Spaces:
Running

Running
added for low
Browse files- .gitignore +1 -0
- app.py +19 -13
- plot.png +0 -0
- result.txt +7 -7
- roc_data.pkl +2 -2
- selected_rows.txt +0 -0
- train.txt +0 -0
- train_info.txt +2 -2
.gitignore
CHANGED
|
@@ -2,3 +2,4 @@ train_info.txt
|
|
| 2 |
train.txt
|
| 3 |
train_label.txt
|
| 4 |
ratio_proportion_change3_2223/sch_largest_100-coded/logs/
|
|
|
|
|
|
| 2 |
train.txt
|
| 3 |
train_label.txt
|
| 4 |
ratio_proportion_change3_2223/sch_largest_100-coded/logs/
|
| 5 |
+
ratio_proportion_change3_2223/sch_largest_100-coded/finetuning/
|
app.py
CHANGED
|
@@ -23,10 +23,23 @@ def process_file(model_name,inc_slider,progress=Progress(track_tqdm=True)):
|
|
| 23 |
# shutil.copyfile(file.name, saved_test_dataset)
|
| 24 |
# shutil.copyfile(label.name, saved_test_label)
|
| 25 |
# shutil.copyfile(info.name, saved_train_info)
|
| 26 |
-
|
| 27 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 28 |
# Load the test_info file and the graduation rate file
|
| 29 |
-
test_info = pd.read_csv(
|
| 30 |
grad_rate_data = pd.DataFrame(pd.read_pickle('school_grduation_rate.pkl'),columns=['school_number','grad_rate']) # Load the grad_rate data
|
| 31 |
|
| 32 |
# Step 1: Extract unique school numbers from test_info
|
|
@@ -53,7 +66,7 @@ def process_file(model_name,inc_slider,progress=Progress(track_tqdm=True)):
|
|
| 53 |
indices = test_info[test_info[0].isin(random_schools)].index.tolist()
|
| 54 |
|
| 55 |
# Load the test file and select rows based on indices
|
| 56 |
-
test = pd.read_csv(
|
| 57 |
selected_rows_df2 = test.loc[indices]
|
| 58 |
|
| 59 |
# Save the selected rows to a file
|
|
@@ -61,14 +74,7 @@ def process_file(model_name,inc_slider,progress=Progress(track_tqdm=True)):
|
|
| 61 |
|
| 62 |
|
| 63 |
# For demonstration purposes, we'll just return the content with the selected model name
|
| 64 |
-
|
| 65 |
-
finetune_task="highGRschool10"
|
| 66 |
-
elif(model_name== "Low Graduated Schools" ):
|
| 67 |
-
finetune_task="highGRschool10"
|
| 68 |
-
elif(model_name=="Full Set"):
|
| 69 |
-
finetune_task="highGRschool10"
|
| 70 |
-
else:
|
| 71 |
-
finetune_task=None
|
| 72 |
# print(checkpoint)
|
| 73 |
progress(0.1, desc="Files created and saved")
|
| 74 |
# if (inc_val<5):
|
|
@@ -81,7 +87,7 @@ def process_file(model_name,inc_slider,progress=Progress(track_tqdm=True)):
|
|
| 81 |
subprocess.run([
|
| 82 |
"python", "new_test_saved_finetuned_model.py",
|
| 83 |
"-workspace_name", "ratio_proportion_change3_2223/sch_largest_100-coded",
|
| 84 |
-
"-finetune_task",
|
| 85 |
"-test_dataset_path","../../../../selected_rows.txt",
|
| 86 |
# "-test_label_path","../../../../train_label.txt",
|
| 87 |
"-finetuned_bert_classifier_checkpoint",
|
|
|
|
| 23 |
# shutil.copyfile(file.name, saved_test_dataset)
|
| 24 |
# shutil.copyfile(label.name, saved_test_label)
|
| 25 |
# shutil.copyfile(info.name, saved_train_info)
|
| 26 |
+
parent_location="ratio_proportion_change3_2223/sch_largest_100-coded/finetuning/"
|
| 27 |
+
if(model_name=="High Graduated Schools"):
|
| 28 |
+
finetune_task="highGRschool10"
|
| 29 |
+
test_info_location=parent_location+"highGRschool10/test_info.txt"
