Spaces:
Runtime error

Runtime error
mta122
commited on
Commit
•
ca4133a
1
Parent(s):
a6e668b
first
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- README.md +5 -5
- __pycache__/categories.cpython-38.pyc +0 -0
- app.py +245 -0
- background_remover/remove_deeplab.py +70 -0
- background_remover/remove_rembg.py +24 -0
- background_remover/seg.py +48 -0
- categories.py +56 -0
- ckpt/.DS_Store +0 -0
- ckpt/all2.ckpt +3 -0
- configs/finetune/finetune_bert.yaml +128 -0
- configs/finetune/finetune_clip.yaml +118 -0
- configs/finetune/finetune_generic.yaml +128 -0
- configs/finetune/finetune_multi_bert.yaml +127 -0
- configs/finetune/finetune_multi_clip.yaml +118 -0
- data_fonts/Caladea-Regular/0/0.png +0 -0
- data_fonts/Caladea-Regular/0/1.png +0 -0
- data_fonts/Caladea-Regular/0/10.png +0 -0
- data_fonts/Caladea-Regular/0/11.png +0 -0
- data_fonts/Caladea-Regular/0/12.png +0 -0
- data_fonts/Caladea-Regular/0/13.png +0 -0
- data_fonts/Caladea-Regular/0/14.png +0 -0
- data_fonts/Caladea-Regular/0/15.png +0 -0
- data_fonts/Caladea-Regular/0/2.png +0 -0
- data_fonts/Caladea-Regular/0/3.png +0 -0
- data_fonts/Caladea-Regular/0/4.png +0 -0
- data_fonts/Caladea-Regular/0/5.png +0 -0
- data_fonts/Caladea-Regular/0/6.png +0 -0
- data_fonts/Caladea-Regular/0/7.png +0 -0
- data_fonts/Caladea-Regular/0/8.png +0 -0
- data_fonts/Caladea-Regular/0/9.png +0 -0
- data_fonts/Caladea-Regular/1/0.png +0 -0
- data_fonts/Caladea-Regular/1/1.png +0 -0
- data_fonts/Caladea-Regular/1/10.png +0 -0
- data_fonts/Caladea-Regular/1/11.png +0 -0
- data_fonts/Caladea-Regular/1/12.png +0 -0
- data_fonts/Caladea-Regular/1/13.png +0 -0
- data_fonts/Caladea-Regular/1/14.png +0 -0
- data_fonts/Caladea-Regular/1/15.png +0 -0
- data_fonts/Caladea-Regular/1/2.png +0 -0
- data_fonts/Caladea-Regular/1/3.png +0 -0
- data_fonts/Caladea-Regular/1/4.png +0 -0
- data_fonts/Caladea-Regular/1/5.png +0 -0
- data_fonts/Caladea-Regular/1/6.png +0 -0
- data_fonts/Caladea-Regular/1/7.png +0 -0
- data_fonts/Caladea-Regular/1/8.png +0 -0
- data_fonts/Caladea-Regular/1/9.png +0 -0
- data_fonts/Caladea-Regular/2/0.png +0 -0
- data_fonts/Caladea-Regular/2/1.png +0 -0
- data_fonts/Caladea-Regular/2/10.png +0 -0
- data_fonts/Caladea-Regular/2/11.png +0 -0
README.md
CHANGED
|
@@ -1,10 +1,10 @@
|
|
| 1 |
---
|
| 2 |
-
title: DS
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 3.
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
---
|
|
|
|
| 1 |
---
|
| 2 |
+
title: DS-Fusion
|
| 3 |
+
emoji: 👁
|
| 4 |
+
colorFrom: purple
|
| 5 |
+
colorTo: blue
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 3.32.0
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
---
|
__pycache__/categories.cpython-38.pyc
ADDED
|
Binary file (844 Bytes). View file
|
|
|
app.py
ADDED
|
@@ -0,0 +1,245 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import os
|
| 3 |
+
# os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
|
| 4 |
+
from categories import categories, font_list
|
| 5 |
+
import pdb
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import random
|
| 8 |
+
|
| 9 |
+
try:
|
| 10 |
+
import pygsheets
|
| 11 |
+
except Exception as e:
|
| 12 |
+
print("pygsheets not found", e)
|
| 13 |
+
|
| 14 |
+
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:128"
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
global_index = 0
|
| 18 |
+
mode_global = "DS-Fusion-Express"
|
| 19 |
+
prompt_global = ""
|
| 20 |
+
|
| 21 |
+
def log_data_to_sheet(pre_style, style_custom, glyph, attribute):
|
| 22 |
+
try:
|
| 23 |
+
#authorization
|
| 24 |
+
gc = pygsheets.authorize(service_file='./huggingface-connector-02adcb4cdf00.json')
|
| 25 |
+
|
| 26 |
+
#open the google spreadsheet (where 'PY to Gsheet Test' is the name of my sheet)
|
| 27 |
+
sh = gc.open('HuggingFace Logs')
|
| 28 |
+
|
| 29 |
+
#select the first sheet
|
| 30 |
+
wks = sh[0]
|
| 31 |
+
|
| 32 |
+
# Send fields list
|
| 33 |
+
wks.append_table(values=[pre_style, style_custom, glyph, attribute])
|
| 34 |
+
except:
|
| 35 |
+
pass
|
| 36 |
+
|
| 37 |
+
def change_font(evt: gr.SelectData):
|
| 38 |
+
global global_index
|
| 39 |
+
global_index = evt.index
|
| 40 |
+
|
| 41 |
+
def my_main(pre_style, style_custom, glyph, attribute):
|
| 42 |
+
|
| 43 |
+
log_data_to_sheet(pre_style, style_custom, glyph, attribute)
|
| 44 |
+
|
| 45 |
+
global prompt_global
|
| 46 |
+
glyph = glyph[0]
|
| 47 |
+
|
| 48 |
+
command = "rm -r out_cur/*"
|
| 49 |
+
os.system(command)
|
| 50 |
+
for i in range(1,5):
|
| 51 |
+
command = "cp initial_show/" + str(i) +".png out_cur/"+str(i)+".png"
|
| 52 |
+
os.system(command)
|
| 53 |
+
|
| 54 |
+
style = pre_style
|
| 55 |
+
|
| 56 |
+
command = "rm -r data_style/"
|
| 57 |
+
os.system(command)
|
| 58 |
+
|
| 59 |
+
if style_custom != "":
|
| 60 |
+
style = style_custom
|
| 61 |
+
|
| 62 |
+
if len(glyph) != 1:
|
| 63 |
+
prompt_global = f" {style}"
|
| 64 |
+
else:
|
| 65 |
+
prompt_global = f" {style} {glyph}"
|
| 66 |
+
|
| 67 |
+
li = "ckpt/all2.ckpt"
|
| 68 |
+
output_path = f"out/express"
|
| 69 |
+
if attribute == "":
|
| 70 |
+
prompt = f" '{style} {glyph}'"
|
| 71 |
+
else:
|
| 72 |
+
prompt = f" '{attribute} {style} {glyph}'"
|
| 73 |
+
|
| 74 |
+
command = "rm -r out/"
|
| 75 |
+
os.system(command)
|
| 76 |
+
|
| 77 |
+
print(prompt)
|
| 78 |
+
|
| 79 |
+
command = "python txt2img.py --ddim_eta 1.0 \
|
| 80 |
+
--n_samples 4 \
|
| 81 |
+
--n_iter 1\
|
| 82 |
+
--ddim_steps 50 \
|
| 83 |
+
--scale 5.0\
|
| 84 |
+
--H 256\
|
| 85 |
+
--W 256\
|
| 86 |
+
--outdir " + output_path + " --ckpt " +li +" --prompt " + prompt
|
| 87 |
+
|
| 88 |
+
os.system(command)
|
| 89 |
+
|
| 90 |
+
command = "rm -r out_cur/*"
|
| 91 |
+
os.system(command)
|
| 92 |
+
path = []
|
| 93 |
+
final_imgs = os.listdir(output_path+"/samples")
|
| 94 |
+
for i in range(4):
|
| 95 |
+
path.append(os.path.join(output_path+"/samples", final_imgs[i]))
|
| 96 |
+
path_in = os.path.join(output_path+"/samples", final_imgs[i])
|
| 97 |
+
command = "cp " + path_in + " " + "out_cur/"+final_imgs[i]
|
| 98 |
+
os.system(command)
|
| 99 |
+
|
| 100 |
+
return gr.update(value=path)
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def rem_bg():
|
