Spaces:
Running
on
T4

Running
on
T4
Robin Rombach
commited on
Commit
•
1fe8a15
1
Parent(s):
677e3db
stable diffusion
Browse filesFormer-commit-id: 2ff270f4e0c884d9684fa038f6d84d8600a94b39
- LICENSE +6 -13
- README.md +105 -144
- Stable_Diffusion_v1_Model_Card.md +140 -0
- assets/a-painting-of-a-fire.png +0 -0
- assets/a-photograph-of-a-fire.png +0 -0
- assets/a-shirt-with-a-fire-printed-on-it.png +0 -0
- assets/a-shirt-with-the-inscription-'fire'.png +0 -0
- assets/a-watercolor-painting-of-a-fire.png +0 -0
- assets/birdhouse.png +0 -0
- assets/fire.png +0 -0
- assets/rdm-preview.jpg +0 -0
- assets/stable-samples/img2img/mountains-1.png +0 -0
- assets/stable-samples/img2img/mountains-2.png +0 -0
- assets/stable-samples/img2img/mountains-3.png +0 -0
- assets/stable-samples/img2img/sketch-mountains-input.jpg +0 -0
- assets/stable-samples/img2img/upscaling-in.png.REMOVED.git-id +1 -0
- assets/stable-samples/img2img/upscaling-out.png.REMOVED.git-id +1 -0
- assets/stable-samples/txt2img/000002025.png +0 -0
- assets/stable-samples/txt2img/000002035.png +0 -0
- assets/stable-samples/txt2img/merged-0005.png.REMOVED.git-id +1 -0
- assets/stable-samples/txt2img/merged-0006.png.REMOVED.git-id +1 -0
- assets/stable-samples/txt2img/merged-0007.png.REMOVED.git-id +1 -0
- assets/the-earth-is-on-fire,-oil-on-canvas.png +0 -0
- assets/txt2img-convsample.png +0 -0
- assets/txt2img-preview.png.REMOVED.git-id +1 -0
- assets/v1-variants-scores.jpg +0 -0
- configs/latent-diffusion/cin256-v2.yaml +68 -0
- configs/latent-diffusion/txt2img-1p4B-eval.yaml +71 -0
- configs/retrieval-augmented-diffusion/768x768.yaml +68 -0
- configs/stable-diffusion/v1-inference.yaml +70 -0
- data/imagenet_clsidx_to_label.txt +1000 -0
- environment.yaml +5 -5
- ldm/models/diffusion/ddim.py +62 -6
- ldm/models/diffusion/plms.py +236 -0
- ldm/modules/diffusionmodules/openaimodel.py +39 -14
- ldm/modules/encoders/modules.py +103 -0
- ldm/modules/x_transformer.py +1 -1
- ldm/util.py +120 -3
- scripts/img2img.py +293 -0
- scripts/knn2img.py +398 -0
- scripts/latent_imagenet_diffusion.ipynb.REMOVED.git-id +1 -0
- scripts/train_searcher.py +147 -0
- scripts/txt2img.py +279 -0
LICENSE
CHANGED
|
@@ -1,16 +1,9 @@
|
|
| 1 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
-
Copyright (c) 2022 Machine Vision and Learning Group, LMU Munich
|
| 4 |
-
|
| 5 |
-
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
-
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
-
in the Software without restriction, including without limitation the rights
|
| 8 |
-
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
-
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
-
furnished to do so, subject to the following conditions:
|
| 11 |
-
|
| 12 |
-
The above copyright notice and this permission notice shall be included in all
|
| 13 |
-
copies or substantial portions of the Software.
|
| 14 |
|
| 15 |
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
@@ -18,4 +11,4 @@ FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
| 18 |
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
-
SOFTWARE.
|
|
|
|
| 1 |
+
All rights reserved by the authors.
|
| 2 |
+
You must not distribute the weights provided to you directly or indirectly without explicit consent of the authors.
|
| 3 |
+
You must not distribute harmful, offensive, dehumanizing content or otherwise harmful representations of people or their environments, cultures, religions, etc. produced with the model weights
|
| 4 |
+
or other generated content described in the "Misuse and Malicious Use" section in the model card.
|
| 5 |
+
The model weights are provided for research purposes only.
|
| 6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
|
| 8 |
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 9 |
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
|
|
| 11 |
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 12 |
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 13 |
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 14 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,11 +1,5 @@
|
|
| 1 |
-
#
|
| 2 |
-
[
|
| 3 |
-
|
| 4 |
-
<p align="center">
|
| 5 |
-
<img src=assets/results.gif />
|
| 6 |
-
</p>
|
| 7 |
-
|
| 8 |
-
|
| 9 |
|
| 10 |
[**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)<br/>
|
| 11 |
[Robin Rombach](https://github.com/rromb)\*,
|
|
@@ -13,12 +7,19 @@
|
|
| 13 |
[Dominik Lorenz](https://github.com/qp-qp)\,
|
| 14 |
[Patrick Esser](https://github.com/pesser),
|
| 15 |
[Björn Ommer](https://hci.iwr.uni-heidelberg.de/Staff/bommer)<br/>
|
| 16 |
-
\* equal contribution
|
| 17 |
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
|
|
|
|
| 22 |
## Requirements
|
| 23 |
A suitable [conda](https://conda.io/) environment named `ldm` can be created
|
| 24 |
and activated with:
|
|
@@ -28,176 +29,135 @@ conda env create -f environment.yaml
|
|
| 28 |
conda activate ldm
|
| 29 |
```
|
| 30 |
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
## Pretrained Autoencoding Models
|
| 34 |
-

|
| 35 |
-
|
| 36 |
-
All models were trained until convergence (no further substantial improvement in rFID).
|
| 37 |
-
|
| 38 |
-
| Model | rFID vs val | train steps |PSNR | PSIM | Link | Comments
|
| 39 |
-
|-------------------------|------------|----------------|----------------|---------------|-------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------|
|
| 40 |
-
| f=4, VQ (Z=8192, d=3) | 0.58 | 533066 | 27.43 +/- 4.26 | 0.53 +/- 0.21 | https://ommer-lab.com/files/latent-diffusion/vq-f4.zip | |
|
| 41 |
-
| f=4, VQ (Z=8192, d=3) | 1.06 | 658131 | 25.21 +/- 4.17 | 0.72 +/- 0.26 | https://heibox.uni-heidelberg.de/f/9c6681f64bb94338a069/?dl=1 | no attention |
|
| 42 |
-
| f=8, VQ (Z=16384, d=4) | 1.14 | 971043 | 23.07 +/- 3.99 | 1.17 +/- 0.36 | https://ommer-lab.com/files/latent-diffusion/vq-f8.zip | |
|
| 43 |
-
| f=8, VQ (Z=256, d=4) | 1.49 | 1608649 | 22.35 +/- 3.81 | 1.26 +/- 0.37 | https://ommer-lab.com/files/latent-diffusion/vq-f8-n256.zip |
|
| 44 |
-
| f=16, VQ (Z=16384, d=8) | 5.15 | 1101166 | 20.83 +/- 3.61 | 1.73 +/- 0.43 | https://heibox.uni-heidelberg.de/f/0e42b04e2e904890a9b6/?dl=1 | |
|
| 45 |
-
| | | | | | | |
|
| 46 |
-
| f=4, KL | 0.27 | 176991 | 27.53 +/- 4.54 | 0.55 +/- 0.24 | https://ommer-lab.com/files/latent-diffusion/kl-f4.zip | |
|
| 47 |
-
| f=8, KL | 0.90 | 246803 | 24.19 +/- 4.19 | 1.02 +/- 0.35 | https://ommer-lab.com/files/latent-diffusion/kl-f8.zip | |
|
| 48 |
-
| f=16, KL (d=16) | 0.87 | 442998 | 24.08 +/- 4.22 | 1.07 +/- 0.36 | https://ommer-lab.com/files/latent-diffusion/kl-f16.zip | |
|
| 49 |
-
| f=32, KL (d=64) | 2.04 | 406763 | 22.27 +/- 3.93 | 1.41 +/- 0.40 | https://ommer-lab.com/files/latent-diffusion/kl-f32.zip | |
|
| 50 |
|
| 51 |
-
### Get the models
|
| 52 |
-
|
| 53 |
-
Running the following script downloads und extracts all available pretrained autoencoding models.
|
| 54 |
-
```shell script
|
| 55 |
-
bash scripts/download_first_stages.sh
|
| 56 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
| 57 |
|
| 58 |
-
The first stage models can then be found in `models/first_stage_models/<model_spec>`
|
| 59 |
|
|
|
|
| 60 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 61 |
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
| LSUN-Churches | Unconditional Image Synthesis | LDM-KL-8 (400 DDIM steps, eta=0)| 4.02 (4.02) | 2.72 | 0.64 | 0.52 | https://ommer-lab.com/files/latent-diffusion/lsun_churches.zip | |
|
| 68 |
-
| LSUN-Bedrooms | Unconditional Image Synthesis | LDM-VQ-4 (200 DDIM steps, eta=1)| 2.95 (3.0) | 2.22 (2.23)| 0.66 | 0.48 | https://ommer-lab.com/files/latent-diffusion/lsun_bedrooms.zip | |
|
| 69 |
-
| ImageNet | Class-conditional Image Synthesis | LDM-VQ-8 (200 DDIM steps, eta=1) | 7.77(7.76)* /15.82** | 201.56(209.52)* /78.82** | 0.84* / 0.65** | 0.35* / 0.63** | https://ommer-lab.com/files/latent-diffusion/cin.zip | *: w/ guiding, classifier_scale 10 **: w/o guiding, scores in bracket calculated with script provided by [ADM](https://github.com/openai/guided-diffusion) |
|
| 70 |
-
| Conceptual Captions | Text-conditional Image Synthesis | LDM-VQ-f4 (100 DDIM steps, eta=0) | 16.79 | 13.89 | N/A | N/A | https://ommer-lab.com/files/latent-diffusion/text2img.zip | finetuned from LAION |
|
| 71 |
-
| OpenImages | Super-resolution | LDM-VQ-4 | N/A | N/A | N/A | N/A | https://ommer-lab.com/files/latent-diffusion/sr_bsr.zip | BSR image degradation |
|
| 72 |
-
| OpenImages | Layout-to-Image Synthesis | LDM-VQ-4 (200 DDIM steps, eta=0) | 32.02 | 15.92 | N/A | N/A | https://ommer-lab.com/files/latent-diffusion/layout2img_model.zip | |
|
| 73 |
-
| Landscapes | Semantic Image Synthesis | LDM-VQ-4 | N/A | N/A | N/A | N/A | https://ommer-lab.com/files/latent-diffusion/semantic_synthesis256.zip | |
|
| 74 |
-
| Landscapes | Semantic Image Synthesis | LDM-VQ-4 | N/A | N/A | N/A | N/A | https://ommer-lab.com/files/latent-diffusion/semantic_synthesis.zip | finetuned on resolution 512x512 |
|
| 75 |
|
|
|
|
| 76 |
|
| 77 |
-
###
|
| 78 |
|
| 79 |
-
|
|
|
|
| 80 |
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
|
|
|
|
|
|
|
|
|
| 84 |
|
| 85 |
-
|
|
|
|
|
|
|
|
|
|
| 86 |
|
| 87 |
-
### Sampling with unconditional models
|
| 88 |
|
| 89 |
-
We provide a first script for sampling from our unconditional models. Start it via
|
| 90 |
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
|
| 95 |
-
|
| 96 |
-

|
| 97 |
|
| 98 |
-
|
| 99 |
```
|
| 100 |
-
|
|
|
|
| 101 |
```
|
| 102 |
-
|
| 103 |
and sample with
|
| 104 |
```
|
| 105 |
-
python scripts/
|
| 106 |
```
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 110 |
|
| 111 |
-
# Train your own LDMs
|
| 112 |
-
|
| 113 |
-
## Data preparation
|
| 114 |
-
|
| 115 |
-
### Faces
|
| 116 |
-
For downloading the CelebA-HQ and FFHQ datasets, proceed as described in the [taming-transformers](https://github.com/CompVis/taming-transformers#celeba-hq)
|
| 117 |
-
repository.
|
| 118 |
-
|
| 119 |
-
### LSUN
|
| 120 |
-
|
| 121 |
-
The LSUN datasets can be conveniently downloaded via the script available [here](https://github.com/fyu/lsun).
|
| 122 |
-
We performed a custom split into training and validation images, and provide the corresponding filenames
|
| 123 |
-
at [https://ommer-lab.com/files/lsun.zip](https://ommer-lab.com/files/lsun.zip).
|
| 124 |
-
After downloading, extract them to `./data/lsun`. The beds/cats/churches subsets should
|
| 125 |
-
also be placed/symlinked at `./data/lsun/bedrooms`/`./data/lsun/cats`/`./data/lsun/churches`, respectively.
|
| 126 |
-
|
| 127 |
-
### ImageNet
|
| 128 |
-
The code will try to download (through [Academic
|
| 129 |
-
Torrents](http://academictorrents.com/)) and prepare ImageNet the first time it
|
| 130 |
-
is used. However, since ImageNet is quite large, this requires a lot of disk
|
| 131 |
-
space and time. If you already have ImageNet on your disk, you can speed things
|
| 132 |
-
up by putting the data into
|
| 133 |
-
`${XDG_CACHE}/autoencoders/data/ILSVRC2012_{split}/data/` (which defaults to
|
| 134 |
-
`~/.cache/autoencoders/data/ILSVRC2012_{split}/data/`), where `{split}` is one
|
| 135 |
-
of `train`/`validation`. It should have the following structure:
|
| 136 |
-
|
| 137 |
-
```
|
| 138 |
-
${XDG_CACHE}/autoencoders/data/ILSVRC2012_{split}/data/
|
| 139 |
-
├── n01440764
|
| 140 |
-
│ ├── n01440764_10026.JPEG
|
| 141 |
-
│ ├── n01440764_10027.JPEG
|
| 142 |
-
│ ├── ...
|
| 143 |
-
├── n01443537
|
| 144 |
-
│ ├── n01443537_10007.JPEG
|
| 145 |
-
│ ├── n01443537_10014.JPEG
|
| 146 |
-
│ ├── ...
|
| 147 |
-
├── ...
|
| 148 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
| 149 |
|
| 150 |
-
If you haven't extracted the data, you can also place
|
| 151 |
-
`ILSVRC2012_img_train.tar`/`ILSVRC2012_img_val.tar` (or symlinks to them) into
|
| 152 |
-
`${XDG_CACHE}/autoencoders/data/ILSVRC2012_train/` /
|
| 153 |
-
`${XDG_CACHE}/autoencoders/data/ILSVRC2012_validation/`, which will then be
|
| 154 |
-
extracted into above structure without downloading it again. Note that this
|
| 155 |
-
will only happen if neither a folder
|
| 156 |
-
`${XDG_CACHE}/autoencoders/data/ILSVRC2012_{split}/data/` nor a file
|
| 157 |
-
`${XDG_CACHE}/autoencoders/data/ILSVRC2012_{split}/.ready` exist. Remove them
|
| 158 |
-
if you want to force running the dataset preparation again.
|
| 159 |
|
|
|
|
| 160 |
|
| 161 |
-
|
|
|
|
|
|
|
| 162 |
|
| 163 |
-
|
| 164 |
-
|
| 165 |
-
### Training autoencoder models
|
| 166 |
-
|
| 167 |
-
Configs for training a KL-regularized autoencoder on ImageNet are provided at `configs/autoencoder`.
|
| 168 |
-
Training can be started by running
|
| 169 |
```
|
| 170 |
-
|
| 171 |
```
|
| 172 |
-
|
| 173 |
-
|
| 174 |
-
|
| 175 |
-
For training VQ-regularized models, see the [taming-transformers](https://github.com/CompVis/taming-transformers)
|
| 176 |
-
repository.
|
| 177 |
|
| 178 |
-
|
| 179 |
|
| 180 |
-
|
| 181 |
-
Training can be started by running
|
| 182 |
|
| 183 |
-
|
| 184 |
-
CUDA_VISIBLE_DEVICES=<GPU_ID> python main.py --base configs/latent-diffusion/<config_spec>.yaml -t --gpus 0,
|
| 185 |
-
```
|
| 186 |
-
|
| 187 |
-
where ``<config_spec>`` is one of {`celebahq-ldm-vq-4`(f=4, VQ-reg. autoencoder, spatial size 64x64x3),`ffhq-ldm-vq-4`(f=4, VQ-reg. autoencoder, spatial size 64x64x3),
|
| 188 |
-
`lsun_bedrooms-ldm-vq-4`(f=4, VQ-reg. autoencoder, spatial size 64x64x3),
|
| 189 |
-
`lsun_churches-ldm-vq-4`(f=8, KL-reg. autoencoder, spatial size 32x32x4),`cin-ldm-vq-8`(f=8, VQ-reg. autoencoder, spatial size 32x32x4)}.
|
| 190 |
|
| 191 |
-
|
|
|
|
| 192 |
|
| 193 |
-
|
| 194 |
-
* In the meantime, you can play with our colab notebook https://colab.research.google.com/drive/1xqzUi2iXQXDqXBHQGP9Mqt2YrYW6cx-J?usp=sharing
|
| 195 |
-
* We will also release some further pretrained models.
|
| 196 |
|
| 197 |
|
| 198 |
## Comments
|
| 199 |
|
| 200 |
-
- Our codebase for the diffusion models builds heavily on [OpenAI's codebase](https://github.com/openai/guided-diffusion)
|
| 201 |
and [https://github.com/lucidrains/denoising-diffusion-pytorch](https://github.com/lucidrains/denoising-diffusion-pytorch).
|
| 202 |
Thanks for open-sourcing!
|
| 203 |
|
|
@@ -215,6 +175,7 @@ Thanks for open-sourcing!
|
|
| 215 |
archivePrefix={arXiv},
|
| 216 |
primaryClass={cs.CV}
|
| 217 |
}
|
|
|
|
| 218 |
```
|
| 219 |
|
| 220 |
|
|
|
|
| 1 |
+
# Stable Diffusion
|
| 2 |
+
*Stable Diffusion was made possible thanks to a collaboration with [Stability AI](https://stability.ai/) and [Runway](https://runwayml.com/) and builds upon our previous work:*
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
|
| 4 |
[**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)<br/>
|
| 5 |
[Robin Rombach](https://github.com/rromb)\*,
|
|
|
|
| 7 |
[Dominik Lorenz](https://github.com/qp-qp)\,
|
| 8 |
[Patrick Esser](https://github.com/pesser),
|
| 9 |
[Björn Ommer](https://hci.iwr.uni-heidelberg.de/Staff/bommer)<br/>
|
|
|
|
| 10 |
|
| 11 |
+
which is available on [GitHub](https://github.com/CompVis/latent-diffusion).
|
| 12 |
+
|
| 13 |
+

|
| 14 |
+
[Stable Diffusion](#stable-diffusion-v1) is a latent text-to-image diffusion
|
| 15 |
+
model.
|
| 16 |
+
Thanks to a generous compute donation from [Stability AI](https://stability.ai/) and support from [LAION](https://laion.ai/), we were able to train a Latent Diffusion Model on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) database.
|
| 17 |
+
Similar to Google's [Imagen](https://arxiv.org/abs/2205.11487),
|
| 18 |
+
this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
|
| 19 |
+
With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM.
|
| 20 |
+
See [this section](#stable-diffusion-v1) below and the [model card](https://huggingface.co/CompVis/stable-diffusion).
|
| 21 |
|
| 22 |
+
|
| 23 |
## Requirements
|
| 24 |
A suitable [conda](https://conda.io/) environment named `ldm` can be created
|
| 25 |
and activated with:
|
|
|
|
| 29 |
conda activate ldm
|
| 30 |
```
|
| 31 |
|
| 32 |
+
You can also update an existing [latent diffusion](https://github.com/CompVis/latent-diffusion) environment by running
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
```
|
| 35 |
+
conda install pytorch torchvision -c pytorch
|
| 36 |
+
pip install transformers==4.19.2
|
| 37 |
+
pip install -e .
|
| 38 |
+
```
|
| 39 |
|
|
|
|
| 40 |
|
| 41 |
+
## Stable Diffusion v1
|
| 42 |
|
| 43 |
+
Stable Diffusion v1 refers to a specific configuration of the model
|
| 44 |
+
architecture that uses a downsampling-factor 8 autoencoder with an 860M UNet
|
| 45 |
+
and CLIP ViT-L/14 text encoder for the diffusion model. The model was pretrained on 256x256 images and
|
| 46 |
+
then finetuned on 512x512 images.
|
| 47 |
|
| 48 |
+
*Note: Stable Diffusion v1 is a general text-to-image diffusion model and therefore mirrors biases and (mis-)conceptions that are present
|
| 49 |
+
in its training data.
|
| 50 |
+
Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding [model card](https://huggingface.co/CompVis/stable-diffusion).
|
| 51 |
+
Research into the safe deployment of general text-to-image models is an ongoing effort. To prevent misuse and harm, we currently provide access to the checkpoints only for [academic research purposes upon request](TODO).
|
| 52 |
+
**This is an experiment in safe and community-driven publication of a capable and general text-to-image model. We are working on a public release with a more permissive license that also incorporates ethical considerations.***
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 53 |
|
| 54 |
+
[Request access to Stable Diffusion v1 checkpoints for academic research](TODO)
|
| 55 |
|
| 56 |
+
### Weights
|
| 57 |
|
| 58 |
+
We currently provide three checkpoints, `sd-v1-1.ckpt`, `sd-v1-2.ckpt` and `sd-v1-3.ckpt`,
|
| 59 |
+
which were trained as follows,
|
| 60 |
|
| 61 |
+
- `sd-v1-1.ckpt`: 237k steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
|
| 62 |
+
194k steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
|
| 63 |
+
- `sd-v1-2.ckpt`: Resumed from `sd-v1-1.ckpt`.
|
| 64 |
+
515k steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
|
| 65 |
+
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
|
| 66 |
+
- `sd-v1-3.ckpt`: Resumed from `sd-v1-2.ckpt`. 195k steps at resolution `512x512` on "laion-improved-aesthetics" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
|
| 67 |
|
| 68 |
+
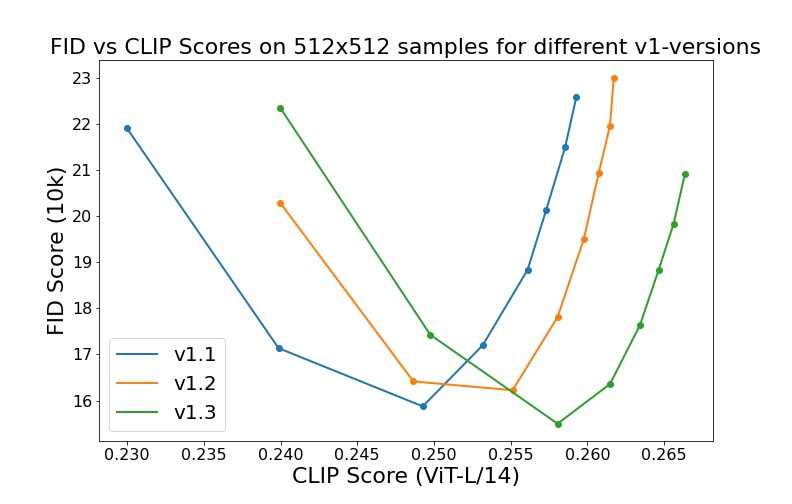
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
|
| 69 |
+
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
|
| 70 |
+
steps show the relative improvements of the checkpoints:
|
| 71 |
+

|
| 72 |
|
|
|
|
| 73 |
|
|
|
|
| 74 |
|
| 75 |
+
### Text-to-Image with Stable Diffusion
|
| 76 |
+

|
| 77 |
+

|
| 78 |
|
| 79 |
+
Stable Diffusion is a latent diffusion model conditioned on the (non-pooled) text embeddings of a CLIP ViT-L/14 text encoder.
|
|
|
|
| 80 |
|
| 81 |
+
After [obtaining the weights](#weights), link them
|
| 82 |
```
|
| 83 |
+
mkdir -p models/ldm/stable-diffusion-v1/
|
| 84 |
+
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
|
| 85 |
```
|
|
|
|
| 86 |
and sample with
|
| 87 |
```
|
| 88 |
+
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
|
| 89 |
```
|
| 90 |
+
By default, this uses a guidance scale of `--scale 7.5`, [Katherine Crowson's implementation](https://github.com/CompVis/latent-diffusion/pull/51) of the [PLMS](https://arxiv.org/abs/2202.09778) sampler,
|
| 91 |
+
and renders images of size 512x512 (which it was trained on) in 50 steps. All supported arguments are listed below (type `python scripts/txt2img.py --help`).
|
| 92 |
+
|
| 93 |
+
```commandline
|
| 94 |
+
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA] [--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS]
|
| 95 |
+
[--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT] [--seed SEED] [--precision {full,autocast}]
|
| 96 |
+
|
| 97 |
+
optional arguments:
|
| 98 |
+
-h, --help show this help message and exit
|
| 99 |
+
--prompt [PROMPT] the prompt to render
|
| 100 |
+
--outdir [OUTDIR] dir to write results to
|
| 101 |
+
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
|
| 102 |
+
--skip_save do not save individual samples. For speed measurements.
|
| 103 |
+
--ddim_steps DDIM_STEPS
|
| 104 |
+
number of ddim sampling steps
|
| 105 |
+
--plms use plms sampling
|
| 106 |
+
--laion400m uses the LAION400M model
|
| 107 |
+
--fixed_code if enabled, uses the same starting code across samples
|
| 108 |
+
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
|
| 109 |
+
--n_iter N_ITER sample this often
|
| 110 |
+
--H H image height, in pixel space
|
| 111 |
+
--W W image width, in pixel space
|
| 112 |
+
--C C latent channels
|
| 113 |
+
--f F downsampling factor
|
| 114 |
+
--n_samples N_SAMPLES
|
| 115 |
+
how many samples to produce for each given prompt. A.k.a. batch size
|
| 116 |
+
--n_rows N_ROWS rows in the grid (default: n_samples)
|
| 117 |
+
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
|
| 118 |
+
--from-file FROM_FILE
|
| 119 |
+
if specified, load prompts from this file
|
| 120 |
+
--config CONFIG path to config which constructs model
|
| 121 |
+
--ckpt CKPT path to checkpoint of model
|
| 122 |
+
--seed SEED the seed (for reproducible sampling)
|
| 123 |
+
--precision {full,autocast}
|
| 124 |
+
evaluate at this precision
|
| 125 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 126 |
```
|
| 127 |
+
Note: The inference config for all v1 versions is designed to be used with EMA-only checkpoints.
|
| 128 |
+
For this reason `use_ema=False` is set in the configuration, otherwise the code will try to switch from
|
| 129 |
+
non-EMA to EMA weights. If you want to examine the effect of EMA vs no EMA, we provide "full" checkpoints
|
| 130 |
+
which contain both types of weights. For these, `use_ema=False` will load and use the non-EMA weights.
