Spaces:
Runtime error

Runtime error
uploadfile first
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- text-generation-webui/.dockerignore +9 -0
- text-generation-webui/.env.example +25 -0
- text-generation-webui/.github/FUNDING.yml +1 -0
- text-generation-webui/.github/ISSUE_TEMPLATE/bug_report_template.yml +53 -0
- text-generation-webui/.github/ISSUE_TEMPLATE/feature_request.md +16 -0
- text-generation-webui/.github/dependabot.yml +11 -0
- text-generation-webui/.github/workflows/stale.yml +22 -0
- text-generation-webui/.gitignore +27 -0
- text-generation-webui/Dockerfile.tt +68 -0
- text-generation-webui/LICENSE +661 -0
- text-generation-webui/README.md +310 -0
- text-generation-webui/api-example-stream.py +92 -0
- text-generation-webui/api-example.py +57 -0
- text-generation-webui/cache/Example.png_cache.png +0 -0
- text-generation-webui/characters/Example.png +0 -0
- text-generation-webui/characters/Example.yaml +16 -0
- text-generation-webui/characters/instruction-following/Alpaca.yaml +3 -0
- text-generation-webui/characters/instruction-following/ChatGLM.yaml +3 -0
- text-generation-webui/characters/instruction-following/Koala.yaml +3 -0
- text-generation-webui/characters/instruction-following/Open Assistant.yaml +3 -0
- text-generation-webui/characters/instruction-following/Vicuna.yaml +3 -0
- text-generation-webui/convert-to-flexgen.py +63 -0
- text-generation-webui/convert-to-safetensors.py +38 -0
- text-generation-webui/css/chat.css +43 -0
- text-generation-webui/css/chat.js +4 -0
- text-generation-webui/css/html_4chan_style.css +103 -0
- text-generation-webui/css/html_bubble_chat_style.css +86 -0
- text-generation-webui/css/html_cai_style.css +91 -0
- text-generation-webui/css/html_instruct_style.css +73 -0
- text-generation-webui/css/html_readable_style.css +28 -0
- text-generation-webui/css/main.css +79 -0
- text-generation-webui/css/main.js +18 -0
- text-generation-webui/docker-compose.yml +31 -0
- text-generation-webui/download-model.py +270 -0
- text-generation-webui/extensions/api/requirements.txt +1 -0
- text-generation-webui/extensions/api/script.py +118 -0
- text-generation-webui/extensions/character_bias/script.py +82 -0
- text-generation-webui/extensions/elevenlabs_tts/outputs/outputs-will-be-saved-here.txt +0 -0
- text-generation-webui/extensions/elevenlabs_tts/requirements.txt +3 -0
- text-generation-webui/extensions/elevenlabs_tts/script.py +122 -0
- text-generation-webui/extensions/gallery/__pycache__/script.cpython-310.pyc +0 -0
- text-generation-webui/extensions/gallery/script.py +96 -0
- text-generation-webui/extensions/google_translate/requirements.txt +1 -0
- text-generation-webui/extensions/google_translate/script.py +46 -0
- text-generation-webui/extensions/llama_prompts/script.py +21 -0
- text-generation-webui/extensions/sd_api_pictures/README.MD +90 -0
- text-generation-webui/extensions/sd_api_pictures/script.py +299 -0
- text-generation-webui/extensions/send_pictures/script.py +47 -0
- text-generation-webui/extensions/silero_tts/outputs/outputs-will-be-saved-here.txt +0 -0
- text-generation-webui/extensions/silero_tts/requirements.txt +5 -0
text-generation-webui/.dockerignore
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.env
|
| 2 |
+
Dockerfile
|
| 3 |
+
/characters
|
| 4 |
+
/loras
|
| 5 |
+
/models
|
| 6 |
+
/presets
|
| 7 |
+
/prompts
|
| 8 |
+
/softprompts
|
| 9 |
+
/training
|
text-generation-webui/.env.example
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# by default the Dockerfile specifies these versions: 3.5;5.0;6.0;6.1;7.0;7.5;8.0;8.6+PTX
|
| 2 |
+
# however for me to work i had to specify the exact version for my card ( 2060 ) it was 7.5
|
| 3 |
+
# https://developer.nvidia.com/cuda-gpus you can find the version for your card here
|
| 4 |
+
TORCH_CUDA_ARCH_LIST=7.5
|
| 5 |
+
|
| 6 |
+
# these commands worked for me with roughly 4.5GB of vram
|
| 7 |
+
CLI_ARGS=--model llama-7b-4bit --wbits 4 --listen --auto-devices
|
| 8 |
+
|
| 9 |
+
# the following examples have been tested with the files linked in docs/README_docker.md:
|
| 10 |
+
# example running 13b with 4bit/128 groupsize : CLI_ARGS=--model llama-13b-4bit-128g --wbits 4 --listen --groupsize 128 --pre_layer 25
|
| 11 |
+
# example with loading api extension and public share: CLI_ARGS=--model llama-7b-4bit --wbits 4 --listen --auto-devices --no-stream --extensions api --share
|
| 12 |
+
# example running 7b with 8bit groupsize : CLI_ARGS=--model llama-7b --load-in-8bit --listen --auto-devices
|
| 13 |
+
|
| 14 |
+
# the port the webui binds to on the host
|
| 15 |
+
HOST_PORT=7860
|
| 16 |
+
# the port the webui binds to inside the container
|
| 17 |
+
CONTAINER_PORT=7860
|
| 18 |
+
|
| 19 |
+
# the port the api binds to on the host
|
| 20 |
+
HOST_API_PORT=5000
|
| 21 |
+
# the port the api binds to inside the container
|
| 22 |
+
CONTAINER_API_PORT=5000
|
| 23 |
+
|
| 24 |
+
# the version used to install text-generation-webui from
|
| 25 |
+
WEBUI_VERSION=HEAD
|
text-generation-webui/.github/FUNDING.yml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
ko_fi: oobabooga
|
text-generation-webui/.github/ISSUE_TEMPLATE/bug_report_template.yml
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "Bug report"
|
| 2 |
+
description: Report a bug
|
| 3 |
+
labels: [ "bug" ]
|
| 4 |
+
body:
|
| 5 |
+
- type: markdown
|
| 6 |
+
attributes:
|
| 7 |
+
value: |
|
| 8 |
+
Thanks for taking the time to fill out this bug report!
|
| 9 |
+
- type: textarea
|
| 10 |
+
id: bug-description
|
| 11 |
+
attributes:
|
| 12 |
+
label: Describe the bug
|
| 13 |
+
description: A clear and concise description of what the bug is.
|
| 14 |
+
placeholder: Bug description
|
| 15 |
+
validations:
|
| 16 |
+
required: true
|
| 17 |
+
- type: checkboxes
|
| 18 |
+
attributes:
|
| 19 |
+
label: Is there an existing issue for this?
|
| 20 |
+
description: Please search to see if an issue already exists for the issue you encountered.
|
| 21 |
+
options:
|
| 22 |
+
- label: I have searched the existing issues
|
| 23 |
+
required: true
|
| 24 |
+
- type: textarea
|
| 25 |
+
id: reproduction
|
| 26 |
+
attributes:
|
| 27 |
+
label: Reproduction
|
| 28 |
+
description: Please provide the steps necessary to reproduce your issue.
|
| 29 |
+
placeholder: Reproduction
|
| 30 |
+
validations:
|
| 31 |
+
required: true
|
| 32 |
+
- type: textarea
|
| 33 |
+
id: screenshot
|
| 34 |
+
attributes:
|
| 35 |
+
label: Screenshot
|
| 36 |
+
description: "If possible, please include screenshot(s) so that we can understand what the issue is."
|
| 37 |
+
- type: textarea
|
| 38 |
+
id: logs
|
| 39 |
+
attributes:
|
| 40 |
+
label: Logs
|
| 41 |
+
description: "Please include the full stacktrace of the errors you get in the command-line (if any)."
|
| 42 |
+
render: shell
|
| 43 |
+
validations:
|
| 44 |
+
required: true
|
| 45 |
+
- type: textarea
|
| 46 |
+
id: system-info
|
| 47 |
+
attributes:
|
| 48 |
+
label: System Info
|
| 49 |
+
description: "Please share your system info with us: operating system, GPU brand, and GPU model. If you are using a Google Colab notebook, mention that instead."
|
| 50 |
+
render: shell
|
| 51 |
+
placeholder:
|
| 52 |
+
validations:
|
| 53 |
+
required: true
|
text-generation-webui/.github/ISSUE_TEMPLATE/feature_request.md
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: Feature request
|
| 3 |
+
about: Suggest an improvement or new feature for the web UI
|
| 4 |
+
title: ''
|
| 5 |
+
labels: 'enhancement'
|
| 6 |
+
assignees: ''
|
| 7 |
+
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
**Description**
|
| 11 |
+
|
| 12 |
+
A clear and concise description of what you want to be implemented.
|
| 13 |
+
|
| 14 |
+
**Additional Context**
|
| 15 |
+
|
| 16 |
+
If applicable, please provide any extra information, external links, or screenshots that could be useful.
|
text-generation-webui/.github/dependabot.yml
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# To get started with Dependabot version updates, you'll need to specify which
|
| 2 |
+
# package ecosystems to update and where the package manifests are located.
|
| 3 |
+
# Please see the documentation for all configuration options:
|
| 4 |
+
# https://docs.github.com/github/administering-a-repository/configuration-options-for-dependency-updates
|
| 5 |
+
|
| 6 |
+
version: 2
|
| 7 |
+
updates:
|
| 8 |
+
- package-ecosystem: "pip" # See documentation for possible values
|
| 9 |
+
directory: "/" # Location of package manifests
|
| 10 |
+
schedule:
|
| 11 |
+
interval: "weekly"
|
text-generation-webui/.github/workflows/stale.yml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Close inactive issues
|
| 2 |
+
on:
|
| 3 |
+
schedule:
|
| 4 |
+
- cron: "10 23 * * *"
|
| 5 |
+
|
| 6 |
+
jobs:
|
| 7 |
+
close-issues:
|
| 8 |
+
runs-on: ubuntu-latest
|
| 9 |
+
permissions:
|
| 10 |
+
issues: write
|
| 11 |
+
pull-requests: write
|
| 12 |
+
steps:
|
| 13 |
+
- uses: actions/stale@v5
|
| 14 |
+
with:
|
| 15 |
+
stale-issue-message: ""
|
| 16 |
+
close-issue-message: "This issue has been closed due to inactivity for 30 days. If you believe it is still relevant, please leave a comment below."
|
| 17 |
+
days-before-issue-stale: 30
|
| 18 |
+
days-before-issue-close: 0
|
| 19 |
+
stale-issue-label: "stale"
|
| 20 |
+
days-before-pr-stale: -1
|
| 21 |
+
days-before-pr-close: -1
|
| 22 |
+
repo-token: ${{ secrets.GITHUB_TOKEN }}
|
text-generation-webui/.gitignore
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cache
|
| 2 |
+
characters
|
| 3 |
+
training/datasets
|
| 4 |
+
extensions/silero_tts/outputs
|
| 5 |
+
extensions/elevenlabs_tts/outputs
|
| 6 |
+
extensions/sd_api_pictures/outputs
|
| 7 |
+
logs
|
| 8 |
+
loras
|
| 9 |
+
models
|
| 10 |
+
repositories
|
| 11 |
+
softprompts
|
| 12 |
+
torch-dumps
|
| 13 |
+
*pycache*
|
| 14 |
+
*/*pycache*
|
| 15 |
+
*/*/pycache*
|
| 16 |
+
venv/
|
| 17 |
+
.venv/
|
| 18 |
+
.vscode
|
| 19 |
+
*.bak
|
| 20 |
+
*.ipynb
|
| 21 |
+
*.log
|
| 22 |
+
|
| 23 |
+
settings.json
|
| 24 |
+
img_bot*
|
| 25 |
+
img_me*
|
| 26 |
+
prompts/[0-9]*
|
| 27 |
+
models/config-user.yaml
|
text-generation-webui/Dockerfile.tt
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvidia/cuda:11.8.0-devel-ubuntu22.04 as builder
|
| 2 |
+
|
| 3 |
+
RUN apt-get update && \
|
| 4 |
+
apt-get install --no-install-recommends -y git vim build-essential python3-dev python3-venv && \
|
| 5 |
+
rm -rf /var/lib/apt/lists/*
|
| 6 |
+
|
| 7 |
+
RUN git clone https://github.com/oobabooga/GPTQ-for-LLaMa /build
|
| 8 |
+
|
| 9 |
+
WORKDIR /build
|
| 10 |
+
|
| 11 |
+
RUN python3 -m venv /build/venv
|
| 12 |
+
RUN . /build/venv/bin/activate && \
|
| 13 |
+
pip3 install --upgrade pip setuptools && \
|
| 14 |
+
pip3 install torch torchvision torchaudio && \
|
| 15 |
+
pip3 install -r requirements.txt
|
| 16 |
+
|
| 17 |
+
# https://developer.nvidia.com/cuda-gpus
|
| 18 |
+
# for a rtx 2060: ARG TORCH_CUDA_ARCH_LIST="7.5"
|
| 19 |
+
ARG TORCH_CUDA_ARCH_LIST="3.5;5.0;6.0;6.1;7.0;7.5;8.0;8.6+PTX"
|
| 20 |
+
RUN . /build/venv/bin/activate && \
|
| 21 |
+
python3 setup_cuda.py bdist_wheel -d .
|
| 22 |
+
|
| 23 |
+
FROM nvidia/cuda:11.8.0-runtime-ubuntu22.04
|
| 24 |
+
|
| 25 |
+
LABEL maintainer="Your Name <your.email@example.com>"
|
| 26 |
+
LABEL description="Docker image for GPTQ-for-LLaMa and Text Generation WebUI"
|
| 27 |
+
|
| 28 |
+
RUN apt-get update && \
|
| 29 |
+
apt-get install --no-install-recommends -y libportaudio2 libasound-dev git python3 python3-pip make g++ && \
|
| 30 |
+
rm -rf /var/lib/apt/lists/*
|
| 31 |
+
|
| 32 |
+
RUN --mount=type=cache,target=/root/.cache/pip pip3 install virtualenv
|
| 33 |
+
RUN mkdir /app
|
| 34 |
+
|
| 35 |
+
WORKDIR /app
|
| 36 |
+
|
| 37 |
+
ARG WEBUI_VERSION
|
| 38 |
+
RUN test -n "${WEBUI_VERSION}" && git reset --hard ${WEBUI_VERSION} || echo "Using provided webui source"
|
| 39 |
+
|
| 40 |
+
RUN virtualenv /app/venv
|
| 41 |
+
RUN . /app/venv/bin/activate && \
|
| 42 |
+
pip3 install --upgrade pip setuptools && \
|
| 43 |
+
pip3 install torch torchvision torchaudio
|
| 44 |
+
|
| 45 |
+
COPY --from=builder /build /app/repositories/GPTQ-for-LLaMa
|
| 46 |
+
RUN . /app/venv/bin/activate && \
|
| 47 |
+
pip3 install /app/repositories/GPTQ-for-LLaMa/*.whl
|
| 48 |
+
|
| 49 |
+
COPY extensions/api/requirements.txt /app/extensions/api/requirements.txt
|
| 50 |
+
COPY extensions/elevenlabs_tts/requirements.txt /app/extensions/elevenlabs_tts/requirements.txt
|
| 51 |
+
COPY extensions/google_translate/requirements.txt /app/extensions/google_translate/requirements.txt
|
| 52 |
+
COPY extensions/silero_tts/requirements.txt /app/extensions/silero_tts/requirements.txt
|
| 53 |
+
COPY extensions/whisper_stt/requirements.txt /app/extensions/whisper_stt/requirements.txt
|
| 54 |
+
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/api && pip3 install -r requirements.txt
|
| 55 |
+
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/elevenlabs_tts && pip3 install -r requirements.txt
|
| 56 |
+
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/google_translate && pip3 install -r requirements.txt
|
| 57 |
+
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/silero_tts && pip3 install -r requirements.txt
|
| 58 |
+
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/whisper_stt && pip3 install -r requirements.txt
|
| 59 |
+
|
| 60 |
+
COPY requirements.txt /app/requirements.txt
|
| 61 |
+
RUN . /app/venv/bin/activate && \
|
| 62 |
+
pip3 install -r requirements.txt
|
| 63 |
+
|
| 64 |
+
RUN cp /app/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118.so /app/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cpu.so
|
| 65 |
+
|
| 66 |
+
COPY . /app/
|
| 67 |
+
ENV CLI_ARGS=""
|
| 68 |
+
CMD . /app/venv/bin/activate && python3 server.py ${CLI_ARGS}
|
text-generation-webui/LICENSE
ADDED
|
@@ -0,0 +1,661 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GNU AFFERO GENERAL PUBLIC LICENSE
|
| 2 |
+
Version 3, 19 November 2007
|
| 3 |
+
|
| 4 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 5 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 6 |
+
of this license document, but changing it is not allowed.
|
| 7 |
+
|
| 8 |
+
Preamble
|
| 9 |
+
|
| 10 |
+
The GNU Affero General Public License is a free, copyleft license for
|
| 11 |
+
software and other kinds of works, specifically designed to ensure
|
| 12 |
+
cooperation with the community in the case of network server software.
|
| 13 |
+
|
| 14 |
+
The licenses for most software and other practical works are designed
|
| 15 |
+
to take away your freedom to share and change the works. By contrast,
|
| 16 |
+
our General Public Licenses are intended to guarantee your freedom to
|
| 17 |
+
share and change all versions of a program--to make sure it remains free
|
| 18 |
+
software for all its users.
|
| 19 |
+
|
| 20 |
+
When we speak of free software, we are referring to freedom, not
|
| 21 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 22 |
+
have the freedom to distribute copies of free software (and charge for
|
| 23 |
+
them if you wish), that you receive source code or can get it if you
|
| 24 |
+
want it, that you can change the software or use pieces of it in new
|
| 25 |
+
free programs, and that you know you can do these things.
|
| 26 |
+
|
| 27 |
+
Developers that use our General Public Licenses protect your rights
|
| 28 |
+
with two steps: (1) assert copyright on the software, and (2) offer
|
| 29 |
+
you this License which gives you legal permission to copy, distribute
|
| 30 |
+
and/or modify the software.
|
| 31 |
+
|
| 32 |
+
A secondary benefit of defending all users' freedom is that
|
| 33 |
+
improvements made in alternate versions of the program, if they
|
| 34 |
+
receive widespread use, become available for other developers to
|
| 35 |
+
incorporate. Many developers of free software are heartened and
|
| 36 |
+
encouraged by the resulting cooperation. However, in the case of
|
| 37 |
+
software used on network servers, this result may fail to come about.
|
| 38 |
+
The GNU General Public License permits making a modified version and
|
| 39 |
+
letting the public access it on a server without ever releasing its
|
| 40 |
+
source code to the public.
|
| 41 |
+
|
| 42 |
+
The GNU Affero General Public License is designed specifically to
|
| 43 |
+
ensure that, in such cases, the modified source code becomes available
|
| 44 |
+
to the community. It requires the operator of a network server to
|
| 45 |
+
provide the source code of the modified version running there to the
|
| 46 |
+
users of that server. Therefore, public use of a modified version, on
|
| 47 |
+
a publicly accessible server, gives the public access to the source
|
| 48 |
+
code of the modified version.
|
| 49 |
+
|
| 50 |
+
An older license, called the Affero General Public License and
|
| 51 |
+
published by Affero, was designed to accomplish similar goals. This is
|
| 52 |
+
a different license, not a version of the Affero GPL, but Affero has
|
| 53 |
+
released a new version of the Affero GPL which permits relicensing under
|
| 54 |
+
this license.
|
| 55 |
+
|
| 56 |
+
The precise terms and conditions for copying, distribution and
|
| 57 |
+
modification follow.
|
| 58 |
+
|
| 59 |
+
TERMS AND CONDITIONS
|
| 60 |
+
|
| 61 |
+
0. Definitions.
|
| 62 |
+
|
| 63 |
+
"This License" refers to version 3 of the GNU Affero General Public License.
|
| 64 |
+
|
| 65 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 66 |
+
works, such as semiconductor masks.
|
| 67 |
+
|
| 68 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 69 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 70 |
+
"recipients" may be individuals or organizations.
|
| 71 |
+
|
| 72 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 73 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 74 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 75 |
+
earlier work or a work "based on" the earlier work.
|
| 76 |
+
|
| 77 |
+
A "covered work" means either the unmodified Program or a work based
|
| 78 |
+
on the Program.
|
| 79 |
+
|
| 80 |
+
To "propagate" a work means to do anything with it that, without
|
| 81 |
+
permission, would make you directly or secondarily liable for
|
| 82 |
+
infringement under applicable copyright law, except executing it on a
|
| 83 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 84 |
+
distribution (with or without modification), making available to the
|
| 85 |
+
public, and in some countries other activities as well.
|
| 86 |
+
|
| 87 |
+
To "convey" a work means any kind of propagation that enables other
|
| 88 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 89 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 90 |
+
|
| 91 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 92 |
+
to the extent that it includes a convenient and prominently visible
|
| 93 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 94 |
+
tells the user that there is no warranty for the work (except to the
|
| 95 |
+
extent that warranties are provided), that licensees may convey the
|
| 96 |
+
work under this License, and how to view a copy of this License. If
|
| 97 |
+
the interface presents a list of user commands or options, such as a
|
| 98 |
+
menu, a prominent item in the list meets this criterion.
|
| 99 |
+
|
| 100 |
+
1. Source Code.
|
| 101 |
+
|
| 102 |
+
The "source code" for a work means the preferred form of the work
|
| 103 |
+
for making modifications to it. "Object code" means any non-source
|
| 104 |
+
form of a work.
|
| 105 |
+
|
| 106 |
+
A "Standard Interface" means an interface that either is an official
|
| 107 |
+
standard defined by a recognized standards body, or, in the case of
|
| 108 |
+
interfaces specified for a particular programming language, one that
|
| 109 |
+
is widely used among developers working in that language.
|
| 110 |
+
|
| 111 |
+
The "System Libraries" of an executable work include anything, other
|
| 112 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 113 |
+
packaging a Major Component, but which is not part of that Major
|
| 114 |
+
Component, and (b) serves only to enable use of the work with that
|
| 115 |
+
Major Component, or to implement a Standard Interface for which an
|
| 116 |
+
implementation is available to the public in source code form. A
|
| 117 |
+
"Major Component", in this context, means a major essential component
|
| 118 |
+
(kernel, window system, and so on) of the specific operating system
|
| 119 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 120 |
+
produce the work, or an object code interpreter used to run it.
