Spaces:
Runtime error

Runtime error

added datasets and virtex
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +1 -0
- datasets/common_30k.model +0 -0
- virtex/CHANGELOG.md +41 -0
- virtex/LICENSE +16 -0
- virtex/README.md +92 -0
- virtex/configs/_base_bicaptioning_R_50_L1_H1024.yaml +66 -0
- virtex/configs/backbone_ablations/bicaptioning_R_101_L1_H1024.yaml +5 -0
- virtex/configs/backbone_ablations/bicaptioning_R_50W2X_L1_H1024.yaml +5 -0
- virtex/configs/backbone_ablations/bicaptioning_R_50_L1_H1024.yaml +1 -0
- virtex/configs/depth_ablations/bicaptioning_R_50_L1_H1024.yaml +1 -0
- virtex/configs/depth_ablations/bicaptioning_R_50_L2_H1024.yaml +5 -0
- virtex/configs/depth_ablations/bicaptioning_R_50_L3_H1024.yaml +5 -0
- virtex/configs/depth_ablations/bicaptioning_R_50_L4_H1024.yaml +5 -0
- virtex/configs/detectron2/_base_faster_rcnn_R_50_C4_BN.yaml +49 -0
- virtex/configs/detectron2/_base_mask_rcnn_R_50_FPN.yaml +75 -0
- virtex/configs/detectron2/coco_segm_default_init_2x.yaml +24 -0
- virtex/configs/detectron2/lvis_segm_default_init_2x.yaml +36 -0
- virtex/configs/detectron2/lvis_segm_imagenet_init_2x.yaml +38 -0
- virtex/configs/detectron2/voc_det_default_init_24k.yaml +28 -0
- virtex/configs/downstream/imagenet_clf.yaml +33 -0
- virtex/configs/downstream/inaturalist_clf.yaml +36 -0
- virtex/configs/downstream/voc07_clf.yaml +15 -0
- virtex/configs/redcaps/gcc_R_50_L6_H512.yaml +35 -0
- virtex/configs/redcaps/miniclip_sbu_R_50_L12_H512.yaml +35 -0
- virtex/configs/redcaps/redcaps_2020_R_50_L6_H512.yaml +35 -0
- virtex/configs/redcaps/redcaps_all_R_50_L6_H512.yaml +35 -0
- virtex/configs/redcaps/sbu_R_50_L6_H512.yaml +35 -0
- virtex/configs/task_ablations/bicaptioning_R_50_L1_H2048.yaml +5 -0
- virtex/configs/task_ablations/captioning_R_50_L1_H2048.yaml +6 -0
- virtex/configs/task_ablations/masked_lm_R_50_L1_H2048.yaml +6 -0
- virtex/configs/task_ablations/multilabel_classification_R_50.yaml +12 -0
- virtex/configs/task_ablations/token_classification_R_50.yaml +9 -0
- virtex/configs/width_ablations/bicaptioning_R_50_L1_H1024.yaml +1 -0
- virtex/configs/width_ablations/bicaptioning_R_50_L1_H2048.yaml +5 -0
- virtex/configs/width_ablations/bicaptioning_R_50_L1_H512.yaml +5 -0
- virtex/configs/width_ablations/bicaptioning_R_50_L1_H768.yaml +5 -0
- virtex/docs/Makefile +19 -0
- virtex/docs/_static/custom.css +115 -0
- virtex/docs/_static/system_figure.jpg +0 -0
- virtex/docs/_templates/layout.html +19 -0
- virtex/docs/conf.py +173 -0
- virtex/docs/index.rst +122 -0
- virtex/docs/virtex/config.rst +18 -0
- virtex/docs/virtex/data.datasets.rst +20 -0
- virtex/docs/virtex/data.readers.rst +8 -0
- virtex/docs/virtex/data.rst +14 -0
- virtex/docs/virtex/data.tokenizers.rst +8 -0
- virtex/docs/virtex/data.transforms.rst +8 -0
- virtex/docs/virtex/factories.rst +56 -0
- virtex/docs/virtex/model_zoo.rst +8 -0
.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
.ipynb_checkpoints/*
|
datasets/common_30k.model
ADDED
|
Binary file (748 kB). View file
|
|
|
virtex/CHANGELOG.md
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ArXiv v1 -> v2 CHANGELOG
|
| 2 |
+
=========================
|
| 3 |
+
|
| 4 |
+
[ArXiv v1](https://arxiv.org/abs/2006.06666v1) was our ECCV 2020 submission (reject). [ArXiv v2](https://arxiv.org/abs/2006.06666v2) is out CVPR 2021 submission (accept). The repository snapshots for these two versions are tagged at [`v0.9`](https://github.com/kdexd/virtex/releases/tag/v0.9) and [`v1.0`](https://github.com/kdexd/virtex/releases/tag/v1.0).
|
| 5 |
+
|
| 6 |
+
While the core motivation and approach is the same, we have made some minor changes in our experiments and evaluation setup. These slightly improve model performances across the board (within decimals). New models are available in [`v1.0` model zoo](http://kdexd.github.io/virtex/virtex/usage/model_zoo.html), however links to old models in `v0.9` will be active till June 30, 2021. We encourage you to use the new models!
|
| 7 |
+
|
| 8 |
+
We have updated the experiment config files for all changes described below.
|
| 9 |
+
|
| 10 |
+
Experiment Changes
|
| 11 |
+
------------------
|
| 12 |
+
|
| 13 |
+
### New Feature:
|
| 14 |
+
|
| 15 |
+
Add a new pretraining task for BERT-style _Masked Language Modeling_. Pre-trained model released in Model Zoo.
|
| 16 |
+
|
| 17 |
+
### Pre-training:
|
| 18 |
+
|
| 19 |
+
- The only change during pre-training is that we do not apply weight decay to LayerNorm and biases in input embedding and transformer layers. We apply weight decay to the biases in output linear layer (before softmax).
|
| 20 |
+
|
| 21 |
+
- Other factors that could affect results:
|
| 22 |
+
- Use official [albumentations.ColorJitter transform](https://albumentations.ai/docs/api_reference/augmentations/transforms/#albumentations.augmentations.transforms.ColorJitter) that mimics torchvision ColorJitter transform. Earlier I implemented [my own ColorJitter](https://github.com/kdexd/virtex/blob/c19e7fc9b98e98af82286ed1537b6f588eaeac44/virtex/data/transforms.py#L156) because albumentations didn't have one.
|
| 23 |
+
- Use PyTorch Native AMP (Automatic Mixed Precision) instead of NVIDIA Apex.
|
| 24 |
+
|
| 25 |
+
### Downstream Evaluations:
|
| 26 |
+
|
| 27 |
+
1. **PASCAL VOC 2007 Linear Classification:** [[diff]](https://github.com/kdexd/virtex/compare/57889ca9829f27b932e92b9e6b51f50f20f2d546..7645cc0d1e3e49f00e347e9873fd020faa2ec62e#diff-b4405dd4879a48ef1e5b1e2801035909584a5f1f32f63d5e793fb50dee077b97)
|
| 28 |
+
- Instead of training linear SVMs on 8192-dimensional average pooled features from ResNet-50 (7x7x2048 —> 2x2x2048), like [(Misra et al. 2019)](https://arxiv.org/abs/1905.01235), we directly train SVMs on 2048-dimensional global average pooled features, following recent works like [SwAV (Caron et al. 2020)](https://arxiv.org/abs/2006.09882).
|
| 29 |
+
- We change the pre-processing: resize shortest edge to 256 pixels, and take center crop of 224 pixels.
|
| 30 |
+
- These improve VOC mAP by 1-2 points everywhere, and makes SVM training faster. Since we select best checkpoint based on this metric, all results on other downstream tasks also change in `ArXiv v2` (But the trends remain same.)
|
| 31 |
+
|
| 32 |
+
2. **ImageNet Linear Evaluation:** [[diff]](https://github.com/kdexd/virtex/compare/57889ca9829f27b932e92b9e6b51f50f20f2d546..7645cc0d1e3e49f00e347e9873fd020faa2ec62e#diff-d3dea1e7bf97d0cfca4b59a47c0a9bb81e78b8827654fe0258df9ce2c3f5f41c)
|
| 33 |
+
- Changed random resized crop scale from (20-100%) to (8-100%) for consistency with evaluations in SSL works like MoCo and SwAV.
|
| 34 |
+
- Use cosine LR decay instead of step decay, following SwAV. Improves accuracy by up to 1%.
|
| 35 |
+
|
| 36 |
+
3. **iNaturalist Fine-tuning:** [[diff]](https://github.com/kdexd/virtex/compare/57889ca9829f27b932e92b9e6b51f50f20f2d546..7645cc0d1e3e49f00e347e9873fd020faa2ec62e#diff-09096da78cfcde3a604ce22d80313f0800225d928cce5ef7334b89a382adfe4d)
|
| 37 |
+
- This evaluation is left unchanged across ArXiv versions, but we fixd a typo in image pre-processing step, present in publicly released config.
|
| 38 |
+
|
| 39 |
+
4. **Detectron2 tasks (COCO and LVIS Instance Segmentation, VOC Detection):**
|
| 40 |
+
- Heavily simplified the script. Updated Detectron2 uses a more memory-efficient SyncBatchNorm and supports AMP.
|
| 41 |
+
|
virtex/LICENSE
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2020, Karan Desai.
|
| 2 |
+
|
| 3 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and
|
| 4 |
+
associated documentation files (the "Software"), to deal in the Software without restriction,
|
| 5 |
+
including without limitation the rights to use, copy, modify, merge, publish, distribute,
|
| 6 |
+
sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is
|
| 7 |
+
furnished to do so, subject to the following conditions:
|
| 8 |
+
|
| 9 |
+
The above copyright notice and this permission notice shall be included in all copies or substantial
|
| 10 |
+
portions of the Software.
