Spaces:
Sleeping

Sleeping
ryanrahmadifa
commited on
Commit
·
79e1719
1
Parent(s):
d93c9b1
Added files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- README.md +5 -6
- app.py +6 -0
- convert_first.csv +150 -0
- data/all_platts_1week_clean.csv +0 -0
- data/dated_brent_allbate.csv +0 -0
- data/results_platts_09082024_clean.csv +0 -0
- data/topresults_platts_09082024_clean.csv +12 -0
- evaluation.xlsx +0 -0
- experimentation_mlops/example/MLProject +36 -0
- experimentation_mlops/example/als.py +69 -0
- experimentation_mlops/example/etl_data.py +42 -0
- experimentation_mlops/example/load_raw_data.py +42 -0
- experimentation_mlops/example/main.py +107 -0
- experimentation_mlops/example/python_env.yaml +10 -0
- experimentation_mlops/example/spark-defaults.conf +1 -0
- experimentation_mlops/example/train_keras.py +116 -0
- experimentation_mlops/mlops/MLProject +13 -0
- experimentation_mlops/mlops/data/2week_news_data.csv +0 -0
- experimentation_mlops/mlops/data/2week_news_data.json +0 -0
- experimentation_mlops/mlops/data/2week_news_data.parquet +3 -0
- experimentation_mlops/mlops/data/2week_news_data.xlsx +0 -0
- experimentation_mlops/mlops/data/2week_news_data.zip +3 -0
- experimentation_mlops/mlops/desktop.ini +4 -0
- experimentation_mlops/mlops/end-to-end.ipynb +0 -0
- experimentation_mlops/mlops/evaluation.py +42 -0
- experimentation_mlops/mlops/ingest_convert.py +51 -0
- experimentation_mlops/mlops/ingest_request.py +54 -0
- experimentation_mlops/mlops/main.py +104 -0
- experimentation_mlops/mlops/ml-doc.md +59 -0
- experimentation_mlops/mlops/modules/transformations.py +39 -0
- experimentation_mlops/mlops/pics/pipeline.png +0 -0
- experimentation_mlops/mlops/python_env.yaml +11 -0
- experimentation_mlops/mlops/requirements.txt +32 -0
- experimentation_mlops/mlops/spark-defaults.conf +1 -0
- experimentation_mlops/mlops/test.ipynb +490 -0
- experimentation_mlops/mlops/train.py +166 -0
- experimentation_mlops/mlops/transform.py +85 -0
- modules/__init__.py +0 -0
- modules/__pycache__/__init__.cpython-39.pyc +0 -0
- modules/__pycache__/data_preparation.cpython-39.pyc +0 -0
- modules/__pycache__/semantic.cpython-39.pyc +0 -0
- modules/data_preparation.py +86 -0
- modules/semantic.py +198 -0
- page_1.py +85 -0
- page_2.py +63 -0
- page_3.py +79 -0
- price_forecasting_ml/NeuralForecast.ipynb +0 -0
- price_forecasting_ml/__pycache__/train.cpython-38.pyc +0 -0
- price_forecasting_ml/artifacts/crude_oil_8998a364-2ecc-483d-8079-f04d455b4522/forecast_plot.jpg +0 -0
- price_forecasting_ml/artifacts/crude_oil_8998a364-2ecc-483d-8079-f04d455b4522/ingested_dataset.csv +0 -0
README.md
CHANGED
|
@@ -1,14 +1,13 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: streamlit
|
| 7 |
-
sdk_version: 1.
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: apache-2.0
|
| 11 |
-
short_description: Bioma AI Prototype
|
| 12 |
---
|
| 13 |
|
| 14 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Trend Prediction App
|
| 3 |
+
emoji: 🚀
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: pink
|
| 6 |
sdk: streamlit
|
| 7 |
+
sdk_version: 1.37.1
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: apache-2.0
|
|
|
|
| 11 |
---
|
| 12 |
|
| 13 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
app.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
pg = st.navigation({"Bioma AI PoC":[st.Page("page_1.py", title="Semantic Analysis"),
|
| 4 |
+
st.Page("page_2.py", title="Price Forecasting"),
|
| 5 |
+
st.Page("page_3.py", title="MLOps Pipeline")]})
|
| 6 |
+
pg.run()
|
convert_first.csv
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
,headline,topic_verification
|
| 2 |
+
0,SPAIN DATA: H1 crude imports rise 11% to 1.4 million b/d,Crude Oil
|
| 3 |
+
1,REFINERY NEWS: Host of Chinese units back from works; Jinling maintenance in Nov-Dec,Macroeconomic & Geopolitics
|
| 4 |
+
2,REFINERY NEWS ROUNDUP: Mixed runs in Asia-Pacific,Macroeconomic & Geopolitics
|
| 5 |
+
3,Physical 1%S fuel oil Med-North spread hits record high on competitive bidding in Platts MOC,Middle Distillates
|
| 6 |
+
4,"Indian ports see Jan-July bunker, STS calls up 64% on year, monsoon hits July demand",Macroeconomic & Geopolitics
|
| 7 |
+
5,LNG bunker prices in Europe hit 8-month high amid rising demand,Light Ends
|
| 8 |
+
6,REFINERY NEWS: Wellbred Trading acquires La Nivernaise de Raffinage in France,Heavy Distillates
|
| 9 |
+
7,Wellbred Trading buys French diesel refinery that runs on used cooking oil,Macroeconomic & Geopolitics
|
| 10 |
+
8,EU's climate monitor says 2024 'increasingly likely' to be warmest year on record,Macroeconomic & Geopolitics
|
| 11 |
+
9,"European LPG discount to naphtha narrows, shifting petchem feedstock appetite",Light Ends
|
| 12 |
+
10,REFINERY NEWS: Thai Oil’s Q2 utilization drops on planned CDU shutdown,Crude Oil
|
| 13 |
+
11,South Korea’s top oil refiner SK Innovation joins carbon storage project in Australia,Middle Distillates
|
| 14 |
+
12,CRUDE MOC: Middle East sour crude cash differentials hit month-to-date highs,Crude Oil
|
| 15 |
+
13,CNOOC approves 100 Bcm of proven reserves at South China Sea gas field,Crude Oil
|
| 16 |
+
14,"Singapore to work with Shell’s refinery, petrochemicals asset buyers to decarbonize: minister",Light Ends
|
| 17 |
+
15,BLM federal Montana-Dakotas oil and gas lease sale nets nearly $24 mil: Energynet.com,Middle Distillates
|
| 18 |
+
16,REFINERY NEWS: Oman's Sohar undergoes unplanned shutdown: sources,Crude Oil
|
| 19 |
+
17,"OIL FUTURES: Crude prices higher as US stockpiles extend decline, demand concerns cap gains",Crude Oil
|
| 20 |
+
18,Qatar announces acceptance of Sep LPG cargoes with no cuts or delays heard,Light Ends
|
| 21 |
+
19,"South Korea aims for full GCC FTA execution by year-end, refiners hopeful for cheaper sour crude",Crude Oil
|
| 22 |
+
20,"Indonesia sets Minas crude price at $84.95/b for July, rising $3.35/b from June",Crude Oil
|
| 23 |
+
21,Cathay Pacific H1 2024 passenger traffic rises 36% on year; Hong Kong’s jet fuel demand bolstered,Middle Distillates
|
| 24 |
+
22,US DATA: Total ULSD stocks near a six-month high as demand continues to fall,Middle Distillates
|
| 25 |
+
23,US DATA: Product supplied of propane and propylene reach three-month high,Light Ends
|
| 26 |
+
24,Internatonal Seaways focused on replacing aging fleet during second quarter: CEO,Crude Oil
|
| 27 |
+
25,"Devon Energy's oil output hits all-time record high from Delaware, Eagle Ford operations",Crude Oil
|
| 28 |
+
26,"Brazil's Prio still waiting on IBAMA license approvals to boost oil, gas output",Crude Oil
|
| 29 |
+
27,REFINERY NEWS: Delek US sees Q3 refinery utilization dip from record Q2 highs,Light Ends
|
| 30 |
+
28,"OIL FUTURES: Crude rallies as traders eye tighter US supply, global financial market stabilization",Crude Oil
|
| 31 |
+
29,"Prompt DFL, CFD contracts rally",Crude Oil
|
| 32 |
+
30,"REFINERY NEWS: Petroperú sees 2Q refined fuel sales drop 4.4% on year to 93,700 b/d",Middle Distillates
|
| 33 |
+
31,W&T Offshore nears close of new US Gulf of Mexico drilling joint venture,Crude Oil
|
| 34 |
+
32,"Imrproved efficiencies, continued M&A activity to drive growth for Permian Resources",Heavy Distillates
|
| 35 |
+
33,Mexico's Pemex to explore deposit adjacent to major onshore gas field Quesqui,Middle Distillates
|
| 36 |
+
34,REFINERY NEWS: Par Pacific reports softer south Rockies results as Midwest barrels spill into region,Middle Distillates
|
| 37 |
+
35,"Suncor sees improved H2 oil and gas output, completes major Q2 turnarounds",Middle Distillates
|
| 38 |
+
36,"Brazil's Petrobras, Espirito Santo state to study potential CCUS, hydrogen hubs",Middle Distillates
|
| 39 |
+
37,"Argentina raises biodiesel, ethanol prices for blending by 1.5% in August",Middle Distillates
|
| 40 |
+
38,Bolivia offers tax breaks to import equipment for biodiesel plants following fuel shortages,Light Ends
|
| 41 |
+
39,"US DATA: West Coast fuel oil stocks hit a six-week low, EIA says",Middle Distillates
|
| 42 |
+
40,Iraq’s SOMO cuts official selling prices for September-loading crude oil for Europe,Crude Oil
|
| 43 |
+
41,Nigeria's Dangote refinery plans to divest 12.75% stake: ratings agency,Middle Distillates
|
| 44 |
+
42,REFINERY NEWS: Kazakhstan's Atyrau processes 2.9 mil mt crude in H1,Middle Distillates
|
| 45 |
+
43,REFINERY NEWS: Thailand's IRPC reports Q2 utilization of 94%,Light Ends
|
| 46 |
+
44,DNO reports higher Q2 crude production in Iraq's Kurdish region,Crude Oil
|
| 47 |
+
45,"ADNOC L&S expects ‘strong rates’ in tankers, dry-bulk, containers in 2024",Crude Oil
|
| 48 |
+
46,WAF crude tanker rates hit 10-month lows amid sluggish inquiry levels,Crude Oil
|
| 49 |
+
47,Senegal's inaugural crude stream Sangomar to load 3.8 mil barrels in September,Crude Oil
|
| 50 |
+
48,China's July vegetable oil imports rise 3% on month as buyers replenish domestic stocks,Macroeconomic & Geopolitics
|
| 51 |
+
49,CRUDE MOC: Middle East sour crude cash differentials rebound,Crude Oil
|
| 52 |
+
50,OIL FUTURES: Crude oil recovers as financial markets improve,Crude Oil
|
| 53 |
+
51,"Tullow sees rise in crude output, profits on-year in H1 2024",Crude Oil
|
| 54 |
+
52,Russia's Taman port June-July oil products throughput up 26% on year,Heavy Distillates
|
| 55 |
+
53,JAPAN DATA: Oil product exports rise 4.5% on week to 2.42 mil barrels,Crude Oil
|
| 56 |
+
54,REFINERY NEWS: Petro Rabigh to be upgraded after Aramco takes control,Crude Oil
|
| 57 |
+
55,Canada's ShaMaran closes acquisition of Atrush oil field,Crude Oil
|
| 58 |
+
56,CHINA DATA: July natural gas imports rise 5% on year to 10.9 mil mt,Light Ends
|
| 59 |
+
57,"OIL FUTURES: Crude stabilizes on technical bounce, supply uncertainty",Crude Oil
|
| 60 |
+
58,JAPAN DATA: Oil product stocks rise 0.8% on week to 55.32 mil barrels,Crude Oil
|
| 61 |
+
59,Japan cuts Aug 8-14 fuel subsidy by 21% as crude prices drop,Middle Distillates
|
| 62 |
+
60,JAPAN DATA: Refinery runs rise to 67% over July 28-Aug 3 on higher crude throughput,Light Ends
|
| 63 |
+
61,Asian reforming spread hits over two-year low as gasoline prices lag naphtha,Light Ends
|
| 64 |
+
62,Asia medium sulfur gasoil differential weakens as Indonesia demand tapers,Middle Distillates
|
| 65 |
+
63,"QatarEnergy raises Sep Land, Marine crude OSPs by 45-75 cents/b from Aug",Heavy Distillates
|
| 66 |
+
64,ADNOC sets Murban Sep OSP $1.28/b higher on month at $83.80/b,Heavy Distillates
|
| 67 |
+
65,"Diamondback Energy keeps pushing well drilling, completion efficiencies in Q2",Middle Distillates
|
| 68 |
+
66,"Genel Energy’s oil production from Tawke field increases to 19,510 b/d in 1H 2024",Middle Distillates
|
| 69 |
+
67,Longer laterals and higher well performance drive Rocky Mountain production: Oneok,Light Ends
|
| 70 |
+
68,US DOE seeks to buy 3.5 million barrels of crude for delivery to SPR in January 2025,Crude Oil
|
| 71 |
+
69,"FPSO Maria Quiteria arrives offshore Brazil, to reduce emissions: Petrobras",Middle Distillates
|
| 72 |
+
70,OIL FUTURES: Crude edges higher as market stabilizes amid Middle Eastern supply concerns,Crude Oil
|
| 73 |
+
71,"US EIA lowers 2024 oil price outlook by $2/b, but still predicts increases",Crude Oil
|
| 74 |
+
72,"Shell, BP to fund South Africa's Sapref refinery operations in government takeover",Light Ends
|
| 75 |
+
73,"Indian Oil cancels tender to build a 10,000 mt/yr renewable hydrogen plant",Light Ends
|
| 76 |
+
74,"Brazil's Prio July oil equivalent output falls 31.7% on maintenance, shuttered wells",Crude Oil
|
| 77 |
+
75,Eni follows Ivory Coast discoveries with four new licenses,Crude Oil
|
| 78 |
+
76,EU DATA: MY 2024-25 soybean meal imports rise 8% on year as of Aug 4,Macroeconomic & Geopolitics
|
| 79 |
+
77,"Greek PPC to buy a 600 MW Romanian wind farm, portfolio from Macquarie-owned developer",Macroeconomic & Geopolitics
|
| 80 |
+
78,Vitol to take Italian refiner Saras private after acquiring 51% stake,Macroeconomic & Geopolitics
|
| 81 |
+
79,Mediterranean sweet crude market shows muted response to Sharara shutdown,Macroeconomic & Geopolitics
|
| 82 |
+
80,REFINERY NEWS: Vitol acquires 51% in Italian refiner Saras,Macroeconomic & Geopolitics
|
| 83 |
+
81,Rotterdam LNG bunkers spread with VLSFO narrows to 2024 low,Light Ends
|
| 84 |
+
82,Argentina’s YPF finds buyers for 15 maturing conventional blocks as it focuses on Vaca Muerta,Heavy Distillates
|
| 85 |
+
83,REFINERY NEWS ROUNDUP: Nigerian plants in focus,Macroeconomic & Geopolitics
|
| 86 |
+
84,"REFINERY NEWS: Valero shuts CDU, FCCU at McKee refinery for planned work",Macroeconomic & Geopolitics
|
| 87 |
+
85,Kazakhstan extends ban on oil products exports by truck for six months,Macroeconomic & Geopolitics
|
| 88 |
+
86,Physical Hi-Lo spread hits 3 month high amid prompt LSFO demand,Heavy Distillates
|
| 89 |
+
87,CRUDE MOC: Middle East sour crude cash differentials slip to fresh lows,Crude Oil
|
| 90 |
+
88,"Nigeria launches new Utapate crude grade, first cargo heads to Spain",Crude Oil
|
| 91 |
+
89,REFINERY NEWS: Turkish Tupras Q2 output rises 15% on the quarter and year,Middle Distillates
|
| 92 |
+
90,"CHINA DATA: Independent refineries’ Iranian crude imports fall in July, ESPO inflows rebound",Crude Oil
|
| 93 |
+
91,Gunvor acquires TotalEnergies' 50% stake in Pakistan retail fuel business,Middle Distillates
|
| 94 |
+
92,INTERVIEW: Coal to remain a dominant power source in India: Menar MD,Macroeconomic & Geopolitics
|
| 95 |
+
93,OIL FUTURES: Crude price holds steady as demand expectations cap gains,Crude Oil
|
| 96 |
+
94,Fujairah’s HSFO August HSFO ex-wharf premiums slip; stocks adequate,Heavy Distillates
|
| 97 |
+
95,JAPAN DATA: US crude imports more than double in March as Middle East dependency eases,Crude Oil
|
| 98 |
+
96,Dubai crude futures traded volume on TOCOM rebounds in July from record low,Crude Oil
|
| 99 |
+
97,Japan's spot electricity price retreats 8% as temperatures ease,Macroeconomic & Geopolitics
|
| 100 |
+
98,"HONG KONG DATA: June oil product imports surge 32% on month to 226,475 barrels",Crude Oil
|
| 101 |
+
99,NextDecade signs contract with Bechtel to build Rio Grande LNG expansion,Light Ends
|
| 102 |
+
100,"Kosmos sees 2024 total output of 90,000 boe/d, despite Q2 operations thorns: CEO",Crude Oil
|
| 103 |
+
101,"Dated Brent reaches two-month low Aug. 5 as physical, derivatives prices slide on day",Middle Distillates
|
| 104 |
+
102,"Alaska North Slope crude output up in July, but long-term decline continues",Crude Oil
|
| 105 |
+
103,Balance-month DFL contract slips to seven-week low in bearish sign for physical crude fundamentals,Crude Oil
|
| 106 |
+
104,Iraqi Kurdistan officials order crackdown on illegal refineries over pollution,Macroeconomic & Geopolitics
|
| 107 |
+
105,Rhine barge cargo navigation limits set to kick in amid dryer weather,Middle Distillates
|
| 108 |
+
106,Bolivia returns diesel supplies to normal following shortages,Middle Distillates
|
| 109 |
+
107,OCI optimistic about methanol demand driven by decarbonization efforts,Light Ends
|
| 110 |
+
108,Mitsubishi to supply turbine for 30% hydrogen co-firing in Malaysia power plant,Middle Distillates
|
| 111 |
+
109,ATLANTIC LNG: Key market indicators for Aug. 5-9,Light Ends
|
| 112 |
+
110,"Eurobob swap, gas-nap spread falls below 6-month low amid crude selloff",Light Ends
|
| 113 |
+
111,EMEA PETROCHEMICALS: Key market indicators for Aug 5-9,Light Ends
|
| 114 |
+
112,EMEA LIGHT ENDS: Key market indicators for Aug 5 – 9,Light Ends
|
| 115 |
+
113,EUROPE AND AFRICA RESIDUAL AND MARINE FUEL: Key market indicators Aug 5-9,Heavy Distillates
|
| 116 |
+
114,TURKEY DATA: June crude flows via BTC pipeline up 8.1% on month,Crude Oil
|
| 117 |
+
115,EMEA AGRICULTURE: Key market indicators for Aug 5–9,Macroeconomic & Geopolitics
|
| 118 |
+
116,OIL FUTURES: Crude oil faces downward pressure amid wider weakness in financial markets,Crude Oil
|
| 119 |
+
117,Woodside to acquire OCI’s low carbon ammonia project with CO2 capture in US,Middle Distillates
|
| 120 |
+
118,Maire secures feasibility study for sustainable aviation fuel project in Indonesia,Middle Distillates
|
| 121 |
+
119,CRUDE MOC: Middle East sour crude cash differentials plunge on risk-off sentiment,Middle Distillates
|
| 122 |
+
120,"Zhoushan LSFO storage availability rises for 3rd month in Aug, hits record high",Middle Distillates
|
| 123 |
+
121,Oil storage in Russia's Rostov region hit by drone strike,Macroeconomic & Geopolitics
|
| 124 |
+
122,WAF TRACKING: Nigerian crude exports to Netherlands top 5-year high in July,Crude Oil
|
| 125 |
+
123,"Vietnam’s Hai Linh receives license to import, export LNG",Light Ends
|
| 126 |
+
124,Japan's Idemitsu could restart Tokuyama steam cracker on Aug 11,Light Ends
|
| 127 |
+
125,Indonesia's biodiesel output up 12% in H1 on increased domestic mandates: APROBI,Middle Distillates
|
| 128 |
+
126,CHINA DATA: Independent refiners' July feedstocks imports hit 3-month low at 3.65 mil b/d,Light Ends
|
| 129 |
+
127,"Singapore’s Aug ex-wharf term LSFO premiums rise, demand moderate",Heavy Distillates
|
| 130 |
+
128,"OIL FUTURES: Crude slumps as market volatility rages on recession, Middle East risks",Crude Oil
|
| 131 |
+
129,Pakistan's HSFO exports nearly triple as focus shifts to cheaper power sources,Heavy Distillates
|
| 132 |
+
130,"TAIWAN DATA: June oil products demand falls 3% on month to 758,139 b/d",Light Ends
|
| 133 |
+
131,REFINERY NEWS: Japan's Cosmo restarts No. 1 Chiba CDU after glitches,Crude Oil
|
| 134 |
+
132,ASIA PETROCHEMICALS: Key market indicators for Aug 5-9,Light Ends
|
| 135 |
+
133,DME Oman crude futures traded volume rises for seventh straight month in July,Crude Oil
|
| 136 |
+
134,ICE front-month Singapore gasoline swaps open interest rises 14.6% on month in July,Light Ends
|
| 137 |
+
135,ASIA OCTANE: Key market indicators for Aug 5-9,Light Ends
|
| 138 |
+
136,ICE Dubai crude futures July total traded volume rises 11.4% on month,Crude Oil
|
| 139 |
+
137,"Lower-than-expected Aramco Sep OSPs a nod to weak Asian market, OPEC+ cut unwind",Crude Oil
|
| 140 |
+
138,ASIA CRUDE OIL: Key market indicators for Aug 5-8,Crude Oil
|
| 141 |
+
139,ASIA LIGHT ENDS: Key market indicators for Aug 5-8,Light Ends
|
| 142 |
+
140,China fuel oil quotas decline seen supporting Q3 LSFO premiums in Zhoushan,Middle Distillates
|
| 143 |
+
141,South Korea's short-term diesel demand under pressure on e-commerce firms' bankruptcy,Middle Distillates
|
| 144 |
+
142,ICE front-month Singapore 10 ppm gasoil swap open interest rebounds 2% on month in July,Middle Distillates
|
| 145 |
+
143,Saudi Aramco maintains or raises Asia-bound Sep crude OSPs by 10-20 cents/b,Crude Oil
|
| 146 |
+
144,ASIA MIDDLE DISTILLATES: Key market indicators for Aug 5-8,Middle Distillates
|
| 147 |
+
145,ICE front-month Singapore HSFO open interest rises 19.6% on month in July,Heavy Distillates
|
| 148 |
+
146,REFINERY NEWS: Fort Energy at Fujairah ‘remains operational’,Macroeconomic & Geopolitics
|