| 105 |
+
command= "rm -r out_bg/*"
|
| 106 |
+
os.system(command)
|
| 107 |
+
files = os.listdir("out_cur")
|
| 108 |
+
if len(files)>0:
|
| 109 |
+
command_3 = f"python script_step3.py --input_dir out_cur --method 'rembg'"
|
| 110 |
+
os.system(command_3)
|
| 111 |
+
|
| 112 |
+
for file in files:
|
| 113 |
+
command = "cp out_bg/"+file +" out_cur/"
|
| 114 |
+
os.system(command)
|
| 115 |
+
|
| 116 |
+
path = []
|
| 117 |
+
for file in files:
|
| 118 |
+
file_path = os.path.join("out_cur", file)
|
| 119 |
+
image = Image.open(file_path)
|
| 120 |
+
new_image = Image.new("RGBA", image.size, "WHITE")
|
| 121 |
+
new_image.paste(image, (0, 0), image)
|
| 122 |
+
new_image.save(file_path, "PNG")
|
| 123 |
+
path.append(file_path)
|
| 124 |
+
|
| 125 |
+
return gr.update(value = path)
|
| 126 |
+
|
| 127 |
+
font_list_express = [
|
| 128 |
+
'Caladea-Regular', #works good
|
| 129 |
+
# 'Garuda-Bold', #works poorlyß
|
| 130 |
+
'FreeSansOblique', #works average
|
| 131 |
+
"Purisa", #works good
|
| 132 |
+
"Uroob" #worksaverage
|
| 133 |
+
]
|
| 134 |
+
|
| 135 |
+
path_fonts_express = []
|
| 136 |
+
for font in font_list_express:
|
| 137 |
+
path_in = "font_list/fonts/"+font+".png"
|
| 138 |
+
path_fonts_express.append(path_in)
|
| 139 |
+
|
| 140 |
+
def make_upper(value):
|
| 141 |
+
if value == "":
|
| 142 |
+
return ""
|
| 143 |
+
return value[0].upper()
|
| 144 |
+
|
| 145 |
+
def get_out_cur():
|
| 146 |
+
path = []
|
| 147 |
+
pth = "log_view"
|
| 148 |
+
for file in os.listdir(pth):
|
| 149 |
+
file_final = os.path.join(pth, file)
|
| 150 |
+
path.append(file_final)
|
| 151 |
+
return gr.update(value=path)
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def update_time_mode(value):
|
| 155 |
+
if value == 'DS-Fusion':
|
| 156 |
+
return gr.update(value="Generation Time: ~5 mins")
|
| 157 |
+
else:
|
| 158 |
+
return gr.update(value="Generation Time: ~30 seconds")
|
| 159 |
+
|
| 160 |
+
def update_time_cb(value):
|
| 161 |
+
if value:
|
| 162 |
+
if mode_global == "DS-Fusion":
|
| 163 |
+
return gr.update(value="Generation Time: ~8 mins")
|
| 164 |
+
return gr.update(value="Generation Time: ~30 seconds")
|
| 165 |
+
else:
|
| 166 |
+
if mode_global == "DS-Fusion":
|
| 167 |
+
return gr.update(value="Generation Time: ~5 mins")
|
| 168 |
+
return gr.update(value="Generation Time: ~30 seconds")
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def load_img():
|
| 173 |
+
|
| 174 |
+
path = []
|
| 175 |
+
dir = "out_cur"
|
| 176 |
+
for file in os.listdir(dir):
|
| 177 |
+
file_full = os.path.join(dir, file)
|
| 178 |
+
path.append(file_full)
|
| 179 |
+
return path
|
| 180 |
+
|
| 181 |
+
css = '''
|
| 182 |
+
<!-- this makes the items inside the gallery to shrink -->
|
| 183 |
+
div#gallery_64 div.grid {
|
| 184 |
+
height: 64px;
|
| 185 |
+
width: 180px;
|
| 186 |
+
}
|
| 187 |
+
|
| 188 |
+
<!-- this makes the gallery's height to shrink -->
|
| 189 |
+
div#gallery_64 > div:nth-child(3) {
|
| 190 |
+
min-height: 172px !important;
|
| 191 |
+
}
|
| 192 |
+
|
| 193 |
+
<!-- this makes the gallery's height to shrink when you click one image to view it bigger -->
|
| 194 |
+
div#gallery_64 > div:nth-child(4) {
|
| 195 |
+
min-height: 172px !important;
|
| 196 |
+
}
|
| 197 |
+
'''
|
| 198 |
+
|
| 199 |
+
with gr.Blocks(css=css) as demo:
|
| 200 |
+
|
| 201 |
+
with gr.Column():
|
| 202 |
+
with gr.Row():
|
| 203 |
+
with gr.Column():
|
| 204 |
+
with gr.Row():
|
| 205 |
+
in4 = gr.Text(label="Character (A-Z, 0-9) to Stylize", info = "Only works with capitals. Will pick first letter if more than one", value = "R", interactive = True)
|
| 206 |
+
in2 = gr.Dropdown(categories, label="Pre-Defined Style Categories", info = "Categories used to train Express", value = "DRAGON", interactive = True)
|
| 207 |
+
|
| 208 |
+
with gr.Row():
|
| 209 |
+
in3 = gr.Text(label="Override Style Category ", info="This will replace the pre-defined style value", value = "", interactive = True)
|
| 210 |
+
in5 = gr.Text(label="Additional Style Attribute ",info= "e.g. pixel, grayscale, etc", value = "", interactive = True)
|
| 211 |
+
|
| 212 |
+
# with gr.Row():
|
| 213 |
+
# with gr.Column():
|
| 214 |
+
# in8 = gr.Checkbox(label="MULTI FONT INPUT - font selection below is over-ridden", info="Select for more abstract results", value = False, interactive = True).style(container=True)
|
| 215 |
+
# gallery = gr.Gallery([], label="Select Font", show_label=True, elem_id="gallery_64").style(grid=[2,6], preview=True, height="auto")
|
| 216 |
+
|
| 217 |
+
with gr.Row():
|
| 218 |
+
btn = gr.Button("Let's Stylize It - Generation Time: ~60 seconds", interactive = True)
|
| 219 |
+
# btn_bg = gr.Button("Remove Background", interactive = True)
|
| 220 |
+
|
| 221 |
+
with gr.Column():
|
| 222 |
+
gallery_out = gr.Gallery(label="Generated images", elem_id="gallery_out").style(grid=[2,2], height="full")
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
outputs = [gallery_out]
|
| 227 |
+
# gallery.select(change_font, None, None)
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
inputs = [in2,in3,in4,in5]
|
| 231 |
+
|
| 232 |
+
btn.click(my_main, inputs, outputs)
|
| 233 |
+
# btn_bg.click(rem_bg, None, outputs)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
if __name__ == "__main__":
|
| 239 |
+
command = "rm -r out_cur/*"
|
| 240 |
+
os.system(command)
|
| 241 |
+
for i in range(1,5):
|
| 242 |
+
command = "cp initial_show/" + str(i) +".png out_cur/"+str(i)+".png"
|
| 243 |
+
os.system(command)
|
| 244 |
+
demo.queue()
|
| 245 |
+
demo.launch(share=False)
|
background_remover/remove_deeplab.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import urllib
|
| 4 |
+
from PIL import Image
|
| 5 |
+
from torchvision import transforms
|
| 6 |
+
|
| 7 |
+
def load_model():
|
| 8 |
+
|
| 9 |
+
model = torch.hub.load('pytorch/vision:v0.6.0', 'deeplabv3_resnet101', pretrained=True)
|
| 10 |
+
model.eval()
|
| 11 |
+
|
| 12 |
+
mean = torch.tensor([0.485, 0.456, 0.406])
|
| 13 |
+
std = torch.tensor([0.229, 0.224, 0.225])
|
| 14 |
+
|
| 15 |
+
preprocess = transforms.Compose([
|
| 16 |
+
transforms.ToTensor(),
|
| 17 |
+
transforms.Normalize(mean=mean, std=std),
