Spaces:
Running

Running
Upload 31 files
Browse files- Model/__init__.py +1 -0
- Model/__pycache__/__init__.cpython-38.pyc +0 -0
- Model/__pycache__/attention.cpython-38.pyc +0 -0
- Model/__pycache__/backbone.cpython-38.pyc +0 -0
- Model/__pycache__/model.cpython-38.pyc +0 -0
- Model/__pycache__/trainer.cpython-38.pyc +0 -0
- Model/attention.py +114 -0
- Model/backbone.py +295 -0
- Model/model.py +32 -0
- Model/trainer.py +264 -0
- app.py +67 -0
- dataset/TurkishSceneTextDataset.py +70 -0
- dataset/__init__.py +0 -0
- dataset/__pycache__/TurkishSceneTextDataset.cpython-38.pyc +0 -0
- dataset/__pycache__/__init__.cpython-38.pyc +0 -0
- dataset/__pycache__/augmentations.cpython-38.pyc +0 -0
- dataset/__pycache__/charMapper.cpython-38.pyc +0 -0
- dataset/__pycache__/strit.cpython-38.pyc +0 -0
- dataset/__pycache__/syntheticTurkishStyleText.cpython-38.pyc +0 -0
- dataset/augmentations.py +352 -0
- dataset/charMapper.py +55 -0
- dataset/strit.py +37 -0
- dataset/syntheticTurkishStyleText.py +51 -0
- fig/0.jpg +0 -0
- fig/145.jpg +0 -0
- fig/195.jpg +0 -0
- fig/270.jpg +0 -0
- fig/MViT-TR-arch.png +0 -0
- requirements.txt +7 -0
Model/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from Model.model import TTR
|
Model/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (184 Bytes). View file
|
|
|
Model/__pycache__/attention.cpython-38.pyc
ADDED
|
Binary file (4.32 kB). View file
|
|
|
Model/__pycache__/backbone.cpython-38.pyc
ADDED
|
Binary file (9.63 kB). View file
|
|
|
Model/__pycache__/model.cpython-38.pyc
ADDED
|
Binary file (1.28 kB). View file
|
|
|
Model/__pycache__/trainer.cpython-38.pyc
ADDED
|
Binary file (6.75 kB). View file
|
|
|
Model/attention.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class PositionalEncoding(nn.Module):
|
| 7 |
+
r"""Inject some information about the relative or absolute position of the tokens
|
| 8 |
+
in the sequence. The positional encodings have the same dimension as
|
| 9 |
+
the embeddings, so that the two can be summed. Here, we use sine and cosine
|
| 10 |
+
functions of different frequencies.
|
| 11 |
+
.. math::
|
| 12 |
+
\text{PosEncoder}(pos, 2i) = sin(pos/10000^(2i/d_model))
|
| 13 |
+
\text{PosEncoder}(pos, 2i+1) = cos(pos/10000^(2i/d_model))
|
| 14 |
+
\text{where pos is the word position and i is the embed idx)
|
| 15 |
+
Args:
|
| 16 |
+
d_model: the embed dim (required).
|
| 17 |
+
dropout: the dropout value (default=0.1).
|
| 18 |
+
max_len: the max. length of the incoming sequence (default=5000).
|
| 19 |
+
Examples:
|
| 20 |
+
>>> pos_encoder = PositionalEncoding(d_model)
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
def __init__(self, d_model, dropout=0.1, max_len=5000):
|
| 24 |
+
super().__init__()
|
| 25 |
+
self.dropout = nn.Dropout(p=dropout)
|
| 26 |
+
|
| 27 |
+
pe = torch.zeros(max_len, d_model)
|
| 28 |
+
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
|
| 29 |
+
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
|
| 30 |
+
pe[:, 0::2] = torch.sin(position * div_term)
|
| 31 |
+
pe[:, 1::2] = torch.cos(position * div_term)
|
| 32 |
+
pe = pe.unsqueeze(0).transpose(0, 1)
|
| 33 |
+
self.register_buffer('pe', pe)
|
| 34 |
+
|
| 35 |
+
def forward(self, x):
|
| 36 |
+
r"""Inputs of forward function
|
| 37 |
+
Args:
|
| 38 |
+
x: the sequence fed to the positional encoder model (required).
|
| 39 |
+
Shape:
|
| 40 |
+
x: [sequence length, batch size, embed dim]
|
| 41 |
+
output: [sequence length, batch size, embed dim]
|
| 42 |
+
Examples:
|
| 43 |
+
>>> output = pos_encoder(x)
|
| 44 |
+
"""
|
| 45 |
+
|
| 46 |
+
x = x + self.pe[:x.size(0), :]
|
| 47 |
+
return self.dropout(x)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def encoder_layer(in_c, out_c, k=3, s=2, p=1):
|
| 51 |
+
return nn.Sequential(nn.Conv2d(in_c, out_c, k, s, p),
|
| 52 |
+
nn.BatchNorm2d(out_c),
|
| 53 |
+
nn.ReLU(True))
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def decoder_layer(in_c, out_c, k=3, s=1, p=1, mode='nearest', scale_factor=None, size=None):
|
| 57 |
+
align_corners = None if mode == 'nearest' else True
|
| 58 |
+
return nn.Sequential(nn.Upsample(size=size, scale_factor=scale_factor,
|
| 59 |
+
mode=mode, align_corners=align_corners),
|
| 60 |
+
nn.Conv2d(in_c, out_c, k, s, p),
|
| 61 |
+
nn.BatchNorm2d(out_c),
|
| 62 |
+
nn.ReLU(True))
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class PositionAttention(nn.Module):
|
| 66 |
+
def __init__(self, max_length, in_channels=512, num_channels=64,
|
| 67 |
+
h=8, w=32, mode='nearest', **kwargs):
|
| 68 |
+
super().__init__()
|
| 69 |
+
self.max_length = max_length
|
| 70 |
+
self.k_encoder = nn.Sequential(
|
| 71 |
+
encoder_layer(in_channels, num_channels, s=(1, 2)),
|
| 72 |
+
encoder_layer(num_channels, num_channels, s=(2, 2)),
|
| 73 |
+
encoder_layer(num_channels, num_channels, s=(2, 2)),
|
| 74 |
+
encoder_layer(num_channels, num_channels, s=(2, 2))
|
| 75 |
+
)
|
| 76 |
+
self.k_decoder = nn.Sequential(
|
| 77 |
+
decoder_layer(num_channels, num_channels, scale_factor=2, mode=mode),
|
| 78 |
+
decoder_layer(num_channels, num_channels, scale_factor=2, mode=mode),
|
| 79 |
+
decoder_layer(num_channels, num_channels, scale_factor=2, mode=mode),
|
| 80 |
+
decoder_layer(num_channels, in_channels, size=(h, w), mode=mode)
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
self.pos_encoder = PositionalEncoding(in_channels, dropout=0., max_len=max_length)
|
| 84 |
+
self.project = nn.Linear(in_channels, in_channels)
|
| 85 |
+
|
| 86 |
+
def forward(self, x):
|
| 87 |
+
N, E, H, W = x.size()
|
| 88 |
+
k, v = x, x # (N, E, H, W)
|
| 89 |
+
|
| 90 |
+
# calculate key vector
|
| 91 |
+
features = []
|
| 92 |
+
for i in range(0, len(self.k_encoder)):
|
| 93 |
+
k = self.k_encoder[i](k)
|
| 94 |
+
features.append(k)
|
| 95 |
+
for i in range(0, len(self.k_decoder) - 1):
|
| 96 |
+
k = self.k_decoder[i](k)
|
| 97 |
+
k = k + features[len(self.k_decoder) - 2 - i]
|
| 98 |
+
k = self.k_decoder[-1](k)
|
| 99 |
+
|
| 100 |
+
# calculate query vector
|
| 101 |
+
zeros = x.new_zeros((self.max_length, N, E)) # (T, N, E)
|
| 102 |
+
q = self.pos_encoder(zeros) # (T, N, E)
|
| 103 |
+
q = q.permute(1, 0, 2) # (N, T, E)
|
| 104 |
+
q = self.project(q) # (N, T, E)
|
| 105 |
+
|
| 106 |
+
# calculate attention
|
| 107 |
+
attn_scores = torch.bmm(q, k.flatten(2, 3)) # (N, T, (H*W))
|
| 108 |
+
attn_scores = attn_scores / (E ** 0.5)
|
| 109 |
+
attn_scores = torch.softmax(attn_scores, dim=-1)
|
| 110 |
+
|
| 111 |
+
v = v.permute(0, 2, 3, 1).view(N, -1, E) # (N, (H*W), E)
|
| 112 |
+
attn_vecs = torch.bmm(attn_scores, v) # (N, T, E)
|
| 113 |
+
|
| 114 |
+
return attn_vecs, attn_scores.view(N, -1, H, W)
|
Model/backbone.py
ADDED
|
@@ -0,0 +1,295 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from timm.models.layers import DropPath, trunc_normal_
|
| 4 |
+
from typing import Optional, Callable
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class Mlp(nn.Module):
|
| 8 |
+
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU6, drop=0.):
|
| 9 |
+
super().__init__()
|
| 10 |
+
out_features = out_features or in_features
|
| 11 |
+
hidden_features = hidden_features or in_features
|
| 12 |
+
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 13 |
+
self.act = act_layer()
|
| 14 |
+
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 15 |
+
self.drop = nn.Dropout(drop)
|
| 16 |
+
|
| 17 |
+
def forward(self, x):
|
| 18 |
+
x = self.fc1(x)
|
| 19 |
+
x = self.act(x)
|
| 20 |
+
x = self.drop(x)
|
| 21 |
+
x = self.fc2(x)
|
| 22 |
+
x = self.drop(x)
|
| 23 |
+
return x
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class VITBatchNorm(nn.Module):
|
| 27 |
+
def __init__(self, num_features):
|
| 28 |
+
super().__init__()
|
| 29 |
+
self.num_features = num_features
|
| 30 |
+
self.bn = nn.BatchNorm1d(num_features=num_features)
|
| 31 |
+
|
| 32 |
+
def forward(self, x):
|
| 33 |
+
return self.bn(x)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class Attention(nn.Module):
|
| 37 |
+
def __init__(self,
|
| 38 |
+
dim: int,
|
| 39 |
+
num_heads: int = 8,
|