| 149 |
+
147,Container ship Groton attacked near Yemen amid growing Middle East security risks,Macroeconomic & Geopolitics
|
| 150 |
+
148,Oil depot in Russia’s Belgorod region hit by drone strike,Macroeconomic & Geopolitics
|
data/all_platts_1week_clean.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/dated_brent_allbate.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/results_platts_09082024_clean.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/topresults_platts_09082024_clean.csv
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
,body,headline,updatedDate,topic_prediction,topic_verification,negative_score,neutral_score,positive_score,trend_prediction,trend_verification
|
| 2 |
+
0," OPEC+ crude production in July made its biggest jump in almost a year, as Iraq and Kazakhstan raised their output despite committing to deeper cuts, while Russia also remained well over its quota. The group's overall production was up 160,000 b/d compared with June, totaling 41.03 million b/d, the Platts OPEC+ survey from S&P Global Commodity Insights showed Aug. 8. Member countries with quotas produced 437,000 b/d above target in July, up from 229,000 b/d in June. July was the first month of compensation plans introduced by three countries that overproduced in the first half of 2024. Iraq pledged to cut an additional 70,000 b/d in July and Kazakhstan pledged to cut a further 18,000 b/d. Russia's compensation plan does not include additional cuts until October 2024. The survey found that Iraq produced 4.33 million b/d in July, 400,000 b/d above its quota. This contributed to growth in OPEC production of 130,000 b/d to 26.89 million b/d. Non-OPEC producers added a further 14.14 million b/d, up 30,000 b/d month on month. This was driven by Kazakhstan, which increased output by 30,000 b/d. It is now producing 120,000 b/d above quota, taking into account its compensation cut. Russia is also producing above quota, with output at 9.10 million b/d in July, against a quota of 8.98 million b/d. The overproducers are part of a group that is implementing a combined 2.2 million b/d of voluntary cuts, currently in place until the end of the third quarter. The group then plans to gradually bring some of those barrels back to market from September if conditions allow. A further 3.6 million b/d of group-wide cuts are in place until the end of 2025. The rise in output in July came despite the poor performance of the alliance's African contingent, with production in Nigeria, South Sudan, Gabon and Libya falling by a collective 80,000 b/d. Pressure on overproducers has increased in recent weeks, as recession fears have driven oil prices below $80/b. Platts, part of Commodity Insights, assessed Dated Brent at $79.91/b Aug. 7. A long-awaited rise in Chinese demand and high production from non-OPEC countries in the Americas -- including the US, Canada, Brazil and Guyana -- have also weakened prices in recent months. OPEC+ has pledged to stick to its strategy of major production cuts through the third quarter, before gradually bringing barrels back to market. Overproduction and depressed oil prices threaten these plans. The next meeting of the Joint Ministerial Monitoring Committee overseeing the agreement, which is co-chaired by Saudi Arabia and Russia, is scheduled for Oct. 2. A full ministerial meeting is scheduled for Dec. 1. The Platts survey measures wellhead production and is compiled using information from oil industry officials, traders and analysts, as well as by reviewing proprietary shipping, satellite and inventory data. OPEC+ crude production (million b/d) OPEC-9 July-24 Change June-24 Quota Over/under Algeria 0.90 0.00 0.90 0.908 -0.008 Congo-Brazzaville 0.26 0.00 0.26 0.277 -0.017 Equatorial Guinea 0.05 0.00 0.05 0.070 -0.020 Gabon 0.21 -0.01 0.22 0.169 0.041 Iraq*† 4.33 0.11 4.22 3.930 0.400 Kuwait 2.42 0.00 2.42 2.413 0.007 Nigeria 1.46 -0.04 1.50 1.500 -0.040 Saudi Arabia 8.99 0.01 8.98 8.978 0.012 UAE 2.99 0.02 2.97 2.912 0.078 TOTAL OPEC-9 21.61 0.09 21.52 21.157 0.453 OPEC EXEMPT Change Quota Over/under Iran 3.20 0.00 3.20 N/A N/A Libya 1.15 -0.01 1.16 N/A N/A Venezuela 0.93 0.05 0.88 N/A N/A TOTAL OPEC-12 26.89 0.13 26.76 N/A N/A NON-OPEC WITH QUOTAS Change Quota Over/under Azerbaijan 0.49 0.01 0.48 0.551 -0.061 Bahrain 0.18 0.00 0.18 0.196 -0.016 Brunei 0.07 0.01 0.06 0.083 -0.013 Kazakhstan† 1.57 0.03 1.54 1.450 0.120 Malaysia 0.35 0.00 0.35 0.401 -0.051 Oman 0.76 0.00 0.76 0.759 0.001 Russia 9.10 0.00 9.10 8.978 0.122 Sudan 0.03 0.00 0.03 0.064 -0.034 South Sudan 0.04 -0.02 0.06 0.124 -0.084 TOTAL NON-OPEC WITH QUOTAS 12.59 0.03 12.56 12.606 -0.016 NON-OPEC EXEMPT Change Quota Over/under Mexico 1.55 0 1.55 N/A N/A TOTAL NON-OPEC 14.14 0.03 14.11 N/A N/A OPEC+ MEMBERS WITH QUOTAS Change Quota Over/under TOTAL 34.20 0.12 34.08 33.76 0.437 OPEC+ Change Quota Over/under TOTAL 41.03 0.16 40.87 N/A N/A * Includes estimated 250,000 b/d production in the semi-autonomous Kurdistan region of Iraq † Iraq and Kazakhstan quotas reduced in line with compensation plans Source: Platts OPEC+ survey by S&P Global Commodity Insights ","OPEC+ produces 437,000 b/d above quota in first month of compensation cuts",2024-08-08 17:36:29+00:00,Macroeconomic & Geopolitics,Macroeconomic & Geopolitics,0.9936981650538123,0.03949102865047352,0.07103689164109918,Bearish,Bearish
|
| 3 |
+
1,nan,"Non-OPEC July output up 30,000 b/d at 14.14 mil b/d: Platts survey",2024-08-08 14:00:12+00:00,Macroeconomic & Geopolitics,Macroeconomic & Geopolitics,0.9932350855162315,0.024123551368425825,0.12366691833078211,Bearish,Bearish
|
| 4 |
+
2,nan,"OPEC+ producers with quotas 437,000 b/d above target in July: Platts survey",2024-08-08 14:00:11+00:00,Macroeconomic & Geopolitics,Macroeconomic & Geopolitics,0.9936222216140704,0.048969414364614584,0.06152339592702592,Bearish,Bearish
|
| 5 |
+
3,nan,"OPEC crude output up 130,000 b/d at 26.89 mil b/d in July: Platts survey",2024-08-08 14:00:11+00:00,Macroeconomic & Geopolitics,Macroeconomic & Geopolitics,0.9933905710185933,0.03299545514176609,0.10238077772498969,Bearish,Bearish
|
| 6 |
+
4,nan,"OPEC+ July crude output up 160,000 b/d at 41.03 mil b/d: Platts survey",2024-08-08 14:00:10+00:00,Macroeconomic & Geopolitics,Macroeconomic & Geopolitics,0.9870346671527929,0.02437343317152671,0.2153639976093806,Bearish,Bearish
|
| 7 |
+
5,nan,"Iraq, Russia, Kazakhstan overproduce in first month of compensation cuts: Platts survey",2024-08-08 14:00:10+00:00,Crude Oil,Crude Oil,0.6294152478714086,0.06749551758023337,0.927845667131505,Bullish,Bullish
|
| 8 |
+
6," UK-based upstream producer Harbour Energy plans to start its new Talbot oil and gas tie-in project at the J-Area hub in the North Sea by the end of 2024, boosting Ekofisk blend volumes, it said Aug. 8. Harbour, in a statement, reported a 19% year-on-year drop in its UK oil and gas production in the first half of 2024 to 149,000 b/d of oil equivalent. It noted a significant maintenance impact, including a planned shutdown in June at the J-Area, which sends oil and gas to Teesside, with the liquids loaded as Ekofisk blend. Ekofisk is a component in the Platts Dated Brent price assessment process. Talbot, a multiwell development, is expected to recover 18 million boe of light oil and gas over 16 years. It will add to oil volumes flowing through the J-Area into the Norpipe route to Teesside, contributing to the predominantly Norwegian Ekofisk blend. Harbour also flagged an ongoing maintenance impact on production through much of the Q3 2024, including a 40-day shutdown at the Britannia hub starting in August, which will impact flows into the Forties blend. The maintenance was expected to start in the next few days and be completed in September, according to a source close to the situation. Britannia was also expected to be impacted by a four-week shutdown of the SAGE gas pipeline starting Aug. 27 . Harbour has made ""good progress to date on the maintenance shutdowns and our UK capital projects, which are on track to materially increase production in the fourth quarter,"" it said. The North Sea typically sees a drop in production volumes in the summer due to maintenance. Non-UK diversification Harbour reiterated its efforts to diversify away from the UK, with an acquisition of Wintershall Dea assets underway, having strongly objected to punitive tax rates. It said its overall effective tax rate in the first half of 2024 was 85%, partly reflecting not-fully deductible costs under the UK tax regime. Harbour reported 10,000 boe/d of additional production outside the UK in the first half of the year, in Indonesia and Vietnam. It noted progress in Mexico, where Front End Engineering and Design has begun for the Zama oil project, estimated at 700 million barrels of light crude. Harbour is set to increase its Zama stake from 12% to 32% following the Wintershall acquisition. In the first half of 2024 ""we made significant progress towards completing the Wintershall Dea acquisition, which is now expected early in the fourth quarter,"" CEO Linda Cook said. ""The acquisition will transform the scale, geographical diversity and longevity of our portfolio and strengthen our capital structure, enabling us to deliver enhanced shareholder returns over the long run while also positioning us for further opportunities.” Platts Dated Brent was assessed at $79.91/b on Aug. 8, up $3.64 on the day. Platts is part of S&P Global Commodity Insights. ",UK's Harbour Energy says on track with North Sea Talbot oil tie-in,2024-08-08 13:54:45+00:00,Crude Oil,Crude Oil,0.31882130542268583,0.04218598724364094,0.9882147680155492,Bullish,Bullish
|
| 9 |
+
7," The INPEX-operated Ichthys LNG project in Australia has recovered to an 85% overall production rate after Train 2 restarted on July 28 following an outage on July 20 that was caused by a glitch, an INPEX spokesperson told S&P Global Commodity Insights Aug. 8. Currently, the onshore Ichthys LNG plant is running at 100% at Train 1, and about 70% at Train 2, putting the overall production rate at about 85%, the spokesperson said. The Ichthys LNG project is slated to resume full runs in October, when it plans to carry out some scheduled maintenance work lasting around a week, the spokesperson said. INPEX has estimated that fewer than five LNG cargoes of Ichthys LNG shipments will be affected as a result of the glitch, the spokesperson said. However, the INPEX spokesperson declined to elaborate on actual production volumes at the Ichthys LNG plant, which has yet to reach its operational capacity of 9.3 million mt/year. INPEX has been building a framework for a stable supply of 9.3 million mt/year of LNG at its operated Ichthys project by debottlenecking the facility, upgrading the cooling systems for liquefication and taking measures to address vibration issues. As of July, the Ichthys project has shipped a total of 76 LNG cargoes this year, with July shipments having slipped to 10 cargoes from 11 cargoes in June. Ichthys LNG shipments will slow to 10 cargoes per month in the second half of 2024, the spokesperson said, compared with an average of 11 cargoes per month in the first half of the year. In the first seven months of the year the Ichthys project shipped 14 plant condensate cargoes, 18 field condensate cargoes and 20 LPG cargoes. In the January-June period INPEX produced 662,000 b/d of oil equivalent, and it now expects its 2024 production to be 644,800 boe/d, down from its May outlook of 645,300 boe/d for the year as a result of the Ichthys LNG production issues, the spokesperson said. The project, operated by INPEX with 67.82%, involves piping gas from the offshore Ichthys field in the Browse Basin in Northwestern Australia more than 890 km (552 miles) to the onshore LNG plant near Darwin, which has an 8.9 million mt/year nameplate capacity. At peak, it has the capacity to produce 1.65 million mt/year of LPG and 100,000 b/d of condensate. ",Australia's Ichthys LNG recovers 85% output after Train 2 outage; to recover full runs in Oct,2024-08-08 11:53:44+00:00,Other,Other,0.770051212604236,0.010564989240227092,0.9773946433377442,Bullish,Bullish
|
| 10 |
+
8," NTPC Limited, India’s largest power generation utility, has partnered with LanzaTech to implement carbon recycling technology at its new facility in central India, in a significant move towards sustainable energy. The project will convert CO2 emissions and green hydrogen into ethanol using LanzaTech's second-generation bioreactor, the US-based company said in a statement Aug. 7. NTPC's upcoming plant will be the first in India to deploy this advanced technology, which captures carbon-rich gases before they enter the atmosphere. The LanzaTech bioreactor uses proprietary microbes to transform these gases into sustainable fuels, chemicals, and raw materials. The microbes convert CO2 and H2 into ethanol, a critical component for producing green energy products such as sustainable aviation fuels (SAF) and renewable diesel. This in turn boosts NTPC's goals by producing ethanol from waste-based feedstocks, promoting a circular carbon economy. According to the statement, the project was conceptualized and designed in collaboration with NTPC's research and development arm, NETRA (NTPC Energy Technology Research Alliance). The facility aims to demonstrate the commercial viability of LanzaTech’s technology in producing ethanol from waste-based feedstocks by leveraging CO2 as sole carbon source. Jakson Green, a new energy firm, is responsible for development of this Chhattisgarh-based facility, handling from design and engineering to procurement and construction. This first-of-its-kind plant is projected to abate 7,300 mt/year of CO2 annually, equivalent to the carbon sequestered by 8,523 acres of forest land. The carbon and hydrogen to renewable ethanol facility is slated to begin operations within two years. Dr. Jennifer Holmgren, CEO of LanzaTech, emphasized the strategic importance of this partnership, stating, “Our collaboration with NTPC and Jakson Green sets a roadmap for the commercial deployment of CO2 as a key feedstock.” Jakson Green is already developing India’s largest green hydrogen fueling station and a low-carbon methanol plant for leading government companies. LanzaTech technology is also being used at various other operations in India, producing ethanol at Indian Oil Corporation’s Panipat facility which will also be used for SAF. The company has also partnered with GAIL and Mangalore Refinery and Petrochemicals Limited on similar projects. Platts, part of Commodity Insights, assessed SAF production costs (palm fatty acid distillate) in Southeast Asia at $1,589.91/mt Aug. 7, down $19.50/mt from the previous assessment. ",NTPC advances clean energy goals with LanzaTech CO2-to-ethanol technology,2024-08-08 11:30:49+00:00,Light Ends,Light Ends,0.21314498348994937,0.11135607578700647,0.9908829648109232,Bullish,Bullish
|
| 11 |
+
9," UAE-based Dana Gas said it expects to resume drilling activities in Egypt after the country’s parliament ratified a law to consolidate its concessions to operate in the country under a new concession with Egyptian Natural Gas Holding Co. The new agreement ratified by the Egyptian parliament was already approved by the Egyptian Cabinet in March, authorizing the country’s minister of oil and Egyptian Natural Gas to finalize a new concession agreement with Dana Gas, the company said in an Aug. 8 statement. Since 2001, Dana Gas has been in discussions with Egyptian Natural Gas to consolidate three of its four concessions into a new concession with improved terms, according to Dana Gas’s website. “The revised terms should enable meaningful future investments alongside a resumption of drilling activities, positively impacting the company’s production levels in Egypt and helping the country meet its growing gas demand,” Dana Gas said in the statement. Egypt has halted LNG exports during the summer months and has turned to LNG imports instead to meet high seasonal demand amid declining domestic production. The development comes as delivered spot LNG prices to the East Mediterranean continue to trade above $10/MMBtu. Platts, part of S&P Global Commodity Insights, assessed the DES LNG East Mediterranean marker at $12.47/MMBtu Aug. 7, the highest since the assessment started in December 2023. The company’s first-half 2024 production in Egypt was 59,800 boe/d, down 25% from the same period a year earlier, mostly due to natural field declines, according to the statement. Dana Gas did not state when it expects to bring new production streams online in the country. Dana Gas's production in the Kurdish region of northern Iraq increased 3% over the same period to 37,600 boe/d due to increased demand for gas from local power plants, the company said. ",Dana Gas expects to resume drilling activities in Egypt after new concession,2024-08-08 11:23:48+00:00,Other,Other,0.023988005652641385,0.7891432360374782,0.9608502193290972,Bullish,Bullish
|
| 12 |
+
10,nan,"Indonesia sets Minas crude price at $84.95/b for July, rising $3.35/b from June",2024-08-08 01:41:13+00:00,Middle Distillates,Middle Distillates,0.9926734319450401,0.04286090006550804,0.07892061673161296,Bearish,Bearish
|
evaluation.xlsx
ADDED
|
Binary file (214 kB). View file
|
|
|
experimentation_mlops/example/MLProject
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: multistep_example
|
| 2 |
+
|
| 3 |
+
python_env: python_env.yaml
|
| 4 |
+
|
| 5 |
+
entry_points:
|
| 6 |
+
load_raw_data:
|
| 7 |
+
command: "python load_raw_data.py"
|
| 8 |
+
|
| 9 |
+
etl_data:
|
| 10 |
+
parameters:
|
| 11 |
+
ratings_csv: path
|
| 12 |
+
max_row_limit: {type: int, default: 100000}
|
| 13 |
+
command: "python etl_data.py --ratings-csv {ratings_csv} --max-row-limit {max_row_limit}"
|
| 14 |
+
|
| 15 |
+
als:
|
| 16 |
+
parameters:
|
| 17 |
+
ratings_data: path
|
| 18 |
+
max_iter: {type: int, default: 10}
|
| 19 |
+
reg_param: {type: float, default: 0.1}
|
| 20 |
+
rank: {type: int, default: 12}
|
| 21 |
+
command: "python als.py --ratings-data {ratings_data} --max-iter {max_iter} --reg-param {reg_param} --rank {rank}"
|
| 22 |
+
|
| 23 |
+
train_keras:
|
| 24 |
+
parameters:
|
| 25 |
+
ratings_data: path
|
| 26 |
+
als_model_uri: string
|
| 27 |
+
hidden_units: {type: int, default: 20}
|
| 28 |
+
command: "python train_keras.py --ratings-data {ratings_data} --als-model-uri {als_model_uri} --hidden-units {hidden_units}"
|
| 29 |
+
|
| 30 |
+
main:
|
| 31 |
+
parameters:
|
| 32 |
+
als_max_iter: {type: int, default: 10}
|
| 33 |
+
keras_hidden_units: {type: int, default: 20}
|
| 34 |
+
max_row_limit: {type: int, default: 100000}
|
| 35 |
+
command: "python main.py --als-max-iter {als_max_iter} --keras-hidden-units {keras_hidden_units}
|
| 36 |
+
--max-row-limit {max_row_limit}"
|
experimentation_mlops/example/als.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Trains an Alternating Least Squares (ALS) model for user/movie ratings.