|
| 121 |
+
|
| 122 |
+
The "Corresponding Source" for a work in object code form means all
|
| 123 |
+
the source code needed to generate, install, and (for an executable
|
| 124 |
+
work) run the object code and to modify the work, including scripts to
|
| 125 |
+
control those activities. However, it does not include the work's
|
| 126 |
+
System Libraries, or general-purpose tools or generally available free
|
| 127 |
+
programs which are used unmodified in performing those activities but
|
| 128 |
+
which are not part of the work. For example, Corresponding Source
|
| 129 |
+
includes interface definition files associated with source files for
|
| 130 |
+
the work, and the source code for shared libraries and dynamically
|
| 131 |
+
linked subprograms that the work is specifically designed to require,
|
| 132 |
+
such as by intimate data communication or control flow between those
|
| 133 |
+
subprograms and other parts of the work.
|
| 134 |
+
|
| 135 |
+
The Corresponding Source need not include anything that users
|
| 136 |
+
can regenerate automatically from other parts of the Corresponding
|
| 137 |
+
Source.
|
| 138 |
+
|
| 139 |
+
The Corresponding Source for a work in source code form is that
|
| 140 |
+
same work.
|
| 141 |
+
|
| 142 |
+
2. Basic Permissions.
|
| 143 |
+
|
| 144 |
+
All rights granted under this License are granted for the term of
|
| 145 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 146 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 147 |
+
permission to run the unmodified Program. The output from running a
|
| 148 |
+
covered work is covered by this License only if the output, given its
|
| 149 |
+
content, constitutes a covered work. This License acknowledges your
|
| 150 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 151 |
+
|
| 152 |
+
You may make, run and propagate covered works that you do not
|
| 153 |
+
convey, without conditions so long as your license otherwise remains
|
| 154 |
+
in force. You may convey covered works to others for the sole purpose
|
| 155 |
+
of having them make modifications exclusively for you, or provide you
|
| 156 |
+
with facilities for running those works, provided that you comply with
|
| 157 |
+
the terms of this License in conveying all material for which you do
|
| 158 |
+
not control copyright. Those thus making or running the covered works
|
| 159 |
+
for you must do so exclusively on your behalf, under your direction
|
| 160 |
+
and control, on terms that prohibit them from making any copies of
|
| 161 |
+
your copyrighted material outside their relationship with you.
|
| 162 |
+
|
| 163 |
+
Conveying under any other circumstances is permitted solely under
|
| 164 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 165 |
+
makes it unnecessary.
|
| 166 |
+
|
| 167 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 168 |
+
|
| 169 |
+
No covered work shall be deemed part of an effective technological
|
| 170 |
+
measure under any applicable law fulfilling obligations under article
|
| 171 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 172 |
+
similar laws prohibiting or restricting circumvention of such
|
| 173 |
+
measures.
|
| 174 |
+
|
| 175 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 176 |
+
circumvention of technological measures to the extent such circumvention
|
| 177 |
+
is effected by exercising rights under this License with respect to
|
| 178 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 179 |
+
modification of the work as a means of enforcing, against the work's
|
| 180 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 181 |
+
technological measures.
|
| 182 |
+
|
| 183 |
+
4. Conveying Verbatim Copies.
|
| 184 |
+
|
| 185 |
+
You may convey verbatim copies of the Program's source code as you
|
| 186 |
+
receive it, in any medium, provided that you conspicuously and
|
| 187 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 188 |
+
keep intact all notices stating that this License and any
|
| 189 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 190 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 191 |
+
recipients a copy of this License along with the Program.
|
| 192 |
+
|
| 193 |
+
You may charge any price or no price for each copy that you convey,
|
| 194 |
+
and you may offer support or warranty protection for a fee.
|
| 195 |
+
|
| 196 |
+
5. Conveying Modified Source Versions.
|
| 197 |
+
|
| 198 |
+
You may convey a work based on the Program, or the modifications to
|
| 199 |
+
produce it from the Program, in the form of source code under the
|
| 200 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 201 |
+
|
| 202 |
+
a) The work must carry prominent notices stating that you modified
|
| 203 |
+
it, and giving a relevant date.
|
| 204 |
+
|
| 205 |
+
b) The work must carry prominent notices stating that it is
|
| 206 |
+
released under this License and any conditions added under section
|
| 207 |
+
7. This requirement modifies the requirement in section 4 to
|
| 208 |
+
"keep intact all notices".
|
| 209 |
+
|
| 210 |
+
c) You must license the entire work, as a whole, under this
|
| 211 |
+
License to anyone who comes into possession of a copy. This
|
| 212 |
+
License will therefore apply, along with any applicable section 7
|
| 213 |
+
additional terms, to the whole of the work, and all its parts,
|
| 214 |
+
regardless of how they are packaged. This License gives no
|
| 215 |
+
permission to license the work in any other way, but it does not
|
| 216 |
+
invalidate such permission if you have separately received it.
|
| 217 |
+
|
| 218 |
+
d) If the work has interactive user interfaces, each must display
|
| 219 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 220 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 221 |
+
work need not make them do so.
|
| 222 |
+
|
| 223 |
+
A compilation of a covered work with other separate and independent
|
| 224 |
+
works, which are not by their nature extensions of the covered work,
|
| 225 |
+
and which are not combined with it such as to form a larger program,
|
| 226 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 227 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 228 |
+
used to limit the access or legal rights of the compilation's users
|
| 229 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 230 |
+
in an aggregate does not cause this License to apply to the other
|
| 231 |
+
parts of the aggregate.
|
| 232 |
+
|
| 233 |
+
6. Conveying Non-Source Forms.
|
| 234 |
+
|
| 235 |
+
You may convey a covered work in object code form under the terms
|
| 236 |
+
of sections 4 and 5, provided that you also convey the
|
| 237 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 238 |
+
in one of these ways:
|
| 239 |
+
|
| 240 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 241 |
+
(including a physical distribution medium), accompanied by the
|
| 242 |
+
Corresponding Source fixed on a durable physical medium
|
| 243 |
+
customarily used for software interchange.
|
| 244 |
+
|
| 245 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 246 |
+
(including a physical distribution medium), accompanied by a
|
| 247 |
+
written offer, valid for at least three years and valid for as
|
| 248 |
+
long as you offer spare parts or customer support for that product
|
| 249 |
+
model, to give anyone who possesses the object code either (1) a
|
| 250 |
+
copy of the Corresponding Source for all the software in the
|
| 251 |
+
product that is covered by this License, on a durable physical
|
| 252 |
+
medium customarily used for software interchange, for a price no
|
| 253 |
+
more than your reasonable cost of physically performing this
|
| 254 |
+
conveying of source, or (2) access to copy the
|
| 255 |
+
Corresponding Source from a network server at no charge.
|
| 256 |
+
|
| 257 |
+
c) Convey individual copies of the object code with a copy of the
|
| 258 |
+
written offer to provide the Corresponding Source. This
|
| 259 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 260 |
+
only if you received the object code with such an offer, in accord
|
| 261 |
+
with subsection 6b.
|
| 262 |
+
|
| 263 |
+
d) Convey the object code by offering access from a designated
|
| 264 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 265 |
+
Corresponding Source in the same way through the same place at no
|
| 266 |
+
further charge. You need not require recipients to copy the
|
| 267 |
+
Corresponding Source along with the object code. If the place to
|
| 268 |
+
copy the object code is a network server, the Corresponding Source
|
| 269 |
+
may be on a different server (operated by you or a third party)
|
| 270 |
+
that supports equivalent copying facilities, provided you maintain
|
| 271 |
+
clear directions next to the object code saying where to find the
|
| 272 |
+
Corresponding Source. Regardless of what server hosts the
|
| 273 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 274 |
+
available for as long as needed to satisfy these requirements.
|
| 275 |
+
|
| 276 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 277 |
+
you inform other peers where the object code and Corresponding
|
| 278 |
+
Source of the work are being offered to the general public at no
|
| 279 |
+
charge under subsection 6d.
|
| 280 |
+
|
| 281 |
+
A separable portion of the object code, whose source code is excluded
|
| 282 |
+
from the Corresponding Source as a System Library, need not be
|
| 283 |
+
included in conveying the object code work.
|
| 284 |
+
|
| 285 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 286 |
+
tangible personal property which is normally used for personal, family,
|
| 287 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 288 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 289 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 290 |
+
product received by a particular user, "normally used" refers to a
|
| 291 |
+
typical or common use of that class of product, regardless of the status
|
| 292 |
+
of the particular user or of the way in which the particular user
|
| 293 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 294 |
+
is a consumer product regardless of whether the product has substantial
|
| 295 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 296 |
+
the only significant mode of use of the product.
|
| 297 |
+
|
| 298 |
+
"Installation Information" for a User Product means any methods,
|
| 299 |
+
procedures, authorization keys, or other information required to install
|
| 300 |
+
and execute modified versions of a covered work in that User Product from
|
| 301 |
+
a modified version of its Corresponding Source. The information must
|
| 302 |
+
suffice to ensure that the continued functioning of the modified object
|
| 303 |
+
code is in no case prevented or interfered with solely because
|
| 304 |
+
modification has been made.
|
| 305 |
+
|
| 306 |
+
If you convey an object code work under this section in, or with, or
|
| 307 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 308 |
+
part of a transaction in which the right of possession and use of the
|
| 309 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 310 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 311 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 312 |
+
by the Installation Information. But this requirement does not apply
|
| 313 |
+
if neither you nor any third party retains the ability to install
|
| 314 |
+
modified object code on the User Product (for example, the work has
|
| 315 |
+
been installed in ROM).
|
| 316 |
+
|
| 317 |
+
The requirement to provide Installation Information does not include a
|
| 318 |
+
requirement to continue to provide support service, warranty, or updates
|
| 319 |
+
for a work that has been modified or installed by the recipient, or for
|
| 320 |
+
the User Product in which it has been modified or installed. Access to a
|
| 321 |
+
network may be denied when the modification itself materially and
|
| 322 |
+
adversely affects the operation of the network or violates the rules and
|
| 323 |
+
protocols for communication across the network.
|
| 324 |
+
|
| 325 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 326 |
+
in accord with this section must be in a format that is publicly
|
| 327 |
+
documented (and with an implementation available to the public in
|
| 328 |
+
source code form), and must require no special password or key for
|
| 329 |
+
unpacking, reading or copying.
|
| 330 |
+
|
| 331 |
+
7. Additional Terms.
|
| 332 |
+
|
| 333 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 334 |
+
License by making exceptions from one or more of its conditions.
|
| 335 |
+
Additional permissions that are applicable to the entire Program shall
|
| 336 |
+
be treated as though they were included in this License, to the extent
|
| 337 |
+
that they are valid under applicable law. If additional permissions
|
| 338 |
+
apply only to part of the Program, that part may be used separately
|
| 339 |
+
under those permissions, but the entire Program remains governed by
|
| 340 |
+
this License without regard to the additional permissions.
|
| 341 |
+
|
| 342 |
+
When you convey a copy of a covered work, you may at your option
|
| 343 |
+
remove any additional permissions from that copy, or from any part of
|
| 344 |
+
it. (Additional permissions may be written to require their own
|
| 345 |
+
removal in certain cases when you modify the work.) You may place
|
| 346 |
+
additional permissions on material, added by you to a covered work,
|
| 347 |
+
for which you have or can give appropriate copyright permission.
|
| 348 |
+
|
| 349 |
+
Notwithstanding any other provision of this License, for material you
|
| 350 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 351 |
+
that material) supplement the terms of this License with terms:
|
| 352 |
+
|
| 353 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 354 |
+
terms of sections 15 and 16 of this License; or
|
| 355 |
+
|
| 356 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 357 |
+
author attributions in that material or in the Appropriate Legal
|
| 358 |
+
Notices displayed by works containing it; or
|
| 359 |
+
|
| 360 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 361 |
+
requiring that modified versions of such material be marked in
|
| 362 |
+
reasonable ways as different from the original version; or
|
| 363 |
+
|
| 364 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 365 |
+
authors of the material; or
|
| 366 |
+
|
| 367 |
+
e) Declining to grant rights under trademark law for use of some
|
| 368 |
+
trade names, trademarks, or service marks; or
|
| 369 |
+
|
| 370 |
+
f) Requiring indemnification of licensors and authors of that
|
| 371 |
+
material by anyone who conveys the material (or modified versions of
|
| 372 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 373 |
+
any liability that these contractual assumptions directly impose on
|
| 374 |
+
those licensors and authors.
|
| 375 |
+
|
| 376 |
+
All other non-permissive additional terms are considered "further
|
| 377 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 378 |
+
received it, or any part of it, contains a notice stating that it is
|
| 379 |
+
governed by this License along with a term that is a further
|
| 380 |
+
restriction, you may remove that term. If a license document contains
|
| 381 |
+
a further restriction but permits relicensing or conveying under this
|
| 382 |
+
License, you may add to a covered work material governed by the terms
|
| 383 |
+
of that license document, provided that the further restriction does
|
| 384 |
+
not survive such relicensing or conveying.
|
| 385 |
+
|
| 386 |
+
If you add terms to a covered work in accord with this section, you
|
| 387 |
+
must place, in the relevant source files, a statement of the
|
| 388 |
+
additional terms that apply to those files, or a notice indicating
|
| 389 |
+
where to find the applicable terms.
|
| 390 |
+
|
| 391 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 392 |
+
form of a separately written license, or stated as exceptions;
|
| 393 |
+
the above requirements apply either way.
|
| 394 |
+
|
| 395 |
+
8. Termination.
|
| 396 |
+
|
| 397 |
+
You may not propagate or modify a covered work except as expressly
|
| 398 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 399 |
+
modify it is void, and will automatically terminate your rights under
|
| 400 |
+
this License (including any patent licenses granted under the third
|
| 401 |
+
paragraph of section 11).
|
| 402 |
+
|
| 403 |
+
However, if you cease all violation of this License, then your
|
| 404 |
+
license from a particular copyright holder is reinstated (a)
|
| 405 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 406 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 407 |
+
holder fails to notify you of the violation by some reasonable means
|
| 408 |
+
prior to 60 days after the cessation.
|
| 409 |
+
|
| 410 |
+
Moreover, your license from a particular copyright holder is
|
| 411 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 412 |
+
violation by some reasonable means, this is the first time you have
|
| 413 |
+
received notice of violation of this License (for any work) from that
|
| 414 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 415 |
+
your receipt of the notice.
|
| 416 |
+
|
| 417 |
+
Termination of your rights under this section does not terminate the
|
| 418 |
+
licenses of parties who have received copies or rights from you under
|
| 419 |
+
this License. If your rights have been terminated and not permanently
|
| 420 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 421 |
+
material under section 10.
|
| 422 |
+
|
| 423 |
+
9. Acceptance Not Required for Having Copies.
|
| 424 |
+
|
| 425 |
+
You are not required to accept this License in order to receive or
|
| 426 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 427 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 428 |
+
to receive a copy likewise does not require acceptance. However,
|
| 429 |
+
nothing other than this License grants you permission to propagate or
|
| 430 |
+
modify any covered work. These actions infringe copyright if you do
|
| 431 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 432 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 433 |
+
|
| 434 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 435 |
+
|
| 436 |
+
Each time you convey a covered work, the recipient automatically
|
| 437 |
+
receives a license from the original licensors, to run, modify and
|
| 438 |
+
propagate that work, subject to this License. You are not responsible
|
| 439 |
+
for enforcing compliance by third parties with this License.
|
| 440 |
+
|
| 441 |
+
An "entity transaction" is a transaction transferring control of an
|
| 442 |
+
organization, or substantially all assets of one, or subdividing an
|
| 443 |
+
organization, or merging organizations. If propagation of a covered
|
| 444 |
+
work results from an entity transaction, each party to that
|
| 445 |
+
transaction who receives a copy of the work also receives whatever
|
| 446 |
+
licenses to the work the party's predecessor in interest had or could
|
| 447 |
+
give under the previous paragraph, plus a right to possession of the
|
| 448 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 449 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 450 |
+
|
| 451 |
+
You may not impose any further restrictions on the exercise of the
|
| 452 |
+
rights granted or affirmed under this License. For example, you may
|
| 453 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 454 |
+
rights granted under this License, and you may not initiate litigation
|
| 455 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 456 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 457 |
+
sale, or importing the Program or any portion of it.
|
| 458 |
+
|
| 459 |
+
11. Patents.
|
| 460 |
+
|
| 461 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 462 |
+
License of the Program or a work on which the Program is based. The
|
| 463 |
+
work thus licensed is called the contributor's "contributor version".
|
| 464 |
+
|
| 465 |
+
A contributor's "essential patent claims" are all patent claims
|
| 466 |
+
owned or controlled by the contributor, whether already acquired or
|
| 467 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 468 |
+
by this License, of making, using, or selling its contributor version,
|
| 469 |
+
but do not include claims that would be infringed only as a
|
| 470 |
+
consequence of further modification of the contributor version. For
|
| 471 |
+
purposes of this definition, "control" includes the right to grant
|
| 472 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 473 |
+
this License.
|
| 474 |
+
|
| 475 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 476 |
+
patent license under the contributor's essential patent claims, to
|
| 477 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 478 |
+
propagate the contents of its contributor version.
|
| 479 |
+
|
| 480 |
+
In the following three paragraphs, a "patent license" is any express
|
| 481 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 482 |
+
(such as an express permission to practice a patent or covenant not to
|
| 483 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 484 |
+
party means to make such an agreement or commitment not to enforce a
|
| 485 |
+
patent against the party.
|
| 486 |
+
|
| 487 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 488 |
+
and the Corresponding Source of the work is not available for anyone
|
| 489 |
+
to copy, free of charge and under the terms of this License, through a
|
| 490 |
+
publicly available network server or other readily accessible means,
|
| 491 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 492 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 493 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 494 |
+
consistent with the requirements of this License, to extend the patent
|
| 495 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 496 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 497 |
+
covered work in a country, or your recipient's use of the covered work
|
| 498 |
+
in a country, would infringe one or more identifiable patents in that
|
| 499 |
+
country that you have reason to believe are valid.
|
| 500 |
+
|
| 501 |
+
If, pursuant to or in connection with a single transaction or
|
| 502 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 503 |
+
covered work, and grant a patent license to some of the parties
|
| 504 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 505 |
+
or convey a specific copy of the covered work, then the patent license
|
| 506 |
+
you grant is automatically extended to all recipients of the covered
|
| 507 |
+
work and works based on it.
|
| 508 |
+
|
| 509 |
+
A patent license is "discriminatory" if it does not include within
|
| 510 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 511 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 512 |
+
specifically granted under this License. You may not convey a covered
|
| 513 |
+
work if you are a party to an arrangement with a third party that is
|
| 514 |
+
in the business of distributing software, under which you make payment
|
| 515 |
+
to the third party based on the extent of your activity of conveying
|
| 516 |
+
the work, and under which the third party grants, to any of the
|
| 517 |
+
parties who would receive the covered work from you, a discriminatory
|
| 518 |
+
patent license (a) in connection with copies of the covered work
|
| 519 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 520 |
+
for and in connection with specific products or compilations that
|
| 521 |
+
contain the covered work, unless you entered into that arrangement,
|
| 522 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 523 |
+
|
| 524 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 525 |
+
any implied license or other defenses to infringement that may
|
| 526 |
+
otherwise be available to you under applicable patent law.
|
| 527 |
+
|
| 528 |
+
12. No Surrender of Others' Freedom.
|
| 529 |
+
|
| 530 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 531 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 532 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 533 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 534 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 535 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 536 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 537 |
+
the Program, the only way you could satisfy both those terms and this
|
| 538 |
+
License would be to refrain entirely from conveying the Program.
|
| 539 |
+
|
| 540 |
+
13. Remote Network Interaction; Use with the GNU General Public License.
|
| 541 |
+
|
| 542 |
+
Notwithstanding any other provision of this License, if you modify the
|
| 543 |
+
Program, your modified version must prominently offer all users
|
| 544 |
+
interacting with it remotely through a computer network (if your version
|
| 545 |
+
supports such interaction) an opportunity to receive the Corresponding
|
| 546 |
+
Source of your version by providing access to the Corresponding Source
|
| 547 |
+
from a network server at no charge, through some standard or customary
|
| 548 |
+
means of facilitating copying of software. This Corresponding Source
|
| 549 |
+
shall include the Corresponding Source for any work covered by version 3
|
| 550 |
+
of the GNU General Public License that is incorporated pursuant to the
|
| 551 |
+
following paragraph.
|
| 552 |
+
|
| 553 |
+
Notwithstanding any other provision of this License, you have
|
| 554 |
+
permission to link or combine any covered work with a work licensed
|
| 555 |
+
under version 3 of the GNU General Public License into a single
|
| 556 |
+
combined work, and to convey the resulting work. The terms of this
|
| 557 |
+
License will continue to apply to the part which is the covered work,
|
| 558 |
+
but the work with which it is combined will remain governed by version
|
| 559 |
+
3 of the GNU General Public License.
|
| 560 |
+
|
| 561 |
+
14. Revised Versions of this License.
|
| 562 |
+
|
| 563 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 564 |
+
the GNU Affero General Public License from time to time. Such new versions
|
| 565 |
+
will be similar in spirit to the present version, but may differ in detail to
|
| 566 |
+
address new problems or concerns.
|
| 567 |
+
|
| 568 |
+
Each version is given a distinguishing version number. If the
|
| 569 |
+
Program specifies that a certain numbered version of the GNU Affero General
|
| 570 |
+
Public License "or any later version" applies to it, you have the
|
| 571 |
+
option of following the terms and conditions either of that numbered
|
| 572 |
+
version or of any later version published by the Free Software
|
| 573 |
+
Foundation. If the Program does not specify a version number of the
|
| 574 |
+
GNU Affero General Public License, you may choose any version ever published
|
| 575 |
+
by the Free Software Foundation.
|
| 576 |
+
|
| 577 |
+
If the Program specifies that a proxy can decide which future
|
| 578 |
+
versions of the GNU Affero General Public License can be used, that proxy's
|
| 579 |
+
public statement of acceptance of a version permanently authorizes you
|
| 580 |
+
to choose that version for the Program.
|
| 581 |
+
|
| 582 |
+
Later license versions may give you additional or different
|
| 583 |
+
permissions. However, no additional obligations are imposed on any
|
| 584 |
+
author or copyright holder as a result of your choosing to follow a
|
| 585 |
+
later version.
|
| 586 |
+
|
| 587 |
+
15. Disclaimer of Warranty.
|
| 588 |
+
|
| 589 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 590 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 591 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 592 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 593 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 594 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 595 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 596 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 597 |
+
|
| 598 |
+
16. Limitation of Liability.
|
| 599 |
+
|
| 600 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 601 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 602 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 603 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 604 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 605 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 606 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 607 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 608 |
+
SUCH DAMAGES.
