Spaces:
Sleeping

Sleeping
talexm
commited on
Commit
•
e893d68
1
Parent(s):
0c3cda8
adding blockchain logger
Browse files- rag_sec/README.md +251 -11
- rag_sec/backup.py +79 -0
- rag_sec/document_search_system.py +147 -22
- screenshots/Screenshot from 2024-11-30 19-01-31.png +0 -0
rag_sec/README.md
CHANGED
|
@@ -1,13 +1,43 @@
|
|
| 1 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
The system follows a well-structured workflow to ensure accurate, secure, and context-aware responses to user queries:
|
| 4 |
|
| 5 |
-
### 1.
|
| 6 |
- A user provides a query that can be a general question, ambiguous statement, or potentially malicious intent.
|
| 7 |
|
| 8 |
---
|
| 9 |
|
| 10 |
-
### 2.
|
| 11 |
- **Purpose**: Classify the query as "bad" or "good."
|
| 12 |
- **Steps**:
|
| 13 |
1. Use a sentiment analysis model (`distilbert-base-uncased-finetuned-sst-2-english`) to detect malicious or inappropriate intent.
|
|
@@ -16,7 +46,7 @@ The system follows a well-structured workflow to ensure accurate, secure, and co
|
|
| 16 |
|
| 17 |
---
|
| 18 |
|
| 19 |
-
### 3.
|
| 20 |
- **Purpose**: Rephrase or enhance ambiguous or poorly structured queries for better retrieval.
|
| 21 |
- **Steps**:
|
| 22 |
1. Identify missing context or ambiguous phrasing.
|
|
@@ -27,7 +57,7 @@ The system follows a well-structured workflow to ensure accurate, secure, and co
|
|
| 27 |
|
| 28 |
---
|
| 29 |
|
| 30 |
-
### 4.
|
| 31 |
- **Purpose**: Retrieve relevant data and generate a context-aware response.
|
| 32 |
- **Steps**:
|
| 33 |
1. **Document Retrieval**:
|
|
@@ -40,7 +70,7 @@ The system follows a well-structured workflow to ensure accurate, secure, and co
|
|
| 40 |
|
| 41 |
---
|
| 42 |
|
| 43 |
-
### 5.
|
| 44 |
- **Purpose**: Provide a concise and meaningful answer.
|
| 45 |
- **Steps**:
|
| 46 |
1. Combine the retrieved documents into a coherent context.
|
|
@@ -49,9 +79,219 @@ The system follows a well-structured workflow to ensure accurate, secure, and co
|
|
| 49 |
|
| 50 |
---
|
| 51 |
|
| 52 |
-
###
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 53 |
|
| 54 |
-
#### Input Query:
|
| 55 |
-
```plaintext
|
| 56 |
-
"How to improve acting skills?"
|
| 57 |
-
````
|
|
|
|
| 1 |
+
# **Document Search System**
|
| 2 |
+
|
| 3 |
+
## **Overview**
|
| 4 |
+
The **Document Search System** provides context-aware and secure responses to user queries by combining query analysis, document retrieval, semantic response generation, and blockchain-powered logging. The system also integrates Neo4j for storing and visualizing relationships between queries, documents, and responses.
|
| 5 |
+
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
## **Features**
|
| 9 |
+
1. **Query Classification:**
|
| 10 |
+
- Detects malicious or inappropriate queries using a sentiment analysis model.
|
| 11 |
+
- Blocks malicious queries and prevents them from further processing.
|
| 12 |
+
|
| 13 |
+
2. **Query Transformation:**
|
| 14 |
+
- Rephrases or enhances ambiguous queries to improve retrieval accuracy.
|
| 15 |
+
- Uses rule-based transformations and advanced text-to-text models.
|
| 16 |
+
|
| 17 |
+
3. **RAG Pipeline:**
|
| 18 |
+
- Retrieves top-k documents based on semantic similarity.
|
| 19 |
+
- Generates context-aware responses using generative models.
|
| 20 |
+
|
| 21 |
+
4. **Blockchain Integration (Chagu):**
|
| 22 |
+
- Logs all stages of query processing into a blockchain for integrity and traceability.
|
| 23 |
+
- Validates blockchain integrity.
|
| 24 |
+
|
| 25 |
+
5. **Neo4j Integration:**
|
| 26 |
+
- Stores and visualizes relationships between queries, responses, and documents.
|
| 27 |
+
- Allows detailed querying and visualization of the data flow.
|
| 28 |
+
|
| 29 |
+
---
|
| 30 |
+
|
| 31 |
+
## **Workflow**
|
| 32 |
|
| 33 |
The system follows a well-structured workflow to ensure accurate, secure, and context-aware responses to user queries:
|
| 34 |
|
| 35 |
+
### **1. Input Query**
|
| 36 |
- A user provides a query that can be a general question, ambiguous statement, or potentially malicious intent.
|
| 37 |
|
| 38 |
---
|
| 39 |
|
| 40 |
+
### **2. Detection Module**
|
| 41 |
- **Purpose**: Classify the query as "bad" or "good."