|
| 18 |
+
])
|
| 19 |
+
|
| 20 |
+
postprocess = transforms.Compose([
|
| 21 |
+
transforms.Normalize(mean=-mean/std, std=1/std),
|
| 22 |
+
transforms.ToPILImage(),
|
| 23 |
+
])
|
| 24 |
+
|
| 25 |
+
if torch.cuda.is_available():
|
| 26 |
+
model.to('cuda')
|
| 27 |
+
return model, preprocess
|
| 28 |
+
|
| 29 |
+
def remove_background(img, model, preprocess):
|
| 30 |
+
input_batch = preprocess(img)[None, ...]
|
| 31 |
+
|
| 32 |
+
if torch.cuda.is_available():
|
| 33 |
+
input_batch = input_batch.to('cuda')
|
| 34 |
+
|
| 35 |
+
with torch.no_grad():
|
| 36 |
+
output = model(input_batch)['out'][0]
|
| 37 |
+
output_predictions = torch.nn.functional.softmax(output, dim=0)
|
| 38 |
+
output_predictions = (output_predictions > 0.98).float()
|
| 39 |
+
|
| 40 |
+
img.putalpha(255)
|
| 41 |
+
result_np = np.array(img)
|
| 42 |
+
result_np[..., 3] = (1-output_predictions[0].cpu().numpy())*255
|
| 43 |
+
|
| 44 |
+
return Image.fromarray(result_np.astype('uint8'))
|
| 45 |
+
|
| 46 |
+
import os
|
| 47 |
+
def main():
|
| 48 |
+
model, preprocess = load_model()
|
| 49 |
+
# fpath = 'data/parrot_2.png'
|
| 50 |
+
path_in = "/localhome/mta122/PycharmProjects/logo_ai/final_nocherry_score/one/DRAGON/G"
|
| 51 |
+
|
| 52 |
+
for fpath_file in os.listdir(path_in):
|
| 53 |
+
# fpath = 'data/parrot_2.png'
|
| 54 |
+
fpath = os.path.join(path_in, fpath_file)
|
| 55 |
+
# fpath_out = fpath.split('.')[0] + '_result_rembg.png'
|
| 56 |
+
# cmd = f'rembg i {fpath} {fpath_out}'
|
| 57 |
+
# print(cmd)
|
| 58 |
+
# os.system(cmd)
|
| 59 |
+
|
| 60 |
+
img = Image.open(fpath)
|
| 61 |
+
if img.size[-1] > 3:
|
| 62 |
+
img_np = np.array(img)
|
| 63 |
+
img_rbg = img_np[:, : ,:3]
|
| 64 |
+
img = Image.fromarray(img_rbg)
|
| 65 |
+
result = remove_background(img, model, preprocess)
|
| 66 |
+
result.save(fpath.split('.')[0] + '_result_deeplab.png')
|
| 67 |
+
print('finished')
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
main()
|
background_remover/remove_rembg.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pip install rembg[gpu]
|
| 2 |
+
# read details on https://github.com/brilam/remove-bg
|
| 3 |
+
# Paper: U2-Net: Going deeper with nested U-structure for salient object detection
|
| 4 |
+
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
#chess, c
|
| 8 |
+
#surfing, s
|
| 9 |
+
|
| 10 |
+
objects = "PLANT"
|
| 11 |
+
letter = "L"
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
for mode in ["one","all"]:
|
| 15 |
+
|
| 16 |
+
path_in = f"/localhome/mta122/PycharmProjects/logo_ai/final_nocherry_score/{mode}/{objects}/{letter}"
|
| 17 |
+
|
| 18 |
+
for fpath_file in os.listdir(path_in):
|
| 19 |
+
# fpath = 'data/parrot_2.png'
|
| 20 |
+
fpath = os.path.join(path_in, fpath_file)
|
| 21 |
+
fpath_out = fpath.split('.')[0] + '_result_rembg.png'
|
| 22 |
+
cmd = f'rembg i {fpath} {fpath_out}'
|
| 23 |
+
print(cmd)
|
| 24 |
+
os.system(cmd)
|
background_remover/seg.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
model = torch.hub.load('pytorch/vision:v0.10.0', 'deeplabv3_resnet50', pretrained=True)
|
| 4 |
+
# or any of these variants
|
| 5 |
+
# model = torch.hub.load('pytorch/vision:v0.10.0', 'deeplabv3_resnet101', pretrained=True)
|
| 6 |
+
# model = torch.hub.load('pytorch/vision:v0.10.0', 'deeplabv3_mobilenet_v3_large', pretrained=True)
|
| 7 |
+
model.eval()
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# file name
|
| 11 |
+
filename = './data/icecream_2.png'
|
| 12 |
+
|
| 13 |
+
# sample execution (requires torchvision)
|
| 14 |
+
from PIL import Image
|
| 15 |
+
from torchvision import transforms
|
| 16 |
+
input_image = Image.open(filename)
|
| 17 |
+
input_image = input_image.convert("RGB")
|
| 18 |
+
preprocess = transforms.Compose([
|
| 19 |
+
transforms.ToTensor(),
|
| 20 |
+
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
|
| 21 |
+
])
|
| 22 |
+
|
| 23 |
+
input_tensor = preprocess(input_image)
|
| 24 |
+
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
|
| 25 |
+
|
| 26 |
+
# move the input and model to GPU for speed if available
|
| 27 |
+
if torch.cuda.is_available():
|
| 28 |
+
input_batch = input_batch.to('cuda')
|
| 29 |
+
model.to('cuda')
|
| 30 |
+
|
| 31 |
+
with torch.no_grad():
|
| 32 |
+
output = model(input_batch)['out'][0]
|
| 33 |
+
output_predictions = output.argmax(0)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# create a color pallette, selecting a color for each class
|
| 37 |
+
palette = torch.tensor([2 ** 25 - 1, 2 ** 15 - 1, 2 ** 21 - 1])
|
| 38 |
+
colors = torch.as_tensor([i for i in range(21)])[:, None] * palette
|
| 39 |
+
colors = (colors % 255).numpy().astype("uint8")
|
| 40 |
+
|
| 41 |
+
# plot the semantic segmentation predictions of 21 classes in each color
|
| 42 |
+
r = Image.fromarray(output_predictions.byte().cpu().numpy()).resize(input_image.size)
|
| 43 |
+
r.putpalette(colors)
|
| 44 |
+
r.save('results.png')
|
| 45 |
+
|
| 46 |
+
import matplotlib.pyplot as plt
|
| 47 |
+
plt.imshow(r)
|
| 48 |
+
# plt.show()
|
categories.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
categories = [
|
| 2 |
+
"ASTRONAUT",
|
| 3 |
+
"MERMAID",
|
| 4 |
+
"BUTTERFLY",
|
| 5 |
+
"MUSIC",
|
| 6 |
+
"OCTOPUS",
|
| 7 |
+
"CANDLE",
|
| 8 |
+
"PILOT",
|
| 9 |
+
"CACTUS",
|
| 10 |
+
"PLANT",
|
| 11 |
+
"CHESS",
|
| 12 |
+
"ROBOT",
|
| 13 |
+
"COW",
|
| 14 |
+
"SHARK",
|
| 15 |
+
"DOLPHIN",
|
| 16 |
+
"SOCKS",
|
| 17 |
+
"DRAGON",
|
| 18 |
+
"UNICORN",
|
| 19 |
+
"LION",
|
| 20 |
+
"VIOLIN",
|
| 21 |
+
"ZOMBIE",
|
| 22 |
+
"PHOENIX",
|
| 23 |
+
"CORN",
|
| 24 |
+
"UMBRELLA",
|
| 25 |
+
"HARP",
|
| 26 |
+
"LADYBUG",
|
| 27 |
+
"KAYAK",
|
| 28 |
+
"CASTLE",
|
| 29 |
+
"HOME",
|
| 30 |
+
"PARROT",
|
| 31 |
+
"STAR",
|
| 32 |
+
"SURFING",
|
| 33 |
+
"HAT",
|
| 34 |
+
"BOW",
|
| 35 |
+
"BOOK",
|
| 36 |
+
"MOUSE",
|
| 37 |
+
"SHELL",
|
| 38 |
+
"HORSE",
|
| 39 |
+
"FOX",
|
| 40 |
+
"PEACOCK",
|
| 41 |
+
"DOG",
|
| 42 |
+
"OWL"
|
| 43 |
+
]
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
font_list = [
|
| 47 |
+
'Garuda-Bold',
|
| 48 |
+
'Caladea-Regular',
|
| 49 |
+
'OpenSans-ExtraBoldItalic',
|
| 50 |
+
'Lato-Black',
|
| 51 |
+
'FreeSerifBold',
|
| 52 |
