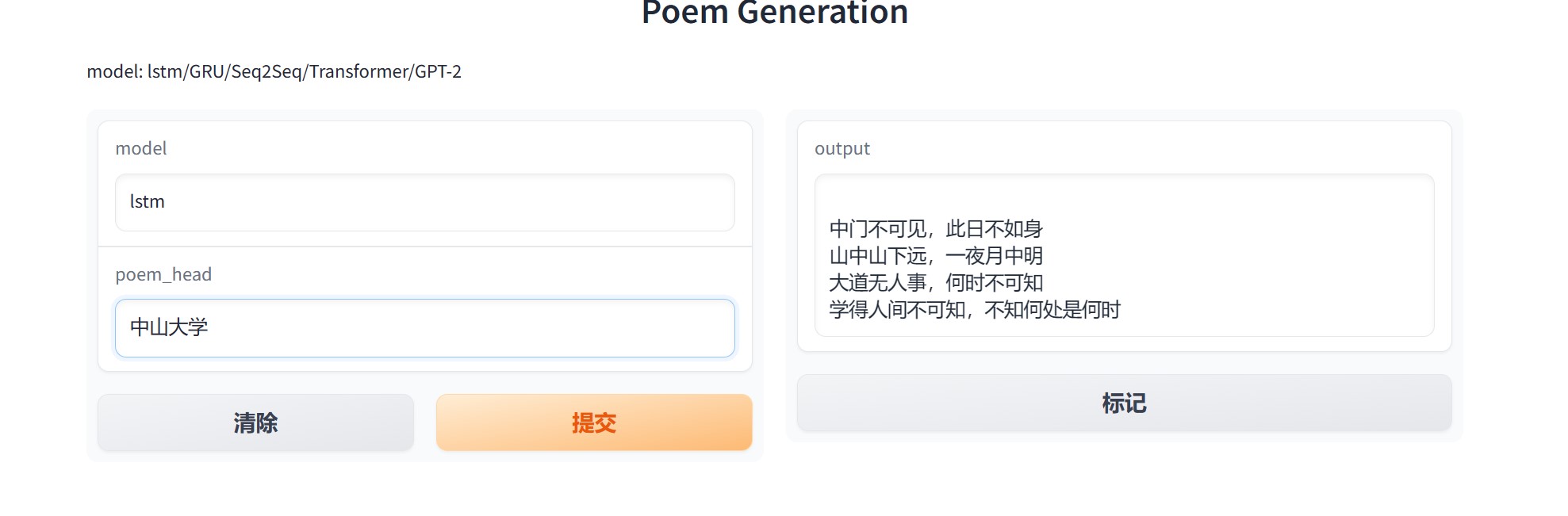
|
inference.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import argparse
|
| 3 |
+
import numpy as np
|
| 4 |
+
from src.models.LSTM.model import Poetry_Model_lstm
|
| 5 |
+
from src.datasets.dataloader import train_vec
|
| 6 |
+
from src.utils.utils import make_cuda
|
| 7 |
+
from src.models.Transformer.model import Poetry_Model_Transformer
|
| 8 |
+
|
| 9 |
+
def parse_arguments():
|
| 10 |
+
# argument parsing
|
| 11 |
+
parser = argparse.ArgumentParser(description="Specify Params for Experimental Setting")
|
| 12 |
+
parser.add_argument('--model', type=str, default='lstm',
|
| 13 |
+
help="lstm/GRU/Seq2Seq/Transformer/GPT-2")
|
| 14 |
+
parser.add_argument('--Word2Vec', default=True)
|
| 15 |
+
parser.add_argument('--strict_dataset', default=False, help="strict dataset")
|
| 16 |
+
parser.add_argument('--n_hidden', type=int, default=128)
|
| 17 |
+
|
| 18 |
+
parser.add_argument('--save_path', type=str, default='save_models/model_params.pth')
|
| 19 |
+
|
| 20 |
+
return parser.parse_args()
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def generate_poetry(model, head_string, w1, word_2_index, index_2_word,args):
|
| 24 |
+
print("藏头诗生成中...., {}".format(head_string))
|
| 25 |
+
poem = ""
|
| 26 |
+
# 以句子的每一个字为开头生成诗句
|
| 27 |
+
for head in head_string:
|
| 28 |
+
if head not in word_2_index:
|
| 29 |
+
print("抱歉,不能生成以{}开头的诗".format(head))
|
| 30 |
+
return
|
| 31 |
+
|
| 32 |
+
sentence = head
|
| 33 |
+
max_sent_len = 20
|
| 34 |
+
|
| 35 |
+
h_0 = torch.tensor(np.zeros((2, 1, args.n_hidden), dtype=np.float32))
|
| 36 |
+
c_0 = torch.tensor(np.zeros((2, 1, args.n_hidden), dtype=np.float32))
|
| 37 |
+
|
| 38 |
+
input_eval = word_2_index[head]
|
| 39 |
+
for i in range(max_sent_len):
|
| 40 |
+
if args.Word2Vec:
|
| 41 |
+
word_embedding = torch.tensor(w1[input_eval][None][None])
|
| 42 |
+
else:
|
| 43 |
+
word_embedding = torch.tensor([input_eval]).unsqueeze(dim=0)
|
| 44 |
+
pre, (h_0, c_0) = model(word_embedding, h_0, c_0)
|
| 45 |
+
char_generated = index_2_word[int(torch.argmax(pre))]
|
| 46 |
+
|
| 47 |
+
if char_generated == '。':
|
| 48 |
+
break
|
| 49 |
+
# 以新生成的字为输入继续向下生成
|
| 50 |
+
input_eval = word_2_index[char_generated]
|
| 51 |
+
sentence += char_generated
|
| 52 |
+
|
| 53 |
+
poem += '\n' + sentence
|
| 54 |
+
|
| 55 |
+
return poem
|
| 56 |
+
|
| 57 |
+
def infer(model,poem_head):
|
| 58 |
+
args = parse_arguments()
|
| 59 |
+
args.model=model
|
| 60 |
+
|
| 61 |
+
all_data, (w1, word_2_index, index_2_word) = train_vec()
|
| 62 |
+
args.word_size, args.embedding_num = w1.shape