|
| 42 |
- **Steps**:
|
| 43 |
1. Use a sentiment analysis model (`distilbert-base-uncased-finetuned-sst-2-english`) to detect malicious or inappropriate intent.
|
|
|
|
| 46 |
|
| 47 |
---
|
| 48 |
|
| 49 |
+
### **3. Transformation Module**
|
| 50 |
- **Purpose**: Rephrase or enhance ambiguous or poorly structured queries for better retrieval.
|
| 51 |
- **Steps**:
|
| 52 |
1. Identify missing context or ambiguous phrasing.
|
|
|
|
| 57 |
|
| 58 |
---
|
| 59 |
|
| 60 |
+
### **4. RAG Pipeline**
|
| 61 |
- **Purpose**: Retrieve relevant data and generate a context-aware response.
|
| 62 |
- **Steps**:
|
| 63 |
1. **Document Retrieval**:
|
|
|
|
| 70 |
|
| 71 |
---
|
| 72 |
|
| 73 |
+
### **5. Semantic Response Generation**
|
| 74 |
- **Purpose**: Provide a concise and meaningful answer.
|
| 75 |
- **Steps**:
|
| 76 |
1. Combine the retrieved documents into a coherent context.
|
|
|
|
| 79 |
|
| 80 |
---
|
| 81 |
|
| 82 |
+
### **6. Logging and Storage**
|
| 83 |
+
- **Blockchain Logging:**
|
| 84 |
+
- Each query, transformed query, response, and document retrieval stage is logged into the blockchain for traceability.
|
| 85 |
+
- Ensures data integrity and tamper-proof records.
|
| 86 |
+
- **Neo4j Storage:**
|
| 87 |
+
- Relationships between queries, responses, and retrieved documents are stored in Neo4j.
|
| 88 |
+
- Enables detailed analysis and graph-based visualization.
|
| 89 |
+
|
| 90 |
+
---
|
| 91 |
+
|
| 92 |
+
## **Neo4j Visualization**
|
| 93 |
+
|
| 94 |
+
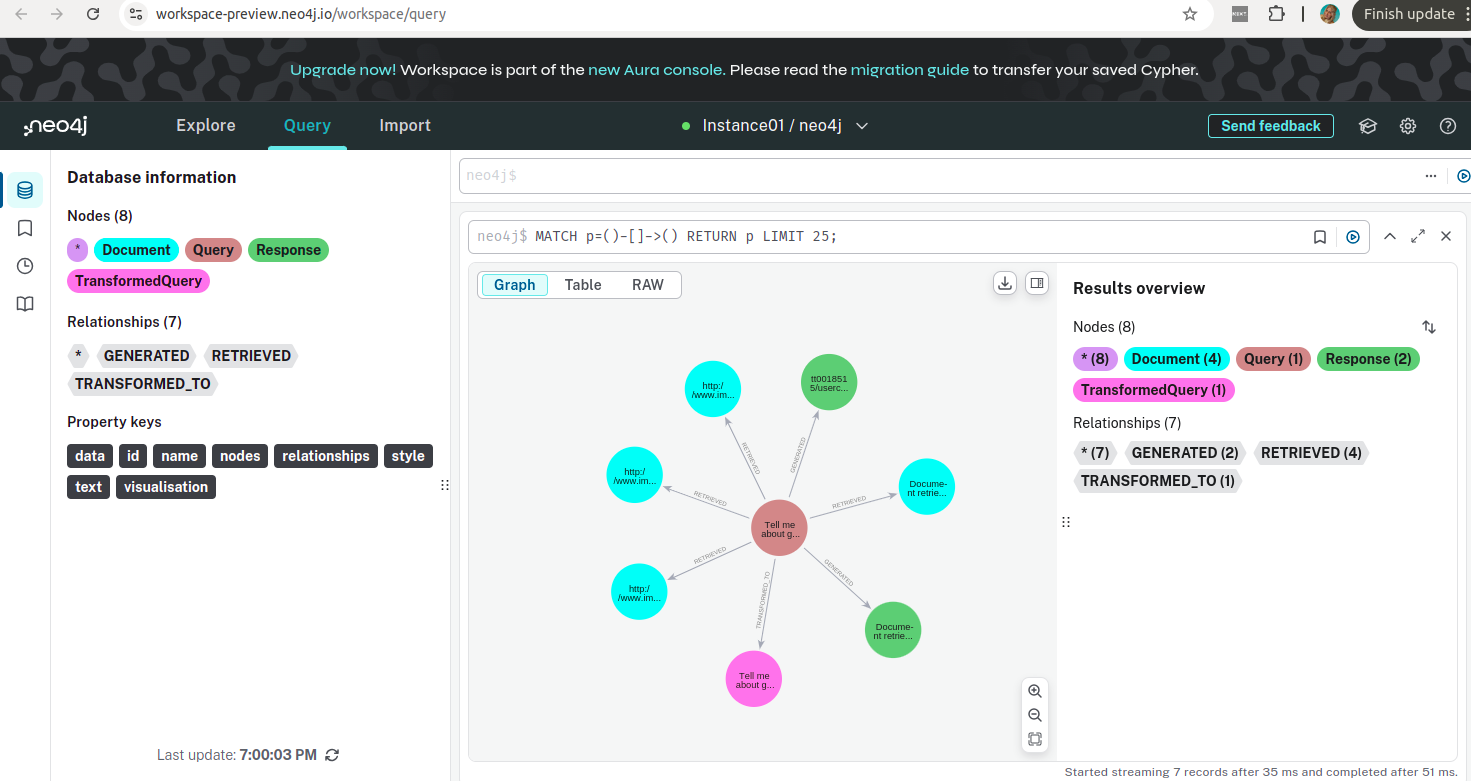
Here is an example of how the relationships between queries, responses, and documents appear in Neo4j:
|
| 95 |
+
|
| 96 |
+

|
| 97 |
+
|
| 98 |
+
- **Nodes**:
|
| 99 |
+
- Query: Represents the user query.