|
| 11 |
+
|
| 12 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT
|
| 13 |
+
NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
|
| 14 |
+
NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES
|
| 15 |
+
OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 16 |
+
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
virtex/README.md
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
VirTex: Learning Visual Representations from Textual Annotations
|
| 2 |
+
================================================================
|
| 3 |
+
|
| 4 |
+
<h4>
|
| 5 |
+
Karan Desai and Justin Johnson
|
| 6 |
+
</br>
|
| 7 |
+
<span style="font-size: 14pt; color: #555555">
|
| 8 |
+
University of Michigan
|
| 9 |
+
</span>
|
| 10 |
+
</h4>
|
| 11 |
+
<hr>
|
| 12 |
+
|
| 13 |
+
**CVPR 2021** [arxiv.org/abs/2006.06666][1]
|
| 14 |
+
|
| 15 |
+
**Model Zoo, Usage Instructions and API docs:** [kdexd.github.io/virtex](https://kdexd.github.io/virtex)
|
| 16 |
+
|
| 17 |
+
VirTex is a pretraining approach which uses semantically dense captions to
|
| 18 |
+
learn visual representations. We train CNN + Transformers from scratch on
|
| 19 |
+
COCO Captions, and transfer the CNN to downstream vision tasks including
|
| 20 |
+
image classification, object detection, and instance segmentation.
|
| 21 |
+
VirTex matches or outperforms models which use ImageNet for pretraining --
|
| 22 |
+
both supervised or unsupervised -- despite using up to 10x fewer images.
|
| 23 |
+
|
| 24 |
+

|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
Get the pretrained ResNet-50 visual backbone from our best performing VirTex
|
| 28 |
+
model in one line *without any installation*!
|
| 29 |
+
|
| 30 |
+
```python
|
| 31 |
+
import torch
|
| 32 |
+
|
| 33 |
+
# That's it, this one line only requires PyTorch.
|
| 34 |
+
model = torch.hub.load("kdexd/virtex", "resnet50", pretrained=True)
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
### Note (For returning users before January 2021):
|
| 38 |
+
|
| 39 |
+
The pretrained models in our model zoo have changed from [`v1.0`](https://github.com/kdexd/virtex/releases/tag/v1.0) onwards.
|
| 40 |
+
They are slightly better tuned than older models, and reproduce the results in our
|
| 41 |
+
CVPR 2021 accepted paper ([arXiv v2](https://arxiv.org/abs/2006.06666v2)).
|
| 42 |
+
Some training and evaluation hyperparams are changed since [`v0.9`](https://github.com/kdexd/virtex/releases/tag/v0.9).
|
| 43 |
+
Please refer [`CHANGELOG.md`](https://github.com/kdexd/virtex/blob/master/CHANGELOG.md)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
Usage Instructions
|
| 47 |
+
------------------
|
| 48 |
+
|
| 49 |
+
1. [How to setup this codebase?][2]
|
| 50 |
+
2. [VirTex Model Zoo][3]
|
| 51 |
+
3. [How to train your VirTex model?][4]
|
| 52 |
+
4. [How to evaluate on downstream tasks?][5]
|
| 53 |
+
|
| 54 |
+
Full documentation is available at [kdexd.github.io/virtex](https://kdexd.github.io/virtex).
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
Citation
|
| 58 |
+
--------
|
| 59 |
+
|
| 60 |
+
If you find this code useful, please consider citing:
|
| 61 |
+
|
| 62 |
+
```text
|
| 63 |
+
@inproceedings{desai2021virtex,
|
| 64 |
+
title={{VirTex: Learning Visual Representations from Textual Annotations}},
|
| 65 |
+
author={Karan Desai and Justin Johnson},
|
| 66 |
+
booktitle={CVPR},
|
| 67 |
+
year={2021}
|
| 68 |
+
}
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
Acknowledgments
|
| 72 |
+
---------------
|
| 73 |
+
|
| 74 |
+
We thank Harsh Agrawal, Mohamed El Banani, Richard Higgins, Nilesh Kulkarni
|
| 75 |
+
and Chris Rockwell for helpful discussions and feedback on the paper. We thank
|
| 76 |
+
Ishan Misra for discussions regarding PIRL evaluation protocol; Saining Xie for
|
| 77 |
+
discussions about replicating iNaturalist evaluation as MoCo; Ross Girshick and
|
| 78 |
+
Yuxin Wu for help with Detectron2 model zoo; Georgia Gkioxari for suggesting
|
| 79 |
+
the Instance Segmentation pretraining task ablation; and Stefan Lee for
|
| 80 |
+
suggestions on figure aesthetics. We thank Jia Deng for access to extra GPUs
|
| 81 |
+
during project development; and UMich ARC-TS team for support with GPU cluster
|
| 82 |
+
management. Finally, we thank all the Starbucks outlets in Ann Arbor for many
|
| 83 |
+
hours of free WiFi. This work was partially supported by the Toyota Research
|
| 84 |
+
Institute (TRI). However, note that this article solely reflects the opinions
|
| 85 |
+
and conclusions of its authors and not TRI or any other Toyota entity.
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
[1]: https://arxiv.org/abs/2006.06666
|
| 89 |
+
[2]: https://kdexd.github.io/virtex/virtex/usage/setup_dependencies.html
|
| 90 |
+
[3]: https://kdexd.github.io/virtex/virtex/usage/model_zoo.html
|
| 91 |
+
[4]: https://kdexd.github.io/virtex/virtex/usage/pretrain.html
|
| 92 |
+
[5]: https://kdexd.github.io/virtex/virtex/usage/downstream.html
|
virtex/configs/_base_bicaptioning_R_50_L1_H1024.yaml
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -----------------------------------------------------------------------------
|
| 2 |
+
# Base config: VirTex pretraining for our "base" bicaptioning model:
|
| 3 |
+
# ResNet-50 + (L = 1, H = 1024) transformer trained for 500K iterations.
|
| 4 |
+
# -----------------------------------------------------------------------------
|
| 5 |
+
RANDOM_SEED: 0
|
| 6 |
+
AMP: true
|
| 7 |
+
CUDNN_BENCHMARK: true
|
| 8 |
+
CUDNN_DETERMINISTIC: false
|
| 9 |
+
|
| 10 |
+
DATA:
|
| 11 |
+
ROOT: "datasets/coco"
|
| 12 |
+
TOKENIZER_MODEL: "datasets/vocab/coco_10k.model"
|
| 13 |
+
VOCAB_SIZE: 10000
|
| 14 |
+
UNK_INDEX: 0
|
| 15 |
+
SOS_INDEX: 1
|
| 16 |
+
EOS_INDEX: 2
|
| 17 |
+
MASK_INDEX: 3
|
| 18 |
+
|
| 19 |
+
IMAGE_CROP_SIZE: 224
|
| 20 |
+
MAX_CAPTION_LENGTH: 30
|
| 21 |
+
|
| 22 |
+
IMAGE_TRANSFORM_TRAIN:
|
| 23 |
+
- "random_resized_crop"
|
| 24 |
+
- "horizontal_flip"
|
| 25 |
+
- "color_jitter"
|
| 26 |
+
- "normalize"
|
| 27 |
+
|
| 28 |
+
IMAGE_TRANSFORM_VAL:
|
| 29 |
+
- "smallest_resize"
|
| 30 |
+
- "center_crop"
|
| 31 |
+
- "normalize"
|
| 32 |
+
|
| 33 |
+
USE_PERCENTAGE: 100.0
|
| 34 |
+
USE_SINGLE_CAPTION: false
|
| 35 |
+
|
| 36 |
+
MODEL:
|
| 37 |
+
NAME: "virtex"
|
| 38 |
+
VISUAL:
|
| 39 |
+
NAME: "torchvision::resnet50"
|
| 40 |
+
PRETRAINED: false
|
| 41 |
+
FROZEN: false
|
| 42 |
+
TEXTUAL:
|
| 43 |
+
NAME: "transdec_postnorm::L1_H1024_A16_F4096"
|
| 44 |
+
DROPOUT: 0.1
|
| 45 |
+
|
| 46 |
+
OPTIM:
|
| 47 |
+
OPTIMIZER_NAME: "sgd"
|
| 48 |
+
SGD_MOMENTUM: 0.9
|
| 49 |
+
WEIGHT_DECAY: 0.0001
|
| 50 |
+
|
| 51 |
+
LOOKAHEAD:
|
| 52 |
+
USE: true
|
| 53 |
+
ALPHA: 0.5
|
| 54 |
+
STEPS: 5
|
| 55 |
+
|
| 56 |
+
BATCH_SIZE: 256
|
| 57 |
+
CNN_LR: 0.2
|
| 58 |
+
LR: 0.001
|
| 59 |
+
NUM_ITERATIONS: 500000
|
| 60 |
+
|
| 61 |
+
WARMUP_STEPS: 10000
|
| 62 |
+
LR_DECAY_NAME: "cosine"
|
| 63 |
+
|
| 64 |
+
NO_DECAY: ".*textual.(embedding|transformer).*(norm.*|bias)"
|
| 65 |
+
CLIP_GRAD_NORM: 10.0
|
| 66 |
+
|
virtex/configs/backbone_ablations/bicaptioning_R_101_L1_H1024.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
VISUAL:
|
| 5 |
+
NAME: "torchvision::resnet101"
|
virtex/configs/backbone_ablations/bicaptioning_R_50W2X_L1_H1024.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
VISUAL:
|
| 5 |
+
NAME: "torchvision::wide_resnet50_2"
|
virtex/configs/backbone_ablations/bicaptioning_R_50_L1_H1024.yaml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
virtex/configs/depth_ablations/bicaptioning_R_50_L1_H1024.yaml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
virtex/configs/depth_ablations/bicaptioning_R_50_L2_H1024.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
TEXTUAL:
|
| 5 |
+
NAME: "transdec_postnorm::L2_H1024_A16_F4096"
|
virtex/configs/depth_ablations/bicaptioning_R_50_L3_H1024.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
TEXTUAL:
|
| 5 |
+
NAME: "transdec_postnorm::L3_H1024_A16_F4096"
|
virtex/configs/depth_ablations/bicaptioning_R_50_L4_H1024.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
TEXTUAL:
|
| 5 |
+
NAME: "transdec_postnorm::L4_H1024_A16_F4096"
|
virtex/configs/detectron2/_base_faster_rcnn_R_50_C4_BN.yaml
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ----------------------------------------------------------------------------
