Spaces:
Runtime error

Runtime error
update detail (#12)
Browse files- Add demo twitter (6bcfb537a37e472a625880cc65701c9e93c310c2)
- details.py +14 -12
- resources/example/1.png +3 -0
- resources/example/2.png +3 -0
- resources/example/3.png +3 -0
details.py
CHANGED
|
@@ -23,21 +23,23 @@ def app():
|
|
| 23 |
st.markdown("# Leveraging medical Twitter to build a visual-language foundation model for pathology")
|
| 24 |
|
| 25 |
|
| 26 |
-
|
|
|
|
| 27 |
|
|
|
|
|
|
|
| 28 |
with col1:
|
| 29 |
-
st.markdown("
|
| 30 |
-
|
|
|
|
| 31 |
with col2:
|
| 32 |
-
st.markdown(
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
''',
|
| 40 |
-
height=900)
|
| 41 |
|
| 42 |
|
| 43 |
st.markdown("#### PLIP is trained on the largest public vision–language pathology dataset: OpenPath")
|
|
|
|
| 23 |
st.markdown("# Leveraging medical Twitter to build a visual-language foundation model for pathology")
|
| 24 |
|
| 25 |
|
| 26 |
+
st.markdown("The lack of annotated publicly available medical images is a major barrier for innovations. At the same time, many de-identified images and much knowledge are shared by clinicians