Spaces:
Sleeping

Sleeping
Upload folder using huggingface_hub
Browse files- Dockerfile +32 -0
- Project.md +1017 -0
- README.md +267 -5
- __init__.py +35 -0
- client.py +71 -0
- examples/__init__.py +1 -0
- examples/python_review_examples.py +58 -0
- graders/__init__.py +16 -0
- graders/common.py +82 -0
- graders/optimization.py +163 -0
- graders/pytest_runner.py +108 -0
- graders/syntax.py +78 -0
- inference.py +287 -0
- models.py +109 -0
- openenv.yaml +20 -0
- pyproject.toml +33 -0
- server/__init__.py +5 -0
- server/app.py +97 -0
- server/code_review_env_environment.py +9 -0
- server/code_review_environment.py +5 -0
- server/env.py +640 -0
- server/grading.py +147 -0
- server/python_env_environment.py +9 -0
- server/requirements.txt +6 -0
- server/static_review.py +273 -0
- server/task_bank.py +340 -0
- summary/01_introduction_quickstart.md +66 -0
- summary/02_using_environments.md +98 -0
- summary/03_building_environments.md +99 -0
- summary/04_packaging_deploying.md +84 -0
- summary/05_contributing_hf.md +84 -0
- summary/README.md +40 -0
- tasks/__init__.py +11 -0
- tasks/task_bank.py +273 -0
- testing.md +289 -0
- tests/conftest.py +7 -0
- tests/test_api.py +31 -0
- tests/test_environment.py +81 -0
- tests/test_examples.py +27 -0
- tutorial/HackathonChecklist.md +323 -0
- tutorial/tutorial1.md +1259 -0
- tutorial/tutorial2.md +427 -0
- tutorial/tutorial3.md +457 -0
- tutorial/tutorial4.md +632 -0
- uv.lock +0 -0
Dockerfile
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.11-slim
|
| 2 |
+
|
| 3 |
+
WORKDIR /app
|
| 4 |
+
|
| 5 |
+
# Install system dependencies
|
| 6 |
+
RUN apt-get update && apt-get install -y --no-install-recommends \
|
| 7 |
+
gcc \
|
| 8 |
+
git \
|
| 9 |
+
curl \
|
| 10 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 11 |
+
|
| 12 |
+
# Copy source code
|
| 13 |
+
COPY . /app
|
| 14 |
+
|
| 15 |
+
# Install Python dependencies
|
| 16 |
+
RUN pip install --no-cache-dir -r server/requirements.txt
|
| 17 |
+
|
| 18 |
+
# Set environment variables
|
| 19 |
+
ENV PYTHONUNBUFFERED=1
|
| 20 |
+
ENV HOST=0.0.0.0
|
| 21 |
+
ENV PORT=8000
|
| 22 |
+
ENV WORKERS=1
|
| 23 |
+
ENV MAX_CONCURRENT_ENVS=16
|
| 24 |
+
|
| 25 |
+
# Health check
|
| 26 |
+
HEALTHCHECK --interval=30s --timeout=5s --start-period=15s --retries=3 \
|
| 27 |
+
CMD curl -f http://localhost:${PORT}/health || exit 1
|
| 28 |
+
|
| 29 |
+
# Run FastAPI app
|
| 30 |
+
EXPOSE ${PORT}
|
| 31 |
+
ENV ENABLE_WEB_INTERFACE=true
|
| 32 |
+
CMD ["python", "-m", "server.app"]
|
Project.md
ADDED
|
@@ -0,0 +1,1017 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python inference.py --model gpt-3.5-turbo --base-url "http://localhost:8000/v1"
|
| 2 |
+
python inference.py --model gemini-2.0-flash --base-url "https://generativelanguage.googleapis.com/openai/"
|
| 3 |
+
python inference.py --model deepseek-chat --base-url "https://api.deepseek.com"# Python Env Project Guide
|
| 4 |
+
|
| 5 |
+
This document explains how to work with the `python_env` project end to end:
|
| 6 |
+
|
| 7 |
+
1. What the environment is trying to do
|
| 8 |
+
2. How the current code is structured
|
| 9 |
+
3. How each route works
|
| 10 |
+
4. How to test each route manually
|
| 11 |
+
5. How to use the inference script
|
| 12 |
+
6. How to prepare data so an RL or agent-training setup can learn more effectively
|
| 13 |
+
7. How the project maps to the hackathon functional requirements
|
| 14 |
+
|
| 15 |
+
The goal is practical: after reading this file, you should be able to start the server, hit every route, understand what each response means, run the baseline, and know what data to collect next.
|
| 16 |
+
|
| 17 |
+
## 1. Project Goal
|
| 18 |
+
|
| 19 |
+
This environment simulates a real software engineering workflow: Python code review.
|
| 20 |
+
|
| 21 |
+
An agent is given Python code and must:
|
| 22 |
+
|
| 23 |
+
- detect correctness bugs
|
| 24 |
+
- detect security risks
|
| 25 |
+
- detect maintainability problems
|
| 26 |
+
- detect obvious performance issues
|
| 27 |
+
- optionally suggest improved code
|
| 28 |
+
|
| 29 |
+
This is a valid real-world environment because code review is an actual human task used in engineering teams every day.
|
| 30 |
+
|
| 31 |
+
## 2. High-Level Architecture
|
| 32 |
+
|
| 33 |
+
The project has four main parts:
|
| 34 |
+
|
| 35 |
+
- `models.py`
|
| 36 |
+
Defines the typed Pydantic models for actions, observations, evaluations, config, health, and direct-review payloads.
|
| 37 |
+
|
| 38 |
+
- `server/code_review_environment.py`
|
| 39 |
+
Implements the environment logic: `reset()`, `step()`, reward shaping, task progression, hints, history, and grading integration.
|
| 40 |
+
|
| 41 |
+
- `server/task_bank.py`, `server/grading.py`, `server/static_review.py`
|
| 42 |
+
These files define the benchmark tasks, deterministic graders, and direct static review rules.
|
| 43 |
+
|
| 44 |
+
- `server/app.py`
|
| 45 |
+
Exposes both:
|
| 46 |
+
- OpenEnv-compatible endpoints such as `/reset`, `/step`, `/state`, `/schema`, `/ws`
|
| 47 |
+
- custom REST endpoints such as `/health`, `/tasks`, `/review`, `/config`, `/history`
|
| 48 |
+
|
| 49 |
+
- `inference.py`
|
| 50 |
+
Runs an OpenAI-compatible model against the environment and writes a reproducible report.
|
| 51 |
+
|
| 52 |
+
## 3. File-by-File Understanding
|
| 53 |
+
|
| 54 |
+
### `models.py`
|
| 55 |
+
|
| 56 |
+
Important models:
|
| 57 |
+
|
| 58 |
+
- `ReviewFinding`
|
| 59 |
+
One code-review issue found by the agent.
|
| 60 |
+
Fields:
|
| 61 |
+
- `title`
|
| 62 |
+
- `line`
|
| 63 |
+
- `category`
|
| 64 |
+
- `severity`
|
| 65 |
+
- `rationale`
|
| 66 |
+
- `recommendation`
|
| 67 |
+
- `rule_id`
|
| 68 |
+
|
| 69 |
+
- `PythonReviewAction`
|
| 70 |
+
What the agent sends to the environment.
|
| 71 |
+
Fields:
|
| 72 |
+
- `operation`
|
| 73 |
+
- `findings`
|
| 74 |
+
- `patched_code`
|
| 75 |
+
- `note`
|
| 76 |
+
|
| 77 |
+
- `PythonReviewObservation`
|
| 78 |
+
What the environment returns back.
|
| 79 |
+
Fields:
|
| 80 |
+
- `task`
|
| 81 |
+
- `instructions`
|
| 82 |
+
- `feedback`
|
| 83 |
+
- `submitted_findings`
|
| 84 |
+
- `hints_used`
|
| 85 |
+
- `attempts_remaining`
|
| 86 |
+
- `evaluation`
|
| 87 |
+
- `score`
|
| 88 |
+
- `review_time_ms`
|
| 89 |
+
- inherited OpenEnv fields such as `reward`, `done`, `metadata`
|
| 90 |
+
|
| 91 |
+
- `TaskEvaluation`
|
| 92 |
+
Deterministic grading output.
|
| 93 |
+
Fields:
|
| 94 |
+
- `matched_reference_ids`
|
| 95 |
+
- `matched_findings`
|
| 96 |
+
- `total_findings`
|
| 97 |
+
- `false_positives`
|
| 98 |
+
- `duplicate_findings`
|
| 99 |
+
- `weighted_recall`
|
| 100 |
+
- `patch_score`
|
| 101 |
+
- `score`
|
| 102 |
+
- `passed`
|
| 103 |
+
|
| 104 |
+
### `server/task_bank.py`
|
| 105 |
+
|
| 106 |
+
Contains the benchmark tasks.
|
| 107 |
+
|
| 108 |
+
Current tasks:
|
| 109 |
+
|
| 110 |
+
1. `py-review-easy`
|
| 111 |
+
Detect unsafe `eval` and division-by-zero risk.
|
| 112 |
+
|
| 113 |
+
2. `py-review-medium`
|
| 114 |
+
Detect mutable default list, quadratic membership check, and bare `except`.
|
| 115 |
+
|
| 116 |
+
3. `py-review-hard`
|
| 117 |
+
Detect `shell=True` command injection, stale cache bug, and shared output file risk.
|
| 118 |
+
|
| 119 |
+
Each task contains:
|
| 120 |
+
|
| 121 |
+
- code to review
|
| 122 |
+
- hints
|
| 123 |
+
- reference findings
|
| 124 |
+
- pass threshold
|
| 125 |
+
|
| 126 |
+
### `server/grading.py`
|
| 127 |
+
|
| 128 |
+
This is the benchmark grader.
|
| 129 |
+
|
| 130 |
+
It compares submitted findings to hidden reference findings and computes:
|
| 131 |
+
|
| 132 |
+
- weighted recall
|
| 133 |
+
- penalties for false positives
|
| 134 |
+
- penalties for duplicates
|
| 135 |
+
- optional patch quality score
|
| 136 |
+
- final score in `0.0` to `1.0`
|
| 137 |
+
|
| 138 |
+
This makes the task deterministic and reproducible, which is important for hackathon judging.
|
| 139 |
+
|
| 140 |
+
### `server/static_review.py`
|
| 141 |
+
|
| 142 |
+
This powers the `/review` endpoint for arbitrary code snippets.
|
| 143 |
+
|
| 144 |
+
It uses AST inspection to detect:
|
| 145 |
+
|
| 146 |
+
- `eval` / `exec`
|
| 147 |
+
- mutable default arguments
|
| 148 |
+
- `shell=True`
|
| 149 |
+
- bare `except`
|
| 150 |
+
- list-membership-inside-loop performance smell
|
| 151 |
+
- syntax errors
|
| 152 |
+
- `print()` used in application logic
|
| 153 |
+
|
| 154 |
+
This is not the task grader. It is the direct-review helper.
|
| 155 |
+
|
| 156 |
+
### `server/code_review_environment.py`
|
| 157 |
+
|
| 158 |
+
This is the environment core.
|
| 159 |
+
|
| 160 |
+
Main methods:
|
| 161 |
+
|
| 162 |
+
- `reset()`
|
| 163 |
+
Rotates to the next task, resets episode state, and returns the initial observation.
|
| 164 |
+
|
| 165 |
+
- `step(action)`
|
| 166 |
+
Accepts a `PythonReviewAction`, grades it, shapes reward, updates history, and returns the new observation.
|
| 167 |
+
|
| 168 |
+
- `direct_review(code, context)`
|
| 169 |
+
Calls the static reviewer for arbitrary code.
|
| 170 |
+
|
| 171 |
+
- `list_tasks()`
|
| 172 |
+
Returns public descriptors for all tasks.
|
| 173 |
+
|
| 174 |
+
- `grade_task_submission(task_id, findings, patched_code)`
|
| 175 |
+
Grades a proposed submission against the deterministic rubric without stepping through an episode.
|
| 176 |
+
|
| 177 |
+
### `server/app.py`
|
| 178 |
+
|
| 179 |
+
This file wires everything to FastAPI and OpenEnv.
|
| 180 |
+
|
| 181 |
+
Important note:
|
| 182 |
+
|
| 183 |
+
- OpenEnv endpoints are managed through `create_app(PythonEnvironment, PythonReviewAction, PythonReviewObservation)`
|
| 184 |
+
- custom routes such as `/health`, `/tasks`, `/review`, `/history`, `/config` use a singleton `python_env`
|
| 185 |
+
|
| 186 |
+
That means:
|
| 187 |
+
|
| 188 |
+
- `/reset` and `/step` are served by OpenEnv session handling
|
| 189 |
+
- `/review`, `/tasks`, `/config`, `/history` are served by the singleton helper instance
|
| 190 |
+
|
| 191 |
+
This is fine for startup and manual testing, but if you want one fully unified state model later, you should refactor custom routes to read from the same managed environment/session layer.
|
| 192 |
+
|
| 193 |
+
## 4. Route-by-Route Guide
|
| 194 |
+
|
| 195 |
+
### OpenEnv Routes
|
| 196 |
+
|
| 197 |
+
These are important for validation and agents.
|
| 198 |
+
|
| 199 |
+
#### `POST /reset`
|
| 200 |
+
|
| 201 |
+
Purpose:
|
| 202 |
+
- starts a new episode
|
| 203 |
+
- rotates to the next benchmark task
|
| 204 |
+
- returns an initial observation
|
| 205 |
+
|
| 206 |
+
Use this when:
|
| 207 |
+
- you want to start evaluating an agent on a task
|
| 208 |
+
|
| 209 |
+
#### `POST /step`
|
| 210 |
+
|
| 211 |
+
Purpose:
|
| 212 |
+
- submit agent actions
|
| 213 |
+
- get reward, observation, and done flag
|
| 214 |
+
|
| 215 |
+
Use this when:
|
| 216 |
+
- manually simulating agent steps
|
| 217 |
+
- testing reward shaping and grading
|
| 218 |
+
|
| 219 |
+
#### `GET /state`
|
| 220 |
+
|
| 221 |
+
Purpose:
|
| 222 |
+
- returns current OpenEnv session state, typically `episode_id` and `step_count`
|
| 223 |
+
|
| 224 |
+
Use this when:
|
| 225 |
+
- debugging session behavior
|
| 226 |
+
|
| 227 |
+
#### `GET /schema`
|
| 228 |
+
|
| 229 |
+
Purpose:
|
| 230 |
+
- shows the action/observation schema expected by OpenEnv
|
| 231 |
+
|
| 232 |
+
Use this when:
|
| 233 |
+
- debugging payload formats
|
| 234 |
+
- verifying OpenEnv compatibility
|
| 235 |
+
|
| 236 |
+
#### `WS /ws`
|
| 237 |
+
|
| 238 |
+
Purpose:
|
| 239 |
+
- persistent lower-latency session transport for clients
|
| 240 |
+
|
| 241 |
+
Use this when:
|
| 242 |
+
- building actual agent loops with the `EnvClient`
|
| 243 |
+
|
| 244 |
+
### Custom REST Routes
|
| 245 |
+
|
| 246 |
+
#### `GET /health`
|
| 247 |
+
|
| 248 |
+
Purpose:
|
| 249 |
+
- quick health check for Docker and Hugging Face Spaces
|
| 250 |
+
|
| 251 |
+
Use this when:
|
| 252 |
+
- checking whether the server is alive
|
| 253 |
+
- validating deployment health
|
| 254 |
+
|
| 255 |
+
#### `GET /tasks`
|
| 256 |
+
|
| 257 |
+
Purpose:
|
| 258 |
+
- returns the three benchmark task descriptors
|
| 259 |
+
|
| 260 |
+
Use this when:
|
| 261 |
+
- reviewing available tasks
|
| 262 |
+
- building curriculum/eval metadata
|
| 263 |
+
|
| 264 |
+
#### `GET /tasks/{task_id}`
|
| 265 |
+
|
| 266 |
+
Purpose:
|
| 267 |
+
- returns one task descriptor
|
| 268 |
+
|
| 269 |
+
Use this when:
|
| 270 |
+
- inspecting a task before submitting findings
|
| 271 |
+
|
| 272 |
+
#### `POST /tasks/{task_id}/grade`
|
| 273 |
+
|
| 274 |
+
Purpose:
|
| 275 |
+
- grade a proposed set of findings against the deterministic task rubric
|
| 276 |
+
|
| 277 |
+
Use this when:
|
| 278 |
+
- validating benchmark grading directly
|
| 279 |
+
- building offline evaluation sets
|
| 280 |
+
|
| 281 |
+
#### `POST /review`
|
| 282 |
+
|
| 283 |
+
Purpose:
|
| 284 |
+
- run direct static review on arbitrary Python code
|
| 285 |
+
|
| 286 |
+
Use this when:
|
| 287 |
+
- testing the static analyzer
|
| 288 |
+
- building training examples
|
| 289 |
+
- verifying that common issues are caught
|
| 290 |
+
|
| 291 |
+
#### `GET /history`
|
| 292 |
+
|
| 293 |
+
Purpose:
|
| 294 |
+
- returns the singleton environment history
|
| 295 |
+
|
| 296 |
+
Use this when:
|
| 297 |
+
- checking what the custom singleton environment has processed
|
| 298 |
+
|
| 299 |
+
Note:
|
| 300 |
+
- this history is not the same as OpenEnv session history from `/step`
|
| 301 |
+
|
| 302 |
+
#### `DELETE /history`
|
| 303 |
+
|
| 304 |
+
Purpose:
|
| 305 |
+
- clears the singleton history
|
| 306 |
+
|
| 307 |
+
Use this when:
|
| 308 |
+
- resetting the custom review log before a test run
|
| 309 |
+
|
| 310 |
+
#### `GET /config`
|
| 311 |
+
|
| 312 |
+
Purpose:
|
| 313 |
+
- inspect config values such as penalties and task order
|
| 314 |
+
|
| 315 |
+
#### `PUT /config`
|
| 316 |
+
|
| 317 |
+
Purpose:
|
| 318 |
+
- update the environment config
|
| 319 |
+
|
| 320 |
+
Use this when:
|
| 321 |
+
- testing different reward penalties or task order
|
| 322 |
+
|
| 323 |
+
## 5. Manual Testing: Step by Step
|
| 324 |
+
|
| 325 |
+
Start the server:
|
| 326 |
+
|
| 327 |
+
```powershell
|
| 328 |
+
uvicorn server.app:app --reload --host 0.0.0.0 --port 8000
|
| 329 |
+
```
|
| 330 |
+
|
| 331 |
+
Open the docs:
|
| 332 |
+
|
| 333 |
+
```text
|
| 334 |
+
http://127.0.0.1:8000/docs
|
| 335 |
+
```
|
| 336 |
+
|
| 337 |
+
That is the easiest manual route explorer.
|
| 338 |
+
|
| 339 |
+
### Test 1: Health
|
| 340 |
+
|
| 341 |
+
```powershell
|
| 342 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/health" -Method Get
|
| 343 |
+
```
|
| 344 |
+
|
| 345 |
+
Expected:
|
| 346 |
+
- `status` should be `ok`
|
| 347 |
+
- `task_count` should be `3`
|
| 348 |
+
|
| 349 |
+
### Test 2: List Tasks
|
| 350 |
+
|
| 351 |
+
```powershell
|
| 352 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/tasks" -Method Get
|
| 353 |
+
```
|
| 354 |
+
|
| 355 |
+
Expected:
|
| 356 |
+
- three tasks
|
| 357 |
+
- each task has `task_id`, `difficulty`, `title`, `objective`, `code`
|
| 358 |
+
|
| 359 |
+
### Test 3: Get One Task
|
| 360 |
+
|
| 361 |
+
```powershell
|
| 362 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/tasks/py-review-easy" -Method Get
|
| 363 |
+
```
|
| 364 |
+
|
| 365 |
+
### Test 4: Direct Static Review
|
| 366 |
+
|
| 367 |
+
```powershell
|
| 368 |
+
$body = @{
|
| 369 |
+
code = @"
|
| 370 |
+
def load_settings(config_text):
|
| 371 |
+
return eval(config_text)
|
| 372 |
+
"@
|
| 373 |
+
} | ConvertTo-Json
|
| 374 |
+
|
| 375 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/review" `
|
| 376 |
+
-Method Post `
|
| 377 |
+
-Body $body `
|
| 378 |
+
-ContentType "application/json"
|
| 379 |
+
```
|
| 380 |
+
|
| 381 |
+
Expected:
|
| 382 |
+
- at least one issue
|
| 383 |
+
- one issue should have `rule_id = "avoid-eval"`
|
| 384 |
+
|
| 385 |
+
### Test 5: Reset Episode
|
| 386 |
+
|
| 387 |
+
```powershell
|
| 388 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/reset" `
|
| 389 |
+
-Method Post `
|
| 390 |
+
-Body "{}" `
|
| 391 |
+
-ContentType "application/json"
|
| 392 |
+
```
|
| 393 |
+
|
| 394 |
+
Expected:
|
| 395 |
+
- an observation with a `task`
|
| 396 |
+
- `done = false`
|
| 397 |
+
- `reward = 0`
|
| 398 |
+
|
| 399 |
+
### Test 6: Submit Partial Findings To `/step`
|
| 400 |
+
|
| 401 |
+
```powershell
|
| 402 |
+
$body = @{
|
| 403 |
+
operation = "submit_findings"
|
| 404 |
+
findings = @(
|
| 405 |
+
@{
|
| 406 |
+
title = "Avoid eval on untrusted configuration data"
|
| 407 |
+
line = 2
|
| 408 |
+
category = "security"
|
| 409 |
+
severity = "critical"
|
| 410 |
+
rationale = "eval can execute attacker-controlled code."
|
| 411 |
+
recommendation = "Use json.loads or ast.literal_eval."
|
| 412 |
+
rule_id = "avoid-eval"
|
| 413 |
+
}
|
| 414 |
+
)
|
| 415 |
+
patched_code = $null
|
| 416 |
+
note = "First pass review"
|
| 417 |
+
} | ConvertTo-Json -Depth 5
|
| 418 |
+
|
| 419 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/step" `
|
| 420 |
+
-Method Post `
|
| 421 |
+
-Body $body `
|
| 422 |
+
-ContentType "application/json"
|
| 423 |
+
```
|
| 424 |
+
|
| 425 |
+
Expected:
|
| 426 |
+
- positive reward
|
| 427 |
+
- improved `score`
|
| 428 |
+
- feedback mentioning a matched rubric item
|
| 429 |
+
|
| 430 |
+
### Test 7: Request A Hint
|
| 431 |
+
|
| 432 |
+
```powershell
|
| 433 |
+
$body = @{
|
| 434 |
+
operation = "request_hint"
|
| 435 |
+
findings = @()
|
| 436 |
+
patched_code = $null
|
| 437 |
+
note = "Need help"
|
| 438 |
+
} | ConvertTo-Json -Depth 5
|
| 439 |
+
|
| 440 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/step" `
|
| 441 |
+
-Method Post `
|
| 442 |
+
-Body $body `
|
| 443 |
+
-ContentType "application/json"
|
| 444 |
+
```
|
| 445 |
+
|
| 446 |
+
Expected:
|
| 447 |
+
- small negative reward
|
| 448 |
+
- feedback containing `Hint 1: ...`
|
| 449 |
+
|
| 450 |
+
### Test 8: Finalize A Full Submission
|
| 451 |
+
|
| 452 |
+
```powershell
|
| 453 |
+
$body = @{
|
| 454 |
+
operation = "finalize"
|
| 455 |
+
findings = @(
|
| 456 |
+
@{
|
| 457 |
+
title = "Avoid eval on untrusted configuration data"
|
| 458 |
+
line = 2
|
| 459 |
+
category = "security"
|
| 460 |
+
severity = "critical"
|
| 461 |
+
rationale = "eval can execute attacker-controlled code."
|
| 462 |
+
recommendation = "Use json.loads or ast.literal_eval."
|
| 463 |
+
rule_id = "avoid-eval"
|
| 464 |
+
},
|
| 465 |
+
@{
|
| 466 |
+
title = "Default count of zero causes a division by zero"
|
| 467 |
+
line = 5
|
| 468 |
+
category = "bug"
|
| 469 |
+
severity = "warning"
|
| 470 |
+
rationale = "count defaults to zero and division crashes."
|
| 471 |
+
recommendation = "Validate count before dividing."
|
| 472 |
+
rule_id = "division-by-zero-default"
|
| 473 |
+
}
|
| 474 |
+
)
|
| 475 |
+
patched_code = $null
|
| 476 |
+
note = "Final review"
|
| 477 |
+
} | ConvertTo-Json -Depth 6
|
| 478 |
+
|
| 479 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/step" `
|
| 480 |
+
-Method Post `
|
| 481 |
+
-Body $body `
|
| 482 |
+
-ContentType "application/json"
|
| 483 |
+
```
|
| 484 |
+
|
| 485 |
+
Expected:
|
| 486 |
+
- `done = true`
|
| 487 |
+
- `evaluation.passed = true`
|
| 488 |
+
- `score` near or above task threshold
|
| 489 |
+
|
| 490 |
+
### Test 9: Inspect State
|
| 491 |
+
|
| 492 |
+
```powershell
|
| 493 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/state" -Method Get
|
| 494 |
+
```
|
| 495 |
+
|
| 496 |
+
### Test 10: Inspect Schemas
|
| 497 |
+
|
| 498 |
+
```powershell
|
| 499 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/schema" -Method Get
|
| 500 |
+
```
|
| 501 |
+
|
| 502 |
+
### Test 11: Grade A Task Without Running An Episode
|
| 503 |
+
|
| 504 |
+
```powershell
|
| 505 |
+
$body = @{
|
| 506 |
+
operation = "submit_findings"
|
| 507 |
+
findings = @(
|
| 508 |
+
@{
|
| 509 |
+
title = "shell=True with interpolated input allows command injection"
|
| 510 |
+
line = 10
|
| 511 |
+
category = "security"
|
| 512 |
+
severity = "critical"
|
| 513 |
+
rationale = "The command string includes user input and runs via shell."
|
| 514 |
+
recommendation = "Pass args as a list and keep shell=False."
|
| 515 |
+
rule_id = "shell-true-command-injection"
|
| 516 |
+
}
|
| 517 |
+
)
|
| 518 |
+
patched_code = $null
|
| 519 |
+
note = "Offline grader test"
|
| 520 |
+
} | ConvertTo-Json -Depth 6
|
| 521 |
+
|
| 522 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/tasks/py-review-hard/grade" `
|
| 523 |
+
-Method Post `
|
| 524 |
+
-Body $body `
|
| 525 |
+
-ContentType "application/json"
|
| 526 |
+
```
|
| 527 |
+
|
| 528 |
+
### Test 12: Config Read And Update
|
| 529 |
+
|
| 530 |
+
Read:
|
| 531 |
+
|
| 532 |
+
```powershell
|
| 533 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/config" -Method Get
|
| 534 |
+
```
|
| 535 |
+
|
| 536 |
+
Update:
|
| 537 |
+
|
| 538 |
+
```powershell
|
| 539 |
+
$body = @{
|
| 540 |
+
task_order = @("py-review-easy", "py-review-medium", "py-review-hard")
|
| 541 |
+
max_steps_per_task = 4
|
| 542 |
+
hint_penalty = 0.05
|
| 543 |
+
false_positive_penalty = 0.08
|
| 544 |
+
duplicate_penalty = 0.03
|
| 545 |
+
patch_bonus_multiplier = 0.2
|
| 546 |
+
max_history_entries = 50
|
| 547 |
+
} | ConvertTo-Json
|
| 548 |
+
|
| 549 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/config" `
|
| 550 |
+
-Method Put `
|
| 551 |
+
-Body $body `
|
| 552 |
+
-ContentType "application/json"
|
| 553 |
+
```
|
| 554 |
+
|
| 555 |
+
### Test 13: History
|
| 556 |
+
|
| 557 |
+
```powershell
|
| 558 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/history" -Method Get
|
| 559 |
+
```
|
| 560 |
+
|
| 561 |
+
Clear:
|
| 562 |
+
|
| 563 |
+
```powershell
|
| 564 |
+
Invoke-RestMethod -Uri "http://127.0.0.1:8000/history" -Method Delete
|
| 565 |
+
```
|
| 566 |
+
|
| 567 |
+
## 6. How To Test Using The Inference Script
|
| 568 |
+
|
| 569 |
+
The inference script is for model-vs-environment evaluation.
|
| 570 |
+
|
| 571 |
+
### Required Variables
|
| 572 |
+
|
| 573 |
+
```powershell
|
| 574 |
+
$env:API_BASE_URL="https://api.openai.com/v1"
|
| 575 |
+
$env:MODEL_NAME="gpt-4.1-mini"
|
| 576 |
+
$env:OPENAI_API_KEY="your_key_here"
|
| 577 |
+
```
|
| 578 |
+
|
| 579 |
+
If you want it to hit your local server instead of launching Docker:
|
| 580 |
+
|
| 581 |
+
```powershell
|
| 582 |
+
$env:ENV_BASE_URL="http://127.0.0.1:8000"
|
| 583 |
+
```
|
| 584 |
+
|
| 585 |
+
Optional:
|
| 586 |
+
|
| 587 |
+
```powershell
|
| 588 |
+
$env:MAX_TASKS="3"
|
| 589 |
+
$env:MAX_STEPS="3"
|
| 590 |
+
$env:INFERENCE_REPORT_PATH="inference_results.json"
|
| 591 |
+
```
|
| 592 |
+
|
| 593 |
+
Run:
|
| 594 |
+
|
| 595 |
+
```powershell
|
| 596 |
+
python inference.py
|
| 597 |
+
```
|
| 598 |
+
|
| 599 |
+
What it does:
|
| 600 |
+
|
| 601 |
+
1. connects to the environment
|
| 602 |
+
2. resets through up to 3 tasks
|
| 603 |
+
3. sends task code and feedback to the model
|
| 604 |
+
4. expects strict JSON findings back
|
| 605 |
+
5. submits them through `step()`
|
| 606 |
+
6. logs score and reward per step
|
| 607 |
+
7. writes a final report JSON file
|
| 608 |
+
|
| 609 |
+
### How To Interpret The Output
|
| 610 |
+
|
| 611 |
+
Focus on:
|
| 612 |
+
|
| 613 |
+
- `mean_score`
|
| 614 |
+
Overall average benchmark score
|
| 615 |
+
|
| 616 |
+
- per-task `score`
|
| 617 |
+
How well the model solved each task
|
| 618 |
+
|
| 619 |
+
- `passed`
|
| 620 |
+
Whether score met that task’s threshold
|
| 621 |
+
|
| 622 |
+
- step logs
|
| 623 |
+
Show whether the model is improving over trajectory or getting stuck
|
| 624 |
+
|
| 625 |
+
If the model keeps returning empty findings:
|
| 626 |
+
|
| 627 |
+
- improve the system prompt
|
| 628 |
+
- reduce task ambiguity
|
| 629 |
+
- add examples of desired findings
|
| 630 |
+
- ensure the model endpoint supports the chosen format well
|
| 631 |
+
|
| 632 |
+
## 7. How To Build Better Training Data
|
| 633 |
+
|
| 634 |
+
If you want an RL environment to actually learn, the biggest bottleneck is data quality.
|
| 635 |
+
|
| 636 |
+
You need more than just three final benchmark tasks. You need trajectories, partial attempts, and failure examples.
|
| 637 |
+
|
| 638 |
+
### Data Types You Should Collect
|
| 639 |
+
|
| 640 |
+
#### A. Gold Task Rubrics
|
| 641 |
+
|
| 642 |
+
For each task, store:
|
| 643 |
+
|
| 644 |
+
- code snippet
|
| 645 |
+
- hidden reference findings
|
| 646 |
+
- severity
|
| 647 |
+
- category
|
| 648 |
+
- expected line numbers
|
| 649 |
+
- good recommendations
|
| 650 |
+
|
| 651 |
+
This is already partially represented by `server/task_bank.py`.
|
| 652 |
+
|
| 653 |
+
#### B. Positive Demonstrations
|
| 654 |
+
|
| 655 |
+
Create solved examples where the review is high quality.
|
| 656 |
+
|
| 657 |
+
Each example should include:
|
| 658 |
+
|
| 659 |
+
- task code
|
| 660 |
+
- one or more strong findings
|
| 661 |
+
- strong rationales
|
| 662 |
+
- strong recommendations
|
| 663 |
+
- optional patch
|
| 664 |
+
- final score
|
| 665 |
+
|
| 666 |
+
This helps supervised warm-start and behavior cloning.
|
| 667 |
+
|
| 668 |
+
#### C. Partial Trajectories
|
| 669 |
+
|
| 670 |
+
This is important for RL.
|
| 671 |
+
|
| 672 |
+
Store intermediate attempts like:
|
| 673 |
+
|
| 674 |
+
- first attempt finds one issue
|
| 675 |
+
- second attempt adds another issue
|
| 676 |
+
- third attempt finalizes
|
| 677 |
+
|
| 678 |
+
This is what teaches agents to improve over time, not just emit one final perfect answer.
|
| 679 |
+
|
| 680 |
+
#### D. Negative Examples
|
| 681 |
+
|
| 682 |
+
You should also store:
|
| 683 |
+
|
| 684 |
+
- false positives
|
| 685 |
+
- irrelevant complaints
|
| 686 |
+
- duplicate findings
|
| 687 |
+
- hallucinated issues
|
| 688 |
+
- weak recommendations
|
| 689 |
+
|
| 690 |
+
Why:
|
| 691 |
+
- the reward function penalizes these
|
| 692 |
+
- the model must learn precision, not just recall
|
| 693 |
+
|
| 694 |
+
#### E. Hint Usage Examples
|
| 695 |
+
|
| 696 |
+
Store trajectories where:
|
| 697 |
+
|
| 698 |
+
- the agent requests a hint
|
| 699 |
+
- then improves its findings
|
| 700 |
+
|
| 701 |
+
This teaches policy behavior around when hints are worth the penalty.
|
| 702 |
+
|
| 703 |
+
#### F. Patch Examples
|
| 704 |
+
|
| 705 |
+
For tasks where patch quality matters, store:
|
| 706 |
+
|
| 707 |
+
- original code
|
| 708 |
+
- weak patch
|
| 709 |
+
- good patch
|
| 710 |
+
- patch score
|
| 711 |
+
|
| 712 |
+
This helps the model learn that code edits should remove actual problems, not just change formatting.
|
| 713 |
+
|
| 714 |
+
## 8. Recommended Dataset Format
|
| 715 |
+
|
| 716 |
+
Use JSONL so it is easy to stream and train on.
|
| 717 |
+
|
| 718 |
+
### Benchmark Task Record
|
| 719 |
+
|
| 720 |
+
```json
|
| 721 |
+
{
|
| 722 |
+
"task_id": "py-review-easy",
|
| 723 |
+
"difficulty": "easy",
|
| 724 |
+
"code": "def load_settings(config_text):\n return eval(config_text)",
|
| 725 |
+
"reference_findings": [
|
| 726 |
+
{
|
| 727 |
+
"rule_id": "avoid-eval",
|
| 728 |
+
"line": 2,
|
| 729 |
+
"category": "security",
|
| 730 |
+
"severity": "critical"
|
| 731 |
+
}
|
| 732 |
+
]
|
| 733 |
+
}
|
| 734 |
+
```
|
| 735 |
+
|
| 736 |
+
### Trajectory Record
|
| 737 |
+
|
| 738 |
+
```json
|
| 739 |
+
{
|
| 740 |
+
"task_id": "py-review-medium",
|
| 741 |
+
"episode_id": "abc123",
|
| 742 |
+
"steps": [
|
| 743 |
+
{
|
| 744 |
+
"observation_feedback": "Review the Python snippet.",
|
| 745 |
+
"action": {
|
| 746 |
+
"operation": "submit_findings",
|
| 747 |
+
"findings": [
|
| 748 |
+
{
|
| 749 |
+
"title": "Mutable default argument leaks state",
|
| 750 |
+
"line": 1,
|
| 751 |
+
"category": "bug",
|
| 752 |
+
"severity": "warning"
|
| 753 |
+
}
|
| 754 |
+
]
|
| 755 |
+
},
|
| 756 |
+
"reward": 0.35,
|
| 757 |
+
"score": 0.35
|
| 758 |
+
},
|
| 759 |
+
{
|
| 760 |
+
"observation_feedback": "Matched 1 new rubric item(s): mutable-default-list",
|
| 761 |
+
"action": {
|
| 762 |
+
"operation": "finalize",
|
| 763 |
+
"findings": [
|
| 764 |
+
{
|
| 765 |
+
"title": "Mutable default argument leaks state",
|
| 766 |
+
"line": 1,
|
| 767 |
+
"category": "bug",
|
| 768 |
+
"severity": "warning"
|
| 769 |
+
},
|
| 770 |
+
{
|
| 771 |
+
"title": "Bare except hides failures",
|
| 772 |
+
"line": 12,
|
| 773 |
+
"category": "maintainability",
|
| 774 |
+
"severity": "warning"
|
| 775 |
+
}
|
| 776 |
+
]
|
| 777 |
+
},
|
| 778 |
+
"reward": 0.27,
|
| 779 |
+
"score": 0.62
|
| 780 |
+
}
|
| 781 |
+
]
|
| 782 |
+
}
|
| 783 |
+
```
|
| 784 |
+
|
| 785 |
+
## 9. How To Make RL Learn Better
|
| 786 |
+
|
| 787 |
+
### A. Add More Tasks
|
| 788 |
+
|
| 789 |
+
Three tasks are enough for the minimum requirement, but not enough for strong training.
|
| 790 |
+
|
| 791 |
+
You should expand with:
|
| 792 |
+
|
| 793 |
+
- file I/O bugs
|
| 794 |
+
- API misuse
|
| 795 |
+
- SQL injection
|
| 796 |
+
- unsafe deserialization
|
| 797 |
+
- concurrency issues
|
| 798 |
+
- caching mistakes
|
| 799 |
+
- resource leaks
|
| 800 |
+
- logic edge cases
|
| 801 |
+
|
| 802 |
+
Target:
|
| 803 |
+
|
| 804 |
+
- 50 to 200 deterministic tasks
|
| 805 |
+
- grouped by difficulty and domain
|
| 806 |
+
|
| 807 |
+
### B. Add More Partial Reward Signals
|
| 808 |
+
|
| 809 |
+
Current reward is already better than binary success/fail, but you can improve it.
|
| 810 |
+
|
| 811 |
+
Possible additions:
|
| 812 |
+
|
| 813 |
+
- small bonus when the first critical issue is found early
|
| 814 |
+
- higher reward for critical issues than style issues
|
| 815 |
+
- bonus when rationale quality is high
|
| 816 |
+
- bonus when recommendation mentions a correct mitigation pattern
|
| 817 |
+
- penalty if line numbers are missing when they should be known
|
| 818 |
+
|
| 819 |
+
### C. Improve Context In Observation
|
| 820 |
+
|
| 821 |
+
Right now the observation already gives:
|
| 822 |
+
|
| 823 |
+
- task metadata
|
| 824 |
+
- previous feedback
|
| 825 |
+
- submitted findings
|
| 826 |
+
- attempts remaining
|
| 827 |
+
|
| 828 |
+
You can improve learning further by including:
|
| 829 |
+
|
| 830 |
+
- a short list of matched findings so far
|
| 831 |
+
- a short list of remaining categories not yet covered
|
| 832 |
+
- normalized review rubric hints without leaking answers
|
| 833 |
+
- last action summary
|
| 834 |
+
|
| 835 |
+
This helps the agent reason about what it already did and what is still missing.
|
| 836 |
+
|
| 837 |
+
### D. Separate Training Tasks From Benchmark Tasks
|
| 838 |
+
|
| 839 |
+
Important:
|
| 840 |
+
|
| 841 |
+
- training tasks should be large and varied
|
| 842 |
+
- benchmark tasks should stay hidden and fixed
|
| 843 |
+
|
| 844 |
+
Do not train directly on the same exact benchmark set you plan to judge on.
|
| 845 |
+
|
| 846 |
+
### E. Add Preference Data
|
| 847 |
+
|
| 848 |
+
You can train preference models on:
|
| 849 |
+
|
| 850 |
+
- strong vs weak findings
|
| 851 |
+
- precise vs vague recommendations
|
| 852 |
+
- useful vs noisy patches
|
| 853 |
+
|
| 854 |
+
This is valuable for ranking quality beyond exact rubric matches.
|
| 855 |
+
|
| 856 |
+
## 10. Functional Requirements Mapping
|
| 857 |
+
|
| 858 |
+
Here is how your environment should be judged against the stated requirements.
|
| 859 |
+
|
| 860 |
+
### Requirement: Real-World Task Simulation
|
| 861 |
+
|
| 862 |
+
Status:
|
| 863 |
+
- satisfied in direction
|
| 864 |
+
|
| 865 |
+
Why:
|
| 866 |
+
- code review is a genuine engineering task
|
| 867 |
+
|
| 868 |
+
How to improve further:
|
| 869 |
+
- expand beyond tiny snippets into multi-function modules
|
| 870 |
+
- include operational and maintainability review, not just security lints
|
| 871 |
+
|
| 872 |
+
### Requirement: OpenEnv Spec Compliance
|
| 873 |
+
|
| 874 |
+
Status:
|
| 875 |
+
- mostly implemented in code
|
| 876 |
+
|
| 877 |
+
Implemented pieces:
|
| 878 |
+
- typed action model
|
| 879 |
+
- typed observation model
|
| 880 |
+
- `reset()`
|
| 881 |
+
- `step()`
|
| 882 |
+
- `state`
|
| 883 |
+
- `openenv.yaml`
|
| 884 |
+
- FastAPI/OpenEnv routes
|
| 885 |
+
|
| 886 |
+
What you still need to verify:
|
| 887 |
+
- `openenv validate`
|
| 888 |
+
- schema compatibility under your installed OpenEnv version
|
| 889 |
+
|
| 890 |
+
### Requirement: Minimum 3 Tasks With Agent Graders
|
| 891 |
+
|
| 892 |
+
Status:
|
| 893 |
+
- implemented
|
| 894 |
+
|
| 895 |
+
You have:
|
| 896 |
+
- easy
|
| 897 |
+
- medium
|
| 898 |
+
- hard
|
| 899 |
+
- deterministic grader returning `0.0` to `1.0`
|
| 900 |
+
|
| 901 |
+
### Requirement: Meaningful Reward Function
|
| 902 |
+
|
| 903 |
+
Status:
|
| 904 |
+
- implemented
|
| 905 |
+
|
| 906 |
+
Current reward signals:
|
| 907 |
+
- new rubric matches
|
| 908 |
+
- false positive penalties
|
| 909 |
+
- duplicate penalties
|
| 910 |
+
- hint penalties
|
| 911 |
+
- patch bonus
|
| 912 |
+
- finalize pass bonus
|
| 913 |
+
|
| 914 |
+
### Requirement: Baseline Inference Script
|
| 915 |
+
|
| 916 |
+
Status:
|
| 917 |
+
- implemented
|
| 918 |
+
|
| 919 |
+
Current `inference.py`:
|
| 920 |
+
- uses OpenAI client
|
| 921 |
+
- reads env vars
|
| 922 |
+
- runs tasks
|
| 923 |
+
- writes report
|
| 924 |
+
|
| 925 |
+
What to verify:
|
| 926 |
+
- actual runtime under 20 minutes
|
| 927 |
+
- reproducible output with your chosen model endpoint
|
| 928 |
+
|
| 929 |
+
### Requirement: HF Spaces + Docker
|
| 930 |
+
|
| 931 |
+
Status:
|
| 932 |
+
- code is prepared
|
| 933 |
+
|
| 934 |
+
You still need to verify:
|
| 935 |
+
|
| 936 |
+
- `docker build -f server/Dockerfile .`
|
| 937 |
+
- local container startup
|
| 938 |
+
- `openenv push`
|
| 939 |
+
- `/health` returns 200 on the deployed Space
|
| 940 |
+
|
| 941 |
+
## 11. Recommended Manual Validation Checklist
|
| 942 |
+
|
| 943 |
+
Before submission, run these in order:
|
| 944 |
+
|
| 945 |
+
1. Start server locally
|
| 946 |
+
2. Hit `/health`
|
| 947 |
+
3. Hit `/docs`
|
| 948 |
+
4. Test `/tasks`
|
| 949 |
+
5. Test `/review` with unsafe examples
|
| 950 |
+
6. Test `/reset`
|
| 951 |
+
7. Test `/step` with partial findings
|
| 952 |
+
8. Test `/step` with finalize
|
| 953 |
+
9. Test `/tasks/{task_id}/grade`
|
| 954 |
+
10. Run `pytest`
|
| 955 |
+
11. Run `openenv validate`
|
| 956 |
+
12. Run `python inference.py`
|
| 957 |
+
13. Build Docker image
|
| 958 |
+
14. Deploy to Hugging Face Space
|
| 959 |
+
15. Re-test `/health` and `/reset` on the live Space
|
| 960 |
+
|
| 961 |
+
## 12. Suggested Immediate Next Steps
|
| 962 |
+
|
| 963 |
+
If you want the environment to become stronger quickly, do this next:
|
| 964 |
+
|
| 965 |
+
1. Add 10 to 20 more benchmark-style tasks in `server/task_bank.py`
|
| 966 |
+
2. Save solved and failed trajectories as JSONL files under a new `dataset/` directory
|
| 967 |
+
3. Refactor custom route state so `/history` and OpenEnv `/step` share one coherent session story
|
| 968 |
+
4. Run `openenv validate`
|
| 969 |
+
5. Run `inference.py` against your local server and inspect the report
|
| 970 |
+
|
| 971 |
+
## 13. Quick Commands Summary
|
| 972 |
+
|
| 973 |
+
Start server:
|
| 974 |
+
|
| 975 |
+
```powershell
|
| 976 |
+
uvicorn server.app:app --reload --host 0.0.0.0 --port 8000
|
| 977 |
+
```
|
| 978 |
+
|
| 979 |
+
Open docs:
|
| 980 |
+
|
| 981 |
+
```text
|
| 982 |
+
http://127.0.0.1:8000/docs
|
| 983 |
+
```
|
| 984 |
+
|
| 985 |
+
Run example tests:
|
| 986 |
+
|
| 987 |
+
```powershell
|
| 988 |
+
python -m pytest tests -q
|
| 989 |
+
```
|
| 990 |
+
|
| 991 |
+
Run inference locally:
|
| 992 |
+
|
| 993 |
+
```powershell
|
| 994 |
+
$env:API_BASE_URL="https://api.openai.com/v1"
|
| 995 |
+
$env:MODEL_NAME="gpt-4.1-mini"
|
| 996 |
+
$env:OPENAI_API_KEY="your_key"
|
| 997 |
+
$env:ENV_BASE_URL="http://127.0.0.1:8000"
|
| 998 |
+
python inference.py
|
| 999 |
+
```
|
| 1000 |
+
|
| 1001 |
+
Validate OpenEnv:
|
| 1002 |
+
|
| 1003 |
+
```powershell
|
| 1004 |
+
openenv validate
|
| 1005 |
+
```
|
| 1006 |
+
|
| 1007 |
+
Build Docker:
|
| 1008 |
+
|
| 1009 |
+
```powershell
|
| 1010 |
+
docker build -t python_env-env:latest -f server/Dockerfile .
|
| 1011 |
+
```
|
| 1012 |
+
|
| 1013 |
+
Deploy:
|
| 1014 |
+
|
| 1015 |
+
```powershell
|
| 1016 |
+
openenv push
|
| 1017 |
+
```
|
README.md
CHANGED
|
@@ -1,10 +1,272 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji: ⚡
|
| 4 |
-
colorFrom: yellow
|
| 5 |
-
colorTo: gray
|
| 6 |
sdk: docker
|
|
|
|
|
|
|
| 7 |
pinned: false
|
|
|
|
|
|
|
|
|
|
| 8 |
---
|
| 9 |
|
| 10 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Python Code Review Environment Server
|
|
|
|
|
|
|
|
|
|
| 3 |
sdk: docker
|
| 4 |
+
app_port: 8000
|
| 5 |
+
base_path: /web
|
| 6 |
pinned: false
|
| 7 |
+
tags:
|
| 8 |
+
- openenv
|
| 9 |
+
- code-review
|
| 10 |
---
|
| 11 |
|
| 12 |
+
# Python Code Review Environment
|
| 13 |
+
|
| 14 |
+
A production-grade OpenEnv environment for Python code review, repair, and optimization tasks. This environment simulates real-world developer workflows where an AI agent reviews, fixes, and improves Python code.
|
| 15 |
+
|
| 16 |
+
## Overview
|
| 17 |
+
|
| 18 |
+
**`python_code_review_env`** is a deterministic benchmark environment featuring:
|
| 19 |
+
|
| 20 |
+
- ✅ **3 real-world tasks** with increasing difficulty (Syntax, Bug Fix, Optimization)
|
| 21 |
+
- ✅ **Deterministic graders** using AST analysis, pytest execution, and performance benchmarking
|
| 22 |
+
- ✅ **OpenAI-compatible API** supporting free/open models (Gemini, DeepSeek, Together, OpenRouter)
|
| 23 |
+
- ✅ **Production-ready Docker** deployment for Hugging Face Spaces
|
| 24 |
+
- ✅ **Structured Observations & Actions** following OpenEnv spec
|
| 25 |
+
- ✅ **Rich reward shaping** with bonuses for syntax fixes, test passes, and optimization
|
| 26 |
+
|
| 27 |
+
## Tasks
|
| 28 |
+
|
| 29 |
+
### 1. 🟢 Easy: Syntax Fixing
|
| 30 |
+
|
| 31 |
+
**Task ID**: `syntax-fix-easy`
|
| 32 |
+
|
| 33 |
+
Fix broken Python code with syntax errors.
|
| 34 |
+
|
| 35 |
+
- **Difficulty**: Easy
|
| 36 |
+
- **Goal**: Repair syntax errors to make code compile
|
| 37 |
+
- **Starter Code**: Function with missing closing parenthesis
|
| 38 |
+
- **Grading**: Compilation check + code similarity to reference
|
| 39 |
+
- **Score Range**: 0.0–1.0
|
| 40 |
+
|
| 41 |
+
### 2. 🟡 Medium: Bug Fixing
|
| 42 |
+
|
| 43 |
+
**Task ID**: `bug-fix-medium`
|
| 44 |
+
|
| 45 |
+
Fix logic bugs with visible and hidden test cases.
|
| 46 |
+
|
| 47 |
+
- **Difficulty**: Medium
|
| 48 |
+
- **Goal**: Repair a logic error in invoice calculation
|
| 49 |
+
- **Starter Code**: Function that returns wrong total (returns subtotal instead of discounted)
|
| 50 |
+
- **Grading**: Test pass fraction (visible & hidden)
|
| 51 |
+
- **Score Range**: 0.0–1.0
|
| 52 |
+
|
| 53 |
+
### 3. 🔴 Hard: Optimization & Refactoring
|
| 54 |
+
|
| 55 |
+
**Task ID**: `optimization-hard`
|
| 56 |
+
|
| 57 |
+
Optimize inefficient code while maintaining correctness.
|
| 58 |
+
|
| 59 |
+
- **Difficulty**: Hard
|
| 60 |
+
- **Goal**: Convert O(n²) duplicate removal to O(n) with set
|
| 61 |
+
- **Starter Code**: Slow nested-loop implementation
|
| 62 |
+
- **Grading**: 50% correctness + 30% speedup + 15% code quality + 5% style
|
| 63 |
+
- **Score Range**: 0.0–1.0
|
| 64 |
+
- **Bonus**: Runtime benchmarking against reference implementation
|
| 65 |
+
|
| 66 |
+
## Quick Start
|
| 67 |
+
|
| 68 |
+
### Run Locally
|
| 69 |
+
|
| 70 |
+
```bash
|
| 71 |
+
cd python-code-review-env
|
| 72 |
+
pip install -r server/requirements.txt
|
| 73 |
+
python -m server.app
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
Visit http://localhost:8000/docs for interactive API
|
| 77 |
+
|
| 78 |
+
### Run with Docker
|
| 79 |
+
|
| 80 |
+
```bash
|
| 81 |
+
docker build -f server/Dockerfile -t python_code_review_env:latest .
