
Young Ho Shin
commited on
Commit
·
36bccd1
1
Parent(s):
c8261bc
Add examples and article.md
Browse files- app.py +33 -5
- article.md +48 -0
- examples/1d32874f02.png +0 -0
- examples/1e466b180d.png +0 -0
- examples/2d3503f427.png +0 -0
- examples/2f9d3c4e43.png +0 -0
- examples/51c5cc2ff5.png +0 -0
- examples/545a492388.png +0 -0
- examples/6a51a30502.png +0 -0
- examples/6bf6832adb.png +0 -0
- examples/7afdeff0e6.png +0 -0
- examples/b8f1e64b1f.png +0 -0
- tokenizer-wordlevel.json +1 -1
app.py
CHANGED
|
@@ -31,13 +31,41 @@ def process_image(image):
|
|
| 31 |
|
| 32 |
return generated_text
|
| 33 |
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
|
| 39 |
iface = gr.Interface(fn=process_image,
|
| 40 |
-
inputs=gr.inputs.Image(type="pil"),
|
| 41 |
outputs=gr.outputs.Textbox(),
|
| 42 |
title=title,
|
| 43 |
description=description,
|
|
|
|
| 31 |
|
| 32 |
return generated_text
|
| 33 |
|
| 34 |
+
# !ls examples | grep png
|
| 35 |
+
|
| 36 |
+
# +
|
| 37 |
+
title = "Convert an image of an equation to LaTeX source code"
|
| 38 |
+
|
| 39 |
+
with open('article.md',mode='r') as file:
|
| 40 |
+
article = file.read()
|
| 41 |
+
|
| 42 |
+
description = """
|
| 43 |
+
This is a demo of machine learning model trained to parse an image and reconstruct the LaTeX source code of an equation.
|
| 44 |
+
To use it, simply upload an image or use one of the example images below and click 'submit'.
|
| 45 |
+
Results will show up in a few seconds.
|
| 46 |
+
|
| 47 |
+
Try rendering the equation [here](https://quicklatex.com/) to compare with the original image.
|
| 48 |
+
(The model is not perfect yet, so you may need to edit the resulting LaTeX a bit to get it to render a good match.)
|
| 49 |
+
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
examples = [
|
| 53 |
+
[ "examples/1d32874f02.png" ],
|
| 54 |
+
[ "examples/1e466b180d.png" ],
|
| 55 |
+
[ "examples/2d3503f427.png" ],
|
| 56 |
+
[ "examples/2f9d3c4e43.png" ],
|
| 57 |
+
[ "examples/51c5cc2ff5.png" ],
|
| 58 |
+
[ "examples/545a492388.png" ],
|
| 59 |
+
[ "examples/6a51a30502.png" ],
|
| 60 |
+
[ "examples/6bf6832adb.png" ],
|
| 61 |
+
[ "examples/7afdeff0e6.png" ],
|
| 62 |
+
[ "examples/b8f1e64b1f.png" ],
|
| 63 |
+
]
|
| 64 |
+
#examples =[["examples/image_0.png"], ["image_1.png"], ["image_2.png"]]
|
| 65 |
+
# -
|
| 66 |
|
| 67 |
iface = gr.Interface(fn=process_image,
|
| 68 |
+
inputs=[gr.inputs.Image(type="pil")],
|
| 69 |
outputs=gr.outputs.Textbox(),
|
| 70 |
title=title,
|
| 71 |
description=description,
|
article.md
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## What's the point of this?
|
| 2 |
+
|
| 3 |
+
LaTeX is the de-facto standard markup language for typesetting pretty equations in academic papers.
|
| 4 |
+
It is extremely feature rich and flexible but very verbose.
|
| 5 |
+
This makes it great for typesetting complex equations, but not very convenient for quick note-taking on the fly.