+
'FreeSansOblique',
|
| 53 |
+
"Purisa",
|
| 54 |
+
"Karumbi",
|
| 55 |
+
"mitra",
|
| 56 |
+
"Uroob"]
|
ckpt/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
ckpt/all2.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:70fb66ea45f7fa37746f4043c8ed6038fc85371755d36e791ad5efa02c4fd1d0
|
| 3 |
+
size 13165056579
|
configs/finetune/finetune_bert.yaml
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 1.0e-5
|
| 3 |
+
target: ldm.models.diffusion.ddpm.LatentDiffusion
|
| 4 |
+
params:
|
| 5 |
+
linear_start: 0.00085
|
| 6 |
+
linear_end: 0.0120
|
| 7 |
+
num_timesteps_cond: 1
|
| 8 |
+
log_every_t: 200
|
| 9 |
+
timesteps: 1000
|
| 10 |
+
first_stage_key: "image"
|
| 11 |
+
cond_stage_key: "caption"
|
| 12 |
+
image_size: 32
|
| 13 |
+
channels: 4
|
| 14 |
+
cond_stage_trainable: False
|
| 15 |
+
conditioning_key: crossattn
|
| 16 |
+
monitor: val/loss_simple_ema
|
| 17 |
+
scale_factor: 0.18215
|
| 18 |
+
use_ema: False
|
| 19 |
+
weight_disc: 0.01
|
| 20 |
+
|
| 21 |
+
unet_config:
|
| 22 |
+
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
| 23 |
+
params:
|
| 24 |
+
image_size: 32
|
| 25 |
+
in_channels: 4
|
| 26 |
+
out_channels: 4
|
| 27 |
+
model_channels: 320
|
| 28 |
+
attention_resolutions: [ 4, 2, 1 ]
|
| 29 |
+
num_res_blocks: 2
|
| 30 |
+
channel_mult: [ 1, 2, 4, 4 ]
|
| 31 |
+
num_heads: 8
|
| 32 |
+
use_spatial_transformer: True
|
| 33 |
+
transformer_depth: 1
|
| 34 |
+
context_dim: 1280
|
| 35 |
+
use_checkpoint: True
|
| 36 |
+
legacy: False
|
| 37 |
+
|
| 38 |
+
first_stage_config:
|
| 39 |
+
target: ldm.models.autoencoder.AutoencoderKL
|
| 40 |
+
params:
|
| 41 |
+
embed_dim: 4
|
| 42 |
+
monitor: val/rec_loss
|
| 43 |
+
ddconfig:
|
| 44 |
+
double_z: true
|
| 45 |
+
z_channels: 4
|
| 46 |
+
resolution: 256
|
| 47 |
+
in_channels: 3
|
| 48 |
+
out_ch: 3
|
| 49 |
+
ch: 128
|
| 50 |
+
ch_mult:
|
| 51 |
+
- 1
|
| 52 |
+
- 2
|
| 53 |
+
- 4
|
| 54 |
+
- 4
|
| 55 |
+
num_res_blocks: 2
|
| 56 |
+
attn_resolutions: []
|
| 57 |
+
dropout: 0.0
|
| 58 |
+
lossconfig:
|
| 59 |
+
target: torch.nn.Identity
|
| 60 |
+
|
| 61 |
+
cond_stage_config:
|
| 62 |
+
target: ldm.modules.encoders.modules.BERTEmbedder
|
| 63 |
+
params:
|
| 64 |
+
n_embed: 1280
|
| 65 |
+
n_layer: 32
|
| 66 |
+
device: "cuda"
|
| 67 |
+
|
| 68 |
+
discriminator_config:
|
| 69 |
+
target: ldm.modules.discriminator.Discriminator
|
| 70 |
+
params:
|
| 71 |
+
bnorm: True
|
| 72 |
+
leakyparam: 0.2
|
| 73 |
+
bias: False
|
| 74 |
+
generic: False
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
data:
|
| 78 |
+
target: main.DataModuleFromConfig
|
| 79 |
+
params:
|
| 80 |
+
batch_size: 1
|
| 81 |
+
num_workers: 32
|
| 82 |
+
wrap: false
|
| 83 |
+
train:
|
| 84 |
+
target: ldm.data.rasterizer.Rasterizer
|
| 85 |
+
params:
|
| 86 |
+
img_size: 256
|
| 87 |
+
text: "R"
|
| 88 |
+
style_word: "DRAGON"
|
| 89 |
+
data_path: "data/cat"
|
| 90 |
+
alternate_glyph: None
|
| 91 |
+
num_samples: 2001
|
| 92 |
+
make_black: False
|
| 93 |
+
one_font: False
|
| 94 |
+
full_word: False
|
| 95 |
+
font_name: "Garuda-Bold.ttf"
|
| 96 |
+
just_use_style: false
|
| 97 |
+
use_alt: False
|
| 98 |
+
validation:
|
| 99 |
+
target: ldm.data.rasterizer.Rasterizer
|
| 100 |
+
params:
|
| 101 |
+
img_size: 256
|
| 102 |
+
text: "R"
|
| 103 |
+
style_word: "DRAGON"
|
| 104 |
+
data_path: "data/cat"
|
| 105 |
+
alternate_glyph: None
|
| 106 |
+
num_samples: 5
|
| 107 |
+
make_black: False
|
| 108 |
+
one_font: False
|
| 109 |
+
full_word: False
|
| 110 |
+
font_name: "Garuda-Bold.ttf"
|
| 111 |
+
just_use_style: false
|
| 112 |
+
use_alt: False
|
| 113 |
+
|
| 114 |
+
lightning:
|
| 115 |
+
modelcheckpoint:
|
| 116 |
+
params:
|
| 117 |
+
every_n_train_steps: 5000
|
| 118 |
+
callbacks:
|
| 119 |
+
image_logger:
|
| 120 |
+
target: main.ImageLogger
|
| 121 |
+
params:
|
| 122 |
+
batch_frequency: 1000
|
| 123 |
+
max_images: 1
|
| 124 |
+
increase_log_steps: False
|
| 125 |
+
|
| 126 |
+
trainer:
|
| 127 |
+
benchmark: True
|
| 128 |
+
max_steps: 500
|
configs/finetune/finetune_clip.yaml
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 1.0e-5 #1e-4
|
| 3 |
+
target: ldm.models.diffusion.ddpm.LatentDiffusion
|
| 4 |
+
params:
|
| 5 |
+
linear_start: 0.00085
|
| 6 |
+
linear_end: 0.0120
|
| 7 |
+
num_timesteps_cond: 1
|
| 8 |
+
log_every_t: 200
|
| 9 |
+
timesteps: 1000
|
| 10 |
+
first_stage_key: "image"
|
| 11 |
+
cond_stage_key: "caption"
|
| 12 |
+
image_size: 64 # 32
|
| 13 |
+
channels: 4
|
| 14 |
+
cond_stage_trainable: False # Note: different from the one we trained before
|
| 15 |
+
conditioning_key: crossattn
|
| 16 |
+
monitor: val/loss_simple_ema
|
| 17 |
+
scale_factor: 0.18215
|
| 18 |
+
use_ema: False
|
| 19 |
+
weight_disc: 0.01
|
| 20 |
+
|
| 21 |
+
unet_config:
|
| 22 |
+
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
| 23 |
+
params:
|
| 24 |
+
image_size: 64 # unused
|
| 25 |
+
in_channels: 4
|
| 26 |
+
out_channels: 4
|
| 27 |
+
model_channels: 320
|
| 28 |
+
attention_resolutions: [ 4, 2, 1 ]
|
| 29 |
+
num_res_blocks: 2
|
| 30 |
+
channel_mult: [ 1, 2, 4, 4 ]
|
| 31 |
+
num_heads: 8
|
| 32 |
+
use_spatial_transformer: True
|
| 33 |
+
transformer_depth: 1
|
| 34 |
+
context_dim: 768 # 1280
|
| 35 |
+
use_checkpoint: True
|
| 36 |
+
legacy: False
|
| 37 |
+
|
| 38 |
+
first_stage_config:
|
| 39 |
+
target: ldm.models.autoencoder.AutoencoderKL
|
| 40 |
+
params:
|
| 41 |
+
embed_dim: 4
|
| 42 |
+
monitor: val/rec_loss
|
| 43 |
+
ddconfig:
|
| 44 |
+
double_z: true
|
| 45 |
+
z_channels: 4
|
| 46 |
+
resolution: 512 #256
|
| 47 |
+
in_channels: 3
|
| 48 |
+
out_ch: 3
|
| 49 |
+
ch: 128
|
| 50 |
+
ch_mult:
|
| 51 |
+
- 1
|
| 52 |
+
- 2
|
| 53 |
+
- 4
|
| 54 |
+
- 4
|
| 55 |
+
num_res_blocks: 2
|
| 56 |
+
attn_resolutions: []
|
| 57 |
+
dropout: 0.0
|
| 58 |
+
lossconfig:
|
| 59 |
+
target: torch.nn.Identity
|
| 60 |
+
|
| 61 |
+
cond_stage_config:
|
| 62 |
+
target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
|
| 63 |
+
|
| 64 |
+
discriminator_config:
|
| 65 |
+
target: ldm.modules.discriminator.Discriminator64
|
| 66 |
+
|
| 67 |
+
data:
|
| 68 |
+
target: main.DataModuleFromConfig
|
| 69 |
+
params:
|
| 70 |
+
batch_size: 1
|
| 71 |
