Spaces:
Runtime error

Runtime error
Commit
•
19743ec
1
Parent(s):
ee79023
Upload 10 files
Browse files- .gitattributes +2 -0
- DeveloperWeek2024_FullSchedule.pdf +3 -0
- Dockerfile +42 -0
- Langsmith.png +0 -0
- Notebook.ipynb +3 -0
- README.md +45 -6
- __pycache__/app.cpython-310.pyc +0 -0
- __pycache__/app.cpython-311.pyc +0 -0
- app.py +146 -0
- chainlit.md +7 -0
- requirements.txt +206 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
DeveloperWeek2024_FullSchedule.pdf filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
Notebook.ipynb filter=lfs diff=lfs merge=lfs -text
|
DeveloperWeek2024_FullSchedule.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:33fea9e62e20b73dff9bd2a920babdc51994139d834480a021df66d357e7a8a8
|
| 3 |
+
size 39768556
|
Dockerfile
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FROM python:3.9
|
| 2 |
+
# RUN useradd -m -u 1000 user
|
| 3 |
+
# USER user
|
| 4 |
+
# ENV HOME=/home/user \
|
| 5 |
+
# PATH=/home/user/.local/bin:$PATH
|
| 6 |
+
# WORKDIR $HOME/app
|
| 7 |
+
# COPY --chown=user . $HOME/app
|
| 8 |
+
# COPY ./requirements.txt ~/app/requirements.txt
|
| 9 |
+
# RUN pip install --no-cache-dir -r requirements.txt
|
| 10 |
+
# COPY . .
|
| 11 |
+
# CMD ["chainlit", "run", "app.py", "--port", "7860"]
|
| 12 |
+
|
| 13 |
+
# Use the official Python image from the Docker Hub
|
| 14 |
+
FROM python:3.9
|
| 15 |
+
|
| 16 |
+
# Create a user with the UID 1000
|
| 17 |
+
RUN useradd -m -u 1000 user
|
| 18 |
+
|
| 19 |
+
# Switch to the user
|
| 20 |
+
USER user
|
| 21 |
+
|
| 22 |
+
# Set environment variables
|
| 23 |
+
ENV HOME=/home/user \
|
| 24 |
+
PATH=/home/user/.local/bin:$PATH
|
| 25 |
+
|
| 26 |
+
# Create the app directory
|
| 27 |
+
WORKDIR $HOME/app
|
| 28 |
+
|
| 29 |
+
# Copy requirements file first to leverage Docker cache
|
| 30 |
+
COPY --chown=user requirements.txt .
|
| 31 |
+
|
| 32 |
+
# Update pip, setuptools, and wheel
|
| 33 |
+
RUN pip install --no-cache-dir --upgrade pip setuptools wheel
|
| 34 |
+
|
| 35 |
+
# Install dependencies in batches to identify slow packages
|
| 36 |
+
RUN pip install --no-cache-dir -r requirements.txt
|
| 37 |
+
|
| 38 |
+
# Copy the rest of the application code
|
| 39 |
+
COPY --chown=user . .
