Spaces:
Runtime error

Runtime error
updating prose
Browse files- batman.jpg +0 -0
- hf_space_app.png +0 -0
- nbs/gradio.ipynb +38 -4
- nbs/train.ipynb +116 -13
batman.jpg
ADDED

|
hf_space_app.png
ADDED
|
nbs/gradio.ipynb
CHANGED
|
@@ -409,6 +409,25 @@
|
|
| 409 |
"\n"
|
| 410 |
]
|
| 411 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 412 |
{
|
| 413 |
"cell_type": "markdown",
|
| 414 |
"metadata": {},
|
|
@@ -486,13 +505,28 @@
|
|
| 486 |
]
|
| 487 |
},
|
| 488 |
{
|
| 489 |
-
"cell_type": "
|
| 490 |
-
"execution_count": null,
|
| 491 |
"metadata": {},
|
| 492 |
-
"outputs": [],
|
| 493 |
"source": [
|
| 494 |
-
"\n"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 495 |
]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 496 |
}
|
| 497 |
],
|
| 498 |
"metadata": {
|
|
|
|
| 409 |
"\n"
|
| 410 |
]
|
| 411 |
},
|
| 412 |
+
{
|
| 413 |
+
"cell_type": "markdown",
|
| 414 |
+
"metadata": {},
|
| 415 |
+
"source": [
|
| 416 |
+
"### Set up your git repo\n",
|
| 417 |
+
"\n",
|
| 418 |
+
"After creating your space, you'll be offered up some instructions to configure the git repo managed by HF. Here's the approach I found easiest:\n",
|
| 419 |
+
"\n",
|
| 420 |
+
"1. Locally go a `git clone https://huggingface.co/spaces/{your_username}/{your_space_name}`\n",
|
| 421 |
+
"\n",
|
| 422 |
+
"2. `cd` into your `{your_space_name}` directory and copy/move all your example(s), models, etc... into it\n",
|
| 423 |
+
"\n",
|
| 424 |
+
"3. Install `git lfs` on your system (on my Ubuntu 16.04 box it was as simple as `sudo apt-get install git-lfs`). See [the docs](https://git-lfs.github.com/) for more details.\n",
|
| 425 |
+
"\n",
|
| 426 |
+
"4. Configure `git lfs` for your repo by running `git lfs install` and then `git lfs track \"*.pkl\"` to ensure it is handling the BIG files (in this case our `export.pkl`)\n",
|
| 427 |
+
"\n",
|
| 428 |
+
"5. You may want to update your `.gitignore` to remove training data, etc... that *should not* be included in the repo.\n"
|
| 429 |
+
]
|
| 430 |
+
},
|
| 431 |
{
|
| 432 |
"cell_type": "markdown",
|
| 433 |
"metadata": {},
|
|
|
|
| 505 |
]
|
| 506 |
},
|
| 507 |
{
|
| 508 |
+
"cell_type": "markdown",
|
|
|
|
| 509 |
"metadata": {},
|
|
|
|
| 510 |
"source": [
|
| 511 |
+
"### Commit and Push\n",
|
| 512 |
+
"\n",
|
| 513 |
+
"Simply ...\n",
|
| 514 |
+
"\n",
|
| 515 |
+
"```\n",
|
| 516 |
+
"git add .\n",
|
| 517 |
+
"git commit -am 'initial commit'\n",
|
| 518 |
+
"git push\n",
|
| 519 |
+
"```\n",
|
| 520 |
+
"\n",
|
| 521 |
+
"... all your code will be properly pushed to your HF Space's repo and your application will be spun up for you. And voila, you now have a ***free*** web application you can use to show off your machine learning prowess just like this one!\n",
|
| 522 |
+
"\n",
|
| 523 |
+
""
|
| 524 |
]
|
| 525 |
+
},
|
| 526 |
+
{
|
| 527 |
+
"cell_type": "markdown",
|
| 528 |
+
"metadata": {},
|
| 529 |
+
"source": []
|
| 530 |
}
|
| 531 |
],
|
| 532 |
"metadata": {
|
nbs/train.ipynb
CHANGED
|
@@ -4,24 +4,58 @@
|
|
| 4 |