|
| 2 |
+
# Train a Faster R-CNN with ResNet-50 and C4 backbone. This config follows
|
| 3 |
+
# Detectron2 format; and is unrelated with our VirTex configs. Params here
|
| 4 |
+
# replicate evaluation protocol as per MoCo (https://arxiv.org/abs/1911.05722).
|
| 5 |
+
# ----------------------------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
INPUT:
|
| 8 |
+
# Input format will always be RGB, consistent with torchvision.
|
| 9 |
+
FORMAT: "RGB"
|
| 10 |
+
MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800)
|
| 11 |
+
MIN_SIZE_TEST: 800
|
| 12 |
+
|
| 13 |
+
MODEL:
|
| 14 |
+
META_ARCHITECTURE: "GeneralizedRCNN"
|
| 15 |
+
|
| 16 |
+
# Train all layers end-to-end by default.
|
| 17 |
+
BACKBONE:
|
| 18 |
+
NAME: build_resnet_backbone
|
| 19 |
+
FREEZE_AT: 0
|
| 20 |
+
|
| 21 |
+
# Fine-tune with SyncBN.
|
| 22 |
+
# STRIDE_IN_1X1 is False for torchvision-like models.
|
| 23 |
+
RESNETS:
|
| 24 |
+
DEPTH: 50
|
| 25 |
+
NORM: SyncBN
|
| 26 |
+
STRIDE_IN_1X1: False
|
| 27 |
+
|
| 28 |
+
RPN:
|
| 29 |
+
PRE_NMS_TOPK_TEST: 6000
|
| 30 |
+
POST_NMS_TOPK_TEST: 1000
|
| 31 |
+
|
| 32 |
+
# ROI head with extra BN layer after res5 stage.
|
| 33 |
+
ROI_HEADS:
|
| 34 |
+
NAME: "Res5ROIHeadsExtraNorm"
|
| 35 |
+
|
| 36 |
+
# ImageNet color mean for torchvision-like models (RGB order).
|
| 37 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 38 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 39 |
+
|
| 40 |
+
SOLVER:
|
| 41 |
+
# This is for 8 GPUs, apply linear scaling for 4 GPUs.
|
| 42 |
+
IMS_PER_BATCH: 16
|
| 43 |
+
BASE_LR: 0.02
|
| 44 |
+
|
| 45 |
+
TEST:
|
| 46 |
+
PRECISE_BN:
|
| 47 |
+
ENABLED: True
|
| 48 |
+
|
| 49 |
+
VERSION: 2
|
virtex/configs/detectron2/_base_mask_rcnn_R_50_FPN.yaml
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ----------------------------------------------------------------------------
|
| 2 |
+
# Train a Mask R-CNN with ResNet-50 and FPN backbone. This config follows
|
| 3 |
+
# Detectron2 format; and is unrelated with our VirTex configs. Params here
|
| 4 |
+
# replicate evaluation protocol as per MoCo (https://arxiv.org/abs/1911.05722).
|
| 5 |
+
# ----------------------------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
INPUT:
|
| 8 |
+
# Input format will always be RGB, consistent with torchvision.
|
| 9 |
+
FORMAT: "RGB"
|
| 10 |
+
MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800)
|
| 11 |
+
MIN_SIZE_TEST: 800
|
| 12 |
+
|
| 13 |
+
MODEL:
|
| 14 |
+
META_ARCHITECTURE: "GeneralizedRCNN"
|
| 15 |
+
|
| 16 |
+
# Train all layers end-to-end by default.
|
| 17 |
+
BACKBONE:
|
| 18 |
+
NAME: "build_resnet_fpn_backbone"
|
| 19 |
+
FREEZE_AT: 0
|
| 20 |
+
|
| 21 |
+
# Fine-tune with SyncBN.
|
| 22 |
+
# STRIDE_IN_1X1 is False for torchvision-like models.
|
| 23 |
+
RESNETS:
|
| 24 |
+
DEPTH: 50
|
| 25 |
+
NORM: "SyncBN"
|
| 26 |
+
STRIDE_IN_1X1: False
|
| 27 |
+
OUT_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 28 |
+
|
| 29 |
+
FPN:
|
| 30 |
+
IN_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 31 |
+
|
| 32 |
+
ANCHOR_GENERATOR:
|
| 33 |
+
# One size for each in feature map
|
| 34 |
+
SIZES: [[32], [64], [128], [256], [512]]
|
| 35 |
+
# Three aspect ratios (same for all in feature maps)
|
| 36 |
+
ASPECT_RATIOS: [[0.5, 1.0, 2.0]]
|
| 37 |
+
|
| 38 |
+
RPN:
|
| 39 |
+
IN_FEATURES: ["p2", "p3", "p4", "p5", "p6"]
|
| 40 |
+
PRE_NMS_TOPK_TRAIN: 2000
|
| 41 |
+
PRE_NMS_TOPK_TEST: 1000
|
| 42 |
+
|
| 43 |
+
POST_NMS_TOPK_TRAIN: 1000
|
| 44 |
+
POST_NMS_TOPK_TEST: 1000
|
| 45 |
+
|
| 46 |
+
ROI_HEADS:
|
| 47 |
+
NAME: "StandardROIHeads"
|
| 48 |
+
IN_FEATURES: ["p2", "p3", "p4", "p5"]
|
| 49 |
+
|
| 50 |
+
ROI_BOX_HEAD:
|
| 51 |
+
NAME: "FastRCNNConvFCHead"
|
| 52 |
+
NUM_FC: 2
|
| 53 |
+
POOLER_RESOLUTION: 7
|
| 54 |
+
|
| 55 |
+
ROI_MASK_HEAD:
|
| 56 |
+
NAME: "MaskRCNNConvUpsampleHead"
|
| 57 |
+
NUM_CONV: 4
|
| 58 |
+
POOLER_RESOLUTION: 14
|
| 59 |
+
|
| 60 |
+
# ImageNet color mean for torchvision-like models (RGB order).
|
| 61 |
+
# These are in [0-255] range as expected by Detectron2. Rest of our codebase
|
| 62 |
+
# uses [0-1] range; but both are equivalent and consistent.
|
| 63 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 64 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 65 |
+
|
| 66 |
+
SOLVER:
|
| 67 |
+
# This is for 8 GPUs, apply linear scaling for 4 GPUs.
|
| 68 |
+
IMS_PER_BATCH: 16
|
| 69 |
+
BASE_LR: 0.02
|
| 70 |
+
|
| 71 |
+
TEST:
|
| 72 |
+
PRECISE_BN:
|
| 73 |
+
ENABLED: True
|
| 74 |
+
|
| 75 |
+
VERSION: 2
|
virtex/configs/detectron2/coco_segm_default_init_2x.yaml
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -----------------------------------------------------------------------------
|
| 2 |
+
# Train a Mask R-CNN R50-FPN backbone on LVIS instance segmentation with any of
|
| 3 |
+
# these weight init: random, imagenet (torchvision), virtex or MoCo.
|
| 4 |
+
# -----------------------------------------------------------------------------
|
| 5 |
+
_BASE_: "_base_mask_rcnn_R_50_FPN.yaml"
|
| 6 |
+
|
| 7 |
+
DATASETS:
|
| 8 |
+
TRAIN: ("coco_2017_train",)
|
| 9 |
+
TEST: ("coco_2017_val",)
|
| 10 |
+
|
| 11 |
+
MODEL:
|
| 12 |
+
MASK_ON: True
|
| 13 |
+
# FPN also has SyncBN, as opposed to no norm (usually).
|
| 14 |
+
FPN:
|
| 15 |
+
NORM: "SyncBN"
|
| 16 |
+
|
| 17 |
+
# This will be ignored, weights will be loaded manually in the script.
|
| 18 |
+
WEIGHTS: ""
|
| 19 |
+
|
| 20 |
+
SOLVER:
|
| 21 |
+
STEPS: (120000, 160000)
|
| 22 |
+
MAX_ITER: 180000
|
| 23 |
+
|
| 24 |
+
VERSION: 2
|
virtex/configs/detectron2/lvis_segm_default_init_2x.yaml
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -----------------------------------------------------------------------------
|
| 2 |
+
# Train a Mask R-CNN R50-FPN backbone on LVIS instance segmentation with any of
|
| 3 |
+
# these weight init: random, virtex or MoCo. (ImageNet init config is separate)
|
| 4 |
+
# -----------------------------------------------------------------------------
|
| 5 |
+
_BASE_: "_base_mask_rcnn_R_50_FPN.yaml"
|
| 6 |
+
|
| 7 |
+
DATASETS:
|
| 8 |
+
TRAIN: ("lvis_v1_train",)
|
| 9 |
+
TEST: ("lvis_v1_val",)
|
| 10 |
+
|
| 11 |
+
DATALOADER:
|
| 12 |
+
SAMPLER_TRAIN: "RepeatFactorTrainingSampler"
|
| 13 |
+
REPEAT_THRESHOLD: 0.001
|
| 14 |
+
|
| 15 |
+
TEST:
|
| 16 |
+
DETECTIONS_PER_IMAGE: 300 # LVIS allows up to 300.