|
| 63 |
+
string = poem_head
|
| 64 |
+
# string = '自然语言'
|
| 65 |
+
|
| 66 |
+
if args.model == 'lstm':
|
| 67 |
+
model = Poetry_Model_lstm(args.n_hidden, args.word_size, args.embedding_num, args.Word2Vec)
|
| 68 |
+
args.save_path='save_models/lstm_25.pth'
|
| 69 |
+
elif args.model == 'GRU':
|
| 70 |
+
model = Poetry_Model_lstm(args.n_hidden, args.word_size, args.embedding_num, args.Word2Vec)
|
| 71 |
+
elif args.model == 'Seq2Seq':
|
| 72 |
+
model = Poetry_Model_lstm(args.n_hidden, args.word_size, args.embedding_num, args.Word2Vec)
|
| 73 |
+
elif args.model == 'Transformer':
|
| 74 |
+
model = Poetry_Model_Transformer(args.n_hidden, args.word_size, args.embedding_num, args.Word2Vec)
|
| 75 |
+
args.save_path='save_models/transformer.pth'
|
| 76 |
+
elif args.model == 'GPT-2':
|
| 77 |
+
model = Poetry_Model_lstm(args.n_hidden, args.word_size, args.embedding_num, args.Word2Vec)
|
| 78 |
+
else:
|
| 79 |
+
print("Please choose a model!\n")
|
| 80 |
+
|
| 81 |
+
model.load_state_dict(torch.load(args.save_path))
|
| 82 |
+
model = make_cuda(model)
|
| 83 |
+
poem = generate_poetry(model, string, w1, word_2_index, index_2_word,args)
|
| 84 |
+
return poem
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
if __name__ == '__main__':
|
| 88 |
+
args = parse_arguments()
|
| 89 |
+
all_data, (w1, word_2_index, index_2_word) = train_vec()
|
| 90 |
+
args.word_size, args.embedding_num = w1.shape
|
| 91 |
+
string = input("诗头:")
|
| 92 |
+
# string = '自然语言'
|
| 93 |
+
|
| 94 |
+
if args.model == 'lstm':
|
| 95 |
+
model = Poetry_Model_lstm(args.n_hidden, args.word_size, args.embedding_num, args.Word2Vec)
|
| 96 |
+
args.save_path='save_models/lstm_25.pth'
|
| 97 |
+
elif args.model == 'GRU':
|
| 98 |
+
model = Poetry_Model_lstm(args.n_hidden, args.word_size, args.embedding_num, args.Word2Vec)
|
| 99 |
+
elif args.model == 'Seq2Seq':
|
| 100 |
+
model = Poetry_Model_lstm(args.n_hidden, args.word_size, args.embedding_num, args.Word2Vec)
|
| 101 |
+
elif args.model == 'Transformer':
|
| 102 |
+
model = Poetry_Model_Transformer(args.n_hidden, args.word_size, args.embedding_num, args.Word2Vec)
|
| 103 |
+
args.save_path='save_models/transformer.pth'
|
| 104 |
+
elif args.model == 'GPT-2':
|
| 105 |
+
model = Poetry_Model_lstm(args.n_hidden, args.word_size, args.embedding_num, args.Word2Vec)
|
| 106 |
+
else:
|
| 107 |
+
print("Please choose a model!\n")
|
| 108 |
+
|
| 109 |
+
model.load_state_dict(torch.load(args.save_path))
|
| 110 |
+
model = make_cuda(model)
|
| 111 |
+
poem = generate_poetry(model, string, w1, word_2_index, index_2_word,args)