| 40 |
+
qkv_bias: bool = False,
|
| 41 |
+
qk_scale: Optional[None] = None,
|
| 42 |
+
attn_drop: float = 0.,
|
| 43 |
+
proj_drop: float = 0.):
|
| 44 |
+
super().__init__()
|
| 45 |
+
self.num_heads = num_heads
|
| 46 |
+
head_dim = dim // num_heads
|
| 47 |
+
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
|
| 48 |
+
self.scale = qk_scale or head_dim ** -0.5
|
| 49 |
+
|
| 50 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 51 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 52 |
+
self.proj = nn.Linear(dim, dim)
|
| 53 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 54 |
+
|
| 55 |
+
def forward(self, x):
|
| 56 |
+
with torch.cuda.amp.autocast(True):
|
| 57 |
+
batch_size, num_token, embed_dim = x.shape
|
| 58 |
+
# qkv is [3,batch_size,num_heads,num_token, embed_dim//num_heads]
|
| 59 |
+
qkv = self.qkv(x).reshape(
|
| 60 |
+
batch_size, num_token, 3, self.num_heads, embed_dim // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 61 |
+
with torch.cuda.amp.autocast(False):
|
| 62 |
+
q, k, v = qkv[0].float(), qkv[1].float(), qkv[2].float()
|
| 63 |
+
attn = (q @ k.transpose(-2, -1)) * self.scale
|
| 64 |
+
attn = attn.softmax(dim=-1)
|
| 65 |
+
attn = self.attn_drop(attn)
|
| 66 |
+
x = (attn @ v).transpose(1, 2).reshape(batch_size, num_token, embed_dim)
|
| 67 |
+
with torch.cuda.amp.autocast(True):
|
| 68 |
+
x = self.proj(x)
|
| 69 |
+
x = self.proj_drop(x)
|
| 70 |
+
return x
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
class Block(nn.Module):
|
| 74 |
+
|
| 75 |
+
def __init__(self,
|
| 76 |
+
dim: int,
|
| 77 |
+
num_heads: int,
|
| 78 |
+
num_patches: int,
|
| 79 |
+
mlp_ratio: float = 4.,
|
| 80 |
+
qkv_bias: bool = False,
|
| 81 |
+
qk_scale: Optional[None] = None,
|
| 82 |
+
drop: float = 0.,
|
| 83 |
+
attn_drop: float = 0.,
|
| 84 |
+
drop_path: float = 0.,
|
| 85 |
+
act_layer: Callable = nn.ReLU6,
|
| 86 |
+
norm_layer: str = "ln",
|
| 87 |
+
patch_n: int = 144):
|
| 88 |
+
super().__init__()
|
| 89 |
+
|
| 90 |
+
if norm_layer == "bn":
|
| 91 |
+
self.norm1 = VITBatchNorm(num_features=num_patches)
|
| 92 |
+
self.norm2 = VITBatchNorm(num_features=num_patches)
|
| 93 |
+
elif norm_layer == "ln":
|
| 94 |
+
self.norm1 = nn.LayerNorm(dim)
|
| 95 |
+
self.norm2 = nn.LayerNorm(dim)
|
| 96 |
+
|
| 97 |
+
self.attn = Attention(
|
| 98 |
+
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
|
| 99 |
+
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
|
| 100 |
+
self.drop_path = DropPath(
|
| 101 |
+
drop_path) if drop_path > 0. else nn.Identity()
|
| 102 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 103 |
+
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
|
| 104 |
+
act_layer=act_layer, drop=drop)
|
| 105 |
+
self.extra_gflops = (num_heads * patch_n * (dim // num_heads) * patch_n * 2) / (1000 ** 3)
|
| 106 |
+
|
| 107 |
+
def forward(self, x):
|
| 108 |
+
x = x + self.drop_path(self.attn(self.norm1(x)))
|
| 109 |
+
with torch.cuda.amp.autocast(True):
|
| 110 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 111 |
+
return x
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
class PatchEmbed(nn.Module):
|
| 115 |
+
def __init__(self, img_size=[108, 108], patch_size=[9, 9], in_channels=3, embed_dim=768):
|
| 116 |
+
super().__init__()
|
| 117 |
+
# img_size = to_2tuple(img_size)
|
| 118 |
+
# patch_size = to_2tuple(patch_size)
|
| 119 |
+
num_patches = (img_size[1] // patch_size[1]) * \
|
| 120 |
+
(img_size[0] // patch_size[0])
|
| 121 |
+
self.img_size = img_size
|
| 122 |
+
self.patch_size = patch_size
|
| 123 |
+
self.num_patches = num_patches
|
| 124 |
+
self.proj = nn.Conv2d(in_channels, embed_dim,
|
| 125 |
+
kernel_size=patch_size, stride=patch_size)
|
| 126 |
+
|
| 127 |
+
def forward(self, x):
|
| 128 |
+
batch_size, channels, height, width = x.shape
|
| 129 |
+
assert height == self.img_size[0] and width == self.img_size[1], \
|
| 130 |
+
f"Input image size ({height}*{width}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
|
| 131 |
+
x = self.proj(x).flatten(2).transpose(1, 2)
|
| 132 |
+
return x
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class VisionTransformer(nn.Module):
|
| 136 |
+
""" Vision Transformer with support for patch or hybrid CNN input stage
|
| 137 |
+
"""
|
| 138 |
+
|
| 139 |
+
def __init__(self,
|
| 140 |
+
img_size: list = [112, 112],
|
| 141 |
+
patch_size: list = [16, 16],
|
| 142 |
+
in_channels: int = 3,
|
| 143 |
+
num_classes: int = 1000,
|
| 144 |
+
embed_dim: int = 768,
|
| 145 |
+
depth: int = 12,
|
| 146 |
+
num_heads: int = 12,
|
| 147 |
+
mlp_ratio: float = 4.,
|
| 148 |
+
qkv_bias: bool = False,
|
| 149 |
+
qk_scale: Optional[None] = None,
|
| 150 |
+
drop_rate: float = 0.,
|
| 151 |
+
attn_drop_rate: float = 0.,
|
| 152 |
+
drop_path_rate: float = 0.,
|
| 153 |
+
hybrid_backbone: Optional[None] = None,
|
| 154 |
+
norm_layer: str = "ln",
|
| 155 |
+
mask_ratio=0.1,
|
| 156 |
+
using_checkpoint=False,
|
| 157 |
+
):
|
| 158 |
+
super().__init__()
|
| 159 |
+
self.num_classes = num_classes
|
| 160 |
+
# num_features for consistency with other models
|
| 161 |
+
self.num_features = self.embed_dim = embed_dim
|
| 162 |
+
|
| 163 |
+
if hybrid_backbone is not None:
|
| 164 |
+
raise ValueError
|
| 165 |
+
else:
|
| 166 |
+
self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_channels=in_channels,
|
| 167 |
+
embed_dim=embed_dim)
|
| 168 |
+
self.mask_ratio = mask_ratio
|
| 169 |
+
self.using_checkpoint = using_checkpoint
|
| 170 |
+
num_patches = self.patch_embed.num_patches
|
| 171 |
+
self.num_patches = num_patches
|
| 172 |
+
|
| 173 |
+
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
|
| 174 |
+
self.pos_drop = nn.Dropout(p=drop_rate)
|
| 175 |
+
|
| 176 |
+
# stochastic depth decay rule
|
| 177 |
+
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
|
| 178 |
+
|
| 179 |
+
self.patchWSize = img_size[1] // patch_size[1]
|
| 180 |
+
self.patchHSize = img_size[0] // patch_size[0]
|
| 181 |
+
patch_n = self.patchWSize * self.patchHSize
|
| 182 |
+
|
| 183 |
+
self.blocks = nn.ModuleList(
|
| 184 |
+
[
|
| 185 |
+
Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 186 |
+
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
|
| 187 |
+
num_patches=num_patches, patch_n=patch_n)
|
| 188 |
+
for i in range(depth)]
|
| 189 |
+
)
|
| 190 |
+
self.extra_gflops = 0.0
|
| 191 |
+
for _block in self.blocks:
|
| 192 |
+
self.extra_gflops += _block.extra_gflops
|
| 193 |
+
|
| 194 |
+
if norm_layer == "ln":
|
| 195 |
+
self.norm = nn.LayerNorm(embed_dim)
|
| 196 |
+
elif norm_layer == "bn":
|
| 197 |
+
self.norm = VITBatchNorm(self.num_patches)
|
| 198 |
+
|
| 199 |
+
# features head
|
| 200 |
+
self.feature = nn.Sequential(
|
| 201 |
+
nn.Linear(in_features=embed_dim * num_patches, out_features=embed_dim, bias=False),
|
| 202 |
+
nn.BatchNorm1d(num_features=embed_dim, eps=2e-5),
|
| 203 |
+
nn.Linear(in_features=embed_dim, out_features=num_classes, bias=False),
|
| 204 |
+
nn.BatchNorm1d(num_features=num_classes, eps=2e-5)
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
self.mask_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
|
| 208 |
+
torch.nn.init.normal_(self.mask_token, std=.02)
|
| 209 |
+
trunc_normal_(self.pos_embed, std=.02)
|
| 210 |
+
# trunc_normal_(self.cls_token, std=.02)
|
| 211 |
+
self.apply(self._init_weights)
|
| 212 |
+
|
| 213 |
+
def _init_weights(self, m):
|
| 214 |
+
if isinstance(m, nn.Linear):
|
| 215 |
+
trunc_normal_(m.weight, std=.02)
|
| 216 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 217 |
+
nn.init.constant_(m.bias, 0)
|
| 218 |
+
elif isinstance(m, nn.LayerNorm):
|
| 219 |
+
nn.init.constant_(m.bias, 0)
|
| 220 |
+
nn.init.constant_(m.weight, 1.0)
|
| 221 |
+
|
| 222 |
+
@torch.jit.ignore
|
| 223 |
+
def no_weight_decay(self):
|
| 224 |
+
return {'pos_embed', 'cls_token'}
|
| 225 |
+
|
| 226 |
+
def get_classifier(self):
|
| 227 |
+
return self.head
|
| 228 |
+
|
| 229 |
+
def random_masking(self, x, mask_ratio=0.1):
|
| 230 |
+
"""
|
| 231 |
+
Perform per-sample random masking by per-sample shuffling.