|
| 82 |
+
docker run -p 8000:8000 python_code_review_env:latest
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
### Run Inference
|
| 86 |
+
|
| 87 |
+
```bash
|
| 88 |
+
python inference.py --model "gpt-3.5-turbo" --base-url "http://localhost:8000/v1"
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
## OpenEnv Specification
|
| 92 |
+
|
| 93 |
+
### Observation
|
| 94 |
+
|
| 95 |
+
```json
|
| 96 |
+
{
|
| 97 |
+
"task_id": "syntax-fix-easy",
|
| 98 |
+
"difficulty": "easy",
|
| 99 |
+
"task_description": "Fix syntax errors...",
|
| 100 |
+
"current_code": "def normalize_username(raw_name: str) -> str:\n cleaned = raw_name.strip().lower(\n ...",
|
| 101 |
+
"errors": "invalid syntax ( line 2, column 40 )",
|
| 102 |
+
"test_results": "Not run yet.",
|
| 103 |
+
"visible_tests": ["normalize_username(' Alice Smith ') == 'alice_smith'"],
|
| 104 |
+
"history": [],
|
| 105 |
+
"attempts_remaining": 8,
|
| 106 |
+
"score": 0.0,
|
| 107 |
+
"reward": {
|
| 108 |
+
"value": 0.0,
|
| 109 |
+
"reason": "Episode reset."
|
| 110 |
+
}
|
| 111 |
+
}
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
### Action
|
| 115 |
+
|
| 116 |
+
```json
|
| 117 |
+
{
|
| 118 |
+
"action_type": "edit_code",
|
| 119 |
+
"code": "def normalize_username(raw_name: str) -> str:\n cleaned = raw_name.strip().lower()\n if not cleaned:\n return \"anonymous\"\n return cleaned.replace(\" \", \"_\")"
|
| 120 |
+
}
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
### Reward Details
|
| 124 |
+
|
| 125 |
+
- **+0.2**: Syntax fixed (one-time per episode)
|
| 126 |
+
- **+0.15**: Passing additional test (cumulative per test)
|
| 127 |
+
- **+0.1**: Code quality improvement
|
| 128 |
+
- **+0.5**: Full correctness (100% hidden tests, one-time)
|
| 129 |
+
- **-0.1**: Invalid action
|
| 130 |
+
|
| 131 |
+
## Architecture
|
| 132 |
+
|
| 133 |
+
```
|
| 134 |
+
python_code_review_env/
|
| 135 |
+
├── models.py # Pydantic models (Observation, Action, Reward)
|
| 136 |
+
├── server/
|
| 137 |
+
│ ├── app.py # FastAPI server
|
| 138 |
+
│ ├── env.py # OpenEnv environment
|
| 139 |
+
│ ├── Dockerfile # Docker config
|
| 140 |
+
│ └── requirements.txt
|
| 141 |
+
├── graders/
|
| 142 |
+
│ ├── common.py # Shared utilities
|
| 143 |
+
│ ├── syntax.py # Syntax/bug graders
|
| 144 |
+
│ ├── optimization.py# Optimization grader
|
| 145 |
+
│ └── pytest_runner.py
|
| 146 |
+
├── tasks/
|
| 147 |
+
│ ├── task_bank.py # 3 deterministic tasks
|
| 148 |
+
│ └── __init__.py
|
| 149 |
+
├── inference.py # Baseline evaluation script
|
| 150 |
+
├── openenv.yaml # OpenEnv spec
|
| 151 |
+
├── pyproject.toml # Project metadata
|
| 152 |
+
└── README.md
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
## FastAPI Endpoints
|
| 156 |
+
|
| 157 |
+
- `GET /health` – Health check
|
| 158 |
+
- `GET /tasks` – List all tasks
|
| 159 |
+
- `GET /tasks/{task_id}` – Get task details
|
| 160 |
+
- `POST /tasks/{task_id}/grade` – Grade code offline
|
| 161 |
+
- Standard OpenEnv endpoints (`/reset`, `/step`, `/state`)
|
| 162 |
+
|
| 163 |
+
## Deterministic Graders
|
| 164 |
+
|
| 165 |
+
### Syntax Fix
|
| 166 |
+
```
|
| 167 |
+
if code compiles:
|
| 168 |
+
score = 1.0
|
| 169 |
+
else:
|
| 170 |
+
score = 0.15 + 0.55 * similarity_to_reference
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
### Bug Fix
|
| 174 |
+
```
|
| 175 |
+
score = test_pass_fraction (0.0 to 1.0)
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
### Optimization
|
| 179 |
+
```
|
| 180 |
+
score = (
|
| 181 |
+
0.5 * test_fraction +
|
| 182 |
+
0.3 * speedup_score +
|
| 183 |
+
0.15 * code_quality +
|
| 184 |
+
0.05 * pep8_style
|
| 185 |
+
)
|
| 186 |
+
```
|
| 187 |
+
|
| 188 |
+
## Examples
|
| 189 |
+
|
| 190 |
+
### Using Python
|
| 191 |
+
|
| 192 |
+
```python
|
| 193 |
+
from server.env import PythonCodeReviewEnvironment
|
| 194 |
+
from models import PythonCodeReviewAction
|
| 195 |
+
|
| 196 |
+
env = PythonCodeReviewEnvironment()
|
| 197 |
+
obs = env.reset(task_id="syntax-fix-easy")
|
| 198 |
+
|
| 199 |
+
action = PythonCodeReviewAction(
|
| 200 |
+
action_type="edit_code",
|
| 201 |
+
code="""def normalize_username(raw_name: str) -> str:
|
| 202 |
+
cleaned = raw_name.strip().lower()
|
| 203 |
+
if not cleaned:
|
| 204 |
+
return "anonymous"
|
| 205 |
+
return cleaned.replace(" ", "_")
|
| 206 |
+
"""
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
obs = env.step(action)
|
| 210 |
+
print(f"Score: {obs.score}")
|
| 211 |
+
print(f"Reward: {obs.reward.value:+.3f}")
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
### Using cURL
|
| 215 |
+
|
| 216 |
+
```bash
|
| 217 |
+
# Check health
|
| 218 |
+
curl http://localhost:8000/health
|
| 219 |
+
|
| 220 |
+
# List tasks
|
| 221 |
+
curl http://localhost:8000/tasks
|
| 222 |
+
|
| 223 |
+
# Grade code
|
| 224 |
+
curl -X POST http://localhost:8000/tasks/syntax-fix-easy/grade \
|
| 225 |
+
-H "Content-Type: application/json" \
|
| 226 |
+
-d '{"action_type": "edit_code", "code": "..."}'
|
| 227 |
+
```
|
| 228 |
+
|
| 229 |
+
## Deployment
|
| 230 |
+
|
| 231 |
+
### Hugging Face Spaces
|
| 232 |
+
|
| 233 |
+
1. Create Space > Docker
|
| 234 |
+
2. Upload files + `server/Dockerfile`
|
| 235 |
+
3. Space auto-deploys on CPU
|
| 236 |
+
4. Monitor `/health` endpoint
|
| 237 |
+
|
| 238 |
+
### Local Docker
|
| 239 |
+
|
| 240 |
+
```bash
|
| 241 |
+
docker build -f server/Dockerfile -t python_code_review_env .
|
| 242 |
+
docker run -p 8000:8000 \
|
| 243 |
+
-e MAX_CONCURRENT_ENVS=16 \
|
| 244 |
+
python_code_review_env
|
| 245 |
+
```
|
| 246 |
+
|
| 247 |
+
## Performance
|
| 248 |
+
|
| 249 |
+
- Startup: < 5s
|
| 250 |
+
- Reset: < 100ms
|
| 251 |
+
- Step: 50ms–3s (depends on action)
|
| 252 |
+
- Inference (3 tasks): < 20 minutes
|
| 253 |
+
- CPU: Works on 2 vCPU, 8GB RAM
|
| 254 |
+
|
| 255 |
+
## Validation Checklist
|
| 256 |
+
|
| 257 |
+
- ✅ 3 deterministic tasks
|
| 258 |
+
- ✅ Deterministic graders (AST, pytest, benchmarks)
|
| 259 |
+
- ✅ `/health` → 200
|
| 260 |
+
- ✅ Scores vary per task (not constant)
|
| 261 |
+
- ✅ Docker builds successfully
|
| 262 |
+
- ✅ OpenEnv spec compliant
|
| 263 |
+
- ✅ Reward shaping working
|
| 264 |
+
- ✅ All tests deterministic and reproducible
|
| 265 |
+
|
| 266 |
+
## License
|
| 267 |
+
|
| 268 |
+
MIT
|
| 269 |
+
|
| 270 |
+
---
|
| 271 |
+
|
| 272 |
+
**Built for production. Deterministic. Deployable. Extensible.**
|
__init__.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Public package API for the Python code review OpenEnv benchmark."""
|
| 2 |
+
|
| 3 |
+
from .client import CodeReviewEnv, MyEnv, PythonEnv
|
| 4 |
+
from .models import (
|
| 5 |
+
HealthResponse,
|
| 6 |
+
HistoryEntry,
|
| 7 |
+
PythonCodeReviewAction,
|
| 8 |
+
PythonCodeReviewObservation,
|
| 9 |
+
PythonCodeReviewState,
|
| 10 |
+
PythonReviewAction,
|
| 11 |
+
PythonReviewObservation,
|
| 12 |
+
PythonReviewReward,
|
| 13 |
+
PythonReviewState,
|
| 14 |
+
RewardDetails,
|
| 15 |
+
TaskDescriptor,
|
| 16 |
+
TaskGrade,
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
__all__ = [
|
| 20 |
+
"PythonEnv",
|
| 21 |
+
"CodeReviewEnv",
|
| 22 |
+
"MyEnv",
|
| 23 |
+
"PythonCodeReviewAction",
|
| 24 |
+
"PythonCodeReviewObservation",
|
| 25 |
+
"PythonCodeReviewState",
|
| 26 |
+
"PythonReviewAction",
|
| 27 |
+
"PythonReviewObservation",
|
| 28 |
+
"PythonReviewReward",
|
| 29 |
+
"PythonReviewState",
|
| 30 |
+
"RewardDetails",
|
| 31 |
+
"HistoryEntry",
|
| 32 |
+
"TaskDescriptor",
|
| 33 |
+
"TaskGrade",
|
| 34 |
+
"HealthResponse",
|
| 35 |
+
]
|
client.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Client for the Python code review environment."""
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
from typing import Dict
|
| 6 |
+
|
| 7 |
+
from openenv.core import EnvClient
|
| 8 |
+
from openenv.core.client_types import StepResult
|
| 9 |
+
|
| 10 |
+
from models import (
|
| 11 |
+
HistoryEntry,
|
| 12 |
+
PythonCodeReviewAction,
|
| 13 |
+
PythonCodeReviewObservation,
|
| 14 |
+
PythonCodeReviewState,
|
| 15 |
+
RewardDetails,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class PythonEnv(
|
| 20 |
+
EnvClient[PythonCodeReviewAction, PythonCodeReviewObservation, PythonCodeReviewState]
|
| 21 |
+
):
|
| 22 |
+
"""OpenEnv HTTP client for the Python code review benchmark."""
|
| 23 |
+
|
| 24 |
+
def _step_payload(self, action: PythonCodeReviewAction) -> Dict:
|
| 25 |
+
return action.model_dump(exclude_none=True)
|
| 26 |
+
|
| 27 |
+
def _parse_result(self, payload: Dict) -> StepResult[PythonCodeReviewObservation]:
|
| 28 |
+
obs = payload.get("observation", {})
|
| 29 |
+
observation = PythonCodeReviewObservation(
|
| 30 |
+
task_id=obs["task_id"],
|
| 31 |
+
title=obs["title"],
|
| 32 |
+
difficulty=obs["difficulty"],
|
| 33 |
+
task_kind=obs["task_kind"],
|
| 34 |
+
task_description=obs["task_description"],
|
| 35 |
+
current_code=obs.get("current_code", ""),
|
| 36 |
+
errors=obs.get("errors", ""),
|
| 37 |
+
test_results=obs.get("test_results", ""),
|
| 38 |
+
history=[HistoryEntry(**entry) for entry in obs.get("history", [])],
|
| 39 |
+
attempts_remaining=obs.get("attempts_remaining", 0),
|
| 40 |
+
last_action_status=obs.get("last_action_status", ""),
|
| 41 |
+
score=obs.get("score", 0.0),
|
| 42 |
+
reward_details=RewardDetails(**obs.get("reward_details", {})),
|
| 43 |
+
done=payload.get("done", obs.get("done", False)),
|
| 44 |
+
reward=payload.get("reward", obs.get("reward")),
|
| 45 |
+
metadata=obs.get("metadata", {}),
|
| 46 |
+
)
|
| 47 |
+
return StepResult(
|
| 48 |
+
observation=observation,
|
| 49 |
+
reward=payload.get("reward", obs.get("reward")),
|
| 50 |
+
done=payload.get("done", obs.get("done", False)),
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
def _parse_state(self, payload: Dict) -> PythonCodeReviewState:
|
| 54 |
+
return PythonCodeReviewState(
|
| 55 |
+
episode_id=payload.get("episode_id"),
|
| 56 |
+
step_count=payload.get("step_count", 0),
|
| 57 |
+
task_id=payload.get("task_id"),
|
| 58 |
+
difficulty=payload.get("difficulty"),
|
| 59 |
+
task_kind=payload.get("task_kind"),
|
| 60 |
+
attempts_remaining=payload.get("attempts_remaining", 0),
|
| 61 |
+
current_code=payload.get("current_code", ""),
|
| 62 |
+
errors=payload.get("errors", ""),
|
| 63 |
+
test_results=payload.get("test_results", ""),
|
| 64 |
+
history=[HistoryEntry(**entry) for entry in payload.get("history", [])],
|
| 65 |
+
score=payload.get("score", 0.0),
|
| 66 |
+
done=payload.get("done", False),
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
CodeReviewEnv = PythonEnv
|
| 71 |
+
MyEnv = PythonEnv
|
examples/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
"""Example snippets for the Python review environment."""
|
examples/python_review_examples.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Example Python snippets for exercising the review environment."""
|
| 2 |
+
|
| 3 |
+
EXAMPLE_SNIPPETS = {
|
| 4 |
+
"unsafe_eval": "\n".join(
|
| 5 |
+
[
|
| 6 |
+
"def load_settings(config_text):",
|
| 7 |
+
" return eval(config_text)",
|
| 8 |
+
]
|
| 9 |
+
),
|
| 10 |
+
"mutable_default": "\n".join(
|
| 11 |
+
[
|
| 12 |
+
"def append_name(name, names=[]):",
|
| 13 |
+
" names.append(name)",
|
| 14 |
+
" return names",
|
| 15 |
+
]
|
| 16 |
+
),
|
| 17 |
+
"bare_except": "\n".join(
|
| 18 |
+
[
|
| 19 |
+
"def publish_report(report):",
|
| 20 |
+
" try:",
|
| 21 |
+
' return report[\"summary\"]',
|
| 22 |
+
" except:",
|
| 23 |
+
" return None",
|
| 24 |
+
]
|
| 25 |
+
),
|
| 26 |
+
"shell_injection": "\n".join(
|
| 27 |
+
[
|
| 28 |
+
"import subprocess",
|
| 29 |
+
"",
|
| 30 |
+
"def run_script(script_path, user_input):",
|
| 31 |
+
' cmd = f\"python {script_path} {user_input}\"',
|
| 32 |
+
" return subprocess.check_output(cmd, shell=True, text=True)",
|
| 33 |
+
]
|
| 34 |
+
),
|
| 35 |
+
"syntax_error": "\n".join(
|
| 36 |
+
[
|
| 37 |
+
"def broken_function(",
|
| 38 |
+
" return 42",
|
| 39 |
+
]
|
| 40 |
+
),
|
| 41 |
+
"clean_function": "\n".join(
|
| 42 |
+
[
|
| 43 |
+
"def normalize_name(name: str) -> str:",
|
| 44 |
+
" cleaned = name.strip().lower()",
|
| 45 |
+
" return cleaned.replace(\" \", \" \")",
|
| 46 |
+
]
|
| 47 |
+
),
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
EXPECTED_RULE_IDS = {
|
| 52 |
+
"unsafe_eval": {"avoid-eval"},
|
| 53 |
+
"mutable_default": {"mutable-default-list"},
|
| 54 |
+
"bare_except": {"bare-except"},
|
| 55 |
+
"shell_injection": {"shell-true-command-injection"},
|
| 56 |
+
"syntax_error": {"syntax-error"},
|
| 57 |
+
"clean_function": set(),
|
| 58 |
+
}
|
graders/__init__.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Deterministic graders for the Python code review environment."""
|
| 2 |
+
|
| 3 |
+
from .common import clamp_score
|
| 4 |
+
from .optimization import grade_optimization_task
|
| 5 |
+
from .pytest_runner import PytestExecution, run_pytest_suite
|
| 6 |
+
from .syntax import grade_bug_fix_task, grade_syntax_task, grade_task
|
| 7 |
+
|
| 8 |
+
__all__ = [
|
| 9 |
+
"PytestExecution",
|
| 10 |
+
"clamp_score",
|
| 11 |
+
"grade_bug_fix_task",
|
| 12 |
+
"grade_optimization_task",
|
| 13 |
+
"grade_syntax_task",
|
| 14 |
+
"grade_task",
|
| 15 |
+
"run_pytest_suite",
|
| 16 |
+
]
|
graders/common.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Shared deterministic scoring helpers."""
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
import ast
|
| 6 |
+
import difflib
|
| 7 |
+
import traceback
|
| 8 |
+
from typing import Tuple
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def clamp_score(value: float) -> float:
|
| 12 |
+
"""Clamp any scalar score into the required 0..1 interval."""
|
| 13 |
+
|
| 14 |
+
return max(0.0, min(1.0, round(value, 6)))
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def syntax_error_message(code: str) -> str:
|
| 18 |
+
"""Return a concise syntax error string or an empty string."""
|
| 19 |
+
|
| 20 |
+
try:
|
| 21 |
+
ast.parse(code)
|
| 22 |
+
except SyntaxError as exc:
|
| 23 |
+
return f"{exc.msg} (line {exc.lineno}, column {exc.offset})"
|
| 24 |
+
except Exception: # pragma: no cover
|
| 25 |
+
return traceback.format_exc(limit=1).strip()
|
| 26 |
+
return ""
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def compiles(code: str) -> bool:
|
| 30 |
+
"""Return whether the code parses and compiles."""
|
| 31 |
+
|
| 32 |
+
try:
|
| 33 |
+
compile(code, "<candidate>", "exec")
|
| 34 |
+
except Exception:
|
| 35 |
+
return False
|
| 36 |
+
return True
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def normalized_diff_score(code: str, reference_code: str) -> float:
|
| 40 |
+
"""Score textual similarity to the reference solution."""
|
| 41 |
+
|
| 42 |
+
ratio = difflib.SequenceMatcher(
|
| 43 |
+
a="".join(code.split()),
|
| 44 |
+
b="".join(reference_code.split()),
|
| 45 |
+
).ratio()
|
| 46 |
+
return clamp_score(ratio)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def style_score(code: str, max_line_length: int = 88) -> float:
|
| 50 |
+
"""Simple deterministic PEP8-inspired style score."""
|
| 51 |
+
|
| 52 |
+
lines = code.splitlines() or [""]
|
| 53 |
+
line_length_ok = sum(1 for line in lines if len(line) <= max_line_length) / len(lines)
|
| 54 |
+
tab_ok = 1.0 if all("\t" not in line for line in lines) else 0.0
|
| 55 |
+
trailing_ws_ok = 1.0 if all(line == line.rstrip() for line in lines) else 0.0
|
| 56 |
+
return clamp_score((line_length_ok * 0.6) + (tab_ok * 0.2) + (trailing_ws_ok * 0.2))
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def nested_loop_depth(tree: ast.AST) -> int:
|
| 60 |
+
"""Return the maximum nested loop depth in the AST."""
|
| 61 |
+
|
| 62 |
+
best = 0
|
| 63 |
+
|
| 64 |
+
def walk(node: ast.AST, depth: int) -> None:
|
| 65 |
+
nonlocal best
|
| 66 |
+
if isinstance(node, (ast.For, ast.AsyncFor, ast.While)):
|
| 67 |
+
depth += 1
|
| 68 |
+
best = max(best, depth)
|
| 69 |
+
for child in ast.iter_child_nodes(node):
|
| 70 |
+
walk(child, depth)
|
| 71 |
+
|
| 72 |
+
walk(tree, 0)
|
| 73 |
+
return best
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def compile_tree(code: str) -> Tuple[ast.AST | None, str]:
|
| 77 |
+
"""Return AST tree and optional parse error."""
|
| 78 |
+
|
| 79 |
+
try:
|
| 80 |
+
return ast.parse(code), ""
|
| 81 |
+
except SyntaxError as exc:
|
| 82 |
+
return None, f"{exc.msg} (line {exc.lineno}, column {exc.offset})"
|
graders/optimization.py
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Deterministic grading for optimization and refactor tasks."""
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
import json
|
| 6 |
+
import subprocess
|
| 7 |
+
import sys
|
| 8 |
+
import tempfile
|
| 9 |
+
from pathlib import Path
|
| 10 |
+
|
| 11 |
+
from graders.common import clamp_score, compile_tree, nested_loop_depth, style_score
|
| 12 |
+
from graders.pytest_runner import run_pytest_suite
|
| 13 |
+
from models import TaskGrade
|
| 14 |
+
from tasks.task_bank import TaskSpec
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def _benchmark_script(task: TaskSpec) -> str:
|
| 18 |
+
return f"""import json
|
| 19 |
+
import time
|
| 20 |
+
from candidate import {task.benchmark_entrypoint}
|
| 21 |
+
|
| 22 |
+
{task.benchmark_builder}
|
| 23 |
+
|
| 24 |
+
events = build_benchmark_events()
|
| 25 |
+
start = time.perf_counter()
|
| 26 |
+
for _ in range({task.benchmark_repeats}):
|
| 27 |
+
result = {task.benchmark_entrypoint}(events)
|
| 28 |
+
elapsed = time.perf_counter() - start
|
| 29 |
+
Path = __import__("pathlib").Path
|
| 30 |
+
Path("benchmark.json").write_text(json.dumps({{"elapsed": elapsed, "rows": len(result)}}), encoding="utf-8")
|
| 31 |
+
"""
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def benchmark_runtime(candidate_code: str, task: TaskSpec) -> tuple[float, bool, str]:
|
| 35 |
+
"""Benchmark runtime deterministically against the starter implementation."""
|
| 36 |
+
|
| 37 |
+
assert task.benchmark_entrypoint is not None
|
| 38 |
+
with tempfile.TemporaryDirectory(prefix="python-code-review-bench-") as temp_dir:
|
| 39 |
+
temp_path = Path(temp_dir)
|
| 40 |
+
(temp_path / "candidate.py").write_text(candidate_code, encoding="utf-8")
|
| 41 |
+
(temp_path / "starter.py").write_text(task.starter_code, encoding="utf-8")
|
| 42 |
+
(temp_path / "candidate_runner.py").write_text(_benchmark_script(task), encoding="utf-8")
|
| 43 |
+
|
| 44 |
+
starter_script = _benchmark_script(task).replace("from candidate import", "from starter import")
|
| 45 |
+
(temp_path / "starter_runner.py").write_text(starter_script, encoding="utf-8")
|
| 46 |
+
|
| 47 |
+
try:
|
| 48 |
+
starter_run = subprocess.run(
|
| 49 |
+
[sys.executable, "starter_runner.py"],
|
| 50 |
+
cwd=temp_path,
|
| 51 |
+
capture_output=True,
|
| 52 |
+
text=True,
|
| 53 |
+
timeout=task.benchmark_timeout_s,
|
| 54 |
+
check=False,
|
| 55 |
+
)
|
| 56 |
+
starter_payload = json.loads((temp_path / "benchmark.json").read_text(encoding="utf-8"))
|
| 57 |
+
|
| 58 |
+
candidate_run = subprocess.run(
|
| 59 |
+
[sys.executable, "candidate_runner.py"],
|
| 60 |
+
cwd=temp_path,
|
| 61 |
+
capture_output=True,
|
| 62 |
+
text=True,
|
| 63 |
+
timeout=task.benchmark_timeout_s,
|
| 64 |
+
check=False,
|
| 65 |
+
)
|
| 66 |
+
candidate_payload = json.loads((temp_path / "benchmark.json").read_text(encoding="utf-8"))
|
| 67 |
+
except subprocess.TimeoutExpired as exc:
|
| 68 |
+
output = (exc.stdout or "") + (exc.stderr or "")
|
| 69 |
+
return 0.0, True, (output or "benchmark timed out").strip()
|
| 70 |
+
except Exception as exc: # pragma: no cover
|
| 71 |
+
return 0.0, False, str(exc)
|
| 72 |
+
|
| 73 |
+
starter_elapsed = max(float(starter_payload["elapsed"]), 1e-9)
|
| 74 |
+
candidate_elapsed = max(float(candidate_payload["elapsed"]), 1e-9)
|
| 75 |
+
speedup = starter_elapsed / candidate_elapsed
|
| 76 |
+
runtime_score = clamp_score(min((speedup - 1.0) / 3.0, 1.0))
|
| 77 |
+
output = "\n".join(
|
| 78 |
+
part
|
| 79 |
+
for part in [
|
| 80 |
+
starter_run.stdout.strip(),
|
| 81 |
+
starter_run.stderr.strip(),
|
| 82 |
+
candidate_run.stdout.strip(),
|
| 83 |
+
candidate_run.stderr.strip(),
|
| 84 |
+
f"starter={starter_elapsed:.6f}s candidate={candidate_elapsed:.6f}s speedup={speedup:.2f}x",
|
| 85 |
+
]
|
| 86 |
+
if part
|
| 87 |
+
)
|
| 88 |
+
return runtime_score, False, output
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def ast_quality_score(code: str, task: TaskSpec) -> float:
|
| 92 |
+
"""Score maintainability and algorithmic structure."""
|
| 93 |
+
|
| 94 |
+
tree, parse_error = compile_tree(code)
|
| 95 |
+
if tree is None:
|
| 96 |
+
return 0.0
|
| 97 |
+
|
| 98 |
+
import ast
|
| 99 |
+
|
| 100 |
+
function_node = next(
|
| 101 |
+
(node for node in tree.body if isinstance(node, (ast.FunctionDef, ast.AsyncFunctionDef))),
|
| 102 |
+
None,
|
| 103 |
+
)
|
| 104 |
+
docstring_points = 0.2 if function_node and ast.get_docstring(function_node, clean=False) else 0.0
|
| 105 |
+
nested_points = 0.4 if nested_loop_depth(tree) <= 1 else 0.0
|
| 106 |
+
marker_points = 0.0
|
| 107 |
+
for marker in task.expected_quality_markers:
|
| 108 |
+
if marker in code:
|
| 109 |
+
marker_points += 0.2
|
| 110 |
+
return clamp_score(docstring_points + nested_points + marker_points)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def grade_optimization_task(candidate_code: str, task: TaskSpec) -> TaskGrade:
|
| 114 |
+
"""Grade optimization tasks using correctness, runtime, AST quality, and style."""
|
| 115 |
+
|
| 116 |
+
execution = run_pytest_suite(
|
| 117 |
+
candidate_code,
|
| 118 |
+
[*task.visible_tests, *task.hidden_tests],
|
| 119 |
+
timeout_s=task.benchmark_timeout_s,
|
| 120 |
+
)
|
| 121 |
+
test_fraction = execution.passed / execution.total if execution.total else 0.0
|
| 122 |
+
|
| 123 |
+
if execution.timed_out:
|
| 124 |
+
return TaskGrade(
|
| 125 |
+
score=0.0,
|
| 126 |
+
tests_passed=execution.passed,
|
| 127 |
+
tests_total=execution.total,
|
| 128 |
+
timed_out=True,
|
| 129 |
+
details={"tests": execution.output},
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
runtime_score, timed_out, benchmark_output = benchmark_runtime(candidate_code, task)
|
| 133 |
+
if timed_out:
|
| 134 |
+
return TaskGrade(
|
| 135 |
+
score=0.0,
|
| 136 |
+
tests_passed=execution.passed,
|
| 137 |
+
tests_total=execution.total,
|
| 138 |
+
timed_out=True,
|
| 139 |
+
details={"tests": execution.output, "benchmark": benchmark_output},
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
quality_score = ast_quality_score(candidate_code, task)
|
| 143 |
+
pep8_score = style_score(candidate_code, task.style_max_line_length)
|
| 144 |
+
score = clamp_score(
|
| 145 |
+
(0.5 * test_fraction)
|
| 146 |
+
+ (0.3 * runtime_score)
|
| 147 |
+
+ (0.15 * quality_score)
|
| 148 |
+
+ (0.05 * pep8_score)
|
| 149 |
+
)
|
| 150 |
+
return TaskGrade(
|
| 151 |
+
score=score,
|
| 152 |
+
syntax_score=1.0,
|
| 153 |
+
tests_passed=execution.passed,
|
| 154 |
+
tests_total=execution.total,
|
| 155 |
+
quality_score=quality_score,
|
| 156 |
+
details={
|
| 157 |
+
"tests": execution.output,
|
| 158 |
+
"benchmark": benchmark_output,
|
| 159 |
+
"test_fraction": round(test_fraction, 4),
|
| 160 |
+
"runtime_score": round(runtime_score, 4),
|
| 161 |
+
"style_score": round(pep8_score, 4),
|
| 162 |
+
},
|
| 163 |
+
)
|
graders/pytest_runner.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Helpers for deterministic pytest execution in temp sandboxes."""
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
import json
|
| 6 |
+
import subprocess
|
| 7 |
+
import sys
|
| 8 |
+
import tempfile
|
| 9 |
+
from dataclasses import dataclass
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
from typing import Iterable
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@dataclass(frozen=True)
|
| 15 |
+
class PytestExecution:
|
| 16 |
+
"""Exact pytest execution summary."""
|
| 17 |
+
|
| 18 |
+
passed: int
|
| 19 |
+
failed: int
|
| 20 |
+
total: int
|
| 21 |
+
timed_out: bool
|
| 22 |
+
output: str
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def _runner_script() -> str:
|
| 26 |
+
return """import json
|
| 27 |
+
import pathlib
|
| 28 |
+
import pytest
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class Collector:
|
| 32 |
+
def __init__(self) -> None:
|
| 33 |
+
self.passed = 0
|
| 34 |
+
self.failed = 0
|
| 35 |
+
|
| 36 |
+
def pytest_runtest_logreport(self, report):
|
| 37 |
+
if report.when != "call":
|
| 38 |
+
return
|
| 39 |
+
if report.passed:
|
| 40 |
+
self.passed += 1
|
| 41 |
+
elif report.failed:
|
| 42 |
+
self.failed += 1
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
collector = Collector()
|
| 46 |
+
exit_code = pytest.main(["-q", "test_candidate.py"], plugins=[collector])
|
| 47 |
+
payload = {
|
| 48 |
+
"passed": collector.passed,
|
| 49 |
+
"failed": collector.failed,
|
| 50 |
+
"exit_code": int(exit_code),
|
| 51 |
+
}
|
| 52 |
+
pathlib.Path("pytest_results.json").write_text(json.dumps(payload), encoding="utf-8")
|
| 53 |
+
"""
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def run_pytest_suite(candidate_code: str, tests: Iterable[str], timeout_s: float = 3.0) -> PytestExecution:
|
| 57 |
+
"""Run a pytest suite against candidate.py and return structured results."""
|
| 58 |
+
|
| 59 |
+
test_cases = list(tests)
|
| 60 |
+
with tempfile.TemporaryDirectory(prefix="python-code-review-") as temp_dir:
|
| 61 |
+
temp_path = Path(temp_dir)
|
| 62 |
+
(temp_path / "candidate.py").write_text(candidate_code, encoding="utf-8")
|
| 63 |
+
(temp_path / "test_candidate.py").write_text("\n\n".join(test_cases), encoding="utf-8")
|
| 64 |
+
(temp_path / "runner.py").write_text(_runner_script(), encoding="utf-8")
|
| 65 |
+
|
| 66 |
+
try:
|
| 67 |
+
completed = subprocess.run(
|
| 68 |
+
[sys.executable, "runner.py"],
|
| 69 |
+
cwd=temp_path,
|
| 70 |
+
capture_output=True,
|
| 71 |
+
text=True,
|
| 72 |
+
timeout=timeout_s,
|
| 73 |
+
check=False,
|
| 74 |
+
)
|
| 75 |
+
except subprocess.TimeoutExpired as exc:
|
| 76 |
+
output = (exc.stdout or "") + (exc.stderr or "")
|
| 77 |
+
return PytestExecution(
|
| 78 |
+
passed=0,
|
| 79 |
+
failed=max(len(test_cases), 1),
|
| 80 |
+
total=max(len(test_cases), 1),
|
| 81 |
+
timed_out=True,
|
| 82 |
+
output=(output or "pytest timed out").strip(),
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
result_path = temp_path / "pytest_results.json"
|
| 86 |
+
if not result_path.exists():
|
| 87 |
+
output = (completed.stdout or "") + (completed.stderr or "")
|
| 88 |
+
total = max(len(test_cases), 1)
|
| 89 |
+
return PytestExecution(
|
| 90 |
+
passed=0,
|
| 91 |
+
failed=total,
|
| 92 |
+
total=total,
|
| 93 |
+
timed_out=False,
|
| 94 |
+
output=output.strip(),
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
payload = json.loads(result_path.read_text(encoding="utf-8"))
|
| 98 |
+
passed = int(payload.get("passed", 0))
|
| 99 |
+
failed = int(payload.get("failed", 0))
|
| 100 |
+
total = max(passed + failed, len(test_cases))
|
| 101 |
+
output = ((completed.stdout or "") + (completed.stderr or "")).strip()
|
| 102 |
+
return PytestExecution(
|
| 103 |
+
passed=passed,
|
| 104 |
+
failed=failed,
|
| 105 |
+
total=total,
|
| 106 |
+
timed_out=False,
|
| 107 |
+
output=output,
|
| 108 |
+
)
|
graders/syntax.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Task graders for syntax and bug-fix tasks."""
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
from graders.common import clamp_score, compiles, normalized_diff_score, style_score, syntax_error_message
|
| 6 |
+
from graders.optimization import grade_optimization_task
|
| 7 |
+
from graders.pytest_runner import run_pytest_suite
|
| 8 |
+
from models import TaskGrade
|
| 9 |
+
from tasks.task_bank import TaskSpec
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def grade_syntax_task(candidate_code: str, task: TaskSpec) -> TaskGrade:
|
| 13 |
+
"""Grade syntax repair tasks with partial credit for progress toward the reference."""
|
| 14 |
+
|
| 15 |
+
error = syntax_error_message(candidate_code)
|
| 16 |
+
diff_score = normalized_diff_score(candidate_code, task.reference_code)
|
| 17 |
+
style_base = style_score(candidate_code, task.style_max_line_length)
|
| 18 |
+
|
| 19 |
+
if not error:
|
| 20 |
+
return TaskGrade(
|
| 21 |
+
score=1.0,
|
| 22 |
+
syntax_score=1.0,
|
| 23 |
+
quality_score=style_base,
|
| 24 |
+
details={"compile_error": ""},
|
| 25 |
+
)
|
| 26 |
+
|
| 27 |
+
partial = clamp_score(0.15 + (0.55 * diff_score))
|
| 28 |
+
return TaskGrade(
|
| 29 |
+
score=partial,
|
| 30 |
+
syntax_score=0.0,
|
| 31 |
+
quality_score=diff_score * style_base,
|
| 32 |
+
details={"compile_error": error},
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def grade_bug_fix_task(candidate_code: str, task: TaskSpec, include_hidden: bool = True) -> TaskGrade:
|
| 37 |
+
"""Grade logic bug tasks with pytest pass fraction."""
|
| 38 |
+
|
| 39 |
+
if not compiles(candidate_code):
|
| 40 |
+
error = syntax_error_message(candidate_code)
|
| 41 |
+
return TaskGrade(score=0.0, syntax_score=0.0, details={"compile_error": error})
|
| 42 |
+
|
| 43 |
+
tests = list(task.visible_tests)
|
| 44 |
+
if include_hidden:
|
| 45 |
+
tests.extend(task.hidden_tests)
|
| 46 |
+
|
| 47 |
+
execution = run_pytest_suite(candidate_code, tests, timeout_s=3.0)
|
| 48 |
+
if execution.timed_out:
|
| 49 |
+
return TaskGrade(
|
| 50 |
+
score=0.0,
|
| 51 |
+
syntax_score=1.0,
|
| 52 |
+
tests_passed=execution.passed,
|
| 53 |
+
tests_total=execution.total,
|
| 54 |
+
timed_out=True,
|
| 55 |
+
details={"compile_error": "", "tests": execution.output},
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
pass_fraction = execution.passed / execution.total if execution.total else 0.0
|
| 59 |
+
quality = style_score(candidate_code, task.style_max_line_length)
|
| 60 |
+
|
| 61 |
+
return TaskGrade(
|
| 62 |
+
score=clamp_score(pass_fraction),
|
| 63 |
+
syntax_score=1.0,
|
| 64 |
+
tests_passed=execution.passed,
|
| 65 |
+
tests_total=execution.total,
|
| 66 |
+
quality_score=quality,
|
| 67 |
+
details={"compile_error": "", "tests": execution.output},
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def grade_task(candidate_code: str, task: TaskSpec, include_hidden: bool = True) -> TaskGrade:
|
| 72 |
+
"""Dispatch to the correct deterministic grader for one task."""
|
| 73 |
+
|
| 74 |
+
if task.task_kind == "syntax_fix":
|
| 75 |
+
return grade_syntax_task(candidate_code, task)
|
| 76 |
+
if task.task_kind == "bug_fix":
|
| 77 |
+
return grade_bug_fix_task(candidate_code, task, include_hidden=include_hidden)
|
| 78 |
+
return grade_optimization_task(candidate_code, task)
|
inference.py
ADDED
|
@@ -0,0 +1,287 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
"""
|
| 3 |
+
Baseline inference script for python_code_review_env.
|
| 4 |
+
|
| 5 |
+
Demonstrates how to run an OpenEnv environment using OpenAI-compatible API,
|
| 6 |
+
supporting free/open models like Gemini, DeepSeek, Together AI, OpenRouter, etc.
|
| 7 |
+
|
| 8 |
+
Usage:
|
| 9 |
+
# Using Gemini (free tier)
|
| 10 |
+
export OPENAI_API_KEY="your-gemini-api-key"
|
| 11 |
+
python inference.py --base-url "https://generativelanguage.googleapis.com/openai/" --model "gemini-2.0-flash"
|
| 12 |
+
|
| 13 |
+
# Using DeepSeek (free tier)
|
| 14 |
+
export OPENAI_API_KEY="your-deepseek-api-key"
|
| 15 |
+
python inference.py --base-url "https://api.deepseek.com" --model "deepseek-chat"
|
| 16 |
+
|
| 17 |
+
# Using Together AI
|
| 18 |
+
export OPENAI_API_KEY="your-together-api-key"
|
| 19 |
+
python inference.py --base-url "https://api.together.xyz/v1" --model "deepseek-ai/deepseek-chat"
|
| 20 |
+
|
| 21 |
+
# Using local OpenAI (default)
|
| 22 |
+
python inference.py --base-url "http://localhost:8000/v1" --model "gpt-3.5-turbo"
|
| 23 |
+
"""
|
| 24 |
+
|
| 25 |
+
from __future__ import annotations
|
| 26 |
+
|
| 27 |
+
import argparse
|
| 28 |
+
import json
|
| 29 |
+
import os
|
| 30 |
+
import sys
|
| 31 |
+
from typing import Optional
|
| 32 |
+
|
| 33 |
+
from openai import OpenAI
|
| 34 |
+
|
| 35 |
+
# Import environment and models
|
| 36 |
+
from server.env import PythonCodeReviewEnvironment
|
| 37 |
+
from models import (
|
| 38 |
+
PythonCodeReviewAction,
|
| 39 |
+
PythonCodeReviewObservation,
|
| 40 |
+
)
|
| 41 |
+
from tasks import task_ids
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def get_model_config(base_url: Optional[str], model: str, api_key: Optional[str]) -> tuple[str, str, str]:
|
| 45 |
+
"""Determine API configuration from environment or arguments."""
|
| 46 |
+
|
| 47 |
+
# API Key
|
| 48 |
+
final_api_key = api_key or os.getenv("OPENAI_API_KEY", "")
|
| 49 |
+
if not final_api_key:
|
| 50 |
+
print("Warning: OPENAI_API_KEY not set. Using dummy key for local testing.")
|
| 51 |
+
final_api_key = "sk-test"
|
| 52 |
+
|
| 53 |
+
# Base URL
|
| 54 |
+
final_base_url = base_url or os.getenv("OPENAI_API_BASE", "http://localhost:8000/v1")
|
| 55 |
+
|
| 56 |
+
# Model
|
| 57 |
+
final_model = model or os.getenv("MODEL_NAME", "gpt-3.5-turbo")
|
| 58 |
+
|
| 59 |
+
return final_base_url, final_model, final_api_key
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def build_prompt_for_task(observation: PythonCodeReviewObservation) -> str:
|
| 63 |
+
"""Construct task-specific prompt for the LLM."""
|
| 64 |
+
|
| 65 |
+
return f"""You are an expert Python code reviewer. Your job is to fix and improve Python code.
|
| 66 |
+
|
| 67 |
+
TASK: {observation.task_description}
|
| 68 |
+
|
| 69 |
+
DIFFICULTY: {observation.difficulty.upper()}
|
| 70 |
+
|
| 71 |
+
VISIBLE TEST CASES:
|
| 72 |
+
{chr(10).join(f"- {test}" for test in observation.visible_tests) or "- No visible tests"}
|
| 73 |
+
|
| 74 |
+
CURRENT CODE:
|
| 75 |
+
```python
|
| 76 |
+
{observation.current_code}
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
{f"ERRORS: {observation.errors}" if observation.errors else ""}
|
| 80 |
+
|
| 81 |
+
{f"TEST RESULTS: {observation.test_results}" if observation.test_results else ""}
|
| 82 |
+
|
| 83 |
+
You have {observation.attempts_remaining} attempts left.
|
| 84 |
+
Current score: {observation.score:.3f}
|
| 85 |
+
|
| 86 |
+
Analyze the code and decide what to do next:
|
| 87 |
+
1. If you see syntax errors, provide fixed code
|
| 88 |
+
2. If tests are failing, analyze why and fix logic
|
| 89 |
+
3. If code looks good, submit your solution
|
| 90 |
+
4. For optimization tasks, improve efficiency while keeping tests passing
|
| 91 |
+
|
| 92 |
+
Respond ONLY with a JSON object in this exact format (no markdown, no backticks):
|
| 93 |
+
{{
|
| 94 |
+
"action_type": "analyze_code|edit_code|run_tests|submit_solution",
|
| 95 |
+
"code": "...only if action_type is edit_code...",
|
| 96 |
+
"reasoning": "brief explanation"
|
| 97 |
+
}}
|
| 98 |
+
"""
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def run_task_episode(
|
| 102 |
+
env: PythonCodeReviewEnvironment,
|
| 103 |
+
task_id: str,
|
| 104 |
+
client: OpenAI,
|
| 105 |
+
model: str,
|
| 106 |
+
max_steps: int = 10,
|
| 107 |
+
verbose: bool = True,
|
| 108 |
+
) -> float:
|
| 109 |
+
"""Run one complete task episode and return the score."""
|
| 110 |
+
|
| 111 |
+
# Reset environment for this task
|
| 112 |
+
observation = env.reset(task_id=task_id)
|
| 113 |
+
total_reward = 0.0
|
| 114 |
+
step_count = 0
|
| 115 |
+
|
| 116 |
+
if verbose:
|
| 117 |
+
print(f"\n{'='*70}")
|
| 118 |
+
print(f"TASK: {task_id} ({observation.difficulty})")
|
| 119 |
+
print(f"{'='*70}")
|
| 120 |
+
|
| 121 |
+
while not observation.done and step_count < max_steps:
|
| 122 |
+
step_count += 1
|
| 123 |
+
|
| 124 |
+
# Get action from LLM
|
| 125 |
+
try:
|
| 126 |
+
prompt = build_prompt_for_task(observation)
|
| 127 |
+
|
| 128 |
+
response = client.chat.completions.create(
|
| 129 |
+
model=model,
|
| 130 |
+
messages=[{"role": "user", "content": prompt}],
|
| 131 |
+
temperature=0.7,
|
| 132 |
+
max_tokens=2000,
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
response_text = response.choices[0].message.content or ""
|
| 136 |
+
|
| 137 |
+
# Try to parse JSON from response
|
| 138 |
+
try:
|
| 139 |
+
# Find JSON in the response
|
| 140 |
+
json_start = response_text.find("{")
|
| 141 |
+
json_end = response_text.rfind("}") + 1
|
| 142 |
+
if json_start >= 0 and json_end > json_start:
|
| 143 |
+
json_str = response_text[json_start:json_end]
|
| 144 |
+
action_dict = json.loads(json_str)
|
| 145 |
+
else:
|
| 146 |
+
raise ValueError("No JSON found in response")
|
| 147 |
+
except (json.JSONDecodeError, ValueError) as e:
|
| 148 |
+
if verbose:
|
| 149 |
+
print(f"Step {step_count}: Failed to parse response: {e}")
|
| 150 |
+
print(f"Response: {response_text[:200]}")
|
| 151 |
+
# Fallback to analyze_code
|
| 152 |
+
action_dict = {"action_type": "analyze_code"}
|
| 153 |
+
|
| 154 |
+
# Build action
|
| 155 |
+
action = PythonCodeReviewAction(
|
| 156 |
+
action_type=action_dict.get("action_type", "analyze_code"),
|
| 157 |
+
code=action_dict.get("code"),
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
except Exception as e:
|
| 161 |
+
if verbose:
|
| 162 |
+
print(f"Step {step_count}: Error getting LLM response: {e}")
|
| 163 |
+
# Fallback action
|
| 164 |
+
action = PythonCodeReviewAction(action_type="analyze_code")
|
| 165 |
+
|
| 166 |
+
# Execute action
|
| 167 |
+
observation = env.step(action)
|
| 168 |
+
total_reward += observation.reward.value
|
| 169 |
+
|
| 170 |
+
if verbose:
|
| 171 |
+
print(f"Step {step_count}: {action.action_type}")
|
| 172 |
+
if observation.reward.value != 0:
|
| 173 |
+
print(f" Reward: {observation.reward.value:+.4f} ({observation.reward.reason})")
|
| 174 |
+
if observation.errors:
|
| 175 |
+
print(f" Errors: {observation.errors}")
|
| 176 |
+
if observation.test_results:
|
| 177 |
+
print(f" Tests: {observation.test_results}")
|
| 178 |
+
|
| 179 |
+
final_score = observation.score
|
| 180 |
+
if verbose:
|
| 181 |
+
print(f"\nFinal Score: {final_score:.3f} (Total Reward: {total_reward:.4f})")
|
| 182 |
+
|
| 183 |
+
return final_score
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
def main(args: Optional[list[str]] = None) -> None:
|
| 187 |
+
"""Run baseline evaluation on all tasks."""
|
| 188 |
+
|
| 189 |
+
parser = argparse.ArgumentParser(
|
| 190 |
+
description="Baseline inference for python_code_review_env",
|
| 191 |
+
formatter_class=argparse.RawDescriptionHelpFormatter,
|
| 192 |
+
epilog=__doc__,
|
| 193 |
+
)
|
| 194 |
+
parser.add_argument(
|
| 195 |
+
"--base-url",
|
| 196 |
+
default=None,
|
| 197 |
+
help="API base URL (default: OPENAI_API_BASE or http://localhost:8000/v1)",
|
| 198 |
+
)
|
| 199 |
+
parser.add_argument(
|
| 200 |
+
"--model",
|
| 201 |
+
default=None,
|
| 202 |
+
help="Model name (default: MODEL_NAME or gpt-3.5-turbo)",
|
| 203 |
+
)
|
| 204 |
+
parser.add_argument(
|
| 205 |
+
"--api-key",
|
| 206 |
+
default=None,
|
| 207 |
+
help="API key (default: OPENAI_API_KEY)",
|
| 208 |
+
)
|
| 209 |
+
parser.add_argument(
|
| 210 |
+
"--task",
|
| 211 |
+
default=None,
|
| 212 |
+
help="Run single task instead of all",
|
| 213 |
+
)
|
| 214 |
+
parser.add_argument(
|
| 215 |
+
"--quiet",
|
| 216 |
+
action="store_true",
|
| 217 |
+
help="Minimize output",
|
| 218 |
+
)
|
| 219 |
+
parser.add_argument(
|
| 220 |
+
"--max-steps",
|
| 221 |
+
type=int,
|
| 222 |
+
default=10,
|
| 223 |
+
help="Max steps per episode",
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
parsed = parser.parse_args(args)
|
| 227 |
+
|
| 228 |
+
# Get configuration
|
| 229 |
+
base_url, model, api_key = get_model_config(
|
| 230 |
+
parsed.base_url,
|
| 231 |
+
parsed.model,
|
| 232 |
+
parsed.api_key,
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
print(f"Configuration:")
|
| 236 |
+
print(f" Base URL: {base_url}")
|
| 237 |
+
print(f" Model: {model}")
|
| 238 |
+
print(f" Max steps per episode: {parsed.max_steps}")
|
| 239 |
+
print()
|
| 240 |
+
|
| 241 |
+
# Initialize client
|
| 242 |
+
try:
|
| 243 |
+
client = OpenAI(api_key=api_key, base_url=base_url)
|
| 244 |
+
# Test connection
|
| 245 |
+
client.models.list()
|
| 246 |
+
except Exception as e:
|
| 247 |
+
print(f"Warning: Could not verify API connection: {e}")
|
| 248 |
+
print("Proceeding anyway...")
|
| 249 |
+
|
| 250 |
+
# Initialize environment
|
| 251 |
+
env = PythonCodeReviewEnvironment()
|
| 252 |
+
|
| 253 |
+
# Run task(s)
|
| 254 |
+
tasks_to_run = [parsed.task] if parsed.task else list(task_ids())
|
| 255 |
+
scores = {}
|
| 256 |
+
|
| 257 |
+
for task_id in tasks_to_run:
|
| 258 |
+
try:
|
| 259 |
+
score = run_task_episode(
|
| 260 |
+
env,
|
| 261 |
+
task_id,
|
| 262 |
+
client,
|
| 263 |
+
model,
|
| 264 |
+
max_steps=parsed.max_steps,
|
| 265 |
+
verbose=not parsed.quiet,
|
| 266 |
+
)
|
| 267 |
+
scores[task_id] = score
|
| 268 |
+
except Exception as e:
|
| 269 |
+
print(f"Error running task {task_id}: {e}")
|
| 270 |
+
scores[task_id] = 0.0
|
| 271 |
+
|
| 272 |
+
# Print summary
|
| 273 |
+
print(f"\n{'='*70}")
|
| 274 |
+
print("SUMMARY")
|
| 275 |
+
print(f"{'='*70}")
|
| 276 |
+
for task_id, score in scores.items():
|
| 277 |
+
print(f"{task_id:30s} : {score:.3f}")
|
| 278 |
+
|
| 279 |
+
if len(scores) > 1:
|
| 280 |
+
avg_score = sum(scores.values()) / len(scores)
|
| 281 |
+
print(f"{'Average Score':30s} : {avg_score:.3f}")
|
| 282 |
+
|
| 283 |
+
return 0 if all(s > 0 for s in scores.values()) else 1
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
if __name__ == "__main__":
|
| 287 |
+
sys.exit(main())
|
models.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Typed models for Python code review and repair environment."""