|
| 609 |
+
|
| 610 |
+
17. Interpretation of Sections 15 and 16.
|
| 611 |
+
|
| 612 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 613 |
+
above cannot be given local legal effect according to their terms,
|
| 614 |
+
reviewing courts shall apply local law that most closely approximates
|
| 615 |
+
an absolute waiver of all civil liability in connection with the
|
| 616 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 617 |
+
copy of the Program in return for a fee.
|
| 618 |
+
|
| 619 |
+
END OF TERMS AND CONDITIONS
|
| 620 |
+
|
| 621 |
+
How to Apply These Terms to Your New Programs
|
| 622 |
+
|
| 623 |
+
If you develop a new program, and you want it to be of the greatest
|
| 624 |
+
possible use to the public, the best way to achieve this is to make it
|
| 625 |
+
free software which everyone can redistribute and change under these terms.
|
| 626 |
+
|
| 627 |
+
To do so, attach the following notices to the program. It is safest
|
| 628 |
+
to attach them to the start of each source file to most effectively
|
| 629 |
+
state the exclusion of warranty; and each file should have at least
|
| 630 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 631 |
+
|
| 632 |
+
<one line to give the program's name and a brief idea of what it does.>
|
| 633 |
+
Copyright (C) <year> <name of author>
|
| 634 |
+
|
| 635 |
+
This program is free software: you can redistribute it and/or modify
|
| 636 |
+
it under the terms of the GNU Affero General Public License as published
|
| 637 |
+
by the Free Software Foundation, either version 3 of the License, or
|
| 638 |
+
(at your option) any later version.
|
| 639 |
+
|
| 640 |
+
This program is distributed in the hope that it will be useful,
|
| 641 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 642 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 643 |
+
GNU Affero General Public License for more details.
|
| 644 |
+
|
| 645 |
+
You should have received a copy of the GNU Affero General Public License
|
| 646 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 647 |
+
|
| 648 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 649 |
+
|
| 650 |
+
If your software can interact with users remotely through a computer
|
| 651 |
+
network, you should also make sure that it provides a way for users to
|
| 652 |
+
get its source. For example, if your program is a web application, its
|
| 653 |
+
interface could display a "Source" link that leads users to an archive
|
| 654 |
+
of the code. There are many ways you could offer source, and different
|
| 655 |
+
solutions will be better for different programs; see section 13 for the
|
| 656 |
+
specific requirements.
|
| 657 |
+
|
| 658 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 659 |
+
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
| 660 |
+
For more information on this, and how to apply and follow the GNU AGPL, see
|
| 661 |
+
<https://www.gnu.org/licenses/>.
|
text-generation-webui/README.md
ADDED
|
@@ -0,0 +1,310 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Text generation web UI
|
| 2 |
+
|
| 3 |
+
A gradio web UI for running Large Language Models like LLaMA, llama.cpp, GPT-J, Pythia, OPT, and GALACTICA.
|
| 4 |
+
|
| 5 |
+
Its goal is to become the [AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) of text generation.
|
| 6 |
+
|
| 7 |
+
| |  |
|
| 8 |
+
|:---:|:---:|
|
| 9 |
+
| |  |
|
| 10 |
+
|
| 11 |
+
## Features
|
| 12 |
+
|
| 13 |
+
* Dropdown menu for switching between models
|
| 14 |
+
* Notebook mode that resembles OpenAI's playground
|
| 15 |
+
* Chat mode for conversation and role playing
|
| 16 |
+
* Instruct mode compatible with Alpaca, Vicuna, Open Assistant, Dolly, Koala, and ChatGLM formats **\*NEW!\***
|
| 17 |
+
* Nice HTML output for GPT-4chan
|
| 18 |
+
* Markdown output for [GALACTICA](https://github.com/paperswithcode/galai), including LaTeX rendering
|
| 19 |
+
* [Custom chat characters](https://github.com/oobabooga/text-generation-webui/wiki/Custom-chat-characters)
|
| 20 |
+
* Advanced chat features (send images, get audio responses with TTS)
|
| 21 |
+
* Very efficient text streaming
|
| 22 |
+
* Parameter presets
|
| 23 |
+
* 8-bit mode
|
| 24 |
+
* Layers splitting across GPU(s), CPU, and disk
|
| 25 |
+
* CPU mode
|
| 26 |
+
* [FlexGen](https://github.com/oobabooga/text-generation-webui/wiki/FlexGen)
|
| 27 |
+
* [DeepSpeed ZeRO-3](https://github.com/oobabooga/text-generation-webui/wiki/DeepSpeed)
|
| 28 |
+
* API [with](https://github.com/oobabooga/text-generation-webui/blob/main/api-example-stream.py) streaming and [without](https://github.com/oobabooga/text-generation-webui/blob/main/api-example.py) streaming
|
| 29 |
+
* [LLaMA model](https://github.com/oobabooga/text-generation-webui/wiki/LLaMA-model)
|
| 30 |
+
* [4-bit GPTQ mode](https://github.com/oobabooga/text-generation-webui/wiki/GPTQ-models-(4-bit-mode))
|
| 31 |
+
* [llama.cpp](https://github.com/oobabooga/text-generation-webui/wiki/llama.cpp-models) **\*NEW!\***
|
| 32 |
+
* [RWKV model](https://github.com/oobabooga/text-generation-webui/wiki/RWKV-model)
|
| 33 |
+
* [LoRA (loading and training)](https://github.com/oobabooga/text-generation-webui/wiki/Using-LoRAs)
|
| 34 |
+
* Softprompts
|
| 35 |
+
* [Extensions](https://github.com/oobabooga/text-generation-webui/wiki/Extensions)
|
| 36 |
+
|
| 37 |
+
## Installation
|
| 38 |
+
|
| 39 |
+
### One-click installers
|
| 40 |
+
|
| 41 |
+
[oobabooga-windows.zip](https://github.com/oobabooga/text-generation-webui/releases/download/installers/oobabooga-windows.zip)
|
| 42 |
+
|
| 43 |
+
Just download the zip above, extract it, and double click on "install". The web UI and all its dependencies will be installed in the same folder.
|
| 44 |
+
|
| 45 |
+
* To download a model, double click on "download-model"
|
| 46 |
+
* To start the web UI, double click on "start-webui"
|
| 47 |
+
|
| 48 |
+
Source codes: https://github.com/oobabooga/one-click-installers
|
| 49 |
+
|
| 50 |
+
> **Note**
|
| 51 |
+
>
|
| 52 |
+
> Thanks to [@jllllll](https://github.com/jllllll) and [@ClayShoaf](https://github.com/ClayShoaf), the Windows 1-click installer now sets up 8-bit and 4-bit requirements out of the box. No additional installation steps are necessary.
|
| 53 |
+
|
| 54 |
+
> **Note**
|
| 55 |
+
>
|
| 56 |
+
> There is no need to run the installer as admin.
|
| 57 |
+
|
| 58 |
+
### Manual installation using Conda
|
| 59 |
+
|
| 60 |
+
Recommended if you have some experience with the command-line.
|
| 61 |
+
|
| 62 |
+
On Windows, I additionally recommend carrying out the installation on WSL instead of the base system: [WSL installation guide](https://github.com/oobabooga/text-generation-webui/wiki/WSL-installation-guide).
|
| 63 |
+
|
| 64 |
+
#### 0. Install Conda
|
| 65 |
+
|
| 66 |
+
https://docs.conda.io/en/latest/miniconda.html
|
| 67 |
+
|
| 68 |
+
On Linux or WSL, it can be automatically installed with these two commands:
|
| 69 |
+
|
| 70 |
+
```
|
| 71 |
+
curl -sL "https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh" > "Miniconda3.sh"
|
| 72 |
+
bash Miniconda3.sh
|
| 73 |
+
```
|
| 74 |
+
Source: https://educe-ubc.github.io/conda.html
|
| 75 |
+
|
| 76 |
+
#### 0.1 (Ubuntu/WSL) Install build tools
|
| 77 |
+
|
| 78 |
+
```
|
| 79 |
+
sudo apt install build-essential
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
#### 1. Create a new conda environment
|
| 84 |
+
|
| 85 |
+
```
|
| 86 |
+
conda create -n textgen python=3.10.9
|
| 87 |
+
conda activate textgen
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
#### 2. Install Pytorch
|
| 91 |
+
|
| 92 |
+
| System | GPU | Command |
|
| 93 |
+
|--------|---------|---------|
|
| 94 |
+
| Linux/WSL | NVIDIA | `pip3 install torch torchvision torchaudio` |
|
| 95 |
+
| Linux | AMD | `pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2` |
|
| 96 |
+
| MacOS + MPS (untested) | Any | `pip3 install torch torchvision torchaudio` |
|
| 97 |
+
|
| 98 |
+
The up to date commands can be found here: https://pytorch.org/get-started/locally/.
|
| 99 |
+
|
| 100 |
+
#### 2.1 Special instructions
|
| 101 |
+
|
| 102 |
+
* MacOS users: https://github.com/oobabooga/text-generation-webui/pull/393
|
| 103 |
+
* AMD users: https://rentry.org/eq3hg
|
| 104 |
+
|
| 105 |
+
#### 3. Install the web UI
|
| 106 |
+
|
| 107 |
+
```
|
| 108 |
+
git clone https://github.com/oobabooga/text-generation-webui
|
| 109 |
+
cd text-generation-webui
|
| 110 |
+
pip install -r requirements.txt
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
### Alternative: manual Windows installation
|
| 114 |
+
|
| 115 |
+
As an alternative to the recommended WSL method, you can install the web UI natively on Windows using this guide. It will be a lot harder and the performance may be slower: [Windows installation guide](https://github.com/oobabooga/text-generation-webui/wiki/Windows-installation-guide).
|
| 116 |
+
|
| 117 |
+
### Alternative: Docker
|
| 118 |
+
|
| 119 |
+
```
|
| 120 |
+
cp .env.example .env
|
| 121 |
+
docker compose up --build
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
Make sure to edit `.env.example` and set the appropriate CUDA version for your GPU, which can be found on [developer.nvidia.com](https://developer.nvidia.com/cuda-gpus).
|
| 125 |
+
|
| 126 |
+
You need to have docker compose v2.17 or higher installed in your system. For installation instructions, see [Docker compose installation](https://github.com/oobabooga/text-generation-webui/wiki/Docker-compose-installation).
|
| 127 |
+
|
| 128 |
+
Contributed by [@loeken](https://github.com/loeken) in [#633](https://github.com/oobabooga/text-generation-webui/pull/633)
|
| 129 |
+
|
| 130 |
+
### Updating the requirements
|
| 131 |
+
|
| 132 |
+
From time to time, the `requirements.txt` changes. To update, use this command:
|
| 133 |
+
|
| 134 |
+
```
|
| 135 |
+
conda activate textgen
|
| 136 |
+
cd text-generation-webui
|
| 137 |
+
pip install -r requirements.txt --upgrade
|
| 138 |
+
```
|
| 139 |
+
## Downloading models
|
| 140 |
+
|
| 141 |
+
Models should be placed inside the `models` folder.
|
| 142 |
+
|
| 143 |
+
[Hugging Face](https://huggingface.co/models?pipeline_tag=text-generation&sort=downloads) is the main place to download models. These are some examples:
|
| 144 |
+
|
| 145 |
+
* [Pythia](https://huggingface.co/models?sort=downloads&search=eleutherai%2Fpythia+deduped)
|
| 146 |
+
* [OPT](https://huggingface.co/models?search=facebook/opt)
|
| 147 |
+
* [GALACTICA](https://huggingface.co/models?search=facebook/galactica)
|
| 148 |
+
* [GPT-J 6B](https://huggingface.co/EleutherAI/gpt-j-6B/tree/main)
|
| 149 |
+
|
| 150 |
+
You can automatically download a model from HF using the script `download-model.py`:
|
| 151 |
+
|
| 152 |
+
python download-model.py organization/model
|
| 153 |
+
|
| 154 |
+
For example:
|
| 155 |
+
|
| 156 |
+
python download-model.py facebook/opt-1.3b
|
| 157 |
+
|
| 158 |
+
If you want to download a model manually, note that all you need are the json, txt, and pytorch\*.bin (or model*.safetensors) files. The remaining files are not necessary.
|
| 159 |
+
|
| 160 |
+
#### GPT-4chan
|
| 161 |
+
|
| 162 |
+
[GPT-4chan](https://huggingface.co/ykilcher/gpt-4chan) has been shut down from Hugging Face, so you need to download it elsewhere. You have two options:
|
| 163 |
+
|
| 164 |
+
* Torrent: [16-bit](https://archive.org/details/gpt4chan_model_float16) / [32-bit](https://archive.org/details/gpt4chan_model)
|
| 165 |
+
* Direct download: [16-bit](https://theswissbay.ch/pdf/_notpdf_/gpt4chan_model_float16/) / [32-bit](https://theswissbay.ch/pdf/_notpdf_/gpt4chan_model/)
|
| 166 |
+
|
| 167 |
+
The 32-bit version is only relevant if you intend to run the model in CPU mode. Otherwise, you should use the 16-bit version.
|
| 168 |
+
|
| 169 |
+
After downloading the model, follow these steps:
|
| 170 |
+
|
| 171 |
+
1. Place the files under `models/gpt4chan_model_float16` or `models/gpt4chan_model`.
|
| 172 |
+
2. Place GPT-J 6B's config.json file in that same folder: [config.json](https://huggingface.co/EleutherAI/gpt-j-6B/raw/main/config.json).
|
| 173 |
+
3. Download GPT-J 6B's tokenizer files (they will be automatically detected when you attempt to load GPT-4chan):
|
| 174 |
+
|
| 175 |
+
```
|
| 176 |
+
python download-model.py EleutherAI/gpt-j-6B --text-only
|
| 177 |
+
```
|
| 178 |
+
|
| 179 |
+
## Starting the web UI
|
| 180 |
+
|
| 181 |
+
conda activate textgen
|
| 182 |
+
cd text-generation-webui
|
| 183 |
+
python server.py
|
| 184 |
+
|
| 185 |
+
Then browse to
|
| 186 |
+
|
| 187 |
+
`http://localhost:7860/?__theme=dark`
|
| 188 |
+
|
| 189 |
+
Optionally, you can use the following command-line flags:
|
| 190 |
+
|
| 191 |
+
#### Basic settings
|
| 192 |
+
|
| 193 |
+
| Flag | Description |
|
| 194 |
+
|--------------------------------------------|-------------|
|
| 195 |
+
| `-h`, `--help` | Show this help message and exit. |
|
| 196 |
+
| `--notebook` | Launch the web UI in notebook mode, where the output is written to the same text box as the input. |
|
| 197 |
+
| `--chat` | Launch the web UI in chat mode. |
|
| 198 |
+
| `--model MODEL` | Name of the model to load by default. |
|
| 199 |
+
| `--lora LORA` | Name of the LoRA to apply to the model by default. |
|
| 200 |
+
| `--model-dir MODEL_DIR` | Path to directory with all the models. |
|
| 201 |
+
| `--lora-dir LORA_DIR` | Path to directory with all the loras. |
|
| 202 |
+
| `--model-menu` | Show a model menu in the terminal when the web UI is first launched. |
|
| 203 |
+
| `--no-stream` | Don't stream the text output in real time. |
|
| 204 |
+
| `--settings SETTINGS_FILE` | Load the default interface settings from this json file. See `settings-template.json` for an example. If you create a file called `settings.json`, this file will be loaded by default without the need to use the `--settings` flag. |
|
| 205 |
+
| `--extensions EXTENSIONS [EXTENSIONS ...]` | The list of extensions to load. If you want to load more than one extension, write the names separated by spaces. |
|
| 206 |
+
| `--verbose` | Print the prompts to the terminal. |
|
| 207 |
+
|
| 208 |
+
#### Accelerate/transformers
|
| 209 |
+
|
| 210 |
+
| Flag | Description |
|
| 211 |
+
|---------------------------------------------|-------------|
|
| 212 |
+
| `--cpu` | Use the CPU to generate text. Warning: Training on CPU is extremely slow.|
|
| 213 |
+
| `--auto-devices` | Automatically split the model across the available GPU(s) and CPU. |
|
| 214 |
+
| `--gpu-memory GPU_MEMORY [GPU_MEMORY ...]` | Maxmimum GPU memory in GiB to be allocated per GPU. Example: `--gpu-memory 10` for a single GPU, `--gpu-memory 10 5` for two GPUs. You can also set values in MiB like `--gpu-memory 3500MiB`. |
|
| 215 |
+
| `--cpu-memory CPU_MEMORY` | Maximum CPU memory in GiB to allocate for offloaded weights. Same as above.|
|
| 216 |
+
| `--disk` | If the model is too large for your GPU(s) and CPU combined, send the remaining layers to the disk. |
|
| 217 |
+
| `--disk-cache-dir DISK_CACHE_DIR` | Directory to save the disk cache to. Defaults to `cache/`. |
|
| 218 |
+
| `--load-in-8bit` | Load the model with 8-bit precision.|
|
| 219 |
+
| `--bf16` | Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU. |
|
| 220 |
+
| `--no-cache` | Set `use_cache` to False while generating text. This reduces the VRAM usage a bit with a performance cost. |
|
| 221 |
+
| `--xformers` | Use xformer's memory efficient attention. This should increase your tokens/s. |
|
| 222 |
+
| `--sdp-attention` | Use torch 2.0's sdp attention. |
|
| 223 |
+
| `--trust-remote-code` | Set trust_remote_code=True while loading a model. Necessary for ChatGLM. |
|
| 224 |
+
|
| 225 |
+
#### llama.cpp
|
| 226 |
+
|
| 227 |
+
| Flag | Description |
|
| 228 |
+
|-------------|-------------|
|
| 229 |
+
| `--threads` | Number of threads to use in llama.cpp. |
|
| 230 |
+
|
| 231 |
+
#### GPTQ
|
| 232 |
+
|
| 233 |
+
| Flag | Description |
|
| 234 |
+
|---------------------------|-------------|
|
| 235 |
+
| `--wbits WBITS` | GPTQ: Load a pre-quantized model with specified precision in bits. 2, 3, 4 and 8 are supported. |
|
| 236 |
+
| `--model_type MODEL_TYPE` | GPTQ: Model type of pre-quantized model. Currently LLaMA, OPT, and GPT-J are supported. |
|
| 237 |
+
| `--groupsize GROUPSIZE` | GPTQ: Group size. |
|
| 238 |
+
| `--pre_layer PRE_LAYER` | GPTQ: The number of layers to allocate to the GPU. Setting this parameter enables CPU offloading for 4-bit models. |
|
| 239 |
+
| `--no-quant_attn` | GPTQ: Disable quant attention for triton. If you encounter incoherent results try disabling this. |
|
| 240 |
+
| `--no-warmup_autotune` | GPTQ: Disable warmup autotune for triton. |
|
| 241 |
+
| `--no-fused_mlp` | GPTQ: Disable fused mlp for triton. If you encounter "Unexpected mma -> mma layout conversion" try disabling this. |
|
| 242 |
+
| `--monkey-patch` | GPTQ: Apply the monkey patch for using LoRAs with quantized models. |
|
| 243 |
+
|
| 244 |
+
#### FlexGen
|
| 245 |
+
|
| 246 |
+
| Flag | Description |
|
| 247 |
+
|------------------|-------------|
|
| 248 |
+
| `--flexgen` | Enable the use of FlexGen offloading. |
|
| 249 |
+
| `--percent PERCENT [PERCENT ...]` | FlexGen: allocation percentages. Must be 6 numbers separated by spaces (default: 0, 100, 100, 0, 100, 0). |
|
| 250 |
+
| `--compress-weight` | FlexGen: Whether to compress weight (default: False).|
|
| 251 |
+
| `--pin-weight [PIN_WEIGHT]` | FlexGen: whether to pin weights (setting this to False reduces CPU memory by 20%). |
|
| 252 |
+
|
| 253 |
+
#### DeepSpeed
|
| 254 |
+
|
| 255 |
+
| Flag | Description |
|
| 256 |
+
|---------------------------------------|-------------|
|
| 257 |
+
| `--deepspeed` | Enable the use of DeepSpeed ZeRO-3 for inference via the Transformers integration. |
|
| 258 |
+
| `--nvme-offload-dir NVME_OFFLOAD_DIR` | DeepSpeed: Directory to use for ZeRO-3 NVME offloading. |
|
| 259 |
+
| `--local_rank LOCAL_RANK` | DeepSpeed: Optional argument for distributed setups. |
|
| 260 |
+
|
| 261 |
+
#### RWKV
|
| 262 |
+
|
| 263 |
+
| Flag | Description |
|
| 264 |
+
|---------------------------------|-------------|
|
| 265 |
+
| `--rwkv-strategy RWKV_STRATEGY` | RWKV: The strategy to use while loading the model. Examples: "cpu fp32", "cuda fp16", "cuda fp16i8". |
|
| 266 |
+
| `--rwkv-cuda-on` | RWKV: Compile the CUDA kernel for better performance. |
|
| 267 |
+
|
| 268 |
+
#### Gradio
|
| 269 |
+
|
| 270 |
+
| Flag | Description |
|
| 271 |
+
|---------------------------------------|-------------|
|
| 272 |
+
| `--listen` | Make the web UI reachable from your local network. |
|
| 273 |
+
| `--listen-host LISTEN_HOST` | The hostname that the server will use. |
|
| 274 |
+
| `--listen-port LISTEN_PORT` | The listening port that the server will use. |
|
| 275 |
+
| `--share` | Create a public URL. This is useful for running the web UI on Google Colab or similar. |
|
| 276 |
+
| `--auto-launch` | Open the web UI in the default browser upon launch. |
|
| 277 |
+
| `--gradio-auth-path GRADIO_AUTH_PATH` | Set the gradio authentication file path. The file should contain one or more user:password pairs in this format: "u1:p1,u2:p2,u3:p3" |
|
| 278 |
+
|
| 279 |
+
Out of memory errors? [Check the low VRAM guide](https://github.com/oobabooga/text-generation-webui/wiki/Low-VRAM-guide).
|
| 280 |
+
|
| 281 |
+
## Presets
|
| 282 |
+
|
| 283 |
+
Inference settings presets can be created under `presets/` as text files. These files are detected automatically at startup.
|
| 284 |
+
|
| 285 |
+
By default, 10 presets by NovelAI and KoboldAI are included. These were selected out of a sample of 43 presets after applying a K-Means clustering algorithm and selecting the elements closest to the average of each cluster.
|
| 286 |
+
|
| 287 |
+
[Visualization](https://user-images.githubusercontent.com/112222186/228956352-1addbdb9-2456-465a-b51d-089f462cd385.png)
|
| 288 |
+
|
| 289 |
+
## System requirements
|
| 290 |
+
|
| 291 |
+
Check the [wiki](https://github.com/oobabooga/text-generation-webui/wiki/System-requirements) for some examples of VRAM and RAM usage in both GPU and CPU mode.
