Spaces:
Sleeping

Sleeping
romnatall
commited on
Commit
•
d3d0074
1
Parent(s):
75139a0
final
Browse files- app.py +41 -15
- images/{olya.jpg → baur.jpg} +0 -0
- images/film_bert.jpg +0 -0
- images/film_lstm.png +0 -0
- images/film_tfidf.jpg +0 -0
- images/roma.png +0 -0
- images/ss.png +0 -0
- images/tf_idf_cm.jpg +0 -0
- images/toxic.png +0 -0
- pages/0film_reviev.py +31 -10
- pages/film_review/model/log_reg_bert.pkl +3 -0
- pages/film_review/model/model_bert.pth +3 -0
- pages/film_review/model/model_bert.py +39 -0
- pages/film_review/model/model_lstm.py +12 -6
app.py
CHANGED
|
@@ -1,8 +1,9 @@
|
|
|
|
|
| 1 |
import streamlit as st
|
| 2 |
from PIL import Image
|
| 3 |
st.title("NLP project")
|
| 4 |
|
| 5 |
-
description_show_options = ['main','film_review','toxic_messages','
|
| 6 |
description_show = st.sidebar.radio("Description", description_show_options)
|
| 7 |
|
| 8 |
if description_show == 'над проектом работали':
|
|
@@ -11,14 +12,14 @@ if description_show == 'над проектом работали':
|
|
| 11 |
col1, col2, col3 = st.columns(3)
|
| 12 |
with col1:
|
| 13 |
|
| 14 |
-
romaimage = Image.open("images/roma.
|
| 15 |
-
st.image(romaimage, caption="Рома |
|
| 16 |
with col2:
|
| 17 |
leraimage = Image.open("images/Lera.png")
|
| 18 |
-
st.image(leraimage, caption="Лера |
|
| 19 |
with col3:
|
| 20 |
-
olyaimage = Image.open("images/
|
| 21 |
-
st.image(olyaimage, caption="Бауржан |
|
| 22 |
elif description_show == 'GPT':
|
| 23 |
st.title("GPT")
|
| 24 |
|
|
@@ -28,19 +29,44 @@ elif description_show == 'main':
|
|
| 28 |
elif description_show == 'film_review':
|
| 29 |
st.title("film_review")
|
| 30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
|
|
|
|
|
|
|
|
|
| 35 |
|
| 36 |
-
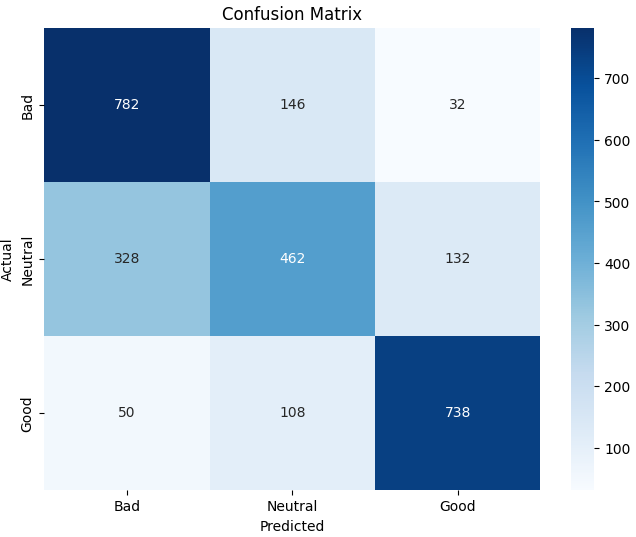
# Bad 0.67 0.81 0.74 960
|
| 37 |
-
# Neutral 0.65 0.50 0.56 922
|
| 38 |
-
# Good 0.82 0.82 0.82 896
|
| 39 |
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
|
|
|
| 43 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 44 |
elif description_show == 'toxic_messages':
|
| 45 |
st.title("toxic_messages")
|
| 46 |
|
|
|
|
| 1 |
+
from math import e
|
| 2 |
import streamlit as st
|
| 3 |
from PIL import Image
|
| 4 |
st.title("NLP project")
|
| 5 |
|
| 6 |
+