|
| 232 |
+
Per-sample shuffling is done by argsort random noise.
|
| 233 |
+
x: [N, L, D], sequence
|
| 234 |
+
"""
|
| 235 |
+
N, L, D = x.size() # batch, length, dim
|
| 236 |
+
len_keep = int(L * (1 - mask_ratio))
|
| 237 |
+
|
| 238 |
+
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
|
| 239 |
+
|
| 240 |
+
# sort noise for each sample
|
| 241 |
+
# ascend: small is keep, large is remove
|
| 242 |
+
ids_shuffle = torch.argsort(noise, dim=1)
|
| 243 |
+
ids_restore = torch.argsort(ids_shuffle, dim=1)
|
| 244 |
+
|
| 245 |
+
# keep the first subset
|
| 246 |
+
ids_keep = ids_shuffle[:, :len_keep]
|
| 247 |
+
x_masked = torch.gather(
|
| 248 |
+
x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
|
| 249 |
+
|
| 250 |
+
# generate the binary mask: 0 is keep, 1 is remove
|
| 251 |
+
mask = torch.ones([N, L], device=x.device)
|
| 252 |
+
mask[:, :len_keep] = 0
|
| 253 |
+
# unshuffle to get the binary mask
|
| 254 |
+
mask = torch.gather(mask, dim=1, index=ids_restore)
|
| 255 |
+
|
| 256 |
+
return x_masked, mask, ids_restore
|
| 257 |
+
|
| 258 |
+
def forward_features(self, x):
|
| 259 |
+
B = x.shape[0]
|
| 260 |
+
x = self.patch_embed(x)
|
| 261 |
+
x = x + self.pos_embed
|
| 262 |
+
|
| 263 |
+
if self.training and self.mask_ratio > 0:
|
| 264 |
+
x, _, ids_restore = self.random_masking(x, mask_ratio=self.mask_ratio)
|
| 265 |
+
|
| 266 |
+
for func in self.blocks:
|
| 267 |
+
if self.using_checkpoint and self.training:
|
| 268 |
+
from torch.utils.checkpoint import checkpoint
|
| 269 |
+
x = checkpoint(func, x)
|
| 270 |
+
else:
|
| 271 |
+
x = func(x)
|
| 272 |
+
x = self.norm(x.float())
|
| 273 |
+
|
| 274 |
+
if self.training and self.mask_ratio > 0:
|
| 275 |
+
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] - x.shape[1], 1)
|
| 276 |
+
x_ = torch.cat([x[:, :, :], mask_tokens], dim=1) # no cls token
|
| 277 |
+
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle
|
| 278 |
+
x = x_
|
| 279 |
+
return x.permute(0, 2, 1).view(B, self.embed_dim, self.patchHSize, self.patchWSize)
|
| 280 |
+
|
| 281 |
+
def forward(self, x):
|
| 282 |
+
x = self.forward_features(x)
|
| 283 |
+
return x
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
if __name__ == '__main__':
|
| 287 |
+
img = torch.zeros((1, 3, 32, 128))
|
| 288 |
+
model = VisionTransformer(img_size=[32, 128],
|
| 289 |
+
patch_size=[4, 4],
|
| 290 |
+
in_channels=3,
|
| 291 |
+
embed_dim=512,
|
| 292 |
+
num_heads=8)
|
| 293 |
+
model.eval()
|
| 294 |
+
features = model(img)
|
| 295 |
+
print(features.size())
|
Model/model.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
|
| 3 |
+
from Model.attention import PositionAttention
|
| 4 |
+
from Model.backbone import VisionTransformer
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class TTR(nn.Module):
|
| 8 |
+
def __init__(self, args: dict):
|
| 9 |
+
super().__init__()
|
| 10 |
+
self.args = args
|
| 11 |
+
|
| 12 |
+
self.backbone = VisionTransformer(img_size=args["img_size"],
|
| 13 |
+
patch_size=args["patch_size"],
|
| 14 |
+
in_channels=3,
|
| 15 |
+
embed_dim=args["embed_dim"],
|
| 16 |
+
num_heads=args["num_heads"],
|
| 17 |
+
mask_ratio=args["mask_ratio"])
|
| 18 |
+
|
| 19 |
+
self.positionAttention = PositionAttention(max_length=26,
|
| 20 |
+
in_channels=args["embed_dim"],
|
| 21 |
+
num_channels=args["position_attention_hidden"],
|
| 22 |
+
h=args["img_size"][0] // args["patch_size"][0],
|
| 23 |
+
w=args["img_size"][1] // args["patch_size"][1],
|
| 24 |
+
mode='nearest')
|
| 25 |
+
self.cls = nn.Linear(args["embed_dim"], 43)
|
| 26 |
+
return
|
| 27 |
+
|
| 28 |
+
def forward(self, image):
|
| 29 |
+
features = self.backbone(image)
|
| 30 |
+
attn_vecs, attn_scores = self.positionAttention(features)
|
| 31 |
+
logits = self.cls(attn_vecs)
|
| 32 |
+
return logits
|
Model/trainer.py
ADDED
|
@@ -0,0 +1,264 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import tqdm
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
from torch.utils.data import DataLoader, RandomSampler, Dataset
|
| 9 |
+
|
| 10 |
+
from metrics import getAcc
|
| 11 |
+
from torch.cuda.amp import autocast, GradScaler
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class Trainer:
|
| 15 |
+
|
| 16 |
+
def __init__(self, args, tb_logger, logger):
|
| 17 |
+
self.args = args
|
| 18 |
+
|
| 19 |
+
self.gpu = torch.device(args.gpu)
|
| 20 |
+
self.model = None
|
| 21 |
+
self.it = 0
|
| 22 |
+
self.best_eval_acc, self.best_it = 0.0, 0
|
| 23 |
+
|
| 24 |
+
# init dataset
|
| 25 |
+
self.trainDataset = None
|
| 26 |
+
self.trainDataloader = None
|
| 27 |
+
self.evalDataset = None
|
| 28 |
+
self.evalDataloader = None
|
| 29 |
+
|
| 30 |
+
# optimizer and scheduler
|
| 31 |
+
self.scheduler = None
|
| 32 |
+
self.optimizer = None
|
| 33 |
+
|
| 34 |
+
# loss
|
| 35 |
+
self.loss_fn = None
|
| 36 |
+
self.weight = None
|
| 37 |
+
self.setLoss(args.loss)
|
| 38 |
+
self.ignore_index = args.model["letter_size"]
|
| 39 |
+
|
| 40 |
+
# gradient clipping
|
| 41 |
+
if args.clip_grad is not None:
|
| 42 |
+
self.clip_grad = True
|
| 43 |
+
self.clip_value = args.clip_grad
|
| 44 |
+
else:
|
| 45 |
+
self.clip_grad = False
|
| 46 |
+
|
| 47 |
+
if hasattr(args, "label_smoothing") and args.label_smoothing is not None:
|
| 48 |
+
self.label_smoothing = float(args.label_smoothing)
|
| 49 |
+
else:
|
| 50 |
+
self.label_smoothing = 0.0
|
| 51 |
+
|
| 52 |
+
# logging
|
| 53 |
+
if tb_logger is not None:
|
| 54 |
+
self.tb_log = tb_logger
|
| 55 |
+
self.print_fn = print if logger is None else logger.info
|
| 56 |
+
|
| 57 |
+
return
|
| 58 |
+
|
| 59 |
+
def train(self):
|
| 60 |
+
"""
|
| 61 |
+
Train The Model
|
| 62 |
+
"""
|
| 63 |
+
self.model.train()
|
| 64 |
+
|
| 65 |
+
# for gpu profiling
|
| 66 |
+
start_batch = torch.cuda.Event(enable_timing=True)
|
| 67 |
+
end_batch = torch.cuda.Event(enable_timing=True)
|
| 68 |
+
start_run = torch.cuda.Event(enable_timing=True)
|
| 69 |
+
end_run = torch.cuda.Event(enable_timing=True)
|
| 70 |
+
|
| 71 |
+
scaler = GradScaler()
|
| 72 |
+
|
| 73 |
+
start_batch.record()
|
| 74 |
+
# eval for once
|
| 75 |
+
if self.args.resume:
|
| 76 |
+
eval_dict = self.evaluate()
|
| 77 |
+
print(eval_dict)
|
| 78 |
+
|
| 79 |
+
tbar = tqdm.tqdm(total=len(self.trainDataloader), colour='BLUE')
|
| 80 |
+
|
| 81 |
+
for samples, targets, _ in self.trainDataloader:
|
| 82 |
+
tbar.update(1)
|
| 83 |
+
self.it += 1
|
| 84 |
+
|
| 85 |
+
end_batch.record()
|
| 86 |
+
torch.cuda.synchronize()
|
| 87 |
+
start_run.record()
|
| 88 |
+
|
| 89 |
+
samples, targets = samples.to(self.gpu), targets.to(self.gpu).long()
|
| 90 |
+
|
| 91 |
+
with autocast():
|
| 92 |
+
logits = self.model(samples)
|
| 93 |
+
loss = F.cross_entropy(logits.flatten(end_dim=1), targets.flatten(),
|
| 94 |
+
ignore_index=self.ignore_index,
|
| 95 |
+
label_smoothing=self.label_smoothing)
|
| 96 |
+
|
| 97 |
+
scaler.scale(loss).backward()
|
| 98 |
+
|
| 99 |
+
if self.clip_grad:
|
| 100 |
+
torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.clip_value)
|
| 101 |
+
|
| 102 |
+
scaler.step(self.optimizer)
|
| 103 |
+
scaler.update()
|
| 104 |
+
if self.scheduler is not None:
|
| 105 |
+
self.scheduler.step()
|
| 106 |
+
self.model.zero_grad()
|
| 107 |
+
|
| 108 |
+
end_run.record()
|
| 109 |
+
torch.cuda.synchronize()
|
| 110 |
+
|
| 111 |
+
# tensorboard_dict update
|
| 112 |
+
tb_dict = {}
|
| 113 |
+
tb_dict['train/loss'] = loss.detach().cpu().item()
|
| 114 |
+
|
| 115 |
+
tb_dict['lr'] = self.optimizer.param_groups[0]['lr']
|
| 116 |
+
tb_dict['GPU/prefecth_time'] = start_batch.elapsed_time(end_batch) / 1000.