|
| 30 |
+
test_location=parent_location+"highGRschool10/test.txt"
|
| 31 |
+
elif(model_name== "Low Graduated Schools" ):
|
| 32 |
+
finetune_task="lowGRschoolAll"
|
| 33 |
+
test_info_location=parent_location+"lowGRschoolAll/test_info.txt"
|
| 34 |
+
test_location=parent_location+"lowGRschoolAll/test.txt"
|
| 35 |
+
elif(model_name=="Full Set"):
|
| 36 |
+
test_info_location=parent_location+"highGRschool10/test_info.txt"
|
| 37 |
+
test_location=parent_location+"highGRschool10/test.txt"
|
| 38 |
+
finetune_task="highGRschool10"
|
| 39 |
+
else:
|
| 40 |
+
finetune_task=None
|
| 41 |
# Load the test_info file and the graduation rate file
|
| 42 |
+
test_info = pd.read_csv(test_info_location, sep=',', header=None, engine='python')
|
| 43 |
grad_rate_data = pd.DataFrame(pd.read_pickle('school_grduation_rate.pkl'),columns=['school_number','grad_rate']) # Load the grad_rate data
|
| 44 |
|
| 45 |
# Step 1: Extract unique school numbers from test_info
|
|
|
|
| 66 |
indices = test_info[test_info[0].isin(random_schools)].index.tolist()
|
| 67 |
|
| 68 |
# Load the test file and select rows based on indices
|
| 69 |
+
test = pd.read_csv(test_location, sep=',', header=None, engine='python')
|
| 70 |
selected_rows_df2 = test.loc[indices]
|
| 71 |
|
| 72 |
# Save the selected rows to a file
|
|
|
|
| 74 |
|
| 75 |
|
| 76 |
# For demonstration purposes, we'll just return the content with the selected model name
|
| 77 |
+
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 78 |
# print(checkpoint)
|
| 79 |
progress(0.1, desc="Files created and saved")
|
| 80 |
# if (inc_val<5):
|
|
|
|
| 87 |
subprocess.run([
|
| 88 |
"python", "new_test_saved_finetuned_model.py",
|
| 89 |
"-workspace_name", "ratio_proportion_change3_2223/sch_largest_100-coded",
|
| 90 |
+
"-finetune_task", finetune_task,
|
| 91 |
"-test_dataset_path","../../../../selected_rows.txt",
|
| 92 |
# "-test_label_path","../../../../train_label.txt",
|
| 93 |
"-finetuned_bert_classifier_checkpoint",
|
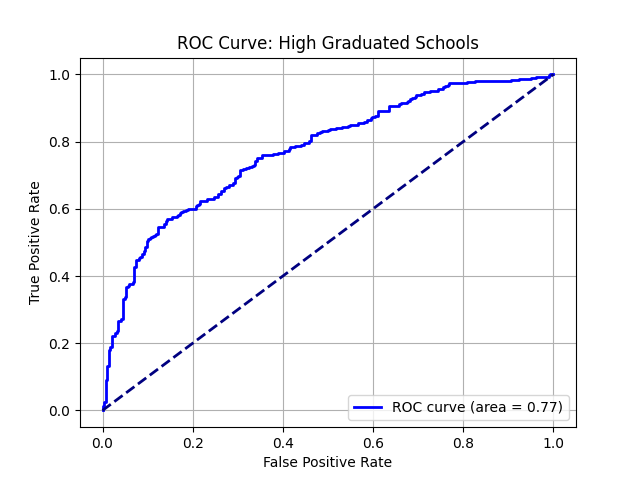
plot.png
CHANGED
|
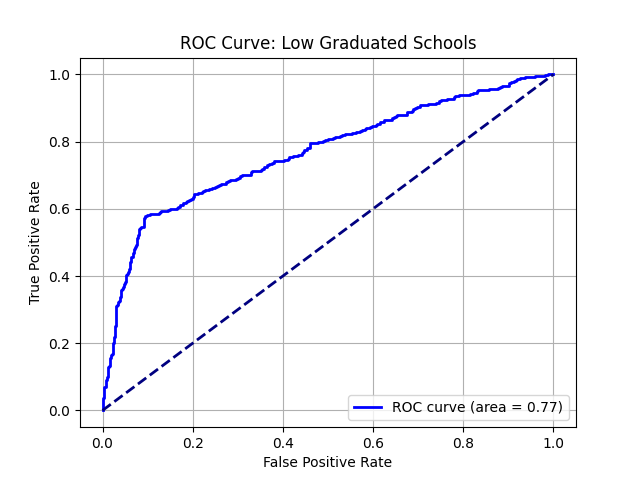
|
result.txt
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
-
avg_loss: 0.
|
| 2 |
-
total_acc:
|
| 3 |
-
precisions: 0.
|
| 4 |
-
recalls: 0.
|
| 5 |
-
f1_scores: 0.
|
| 6 |
-
time_taken_from_start:
|
| 7 |
-
auc_score: 0.
|
|
|
|
| 1 |
+
avg_loss: 0.5569005310535431
|
| 2 |
+
total_acc: 74.30213464696223
|
| 3 |
+
precisions: 0.7660032941165892
|
| 4 |
+
recalls: 0.7430213464696224
|
| 5 |
+
f1_scores: 0.7359098644855878
|
| 6 |
+
time_taken_from_start: 41.834863901138306
|
| 7 |
+
auc_score: 0.7675472675472674
|
roc_data.pkl
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c022a6b5eaa8a1a3c8cb6f10578afc01f92a1f9800ec4ebe1ab78b22b3ddd988
|
| 3 |
+
size 10685
|
selected_rows.txt
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
train.txt
DELETED
|
The diff for this file is too large to render.
See raw diff
|
|
|
train_info.txt
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ef4862f5c282efdfa49e13ed0f6cb344abcb7ae07fdfba535d48193bb8a3c1ed
|
| 3 |
+
size 81939614
|