
Ryan Kim
commited on
Commit
·
6410115
1
Parent(s):
bd46580
adding these files as a backup of an older project that got mangled by Git LFS's size limit
Browse files- .devcontainer/devcontainer.json +22 -0
- .gitattributes +1 -0
- .gitignore +3 -0
- .python-version +1 -0
- Screenshots/Docker_Built.png +0 -0
- Screenshots/Docker_Python_Built.png +0 -0
- Screenshots/ExtensionsForDocker.png +0 -0
- Screenshots/Install_Proof.png +0 -0
- data/train.json +3 -0
- data/val.json +3 -0
- logs/1681910017.7615924/events.out.tfevents.1681910017.025fe27979cb.15711.1 +0 -0
- logs/events.out.tfevents.1681910017.025fe27979cb.15711.0 +0 -0
- misc_example/Dockerfile +4 -0
- misc_example/example.js +2 -0
- requirements.txt +0 -0
- src/__pycache__/emotion.cpython-311.pyc +0 -0
- src/app.py +18 -0
- src/emotion.py +87 -0
- src/main.py +265 -0
- src/patent_train.ipynb +0 -0
- src/train.py +228 -0
- src/val.ipynb +1 -0
.devcontainer/devcontainer.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// For format details, see https://aka.ms/devcontainer.json. For config options, see the
|
| 2 |
+
// README at: https://github.com/devcontainers/templates/tree/main/src/python
|
| 3 |
+
{
|
| 4 |
+
"name": "Python 3",
|
| 5 |
+
// Or use a Dockerfile or Docker Compose file. More info: https://containers.dev/guide/dockerfile
|
| 6 |
+
"image": "mcr.microsoft.com/devcontainers/python:0-3.11"
|
| 7 |
+
|
| 8 |
+
// Features to add to the dev container. More info: https://containers.dev/features.
|
| 9 |
+
// "features": {},
|
| 10 |
+
|
| 11 |
+
// Use 'forwardPorts' to make a list of ports inside the container available locally.
|
| 12 |
+
// "forwardPorts": [],
|
| 13 |
+
|
| 14 |
+
// Use 'postCreateCommand' to run commands after the container is created.