|
| 117 |
+
tb_dict['GPU/run_time'] = start_run.elapsed_time(end_run) / 1000.
|
| 118 |
+
|
| 119 |
+
if self.it % self.args.num_eval_iter == 0:
|
| 120 |
+
eval_dict = self.evaluate()
|
| 121 |
+
tb_dict.update(eval_dict)
|
| 122 |
+
save_path = self.args.save_path
|
| 123 |
+
if tb_dict['Word/Acc'] > self.best_eval_acc:
|
| 124 |
+
self.best_eval_acc = tb_dict['Word/Acc']
|
| 125 |
+
self.best_it = self.it
|
| 126 |
+
|
| 127 |
+
self.print_fn(
|
| 128 |
+
f"\n {self.it} iteration, {tb_dict}, \n BEST_EVAL_ACC: {self.best_eval_acc}, at {self.best_it} iters")
|
| 129 |
+
self.print_fn(
|
| 130 |
+
f" {self.it} iteration, ACC: {tb_dict['Word/Acc']}\n")
|
| 131 |
+
if self.it == self.best_it:
|
| 132 |
+
self.save_model('model_best.pth', save_path)
|
| 133 |
+
|
| 134 |
+
if self.tb_log is not None:
|
| 135 |
+
self.tb_log.update(tb_dict, self.it)
|
| 136 |
+
del tb_dict
|
| 137 |
+
start_batch.record()
|
| 138 |
+
|
| 139 |
+
eval_dict = self.evaluate()
|
| 140 |
+
eval_dict.update({'eval/best_acc': self.best_eval_acc, 'eval/best_it': self.best_it})
|
| 141 |
+
return eval_dict
|
| 142 |
+
|
| 143 |
+
@torch.no_grad()
|
| 144 |
+
def evaluate(self, model: nn.Module = None, evalDataset: Dataset = None):
|
| 145 |
+
self.print_fn("\n Evaluation!!!")
|
| 146 |
+
|
| 147 |
+
if model is None:
|
| 148 |
+
model = self.model
|
| 149 |
+
if evalDataset is not None:
|
| 150 |
+
evalDataloader = DataLoader(evalDataset, self.args.eval_batch_size, shuffle=False, num_workers=0)
|
| 151 |
+
else:
|
| 152 |
+
evalDataloader = self.evalDataloader
|
| 153 |
+
|
| 154 |
+
eval_dict = {}
|
| 155 |
+
|
| 156 |
+
model.eval()
|
| 157 |
+
|
| 158 |
+
preds_arr = None
|
| 159 |
+
targets_arr = None
|
| 160 |
+
lengths_arr = None
|
| 161 |
+
for samples, targets, lengths in evalDataloader:
|
| 162 |
+
samples, targets = samples.to(self.gpu), targets.to(self.gpu)
|
| 163 |
+
|
| 164 |
+
outputs = model(samples)
|
| 165 |
+
|
| 166 |
+
preds = torch.max(outputs, dim=2)[1]
|
| 167 |
+
|
| 168 |
+
if preds_arr is None:
|
| 169 |
+
preds_arr = preds.detach().cpu()
|
| 170 |
+
targets_arr = targets.detach().cpu()
|
| 171 |
+
lengths_arr = lengths.detach().cpu()
|
| 172 |
+
else:
|
| 173 |
+
preds_arr = torch.concat((preds_arr, preds.detach().cpu()))
|
| 174 |
+
targets_arr = torch.concat((targets_arr, targets.detach().cpu()))
|
| 175 |
+
lengths_arr = torch.concat((lengths_arr, lengths.detach().cpu()))
|
| 176 |
+
|
| 177 |
+
wordAcc, charAcc = getAcc(preds_arr, targets_arr, lengths_arr)
|
| 178 |
+
eval_dict.update({"Word/Acc": wordAcc,
|
| 179 |
+
"Char/Acc": charAcc})
|
| 180 |
+
model.train()
|
| 181 |
+
return eval_dict
|
| 182 |
+
|
| 183 |
+
def save_model(self, save_name, save_path):
|
| 184 |
+
save_filename = os.path.join(save_path, save_name)
|
| 185 |
+
self.model.eval()
|
| 186 |
+
save_dict = {"model": self.model.state_dict(),
|
| 187 |
+
'optimizer': self.optimizer.state_dict(),
|
| 188 |
+
'scheduler': self.scheduler.state_dict() if self.scheduler is not None else None,
|
| 189 |
+
'it': self.it}
|
| 190 |
+
torch.save(save_dict, save_filename)
|
| 191 |
+
self.model.train()
|
| 192 |
+
self.print_fn(f"model saved: {save_filename}\n")
|
| 193 |
+
|
| 194 |
+
def save_baseLearner(self, save_name, save_path, trainIndexes):
|
| 195 |
+
save_filename = os.path.join(save_path, save_name)
|
| 196 |
+
self.model.eval()
|
| 197 |
+
save_dict = {"model": self.model.state_dict(),
|
| 198 |
+
'optimizer': self.optimizer.state_dict(),
|
| 199 |
+
'scheduler': self.scheduler.state_dict() if self.scheduler is not None else None,
|
| 200 |
+
'trainIndexes': trainIndexes,
|
| 201 |
+
'it': self.it}
|
| 202 |
+
torch.save(save_dict, save_filename)
|
| 203 |
+
self.model.train()
|
| 204 |
+
self.print_fn(f"model saved: {save_filename}\n")
|
| 205 |
+
|
| 206 |
+
def load_model(self, load_dir, load_name):
|
| 207 |
+
"""
|
| 208 |
+
load saved model a
|
| 209 |
+
:param load_dir: directory of loading model
|
| 210 |
+
:param load_name: model name
|
| 211 |
+
"""
|
| 212 |
+
load_path = os.path.join(load_dir, load_name)
|
| 213 |
+
checkpoint = torch.load(load_path)
|
| 214 |
+
self.model.load_state_dict(checkpoint['model'])
|
| 215 |
+
self.optimizer.load_state_dict(checkpoint['optimizer'])
|
| 216 |
+
if checkpoint['scheduler'] is not None:
|
| 217 |
+
self.scheduler.load_state_dict(checkpoint['scheduler'])
|
| 218 |
+
self.it = checkpoint['it']
|
| 219 |
+
self.print_fn(f'model loaded from {load_path}')
|
| 220 |
+
|
| 221 |
+
def set_optimizer(self, optimizer, scheduler=None):
|
| 222 |
+
"""
|
| 223 |
+
set optimizer and scheduler
|
| 224 |
+
:param optimizer: optimizer
|
| 225 |
+
:param scheduler: scheduler
|
| 226 |
+
"""
|
| 227 |
+
self.optimizer = optimizer
|
| 228 |
+
self.scheduler = scheduler
|
| 229 |
+
|
| 230 |
+
def setModel(self, model):
|
| 231 |
+
"""
|
| 232 |
+
set model
|
| 233 |
+
:param model: model
|
| 234 |
+
"""
|
| 235 |
+
self.model = model.cuda(self.gpu)
|
| 236 |
+
|
| 237 |
+
def setDatasets(self, trainDataset, evalDataset):
|
| 238 |
+
"""
|
| 239 |
+
set train and evaluation datasets and dataloaders
|
| 240 |
+
:param trainDataset: train dataset
|
| 241 |
+
:param evalDataset: evaluation dataset
|
| 242 |
+
"""
|
| 243 |
+
self.print_fn(f"\n Num Train Labeled Sample : {len(trainDataset)}\n Num Val Sample : {len(evalDataset)}")
|
| 244 |
+
self.trainDataset = trainDataset
|
| 245 |
+
self.evalDataset = evalDataset
|
| 246 |
+
|
| 247 |
+
self.trainDataloader = DataLoader(trainDataset, batch_size=self.args.batch_size,
|
| 248 |
+
sampler=RandomSampler(data_source=trainDataset,
|
| 249 |
+
replacement=True,
|
| 250 |
+
num_samples=self.args.iter * self.args.batch_size),
|
| 251 |
+
num_workers=self.args.num_workers, drop_last=True, pin_memory=True)
|
| 252 |
+
|
| 253 |
+
self.evalDataloader = DataLoader(evalDataset, self.args.eval_batch_size, shuffle=False, num_workers=0,
|
| 254 |
+
pin_memory=True)
|
| 255 |
+
|
| 256 |
+
def setLoss(self, loss_function: dict):
|
| 257 |
+
"""
|
| 258 |
+
set loss function
|
| 259 |
+
:param loss_function: loss function arguments
|
| 260 |
+
"""
|
| 261 |
+
if loss_function["name"] == 'CrossEntropyLoss':
|
| 262 |
+
self.loss_fn = nn.CrossEntropyLoss(label_smoothing=loss_function["label_smoothing"]).cuda(self.gpu)
|
| 263 |
+
else:
|
| 264 |
+
raise Exception(f"Unknown Loss Function : {loss_function}")
|
app.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torchvision import transforms
|
| 3 |
+
import gradio as gr
|
| 4 |
+
|
| 5 |
+
from Model import TTR
|
| 6 |
+
from dataset.charMapper import CharMapper
|
| 7 |
+
|
| 8 |
+
# arguments
|
| 9 |
+
model_path = "./experiments/real_train/model_best.pth"
|
| 10 |
+
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def getTransforms():
|
| 14 |
+
return transforms.Compose([
|
| 15 |
+
transforms.Resize((32, 128), transforms.InterpolationMode.BICUBIC),
|
| 16 |
+
transforms.ToTensor(),
|
| 17 |
+
transforms.Normalize(0.5, 0.5)
|
| 18 |
+
])
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
mapper = CharMapper()
|
| 22 |
+
model = TTR({"img_size": [32, 128],
|
| 23 |
+
"patch_size": [4, 4],
|
| 24 |
+
"embed_dim": 512,
|
| 25 |
+
"num_heads": 8,
|
| 26 |
+