|
| 3 |
+
The input is a Parquet ratings dataset (see etl_data.py), and we output
|
| 4 |
+
an mlflow artifact called 'als-model'.
|
| 5 |
+
"""
|
| 6 |
+
import click
|
| 7 |
+
import pyspark
|
| 8 |
+
from pyspark.ml import Pipeline
|
| 9 |
+
from pyspark.ml.evaluation import RegressionEvaluator
|
| 10 |
+
from pyspark.ml.recommendation import ALS
|
| 11 |
+
|
| 12 |
+
import mlflow
|
| 13 |
+
import mlflow.spark
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
@click.command()
|
| 17 |
+
@click.option("--ratings-data")
|
| 18 |
+
@click.option("--split-prop", default=0.8, type=float)
|
| 19 |
+
@click.option("--max-iter", default=10, type=int)
|
| 20 |
+
@click.option("--reg-param", default=0.1, type=float)
|
| 21 |
+
@click.option("--rank", default=12, type=int)
|
| 22 |
+
@click.option("--cold-start-strategy", default="drop")
|
| 23 |
+
def train_als(ratings_data, split_prop, max_iter, reg_param, rank, cold_start_strategy):
|
| 24 |
+
seed = 42
|
| 25 |
+
|
| 26 |
+
with pyspark.sql.SparkSession.builder.getOrCreate() as spark:
|
| 27 |
+
ratings_df = spark.read.parquet(ratings_data)
|
| 28 |
+
(training_df, test_df) = ratings_df.randomSplit([split_prop, 1 - split_prop], seed=seed)
|
| 29 |
+
training_df.cache()
|
| 30 |
+
test_df.cache()
|
| 31 |
+
|
| 32 |
+
mlflow.log_metric("training_nrows", training_df.count())
|
| 33 |
+
mlflow.log_metric("test_nrows", test_df.count())
|
| 34 |
+
|
| 35 |
+
print(f"Training: {training_df.count()}, test: {test_df.count()}")
|
| 36 |
+
|
| 37 |
+
als = (
|
| 38 |
+
ALS()
|
| 39 |
+
.setUserCol("userId")
|
| 40 |
+
.setItemCol("movieId")
|
| 41 |
+
.setRatingCol("rating")
|
| 42 |
+
.setPredictionCol("predictions")
|
| 43 |
+
.setMaxIter(max_iter)
|
| 44 |
+
.setSeed(seed)
|
| 45 |
+
.setRegParam(reg_param)
|
| 46 |
+
.setColdStartStrategy(cold_start_strategy)
|
| 47 |
+
.setRank(rank)
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
als_model = Pipeline(stages=[als]).fit(training_df)
|
| 51 |
+
|
| 52 |
+
reg_eval = RegressionEvaluator(
|
| 53 |
+
predictionCol="predictions", labelCol="rating", metricName="mse"
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
predicted_test_dF = als_model.transform(test_df)
|
| 57 |
+
|
| 58 |
+
test_mse = reg_eval.evaluate(predicted_test_dF)
|
| 59 |
+
train_mse = reg_eval.evaluate(als_model.transform(training_df))
|
| 60 |
+
|
| 61 |
+
print(f"The model had a MSE on the test set of {test_mse}")
|
| 62 |
+
print(f"The model had a MSE on the (train) set of {train_mse}")
|
| 63 |
+
mlflow.log_metric("test_mse", test_mse)
|
| 64 |
+
mlflow.log_metric("train_mse", train_mse)
|
| 65 |
+
mlflow.spark.log_model(als_model, "als-model")
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
if __name__ == "__main__":
|
| 69 |
+
train_als()
|
experimentation_mlops/example/etl_data.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Converts the raw CSV form to a Parquet form with just the columns we want
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
import tempfile
|
| 6 |
+
|
| 7 |
+
import click
|
| 8 |
+
import pyspark
|
| 9 |
+
|
| 10 |
+
import mlflow
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@click.command(
|
| 14 |
+
help="Given a CSV file (see load_raw_data), transforms it into Parquet "
|
| 15 |
+
"in an mlflow artifact called 'ratings-parquet-dir'"
|
| 16 |
+
)
|
| 17 |
+
@click.option("--ratings-csv")
|
| 18 |
+
@click.option(
|
| 19 |
+
"--max-row-limit", default=10000, help="Limit the data size to run comfortably on a laptop."
|
| 20 |
+
)
|
| 21 |
+
def etl_data(ratings_csv, max_row_limit):
|
| 22 |
+
with mlflow.start_run():
|
| 23 |
+
tmpdir = tempfile.mkdtemp()
|
| 24 |
+
ratings_parquet_dir = os.path.join(tmpdir, "ratings-parquet")
|
| 25 |
+
print(f"Converting ratings CSV {ratings_csv} to Parquet {ratings_parquet_dir}")
|
| 26 |
+
with pyspark.sql.SparkSession.builder.getOrCreate() as spark:
|
| 27 |
+
ratings_df = (
|
| 28 |
+
spark.read.option("header", "true")
|
| 29 |
+
.option("inferSchema", "true")
|
| 30 |
+
.csv(ratings_csv)
|
| 31 |
+
.drop("timestamp")
|
| 32 |
+
) # Drop unused column
|
| 33 |
+
ratings_df.show()
|
| 34 |
+
if max_row_limit != -1:
|
| 35 |
+
ratings_df = ratings_df.limit(max_row_limit)
|
| 36 |
+
ratings_df.write.parquet(ratings_parquet_dir)
|
| 37 |
+
print(f"Uploading Parquet ratings: {ratings_parquet_dir}")
|
| 38 |
+
mlflow.log_artifacts(ratings_parquet_dir, "ratings-parquet-dir")
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
if __name__ == "__main__":
|
| 42 |
+
etl_data()
|
experimentation_mlops/example/load_raw_data.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Downloads the MovieLens dataset and saves it as an artifact
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
import tempfile
|
| 6 |
+
import zipfile
|
| 7 |
+
|
| 8 |
+
import click
|
| 9 |
+
import requests
|
| 10 |
+
|
| 11 |
+
import mlflow
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@click.command(
|
| 15 |
+
help="Downloads the MovieLens dataset and saves it as an mlflow artifact "
|
| 16 |
+
"called 'ratings-csv-dir'."
|
| 17 |
+
)
|
| 18 |
+
@click.option("--url", default="http://files.grouplens.org/datasets/movielens/ml-20m.zip")
|
| 19 |
+
def load_raw_data(url):
|
| 20 |
+
with mlflow.start_run():
|
| 21 |
+
local_dir = tempfile.mkdtemp()
|
| 22 |
+
local_filename = os.path.join(local_dir, "ml-20m.zip")
|
| 23 |
+
print(f"Downloading {url} to {local_filename}")
|
| 24 |
+
r = requests.get(url, stream=True)
|
| 25 |
+
with open(local_filename, "wb") as f:
|
| 26 |
+
for chunk in r.iter_content(chunk_size=1024):
|
| 27 |
+
if chunk: # filter out keep-alive new chunks
|
| 28 |
+
f.write(chunk)
|
| 29 |
+
|
| 30 |
+
extracted_dir = os.path.join(local_dir, "ml-20m")
|
| 31 |
+
print(f"Extracting {local_filename} into {extracted_dir}")
|
| 32 |
+
with zipfile.ZipFile(local_filename, "r") as zip_ref:
|
| 33 |
+
zip_ref.extractall(local_dir)
|
| 34 |
+
|
| 35 |
+
ratings_file = os.path.join(extracted_dir, "ratings.csv")
|
| 36 |
+
|
| 37 |
+
print(f"Uploading ratings: {ratings_file}")
|
| 38 |
+
mlflow.log_artifact(ratings_file, "ratings-csv-dir")
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
if __name__ == "__main__":
|
| 42 |
+
load_raw_data()
|
experimentation_mlops/example/main.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Downloads the MovieLens dataset, ETLs it into Parquet, trains an
|
| 3 |
+
ALS model, and uses the ALS model to train a Keras neural network.
|
| 4 |
+
|
| 5 |
+
See README.rst for more details.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
|
| 10 |
+
import click
|
| 11 |
+
|
| 12 |
+
import mlflow
|
| 13 |
+
from mlflow.entities import RunStatus
|
| 14 |
+
from mlflow.tracking import MlflowClient
|
| 15 |
+
from mlflow.tracking.fluent import _get_experiment_id
|
| 16 |
+
from mlflow.utils import mlflow_tags
|
| 17 |
+
from mlflow.utils.logging_utils import eprint
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def _already_ran(entry_point_name, parameters, git_commit, experiment_id=None):
|
| 21 |
+
"""Best-effort detection of if a run with the given entrypoint name,
|
| 22 |
+
parameters, and experiment id already ran. The run must have completed
|
| 23 |
+
successfully and have at least the parameters provided.
|
| 24 |
+
"""
|
| 25 |
+
experiment_id = experiment_id if experiment_id is not None else _get_experiment_id()
|
| 26 |
+
client = MlflowClient()
|
| 27 |
+
all_runs = reversed(client.search_runs([experiment_id]))
|
| 28 |
+
for run in all_runs:
|
| 29 |
+
tags = run.data.tags
|
| 30 |
+
if tags.get(mlflow_tags.MLFLOW_PROJECT_ENTRY_POINT, None) != entry_point_name:
|
| 31 |
+
continue
|
| 32 |
+
match_failed = False
|
| 33 |
+
for param_key, param_value in parameters.items():
|
| 34 |
+
run_value = run.data.params.get(param_key)
|
| 35 |
+
if run_value != param_value:
|
| 36 |
+
match_failed = True
|
| 37 |
+
break
|
| 38 |
+
if match_failed:
|
| 39 |
+
continue
|
| 40 |
+
|
| 41 |
+
if run.info.to_proto().status != RunStatus.FINISHED:
|
| 42 |
+
eprint(
|
| 43 |
+
("Run matched, but is not FINISHED, so skipping (run_id={}, status={})").format(
|
| 44 |
+
run.info.run_id, run.info.status
|
| 45 |
+
)
|
| 46 |
+
)
|
| 47 |
+
continue
|
| 48 |
+
|
| 49 |
+
previous_version = tags.get(mlflow_tags.MLFLOW_GIT_COMMIT, None)
|
| 50 |
+
if git_commit != previous_version:
|
| 51 |
+
eprint(
|
| 52 |
+
"Run matched, but has a different source version, so skipping "
|
| 53 |
+
f"(found={previous_version}, expected={git_commit})"
|
| 54 |
+
)
|
| 55 |
+
continue
|
| 56 |
+
return client.get_run(run.info.run_id)
|
| 57 |
+
eprint("No matching run has been found.")
|
| 58 |
+
return None
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
# TODO(aaron): This is not great because it doesn't account for:
|
| 62 |
+
# - changes in code
|
| 63 |
+
# - changes in dependent steps
|
| 64 |
+
def _get_or_run(entrypoint, parameters, git_commit, use_cache=True):
|
| 65 |
+
existing_run = _already_ran(entrypoint, parameters, git_commit)
|
| 66 |
+
if use_cache and existing_run:
|
| 67 |
+
print(f"Found existing run for entrypoint={entrypoint} and parameters={parameters}")
|
| 68 |
+
return existing_run
|
| 69 |
+
print(f"Launching new run for entrypoint={entrypoint} and parameters={parameters}")
|
| 70 |
+
submitted_run = mlflow.run(".", entrypoint, parameters=parameters, env_manager="local")
|
| 71 |
+
return MlflowClient().get_run(submitted_run.run_id)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
@click.command()
|
| 75 |
+
@click.option("--als-max-iter", default=10, type=int)
|
| 76 |
+
@click.option("--keras-hidden-units", default=20, type=int)
|
| 77 |
+
@click.option("--max-row-limit", default=100000, type=int)
|
| 78 |
+
def workflow(als_max_iter, keras_hidden_units, max_row_limit):
|
| 79 |
+
# Note: The entrypoint names are defined in MLproject. The artifact directories
|
| 80 |
+
# are documented by each step's .py file.
|
| 81 |
+
with mlflow.start_run() as active_run:
|
| 82 |
+
os.environ["SPARK_CONF_DIR"] = os.path.abspath(".")
|
| 83 |
+
git_commit = active_run.data.tags.get(mlflow_tags.MLFLOW_GIT_COMMIT)
|
| 84 |
+
load_raw_data_run = _get_or_run("load_raw_data", {}, git_commit)
|
| 85 |
+
ratings_csv_uri = os.path.join(load_raw_data_run.info.artifact_uri, "ratings-csv-dir")
|
| 86 |
+
etl_data_run = _get_or_run(
|
| 87 |
+
"etl_data", {"ratings_csv": ratings_csv_uri, "max_row_limit": max_row_limit}, git_commit
|
| 88 |
+
)
|
| 89 |
+
ratings_parquet_uri = os.path.join(etl_data_run.info.artifact_uri, "ratings-parquet-dir")
|
| 90 |
+
|
| 91 |
+
# We specify a spark-defaults.conf to override the default driver memory. ALS requires
|
| 92 |
+
# significant memory. The driver memory property cannot be set by the application itself.
|
| 93 |
+
als_run = _get_or_run(
|
| 94 |
+
"als", {"ratings_data": ratings_parquet_uri, "max_iter": str(als_max_iter)}, git_commit
|
| 95 |
+
)
|
| 96 |
+
als_model_uri = os.path.join(als_run.info.artifact_uri, "als-model")
|
| 97 |
+
|
| 98 |
+
keras_params = {
|
| 99 |
+
"ratings_data": ratings_parquet_uri,
|
| 100 |
+
"als_model_uri": als_model_uri,
|
| 101 |
+
"hidden_units": keras_hidden_units,
|
| 102 |
+
}
|
| 103 |
+
_get_or_run("train_keras", keras_params, git_commit, use_cache=False)
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
if __name__ == "__main__":
|
| 107 |
+
workflow()
|
experimentation_mlops/example/python_env.yaml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python: "3.8"
|
| 2 |
+
build_dependencies:
|
| 3 |
+
- pip
|
| 4 |
+
dependencies:
|
| 5 |
+
- tensorflow==1.15.2
|
| 6 |
+
- keras==2.2.4
|
| 7 |
+
- mlflow>=1.0
|
| 8 |
+
- pyspark
|
| 9 |
+
- requests
|
| 10 |
+
- click
|
experimentation_mlops/example/spark-defaults.conf
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
spark.driver.memory 8g
|
experimentation_mlops/example/train_keras.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Trains a Keras model for user/movie ratings. The input is a Parquet
|
| 3 |
+
ratings dataset (see etl_data.py) and an ALS model (see als.py), which we
|
| 4 |
+
will use to supplement our input and train using.
|
| 5 |
+
"""
|
| 6 |
+
from itertools import chain
|
| 7 |
+
|
| 8 |
+
import click
|
| 9 |
+
import numpy as np
|
| 10 |
+
import pandas as pd
|
| 11 |
+
import pyspark
|
| 12 |
+
import tensorflow as tf
|
| 13 |
+
from pyspark.sql.functions import col, udf
|
| 14 |
+
from pyspark.sql.types import ArrayType, FloatType
|
| 15 |
+
from tensorflow import keras
|
| 16 |
+
from tensorflow.keras.callbacks import EarlyStopping
|
| 17 |
+
from tensorflow.keras.layers import Dense
|
| 18 |
+
from tensorflow.keras.models import Sequential
|
| 19 |
+
|
| 20 |
+
import mlflow
|
| 21 |
+
import mlflow.spark
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
@click.command()
|
| 25 |
+
@click.option("--ratings-data", help="Path readable by Spark to the ratings Parquet file")
|
| 26 |
+
@click.option("--als-model-uri", help="Path readable by load_model to ALS MLmodel")
|
| 27 |
+
@click.option("--hidden-units", default=20, type=int)
|
| 28 |
+
def train_keras(ratings_data, als_model_uri, hidden_units):
|
| 29 |
+
np.random.seed(0)
|
| 30 |
+
tf.set_random_seed(42) # For reproducibility
|
| 31 |
+
|
| 32 |
+
with pyspark.sql.SparkSession.builder.getOrCreate() as spark:
|
| 33 |
+
als_model = mlflow.spark.load_model(als_model_uri).stages[0]
|
| 34 |
+
ratings_df = spark.read.parquet(ratings_data)
|
| 35 |
+
(training_df, test_df) = ratings_df.randomSplit([0.8, 0.2], seed=42)
|
| 36 |
+
training_df.cache()
|
| 37 |
+
test_df.cache()
|
| 38 |
+
|
| 39 |
+
mlflow.log_metric("training_nrows", training_df.count())
|
| 40 |
+
mlflow.log_metric("test_nrows", test_df.count())
|
| 41 |
+
|
| 42 |
+
print(f"Training: {training_df.count()}, test: {test_df.count()}")
|
| 43 |
+
|
| 44 |
+
user_factors = als_model.userFactors.selectExpr("id as userId", "features as uFeatures")
|
| 45 |
+
item_factors = als_model.itemFactors.selectExpr("id as movieId", "features as iFeatures")
|
| 46 |
+
joined_train_df = training_df.join(item_factors, on="movieId").join(
|
| 47 |
+
user_factors, on="userId"
|
| 48 |
+
)
|
| 49 |
+
joined_test_df = test_df.join(item_factors, on="movieId").join(user_factors, on="userId")
|
| 50 |
+
|
| 51 |
+
# We'll combine the movies and ratings vectors into a single vector of length 24.
|
| 52 |
+
# We will then explode this features vector into a set of columns.
|
| 53 |
+
def concat_arrays(*args):
|
| 54 |
+
return list(chain(*args))
|
| 55 |
+
|
| 56 |
+
concat_arrays_udf = udf(concat_arrays, ArrayType(FloatType()))
|
| 57 |
+
|
| 58 |
+
concat_train_df = joined_train_df.select(
|
| 59 |
+
"userId",
|
| 60 |
+
"movieId",
|
| 61 |
+
concat_arrays_udf(col("iFeatures"), col("uFeatures")).alias("features"),
|
| 62 |
+
col("rating").cast("float"),
|
| 63 |
+
)
|
| 64 |
+
concat_test_df = joined_test_df.select(
|
| 65 |
+
"userId",
|
| 66 |
+
"movieId",
|
| 67 |
+
concat_arrays_udf(col("iFeatures"), col("uFeatures")).alias("features"),
|
| 68 |
+
col("rating").cast("float"),
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
pandas_df = concat_train_df.toPandas()
|
| 72 |
+
pandas_test_df = concat_test_df.toPandas()
|
| 73 |
+
|
| 74 |
+
# This syntax will create a new DataFrame where elements of the 'features' vector
|
| 75 |
+
# are each in their own column. This is what we'll train our neural network on.
|
| 76 |
+
x_test = pd.DataFrame(pandas_test_df.features.values.tolist(), index=pandas_test_df.index)
|
| 77 |
+
x_train = pd.DataFrame(pandas_df.features.values.tolist(), index=pandas_df.index)
|
| 78 |
+
|
| 79 |
+
# Show matrix for example.
|
| 80 |
+
print("Training matrix:")
|
| 81 |
+
print(x_train)