|
| 17 |
+
|
| 18 |
+
MODEL:
|
| 19 |
+
MASK_ON: True
|
| 20 |
+
# FPN also has SyncBN, as opposed to no norm (usually).
|
| 21 |
+
FPN:
|
| 22 |
+
NORM: "SyncBN"
|
| 23 |
+
|
| 24 |
+
ROI_HEADS:
|
| 25 |
+
NUM_CLASSES: 1203
|
| 26 |
+
SCORE_THRESH_TEST: 0.0001
|
| 27 |
+
|
| 28 |
+
# This will be ignored, weights will be loaded manually in the script.
|
| 29 |
+
WEIGHTS: ""
|
| 30 |
+
|
| 31 |
+
SOLVER:
|
| 32 |
+
STEPS: (120000, 160000)
|
| 33 |
+
MAX_ITER: 180000
|
| 34 |
+
|
| 35 |
+
VERSION: 2
|
| 36 |
+
|
virtex/configs/detectron2/lvis_segm_imagenet_init_2x.yaml
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -----------------------------------------------------------------------------
|
| 2 |
+
# Train a Mask R-CNN R50-FPN backbone on LVIS instance segmentation
|
| 3 |
+
# with weights initialized from supervised ImageNet pretraining (torchvision).
|
| 4 |
+
# Key difference is that fine-tuning here happens with BN frozen.
|
| 5 |
+
# -----------------------------------------------------------------------------
|
| 6 |
+
_BASE_: "_base_mask_rcnn_R_50_FPN.yaml"
|
| 7 |
+
|
| 8 |
+
DATASETS:
|
| 9 |
+
TRAIN: ("lvis_v1_train",)
|
| 10 |
+
TEST: ("lvis_v1_val",)
|
| 11 |
+
|
| 12 |
+
DATALOADER:
|
| 13 |
+
SAMPLER_TRAIN: "RepeatFactorTrainingSampler"
|
| 14 |
+
REPEAT_THRESHOLD: 0.001
|
| 15 |
+
|
| 16 |
+
TEST:
|
| 17 |
+
DETECTIONS_PER_IMAGE: 300 # LVIS allows up to 300.
|
| 18 |
+
|
| 19 |
+
MODEL:
|
| 20 |
+
MASK_ON: True
|
| 21 |
+
RESNETS:
|
| 22 |
+
NORM: "FrozenBN"
|
| 23 |
+
|
| 24 |
+
# Do not tune with SyncBN for ImageNet init from LVIS.
|
| 25 |
+
ROI_HEADS:
|
| 26 |
+
NUM_CLASSES: 1203
|
| 27 |
+
SCORE_THRESH_TEST: 0.0001
|
| 28 |
+
|
| 29 |
+
# This will be ignored, weights will be loaded manually in the script.
|
| 30 |
+
WEIGHTS: ""
|
| 31 |
+
|
| 32 |
+
SOLVER:
|
| 33 |
+
STEPS: (120000, 160000)
|
| 34 |
+
MAX_ITER: 180000
|
| 35 |
+
|
| 36 |
+
VERSION: 2
|
| 37 |
+
|
| 38 |
+
|
virtex/configs/detectron2/voc_det_default_init_24k.yaml
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -----------------------------------------------------------------------------
|
| 2 |
+
# Train a Faster R-CNN with R50-C4 backbone on VOC07+12 detection with any of
|
| 3 |
+
# these weight init: random, imagenet (torchvision), virtex or MoCo.
|
| 4 |
+
# -----------------------------------------------------------------------------
|
| 5 |
+
_BASE_: "_base_faster_rcnn_R_50_C4_BN.yaml"
|
| 6 |
+
|
| 7 |
+
DATASETS:
|
| 8 |
+
TRAIN: ("voc_2007_trainval", "voc_2012_trainval")
|
| 9 |
+
TEST: ("voc_2007_test",)
|
| 10 |
+
|
| 11 |
+
INPUT:
|
| 12 |
+
MIN_SIZE_TRAIN: (480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800)
|
| 13 |
+
MIN_SIZE_TEST: 800
|
| 14 |
+
|
| 15 |
+
MODEL:
|
| 16 |
+
MASK_ON: False
|
| 17 |
+
ROI_HEADS:
|
| 18 |
+
NUM_CLASSES: 20
|
| 19 |
+
|
| 20 |
+
# This will be ignored, weights will be loaded manually in the script.
|
| 21 |
+
WEIGHTS: ""
|
| 22 |
+
|
| 23 |
+
SOLVER:
|
| 24 |
+
STEPS: (18000, 22000)
|
| 25 |
+
MAX_ITER: 24000
|
| 26 |
+
WARMUP_ITERS: 100
|
| 27 |
+
|
| 28 |
+
VERSION: 2
|
virtex/configs/downstream/imagenet_clf.yaml
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
RANDOM_SEED: 0
|
| 2 |
+
# Don't need AMP to train a tiny linear layer.
|
| 3 |
+
AMP: false
|
| 4 |
+
CUDNN_BENCHMARK: true
|
| 5 |
+
CUDNN_DETERMINISTIC: false
|
| 6 |
+
|
| 7 |
+
DATA:
|
| 8 |
+
ROOT: "datasets/imagenet"
|
| 9 |
+
IMAGE_TRANSFORM_TRAIN:
|
| 10 |
+
- "random_resized_crop::{'scale': (0.08, 1.0)}"
|
| 11 |
+
- "horizontal_flip"
|
| 12 |
+
- "normalize"
|
| 13 |
+
IMAGE_TRANSFORM_VAL:
|
| 14 |
+
- "smallest_resize"
|
| 15 |
+
- "center_crop"
|
| 16 |
+
- "normalize"
|
| 17 |
+
|
| 18 |
+
MODEL:
|
| 19 |
+
VISUAL:
|
| 20 |
+
FROZEN: true
|
| 21 |
+
|
| 22 |
+
OPTIM:
|
| 23 |
+
BATCH_SIZE: 256
|
| 24 |
+
SGD_MOMENTUM: 0.9
|
| 25 |
+
WEIGHT_DECAY: 0.0
|
| 26 |
+
NO_DECAY: "none"
|
| 27 |
+
LOOKAHEAD:
|
| 28 |
+
USE: false
|
| 29 |
+
|
| 30 |
+
LR: 0.3
|
| 31 |
+
WARMUP_STEPS: 0
|
| 32 |
+
LR_DECAY_NAME: "cosine"
|
| 33 |
+
NUM_ITERATIONS: 500500 # 100 epochs
|
virtex/configs/downstream/inaturalist_clf.yaml
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
RANDOM_SEED: 0
|
| 2 |
+
AMP: true
|
| 3 |
+
CUDNN_BENCHMARK: true
|
| 4 |
+
CUDNN_DETERMINISTIC: false
|
| 5 |
+
|
| 6 |
+
DATA:
|
| 7 |
+
ROOT: "datasets/inaturalist"
|
| 8 |
+
IMAGE_TRANSFORM_TRAIN:
|
| 9 |
+
- "random_resized_crop::{'scale': (0.08, 1.0)}"
|
| 10 |
+
- "horizontal_flip"
|
| 11 |
+
- "normalize"
|
| 12 |
+
IMAGE_TRANSFORM_VAL:
|
| 13 |
+
- "smallest_resize"
|
| 14 |
+
- "center_crop"
|
| 15 |
+
- "normalize"
|
| 16 |
+
|
| 17 |
+
MODEL:
|
| 18 |
+
VISUAL:
|
| 19 |
+
FROZEN: false
|
| 20 |
+
|
| 21 |
+
OPTIM:
|
| 22 |
+
BATCH_SIZE: 256
|
| 23 |
+
SGD_MOMENTUM: 0.9
|
| 24 |
+
WEIGHT_DECAY: 0.0001
|
| 25 |
+
NO_DECAY: "none"
|
| 26 |
+
LOOKAHEAD:
|
| 27 |
+
USE: false
|
| 28 |
+
|
| 29 |
+
LR: 0.025
|
| 30 |
+
WARMUP_STEPS: 0
|
| 31 |
+
LR_DECAY_NAME: multistep
|
| 32 |
+
LR_GAMMA: 0.1
|
| 33 |
+
LR_STEPS:
|
| 34 |
+
- 119700 # 70 epochs
|
| 35 |
+
- 153900 # 90 epochs
|
| 36 |
+
NUM_ITERATIONS: 171000 # 100 epochs
|
virtex/configs/downstream/voc07_clf.yaml
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
RANDOM_SEED: 0
|
| 2 |
+
DATA:
|
| 3 |
+
ROOT: datasets/VOC2007
|
| 4 |
+
IMAGE_TRANSFORM_TRAIN:
|
| 5 |
+
- smallest_resize
|
| 6 |
+
- center_crop
|
| 7 |
+
- normalize
|
| 8 |
+
IMAGE_TRANSFORM_VAL:
|
| 9 |
+
- smallest_resize
|
| 10 |
+
- center_crop
|
| 11 |
+
- normalize
|
| 12 |
+
|
| 13 |
+
OPTIM:
|
| 14 |
+
# Only used for feature extraction, doesn't mean much.
|
| 15 |
+
BATCH_SIZE: 128
|
virtex/configs/redcaps/gcc_R_50_L6_H512.yaml
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
AMP: True
|
| 4 |
+
|
| 5 |
+
DATA:
|
| 6 |
+
ROOT: "datasets/gcc/tarfiles/*.tar"
|
| 7 |
+
TOKENIZER_MODEL: "datasets/vocab/common_30k.model"
|
| 8 |
+
VOCAB_SIZE: 30000
|
| 9 |
+
UNK_INDEX: 0
|
| 10 |
+
SOS_INDEX: 1
|
| 11 |
+
EOS_INDEX: 2
|
| 12 |
+
MASK_INDEX: 3
|
| 13 |
+
|
| 14 |
+
MAX_CAPTION_LENGTH: 50
|
| 15 |
+
|
| 16 |
+
MODEL:
|
| 17 |
+
NAME: "virtex_web"
|
| 18 |
+
TEXTUAL:
|
| 19 |
+
NAME: "transdec_prenorm::L6_H512_A8_F2048"
|
| 20 |
+
|
| 21 |
+
LABEL_SMOOTHING: 0.1
|
| 22 |
+
|
| 23 |
+
OPTIM:
|
| 24 |
+
OPTIMIZER_NAME: "adamw"
|
| 25 |
+
WEIGHT_DECAY: 0.01
|
| 26 |
+
LOOKAHEAD:
|
| 27 |
+
USE: false
|
| 28 |
+
|
| 29 |
+
BATCH_SIZE: 256
|
| 30 |
+
CNN_LR: 0.0005
|
| 31 |
+
LR: 0.0005
|
| 32 |
+
NUM_ITERATIONS: 1500000
|
| 33 |
+
|
| 34 |
+
WARMUP_STEPS: 10000
|
| 35 |
+
LR_DECAY_NAME: "cosine"
|
virtex/configs/redcaps/miniclip_sbu_R_50_L12_H512.yaml
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
AMP: True
|
| 4 |
+
|
| 5 |
+
DATA:
|
| 6 |
+
ROOT: "datasets/sbu/tarfiles/*.tar"
|
| 7 |
+
TOKENIZER_MODEL: "datasets/vocab/common_30k.model"
|
| 8 |
+
VOCAB_SIZE: 30000
|
| 9 |
+
UNK_INDEX: 0
|
| 10 |
+
SOS_INDEX: 1
|
| 11 |
+
EOS_INDEX: 2
|
| 12 |
+
MASK_INDEX: 3
|
| 13 |
+
|
| 14 |
+
MAX_CAPTION_LENGTH: 50
|
| 15 |
+
|
| 16 |
+
MODEL:
|
| 17 |
+
NAME: "miniclip_web"
|
| 18 |
+
TEXTUAL:
|
| 19 |
+
NAME: "transenc_prenorm::L12_H512_A8_F2048"
|
| 20 |
+
LABEL_SMOOTHING: 0.1
|
| 21 |
+
|
| 22 |
+
OPTIM:
|
| 23 |
+
OPTIMIZER_NAME: "adamw"
|
| 24 |
+
WEIGHT_DECAY: 0.01
|
| 25 |
+
|
| 26 |
+
LOOKAHEAD:
|
| 27 |
+
USE: false
|
| 28 |
+
|
| 29 |
+
BATCH_SIZE: 256
|
| 30 |
+
CNN_LR: 0.0005
|
| 31 |
+
LR: 0.0005
|
| 32 |
+
NUM_ITERATIONS: 1500000
|
| 33 |
+
|
| 34 |
+
WARMUP_STEPS: 10000
|
| 35 |
+
LR_DECAY_NAME: "cosine"
|
virtex/configs/redcaps/redcaps_2020_R_50_L6_H512.yaml
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
AMP: True
|
| 4 |
+
|
| 5 |
+
DATA:
|
| 6 |
+
ROOT: "datasets/redcaps/tarfiles/*_2020_*.tar"
|
| 7 |
+
TOKENIZER_MODEL: "datasets/vocab/common_30k.model"
|
| 8 |
+
VOCAB_SIZE: 30000
|
| 9 |
+
UNK_INDEX: 0
|
| 10 |
+
SOS_INDEX: 1
|
| 11 |
+
EOS_INDEX: 2
|
| 12 |
+
MASK_INDEX: 3
|
| 13 |
+
|
| 14 |
+
MAX_CAPTION_LENGTH: 50
|
| 15 |
+
|
| 16 |
+
MODEL:
|
| 17 |
+
NAME: "virtex_web"
|
| 18 |
+
TEXTUAL:
|
| 19 |
+
NAME: "transdec_prenorm::L6_H512_A8_F2048"
|
| 20 |
+
LABEL_SMOOTHING: 0.1
|
| 21 |
+
|
| 22 |
+
OPTIM:
|
| 23 |
+
OPTIMIZER_NAME: "adamw"
|
| 24 |
+
WEIGHT_DECAY: 0.01
|
| 25 |
+
|
| 26 |
+
LOOKAHEAD:
|
| 27 |
+
USE: false
|
| 28 |
+
|
| 29 |
+
BATCH_SIZE: 256
|
| 30 |
+
CNN_LR: 0.0005
|
| 31 |
+
LR: 0.0005
|
| 32 |
+
NUM_ITERATIONS: 1500000
|
| 33 |
+
|
| 34 |
+
WARMUP_STEPS: 10000
|
| 35 |
+
LR_DECAY_NAME: "cosine"
|
virtex/configs/redcaps/redcaps_all_R_50_L6_H512.yaml
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
AMP: True
|
| 4 |
+
|
| 5 |
+
DATA:
|
| 6 |
+
ROOT: "datasets/redcaps/tarfiles/*.tar"
|
| 7 |
+
TOKENIZER_MODEL: "datasets/vocab/common_30k.model"
|
| 8 |
+
VOCAB_SIZE: 30000
|
| 9 |
+
UNK_INDEX: 0
|
| 10 |
+
SOS_INDEX: 1
|
| 11 |
+
EOS_INDEX: 2
|
| 12 |
+
MASK_INDEX: 3
|
| 13 |
+
|
| 14 |
+
MAX_CAPTION_LENGTH: 50
|
| 15 |
+
|
| 16 |
+
MODEL:
|
| 17 |
+
NAME: "virtex_web"
|
| 18 |
+
TEXTUAL:
|
| 19 |
+
NAME: "transdec_prenorm::L6_H512_A8_F2048"
|
| 20 |
+
LABEL_SMOOTHING: 0.1
|
| 21 |
+
|
| 22 |
+
OPTIM:
|
| 23 |
+
OPTIMIZER_NAME: "adamw"
|
| 24 |
+
WEIGHT_DECAY: 0.01
|
| 25 |
+
|
| 26 |
+
LOOKAHEAD:
|
| 27 |
+
USE: false
|
| 28 |
+
|
| 29 |
+
BATCH_SIZE: 256
|
| 30 |
+
CNN_LR: 0.0005
|
| 31 |
+
LR: 0.0005
|
| 32 |
+
NUM_ITERATIONS: 1500000
|
| 33 |
+
|
| 34 |
+
WARMUP_STEPS: 10000
|
| 35 |
+
LR_DECAY_NAME: "cosine"
|
virtex/configs/redcaps/sbu_R_50_L6_H512.yaml
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
AMP: True
|
| 4 |
+
|
| 5 |
+
DATA:
|
| 6 |
+
ROOT: "datasets/sbu/tarfiles/*.tar"
|
| 7 |
+
TOKENIZER_MODEL: "datasets/vocab/common_30k.model"
|
| 8 |
+
VOCAB_SIZE: 30000
|
| 9 |
+
UNK_INDEX: 0
|
| 10 |
+
SOS_INDEX: 1
|
| 11 |
+
EOS_INDEX: 2
|
| 12 |
+
MASK_INDEX: 3
|
| 13 |
+
|
| 14 |
+
MAX_CAPTION_LENGTH: 50
|
| 15 |
+
|
| 16 |
+
MODEL:
|
| 17 |
+
NAME: "virtex_web"
|
| 18 |
+
TEXTUAL:
|
| 19 |
+
NAME: "transdec_prenorm::L6_H512_A8_F2048"
|
| 20 |
+
LABEL_SMOOTHING: 0.1
|
| 21 |
+
|
| 22 |
+
OPTIM:
|
| 23 |
+
OPTIMIZER_NAME: "adamw"
|
| 24 |
+
WEIGHT_DECAY: 0.01
|
| 25 |
+
|
| 26 |
+
LOOKAHEAD:
|
| 27 |
+
USE: false
|
| 28 |
+
|
| 29 |
+
BATCH_SIZE: 256
|
| 30 |
+
CNN_LR: 0.0005
|
| 31 |
+
LR: 0.0005
|
| 32 |
+
NUM_ITERATIONS: 1500000
|
| 33 |
+
|
| 34 |
+
WARMUP_STEPS: 10000
|
| 35 |
+
LR_DECAY_NAME: "cosine"
|
virtex/configs/task_ablations/bicaptioning_R_50_L1_H2048.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
TEXTUAL:
|
| 5 |
+
NAME: "transdec_postnorm::L1_H2048_A32_F8192"
|
virtex/configs/task_ablations/captioning_R_50_L1_H2048.yaml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
NAME: "captioning"
|
| 5 |
+
TEXTUAL:
|
| 6 |
+
NAME: "transdec_postnorm::L1_H2048_A32_F8192"
|
virtex/configs/task_ablations/masked_lm_R_50_L1_H2048.yaml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
NAME: "masked_lm"
|
| 5 |
+
TEXTUAL:
|
| 6 |
+
NAME: "transdec_postnorm::L1_H2048_A32_F8192"
|
virtex/configs/task_ablations/multilabel_classification_R_50.yaml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
DATA:
|
| 4 |
+
VOCAB_SIZE: 81
|
| 5 |
+
|
| 6 |
+
MODEL:
|
| 7 |
+
NAME: "multilabel_classification"
|
| 8 |
+
TEXTUAL:
|
| 9 |
+
NAME: "none"
|
| 10 |
+
|
| 11 |
+
OPTIM:
|
| 12 |
+
NO_DECAY: "none"
|
virtex/configs/task_ablations/token_classification_R_50.yaml
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
NAME: "token_classification"
|
| 5 |
+
TEXTUAL:
|
| 6 |
+
NAME: "none"
|
| 7 |
+
|
| 8 |
+
OPTIM:
|
| 9 |
+
NO_DECAY: "none"
|
virtex/configs/width_ablations/bicaptioning_R_50_L1_H1024.yaml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
virtex/configs/width_ablations/bicaptioning_R_50_L1_H2048.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
TEXTUAL:
|
| 5 |
+
NAME: "transdec_postnorm::L1_H2048_A32_F8192"
|
virtex/configs/width_ablations/bicaptioning_R_50_L1_H512.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
TEXTUAL:
|
| 5 |
+
NAME: "transdec_postnorm::L1_H512_A8_F2048"
|
virtex/configs/width_ablations/bicaptioning_R_50_L1_H768.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../_base_bicaptioning_R_50_L1_H1024.yaml"
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
TEXTUAL:
|
| 5 |
+
NAME: "transdec_postnorm::L1_H768_A12_F3072"
|
virtex/docs/Makefile
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Minimal makefile for Sphinx documentation
|
| 2 |
+
#
|
| 3 |
+
|
| 4 |
+
# You can set these variables from the command line.
|
| 5 |
+
SPHINXOPTS =
|
| 6 |
+
SPHINXBUILD = sphinx-build
|
| 7 |
+
SOURCEDIR = .