+
num_workers: 32
|
| 72 |
+
wrap: false
|
| 73 |
+
train:
|
| 74 |
+
target: ldm.data.rasterizer.Rasterizer
|
| 75 |
+
params:
|
| 76 |
+
img_size: 256
|
| 77 |
+
text: "R"
|
| 78 |
+
style_word: "DRAGON"
|
| 79 |
+
data_path: "data/cat"
|
| 80 |
+
alternate_glyph: None
|
| 81 |
+
num_samples: 2001
|
| 82 |
+
make_black: False
|
| 83 |
+
one_font: False
|
| 84 |
+
full_word: False
|
| 85 |
+
font_name: "Garuda-Bold.ttf"
|
| 86 |
+
just_use_style: false
|
| 87 |
+
use_alt: False
|
| 88 |
+
validation:
|
| 89 |
+
target: ldm.data.rasterizer.Rasterizer
|
| 90 |
+
params:
|
| 91 |
+
img_size: 256
|
| 92 |
+
text: "R"
|
| 93 |
+
style_word: "DRAGON"
|
| 94 |
+
data_path: "data/cat"
|
| 95 |
+
alternate_glyph: None
|
| 96 |
+
num_samples: 5
|
| 97 |
+
make_black: False
|
| 98 |
+
one_font: False
|
| 99 |
+
full_word: False
|
| 100 |
+
font_name: "Garuda-Bold.ttf"
|
| 101 |
+
just_use_style: false
|
| 102 |
+
use_alt: False
|
| 103 |
+
|
| 104 |
+
lightning:
|
| 105 |
+
modelcheckpoint:
|
| 106 |
+
params:
|
| 107 |
+
every_n_train_steps: 200
|
| 108 |
+
callbacks:
|
| 109 |
+
image_logger:
|
| 110 |
+
target: main.ImageLogger
|
| 111 |
+
params:
|
| 112 |
+
batch_frequency: 100
|
| 113 |
+
max_images: 1
|
| 114 |
+
increase_log_steps: False
|
| 115 |
+
|
| 116 |
+
trainer:
|
| 117 |
+
benchmark: True
|
| 118 |
+
max_steps: 1001
|
configs/finetune/finetune_generic.yaml
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 1.0e-5
|
| 3 |
+
target: ldm.models.diffusion.ddpm.LatentDiffusion
|
| 4 |
+
params:
|
| 5 |
+
linear_start: 0.00085
|
| 6 |
+
linear_end: 0.0120
|
| 7 |
+
num_timesteps_cond: 1
|
| 8 |
+
log_every_t: 200
|
| 9 |
+
timesteps: 1000
|
| 10 |
+
first_stage_key: "image"
|
| 11 |
+
cond_stage_key: "caption"
|
| 12 |
+
image_size: 32
|
| 13 |
+
channels: 4
|
| 14 |
+
cond_stage_trainable: False
|
| 15 |
+
conditioning_key: crossattn
|
| 16 |
+
monitor: val/loss_simple_ema
|
| 17 |
+
scale_factor: 0.18215
|
| 18 |
+
use_ema: False
|
| 19 |
+
weight_disc: 0.01
|
| 20 |
+
|
| 21 |
+
unet_config:
|
| 22 |
+
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
| 23 |
+
params:
|
| 24 |
+
image_size: 32
|
| 25 |
+
in_channels: 4
|
| 26 |
+
out_channels: 4
|
| 27 |
+
model_channels: 320
|
| 28 |
+
attention_resolutions: [ 4, 2, 1 ]
|
| 29 |
+
num_res_blocks: 2
|
| 30 |
+
channel_mult: [ 1, 2, 4, 4 ]
|
| 31 |
+
num_heads: 8
|
| 32 |
+
use_spatial_transformer: True
|
| 33 |
+
transformer_depth: 1
|
| 34 |
+
context_dim: 1280
|
| 35 |
+
use_checkpoint: True
|
| 36 |
+
legacy: False
|
| 37 |
+
|
| 38 |
+
first_stage_config:
|
| 39 |
+
target: ldm.models.autoencoder.AutoencoderKL
|
| 40 |
+
params:
|
| 41 |
+
embed_dim: 4
|
| 42 |
+
monitor: val/rec_loss
|
| 43 |
+
ddconfig:
|
| 44 |
+
double_z: true
|
| 45 |
+
z_channels: 4
|
| 46 |
+
resolution: 256
|
| 47 |
+
in_channels: 3
|
| 48 |
+
out_ch: 3
|
| 49 |
+
ch: 128
|
| 50 |
+
ch_mult:
|
| 51 |
+
- 1
|
| 52 |
+
- 2
|
| 53 |
+
- 4
|
| 54 |
+
- 4
|
| 55 |
+
num_res_blocks: 2
|
| 56 |
+
attn_resolutions: []
|
| 57 |
+
dropout: 0.0
|
| 58 |
+
lossconfig:
|
| 59 |
+
target: torch.nn.Identity
|
| 60 |
+
|
| 61 |
+
cond_stage_config:
|
| 62 |
+
target: ldm.modules.encoders.modules.BERTEmbedder
|
| 63 |
+
params:
|
| 64 |
+
n_embed: 1280
|
| 65 |
+
n_layer: 32
|
| 66 |
+
device: "cuda"
|
| 67 |
+
|
| 68 |
+
discriminator_config:
|
| 69 |
+
target: ldm.modules.discriminator.Discriminator
|
| 70 |
+
params:
|
| 71 |
+
bnorm: True
|
| 72 |
+
leakyparam: 0.2
|
| 73 |
+
bias: False
|
| 74 |
+
generic: True
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
data:
|
| 78 |
+
target: main.DataModuleFromConfig
|
| 79 |
+
params:
|
| 80 |
+
batch_size: 1
|
| 81 |
+
num_workers: 32
|
| 82 |
+
wrap: false
|
| 83 |
+
train:
|
| 84 |
+
target: ldm.data.rasterizer.Rasterizer
|
| 85 |
+
params:
|
| 86 |
+
img_size: 256
|
| 87 |
+
text: "R"
|
| 88 |
+
style_word: "DRAGON"
|
| 89 |
+
data_path: "data/cat"
|
| 90 |
+
alternate_glyph: None
|
| 91 |
+
num_samples: 2001
|
| 92 |
+
make_black: False
|
| 93 |
+
one_font: False
|
| 94 |
+
full_word: False
|
| 95 |
+
font_name: "Garuda-Bold.ttf"
|
| 96 |
+
just_use_style: false
|
| 97 |
+
use_alt: False
|
| 98 |
+
validation:
|
| 99 |
+
target: ldm.data.rasterizer.Rasterizer
|
| 100 |
+
params:
|
| 101 |
+
img_size: 256
|
| 102 |
+
text: "R"
|
| 103 |
+
style_word: "DRAGON"
|
| 104 |
+
data_path: "data/cat"
|
| 105 |
+
alternate_glyph: None
|
| 106 |
+
num_samples: 5
|
| 107 |
+
make_black: False
|
| 108 |
+
one_font: False
|
| 109 |
+
full_word: False
|
| 110 |
+
font_name: "Garuda-Bold.ttf"
|
| 111 |
+
just_use_style: false
|
| 112 |
+
use_alt: False
|
| 113 |
+
|
| 114 |
+
lightning:
|
| 115 |
+
modelcheckpoint:
|
| 116 |
+
params:
|
| 117 |
+
every_n_train_steps: 5000
|
| 118 |
+
callbacks:
|
| 119 |
+
image_logger:
|
| 120 |
+
target: main.ImageLogger
|
| 121 |
+
params:
|
| 122 |
+
batch_frequency: 1000
|
| 123 |
+
max_images: 1
|
| 124 |
+
increase_log_steps: False
|
| 125 |
+
|
| 126 |
+
trainer:
|
| 127 |
+
benchmark: True
|
| 128 |
+
max_steps: 500
|
configs/finetune/finetune_multi_bert.yaml
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 1.0e-5 #1e-4
|
| 3 |
+
target: ldm.models.diffusion.ddpm.LatentDiffusion
|
| 4 |
+
params:
|
| 5 |
+
linear_start: 0.00085
|
| 6 |
+
linear_end: 0.0120
|
| 7 |
+
num_timesteps_cond: 1
|
| 8 |
+
log_every_t: 200
|
| 9 |
+
timesteps: 1000
|
| 10 |
+
first_stage_key: "image"
|
| 11 |
+
cond_stage_key: "caption"
|
| 12 |
+
image_size: 32 # 32
|
| 13 |
+
channels: 4
|
| 14 |
+
cond_stage_trainable: False # Note: different from the one we trained before
|
| 15 |
+
conditioning_key: crossattn
|
| 16 |
+
monitor: val/loss_simple_ema
|
| 17 |
+
scale_factor: 0.18215
|
| 18 |
+
use_ema: False
|
| 19 |
+
weight_disc: 0.01
|
| 20 |
+
|
| 21 |
+
unet_config:
|
| 22 |
+
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
| 23 |
+
params:
|
| 24 |
+
image_size: 32 # unused
|
| 25 |
+
in_channels: 4
|
| 26 |
+
out_channels: 4
|
| 27 |
+
model_channels: 320
|
| 28 |
+
attention_resolutions: [ 4, 2, 1 ]
|
| 29 |
+
num_res_blocks: 2
|
| 30 |
+
channel_mult: [ 1, 2, 4, 4 ]
|
| 31 |
+
num_heads: 8
|
| 32 |
+
use_spatial_transformer: True
|