description_show_options = ['main','film_review','toxic_messages','над проектом работали']
|
| 7 |
description_show = st.sidebar.radio("Description", description_show_options)
|
| 8 |
|
| 9 |
if description_show == 'над проектом работали':
|
|
|
|
| 12 |
col1, col2, col3 = st.columns(3)
|
| 13 |
with col1:
|
| 14 |
|
| 15 |
+
romaimage = Image.open("images/roma.png")
|
| 16 |
+
st.image(romaimage, caption="Рома | custom attention enjoyer | DevOps", use_column_width=True, )
|
| 17 |
with col2:
|
| 18 |
leraimage = Image.open("images/Lera.png")
|
| 19 |
+
st.image(leraimage, caption="Лера | GPT bender | Data Scientist", use_column_width=True)
|
| 20 |
with col3:
|
| 21 |
+
olyaimage = Image.open("images/baur.jpg")
|
| 22 |
+
st.image(olyaimage, caption="Бауржан | TF/IDF master | Frontender", use_column_width=True)
|
| 23 |
elif description_show == 'GPT':
|
| 24 |
st.title("GPT")
|
| 25 |
|
|
|
|
| 29 |
elif description_show == 'film_review':
|
| 30 |
st.title("film_review")
|
| 31 |
|
| 32 |
+
st.write("------------")
|
| 33 |
+
st.write("BERT embedding + LSTM + roman attention")
|
| 34 |
+
text = """Weighted F1-score: 0.70\n
|
| 35 |
+
Classification Report:
|
| 36 |
+
precision recall f1-score support
|
| 37 |
+
Bad 0.67 0.81 0.74 960
|
| 38 |
+
Neutral 0.65 0.50 0.56 922
|
| 39 |
+
Good 0.82 0.82 0.82 896
|
| 40 |
+
-----
|
| 41 |
+
accuracy 0.71 2778
|
| 42 |
+
macro avg 0.71 0.71 0.71 2778
|
| 43 |
+
weighted avg 0.71 0.71 0.71 2778"""
|
| 44 |
+
st.markdown(text)
|
| 45 |
+
png = Image.open("images/film_lstm.png")
|
| 46 |
+
st.image(png, use_column_width=True)
|
| 47 |
|
| 48 |
+
st.write("------------")
|
| 49 |
+
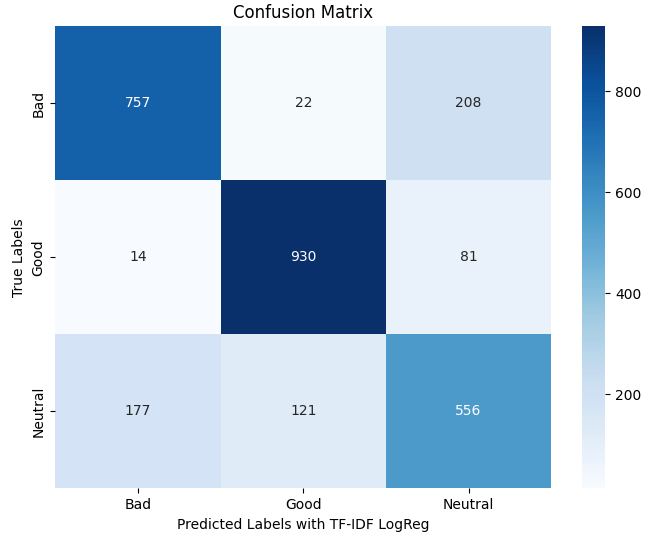
st.write("tf-idf + Logreg")
|
| 50 |
+
png = Image.open("images/film_tfidf.jpg")
|
| 51 |
+
st.image(png, use_column_width=True)
|
| 52 |
+
png = Image.open("images/tf_idf_cm.jpg")
|
| 53 |
+
st.image(png, use_column_width=True)
|
| 54 |
|
|
|
|
|
|
|
|
|
|
| 55 |
|
| 56 |
+
st.write("------------")
|
| 57 |
+
st.write("Bert embedding + LogReg")
|
| 58 |
+
png = Image.open("images/film_bert.jpg")
|
| 59 |
+
st.image(png, use_column_width=True)
|
| 60 |
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
elif description_show == 'toxic_messages':
|
| 66 |
+
st.title("toxic_messages")
|
| 67 |
+
