
Switch to streamlit with markdown, add T5X pre-trained models
Browse files- .gitattributes +12 -0
- EVALUATION.md +59 -0
- INTRO.md +26 -0
- PRETRAINING.md +71 -0
- README.md +4 -3
- REMARKS.md +24 -0
- adafactor_vs_adam_pretrain.png +0 -0
- app.py +317 -0
- bfloat16_loss.png +0 -0
- eval_summ_rouge1_202302.png +3 -0
- eval_t5_dutch_english.png +3 -0
- eval_transl_bleu_202302.png +3 -0
- evaluation_t5_dutch_english.png +0 -0
- optim_lr_summarization.png +0 -0
- requirements.txt +14 -0
- style.css +21 -11
- t5v1_1eval_loss_and_accuracy.png +0 -0
- train_loss_eval_summarization.png +0 -0
- train_loss_eval_t5_translation.png +0 -0
- training_base_36l_losses.png +0 -0
- training_losses_summarization_sweep.png +0 -0
.gitattributes
CHANGED
|
@@ -25,3 +25,15 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 25 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 26 |
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 27 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 25 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 26 |
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
| 27 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
train_loss_eval_t5_translation.png filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
eval_t5_dutch_english.png filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
eval_transl_bleu_202302.png filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
evaluation_t5_dutch_english.png filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
optim_lr_summarization.png filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
t5v1_1eval_loss_and_accuracy.png filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
train_loss_eval_summarization.png filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
adafactor_vs_adam_pretrain.png filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
bfloat16_loss.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
eval_summ_rouge1_202302.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
training_base_36l_losses.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
training_losses_summarization_sweep.png filter=lfs diff=lfs merge=lfs -text
|
EVALUATION.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Evaluation
|
| 2 |
+
|
| 3 |
+
### Running evaluation runs
|
| 4 |
+
|
| 5 |
+
Each pre-trained model was evaluated by fine-tuning on summarization and translation. The learning-rate was set to
|
| 6 |
+
a constant schedule after a small warmup of 32 steps.
|
| 7 |
+
Fine-tuning for evaluation was done on a limited set of 50K examples from the fine-tuning datasets.
|
| 8 |
+
|
| 9 |
+
| | Summarization | Translation |
|
| 10 |
+
|-----------------:|------------------|-------------------|
|
| 11 |
+
| Dataset | CNN Dailymail NL | CCMatrix en -> nl |
|
| 12 |
+
| #train samples | 50K | 50K |
|
| 13 |
+
| Optimizer | AdamW | AdamW |
|
| 14 |
+
| learning rate | 0.001 | 0.0005 |
|
| 15 |
+
| source length | 1024 | 128 |
|
| 16 |
+
| target length | 142 | 128 |
|
| 17 |
+
| #eval samples | 1000 | 1000 |
|
| 18 |
+
| wandb link | [eval_summ](https://wandb.ai/yepster/eval_dutch_cnndaily_202302_flax)|[eval_transl](https://wandb.ai/yepster/eval_dutch_ccmatrix_202302_flax) |
|
| 19 |
+
|
| 20 |
+
The graph below shows the Rouge1 score for the summarization runs, evaluated
|
| 21 |
+
after 25K and 50K examples on the [CNN Dailymail Dutch](https://huggingface.co/datasets/yhavinga/cnn_dailymail_dutch) dataset:
|
| 22 |
+
|
| 23 |
+

|
| 24 |
+
|
| 25 |
+
* Flan models perform almost instantly well on the summarization task, with `flan-t5-small`
|
| 26 |
+
showing performance comparable to Dutch T5 base models.
|
| 27 |
+
* After 50K examples, the `ul2` models exhibit similar performance to the `flan` models.
|
| 28 |
+
* I am surprised by the consistent bad scores for the `long-t5` runs. I've retried the fine-tuning of these models with
|
| 29 |
+
`float32` instead of `bfloat16`, but the results were the same. Maybe this is normal behaviour for these models
|
| 30 |
+
targeted at dealing with longer sequence lengths.
|
| 31 |
+
|
| 32 |
+
The graph below shows the Bleu score for the translation runs, evaluated at step 25K and
|
| 33 |
+
50K on the [CCMatrix](https://huggingface.co/datasets/yhavinga/ccmatrix_en_nl) dataset, from
|
| 34 |
+
English to Dutch:
|
| 35 |
+
|
| 36 |
+

|
| 37 |
+
|
| 38 |
+
* For the translation task from English to Dutch, the Dutch+English pre-trained models perform well. Also
|
| 39 |
+
`ul2` pre-trained models are consistently better than their `Flan`, `T5 Dutch` and
|
| 40 |
+
`mT5` counterparts.
|
| 41 |
+
* Like with the summarization task, the `long-t5` models show bad performance, even after 50K examples. I do not understand
|
| 42 |
+
cannot explain this at all for this translation task. With a sequence length of 128 input and output
|
| 43 |
+
tokens, the sliding attention window with radius length 127 of the `long-t5` models should be able to handle this.
|
| 44 |
+
|
| 45 |
+
The figure below shows the evaluation scores for most models, with summarization Rouge1 on the x-axis (higher is better),
|
| 46 |
+
and translation English to Dutch Bleu score on the y-axis (higher is better).
|
| 47 |
+
The point size is proportional to the model size. UL2 models are blue, Flan models
|
| 48 |
+
red, mT5 green and the other models black.
|
| 49 |
+
|
| 50 |
+