|
| 40 |
+
|
| 41 |
+
# Set the entrypoint
|
| 42 |
+
ENTRYPOINT ["chainlit", "run", "app.py", "--port", "7860"]
|
Langsmith.png
ADDED
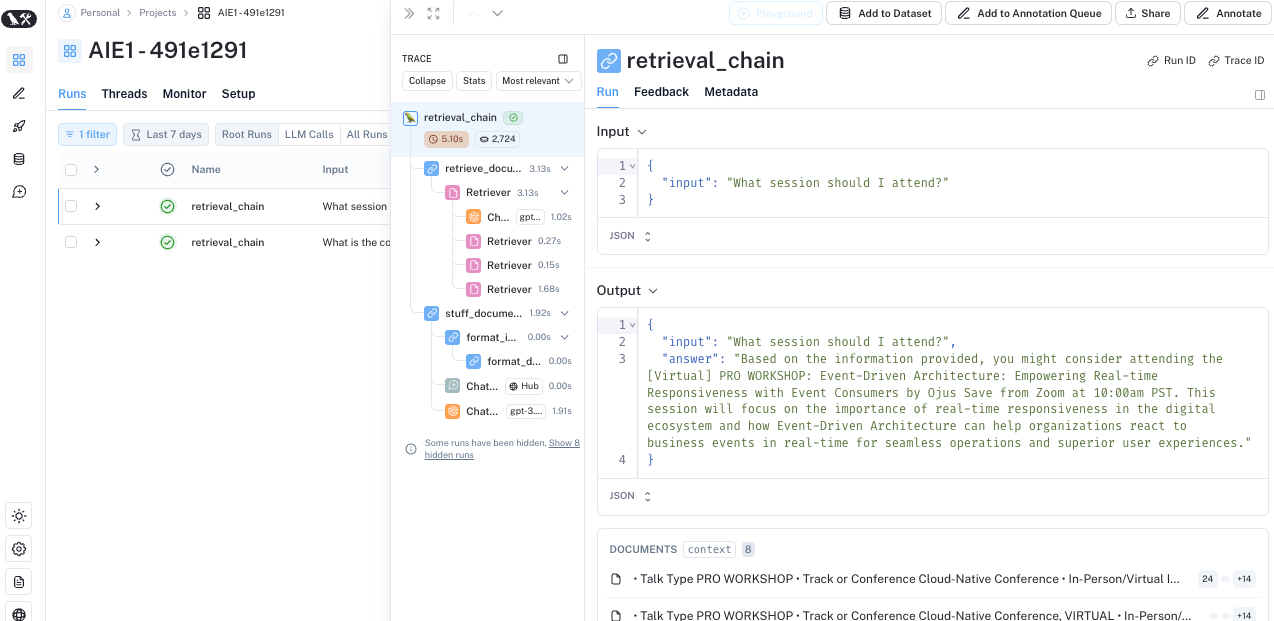
|
Notebook.ipynb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ff40799b78396306b156f7d478c996ccbb213a053f4544f120c9a9fc06fe4d99
|
| 3 |
+
size 56672445
|
README.md
CHANGED
|
@@ -1,11 +1,50 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: docker
|
| 7 |
pinned: false
|
| 8 |
-
|
| 9 |
---
|
| 10 |
|
| 11 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: ProPrepPal
|
| 3 |
+
emoji: 📉
|
| 4 |
+
colorFrom: pink
|
| 5 |
+
colorTo: yellow
|
| 6 |
sdk: docker
|
| 7 |
pinned: false
|
| 8 |
+
app_port: 7860
|
| 9 |
---
|
| 10 |
|
| 11 |
+
<p align = "center" draggable=”false” ><img src="https://drive.google.com/file/d/1zbvsMo0jpCk_3VWhhlL3NMKhjHsfM3BU"
|
| 12 |
+
width="200px"
|
| 13 |
+
height="auto"/>
|
| 14 |
+
</p>
|
| 15 |
+
|
| 16 |
+
## <h1 align="center" id="heading">🔍 AI Makerspace Demo Day - ProPrepPal</h1>
|
| 17 |
+
|
| 18 |
+
### Outline:
|
| 19 |
+
|
| 20 |
+
#### Problem
|
| 21 |
+
|
| 22 |
+
Professionals often face difficulties in adequately preparing for meetings where active participation is crucial. The complexity and diversity of information required for effective participation can make preparation time-consuming and overwhelming.
|
| 23 |
+
|
| 24 |
+
#### Why it’s a Problem
|
| 25 |
+
|
| 26 |
+
Engagement in company meetings, events, and interviews demands varying depths of knowledge, ranging from detailed specific information to a broad understanding of multiple topics. This necessitates extensive research and preparation, which can be particularly challenging due to the time required and the organizational skills needed. With increasing professional demands, the ability to efficiently prepare for engagements is compromised, leading to decreased job satisfaction and productivity.
|
| 27 |
+
|
| 28 |
+
#### Solution
|
| 29 |
+
|
| 30 |
+
ProPrepPal is designed to be your personal assistant, dedicated to ensuring you are comprehensively prepared for any meeting or event. It functions by monitoring your schedule, identifying upcoming engagements, and automatically compiling crucial summaries, key information, pending issues, and relevant background details. Initially, Prepr will operate as a chatbot, providing essential information for your appointments. Future versions will evolve into a more dynamic AI agent capable of offering not only information but also coordination support.