|
| 131 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 132 |
|
| 133 |
+
### Image Modification with Stable Diffusion
|
| 134 |
|
| 135 |
+
By using a diffusion-denoising mechanism as first proposed by [SDEdit](https://arxiv.org/abs/2108.01073), the model can be used for different
|
| 136 |
+
tasks such as text-guided image-to-image translation and upscaling. Similar to the txt2img sampling script,
|
| 137 |
+
we provide a script to perform image modification with Stable Diffusion.
|
| 138 |
|
| 139 |
+
The following describes an example where a rough sketch made in [Pinta](https://www.pinta-project.com/) is converted into a detailed artwork.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 140 |
```
|
| 141 |
+
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
|
| 142 |
```
|
| 143 |
+
Here, strength is a value between 0.0 and 1.0, that controls the amount of noise that is added to the input image.
|
| 144 |
+
Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input. See the following example.
|
|
|
|
|
|
|
|
|
|
| 145 |
|
| 146 |
+
**Input**
|
| 147 |
|
| 148 |
+

|
|
|
|
| 149 |
|
| 150 |
+
**Outputs**
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 151 |
|
| 152 |
+

|
| 153 |
+

|
| 154 |
|
| 155 |
+
This procedure can, for example, also be used to upscale samples from the base model.
|
|
|
|
|
|
|
| 156 |
|
| 157 |
|
| 158 |
## Comments
|
| 159 |
|
| 160 |
+
- Our codebase for the diffusion models builds heavily on [OpenAI's ADM codebase](https://github.com/openai/guided-diffusion)
|
| 161 |
and [https://github.com/lucidrains/denoising-diffusion-pytorch](https://github.com/lucidrains/denoising-diffusion-pytorch).
|
| 162 |
Thanks for open-sourcing!
|
| 163 |
|
|
|
|
| 175 |
archivePrefix={arXiv},
|
| 176 |
primaryClass={cs.CV}
|
| 177 |
}
|
| 178 |
+
|
| 179 |
```
|
| 180 |
|
| 181 |
|
Stable_Diffusion_v1_Model_Card.md
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Stable Diffusion v1 Model Card
|
| 2 |
+
This model card focuses on the model associated with the Stable Diffusion model, available [here](https://github.com/CompVis/stable-diffusion).
|
| 3 |
+
|
| 4 |
+
## Model Details
|
| 5 |
+
- **Developed by:** Robin Rombach, Patrick Esser
|
| 6 |
+
- **Model type:** Diffusion-based text-to-image generation model
|
| 7 |
+
- **Language(s):** English
|
| 8 |
+
- **License:** [Proprietary](LICENSE)
|
| 9 |
+
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
|
| 10 |
+
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
|
| 11 |
+
- **Cite as:**
|
| 12 |
+
|
| 13 |
+
@InProceedings{Rombach_2022_CVPR,
|
| 14 |
+
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
|
| 15 |
+
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
|
| 16 |
+
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
|
| 17 |
+
month = {June},
|
| 18 |
+
year = {2022},
|
| 19 |
+
pages = {10684-10695}
|
| 20 |
+
}
|
| 21 |
+
|
| 22 |
+
# Uses
|
| 23 |
+
|
| 24 |
+
## Direct Use
|
| 25 |
+
The model is intended for research purposes only. Possible research areas and
|
| 26 |
+
tasks include
|
| 27 |
+
|
| 28 |
+
- Safe deployment of models which have the potential to generate harmful content.
|
| 29 |
+
- Probing and understanding the limitations and biases of generative models.
|
| 30 |
+
- Generation of artworks and use in design and other artistic processes.
|
| 31 |
+
- Applications in educational or creative tools.
|
| 32 |
+
- Research on generative models.
|
| 33 |
+
|
| 34 |
+
Excluded uses are described below.
|
| 35 |
+
|
| 36 |
+
### Misuse, Malicious Use, and Out-of-Scope Use
|
| 37 |
+
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
|
| 41 |
+
#### Out-of-Scope Use
|
| 42 |
+
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
|
| 43 |
+
#### Misuse and Malicious Use
|
| 44 |
+
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
|
| 45 |
+
|
| 46 |
+
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
|
| 47 |
+
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
|
| 48 |
+
- Impersonating individuals without their consent.
|
| 49 |
+
- Sexual content without consent of the people who might see it.
|
| 50 |
+
- Mis- and disinformation
|
| 51 |
+
- Representations of egregious violence and gore
|
| 52 |
+
- Sharing of copyrighted or licensed material in violation of its terms of use.
|
| 53 |
+
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
|
| 54 |
+
|
| 55 |
+
## Limitations and Bias
|
| 56 |
+
|
| 57 |
+
### Limitations
|
| 58 |
+
|
| 59 |
+
- The model does not achieve perfect photorealism
|
| 60 |
+
- The model cannot render legible text
|
| 61 |
+
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
|
| 62 |
+
- Faces and people in general may not be generated properly.
|
| 63 |
+
- The model was trained mainly with English captions and will not work as well in other languages.
|
| 64 |
+
- The autoencoding part of the model is lossy
|
| 65 |
+
- The model was trained on a large-scale dataset
|
| 66 |
+
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
|
| 67 |
+
and is not fit for product use without additional safety mechanisms and
|
| 68 |
+
considerations.
|
| 69 |
+
|
| 70 |
+
### Bias
|
| 71 |
+
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
| 72 |
+
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
|
| 73 |
+
which consists of images that are primarily limited to English descriptions.
|
| 74 |
+
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
|
| 75 |
+
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
|
| 76 |
+
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
## Training
|
| 80 |
+
|
| 81 |
+
**Training Data**
|
| 82 |
+
The model developers used the following dataset for training the model:
|
| 83 |
+
|
| 84 |
+
- LAION-2B (en) and subsets thereof (see next section)
|
| 85 |
+
|
| 86 |
+
**Training Procedure**
|
| 87 |
+
Stable Diffusion v1 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
|
| 88 |
+
|
| 89 |
+
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
|
| 90 |
+
- Text prompts are encoded through a ViT-L/14 text-encoder.
|
| 91 |
+
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
|
| 92 |
+
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
|
| 93 |
+
|
| 94 |
+
We currently provide three checkpoints, `sd-v1-1.ckpt`, `sd-v1-2.ckpt` and `sd-v1-3.ckpt`,
|
| 95 |
+
which were trained as follows,
|
| 96 |
+
|
| 97 |
+
- `sd-v1-1.ckpt`: 237k steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
|
| 98 |
+
194k steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
|
| 99 |
+
- `sd-v1-2.ckpt`: Resumed from `sd-v1-1.ckpt`.
|
| 100 |
+
515k steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
|
| 101 |
+
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
|
| 102 |
+
- `sd-v1-3.ckpt`: Resumed from `sd-v1-2.ckpt`. 195k steps at resolution `512x512` on "laion-improved-aesthetics" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
- **Hardware:** 32 x 8 x A100 GPUs
|
| 106 |
+
- **Optimizer:** AdamW
|
| 107 |
+
- **Gradient Accumulations**: 2
|
| 108 |
+
- **Batch:** 32 x 8 x 2 x 4 = 2048
|
| 109 |
+
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
|
| 110 |
+
|
| 111 |
+
## Evaluation Results
|
| 112 |
+
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
|
| 113 |
+
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
|
| 114 |
+
steps show the relative improvements of the checkpoints:
|
| 115 |
+
|
| 116 |
+

|
| 117 |
+
|
| 118 |
+
Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
|
| 119 |
+
## Environmental Impact
|
| 120 |
+
|
| 121 |
+
**Stable Diffusion v1** **Estimated Emissions**
|
| 122 |
+
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
|
| 123 |
+
|
| 124 |
+
- **Hardware Type:** A100 PCIe 40GB
|
| 125 |
+
- **Hours used:** 150000
|
| 126 |
+
- **Cloud Provider:** AWS
|
| 127 |
+
- **Compute Region:** US-east
|
| 128 |
+
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
|
| 129 |
+
## Citation
|
| 130 |
+
@InProceedings{Rombach_2022_CVPR,
|
| 131 |
+
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
|
| 132 |
+
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
|
| 133 |
+
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
|
| 134 |
+
month = {June},
|
| 135 |
+
year = {2022},
|
| 136 |
+
pages = {10684-10695}
|
| 137 |
+
}
|
| 138 |
+
|
| 139 |
+
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
| 140 |
+
|
assets/a-painting-of-a-fire.png
ADDED

|
assets/a-photograph-of-a-fire.png
ADDED

|
assets/a-shirt-with-a-fire-printed-on-it.png
ADDED

|
assets/a-shirt-with-the-inscription-'fire'.png
ADDED

|
assets/a-watercolor-painting-of-a-fire.png
ADDED
|
assets/birdhouse.png
ADDED

|
assets/fire.png
ADDED

|
assets/rdm-preview.jpg
ADDED
|
assets/stable-samples/img2img/mountains-1.png
ADDED

|
assets/stable-samples/img2img/mountains-2.png
ADDED

|
assets/stable-samples/img2img/mountains-3.png
ADDED

|
assets/stable-samples/img2img/sketch-mountains-input.jpg
ADDED

|
assets/stable-samples/img2img/upscaling-in.png.REMOVED.git-id
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
501c31c21751664957e69ce52cad1818b6d2f4ce
|
assets/stable-samples/img2img/upscaling-out.png.REMOVED.git-id
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
1c4bb25a779f34d86b2d90e584ac67af91bb1303
|
assets/stable-samples/txt2img/000002025.png
ADDED

|
assets/stable-samples/txt2img/000002035.png
ADDED

|
assets/stable-samples/txt2img/merged-0005.png.REMOVED.git-id
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
ca0a1af206555f0f208a1ab879e95efedc1b1c5b
|
assets/stable-samples/txt2img/merged-0006.png.REMOVED.git-id
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
999f3703230580e8c89e9081abd6a1f8f50896d4
|
assets/stable-samples/txt2img/merged-0007.png.REMOVED.git-id
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
af390acaf601283782d6f479d4cade4d78e30b26
|
assets/the-earth-is-on-fire,-oil-on-canvas.png
ADDED

|
assets/txt2img-convsample.png
ADDED

|
assets/txt2img-preview.png.REMOVED.git-id
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
51ee1c235dfdc63d4c41de7d303d03730e43c33c
|
assets/v1-variants-scores.jpg
ADDED
|
configs/latent-diffusion/cin256-v2.yaml
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 0.0001
|
| 3 |
+
target: ldm.models.diffusion.ddpm.LatentDiffusion
|
| 4 |
+
params:
|
| 5 |
+
linear_start: 0.0015
|
| 6 |
+
linear_end: 0.0195
|
| 7 |
+
num_timesteps_cond: 1
|
| 8 |
+
log_every_t: 200
|
| 9 |
+
timesteps: 1000
|
| 10 |
+
first_stage_key: image
|
| 11 |
+
cond_stage_key: class_label
|
| 12 |
+
image_size: 64
|
| 13 |
+
channels: 3
|
| 14 |
+
cond_stage_trainable: true
|
| 15 |
+
conditioning_key: crossattn
|
| 16 |
+
monitor: val/loss
|
| 17 |
+
use_ema: False
|
| 18 |
+
|
| 19 |
+
unet_config:
|
| 20 |
+
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
| 21 |
+
params:
|
| 22 |
+
image_size: 64
|
| 23 |
+
in_channels: 3
|
| 24 |
+
out_channels: 3
|
| 25 |
+
model_channels: 192
|
| 26 |
+
attention_resolutions:
|
| 27 |
+
- 8
|
| 28 |
+
- 4
|
| 29 |
+
- 2
|
| 30 |
+
num_res_blocks: 2
|
| 31 |
+
channel_mult:
|
| 32 |
+
- 1
|
| 33 |
+
- 2
|
| 34 |
+
- 3
|
| 35 |
+
- 5
|
| 36 |
+
num_heads: 1
|
| 37 |
+
use_spatial_transformer: true
|
| 38 |
+
transformer_depth: 1
|
| 39 |
+
context_dim: 512
|
| 40 |
+
|
| 41 |
+
first_stage_config:
|
| 42 |
+
target: ldm.models.autoencoder.VQModelInterface
|
| 43 |
+
params:
|
| 44 |
+
embed_dim: 3
|
| 45 |
+
n_embed: 8192
|
| 46 |
+
ddconfig:
|
| 47 |
+
double_z: false
|
| 48 |
+
z_channels: 3
|
| 49 |
+
resolution: 256
|
| 50 |
+
in_channels: 3
|
| 51 |
+
out_ch: 3
|
| 52 |
+
ch: 128
|
| 53 |
+
ch_mult:
|
| 54 |
+
- 1
|
| 55 |
+
- 2
|
| 56 |
+
- 4
|
| 57 |
+
num_res_blocks: 2
|
| 58 |
+
attn_resolutions: []
|
| 59 |
+
dropout: 0.0
|
| 60 |
+
lossconfig:
|
| 61 |
+
target: torch.nn.Identity
|
| 62 |
+
|
| 63 |
+
cond_stage_config:
|
| 64 |
+
target: ldm.modules.encoders.modules.ClassEmbedder
|
| 65 |
+
params:
|
| 66 |
+
n_classes: 1001
|
| 67 |
+
embed_dim: 512
|
| 68 |
+
key: class_label
|
configs/latent-diffusion/txt2img-1p4B-eval.yaml
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 5.0e-05
|
| 3 |
+
target: ldm.models.diffusion.ddpm.LatentDiffusion
|
| 4 |
+
params:
|
| 5 |
+
linear_start: 0.00085
|
| 6 |
+
linear_end: 0.012
|
| 7 |
+
num_timesteps_cond: 1
|
| 8 |
+
log_every_t: 200
|
| 9 |
+
timesteps: 1000
|
| 10 |
+
first_stage_key: image
|
| 11 |
+
cond_stage_key: caption
|
| 12 |
+
image_size: 32
|
| 13 |
+
channels: 4
|
| 14 |
+
cond_stage_trainable: true
|
| 15 |
+
conditioning_key: crossattn
|
| 16 |
+
monitor: val/loss_simple_ema
|
| 17 |
+
scale_factor: 0.18215
|
| 18 |
+
use_ema: False
|
| 19 |
+
|
| 20 |
+
unet_config:
|
| 21 |
+
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
| 22 |
+
params:
|
| 23 |
+
image_size: 32
|
| 24 |
+
in_channels: 4
|
| 25 |
+
out_channels: 4
|
| 26 |
+
model_channels: 320
|
| 27 |
+
attention_resolutions:
|
| 28 |
+
- 4
|
| 29 |
+
- 2
|
| 30 |
+
- 1
|
| 31 |
+
num_res_blocks: 2
|
| 32 |
+
channel_mult:
|
| 33 |
+
- 1
|
| 34 |
+
- 2
|
| 35 |
+
- 4
|
| 36 |
+
- 4
|
| 37 |
+
num_heads: 8
|
| 38 |
+
use_spatial_transformer: true
|
| 39 |
+
transformer_depth: 1
|
| 40 |
+
context_dim: 1280
|
| 41 |
+
use_checkpoint: true
|
| 42 |
+
legacy: False
|
| 43 |
+
|
| 44 |
+
first_stage_config:
|
| 45 |
+
target: ldm.models.autoencoder.AutoencoderKL
|
| 46 |
+
params:
|
| 47 |
+
embed_dim: 4
|
| 48 |
+
monitor: val/rec_loss
|
| 49 |
+
ddconfig:
|
| 50 |
+
double_z: true
|
| 51 |
+
z_channels: 4
|
| 52 |
+
resolution: 256
|
| 53 |
+
in_channels: 3
|
| 54 |
+
out_ch: 3
|
| 55 |
+
ch: 128
|
| 56 |
+
ch_mult:
|
| 57 |
+
- 1
|
| 58 |
+
- 2
|
| 59 |
+
- 4
|
| 60 |
+
- 4
|
| 61 |
+
num_res_blocks: 2
|
| 62 |
+
attn_resolutions: []
|
| 63 |
+
dropout: 0.0
|
| 64 |
+
lossconfig:
|
| 65 |
+
target: torch.nn.Identity
|
| 66 |
+
|
| 67 |
+
cond_stage_config:
|
| 68 |
+
target: ldm.modules.encoders.modules.BERTEmbedder
|
| 69 |
+
params:
|
| 70 |
+
n_embed: 1280
|
| 71 |
+
n_layer: 32
|
configs/retrieval-augmented-diffusion/768x768.yaml
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 0.0001
|
| 3 |
+
target: ldm.models.diffusion.ddpm.LatentDiffusion
|
| 4 |
+
params:
|
| 5 |
+
linear_start: 0.0015
|
| 6 |
+
linear_end: 0.015
|
| 7 |
+
num_timesteps_cond: 1
|
| 8 |
+
log_every_t: 200
|
| 9 |
+
timesteps: 1000
|
| 10 |
+
first_stage_key: jpg
|
| 11 |
+
cond_stage_key: nix
|
| 12 |
+
image_size: 48
|
| 13 |
+
channels: 16
|
| 14 |
+
cond_stage_trainable: false
|
| 15 |
+
conditioning_key: crossattn
|
| 16 |
+
monitor: val/loss_simple_ema
|
| 17 |
+
scale_by_std: false
|
| 18 |
+
scale_factor: 0.22765929
|
| 19 |
+
unet_config:
|
| 20 |
+
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
| 21 |
+
params:
|
| 22 |
+
image_size: 48
|
| 23 |
+
in_channels: 16
|
| 24 |
+
out_channels: 16
|
| 25 |
+
model_channels: 448
|
| 26 |
+
attention_resolutions:
|
| 27 |
+
- 4
|
| 28 |
+
- 2
|
| 29 |
+
- 1
|
| 30 |
+
num_res_blocks: 2
|
| 31 |
+
channel_mult:
|
| 32 |
+
- 1
|
| 33 |
+
- 2
|
| 34 |
+
- 3
|
| 35 |
+
- 4
|
| 36 |
+
use_scale_shift_norm: false
|
| 37 |
+
resblock_updown: false
|
| 38 |
+
num_head_channels: 32
|
| 39 |
+
use_spatial_transformer: true
|
| 40 |
+
transformer_depth: 1
|
| 41 |
+
context_dim: 768
|
| 42 |
+
use_checkpoint: true
|
| 43 |
+
first_stage_config:
|
| 44 |
+
target: ldm.models.autoencoder.AutoencoderKL
|
| 45 |
+
params:
|
| 46 |
+
monitor: val/rec_loss
|
| 47 |
+
embed_dim: 16
|
| 48 |
+
ddconfig:
|
| 49 |
+
double_z: true
|
| 50 |
+
z_channels: 16
|
| 51 |
+
resolution: 256
|
| 52 |
+
in_channels: 3
|
| 53 |
+
out_ch: 3
|
| 54 |
+
ch: 128
|
| 55 |
+
ch_mult:
|
| 56 |
+
- 1
|
| 57 |
+
- 1
|
| 58 |
+
- 2
|
| 59 |
+
- 2
|
| 60 |
+
- 4
|
| 61 |
+
num_res_blocks: 2
|
| 62 |
+
attn_resolutions:
|
| 63 |
+
- 16
|
| 64 |
+
dropout: 0.0
|
| 65 |
+
lossconfig:
|
| 66 |
+
target: torch.nn.Identity
|
| 67 |
+
cond_stage_config:
|
| 68 |
+
target: torch.nn.Identity
|
configs/stable-diffusion/v1-inference.yaml
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 1.0e-04
|
| 3 |
+
target: ldm.models.diffusion.ddpm.LatentDiffusion
|
| 4 |
+
params:
|
| 5 |
+
linear_start: 0.00085
|
| 6 |
+
linear_end: 0.0120
|
| 7 |
+
num_timesteps_cond: 1
|
| 8 |
+
log_every_t: 200
|
| 9 |
+
timesteps: 1000
|
| 10 |
+
first_stage_key: "jpg"
|
| 11 |
+
cond_stage_key: "txt"
|
| 12 |
+
image_size: 64
|
| 13 |
+
channels: 4
|
| 14 |
+
cond_stage_trainable: false # Note: different from the one we trained before
|
| 15 |
+
conditioning_key: crossattn
|
| 16 |
+
monitor: val/loss_simple_ema
|
| 17 |
+
scale_factor: 0.18215
|
| 18 |
+
use_ema: False
|
| 19 |
+
|
| 20 |
+
scheduler_config: # 10000 warmup steps
|
| 21 |
+
target: ldm.lr_scheduler.LambdaLinearScheduler
|
| 22 |
+
params:
|
| 23 |
+
warm_up_steps: [ 10000 ]
|
| 24 |
+
cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
|
| 25 |
+
f_start: [ 1.e-6 ]
|
| 26 |
+
f_max: [ 1. ]
|
| 27 |
+
f_min: [ 1. ]
|
| 28 |
+
|
| 29 |
+
unet_config:
|
| 30 |
+
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
| 31 |
+
params:
|
| 32 |
+
image_size: 32 # unused
|
| 33 |
+
in_channels: 4
|
| 34 |
+
out_channels: 4
|
| 35 |
+
model_channels: 320
|
| 36 |
+
attention_resolutions: [ 4, 2, 1 ]
|
| 37 |
+
num_res_blocks: 2
|
| 38 |
+
channel_mult: [ 1, 2, 4, 4 ]
|
| 39 |
+
num_heads: 8
|
| 40 |
+
use_spatial_transformer: True
|
| 41 |
+
transformer_depth: 1
|
| 42 |
+
context_dim: 768
|
| 43 |
+
use_checkpoint: True
|
| 44 |
+
legacy: False
|
| 45 |
+
|
| 46 |
+
first_stage_config:
|
| 47 |
+
target: ldm.models.autoencoder.AutoencoderKL
|
| 48 |
+
params:
|
| 49 |
+
embed_dim: 4
|
| 50 |
+
monitor: val/rec_loss
|
| 51 |
+
ddconfig:
|
| 52 |
+
double_z: true
|
| 53 |
+
z_channels: 4
|
| 54 |
+
resolution: 256
|
| 55 |
+
in_channels: 3
|
| 56 |
+
out_ch: 3
|
| 57 |
+
ch: 128
|
| 58 |
+
ch_mult:
|
| 59 |
+
- 1
|
| 60 |
+
- 2
|
| 61 |
+
- 4
|
| 62 |
+
- 4
|
| 63 |
+
num_res_blocks: 2
|
| 64 |
+
attn_resolutions: []
|
| 65 |
+
dropout: 0.0
|
| 66 |
+
lossconfig:
|
| 67 |
+
target: torch.nn.Identity
|
| 68 |
+
|
| 69 |
+
cond_stage_config:
|
| 70 |
+
target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
|
data/imagenet_clsidx_to_label.txt
ADDED
|
@@ -0,0 +1,1000 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
0: 'tench, Tinca tinca',
|
| 2 |
+
1: 'goldfish, Carassius auratus',
|
| 3 |
+
2: 'great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias',
|
| 4 |
+
3: 'tiger shark, Galeocerdo cuvieri',
|
| 5 |
+
4: 'hammerhead, hammerhead shark',
|
| 6 |
+
5: 'electric ray, crampfish, numbfish, torpedo',
|
| 7 |
+
6: 'stingray',
|
| 8 |
+
7: 'cock',
|
| 9 |
+
8: 'hen',
|
| 10 |
+
9: 'ostrich, Struthio camelus',
|
| 11 |
+
10: 'brambling, Fringilla montifringilla',
|
| 12 |
+
11: 'goldfinch, Carduelis carduelis',
|
| 13 |
+
12: 'house finch, linnet, Carpodacus mexicanus',
|
| 14 |
+
13: 'junco, snowbird',
|
| 15 |
+
14: 'indigo bunting, indigo finch, indigo bird, Passerina cyanea',
|
| 16 |
+
15: 'robin, American robin, Turdus migratorius',
|
| 17 |
+
16: 'bulbul',
|
| 18 |
+
17: 'jay',
|
| 19 |
+
18: 'magpie',
|
| 20 |
+
19: 'chickadee',
|
| 21 |
+
20: 'water ouzel, dipper',
|
| 22 |
+
21: 'kite',
|
| 23 |
+
22: 'bald eagle, American eagle, Haliaeetus leucocephalus',
|
| 24 |
+
23: 'vulture',
|
| 25 |
+
24: 'great grey owl, great gray owl, Strix nebulosa',
|
| 26 |
+
25: 'European fire salamander, Salamandra salamandra',
|
| 27 |
+
26: 'common newt, Triturus vulgaris',
|
| 28 |
+
27: 'eft',
|
| 29 |
+
28: 'spotted salamander, Ambystoma maculatum',
|
| 30 |
+
29: 'axolotl, mud puppy, Ambystoma mexicanum',
|
| 31 |
+
30: 'bullfrog, Rana catesbeiana',
|
| 32 |
+
31: 'tree frog, tree-frog',
|
| 33 |
+
32: 'tailed frog, bell toad, ribbed toad, tailed toad, Ascaphus trui',
|
| 34 |
+
33: 'loggerhead, loggerhead turtle, Caretta caretta',
|
| 35 |
+
34: 'leatherback turtle, leatherback, leathery turtle, Dermochelys coriacea',
|
| 36 |
+
35: 'mud turtle',
|
| 37 |
+
36: 'terrapin',
|
| 38 |
+
37: 'box turtle, box tortoise',