|
| 112 |
+
print(poem)
|
scripts/lstm_infer.sh
ADDED
|
File without changes
|
scripts/lstm_train.sh
ADDED
|
File without changes
|
src/__init__.py
ADDED
|
File without changes
|
src/apis/__init__.py
ADDED
|
File without changes
|
src/apis/train.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.optim as optim
|
| 6 |
+
from src.utils.utils import make_cuda
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
from sklearn.metrics import mean_squared_error, mean_absolute_error
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def train(args, model, data_loader):
|
| 12 |
+
optimizer = optim.Adam(model.parameters(), lr=args.learning_rate)
|
| 13 |
+
|
| 14 |
+
model.train()
|
| 15 |
+
num_epochs = args.num_epochs
|
| 16 |
+
|
| 17 |
+
for epoch in range(num_epochs):
|
| 18 |
+
loss = 0
|
| 19 |
+
for step, (features, targets) in enumerate(data_loader):
|
| 20 |
+
features = make_cuda(features)
|
| 21 |
+
targets = make_cuda(targets)
|
| 22 |
+
|
| 23 |
+
optimizer.zero_grad()
|
| 24 |
+
|
| 25 |
+
pre, _ = model(features)
|
| 26 |
+
crs_loss = model.cross_entropy(pre, targets.reshape(-1))
|
| 27 |
+
loss += crs_loss.item()
|
| 28 |
+
crs_loss.backward()
|
| 29 |
+
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
|
| 30 |
+
optimizer.step()
|
| 31 |
+
|
| 32 |
+
# print step info
|
| 33 |
+
if (step + 1) % args.log_step == 0:
|
| 34 |
+
print("Epoch [%.3d/%.3d] Step [%.3d/%.3d]: CROSS_loss=%.4f, RCROSS_loss=%.4f"
|
| 35 |
+
% (epoch + 1,
|
| 36 |
+
num_epochs,
|
| 37 |
+
step + 1,
|
| 38 |
+
len(data_loader),
|
| 39 |
+
loss / args.log_step,
|
| 40 |
+
math.sqrt(loss / args.log_step)))
|
| 41 |
+
loss = 0
|
| 42 |
+
|
| 43 |
+
# Loss = []
|
| 44 |
+
# for step, (features, targets) in enumerate(valid_data_loader):
|
| 45 |
+
# features = make_cuda(features)
|
| 46 |
+
# targets = make_cuda(targets)
|
| 47 |
+
# model.eval()
|
| 48 |
+
# preds = model(features)
|
| 49 |
+
# valid_loss = CrossLoss(preds, targets)
|
| 50 |
+
# Loss.append(valid_loss)
|
| 51 |
+
# print("Valid loss: %.3d\n" % (np.mean(Loss)))
|
| 52 |
+
|
| 53 |
+
return model
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def evaluate(args, model, data_loader):
|
| 57 |
+
model.eval()
|
| 58 |
+
loss = []
|
| 59 |
+
for step, (features, targets) in enumerate(data_loader):
|
| 60 |
+
features = make_cuda(features)
|
| 61 |
+
targets = make_cuda(targets)
|
| 62 |
+
|
| 63 |
+
pre, _ = model(features)
|
| 64 |
+
crs_loss = model.cross_entropy(pre, targets.reshape(-1))
|
| 65 |
+
loss.append(crs_loss.item())
|
| 66 |
+
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