|
| 51 |
+
|
| 52 |
+
* For clarity not all models are shown. `t5-base-36L-dutch-english-cased` is model with
|
| 53 |
+
scores comparable to `ul2-large-dutch-english`, but with slower inference. All long-t5
|
| 54 |
+
runs are left out, as well as the `t5-v1.1-large-dutch-cased` model whose translation fine-tuning
|
| 55 |
+
diverged.
|
| 56 |
+
* Across the board, for translation the models pre-trained with Dutch+English or Dutch converge faster than other models.
|
| 57 |
+
I was surprised to see `t5-xl-4l` among the best models on translation, as it has only 4 layers, and previous tests
|
| 58 |
+
showed that it had a very bad performance (In those tests I had forgot to force set the dropout rate to 0.0, and
|
| 59 |
+
apparently this model was very sensitive to dropout).
|
INTRO.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Dutch T5 models : UL2, T5, ByT5 and Long-T5 🇳🇱🇧🇪
|
| 2 |
+
|
| 3 |
+
TL;DR: ul2-small-dutch(-english) and larger models are fit for Dutch text-to-text tasks.
|
| 4 |
+
|
| 5 |
+
During the [HuggingFace Flax/Jax community week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) in the summer of 2021,
|
| 6 |
+
I was granted access to Google's TPU Research Cloud (TRC),
|
| 7 |
+
a cloud-based platform for machine learning research and development that provides access to Google's
|
| 8 |
+
Tensor Processing Units (TPUs). My goal was to address the (then) shortage of T5 models for the Dutch language.
|
| 9 |
+
-- T5 is a state-of-the-art AI model architecture that can handle text as input and output,
|
| 10 |
+
making it an ideal tool for NLP tasks such as summarization, translation, and question-answering --
|
| 11 |
+
Since then, with extended access to the TRC, I have been able to train a variety of T5 models for Dutch.
|
| 12 |
+
|
| 13 |
+
Relevant papers are:
|
| 14 |
+
|
| 15 |
+
* **[Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683)** by *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu*.
|
| 16 |
+
* **[ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning](https://arxiv.org/abs/2111.10952)** by *Vamsi Aribandi, Yi Tay, Tal Schuster, Jinfeng Rao, Huaixiu Steven Zheng, Sanket Vaibhav Mehta, Honglei Zhuang, Vinh Q. Tran, Dara Bahri, Jianmo Ni, Jai Gupta, Kai Hui, Sebastian Ruder, Donald Metzler*.
|
| 17 |
+
* **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
|
| 18 |
+
* **[ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)** by *Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel*
|
| 19 |
+
* **[LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)** by *Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang*
|
| 20 |
+
* **[Scaling Up Models and Data with t5x and seqio](https://arxiv.org/abs/2203.17189)** by *Adam Roberts, Hyung Won Chung, Anselm Levskaya, Gaurav Mishra, James Bradbury, Daniel Andor, Sharan Narang, Brian Lester, Colin Gaffney, Afroz Mohiuddin, Curtis Hawthorne, Aitor Lewkowycz, Alex Salcianu, Marc van Zee, Jacob Austin, Sebastian Goodman, Livio Baldini Soares, Haitang Hu, Sasha Tsvyashchenko, Aakanksha Chowdhery, Jasmijn Bastings, Jannis Bulian, Xavier Garcia, Jianmo Ni, Andrew Chen, Kathleen Kenealy, Jonathan H. Clark, Stephan Lee, Dan Garrette, James Lee-Thorp, Colin Raffel, Noam Shazeer, Marvin Ritter, Maarten Bosma, Alexandre Passos, Jeremy Maitin-Shepard, Noah Fiedel, Mark Omernick, Brennan Saeta, Ryan Sepassi, Alexander Spiridonov, Joshua Newlan, Andrea Gesmundo*
|
| 21 |
+
* **[UL2: Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131)** by *Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Denny Zhou, Neil Houlsby, Donald Metzler*
|
| 22 |
+
|
| 23 |
+
Background on Google's TPU VM's and how to use the Huggingface transformers library to pre-train models can be found
|
| 24 |
+
at the following links
|
| 25 |
+
* https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104
|
| 26 |
+
* https://github.com/huggingface/transformers/tree/main/examples/research_projects/jax-projects#talks
|
PRETRAINING.md
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Pre-training
|
| 2 |
+
|
| 3 |
+
### mC4 dataset
|
| 4 |
+
|
| 5 |
+
Together with the T5 model architecture and SeqIO, the T5 authors also created and released
|
| 6 |
+
the multilingual [mC4 dataset](https://huggingface.co/datasets/allenai/c4).
|
| 7 |
+
It was made available by AllenNLP on the HuggingFace Dataset hub.
|
| 8 |
+
Our team confirmed that the Dutch portion of the mC4 dataset was deduplicated,
|
| 9 |
+
and we cleaned the Dutch portion of the mC4 dataset using [code adapted](https://gitlab.com/yhavinga/c4nlpreproc) from the TensorFlow C4 dataset.
|
| 10 |
+
The resulting [mc4_nl_cleaned](https://huggingface.co/datasets/yhavinga/mc4_nl_cleaned) dataset on the HuggingFace hub
|
| 11 |
+
has configs for several sizes, and also configs for mixed Dutch and English
|
| 12 |
+
texts, e.g. [micro_en_nl](https://huggingface.co/datasets/yhavinga/mc4_nl_cleaned/viewer/micro_en_nl/train).
|
| 13 |
+
The `_en_nl` configs were added to accommodate multi-language pre-training
|
| 14 |
+
with the Huggingface pre-training script, that accepts only a single dataset as input.
|
| 15 |
+
Cleaned English C4 is roughly 5 times larger than its Dutch counterpart. Therefore,
|
| 16 |
+
interleaving the datasets in a 1:1 ratio results in discarding approximately 80% of the English data.
|
| 17 |
+
(When pre-training with T5X and SeqIO, it is possible to define task mixtures that include multiple datasets,
|
| 18 |
+
so these `_en_nl` configs are not needed.)
|
| 19 |
+
|
| 20 |
+
The full, cleaned Dutch mC4 dataset is 151GB and remains (as of June 2022) the largest available Dutch
|
| 21 |
+
corpus on the HuggingFace Dataset hub.
|
| 22 |
+
|
| 23 |
+
### Additional books, Wikipedia and Dutch news articles datasets
|
| 24 |
+
|
| 25 |
+
The `t5_1_1` and `ul2` models have also been trained on Dutch books, the Dutch subset of Wikipedia (2022-03-20),
|
| 26 |
+
the English subset of Wikipedia (2022-03-01), and a subset of "mc4_nl_cleaned" containing only texts
|
| 27 |
+