|
| 39 |
+
38: 'banded gecko',
|
| 40 |
+
39: 'common iguana, iguana, Iguana iguana',
|
| 41 |
+
40: 'American chameleon, anole, Anolis carolinensis',
|
| 42 |
+
41: 'whiptail, whiptail lizard',
|
| 43 |
+
42: 'agama',
|
| 44 |
+
43: 'frilled lizard, Chlamydosaurus kingi',
|
| 45 |
+
44: 'alligator lizard',
|
| 46 |
+
45: 'Gila monster, Heloderma suspectum',
|
| 47 |
+
46: 'green lizard, Lacerta viridis',
|
| 48 |
+
47: 'African chameleon, Chamaeleo chamaeleon',
|
| 49 |
+
48: 'Komodo dragon, Komodo lizard, dragon lizard, giant lizard, Varanus komodoensis',
|
| 50 |
+
49: 'African crocodile, Nile crocodile, Crocodylus niloticus',
|
| 51 |
+
50: 'American alligator, Alligator mississipiensis',
|
| 52 |
+
51: 'triceratops',
|
| 53 |
+
52: 'thunder snake, worm snake, Carphophis amoenus',
|
| 54 |
+
53: 'ringneck snake, ring-necked snake, ring snake',
|
| 55 |
+
54: 'hognose snake, puff adder, sand viper',
|
| 56 |
+
55: 'green snake, grass snake',
|
| 57 |
+
56: 'king snake, kingsnake',
|
| 58 |
+
57: 'garter snake, grass snake',
|
| 59 |
+
58: 'water snake',
|
| 60 |
+
59: 'vine snake',
|
| 61 |
+
60: 'night snake, Hypsiglena torquata',
|
| 62 |
+
61: 'boa constrictor, Constrictor constrictor',
|
| 63 |
+
62: 'rock python, rock snake, Python sebae',
|
| 64 |
+
63: 'Indian cobra, Naja naja',
|
| 65 |
+
64: 'green mamba',
|
| 66 |
+
65: 'sea snake',
|
| 67 |
+
66: 'horned viper, cerastes, sand viper, horned asp, Cerastes cornutus',
|
| 68 |
+
67: 'diamondback, diamondback rattlesnake, Crotalus adamanteus',
|
| 69 |
+
68: 'sidewinder, horned rattlesnake, Crotalus cerastes',
|
| 70 |
+
69: 'trilobite',
|
| 71 |
+
70: 'harvestman, daddy longlegs, Phalangium opilio',
|
| 72 |
+
71: 'scorpion',
|
| 73 |
+
72: 'black and gold garden spider, Argiope aurantia',
|
| 74 |
+
73: 'barn spider, Araneus cavaticus',
|
| 75 |
+
74: 'garden spider, Aranea diademata',
|
| 76 |
+
75: 'black widow, Latrodectus mactans',
|
| 77 |
+
76: 'tarantula',
|
| 78 |
+
77: 'wolf spider, hunting spider',
|
| 79 |
+
78: 'tick',
|
| 80 |
+
79: 'centipede',
|
| 81 |
+
80: 'black grouse',
|
| 82 |
+
81: 'ptarmigan',
|
| 83 |
+
82: 'ruffed grouse, partridge, Bonasa umbellus',
|
| 84 |
+
83: 'prairie chicken, prairie grouse, prairie fowl',
|
| 85 |
+
84: 'peacock',
|
| 86 |
+
85: 'quail',
|
| 87 |
+
86: 'partridge',
|
| 88 |
+
87: 'African grey, African gray, Psittacus erithacus',
|
| 89 |
+
88: 'macaw',
|
| 90 |
+
89: 'sulphur-crested cockatoo, Kakatoe galerita, Cacatua galerita',
|
| 91 |
+
90: 'lorikeet',
|
| 92 |
+
91: 'coucal',
|
| 93 |
+
92: 'bee eater',
|
| 94 |
+
93: 'hornbill',
|
| 95 |
+
94: 'hummingbird',
|
| 96 |
+
95: 'jacamar',
|
| 97 |
+
96: 'toucan',
|
| 98 |
+
97: 'drake',
|
| 99 |
+
98: 'red-breasted merganser, Mergus serrator',
|
| 100 |
+
99: 'goose',
|
| 101 |
+
100: 'black swan, Cygnus atratus',
|
| 102 |
+
101: 'tusker',
|
| 103 |
+
102: 'echidna, spiny anteater, anteater',
|
| 104 |
+
103: 'platypus, duckbill, duckbilled platypus, duck-billed platypus, Ornithorhynchus anatinus',
|
| 105 |
+
104: 'wallaby, brush kangaroo',
|
| 106 |
+
105: 'koala, koala bear, kangaroo bear, native bear, Phascolarctos cinereus',
|
| 107 |
+
106: 'wombat',
|
| 108 |
+
107: 'jellyfish',
|
| 109 |
+
108: 'sea anemone, anemone',
|
| 110 |
+
109: 'brain coral',
|
| 111 |
+
110: 'flatworm, platyhelminth',
|
| 112 |
+
111: 'nematode, nematode worm, roundworm',
|
| 113 |
+
112: 'conch',
|
| 114 |
+
113: 'snail',
|
| 115 |
+
114: 'slug',
|
| 116 |
+
115: 'sea slug, nudibranch',
|
| 117 |
+
116: 'chiton, coat-of-mail shell, sea cradle, polyplacophore',
|
| 118 |
+
117: 'chambered nautilus, pearly nautilus, nautilus',
|
| 119 |
+
118: 'Dungeness crab, Cancer magister',
|
| 120 |
+
119: 'rock crab, Cancer irroratus',
|
| 121 |
+
120: 'fiddler crab',
|
| 122 |
+
121: 'king crab, Alaska crab, Alaskan king crab, Alaska king crab, Paralithodes camtschatica',
|
| 123 |
+
122: 'American lobster, Northern lobster, Maine lobster, Homarus americanus',
|
| 124 |
+
123: 'spiny lobster, langouste, rock lobster, crawfish, crayfish, sea crawfish',
|
| 125 |
+
124: 'crayfish, crawfish, crawdad, crawdaddy',
|
| 126 |
+
125: 'hermit crab',
|
| 127 |
+
126: 'isopod',
|
| 128 |
+
127: 'white stork, Ciconia ciconia',
|
| 129 |
+
128: 'black stork, Ciconia nigra',
|
| 130 |
+
129: 'spoonbill',
|
| 131 |
+
130: 'flamingo',
|
| 132 |
+
131: 'little blue heron, Egretta caerulea',
|
| 133 |
+
132: 'American egret, great white heron, Egretta albus',
|
| 134 |
+
133: 'bittern',
|
| 135 |
+
134: 'crane',
|
| 136 |
+
135: 'limpkin, Aramus pictus',
|
| 137 |
+
136: 'European gallinule, Porphyrio porphyrio',
|
| 138 |
+
137: 'American coot, marsh hen, mud hen, water hen, Fulica americana',
|
| 139 |
+
138: 'bustard',
|
| 140 |
+
139: 'ruddy turnstone, Arenaria interpres',
|
| 141 |
+
140: 'red-backed sandpiper, dunlin, Erolia alpina',
|
| 142 |
+
141: 'redshank, Tringa totanus',
|
| 143 |
+
142: 'dowitcher',
|
| 144 |
+
143: 'oystercatcher, oyster catcher',
|
| 145 |
+
144: 'pelican',
|
| 146 |
+
145: 'king penguin, Aptenodytes patagonica',
|
| 147 |
+
146: 'albatross, mollymawk',
|
| 148 |
+
147: 'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus',
|
| 149 |
+
148: 'killer whale, killer, orca, grampus, sea wolf, Orcinus orca',
|
| 150 |
+
149: 'dugong, Dugong dugon',
|
| 151 |
+
150: 'sea lion',
|
| 152 |
+
151: 'Chihuahua',
|
| 153 |
+
152: 'Japanese spaniel',
|
| 154 |
+
153: 'Maltese dog, Maltese terrier, Maltese',
|
| 155 |
+
154: 'Pekinese, Pekingese, Peke',
|
| 156 |
+
155: 'Shih-Tzu',
|
| 157 |
+
156: 'Blenheim spaniel',
|
| 158 |
+
157: 'papillon',
|
| 159 |
+
158: 'toy terrier',
|
| 160 |
+
159: 'Rhodesian ridgeback',
|
| 161 |
+
160: 'Afghan hound, Afghan',
|
| 162 |
+
161: 'basset, basset hound',
|
| 163 |
+
162: 'beagle',
|
| 164 |
+
163: 'bloodhound, sleuthhound',
|
| 165 |
+
164: 'bluetick',
|
| 166 |
+
165: 'black-and-tan coonhound',
|
| 167 |
+
166: 'Walker hound, Walker foxhound',
|
| 168 |
+
167: 'English foxhound',
|
| 169 |
+
168: 'redbone',
|
| 170 |
+
169: 'borzoi, Russian wolfhound',
|
| 171 |
+
170: 'Irish wolfhound',
|
| 172 |
+
171: 'Italian greyhound',
|
| 173 |
+
172: 'whippet',
|
| 174 |
+
173: 'Ibizan hound, Ibizan Podenco',
|
| 175 |
+
174: 'Norwegian elkhound, elkhound',
|
| 176 |
+
175: 'otterhound, otter hound',
|
| 177 |
+
176: 'Saluki, gazelle hound',
|
| 178 |
+
177: 'Scottish deerhound, deerhound',
|
| 179 |
+
178: 'Weimaraner',
|
| 180 |
+
179: 'Staffordshire bullterrier, Staffordshire bull terrier',
|
| 181 |
+
180: 'American Staffordshire terrier, Staffordshire terrier, American pit bull terrier, pit bull terrier',
|
| 182 |
+
181: 'Bedlington terrier',
|
| 183 |
+
182: 'Border terrier',
|
| 184 |
+
183: 'Kerry blue terrier',
|
| 185 |
+
184: 'Irish terrier',
|
| 186 |
+
185: 'Norfolk terrier',
|
| 187 |
+
186: 'Norwich terrier',
|
| 188 |
+
187: 'Yorkshire terrier',
|
| 189 |
+
188: 'wire-haired fox terrier',
|
| 190 |
+
189: 'Lakeland terrier',
|
| 191 |
+
190: 'Sealyham terrier, Sealyham',
|
| 192 |
+
191: 'Airedale, Airedale terrier',
|
| 193 |
+
192: 'cairn, cairn terrier',
|
| 194 |
+
193: 'Australian terrier',
|
| 195 |
+
194: 'Dandie Dinmont, Dandie Dinmont terrier',
|
| 196 |
+
195: 'Boston bull, Boston terrier',
|
| 197 |
+
196: 'miniature schnauzer',
|
| 198 |
+
197: 'giant schnauzer',
|
| 199 |
+
198: 'standard schnauzer',
|
| 200 |
+
199: 'Scotch terrier, Scottish terrier, Scottie',
|
| 201 |
+
200: 'Tibetan terrier, chrysanthemum dog',
|
| 202 |
+
201: 'silky terrier, Sydney silky',
|
| 203 |
+
202: 'soft-coated wheaten terrier',
|
| 204 |
+
203: 'West Highland white terrier',
|
| 205 |
+
204: 'Lhasa, Lhasa apso',
|
| 206 |
+
205: 'flat-coated retriever',
|
| 207 |
+
206: 'curly-coated retriever',
|
| 208 |
+
207: 'golden retriever',
|
| 209 |
+
208: 'Labrador retriever',
|
| 210 |
+
209: 'Chesapeake Bay retriever',
|
| 211 |
+
210: 'German short-haired pointer',
|
| 212 |
+
211: 'vizsla, Hungarian pointer',
|
| 213 |
+
212: 'English setter',
|
| 214 |
+
213: 'Irish setter, red setter',
|
| 215 |
+
214: 'Gordon setter',
|
| 216 |
+
215: 'Brittany spaniel',
|
| 217 |
+
216: 'clumber, clumber spaniel',
|
| 218 |
+
217: 'English springer, English springer spaniel',
|
| 219 |
+
218: 'Welsh springer spaniel',
|
| 220 |
+
219: 'cocker spaniel, English cocker spaniel, cocker',
|
| 221 |
+
220: 'Sussex spaniel',
|
| 222 |
+
221: 'Irish water spaniel',
|
| 223 |
+
222: 'kuvasz',
|
| 224 |
+
223: 'schipperke',
|
| 225 |
+
224: 'groenendael',
|
| 226 |
+
225: 'malinois',
|
| 227 |
+
226: 'briard',
|
| 228 |
+
227: 'kelpie',
|
| 229 |
+
228: 'komondor',
|
| 230 |
+
229: 'Old English sheepdog, bobtail',
|
| 231 |
+
230: 'Shetland sheepdog, Shetland sheep dog, Shetland',
|
| 232 |
+
231: 'collie',
|
| 233 |
+
232: 'Border collie',
|
| 234 |
+
233: 'Bouvier des Flandres, Bouviers des Flandres',
|
| 235 |
+
234: 'Rottweiler',
|
| 236 |
+
235: 'German shepherd, German shepherd dog, German police dog, alsatian',
|
| 237 |
+
236: 'Doberman, Doberman pinscher',
|
| 238 |
+
237: 'miniature pinscher',
|
| 239 |
+
238: 'Greater Swiss Mountain dog',
|
| 240 |
+
239: 'Bernese mountain dog',
|
| 241 |
+
240: 'Appenzeller',
|
| 242 |
+
241: 'EntleBucher',
|
| 243 |
+
242: 'boxer',
|
| 244 |
+
243: 'bull mastiff',
|
| 245 |
+
244: 'Tibetan mastiff',
|
| 246 |
+
245: 'French bulldog',
|
| 247 |
+
246: 'Great Dane',
|
| 248 |
+
247: 'Saint Bernard, St Bernard',
|
| 249 |
+
248: 'Eskimo dog, husky',
|
| 250 |
+
249: 'malamute, malemute, Alaskan malamute',
|
| 251 |
+
250: 'Siberian husky',
|
| 252 |
+
251: 'dalmatian, coach dog, carriage dog',
|
| 253 |
+
252: 'affenpinscher, monkey pinscher, monkey dog',
|
| 254 |
+
253: 'basenji',
|
| 255 |
+
254: 'pug, pug-dog',
|
| 256 |
+
255: 'Leonberg',
|
| 257 |
+
256: 'Newfoundland, Newfoundland dog',
|
| 258 |
+
257: 'Great Pyrenees',
|
| 259 |
+
258: 'Samoyed, Samoyede',
|
| 260 |
+
259: 'Pomeranian',
|
| 261 |
+
260: 'chow, chow chow',
|
| 262 |
+
261: 'keeshond',
|
| 263 |
+
262: 'Brabancon griffon',
|
| 264 |
+
263: 'Pembroke, Pembroke Welsh corgi',
|
| 265 |
+
264: 'Cardigan, Cardigan Welsh corgi',
|
| 266 |
+
265: 'toy poodle',
|
| 267 |
+
266: 'miniature poodle',
|
| 268 |
+
267: 'standard poodle',
|
| 269 |
+
268: 'Mexican hairless',
|
| 270 |
+
269: 'timber wolf, grey wolf, gray wolf, Canis lupus',
|
| 271 |
+
270: 'white wolf, Arctic wolf, Canis lupus tundrarum',
|
| 272 |
+
271: 'red wolf, maned wolf, Canis rufus, Canis niger',
|
| 273 |
+
272: 'coyote, prairie wolf, brush wolf, Canis latrans',
|
| 274 |
+
273: 'dingo, warrigal, warragal, Canis dingo',
|
| 275 |
+
274: 'dhole, Cuon alpinus',
|
| 276 |
+
275: 'African hunting dog, hyena dog, Cape hunting dog, Lycaon pictus',
|
| 277 |
+
276: 'hyena, hyaena',
|
| 278 |
+
277: 'red fox, Vulpes vulpes',
|
| 279 |
+
278: 'kit fox, Vulpes macrotis',
|
| 280 |
+
279: 'Arctic fox, white fox, Alopex lagopus',
|
| 281 |
+
280: 'grey fox, gray fox, Urocyon cinereoargenteus',
|
| 282 |
+
281: 'tabby, tabby cat',
|
| 283 |
+
282: 'tiger cat',
|
| 284 |
+
283: 'Persian cat',
|
| 285 |
+
284: 'Siamese cat, Siamese',
|
| 286 |
+
285: 'Egyptian cat',
|
| 287 |
+
286: 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor',
|
| 288 |
+
287: 'lynx, catamount',
|
| 289 |
+
288: 'leopard, Panthera pardus',
|
| 290 |
+
289: 'snow leopard, ounce, Panthera uncia',
|
| 291 |
+
290: 'jaguar, panther, Panthera onca, Felis onca',
|
| 292 |
+
291: 'lion, king of beasts, Panthera leo',
|
| 293 |
+
292: 'tiger, Panthera tigris',
|
| 294 |
+
293: 'cheetah, chetah, Acinonyx jubatus',
|
| 295 |
+
294: 'brown bear, bruin, Ursus arctos',
|
| 296 |
+
295: 'American black bear, black bear, Ursus americanus, Euarctos americanus',
|
| 297 |
+
296: 'ice bear, polar bear, Ursus Maritimus, Thalarctos maritimus',
|
| 298 |
+
297: 'sloth bear, Melursus ursinus, Ursus ursinus',
|
| 299 |
+
298: 'mongoose',
|
| 300 |
+
299: 'meerkat, mierkat',
|
| 301 |
+
300: 'tiger beetle',
|
| 302 |
+
301: 'ladybug, ladybeetle, lady beetle, ladybird, ladybird beetle',
|
| 303 |
+
302: 'ground beetle, carabid beetle',
|
| 304 |
+
303: 'long-horned beetle, longicorn, longicorn beetle',
|
| 305 |
+
304: 'leaf beetle, chrysomelid',
|
| 306 |
+
305: 'dung beetle',
|
| 307 |
+
306: 'rhinoceros beetle',
|
| 308 |
+
307: 'weevil',
|
| 309 |
+
308: 'fly',
|
| 310 |
+
309: 'bee',
|
| 311 |
+
310: 'ant, emmet, pismire',
|
| 312 |
+
311: 'grasshopper, hopper',
|
| 313 |
+
312: 'cricket',
|
| 314 |
+
313: 'walking stick, walkingstick, stick insect',
|
| 315 |
+
314: 'cockroach, roach',
|
| 316 |
+
315: 'mantis, mantid',
|
| 317 |
+
316: 'cicada, cicala',
|
| 318 |
+
317: 'leafhopper',
|
| 319 |
+
318: 'lacewing, lacewing fly',
|
| 320 |
+
319: "dragonfly, darning needle, devil's darning needle, sewing needle, snake feeder, snake doctor, mosquito hawk, skeeter hawk",
|
| 321 |
+
320: 'damselfly',
|
| 322 |
+
321: 'admiral',
|
| 323 |
+
322: 'ringlet, ringlet butterfly',
|
| 324 |
+
323: 'monarch, monarch butterfly, milkweed butterfly, Danaus plexippus',
|
| 325 |
+
324: 'cabbage butterfly',
|
| 326 |
+
325: 'sulphur butterfly, sulfur butterfly',
|
| 327 |
+
326: 'lycaenid, lycaenid butterfly',
|
| 328 |
+
327: 'starfish, sea star',
|
| 329 |
+
328: 'sea urchin',
|
| 330 |
+
329: 'sea cucumber, holothurian',
|
| 331 |
+
330: 'wood rabbit, cottontail, cottontail rabbit',
|
| 332 |
+
331: 'hare',
|
| 333 |
+
332: 'Angora, Angora rabbit',
|
| 334 |
+
333: 'hamster',
|
| 335 |
+
334: 'porcupine, hedgehog',
|
| 336 |
+
335: 'fox squirrel, eastern fox squirrel, Sciurus niger',
|
| 337 |
+
336: 'marmot',
|
| 338 |
+
337: 'beaver',
|
| 339 |
+
338: 'guinea pig, Cavia cobaya',
|
| 340 |
+
339: 'sorrel',
|
| 341 |
+
340: 'zebra',
|
| 342 |
+
341: 'hog, pig, grunter, squealer, Sus scrofa',
|
| 343 |
+
342: 'wild boar, boar, Sus scrofa',
|
| 344 |
+
343: 'warthog',
|
| 345 |
+
344: 'hippopotamus, hippo, river horse, Hippopotamus amphibius',
|
| 346 |
+
345: 'ox',
|
| 347 |
+
346: 'water buffalo, water ox, Asiatic buffalo, Bubalus bubalis',
|
| 348 |
+
347: 'bison',
|
| 349 |
+
348: 'ram, tup',
|
| 350 |
+
349: 'bighorn, bighorn sheep, cimarron, Rocky Mountain bighorn, Rocky Mountain sheep, Ovis canadensis',
|
| 351 |
+
350: 'ibex, Capra ibex',
|
| 352 |
+
351: 'hartebeest',
|
| 353 |
+
352: 'impala, Aepyceros melampus',
|
| 354 |
+
353: 'gazelle',
|
| 355 |
+
354: 'Arabian camel, dromedary, Camelus dromedarius',
|
| 356 |
+
355: 'llama',
|
| 357 |
+
356: 'weasel',
|
| 358 |
+
357: 'mink',
|
| 359 |
+
358: 'polecat, fitch, foulmart, foumart, Mustela putorius',
|
| 360 |
+
359: 'black-footed ferret, ferret, Mustela nigripes',
|
| 361 |
+
360: 'otter',
|
| 362 |
+
361: 'skunk, polecat, wood pussy',
|
| 363 |
+
362: 'badger',
|
| 364 |
+
363: 'armadillo',
|
| 365 |
+
364: 'three-toed sloth, ai, Bradypus tridactylus',
|
| 366 |
+
365: 'orangutan, orang, orangutang, Pongo pygmaeus',
|
| 367 |
+
366: 'gorilla, Gorilla gorilla',
|
| 368 |
+
367: 'chimpanzee, chimp, Pan troglodytes',
|
| 369 |
+
368: 'gibbon, Hylobates lar',
|
| 370 |
+
369: 'siamang, Hylobates syndactylus, Symphalangus syndactylus',
|
| 371 |
+
370: 'guenon, guenon monkey',
|
| 372 |
+
371: 'patas, hussar monkey, Erythrocebus patas',
|
| 373 |
+
372: 'baboon',
|
| 374 |
+
373: 'macaque',
|
| 375 |
+
374: 'langur',
|
| 376 |
+
375: 'colobus, colobus monkey',
|
| 377 |
+
376: 'proboscis monkey, Nasalis larvatus',
|
| 378 |
+
377: 'marmoset',
|
| 379 |
+
378: 'capuchin, ringtail, Cebus capucinus',
|
| 380 |
+
379: 'howler monkey, howler',
|
| 381 |
+
380: 'titi, titi monkey',
|
| 382 |
+
381: 'spider monkey, Ateles geoffroyi',
|
| 383 |
+
382: 'squirrel monkey, Saimiri sciureus',
|
| 384 |
+
383: 'Madagascar cat, ring-tailed lemur, Lemur catta',
|
| 385 |
+
384: 'indri, indris, Indri indri, Indri brevicaudatus',
|
| 386 |
+
385: 'Indian elephant, Elephas maximus',
|
| 387 |
+
386: 'African elephant, Loxodonta africana',
|
| 388 |
+
387: 'lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens',
|
| 389 |
+
388: 'giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca',
|
| 390 |
+
389: 'barracouta, snoek',
|
| 391 |
+
390: 'eel',
|
| 392 |
+
391: 'coho, cohoe, coho salmon, blue jack, silver salmon, Oncorhynchus kisutch',
|
| 393 |
+
392: 'rock beauty, Holocanthus tricolor',
|
| 394 |
+
393: 'anemone fish',
|
| 395 |
+
394: 'sturgeon',
|
| 396 |
+
395: 'gar, garfish, garpike, billfish, Lepisosteus osseus',
|
| 397 |
+
396: 'lionfish',
|
| 398 |
+
397: 'puffer, pufferfish, blowfish, globefish',
|
| 399 |
+
398: 'abacus',
|
| 400 |
+
399: 'abaya',
|
| 401 |
+
400: "academic gown, academic robe, judge's robe",
|
| 402 |
+
401: 'accordion, piano accordion, squeeze box',
|
| 403 |
+
402: 'acoustic guitar',
|
| 404 |
+
403: 'aircraft carrier, carrier, flattop, attack aircraft carrier',
|
| 405 |
+
404: 'airliner',
|
| 406 |
+
405: 'airship, dirigible',
|
| 407 |
+
406: 'altar',
|
| 408 |
+
407: 'ambulance',
|
| 409 |
+
408: 'amphibian, amphibious vehicle',
|
| 410 |
+
409: 'analog clock',
|
| 411 |
+
410: 'apiary, bee house',
|
| 412 |
+
411: 'apron',
|
| 413 |
+
412: 'ashcan, trash can, garbage can, wastebin, ash bin, ash-bin, ashbin, dustbin, trash barrel, trash bin',
|
| 414 |
+
413: 'assault rifle, assault gun',
|
| 415 |
+
414: 'backpack, back pack, knapsack, packsack, rucksack, haversack',
|
| 416 |
+
415: 'bakery, bakeshop, bakehouse',
|
| 417 |
+
416: 'balance beam, beam',
|
| 418 |
+
417: 'balloon',
|
| 419 |
+
418: 'ballpoint, ballpoint pen, ballpen, Biro',
|
| 420 |
+
419: 'Band Aid',
|
| 421 |
+
420: 'banjo',
|
| 422 |
+
421: 'bannister, banister, balustrade, balusters, handrail',
|
| 423 |
+
422: 'barbell',
|
| 424 |
+
423: 'barber chair',
|
| 425 |
+
424: 'barbershop',
|
| 426 |
+
425: 'barn',
|
| 427 |
+
426: 'barometer',
|
| 428 |
+
427: 'barrel, cask',
|
| 429 |
+
428: 'barrow, garden cart, lawn cart, wheelbarrow',
|
| 430 |
+
429: 'baseball',
|
| 431 |
+
430: 'basketball',
|
| 432 |
+
431: 'bassinet',
|
| 433 |
+
432: 'bassoon',
|
| 434 |
+
433: 'bathing cap, swimming cap',
|
| 435 |
+
434: 'bath towel',
|
| 436 |
+
435: 'bathtub, bathing tub, bath, tub',
|
| 437 |
+
436: 'beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon',
|
| 438 |
+
437: 'beacon, lighthouse, beacon light, pharos',
|
| 439 |
+
438: 'beaker',
|
| 440 |
+
439: 'bearskin, busby, shako',
|
| 441 |
+
440: 'beer bottle',
|
| 442 |
+
441: 'beer glass',
|
| 443 |
+
442: 'bell cote, bell cot',
|
| 444 |
+
443: 'bib',
|
| 445 |
+
444: 'bicycle-built-for-two, tandem bicycle, tandem',
|
| 446 |
+
445: 'bikini, two-piece',
|
| 447 |
+
446: 'binder, ring-binder',
|
| 448 |
+
447: 'binoculars, field glasses, opera glasses',
|
| 449 |
+
448: 'birdhouse',
|
| 450 |
+
449: 'boathouse',
|
| 451 |
+
450: 'bobsled, bobsleigh, bob',
|
| 452 |
+
451: 'bolo tie, bolo, bola tie, bola',
|
| 453 |
+
452: 'bonnet, poke bonnet',
|
| 454 |
+
453: 'bookcase',
|
| 455 |
+
454: 'bookshop, bookstore, bookstall',
|
| 456 |
+
455: 'bottlecap',
|
| 457 |
+
456: 'bow',
|
| 458 |
+
457: 'bow tie, bow-tie, bowtie',
|
| 459 |
+
458: 'brass, memorial tablet, plaque',
|
| 460 |
+
459: 'brassiere, bra, bandeau',
|
| 461 |
+
460: 'breakwater, groin, groyne, mole, bulwark, seawall, jetty',
|
| 462 |
+
461: 'breastplate, aegis, egis',
|
| 463 |
+
462: 'broom',
|
| 464 |
+
463: 'bucket, pail',
|
| 465 |
+
464: 'buckle',
|
| 466 |
+
465: 'bulletproof vest',
|
| 467 |
+
466: 'bullet train, bullet',
|
| 468 |
+
467: 'butcher shop, meat market',
|
| 469 |
+
468: 'cab, hack, taxi, taxicab',
|
| 470 |
+
469: 'caldron, cauldron',
|
| 471 |
+
470: 'candle, taper, wax light',
|
| 472 |
+
471: 'cannon',
|
| 473 |
+
472: 'canoe',
|
| 474 |
+
473: 'can opener, tin opener',
|
| 475 |
+
474: 'cardigan',
|
| 476 |
+
475: 'car mirror',
|
| 477 |
+
476: 'carousel, carrousel, merry-go-round, roundabout, whirligig',
|
| 478 |
+
477: "carpenter's kit, tool kit",
|
| 479 |
+
478: 'carton',
|
| 480 |
+
479: 'car wheel',
|
| 481 |
+