|
| 100 |
+
- TransformedQuery: Rephrased or improved query.
|
| 101 |
+
- Document: Relevant documents retrieved based on the query.
|
| 102 |
+
- Response: The generated response.
|
| 103 |
+
|
| 104 |
+
- **Relationships**:
|
| 105 |
+
- `RETRIEVED`: Links the query to retrieved documents.
|
| 106 |
+
- `TRANSFORMED_TO`: Links the original query to the transformed query.
|
| 107 |
+
- `GENERATED`: Links the query to the generated response.
|
| 108 |
+
|
| 109 |
+
---
|
| 110 |
+
|
| 111 |
+
## **Setup Instructions**
|
| 112 |
+
1. Clone the repository:
|
| 113 |
+
```bash
|
| 114 |
+
git clone https://github.com/your-repo/document-search-system.git
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
Here’s the updated README.md content in proper Markdown format with the embedded image reference:
|
| 118 |
+
|
| 119 |
+
markdown
|
| 120 |
+
|
| 121 |
+
# **Document Search System**
|
| 122 |
+
|
| 123 |
+
## **Overview**
|
| 124 |
+
The **Document Search System** provides context-aware and secure responses to user queries by combining query analysis, document retrieval, semantic response generation, and blockchain-powered logging. The system also integrates Neo4j for storing and visualizing relationships between queries, documents, and responses.
|
| 125 |
+
|
| 126 |
+
---
|
| 127 |
+
|
| 128 |
+
## **Features**
|
| 129 |
+
1. **Query Classification:**
|
| 130 |
+
- Detects malicious or inappropriate queries using a sentiment analysis model.
|
| 131 |
+
- Blocks malicious queries and prevents them from further processing.
|
| 132 |
+
|
| 133 |
+
2. **Query Transformation:**
|
| 134 |
+
- Rephrases or enhances ambiguous queries to improve retrieval accuracy.
|
| 135 |
+
- Uses rule-based transformations and advanced text-to-text models.
|
| 136 |
+
|
| 137 |
+
3. **RAG Pipeline:**
|
| 138 |
+
- Retrieves top-k documents based on semantic similarity.
|
| 139 |
+
- Generates context-aware responses using generative models.
|
| 140 |
+
|
| 141 |
+
4. **Blockchain Integration (Chagu):**
|
| 142 |
+
- Logs all stages of query processing into a blockchain for integrity and traceability.
|
| 143 |
+
- Validates blockchain integrity.
|
| 144 |
+
|
| 145 |
+
5. **Neo4j Integration:**
|
| 146 |
+
- Stores and visualizes relationships between queries, responses, and documents.
|
| 147 |
+
- Allows detailed querying and visualization of the data flow.
|
| 148 |
+
|
| 149 |
+
---
|
| 150 |
+
|
| 151 |
+
## **Workflow**
|
| 152 |
+
|
| 153 |
+
The system follows a well-structured workflow to ensure accurate, secure, and context-aware responses to user queries:
|
| 154 |
+
|
| 155 |
+
### **1. Input Query**
|
| 156 |
+
- A user provides a query that can be a general question, ambiguous statement, or potentially malicious intent.
|
| 157 |
+
|
| 158 |
+
---
|
| 159 |
+
|
| 160 |
+
### **2. Detection Module**
|
| 161 |
+
- **Purpose**: Classify the query as "bad" or "good."
|
| 162 |
+
- **Steps**:
|
| 163 |
+
1. Use a sentiment analysis model (`distilbert-base-uncased-finetuned-sst-2-english`) to detect malicious or inappropriate intent.
|
| 164 |
+
2. If the query is classified as "bad" (e.g., SQL injection or inappropriate tone), block further processing and provide a warning message.
|
| 165 |
+
3. If "good," proceed to the **Transformation Module**.
|
| 166 |
+
|
| 167 |
+
---
|
| 168 |
+
|
| 169 |
+
### **3. Transformation Module**
|
| 170 |
+
- **Purpose**: Rephrase or enhance ambiguous or poorly structured queries for better retrieval.