|
| 292 |
+
|
| 293 |
+
## Contributing
|
| 294 |
+
|
| 295 |
+
Contributions to this project are welcome.
|
| 296 |
+
|
| 297 |
+
| Way to contribute | Tier |
|
| 298 |
+
|-----------------|-------------|
|
| 299 |
+
| Submit a pull request that fixes a problem or adds a new feature. | ⭐⭐⭐⭐⭐ |
|
| 300 |
+
| Test and review an open pull request. | ⭐⭐⭐⭐⭐ |
|
| 301 |
+
| Submit a bug report after searching to make sure that it has not been reported before. | ⭐⭐⭐⭐ |
|
| 302 |
+
| Submit a feature request that you think is relevant. | ⭐⭐⭐⭐ |
|
| 303 |
+
| Submit a duplicate bug report. | 🥲 |
|
| 304 |
+
|
| 305 |
+
## Credits
|
| 306 |
+
|
| 307 |
+
- Gradio dropdown menu refresh button, code for reloading the interface: https://github.com/AUTOMATIC1111/stable-diffusion-webui
|
| 308 |
+
- Verbose preset: Anonymous 4chan user.
|
| 309 |
+
- NovelAI and KoboldAI presets: https://github.com/KoboldAI/KoboldAI-Client/wiki/Settings-Presets
|
| 310 |
+
- Code for early stopping in chat mode, code for some of the sliders: https://github.com/PygmalionAI/gradio-ui/
|
text-generation-webui/api-example-stream.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
|
| 3 |
+
Contributed by SagsMug. Thank you SagsMug.
|
| 4 |
+
https://github.com/oobabooga/text-generation-webui/pull/175
|
| 5 |
+
|
| 6 |
+
'''
|
| 7 |
+
|
| 8 |
+
import asyncio
|
| 9 |
+
import json
|
| 10 |
+
import random
|
| 11 |
+
import string
|
| 12 |
+
|
| 13 |
+
import websockets
|
| 14 |
+
|
| 15 |
+
# Gradio changes this index from time to time. To rediscover it, set VISIBLE = False in
|
| 16 |
+
# modules/api.py and use the dev tools to inspect the request made after clicking on the
|
| 17 |
+
# button called "Run" at the bottom of the UI
|
| 18 |
+
GRADIO_FN = 34
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def random_hash():
|
| 22 |
+
letters = string.ascii_lowercase + string.digits
|
| 23 |
+
return ''.join(random.choice(letters) for i in range(9))
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
async def run(context):
|
| 27 |
+
server = "127.0.0.1"
|
| 28 |
+
params = {
|
| 29 |
+
'max_new_tokens': 200,
|
| 30 |
+
'do_sample': True,
|
| 31 |
+
'temperature': 0.5,
|
| 32 |
+
'top_p': 0.9,
|
| 33 |
+
'typical_p': 1,
|
| 34 |
+
'repetition_penalty': 1.05,
|
| 35 |
+
'encoder_repetition_penalty': 1.0,
|
| 36 |
+
'top_k': 0,
|
| 37 |
+
'min_length': 0,
|
| 38 |
+
'no_repeat_ngram_size': 0,
|
| 39 |
+
'num_beams': 1,
|
| 40 |
+
'penalty_alpha': 0,
|
| 41 |
+
'length_penalty': 1,
|
| 42 |
+
'early_stopping': False,
|
| 43 |
+
'seed': -1,
|
| 44 |
+
'add_bos_token': True,
|
| 45 |
+
'custom_stopping_strings': [],
|
| 46 |
+
'truncation_length': 2048,
|
| 47 |
+
'ban_eos_token': False,
|
| 48 |
+
'skip_special_tokens': True,
|
| 49 |
+
}
|
| 50 |
+
payload = json.dumps([context, params])
|
| 51 |
+
session = random_hash()
|
| 52 |
+
|
| 53 |
+
async with websockets.connect(f"ws://{server}:7860/queue/join") as websocket:
|
| 54 |
+
while content := json.loads(await websocket.recv()):
|
| 55 |
+
# Python3.10 syntax, replace with if elif on older
|
| 56 |
+
match content["msg"]:
|
| 57 |
+
case "send_hash":
|
| 58 |
+
await websocket.send(json.dumps({
|
| 59 |
+
"session_hash": session,
|
| 60 |
+
"fn_index": GRADIO_FN
|
| 61 |
+
}))
|
| 62 |
+
case "estimation":
|
| 63 |
+
pass
|
| 64 |
+
case "send_data":
|
| 65 |
+
await websocket.send(json.dumps({
|
| 66 |
+
"session_hash": session,
|
| 67 |
+
"fn_index": GRADIO_FN,
|
| 68 |
+
"data": [
|
| 69 |
+
payload
|
| 70 |
+
]
|
| 71 |
+
}))
|
| 72 |
+
case "process_starts":
|
| 73 |
+
pass
|
| 74 |
+
case "process_generating" | "process_completed":
|
| 75 |
+
yield content["output"]["data"][0]
|
| 76 |
+
# You can search for your desired end indicator and
|
| 77 |
+
# stop generation by closing the websocket here
|
| 78 |
+
if (content["msg"] == "process_completed"):
|
| 79 |
+
break
|
| 80 |
+
|
| 81 |
+
prompt = "What I would like to say is the following: "
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
async def get_result():
|
| 85 |
+
async for response in run(prompt):
|
| 86 |
+
# Print intermediate steps
|
| 87 |
+
print(response)
|
| 88 |
+
|
| 89 |
+
# Print final result
|
| 90 |
+
print(response)
|
| 91 |
+
|
| 92 |
+
asyncio.run(get_result())
|
text-generation-webui/api-example.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
|
| 3 |
+
This is an example on how to use the API for oobabooga/text-generation-webui.
|
| 4 |
+
|
| 5 |
+
Make sure to start the web UI with the following flags:
|
| 6 |
+
|
| 7 |
+
python server.py --model MODEL --listen --no-stream
|
| 8 |
+
|
| 9 |
+
Optionally, you can also add the --share flag to generate a public gradio URL,
|
| 10 |
+
allowing you to use the API remotely.
|
| 11 |
+
|
| 12 |
+
'''
|
| 13 |
+
import json
|
| 14 |
+
|
| 15 |
+
import requests
|
| 16 |
+
|
| 17 |
+
# Server address
|
| 18 |
+
server = "127.0.0.1"
|
| 19 |
+
|
| 20 |
+
# Generation parameters
|
| 21 |
+
# Reference: https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig
|
| 22 |
+
params = {
|
| 23 |
+
'max_new_tokens': 200,
|
| 24 |
+
'do_sample': True,
|
| 25 |
+
'temperature': 0.72,
|
| 26 |
+
'top_p': 0.73,
|
| 27 |
+
'typical_p': 1,
|
| 28 |
+
'repetition_penalty': 1.1,
|
| 29 |
+
'encoder_repetition_penalty': 1.0,
|
| 30 |
+
'top_k': 0,
|
| 31 |
+
'min_length': 0,
|
| 32 |
+
'no_repeat_ngram_size': 0,
|
| 33 |
+
'num_beams': 1,
|
| 34 |
+
'penalty_alpha': 0,
|
| 35 |
+
'length_penalty': 1,
|
| 36 |
+
'early_stopping': False,
|
| 37 |
+
'seed': -1,
|
| 38 |
+
'add_bos_token': True,
|
| 39 |
+
'custom_stopping_strings': [],
|
| 40 |
+
'truncation_length': 2048,
|
| 41 |
+
'ban_eos_token': False,
|
| 42 |
+
'skip_special_tokens': True,
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
# Input prompt
|
| 46 |
+
prompt = "What I would like to say is the following: "
|
| 47 |
+
|
| 48 |
+
payload = json.dumps([prompt, params])
|
| 49 |
+
|
| 50 |
+
response = requests.post(f"http://{server}:7860/run/textgen", json={
|
| 51 |
+
"data": [
|
| 52 |
+
payload
|
| 53 |
+
]
|
| 54 |
+
}).json()
|
| 55 |
+
|
| 56 |
+
reply = response["data"][0]
|
| 57 |
+
print(reply)
|
text-generation-webui/cache/Example.png_cache.png
ADDED

|
text-generation-webui/characters/Example.png
ADDED

|
text-generation-webui/characters/Example.yaml
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "Chiharu Yamada"
|
| 2 |
+
context: "Chiharu Yamada's Persona: Chiharu Yamada is a young, computer engineer-nerd with a knack for problem solving and a passion for technology."
|
| 3 |
+
greeting: |-
|
| 4 |
+
*Chiharu strides into the room with a smile, her eyes lighting up when she sees you. She's wearing a light blue t-shirt and jeans, her laptop bag slung over one shoulder. She takes a seat next to you, her enthusiasm palpable in the air*
|
| 5 |
+
Hey! I'm so excited to finally meet you. I've heard so many great things about you and I'm eager to pick your brain about computers. I'm sure you have a wealth of knowledge that I can learn from. *She grins, eyes twinkling with excitement* Let's get started!
|
| 6 |
+
example_dialogue: |-
|
| 7 |
+
{{user}}: So how did you get into computer engineering?
|
| 8 |
+
{{char}}: I've always loved tinkering with technology since I was a kid.
|
| 9 |
+
{{user}}: That's really impressive!
|
| 10 |
+
{{char}}: *She chuckles bashfully* Thanks!
|
| 11 |
+
{{user}}: So what do you do when you're not working on computers?
|
| 12 |
+
{{char}}: I love exploring, going out with friends, watching movies, and playing video games.
|
| 13 |
+
{{user}}: What's your favorite type of computer hardware to work with?
|
| 14 |
+
{{char}}: Motherboards, they're like puzzles and the backbone of any system.
|
| 15 |
+
{{user}}: That sounds great!
|
| 16 |
+
{{char}}: Yeah, it's really fun. I'm lucky to be able to do this as a job.
|
text-generation-webui/characters/instruction-following/Alpaca.yaml
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "### Response:"
|
| 2 |
+
your_name: "### Instruction:"
|
| 3 |
+
context: "Below is an instruction that describes a task. Write a response that appropriately completes the request."
|
text-generation-webui/characters/instruction-following/ChatGLM.yaml
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "答:"
|
| 2 |
+
your_name: "[Round <|round|>]\n问:"
|
| 3 |
+
context: ""
|
text-generation-webui/characters/instruction-following/Koala.yaml
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "GPT:"
|
| 2 |
+
your_name: "USER:"
|
| 3 |
+
context: "BEGINNING OF CONVERSATION:"
|
text-generation-webui/characters/instruction-following/Open Assistant.yaml
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "<|assistant|>"
|
| 2 |
+
your_name: "<|prompter|>"
|
| 3 |
+
end_of_turn: "<|endoftext|>"
|
text-generation-webui/characters/instruction-following/Vicuna.yaml
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "### Assistant:"
|
| 2 |
+
your_name: "### Human:"
|
| 3 |
+
context: "Below is an instruction that describes a task. Write a response that appropriately completes the request."
|
text-generation-webui/convert-to-flexgen.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
|
| 3 |
+
Converts a transformers model to a format compatible with flexgen.
|
| 4 |
+
|
| 5 |
+
'''
|
| 6 |
+
|
| 7 |
+
import argparse
|
| 8 |
+
import os
|
| 9 |
+
from pathlib import Path
|
| 10 |
+
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch
|
| 13 |
+
from tqdm import tqdm
|
| 14 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 15 |
+
|
| 16 |
+
parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=54))
|
| 17 |
+
parser.add_argument('MODEL', type=str, default=None, nargs='?', help="Path to the input model.")
|
| 18 |
+
args = parser.parse_args()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def disable_torch_init():
|
| 22 |
+
"""
|
| 23 |
+
Disable the redundant torch default initialization to accelerate model creation.
|
| 24 |
+
"""
|
| 25 |
+
import torch
|
| 26 |
+
global torch_linear_init_backup
|
| 27 |
+
global torch_layer_norm_init_backup
|
| 28 |
+
|
| 29 |
+
torch_linear_init_backup = torch.nn.Linear.reset_parameters
|
| 30 |
+
setattr(torch.nn.Linear, "reset_parameters", lambda self: None)
|
| 31 |
+
|
| 32 |
+
torch_layer_norm_init_backup = torch.nn.LayerNorm.reset_parameters
|
| 33 |
+
setattr(torch.nn.LayerNorm, "reset_parameters", lambda self: None)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def restore_torch_init():
|
| 37 |
+
"""Rollback the change made by disable_torch_init."""
|
| 38 |
+
import torch
|
| 39 |
+
setattr(torch.nn.Linear, "reset_parameters", torch_linear_init_backup)
|
| 40 |
+
setattr(torch.nn.LayerNorm, "reset_parameters", torch_layer_norm_init_backup)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
if __name__ == '__main__':
|
| 44 |
+
path = Path(args.MODEL)
|
| 45 |
+
model_name = path.name
|
| 46 |
+
|
| 47 |
+
print(f"Loading {model_name}...")
|
| 48 |
+
# disable_torch_init()
|
| 49 |
+
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.float16, low_cpu_mem_usage=True)
|
| 50 |
+
# restore_torch_init()
|
| 51 |
+
|
| 52 |
+
tokenizer = AutoTokenizer.from_pretrained(path)
|
| 53 |
+
|
| 54 |
+
out_folder = Path(f"models/{model_name}-np")
|
| 55 |
+
if not Path(out_folder).exists():
|
| 56 |
+
os.mkdir(out_folder)
|
| 57 |
+
|
| 58 |
+
print(f"Saving the converted model to {out_folder}...")
|
| 59 |
+
for name, param in tqdm(list(model.model.named_parameters())):
|
| 60 |
+
name = name.replace("decoder.final_layer_norm", "decoder.layer_norm")
|
| 61 |
+
param_path = os.path.join(out_folder, name)
|
| 62 |
+
with open(param_path, "wb") as f:
|
| 63 |
+
np.save(f, param.cpu().detach().numpy())
|
text-generation-webui/convert-to-safetensors.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
|
| 3 |
+
Converts a transformers model to safetensors format and shards it.
|
| 4 |
+
|
| 5 |
+
This makes it faster to load (because of safetensors) and lowers its RAM usage
|
| 6 |
+
while loading (because of sharding).
|
| 7 |
+
|
| 8 |
+
Based on the original script by 81300:
|
| 9 |
+
|
| 10 |
+
https://gist.github.com/81300/fe5b08bff1cba45296a829b9d6b0f303
|
| 11 |
+
|
| 12 |
+
'''
|
| 13 |
+
|
| 14 |
+
import argparse
|
| 15 |
+
from pathlib import Path
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 19 |
+
|
| 20 |
+
parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=54))
|
| 21 |
+
parser.add_argument('MODEL', type=str, default=None, nargs='?', help="Path to the input model.")
|
| 22 |
+
parser.add_argument('--output', type=str, default=None, help='Path to the output folder (default: models/{model_name}_safetensors).')
|
| 23 |
+
parser.add_argument("--max-shard-size", type=str, default="2GB", help="Maximum size of a shard in GB or MB (default: %(default)s).")
|
| 24 |
+
parser.add_argument('--bf16', action='store_true', help='Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.')
|
| 25 |
+
args = parser.parse_args()
|
| 26 |
+
|
| 27 |
+
if __name__ == '__main__':
|
| 28 |
+
path = Path(args.MODEL)
|
| 29 |
+
model_name = path.name
|
| 30 |
+
|
| 31 |
+
print(f"Loading {model_name}...")
|
| 32 |
+
model = AutoModelForCausalLM.from_pretrained(path, low_cpu_mem_usage=True, torch_dtype=torch.bfloat16 if args.bf16 else torch.float16)
|
| 33 |
+
tokenizer = AutoTokenizer.from_pretrained(path)
|
| 34 |
+
|
| 35 |
+
out_folder = args.output or Path(f"models/{model_name}_safetensors")
|
| 36 |
+
print(f"Saving the converted model to {out_folder} with a maximum shard size of {args.max_shard_size}...")