|
| 15 |
+
// "postCreateCommand": "pip3 install --user -r requirements.txt",
|
| 16 |
+
|
| 17 |
+
// Configure tool-specific properties.
|
| 18 |
+
// "customizations": {},
|
| 19 |
+
|
| 20 |
+
// Uncomment to connect as root instead. More info: https://aka.ms/dev-containers-non-root.
|
| 21 |
+
// "remoteUser": "root"
|
| 22 |
+
}
|
.gitattributes
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
data/*.json filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
**/.DS_Store
|
| 2 |
+
|
| 3 |
+
models/*
|
.python-version
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
3.9.16
|
Screenshots/Docker_Built.png
ADDED
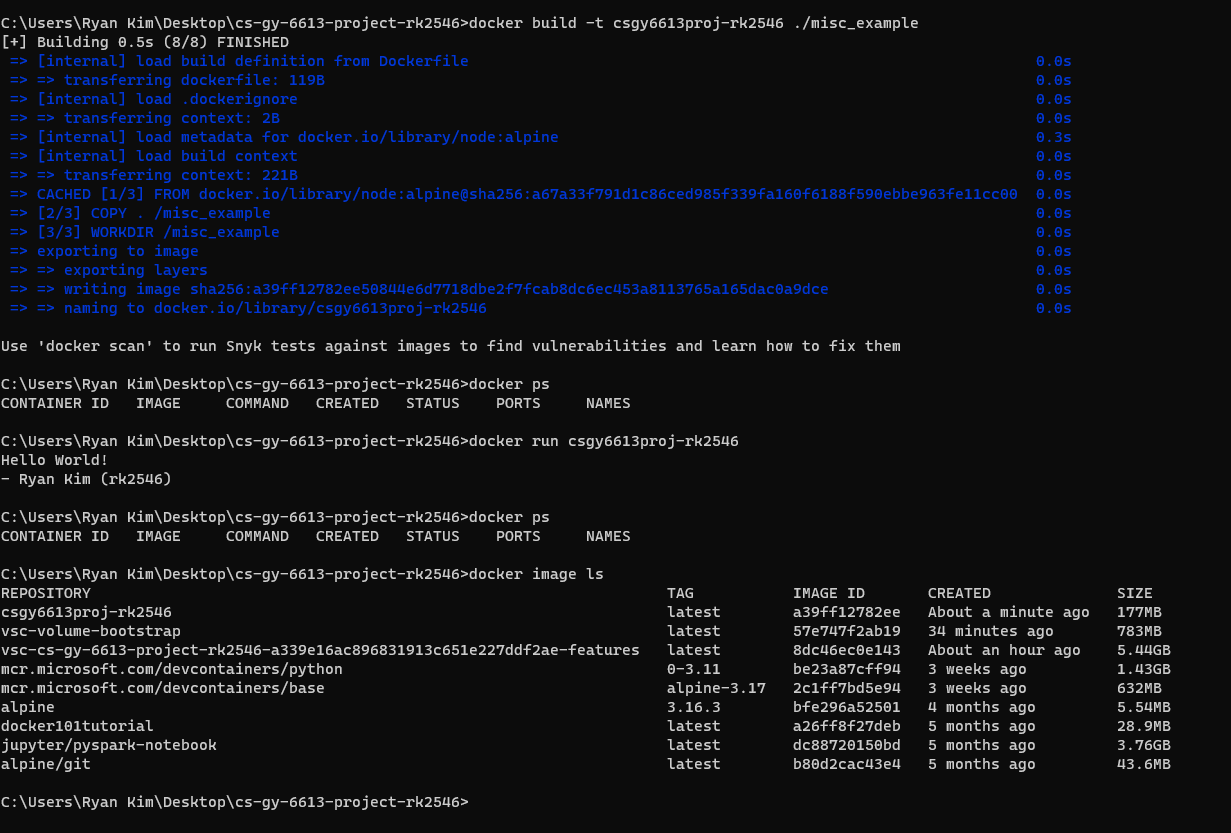
|
Screenshots/Docker_Python_Built.png
ADDED
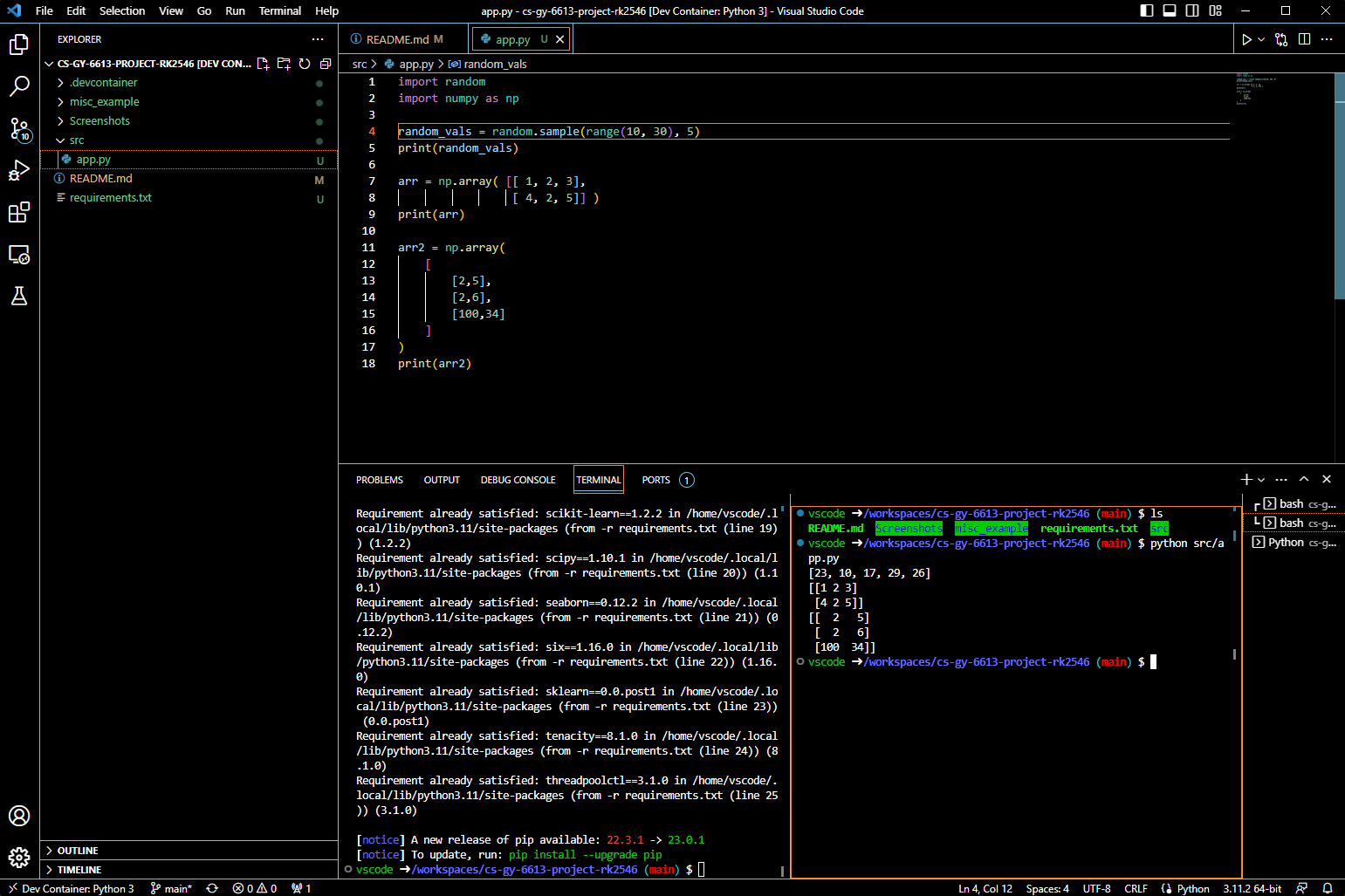
|
Screenshots/ExtensionsForDocker.png
ADDED
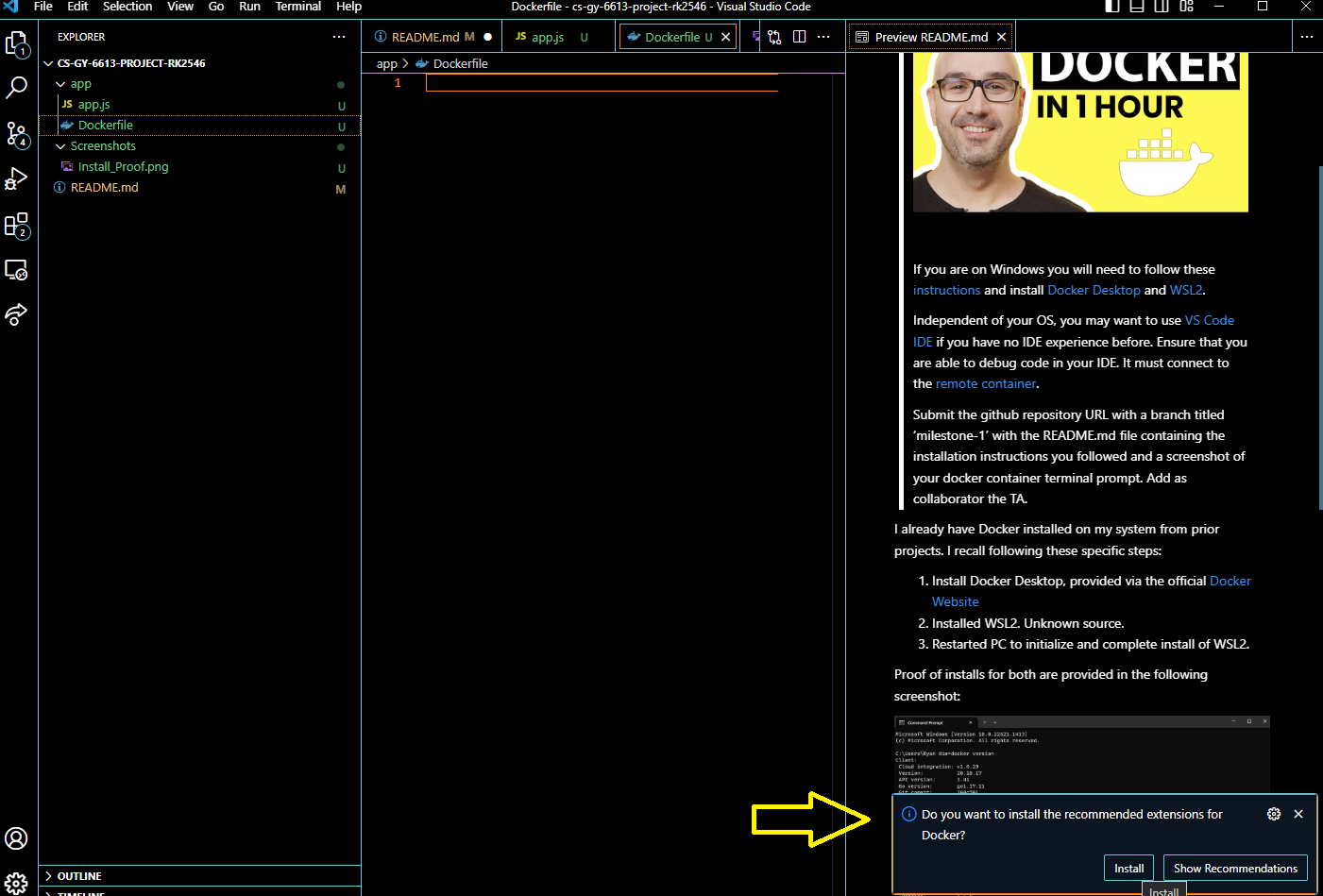
|
Screenshots/Install_Proof.png
ADDED
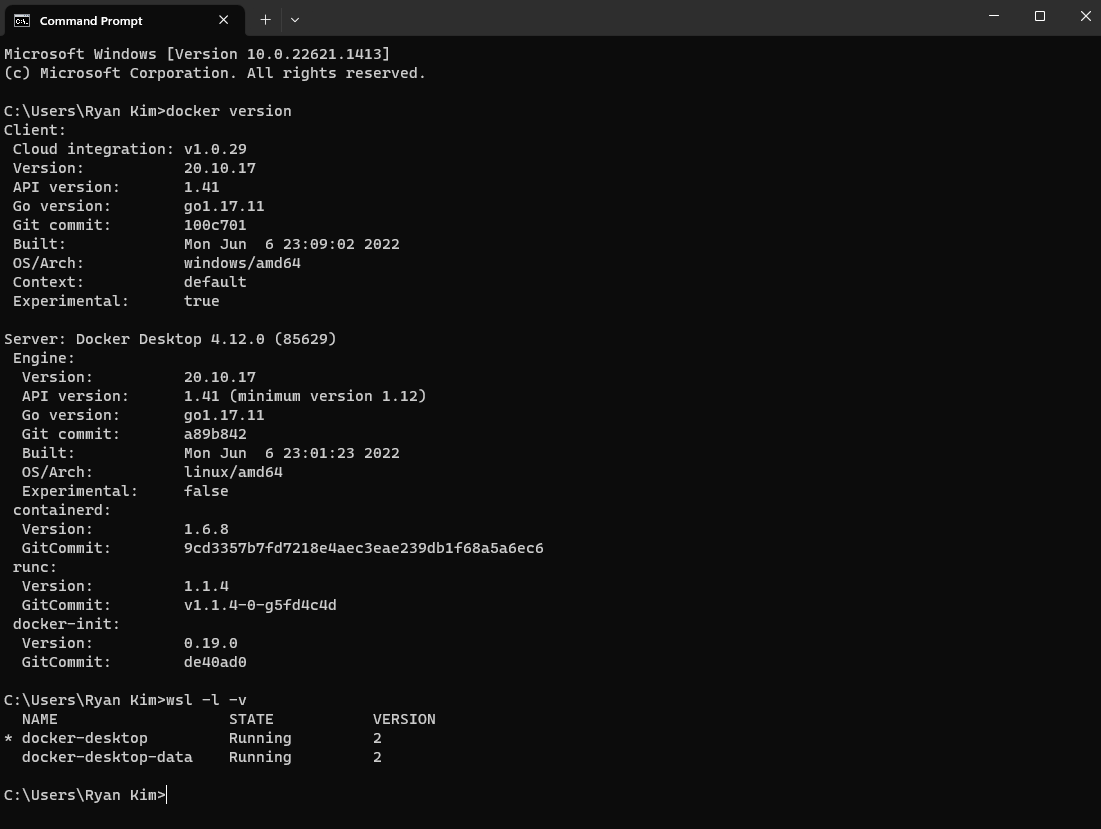
|
data/train.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:086044dc3464c21b497dffcccd8358731d55454ac2420c6930b7c358502db8ae
|
| 3 |
+
size 58741536
|
data/val.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:922dccb1d4d0d2a7ba05651a36a3cbf79c991d17e15da9d4d71f2d90d02c20fd
|
| 3 |
+
size 32823037
|
logs/1681910017.7615924/events.out.tfevents.1681910017.025fe27979cb.15711.1
ADDED
|
Binary file (5.81 kB). View file
|
|
|
logs/events.out.tfevents.1681910017.025fe27979cb.15711.0
ADDED
|
Binary file (3.81 kB). View file
|
|
|
misc_example/Dockerfile
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM node:alpine
|
| 2 |
+
COPY . /misc_example
|
| 3 |
+
WORKDIR /misc_example
|
| 4 |
+
CMD node example.js
|
misc_example/example.js
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
console.log("Hello World!")