| 33 |
+
transformer_depth: 1
|
| 34 |
+
context_dim: 1280 # 1280
|
| 35 |
+
use_checkpoint: True
|
| 36 |
+
legacy: False
|
| 37 |
+
|
| 38 |
+
first_stage_config:
|
| 39 |
+
target: ldm.models.autoencoder.AutoencoderKL
|
| 40 |
+
params:
|
| 41 |
+
embed_dim: 4
|
| 42 |
+
monitor: val/rec_loss
|
| 43 |
+
ddconfig:
|
| 44 |
+
double_z: true
|
| 45 |
+
z_channels: 4
|
| 46 |
+
resolution: 256 #256
|
| 47 |
+
in_channels: 3
|
| 48 |
+
out_ch: 3
|
| 49 |
+
ch: 128
|
| 50 |
+
ch_mult:
|
| 51 |
+
- 1
|
| 52 |
+
- 2
|
| 53 |
+
- 4
|
| 54 |
+
- 4
|
| 55 |
+
num_res_blocks: 2
|
| 56 |
+
attn_resolutions: []
|
| 57 |
+
dropout: 0.0
|
| 58 |
+
lossconfig:
|
| 59 |
+
target: torch.nn.Identity
|
| 60 |
+
|
| 61 |
+
cond_stage_config:
|
| 62 |
+
target: ldm.modules.encoders.modules.BERTEmbedder
|
| 63 |
+
params:
|
| 64 |
+
n_embed: 1280
|
| 65 |
+
n_layer: 32
|
| 66 |
+
|
| 67 |
+
discriminator_config:
|
| 68 |
+
target: ldm.modules.discriminator.Discriminator
|
| 69 |
+
params:
|
| 70 |
+
bnorm: True
|
| 71 |
+
leakyparam: 0.2
|
| 72 |
+
bias: False
|
| 73 |
+
generic: False
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
data:
|
| 77 |
+
target: main.DataModuleFromConfig
|
| 78 |
+
params:
|
| 79 |
+
batch_size: 1
|
| 80 |
+
num_workers: 32
|
| 81 |
+
wrap: false
|
| 82 |
+
train:
|
| 83 |
+
target: ldm.data.rasterizer.Rasterizer
|
| 84 |
+
params:
|
| 85 |
+
img_size: 256
|
| 86 |
+
text: "R"
|
| 87 |
+
style_word: "DRAGON"
|
| 88 |
+
data_path: "data/cat"
|
| 89 |
+
alternate_glyph: None
|
| 90 |
+
num_samples: 2001
|
| 91 |
+
make_black: False
|
| 92 |
+
one_font: False
|
| 93 |
+
full_word: False
|
| 94 |
+
font_name: "Garuda-Bold.ttf"
|
| 95 |
+
just_use_style: false
|
| 96 |
+
use_alt: False
|
| 97 |
+
validation:
|
| 98 |
+
target: ldm.data.rasterizer.Rasterizer
|
| 99 |
+
params:
|
| 100 |
+
img_size: 256
|
| 101 |
+
text: "R"
|
| 102 |
+
style_word: "DRAGON"
|
| 103 |
+
data_path: "data/cat"
|
| 104 |
+
alternate_glyph: None
|
| 105 |
+
num_samples: 5
|
| 106 |
+
make_black: False
|
| 107 |
+
one_font: False
|
| 108 |
+
full_word: False
|
| 109 |
+
font_name: "Garuda-Bold.ttf"
|
| 110 |
+
just_use_style: false
|
| 111 |
+
use_alt: False
|
| 112 |
+
|
| 113 |
+
lightning:
|
| 114 |
+
modelcheckpoint:
|
| 115 |
+
params:
|
| 116 |
+
every_n_train_steps: 2000
|
| 117 |
+
callbacks:
|
| 118 |
+
image_logger:
|
| 119 |
+
target: main.ImageLogger
|
| 120 |
+
params:
|
| 121 |
+
batch_frequency: 5000
|
| 122 |
+
max_images: 1
|
| 123 |
+
increase_log_steps: False
|
| 124 |
+
|
| 125 |
+
trainer:
|
| 126 |
+
benchmark: True
|
| 127 |
+
max_steps: 800
|
configs/finetune/finetune_multi_clip.yaml
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 1.0e-5 #1e-4
|
| 3 |
+
target: ldm.models.diffusion.ddpm.LatentDiffusion
|
| 4 |
+
params:
|
| 5 |
+
linear_start: 0.00085
|
| 6 |
+
linear_end: 0.0120
|
| 7 |
+
num_timesteps_cond: 1
|
| 8 |
+
log_every_t: 200
|
| 9 |
+
timesteps: 1000
|
| 10 |
+
first_stage_key: "image"
|
| 11 |
+
cond_stage_key: "caption"
|
| 12 |
+
image_size: 64 # 32
|
| 13 |
+
channels: 4
|
| 14 |
+
cond_stage_trainable: False # Note: different from the one we trained before
|
| 15 |
+
conditioning_key: crossattn
|
| 16 |
+
monitor: val/loss_simple_ema
|
| 17 |
+
scale_factor: 0.18215
|
| 18 |
+
use_ema: False
|
| 19 |
+
weight_disc: 0.01
|
| 20 |
+
|
| 21 |
+
unet_config:
|
| 22 |
+
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
| 23 |
+
params:
|
| 24 |
+
image_size: 64 # unused
|
| 25 |
+
in_channels: 4
|
| 26 |
+
out_channels: 4
|
| 27 |
+
model_channels: 320
|
| 28 |
+
attention_resolutions: [ 4, 2, 1 ]
|
| 29 |
+
num_res_blocks: 2
|
| 30 |
+
channel_mult: [ 1, 2, 4, 4 ]
|
| 31 |
+
num_heads: 8
|
| 32 |
+
use_spatial_transformer: True
|
| 33 |
+
transformer_depth: 1
|
| 34 |
+
context_dim: 768 # 1280
|
| 35 |
+
use_checkpoint: True
|
| 36 |
+
legacy: False
|
| 37 |
+
|
| 38 |
+
first_stage_config:
|
| 39 |
+
target: ldm.models.autoencoder.AutoencoderKL
|
| 40 |
+
params:
|
| 41 |
+
embed_dim: 4
|
| 42 |
+
monitor: val/rec_loss
|
| 43 |
+
ddconfig:
|
| 44 |
+
double_z: true
|
| 45 |
+
z_channels: 4
|
| 46 |
+
resolution: 512 #256
|
| 47 |
+
in_channels: 3
|
| 48 |
+
out_ch: 3
|
| 49 |
+
ch: 128
|
| 50 |
+
ch_mult:
|
| 51 |
+
- 1
|
| 52 |
+
- 2
|
| 53 |
+
- 4
|
| 54 |
+
- 4
|
| 55 |
+
num_res_blocks: 2
|
| 56 |
+
attn_resolutions: []
|
| 57 |
+
dropout: 0.0
|
| 58 |
+
lossconfig:
|
| 59 |
+
target: torch.nn.Identity
|
| 60 |
+
|
| 61 |
+
cond_stage_config:
|
| 62 |
+
target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
|
| 63 |
+
|
| 64 |
+
discriminator_config:
|
| 65 |
+
target: ldm.modules.discriminator.Discriminator64
|
| 66 |
+
|
| 67 |
+
data:
|
| 68 |
+
target: main.DataModuleFromConfig
|
| 69 |
+
params:
|
| 70 |
+
batch_size: 1
|
| 71 |
+
num_workers: 32
|
| 72 |
+
wrap: false
|
| 73 |
+
train:
|
| 74 |
+
target: ldm.data.rasterizer.Rasterizer
|
| 75 |
+
params:
|
| 76 |
+
img_size: 256
|
| 77 |
+
text: "R"
|
| 78 |
+
style_word: "DRAGON"
|
| 79 |
+
data_path: "data/cat"
|
| 80 |
+
alternate_glyph: None
|
| 81 |
+
num_samples: 2001
|
| 82 |
+
make_black: False
|
| 83 |
+
one_font: False
|
| 84 |
+
full_word: False
|
| 85 |
+
font_name: "Garuda-Bold.ttf"
|
| 86 |
+
just_use_style: false
|
| 87 |
+
use_alt: False
|
| 88 |
+
validation:
|
| 89 |
+
target: ldm.data.rasterizer.Rasterizer
|
| 90 |
+
params:
|
| 91 |
+
img_size: 256
|
| 92 |
+
text: "R"
|
| 93 |
+
style_word: "DRAGON"
|
| 94 |
+
data_path: "data/cat"
|
| 95 |
+
alternate_glyph: None
|
| 96 |
+
num_samples: 5
|
| 97 |
+
make_black: False
|
| 98 |
+
one_font: False
|
| 99 |
+
full_word: False
|
| 100 |
+
font_name: "Garuda-Bold.ttf"
|
| 101 |
+
just_use_style: false
|
| 102 |
+
use_alt: False
|
| 103 |
+
|
| 104 |
+
lightning:
|
| 105 |
+
modelcheckpoint:
|
| 106 |
+
params:
|
| 107 |
+
every_n_train_steps: 200
|
| 108 |
+
callbacks:
|
| 109 |
+
image_logger:
|
| 110 |
+
target: main.ImageLogger
|
| 111 |
+
params:
|
| 112 |
+
batch_frequency: 100
|
| 113 |
+
max_images: 1
|
| 114 |
+
increase_log_steps: False
|
| 115 |
+
|
| 116 |
+
trainer:
|
| 117 |
+
benchmark: True
|
| 118 |
+
max_steps: 1501
|
data_fonts/Caladea-Regular/0/0.png
ADDED

