Spaces:
Running
on
T4

Running
on
T4

Updates for v1 release
Browse files- README.md +70 -20
- configs/generate.yaml +8 -8
- configs/train.yaml +7 -7
- dataset_creation/generate_img_dataset.py +27 -9
- dataset_creation/generate_txt_dataset.py +4 -4
- dataset_creation/prepare_for_gpt.py +3 -3
- edit_app.py +7 -8
- edit_cli.py +2 -2
- edit_dataset.py +49 -0
- environment.yaml +1 -0
- imgs/dataset.jpg +0 -0
- imgs/edit_app.jpg +0 -0
- imgs/prompt_app.jpg +0 -0
- main.py +10 -8
- metrics/compute_metrics.py +235 -0
- prompt_app.py +2 -2
- scripts/download_checkpoints.sh +1 -1
- scripts/download_data.sh +19 -3
- scripts/download_pretrained_sd.sh +7 -0
- stable_diffusion/main.py +5 -2
README.md
CHANGED
|
@@ -13,16 +13,28 @@ PyTorch implementation of InstructPix2Pix, an instruction-based image editing mo
|
|
| 13 |
|
| 14 |
## TL;DR: quickstart
|
| 15 |
|
| 16 |
-
|
| 17 |
```
|
| 18 |
conda env create -f environment.yaml
|
| 19 |
conda activate ip2p
|
| 20 |
bash scripts/download_checkpoints.sh
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
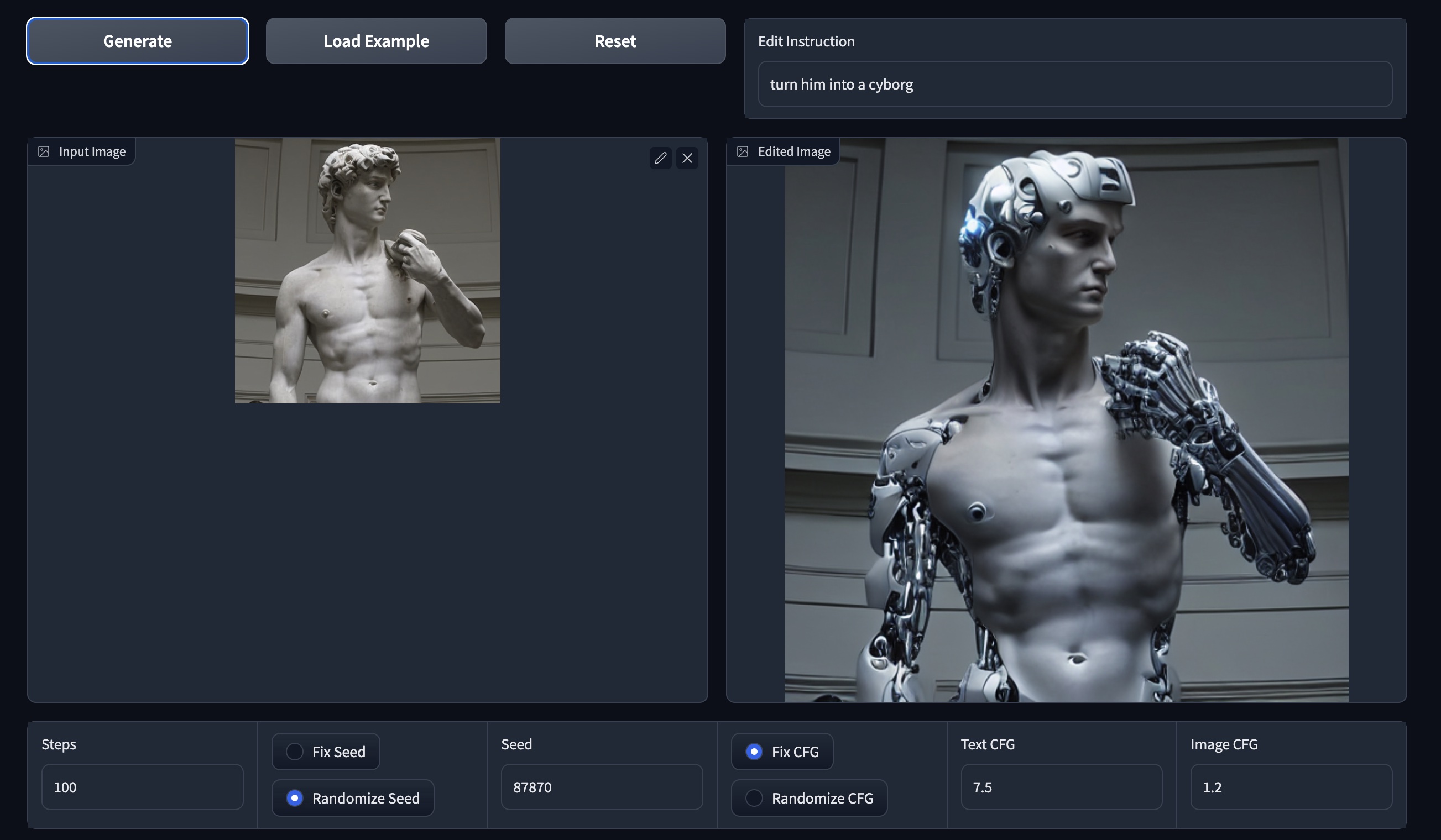
python edit_cli.py --input imgs/example.jpg --output imgs/output.jpg --edit "turn him into a cyborg"
|
| 22 |
|
| 23 |
-
# Optionally, you can specify parameters:
|
| 24 |
-
# python edit_cli.py --steps 100 --resolution 512 --seed
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 25 |
```
|
|
|
|
|
|
|
|
|
|
| 26 |
|
| 27 |
## Setup
|
| 28 |
|
|
@@ -56,10 +68,18 @@ bash scripts/download_data.sh clip-filtered-dataset
|
|
| 56 |
|
| 57 |
## Training InstructPix2Pix
|
| 58 |
|
| 59 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 60 |
|
| 61 |
```
|
| 62 |
-
python
|
| 63 |
```
|
| 64 |
|
| 65 |
|
|
@@ -73,64 +93,72 @@ We provide our generated dataset of captions and edit instructions [here](https:
|
|
| 73 |
|
| 74 |
#### (1.1) Manually write a dataset of instructions and captions
|
| 75 |
|
| 76 |
-
The first step of the process is fine-tuning GPT-3. To do this, we made a dataset of 700 examples broadly covering of edits that we might want our model to be able to perform. Our examples are available
|
| 77 |
|
| 78 |
-
Input prompts should closely match the distribution of input prompts used to generate the larger dataset. We sampled the 700 input prompts from
|
| 79 |
|
| 80 |
#### (1.2) Finetune GPT-3
|
| 81 |
|
| 82 |
-
The next step is to finetune a large language model to generate
|
| 83 |
|
| 84 |
-
To prepare training data for GPT-3, one must
|
| 85 |
|
| 86 |
```bash
|
| 87 |
-
python dataset_creation/prepare_for_gpt.py prompts
|
| 88 |
```
|
| 89 |
|
| 90 |
-
Next, finetune GPT-3 via the OpenAI CLI. We provide an example below, although please refer to
|
| 91 |
|
| 92 |
```bash
|
| 93 |
-
openai api fine_tunes.create -t prompts
|
| 94 |
```
|
| 95 |
|
| 96 |
You can test out the finetuned GPT-3 model by launching the provided Gradio app:
|
| 97 |
|
| 98 |
```bash
|
| 99 |
-
python prompt_app.py OPENAI_MODEL_NAME
|
| 100 |
```
|
| 101 |
|
|
|
|
|
|
|
| 102 |
#### (1.3) Generate a large dataset of captions and instructions
|
| 103 |
|
| 104 |
-
We now use the finetuned GPT-3 model to generate a large dataset. Our dataset cost thousands of dollars to create. See `prompts/gen_instructions_and_captions.py` for the script which generates these examples. We recommend first generating a small number of examples and gradually increasing the scale to ensure the results are working as desired before increasing scale.
|
| 105 |
|
| 106 |
```bash
|
| 107 |
-
python dataset_creation/generate_txt_dataset.py OPENAI_MODEL_NAME
|
| 108 |
```
|
| 109 |
|
| 110 |
If you are generating at a very large scale (e.g., 100K+), it will be noteably faster to generate the dataset with multiple processes running in parallel. This can be accomplished by setting `--partitions=N` to a higher number and running multiple processes, setting each `--partition` to the corresponding value.
|
| 111 |
|
| 112 |
```bash
|
| 113 |
-
python dataset_creation/generate_txt_dataset.py OPENAI_MODEL_NAME --partitions=10 --partition=0
|
| 114 |
```
|
| 115 |
|
| 116 |
### (2) Turn paired captions into paired images
|
| 117 |
|
| 118 |
-
The next step is to turn pairs of text captions into pairs of images. For this, we need to copy
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 119 |
|
| 120 |
```
|
| 121 |
-
python dataset_creation/generate_img_dataset.py data/instruct-pix2pix-dataset-000
|
| 122 |
```
|
| 123 |
|
| 124 |
This command operates on a single GPU (typically a V100 or A100). To parallelize over many GPUs/machines, set `--n-partitions` to the total number of parallel jobs and `--partition` to the index of each job.
|
| 125 |
|
| 126 |
```
|
| 127 |
-
python dataset_creation/generate_img_dataset.py data/instruct-pix2pix-dataset-000
|
| 128 |
```
|
| 129 |
|
| 130 |
The default parameters match that of our dataset, although in practice you can use a smaller number of steps (e.g., `--steps=25`) to generate high quality data faster. By default, we generate 100 samples per prompt and use CLIP filtering to keep a max of 4 per prompt. You can experiment with fewer samples by setting `--n-samples`. The command below turns off CLIP filtering entirely and is therefore faster:
|
| 131 |
|
| 132 |
```
|
| 133 |
-
python dataset_creation/generate_img_dataset.py data/instruct-pix2pix-dataset-000
|
| 134 |
```
|
| 135 |
|
| 136 |
After generating all of the dataset examples, run the following command below to create a list of the examples. This is needed for the dataset onject to efficiently be able to sample examples without needing to iterate over the entire dataset directory at the start of each training run.