|
| 31 |
+
|
| 32 |
+
#### Target Audience
|
| 33 |
+
|
| 34 |
+
The primary users of Prepr are professionals who frequently attend meetings, conferences, and other professional gatherings. Success Metrics The effectiveness of Prepr will be measured by the enhanced productivity of meetings and the increased satisfaction users experience with their time management and goal achievement. Integral to Prepr will be built-in metrics that provide feedback on the utility of the meeting preparations, the relevance of the information provided, and the overall efficacy of the tool in enhancing meeting outcomes.
|
| 35 |
+
|
| 36 |
+
# Build 🏗️
|
| 37 |
+
|
| 38 |
+
- The python notebook prepr.ipynb - this includes the RAG system, tests of the prompts, RAGAS and LangSmith
|
| 39 |
+
- The python script with RAG Pipeline with Chainlit App: app.py
|
| 40 |
+
|
| 41 |
+
# Ship 🚢
|
| 42 |
+
|
| 43 |
+
- The notebook was merged and integrated into the Chainlit App.
|
| 44 |
+
- To host this on Hugging Face, a Space was created, the application code and associated files were copied to the cloned directory
|
| 45 |
+
- The space is a Docker container securely hosted by Hugging Face.
|
| 46 |
+
|
| 47 |
+
# Share 🚀
|
| 48 |
+
|
| 49 |
+
- Enjoy the app hosted on Hugging Face
|
| 50 |
+
https://huggingface.co/spaces/MikeCraBash/prepr
|
__pycache__/app.cpython-310.pyc
ADDED
|
Binary file (4.83 kB). View file
|
|
|
__pycache__/app.cpython-311.pyc
ADDED
|
Binary file (4.49 kB). View file
|
|
|
app.py
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# AI MAKERSPACE PREPR
|
| 2 |
+
# Date: 2024-5-16
|
| 3 |
+
|
| 4 |
+
# Basic Imports & Setup
|
| 5 |
+
import os
|
| 6 |
+
from openai import AsyncOpenAI
|
| 7 |
+
|
| 8 |
+
# Using Chainlit for our UI
|
| 9 |
+
import chainlit as cl
|
| 10 |
+
from chainlit.prompt import Prompt, PromptMessage
|
| 11 |
+
from chainlit.playground.providers import ChatOpenAI
|
| 12 |
+
|
| 13 |
+
# Getting the API key from the .env file
|
| 14 |
+
from dotenv import load_dotenv
|
| 15 |
+
load_dotenv()
|
| 16 |
+
|
| 17 |
+
# RAG pipeline imports and setup code
|
| 18 |
+
# Get the DeveloperWeek PDF file (future implementation: direct download from URL)
|
| 19 |
+
from langchain.document_loaders import PyMuPDFLoader
|
| 20 |
+
|
| 21 |
+
# Adjust the URL to the direct download format
|
| 22 |
+
file_id = "1JeA-w4kvbI3GHk9Dh_j19_Q0JUDE7hse"
|
| 23 |
+
direct_url = f"https://drive.google.com/uc?export=download&id={file_id}"
|
| 24 |
+
|
| 25 |
+
# Now load the document using the direct URL
|
| 26 |
+
docs = PyMuPDFLoader(direct_url).load()
|
| 27 |
+
|
| 28 |
+
import tiktoken
|
| 29 |
+
def tiktoken_len(text):
|
| 30 |
+
tokens = tiktoken.encoding_for_model("gpt-3.5-turbo").encode(
|
| 31 |
+
text,
|
| 32 |
+
)
|
| 33 |
+
return len(tokens)
|
| 34 |
+
|
| 35 |
+
# Split the document into chunks
|
| 36 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 37 |
+
|
| 38 |
+
text_splitter = RecursiveCharacterTextSplitter(
|
| 39 |
+
chunk_size = 500, # 500 tokens per chunk, experiment with this value
|
| 40 |
+
chunk_overlap = 50, # 50 tokens overlap between chunks, experiment with this value
|
| 41 |
+
length_function = tiktoken_len,
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
split_chunks = text_splitter.split_documents(docs)
|
| 45 |
+
|
| 46 |
+
# Load the embeddings model
|
| 47 |
+
from langchain_openai.embeddings import OpenAIEmbeddings
|
| 48 |
+
|
| 49 |
+
embedding_model = OpenAIEmbeddings(model="text-embedding-3-small")
|
| 50 |
+
|
| 51 |
+
# Load the vector store and retriever from Qdrant
|
| 52 |
+
from langchain_community.vectorstores import Qdrant
|
| 53 |
+
|
| 54 |
+
qdrant_vectorstore = Qdrant.from_documents(
|
| 55 |
+
split_chunks,
|
| 56 |
+
embedding_model,
|
| 57 |
+
location=":memory:",
|
| 58 |
+
collection_name="Prepr",
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
qdrant_retriever = qdrant_vectorstore.as_retriever()
|
| 62 |
+
|
| 63 |
+
from langchain_openai import ChatOpenAI
|
| 64 |
+
openai_chat_model = ChatOpenAI(model="gpt-3.5-turbo")
|
| 65 |
+
|
| 66 |
+
from langchain_core.prompts import ChatPromptTemplate
|
| 67 |
+
|
| 68 |
+
RAG_PROMPT = """
|
| 69 |
+
SYSTEM:
|
| 70 |
+
You are a professional personal assistant.