from Dutch and Belgian newspapers. Mixing in the these datasets was done to bias the model towards
|
| 28 |
+
descriptions of events in the Netherlands and Belgium.
|
| 29 |
+
|
| 30 |
+
### Pre-Training Objectives
|
| 31 |
+
|
| 32 |
+
The T5 models are pre-trained using the [span corruption](https://arxiv.org/abs/1910.10683) denoising objective.
|
| 33 |
+
15% of the tokens in the text are masked, and each span
|
| 34 |
+
of masked tokens is replaced with a special token known as a sentinel token, where each span is assigned
|
| 35 |
+
its own sentinel token. The model is then trained to predict for each sentinel token the original text
|
| 36 |
+
that was replaced by the sentinel tokens.
|
| 37 |
+
|
| 38 |
+
The UL2 models are pre-trained with the [Mixture-of-Denoisers (MoD)](https://arxiv.org/abs/2205.05131) objective, that combines diverse pre-training
|
| 39 |
+
paradigms together. UL2 frames different objective functions for training language models as denoising tasks, where
|
| 40 |
+
the model has to recover missing sub-sequences of a given input. During pre-training it uses a novel mixture-of-denoisers
|
| 41 |
+
that samples from a varied set of such objectives, each with different configurations. UL2 is trained using a mixture of
|
| 42 |
+
three denoising tasks:
|
| 43 |
+
|
| 44 |
+
1. R-denoising (or regular span corruption), which emulates the standard T5 span corruption objective;
|
| 45 |
+
2. X-denoising (or extreme span corruption); and
|
| 46 |
+
3. S-denoising (or sequential PrefixLM).
|
| 47 |
+
|
| 48 |
+
### Pre-training software
|
| 49 |
+
|
| 50 |
+
#### Huggingface [run_t5_mlm_flax.py](https://github.com/huggingface/transformers/blob/main/examples/flax/language-modeling/run_t5_mlm_flax.py)
|
| 51 |
+
|
| 52 |
+
All models except `t5_1_1` and `ul2` were pre-trained using the Huggingface `run_t5_mlm_flax.py` script.
|
| 53 |
+
This script is a good fit if you want to get a grasp what's needed to pre-train a language model
|
| 54 |
+
with Flax and Jax, since all data preparation, model instantiation, loss function, and training loop are
|
| 55 |
+
contained in a single file.
|
| 56 |
+
|
| 57 |
+
#### Google's [T5X](https://github.com/google-research/t5x)
|
| 58 |
+
|
| 59 |
+
The Dutch `t5_1_1` and `ul2` models were pre-trained using T5X. This is a modular framework that can be used for
|
| 60 |
+
pre-training, fine-tuning, and evaluation of T5 models. Because of its modular and pluggable design,
|
| 61 |
+
by only supplying a few configuration and code files, it is possible to pre-train with your own definitions.
|
| 62 |
+
It is even possible to define custom neural network layers and architectures, though I did not do this and only
|
| 63 |
+
pre-trained the default T5 encoder-decoder architecture, and varied only the pre-training objective, and the
|
| 64 |
+
datasets used and mixed with SeqIO.
|
| 65 |
+
|
| 66 |
+
#### Conversion script from T5X to HF
|
| 67 |
+
|
| 68 |
+
The T5X models were converted to Huggingface Flax T5 format using a script that was adapted from the
|
| 69 |
+
[T5X checkpoint to HuggingFace Flax conversion script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/convert_t5x_checkpoint_to_flax.py).
|
| 70 |
+
This script was modified to cast weights to bf16, and to also convert to pytorch format.
|
| 71 |
+
For this conversion to be successful, the T5X model had to be saved with `use_gda=False` set in the GIN file.
|
README.md
CHANGED
|
@@ -1,10 +1,11 @@
|
|
| 1 |
---
|
| 2 |
title: Pre-training Dutch T5 Models
|
| 3 |
emoji: 🚀
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
-
sdk:
|
| 7 |
pinned: false
|
|
|
|
| 8 |
license: afl-3.0
|
| 9 |
---
|
| 10 |
|
| 1 |
---
|
| 2 |
title: Pre-training Dutch T5 Models
|
| 3 |
emoji: 🚀
|
| 4 |
+
colorFrom: blue
|
| 5 |
+
colorTo: pink
|
| 6 |
+
sdk: streamlit
|
| 7 |
pinned: false
|
| 8 |
+
app_file: app.py
|
| 9 |
license: afl-3.0
|
| 10 |
---
|
| 11 |
|
REMARKS.md
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Miscellaneous remarks
|
| 2 |
+
|
| 3 |
+
* Use loss regularization if you train with `bfloat16` (more info below)
|
| 4 |
+
* Beware of the dropout rate in the config.json file.
|
| 5 |
+
Check in a model's `config.json` what the dropout rate has been set to. Unless you
|
| 6 |
+
intend to run many epochs on the same data, its worth to try a training run without dropout.
|
| 7 |
+
If you want to compare losses, be sure to set the dropout rate equal.
|
| 8 |
+
The smaller models can probably always be trained without.
|
| 9 |
+
* For the translation task, I am not sure that a 'deep-narrow' model (e.g. base-nl36) is better than a normal model
|
| 10 |
+
or even a 'wide-deep' model.
|
| 11 |
+
* Training with more layers is much slower than you'd expect from the increased model size.
|
| 12 |
+
It is also more difficult to get batch size and learning rate right. Below is a section
|
| 13 |
+
about finding the right hyperparameters for the base-36L training.
|
| 14 |
+
* The 'larger' models are not only harder to pre-train, but also harder to fine-tune. The optimizer eats up a lot of
|
| 15 |
+
space, and the amount of memory required also depends on the length of source and target sequences.
|
| 16 |
+
* PyCharms remote debugging features are useful to inspect variables on either a TPU VM or your deep-learning rig.
|
| 17 |
+
* When increasing the batch size, increase the learning rate. bs * 2 -> lr * sqrt(2) is a good heuristic but mileage may
|
| 18 |
+
vary.
|
| 19 |
+
* Translation evaluation: the low score of the 128 seq len models on opus books may be because of the brevity penaly...
|
| 20 |
+
that books may have sentences longer than 128 tokens.
|
| 21 |
+
* Dataset quality is a key success factor. Do not expect a model to magically turn mediocre data into magic. This holds for
|
| 22 |
+
the pre-training data, fine-tuning and also evaluating.
|
| 23 |
+
* Good Bleu score does not necessarily mean fluent text. Evaluation loss on a large translation dataset might be
|
| 24 |
+
better suited for model comparison.
|
adafactor_vs_adam_pretrain.png
CHANGED