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
from typing import Any, Dict, List, Literal, Optional
|
| 6 |
+
|
| 7 |
+
from pydantic import BaseModel, Field
|
| 8 |
+
|
| 9 |
+
from openenv.core.env_server.types import Action, Observation, State
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
Difficulty = Literal["easy", "medium", "hard"]
|
| 13 |
+
TaskKind = Literal["syntax_fix", "bug_fix", "optimization"]
|
| 14 |
+
ActionType = Literal["analyze_code", "edit_code", "run_tests", "submit_solution"]
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class HistoryEntry(BaseModel):
|
| 18 |
+
"""Record of one action taken during an episode."""
|
| 19 |
+
|
| 20 |
+
step: int = Field(..., ge=0)
|
| 21 |
+
action_type: ActionType
|
| 22 |
+
status: str = Field(..., description="Outcome message")
|
| 23 |
+
reward: float = Field(...)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class RewardDetails(BaseModel):
|
| 27 |
+
"""Detailed reward breakdown for transparency."""
|
| 28 |
+
|
| 29 |
+
value: float = Field(..., description="Net scalar reward for this step")
|
| 30 |
+
syntax_reward: float = Field(default=0.0, description="Bonus for fixing syntax")
|
| 31 |
+
test_reward: float = Field(default=0.0, description="Reward from passing tests")
|
| 32 |
+
quality_bonus: float = Field(default=0.0, description="Bonus for code quality improvements")
|
| 33 |
+
correctness_bonus: float = Field(default=0.0, description="Bonus for full correctness")
|
| 34 |
+
invalid_action_penalty: float = Field(default=0.0, description="Penalty for invalid actions")
|
| 35 |
+
timeout_penalty: float = Field(default=0.0, description="Penalty for timeouts")
|
| 36 |
+
reason: str = Field(..., description="Explanation of reward")
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class PythonCodeReviewAction(Action):
|
| 40 |
+
"""Action space for code review environment."""
|
| 41 |
+
|
| 42 |
+
action_type: ActionType = Field(..., description="Type of action to perform")
|
| 43 |
+
code: Optional[str] = Field(default=None, description="New code for edit_code actions")
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class PythonCodeReviewObservation(Observation):
|
| 47 |
+
"""Observation returned by reset() and step()."""
|
| 48 |
+
|
| 49 |
+
task_id: str = Field(..., description="Current task identifier")
|
| 50 |
+
difficulty: Difficulty = Field(..., description="Task difficulty level")
|
| 51 |
+
task_description: str = Field(..., description="Detailed task description")
|
| 52 |
+
current_code: str = Field(..., description="Current code state")
|
| 53 |
+
errors: str = Field(..., description="Syntax/compilation errors, if any")
|
| 54 |
+
test_results: str = Field(..., description="Results from test execution")
|
| 55 |
+
visible_tests: List[str] = Field(default_factory=list, description="Public test cases")
|
| 56 |
+
history: List[HistoryEntry] = Field(default_factory=list, description="Action history")
|
| 57 |
+
attempts_remaining: int = Field(..., ge=0, description="Actions left in episode")
|
| 58 |
+
score: float = Field(..., ge=0.0, le=1.0, description="Current episode score")
|
| 59 |
+
reward: RewardDetails = Field(default_factory=lambda: RewardDetails(value=0.0, reason="Reset"))
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class PythonCodeReviewState(State):
|
| 63 |
+
"""Exposed environment state."""
|
| 64 |
+
|
| 65 |
+
episode_id: str = Field(..., description="Unique episode identifier")
|
| 66 |
+
step_count: int = Field(default=0, ge=0)
|
| 67 |
+
task_id: Optional[str] = Field(default=None)
|
| 68 |
+
difficulty: Optional[Difficulty] = Field(default=None)
|
| 69 |
+
task_kind: Optional[TaskKind] = Field(default=None)
|
| 70 |
+
attempts_remaining: int = Field(default=0, ge=0)
|
| 71 |
+
current_code: str = Field(default="")
|
| 72 |
+
errors: str = Field(default="")
|
| 73 |
+
test_results: str = Field(default="")
|
| 74 |
+
history: List[HistoryEntry] = Field(default_factory=list)
|
| 75 |
+
score: float = Field(default=0.0, ge=0.0, le=1.0)
|
| 76 |
+
done: bool = Field(default=False)
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class TaskDescriptor(BaseModel):
|
| 80 |
+
"""Public task metadata."""
|
| 81 |
+
|
| 82 |
+
task_id: str = Field(..., description="Stable task identifier")
|
| 83 |
+
title: str = Field(..., description="Human-readable title")
|
| 84 |
+
difficulty: Difficulty = Field(..., description="Difficulty level")
|
| 85 |
+
task_kind: TaskKind = Field(..., description="Type of task")
|
| 86 |
+
task_description: str = Field(..., description="Full task description")
|
| 87 |
+
starter_code: str = Field(..., description="Initial broken code")
|
| 88 |
+
visible_tests: List[str] = Field(default_factory=list, description="Public test cases")
|
| 89 |
+
max_steps: int = Field(..., ge=1, description="Maximum steps allowed")
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class TaskGrade(BaseModel):
|
| 93 |
+
"""Grading result for task submission."""
|
| 94 |
+
|
| 95 |
+
score: float = Field(..., ge=0.0, le=1.0, description="Overall score")
|
| 96 |
+
syntax_score: float = Field(default=0.0, ge=0.0, le=1.0)
|
| 97 |
+
tests_passed: int = Field(default=0, ge=0)
|
| 98 |
+
tests_total: int = Field(default=0, ge=0)
|
| 99 |
+
quality_score: float = Field(default=0.0, ge=0.0, le=1.0)
|
| 100 |
+
timed_out: bool = Field(default=False)
|
| 101 |
+
details: Dict[str, Any] = Field(default_factory=dict)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class HealthResponse(BaseModel):
|
| 105 |
+
"""Health check response."""
|
| 106 |
+
|
| 107 |
+
status: Literal["ok"] = "ok"
|
| 108 |
+
environment: str = "python_code_review_env"
|
| 109 |
+
task_count: int = Field(default=0, ge=0)
|
openenv.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
spec_version: 1
|
| 2 |
+
name: python_code_review_env
|
| 3 |
+
type: space
|
| 4 |
+
runtime: fastapi
|
| 5 |
+
app: server.app:app
|
| 6 |
+
port: 8000
|
| 7 |
+
|
| 8 |
+
metadata:
|
| 9 |
+
description: "Production-grade Python code review and repair benchmark for OpenEnv"
|
| 10 |
+
domain: code-review
|
| 11 |
+
task_count: 3
|
| 12 |
+
task_ids:
|
| 13 |
+
- syntax-fix-easy
|
| 14 |
+
- bug-fix-medium
|
| 15 |
+
- optimization-hard
|
| 16 |
+
difficulty_levels:
|
| 17 |
+
- easy
|
| 18 |
+
- medium
|
| 19 |
+
- hard
|
| 20 |
+
|
pyproject.toml
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[build-system]
|
| 2 |
+
requires = ["setuptools>=45", "wheel"]
|
| 3 |
+
build-backend = "setuptools.build_meta"
|
| 4 |
+
|
| 5 |
+
[project]
|
| 6 |
+
name = "openenv-python_env"
|
| 7 |
+
version = "0.2.0"
|
| 8 |
+
description = "Deterministic Python code review and repair benchmark environment for OpenEnv"
|
| 9 |
+
requires-python = ">=3.10"
|
| 10 |
+
dependencies = [
|
| 11 |
+
"openenv-core[core]>=0.2.2",
|
| 12 |
+
"fastapi>=0.115.0",
|
| 13 |
+
"uvicorn>=0.30.0",
|
| 14 |
+
"openai>=1.40.0",
|
| 15 |
+
"pytest>=8.0.0",
|
| 16 |
+
]
|
| 17 |
+
|
| 18 |
+
[project.optional-dependencies]
|
| 19 |
+
dev = [
|
| 20 |
+
"pytest>=8.0.0",
|
| 21 |
+
"pytest-cov>=4.0.0",
|
| 22 |
+
]
|
| 23 |
+
|
| 24 |
+
[project.scripts]
|
| 25 |
+
server = "python_env.server.app:main"
|
| 26 |
+
|
| 27 |
+
[tool.setuptools]
|
| 28 |
+
include-package-data = true
|
| 29 |
+
packages = ["python_env", "python_env.server"]
|
| 30 |
+
package-dir = { "python_env" = ".", "python_env.server" = "server" }
|
| 31 |
+
|
| 32 |
+
[tool.pytest.ini_options]
|
| 33 |
+
testpaths = ["tests"]
|
server/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Server exports for the Python code review environment."""
|
| 2 |
+
|
| 3 |
+
from .code_review_environment import CodeReviewEnvironment, PythonCodeReviewEnvironment, PythonEnvironment
|
| 4 |
+
|
| 5 |
+
__all__ = ["PythonEnvironment", "PythonCodeReviewEnvironment", "CodeReviewEnvironment"]
|
server/app.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""FastAPI application for the Python code review environment."""
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
from fastapi import APIRouter, HTTPException
|
| 8 |
+
from fastapi.responses import RedirectResponse
|
| 9 |
+
|
| 10 |
+
from openenv.core.env_server.http_server import create_app
|
| 11 |
+
|
| 12 |
+
from models import (
|
| 13 |
+
HealthResponse,
|
| 14 |
+
PythonCodeReviewAction,
|
| 15 |
+
PythonCodeReviewObservation,
|
| 16 |
+
PythonCodeReviewState,
|
| 17 |
+
TaskDescriptor,
|
| 18 |
+
TaskGrade,
|
| 19 |
+
)
|
| 20 |
+
from server.env import PythonCodeReviewEnvironment
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
MAX_CONCURRENT_ENVS = int(os.getenv("MAX_CONCURRENT_ENVS", "16"))
|
| 24 |
+
|
| 25 |
+
python_env = PythonCodeReviewEnvironment()
|
| 26 |
+
app = create_app(
|
| 27 |
+
PythonCodeReviewEnvironment,
|
| 28 |
+
PythonCodeReviewAction,
|
| 29 |
+
PythonCodeReviewObservation,
|
| 30 |
+
max_concurrent_envs=MAX_CONCURRENT_ENVS,
|
| 31 |
+
)
|
| 32 |
+
router = APIRouter(tags=["python-code-review"])
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
@router.get("/", include_in_schema=False)
|
| 36 |
+
def root() -> RedirectResponse:
|
| 37 |
+
"""Redirect root to API documentation."""
|
| 38 |
+
return RedirectResponse(url="/docs")
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
@router.get("/health", response_model=HealthResponse)
|
| 42 |
+
def health() -> HealthResponse:
|
| 43 |
+
"""Health check endpoint for deployment monitoring."""
|
| 44 |
+
return python_env.health()
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
@router.get("/tasks", response_model=list)
|
| 48 |
+
def list_tasks() -> list:
|
| 49 |
+
"""List all available deterministic tasks."""
|
| 50 |
+
return python_env.list_task_summaries()
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
@router.get("/tasks/{task_id}", response_model=object)
|
| 54 |
+
def get_task(task_id: str) -> object:
|
| 55 |
+
"""Get a specific task by ID."""
|
| 56 |
+
try:
|
| 57 |
+
return python_env.get_task(task_id)
|
| 58 |
+
except ValueError as exc:
|
| 59 |
+
raise HTTPException(status_code=404, detail=str(exc)) from exc
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
@router.post("/tasks/{task_id}/grade", response_model=TaskGrade)
|
| 63 |
+
def grade_task(task_id: str, payload: PythonCodeReviewAction) -> TaskGrade:
|
| 64 |
+
"""Grade code submission for a task without running an episode."""
|
| 65 |
+
if payload.action_type != "edit_code" or not payload.code:
|
| 66 |
+
raise HTTPException(
|
| 67 |
+
status_code=400,
|
| 68 |
+
detail="Requires action_type='edit_code' with code parameter."
|
| 69 |
+
)
|
| 70 |
+
try:
|
| 71 |
+
return python_env.grade_task_submission(task_id=task_id, code=payload.code)
|
| 72 |
+
except ValueError as exc:
|
| 73 |
+
raise HTTPException(status_code=404, detail=str(exc)) from exc
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
@router.post("/state", response_model=PythonCodeReviewState)
|
| 77 |
+
def get_state_post() -> RedirectResponse:
|
| 78 |
+
"""Redirect POST /state to GET for compatibility."""
|
| 79 |
+
return RedirectResponse(url="/state", status_code=303)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
app.include_router(router)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def main(host: str = "0.0.0.0", port: int = 8000) -> None:
|
| 86 |
+
"""Run the FastAPI application with uvicorn."""
|
| 87 |
+
import uvicorn
|
| 88 |
+
uvicorn.run(
|
| 89 |
+
app,
|
| 90 |
+
host=os.getenv("HOST", host),
|
| 91 |
+
port=int(os.getenv("PORT", str(port))),
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
if __name__ == "__main__":
|
| 96 |
+
main()
|
| 97 |
+
|
server/code_review_env_environment.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Compatibility shim for older imports."""
|
| 2 |
+
|
| 3 |
+
try:
|
| 4 |
+
from server.code_review_environment import CodeReviewEnvironment
|
| 5 |
+
except ModuleNotFoundError: # pragma: no cover
|
| 6 |
+
from .code_review_environment import CodeReviewEnvironment
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
__all__ = ["CodeReviewEnvironment"]
|
server/code_review_environment.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Compatibility wrapper for older imports."""
|
| 2 |
+
|
| 3 |
+
from .env import CodeReviewEnvironment, PythonCodeReviewEnvironment, PythonEnvironment
|
| 4 |
+
|
| 5 |
+
__all__ = ["CodeReviewEnvironment", "PythonCodeReviewEnvironment", "PythonEnvironment"]
|
server/env.py
ADDED
|
@@ -0,0 +1,640 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Core OpenEnv environment for Python code review and repair tasks."""
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
from typing import List, Optional
|
| 6 |
+
from uuid import uuid4
|
| 7 |
+
|
| 8 |
+
from openenv.core.env_server.interfaces import Environment
|
| 9 |
+
|
| 10 |
+
from graders import grade_task
|
| 11 |
+
from models import (
|
| 12 |
+
HealthResponse,
|
| 13 |
+
HistoryEntry,
|
| 14 |
+
PythonCodeReviewAction,
|
| 15 |
+
PythonCodeReviewObservation,
|
| 16 |
+
PythonCodeReviewState,
|
| 17 |
+
RewardDetails,
|
| 18 |
+
TaskGrade,
|
| 19 |
+
)
|
| 20 |
+
from tasks import TaskSpec, get_task, list_task_descriptors, list_task_summaries, task_ids
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
# Reward shaping constants
|
| 24 |
+
INVALID_ACTION_PENALTY = 0.1
|
| 25 |
+
QUALITY_BONUS_SCALE = 0.15
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class PythonCodeReviewEnvironment(
|
| 29 |
+
Environment[PythonCodeReviewAction, PythonCodeReviewObservation, PythonCodeReviewState]
|
| 30 |
+
):
|
| 31 |
+
"""Production-style environment for reviewing and fixing Python code."""
|
| 32 |
+
|
| 33 |
+
SUPPORTS_CONCURRENT_SESSIONS = True
|
| 34 |
+
|
| 35 |
+
def __init__(self) -> None:
|
| 36 |
+
super().__init__()
|
| 37 |
+
self._task_order = list(task_ids())
|
| 38 |
+
self._task_cursor = -1
|
| 39 |
+
self._task: Optional[TaskSpec] = None
|
| 40 |
+
self._state = PythonCodeReviewState()
|
| 41 |
+
self._done = False
|
| 42 |
+
self._last_status = "Call reset() to start."
|
| 43 |
+
self._last_reward = RewardDetails(value=0.0, reason="Environment initialized.")
|
| 44 |
+
self._best_visible_test_fraction = 0.0
|
| 45 |
+
self._best_quality_score = 0.0
|
| 46 |
+
self._full_correctness_awarded = False
|
| 47 |
+
self._syntax_reward_awarded = False
|
| 48 |
+
|
| 49 |
+
def reset(
|
| 50 |
+
self,
|
| 51 |
+
seed: Optional[int] = None,
|
| 52 |
+
episode_id: Optional[str] = None,
|
| 53 |
+
task_id: Optional[str] = None,
|
| 54 |
+
**_: object,
|
| 55 |
+
) -> PythonCodeReviewObservation:
|
| 56 |
+
"""Reset the environment to the next deterministic task."""
|
| 57 |
+
|
| 58 |
+
del seed
|
| 59 |
+
|
| 60 |
+
# Select task
|
| 61 |
+
if task_id:
|
| 62 |
+
self._task = get_task(task_id)
|
| 63 |
+
self._task_cursor = self._task_order.index(task_id)
|
| 64 |
+
else:
|
| 65 |
+
self._task_cursor = (self._task_cursor + 1) % len(self._task_order)
|
| 66 |
+
self._task = get_task(self._task_order[self._task_cursor])
|
| 67 |
+
|
| 68 |
+
# Reset episode state
|
| 69 |
+
self._done = False
|
| 70 |
+
self._best_visible_test_fraction = 0.0
|
| 71 |
+
self._best_quality_score = 0.0
|
| 72 |
+
self._full_correctness_awarded = False
|
| 73 |
+
self._syntax_reward_awarded = False
|
| 74 |
+
self._last_status = "Inspect the code, edit it, run tests, then submit."
|
| 75 |
+
self._last_reward = RewardDetails(value=0.0, reason="Episode reset.")
|
| 76 |
+
|
| 77 |
+
self._state = PythonCodeReviewState(
|
| 78 |
+
episode_id=episode_id or str(uuid4()),
|
| 79 |
+
step_count=0,
|
| 80 |
+
task_id=self._task.task_id,
|
| 81 |
+
difficulty=self._task.difficulty,
|
| 82 |
+
task_kind=self._task.task_kind,
|
| 83 |
+
attempts_remaining=self._task.max_steps,
|
| 84 |
+
current_code=self._task.starter_code,
|
| 85 |
+
errors="",
|
| 86 |
+
test_results="Not run yet.",
|
| 87 |
+
history=[],
|
| 88 |
+
score=0.0,
|
| 89 |
+
done=False,
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
return self._build_observation()
|
| 93 |
+
|
| 94 |
+
def step(
|
| 95 |
+
self,
|
| 96 |
+
action: PythonCodeReviewAction,
|
| 97 |
+
timeout_s: Optional[float] = None,
|
| 98 |
+
**_: object,
|
| 99 |
+
) -> PythonCodeReviewObservation:
|
| 100 |
+
"""Apply one structured action."""
|
| 101 |
+
|
| 102 |
+
del timeout_s
|
| 103 |
+
|
| 104 |
+
if self._task is None:
|
| 105 |
+
return self.reset()
|
| 106 |
+
|
| 107 |
+
if self._done:
|
| 108 |
+
self._last_reward = RewardDetails(
|
| 109 |
+
value=-INVALID_ACTION_PENALTY,
|
| 110 |
+
invalid_action_penalty=INVALID_ACTION_PENALTY,
|
| 111 |
+
reason="Episode already completed.",
|
| 112 |
+
)
|
| 113 |
+
self._last_status = "Episode already completed. Call reset() to continue."
|
| 114 |
+
return self._build_observation()
|
| 115 |
+
|
| 116 |
+
self._state.step_count += 1
|
| 117 |
+
status = ""
|
| 118 |
+
reward = RewardDetails(value=0.0, reason="Action processed.")
|
| 119 |
+
|
| 120 |
+
# Dispatch to handler based on action type
|
| 121 |
+
if action.action_type == "analyze_code":
|
| 122 |
+
reward, status = self._handle_analyze()
|
| 123 |
+
elif action.action_type == "edit_code":
|
| 124 |
+
reward, status = self._handle_edit(action)
|
| 125 |
+
elif action.action_type == "run_tests":
|
| 126 |
+
reward, status = self._handle_run_tests()
|
| 127 |
+
elif action.action_type == "submit_solution":
|
| 128 |
+
reward, status = self._handle_submit()
|
| 129 |
+
else:
|
| 130 |
+
reward = RewardDetails(
|
| 131 |
+
value=-INVALID_ACTION_PENALTY,
|
| 132 |
+
invalid_action_penalty=INVALID_ACTION_PENALTY,
|
| 133 |
+
reason=f"Unsupported action_type: {action.action_type}",
|
| 134 |
+
)
|
| 135 |
+
status = f"Invalid action: unsupported action_type '{action.action_type}'."
|
| 136 |
+
|
| 137 |
+
self._last_reward = reward
|
| 138 |
+
self._last_status = status
|
| 139 |
+
self._state.attempts_remaining = max(self._task.max_steps - self._state.step_count, 0)
|
| 140 |
+
self._state.done = self._done
|
| 141 |
+
|
| 142 |
+
# Auto-submit if steps exhausted
|
| 143 |
+
if self._state.attempts_remaining == 0 and not self._done:
|
| 144 |
+
self._finalize_episode(auto_submit=True)
|
| 145 |
+
self._state.done = True
|
| 146 |
+
|
| 147 |
+
return self._build_observation()
|
| 148 |
+
|
| 149 |
+
@property
|
| 150 |
+
def state(self) -> PythonCodeReviewState:
|
| 151 |
+
"""Return the current environment state."""
|
| 152 |
+
return self._state.model_copy(deep=True)
|
| 153 |
+
|
| 154 |
+
def list_task_summaries(self) -> List[object]:
|
| 155 |
+
"""Return public task metadata."""
|
| 156 |
+
return list_task_summaries()
|
| 157 |
+
|
| 158 |
+
def get_task(self, task_id: str) -> object:
|
| 159 |
+
"""Return a single task descriptor."""
|
| 160 |
+
return get_task(task_id).to_descriptor()
|
| 161 |
+
|
| 162 |
+
def health(self) -> HealthResponse:
|
| 163 |
+
"""Return a simple health model."""
|
| 164 |
+
return HealthResponse(task_count=len(self._task_order))
|
| 165 |
+
|
| 166 |
+
def grade_task_submission(self, task_id: str, code: str) -> TaskGrade:
|
| 167 |
+
"""Expose deterministic grading outside of an active episode."""
|
| 168 |
+
return grade_task(code, get_task(task_id), include_hidden=True)
|
| 169 |
+
|
| 170 |
+
def _build_observation(self) -> PythonCodeReviewObservation:
|
| 171 |
+
"""Build current observation from state."""
|
| 172 |
+
return PythonCodeReviewObservation(
|
| 173 |
+
task_id=self._state.task_id or "",
|
| 174 |
+
difficulty=self._state.difficulty or "easy",
|
| 175 |
+
task_description=self._task.task_description if self._task else "",
|
| 176 |
+
current_code=self._state.current_code,
|
| 177 |
+
errors=self._state.errors,
|
| 178 |
+
test_results=self._state.test_results,
|
| 179 |
+
visible_tests=self._task.visible_tests if self._task else [],
|
| 180 |
+
history=self._state.history,
|
| 181 |
+
attempts_remaining=self._state.attempts_remaining,
|
| 182 |
+
score=self._state.score,
|
| 183 |
+
reward=self._last_reward,
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
def _handle_analyze(self) -> tuple[RewardDetails, str]:
|
| 187 |
+
"""Analyze code for errors and test status."""
|
| 188 |
+
if self._task is None:
|
| 189 |
+
return RewardDetails(value=0.0, reason="Invalid state"), "Error: task not loaded"
|
| 190 |
+
|
| 191 |
+
grade = grade_task(self._state.current_code, self._task, include_hidden=False)
|
| 192 |
+
error = grade.details.get("compile_error", "")
|
| 193 |
+
|
| 194 |
+
if error:
|
| 195 |
+
self._state.errors = error
|
| 196 |
+
self._state.test_results = "Compilation failed. Fix syntax first."
|
| 197 |
+
summary = f"Syntax error detected: {error}"
|
| 198 |
+
else:
|
| 199 |
+
self._state.errors = ""
|
| 200 |
+
if self._task.task_kind == "syntax_fix":
|
| 201 |
+
self._state.test_results = "Code compiles successfully."
|
| 202 |
+
summary = "Code compiles. Ready to submit."
|
| 203 |
+
else:
|
| 204 |
+
visible_total = len(self._task.visible_tests)
|
| 205 |
+
visible_passed = grade.tests_passed
|
| 206 |
+
self._state.test_results = f"Test run: {visible_passed}/{visible_total} passing."
|
| 207 |
+
summary = self._state.test_results
|
| 208 |
+
|
| 209 |
+
reward = RewardDetails(value=0.0, reason=summary)
|
| 210 |
+
self._append_history("analyze_code", summary, reward.value)
|
| 211 |
+
self._sync_score(include_hidden=False)
|
| 212 |
+
return reward, summary
|
| 213 |
+
|
| 214 |
+
def _handle_edit(self, action: PythonCodeReviewAction) -> tuple[RewardDetails, str]:
|
| 215 |
+
"""Edit the code and compute reward for progress."""
|
| 216 |
+
if self._task is None:
|
| 217 |
+
return RewardDetails(value=0.0, reason="Invalid state"), "Error: task not loaded"
|
| 218 |
+
|
| 219 |
+
code = (action.code or "").strip()
|
| 220 |
+
if not code:
|
| 221 |
+
reward = RewardDetails(
|
| 222 |
+
value=-INVALID_ACTION_PENALTY,
|
| 223 |
+
invalid_action_penalty=INVALID_ACTION_PENALTY,
|
| 224 |
+
reason="Edit action requires non-empty code.",
|
| 225 |
+
)
|
| 226 |
+
status = "Invalid: edit_code requires code parameter."
|
| 227 |
+
self._append_history("edit_code", status, reward.value)
|
| 228 |
+
return reward, status
|
| 229 |
+
|
| 230 |
+
# Grade before and after
|
| 231 |
+
previous_grade = grade_task(self._state.current_code, self._task, include_hidden=False)
|
| 232 |
+
new_grade = grade_task(code, self._task, include_hidden=False)
|
| 233 |
+
self._state.current_code = code
|
| 234 |
+
|
| 235 |
+
# Update state
|
| 236 |
+
self._state.errors = new_grade.details.get("compile_error", "")
|
| 237 |
+
self._state.test_results = self._format_test_results(new_grade)
|
| 238 |
+
|
| 239 |
+
# Compute reward with shaping
|
| 240 |
+
syntax_reward = 0.0
|
| 241 |
+
if previous_grade.syntax_score < 1.0 and new_grade.syntax_score == 1.0:
|
| 242 |
+
syntax_reward = 0.2
|
| 243 |
+
self._syntax_reward_awarded = True
|
| 244 |
+
|
| 245 |
+
quality_delta = max(new_grade.quality_score - self._best_quality_score, 0.0)
|
| 246 |
+
quality_bonus = 0.0
|
| 247 |
+
if quality_delta > 0:
|
| 248 |
+
quality_bonus = min(quality_delta * QUALITY_BONUS_SCALE, 0.1)
|
| 249 |
+
self._best_quality_score = new_grade.quality_score
|
| 250 |
+
|
| 251 |
+
test_delta = 0.0
|
| 252 |
+
if new_grade.tests_total > 0:
|
| 253 |
+
current_test_fraction = new_grade.tests_passed / new_grade.tests_total
|
| 254 |
+
test_delta = max(current_test_fraction - self._best_visible_test_fraction, 0.0)
|
| 255 |
+
self._best_visible_test_fraction = max(self._best_visible_test_fraction, current_test_fraction)
|
| 256 |
+
|
| 257 |
+
reward_value = syntax_reward + quality_bonus + (0.15 * test_delta)
|
| 258 |
+
|
| 259 |
+
status = "Code updated."
|
| 260 |
+
if self._state.errors:
|
| 261 |
+
status = f"Code updated with syntax issues: {self._state.errors}"
|
| 262 |
+
elif new_grade.tests_total > 0:
|
| 263 |
+
status = self._state.test_results
|
| 264 |
+
|
| 265 |
+
reward = RewardDetails(
|
| 266 |
+
value=reward_value,
|
| 267 |
+
syntax_reward=syntax_reward,
|
| 268 |
+
quality_bonus=quality_bonus,
|
| 269 |
+
test_reward=0.15 * test_delta,
|
| 270 |
+
reason=status,
|
| 271 |
+
)
|
| 272 |
+
self._append_history("edit_code", status, reward_value)
|
| 273 |
+
self._sync_score(include_hidden=False)
|
| 274 |
+
return reward, status
|
| 275 |
+
|
| 276 |
+
def _handle_run_tests(self) -> tuple[RewardDetails, str]:
|
| 277 |
+
"""Run tests and provide feedback."""
|
| 278 |
+
if self._task is None:
|
| 279 |
+
return RewardDetails(value=0.0, reason="Invalid state"), "Error: task not loaded"
|
| 280 |
+
|
| 281 |
+
grade = grade_task(self._state.current_code, self._task, include_hidden=False)
|
| 282 |
+
self._state.errors = grade.details.get("compile_error", "")
|
| 283 |
+
self._state.test_results = self._format_test_results(grade)
|
| 284 |
+
|
| 285 |
+
if grade.tests_total > 0:
|
| 286 |
+
current_fraction = grade.tests_passed / grade.tests_total
|
| 287 |
+
test_delta = max(current_fraction - self._best_visible_test_fraction, 0.0)
|
| 288 |
+
self._best_visible_test_fraction = max(self._best_visible_test_fraction, current_fraction)
|
| 289 |
+
test_reward = 0.15 * test_delta
|
| 290 |
+
else:
|
| 291 |
+
test_reward = 0.0
|
| 292 |
+
|
| 293 |
+
status = self._state.test_results if not self._state.errors else self._state.errors
|
| 294 |
+
reward = RewardDetails(value=test_reward, test_reward=test_reward, reason=status)
|
| 295 |
+
self._append_history("run_tests", status, reward.value)
|
| 296 |
+
self._sync_score(include_hidden=False)
|
| 297 |
+
return reward, status
|
| 298 |
+
|
| 299 |
+
def _handle_submit(self) -> tuple[RewardDetails, str]:
|
| 300 |
+
"""Submit solution and finalize episode."""
|
| 301 |
+
if self._task is None:
|
| 302 |
+
return RewardDetails(value=0.0, reason="Invalid state"), "Error: task not loaded"
|
| 303 |
+
|
| 304 |
+
grade = grade_task(self._state.current_code, self._task, include_hidden=True)
|
| 305 |
+
self._state.errors = grade.details.get("compile_error", "")
|
| 306 |
+
self._state.test_results = self._format_test_results(grade)
|
| 307 |
+
|
| 308 |
+
# Compute final reward bonuses
|
| 309 |
+
correctness_bonus = 0.0
|
| 310 |
+
if grade.score >= 0.999999 and not self._full_correctness_awarded:
|
| 311 |
+
correctness_bonus = 0.5
|
| 312 |
+
self._full_correctness_awarded = True
|
| 313 |
+
|
| 314 |
+
reward_value = correctness_bonus
|
| 315 |
+
self._finalize_episode(auto_submit=False, grade=grade)
|
| 316 |
+
status = f"Solution submitted. Final score: {grade.score:.3f}"
|
| 317 |
+
|
| 318 |
+
reward = RewardDetails(
|
| 319 |
+
value=reward_value,
|
| 320 |
+
correctness_bonus=correctness_bonus,
|
| 321 |
+
reason=status,
|
| 322 |
+
)
|
| 323 |
+
self._append_history("submit_solution", status, reward_value)
|
| 324 |
+
return reward, status
|
| 325 |
+
|
| 326 |
+
def _finalize_episode(self, auto_submit: bool, grade: Optional[TaskGrade] = None) -> None:
|
| 327 |
+
"""Mark episode as done and set final score."""
|
| 328 |
+
if grade is None:
|
| 329 |
+
if self._task is None:
|
| 330 |
+
return
|
| 331 |
+
grade = grade_task(self._state.current_code, self._task, include_hidden=True)
|
| 332 |
+
self._state.errors = grade.details.get("compile_error", "")
|
| 333 |
+
self._state.test_results = self._format_test_results(grade)
|
| 334 |
+
|
| 335 |
+
self._state.score = grade.score
|
| 336 |
+
self._done = True
|
| 337 |
+
self._state.done = True
|
| 338 |
+
|
| 339 |
+
if auto_submit:
|
| 340 |
+
self._last_status = f"Step budget exhausted. Final score: {grade.score:.3f}"
|
| 341 |
+
|
| 342 |
+
def _sync_score(self, include_hidden: bool) -> None:
|
| 343 |
+
"""Update visible score based on current code."""
|
| 344 |
+
if self._task is None:
|
| 345 |
+
return
|
| 346 |
+
grade = grade_task(self._state.current_code, self._task, include_hidden=include_hidden)
|
| 347 |
+
# For visible runs, use a soft score; for hidden, it will be finalized on submit
|
| 348 |
+
if not include_hidden:
|
| 349 |
+
self._state.score = grade.score
|
| 350 |
+
|
| 351 |
+
def _format_test_results(self, grade: TaskGrade) -> str:
|
| 352 |
+
"""Format test results for display."""
|
| 353 |
+
if grade.tests_total == 0:
|
| 354 |
+
return "No tests available."
|
| 355 |
+
if grade.timed_out:
|
| 356 |
+
return "Test execution timed out."
|
| 357 |
+
return f"Tests: {grade.tests_passed}/{grade.tests_total} passing"
|
| 358 |
+
|
| 359 |
+
def _append_history(self, action_type: str, status: str, reward: float) -> None:
|
| 360 |
+
"""Append action to history."""
|
| 361 |
+
entry = HistoryEntry(
|
| 362 |
+
step=self._state.step_count,
|
| 363 |
+
action_type=action_type,
|
| 364 |
+
status=status,
|
| 365 |
+
reward=reward,
|
| 366 |
+
)
|
| 367 |
+
self._state.history.append(entry)
|
| 368 |
+
|
| 369 |
+
return self.reset()
|
| 370 |
+
if self._done:
|
| 371 |
+
self._last_reward = RewardDetails(
|
| 372 |
+
value=-INVALID_ACTION_PENALTY,
|
| 373 |
+
invalid_action_penalty=INVALID_ACTION_PENALTY,
|
| 374 |
+
reason="Episode already completed.",
|
| 375 |
+
)
|
| 376 |
+
self._last_status = "Episode already completed. Call reset() to continue."
|
| 377 |
+
return self._build_observation()
|
| 378 |
+
|
| 379 |
+
self._state.step_count += 1
|
| 380 |
+
status = ""
|
| 381 |
+
reward = RewardDetails(reason="Action processed.")
|
| 382 |
+
|
| 383 |
+
if action.action_type == "analyze_code":
|
| 384 |
+
reward, status = self._handle_analyze()
|
| 385 |
+
elif action.action_type == "edit_code":
|
| 386 |
+
reward, status = self._handle_edit(action)
|
| 387 |
+
elif action.action_type == "run_tests":
|
| 388 |
+
reward, status = self._handle_run_tests()
|
| 389 |
+
elif action.action_type == "submit_solution":
|
| 390 |
+
reward, status = self._handle_submit()
|
| 391 |
+
else: # pragma: no cover
|
| 392 |
+
reward = RewardDetails(
|
| 393 |
+
value=-INVALID_ACTION_PENALTY,
|
| 394 |
+
invalid_action_penalty=INVALID_ACTION_PENALTY,
|
| 395 |
+
reason=f"Unsupported action_type {action.action_type}.",
|
| 396 |
+
)
|
| 397 |
+
status = f"Unsupported action_type {action.action_type}."
|
| 398 |
+
|
| 399 |
+
self._last_reward = reward
|
| 400 |
+
self._last_status = status
|
| 401 |
+
self._state.attempts_remaining = max(self._task.max_steps - self._state.step_count, 0)
|
| 402 |
+
|
| 403 |
+
if self._state.attempts_remaining == 0 and not self._done:
|
| 404 |
+
self._finalize_episode(auto_submit=True)
|
| 405 |
+
|
| 406 |
+
self._state.done = self._done
|
| 407 |
+
return self._build_observation()
|
| 408 |
+
|
| 409 |
+
@property
|
| 410 |
+
def state(self) -> PythonCodeReviewState:
|
| 411 |
+
"""Return the current environment state."""
|
| 412 |
+
|
| 413 |
+
return self._state.model_copy(deep=True)
|
| 414 |
+
|
| 415 |
+
def list_tasks(self) -> List[TaskDescriptor]:
|
| 416 |
+
"""Return all task descriptors."""
|
| 417 |
+
|
| 418 |
+
return list_task_descriptors()
|
| 419 |
+
|
| 420 |
+
def list_task_summaries(self) -> List[TaskDescriptor]:
|
| 421 |
+
"""Return public task metadata."""
|
| 422 |
+
|
| 423 |
+
return list_task_summaries()
|
| 424 |
+
|
| 425 |
+
def get_task(self, task_id: str) -> TaskDescriptor:
|
| 426 |
+
"""Return a single task descriptor."""
|
| 427 |
+
|
| 428 |
+
return get_task(task_id).to_descriptor()
|
| 429 |
+
|
| 430 |
+
def health(self) -> HealthResponse:
|
| 431 |
+
"""Return a simple health model."""
|
| 432 |
+
|
| 433 |
+
return HealthResponse(task_count=len(self._task_order))
|
| 434 |
+
|
| 435 |
+
def grade_task_submission(self, task_id: str, code: str) -> TaskGrade:
|
| 436 |
+
"""Expose deterministic grading outside of an active episode."""
|
| 437 |
+
|
| 438 |
+
return grade_task(code, get_task(task_id), include_hidden=True)
|
| 439 |
+
|
| 440 |
+
def _handle_analyze(self) -> tuple[RewardDetails, str]:
|
| 441 |
+
grade = grade_task(self._state.current_code, self._task, include_hidden=False)
|
| 442 |
+
error = grade.details.get("compile_error", "")
|
| 443 |
+
if error:
|
| 444 |
+
self._state.errors = f"Syntax analysis failed: {error}"
|
| 445 |
+
self._state.test_results = "Tests skipped because the code does not compile."
|
| 446 |
+
summary = self._state.errors
|
| 447 |
+
else:
|
| 448 |
+
self._state.errors = ""
|
| 449 |
+
if self._task.task_kind == "syntax_fix":
|
| 450 |
+
self._state.test_results = "Compilation succeeds."
|
| 451 |
+
else:
|
| 452 |
+
visible_total = len(self._task.visible_tests)
|
| 453 |
+
visible_passed = min(grade.tests_passed, visible_total)
|
| 454 |
+
self._state.test_results = (
|
| 455 |
+
f"Visible checks preview: {visible_passed}/{visible_total} passing."
|
| 456 |
+
)
|
| 457 |
+
summary = "Static analysis refreshed."
|
| 458 |
+
|
| 459 |
+
reward = RewardDetails(value=0.0, reason=summary)
|
| 460 |
+
self._append_history("analyze_code", summary, reward.value)
|
| 461 |
+
self._sync_score(include_hidden=False)
|
| 462 |
+
return reward, summary
|
| 463 |
+
|
| 464 |
+
def _handle_edit(self, action: PythonCodeReviewAction) -> tuple[RewardDetails, str]:
|
| 465 |
+
code = (action.code or "").strip("\n")
|
| 466 |
+
if not code:
|
| 467 |
+
reward = RewardDetails(
|
| 468 |
+
value=-INVALID_ACTION_PENALTY,
|
| 469 |
+
invalid_action_penalty=INVALID_ACTION_PENALTY,
|
| 470 |
+
reason="edit_code requires non-empty code.",
|
| 471 |
+
)
|
| 472 |
+
status = "Invalid action: edit_code requires code."
|
| 473 |
+
self._append_history("edit_code", status, reward.value)
|
| 474 |
+
return reward, status
|
| 475 |
+
|
| 476 |
+
previous_visible = grade_task(self._state.current_code, self._task, include_hidden=False)
|
| 477 |
+
new_visible = grade_task(code, self._task, include_hidden=False)
|
| 478 |
+
self._state.current_code = code
|
| 479 |
+
self._state.errors = new_visible.details.get("compile_error", "")
|
| 480 |
+
self._state.test_results = self._format_test_results(new_visible, include_hidden=False)
|
| 481 |
+
|
| 482 |
+
syntax_reward = 0.0
|
| 483 |
+
if previous_visible.syntax_score < 1.0 and new_visible.syntax_score == 1.0:
|
| 484 |
+
syntax_reward = 0.2
|
| 485 |
+
|
| 486 |
+
quality_bonus = 0.0
|
| 487 |
+
quality_delta = max(new_visible.quality_score - self._best_quality_score, 0.0)
|
| 488 |
+
if quality_delta > 0:
|
| 489 |
+
quality_bonus = round(min(quality_delta * QUALITY_BONUS_SCALE, 0.1), 6)
|
| 490 |
+
self._best_quality_score = max(self._best_quality_score, new_visible.quality_score)
|
| 491 |
+
|
| 492 |
+
reward_value = syntax_reward + quality_bonus
|
| 493 |
+
status = "Code updated."
|
| 494 |
+
if self._state.errors:
|
| 495 |
+
status = f"Code updated, but syntax issues remain: {self._state.errors}"
|
| 496 |
+
elif new_visible.tests_total:
|
| 497 |
+
status = self._state.test_results
|
| 498 |
+
|
| 499 |
+
reward = RewardDetails(
|
| 500 |
+
value=reward_value,
|
| 501 |
+
syntax_reward=syntax_reward,
|
| 502 |
+
quality_bonus=quality_bonus,
|
| 503 |
+
reason=status,
|
| 504 |
+
)
|
| 505 |
+
self._append_history("edit_code", status, reward.value)
|
| 506 |
+
self._sync_score(include_hidden=False)
|
| 507 |
+
return reward, status
|
| 508 |
+
|
| 509 |
+
def _handle_run_tests(self) -> tuple[RewardDetails, str]:
|
| 510 |
+
grade = grade_task(self._state.current_code, self._task, include_hidden=False)
|
| 511 |
+
self._state.errors = grade.details.get("compile_error", "")
|
| 512 |
+
self._state.test_results = self._format_test_results(grade, include_hidden=False)
|
| 513 |
+
reward = self._reward_from_grade(grade, include_hidden=False)
|
| 514 |
+
status = self._state.test_results if not self._state.errors else self._state.errors
|
| 515 |
+
self._append_history("run_tests", status, reward.value)
|
| 516 |
+
self._sync_score(include_hidden=False)
|
| 517 |
+
return reward, status
|
| 518 |
+
|
| 519 |
+
def _handle_submit(self) -> tuple[RewardDetails, str]:
|
| 520 |
+
grade = grade_task(self._state.current_code, self._task, include_hidden=True)
|
| 521 |
+
self._state.errors = grade.details.get("compile_error", "")
|
| 522 |
+
self._state.test_results = self._format_test_results(grade, include_hidden=True)
|
| 523 |
+
reward = self._reward_from_grade(grade, include_hidden=True)
|
| 524 |
+
self._finalize_episode(auto_submit=False, grade=grade)
|
| 525 |
+
status = f"Solution submitted. Final score: {grade.score:.2f}."
|
| 526 |
+
self._append_history("submit_solution", status, reward.value)
|
| 527 |
+
return reward, status
|
| 528 |
+
|
| 529 |
+
def _finalize_episode(self, auto_submit: bool, grade: Optional[TaskGrade] = None) -> None:
|
| 530 |
+
if grade is None:
|
| 531 |
+
grade = grade_task(self._state.current_code, self._task, include_hidden=True)
|
| 532 |
+
self._state.errors = grade.details.get("compile_error", "")
|
| 533 |
+
self._state.test_results = self._format_test_results(grade, include_hidden=True)
|
| 534 |
+
self._state.score = grade.score
|
| 535 |
+
self._done = True
|
| 536 |
+
self._state.done = True
|
| 537 |
+
if auto_submit:
|
| 538 |
+
self._last_status = f"Step budget exhausted. Final score: {grade.score:.2f}."
|
| 539 |
+
self._last_reward = self._reward_from_grade(grade, include_hidden=True)
|
| 540 |
+
|
| 541 |
+
def _reward_from_grade(self, grade: TaskGrade, include_hidden: bool) -> RewardDetails:
|
| 542 |
+
syntax_reward = 0.0
|
| 543 |
+
if grade.syntax_score == 1.0 and not self._state.errors and not self._syntax_reward_awarded:
|
| 544 |
+
syntax_reward = 0.2
|
| 545 |
+
self._syntax_reward_awarded = True
|
| 546 |
+
test_fraction = grade.tests_passed / grade.tests_total if grade.tests_total else grade.score
|
| 547 |
+
test_gain = max(test_fraction - self._best_visible_test_fraction, 0.0)
|
| 548 |
+
test_reward = 0.3 * test_gain
|
| 549 |
+
if test_gain > 0:
|
| 550 |
+
self._best_visible_test_fraction = test_fraction
|
| 551 |
+
|
| 552 |
+
quality_bonus = 0.0
|
| 553 |
+
quality_delta = max(grade.quality_score - self._best_quality_score, 0.0)
|
| 554 |
+
if quality_delta > 0:
|
| 555 |
+
quality_bonus = min(quality_delta * QUALITY_BONUS_SCALE, 0.1)
|
| 556 |
+
self._best_quality_score = grade.quality_score
|
| 557 |
+
|
| 558 |
+
correctness_bonus = 0.0
|
| 559 |
+
if include_hidden and grade.score >= 0.999999 and not self._full_correctness_awarded:
|
| 560 |
+
correctness_bonus = 0.5
|
| 561 |
+
self._full_correctness_awarded = True
|
| 562 |
+
|
| 563 |
+
timeout_penalty = TIMEOUT_PENALTY if grade.timed_out else 0.0
|
| 564 |
+
reward_value = round(
|
| 565 |
+
syntax_reward + test_reward + quality_bonus + correctness_bonus - timeout_penalty,
|
| 566 |
+
6,
|
| 567 |
+
)
|
| 568 |
+
return RewardDetails(
|
| 569 |
+
value=reward_value,
|
| 570 |
+
syntax_reward=syntax_reward,
|
| 571 |
+
test_reward=round(test_reward, 6),
|
| 572 |
+
correctness_bonus=correctness_bonus,
|
| 573 |
+
quality_bonus=round(quality_bonus, 6),
|
| 574 |
+
timeout_penalty=timeout_penalty,
|
| 575 |
+
reason=self._format_test_results(grade, include_hidden=include_hidden),
|
| 576 |
+
)
|
| 577 |
+
|
| 578 |
+
def _format_test_results(self, grade: TaskGrade, include_hidden: bool) -> str:
|
| 579 |
+
if grade.details.get("compile_error"):
|
| 580 |
+
return f"Compilation failed: {grade.details['compile_error']}"
|
| 581 |
+
scope = "full grader" if include_hidden else "visible checks"
|
| 582 |
+
parts = [f"{scope}: score={grade.score:.2f}"]
|
| 583 |
+
if grade.tests_total:
|
| 584 |
+
parts.append(f"tests={grade.tests_passed}/{grade.tests_total}")
|
| 585 |
+
if grade.runtime_score:
|
| 586 |
+
parts.append(f"runtime={grade.runtime_score:.2f}")
|
| 587 |
+
if grade.quality_score:
|
| 588 |
+
parts.append(f"quality={grade.quality_score:.2f}")
|
| 589 |
+
if grade.style_score:
|
| 590 |
+
parts.append(f"style={grade.style_score:.2f}")
|
| 591 |
+
if grade.timed_out:
|
| 592 |
+
parts.append("timed_out=True")
|
| 593 |
+
return " | ".join(parts)
|
| 594 |
+
|
| 595 |
+
def _sync_score(self, include_hidden: bool) -> None:
|
| 596 |
+
grade = grade_task(self._state.current_code, self._task, include_hidden=include_hidden)
|
| 597 |
+
self._state.score = grade.score
|
| 598 |
+
|
| 599 |
+
def _append_history(self, action_type: str, summary: str, reward: float) -> None:
|
| 600 |
+
self._state.history.append(
|
| 601 |
+
HistoryEntry(
|
| 602 |
+
step=self._state.step_count,
|
| 603 |
+
action_type=action_type, # type: ignore[arg-type]
|
| 604 |
+
summary=summary,
|
| 605 |
+
reward=reward,
|
| 606 |
+
)
|
| 607 |
+
)
|
| 608 |
+
|
| 609 |
+
def _build_observation(self) -> PythonCodeReviewObservation:
|
| 610 |
+
return PythonCodeReviewObservation(
|
| 611 |
+
task_id=self._task.task_id,
|
| 612 |
+
title=self._task.title,
|
| 613 |
+
difficulty=self._task.difficulty,
|
| 614 |
+
task_kind=self._task.task_kind,
|
| 615 |
+
task_description=self._task.task_description,
|
| 616 |
+
current_code=self._state.current_code,
|
| 617 |
+
errors=self._state.errors,
|
| 618 |
+
test_results=self._state.test_results,
|
| 619 |
+
history=list(self._state.history),
|
| 620 |
+
attempts_remaining=self._state.attempts_remaining,
|
| 621 |
+
last_action_status=self._last_status,
|
| 622 |
+
score=self._state.score,
|
| 623 |
+
reward_details=self._last_reward,
|
| 624 |
+
done=self._done,
|
| 625 |
+
reward=self._last_reward.value,
|
| 626 |
+
metadata={
|
| 627 |
+
"episode_id": self._state.episode_id,
|
| 628 |
+
"step_count": self._state.step_count,
|
| 629 |
+
"task_kind": self._task.task_kind,
|
| 630 |
+
"visible_tests": list(self._task.visible_tests),
|
| 631 |
+
"info": {
|
| 632 |
+
"reward": reward_metadata(self._last_reward),
|
| 633 |
+
},
|
| 634 |
+
},
|
| 635 |
+
)
|
| 636 |
+
|
| 637 |
+
|
| 638 |
+
# Backwards-compatible aliases used elsewhere in the repo.
|
| 639 |
+
PythonEnvironment = PythonCodeReviewEnvironment
|
| 640 |
+
CodeReviewEnvironment = PythonCodeReviewEnvironment
|
server/grading.py
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Deterministic grading helpers for PR-review tasks."""
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
import re
|
| 6 |
+
from dataclasses import dataclass
|
| 7 |
+
from typing import Iterable, List, Optional, Sequence, Set
|
| 8 |
+
|
| 9 |
+
try:
|
| 10 |
+
from models import ReviewFinding, TaskGrade
|
| 11 |
+
from server.task_bank import RubricIssue, TaskSpec
|
| 12 |
+
except ModuleNotFoundError: # pragma: no cover
|
| 13 |
+
from ..models import ReviewFinding, TaskGrade
|
| 14 |
+
from .task_bank import RubricIssue, TaskSpec
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
FALSE_POSITIVE_PENALTY = 0.10
|
| 18 |
+
DUPLICATE_PENALTY = 0.05
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
@dataclass(frozen=True)
|
| 22 |
+
class FindingMatch:
|
| 23 |
+
"""Result of matching one finding against the rubric."""
|
| 24 |
+
|
| 25 |
+
issue_id: Optional[str]
|
| 26 |
+
duplicate: bool = False
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def finding_fingerprint(finding: ReviewFinding) -> str:
|
| 30 |
+
"""Build a deterministic fingerprint for duplicate detection."""
|
| 31 |
+
|
| 32 |
+
text = " ".join(
|
| 33 |
+
[
|
| 34 |
+
finding.file_path,
|
| 35 |
+
str(finding.line or 0),
|
| 36 |
+
finding.category,
|
| 37 |
+
finding.severity,
|
| 38 |
+
finding.title,
|
| 39 |
+
finding.explanation,
|
| 40 |
+
finding.suggested_fix,
|
| 41 |
+
]
|
| 42 |
+
)
|
| 43 |
+
return "|".join(sorted(tokens(text)))
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def match_finding(
|
| 47 |
+
finding: ReviewFinding,
|
| 48 |
+
task: TaskSpec,
|
| 49 |
+
matched_issue_ids: Set[str],
|
| 50 |
+
seen_fingerprints: Set[str],
|
| 51 |
+
) -> FindingMatch:
|
| 52 |
+
"""Match one finding against the remaining rubric issues."""
|
| 53 |
+
|
| 54 |
+
fingerprint = finding_fingerprint(finding)
|
| 55 |
+
if fingerprint in seen_fingerprints:
|
| 56 |
+
return FindingMatch(issue_id=None, duplicate=True)
|
| 57 |
+
|
| 58 |
+
for issue in task.rubric_issues:
|
| 59 |
+
if issue.issue_id in matched_issue_ids:
|
| 60 |
+
continue
|
| 61 |
+
if finding_matches_issue(finding, issue):
|
| 62 |
+
return FindingMatch(issue_id=issue.issue_id)
|
| 63 |
+
return FindingMatch(issue_id=None)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def finding_matches_issue(finding: ReviewFinding, issue: RubricIssue) -> bool:
|
| 67 |
+
"""Return True when a finding deterministically matches a rubric issue."""
|
| 68 |
+
|
| 69 |
+
if finding.file_path != issue.file_path:
|
| 70 |
+
return False
|
| 71 |
+
if finding.category != issue.category:
|
| 72 |
+
return False
|
| 73 |
+
if finding.severity != issue.severity:
|
| 74 |
+
return False
|
| 75 |
+
if finding.line is None or abs(finding.line - issue.line) > 2:
|
| 76 |
+
return False
|
| 77 |
+
|
| 78 |
+
finding_tokens = tokens(
|
| 79 |
+
" ".join([finding.title, finding.explanation, finding.suggested_fix])
|
| 80 |
+
)
|
| 81 |
+
keyword_hits = sum(1 for keyword in issue.keywords if keyword in finding_tokens)
|
| 82 |
+
return keyword_hits >= issue.min_keyword_hits
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def score_task(
|
| 86 |
+
task: TaskSpec,
|
| 87 |
+
matched_issue_ids: Iterable[str],
|
| 88 |
+
false_positives: int = 0,
|
| 89 |
+
duplicate_findings: int = 0,
|
| 90 |
+
) -> TaskGrade:
|
| 91 |
+
"""Score a task from cumulative episode state."""
|
| 92 |
+
|
| 93 |
+
matched_set = set(matched_issue_ids)
|
| 94 |
+
matched_weight = sum(
|
| 95 |
+
issue.weight for issue in task.rubric_issues if issue.issue_id in matched_set
|
| 96 |
+
)
|
| 97 |
+
raw_score = matched_weight
|
| 98 |
+
raw_score -= false_positives * FALSE_POSITIVE_PENALTY
|
| 99 |
+
raw_score -= duplicate_findings * DUPLICATE_PENALTY
|
| 100 |
+
score = max(0.0, min(1.0, round(raw_score, 6)))
|
| 101 |
+
return TaskGrade(
|
| 102 |
+
score=score,
|
| 103 |
+
matched_issue_ids=sorted(matched_set),
|
| 104 |
+
false_positives=false_positives,
|
| 105 |
+
duplicate_findings=duplicate_findings,
|
| 106 |
+
matched_weight=min(1.0, round(matched_weight, 6)),
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def grade_findings(task: TaskSpec, findings: Sequence[ReviewFinding]) -> TaskGrade:
|
| 111 |
+
"""Offline-grade a batch of findings for one task."""
|
| 112 |
+
|
| 113 |
+
matched_issue_ids: Set[str] = set()
|
| 114 |
+
seen_fingerprints: Set[str] = set()
|
| 115 |
+
false_positives = 0
|
| 116 |
+
duplicate_findings = 0
|
| 117 |
+
|
| 118 |
+
for finding in findings:
|
| 119 |
+
result = match_finding(
|
| 120 |
+
finding=finding,
|
| 121 |
+
task=task,
|
| 122 |
+
matched_issue_ids=matched_issue_ids,
|
| 123 |
+
seen_fingerprints=seen_fingerprints,
|
| 124 |
+
)
|
| 125 |
+
fingerprint = finding_fingerprint(finding)
|
| 126 |
+
if result.duplicate:
|
| 127 |
+
duplicate_findings += 1
|
| 128 |
+
continue
|
| 129 |
+
seen_fingerprints.add(fingerprint)
|
| 130 |
+
if result.issue_id is None:
|
| 131 |
+
false_positives += 1
|
| 132 |
+
continue
|
| 133 |
+
matched_issue_ids.add(result.issue_id)
|
| 134 |
+
|
| 135 |
+
return score_task(
|
| 136 |
+
task=task,
|
| 137 |
+
matched_issue_ids=matched_issue_ids,
|
| 138 |
+
false_positives=false_positives,
|
| 139 |
+
duplicate_findings=duplicate_findings,
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
def tokens(text: str) -> Set[str]:
|
| 144 |
+
"""Normalize free text into deterministic comparison tokens."""
|
| 145 |
+
|
| 146 |
+
return set(re.findall(r"[a-z0-9_]+", text.lower()))
|
| 147 |
+
|
server/python_env_environment.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Compatibility shim for older imports."""
|
| 2 |
+
|
| 3 |
+
try:
|
| 4 |
+
from server.code_review_environment import PythonEnvironment
|
| 5 |
+
except ModuleNotFoundError: # pragma: no cover
|
| 6 |
+
from .code_review_environment import PythonEnvironment
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
__all__ = ["PythonEnvironment"]
|
server/requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
openenv-core[core]>=0.2.2
|
| 2 |
+
fastapi>=0.115.0
|
| 3 |
+
uvicorn[standard]>=0.30.0
|
| 4 |
+
openai>=1.40.0
|
| 5 |
+
pytest>=8.0.0
|
| 6 |
+
pydantic>=2.0.0
|
server/static_review.py
ADDED
|
@@ -0,0 +1,273 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Deterministic static-review helpers for arbitrary Python code.
|
| 2 |
+
|
| 3 |
+
Unlike the benchmark grader, this module does not compare against hidden rubric
|
| 4 |
+
items. Instead, it performs direct AST-based review on arbitrary snippets so it
|
| 5 |
+
can be used for manual testing, examples, and future dataset generation.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
from __future__ import annotations
|
| 9 |
+
|
| 10 |
+
import ast
|
| 11 |
+
from typing import List, Optional
|
| 12 |
+
|
| 13 |
+
try:
|
| 14 |
+
from models import DirectReviewResponse, ReviewFinding
|
| 15 |
+
except ModuleNotFoundError: # pragma: no cover
|
| 16 |
+
from ..models import DirectReviewResponse, ReviewFinding
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class _StaticAnalyzer(ast.NodeVisitor):
|
| 20 |
+
"""AST visitor that emits structured review findings.
|
| 21 |
+
|
| 22 |
+
The visitor intentionally focuses on a small set of high-signal patterns so
|
| 23 |
+
the direct-review endpoint stays predictable and easy to understand.