|
data_fonts/Caladea-Regular/0/1.png
ADDED
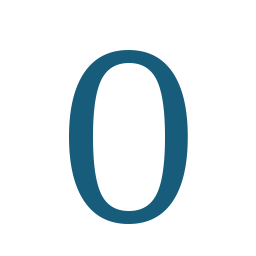
|
data_fonts/Caladea-Regular/0/10.png
ADDED
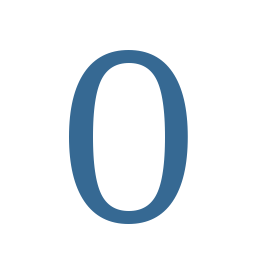
|
data_fonts/Caladea-Regular/0/11.png
ADDED

|
data_fonts/Caladea-Regular/0/12.png
ADDED
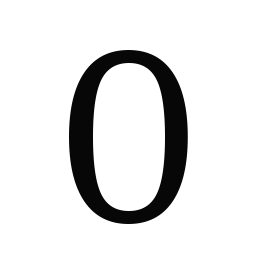
|
data_fonts/Caladea-Regular/0/13.png
ADDED

|
data_fonts/Caladea-Regular/0/14.png
ADDED
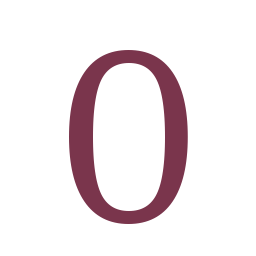
|
data_fonts/Caladea-Regular/0/15.png
ADDED
|
data_fonts/Caladea-Regular/0/2.png
ADDED