png = Image.open("images/toxic.png")
|
| 68 |
+
st.image(png, use_column_width=True)
|
| 69 |
+
|
| 70 |
elif description_show == 'toxic_messages':
|
| 71 |
st.title("toxic_messages")
|
| 72 |
|
images/{olya.jpg → baur.jpg}
RENAMED
|
File without changes
|
images/film_bert.jpg
ADDED

|
images/film_lstm.png
ADDED
|
images/film_tfidf.jpg
ADDED
|
images/roma.png
ADDED

|
images/ss.png
ADDED
|
images/tf_idf_cm.jpg
ADDED
|
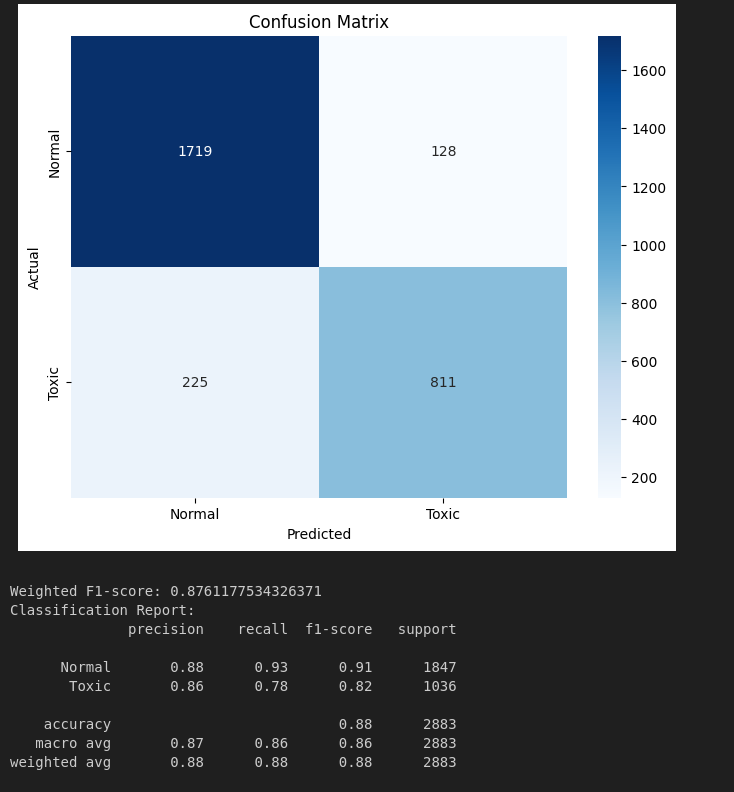
images/toxic.png
ADDED
|
pages/0film_reviev.py
CHANGED
|
@@ -7,6 +7,20 @@ st.title("film_review")
|
|
| 7 |
input_text = st.text_area("Enter your text")
|
| 8 |
from pages.film_review.model.model_lstm import *
|
| 9 |
from pages.film_review.model.model_logreg import *
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
|
| 11 |
@st.cache_resource
|
| 12 |
def get_model():
|
|
@@ -16,15 +30,22 @@ model.eval()
|
|
| 16 |
dec = {0:'отрицательный',1:'нейтральный',2:'положительный'}
|
| 17 |
|
| 18 |
if input_text:
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 27 |
|
| 28 |
|
| 29 |
-
else:
|
| 30 |
-
st.write("No text entered")
|
|
|
|
| 7 |
input_text = st.text_area("Enter your text")
|
| 8 |
from pages.film_review.model.model_lstm import *
|
| 9 |
from pages.film_review.model.model_logreg import *
|
| 10 |
+
from pages.film_review.model.model_bert import *
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
import time
|
| 14 |
+
|
| 15 |
+
class Timer:
|
| 16 |
+
def __enter__(self):
|
| 17 |
+
self.start_time = time.time()
|
| 18 |
+
return self
|
| 19 |
+
|
| 20 |
+
def __exit__(self, *args):
|
| 21 |
+
self.end_time = time.time()
|
| 22 |
+
self.execution_time = self.end_time - self.start_time
|
| 23 |
+
|
| 24 |
|
| 25 |
@st.cache_resource
|
| 26 |
def get_model():
|
|
|
|
| 30 |
dec = {0:'отрицательный',1:'нейтральный',2:'положительный'}
|
| 31 |
|
| 32 |
if input_text:
|
| 33 |
+
|
| 34 |
+
with Timer() as t:
|
| 35 |
+
with torch.no_grad():
|
| 36 |
+
ans = torch.nn.functional.softmax(model(input_text), dim=1)
|
| 37 |
+
idx = torch.argmax(ans, dim=1).item()
|
| 38 |
+
st.write(f'LSTM - отзыв: {dec[idx]}, уверенность: { round(ans[0][idx].item(),2)}')
|
| 39 |
+
st.write("Время выполнения:", round(t.execution_time*1000, 2), "миллисекунд")
|
| 40 |
+
|
| 41 |
+