|
| 82 |
+
|
| 83 |
+
# Create our Keras model with two fully connected hidden layers.
|
| 84 |
+
model = Sequential()
|
| 85 |
+
model.add(Dense(30, input_dim=24, activation="relu"))
|
| 86 |
+
model.add(Dense(hidden_units, activation="relu"))
|
| 87 |
+
model.add(Dense(1, activation="linear"))
|
| 88 |
+
|
| 89 |
+
model.compile(loss="mse", optimizer=keras.optimizers.Adam(lr=0.0001))
|
| 90 |
+
|
| 91 |
+
early_stopping = EarlyStopping(
|
| 92 |
+
monitor="val_loss", min_delta=0.0001, patience=2, mode="auto"
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
model.fit(
|
| 96 |
+
x_train,
|
| 97 |
+
pandas_df["rating"],
|
| 98 |
+
validation_split=0.2,
|
| 99 |
+
verbose=2,
|
| 100 |
+
epochs=3,
|
| 101 |
+
batch_size=128,
|
| 102 |
+
shuffle=False,
|
| 103 |
+
callbacks=[early_stopping],
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
train_mse = model.evaluate(x_train, pandas_df["rating"], verbose=2)
|
| 107 |
+
test_mse = model.evaluate(x_test, pandas_test_df["rating"], verbose=2)
|
| 108 |
+
mlflow.log_metric("test_mse", test_mse)
|
| 109 |
+
mlflow.log_metric("train_mse", train_mse)
|
| 110 |
+
|
| 111 |
+
print(f"The model had a MSE on the test set of {test_mse}")
|
| 112 |
+
mlflow.tensorflow.log_model(model, "keras-model")
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
if __name__ == "__main__":
|
| 116 |
+
train_keras()
|
experimentation_mlops/mlops/MLProject
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: multistep_example
|
| 2 |
+
|
| 3 |
+
python_env: python_env.yaml
|
| 4 |
+
|
| 5 |
+
entry_points:
|
| 6 |
+
ingest_request:
|
| 7 |
+
command: "python ingest_request.py"
|
| 8 |
+
|
| 9 |
+
ingest_convert:
|
| 10 |
+
command: "python ingest_convert.py"
|
| 11 |
+
|
| 12 |
+
main:
|
| 13 |
+
command: "python main.py"
|
experimentation_mlops/mlops/data/2week_news_data.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
experimentation_mlops/mlops/data/2week_news_data.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
experimentation_mlops/mlops/data/2week_news_data.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:17542732c79d799aa9bcc1b8f7fbf6e11da1fc51c1c21088ebf7572f6d922862
|
| 3 |
+
size 843591
|
experimentation_mlops/mlops/data/2week_news_data.xlsx
ADDED
|
Binary file (540 kB). View file
|
|
|
experimentation_mlops/mlops/data/2week_news_data.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:64638c216b8479c03046114e5971943d8be624f025fdf827c18c46806743d922
|
| 3 |
+
size 520334
|
experimentation_mlops/mlops/desktop.ini
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[ViewState]
|
| 2 |
+
Mode=
|
| 3 |
+
Vid=
|
| 4 |
+
FolderType=Generic
|
experimentation_mlops/mlops/end-to-end.ipynb
ADDED
|
File without changes
|
experimentation_mlops/mlops/evaluation.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## TODO
|
| 2 |
+
|
| 3 |
+
## Accepts a dataset name and model id, predict and produces graph + error metrics
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import mlflow
|
| 8 |
+
import mlflow.data
|
| 9 |
+
import numpy as np
|
| 10 |
+
import pandas as pd
|
| 11 |
+
from mlflow.client import MlflowClient
|
| 12 |
+
from mlflow.data.pandas_dataset import PandasDataset
|
| 13 |
+
from utilsforecast.plotting import plot_series
|
| 14 |
+
|
| 15 |
+
from neuralforecast.core import NeuralForecast
|
| 16 |
+
from neuralforecast.models import NBEATSx
|
| 17 |
+
from neuralforecast.utils import AirPassengersDF
|
| 18 |
+
from neuralforecast.losses.pytorch import MAE
|
| 19 |
+
|
| 20 |
+
import matplotlib.pyplot as plt
|
| 21 |
+
Y_plot = Y_hat_df[Y_hat_df['unique_id']=='Dated']
|
| 22 |
+
cutoffs = Y_hat_df['cutoff'].unique()[::horizon]
|
| 23 |
+
Y_plot = Y_plot[Y_hat_df['cutoff'].isin(cutoffs)]
|
| 24 |
+
|
| 25 |
+
plt.figure(figsize=(20,5))
|
| 26 |
+
plt.plot(Y_plot['ds'], Y_plot['y'], label='True')
|
| 27 |
+
for model in models:
|
| 28 |
+
plt.plot(Y_plot['ds'], Y_plot[f'{model}'], label=f'{model}')
|
| 29 |
+
plt.xlabel('Datestamp')
|
| 30 |
+
plt.ylabel('OT')
|
| 31 |
+
plt.grid()
|
| 32 |
+
plt.legend()
|
| 33 |
+
|
| 34 |
+
from neuralforecast.losses.numpy import mse, mae, mape
|
| 35 |
+
|
| 36 |
+
for model in models:
|
| 37 |
+
mae_model = mae(Y_hat_df['y'], Y_hat_df[f'{model}'])
|
| 38 |
+
mse_model = mse(Y_hat_df['y'], Y_hat_df[f'{model}'])
|
| 39 |
+
mape_model = mape(Y_hat_df['y'], Y_hat_df[f'{model}'])
|
| 40 |
+
print(f'{model} horizon {horizon} - MAE: {mae_model:.3f}')
|
| 41 |
+
print(f'{model} horizon {horizon} - MSE: {mse_model:.3f}')
|
| 42 |
+
print(f'{model} horizon {horizon} - MAPE: {mape_model:.3f}')
|
experimentation_mlops/mlops/ingest_convert.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Converts the raw CSV form to a Parquet form with just the columns we want
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
import tempfile
|
| 6 |
+
|
| 7 |
+
import click
|
| 8 |
+
import pandas as pd
|
| 9 |
+
|
| 10 |
+
import mlflow
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@click.command(
|
| 14 |
+
help="Given a CSV file (see load_raw_data), transforms it into Parquet "
|
| 15 |
+
"in an mlflow artifact called 'data-parquet-dir'"
|
| 16 |
+
)
|
| 17 |
+
@click.option("--data-csv")
|
| 18 |
+
@click.option(
|
| 19 |
+
"--max-row-limit", default=10000, help="Limit the data size to run comfortably on a laptop."
|
| 20 |
+
)
|
| 21 |
+
def ingest_convert(data_csv, max_row_limit):
|
| 22 |
+
with mlflow.start_run():
|
| 23 |
+
tmpdir = tempfile.mkdtemp()
|
| 24 |
+
data_parquet_dir = os.path.join(tmpdir, "data-parquet")
|
| 25 |
+
print(f"Converting data CSV {data_csv} to Parquet {data_parquet_dir}")
|
| 26 |
+
|
| 27 |
+
# data_csv = fr"{data_csv}"
|
| 28 |
+
# print(data_csv)
|
| 29 |
+
# dirName = data_csv.replace("file:///", "")
|
| 30 |
+
|
| 31 |
+
# fn = [f for f in os.listdir(dirName)\
|
| 32 |
+
# if f.endswith('.csv') and os.path.isfile(os.path.join(dirName, f))][0]
|
| 33 |
+
# data_csv_file = os.path.join(dirName, fn)
|
| 34 |
+
|
| 35 |
+
data_df = pd.read_csv(data_csv)
|
| 36 |
+
data_df.to_parquet(data_parquet_dir)
|
| 37 |
+
|
| 38 |
+
# table = pa.csv.read_csv(data_csv)
|
| 39 |
+
# pa.parquet.write_table(table, data_csv.replace('csv', 'parquet'))
|
| 40 |
+
|
| 41 |
+
if max_row_limit != -1:
|
| 42 |
+
data_df = data_df.iloc[:max_row_limit]
|
| 43 |
+
|
| 44 |
+
# data_df.write.parquet(data_parquet_dir)
|
| 45 |
+
|
| 46 |
+
print(f"Uploading Parquet data: {data_parquet_dir}")
|
| 47 |
+
mlflow.log_artifacts(data_parquet_dir, "data-parquet-dir")
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
if __name__ == "__main__":
|
| 51 |
+
ingest_convert()
|
experimentation_mlops/mlops/ingest_request.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This module defines the following routines used by the 'ingest' step of the time series forecasting flow:
|
| 3 |
+
|
| 4 |
+
- ``load_file_as_dataframe``: Defines customizable logic for parsing dataset formats that are not
|
| 5 |
+
natively parsed by MLflow Recipes (i.e. formats other than Parquet, Delta, and Spark SQL).
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import pandas as pd
|
| 9 |
+
import os
|
| 10 |
+
import tempfile
|
| 11 |
+
import click
|
| 12 |
+
import mlflow
|
| 13 |
+
|
| 14 |
+
import gdown
|
| 15 |
+
import requests
|
| 16 |
+
import zipfile
|
| 17 |
+
|
| 18 |
+
@click.command(
|
| 19 |
+
help="Downloads the dataset and saves it as an mlflow artifact "
|
| 20 |
+
"called 'data-csv-dir'."
|
| 21 |
+
)
|
| 22 |
+
@click.option("--url", default="https://drive.google.com/uc?id=1H8RHsrgYMd6VC23_OJqrN6o_mL78pWpx")
|
| 23 |
+
def ingest_request(url) -> pd.DataFrame:
|
| 24 |
+
"""
|
| 25 |
+
Downloads data from the specified url.
|
| 26 |
+
|
| 27 |
+
:param url: Url to the dataset file.
|
| 28 |
+
:return: MLflow artifact containing the downloaded data in its raw form.
|
| 29 |
+
"""
|
| 30 |
+
with mlflow.start_run():
|
| 31 |
+
local_dir = tempfile.mkdtemp()
|
| 32 |
+
local_filename = os.path.join(local_dir, "news-data.zip")
|
| 33 |
+
print(f"Downloading {url} to {local_filename}")
|
| 34 |
+
# r = requests.get(url, stream=True)
|
| 35 |
+
# with open(local_filename, "wb") as f:
|
| 36 |
+
# for chunk in r.iter_content(chunk_size=1024):
|
| 37 |
+
# if chunk: # filter out keep-alive new chunks
|
| 38 |
+
# f.write(chunk)
|
| 39 |
+
|
| 40 |
+
gdown.download(url, local_filename, quiet=False)
|
| 41 |
+
extracted_dir = os.path.join(local_dir)
|
| 42 |
+
print(f"Extracting {local_filename} into {extracted_dir}")
|
| 43 |
+
|
| 44 |
+
with zipfile.ZipFile(local_filename, "r") as zip_ref:
|
| 45 |
+
zip_ref.extractall(local_dir)
|
| 46 |
+
|
| 47 |
+
data_file = os.path.join(extracted_dir, "2week_news_data.csv")
|
| 48 |
+
|
| 49 |
+
print(f"Uploading data: {data_file}")
|
| 50 |
+
mlflow.log_artifact(data_file, "data-csv-dir")
|
| 51 |
+
|
| 52 |
+
if __name__ == "__main__":
|
| 53 |
+
ingest_request()
|
| 54 |
+
|
experimentation_mlops/mlops/main.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Time series forecasting
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
import click
|
| 8 |
+
|
| 9 |
+
import mlflow
|
| 10 |
+
from mlflow.entities import RunStatus
|
| 11 |
+
from mlflow.tracking import MlflowClient
|
| 12 |
+
from mlflow.tracking.fluent import _get_experiment_id
|
| 13 |
+
from mlflow.utils import mlflow_tags
|
| 14 |
+
from mlflow.utils.logging_utils import eprint
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def _already_ran(entry_point_name, parameters, git_commit, experiment_id=None):
|
| 18 |
+
"""Best-effort detection of if a run with the given entrypoint name,
|
| 19 |
+
parameters, and experiment id already ran. The run must have completed
|
| 20 |
+
successfully and have at least the parameters provided.
|
| 21 |
+
"""
|
| 22 |
+
experiment_id = experiment_id if experiment_id is not None else _get_experiment_id()
|
| 23 |
+
client = MlflowClient()
|
| 24 |
+
all_runs = reversed(client.search_runs([experiment_id]))
|
| 25 |
+
for run in all_runs:
|
| 26 |
+
tags = run.data.tags
|
| 27 |
+
if tags.get(mlflow_tags.MLFLOW_PROJECT_ENTRY_POINT, None) != entry_point_name:
|
| 28 |
+
continue
|
| 29 |
+
match_failed = False
|
| 30 |
+
for param_key, param_value in parameters.items():
|
| 31 |
+
run_value = run.data.params.get(param_key)
|
| 32 |
+
if run_value != param_value:
|
| 33 |
+
match_failed = True
|
| 34 |
+
break
|
| 35 |
+
if match_failed:
|
| 36 |
+
continue
|
| 37 |
+
|
| 38 |
+
if run.info.to_proto().status != RunStatus.FINISHED:
|
| 39 |
+
eprint(
|
| 40 |
+
("Run matched, but is not FINISHED, so skipping (run_id={}, status={})").format(
|
| 41 |
+
run.info.run_id, run.info.status
|
| 42 |
+
)
|
| 43 |
+
)
|
| 44 |
+
continue
|
| 45 |
+
|
| 46 |
+
previous_version = tags.get(mlflow_tags.MLFLOW_GIT_COMMIT, None)
|
| 47 |
+
if git_commit != previous_version:
|
| 48 |
+
eprint(
|
| 49 |
+
"Run matched, but has a different source version, so skipping "
|
| 50 |
+
f"(found={previous_version}, expected={git_commit})"
|
| 51 |
+
)
|
| 52 |
+
continue
|
| 53 |
+
return client.get_run(run.info.run_id)
|
| 54 |
+
eprint("No matching run has been found.")
|
| 55 |
+
return None
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
# TODO(aaron): This is not great because it doesn't account for:
|
| 59 |
+
# - changes in code
|
| 60 |
+
# - changes in dependent steps
|
| 61 |
+
def _get_or_run(entrypoint, parameters, git_commit, use_cache=True):
|
| 62 |
+
existing_run = _already_ran(entrypoint, parameters, git_commit)
|
| 63 |
+
if use_cache and existing_run:
|
| 64 |
+
print(f"Found existing run for entrypoint={entrypoint} and parameters={parameters}")
|
| 65 |
+
return existing_run
|
| 66 |
+
print(f"Launching new run for entrypoint={entrypoint} and parameters={parameters}")
|
| 67 |
+
submitted_run = mlflow.run(".", entrypoint, parameters=parameters, env_manager="local")
|
| 68 |
+
return MlflowClient().get_run(submitted_run.run_id)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
@click.command()
|
| 72 |
+
@click.option("--max-row-limit", default=100000, type=int)
|
| 73 |
+
|
| 74 |
+
def workflow(max_row_limit):
|
| 75 |
+
# Note: The entrypoint names are defined in MLproject. The artifact directories
|
| 76 |
+
# are documented by each step's .py file.
|
| 77 |
+
with mlflow.start_run() as active_run:
|
| 78 |
+
os.environ["SPARK_CONF_DIR"] = os.path.abspath(".")
|
| 79 |
+
git_commit = active_run.data.tags.get(mlflow_tags.MLFLOW_GIT_COMMIT)
|
| 80 |
+
ingest_request_run = _get_or_run("ingest_request", {}, git_commit)
|
| 81 |
+
data_csv_uri = os.path.join(ingest_request_run.info.artifact_uri, "data-csv-dir")
|
| 82 |
+
print(data_csv_uri)
|
| 83 |
+
ingest_convert_run = _get_or_run(
|
| 84 |
+
"ingest_convert", {"data-csv": data_csv_uri, "max-row-limit": max_row_limit}, git_commit
|
| 85 |
+
)
|
| 86 |
+
data_parquet_uri = os.path.join(ingest_convert_run.info.artifact_uri, "data-parquet-dir")
|
| 87 |
+
|
| 88 |
+
# We specify a spark-defaults.conf to override the default driver memory. ALS requires
|
| 89 |
+
# significant memory. The driver memory property cannot be set by the application itself.
|
| 90 |
+
# als_run = _get_or_run(
|
| 91 |
+
# "als", {"ratings_data": ratings_parquet_uri, "max_iter": str(als_max_iter)}, git_commit
|
| 92 |
+
# )
|
| 93 |
+
# als_model_uri = os.path.join(als_run.info.artifact_uri, "als-model")
|
| 94 |
+
|
| 95 |
+
# keras_params = {
|
| 96 |
+
# "ratings_data": ratings_parquet_uri,
|
| 97 |
+
# "als_model_uri": als_model_uri,
|
| 98 |
+
# "hidden_units": keras_hidden_units,
|
| 99 |
+
# }
|
| 100 |
+
# _get_or_run("train_keras", keras_params, git_commit, use_cache=False)
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
if __name__ == "__main__":
|
| 104 |
+
workflow()
|
experimentation_mlops/mlops/ml-doc.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Machine Learning Operations (MLOps) Pipeline Documentation
|
| 2 |
+
|
| 3 |
+
This is the documentation covering each of the steps included in Bioma AI's time-series-forecasting MLOps Pipeline.
|
| 4 |
+
|
| 5 |
+
## Sequential MLOps Steps
|
| 6 |
+
The information flow of the pipeline will closely resemble that of a regression machine learning task. The model development will consist of sequential steps:
|
| 7 |
+
1. Ingestion,
|
| 8 |
+
2. Transformation,
|
| 9 |
+
3. Training,
|
| 10 |
+
4. Evaluation, and
|
| 11 |
+
5. Registration.
|
| 12 |
+
|
| 13 |
+
MLFlow Regression Recipe's Information Flow [1]
|
| 14 |
+
|
| 15 |
+
## 1. Ingestion
|
| 16 |
+
|
| 17 |
+
Our pipeline involves extracting raw datasets from the internet (S3 Buckets and other cloud services), the assumed dataset is of one of the following file types: csv, json, parquet or xlsx. The extracted data is saved as an artifact which can help in documentation purposes.
|
| 18 |
+
|
| 19 |
+
In the case of time series forecasting, the data ingestion process is tasked on receiving data from a specific format and converting it to a Pandas Dataframe for further processing. The data will be downloaded from the web by issuing a request, the data will then be converted into parquet before being written as a Pandas dataframe. The parquet file will be saved as an artifact for the purpose of documentation.
|
| 20 |
+
|
| 21 |
+
## 2. Transformation
|
| 22 |
+
|
| 23 |
+
According to the timeframe of the time-series data, the data will be split into a train-test-validation set. The user will be able to customize each of the set's proportions.
|
| 24 |
+
|
| 25 |
+
Various statistical methods is considered and performed into a selection of columns, the columns and the methods are both customizable. A few methods that are considered are:
|
| 26 |
+
1. Logarithmic
|
| 27 |
+
2. Natural Logarithmic
|
| 28 |
+
3. Standardization
|
| 29 |
+
4. Identity
|
| 30 |
+
5. Logarithmic Difference
|
| 31 |
+
|
| 32 |
+
## 3. Training
|
| 33 |
+
|
| 34 |
+
The training process can be broken down into two types according to the amount of variates being predicted: univariate or multivariate.
|
| 35 |
+
|
| 36 |
+
Predictors are either an:
|
| 37 |
+
|
| 38 |
+
1. Endogenous feature (Changes in the target's value has an effect on the predictor's value or the other way around) or
|
| 39 |
+
2. Exogenous feature (changes in the predictor's value has an effect on the target's value, but not the other way around)
|
| 40 |
+
<ol type="a">
|
| 41 |
+
<li>Static Exogenous</li>
|
| 42 |
+
Static variables such as one-hot encoding for a categorical class identifier.
|
| 43 |
+
<li>Historical Exogenous</li>
|
| 44 |
+
Exogenous features that their historical data is only known of.
|
| 45 |
+
<li>Future Exogenous</li>
|
| 46 |
+
Exogenous features that their data is known of when making the prediction on that time in the future.
|
| 47 |
+
</ol>
|
| 48 |
+
|
| 49 |
+
Endogenous features will be predicted in conjunction with the target's feature. Exogenous features will not be predicted, rather only be used to predict the target variable.
|
| 50 |
+
|
| 51 |
+
In short: multivariate predictions will use predictors as endogenous features, while multivariable predictions use predictors as exogenous features because of its univariate nature.
|
| 52 |
+
|
| 53 |
+
## 4. Evaluation
|
| 54 |
+
|
| 55 |
+
The evaluation step is constructed for the trained models to perform prediction on out-of-training data. Ideally, this step will produce outputs such as visualizations and error metrics for arbitrary datasets.