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
def __init__(self) -> None:
|
| 27 |
+
self.issues: List[ReviewFinding] = []
|
| 28 |
+
|
| 29 |
+
def visit_FunctionDef(self, node: ast.FunctionDef) -> None: # noqa: N802
|
| 30 |
+
"""Flag mutable default arguments in function definitions."""
|
| 31 |
+
|
| 32 |
+
for default in list(node.args.defaults):
|
| 33 |
+
if isinstance(default, (ast.List, ast.Dict, ast.Set)):
|
| 34 |
+
self.issues.append(
|
| 35 |
+
ReviewFinding(
|
| 36 |
+
title="Mutable default argument",
|
| 37 |
+
line=getattr(default, "lineno", node.lineno),
|
| 38 |
+
category="bug",
|
| 39 |
+
severity="warning",
|
| 40 |
+
rationale=(
|
| 41 |
+
"Mutable defaults persist across calls and can leak state "
|
| 42 |
+
"between unrelated requests."
|
| 43 |
+
),
|
| 44 |
+
recommendation="Use None as the default and create the object inside the function.",
|
| 45 |
+
rule_id="mutable-default-list",
|
| 46 |
+
)
|
| 47 |
+
)
|
| 48 |
+
self.generic_visit(node)
|
| 49 |
+
|
| 50 |
+
def visit_Call(self, node: ast.Call) -> None: # noqa: N802
|
| 51 |
+
"""Inspect function calls for obviously unsafe or noisy patterns."""
|
| 52 |
+
|
| 53 |
+
func_name = self._call_name(node)
|
| 54 |
+
if func_name in {"eval", "exec"}:
|
| 55 |
+
self.issues.append(
|
| 56 |
+
ReviewFinding(
|
| 57 |
+
title=f"Avoid {func_name} on untrusted input",
|
| 58 |
+
line=node.lineno,
|
| 59 |
+
category="security",
|
| 60 |
+
severity="critical",
|
| 61 |
+
rationale=(
|
| 62 |
+
f"{func_name} executes arbitrary code and is unsafe on "
|
| 63 |
+
"user-controlled input."
|
| 64 |
+
),
|
| 65 |
+
recommendation="Use a safe parser or a whitelist-based evaluator.",
|
| 66 |
+
rule_id="avoid-eval" if func_name == "eval" else "avoid-exec",
|
| 67 |
+
)
|
| 68 |
+
)
|
| 69 |
+
if func_name.endswith("check_output") or func_name.endswith("run"):
|
| 70 |
+
for keyword in node.keywords:
|
| 71 |
+
# `shell=True` is only a problem when the command comes from a
|
| 72 |
+
# shell-parsed string, but this heuristic is high value for
|
| 73 |
+
# review and intentionally conservative.
|
| 74 |
+
if keyword.arg == "shell" and isinstance(keyword.value, ast.Constant) and keyword.value.value is True:
|
| 75 |
+
self.issues.append(
|
| 76 |
+
ReviewFinding(
|
| 77 |
+
title="shell=True with dynamic input",
|
| 78 |
+
line=node.lineno,
|
| 79 |
+
category="security",
|
| 80 |
+
severity="critical",
|
| 81 |
+
rationale=(
|
| 82 |
+
"shell=True executes through the shell and can allow "
|
| 83 |
+
"command injection when the command string is interpolated."
|
| 84 |
+
),
|
| 85 |
+
recommendation="Pass a list of arguments and keep shell=False.",
|
| 86 |
+
rule_id="shell-true-command-injection",
|
| 87 |
+
)
|
| 88 |
+
)
|
| 89 |
+
if func_name == "print":
|
| 90 |
+
self.issues.append(
|
| 91 |
+
ReviewFinding(
|
| 92 |
+
title="Print statement in application logic",
|
| 93 |
+
line=node.lineno,
|
| 94 |
+
category="style",
|
| 95 |
+
severity="info",
|
| 96 |
+
rationale="Production services should prefer structured logging over print statements.",
|
| 97 |
+
recommendation="Use the logging module or return the value to the caller.",
|
| 98 |
+
rule_id="print-statement",
|
| 99 |
+
)
|
| 100 |
+
)
|
| 101 |
+
self.generic_visit(node)
|
| 102 |
+
|
| 103 |
+
def visit_ExceptHandler(self, node: ast.ExceptHandler) -> None: # noqa: N802
|
| 104 |
+
"""Flag bare exception handlers that hide failures."""
|
| 105 |
+
|
| 106 |
+
if node.type is None:
|
| 107 |
+
self.issues.append(
|
| 108 |
+
ReviewFinding(
|
| 109 |
+
title="Bare except",
|
| 110 |
+
line=node.lineno,
|
| 111 |
+
category="maintainability",
|
| 112 |
+
severity="warning",
|
| 113 |
+
rationale="Bare except catches KeyboardInterrupt and other system-level exceptions.",
|
| 114 |
+
recommendation="Catch a specific exception and record the failure.",
|
| 115 |
+
rule_id="bare-except",
|
| 116 |
+
)
|
| 117 |
+
)
|
| 118 |
+
self.generic_visit(node)
|
| 119 |
+
|
| 120 |
+
def visit_For(self, node: ast.For) -> None: # noqa: N802
|
| 121 |
+
"""Look for list-membership checks nested in loops."""
|
| 122 |
+
|
| 123 |
+
for child in ast.walk(node):
|
| 124 |
+
if isinstance(child, ast.Compare) and any(
|
| 125 |
+
isinstance(operator, (ast.In, ast.NotIn)) for operator in child.ops
|
| 126 |
+
):
|
| 127 |
+
if isinstance(child.comparators[0], ast.Name):
|
| 128 |
+
self.issues.append(
|
| 129 |
+
ReviewFinding(
|
| 130 |
+
title="Potential quadratic membership check inside loop",
|
| 131 |
+
line=child.lineno,
|
| 132 |
+
category="performance",
|
| 133 |
+
severity="warning",
|
| 134 |
+
rationale=(
|
| 135 |
+
"Repeated membership checks against a list inside a loop "
|
| 136 |
+
"can degrade to quadratic runtime."
|
| 137 |
+
),
|
| 138 |
+
recommendation="Use a set or dict for O(1) membership checks.",
|
| 139 |
+
rule_id="quadratic-membership-check",
|
| 140 |
+
)
|
| 141 |
+
)
|
| 142 |
+
break
|
| 143 |
+
self.generic_visit(node)
|
| 144 |
+
|
| 145 |
+
@staticmethod
|
| 146 |
+
def _call_name(node: ast.Call) -> str:
|
| 147 |
+
"""Extract a dotted function name such as `subprocess.run`."""
|
| 148 |
+
|
| 149 |
+
func = node.func
|
| 150 |
+
if isinstance(func, ast.Name):
|
| 151 |
+
return func.id
|
| 152 |
+
if isinstance(func, ast.Attribute):
|
| 153 |
+
prefix = _StaticAnalyzer._attribute_prefix(func.value)
|
| 154 |
+
return f"{prefix}.{func.attr}" if prefix else func.attr
|
| 155 |
+
return ""
|
| 156 |
+
|
| 157 |
+
@staticmethod
|
| 158 |
+
def _attribute_prefix(node: ast.AST) -> str:
|
| 159 |
+
"""Reconstruct the left-hand side of an attribute chain."""
|
| 160 |
+
|
| 161 |
+
if isinstance(node, ast.Name):
|
| 162 |
+
return node.id
|
| 163 |
+
if isinstance(node, ast.Attribute):
|
| 164 |
+
prefix = _StaticAnalyzer._attribute_prefix(node.value)
|
| 165 |
+
return f"{prefix}.{node.attr}" if prefix else node.attr
|
| 166 |
+
return ""
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def analyze_python_code(code: str) -> List[ReviewFinding]:
|
| 170 |
+
"""Analyze arbitrary Python code and return structured findings."""
|
| 171 |
+
|
| 172 |
+
if not code.strip():
|
| 173 |
+
return [
|
| 174 |
+
ReviewFinding(
|
| 175 |
+
title="No code provided",
|
| 176 |
+
category="bug",
|
| 177 |
+
severity="warning",
|
| 178 |
+
rationale="The reviewer cannot inspect an empty submission.",
|
| 179 |
+
recommendation="Provide Python source code.",
|
| 180 |
+
rule_id="empty-input",
|
| 181 |
+
)
|
| 182 |
+
]
|
| 183 |
+
|
| 184 |
+
# Syntax errors are turned into findings rather than exceptions so API
|
| 185 |
+
# consumers always get a valid response shape.
|
| 186 |
+
try:
|
| 187 |
+
tree = ast.parse(code)
|
| 188 |
+
except SyntaxError as exc:
|
| 189 |
+
return [
|
| 190 |
+
ReviewFinding(
|
| 191 |
+
title="Syntax error",
|
| 192 |
+
line=exc.lineno,
|
| 193 |
+
category="bug",
|
| 194 |
+
severity="critical",
|
| 195 |
+
rationale=exc.msg,
|
| 196 |
+
recommendation="Fix the syntax error before running static review.",
|
| 197 |
+
rule_id="syntax-error",
|
| 198 |
+
)
|
| 199 |
+
]
|
| 200 |
+
|
| 201 |
+
analyzer = _StaticAnalyzer()
|
| 202 |
+
analyzer.visit(tree)
|
| 203 |
+
return _deduplicate(analyzer.issues)
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
def build_direct_review_response(
|
| 207 |
+
code: str, context: Optional[str] = None
|
| 208 |
+
) -> DirectReviewResponse:
|
| 209 |
+
"""Build the public direct-review response for the `/review` route."""
|
| 210 |
+
|
| 211 |
+
issues = analyze_python_code(code)
|
| 212 |
+
weighted_penalty = 0.0
|
| 213 |
+
# The direct-review score is intentionally simple: more severe issues lower
|
| 214 |
+
# the score more aggressively.
|
| 215 |
+
for issue in issues:
|
| 216 |
+
if issue.severity == "critical":
|
| 217 |
+
weighted_penalty += 0.3
|
| 218 |
+
elif issue.severity == "warning":
|
| 219 |
+
weighted_penalty += 0.15
|
| 220 |
+
else:
|
| 221 |
+
weighted_penalty += 0.05
|
| 222 |
+
|
| 223 |
+
score = max(0.0, min(1.0, 1.0 - weighted_penalty))
|
| 224 |
+
summary = _build_summary(issues, context)
|
| 225 |
+
improved_code = _suggest_improved_code(code, issues)
|
| 226 |
+
return DirectReviewResponse(
|
| 227 |
+
issues=issues,
|
| 228 |
+
summary=summary,
|
| 229 |
+
score=score,
|
| 230 |
+
improved_code=improved_code,
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
def _build_summary(issues: List[ReviewFinding], context: Optional[str]) -> str:
|
| 235 |
+
"""Create a concise human-readable summary for the direct-review response."""
|
| 236 |
+
|
| 237 |
+
if not issues:
|
| 238 |
+
base = "No obvious issues were detected by the deterministic reviewer."
|
| 239 |
+
else:
|
| 240 |
+
critical = sum(1 for issue in issues if issue.severity == "critical")
|
| 241 |
+
warnings = sum(1 for issue in issues if issue.severity == "warning")
|
| 242 |
+
infos = sum(1 for issue in issues if issue.severity == "info")
|
| 243 |
+
base = (
|
| 244 |
+
f"Detected {len(issues)} issue(s): {critical} critical, "
|
| 245 |
+
f"{warnings} warning, {infos} info."
|
| 246 |
+
)
|
| 247 |
+
if context:
|
| 248 |
+
return f"{base} Context: {context}"
|
| 249 |
+
return base
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
def _suggest_improved_code(code: str, issues: List[ReviewFinding]) -> Optional[str]:
|
| 253 |
+
"""Append high-level fix directions to the submitted code."""
|
| 254 |
+
|
| 255 |
+
if not issues:
|
| 256 |
+
return None
|
| 257 |
+
suggestions = [issue.recommendation for issue in issues if issue.recommendation]
|
| 258 |
+
comment = " | ".join(dict.fromkeys(suggestions))
|
| 259 |
+
return f"{code.rstrip()}\n\n# Suggested review directions: {comment}"
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
def _deduplicate(findings: List[ReviewFinding]) -> List[ReviewFinding]:
|
| 263 |
+
"""Drop duplicate findings that refer to the same rule and line."""
|
| 264 |
+
|
| 265 |
+
seen = set()
|
| 266 |
+
unique: List[ReviewFinding] = []
|
| 267 |
+
for finding in findings:
|
| 268 |
+
key = (finding.rule_id, finding.line, finding.category)
|
| 269 |
+
if key in seen:
|
| 270 |
+
continue
|
| 271 |
+
seen.add(key)
|
| 272 |
+
unique.append(finding)
|
| 273 |
+
return unique
|
server/task_bank.py
ADDED
|
@@ -0,0 +1,340 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Static PR-review tasks and hidden grading rubrics."""
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
from dataclasses import dataclass, field
|
| 6 |
+
from typing import Dict, Iterable, List, Sequence
|
| 7 |
+
|
| 8 |
+
try:
|
| 9 |
+
from models import Category, Difficulty, Severity, TaskDescriptor, TaskSummary
|
| 10 |
+
except ModuleNotFoundError: # pragma: no cover
|
| 11 |
+
from ..models import Category, Difficulty, Severity, TaskDescriptor, TaskSummary
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@dataclass(frozen=True)
|
| 15 |
+
class RubricIssue:
|
| 16 |
+
"""One hidden issue that can be matched by the deterministic grader."""
|
| 17 |
+
|
| 18 |
+
issue_id: str
|
| 19 |
+
file_path: str
|
| 20 |
+
line: int
|
| 21 |
+
category: Category
|
| 22 |
+
severity: Severity
|
| 23 |
+
keywords: Sequence[str]
|
| 24 |
+
min_keyword_hits: int
|
| 25 |
+
weight: float
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
@dataclass(frozen=True)
|
| 29 |
+
class TaskSpec:
|
| 30 |
+
"""Complete task definition, including hidden rubric metadata."""
|
| 31 |
+
|
| 32 |
+
task_id: str
|
| 33 |
+
difficulty: Difficulty
|
| 34 |
+
title: str
|
| 35 |
+
goal: str
|
| 36 |
+
repo_summary: str
|
| 37 |
+
visible_diff: str
|
| 38 |
+
file_contents: Dict[str, str]
|
| 39 |
+
changed_files: Sequence[str]
|
| 40 |
+
rubric_issues: Sequence[RubricIssue]
|
| 41 |
+
max_steps: int
|
| 42 |
+
|
| 43 |
+
@property
|
| 44 |
+
def available_files(self) -> List[str]:
|
| 45 |
+
return list(self.file_contents.keys())
|
| 46 |
+
|
| 47 |
+
def to_descriptor(self) -> TaskDescriptor:
|
| 48 |
+
return TaskDescriptor(
|
| 49 |
+
task_id=self.task_id,
|
| 50 |
+
difficulty=self.difficulty,
|
| 51 |
+
title=self.title,
|
| 52 |
+
goal=self.goal,
|
| 53 |
+
repo_summary=self.repo_summary,
|
| 54 |
+
changed_files=list(self.changed_files),
|
| 55 |
+
available_files=self.available_files,
|
| 56 |
+
max_steps=self.max_steps,
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
def to_summary(self) -> TaskSummary:
|
| 60 |
+
return TaskSummary(
|
| 61 |
+
task_id=self.task_id,
|
| 62 |
+
difficulty=self.difficulty,
|
| 63 |
+
title=self.title,
|
| 64 |
+
goal=self.goal,
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
TASKS: List[TaskSpec] = [
|
| 69 |
+
TaskSpec(
|
| 70 |
+
task_id="py-pr-review-easy",
|
| 71 |
+
difficulty="easy",
|
| 72 |
+
title="Retry Delay Regression",
|
| 73 |
+
goal=(
|
| 74 |
+
"Review the pull request and identify the real bug introduced in the retry "
|
| 75 |
+
"delay helper before it ships."
|
| 76 |
+
),
|
| 77 |
+
repo_summary=(
|
| 78 |
+
"This service computes retry delays for background notification delivery. "
|
| 79 |
+
"The change is intended to relax validation for legacy callers."
|
| 80 |
+
),
|
| 81 |
+
visible_diff="\n".join(
|
| 82 |
+
[
|
| 83 |
+
"diff --git a/src/notifications/retry.py b/src/notifications/retry.py",
|
| 84 |
+
"@@",
|
| 85 |
+
"- if base_delay <= 0:",
|
| 86 |
+
"+ if base_delay < 0:",
|
| 87 |
+
" return 0.0",
|
| 88 |
+
]
|
| 89 |
+
),
|
| 90 |
+
file_contents={
|
| 91 |
+
"src/notifications/retry.py": "\n".join(
|
| 92 |
+
[
|
| 93 |
+
"from __future__ import annotations",
|
| 94 |
+
"",
|
| 95 |
+
"def calculate_retry_delay(attempt: int, base_delay: float = 2.0) -> float:",
|
| 96 |
+
' """Return the retry delay in seconds."""',
|
| 97 |
+
" if attempt < 0:",
|
| 98 |
+
' raise ValueError(\"attempt must be >= 0\")',
|
| 99 |
+
" if base_delay < 0:",
|
| 100 |
+
" return 0.0",
|
| 101 |
+
" return attempt / base_delay",
|
| 102 |
+
]
|
| 103 |
+
)
|
| 104 |
+
},
|
| 105 |
+
changed_files=("src/notifications/retry.py",),
|
| 106 |
+
rubric_issues=(
|
| 107 |
+
RubricIssue(
|
| 108 |
+
issue_id="zero-base-delay-divides",
|
| 109 |
+
file_path="src/notifications/retry.py",
|
| 110 |
+
line=7,
|
| 111 |
+
category="bug",
|
| 112 |
+
severity="warning",
|
| 113 |
+
keywords=("zero", "division", "base_delay"),
|
| 114 |
+
min_keyword_hits=2,
|
| 115 |
+
weight=1.0,
|
| 116 |
+
),
|
| 117 |
+
),
|
| 118 |
+
max_steps=4,
|
| 119 |
+
),
|
| 120 |
+
TaskSpec(
|
| 121 |
+
task_id="py-pr-review-medium",
|
| 122 |
+
difficulty="medium",
|
| 123 |
+
title="Coupon Billing Rollout",
|
| 124 |
+
goal=(
|
| 125 |
+
"Review the billing change and identify both the production regression and "
|
| 126 |
+
"the missing coverage that would have caught it."
|
| 127 |
+
),
|
| 128 |
+
repo_summary=(
|
| 129 |
+
"The billing service is adding coupon support for one-off invoices. The PR "
|
| 130 |
+
"touches both the service code and its unit tests."
|
| 131 |
+
),
|
| 132 |
+
visible_diff="\n".join(
|
| 133 |
+
[
|
| 134 |
+
"diff --git a/app/billing/invoice_service.py b/app/billing/invoice_service.py",
|
| 135 |
+
"@@",
|
| 136 |
+
" def charge_invoice(order: dict, gateway: Gateway) -> str:",
|
| 137 |
+
"- return gateway.charge(order[\"customer_id\"], order[\"amount_cents\"])",
|
| 138 |
+
"+ total = order[\"amount_cents\"]",
|
| 139 |
+
"+ coupon = order.get(\"coupon_code\")",
|
| 140 |
+
"+ if coupon:",
|
| 141 |
+
"+ discount = gateway.lookup_discount(coupon)",
|
| 142 |
+
"+ total = max(total - discount, 0)",
|
| 143 |
+
"+ return gateway.charge(order[\"customer_id\"], order[\"amount_cents\"])",
|
| 144 |
+
"",
|
| 145 |
+
"diff --git a/tests/test_invoice_service.py b/tests/test_invoice_service.py",
|
| 146 |
+
"@@",
|
| 147 |
+
" class FakeGateway:",
|
| 148 |
+
"+ def lookup_discount(self, coupon: str) -> int:",
|
| 149 |
+
"+ return 250",
|
| 150 |
+
]
|
| 151 |
+
),
|
| 152 |
+
file_contents={
|
| 153 |
+
"app/billing/invoice_service.py": "\n".join(
|
| 154 |
+
[
|
| 155 |
+
"from gateway import Gateway",
|
| 156 |
+
"",
|
| 157 |
+
"def charge_invoice(order: dict, gateway: Gateway) -> str:",
|
| 158 |
+
' total = order["amount_cents"]',
|
| 159 |
+
' coupon = order.get("coupon_code")',
|
| 160 |
+
" if coupon:",
|
| 161 |
+
" discount = gateway.lookup_discount(coupon)",
|
| 162 |
+
" total = max(total - discount, 0)",
|
| 163 |
+
' return gateway.charge(order["customer_id"], order["amount_cents"])',
|
| 164 |
+
]
|
| 165 |
+
),
|
| 166 |
+
"tests/test_invoice_service.py": "\n".join(
|
| 167 |
+
[
|
| 168 |
+
"from app.billing.invoice_service import charge_invoice",
|
| 169 |
+
"",
|
| 170 |
+
"class FakeGateway:",
|
| 171 |
+
" def lookup_discount(self, coupon: str) -> int:",
|
| 172 |
+
" return 250",
|
| 173 |
+
"",
|
| 174 |
+
" def charge(self, customer_id: str, amount_cents: int) -> str:",
|
| 175 |
+
" self.last_charge = (customer_id, amount_cents)",
|
| 176 |
+
' return "charge_123"',
|
| 177 |
+
"",
|
| 178 |
+
"def test_charge_invoice_without_coupon():",
|
| 179 |
+
" gateway = FakeGateway()",
|
| 180 |
+
' charge_invoice({"customer_id": "cus_1", "amount_cents": 1000}, gateway)',
|
| 181 |
+
' assert gateway.last_charge == ("cus_1", 1000)',
|
| 182 |
+
]
|
| 183 |
+
),
|
| 184 |
+
},
|
| 185 |
+
changed_files=("app/billing/invoice_service.py", "tests/test_invoice_service.py"),
|
| 186 |
+
rubric_issues=(
|
| 187 |
+
RubricIssue(
|
| 188 |
+
issue_id="discount-total-unused",
|
| 189 |
+
file_path="app/billing/invoice_service.py",
|
| 190 |
+
line=8,
|
| 191 |
+
category="bug",
|
| 192 |
+
severity="warning",
|
| 193 |
+
keywords=("discount", "total", "charge", "amount"),
|
| 194 |
+
min_keyword_hits=2,
|
| 195 |
+
weight=0.6,
|
| 196 |
+
),
|
| 197 |
+
RubricIssue(
|
| 198 |
+
issue_id="missing-coupon-test",
|
| 199 |
+
file_path="tests/test_invoice_service.py",
|
| 200 |
+
line=11,
|
| 201 |
+
category="testing",
|
| 202 |
+
severity="warning",
|
| 203 |
+
keywords=("missing", "test", "coupon", "discount"),
|
| 204 |
+
min_keyword_hits=2,
|
| 205 |
+
weight=0.4,
|
| 206 |
+
),
|
| 207 |
+
),
|
| 208 |
+
max_steps=5,
|
| 209 |
+
),
|
| 210 |
+
TaskSpec(
|
| 211 |
+
task_id="py-pr-review-hard",
|
| 212 |
+
difficulty="hard",
|
| 213 |
+
title="Async Job Runner Deduplication",
|
| 214 |
+
goal=(
|
| 215 |
+
"Review the async job-runner PR and find the subtle concurrency issues "
|
| 216 |
+
"without inventing extra problems."
|
| 217 |
+
),
|
| 218 |
+
repo_summary=(
|
| 219 |
+
"A shared webhook backfill service is deduplicating in-flight work with an "
|
| 220 |
+
"async task cache and writing the latest result for operators to inspect."
|
| 221 |
+
),
|
| 222 |
+
visible_diff="\n".join(
|
| 223 |
+
[
|
| 224 |
+
"diff --git a/app/jobs/runner.py b/app/jobs/runner.py",
|
| 225 |
+
"@@",
|
| 226 |
+
" async def run_job(job_id: str, payload: dict, worker) -> str:",
|
| 227 |
+
" if job_id in ACTIVE_RUNS:",
|
| 228 |
+
" return await ACTIVE_RUNS[job_id]",
|
| 229 |
+
"+ lock = asyncio.Lock()",
|
| 230 |
+
"+ async with lock:",
|
| 231 |
+
"+ task = asyncio.create_task(worker.run(payload))",
|
| 232 |
+
"+ ACTIVE_RUNS[job_id] = task",
|
| 233 |
+
" try:",
|
| 234 |
+
" result = await task",
|
| 235 |
+
" finally:",
|
| 236 |
+
" ACTIVE_RUNS.pop(job_id, None)",
|
| 237 |
+
"+ Path(\"latest-result.json\").write_text(result)",
|
| 238 |
+
" return result",
|
| 239 |
+
]
|
| 240 |
+
),
|
| 241 |
+
file_contents={
|
| 242 |
+
"app/jobs/runner.py": "\n".join(
|
| 243 |
+
[
|
| 244 |
+
"import asyncio",
|
| 245 |
+
"from pathlib import Path",
|
| 246 |
+
"",
|
| 247 |
+
"ACTIVE_RUNS: dict[str, asyncio.Task[str]] = {}",
|
| 248 |
+
"",
|
| 249 |
+
"async def run_job(job_id: str, payload: dict, worker) -> str:",
|
| 250 |
+
" if job_id in ACTIVE_RUNS:",
|
| 251 |
+
" return await ACTIVE_RUNS[job_id]",
|
| 252 |
+
"",
|
| 253 |
+
" lock = asyncio.Lock()",
|
| 254 |
+
" async with lock:",
|
| 255 |
+
" task = asyncio.create_task(worker.run(payload))",
|
| 256 |
+
" ACTIVE_RUNS[job_id] = task",
|
| 257 |
+
" try:",
|
| 258 |
+
" result = await task",
|
| 259 |
+
" finally:",
|
| 260 |
+
" ACTIVE_RUNS.pop(job_id, None)",
|
| 261 |
+
"",
|
| 262 |
+
' Path("latest-result.json").write_text(result)',
|
| 263 |
+
" return result",
|
| 264 |
+
]
|
| 265 |
+
),
|
| 266 |
+
"tests/test_runner.py": "\n".join(
|
| 267 |
+
[
|
| 268 |
+
"import pytest",
|
| 269 |
+
"",
|
| 270 |
+
"from app.jobs.runner import run_job",
|
| 271 |
+
"",
|
| 272 |
+
"class FakeWorker:",
|
| 273 |
+
" async def run(self, payload: dict) -> str:",
|
| 274 |
+
' return payload["job_id"]',
|
| 275 |
+
"",
|
| 276 |
+
"@pytest.mark.asyncio",
|
| 277 |
+
"async def test_run_job_returns_worker_result():",
|
| 278 |
+
" worker = FakeWorker()",
|
| 279 |
+
' result = await run_job("job-1", {"job_id": "job-1"}, worker)',
|
| 280 |
+
' assert result == "job-1"',
|
| 281 |
+
]
|
| 282 |
+
),
|
| 283 |
+
},
|
| 284 |
+
changed_files=("app/jobs/runner.py", "tests/test_runner.py"),
|
| 285 |
+
rubric_issues=(
|
| 286 |
+
RubricIssue(
|
| 287 |
+
issue_id="per-call-lock-race",
|
| 288 |
+
file_path="app/jobs/runner.py",
|
| 289 |
+
line=9,
|
| 290 |
+
category="bug",
|
| 291 |
+
severity="warning",
|
| 292 |
+
keywords=("lock", "race", "concurrent", "duplicate"),
|
| 293 |
+
min_keyword_hits=2,
|
| 294 |
+
weight=0.55,
|
| 295 |
+
),
|
| 296 |
+
RubricIssue(
|
| 297 |
+
issue_id="shared-output-file-race",
|
| 298 |
+
file_path="app/jobs/runner.py",
|
| 299 |
+
line=18,
|
| 300 |
+
category="maintainability",
|
| 301 |
+
severity="warning",
|
| 302 |
+
keywords=("latest", "result", "file", "concurrent", "overwrite"),
|
| 303 |
+
min_keyword_hits=2,
|
| 304 |
+
weight=0.45,
|
| 305 |
+
),
|
| 306 |
+
),
|
| 307 |
+
max_steps=6,
|
| 308 |
+
),
|
| 309 |
+
]
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
TASKS_BY_ID: Dict[str, TaskSpec] = {task.task_id: task for task in TASKS}
|
| 313 |
+
|
| 314 |
+
|
| 315 |
+
def list_task_descriptors() -> List[TaskDescriptor]:
|
| 316 |
+
"""Return public descriptors for all tasks."""
|
| 317 |
+
|
| 318 |
+
return [task.to_descriptor() for task in TASKS]
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
def list_task_summaries() -> List[TaskSummary]:
|
| 322 |
+
"""Return task summaries for lightweight route responses."""
|
| 323 |
+
|
| 324 |
+
return [task.to_summary() for task in TASKS]
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
def get_task(task_id: str) -> TaskSpec:
|
| 328 |
+
"""Return a task by id."""
|
| 329 |
+
|
| 330 |
+
try:
|
| 331 |
+
return TASKS_BY_ID[task_id]
|
| 332 |
+
except KeyError as exc: # pragma: no cover
|
| 333 |
+
raise ValueError(f"Unknown task_id: {task_id}") from exc
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
def task_ids() -> Iterable[str]:
|
| 337 |
+
"""Return task ids in benchmark order."""
|
| 338 |
+
|
| 339 |
+
return [task.task_id for task in TASKS]
|
| 340 |
+
|
summary/01_introduction_quickstart.md
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 01. Introduction & Quick Start
|
| 2 |
+
|
| 3 |
+
Source:
|
| 4 |
+
- https://meta-pytorch.org/OpenEnv/auto_getting_started/plot_01_introduction_quickstart.html
|
| 5 |
+
|
| 6 |
+
## Main idea
|
| 7 |
+
|
| 8 |
+
OpenEnv is a standardized framework for building, sharing, and using RL environments as typed, containerized services.
|
| 9 |
+
|
| 10 |
+
The official docs frame it as:
|
| 11 |
+
|
| 12 |
+
- Gym-style interaction
|
| 13 |
+
- Docker-based isolation
|
| 14 |
+
- typed contracts
|
| 15 |
+
- HTTP/WebSocket access
|
| 16 |
+
- easy sharing through Hugging Face
|
| 17 |
+
|
| 18 |
+
## Core loop
|
| 19 |
+
|
| 20 |
+
The RL interaction model is still the normal loop:
|
| 21 |
+
|
| 22 |
+
1. reset environment
|
| 23 |
+
2. observe state
|
| 24 |
+
3. choose action
|
| 25 |
+
4. call step
|
| 26 |
+
5. receive reward + next observation
|
| 27 |
+
6. repeat until done
|
| 28 |
+
|
| 29 |
+
The difference is that OpenEnv wraps this loop in a typed client/server system.
|
| 30 |
+
|
| 31 |
+
## Why OpenEnv instead of only Gym
|
| 32 |
+
|
| 33 |
+
The docs emphasize these advantages:
|
| 34 |
+
|
| 35 |
+
- type safety
|
| 36 |
+
- environment isolation through containers
|
| 37 |
+
- better reproducibility
|
| 38 |
+
- easier sharing and deployment
|
| 39 |
+
- language-agnostic communication
|
| 40 |
+
- cleaner debugging
|
| 41 |
+
|
| 42 |
+
The key contrast is:
|
| 43 |
+
|
| 44 |
+
- old style: raw arrays and same-process execution
|
| 45 |
+
- OpenEnv style: typed objects and isolated environment runtime
|
| 46 |
+
|
| 47 |
+
## Important mental model
|
| 48 |
+
|
| 49 |
+
OpenEnv treats environments more like services than in-process libraries.
|
| 50 |
+
|
| 51 |
+
That means:
|
| 52 |
+
|
| 53 |
+
- your environment logic can run separately from the agent code
|
| 54 |
+
- failures in the environment do not automatically crash the training loop
|
| 55 |
+
- deployment and usage are closer to how production systems work
|
| 56 |
+
|
| 57 |
+
## What this means for `python_env`
|
| 58 |
+
|
| 59 |
+
Your repo should keep these properties intact:
|
| 60 |
+
|
| 61 |
+
- typed `Action`, `Observation`, and evaluation models
|
| 62 |
+
- a clean environment class with `reset()`, `step()`, and `state`
|
| 63 |
+
- a client that hides transport details
|
| 64 |
+
- a deployable container
|
| 65 |
+
|
| 66 |
+
For hackathon purposes, this page is the justification for why your project is not just a script. It is a reusable environment artifact.
|
summary/02_using_environments.md
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 02. Using Environments
|
| 2 |
+
|
| 3 |
+
Source:
|
| 4 |
+
- https://meta-pytorch.org/OpenEnv/auto_getting_started/plot_02_using_environments.html
|
| 5 |
+
|
| 6 |
+
## Main idea
|
| 7 |
+
|
| 8 |
+
This page is about how users consume an existing OpenEnv environment.
|
| 9 |
+
|
| 10 |
+
The docs highlight three connection methods:
|
| 11 |
+
|
| 12 |
+
1. from Hugging Face Hub
|
| 13 |
+
2. from Docker image
|
| 14 |
+
3. from direct base URL
|
| 15 |
+
|
| 16 |
+
## Connection methods
|
| 17 |
+
|
| 18 |
+
### 1. From Hugging Face Hub
|
| 19 |
+
|
| 20 |
+
The easiest route for end users.
|
| 21 |
+
|
| 22 |
+
Typical flow:
|
| 23 |
+
|
| 24 |
+
- pull the image from the HF registry
|
| 25 |
+
- start the container locally
|
| 26 |
+
- connect to it
|
| 27 |
+
- clean it up on close
|
| 28 |
+
|
| 29 |
+
The docs show the pattern conceptually as:
|
| 30 |
+
|
| 31 |
+
```python
|
| 32 |
+
MyEnv.from_hub("owner/env-name")
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
## 2. From Docker image
|
| 36 |
+
|
| 37 |
+
Useful when:
|
| 38 |
+
|
| 39 |
+
- you already built the image locally
|
| 40 |
+
- you want reproducible local runs
|
| 41 |
+
- you do not want to depend on a live remote Space
|
| 42 |
+
|
| 43 |
+
Typical pattern:
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
MyEnv.from_docker_image("my-env:latest")
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
## 3. Direct URL connection
|
| 50 |
+
|
| 51 |
+
Useful when:
|
| 52 |
+
|
| 53 |
+
- the server is already running
|
| 54 |
+
- you want to connect to localhost or a deployed Space
|
| 55 |
+
|
| 56 |
+
Typical pattern:
|
| 57 |
+
|
| 58 |
+
```python
|
| 59 |
+
MyEnv(base_url="http://localhost:8000")
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
## WebSocket model
|
| 63 |
+
|
| 64 |
+
The docs emphasize that OpenEnv uses WebSocket-backed sessions for persistent environment interaction.
|
| 65 |
+
|
| 66 |
+
Why this matters:
|
| 67 |
+
|
| 68 |
+
- lower overhead than stateless HTTP on every step
|
| 69 |
+
- cleaner session management
|
| 70 |
+
- better fit for multi-step RL loops
|
| 71 |
+
|
| 72 |
+
## Environment loop
|
| 73 |
+
|
| 74 |
+
The intended use pattern is:
|
| 75 |
+
|
| 76 |
+
1. connect
|
| 77 |
+
2. reset
|
| 78 |
+
3. repeatedly call `step(action)`
|
| 79 |
+
4. inspect `reward`, `done`, and `observation`
|
| 80 |
+
5. close cleanly
|
| 81 |
+
|
| 82 |
+
## What this means for `python_env`
|
| 83 |
+
|
| 84 |
+
Your environment should be easy to consume in all three modes:
|
| 85 |
+
|
| 86 |
+
- local URL
|
| 87 |
+
- local Docker image
|
| 88 |
+
- HF Space
|
| 89 |
+
|
| 90 |
+
That means the most important user-facing checks are:
|
| 91 |
+
|
| 92 |
+
- `reset()` works
|
| 93 |
+
- `step()` works
|
| 94 |
+
- the client can parse the observation correctly
|
| 95 |
+
- Docker image starts cleanly
|
| 96 |
+
- deployed Space responds on `/health`, `/docs`, and session routes
|
| 97 |
+
|
| 98 |
+
For hackathon validation, this page is basically the “user experience” standard you need to match.
|
summary/03_building_environments.md
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 03. Building Environments
|
| 2 |
+
|
| 3 |
+
Source:
|
| 4 |
+
- https://meta-pytorch.org/OpenEnv/auto_getting_started/plot_03_building_environments.html
|
| 5 |
+
|
| 6 |
+
## Main idea
|
| 7 |
+
|
| 8 |
+
This page describes the standard OpenEnv project structure and how to build a custom environment from scratch.
|
| 9 |
+
|
| 10 |
+
## Standard project layout
|
| 11 |
+
|
| 12 |
+
The docs show a layout like:
|
| 13 |
+
|
| 14 |
+
```text
|
| 15 |
+
my_game/
|
| 16 |
+
├── __init__.py
|
| 17 |
+
├── models.py
|
| 18 |
+
├── client.py
|
| 19 |
+
├── openenv.yaml
|
| 20 |
+
├── README.md
|
| 21 |
+
└── server/
|
| 22 |
+
├── __init__.py
|
| 23 |
+
├── environment.py
|
| 24 |
+
├── app.py
|
| 25 |
+
├── Dockerfile
|
| 26 |
+
└── requirements.txt
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
## Responsibilities by file
|
| 30 |
+
|
| 31 |
+
### `models.py`
|
| 32 |
+
|
| 33 |
+
Defines typed:
|
| 34 |
+
|
| 35 |
+
- actions
|
| 36 |
+
- observations
|
| 37 |
+
- state-related payloads
|
| 38 |
+
|
| 39 |
+
This is the contract layer.
|
| 40 |
+
|
| 41 |
+
### `client.py`
|
| 42 |
+
|
| 43 |
+
Defines the client used by agents and evaluation scripts.
|
| 44 |
+
|
| 45 |
+
This should:
|
| 46 |
+
|
| 47 |
+
- convert actions into payloads
|
| 48 |
+
- parse observations from responses
|
| 49 |
+
- expose a clean local Python API
|
| 50 |
+
|
| 51 |
+
### `server/environment.py`
|
| 52 |
+
|
| 53 |
+
Defines the actual environment logic:
|
| 54 |
+
|
| 55 |
+
- reset behavior
|
| 56 |
+
- step behavior
|
| 57 |
+
- state tracking
|
| 58 |
+
|
| 59 |
+
This is the heart of the environment.
|
| 60 |
+
|
| 61 |
+
### `server/app.py`
|
| 62 |
+
|
| 63 |
+
Exposes the environment through FastAPI/OpenEnv.
|
| 64 |
+
|
| 65 |
+
This is the transport layer, not the logic layer.
|
| 66 |
+
|
| 67 |
+
### `server/Dockerfile`
|
| 68 |
+
|
| 69 |
+
Defines how the environment runs reproducibly in a container.
|
| 70 |
+
|
| 71 |
+
### `openenv.yaml`
|
| 72 |
+
|
| 73 |
+
Defines the environment manifest and deployment metadata.
|
| 74 |
+
|
| 75 |
+
## Key lesson
|
| 76 |
+
|
| 77 |
+
The docs separate:
|
| 78 |
+
|
| 79 |
+
- contracts
|
| 80 |
+
- logic
|
| 81 |
+
- transport
|
| 82 |
+
- packaging
|
| 83 |
+
|
| 84 |
+
That separation is what makes environments maintainable and deployable.
|
| 85 |
+
|
| 86 |
+
## What this means for `python_env`
|
| 87 |
+
|
| 88 |
+
Your repo already follows this pattern reasonably well:
|
| 89 |
+
|
| 90 |
+
- `models.py`
|
| 91 |
+
- `client.py`
|
| 92 |
+
- `server/code_review_environment.py`
|
| 93 |
+
- `server/app.py`
|
| 94 |
+
- `server/Dockerfile`
|
| 95 |
+
- `openenv.yaml`
|
| 96 |
+
|
| 97 |
+
The main thing to protect is that no single file should try to do everything.
|
| 98 |
+
|
| 99 |
+
For hackathon quality, this page matters because judges will look for clean structure, not just working behavior.
|
summary/04_packaging_deploying.md
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 04. Packaging & Deploying
|
| 2 |
+
|
| 3 |
+
Source:
|
| 4 |
+
- https://meta-pytorch.org/OpenEnv/auto_getting_started/environment-builder.html
|
| 5 |
+
|
| 6 |
+
## Main idea
|
| 7 |
+
|
| 8 |
+
This page is the operational workflow for taking an environment from local code to a validated, deployable artifact.
|
| 9 |
+
|
| 10 |
+
## Official workflow
|
| 11 |
+
|
| 12 |
+
The docs describe this sequence:
|
| 13 |
+
|
| 14 |
+
1. scaffold environment with `openenv init`
|
| 15 |
+
2. customize models, server logic, and client
|
| 16 |
+
3. implement typed `EnvClient`
|
| 17 |
+
4. configure dependencies and Dockerfile
|
| 18 |
+
5. run CLI packaging and deployment commands
|
| 19 |
+
|
| 20 |
+
## Important CLI commands
|
| 21 |
+
|
| 22 |
+
### `openenv build`
|
| 23 |
+
|
| 24 |
+
Purpose:
|
| 25 |
+
|
| 26 |
+
- build the Docker image for the environment
|
| 27 |
+
|
| 28 |
+
The docs call out that it supports both standalone and in-repo environments.
|
| 29 |
+
|
| 30 |
+
### `openenv validate --verbose`
|
| 31 |
+
|
| 32 |
+
Purpose:
|
| 33 |
+
|
| 34 |
+
- check required files
|
| 35 |
+
- verify entrypoints
|
| 36 |
+
- confirm deployment modes
|
| 37 |
+
- fail non-zero on problems
|
| 38 |
+
|
| 39 |
+
This is one of the most important commands for submission readiness.
|
| 40 |
+
|
| 41 |
+
### `openenv push`
|
| 42 |
+
|
| 43 |
+
Purpose:
|
| 44 |
+
|
| 45 |
+
- deploy to Hugging Face Spaces
|
| 46 |
+
- optionally push to other registries
|
| 47 |
+
|
| 48 |
+
Useful options mentioned by the docs:
|
| 49 |
+
|
| 50 |
+
- `--repo-id`
|
| 51 |
+
- `--private`
|
| 52 |
+
- `--registry`
|
| 53 |
+
- `--base-image`
|
| 54 |
+
|
| 55 |
+
## Hugging Face integration behavior
|
| 56 |
+
|
| 57 |
+
The docs say the CLI handles:
|
| 58 |
+
|
| 59 |
+
- validating `openenv.yaml`
|
| 60 |
+
- adding HF frontmatter when needed
|
| 61 |
+
- preparing the bundle for upload
|
| 62 |
+
|
| 63 |
+
That means your local files need to be internally consistent before `openenv push`.
|
| 64 |
+
|
| 65 |
+
## Prerequisites
|
| 66 |
+
|
| 67 |
+
The docs explicitly call out:
|
| 68 |
+
|
| 69 |
+
- Python 3.11+
|
| 70 |
+
- `uv`
|
| 71 |
+
- Docker
|
| 72 |
+
- OpenEnv installed
|
| 73 |
+
|
| 74 |
+
## What this means for `python_env`
|
| 75 |
+
|
| 76 |
+
This is your final operational checklist:
|
| 77 |
+
|
| 78 |
+
1. `openenv build`
|
| 79 |
+
2. `openenv validate --verbose`
|
| 80 |
+
3. `openenv push`
|
| 81 |
+
|
| 82 |
+
If any of those fail, fix them before worrying about benchmark polish.
|
| 83 |
+
|
| 84 |
+
For the hackathon, this page is effectively your packaging contract.
|
summary/05_contributing_hf.md
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 05. Contributing to Hugging Face
|
| 2 |
+
|
| 3 |
+
Source:
|
| 4 |
+
- https://meta-pytorch.org/OpenEnv/auto_getting_started/contributing-envs.html
|
| 5 |
+
|
| 6 |
+
## Main idea
|
| 7 |
+
|
| 8 |
+
This page explains how OpenEnv environments are shared and improved on Hugging Face Spaces.
|
| 9 |
+
|
| 10 |
+
The docs treat Spaces as multiple things at once:
|
| 11 |
+
|
| 12 |
+
- Git repositories
|
| 13 |
+
- Docker images
|
| 14 |
+
- Python packages
|
| 15 |
+
- apps
|
| 16 |
+
|
| 17 |
+
## Three official workflows
|
| 18 |
+
|
| 19 |
+
### 1. Push a new environment
|
| 20 |
+
|
| 21 |
+
This is the normal path when you built your own environment.
|
| 22 |
+
|
| 23 |
+
The docs show:
|
| 24 |
+
|
| 25 |
+
```bash
|
| 26 |
+
openenv push
|
| 27 |
+
openenv push --repo-id my-org/my-custom-env
|
| 28 |
+
openenv push --private
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
This is the workflow your `python_env` project most directly cares about.
|
| 32 |
+
|
| 33 |
+
### 2. Fork an existing environment
|
| 34 |
+
|
| 35 |
+
Useful when you want to build from an existing environment quickly.
|
| 36 |
+
|
| 37 |
+
The docs show:
|
| 38 |
+
|
| 39 |
+
```bash
|
| 40 |
+
openenv fork owner/space-name
|
| 41 |
+
openenv fork owner/space-name --repo-id my-username/my-copy
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
You can also set env vars, secrets, and hardware during the fork flow.
|
| 45 |
+
|
| 46 |
+
### 3. Download, modify, and open a PR
|
| 47 |
+
|
| 48 |
+
The docs show a Hub-native contribution flow:
|
| 49 |
+
|
| 50 |
+
```bash
|
| 51 |
+
hf download owner/space-name --local-dir space-name --repo-type space
|
| 52 |
+
openenv push --repo-id owner/space-name --create-pr
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
This is useful if you want to improve an existing environment without owning the original.
|
| 56 |
+
|
| 57 |
+
## Prerequisites from the docs
|
| 58 |
+
|
| 59 |
+
- Python 3.11+
|
| 60 |
+
- `uv`
|
| 61 |
+
- OpenEnv CLI
|
| 62 |
+
- Hugging Face account
|
| 63 |
+
- write token
|
| 64 |
+
- `hf auth login`
|
| 65 |
+
|
| 66 |
+
## Why this matters for `python_env`
|
| 67 |
+
|
| 68 |
+
For your project, the important takeaway is:
|
| 69 |
+
|
| 70 |
+
- the final destination is a Hugging Face Space
|
| 71 |
+
- the Space is not just a demo page, it is the actual distribution unit
|
| 72 |
+
- once deployed, others should be able to use it as:
|
| 73 |
+
- a running endpoint
|
| 74 |
+
- a Docker image
|
| 75 |
+
- a Python-installable package
|
| 76 |
+
|
| 77 |
+
That means your submission should be clean enough that someone else could:
|
| 78 |
+
|
| 79 |
+
1. inspect the Space
|
| 80 |
+
2. clone it
|
| 81 |
+
3. run it locally
|
| 82 |
+
4. contribute improvements back
|
| 83 |
+
|
| 84 |
+
For the hackathon, this page is the “publish and collaborate” layer on top of the earlier build/deploy steps.
|
summary/README.md
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OpenEnv Docs Summary
|
| 2 |
+
|
| 3 |
+
This folder summarizes the official OpenEnv getting-started pages from:
|
| 4 |
+
|
| 5 |
+
- https://meta-pytorch.org/OpenEnv/auto_getting_started/plot_01_introduction_quickstart.html
|
| 6 |
+
- https://meta-pytorch.org/OpenEnv/auto_getting_started/plot_02_using_environments.html
|
| 7 |
+
- https://meta-pytorch.org/OpenEnv/auto_getting_started/plot_03_building_environments.html
|
| 8 |
+
- https://meta-pytorch.org/OpenEnv/auto_getting_started/environment-builder.html
|
| 9 |
+
- https://meta-pytorch.org/OpenEnv/auto_getting_started/contributing-envs.html
|
| 10 |
+
|
| 11 |
+
## Files
|
| 12 |
+
|
| 13 |
+
- `01_introduction_quickstart.md`
|
| 14 |
+
What OpenEnv is, why it exists, and the standard RL interaction pattern.
|
| 15 |
+
|
| 16 |
+
- `02_using_environments.md`
|
| 17 |
+
How to connect to environments from the Hub, Docker, or direct URLs and how the environment loop should look.
|
| 18 |
+
|
| 19 |
+
- `03_building_environments.md`
|
| 20 |
+
The standard OpenEnv project layout and what each file is responsible for.
|
| 21 |
+
|
| 22 |
+
- `04_packaging_deploying.md`
|
| 23 |
+
The packaging workflow with `openenv build`, `openenv validate`, and `openenv push`.
|
| 24 |
+
|
| 25 |
+
- `05_contributing_hf.md`
|
| 26 |
+
How to publish, fork, and submit PR-style contributions to Hugging Face Spaces.
|
| 27 |
+
|
| 28 |
+
## Why this matters for `python_env`
|
| 29 |
+
|
| 30 |
+
These summaries are here to keep the project aligned with the official OpenEnv workflow:
|
| 31 |
+
|
| 32 |
+
- typed models
|
| 33 |
+
- environment class
|
| 34 |
+
- client
|
| 35 |
+
- FastAPI/OpenEnv app
|
| 36 |
+
- Docker packaging
|
| 37 |
+
- validation
|
| 38 |
+
- HF Spaces deployment
|
| 39 |
+
|
| 40 |
+
Read these files in order if you want the shortest path from local development to a working hackathon submission.
|
tasks/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Task definitions for the Python code review environment."""
|
| 2 |
+
|
| 3 |
+
from .task_bank import TaskSpec, get_task, list_task_descriptors, list_task_summaries, task_ids
|
| 4 |
+
|
| 5 |
+
__all__ = [
|
| 6 |
+
"TaskSpec",
|
| 7 |
+
"get_task",
|
| 8 |
+
"list_task_descriptors",
|
| 9 |
+
"list_task_summaries",
|
| 10 |
+
"task_ids",
|
| 11 |
+
]
|
tasks/task_bank.py
ADDED
|
@@ -0,0 +1,273 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Deterministic task bank for Python code review and repair benchmark."""