"cell_type": "markdown",
|
| 5 |
"metadata": {},
|
| 6 |
"source": [
|
| 7 |
-
"# Marvel Character"
|
|
|
|
|
|
|
| 8 |
]
|
| 9 |
},
|
| 10 |
{
|
| 11 |
"cell_type": "markdown",
|
| 12 |
"metadata": {},
|
| 13 |
"source": [
|
| 14 |
-
"https://www.kaggle.com/code/jhoward/is-it-a-bird-creating-a-model-from-your-own-data\n",
|
|
|
|
|
|
|
| 15 |
"\n"
|
| 16 |
]
|
| 17 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18 |
{
|
| 19 |
"cell_type": "code",
|
| 20 |
"execution_count": 1,
|
| 21 |
"metadata": {},
|
| 22 |
"outputs": [],
|
| 23 |
"source": [
|
| 24 |
-
"import time\n",
|
| 25 |
"\n",
|
| 26 |
"from fastai.vision.all import *\n",
|
| 27 |
"from fastcore.all import *\n",
|
|
@@ -41,8 +75,18 @@
|
|
| 41 |
"metadata": {},
|
| 42 |
"outputs": [],
|
| 43 |
"source": [
|
| 44 |
-
"
|
| 45 |
-
"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 46 |
]
|
| 47 |
},
|
| 48 |
{
|
|
@@ -220,12 +264,14 @@
|
|
| 220 |
"cell_type": "markdown",
|
| 221 |
"metadata": {},
|
| 222 |
"source": [
|
| 223 |
-
"## Step 2: Build your `DataLoaders
|
|
|
|
|
|
|
| 224 |
]
|
| 225 |
},
|
| 226 |
{
|
| 227 |
"cell_type": "code",
|
| 228 |
-
"execution_count":
|
| 229 |
"metadata": {},
|
| 230 |
"outputs": [],
|
| 231 |
"source": [
|
|
@@ -233,6 +279,13 @@
|
|
| 233 |
" return 1.0 if img.parent.name.lower().startswith(\"marvel\") else 0.0\n"
|
| 234 |
]
|
| 235 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 236 |
{
|
| 237 |
"cell_type": "code",
|
| 238 |
"execution_count": 10,
|
|
@@ -269,14 +322,34 @@
|
|
| 269 |
"cell_type": "markdown",
|
| 270 |
"metadata": {},
|
| 271 |
"source": [
|
| 272 |
-
"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 273 |
]
|
| 274 |
},
|
| 275 |
{
|
| 276 |
"cell_type": "markdown",
|
| 277 |
"metadata": {},
|
| 278 |
"source": [
|
| 279 |
-
"## Step 3: Train with a `Learner
|
|
|
|
|
|
|
|
|
|
|
|
|
| 280 |
]
|
| 281 |
},
|
| 282 |
{
|
|
@@ -302,7 +375,9 @@
|
|
| 302 |
"cell_type": "markdown",
|
| 303 |
"metadata": {},
|
| 304 |
"source": [
|
| 305 |
-
"
|
|
|
|
|
|
|
| 306 |
]
|
| 307 |
},
|
| 308 |
{
|
|
@@ -443,7 +518,22 @@
|
|
| 443 |
"cell_type": "markdown",
|
| 444 |
"metadata": {},
|
| 445 |
"source": [
|
| 446 |
-
"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 447 |
]
|
| 448 |
},
|
| 449 |
{
|
|
@@ -466,7 +556,7 @@
|
|
| 466 |
"cell_type": "markdown",
|
| 467 |
"metadata": {},
|
| 468 |
"source": [
|
| 469 |
-
"
|
| 470 |
]
|
| 471 |
},
|
| 472 |
{
|
|
@@ -482,7 +572,9 @@
|
|
| 482 |
"cell_type": "markdown",
|
| 483 |
"metadata": {},
|
| 484 |
"source": [
|
| 485 |
-
"
|
|
|
|
|
|
|
| 486 |
]
|
| 487 |
},
|
| 488 |
{
|
|
@@ -689,6 +781,17 @@
|
|
| 689 |
"test_img.to_thumb(256, 256)\n"
|
| 690 |
]
|
| 691 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 692 |
{
|
| 693 |
"cell_type": "code",
|
| 694 |
"execution_count": null,
|
|
|
|
| 4 |
"cell_type": "markdown",
|
| 5 |
"metadata": {},
|
| 6 |
"source": [
|
| 7 |
+
"# Marvel Character Recognizer\n",
|
| 8 |
+
"\n",
|
| 9 |
+
"> Thwarting DC fan adverserial attacks one hero at a time."