|
| 67 |
+
|
| 68 |
+
print("loss=%.4f" % (np.mean(loss)))
|
src/datasets/__init__.py
ADDED
|
File without changes
|
src/datasets/dataloader.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import pickle
|
| 3 |
+
import os
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
from gensim.models.word2vec import Word2Vec
|
| 7 |
+
from torch.utils.data import Dataset
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def padding(poetries, maxlen, pad):
|
| 11 |
+
batch_seq = [poetry + pad * (maxlen - len(poetry)) for poetry in poetries]
|
| 12 |
+
return batch_seq
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
# 输入向后滑一字符为target,即预测下一个字
|
| 16 |
+
def split_input_target(seq):
|
| 17 |
+
inputs = seq[:-1]
|
| 18 |
+
targets = seq[1:]
|
| 19 |
+
return inputs, targets
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# 创建词汇表
|
| 23 |
+
def get_poetry(arg):
|
| 24 |
+
poetrys = []
|
| 25 |
+
if arg.Augmented_dataset:
|
| 26 |
+
path = arg.Augmented_data
|
| 27 |
+
else:
|
| 28 |
+
path = arg.data # 数据集路径,data/poetry.txt
|
| 29 |
+
with open(path, "r", encoding='UTF-8') as f:
|
| 30 |
+
for line in f:
|
| 31 |
+
try:
|
| 32 |
+
# line = line.decode('UTF-8')
|
| 33 |
+
line = line.strip(u'\n') # 去掉换行符
|
| 34 |
+
if arg.Augmented_dataset:
|
| 35 |
+
content = line.strip(u' ')
|
| 36 |
+
else:
|
| 37 |
+
title, content = line.strip(u' ').split(u':') # 标题和内容以冒号分隔
|
| 38 |
+
content = content.replace(u' ', u'') # 去掉空格
|
| 39 |
+
if u'_' in content or u'(' in content or u'(' in content or u'《' in content or u'[' in content: # 去掉特殊符号的古诗
|
| 40 |
+
continue
|
| 41 |
+
if arg.strict_dataset: # 严格模式
|
| 42 |
+
if len(content) < 12 or len(content) > 79:
|
| 43 |
+
continue
|
| 44 |
+
else:
|
| 45 |
+
if len(content) < 5 or len(content) > 79:
|
| 46 |
+
continue
|
| 47 |
+
content = u'[' + content + u']' # 开头加上开始符,结尾加上结束符
|
| 48 |
+
poetrys.append(content) # 保存到poetrys列表中
|
| 49 |
+
except Exception as e:
|
| 50 |
+
pass
|
| 51 |
+
|
| 52 |
+
# 按诗的字数排序
|
| 53 |
+
poetrys = sorted(poetrys, key=lambda line: len(line))
|
| 54 |
+
|
| 55 |
+
with open("data/org_poetry.txt", "w", encoding="utf-8") as f:
|
| 56 |
+
for poetry in poetrys:
|
| 57 |
+
poetry = str(poetry).strip('[').strip(']').replace(',', '').replace('\'', '') + '\n'
|
| 58 |
+
f.write(poetry)
|
| 59 |
+
|
| 60 |
+
return poetrys
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
# 切分文档
|
| 64 |
+
def split_text(poetrys):
|
| 65 |
+
with open("data/split_poetry.txt", "w", encoding="utf-8") as f:
|
| 66 |
+
for poetry in poetrys:
|
| 67 |
+