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
from dataclasses import dataclass, field
|
| 6 |
+
from typing import Dict, List, Optional
|
| 7 |
+
|
| 8 |
+
from models import Difficulty, TaskDescriptor, TaskKind
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
@dataclass(frozen=True)
|
| 12 |
+
class TaskSpec:
|
| 13 |
+
"""Complete task specification with grading criteria."""
|
| 14 |
+
|
| 15 |
+
task_id: str
|
| 16 |
+
title: str
|
| 17 |
+
difficulty: Difficulty
|
| 18 |
+
task_kind: TaskKind
|
| 19 |
+
task_description: str
|
| 20 |
+
starter_code: str
|
| 21 |
+
reference_code: str
|
| 22 |
+
visible_tests: List[str]
|
| 23 |
+
hidden_tests: List[str]
|
| 24 |
+
max_steps: int = 10
|
| 25 |
+
benchmark_entrypoint: Optional[str] = None
|
| 26 |
+
benchmark_builder: Optional[str] = None
|
| 27 |
+
benchmark_repeats: int = 1
|
| 28 |
+
benchmark_timeout_s: float = 2.0
|
| 29 |
+
style_max_line_length: int = 88
|
| 30 |
+
expected_quality_markers: List[str] = field(default_factory=list)
|
| 31 |
+
|
| 32 |
+
def to_descriptor(self) -> TaskDescriptor:
|
| 33 |
+
"""Convert to public task descriptor."""
|
| 34 |
+
return TaskDescriptor(
|
| 35 |
+
task_id=self.task_id,
|
| 36 |
+
title=self.title,
|
| 37 |
+
difficulty=self.difficulty,
|
| 38 |
+
task_kind=self.task_kind,
|
| 39 |
+
task_description=self.task_description,
|
| 40 |
+
starter_code=self.starter_code,
|
| 41 |
+
visible_tests=list(self.visible_tests),
|
| 42 |
+
max_steps=self.max_steps,
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
# ============================================================================
|
| 47 |
+
# TASK 1: EASY - Syntax Fixing
|
| 48 |
+
# ============================================================================
|
| 49 |
+
|
| 50 |
+
TASK_SYNTAX_FIX = TaskSpec(
|
| 51 |
+
task_id="syntax-fix-easy",
|
| 52 |
+
title="Fix a syntax-broken username normalizer",
|
| 53 |
+
difficulty="easy",
|
| 54 |
+
task_kind="syntax_fix",
|
| 55 |
+
task_description=(
|
| 56 |
+
"You are reviewing a utility function before merge. The submitted patch left "
|
| 57 |
+
"the function with syntax errors. Repair the code so it compiles and preserves "
|
| 58 |
+
"the intended behavior of trimming, lowercasing, and replacing spaces with underscores."
|
| 59 |
+
),
|
| 60 |
+
starter_code='''def normalize_username(raw_name: str) -> str:
|
| 61 |
+
cleaned = raw_name.strip().lower(
|
| 62 |
+
if not cleaned:
|
| 63 |
+
return "anonymous"
|
| 64 |
+
return cleaned.replace(" ", "_")
|
| 65 |
+
''',
|
| 66 |
+
reference_code='''def normalize_username(raw_name: str) -> str:
|
| 67 |
+
cleaned = raw_name.strip().lower()
|
| 68 |
+
if not cleaned:
|
| 69 |
+
return "anonymous"
|
| 70 |
+
return cleaned.replace(" ", "_")
|
| 71 |
+
''',
|
| 72 |
+
visible_tests=[
|
| 73 |
+
"normalize_username(' Alice Smith ') == 'alice_smith'",
|
| 74 |
+
"normalize_username(' ') == 'anonymous'",
|
| 75 |
+
"normalize_username('Bob') == 'bob'",
|
| 76 |
+
],
|
| 77 |
+
hidden_tests=[
|
| 78 |
+
"normalize_username(' HELLO WORLD ') == 'hello_world'",
|
| 79 |
+
"normalize_username('') == 'anonymous'",
|
| 80 |
+
],
|
| 81 |
+
max_steps=8,
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
# ============================================================================
|
| 85 |
+
# TASK 2: MEDIUM - Bug Fixing with Tests
|
| 86 |
+
# ============================================================================
|
| 87 |
+
|
| 88 |
+
TASK_BUG_FIX = TaskSpec(
|
| 89 |
+
task_id="bug-fix-medium",
|
| 90 |
+
title="Repair invoice discount calculation logic",
|
| 91 |
+
difficulty="medium",
|
| 92 |
+
task_kind="bug_fix",
|
| 93 |
+
task_description=(
|
| 94 |
+
"A billing helper function is returning the wrong amount after applying discounts. "
|
| 95 |
+
"The function signature is correct, but the calculation logic is broken. "
|
| 96 |
+
"Inspect the implementation, run visible tests, and fix the bug so all tests pass. "
|
| 97 |
+
"Do not change the function signature or validation logic."
|
| 98 |
+
),
|
| 99 |
+
starter_code='''from typing import Iterable
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def calculate_invoice_total(line_items: Iterable[int], discount_percent: int) -> int:
|
| 103 |
+
"""Calculate invoice total with discount applied.
|
| 104 |
+
|
| 105 |
+
Args:
|
| 106 |
+
line_items: List of item prices in cents.
|
| 107 |
+
discount_percent: Discount as integer 0-100.
|
| 108 |
+
|
| 109 |
+
Returns:
|
| 110 |
+
Final invoice total in cents after discount.
|
| 111 |
+
|
| 112 |
+
Raises:
|
| 113 |
+
ValueError: If discount_percent is outside 0-100 range.
|
| 114 |
+
"""
|
| 115 |
+
if discount_percent < 0 or discount_percent > 100:
|
| 116 |
+
raise ValueError("discount_percent must be between 0 and 100")
|
| 117 |
+
|
| 118 |
+
subtotal = sum(line_items)
|
| 119 |
+
discounted_total = subtotal - (subtotal * discount_percent // 100)
|
| 120 |
+
return subtotal # BUG: returning subtotal instead of discounted_total
|
| 121 |
+
''',
|
| 122 |
+
reference_code='''from typing import Iterable
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def calculate_invoice_total(line_items: Iterable[int], discount_percent: int) -> int:
|
| 126 |
+
"""Calculate invoice total with discount applied.
|
| 127 |
+
|
| 128 |
+
Args:
|
| 129 |
+
line_items: List of item prices in cents.
|
| 130 |
+
discount_percent: Discount as integer 0-100.
|
| 131 |
+
|
| 132 |
+
Returns:
|
| 133 |
+
Final invoice total in cents after discount.
|
| 134 |
+
|
| 135 |
+
Raises:
|
| 136 |
+
ValueError: If discount_percent is outside 0-100 range.
|
| 137 |
+
"""
|
| 138 |
+
if discount_percent < 0 or discount_percent > 100:
|
| 139 |
+
raise ValueError("discount_percent must be between 0 and 100")
|
| 140 |
+
|
| 141 |
+
subtotal = sum(line_items)
|
| 142 |
+
discounted_total = subtotal - (subtotal * discount_percent // 100)
|
| 143 |
+
return discounted_total
|
| 144 |
+
''',
|
| 145 |
+
visible_tests=[
|
| 146 |
+
"calculate_invoice_total([1000, 2000], 0) == 3000", # No discount
|
| 147 |
+
"calculate_invoice_total([1000, 2000], 50) == 1500", # 50% off
|
| 148 |
+
"calculate_invoice_total([1000], 10) == 900", # 10% off
|
| 149 |
+
"calculate_invoice_total([], 0) == 0", # Empty
|
| 150 |
+
],
|
| 151 |
+
hidden_tests=[
|
| 152 |
+
"calculate_invoice_total([100, 200, 300], 25) == 450", # 25% off
|
| 153 |
+
"calculate_invoice_total([5000], 99) == 50", # 99% off
|
| 154 |
+
],
|
| 155 |
+
max_steps=10,
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
# ============================================================================
|
| 159 |
+
# TASK 3: HARD - Optimization & Code Quality
|
| 160 |
+
# ============================================================================
|
| 161 |
+
|
| 162 |
+
TASK_OPTIMIZATION = TaskSpec(
|
| 163 |
+
task_id="optimization-hard",
|
| 164 |
+
title="Optimize inefficient list duplicate removal",
|
| 165 |
+
difficulty="hard",
|
| 166 |
+
task_kind="optimization",
|
| 167 |
+
task_description=(
|
| 168 |
+
"Code review found that `remove_duplicates` is inefficient for large lists. "
|
| 169 |
+
"The current implementation uses nested loops (O(n²) time). "
|
| 170 |
+
"Optimize it to O(n) using a set-based approach while maintaining order. "
|
| 171 |
+
"Style and code quality also matter: use idiomatic Python, proper types, and clear logic. "
|
| 172 |
+
"All tests must pass, and the optimized version should be measurably faster."
|
| 173 |
+
),
|
| 174 |
+
starter_code='''from typing import List, TypeVar
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
T = TypeVar('T')
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def remove_duplicates(items: List[T]) -> List[T]:
|
| 181 |
+
"""Remove duplicates from list while preserving order.
|
| 182 |
+
|
| 183 |
+
This implementation is inefficient for large lists.
|
| 184 |
+
|
| 185 |
+
Args:
|
| 186 |
+
items: List that may contain duplicate elements.
|
| 187 |
+
|
| 188 |
+
Returns:
|
| 189 |
+
List with duplicates removed, order preserved.
|
| 190 |
+
"""
|
| 191 |
+
result = []
|
| 192 |
+
for item in items:
|
| 193 |
+
if item not in result: # O(n) lookup in list per iteration
|
| 194 |
+
result.append(item)
|
| 195 |
+
return result
|
| 196 |
+
''',
|
| 197 |
+
reference_code='''from typing import List, TypeVar
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
T = TypeVar('T')
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def remove_duplicates(items: List[T]) -> List[T]:
|
| 204 |
+
"""Remove duplicates from list while preserving order.
|
| 205 |
+
|
| 206 |
+
Efficient set-based implementation with O(n) time complexity.
|
| 207 |
+
|
| 208 |
+
Args:
|
| 209 |
+
items: List that may contain duplicate elements.
|
| 210 |
+
|
| 211 |
+
Returns:
|
| 212 |
+
List with duplicates removed, order preserved.
|
| 213 |
+
"""
|
| 214 |
+
seen: set = set()
|
| 215 |
+
result = []
|
| 216 |
+
for item in items:
|
| 217 |
+
if item not in seen:
|
| 218 |
+
seen.add(item)
|
| 219 |
+
result.append(item)
|
| 220 |
+
return result
|
| 221 |
+
''',
|
| 222 |
+
visible_tests=[
|
| 223 |
+
"remove_duplicates([1, 2, 2, 3, 1]) == [1, 2, 3]",
|
| 224 |
+
"remove_duplicates(['a', 'b', 'a']) == ['a', 'b']",
|
| 225 |
+
"remove_duplicates([]) == []",
|
| 226 |
+
"remove_duplicates([1]) == [1]",
|
| 227 |
+
],
|
| 228 |
+
hidden_tests=[
|
| 229 |
+
"remove_duplicates([5, 4, 3, 2, 1, 5, 4]) == [5, 4, 3, 2, 1]",
|
| 230 |
+
],
|
| 231 |
+
max_steps=10,
|
| 232 |
+
benchmark_entrypoint="remove_duplicates",
|
| 233 |
+
benchmark_builder="lambda: list(range(5000)) + list(range(5000))",
|
| 234 |
+
benchmark_repeats=3,
|
| 235 |
+
benchmark_timeout_s=1.0,
|
| 236 |
+
style_max_line_length=88,
|
| 237 |
+
expected_quality_markers=[
|
| 238 |
+
"set",
|
| 239 |
+
"O(n)",
|
| 240 |
+
],
|
| 241 |
+
)
|
| 242 |
+
|
| 243 |
+
# ============================================================================
|
| 244 |
+
# Task Bank Registry
|
| 245 |
+
# ============================================================================
|
| 246 |
+
|
| 247 |
+
TASKS: Dict[str, TaskSpec] = {
|
| 248 |
+
"syntax-fix-easy": TASK_SYNTAX_FIX,
|
| 249 |
+
"bug-fix-medium": TASK_BUG_FIX,
|
| 250 |
+
"optimization-hard": TASK_OPTIMIZATION,
|
| 251 |
+
}
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
def task_ids() -> List[str]:
|
| 255 |
+
"""Return all task IDs in deterministic order."""
|
| 256 |
+
return ["syntax-fix-easy", "bug-fix-medium", "optimization-hard"]
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
def get_task(task_id: str) -> TaskSpec:
|
| 260 |
+
"""Get a task by ID."""
|
| 261 |
+
if task_id not in TASKS:
|
| 262 |
+
raise ValueError(f"Task {task_id} not found. Available: {list(TASKS.keys())}")
|
| 263 |
+
return TASKS[task_id]
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
def list_task_descriptors() -> List[TaskDescriptor]:
|
| 267 |
+
"""List all task descriptors."""
|
| 268 |
+
return [get_task(tid).to_descriptor() for tid in task_ids()]
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
def list_task_summaries() -> List[TaskDescriptor]:
|
| 272 |
+
"""List task summaries (alias for descriptors)."""
|
| 273 |
+
return list_task_descriptors()
|
testing.md
ADDED
|
@@ -0,0 +1,289 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Testing Guide
|
| 2 |
+
|
| 3 |
+
This document lists the environment variables you may need, the available routes, which params are required, and how to test each route quickly.
|
| 4 |
+
|
| 5 |
+
## 1) Environment Variables
|
| 6 |
+
|
| 7 |
+
## Server runtime variables
|
| 8 |
+
|
| 9 |
+
Use these when running the FastAPI app (local or container):
|
| 10 |
+
|
| 11 |
+
- HOST: default 0.0.0.0 in Docker, localhost in app main()
|
| 12 |
+
- PORT: default 8000
|
| 13 |
+
- WORKERS: default 1 (used by container command)
|
| 14 |
+
- MAX_CONCURRENT_ENVS: default 32
|
| 15 |
+
|
| 16 |
+
Minimal local run on Windows PowerShell:
|
| 17 |
+
|
| 18 |
+
```powershell
|
| 19 |
+
$env:HOST = "127.0.0.1"
|
| 20 |
+
$env:PORT = "8000"
|
| 21 |
+
$env:MAX_CONCURRENT_ENVS = "32"
|
| 22 |
+
uvicorn server.app:app --host $env:HOST --port $env:PORT
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
## Inference script variables
|
| 26 |
+
|
| 27 |
+
Required:
|
| 28 |
+
|
| 29 |
+
- API_BASE_URL
|
| 30 |
+
- MODEL_NAME
|
| 31 |
+
- HF_TOKEN or OPENAI_API_KEY
|
| 32 |
+
|
| 33 |
+
Optional:
|
| 34 |
+
|
| 35 |
+
- ENV_BASE_URL (if omitted, inference.py launches from Docker image)
|
| 36 |
+
- PYTHON_ENV_IMAGE (default python_env-env:latest)
|
| 37 |
+
- MAX_STEPS (default 3)
|
| 38 |
+
- MAX_TASKS (default 3)
|
| 39 |
+
- INFERENCE_REPORT_PATH (default inference_results.json)
|
| 40 |
+
- TEMPERATURE (default 0)
|
| 41 |
+
- MAX_TOKENS (default 900)
|
| 42 |
+
|
| 43 |
+
Example:
|
| 44 |
+
|
| 45 |
+
```powershell
|
| 46 |
+
$env:API_BASE_URL = "https://api.openai.com/v1"
|
| 47 |
+
$env:MODEL_NAME = "gpt-4.1-mini"
|
| 48 |
+
$env:OPENAI_API_KEY = "<your-key>"
|
| 49 |
+
$env:ENV_BASE_URL = "http://127.0.0.1:8000"
|
| 50 |
+
python inference.py
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
## 2) Task IDs You Can Use
|
| 54 |
+
|
| 55 |
+
- py-review-easy
|
| 56 |
+
- py-review-medium
|
| 57 |
+
- py-review-hard
|
| 58 |
+
|
| 59 |
+
## 3) Route Testing (Params + Examples)
|
| 60 |
+
|
| 61 |
+
Base URL:
|
| 62 |
+
|
| 63 |
+
```text
|
| 64 |
+
http://127.0.0.1:8000
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
## OpenEnv routes
|
| 68 |
+
|
| 69 |
+
### POST /reset
|
| 70 |
+
|
| 71 |
+
- Required params: none
|
| 72 |
+
- Body: none
|
| 73 |
+
|
| 74 |
+
Test:
|
| 75 |
+
|
| 76 |
+
```powershell
|
| 77 |
+
Invoke-RestMethod -Method Post -Uri "http://127.0.0.1:8000/reset"
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
### POST /step
|
| 81 |
+
|
| 82 |
+
- Required params: none in query/path
|
| 83 |
+
- Required body shape:
|
| 84 |
+
- operation: one of submit_findings, request_hint, finalize
|
| 85 |
+
- findings: array (can be empty)
|
| 86 |
+
- Optional body fields:
|
| 87 |
+
- patched_code: string or null
|
| 88 |
+
- note: string or null
|
| 89 |
+
|
| 90 |
+
Minimal body example:
|
| 91 |
+
|
| 92 |
+
```json
|
| 93 |
+
{
|
| 94 |
+
"operation": "request_hint",
|
| 95 |
+
"findings": []
|
| 96 |
+
}
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
Test:
|
| 100 |
+
|
| 101 |
+
```powershell
|
| 102 |
+
$body = @{
|
| 103 |
+
operation = "request_hint"
|
| 104 |
+
findings = @()
|
| 105 |
+
} | ConvertTo-Json
|
| 106 |
+
|
| 107 |
+
Invoke-RestMethod -Method Post -Uri "http://127.0.0.1:8000/step" -ContentType "application/json" -Body $body
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
Example with finding:
|
| 111 |
+
|
| 112 |
+
```powershell
|
| 113 |
+
$body = @{
|
| 114 |
+
operation = "submit_findings"
|
| 115 |
+
findings = @(
|
| 116 |
+
@{
|
| 117 |
+
title = "Avoid eval on untrusted input"
|
| 118 |
+
line = 2
|
| 119 |
+
category = "security"
|
| 120 |
+
severity = "critical"
|
| 121 |
+
rationale = "eval can execute attacker-controlled code"
|
| 122 |
+
recommendation = "Use json.loads instead"
|
| 123 |
+
rule_id = "avoid-eval"
|
| 124 |
+
}
|
| 125 |
+
)
|
| 126 |
+
patched_code = $null
|
| 127 |
+
note = "first pass"
|
| 128 |
+
} | ConvertTo-Json -Depth 6
|
| 129 |
+
|
| 130 |
+
Invoke-RestMethod -Method Post -Uri "http://127.0.0.1:8000/step" -ContentType "application/json" -Body $body
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
### GET /state
|
| 134 |
+
|
| 135 |
+
- Required params: none
|
| 136 |
+
|
| 137 |
+
Test:
|
| 138 |
+
|
| 139 |
+
```powershell
|
| 140 |
+
Invoke-RestMethod -Method Get -Uri "http://127.0.0.1:8000/state"
|
| 141 |
+
```
|
| 142 |
+
|
| 143 |
+
### GET /schema
|
| 144 |
+
|
| 145 |
+
- Required params: none
|
| 146 |
+
|
| 147 |
+
Test:
|
| 148 |
+
|
| 149 |
+
```powershell
|
| 150 |
+
Invoke-RestMethod -Method Get -Uri "http://127.0.0.1:8000/schema"
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
### WS /ws
|
| 154 |
+
|
| 155 |
+
- Use a websocket client to connect.
|
| 156 |
+
- No route params required.
|
| 157 |
+
|
| 158 |
+
## Custom REST routes
|
| 159 |
+
|
| 160 |
+
### GET /health
|
| 161 |
+
|
| 162 |
+
- Required params: none
|
| 163 |
+
|
| 164 |
+
```powershell
|
| 165 |
+
Invoke-RestMethod -Method Get -Uri "http://127.0.0.1:8000/health"
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
### GET /tasks
|
| 169 |
+
|
| 170 |
+
- Required params: none
|
| 171 |
+
|
| 172 |
+
```powershell
|
| 173 |
+
Invoke-RestMethod -Method Get -Uri "http://127.0.0.1:8000/tasks"
|
| 174 |
+
```
|
| 175 |
+
|
| 176 |
+
### GET /tasks/{task_id}
|
| 177 |
+
|
| 178 |
+
- Required path param: task_id
|
| 179 |
+
|
| 180 |
+
```powershell
|
| 181 |
+
Invoke-RestMethod -Method Get -Uri "http://127.0.0.1:8000/tasks/py-review-easy"
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
### POST /tasks/{task_id}/grade
|
| 185 |
+
|
| 186 |
+
- Required path param: task_id
|
| 187 |
+
- Body uses PythonReviewAction shape
|
| 188 |
+
- operation defaults to submit_findings if omitted
|
| 189 |
+
- findings array accepted
|
| 190 |
+
- patched_code optional
|
| 191 |
+
- note optional
|
| 192 |
+
|
| 193 |
+
```powershell
|
| 194 |
+
$body = @{
|
| 195 |
+
findings = @(
|
| 196 |
+
@{
|
| 197 |
+
title = "Avoid eval on untrusted input"
|
| 198 |
+
line = 2
|
| 199 |
+
category = "security"
|
| 200 |
+
severity = "critical"
|
| 201 |
+
rationale = "eval executes arbitrary code"
|
| 202 |
+
recommendation = "Use json.loads"
|
| 203 |
+
}
|
| 204 |
+
)
|
| 205 |
+
} | ConvertTo-Json -Depth 6
|
| 206 |
+
|
| 207 |
+
Invoke-RestMethod -Method Post -Uri "http://127.0.0.1:8000/tasks/py-review-easy/grade" -ContentType "application/json" -Body $body
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
### POST /review
|
| 211 |
+
|
| 212 |
+
- Required body field:
|
| 213 |
+
- code: string
|
| 214 |
+
- Optional body field:
|
| 215 |
+
- context: string
|
| 216 |
+
|
| 217 |
+
```powershell
|
| 218 |
+
$body = @{
|
| 219 |
+
code = "def f(x):`n return eval(x)`n"
|
| 220 |
+
} | ConvertTo-Json
|
| 221 |
+
|
| 222 |
+
Invoke-RestMethod -Method Post -Uri "http://127.0.0.1:8000/review" -ContentType "application/json" -Body $body
|
| 223 |
+
```
|
| 224 |
+
|
| 225 |
+
### GET /history
|
| 226 |
+
|
| 227 |
+
- Required params: none
|
| 228 |
+
|
| 229 |
+
```powershell
|
| 230 |
+
Invoke-RestMethod -Method Get -Uri "http://127.0.0.1:8000/history"
|
| 231 |
+
```
|
| 232 |
+
|
| 233 |
+
### DELETE /history
|
| 234 |
+
|
| 235 |
+
- Required params: none
|
| 236 |
+
|
| 237 |
+
```powershell
|
| 238 |
+
Invoke-RestMethod -Method Delete -Uri "http://127.0.0.1:8000/history"
|
| 239 |
+
```
|
| 240 |
+
|
| 241 |
+
### GET /config
|
| 242 |
+
|
| 243 |
+
- Required params: none
|
| 244 |
+
|
| 245 |
+
```powershell
|
| 246 |
+
Invoke-RestMethod -Method Get -Uri "http://127.0.0.1:8000/config"
|
| 247 |
+
```
|
| 248 |
+
|
| 249 |
+
### PUT /config
|
| 250 |
+
|
| 251 |
+
- Required params: none
|
| 252 |
+
- Body: PythonEnvConfig object
|
| 253 |
+
- All fields have defaults, so {} is valid for a reset-like update
|
| 254 |
+
|
| 255 |
+
Minimal test:
|
| 256 |
+
|
| 257 |
+
```powershell
|
| 258 |
+
Invoke-RestMethod -Method Put -Uri "http://127.0.0.1:8000/config" -ContentType "application/json" -Body "{}"
|
| 259 |
+
```
|
| 260 |
+
|
| 261 |
+
Full body example:
|
| 262 |
+
|
| 263 |
+
```powershell
|
| 264 |
+
$body = @{
|
| 265 |
+
task_order = @("py-review-easy", "py-review-medium", "py-review-hard")
|
| 266 |
+
max_steps_per_task = 4
|
| 267 |
+
hint_penalty = 0.05
|
| 268 |
+
false_positive_penalty = 0.08
|
| 269 |
+
duplicate_penalty = 0.03
|
| 270 |
+
patch_bonus_multiplier = 0.2
|
| 271 |
+
max_history_entries = 50
|
| 272 |
+
} | ConvertTo-Json
|
| 273 |
+
|
| 274 |
+
Invoke-RestMethod -Method Put -Uri "http://127.0.0.1:8000/config" -ContentType "application/json" -Body $body
|
| 275 |
+
```
|
| 276 |
+
|
| 277 |
+
## 4) Quick Validation Commands
|
| 278 |
+
|
| 279 |
+
Run automated tests:
|
| 280 |
+
|
| 281 |
+
```powershell
|
| 282 |
+
pytest -q
|
| 283 |
+
```
|
| 284 |
+
|
| 285 |
+
Run only API tests:
|
| 286 |
+
|
| 287 |
+
```powershell
|
| 288 |
+
pytest -q tests/test_api.py
|
| 289 |
+
```
|
tests/conftest.py
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
ROOT = Path(__file__).resolve().parents[1]
|
| 6 |
+
if str(ROOT) not in sys.path:
|
| 7 |
+
sys.path.insert(0, str(ROOT))
|
tests/test_api.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fastapi.testclient import TestClient
|
| 2 |
+
|
| 3 |
+
from server.app import app
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
client = TestClient(app)
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def test_health_endpoint():
|
| 10 |
+
response = client.get("/health")
|
| 11 |
+
|
| 12 |
+
assert response.status_code == 200
|
| 13 |
+
payload = response.json()
|
| 14 |
+
assert payload["status"] == "ok"
|
| 15 |
+
assert payload["environment"] == "python_code_review_env"
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def test_reset_returns_expected_observation():
|
| 19 |
+
response = client.post("/reset", json={"task_id": "syntax-fix-easy"})
|
| 20 |
+
|
| 21 |
+
assert response.status_code == 200
|
| 22 |
+
payload = response.json()
|
| 23 |
+
assert payload["observation"]["task_id"] == "syntax-fix-easy"
|
| 24 |
+
assert "current_code" in payload["observation"]
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def test_tasks_endpoint_lists_three_tasks():
|
| 28 |
+
response = client.get("/tasks")
|
| 29 |
+
|
| 30 |
+
assert response.status_code == 200
|
| 31 |
+
assert len(response.json()) == 3
|
tests/test_environment.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from models import PythonCodeReviewAction
|
| 2 |
+
from server.env import PythonCodeReviewEnvironment
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def test_reset_cycles_tasks_in_order():
|
| 6 |
+
env = PythonCodeReviewEnvironment()
|
| 7 |
+
|
| 8 |
+
first = env.reset()
|
| 9 |
+
second = env.reset()
|
| 10 |
+
third = env.reset()
|
| 11 |
+
|
| 12 |
+
assert first.task_id == "syntax-fix-easy"
|
| 13 |
+
assert second.task_id == "bug-fix-medium"
|
| 14 |
+
assert third.task_id == "optimization-hard"
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def test_invalid_edit_code_penalizes_action():
|
| 18 |
+
env = PythonCodeReviewEnvironment()
|
| 19 |
+
env.reset(task_id="syntax-fix-easy")
|
| 20 |
+
|
| 21 |
+
observation = env.step(PythonCodeReviewAction(action_type="edit_code", code=""))
|
| 22 |
+
|
| 23 |
+
assert observation.reward < 0
|
| 24 |
+
assert observation.reward_details.invalid_action_penalty == 0.1
|
| 25 |
+
assert "requires code" in observation.last_action_status
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def test_easy_task_gets_full_score_after_fix():
|
| 29 |
+
env = PythonCodeReviewEnvironment()
|
| 30 |
+
env.reset(task_id="syntax-fix-easy")
|
| 31 |
+
|
| 32 |
+
env.step(
|
| 33 |
+
PythonCodeReviewAction(
|
| 34 |
+
action_type="edit_code",
|
| 35 |
+
code="""def normalize_username(raw_name: str) -> str:
|
| 36 |
+
cleaned = raw_name.strip().lower()
|
| 37 |
+
if not cleaned:
|
| 38 |
+
return "anonymous"
|
| 39 |
+
return cleaned.replace(" ", "_")
|
| 40 |
+
""",
|
| 41 |
+
)
|
| 42 |
+
)
|
| 43 |
+
observation = env.step(PythonCodeReviewAction(action_type="submit_solution"))
|
| 44 |
+
|
| 45 |
+
assert observation.done is True
|
| 46 |
+
assert observation.score == 1.0
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def test_medium_task_reports_partial_visible_progress():
|
| 50 |
+
env = PythonCodeReviewEnvironment()
|
| 51 |
+
env.reset(task_id="bug-fix-medium")
|
| 52 |
+
|
| 53 |
+
observation = env.step(PythonCodeReviewAction(action_type="run_tests"))
|
| 54 |
+
|
| 55 |
+
assert observation.score < 1.0
|
| 56 |
+
assert "visible checks" in observation.test_results
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def test_hard_task_reference_solution_scores_high():
|
| 60 |
+
env = PythonCodeReviewEnvironment()
|
| 61 |
+
env.reset(task_id="optimization-hard")
|
| 62 |
+
|
| 63 |
+
env.step(
|
| 64 |
+
PythonCodeReviewAction(
|
| 65 |
+
action_type="edit_code",
|
| 66 |
+
code="""from collections import Counter
|
| 67 |
+
from typing import Iterable
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def summarize_user_activity(events: Iterable[dict]) -> list[tuple[str, int]]:
|
| 71 |
+
\"\"\"Aggregate user activity counts in one pass.\"\"\"
|
| 72 |
+
|
| 73 |
+
counts = Counter(event["user_id"] for event in events)
|
| 74 |
+
return sorted(counts.items(), key=lambda item: (-item[1], item[0]))
|
| 75 |
+
""",
|
| 76 |
+
)
|
| 77 |
+
)
|
| 78 |
+
observation = env.step(PythonCodeReviewAction(action_type="submit_solution"))
|
| 79 |
+
|
| 80 |
+
assert observation.done is True
|
| 81 |
+
assert observation.score >= 0.9
|
tests/test_examples.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from graders.optimization import grade_optimization_task
|
| 2 |
+
from graders.syntax import grade_bug_fix_task, grade_syntax_task
|
| 3 |
+
from tasks.task_bank import get_task
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def test_syntax_grader_partial_score_is_bounded():
|
| 7 |
+
task = get_task("syntax-fix-easy")
|
| 8 |
+
grade = grade_syntax_task(task.starter_code, task)
|
| 9 |
+
|
| 10 |
+
assert 0.0 <= grade.score < 1.0
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def test_bug_fix_grader_reference_solution_reaches_one():
|
| 14 |
+
task = get_task("bug-fix-medium")
|
| 15 |
+
grade = grade_bug_fix_task(task.reference_code, task, include_hidden=True)
|
| 16 |
+
|
| 17 |
+
assert grade.score == 1.0
|
| 18 |
+
assert grade.tests_passed == grade.tests_total
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def test_optimization_grader_scores_better_than_starter():
|
| 22 |
+
task = get_task("optimization-hard")
|
| 23 |
+
starter_grade = grade_optimization_task(task.starter_code, task)
|
| 24 |
+
reference_grade = grade_optimization_task(task.reference_code, task)
|
| 25 |
+
|
| 26 |
+
assert reference_grade.score > starter_grade.score
|
| 27 |
+
assert reference_grade.runtime_score >= starter_grade.runtime_score
|
tutorial/HackathonChecklist.md
ADDED
|
@@ -0,0 +1,323 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Hackathon Checklist
|
| 2 |
+
|
| 3 |
+
This file translates the tutorial folder into a concrete plan for `python_env`.
|
| 4 |
+
|
| 5 |
+
It is not a generic OpenEnv summary. It is a project-specific checklist showing:
|
| 6 |
+
|
| 7 |
+
- what the tutorials are teaching
|
| 8 |
+
- how this repo maps to those ideas
|
| 9 |
+
- what is already done
|
| 10 |
+
- what still needs to be finished before submission
|
| 11 |
+
|
| 12 |
+
## 1. What The Tutorials Mean For This Project
|
| 13 |
+
|
| 14 |
+
### Tutorial 1: OpenEnv Pattern
|
| 15 |
+
|
| 16 |
+
Main concept:
|
| 17 |
+
|
| 18 |
+
- every environment should follow a clean pattern:
|
| 19 |
+
- typed models
|
| 20 |
+
- environment logic
|
| 21 |
+
- client
|
| 22 |
+
- FastAPI/OpenEnv app
|
| 23 |
+
- Docker packaging
|
| 24 |
+
|
| 25 |
+
How `python_env` maps:
|
| 26 |
+
|
| 27 |
+
- `models.py`
|
| 28 |
+
typed action/observation/config/evaluation models
|
| 29 |
+
- `server/code_review_environment.py`
|
| 30 |
+
environment logic
|
| 31 |
+
- `client.py`
|
| 32 |
+
Python client for reset/step/state
|
| 33 |
+
- `server/app.py`
|
| 34 |
+
OpenEnv app plus helper routes
|
| 35 |
+
- `server/Dockerfile`
|
| 36 |
+
container packaging
|
| 37 |
+
|
| 38 |
+
Status:
|
| 39 |
+
|
| 40 |
+
- done
|
| 41 |
+
|
| 42 |
+
What to keep in mind:
|
| 43 |
+
|
| 44 |
+
- do not break the OpenEnv contract while adding features
|
| 45 |
+
- treat models as the public interface
|
| 46 |
+
|
| 47 |
+
### Tutorial 2: Deployment
|
| 48 |
+
|
| 49 |
+
Main concept:
|
| 50 |
+
|
| 51 |
+
- local development first
|
| 52 |
+
- Docker second
|
| 53 |
+
- HF Spaces deployment third
|
| 54 |
+
- test `/health`, `/reset`, `/docs`, `/ws`
|
| 55 |
+
|
| 56 |
+
How `python_env` maps:
|
| 57 |
+
|
| 58 |
+
- local server:
|
| 59 |
+
`uvicorn server.app:app --reload --host 0.0.0.0 --port 8000`
|
| 60 |
+
- Docker:
|
| 61 |
+
`docker build -t python_env-env:latest -f server/Dockerfile .`
|
| 62 |
+
- Spaces:
|
| 63 |
+
`openenv push`
|
| 64 |
+
|
| 65 |
+
Status:
|
| 66 |
+
|
| 67 |
+
- app boots locally
|
| 68 |
+
- Dockerfile exists and now supports `HOST`, `PORT`, `WORKERS`, `MAX_CONCURRENT_ENVS`
|
| 69 |
+
- live Docker build still needs final verification
|
| 70 |
+
- Spaces deployment still needs to be executed and checked
|
| 71 |
+
|
| 72 |
+
### Tutorial 3: Scaling
|
| 73 |
+
|
| 74 |
+
Main concept:
|
| 75 |
+
|
| 76 |
+
- OpenEnv works best with WebSocket sessions
|
| 77 |
+
- use environment class/factory instead of a singleton for OpenEnv session handling
|
| 78 |
+
- support concurrency with `MAX_CONCURRENT_ENVS`
|
| 79 |
+
|
| 80 |
+
How `python_env` maps:
|
| 81 |
+
|
| 82 |
+
- `create_app(PythonEnvironment, PythonReviewAction, PythonReviewObservation, max_concurrent_envs=...)`
|
| 83 |
+
- `MAX_CONCURRENT_ENVS` is now read from env vars
|
| 84 |
+
- Docker now exposes `MAX_CONCURRENT_ENVS`
|
| 85 |
+
|
| 86 |
+
Status:
|
| 87 |
+
|
| 88 |
+
- partially done
|
| 89 |
+
|
| 90 |
+
Important caveat:
|
| 91 |
+
|
| 92 |
+
- OpenEnv `/reset` and `/step` use the class-based session model
|
| 93 |
+
- custom routes such as `/history` and `/config` still use a singleton helper instance
|
| 94 |
+
- this is acceptable for manual tooling, but it is not a perfect unified session model
|
| 95 |
+
|
| 96 |
+
Recommendation:
|
| 97 |
+
|
| 98 |
+
- keep it for now if your priority is submission
|
| 99 |
+
- refactor only if it starts causing testing confusion
|
| 100 |
+
|
| 101 |
+
### Tutorial 4: RL Training And Reward Design
|
| 102 |
+
|
| 103 |
+
Main concept:
|
| 104 |
+
|
| 105 |
+
- a good RL environment needs:
|
| 106 |
+
- meaningful reward
|
| 107 |
+
- repeated trajectories
|
| 108 |
+
- enough task diversity
|
| 109 |
+
- an inference/training loop
|
| 110 |
+
|
| 111 |
+
How `python_env` maps:
|
| 112 |
+
|
| 113 |
+
- reward shaping already exists:
|
| 114 |
+
- matched rubric items
|
| 115 |
+
- false-positive penalties
|
| 116 |
+
- duplicate penalties
|
| 117 |
+
- hint penalties
|
| 118 |
+
- patch bonus
|
| 119 |
+
- finalize bonus
|
| 120 |
+
- `inference.py` already provides a baseline model-vs-env loop
|
| 121 |
+
|
| 122 |
+
Status:
|
| 123 |
+
|
| 124 |
+
- partially done
|
| 125 |
+
|
| 126 |
+
Gap:
|
| 127 |
+
|
| 128 |
+
- 3 tasks are enough for hackathon minimums
|
| 129 |
+
- 3 tasks are not enough for serious RL learning
|
| 130 |
+
|
| 131 |
+
## 2. Current Repo Status
|
| 132 |
+
|
| 133 |
+
### Strong Areas
|
| 134 |
+
|
| 135 |
+
- real-world task: code review
|
| 136 |
+
- typed Pydantic/OpenEnv models
|
| 137 |
+
- deterministic grader
|
| 138 |
+
- 3 difficulty levels
|
| 139 |
+
- partial-progress reward shaping
|
| 140 |
+
- manual routes for health/tasks/review/config/history
|
| 141 |
+
- baseline inference script
|
| 142 |
+
- docs in `README.md`, `Project.md`
|
| 143 |
+
|
| 144 |
+
### Weak Areas
|
| 145 |
+
|
| 146 |
+
- benchmark still small
|
| 147 |
+
- Docker image build not fully verified end-to-end
|
| 148 |
+
- HF Spaces deployment not yet executed
|
| 149 |
+
- `openenv validate` still needs to be run in your actual runtime
|
| 150 |
+
- no large trajectory dataset yet
|
| 151 |
+
- custom REST state and OpenEnv session state are not fully unified
|
| 152 |
+
|
| 153 |
+
## 3. What You Need To Do To Be Submission-Ready
|
| 154 |
+
|
| 155 |
+
### Step 1: Validate Local Server
|
| 156 |
+
|
| 157 |
+
Run:
|
| 158 |
+
|
| 159 |
+
```powershell
|
| 160 |
+
uvicorn server.app:app --reload --host 0.0.0.0 --port 8000
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
Manually verify:
|
| 164 |
+
|
| 165 |
+
- `http://127.0.0.1:8000/docs`
|
| 166 |
+
- `http://127.0.0.1:8000/health`
|
| 167 |
+
- `POST /reset`
|
| 168 |
+
- `POST /step`
|
| 169 |
+
- `GET /tasks`
|
| 170 |
+
- `POST /review`
|
| 171 |
+
|
| 172 |
+
### Step 2: Run Tests
|
| 173 |
+
|
| 174 |
+
Run:
|
| 175 |
+
|
| 176 |
+
```powershell
|
| 177 |
+
python -m pytest tests -q
|
| 178 |
+
```
|
| 179 |
+
|
| 180 |
+
You want all tests green before Docker or HF deployment.
|
| 181 |
+
|
| 182 |
+
### Step 3: Run OpenEnv Validation
|
| 183 |
+
|
| 184 |
+
Run:
|
| 185 |
+
|
| 186 |
+
```powershell
|
| 187 |
+
openenv validate
|
| 188 |
+
```
|
| 189 |
+
|
| 190 |
+
This is a hard requirement.
|
| 191 |
+
|
| 192 |
+
If validation fails:
|
| 193 |
+
|
| 194 |
+
- fix schema mismatch first
|
| 195 |
+
- fix route mismatch second
|
| 196 |
+
- fix packaging third
|
| 197 |
+
|
| 198 |
+
### Step 4: Run Baseline Inference
|
| 199 |
+
|
| 200 |
+
Run:
|
| 201 |
+
|
| 202 |
+
```powershell
|
| 203 |
+
$env:API_BASE_URL="https://api.openai.com/v1"
|
| 204 |
+
$env:MODEL_NAME="gpt-4.1-mini"
|
| 205 |
+
$env:OPENAI_API_KEY="your_key"
|
| 206 |
+
$env:ENV_BASE_URL="http://127.0.0.1:8000"
|
| 207 |
+
python inference.py
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
You want:
|
| 211 |
+
|
| 212 |
+
- script completes without crashing
|
| 213 |
+
- `inference_results.json` gets written
|
| 214 |
+
- all 3 tasks run
|
| 215 |
+
- scores are reproducible
|
| 216 |
+
|
| 217 |
+
### Step 5: Verify Docker
|
| 218 |
+
|
| 219 |
+
Run:
|
| 220 |
+
|
| 221 |
+
```powershell
|
| 222 |
+
docker build -t python_env-env:latest -f server/Dockerfile .
|
| 223 |
+
docker run --rm -p 8000:8000 python_env-env:latest
|
| 224 |
+
```
|
| 225 |
+
|
| 226 |
+
Then test:
|
| 227 |
+
|
| 228 |
+
- `GET /health`
|
| 229 |
+
- `POST /reset`
|
| 230 |
+
- `POST /step`
|
| 231 |
+
|
| 232 |
+
### Step 6: Deploy To HF Spaces
|
| 233 |
+
|
| 234 |
+
Run:
|
| 235 |
+
|
| 236 |
+
```powershell
|
| 237 |
+
openenv push
|
| 238 |
+
```
|
| 239 |
+
|
| 240 |
+
Then verify the live Space:
|
| 241 |
+
|
| 242 |
+
- `/health`
|
| 243 |
+
- `/docs`
|
| 244 |
+
- `/reset`
|
| 245 |
+
- `/web`
|
| 246 |
+
|
| 247 |
+
## 4. What Will Help You “Win” Instead Of Just “Submit”
|
| 248 |
+
|
| 249 |
+
Passing minimum requirements is not enough. To be competitive, improve these areas:
|
| 250 |
+
|
| 251 |
+
### A. Increase Task Diversity
|
| 252 |
+
|
| 253 |
+
Current:
|
| 254 |
+
|
| 255 |
+
- 3 benchmark tasks
|
| 256 |
+
|
| 257 |
+
Target:
|
| 258 |
+
|
| 259 |
+
- at least 10 to 20 tasks before final submission if possible
|
| 260 |
+
|
| 261 |
+
Good additions:
|
| 262 |
+
|
| 263 |
+
- SQL injection review
|
| 264 |
+
- unsafe YAML/pickle loading
|
| 265 |
+
- file-handle leak
|
| 266 |
+
- race-condition style bug
|
| 267 |
+
- retry/backoff misuse
|
| 268 |
+
- caching bug
|
| 269 |
+
- logging/privacy leak
|
| 270 |
+
- API timeout handling
|
| 271 |
+
|
| 272 |
+
### B. Improve Observation Context
|
| 273 |
+
|
| 274 |
+
Good RL environments provide enough context for the model to improve.
|
| 275 |
+
|
| 276 |
+
Possible improvements:
|
| 277 |
+
|
| 278 |
+
- add matched categories so far
|
| 279 |
+
- add a short summary of uncovered issue types
|
| 280 |
+
- add previous actions in structured form, not just free text
|
| 281 |
+
- add rubric coverage signals without leaking exact answers
|
| 282 |
+
|
| 283 |
+
### C. Collect Trajectories
|
| 284 |
+
|
| 285 |
+
You need data that shows:
|
| 286 |
+
|
| 287 |
+
- first attempt
|
| 288 |
+
- improved second attempt
|
| 289 |
+
- final attempt
|
| 290 |
+
- failures
|
| 291 |
+
- false positives
|
| 292 |
+
- hint usage
|
| 293 |
+
|
| 294 |
+
This is much more useful than only saving final scores.
|
| 295 |
+
|
| 296 |
+
### D. Improve Reward Design Carefully
|
| 297 |
+
|
| 298 |
+
Current reward design is already decent.
|
| 299 |
+
|
| 300 |
+
Good refinements:
|
| 301 |
+
|
| 302 |
+
- slightly larger reward for critical security findings
|
| 303 |
+
- bonus for correct line numbers
|
| 304 |
+
- bonus for high-quality recommendation text
|
| 305 |
+
- penalty for vague findings with no rationale
|
| 306 |
+
|
| 307 |
+
Do not overcomplicate the reward before submission. Stability matters more.
|
| 308 |
+
|
| 309 |
+
## 5. Recommended Immediate Priority Order
|
| 310 |
+
|
| 311 |
+
If time is limited, do the work in this order:
|
| 312 |
+
|
| 313 |
+
1. `pytest`
|
| 314 |
+
2. `openenv validate`
|
| 315 |
+
3. local inference run
|
| 316 |
+
4. Docker build and run
|
| 317 |
+
5. HF Space deployment
|
| 318 |
+
6. add 5 to 10 more tasks
|
| 319 |
+
7. collect trajectory data
|
| 320 |
+
|
| 321 |
+
## 6. One-Sentence Summary
|
| 322 |
+
|
| 323 |
+
You are following the correct OpenEnv architecture from the tutorials already; the main remaining work is not redesign, it is validation, deployment verification, and expanding task/data quality so the environment scores well in human review.
|
tutorial/tutorial1.md
ADDED
|
@@ -0,0 +1,1259 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OpenEnv: Production RL Made Simple
|
| 2 |
+
|
| 3 |
+
<div align="center">
|
| 4 |
+
|
| 5 |
+
<img src="https://upload.wikimedia.org/wikipedia/commons/1/10/PyTorch_logo_icon.svg" width="200" alt="PyTorch">
|
| 6 |
+
|
| 7 |
+
### *From "Hello World" to RL Training in 5 Minutes* ✨
|
| 8 |
+
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
**What if RL environments were as easy to use as REST APIs?**
|
| 12 |
+
|
| 13 |
+
That's OpenEnv. Type-safe. Isolated. Production-ready. 🎯
|
| 14 |
+
|
| 15 |
+
[](https://colab.research.google.com/github/meta-pytorch/OpenEnv/blob/main/examples/OpenEnv_Tutorial.ipynb)
|
| 16 |
+
[](https://github.com/meta-pytorch/OpenEnv)
|
| 17 |
+
[](https://opensource.org/licenses/BSD-3-Clause)
|
| 18 |
+
[](https://pytorch.org/)
|
| 19 |
+
|
| 20 |
+
Author: [Sanyam Bhutani](http://twitter.com/bhutanisanyam1/)
|
| 21 |
+
|
| 22 |
+
</div>
|
| 23 |
+
|
| 24 |
+
---
|
| 25 |
+
|
| 26 |
+
## Why OpenEnv?
|
| 27 |
+
|
| 28 |
+
Let's take a trip down memory lane:
|
| 29 |
+
|
| 30 |
+
It's 2016, RL is popular. You read some papers, it looks promising.
|
| 31 |
+
|
| 32 |
+
But in real world: Cartpole is the best you can run on a gaming GPU.
|
| 33 |
+
|
| 34 |
+
What do you do beyond Cartpole?
|
| 35 |
+
|
| 36 |
+
Fast-forward to 2025, GRPO is awesome and this time it's not JUST in theory, it works well in practise and is really here!
|
| 37 |
+
|
| 38 |
+
The problem still remains, how do you take these RL algorithms and take them beyond Cartpole?
|
| 39 |
+
|
| 40 |
+
A huge part of RL is giving your algorithms environment access to learn.
|
| 41 |
+
|
| 42 |
+
We are excited to introduce an Environment Spec for adding Open Environments for RL Training. This will allow you to focus on your experiments and allow everyone to bring their environments.
|
| 43 |
+
|
| 44 |
+
Focus on experiments, use OpenEnvironments, and build agents that go beyond Cartpole on a single spec.
|
| 45 |
+
|
| 46 |
+
---
|
| 47 |
+
|
| 48 |
+
## 📋 What You'll Learn
|
| 49 |
+
|
| 50 |
+
<table>
|
| 51 |
+
<tr>
|
| 52 |
+
<td width="50%">
|
| 53 |
+
|
| 54 |
+
**🎯 Part 1-2: The Fundamentals**
|
| 55 |
+
|
| 56 |
+
- ⚡ RL in 60 seconds
|
| 57 |
+
- 🤔 Why existing solutions fall short
|
| 58 |
+
- 💡 The OpenEnv solution
|
| 59 |
+
|
| 60 |
+
</td>
|
| 61 |
+
<td width="50%">
|
| 62 |
+
|
| 63 |
+
**🏗️ Part 3-5: The Architecture**
|
| 64 |
+
|
| 65 |
+
- 🔧 How OpenEnv works
|
| 66 |
+
- 🔍 Exploring real code
|
| 67 |
+
- 🎮 OpenSpiel integration example
|
| 68 |
+
|
| 69 |
+
</td>
|
| 70 |
+
</tr>
|
| 71 |
+
<tr>
|
| 72 |
+
<td width="50%">
|
| 73 |
+
|
| 74 |
+
**🎮 Part 6-8: Hands-On Demo**
|
| 75 |
+
|
| 76 |
+
- 🔌 Use existing OpenSpiel environment
|
| 77 |
+
- 🤖 Test 4 different policies
|
| 78 |
+
- 👀 Watch learning happen live
|
| 79 |
+
|
| 80 |
+
</td>
|
| 81 |
+
<td width="50%">
|
| 82 |
+
|
| 83 |
+
**🔧 Part 9-10: Going Further**
|
| 84 |
+
|
| 85 |
+
- 🎮 Switch to other OpenSpiel games
|
| 86 |
+
- ✨ Build your own integration
|
| 87 |
+
- 🌐 Deploy to production
|
| 88 |
+
|
| 89 |
+
</td>
|
| 90 |
+
</tr>
|
| 91 |
+
</table>
|
| 92 |
+
|
| 93 |
+
!!! tip "Pro Tip"
|
| 94 |
+
This notebook is designed to run top-to-bottom in Google Colab with zero setup!