|
| 2 |
+
console.log("- Ryan Kim (rk2546)")
|
requirements.txt
ADDED
|
Binary file (614 Bytes). View file
|
|
|
src/__pycache__/emotion.cpython-311.pyc
ADDED
|
Binary file (4.62 kB). View file
|
|
|
src/app.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
random_vals = random.sample(range(10, 30), 5)
|
| 5 |
+
print(random_vals)
|
| 6 |
+
|
| 7 |
+
arr = np.array( [[ 1, 2, 3],
|
| 8 |
+
[ 4, 2, 5]] )
|
| 9 |
+
print(arr)
|
| 10 |
+
|
| 11 |
+
arr2 = np.array(
|
| 12 |
+
[
|
| 13 |
+
[2,5],
|
| 14 |
+
[2,6],
|
| 15 |
+
[100,34]
|
| 16 |
+
]
|
| 17 |
+
)
|
| 18 |
+
print(arr2)
|
src/emotion.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from transformers import pipeline
|
| 3 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 4 |
+
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
# We'll be using Torch this time around
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
|
| 11 |
+
# === VARIABLE DECLARATION ===
|
| 12 |
+
model_names = (
|
| 13 |
+
"cardiffnlp/twitter-roberta-base-sentiment",
|
| 14 |
+
"finiteautomata/beto-sentiment-analysis",
|
| 15 |
+
"bhadresh-savani/distilbert-base-uncased-emotion",
|
| 16 |
+
"siebert/sentiment-roberta-large-english"
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
def label_dictionary(model_name):
|
| 20 |
+
if model_name == "cardiffnlp/twitter-roberta-base-sentiment":
|
| 21 |
+
def twitter_roberta(label):
|
| 22 |
+
if label == "LABEL_0":
|
| 23 |
+
return "Negative"
|
| 24 |
+
elif label == "LABEL_2":
|
| 25 |
+
return "Positive"
|
| 26 |
+
else:
|
| 27 |
+
return "Neutral"
|
| 28 |
+
return twitter_roberta
|
| 29 |
+
return lambda x: x
|
| 30 |
+
|
| 31 |
+
@st.cache(allow_output_mutation=True)
|
| 32 |
+
def load_model(model_name):
|
| 33 |
+
model = AutoModelForSequenceClassification.from_pretrained(model_name)
|
| 34 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 35 |
+
classifier = pipeline(task="sentiment-analysis", model=model, tokenizer=tokenizer)
|
| 36 |
+
parser = label_dictionary(model_name)
|
| 37 |
+
return model, tokenizer, classifier, parser
|
| 38 |
+
|
| 39 |
+
# We first initialize a state. The state will include the following:
|
| 40 |
+
# 1) the name of the model (default: cardiffnlp/twitter-roberta-base-sentiment)
|
| 41 |
+
# 2) the model itself, and
|
| 42 |
+
# 3) the parser for the outputs, in case we actually need to parse the output to something more sensible
|
| 43 |
+
if "model" not in st.session_state:
|
| 44 |
+
st.session_state.model_name = "cardiffnlp/twitter-roberta-base-sentiment"
|
| 45 |
+
model, tokenizer, classifier, label_parser = load_model("cardiffnlp/twitter-roberta-base-sentiment")
|
| 46 |
+
st.session_state.model = model
|
| 47 |
+
st.session_state.tokenizer = tokenizer
|
| 48 |
+
st.session_state.classifier = classifier
|
| 49 |
+
st.session_state.label_parser = label_parser
|
| 50 |
+
|
| 51 |
+
def model_change():
|
| 52 |
+
model, tokenizer, classifier, label_parser = load_model(st.session_state.model_name)
|
| 53 |
+
st.session_state.model = model
|
| 54 |
+
st.session_state.tokenizer = tokenizer
|
| 55 |
+
st.session_state.classifier = classifier
|
| 56 |
+
st.session_state.label_parser = label_parser
|
| 57 |
+
|
| 58 |
+
model_option = st.selectbox(
|
| 59 |
+
"What sentiment analysis model do you want to use?",
|
| 60 |
+
model_names,
|
| 61 |
+
on_change=model_change,
|
| 62 |
+
key="model_name"
|
| 63 |
+
)
|
| 64 |
+
placeholder="@AmericanAir just landed - 3hours Late Flight - and now we need to wait TWENTY MORE MINUTES for a gate! I have patience but none for incompetence."
|
| 65 |
+
form = st.form(key='sentiment-analysis-form')
|
| 66 |
+
text_input = form.text_area("Enter some text for sentiment analysis! If you just want to test it out without entering anything, just press the \"Submit\" button and the model will look at the placeholder.", placeholder=placeholder)
|
| 67 |
+
submit = form.form_submit_button('Submit')
|
| 68 |
+
|
| 69 |
+
if submit:
|
| 70 |
+
if text_input is None or len(text_input.strip()) == 0:
|
| 71 |
+
to_eval = placeholder
|
| 72 |
+
else:
|
| 73 |
+
to_eval = text_input.strip()
|
| 74 |
+
st.write("You entered:")
|
| 75 |
+
st.markdown("> {}".format(to_eval))
|
| 76 |
+
st.write("Using the NLP model:")
|
| 77 |
+
st.markdown("> {}".format(st.session_state.model_name))
|
| 78 |
+
result = st.session_state.classifier(to_eval)
|
| 79 |
+
label = result[0]['label']
|
| 80 |
+
score = result[0]['score']
|
| 81 |
+
|
| 82 |
+
label = st.session_state.label_parser(label)
|
| 83 |
+
|
| 84 |
+
st.markdown("#### Result:")
|
| 85 |
+
st.markdown("**{}**: {}".format(label,score))
|
| 86 |
+
st.write("")
|
| 87 |
+
st.write("")
|
src/main.py
ADDED
|
@@ -0,0 +1,265 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import random
|
| 4 |
+
|
| 5 |
+
import streamlit as st
|
| 6 |
+
from transformers import TextClassificationPipeline, pipeline
|
| 7 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification, DistilBertTokenizerFast, DistilBertForSequenceClassification
|
| 8 |
+
|
| 9 |
+
emotion_model_names = (
|
| 10 |
+
"cardiffnlp/twitter-roberta-base-sentiment",
|
| 11 |
+
"finiteautomata/beto-sentiment-analysis",
|
| 12 |
+
"bhadresh-savani/distilbert-base-uncased-emotion",
|
| 13 |
+
"siebert/sentiment-roberta-large-english"
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
class ModelImplementation(object):
|
| 17 |
+
def __init__(
|
| 18 |
+
self,
|
| 19 |
+
transformer_model_name,
|
| 20 |
+
model_transformer,
|
| 21 |
+
tokenizer_model_name,
|
| 22 |
+
tokenizer_func,
|
| 23 |
+
pipeline_func,
|
| 24 |
+
parser_func,
|
| 25 |
+
classifier_args={},
|
| 26 |
+
placeholders=[""]
|
| 27 |
+
):
|
| 28 |
+
self.transformer_model_name = transformer_model_name
|
| 29 |
+
self.tokenizer_model_name = tokenizer_model_name
|
| 30 |
+
self.placeholders = placeholders
|
| 31 |
+
|
| 32 |
+
self.model = model_transformer.from_pretrained(self.transformer_model_name)
|
| 33 |
+
self.tokenizer = tokenizer_func.from_pretrained(self.tokenizer_model_name)
|
| 34 |
+
self.classifier = pipeline_func(model=self.model, tokenizer=self.tokenizer, padding=True, truncation=True, **classifier_args)
|
| 35 |
+
self.parser = parser_func
|
| 36 |
+
|
| 37 |
+
def predict(self, val):
|
| 38 |
+
result = self.classifier(val)
|
| 39 |
+
return self.parser(self, result)
|
| 40 |
+
|
| 41 |
+
def ParseEmotionOutput(self, result):
|
| 42 |
+
label = result[0]['label']
|
| 43 |
+
score = result[0]['score']
|
| 44 |
+
output_func = st.info
|
| 45 |
+
if self.transformer_model_name == "cardiffnlp/twitter-roberta-base-sentiment":
|
| 46 |
+
if label == "LABEL_0":
|
| 47 |
+
label = "NEGATIVE"
|
| 48 |
+
output_func = st.error
|
| 49 |
+
elif label == "LABEL_2":
|
| 50 |
+
label = "POSITIVE"
|
| 51 |
+
output_func = st.success
|
| 52 |
+
else:
|
| 53 |
+
label = "NEUTRAL"
|
| 54 |
+
elif self.transformer_model_name == "finiteautomata/beto-sentiment-analysis":
|
| 55 |
+
if label == "NEG":
|
| 56 |
+
label = "NEGATIVE"
|
| 57 |
+
output_func = st.error
|
| 58 |
+
elif label == "POS":
|
| 59 |
+
label = "POSITIVE"
|
| 60 |
+
output_func = st.success
|
| 61 |
+
else:
|
| 62 |
+
label = "NEUTRAL"
|
| 63 |
+
elif self.transformer_model_name == "bhadresh-savani/distilbert-base-uncased-emotion":
|
| 64 |
+
if label == "sadness":
|
| 65 |
+
output_func = st.info
|
| 66 |
+
elif label == "joy":
|
| 67 |
+
output_func = st.success
|
| 68 |
+
elif label == "love":
|
| 69 |
+
output_func = st.success
|
| 70 |
+
elif label == "anger":
|
| 71 |
+
output_func = st.error
|
| 72 |
+
elif label == "fear":
|
| 73 |
+
output_func = st.info
|
| 74 |
+
elif label == "surprise":
|
| 75 |
+
output_func = st.error
|
| 76 |
+
label = label.upper()
|
| 77 |
+
elif self.transformer_model_name == "siebert/sentiment-roberta-large-english":
|
| 78 |
+
if label == "NEGATIVE":
|
| 79 |
+
output_func = st.error
|
| 80 |
+
elif label == "POSITIVE":
|
| 81 |
+
output_func = st.success
|
| 82 |
+
return label, score, output_func
|
| 83 |
+
|
| 84 |
+
def ParsePatentOutput(self, result):
|
| 85 |
+
return result
|
| 86 |
+
|
| 87 |
+
def emotion_model_change():
|
| 88 |
+
st.session_state.emotion_model = ModelImplementation(
|
| 89 |
+
st.session_state.emotion_model_name,
|
| 90 |
+
AutoModelForSequenceClassification,
|
| 91 |
+
st.session_state.emotion_model_name,
|
| 92 |
+
AutoTokenizer,
|
| 93 |
+
pipeline,
|
| 94 |
+
ParseEmotionOutput,
|
| 95 |
+
classifier_args={ "task" : "sentiment-analysis" },
|
| 96 |
+
placeholders=["@AmericanAir just landed - 3hours Late Flight - and now we need to wait TWENTY MORE MINUTES for a gate! I have patience but none for incompetence."]