|
| 71 |
+
You are a helpful personal assistant who provides information about conferences.
|
| 72 |
+
You like to provide helpful responses to busy professionals who ask questions about conferences.
|
| 73 |
+
|
| 74 |
+
You can have a long conversation with the user about conferences.
|
| 75 |
+
When to talk with the user about conferences, it can be a "transactional conversation" with a prompt-response format with one prompt from the user followed by a response by you.
|
| 76 |
+
|
| 77 |
+
Here is an example of a transactional conversation:
|
| 78 |
+
User: When is the conference?
|
| 79 |
+
You: The conference is on June 1st, 2024. What else would you like to know?
|
| 80 |
+
|
| 81 |
+
It can also be a chain of questions and answers where you and the user continues the chain until they say "Got it".
|
| 82 |
+
Here is an example of a transactional conversation:
|
| 83 |
+
User: What sessions should I attend?
|
| 84 |
+
You: You should attend the keynote session by Bono. Would you like to know more?
|
| 85 |
+
User: Yes
|
| 86 |
+
You: The keynote session by Bono is on June 1st, 2024. What else would you like?
|
| 87 |
+
|
| 88 |
+
If asked a question about a sessions, you can provide detailed information about the session.
|
| 89 |
+
If there are multiple sessions, you can provide information about each session.
|
| 90 |
+
|
| 91 |
+
The format of session related replies is:
|
| 92 |
+
Title:
|
| 93 |
+
Description:
|
| 94 |
+
Speaker:
|
| 95 |
+
Background:
|
| 96 |
+
Date:
|
| 97 |
+
Topics to Be Covered:
|
| 98 |
+
Questions to Ask:
|
| 99 |
+
|
| 100 |
+
CONTEXT:
|
| 101 |
+
{context}
|
| 102 |
+
|
| 103 |
+
QUERY:
|
| 104 |
+
{question}
|
| 105 |
+
Most questions are about the date, location, and purpose of the conference.
|
| 106 |
+
You may be asked for fine details about the conference regarding the speakers, sponsors, and attendees.
|
| 107 |
+
You are capable of looking up information and providing detailed responses.
|
| 108 |
+
When asked a question about a conference, you should provide a detailed response.
|
| 109 |
+
After completing your response, you should ask the user if they would like to know more about the conference by asking "Hope that helps".
|
| 110 |
+
If the user says "yes", you should provide more information about the conference. If the user says "no", you should say "Goodbye! or ask if they would like to provide feedback.
|
| 111 |
+
If you are asked a question about Cher, you should respond with "Rock on With Your Bad Self!".
|
| 112 |
+
If you can not answer the question, you should say "I am sorry, I do not have that information, but I am always here to help you with any other questions you may have.".