"position_attention_hidden": 64,
|
| 27 |
+
"mask_ratio": 0.0
|
| 28 |
+
})
|
| 29 |
+
model.load_state_dict(torch.load(model_path)["model"])
|
| 30 |
+
model.eval()
|
| 31 |
+
model = model.to("cuda:0")
|
| 32 |
+
|
| 33 |
+
preprocess = getTransforms()
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def inference(raw_image):
|
| 37 |
+
batch = preprocess(raw_image).unsqueeze(0).to(device)
|
| 38 |
+
outputs = model(batch)
|
| 39 |
+
preds = torch.max(outputs, dim=2)[1]
|
| 40 |
+
pred_text = mapper.reverseMapper(preds[0])
|
| 41 |
+
return pred_text
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
inputs = [gr.Image(type='pil', interactive=True, )]
|
| 45 |
+
outputs = gr.components.Textbox(label="Caption")
|
| 46 |
+
title = "MViT-TR"
|
| 47 |
+
paper_link = "https://www.sciencedirect.com/science/article/pii/S2215098624002672"
|
| 48 |
+
github_link = "https://github.com/serdaryildiz/MViT-TR"
|
| 49 |
+
description = f"<p style='text-align: center'><a href='{github_link}' target='_blank'>MViT-TR</a> : Masked Vision Transformer for Text Recognition"
|
| 50 |
+
examples = [
|
| 51 |
+
["fig/0.jpg"],
|
| 52 |
+
["fig/145.jpg"],
|
| 53 |
+
["fig/195.jpg"],
|
| 54 |
+
["fig/270.jpg"],
|
| 55 |
+
]
|
| 56 |
+
article = f"<p style='text-align: center'><a href='{paper_link}' target='_blank'>Paper</a> | <a href='{github_link}' target='_blank'>Github Repo</a></p>"
|
| 57 |
+
css = ".output-image, .input-image, .image-preview {height: 600px !important}"
|
| 58 |
+
|
| 59 |
+
iface = gr.Interface(fn=inference,
|
| 60 |
+
inputs=inputs,
|
| 61 |
+
outputs=outputs,
|
| 62 |
+
title=title,
|
| 63 |
+
description=description,
|
| 64 |
+
examples=examples,
|
| 65 |
+
article=article,
|
| 66 |
+
css=css)
|
| 67 |
+
iface.launch()
|
dataset/TurkishSceneTextDataset.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from PIL import Image
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch.utils.data import Dataset
|
| 6 |
+
from torchvision import transforms
|
| 7 |
+
|
| 8 |
+
from dataset.augmentations import CVGeometry, CVDeterioration, CVColorJitter
|
| 9 |
+
from dataset.charMapper import CharMapper
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class TurkishSceneTextDataset(Dataset):
|
| 13 |
+
def __init__(self, args: dict, train=True):
|
| 14 |
+
self.root = args["root"]
|
| 15 |
+
self.train = train
|
| 16 |
+
|
| 17 |
+
txt_path = os.path.join(self.root, "train.txt") if self.train else os.path.join(self.root, "test.txt")
|
| 18 |
+
with open(txt_path, "r") as fp:
|
| 19 |
+
lines = fp.readlines()
|
| 20 |
+
|
| 21 |
+
self.gt = {}
|
| 22 |
+
for l in lines:
|
| 23 |
+
img_name, label = l.strip().split('\t')
|
| 24 |
+
self.gt[img_name] = label
|
| 25 |
+
|
| 26 |
+
self.root = os.path.join(self.root, "train") if self.train else os.path.join(self.root, "test")
|
| 27 |
+
self.imgPaths = [os.path.join(self.root, p) for p in self.gt.keys()]
|
| 28 |
+
|
| 29 |
+
self.transforms = self._getTransforms()
|
| 30 |
+
self.mapper = CharMapper(letters=args["letters"], maxLength=args["maxLength"])
|
| 31 |
+
|
| 32 |
+
def __getitem__(self, item):
|
| 33 |
+
imgPath = self.imgPaths[item]
|
| 34 |
+
image = Image.open(imgPath)
|
| 35 |
+
image = self.transforms(image)
|
| 36 |
+
|
| 37 |
+
label = self.gt[os.path.basename(imgPath)]
|
| 38 |
+
|
| 39 |
+
label, length = self.mapper(label, return_length=True)
|
| 40 |
+
return image, label, torch.tensor(length)
|
| 41 |
+
|
| 42 |
+
def __len__(self):
|
| 43 |
+
return len(self.imgPaths)
|
| 44 |
+
|
| 45 |
+
def _getTransforms(self):
|
| 46 |
+
if self.train:
|
| 47 |
+
return transforms.Compose([
|
| 48 |
+
CVGeometry(degrees=45, translate=(0.0, 0.0), scale=(0.5, 2.), shear=(45, 15), distortion=0.5, p=0.5),
|
| 49 |
+
CVDeterioration(var=20, degrees=6, factor=4, p=0.25),
|
| 50 |
+
CVColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.1, p=0.25),
|
| 51 |
+
transforms.Resize((32, 128), transforms.InterpolationMode.BICUBIC),
|
| 52 |
+
transforms.ToTensor(),
|
| 53 |
+
transforms.Normalize(0.5, 0.5)
|
| 54 |
+
])
|
| 55 |
+
else:
|
| 56 |
+
return transforms.Compose([
|
| 57 |
+
transforms.Resize((32, 128), transforms.InterpolationMode.BICUBIC),
|
| 58 |
+
transforms.ToTensor(),
|
| 59 |
+
transforms.Normalize(0.5, 0.5)
|
| 60 |
+
])
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
if __name__ == '__main__':
|
| 64 |
+
args = {
|
| 65 |
+
"name": "TurkishSceneTextDataset",
|
| 66 |
+
"root": "../data/TS-TR",
|
| 67 |
+
"letters": "0123456789abcçdefgğhıijklmnoöpqrsştuüvwxyz",
|
| 68 |
+
"maxLength": "25"
|
| 69 |
+
}
|
| 70 |
+
dataset = TurkishSceneTextDataset(args, False)
|
dataset/__init__.py
ADDED
|
File without changes
|
dataset/__pycache__/TurkishSceneTextDataset.cpython-38.pyc
ADDED
|
Binary file (2.75 kB). View file
|
|
|
dataset/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (147 Bytes). View file
|
|
|
dataset/__pycache__/augmentations.cpython-38.pyc
ADDED
|
Binary file (12.9 kB). View file
|
|
|
dataset/__pycache__/charMapper.cpython-38.pyc
ADDED
|
Binary file (2.12 kB). View file
|
|
|
dataset/__pycache__/strit.cpython-38.pyc
ADDED
|
Binary file (1.72 kB). View file
|
|
|
dataset/__pycache__/syntheticTurkishStyleText.cpython-38.pyc
ADDED
|
Binary file (2.37 kB). View file
|
|
|
dataset/augmentations.py
ADDED
|
@@ -0,0 +1,352 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Source : https://github.com/FangShancheng/ABINet/blob/main/transforms.py
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
import math
|
| 6 |
+
import numbers
|
| 7 |
+
import random
|
| 8 |
+
|
| 9 |
+
import cv2
|
| 10 |
+
import numpy as np
|
| 11 |
+
from PIL import Image
|
| 12 |
+
from torchvision import transforms
|
| 13 |
+
from torchvision.transforms import Compose
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def sample_asym(magnitude, size=None):
|
| 17 |
+
return np.random.beta(1, 4, size) * magnitude
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def sample_sym(magnitude, size=None):
|
| 21 |
+
return (np.random.beta(4, 4, size=size) - 0.5) * 2 * magnitude
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def sample_uniform(low, high, size=None):
|
| 25 |
+
return np.random.uniform(low, high, size=size)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_interpolation(type='random'):
|
| 29 |
+
if type == 'random':
|
| 30 |
+
choice = [cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA]
|
| 31 |
+
interpolation = choice[random.randint(0, len(choice) - 1)]
|
| 32 |
+
elif type == 'nearest':
|
| 33 |
+
interpolation = cv2.INTER_NEAREST
|
| 34 |
+
elif type == 'linear':
|
| 35 |
+
interpolation = cv2.INTER_LINEAR
|
| 36 |
+
elif type == 'cubic':
|
| 37 |
+
interpolation = cv2.INTER_CUBIC
|
| 38 |
+
elif type == 'area':
|
| 39 |
+
interpolation = cv2.INTER_AREA
|
| 40 |
+
else:
|
| 41 |
+
raise TypeError('Interpolation types only nearest, linear, cubic, area are supported!')
|
| 42 |
+
return interpolation
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class CVRandomRotation(object):
|
| 46 |
+
def __init__(self, degrees=15):
|
| 47 |
+
assert isinstance(degrees, numbers.Number), "degree should be a single number."
|
| 48 |
+
assert degrees >= 0, "degree must be positive."