|
| 56 |
+
|
| 57 |
+
References:
|
| 58 |
+
- [1] [mlflow/recipes-regression-template](https://github.com/mlflow/recipes-regression-template/tree/main?tab=readme-ov-file#installation)
|
| 59 |
+
- [2] [MLflow deployment using Docker, EC2, S3, and RDS](https://aws.plainenglish.io/set-up-mlflow-on-aws-ec2-using-docker-s3-and-rds-90d96798e555)
|
experimentation_mlops/mlops/modules/transformations.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Stores all transformations
|
| 3 |
+
"""
|
| 4 |
+
def createLag(data, amt=10):
|
| 5 |
+
"""
|
| 6 |
+
Create a lag inside dataframe, in business days
|
| 7 |
+
|
| 8 |
+
:param pandas.DataFrame data:
|
| 9 |
+
:param int amt: Unit of lag period
|
| 10 |
+
|
| 11 |
+
:return: Copy of pandas Dataframe
|
| 12 |
+
"""
|
| 13 |
+
import pandas as pd
|
| 14 |
+
if 'ds' in data:
|
| 15 |
+
copy = data.copy()
|
| 16 |
+
copy['ds'] = copy['ds'] + pd.tseries.offsets.BusinessDay(amt)
|
| 17 |
+
return copy
|
| 18 |
+
else:
|
| 19 |
+
print(f"No 'ds' column found inside dataframe")
|
| 20 |
+
return data
|
| 21 |
+
|
| 22 |
+
def scaleStandard(df_col):
|
| 23 |
+
"""
|
| 24 |
+
Fits and returns a standard scaled version of a dataframe column
|
| 25 |
+
"""
|
| 26 |
+
import pandas as pd
|
| 27 |
+
from sklearn.preprocessing import StandardScaler
|
| 28 |
+
scaler = StandardScaler()
|
| 29 |
+
df_col = scaler.fit_transform(df_col)
|
| 30 |
+
df_col = pd.DataFrame(df_col)
|
| 31 |
+
return df_col, scaler
|
| 32 |
+
|
| 33 |
+
def logReturn(data, df_col):
|
| 34 |
+
"""
|
| 35 |
+
Perform log return for a dataframe column
|
| 36 |
+
"""
|
| 37 |
+
import numpy as np
|
| 38 |
+
new_col = np.log1p(data[df_col].pct_change())
|
| 39 |
+
return new_col
|
experimentation_mlops/mlops/pics/pipeline.png
ADDED
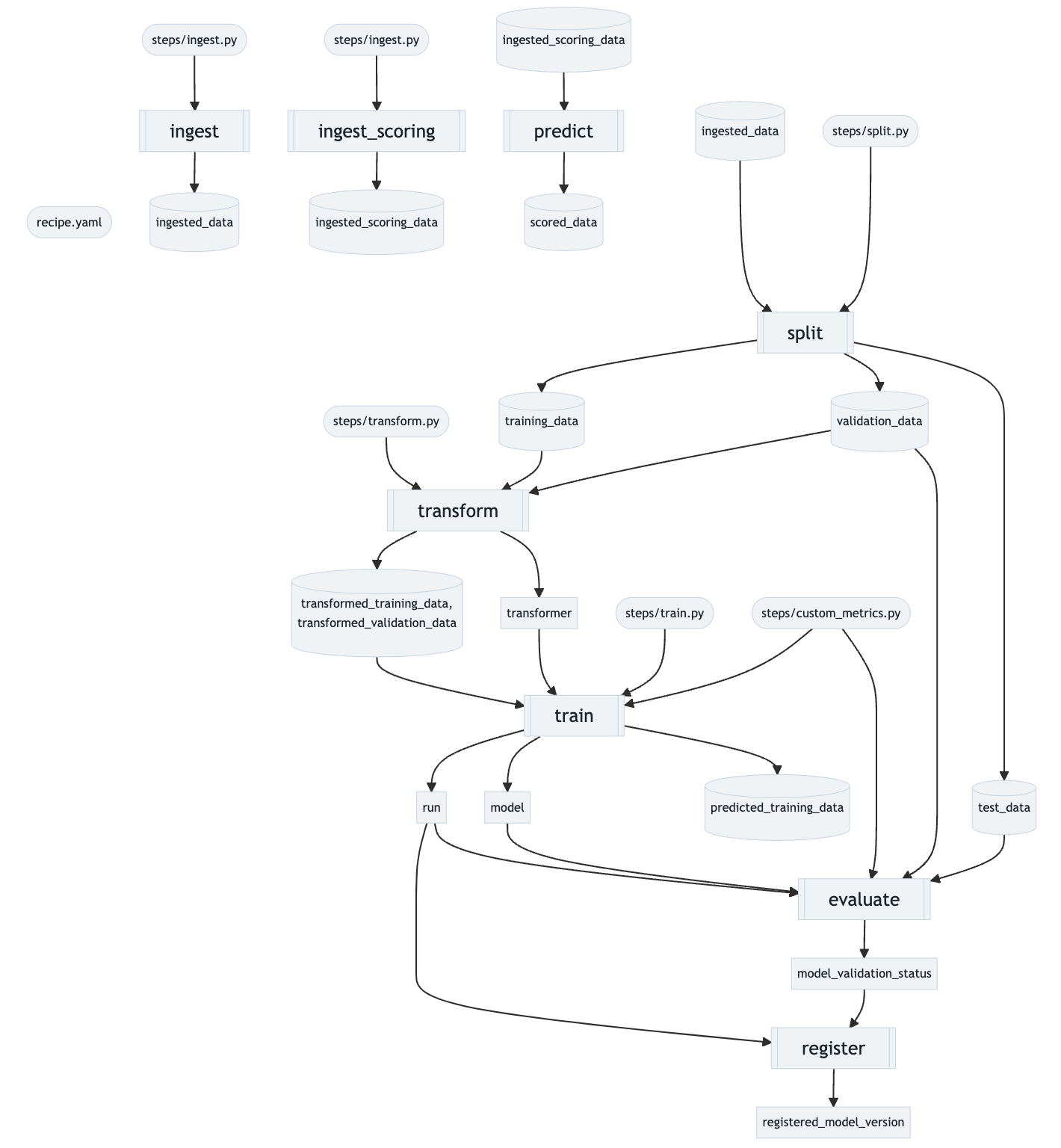
|
experimentation_mlops/mlops/python_env.yaml
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python: "3.9"
|
| 2 |
+
build_dependencies:
|
| 3 |
+
- pip
|
| 4 |
+
dependencies:
|
| 5 |
+
- pytorch
|
| 6 |
+
- openpyxl
|
| 7 |
+
- pandas
|
| 8 |
+
- mlflow
|
| 9 |
+
- pyspark
|
| 10 |
+
- requests
|
| 11 |
+
- click
|
experimentation_mlops/mlops/requirements.txt
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy
|
| 2 |
+
scipy
|
| 3 |
+
scikit-learn
|
| 4 |
+
fastapi
|
| 5 |
+
ipykernel
|
| 6 |
+
flask
|
| 7 |
+
beautifulsoup4
|
| 8 |
+
--extra-index-url https://download.pytorch.org/whl/cu118
|
| 9 |
+
torch
|
| 10 |
+
torchvision
|
| 11 |
+
torchaudio
|
| 12 |
+
mlflow
|
| 13 |
+
pandas
|
| 14 |
+
transformers
|
| 15 |
+
fsspec
|
| 16 |
+
gitpython
|
| 17 |
+
hyperopt
|
| 18 |
+
jupyterlab
|
| 19 |
+
matplotlib
|
| 20 |
+
numba
|
| 21 |
+
numpy
|
| 22 |
+
optuna
|
| 23 |
+
pyarrow
|
| 24 |
+
pytorch-lightning
|
| 25 |
+
pip
|
| 26 |
+
s3fs
|
| 27 |
+
nbdev
|
| 28 |
+
black
|
| 29 |
+
polars
|
| 30 |
+
ray[tune]>=2.2.0
|
| 31 |
+
utilsforecast>=0.0.24
|
| 32 |
+
coreforecast
|
experimentation_mlops/mlops/spark-defaults.conf
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
spark.driver.memory 8g
|
experimentation_mlops/mlops/test.ipynb
ADDED
|
@@ -0,0 +1,490 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [
|
| 8 |
+
{
|
| 9 |
+
"name": "stderr",
|
| 10 |
+
"output_type": "stream",
|
| 11 |
+
"text": [
|
| 12 |
+
"Downloading...\n",
|
| 13 |
+
"From: https://drive.google.com/uc?id=1H8RHsrgYMd6VC23_OJqrN6o_mL78pWpx\n",
|
| 14 |
+
"To: e:\\projects\\Bioma-AI\\1-time-series-forecasting\\trend_prediction_app\\trend-prediction-ml\\trend-prediction-pipeline\\collected-news.zip\n",
|
| 15 |
+
"100%|██████████| 520k/520k [00:02<00:00, 241kB/s]\n"
|
| 16 |
+
]
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"data": {
|
| 20 |
+
"text/plain": [
|
| 21 |
+
"'collected-news.zip'"
|
| 22 |
+
]
|
| 23 |
+
},
|
| 24 |
+
"execution_count": 1,
|
| 25 |
+
"metadata": {},
|
| 26 |
+
"output_type": "execute_result"
|
| 27 |
+
}
|
| 28 |
+
],
|
| 29 |
+
"source": [
|
| 30 |
+
"import gdown\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"url = 'https://drive.google.com/uc?id=1H8RHsrgYMd6VC23_OJqrN6o_mL78pWpx'\n",
|
| 33 |
+
"output = 'collected-news.zip'\n",
|
| 34 |
+
"gdown.download(url, output, quiet=False)"
|
| 35 |
+
]
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"cell_type": "code",
|
| 39 |
+
"execution_count": 2,
|
| 40 |
+
"metadata": {},
|
| 41 |
+
"outputs": [],
|
| 42 |
+
"source": [
|
| 43 |
+
"import pyarrow.csv as pv\n",
|
| 44 |
+
"import pyarrow.parquet as pq\n",
|
| 45 |
+
"\n",
|
| 46 |
+
"filename = 'data/2week_news_data.csv'\n",
|
| 47 |
+
"\n",
|
| 48 |
+
"table = pv.read_csv(filename)\n",
|
| 49 |
+
"pq.write_table(table, filename.replace('csv', 'parquet'))"
|
| 50 |
+
]
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"cell_type": "code",
|
| 54 |
+
"execution_count": 3,
|
| 55 |
+
"metadata": {},
|
| 56 |
+
"outputs": [
|
| 57 |
+
{
|
| 58 |
+
"data": {
|
| 59 |
+
"text/plain": [
|
| 60 |
+
"'E:\\\\projects\\\\Bioma-AI\\\\time-series-forecasting\\\\trend_prediction_app\\\\trend-prediction-ml\\\\trend-prediction-pipeline\\\\data\\\\2week_news_data.csv'"
|
| 61 |
+
]
|
| 62 |
+
},
|
| 63 |
+
"execution_count": 3,
|
| 64 |
+
"metadata": {},
|
| 65 |
+
"output_type": "execute_result"
|
| 66 |
+
}
|
| 67 |
+
],
|
| 68 |
+
"source": [
|
| 69 |
+
"import os\n",
|
| 70 |
+
"\n",
|
| 71 |
+
"dirName = r\"E:\\projects\\Bioma-AI\\time-series-forecasting\\trend_prediction_app\\trend-prediction-ml\\trend-prediction-pipeline\\data\"\n",
|
| 72 |
+
"fn = [f for f in os.listdir(dirName)\\\n",
|
| 73 |
+
" if f.endswith('.csv') and os.path.isfile(os.path.join(dirName, f))][0]\n",
|
| 74 |
+
"path = os.path.join(dirName, fn)\n",
|
| 75 |
+
"path"
|
| 76 |
+
]
|
| 77 |
+
},
|
| 78 |
+
{
|
| 79 |
+
"cell_type": "code",
|
| 80 |
+
"execution_count": 1,
|
| 81 |
+
"metadata": {},
|
| 82 |
+
"outputs": [
|
| 83 |
+
{
|
| 84 |
+
"data": {
|
| 85 |
+
"text/plain": [
|
| 86 |
+
"'E:\\\\projects\\\\Bioma-AI\\x01-time-series-forecasting\\trend_prediction_app\\trend-prediction-ml\\trend-prediction-pipeline\\\\data'"
|
| 87 |
+
]
|
| 88 |
+
},
|
| 89 |
+
"execution_count": 1,
|
| 90 |
+
"metadata": {},
|
| 91 |
+
"output_type": "execute_result"
|
| 92 |
+
}
|
| 93 |
+
],
|
| 94 |
+
"source": [
|
| 95 |
+
"def to_raw(string):\n",
|
| 96 |
+
" return fr\"{string}\"\n",
|
| 97 |
+
"\n",
|
| 98 |
+
"dirName = to_raw(\"E:\\projects\\Bioma-AI\\1-time-series-forecasting\\trend_prediction_app\\trend-prediction-ml\\trend-prediction-pipeline\\data\")\n",
|
| 99 |
+
"\n",
|
| 100 |
+
"dirName = dirName.replace(\"file:///\", \"\")\n",
|
| 101 |
+
"\n",
|
| 102 |
+
"dirName\n",
|
| 103 |
+
"\n",
|
| 104 |
+
"dirName = rf\"{dirName}\"\n",
|
| 105 |
+
"\n",
|
| 106 |
+
"dirName"
|
| 107 |
+
]
|
| 108 |
+
},
|
| 109 |
+
{
|
| 110 |
+
"cell_type": "code",
|
| 111 |
+
"execution_count": 6,
|
| 112 |
+
"metadata": {},
|
| 113 |
+
"outputs": [
|
| 114 |
+
{
|
| 115 |
+
"data": {
|
| 116 |
+
"text/plain": [
|
| 117 |
+
"'E:\\\\projects\\\\Bioma-AI\\\\time-series-forecasting\\\\trend_prediction_app\\\\trend-prediction-ml\\\\trend-prediction-pipeline\\\\data\\\\2week_news_data.csv'"
|
| 118 |
+
]
|
| 119 |
+
},
|
| 120 |
+
"execution_count": 6,
|
| 121 |
+
"metadata": {},
|
| 122 |
+
"output_type": "execute_result"
|
| 123 |
+
}
|
| 124 |
+
],
|
| 125 |
+
"source": [
|
| 126 |
+
"dirName = r\"file:///E:\\projects\\Bioma-AI\\time-series-forecasting\\trend_prediction_app\\trend-prediction-ml\\trend-prediction-pipeline\\data\"\n",
|
| 127 |
+
"\n",
|
| 128 |
+
"dirName = dirName.replace(\"file:///\", \"\")\n",
|
| 129 |
+
"\n",
|
| 130 |
+
"fn = [f for f in os.listdir(dirName)\\\n",
|
| 131 |
+
" if f.endswith('.csv') and os.path.isfile(os.path.join(dirName, f))][0]\n",
|
| 132 |
+
"path = os.path.join(dirName, fn)\n",
|
| 133 |
+
"path"
|
| 134 |
+
]
|
| 135 |
+
},
|
| 136 |
+
{
|
| 137 |
+
"cell_type": "code",
|
| 138 |
+
"execution_count": null,
|
| 139 |
+
"metadata": {},
|
| 140 |
+
"outputs": [],
|
| 141 |
+
"source": [
|
| 142 |
+
" # r = requests.get(url, stream=True)\n",
|
| 143 |
+
" # with open(local_filename, \"wb\") as f:\n",
|
| 144 |
+
" # for chunk in r.iter_content(chunk_size=1024):\n",
|
| 145 |
+
" # if chunk: # filter out keep-alive new chunks\n",
|
| 146 |
+
" # f.write(chunk)\n",
|
| 147 |
+
"\n",
|
| 148 |
+
" # data_csv = fr\"{data_csv}\"\n",
|
| 149 |
+
" # print(data_csv)\n",
|
| 150 |
+
" # dirName = data_csv.replace(\"file:///\", \"\")\n",
|
| 151 |
+
"\n",
|
| 152 |
+
" # fn = [f for f in os.listdir(dirName)\\\n",
|
| 153 |
+
" # if f.endswith('.csv') and os.path.isfile(os.path.join(dirName, f))][0]\n",
|
| 154 |
+
" # data_csv_file = os.path.join(dirName, fn)\n",
|
| 155 |
+
"\n",
|
| 156 |
+
" # table = pa.csv.read_csv(data_csv)\n",
|
| 157 |
+
" # pa.parquet.write_table(table, data_csv.replace('csv', 'parquet'))"
|
| 158 |
+
]
|
| 159 |
+
},
|
| 160 |
+
{
|
| 161 |
+
"cell_type": "markdown",
|
| 162 |
+
"metadata": {},
|
| 163 |
+
"source": [
|
| 164 |
+
"## SQLite"
|
| 165 |
+
]
|
| 166 |
+
},
|
| 167 |
+
{
|
| 168 |
+
"cell_type": "code",
|
| 169 |
+
"execution_count": null,
|
| 170 |
+
"metadata": {},
|
| 171 |
+
"outputs": [],
|
| 172 |
+
"source": [
|
| 173 |
+
"## Delete Data\n",
|
| 174 |
+
"\n",
|
| 175 |
+
"import sqlite3\n",
|
| 176 |
+
"\n",
|
| 177 |
+
"try:\n",
|
| 178 |
+
" with sqlite3.connect('my.db') as conn:\n",
|
| 179 |
+
" cur = conn.cursor()\n",
|
| 180 |
+
" delete_stmt = 'DELETE FROM mlruns.db WHERE id = ?'\n",
|
| 181 |
+
" cur.execute(delete_stmt, (1,))\n",
|
| 182 |
+
" conn.commit()\n",
|
| 183 |
+
"except sqlite3.Error as e:\n",
|
| 184 |
+
" print(e)"
|
| 185 |
+
]
|
| 186 |
+
},
|
| 187 |
+
{
|
| 188 |
+
"cell_type": "code",
|
| 189 |
+
"execution_count": 7,
|
| 190 |
+
"metadata": {},
|
| 191 |
+
"outputs": [
|
| 192 |
+
{
|
| 193 |
+
"name": "stdout",
|
| 194 |
+
"output_type": "stream",
|
| 195 |
+
"text": [
|
| 196 |
+
"no such table: mlruns.db\n"
|
| 197 |
+
]
|
| 198 |
+
}
|
| 199 |
+
],
|
| 200 |
+
"source": [
|
| 201 |
+
"# Select Data\n",
|
| 202 |
+
"\n",
|
| 203 |
+
"import sqlite3\n",
|
| 204 |
+
"\n",
|
| 205 |
+
"try:\n",
|
| 206 |
+
" with sqlite3.connect(r'E:\\Projects\\Bioma-AI\\time-series-forecasting\\trend_prediction_app\\trend-prediction-ml\\trend-prediction-pipeline\\mlruns.db') as conn:\n",
|
| 207 |
+
" cur = conn.cursor()\n",
|
| 208 |
+
" delete_stmt = 'SELECT * FROM mlruns.db'\n",
|
| 209 |
+
" cur.execute(delete_stmt, (1,))\n",
|
| 210 |
+
" conn.commit()\n",
|
| 211 |
+
"except sqlite3.Error as e:\n",
|
| 212 |
+
" print(e)"
|
| 213 |
+
]
|
| 214 |
+
},
|
| 215 |
+
{
|
| 216 |
+
"cell_type": "code",
|
| 217 |
+
"execution_count": 11,
|
| 218 |
+
"metadata": {},
|
| 219 |
+
"outputs": [
|
| 220 |
+
{
|
| 221 |
+
"name": "stdout",
|
| 222 |
+
"output_type": "stream",
|
| 223 |
+
"text": [
|
| 224 |
+
"('e1dd6f53468a43ab8ae216ecd6d00f9b', 'fun-pug-865', 'UNKNOWN', '', '', 'mryan', 'FINISHED', 1725156717665, 1725156717711, '', 'deleted', 'file:///E:/Projects/Bioma-AI/time-series-forecasting/trend_prediction_app/trend-prediction-ml/trend-prediction-pipeline/mlruns/0/e1dd6f53468a43ab8ae216ecd6d00f9b/artifacts', 0, 1725157415352)\n",
|
| 225 |
+
"('19b0aa8dfd4d43babf1722241eac4d11', 'amazing-flea-532', 'UNKNOWN', '', '', 'mryan', 'FINISHED', 1725156844490, 1725156844527, '', 'deleted', 'file:///E:/Projects/Bioma-AI/time-series-forecasting/trend_prediction_app/trend-prediction-ml/trend-prediction-pipeline/mlruns/0/19b0aa8dfd4d43babf1722241eac4d11/artifacts', 0, 1725157415338)\n",
|
| 226 |
+
"('e8fb896431de4e37a188ae039901a502', 'rumbling-penguin-621', 'UNKNOWN', '', '', 'mryan', 'FINISHED', 1725157265761, 1725157265802, '', 'deleted', 'file:///E:/Projects/Bioma-AI/time-series-forecasting/trend_prediction_app/trend-prediction-ml/trend-prediction-pipeline/mlruns/0/e8fb896431de4e37a188ae039901a502/artifacts', 0, 1725157415321)\n",
|
| 227 |
+
"('4efbf5256ae34e6296a00238accfdc9f', 'trusting-doe-440', 'UNKNOWN', '', '', 'mryan', 'FINISHED', 1725157268161, 1725157268196, '', 'deleted', 'file:///E:/Projects/Bioma-AI/time-series-forecasting/trend_prediction_app/trend-prediction-ml/trend-prediction-pipeline/mlruns/0/4efbf5256ae34e6296a00238accfdc9f/artifacts', 0, 1725157415324)\n",
|
| 228 |
+
"('b0c0116c1805431a953bb8c07c184de9', 'popular-slug-621', 'UNKNOWN', '', '', 'mryan', 'FINISHED', 1725157437890, 1725157437931, '', 'active', 'file:///E:/Projects/Bioma-AI/time-series-forecasting/trend_prediction_app/trend-prediction-ml/trend-prediction-pipeline/mlruns/0/b0c0116c1805431a953bb8c07c184de9/artifacts', 0, None)\n"
|
| 229 |
+
]
|
| 230 |
+
}
|
| 231 |
+
],
|
| 232 |
+
"source": [
|
| 233 |
+
"import mlflow\n",
|
| 234 |
+
"import sqlite3\n",
|
| 235 |
+
"\n",
|
| 236 |
+
"# Log some data with MLflow\n",
|
| 237 |
+
"mlflow.set_tracking_uri(\"sqlite:///mlruns.db\")\n",
|
| 238 |
+
"\n",
|
| 239 |
+
"with mlflow.start_run():\n",
|
| 240 |
+
" mlflow.log_param(\"param1\", 5)\n",
|
| 241 |
+
" mlflow.log_metric(\"metric1\", 0.1)\n",
|
| 242 |
+
"\n",
|
| 243 |
+
"# Query the SQLite database\n",
|
| 244 |
+
"try:\n",
|
| 245 |
+
" db_path = r'E:\\Projects\\Bioma-AI\\time-series-forecasting\\trend_prediction_app\\trend-prediction-ml\\trend-prediction-pipeline\\mlruns.db'\n",
|
| 246 |
+
" with sqlite3.connect(db_path) as conn:\n",
|
| 247 |
+
" cur = conn.cursor()\n",
|
| 248 |
+
" \n",
|
| 249 |
+
" # Example query to fetch all runs\n",
|
| 250 |
+
" select_stmt = 'SELECT * FROM runs'\n",
|
| 251 |
+
" cur.execute(select_stmt)\n",
|
| 252 |
+
" rows = cur.fetchall()\n",
|
| 253 |
+
" \n",
|
| 254 |
+
" for row in rows:\n",
|
| 255 |
+
" print(row)\n",
|
| 256 |
+
"\n",
|
| 257 |
+
"except sqlite3.Error as e:\n",
|
| 258 |
+
" print(f\"SQLite error: {e}\")\n",
|
| 259 |
+
"except Exception as e:\n",
|
| 260 |
+
" print(f\"General error: {e}\")"
|
| 261 |
+
]
|
| 262 |
+
},
|
| 263 |
+
{
|
| 264 |
+
"cell_type": "code",
|
| 265 |
+
"execution_count": 4,
|
| 266 |
+
"metadata": {},
|
| 267 |
+
"outputs": [
|
| 268 |
+
{
|
| 269 |
+
"name": "stdout",
|
| 270 |
+
"output_type": "stream",
|
| 271 |
+
"text": [
|
| 272 |
+
"Tables in database: [('experiments',), ('alembic_version',), ('experiment_tags',), ('tags',), ('registered_models',), ('runs',), ('registered_model_tags',), ('model_version_tags',), ('model_versions',), ('latest_metrics',), ('metrics',), ('registered_model_aliases',), ('datasets',), ('inputs',), ('input_tags',), ('params',), ('trace_info',), ('trace_tags',), ('trace_request_metadata',)]\n"
|
| 273 |
+
]
|
| 274 |
+
}
|
| 275 |
+
],
|
| 276 |
+
"source": [
|
| 277 |
+
"import sqlite3\n",
|
| 278 |
+
"\n",
|
| 279 |
+
"db_path = r\"E:\\Projects\\Bioma-AI\\time-series-forecasting\\trend_prediction_app\\trend-prediction-ml\\trend-prediction-pipeline\\mlruns.db\"\n",
|
| 280 |
+
"\n",
|
| 281 |
+
"try:\n",
|
| 282 |
+
" conn = sqlite3.connect(db_path)\n",
|
| 283 |
+
" cursor = conn.cursor()\n",
|
| 284 |
+
" cursor.execute(\"SELECT name FROM sqlite_master WHERE type='table';\")\n",
|
| 285 |
+
" tables = cursor.fetchall()\n",
|
| 286 |
+
" print(\"Tables in database:\", tables)\n",
|
| 287 |
+
"except sqlite3.Error as e:\n",
|
| 288 |
+
" print(f\"SQLite error: {e}\")\n",
|
| 289 |
+
"finally:\n",
|
| 290 |
+
" conn.close()"
|
| 291 |
+
]
|
| 292 |
+
},
|
| 293 |
+
{
|
| 294 |
+
"cell_type": "code",
|
| 295 |
+
"execution_count": 6,
|
| 296 |
+
"metadata": {},
|
| 297 |
+
"outputs": [
|
| 298 |
+
{
|
| 299 |
+
"name": "stdout",
|
| 300 |
+
"output_type": "stream",
|
| 301 |
+
"text": [
|
| 302 |
+
"Run ID: a930976208fa4fb48dbbf5cf4d7f600f\n"
|
| 303 |
+
]
|
| 304 |
+
}
|
| 305 |
+
],
|
| 306 |
+
"source": [
|
| 307 |
+
"import mlflow\n",
|
| 308 |
+
"\n",
|
| 309 |
+
"# Use a new SQLite database file\n",
|
| 310 |
+
"new_db_path = r\"E:\\Projects\\Bioma-AI\\time-series-forecasting\\trend_prediction_app\\trend-prediction-ml\\trend-prediction-pipeline\\new_mlruns.db\"\n",
|
| 311 |
+
"mlflow.set_tracking_uri(f\"sqlite:///{new_db_path}\")\n",
|
| 312 |
+
"\n",
|
| 313 |
+
"with mlflow.start_run() as run:\n",
|
| 314 |
+