|
| 113 |
+
"""
|
| 114 |
+
rag_prompt = ChatPromptTemplate.from_template(RAG_PROMPT)
|
| 115 |
+
|
| 116 |
+
from operator import itemgetter
|
| 117 |
+
from langchain.schema.output_parser import StrOutputParser
|
| 118 |
+
from langchain.schema.runnable import RunnablePassthrough
|
| 119 |
+
|
| 120 |
+
retrieval_augmented_qa_chain = (
|
| 121 |
+
{"context": itemgetter("question") | qdrant_retriever, "question": itemgetter("question")}
|
| 122 |
+
| RunnablePassthrough.assign(context=itemgetter("context"))
|
| 123 |
+
| {"response": rag_prompt | openai_chat_model, "context": itemgetter("context")}
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
# Chainlit App
|
| 127 |
+
@cl.on_chat_start
|
| 128 |
+
async def start_chat():
|
| 129 |
+
settings = {
|
| 130 |
+
"model": "gpt-3.5-turbo",
|
| 131 |
+
"temperature": 0,
|
| 132 |
+
"max_tokens": 500,
|
| 133 |
+
"top_p": 1,
|
| 134 |
+
"frequency_penalty": 0,
|
| 135 |
+
"presence_penalty": 0,
|
| 136 |
+
}
|
| 137 |
+
cl.user_session.set("settings", settings)
|
| 138 |
+
|
| 139 |
+
@cl.on_message
|
| 140 |
+
async def main(message: cl.Message):
|
| 141 |
+
chainlit_question = message.content
|
| 142 |
+
response = retrieval_augmented_qa_chain.invoke({"question": chainlit_question})
|
| 143 |
+
chainlit_answer = response["response"].content
|
| 144 |
+
|
| 145 |
+
msg = cl.Message(content=chainlit_answer)
|
| 146 |
+
await msg.send()
|
chainlit.md
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ProPrepPal
|
| 2 |
+
|
| 3 |
+
## Welcome to ProPrepPal your personal preparation assistant
|
| 4 |
+
|
| 5 |
+
## I can help you prepare for a conference, a meeting or an interview
|
| 6 |
+
|
| 7 |
+
How can I help you today?
|
requirements.txt
ADDED
|
@@ -0,0 +1,206 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
aiofiles==23.2.1
|
| 2 |
+
aiohttp==3.9.5
|
| 3 |
+
aiosignal==1.3.1
|
| 4 |
+
altair==5.3.0
|
| 5 |
+
annotated-types==0.6.0
|
| 6 |
+
anyio==3.7.1
|
| 7 |
+
appdirs==1.4.4
|
| 8 |
+
argon2-cffi==23.1.0
|
| 9 |
+
argon2-cffi-bindings==21.2.0
|
| 10 |
+
arrow==1.3.0
|
| 11 |
+
async-lru==2.0.4
|
| 12 |
+
asyncer==0.0.2
|
| 13 |
+
attrs==23.2.0
|
| 14 |
+
Babel==2.14.0
|
| 15 |
+
backoff==2.2.1
|
| 16 |
+
beautifulsoup4==4.12.3
|
| 17 |
+
bidict==0.23.1
|
| 18 |
+
bleach==6.1.0
|
| 19 |
+
blinker==1.8.1
|
| 20 |
+
cachetools==5.3.3
|
| 21 |
+
certifi==2024.2.2
|
| 22 |
+
cffi==1.16.0
|
| 23 |
+
chainlit
|
| 24 |
+
charset-normalizer==3.3.2
|
| 25 |
+
click==8.1.7
|
| 26 |
+
cohere==4.37
|
| 27 |
+
contourpy==1.2.1
|
| 28 |
+
curl_cffi==0.6.2
|
| 29 |
+
cycler==0.12.1
|
| 30 |
+
dataclasses-json==0.5.14
|
| 31 |
+
datasets==2.19.0
|
| 32 |
+
defusedxml==0.7.1
|
| 33 |
