Spaces:
Runtime error

Runtime error
ambujraj2001
commited on
Commit
•
e291f2f
1
Parent(s):
34fff5f
done
Browse files- app.py +31 -0
- image.png +0 -0
- main.py +28 -0
- model.sav +3 -0
- requirements,txt +2 -0
- tokenizer.sav +3 -0
app.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import joblib
|
| 3 |
+
from PIL import Image
|
| 4 |
+
|
| 5 |
+
with st.sidebar:
|
| 6 |
+
st.subheader('English to Hindi Translator')
|
| 7 |
+
st.write('This model is trained on OPUS dataset. This open parallel is the collection of translated texts from the web. It also includes translations of Wikipedia, WikiSource, WikiBooks, WikiNews and WikiQuote web pages.Built using MarianMT model')
|
| 8 |
+
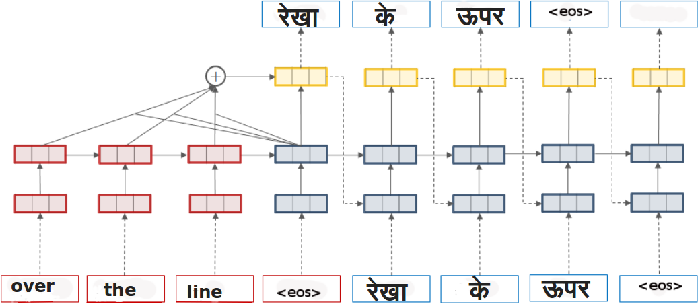
image = Image.open('image.png')
|
| 9 |
+
st.image(image, caption='MarianMT model')
|
| 10 |
+
add_selectbox = st.sidebar.text(
|
| 11 |
+
"Members: \n"
|
| 12 |
+
"\tRajat Sharma\n"
|
| 13 |
+
"\tTanisha Bhargava\n"
|
| 14 |
+
"\tAyush Chouraisa\n"
|
| 15 |
+
"\tAyush Chourasia\n"
|
| 16 |
+
"\tPallavi\n"
|
| 17 |
+
"\tSmriti\n"
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
st.header("English to Hindi Translator")
|
| 22 |
+
text = st.text_input("Enter text to translate")
|
| 23 |
+
if st.button("Translate"):
|
| 24 |
+
with st.spinner("Translating..."):
|
| 25 |
+
model = joblib.load('model.sav')
|
| 26 |
+
tokenizer = joblib.load('tokenizer.sav')
|
| 27 |
+
input_ids = tokenizer.encode(text, return_tensors="pt", padding=True)
|
| 28 |
+
outputs = model.generate(input_ids)
|
| 29 |
+
decoded_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 30 |
+
st.success("Done!")
|
| 31 |
+
st.write("Hindi Translation: ",decoded_text)
|
image.png
ADDED
|
main.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
| 2 |
+
import joblib
|
| 3 |
+
|
| 4 |
+
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-hi")
|
| 5 |
+
model = AutoModelForSeq2SeqLM.from_pretrained("Helsinki-NLP/opus-mt-en-hi")
|
| 6 |
+
joblib.dump(model, 'model.sav')
|
| 7 |
+
loaded_model = joblib.load('model.sav')
|
| 8 |
+
joblib.dump(tokenizer, 'tokenizer.sav')
|
| 9 |
+
loaded_tokenizer = joblib.load('tokenizer.sav')
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def translator(text):
|
| 13 |
+
# function to translate english text to hindi
|
| 14 |
+
input_ids = loaded_tokenizer.encode(text, return_tensors="pt", padding=True)
|
| 15 |
+
outputs = loaded_model.generate(input_ids)
|
| 16 |
+
decoded_text = loaded_tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 17 |
+
return decoded_text
|
| 18 |
+
|
| 19 |
+
texts = ["I spend a few hours a day maintaining my website.",
|
| 20 |
+
"Where do random thoughts come from?",
|
| 21 |
+
"I can't believe that she is older than my mother.",
|
| 22 |
+
"My Mum tries to be cool by saying that she likes all the same things that I do",
|
| 23 |
+
"A song can make or ruin a person’s day if they let it get to them."]
|
| 24 |
+
|
| 25 |
+
for text in texts:
|
| 26 |
+
print("English Text: ", text)
|
| 27 |
+
print("Hindi Translation: ", translator(text))
|
| 28 |
+
print("*"*50,"\n")
|
model.sav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9eefa7f19a6d77d5cb59e8e3ba415a5117ec63f4f461ab3f304a075f64487bd5
|
| 3 |
+
size 305880976
|
requirements,txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
streamlit
|
| 2 |
+
joblib
|
tokenizer.sav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e242deb2f9fc0ed01de2db8fb16d4923bb7dc1b8b6314de24e52a233ee02cc6a
|
| 3 |
+
size 1687217
|