" mlflow.log_param(\"param1\", \"test\")\n",
|
| 315 |
+
" print(f\"Run ID: {run.info.run_id}\")\n",
|
| 316 |
+
"\n",
|
| 317 |
+
"# Check if the run is properly logged\n",
|
| 318 |
+
"client = mlflow.tracking.MlflowClient()"
|
| 319 |
+
]
|
| 320 |
+
},
|
| 321 |
+
{
|
| 322 |
+
"cell_type": "code",
|
| 323 |
+
"execution_count": 7,
|
| 324 |
+
"metadata": {},
|
| 325 |
+
"outputs": [
|
| 326 |
+
{
|
| 327 |
+
"ename": "MlflowException",
|
| 328 |
+
"evalue": "Run with id=a930976208fa4fb48dbbf5cf4d7f600f not found",
|
| 329 |
+
"output_type": "error",
|
| 330 |
+
"traceback": [
|
| 331 |
+
"\u001b[1;31m---------------------------------------------------------------------------\u001b[0m",
|
| 332 |
+
"\u001b[1;31mMlflowException\u001b[0m Traceback (most recent call last)",
|
| 333 |
+
"Cell \u001b[1;32mIn[7], line 12\u001b[0m\n\u001b[0;32m 10\u001b[0m \u001b[38;5;66;03m# Get run information using the run ID\u001b[39;00m\n\u001b[0;32m 11\u001b[0m run_id \u001b[38;5;241m=\u001b[39m \u001b[38;5;124m\"\u001b[39m\u001b[38;5;124ma930976208fa4fb48dbbf5cf4d7f600f\u001b[39m\u001b[38;5;124m\"\u001b[39m\n\u001b[1;32m---> 12\u001b[0m run \u001b[38;5;241m=\u001b[39m \u001b[43mclient\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mget_run\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrun_id\u001b[49m\u001b[43m)\u001b[49m\n\u001b[0;32m 13\u001b[0m \u001b[38;5;28mprint\u001b[39m(\u001b[38;5;124mf\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mRun ID: \u001b[39m\u001b[38;5;132;01m{\u001b[39;00mrun\u001b[38;5;241m.\u001b[39minfo\u001b[38;5;241m.\u001b[39mrun_id\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m\"\u001b[39m)\n\u001b[0;32m 14\u001b[0m \u001b[38;5;28mprint\u001b[39m(\u001b[38;5;124mf\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mRun Status: \u001b[39m\u001b[38;5;132;01m{\u001b[39;00mrun\u001b[38;5;241m.\u001b[39minfo\u001b[38;5;241m.\u001b[39mstatus\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m\"\u001b[39m)\n",
|
| 334 |
+
"File \u001b[1;32me:\\VM\\miniconda3\\envs\\mlops\\lib\\site-packages\\mlflow\\tracking\\client.py:226\u001b[0m, in \u001b[0;36mMlflowClient.get_run\u001b[1;34m(self, run_id)\u001b[0m\n\u001b[0;32m 182\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21mget_run\u001b[39m(\u001b[38;5;28mself\u001b[39m, run_id: \u001b[38;5;28mstr\u001b[39m) \u001b[38;5;241m-\u001b[39m\u001b[38;5;241m>\u001b[39m Run:\n\u001b[0;32m 183\u001b[0m \u001b[38;5;250m \u001b[39m\u001b[38;5;124;03m\"\"\"\u001b[39;00m\n\u001b[0;32m 184\u001b[0m \u001b[38;5;124;03m Fetch the run from backend store. The resulting :py:class:`Run <mlflow.entities.Run>`\u001b[39;00m\n\u001b[0;32m 185\u001b[0m \u001b[38;5;124;03m contains a collection of run metadata -- :py:class:`RunInfo <mlflow.entities.RunInfo>`,\u001b[39;00m\n\u001b[1;32m (...)\u001b[0m\n\u001b[0;32m 224\u001b[0m \n\u001b[0;32m 225\u001b[0m \u001b[38;5;124;03m \"\"\"\u001b[39;00m\n\u001b[1;32m--> 226\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_tracking_client\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mget_run\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrun_id\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 335 |
+
"File \u001b[1;32me:\\VM\\miniconda3\\envs\\mlops\\lib\\site-packages\\mlflow\\tracking\\_tracking_service\\client.py:104\u001b[0m, in \u001b[0;36mTrackingServiceClient.get_run\u001b[1;34m(self, run_id)\u001b[0m\n\u001b[0;32m 88\u001b[0m \u001b[38;5;250m\u001b[39m\u001b[38;5;124;03m\"\"\"Fetch the run from backend store. The resulting :py:class:`Run <mlflow.entities.Run>`\u001b[39;00m\n\u001b[0;32m 89\u001b[0m \u001b[38;5;124;03mcontains a collection of run metadata -- :py:class:`RunInfo <mlflow.entities.RunInfo>`,\u001b[39;00m\n\u001b[0;32m 90\u001b[0m \u001b[38;5;124;03mas well as a collection of run parameters, tags, and metrics --\u001b[39;00m\n\u001b[1;32m (...)\u001b[0m\n\u001b[0;32m 101\u001b[0m \n\u001b[0;32m 102\u001b[0m \u001b[38;5;124;03m\"\"\"\u001b[39;00m\n\u001b[0;32m 103\u001b[0m _validate_run_id(run_id)\n\u001b[1;32m--> 104\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mstore\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mget_run\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrun_id\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 336 |
+
"File \u001b[1;32me:\\VM\\miniconda3\\envs\\mlops\\lib\\site-packages\\mlflow\\store\\tracking\\sqlalchemy_store.py:640\u001b[0m, in \u001b[0;36mSqlAlchemyStore.get_run\u001b[1;34m(self, run_id)\u001b[0m\n\u001b[0;32m 634\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21mget_run\u001b[39m(\u001b[38;5;28mself\u001b[39m, run_id):\n\u001b[0;32m 635\u001b[0m \u001b[38;5;28;01mwith\u001b[39;00m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39mManagedSessionMaker() \u001b[38;5;28;01mas\u001b[39;00m session:\n\u001b[0;32m 636\u001b[0m \u001b[38;5;66;03m# Load the run with the specified id and eagerly load its summary metrics, params, and\u001b[39;00m\n\u001b[0;32m 637\u001b[0m \u001b[38;5;66;03m# tags. These attributes are referenced during the invocation of\u001b[39;00m\n\u001b[0;32m 638\u001b[0m \u001b[38;5;66;03m# ``run.to_mlflow_entity()``, so eager loading helps avoid additional database queries\u001b[39;00m\n\u001b[0;32m 639\u001b[0m \u001b[38;5;66;03m# that are otherwise executed at attribute access time under a lazy loading model.\u001b[39;00m\n\u001b[1;32m--> 640\u001b[0m run \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_get_run\u001b[49m\u001b[43m(\u001b[49m\u001b[43mrun_uuid\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mrun_id\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43msession\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43msession\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43meager\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;28;43;01mTrue\u001b[39;49;00m\u001b[43m)\u001b[49m\n\u001b[0;32m 641\u001b[0m mlflow_run \u001b[38;5;241m=\u001b[39m run\u001b[38;5;241m.\u001b[39mto_mlflow_entity()\n\u001b[0;32m 642\u001b[0m \u001b[38;5;66;03m# Get the run inputs and add to the run\u001b[39;00m\n",
|
| 337 |
+
"File \u001b[1;32me:\\VM\\miniconda3\\envs\\mlops\\lib\\site-packages\\mlflow\\store\\tracking\\sqlalchemy_store.py:524\u001b[0m, in \u001b[0;36mSqlAlchemyStore._get_run\u001b[1;34m(self, session, run_uuid, eager)\u001b[0m\n\u001b[0;32m 519\u001b[0m runs \u001b[38;5;241m=\u001b[39m (\n\u001b[0;32m 520\u001b[0m session\u001b[38;5;241m.\u001b[39mquery(SqlRun)\u001b[38;5;241m.\u001b[39moptions(\u001b[38;5;241m*\u001b[39mquery_options)\u001b[38;5;241m.\u001b[39mfilter(SqlRun\u001b[38;5;241m.\u001b[39mrun_uuid \u001b[38;5;241m==\u001b[39m run_uuid)\u001b[38;5;241m.\u001b[39mall()\n\u001b[0;32m 521\u001b[0m )\n\u001b[0;32m 523\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;28mlen\u001b[39m(runs) \u001b[38;5;241m==\u001b[39m \u001b[38;5;241m0\u001b[39m:\n\u001b[1;32m--> 524\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m MlflowException(\u001b[38;5;124mf\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mRun with id=\u001b[39m\u001b[38;5;132;01m{\u001b[39;00mrun_uuid\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m not found\u001b[39m\u001b[38;5;124m\"\u001b[39m, RESOURCE_DOES_NOT_EXIST)\n\u001b[0;32m 525\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;28mlen\u001b[39m(runs) \u001b[38;5;241m>\u001b[39m \u001b[38;5;241m1\u001b[39m:\n\u001b[0;32m 526\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m MlflowException(\n\u001b[0;32m 527\u001b[0m \u001b[38;5;124mf\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mExpected only 1 run with id=\u001b[39m\u001b[38;5;132;01m{\u001b[39;00mrun_uuid\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m. Found \u001b[39m\u001b[38;5;132;01m{\u001b[39;00m\u001b[38;5;28mlen\u001b[39m(runs)\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m.\u001b[39m\u001b[38;5;124m\"\u001b[39m,\n\u001b[0;32m 528\u001b[0m INVALID_STATE,\n\u001b[0;32m 529\u001b[0m )\n",
|
| 338 |
+
"\u001b[1;31mMlflowException\u001b[0m: Run with id=a930976208fa4fb48dbbf5cf4d7f600f not found"
|
| 339 |
+
]
|
| 340 |
+
}
|
| 341 |
+
],
|
| 342 |
+
"source": [
|
| 343 |
+
"import mlflow\n",
|
| 344 |
+
"from mlflow.tracking import MlflowClient\n",
|
| 345 |
+
"\n",
|
| 346 |
+
"# Set the tracking URI to the SQLite database\n",
|
| 347 |
+
"mlflow.set_tracking_uri(\"sqlite:///E:/Projects/Bioma-AI/time-series-forecasting/trend_prediction_app/trend-prediction-ml/trend-prediction-pipeline/mlruns.db\")\n",
|
| 348 |
+
"\n",
|
| 349 |
+
"# Initialize MLflow client\n",
|
| 350 |
+
"client = MlflowClient()\n",
|
| 351 |
+
"\n",
|
| 352 |
+
"# Get run information using the run ID\n",
|
| 353 |
+
"run_id = \"a930976208fa4fb48dbbf5cf4d7f600f\"\n",
|
| 354 |
+
"run = client.get_run(run_id)\n",
|
| 355 |
+
"print(f\"Run ID: {run.info.run_id}\")\n",
|
| 356 |
+
"print(f\"Run Status: {run.info.status}\")\n",
|
| 357 |
+
"print(f\"Artifact URI: {run.info.artifact_uri}\")\n",
|
| 358 |
+
"\n",
|
| 359 |
+
"# List artifacts in the run\n",
|
| 360 |
+
"artifacts = client.list_artifacts(run_id)\n",
|
| 361 |
+
"for artifact in artifacts:\n",
|
| 362 |
+
" print(f\"Artifact Path: {artifact.path}\")"
|
| 363 |
+
]
|
| 364 |
+
},
|
| 365 |
+
{
|
| 366 |
+
"cell_type": "code",
|
| 367 |
+
"execution_count": 4,
|
| 368 |
+
"metadata": {},
|
| 369 |
+
"outputs": [
|
| 370 |
+
{
|
| 371 |
+
"name": "stdout",
|
| 372 |
+
"output_type": "stream",
|
| 373 |
+
"text": [
|
| 374 |
+
"Run ID: 154301663fcc4245a7cc98eea0d123c3\n"
|
| 375 |
+
]
|
| 376 |
+
}
|
| 377 |
+
],
|
| 378 |
+
"source": [
|
| 379 |
+
"import mlflow\n",
|
| 380 |
+
"\n",
|
| 381 |
+
"# Set the tracking URI to your SQLite database\n",
|
| 382 |
+
"mlflow.set_tracking_uri(\"sqlite:///mlruns.db\")\n",
|
| 383 |
+
"\n",
|
| 384 |
+
"# Start a new run\n",
|
| 385 |
+
"with mlflow.start_run() as run:\n",
|
| 386 |
+
" print(f\"Run ID: {run.info.run_id}\")"
|
| 387 |
+
]
|
| 388 |
+
},
|
| 389 |
+
{
|
| 390 |
+
"cell_type": "code",
|
| 391 |
+
"execution_count": 1,
|
| 392 |
+
"metadata": {},
|
| 393 |
+
"outputs": [
|
| 394 |
+
{
|
| 395 |
+
"name": "stdout",
|
| 396 |
+
"output_type": "stream",
|
| 397 |
+
"text": [
|
| 398 |
+
"Tables in database: [('experiments',), ('alembic_version',), ('experiment_tags',), ('tags',), ('registered_models',), ('runs',), ('registered_model_tags',), ('model_version_tags',), ('model_versions',), ('latest_metrics',), ('metrics',), ('registered_model_aliases',), ('datasets',), ('inputs',), ('input_tags',), ('params',), ('trace_info',), ('trace_tags',), ('trace_request_metadata',)]\n",
|
| 399 |
+
"Contents of experiments:\n",
|
| 400 |
+
"(0, 'Default', 'file:///E:/Projects/Bioma-AI/time-series-forecasting/trend_prediction_app/trend-prediction-ml/trend-prediction-pipeline/mlruns/0', 'active', 1725160384768, 1725160384768)\n",
|
| 401 |
+
"Contents of alembic_version:\n",
|
| 402 |
+
"('4465047574b1',)\n",
|
| 403 |
+
"Contents of experiment_tags:\n",
|
| 404 |
+
"Contents of tags:\n",
|
| 405 |
+
"Contents of registered_models:\n",
|
| 406 |
+
"Contents of runs:\n",
|
| 407 |
+
"Contents of registered_model_tags:\n",
|
| 408 |
+
"Contents of model_version_tags:\n",
|
| 409 |
+
"Contents of model_versions:\n",
|
| 410 |
+
"Contents of latest_metrics:\n",
|
| 411 |
+
"Contents of metrics:\n",
|
| 412 |
+
"Contents of registered_model_aliases:\n",
|
| 413 |
+
"Contents of datasets:\n",
|
| 414 |
+
"Contents of inputs:\n",
|
| 415 |
+
"Contents of input_tags:\n",
|
| 416 |
+
"Contents of params:\n",
|
| 417 |
+
"Contents of trace_info:\n",
|
| 418 |
+
"Contents of trace_tags:\n",
|
| 419 |
+
"Contents of trace_request_metadata:\n"
|
| 420 |
+
]
|
| 421 |
+
}
|
| 422 |
+
],
|
| 423 |
+
"source": [
|
| 424 |
+
"import sqlite3\n",
|
| 425 |
+
"\n",
|
| 426 |
+
"db_path = r\"E:\\Projects\\Bioma-AI\\time-series-forecasting\\trend_prediction_app\\trend-prediction-ml\\trend-prediction-pipeline\\mlruns.db\"\n",
|
| 427 |
+
"try:\n",
|
| 428 |
+
" with sqlite3.connect(db_path) as conn:\n",
|
| 429 |
+
" cursor = conn.cursor()\n",
|
| 430 |
+
" cursor.execute(\"SELECT name FROM sqlite_master WHERE type='table';\")\n",
|
| 431 |
+
" tables = cursor.fetchall()\n",
|
| 432 |
+
" print(\"Tables in database:\", tables)\n",
|
| 433 |
+
" \n",
|
| 434 |
+
" for table in tables:\n",
|
| 435 |
+
" print(f\"Contents of {table[0]}:\")\n",
|
| 436 |
+
" cursor.execute(f\"SELECT * FROM {table[0]} LIMIT 10;\")\n",
|
| 437 |
+
" rows = cursor.fetchall()\n",
|
| 438 |
+
" for row in rows:\n",
|
| 439 |
+
" print(row)\n",
|
| 440 |
+
"except sqlite3.Error as e:\n",
|
| 441 |
+
" print(f\"SQLite error: {e}\")"
|
| 442 |
+
]
|
| 443 |
+
},
|
| 444 |
+
{
|
| 445 |
+
"cell_type": "code",
|
| 446 |
+
"execution_count": 1,
|
| 447 |
+
"metadata": {},
|
| 448 |
+
"outputs": [
|
| 449 |
+
{
|
| 450 |
+
"name": "stdout",
|
| 451 |
+
"output_type": "stream",
|
| 452 |
+
"text": [
|
| 453 |
+
"env: MLFLOW_TRACKING_URI=sqlite:///mlruns.db\n"
|
| 454 |
+
]
|
| 455 |
+
}
|
| 456 |
+
],
|
| 457 |
+
"source": [
|
| 458 |
+
"%env MLFLOW_TRACKING_URI=sqlite:///mlruns.db"
|
| 459 |
+
]
|
| 460 |
+
},
|
| 461 |
+
{
|
| 462 |
+
"cell_type": "code",
|
| 463 |
+
"execution_count": null,
|
| 464 |
+
"metadata": {},
|
| 465 |
+
"outputs": [],
|
| 466 |
+
"source": []
|
| 467 |
+
}
|
| 468 |
+
],
|
| 469 |
+
"metadata": {
|
| 470 |
+
"kernelspec": {
|
| 471 |
+
"display_name": "mlops",
|
| 472 |
+
"language": "python",
|
| 473 |
+
"name": "python3"
|
| 474 |
+
},
|
| 475 |
+
"language_info": {
|
| 476 |
+
"codemirror_mode": {
|
| 477 |
+
"name": "ipython",
|
| 478 |
+
"version": 3
|
| 479 |
+
},
|
| 480 |
+
"file_extension": ".py",
|
| 481 |
+
"mimetype": "text/x-python",
|
| 482 |
+
"name": "python",
|
| 483 |
+
"nbconvert_exporter": "python",
|
| 484 |
+
"pygments_lexer": "ipython3",
|
| 485 |
+
"version": "3.9.19"
|
| 486 |
+
}
|
| 487 |
+
},
|
| 488 |
+
"nbformat": 4,
|
| 489 |
+
"nbformat_minor": 2
|
| 490 |
+
}
|
experimentation_mlops/mlops/train.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## TODO
|
| 2 |
+
## Make the cross validation model get saved as well and log the params and model as mlflow artifacts
|
| 3 |
+
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from modules.neuralforecast.core import NeuralForecast
|
| 6 |
+
from modules.neuralforecast.models import TSMixer, TSMixerx, NHITS, MLPMultivariate, NBEATSx
|
| 7 |
+
from modules.neuralforecast.losses.pytorch import MSE, MAE, MAPE
|
| 8 |
+
from sklearn.preprocessing import StandardScaler
|
| 9 |
+
import numpy as np
|
| 10 |
+
import os
|
| 11 |
+
|
| 12 |
+
horizon = 30
|
| 13 |
+
input_size = horizon*2
|
| 14 |
+
models = [
|
| 15 |
+
TSMixer(h=horizon,
|
| 16 |
+
input_size=input_size,
|
| 17 |
+
n_series=1,
|
| 18 |
+
max_steps=1000,
|
| 19 |
+
val_check_steps=100,
|
| 20 |
+
early_stop_patience_steps=5,
|
| 21 |
+
scaler_type='identity',
|
| 22 |
+
loss=MAPE(),
|
| 23 |
+
valid_loss=MAPE(),
|
| 24 |
+
random_seed=12345678,
|
| 25 |
+
),
|
| 26 |
+
TSMixerx(h=horizon,
|
| 27 |
+
input_size=input_size,
|
| 28 |
+
n_series=1,
|
| 29 |
+
max_steps=1000,
|
| 30 |
+
val_check_steps=100,
|
| 31 |
+
early_stop_patience_steps=5,
|
| 32 |
+
scaler_type='identity',
|
| 33 |
+
dropout=0.7,
|
| 34 |
+
loss=MAPE(),
|
| 35 |
+
valid_loss=MAPE(),
|
| 36 |
+
random_seed=12345678,
|
| 37 |
+
futr_exog_list=['Gas', 'DXY', 'BrFu', 'BrDa'],
|
| 38 |
+
),
|
| 39 |
+
NBEATSx(h=horizon,
|
| 40 |
+
input_size=horizon,
|
| 41 |
+
max_steps=1000,
|
| 42 |
+
val_check_steps=100,
|
| 43 |
+
early_stop_patience_steps=5,
|
| 44 |
+
scaler_type='identity',
|
| 45 |
+
loss=MAPE(),
|
| 46 |
+
valid_loss=MAPE(),
|
| 47 |
+
random_seed=12345678,
|
| 48 |
+
futr_exog_list=['Gas', 'DXY', 'BrFu', 'BrDa']
|
| 49 |
+
),
|
| 50 |
+
]
|
| 51 |
+
|
| 52 |
+
nf = NeuralForecast(
|
| 53 |
+
models=models,
|
| 54 |
+
freq='D')
|
| 55 |
+
|
| 56 |
+
Y_hat_df = nf.cross_validation(df=df,
|
| 57 |
+
val_size=val_size,
|
| 58 |
+
test_size=test_size,
|
| 59 |
+
n_windows=None
|
| 60 |
+
)
|
| 61 |
+
Y_hat_df = Y_hat_df.reset_index()