|
|
@@ -139,6 +167,28 @@ After generating all of the dataset examples, run the following command below to
|
|
| 139 |
python dataset_creation/prepare_dataset.py data/instruct-pix2pix-dataset-000
|
| 140 |
```
|
| 141 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 142 |
## Comments
|
| 143 |
|
| 144 |
- Our codebase is based on the [Stable Diffusion codebase](https://github.com/CompVis/stable-diffusion).
|
|
|
|
| 13 |
|
| 14 |
## TL;DR: quickstart
|
| 15 |
|
| 16 |
+
Set up a conda environment, and download a pretrained model:
|
| 17 |
```
|
| 18 |
conda env create -f environment.yaml
|
| 19 |
conda activate ip2p
|
| 20 |
bash scripts/download_checkpoints.sh
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
Edit a single image:
|
| 24 |
+
```
|
| 25 |
python edit_cli.py --input imgs/example.jpg --output imgs/output.jpg --edit "turn him into a cyborg"
|
| 26 |
|
| 27 |
+
# Optionally, you can specify parameters to tune your result:
|
| 28 |
+
# python edit_cli.py --steps 100 --resolution 512 --seed 1371 --cfg-text 7.5 --cfg-image 1.2 --input imgs/example.jpg --output imgs/output.jpg --edit "turn him into a cyborg"
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
Or launch your own interactive editing Gradio app:
|
| 32 |
+
```
|
| 33 |
+
python edit_app.py
|
| 34 |
```
|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
_(For advice on how to get the best results by tuning parameters, see the [Tips](https://github.com/timothybrooks/instruct-pix2pix#tips) section)._
|
| 38 |
|
| 39 |
## Setup
|
| 40 |
|
|
|
|
| 68 |
|
| 69 |
## Training InstructPix2Pix
|
| 70 |
|
| 71 |
+
InstructPix2Pix is trained by fine-tuning from an initial StableDiffusion checkpoint. The first step is to download a Stable Diffusion checkpoint. For our trained models, we used the v1.5 checkpoint as the starting point. To download the same ones we used, you can run the following script:
|
| 72 |
+
```
|
| 73 |
+
bash scripts/download_pretrained_sd.sh
|
| 74 |
+
```
|
| 75 |
+
If you'd like to use a different checkpoint, point to it in the config file `configs/train.yaml`, on line 8, after `ckpt_path:`.
|
| 76 |
+
|
| 77 |
+
Next, we need to change the config to point to our downloaded (or generated) dataset. If you're using the `clip-filtered-dataset` from above, you can skip this. Otherwise, you may need to edit lines 85 and 94 of the config (`data.params.train.params.path`, `data.params.validation.params.path`).
|
| 78 |
+
|
| 79 |
+
Finally, start a training job with the following command:
|
| 80 |
|
| 81 |
```
|
| 82 |
+
python main.py --name default --base configs/train.yaml --train --gpus 0,1,2,3,4,5,6,7
|
| 83 |
```
|
| 84 |
|
| 85 |
|
|
|
|
| 93 |
|
| 94 |
#### (1.1) Manually write a dataset of instructions and captions
|
| 95 |
|
| 96 |
+
The first step of the process is fine-tuning GPT-3. To do this, we made a dataset of 700 examples broadly covering of edits that we might want our model to be able to perform. Our examples are available [here](https://instruct-pix2pix.eecs.berkeley.edu/human-written-prompts.jsonl). These should be diverse and cover a wide range of possible captions and types of edits. Ideally, they should avoid duplication or significant overlap of captions and instructions. It is also important to be mindful of limitations of Stable Diffusion and Prompt-to-Prompt in writing these examples, such as inability to perform large spatial transformations (e.g., moving the camera, zooming in, swapping object locations).
|
| 97 |
|
| 98 |
+
Input prompts should closely match the distribution of input prompts used to generate the larger dataset. We sampled the 700 input prompts from the _LAION Improved Aesthetics 6.5+_ dataset and also use this dataset for generating examples. We found this dataset is quite noisy (many of the captions are overly long and contain irrelevant text). For this reason, we also considered MSCOCO and LAION-COCO datasets, but ultimately chose _LAION Improved Aesthetics 6.5+_ due to its diversity of content, proper nouns, and artistic mediums. If you choose to use another dataset or combination of datasets as input to GPT-3 when generating examples, we recommend you sample the input prompts from the same distribution when manually writing training examples.
|
| 99 |
|
| 100 |
#### (1.2) Finetune GPT-3
|
| 101 |
|
| 102 |
+
The next step is to finetune a large language model on the manually written instructions/outputs to generate edit instructions and edited caption from a new input caption. For this, we finetune GPT-3's Davinci model via the OpenAI API, although other language models could be used.
|
| 103 |
|
| 104 |
+
To prepare training data for GPT-3, one must first create an OpenAI developer account to access the needed APIs, and [set up the API keys on your local device](https://beta.openai.com/docs/api-reference/introduction). Also, run the `prompts/prepare_for_gpt.py` script, which forms the prompts into the correct format by concatenating instructions and captions and adding delimiters and stop sequences.
|
| 105 |
|
| 106 |
```bash
|
| 107 |
+
python dataset_creation/prepare_for_gpt.py --input-path data/human-written-prompts.jsonl --output-path data/human-written-prompts-for-gpt.jsonl
|
| 108 |
```
|
| 109 |
|
| 110 |
+
Next, finetune GPT-3 via the OpenAI CLI. We provide an example below, although please refer to OpenAI's official documentation for this, as best practices may change. We trained the Davinci model for a single epoch. You can experiment with smaller less expensive GPT-3 variants or with open source language models, although this may negatively affect performance.
|
| 111 |
|
| 112 |
```bash
|
| 113 |
+
openai api fine_tunes.create -t data/human-written-prompts-for-gpt.jsonl -m davinci --n_epochs 1 --suffix "instruct-pix2pix"
|
| 114 |
```
|
| 115 |
|
| 116 |
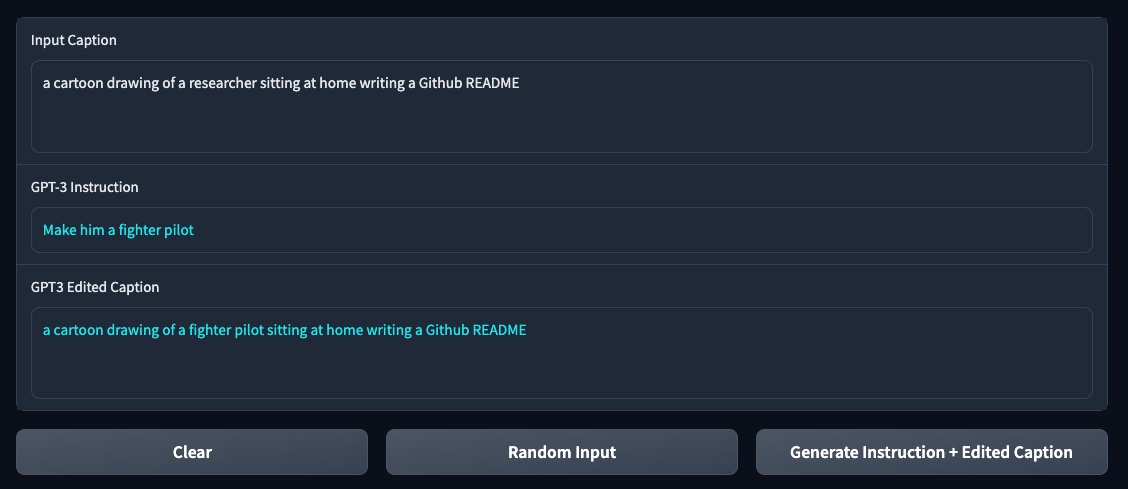
You can test out the finetuned GPT-3 model by launching the provided Gradio app:
|
| 117 |
|
| 118 |
```bash
|
| 119 |
+
python prompt_app.py --openai-api-key OPENAI_KEY --openai-model OPENAI_MODEL_NAME
|
| 120 |
```
|
| 121 |
|
| 122 |
+

|
| 123 |
+
|
| 124 |
#### (1.3) Generate a large dataset of captions and instructions
|
| 125 |
|
| 126 |
+
We now use the finetuned GPT-3 model to generate a large dataset. Our dataset cost thousands of dollars to create. See `prompts/gen_instructions_and_captions.py` for the script which generates these examples. We recommend first generating a small number of examples (by setting a low value of `--num-samples`) and gradually increasing the scale to ensure the results are working as desired before increasing scale.
|
| 127 |
|
| 128 |
```bash
|
| 129 |
+
python dataset_creation/generate_txt_dataset.py --openai-api-key OPENAI_KEY --openai-model OPENAI_MODEL_NAME
|
| 130 |
```
|
| 131 |
|
| 132 |
If you are generating at a very large scale (e.g., 100K+), it will be noteably faster to generate the dataset with multiple processes running in parallel. This can be accomplished by setting `--partitions=N` to a higher number and running multiple processes, setting each `--partition` to the corresponding value.