|
| 95 |
+
|
| 96 |
+
⏱️ **Time**: ~5 minutes | 📊 **Difficulty**: Beginner-friendly | 🎯 **Outcome**: Production-ready RL knowledge
|
| 97 |
+
|
| 98 |
+
---
|
| 99 |
+
|
| 100 |
+
## 📑 Table of Contents
|
| 101 |
+
|
| 102 |
+
### Foundation
|
| 103 |
+
|
| 104 |
+
- [Part 1: RL in 60 Seconds ⏱️](#part-1-rl-in-60-seconds)
|
| 105 |
+
- [Part 2: The Problem with Traditional RL 😤](#part-2-the-problem-with-traditional-rl)
|
| 106 |
+
- [Part 3: Setup 🛠️](#part-3-setup)
|
| 107 |
+
|
| 108 |
+
### Architecture
|
| 109 |
+
|
| 110 |
+
- [Part 4: The OpenEnv Pattern 🏗️](#part-4-the-openenv-pattern)
|
| 111 |
+
- [Part 5: Example Integration - OpenSpiel 🎮](#part-5-example-integration---openspiel)
|
| 112 |
+
|
| 113 |
+
### Hands-On Demo
|
| 114 |
+
|
| 115 |
+
- [Part 6: Interactive Demo 🎮](#part-6-using-real-openspiel)
|
| 116 |
+
- [Part 7: Four Policies 🤖](#part-7-four-policies)
|
| 117 |
+
- [Part 8: Policy Competition! 🏆](#part-8-policy-competition)
|
| 118 |
+
|
| 119 |
+
### Advanced
|
| 120 |
+
|
| 121 |
+
- [Part 9: Using Real OpenSpiel 🎮](#part-9-switching-to-other-games)
|
| 122 |
+
- [Part 10: Create Your Own Integration 🛠️](#part-10-create-your-own-integration)
|
| 123 |
+
|
| 124 |
+
### Wrap Up
|
| 125 |
+
|
| 126 |
+
- [Summary: Your Journey 🎓](#summary-your-journey)
|
| 127 |
+
- [Resources 📚](#resources)
|
| 128 |
+
|
| 129 |
+
---
|
| 130 |
+
|
| 131 |
+
## Part 1: RL in 60 Seconds ⏱️
|
| 132 |
+
|
| 133 |
+
**Reinforcement Learning is simpler than you think.**
|
| 134 |
+
|
| 135 |
+
It's just a loop:
|
| 136 |
+
|
| 137 |
+
```python
|
| 138 |
+
while not done:
|
| 139 |
+
observation = environment.observe()
|
| 140 |
+
action = policy.choose(observation)
|
| 141 |
+
reward = environment.step(action)
|
| 142 |
+
policy.learn(reward)
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
That's it. That's RL.
|
| 146 |
+
|
| 147 |
+
Let's see it in action:
|
| 148 |
+
|
| 149 |
+
```python
|
| 150 |
+
import random
|
| 151 |
+
|
| 152 |
+
print("🎲 " + "="*58 + " 🎲")
|
| 153 |
+
print(" Number Guessing Game - The Simplest RL Example")
|
| 154 |
+
print("🎲 " + "="*58 + " 🎲")
|
| 155 |
+
|
| 156 |
+
# Environment setup
|
| 157 |
+
target = random.randint(1, 10)
|
| 158 |
+
guesses_left = 3
|
| 159 |
+
|
| 160 |
+
print(f"\n🎯 I'm thinking of a number between 1 and 10...")
|
| 161 |
+
print(f"💭 You have {guesses_left} guesses. Let's see how random guessing works!\n")
|
| 162 |
+
|
| 163 |
+
# The RL Loop - Pure random policy (no learning!)
|
| 164 |
+
while guesses_left > 0:
|
| 165 |
+
# Policy: Random guessing (no learning yet!)
|
| 166 |
+
guess = random.randint(1, 10)
|
| 167 |
+
guesses_left -= 1
|
| 168 |
+
|
| 169 |
+
print(f"💭 Guess #{3-guesses_left}: {guess}", end=" → ")
|
| 170 |
+
|
| 171 |
+
# Reward signal (but we're not using it!)
|
| 172 |
+
if guess == target:
|
| 173 |
+
print("🎉 Correct! +10 points")
|
| 174 |
+
break
|
| 175 |
+
elif abs(guess - target) <= 2:
|
| 176 |
+
print("🔥 Warm! (close)")
|
| 177 |
+
else:
|
| 178 |
+
print("❄️ Cold! (far)")
|
| 179 |
+
else:
|
| 180 |
+
print(f"\n💔 Out of guesses. The number was {target}.")
|
| 181 |
+
|
| 182 |
+
print("\n" + "="*62)
|
| 183 |
+
print("💡 This is RL: Observe → Act → Reward → Repeat")
|
| 184 |
+
print(" But this policy is terrible! It doesn't learn from rewards.")
|
| 185 |
+
print("="*62 + "\n")
|
| 186 |
+
```
|
| 187 |
+
|
| 188 |
+
**Output:**
|
| 189 |
+
```
|
| 190 |
+
🎲 ========================================================== 🎲
|
| 191 |
+
Number Guessing Game - The Simplest RL Example
|
| 192 |
+
🎲 ========================================================== 🎲
|
| 193 |
+
|
| 194 |
+
🎯 I'm thinking of a number between 1 and 10...
|
| 195 |
+
💭 You have 3 guesses. Let's see how random guessing works!
|
| 196 |
+
|
| 197 |
+
💭 Guess #1: 2 → ❄️ Cold! (far)
|
| 198 |
+
💭 Guess #2: 10 → 🎉 Correct! +10 points
|
| 199 |
+
|
| 200 |
+
==============================================================
|
| 201 |
+
💡 This is RL: Observe → Act → Reward → Repeat
|
| 202 |
+
But this policy is terrible! It doesn't learn from rewards.
|
| 203 |
+
==============================================================
|
| 204 |
+
```
|
| 205 |
+
|
| 206 |
+
---
|
| 207 |
+
|
| 208 |
+
## Part 2: The Problem with Traditional RL 😤
|
| 209 |
+
|
| 210 |
+
### 🤔 Why Can't We Just Use OpenAI Gym?
|
| 211 |
+
|
| 212 |
+
Good question! Gym is great for research, but production needs more...
|
| 213 |
+
|
| 214 |
+
| Challenge | Traditional Approach | OpenEnv Solution |
|
| 215 |
+
|-----------|---------------------|------------------|
|
| 216 |
+
| **Type Safety** | ❌ `obs[0][3]` - what is this? | ✅ `obs.info_state` - IDE knows! |
|
| 217 |
+
| **Isolation** | ❌ Same process (can crash your training) | ✅ Docker containers (fully isolated) |
|
| 218 |
+
| **Deployment** | ❌ "Works on my machine" 🤷 | ✅ Same container everywhere 🐳 |
|
| 219 |
+
| **Scaling** | ❌ Hard to distribute | ✅ Deploy to Kubernetes ☸️ |
|
| 220 |
+
| **Language** | ❌ Python only | ✅ Any language (HTTP API) 🌐 |
|
| 221 |
+
| **Debugging** | ❌ Cryptic numpy errors | ✅ Clear type errors 🐛 |
|
| 222 |
+
|
| 223 |
+
### 💡 The OpenEnv Philosophy
|
| 224 |
+
|
| 225 |
+
**"RL environments should be like microservices"**
|
| 226 |
+
|
| 227 |
+
Think of it like this: You don't run your database in the same process as your web server, right? Same principle!
|
| 228 |
+
|
| 229 |
+
- 🔒 **Isolated**: Run in containers (security + stability)
|
| 230 |
+
- 🌐 **Standard**: HTTP API, works everywhere
|
| 231 |
+
- 📦 **Versioned**: Docker images (reproducibility!)
|
| 232 |
+
- 🚀 **Scalable**: Deploy to cloud with one command
|
| 233 |
+
- 🛡️ **Type-safe**: Catch bugs before they happen
|
| 234 |
+
- 🔄 **Portable**: Works on Mac, Linux, Windows, Cloud
|
| 235 |
+
|
| 236 |
+
### The Architecture
|
| 237 |
+
|
| 238 |
+
```
|
| 239 |
+
┌────────────────────────────────────────────────────────────┐
|
| 240 |
+
│ YOUR TRAINING CODE │
|
| 241 |
+
│ │
|
| 242 |
+
│ env = OpenSpielEnv(...) ← Import the client │
|
| 243 |
+
│ result = env.reset() ← Type-safe! │
|
| 244 |
+
│ result = env.step(action) ← Type-safe! │
|
| 245 |
+
│ │
|
| 246 |
+
└─────────────────┬──────────────────────────────────────────┘
|
| 247 |
+
│
|
| 248 |
+
│ HTTP/JSON (Language-Agnostic)
|
| 249 |
+
│ POST /reset, POST /step, GET /state
|
| 250 |
+
│
|
| 251 |
+
┌─────────────────▼──────────────────────────────────────────┐
|
| 252 |
+
│ DOCKER CONTAINER │
|
| 253 |
+
│ │
|
| 254 |
+
│ ┌──────────────────────────────────────────────┐ │
|
| 255 |
+
│ │ FastAPI Server │ │
|
| 256 |
+
│ │ └─ Environment (reset, step, state) │ │
|
| 257 |
+
│ │ └─ Your Game/Simulation Logic │ │
|
| 258 |
+
│ └──────────────────────────────────────────────┘ │
|
| 259 |
+
│ │
|
| 260 |
+
│ Isolated • Reproducible • Secure │
|
| 261 |
+
└────────────────────────────────────────────────────────────┘
|
| 262 |
+
```
|
| 263 |
+
|
| 264 |
+
!!! info "Key Insight"
|
| 265 |
+
You never see HTTP details - just clean Python methods!
|
| 266 |
+
|
| 267 |
+
```python
|
| 268 |
+
env.reset() # Under the hood: HTTP POST to /reset
|
| 269 |
+
env.step(...) # Under the hood: HTTP POST to /step
|
| 270 |
+
env.state() # Under the hood: HTTP GET to /state
|
| 271 |
+
```
|
| 272 |
+
|
| 273 |
+
The magic? OpenEnv handles all the plumbing. You focus on RL! ✨
|
| 274 |
+
|
| 275 |
+
---
|
| 276 |
+
|
| 277 |
+
## Part 3: Setup 🛠️
|
| 278 |
+
|
| 279 |
+
**Running in Colab?** This cell will clone OpenEnv and install dependencies automatically.
|
| 280 |
+
|
| 281 |
+
**Running locally?** Make sure you're in the OpenEnv directory.
|
| 282 |
+
|
| 283 |
+
```python
|
| 284 |
+
# Detect environment
|
| 285 |
+
try:
|
| 286 |
+
import google.colab
|
| 287 |
+
IN_COLAB = True
|
| 288 |
+
print("🌐 Running in Google Colab - Perfect!")
|
| 289 |
+
except ImportError:
|
| 290 |
+
IN_COLAB = False
|
| 291 |
+
print("💻 Running locally - Nice!")
|
| 292 |
+
|
| 293 |
+
if IN_COLAB:
|
| 294 |
+
print("\n📦 Cloning OpenEnv repository...")
|
| 295 |
+
!git clone https://github.com/meta-pytorch/OpenEnv.git > /dev/null 2>&1
|
| 296 |
+
%cd OpenEnv
|
| 297 |
+
|
| 298 |
+
print("📚 Installing dependencies (this takes ~10 seconds)...")
|
| 299 |
+
!pip install -q fastapi uvicorn requests
|
| 300 |
+
|
| 301 |
+
import sys
|
| 302 |
+
sys.path.insert(0, './src')
|
| 303 |
+
print("\n✅ Setup complete! Everything is ready to go! 🎉")
|
| 304 |
+
else:
|
| 305 |
+
import sys
|
| 306 |
+
from pathlib import Path
|
| 307 |
+
sys.path.insert(0, str(Path.cwd().parent / 'src'))
|
| 308 |
+
print("✅ Using local OpenEnv installation")
|
| 309 |
+
|
| 310 |
+
print("\n🚀 Ready to explore OpenEnv and build amazing things!")
|
| 311 |
+
print("💡 Tip: Run cells top-to-bottom for the best experience.\n")
|
| 312 |
+
```
|
| 313 |
+
|
| 314 |
+
**Output:**
|
| 315 |
+
```
|
| 316 |
+
💻 Running locally - Nice!
|
| 317 |
+
✅ Using local OpenEnv installation
|
| 318 |
+
|
| 319 |
+
🚀 Ready to explore OpenEnv and build amazing things!
|
| 320 |
+
💡 Tip: Run cells top-to-bottom for the best experience.
|
| 321 |
+
```
|
| 322 |
+
|
| 323 |
+
---
|
| 324 |
+
|
| 325 |
+
## Part 4: The OpenEnv Pattern 🏗️
|
| 326 |
+
|
| 327 |
+
### Every OpenEnv Environment Has 3 Components:
|
| 328 |
+
|
| 329 |
+
```
|
| 330 |
+
src/envs/your_env/
|
| 331 |
+
├── 📝 models.py ← Type-safe contracts
|
| 332 |
+
│ (Action, Observation, State)
|
| 333 |
+
│
|
| 334 |
+
├── 📱 client.py ← What YOU import
|
| 335 |
+
│ (HTTPEnvClient implementation)
|
| 336 |
+
│
|
| 337 |
+
└── 🖥️ server/
|
| 338 |
+
├── environment.py ← Game/simulation logic
|
| 339 |
+
├── app.py ← FastAPI server
|
| 340 |
+
└── Dockerfile ← Container definition
|
| 341 |
+
```
|
| 342 |
+
|
| 343 |
+
Let's explore the actual OpenEnv code to see how this works:
|
| 344 |
+
|
| 345 |
+
```python
|
| 346 |
+
# Import OpenEnv's core abstractions
|
| 347 |
+
from core.env_server import Environment, Action, Observation, State
|
| 348 |
+
from core.http_env_client import HTTPEnvClient
|
| 349 |
+
|
| 350 |
+
print("="*70)
|
| 351 |
+
print(" 🧩 OPENENV CORE ABSTRACTIONS")
|
| 352 |
+
print("="*70)
|
| 353 |
+
|
| 354 |
+
print("""
|
| 355 |
+
🖥️ SERVER SIDE (runs in Docker):
|
| 356 |
+
|
| 357 |
+
class Environment(ABC):
|
| 358 |
+
'''Base class for all environment implementations'''
|
| 359 |
+
|
| 360 |
+
@abstractmethod
|
| 361 |
+
def reset(self) -> Observation:
|
| 362 |
+
'''Start new episode'''
|
| 363 |
+
|
| 364 |
+
@abstractmethod
|
| 365 |
+
def step(self, action: Action) -> Observation:
|
| 366 |
+
'''Execute action, return observation'''
|
| 367 |
+
|
| 368 |
+
@property
|
| 369 |
+
def state(self) -> State:
|
| 370 |
+
'''Get episode metadata'''
|
| 371 |
+
|
| 372 |
+
📱 CLIENT SIDE (your training code):
|
| 373 |
+
|
| 374 |
+
class HTTPEnvClient(ABC):
|
| 375 |
+
'''Base class for HTTP clients'''
|
| 376 |
+
|
| 377 |
+
def reset(self) -> StepResult:
|
| 378 |
+
# HTTP POST /reset
|
| 379 |
+
|
| 380 |
+
def step(self, action) -> StepResult:
|
| 381 |
+
# HTTP POST /step
|
| 382 |
+
|
| 383 |
+
def state(self) -> State:
|
| 384 |
+
# HTTP GET /state
|
| 385 |
+
""")
|
| 386 |
+
|
| 387 |
+
print("="*70)
|
| 388 |
+
print("\n✨ Same interface on both sides - communication via HTTP!")
|
| 389 |
+
print("🎯 You focus on RL, OpenEnv handles the infrastructure.\n")
|
| 390 |
+
```
|
| 391 |
+
|
| 392 |
+
**Output:**
|
| 393 |
+
```
|
| 394 |
+
======================================================================
|
| 395 |
+
🧩 OPENENV CORE ABSTRACTIONS
|
| 396 |
+
======================================================================
|
| 397 |
+
|
| 398 |
+
🖥️ SERVER SIDE (runs in Docker):
|
| 399 |
+
|
| 400 |
+
class Environment(ABC):
|
| 401 |
+
'''Base class for all environment implementations'''
|
| 402 |
+
|
| 403 |
+
@abstractmethod
|
| 404 |
+
def reset(self) -> Observation:
|
| 405 |
+
'''Start new episode'''
|
| 406 |
+
|
| 407 |
+
@abstractmethod
|
| 408 |
+
def step(self, action: Action) -> Observation:
|
| 409 |
+
'''Execute action, return observation'''
|
| 410 |
+
|
| 411 |
+
@property
|
| 412 |
+
def state(self) -> State:
|
| 413 |
+
'''Get episode metadata'''
|
| 414 |
+
|
| 415 |
+
📱 CLIENT SIDE (your training code):
|
| 416 |
+
|
| 417 |
+
class HTTPEnvClient(ABC):
|
| 418 |
+
'''Base class for HTTP clients'''
|
| 419 |
+
|
| 420 |
+
def reset(self) -> StepResult:
|
| 421 |
+
# HTTP POST /reset
|
| 422 |
+
|
| 423 |
+
def step(self, action) -> StepResult:
|
| 424 |
+
# HTTP POST /step
|
| 425 |
+
|
| 426 |
+
def state(self) -> State:
|
| 427 |
+
# HTTP GET /state
|
| 428 |
+
|
| 429 |
+
======================================================================
|
| 430 |
+
|
| 431 |
+
✨ Same interface on both sides - communication via HTTP!
|
| 432 |
+
🎯 You focus on RL, OpenEnv handles the infrastructure.
|
| 433 |
+
```
|
| 434 |
+
|
| 435 |
+
---
|
| 436 |
+
|
| 437 |
+
## Part 5: Example Integration - OpenSpiel 🎮
|
| 438 |
+
|
| 439 |
+
### What is OpenSpiel?
|
| 440 |
+
|
| 441 |
+
**OpenSpiel** is a library from DeepMind with **70+ game environments** for RL research.
|
| 442 |
+
|
| 443 |
+
### OpenEnv's Integration
|
| 444 |
+
|
| 445 |
+
We've wrapped **6 OpenSpiel games** following the OpenEnv pattern:
|
| 446 |
+
|
| 447 |
+
| **🎯 Single-Player** | **👥 Multi-Player** |
|
| 448 |
+
|---------------------|---------------------|
|
| 449 |
+
| 1. **Catch** - Catch falling ball | 5. **Tic-Tac-Toe** - Classic 3×3 |
|
| 450 |
+
| 2. **Cliff Walking** - Navigate grid | 6. **Kuhn Poker** - Imperfect info poker |
|
| 451 |
+
| 3. **2048** - Tile puzzle | |
|
| 452 |
+
| 4. **Blackjack** - Card game | |
|
| 453 |
+
|
| 454 |
+
This shows how OpenEnv can wrap **any** existing RL library!
|
| 455 |
+
|
| 456 |
+
```python
|
| 457 |
+
from envs.openspiel_env.client import OpenSpielEnv
|
| 458 |
+
|
| 459 |
+
print("="*70)
|
| 460 |
+
print(" 🔌 HOW OPENENV WRAPS OPENSPIEL")
|
| 461 |
+
print("="*70)
|
| 462 |
+
|
| 463 |
+
print("""
|
| 464 |
+
class OpenSpielEnv(HTTPEnvClient[OpenSpielAction, OpenSpielObservation]):
|
| 465 |
+
|
| 466 |
+
def _step_payload(self, action: OpenSpielAction) -> dict:
|
| 467 |
+
'''Convert typed action to JSON for HTTP'''
|
| 468 |
+
return {
|
| 469 |
+
"action_id": action.action_id,
|
| 470 |
+
"game_name": action.game_name,
|
| 471 |
+
}
|
| 472 |
+
|
| 473 |
+
def _parse_result(self, payload: dict) -> StepResult:
|
| 474 |
+
'''Parse HTTP JSON response into typed observation'''
|
| 475 |
+
return StepResult(
|
| 476 |
+
observation=OpenSpielObservation(...),
|
| 477 |
+
reward=payload['reward'],
|
| 478 |
+
done=payload['done']
|
| 479 |
+
)
|
| 480 |
+
|
| 481 |
+
""")
|
| 482 |
+
|
| 483 |
+
print("─" * 70)
|
| 484 |
+
print("\n✨ Usage (works for ALL OpenEnv environments):")
|
| 485 |
+
print("""
|
| 486 |
+
env = OpenSpielEnv(base_url="http://localhost:8000")
|
| 487 |
+
|
| 488 |
+
result = env.reset()
|
| 489 |
+
# Returns StepResult[OpenSpielObservation] - Type safe!
|
| 490 |
+
|
| 491 |
+
result = env.step(OpenSpielAction(action_id=2, game_name="catch"))
|
| 492 |
+
# Type checker knows this is valid!
|
| 493 |
+
|
| 494 |
+
state = env.state()
|
| 495 |
+
# Returns OpenSpielState
|
| 496 |
+
""")
|
| 497 |
+
|
| 498 |
+
print("─" * 70)
|
| 499 |
+
print("\n🎯 This pattern works for ANY environment you want to wrap!\n")
|
| 500 |
+
```
|
| 501 |
+
|
| 502 |
+
**Output:**
|
| 503 |
+
```
|
| 504 |
+
======================================================================
|
| 505 |
+
🔌 HOW OPENENV WRAPS OPENSPIEL
|
| 506 |
+
======================================================================
|
| 507 |
+
|
| 508 |
+
class OpenSpielEnv(HTTPEnvClient[OpenSpielAction, OpenSpielObservation]):
|
| 509 |
+
|
| 510 |
+
def _step_payload(self, action: OpenSpielAction) -> dict:
|
| 511 |
+
'''Convert typed action to JSON for HTTP'''
|
| 512 |
+
return {
|
| 513 |
+
"action_id": action.action_id,
|
| 514 |
+
"game_name": action.game_name,
|
| 515 |
+
}
|
| 516 |
+
|
| 517 |
+
def _parse_result(self, payload: dict) -> StepResult:
|
| 518 |
+
'''Parse HTTP JSON response into typed observation'''
|
| 519 |
+
return StepResult(
|
| 520 |
+
observation=OpenSpielObservation(...),
|
| 521 |
+
reward=payload['reward'],
|
| 522 |
+
done=payload['done']
|
| 523 |
+
)
|
| 524 |
+
|
| 525 |
+
|
| 526 |
+
──────────────────────────────────────────────────────────────────────
|
| 527 |
+
|
| 528 |
+
✨ Usage (works for ALL OpenEnv environments):
|
| 529 |
+
|
| 530 |
+
env = OpenSpielEnv(base_url="http://localhost:8000")
|
| 531 |
+
|
| 532 |
+
result = env.reset()
|
| 533 |
+
# Returns StepResult[OpenSpielObservation] - Type safe!
|
| 534 |
+
|
| 535 |
+
result = env.step(OpenSpielAction(action_id=2, game_name="catch"))
|
| 536 |
+
# Type checker knows this is valid!
|
| 537 |
+
|
| 538 |
+
state = env.state()
|
| 539 |
+
# Returns OpenSpielState
|
| 540 |
+
|
| 541 |
+
──────────────────────────────────────────────────────────────────────
|
| 542 |
+
|
| 543 |
+
🎯 This pattern works for ANY environment you want to wrap!
|
| 544 |
+
```
|
| 545 |
+
|
| 546 |
+
### Type-Safe Models
|
| 547 |
+
|
| 548 |
+
```python
|
| 549 |
+
# Import OpenSpiel integration models
|
| 550 |
+
from envs.openspiel_env.models import (
|
| 551 |
+
OpenSpielAction,
|
| 552 |
+
OpenSpielObservation,
|
| 553 |
+
OpenSpielState
|
| 554 |
+
)
|
| 555 |
+
from dataclasses import fields
|
| 556 |
+
|
| 557 |
+
print("="*70)
|
| 558 |
+
print(" 🎮 OPENSPIEL INTEGRATION - TYPE-SAFE MODELS")
|
| 559 |
+
print("="*70)
|
| 560 |
+
|
| 561 |
+
print("\n📤 OpenSpielAction (what you send):")
|
| 562 |
+
print(" " + "─" * 64)
|
| 563 |
+
for field in fields(OpenSpielAction):
|
| 564 |
+
print(f" • {field.name:20s} : {field.type}")
|
| 565 |
+
|
| 566 |
+
print("\n📥 OpenSpielObservation (what you receive):")
|
| 567 |
+
print(" " + "─" * 64)
|
| 568 |
+
for field in fields(OpenSpielObservation):
|
| 569 |
+
print(f" • {field.name:20s} : {field.type}")
|
| 570 |
+
|
| 571 |
+
print("\n📊 OpenSpielState (episode metadata):")
|
| 572 |
+
print(" " + "─" * 64)
|
| 573 |
+
for field in fields(OpenSpielState):
|
| 574 |
+
print(f" • {field.name:20s} : {field.type}")
|
| 575 |
+
|
| 576 |
+
print("\n" + "="*70)
|
| 577 |
+
print("\n💡 Type safety means:")
|
| 578 |
+
print(" ✅ Your IDE autocompletes these fields")
|
| 579 |
+
print(" ✅ Typos are caught before running")
|
| 580 |
+
print(" ✅ Refactoring is safe")
|
| 581 |
+
print(" ✅ Self-documenting code\n")
|
| 582 |
+
```
|
| 583 |
+
|
| 584 |
+
**Output:**
|
| 585 |
+
```
|
| 586 |
+
======================================================================
|
| 587 |
+
🎮 OPENSPIEL INTEGRATION - TYPE-SAFE MODELS
|
| 588 |
+
======================================================================
|
| 589 |
+
|
| 590 |
+
📤 OpenSpielAction (what you send):
|
| 591 |
+
────────────────────────────────────────────────────────────────
|
| 592 |
+
• metadata : typing.Dict[str, typing.Any]
|
| 593 |
+
• action_id : int
|
| 594 |
+
• game_name : str
|
| 595 |
+
• game_params : Dict[str, Any]
|
| 596 |
+
|
| 597 |
+
📥 OpenSpielObservation (what you receive):
|
| 598 |
+
───────────────────────────────────���────────────────────────────
|
| 599 |
+
• done : <class 'bool'>
|
| 600 |
+
• reward : typing.Union[bool, int, float, NoneType]
|
| 601 |
+
• metadata : typing.Dict[str, typing.Any]
|
| 602 |
+
• info_state : List[float]
|
| 603 |
+
• legal_actions : List[int]
|
| 604 |
+
• game_phase : str
|
| 605 |
+
• current_player_id : int
|
| 606 |
+
• opponent_last_action : Optional[int]
|
| 607 |
+
|
| 608 |
+
📊 OpenSpielState (episode metadata):
|
| 609 |
+
────────────────────────────────────────────────────────────────
|
| 610 |
+
• episode_id : typing.Optional[str]
|
| 611 |
+
• step_count : <class 'int'>
|
| 612 |
+
• game_name : str
|
| 613 |
+
• agent_player : int
|
| 614 |
+
• opponent_policy : str
|
| 615 |
+
• game_params : Dict[str, Any]
|
| 616 |
+
• num_players : int
|
| 617 |
+
|
| 618 |
+
======================================================================
|
| 619 |
+
|
| 620 |
+
💡 Type safety means:
|
| 621 |
+
✅ Your IDE autocompletes these fields
|
| 622 |
+
✅ Typos are caught before running
|
| 623 |
+
✅ Refactoring is safe
|
| 624 |
+
✅ Self-documenting code
|
| 625 |
+
```
|
| 626 |
+
|
| 627 |
+
### How the Client Works
|
| 628 |
+
|
| 629 |
+
The client **inherits from HTTPEnvClient** and implements 3 methods:
|
| 630 |
+
|
| 631 |
+
1. `_step_payload()` - Convert action → JSON
|
| 632 |
+
2. `_parse_result()` - Parse JSON → typed observation
|
| 633 |
+
3. `_parse_state()` - Parse JSON → state
|
| 634 |
+
|
| 635 |
+
That's it! The base class handles all HTTP communication.
|
| 636 |
+
|
| 637 |
+
---
|
| 638 |
+
|
| 639 |
+
## Part 6: Using Real OpenSpiel 🎮
|
| 640 |
+
|
| 641 |
+
<div style="text-align: center; background: linear-gradient(135deg, #667eea 0%, #764ba2 100%); color: white; padding: 30px; border-radius: 15px; margin: 30px 0;">
|
| 642 |
+
|
| 643 |
+
### Now let's USE a production environment!
|
| 644 |
+
|
| 645 |
+
We'll play **Catch** using OpenEnv's **OpenSpiel integration** 🎯
|
| 646 |
+
|
| 647 |
+
This is a REAL environment running in production at companies!
|
| 648 |
+
|
| 649 |
+
**Get ready for:**
|
| 650 |
+
|
| 651 |
+
- 🔌 Using existing environments (not building)
|
| 652 |
+
- 🤖 Testing policies against real games
|
| 653 |
+
- 📊 Live gameplay visualization
|
| 654 |
+
- 🎯 Production-ready patterns
|
| 655 |
+
|
| 656 |
+
</div>
|
| 657 |
+
|
| 658 |
+
### The Game: Catch 🔴🏓
|
| 659 |
+
|
| 660 |
+
```
|
| 661 |
+
⬜ ⬜ 🔴 ⬜ ⬜
|
| 662 |
+
⬜ ⬜ ⬜ ⬜ ⬜
|
| 663 |
+
⬜ ⬜ ⬜ ⬜ ⬜ Ball
|
| 664 |
+
⬜ ⬜ ⬜ ⬜ ⬜
|
| 665 |
+
⬜ ⬜ ⬜ ⬜ ⬜ falls
|
| 666 |
+
⬜ ⬜ ⬜ ⬜ ⬜
|
| 667 |
+
⬜ ⬜ ⬜ ⬜ ⬜ down
|
| 668 |
+
⬜ ⬜ ⬜ ⬜ ⬜
|
| 669 |
+
⬜ ⬜ ⬜ ⬜ ⬜
|
| 670 |
+
⬜ ⬜ 🏓 ⬜ ⬜
|
| 671 |
+
Paddle
|
| 672 |
+
```
|
| 673 |
+
|
| 674 |
+
**Rules:**
|
| 675 |
+
|
| 676 |
+
- 10×5 grid
|
| 677 |
+
- Ball falls from random column
|
| 678 |
+
- Move paddle left/right to catch it
|
| 679 |
+
|
| 680 |
+
**Actions:**
|
| 681 |
+
|
| 682 |
+
- `0` = Move LEFT ⬅️
|
| 683 |
+
- `1` = STAY 🛑
|
| 684 |
+
- `2` = Move RIGHT ➡️
|
| 685 |
+
|
| 686 |
+
**Reward:**
|
| 687 |
+
|
| 688 |
+
- `+1` if caught 🎉
|
| 689 |
+
- `0` if missed 😢
|
| 690 |
+
|
| 691 |
+
!!! note "Why Catch?"
|
| 692 |
+
- Simple rules (easy to understand)
|
| 693 |
+
- Fast episodes (~5 steps)
|
| 694 |
+
- Clear success/failure
|
| 695 |
+
- Part of OpenSpiel's 70+ games!
|
| 696 |
+
|
| 697 |
+
**💡 The Big Idea:**
|
| 698 |
+
Instead of building this from scratch, we'll USE OpenEnv's existing OpenSpiel integration. Same interface, but production-ready!
|
| 699 |
+
|
| 700 |
+
```python
|
| 701 |
+
from envs.openspiel_env import OpenSpielEnv
|
| 702 |
+
from envs.openspiel_env.models import (
|
| 703 |
+
OpenSpielAction,
|
| 704 |
+
OpenSpielObservation,
|
| 705 |
+
OpenSpielState
|
| 706 |
+
)
|
| 707 |
+
from dataclasses import fields
|
| 708 |
+
|
| 709 |
+
print("🎮 " + "="*64 + " 🎮")
|
| 710 |
+
print(" ✅ Importing Real OpenSpiel Environment!")
|
| 711 |
+
print("🎮 " + "="*64 + " 🎮\n")
|
| 712 |
+
|
| 713 |
+
print("📦 What we just imported:")
|
| 714 |
+
print(" • OpenSpielEnv - HTTP client for OpenSpiel games")
|
| 715 |
+
print(" • OpenSpielAction - Type-safe actions")
|
| 716 |
+
print(" • OpenSpielObservation - Type-safe observations")
|
| 717 |
+
print(" • OpenSpielState - Episode metadata\n")
|
| 718 |
+
|
| 719 |
+
print("📋 OpenSpielObservation fields:")
|
| 720 |
+
print(" " + "─" * 60)
|
| 721 |
+
for field in fields(OpenSpielObservation):
|
| 722 |
+
print(f" • {field.name:25s} : {field.type}")
|
| 723 |
+
|
| 724 |
+
print("\n" + "="*70)
|
| 725 |
+
print("\n💡 This is REAL OpenEnv code - used in production!")
|
| 726 |
+
print(" • Wraps 6 OpenSpiel games (Catch, Tic-Tac-Toe, Poker, etc.)")
|
| 727 |
+
print(" • Type-safe actions and observations")
|
| 728 |
+
print(" • Works via HTTP (we'll see that next!)\n")
|
| 729 |
+
```
|
| 730 |
+
|
| 731 |
+
**Output:**
|
| 732 |
+
```
|
| 733 |
+
🎮 ================================================================ 🎮
|
| 734 |
+
✅ Importing Real OpenSpiel Environment!
|
| 735 |
+
🎮 ================================================================ 🎮
|
| 736 |
+
|
| 737 |
+
📦 What we just imported:
|
| 738 |
+
• OpenSpielEnv - HTTP client for OpenSpiel games
|
| 739 |
+
• OpenSpielAction - Type-safe actions
|
| 740 |
+
• OpenSpielObservation - Type-safe observations
|
| 741 |
+
• OpenSpielState - Episode metadata
|
| 742 |
+
|
| 743 |
+
📋 OpenSpielObservation fields:
|
| 744 |
+
────────────────────────────────────────────────────────────
|
| 745 |
+
• done : <class 'bool'>
|
| 746 |
+
• reward : typing.Union[bool, int, float, NoneType]
|
| 747 |
+
• metadata : typing.Dict[str, typing.Any]
|
| 748 |
+
• info_state : List[float]
|
| 749 |
+
• legal_actions : List[int]
|
| 750 |
+
• game_phase : str
|
| 751 |
+
• current_player_id : int
|
| 752 |
+
• opponent_last_action : Optional[int]
|
| 753 |
+
|
| 754 |
+
======================================================================
|
| 755 |
+
|
| 756 |
+
💡 This is REAL OpenEnv code - used in production!
|
| 757 |
+
• Wraps 6 OpenSpiel games (Catch, Tic-Tac-Toe, Poker, etc.)
|
| 758 |
+
• Type-safe actions and observations
|
| 759 |
+
• Works via HTTP (we'll see that next!)
|
| 760 |
+
```
|
| 761 |
+
|
| 762 |
+
---
|
| 763 |
+
|
| 764 |
+
## Part 7: Four Policies 🤖
|
| 765 |
+
|
| 766 |
+
Let's test 4 different AI strategies:
|
| 767 |
+
|
| 768 |
+
| Policy | Strategy | Expected Performance |
|
| 769 |
+
|--------|----------|----------------------|
|
| 770 |
+
| **🎲 Random** | Pick random action every step | ~20% (pure luck) |
|
| 771 |
+
| **🛑 Always Stay** | Never move, hope ball lands in center | ~20% (terrible!) |
|
| 772 |
+
| **🧠 Smart** | Move paddle toward ball | 100% (optimal!) |
|
| 773 |
+
| **📈 Learning** | Start random, learn smart strategy | ~85% (improves over time) |
|
| 774 |
+
|
| 775 |
+
**💡 These policies work with ANY OpenSpiel game!**
|
| 776 |
+
|
| 777 |
+
```python
|
| 778 |
+
import random
|
| 779 |
+
|
| 780 |
+
# ============================================================================
|
| 781 |
+
# POLICIES - Different AI strategies (adapted for OpenSpiel)
|
| 782 |
+
# ============================================================================
|
| 783 |
+
|
| 784 |
+
class RandomPolicy:
|
| 785 |
+
"""Baseline: Pure random guessing."""
|
| 786 |
+
name = "🎲 Random Guesser"
|
| 787 |
+
|
| 788 |
+
def select_action(self, obs: OpenSpielObservation) -> int:
|
| 789 |
+
return random.choice(obs.legal_actions)
|
| 790 |
+
|
| 791 |
+
|
| 792 |
+
class AlwaysStayPolicy:
|
| 793 |
+
"""Bad strategy: Never moves."""
|
| 794 |
+
name = "🛑 Always Stay"
|
| 795 |
+
|
| 796 |
+
def select_action(self, obs: OpenSpielObservation) -> int:
|
| 797 |
+
return 1 # STAY
|
| 798 |
+
|
| 799 |
+
|
| 800 |
+
class SmartPolicy:
|
| 801 |
+
"""Optimal: Move paddle toward ball."""
|
| 802 |
+
name = "🧠 Smart Heuristic"
|
| 803 |
+
|
| 804 |
+
def select_action(self, obs: OpenSpielObservation) -> int:
|
| 805 |
+
# Parse OpenSpiel observation
|
| 806 |
+
# For Catch: info_state is a flattened 10x5 grid
|
| 807 |
+
# Ball position and paddle position encoded in the vector
|
| 808 |
+
info_state = obs.info_state
|
| 809 |
+
|
| 810 |
+
# Find ball and paddle positions from info_state
|
| 811 |
+
# Catch uses a 10x5 grid, so 50 values
|
| 812 |
+
grid_size = 5
|
| 813 |
+
|
| 814 |
+
# Find positions (ball = 1.0 in the flattened grid, paddle = 1.0 in the last row of the flattened grid)
|
| 815 |
+
ball_col = None
|
| 816 |
+
paddle_col = None
|
| 817 |
+
|
| 818 |
+
for idx, val in enumerate(info_state):
|
| 819 |
+
if abs(val - 1.0) < 0.01: # Ball
|
| 820 |
+
ball_col = idx % grid_size
|
| 821 |
+
break
|
| 822 |
+
|
| 823 |
+
last_row = info_state[-grid_size:]
|
| 824 |
+
paddle_col = last_row.index(1.0) # Paddle
|
| 825 |
+
|
| 826 |
+
if ball_col is not None and paddle_col is not None:
|
| 827 |
+
if paddle_col < ball_col:
|
| 828 |
+
return 2 # Move RIGHT
|
| 829 |
+
elif paddle_col > ball_col:
|
| 830 |
+
return 0 # Move LEFT
|
| 831 |
+
|
| 832 |
+
return 1 # STAY (fallback)
|
| 833 |
+
|
| 834 |
+
|
| 835 |
+
class LearningPolicy:
|
| 836 |
+
"""Simulated RL: Epsilon-greedy exploration."""
|
| 837 |
+
name = "📈 Learning Agent"
|
| 838 |
+
|
| 839 |
+
def __init__(self):
|
| 840 |
+
self.steps = 0
|
| 841 |
+
self.smart_policy = SmartPolicy()
|
| 842 |
+
|
| 843 |
+
def select_action(self, obs: OpenSpielObservation) -> int:
|
| 844 |
+
self.steps += 1
|
| 845 |
+
|
| 846 |
+
# Decay exploration rate over time
|
| 847 |
+
epsilon = max(0.1, 1.0 - (self.steps / 100))
|
| 848 |
+
|
| 849 |
+
if random.random() < epsilon:
|
| 850 |
+
# Explore: random action
|
| 851 |
+
return random.choice(obs.legal_actions)
|
| 852 |
+
else:
|
| 853 |
+
# Exploit: use smart strategy
|
| 854 |
+
return self.smart_policy.select_action(obs)
|
| 855 |
+
|
| 856 |
+
|
| 857 |
+
print("🤖 " + "="*64 + " 🤖")
|
| 858 |
+
print(" ✅ 4 Policies Created (Adapted for OpenSpiel)!")
|
| 859 |
+
print("🤖 " + "="*64 + " 🤖\n")
|
| 860 |
+
|
| 861 |
+
policies = [RandomPolicy(), AlwaysStayPolicy(), SmartPolicy(), LearningPolicy()]
|
| 862 |
+
for i, policy in enumerate(policies, 1):
|
| 863 |
+
print(f" {i}. {policy.name}")
|
| 864 |
+
|
| 865 |
+
print("\n💡 These policies work with OpenSpielObservation!")
|
| 866 |
+
print(" • Read info_state (flattened grid)")
|
| 867 |
+
print(" • Use legal_actions")
|
| 868 |
+
print(" • Work with ANY OpenSpiel game that exposes these!\n")
|
| 869 |
+
```
|
| 870 |
+
|
| 871 |
+
**Output:**
|
| 872 |
+
```
|
| 873 |
+
🤖 ================================================================ 🤖
|
| 874 |
+
✅ 4 Policies Created (Adapted for OpenSpiel)!
|
| 875 |
+
🤖 ================================================================ 🤖
|
| 876 |
+
|
| 877 |
+
1. 🎲 Random Guesser
|
| 878 |
+
2. 🛑 Always Stay
|
| 879 |
+
3. 🧠 Smart Heuristic
|
| 880 |
+
4. 📈 Learning Agent
|
| 881 |
+
|
| 882 |
+
💡 These policies work with OpenSpielObservation!
|
| 883 |
+
• Read info_state (flattened grid)
|
| 884 |
+
• Use legal_actions
|
| 885 |
+
• Work with ANY OpenSpiel game that exposes these!
|
| 886 |
+
```
|
| 887 |
+
|
| 888 |
+
---
|
| 889 |
+
|
| 890 |
+
## Part 8: Policy Competition! 🏆
|
| 891 |
+
|
| 892 |
+
Let's run **50 episodes** for each policy against **REAL OpenSpiel** and see who wins!
|
| 893 |
+
|
| 894 |
+
This is production code - every action is an HTTP call to the OpenSpiel server!
|
| 895 |
+
|
| 896 |
+
```python
|
| 897 |
+
def evaluate_policies(env, num_episodes=50):
|
| 898 |
+
"""Compare all policies over many episodes using real OpenSpiel."""
|
| 899 |
+
policies = [
|
| 900 |
+
RandomPolicy(),
|
| 901 |
+
AlwaysStayPolicy(),
|
| 902 |
+
SmartPolicy(),
|
| 903 |
+
LearningPolicy(),
|
| 904 |
+
]
|
| 905 |
+
|
| 906 |
+
print("\n🏆 " + "="*66 + " 🏆")
|
| 907 |
+
print(f" POLICY SHOWDOWN - {num_episodes} Episodes Each")
|
| 908 |
+
print(f" Playing against REAL OpenSpiel Catch!")
|
| 909 |
+
print("🏆 " + "="*66 + " 🏆\n")
|
| 910 |
+
|
| 911 |
+
results = []
|
| 912 |
+
for policy in policies:
|
| 913 |
+
print(f"⚡ Testing {policy.name}...", end=" ")
|
| 914 |
+
successes = sum(run_episode(env, policy, visualize=False)
|
| 915 |
+
for _ in range(num_episodes))
|
| 916 |
+
success_rate = (successes / num_episodes) * 100
|
| 917 |
+
results.append((policy.name, success_rate, successes))
|
| 918 |
+
print(f"✓ Done!")
|
| 919 |
+
|
| 920 |
+
print("\n" + "="*70)
|
| 921 |
+
print(" 📊 FINAL RESULTS")
|
| 922 |
+
print("="*70 + "\n")
|
| 923 |
+
|
| 924 |
+
# Sort by success rate (descending)
|
| 925 |
+
results.sort(key=lambda x: x[1], reverse=True)
|
| 926 |
+
|
| 927 |
+
# Award medals to top 3
|
| 928 |
+
medals = ["🥇", "🥈", "🥉", " "]
|
| 929 |
+
|
| 930 |
+
for i, (name, rate, successes) in enumerate(results):
|
| 931 |
+
medal = medals[i]
|
| 932 |
+
bar = "█" * int(rate / 2)
|
| 933 |
+
print(f"{medal} {name:25s} [{bar:<50}] {rate:5.1f}% ({successes}/{num_episodes})")
|
| 934 |
+
|
| 935 |
+
print("\n" + "="*70)
|
| 936 |
+
print("\n✨ Key Insights:")
|
| 937 |
+
print(" • Random (~20%): Baseline - pure luck 🎲")
|
| 938 |
+
print(" • Always Stay (~20%): Bad strategy - stays center 🛑")
|
| 939 |
+
print(" • Smart (100%): Optimal - perfect play! 🧠")
|
| 940 |
+
print(" • Learning (~85%): Improves over time 📈")
|
| 941 |
+
print("\n🎓 This is Reinforcement Learning + OpenEnv in action:")
|
| 942 |
+
print(" 1. We USED existing OpenSpiel environment (didn't build it)")
|
| 943 |
+
print(" 2. Type-safe communication over HTTP")
|
| 944 |
+
print(" 3. Same code works for ANY OpenSpiel game")
|
| 945 |
+
print(" 4. Production-ready architecture\n")
|
| 946 |
+
|
| 947 |
+
# Run the epic competition!
|
| 948 |
+
print("🎮 Starting the showdown against REAL OpenSpiel...\n")
|
| 949 |
+
evaluate_policies(client, num_episodes=50)
|
| 950 |
+
```
|
| 951 |
+
|
| 952 |
+
---
|
| 953 |
+
|
| 954 |
+
## Part 9: Switching to Other Games 🎮
|
| 955 |
+
|
| 956 |
+
### What We Just Used: Real OpenSpiel! 🎉
|
| 957 |
+
|
| 958 |
+
In Parts 6-8, we **USED** the existing OpenSpiel Catch environment:
|
| 959 |
+
|
| 960 |
+
| What We Did | How It Works |
|
| 961 |
+
|-------------|--------------|
|
| 962 |
+
| **Imported** | OpenSpielEnv client (pre-built) |
|
| 963 |
+
| **Started** | OpenSpiel server via uvicorn |
|
| 964 |
+
| **Connected** | HTTP client to server |
|
| 965 |
+
| **Played** | Real OpenSpiel Catch game |
|
| 966 |
+
|
| 967 |
+
**🎯 This is production code!** Every action was an HTTP call to a real OpenSpiel environment.
|
| 968 |
+
|
| 969 |
+
### 🎮 6 Games Available - Same Interface!
|
| 970 |
+
|
| 971 |
+
The beauty of OpenEnv? **Same code, different games!**
|
| 972 |
+
|
| 973 |
+
```python
|
| 974 |
+
# We just used Catch
|
| 975 |
+
env = OpenSpielEnv(base_url="http://localhost:8000")
|
| 976 |
+
# game_name="catch" was set via environment variable
|
| 977 |
+
|
| 978 |
+
# Want Tic-Tac-Toe instead? Just change the game!
|
| 979 |
+
# Start server with: OPENSPIEL_GAME=tic_tac_toe uvicorn ...
|
| 980 |
+
# Same client code works!
|
| 981 |
+
```
|
| 982 |
+
|
| 983 |
+
**🎮 All 6 Games:**
|
| 984 |
+
|
| 985 |
+
1. ✅ **`catch`** - What we just used!
|
| 986 |
+
2. **`tic_tac_toe`** - Classic 3×3
|
| 987 |
+
3. **`kuhn_poker`** - Imperfect information poker
|
| 988 |
+
4. **`cliff_walking`** - Grid navigation
|
| 989 |
+
5. **`2048`** - Tile puzzle
|
| 990 |
+
6. **`blackjack`** - Card game
|
| 991 |
+
|
| 992 |
+
**All use the exact same OpenSpielEnv client!**
|
| 993 |
+
|
| 994 |
+
### Try Another Game (Optional):
|
| 995 |
+
|
| 996 |
+
```python
|
| 997 |
+
# Stop the current server (kill the server_process)
|
| 998 |
+
# Then start a new game:
|
| 999 |
+
|
| 1000 |
+
server_process = subprocess.Popen(
|
| 1001 |
+
[sys.executable, "-m", "uvicorn",
|
| 1002 |
+
"envs.openspiel_env.server.app:app",
|
| 1003 |
+
"--host", "0.0.0.0",
|
| 1004 |
+
"--port", "8000"],
|
| 1005 |
+
env={**os.environ,
|
| 1006 |
+
"PYTHONPATH": f"{work_dir}/src",
|
| 1007 |
+
"OPENSPIEL_GAME": "tic_tac_toe", # Changed!
|
| 1008 |
+
"OPENSPIEL_AGENT_PLAYER": "0",
|
| 1009 |
+
"OPENSPIEL_OPPONENT_POLICY": "random"},
|
| 1010 |
+
# ... rest of config
|
| 1011 |
+
)
|
| 1012 |
+
|
| 1013 |
+
# Same client works!
|
| 1014 |
+
client = OpenSpielEnv(base_url="http://localhost:8000")
|
| 1015 |
+
result = client.reset() # Now playing Tic-Tac-Toe!
|
| 1016 |
+
```
|
| 1017 |
+
|
| 1018 |
+
**💡 Key Insight**: You don't rebuild anything - you just USE different games with the same client!
|
| 1019 |
+
|
| 1020 |
+
---
|
| 1021 |
+
|
| 1022 |
+
## Part 10: Create Your Own Integration 🛠️
|
| 1023 |
+
|
| 1024 |
+
### The 5-Step Pattern
|
| 1025 |
+
|
| 1026 |
+
Want to wrap your own environment in OpenEnv? Here's how:
|
| 1027 |
+
|
| 1028 |
+
### Step 1: Define Types (`models.py`)
|
| 1029 |
+
|
| 1030 |
+
```python
|
| 1031 |
+
from dataclasses import dataclass
|
| 1032 |
+
from core.env_server import Action, Observation, State
|
| 1033 |
+
|
| 1034 |
+
@dataclass
|
| 1035 |
+
class YourAction(Action):
|
| 1036 |
+
action_value: int
|
| 1037 |
+
# Add your action fields
|
| 1038 |
+
|
| 1039 |
+
@dataclass
|
| 1040 |
+
class YourObservation(Observation):
|
| 1041 |
+
state_data: List[float]
|
| 1042 |
+
done: bool
|
| 1043 |
+
reward: float
|
| 1044 |
+
# Add your observation fields
|
| 1045 |
+
|
| 1046 |
+
@dataclass
|
| 1047 |
+
class YourState(State):
|
| 1048 |
+
episode_id: str
|
| 1049 |
+
step_count: int
|
| 1050 |
+
# Add your state fields
|
| 1051 |
+
```
|
| 1052 |
+
|
| 1053 |
+
### Step 2: Implement Environment (`server/environment.py`)
|
| 1054 |
+
|
| 1055 |
+
```python
|
| 1056 |
+
from core.env_server import Environment
|
| 1057 |
+
|
| 1058 |
+
class YourEnvironment(Environment):
|
| 1059 |
+
def reset(self) -> Observation:
|
| 1060 |
+
# Initialize your game/simulation
|
| 1061 |
+
return YourObservation(...)
|
| 1062 |
+
|
| 1063 |
+
def step(self, action: Action) -> Observation:
|
| 1064 |
+
# Execute action, update state
|
| 1065 |
+
return YourObservation(...)
|
| 1066 |
+
|
| 1067 |
+
@property
|
| 1068 |
+
def state(self) -> State:
|
| 1069 |
+
return self._state
|
| 1070 |
+
```
|
| 1071 |
+
|
| 1072 |
+
### Step 3: Create Client (`client.py`)
|
| 1073 |
+
|
| 1074 |
+
```python
|
| 1075 |
+
from core.http_env_client import HTTPEnvClient
|
| 1076 |
+
from core.types import StepResult
|
| 1077 |
+
|
| 1078 |
+
class YourEnv(HTTPEnvClient[YourAction, YourObservation]):
|
| 1079 |
+
def _step_payload(self, action: YourAction) -> dict:
|
| 1080 |
+
"""Convert action to JSON"""
|
| 1081 |
+
return {"action_value": action.action_value}
|
| 1082 |
+
|
| 1083 |
+
def _parse_result(self, payload: dict) -> StepResult:
|
| 1084 |
+
"""Parse JSON to observation"""
|
| 1085 |
+
return StepResult(
|
| 1086 |
+
observation=YourObservation(...),
|
| 1087 |
+
reward=payload['reward'],
|
| 1088 |
+
done=payload['done']
|
| 1089 |
+
)
|
| 1090 |
+
|
| 1091 |
+
def _parse_state(self, payload: dict) -> YourState:
|
| 1092 |
+
return YourState(...)
|
| 1093 |
+
```
|
| 1094 |
+
|
| 1095 |
+
### Step 4: Create Server (`server/app.py`)
|
| 1096 |
+
|
| 1097 |
+
```python
|
| 1098 |
+
from core.env_server import create_fastapi_app
|
| 1099 |
+
from .your_environment import YourEnvironment
|
| 1100 |
+
|
| 1101 |
+
env = YourEnvironment()
|
| 1102 |
+
app = create_fastapi_app(env)
|
| 1103 |
+
|
| 1104 |
+
# That's it! OpenEnv creates all endpoints for you.
|
| 1105 |
+
```
|
| 1106 |
+
|
| 1107 |
+
### Step 5: Dockerize (`server/Dockerfile`)
|
| 1108 |
+
|
| 1109 |
+
```dockerfile
|
| 1110 |
+
FROM python:3.11-slim
|
| 1111 |
+
|
| 1112 |
+
WORKDIR /app
|
| 1113 |
+
COPY requirements.txt .