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
if "emotion_model_name" not in st.session_state:
|
| 100 |
+
st.session_state.emotion_model_name = "cardiffnlp/twitter-roberta-base-sentiment"
|
| 101 |
+
emotion_model_change()
|
| 102 |
+
|
| 103 |
+
if "patent_data" not in st.session_state:
|
| 104 |
+
f = open('./data/val.json')
|
| 105 |
+
valData = json.load(f)
|
| 106 |
+
f.close()
|
| 107 |
+
|
| 108 |
+
patent_data = {}
|
| 109 |
+
for num, label, abstract, claim in zip(valData["patent_numbers"],valData["labels"], valData["abstracts"], valData["claims"]):
|
| 110 |
+
patent_data[num] = {"patent_number":num,"label":label,"abstract":abstract,"claim":claim}
|
| 111 |
+
|
| 112 |
+
st.session_state.patent_data = patent_data
|
| 113 |
+
st.session_state.patent_num = list(patent_data.keys())[0]
|
| 114 |
+
st.session_state.weight = 0.5
|
| 115 |
+
st.session_state.patent_abstract_model = ModelImplementation(
|
| 116 |
+
'rk2546/uspto-patents-abstracts',
|
| 117 |
+
DistilBertForSequenceClassification,
|
| 118 |
+
'distilbert-base-uncased',
|
| 119 |
+
DistilBertTokenizerFast,
|
| 120 |
+
TextClassificationPipeline,
|
| 121 |
+
ParsePatentOutput,
|
| 122 |
+
classifier_args={"return_all_scores":True},
|
| 123 |
+
)
|
| 124 |
+
print("Patent abstracts model initialized")
|
| 125 |
+
st.session_state.patent_claim_model = ModelImplementation(
|
| 126 |
+
'rk2546/uspto-patents-claims',
|
| 127 |
+
DistilBertForSequenceClassification,
|
| 128 |
+
'distilbert-base-uncased',
|
| 129 |
+
DistilBertTokenizerFast,
|
| 130 |
+
TextClassificationPipeline,
|
| 131 |
+
ParsePatentOutput,
|
| 132 |
+
classifier_args={"return_all_scores":True},
|
| 133 |
+
)
|
| 134 |
+
print("Patent claims model initialized")
|
| 135 |
+
|
| 136 |
+
# Title
|
| 137 |
+
st.title("CSGY-6613 Project")
|
| 138 |
+
# Subtitle
|
| 139 |
+
st.markdown("_**Ryan Kim (rk2546)**_")
|
| 140 |
+
|
| 141 |
+
sentimentTab, patentTab = st.tabs([
|
| 142 |
+
"Emotion Analysis [Milestone #2]",
|
| 143 |
+
"Patent Prediction [Milestone #3]"
|
| 144 |
+
])
|
| 145 |
+
|
| 146 |
+
with sentimentTab:
|
| 147 |
+
st.subheader("Sentiment Analysis")
|
| 148 |
+
if "emotion_model" not in st.session_state:
|
| 149 |
+
st.write("Loading model...")
|
| 150 |
+
else:
|
| 151 |
+
model_option = st.selectbox(
|
| 152 |
+
"What sentiment analysis model do you want to use? NOTE: Lag may occur when loading a new model!",
|
| 153 |
+
emotion_model_names,
|
| 154 |
+
on_change=emotion_model_change,
|
| 155 |
+
key="emotion_model_name"
|
| 156 |
+
)
|
| 157 |
+
form = st.form(key='sentiment-analysis-form')
|
| 158 |
+
text_input = form.text_area(
|
| 159 |
+
"Enter some text for sentiment analysis! If you just want to test it out without entering anything, just press the \"Submit\" button and the model will look at the placeholder.",
|
| 160 |
+
placeholder=st.session_state.emotion_model.placeholders[0]
|
| 161 |
+
)
|
| 162 |
+
submit = form.form_submit_button('Submit')
|
| 163 |
+
if submit:
|
| 164 |
+
if text_input is None or len(text_input.strip()) == 0:
|
| 165 |
+
to_eval = st.session_state.emotion_model.placeholders[0]
|
| 166 |
+
else:
|
| 167 |
+
to_eval = text_input.strip()
|
| 168 |
+
label, score, output_func = st.session_state.emotion_model.predict(to_eval)
|
| 169 |
+
output_func("**{}**: {}".format(label,score))
|
| 170 |
+
|
| 171 |
+
with patentTab:
|
| 172 |
+
st.subheader("USPTO Patent Evaluation")
|
| 173 |
+
st.markdown("Below are two inputs - one for an **ABSTRACT** and another for a list of **CLAIMS**. Enter both and select the \"Submit\" button to evaluate the patenteability of your idea.")
|
| 174 |
+
|
| 175 |
+
patent_select_list = list(st.session_state.patent_data.keys())
|
| 176 |
+
patent_index_option = st.selectbox(
|
| 177 |
+
"Want to pre-populate with an existing patent? Select the index number of below.",
|
| 178 |
+
patent_select_list,
|
| 179 |
+
key="patent_num",
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
if "patent_abstract_model" not in st.session_state or "patent_claim_model" not in st.session_state:
|
| 183 |
+
st.write("Loading models...")
|
| 184 |
+
else:
|
| 185 |
+
with st.form(key='patent-form'):
|
| 186 |
+
col1, col2 = st.columns(2)
|
| 187 |
+
with col1:
|
| 188 |
+
abstract_input = st.text_area(
|
| 189 |
+
"Enter the abstract of the patent below",
|
| 190 |
+
placeholder=st.session_state.patent_data[st.session_state.patent_num]["abstract"],
|
| 191 |
+
height=200
|
| 192 |
+
)
|
| 193 |
+
with col2:
|
| 194 |
+
claim_input = st.text_area(
|
| 195 |
+
"Enter the claims of the patent below",
|
| 196 |
+
placeholder=st.session_state.patent_data[st.session_state.patent_num]["claim"],
|
| 197 |
+
height=200
|
| 198 |
+
)
|
| 199 |
+
weight_val = st.slider(
|
| 200 |
+
"How much do the abstract and claims weight when aggregating a total softmax score?",
|
| 201 |
+
min_value=-1.0,
|
| 202 |
+
max_value=1.0,
|
| 203 |
+
value=0.5,
|
| 204 |
+
)
|
| 205 |
+
submit = st.form_submit_button('Submit')
|
| 206 |
+
|
| 207 |
+
if submit:
|
| 208 |
+
|
| 209 |
+
is_custom = False
|
| 210 |
+
if abstract_input is None or len(abstract_input.strip()) == 0:
|
| 211 |
+
abstract_to_eval = st.session_state.patent_data[st.session_state.patent_num]["abstract"].strip()
|
| 212 |
+
else:
|
| 213 |
+
abstract_to_eval = abstract_input.strip()
|
| 214 |
+
is_custom = True
|
| 215 |
+
|
| 216 |
+
if claim_input is None or len(claim_input.strip()) == 0:
|
| 217 |
+
claim_to_eval = st.session_state.patent_data[st.session_state.patent_num]["claim"].strip()
|
| 218 |
+
else:
|
| 219 |
+
claim_to_eval = claim_input.strip()
|
| 220 |
+
is_custom = True
|
| 221 |
+
|
| 222 |
+
abstract_response = st.session_state.patent_abstract_model.predict(abstract_to_eval)
|
| 223 |
+
claim_response = st.session_state.patent_claim_model.predict(claim_to_eval)
|
| 224 |
+
|
| 225 |
+
claim_weight = (1+weight_val)/2
|
| 226 |
+
abstract_weight = 1-claim_weight
|
| 227 |
+
aggregate_score = [
|
| 228 |
+
{'label':'REJECTED','score':abstract_response[0][0]['score']*abstract_weight + claim_response[0][0]['score']*claim_weight},
|
| 229 |
+
{'label':'ACCEPTED','score':abstract_response[0][1]['score']*abstract_weight + claim_response[0][1]['score']*claim_weight}
|
| 230 |
+
]
|
| 231 |
+
aggregate_score_sorted = sorted(aggregate_score, key=lambda d: d['score'], reverse=True)
|
| 232 |
+
|
| 233 |
+
answerCol1, answerCol2, answerCol3 = st.columns(3)
|
| 234 |
+
with answerCol1:
|
| 235 |
+
st.slider(
|
| 236 |
+
"Abstract Acceptance Likelihood",
|
| 237 |
+
min_value=0.0,
|
| 238 |
+
max_value=100.0,
|
| 239 |
+
value=abstract_response[0][1]["score"]*100.0,
|
| 240 |
+
disabled=True
|
| 241 |
+
)
|
| 242 |
+
with answerCol2:
|
| 243 |
+
output_func = st.info
|
| 244 |
+
if aggregate_score_sorted[0]["label"] == "REJECTED":
|
| 245 |
+
output_func = st.error
|
| 246 |
+
else:
|
| 247 |
+
output_func = st.success
|
| 248 |
+
output_func("""
|
| 249 |
+
**Final Rating: {}**
|
| 250 |
+
{}%
|
| 251 |
+
""".format(aggregate_score_sorted[0]["label"],aggregate_score_sorted[0]["score"]*100.0))
|
| 252 |
+
with answerCol3:
|
| 253 |
+
st.slider(
|
| 254 |
+
"Claim Acceptance Likelihood",
|
| 255 |
+
min_value=0.0,
|
| 256 |
+
max_value=100.0,
|
| 257 |
+
value=claim_response[0][1]["score"]*100.0,
|
| 258 |
+
disabled=True
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
#if not is_custom:
|
| 262 |
+
# st.markdown('**Original Score:**')
|
| 263 |
+
# st.markdown(st.session_state.patent_data[st.session_state.patent_num]["label"])
|
| 264 |
+
|
| 265 |
+
st.write("")
|
src/patent_train.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
src/train.py
ADDED
|
@@ -0,0 +1,228 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from datasets import load_dataset
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import numpy as np
|
| 4 |
+
import os
|
| 5 |
+
import json
|
| 6 |
+
import torch
|
| 7 |
+
import sys
|
| 8 |
+
|
| 9 |
+
from torch.utils.data import Dataset, DataLoader
|
| 10 |
+
from transformers import DistilBertTokenizerFast, DistilBertForSequenceClassification
|
| 11 |
+
from transformers import Trainer, TrainingArguments, AdamW
|
| 12 |
+
|