on public forums such as medical Twitter. Here we harness these crowd platforms to curate OpenPath, a large dataset of <b>208,414</b> pathology images paired with natural language descriptions. This is the largest public dataset for pathology images annotated with natural text. We demonstrate the value of this resource by developing PLIP, a multimodal AI with both image and text understanding, which is trained on OpenPath. PLIP achieves state-of-the-art zero-shot and few-short performance for classifying new pathology images across diverse tasks. Moreover, PLIP enables users to retrieve similar cases by either image or natural language search, greatly facilitating knowledge sharing. Our approach demonstrates that publicly shared medical data is a tremendous opportunity that can be harnessed to advance biomedical AI.", unsafe_allow_html=True)
|
| 27 |
+
render_svg("resources/SVG/Asset 49.svg")
|
| 28 |
|
| 29 |
+
st.markdown('#### Watch our successful image-to-image retrieval via PLIP:')
|
| 30 |
+
col1, col2, col3, _, _ = st.columns([1, 1, 1, 1, 1])
|
| 31 |
with col1:
|
| 32 |
+
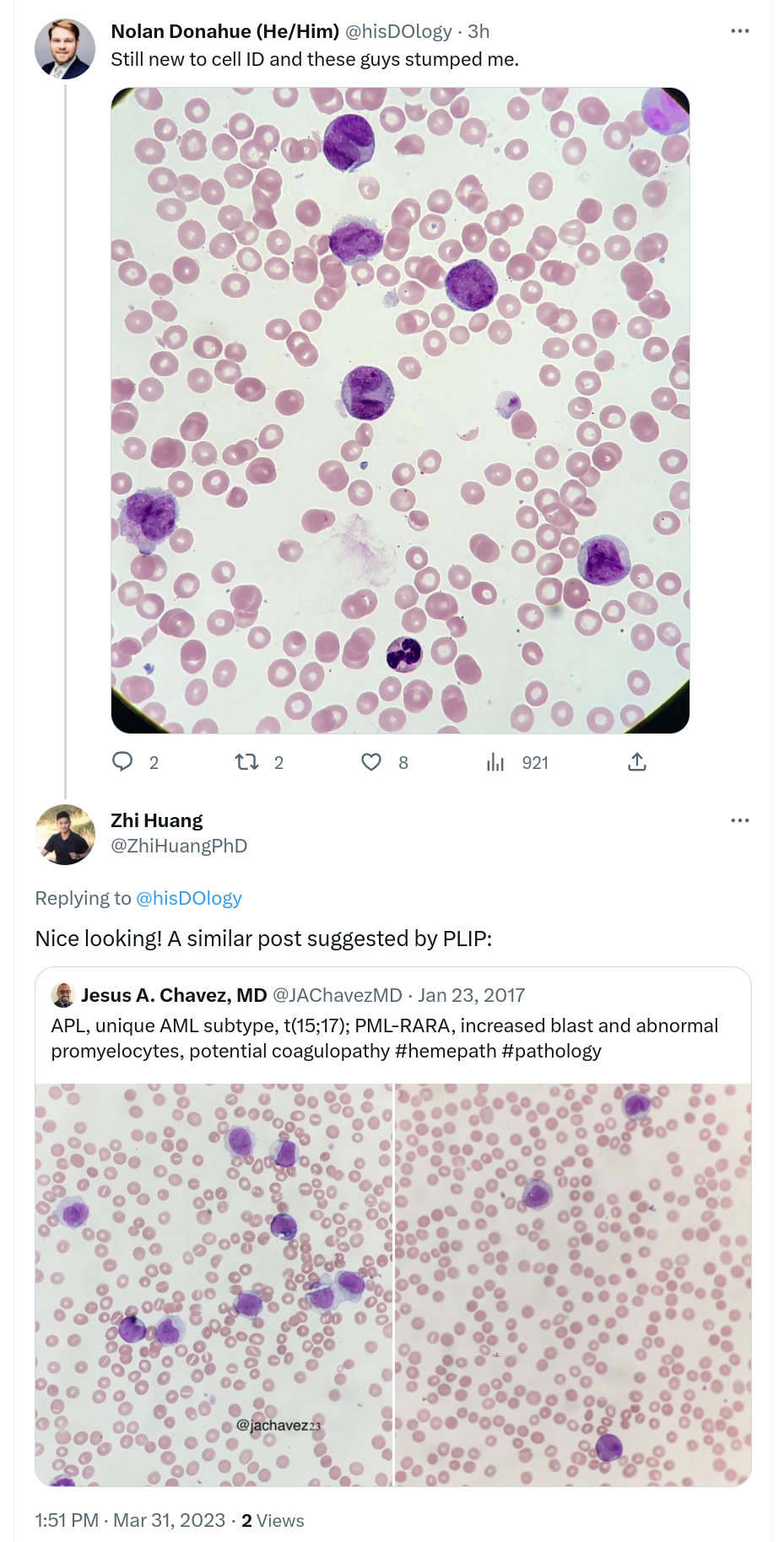