st.write("------------")
|
| 42 |
+
with Timer() as t:
|
| 43 |
+
st.write(f'Logreg - отзыв: {dec[ predict_tfidf(input_text)[0]]}')
|
| 44 |
+
st.write("Время выполнения:", round(t.execution_time*1000, 2), "миллисекунд")
|
| 45 |
+
|
| 46 |
+
st.write("------------")
|
| 47 |
+
with Timer() as t:
|
| 48 |
+
st.write(f'Bert - отзыв: {dec[ predict_bert(input_text)]}')
|
| 49 |
+
st.write("Время выполнения:", round(t.execution_time*1000, 2), "миллисекунд")
|
| 50 |
|
| 51 |
|
|
|
|
|
|
pages/film_review/model/log_reg_bert.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7a6dc8a96c93ed97b248f73955cfe28998ab5bc360d2635dcc7129aa92425361
|
| 3 |
+
size 8225
|
pages/film_review/model/model_bert.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5d74ff4026ce64a4c33dda7730aa03c771b097cc1f0ea3d79d69935482559209
|
| 3 |
+
size 13420
|
pages/film_review/model/model_bert.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
from transformers import AutoTokenizer, AutoModel
|
| 4 |
+
from sklearn.linear_model import LogisticRegression
|
| 5 |
+
import streamlit as st
|
| 6 |
+
import pickle
|
| 7 |
+
import streamlit as st
|
| 8 |
+
|
| 9 |
+
@st.cache_resource
|
| 10 |
+
def get_model():
|
| 11 |
+
model = AutoModel.from_pretrained("cointegrated/rubert-tiny2")
|
| 12 |
+
tokenizer = AutoTokenizer.from_pretrained("cointegrated/rubert-tiny2")
|
| 13 |
+
return model, tokenizer
|
| 14 |
+
|
| 15 |
+
def predict_bert(input_text):
|
| 16 |
+
MAX_LEN = 300
|
| 17 |
+
|
| 18 |
+
model, tokenizer = get_model()
|
| 19 |
+
|
| 20 |
+
tokenized_input = tokenizer.encode(input_text, add_special_tokens=True, truncation=True, max_length=MAX_LEN)
|
| 21 |
+
padded_input = np.array(tokenized_input + [0]*(MAX_LEN-len(tokenized_input)))
|
| 22 |
+
attention_mask = np.where(padded_input != 0, 1, 0)
|
| 23 |
+
|
| 24 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 25 |
+
model.to(device)
|
| 26 |
+
|
| 27 |
+
with torch.no_grad():
|
| 28 |
+
input_tensor = torch.tensor(padded_input).unsqueeze(0).to(device)
|
| 29 |
+
attention_mask_tensor = torch.tensor(attention_mask).unsqueeze(0).to(device)
|
| 30 |
+
last_hidden_states = model(input_tensor, attention_mask=attention_mask_tensor)[0]
|
| 31 |
+
|
| 32 |
+
features = last_hidden_states[:,0,:].cpu().numpy()
|
| 33 |