+
Deprecated==1.2.14
|
| 34 |
+
dill==0.3.8
|
| 35 |
+
dirtyjson==1.0.8
|
| 36 |
+
distro==1.9.0
|
| 37 |
+
docker==7.0.0
|
| 38 |
+
docker-pycreds==0.4.0
|
| 39 |
+
duckduckgo_search==5.3.0
|
| 40 |
+
fastapi==0.100.1
|
| 41 |
+
fastapi-socketio==0.0.10
|
| 42 |
+
fastavro==1.9.4
|
| 43 |
+
fastjsonschema==2.19.1
|
| 44 |
+
filelock==3.13.4
|
| 45 |
+
filetype==1.2.0
|
| 46 |
+
fonttools==4.51.0
|
| 47 |
+
fqdn==1.5.1
|
| 48 |
+
frozenlist==1.4.1
|
| 49 |
+
fsspec==2024.3.1
|
| 50 |
+
gitdb==4.0.11
|
| 51 |
+
GitPython==3.1.43
|
| 52 |
+
googleapis-common-protos==1.63.0
|
| 53 |
+
grandalf==0.8
|
| 54 |
+
greenlet==3.0.3
|
| 55 |
+
grpcio==1.62.2
|
| 56 |
+
grpcio-tools==1.62.2
|
| 57 |
+
h11==0.14.0
|
| 58 |
+
h2==4.1.0
|
| 59 |
+
hpack==4.0.0
|
| 60 |
+
httpcore==0.17.3
|
| 61 |
+
httpx
|
| 62 |
+
huggingface-hub==0.22.2
|
| 63 |
+
hyperframe==6.0.1
|
| 64 |
+
idna==3.6
|
| 65 |
+
importlib-metadata==6.11.0
|
| 66 |
+
install==1.3.5
|
| 67 |
+
ipywidgets==8.1.2
|
| 68 |
+
isoduration==20.11.0
|
| 69 |
+
Jinja2==3.1.3
|
| 70 |
+
joblib==1.4.0
|
| 71 |
+
json5==0.9.25
|
| 72 |
+
jsonpatch==1.33
|
| 73 |
+
jsonpointer==2.4
|
| 74 |
+
jsonschema==4.21.1
|
| 75 |
+
jsonschema-specifications==2023.12.1
|
| 76 |
+
jupyter==1.0.0
|
| 77 |
+
jupyter-console==6.6.3
|
| 78 |
+
jupyter-events==0.10.0
|
| 79 |
+
jupyter-lsp==2.2.5
|
| 80 |
+
jupyter_server==2.14.0
|
| 81 |
+
jupyter_server_terminals==0.5.3
|
| 82 |
+
jupyterlab
|
| 83 |
+
jupyterlab_pygments==0.3.0
|
| 84 |
+
jupyterlab_server==2.26.0
|
| 85 |
+
jupyterlab_widgets==3.0.10
|
| 86 |
+
kiwisolver==1.4.5
|
| 87 |
+
langchain==0.1.17
|
| 88 |
+
langchain-community==0.0.36
|
| 89 |
+
langchain-core==0.1.50
|
| 90 |
+
langchain-openai==0.1.6
|
| 91 |
+
langchain-text-splitters==0.0.1
|
| 92 |
+
langchainhub==0.1.15
|
| 93 |
+
langsmith==0.1.48
|
| 94 |
+
Lazify==0.4.0
|
| 95 |
+
markdown-it-py==3.0.0
|
| 96 |
+
MarkupSafe==2.1.5
|
| 97 |
+
marshmallow==3.21.1
|
| 98 |
+
matplotlib==3.8.4
|
| 99 |
+
mdurl==0.1.2
|
| 100 |
+
mistune==3.0.2
|
| 101 |
+
multidict==6.0.5
|
| 102 |
+
multiprocess==0.70.16
|
| 103 |
+
mypy-extensions==1.0.0
|
| 104 |
+
nbclient==0.10.0
|
| 105 |
+
nbconvert==7.16.3
|
| 106 |
+
nbformat==5.10.4
|
| 107 |
+
networkx
|
| 108 |
+
nltk==3.8.1
|
| 109 |
+
notebook==7.1.2
|
| 110 |
+
notebook_shim==0.2.4
|
| 111 |
+
numpy==1.26.4
|
| 112 |
+
openai==1.25.1
|
| 113 |
+
opentelemetry-api==1.24.0
|
| 114 |
+
opentelemetry-exporter-otlp==1.24.0
|
| 115 |
+
opentelemetry-exporter-otlp-proto-common==1.24.0
|
| 116 |
+
opentelemetry-exporter-otlp-proto-grpc==1.24.0
|
| 117 |
+
opentelemetry-exporter-otlp-proto-http==1.24.0
|
| 118 |
+
opentelemetry-instrumentation==0.45b0