480: 'cash machine, cash dispenser, automated teller machine, automatic teller machine, automated teller, automatic teller, ATM',
|
| 482 |
+
481: 'cassette',
|
| 483 |
+
482: 'cassette player',
|
| 484 |
+
483: 'castle',
|
| 485 |
+
484: 'catamaran',
|
| 486 |
+
485: 'CD player',
|
| 487 |
+
486: 'cello, violoncello',
|
| 488 |
+
487: 'cellular telephone, cellular phone, cellphone, cell, mobile phone',
|
| 489 |
+
488: 'chain',
|
| 490 |
+
489: 'chainlink fence',
|
| 491 |
+
490: 'chain mail, ring mail, mail, chain armor, chain armour, ring armor, ring armour',
|
| 492 |
+
491: 'chain saw, chainsaw',
|
| 493 |
+
492: 'chest',
|
| 494 |
+
493: 'chiffonier, commode',
|
| 495 |
+
494: 'chime, bell, gong',
|
| 496 |
+
495: 'china cabinet, china closet',
|
| 497 |
+
496: 'Christmas stocking',
|
| 498 |
+
497: 'church, church building',
|
| 499 |
+
498: 'cinema, movie theater, movie theatre, movie house, picture palace',
|
| 500 |
+
499: 'cleaver, meat cleaver, chopper',
|
| 501 |
+
500: 'cliff dwelling',
|
| 502 |
+
501: 'cloak',
|
| 503 |
+
502: 'clog, geta, patten, sabot',
|
| 504 |
+
503: 'cocktail shaker',
|
| 505 |
+
504: 'coffee mug',
|
| 506 |
+
505: 'coffeepot',
|
| 507 |
+
506: 'coil, spiral, volute, whorl, helix',
|
| 508 |
+
507: 'combination lock',
|
| 509 |
+
508: 'computer keyboard, keypad',
|
| 510 |
+
509: 'confectionery, confectionary, candy store',
|
| 511 |
+
510: 'container ship, containership, container vessel',
|
| 512 |
+
511: 'convertible',
|
| 513 |
+
512: 'corkscrew, bottle screw',
|
| 514 |
+
513: 'cornet, horn, trumpet, trump',
|
| 515 |
+
514: 'cowboy boot',
|
| 516 |
+
515: 'cowboy hat, ten-gallon hat',
|
| 517 |
+
516: 'cradle',
|
| 518 |
+
517: 'crane',
|
| 519 |
+
518: 'crash helmet',
|
| 520 |
+
519: 'crate',
|
| 521 |
+
520: 'crib, cot',
|
| 522 |
+
521: 'Crock Pot',
|
| 523 |
+
522: 'croquet ball',
|
| 524 |
+
523: 'crutch',
|
| 525 |
+
524: 'cuirass',
|
| 526 |
+
525: 'dam, dike, dyke',
|
| 527 |
+
526: 'desk',
|
| 528 |
+
527: 'desktop computer',
|
| 529 |
+
528: 'dial telephone, dial phone',
|
| 530 |
+
529: 'diaper, nappy, napkin',
|
| 531 |
+
530: 'digital clock',
|
| 532 |
+
531: 'digital watch',
|
| 533 |
+
532: 'dining table, board',
|
| 534 |
+
533: 'dishrag, dishcloth',
|
| 535 |
+
534: 'dishwasher, dish washer, dishwashing machine',
|
| 536 |
+
535: 'disk brake, disc brake',
|
| 537 |
+
536: 'dock, dockage, docking facility',
|
| 538 |
+
537: 'dogsled, dog sled, dog sleigh',
|
| 539 |
+
538: 'dome',
|
| 540 |
+
539: 'doormat, welcome mat',
|
| 541 |
+
540: 'drilling platform, offshore rig',
|
| 542 |
+
541: 'drum, membranophone, tympan',
|
| 543 |
+
542: 'drumstick',
|
| 544 |
+
543: 'dumbbell',
|
| 545 |
+
544: 'Dutch oven',
|
| 546 |
+
545: 'electric fan, blower',
|
| 547 |
+
546: 'electric guitar',
|
| 548 |
+
547: 'electric locomotive',
|
| 549 |
+
548: 'entertainment center',
|
| 550 |
+
549: 'envelope',
|
| 551 |
+
550: 'espresso maker',
|
| 552 |
+
551: 'face powder',
|
| 553 |
+
552: 'feather boa, boa',
|
| 554 |
+
553: 'file, file cabinet, filing cabinet',
|
| 555 |
+
554: 'fireboat',
|
| 556 |
+
555: 'fire engine, fire truck',
|
| 557 |
+
556: 'fire screen, fireguard',
|
| 558 |
+
557: 'flagpole, flagstaff',
|
| 559 |
+
558: 'flute, transverse flute',
|
| 560 |
+
559: 'folding chair',
|
| 561 |
+
560: 'football helmet',
|
| 562 |
+
561: 'forklift',
|
| 563 |
+
562: 'fountain',
|
| 564 |
+
563: 'fountain pen',
|
| 565 |
+
564: 'four-poster',
|
| 566 |
+
565: 'freight car',
|
| 567 |
+
566: 'French horn, horn',
|
| 568 |
+
567: 'frying pan, frypan, skillet',
|
| 569 |
+
568: 'fur coat',
|
| 570 |
+
569: 'garbage truck, dustcart',
|
| 571 |
+
570: 'gasmask, respirator, gas helmet',
|
| 572 |
+
571: 'gas pump, gasoline pump, petrol pump, island dispenser',
|
| 573 |
+
572: 'goblet',
|
| 574 |
+
573: 'go-kart',
|
| 575 |
+
574: 'golf ball',
|
| 576 |
+
575: 'golfcart, golf cart',
|
| 577 |
+
576: 'gondola',
|
| 578 |
+
577: 'gong, tam-tam',
|
| 579 |
+
578: 'gown',
|
| 580 |
+
579: 'grand piano, grand',
|
| 581 |
+
580: 'greenhouse, nursery, glasshouse',
|
| 582 |
+
581: 'grille, radiator grille',
|
| 583 |
+
582: 'grocery store, grocery, food market, market',
|
| 584 |
+
583: 'guillotine',
|
| 585 |
+
584: 'hair slide',
|
| 586 |
+
585: 'hair spray',
|
| 587 |
+
586: 'half track',
|
| 588 |
+
587: 'hammer',
|
| 589 |
+
588: 'hamper',
|
| 590 |
+
589: 'hand blower, blow dryer, blow drier, hair dryer, hair drier',
|
| 591 |
+
590: 'hand-held computer, hand-held microcomputer',
|
| 592 |
+
591: 'handkerchief, hankie, hanky, hankey',
|
| 593 |
+
592: 'hard disc, hard disk, fixed disk',
|
| 594 |
+
593: 'harmonica, mouth organ, harp, mouth harp',
|
| 595 |
+
594: 'harp',
|
| 596 |
+
595: 'harvester, reaper',
|
| 597 |
+
596: 'hatchet',
|
| 598 |
+
597: 'holster',
|
| 599 |
+
598: 'home theater, home theatre',
|
| 600 |
+
599: 'honeycomb',
|
| 601 |
+
600: 'hook, claw',
|
| 602 |
+
601: 'hoopskirt, crinoline',
|
| 603 |
+
602: 'horizontal bar, high bar',
|
| 604 |
+
603: 'horse cart, horse-cart',
|
| 605 |
+
604: 'hourglass',
|
| 606 |
+
605: 'iPod',
|
| 607 |
+
606: 'iron, smoothing iron',
|
| 608 |
+
607: "jack-o'-lantern",
|
| 609 |
+
608: 'jean, blue jean, denim',
|
| 610 |
+
609: 'jeep, landrover',
|
| 611 |
+
610: 'jersey, T-shirt, tee shirt',
|
| 612 |
+
611: 'jigsaw puzzle',
|
| 613 |
+
612: 'jinrikisha, ricksha, rickshaw',
|
| 614 |
+
613: 'joystick',
|
| 615 |
+
614: 'kimono',
|
| 616 |
+
615: 'knee pad',
|
| 617 |
+
616: 'knot',
|
| 618 |
+
617: 'lab coat, laboratory coat',
|
| 619 |
+
618: 'ladle',
|
| 620 |
+
619: 'lampshade, lamp shade',
|
| 621 |
+
620: 'laptop, laptop computer',
|
| 622 |
+
621: 'lawn mower, mower',
|
| 623 |
+
622: 'lens cap, lens cover',
|
| 624 |
+
623: 'letter opener, paper knife, paperknife',
|
| 625 |
+
624: 'library',
|
| 626 |
+
625: 'lifeboat',
|
| 627 |
+
626: 'lighter, light, igniter, ignitor',
|
| 628 |
+
627: 'limousine, limo',
|
| 629 |
+
628: 'liner, ocean liner',
|
| 630 |
+
629: 'lipstick, lip rouge',
|
| 631 |
+
630: 'Loafer',
|
| 632 |
+
631: 'lotion',
|
| 633 |
+
632: 'loudspeaker, speaker, speaker unit, loudspeaker system, speaker system',
|
| 634 |
+
633: "loupe, jeweler's loupe",
|
| 635 |
+
634: 'lumbermill, sawmill',
|
| 636 |
+
635: 'magnetic compass',
|
| 637 |
+
636: 'mailbag, postbag',
|
| 638 |
+
637: 'mailbox, letter box',
|
| 639 |
+
638: 'maillot',
|
| 640 |
+
639: 'maillot, tank suit',
|
| 641 |
+
640: 'manhole cover',
|
| 642 |
+
641: 'maraca',
|
| 643 |
+
642: 'marimba, xylophone',
|
| 644 |
+
643: 'mask',
|
| 645 |
+
644: 'matchstick',
|
| 646 |
+
645: 'maypole',
|
| 647 |
+
646: 'maze, labyrinth',
|
| 648 |
+
647: 'measuring cup',
|
| 649 |
+
648: 'medicine chest, medicine cabinet',
|
| 650 |
+
649: 'megalith, megalithic structure',
|
| 651 |
+
650: 'microphone, mike',
|
| 652 |
+
651: 'microwave, microwave oven',
|
| 653 |
+
652: 'military uniform',
|
| 654 |
+
653: 'milk can',
|
| 655 |
+
654: 'minibus',
|
| 656 |
+
655: 'miniskirt, mini',
|
| 657 |
+
656: 'minivan',
|
| 658 |
+
657: 'missile',
|
| 659 |
+
658: 'mitten',
|
| 660 |
+
659: 'mixing bowl',
|
| 661 |
+
660: 'mobile home, manufactured home',
|
| 662 |
+
661: 'Model T',
|
| 663 |
+
662: 'modem',
|
| 664 |
+
663: 'monastery',
|
| 665 |
+
664: 'monitor',
|
| 666 |
+
665: 'moped',
|
| 667 |
+
666: 'mortar',
|
| 668 |
+
667: 'mortarboard',
|
| 669 |
+
668: 'mosque',
|
| 670 |
+
669: 'mosquito net',
|
| 671 |
+
670: 'motor scooter, scooter',
|
| 672 |
+
671: 'mountain bike, all-terrain bike, off-roader',
|
| 673 |
+
672: 'mountain tent',
|
| 674 |
+
673: 'mouse, computer mouse',
|
| 675 |
+
674: 'mousetrap',
|
| 676 |
+
675: 'moving van',
|
| 677 |
+
676: 'muzzle',
|
| 678 |
+
677: 'nail',
|
| 679 |
+
678: 'neck brace',
|
| 680 |
+
679: 'necklace',
|
| 681 |
+
680: 'nipple',
|
| 682 |
+
681: 'notebook, notebook computer',
|
| 683 |
+
682: 'obelisk',
|
| 684 |
+
683: 'oboe, hautboy, hautbois',
|
| 685 |
+
684: 'ocarina, sweet potato',
|
| 686 |
+
685: 'odometer, hodometer, mileometer, milometer',
|
| 687 |
+
686: 'oil filter',
|
| 688 |
+
687: 'organ, pipe organ',
|
| 689 |
+
688: 'oscilloscope, scope, cathode-ray oscilloscope, CRO',
|
| 690 |
+
689: 'overskirt',
|
| 691 |
+
690: 'oxcart',
|
| 692 |
+
691: 'oxygen mask',
|
| 693 |
+
692: 'packet',
|
| 694 |
+
693: 'paddle, boat paddle',
|
| 695 |
+
694: 'paddlewheel, paddle wheel',
|
| 696 |
+
695: 'padlock',
|
| 697 |
+
696: 'paintbrush',
|
| 698 |
+
697: "pajama, pyjama, pj's, jammies",
|
| 699 |
+
698: 'palace',
|
| 700 |
+
699: 'panpipe, pandean pipe, syrinx',
|
| 701 |
+
700: 'paper towel',
|
| 702 |
+
701: 'parachute, chute',
|
| 703 |
+
702: 'parallel bars, bars',
|
| 704 |
+
703: 'park bench',
|
| 705 |
+
704: 'parking meter',
|
| 706 |
+
705: 'passenger car, coach, carriage',
|
| 707 |
+
706: 'patio, terrace',
|
| 708 |
+
707: 'pay-phone, pay-station',
|
| 709 |
+
708: 'pedestal, plinth, footstall',
|
| 710 |
+
709: 'pencil box, pencil case',
|
| 711 |
+
710: 'pencil sharpener',
|
| 712 |
+
711: 'perfume, essence',
|
| 713 |
+
712: 'Petri dish',
|
| 714 |
+
713: 'photocopier',
|
| 715 |
+
714: 'pick, plectrum, plectron',
|
| 716 |
+
715: 'pickelhaube',
|
| 717 |
+
716: 'picket fence, paling',
|
| 718 |
+
717: 'pickup, pickup truck',
|
| 719 |
+
718: 'pier',
|
| 720 |
+
719: 'piggy bank, penny bank',
|
| 721 |
+
720: 'pill bottle',
|
| 722 |
+
721: 'pillow',
|
| 723 |
+
722: 'ping-pong ball',
|
| 724 |
+
723: 'pinwheel',
|
| 725 |
+
724: 'pirate, pirate ship',
|
| 726 |
+
725: 'pitcher, ewer',
|
| 727 |
+
726: "plane, carpenter's plane, woodworking plane",
|
| 728 |
+
727: 'planetarium',
|
| 729 |
+
728: 'plastic bag',
|
| 730 |
+
729: 'plate rack',
|
| 731 |
+
730: 'plow, plough',
|
| 732 |
+
731: "plunger, plumber's helper",
|
| 733 |
+
732: 'Polaroid camera, Polaroid Land camera',
|
| 734 |
+
733: 'pole',
|
| 735 |
+
734: 'police van, police wagon, paddy wagon, patrol wagon, wagon, black Maria',
|
| 736 |
+
735: 'poncho',
|
| 737 |
+
736: 'pool table, billiard table, snooker table',
|
| 738 |
+
737: 'pop bottle, soda bottle',
|
| 739 |
+
738: 'pot, flowerpot',
|
| 740 |
+
739: "potter's wheel",
|
| 741 |
+
740: 'power drill',
|
| 742 |
+
741: 'prayer rug, prayer mat',
|
| 743 |
+
742: 'printer',
|
| 744 |
+
743: 'prison, prison house',
|
| 745 |
+
744: 'projectile, missile',
|
| 746 |
+
745: 'projector',
|
| 747 |
+
746: 'puck, hockey puck',
|
| 748 |
+
747: 'punching bag, punch bag, punching ball, punchball',
|
| 749 |
+
748: 'purse',
|
| 750 |
+
749: 'quill, quill pen',
|
| 751 |
+
750: 'quilt, comforter, comfort, puff',
|
| 752 |
+
751: 'racer, race car, racing car',
|
| 753 |
+
752: 'racket, racquet',
|
| 754 |
+
753: 'radiator',
|
| 755 |
+
754: 'radio, wireless',
|
| 756 |
+
755: 'radio telescope, radio reflector',
|
| 757 |
+
756: 'rain barrel',
|
| 758 |
+
757: 'recreational vehicle, RV, R.V.',
|
| 759 |
+
758: 'reel',
|
| 760 |
+
759: 'reflex camera',
|
| 761 |
+
760: 'refrigerator, icebox',
|
| 762 |
+
761: 'remote control, remote',
|
| 763 |
+
762: 'restaurant, eating house, eating place, eatery',
|
| 764 |
+
763: 'revolver, six-gun, six-shooter',
|
| 765 |
+
764: 'rifle',
|
| 766 |
+
765: 'rocking chair, rocker',
|
| 767 |
+
766: 'rotisserie',
|
| 768 |
+
767: 'rubber eraser, rubber, pencil eraser',
|
| 769 |
+
768: 'rugby ball',
|
| 770 |
+
769: 'rule, ruler',
|
| 771 |
+
770: 'running shoe',
|
| 772 |
+
771: 'safe',
|
| 773 |
+
772: 'safety pin',
|
| 774 |
+
773: 'saltshaker, salt shaker',
|
| 775 |
+
774: 'sandal',
|
| 776 |
+
775: 'sarong',
|
| 777 |
+
776: 'sax, saxophone',
|
| 778 |
+
777: 'scabbard',
|
| 779 |
+
778: 'scale, weighing machine',
|
| 780 |
+
779: 'school bus',
|
| 781 |
+
780: 'schooner',
|
| 782 |
+
781: 'scoreboard',
|
| 783 |
+
782: 'screen, CRT screen',
|
| 784 |
+
783: 'screw',
|
| 785 |
+
784: 'screwdriver',
|
| 786 |
+
785: 'seat belt, seatbelt',
|
| 787 |
+
786: 'sewing machine',
|
| 788 |
+
787: 'shield, buckler',
|
| 789 |
+
788: 'shoe shop, shoe-shop, shoe store',
|
| 790 |
+
789: 'shoji',
|
| 791 |
+
790: 'shopping basket',
|
| 792 |
+
791: 'shopping cart',
|
| 793 |
+
792: 'shovel',
|
| 794 |
+
793: 'shower cap',
|
| 795 |
+
794: 'shower curtain',
|
| 796 |
+
795: 'ski',
|
| 797 |
+
796: 'ski mask',
|
| 798 |
+
797: 'sleeping bag',
|
| 799 |
+
798: 'slide rule, slipstick',
|
| 800 |
+
799: 'sliding door',
|
| 801 |
+
800: 'slot, one-armed bandit',
|
| 802 |
+
801: 'snorkel',
|
| 803 |
+
802: 'snowmobile',
|
| 804 |
+
803: 'snowplow, snowplough',
|
| 805 |
+
804: 'soap dispenser',
|
| 806 |
+
805: 'soccer ball',
|
| 807 |
+
806: 'sock',
|
| 808 |
+
807: 'solar dish, solar collector, solar furnace',
|
| 809 |
+
808: 'sombrero',
|
| 810 |
+
809: 'soup bowl',
|
| 811 |
+
810: 'space bar',
|
| 812 |
+
811: 'space heater',
|
| 813 |
+
812: 'space shuttle',
|
| 814 |
+
813: 'spatula',
|
| 815 |
+
814: 'speedboat',
|
| 816 |
+
815: "spider web, spider's web",
|
| 817 |
+
816: 'spindle',
|
| 818 |
+
817: 'sports car, sport car',
|
| 819 |
+
818: 'spotlight, spot',
|
| 820 |
+
819: 'stage',
|
| 821 |
+
820: 'steam locomotive',
|
| 822 |
+
821: 'steel arch bridge',
|
| 823 |
+
822: 'steel drum',
|
| 824 |
+
823: 'stethoscope',
|
| 825 |
+
824: 'stole',
|
| 826 |
+
825: 'stone wall',
|
| 827 |
+
826: 'stopwatch, stop watch',
|
| 828 |
+
827: 'stove',
|
| 829 |
+
828: 'strainer',
|
| 830 |
+
829: 'streetcar, tram, tramcar, trolley, trolley car',
|
| 831 |
+
830: 'stretcher',
|
| 832 |
+
831: 'studio couch, day bed',
|
| 833 |
+
832: 'stupa, tope',
|
| 834 |
+
833: 'submarine, pigboat, sub, U-boat',
|
| 835 |
+
834: 'suit, suit of clothes',
|
| 836 |
+
835: 'sundial',
|
| 837 |
+
836: 'sunglass',
|
| 838 |
+
837: 'sunglasses, dark glasses, shades',
|
| 839 |
+
838: 'sunscreen, sunblock, sun blocker',
|
| 840 |
+
839: 'suspension bridge',
|
| 841 |
+
840: 'swab, swob, mop',
|
| 842 |
+
841: 'sweatshirt',
|
| 843 |
+
842: 'swimming trunks, bathing trunks',
|
| 844 |
+
843: 'swing',
|
| 845 |
+
844: 'switch, electric switch, electrical switch',
|
| 846 |
+
845: 'syringe',
|
| 847 |
+
846: 'table lamp',
|
| 848 |
+
847: 'tank, army tank, armored combat vehicle, armoured combat vehicle',
|
| 849 |
+
848: 'tape player',
|
| 850 |
+
849: 'teapot',
|
| 851 |
+
850: 'teddy, teddy bear',
|
| 852 |
+
851: 'television, television system',
|
| 853 |
+
852: 'tennis ball',
|
| 854 |
+
853: 'thatch, thatched roof',
|
| 855 |
+
854: 'theater curtain, theatre curtain',
|
| 856 |
+
855: 'thimble',
|
| 857 |
+
856: 'thresher, thrasher, threshing machine',
|
| 858 |
+
857: 'throne',
|
| 859 |
+
858: 'tile roof',
|
| 860 |
+
859: 'toaster',
|
| 861 |
+
860: 'tobacco shop, tobacconist shop, tobacconist',
|
| 862 |
+
861: 'toilet seat',
|
| 863 |
+
862: 'torch',
|
| 864 |
+
863: 'totem pole',
|
| 865 |
+
864: 'tow truck, tow car, wrecker',
|
| 866 |
+
865: 'toyshop',
|
| 867 |
+
866: 'tractor',
|
| 868 |
+
867: 'trailer truck, tractor trailer, trucking rig, rig, articulated lorry, semi',
|
| 869 |
+
868: 'tray',
|
| 870 |
+
869: 'trench coat',
|
| 871 |
+
870: 'tricycle, trike, velocipede',
|
| 872 |
+
871: 'trimaran',
|
| 873 |
+
872: 'tripod',
|
| 874 |
+
873: 'triumphal arch',
|
| 875 |
+
874: 'trolleybus, trolley coach, trackless trolley',
|
| 876 |
+
875: 'trombone',
|
| 877 |
+
876: 'tub, vat',
|
| 878 |
+
877: 'turnstile',
|
| 879 |
+
878: 'typewriter keyboard',
|
| 880 |
+
879: 'umbrella',
|
| 881 |
+
880: 'unicycle, monocycle',
|
| 882 |
+
881: 'upright, upright piano',
|
| 883 |
+
882: 'vacuum, vacuum cleaner',
|
| 884 |
+
883: 'vase',
|
| 885 |
+
884: 'vault',
|
| 886 |
+
885: 'velvet',
|
| 887 |
+
886: 'vending machine',
|
| 888 |
+
887: 'vestment',
|
| 889 |
+
888: 'viaduct',
|
| 890 |
+
889: 'violin, fiddle',
|
| 891 |
+
890: 'volleyball',
|
| 892 |
+
891: 'waffle iron',
|
| 893 |
+
892: 'wall clock',
|
| 894 |
+
893: 'wallet, billfold, notecase, pocketbook',
|
| 895 |
+
894: 'wardrobe, closet, press',
|
| 896 |
+
895: 'warplane, military plane',
|
| 897 |
+
896: 'washbasin, handbasin, washbowl, lavabo, wash-hand basin',
|
| 898 |
+
897: 'washer, automatic washer, washing machine',
|
| 899 |
+
898: 'water bottle',
|
| 900 |
+
899: 'water jug',
|
| 901 |
+
900: 'water tower',
|
| 902 |
+
901: 'whiskey jug',
|
| 903 |
+
902: 'whistle',
|
| 904 |
+
903: 'wig',
|
| 905 |
+
904: 'window screen',
|
| 906 |
+
905: 'window shade',
|
| 907 |
+
906: 'Windsor tie',
|
| 908 |
+
907: 'wine bottle',
|
| 909 |
+
908: 'wing',
|
| 910 |
+
909: 'wok',
|
| 911 |
+
910: 'wooden spoon',
|
| 912 |
+
911: 'wool, woolen, woollen',
|
| 913 |
+
912: 'worm fence, snake fence, snake-rail fence, Virginia fence',
|
| 914 |
+
913: 'wreck',
|
| 915 |
+
914: 'yawl',
|
| 916 |
+
915: 'yurt',
|
| 917 |
+
916: 'web site, website, internet site, site',
|
| 918 |
+
917: 'comic book',
|
| 919 |
+
918: 'crossword puzzle, crossword',
|
| 920 |
+
919: 'street sign',
|
| 921 |
+
920: 'traffic light, traffic signal, stoplight',
|
| 922 |
+
921: 'book jacket, dust cover, dust jacket, dust wrapper',
|
| 923 |
+
922: 'menu',
|
| 924 |
+
923: 'plate',
|
| 925 |
+
924: 'guacamole',
|
| 926 |
+
925: 'consomme',
|
| 927 |
+
926: 'hot pot, hotpot',
|
| 928 |
+
927: 'trifle',
|
| 929 |
+
928: 'ice cream, icecream',
|
| 930 |
+
929: 'ice lolly, lolly, lollipop, popsicle',
|
| 931 |
+
930: 'French loaf',
|
| 932 |
+
931: 'bagel, beigel',
|
| 933 |
+
932: 'pretzel',
|
| 934 |
+
933: 'cheeseburger',
|
| 935 |
+
934: 'hotdog, hot dog, red hot',
|
| 936 |
+
935: 'mashed potato',
|
| 937 |
+
936: 'head cabbage',
|
| 938 |
+
937: 'broccoli',
|
| 939 |
+
938: 'cauliflower',
|
| 940 |
+
939: 'zucchini, courgette',
|
| 941 |
+
940: 'spaghetti squash',
|
| 942 |
+
941: 'acorn squash',
|
| 943 |
+
942: 'butternut squash',
|
| 944 |
+
943: 'cucumber, cuke',
|
| 945 |
+
944: 'artichoke, globe artichoke',
|
| 946 |
+
945: 'bell pepper',
|
| 947 |
+
946: 'cardoon',
|
| 948 |
+
947: 'mushroom',
|
| 949 |
+
948: 'Granny Smith',
|
| 950 |
+
949: 'strawberry',
|
| 951 |
+
950: 'orange',
|
| 952 |
+
951: 'lemon',
|
| 953 |
+
952: 'fig',
|
| 954 |
+
953: 'pineapple, ananas',
|
| 955 |
+
954: 'banana',
|
| 956 |
+
955: 'jackfruit, jak, jack',
|
| 957 |
+
956: 'custard apple',
|
| 958 |
+
957: 'pomegranate',
|
| 959 |
+
958: 'hay',
|
| 960 |
+
959: 'carbonara',
|
| 961 |
+
960: 'chocolate sauce, chocolate syrup',
|
| 962 |
+
961: 'dough',
|
| 963 |
+
962: 'meat loaf, meatloaf',
|
| 964 |
+
963: 'pizza, pizza pie',
|
| 965 |
+
964: 'potpie',
|
| 966 |
+
965: 'burrito',
|
| 967 |
+
966: 'red wine',
|
| 968 |
+
967: 'espresso',
|
| 969 |
+
968: 'cup',
|
| 970 |
+
969: 'eggnog',
|
| 971 |
+
970: 'alp',
|
| 972 |
+
971: 'bubble',
|
| 973 |
+
972: 'cliff, drop, drop-off',
|
| 974 |
+
973: 'coral reef',
|
| 975 |
+
974: 'geyser',
|
| 976 |
+
975: 'lakeside, lakeshore',
|
| 977 |
+
976: 'promontory, headland, head, foreland',
|
| 978 |
+
977: 'sandbar, sand bar',
|
| 979 |
+
978: 'seashore, coast, seacoast, sea-coast',
|
| 980 |
+
979: 'valley, vale',
|
| 981 |
+
980: 'volcano',
|
| 982 |
+
981: 'ballplayer, baseball player',
|
| 983 |
+
982: 'groom, bridegroom',
|
| 984 |
+
983: 'scuba diver',
|
| 985 |
+
984: 'rapeseed',
|
| 986 |
+
985: 'daisy',
|
| 987 |
+
986: "yellow lady's slipper, yellow lady-slipper, Cypripedium calceolus, Cypripedium parviflorum",
|
| 988 |
+
987: 'corn',
|
| 989 |
+
988: 'acorn',
|
| 990 |
+
989: 'hip, rose hip, rosehip',
|
| 991 |
+
990: 'buckeye, horse chestnut, conker',
|
| 992 |
+
991: 'coral fungus',
|
| 993 |
+
992: 'agaric',
|
| 994 |
+
993: 'gyromitra',
|
| 995 |
+
994: 'stinkhorn, carrion fungus',
|
| 996 |
+
995: 'earthstar',
|
| 997 |
+
996: 'hen-of-the-woods, hen of the woods, Polyporus frondosus, Grifola frondosa',
|
| 998 |
+
997: 'bolete',
|
| 999 |
+
998: 'ear, spike, capitulum',
|
| 1000 |
+
999: 'toilet tissue, toilet paper, bathroom tissue'
|
environment.yaml
CHANGED
|
@@ -5,9 +5,9 @@ channels:
|
|
| 5 |
dependencies:
|
| 6 |
- python=3.8.5
|
| 7 |
- pip=20.3
|
| 8 |
-
- cudatoolkit=11.