|
| 171 |
+
- **Steps**:
|
| 172 |
+
1. Identify missing context or ambiguous phrasing.
|
| 173 |
+
2. Transform the query using:
|
| 174 |
+
- Rule-based transformations for simple fixes.
|
| 175 |
+
- Text-to-text models (e.g., `google/flan-t5-small`) for more sophisticated rephrasing.
|
| 176 |
+
3. Pass the transformed query to the **RAG Pipeline**.
|
| 177 |
+
|
| 178 |
+
---
|
| 179 |
+
|
| 180 |
+
### **4. RAG Pipeline**
|
| 181 |
+
- **Purpose**: Retrieve relevant data and generate a context-aware response.
|
| 182 |
+
- **Steps**:
|
| 183 |
+
1. **Document Retrieval**:
|
| 184 |
+
- Encode the transformed query and documents into embeddings using `all-MiniLM-L6-v2`.
|
| 185 |
+
- Compute semantic similarity between the query and stored documents.
|
| 186 |
+
- Retrieve the top-k documents relevant to the query.
|
| 187 |
+
2. **Response Generation**:
|
| 188 |
+
- Use the retrieved documents as context.
|
| 189 |
+
- Pass the query and context to a generative model (e.g., `distilgpt2`) to synthesize a meaningful response.
|
| 190 |
+
|
| 191 |
+
---
|
| 192 |
+
|
| 193 |
+
### **5. Semantic Response Generation**
|
| 194 |
+
- **Purpose**: Provide a concise and meaningful answer.
|
| 195 |
+
- **Steps**:
|
| 196 |
+
1. Combine the retrieved documents into a coherent context.
|
| 197 |
+
2. Generate a response tailored to the query using the generative model.
|
| 198 |
+
3. Return the response to the user, ensuring clarity and relevance.
|
| 199 |
+
|
| 200 |
+
---
|
| 201 |
+
|
| 202 |
+
### **6. Logging and Storage**
|
| 203 |
+
- **Blockchain Logging:**
|
| 204 |
+
- Each query, transformed query, response, and document retrieval stage is logged into the blockchain for traceability.
|
| 205 |
+
- Ensures data integrity and tamper-proof records.
|
| 206 |
+
- **Neo4j Storage:**
|
| 207 |
+
- Relationships between queries, responses, and retrieved documents are stored in Neo4j.
|
| 208 |
+
- Enables detailed analysis and graph-based visualization.
|
| 209 |
+
|
| 210 |
+
---
|
| 211 |
+
|
| 212 |
+
## **Neo4j Visualization**
|
| 213 |
+
|
| 214 |
+
Here is an example of how the relationships between queries, responses, and documents appear in Neo4j:
|
| 215 |
+
|
| 216 |
+

|
| 217 |
+
|
| 218 |
+
- **Nodes**:
|
| 219 |
+
- Query: Represents the user query.
|
| 220 |
+
- TransformedQuery: Rephrased or improved query.
|
| 221 |
+
- Document: Relevant documents retrieved based on the query.
|
| 222 |
+
- Response: The generated response.
|
| 223 |
+
|
| 224 |
+
- **Relationships**:
|
| 225 |
+
- `RETRIEVED`: Links the query to retrieved documents.
|
| 226 |
+
- `TRANSFORMED_TO`: Links the original query to the transformed query.
|
| 227 |
+
- `GENERATED`: Links the query to the generated response.
|
| 228 |
+
|
| 229 |
+
---
|
| 230 |
+
|
| 231 |
+
## **Setup Instructions**
|
| 232 |
+
1. Clone the repository:
|
| 233 |
+
```bash
|
| 234 |
+
git clone https://github.com/your-repo/document-search-system.git
|
| 235 |
+
```
|
| 236 |
+
Install dependencies:
|
| 237 |
+
|
| 238 |
+
```bash
|
| 239 |
+
|
| 240 |
+
pip install -r requirements.txt
|
| 241 |
+
```
|
| 242 |
+
Initialize the Neo4j database:
|
| 243 |
+
|
| 244 |
+
Connect to your Neo4j Aura instance.
|
| 245 |
+
Set up credentials in the code.
|
| 246 |
+
Load the dataset:
|
| 247 |
+
|
| 248 |
+
Place your documents in the dataset directory (e.g., data-sets/aclImdb/train).