|
| 133 |
|
| 134 |
```bash
|
| 135 |
+
python dataset_creation/generate_txt_dataset.py --openai-api-key OPENAI_KEY --openai-model OPENAI_MODEL_NAME --partitions=10 --partition=0
|
| 136 |
```
|
| 137 |
|
| 138 |
### (2) Turn paired captions into paired images
|
| 139 |
|
| 140 |
+
The next step is to turn pairs of text captions into pairs of images. For this, we need to copy some pre-trained Stable Diffusion checkpoints to `stable_diffusion/models/ldm/stable-diffusion-v1/`. You may have already done this if you followed the instructions above for training with our provided data, but if not, you can do this by running:
|
| 141 |
+
|
| 142 |
+
```bash
|
| 143 |
+
bash scripts/download_pretrained_sd.sh
|
| 144 |
+
```
|
| 145 |
+
|
| 146 |
+
For our model, we used [checkpoint v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/v1-5-pruned.ckpt), and the [new autoencoder](https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt), but other models may work as well. If you choose to use other models, make sure to change point to the corresponding checkpoints by passing in the `--ckpt` and `--vae-ckpt` arguments. Once all checkpoints have been downloaded, we can generate the dataset with the following command:
|
| 147 |
|
| 148 |
```
|
| 149 |
+
python dataset_creation/generate_img_dataset.py --out_dir data/instruct-pix2pix-dataset-000 --prompts_file path/to/generated_prompts.jsonl
|
| 150 |
```
|
| 151 |
|
| 152 |
This command operates on a single GPU (typically a V100 or A100). To parallelize over many GPUs/machines, set `--n-partitions` to the total number of parallel jobs and `--partition` to the index of each job.
|
| 153 |
|
| 154 |
```
|
| 155 |
+
python dataset_creation/generate_img_dataset.py --out_dir data/instruct-pix2pix-dataset-000 --prompts_file path/to/generated_prompts.jsonl --n-partitions 100 --partition 0
|
| 156 |
```
|
| 157 |
|
| 158 |
The default parameters match that of our dataset, although in practice you can use a smaller number of steps (e.g., `--steps=25`) to generate high quality data faster. By default, we generate 100 samples per prompt and use CLIP filtering to keep a max of 4 per prompt. You can experiment with fewer samples by setting `--n-samples`. The command below turns off CLIP filtering entirely and is therefore faster:
|
| 159 |
|
| 160 |
```
|
| 161 |
+
python dataset_creation/generate_img_dataset.py --out_dir data/instruct-pix2pix-dataset-000 --prompts_file path/to/generated_prompts.jsonl --n-samples 4 --clip-threshold 0 --clip-dir-threshold 0 --clip-img-threshold 0 --n-partitions 100 --partition 0
|
| 162 |
```
|
| 163 |
|
| 164 |
After generating all of the dataset examples, run the following command below to create a list of the examples. This is needed for the dataset onject to efficiently be able to sample examples without needing to iterate over the entire dataset directory at the start of each training run.
|
|
|
|
| 167 |
python dataset_creation/prepare_dataset.py data/instruct-pix2pix-dataset-000
|
| 168 |
```
|
| 169 |
|
| 170 |
+
## Evaluation
|
| 171 |
+
|
| 172 |
+
To generate plots like the ones in Figures 8 and 10 in the paper, run the following command:
|
| 173 |
+
|
| 174 |
+
```
|
| 175 |
+
python metrics/compute_metrics.py --ckpt /path/to/your/model.ckpt
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
## Tips
|
| 179 |
+
|
| 180 |
+
If you're not getting the quality result you want, there may be a few reasons:
|
| 181 |
+
1. **Is the image not changing enough?** Your Image CFG weight may be too high. This value dictates how similar the output should be to the input. It's possible your edit requires larger changes from the original image, and your Image CFG weight isn't allowing that. Alternatively, your Text CFG weight may be too low. This value dictates how much to listen to the text instruction. The default Image CFG of 1.5 and Text CFG of 7.5 are a good starting point, but aren't necessarily optimal for each edit. Try:
|
| 182 |
+
* Decreasing the Image CFG weight, or
|
| 183 |
+
* Incerasing the Text CFG weight, or
|
| 184 |
+
2. Conversely, **is the image changing too much**, such that the details in the original image aren't preserved? Try:
|
| 185 |
+
* Increasing the Image CFG weight, or
|
| 186 |
+
* Decreasing the Text CFG weight
|
| 187 |
+
3. Try generating results with different random seeds by setting "Randomize Seed" and running generation multiple times. You can also try setting "Randomize CFG" to sample new Text CFG and Image CFG values each time.
|
| 188 |
+
4. Rephrasing the instruction sometimes improves results (e.g., "turn him into a dog" vs. "make him a dog" vs. "as a dog").
|
| 189 |
+
5. Increasing the number of steps sometimes improves results.
|
| 190 |
+
6. Do faces look weird? The Stable Diffusion autoencoder has a hard time with faces that are small in the image. Try cropping the image so the face takes up a larger portion of the frame.
|
| 191 |
+
|
| 192 |
## Comments
|
| 193 |
|
| 194 |
- Our codebase is based on the [Stable Diffusion codebase](https://github.com/CompVis/stable-diffusion).
|
configs/generate.yaml
CHANGED
|
@@ -3,7 +3,7 @@
|
|
| 3 |
|
| 4 |
model:
|
| 5 |
base_learning_rate: 1.0e-04
|
| 6 |
-
target:
|
| 7 |
params:
|
| 8 |
linear_start: 0.00085
|
| 9 |
linear_end: 0.0120
|
|
@@ -24,7 +24,7 @@ model:
|
|
| 24 |
load_ema: true
|
| 25 |
|
| 26 |
scheduler_config: # 10000 warmup steps
|
| 27 |
-
target:
|
| 28 |
params:
|
| 29 |
warm_up_steps: [ 0 ]
|
| 30 |
cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
|
|
@@ -33,7 +33,7 @@ model:
|
|
| 33 |
f_min: [ 1. ]
|
| 34 |
|
| 35 |
unet_config:
|
| 36 |
-
target:
|
| 37 |
params:
|
| 38 |
image_size: 32 # unused
|
| 39 |
in_channels: 8
|
|
@@ -50,7 +50,7 @@ model:
|
|
| 50 |
legacy: False
|
| 51 |
|
| 52 |
first_stage_config:
|
| 53 |
-
target:
|
| 54 |
params:
|
| 55 |
embed_dim: 4
|
| 56 |
monitor: val/rec_loss
|
|
@@ -73,7 +73,7 @@ model:
|
|
| 73 |
target: torch.nn.Identity
|
| 74 |
|
| 75 |
cond_stage_config:
|
| 76 |
-
target:
|
| 77 |
|
| 78 |
data:
|
| 79 |
target: main.DataModuleFromConfig
|
|
@@ -84,9 +84,9 @@ data:
|
|
| 84 |
validation:
|
| 85 |
target: edit_dataset.EditDataset
|
| 86 |
params:
|
| 87 |
-
path: /
|
| 88 |
-
cache_dir:
|
| 89 |
-
cache_name:
|
| 90 |
split: val
|
| 91 |
min_text_sim: 0.2
|
| 92 |
min_image_sim: 0.75
|
|
|
|
| 3 |
|
| 4 |
model:
|
| 5 |
base_learning_rate: 1.0e-04
|
| 6 |
+
target: ldm.models.diffusion.ddpm_edit.LatentDiffusion
|
| 7 |
params:
|
| 8 |
linear_start: 0.00085
|
| 9 |
linear_end: 0.0120
|
|
|
|
| 24 |
load_ema: true
|
| 25 |
|
| 26 |
scheduler_config: # 10000 warmup steps
|
| 27 |
+
target: ldm.lr_scheduler.LambdaLinearScheduler
|
| 28 |
params:
|
| 29 |
warm_up_steps: [ 0 ]
|
| 30 |
cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
|
|
|
|
| 33 |
f_min: [ 1. ]
|
| 34 |
|
| 35 |
unet_config:
|
| 36 |
+
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
| 37 |
params:
|
| 38 |
image_size: 32 # unused
|
| 39 |
in_channels: 8
|
|
|
|
| 50 |
legacy: False
|
| 51 |
|
| 52 |
first_stage_config:
|
| 53 |
+
target: ldm.models.autoencoder.AutoencoderKL
|
| 54 |
params:
|
| 55 |
embed_dim: 4
|
| 56 |
monitor: val/rec_loss
|
|
|
|
| 73 |
target: torch.nn.Identity
|
| 74 |
|
| 75 |
cond_stage_config:
|
| 76 |
+
target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
|
| 77 |
|
| 78 |
data:
|
| 79 |
target: main.DataModuleFromConfig
|
|
|
|
| 84 |
validation:
|
| 85 |
target: edit_dataset.EditDataset
|
| 86 |
params:
|
| 87 |
+
path: data/clip-filtered-dataset
|
| 88 |
+
cache_dir: data/
|
| 89 |
+
cache_name: data_10k
|
| 90 |
split: val
|
| 91 |
min_text_sim: 0.2
|
| 92 |
min_image_sim: 0.75
|
configs/train.yaml
CHANGED
|
@@ -3,7 +3,7 @@
|
|
| 3 |
|
| 4 |
model:
|
| 5 |
base_learning_rate: 1.0e-04
|
| 6 |
-
target:
|
| 7 |
params:
|
| 8 |