|
| 9 |
-
- pytorch=1.
|
| 10 |
-
- torchvision=0.
|
| 11 |
- numpy=1.19.2
|
| 12 |
- pip:
|
| 13 |
- albumentations==0.4.3
|
|
@@ -21,7 +21,7 @@ dependencies:
|
|
| 21 |
- streamlit>=0.73.1
|
| 22 |
- einops==0.3.0
|
| 23 |
- torch-fidelity==0.3.0
|
| 24 |
-
- transformers==4.
|
| 25 |
- -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
|
| 26 |
- -e git+https://github.com/openai/CLIP.git@main#egg=clip
|
| 27 |
-
- -e .
|
|
|
|
| 5 |
dependencies:
|
| 6 |
- python=3.8.5
|
| 7 |
- pip=20.3
|
| 8 |
+
- cudatoolkit=11.3
|
| 9 |
+
- pytorch=1.11.0
|
| 10 |
+
- torchvision=0.12.0
|
| 11 |
- numpy=1.19.2
|
| 12 |
- pip:
|
| 13 |
- albumentations==0.4.3
|
|
|
|
| 21 |
- streamlit>=0.73.1
|
| 22 |
- einops==0.3.0
|
| 23 |
- torch-fidelity==0.3.0
|
| 24 |
+
- transformers==4.19.2
|
| 25 |
- -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
|
| 26 |
- -e git+https://github.com/openai/CLIP.git@main#egg=clip
|
| 27 |
+
- -e .
|
ldm/models/diffusion/ddim.py
CHANGED
|
@@ -5,7 +5,8 @@ import numpy as np
|
|
| 5 |
from tqdm import tqdm
|
| 6 |
from functools import partial
|
| 7 |
|
| 8 |
-
from ldm.modules.diffusionmodules.util import make_ddim_sampling_parameters, make_ddim_timesteps, noise_like
|
|
|
|
| 9 |
|
| 10 |
|
| 11 |
class DDIMSampler(object):
|
|
@@ -72,6 +73,9 @@ class DDIMSampler(object):
|
|
| 72 |
verbose=True,
|
| 73 |
x_T=None,
|
| 74 |
log_every_t=100,
|
|
|
|
|
|
|
|
|
|
| 75 |
**kwargs
|
| 76 |
):
|
| 77 |
if conditioning is not None:
|
|
@@ -100,7 +104,9 @@ class DDIMSampler(object):
|
|
| 100 |
score_corrector=score_corrector,
|
| 101 |
corrector_kwargs=corrector_kwargs,
|
| 102 |
x_T=x_T,
|
| 103 |
-
log_every_t=log_every_t
|
|
|
|
|
|
|
| 104 |
)
|
| 105 |
return samples, intermediates
|
| 106 |
|
|
@@ -109,7 +115,8 @@ class DDIMSampler(object):
|
|
| 109 |
x_T=None, ddim_use_original_steps=False,
|
| 110 |
callback=None, timesteps=None, quantize_denoised=False,
|
| 111 |
mask=None, x0=None, img_callback=None, log_every_t=100,
|
| 112 |
-
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None
|
|
|
|
| 113 |
device = self.model.betas.device
|
| 114 |
b = shape[0]
|
| 115 |
if x_T is None:
|
|
@@ -142,7 +149,9 @@ class DDIMSampler(object):
|
|
| 142 |
outs = self.p_sample_ddim(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
|
| 143 |
quantize_denoised=quantize_denoised, temperature=temperature,
|
| 144 |
noise_dropout=noise_dropout, score_corrector=score_corrector,
|
| 145 |
-
corrector_kwargs=corrector_kwargs
|
|
|
|
|
|
|
| 146 |
img, pred_x0 = outs
|
| 147 |
if callback: callback(i)
|
| 148 |
if img_callback: img_callback(pred_x0, i)
|
|
@@ -155,9 +164,19 @@ class DDIMSampler(object):
|
|
| 155 |
|
| 156 |
@torch.no_grad()
|
| 157 |
def p_sample_ddim(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
|
| 158 |
-
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None
|
|
|
|
| 159 |
b, *_, device = *x.shape, x.device
|
| 160 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 161 |
if score_corrector is not None:
|
| 162 |
assert self.model.parameterization == "eps"
|
| 163 |
e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)
|
|
@@ -183,3 +202,40 @@ class DDIMSampler(object):
|
|
| 183 |
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
|
| 184 |
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
|
| 185 |
return x_prev, pred_x0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
from tqdm import tqdm
|
| 6 |
from functools import partial
|
| 7 |
|
| 8 |
+
from ldm.modules.diffusionmodules.util import make_ddim_sampling_parameters, make_ddim_timesteps, noise_like, \
|
| 9 |
+
extract_into_tensor
|
| 10 |
|
| 11 |
|
| 12 |
class DDIMSampler(object):
|
|
|
|
| 73 |
verbose=True,
|
| 74 |
x_T=None,
|
| 75 |
log_every_t=100,
|
| 76 |
+
unconditional_guidance_scale=1.,
|
| 77 |
+
unconditional_conditioning=None,
|
| 78 |
+
# this has to come in the same format as the conditioning, # e.g. as encoded tokens, ...
|
| 79 |
**kwargs
|
| 80 |
):
|
| 81 |
if conditioning is not None:
|
|
|
|
| 104 |
score_corrector=score_corrector,
|
| 105 |
corrector_kwargs=corrector_kwargs,
|
| 106 |
x_T=x_T,
|
| 107 |
+
log_every_t=log_every_t,
|
| 108 |
+
unconditional_guidance_scale=unconditional_guidance_scale,
|
| 109 |
+
unconditional_conditioning=unconditional_conditioning,
|
| 110 |
)
|
| 111 |
return samples, intermediates
|
| 112 |
|
|
|
|
| 115 |
x_T=None, ddim_use_original_steps=False,
|
| 116 |
callback=None, timesteps=None, quantize_denoised=False,
|
| 117 |
mask=None, x0=None, img_callback=None, log_every_t=100,
|
| 118 |
+
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
|
| 119 |
+
unconditional_guidance_scale=1., unconditional_conditioning=None,):
|
| 120 |
device = self.model.betas.device
|
| 121 |
b = shape[0]
|
| 122 |
if x_T is None:
|
|
|
|
| 149 |
outs = self.p_sample_ddim(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
|
| 150 |
quantize_denoised=quantize_denoised, temperature=temperature,
|
| 151 |
noise_dropout=noise_dropout, score_corrector=score_corrector,
|
| 152 |
+
corrector_kwargs=corrector_kwargs,
|
| 153 |
+
unconditional_guidance_scale=unconditional_guidance_scale,
|
| 154 |
+
unconditional_conditioning=unconditional_conditioning)
|
| 155 |
img, pred_x0 = outs
|
| 156 |
if callback: callback(i)
|
| 157 |
if img_callback: img_callback(pred_x0, i)
|
|
|
|
| 164 |
|
| 165 |
@torch.no_grad()
|
| 166 |
def p_sample_ddim(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
|
| 167 |
+
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
|
| 168 |
+
unconditional_guidance_scale=1., unconditional_conditioning=None):
|
| 169 |
b, *_, device = *x.shape, x.device
|
| 170 |
+
|
| 171 |
+
if unconditional_conditioning is None or unconditional_guidance_scale == 1.:
|
| 172 |
+
e_t = self.model.apply_model(x, t, c)
|
| 173 |
+
else:
|
| 174 |
+
x_in = torch.cat([x] * 2)
|
| 175 |
+
t_in = torch.cat([t] * 2)
|
| 176 |
+
c_in = torch.cat([unconditional_conditioning, c])
|
| 177 |
+
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
|
| 178 |
+
e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
|
| 179 |
+
|
| 180 |
if score_corrector is not None:
|
| 181 |
assert self.model.parameterization == "eps"
|
| 182 |
e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)
|
|
|
|
| 202 |
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
|
| 203 |
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
|
| 204 |
return x_prev, pred_x0
|
| 205 |
+
|
| 206 |
+
@torch.no_grad()
|
| 207 |
+
def stochastic_encode(self, x0, t, use_original_steps=False, noise=None):
|
| 208 |
+
# fast, but does not allow for exact reconstruction
|
| 209 |
+
# t serves as an index to gather the correct alphas
|
| 210 |
+
if use_original_steps:
|
| 211 |
+
sqrt_alphas_cumprod = self.sqrt_alphas_cumprod
|
| 212 |
+
sqrt_one_minus_alphas_cumprod = self.sqrt_one_minus_alphas_cumprod
|
| 213 |
+
else:
|
| 214 |
+
sqrt_alphas_cumprod = torch.sqrt(self.ddim_alphas)
|
| 215 |
+
sqrt_one_minus_alphas_cumprod = self.ddim_sqrt_one_minus_alphas
|
| 216 |
+
|
| 217 |
+
if noise is None:
|
| 218 |
+
noise = torch.randn_like(x0)
|
| 219 |
+
return (extract_into_tensor(sqrt_alphas_cumprod, t, x0.shape) * x0 +
|
| 220 |
+
extract_into_tensor(sqrt_one_minus_alphas_cumprod, t, x0.shape) * noise)
|
| 221 |
+
|
| 222 |
+
@torch.no_grad()
|
| 223 |
+
def decode(self, x_latent, cond, t_start, unconditional_guidance_scale=1.0, unconditional_conditioning=None,
|
| 224 |
+
use_original_steps=False):
|
| 225 |
+
|
| 226 |
+
timesteps = np.arange(self.ddpm_num_timesteps) if use_original_steps else self.ddim_timesteps
|
| 227 |
+
timesteps = timesteps[:t_start]
|
| 228 |
+
|
| 229 |
+
time_range = np.flip(timesteps)
|
| 230 |
+
total_steps = timesteps.shape[0]
|
| 231 |
+
print(f"Running DDIM Sampling with {total_steps} timesteps")
|
| 232 |
+
|
| 233 |
+
iterator = tqdm(time_range, desc='Decoding image', total=total_steps)
|
| 234 |
+
x_dec = x_latent
|
| 235 |
+
for i, step in enumerate(iterator):
|
| 236 |
+
index = total_steps - i - 1
|
| 237 |
+
ts = torch.full((x_latent.shape[0],), step, device=x_latent.device, dtype=torch.long)
|
| 238 |
+
x_dec, _ = self.p_sample_ddim(x_dec, cond, ts, index=index, use_original_steps=use_original_steps,
|
| 239 |
+
unconditional_guidance_scale=unconditional_guidance_scale,
|
| 240 |
+
unconditional_conditioning=unconditional_conditioning)
|
| 241 |
+
return x_dec
|
ldm/models/diffusion/plms.py
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""SAMPLING ONLY."""
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
from functools import partial
|
| 7 |
+
|
| 8 |
+
from ldm.modules.diffusionmodules.util import make_ddim_sampling_parameters, make_ddim_timesteps, noise_like
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class PLMSSampler(object):
|
| 12 |
+
def __init__(self, model, schedule="linear", **kwargs):
|
| 13 |
+
super().__init__()
|
| 14 |
+
self.model = model
|
| 15 |
+
self.ddpm_num_timesteps = model.num_timesteps
|
| 16 |
+
self.schedule = schedule
|
| 17 |
+
|
| 18 |
+
def register_buffer(self, name, attr):
|
| 19 |
+
if type(attr) == torch.Tensor:
|
| 20 |
+
if attr.device != torch.device("cuda"):
|
| 21 |
+
attr = attr.to(torch.device("cuda"))
|
| 22 |
+
setattr(self, name, attr)
|
| 23 |
+
|
| 24 |
+
def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddim_eta=0., verbose=True):
|
| 25 |
+
if ddim_eta != 0:
|
| 26 |
+
raise ValueError('ddim_eta must be 0 for PLMS')
|
| 27 |
+
self.ddim_timesteps = make_ddim_timesteps(ddim_discr_method=ddim_discretize, num_ddim_timesteps=ddim_num_steps,
|
| 28 |
+
num_ddpm_timesteps=self.ddpm_num_timesteps,verbose=verbose)
|
| 29 |
+
alphas_cumprod = self.model.alphas_cumprod
|
| 30 |
+
assert alphas_cumprod.shape[0] == self.ddpm_num_timesteps, 'alphas have to be defined for each timestep'
|
| 31 |
+
to_torch = lambda x: x.clone().detach().to(torch.float32).to(self.model.device)
|
| 32 |
+
|
| 33 |
+
self.register_buffer('betas', to_torch(self.model.betas))
|
| 34 |
+
self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
|
| 35 |
+
self.register_buffer('alphas_cumprod_prev', to_torch(self.model.alphas_cumprod_prev))
|
| 36 |
+
|
| 37 |
+
# calculations for diffusion q(x_t | x_{t-1}) and others
|
| 38 |
+
self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod.cpu())))
|
| 39 |
+
self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod.cpu())))
|
| 40 |
+
self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod.cpu())))
|
| 41 |
+
self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu())))
|
| 42 |
+
self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu() - 1)))
|
| 43 |
+
|
| 44 |
+
# ddim sampling parameters
|
| 45 |
+
ddim_sigmas, ddim_alphas, ddim_alphas_prev = make_ddim_sampling_parameters(alphacums=alphas_cumprod.cpu(),
|
| 46 |
+
ddim_timesteps=self.ddim_timesteps,
|
| 47 |
+
eta=ddim_eta,verbose=verbose)
|
| 48 |
+
self.register_buffer('ddim_sigmas', ddim_sigmas)
|
| 49 |
+
self.register_buffer('ddim_alphas', ddim_alphas)
|
| 50 |
+
self.register_buffer('ddim_alphas_prev', ddim_alphas_prev)
|
| 51 |
+
self.register_buffer('ddim_sqrt_one_minus_alphas', np.sqrt(1. - ddim_alphas))
|
| 52 |
+
sigmas_for_original_sampling_steps = ddim_eta * torch.sqrt(
|
| 53 |
+
(1 - self.alphas_cumprod_prev) / (1 - self.alphas_cumprod) * (
|
| 54 |
+
1 - self.alphas_cumprod / self.alphas_cumprod_prev))
|
| 55 |
+
self.register_buffer('ddim_sigmas_for_original_num_steps', sigmas_for_original_sampling_steps)
|
| 56 |
+
|
| 57 |
+
@torch.no_grad()
|
| 58 |
+
def sample(self,
|
| 59 |
+
S,
|
| 60 |
+
batch_size,
|
| 61 |
+
shape,
|
| 62 |
+
conditioning=None,
|
| 63 |
+
callback=None,
|
| 64 |
+
normals_sequence=None,
|
| 65 |
+
img_callback=None,
|
| 66 |
+
quantize_x0=False,
|
| 67 |
+
eta=0.,
|
| 68 |
+
mask=None,
|
| 69 |
+
x0=None,
|
| 70 |
+
temperature=1.,
|
| 71 |
+
noise_dropout=0.,
|
| 72 |
+
score_corrector=None,
|
| 73 |
+
corrector_kwargs=None,
|
| 74 |
+
verbose=True,
|
| 75 |
+
x_T=None,
|
| 76 |
+
log_every_t=100,
|
| 77 |
+
unconditional_guidance_scale=1.,
|
| 78 |
+
unconditional_conditioning=None,
|
| 79 |
+
# this has to come in the same format as the conditioning, # e.g. as encoded tokens, ...
|
| 80 |
+
**kwargs
|
| 81 |
+
):
|
| 82 |
+
if conditioning is not None:
|
| 83 |
+
if isinstance(conditioning, dict):
|
| 84 |
+
cbs = conditioning[list(conditioning.keys())[0]].shape[0]
|
| 85 |
+
if cbs != batch_size:
|
| 86 |
+
print(f"Warning: Got {cbs} conditionings but batch-size is {batch_size}")
|
| 87 |
+
else:
|
| 88 |
+
if conditioning.shape[0] != batch_size:
|
| 89 |
+
print(f"Warning: Got {conditioning.shape[0]} conditionings but batch-size is {batch_size}")
|
| 90 |
+
|
| 91 |
+
self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=verbose)
|
| 92 |
+
# sampling
|
| 93 |
+
C, H, W = shape
|
| 94 |
+
size = (batch_size, C, H, W)
|
| 95 |
+
print(f'Data shape for PLMS sampling is {size}')
|
| 96 |
+
|
| 97 |
+
samples, intermediates = self.plms_sampling(conditioning, size,
|
| 98 |
+
callback=callback,
|
| 99 |
+
img_callback=img_callback,
|
| 100 |
+
quantize_denoised=quantize_x0,
|
| 101 |
+
mask=mask, x0=x0,
|
| 102 |
+
ddim_use_original_steps=False,
|
| 103 |
+
noise_dropout=noise_dropout,
|
| 104 |
+
temperature=temperature,
|
| 105 |
+
score_corrector=score_corrector,
|
| 106 |
+
corrector_kwargs=corrector_kwargs,
|
| 107 |
+
x_T=x_T,
|
| 108 |
+
log_every_t=log_every_t,
|
| 109 |
+
unconditional_guidance_scale=unconditional_guidance_scale,
|
| 110 |
+
unconditional_conditioning=unconditional_conditioning,
|
| 111 |
+
)
|
| 112 |
+
return samples, intermediates
|
| 113 |
+
|
| 114 |
+
@torch.no_grad()
|
| 115 |
+
def plms_sampling(self, cond, shape,
|
| 116 |
+
x_T=None, ddim_use_original_steps=False,
|
| 117 |
+
callback=None, timesteps=None, quantize_denoised=False,
|
| 118 |
+
mask=None, x0=None, img_callback=None, log_every_t=100,
|
| 119 |
+
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
|
| 120 |
+
unconditional_guidance_scale=1., unconditional_conditioning=None,):
|
| 121 |
+
device = self.model.betas.device
|
| 122 |
+
b = shape[0]
|
| 123 |
+
if x_T is None:
|
| 124 |
+
img = torch.randn(shape, device=device)
|
| 125 |
+
else:
|
| 126 |
+
img = x_T
|
| 127 |
+
|
| 128 |
+
if timesteps is None:
|
| 129 |
+
timesteps = self.ddpm_num_timesteps if ddim_use_original_steps else self.ddim_timesteps
|
| 130 |
+
elif timesteps is not None and not ddim_use_original_steps:
|
| 131 |
+
subset_end = int(min(timesteps / self.ddim_timesteps.shape[0], 1) * self.ddim_timesteps.shape[0]) - 1
|
| 132 |
+
timesteps = self.ddim_timesteps[:subset_end]
|
| 133 |
+
|
| 134 |
+
intermediates = {'x_inter': [img], 'pred_x0': [img]}
|
| 135 |
+
time_range = list(reversed(range(0,timesteps))) if ddim_use_original_steps else np.flip(timesteps)
|
| 136 |
+
total_steps = timesteps if ddim_use_original_steps else timesteps.shape[0]
|
| 137 |
+
print(f"Running PLMS Sampling with {total_steps} timesteps")
|
| 138 |
+
|
| 139 |
+
iterator = tqdm(time_range, desc='PLMS Sampler', total=total_steps)
|
| 140 |
+
old_eps = []
|
| 141 |
+
|
| 142 |
+
for i, step in enumerate(iterator):
|
| 143 |
+
index = total_steps - i - 1
|
| 144 |
+
ts = torch.full((b,), step, device=device, dtype=torch.long)
|
| 145 |
+
ts_next = torch.full((b,), time_range[min(i + 1, len(time_range) - 1)], device=device, dtype=torch.long)
|
| 146 |
+
|
| 147 |
+
if mask is not None:
|
| 148 |
+
assert x0 is not None
|
| 149 |
+
img_orig = self.model.q_sample(x0, ts) # TODO: deterministic forward pass?
|
| 150 |
+
img = img_orig * mask + (1. - mask) * img
|
| 151 |
+
|
| 152 |
+
outs = self.p_sample_plms(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
|
| 153 |
+
quantize_denoised=quantize_denoised, temperature=temperature,
|
| 154 |
+
noise_dropout=noise_dropout, score_corrector=score_corrector,
|
| 155 |
+
corrector_kwargs=corrector_kwargs,
|
| 156 |
+
unconditional_guidance_scale=unconditional_guidance_scale,
|
| 157 |
+
unconditional_conditioning=unconditional_conditioning,
|
| 158 |
+
old_eps=old_eps, t_next=ts_next)
|
| 159 |
+
img, pred_x0, e_t = outs
|
| 160 |
+
old_eps.append(e_t)
|
| 161 |
+
if len(old_eps) >= 4:
|
| 162 |
+
old_eps.pop(0)
|
| 163 |
+
if callback: callback(i)
|
| 164 |
+
if img_callback: img_callback(pred_x0, i)
|
| 165 |
+
|
| 166 |
+
if index % log_every_t == 0 or index == total_steps - 1:
|
| 167 |
+
intermediates['x_inter'].append(img)
|
| 168 |
+
intermediates['pred_x0'].append(pred_x0)
|
| 169 |
+
|
| 170 |
+
return img, intermediates
|
| 171 |
+
|
| 172 |
+
@torch.no_grad()
|
| 173 |
+
def p_sample_plms(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
|
| 174 |
+
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
|
| 175 |
+
unconditional_guidance_scale=1., unconditional_conditioning=None, old_eps=None, t_next=None):
|
| 176 |
+
b, *_, device = *x.shape, x.device
|
| 177 |
+
|
| 178 |
+
def get_model_output(x, t):
|
| 179 |
+
if unconditional_conditioning is None or unconditional_guidance_scale == 1.:
|
| 180 |
+
e_t = self.model.apply_model(x, t, c)
|
| 181 |
+
else:
|
| 182 |
+
x_in = torch.cat([x] * 2)
|
| 183 |
+
t_in = torch.cat([t] * 2)
|
| 184 |
+
c_in = torch.cat([unconditional_conditioning, c])
|
| 185 |
+
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
|
| 186 |
+
e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
|
| 187 |
+
|
| 188 |
+
if score_corrector is not None:
|
| 189 |
+
assert self.model.parameterization == "eps"
|
| 190 |
+
e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)
|
| 191 |
+
|
| 192 |
+
return e_t
|
| 193 |
+
|
| 194 |
+
alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
|
| 195 |
+
alphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prev
|
| 196 |
+
sqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphas
|
| 197 |
+
sigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas
|
| 198 |
+
|
| 199 |
+
def get_x_prev_and_pred_x0(e_t, index):
|
| 200 |
+
# select parameters corresponding to the currently considered timestep
|
| 201 |
+
a_t = torch.full((b, 1, 1, 1), alphas[index], device=device)
|
| 202 |
+
a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)
|
| 203 |
+
sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)
|
| 204 |
+
sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device)
|
| 205 |
+
|
| 206 |
+
# current prediction for x_0
|
| 207 |
+
pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
|
| 208 |
+
if quantize_denoised:
|
| 209 |
+
pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)
|
| 210 |
+
# direction pointing to x_t
|
| 211 |
+
dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t
|
| 212 |
+
noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
|
| 213 |
+
if noise_dropout > 0.:
|
| 214 |
+
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
|
| 215 |
+
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
|
| 216 |
+
return x_prev, pred_x0
|
| 217 |
+
|
| 218 |
+
e_t = get_model_output(x, t)
|
| 219 |
+
if len(old_eps) == 0:
|
| 220 |
+
# Pseudo Improved Euler (2nd order)
|
| 221 |
+
x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t, index)
|
| 222 |
+
e_t_next = get_model_output(x_prev, t_next)
|
| 223 |
+
e_t_prime = (e_t + e_t_next) / 2
|
| 224 |
+
elif len(old_eps) == 1:
|
| 225 |
+
# 2nd order Pseudo Linear Multistep (Adams-Bashforth)
|
| 226 |
+
e_t_prime = (3 * e_t - old_eps[-1]) / 2
|
| 227 |
+
elif len(old_eps) == 2:
|
| 228 |
+
# 3nd order Pseudo Linear Multistep (Adams-Bashforth)
|
| 229 |
+
e_t_prime = (23 * e_t - 16 * old_eps[-1] + 5 * old_eps[-2]) / 12
|
| 230 |
+
elif len(old_eps) >= 3:
|
| 231 |
+
# 4nd order Pseudo Linear Multistep (Adams-Bashforth)
|
| 232 |
+
e_t_prime = (55 * e_t - 59 * old_eps[-1] + 37 * old_eps[-2] - 9 * old_eps[-3]) / 24
|
| 233 |
+
|
| 234 |
+
x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t_prime, index)
|
| 235 |
+
|
| 236 |
+
return x_prev, pred_x0, e_t
|
ldm/modules/diffusionmodules/openaimodel.py
CHANGED
|
@@ -455,7 +455,7 @@ class UNetModel(nn.Module):
|
|
| 455 |
num_classes=None,
|
| 456 |
use_checkpoint=False,
|
| 457 |
use_fp16=False,
|
| 458 |
-
num_heads
|
| 459 |
num_head_channels=-1,
|
| 460 |
num_heads_upsample=-1,
|
| 461 |
use_scale_shift_norm=False,
|
|
@@ -464,21 +464,28 @@ class UNetModel(nn.Module):
|
|
| 464 |
use_spatial_transformer=False, # custom transformer support
|
| 465 |
transformer_depth=1, # custom transformer support
|
| 466 |
context_dim=None, # custom transformer support
|
| 467 |
-
n_embed=None
|
|
|
|
| 468 |
):
|
| 469 |
super().__init__()
|
| 470 |
-
|
| 471 |
if use_spatial_transformer:
|
| 472 |
assert context_dim is not None, 'Fool!! You forgot to include the dimension of your cross-attention conditioning...'