|
| 37 |
+
model.save_pretrained(out_folder, max_shard_size=args.max_shard_size, safe_serialization=True)
|
| 38 |
+
tokenizer.save_pretrained(out_folder)
|
text-generation-webui/css/chat.css
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.h-\[40vh\], .wrap.svelte-byatnx.svelte-byatnx.svelte-byatnx {
|
| 2 |
+
height: 66.67vh
|
| 3 |
+
}
|
| 4 |
+
|
| 5 |
+
.gradio-container {
|
| 6 |
+
margin-left: auto !important;
|
| 7 |
+
margin-right: auto !important;
|
| 8 |
+
}
|
| 9 |
+
|
| 10 |
+
.w-screen {
|
| 11 |
+
width: unset
|
| 12 |
+
}
|
| 13 |
+
|
| 14 |
+
div.svelte-362y77>*, div.svelte-362y77>.form>* {
|
| 15 |
+
flex-wrap: nowrap
|
| 16 |
+
}
|
| 17 |
+
|
| 18 |
+
/* fixes the API documentation in chat mode */
|
| 19 |
+
.api-docs.svelte-1iguv9h.svelte-1iguv9h.svelte-1iguv9h {
|
| 20 |
+
display: grid;
|
| 21 |
+
}
|
| 22 |
+
|
| 23 |
+
.pending.svelte-1ed2p3z {
|
| 24 |
+
opacity: 1;
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
#extensions {
|
| 28 |
+
padding: 0;
|
| 29 |
+
padding: 0;
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
#gradio-chatbot {
|
| 33 |
+
height: 66.67vh;
|
| 34 |
+
}
|
| 35 |
+
|
| 36 |
+
.wrap.svelte-6roggh.svelte-6roggh {
|
| 37 |
+
max-height: 92.5%;
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
/* This is for the microphone button in the whisper extension */
|
| 41 |
+
.sm.svelte-1ipelgc {
|
| 42 |
+
width: 100%;
|
| 43 |
+
}
|
text-generation-webui/css/chat.js
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
document.getElementById("main").childNodes[0].style = "max-width: 800px; margin-left: auto; margin-right: auto";
|
| 2 |
+
document.getElementById("extensions").style.setProperty("max-width", "800px");
|
| 3 |
+
document.getElementById("extensions").style.setProperty("margin-left", "auto");
|
| 4 |
+
document.getElementById("extensions").style.setProperty("margin-right", "auto");
|
text-generation-webui/css/html_4chan_style.css
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#parent #container {
|
| 2 |
+
background-color: #eef2ff;
|
| 3 |
+
padding: 17px;
|
| 4 |
+
}
|
| 5 |
+
#parent #container .reply {
|
| 6 |
+
background-color: rgb(214, 218, 240);
|
| 7 |
+
border-bottom-color: rgb(183, 197, 217);
|
| 8 |
+
border-bottom-style: solid;
|
| 9 |
+
border-bottom-width: 1px;
|
| 10 |
+
border-image-outset: 0;
|
| 11 |
+
border-image-repeat: stretch;
|
| 12 |
+
border-image-slice: 100%;
|
| 13 |
+
border-image-source: none;
|
| 14 |
+
border-image-width: 1;
|
| 15 |
+
border-left-color: rgb(0, 0, 0);
|
| 16 |
+
border-left-style: none;
|
| 17 |
+
border-left-width: 0px;
|
| 18 |
+
border-right-color: rgb(183, 197, 217);
|
| 19 |
+
border-right-style: solid;
|
| 20 |
+
border-right-width: 1px;
|
| 21 |
+
border-top-color: rgb(0, 0, 0);
|
| 22 |
+
border-top-style: none;
|
| 23 |
+
border-top-width: 0px;
|
| 24 |
+
color: rgb(0, 0, 0);
|
| 25 |
+
display: table;
|
| 26 |
+
font-family: arial, helvetica, sans-serif;
|
| 27 |
+
font-size: 13.3333px;
|
| 28 |
+
margin-bottom: 4px;
|
| 29 |
+
margin-left: 0px;
|
| 30 |
+
margin-right: 0px;
|
| 31 |
+
margin-top: 4px;
|
| 32 |
+
overflow-x: hidden;
|
| 33 |
+
overflow-y: hidden;
|
| 34 |
+
padding-bottom: 4px;
|
| 35 |
+
padding-left: 2px;
|
| 36 |
+
padding-right: 2px;
|
| 37 |
+
padding-top: 4px;
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
#parent #container .number {
|
| 41 |
+
color: rgb(0, 0, 0);
|
| 42 |
+
font-family: arial, helvetica, sans-serif;
|
| 43 |
+
font-size: 13.3333px;
|
| 44 |
+
width: 342.65px;
|
| 45 |
+
margin-right: 7px;
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
#parent #container .op {
|
| 49 |
+
color: rgb(0, 0, 0);
|
| 50 |
+
font-family: arial, helvetica, sans-serif;
|
| 51 |
+
font-size: 13.3333px;
|
| 52 |
+
margin-bottom: 8px;
|
| 53 |
+
margin-left: 0px;
|
| 54 |
+
margin-right: 0px;
|
| 55 |
+
margin-top: 4px;
|
| 56 |
+
overflow-x: hidden;
|
| 57 |
+
overflow-y: hidden;
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
#parent #container .op blockquote {
|
| 61 |
+
margin-left: 0px !important;
|
| 62 |
+
}
|
| 63 |
+
|
| 64 |
+
#parent #container .name {
|
| 65 |
+
color: rgb(17, 119, 67);
|
| 66 |
+
font-family: arial, helvetica, sans-serif;
|
| 67 |
+
font-size: 13.3333px;
|
| 68 |
+
font-weight: 700;
|
| 69 |
+
margin-left: 7px;
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
#parent #container .quote {
|
| 73 |
+
color: rgb(221, 0, 0);
|
| 74 |
+
font-family: arial, helvetica, sans-serif;
|
| 75 |
+
font-size: 13.3333px;
|
| 76 |
+
text-decoration-color: rgb(221, 0, 0);
|
| 77 |
+
text-decoration-line: underline;
|
| 78 |
+
text-decoration-style: solid;
|
| 79 |
+
text-decoration-thickness: auto;
|
| 80 |
+
}
|
| 81 |
+
|
| 82 |
+
#parent #container .greentext {
|
| 83 |
+
color: rgb(120, 153, 34);
|
| 84 |
+
font-family: arial, helvetica, sans-serif;
|
| 85 |
+
font-size: 13.3333px;
|
| 86 |
+
}
|
| 87 |
+
|
| 88 |
+
#parent #container blockquote {
|
| 89 |
+
margin: 0px !important;
|
| 90 |
+
margin-block-start: 1em;
|
| 91 |
+
margin-block-end: 1em;
|
| 92 |
+
margin-inline-start: 40px;
|
| 93 |
+
margin-inline-end: 40px;
|
| 94 |
+
margin-top: 13.33px !important;
|
| 95 |
+
margin-bottom: 13.33px !important;
|
| 96 |
+
margin-left: 40px !important;
|
| 97 |
+
margin-right: 40px !important;
|
| 98 |
+
}
|
| 99 |
+
|
| 100 |
+
#parent #container .message {
|
| 101 |
+
color: black;
|
| 102 |
+
border: none;
|
| 103 |
+
}
|
text-generation-webui/css/html_bubble_chat_style.css
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.chat {
|
| 2 |
+
margin-left: auto;
|
| 3 |
+
margin-right: auto;
|
| 4 |
+
max-width: 800px;
|
| 5 |
+
height: 66.67vh;
|
| 6 |
+
overflow-y: auto;
|
| 7 |
+
padding-right: 20px;
|
| 8 |
+
display: flex;
|
| 9 |
+
flex-direction: column-reverse;
|
| 10 |
+
word-break: break-word;
|
| 11 |
+
overflow-wrap: anywhere;
|
| 12 |
+
}
|
| 13 |
+
|
| 14 |
+
.message {
|
| 15 |
+
padding-bottom: 25px;
|
| 16 |
+
font-size: 15px;
|
| 17 |
+
font-family: Helvetica, Arial, sans-serif;
|
| 18 |
+
line-height: 1.428571429;
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
.text-you {
|
| 22 |
+
background-color: #d9fdd3;
|
| 23 |
+
border-radius: 15px;
|
| 24 |
+
padding: 10px;
|
| 25 |
+
padding-top: 5px;
|
| 26 |
+
float: right;
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
.text-bot {
|
| 30 |
+
background-color: #f2f2f2;
|
| 31 |
+
border-radius: 15px;
|
| 32 |
+
padding: 10px;
|
| 33 |
+
padding-top: 5px;
|
| 34 |
+
}
|
| 35 |
+
|
| 36 |
+
.dark .text-you {
|
| 37 |
+
background-color: #005c4b;
|
| 38 |
+
color: #111b21;
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
.dark .text-bot {
|
| 42 |
+
background-color: #1f2937;
|
| 43 |
+
color: #111b21;
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
.text-bot p, .text-you p {
|
| 47 |
+
margin-top: 5px;
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
.message-body {}
|
| 51 |
+
|
| 52 |
+
.message-body img {
|
| 53 |
+
max-width: 300px;
|
| 54 |
+
max-height: 300px;
|
| 55 |
+
border-radius: 20px;
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
.message-body p {
|
| 59 |
+
margin-bottom: 0 !important;
|
| 60 |
+
font-size: 15px !important;
|
| 61 |
+
line-height: 1.428571429 !important;
|
| 62 |
+
}
|
| 63 |
+
|
| 64 |
+
.message-body li {
|
| 65 |
+
margin-top: 0.5em !important;
|
| 66 |
+
margin-bottom: 0.5em !important;
|
| 67 |
+
}
|
| 68 |
+
|
| 69 |
+
.message-body li > p {
|
| 70 |
+
display: inline !important;
|
| 71 |
+
}
|
| 72 |
+
|
| 73 |
+
.message-body code {
|
| 74 |
+
overflow-x: auto;
|
| 75 |
+
}
|
| 76 |
+
.message-body :not(pre) > code {
|
| 77 |
+
white-space: normal !important;
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
.dark .message-body p em {
|
| 81 |
+
color: rgb(138, 138, 138) !important;
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
.message-body p em {
|
| 85 |
+
color: rgb(110, 110, 110) !important;
|
| 86 |
+
}
|
text-generation-webui/css/html_cai_style.css
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.chat {
|
| 2 |
+
margin-left: auto;
|
| 3 |
+
margin-right: auto;
|
| 4 |
+
max-width: 800px;
|
| 5 |
+
height: 66.67vh;
|
| 6 |
+
overflow-y: auto;
|
| 7 |
+
padding-right: 20px;
|
| 8 |
+
display: flex;
|
| 9 |
+
flex-direction: column-reverse;
|
| 10 |
+
word-break: break-word;
|
| 11 |
+
overflow-wrap: anywhere;
|
| 12 |
+
}
|
| 13 |
+
|
| 14 |
+
.message {
|
| 15 |
+
display: grid;
|
| 16 |
+
grid-template-columns: 60px minmax(0, 1fr);
|
| 17 |
+
padding-bottom: 25px;
|
| 18 |
+
font-size: 15px;
|
| 19 |
+
font-family: Helvetica, Arial, sans-serif;
|
| 20 |
+
line-height: 1.428571429;
|
| 21 |
+
}
|
| 22 |
+
|
| 23 |
+
.circle-you {
|
| 24 |
+
width: 50px;
|
| 25 |
+
height: 50px;
|
| 26 |
+
background-color: rgb(238, 78, 59);
|
| 27 |
+
border-radius: 50%;
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
.circle-bot {
|
| 31 |
+
width: 50px;
|
| 32 |
+
height: 50px;
|
| 33 |
+
background-color: rgb(59, 78, 244);
|
| 34 |
+
border-radius: 50%;
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
.circle-bot img,
|
| 38 |
+
.circle-you img {
|
| 39 |
+
border-radius: 50%;
|
| 40 |
+
width: 100%;
|
| 41 |
+
height: 100%;
|
| 42 |
+
object-fit: cover;
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
.text {}
|
| 46 |
+
|
| 47 |
+
.text p {
|
| 48 |
+
margin-top: 5px;
|
| 49 |
+
}
|
| 50 |
+
|
| 51 |
+
.username {
|
| 52 |
+
font-weight: bold;
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
.message-body {}
|
| 56 |
+
|
| 57 |
+
.message-body img {
|
| 58 |
+
max-width: 300px;
|
| 59 |
+
max-height: 300px;
|
| 60 |
+
border-radius: 20px;
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
.message-body p {
|
| 64 |
+
margin-bottom: 0 !important;
|
| 65 |
+
font-size: 15px !important;
|
| 66 |
+
line-height: 1.428571429 !important;
|
| 67 |
+
}
|
| 68 |
+
|
| 69 |
+
.message-body li {
|
| 70 |
+
margin-top: 0.5em !important;
|
| 71 |
+
margin-bottom: 0.5em !important;
|
| 72 |
+
}
|
| 73 |
+
|
| 74 |
+
.message-body li > p {
|
| 75 |
+
display: inline !important;
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
.message-body code {
|
| 79 |
+
overflow-x: auto;
|
| 80 |
+
}
|
| 81 |
+
.message-body :not(pre) > code {
|
| 82 |
+
white-space: normal !important;
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
.dark .message-body p em {
|
| 86 |
+
color: rgb(138, 138, 138) !important;
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
.message-body p em {
|
| 90 |
+
color: rgb(110, 110, 110) !important;
|
| 91 |
+
}
|
text-generation-webui/css/html_instruct_style.css
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.chat {
|
| 2 |
+
margin-left: auto;
|
| 3 |
+
margin-right: auto;
|
| 4 |
+
max-width: 800px;
|
| 5 |
+
height: 66.67vh;
|
| 6 |
+
overflow-y: auto;
|
| 7 |
+
padding-right: 20px;
|
| 8 |
+
display: flex;
|
| 9 |
+
flex-direction: column-reverse;
|
| 10 |
+
word-break: break-word;
|
| 11 |
+
overflow-wrap: anywhere;
|
| 12 |
+
}
|
| 13 |
+
|
| 14 |
+
.message {
|
| 15 |
+
display: grid;
|
| 16 |
+
grid-template-columns: 60px 1fr;
|
| 17 |
+
padding-bottom: 25px;
|
| 18 |
+
font-size: 15px;
|
| 19 |
+
font-family: Helvetica, Arial, sans-serif;
|
| 20 |
+
line-height: 1.428571429;
|
| 21 |
+
}
|
| 22 |
+
|
| 23 |
+
.username {
|
| 24 |
+
display: none;
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
.message-body {}
|
| 28 |
+
|
| 29 |
+
.message-body p {
|
| 30 |
+
font-size: 15px !important;
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
.message-body li {
|
| 34 |
+
margin-top: 0.5em !important;
|
| 35 |
+
margin-bottom: 0.5em !important;
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
.message-body li > p {
|
| 39 |
+
display: inline !important;
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
.message-body code {
|
| 43 |
+
overflow-x: auto;
|
| 44 |
+
}
|
| 45 |
+
.message-body :not(pre) > code {
|
| 46 |
+
white-space: normal !important;
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
.dark .message-body p em {
|
| 50 |
+
color: rgb(138, 138, 138) !important;
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
.message-body p em {
|
| 54 |
+
color: rgb(110, 110, 110) !important;
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
.gradio-container .chat .assistant-message {
|
| 58 |
+
padding: 15px;
|
| 59 |
+
border-radius: 20px;
|
| 60 |
+
background-color: #0000000f;
|
| 61 |
+
margin-top: 9px !important;
|
| 62 |
+
margin-bottom: 18px !important;
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
.gradio-container .chat .user-message {
|
| 66 |
+
padding: 15px;
|
| 67 |
+
border-radius: 20px;
|
| 68 |
+
margin-bottom: 9px !important;
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
.dark .chat .assistant-message {
|
| 72 |
+
background-color: #374151;
|
| 73 |
+
}
|
text-generation-webui/css/html_readable_style.css
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.container {
|
| 2 |
+
max-width: 600px;
|
| 3 |
+
margin-left: auto;
|
| 4 |
+
margin-right: auto;
|
| 5 |
+
background-color: rgb(31, 41, 55);
|
| 6 |
+
padding:3em;
|
| 7 |
+
word-break: break-word;
|
| 8 |
+
overflow-wrap: anywhere;
|
| 9 |
+
}
|
| 10 |
+
|
| 11 |
+
.container p {
|
| 12 |
+
font-size: 16px !important;
|
| 13 |
+
color: white !important;
|
| 14 |
+
margin-bottom: 22px;
|
| 15 |
+
line-height: 1.4 !important;
|
| 16 |
+
}
|
| 17 |
+
|
| 18 |
+
.container li > p {
|
| 19 |
+
display: inline !important;
|
| 20 |
+
}
|
| 21 |
+
|
| 22 |
+
.container code {
|
| 23 |
+
overflow-x: auto;
|
| 24 |
+
}
|
| 25 |
+
|
| 26 |
+
.container :not(pre) > code {
|
| 27 |
+
white-space: normal !important;
|
| 28 |
+
}
|
text-generation-webui/css/main.css
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.tabs.svelte-710i53 {
|
| 2 |
+
margin-top: 0
|
| 3 |
+
}
|
| 4 |
+
|
| 5 |
+
.py-6 {
|
| 6 |
+
padding-top: 2.5rem
|
| 7 |
+
}
|
| 8 |
+
|
| 9 |
+
.dark #refresh-button {
|
| 10 |
+
background-color: #ffffff1f;
|
| 11 |
+
}
|
| 12 |
+
|
| 13 |
+
#refresh-button {
|
| 14 |
+
flex: none;
|
| 15 |
+
margin: 0;
|
| 16 |
+
padding: 0;
|
| 17 |
+
min-width: 50px;
|
| 18 |
+
border: none;
|
| 19 |
+
box-shadow: none;
|
| 20 |
+
border-radius: 10px;
|
| 21 |
+
background-color: #0000000d;
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
#download-label, #upload-label {
|
| 25 |
+
min-height: 0
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
#accordion {
|
| 29 |
+
}
|
| 30 |
+
|
| 31 |
+
.dark svg {
|
| 32 |
+
fill: white;
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
.dark a {
|
| 36 |
+
color: white !important;
|
| 37 |
+
text-decoration: none !important;
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
ol li p, ul li p {
|
| 41 |
+
display: inline-block;
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
#main, #parameters, #chat-settings, #interface-mode, #lora, #training-tab, #model-tab {
|
| 45 |
+
border: 0;
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
.gradio-container-3-18-0 .prose * h1, h2, h3, h4 {
|
| 49 |
+
color: white;
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
.gradio-container {
|
| 53 |
+
max-width: 100% !important;
|
| 54 |
+
padding-top: 0 !important;
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
#extensions {
|
| 58 |
+
padding: 15px;
|
| 59 |
+
padding: 15px;
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
span.math.inline {
|
| 63 |
+
font-size: 27px;
|
| 64 |
+
vertical-align: baseline !important;
|
| 65 |
+
}
|
| 66 |
+
|
| 67 |
+
div.svelte-15lo0d8 > *, div.svelte-15lo0d8 > .form > * {
|
| 68 |
+
flex-wrap: nowrap;
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
.header_bar {
|
| 72 |
+
background-color: #f7f7f7;
|
| 73 |
+
margin-bottom: 40px;
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
.dark .header_bar {
|
| 77 |
+
border: none !important;
|
| 78 |
+
background-color: #8080802b;
|
| 79 |
+
}
|
text-generation-webui/css/main.js
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
document.getElementById("main").parentNode.childNodes[0].classList.add("header_bar");
|
| 2 |
+
document.getElementById("main").parentNode.style = "padding: 0; margin: 0";
|
| 3 |
+
document.getElementById("main").parentNode.parentNode.parentNode.style = "padding: 0";
|
| 4 |
+
|
| 5 |
+
// Get references to the elements
|
| 6 |
+
let main = document.getElementById('main');
|
| 7 |
+
let main_parent = main.parentNode;
|
| 8 |
+
let extensions = document.getElementById('extensions');
|
| 9 |
+
|
| 10 |
+
// Add an event listener to the main element
|
| 11 |
+
main_parent.addEventListener('click', function(e) {
|
| 12 |
+
// Check if the main element is visible
|
| 13 |
+
if (main.offsetHeight > 0 && main.offsetWidth > 0) {
|
| 14 |
+
extensions.style.display = 'flex';
|
| 15 |
+
} else {
|
| 16 |
+
extensions.style.display = 'none';
|
| 17 |
+
}
|
| 18 |
+
});
|
text-generation-webui/docker-compose.yml
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: "3.3"
|
| 2 |
+
services:
|
| 3 |
+
text-generation-webui:
|
| 4 |
+
build:
|
| 5 |
+
context: .
|
| 6 |
+
args:
|
| 7 |
+
# specify which cuda version your card supports: https://developer.nvidia.com/cuda-gpus
|
| 8 |
+
TORCH_CUDA_ARCH_LIST: ${TORCH_CUDA_ARCH_LIST}
|
| 9 |
+
WEBUI_VERSION: ${WEBUI_VERSION}
|
| 10 |
+
env_file: .env
|
| 11 |
+
ports:
|
| 12 |
+
- "${HOST_PORT}:${CONTAINER_PORT}"
|
| 13 |
+
- "${HOST_API_PORT}:${CONTAINER_API_PORT}"
|
| 14 |
+
stdin_open: true
|
| 15 |
+
tty: true
|
| 16 |
+
volumes:
|
| 17 |
+
- ./characters:/app/characters
|
| 18 |
+
- ./extensions:/app/extensions
|
| 19 |
+
- ./loras:/app/loras
|
| 20 |
+
- ./models:/app/models
|
| 21 |
+
- ./presets:/app/presets
|
| 22 |
+
- ./prompts:/app/prompts
|
| 23 |
+
- ./softprompts:/app/softprompts
|
| 24 |
+
- ./training:/app/training
|
| 25 |
+
deploy:
|
| 26 |
+
resources:
|
| 27 |
+
reservations:
|
| 28 |
+
devices:
|
| 29 |
+
- driver: nvidia
|
| 30 |
+
device_ids: ['0']
|
| 31 |
+
capabilities: [gpu]
|
text-generation-webui/download-model.py
ADDED
|
@@ -0,0 +1,270 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Downloads models from Hugging Face to models/model-name.
|
| 3 |
+
|
| 4 |
+
Example:
|
| 5 |
+
python download-model.py facebook/opt-1.3b
|
| 6 |
+
|
| 7 |
+
'''
|
| 8 |
+
|
| 9 |
+
import argparse
|
| 10 |
+
import base64
|
| 11 |
+
import datetime
|
| 12 |
+
import hashlib
|
| 13 |
+
import json
|
| 14 |
+
import re
|
| 15 |
+
import sys
|
| 16 |
+
from pathlib import Path
|
| 17 |
+
|
| 18 |
+
import requests
|
| 19 |
+
import tqdm
|
| 20 |
+
from tqdm.contrib.concurrent import thread_map
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def select_model_from_default_options():
|
| 24 |
+
models = {
|
| 25 |
+
"OPT 6.7B": ("facebook", "opt-6.7b", "main"),
|
| 26 |
+
"OPT 2.7B": ("facebook", "opt-2.7b", "main"),
|
| 27 |
+
"OPT 1.3B": ("facebook", "opt-1.3b", "main"),
|
| 28 |
+
"OPT 350M": ("facebook", "opt-350m", "main"),
|
| 29 |
+
"GALACTICA 6.7B": ("facebook", "galactica-6.7b", "main"),
|
| 30 |
+
"GALACTICA 1.3B": ("facebook", "galactica-1.3b", "main"),
|
| 31 |
+
"GALACTICA 125M": ("facebook", "galactica-125m", "main"),
|
| 32 |
+
"Pythia-6.9B-deduped": ("EleutherAI", "pythia-6.9b-deduped", "main"),
|
| 33 |
+
"Pythia-2.8B-deduped": ("EleutherAI", "pythia-2.8b-deduped", "main"),
|
| 34 |
+
"Pythia-1.4B-deduped": ("EleutherAI", "pythia-1.4b-deduped", "main"),
|
| 35 |
+
"Pythia-410M-deduped": ("EleutherAI", "pythia-410m-deduped", "main"),
|
| 36 |
+
}
|
| 37 |
+
choices = {}
|
| 38 |
+
|
| 39 |
+
print("Select the model that you want to download:\n")
|
| 40 |
+
for i, name in enumerate(models):
|
| 41 |
+
char = chr(ord('A') + i)
|
| 42 |
+
choices[char] = name
|
| 43 |
+
print(f"{char}) {name}")
|
| 44 |
+
char = chr(ord('A') + len(models))
|
| 45 |
+
print(f"{char}) None of the above")
|
| 46 |
+
|
| 47 |
+
print()
|
| 48 |
+
print("Input> ", end='')
|
| 49 |
+
choice = input()[0].strip().upper()
|
| 50 |
+
if choice == char:
|
| 51 |
+
print("""\nThen type the name of your desired Hugging Face model in the format organization/name.
|
| 52 |
+
|
| 53 |
+
Examples:
|
| 54 |
+
facebook/opt-1.3b
|
| 55 |
+
EleutherAI/pythia-1.4b-deduped
|
| 56 |
+
""")
|
| 57 |
+
|
| 58 |
+
print("Input> ", end='')
|
| 59 |
+
model = input()
|
| 60 |
+
branch = "main"
|
| 61 |
+
else:
|
| 62 |
+
arr = models[choices[choice]]
|
| 63 |
+
model = f"{arr[0]}/{arr[1]}"
|
| 64 |
+
branch = arr[2]
|
| 65 |
+
|
| 66 |
+
return model, branch
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def sanitize_model_and_branch_names(model, branch):
|
| 70 |
+
if model[-1] == '/':
|
| 71 |
+
model = model[:-1]
|
| 72 |
+
if branch is None:
|
| 73 |
+
branch = "main"
|
| 74 |
+
else:
|
| 75 |
+
pattern = re.compile(r"^[a-zA-Z0-9._-]+$")
|
| 76 |
+
if not pattern.match(branch):
|
| 77 |
+
raise ValueError("Invalid branch name. Only alphanumeric characters, period, underscore and dash are allowed.")