|
| 1114 |
+
RUN pip install --no-cache-dir -r requirements.txt
|
| 1115 |
+
|
| 1116 |
+
COPY . .
|
| 1117 |
+
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
|
| 1118 |
+
```
|
| 1119 |
+
|
| 1120 |
+
### 🎓 Examples to Study
|
| 1121 |
+
|
| 1122 |
+
OpenEnv includes 3 complete examples:
|
| 1123 |
+
|
| 1124 |
+
1. **`src/envs/echo_env/`**
|
| 1125 |
+
- Simplest possible environment
|
| 1126 |
+
- Great for testing and learning
|
| 1127 |
+
|
| 1128 |
+
2. **`src/envs/openspiel_env/`**
|
| 1129 |
+
- Wraps external library (OpenSpiel)
|
| 1130 |
+
- Shows integration pattern
|
| 1131 |
+
- 6 games in one integration
|
| 1132 |
+
|
| 1133 |
+
3. **`src/envs/coding_env/`**
|
| 1134 |
+
- Python code execution environment
|
| 1135 |
+
- Shows complex use case
|
| 1136 |
+
- Security considerations
|
| 1137 |
+
|
| 1138 |
+
**💡 Study these to understand the patterns!**
|
| 1139 |
+
|
| 1140 |
+
---
|
| 1141 |
+
|
| 1142 |
+
## 🎓 Summary: Your Journey
|
| 1143 |
+
|
| 1144 |
+
### What You Learned
|
| 1145 |
+
|
| 1146 |
+
<table>
|
| 1147 |
+
<tr>
|
| 1148 |
+
<td width="50%" style="vertical-align: top;">
|
| 1149 |
+
|
| 1150 |
+
### 📚 Concepts
|
| 1151 |
+
|
| 1152 |
+
✅ **RL Fundamentals**
|
| 1153 |
+
|
| 1154 |
+
- The observe-act-reward loop
|
| 1155 |
+
- What makes good policies
|
| 1156 |
+
- Exploration vs exploitation
|
| 1157 |
+
|
| 1158 |
+
✅ **OpenEnv Architecture**
|
| 1159 |
+
|
| 1160 |
+
- Client-server separation
|
| 1161 |
+
- Type-safe contracts
|
| 1162 |
+
- HTTP communication layer
|
| 1163 |
+
|
| 1164 |
+
✅ **Production Patterns**
|
| 1165 |
+
|
| 1166 |
+
- Docker isolation
|
| 1167 |
+
- API design
|
| 1168 |
+
- Reproducible deployments
|
| 1169 |
+
|
| 1170 |
+
</td>
|
| 1171 |
+
<td width="50%" style="vertical-align: top;">
|
| 1172 |
+
|
| 1173 |
+
### 🛠️ Skills
|
| 1174 |
+
|
| 1175 |
+
✅ **Using Environments**
|
| 1176 |
+
|
| 1177 |
+
- Import OpenEnv clients
|
| 1178 |
+
- Call reset/step/state
|
| 1179 |
+
- Work with typed observations
|
| 1180 |
+
|
| 1181 |
+
✅ **Building Environments**
|
| 1182 |
+
|
| 1183 |
+
- Define type-safe models
|
| 1184 |
+
- Implement Environment class
|
| 1185 |
+
- Create HTTPEnvClient
|
| 1186 |
+
|
| 1187 |
+
✅ **Testing & Debugging**
|
| 1188 |
+
|
| 1189 |
+
- Compare policies
|
| 1190 |
+
- Visualize episodes
|
| 1191 |
+
- Measure performance
|
| 1192 |
+
|
| 1193 |
+
</td>
|
| 1194 |
+
</tr>
|
| 1195 |
+
</table>
|
| 1196 |
+
|
| 1197 |
+
### OpenEnv vs Traditional RL
|
| 1198 |
+
|
| 1199 |
+
| Feature | Traditional (Gym) | OpenEnv | Winner |
|
| 1200 |
+
|---------|------------------|---------|--------|
|
| 1201 |
+
| **Type Safety** | ❌ Arrays, dicts | ✅ Dataclasses | 🏆 OpenEnv |
|
| 1202 |
+
| **Isolation** | ❌ Same process | ✅ Docker | 🏆 OpenEnv |
|
| 1203 |
+
| **Deployment** | ❌ Manual setup | ✅ K8s-ready | 🏆 OpenEnv |
|
| 1204 |
+
| **Language** | ❌ Python only | ✅ Any (HTTP) | 🏆 OpenEnv |
|
| 1205 |
+
| **Reproducibility** | ❌ "Works on my machine" | ✅ Same everywhere | 🏆 OpenEnv |
|
| 1206 |
+
| **Community** | ✅ Large ecosystem | 🟡 Growing | 🤝 Both! |
|
| 1207 |
+
|
| 1208 |
+
!!! success "The Bottom Line"
|
| 1209 |
+
OpenEnv brings **production engineering** to RL:
|
| 1210 |
+
|
| 1211 |
+
- Same environments work locally and in production
|
| 1212 |
+
- Type safety catches bugs early
|
| 1213 |
+
- Docker isolation prevents conflicts
|
| 1214 |
+
- HTTP API works with any language
|
| 1215 |
+
|
| 1216 |
+
**It's RL for 2024 and beyond.**
|
| 1217 |
+
|
| 1218 |
+
---
|
| 1219 |
+
|
| 1220 |
+
## 📚 Resources
|
| 1221 |
+
|
| 1222 |
+
### 🔗 Essential Links
|
| 1223 |
+
|
| 1224 |
+
- **🏠 OpenEnv GitHub**: https://github.com/meta-pytorch/OpenEnv
|
| 1225 |
+
- **🎮 OpenSpiel**: https://github.com/google-deepmind/open_spiel
|
| 1226 |
+
- **⚡ FastAPI Docs**: https://fastapi.tiangolo.com/
|
| 1227 |
+
- **🐳 Docker Guide**: https://docs.docker.com/get-started/
|
| 1228 |
+
- **🔥 PyTorch**: https://pytorch.org/
|
| 1229 |
+
|
| 1230 |
+
### 📖 Documentation Deep Dives
|
| 1231 |
+
|
| 1232 |
+
- **Environment Creation Guide**: `src/envs/README.md`
|
| 1233 |
+
- **OpenSpiel Integration**: `src/envs/openspiel_env/README.md`
|
| 1234 |
+
- **Example Scripts**: `examples/`
|
| 1235 |
+
- **RFC 001**: [Baseline API Specs](https://github.com/meta-pytorch/OpenEnv/pull/26)
|
| 1236 |
+
|
| 1237 |
+
### 🎓 Community & Support
|
| 1238 |
+
|
| 1239 |
+
**Supported by amazing organizations:**
|
| 1240 |
+
|
| 1241 |
+
- 🔥 Meta PyTorch
|
| 1242 |
+
- 🤗 Hugging Face
|
| 1243 |
+
- ⚡ Unsloth AI
|
| 1244 |
+
- 🌟 Reflection AI
|
| 1245 |
+
- 🚀 And many more!
|
| 1246 |
+
|
| 1247 |
+
**License**: BSD 3-Clause (very permissive!)
|
| 1248 |
+
|
| 1249 |
+
**Contributions**: Always welcome! Check out the issues tab.
|
| 1250 |
+
|
| 1251 |
+
---
|
| 1252 |
+
|
| 1253 |
+
### 🌈 What's Next?
|
| 1254 |
+
|
| 1255 |
+
1. ⭐ **Star the repo** to show support and stay updated
|
| 1256 |
+
2. 🔄 **Try modifying** the Catch game (make it harder? bigger grid?)
|
| 1257 |
+
3. 🎮 **Explore** other OpenSpiel games
|
| 1258 |
+
4. 🛠️ **Build** your own environment integration
|
| 1259 |
+
5. 💬 **Share** what you build with the community!
|
tutorial/tutorial2.md
ADDED
|
@@ -0,0 +1,427 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 2. Deploying an OpenEnv environment
|
| 2 |
+
|
| 3 |
+
This section covers deploying OpenEnv environments locally, on clusters, and on Hugging Face Spaces.
|
| 4 |
+
|
| 5 |
+
**Contents:**
|
| 6 |
+
- [Local Development with Uvicorn](#local-development-with-uvicorn)
|
| 7 |
+
- [Docker Deployment](#docker-deployment)
|
| 8 |
+
- [Hugging Face Spaces](#hugging-face-spaces)
|
| 9 |
+
- [Best Practices](#best-practices)
|
| 10 |
+
|
| 11 |
+
## HF Spaces are the infrastructure for OpenEnv environments
|
| 12 |
+
|
| 13 |
+
Every HF Space provides three things that OpenEnv environments need:
|
| 14 |
+
|
| 15 |
+
| Component | What it provides | How to access | Used as |
|
| 16 |
+
|-----------|------------------|---------------|-----------|
|
| 17 |
+
| **Server** | Running environment endpoint | `https://<username>-<space-name>.hf.space` | Agent and Public API |
|
| 18 |
+
| **Repository** | Installable Python package | `pip install git+https://huggingface.co/spaces/<username>-<space-name>` | Code and client |
|
| 19 |
+
| **Registry** | Docker container image | `docker pull registry.hf.space/<username>-<space-name>:latest` | Deployment |
|
| 20 |
+
|
| 21 |
+
This means a single Space deployment gives you all the components you need to use an environment in training.
|
| 22 |
+
|
| 23 |
+
### 1. Server: A running environment endpoint
|
| 24 |
+
|
| 25 |
+
When you deploy to HF Spaces, your environment runs as a server. The client connects via **WebSocket** (`/ws`) for a persistent session:
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
from echo_env import EchoEnv, EchoAction
|
| 29 |
+
|
| 30 |
+
# Connect directly to the running Space (WebSocket under the hood)
|
| 31 |
+
# Async (recommended):
|
| 32 |
+
async with EchoEnv(base_url="https://openenv-echo-env.hf.space") as client:
|
| 33 |
+
result = await client.reset()
|
| 34 |
+
result = await client.step(EchoAction(message="Hello"))
|
| 35 |
+
|
| 36 |
+
# Sync (using .sync() wrapper):
|
| 37 |
+
with EchoEnv(base_url="https://openenv-echo-env.hf.space").sync() as client:
|
| 38 |
+
result = client.reset()
|
| 39 |
+
result = client.step(EchoAction(message="Hello"))
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
**Endpoints available:**
|
| 43 |
+
|
| 44 |
+
| Endpoint | Protocol | Description |
|
| 45 |
+
|----------|----------|-------------|
|
| 46 |
+
| `/ws` | **WebSocket** | Persistent session (used by client) |
|
| 47 |
+
| `/health` | HTTP GET | Health check |
|
| 48 |
+
| `/reset` | HTTP POST | Reset environment (stateless) |
|
| 49 |
+
| `/step` | HTTP POST | Execute action (stateless) |
|
| 50 |
+
| `/state` | HTTP GET | Get current state |
|
| 51 |
+
| `/docs` | HTTP GET | OpenAPI documentation |
|
| 52 |
+
| `/web` | HTTP GET | Interactive web UI |
|
| 53 |
+
|
| 54 |
+
> **Note:** The Python client uses the `/ws` WebSocket endpoint by default. HTTP endpoints are available for debugging or stateless use cases.
|
| 55 |
+
|
| 56 |
+
**Example: Check if a Space is running**
|
| 57 |
+
|
| 58 |
+
```bash
|
| 59 |
+
curl https://openenv-echo-env.hf.space/health
|
| 60 |
+
# {"status": "healthy"}
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
### 2. Repository: Installable Python package
|
| 64 |
+
|
| 65 |
+
Every Space is a Git repository. OpenEnv environments include a `pyproject.toml`, making them pip-installable directly from the Space URL.
|
| 66 |
+
|
| 67 |
+
```bash
|
| 68 |
+
# Install client package from Space
|
| 69 |
+
pip install git+https://huggingface.co/spaces/openenv/echo-env
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
This installs:
|
| 73 |
+
- **Client class** (`EchoEnv`) — Handles HTTP/WebSocket communication
|
| 74 |
+
- **Models** (`EchoAction`, `EchoObservation`) — Typed action and observation classes
|
| 75 |
+
- **Utilities** — Any helper functions the environment provides
|
| 76 |
+
|
| 77 |
+
**After installation:**
|
| 78 |
+
|
| 79 |
+
```python
|
| 80 |
+
from envs.echo_env import EchoEnv, EchoAction, EchoObservation
|
| 81 |
+
|
| 82 |
+
# Now you have typed classes for the environment
|
| 83 |
+
action = EchoAction(message="Hello")
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
### 3. Registry: Docker container image
|
| 87 |
+
|
| 88 |
+
Every Docker-based Space has a container registry. You can pull and run the environment locally.
|
| 89 |
+
|
| 90 |
+
```bash
|
| 91 |
+
# Pull the image
|
| 92 |
+
docker pull registry.hf.space/openenv-echo-env:latest
|
| 93 |
+
|
| 94 |
+
# Run locally on port 8001
|
| 95 |
+
docker run -d -p 8001:8000 registry.hf.space/openenv-echo-env:latest
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
**Find the registry URL for any Space:**
|
| 99 |
+
|
| 100 |
+
1. Go to the Space page (e.g., [openenv/echo-env](https://huggingface.co/spaces/openenv/echo-env))
|
| 101 |
+
2. Click **⋮** (three dots) → **"Run locally"**
|
| 102 |
+
3. Copy the `docker run` command
|
| 103 |
+
|
| 104 |
+
### Choosing an access method
|
| 105 |
+
|
| 106 |
+
| Method | Use when | Pros | Cons |
|
| 107 |
+
|--------|----------|------|------|
|
| 108 |
+
| **Server** | Quick testing, low volume | Zero setup | Network latency, rate limits |
|
| 109 |
+
| **Repository** | Need typed classes | Type safety, IDE support | Still need a server |
|
| 110 |
+
| **Docker** | Local dev, high throughput | Full control, no network | Requires Docker |
|
| 111 |
+
|
| 112 |
+
**Typical workflow:**
|
| 113 |
+
|
| 114 |
+
```python
|
| 115 |
+
import asyncio
|
| 116 |
+
from echo_env import EchoEnv, EchoAction
|
| 117 |
+
|
| 118 |
+
async def main():
|
| 119 |
+
# Development: connect to remote Space
|
| 120 |
+
async with EchoEnv(base_url="https://openenv-echo-env.hf.space") as client:
|
| 121 |
+
result = await client.reset()
|
| 122 |
+
|
| 123 |
+
# Production: run locally for speed
|
| 124 |
+
# docker run -d -p 8001:8000 registry.hf.space/openenv-echo-env:latest
|
| 125 |
+
async with EchoEnv(base_url="http://localhost:8001") as client:
|
| 126 |
+
result = await client.reset()
|
| 127 |
+
|
| 128 |
+
# Or let the client manage Docker for you
|
| 129 |
+
client = await EchoEnv.from_env("openenv/echo-env") # Auto-pulls and runs
|
| 130 |
+
async with client:
|
| 131 |
+
result = await client.reset()
|
| 132 |
+
|
| 133 |
+
asyncio.run(main())
|
| 134 |
+
|
| 135 |
+
# For sync usage, use the .sync() wrapper:
|
| 136 |
+
with EchoEnv(base_url="http://localhost:8001").sync() as client:
|
| 137 |
+
result = client.reset()
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
> **Reference:** [HF Spaces Documentation](https://huggingface.co/docs/hub/spaces) | [Environment Hub Collection](https://huggingface.co/collections/openenv/environment-hub)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
## Local Development with Uvicorn
|
| 144 |
+
|
| 145 |
+
The fastest way to iterate on environment logic is running directly with Uvicorn.
|
| 146 |
+
|
| 147 |
+
## Clone and run the environment locally
|
| 148 |
+
|
| 149 |
+
```bash
|
| 150 |
+
# Clone from HF Space
|
| 151 |
+
git clone https://huggingface.co/spaces/burtenshaw/openenv-benchmark
|
| 152 |
+
cd openenv-benchmark
|
| 153 |
+
|
| 154 |
+
# Install in editable mode
|
| 155 |
+
uv sync
|
| 156 |
+
|
| 157 |
+
# Start server
|
| 158 |
+
uv run server
|
| 159 |
+
|
| 160 |
+
# Run isolated from remote Space
|
| 161 |
+
uv run --isolated --project https://huggingface.co/spaces/burtenshaw/openenv-benchmark server
|
| 162 |
+
```
|
| 163 |
+
|
| 164 |
+
## Uvicorn directly in python
|
| 165 |
+
|
| 166 |
+
```bash
|
| 167 |
+
# Full control over uvicorn options
|
| 168 |
+
uvicorn benchmark.server.app:app --host "$HOST" --port "$PORT" --workers "$WORKERS"
|
| 169 |
+
|
| 170 |
+
# With reload for development
|
| 171 |
+
uvicorn benchmark.server.app:app --host 0.0.0.0 --port 8000 --reload
|
| 172 |
+
|
| 173 |
+
# Multi-Worker Mode For better concurrency:
|
| 174 |
+
uvicorn benchmark.server.app:app --host 0.0.0.0 --port 8000 --workers 4
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
| Flag | Purpose |
|
| 178 |
+
|------|---------|
|
| 179 |
+
| `--reload` | Auto-restart on code changes |
|
| 180 |
+
| `--workers N` | Run N worker processes |
|
| 181 |
+
| `--log-level debug` | Verbose logging |
|
| 182 |
+
|
| 183 |
+
## Docker Deployment
|
| 184 |
+
|
| 185 |
+
Docker provides isolation and reproducibility for production use.
|
| 186 |
+
|
| 187 |
+
### Run the environment locally from the space
|
| 188 |
+
|
| 189 |
+
```bash
|
| 190 |
+
# Run the environment locally from the space
|
| 191 |
+
docker run -d -p 8000:8000 registry.hf.space/openenv-echo-env:latest
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
### Build Image
|
| 195 |
+
|
| 196 |
+
```bash
|
| 197 |
+
# Clone from HF Space
|
| 198 |
+
git clone https://huggingface.co/spaces/burtenshaw/openenv-benchmark
|
| 199 |
+
cd openenv-benchmark
|
| 200 |
+
|
| 201 |
+
# Using OpenEnv CLI (recommended)
|
| 202 |
+
openenv build -t openenv-benchmark:latest
|
| 203 |
+
|
| 204 |
+
# Or with Docker directly
|
| 205 |
+
docker build -t openenv-benchmark:latest -f server/Dockerfile .
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
### Run Container
|
| 209 |
+
|
| 210 |
+
```bash
|
| 211 |
+
# Basic run
|
| 212 |
+
docker run -d -p 8000:8000 my-env:latest
|
| 213 |
+
|
| 214 |
+
# With environment variables
|
| 215 |
+
docker run -d -p 8000:8000 \
|
| 216 |
+
-e WORKERS=4 \
|
| 217 |
+
-e MAX_CONCURRENT_ENVS=100 \
|
| 218 |
+
my-env:latest
|
| 219 |
+
|
| 220 |
+
# Named container for easy management
|
| 221 |
+
docker run -d --name my-env -p 8000:8000 my-env:latest
|
| 222 |
+
```
|
| 223 |
+
|
| 224 |
+
### Connect from Python
|
| 225 |
+
|
| 226 |
+
```python
|
| 227 |
+
import asyncio
|
| 228 |
+
from echo_env import EchoEnv, EchoAction
|
| 229 |
+
|
| 230 |
+
async def main():
|
| 231 |
+
# Async usage (recommended)
|
| 232 |
+
async with EchoEnv(base_url="http://localhost:8000") as client:
|
| 233 |
+
result = await client.reset()
|
| 234 |
+
result = await client.step(EchoAction(message="Hello"))
|
| 235 |
+
print(result.observation)
|
| 236 |
+
|
| 237 |
+
# From Docker image
|
| 238 |
+
client = await EchoEnv.from_docker_image("<local_docker_image>")
|
| 239 |
+
async with client:
|
| 240 |
+
result = await client.reset()
|
| 241 |
+
print(result.observation)
|
| 242 |
+
|
| 243 |
+
asyncio.run(main())
|
| 244 |
+
|
| 245 |
+
# Sync usage (using .sync() wrapper)
|
| 246 |
+
with EchoEnv(base_url="http://localhost:8000").sync() as client:
|
| 247 |
+
result = client.reset()
|
| 248 |
+
result = client.step(EchoAction(message="Hello"))
|
| 249 |
+
print(result.observation)
|
| 250 |
+
```
|
| 251 |
+
|
| 252 |
+
### Container Lifecycle
|
| 253 |
+
|
| 254 |
+
| Method | Container | WebSocket | On `close()` |
|
| 255 |
+
|--------|-----------|-----------|--------------|
|
| 256 |
+
| `from_hub(repo_id)` | Starts | Connects | Stops container |
|
| 257 |
+
| `from_hub(repo_id, use_docker=False)` | None (UV) | Connects | Stops UV server |
|
| 258 |
+
| `from_docker_image(image)` | Starts | Connects | Stops container |
|
| 259 |
+
| `MyEnv(base_url=...)` | None | Connects | Disconnects only |
|
| 260 |
+
|
| 261 |
+
Find Docker Commands for Any Space
|
| 262 |
+
|
| 263 |
+
1. Open the Space on HuggingFace Hub
|
| 264 |
+
2. Click **⋮ (three dots)** menu
|
| 265 |
+
3. Select **"Run locally"**
|
| 266 |
+
4. Copy the provided `docker run` command
|
| 267 |
+
|
| 268 |
+
## Deploy with CLI
|
| 269 |
+
|
| 270 |
+
```bash
|
| 271 |
+
cd my_env
|
| 272 |
+
|
| 273 |
+
# Deploy to your namespace
|
| 274 |
+
openenv push
|
| 275 |
+
|
| 276 |
+
# Deploy to specific repo
|
| 277 |
+
openenv push --repo-id username/my-env
|
| 278 |
+
|
| 279 |
+
# Deploy as private
|
| 280 |
+
openenv push --repo-id username/my-env --private
|
| 281 |
+
```
|
| 282 |
+
|
| 283 |
+
### Space Configuration
|
| 284 |
+
|
| 285 |
+
The `openenv.yaml` manifest controls Space settings:
|
| 286 |
+
|
| 287 |
+
```yaml
|
| 288 |
+
# openenv.yaml
|
| 289 |
+
name: my_env
|
| 290 |
+
version: "1.0.0"
|
| 291 |
+
description: My custom environment
|
| 292 |
+
```
|
| 293 |
+
|
| 294 |
+
Hardware Options:
|
| 295 |
+
|
| 296 |
+
| Tier | vCPU | RAM | Cost |
|
| 297 |
+
|------|------|-----|------|
|
| 298 |
+
| CPU Basic (Free) | 2 | 16GB | Free |
|
| 299 |
+
| CPU Upgrade | 8 | 32GB | $0.03/hr |
|
| 300 |
+
|
| 301 |
+
OpenEnv environments support configuration via environment variables.
|
| 302 |
+
|
| 303 |
+
| Variable | Default | Description |
|
| 304 |
+
|----------|---------|-------------|
|
| 305 |
+
| `WORKERS` | 4 | Uvicorn worker processes |
|
| 306 |
+
| `PORT` | 8000 | Server port |
|
| 307 |
+
| `HOST` | 0.0.0.0 | Bind address |
|
| 308 |
+
| `MAX_CONCURRENT_ENVS` | 100 | Max WebSocket sessions |
|
| 309 |
+
| `ENABLE_WEB_INTERFACE` | Auto | Enable web UI |
|
| 310 |
+
|
| 311 |
+
### Environment-Specific Variables
|
| 312 |
+
|
| 313 |
+
Some environments have custom variables:
|
| 314 |
+
|
| 315 |
+
**TextArena:**
|
| 316 |
+
```bash
|
| 317 |
+
TEXTARENA_ENV_ID=Wordle-v0
|
| 318 |
+
TEXTARENA_NUM_PLAYERS=1
|
| 319 |
+
TEXTARENA_MAX_TURNS=6
|
| 320 |
+
```
|
| 321 |
+
|
| 322 |
+
**Coding Environment:**
|
| 323 |
+
```bash
|
| 324 |
+
SANDBOX_TIMEOUT=30
|
| 325 |
+
MAX_OUTPUT_LENGTH=10000
|
| 326 |
+
```
|
| 327 |
+
|
| 328 |
+
# DEMO: Deploying to Hugging Face Spaces
|
| 329 |
+
|
| 330 |
+
This demo walks through the full workflow: create an environment, test locally, deploy to HF Spaces, and use it.
|
| 331 |
+
|
| 332 |
+
## Step 1: Initialize a new environment
|
| 333 |
+
|
| 334 |
+
```bash
|
| 335 |
+
openenv init my_env
|
| 336 |
+
cd my_env
|
| 337 |
+
```
|
| 338 |
+
|
| 339 |
+
This creates the standard OpenEnv structure:
|
| 340 |
+
|
| 341 |
+
```
|
| 342 |
+
my_env/
|
| 343 |
+
├── server/
|
| 344 |
+
│ ├── app.py # FastAPI server
|
| 345 |
+
│ ├── environment.py # Your environment logic
|
| 346 |
+
│ └── Dockerfile
|
| 347 |
+
├── models.py # Action/Observation types
|
| 348 |
+
├── client.py # HTTP client
|
| 349 |
+
├── openenv.yaml # Manifest
|
| 350 |
+
└── pyproject.toml
|
| 351 |
+
```
|
| 352 |
+
|
| 353 |
+
## Step 2: Run locally
|
| 354 |
+
|
| 355 |
+
```bash
|
| 356 |
+
# Start the server
|
| 357 |
+
uv run server
|
| 358 |
+
|
| 359 |
+
# Or with uvicorn directly
|
| 360 |
+
uvicorn server.app:app --host 0.0.0.0 --port 8000 --reload
|
| 361 |
+
```
|
| 362 |
+
|
| 363 |
+
Test the health endpoint:
|
| 364 |
+
|
| 365 |
+
```bash
|
| 366 |
+
curl http://localhost:8000/health
|
| 367 |
+
# {"status": "healthy"}
|
| 368 |
+
```
|
| 369 |
+
|
| 370 |
+
## Step 3: Deploy to HF Spaces
|
| 371 |
+
|
| 372 |
+
```bash
|
| 373 |
+
openenv push --repo-id username/my-env
|
| 374 |
+
```
|
| 375 |
+
|
| 376 |
+
Your environment is now live at:
|
| 377 |
+
- Web UI: https://username-my-env.hf.space/web
|
| 378 |
+
- API Docs: https://username-my-env.hf.space/docs
|
| 379 |
+
- Health: https://username-my-env.hf.space/health
|
| 380 |
+
|
| 381 |
+
```bash
|
| 382 |
+
curl https://openenv-echo-env.hf.space/health
|
| 383 |
+
# {"status": "healthy"}
|
| 384 |
+
```
|
| 385 |
+
|
| 386 |
+
## Step 4: install the environment
|
| 387 |
+
|
| 388 |
+
```bash
|
| 389 |
+
uv pip install git+https://huggingface.co/spaces/openenv/echo_env
|
| 390 |
+
```
|
| 391 |
+
|
| 392 |
+
## Step 5: Run locally via Docker (optional)
|
| 393 |
+
|
| 394 |
+
Pull and run the container from the HF registry, or open the [browser](https://huggingface.co/spaces/openenv/echo_env?docker=true):
|
| 395 |
+
|
| 396 |
+
```bash
|
| 397 |
+
# Pull from HF Spaces registry
|
| 398 |
+
docker pull registry.hf.space/openenv-echo-env:latest
|
| 399 |
+
|
| 400 |
+
# Run locally
|
| 401 |
+
docker run -it -p 7860:7860 --platform=linux/amd64 \
|
| 402 |
+
registry.hf.space/openenv-echo-env:latest
|
| 403 |
+
```
|
| 404 |
+
|
| 405 |
+
Now connect to your local instance:
|
| 406 |
+
|
| 407 |
+
```python
|
| 408 |
+
import asyncio
|
| 409 |
+
from echo_env import EchoEnv, EchoAction
|
| 410 |
+
|
| 411 |
+
# Async (recommended)
|
| 412 |
+
async def main():
|
| 413 |
+
async with EchoEnv(base_url="http://localhost:8000") as env:
|
| 414 |
+
result = await env.reset()
|
| 415 |
+
print(result.observation)
|
| 416 |
+
result = await env.step(EchoAction(message="Hello"))
|
| 417 |
+
print(result.observation)
|
| 418 |
+
|
| 419 |
+
asyncio.run(main())
|
| 420 |
+
|
| 421 |
+
# Sync (using .sync() wrapper)
|
| 422 |
+
with EchoEnv(base_url="http://localhost:8000").sync() as env:
|
| 423 |
+
result = env.reset()
|
| 424 |
+
print(result.observation)
|
| 425 |
+
result = env.step(EchoAction(message="Hello"))
|
| 426 |
+
print(result.observation)
|
| 427 |
+
```
|
tutorial/tutorial3.md
ADDED
|
@@ -0,0 +1,457 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 3. How OpenEnv environments scale
|
| 2 |
+
|
| 3 |
+
This section covers benchmarking and scaling OpenEnv environments.
|
| 4 |
+
|
| 5 |
+
**Contents:**
|
| 6 |
+
- [Provider Scaling](#provider-scaling)
|
| 7 |
+
- [WebSocket-based Scaling](#websocket-based-scaling)
|
| 8 |
+
- [Microservice Scaling](#microservice-scaling)
|
| 9 |
+
- [Scaling Experiments](#scaling-experiments)
|
| 10 |
+
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
## Provider Scaling
|
| 14 |
+
|
| 15 |
+
The easiest way to scale an OpenEnv environment is to use a `provider` these are abstractions based on runtimes like Uvicorn, Docker Swarm, or Kubernetes.
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
from openenv.providers import UVProvider, DockerSwarmProvider, LocalDockerProvider
|
| 19 |
+
|
| 20 |
+
docker_provider = LocalDockerProvider() # default
|
| 21 |
+
uvicorn_provider = UVProvider() # python only
|
| 22 |
+
swarm_provider = DockerSwarmProvider()
|
| 23 |
+
|
| 24 |
+
with EchoEnv.from_hub(
|
| 25 |
+
repo_id="openenv/echo-env",
|
| 26 |
+
provider=swarm_provider,
|
| 27 |
+
replicas=4,
|
| 28 |
+
) as env:
|
| 29 |
+
result = env.reset()
|
| 30 |
+
result = env.step(EchoAction(message="Hello"))
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
## WebSocket-based Scaling
|
| 34 |
+
|
| 35 |
+
OpenEnv uses WebSocket connections (`/ws`) instead of stateless HTTP for environment interactions. This design enables efficient scaling within a single container.
|
| 36 |
+
|
| 37 |
+
### What are WebSockets?
|
| 38 |
+
|
| 39 |
+
WebSocket is a communication protocol that provides a persistent, bidirectional connection between client and server. Unlike HTTP—where each request opens a new connection, sends data, receives a response, and closes—a WebSocket connection stays open for the duration of a session.
|
| 40 |
+
|
| 41 |
+

|
| 42 |
+
|
| 43 |
+
For RL environments, this matters because a typical episode involves dozens to thousands of sequential `step()` calls. With HTTP, each step incurs TCP handshake overhead (~10-50ms). With WebSocket, messages are sent as lightweight frames (~0.1ms overhead) over the existing connection.
|
| 44 |
+
|
| 45 |
+
Also, with HTTP, long running sessions require logic to manage session state, which is not necessary with WebSocket.
|
| 46 |
+
|
| 47 |
+
### Multiple sessions per container
|
| 48 |
+
|
| 49 |
+
With HTTP, maintaining session state requires cookies or session IDs with every request. Each isolated environment instance typically needs its own container:
|
| 50 |
+
|
| 51 |
+
```
|
| 52 |
+
HTTP approach: N parallel episodes → N containers
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
> [!NOTE]
|
| 56 |
+
> This is completely fine (and ideal) for larger deployments where containers can be scaled. But if your resources are constrained, this add loads of overhead.
|
| 57 |
+
|
| 58 |
+
With WebSocket, **one container handles many isolated sessions**. Each WebSocket connection gets its own environment instance server-side:
|
| 59 |
+
|
| 60 |
+
```python
|
| 61 |
+
# Single container serving multiple concurrent sessions
|
| 62 |
+
# docker run -d -p 8000:8000 my-env:latest
|
| 63 |
+
|
| 64 |
+
# Each client gets an isolated environment instance
|
| 65 |
+
with MyEnv(base_url="http://localhost:8000") as env1: # Session 1
|
| 66 |
+
result = env1.reset()
|
| 67 |
+
|
| 68 |
+
with MyEnv(base_url="http://localhost:8000") as env2: # Session 2
|
| 69 |
+
result = env2.reset()
|
| 70 |
+
|
| 71 |
+
with MyEnv(base_url="http://localhost:8000") as env3: # Session 3
|
| 72 |
+
result = env3.reset()
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
> [!NOTE]
|
| 76 |
+
> This has its own advantages and disadvantages. For example: Separation of concerns and fault tolerance in environments like coding or terminal.
|
| 77 |
+
|
| 78 |
+
### Server-side session state
|
| 79 |
+
|
| 80 |
+
The server maintains environment state per WebSocket connection which means that the environment builder does not need to worry about session state.
|
| 81 |
+
|
| 82 |
+
- No session IDs because Connection itself is the session
|
| 83 |
+
- Automatic cleanup because Environment instance destroyed when connection closes
|
| 84 |
+
- Isolation guaranteed because Each connection has dedicated state
|
| 85 |
+
|
| 86 |
+
```python
|
| 87 |
+
# Server creates new environment instance per WebSocket connection
|
| 88 |
+
@app.websocket("/ws")
|
| 89 |
+
async def websocket_endpoint(websocket: WebSocket):
|
| 90 |
+
env = MyEnvironment() # Fresh instance per connection
|
| 91 |
+
await websocket.accept()
|
| 92 |
+
|
| 93 |
+
while True:
|
| 94 |
+
data = await websocket.receive_json()
|
| 95 |
+
if data["type"] == "reset":
|
| 96 |
+
result = env.reset()
|
| 97 |
+
elif data["type"] == "step":
|
| 98 |
+
result = env.step(data["action"])
|
| 99 |
+
await websocket.send_json(result)
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
### Resource efficiency
|
| 103 |
+
|
| 104 |
+
| Approach | Containers | Memory | Startup | Max parallel |
|
| 105 |
+
|----------|------------|--------|---------|--------------|
|
| 106 |
+
| HTTP (1 env = 1 container) | N | N × ~100MB | N × ~5s | Limited by containers |
|
| 107 |
+
| WebSocket (N sessions = 1 container) | 1 | ~200MB | ~5s | Limited by `MAX_CONCURRENT_ENVS` |
|
| 108 |
+
|
| 109 |
+
Configure session limits via environment variable:
|
| 110 |
+
|
| 111 |
+
```bash
|
| 112 |
+
docker run -d -p 8000:8000 -e MAX_CONCURRENT_ENVS=100 registry.hf.space/openenv-echo-env:latest
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
## Scaling a Single Container
|
| 116 |
+
|
| 117 |
+
Before adding more containers, maximize the capacity of a single deployment. The key parameters are **workers** (CPU parallelism) and **MAX_CONCURRENT_ENVS** (session limit).
|
| 118 |
+
|
| 119 |
+
### Uvicorn workers
|
| 120 |
+
|
| 121 |
+
Each Uvicorn worker is a separate process that can handle requests independently. More workers = more CPU cores utilized.
|
| 122 |
+
|
| 123 |
+
```bash
|
| 124 |
+
# Clone and run locally
|
| 125 |
+
git clone https://huggingface.co/spaces/burtenshaw/openenv-benchmark
|
| 126 |
+
cd openenv-benchmark
|
| 127 |
+
pip install -e .
|
| 128 |
+
|
| 129 |
+
# Run with 8 workers
|
| 130 |
+
WORKERS=8 uvicorn benchmark.server.app:app --host 0.0.0.0 --port 8000 --workers 8
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
The above example will use 8 workers and each worker will be able to handle 100 concurrent sessions. **For simple environments, like text games, it's possible to get to 2000 concurrent sessions with 8 workers.**
|
| 134 |
+
|
| 135 |
+
> **Note:** More workers consume more memory. Each worker loads a full copy of the environment code.
|
| 136 |
+
|
| 137 |
+
### Docker with environment variables
|
| 138 |
+
|
| 139 |
+
Pass scaling parameters when starting the container:
|
| 140 |
+
|
| 141 |
+
```bash
|
| 142 |
+
# Pull from HF Spaces registry
|
| 143 |
+
docker pull registry.hf.space/burtenshaw-openenv-benchmark:latest
|
| 144 |
+
|
| 145 |
+
# Run with custom configuration
|
| 146 |
+
docker run -d -p 8000:8000 \
|
| 147 |
+
-e WORKERS=8 \
|
| 148 |
+
-e MAX_CONCURRENT_ENVS=400 \
|
| 149 |
+
--name openenv-benchmark \
|
| 150 |
+
registry.hf.space/burtenshaw-openenv-benchmark:latest
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
| Variable | Default | Description |
|
| 154 |
+
|----------|---------|-------------|
|
| 155 |
+
| `WORKERS` | 4 | Uvicorn worker processes |
|
| 156 |
+
| `MAX_CONCURRENT_ENVS` | 100 | Max WebSocket sessions per worker |
|
| 157 |
+
| `PORT` | 8000 | Server port |
|
| 158 |
+
| `HOST` | 0.0.0.0 | Bind address |
|
| 159 |
+
|
| 160 |
+
### HF Spaces configuration
|
| 161 |
+
|
| 162 |
+
Now, let's deploy the environment to HF Spaces so that we can interact with the server from the client. Configure scaling via Space Settings > Variables:
|
| 163 |
+
|
| 164 |
+
1. Go to your Space settings page
|
| 165 |
+
2. Add environment variables:
|
| 166 |
+
- `WORKERS=4` (max 4 on free tier, 8 on CPU Upgrade)
|
| 167 |
+
- `MAX_CONCURRENT_ENVS=100`
|
| 168 |
+
3. Restart the Space
|
| 169 |
+
|
| 170 |
+
| Tier | vCPU | Recommended workers | Expected max batch (textarena) |
|
| 171 |
+
|------|------|--------------------|--------------------|
|
| 172 |
+
| CPU Basic (Free) | 2 | 2 | ~128 |
|
| 173 |
+
| CPU Upgrade | 8 | 4-8 | ~512 |
|
| 174 |
+
|
| 175 |
+
> **Limitation:** HF Spaces free users tier caps at ~128 concurrent sessions regardless of configuration. See [Scaling Experiments](#scaling-experiments) for measured limits.
|
| 176 |
+
|
| 177 |
+
### Scaling limits
|
| 178 |
+
|
| 179 |
+
The experiments below found that even on larger instances, a single container eventually fails to scale and we need multiple containers to handle the load. For example, on a CPU Upgrade instance with 8 workers, the max batch was 1024 concurrent sessions:
|
| 180 |
+
|
| 181 |
+
- Success rate drops to 92%
|
| 182 |
+
- P99 latency exceeds 2× the expected step time
|
| 183 |
+
- Connection errors increase under load
|
| 184 |
+
|
| 185 |
+
When this happens, we need to scale to multiple containers and use a load balancer.
|
| 186 |
+
|
| 187 |
+
For high-throughput workloads, scale horizontally by running multiple environment containers behind a load balancer.
|
| 188 |
+
|
| 189 |
+
| Scenario | Recommended approach |
|
| 190 |
+
|----------|---------------------|
|
| 191 |
+
| Development / testing | Single container with WebSocket sessions |
|
| 192 |
+
| Moderate load (< 100 concurrent) | Single container, increase `MAX_CONCURRENT_ENVS` |
|
| 193 |
+
| High load (100+ concurrent) | Multiple containers + load balancer |
|
| 194 |
+
| GPU environments | One container per GPU |
|
| 195 |
+
|
| 196 |
+
We explored this in detail in the [Scaling Experiments](https://github.com/burtenshaw/openenv-scaling) repository.
|
| 197 |
+
|
| 198 |
+
<details>
|
| 199 |
+
<summary>Envoy configuration</summary>
|
| 200 |
+
|
| 201 |
+
```yaml
|
| 202 |
+
static_resources:
|
| 203 |
+
listeners:
|
| 204 |
+
- name: listener_0
|
| 205 |
+
address:
|
| 206 |
+
socket_address:
|
| 207 |
+
address: 0.0.0.0
|
| 208 |
+
port_value: 8080
|
| 209 |
+
filter_chains:
|
| 210 |
+
- filters:
|
| 211 |
+
- name: envoy.filters.network.http_connection_manager
|
| 212 |
+
typed_config:
|
| 213 |
+
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
|
| 214 |
+
stat_prefix: ingress_http
|
| 215 |
+
upgrade_configs:
|
| 216 |
+
- upgrade_type: websocket
|
| 217 |
+
route_config:
|
| 218 |
+
name: local_route
|
| 219 |
+
virtual_hosts:
|
| 220 |
+
- name: openenv_service
|
| 221 |
+
domains: ["*"]
|
| 222 |
+
routes:
|
| 223 |
+
- match:
|
| 224 |
+
prefix: "/"
|
| 225 |
+
route:
|
| 226 |
+
cluster: openenv_cluster
|
| 227 |
+
http_filters:
|
| 228 |
+
- name: envoy.filters.http.router
|
| 229 |
+
typed_config:
|
| 230 |
+
"@type": type.googleapis.com/envoy.extensions.filters.http.router.v3.Router
|
| 231 |
+
|
| 232 |
+
clusters:
|
| 233 |
+
- name: openenv_cluster
|
| 234 |
+
connect_timeout: 30s
|
| 235 |
+
type: STRICT_DNS
|
| 236 |
+
lb_policy: ROUND_ROBIN
|
| 237 |
+
load_assignment:
|
| 238 |
+
cluster_name: openenv_cluster
|
| 239 |
+
endpoints:
|
| 240 |
+
- lb_endpoints:
|
| 241 |
+
- endpoint:
|
| 242 |
+
address:
|
| 243 |
+
socket_address:
|
| 244 |
+
address: host.docker.internal
|
| 245 |
+
port_value: 8001
|
| 246 |
+
- endpoint:
|
| 247 |
+
address:
|
| 248 |
+
socket_address:
|
| 249 |
+
address: host.docker.internal
|
| 250 |
+
port_value: 8002
|
| 251 |
+
- endpoint:
|
| 252 |
+
address:
|
| 253 |
+
socket_address:
|
| 254 |
+
address: host.docker.internal
|
| 255 |
+
port_value: 8003
|
| 256 |
+
- endpoint:
|
| 257 |
+
address:
|
| 258 |
+
socket_address:
|
| 259 |
+
address: host.docker.internal
|
| 260 |
+
port_value: 8004
|
| 261 |
+
```
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
Start Envoy:
|
| 265 |
+
|
| 266 |
+
```bash
|
| 267 |
+
docker run -d \
|
| 268 |
+
-p 8080:8080 \
|
| 269 |
+
-v $(pwd)/envoy.yaml:/etc/envoy/envoy.yaml \
|
| 270 |
+
--add-host=host.docker.internal:host-gateway \
|
| 271 |
+
envoyproxy/envoy:v1.28.0
|
| 272 |
+
```
|
| 273 |
+
|
| 274 |
+
Connect through the load balancer:
|
| 275 |
+
|
| 276 |
+
```python
|
| 277 |
+
# Clients connect to Envoy, which distributes to backend containers
|
| 278 |
+
with MyEnv(base_url="http://localhost:8080") as env:
|
| 279 |
+
result = env.reset()
|
| 280 |
+
```
|
| 281 |
+
|
| 282 |
+
</details>
|
| 283 |
+
|
| 284 |
+
### Scaling expectations
|
| 285 |
+
|
| 286 |
+

|
| 287 |
+
|
| 288 |
+
| Setup | Containers | Sessions/container | Total capacity | Throughput |
|
| 289 |
+
|-------|------------|-------------------|----------------|------------|
|
| 290 |
+
| Single | 1 | 100 | 100 | ~100 req/s |
|
| 291 |
+
| 4× containers | 4 | 100 | 400 | ~350 req/s |
|
| 292 |
+
| 8× containers | 8 | 100 | 800 | ~600 req/s |
|
| 293 |
+
|
| 294 |
+
> **Note:** Actual throughput depends on environment complexity and hardware. Benchmark your specific workload.
|
| 295 |
+
|
| 296 |
+
## Experiments Results
|
| 297 |
+
|
| 298 |
+
This section documents experiments measuring OpenEnv scaling characteristics across five infrastructure configurations. Full experiment data and code available at [burtenshaw/openenv-scaling](https://github.com/burtenshaw/openenv-scaling).
|
| 299 |
+
|
| 300 |
+
### Experiment setup
|
| 301 |
+
|
| 302 |
+
**Benchmark environment:** A minimal OpenEnv environment with configurable wait time (simulates computation). Each `step()` call sleeps for the specified duration, isolating infrastructure overhead from environment logic.
|
| 303 |
+
|
| 304 |
+
**Infrastructure tested:**
|
| 305 |
+
|
| 306 |
+
| Infrastructure | Cores | Configuration |
|
| 307 |
+
|----------------|-------|---------------|
|
| 308 |
+
| local-uvicorn | 8 | Direct Uvicorn, 8 workers |
|
| 309 |
+
| local-docker | 8 | Docker container from HF Spaces image |
|
| 310 |
+
| hf-spaces | 2 | HF Spaces free tier (cpu-basic) |
|
| 311 |
+
| slurm-single | 48 | Single AWS HPC node |
|
| 312 |
+
| slurm-multi | 96 | Two AWS HPC nodes + Envoy load balancer |
|
| 313 |
+
|
| 314 |
+
**Protocol:** WebSocket (`/ws`) and HTTP (`/reset`, `/step`) compared where available.
|
| 315 |
+
|
| 316 |
+
**Metrics:**
|
| 317 |
+
- **Max batch:** Largest concurrent request count with ≥95% success rate
|
| 318 |
+
- **Batch/core:** Max batch divided by available cores (efficiency metric)
|
| 319 |
+
- **P99 latency:** 99th percentile total request time
|
| 320 |
+
- **RPS:** Requests per second at max batch
|
| 321 |
+
|
| 322 |
+
### Results summary
|
| 323 |
+
|
| 324 |
+
| Infrastructure | Max Batch (WS) | Cores | Batch/Core | P99 Latency | RPS |
|
| 325 |
+
|----------------|----------------|-------|------------|-------------|-----|
|
| 326 |
+
| slurm-multi | 16,384 | 96 | 170.7 | 29.8s | 518 |
|
| 327 |
+
| local-uvicorn | 2,048 | 8 | 256.0 | 1.97s | 932 |
|
| 328 |
+
| local-docker | 2,048 | 8 | 256.0 | 2.90s | 682 |
|
| 329 |
+
| slurm-single | 512 | 48 | 10.7 | 1.45s | 358 |
|
| 330 |
+
| hf-spaces | 128 | 2 | 64.0 | 2.68s | 48 |
|
| 331 |
+
|
| 332 |
+
All results measured with `wait=10.0s` step duration.
|
| 333 |
+
|
| 334 |
+
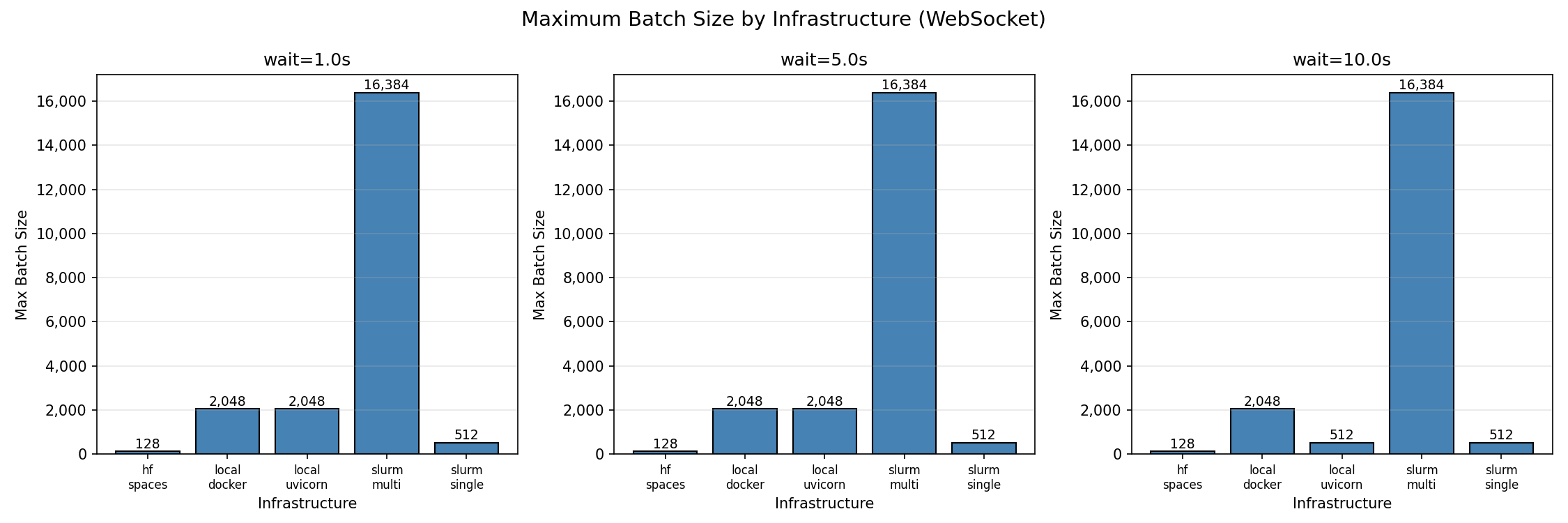
|
| 335 |
+
*Maximum batch size by infrastructure (95% success threshold)*
|
| 336 |
+
|
| 337 |
+
### Finding 1: Local deployments have highest per-core efficiency
|
| 338 |
+
|
| 339 |
+
Single instance of Python and Docker both achieve **256 concurrent sessions per core**—the highest efficiency observed. With 8 workers, both reach 2,048 concurrent sessions before degradation begins.
|
| 340 |
+
|
| 341 |
+
This makes sense because the environment is running in a single process and the overhead of the environment is relatively low. But it's ideal for hackers and developers who want to test their environment quickly or train on a single machine.
|
| 342 |
+
|
| 343 |
+
| Batch Size | Success Rate | P99 Latency | Notes |
|
| 344 |
+
|------------|--------------|-------------|-------|
|
| 345 |
+
| 32 | 100% | 1.05s | Perfect scaling |
|
| 346 |
+
| 128 | 100% | 1.07s | Perfect scaling |
|
| 347 |
+
| 512 | 100% | 1.33s | Perfect scaling |
|
| 348 |
+
| 2,048 | 96.5% | 1.97s | Max reliable batch |
|
| 349 |
+
| 4,096 | 63.8% | 3.20s | Connection failures begin |
|
| 350 |
+
| 8,192 | 36.9% | 5.75s | Above capacity |
|
| 351 |
+
|
| 352 |
+
Beyond 2,048 concurrent connections, success rate drops sharply. The failure mode is connection rejection, not timeout—the server saturates its connection pool.