|

|
Git LFS Details
|
app.py
ADDED
|
@@ -0,0 +1,317 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
|
| 3 |
+
import psutil
|
| 4 |
+
import streamlit as st
|
| 5 |
+
|
| 6 |
+
IMAGE_WIDTHS=900
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def main():
|
| 10 |
+
st.set_page_config( # Alternate names: setup_page, page, layout
|
| 11 |
+
page_title="Pre-training Dutch T5 models", # String or None. Strings get appended with "• Streamlit".
|
| 12 |
+
layout="wide", # Can be "centered" or "wide". In the future also "dashboard", etc.
|
| 13 |
+
initial_sidebar_state="collapsed", # Can be "auto", "expanded", "collapsed"
|
| 14 |
+
page_icon="📑", # String, anything supported by st.image, or None.
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
with open("style.css") as f:
|
| 18 |
+
st.markdown(f"<style>{f.read()}</style>", unsafe_allow_html=True)
|
| 19 |
+
|
| 20 |
+
with open("INTRO.md", "r") as f:
|
| 21 |
+
st.markdown(f.read())
|
| 22 |
+
|
| 23 |
+
with open("PRETRAINING.md", "r") as f:
|
| 24 |
+
st.markdown(f.read())
|
| 25 |
+
|
| 26 |
+
st.markdown("""## Evaluation
|
| 27 |
+
|
| 28 |
+
### Running evaluation runs
|
| 29 |
+
|
| 30 |
+
Each pre-trained model was evaluated by fine-tuning on summarization and translation. The learning-rate was set to
|
| 31 |
+
a constant schedule after a small warmup of 32 steps.
|
| 32 |
+
Fine-tuning for evaluation was done on a limited set of 50K examples from the fine-tuning datasets.
|
| 33 |
+
|
| 34 |
+
| | Summarization | Translation |
|
| 35 |
+
|-----------------:|------------------|-------------------|
|
| 36 |
+
| Dataset | CNN Dailymail NL | CCMatrix en -> nl |
|
| 37 |
+
| #train samples | 50K | 50K |
|
| 38 |
+
| Optimizer | AdamW | AdamW |
|
| 39 |
+
| learning rate | 0.001 | 0.0005 |
|
| 40 |
+
| source length | 1024 | 128 |
|
| 41 |
+
| target length | 142 | 128 |
|
| 42 |
+
| #eval samples | 1000 | 1000 |
|
| 43 |
+
| wandb link | [eval_summ](https://wandb.ai/yepster/eval_dutch_cnndaily_202302_flax)|[eval_transl](https://wandb.ai/yepster/eval_dutch_ccmatrix_202302_flax) |
|
| 44 |
+
|
| 45 |
+
#### Summarization
|
| 46 |
+
|
| 47 |
+
The graph below ([Wandb link](https://api.wandb.ai/links/yepster/hpab7khl)) shows the Rouge1 score for the summarization runs, evaluated
|
| 48 |
+
after 25K and 50K examples on the [CNN Dailymail Dutch](https://huggingface.co/datasets/yhavinga/cnn_dailymail_dutch) dataset:
|
| 49 |
+
""")
|
| 50 |
+
st.image("eval_summ_rouge1_202302.png", width=IMAGE_WIDTHS)
|
| 51 |
+
st.markdown("""* Flan models perform almost instantly well on the summarization task, with `flan-t5-small`
|
| 52 |
+
showing performance comparable to Dutch T5 base models.
|
| 53 |
+
* After 50K examples, the `ul2` models exhibit similar performance to the `flan` models.
|
| 54 |
+
* I am surprised by the consistent bad scores for the `long-t5` runs. I've retried the fine-tuning of these models with
|
| 55 |
+
`float32` instead of `bfloat16`, but the results were the same. Maybe this is normal behaviour for these models
|
| 56 |
+
targeted at dealing with longer sequence lengths.
|
| 57 |
+
|
| 58 |
+
#### Translation
|
| 59 |
+
|
| 60 |
+
The graph below ([WandB link](https://wandb.ai/yepster/eval_dutch_ccmatrix_202302_flax/reports/eval_ds_0-score-23-02-11-17-32-48---VmlldzozNTM0NTIy) shows the Bleu score for the translation runs, evaluated at step 25K and
|
| 61 |
+
50K on the [CCMatrix](https://huggingface.co/datasets/yhavinga/ccmatrix_en_nl) dataset, from
|
| 62 |
+
English to Dutch:
|
| 63 |
+
""")
|
| 64 |
+
st.image("eval_transl_bleu_202302.png", width=IMAGE_WIDTHS)
|
| 65 |
+
st.markdown("""* For the translation task from English to Dutch, the Dutch+English pre-trained models perform well. Also
|
| 66 |
+
`UL2 Dutch` pre-trained Dutch models are consistently better than their `Flan`, `T5 Dutch` and
|
| 67 |
+
`mT5` counterparts of the comparable size.
|
| 68 |
+
* Like with the summarization task, the `long-t5` models show bad performance, even after 50K examples. I do not understand
|
| 69 |
+
cannot explain this at all for this translation task. With a sequence length of 128 input and output
|
| 70 |
+
tokens, the sliding attention window with radius length 127 of the `long-t5` models should be able to handle this.
|
| 71 |
+
|
| 72 |
+
The figure below shows the evaluation scores for most models, with summarization Rouge1 on the x-axis (higher is better),
|
| 73 |
+
and translation English to Dutch Bleu score on the y-axis (higher is better).
|
| 74 |
+
The point size is proportional to the model size. UL2 models are blue, Flan models
|
| 75 |
+
red, mT5 green and the other models black.
|
| 76 |
+
""")
|
| 77 |
+
st.image("eval_t5_dutch_english.png", width=IMAGE_WIDTHS)
|
| 78 |
+
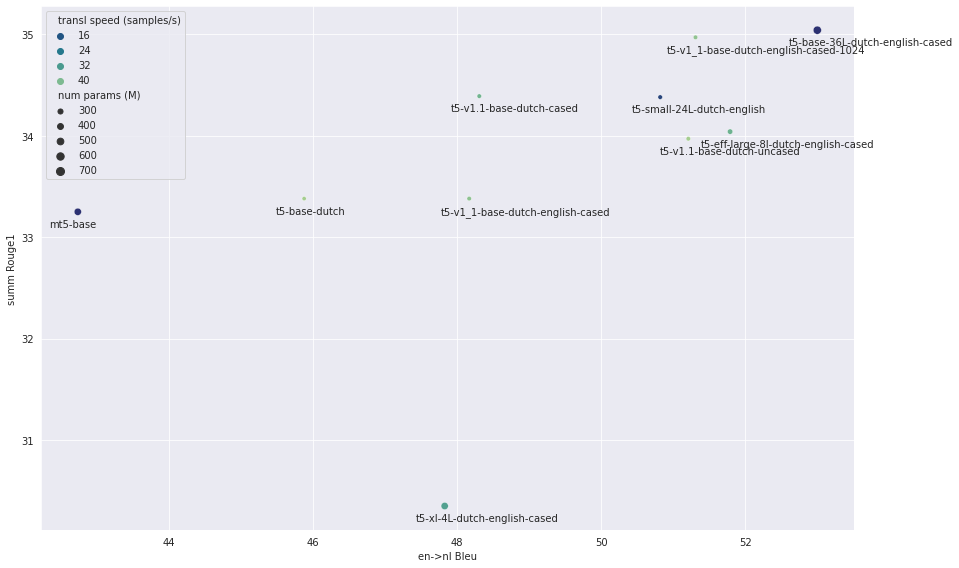
st.markdown("""* For clarity, not all models are shown.
|
| 79 |
+
Among the omitted are `t5-base-36L-dutch-english-cased` with scores comparable to `ul2-large-dutch-english`, but slower inference.
|
| 80 |
+
The `long-t5` models had such a bad performance that they could not be graphed without cluttering the other models together.
|
| 81 |
+
Also fine-tuning `t5-v1.1-large-dutch-cased` with the fixed settings for learning rate and batch size diverged.
|
| 82 |
+
* Across the board, for translation the models pre-trained with Dutch+English or Dutch converge faster than other models.
|
| 83 |
+
I was surprised to see `t5-xl-4l` among the best models on translation, as it has only 4 layers, and previous tests
|
| 84 |
+
showed that it had a very bad performance (In those tests I had forgot to force set the dropout rate to 0.0, and
|
| 85 |
+