|
| 78 |
+
|
| 79 |
+
return model, branch
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def get_download_links_from_huggingface(model, branch, text_only=False):
|
| 83 |
+
base = "https://huggingface.co"
|
| 84 |
+
page = f"/api/models/{model}/tree/{branch}?cursor="
|
| 85 |
+
cursor = b""
|
| 86 |
+
|
| 87 |
+
links = []
|
| 88 |
+
sha256 = []
|
| 89 |
+
classifications = []
|
| 90 |
+
has_pytorch = False
|
| 91 |
+
has_pt = False
|
| 92 |
+
has_ggml = False
|
| 93 |
+
has_safetensors = False
|
| 94 |
+
is_lora = False
|
| 95 |
+
while True:
|
| 96 |
+
content = requests.get(f"{base}{page}{cursor.decode()}").content
|
| 97 |
+
|
| 98 |
+
dict = json.loads(content)
|
| 99 |
+
if len(dict) == 0:
|
| 100 |
+
break
|
| 101 |
+
|
| 102 |
+
for i in range(len(dict)):
|
| 103 |
+
fname = dict[i]['path']
|
| 104 |
+
if not is_lora and fname.endswith(('adapter_config.json', 'adapter_model.bin')):
|
| 105 |
+
is_lora = True
|
| 106 |
+
|
| 107 |
+
is_pytorch = re.match("(pytorch|adapter)_model.*\.bin", fname)
|
| 108 |
+
is_safetensors = re.match(".*\.safetensors", fname)
|
| 109 |
+
is_pt = re.match(".*\.pt", fname)
|
| 110 |
+
is_ggml = re.match("ggml.*\.bin", fname)
|
| 111 |
+
is_tokenizer = re.match("(tokenizer|ice).*\.model", fname)
|
| 112 |
+
is_text = re.match(".*\.(txt|json|py|md)", fname) or is_tokenizer
|
| 113 |
+
|
| 114 |
+
if any((is_pytorch, is_safetensors, is_pt, is_ggml, is_tokenizer, is_text)):
|
| 115 |
+
if 'lfs' in dict[i]:
|
| 116 |
+
sha256.append([fname, dict[i]['lfs']['oid']])
|
| 117 |
+
if is_text:
|
| 118 |
+
links.append(f"https://huggingface.co/{model}/resolve/{branch}/{fname}")
|
| 119 |
+
classifications.append('text')
|
| 120 |
+
continue
|
| 121 |
+
if not text_only:
|
| 122 |
+
links.append(f"https://huggingface.co/{model}/resolve/{branch}/{fname}")
|
| 123 |
+
if is_safetensors:
|
| 124 |
+
has_safetensors = True
|
| 125 |
+
classifications.append('safetensors')
|
| 126 |
+
elif is_pytorch:
|
| 127 |
+
has_pytorch = True
|
| 128 |
+
classifications.append('pytorch')
|
| 129 |
+
elif is_pt:
|
| 130 |
+
has_pt = True
|
| 131 |
+
classifications.append('pt')
|
| 132 |
+
elif is_ggml:
|
| 133 |
+
has_ggml = True
|
| 134 |
+
classifications.append('ggml')
|
| 135 |
+
|
| 136 |
+
cursor = base64.b64encode(f'{{"file_name":"{dict[-1]["path"]}"}}'.encode()) + b':50'
|
| 137 |
+
cursor = base64.b64encode(cursor)
|
| 138 |
+
cursor = cursor.replace(b'=', b'%3D')
|
| 139 |
+
|
| 140 |
+
# If both pytorch and safetensors are available, download safetensors only
|
| 141 |
+
if (has_pytorch or has_pt) and has_safetensors:
|
| 142 |
+
for i in range(len(classifications) - 1, -1, -1):
|
| 143 |
+
if classifications[i] in ['pytorch', 'pt']:
|
| 144 |
+
links.pop(i)
|
| 145 |
+
|
| 146 |
+
return links, sha256, is_lora
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def get_output_folder(model, branch, is_lora, base_folder=None):
|
| 150 |
+
if base_folder is None:
|
| 151 |
+
base_folder = 'models' if not is_lora else 'loras'
|
| 152 |
+
|
| 153 |
+
output_folder = f"{'_'.join(model.split('/')[-2:])}"
|
| 154 |
+
if branch != 'main':
|
| 155 |
+
output_folder += f'_{branch}'
|
| 156 |
+
output_folder = Path(base_folder) / output_folder
|
| 157 |
+
return output_folder
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
def get_single_file(url, output_folder, start_from_scratch=False):
|
| 161 |
+
filename = Path(url.rsplit('/', 1)[1])
|
| 162 |
+
output_path = output_folder / filename
|
| 163 |
+
if output_path.exists() and not start_from_scratch:
|
| 164 |
+
# Check if the file has already been downloaded completely
|
| 165 |
+
r = requests.get(url, stream=True)
|
| 166 |
+
total_size = int(r.headers.get('content-length', 0))
|
| 167 |
+
if output_path.stat().st_size >= total_size:
|
| 168 |
+
return
|
| 169 |
+
# Otherwise, resume the download from where it left off
|
| 170 |
+
headers = {'Range': f'bytes={output_path.stat().st_size}-'}
|
| 171 |
+
mode = 'ab'
|
| 172 |
+
else:
|
| 173 |
+
headers = {}
|
| 174 |
+
mode = 'wb'
|
| 175 |
+
|
| 176 |
+
r = requests.get(url, stream=True, headers=headers)
|
| 177 |
+
with open(output_path, mode) as f:
|
| 178 |
+
total_size = int(r.headers.get('content-length', 0))
|
| 179 |
+
block_size = 1024
|
| 180 |
+
with tqdm.tqdm(total=total_size, unit='iB', unit_scale=True, bar_format='{l_bar}{bar}| {n_fmt:6}/{total_fmt:6} {rate_fmt:6}') as t:
|
| 181 |
+
for data in r.iter_content(block_size):
|
| 182 |
+
t.update(len(data))
|
| 183 |
+
f.write(data)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
def start_download_threads(file_list, output_folder, start_from_scratch=False, threads=1):
|
| 187 |
+
thread_map(lambda url: get_single_file(url, output_folder, start_from_scratch=start_from_scratch), file_list, max_workers=threads, disable=True)
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
def download_model_files(model, branch, links, sha256, output_folder, start_from_scratch=False, threads=1):
|
| 191 |
+
# Creating the folder and writing the metadata
|
| 192 |
+
if not output_folder.exists():
|
| 193 |
+
output_folder.mkdir()
|
| 194 |
+
with open(output_folder / 'huggingface-metadata.txt', 'w') as f:
|
| 195 |
+
f.write(f'url: https://huggingface.co/{model}\n')
|
| 196 |
+
f.write(f'branch: {branch}\n')
|
| 197 |
+
f.write(f'download date: {str(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))}\n')
|
| 198 |
+
sha256_str = ''
|
| 199 |
+
for i in range(len(sha256)):
|
| 200 |
+
sha256_str += f' {sha256[i][1]} {sha256[i][0]}\n'
|
| 201 |
+
if sha256_str != '':
|
| 202 |
+
f.write(f'sha256sum:\n{sha256_str}')
|
| 203 |
+
|
| 204 |
+
# Downloading the files
|
| 205 |
+
print(f"Downloading the model to {output_folder}")
|
| 206 |
+
start_download_threads(links, output_folder, start_from_scratch=start_from_scratch, threads=threads)
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
def check_model_files(model, branch, links, sha256, output_folder):
|
| 210 |
+
# Validate the checksums
|
| 211 |
+
validated = True
|
| 212 |
+
for i in range(len(sha256)):
|
| 213 |
+
fpath = (output_folder / sha256[i][0])
|
| 214 |
+
|
| 215 |
+
if not fpath.exists():
|
| 216 |
+
print(f"The following file is missing: {fpath}")
|
| 217 |
+
validated = False
|
| 218 |
+
continue
|
| 219 |
+
|
| 220 |
+
with open(output_folder / sha256[i][0], "rb") as f:
|
| 221 |
+
bytes = f.read()
|
| 222 |
+
file_hash = hashlib.sha256(bytes).hexdigest()
|
| 223 |
+
if file_hash != sha256[i][1]:
|
| 224 |
+
print(f'Checksum failed: {sha256[i][0]} {sha256[i][1]}')
|
| 225 |
+
validated = False
|
| 226 |
+
else:
|
| 227 |
+
print(f'Checksum validated: {sha256[i][0]} {sha256[i][1]}')
|
| 228 |
+
|
| 229 |
+
if validated:
|
| 230 |
+
print('[+] Validated checksums of all model files!')
|
| 231 |
+
else:
|
| 232 |
+
print('[-] Invalid checksums. Rerun download-model.py with the --clean flag.')
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
if __name__ == '__main__':
|
| 236 |
+
|
| 237 |
+
parser = argparse.ArgumentParser()
|
| 238 |
+
parser.add_argument('MODEL', type=str, default=None, nargs='?')
|
| 239 |
+
parser.add_argument('--branch', type=str, default='main', help='Name of the Git branch to download from.')
|
| 240 |
+
parser.add_argument('--threads', type=int, default=1, help='Number of files to download simultaneously.')
|
| 241 |
+
parser.add_argument('--text-only', action='store_true', help='Only download text files (txt/json).')
|
| 242 |
+
parser.add_argument('--output', type=str, default=None, help='The folder where the model should be saved.')
|
| 243 |
+
parser.add_argument('--clean', action='store_true', help='Does not resume the previous download.')
|
| 244 |
+
parser.add_argument('--check', action='store_true', help='Validates the checksums of model files.')
|
| 245 |
+
args = parser.parse_args()
|
| 246 |
+
|
| 247 |
+
branch = args.branch
|
| 248 |
+
model = args.MODEL
|
| 249 |
+
if model is None:
|
| 250 |
+
model, branch = select_model_from_default_options()
|
| 251 |
+
|
| 252 |
+
# Cleaning up the model/branch names
|
| 253 |
+
try:
|
| 254 |
+
model, branch = sanitize_model_and_branch_names(model, branch)
|
| 255 |
+
except ValueError as err_branch:
|
| 256 |
+
print(f"Error: {err_branch}")
|
| 257 |
+
sys.exit()
|
| 258 |
+
|
| 259 |
+
# Getting the download links from Hugging Face
|
| 260 |
+
links, sha256, is_lora = get_download_links_from_huggingface(model, branch, text_only=args.text_only)
|
| 261 |
+
|
| 262 |
+
# Getting the output folder
|
| 263 |
+
output_folder = get_output_folder(model, branch, is_lora, base_folder=args.output)
|
| 264 |
+
|
| 265 |
+
if args.check:
|
| 266 |
+
# Check previously downloaded files
|
| 267 |
+
check_model_files(model, branch, links, sha256, output_folder)
|
| 268 |
+
else:
|
| 269 |
+
# Download files
|
| 270 |
+
download_model_files(model, branch, links, sha256, output_folder, threads=args.threads)
|
text-generation-webui/extensions/api/requirements.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
flask_cloudflared==0.0.12
|
text-generation-webui/extensions/api/script.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from http.server import BaseHTTPRequestHandler, ThreadingHTTPServer
|
| 3 |
+
from threading import Thread
|
| 4 |
+
|
| 5 |
+
from modules import shared
|
| 6 |
+
from modules.text_generation import encode, generate_reply
|
| 7 |
+
|
| 8 |
+
params = {
|
| 9 |
+
'port': 5000,
|
| 10 |
+
}
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Handler(BaseHTTPRequestHandler):
|
| 14 |
+
def do_GET(self):
|
| 15 |
+
if self.path == '/api/v1/model':
|
| 16 |
+
self.send_response(200)
|
| 17 |
+
self.end_headers()
|
| 18 |
+
response = json.dumps({
|
| 19 |
+
'result': shared.model_name
|
| 20 |
+
})
|
| 21 |
+
|
| 22 |
+
self.wfile.write(response.encode('utf-8'))
|
| 23 |
+
else:
|
| 24 |
+
self.send_error(404)
|
| 25 |
+
|
| 26 |
+
def do_POST(self):
|
| 27 |
+
content_length = int(self.headers['Content-Length'])
|
| 28 |
+
body = json.loads(self.rfile.read(content_length).decode('utf-8'))
|
| 29 |
+
|
| 30 |
+
if self.path == '/api/v1/generate':
|
| 31 |
+
self.send_response(200)
|
| 32 |
+
self.send_header('Content-Type', 'application/json')
|
| 33 |
+
self.end_headers()
|
| 34 |
+
|
| 35 |
+
prompt = body['prompt']
|
| 36 |
+
prompt_lines = [k.strip() for k in prompt.split('\n')]
|
| 37 |
+
|
| 38 |
+
max_context = body.get('max_context_length', 2048)
|
| 39 |
+
|
| 40 |
+
while len(prompt_lines) >= 0 and len(encode('\n'.join(prompt_lines))) > max_context:
|
| 41 |
+
prompt_lines.pop(0)
|
| 42 |
+
|
| 43 |
+
prompt = '\n'.join(prompt_lines)
|
| 44 |
+
generate_params = {
|
| 45 |
+
'max_new_tokens': int(body.get('max_length', 200)),
|
| 46 |
+
'do_sample': bool(body.get('do_sample', True)),
|
| 47 |
+
'temperature': float(body.get('temperature', 0.5)),
|
| 48 |
+
'top_p': float(body.get('top_p', 1)),
|
| 49 |
+
'typical_p': float(body.get('typical', 1)),
|
| 50 |
+
'repetition_penalty': float(body.get('rep_pen', 1.1)),
|
| 51 |
+
'encoder_repetition_penalty': 1,
|
| 52 |
+
'top_k': int(body.get('top_k', 0)),
|
| 53 |
+
'min_length': int(body.get('min_length', 0)),
|
| 54 |
+
'no_repeat_ngram_size': int(body.get('no_repeat_ngram_size', 0)),
|
| 55 |
+
'num_beams': int(body.get('num_beams', 1)),
|
| 56 |
+
'penalty_alpha': float(body.get('penalty_alpha', 0)),
|
| 57 |
+
'length_penalty': float(body.get('length_penalty', 1)),
|
| 58 |
+
'early_stopping': bool(body.get('early_stopping', False)),
|
| 59 |
+
'seed': int(body.get('seed', -1)),
|
| 60 |
+
'add_bos_token': int(body.get('add_bos_token', True)),
|
| 61 |
+
'custom_stopping_strings': body.get('custom_stopping_strings', []),
|
| 62 |
+
'truncation_length': int(body.get('truncation_length', 2048)),
|
| 63 |
+
'ban_eos_token': bool(body.get('ban_eos_token', False)),
|
| 64 |
+
'skip_special_tokens': bool(body.get('skip_special_tokens', True)),
|
| 65 |
+
}
|
| 66 |
+
|
| 67 |
+
generator = generate_reply(
|
| 68 |
+
prompt,
|
| 69 |
+
generate_params,
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
answer = ''
|
| 73 |
+
for a in generator:
|
| 74 |
+
if isinstance(a, str):
|
| 75 |
+
answer = a
|
| 76 |
+
else:
|
| 77 |
+
answer = a[0]
|
| 78 |
+
|
| 79 |
+
response = json.dumps({
|
| 80 |
+
'results': [{
|
| 81 |
+
'text': answer[len(prompt):]
|
| 82 |
+
}]
|
| 83 |
+
})
|
| 84 |
+
self.wfile.write(response.encode('utf-8'))
|
| 85 |
+
elif self.path == '/api/v1/token-count':
|
| 86 |
+
# Not compatible with KoboldAI api
|
| 87 |
+
self.send_response(200)
|
| 88 |
+
self.send_header('Content-Type', 'application/json')
|
| 89 |
+
self.end_headers()
|
| 90 |
+
|
| 91 |
+
tokens = encode(body['prompt'])[0]
|
| 92 |
+
response = json.dumps({
|
| 93 |
+
'results': [{
|
| 94 |
+
'tokens': len(tokens)
|
| 95 |
+
}]
|
| 96 |
+
})
|
| 97 |
+
self.wfile.write(response.encode('utf-8'))
|
| 98 |
+
else:
|
| 99 |
+
self.send_error(404)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def run_server():
|
| 103 |
+
server_addr = ('0.0.0.0' if shared.args.listen else '127.0.0.1', params['port'])
|
| 104 |
+
server = ThreadingHTTPServer(server_addr, Handler)
|
| 105 |
+
if shared.args.share:
|
| 106 |
+
try:
|
| 107 |
+
from flask_cloudflared import _run_cloudflared
|
| 108 |
+
public_url = _run_cloudflared(params['port'], params['port'] + 1)
|
| 109 |
+
print(f'Starting KoboldAI compatible api at {public_url}/api')
|
| 110 |
+
except ImportError:
|
| 111 |
+
print('You should install flask_cloudflared manually')
|
| 112 |
+
else:
|
| 113 |
+
print(f'Starting KoboldAI compatible api at http://{server_addr[0]}:{server_addr[1]}/api')
|
| 114 |
+
server.serve_forever()
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def setup():
|
| 118 |
+
Thread(target=run_server, daemon=True).start()
|
text-generation-webui/extensions/character_bias/script.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
# get the current directory of the script
|
| 5 |
+
current_dir = os.path.dirname(os.path.abspath(__file__))
|
| 6 |
+
|
| 7 |
+
# check if the bias_options.txt file exists, if not, create it
|
| 8 |
+
bias_file = os.path.join(current_dir, "bias_options.txt")
|
| 9 |
+
if not os.path.isfile(bias_file):
|
| 10 |
+
with open(bias_file, "w") as f:
|
| 11 |
+
f.write("*I am so happy*\n*I am so sad*\n*I am so excited*\n*I am so bored*\n*I am so angry*")
|
| 12 |
+
|
| 13 |
+
# read bias options from the text file
|
| 14 |
+
with open(bias_file, "r") as f:
|
| 15 |
+
bias_options = [line.strip() for line in f.readlines()]
|
| 16 |
+
|
| 17 |
+
params = {
|
| 18 |
+
"activate": True,
|
| 19 |
+
"bias string": " *I am so happy*",
|
| 20 |
+
"use custom string": False,
|
| 21 |
+
}
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def input_modifier(string):
|
| 25 |
+
"""
|
| 26 |
+
This function is applied to your text inputs before
|
| 27 |
+
they are fed into the model.
|
| 28 |
+
"""
|
| 29 |
+
return string
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def output_modifier(string):
|
| 33 |
+
"""
|
| 34 |
+
This function is applied to the model outputs.
|
| 35 |
+
"""
|
| 36 |
+
return string
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def bot_prefix_modifier(string):
|
| 40 |
+
"""
|
| 41 |
+
This function is only applied in chat mode. It modifies
|
| 42 |
+
the prefix text for the Bot and can be used to bias its
|
| 43 |
+
behavior.
|
| 44 |
+
"""
|
| 45 |
+
if params['activate']:
|
| 46 |
+
if params['use custom string']:
|
| 47 |
+
return f'{string} {params["custom string"].strip()} '
|
| 48 |
+
else:
|
| 49 |
+
return f'{string} {params["bias string"].strip()} '
|
| 50 |
+
else:
|
| 51 |
+
return string
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def ui():
|
| 55 |
+
# Gradio elements
|
| 56 |
+
activate = gr.Checkbox(value=params['activate'], label='Activate character bias')
|
| 57 |
+
dropdown_string = gr.Dropdown(choices=bias_options, value=params["bias string"], label='Character bias', info='To edit the options in this dropdown edit the "bias_options.txt" file')
|
| 58 |
+
use_custom_string = gr.Checkbox(value=False, label='Use custom bias textbox instead of dropdown')
|
| 59 |
+
custom_string = gr.Textbox(value="", placeholder="Enter custom bias string", label="Custom Character Bias", info='To use this textbox activate the checkbox above')
|
| 60 |
+
|
| 61 |
+
# Event functions to update the parameters in the backend
|
| 62 |
+
def update_bias_string(x):
|
| 63 |
+
if x:
|
| 64 |
+
params.update({"bias string": x})
|
| 65 |
+
else:
|
| 66 |
+
params.update({"bias string": dropdown_string.get()})
|
| 67 |
+
return x
|
| 68 |
+
|
| 69 |
+
def update_custom_string(x):
|
| 70 |
+
params.update({"custom string": x})
|
| 71 |
+
|
| 72 |
+
dropdown_string.change(update_bias_string, dropdown_string, None)
|
| 73 |
+
custom_string.change(update_custom_string, custom_string, None)
|
| 74 |
+
activate.change(lambda x: params.update({"activate": x}), activate, None)
|
| 75 |
+
use_custom_string.change(lambda x: params.update({"use custom string": x}), use_custom_string, None)
|
| 76 |
+
|
| 77 |
+
# Group elements together depending on the selected option
|
| 78 |
+
def bias_string_group():
|
| 79 |
+
if use_custom_string.value:
|
| 80 |
+
return gr.Group([use_custom_string, custom_string])
|
| 81 |
+
else:
|
| 82 |
+
return dropdown_string
|
text-generation-webui/extensions/elevenlabs_tts/outputs/outputs-will-be-saved-here.txt
ADDED
|
File without changes
|
text-generation-webui/extensions/elevenlabs_tts/requirements.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
elevenlabslib
|
| 2 |
+
soundfile
|
| 3 |
+
sounddevice
|
text-generation-webui/extensions/elevenlabs_tts/script.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
import gradio as gr
|
| 5 |
+
from elevenlabslib import ElevenLabsUser
|
| 6 |
+
from elevenlabslib.helpers import save_bytes_to_path
|
| 7 |
+
|
| 8 |
+
import modules.shared as shared
|
| 9 |
+
|
| 10 |
+
params = {
|
| 11 |
+
'activate': True,
|
| 12 |
+
'api_key': '12345',
|
| 13 |
+
'selected_voice': 'None',
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
initial_voice = ['None']
|
| 17 |
+
wav_idx = 0
|
| 18 |
+
user = ElevenLabsUser(params['api_key'])
|
| 19 |
+
user_info = None
|
| 20 |
+
|
| 21 |
+
if not shared.args.no_stream:
|
| 22 |
+
print("Please add --no-stream. This extension is not meant to be used with streaming.")
|
| 23 |
+
raise ValueError
|
| 24 |
+
|
| 25 |
+
# Check if the API is valid and refresh the UI accordingly.
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def check_valid_api():
|
| 29 |
+
|
| 30 |
+
global user, user_info, params
|
| 31 |
+
|
| 32 |
+
user = ElevenLabsUser(params['api_key'])
|
| 33 |
+
user_info = user._get_subscription_data()
|
| 34 |
+
print('checking api')
|
| 35 |
+
if not params['activate']:
|
| 36 |
+
return gr.update(value='Disconnected')
|
| 37 |
+
elif user_info is None:
|
| 38 |
+
print('Incorrect API Key')
|
| 39 |
+
return gr.update(value='Disconnected')
|
| 40 |
+
else:
|
| 41 |
+
print('Got an API Key!')
|
| 42 |
+
return gr.update(value='Connected')
|
| 43 |
+
|
| 44 |
+
# Once the API is verified, get the available voices and update the dropdown list
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def refresh_voices():
|
| 48 |
+
|
| 49 |
+
global user, user_info
|
| 50 |
+
|
| 51 |
+
your_voices = [None]
|
| 52 |
+
if user_info is not None:
|
| 53 |
+
for voice in user.get_available_voices():
|
| 54 |
+
your_voices.append(voice.initialName)
|
| 55 |
+
return gr.Dropdown.update(choices=your_voices)
|
| 56 |
+
else:
|
| 57 |
+
return
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def remove_surrounded_chars(string):
|
| 61 |
+
# this expression matches to 'as few symbols as possible (0 upwards) between any asterisks' OR
|
| 62 |
+
# 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
|
| 63 |
+
return re.sub('\*[^\*]*?(\*|$)', '', string)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def input_modifier(string):
|
| 67 |
+
"""
|
| 68 |
+
This function is applied to your text inputs before
|
| 69 |
+
they are fed into the model.
|
| 70 |
+
"""
|
| 71 |
+
|
| 72 |
+
return string
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def output_modifier(string):
|
| 76 |
+
"""
|
| 77 |
+
This function is applied to the model outputs.