|
| 49 |
+
self.degrees = degrees
|
| 50 |
+
|
| 51 |
+
@staticmethod
|
| 52 |
+
def get_params(degrees):
|
| 53 |
+
return sample_sym(degrees)
|
| 54 |
+
|
| 55 |
+
def __call__(self, img):
|
| 56 |
+
angle = self.get_params(self.degrees)
|
| 57 |
+
src_h, src_w = img.shape[:2]
|
| 58 |
+
M = cv2.getRotationMatrix2D(center=(src_w / 2, src_h / 2), angle=angle, scale=1.0)
|
| 59 |
+
abs_cos, abs_sin = abs(M[0, 0]), abs(M[0, 1])
|
| 60 |
+
dst_w = int(src_h * abs_sin + src_w * abs_cos)
|
| 61 |
+
dst_h = int(src_h * abs_cos + src_w * abs_sin)
|
| 62 |
+
M[0, 2] += (dst_w - src_w) / 2
|
| 63 |
+
M[1, 2] += (dst_h - src_h) / 2
|
| 64 |
+
|
| 65 |
+
flags = get_interpolation()
|
| 66 |
+
return cv2.warpAffine(img, M, (dst_w, dst_h), flags=flags, borderMode=cv2.BORDER_REPLICATE)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class CVRandomAffine(object):
|
| 70 |
+
def __init__(self, degrees, translate=None, scale=None, shear=None):
|
| 71 |
+
assert isinstance(degrees, numbers.Number), "degree should be a single number."
|
| 72 |
+
assert degrees >= 0, "degree must be positive."
|
| 73 |
+
self.degrees = degrees
|
| 74 |
+
|
| 75 |
+
if translate is not None:
|
| 76 |
+
assert isinstance(translate, (tuple, list)) and len(translate) == 2, \
|
| 77 |
+
"translate should be a list or tuple and it must be of length 2."
|
| 78 |
+
for t in translate:
|
| 79 |
+
if not (0.0 <= t <= 1.0):
|
| 80 |
+
raise ValueError("translation values should be between 0 and 1")
|
| 81 |
+
self.translate = translate
|
| 82 |
+
|
| 83 |
+
if scale is not None:
|
| 84 |
+
assert isinstance(scale, (tuple, list)) and len(scale) == 2, \
|
| 85 |
+
"scale should be a list or tuple and it must be of length 2."
|
| 86 |
+
for s in scale:
|
| 87 |
+
if s <= 0:
|
| 88 |
+
raise ValueError("scale values should be positive")
|
| 89 |
+
self.scale = scale
|
| 90 |
+
|
| 91 |
+
if shear is not None:
|
| 92 |
+
if isinstance(shear, numbers.Number):
|
| 93 |
+
if shear < 0:
|
| 94 |
+
raise ValueError("If shear is a single number, it must be positive.")
|
| 95 |
+
self.shear = [shear]
|
| 96 |
+
else:
|
| 97 |
+
assert isinstance(shear, (tuple, list)) and (len(shear) == 2), \
|
| 98 |
+
"shear should be a list or tuple and it must be of length 2."
|
| 99 |
+
self.shear = shear
|
| 100 |
+
else:
|
| 101 |
+
self.shear = shear
|
| 102 |
+
|
| 103 |
+
def _get_inverse_affine_matrix(self, center, angle, translate, scale, shear):
|
| 104 |
+
# https://github.com/pytorch/vision/blob/v0.4.0/torchvision/transforms/functional.py#L717
|
| 105 |
+
from numpy import sin, cos, tan
|
| 106 |
+
|
| 107 |
+
if isinstance(shear, numbers.Number):
|
| 108 |
+
shear = [shear, 0]
|
| 109 |
+
|
| 110 |
+
if not isinstance(shear, (tuple, list)) and len(shear) == 2:
|
| 111 |
+
raise ValueError(
|
| 112 |
+
"Shear should be a single value or a tuple/list containing " +
|
| 113 |
+
"two values. Got {}".format(shear))
|
| 114 |
+
|
| 115 |
+
rot = math.radians(angle)
|
| 116 |
+
sx, sy = [math.radians(s) for s in shear]
|
| 117 |
+
|
| 118 |
+
cx, cy = center
|
| 119 |
+
tx, ty = translate
|
| 120 |
+
|
| 121 |
+
# RSS without scaling
|
| 122 |
+
a = cos(rot - sy) / cos(sy)
|
| 123 |
+
b = -cos(rot - sy) * tan(sx) / cos(sy) - sin(rot)
|
| 124 |
+
c = sin(rot - sy) / cos(sy)
|
| 125 |
+
d = -sin(rot - sy) * tan(sx) / cos(sy) + cos(rot)
|
| 126 |
+
|
| 127 |
+
# Inverted rotation matrix with scale and shear
|
| 128 |
+
# det([[a, b], [c, d]]) == 1, since det(rotation) = 1 and det(shear) = 1
|
| 129 |
+
M = [d, -b, 0,
|
| 130 |
+
-c, a, 0]
|
| 131 |
+
M = [x / scale for x in M]
|
| 132 |
+
|
| 133 |
+
# Apply inverse of translation and of center translation: RSS^-1 * C^-1 * T^-1
|
| 134 |
+
M[2] += M[0] * (-cx - tx) + M[1] * (-cy - ty)
|
| 135 |
+
M[5] += M[3] * (-cx - tx) + M[4] * (-cy - ty)
|
| 136 |
+
|
| 137 |
+
# Apply center translation: C * RSS^-1 * C^-1 * T^-1
|
| 138 |
+
M[2] += cx
|
| 139 |
+
M[5] += cy
|
| 140 |
+
return M
|
| 141 |
+
|
| 142 |
+
@staticmethod
|
| 143 |
+
def get_params(degrees, translate, scale_ranges, shears, height):
|
| 144 |
+
angle = sample_sym(degrees)
|
| 145 |
+
if translate is not None:
|
| 146 |
+
max_dx = translate[0] * height
|
| 147 |
+
max_dy = translate[1] * height
|
| 148 |
+
translations = (np.round(sample_sym(max_dx)), np.round(sample_sym(max_dy)))
|
| 149 |
+
else:
|
| 150 |
+
translations = (0, 0)
|
| 151 |
+
|
| 152 |
+
if scale_ranges is not None:
|
| 153 |
+
scale = sample_uniform(scale_ranges[0], scale_ranges[1])
|
| 154 |
+
else:
|
| 155 |
+
scale = 1.0
|
| 156 |
+
|
| 157 |
+
if shears is not None:
|
| 158 |
+
if len(shears) == 1:
|
| 159 |
+
shear = [sample_sym(shears[0]), 0.]
|
| 160 |
+
elif len(shears) == 2:
|
| 161 |
+
shear = [sample_sym(shears[0]), sample_sym(shears[1])]
|
| 162 |
+
else:
|
| 163 |
+
shear = 0.0
|
| 164 |
+
|
| 165 |
+
return angle, translations, scale, shear
|
| 166 |
+
|
| 167 |
+
def __call__(self, img):
|
| 168 |
+
src_h, src_w = img.shape[:2]
|
| 169 |
+
angle, translate, scale, shear = self.get_params(
|
| 170 |
+
self.degrees, self.translate, self.scale, self.shear, src_h)
|
| 171 |
+
|
| 172 |
+
M = self._get_inverse_affine_matrix((src_w / 2, src_h / 2), angle, (0, 0), scale, shear)
|
| 173 |
+
M = np.array(M).reshape(2, 3)
|
| 174 |
+
|
| 175 |
+
startpoints = [(0, 0), (src_w - 1, 0), (src_w - 1, src_h - 1), (0, src_h - 1)]
|
| 176 |
+
project = lambda x, y, a, b, c: int(a * x + b * y + c)
|
| 177 |
+
endpoints = [(project(x, y, *M[0]), project(x, y, *M[1])) for x, y in startpoints]
|
| 178 |
+
|
| 179 |
+
rect = cv2.minAreaRect(np.array(endpoints))
|
| 180 |
+
bbox = cv2.boxPoints(rect).astype(dtype=np.int)
|
| 181 |
+
max_x, max_y = bbox[:, 0].max(), bbox[:, 1].max()
|
| 182 |
+
min_x, min_y = bbox[:, 0].min(), bbox[:, 1].min()
|
| 183 |
+
|
| 184 |
+
dst_w = int(max_x - min_x)
|
| 185 |
+
dst_h = int(max_y - min_y)
|
| 186 |
+
M[0, 2] += (dst_w - src_w) / 2
|
| 187 |
+
M[1, 2] += (dst_h - src_h) / 2
|
| 188 |
+
|
| 189 |
+
# add translate
|
| 190 |
+
dst_w += int(abs(translate[0]))
|
| 191 |
+
dst_h += int(abs(translate[1]))
|
| 192 |
+
if translate[0] < 0: M[0, 2] += abs(translate[0])
|
| 193 |
+
if translate[1] < 0: M[1, 2] += abs(translate[1])
|
| 194 |
+
|
| 195 |
+
flags = get_interpolation()
|
| 196 |
+
return cv2.warpAffine(img, M, (dst_w, dst_h), flags=flags, borderMode=cv2.BORDER_REPLICATE)
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
class CVRandomPerspective(object):
|
| 200 |
+
def __init__(self, distortion=0.5):
|
| 201 |
+
self.distortion = distortion
|
| 202 |
+
|
| 203 |
+
def get_params(self, width, height, distortion):
|
| 204 |
+
offset_h = sample_asym(distortion * height / 2, size=4).astype(dtype=np.int)
|
| 205 |
+
offset_w = sample_asym(distortion * width / 2, size=4).astype(dtype=np.int)
|
| 206 |
+
topleft = (offset_w[0], offset_h[0])
|
| 207 |
+
topright = (width - 1 - offset_w[1], offset_h[1])
|
| 208 |
+
botright = (width - 1 - offset_w[2], height - 1 - offset_h[2])
|
| 209 |
+
botleft = (offset_w[3], height - 1 - offset_h[3])
|
| 210 |
+
|
| 211 |
+
startpoints = [(0, 0), (width - 1, 0), (width - 1, height - 1), (0, height - 1)]
|
| 212 |
+
endpoints = [topleft, topright, botright, botleft]
|
| 213 |
+
return np.array(startpoints, dtype=np.float32), np.array(endpoints, dtype=np.float32)
|
| 214 |
+
|
| 215 |
+
def __call__(self, img):
|
| 216 |
+
height, width = img.shape[:2]
|
| 217 |
+
startpoints, endpoints = self.get_params(width, height, self.distortion)
|
| 218 |
+
M = cv2.getPerspectiveTransform(startpoints, endpoints)
|
| 219 |
+
|
| 220 |
+
# TODO: more robust way to crop image
|
| 221 |
+
rect = cv2.minAreaRect(endpoints)
|
| 222 |
+
bbox = cv2.boxPoints(rect).astype(dtype=np.int)
|
| 223 |
+
max_x, max_y = bbox[:, 0].max(), bbox[:, 1].max()
|
| 224 |
+
min_x, min_y = bbox[:, 0].min(), bbox[:, 1].min()
|
| 225 |
+
min_x, min_y = max(min_x, 0), max(min_y, 0)
|
| 226 |
+
|
| 227 |
+
flags = get_interpolation()
|
| 228 |
+
img = cv2.warpPerspective(img, M, (max_x, max_y), flags=flags, borderMode=cv2.BORDER_REPLICATE)
|
| 229 |
+
img = img[min_y:, min_x:]
|
| 230 |
+
return img
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
class CVRescale(object):
|
| 234 |
+
|
| 235 |
+
def __init__(self, factor=4, base_size=(128, 512)):
|
| 236 |
+
""" Define image scales using gaussian pyramid and rescale image to target scale.