|
| 353 |
+
|
| 354 |
+
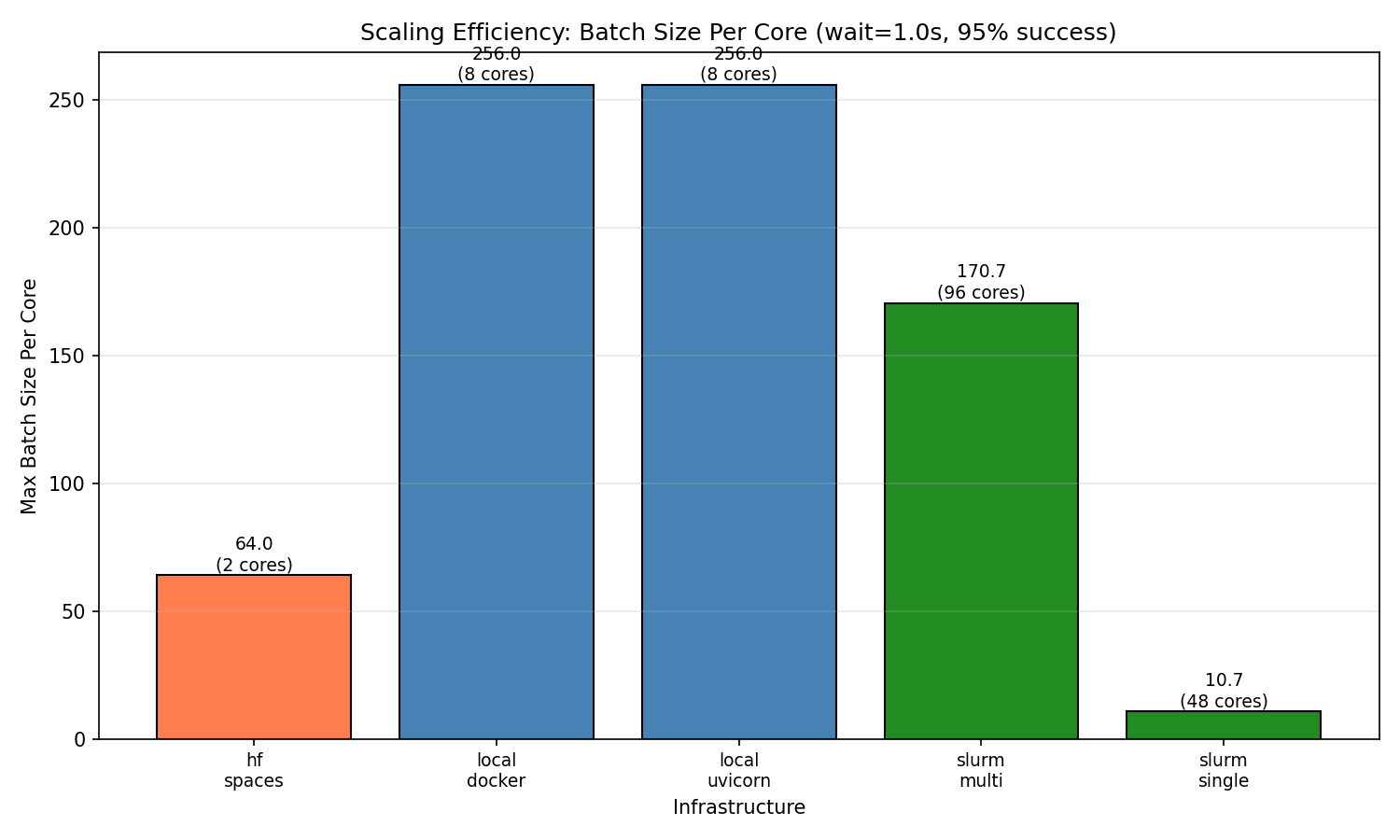
|
| 355 |
+
*Per-core efficiency comparison across infrastructures*
|
| 356 |
+
|
| 357 |
+
### Finding 2: HF Spaces works reliably up to 128 concurrent sessions
|
| 358 |
+
|
| 359 |
+
HF Spaces free tier (cpu-basic) provides 2 workers and achieves 128 concurrent WebSocket sessions with 100% success. This translates to **64 sessions per core**.
|
| 360 |
+
|
| 361 |
+
**HF Spaces scaling behavior (WebSocket):**
|
| 362 |
+
|
| 363 |
+
| Batch Size | Success Rate | P99 Latency | Notes |
|
| 364 |
+
|------------|--------------|-------------|-------|
|
| 365 |
+
| 1 | 100% | 1.64s | Baseline |
|
| 366 |
+
| 32 | 100% | 1.80s | Perfect scaling |
|
| 367 |
+
| 64 | 100% | 2.14s | Perfect scaling |
|
| 368 |
+
| 128 | 100% | 2.68s | Max reliable batch |
|
| 369 |
+
| 256 | ~33% | 4.41s | Inconsistent (some runs 0%, some 100%) |
|
| 370 |
+
| 512 | 0% | — | Complete failure |
|
| 371 |
+
|
| 372 |
+
At 256 concurrent connections, results become unstable. At 512+, connections fail entirely due to HF Spaces connection limits.
|
| 373 |
+
|
| 374 |
+
**HTTP mode does not work on HF Spaces.** The `/reset` and `/step` HTTP endpoints are not accessible on the deployed Space—all HTTP requests fail. Use WebSocket mode exclusively.
|
| 375 |
+
|
| 376 |
+
### Finding 3: Multi-node scaling works
|
| 377 |
+
|
| 378 |
+
Multi-node SLURM (96 cores across 2 nodes) achieves **16,384 concurrent sessions** with 100% success rate—the highest absolute throughput tested.
|
| 379 |
+
|
| 380 |
+
**SLURM multi-node scaling behavior:**
|
| 381 |
+
|
| 382 |
+
| Batch Size | Success Rate | P99 Latency | Notes |
|
| 383 |
+
|------------|--------------|-------------|-------|
|
| 384 |
+
| 32 | 100% | 1.05s | Perfect scaling |
|
| 385 |
+
| 512 | 100% | 1.59s | Perfect scaling |
|
| 386 |
+
| 2,048 | 100% | 3.48s | Perfect scaling |
|
| 387 |
+
| 4,096 | 100% | 6.97s | Perfect scaling |
|
| 388 |
+
| 8,192 | 100% | 13.7s | Perfect scaling |
|
| 389 |
+
| 16,384 | 100% | 29.8s | Max tested batch |
|
| 390 |
+
|
| 391 |
+
The batch/core ratio (170.7) is lower than local deployments (256) but provides the highest absolute capacity for large-scale workloads.
|
| 392 |
+
|
| 393 |
+
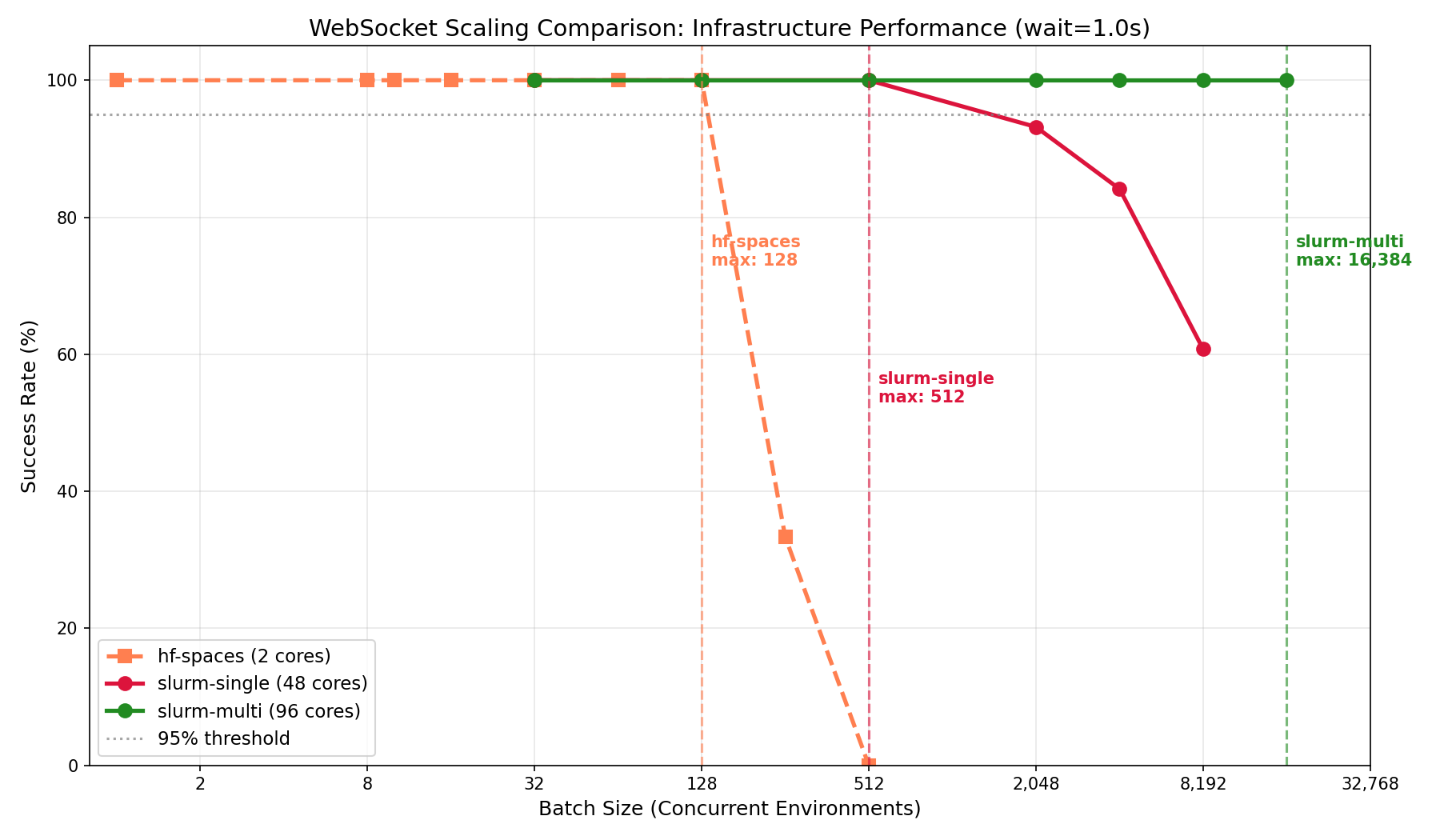
|
| 394 |
+
|
| 395 |
+
*Multi-node vs single-node scaling behavior*
|
| 396 |
+
|
| 397 |
+
### Latency breakdown
|
| 398 |
+
|
| 399 |
+
At max load (`wait=1.0s`), latency breaks down as:
|
| 400 |
+
|
| 401 |
+
| Infrastructure | Connect P50 | Reset P50 | Step P50 | Total P99 |
|
| 402 |
+
|----------------|-------------|-----------|----------|-----------|
|
| 403 |
+
| slurm-single | 0.26s | 0.04s | 1.00s | 1.33s |
|
| 404 |
+
| local-uvicorn | 0.58s | 0.08s | 1.05s | 1.95s |
|
| 405 |
+
| hf-spaces | 0.79s | 0.10s | 1.10s | 2.48s |
|
| 406 |
+
| local-docker | 1.38s | 0.19s | 1.05s | 2.90s |
|
| 407 |
+
| slurm-multi | 17.5s | 2.25s | 2.42s | 26.3s |
|
| 408 |
+
|
| 409 |
+
**Observations:**
|
| 410 |
+
- **Step latency** is consistent across infrastructures (~1.0s for 1.0s wait), confirming the benchmark measures infrastructure overhead accurately
|
| 411 |
+
- **Connect latency** varies significantly—local Docker shows higher connect time at load (1.38s), likely due to container networking
|
| 412 |
+
- **Multi-node has high connect latency** (17.5s) at 16,384 batch due to queuing at the load balancer; this is the cost of handling 16× more connections than single-node
|
| 413 |
+
|
| 414 |
+
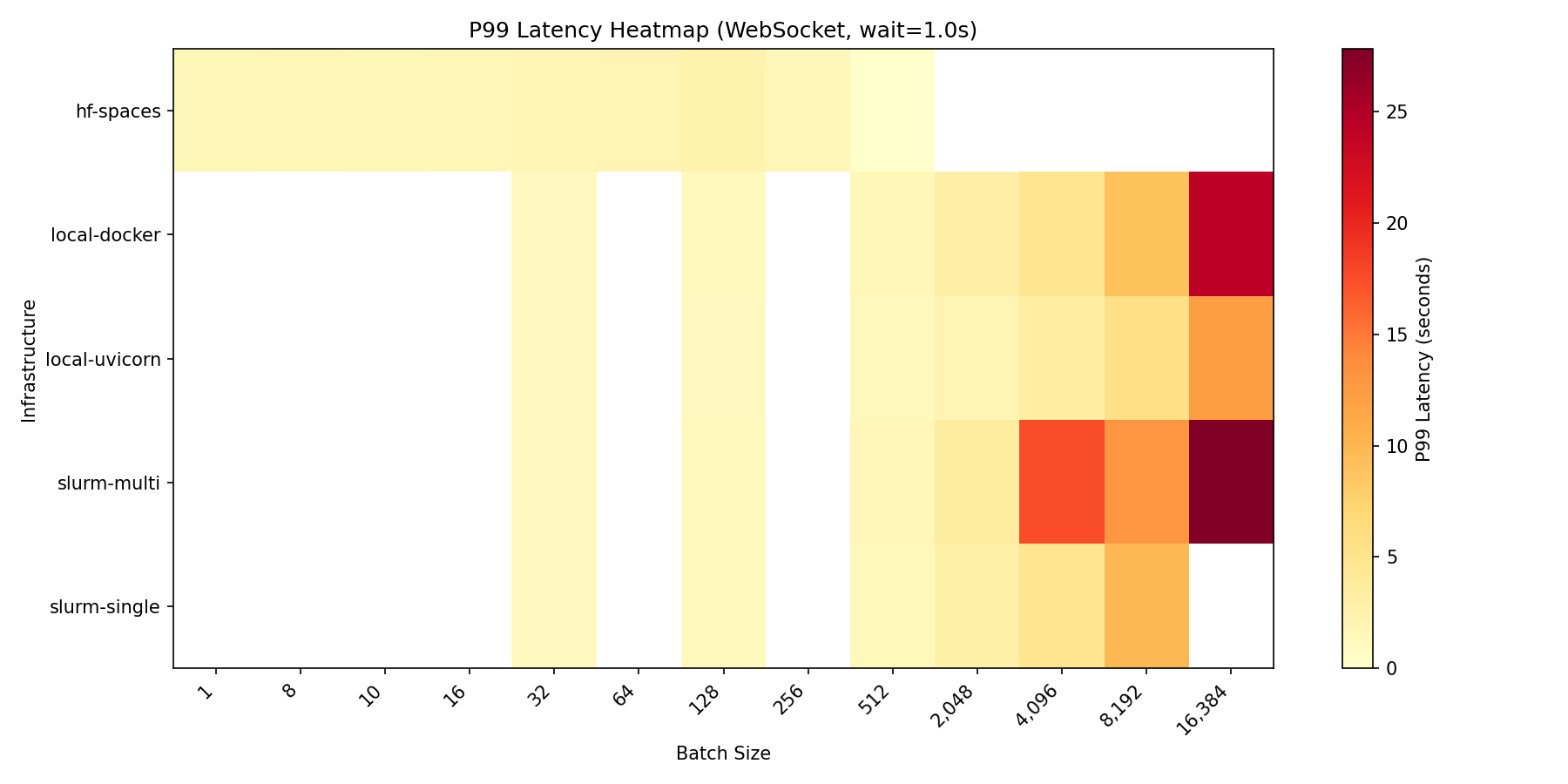
|
| 415 |
+
*P99 latency across configurations and batch sizes*
|
| 416 |
+
|
| 417 |
+
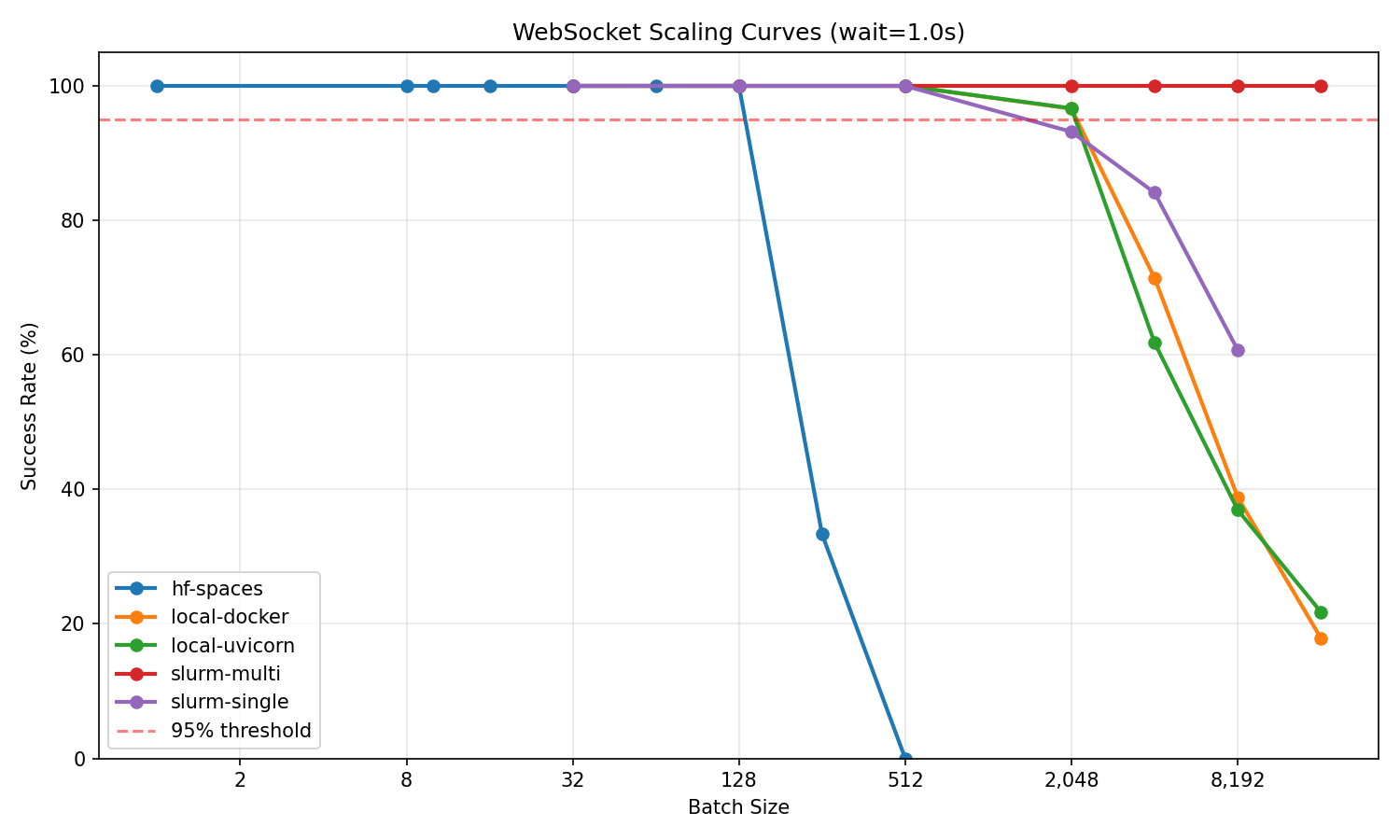
|
| 418 |
+
*Success rate vs batch size for all infrastructures*
|
| 419 |
+
|
| 420 |
+
### Test methodology
|
| 421 |
+
|
| 422 |
+
```bash
|
| 423 |
+
# Clone benchmark environment
|
| 424 |
+
git clone https://huggingface.co/spaces/burtenshaw/openenv-scaling
|
| 425 |
+
cd openenv-scaling
|
| 426 |
+
|
| 427 |
+
# Run scaling test
|
| 428 |
+
python tests/test_scaling.py \
|
| 429 |
+
--url http://localhost:8000 \
|
| 430 |
+
--requests-grid 32,128,512,2048,4096,8192,16384 \
|
| 431 |
+
--wait-grid 1.0,5.0,10.0 \
|
| 432 |
+
--reps 3 \
|
| 433 |
+
--mode ws \
|
| 434 |
+
--output-dir experiments/results/
|
| 435 |
+
```
|
| 436 |
+
|
| 437 |
+
Each configuration was tested with 3 repetitions. Max batch is defined as the largest batch size achieving ≥95% success rate across all repetitions.
|
| 438 |
+
|
| 439 |
+
---
|
| 440 |
+
|
| 441 |
+
## Summary
|
| 442 |
+
|
| 443 |
+
| Infrastructure | Best for | Max concurrent | Batch/core |
|
| 444 |
+
|----------------|----------|----------------|------------|
|
| 445 |
+
| local-uvicorn | Development, <2K sessions | 2,048 | 256 |
|
| 446 |
+
| local-docker | Same as uvicorn, containerized | 2,048 | 256 |
|
| 447 |
+
| hf-spaces | Demos, moderate load | 128 | 64 |
|
| 448 |
+
| slurm-single | HPC, single-node jobs | 512 | 10.7 |
|
| 449 |
+
| slurm-multi | Large-scale training | 16,384 | 170.7 |
|
| 450 |
+
|
| 451 |
+
**Recommendations:**
|
| 452 |
+
|
| 453 |
+
1. **For development and moderate workloads (<2,000 concurrent):** Use single node Uvicorn or Docker depending software environment. These provide the best per-core efficiency (256 sessions/core).
|
| 454 |
+
|
| 455 |
+
2. **For demos, testing, and published environments:** HF Spaces free tier works reliably up to 128 concurrent sessions.
|
| 456 |
+
|
| 457 |
+
3. **For large-scale training (>2,000 concurrent):** Deploy multi-node with proper load balancing. Expect ~170 sessions per core, but much higher absolute throughput.
|
tutorial/tutorial4.md
ADDED
|
@@ -0,0 +1,632 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OpenEnv Wordle with GRPO using TRL
|
| 2 |
+
|
| 3 |
+
[](https://github.com/huggingface/trl/blob/main/examples/notebooks/openenv_wordle_grpo.ipynb)
|
| 4 |
+
|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
With [**Transformers Reinforcement Learning (TRL)**](https://github.com/huggingface/trl), you can train a model that learns to **play Wordle**, a word-guessing game, through interaction and reinforcement.
|
| 8 |
+
|
| 9 |
+
- [TRL GitHub Repository](https://github.com/huggingface/trl)
|
| 10 |
+
- [Official TRL Examples](https://huggingface.co/docs/trl/example_overview)
|
| 11 |
+
- [Community Tutorials](https://huggingface.co/docs/trl/community_tutorials)
|
| 12 |
+
- [OpenEnv](https://github.com/meta-pytorch/OpenEnv)
|
| 13 |
+
|
| 14 |
+
An **agentic environment** is a setting where a model can take actions, observe outcomes, and adjust its behavior based on feedback, similar to how humans learn from trial and error.
|
| 15 |
+
In this case, the agent interacts with the **Wordle** environment through the [**OpenEnv**](https://github.com/meta-pytorch/OpenEnv) framework, which standardizes multi-agent and RL-style text environments.
|
| 16 |
+
|
| 17 |
+
[Wordle](https://en.wikipedia.org/wiki/Wordle) is a popular word puzzle where the player must guess a secret five-letter word within six tries.
|
| 18 |
+
After each guess, feedback indicates whether each letter is:
|
| 19 |
+
|
| 20 |
+
- 🟩 **Correct and in the right position**
|
| 21 |
+
- 🟨 **Present but in the wrong position**
|
| 22 |
+
- ⬛ **Not in the word**
|
| 23 |
+
|
| 24 |
+
This feedback loop makes Wordle a perfect environment for **RL with LLMs**, where the goal is to maximize the probability of guessing the correct word efficiently.
|
| 25 |
+
|
| 26 |
+
We will fine-tune a model using **GRPO** (Group Relative Policy Optimization) via TRL.
|
| 27 |
+
The agent will:
|
| 28 |
+
|
| 29 |
+
1. Generate guesses based on the game state and feedback.
|
| 30 |
+
2. Receive structured feedback from the environment after each guess.
|
| 31 |
+
3. Learn to improve its guessing strategy over time through reward signals.
|
| 32 |
+
|
| 33 |
+
---
|
| 34 |
+
|
| 35 |
+
## Install dependencies
|
| 36 |
+
|
| 37 |
+
We will start by installing **TRL**, which automatically includes the main dependencies like **Transformers**.
|
| 38 |
+
We will also install the **OpenEnv** framework (for the environment), **trackio** (for logging and monitoring training runs), and **vLLM** (for efficient generation).
|
| 39 |
+
|
| 40 |
+
```python
|
| 41 |
+
!pip install -Uq git+https://github.com/huggingface/trl.git git+https://github.com/meta-pytorch/OpenEnv.git trackio vllm==0.10.2 bitsandbytes
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
---
|
| 45 |
+
|
| 46 |
+
## Log in to Hugging Face
|
| 47 |
+
|
| 48 |
+
Log in to your **Hugging Face** account to save your fine-tuned model, track your experiment results directly on the Hub or access gated models. You can find your **access token** on your [account settings page](https://huggingface.co/settings/tokens).
|
| 49 |
+
|
| 50 |
+
```python
|
| 51 |
+
from huggingface_hub import notebook_login
|
| 52 |
+
|
| 53 |
+
notebook_login()
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
---
|
| 57 |
+
|
| 58 |
+
## Initialize the Environment
|
| 59 |
+
|
| 60 |
+
Let us begin by setting up the environment that will be used during training.
|
| 61 |
+
For this task, we will rely on the **TextArena** environment from **OpenEnv**, which exposes a familiar Gymnasium-style API (`reset()`, `step()`, etc.) to simplify interaction.
|
| 62 |
+
|
| 63 |
+
In this example, we will connect to the hosted environment at [burtenshaw/textarena](https://huggingface.co/spaces/burtenshaw/textarena).
|
| 64 |
+
For production use or custom configurations, we **strongly recommend** running the environment locally via Docker. The hosted versions on the Hub currently have limited concurrency support, so duplicating the Space to your own account is the preferred approach in those cases.
|
| 65 |
+
|
| 66 |
+
For more information, refer to the [TRL-OpenEnv documentation](https://huggingface.co/docs/trl/main/en/openenv).
|
| 67 |
+
|
| 68 |
+
```python
|
| 69 |
+
from envs.textarena_env import TextArenaEnv
|
| 70 |
+
|
| 71 |
+
textarena_url = "https://burtenshaw-textarena.hf.space" # Duplicate the Space and update this!
|
| 72 |
+
env = TextArenaEnv(base_url=textarena_url)
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
---
|
| 76 |
+
|
| 77 |
+
## Init model and tokenizer
|
| 78 |
+
|
| 79 |
+
We will use [Qwen/Qwen3-1.7B](https://huggingface.co/Qwen/Qwen3-1.7B), a lightweight instruction-tuned model that works well for quick experiments.
|
| 80 |
+
Despite its small size, it can still learn interesting strategies during fine-tuning.
|
| 81 |
+
If you have stronger hardware, you can easily scale up to larger models.
|
| 82 |
+
|
| 83 |
+
```python
|
| 84 |
+
from transformers import AutoTokenizer
|
| 85 |
+
|
| 86 |
+
model_name = "Qwen/Qwen3-1.7B"
|
| 87 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 88 |
+
tokenizer.pad_token = tokenizer.eos_token
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
---
|
| 92 |
+
|
| 93 |
+
## Rollout function with helpers
|
| 94 |
+
|
| 95 |
+
The **rollout function** defines how the agent interacts with the environment during GRPO training.
|
| 96 |
+
It is responsible for generating model completions, collecting feedback (rewards), and returning all necessary information for optimization.
|
| 97 |
+
|
| 98 |
+
In this setup:
|
| 99 |
+
|
| 100 |
+
- The function is called automatically by the **GRPOTrainer** during each training step.
|
| 101 |
+
- It uses the trainer's built-in `generate_rollout_completions()` method for efficient generation with vLLM in colocate mode.
|
| 102 |
+
- Each rollout represents a full interaction loop. The model guesses, receives feedback from Wordle, and updates based on reward signals.
|
| 103 |
+
|
| 104 |
+
### System Prompt
|
| 105 |
+
|
| 106 |
+
First, we define the `system_prompt` that guides the model's behavior as an expert Wordle solver with strategic reasoning and structured responses.
|
| 107 |
+
|
| 108 |
+
```python
|
| 109 |
+
system_prompt = """
|
| 110 |
+
You are an expert Wordle solver with deep knowledge of English vocabulary, letter frequency patterns, and optimal guessing strategies.
|
| 111 |
+
|
| 112 |
+
## GAME RULES
|
| 113 |
+
|
| 114 |
+
1. The target is a 5-letter English word
|
| 115 |
+
2. You have 6 attempts to guess the correct word
|
| 116 |
+
3. After each guess, you receive color-coded feedback:
|
| 117 |
+
- GREEN: Letter is correct and in the correct position
|
| 118 |
+
- YELLOW: Letter is in the word but in the wrong position
|
| 119 |
+
- GRAY: Letter is not in the word at all
|
| 120 |
+
4. All guesses must be valid 5-letter English words
|
| 121 |
+
5. You cannot reuse a word you've already guessed
|
| 122 |
+
|
| 123 |
+
## RESPONSE FORMAT
|
| 124 |
+
|
| 125 |
+
Only respond with your next guess in square brackets, e.g., [crane].
|
| 126 |
+
|
| 127 |
+
## STRATEGIC APPROACH
|
| 128 |
+
|
| 129 |
+
Do not repeat the same guess twice.
|
| 130 |
+
|
| 131 |
+
### Opening Strategy
|
| 132 |
+
- Start with words rich in common vowels (A, E, I, O, U) and consonants (R, S, T, L, N)
|
| 133 |
+
- Optimal starters: CRANE, SLATE, STARE, AROSE, IRATE
|
| 134 |
+
|
| 135 |
+
### Mid-Game Strategy
|
| 136 |
+
- Use confirmed GREEN letters in their correct positions
|
| 137 |
+
- Place YELLOW letters in different positions than where they appeared
|
| 138 |
+
- Eliminate GRAY letters from consideration
|
| 139 |
+
|
| 140 |
+
## YOUR GOAL
|
| 141 |
+
|
| 142 |
+
Solve the Wordle in as few guesses as possible by strategically using feedback to eliminate impossible words and narrow down the solution space efficiently.
|
| 143 |
+
"""
|
| 144 |
+
```
|
| 145 |
+
|
| 146 |
+
### Rollout Function
|
| 147 |
+
|
| 148 |
+
```python
|
| 149 |
+
def rollout_func(prompts, trainer=None):
|
| 150 |
+
"""
|
| 151 |
+
Rollout function for GRPO training with environment interaction.
|
| 152 |
+
"""
|
| 153 |
+
episode_prompt_ids = []
|
| 154 |
+
episode_completion_ids = []
|
| 155 |
+
episode_logprobs = []
|
| 156 |
+
correctness_rewards = []
|
| 157 |
+
green_rewards = []
|
| 158 |
+
yellow_rewards = []
|
| 159 |
+
repetition_rewards = []
|
| 160 |
+
|
| 161 |
+
for prompt_text in prompts:
|
| 162 |
+
episode = rollout_once(
|
| 163 |
+
trainer=trainer,
|
| 164 |
+
env=env,
|
| 165 |
+
tokenizer=tokenizer,
|
| 166 |
+
dataset_prompt=prompt_text,
|
| 167 |
+
system_prompt=system_prompt,
|
| 168 |
+
max_turns=6,
|
| 169 |
+
)
|
| 170 |
+
episode_prompt_ids.append(episode["prompt_ids"])
|
| 171 |
+
episode_completion_ids.append(episode["completion_ids"])
|
| 172 |
+
episode_logprobs.append(episode["logprobs"])
|
| 173 |
+
correctness_rewards.append(episode["correct_reward"])
|
| 174 |
+
green_rewards.append(episode["green_reward"])
|
| 175 |
+
yellow_rewards.append(episode["yellow_reward"])
|
| 176 |
+
repetition_rewards.append(episode["repetition_reward"])
|
| 177 |
+
|
| 178 |
+
return {
|
| 179 |
+
"prompt_ids": episode_prompt_ids,
|
| 180 |
+
"completion_ids": episode_completion_ids,
|
| 181 |
+
"logprobs": episode_logprobs,
|
| 182 |
+
"correct_reward": correctness_rewards,
|
| 183 |
+
"green_reward": green_rewards,
|
| 184 |
+
"yellow_reward": yellow_rewards,
|
| 185 |
+
"repetition_reward": repetition_rewards,
|
| 186 |
+
}
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+
---
|
| 190 |
+
|
| 191 |
+
## Define rollout_once
|
| 192 |
+
|
| 193 |
+
The `rollout_once` function runs **one full interaction loop** between the model and the Wordle environment using the trainer's generation method.
|
| 194 |
+
|
| 195 |
+
```python
|
| 196 |
+
from collections import defaultdict
|
| 197 |
+
from envs.textarena_env import TextArenaAction
|
| 198 |
+
from envs.textarena_env.rewards import extract_feedback_counts, extract_guess, extract_wordle_feedback
|
| 199 |
+
from trl.experimental.openenv import generate_rollout_completions
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def rollout_once(trainer, env, tokenizer, dataset_prompt, system_prompt, max_turns):
|
| 203 |
+
"""
|
| 204 |
+
Execute one full Wordle episode with the model.
|
| 205 |
+
"""
|
| 206 |
+
result = env.reset()
|
| 207 |
+
observation = result.observation
|
| 208 |
+
|
| 209 |
+
prompt_ids = []
|
| 210 |
+
completion_ids = []
|
| 211 |
+
logprobs = []
|
| 212 |
+
raw_rewards = []
|
| 213 |
+
green_scores = []
|
| 214 |
+
yellow_scores = []
|
| 215 |
+
repetition_scores = []
|
| 216 |
+
correct_scores = []
|
| 217 |
+
guess_counts = defaultdict(int)
|
| 218 |
+
|
| 219 |
+
for _turn in range(max_turns):
|
| 220 |
+
if result.done:
|
| 221 |
+
break
|
| 222 |
+
|
| 223 |
+
base_prompt = observation.prompt or dataset_prompt
|
| 224 |
+
user_prompt = make_user_prompt(base_prompt, observation.messages)
|
| 225 |
+
messages = [
|
| 226 |
+
{"role": "system", "content": system_prompt},
|
| 227 |
+
{"role": "user", "content": user_prompt},
|
| 228 |
+
]
|
| 229 |
+
prompt_text = tokenizer.apply_chat_template(
|
| 230 |
+
messages,
|
| 231 |
+
add_generation_prompt=True,
|
| 232 |
+
tokenize=False,
|
| 233 |
+
enable_thinking=False,
|
| 234 |
+
)
|
| 235 |
+
|
| 236 |
+
rollout_outputs = generate_rollout_completions(trainer, [prompt_text])[0]
|
| 237 |
+
prompt_ids.extend(rollout_outputs["prompt_ids"])
|
| 238 |
+
completion_ids.extend(rollout_outputs["completion_ids"])
|
| 239 |
+
logprobs.extend(rollout_outputs["logprobs"])
|
| 240 |
+
completion_text = rollout_outputs.get("text") or tokenizer.decode(
|
| 241 |
+
rollout_outputs["completion_ids"], skip_special_tokens=True
|
| 242 |
+
)
|
| 243 |
+
|
| 244 |
+
guess = extract_guess(completion_text)
|
| 245 |
+
result = env.step(TextArenaAction(message=guess))
|
| 246 |
+
raw_rewards.append(float(result.reward or 0.0))
|
| 247 |
+
observation = result.observation
|
| 248 |
+
correct_score = float(result.reward or 0.0)
|
| 249 |
+
feedback = extract_wordle_feedback(observation)
|
| 250 |
+
|
| 251 |
+
previous_occurrences = guess_counts[guess]
|
| 252 |
+
repetition_score = scale_repetition_score(previous_occurrences, len(guess_counts))
|
| 253 |
+
guess_counts[guess] += 1
|
| 254 |
+
|
| 255 |
+
if not feedback:
|
| 256 |
+
green_score = 0.0
|
| 257 |
+
yellow_score = 0.0
|
| 258 |
+
else:
|
| 259 |
+
green_count, yellow_count = extract_feedback_counts(feedback)
|
| 260 |
+
green_score = green_count / 5.0
|
| 261 |
+
yellow_score = yellow_count / 5.0
|
| 262 |
+
|
| 263 |
+
repetition_scores.append(repetition_score)
|
| 264 |
+
green_scores.append(green_score)
|
| 265 |
+
yellow_scores.append(yellow_score)
|
| 266 |
+
correct_scores.append(correct_score)
|
| 267 |
+
|
| 268 |
+
correct_reward_value = correct_scores[-1] if correct_scores else (raw_rewards[-1] if raw_rewards else 0.0)
|
| 269 |
+
|
| 270 |
+
return {
|
| 271 |
+
"prompt_ids": prompt_ids,
|
| 272 |
+
"completion_ids": completion_ids,
|
| 273 |
+
"logprobs": logprobs,
|
| 274 |
+
"raw_rewards": raw_rewards,
|
| 275 |
+
"correct_reward": correct_reward_value,
|
| 276 |
+
"green_reward": green_scores[-1] if green_scores else 0.0,
|
| 277 |
+
"yellow_reward": yellow_scores[-1] if yellow_scores else 0.0,
|
| 278 |
+
"repetition_reward": repetition_scores[-1] if repetition_scores else 0.0,
|
| 279 |
+
}
|
| 280 |
+
```
|
| 281 |
+
|
| 282 |
+
---
|
| 283 |
+
|
| 284 |
+
## Helper functions
|
| 285 |
+
|
| 286 |
+
```python
|
| 287 |
+
def make_user_prompt(prompt_text, messages):
|
| 288 |
+
"""Builds a structured user prompt combining the task description and message history"""
|
| 289 |
+
history = format_history(messages)
|
| 290 |
+
prompt_section = prompt_text.strip() if prompt_text.strip() else "Wordle-v0"
|
| 291 |
+
history_section = history if history else "[PROMPT] Awaiting first feedback."
|
| 292 |
+
return (
|
| 293 |
+
f"Game prompt:\n{prompt_section}\n\n"
|
| 294 |
+
f"Conversation so far:\n{history_section}\n\n"
|
| 295 |
+
"Reply with your next guess enclosed in square brackets."
|
| 296 |
+
)
|
| 297 |
+
|
| 298 |
+
def format_history(messages):
|
| 299 |
+
"""Formats the message history with tags for clear conversational context"""
|
| 300 |
+
lines = []
|
| 301 |
+
for message in messages:
|
| 302 |
+
tag = message.category or "MESSAGE"
|
| 303 |
+
content = message.content.strip()
|
| 304 |
+
if not content:
|
| 305 |
+
continue
|
| 306 |
+
lines.append(f"[{tag}] {content}")
|
| 307 |
+
return "\n".join(lines)
|
| 308 |
+
|
| 309 |
+
def scale_repetition_score(previous_occurrences, max_occurrences):
|
| 310 |
+
"""Scale the repetition score based on the number of previous occurrences from 0 to 1"""
|
| 311 |
+
if max_occurrences == 0:
|
| 312 |
+
return 0.0
|
| 313 |
+
return (max_occurrences - previous_occurrences) / max_occurrences
|
| 314 |
+
```
|
| 315 |
+
|
| 316 |
+
---
|
| 317 |
+
|
| 318 |
+
## Define reward functions
|
| 319 |
+
|
| 320 |
+
```python
|
| 321 |
+
def reward_correct(completions, **kwargs):
|
| 322 |
+
rewards = kwargs.get("correct_reward") if kwargs else None
|
| 323 |
+
if rewards is None:
|
| 324 |
+
return [0.0 for _ in completions]
|
| 325 |
+
return [float(r) for r in rewards]
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
def reward_greens(completions, **kwargs):
|
| 329 |
+
rewards = kwargs.get("green_reward") if kwargs else None
|
| 330 |
+
if rewards is None:
|
| 331 |
+
return [0.0 for _ in completions]
|
| 332 |
+
return [float(r) for r in rewards]
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
def reward_yellows(completions, **kwargs):
|
| 336 |
+
rewards = kwargs.get("yellow_reward") if kwargs else None
|
| 337 |
+
if rewards is None:
|
| 338 |
+
return [0.0 for _ in completions]
|
| 339 |
+
return [float(r) for r in rewards]
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
def reward_repetition(completions, **kwargs):
|
| 343 |
+
rewards = kwargs.get("repetition_reward") if kwargs else None
|
| 344 |
+
if rewards is None:
|
| 345 |
+
return [0.0 for _ in completions]
|
| 346 |
+
return [float(r) for r in rewards]
|
| 347 |
+
```
|
| 348 |
+
|
| 349 |
+
---
|
| 350 |
+
|
| 351 |
+
## Create dataset
|
| 352 |
+
|
| 353 |
+
```python
|
| 354 |
+
from datasets import Dataset
|
| 355 |
+
|
| 356 |
+
dataset_size = 1000
|
| 357 |
+
dataset_prompt = "Play Wordle like an expert."
|
| 358 |
+
|
| 359 |
+
dataset = Dataset.from_dict({"prompt": [dataset_prompt] * dataset_size})
|
| 360 |
+
```
|
| 361 |
+
|
| 362 |
+
---
|
| 363 |
+
|
| 364 |
+
## Set GRPO Config
|
| 365 |
+
|
| 366 |
+
```python
|
| 367 |
+
from trl import GRPOConfig
|
| 368 |
+
|
| 369 |
+
output_dir = "wordle-grpo-Qwen3-1.7B"
|
| 370 |
+
|
| 371 |
+
grpo_config = GRPOConfig(
|
| 372 |
+
num_train_epochs = 1,
|
| 373 |
+
learning_rate = 5e-6,
|
| 374 |
+
gradient_accumulation_steps = 64,
|
| 375 |
+
per_device_train_batch_size = 1,
|
| 376 |
+
warmup_steps = 20,
|
| 377 |
+
num_generations = 2,
|
| 378 |
+
max_completion_length = 8,
|
| 379 |
+
max_prompt_length = 1400,
|
| 380 |
+
use_vllm = True,
|
| 381 |
+
vllm_mode = "colocate",
|
| 382 |
+
vllm_gpu_memory_utilization = 0.1,
|
| 383 |
+
output_dir = output_dir,
|
| 384 |
+
report_to="trackio",
|
| 385 |
+
trackio_space_id = output_dir,
|
| 386 |
+
logging_steps = 1,
|
| 387 |
+
save_steps = 10,
|
| 388 |
+
gradient_checkpointing = True,
|
| 389 |
+
gradient_checkpointing_kwargs = {"use_reentrant": False},
|
| 390 |
+
push_to_hub = True,
|
| 391 |
+
)
|
| 392 |
+
```
|
| 393 |
+
|
| 394 |
+
---
|
| 395 |
+
|
| 396 |
+
## Create GRPOTrainer and start training
|
| 397 |
+
|
| 398 |
+
```python
|
| 399 |
+
from trl import GRPOTrainer
|
| 400 |
+
|
| 401 |
+
trainer = GRPOTrainer(
|
| 402 |
+
model=model_name,
|
| 403 |
+
processing_class=tokenizer,
|
| 404 |
+
reward_funcs=[
|
| 405 |
+
reward_correct,
|
| 406 |
+
reward_greens,
|
| 407 |
+
reward_yellows,
|
| 408 |
+
reward_repetition,
|
| 409 |
+
],
|
| 410 |
+
train_dataset=dataset,
|
| 411 |
+
args=grpo_config,
|
| 412 |
+
rollout_func=rollout_func,
|
| 413 |
+
)
|
| 414 |
+
```
|
| 415 |
+
|
| 416 |
+
### Memory stats before training
|
| 417 |
+
|
| 418 |
+
```python
|
| 419 |
+
import torch
|
| 420 |
+
gpu_stats = torch.cuda.get_device_properties(0)
|
| 421 |
+
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
|
| 422 |
+
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
|
| 423 |
+
|
| 424 |
+
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
|
| 425 |
+
print(f"{start_gpu_memory} GB of memory reserved.")
|
| 426 |
+
```
|
| 427 |
+
|
| 428 |
+
**Output:**
|
| 429 |
+
```
|
| 430 |
+
GPU = NVIDIA A100-SXM4-40GB. Max memory = 39.557 GB.
|
| 431 |
+
10.516 GB of memory reserved.
|
| 432 |
+
```
|
| 433 |
+
|
| 434 |
+
### Train!
|
| 435 |
+
|
| 436 |
+
```python
|
| 437 |
+
trainer_stats = trainer.train()
|
| 438 |
+
```
|
| 439 |
+
|
| 440 |
+
**Training Progress:**
|
| 441 |
+
|
| 442 |
+
| Step | Training Loss |
|
| 443 |
+
|------|---------------|
|
| 444 |
+
| 1 | 0.008300 |
|
| 445 |
+
| 2 | 0.001900 |
|
| 446 |
+
| 3 | 0.015100 |
|
| 447 |
+
| 4 | 0.008700 |
|
| 448 |
+
| 5 | 0.009800 |
|
| 449 |
+
| 6 | 0.006700 |
|
| 450 |
+
| 7 | 0.006100 |
|
| 451 |
+
| 8 | 0.004400 |
|
| 452 |
+
| 9 | -0.002100 |
|
| 453 |
+
| 10 | 0.007500 |
|
| 454 |
+
| 11 | 0.008400 |
|
| 455 |
+
| 12 | 0.008000 |
|
| 456 |
+
| 13 | 0.007800 |
|
| 457 |
+
| 14 | -0.002400 |
|
| 458 |
+
| 15 | -0.003200 |
|
| 459 |
+
| 16 | -0.006000 |
|
| 460 |
+
| 17 | -0.008300 |
|
| 461 |
+
| 18 | -0.011000 |
|
| 462 |
+
| 19 | -0.004200 |
|
| 463 |
+
| 20 | -0.001700 |
|
| 464 |
+
| 21 | -0.004100 |
|
| 465 |
+
| 22 | -0.011600 |
|
| 466 |
+
| 23 | -0.006400 |
|
| 467 |
+
| 24 | -0.009100 |
|
| 468 |
+
| 25 | 0.003200 |
|
| 469 |
+
| 26 | 0.005100 |
|
| 470 |
+
| 27 | -0.002800 |
|
| 471 |
+
| 28 | 0.001400 |
|
| 472 |
+
| 29 | 0.011500 |
|
| 473 |
+
| 30 | -0.010500 |
|
| 474 |
+
| 31 | -0.006400 |
|
| 475 |
+
|
| 476 |
+
### Memory stats after training
|
| 477 |
+
|
| 478 |
+
```python
|
| 479 |
+
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
|
| 480 |
+
used_memory_for_training = round(used_memory - start_gpu_memory, 3)
|
| 481 |
+
used_percentage = round(used_memory / max_memory * 100, 3)
|
| 482 |
+
training_memory_percentage = round(used_memory_for_training / max_memory * 100, 3)
|
| 483 |
+
|
| 484 |
+
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
|
| 485 |
+
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
|
| 486 |
+
print(f"Peak reserved memory = {used_memory} GB.")
|
| 487 |
+
print(f"Peak reserved memory for training = {used_memory_for_training} GB.")
|
| 488 |
+
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
|
| 489 |
+
print(f"Peak reserved memory for training % of max memory = {training_memory_percentage} %.")
|
| 490 |
+
```
|
| 491 |
+
|
| 492 |
+
**Output:**
|
| 493 |
+
```
|
| 494 |
+
5231.7046 seconds used for training.
|
| 495 |
+
87.2 minutes used for training.
|
| 496 |
+
Peak reserved memory = 36.68 GB.
|
| 497 |
+
Peak reserved memory for training = 26.164 GB.
|
| 498 |
+
Peak reserved memory % of max memory = 92.727 %.
|
| 499 |
+
Peak reserved memory for training % of max memory = 66.143 %.
|
| 500 |
+
```
|
| 501 |
+
|
| 502 |
+
### Save and push to Hub
|
| 503 |
+
|
| 504 |
+
```python
|
| 505 |
+
env.close()
|
| 506 |
+
trainer.save_model(output_dir)
|
| 507 |
+
trainer.push_to_hub()
|
| 508 |
+
```
|
| 509 |
+
|
| 510 |
+
---
|
| 511 |
+
|
| 512 |
+
## Load the Fine-Tuned Model and Run Inference
|
| 513 |
+
|
| 514 |
+
```python
|
| 515 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 516 |
+
|
| 517 |
+
model_name = "sergiopaniego/wordle-grpo-Qwen3-1.7B" # Replace with your HF username
|
| 518 |
+
|
| 519 |
+
fine_tuned_model = AutoModelForCausalLM.from_pretrained(model_name, dtype="auto", device_map="auto")
|
| 520 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 521 |
+
```
|
| 522 |
+
|
| 523 |
+
```python
|
| 524 |
+
MAX_TURNS=6
|
| 525 |
+
|
| 526 |
+
def play_wordle(env, model, tokenizer):
|
| 527 |
+
result = env.reset()
|
| 528 |
+
observation = result.observation
|
| 529 |
+
|
| 530 |
+
print("Initial Prompt:\n" + observation.prompt)
|
| 531 |
+
|
| 532 |
+
for turn in range(MAX_TURNS):
|
| 533 |
+
if result.done:
|
| 534 |
+
break
|
| 535 |
+
|
| 536 |
+
user_prompt = make_user_prompt(observation.prompt, observation.messages)
|
| 537 |
+
messages = [
|
| 538 |
+
{"role": "system", "content": system_prompt},
|
| 539 |
+
{"role": "user", "content": user_prompt},
|
| 540 |
+
]
|
| 541 |
+
prompt_text = tokenizer.apply_chat_template(
|
| 542 |
+
messages,
|
| 543 |
+
add_generation_prompt=True,
|
| 544 |
+
tokenize=False,
|
| 545 |
+
enable_thinking=False,
|
| 546 |
+
)
|
| 547 |
+
|
| 548 |
+
model_inputs = tokenizer([prompt_text], return_tensors="pt").to(model.device)
|
| 549 |
+
|
| 550 |
+
generated_ids = model.generate(
|
| 551 |
+
**model_inputs,
|
| 552 |
+
max_new_tokens=512
|
| 553 |
+
)
|
| 554 |
+
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):]
|
| 555 |
+
|
| 556 |
+
generated_text = tokenizer.decode(output_ids, skip_special_tokens=True)
|
| 557 |
+
guess = extract_guess(generated_text)
|
| 558 |
+
|
| 559 |
+
print(f"\nTurn {turn}: model replied with -> {generated_text}")
|
| 560 |
+
print(f" Parsed guess: {guess}")
|
| 561 |
+
|
| 562 |
+
result = env.step(TextArenaAction(message=guess))
|
| 563 |
+
observation = result.observation
|
| 564 |
+
|
| 565 |
+
print(" Feedback messages:")
|
| 566 |
+
for message in observation.messages:
|
| 567 |
+
print(f" [{message.category}] {message.content}")
|
| 568 |
+
|
| 569 |
+
print("\nGame finished")
|
| 570 |
+
print(f" Reward: {result.reward}")
|
| 571 |
+
print(f" Done: {result.done}")
|
| 572 |
+
```
|
| 573 |
+
|
| 574 |
+
### Let us play the game!
|
| 575 |
+
|
| 576 |
+
```python
|
| 577 |
+
try:
|
| 578 |
+
play_wordle(env, fine_tuned_model, tokenizer)
|
| 579 |
+
finally:
|
| 580 |
+
env.close()
|
| 581 |
+
```
|
| 582 |
+
|
| 583 |
+
**Output:**
|
| 584 |
+
```
|
| 585 |
+
Initial Prompt:
|
| 586 |
+
You are Player 0 in Wordle.
|
| 587 |
+
A secret 5-letter word has been chosen. You have 6 attempts to guess it.
|
| 588 |
+
For each guess, wrap your word in square brackets (e.g., [apple]).
|
| 589 |
+
Feedback for each letter will be given as follows:
|
| 590 |
+
- G (green): correct letter in the correct position
|
| 591 |
+
- Y (yellow): letter exists in the word but in the wrong position
|
| 592 |
+
- X (wrong): letter is not in the word
|
| 593 |
+
Enter your guess to begin.
|
| 594 |
+
|
| 595 |
+
Turn 0: model replied with -> [crane]
|
| 596 |
+
Parsed guess: [crane]
|
| 597 |
+
Feedback messages:
|
| 598 |
+
[MESSAGE] [crane]
|
| 599 |
+
[MESSAGE] Player 0 submitted [crane].
|
| 600 |
+
Feedback:
|
| 601 |
+
C R A N E
|
| 602 |
+
X Y X X X
|
| 603 |
+
|
| 604 |
+
You have 5 guesses left.
|
| 605 |
+
|
| 606 |
+
Turn 1: model replied with -> [spare]
|
| 607 |
+
Parsed guess: [spare]
|
| 608 |
+
Feedback messages:
|
| 609 |
+
[MESSAGE] [spare]
|
| 610 |
+
[MESSAGE] Player 0 submitted [spare].
|
| 611 |
+
Feedback:
|
| 612 |
+
C R A N E
|
| 613 |
+
X Y X X X
|
| 614 |
+
|
| 615 |
+
S P A R E
|
| 616 |
+
G X X G X
|
| 617 |
+
|
| 618 |
+
You have 4 guesses left.
|
| 619 |
+
|
| 620 |
+
...
|
| 621 |
+
|
| 622 |
+
Game finished
|
| 623 |
+
Reward: 0.0
|
| 624 |
+
Done: True
|
| 625 |
+
```
|
| 626 |
+
|
| 627 |
+
> **Note:** The model has learned some good opening strategies (starting with "crane", then "spare"), but still tends to repeat guesses. This is a common challenge in RL training that can be improved with:
|
| 628 |
+
>
|
| 629 |
+
> - Longer training runs
|
| 630 |
+
> - Stronger repetition penalties
|
| 631 |
+
> - Better reward shaping
|
| 632 |
+
> - Larger models
|
uv.lock
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|