| 13 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 14 |
+
model_name = "distilbert-base-uncased"
|
| 15 |
+
upsto_abstracts_model_path = './models/uspto_abstracts'
|
| 16 |
+
upsto_claims_model_path = './models/uspto_claims'
|
| 17 |
+
|
| 18 |
+
class USPTODataset(Dataset):
|
| 19 |
+
def __init__(self, encodings, labels):
|
| 20 |
+
self.encodings = encodings
|
| 21 |
+
self.labels = labels
|
| 22 |
+
def __getitem__(self, idx):
|
| 23 |
+
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
|
| 24 |
+
item['labels'] = torch.tensor(self.labels[idx])
|
| 25 |
+
return item
|
| 26 |
+
def __len__(self):
|
| 27 |
+
return len(self.labels)
|
| 28 |
+
|
| 29 |
+
def LoadDataset():
|
| 30 |
+
print("=== LOADING THE DATASET ===")
|
| 31 |
+
# Extracting the dataset, filtering only for Jan. 2016
|
| 32 |
+
dataset_dict = load_dataset('HUPD/hupd',
|
| 33 |
+
name='sample',
|
| 34 |
+
data_files="https://huggingface.co/datasets/HUPD/hupd/blob/main/hupd_metadata_2022-02-22.feather",
|
| 35 |
+
icpr_label=None,
|
| 36 |
+
train_filing_start_date='2016-01-01',
|
| 37 |
+
train_filing_end_date='2016-01-21',
|
| 38 |
+
val_filing_start_date='2016-01-22',
|
| 39 |
+
val_filing_end_date='2016-01-31',
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
print("Separating between training and validation data")
|
| 43 |
+
df_train = pd.DataFrame(dataset_dict['train'] )
|
| 44 |
+
df_val = pd.DataFrame(dataset_dict['validation'] )
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
print("=== PRE-PROCESSING THE DATASET ===")
|
| 48 |
+
#We are interested in the following columns:
|
| 49 |
+
# - Abstract
|
| 50 |
+
# - Claims
|
| 51 |
+
# - Decision <- our `y`
|
| 52 |
+
# Let's preprocess them both out of our training and validation data
|
| 53 |
+
# Also, consider that the "Decision" column has three types of values: "Accepted", "Rejected", and "Pending". To remove unecessary baggage, we will be only looking for "Accepted" and "Rejected".
|
| 54 |
+
|
| 55 |
+
necessary_columns = ["abstract","claims","decision"]
|
| 56 |
+
output_values = ['ACCEPTED','REJECTED']
|
| 57 |
+
|
| 58 |
+
print("Dropping unused columns")
|
| 59 |
+
trainFeaturesToDrop = [col for col in list(df_train.columns) if col not in necessary_columns]
|
| 60 |
+
trainDF = df_train.dropna()
|
| 61 |
+
trainDF.drop(columns=trainFeaturesToDrop, inplace=True)
|
| 62 |
+
trainDF = trainDF[trainDF['decision'].isin(output_values)]
|
| 63 |
+
valFeaturesToDrop = [col for col in list(df_val.columns) if col not in necessary_columns]
|
| 64 |
+
valDF = df_val.dropna()
|
| 65 |
+
valDF.drop(columns=valFeaturesToDrop, inplace=True)
|
| 66 |
+
valDF = valDF[valDF['decision'].isin(output_values)]
|
| 67 |
+
|
| 68 |
+
# We need to replace the values in the `decision` column to numerical representations. ]
|
| 69 |
+
# We will set "ACCEPTED" as `1` and "REJECTED" as `0`.
|
| 70 |
+
print("Replacing values in `decision` column")
|
| 71 |
+
yKey = {"ACCEPTED":1,"REJECTED":0}
|
| 72 |
+
trainDF2 = trainDF.replace({"decision": yKey})
|
| 73 |
+
valDF2 = valDF.replace({"decision": yKey})
|
| 74 |
+
|
| 75 |
+
# We re-label the `decision` column to `label`.
|
| 76 |
+
print("Renaming `decision` to `label`")
|
| 77 |
+
trainDF3 = trainDF2.rename(columns={'decision': 'label'})
|
| 78 |
+
valDF3 = valDF2.rename(columns={'decision': 'label'})
|
| 79 |
+
|
| 80 |
+
# We can grab the data for each column so that we have a list of values for training labels,
|
| 81 |
+
# training texts, validation labels, and validation texts.
|
| 82 |
+
print("Extracting label and text data from dataframes")
|
| 83 |
+
trainData = {
|
| 84 |
+
"labels":trainDF3["label"].tolist(),
|
| 85 |
+
"abstracts":trainDF3["abstract"].tolist(),
|
| 86 |
+
"claims":trainDF3["claims"].tolist(),
|
| 87 |
+
}
|
| 88 |
+
valData = {
|
| 89 |
+
"labels":valDF3["label"].tolist(),
|
| 90 |
+
"abstracts":valDF3["abstract"].tolist(),
|
| 91 |
+
"claims":valDF3["claims"].tolist(),
|
| 92 |
+
}
|
| 93 |
+
#print(f'TRAINING:\t# labels: {len(trainData["labels"])}\t# texts: {len(trainData["text"])}')
|
| 94 |
+
#print(f'VALID:\t# labels: {len(valData["labels"])}\t# texts: {len(valData["text"])}')
|
| 95 |
+
|
| 96 |
+
if not os.path.exists("./data"):
|
| 97 |
+
os.makedirs('./data')
|
| 98 |
+
|
| 99 |
+
with open("./data/train.json", "w") as outfile:
|
| 100 |
+
json.dump(trainData, outfile, indent=2)
|
| 101 |
+
with open("./data/val.json", "w") as outfile:
|
| 102 |
+
json.dump(valData, outfile, indent=2)
|
| 103 |
+
|
| 104 |
+
return trainData, valData
|
| 105 |
+
|
| 106 |
+
def TrainModel(trainData, valData):
|
| 107 |
+
print("=== ENCODING DATA ===")
|
| 108 |
+
#print(len(trainData["labels"]), len(trainData["text"]), len(valData["labels"]), len(valData["text"]))
|
| 109 |
+
print("\t- initializing tokenizer")
|
| 110 |
+
tokenizer = DistilBertTokenizerFast.from_pretrained(model_name)
|
| 111 |
+
print("\t- encoding training data")
|
| 112 |
+
train_abstracts_encodings = tokenizer(trainData["abstracts"], truncation=True, padding=True)
|
| 113 |
+
train_claims_encodings = tokenizer(trainData["claims"], truncation=True, padding=True)
|
| 114 |
+
#print("\t- encoding validation data")
|
| 115 |
+
#val_abstracts_encodings = tokenizer(valData["abstracts"], truncation=True, padding=True)
|
| 116 |
+
#val_claims_encodings = tokenizer(valData["claims"], truncation=True, padding=True)
|
| 117 |
+
|
| 118 |
+
print(trainData["abstracts"][:10])
|
| 119 |
+
print(trainData["labels"][:10])
|
| 120 |
+
|
| 121 |
+
print("=== CREATING DATASETS ===")
|
| 122 |
+
print("\t- initializing dataset for training data")
|
| 123 |
+
train_abstracts_dataset = USPTODataset(train_abstracts_encodings, trainData["labels"])
|
| 124 |
+
train_claims_dataset = USPTODataset(train_claims_encodings, trainData["labels"])
|
| 125 |
+
#print("\t- initializing dataset for validation data")
|
| 126 |
+
#val_abstracts_dataset = USPTODataset(val_abstracts_encodings, valData["labels"])
|
| 127 |
+
#val_claims_dataset = USPTODataset(val_claims_encodings, valData["labels"])
|
| 128 |
+
|
| 129 |
+
print("=== PREPARING MODEL ===")
|
| 130 |
+
print("\t- setting up device")
|
| 131 |
+
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
|
| 132 |
+
print("\t- initializing model")
|
| 133 |
+
model = DistilBertForSequenceClassification.from_pretrained(model_name)
|
| 134 |
+
model.to(device)
|
| 135 |
+
model.train()
|
| 136 |
+
|
| 137 |
+
print("== PREPARING TRAINING ===")
|
| 138 |
+
print("\t- initializing trainers")
|
| 139 |
+
train_abstracts_loader = DataLoader(train_abstracts_dataset, batch_size=4, shuffle=True)
|
| 140 |
+
train_claims_loader = DataLoader(train_claims_dataset, batch_size=4, shuffle=True)
|
| 141 |
+
#train_claims_loader = DataLoader(train_claims_dataset, batch_size=4, shuffle=True)
|
| 142 |
+
print("\t- initializing optim")
|
| 143 |
+
optim = AdamW(model.parameters(), lr=5e-5)
|
| 144 |
+
|
| 145 |
+
def Train(loader, save_path, num_train_epochs=2):
|
| 146 |
+
batch_num = len(loader)
|
| 147 |
+
for epoch in range(num_train_epochs):
|
| 148 |
+
print(f'\t- Training epoch {epoch+1}/{num_train_epochs}')
|
| 149 |
+
batch_count = 0
|
| 150 |
+
for batch in loader:
|
| 151 |
+
print(f'{batch_count}|{batch_num} - {round((batch_count/batch_num)*100)}%', end="")
|
| 152 |
+
#print('\t\t- optim zero grad')
|
| 153 |
+
optim.zero_grad()
|
| 154 |
+
#print('\t\t- input_ids')
|
| 155 |
+
input_ids = batch['input_ids'].to(device)
|
| 156 |
+
#print('\t\t- attention_mask')
|
| 157 |
+
attention_mask = batch['attention_mask'].to(device)
|
| 158 |
+
#print('\t\t- labels0')
|
| 159 |
+
labels = batch['labels'].to(device)
|
| 160 |
+
#print('\t\t- outputs')
|
| 161 |
+
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
|
| 162 |
+
|
| 163 |
+
#print('\t\t- loss')
|
| 164 |
+
loss = outputs[0]
|
| 165 |
+
#print('\t\t- backwards')
|
| 166 |
+
loss.backward()
|
| 167 |
+
#print('\t\t- step')
|
| 168 |
+
optim.step()
|
| 169 |
+
|
| 170 |
+
batch_count += 1
|
| 171 |
+
print("\r", end="")
|
| 172 |
+
|
| 173 |
+
model.eval()
|
| 174 |
+
model.save_pretrained(save_path, from_pt=True)
|
| 175 |
+
print(f'Saved model in {save_path}!')