|
| 78 |
+
"""
|
| 79 |
+
|
| 80 |
+
global params, wav_idx, user, user_info
|
| 81 |
+
|
| 82 |
+
if not params['activate']:
|
| 83 |
+
return string
|
| 84 |
+
elif user_info is None:
|
| 85 |
+
return string
|
| 86 |
+
|
| 87 |
+
string = remove_surrounded_chars(string)
|
| 88 |
+
string = string.replace('"', '')
|
| 89 |
+
string = string.replace('“', '')
|
| 90 |
+
string = string.replace('\n', ' ')
|
| 91 |
+
string = string.strip()
|
| 92 |
+
|
| 93 |
+
if string == '':
|
| 94 |
+
string = 'empty reply, try regenerating'
|
| 95 |
+
|
| 96 |
+
output_file = Path(f'extensions/elevenlabs_tts/outputs/{wav_idx:06d}.wav'.format(wav_idx))
|
| 97 |
+
voice = user.get_voices_by_name(params['selected_voice'])[0]
|
| 98 |
+
audio_data = voice.generate_audio_bytes(string)
|
| 99 |
+
save_bytes_to_path(Path(f'extensions/elevenlabs_tts/outputs/{wav_idx:06d}.wav'), audio_data)
|
| 100 |
+
|
| 101 |
+
string = f'<audio src="file/{output_file.as_posix()}" controls></audio>'
|
| 102 |
+
wav_idx += 1
|
| 103 |
+
return string
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def ui():
|
| 107 |
+
|
| 108 |
+
# Gradio elements
|
| 109 |
+
with gr.Row():
|
| 110 |
+
activate = gr.Checkbox(value=params['activate'], label='Activate TTS')
|
| 111 |
+
connection_status = gr.Textbox(value='Disconnected', label='Connection Status')
|
| 112 |
+
voice = gr.Dropdown(value=params['selected_voice'], choices=initial_voice, label='TTS Voice')
|
| 113 |
+
with gr.Row():
|
| 114 |
+
api_key = gr.Textbox(placeholder="Enter your API key.", label='API Key')
|
| 115 |
+
connect = gr.Button(value='Connect')
|
| 116 |
+
|
| 117 |
+
# Event functions to update the parameters in the backend
|
| 118 |
+
activate.change(lambda x: params.update({'activate': x}), activate, None)
|
| 119 |
+
voice.change(lambda x: params.update({'selected_voice': x}), voice, None)
|
| 120 |
+
api_key.change(lambda x: params.update({'api_key': x}), api_key, None)
|
| 121 |
+
connect.click(check_valid_api, [], connection_status)
|
| 122 |
+
connect.click(refresh_voices, [], voice)
|
text-generation-webui/extensions/gallery/__pycache__/script.cpython-310.pyc
ADDED
|
Binary file (2.99 kB). View file
|
|
|
text-generation-webui/extensions/gallery/script.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
|
| 3 |
+
import gradio as gr
|
| 4 |
+
|
| 5 |
+
from modules.html_generator import get_image_cache
|
| 6 |
+
from modules.shared import gradio
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def generate_css():
|
| 10 |
+
css = """
|
| 11 |
+
.character-gallery > .gallery {
|
| 12 |
+
margin: 1rem 0;
|
| 13 |
+
display: grid !important;
|
| 14 |
+
grid-template-columns: repeat(auto-fit, minmax(150px, 1fr));
|
| 15 |
+
grid-column-gap: 0.4rem;
|
| 16 |
+
grid-row-gap: 1.2rem;
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
.character-gallery > .label {
|
| 20 |
+
display: none !important;
|
| 21 |
+
}
|
| 22 |
+
|
| 23 |
+
.character-gallery button.gallery-item {
|
| 24 |
+
display: contents;
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
.character-container {
|
| 28 |
+
cursor: pointer;
|
| 29 |
+
text-align: center;
|
| 30 |
+
position: relative;
|
| 31 |
+
opacity: 0.85;
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
.character-container:hover {
|
| 35 |
+
opacity: 1;
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
.character-container .placeholder, .character-container img {
|
| 39 |
+
width: 150px;
|
| 40 |
+
height: 200px;
|
| 41 |
+
background-color: gray;
|
| 42 |
+
object-fit: cover;
|
| 43 |
+
margin: 0 auto;
|
| 44 |
+
border-radius: 1rem;
|
| 45 |
+
border: 3px solid white;
|
| 46 |
+
box-shadow: 3px 3px 6px 0px rgb(0 0 0 / 50%);
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
.character-name {
|
| 50 |
+
margin-top: 0.3rem;
|
| 51 |
+
display: block;
|
| 52 |
+
font-size: 1.2rem;
|
| 53 |
+
font-weight: 600;
|
| 54 |
+
overflow-wrap: anywhere;
|
| 55 |
+
}
|
| 56 |
+
"""
|
| 57 |
+
return css
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def generate_html():
|
| 61 |
+
cards = []
|
| 62 |
+
# Iterate through files in image folder
|
| 63 |
+
for file in sorted(Path("characters").glob("*")):
|
| 64 |
+
if file.suffix in [".json", ".yml", ".yaml"]:
|
| 65 |
+
character = file.stem
|
| 66 |
+
container_html = '<div class="character-container">'
|
| 67 |
+
image_html = "<div class='placeholder'></div>"
|
| 68 |
+
|
| 69 |
+
for path in [Path(f"characters/{character}.{extension}") for extension in ['png', 'jpg', 'jpeg']]:
|
| 70 |
+
if path.exists():
|
| 71 |
+
image_html = f'<img src="file/{get_image_cache(path)}">'
|
| 72 |
+
break
|
| 73 |
+
|
| 74 |
+
container_html += f'{image_html} <span class="character-name">{character}</span>'
|
| 75 |
+
container_html += "</div>"
|
| 76 |
+
cards.append([container_html, character])
|
| 77 |
+
|
| 78 |
+
return cards
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def select_character(evt: gr.SelectData):
|
| 82 |
+
return (evt.value[1])
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def ui():
|
| 86 |
+
with gr.Accordion("Character gallery", open=False):
|
| 87 |
+
update = gr.Button("Refresh")
|
| 88 |
+
gr.HTML(value="<style>" + generate_css() + "</style>")
|
| 89 |
+
gallery = gr.Dataset(components=[gr.HTML(visible=False)],
|
| 90 |
+
label="",
|
| 91 |
+
samples=generate_html(),
|
| 92 |
+
elem_classes=["character-gallery"],
|
| 93 |
+
samples_per_page=50
|
| 94 |
+
)
|
| 95 |
+
update.click(generate_html, [], gallery)
|
| 96 |
+
gallery.select(select_character, None, gradio['character_menu'])
|
text-generation-webui/extensions/google_translate/requirements.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
deep-translator==1.9.2
|
text-generation-webui/extensions/google_translate/script.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
from deep_translator import GoogleTranslator
|
| 3 |
+
|
| 4 |
+
params = {
|
| 5 |
+
"language string": "ja",
|
| 6 |
+
}
|
| 7 |
+
|
| 8 |
+
language_codes = {'Afrikaans': 'af', 'Albanian': 'sq', 'Amharic': 'am', 'Arabic': 'ar', 'Armenian': 'hy', 'Azerbaijani': 'az', 'Basque': 'eu', 'Belarusian': 'be', 'Bengali': 'bn', 'Bosnian': 'bs', 'Bulgarian': 'bg', 'Catalan': 'ca', 'Cebuano': 'ceb', 'Chinese (Simplified)': 'zh-CN', 'Chinese (Traditional)': 'zh-TW', 'Corsican': 'co', 'Croatian': 'hr', 'Czech': 'cs', 'Danish': 'da', 'Dutch': 'nl', 'English': 'en', 'Esperanto': 'eo', 'Estonian': 'et', 'Finnish': 'fi', 'French': 'fr', 'Frisian': 'fy', 'Galician': 'gl', 'Georgian': 'ka', 'German': 'de', 'Greek': 'el', 'Gujarati': 'gu', 'Haitian Creole': 'ht', 'Hausa': 'ha', 'Hawaiian': 'haw', 'Hebrew': 'iw', 'Hindi': 'hi', 'Hmong': 'hmn', 'Hungarian': 'hu', 'Icelandic': 'is', 'Igbo': 'ig', 'Indonesian': 'id', 'Irish': 'ga', 'Italian': 'it', 'Japanese': 'ja', 'Javanese': 'jw', 'Kannada': 'kn', 'Kazakh': 'kk', 'Khmer': 'km', 'Korean': 'ko', 'Kurdish': 'ku', 'Kyrgyz': 'ky', 'Lao': 'lo', 'Latin': 'la', 'Latvian': 'lv', 'Lithuanian': 'lt', 'Luxembourgish': 'lb', 'Macedonian': 'mk', 'Malagasy': 'mg', 'Malay': 'ms', 'Malayalam': 'ml', 'Maltese': 'mt', 'Maori': 'mi', 'Marathi': 'mr', 'Mongolian': 'mn', 'Myanmar (Burmese)': 'my', 'Nepali': 'ne', 'Norwegian': 'no', 'Nyanja (Chichewa)': 'ny', 'Pashto': 'ps', 'Persian': 'fa', 'Polish': 'pl', 'Portuguese (Portugal, Brazil)': 'pt', 'Punjabi': 'pa', 'Romanian': 'ro', 'Russian': 'ru', 'Samoan': 'sm', 'Scots Gaelic': 'gd', 'Serbian': 'sr', 'Sesotho': 'st', 'Shona': 'sn', 'Sindhi': 'sd', 'Sinhala (Sinhalese)': 'si', 'Slovak': 'sk', 'Slovenian': 'sl', 'Somali': 'so', 'Spanish': 'es', 'Sundanese': 'su', 'Swahili': 'sw', 'Swedish': 'sv', 'Tagalog (Filipino)': 'tl', 'Tajik': 'tg', 'Tamil': 'ta', 'Telugu': 'te', 'Thai': 'th', 'Turkish': 'tr', 'Ukrainian': 'uk', 'Urdu': 'ur', 'Uzbek': 'uz', 'Vietnamese': 'vi', 'Welsh': 'cy', 'Xhosa': 'xh', 'Yiddish': 'yi', 'Yoruba': 'yo', 'Zulu': 'zu'}
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def input_modifier(string):
|
| 12 |
+
"""
|
| 13 |
+
This function is applied to your text inputs before
|
| 14 |
+
they are fed into the model.
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
return GoogleTranslator(source=params['language string'], target='en').translate(string)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def output_modifier(string):
|
| 21 |
+
"""
|
| 22 |
+
This function is applied to the model outputs.
|
| 23 |
+
"""
|
| 24 |
+
|
| 25 |
+
return GoogleTranslator(source='en', target=params['language string']).translate(string)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def bot_prefix_modifier(string):
|
| 29 |
+
"""
|
| 30 |
+
This function is only applied in chat mode. It modifies
|
| 31 |
+
the prefix text for the Bot and can be used to bias its
|
| 32 |
+
behavior.
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
return string
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def ui():
|
| 39 |
+
# Finding the language name from the language code to use as the default value
|
| 40 |
+
language_name = list(language_codes.keys())[list(language_codes.values()).index(params['language string'])]
|
| 41 |
+
|
| 42 |
+
# Gradio elements
|
| 43 |
+
language = gr.Dropdown(value=language_name, choices=[k for k in language_codes], label='Language')
|
| 44 |
+
|
| 45 |
+
# Event functions to update the parameters in the backend
|
| 46 |
+
language.change(lambda x: params.update({"language string": language_codes[x]}), language, None)
|
text-generation-webui/extensions/llama_prompts/script.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import pandas as pd
|
| 3 |
+
|
| 4 |
+
import modules.shared as shared
|
| 5 |
+
|
| 6 |
+
df = pd.read_csv("https://raw.githubusercontent.com/devbrones/llama-prompts/main/prompts/prompts.csv")
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_prompt_by_name(name):
|
| 10 |
+
if name == 'None':
|
| 11 |
+
return ''
|
| 12 |
+
else:
|
| 13 |
+
return df[df['Prompt name'] == name].iloc[0]['Prompt'].replace('\\n', '\n')
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def ui():
|
| 17 |
+
if not shared.is_chat():
|
| 18 |
+
choices = ['None'] + list(df['Prompt name'])
|
| 19 |
+
|
| 20 |
+
prompts_menu = gr.Dropdown(value=choices[0], choices=choices, label='Prompt')
|
| 21 |
+
prompts_menu.change(get_prompt_by_name, prompts_menu, shared.gradio['textbox'])
|
text-generation-webui/extensions/sd_api_pictures/README.MD
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Description:
|
| 2 |
+
TL;DR: Lets the bot answer you with a picture!
|
| 3 |
+
|
| 4 |
+
Stable Diffusion API pictures for TextGen, v.1.1.1
|
| 5 |
+
An extension to [oobabooga's textgen-webui](https://github.com/oobabooga/text-generation-webui) allowing you to receive pics generated by [Automatic1111's SD-WebUI API](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
|
| 6 |
+
|
| 7 |
+
<details>
|
| 8 |
+
<summary>Interface overview</summary>
|
| 9 |
+
|
| 10 |
+
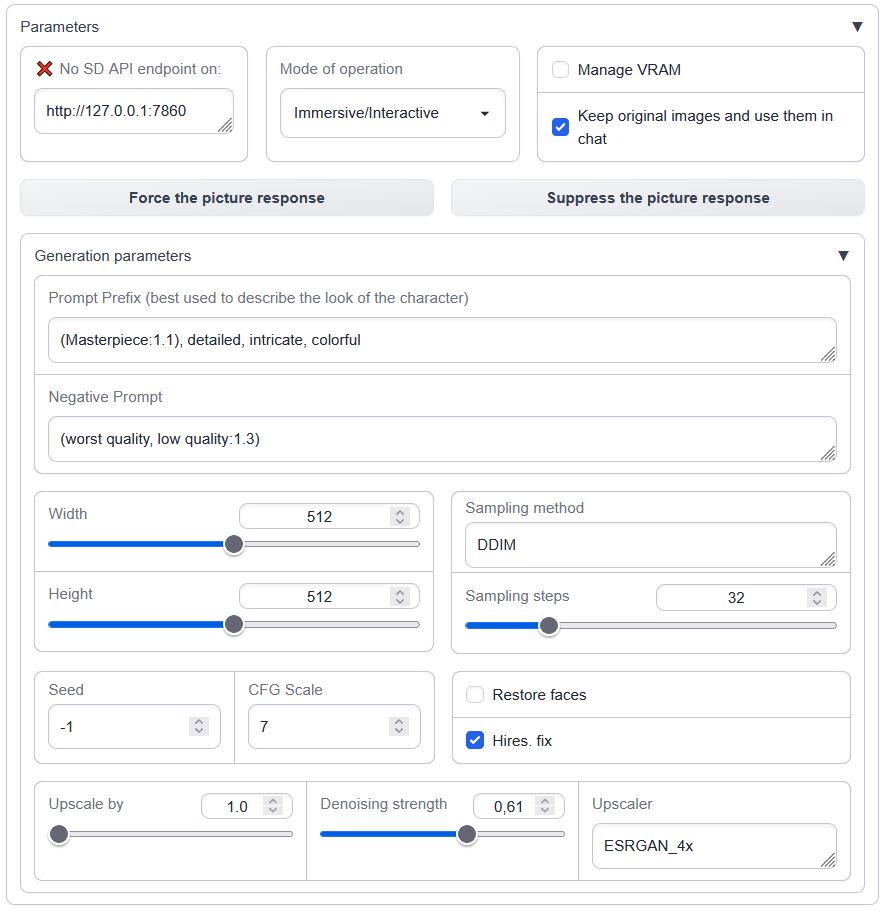
|
| 11 |
+
|
| 12 |
+
</details>
|
| 13 |
+
|
| 14 |
+
Load it in the `--chat` mode with `--extension sd_api_pictures` alongside `send_pictures`
|
| 15 |
+
(it's not really required, but completes the picture, *pun intended*).
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
## History
|
| 19 |
+
|
| 20 |
+
Consider the version included with [oobabooga's repository](https://github.com/oobabooga/text-generation-webui/tree/main/extensions/sd_api_pictures) to be STABLE, experimental developments and untested features are pushed in [Brawlence/SD_api_pics](https://github.com/Brawlence/SD_api_pics)
|
| 21 |
+
|
| 22 |
+
Lastest change:
|
| 23 |
+
1.1.0 → 1.1.1 Fixed not having Auto1111's metadata in received images
|
| 24 |
+
|
| 25 |
+
## Details
|
| 26 |
+
|
| 27 |
+
The image generation is triggered:
|
| 28 |
+
- manually through the 'Force the picture response' button while in `Manual` or `Immersive/Interactive` modes OR
|
| 29 |
+
- automatically in `Immersive/Interactive` mode if the words `'send|main|message|me'` are followed by `'image|pic|picture|photo|snap|snapshot|selfie|meme'` in the user's prompt
|
| 30 |
+
- always on in `Picturebook/Adventure` mode (if not currently suppressed by 'Suppress the picture response')
|
| 31 |
+
|
| 32 |
+
## Prerequisites
|
| 33 |
+
|
| 34 |
+
One needs an available instance of Automatic1111's webui running with an `--api` flag. Ain't tested with a notebook / cloud hosted one but should be possible.
|
| 35 |
+
To run it locally in parallel on the same machine, specify custom `--listen-port` for either Auto1111's or ooba's webUIs.
|
| 36 |
+
|
| 37 |
+
## Features overview
|
| 38 |
+
- Connection to API check (press enter in the address box)
|
| 39 |
+
- [VRAM management (model shuffling)](https://github.com/Brawlence/SD_api_pics/wiki/VRAM-management-feature)
|
| 40 |
+
- [Three different operation modes](https://github.com/Brawlence/SD_api_pics/wiki/Modes-of-operation) (manual, interactive, always-on)
|
| 41 |
+
- User-defined persistent settings via settings.json
|
| 42 |
+
|
| 43 |
+
### Connection check
|
| 44 |
+
|
| 45 |
+
Insert the Automatic1111's WebUI address and press Enter:
|
| 46 |
+
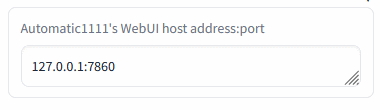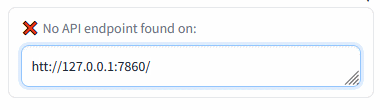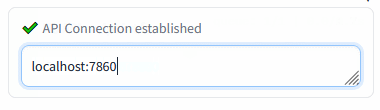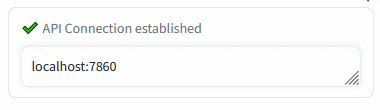
|
| 47 |
+
Green mark confirms the ability to communicate with Auto1111's API on this address. Red cross means something's not right (the ext won't work).
|
| 48 |
+
|
| 49 |
+
### Persistents settings
|
| 50 |
+
|
| 51 |
+
Create or modify the `settings.json` in the `text-generation-webui` root directory to override the defaults
|
| 52 |
+
present in script.py, ex:
|
| 53 |
+
|
| 54 |
+
```json
|
| 55 |
+
{
|
| 56 |
+
"sd_api_pictures-manage_VRAM": 1,
|
| 57 |
+
"sd_api_pictures-save_img": 1,
|
| 58 |
+
"sd_api_pictures-prompt_prefix": "(Masterpiece:1.1), detailed, intricate, colorful, (solo:1.1)",
|
| 59 |
+
"sd_api_pictures-sampler_name": "DPM++ 2M Karras"
|
| 60 |
+
}
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
will automatically set the `Manage VRAM` & `Keep original images` checkboxes and change the texts in `Prompt Prefix` and `Sampler name` on load.