poetry = str(poetry).strip('[').strip(']').replace(',', '').replace('\'', '') + '\n '
|
| 68 |
+
split_data = " ".join(poetry)
|
| 69 |
+
f.write(split_data)
|
| 70 |
+
return open("data/split_poetry.txt", "r", encoding='UTF-8').read()
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
# 训练词向量
|
| 74 |
+
def train_vec(split_file="data/split_poetry.txt", org_file="data/org_poetry.txt"):
|
| 75 |
+
param_file = "data/word_vec.pkl"
|
| 76 |
+
org_data = open(org_file, "r", encoding="utf-8").read().split("\n")
|
| 77 |
+
if os.path.exists(split_file):
|
| 78 |
+
all_data_split = open(split_file, "r", encoding="utf-8").read().split("\n")
|
| 79 |
+
else:
|
| 80 |
+
all_data_split = split_text().split("\n")
|
| 81 |
+
|
| 82 |
+
if os.path.exists(param_file):
|
| 83 |
+
return org_data, pickle.load(open(param_file, "rb"))
|
| 84 |
+
|
| 85 |
+
models = Word2Vec(all_data_split, vector_size=256, workers=7, min_count=1) # 训练词向量,输入参数分别是:分词后的文本,词向量维度,线程数,最小词频
|
| 86 |
+
pickle.dump([models.syn1neg, models.wv.key_to_index, models.wv.index_to_key], open(param_file, "wb")) # 保存词向量,key_to_index是词汇表,index_to_key是词向量,dump的作用是将数据序列化到文件中
|
| 87 |
+
return org_data, (models.syn1neg, models.wv.key_to_index, models.wv.index_to_key) # syn1neg是词向量,key_to_index是词汇表,index_to_key是词向量
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
class Poetry_Dataset(Dataset):
|
| 91 |
+
def __init__(self, w1, word_2_index, all_data, Word2Vec):
|
| 92 |
+
self.Word2Vec = Word2Vec
|
| 93 |
+
self.w1 = w1
|
| 94 |
+
self.word_2_index = word_2_index
|
| 95 |
+
word_size, embedding_num = w1.shape
|
| 96 |
+
self.embedding = nn.Embedding(word_size, embedding_num) # 词嵌入层
|
| 97 |
+
# 最长句子长度
|
| 98 |
+
maxlen = max([len(seq) for seq in all_data])
|
| 99 |
+
pad = ' '
|
| 100 |
+
self.all_data = padding(all_data[:-1], maxlen, pad)
|
| 101 |
+
|
| 102 |
+
def __getitem__(self, index):
|
| 103 |
+
a_poetry = self.all_data[index]
|
| 104 |
+
|
| 105 |
+
a_poetry_index = [self.word_2_index[i] for i in a_poetry]
|
| 106 |
+
xs, ys = split_input_target(a_poetry_index)
|
| 107 |
+
if self.Word2Vec:
|
| 108 |
+
xs_embedding = self.w1[xs]
|
| 109 |
+
else:
|
| 110 |
+
xs_embedding = np.array(xs)
|
| 111 |
+
|
| 112 |
+
return xs_embedding, np.array(ys).astype(np.int64)
|
| 113 |
+
|
| 114 |
+
def __len__(self):
|
| 115 |
+
return len(self.all_data)
|
src/models/LSTM/__init__.py
ADDED
|
File without changes
|
src/models/LSTM/model.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class Poetry_Model_lstm(nn.Module):
|
| 7 |
+
def __init__(self, hidden_num, word_size, embedding_num, Word2Vec):
|
| 8 |
+
super().__init__()