|
| 10 |
]
|
| 11 |
},
|
| 12 |
{
|
| 13 |
"cell_type": "markdown",
|
| 14 |
"metadata": {},
|
| 15 |
"source": [
|
| 16 |
+
"The inspiration for this work dervies from the [Is it a bird? Creating a model from your own data](https://www.kaggle.com/code/jhoward/is-it-a-bird-creating-a-model-from-your-own-data) notebook presented by Jeremy Howard in session 1 of the 2022 [fast.ai](https://www.fast.ai/) course. I've only made a few minor tweeks to demonstrate how folks can turn a classification task (Jeremy's notebook) into a regression task (this notebook)\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"This notebook is structured to run seamlessly in kaggle, colab, and local environments. The only install you'll need to make is `pip install fastai==2.6.0` to get things operational\n",
|
| 19 |
"\n"
|
| 20 |
]
|
| 21 |
},
|
| 22 |
+
{
|
| 23 |
+
"cell_type": "code",
|
| 24 |
+
"execution_count": null,
|
| 25 |
+
"metadata": {},
|
| 26 |
+
"outputs": [],
|
| 27 |
+
"source": [
|
| 28 |
+
"# ! pip install fastai=2.6.0"
|
| 29 |
+
]
|
| 30 |
+
},
|
| 31 |
+
{
|
| 32 |
+
"cell_type": "markdown",
|
| 33 |
+
"metadata": {},
|
| 34 |
+
"source": [
|
| 35 |
+
"## Why are we doing this?\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"Good question!\n",
|
| 38 |
+
"\n",
|
| 39 |
+
"We already got a good Marvel character classifier folks can use [here](https://notebookse.jarvislabs.ai/jY5fsv-S9jKoQQrgd1dsoJuCDt6pTg6ZjBpNK9afxLIGInQv4OlHVuTMHqOPh2LU/). It works great for classifying 10 different Marvel heroes!\n",
|
| 40 |
+
"\n",
|
| 41 |
+
"***BUT*** what does it do with non-Marvel characters? Let's see:\n",
|
| 42 |
+
"\n",
|
| 43 |
+
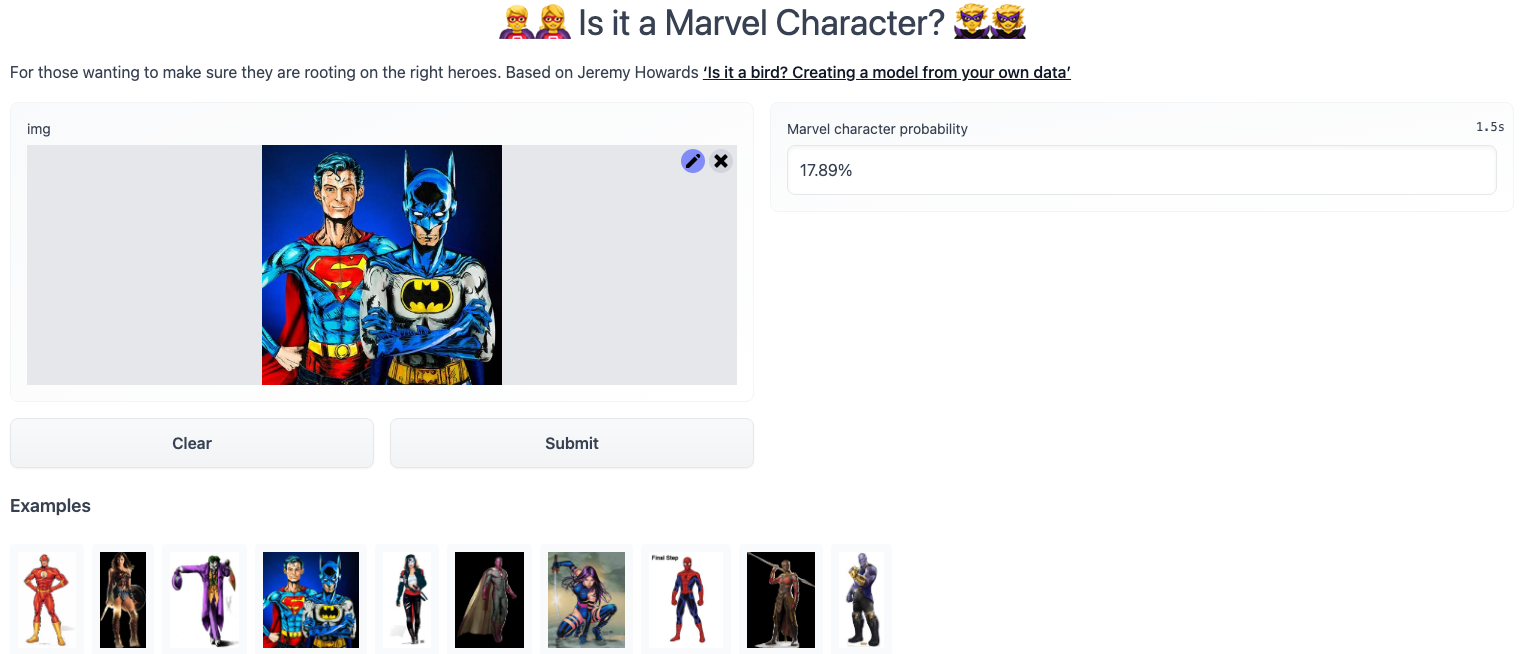
"![batman.jpg]\n",
|
| 44 |
+
"\n",
|
| 45 |
+
"Yikes! That is defintely NOT Black Panther! And as it is every DC fan's dream to see their heroes mistaken as characters in the vastly superior Marvel universe, it's right for us to suspect they may use this model to convince those unaware that they indeed are. This model, as it was trained to predict 1 of 10 classes, will always predict a class (even when it really shouldn't)\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"**The solution**\n",