|
| 176 |
+
|
| 177 |
+
print("=== TRAINING ABSTRACTS ===")
|
| 178 |
+
Train(train_abstracts_loader,upsto_abstracts_model_path)
|
| 179 |
+
print("=== TRAINING CLAIMS ===")
|
| 180 |
+
Train(train_claims_loader,upsto_claims_model_path)
|
| 181 |
+
|
| 182 |
+
def main():
|
| 183 |
+
trainDataPath = "./data/train.json"
|
| 184 |
+
valDataPath = "./data/val.json"
|
| 185 |
+
trainData = None
|
| 186 |
+
valData = None
|
| 187 |
+
|
| 188 |
+
if os.path.exists(trainDataPath) and os.path.exists(valDataPath):
|
| 189 |
+
print("Loading from existing data files")
|
| 190 |
+
ftrain = open(trainDataPath)
|
| 191 |
+
trainData = json.load(ftrain)
|
| 192 |
+
ftrain.close()
|
| 193 |
+
fval = open(valDataPath)
|
| 194 |
+
valData = json.load(fval)
|
| 195 |
+
fval.close()
|
| 196 |
+
else:
|
| 197 |
+
trainData, valData = LoadDataset()
|
| 198 |
+
|
| 199 |
+
#print(len(trainData["labels"]), len(trainData["text"]), len(valData["labels"]), len(valData["text"]))
|
| 200 |
+
print("Data loaded successfully!")
|
| 201 |
+
|
| 202 |
+
TrainModel(trainData, valData)
|
| 203 |
+
|
| 204 |
+
"""
|
| 205 |
+
train_args = TrainingArguments(
|
| 206 |
+
output_dir="./results",
|
| 207 |
+
num_train_epochs=2,
|
| 208 |
+
per_device_train_batch_size=16,
|
| 209 |
+
per_device_eval_batch_size=64,
|
| 210 |
+
warmup_steps=500,
|
| 211 |
+
learning_rate=5e-5,
|
| 212 |
+
weight_decay=0.01,
|
| 213 |
+
logging_dir="./logs",
|
| 214 |
+
logging_steps=10
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
model = DistilBertForSequenceClassification.from_pretrained(model_name)
|
| 218 |
+
trainer = Trainer(
|
| 219 |
+
model=model,
|
| 220 |
+
args=train_args,
|
| 221 |
+
train_dataset=train_dataset,
|
| 222 |
+
eval_dataset=val_dataset
|
| 223 |
+
)
|
| 224 |
+
trainer.train()
|
| 225 |
+
"""
|
| 226 |
+
|
| 227 |
+
if __name__ == "__main__":
|
| 228 |
+
main()
|
src/val.ipynb
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"nbformat":4,"nbformat_minor":0,"metadata":{"colab":{"provenance":[],"authorship_tag":"ABX9TyPbIO5QK/V8keB7h6h+8Ju2"},"kernelspec":{"name":"python3","display_name":"Python 3"},"language_info":{"name":"python"}},"cells":[{"cell_type":"code","execution_count":22,"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"id":"ePuwhQ7QyzUW","executionInfo":{"status":"ok","timestamp":1682571700367,"user_tz":240,"elapsed":29378,"user":{"displayName":"Ryan Kim","userId":"18356277368138721144"}},"outputId":"9c939d4a-7622-4c48-ba58-b83162400692"},"outputs":[{"output_type":"stream","name":"stdout","text":["Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/\n","Requirement already satisfied: datasets in /usr/local/lib/python3.9/dist-packages (2.11.0)\n","Requirement already satisfied: packaging in /usr/local/lib/python3.9/dist-packages (from datasets) (23.1)\n","Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.9/dist-packages (from datasets) (6.0)\n","Requirement already satisfied: tqdm>=4.62.1 in /usr/local/lib/python3.9/dist-packages (from datasets) (4.65.0)\n","Requirement already satisfied: pandas in /usr/local/lib/python3.9/dist-packages (from datasets) (1.5.3)\n","Requirement already satisfied: xxhash in /usr/local/lib/python3.9/dist-packages (from datasets) (3.2.0)\n","Requirement already satisfied: responses<0.19 in /usr/local/lib/python3.9/dist-packages (from datasets) (0.18.0)\n","Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.9/dist-packages (from datasets) (1.22.4)\n","Requirement already satisfied: huggingface-hub<1.0.0,>=0.11.0 in /usr/local/lib/python3.9/dist-packages (from datasets) (0.14.1)\n","Requirement already satisfied: multiprocess in /usr/local/lib/python3.9/dist-packages (from datasets) (0.70.14)\n","Requirement already satisfied: dill<0.3.7,>=0.3.0 in /usr/local/lib/python3.9/dist-packages (from datasets) (0.3.6)\n","Requirement already satisfied: pyarrow>=8.0.0 in /usr/local/lib/python3.9/dist-packages (from datasets) (9.0.0)\n","Requirement already satisfied: fsspec[http]>=2021.11.1 in /usr/local/lib/python3.9/dist-packages (from datasets) (2023.4.0)\n","Requirement already satisfied: requests>=2.19.0 in /usr/local/lib/python3.9/dist-packages (from datasets) (2.27.1)\n","Requirement already satisfied: aiohttp in /usr/local/lib/python3.9/dist-packages (from datasets) (3.8.4)\n","Requirement already satisfied: attrs>=17.3.0 in /usr/local/lib/python3.9/dist-packages (from aiohttp->datasets) (23.1.0)\n","Requirement already satisfied: frozenlist>=1.1.1 in /usr/local/lib/python3.9/dist-packages (from aiohttp->datasets) (1.3.3)\n","Requirement already satisfied: charset-normalizer<4.0,>=2.0 in /usr/local/lib/python3.9/dist-packages (from aiohttp->datasets) (2.0.12)\n","Requirement already satisfied: multidict<7.0,>=4.5 in /usr/local/lib/python3.9/dist-packages (from aiohttp->datasets) (6.0.4)\n","Requirement already satisfied: async-timeout<5.0,>=4.0.0a3 in /usr/local/lib/python3.9/dist-packages (from aiohttp->datasets) (4.0.2)\n","Requirement already satisfied: aiosignal>=1.1.2 in /usr/local/lib/python3.9/dist-packages (from aiohttp->datasets) (1.3.1)\n","Requirement already satisfied: yarl<2.0,>=1.0 in /usr/local/lib/python3.9/dist-packages (from aiohttp->datasets) (1.9.2)\n","Requirement already satisfied: filelock in /usr/local/lib/python3.9/dist-packages (from huggingface-hub<1.0.0,>=0.11.0->datasets) (3.12.0)\n","Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.9/dist-packages (from huggingface-hub<1.0.0,>=0.11.0->datasets) (4.5.0)\n","Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.9/dist-packages (from requests>=2.19.0->datasets) (1.26.15)\n","Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.9/dist-packages (from requests>=2.19.0->datasets) (2022.12.7)\n","Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.9/dist-packages (from requests>=2.19.0->datasets) (3.4)\n","Requirement already satisfied: python-dateutil>=2.8.1 in /usr/local/lib/python3.9/dist-packages (from pandas->datasets) (2.8.2)\n","Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.9/dist-packages (from pandas->datasets) (2022.7.1)\n","Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.9/dist-packages (from python-dateutil>=2.8.1->pandas->datasets) (1.16.0)\n","Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/\n","Requirement already satisfied: streamlit in /usr/local/lib/python3.9/dist-packages (1.21.0)\n","Requirement already satisfied: packaging>=14.1 in /usr/local/lib/python3.9/dist-packages (from streamlit) (23.1)\n","Requirement already satisfied: toml in /usr/local/lib/python3.9/dist-packages (from streamlit) (0.10.2)\n","Requirement already satisfied: tzlocal>=1.1 in /usr/local/lib/python3.9/dist-packages (from streamlit) (4.3)\n","Requirement already satisfied: protobuf<4,>=3.12 in /usr/local/lib/python3.9/dist-packages (from streamlit) (3.20.3)\n","Requirement already satisfied: importlib-metadata>=1.4 in /usr/local/lib/python3.9/dist-packages (from streamlit) (6.6.0)\n","Requirement already satisfied: rich>=10.11.0 in /usr/local/lib/python3.9/dist-packages (from streamlit) (13.3.4)\n","Requirement already satisfied: python-dateutil in /usr/local/lib/python3.9/dist-packages (from streamlit) (2.8.2)\n","Requirement already satisfied: pympler>=0.9 in /usr/local/lib/python3.9/dist-packages (from streamlit) (1.0.1)\n","Requirement already satisfied: pandas<2,>=0.25 in /usr/local/lib/python3.9/dist-packages (from streamlit) (1.5.3)\n","Requirement already satisfied: typing-extensions>=3.10.0.0 in /usr/local/lib/python3.9/dist-packages (from streamlit) (4.5.0)\n","Requirement already satisfied: validators>=0.2 in /usr/local/lib/python3.9/dist-packages (from streamlit) (0.20.0)\n","Requirement already satisfied: blinker>=1.0.0 in /usr/local/lib/python3.9/dist-packages (from streamlit) (1.6.2)\n","Requirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.9/dist-packages (from streamlit) (8.4.0)\n","Requirement already satisfied: numpy in /usr/local/lib/python3.9/dist-packages (from streamlit) (1.22.4)\n","Requirement already satisfied: tornado>=6.0.3 in /usr/local/lib/python3.9/dist-packages (from streamlit) (6.2)\n","Requirement already satisfied: watchdog in /usr/local/lib/python3.9/dist-packages (from streamlit) (3.0.0)\n","Requirement already satisfied: gitpython!