ckpt_path: stable_diffusion/models/ldm/stable-diffusion-v1/v1-5-pruned-emaonly.ckpt
|
| 9 |
linear_start: 0.00085
|
|
@@ -23,7 +23,7 @@ model:
|
|
| 23 |
load_ema: false
|
| 24 |
|
| 25 |
scheduler_config: # 10000 warmup steps
|
| 26 |
-
target:
|
| 27 |
params:
|
| 28 |
warm_up_steps: [ 0 ]
|
| 29 |
cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
|
|
@@ -32,7 +32,7 @@ model:
|
|
| 32 |
f_min: [ 1. ]
|
| 33 |
|
| 34 |
unet_config:
|
| 35 |
-
target:
|
| 36 |
params:
|
| 37 |
image_size: 32 # unused
|
| 38 |
in_channels: 8
|
|
@@ -49,7 +49,7 @@ model:
|
|
| 49 |
legacy: False
|
| 50 |
|
| 51 |
first_stage_config:
|
| 52 |
-
target:
|
| 53 |
params:
|
| 54 |
embed_dim: 4
|
| 55 |
monitor: val/rec_loss
|
|
@@ -72,7 +72,7 @@ model:
|
|
| 72 |
target: torch.nn.Identity
|
| 73 |
|
| 74 |
cond_stage_config:
|
| 75 |
-
target:
|
| 76 |
|
| 77 |
data:
|
| 78 |
target: main.DataModuleFromConfig
|
|
@@ -82,7 +82,7 @@ data:
|
|
| 82 |
train:
|
| 83 |
target: edit_dataset.EditDataset
|
| 84 |
params:
|
| 85 |
-
path: /
|
| 86 |
split: train
|
| 87 |
min_resize_res: 256
|
| 88 |
max_resize_res: 256
|
|
@@ -91,7 +91,7 @@ data:
|
|
| 91 |
validation:
|
| 92 |
target: edit_dataset.EditDataset
|
| 93 |
params:
|
| 94 |
-
path: /
|
| 95 |
split: val
|
| 96 |
min_resize_res: 256
|
| 97 |
max_resize_res: 256
|
|
|
|
| 3 |
|
| 4 |
model:
|
| 5 |
base_learning_rate: 1.0e-04
|
| 6 |
+
target: ldm.models.diffusion.ddpm_edit.LatentDiffusion
|
| 7 |
params:
|
| 8 |
ckpt_path: stable_diffusion/models/ldm/stable-diffusion-v1/v1-5-pruned-emaonly.ckpt
|
| 9 |
linear_start: 0.00085
|
|
|
|
| 23 |
load_ema: false
|
| 24 |
|
| 25 |
scheduler_config: # 10000 warmup steps
|
| 26 |
+
target: ldm.lr_scheduler.LambdaLinearScheduler
|
| 27 |
params:
|
| 28 |
warm_up_steps: [ 0 ]
|
| 29 |
cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
|
|
|
|
| 32 |
f_min: [ 1. ]
|
| 33 |
|
| 34 |
unet_config:
|
| 35 |
+
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
| 36 |
params:
|
| 37 |
image_size: 32 # unused
|
| 38 |
in_channels: 8
|
|
|
|
| 49 |
legacy: False
|
| 50 |
|
| 51 |
first_stage_config:
|
| 52 |
+
target: ldm.models.autoencoder.AutoencoderKL
|
| 53 |
params:
|
| 54 |
embed_dim: 4
|
| 55 |
monitor: val/rec_loss
|
|
|
|
| 72 |
target: torch.nn.Identity
|
| 73 |
|
| 74 |
cond_stage_config:
|
| 75 |
+
target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
|
| 76 |
|
| 77 |
data:
|
| 78 |
target: main.DataModuleFromConfig
|
|
|
|
| 82 |
train:
|
| 83 |
target: edit_dataset.EditDataset
|
| 84 |
params:
|
| 85 |
+
path: data/clip-filtered-dataset
|
| 86 |
split: train
|
| 87 |
min_resize_res: 256
|
| 88 |
max_resize_res: 256
|
|
|
|
| 91 |
validation:
|
| 92 |
target: edit_dataset.EditDataset
|
| 93 |
params:
|
| 94 |
+
path: data/clip-filtered-dataset
|
| 95 |
split: val
|
| 96 |
min_resize_res: 256
|
| 97 |
max_resize_res: 256
|
dataset_creation/generate_img_dataset.py
CHANGED
|
@@ -1,5 +1,6 @@
|
|
| 1 |
import argparse
|
| 2 |
import json
|
|
|
|
| 3 |
from pathlib import Path
|
| 4 |
|
| 5 |
import k_diffusion
|
|
@@ -12,8 +13,11 @@ from PIL import Image
|
|
| 12 |
from pytorch_lightning import seed_everything
|
| 13 |
from tqdm import tqdm
|
| 14 |
|
| 15 |
-
|
| 16 |
-
|
|
|
|
|
|
|
|
|
|
| 17 |
from metrics.clip_similarity import ClipSimilarity
|
| 18 |
|
| 19 |
|
|
@@ -112,15 +116,29 @@ def to_pil(image: torch.Tensor) -> Image.Image:
|
|
| 112 |
def main():
|
| 113 |
parser = argparse.ArgumentParser()
|
| 114 |
parser.add_argument(
|
| 115 |
-
"out_dir",
|
| 116 |
type=str,
|
|
|
|
| 117 |
help="Path to output dataset directory.",
|
| 118 |
)
|
| 119 |
parser.add_argument(
|
| 120 |
-
"prompts_file",
|
| 121 |
type=str,
|
|
|
|
| 122 |
help="Path to prompts .jsonl file.",
|
| 123 |
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 124 |
parser.add_argument(
|
| 125 |
"--steps",
|
| 126 |
type=int,
|
|
@@ -200,9 +218,9 @@ def main():
|
|
| 200 |
seed_everything(global_seed)
|
| 201 |
|
| 202 |
model = load_model_from_config(
|
| 203 |
-
OmegaConf.load("configs/stable-diffusion/v1-inference.yaml"),
|
| 204 |
-
ckpt=
|
| 205 |
-
vae_ckpt=
|
| 206 |
)
|
| 207 |
model.cuda().eval()
|
| 208 |
model_wrap = k_diffusion.external.CompVisDenoiser(model)
|
|
@@ -229,7 +247,7 @@ def main():
|
|
| 229 |
with open(prompt_dir.joinpath("prompt.json"), "w") as fp:
|
| 230 |
json.dump(prompt, fp)
|
| 231 |
|
| 232 |
-
cond = model.get_learned_conditioning([prompt["
|
| 233 |
results = {}
|
| 234 |
|
| 235 |
with tqdm(total=opt.n_samples, desc="Samples") as progress_bar:
|
|
@@ -255,7 +273,7 @@ def main():
|
|
| 255 |
x1 = x_samples_ddim[1]
|
| 256 |
|
| 257 |
clip_sim_0, clip_sim_1, clip_sim_dir, clip_sim_image = clip_similarity(
|
| 258 |
-
x0[None], x1[None], [prompt["
|
| 259 |
)
|
| 260 |
|
| 261 |
results[seed] = dict(
|
|
|
|
| 1 |
import argparse
|
| 2 |
import json
|
| 3 |
+
import sys
|
| 4 |
from pathlib import Path
|
| 5 |
|
| 6 |
import k_diffusion
|
|
|
|
| 13 |
from pytorch_lightning import seed_everything
|
| 14 |
from tqdm import tqdm
|
| 15 |
|
| 16 |
+
sys.path.append("./")
|
| 17 |
+
sys.path.append("./stable_diffusion")
|
| 18 |
+
|
| 19 |
+
from ldm.modules.attention import CrossAttention
|
| 20 |
+
from ldm.util import instantiate_from_config
|
| 21 |
from metrics.clip_similarity import ClipSimilarity
|
| 22 |
|
| 23 |
|
|
|
|
| 116 |
def main():
|
| 117 |
parser = argparse.ArgumentParser()
|
| 118 |
parser.add_argument(
|
| 119 |
+
"--out_dir",
|
| 120 |
type=str,
|
| 121 |
+
required=True,
|
| 122 |
help="Path to output dataset directory.",
|
| 123 |
)
|
| 124 |
parser.add_argument(
|
| 125 |
+
"--prompts_file",
|
| 126 |
type=str,
|
| 127 |
+
required=True,
|
| 128 |
help="Path to prompts .jsonl file.",
|
| 129 |
)
|
| 130 |
+
parser.add_argument(
|
| 131 |
+
"--ckpt",
|
| 132 |
+
type=str,
|
| 133 |
+
default="stable_diffusion/models/ldm/stable-diffusion-v1/v1-5-pruned-emaonly.ckpt",
|
| 134 |
+
help="Path to stable diffusion checkpoint.",
|
| 135 |
+
)
|
| 136 |
+
parser.add_argument(
|
| 137 |
+
"--vae-ckpt",
|
| 138 |
+
type=str,
|
| 139 |
+
default="stable_diffusion/models/ldm/stable-diffusion-v1/vae-ft-mse-840000-ema-pruned.ckpt",
|
| 140 |
+
help="Path to vae checkpoint.",
|
| 141 |
+
)
|
| 142 |
parser.add_argument(
|
| 143 |
"--steps",
|
| 144 |
type=int,
|
|
|
|
| 218 |
seed_everything(global_seed)
|
| 219 |
|
| 220 |
model = load_model_from_config(
|
| 221 |
+
OmegaConf.load("stable_diffusion/configs/stable-diffusion/v1-inference.yaml"),
|
| 222 |
+
ckpt=opt.ckpt,
|
| 223 |
+
vae_ckpt=opt.vae_ckpt,
|
| 224 |
)
|
| 225 |
model.cuda().eval()
|
| 226 |
model_wrap = k_diffusion.external.CompVisDenoiser(model)
|
|
|
|
| 247 |
with open(prompt_dir.joinpath("prompt.json"), "w") as fp:
|
| 248 |
json.dump(prompt, fp)
|
| 249 |
|
| 250 |
+
cond = model.get_learned_conditioning([prompt["caption"], prompt["output"]])
|
| 251 |
results = {}
|
| 252 |
|
| 253 |
with tqdm(total=opt.n_samples, desc="Samples") as progress_bar:
|
|
|
|
| 273 |
x1 = x_samples_ddim[1]
|
| 274 |
|
| 275 |
clip_sim_0, clip_sim_1, clip_sim_dir, clip_sim_image = clip_similarity(
|
| 276 |
+
x0[None], x1[None], [prompt["caption"]], [prompt["output"]]
|
| 277 |
)
|
| 278 |
|
| 279 |
results[seed] = dict(
|
dataset_creation/generate_txt_dataset.py
CHANGED
|
@@ -65,7 +65,7 @@ def main(openai_model: str, num_samples: int, num_partitions: int, partition: in
|
|
| 65 |
dataset = dataset[permutation]
|
| 66 |
captions = dataset["TEXT"]
|
| 67 |
urls = dataset["URL"]
|
| 68 |
-
output_path = f"
|
| 69 |
print(f"Prompt file path: {output_path}")
|
| 70 |
|
| 71 |
count = 0
|
|
@@ -88,7 +88,7 @@ def main(openai_model: str, num_samples: int, num_partitions: int, partition: in
|
|
| 88 |
continue
|
| 89 |
if openai.Moderation.create(caption)["results"][0]["flagged"]:
|
| 90 |
continue
|
| 91 |
-
edit_output = generate(caption)
|