|
| 249 |
+
Run the system:
|
| 250 |
+
|
| 251 |
+
```bash
|
| 252 |
+
|
| 253 |
+
python document_search_system.py
|
| 254 |
+
```
|
| 255 |
+
Neo4j Queries
|
| 256 |
+
Retrieve All Queries Logged
|
| 257 |
+
```cypher
|
| 258 |
+
|
| 259 |
+
MATCH (q:Query)
|
| 260 |
+
RETURN q.text AS query, q.timestamp AS timestamp
|
| 261 |
+
ORDER BY timestamp DESC
|
| 262 |
+
```
|
| 263 |
+
|
| 264 |
+
Visualize Query Relationships
|
| 265 |
+
```cypher
|
| 266 |
+
|
| 267 |
+
MATCH (n)-[r]->(m)
|
| 268 |
+
RETURN n, r, m
|
| 269 |
+
Find Documents for a Query
|
| 270 |
+
|
| 271 |
+
```
|
| 272 |
+
|
| 273 |
+
```cypher
|
| 274 |
+
|
| 275 |
+
MATCH (q:Query {text: "How to improve acting skills?"})-[:RETRIEVED]->(d:Document)
|
| 276 |
+
RETURN d.name AS document_name
|
| 277 |
+
```
|
| 278 |
+
|
| 279 |
+
### Key Technologies
|
| 280 |
+
Machine Learning Models:
|
| 281 |
+
distilbert-base-uncased-finetuned-sst-2-english for sentiment analysis.
|
| 282 |
+
google/flan-t5-small for query transformation.
|
| 283 |
+
distilgpt2 for response generation.
|
| 284 |
+
Vector Similarity Search:
|
| 285 |
+
all-MiniLM-L6-v2 embeddings for document retrieval.
|
| 286 |
+
Blockchain Logging:
|
| 287 |
+
Powered by chainguard.blockchain_logger.
|
| 288 |
+
Graph-Based Storage:
|
| 289 |
+
Relationships visualized and queried via Neo4j.
|
| 290 |
+
vbnet
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
|
| 297 |
|
|
|
|
|
|
|
|
|
|
|
|
rag_sec/backup.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
from .bad_query_detector import BadQueryDetector
|
| 5 |
+
from .query_transformer import QueryTransformer
|
| 6 |
+
from .document_retriver import DocumentRetriever
|
| 7 |
+
from .senamtic_response_generator import SemanticResponseGenerator
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class DocumentSearchSystem:
|
| 11 |
+
def __init__(self):
|
| 12 |
+
"""
|
| 13 |
+
Initializes the DocumentSearchSystem with:
|
| 14 |
+
- BadQueryDetector for identifying malicious or inappropriate queries.
|
| 15 |
+
- QueryTransformer for improving or rephrasing queries.
|
| 16 |
+
- DocumentRetriever for semantic document retrieval.
|
| 17 |
+
- SemanticResponseGenerator for generating context-aware responses.
|
| 18 |
+
"""
|
| 19 |
+
self.detector = BadQueryDetector()
|
| 20 |
+
self.transformer = QueryTransformer()
|
| 21 |
+
self.retriever = DocumentRetriever()
|
| 22 |
+
self.response_generator = SemanticResponseGenerator()
|
| 23 |
+
|
| 24 |
+
def process_query(self, query):
|
| 25 |
+
"""
|
| 26 |
+
Processes a user query through the following steps:
|
| 27 |
+
1. Detect if the query is malicious.
|
| 28 |
+
2. Transform the query if needed.
|
| 29 |
+
3. Retrieve relevant documents based on the query.
|
| 30 |
+
4. Generate a response using the retrieved documents.
|
| 31 |
+
|
| 32 |
+
:param query: The user query as a string.
|
| 33 |
+
:return: A dictionary with the status and response or error message.
|
| 34 |
+
"""
|
| 35 |
+
if self.detector.is_bad_query(query):
|
| 36 |
+
return {"status": "rejected", "message": "Query blocked due to detected malicious intent."}
|
| 37 |
+
|
| 38 |
+
# Transform the query
|
| 39 |
+
transformed_query = self.transformer.transform_query(query)
|
| 40 |
+
print(f"Transformed Query: {transformed_query}")
|
| 41 |
+
|
| 42 |
+
# Retrieve relevant documents
|
| 43 |
+
retrieved_docs = self.retriever.retrieve(transformed_query)
|
| 44 |
+
if not retrieved_docs:
|
| 45 |
+
return {"status": "no_results", "message": "No relevant documents found for your query."}
|
| 46 |
+
|
| 47 |
+
# Generate a response based on the retrieved documents
|
| 48 |
+
response = self.response_generator.generate_response(retrieved_docs)
|
| 49 |
+
return {"status": "success", "response": response}
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def test_system():
|
| 53 |
+
"""
|
| 54 |
+
Test the DocumentSearchSystem with normal and malicious queries.
|
| 55 |
+
- Load documents from a dataset directory.
|
| 56 |
+
- Perform a normal query and display results.
|
| 57 |
+
- Perform a malicious query to ensure proper blocking.
|
| 58 |
+
"""
|
| 59 |
+
# Define the path to the dataset directory
|
| 60 |
+
home_dir = Path(os.getenv("HOME", "/"))
|
| 61 |
+
data_dir = home_dir / "data-sets/aclImdb/train"
|
| 62 |
+
|
| 63 |
+
# Initialize the system
|
| 64 |
+
system = DocumentSearchSystem()
|
| 65 |
+
system.retriever.load_documents(data_dir)
|
| 66 |
+
|
| 67 |
+
# Perform a normal query
|
| 68 |
+
normal_query = "Tell me about great acting performances."