apparently this model was very sensitive to dropout).
|
| 86 |
+
""")
|
| 87 |
+
|
| 88 |
+
with open("REMARKS.md", "r") as f:
|
| 89 |
+
st.markdown(f.read())
|
| 90 |
+
|
| 91 |
+
st.markdown("""### Bfloat16 datatype requires loss regularization
|
| 92 |
+
|
| 93 |
+
When training models with `bfloat16` and without loss regularization (default), the training losses would plateau or
|
| 94 |
+
diverge. The graph below displays the results of different attempts
|
| 95 |
+
to train [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english).
|
| 96 |
+
The legend indicates the optimizer, data type, learning rate, total batch size, and learning rate schedule used.
|
| 97 |
+
As you can see, all attempts to train with `bfloat16` failed.
|
| 98 |
+
""")
|
| 99 |
+
st.image("bfloat16_loss.png", width=IMAGE_WIDTHS)
|
| 100 |
+
st.markdown("""The solution was found when peeking at T5X and the T5 gin configs, where I noticed a `z_loss` parameter,
|
| 101 |
+
always set to 1e-4. This factor is used in the [cross entropy loss](https://github.com/google-research/t5x/blob/a319e559b4f72bffab91821487382ef4c25dfcf4/t5x/losses.py#L26)
|
| 102 |
+
function, with the purpose to pull the weights towards zero.
|
| 103 |
+
I experimented with adding this regularization term in the HF pre-training script,
|
| 104 |
+
and the `bfloat16` training runs did not exhibit the problems illustrated above anymore.
|
| 105 |
+
|
| 106 |
+
When watching Andrej Karpathy [explaining an additional loss term
|
| 107 |
+
called 'regularization loss'](https://youtu.be/PaCmpygFfXo?t=6720) (L2 regularization), it appeared similar
|
| 108 |
+
to the regularization term added in T5X's cross entropy loss function.
|
| 109 |
+
The Optax optimizer, used in the HuggingFace script, mentions weight decay for AdaFactor (and AdamW)
|
| 110 |
+
but also mentions that L2 regularization does not work as expected with adaptive gradient
|
| 111 |
+
algorithms. It might be the case that setting a non-zero `weight_decay_rate` in the Optax Adafactor call
|
| 112 |
+
in the HuggingFace pre-training script is an alternative to adding the `z_loss` term, to solve the bfloat16 issues, but
|
| 113 |
+
I haven't tested this yet.
|
| 114 |
+
""")
|
| 115 |
+
|
| 116 |
+
st.markdown("""### Which optimizer and lr to use
|
| 117 |
+
|
| 118 |
+
During the Flax/Jax Community week in '21, our team quickly decided on using Adafactor with learning rate 5e-3.
|
| 119 |
+
I believed that a more optimal setting could be found with more time.
|
| 120 |
+
After conducting seven WandB sweeps with
|
| 121 |
+
Adafactor, AdamW and Distributed Shampoo (experimental PJIT version from Dall-E mini),
|
| 122 |
+
a better setting had not been found. The graph below shows the runs from all 7 sweeps combined.
|
| 123 |
+
-- (I apologize for the confusion in the legend; I was unable to display the optimizer in the legend
|
| 124 |
+
because the initial version of the training script had the optimizer as a boolean, which I later
|
| 125 |
+
changed to a string with the optimizer name.) --
|
| 126 |
+
All runs in the graph below that achieve a loss below 4 use **Adafactor**.
|
| 127 |
+
Peach-sweep-6 is represented by a dashed orange line and had a learning rate of **5e-3**.
|
| 128 |
+
""")
|
| 129 |
+
|
| 130 |
+
st.image("adafactor_vs_adam_pretrain.png", width=IMAGE_WIDTHS)
|
| 131 |
+
st.markdown("""While there probably is a setting that will allow Adam and Shampoo to also converge fast below loss 4.0, I was unable
|
| 132 |
+
to find it. In a recent tweet Lucas Nestler had more success with Shampoo (https://twitter.com/_clashluke/status/1535994026876252160)
|
| 133 |
+
so maybe I need to revisit the attempt with the latest upstream code bases.
|
| 134 |
+
|
| 135 |
+
Later, when pre-training with T5X, I found that its custom Adafactor implementation with the default settings of the T5X gin configs,
|
| 136 |
+
a learning rate of 0.001 and inverse square root learning rate decay, worked well.
|
| 137 |
+
""")
|
| 138 |
+
|
| 139 |
+
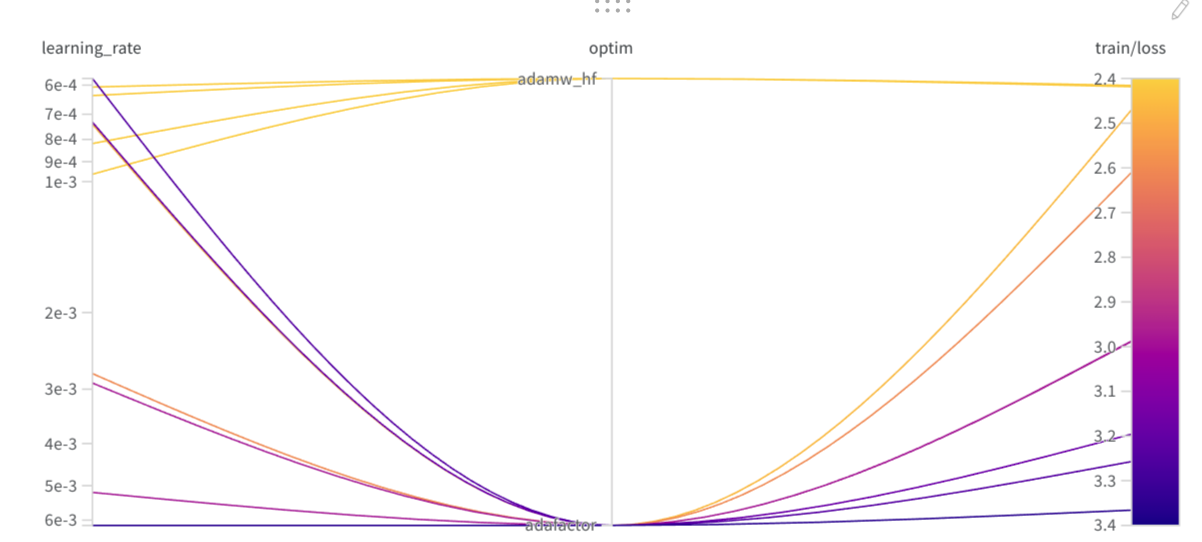
st.markdown("""### Optimizer and learning rate used for summarization
|
| 140 |
+
|
| 141 |
+
Finetuning summarization requires more memory than translation due to the longer sequence lengths involved.
|
| 142 |
+
I wondered if I could use Adafactor instead of Adam and ran
|
| 143 |
+
a sweep to test this. The sweep was configured with Hyperband, so not all training runs completed to the end.
|
| 144 |
+
""")
|
| 145 |
+
st.image("optim_lr_summarization.png", width=IMAGE_WIDTHS)
|
| 146 |
+
st.markdown("""The training losses are graphed below:
|
| 147 |
+
""")
|
| 148 |
+
|
| 149 |
+
st.image("training_losses_summarization_sweep.png", width=IMAGE_WIDTHS)
|
| 150 |
+
st.markdown("""
|
| 151 |
+
While the Adafactor run with learning rate 7e-4 came close to the Adam runs, the consistent stability of training with Adam
|
| 152 |
+
made me stick with Adam as optimizer for evaluation runs on the several models. For translation the results were similar, though in the end I needed to configure a lower learning rate for all
|
| 153 |
+
models to converge during fine-tuning.
|
| 154 |
+
""")
|
| 155 |
+
|
| 156 |
+
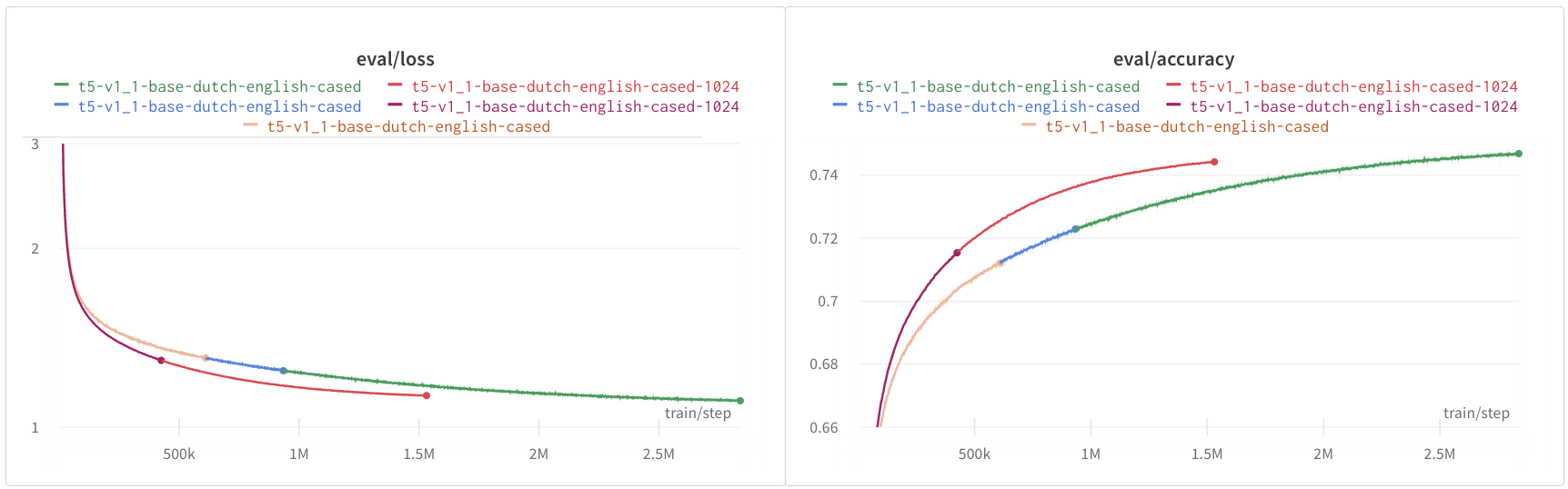
st.markdown("""### Sequence length 512 or 1024
|
| 157 |
+
|
| 158 |
+
The models `t5-v1_1-base-dutch-english-cased` and `t5-v1_1-base-dutch-english-cased-1024` have the same model dimensions,
|
| 159 |
+
but are pre-trained on different sequence lenghts, 512 and 1024 respectively.
|
| 160 |
+
The evaluation loss and accuracy of the models do not look too different. Since training of the 1024 sequence length model was
|
| 161 |
+