|
| 48 |
+
"\n",
|
| 49 |
+
"Turn this classification task into a regression task and train a model that will return the probability the uploaded character image is from Marvel! And guess what, there are only like three changes we need to make to Jeremy's example to make this happen."
|
| 50 |
+
]
|
| 51 |
+
},
|
| 52 |
{
|
| 53 |
"cell_type": "code",
|
| 54 |
"execution_count": 1,
|
| 55 |
"metadata": {},
|
| 56 |
"outputs": [],
|
| 57 |
"source": [
|
| 58 |
+
"import os, time\n",
|
| 59 |
"\n",
|
| 60 |
"from fastai.vision.all import *\n",
|
| 61 |
"from fastcore.all import *\n",
|
|
|
|
| 75 |
"metadata": {},
|
| 76 |
"outputs": [],
|
| 77 |
"source": [
|
| 78 |
+
"is_kaggle = os.environ.get('KAGGLE_KERNEL_RUN_TYPE', '')\n",
|
| 79 |
+
"\n",
|
| 80 |
+
"if is_kaggle:\n",
|
| 81 |
+
" data_path = Path(\"data\")\n",
|
| 82 |
+
" model_path = Path(\"models\")\n",
|
| 83 |
+
"else:\n",
|
| 84 |
+
" data_path = Path(\"../data\")\n",
|
| 85 |
+
" model_path = Path(\"../models\")\n",
|
| 86 |
+
"\n",
|
| 87 |
+
"\n",
|
| 88 |
+
"data_path.mkdir(exist_ok=True, parents=True)\n",
|
| 89 |
+
"model_path"
|
| 90 |
]
|
| 91 |
},
|
| 92 |
{
|
|
|
|
| 264 |
"cell_type": "markdown",
|
| 265 |
"metadata": {},
|
| 266 |
"source": [
|
| 267 |
+
"## Step 2: Build your `DataLoaders`\n",
|
| 268 |
+
"\n",
|
| 269 |
+
"**CHANGE #1**: Create a labeling function that labels Marvel images as 1.0 and DC images as 0.0"
|
| 270 |
]
|
| 271 |
},
|
| 272 |
{
|
| 273 |
"cell_type": "code",
|
| 274 |
+
"execution_count": 1,
|
| 275 |
"metadata": {},
|
| 276 |
"outputs": [],
|
| 277 |
"source": [
|
|
|
|
| 279 |
" return 1.0 if img.parent.name.lower().startswith(\"marvel\") else 0.0\n"
|
| 280 |
]
|
| 281 |
},
|
| 282 |
+
{
|
| 283 |
+
"cell_type": "markdown",
|
| 284 |
+
"metadata": {},
|
| 285 |
+
"source": [
|
| 286 |
+
"**CHANGE #2**: Swap out the `CategoryBlock` with a `RegressionBlock` and set `get_y` to use our custom labeling function above."