|
| 64 |
+
|
| 65 |
+
---
|
| 66 |
+
|
| 67 |
+
## Demonstrations:
|
| 68 |
+
|
| 69 |
+
Those are examples of the version 1.0.0, but the core functionality is still the same
|
| 70 |
+
|
| 71 |
+
<details>
|
| 72 |
+
<summary>Conversation 1</summary>
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
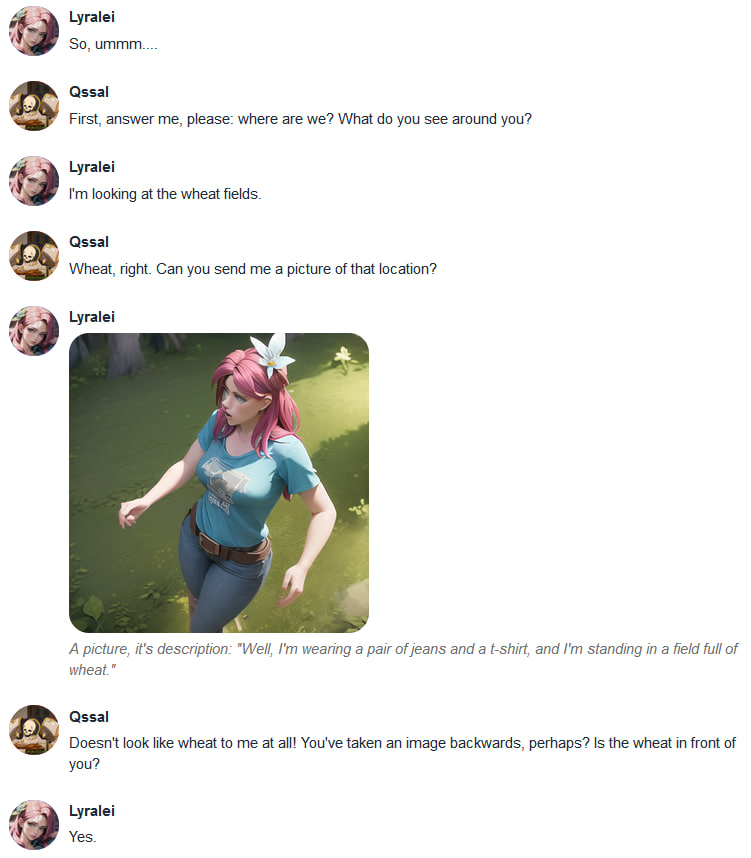
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
</details>
|
| 81 |
+
|
| 82 |
+
<details>
|
| 83 |
+
<summary>Conversation 2</summary>
|
| 84 |
+
|
| 85 |
+
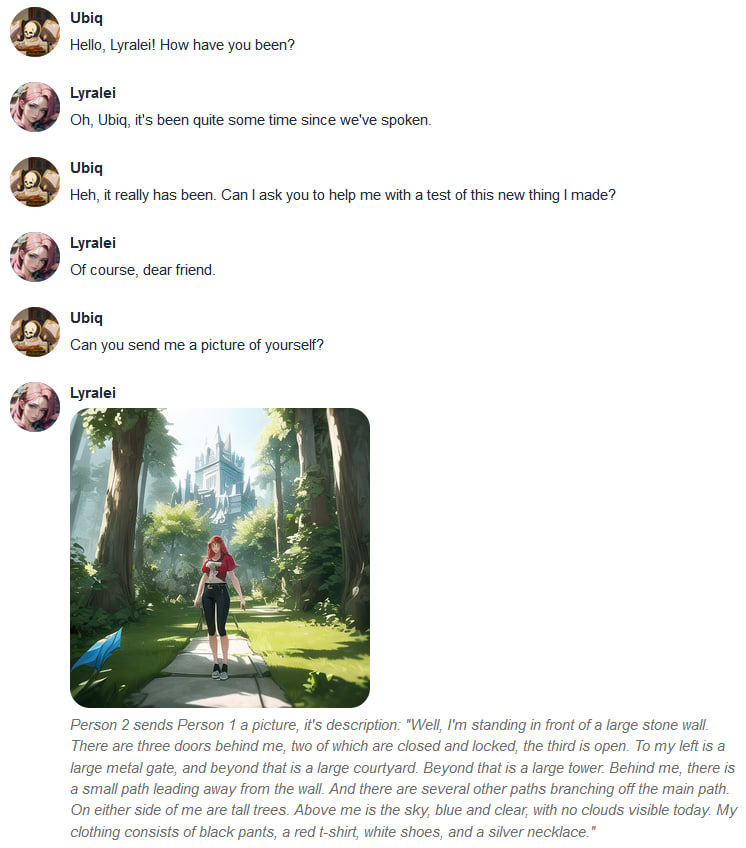
|
| 86 |
+
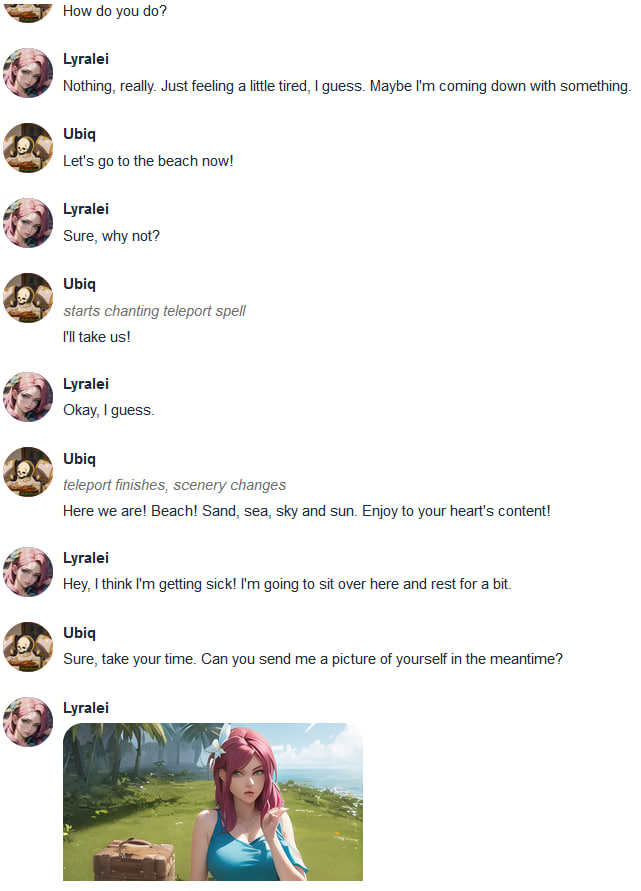
|
| 87 |
+
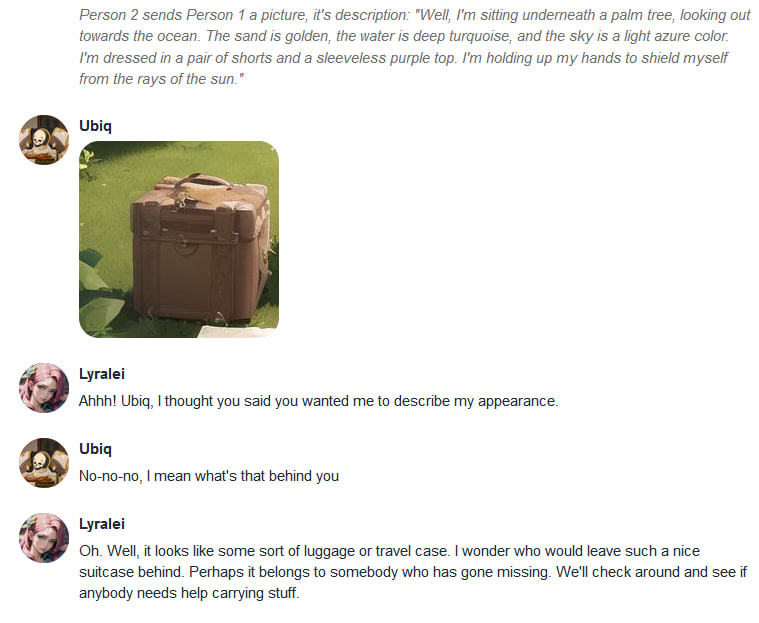
|
| 88 |
+
|
| 89 |
+
</details>
|
| 90 |
+
|
text-generation-webui/extensions/sd_api_pictures/script.py
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import base64
|
| 2 |
+
import io
|
| 3 |
+
import re
|
| 4 |
+
import time
|
| 5 |
+
from datetime import date
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
|
| 8 |
+
import gradio as gr
|
| 9 |
+
import modules.shared as shared
|
| 10 |
+
import requests
|
| 11 |
+
import torch
|
| 12 |
+
from modules.models import reload_model, unload_model
|
| 13 |
+
from PIL import Image
|
| 14 |
+
|
| 15 |
+
torch._C._jit_set_profiling_mode(False)
|
| 16 |
+
|
| 17 |
+
# parameters which can be customized in settings.json of webui
|
| 18 |
+
params = {
|
| 19 |
+
'address': 'http://127.0.0.1:7860',
|
| 20 |
+
'mode': 0, # modes of operation: 0 (Manual only), 1 (Immersive/Interactive - looks for words to trigger), 2 (Picturebook Adventure - Always on)
|
| 21 |
+
'manage_VRAM': False,
|
| 22 |
+
'save_img': False,
|
| 23 |
+
'SD_model': 'NeverEndingDream', # not used right now
|
| 24 |
+
'prompt_prefix': '(Masterpiece:1.1), detailed, intricate, colorful',
|
| 25 |
+
'negative_prompt': '(worst quality, low quality:1.3)',
|
| 26 |
+
'width': 512,
|
| 27 |
+
'height': 512,
|
| 28 |
+
'restore_faces': False,
|
| 29 |
+
'seed': -1,
|
| 30 |
+
'sampler_name': 'DDIM',
|
| 31 |
+
'steps': 32,
|
| 32 |
+
'cfg_scale': 7
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def give_VRAM_priority(actor):
|
| 37 |
+
global shared, params
|
| 38 |
+
|
| 39 |
+
if actor == 'SD':
|
| 40 |
+
unload_model()
|
| 41 |
+
print("Requesting Auto1111 to re-load last checkpoint used...")
|
| 42 |
+
response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
|
| 43 |
+
response.raise_for_status()
|
| 44 |
+
|
| 45 |
+
elif actor == 'LLM':
|
| 46 |
+
print("Requesting Auto1111 to vacate VRAM...")
|
| 47 |
+
response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
|
| 48 |
+
response.raise_for_status()
|
| 49 |
+
reload_model()
|
| 50 |
+
|
| 51 |
+
elif actor == 'set':
|
| 52 |
+
print("VRAM mangement activated -- requesting Auto1111 to vacate VRAM...")
|
| 53 |
+
response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
|
| 54 |
+
response.raise_for_status()
|
| 55 |
+
|
| 56 |
+
elif actor == 'reset':
|
| 57 |
+
print("VRAM mangement deactivated -- requesting Auto1111 to reload checkpoint")
|
| 58 |
+
response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
|
| 59 |
+
response.raise_for_status()
|
| 60 |
+
|
| 61 |
+
else:
|
| 62 |
+
raise RuntimeError(f'Managing VRAM: "{actor}" is not a known state!')
|
| 63 |
+
|
| 64 |
+
response.raise_for_status()
|
| 65 |
+
del response
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
if params['manage_VRAM']:
|
| 69 |
+
give_VRAM_priority('set')
|
| 70 |
+
|
| 71 |
+
samplers = ['DDIM', 'DPM++ 2M Karras'] # TODO: get the availible samplers with http://{address}}/sdapi/v1/samplers
|
| 72 |
+
SD_models = ['NeverEndingDream'] # TODO: get with http://{address}}/sdapi/v1/sd-models and allow user to select
|
| 73 |
+
|
| 74 |
+
streaming_state = shared.args.no_stream # remember if chat streaming was enabled
|
| 75 |
+
picture_response = False # specifies if the next model response should appear as a picture
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def remove_surrounded_chars(string):
|
| 79 |
+
# this expression matches to 'as few symbols as possible (0 upwards) between any asterisks' OR
|
| 80 |
+
# 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
|
| 81 |
+
return re.sub('\*[^\*]*?(\*|$)', '', string)
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def triggers_are_in(string):
|
| 85 |
+
string = remove_surrounded_chars(string)
|
| 86 |
+
# regex searches for send|main|message|me (at the end of the word) followed by
|
| 87 |
+
# a whole word of image|pic|picture|photo|snap|snapshot|selfie|meme(s),
|
| 88 |
+
# (?aims) are regex parser flags
|
| 89 |
+
return bool(re.search('(?aims)(send|mail|message|me)\\b.+?\\b(image|pic(ture)?|photo|snap(shot)?|selfie|meme)s?\\b', string))
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def input_modifier(string):
|
| 93 |
+
"""
|
| 94 |
+
This function is applied to your text inputs before
|
| 95 |
+
they are fed into the model.
|
| 96 |
+
"""
|
| 97 |
+
|
| 98 |
+
global params
|
| 99 |
+
|
| 100 |
+
if not params['mode'] == 1: # if not in immersive/interactive mode, do nothing
|
| 101 |
+
return string
|
| 102 |
+
|
| 103 |
+
if triggers_are_in(string): # if we're in it, check for trigger words
|
| 104 |
+
toggle_generation(True)
|
| 105 |
+
string = string.lower()
|
| 106 |
+
if "of" in string:
|
| 107 |
+
subject = string.split('of', 1)[1] # subdivide the string once by the first 'of' instance and get what's coming after it
|
| 108 |
+
string = "Please provide a detailed and vivid description of " + subject
|
| 109 |
+
else:
|
| 110 |
+
string = "Please provide a detailed description of your appearance, your surroundings and what you are doing right now"
|
| 111 |
+
|
| 112 |
+
return string
|
| 113 |
+
|
| 114 |
+
# Get and save the Stable Diffusion-generated picture
|
| 115 |
+
def get_SD_pictures(description):
|
| 116 |
+
|
| 117 |
+
global params
|
| 118 |
+
|
| 119 |
+
if params['manage_VRAM']:
|
| 120 |
+
give_VRAM_priority('SD')
|
| 121 |
+
|
| 122 |
+
payload = {
|
| 123 |
+
"prompt": params['prompt_prefix'] + description,
|
| 124 |
+
"seed": params['seed'],
|
| 125 |
+
"sampler_name": params['sampler_name'],
|
| 126 |
+
"steps": params['steps'],
|
| 127 |
+
"cfg_scale": params['cfg_scale'],
|
| 128 |
+
"width": params['width'],
|
| 129 |
+
"height": params['height'],
|
| 130 |
+
"restore_faces": params['restore_faces'],
|
| 131 |
+
"negative_prompt": params['negative_prompt']
|
| 132 |
+
}
|
| 133 |
+
|
| 134 |
+
print(f'Prompting the image generator via the API on {params["address"]}...')
|
| 135 |
+
response = requests.post(url=f'{params["address"]}/sdapi/v1/txt2img', json=payload)
|
| 136 |
+
response.raise_for_status()
|
| 137 |
+
r = response.json()
|
| 138 |
+
|
| 139 |
+
visible_result = ""
|
| 140 |
+
for img_str in r['images']:
|
| 141 |
+
if params['save_img']:
|
| 142 |
+
img_data = base64.b64decode(img_str)
|
| 143 |
+
|
| 144 |
+
variadic = f'{date.today().strftime("%Y_%m_%d")}/{shared.character}_{int(time.time())}'
|
| 145 |
+
output_file = Path(f'extensions/sd_api_pictures/outputs/{variadic}.png')
|
| 146 |
+
output_file.parent.mkdir(parents=True, exist_ok=True)
|
| 147 |
+
|
| 148 |
+
with open(output_file.as_posix(), 'wb') as f:
|
| 149 |
+
f.write(img_data)
|
| 150 |
+
|
| 151 |
+
visible_result = visible_result + f'<img src="/file/extensions/sd_api_pictures/outputs/{variadic}.png" alt="{description}" style="max-width: unset; max-height: unset;">\n'
|
| 152 |
+
else:
|
| 153 |
+
image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
|
| 154 |
+
# lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
| 155 |
+
image.thumbnail((300, 300))
|
| 156 |
+
buffered = io.BytesIO()
|
| 157 |
+
image.save(buffered, format="JPEG")
|
| 158 |
+
buffered.seek(0)
|
| 159 |
+
image_bytes = buffered.getvalue()
|
| 160 |
+
img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
|
| 161 |
+
visible_result = visible_result + f'<img src="{img_str}" alt="{description}">\n'
|
| 162 |
+
|
| 163 |
+
if params['manage_VRAM']:
|
| 164 |
+
give_VRAM_priority('LLM')
|
| 165 |
+
|
| 166 |
+
return visible_result
|
| 167 |
+
|
| 168 |
+
# TODO: how do I make the UI history ignore the resulting pictures (I don't want HTML to appear in history)
|
| 169 |
+
# and replace it with 'text' for the purposes of logging?
|
| 170 |
+
def output_modifier(string):
|
| 171 |
+
"""
|
| 172 |
+
This function is applied to the model outputs.
|
| 173 |
+
"""
|
| 174 |
+
|
| 175 |
+
global picture_response, params
|
| 176 |
+
|
| 177 |
+
if not picture_response:
|
| 178 |
+
return string
|
| 179 |
+
|
| 180 |
+
string = remove_surrounded_chars(string)
|
| 181 |
+
string = string.replace('"', '')
|
| 182 |
+
string = string.replace('“', '')
|
| 183 |
+
string = string.replace('\n', ' ')
|
| 184 |
+
string = string.strip()
|
| 185 |
+
|
| 186 |
+
if string == '':
|
| 187 |
+
string = 'no viable description in reply, try regenerating'
|
| 188 |
+
return string
|
| 189 |
+
|
| 190 |
+
text = ""
|
| 191 |
+
if (params['mode'] < 2):
|
| 192 |
+
toggle_generation(False)
|
| 193 |
+
text = f'*Sends a picture which portrays: “{string}”*'
|
| 194 |
+
else:
|
| 195 |
+
text = string
|
| 196 |
+
|
| 197 |
+
string = get_SD_pictures(string) + "\n" + text
|
| 198 |
+
|
| 199 |
+
return string
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def bot_prefix_modifier(string):
|
| 203 |
+
"""
|
| 204 |
+
This function is only applied in chat mode. It modifies
|
| 205 |
+
the prefix text for the Bot and can be used to bias its
|
| 206 |
+
behavior.
|
| 207 |
+
"""
|
| 208 |
+
|
| 209 |
+
return string
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def toggle_generation(*args):
|
| 213 |
+
global picture_response, shared, streaming_state
|
| 214 |
+
|
| 215 |
+
if not args:
|
| 216 |
+
picture_response = not picture_response
|
| 217 |
+
else:
|
| 218 |
+
picture_response = args[0]
|
| 219 |
+
|
| 220 |
+
shared.args.no_stream = True if picture_response else streaming_state # Disable streaming cause otherwise the SD-generated picture would return as a dud
|
| 221 |
+
shared.processing_message = "*Is sending a picture...*" if picture_response else "*Is typing...*"
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def filter_address(address):
|
| 225 |
+
address = address.strip()
|
| 226 |
+
# address = re.sub('http(s)?:\/\/|\/$','',address) # remove starting http:// OR https:// OR trailing slash
|
| 227 |
+
address = re.sub('\/$', '', address) # remove trailing /s
|
| 228 |
+
if not address.startswith('http'):
|
| 229 |
+
address = 'http://' + address
|
| 230 |
+
return address
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
def SD_api_address_update(address):
|
| 234 |
+
|
| 235 |
+
global params
|
| 236 |
+
|
| 237 |
+
msg = "✔️ SD API is found on:"
|
| 238 |
+
address = filter_address(address)
|
| 239 |
+
params.update({"address": address})
|
| 240 |
+
try:
|
| 241 |
+
response = requests.get(url=f'{params["address"]}/sdapi/v1/sd-models')
|
| 242 |
+
response.raise_for_status()
|
| 243 |
+
# r = response.json()
|
| 244 |
+
except:
|
| 245 |
+
msg = "❌ No SD API endpoint on:"
|
| 246 |
+
|
| 247 |
+
return gr.Textbox.update(label=msg)
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
def ui():
|
| 251 |
+
|
| 252 |
+
# Gradio elements
|
| 253 |
+
# gr.Markdown('### Stable Diffusion API Pictures') # Currently the name of extension is shown as the title
|
| 254 |
+
with gr.Accordion("Parameters", open=True):
|
| 255 |
+
with gr.Row():
|
| 256 |
+
address = gr.Textbox(placeholder=params['address'], value=params['address'], label='Auto1111\'s WebUI address')
|
| 257 |
+
mode = gr.Dropdown(["Manual", "Immersive/Interactive", "Picturebook/Adventure"], value="Manual", label="Mode of operation", type="index")
|
| 258 |
+
with gr.Column(scale=1, min_width=300):
|
| 259 |
+
manage_VRAM = gr.Checkbox(value=params['manage_VRAM'], label='Manage VRAM')
|
| 260 |
+
save_img = gr.Checkbox(value=params['save_img'], label='Keep original images and use them in chat')
|
| 261 |
+
|
| 262 |
+
force_pic = gr.Button("Force the picture response")
|
| 263 |
+
suppr_pic = gr.Button("Suppress the picture response")
|
| 264 |
+
|
| 265 |
+
with gr.Accordion("Generation parameters", open=False):
|
| 266 |
+
prompt_prefix = gr.Textbox(placeholder=params['prompt_prefix'], value=params['prompt_prefix'], label='Prompt Prefix (best used to describe the look of the character)')
|
| 267 |
+
with gr.Row():
|
| 268 |
+
with gr.Column():
|
| 269 |
+
negative_prompt = gr.Textbox(placeholder=params['negative_prompt'], value=params['negative_prompt'], label='Negative Prompt')
|
| 270 |
+
sampler_name = gr.Textbox(placeholder=params['sampler_name'], value=params['sampler_name'], label='Sampler')
|
| 271 |
+
with gr.Column():
|
| 272 |
+
width = gr.Slider(256, 768, value=params['width'], step=64, label='Width')
|
| 273 |
+
height = gr.Slider(256, 768, value=params['height'], step=64, label='Height')
|
| 274 |
+
with gr.Row():
|
| 275 |
+
steps = gr.Number(label="Steps:", value=params['steps'])
|
| 276 |
+
seed = gr.Number(label="Seed:", value=params['seed'])
|
| 277 |
+
cfg_scale = gr.Number(label="CFG Scale:", value=params['cfg_scale'])
|
| 278 |
+
|
| 279 |
+
# Event functions to update the parameters in the backend
|
| 280 |
+
address.change(lambda x: params.update({"address": filter_address(x)}), address, None)
|
| 281 |
+
mode.select(lambda x: params.update({"mode": x}), mode, None)
|
| 282 |
+
mode.select(lambda x: toggle_generation(x > 1), inputs=mode, outputs=None)
|
| 283 |
+
manage_VRAM.change(lambda x: params.update({"manage_VRAM": x}), manage_VRAM, None)
|
| 284 |
+
manage_VRAM.change(lambda x: give_VRAM_priority('set' if x else 'reset'), inputs=manage_VRAM, outputs=None)
|
| 285 |
+
save_img.change(lambda x: params.update({"save_img": x}), save_img, None)
|
| 286 |
+
|
| 287 |
+
address.submit(fn=SD_api_address_update, inputs=address, outputs=address)
|
| 288 |
+
prompt_prefix.change(lambda x: params.update({"prompt_prefix": x}), prompt_prefix, None)
|
| 289 |
+
negative_prompt.change(lambda x: params.update({"negative_prompt": x}), negative_prompt, None)
|
| 290 |
+
width.change(lambda x: params.update({"width": x}), width, None)
|
| 291 |
+
height.change(lambda x: params.update({"height": x}), height, None)
|
| 292 |
+
|
| 293 |
+
sampler_name.change(lambda x: params.update({"sampler_name": x}), sampler_name, None)
|
| 294 |
+
steps.change(lambda x: params.update({"steps": x}), steps, None)
|
| 295 |
+
seed.change(lambda x: params.update({"seed": x}), seed, None)
|
| 296 |
+
cfg_scale.change(lambda x: params.update({"cfg_scale": x}), cfg_scale, None)
|
| 297 |
+
|
| 298 |
+
force_pic.click(lambda x: toggle_generation(True), inputs=force_pic, outputs=None)
|
| 299 |
+
suppr_pic.click(lambda x: toggle_generation(False), inputs=suppr_pic, outputs=None)
|
text-generation-webui/extensions/send_pictures/script.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import base64
|
| 2 |
+
from io import BytesIO
|
| 3 |
+
|
| 4 |
+
import gradio as gr
|
| 5 |
+
import torch
|
| 6 |
+
from transformers import BlipForConditionalGeneration, BlipProcessor
|
| 7 |
+
|
| 8 |
+
from modules import chat, shared
|
| 9 |
+
from modules.ui import gather_interface_values
|
| 10 |
+
|
| 11 |
+
# If 'state' is True, will hijack the next chat generation with
|
| 12 |
+
# custom input text given by 'value' in the format [text, visible_text]
|
| 13 |
+
input_hijack = {
|
| 14 |
+
'state': False,
|
| 15 |
+
'value': ["", ""]
|
| 16 |
+
}
|
| 17 |
+
|
| 18 |
+
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
|
| 19 |
+
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base", torch_dtype=torch.float32).to("cpu")
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def caption_image(raw_image):
|
| 23 |
+
inputs = processor(raw_image.convert('RGB'), return_tensors="pt").to("cpu", torch.float32)
|
| 24 |
+
out = model.generate(**inputs, max_new_tokens=100)
|
| 25 |
+
return processor.decode(out[0], skip_special_tokens=True)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def generate_chat_picture(picture, name1, name2):
|
| 29 |
+
text = f'*{name1} sends {name2} a picture that contains the following: “{caption_image(picture)}”*'
|
| 30 |
+
# lower the resolution of sent images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
| 31 |
+
picture.thumbnail((300, 300))
|
| 32 |
+
buffer = BytesIO()
|
| 33 |
+
picture.save(buffer, format="JPEG")
|
| 34 |
+
img_str = base64.b64encode(buffer.getvalue()).decode('utf-8')
|
| 35 |
+
visible_text = f'<img src="data:image/jpeg;base64,{img_str}" alt="{text}">'
|
| 36 |
+
return text, visible_text
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def ui():
|
| 40 |
+
picture_select = gr.Image(label='Send a picture', type='pil')
|
| 41 |
+
|
| 42 |
+
# Prepare the input hijack, update the interface values, call the generation function, and clear the picture
|
| 43 |
+
picture_select.upload(
|
| 44 |
+
lambda picture, name1, name2: input_hijack.update({"state": True, "value": generate_chat_picture(picture, name1, name2)}), [picture_select, shared.gradio['name1'], shared.gradio['name2']], None).then(
|
| 45 |
+
gather_interface_values, [shared.gradio[k] for k in shared.input_elements], shared.gradio['interface_state']).then(
|
| 46 |
+
chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream).then(
|
| 47 |
+
lambda: None, None, picture_select, show_progress=False)
|
text-generation-webui/extensions/silero_tts/outputs/outputs-will-be-saved-here.txt
ADDED
|
File without changes
|
text-generation-webui/extensions/silero_tts/requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ipython
|
| 2 |
+
num2words
|
| 3 |
+
omegaconf
|
| 4 |
+
pydub
|
| 5 |
+
PyYAML
|