|
| 8 |
+
BUILDDIR = ../../virtex-sphinx
|
| 9 |
+
|
| 10 |
+
# Put it first so that "make" without argument is like "make help".
|
| 11 |
+
help:
|
| 12 |
+
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
| 13 |
+
|
| 14 |
+
.PHONY: help Makefile
|
| 15 |
+
|
| 16 |
+
# Catch-all target: route all unknown targets to Sphinx using the new
|
| 17 |
+
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
| 18 |
+
%: Makefile
|
| 19 |
+
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
virtex/docs/_static/custom.css
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
body {
|
| 2 |
+
padding: 40px 0 0 0;
|
| 3 |
+
font-size: 12pt;
|
| 4 |
+
font-family: Inconsolata !important;
|
| 5 |
+
}
|
| 6 |
+
|
| 7 |
+
/* Monospace everywhere */
|
| 8 |
+
h1, h2, h3, h4, div.sphinxsidebar h1, div.sphinxsidebar h2,
|
| 9 |
+
div.sphinxsidebar h3, div.sphinxsidebar h4, div.body h1,
|
| 10 |
+
div.body h2, div.body h3, div.body h4, .admonition-title {
|
| 11 |
+
font-family: monospace !important;
|
| 12 |
+
}
|
| 13 |
+
|
| 14 |
+
/* Make main content wider */
|
| 15 |
+
div.document {
|
| 16 |
+
margin: auto;
|
| 17 |
+
width: 65%;
|
| 18 |
+
}
|
| 19 |
+
|
| 20 |
+
/* Make sidebar slightly wider. */
|
| 21 |
+
div.sphinxsidebar {
|
| 22 |
+
width: 250px;
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
div.bodywrapper {
|
| 26 |
+
margin: 0 0 0 250px;
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
div.body {
|
| 30 |
+
color: black;
|
| 31 |
+
max-width: 100%
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
/* Darker headings */
|
| 35 |
+
h1, h2, h3, h4, div.sphinxsidebar h1, div.sphinxsidebar h2,
|
| 36 |
+
div.sphinxsidebar h3, div.sphinxsidebar h4, div.body h1,
|
| 37 |
+
div.body h2, div.body h3, div.body h4 {
|
| 38 |
+
color: black;
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
@media screen and (max-width: 875px) {
|
| 42 |
+
div.sphinxsidebar {
|
| 43 |
+
background-color: white;
|
| 44 |
+
}
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
/* Darker bold words */
|
| 48 |
+
strong {
|
| 49 |
+
color: #252525;
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
/* TOC tree tag, view source link & permalink anchor styling. */
|
| 53 |
+
div.sphinxsidebar a, .viewcode-link, a.reference {
|
| 54 |
+
color: darkgreen;
|
| 55 |
+
text-decoration: none;
|
| 56 |
+
border-bottom: 1px dashed green;
|
| 57 |
+
text-underline-position: under;
|
| 58 |
+
}
|
| 59 |
+
a.headerlink {
|
| 60 |
+
color: black;
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
/* TOC tree tag, view source link & permalink anchor styling. */
|
| 64 |
+
div.sphinxsidebar a:hover, .viewcode-link:hover, a.reference:hover,
|
| 65 |
+
a.headerlink:hover {
|
| 66 |
+
font-weight: 700;
|
| 67 |
+
border-bottom: 1px solid green;
|
| 68 |
+
}
|
| 69 |
+
|
| 70 |
+
/* Add a light background to class signatures. */
|
| 71 |
+
dl.class > dt:first-of-type, dl.function > dt:first-of-type,
|
| 72 |
+
dl.method > dt:first-of-type, dl.classmethod > dt:first-of-type,
|
| 73 |
+
dl.attribute > dt:first-of-type, dl.data > dt:first-of-type {
|
| 74 |
+
font-size: 14pt;
|
| 75 |
+
background-color: #d8f6e9;
|
| 76 |
+
padding: 10px 20px 10px 10px;
|
| 77 |
+
border: 1px solid #1b5e20;
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
/* Add lightgrey background to code snippets. */
|
| 81 |
+
pre {
|
| 82 |
+
background-color: #eeeeee !important;
|
| 83 |
+
border: 1pt solid #999999;
|
| 84 |
+
border-radius: 5px;
|
| 85 |
+
}
|
| 86 |
+
|
| 87 |
+
/* Dark orange-red comments in code snippets. */
|
| 88 |
+
.highlight .c1 {
|
| 89 |
+
color: #dd4533;
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
.admonition, .note {
|
| 93 |
+
background-color: #fed8b1 !important;
|
| 94 |
+
border: 1pt solid #ff7700;
|
| 95 |
+
border-radius: 5px;
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
/* Make "Parameters" subsection wider - display heading and content vertically. */
|
| 99 |
+
dl.field-list {
|
| 100 |
+
display: block;
|
| 101 |
+
}
|
| 102 |
+
|
| 103 |
+
/* Increase font size of subsection headings ("Parameters", "Examples" etc.) */
|
| 104 |
+
.rubric, dl.field-list > dt.field-odd, dl.field-list > dt.field-even {
|
| 105 |
+
color: black;
|
| 106 |
+
font-size: 18pt;
|
| 107 |
+
font-weight: bold;
|
| 108 |
+
padding: 0px;
|
| 109 |
+
margin: 20px 0px 20px 0px;
|
| 110 |
+
}
|
| 111 |
+
|
| 112 |
+
/* Add margins around methods and properties. */
|
| 113 |
+
.py {
|
| 114 |
+
margin: 20px 0px 20px 0px;
|
| 115 |
+
}
|
virtex/docs/_static/system_figure.jpg
ADDED
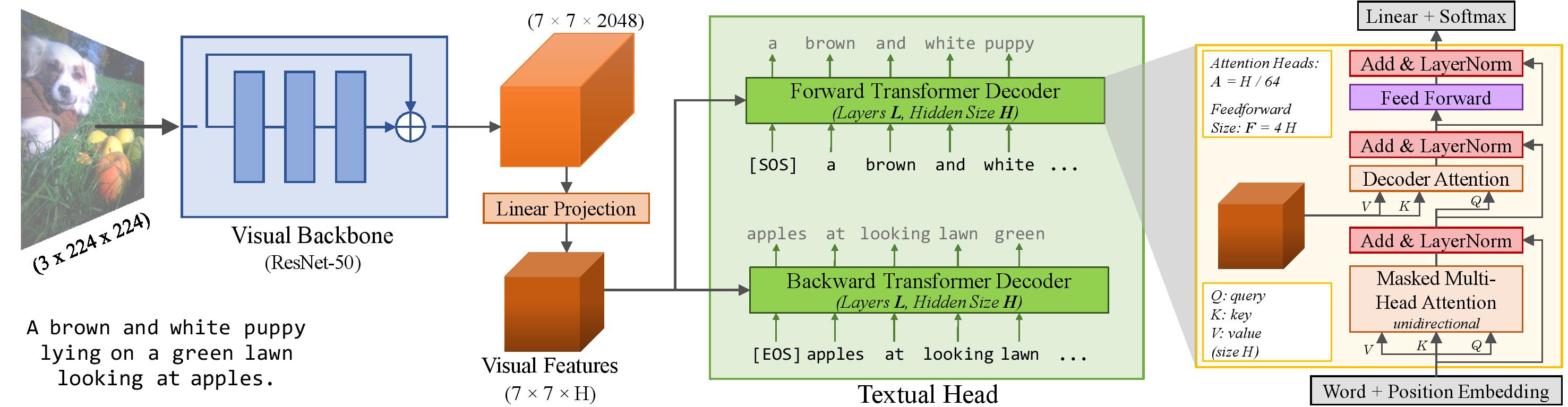
|
virtex/docs/_templates/layout.html
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{% extends "!layout.html" %}
|
| 2 |
+
|
| 3 |
+
{% block htmltitle %}
|
| 4 |
+
|
| 5 |
+
<!-- Global site tag (gtag.js) - Google Analytics -->
|
| 6 |
+
<script async src="https://www.googletagmanager.com/gtag/js?id=UA-120523111-2"></script>
|
| 7 |
+
<script>
|
| 8 |
+
window.dataLayer = window.dataLayer || [];
|
| 9 |
+
function gtag(){dataLayer.push(arguments);}
|
| 10 |
+
gtag('js', new Date());
|
| 11 |
+
|
| 12 |
+
gtag('config', 'UA-120523111-2');
|
| 13 |
+
</script>
|
| 14 |
+
|
| 15 |
+
<link href="https://fonts.googleapis.com/css?family=Inconsolata&display=swap" rel="stylesheet">
|
| 16 |
+
<link href="https://fonts.googleapis.com/css?family=Ubuntu+Mono&display=swap" rel="stylesheet">
|
| 17 |
+
|
| 18 |
+
{{ super() }}
|
| 19 |
+
{% endblock %}
|
virtex/docs/conf.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Configuration file for the Sphinx documentation builder.