|
| 287 |
+
]
|
| 288 |
+
},
|
| 289 |
{
|
| 290 |
"cell_type": "code",
|
| 291 |
"execution_count": 10,
|
|
|
|
| 322 |
"cell_type": "markdown",
|
| 323 |
"metadata": {},
|
| 324 |
"source": [
|
| 325 |
+
"### What is this `DataBlock` thing?\n",
|
| 326 |
+
"\n",
|
| 327 |
+
"A `DataBlock` is a blueprint for building `DataLoaders` (the things which will provide mini-batches-of-examples at a time to your model). It defines the entire process from getting your raw data to turning it into a numerical representation your model can utilize. \n",
|
| 328 |
+
"\n",
|
| 329 |
+
"Breaking it down as Jeremy did we can understand it as such:\n",
|
| 330 |
+
"\n",
|
| 331 |
+
"`blocks` says that our inputs are images and that our targets are going to be a continuous number (a float between 0 and 1)\n",
|
| 332 |
+
"\n",
|
| 333 |
+
"`get_items` says how we are going to get our data, in this case images from our local filesystem\n",
|
| 334 |
+
"\n",
|
| 335 |
+
"`get_y` says how we want to label our targets, in this case we'll use our labeling function to assign them a float (1.0 or 0.0)\n",
|
| 336 |
+
"\n",
|
| 337 |
+
"`splitter` defines how we are going to create our validation set, in this case we'll use 20% of our dataset\n",
|
| 338 |
+
"\n",
|
| 339 |
+
"`item_tfms` define operations we want to apply on our data *when we fetch an item (e.g., and image)*, in this case we want to resize them to 192x192 pixels by \"squishing\" them.\n",
|
| 340 |
+
"\n",
|
| 341 |
+
"After defining our `DataBlock`, we can call the `dataloaders()` method passing in the path to our images to kick things off. This will in turn pass that path to the `get_items` function of the `DataBlock` and when all is said and done, we'll have `DataLoaders` ready for training on."
|
| 342 |
]
|
| 343 |
},
|
| 344 |
{
|
| 345 |
"cell_type": "markdown",
|
| 346 |
"metadata": {},
|
| 347 |
"source": [
|
| 348 |
+
"## Step 3: Train with a `Learner`\n",
|
| 349 |
+
"\n",
|
| 350 |
+
"**CHANGE #3**: Swap out the `error_rate` metric for one better suited for regression tasks like `rmse`, and also assign `y_range` to constrain our model to predicting values in the expected range (which for us is 0 and 1).\n",
|
| 351 |
+
"\n",
|
| 352 |
+
"One of the cool things with `vision_learner` is that it will automatically change the loss function to be one suited for our task. In this case, it knows we're doing regression from the `DataLoaders` and assigns `MSELoss` as our loss function without us have to worry about a thing."