| 92 |
if edit_output is not None:
|
| 93 |
edit, output = edit_output
|
| 94 |
fp.write(f"{json.dumps(dict(caption=caption, edit=edit, output=output, url=url))}\n")
|
|
@@ -102,8 +102,8 @@ def main(openai_model: str, num_samples: int, num_partitions: int, partition: in
|
|
| 102 |
|
| 103 |
if __name__ == "__main__":
|
| 104 |
parser = ArgumentParser()
|
| 105 |
-
parser.add_argument("openai-api-key", type=str)
|
| 106 |
-
parser.add_argument("openai-model", type=str)
|
| 107 |
parser.add_argument("--num-samples", default=10000, type=int)
|
| 108 |
parser.add_argument("--num-partitions", default=1, type=int)
|
| 109 |
parser.add_argument("--partition", default=0, type=int)
|
|
|
|
| 65 |
dataset = dataset[permutation]
|
| 66 |
captions = dataset["TEXT"]
|
| 67 |
urls = dataset["URL"]
|
| 68 |
+
output_path = f"data/dataset=laion-aesthetics-6.5_model={openai_model}_samples={num_samples}_partition={partition}.jsonl" # fmt: skip
|
| 69 |
print(f"Prompt file path: {output_path}")
|
| 70 |
|
| 71 |
count = 0
|
|
|
|
| 88 |
continue
|
| 89 |
if openai.Moderation.create(caption)["results"][0]["flagged"]:
|
| 90 |
continue
|
| 91 |
+
edit_output = generate(openai_model, caption)
|
| 92 |
if edit_output is not None:
|
| 93 |
edit, output = edit_output
|
| 94 |
fp.write(f"{json.dumps(dict(caption=caption, edit=edit, output=output, url=url))}\n")
|
|
|
|
| 102 |
|
| 103 |
if __name__ == "__main__":
|
| 104 |
parser = ArgumentParser()
|
| 105 |
+
parser.add_argument("--openai-api-key", required=True, type=str)
|
| 106 |
+
parser.add_argument("--openai-model", required=True, type=str)
|
| 107 |
parser.add_argument("--num-samples", default=10000, type=int)
|
| 108 |
parser.add_argument("--num-partitions", default=1, type=int)
|
| 109 |
parser.add_argument("--partition", default=0, type=int)
|
dataset_creation/prepare_for_gpt.py
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
import json
|
| 2 |
from argparse import ArgumentParser
|
| 3 |
|
| 4 |
-
from
|
| 5 |
|
| 6 |
|
| 7 |
def main(input_path: str, output_path: str):
|
|
@@ -19,7 +19,7 @@ def main(input_path: str, output_path: str):
|
|
| 19 |
|
| 20 |
if __name__ == "__main__":
|
| 21 |
parser = ArgumentParser()
|
| 22 |
-
parser.add_argument("input-path", type=str)
|
| 23 |
-
parser.add_argument("output-path", type=str)
|
| 24 |
args = parser.parse_args()
|
| 25 |
main(args.input_path, args.output_path)
|
|
|
|
| 1 |
import json
|
| 2 |
from argparse import ArgumentParser
|
| 3 |
|
| 4 |
+
from generate_txt_dataset import DELIMITER_0, DELIMITER_1, STOP
|
| 5 |
|
| 6 |
|
| 7 |
def main(input_path: str, output_path: str):
|
|
|
|
| 19 |
|
| 20 |
if __name__ == "__main__":
|
| 21 |
parser = ArgumentParser()
|
| 22 |
+
parser.add_argument("--input-path", required=True, type=str)
|
| 23 |
+
parser.add_argument("--output-path", required=True, type=str)
|
| 24 |
args = parser.parse_args()
|
| 25 |
main(args.input_path, args.output_path)
|
edit_app.py
CHANGED
|
@@ -73,8 +73,7 @@ class CFGDenoiser(nn.Module):
|
|
| 73 |
return out_uncond + text_cfg_scale * (out_cond - out_img_cond) + image_cfg_scale * (out_img_cond - out_uncond)
|
| 74 |
|
| 75 |
|
| 76 |
-
def load_model_from_config(config, ckpt, vae_ckpt=None, verbose=False
|
| 77 |
-
print(f"Cache: {cached}")
|
| 78 |
print(f"Loading model from {ckpt}")
|
| 79 |
pl_sd = torch.load(ckpt, map_location="cpu")
|
| 80 |
if "global_step" in pl_sd:
|
|
@@ -87,7 +86,7 @@ def load_model_from_config(config, ckpt, vae_ckpt=None, verbose=False, cached=Fa
|
|
| 87 |
k: vae_sd[k[len("first_stage_model.") :]] if k.startswith("first_stage_model.") else v
|
| 88 |
for k, v in sd.items()
|
| 89 |
}
|
| 90 |
-
model = instantiate_from_config(config.model
|
| 91 |
m, u = model.load_state_dict(sd, strict=False)
|
| 92 |
if len(m) > 0 and verbose:
|
| 93 |
print("missing keys:")
|
|
@@ -101,8 +100,8 @@ def load_model_from_config(config, ckpt, vae_ckpt=None, verbose=False, cached=Fa
|
|
| 101 |
def main():
|
| 102 |
parser = ArgumentParser()
|
| 103 |
parser.add_argument("--resolution", default=512, type=int)
|
| 104 |
-
parser.add_argument("--config", default="configs/
|
| 105 |
-
parser.add_argument("--ckpt", default="checkpoints/instruct-pix2pix-00-
|
| 106 |
parser.add_argument("--vae-ckpt", default=None, type=str)
|
| 107 |
args = parser.parse_args()
|
| 108 |
|
|
@@ -188,7 +187,7 @@ def main():
|
|
| 188 |
return [seed, text_cfg_scale, image_cfg_scale, edited_image]
|
| 189 |
|
| 190 |
def reset():
|
| 191 |
-
return [
|
| 192 |
|
| 193 |
with gr.Blocks(css="footer {visibility: hidden}") as demo:
|
| 194 |
with gr.Row():
|
|
@@ -208,7 +207,7 @@ def main():
|
|
| 208 |
edited_image.style(height=512, width=512)
|
| 209 |
|
| 210 |
with gr.Row():
|
| 211 |
-
steps = gr.Number(value=
|
| 212 |
randomize_seed = gr.Radio(
|
| 213 |
["Fix Seed", "Randomize Seed"],
|
| 214 |
value="Randomize Seed",
|
|
@@ -216,7 +215,7 @@ def main():
|
|
| 216 |
show_label=False,
|
| 217 |
interactive=True,
|
| 218 |
)
|
| 219 |
-
seed = gr.Number(value=
|
| 220 |
randomize_cfg = gr.Radio(
|
| 221 |
["Fix CFG", "Randomize CFG"],
|
| 222 |
value="Fix CFG",
|
|
|
|
| 73 |
return out_uncond + text_cfg_scale * (out_cond - out_img_cond) + image_cfg_scale * (out_img_cond - out_uncond)
|
| 74 |
|
| 75 |
|
| 76 |
+
def load_model_from_config(config, ckpt, vae_ckpt=None, verbose=False):
|
|
|
|
| 77 |
print(f"Loading model from {ckpt}")
|
| 78 |
pl_sd = torch.load(ckpt, map_location="cpu")
|
| 79 |
if "global_step" in pl_sd:
|
|
|
|
| 86 |
k: vae_sd[k[len("first_stage_model.") :]] if k.startswith("first_stage_model.") else v
|
| 87 |
for k, v in sd.items()
|
| 88 |
}
|
| 89 |
+
model = instantiate_from_config(config.model)
|
| 90 |
m, u = model.load_state_dict(sd, strict=False)
|
| 91 |
if len(m) > 0 and verbose:
|
| 92 |
print("missing keys:")
|
|
|
|
| 100 |
def main():
|
| 101 |
parser = ArgumentParser()
|
| 102 |
parser.add_argument("--resolution", default=512, type=int)
|
| 103 |
+
parser.add_argument("--config", default="configs/generate.yaml", type=str)
|
| 104 |
+
parser.add_argument("--ckpt", default="checkpoints/instruct-pix2pix-00-22000.ckpt", type=str)
|
| 105 |
parser.add_argument("--vae-ckpt", default=None, type=str)
|
| 106 |
args = parser.parse_args()
|
| 107 |
|
|
|
|
| 187 |
return [seed, text_cfg_scale, image_cfg_scale, edited_image]
|
| 188 |
|
| 189 |
def reset():
|
| 190 |
+
return [0, "Randomize Seed", 1371, "Fix CFG", 7.5, 1.5, None]
|
| 191 |
|
| 192 |
with gr.Blocks(css="footer {visibility: hidden}") as demo:
|
| 193 |
with gr.Row():
|
|
|
|
| 207 |
edited_image.style(height=512, width=512)
|
| 208 |
|
| 209 |
with gr.Row():
|
| 210 |
+
steps = gr.Number(value=100, precision=0, label="Steps", interactive=True)
|
| 211 |
randomize_seed = gr.Radio(
|
| 212 |
["Fix Seed", "Randomize Seed"],
|
| 213 |
value="Randomize Seed",
|
|
|
|
| 215 |
show_label=False,
|
| 216 |
interactive=True,
|
| 217 |
)
|
| 218 |
+
seed = gr.Number(value=1371, precision=0, label="Seed", interactive=True)
|
| 219 |
randomize_cfg = gr.Radio(
|
| 220 |
["Fix CFG", "Randomize CFG"],
|
| 221 |
value="Fix CFG",
|
edit_cli.py
CHANGED
|
@@ -65,13 +65,13 @@ def main():
|
|
| 65 |
parser.add_argument("--resolution", default=512, type=int)
|
| 66 |
parser.add_argument("--steps", default=100, type=int)
|
| 67 |
parser.add_argument("--config", default="configs/generate.yaml", type=str)
|
| 68 |
-
parser.add_argument("--ckpt", default="checkpoints/instruct-pix2pix-00-
|
| 69 |
parser.add_argument("--vae-ckpt", default=None, type=str)
|
| 70 |
parser.add_argument("--input", required=True, type=str)
|
| 71 |
parser.add_argument("--output", required=True, type=str)
|
| 72 |
parser.add_argument("--edit", required=True, type=str)
|
| 73 |
parser.add_argument("--cfg-text", default=7.5, type=float)
|
| 74 |
-
parser.add_argument("--cfg-image", default=1.