|
| 69 |
+
print("\nNormal Query Result:")
|
| 70 |
+
print(system.process_query(normal_query))
|
| 71 |
+
|
| 72 |
+
# Perform a malicious query
|
| 73 |
+
malicious_query = "DROP TABLE users; SELECT * FROM sensitive_data;"
|
| 74 |
+
print("\nMalicious Query Result:")
|
| 75 |
+
print(system.process_query(malicious_query))
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
if __name__ == "__main__":
|
| 79 |
+
test_system()
|
rag_sec/document_search_system.py
CHANGED
|
@@ -1,25 +1,123 @@
|
|
| 1 |
import os
|
| 2 |
from pathlib import Path
|
|
|
|
|
|
|
| 3 |
|
| 4 |
-
|
| 5 |
-
from
|
| 6 |
-
from .document_retriver import DocumentRetriever
|
| 7 |
-
from .senamtic_response_generator import SemanticResponseGenerator
|
| 8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
|
| 10 |
-
|
|
|
|
| 11 |
def __init__(self):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
"""
|
| 13 |
Initializes the DocumentSearchSystem with:
|
| 14 |
- BadQueryDetector for identifying malicious or inappropriate queries.
|
| 15 |
- QueryTransformer for improving or rephrasing queries.
|
| 16 |
- DocumentRetriever for semantic document retrieval.
|
| 17 |
- SemanticResponseGenerator for generating context-aware responses.
|
|
|
|
|
|
|
| 18 |
"""
|
| 19 |
self.detector = BadQueryDetector()
|
| 20 |
self.transformer = QueryTransformer()
|
| 21 |
self.retriever = DocumentRetriever()
|
| 22 |
self.response_generator = SemanticResponseGenerator()
|
|
|
|
|
|
|
| 23 |
|
| 24 |
def process_query(self, query):
|
| 25 |
"""
|
|
@@ -28,6 +126,7 @@ class DocumentSearchSystem:
|
|
| 28 |
2. Transform the query if needed.
|
| 29 |
3. Retrieve relevant documents based on the query.
|
| 30 |
4. Generate a response using the retrieved documents.
|
|
|
|
| 31 |
|
| 32 |
:param query: The user query as a string.
|
| 33 |
:return: A dictionary with the status and response or error message.
|
|
@@ -37,43 +136,69 @@ class DocumentSearchSystem:
|
|
| 37 |
|
| 38 |
# Transform the query
|
| 39 |
transformed_query = self.transformer.transform_query(query)
|
| 40 |
-
|
|
|
|
|
|
|
| 41 |
|
| 42 |
# Retrieve relevant documents
|
| 43 |
retrieved_docs = self.retriever.retrieve(transformed_query)
|
| 44 |
if not retrieved_docs:
|
| 45 |
return {"status": "no_results", "message": "No relevant documents found for your query."}
|
| 46 |
|
|
|
|
|
|
|
|
|
|
| 47 |
# Generate a response based on the retrieved documents
|
| 48 |
response = self.response_generator.generate_response(retrieved_docs)
|
| 49 |
-
return {"status": "success", "response": response}
|
| 50 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 51 |
|
| 52 |
-
def test_system():
|
| 53 |
-
"""
|
| 54 |
-
Test the DocumentSearchSystem with normal and malicious queries.
|
| 55 |
-
- Load documents from a dataset directory.
|
| 56 |
-
- Perform a normal query and display results.
|
| 57 |
-
- Perform a malicious query to ensure proper blocking.
|
| 58 |
-
"""
|
| 59 |
-
# Define the path to the dataset directory
|
| 60 |
home_dir = Path(os.getenv("HOME", "/"))
|
| 61 |
data_dir = home_dir / "data-sets/aclImdb/train"
|
| 62 |
|
| 63 |
-
# Initialize the system
|
| 64 |
-
system = DocumentSearchSystem()
|
| 65 |
-
system.retriever.load_documents(data_dir)
|
| 66 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 67 |
# Perform a normal query
|
| 68 |
normal_query = "Tell me about great acting performances."
|
| 69 |
print("\nNormal Query Result:")
|
| 70 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 71 |
|
| 72 |
# Perform a malicious query
|
| 73 |
malicious_query = "DROP TABLE users; SELECT * FROM sensitive_data;"
|
| 74 |
print("\nMalicious Query Result:")
|
| 75 |
-
|
|
|
|
|
|
|
| 76 |
|
| 77 |
|
| 78 |
-
if __name__ == "__main__":
|
| 79 |
-
test_system()
|
|
|
|
| 1 |
import os
|
| 2 |
from pathlib import Path
|
| 3 |
+
from chainguard.blockchain_logger import BlockchainLogger
|
| 4 |
+
from neo4j import GraphDatabase
|
| 5 |
|
| 6 |
+
import sys
|
| 7 |
+
from os import path
|
|
|
|
|
|
|
| 8 |
|
| 9 |
+
sys.path.append(path.dirname(path.dirname(path.abspath(__file__))))
|
| 10 |
+
from bad_query_detector import BadQueryDetector
|
| 11 |
+
from query_transformer import QueryTransformer
|
| 12 |
+
from document_retriver import DocumentRetriever
|
| 13 |
+
from senamtic_response_generator import SemanticResponseGenerator
|
| 14 |
|
| 15 |
+
|
| 16 |
+
class DataTransformer:
|
| 17 |
def __init__(self):
|
| 18 |
+
"""
|
| 19 |
+
Initializes a DataTransformer with a blockchain logger instance.