very slow and didn't converge a was was very slow, I stopped it early. The figure below shows the evaluation
|
| 162 |
+
loss and accuracy.
|
| 163 |
+
""")
|
| 164 |
+
st.image("t5v1_1eval_loss_and_accuracy.png", width=IMAGE_WIDTHS)
|
| 165 |
+
st.markdown("""The 512 sequence length model was trained for 10 epochs of the `small` nl+en config (186B tokens total) and the 1024
|
| 166 |
+
sequence length model about 2 epochs of the `large` nl+en config (100B tokens total). While I expected both models to
|
| 167 |
+
perform similarly on downstream tasks, the 1024 sequence length model has better scores for both
|
| 168 |
+
summarization and translation.
|
| 169 |
+
""")
|
| 170 |
+
|
| 171 |
+
st.markdown("""## Model lists
|
| 172 |
+
|
| 173 |
+
### t5_1_1
|
| 174 |
+
|
| 175 |
+
TODO
|
| 176 |
+
|
| 177 |
+
### UL2 Dutch English
|
| 178 |
+
|
| 179 |
+
These models have been trained with T5X on mc4_nl_cleaned, books, Wikipedia and news.
|
| 180 |
+
|
| 181 |
+
| | ul2-base-dutch-english | ul2-large-dutch-english | ul2-small-dutch-english |
|
| 182 |
+
|:---------------------|:-------------------------|:--------------------------|:--------------------------|
|
| 183 |
+
| model_type | t5 | t5 | t5 |
|
| 184 |
+
| _pipeline_tag | text2text-generation | text2text-generation | text2text-generation |
|
| 185 |
+
| d_model | 768 | 1024 | 512 |
|
| 186 |
+
| d_ff | 2048 | 2816 | 1024 |
|
| 187 |
+
| num_heads | 12 | 16 | 6 |
|
| 188 |
+
| d_kv | 64 | 64 | 64 |
|
| 189 |
+
| num_layers | 12 | 24 | 8 |
|
| 190 |
+
| num_decoder_layers | 12 | 24 | 8 |
|
| 191 |
+
| feed_forward_proj | gated-gelu | gated-gelu | gated-gelu |
|
| 192 |
+
| dense_act_fn | gelu_new | gelu_new | gelu_new |
|
| 193 |
+
| vocab_size | 32128 | 32128 | 32128 |
|
| 194 |
+
| tie_word_embeddings | 0 | 0 | 0 |
|
| 195 |
+
| torch_dtype | float32 | float32 | float32 |
|
| 196 |
+
| _gin_batch_size | 128 | 64 | 128 |
|
| 197 |
+
| _gin_z_loss | 0.0001 | 0.0001 | 0.0001 |
|
| 198 |
+
| _gin_t5_config_dtype | 'bfloat16' | 'bfloat16' | 'bfloat16' |
|
| 199 |
+
|
| 200 |
+
### UL2 Dutch
|
| 201 |
+
|
| 202 |
+
These models have been trained with T5X on mc4_nl_cleaned, books, Wikipedia and news.
|
| 203 |
+
|
| 204 |
+
| | ul2-base-dutch | ul2-base-nl36-dutch | ul2-large-dutch | ul2-small-dutch |
|
| 205 |
+
|:---------------------|:---------------------|:----------------------|:---------------------|:---------------------|
|
| 206 |
+
| model_type | t5 | t5 | t5 | t5 |
|
| 207 |
+
| _pipeline_tag | text2text-generation | text2text-generation | text2text-generation | text2text-generation |
|
| 208 |
+
| d_model | 768 | 768 | 1024 | 512 |
|
| 209 |
+
| d_ff | 2048 | 3072 | 2816 | 1024 |
|
| 210 |
+
| num_heads | 12 | 12 | 16 | 6 |
|
| 211 |
+
| d_kv | 64 | 64 | 64 | 64 |
|
| 212 |
+
| num_layers | 12 | 36 | 24 | 8 |
|
| 213 |
+
| num_decoder_layers | 12 | 36 | 24 | 8 |
|
| 214 |
+
| feed_forward_proj | gated-gelu | gated-gelu | gated-gelu | gated-gelu |
|
| 215 |
+
| dense_act_fn | gelu_new | gelu_new | gelu_new | gelu_new |
|
| 216 |
+
| vocab_size | 32128 | 32128 | 32128 | 32128 |
|
| 217 |
+
| tie_word_embeddings | 0 | 0 | 0 | 0 |
|
| 218 |
+
| torch_dtype | float32 | float32 | float32 | float32 |
|
| 219 |
+
| _gin_batch_size | 128 | 64 | 64 | 128 |
|
| 220 |
+
| _gin_z_loss | 0.0001 | 0.0001 | 0.0001 | 0.0001 |
|
| 221 |
+
| _gin_t5_config_dtype | 'bfloat16' | 'bfloat16' | 'bfloat16' | 'bfloat16' |
|
| 222 |
+
|
| 223 |
+
### T5 models Dutch and Dutch/English
|
| 224 |
+
|
| 225 |
+
These models have been trained with the HuggingFace 🤗 run_t5_mlm_flax.py script on mc4_nl_cleaned.
|
| 226 |
+
Most notable differences are the model sizes, activation function, and the dropout rate used during
|
| 227 |
+
pre-training. The T5-eff models are models that differ in their number of layers. The table will list
|
| 228 |
+
the several dimensions of these models.
|
| 229 |
+
|
| 230 |
+
| | [t5-base-dutch](https://huggingface.co/yhavinga/t5-base-dutch) | [t5-v1.1-base-dutch-uncased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-uncased) | [t5-v1.1-base-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-cased) | [t5-v1.1-large-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-large-dutch-cased) | [t5-v1_1-base-dutch-english-cased](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased) | [t5-v1_1-base-dutch-english-cased-1024](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased-1024) | [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english) | [t5-xl-4L-dutch-english-cased](https://huggingface.co/yhavinga/t5-xl-4L-dutch-english-cased) | [t5-base-36L-dutch-english-cased](https://huggingface.co/yhavinga/t5-base-36L-dutch-english-cased) | [t5-eff-xl-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-xl-8l-dutch-english-cased) | [t5-eff-large-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-large-8l-dutch-english-cased) |
|
| 231 |
+
|:------------------|:----------------|:-----------------------------|:---------------------------|:----------------------------|:-----------------------------------|:----------------------------------------|:-----------------------------|:-------------------------------|:----------------------------------|:-----------------------------------|:--------------------------------------|
|
| 232 |
+
| *type* | t5 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5 eff | t5 eff | t5 eff | t5 eff | t5 eff |
|
| 233 |
+
| *d_model* | 768 | 768 | 768 | 1024 | 768 | 768 | 512 | 2048 | 768 | 1024 | 1024 |
|
| 234 |
+
| *d_ff* | 3072 | 2048 | 2048 | 2816 | 2048 | 2048 | 1920 | 5120 | 2560 | 16384 | 4096 |
|
| 235 |
+
| *num_heads* | 12 | 12 | 12 | 16 | 12 | 12 | 8 | 32 | 12 | 32 | 16 |