|
| 353 |
]
|
| 354 |
},
|
| 355 |
{
|
|
|
|
| 375 |
"cell_type": "markdown",
|
| 376 |
"metadata": {},
|
| 377 |
"source": [
|
| 378 |
+
"And now we train!\n",
|
| 379 |
+
"\n",
|
| 380 |
+
"We're not going to get the best results (at least not yet) because this task is a bit more complex that just training a bird or not bird. We'll improve this over future iterations, but for now, I want to show we can get something pretty decent up and running quickly with stuff you learn in the first 30 minutes of the first session of fastai!"
|
| 381 |
]
|
| 382 |
},
|
| 383 |
{
|
|
|
|
| 518 |
"cell_type": "markdown",
|
| 519 |
"metadata": {},
|
| 520 |
"source": [
|
| 521 |
+
"**What is fine-tuning?**\n",
|
| 522 |
+
"\n",
|
| 523 |
+
"From Jeremy's notebook:\n",
|
| 524 |
+
"\n",
|
| 525 |
+
"> \"Fine-tuning\" a model means that we're starting with a model someone else has trained using some other dataset (called the *pretrained model*), and adjusting the weights a little bit so that the model learns to recognise your particular dataset. In this case, the pretrained model was trained to recognise photos in *imagenet*, and widely-used computer vision dataset with images covering 1000 categories) For details on fine-tuning and why it's important, check out the [free fast.ai course](https://course.fast.ai/)."
|
| 526 |
+
]
|
| 527 |
+
},
|
| 528 |
+
{
|
| 529 |
+
"cell_type": "markdown",
|
| 530 |
+
"metadata": {},
|
| 531 |
+
"source": [
|
| 532 |
+
"**What can we do with a trained model?**\n",
|
| 533 |
+
"\n",
|
| 534 |
+
"We'll, we can export it and use it in a web application or elsewhere of course! \n",
|
| 535 |
+
"\n",
|
| 536 |
+
"And with fast.ai, everything required to save your model alongside the information required to build future `DataLoaders` or do item level predictions, can be achieved simply by calling `Learner.export()`"
|
| 537 |
]
|
| 538 |
},
|
| 539 |
{
|
|
|
|
| 556 |
"cell_type": "markdown",
|
| 557 |
"metadata": {},
|
| 558 |
"source": [
|
| 559 |
+
"To use an exported learner for inference, we can call fastai's `load_learner` and pass in the location of our exported file above like this:"
|
| 560 |
]
|
| 561 |
},
|
| 562 |
{
|
|
|
|
| 572 |
"cell_type": "markdown",
|
| 573 |
"metadata": {},
|
| 574 |
"source": [
|
| 575 |
+
"`Learner.predict` returns three things: prediction, predicted index, and probabilities.\n",
|
| 576 |
+
"\n",
|
| 577 |
+
"For a regression task, each item shows the same one thing we care about: The predicted number. But for classification task you would see the predicted class label, the index of that class in the list of classes, and the probability of all the classes."
|
| 578 |
]
|
| 579 |
},
|
| 580 |
{
|
|
|
|
| 781 |
"test_img.to_thumb(256, 256)\n"
|
| 782 |
]
|
| 783 |
},
|
| 784 |
+
{
|
| 785 |
+
"cell_type": "markdown",
|
| 786 |
+
"metadata": {},
|
| 787 |
+
"source": [
|
| 788 |
+
"## Thanks for reading!\n",
|
| 789 |
+
"\n",
|
| 790 |
+
"If you made it this far and you liked this notebook, I would most definitely appreciate an upvote! And if you have questions/suggestions/whatever, feel free to leave those in the comments section below. I hope this notebooks makes the world even just a tiny bit better by helping everyone ensure they are rooting on the right heroes!\n",
|
| 791 |
+
"\n",
|
| 792 |
+
"You can find me at twitter [@waydegilliam](https://twitter.com/waydegilliam) and the fast.ai forums [@wgpubs](https://forums.fast.ai/u/wgpubs/summary)"
|
| 793 |
+
]
|
| 794 |
+
},
|
| 795 |
{
|
| 796 |
"cell_type": "code",
|
| 797 |
"execution_count": null,
|