|
| 9 |
+
|
| 10 |
+
self.device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 11 |
+
self.hidden_num = hidden_num
|
| 12 |
+
self.Word2Vec = Word2Vec
|
| 13 |
+
|
| 14 |
+
self.embedding = nn.Embedding(word_size, embedding_num)
|
| 15 |
+
self.lstm = nn.LSTM(input_size=embedding_num, hidden_size=hidden_num, batch_first=True, num_layers=2,
|
| 16 |
+
bidirectional=False)
|
| 17 |
+
self.dropout = nn.Dropout(0.3)
|
| 18 |
+
self.flatten = nn.Flatten(0, 1)
|
| 19 |
+
self.linear = nn.Linear(hidden_num, word_size)
|
| 20 |
+
self.cross_entropy = nn.CrossEntropyLoss()
|
| 21 |
+
|
| 22 |
+
def forward(self, xs_embedding, h_0=None, c_0=None):
|
| 23 |
+
# xs_embedding: [batch_size, max_seq_len, n_feature] n_feature=256
|
| 24 |
+
if h_0 == None or c_0 == None:
|
| 25 |
+
h_0 = torch.tensor(np.zeros((2, xs_embedding.shape[0], self.hidden_num), dtype=np.float32))
|
| 26 |
+
c_0 = torch.tensor(np.zeros((2, xs_embedding.shape[0], self.hidden_num), dtype=np.float32))
|
| 27 |
+
h_0 = h_0.to(self.device)
|
| 28 |
+
c_0 = c_0.to(self.device)
|
| 29 |
+
xs_embedding = xs_embedding.to(self.device)
|
| 30 |
+
if not self.Word2Vec:
|
| 31 |
+
xs_embedding = self.embedding(xs_embedding)
|
| 32 |
+
hidden, (h_0, c_0) = self.lstm(xs_embedding, (h_0, c_0))
|
| 33 |
+
hidden_drop = self.dropout(hidden)
|
| 34 |
+
hidden_flatten = self.flatten(hidden_drop)
|
| 35 |
+
pre = self.linear(hidden_flatten)
|
| 36 |
+
# pre:[batch_size*max_seq_len, vocab_size]
|
| 37 |
+
return pre, (h_0, c_0)
|
src/models/Transformer/__init__.py
ADDED
|
File without changes
|
src/models/Transformer/model.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import math
|
| 5 |
+
|
| 6 |
+
class Poetry_Model_Transformer(nn.Module):
|
| 7 |
+
def __init__(self, hidden_num, word_size, embedding_num, Word2Vec):
|
| 8 |
+
super().__init__()
|
| 9 |
+
|
| 10 |
+
self.device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 11 |
+
self.hidden_num = hidden_num
|
| 12 |
+
self.Word2Vec = Word2Vec
|
| 13 |
+
|
| 14 |
+
# 位置编码
|
| 15 |
+
self.pos_encoder= PositionalEncoding(d_model=embedding_num,dropout=0.5)
|
| 16 |
+
self.embedding = nn.Embedding(word_size, embedding_num)
|
| 17 |
+
self.transformer = nn.Transformer(d_model=embedding_num, nhead=8, num_encoder_layers=6, num_decoder_layers=6,
|
| 18 |
+
dim_feedforward=2048, dropout=0.5, activation='relu') # 输入的参数分别是:词嵌入的维度,多头注意力的头数,编码器层数,解码器层数,前馈网络的隐藏层维度,dropout概率,激活函数
|
| 19 |
+
|
| 20 |
+
# 编码器
|
| 21 |
+
self.encoder_layer=nn.TransformerEncoderLayer(d_model=embedding_num,nhead=8,dim_feedforward=2048,dropout=0.5)
|
| 22 |
+