|
| 236 |
+
| *d_kv* | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 128 | 64 |
|
| 237 |
+
| *num_layers* | 12 | 12 | 12 | 24 | 12 | 12 | 24 | 4 | 36 | 8 | 8 |
|
| 238 |
+
| *num parameters* | 223M | 248M | 248M | 783M | 248M | 248M | 250M | 585M | 729M | 1241M | 335M |
|
| 239 |
+
| *feed_forward_proj* | relu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu |
|
| 240 |
+
| *dropout* | 0.1 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 |
|
| 241 |
+
| *dataset* | mc4_nl_cleaned | mc4_nl_cleaned full | mc4_nl_cleaned full | mc4_nl_cleaned | mc4_nl_cleaned small_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl |
|
| 242 |
+
| *tr. seq len* | 512 | 1024 | 1024 | 512 | 512 | 1024 | 512 | 512 | 512 | 512 | 512 |
|
| 243 |
+
| *batch size* | 128 | 64 | 64 | 64 | 128 | 64 | 128 | 512 | 512 | 64 | 128 |
|
| 244 |
+
| *total steps* | 527500 | 1014525 | 1210154 | 1120k/2427498 | 2839630 | 1520k/3397024 | 851852 | 212963 | 212963 | 538k/1703705 | 851850 |
|
| 245 |
+
| *epochs* | 1 | 2 | 2 | 2 | 10 | 4 | 1 | 1 | 1 | 1 | 1 |
|
| 246 |
+
| *duration* | 2d9h | 5d5h | 6d6h | 8d13h | 11d18h | 9d1h | 4d10h | 6d1h | 17d15h | 4d 19h | 3d 23h |
|
| 247 |
+
| *optimizer* | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor |
|
| 248 |
+
| *lr* | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.009 | 0.005 | 0.005 |
|
| 249 |
+
| *warmup* | 10000.0 | 10000.0 | 10000.0 | 10000.0 | 10000.0 | 5000.0 | 20000.0 | 2500.0 | 1000.0 | 1500.0 | 1500.0 |
|
| 250 |
+
| *eval loss* | 1,38 | 1,20 | 0,96 | 1,07 | 1,11 | 1,13 | 1,18 | 1,27 | 1,05 | 1,3019 | 1,15 |
|
| 251 |
+
| *eval acc* | 0,70 | 0,73 | 0,78 | 0,76 | 0,75 | 0,74 | 0,74 | 0,72 | 0,76 | 0,71 | 0,74 |
|
| 252 |
+
|
| 253 |
+
### Long-T5 models
|
| 254 |
+
|
| 255 |
+
These models have been trained with the HuggingFace 🤗 run_t5_mlm_flax.py script on mc4_nl_cleaned.
|
| 256 |
+
|
| 257 |
+
### Byt5 small
|
| 258 |
+
|
| 259 |
+
This model has been trained with the HuggingFace 🤗 run_t5_mlm_flax.py script on mc4_nl_cleaned.
|
| 260 |
+
|
| 261 |
+
TODO
|
| 262 |
+
|
| 263 |
+
### Fine-tuned translation models on ccmatrix
|
| 264 |
+
|
| 265 |
+
The models `t5-small-24L-dutch-english` and `t5-base-36L-dutch-english` have been fine-tuned for both language
|
| 266 |
+
directions on the first 25M samples from CCMatrix, giving a total of 50M training samples.
|
| 267 |
+
Evaluation is performed on out-of-sample CCMatrix and also on Tatoeba and Opus Books.
|
| 268 |
+
The `_bp` columns list the *brevity penalty*. The `avg_bleu` score is the bleu score
|
| 269 |
+
averaged over all three evaluation datasets. The best scores displayed in bold for both translation directions.
|
| 270 |
+
|
| 271 |
+
| | [t5-base-36L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-base-36L-ccmatrix-multi) | [t5-base-36L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-base-36L-ccmatrix-multi) | [t5-small-24L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-small-24L-ccmatrix-multi) | [t5-small-24L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-small-24L-ccmatrix-multi) |
|
| 272 |
+
|:-----------------------|:-----------------------------|:-----------------------------|:------------------------------|:------------------------------|
|
| 273 |
+
| *source_lang* | en | nl | en | nl |
|
| 274 |
+
| *target_lang* | nl | en | nl | en |
|
| 275 |
+
| *source_prefix* | translate English to Dutch: | translate Dutch to English: | translate English to Dutch: | translate Dutch to English: |
|
| 276 |
+
| *ccmatrix_bleu* | **56.8** | 62.8 | 57.4 | **63.1** |
|
| 277 |
+
| *tatoeba_bleu* | **46.6** | **52.8** | 46.4 | 51.7 |
|
| 278 |
+
| *opus_books_bleu* | **13.5** | **24.9** | 12.9 | 23.4 |
|
| 279 |
+
| *ccmatrix_bp* | 0.95 | 0.96 | 0.95 | 0.96 |
|
| 280 |
+
| *tatoeba_bp* | 0.97 | 0.94 | 0.98 | 0.94 |
|
| 281 |
+
| *opus_books_bp* | 0.8 | 0.94 | 0.77 | 0.89 |
|
| 282 |
+
| *avg_bleu* | **38.96** | **46.86** | 38.92 | 46.06 |
|
| 283 |
+
| *max_source_length* | 128 | 128 | 128 | 128 |
|
| 284 |
+
| *max_target_length* | 128 | 128 | 128 | 128 |
|
| 285 |
+
| *adam_beta1* | 0.9 | 0.9 | 0.9 | 0.9 |
|
| 286 |
+
| *adam_beta2* | 0.997 | 0.997 | 0.997 | 0.997 |
|
| 287 |
+
| *weight_decay* | 0.05 | 0.05 | 0.002 | 0.002 |
|
| 288 |
+
| *lr* | 5e-05 | 5e-05 | 0.0005 | 0.0005 |
|
| 289 |
+
| *label_smoothing_factor* | 0.15 | 0.15 | 0.1 | 0.1 |
|
| 290 |
+
| *train_batch_size* | 128 | 128 | 128 | 128 |
|
| 291 |
+
| *warmup_steps* | 2000 | 2000 | 2000 | 2000 |
|
| 292 |
+
| *total steps* | 390625 | 390625 | 390625 | 390625 |
|
| 293 |
+
| *duration* | 4d 5h | 4d 5h | 3d 2h | 3d 2h |
|
| 294 |
+
| *num parameters* | 729M | 729M | 250M | 250M |
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
## Acknowledgements
|
| 298 |
+
|
| 299 |
+
This project would not have been possible without compute generously provided by Google through the
|
| 300 |
+
[TPU Research Cloud](https://sites.research.google/trc/). The HuggingFace 🤗 ecosystem was instrumental in all parts
|
| 301 |
+
of the training. Weights & Biases made it possible to keep track of many training sessions
|
| 302 |
+
and orchestrate hyperparameter sweeps with insightful visualizations.
|
| 303 |
+
|
| 304 |
+
Created by [Yeb Havinga](https://www.linkedin.com/in/yeb-havinga-86530825/)
|
| 305 |
+
""")
|
| 306 |
+
|
| 307 |
+
st.write(
|
| 308 |
+
f"""
|
| 309 |
+
---
|
| 310 |
+
*Memory: {memory.total / 10**9:.2f}GB, used: {memory.percent}%, available: {memory.available / 10**9:.2f}GB*
|
| 311 |
+
"""
|
| 312 |
+
)
|
| 313 |
+
|
| 314 |
+
|
| 315 |
+
if __name__ == "__main__":
|
| 316 |
+
memory = psutil.virtual_memory()
|
| 317 |
+
main()
|
bfloat16_loss.png
CHANGED