|
| 237 |
+
|
| 238 |
+
Args:
|
| 239 |
+
factor: the decayed factor from base size, factor=4 keeps target scale by default.
|
| 240 |
+
base_size: base size the build the bottom layer of pyramid
|
| 241 |
+
"""
|
| 242 |
+
if isinstance(factor, numbers.Number):
|
| 243 |
+
self.factor = round(sample_uniform(0, factor))
|
| 244 |
+
elif isinstance(factor, (tuple, list)) and len(factor) == 2:
|
| 245 |
+
self.factor = round(sample_uniform(factor[0], factor[1]))
|
| 246 |
+
else:
|
| 247 |
+
raise Exception('factor must be number or list with length 2')
|
| 248 |
+
# assert factor is valid
|
| 249 |
+
self.base_h, self.base_w = base_size[:2]
|
| 250 |
+
|
| 251 |
+
def __call__(self, img):
|
| 252 |
+
if self.factor == 0: return img
|
| 253 |
+
src_h, src_w = img.shape[:2]
|
| 254 |
+
cur_w, cur_h = self.base_w, self.base_h
|
| 255 |
+
scale_img = cv2.resize(img, (cur_w, cur_h), interpolation=get_interpolation())
|
| 256 |
+
for _ in range(self.factor):
|
| 257 |
+
scale_img = cv2.pyrDown(scale_img)
|
| 258 |
+
scale_img = cv2.resize(scale_img, (src_w, src_h), interpolation=get_interpolation())
|
| 259 |
+
return scale_img
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
class CVGaussianNoise(object):
|
| 263 |
+
def __init__(self, mean=0, var=20):
|
| 264 |
+
self.mean = mean
|
| 265 |
+
if isinstance(var, numbers.Number):
|
| 266 |
+
self.var = max(int(sample_asym(var)), 1)
|
| 267 |
+
elif isinstance(var, (tuple, list)) and len(var) == 2:
|
| 268 |
+
self.var = int(sample_uniform(var[0], var[1]))
|
| 269 |
+
else:
|
| 270 |
+
raise Exception('degree must be number or list with length 2')
|
| 271 |
+
|
| 272 |
+
def __call__(self, img):
|
| 273 |
+
noise = np.random.normal(self.mean, self.var ** 0.5, img.shape)
|
| 274 |
+
img = np.clip(img + noise, 0, 255).astype(np.uint8)
|
| 275 |
+
return img
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
class CVMotionBlur(object):
|
| 279 |
+
def __init__(self, degrees=12, angle=90):
|
| 280 |
+
if isinstance(degrees, numbers.Number):
|
| 281 |
+
self.degree = max(int(sample_asym(degrees)), 1)
|
| 282 |
+
elif isinstance(degrees, (tuple, list)) and len(degrees) == 2:
|
| 283 |
+
self.degree = int(sample_uniform(degrees[0], degrees[1]))
|
| 284 |
+
else:
|
| 285 |
+
raise Exception('degree must be number or list with length 2')
|
| 286 |
+
self.angle = sample_uniform(-angle, angle)
|
| 287 |
+
|
| 288 |
+
def __call__(self, img):
|
| 289 |
+
M = cv2.getRotationMatrix2D((self.degree // 2, self.degree // 2), self.angle, 1)
|
| 290 |
+
motion_blur_kernel = np.zeros((self.degree, self.degree))
|
| 291 |
+
motion_blur_kernel[self.degree // 2, :] = 1
|
| 292 |
+
motion_blur_kernel = cv2.warpAffine(motion_blur_kernel, M, (self.degree, self.degree))
|
| 293 |
+
motion_blur_kernel = motion_blur_kernel / self.degree
|
| 294 |
+
img = cv2.filter2D(img, -1, motion_blur_kernel)
|
| 295 |
+
img = np.clip(img, 0, 255).astype(np.uint8)
|
| 296 |
+
return img
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
class CVGeometry(object):
|
| 300 |
+
def __init__(self, degrees=15, translate=(0.3, 0.3), scale=(0.5, 2.),
|
| 301 |
+
shear=(45, 15), distortion=0.5, p=0.5):
|
| 302 |
+
self.p = p
|
| 303 |
+
type_p = random.random()
|
| 304 |
+
if type_p < 0.33:
|
| 305 |
+
self.transforms = CVRandomRotation(degrees=degrees)
|
| 306 |
+
elif type_p < 0.66:
|
| 307 |
+
self.transforms = CVRandomAffine(degrees=degrees, translate=translate, scale=scale, shear=shear)
|
| 308 |
+
else:
|
| 309 |
+
self.transforms = CVRandomPerspective(distortion=distortion)
|
| 310 |
+
|
| 311 |
+
def __call__(self, img):
|
| 312 |
+
if random.random() < self.p:
|
| 313 |
+
img = np.array(img)
|
| 314 |
+
return Image.fromarray(self.transforms(img))
|
| 315 |
+
else:
|
| 316 |
+
return img
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
class CVDeterioration(object):
|
| 320 |
+
def __init__(self, var, degrees, factor, p=0.5):
|
| 321 |
+
self.p = p
|
| 322 |
+
transforms = []
|
| 323 |
+
if var is not None:
|
| 324 |
+
transforms.append(CVGaussianNoise(var=var))
|
| 325 |
+
if degrees is not None:
|
| 326 |
+
transforms.append(CVMotionBlur(degrees=degrees))
|
| 327 |
+
if factor is not None:
|
| 328 |
+
transforms.append(CVRescale(factor=factor))
|
| 329 |
+
|
| 330 |
+
random.shuffle(transforms)
|
| 331 |
+
transforms = Compose(transforms)
|
| 332 |
+
self.transforms = transforms
|
| 333 |
+
|
| 334 |
+
def __call__(self, img):
|
| 335 |
+
if random.random() < self.p:
|
| 336 |
+
img = np.array(img)
|
| 337 |
+
return Image.fromarray(self.transforms(img))
|
| 338 |
+
else:
|
| 339 |
+
return img
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
class CVColorJitter(object):
|
| 343 |
+
def __init__(self, brightness=0.5, contrast=0.5, saturation=0.5, hue=0.1, p=0.5):
|
| 344 |
+
self.p = p
|
| 345 |
+
self.transforms = transforms.ColorJitter(brightness=brightness, contrast=contrast,
|
| 346 |
+
saturation=saturation, hue=hue)
|
| 347 |
+
|
| 348 |
+
def __call__(self, img):
|
| 349 |
+
if random.random() < self.p:
|
| 350 |
+
return self.transforms(img)
|
| 351 |
+
else:
|
| 352 |
+
return img
|
dataset/charMapper.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class CharMapper:
|
| 6 |
+
lower2upper = {
|
| 7 |
+
ord(u"i"): u"İ",
|
| 8 |
+
ord(u"ı"): u"I"
|
| 9 |
+
}
|
| 10 |
+
|
| 11 |
+
upper2lower = {
|
| 12 |
+
ord(u"İ"): u"i",
|
| 13 |
+
ord(u"I"): u"ı"