|
| 2 |
+
#
|
| 3 |
+
# This file only contains a selection of the most common options. For a full
|
| 4 |
+
# list see the documentation:
|
| 5 |
+
# http://www.sphinx-doc.org/en/master/config
|
| 6 |
+
|
| 7 |
+
# -- Path setup --------------------------------------------------------------
|
| 8 |
+
|
| 9 |
+
# If extensions (or modules to document with autodoc) are in another directory,
|
| 10 |
+
# add these directories to sys.path here. If the directory is relative to the
|
| 11 |
+
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
| 12 |
+
#
|
| 13 |
+
import inspect
|
| 14 |
+
import os
|
| 15 |
+
import sys
|
| 16 |
+
|
| 17 |
+
sys.path.insert(0, os.path.abspath("../"))
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# -- Project information -----------------------------------------------------
|
| 21 |
+
|
| 22 |
+
project = "virtex"
|
| 23 |
+
copyright = "2021, Karan Desai and Justin Johnson"
|
| 24 |
+
author = "Karan Desai"
|
| 25 |
+
|
| 26 |
+
# The full version, including alpha/beta/rc tags
|
| 27 |
+
release = "1.1"
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
# -- General configuration ---------------------------------------------------
|
| 31 |
+
|
| 32 |
+
# Add any Sphinx extension module names here, as strings. They can be
|
| 33 |
+
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
| 34 |
+
# ones.
|
| 35 |
+
extensions = [
|
| 36 |
+
"sphinx.ext.autodoc",
|
| 37 |
+
"sphinx.ext.coverage",
|
| 38 |
+
"sphinx.ext.doctest",
|
| 39 |
+
"sphinx.ext.linkcode",
|
| 40 |
+
"sphinx.ext.autosummary",
|
| 41 |
+
"sphinx.ext.coverage",
|
| 42 |
+
"sphinx.ext.intersphinx",
|
| 43 |
+
"sphinx.ext.mathjax",
|
| 44 |
+
"sphinx_copybutton",
|
| 45 |
+
"numpydoc",
|
| 46 |
+
]
|
| 47 |
+
|
| 48 |
+
# Add any paths that contain templates here, relative to this directory.
|
| 49 |
+
templates_path = ["_templates"]
|
| 50 |
+
|
| 51 |
+
# The suffix(es) of source filenames.
|
| 52 |
+
# You can specify multiple suffix as a list of string:
|
| 53 |
+
#
|
| 54 |
+
# source_suffix = ['.rst', '.md']
|
| 55 |
+
source_suffix = ".rst"
|
| 56 |
+
|
| 57 |
+
# The master toctree document.
|
| 58 |
+
master_doc = "index"
|
| 59 |
+
|
| 60 |
+
# The version info for the project you're documenting, acts as replacement for
|
| 61 |
+
# |version| and |release|, also used in various other places throughout the
|
| 62 |
+
# built documents.
|
| 63 |
+
#
|
| 64 |
+
# This version is used underneath the title on the index page.
|
| 65 |
+
version = "1.1"
|
| 66 |
+
# The following is used if you need to also include a more detailed version.
|
| 67 |
+
release = "1.1"
|
| 68 |
+
|
| 69 |
+
# The language for content autogenerated by Sphinx. Refer to documentation
|
| 70 |
+
# for a list of supported languages.
|
| 71 |
+
#
|
| 72 |
+
# This is also used if you do content translation via gettext catalogs.
|
| 73 |
+
# Usually you set "language" from the command line for these cases.
|
| 74 |
+
language = "en"
|
| 75 |
+
|
| 76 |
+
# List of patterns, relative to source directory, that match files and
|
| 77 |
+
# directories to ignore when looking for source files.
|
| 78 |
+
# This patterns also effect to html_static_path and html_extra_path
|
| 79 |
+
exclude_patterns = ["_build"]
|
| 80 |
+
|
| 81 |
+
# The name of the Pygments (syntax highlighting) style to use.
|
| 82 |
+
pygments_style = "sphinx"
|
| 83 |
+
|
| 84 |
+
# If true, `todo` and `todoList` produce output, else they produce nothing.
|
| 85 |
+
todo_include_todos = False
|
| 86 |
+
|
| 87 |
+
numpydoc_show_class_members = False
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
# -- Options for HTML output ----------------------------------------------
|
| 91 |
+
|
| 92 |
+
# The theme to use for HTML and HTML Help pages. See the documentation for
|
| 93 |
+
# a list of builtin themes.
|
| 94 |
+
#
|
| 95 |
+
html_theme = "alabaster"
|
| 96 |
+
|
| 97 |
+
# html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
|
| 98 |
+
|
| 99 |
+
# Theme options are theme-specific and customize the look and feel of a theme
|
| 100 |
+
# further. For a list of options available for each theme, see the
|
| 101 |
+
# documentation.
|
| 102 |
+
#
|
| 103 |
+
# html_theme_options = {"collapse_navigation": False, "display_version": True}
|
| 104 |
+
|
| 105 |
+
# Add any paths that contain custom static files (such as style sheets) here,
|
| 106 |
+
# relative to this directory. They are copied after the builtin static files,
|
| 107 |
+
# so a file named "default.css" will overwrite the builtin "default.css".
|
| 108 |
+
html_static_path = ["_static"]
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
# -- Autodoc configuration ------------------------------------------------
|
| 112 |
+
|
| 113 |
+
autodoc_default_options = {
|
| 114 |
+
"members": True,
|
| 115 |
+
"member-order": "bysource",
|
| 116 |
+
"private-members": True,
|
| 117 |
+
"show-inheritance": True,
|
| 118 |
+
}
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
# -- Intersphinx configuration --------------------------------------------
|
| 122 |
+
|
| 123 |
+
intersphinx_mapping = {
|
| 124 |
+
"torch": ("https://pytorch.org/docs/stable/", None),
|
| 125 |
+
"albumentations": ("https://albumentations.readthedocs.io/en/latest/", None),
|
| 126 |
+
}
|
| 127 |
+
|
| 128 |
+
# -- Miscellaneous Extra Tweaks -------------------------------------------
|
| 129 |
+
|
| 130 |
+
# make github links resolve
|
| 131 |
+
def linkcode_resolve(domain, info):
|
| 132 |
+
"""
|
| 133 |
+
Determine the URL corresponding to Python object
|
| 134 |
+
This code is from
|
| 135 |
+
https://github.com/numpy/numpy/blob/master/doc/source/conf.py#L290
|
| 136 |
+
and https://github.com/Lasagne/Lasagne/pull/262
|
| 137 |
+
"""
|
| 138 |
+
if domain != "py":
|
| 139 |
+
return None
|
| 140 |
+
|
| 141 |
+
modname = info["module"]
|
| 142 |
+
fullname = info["fullname"]
|
| 143 |
+
|
| 144 |
+
submod = sys.modules.get(modname)
|
| 145 |
+
if submod is None:
|
| 146 |
+
return None
|
| 147 |
+
|
| 148 |
+
obj = submod
|
| 149 |
+
for part in fullname.split("."):
|
| 150 |
+
try:
|
| 151 |
+
obj = getattr(obj, part)
|
| 152 |
+
except: # noqa: E722
|
| 153 |
+
return None
|
| 154 |
+
|
| 155 |
+
try:
|
| 156 |
+
fn = inspect.getsourcefile(obj)
|
| 157 |
+
except: # noqa: E722
|
| 158 |
+
fn = None
|
| 159 |
+
if not fn:
|
| 160 |
+
return None
|
| 161 |
+
|
| 162 |
+
try:
|
| 163 |
+
source, lineno = inspect.getsourcelines(obj)
|
| 164 |
+
except: # noqa: E722
|
| 165 |
+
lineno = None
|
| 166 |
+
|
| 167 |
+
if lineno:
|
| 168 |
+
linespec = "#L%d-L%d" % (lineno, lineno + len(source) - 1)
|
| 169 |
+
else:
|
| 170 |
+
linespec = ""
|
| 171 |
+
|
| 172 |
+
filename = info["module"].replace(".", "/")
|
| 173 |
+
return f"https://github.com/kdexd/virtex/blob/master/{filename}.py{linespec}"
|
virtex/docs/index.rst
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. raw:: html
|
| 2 |
+
|
| 3 |
+
<h1 style="text-align: center">
|
| 4 |
+
VirTex: Learning Visual Representations from Textual Annotations
|
| 5 |
+
</h1>
|
| 6 |
+
<h4 style="text-align: center">
|
| 7 |
+
Karan Desai and Justin Johnson
|
| 8 |
+
</br>
|
| 9 |
+
<span style="font-size: 14pt; color: #555555">
|
| 10 |
+
University of Michigan
|
| 11 |
+
</span>
|
| 12 |
+
</h4>
|
| 13 |
+
<hr>
|
| 14 |
+
|
| 15 |
+
<h4 style="text-align: center">
|
| 16 |
+
Abstract
|
| 17 |
+
</h4>
|
| 18 |
+
|
| 19 |
+
<p style="text-align: justify">
|
| 20 |
+
The de-facto approach to many vision tasks is to start from pretrained
|
| 21 |
+
visual representations, typically learned via supervised training on
|
| 22 |
+
ImageNet. Recent methods have explored unsupervised pretraining to scale to
|
| 23 |
+
vast quantities of unlabeled images. In contrast, we aim to learn
|
| 24 |
+
high-quality visual representations from fewer images. To this end we
|
| 25 |
+
revisit supervised pretraining, and seek data-efficient alternatives to
|
| 26 |
+
classification-based pretraining. We propose VirTex -- a pretraining
|
| 27 |
+
approach using semantically dense captions to learn visual representations.
|
| 28 |
+
We train convolutional networks from scratch on COCO Captions, and transfer
|
| 29 |
+
them to downstream recognition tasks including image classification, object
|
| 30 |
+
detection, and instance segmentation. On all tasks, VirTex yields features
|
| 31 |
+
that match or exceed those learned on ImageNet -- supervised or unsupervised
|
| 32 |
+
-- despite using up to ten times fewer images.
|
| 33 |
+
</p>
|
| 34 |
+
|
| 35 |
+
**CVPR 2021. Paper available at:** `arxiv.org/abs/2006.06666 <https://arxiv.org/abs/2006.06666>`_.
|
| 36 |
+
|
| 37 |
+
**Code available at:** `github.com/kdexd/virtex <https://github.com/kdexd/virtex>`_.
|
| 38 |
+
|
| 39 |
+
.. image:: _static/system_figure.jpg
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
Get the pretrained ResNet-50 visual backbone from our best performing VirTex
|
| 43 |
+
model in one line *without any installation*!
|
| 44 |
+
|
| 45 |
+
.. code-block:: python
|
| 46 |
+
|
| 47 |
+
import torch
|
| 48 |
+
|
| 49 |
+
# That's it, this one line only requires PyTorch.
|
| 50 |
+
model = torch.hub.load("kdexd/virtex", "resnet50", pretrained=True)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
More details in :doc:`virtex/usage/model_zoo`. Next, dive deeper into our
|
| 54 |
+
code with User Guide and API References!