|

|
Git LFS Details
|
eval_summ_rouge1_202302.png
ADDED

|
Git LFS Details
|
eval_t5_dutch_english.png
ADDED

|
Git LFS Details
|
eval_transl_bleu_202302.png
ADDED
|
|
Git LFS Details
|
evaluation_t5_dutch_english.png
CHANGED

|
|
Git LFS Details
|
optim_lr_summarization.png
CHANGED
|

|
Git LFS Details
|
requirements.txt
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#-f https://download.pytorch.org/whl/torch_stable.html
|
| 2 |
+
-f https://download.pytorch.org/whl/cu116
|
| 3 |
+
-f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
|
| 4 |
+
protobuf<3.20
|
| 5 |
+
pandas
|
| 6 |
+
torch
|
| 7 |
+
transformers>=4.13.0
|
| 8 |
+
langdetect
|
| 9 |
+
psutil
|
| 10 |
+
jax[cuda]==0.3.16
|
| 11 |
+
chex>=0.1.4
|
| 12 |
+
##jaxlib==0.1.67
|
| 13 |
+
flax>=0.5.3
|
| 14 |
+
sentencepiece
|
style.css
CHANGED
|
@@ -1,37 +1,46 @@
|
|
| 1 |
body {
|
| 2 |
padding: 2rem;
|
| 3 |
font-family: -apple-system, BlinkMacSystemFont, "Arial", sans-serif;
|
|
|
|
|
|
|
|
|
|
| 4 |
}
|
| 5 |
|
| 6 |
h1 {
|
| 7 |
-
font-size:
|
| 8 |
margin-top: 0;
|
|
|
|
| 9 |
}
|
| 10 |
|
| 11 |
h2 {
|
| 12 |
-
font-size:
|
| 13 |
margin-top: 0;
|
|
|
|
| 14 |
}
|
| 15 |
|
| 16 |
|
| 17 |
h3 {
|
| 18 |
-
font-size:
|
| 19 |
margin-top: 0;
|
|
|
|
| 20 |
}
|
| 21 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
|
| 23 |
p {
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
margin-
|
| 27 |
-
margin-top: 5px;
|
| 28 |
}
|
| 29 |
|
| 30 |
li {
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
margin-
|
| 34 |
-
margin-top: 2px;
|
| 35 |
}
|
| 36 |
|
| 37 |
.card {
|
|
@@ -40,6 +49,7 @@ li {
|
|
| 40 |
padding: 16px;
|
| 41 |
border: 1px solid lightgray;
|
| 42 |
border-radius: 16px;
|
|
|
|
| 43 |
}
|
| 44 |
|
| 45 |
.card p:last-child {
|
| 1 |
body {
|
| 2 |
padding: 2rem;
|
| 3 |
font-family: -apple-system, BlinkMacSystemFont, "Arial", sans-serif;
|
| 4 |
+
color: #333; /* Dark gray color */
|
| 5 |
+
font-size: 18px; /* Increased font size */
|
| 6 |
+
line-height: 1.6; /* Improved line spacing */
|
| 7 |
}
|
| 8 |
|
| 9 |
h1 {
|
| 10 |
+
font-size: 36px;
|
| 11 |
margin-top: 0;
|
| 12 |
+
color: #333; /* Dark gray color */
|
| 13 |
}
|
| 14 |
|
| 15 |
h2 {
|
| 16 |
+
font-size: 28px;
|
| 17 |
margin-top: 0;
|
| 18 |
+
color: #333; /* Dark gray color */
|
| 19 |
}
|
| 20 |
|
| 21 |
|
| 22 |
h3 {
|
| 23 |
+
font-size: 24px;
|
| 24 |
margin-top: 0;
|
| 25 |
+
color: #333; /* Dark gray color */
|
| 26 |
}
|
| 27 |
|
| 28 |
+
h4 {
|
| 29 |
+
font-size: 20px;
|
| 30 |
+
margin-top: 0;
|
| 31 |
+
color: #333; /* Dark gray color */
|
| 32 |
+
}
|
| 33 |
|
| 34 |
p {
|
| 35 |
+
font-size: 18px;
|
| 36 |
+
margin-bottom: 20px;
|
| 37 |
+
margin-top: 10px;
|
|
|
|
| 38 |
}
|
| 39 |
|
| 40 |
li {
|
| 41 |
+
font-size: 16px;
|
| 42 |
+
margin-bottom: 10px;
|
| 43 |
+
margin-top: 10px;
|
|
|
|
| 44 |
}
|
| 45 |
|
| 46 |
.card {
|
| 49 |
padding: 16px;
|
| 50 |
border: 1px solid lightgray;
|
| 51 |
border-radius: 16px;
|
| 52 |
+
background-color: #f8f8f8; /* Light gray background color */
|
| 53 |
}
|
| 54 |
|
| 55 |
.card p:last-child {
|
t5v1_1eval_loss_and_accuracy.png
CHANGED
|

|
Git LFS Details
|
train_loss_eval_summarization.png
CHANGED

|

|
Git LFS Details
|
train_loss_eval_t5_translation.png
CHANGED
|
|
|
|
Git LFS Details
|
training_base_36l_losses.png
CHANGED

|

|
Git LFS Details
|
training_losses_summarization_sweep.png
CHANGED

|

|
Git LFS Details
|