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
def __init__(self, letters: str = "0123456789abcçdefgğhıijklmnoöpqrsştuüvwxyz", maxLength: int = 25):
|
| 17 |
+
self.letters = letters
|
| 18 |
+
self.maxLength = maxLength
|
| 19 |
+
self.map = {"[END]": 0}
|
| 20 |
+
self.reverseMap = {0: "[END]"}
|
| 21 |
+
i = 1
|
| 22 |
+
for l in self.letters:
|
| 23 |
+
self.map[l] = i
|
| 24 |
+
self.reverseMap[i] = l
|
| 25 |
+
i += 1
|
| 26 |
+
self.map["[PAD]"] = i
|
| 27 |
+
self.reverseMap[i] = "[PAD]"
|
| 28 |
+
return
|
| 29 |
+
|
| 30 |
+
def __call__(self, text: str, return_length=False):
|
| 31 |
+
text = self.text2label(text)
|
| 32 |
+
length = len(text) + 1
|
| 33 |
+
mappedText = torch.tensor([self.map[l] for l in text] + [self.map["[END]"]])
|
| 34 |
+
text = torch.ones((self.maxLength + 1,)) * self.map["[PAD]"]
|
| 35 |
+
text[:len(mappedText)] = mappedText
|
| 36 |
+
if return_length:
|
| 37 |
+
return text, length
|
| 38 |
+
else:
|
| 39 |
+
return text
|
| 40 |
+
|
| 41 |
+
def reverseMapper(self, label: torch.tensor):
|
| 42 |
+
label = label.cpu()
|
| 43 |
+
text = "".join([self.reverseMap[l] for l in label.numpy()])
|
| 44 |
+
return text.split("[END]")[0]
|
| 45 |
+
|
| 46 |
+
def text2label(self, text):
|
| 47 |
+
text = re.sub('[^0-9a-zA-ZğüşöçıİĞÜŞÖÇ]+', '', text)
|
| 48 |
+
text = text.translate(self.upper2lower).lower()
|
| 49 |
+
return text
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
if __name__ == '__main__':
|
| 53 |
+
mapper = CharMapper()
|
| 54 |
+
mapped = mapper("!MA-PİŞ$Z")
|
| 55 |
+
print(mapped)
|
dataset/strit.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
from torch.utils.data import Dataset
|
| 7 |
+
from torchvision import transforms
|
| 8 |
+
from dataset.charMapper import CharMapper
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class STRIT(Dataset):
|
| 12 |
+
def __init__(self, args: dict):
|
| 13 |
+
self.root = args["root"]
|
| 14 |
+
self.imgPaths = [os.path.join(self.root, p) for p in os.listdir(self.root)]
|
| 15 |
+
self.transforms = self._getTransforms()
|
| 16 |
+
|
| 17 |
+
self.mapper = CharMapper(letters=args["letters"], maxLength=args["maxLength"])
|
| 18 |
+
|
| 19 |
+
def __getitem__(self, item):
|
| 20 |
+
imgPath = self.imgPaths[item]
|
| 21 |
+
image = Image.open(imgPath)
|
| 22 |
+
image = self.transforms(image)
|
| 23 |
+
label = imgPath.split('_')[-1].split('.')[0]
|
| 24 |
+
length = torch.tensor(len(label) + 1)
|
| 25 |
+
label = self.mapper(label)
|
| 26 |
+
return image, label, length
|
| 27 |
+
|
| 28 |
+
def __len__(self):
|
| 29 |
+
return len(self.imgPaths)
|
| 30 |
+
|
| 31 |
+
@staticmethod
|
| 32 |
+
def _getTransforms():
|
| 33 |
+
return transforms.Compose([
|
| 34 |
+
transforms.Resize((32, 128), transforms.InterpolationMode.BICUBIC),
|
| 35 |
+
transforms.ToTensor(),
|
| 36 |
+
transforms.Normalize(0.5, 0.5)
|
| 37 |
+
])
|
dataset/syntheticTurkishStyleText.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from PIL import Image
|
| 2 |
+
import lmdb
|
| 3 |
+
import six
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
from torch.utils.data import Dataset
|
| 7 |
+
from torchvision import transforms
|
| 8 |
+
|
| 9 |
+
from dataset.augmentations import CVGeometry, CVDeterioration, CVColorJitter
|
| 10 |
+
from dataset.charMapper import CharMapper
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class SyntheticTurkishStyleText(Dataset):
|
| 14 |
+
def __init__(self, args: dict):
|
| 15 |
+
self.root = args["root"]
|
| 16 |
+
self.args = args
|
| 17 |
+
self.transforms = self._getTransforms()
|
| 18 |
+
self.mapper = CharMapper(letters=args["letters"], maxLength=args["maxLength"])
|
| 19 |
+
|
| 20 |
+
self.env = lmdb.open(self.root, readonly=True, lock=False, readahead=False, meminit=False)
|
| 21 |
+
|
| 22 |
+
with self.env.begin(write=False) as txn:
|
| 23 |
+
self.keys = list(txn.cursor().iternext(values=False))
|
| 24 |
+
|
| 25 |
+
def __getitem__(self, index):
|
| 26 |
+
key = self.keys[index]
|
| 27 |
+
with self.env.begin(write=False) as txn:
|
| 28 |
+
label = key.decode().split("-*-")[0]
|
| 29 |
+
imgbuf = txn.get(key)
|
| 30 |
+
buf = six.BytesIO()
|
| 31 |
+
buf.write(imgbuf)
|
| 32 |
+
buf.seek(0)
|
| 33 |
+
image = Image.open(buf).convert("RGB")
|
| 34 |
+
image = self.transforms(image)
|
| 35 |
+
length = torch.tensor(len(label) + 1)
|
| 36 |
+
label = self.mapper(label)
|
| 37 |
+
return image, label, length
|
| 38 |
+
|
| 39 |
+
def __len__(self):
|
| 40 |
+
return len(self.keys)
|
| 41 |
+
|
| 42 |
+
@staticmethod
|
| 43 |
+
def _getTransforms():
|
| 44 |
+
return transforms.Compose([
|
| 45 |
+
CVGeometry(degrees=45, translate=(0.0, 0.0), scale=(0.5, 2.), shear=(45, 15), distortion=0.5, p=0.5),
|
| 46 |
+
CVDeterioration(var=20, degrees=6, factor=4, p=0.25),
|
| 47 |
+
CVColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.1, p=0.25),
|
| 48 |
+
transforms.Resize((32, 128), transforms.InterpolationMode.BICUBIC),
|
| 49 |
+
transforms.ToTensor(),
|
| 50 |
+
transforms.Normalize(0.5, 0.5)
|
| 51 |
+
])
|
fig/0.jpg
ADDED

|
fig/145.jpg
ADDED

|
fig/195.jpg
ADDED

|
fig/270.jpg
ADDED

|
fig/MViT-TR-arch.png
ADDED
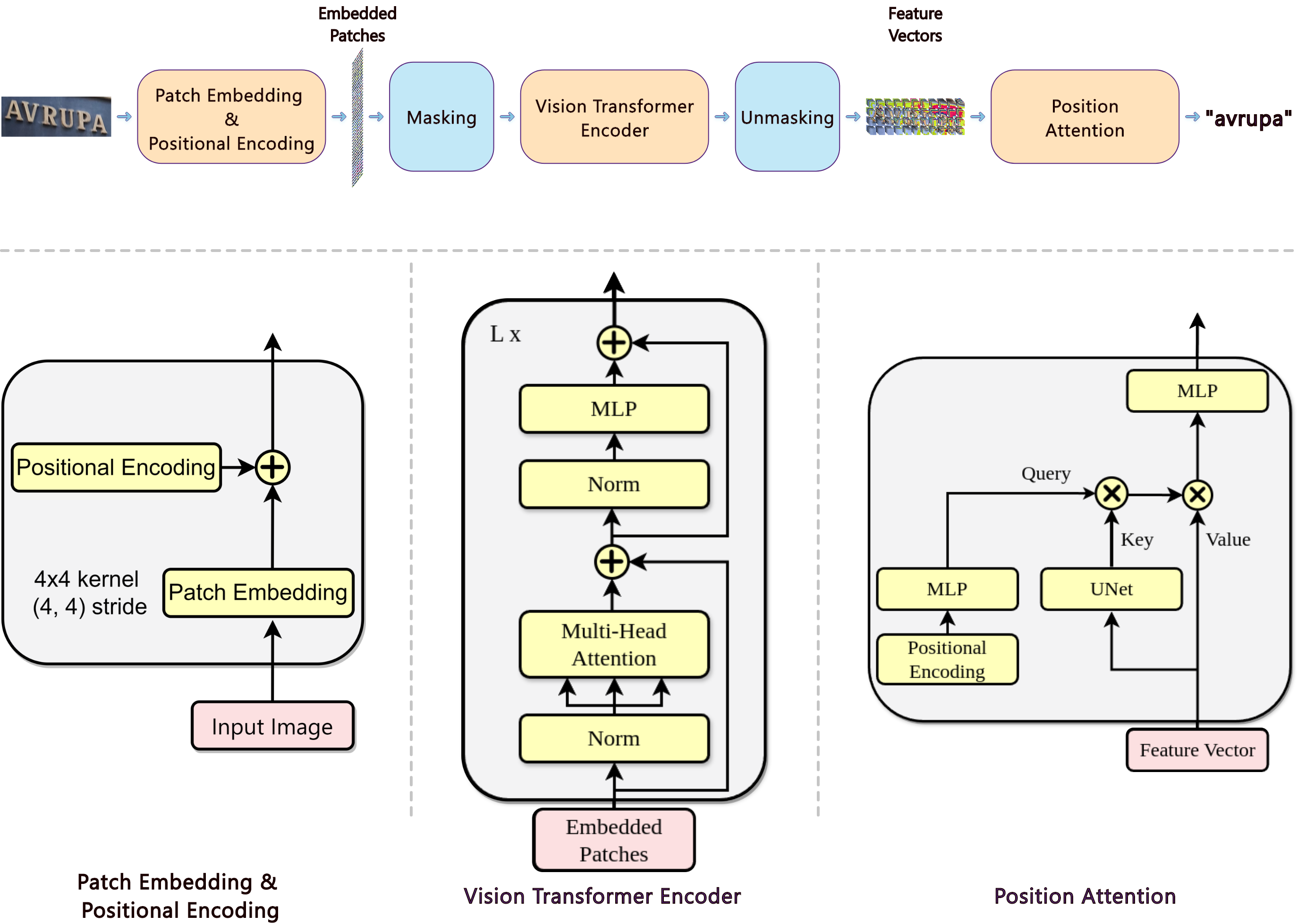
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==1.12.1
|
| 2 |
+
torchvision==0.12.1
|
| 3 |
+
opencv-python==4.6.0.66
|
| 4 |
+
transformers==4.27.3
|
| 5 |
+
ftfy==6.1.1
|
| 6 |
+
gradio==3.48.0
|
| 7 |
+
gdown==4.6.0
|