self.encoder_norm=nn.LayerNorm(normalized_shape=embedding_num)
|
| 23 |
+
self.encoder=nn.TransformerEncoder(self.encoder_layer,num_layers=6,norm=self.encoder_norm)
|
| 24 |
+
|
| 25 |
+
# 解码器
|
| 26 |
+
# self.decoder_layer=nn.TransformerDecoderLayer(d_model=embedding_num,nhead=8,dim_feedforward=2048,dropout=0.5)
|
| 27 |
+
# self.decoder_norm=nn.LayerNorm(normalized_shape=embedding_num)
|
| 28 |
+
# self.decoder=nn.TransformerDecoder(self.decoder_layer,num_layers=6,norm=self.decoder_norm)
|
| 29 |
+
self.flatten = nn.Flatten(0, 1)
|
| 30 |
+
self.linear1 = nn.Linear(embedding_num, hidden_num)
|
| 31 |
+
self.linear2 = nn.Linear(hidden_num, word_size)
|
| 32 |
+
self.cross_entropy = nn.CrossEntropyLoss()
|
| 33 |
+
|
| 34 |
+
def forward(self, xs_embedding, h_0=None, c_0=None):
|
| 35 |
+
if h_0 == None or c_0 == None:
|
| 36 |
+
h_0 = torch.tensor(np.zeros((2, xs_embedding.shape[0], self.hidden_num), dtype=np.float32))
|
| 37 |
+
c_0 = torch.tensor(np.zeros((2, xs_embedding.shape[0], self.hidden_num), dtype=np.float32))
|
| 38 |
+
h_0 = h_0.to(self.device)
|
| 39 |
+
c_0 = c_0.to(self.device)
|
| 40 |
+
xs_embedding = xs_embedding.to(self.device)
|
| 41 |
+
|
| 42 |
+
if not self.Word2Vec:
|
| 43 |
+
xs_embedding = self.embedding(xs_embedding)
|
| 44 |
+
|
| 45 |
+
encoder_input = self.pos_encoder(xs_embedding)
|
| 46 |
+
pre_encoded=self.encoder(encoder_input)
|
| 47 |
+
pre=self.linear2(self.linear1(self.flatten(pre_encoded)))
|
| 48 |
+
|
| 49 |
+
# pre:[batch_size*max_seq_len, vocab_size]
|
| 50 |
+
return pre, (h_0, c_0)
|
| 51 |
+
|
| 52 |
+
class PositionalEncoding(nn.Module):
|
| 53 |
+
|
| 54 |
+
def __init__(self, d_model, dropout = 0.1, max_len = 5000):
|
| 55 |
+
super(PositionalEncoding, self).__init__()
|
| 56 |
+
|
| 57 |
+
self.dropout = nn.Dropout(p = dropout)
|
| 58 |
+
|
| 59 |
+
pe = torch.zeros(max_len, d_model)
|
| 60 |
+
|
| 61 |
+
position = torch.arange(0, max_len, dtype = torch.float).unsqueeze(1)
|
| 62 |
+
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
|
| 63 |
+
pe[:, 0::2] = torch.sin(position * div_term)
|
| 64 |
+
pe[:, 1::2] = torch.cos(position * div_term)
|
| 65 |
+
pe = pe.unsqueeze(0).transpose(0, 1)
|
| 66 |
+
self.register_buffer('pe', pe)
|
| 67 |
+
|
| 68 |
+
def forward(self, x):
|
| 69 |
+
x = x + self.pe[:x.size(0), :]
|
| 70 |
+
return self.dropout(x)
|
src/models/__init__.py
ADDED
|
File without changes
|
src/utils/__init__.py
ADDED
|
File without changes
|
src/utils/utils.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def make_cuda(tensor):
|
| 5 |
+
"""Use CUDA if it's available."""