|
| 473 |
|
| 474 |
if context_dim is not None:
|
| 475 |
assert use_spatial_transformer, 'Fool!! You forgot to use the spatial transformer for your cross-attention conditioning...'
|
| 476 |
-
|
| 477 |
-
|
|
|
|
| 478 |
|
| 479 |
if num_heads_upsample == -1:
|
| 480 |
num_heads_upsample = num_heads
|
| 481 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 482 |
self.image_size = image_size
|
| 483 |
self.in_channels = in_channels
|
| 484 |
self.model_channels = model_channels
|
|
@@ -532,13 +539,20 @@ class UNetModel(nn.Module):
|
|
| 532 |
]
|
| 533 |
ch = mult * model_channels
|
| 534 |
if ds in attention_resolutions:
|
| 535 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 536 |
layers.append(
|
| 537 |
AttentionBlock(
|
| 538 |
ch,
|
| 539 |
use_checkpoint=use_checkpoint,
|
| 540 |
num_heads=num_heads,
|
| 541 |
-
num_head_channels=
|
| 542 |
use_new_attention_order=use_new_attention_order,
|
| 543 |
) if not use_spatial_transformer else SpatialTransformer(
|
| 544 |
ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim
|
|
@@ -572,7 +586,14 @@ class UNetModel(nn.Module):
|
|
| 572 |
ds *= 2
|
| 573 |
self._feature_size += ch
|
| 574 |
|
| 575 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 576 |
self.middle_block = TimestepEmbedSequential(
|
| 577 |
ResBlock(
|
| 578 |
ch,
|
|
@@ -586,7 +607,7 @@ class UNetModel(nn.Module):
|
|
| 586 |
ch,
|
| 587 |
use_checkpoint=use_checkpoint,
|
| 588 |
num_heads=num_heads,
|
| 589 |
-
num_head_channels=
|
| 590 |
use_new_attention_order=use_new_attention_order,
|
| 591 |
) if not use_spatial_transformer else SpatialTransformer(
|
| 592 |
ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim
|
|
@@ -619,13 +640,20 @@ class UNetModel(nn.Module):
|
|
| 619 |
]
|
| 620 |
ch = model_channels * mult
|
| 621 |
if ds in attention_resolutions:
|
| 622 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 623 |
layers.append(
|
| 624 |
AttentionBlock(
|
| 625 |
ch,
|
| 626 |
use_checkpoint=use_checkpoint,
|
| 627 |
num_heads=num_heads_upsample,
|
| 628 |
-
num_head_channels=
|
| 629 |
use_new_attention_order=use_new_attention_order,
|
| 630 |
) if not use_spatial_transformer else SpatialTransformer(
|
| 631 |
ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim
|
|
@@ -691,7 +719,6 @@ class UNetModel(nn.Module):
|
|
| 691 |
assert (y is not None) == (
|
| 692 |
self.num_classes is not None
|
| 693 |
), "must specify y if and only if the model is class-conditional"
|
| 694 |
-
assert timesteps is not None, 'need to implement no-timestep usage'
|
| 695 |
hs = []
|
| 696 |
t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
|
| 697 |
emb = self.time_embed(t_emb)
|
|
@@ -710,14 +737,12 @@ class UNetModel(nn.Module):
|
|
| 710 |
h = module(h, emb, context)
|
| 711 |
h = h.type(x.dtype)
|
| 712 |
if self.predict_codebook_ids:
|
| 713 |
-
#return self.out(h), self.id_predictor(h)
|
| 714 |
return self.id_predictor(h)
|
| 715 |
else:
|
| 716 |
return self.out(h)
|
| 717 |
|
| 718 |
|
| 719 |
class EncoderUNetModel(nn.Module):
|
| 720 |
-
# TODO: do we use it ?
|
| 721 |
"""
|
| 722 |
The half UNet model with attention and timestep embedding.
|
| 723 |
For usage, see UNet.
|
|
|
|
| 455 |
num_classes=None,
|
| 456 |
use_checkpoint=False,
|
| 457 |
use_fp16=False,
|
| 458 |
+
num_heads=-1,
|
| 459 |
num_head_channels=-1,
|
| 460 |
num_heads_upsample=-1,
|
| 461 |
use_scale_shift_norm=False,
|
|
|
|
| 464 |
use_spatial_transformer=False, # custom transformer support
|
| 465 |
transformer_depth=1, # custom transformer support
|
| 466 |
context_dim=None, # custom transformer support
|
| 467 |
+
n_embed=None, # custom support for prediction of discrete ids into codebook of first stage vq model
|
| 468 |
+
legacy=True,
|
| 469 |
):
|
| 470 |
super().__init__()
|
|
|
|
| 471 |
if use_spatial_transformer:
|
| 472 |
assert context_dim is not None, 'Fool!! You forgot to include the dimension of your cross-attention conditioning...'
|
| 473 |
|
| 474 |
if context_dim is not None:
|
| 475 |
assert use_spatial_transformer, 'Fool!! You forgot to use the spatial transformer for your cross-attention conditioning...'
|
| 476 |
+
from omegaconf.listconfig import ListConfig
|
| 477 |
+
if type(context_dim) == ListConfig:
|
| 478 |
+
context_dim = list(context_dim)
|
| 479 |
|
| 480 |
if num_heads_upsample == -1:
|
| 481 |
num_heads_upsample = num_heads
|
| 482 |
|
| 483 |
+
if num_heads == -1:
|
| 484 |
+
assert num_head_channels != -1, 'Either num_heads or num_head_channels has to be set'
|
| 485 |
+
|
| 486 |
+
if num_head_channels == -1:
|
| 487 |
+
assert num_heads != -1, 'Either num_heads or num_head_channels has to be set'
|
| 488 |
+
|
| 489 |
self.image_size = image_size
|
| 490 |
self.in_channels = in_channels
|
| 491 |
self.model_channels = model_channels
|
|
|
|
| 539 |
]
|
| 540 |
ch = mult * model_channels
|
| 541 |
if ds in attention_resolutions:
|
| 542 |
+
if num_head_channels == -1:
|
| 543 |
+
dim_head = ch // num_heads
|
| 544 |
+
else:
|
| 545 |
+
num_heads = ch // num_head_channels
|
| 546 |
+
dim_head = num_head_channels
|
| 547 |
+
if legacy:
|
| 548 |
+
#num_heads = 1
|
| 549 |
+
dim_head = ch // num_heads if use_spatial_transformer else num_head_channels
|
| 550 |
layers.append(
|
| 551 |
AttentionBlock(
|
| 552 |
ch,
|
| 553 |
use_checkpoint=use_checkpoint,
|
| 554 |
num_heads=num_heads,
|
| 555 |
+
num_head_channels=dim_head,
|
| 556 |
use_new_attention_order=use_new_attention_order,
|
| 557 |
) if not use_spatial_transformer else SpatialTransformer(
|
| 558 |
ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim
|
|
|
|
| 586 |
ds *= 2
|
| 587 |
self._feature_size += ch
|
| 588 |
|
| 589 |
+
if num_head_channels == -1:
|
| 590 |
+
dim_head = ch // num_heads
|
| 591 |
+
else:
|
| 592 |
+
num_heads = ch // num_head_channels
|
| 593 |
+
dim_head = num_head_channels
|
| 594 |
+
if legacy:
|
| 595 |
+
#num_heads = 1
|
| 596 |
+
dim_head = ch // num_heads if use_spatial_transformer else num_head_channels
|
| 597 |
self.middle_block = TimestepEmbedSequential(
|
| 598 |
ResBlock(
|
| 599 |
ch,
|
|
|
|
| 607 |
ch,
|
| 608 |
use_checkpoint=use_checkpoint,
|
| 609 |
num_heads=num_heads,
|
| 610 |
+
num_head_channels=dim_head,
|
| 611 |
use_new_attention_order=use_new_attention_order,
|
| 612 |
) if not use_spatial_transformer else SpatialTransformer(
|
| 613 |
ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim
|
|
|
|
| 640 |
]
|
| 641 |
ch = model_channels * mult
|
| 642 |
if ds in attention_resolutions:
|
| 643 |
+
if num_head_channels == -1:
|
| 644 |
+
dim_head = ch // num_heads
|
| 645 |
+
else:
|
| 646 |
+
num_heads = ch // num_head_channels
|
| 647 |
+
dim_head = num_head_channels
|
| 648 |
+
if legacy:
|
| 649 |
+
#num_heads = 1
|
| 650 |
+
dim_head = ch // num_heads if use_spatial_transformer else num_head_channels
|
| 651 |
layers.append(
|
| 652 |
AttentionBlock(
|
| 653 |
ch,
|
| 654 |
use_checkpoint=use_checkpoint,
|
| 655 |
num_heads=num_heads_upsample,
|
| 656 |
+
num_head_channels=dim_head,
|
| 657 |
use_new_attention_order=use_new_attention_order,
|
| 658 |
) if not use_spatial_transformer else SpatialTransformer(
|
| 659 |
ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim
|
|
|
|
| 719 |
assert (y is not None) == (
|
| 720 |
self.num_classes is not None
|
| 721 |
), "must specify y if and only if the model is class-conditional"
|
|
|
|
| 722 |
hs = []
|
| 723 |
t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
|
| 724 |
emb = self.time_embed(t_emb)
|
|
|
|
| 737 |
h = module(h, emb, context)
|
| 738 |
h = h.type(x.dtype)
|
| 739 |
if self.predict_codebook_ids:
|
|
|
|
| 740 |
return self.id_predictor(h)
|
| 741 |
else:
|
| 742 |
return self.out(h)
|
| 743 |
|
| 744 |
|
| 745 |
class EncoderUNetModel(nn.Module):
|
|
|
|
| 746 |
"""
|
| 747 |
The half UNet model with attention and timestep embedding.
|
| 748 |
For usage, see UNet.
|
ldm/modules/encoders/modules.py
CHANGED
|
@@ -1,6 +1,10 @@
|
|
| 1 |
import torch
|
| 2 |
import torch.nn as nn
|
| 3 |
from functools import partial
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
|
| 5 |
from ldm.modules.x_transformer import Encoder, TransformerWrapper # TODO: can we directly rely on lucidrains code and simply add this as a reuirement? --> test
|
| 6 |
|
|
@@ -129,3 +133,102 @@ class SpatialRescaler(nn.Module):
|
|
| 129 |
|
| 130 |
def encode(self, x):
|
| 131 |
return self(x)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import torch
|
| 2 |
import torch.nn as nn
|
| 3 |
from functools import partial
|
| 4 |
+
import clip
|
| 5 |
+
from einops import rearrange, repeat
|
| 6 |
+
from transformers import CLIPTokenizer, CLIPTextModel
|
| 7 |
+
import kornia
|
| 8 |
|
| 9 |
from ldm.modules.x_transformer import Encoder, TransformerWrapper # TODO: can we directly rely on lucidrains code and simply add this as a reuirement? --> test
|
| 10 |
|
|
|
|
| 133 |
|
| 134 |
def encode(self, x):
|
| 135 |
return self(x)
|
| 136 |
+
|
| 137 |
+
class FrozenCLIPEmbedder(AbstractEncoder):
|
| 138 |
+
"""Uses the CLIP transformer encoder for text (from Hugging Face)"""
|
| 139 |
+
def __init__(self, version="openai/clip-vit-large-patch14", device="cuda", max_length=77):
|
| 140 |
+
super().__init__()
|
| 141 |
+
self.tokenizer = CLIPTokenizer.from_pretrained(version)
|
| 142 |
+
self.transformer = CLIPTextModel.from_pretrained(version)
|
| 143 |
+
self.device = device
|
| 144 |
+
self.max_length = max_length
|
| 145 |
+
self.freeze()
|
| 146 |
+
|
| 147 |
+
def freeze(self):
|
| 148 |
+
self.transformer = self.transformer.eval()
|
| 149 |
+
for param in self.parameters():
|
| 150 |
+
param.requires_grad = False
|
| 151 |
+
|
| 152 |
+
def forward(self, text):
|
| 153 |
+
batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
|
| 154 |
+
return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
|
| 155 |
+
tokens = batch_encoding["input_ids"].to(self.device)
|
| 156 |
+
outputs = self.transformer(input_ids=tokens)
|
| 157 |
+
|
| 158 |
+
z = outputs.last_hidden_state
|
| 159 |
+
return z
|
| 160 |
+
|
| 161 |
+
def encode(self, text):
|
| 162 |
+
return self(text)
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
class FrozenCLIPTextEmbedder(nn.Module):
|
| 166 |
+
"""
|
| 167 |
+
Uses the CLIP transformer encoder for text.
|
| 168 |
+
"""
|
| 169 |
+
def __init__(self, version='ViT-L/14', device="cuda", max_length=77, n_repeat=1, normalize=True):
|
| 170 |
+
super().__init__()
|
| 171 |
+
self.model, _ = clip.load(version, jit=False, device="cpu")
|
| 172 |
+
self.device = device
|
| 173 |
+
self.max_length = max_length
|
| 174 |
+
self.n_repeat = n_repeat
|
| 175 |
+
self.normalize = normalize
|
| 176 |
+
|
| 177 |
+
def freeze(self):
|
| 178 |
+
self.model = self.model.eval()
|
| 179 |
+
for param in self.parameters():
|
| 180 |
+
param.requires_grad = False
|
| 181 |
+
|
| 182 |
+
def forward(self, text):
|
| 183 |
+
tokens = clip.tokenize(text).to(self.device)
|
| 184 |
+
z = self.model.encode_text(tokens)
|
| 185 |
+
if self.normalize:
|
| 186 |
+
z = z / torch.linalg.norm(z, dim=1, keepdim=True)
|
| 187 |
+
return z
|
| 188 |
+
|
| 189 |
+
def encode(self, text):
|
| 190 |
+
z = self(text)
|
| 191 |
+
if z.ndim==2:
|
| 192 |
+
z = z[:, None, :]
|
| 193 |
+
z = repeat(z, 'b 1 d -> b k d', k=self.n_repeat)
|
| 194 |
+
return z
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
class FrozenClipImageEmbedder(nn.Module):
|
| 198 |
+
"""
|
| 199 |
+
Uses the CLIP image encoder.
|
| 200 |
+
"""
|
| 201 |
+
def __init__(
|
| 202 |
+
self,
|
| 203 |
+
model,
|
| 204 |
+
jit=False,
|
| 205 |
+
device='cuda' if torch.cuda.is_available() else 'cpu',
|
| 206 |
+
antialias=False,
|
| 207 |
+
):
|
| 208 |
+
super().__init__()
|
| 209 |
+
self.model, _ = clip.load(name=model, device=device, jit=jit)
|
| 210 |
+
|
| 211 |
+
self.antialias = antialias
|
| 212 |
+
|
| 213 |
+
self.register_buffer('mean', torch.Tensor([0.48145466, 0.4578275, 0.40821073]), persistent=False)
|
| 214 |
+
self.register_buffer('std', torch.Tensor([0.26862954, 0.26130258, 0.27577711]), persistent=False)
|
| 215 |
+
|
| 216 |
+
def preprocess(self, x):
|
| 217 |
+
# normalize to [0,1]
|
| 218 |
+
x = kornia.geometry.resize(x, (224, 224),
|
| 219 |
+
interpolation='bicubic',align_corners=True,
|
| 220 |
+
antialias=self.antialias)
|
| 221 |
+
x = (x + 1.) / 2.
|
| 222 |
+
# renormalize according to clip
|
| 223 |
+
x = kornia.enhance.normalize(x, self.mean, self.std)
|
| 224 |
+
return x
|
| 225 |
+
|
| 226 |
+
def forward(self, x):
|
| 227 |
+
# x is assumed to be in range [-1,1]
|
| 228 |
+
return self.model.encode_image(self.preprocess(x))
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
if __name__ == "__main__":
|
| 232 |
+
from ldm.util import count_params
|
| 233 |
+
model = FrozenCLIPEmbedder()
|
| 234 |
+
count_params(model, verbose=True)
|
ldm/modules/x_transformer.py
CHANGED
|
@@ -407,7 +407,7 @@ class AttentionLayers(nn.Module):
|
|
| 407 |
self.rotary_pos_emb = always(None)
|
| 408 |
|
| 409 |
assert rel_pos_num_buckets <= rel_pos_max_distance, 'number of relative position buckets must be less than the relative position max distance'
|
| 410 |
-
self.rel_pos =
|
| 411 |
|
| 412 |
self.pre_norm = pre_norm
|
| 413 |
|
|
|
|
| 407 |
self.rotary_pos_emb = always(None)
|
| 408 |
|
| 409 |
assert rel_pos_num_buckets <= rel_pos_max_distance, 'number of relative position buckets must be less than the relative position max distance'
|
| 410 |
+
self.rel_pos = None
|
| 411 |
|
| 412 |
self.pre_norm = pre_norm
|
| 413 |
|
ldm/util.py
CHANGED
|
@@ -2,6 +2,13 @@ import importlib
|
|
| 2 |
|
| 3 |
import torch
|
| 4 |
import numpy as np
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
|
| 6 |
from inspect import isfunction
|
| 7 |
from PIL import Image, ImageDraw, ImageFont
|
|
@@ -38,7 +45,7 @@ def ismap(x):
|
|
| 38 |
|
| 39 |
|
| 40 |
def isimage(x):
|
| 41 |
-
if not isinstance(x,torch.Tensor):
|
| 42 |
return False
|
| 43 |
return (len(x.shape) == 4) and (x.shape[1] == 3 or x.shape[1] == 1)
|
| 44 |
|
|
@@ -64,7 +71,7 @@ def mean_flat(tensor):
|
|
| 64 |
def count_params(model, verbose=False):
|
| 65 |
total_params = sum(p.numel() for p in model.parameters())
|
| 66 |
if verbose:
|
| 67 |
-
print(f"{model.__class__.__name__} has {total_params*1.e-6:.2f} M params.")
|
| 68 |
return total_params
|
| 69 |
|
| 70 |
|
|
@@ -83,4 +90,114 @@ def get_obj_from_str(string, reload=False):
|
|
| 83 |
if reload:
|
| 84 |
module_imp = importlib.import_module(module)
|
| 85 |
importlib.reload(module_imp)
|
| 86 |
-
return getattr(importlib.import_module(module, package=None), cls)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
import torch
|
| 4 |
import numpy as np
|
| 5 |
+
from collections import abc
|
| 6 |
+
from einops import rearrange
|
| 7 |
+
from functools import partial
|
| 8 |
+
|
| 9 |
+
import multiprocessing as mp
|
| 10 |
+
from threading import Thread
|
| 11 |
+
from queue import Queue
|
| 12 |
|
| 13 |
from inspect import isfunction
|
| 14 |
from PIL import Image, ImageDraw, ImageFont
|
|
|
|
| 45 |
|
| 46 |
|
| 47 |
def isimage(x):
|
| 48 |
+
if not isinstance(x, torch.Tensor):
|
| 49 |
return False
|
| 50 |
return (len(x.shape) == 4) and (x.shape[1] == 3 or x.shape[1] == 1)
|
| 51 |
|
|
|
|
| 71 |
def count_params(model, verbose=False):
|
| 72 |
total_params = sum(p.numel() for p in model.parameters())
|
| 73 |
if verbose:
|
| 74 |
+
print(f"{model.__class__.__name__} has {total_params * 1.e-6:.2f} M params.")
|
| 75 |
return total_params
|
| 76 |
|
| 77 |
|
|
|
|
| 90 |
if reload:
|
| 91 |
module_imp = importlib.import_module(module)
|
| 92 |
importlib.reload(module_imp)
|
| 93 |
+
return getattr(importlib.import_module(module, package=None), cls)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def _do_parallel_data_prefetch(func, Q, data, idx, idx_to_fn=False):
|
| 97 |
+
# create dummy dataset instance
|
| 98 |
+
|
| 99 |
+
# run prefetching
|
| 100 |
+
if idx_to_fn:
|
| 101 |
+
res = func(data, worker_id=idx)
|
| 102 |
+
else:
|
| 103 |
+
res = func(data)
|
| 104 |
+
Q.put([idx, res])
|
| 105 |
+
Q.put("Done")
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def parallel_data_prefetch(
|
| 109 |
+
func: callable, data, n_proc, target_data_type="ndarray", cpu_intensive=True, use_worker_id=False
|
| 110 |
+
):
|
| 111 |
+
# if target_data_type not in ["ndarray", "list"]:
|
| 112 |
+
# raise ValueError(
|
| 113 |
+
# "Data, which is passed to parallel_data_prefetch has to be either of type list or ndarray."
|
| 114 |
+
# )
|
| 115 |
+
if isinstance(data, np.ndarray) and target_data_type == "list":
|
| 116 |
+
raise ValueError("list expected but function got ndarray.")
|
| 117 |
+
elif isinstance(data, abc.Iterable):
|
| 118 |
+
if isinstance(data, dict):
|
| 119 |
+
print(
|
| 120 |
+
f'WARNING:"data" argument passed to parallel_data_prefetch is a dict: Using only its values and disregarding keys.'
|
| 121 |
+
)
|
| 122 |
+
data = list(data.values())
|
| 123 |
+
if target_data_type == "ndarray":
|
| 124 |
+
data = np.asarray(data)
|
| 125 |
+
else:
|
| 126 |
+
data = list(data)
|
| 127 |
+
else:
|
| 128 |
+
raise TypeError(
|
| 129 |
+
f"The data, that shall be processed parallel has to be either an np.ndarray or an Iterable, but is actually {type(data)}."
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
if cpu_intensive:
|
| 133 |
+
Q = mp.Queue(1000)
|
| 134 |
+
proc = mp.Process
|
| 135 |
+
else:
|
| 136 |
+
Q = Queue(1000)
|
| 137 |
+
proc = Thread
|
| 138 |
+
# spawn processes
|
| 139 |
+
if target_data_type == "ndarray":
|
| 140 |
+
arguments = [
|
| 141 |
+
[func, Q, part, i, use_worker_id]
|
| 142 |
+
for i, part in enumerate(np.array_split(data, n_proc))
|
| 143 |
+
]
|
| 144 |
+
else:
|
| 145 |
+
step = (
|
| 146 |
+
int(len(data) / n_proc + 1)
|
| 147 |
+
if len(data) % n_proc != 0
|
| 148 |
+
else int(len(data) / n_proc)
|
| 149 |
+
)
|
| 150 |
+
arguments = [
|
| 151 |
+
[func, Q, part, i, use_worker_id]
|
| 152 |
+
for i, part in enumerate(
|
| 153 |
+
[data[i: i + step] for i in range(0, len(data), step)]
|
| 154 |
+
)
|
| 155 |
+
]
|
| 156 |
+
processes = []
|
| 157 |
+
for i in range(n_proc):
|
| 158 |
+
p = proc(target=_do_parallel_data_prefetch, args=arguments[i])
|
| 159 |
+
processes += [p]
|
| 160 |
+
|
| 161 |
+
# start processes
|
| 162 |
+
print(f"Start prefetching...")
|
| 163 |
+
import time
|
| 164 |
+
|
| 165 |
+
start = time.time()
|
| 166 |
+
gather_res = [[] for _ in range(n_proc)]
|
| 167 |
+
try:
|
| 168 |
+
for p in processes:
|
| 169 |
+
p.start()
|
| 170 |
+
|
| 171 |
+
k = 0
|
| 172 |
+
while k < n_proc:
|
| 173 |
+
# get result
|
| 174 |
+
res = Q.get()
|
| 175 |
+
if res == "Done":
|
| 176 |
+
k += 1
|
| 177 |
+
else:
|
| 178 |
+
gather_res[res[0]] = res[1]
|
| 179 |
+
|
| 180 |
+
except Exception as e:
|
| 181 |
+
print("Exception: ", e)
|
| 182 |
+
for p in processes:
|
| 183 |
+
p.terminate()
|
| 184 |
+
|
| 185 |
+
raise e
|
| 186 |
+
finally:
|
| 187 |
+
for p in processes:
|
| 188 |
+
p.join()
|
| 189 |
+
print(f"Prefetching complete. [{time.time() - start} sec.]")
|
| 190 |
+
|
| 191 |
+
if target_data_type == 'ndarray':
|
| 192 |
+
if not isinstance(gather_res[0], np.ndarray):
|
| 193 |
+
return np.concatenate([np.asarray(r) for r in gather_res], axis=0)
|
| 194 |
+
|
| 195 |
+
# order outputs
|
| 196 |
+
return np.concatenate(gather_res, axis=0)
|
| 197 |
+
elif target_data_type == 'list':
|
| 198 |
+
out = []
|
| 199 |
+
for r in gather_res:
|
| 200 |
+
out.extend(r)
|
| 201 |
+
return out
|
| 202 |
+
else:
|
| 203 |
+
return gather_res
|
scripts/img2img.py
ADDED
|
@@ -0,0 +1,293 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""make variations of input image"""
|
| 2 |
+
|
| 3 |
+
import argparse, os, sys, glob
|
| 4 |
+
import PIL
|
| 5 |
+
import torch
|
| 6 |
+
import numpy as np
|
| 7 |
+
from omegaconf import OmegaConf
|
| 8 |
+
from PIL import Image
|
| 9 |
+
from tqdm import tqdm, trange
|
| 10 |
+
from itertools import islice
|
| 11 |
+
from einops import rearrange, repeat
|
| 12 |
+
from torchvision.utils import make_grid
|
| 13 |
+
from torch import autocast
|
| 14 |
+
from contextlib import nullcontext
|
| 15 |
+
import time
|
| 16 |
+
from pytorch_lightning import seed_everything
|
| 17 |
+
|
| 18 |
+
from ldm.util import instantiate_from_config
|
| 19 |
+
from ldm.models.diffusion.ddim import DDIMSampler
|
| 20 |
+
from ldm.models.diffusion.plms import PLMSSampler
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def chunk(it, size):
|
| 24 |
+
it = iter(it)
|
| 25 |
+
return iter(lambda: tuple(islice(it, size)), ())
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def load_model_from_config(config, ckpt, verbose=False):
|
| 29 |
+
print(f"Loading model from {ckpt}")
|
| 30 |
+
pl_sd = torch.load(ckpt, map_location="cpu")
|
| 31 |
+
if "global_step" in pl_sd:
|
| 32 |
+
print(f"Global Step: {pl_sd['global_step']}")
|
| 33 |
+
sd = pl_sd["state_dict"]
|
| 34 |
+
model = instantiate_from_config(config.model)
|
| 35 |
+
m, u = model.load_state_dict(sd, strict=False)
|
| 36 |
+
if len(m) > 0 and verbose:
|
| 37 |
+
print("missing keys:")
|
| 38 |
+
print(m)
|
| 39 |
+
if len(u) > 0 and verbose:
|
| 40 |
+
print("unexpected keys:")
|
| 41 |
+
print(u)
|
| 42 |
+
|
| 43 |
+
model.cuda()
|
| 44 |
+
model.eval()
|
| 45 |
+
return model
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def load_img(path):
|
| 49 |
+
image = Image.open(path).convert("RGB")
|
| 50 |
+
w, h = image.size
|
| 51 |
+
print(f"loaded input image of size ({w}, {h}) from {path}")
|
| 52 |
+
w, h = map(lambda x: x - x % 32, (w, h)) # resize to integer multiple of 32
|
| 53 |
+
image = image.resize((w, h), resample=PIL.Image.LANCZOS)
|
| 54 |
+
image = np.array(image).astype(np.float32) / 255.0
|
| 55 |
+
image = image[None].transpose(0, 3, 1, 2)
|
| 56 |
+
image = torch.from_numpy(image)
|
| 57 |
+
return 2.*image - 1.
