Spaces:
Paused

Paused
added dockerfile and chainlit python files
Browse files- Dockerfile +11 -0
- README.md +14 -10
- app.py +79 -0
- chainlit.md +15 -0
- public/image1.png +0 -0
- requirements.txt +5 -0
Dockerfile
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.11
|
| 2 |
+
RUN useradd -m -u 1000 user
|
| 3 |
+
USER user
|
| 4 |
+
ENV HOME=/home/user \
|
| 5 |
+
PATH=/home/user/.local/bin:$PATH
|
| 6 |
+
WORKDIR $HOME/app
|
| 7 |
+
COPY --chown=user . $HOME/app
|
| 8 |
+
COPY ./requirements.txt ~/app/requirements.txt
|
| 9 |
+
RUN pip install -r requirements.txt
|
| 10 |
+
COPY . .
|
| 11 |
+
CMD ["chainlit", "run", "app.py", "--port", "7860"]
|
README.md
CHANGED
|
@@ -1,10 +1,14 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ChatWithPinecone 🌲
|
| 2 |
+
|
| 3 |
+
This is a conversational application integrating multiple technologies: Pinecone, OpenAI embeddings, and the Chainlit framework. Here's an analysis of its key components and functionality:
|
| 4 |
+
|
| 5 |
+
An index in Pinecone is was created to store and retriev vectorized data. OpenAI embeddings were used to convert text to vectors so they can be stored and searched in the Pinecone index.
|
| 6 |
+
|
| 7 |
+
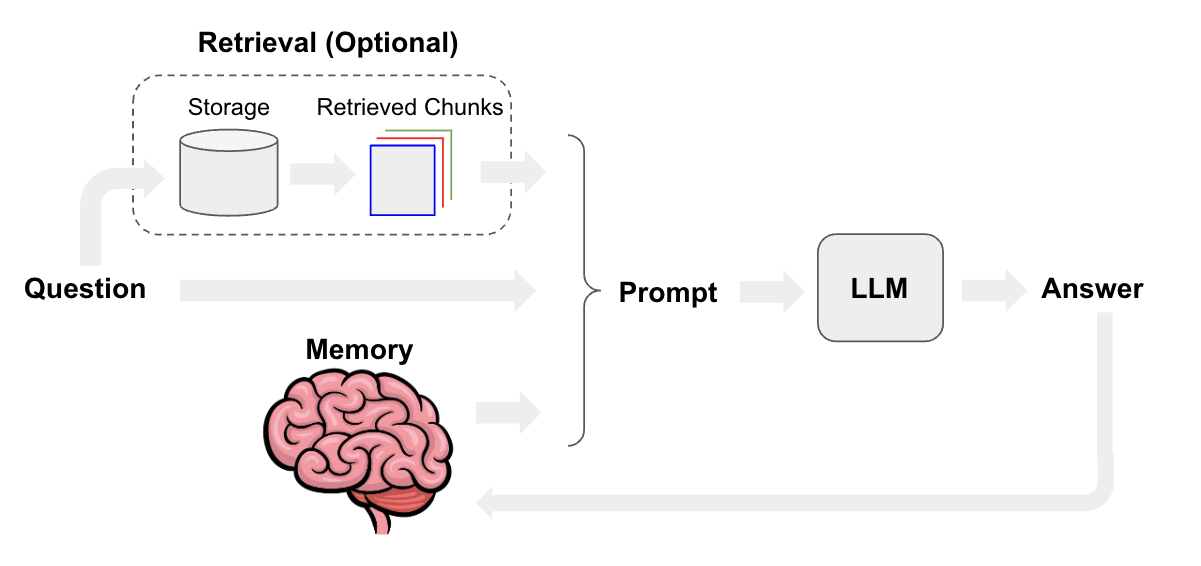
The following diagram shows the flow of data in the application:
|
| 8 |
+
|
| 9 |
+
1. The user enters a message in the chatbot.
|
| 10 |
+
2. The message is sent to the Pinecone Storage Index.
|
| 11 |
+
3. The user's prompt is vectorized using OpenAI embeddings and sent to the Pinecone Storage Index to retrieve the top three documents relating to the prompt.
|
| 12 |
+
4. The top three documents are summarized from an LLM providing an answer back to the user.
|
| 13 |
+
|
| 14 |
+