+
|
| 34 |
+
with open('pages/film_review/model/log_reg_bert.pkl', 'rb') as f:
|
| 35 |
+
loaded_model = pickle.load(f)
|
| 36 |
+
|
| 37 |
+
prediction = loaded_model.predict(features)
|
| 38 |
+
|
| 39 |
+
return prediction[0]
|
pages/film_review/model/model_lstm.py
CHANGED
|
@@ -1,9 +1,11 @@
|
|
| 1 |
ATTENTION_SIZE=10
|
| 2 |
HIDDEN_SIZE=300
|
| 3 |
INPUT_SIZE=312
|
|
|
|
| 4 |
import torch
|
| 5 |
from transformers import AutoTokenizer, AutoModel
|
| 6 |
import torch.nn as nn
|
|
|
|
| 7 |
|
| 8 |
class RomanAttention(nn.Module):
|
| 9 |
def __init__(self, hidden_size: int = HIDDEN_SIZE) -> None:
|
|
@@ -31,14 +33,18 @@ class RomanAttention(nn.Module):
|
|
| 31 |
|
| 32 |
import pytorch_lightning as lg
|
| 33 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
|
| 35 |
-
|
| 36 |
-
emb=m.embeddings
|
| 37 |
-
#emb.dropout=nn.Dropout(0)
|
| 38 |
-
for param in emb.parameters():
|
| 39 |
-
param.requires_grad = False
|
| 40 |
|
| 41 |
-
tokenizer = AutoTokenizer.from_pretrained("cointegrated/rubert-tiny2")
|
| 42 |
def tokenize(text):
|
| 43 |
t=tokenizer(text, padding=True, truncation=True,pad_to_multiple_of=300,max_length=300)['input_ids']
|
| 44 |
if len(t) <30:
|
|
|
|
| 1 |
ATTENTION_SIZE=10
|
| 2 |
HIDDEN_SIZE=300
|
| 3 |
INPUT_SIZE=312
|
| 4 |
+
from math import e
|
| 5 |
import torch
|
| 6 |
from transformers import AutoTokenizer, AutoModel
|
| 7 |
import torch.nn as nn
|
| 8 |
+
import streamlit as st
|
| 9 |
|
| 10 |
class RomanAttention(nn.Module):
|
| 11 |
def __init__(self, hidden_size: int = HIDDEN_SIZE) -> None:
|
|
|
|
| 33 |
|
| 34 |
import pytorch_lightning as lg
|
| 35 |
|
| 36 |
+
@st.cache_resource
|
| 37 |
+
def load_model():
|
| 38 |
+
m = AutoModel.from_pretrained("cointegrated/rubert-tiny2")
|
| 39 |
+
emb=m.embeddings
|
| 40 |
+
#emb.dropout=nn.Dropout(0)
|
| 41 |
+
for param in emb.parameters():
|
| 42 |
+
param.requires_grad = False
|
| 43 |
+
tokenizer = AutoTokenizer.from_pretrained("cointegrated/rubert-tiny2")
|
| 44 |
+
return emb, tokenizer
|
| 45 |
|
| 46 |
+
emb, tokenizer = load_model()
|
|
|
|
|
|
|
|
|
|
|
|
|
| 47 |
|
|
|
|
| 48 |
def tokenize(text):
|
| 49 |
t=tokenizer(text, padding=True, truncation=True,pad_to_multiple_of=300,max_length=300)['input_ids']
|
| 50 |
if len(t) <30:
|