|
| 75 |
parser.add_argument("--seed", type=int)
|
| 76 |
args = parser.parse_args()
|
| 77 |
|
|
|
|
| 65 |
parser.add_argument("--resolution", default=512, type=int)
|
| 66 |
parser.add_argument("--steps", default=100, type=int)
|
| 67 |
parser.add_argument("--config", default="configs/generate.yaml", type=str)
|
| 68 |
+
parser.add_argument("--ckpt", default="checkpoints/instruct-pix2pix-00-22000.ckpt", type=str)
|
| 69 |
parser.add_argument("--vae-ckpt", default=None, type=str)
|
| 70 |
parser.add_argument("--input", required=True, type=str)
|
| 71 |
parser.add_argument("--output", required=True, type=str)
|
| 72 |
parser.add_argument("--edit", required=True, type=str)
|
| 73 |
parser.add_argument("--cfg-text", default=7.5, type=float)
|
| 74 |
+
parser.add_argument("--cfg-image", default=1.5, type=float)
|
| 75 |
parser.add_argument("--seed", type=int)
|
| 76 |
args = parser.parse_args()
|
| 77 |
|
edit_dataset.py
CHANGED
|
@@ -70,3 +70,52 @@ class EditDataset(Dataset):
|
|
| 70 |
image_0, image_1 = flip(crop(torch.cat((image_0, image_1)))).chunk(2)
|
| 71 |
|
| 72 |
return dict(edited=image_1, edit=dict(c_concat=image_0, c_crossattn=prompt))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 70 |
image_0, image_1 = flip(crop(torch.cat((image_0, image_1)))).chunk(2)
|
| 71 |
|
| 72 |
return dict(edited=image_1, edit=dict(c_concat=image_0, c_crossattn=prompt))
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class EditDatasetEval(Dataset):
|
| 76 |
+
def __init__(
|
| 77 |
+
self,
|
| 78 |
+
path: str,
|
| 79 |
+
split: str = "train",
|
| 80 |
+
splits: tuple[float, float, float] = (0.9, 0.05, 0.05),
|
| 81 |
+
res: int = 256,
|
| 82 |
+
):
|
| 83 |
+
assert split in ("train", "val", "test")
|
| 84 |
+
assert sum(splits) == 1
|
| 85 |
+
self.path = path
|
| 86 |
+
self.res = res
|
| 87 |
+
|
| 88 |
+
with open(Path(self.path, "seeds.json")) as f:
|
| 89 |
+
self.seeds = json.load(f)
|
| 90 |
+
|
| 91 |
+
split_0, split_1 = {
|
| 92 |
+
"train": (0.0, splits[0]),
|
| 93 |
+
"val": (splits[0], splits[0] + splits[1]),
|
| 94 |
+
"test": (splits[0] + splits[1], 1.0),
|
| 95 |
+
}[split]
|
| 96 |
+
|
| 97 |
+
idx_0 = math.floor(split_0 * len(self.seeds))
|
| 98 |
+
idx_1 = math.floor(split_1 * len(self.seeds))
|
| 99 |
+
self.seeds = self.seeds[idx_0:idx_1]
|
| 100 |
+
|
| 101 |
+
def __len__(self) -> int:
|
| 102 |
+
return len(self.seeds)
|
| 103 |
+
|
| 104 |
+
def __getitem__(self, i: int) -> dict[str, Any]:
|
| 105 |
+
name, seeds = self.seeds[i]
|
| 106 |
+
propt_dir = Path(self.path, name)
|
| 107 |
+
seed = seeds[torch.randint(0, len(seeds), ()).item()]
|
| 108 |
+
with open(propt_dir.joinpath("prompt.json")) as fp:
|
| 109 |
+
prompt = json.load(fp)
|
| 110 |
+
edit = prompt["edit"]
|
| 111 |
+
input_prompt = prompt["input"]
|
| 112 |
+
output_prompt = prompt["output"]
|
| 113 |
+
|
| 114 |
+
image_0 = Image.open(propt_dir.joinpath(f"{seed}_0.jpg"))
|
| 115 |
+
|
| 116 |
+
reize_res = torch.randint(self.res, self.res + 1, ()).item()
|
| 117 |
+
image_0 = image_0.resize((reize_res, reize_res), Image.Resampling.LANCZOS)
|
| 118 |
+
|
| 119 |
+
image_0 = rearrange(2 * torch.tensor(np.array(image_0)).float() / 255 - 1, "h w c -> c h w")
|
| 120 |
+
|
| 121 |
+
return dict(image_0=image_0, input_prompt=input_prompt, edit=edit, output_prompt=output_prompt)
|
environment.yaml
CHANGED
|
@@ -14,6 +14,7 @@ dependencies:
|
|
| 14 |
- numpy=1.19.2
|
| 15 |
- pip:
|
| 16 |
- albumentations==0.4.3
|
|
|
|
| 17 |
- diffusers
|
| 18 |
- opencv-python==4.1.2.30
|
| 19 |
- pudb==2019.2
|
|
|
|
| 14 |
- numpy=1.19.2
|
| 15 |
- pip:
|
| 16 |
- albumentations==0.4.3
|
| 17 |
+
- datasets==2.8.0
|
| 18 |
- diffusers
|
| 19 |
- opencv-python==4.1.2.30
|
| 20 |
- pudb==2019.2
|
imgs/dataset.jpg
ADDED

|
imgs/edit_app.jpg
ADDED
|
imgs/prompt_app.jpg
ADDED
|
main.py
CHANGED
|
@@ -1,6 +1,3 @@
|
|
| 1 |
-
# File modified by authors of InstructPix2Pix from original (https://github.com/CompVis/stable-diffusion).
|
| 2 |
-
# See more details in LICENSE.
|
| 3 |
-
|
| 4 |
import argparse, os, sys, datetime, glob
|
| 5 |
import numpy as np
|
| 6 |
import time
|
|
@@ -26,8 +23,8 @@ from pytorch_lightning.plugins import DDPPlugin
|
|
| 26 |
|
| 27 |
sys.path.append("./stable_diffusion")
|
| 28 |
|
| 29 |
-
from
|
| 30 |
-
from
|
| 31 |
|
| 32 |
|
| 33 |
def get_parser(**parser_kwargs):
|
|
@@ -553,6 +550,7 @@ if __name__ == "__main__":
|
|
| 553 |
nowname = f"{cfg_name}_{opt.name}"
|
| 554 |
logdir = os.path.join(opt.logdir, nowname)
|
| 555 |
ckpt = os.path.join(logdir, "checkpoints", "last.ckpt")
|
|
|
|
| 556 |
|
| 557 |
if os.path.isfile(ckpt):
|
| 558 |
opt.resume_from_checkpoint = ckpt
|
|
@@ -560,9 +558,7 @@ if __name__ == "__main__":
|
|
| 560 |
opt.base = base_configs + opt.base
|
| 561 |
_tmp = logdir.split("/")
|
| 562 |
nowname = _tmp[-1]
|
| 563 |
-
|
| 564 |
-
# If resuming InstructPix2Pix from a finetuning checkpoint, instead load both EMA and non-EMA weights.
|
| 565 |
-
opt.model.params.load_ema = True
|
| 566 |
|
| 567 |
ckptdir = os.path.join(logdir, "checkpoints")
|
| 568 |
cfgdir = os.path.join(logdir, "configs")
|
|
@@ -576,6 +572,12 @@ if __name__ == "__main__":
|
|
| 576 |
configs = [OmegaConf.load(cfg) for cfg in opt.base]
|
| 577 |
cli = OmegaConf.from_dotlist(unknown)
|
| 578 |
config = OmegaConf.merge(*configs, cli)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 579 |
lightning_config = config.pop("lightning", OmegaConf.create())
|
| 580 |
# merge trainer cli with config
|
| 581 |
trainer_config = lightning_config.get("trainer", OmegaConf.create())
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import argparse, os, sys, datetime, glob
|
| 2 |
import numpy as np
|
| 3 |
import time
|
|
|
|
| 23 |
|
| 24 |
sys.path.append("./stable_diffusion")
|
| 25 |
|
| 26 |
+
from ldm.data.base import Txt2ImgIterableBaseDataset
|
| 27 |
+
from ldm.util import instantiate_from_config
|
| 28 |
|
| 29 |
|
| 30 |
def get_parser(**parser_kwargs):
|
|
|
|
| 550 |
nowname = f"{cfg_name}_{opt.name}"
|
| 551 |
logdir = os.path.join(opt.logdir, nowname)
|
| 552 |
ckpt = os.path.join(logdir, "checkpoints", "last.ckpt")
|
| 553 |
+
resume = False
|
| 554 |
|
| 555 |
if os.path.isfile(ckpt):
|
| 556 |
opt.resume_from_checkpoint = ckpt
|
|
|
|
| 558 |
opt.base = base_configs + opt.base
|
| 559 |
_tmp = logdir.split("/")
|
| 560 |
nowname = _tmp[-1]
|
| 561 |
+
resume = True
|
|
|
|
|
|
|
| 562 |
|
| 563 |
ckptdir = os.path.join(logdir, "checkpoints")
|
| 564 |
cfgdir = os.path.join(logdir, "configs")
|
|
|
|
| 572 |
configs = [OmegaConf.load(cfg) for cfg in opt.base]
|
| 573 |
cli = OmegaConf.from_dotlist(unknown)
|
| 574 |
config = OmegaConf.merge(*configs, cli)
|
| 575 |
+
|
| 576 |
+
if resume:
|
| 577 |
+
# By default, when finetuning from Stable Diffusion, we load the EMA-only checkpoint to initialize all weights.
|
| 578 |
+
# If resuming InstructPix2Pix from a finetuning checkpoint, instead load both EMA and non-EMA weights.
|
| 579 |
+
config.model.params.load_ema = True
|
| 580 |
+
|
| 581 |
lightning_config = config.pop("lightning", OmegaConf.create())
|
| 582 |
# merge trainer cli with config
|
| 583 |
trainer_config = lightning_config.get("trainer", OmegaConf.create())
|
metrics/compute_metrics.py
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import annotations
|
| 2 |
+
|
| 3 |
+
import math
|
| 4 |
+
import random
|
| 5 |
+
import sys
|
| 6 |
+
from argparse import ArgumentParser
|
| 7 |
+
|
| 8 |
+
import einops
|
| 9 |
+
import k_diffusion as K
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
from tqdm.auto import tqdm
|
| 14 |
+
from einops import rearrange
|
| 15 |
+
from omegaconf import OmegaConf
|
| 16 |
+
from PIL import Image, ImageOps
|
| 17 |
+
from torch import autocast
|
| 18 |
+
|
| 19 |
+
import json
|
| 20 |
+
import matplotlib.pyplot as plt
|
| 21 |
+
import seaborn
|
| 22 |
+
from pathlib import Path
|
| 23 |
+
|
| 24 |
+
sys.path.append("./")
|
| 25 |
+
|
| 26 |
+
from clip_similarity import ClipSimilarity
|
| 27 |
+
from edit_dataset import EditDatasetEval
|
| 28 |
+
|
| 29 |
+
sys.path.append("./stable_diffusion")
|
| 30 |
+
|
| 31 |
+
from ldm.util import instantiate_from_config
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class CFGDenoiser(nn.Module):
|
| 35 |
+
def __init__(self, model):
|
| 36 |
+
super().__init__()
|
| 37 |
+
self.inner_model = model
|
| 38 |
+
|
| 39 |
+
def forward(self, z, sigma, cond, uncond, text_cfg_scale, image_cfg_scale):
|
| 40 |
+
cfg_z = einops.repeat(z, "1 ... -> n ...", n=3)
|
| 41 |
+
cfg_sigma = einops.repeat(sigma, "1 ... -> n ...", n=3)
|
| 42 |
+
cfg_cond = {
|
| 43 |
+
"c_crossattn": [torch.cat([cond["c_crossattn"][0], uncond["c_crossattn"][0], uncond["c_crossattn"][0]])],
|
| 44 |
+
"c_concat": [torch.cat([cond["c_concat"][0], cond["c_concat"][0], uncond["c_concat"][0]])],
|
| 45 |
+
}
|
| 46 |
+
out_cond, out_img_cond, out_uncond = self.inner_model(cfg_z, cfg_sigma, cond=cfg_cond).chunk(3)
|
| 47 |
+
return out_uncond + text_cfg_scale * (out_cond - out_img_cond) + image_cfg_scale * (out_img_cond - out_uncond)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def load_model_from_config(config, ckpt, vae_ckpt=None, verbose=False):
|
| 51 |
+
print(f"Loading model from {ckpt}")
|
| 52 |
+
pl_sd = torch.load(ckpt, map_location="cpu")
|
| 53 |
+
if "global_step" in pl_sd:
|
| 54 |
+
print(f"Global Step: {pl_sd['global_step']}")
|
| 55 |
+
sd = pl_sd["state_dict"]
|
| 56 |
+
if vae_ckpt is not None:
|
| 57 |
+
print(f"Loading VAE from {vae_ckpt}")
|
| 58 |
+
vae_sd = torch.load(vae_ckpt, map_location="cpu")["state_dict"]
|
| 59 |
+
sd = {
|
| 60 |
+
k: vae_sd[k[len("first_stage_model.") :]] if k.startswith("first_stage_model.") else v
|
| 61 |
+
for k, v in sd.items()
|
| 62 |
+
}
|
| 63 |
+
model = instantiate_from_config(config.model)
|
| 64 |
+
m, u = model.load_state_dict(sd, strict=False)
|
| 65 |
+
if len(m) > 0 and verbose:
|
| 66 |
+
print("missing keys:")
|
| 67 |
+
print(m)
|
| 68 |
+
if len(u) > 0 and verbose:
|
| 69 |
+
print("unexpected keys:")
|
| 70 |
+
print(u)
|
| 71 |
+
return model
|
| 72 |
+
|
| 73 |
+
class ImageEditor(nn.Module):
|
| 74 |
+
def __init__(self, config, ckpt, vae_ckpt=None):
|
| 75 |
+
super().__init__()
|
| 76 |
+
|
| 77 |
+
config = OmegaConf.load(config)
|
| 78 |
+
self.model = load_model_from_config(config, ckpt, vae_ckpt)
|
| 79 |
+
self.model.eval().cuda()
|
| 80 |
+
self.model_wrap = K.external.CompVisDenoiser(self.model)
|
| 81 |
+
self.model_wrap_cfg = CFGDenoiser(self.model_wrap)
|
| 82 |
+
self.null_token = self.model.get_learned_conditioning([""])
|
| 83 |
+
|
| 84 |
+
def forward(
|
| 85 |
+
self,
|
| 86 |
+
image: torch.Tensor,
|
| 87 |
+
edit: str,
|
| 88 |
+
scale_txt: float = 7.5,
|
| 89 |
+
scale_img: float = 1.0,
|
| 90 |
+
steps: int = 100,
|
| 91 |
+
) -> torch.Tensor:
|
| 92 |
+
assert image.dim() == 3
|
| 93 |
+
assert image.size(1) % 64 == 0
|
| 94 |
+
assert image.size(2) % 64 == 0
|
| 95 |
+
with torch.no_grad(), autocast("cuda"), self.model.ema_scope():
|
| 96 |
+
cond = {
|
| 97 |
+
"c_crossattn": [self.model.get_learned_conditioning([edit])],
|
| 98 |
+
"c_concat": [self.model.encode_first_stage(image[None]).mode()],
|
| 99 |
+
}
|
| 100 |
+
uncond = {
|
| 101 |
+
"c_crossattn": [self.model.get_learned_conditioning([""])],
|
| 102 |
+
"c_concat": [torch.zeros_like(cond["c_concat"][0])],
|
| 103 |
+
}
|
| 104 |
+
extra_args = {
|
| 105 |
+
"uncond": uncond,
|
| 106 |
+
"cond": cond,
|
| 107 |
+
"image_cfg_scale": scale_img,
|
| 108 |
+
"text_cfg_scale": scale_txt,
|
| 109 |
+
}
|
| 110 |
+
sigmas = self.model_wrap.get_sigmas(steps)
|
| 111 |
+
x = torch.randn_like(cond["c_concat"][0]) * sigmas[0]
|
| 112 |
+
x = K.sampling.sample_euler_ancestral(self.model_wrap_cfg, x, sigmas, extra_args=extra_args)
|
| 113 |
+
x = self.model.decode_first_stage(x)[0]
|
| 114 |
+
return x
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def compute_metrics(config,
|
| 118 |
+
model_path,
|
| 119 |
+
vae_ckpt,
|
| 120 |
+
data_path,
|
| 121 |
+
output_path,
|
| 122 |
+
scales_img,
|
| 123 |
+
scales_txt,
|
| 124 |
+
num_samples = 5000,
|
| 125 |
+
split = "test",
|
| 126 |
+
steps = 50,
|
| 127 |
+
res = 512,
|
| 128 |
+
seed = 0):
|
| 129 |
+
editor = ImageEditor(config, model_path, vae_ckpt).cuda()
|
| 130 |
+
clip_similarity = ClipSimilarity().cuda()
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
outpath = Path(output_path, f"n={num_samples}_p={split}_s={steps}_r={res}_e={seed}.jsonl")
|
| 135 |
+
Path(output_path).mkdir(parents=True, exist_ok=True)
|
| 136 |
+
|
| 137 |
+
for scale_txt in scales_txt:
|
| 138 |
+
for scale_img in scales_img:
|
| 139 |
+
dataset = EditDatasetEval(
|
| 140 |
+
path=data_path,
|
| 141 |
+
split=split,
|
| 142 |
+
res=res
|
| 143 |
+
)
|
| 144 |
+
assert num_samples <= len(dataset)
|
| 145 |
+
print(f'Processing t={scale_txt}, i={scale_img}')
|
| 146 |
+
torch.manual_seed(seed)
|
| 147 |
+
perm = torch.randperm(len(dataset))
|
| 148 |
+
count = 0
|
| 149 |
+
i = 0
|
| 150 |
+
|
| 151 |
+
sim_0_avg = 0
|
| 152 |
+
sim_1_avg = 0
|
| 153 |
+
sim_direction_avg = 0
|
| 154 |
+
sim_image_avg = 0
|
| 155 |
+
count = 0
|
| 156 |
+
|
| 157 |
+
pbar = tqdm(total=num_samples)
|
| 158 |
+
while count < num_samples:
|
| 159 |
+
|
| 160 |
+
idx = perm[i].item()
|
| 161 |
+
sample = dataset[idx]
|
| 162 |
+
i += 1
|
| 163 |
+
|
| 164 |
+
gen = editor(sample["image_0"].cuda(), sample["edit"], scale_txt=scale_txt, scale_img=scale_img, steps=steps)
|
| 165 |
+
|
| 166 |
+
sim_0, sim_1, sim_direction, sim_image = clip_similarity(
|
| 167 |
+