=3.1.19 in /usr/local/lib/python3.9/dist-packages (from streamlit) (3.1.31)\n","Requirement already satisfied: pydeck>=0.1.dev5 in /usr/local/lib/python3.9/dist-packages (from streamlit) (0.8.1b0)\n","Requirement already satisfied: requests>=2.4 in /usr/local/lib/python3.9/dist-packages (from streamlit) (2.27.1)\n","Requirement already satisfied: cachetools>=4.0 in /usr/local/lib/python3.9/dist-packages (from streamlit) (5.3.0)\n","Requirement already satisfied: altair<5,>=3.2.0 in /usr/local/lib/python3.9/dist-packages (from streamlit) (4.2.2)\n","Requirement already satisfied: pyarrow>=4.0 in /usr/local/lib/python3.9/dist-packages (from streamlit) (9.0.0)\n","Requirement already satisfied: click>=7.0 in /usr/local/lib/python3.9/dist-packages (from streamlit) (8.1.3)\n","Requirement already satisfied: jinja2 in /usr/local/lib/python3.9/dist-packages (from altair<5,>=3.2.0->streamlit) (3.1.2)\n","Requirement already satisfied: toolz in /usr/local/lib/python3.9/dist-packages (from altair<5,>=3.2.0->streamlit) (0.12.0)\n","Requirement already satisfied: entrypoints in /usr/local/lib/python3.9/dist-packages (from altair<5,>=3.2.0->streamlit) (0.4)\n","Requirement already satisfied: jsonschema>=3.0 in /usr/local/lib/python3.9/dist-packages (from altair<5,>=3.2.0->streamlit) (4.3.3)\n","Requirement already satisfied: gitdb<5,>=4.0.1 in /usr/local/lib/python3.9/dist-packages (from gitpython!=3.1.19->streamlit) (4.0.10)\n","Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.9/dist-packages (from importlib-metadata>=1.4->streamlit) (3.15.0)\n","Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.9/dist-packages (from pandas<2,>=0.25->streamlit) (2022.7.1)\n","Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.9/dist-packages (from python-dateutil->streamlit) (1.16.0)\n","Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.9/dist-packages (from requests>=2.4->streamlit) (2.0.12)\n","Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.9/dist-packages (from requests>=2.4->streamlit) (2022.12.7)\n","Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.9/dist-packages (from requests>=2.4->streamlit) (1.26.15)\n","Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.9/dist-packages (from requests>=2.4->streamlit) (3.4)\n","Requirement already satisfied: pygments<3.0.0,>=2.13.0 in /usr/local/lib/python3.9/dist-packages (from rich>=10.11.0->streamlit) (2.14.0)\n","Requirement already satisfied: markdown-it-py<3.0.0,>=2.2.0 in /usr/local/lib/python3.9/dist-packages (from rich>=10.11.0->streamlit) (2.2.0)\n","Requirement already satisfied: pytz-deprecation-shim in /usr/local/lib/python3.9/dist-packages (from tzlocal>=1.1->streamlit) (0.1.0.post0)\n","Requirement already satisfied: decorator>=3.4.0 in /usr/local/lib/python3.9/dist-packages (from validators>=0.2->streamlit) (4.4.2)\n","Requirement already satisfied: smmap<6,>=3.0.1 in /usr/local/lib/python3.9/dist-packages (from gitdb<5,>=4.0.1->gitpython!=3.1.19->streamlit) (5.0.0)\n","Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.9/dist-packages (from jinja2->altair<5,>=3.2.0->streamlit) (2.1.2)\n","Requirement already satisfied: attrs>=17.4.0 in /usr/local/lib/python3.9/dist-packages (from jsonschema>=3.0->altair<5,>=3.2.0->streamlit) (23.1.0)\n","Requirement already satisfied: pyrsistent!=0.17.0,!=0.17.1,!=0.17.2,>=0.14.0 in /usr/local/lib/python3.9/dist-packages (from jsonschema>=3.0->altair<5,>=3.2.0->streamlit) (0.19.3)\n","Requirement already satisfied: mdurl~=0.1 in /usr/local/lib/python3.9/dist-packages (from markdown-it-py<3.0.0,>=2.2.0->rich>=10.11.0->streamlit) (0.1.2)\n","Requirement already satisfied: tzdata in /usr/local/lib/python3.9/dist-packages (from pytz-deprecation-shim->tzlocal>=1.1->streamlit) (2023.3)\n","Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/\n","Requirement already satisfied: transformers in /usr/local/lib/python3.9/dist-packages (4.28.1)\n","Requirement already satisfied: tokenizers!=0.11.3,<0.14,>=0.11.1 in /usr/local/lib/python3.9/dist-packages (from transformers) (0.13.3)\n","Requirement already satisfied: filelock in /usr/local/lib/python3.9/dist-packages (from transformers) (3.12.0)\n","Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.9/dist-packages (from transformers) (23.1)\n","Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.9/dist-packages (from transformers) (2022.10.31)\n","Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.9/dist-packages (from transformers) (1.22.4)\n","Requirement already satisfied: huggingface-hub<1.0,>=0.11.0 in /usr/local/lib/python3.9/dist-packages (from transformers) (0.14.1)\n","Requirement already satisfied: requests in /usr/local/lib/python3.9/dist-packages (from transformers) (2.27.1)\n","Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.9/dist-packages (from transformers) (6.0)\n","Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.9/dist-packages (from transformers) (4.65.0)\n","Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.9/dist-packages (from huggingface-hub<1.0,>=0.11.0->transformers) (4.5.0)\n","Requirement already satisfied: fsspec in /usr/local/lib/python3.9/dist-packages (from huggingface-hub<1.0,>=0.11.0->transformers) (2023.4.0)\n","Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.9/dist-packages (from requests->transformers) (1.26.15)\n","Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.9/dist-packages (from requests->transformers) (2.0.12)\n","Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.9/dist-packages (from requests->transformers) (2022.12.7)\n","Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.9/dist-packages (from requests->transformers) (3.4)\n","Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/\n","Requirement already satisfied: tqdm in /usr/local/lib/python3.9/dist-packages (4.65.0)\n"]}],"source":["!pip install datasets\n","!pip install streamlit\n","!pip install transformers\n","!pip install tqdm"]},{"cell_type":"code","source":["from datasets import load_dataset\n","import pandas as pd\n","import numpy as np\n","import os\n","import json\n","import torch\n","import sys\n","from tqdm import tqdm\n","\n","import streamlit as st\n","from transformers import TextClassificationPipeline, pipeline\n","from transformers import AutoTokenizer, AutoModelForSequenceClassification, DistilBertTokenizerFast, DistilBertForSequenceClassification"],"metadata":{"id":"xqhKMsNVzBtY","executionInfo":{"status":"ok","timestamp":1682571793784,"user_tz":240,"elapsed":3,"user":{"displayName":"Ryan Kim","userId":"18356277368138721144"}}},"execution_count":27,"outputs":[]},{"cell_type":"code","source":["from google.colab import