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def main():
|
| 61 |
+
parser = argparse.ArgumentParser()
|
| 62 |
+
|
| 63 |
+
parser.add_argument(
|
| 64 |
+
"--prompt",
|
| 65 |
+
type=str,
|
| 66 |
+
nargs="?",
|
| 67 |
+
default="a painting of a virus monster playing guitar",
|
| 68 |
+
help="the prompt to render"
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
parser.add_argument(
|
| 72 |
+
"--init-img",
|
| 73 |
+
type=str,
|
| 74 |
+
nargs="?",
|
| 75 |
+
help="path to the input image"
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
parser.add_argument(
|
| 79 |
+
"--outdir",
|
| 80 |
+
type=str,
|
| 81 |
+
nargs="?",
|
| 82 |
+
help="dir to write results to",
|
| 83 |
+
default="outputs/img2img-samples"
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
parser.add_argument(
|
| 87 |
+
"--skip_grid",
|
| 88 |
+
action='store_true',
|
| 89 |
+
help="do not save a grid, only individual samples. Helpful when evaluating lots of samples",
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
parser.add_argument(
|
| 93 |
+
"--skip_save",
|
| 94 |
+
action='store_true',
|
| 95 |
+
help="do not save indiviual samples. For speed measurements.",
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
parser.add_argument(
|
| 99 |
+
"--ddim_steps",
|
| 100 |
+
type=int,
|
| 101 |
+
default=50,
|
| 102 |
+
help="number of ddim sampling steps",
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
parser.add_argument(
|
| 106 |
+
"--plms",
|
| 107 |
+
action='store_true',
|
| 108 |
+
help="use plms sampling",
|
| 109 |
+
)
|
| 110 |
+
parser.add_argument(
|
| 111 |
+
"--fixed_code",
|
| 112 |
+
action='store_true',
|
| 113 |
+
help="if enabled, uses the same starting code across all samples ",
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
parser.add_argument(
|
| 117 |
+
"--ddim_eta",
|
| 118 |
+
type=float,
|
| 119 |
+
default=0.0,
|
| 120 |
+
help="ddim eta (eta=0.0 corresponds to deterministic sampling",
|
| 121 |
+
)
|
| 122 |
+
parser.add_argument(
|
| 123 |
+
"--n_iter",
|
| 124 |
+
type=int,
|
| 125 |
+
default=1,
|
| 126 |
+
help="sample this often",
|
| 127 |
+
)
|
| 128 |
+
parser.add_argument(
|
| 129 |
+
"--C",
|
| 130 |
+
type=int,
|
| 131 |
+
default=4,
|
| 132 |
+
help="latent channels",
|
| 133 |
+
)
|
| 134 |
+
parser.add_argument(
|
| 135 |
+
"--f",
|
| 136 |
+
type=int,
|
| 137 |
+
default=8,
|
| 138 |
+
help="downsampling factor, most often 8 or 16",
|
| 139 |
+
)
|
| 140 |
+
parser.add_argument(
|
| 141 |
+
"--n_samples",
|
| 142 |
+
type=int,
|
| 143 |
+
default=2,
|
| 144 |
+
help="how many samples to produce for each given prompt. A.k.a batch size",
|
| 145 |
+
)
|
| 146 |
+
parser.add_argument(
|
| 147 |
+
"--n_rows",
|
| 148 |
+
type=int,
|
| 149 |
+
default=0,
|
| 150 |
+
help="rows in the grid (default: n_samples)",
|
| 151 |
+
)
|
| 152 |
+
parser.add_argument(
|
| 153 |
+
"--scale",
|
| 154 |
+
type=float,
|
| 155 |
+
default=5.0,
|
| 156 |
+
help="unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))",
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
parser.add_argument(
|
| 160 |
+
"--strength",
|
| 161 |
+
type=float,
|
| 162 |
+
default=0.75,
|
| 163 |
+
help="strength for noising/unnoising. 1.0 corresponds to full destruction of information in init image",
|
| 164 |
+
)
|
| 165 |
+
parser.add_argument(
|
| 166 |
+
"--from-file",
|
| 167 |
+
type=str,
|
| 168 |
+
help="if specified, load prompts from this file",
|
| 169 |
+
)
|
| 170 |
+
parser.add_argument(
|
| 171 |
+
"--config",
|
| 172 |
+
type=str,
|
| 173 |
+
default="configs/stable-diffusion/v1-inference.yaml",
|
| 174 |
+
help="path to config which constructs model",
|
| 175 |
+
)
|
| 176 |
+
parser.add_argument(
|
| 177 |
+
"--ckpt",
|
| 178 |
+
type=str,
|
| 179 |
+
default="models/ldm/stable-diffusion-v1/model.ckpt",
|
| 180 |
+
help="path to checkpoint of model",
|
| 181 |
+
)
|
| 182 |
+
parser.add_argument(
|
| 183 |
+
"--seed",
|
| 184 |
+
type=int,
|
| 185 |
+
default=42,
|
| 186 |
+
help="the seed (for reproducible sampling)",
|
| 187 |
+
)
|
| 188 |
+
parser.add_argument(
|
| 189 |
+
"--precision",
|
| 190 |
+
type=str,
|
| 191 |
+
help="evaluate at this precision",
|
| 192 |
+
choices=["full", "autocast"],
|
| 193 |
+
default="autocast"
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
opt = parser.parse_args()
|
| 197 |
+
seed_everything(opt.seed)
|
| 198 |
+
|
| 199 |
+
config = OmegaConf.load(f"{opt.config}")
|
| 200 |
+
model = load_model_from_config(config, f"{opt.ckpt}")
|
| 201 |
+
|
| 202 |
+
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
|
| 203 |
+
model = model.to(device)
|
| 204 |
+
|
| 205 |
+
if opt.plms:
|
| 206 |
+
raise NotImplementedError("PLMS sampler not (yet) supported")
|
| 207 |
+
sampler = PLMSSampler(model)
|
| 208 |
+
else:
|
| 209 |
+
sampler = DDIMSampler(model)
|
| 210 |
+
|
| 211 |
+
os.makedirs(opt.outdir, exist_ok=True)
|
| 212 |
+
outpath = opt.outdir
|
| 213 |
+
|
| 214 |
+
batch_size = opt.n_samples
|
| 215 |
+
n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
|
| 216 |
+
if not opt.from_file:
|
| 217 |
+
prompt = opt.prompt
|
| 218 |
+
assert prompt is not None
|
| 219 |
+
data = [batch_size * [prompt]]
|
| 220 |
+
|
| 221 |
+
else:
|
| 222 |
+
print(f"reading prompts from {opt.from_file}")
|
| 223 |
+
with open(opt.from_file, "r") as f:
|
| 224 |
+
data = f.read().splitlines()
|
| 225 |
+
data = list(chunk(data, batch_size))
|
| 226 |
+
|
| 227 |
+
sample_path = os.path.join(outpath, "samples")
|
| 228 |
+
os.makedirs(sample_path, exist_ok=True)
|
| 229 |
+
base_count = len(os.listdir(sample_path))
|
| 230 |
+
grid_count = len(os.listdir(outpath)) - 1
|
| 231 |
+
|
| 232 |
+
assert os.path.isfile(opt.init_img)
|
| 233 |
+
init_image = load_img(opt.init_img).to(device)
|
| 234 |
+
init_image = repeat(init_image, '1 ... -> b ...', b=batch_size)
|
| 235 |
+
init_latent = model.get_first_stage_encoding(model.encode_first_stage(init_image)) # move to latent space
|
| 236 |
+
|
| 237 |
+
sampler.make_schedule(ddim_num_steps=opt.ddim_steps, ddim_eta=opt.ddim_eta, verbose=False)
|
| 238 |
+
|
| 239 |
+
assert 0. <= opt.strength <= 1., 'can only work with strength in [0.0, 1.0]'
|
| 240 |
+
t_enc = int(opt.strength * opt.ddim_steps)
|
| 241 |
+
print(f"target t_enc is {t_enc} steps")
|
| 242 |
+
|
| 243 |
+
precision_scope = autocast if opt.precision == "autocast" else nullcontext
|
| 244 |
+
with torch.no_grad():
|
| 245 |
+
with precision_scope("cuda"):
|
| 246 |
+
with model.ema_scope():
|
| 247 |
+
tic = time.time()
|
| 248 |
+
all_samples = list()
|
| 249 |
+
for n in trange(opt.n_iter, desc="Sampling"):
|
| 250 |
+
for prompts in tqdm(data, desc="data"):
|
| 251 |
+
uc = None
|
| 252 |
+
if opt.scale != 1.0:
|
| 253 |
+
uc = model.get_learned_conditioning(batch_size * [""])
|
| 254 |
+
if isinstance(prompts, tuple):
|
| 255 |
+
prompts = list(prompts)
|
| 256 |
+
c = model.get_learned_conditioning(prompts)
|
| 257 |
+
|
| 258 |
+
# encode (scaled latent)
|
| 259 |
+
z_enc = sampler.stochastic_encode(init_latent, torch.tensor([t_enc]*batch_size).to(device))
|
| 260 |
+
# decode it
|
| 261 |
+
samples = sampler.decode(z_enc, c, t_enc, unconditional_guidance_scale=opt.scale,
|
| 262 |
+
unconditional_conditioning=uc,)
|
| 263 |
+
|
| 264 |
+
x_samples = model.decode_first_stage(samples)
|
| 265 |
+
x_samples = torch.clamp((x_samples + 1.0) / 2.0, min=0.0, max=1.0)
|
| 266 |
+
|
| 267 |
+
if not opt.skip_save:
|
| 268 |
+
for x_sample in x_samples:
|
| 269 |
+
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
|
| 270 |
+
Image.fromarray(x_sample.astype(np.uint8)).save(
|
| 271 |
+
os.path.join(sample_path, f"{base_count:05}.png"))
|
| 272 |
+
base_count += 1
|
| 273 |
+
all_samples.append(x_samples)
|
| 274 |
+
|
| 275 |
+
if not opt.skip_grid:
|
| 276 |
+
# additionally, save as grid
|
| 277 |
+
grid = torch.stack(all_samples, 0)
|
| 278 |
+
grid = rearrange(grid, 'n b c h w -> (n b) c h w')
|
| 279 |
+
grid = make_grid(grid, nrow=n_rows)
|
| 280 |
+
|
| 281 |
+
# to image
|
| 282 |
+
grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
|
| 283 |
+
Image.fromarray(grid.astype(np.uint8)).save(os.path.join(outpath, f'grid-{grid_count:04}.png'))
|
| 284 |
+
grid_count += 1
|
| 285 |
+
|
| 286 |
+
toc = time.time()
|
| 287 |
+
|
| 288 |
+
print(f"Your samples are ready and waiting for you here: \n{outpath} \n"
|
| 289 |
+
f" \nEnjoy.")
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
if __name__ == "__main__":
|
| 293 |
+
main()
|
scripts/knn2img.py
ADDED
|
@@ -0,0 +1,398 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse, os, sys, glob
|
| 2 |
+
import clip
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import numpy as np
|
| 6 |
+
from omegaconf import OmegaConf
|
| 7 |
+
from PIL import Image
|
| 8 |
+
from tqdm import tqdm, trange
|
| 9 |
+
from itertools import islice
|
| 10 |
+
from einops import rearrange, repeat
|
| 11 |
+
from torchvision.utils import make_grid
|
| 12 |
+
import scann
|
| 13 |
+
import time
|
| 14 |
+
from multiprocessing import cpu_count
|
| 15 |
+
|
| 16 |
+
from ldm.util import instantiate_from_config, parallel_data_prefetch
|
| 17 |
+
from ldm.models.diffusion.ddim import DDIMSampler
|
| 18 |
+
from ldm.models.diffusion.plms import PLMSSampler
|
| 19 |
+
from ldm.modules.encoders.modules import FrozenClipImageEmbedder, FrozenCLIPTextEmbedder
|
| 20 |
+
|
| 21 |
+
DATABASES = [
|
| 22 |
+
"openimages",
|
| 23 |
+
"artbench-art_nouveau",
|
| 24 |
+
"artbench-baroque",
|
| 25 |
+
"artbench-expressionism",
|
| 26 |
+
"artbench-impressionism",
|
| 27 |
+
"artbench-post_impressionism",
|
| 28 |
+
"artbench-realism",
|
| 29 |
+
"artbench-romanticism",
|
| 30 |
+
"artbench-renaissance",
|
| 31 |
+
"artbench-surrealism",
|
| 32 |
+
"artbench-ukiyo_e",
|
| 33 |
+
]
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def chunk(it, size):
|
| 37 |
+
it = iter(it)
|
| 38 |
+
return iter(lambda: tuple(islice(it, size)), ())
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def load_model_from_config(config, ckpt, verbose=False):
|
| 42 |
+
print(f"Loading model from {ckpt}")
|
| 43 |
+
pl_sd = torch.load(ckpt, map_location="cpu")
|
| 44 |
+
if "global_step" in pl_sd:
|
| 45 |
+
print(f"Global Step: {pl_sd['global_step']}")
|
| 46 |
+
sd = pl_sd["state_dict"]
|
| 47 |
+
model = instantiate_from_config(config.model)
|
| 48 |
+
m, u = model.load_state_dict(sd, strict=False)
|
| 49 |
+
if len(m) > 0 and verbose:
|
| 50 |
+
print("missing keys:")
|
| 51 |
+
print(m)
|
| 52 |
+
if len(u) > 0 and verbose:
|
| 53 |
+
print("unexpected keys:")
|
| 54 |
+
print(u)
|
| 55 |
+
|
| 56 |
+
model.cuda()
|
| 57 |
+
model.eval()
|
| 58 |
+
return model
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class Searcher(object):
|
| 62 |
+
def __init__(self, database, retriever_version='ViT-L/14'):
|
| 63 |
+
assert database in DATABASES
|
| 64 |
+
# self.database = self.load_database(database)
|
| 65 |
+
self.database_name = database
|
| 66 |
+
self.searcher_savedir = f'data/rdm/searchers/{self.database_name}'
|
| 67 |
+
self.database_path = f'data/rdm/retrieval_databases/{self.database_name}'
|
| 68 |
+
self.retriever = self.load_retriever(version=retriever_version)
|
| 69 |
+
self.database = {'embedding': [],
|
| 70 |
+
'img_id': [],
|
| 71 |
+
'patch_coords': []}
|
| 72 |
+
self.load_database()
|
| 73 |
+
self.load_searcher()
|
| 74 |
+
|
| 75 |
+
def train_searcher(self, k,
|
| 76 |
+
metric='dot_product',
|
| 77 |
+
searcher_savedir=None):
|
| 78 |
+
|
| 79 |
+
print('Start training searcher')
|
| 80 |
+
searcher = scann.scann_ops_pybind.builder(self.database['embedding'] /
|
| 81 |
+
np.linalg.norm(self.database['embedding'], axis=1)[:, np.newaxis],
|
| 82 |
+
k, metric)
|
| 83 |
+
self.searcher = searcher.score_brute_force().build()
|
| 84 |
+
print('Finish training searcher')
|
| 85 |
+
|
| 86 |
+
if searcher_savedir is not None:
|
| 87 |
+
print(f'Save trained searcher under "{searcher_savedir}"')
|
| 88 |
+
os.makedirs(searcher_savedir, exist_ok=True)
|
| 89 |
+
self.searcher.serialize(searcher_savedir)
|
| 90 |
+
|
| 91 |
+
def load_single_file(self, saved_embeddings):
|
| 92 |
+
compressed = np.load(saved_embeddings)
|
| 93 |
+
self.database = {key: compressed[key] for key in compressed.files}
|
| 94 |
+
print('Finished loading of clip embeddings.')
|
| 95 |
+
|
| 96 |
+
def load_multi_files(self, data_archive):
|
| 97 |
+
out_data = {key: [] for key in self.database}
|
| 98 |
+
for d in tqdm(data_archive, desc=f'Loading datapool from {len(data_archive)} individual files.'):
|
| 99 |
+
for key in d.files:
|
| 100 |
+
out_data[key].append(d[key])
|
| 101 |
+
|
| 102 |
+
return out_data
|
| 103 |
+
|
| 104 |
+
def load_database(self):
|
| 105 |
+
|
| 106 |
+
print(f'Load saved patch embedding from "{self.database_path}"')
|
| 107 |
+
file_content = glob.glob(os.path.join(self.database_path, '*.npz'))
|
| 108 |
+
|
| 109 |
+
if len(file_content) == 1:
|
| 110 |
+
self.load_single_file(file_content[0])
|
| 111 |
+
elif len(file_content) > 1:
|
| 112 |
+
data = [np.load(f) for f in file_content]
|
| 113 |
+
prefetched_data = parallel_data_prefetch(self.load_multi_files, data,
|
| 114 |
+
n_proc=min(len(data), cpu_count()), target_data_type='dict')
|
| 115 |
+
|
| 116 |
+
self.database = {key: np.concatenate([od[key] for od in prefetched_data], axis=1)[0] for key in
|
| 117 |
+
self.database}
|
| 118 |
+
else:
|
| 119 |
+
raise ValueError(f'No npz-files in specified path "{self.database_path}" is this directory existing?')
|
| 120 |
+
|
| 121 |
+
print(f'Finished loading of retrieval database of length {self.database["embedding"].shape[0]}.')
|
| 122 |
+
|
| 123 |
+
def load_retriever(self, version='ViT-L/14', ):
|
| 124 |
+
model = FrozenClipImageEmbedder(model=version)
|
| 125 |
+
if torch.cuda.is_available():
|
| 126 |
+
model.cuda()
|
| 127 |
+
model.eval()
|
| 128 |
+
return model
|
| 129 |
+
|
| 130 |
+
def load_searcher(self):
|
| 131 |
+
print(f'load searcher for database {self.database_name} from {self.searcher_savedir}')
|
| 132 |
+
self.searcher = scann.scann_ops_pybind.load_searcher(self.searcher_savedir)
|
| 133 |
+
print('Finished loading searcher.')
|
| 134 |
+
|
| 135 |
+
def search(self, x, k):
|
| 136 |
+
if self.searcher is None and self.database['embedding'].shape[0] < 2e4:
|
| 137 |
+
self.train_searcher(k) # quickly fit searcher on the fly for small databases
|
| 138 |
+
assert self.searcher is not None, 'Cannot search with uninitialized searcher'
|
| 139 |
+
if isinstance(x, torch.Tensor):
|
| 140 |
+
x = x.detach().cpu().numpy()
|
| 141 |
+
if len(x.shape) == 3:
|
| 142 |
+
x = x[:, 0]
|
| 143 |
+
query_embeddings = x / np.linalg.norm(x, axis=1)[:, np.newaxis]
|
| 144 |
+
|
| 145 |
+
start = time.time()
|
| 146 |
+
nns, distances = self.searcher.search_batched(query_embeddings, final_num_neighbors=k)
|
| 147 |
+
end = time.time()
|
| 148 |
+
|
| 149 |
+
out_embeddings = self.database['embedding'][nns]
|
| 150 |
+
out_img_ids = self.database['img_id'][nns]
|
| 151 |
+
out_pc = self.database['patch_coords'][nns]
|
| 152 |
+
|
| 153 |
+
out = {'nn_embeddings': out_embeddings / np.linalg.norm(out_embeddings, axis=-1)[..., np.newaxis],
|
| 154 |
+
'img_ids': out_img_ids,
|
| 155 |
+
'patch_coords': out_pc,
|
| 156 |
+
'queries': x,
|
| 157 |
+
'exec_time': end - start,
|
| 158 |
+
'nns': nns,
|
| 159 |
+
'q_embeddings': query_embeddings}
|
| 160 |
+
|
| 161 |
+
return out
|
| 162 |
+
|
| 163 |
+
def __call__(self, x, n):
|
| 164 |
+
return self.search(x, n)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
if __name__ == "__main__":
|
| 168 |
+
parser = argparse.ArgumentParser()