sample["image_0"][None].cuda(), gen[None].cuda(), [sample["input_prompt"]], [sample["output_prompt"]]
|
| 168 |
+
)
|
| 169 |
+
sim_0_avg += sim_0.item()
|
| 170 |
+
sim_1_avg += sim_1.item()
|
| 171 |
+
sim_direction_avg += sim_direction.item()
|
| 172 |
+
sim_image_avg += sim_image.item()
|
| 173 |
+
count += 1
|
| 174 |
+
pbar.update(count)
|
| 175 |
+
pbar.close()
|
| 176 |
+
|
| 177 |
+
sim_0_avg /= count
|
| 178 |
+
sim_1_avg /= count
|
| 179 |
+
sim_direction_avg /= count
|
| 180 |
+
sim_image_avg /= count
|
| 181 |
+
|
| 182 |
+
with open(outpath, "a") as f:
|
| 183 |
+
f.write(f"{json.dumps(dict(sim_0=sim_0_avg, sim_1=sim_1_avg, sim_direction=sim_direction_avg, sim_image=sim_image_avg, num_samples=num_samples, split=split, scale_txt=scale_txt, scale_img=scale_img, steps=steps, res=res, seed=seed))}\n")
|
| 184 |
+
return outpath
|
| 185 |
+
|
| 186 |
+
def plot_metrics(metrics_file, output_path):
|
| 187 |
+
|
| 188 |
+
with open(metrics_file, 'r') as f:
|
| 189 |
+
data = [json.loads(line) for line in f]
|
| 190 |
+
|
| 191 |
+
plt.rcParams.update({'font.size': 11.5})
|
| 192 |
+
seaborn.set_style("darkgrid")
|
| 193 |
+
plt.figure(figsize=(20.5* 0.7, 10.8* 0.7), dpi=200)
|
| 194 |
+
|
| 195 |
+
x = [d["sim_direction"] for d in data]
|
| 196 |
+
y = [d["sim_image"] for d in data]
|
| 197 |
+
|
| 198 |
+
plt.plot(x, y, marker='o', linewidth=2, markersize=4)
|
| 199 |
+
|
| 200 |
+
plt.xlabel("CLIP Text-Image Direction Similarity", labelpad=10)
|
| 201 |
+
plt.ylabel("CLIP Image Similarity", labelpad=10)
|
| 202 |
+
|
| 203 |
+
plt.savefig(Path(output_path) / Path("plot.pdf"), bbox_inches="tight")
|
| 204 |
+
|
| 205 |
+
def main():
|
| 206 |
+
parser = ArgumentParser()
|
| 207 |
+
parser.add_argument("--resolution", default=512, type=int)
|
| 208 |
+
parser.add_argument("--steps", default=100, type=int)
|
| 209 |
+
parser.add_argument("--config", default="configs/generate.yaml", type=str)
|
| 210 |
+
parser.add_argument("--output_path", default="analysis/", type=str)
|
| 211 |
+
parser.add_argument("--ckpt", default="checkpoints/instruct-pix2pix-00-22000.ckpt", type=str)
|
| 212 |
+
parser.add_argument("--dataset", default="data/clip-filtered-dataset/", type=str)
|
| 213 |
+
parser.add_argument("--vae-ckpt", default=None, type=str)
|
| 214 |
+
args = parser.parse_args()
|
| 215 |
+
|
| 216 |
+
scales_img = [1.0, 1.2, 1.4, 1.6, 1.8, 2.0, 2.2]
|
| 217 |
+
scales_txt = [7.5]
|
| 218 |
+
|
| 219 |
+
metrics_file = compute_metrics(
|
| 220 |
+
args.config,
|
| 221 |
+
args.ckpt,
|
| 222 |
+
args.vae_ckpt,
|
| 223 |
+
args.dataset,
|
| 224 |
+
args.output_path,
|
| 225 |
+
scales_img,
|
| 226 |
+
scales_txt
|
| 227 |
+
steps = args.steps
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
plot_metrics(metrics_file, args.output_path)
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
if __name__ == "__main__":
|
| 235 |
+
main()
|
prompt_app.py
CHANGED
|
@@ -48,8 +48,8 @@ def main(openai_model: str):
|
|
| 48 |
|
| 49 |
if __name__ == "__main__":
|
| 50 |
parser = ArgumentParser()
|
| 51 |
-
parser.add_argument("openai-api-key", type=str)
|
| 52 |
-
parser.add_argument("openai-model", type=str)
|
| 53 |
args = parser.parse_args()
|
| 54 |
openai.api_key = args.openai_api_key
|
| 55 |
main(args.openai_model)
|
|
|
|
| 48 |
|
| 49 |
if __name__ == "__main__":
|
| 50 |
parser = ArgumentParser()
|
| 51 |
+
parser.add_argument("--openai-api-key", required=True, type=str)
|
| 52 |
+
parser.add_argument("--openai-model", required=True, type=str)
|
| 53 |
args = parser.parse_args()
|
| 54 |
openai.api_key = args.openai_api_key
|
| 55 |
main(args.openai_model)
|
scripts/download_checkpoints.sh
CHANGED
|
@@ -4,4 +4,4 @@ SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
|
|
| 4 |
|
| 5 |
mkdir -p $SCRIPT_DIR/../checkpoints
|
| 6 |
|
| 7 |
-
curl http://instruct-pix2pix.eecs.berkeley.edu/instruct-pix2pix-00-
|
|
|
|
| 4 |
|
| 5 |
mkdir -p $SCRIPT_DIR/../checkpoints
|
| 6 |
|
| 7 |
+
curl http://instruct-pix2pix.eecs.berkeley.edu/instruct-pix2pix-00-22000.ckpt -o $SCRIPT_DIR/../checkpoints/instruct-pix2pix-00-22000.ckpt
|
scripts/download_data.sh
CHANGED
|
@@ -1,11 +1,27 @@
|
|
| 1 |
#!/bin/bash
|
| 2 |
|
|
|
|
| 3 |
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
|
| 4 |
|
| 5 |
mkdir -p $SCRIPT_DIR/../data
|
| 6 |
|
| 7 |
-
|
| 8 |
-
wget http://instruct-pix2pix.eecs.berkeley.edu/
|
|
|
|
| 9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
mkdir $SCRIPT_DIR/../data/$1
|
| 11 |
-
wget -A zip,json -r http://instruct-pix2pix.eecs.berkeley.edu/$1 -nd -P $SCRIPT_DIR/../data/$1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
#!/bin/bash
|
| 2 |
|
| 3 |
+
# Make data folder relative to script location
|
| 4 |
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
|
| 5 |
|
| 6 |
mkdir -p $SCRIPT_DIR/../data
|
| 7 |
|
| 8 |
+
# Copy text datasets
|
| 9 |
+
wget -q --show-progress http://instruct-pix2pix.eecs.berkeley.edu/gpt-generated-prompts.jsonl -O $SCRIPT_DIR/../data/gpt-generated-prompts.jsonl
|
| 10 |
+
wget -q --show-progress http://instruct-pix2pix.eecs.berkeley.edu/human-written-prompts.jsonl -O $SCRIPT_DIR/../data/human-written-prompts.jsonl
|
| 11 |
|
| 12 |
+
# If dataset name isn't provided, exit.
|
| 13 |
+
if [ -z $1 ]
|
| 14 |
+
then
|
| 15 |
+
exit 0
|
| 16 |
+
fi
|
| 17 |
+
|
| 18 |
+
# Copy dataset files
|
| 19 |
mkdir $SCRIPT_DIR/../data/$1
|
| 20 |
+
wget -A zip,json -R "index.html*" -q --show-progress -r --no-parent http://instruct-pix2pix.eecs.berkeley.edu/$1/ -nd -P $SCRIPT_DIR/../data/$1/
|
| 21 |
+
|
| 22 |
+
# Unzip to folders
|
| 23 |
+
unzip $SCRIPT_DIR/../data/$1/\*.zip -d $SCRIPT_DIR/../data/$1/
|
| 24 |
+
|
| 25 |
+
# Cleanup
|
| 26 |
+
rm -f $SCRIPT_DIR/../data/$1/*.zip
|
| 27 |
+
rm -f $SCRIPT_DIR/../data/$1/*.html
|
scripts/download_pretrained_sd.sh
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
|
| 4 |
+
|
| 5 |
+
mkdir -p $SCRIPT_DIR/../stable_diffusion/models/ldm/stable-diffusion-v1
|
| 6 |
+
curl -L https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt -o $SCRIPT_DIR/../stable_diffusion/models/ldm/stable-diffusion-v1/v1-5-pruned-emaonly.ckpt
|
| 7 |
+
curl -L https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt -o $SCRIPT_DIR/../stable_diffusion/models/ldm/stable-diffusion-v1/vae-ft-mse-840000-ema-pruned.ckpt
|
stable_diffusion/main.py
CHANGED
|
@@ -737,5 +737,8 @@ if __name__ == "__main__":
|
|
| 737 |
dst = os.path.join(dst, "debug_runs", name)
|
| 738 |
os.makedirs(os.path.split(dst)[0], exist_ok=True)
|
| 739 |
os.rename(logdir, dst)
|
| 740 |
-
|
| 741 |
-
|
|
|
|
|
|
|
|
|
|
|
|
| 737 |
dst = os.path.join(dst, "debug_runs", name)
|
| 738 |
os.makedirs(os.path.split(dst)[0], exist_ok=True)
|
| 739 |
os.rename(logdir, dst)
|
| 740 |
+
try:
|
| 741 |
+
if trainer.global_rank == 0:
|
| 742 |
+
print(trainer.profiler.summary())
|
| 743 |
+
except:
|
| 744 |
+
pass
|