|
| 6 |
+
|
| 7 |
+
For example, here's a short equation from [this page](https://en.wikipedia.org/wiki/Quantum_electrodynamics) on Wikipedia about Quantum Electrodynamics
|
| 8 |
+
and the corresponding LaTeX code:
|
| 9 |
+
|
| 10 |
+

|
| 11 |
+
|
| 12 |
+
```
|
| 13 |
+
{\displaystyle {\mathcal {L}}={\bar {\psi }}(i\gamma ^{\mu }D_{\mu }-m)\psi -{\frac {1}{4}}F_{\mu \nu }F^{\mu \nu },}
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
This demo is a first step in solving that problem.
|
| 18 |
+
Eventually, you'll be able to take a quick screenshot of an equation from a paper
|
| 19 |
+
and a program built with this model will generate its corresponding LaTeX source code
|
| 20 |
+
so that you can just copy/paste straight into your personal notes.
|
| 21 |
+
No more endless googling obscure LaTeX syntax!
|
| 22 |
+
|
| 23 |
+
## How does it work?
|
| 24 |
+
|
| 25 |
+
Because this problem involves looking at an image and generating valid LaTeX code,
|
| 26 |
+
the model needs to understand both Computer Vision (CV) and Natural Language Processing (NLP).
|
| 27 |
+
There are some other projects that aim to solve the same problem with some very interesting architectures
|
| 28 |
+
that generally involve some kind of "encoder" that looks at the image and extracts and encodes the information about the equation from the image,
|
| 29 |
+
and a "decoder" that takes that information and translates it into what is hopefully both valid and accurate LaTeX code.
|
| 30 |
+
|
| 31 |
+
Examples:
|
| 32 |
+
...
|
| 33 |
+
|
| 34 |
+
I chose to tackle this problem with transfer learning.
|
| 35 |
+
The biggest reason for this is computing constraints -
|
| 36 |
+
I don't have unlimited access to GPU hours and wanted training to be reasonably fast, on the order of a couple of hours.
|
| 37 |
+
There are some other benefits to this approach,
|
| 38 |
+
e.g. the architecture is already proven to be robust enough for various applications, so less time spent on trial and error.
|
| 39 |
+
|
| 40 |
+
I chose TrOCR, an OCR machine learning model trained by Microsoft on SRIOE data to produce text from receipts.
|
| 41 |
+
|
| 42 |
+
<p style='text-align: center'>Made by Young Ho Shin</p>
|
| 43 |
+
<p style='text-align: center'>
|
| 44 |
+
<a href = "mailto: yhshin.data@gmail.com">Email</a> |
|
| 45 |
+
<a href='https://www.github.com/yhshin11'>Github</a> |
|
| 46 |
+
<a href='https://www.linkedin.com/in/young-ho-shin-3995051b9/'>Linkedin</a>
|
| 47 |
+
|
| 48 |
+
</p>
|
examples/1d32874f02.png
ADDED
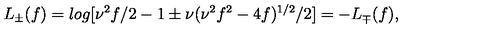
|
examples/1e466b180d.png
ADDED
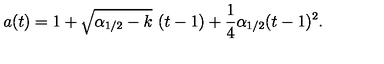
|
examples/2d3503f427.png
ADDED
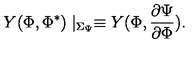
|
examples/2f9d3c4e43.png
ADDED
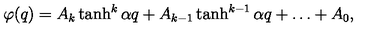
|
examples/51c5cc2ff5.png
ADDED
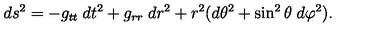
|
examples/545a492388.png
ADDED
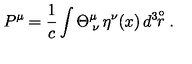
|
examples/6a51a30502.png
ADDED
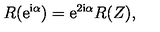
|
examples/6bf6832adb.png
ADDED

|
examples/7afdeff0e6.png
ADDED
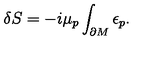
|
examples/b8f1e64b1f.png
ADDED
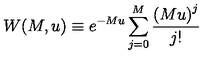
|
tokenizer-wordlevel.json
CHANGED
|
@@ -349,4 +349,4 @@
|
|
| 349 |
},
|
| 350 |
"unk_token": "[UNK]"
|
| 351 |
}
|
| 352 |
-
}
|
|
|
|
| 349 |
},
|
| 350 |
"unk_token": "[UNK]"
|
| 351 |
}
|
| 352 |
+
}
|