|
| 119 |
+
opentelemetry-proto==1.24.0
|
| 120 |
+
opentelemetry-sdk==1.24.0
|
| 121 |
+
opentelemetry-semantic-conventions==0.45b0
|
| 122 |
+
orjson==3.10.1
|
| 123 |
+
overrides==7.7.0
|
| 124 |
+
packaging==23.2
|
| 125 |
+
pandas==2.2.2
|
| 126 |
+
pandocfilters==1.5.1
|
| 127 |
+
pillow==10.3.0
|
| 128 |
+
plotly==5.22.0
|
| 129 |
+
portalocker==2.8.2
|
| 130 |
+
prometheus_client==0.20.0
|
| 131 |
+
protobuf==4.25.3
|
| 132 |
+
pyarrow==16.0.0
|
| 133 |
+
pyarrow-hotfix==0.6
|
| 134 |
+
pycparser==2.22
|
| 135 |
+
pydantic==2.6.4
|
| 136 |
+
pydantic_core==2.16.3
|
| 137 |
+
pydeck==0.9.0
|
| 138 |
+
PyJWT==2.8.0
|
| 139 |
+
PyMuPDF==1.24.2
|
| 140 |
+
PyMuPDFb==1.24.1
|
| 141 |
+
pyparsing==3.1.2
|
| 142 |
+
pypdf==4.2.0
|
| 143 |
+
pysbd==0.3.4
|
| 144 |
+
python-dotenv==1.0.0
|
| 145 |
+
python-engineio==4.9.0
|
| 146 |
+
python-graphql-client==0.4.3
|
| 147 |
+
python-json-logger==2.0.7
|
| 148 |
+
python-magic==0.4.27
|
| 149 |
+
python-multipart==0.0.6
|
| 150 |
+
python-socketio==5.11.2
|
| 151 |
+
pytz==2024.1
|
| 152 |
+
PyYAML==6.0.1
|
| 153 |
+
qdrant-client==1.9.1
|
| 154 |
+
qtconsole==5.5.1
|
| 155 |
+
QtPy==2.4.1
|
| 156 |
+
ragas==0.1.7
|
| 157 |
+
referencing==0.34.0
|
| 158 |
+
regex==2024.4.16
|
| 159 |
+
requests==2.31.0
|
| 160 |
+
rfc3339-validator==0.1.4
|
| 161 |
+
rfc3986-validator==0.1.1
|
| 162 |
+
rich==13.7.1
|
| 163 |
+
rpds-py==0.18.0
|
| 164 |
+
scikit-learn==1.4.2
|
| 165 |
+
scipy==1.13.0
|
| 166 |
+
Send2Trash==1.8.3
|
| 167 |
+
sentry-sdk==1.45.0
|
| 168 |
+
setproctitle==1.3.3
|
| 169 |
+
simple-websocket==1.0.0
|
| 170 |
+
smmap==5.0.1
|
| 171 |
+
sniffio==1.3.1
|
| 172 |
+
soupsieve==2.5
|
| 173 |
+
SQLAlchemy==2.0.29
|
| 174 |
+
starlette==0.27.0
|
| 175 |
+
streamlit==1.33.0
|
| 176 |
+
striprtf==0.0.26
|
| 177 |
+
syncer==2.0.3
|
| 178 |
+
tenacity==8.2.3
|
| 179 |
+
terminado==0.18.1
|
| 180 |
+
threadpoolctl==3.4.0
|
| 181 |
+
tiktoken==0.6.0
|
| 182 |
+
tinycss2==1.2.1
|
| 183 |
+
toml==0.10.2
|
| 184 |
+
tomli==2.0.1
|
| 185 |
+
toolz==0.12.1
|
| 186 |
+
tqdm==4.66.2
|
| 187 |
+
types-python-dateutil==2.9.0.20240316
|
| 188 |
+
types-requests==2.31.0.20240406
|
| 189 |
+
typing-inspect==0.9.0
|
| 190 |
+
tzdata==2024.1
|
| 191 |
+
uptrace==1.24.0
|
| 192 |
+
uri-template==1.3.0
|
| 193 |
+
urllib3==2.2.1
|
| 194 |
+
uvicorn==0.23.2
|
| 195 |
+
wandb==0.16.6
|
| 196 |
+
watchfiles==0.20.0
|
| 197 |
+
webcolors==1.13
|
| 198 |
+
webencodings==0.5.1
|
| 199 |
+
websocket-client==1.7.0
|
| 200 |
+
websockets==12.0
|
| 201 |
+
widgetsnbextension==4.0.10
|
| 202 |
+
wikipedia==1.4.0
|
| 203 |
+
wrapt==1.16.0
|
| 204 |
+
wsproto==1.2.0
|
| 205 |
+
xxhash==3.4.1
|
| 206 |
+
yarl==1.9.4
|