Spaces:
Build error

Build error

Add 'template' and 'bert-mouth' visuals back
Browse files- app.py +2 -2
- assets/bert-mouth.png +0 -0
- assets/template.png +0 -0
app.py
CHANGED
|
@@ -470,7 +470,7 @@ def run():
|
|
| 470 |
we may take the sentence we wish to classify and append the text "Overall, this
|
| 471 |
movie was ____." and feed it into a language model like so:
|
| 472 |
''')
|
| 473 |
-
|
| 474 |
st.markdown('''
|
| 475 |
By measuring whether the language model assigns a higher probability to
|
| 476 |
words that are associated with a **positive** sentiment ("good", "great",
|
|
@@ -496,7 +496,7 @@ def run():
|
|
| 496 |
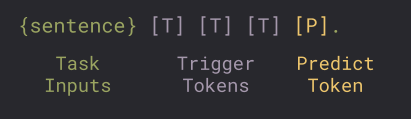
a number of *trigger tokens* that will automatically be learned by the
|
| 497 |
model and the *predict token* that the model will fill in:
|
| 498 |
''')
|
| 499 |
-
|
| 500 |
st.markdown(
|
| 501 |
'''
|
| 502 |
In each iteration of the search process:
|
|
|
|
| 470 |
we may take the sentence we wish to classify and append the text "Overall, this
|
| 471 |
movie was ____." and feed it into a language model like so:
|
| 472 |
''')
|
| 473 |
+
st.image('assets/bert-mouth.png', use_column_width=True)
|
| 474 |
st.markdown('''
|
| 475 |
By measuring whether the language model assigns a higher probability to
|
| 476 |
words that are associated with a **positive** sentiment ("good", "great",
|
|
|
|
| 496 |
a number of *trigger tokens* that will automatically be learned by the
|
| 497 |
model and the *predict token* that the model will fill in:
|
| 498 |
''')
|
| 499 |
+
st.image('assets/template.png', use_column_width=True)
|
| 500 |
st.markdown(
|
| 501 |
'''
|
| 502 |
In each iteration of the search process:
|
assets/bert-mouth.png
ADDED

|
assets/template.png
ADDED
|