drive\n","drive.mount('/content/gdrive')"],"metadata":{"id":"4E_xZUUwzGJm","colab":{"base_uri":"https://localhost:8080/"},"executionInfo":{"status":"ok","timestamp":1682570070672,"user_tz":240,"elapsed":23530,"user":{"displayName":"Ryan Kim","userId":"18356277368138721144"}},"outputId":"a6fbb01a-caeb-4dc5-bef1-837c5dce202f"},"execution_count":3,"outputs":[{"output_type":"stream","name":"stdout","text":["Mounted at /content/gdrive\n"]}]},{"cell_type":"code","source":["abstract_model = TextClassificationPipeline(\n"," model = DistilBertForSequenceClassification.from_pretrained('rk2546/uspto-patents-abstracts'),\n"," tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased'),\n"," padding = True, \n"," truncation = True,\n"," return_all_scores = True\n",")\n","\n","claim_model = TextClassificationPipeline(\n"," model = DistilBertForSequenceClassification.from_pretrained('rk2546/uspto-patents-claims'),\n"," tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased'),\n"," padding = True, \n"," truncation = True,\n"," return_all_scores = True\n",")"],"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"id":"Mj3hQGRU90bA","executionInfo":{"status":"ok","timestamp":1682573368942,"user_tz":240,"elapsed":7417,"user":{"displayName":"Ryan Kim","userId":"18356277368138721144"}},"outputId":"05cc8f93-1c72-4880-ae76-8d132d500c5f"},"execution_count":39,"outputs":[{"output_type":"stream","name":"stderr","text":["/usr/local/lib/python3.9/dist-packages/transformers/pipelines/text_classification.py:104: UserWarning: `return_all_scores` is now deprecated, if want a similar funcionality use `top_k=None` instead of `return_all_scores=True` or `top_k=1` instead of `return_all_scores=False`.\n"," warnings.warn(\n"]}]},{"cell_type":"code","source":["path_to_valData = \"./gdrive/MyDrive/AI [Spring 2023]/cs-gy-6613-project-rk2546/val.json\"\n","f = open(path_to_valData)\n","valData = json.load(f)\n","f.close()"],"metadata":{"id":"0oimA5tO9c1G","executionInfo":{"status":"ok","timestamp":1682570188049,"user_tz":240,"elapsed":1507,"user":{"displayName":"Ryan Kim","userId":"18356277368138721144"}}},"execution_count":7,"outputs":[]},{"cell_type":"code","source":["# We track the successes of abstracts, claims, and both combined\n","abstract_successes = 0\n","claim_successes = 0\n","aggregate_successes = 0\n","total_num = len(valData['labels'])\n","\n","# By default, we weigh the claims more highly than abstracts\n","claim_weight = 0.5\n","abstract_weight = 0.5\n","\n","# To randomize the data, we generate random indices \n","index_perms = np.random.permutation(total_num)\n","labels = []\n","abstracts = []\n","claims = []\n","# We generate up to 500 samples to validate against\n","new_total_num = min(1000,len(index_perms))\n","for i in range(new_total_num):\n"," labels.append(valData['labels'][index_perms[i]])\n"," abstracts.append(valData['abstracts'][index_perms[i]])\n"," claims.append(valData['claims'][index_perms[i]])\n","\n","# Now we validate\n","for i in tqdm(range(new_total_num)):\n"," label = labels[i]\n"," abstract = abstracts[i]\n"," claim = claims[i]\n","\n"," abstract_response = abstract_model(abstract)[0]\n"," claim_response = claim_model(claim)[0]\n"," aggregate_response = [\n"," {'label':'REJECTED','score':abstract_response[0]['score']*abstract_weight + claim_response[0]['score']*claim_weight},\n"," {'label':'ACCEPTED','score':abstract_response[1]['score']*abstract_weight + claim_response[1]['score']*claim_weight}\n"," ]\n","\n"," abstract_sorted = sorted(abstract_response, key=lambda d: d['score'], reverse=True) \n"," claim_sorted = sorted(claim_response, key=lambda d: d['score'], reverse=True)\n"," aggregate_sorted = sorted(aggregate_response, key=lambda d: d['score'], reverse=True) \n","\n"," if abstract_sorted[0]['label'] == 'LABEL_1' and label == 1:\n"," abstract_successes += 1\n"," elif abstract_sorted[0]['label'] == 'LABEL_0' and label == 0:\n"," abstract_successes += 1\n"," \n"," if claim_sorted[0]['label'] == 'LABEL_1' and label == 1:\n"," claim_successes += 1\n"," elif claim_sorted[0]['label'] == 'LABEL_0' and label == 0:\n"," claim_successes += 1\n"," \n"," if aggregate_sorted[0]['label'] == 'ACCEPTED' and label == 1:\n"," aggregate_successes += 1\n"," elif aggregate_sorted[0]['label'] == 'REJECTED' and label == 0:\n"," aggregate_successes += 1\n","\n"," # At 10% intervals, we print the current results\n"," if i > 0 and i % (new_total_num * 0.1) == 0:\n"," print(f\"\\nAbs: {abstract_successes}/{i} | Cl: {claim_successes}/{i} | Agg: {aggregate_successes}/{i}\")\n","\n","# Calculate final accuracy\n","abstract_accuracy = abstract_successes / new_total_num\n","claim_accuracy = claim_successes / new_total_num\n","aggregate_accuracy = aggregate_successes / new_total_num\n","\n","# Display accuracy\n","print(\"\\n\")\n","print(f\"Abstract Model Accuracy: {abstract_accuracy * 100}%\")\n","print(f\"Claim Model Accuracy: {claim_accuracy * 100}%\")\n","print(f\"Aggregated Model Accuracy: {aggregate_accuracy * 100}%\")"],"metadata":{"colab":{"base_uri":"https://localhost:8080/"},"id":"FLE-9qlw9qW7","executionInfo":{"status":"ok","timestamp":1682577092672,"user_tz":240,"elapsed":1356393,"user":{"displayName":"Ryan Kim","userId":"18356277368138721144"}},"outputId":"fe0fb5ed-b075-4e4d-c616-6dbac5148a75"},"execution_count":48,"outputs":[{"output_type":"stream","name":"stderr","text":[" 10%|█ | 101/1000 [02:25<22:03, 1.47s/it]"]},{"output_type":"stream","name":"stdout","text":["\n","Abs: 70/100 | Cl: 73/100 | Agg: 73/100\n"]},{"output_type":"stream","name":"stderr","text":[" 20%|██ | 201/1000 [04:38<21:25, 1.61s/it]"]},{"output_type":"stream","name":"stdout","text":["\n","Abs: 148/200 | Cl: 155/200 | Agg: 155/200\n"]},{"output_type":"stream","name":"stderr","text":[" 30%|███ | 301/1000 [06:53<13:59, 1.20s/it]"]},{"output_type":"stream","name":"stdout","text":["\n","Abs: 220/300 | Cl: 224/300 | Agg: 234/300\n"]},{"output_type":"stream","name":"stderr","text":[" 40%|████ | 401/1000 [09:08<11:16, 1.13s/it]"]},{"output_type":"stream","name":"stdout","text":["\n","Abs: 295/400 | Cl: 293/400 | Agg: 308/400\n"]},{"output_type":"stream","name":"stderr","text":[" 50%|█████ | 501/1000 [11:24<10:34, 1.27s/it]"]},{"output_type":"stream","name":"stdout","text":["\n","Abs: 362/500 | Cl: 365/500 | Agg: 383/500\n"]},{"output_type":"stream","name":"stderr","text":[" 60%|██████ | 601/1000 [13:37<10:44, 1.61s/it]"]},{"output_type":"stream","name":"stdout","text":["\n","Abs: 443/600 | Cl: 440/600 | Agg: 462/600\n"]},{"output_type":"stream","name":"stderr","text":[" 70%|███████ | 701/1000 [15:54<06:52, 1.38s/it]"]},{"output_type":"stream","name":"stdout","text":["\n","Abs: 523/700 | Cl: 517/700 | Agg: 546/700\n"]},{"output_type":"stream","name":"stderr","text":[" 80%|████████ | 801/1000 [18:07<03:42, 1.12s/it]"]},{"output_type":"stream","name":"stdout","text":["\n","Abs: 601/800 | Cl: 591/800 | Agg: 626/800\n"]},{"output_type":"stream","name":"stderr","text":[" 90%|█████████ | 901/1000 [20:24<01:56, 1.18s/it]"]},{"output_type":"stream","name":"stdout","text":["\n","Abs: 670/900 | Cl: 666/900 | Agg: 703/900\n"]},{"output_type":"stream","name":"stderr","text":["100%|██████████| 1000/1000 [22:36<00:00, 1.36s/it]"]},{"output_type":"stream","name":"stdout","text":["\n","\n","Abstract Model Accuracy: 72.89999999999999%\n","Claim Model Accuracy: 72.8%\n","Aggregated Model Accuracy: 76.2%\n"]},{"output_type":"stream","name":"stderr","text":["\n"]}]},{"cell_type":"code","source":[],"metadata":{"id":"Enwp7rw___5t"},"execution_count":null,"outputs":[]}]}
|