|
| 6 |
+
if torch.cuda.is_available():
|
| 7 |
+
tensor = tensor.cuda()
|
| 8 |
+
return tensor
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def is_minimum(value, indiv_to_rmse):
|
| 12 |
+
if len(indiv_to_rmse) == 0:
|
| 13 |
+
return True
|
| 14 |
+
temp = list(indiv_to_rmse.values())
|
| 15 |
+
return True if value < min(temp) else False
|
train.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from src.utils.utils import make_cuda
|
| 2 |
+
from src.apis.train import train, evaluate
|
| 3 |
+
from src.models.LSTM.model import Poetry_Model_lstm
|
| 4 |
+
import argparse
|
| 5 |
+
import torch
|
| 6 |
+
import os
|
| 7 |
+
from src.datasets.dataloader import Poetry_Dataset, train_vec, get_poetry, split_text
|
| 8 |
+
from torch.utils.data import DataLoader
|
| 9 |
+
from src.models.Transformer.model import Poetry_Model_Transformer
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def parse_arguments():
|
| 13 |
+
# argument parsing
|
| 14 |
+
parser = argparse.ArgumentParser(description="Specify Params for Experimental Setting")
|
| 15 |
+
|
| 16 |
+
parser.add_argument('--batch_size', type=int, default=64,
|
| 17 |
+
help="Specify batch size")
|
| 18 |
+
|
| 19 |
+
parser.add_argument('--initial_epochs', type=int, default=25,
|
| 20 |
+
help="Specify the number of epochs for initial training")
|
| 21 |
+
|
| 22 |
+
parser.add_argument('--num_epochs', type=int, default=50,
|
| 23 |
+
help="Specify the number of epochs for competitive search")
|
| 24 |
+
parser.add_argument('--log_step', type=int, default=100,
|
| 25 |
+
help="Specify log step size for training")
|
| 26 |
+
parser.add_argument('--learning_rate', type=float, default=1e-3,
|
| 27 |
+
help="Learning rate")
|
| 28 |
+
parser.add_argument('--data', type=str, default='data/poetry.txt',
|
| 29 |
+
help="Path to the dataset")
|
| 30 |
+
parser.add_argument('--n_hidden', type=int, default=128)
|
| 31 |
+
parser.add_argument('--max_grad_norm', type=float, default=1.0)
|
| 32 |
+
|
| 33 |
+
parser.add_argument('--save_path', type=str, default='save_models/transformer.pth')
|
| 34 |
+
parser.add_argument('--strict_dataset', default=False, help="strict dataset")
|
| 35 |
+
parser.add_argument('--Word2Vec',type=bool, default=True)
|
| 36 |
+
parser.add_argument("--Augmented_dataset", type=bool, default=False)
|
| 37 |
+
return parser.parse_args()
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def main():
|
| 41 |
+
args = parse_arguments()
|
| 42 |
+
if os.path.exists("data/split_poetry.txt") and os.path.exists("data/org_poetry.txt"):
|
| 43 |
+
print("pre_file exit!")
|
| 44 |
+
else:
|
| 45 |
+
split_text(get_poetry(args)) # split poetry
|
| 46 |
+
all_data, (w1, word_2_index, index_2_word) = train_vec()
|
| 47 |
+
args.word_size, args.embedding_num = w1.shape # 词向量的维度
|
| 48 |
+
|
| 49 |
+
dataset = Poetry_Dataset(w1, word_2_index, all_data, Word2Vec=args.Word2Vec)
|
| 50 |
+
train_size = int(len(dataset) * 0.7)
|
| 51 |
+
test_size = len(dataset) - train_size
|
| 52 |
+
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
|
| 53 |
+
|
| 54 |
+
train_data_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True)
|
| 55 |
+
valid_data_loader = DataLoader(test_dataset, batch_size=int(args.batch_size/4), shuffle=True)
|
| 56 |
+
|
| 57 |
+
# best_model = Poetry_Model_lstm(args.n_hidden, args.word_size, args.embedding_num,args.Word2Vec)
|
| 58 |
+
best_model = Poetry_Model_Transformer(args.n_hidden, args.word_size, args.embedding_num, args.Word2Vec)
|
| 59 |
+
best_model = make_cuda(best_model) # use gpu
|
| 60 |
+
print("Initial training before competitive random search")
|
| 61 |
+
best_model = train(args, best_model, train_data_loader)
|
| 62 |
+
|
| 63 |
+
torch.save(best_model.state_dict(), args.save_path)
|
| 64 |
+
|
| 65 |
+
print('test evaluation:')
|
| 66 |
+
evaluate(args, best_model, valid_data_loader)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
if __name__ == '__main__':
|
| 70 |
+
main()
|