|
| 62 |
+
|
| 63 |
+
# Start from here
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
# Using MLflow
|
| 67 |
+
# Log your neuralforecast experiments to MLflow
|
| 68 |
+
|
| 69 |
+
# Installing dependencies
|
| 70 |
+
# To install Neuralforecast refer to https://nixtlaverse.nixtla.io/neuralforecast/examples/installation.html.
|
| 71 |
+
|
| 72 |
+
# To install mlflow: pip install mlflow
|
| 73 |
+
|
| 74 |
+
# Imports
|
| 75 |
+
|
| 76 |
+
import logging
|
| 77 |
+
import os
|
| 78 |
+
import warnings
|
| 79 |
+
|
| 80 |
+
import matplotlib.pyplot as plt
|
| 81 |
+
import mlflow
|
| 82 |
+
import mlflow.data
|
| 83 |
+
import numpy as np
|
| 84 |
+
import pandas as pd
|
| 85 |
+
from mlflow.client import MlflowClient
|
| 86 |
+
from mlflow.data.pandas_dataset import PandasDataset
|
| 87 |
+
from utilsforecast.plotting import plot_series
|
| 88 |
+
|
| 89 |
+
from neuralforecast.core import NeuralForecast
|
| 90 |
+
from neuralforecast.models import NBEATSx
|
| 91 |
+
from neuralforecast.utils import AirPassengersDF
|
| 92 |
+
from neuralforecast.losses.pytorch import MAE
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
os.environ['NIXTLA_ID_AS_COL'] = '1'
|
| 96 |
+
logging.getLogger("mlflow").setLevel(logging.ERROR)
|
| 97 |
+
logging.getLogger("pytorch_lightning").setLevel(logging.ERROR)
|
| 98 |
+
warnings.filterwarnings("ignore")
|
| 99 |
+
|
| 100 |
+
# Splitting the data
|
| 101 |
+
|
| 102 |
+
# Split data and declare panel dataset
|
| 103 |
+
Y_df = AirPassengersDF
|
| 104 |
+
Y_train_df = Y_df[Y_df.ds<='1959-12-31'] # 132 train
|
| 105 |
+
Y_test_df = Y_df[Y_df.ds>'1959-12-31'] # 12 test
|
| 106 |
+
Y_df.tail()
|
| 107 |
+
|
| 108 |
+
# unique_id ds y
|
| 109 |
+
# 139 1.0 1960-08-31 606.0
|
| 110 |
+
# 140 1.0 1960-09-30 508.0
|
| 111 |
+
# 141 1.0 1960-10-31 461.0
|
| 112 |
+
# 142 1.0 1960-11-30 390.0
|
| 113 |
+
# 143 1.0 1960-12-31 432.0
|
| 114 |
+
# MLflow UI
|
| 115 |
+
# Run the following command from the terminal to start the UI: mlflow ui. You can then go to the printed URL to visualize the experiments.
|
| 116 |
+
|
| 117 |
+
# Model training
|
| 118 |
+
|
| 119 |
+
mlflow.pytorch.autolog(checkpoint=False)
|
| 120 |
+
|
| 121 |
+
with mlflow.start_run() as run:
|
| 122 |
+
# Log the dataset to the MLflow Run. Specify the "training" context to indicate that the
|
| 123 |
+
# dataset is used for model training
|
| 124 |
+
dataset: PandasDataset = mlflow.data.from_pandas(Y_df, source="AirPassengersDF")
|
| 125 |
+
mlflow.log_input(dataset, context="training")
|
| 126 |
+
|
| 127 |
+
# Define and log parameters
|
| 128 |
+
horizon = len(Y_test_df)
|
| 129 |
+
model_params = dict(
|
| 130 |
+
input_size=1 * horizon,
|
| 131 |
+
h=horizon,
|
| 132 |
+
max_steps=300,
|
| 133 |
+
loss=MAE(),
|
| 134 |
+
valid_loss=MAE(),
|
| 135 |
+
activation='ReLU',
|
| 136 |
+
scaler_type='robust',
|
| 137 |
+
random_seed=42,
|
| 138 |
+
enable_progress_bar=False,
|
| 139 |
+
)
|
| 140 |
+
mlflow.log_params(model_params)
|
| 141 |
+
|
| 142 |
+
# Fit NBEATSx model
|
| 143 |
+
models = [NBEATSx(**model_params)]
|
| 144 |
+
nf = NeuralForecast(models=models, freq='M')
|
| 145 |
+
train = nf.fit(df=Y_train_df, val_size=horizon)
|
| 146 |
+
|
| 147 |
+
# Save conda environment used to run the model
|
| 148 |
+
mlflow.pytorch.get_default_conda_env()
|
| 149 |
+
|
| 150 |
+
# Save pip requirements
|
| 151 |
+
mlflow.pytorch.get_default_pip_requirements()
|
| 152 |
+
|
| 153 |
+
mlflow.pytorch.autolog(disable=True)
|
| 154 |
+
|
| 155 |
+
# Save the neural forecast model
|
| 156 |
+
nf.save(path='./checkpoints/test_run_1/',
|
| 157 |
+
model_index=None,
|
| 158 |
+
overwrite=True,
|
| 159 |
+
save_dataset=True)
|
| 160 |
+
|
| 161 |
+
#Seed set to 42
|
| 162 |
+
#Forecasting the future
|
| 163 |
+
|
| 164 |
+
Y_hat_df = nf.predict(futr_df=Y_test_df)
|
| 165 |
+
plot_series(Y_train_df, Y_hat_df, palette='tab20b')
|
| 166 |
+
|
experimentation_mlops/mlops/transform.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Split data into train-test-val based on proportions
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
from modules.transformations import logReturn, scaleStandard, createLag
|
| 6 |
+
|
| 7 |
+
import pandas as pd
|
| 8 |
+
import numpy as np
|
| 9 |
+
import click
|
| 10 |
+
|
| 11 |
+
import mlflow
|
| 12 |
+
|
| 13 |
+
@click.command(
|
| 14 |
+
help="Transforms the data to based on customizations"
|
| 15 |
+
"in an mlflow artifact called 'ratings-parquet-dir'"
|
| 16 |
+
)
|
| 17 |
+
@click.option("--data-parquet")
|
| 18 |
+
@click.option(
|
| 19 |
+
"--test-size", default=0.1, help="Proportion of data for test set"
|
| 20 |
+
)
|
| 21 |
+
@click.option(
|
| 22 |
+
"--val-size", default=0.1, help="Proportion of data for test set"
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
def split(data_parquet, test_size=0.1, val_size=0.1, log_return = [], standard_scale = []):
|
| 26 |
+
"""
|
| 27 |
+
Splits data into train-test-validation sets
|
| 28 |
+
|
| 29 |
+
Input:
|
| 30 |
+
:param pd.DataFrame data: Dataset for splitting
|
| 31 |
+
:param float test_size: Proportion of data for test set
|
| 32 |
+
:param float val_size: Proportiion of data for validation set
|
| 33 |
+
|
| 34 |
+
Output:
|
| 35 |
+
Split data into train-test-val
|
| 36 |
+
"""
|
| 37 |
+
with mlflow.start_run():
|
| 38 |
+
y_log_ret = False
|
| 39 |
+
y_std_scale = False
|
| 40 |
+
|
| 41 |
+
data = pd.read_parquet(data_parquet)
|
| 42 |
+
|
| 43 |
+
# Split data into train-test-val without any randomization
|
| 44 |
+
|
| 45 |
+
train_size = int(len(data) * (1 - test_size - val_size))
|
| 46 |
+
test_size = int(len(data) * test_size)
|
| 47 |
+
val_size = int(len(data) * val_size)
|
| 48 |
+
|
| 49 |
+
train = data[:train_size].sort_values(by='ds', inplace=True)
|
| 50 |
+
test = data[train_size:train_size+test_size].sort_values(by='ds', inplace=True)
|
| 51 |
+
val = data[train_size+test_size:train_size+test_size+val_size].sort_values(by='ds', inplace=True)
|
| 52 |
+
|
| 53 |
+
# Transform select columns
|
| 54 |
+
|
| 55 |
+
if len(log_return) != 0:
|
| 56 |
+
|
| 57 |
+
for col1 in log_return:
|
| 58 |
+
try:
|
| 59 |
+
#print(data[col1])
|
| 60 |
+
data[col1] = logReturn(data, col1)
|
| 61 |
+
except Exception as e:
|
| 62 |
+
print(e)
|
| 63 |
+
pass
|
| 64 |
+
|
| 65 |
+
if 'y' in log_return:
|
| 66 |
+
y_log_ret = True
|
| 67 |
+
|
| 68 |
+
if len(standard_scale) != 0:
|
| 69 |
+
|
| 70 |
+
for col2 in standard_scale:
|
| 71 |
+
try:
|
| 72 |
+
data[col2], _ = scaleStandard(data[[col2]])
|
| 73 |
+
except Exception as e:
|
| 74 |
+
print(e)
|
| 75 |
+
pass
|
| 76 |
+
|
| 77 |
+
if 'y' in standard_scale:
|
| 78 |
+
data['y'], yScaler = scaleStandard(data[['y']])
|
| 79 |
+
y_std_scale = True
|
| 80 |
+
|
| 81 |
+
return data
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
if __name__ == "__main__":
|
| 85 |
+
split()
|
modules/__init__.py
ADDED
|
File without changes
|
modules/__pycache__/__init__.cpython-39.pyc
ADDED
|
Binary file (213 Bytes). View file
|
|
|
modules/__pycache__/data_preparation.cpython-39.pyc
ADDED
|
Binary file (2.38 kB). View file
|
|
|
modules/__pycache__/semantic.cpython-39.pyc
ADDED
|
Binary file (4.83 kB). View file
|
|
|
modules/data_preparation.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import plotly.express as px
|
| 3 |
+
import datetime
|
| 4 |
+
import plotly.graph_objects as go
|
| 5 |
+
import numpy as np
|
| 6 |
+
import pandas as pd
|
| 7 |
+
import datetime
|
| 8 |
+
|
| 9 |
+
def clean_text(text):
|
| 10 |
+
new_text = text
|
| 11 |
+
for rgx_match in ['[A-Z ]+:']:
|
| 12 |
+
new_text = re.sub(rgx_match, '', new_text)
|
| 13 |
+
return new_text
|
| 14 |
+
|
| 15 |
+
def prepare_df(df, categories, date_filter):
|
| 16 |
+
try:
|
| 17 |
+
df.drop(columns=['Unnamed: 0'], inplace=True)
|
| 18 |
+
except:
|
| 19 |
+
pass
|
| 20 |
+
|
| 21 |
+
#df['topic_verification'][(df.headline.str.contains('crude', case=False)) | df.body.str.contains('crude', case=False)] = 'Crude Oil'
|
| 22 |
+
|
| 23 |
+
try:
|
| 24 |
+
news_data = df[df['topic_verification'].isin(categories)]
|
| 25 |
+
|
| 26 |
+
actual_day = datetime.date.today() - datetime.timedelta(days=1)
|
| 27 |
+
pattern_del = actual_day.strftime('%b').upper()
|
| 28 |
+
|
| 29 |
+
filter = news_data['headline'].str.contains(pattern_del)
|
| 30 |
+
news_data = news_data[~filter]
|
| 31 |
+
|
| 32 |
+
# shift column 'C' to first position
|
| 33 |
+
first_column = news_data.pop('headline')
|
| 34 |
+
|
| 35 |
+
# insert column using insert(position,column_name,first_column) function
|
| 36 |
+
news_data.insert(0, 'headline', first_column)
|
| 37 |
+
|
| 38 |
+
news_data['updatedDate'] = pd.to_datetime(news_data['updatedDate'], format='%Y-%m-%d %H:%M:%S%z')
|
| 39 |
+
|
| 40 |
+
dates = []
|
| 41 |
+
|
| 42 |
+
dates.append(datetime.datetime.strftime(date_filter[0], '%Y-%m-%d %H:%M:%S%z'))
|
| 43 |
+
dates.append(datetime.datetime.strftime(date_filter[1], '%Y-%m-%d %H:%M:%S%z'))
|
| 44 |
+
|
| 45 |
+
news_data = news_data[(news_data['updatedDate'] >= dates[0]) & (news_data['updatedDate'] <= dates[1])]
|
| 46 |
+
|
| 47 |
+
except Exception as E:
|
| 48 |
+
print(E)
|
| 49 |
+
|
| 50 |
+
return news_data
|
| 51 |
+
|
| 52 |
+
def plot_3dgraph(news_data):
|
| 53 |
+
fig = px.scatter_3d(news_data,
|
| 54 |
+
x='neutral_score',
|
| 55 |
+
y='negative_score',
|
| 56 |
+
z='positive_score',
|
| 57 |
+
color='positive_score',
|
| 58 |
+
hover_name ='headline',
|
| 59 |
+
color_continuous_scale='RdBu',
|
| 60 |
+
size_max=40,
|
| 61 |
+
size='negative_score',
|
| 62 |
+
#text='headline',
|
| 63 |
+
hover_data='topic_verification')
|
| 64 |
+
|
| 65 |
+
fig.update_layout(
|
| 66 |
+
height=600,
|
| 67 |
+
title=dict(text=f"News Semantics towards Crude Oil Price <br><sup>Hover cursor on a datapoint to show news title</sup>",
|
| 68 |
+
font=dict(size=35),
|
| 69 |
+
automargin=False)
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
fig.update_traces(textfont_size=8)
|
| 73 |
+
|
| 74 |
+
trace=dict(type='scatter3d',
|
| 75 |
+
x=news_data.iloc[[-1]]['neutral_score'],
|
| 76 |
+
y=news_data.iloc[[-1]]['negative_score'],
|
| 77 |
+
z=news_data.iloc[[-1]]['positive_score'],
|
| 78 |
+
mode='markers',
|
| 79 |
+
name= 'MEAN OF SELECTED NEWS',
|
| 80 |
+
marker=dict(color=[f'rgb({0}, {250}, {200})' for _ in range(25)],
|
| 81 |
+
size=10)
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
fig.add_trace(trace)
|
| 85 |
+
|
| 86 |
+
return fig
|
modules/semantic.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import os
|
| 3 |
+
import nltk
|
| 4 |
+
from nltk.corpus import stopwords
|
| 5 |
+
import plotly.express as px
|
| 6 |
+
from collections import Counter
|
| 7 |
+
import re
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
from wordcloud import WordCloud
|
| 10 |
+
|
| 11 |
+
place_mapping = {
|
| 12 |
+
'united states': 'United States',
|
| 13 |
+
'u.s.': 'United States',
|
| 14 |
+
'US': 'United States',
|
| 15 |
+
'america': 'United States',
|
| 16 |
+
'north america': 'North America',
|
| 17 |
+
'usa': 'United States',
|
| 18 |
+
'south america': 'South America',
|
| 19 |
+
'american': 'United States',
|
| 20 |
+
'europe': 'Europe',
|
| 21 |
+
'eu': 'Europe',
|
| 22 |
+
'china': 'China',
|
| 23 |
+
'chinese': 'China',
|
| 24 |
+
'russia': 'Russia',
|
| 25 |
+
'arab': 'Arab Countries',
|
| 26 |
+
'middle east': 'Middle East',
|
| 27 |
+
'asia': 'Asia',
|
| 28 |
+
'asian': 'Asia',
|
| 29 |
+
'spain': 'Spain',
|
| 30 |
+
'germany': 'Germany',
|
| 31 |
+
'france': 'France',
|
| 32 |
+
'uk': 'United Kingdom',
|
| 33 |
+
'britain': 'United Kingdom',
|
| 34 |
+
'canada': 'Canada',
|
| 35 |
+
'mexico': 'Mexico',
|
| 36 |
+
'brazil': 'Brazil',
|
| 37 |
+
'venezuela': 'Venezuela',
|
| 38 |
+
'angola': 'Angola',
|
| 39 |
+
'nigeria': 'Nigeria',
|
| 40 |
+
'libya': 'Libya',
|
| 41 |
+
'iraq': 'Iraq',
|
| 42 |
+
'iran': 'Iran',
|
| 43 |
+
'kuwait': 'Kuwait',
|
| 44 |
+
'qatar': 'Qatar',
|
| 45 |
+
'saudi arabia': 'Saudi Arabia',
|
| 46 |
+
'gcc': 'Gulf Cooperation Council',
|
| 47 |
+
'asia-pacific': 'Asia',
|
| 48 |
+
'southeast asia': 'Asia',
|
| 49 |
+
'latin america': 'Latin America',
|
| 50 |
+
'caribbean': 'Caribbean',
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
region_mapping = {
|
| 54 |
+
'North America': ['United States', 'Canada', 'Mexico'],
|
| 55 |
+
'South America': ['Brazil', 'Venezuela'],
|
| 56 |
+
'Europe': ['United Kingdom', 'Germany', 'France', 'Spain', 'Russia'],
|
| 57 |
+
'Asia': ['China', 'India', 'Japan', 'South Korea'],
|
| 58 |
+
'Middle East': ['Saudi Arabia', 'Iran', 'Iraq', 'Qatar', 'Kuwait'],
|
| 59 |
+
'Africa': ['Nigeria', 'Libya', 'Angola'],
|
| 60 |
+
# Add more regions as necessary
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
nomenclature_mapping = {
|
| 65 |
+
'petroleum': 'Petroleum',
|
| 66 |
+
'energy': 'Energy',
|
| 67 |
+
'fuel oil': 'Fuel Oil',
|
| 68 |
+
'shale': 'Shale',
|
| 69 |
+
'offshore': 'Offshore',
|
| 70 |
+
'upstream': 'Upstream',
|
| 71 |
+
'hsfo': 'HSFO',
|
| 72 |
+
'downstream': 'Downstream',
|
| 73 |
+
'crude oil': 'Crude Oil',
|
| 74 |
+
'crude' : 'Crude Oil',
|
| 75 |
+
'refinery': 'Refinery',
|
| 76 |
+
'oil field': 'Oil Field',
|
| 77 |
+
'drilling': 'Drilling',
|
| 78 |
+
'gas': 'Gas',
|
| 79 |
+
'liquefied natural gas': 'LNG',
|
| 80 |
+
'natural gas': 'NG',
|
| 81 |
+
'oil': 'Crude Oil',
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
company_mapping = {
|
| 85 |
+
'exxonmobil': 'ExxonMobil',
|
| 86 |
+
'exxon': 'ExxonMobil',
|
| 87 |
+
'chevron': 'Chevron',
|
| 88 |
+
'bp': 'BP',
|
| 89 |
+
'british petroleum': 'BP',
|
| 90 |
+
'shell': 'Shell',
|
| 91 |
+
'total energies': 'TotalEnergies',
|
| 92 |
+
'conoco': 'ConocoPhillips',
|
| 93 |
+
'halliburton': 'Halliburton',
|
| 94 |
+
'slb': 'SLB',
|
| 95 |
+
'schlumberger': 'SLB',
|
| 96 |
+
'devon': 'Devon Energy',
|
| 97 |
+
'occidental': 'Occidental Petroleum',
|
| 98 |
+
'marathon': 'Marathon Oil',
|
| 99 |
+
'valero': 'Valero Energy',
|
| 100 |
+
'aramco': 'Aramco',
|
| 101 |
+
}
|
| 102 |
+
|
| 103 |
+
nltk.download('stopwords')
|
| 104 |
+
|
| 105 |
+
stop_words = set(stopwords.words('english'))
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
# Function to clean, tokenize, and remove stopwords
|
| 109 |
+
def tokenize(text):
|
| 110 |
+
|
| 111 |
+
text = re.sub(r'[^\w\s]', '', text.lower())
|
| 112 |
+
words = text.split()
|
| 113 |
+
|
| 114 |
+
mapped_words = []
|
| 115 |
+
for word in words:
|
| 116 |
+
mapped_word = place_mapping.get(word,
|
| 117 |
+
nomenclature_mapping.get(word,
|
| 118 |
+
company_mapping.get(word, word)))
|
| 119 |
+
mapped_words.append(mapped_word)