|
app.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
from langchain.embeddings.openai import OpenAIEmbeddings
|
| 4 |
+
from langchain.vectorstores.pinecone import Pinecone
|
| 5 |
+
from langchain.chains import ConversationalRetrievalChain
|
| 6 |
+
from langchain.chat_models import ChatOpenAI
|
| 7 |
+
from langchain.memory import ChatMessageHistory, ConversationBufferMemory
|
| 8 |
+
from langchain.docstore.document import Document
|
| 9 |
+
import pinecone
|
| 10 |
+
import chainlit as cl
|
| 11 |
+
|
| 12 |
+
pinecone.init(
|
| 13 |
+
api_key=os.environ.get("PINECONE_API_KEY"),
|
| 14 |
+
environment=os.environ.get("PINECONE_ENV"),
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
index_name = "langchain-demo"
|
| 19 |
+
embeddings = OpenAIEmbeddings()
|
| 20 |
+
|
| 21 |
+
welcome_message = "Welcome to the Chainlit Pinecone demo! Ask anything about Shakespeare's King Lear vectorized documents from Pinecone DB."
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
@cl.on_chat_start
|
| 25 |
+
async def start():
|
| 26 |
+
await cl.Message(content=welcome_message).send()
|
| 27 |
+
docsearch = Pinecone.from_existing_index(
|
| 28 |
+
index_name=index_name, embedding=embeddings
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
message_history = ChatMessageHistory()
|
| 32 |
+
|
| 33 |
+
memory = ConversationBufferMemory(
|
| 34 |
+
memory_key="chat_history",
|
| 35 |
+
output_key="answer",
|
| 36 |
+
chat_memory=message_history,
|
| 37 |
+
return_messages=True,
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
chain = ConversationalRetrievalChain.from_llm(
|
| 41 |
+
ChatOpenAI(
|
| 42 |
+
model_name="gpt-3.5-turbo",
|
| 43 |
+
temperature=0,
|
| 44 |
+
streaming=True),
|
| 45 |
+
chain_type="stuff",
|
| 46 |
+
retriever=docsearch.as_retriever(search_kwargs={'k': 3}), # I only want maximum of three document back with the highest similarity score
|
| 47 |
+
memory=memory,
|
| 48 |
+
return_source_documents=True,
|
| 49 |
+
)
|
| 50 |
+
cl.user_session.set("chain", chain)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
@cl.on_message
|
| 54 |
+
async def main(message: cl.Message):
|
| 55 |
+
chain = cl.user_session.get("chain") # type: ConversationalRetrievalChain
|
| 56 |
+
|
| 57 |
+
cb = cl.AsyncLangchainCallbackHandler()
|
| 58 |
+
|
| 59 |
+
res = await chain.acall(message.content, callbacks=[cb])
|
| 60 |
+
answer = res["answer"]
|
| 61 |
+
source_documents = res["source_documents"] # type: List[Document]
|
| 62 |
+
|
| 63 |
+
text_elements = [] # type: List[cl.Text]
|
| 64 |
+
|
| 65 |
+
if source_documents:
|
| 66 |
+
for source_idx, source_doc in enumerate(source_documents):
|
| 67 |
+
source_name = f"source_{source_idx}"
|
| 68 |
+
# Create the text element referenced in the message
|
| 69 |
+
text_elements.append(
|
| 70 |
+
cl.Text(content=source_doc.page_content, name=source_name)
|
| 71 |
+
)
|
| 72 |
+
source_names = [text_el.name for text_el in text_elements]
|
| 73 |
+
|
| 74 |
+
if source_names:
|
| 75 |
+
answer += f"\nSources: {', '.join(source_names)}"
|
| 76 |
+
else:
|
| 77 |
+
answer += "\nNo sources found"
|
| 78 |
+
|
| 79 |
+
await cl.Message(content=answer, elements=text_elements).send()
|
chainlit.md
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### ChatWithPinecone 🌲
|
| 2 |
+
|
| 3 |
+
This is a conversational application integrating multiple technologies: Pinecone, OpenAI embeddings, and the Chainlit framework. Here's an analysis of its key components and functionality:
|
| 4 |
+
|
| 5 |
+
An index in Pinecone is was created to store and retriev vectorized data. OpenAI embeddings were used to convert text to vectors so they can be stored and searched in the Pinecone index.
|
| 6 |
+
|
| 7 |
+
The following diagram shows the flow of data in the application:
|
| 8 |
+
|
| 9 |
+
1. The user enters a message in the chatbot.
|
| 10 |
+
2. The message is sent to the Pinecone Storage Index.
|
| 11 |
+
3. The user's prompt is vectorized using OpenAI embeddings and sent to the Pinecone Storage Index to retrieve the top three documents relating to the prompt.
|
| 12 |
+
4. The top three documents are summarized from an LLM providing an answer back to the user.
|
| 13 |
+
5. In-store memory is enabled using LangChain's memory caching feature. This allows the application to store the top three documents in memory for faster retrieval.
|
| 14 |
+
|
| 15 |
+

|
public/image1.png
ADDED
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pinecone-client==2.2.1
|
| 2 |
+
tiktoken==0.3.3
|
| 3 |
+
langchain
|
| 4 |
+
chainlit
|
| 5 |
+
openai
|