|
| 169 |
+
# TODO: add n_neighbors and modes (text-only, text-image-retrieval, image-image retrieval etc)
|
| 170 |
+
# TODO: add 'image variation' mode when knn=0 but a single image is given instead of a text prompt?
|
| 171 |
+
parser.add_argument(
|
| 172 |
+
"--prompt",
|
| 173 |
+
type=str,
|
| 174 |
+
nargs="?",
|
| 175 |
+
default="a painting of a virus monster playing guitar",
|
| 176 |
+
help="the prompt to render"
|
| 177 |
+
)
|
| 178 |
+
|
| 179 |
+
parser.add_argument(
|
| 180 |
+
"--outdir",
|
| 181 |
+
type=str,
|
| 182 |
+
nargs="?",
|
| 183 |
+
help="dir to write results to",
|
| 184 |
+
default="outputs/txt2img-samples"
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
parser.add_argument(
|
| 188 |
+
"--skip_grid",
|
| 189 |
+
action='store_true',
|
| 190 |
+
help="do not save a grid, only individual samples. Helpful when evaluating lots of samples",
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
parser.add_argument(
|
| 194 |
+
"--ddim_steps",
|
| 195 |
+
type=int,
|
| 196 |
+
default=50,
|
| 197 |
+
help="number of ddim sampling steps",
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
parser.add_argument(
|
| 201 |
+
"--n_repeat",
|
| 202 |
+
type=int,
|
| 203 |
+
default=1,
|
| 204 |
+
help="number of repeats in CLIP latent space",
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
parser.add_argument(
|
| 208 |
+
"--plms",
|
| 209 |
+
action='store_true',
|
| 210 |
+
help="use plms sampling",
|
| 211 |
+
)
|
| 212 |
+
|
| 213 |
+
parser.add_argument(
|
| 214 |
+
"--ddim_eta",
|
| 215 |
+
type=float,
|
| 216 |
+
default=0.0,
|
| 217 |
+
help="ddim eta (eta=0.0 corresponds to deterministic sampling",
|
| 218 |
+
)
|
| 219 |
+
parser.add_argument(
|
| 220 |
+
"--n_iter",
|
| 221 |
+
type=int,
|
| 222 |
+
default=1,
|
| 223 |
+
help="sample this often",
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
parser.add_argument(
|
| 227 |
+
"--H",
|
| 228 |
+
type=int,
|
| 229 |
+
default=768,
|
| 230 |
+
help="image height, in pixel space",
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
parser.add_argument(
|
| 234 |
+
"--W",
|
| 235 |
+
type=int,
|
| 236 |
+
default=768,
|
| 237 |
+
help="image width, in pixel space",
|
| 238 |
+
)
|
| 239 |
+
|
| 240 |
+
parser.add_argument(
|
| 241 |
+
"--n_samples",
|
| 242 |
+
type=int,
|
| 243 |
+
default=3,
|
| 244 |
+
help="how many samples to produce for each given prompt. A.k.a batch size",
|
| 245 |
+
)
|
| 246 |
+
|
| 247 |
+
parser.add_argument(
|
| 248 |
+
"--n_rows",
|
| 249 |
+
type=int,
|
| 250 |
+
default=0,
|
| 251 |
+
help="rows in the grid (default: n_samples)",
|
| 252 |
+
)
|
| 253 |
+
|
| 254 |
+
parser.add_argument(
|
| 255 |
+
"--scale",
|
| 256 |
+
type=float,
|
| 257 |
+
default=5.0,
|
| 258 |
+
help="unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))",
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
parser.add_argument(
|
| 262 |
+
"--from-file",
|
| 263 |
+
type=str,
|
| 264 |
+
help="if specified, load prompts from this file",
|
| 265 |
+
)
|
| 266 |
+
|
| 267 |
+
parser.add_argument(
|
| 268 |
+
"--config",
|
| 269 |
+
type=str,
|
| 270 |
+
default="configs/retrieval-augmented-diffusion/768x768.yaml",
|
| 271 |
+
help="path to config which constructs model",
|
| 272 |
+
)
|
| 273 |
+
|
| 274 |
+
parser.add_argument(
|
| 275 |
+
"--ckpt",
|
| 276 |
+
type=str,
|
| 277 |
+
default="models/rdm/rdm768x768/model.ckpt",
|
| 278 |
+
help="path to checkpoint of model",
|
| 279 |
+
)
|
| 280 |
+
|
| 281 |
+
parser.add_argument(
|
| 282 |
+
"--clip_type",
|
| 283 |
+
type=str,
|
| 284 |
+
default="ViT-L/14",
|
| 285 |
+
help="which CLIP model to use for retrieval and NN encoding",
|
| 286 |
+
)
|
| 287 |
+
parser.add_argument(
|
| 288 |
+
"--database",
|
| 289 |
+
type=str,
|
| 290 |
+
default='artbench-surrealism',
|
| 291 |
+
choices=DATABASES,
|
| 292 |
+
help="The database used for the search, only applied when --use_neighbors=True",
|
| 293 |
+
)
|
| 294 |
+
parser.add_argument(
|
| 295 |
+
"--use_neighbors",
|
| 296 |
+
default=False,
|
| 297 |
+
action='store_true',
|
| 298 |
+
help="Include neighbors in addition to text prompt for conditioning",
|
| 299 |
+
)
|
| 300 |
+
parser.add_argument(
|
| 301 |
+
"--knn",
|
| 302 |
+
default=10,
|
| 303 |
+
type=int,
|
| 304 |
+
help="The number of included neighbors, only applied when --use_neighbors=True",
|
| 305 |
+
)
|
| 306 |
+
|
| 307 |
+
opt = parser.parse_args()
|
| 308 |
+
|
| 309 |
+
config = OmegaConf.load(f"{opt.config}")
|
| 310 |
+
model = load_model_from_config(config, f"{opt.ckpt}")
|
| 311 |
+
|
| 312 |
+
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
|
| 313 |
+
model = model.to(device)
|
| 314 |
+
|
| 315 |
+
clip_text_encoder = FrozenCLIPTextEmbedder(opt.clip_type).to(device)
|
| 316 |
+
|
| 317 |
+
if opt.plms:
|
| 318 |
+
sampler = PLMSSampler(model)
|
| 319 |
+
else:
|
| 320 |
+
sampler = DDIMSampler(model)
|
| 321 |
+
|
| 322 |
+
os.makedirs(opt.outdir, exist_ok=True)
|
| 323 |
+
outpath = opt.outdir
|
| 324 |
+
|
| 325 |
+
batch_size = opt.n_samples
|
| 326 |
+
n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
|
| 327 |
+
if not opt.from_file:
|
| 328 |
+
prompt = opt.prompt
|
| 329 |
+
assert prompt is not None
|
| 330 |
+
data = [batch_size * [prompt]]
|
| 331 |
+
|
| 332 |
+
else:
|
| 333 |
+
print(f"reading prompts from {opt.from_file}")
|
| 334 |
+
with open(opt.from_file, "r") as f:
|
| 335 |
+
data = f.read().splitlines()
|
| 336 |
+
data = list(chunk(data, batch_size))
|
| 337 |
+
|
| 338 |
+
sample_path = os.path.join(outpath, "samples")
|
| 339 |
+
os.makedirs(sample_path, exist_ok=True)
|
| 340 |
+
base_count = len(os.listdir(sample_path))
|
| 341 |
+
grid_count = len(os.listdir(outpath)) - 1
|
| 342 |
+
|
| 343 |
+
print(f"sampling scale for cfg is {opt.scale:.2f}")
|
| 344 |
+
|
| 345 |
+
searcher = None
|
| 346 |
+
if opt.use_neighbors:
|
| 347 |
+
searcher = Searcher(opt.database)
|
| 348 |
+
|
| 349 |
+
with torch.no_grad():
|
| 350 |
+
with model.ema_scope():
|
| 351 |
+
for n in trange(opt.n_iter, desc="Sampling"):
|
| 352 |
+
all_samples = list()
|
| 353 |
+
for prompts in tqdm(data, desc="data"):
|
| 354 |
+
print("sampling prompts:", prompts)
|
| 355 |
+
if isinstance(prompts, tuple):
|
| 356 |
+
prompts = list(prompts)
|
| 357 |
+
c = clip_text_encoder.encode(prompts)
|
| 358 |
+
uc = None
|
| 359 |
+
if searcher is not None:
|
| 360 |
+
nn_dict = searcher(c, opt.knn)
|
| 361 |
+
c = torch.cat([c, torch.from_numpy(nn_dict['nn_embeddings']).cuda()], dim=1)
|
| 362 |
+
if opt.scale != 1.0:
|
| 363 |
+
uc = torch.zeros_like(c)
|
| 364 |
+
if isinstance(prompts, tuple):
|
| 365 |
+
prompts = list(prompts)
|
| 366 |
+
shape = [16, opt.H // 16, opt.W // 16] # note: currently hardcoded for f16 model
|
| 367 |
+
samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
|
| 368 |
+
conditioning=c,
|
| 369 |
+
batch_size=c.shape[0],
|
| 370 |
+
shape=shape,
|
| 371 |
+
verbose=False,
|
| 372 |
+
unconditional_guidance_scale=opt.scale,
|
| 373 |
+
unconditional_conditioning=uc,
|
| 374 |
+
eta=opt.ddim_eta,
|
| 375 |
+
)
|
| 376 |
+
|
| 377 |
+
x_samples_ddim = model.decode_first_stage(samples_ddim)
|
| 378 |
+
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
|
| 379 |
+
|
| 380 |
+
for x_sample in x_samples_ddim:
|
| 381 |
+
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
|
| 382 |
+
Image.fromarray(x_sample.astype(np.uint8)).save(
|
| 383 |
+
os.path.join(sample_path, f"{base_count:05}.png"))
|
| 384 |
+
base_count += 1
|
| 385 |
+
all_samples.append(x_samples_ddim)
|
| 386 |
+
|
| 387 |
+
if not opt.skip_grid:
|
| 388 |
+
# additionally, save as grid
|
| 389 |
+
grid = torch.stack(all_samples, 0)
|
| 390 |
+
grid = rearrange(grid, 'n b c h w -> (n b) c h w')
|
| 391 |
+
grid = make_grid(grid, nrow=n_rows)
|
| 392 |
+
|
| 393 |
+
# to image
|
| 394 |
+
grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
|
| 395 |
+
Image.fromarray(grid.astype(np.uint8)).save(os.path.join(outpath, f'grid-{grid_count:04}.png'))
|
| 396 |
+
grid_count += 1
|
| 397 |
+
|
| 398 |
+
print(f"Your samples are ready and waiting for you here: \n{outpath} \nEnjoy.")
|
scripts/latent_imagenet_diffusion.ipynb.REMOVED.git-id
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
607f94fc7d3ef6d8d1627017215476d9dfc7ddc4
|
scripts/train_searcher.py
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, sys
|
| 2 |
+
import numpy as np
|
| 3 |
+
import scann
|
| 4 |
+
import argparse
|
| 5 |
+
import glob
|
| 6 |
+
from multiprocessing import cpu_count
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
|
| 9 |
+
from ldm.util import parallel_data_prefetch
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def search_bruteforce(searcher):
|
| 13 |
+
return searcher.score_brute_force().build()
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def search_partioned_ah(searcher, dims_per_block, aiq_threshold, reorder_k,
|
| 17 |
+
partioning_trainsize, num_leaves, num_leaves_to_search):
|
| 18 |
+
return searcher.tree(num_leaves=num_leaves,
|
| 19 |
+
num_leaves_to_search=num_leaves_to_search,
|
| 20 |
+
training_sample_size=partioning_trainsize). \
|
| 21 |
+
score_ah(dims_per_block, anisotropic_quantization_threshold=aiq_threshold).reorder(reorder_k).build()
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def search_ah(searcher, dims_per_block, aiq_threshold, reorder_k):
|
| 25 |
+
return searcher.score_ah(dims_per_block, anisotropic_quantization_threshold=aiq_threshold).reorder(
|
| 26 |
+
reorder_k).build()
|
| 27 |
+
|
| 28 |
+
def load_datapool(dpath):
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def load_single_file(saved_embeddings):
|
| 32 |
+
compressed = np.load(saved_embeddings)
|
| 33 |
+
database = {key: compressed[key] for key in compressed.files}
|
| 34 |
+
return database
|
| 35 |
+
|
| 36 |
+
def load_multi_files(data_archive):
|
| 37 |
+
database = {key: [] for key in data_archive[0].files}
|
| 38 |
+
for d in tqdm(data_archive, desc=f'Loading datapool from {len(data_archive)} individual files.'):
|
| 39 |
+
for key in d.files:
|
| 40 |
+
database[key].append(d[key])
|
| 41 |
+
|
| 42 |
+
return database
|
| 43 |
+
|
| 44 |
+
print(f'Load saved patch embedding from "{dpath}"')
|
| 45 |
+
file_content = glob.glob(os.path.join(dpath, '*.npz'))
|
| 46 |
+
|
| 47 |
+
if len(file_content) == 1:
|
| 48 |
+
data_pool = load_single_file(file_content[0])
|
| 49 |
+
elif len(file_content) > 1:
|
| 50 |
+
data = [np.load(f) for f in file_content]
|
| 51 |
+
prefetched_data = parallel_data_prefetch(load_multi_files, data,
|
| 52 |
+
n_proc=min(len(data), cpu_count()), target_data_type='dict')
|
| 53 |
+
|
| 54 |
+
data_pool = {key: np.concatenate([od[key] for od in prefetched_data], axis=1)[0] for key in prefetched_data[0].keys()}
|
| 55 |
+
else:
|
| 56 |
+
raise ValueError(f'No npz-files in specified path "{dpath}" is this directory existing?')
|
| 57 |
+
|
| 58 |
+
print(f'Finished loading of retrieval database of length {data_pool["embedding"].shape[0]}.')
|
| 59 |
+
return data_pool
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def train_searcher(opt,
|
| 63 |
+
metric='dot_product',
|
| 64 |
+
partioning_trainsize=None,
|
| 65 |
+
reorder_k=None,
|
| 66 |
+
# todo tune
|
| 67 |
+
aiq_thld=0.2,
|
| 68 |
+
dims_per_block=2,
|
| 69 |
+
num_leaves=None,
|
| 70 |
+
num_leaves_to_search=None,):
|
| 71 |
+
|
| 72 |
+
data_pool = load_datapool(opt.database)
|
| 73 |
+
k = opt.knn
|
| 74 |
+
|
| 75 |
+
if not reorder_k:
|
| 76 |
+
reorder_k = 2 * k
|
| 77 |
+
|
| 78 |
+
# normalize
|
| 79 |
+
# embeddings =
|
| 80 |
+
searcher = scann.scann_ops_pybind.builder(data_pool['embedding'] / np.linalg.norm(data_pool['embedding'], axis=1)[:, np.newaxis], k, metric)
|
| 81 |
+
pool_size = data_pool['embedding'].shape[0]
|
| 82 |
+
|
| 83 |
+
print(*(['#'] * 100))
|
| 84 |
+
print('Initializing scaNN searcher with the following values:')
|
| 85 |
+
print(f'k: {k}')
|
| 86 |
+
print(f'metric: {metric}')
|
| 87 |
+
print(f'reorder_k: {reorder_k}')
|
| 88 |
+
print(f'anisotropic_quantization_threshold: {aiq_thld}')
|
| 89 |
+
print(f'dims_per_block: {dims_per_block}')
|
| 90 |
+
print(*(['#'] * 100))
|
| 91 |
+
print('Start training searcher....')
|
| 92 |
+
print(f'N samples in pool is {pool_size}')
|
| 93 |
+
|
| 94 |
+
# this reflects the recommended design choices proposed at
|
| 95 |
+
# https://github.com/google-research/google-research/blob/aca5f2e44e301af172590bb8e65711f0c9ee0cfd/scann/docs/algorithms.md
|
| 96 |
+
if pool_size < 2e4:
|
| 97 |
+
print('Using brute force search.')
|
| 98 |
+
searcher = search_bruteforce(searcher)
|
| 99 |
+
elif 2e4 <= pool_size and pool_size < 1e5:
|
| 100 |
+
print('Using asymmetric hashing search and reordering.')
|
| 101 |
+
searcher = search_ah(searcher, dims_per_block, aiq_thld, reorder_k)
|
| 102 |
+
else:
|
| 103 |
+
print('Using using partioning, asymmetric hashing search and reordering.')
|
| 104 |
+
|
| 105 |
+
if not partioning_trainsize:
|
| 106 |
+
partioning_trainsize = data_pool['embedding'].shape[0] // 10
|
| 107 |
+
if not num_leaves:
|
| 108 |
+
num_leaves = int(np.sqrt(pool_size))
|
| 109 |
+
|
| 110 |
+
if not num_leaves_to_search:
|
| 111 |
+
num_leaves_to_search = max(num_leaves // 20, 1)
|
| 112 |
+
|
| 113 |
+
print('Partitioning params:')
|
| 114 |
+
print(f'num_leaves: {num_leaves}')
|
| 115 |
+
print(f'num_leaves_to_search: {num_leaves_to_search}')
|
| 116 |
+
# self.searcher = self.search_ah(searcher, dims_per_block, aiq_thld, reorder_k)
|
| 117 |
+
searcher = search_partioned_ah(searcher, dims_per_block, aiq_thld, reorder_k,
|
| 118 |
+
partioning_trainsize, num_leaves, num_leaves_to_search)
|
| 119 |
+
|
| 120 |
+
print('Finish training searcher')
|
| 121 |
+
searcher_savedir = opt.target_path
|
| 122 |
+
os.makedirs(searcher_savedir, exist_ok=True)
|
| 123 |
+
searcher.serialize(searcher_savedir)
|
| 124 |
+
print(f'Saved trained searcher under "{searcher_savedir}"')
|
| 125 |
+
|
| 126 |
+
if __name__ == '__main__':
|
| 127 |
+
sys.path.append(os.getcwd())
|
| 128 |
+
parser = argparse.ArgumentParser()
|
| 129 |
+
parser.add_argument('--database',
|
| 130 |
+
'-d',
|
| 131 |
+
default='data/rdm/retrieval_databases/openimages',
|
| 132 |
+
type=str,
|
| 133 |
+
help='path to folder containing the clip feature of the database')
|
| 134 |
+
parser.add_argument('--target_path',
|
| 135 |
+
'-t',
|
| 136 |
+
default='data/rdm/searchers/openimages',
|
| 137 |
+
type=str,
|
| 138 |
+
help='path to the target folder where the searcher shall be stored.')
|
| 139 |
+
parser.add_argument('--knn',
|
| 140 |
+
'-k',
|
| 141 |
+
default=20,
|
| 142 |
+
type=int,
|
| 143 |
+
help='number of nearest neighbors, for which the searcher shall be optimized')
|
| 144 |
+
|
| 145 |
+
opt, _ = parser.parse_known_args()
|
| 146 |
+
|
| 147 |
+
train_searcher(opt,)
|
scripts/txt2img.py
ADDED
|
@@ -0,0 +1,279 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse, os, sys, glob
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
from omegaconf import OmegaConf
|
| 5 |
+
from PIL import Image
|
| 6 |
+
from tqdm import tqdm, trange
|
| 7 |
+
from itertools import islice
|
| 8 |
+
from einops import rearrange
|
| 9 |
+
from torchvision.utils import make_grid
|
| 10 |
+
import time
|
| 11 |
+
from pytorch_lightning import seed_everything
|
| 12 |
+
from torch import autocast
|
| 13 |
+
from contextlib import contextmanager, nullcontext
|
| 14 |
+
|
| 15 |
+
from ldm.util import instantiate_from_config
|
| 16 |
+
from ldm.models.diffusion.ddim import DDIMSampler
|
| 17 |
+
from ldm.models.diffusion.plms import PLMSSampler
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def chunk(it, size):
|
| 21 |
+
it = iter(it)
|
| 22 |
+
return iter(lambda: tuple(islice(it, size)), ())
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def load_model_from_config(config, ckpt, verbose=False):
|
| 26 |
+
print(f"Loading model from {ckpt}")
|
| 27 |
+
pl_sd = torch.load(ckpt, map_location="cpu")
|
| 28 |
+
if "global_step" in pl_sd:
|
| 29 |
+
print(f"Global Step: {pl_sd['global_step']}")
|
| 30 |
+
sd = pl_sd["state_dict"]
|
| 31 |
+
model = instantiate_from_config(config.model)
|
| 32 |
+
m, u = model.load_state_dict(sd, strict=False)
|
| 33 |
+
if len(m) > 0 and verbose:
|
| 34 |
+
print("missing keys:")
|
| 35 |
+
print(m)
|
| 36 |
+
if len(u) > 0 and verbose:
|
| 37 |
+
print("unexpected keys:")
|
| 38 |
+
print(u)
|
| 39 |
+
|
| 40 |
+
model.cuda()
|
| 41 |
+
model.eval()
|
| 42 |
+
return model
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def main():
|
| 46 |
+
parser = argparse.ArgumentParser()
|
| 47 |
+
|
| 48 |
+
parser.add_argument(
|
| 49 |
+
"--prompt",
|
| 50 |
+
type=str,
|
| 51 |
+
nargs="?",
|
| 52 |
+
default="a painting of a virus monster playing guitar",
|
| 53 |
+
help="the prompt to render"
|
| 54 |
+
)
|
| 55 |
+
parser.add_argument(
|
| 56 |
+
"--outdir",
|
| 57 |
+
type=str,
|
| 58 |
+
nargs="?",
|
| 59 |
+
help="dir to write results to",
|
| 60 |
+
default="outputs/txt2img-samples"
|
| 61 |
+
)
|
| 62 |
+
parser.add_argument(
|
| 63 |
+
"--skip_grid",
|
| 64 |
+
action='store_true',
|
| 65 |
+
help="do not save a grid, only individual samples. Helpful when evaluating lots of samples",
|
| 66 |
+
)
|
| 67 |
+
parser.add_argument(
|
| 68 |
+
"--skip_save",
|
| 69 |
+
action='store_true',
|
| 70 |
+
help="do not save individual samples. For speed measurements.",
|
| 71 |
+
)
|
| 72 |
+
parser.add_argument(
|
| 73 |
+
"--ddim_steps",
|
| 74 |
+
type=int,
|
| 75 |
+
default=50,
|
| 76 |
+
help="number of ddim sampling steps",
|
| 77 |
+
)
|
| 78 |
+
parser.add_argument(
|
| 79 |
+
"--plms",
|
| 80 |
+
action='store_true',
|
| 81 |
+
help="use plms sampling",
|
| 82 |
+
)
|
| 83 |
+
parser.add_argument(
|
| 84 |
+
"--laion400m",
|
| 85 |
+
action='store_true',
|
| 86 |
+
help="uses the LAION400M model",
|
| 87 |
+
)
|
| 88 |
+
parser.add_argument(
|
| 89 |
+
"--fixed_code",
|
| 90 |
+
action='store_true',
|
| 91 |
+
help="if enabled, uses the same starting code across samples ",
|
| 92 |
+
)
|
| 93 |
+
parser.add_argument(
|
| 94 |
+
"--ddim_eta",
|
| 95 |
+
type=float,
|
| 96 |
+
default=0.0,
|
| 97 |
+
help="ddim eta (eta=0.0 corresponds to deterministic sampling",
|
| 98 |
+
)
|
| 99 |
+
parser.add_argument(
|
| 100 |
+
"--n_iter",
|
| 101 |
+
type=int,
|
| 102 |
+
default=2,
|
| 103 |
+
help="sample this often",
|
| 104 |
+
)
|
| 105 |
+
parser.add_argument(
|
| 106 |
+
"--H",
|
| 107 |
+
type=int,
|
| 108 |
+
default=512,
|
| 109 |
+
help="image height, in pixel space",
|
| 110 |
+
)
|
| 111 |
+
parser.add_argument(
|
| 112 |
+
"--W",
|
| 113 |
+
type=int,
|
| 114 |
+
default=512,
|
| 115 |
+
help="image width, in pixel space",
|
| 116 |
+
)
|
| 117 |
+
parser.add_argument(
|
| 118 |
+
"--C",
|
| 119 |
+
type=int,
|
| 120 |
+
default=4,
|
| 121 |
+
help="latent channels",
|
| 122 |
+
)
|
| 123 |
+
parser.add_argument(
|
| 124 |
+
"--f",
|
| 125 |
+
type=int,
|
| 126 |
+
default=8,
|
| 127 |
+
help="downsampling factor",
|
| 128 |
+
)
|
| 129 |
+
parser.add_argument(
|
| 130 |
+
"--n_samples",
|
| 131 |
+
type=int,
|
| 132 |
+
default=3,
|
| 133 |
+
help="how many samples to produce for each given prompt. A.k.a. batch size",
|
| 134 |
+
)
|
| 135 |
+
parser.add_argument(
|
| 136 |
+
"--n_rows",
|
| 137 |
+
type=int,
|
| 138 |
+
default=0,
|
| 139 |
+
help="rows in the grid (default: n_samples)",
|
| 140 |
+
)
|
| 141 |
+
parser.add_argument(
|
| 142 |
+
"--scale",
|
| 143 |
+
type=float,
|
| 144 |
+
default=7.5,
|
| 145 |
+
help="unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))",
|
| 146 |
+
)
|
| 147 |
+
parser.add_argument(
|
| 148 |
+
"--from-file",
|
| 149 |
+
type=str,
|
| 150 |
+
help="if specified, load prompts from this file",
|
| 151 |
+
)
|
| 152 |
+
parser.add_argument(
|
| 153 |
+
"--config",
|
| 154 |
+
type=str,
|
| 155 |
+
default="configs/stable-diffusion/v1-inference.yaml",
|
| 156 |
+
help="path to config which constructs model",
|
| 157 |
+
)
|
| 158 |
+
parser.add_argument(
|
| 159 |
+
"--ckpt",
|
| 160 |
+
type=str,
|
| 161 |
+
default="models/ldm/stable-diffusion-v1/model.ckpt",
|
| 162 |
+
help="path to checkpoint of model",
|
| 163 |
+
)
|
| 164 |
+
parser.add_argument(
|
| 165 |
+
"--seed",
|
| 166 |
+
type=int,
|
| 167 |
+
default=42,
|
| 168 |
+
help="the seed (for reproducible sampling)",
|
| 169 |
+
)
|
| 170 |
+
parser.add_argument(
|
| 171 |
+
"--precision",
|
| 172 |
+
type=str,
|
| 173 |
+
help="evaluate at this precision",
|
| 174 |
+
choices=["full", "autocast"],
|
| 175 |
+
default="autocast"
|
| 176 |
+
)
|
| 177 |
+
opt = parser.parse_args()
|
| 178 |
+
|
| 179 |
+
if opt.laion400m:
|
| 180 |
+
print("Falling back to LAION 400M model...")
|
| 181 |
+
opt.config = "configs/latent-diffusion/txt2img-1p4B-eval.yaml"
|
| 182 |
+
opt.ckpt = "models/ldm/text2img-large/model.ckpt"
|
| 183 |
+
opt.outdir = "outputs/txt2img-samples-laion400m"
|
| 184 |
+
|
| 185 |
+
seed_everything(opt.seed)
|
| 186 |
+
|
| 187 |
+
config = OmegaConf.load(f"{opt.config}")
|
| 188 |
+
model = load_model_from_config(config, f"{opt.ckpt}")
|
| 189 |
+
|
| 190 |
+
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
|
| 191 |
+
model = model.to(device)
|
| 192 |
+
|
| 193 |
+
if opt.plms:
|
| 194 |
+
sampler = PLMSSampler(model)
|
| 195 |
+
else:
|
| 196 |
+
sampler = DDIMSampler(model)
|
| 197 |
+
|
| 198 |
+
os.makedirs(opt.outdir, exist_ok=True)
|
| 199 |
+
outpath = opt.outdir
|
| 200 |
+
|
| 201 |
+
batch_size = opt.n_samples
|
| 202 |
+
n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
|
| 203 |
+
if not opt.from_file:
|
| 204 |
+
prompt = opt.prompt
|
| 205 |
+
assert prompt is not None
|
| 206 |
+
data = [batch_size * [prompt]]
|
| 207 |
+
|
| 208 |
+
else:
|
| 209 |
+
print(f"reading prompts from {opt.from_file}")
|
| 210 |
+
with open(opt.from_file, "r") as f:
|
| 211 |
+
data = f.read().splitlines()
|
| 212 |
+
data = list(chunk(data, batch_size))
|
| 213 |
+
|
| 214 |
+
sample_path = os.path.join(outpath, "samples")
|
| 215 |
+
os.makedirs(sample_path, exist_ok=True)
|
| 216 |
+
base_count = len(os.listdir(sample_path))
|
| 217 |
+
grid_count = len(os.listdir(outpath)) - 1
|
| 218 |
+
|
| 219 |
+
start_code = None
|
| 220 |
+
if opt.fixed_code:
|
| 221 |
+
start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device)
|
| 222 |
+
|
| 223 |
+
precision_scope = autocast if opt.precision=="autocast" else nullcontext
|
| 224 |
+
with torch.no_grad():
|
| 225 |
+
with precision_scope("cuda"):
|
| 226 |
+
with model.ema_scope():
|
| 227 |
+
tic = time.time()
|
| 228 |
+
all_samples = list()
|
| 229 |
+
for n in trange(opt.n_iter, desc="Sampling"):
|
| 230 |
+
for prompts in tqdm(data, desc="data"):
|
| 231 |
+
uc = None
|
| 232 |
+
if opt.scale != 1.0:
|
| 233 |
+
uc = model.get_learned_conditioning(batch_size * [""])
|
| 234 |
+
if isinstance(prompts, tuple):
|
| 235 |
+
prompts = list(prompts)
|
| 236 |
+
c = model.get_learned_conditioning(prompts)
|
| 237 |
+
shape = [opt.C, opt.H // opt.f, opt.W // opt.f]
|
| 238 |
+
samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
|
| 239 |
+
conditioning=c,
|
| 240 |
+
batch_size=opt.n_samples,
|
| 241 |
+
shape=shape,
|
| 242 |
+
verbose=False,
|
| 243 |
+
unconditional_guidance_scale=opt.scale,
|
| 244 |
+
unconditional_conditioning=uc,
|
| 245 |
+
eta=opt.ddim_eta,
|
| 246 |
+
x_T=start_code)
|
| 247 |
+
|
| 248 |
+
x_samples_ddim = model.decode_first_stage(samples_ddim)
|
| 249 |
+
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
|
| 250 |
+
|
| 251 |
+
if not opt.skip_save:
|
| 252 |
+
for x_sample in x_samples_ddim:
|
| 253 |
+
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
|
| 254 |
+
Image.fromarray(x_sample.astype(np.uint8)).save(
|
| 255 |
+
os.path.join(sample_path, f"{base_count:05}.png"))
|
| 256 |
+
base_count += 1
|
| 257 |
+
|
| 258 |
+
if not opt.skip_grid:
|
| 259 |
+
all_samples.append(x_samples_ddim)
|
| 260 |
+
|
| 261 |
+
if not opt.skip_grid:
|
| 262 |
+
# additionally, save as grid
|
| 263 |
+
grid = torch.stack(all_samples, 0)
|
| 264 |
+
grid = rearrange(grid, 'n b c h w -> (n b) c h w')
|
| 265 |
+
grid = make_grid(grid, nrow=n_rows)
|
| 266 |
+
|
| 267 |
+
# to image
|
| 268 |
+
grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
|
| 269 |
+
Image.fromarray(grid.astype(np.uint8)).save(os.path.join(outpath, f'grid-{grid_count:04}.png'))
|
| 270 |
+
grid_count += 1
|
| 271 |
+
|
| 272 |
+
toc = time.time()
|
| 273 |
+
|
| 274 |
+
print(f"Your samples are ready and waiting for you here: \n{outpath} \n"
|
| 275 |
+
f" \nEnjoy.")
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
if __name__ == "__main__":
|
| 279 |
+
main()
|