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
User Guide
|
| 58 |
+
----------
|
| 59 |
+
|
| 60 |
+
.. toctree::
|
| 61 |
+
:maxdepth: 2
|
| 62 |
+
|
| 63 |
+
virtex/usage/setup_dependencies
|
| 64 |
+
virtex/usage/model_zoo
|
| 65 |
+
virtex/usage/pretrain
|
| 66 |
+
virtex/usage/downstream
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
API Reference
|
| 70 |
+
-------------
|
| 71 |
+
|
| 72 |
+
.. toctree::
|
| 73 |
+
:maxdepth: 2
|
| 74 |
+
|
| 75 |
+
virtex/config
|
| 76 |
+
virtex/factories
|
| 77 |
+
virtex/data
|
| 78 |
+
virtex/models
|
| 79 |
+
virtex/modules
|
| 80 |
+
virtex/optim
|
| 81 |
+
virtex/utils
|
| 82 |
+
virtex/model_zoo
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
Citation
|
| 86 |
+
--------
|
| 87 |
+
|
| 88 |
+
If you find this code useful, please consider citing:
|
| 89 |
+
|
| 90 |
+
.. code-block:: text
|
| 91 |
+
|
| 92 |
+
@inproceedings{desai2021virtex,
|
| 93 |
+
title={{VirTex: Learning Visual Representations from Textual Annotations}},
|
| 94 |
+
author={Karan Desai and Justin Johnson},
|
| 95 |
+
booktitle={CVPR},
|
| 96 |
+
year={2021}
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
Acknowledgments
|
| 101 |
+
---------------
|
| 102 |
+
|
| 103 |
+
We thank Harsh Agrawal, Mohamed El Banani, Richard Higgins, Nilesh Kulkarni
|
| 104 |
+
and Chris Rockwell for helpful discussions and feedback on the paper. We thank
|
| 105 |
+
Ishan Misra for discussions regarding PIRL evaluation protocol; Saining Xie for
|
| 106 |
+
discussions about replicating iNaturalist evaluation as MoCo; Ross Girshick and
|
| 107 |
+
Yuxin Wu for help with Detectron2 model zoo; Georgia Gkioxari for suggesting
|
| 108 |
+
the Instance Segmentation pretraining task ablation; and Stefan Lee for
|
| 109 |
+
suggestions on figure aesthetics. We thank Jia Deng for access to extra GPUs
|
| 110 |
+
during project development; and UMich ARC-TS team for support with GPU cluster
|
| 111 |
+
management. Finally, we thank all the Starbucks outlets in Ann Arbor for many
|
| 112 |
+
hours of free WiFi. This work was partially supported by the Toyota Research
|
| 113 |
+
Institute (TRI). However, note that this article solely reflects the opinions
|
| 114 |
+
and conclusions of its authors and not TRI or any other Toyota entity.
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
Indices and Tables
|
| 118 |
+
------------------
|
| 119 |
+
|
| 120 |
+
* :ref:`genindex`
|
| 121 |
+
* :ref:`modindex`
|
| 122 |
+
* :ref:`search`
|
virtex/docs/virtex/config.rst
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
virtex.config
|
| 2 |
+
=============
|
| 3 |
+
|
| 4 |
+
.. raw:: html
|
| 5 |
+
|
| 6 |
+
<hr>
|
| 7 |
+
|
| 8 |
+
.. automodule:: virtex.config
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
Config References
|
| 12 |
+
-----------------
|
| 13 |
+
|
| 14 |
+
.. literalinclude:: ../../virtex/config.py
|
| 15 |
+
:language: python
|
| 16 |
+
:linenos:
|
| 17 |
+
:lines: 46-206
|
| 18 |
+
:dedent: 8
|
virtex/docs/virtex/data.datasets.rst
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
virtex.data.datasets
|
| 2 |
+
====================
|
| 3 |
+
|
| 4 |
+
.. raw:: html
|
| 5 |
+
|
| 6 |
+
<hr>
|
| 7 |
+
|
| 8 |
+
Pretraining Datasets
|
| 9 |
+
--------------------
|
| 10 |
+
|
| 11 |
+
.. automodule:: virtex.data.datasets.captioning
|
| 12 |
+
|
| 13 |
+
.. automodule:: virtex.data.datasets.classification
|
| 14 |
+
|
| 15 |
+
------------------------------------------------------------------------------
|
| 16 |
+
|
| 17 |
+
Downstream Datasets
|
| 18 |
+
-------------------
|
| 19 |
+
|
| 20 |
+
.. automodule:: virtex.data.datasets.downstream
|
virtex/docs/virtex/data.readers.rst
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
virtex.data.readers
|
| 2 |
+
===================
|
| 3 |
+
|
| 4 |
+
.. raw:: html
|
| 5 |
+
|
| 6 |
+
<hr>
|
| 7 |
+
|
| 8 |
+
.. automodule:: virtex.data.readers
|
virtex/docs/virtex/data.rst
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
virtex.data
|
| 2 |
+
===========
|
| 3 |
+
|
| 4 |
+
.. raw:: html
|
| 5 |
+
|
| 6 |
+
<hr>
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
.. toctree::
|
| 10 |
+
|
| 11 |
+
data.readers
|
| 12 |
+
data.datasets
|
| 13 |
+
data.tokenizers
|
| 14 |
+
data.transforms
|
virtex/docs/virtex/data.tokenizers.rst
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
virtex.data.tokenizers
|
| 2 |
+
======================
|
| 3 |
+
|
| 4 |
+
.. raw:: html
|
| 5 |
+
|
| 6 |
+
<hr>
|
| 7 |
+
|
| 8 |
+
.. automodule:: virtex.data.tokenizers
|
virtex/docs/virtex/data.transforms.rst
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
virtex.data.transforms
|
| 2 |
+
======================
|
| 3 |
+
|
| 4 |
+
.. raw:: html
|
| 5 |
+
|
| 6 |
+
<hr>
|
| 7 |
+
|
| 8 |
+
.. automodule:: virtex.data.transforms
|
virtex/docs/virtex/factories.rst
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
virtex.factories
|
| 2 |
+
================
|
| 3 |
+
|
| 4 |
+
.. raw:: html
|
| 5 |
+
|
| 6 |
+
<hr>
|
| 7 |
+
|
| 8 |
+
.. First only include the top-level module, and base class docstrings.
|
| 9 |
+
|
| 10 |
+
.. automodule:: virtex.factories
|
| 11 |
+
:no-members:
|
| 12 |
+
|
| 13 |
+
.. autoclass:: virtex.factories.Factory
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
------------------------------------------------------------------------------
|
| 17 |
+
|
| 18 |
+
Dataloading-related Factories
|
| 19 |
+
-----------------------------
|
| 20 |
+
|
| 21 |
+
.. autoclass:: virtex.factories.TokenizerFactory
|
| 22 |
+
:members: from_config
|
| 23 |
+
|
| 24 |
+
.. autoclass:: virtex.factories.ImageTransformsFactory
|
| 25 |
+
:members: from_config
|
| 26 |
+
|
| 27 |
+
.. autoclass:: virtex.factories.PretrainingDatasetFactory
|
| 28 |
+
:members: from_config
|
| 29 |
+
|
| 30 |
+
.. autoclass:: virtex.factories.DownstreamDatasetFactory
|
| 31 |
+
:members: from_config
|
| 32 |
+
|
| 33 |
+
------------------------------------------------------------------------------
|
| 34 |
+
|
| 35 |
+
Modeling-related Factories
|
| 36 |
+
--------------------------
|
| 37 |
+
|
| 38 |
+
.. autoclass:: virtex.factories.VisualBackboneFactory
|
| 39 |
+
:members: from_config
|
| 40 |
+
|
| 41 |
+
.. autoclass:: virtex.factories.TextualHeadFactory
|
| 42 |
+
:members: from_config
|
| 43 |
+
|
| 44 |
+
.. autoclass:: virtex.factories.PretrainingModelFactory
|
| 45 |
+
:members: from_config
|
| 46 |
+
|
| 47 |
+
------------------------------------------------------------------------------
|
| 48 |
+
|
| 49 |
+
Optimization-related Factories
|
| 50 |
+
------------------------------
|
| 51 |
+
|
| 52 |
+
.. autoclass:: virtex.factories.OptimizerFactory
|
| 53 |
+
:members: from_config
|
| 54 |
+
|
| 55 |
+
.. autoclass:: virtex.factories.LRSchedulerFactory
|
| 56 |
+
:members: from_config
|
virtex/docs/virtex/model_zoo.rst
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
virtex.model_zoo
|
| 2 |
+
================
|
| 3 |
+
|
| 4 |
+
.. raw:: html
|
| 5 |
+
|
| 6 |
+
<hr>
|
| 7 |
+
|
| 8 |
+
.. automodule:: virtex.model_zoo.model_zoo
|