

upload
Browse files
README.md
DELETED
|
@@ -1,63 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: ChatPaper
|
| 3 |
-
emoji: 📕
|
| 4 |
-
colorFrom: pink
|
| 5 |
-
colorTo: purple
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 0.6.2
|
| 8 |
-
app_file: frontend.py
|
| 9 |
-
license: gpl-3.0
|
| 10 |
-
---
|
| 11 |
-
|
| 12 |
-
# ChatPaper
|
| 13 |
-
Yet another paper reading assistant, similar as [ChatPDF](https://www.chatpdf.com/).
|
| 14 |
-
|
| 15 |
-
## Setup
|
| 16 |
-
|
| 17 |
-
1. Install dependencies (tested on Python 3.9)
|
| 18 |
-
|
| 19 |
-
```bash
|
| 20 |
-
pip install -r requirements.txt
|
| 21 |
-
```
|
| 22 |
-
|
| 23 |
-
2. Setup GROBID local server
|
| 24 |
-
|
| 25 |
-
```bash
|
| 26 |
-
bash serve_grobid.sh
|
| 27 |
-
```
|
| 28 |
-
|
| 29 |
-
3. Setup backend
|
| 30 |
-
|
| 31 |
-
```bash
|
| 32 |
-
python backend.py --port 5000 --host localhost
|
| 33 |
-
```
|
| 34 |
-
|
| 35 |
-
4. Frontend
|
| 36 |
-
|
| 37 |
-
```bash
|
| 38 |
-
streamlit run frontend.py --server.port 8502 --server.host localhost
|
| 39 |
-
```
|
| 40 |
-
|
| 41 |
-
## Demo Example
|
| 42 |
-
|
| 43 |
-
- Prepare an [OpenAI API key](https://platform.openai.com/account/api-keys) and then upload a PDF to start chatting with the paper.
|
| 44 |
-
|
| 45 |
-
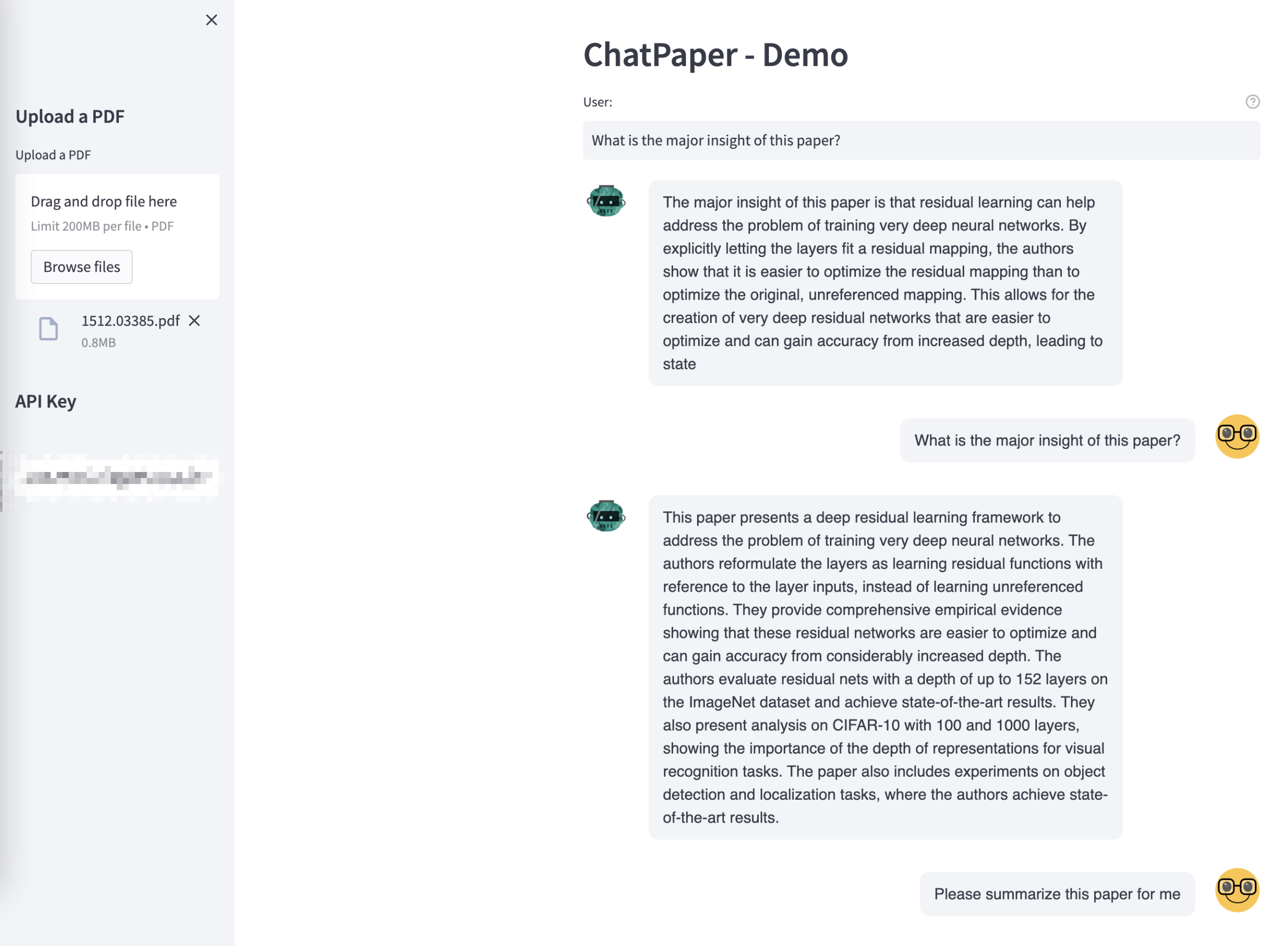
|
| 46 |
-
|
| 47 |
-
## Implementation Details
|
| 48 |
-
|
| 49 |
-
- Greedy Dynamic Context: Since the max token limit, we select the most relevant paragraphs in the pdf for each user query. Our model split the text input and output by the chatbot into four part: system_prompt (S), dynamic_source (D), user_query (Q), and model_answer(A). So upon each query, we first rank all the paragraphs by using a sentence_embedding model to calculate the similarity distance between the query embedding and all source embeddings. Then we compose the dynamic_source using a greedy method by to gradually push all relevant paragraphs (maintaing D <= MAX_TOKEN_LIMIT - Q - S - A - SOME_OVERHEAD).
|
| 50 |
-
|
| 51 |
-
- Context Truncating: When context is too long, we now we simply pop out the first QA-pair.
|
| 52 |
-
|
| 53 |
-
## TODO
|
| 54 |
-
|
| 55 |
-
- [ ] **Context Condense**: how to deal with long context? maybe we can tune a soft prompt to condense the context
|
| 56 |
-
- [ ] **Poping context out based on similarity**
|
| 57 |
-
|
| 58 |
-
## References
|
| 59 |
-
|
| 60 |
-
1. SciPDF Parser: https://github.com/titipata/scipdf_parser
|
| 61 |
-
2. St-chat: https://github.com/AI-Yash/st-chat
|
| 62 |
-
3. Sentence-transformers: https://github.com/UKPLab/sentence-transformers
|
| 63 |
-
4. ChatGPT Chatbot Wrapper: https://github.com/acheong08/ChatGPT
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|