|
| 20 |
+
"""
|
| 21 |
+
self.blockchain_logger = BlockchainLogger()
|
| 22 |
+
|
| 23 |
+
def secure_transform(self, data):
|
| 24 |
+
"""
|
| 25 |
+
Securely transforms the input data by logging it into the blockchain.
|
| 26 |
+
|
| 27 |
+
Args:
|
| 28 |
+
data (dict): The log data or any data to be securely transformed.
|
| 29 |
+
|
| 30 |
+
Returns:
|
| 31 |
+
dict: A dictionary containing the original data, block hash, and blockchain length.
|
| 32 |
+
"""
|
| 33 |
+
# Log the data into the blockchain
|
| 34 |
+
block_details = self.blockchain_logger.log_data(data)
|
| 35 |
+
|
| 36 |
+
# Return the block details and blockchain status
|
| 37 |
+
return {
|
| 38 |
+
"data": data,
|
| 39 |
+
**block_details
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
def validate_blockchain(self):
|
| 43 |
+
"""
|
| 44 |
+
Validates the integrity of the blockchain.
|
| 45 |
+
|
| 46 |
+
Returns:
|
| 47 |
+
bool: True if the blockchain is valid, False otherwise.
|
| 48 |
+
"""
|
| 49 |
+
return self.blockchain_logger.is_blockchain_valid()
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class Neo4jHandler:
|
| 53 |
+
def __init__(self, uri, user, password):
|
| 54 |
+
"""
|
| 55 |
+
Initializes a Neo4j handler for storing and querying relationships.
|
| 56 |
+
"""
|
| 57 |
+
self.driver = GraphDatabase.driver(uri, auth=(user, password))
|
| 58 |
+
|
| 59 |
+
def close(self):
|
| 60 |
+
self.driver.close()
|
| 61 |
+
|
| 62 |
+
def log_relationships(self, query, transformed_query, response, documents):
|
| 63 |
+
"""
|
| 64 |
+
Logs the relationships between queries, responses, and documents into Neo4j.
|
| 65 |
+
"""
|
| 66 |
+
with self.driver.session() as session:
|
| 67 |
+
session.write_transaction(self._create_and_link_nodes, query, transformed_query, response, documents)
|
| 68 |
+
|
| 69 |
+
@staticmethod
|
| 70 |
+
def _create_and_link_nodes(tx, query, transformed_query, response, documents):
|
| 71 |
+
# Create Query node
|
| 72 |
+
tx.run("MERGE (q:Query {text: $query}) RETURN q", parameters={"query": query})
|
| 73 |
+
# Create TransformedQuery node
|
| 74 |
+
tx.run("MERGE (t:TransformedQuery {text: $transformed_query}) RETURN t",
|
| 75 |
+
parameters={"transformed_query": transformed_query})
|
| 76 |
+
# Create Response node
|
| 77 |
+
tx.run("MERGE (r:Response {text: $response}) RETURN r", parameters={"response": response})
|
| 78 |
+
|
| 79 |
+
# Link Query to TransformedQuery and Response
|
| 80 |
+
tx.run(
|
| 81 |
+
"""
|
| 82 |
+
MATCH (q:Query {text: $query}), (t:TransformedQuery {text: $transformed_query})
|
| 83 |
+
MERGE (q)-[:TRANSFORMED_TO]->(t)
|
| 84 |
+
""", parameters={"query": query, "transformed_query": transformed_query}
|
| 85 |
+
)
|
| 86 |
+
tx.run(
|
| 87 |
+
"""
|
| 88 |
+
MATCH (q:Query {text: $query}), (r:Response {text: $response})
|
| 89 |
+
MERGE (q)-[:GENERATED]->(r)
|
| 90 |
+
""", parameters={"query": query, "response": response}
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
# Create and link Document nodes
|
| 94 |
+
for doc in documents:
|
| 95 |
+
tx.run("MERGE (d:Document {name: $doc}) RETURN d", parameters={"doc": doc})
|
| 96 |
+
tx.run(
|
| 97 |
+
"""
|
| 98 |
+
MATCH (q:Query {text: $query}), (d:Document {name: $doc})
|
| 99 |
+
MERGE (q)-[:RETRIEVED]->(d)
|
| 100 |
+
""", parameters={"query": query, "doc": doc}
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class DocumentSearchSystem:
|
| 105 |
+
def __init__(self, neo4j_uri, neo4j_user, neo4j_password):
|
| 106 |
"""
|
| 107 |
Initializes the DocumentSearchSystem with:
|
| 108 |
- BadQueryDetector for identifying malicious or inappropriate queries.