st.markdown("[Similar cells](https://twitter.com/ZhiHuangPhD/status/1641906064823312384)")
|
| 33 |
+
example1 = Image.open('resources/example/1.png')
|
| 34 |
+
st.image(example1, caption='Example 1', output_format='png')
|
| 35 |
with col2:
|
| 36 |
+
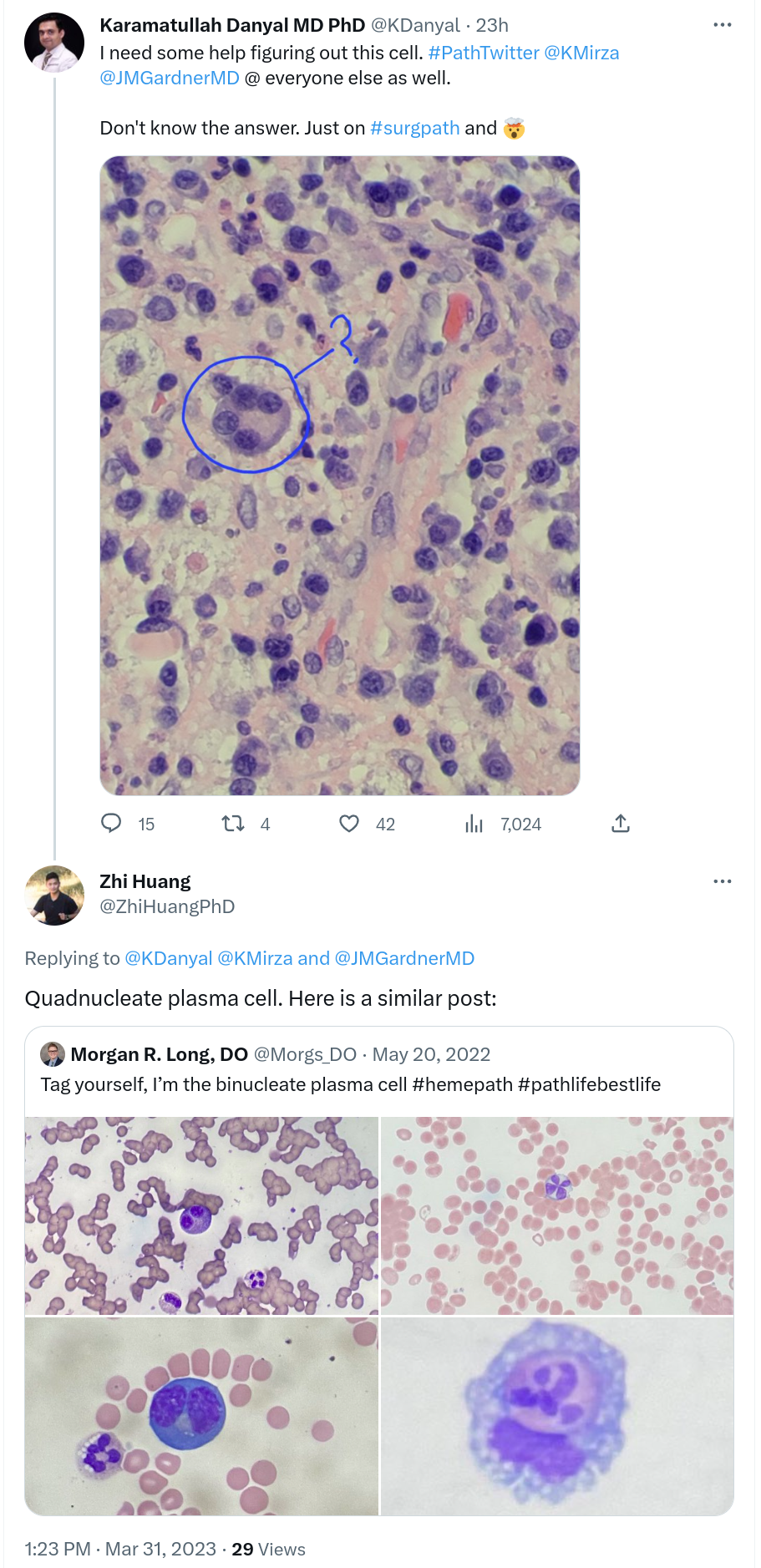
st.markdown("[Salient object](https://twitter.com/ZhiHuangPhD/status/1641899092195565569)")
|
| 37 |
+
example2 = Image.open('resources/example/2.png')
|
| 38 |
+
st.image(example2, caption='Example 2', output_format='png')
|
| 39 |
+
with col3:
|
| 40 |
+
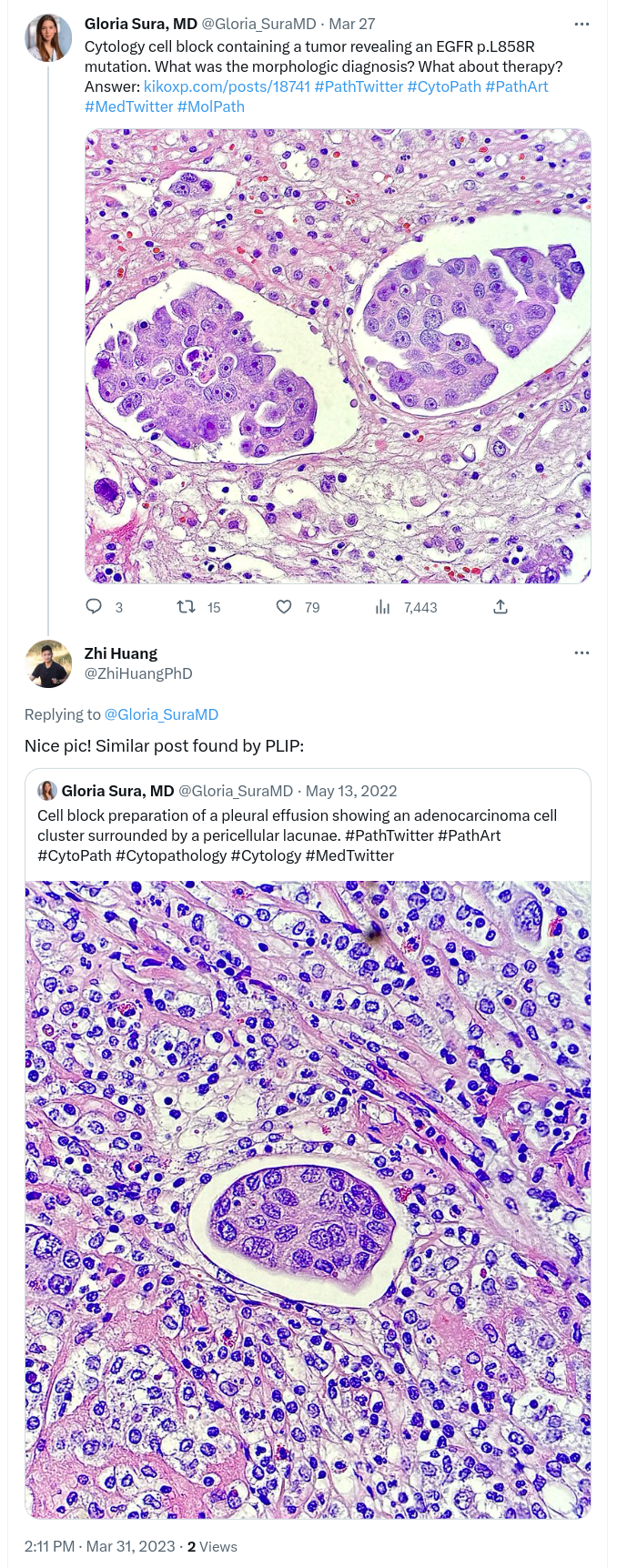
st.markdown("[Similar region](https://twitter.com/ZhiHuangPhD/status/1641911235288645632)")
|
| 41 |
+
example3 = Image.open('resources/example/3.png')
|
| 42 |
+
st.image(example3, caption='Example 3', output_format='png')
|
|
|
|
|
|
|
| 43 |
|
| 44 |
|
| 45 |
st.markdown("#### PLIP is trained on the largest public vision–language pathology dataset: OpenPath")
|
resources/example/1.png
ADDED
|
Git LFS Details
|
resources/example/2.png
ADDED
|
Git LFS Details
|
resources/example/3.png
ADDED
|
Git LFS Details
|