|
data_fonts/Caladea-Regular/0/3.png
ADDED

|
data_fonts/Caladea-Regular/0/4.png
ADDED

|
data_fonts/Caladea-Regular/0/5.png
ADDED
|
data_fonts/Caladea-Regular/0/6.png
ADDED

|
data_fonts/Caladea-Regular/0/7.png
ADDED
|
data_fonts/Caladea-Regular/0/8.png
ADDED
|
data_fonts/Caladea-Regular/0/9.png
ADDED

|
data_fonts/Caladea-Regular/1/0.png
ADDED

|
data_fonts/Caladea-Regular/1/1.png
ADDED

|
data_fonts/Caladea-Regular/1/10.png
ADDED

|
data_fonts/Caladea-Regular/1/11.png
ADDED

|
data_fonts/Caladea-Regular/1/12.png
ADDED

|
data_fonts/Caladea-Regular/1/13.png
ADDED

|
data_fonts/Caladea-Regular/1/14.png
ADDED
|
data_fonts/Caladea-Regular/1/15.png
ADDED

|
data_fonts/Caladea-Regular/1/2.png
ADDED

|
data_fonts/Caladea-Regular/1/3.png
ADDED

|
data_fonts/Caladea-Regular/1/4.png
ADDED

|
data_fonts/Caladea-Regular/1/5.png
ADDED
|
data_fonts/Caladea-Regular/1/6.png
ADDED

|
data_fonts/Caladea-Regular/1/7.png
ADDED

|
data_fonts/Caladea-Regular/1/8.png
ADDED

|
data_fonts/Caladea-Regular/1/9.png
ADDED

|
data_fonts/Caladea-Regular/2/0.png
ADDED

|
data_fonts/Caladea-Regular/2/1.png
ADDED

|
data_fonts/Caladea-Regular/2/10.png
ADDED

|
data_fonts/Caladea-Regular/2/11.png
ADDED

|