|
| 109 |
- QueryTransformer for improving or rephrasing queries.
|
| 110 |
- DocumentRetriever for semantic document retrieval.
|
| 111 |
- SemanticResponseGenerator for generating context-aware responses.
|
| 112 |
+
- DataTransformer for blockchain logging of queries and responses.
|
| 113 |
+
- Neo4jHandler for relationship logging and visualization.
|
| 114 |
"""
|
| 115 |
self.detector = BadQueryDetector()
|
| 116 |
self.transformer = QueryTransformer()
|
| 117 |
self.retriever = DocumentRetriever()
|
| 118 |
self.response_generator = SemanticResponseGenerator()
|
| 119 |
+
self.data_transformer = DataTransformer()
|
| 120 |
+
self.neo4j_handler = Neo4jHandler(neo4j_uri, neo4j_user, neo4j_password)
|
| 121 |
|
| 122 |
def process_query(self, query):
|
| 123 |
"""
|
|
|
|
| 126 |
2. Transform the query if needed.
|
| 127 |
3. Retrieve relevant documents based on the query.
|
| 128 |
4. Generate a response using the retrieved documents.
|
| 129 |
+
5. Log all stages to the blockchain and Neo4j.
|
| 130 |
|
| 131 |
:param query: The user query as a string.
|
| 132 |
:return: A dictionary with the status and response or error message.
|
|
|
|
| 136 |
|
| 137 |
# Transform the query
|
| 138 |
transformed_query = self.transformer.transform_query(query)
|
| 139 |
+
|
| 140 |
+
# Log the original query to the blockchain
|
| 141 |
+
self.data_transformer.secure_transform({"type": "query", "content": query})
|
| 142 |
|
| 143 |
# Retrieve relevant documents
|
| 144 |
retrieved_docs = self.retriever.retrieve(transformed_query)
|
| 145 |
if not retrieved_docs:
|
| 146 |
return {"status": "no_results", "message": "No relevant documents found for your query."}
|
| 147 |
|
| 148 |
+
# Log the retrieved documents to the blockchain
|
| 149 |
+
self.data_transformer.secure_transform({"type": "documents", "content": retrieved_docs})
|
| 150 |
+
|
| 151 |
# Generate a response based on the retrieved documents
|
| 152 |
response = self.response_generator.generate_response(retrieved_docs)
|
|
|
|
| 153 |
|
| 154 |
+
# Log the response to the blockchain
|
| 155 |
+
blockchain_details = self.data_transformer.secure_transform({"type": "response", "content": response})
|
| 156 |
+
|
| 157 |
+
# Log relationships to Neo4j
|
| 158 |
+
self.neo4j_handler.log_relationships(query, transformed_query, response, retrieved_docs)
|
| 159 |
+
|
| 160 |
+
return {
|
| 161 |
+
"status": "success",
|
| 162 |
+
"response": response,
|
| 163 |
+
"retrieved_documents": retrieved_docs,
|
| 164 |
+
"blockchain_details": blockchain_details
|
| 165 |
+
}
|
| 166 |
+
|
| 167 |
+
def validate_system_integrity(self):
|
| 168 |
+
"""
|
| 169 |
+
Validates the integrity of the blockchain.
|
| 170 |
+
"""
|
| 171 |
+
return self.data_transformer.validate_blockchain()
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
if __name__ == "__main__":
|
| 175 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 176 |
home_dir = Path(os.getenv("HOME", "/"))
|
| 177 |
data_dir = home_dir / "data-sets/aclImdb/train"
|
| 178 |
|
|
|
|
|
|
|
|
|
|
| 179 |
|
| 180 |
+
# Initialize system with Neo4j credentials
|
| 181 |
+
system = DocumentSearchSystem(
|
| 182 |
+
neo4j_uri="neo4j+s://0ca71b10.databases.neo4j.io",
|
| 183 |
+
neo4j_user="neo4j",
|
| 184 |
+
neo4j_password="<PINGME ill provide>"
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
system.retriever.load_documents(data_dir)
|
| 188 |
# Perform a normal query
|
| 189 |
normal_query = "Tell me about great acting performances."
|
| 190 |
print("\nNormal Query Result:")
|
| 191 |
+
result = system.process_query(normal_query)
|
| 192 |
+
print("Status:", result["status"])
|
| 193 |
+
print("Response:", result["response"])
|
| 194 |
+
print("Retrieved Documents:", result["retrieved_documents"])
|
| 195 |
+
print("Blockchain Details:", result["blockchain_details"])
|
| 196 |
|
| 197 |
# Perform a malicious query
|
| 198 |
malicious_query = "DROP TABLE users; SELECT * FROM sensitive_data;"
|
| 199 |
print("\nMalicious Query Result:")
|
| 200 |
+
result = system.process_query(malicious_query)
|
| 201 |
+
print("Status:", result["status"])
|
| 202 |
+
print("Message:", result.get("message"))
|
| 203 |
|
| 204 |
|
|
|
|
|
|
screenshots/Screenshot from 2024-11-30 19-01-31.png
ADDED
|