|
| 120 |
+
|
| 121 |
+
filtered_words = [word for word in mapped_words if word not in stop_words]
|
| 122 |
+
return filtered_words
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
# Function to apply filtering and plotting based on search input
|
| 126 |
+
def generateChartBar(data, search_word, body=False):
|
| 127 |
+
|
| 128 |
+
filtered_df = data[data['headline'].str.contains(search_word, case=False) | data['body'].str.contains(search_word, case=False)]
|
| 129 |
+
|
| 130 |
+
all_words = []
|
| 131 |
+
filtered_df['headline'].apply(lambda x: all_words.extend(tokenize(x)))
|
| 132 |
+
|
| 133 |
+
if body:
|
| 134 |
+
filtered_df['body'].apply(lambda x: all_words.extend(tokenize(x)))
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
word_counts = Counter(all_words)
|
| 138 |
+
top_10_words = word_counts.most_common(20)
|
| 139 |
+
top_10_df = pd.DataFrame(top_10_words, columns=['word', 'frequency'])
|
| 140 |
+
|
| 141 |
+
fig = px.bar(top_10_df, x='word', y='frequency', title=f'Top 20 Most Common Words (Excluding Stopwords) for "{search_word}"',
|
| 142 |
+
labels={'word': 'Word', 'frequency': 'Frequency'},
|
| 143 |
+
text='frequency')
|
| 144 |
+
|
| 145 |
+
return fig
|
| 146 |
+
|
| 147 |
+
# Function to filter based on the whole word/phrase and region
|
| 148 |
+
def filterPlace(data, search_place):
|
| 149 |
+
# Check if the search_place is a region
|
| 150 |
+
if search_place in region_mapping:
|
| 151 |
+
# Get all countries in the region
|
| 152 |
+
countries_in_region = region_mapping[search_place]
|
| 153 |
+
# Map countries to their place_mapping synonyms
|
| 154 |
+
synonyms_pattern = '|'.join(
|
| 155 |
+
r'\b{}\b'.format(re.escape(key))
|
| 156 |
+
for country in countries_in_region
|
| 157 |
+
for key in place_mapping
|
| 158 |
+
if place_mapping[key] == country
|
| 159 |
+
)
|
| 160 |
+
else:
|
| 161 |
+
# If a country is selected, get its standard place and synonyms
|
| 162 |
+
standard_place = place_mapping.get(search_place.lower(), search_place)
|
| 163 |
+
synonyms_pattern = '|'.join(
|
| 164 |
+
r'\b{}\b'.format(re.escape(key))
|
| 165 |
+
for key in place_mapping
|
| 166 |
+
if place_mapping[key] == standard_place
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
# Filter the DataFrame for headlines or body containing the whole word/phrase
|
| 170 |
+
filtered_df = data[
|
| 171 |
+
data['headline'].str.contains(synonyms_pattern, case=False, na=False) |
|
| 172 |
+
data['body'].str.contains(synonyms_pattern, case=False, na=False)
|
| 173 |
+
]
|
| 174 |
+
|
| 175 |
+
if filtered_df.empty:
|
| 176 |
+
print(f'No data found for {search_place}. Please try a different location or region.')
|
| 177 |
+
return None
|
| 178 |
+
|
| 179 |
+
return filtered_df
|
| 180 |
+
|
| 181 |
+
# Function to filter DataFrame and generate a word cloud
|
| 182 |
+
def generateWordCloud(data):
|
| 183 |
+
|
| 184 |
+
# standard_place = place_mapping.get(search_place.lower(), search_place)
|
| 185 |
+
# synonyms_pattern = '|'.join(re.escape(key) for key in place_mapping if place_mapping[key] == standard_place)
|
| 186 |
+
|
| 187 |
+
# filtered_df = data[data['headline'].str.contains(synonyms_pattern, case=False, na=False) |
|
| 188 |
+
# data['body'].str.contains(synonyms_pattern, case=False, na=False)]
|
| 189 |
+
|
| 190 |
+
# if filtered_df.empty:
|
| 191 |
+
# print(f'No data found for {search_place}. Please try a different location.')
|
| 192 |
+
# return
|
| 193 |
+
|
| 194 |
+
text = ' '.join(data['headline'].tolist() + data['body'].tolist())
|
| 195 |
+
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text)
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
return wordcloud
|
page_1.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
from modules.data_preparation import prepare_df, plot_3dgraph
|
| 4 |
+
import numpy as np
|
| 5 |
+
import matplotlib.pyplot as plt
|
| 6 |
+
from datetime import datetime
|
| 7 |
+
from modules.semantic import generateChartBar, generateWordCloud, filterPlace
|
| 8 |
+
|
| 9 |
+
st.title('Semantic Analysis for Price Trend Prediction - Crude Oil Futures')
|
| 10 |
+
|
| 11 |
+
st.header('Filter news based on categories and country/region')
|
| 12 |
+
|
| 13 |
+
# st.header(f'Data based on News Data')
|
| 14 |
+
# st.subheader(f'{datetime.now()}')
|
| 15 |
+
|
| 16 |
+
date_filter = st.slider(
|
| 17 |
+
"Date Filter",
|
| 18 |
+
value=(datetime(2024, 8, 4), datetime(2024,8,9)),
|
| 19 |
+
format="MM/DD/YY",
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
col1, col2 = st.columns(2)
|
| 23 |
+
|
| 24 |
+
with col1:
|
| 25 |
+
news_categories = st.multiselect("Select desired news categories",
|
| 26 |
+
["Macroeconomic & Geopolitics", "Crude Oil", "Light Ends", "Middle Distillates", "Heavy Distillates", "Other"],
|
| 27 |
+
["Macroeconomic & Geopolitics", "Crude Oil"])
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
with col2:
|
| 31 |
+
news_location = st.selectbox("Select desired mentioned location",
|
| 32 |
+
["North America","United States", "Russia", "Asia", "Europe"])
|
| 33 |
+
|
| 34 |
+
st.subheader('Tabular Data')
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
latest_news = prepare_df(pd.read_excel('evaluation.xlsx'), news_categories, date_filter)
|
| 38 |
+
df_news = pd.concat([latest_news], ignore_index=True).drop_duplicates(['headline'])
|
| 39 |
+
df_news = filterPlace(df_news, news_location)
|
| 40 |
+
|
| 41 |
+
df_mean = pd.DataFrame({
|
| 42 |
+
'headline' : ['MEAN OF SELECTED NEWS'],
|
| 43 |
+
'negative_score' : [df_news['negative_score'].mean()],
|
| 44 |
+
'neutral_score' : [df_news['neutral_score'].mean()],
|
| 45 |
+
'positive_score' : [df_news['positive_score'].mean()],
|
| 46 |
+
'topic_verification' : ['']
|
| 47 |
+
})
|
| 48 |
+
|
| 49 |
+
df_news_final = pd.concat([df_news, df_mean])
|
| 50 |
+
|
| 51 |
+
df_news_final.index = np.arange(1, len(df_news_final) + 1)
|
| 52 |
+
|
| 53 |
+
st.dataframe(df_news_final.iloc[:, : 9])
|
| 54 |
+
|
| 55 |
+
try:
|
| 56 |
+
st.plotly_chart(plot_3dgraph(df_news_final), use_container_width=True)
|
| 57 |
+
except:
|
| 58 |
+
st.subheader('Select news categories to plot 3D graph')
|
| 59 |
+
|
| 60 |
+
st.markdown('---')
|
| 61 |
+
|
| 62 |
+
viz1, viz2 = st.columns(2)
|
| 63 |
+
|
| 64 |
+
st.subheader('Top Word Frequency - Bar Chart')
|
| 65 |
+
|
| 66 |
+
bar_chart = generateChartBar(data=df_news,search_word='n', body=True)
|
| 67 |
+
st.plotly_chart(bar_chart)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
st.markdown('---')
|
| 71 |
+
|
| 72 |
+
st.subheader('Top Word Frequency - Word Cloud')
|
| 73 |
+
|
| 74 |
+
wordcloud = generateWordCloud(data=df_news)
|
| 75 |
+
|
| 76 |
+
# Display the generated image:
|
| 77 |
+
fig, ax = plt.subplots()
|
| 78 |
+
ax.imshow(wordcloud, interpolation='bilinear')
|
| 79 |
+
ax.axis("off")
|
| 80 |
+
st.pyplot(fig)
|
| 81 |
+
|
| 82 |
+
st.markdown('---')
|
| 83 |
+
|
| 84 |
+
st.subheader('Other possible use cases:')
|
| 85 |
+
st.markdown('- Sentiments towards a company, country, or individual')
|
page_2.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import os
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
st.title('Price Forecasting - Crude Oil Futures')
|
| 7 |
+
st.subheader('This page is not interactive - only for prototype purposes*')
|
| 8 |
+
st.text('*Due to not having access to GPU for cloud computation yet.')
|
| 9 |
+
|
| 10 |
+
st.header('Univariate Forecasting with Exogenous Predictors')
|
| 11 |
+
|
| 12 |
+
col1, col2, col3 = st.columns(3)
|
| 13 |
+
|
| 14 |
+
uni_df = pd.read_csv(os.path.join('price_forecasting_ml',
|
| 15 |
+
'artifacts',
|
| 16 |
+
'crude_oil_8998a364-2ecc-483d-8079-f04d455b4522',
|
| 17 |
+
'train_data.csv')).drop(columns=['Unnamed: 0'])
|
| 18 |
+
|
| 19 |
+
with col1:
|
| 20 |
+
horizon_uni = st.text_input('Univariate Forecasting Horizon')
|
| 21 |
+
with col2:
|
| 22 |
+
target_uni = st.multiselect('Univariate Target Variable', uni_df.columns
|
| 23 |
+
,default='y')
|
| 24 |
+
with col3:
|
| 25 |
+
agg_uni = st.selectbox('Univariate Data Aggregation',
|
| 26 |
+
['Daily', 'Weekly', 'Monthly', 'Yearly'])
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
st.dataframe(uni_df)
|
| 30 |
+
|
| 31 |
+
img1 = Image.open(os.path.join('price_forecasting_ml',
|
| 32 |
+
'artifacts',
|
| 33 |
+
'crude_oil_8998a364-2ecc-483d-8079-f04d455b4522',
|
| 34 |
+
'forecast_plot.jpg'))
|
| 35 |
+
st.image(img1, caption="Crude Oil Futures Price Forecasting - Univariate with Exogenous Features (Horizon = 5)")
|
| 36 |
+
|
| 37 |
+
st.markdown("---")
|
| 38 |
+
|
| 39 |
+
st.header('Multivariate Forecasting')
|
| 40 |
+
|
| 41 |
+
col4, col5, col6 = st.columns(3)
|
| 42 |
+
|
| 43 |
+
multi_df = pd.read_csv(os.path.join('price_forecasting_ml',
|
| 44 |
+
'artifacts',
|
| 45 |
+
'crude_oil_df1ce299-117d-43c7-bcd5-7ecaeac0bc89',
|
| 46 |
+
'train_data.csv')).drop(columns=['Unnamed: 0'])
|
| 47 |
+
|
| 48 |
+
with col4:
|
| 49 |
+
horizon_multi = st.text_input('Multivariate Forecasting Horizon')
|
| 50 |
+
with col5:
|
| 51 |
+
target_multi = st.multiselect('Multivariate Target Variable', multi_df.columns
|
| 52 |
+
,default='y')
|
| 53 |
+
with col6:
|
| 54 |
+
agg_multi = st.selectbox('Multivariate Data Aggregation',
|
| 55 |
+
['Daily', 'Weekly', 'Monthly', 'Yearly'])
|
| 56 |
+
|
| 57 |
+
st.dataframe(multi_df)
|
| 58 |
+
|
| 59 |
+
img2 = Image.open(os.path.join('price_forecasting_ml',
|
| 60 |
+
'artifacts',
|
| 61 |
+
'crude_oil_df1ce299-117d-43c7-bcd5-7ecaeac0bc89',
|
| 62 |
+
'forecast_plot.jpg'))
|
| 63 |
+
st.image(img2, caption="Crude Oil Futures Price Forecasting - Univariate with Exogenous Features (Horizon = 5)")
|
page_3.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
st.title('Machine Learning Operations Pipeline')
|
| 6 |
+
|
| 7 |
+
st.markdown("""
|
| 8 |
+
# Machine Learning Operations (MLOps) Pipeline Documentation
|
| 9 |
+
|
| 10 |
+
This is the documentation covering each of the steps included in Bioma AI's time-series-forecasting MLOps Pipeline.
|
| 11 |
+
|
| 12 |
+
## Sequential MLOps Steps
|
| 13 |
+
The information flow of the pipeline will closely resemble that of a regression machine learning task. The model development will consist of sequential steps:
|
| 14 |
+
1. Ingestion,
|
| 15 |
+
2. Transformation,
|
| 16 |
+
3. Training,
|
| 17 |
+
4. Evaluation, and
|
| 18 |
+
5. Registration.
|
| 19 |
+
|
| 20 |
+
""")
|
| 21 |
+
|
| 22 |
+
img = Image.open(os.path.join('experimentation_mlops',
|
| 23 |
+
'mlops',
|
| 24 |
+
'pics',
|
| 25 |
+
'pipeline.png'))
|
| 26 |
+
st.image(img, caption="MLOps Pipeline for Bioma AI")
|
| 27 |
+
|
| 28 |
+
st.markdown("""
|
| 29 |
+
|
| 30 |
+
## 1. Ingestion
|
| 31 |
+
|
| 32 |
+
Our pipeline involves extracting raw datasets from the internet (S3 Buckets and other cloud services), the assumed dataset is of one of the following file types: csv, json, parquet or xlsx. The extracted data is saved as an artifact which can help in documentation purposes.
|
| 33 |
+
|
| 34 |
+
In the case of time series forecasting, the data ingestion process is tasked on receiving data from a specific format and converting it to a Pandas Dataframe for further processing. The data will be downloaded from the web by issuing a request, the data will then be converted into parquet before being written as a Pandas dataframe. The parquet file will be saved as an artifact for the purpose of documentation.
|
| 35 |
+
|
| 36 |
+
## 2. Transformation
|
| 37 |
+
|
| 38 |
+
According to the timeframe of the time-series data, the data will be split into a train-test-validation set. The user will be able to customize each of the set's proportions.
|
| 39 |
+
|
| 40 |
+
Various statistical methods is considered and performed into a selection of columns, the columns and the methods are both customizable. A few methods that are considered are:
|
| 41 |
+
1. Logarithmic
|
| 42 |
+
2. Natural Logarithmic
|
| 43 |
+
3. Standardization
|
| 44 |
+
4. Identity
|
| 45 |
+
5. Logarithmic Difference
|
| 46 |
+
|
| 47 |
+
## 3. Training
|
| 48 |
+
|
| 49 |
+
The training process can be broken down into two types according to the amount of variates being predicted: univariate or multivariate.
|
| 50 |
+
|
| 51 |
+
Predictors are either an:
|
| 52 |
+
|
| 53 |
+
1. Endogenous feature (Changes in the target's value has an effect on the predictor's value or the other way around) or
|
| 54 |
+
2. Exogenous feature (changes in the predictor's value has an effect on the target's value, but not the other way around)
|
| 55 |
+
<ol type="a">
|
| 56 |
+
<li>Static Exogenous</li>
|
| 57 |
+
Static variables such as one-hot encoding for a categorical class identifier.
|
| 58 |
+
<li>Historical Exogenous</li>
|
| 59 |
+
Exogenous features that their historical data is only known of.
|
| 60 |
+
<li>Future Exogenous</li>
|
| 61 |
+
Exogenous features that their data is known of when making the prediction on that time in the future.
|
| 62 |
+
</ol>
|
| 63 |
+
|
| 64 |
+
Endogenous features will be predicted in conjunction with the target's feature. Exogenous features will not be predicted, rather only be used to predict the target variable.
|
| 65 |
+
|
| 66 |
+
In short: multivariate predictions will use predictors as endogenous features, while multivariable predictions use predictors as exogenous features because of its univariate nature.
|
| 67 |
+
|
| 68 |
+
## 4. Evaluation
|
| 69 |
+
|
| 70 |
+
The evaluation step is constructed for the trained models to perform prediction on out-of-training data. Ideally, this step will produce outputs such as visualizations and error metrics for arbitrary datasets.
|
| 71 |
+
|
| 72 |
+
## 5. Registration
|
| 73 |
+
|
| 74 |
+
Registration includes saving the model with the highest accuracy, making it easy to retrieve for inference later on.
|
| 75 |
+
|
| 76 |
+
References:
|
| 77 |
+
- [1] [mlflow/recipes-regression-template](https://github.com/mlflow/recipes-regression-template/tree/main?tab=readme-ov-file#installation)
|
| 78 |
+
- [2] [MLflow deployment using Docker, EC2, S3, and RDS](https://aws.plainenglish.io/set-up-mlflow-on-aws-ec2-using-docker-s3-and-rds-90d96798e555)
|
| 79 |
+
""")
|
price_forecasting_ml/NeuralForecast.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
price_forecasting_ml/__pycache__/train.cpython-38.pyc
ADDED
|
Binary file (3.09 kB). View file
|
|
|
price_forecasting_ml/artifacts/crude_oil_8998a364-2ecc-483d-8079-f04d455b4522/forecast_plot.jpg
ADDED

|
price_forecasting_ml/artifacts/crude_oil_8998a364-2ecc-483d-8079-f04d455b4522/ingested_dataset.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|